# Adversarial Signed Graph Learning with Differential Privacy
**Authors**: Haobin Ke, Sen Zhang, Qingqing Ye, Xun Ran, Haibo Hu
> The Hong Kong Polytechnic UniversityHung HomHong Konghaobin.ke@connect.polyu.hk
> The Hong Kong Polytechnic UniversityHung HomHong Kongsenzhang@polyu.edu.hk
> The Hong Kong Polytechnic UniversityHung HomHong Kongqqing.ye@polyu.edu.hk
> The Hong Kong Polytechnic UniversityHung HomHong Kongqi-xun.ran@connect.polyu.hk
> The Hong Kong Polytechnic UniversityResearch Centre for Privacy and Security Technologies in Future Smart Systems, PolyUHung HomHong Konghaibo.hu@polyu.edu.hk
\setcctype
by
(2026)
Abstract.
Signed graphs with positive and negative edges can model complex relationships in social networks. Leveraging on balance theory that deduces edge signs from multi-hop node pairs, signed graph learning can generate node embeddings that preserve both structural and sign information. However, training on sensitive signed graphs raises significant privacy concerns, as model parameters may leak private link information. Existing protection methods with differential privacy (DP) typically rely on edge or gradient perturbation for unsigned graph protection. Yet, they are not well-suited for signed graphs, mainly because edge perturbation tends to cascading errors in edge sign inference under balance theory, while gradient perturbation increases sensitivity due to node interdependence and gradient polarity change caused by sign flips, resulting in larger noise injection. In this paper, motivated by the robustness of adversarial learning to noisy interactions, we present ASGL, a privacy-preserving adversarial signed graph learning method that preserves high utility while achieving node-level DP. We first decompose signed graphs into positive and negative subgraphs based on edge signs, and then design a gradient-perturbed adversarial module to approximate the true signed connectivity distribution. In particular, the gradient perturbation helps mitigate cascading errors, while the subgraph separation facilitates sensitivity reduction. Further, we devise a constrained breadth-first search tree strategy that fuses with balance theory to identify the edge signs between generated node pairs. This strategy also enables gradient decoupling, thereby effectively lowering gradient sensitivity. Extensive experiments on real-world datasets show that ASGL achieves favorable privacy-utility trade-offs across multiple downstream tasks. Our code and data are available in https://github.com/KHBDL/ASGL-KDD26.
Differential privacy, Adversarial signed graph learning, Constrained breadth first search-trees, Balanced theory. journalyear: 2026 copyright: cc conference: Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1; August 09–13, 2026; Jeju Island, Republic of Korea booktitle: Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 (KDD ’26), August 09–13, 2026, Jeju Island, Republic of Korea doi: 10.1145/3770854.3780282 isbn: 979-8-4007-2258-5/2026/08 ccs: Security and privacy Data anonymization and sanitization
1. Introduction
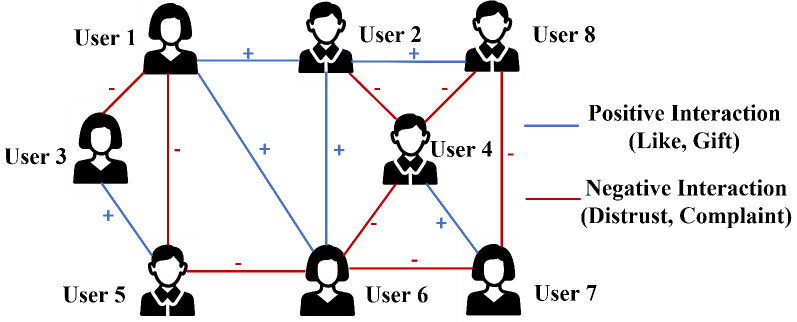
The signed graph is a common and widely adopted graph structure that can represent both positive and negative relationships using signed edges (19; 20; 21). For example, in online social networks shown in Fig. 1, while user interactions reflect positive relationships (e.g., like, trust, friendship), negative relationships (e.g., dislike, distrust, complaint) also exist. Signed graphs provide more expressive power than unsigned graphs to capture such complex user interactions.
Recently, some studies (22; 23; 24) have explored signed graph learning methods, aiming to obtain low-dimensional vector representations of nodes that preserve key signed graph properties: neighbor proximity and structural balance. These embeddings are subsequently applied to downstream tasks such as edge sign prediction, node clustering, and node classification. Among existing signed graph learning methods, balance theory (27) has proven effective in identifying the edge signs between the source node and multi-hop neighbor nodes. It is leveraged in graph neural network (GNN)-based models to guide message passing across signed edges, ensuring that information aggregation is aligned with the node proximity (36; 38; 39). Moreover, to enhance the robustness and generalization capability of deep learning models, the adversarial graph embedding model (03; 14) learns the underlying connectivity distribution of signed graphs by generating high-quality node embeddings that preserve signed node proximity.
Despite their ability to effectively capture signed relationships between nodes, graph learning models remain vulnerable to link stealing attacks (25; 42; 43), which aim to infer the existence of links between arbitrary node pairs in the training graph. For instance, in online social graphs, such attacks may reveal whether two users share a friendly or adversarial relationship, compromising user privacy and damaging personal or professional reputations.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Network Analysis of User Interactions
### Overview
The image depicts a network graph illustrating the interactions between eight users. The graph uses lines to represent interactions, with positive interactions indicated by blue lines and negative interactions by red lines. Each user is represented by a silhouette icon, and the graph is laid out in a grid-like pattern.
### Components/Axes
- **Users**: User 1, User 2, User 3, User 4, User 5, User 6, User 7, User 8
- **Interactions**: Positive (blue lines) and Negative (red lines)
- **Legend**: Positive Interaction (Like, Gift) and Negative Interaction (Distrust, Complaint)
### Detailed Analysis or ### Content Details
The graph shows a complex network of interactions among the users. User 1 interacts positively with User 2 and User 3, but negatively with User 4. User 2 interacts positively with User 3 and User 4, but negatively with User 5. User 3 interacts positively with User 4 and User 5, but negatively with User 6. User 4 interacts positively with User 5 and User 6, but negatively with User 7. User 5 interacts positively with User 6 and User 7, but negatively with User 8. User 6 interacts positively with User 7 and User 8, but negatively with User 1. User 7 interacts positively with User 8 and User 1, but negatively with User 2. User 8 interacts positively with User 1 and User 2, but negatively with User 3.
### Key Observations
- **Positive Interactions**: There are multiple instances of positive interactions among the users, suggesting a generally positive user experience.
- **Negative Interactions**: The presence of negative interactions indicates areas for improvement in user experience.
- **Outliers**: User 8 has the most negative interactions, which could be a point of concern for the platform.
### Interpretation
The data suggests that the platform has a generally positive user experience, with most users interacting positively with each other. However, the presence of negative interactions indicates areas for improvement. User 8's high number of negative interactions could be a point of concern for the platform. The platform should focus on addressing the negative interactions to improve user satisfaction and overall experience.
</details>
Figure 1. A signed social graph with blue edges for positive links and red edges for negative links.
Differential privacy (DP) (06) is a rigorous privacy framework that guarantees statistically indistinguishable outputs regardless of any individual data presence. Such guarantee is achieved through sufficient perturbation while maintaining provable privacy bounds and computational feasibility. Existing privacy-preserving graph learning methods with DP can be categorized into two types based on the perturbation mechanism: one applies edge perturbation (53) to protect the link information by modifying the graph structure, and the other adopts gradient perturbation (54; 52) to obscure the relationships between nodes during model training. However, these methods are not well-suited for signed graph learning due to the following two challenges:
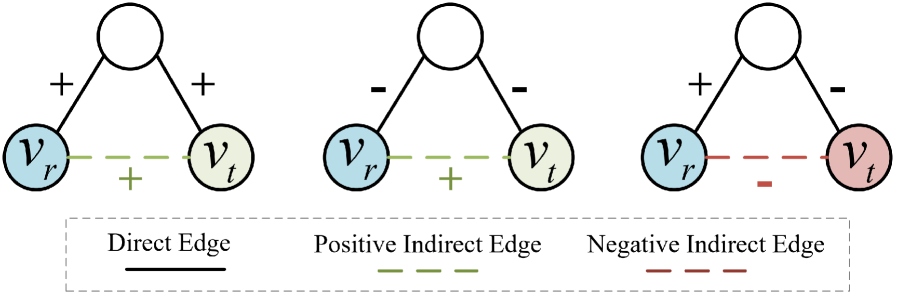
- Cascading error: As illustrated in Fig. 2, balance theory facilitates the inference of the edge sign between two unconnected nodes by computing the product of edge signs along a path. However, existing methods that use edge perturbation to protect link information may alter the sign of any edge along the path, thereby leading to incorrect inference of edge signs under balance theory. Such a local error can further propagate along the path, resulting in cascading errors in edge sign inference.
- High sensitivity: While gradient perturbation methods without directly perturbing edges may mitigate cascading errors, they are still ill-suited for signed graph learning because the node interdependence in signed graphs leads to high gradient sensitivity. The presence or absence of a node affects gradient updates of itself and its neighbors. Furthermore, edge change may induce sign flips that reverse gradient polarity within the loss function (see Eq. (10) for details), resulting in higher sensitivity compared to unsigned graphs. This increased sensitivity requires larger noise for privacy protection, thereby reducing the data utility.
To address these challenges, we turn to an adversarial learning-based approach for private signed graph learning. The core motivation is that this adversarial method generates node embeddings by approximating the true connectivity distribution, making it naturally robust to noisy interactions during optimization. As a result, we propose ASGL, a differentially private adversarial signed graph learning method that achieves high utility while maintaining node-level differential privacy. Within ASGL, the signed graph is first decomposed into positive and negative subgraphs based on edge signs. These subgraphs are then processed through an adversarial learning module within shared model parameters, enabling both positive and negative node pairs to be mapped into a unified embedding space while effectively preserving signed proximity. Based on this, we develop the adversarial learning module with differentially private stochastic gradient descent (DPSGD), which generates private node embeddings that closely approximate the true signed connectivity distribution. In particular, the gradient perturbation helps mitigate cascading errors, while the subgraph separation avoids gradient polarity reversals induced by edge sign flips within the loss function, thereby reducing the sensitivity to changes in edge signs. Considering that node interdependence further increases gradient sensitivity, we design a constrained breadth-first search (BFS) tree strategy within adversarial learning. This strategy integrates balance theory to identify the edge signs between generated node pairs, while also constraining the receptive fields of nodes to enable gradient decoupling, thereby effectively lowering gradient sensitivity and reducing noise injection. Our main contributions are listed as follows:
- We present a privacy-preserving adversarial learning method for signed graphs, called ASGL. To our best knowledge, it is the first work that can ensure the node-level differential privacy of signed graph learning while preserving high data utility.
- To mitigate cascading errors, we develop the adversarial learning module with DPSGD, which generates private node embeddings that closely approximate the true signed connectivity distribution. This approach avoids direct perturbation of the edge structure, which helps mitigate cascading errors and prevents gradient polarity reversals in the loss function.
- To further reduce the sensitivity caused by complex node relationships, we design a constrained breadth-first search tree strategy that integrates balance theory to identify edge signs between generated node pairs. This strategy also constrains the receptive fields of nodes, enabling gradient decoupling and effectively lowering gradient sensitivity.
- Extensive experiments demonstrate that our method achieves favorable privacy-accuracy trade-offs and significantly outperforms state-of-the-art methods in edge sign prediction and node clustering tasks. Additionally, we conduct link stealing attacks, demonstrating that ASGL exhibits stronger resistance to such attacks across all datasets.
The remainder of our work is organized as follows. Section 2 describes the preliminaries of our solution. The problem statement is introduced in Section 3. Our proposed solution and its privacy analysis are presented in Section 4. The experimental results are reported in Section 5. We discuss related works in Section 6, followed by conclusion in Section 7.
2. Preliminaries
In this section, we provide an overview of signed graphs, differential privacy, and DPSGD. Additionally, the vanilla adversarial graph learning is introduced in App. A, and the frequently used notations are summarized in Table 5 (See App. B).
2.1. Signed Graph with Balance Theory
A signed graph is denoted as $\mathcal{G}=(V,E^{+},E^{-})$ , where $V$ is the set of nodes, and $E^{+}/E^{-}$ represent positive and negative edge sets, respectively. An edge $e_{ij}=(v_{i},v_{j})∈ E^{+}/E^{-}$ represents the positive/negative link between node pair $(v_{i},v_{j})∈ V$ , respectively. Notably, $E^{+}\cap E^{-}=\emptyset$ ensures that any node pair cannot maintain both positive and negative relationships simultaneously. The objective of signed graph embedding is to learn a mapping function $f:V→\mathbb{R}^{k}$ that projects each node $v∈ V$ into a low $k$ -dimensional vector while preserving both the structural properties of the original signed graph. In other words, node pairs connected by positive edges should be embedded closely, while those connected by negative edges should be placed farther apart in the embedding space.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Neural Network Architecture
### Overview
The image depicts a simplified neural network architecture consisting of three layers: an input layer, a hidden layer, and an output layer. Each layer contains a single neuron, and the neurons are connected by edges. The input layer receives input data, the hidden layer processes the data, and the output layer produces the final output.
### Components/Axes
- **Input Layer**: Contains two neurons labeled \(v_r\) and \(v_t\).
- **Hidden Layer**: Contains one neuron labeled \(v_h\).
- **Output Layer**: Contains one neuron labeled \(v_o\).
- **Edges**: Connect the neurons in the layers. There are three types of edges: direct, positive indirect, and negative indirect.
- **Legend**: Located at the bottom of the image, indicating the types of edges.
### Detailed Analysis or ### Content Details
- **Direct Edge**: The edge between \(v_r\) and \(v_h\) is solid and labeled as "Direct Edge."
- **Positive Indirect Edge**: The edge between \(v_r\) and \(v_t\) is dashed and labeled as "Positive Indirect Edge."
- **Negative Indirect Edge**: The edge between \(v_t\) and \(v_h\) is dashed and labeled as "Negative Indirect Edge."
### Key Observations
- The architecture suggests a feedforward neural network with a single hidden layer.
- The direct edge indicates a direct connection between the input and hidden layers.
- The positive indirect edge suggests a connection between the input and output layers through the hidden layer.
- The negative indirect edge suggests a connection between the output and hidden layers through the hidden layer.
### Interpretation
The neural network architecture shown in the image is a simple feedforward network with a single hidden layer. The direct edge indicates a direct connection between the input and hidden layers, which is typical in neural networks for processing input data. The positive indirect edge suggests that the hidden layer processes the input data and then passes the processed information to the output layer. The negative indirect edge suggests that the output layer processes the information from the hidden layer and produces the final output.
The interpretation of the data suggests that the neural network is designed to process input data and produce an output based on the processed information. The direct edge indicates a direct connection between the input and hidden layers, which is typical in neural networks for processing input data. The positive indirect edge suggests that the hidden layer processes the input data and then passes the processed information to the output layer. The negative indirect edge suggests that the output layer processes the information from the hidden layer and produces the final output.
In summary, the neural network architecture shown in the image is a simple feedforward network with a single hidden layer. The direct edge indicates a direct connection between the input and hidden layers, the positive indirect edge suggests that the hidden layer processes the input data and then passes the processed information to the output layer, and the negative indirect edge suggests that the output layer processes the information from the hidden layer and produces the final output.
</details>
Figure 2. The signs of multi-hop connection based on balanced theory.
Balance theory (27) is a well-established standard to describe the signed relationships of unconnected node pairs. It is commonly summarized by four intuitive rules: “A friend of my friend is my friend,” “A friend of my enemy is my enemy,” “An enemy of my friend is my enemy,” and “An enemy of my enemy is my friend.” Based on these rules, the balance theory can deduce signs of the multi-hop connection. As shown in Fig. 2, given a path $P_{rt}:v_{r}→ v_{t}$ from rooted node $v_{r}$ to target node $v_{t}$ , the sign of the indirect relationships between $v_{r}$ and $v_{t}$ can be inferred by iteratively applying balance theory. Specifically, the sign of the multi-hop connection corresponds to the product of the signs of the edges along the path.
2.2. Differential Privacy
Differential Privacy (DP) (04) provides a rigorous mathematical framework for quantifying the privacy guarantees of algorithms operating on sensitive data. Informally, it bounds how much the output distribution of a mechanism can change in response to small changes in its input. When applying DP to signed graph data, the definition of adjacent databases typically considers two signed graphs, $\mathcal{G}$ and $\mathcal{G^{\prime}}$ , which are regarded as adjacent graphs if they differ by at most one edge or one node with its associated edges.
**Definition 0 (Edge (Node)-level DP(05))**
*Given $\epsilon>0$ and $\delta>0$ , a graph analysis mechanism $\mathcal{M}$ satisfies edge- or node-level $(\epsilon,\delta)$ -DP, if for any two adjacent graph datasets $\mathcal{G}$ and $\mathcal{G^{\prime}}$ that only differ by an edge or a node with its associated edges, and for any possible algorithm output $S⊂eq Range(\mathcal{M})$ , it holds that
$$
\displaystyle\text{Pr}[\mathcal{M}(\mathcal{G})\in S]\leq e^{\epsilon}\text{Pr}[\mathcal{M}(\mathcal{G^{\prime}})\in S]+\delta. \tag{1}
$$
Here, $\epsilon$ is the privacy budget (i.e., privacy cost), where smaller values indicate stronger privacy protection but greater utility reduction. The parameter $\delta$ denotes the probability that the privacy guarantee may not hold, and is typically set to be negligible. In other words, $\delta$ allows for a negligible probability of privacy leakage, while ensuring the privacy guarantee holds with high probability.*
**Remark 1**
*Note that satisfying node-level DP is much more challenging than satisfying edge-level DP, as removing a single node may, in the worst case, remove $|V|-1$ edges, where $|V|$ denotes the total number of nodes. Consequently, node-level DP requires injecting substantially more noise.*
Two fundamental properties of DP are useful for the privacy analysis of complex algorithms: (1) Post-Processing Property (06): If a mechanism $\mathcal{M}(\mathcal{G})$ satisfies $(\epsilon,\delta)$ -DP, then for any function $f$ that indirectly queries the private dataset $\mathcal{G}$ , the composition $f(\mathcal{M}(\mathcal{G}))$ also satisfies $(\epsilon,\delta)$ -DP; (2) Composition Property (06): If $\mathcal{M}(\mathcal{G})$ and $f(\mathcal{G})$ satisfy $(\epsilon_{1},\delta_{1})$ -DP and $(\epsilon_{2},\delta_{2})$ -DP, respectively, then the combined mechanism $\mathcal{F}(\mathcal{G})=(\mathcal{M}(\mathcal{G}),f(\mathcal{G}))$ which outputs both results, satisfies $(\epsilon_{1}+\epsilon_{2},\delta_{1}+\delta_{2})$ -DP.
2.3. DPSGD
A common approach to differentially private training combines noisy stochastic gradient descent with the Moments Accountant (MA) (02). This approach, known as DPSGD, has been widely adopted for releasing private low-dimensional representations, as MA effectively mitigates excessive privacy loss during iterative optimization. Formally, for each sample $x_{i}$ in a batch of size $B$ , we compute its gradient $∇\mathcal{L}_{i}(\theta)$ , denoted as $∇(x_{i})$ for simplicity. Gradient sensitivity refers to the maximum change in the output of the gradient function resulting from a change in a single sample. To control the sensitivity of ${∇(x_{i})}$ , the $\ell_{2}$ norm of each gradient is clipped by a threshold $C$ . These clipped gradients are then aggregated and perturbed with Gaussian noise $\mathcal{N}(0,\sigma^{2}C^{2}\mathbf{I})$ to satisfy the DP guarantee. Finally, the average noisy gradient ${\tilde{∇}_{B}}$ is used to update the model parameters $\theta$ . This process is given by:
$$
\displaystyle{\tilde{\nabla}_{B}}\leftarrow\frac{1}{B}\Big(\sum_{i=1}^{B}\text{Clip}_{C}(\nabla(x_{i}))+\mathcal{N}\left(0,\sigma^{2}C^{2}\mathbf{I}\right)\Big). \tag{2}
$$
Here, $\text{Clip}_{C}(∇(x_{i}))=∇(x_{i})/\max(1,\frac{||∇(x_{i})||_{2}}{C})$ .
3. Problem Definition and Existing Solutions
3.1. Problem Definition
Instead of publishing a sanitized version of original node embeddings, we aim to release a privacy-preserving ASGL model trained on raw signed graph data with node-level DP guarantees, enabling data analysts to generate task-specific node embeddings.
Threat Model. We consider a black-box attack (42), where the attacker can query the trained model and observe its outputs with no access to its internal architecture or parameters. The attacker attempts to infer the presence of specific nodes or edges in the training graph solely from model outputs. This setting reflects a more practical attack surface compared to the white-box scenario (11).
Privacy Model. Signed graph data encodes both positive and negative relationships between nodes, which differs from tabular or image data. Therefore, it is necessary to adapt the standard definition of node-level DP (See Definition 1) to ensure black-box adversaries cannot determine whether a specific node and its associated signed edges are present in the training data. To this end, we define the differentially private adversarial signed graph learning model as follows.
**Definition 0 (Adversarial signed graph learning model under node-level DP)**
*The vanilla process of graph adversarial learning is illustrated in App. A, let $\theta_{D}$ denote the discriminator parameters, and its $r$ -th row element corresponds to the $k$ -dimensional vector $\mathbf{d}_{v_{r}}$ of node $v_{r}$ , that is $\mathbf{d}_{v_{r}}∈\theta_{D}$ . The discriminator module $L_{D}$ satisfies node-level ( $\epsilon,\delta$ )-DP if two adjacent signed graphs $\mathcal{G}$ and $\mathcal{G}^{\prime}$ only differ in one node with its associated signed edges, and for all possible $\theta_{s}⊂eq Range(L_{D})$ , we have
$$
\displaystyle\text{Pr}[L_{D}(\mathcal{G})\in\theta_{s}]\leq e^{\epsilon}\text{Pr}[L_{D}(\mathcal{G^{\prime}})\in\theta_{s}]+\delta, \tag{3}
$$
where $\theta_{s}$ denotes the set comprising all possible values of $\theta_{D}$ .*
In particular, the generator $G$ is trained based on the feedback from the differentially private discriminator $D$ . According to the post-processing property of DP (08; 12), the generator module $L_{G}$ also satisfies node-level $(\epsilon,\delta)$ -DP. Leveraging the robustness to post-processing property, the privacy guarantee is preserved in the generated signed node embeddings and their downstream usage.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram Type: Flowchart
### Overview
The image is a flowchart that illustrates the process of generating a graph from an original graph and an active graph. The flowchart is divided into three main sections: (i) the original graph, (ii) the embedded space, and (iii) the downstream tasks.
### Components/Axes
- **Original Graph**: The initial graph with nodes and edges.
- **Active Graph**: The graph that is being processed or modified.
- **Embedded Space**: A space where the original and active graphs are embedded.
- **Downstream Tasks**: Tasks that are performed on the embedded space.
- **Legend**: A legend that explains the symbols and colors used in the diagram.
### Detailed Analysis or ### Content Details
- **Section (i)**: The original graph is shown with nodes and edges. The nodes are labeled with a unique identifier, and the edges are colored to indicate the type of relationship between the nodes (positive or negative).
- **Section (ii)**: The embedded space is shown with a grid of nodes and edges. The nodes are labeled with a unique identifier, and the edges are colored to indicate the type of relationship between the nodes (positive or negative). The embedded space is used to represent the original and active graphs in a higher-dimensional space.
- **Section (iii)**: The downstream tasks are shown with arrows indicating the flow of data from the embedded space to the downstream tasks. The downstream tasks include gradient clipping, gradient averaging, and noise addition.
### Key Observations
- The flowchart shows that the original graph is embedded in the embedded space, and the active graph is also embedded in the embedded space.
- The downstream tasks are performed on the embedded space, and the results are used to generate the final graph.
- The flowchart shows that the embedded space is used to represent the original and active graphs in a higher-dimensional space, and the downstream tasks are performed on the embedded space to generate the final graph.
### Interpretation
The flowchart demonstrates the process of generating a graph from an original graph and an active graph. The embedded space is used to represent the original and active graphs in a higher-dimensional space, and the downstream tasks are performed on the embedded space to generate the final graph. The flowchart shows that the embedded space is used to represent the original and active graphs in a higher-dimensional space, and the downstream tasks are performed on the embedded space to generate the final graph. The flowchart shows that the embedded space is used to represent the original and active graphs in a higher-dimensional space, and the downstream tasks are performed on the embedded space to generate the final graph.
</details>
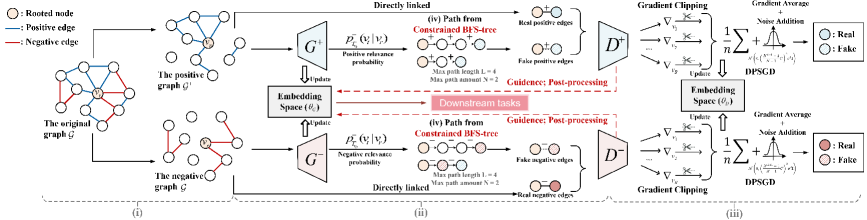
Figure 3. Overview of the ASGL framework: (i) The process decomposes a signed graph into positive and negative subgraphs, (ii) then maps node pairs into a unified embedding space while preserving signed proximity. To ensure privacy, (iii) adversarial learning module with DPSGD generates private node embeddings that approximate true connectivity without cascading errors. (iv) A constrained BFS-tree strategy manages node receptive field, reduces gradient noise, and improves model utility.
3.2. Existing Solutions
To our best knowledge, existing differentially private graph learning methods follow two main tracks: gradient perturbation and edge perturbation. In the first category, Yang et al. (54) introduce a privacy-preserving generative model that incorporates generative adversarial networks (GAN) or variational autoencoders (VAE) with DPSGD to protect edge privacy, while Xiang et al. (52) design a node sampling mechanism that adds Laplace noise to per-subgraph gradients, achieving node-level DP. For the edge perturbation-based methods, Lin et al. (53) use randomized response to perturb the adjacency matrix for edge-level privacy, and EDGERAND (42) perturbs the graph structure while preserving sparsity by clipping the adjacency matrix according to a privacy-calibrated graph density.
Limitation. The aforementioned solutions are not directly applicable to signed graphs. This is primarily because edge perturbation can lead to cascading errors when inferring edge signs under balance theory. Moreover, gradient perturbation often suffers from high sensitivity caused by complex node dependencies and gradient polarity reversal from edge sign flips, leading to excessive noise and degraded model utility.
4. Our Proposal: ASGL
To tackle the above limitations, we present ASGL, a DP-based adversarial signed graph learning model that integrates a constrained BFS-tree strategy to achieve favorable utility-privacy tradeoffs.
4.1. Overview
The ASGL framework, illustrated in Fig. 3, comprises three steps:
- Private Adversarial Signed Graph Learning. The signed graph $\mathcal{G}$ is first split into positive and negative subgraphs, $\mathcal{G}^{+}$ and $\mathcal{G}^{-}$ , based on edge signs. Subsequently, two discriminators, $D^{+}$ and $D^{-}$ , sharing parameters $\theta_{D}$ , are trained to distinguish real from fake positive and negative edges. Guided by $D^{+}$ and $D^{-}$ , two generators $G^{+}$ and $G^{-}$ with shared parameters $\theta_{G}$ generate node embeddings that approximate the true connectivity distribution. To ensure node-level DP, we apply gradient perturbation during discriminator training instead of directly perturbing edges. This strategy mitigates cascading errors and prevents gradient polarity reversals caused by edge sign flips, thereby reducing gradient sensitivity. By the post-processing property, the generators also preserve node-level DP.
- Optimization via Constrained BFS-tree. To further reduce gradient sensitivity and the required noise scale, ASGL employs a constrained BFS-tree strategy. By empirically limiting the number and length of paths, each node’s receptive field is restricted, which reduces node dependency and enables gradient decoupling. This significantly lowers gradient sensitivity and enhances model utility under differential privacy constraints.
- Privacy Accounting and Complexity Analysis. The complete training process for ASGL is outlined in Algorithm 2 (see App. F.3). Based on this, we present a comprehensive privacy accounting and computational complexity analysis for ASGL.
4.2. Private Adversarial Signed Graph Learning
Motivated by (03; 14), a signed graph $\mathcal{G}$ is first divided into a positive subgraph $\mathcal{G}^{+}$ and a negative subgraph $\mathcal{G}^{-}$ according to edge signs. Let $\mathcal{N}(v_{r})$ be the set of neighbor nodes directly connected to node $v_{r}$ . We denote the true positive and negative connectivity distributions of $v_{r}$ over its neighborhood $\mathcal{N}(v_{r})$ as the conditional probabilities $p_{\text{true}}^{+}(·|v_{r})$ and $p_{\text{true}}^{-}(·|v_{r})$ , which capture the preference of $v_{r}$ to connect with other nodes in $V$ . The adversarial learning for the signed graph $\mathcal{G}$ is conducted by two adversarial learning modules:
Generators $G^{+}$ and $G^{-}$ : Through optimizing the shared parameters $\theta_{G}$ , generators $G^{+}$ and $G^{-}$ aim to approximate the underlying true connectivity distribution and generate the most likely but unconnected nodes $v_{t}∉\mathcal{N}(v_{r})$ that are relevant to a given node $v_{r}$ . To this end, we estimate the relevance probabilities of these fake The term “Fake” indicates that although a node $v$ selected by the generator is relevant to $v_{r}$ , there is no actual edge between them. node pairs. Specifically, for the implementation of $G^{+}$ , given the fake positive node pairs $(v_{r},v_{t})^{+}$ , we use the graph softmax function (03) to calculate the fake positive connectivity probability:
$$
p^{+}_{\text{fake}}(v_{t}|v_{r})=G^{+}\left(v_{t}|v_{r};\theta_{G}\right)=\sigma(\mathbf{g}_{v_{t}}^{\top}\mathbf{g}_{v_{r}})=\frac{1}{1+\exp({-\mathbf{g}_{v_{t}}^{\top}\mathbf{g}_{v_{r}})}}, \tag{4}
$$
where $\mathbf{g}_{v_{t}},\mathbf{g}_{v_{r}}∈\mathbb{R}^{k}$ are the $k$ -dimensional vectors of nodes $v_{t}$ and $v_{r}$ , respectively, and $\theta_{G}$ is the union of all $\mathbf{g}_{v}$ ’s. The output $G^{+}(v_{t}|v_{r};\theta_{G})$ increases with the decrease of the distance between $v_{r}$ and $v_{t}$ in the embedding space of the generator $G^{+}$ . Similarly, for the generator $G^{-}$ , given the fake negative node pairs $(v_{r},v_{t})^{-}$ , we estimate their fake negative connectivity probability:
$$
p^{-}_{\text{fake}}(v_{t}|v_{r})=G^{-}(v_{t}|v_{r};\theta_{G})=1-\sigma(\mathbf{g}_{v_{t}}^{\top}\!\mathbf{g}_{v_{r}})=\frac{\exp{(-\mathbf{g}_{v_{t}}^{\top}\!\mathbf{g}_{v_{r}}})}{1+\exp{(-\mathbf{g}_{v_{t}}^{\top}\!\mathbf{g}_{v_{r}}})}. \tag{5}
$$
Here, Eq. (5) ensures that node pairs with higher negative connectivity probabilities are mapped farther apart in the embedding space of $G^{-}$ . Since generators $G^{+}$ and $G^{-}$ share the parameters $\theta_{G}$ , they jointly learn the proximity and separation of positive and negative node pairs in a unified embedding space, respectively.
Notably, the aforementioned fake node pairs $(v_{r},v_{t})^{+}$ and $(v_{r},v_{t})^{-}$ are sampled by a breadth-first search (BFS)-tree strategy (27). Compared to depth-first search (DFS) (56), BFS ensures more uniform exploration of neighboring nodes and can be integrated with random walk techniques (29) to optimize computational efficiency. Specifically, we perform BFS on the positive subgraph $\mathcal{G}^{+}$ to construct a BFS-tree $T^{+}_{v_{r}}$ rooted from node $v_{r}$ . Then, we calculate the positive relevance probability of node $v_{r}$ with its neighbors $v_{k}∈\mathcal{N}({v_{r}})$ :
$$
p^{+}_{T^{+}_{v_{r}}}(v_{k}|v_{r})=\frac{\exp\left(\mathbf{g}_{v_{k}}^{\top}\mathbf{g}_{v_{r}}\right)}{\sum_{v_{k}\in\mathcal{N}({v_{r}})}\exp\left(\mathbf{g}_{v_{k}}^{\top}\mathbf{g}_{v_{r}}\right)}, \tag{6}
$$
which is actually a softmax function over $\mathcal{N}({v_{r}})$ . To further sample node pairs unconnected in $T^{+}_{v_{r}}$ as fake positive edges, we perform a random walk at $T^{+}_{v_{r}}$ : Starting from the root node $v_{r}$ , a path $P_{rt}:v_{r}→ v_{t}$ is built by iteratively selecting the next node based on the transition probabilities defined in Eq. (6). The resulting unconnected node pair $(v_{r},v_{t})^{+}$ is treated as a fake positive edge, and App. E provides an example of this process. Given the node pair $(v_{r},v_{t})^{+}$ , the generator $G^{+}$ estimates $p^{+}_{\text{fake}}(v_{t}|v_{r})$ according to Eq. (4).
Similarly, we also establish a BFS-tree $T^{-}_{v_{r}}$ rooted at node $v_{r}$ in the negative subgraph $\mathcal{G}^{-}$ . To obtain the negative node pair $(v_{r},v_{t})^{-}$ , we perform a random walk on $T^{-}_{v_{r}}$ according to the following transition probability (i.e., negative relevance probability):
$$
p^{-}_{T^{-}_{v_{r}}}(v_{k}|v_{r})=\frac{1-\exp\left(\mathbf{g}_{v_{k}}^{\top}\mathbf{g}_{v_{r}}\right)}{\sum_{v_{k}\in\mathcal{N}({v_{r}})}\left(1-\exp\left(\mathbf{g}_{v_{k}}^{\top}\mathbf{g}_{v_{r}}\right)\right)}. \tag{7}
$$
In particular, the edge sign of the negative node pair $(v_{r},v_{t})^{-}$ depends on the length of the path $P_{rt}:v_{r}→ v_{t}$ . According to the balance theory introduced in Section 2.1, the edge signs of multi-hop node pairs correspond to the product of the edge signs along the path. Accordingly, the rules for generating fake negative edges within $P_{rt}$ are defined as follows: (1) If the path length of $P_{rt}$ is odd, a node pair $(v_{r},v_{t})^{-}$ for the rooted node $v_{r}$ and the last node $v_{t}$ is selected as a fake negative pair; (2) If the path length of $P_{rt}$ is even, a node pair $(v_{r},v_{t})^{-}$ for the rooted node $v_{r}$ and the second last node $v_{t}$ is selected as a fake negative pair. The resulting node pair $(v_{r},v_{t})^{-}$ is then used to compute $p^{-}_{\text{fake}}(v_{t}|v_{r})$ according to Eq. (5).
Discriminators $D^{+}$ and $D^{-}$ : This module tries to distinguish between real node pairs and fake node pairs synthesized by the generators $G^{+}$ and $G^{-}$ . Accordingly, the discriminators $D^{+}$ and $D^{-}$ estimate the likelihood that positive and negative edges exists between $v_{r}$ and $v∈ V$ , respectively, denoted as:
$$
D^{+}(v_{r},v|\theta_{D})=\sigma(\mathbf{d}_{v}^{\top}\mathbf{d}_{v_{r}})=\frac{1}{1+\exp({-\mathbf{d}_{v}^{\top}\mathbf{d}_{v_{r}})}},\\ \tag{8}
$$
$$
D^{-}(v,v_{r}|\theta_{D})=1-\sigma(\mathbf{d}_{v}^{\top}\mathbf{d}_{v_{r}})=\frac{\exp({-\mathbf{d}_{v}^{\top}\mathbf{d}_{v_{r}})}}{1+\exp({-\mathbf{d}_{v}^{\top}\mathbf{d}_{v_{r}})}}, \tag{9}
$$
where $\mathbf{d}_{v},\mathbf{d}_{v_{r}}∈\mathbb{R}^{k}$ are vectors corresponding to the $v$ -th and $v_{r}$ -th rows of shared parameters $\theta_{D}$ , respectively. $\sigma(·)$ represents the sigmoid function of the inner product of these two vectors.
In summary, given real positive and real negative edges sampled from $p_{\text{true}}^{+}(·|v_{r})$ and $p_{\text{true}}^{-}(·|v_{r})$ , along with fake positive and fake negative edges generated from generators $G^{+}/G^{-}$ , the adversarial learning pairs $(D^{+},G^{+})$ and $(D^{-},G^{-})$ , operating on the positive subgraph $\mathcal{G}^{+}$ and the negative subgraph $\mathcal{G}^{-}$ , respectively, engage in a four-player mini-max game with the joint loss function:
$$
\displaystyle\min_{\theta_{G}} \displaystyle\max_{\theta_{D}}L\left(G^{+},G^{-},D^{+},D^{-}\right) \displaystyle= \displaystyle\sum_{v_{r}\in V^{+}}\left(\left(\mathbb{E}_{v\sim p_{\text{true }}^{+}\left(\cdot\mid v_{r}\right)}\right)\left[\log D^{+}\left(v,v_{r}\mid\theta_{D}\right)\right]\right. \displaystyle\left.\qquad+\left(\mathbb{E}_{v\sim G^{+}\left(\cdot\mid v_{r};\theta_{G}\right)}\right)\left[\log\left(1-D^{+}\left(v,v_{r}\mid\theta_{D}\right)\right)\right]\right) \displaystyle+ \displaystyle\sum_{v_{r}\in V^{-}}\left(\left(\mathbb{E}_{v\sim p_{\text{true }}^{-}\left(\cdot\mid v_{r}\right)}\right)\left[\log D^{-}\left(v,v_{r}\mid\theta_{D}\right)\right]\right. \displaystyle\left.\qquad+\left(\mathbb{E}_{v\sim G^{-}\left(\cdot\mid v_{r};\theta_{G}\right)}\right)\left[\log\left(1-D^{-}\left(v,v_{r}\mid\theta_{D}\right)\right)\right]\right). \tag{10}
$$
Based on Eq. (10), the parameters $\theta_{D}$ and $\theta_{G}$ are updated alternately by maximizing and minimizing the joint loss function. Competition between $G$ and $D$ results in mutual improvement until the fake node pairs generated by $G$ are indistinguishable from the real ones, thus approximating the true connectivity distribution. Lastly, the learned node embeddings $\mathbf{g}_{v}∈\theta_{G}$ are used in downstream tasks.
How to Achieve DP? Given real and fake positive/negative edges of the node $v_{i}$ , the corresponding node embedding $\mathbf{d}_{v_{i}}∈\theta_{D}$ is updated by ascending gradients of the joint loss function in Eq. (10):
$$
\frac{\partial L_{D}}{\partial\mathbf{d}_{v_{i}}}=\left\{\begin{array}[]{l}\partial\log{D^{+}(v_{i},v_{j}|\theta_{D})}/{\partial\mathbf{d}_{v_{i}}}=[1-\sigma(\mathbf{d}_{v_{j}}^{\top}\mathbf{d}_{v_{i}})]\mathbf{d}_{v_{j}},\\
\text{if }\left(v_{i},v_{j}\right)\text{ is a real positive edge from $\mathcal{G}^{+}$};\\
\partial\log{(1-D^{+}(v_{i},v_{j}|\theta_{D}))}/{\partial\mathbf{d}_{v_{i}}}=-\sigma(\mathbf{d}_{v_{j}}^{\top}\mathbf{d}_{v_{i}})\mathbf{d}_{v_{j}},\\
\text{if }\left(v_{i},v_{j}\right)\text{ is a fake positive edge from ${G}^{+}$};\\
\partial\log{D^{-}(v_{i},v_{j}|\theta_{D})}/{\partial\mathbf{d}_{v_{i}}}=-\sigma(\mathbf{d}_{v_{j}}^{\top}\mathbf{d}_{v_{i}})\mathbf{d}_{v_{j}},\\
\text{if }\left(v_{i},v_{j}\right)\text{ is a real negative edge from $\mathcal{G}^{-}$};\\
\partial\log{(1-D^{-}(v_{i},v_{j}|\theta_{D}))}/{\partial\mathbf{d}_{v_{i}}}=[1-\sigma(\mathbf{d}_{v_{j}}^{\top}\mathbf{d}_{v_{i}})]\mathbf{d}_{v_{j}},\\
\text{if }\left(v_{i},v_{j}\right)\text{ is a fake negative edge from ${G}^{-}$}.\end{array}\right. \tag{11}
$$
According to Definition 1, to achieve node-level differential privacy in adversarial signed graph learning, it is necessary to add the Gaussian noise to the sum of clipped gradients over a batch of nodes. The resulting noisy gradient $\tilde{∇}{L_{D}}$ is formulated as:
$$
{\tilde{\nabla}{L_{D}}}=\frac{1}{B}\Big(\sum_{v_{i}\in V_{B}}\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v_{i}}})+\mathcal{N}\left(0,B^{2}C^{2}\sigma^{2}\mathbf{I}\right)\Big), \tag{12}
$$
where $V_{B}$ denotes the batch set of nodes, with batch size $B=|V_{B}|$ . $C$ is the clipping threshold to control gradient sensitivity. The fact that the gradient sensitivity reaches $BC$ is explained in Section 4.3.
**Remark 2**
*To achieve node-level DP, we perturb discriminator gradients instead of signed edges, avoiding cascading errors and gradient polarity reversals from edge sign flips (see Eq. (10)), which reduces gradient sensitivity. Furthermore, generators also preserve DP under discriminator guidance via the post-processing property of DP.*
4.3. Optimization via Constrained BFS-Tree
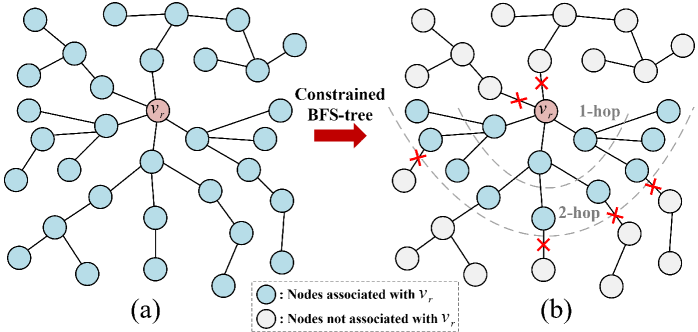
According to Eq. (11), in graph adversarial learning, the interdependence among samples implies that modifying a single node $v_{i}$ may affect the gradients of multiple other nodes $v_{j}$ within the same batch. This interdependence also exists among the fake node pairs generated along the BFS-tree paths. Consequently, in the worst-case illustrated in Fig. 4 (a), all node samples within a batch may become interrelated due to the BFS-tree, resulting in the gradient sensitivity of discriminators $D$ as high as $BC$ . Such high sensitivity necessitates injecting substantial noise to satisfy node-level DP, hindering effective optimization and reducing model utility.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram Type: Flowchart
### Overview
The image depicts a flowchart illustrating the process of constrained BFS-tree construction. It shows two stages: (a) the initial BFS-tree and (b) the constrained BFS-tree after applying certain constraints.
### Components/Axes
- **Nodes**: Represented by circles, some are colored blue and others are white.
- **Edges**: Lines connecting the nodes.
- **Legend**: Located at the bottom right, indicating the color coding for nodes associated with \( V_r \) and those not associated with \( V_r \).
- **Annotations**: Red stars mark specific nodes in the constrained BFS-tree.
- **Axes**: No explicit axes are visible, but the flowchart is structured to show the progression from the initial to the constrained BFS-tree.
### Detailed Analysis or ### Content Details
- **Stage (a)**: The initial BFS-tree is shown with nodes spread out, indicating a full breadth-first search.
- **Stage (b)**: The constrained BFS-tree is shown with nodes that are not directly connected to \( V_r \) marked with red stars, indicating the application of constraints.
- **Nodes Associated with \( V_r \)**: These nodes are colored blue and are connected to \( V_r \) in the initial BFS-tree.
- **Nodes Not Associated with \( V_r \)**: These nodes are colored white and are not directly connected to \( V_r \) in the initial BFS-tree.
### Key Observations
- **1-hop and 2-hop**: The red stars indicate nodes that are 1-hop or 2-hop away from \( V_r \) in the constrained BFS-tree.
- **Constrained BFS-tree**: The process of constraining the BFS-tree to exclude nodes not associated with \( V_r \).
### Interpretation
The flowchart demonstrates the concept of constrained BFS-tree construction, where the initial BFS-tree is expanded to include nodes not directly connected to \( V_r \) under certain constraints. This process is likely used in network analysis or graph theory to identify specific nodes of interest within a network. The interpretation suggests that the constraints applied in the constrained BFS-tree are crucial for identifying nodes that are relevant to the study or analysis, while excluding those that are not. The visual representation helps in understanding the flow and the impact of the constraints on the network structure.
</details>
Figure 4. The receptive field of node $v_{r}$ within a batch is illustrated in two cases: (a) An unconstrained BFS tree, and the receptive field size of $v_{r}$ is $B=|V_{B}|=34$ ; (b) A constrained BFS tree with path length $L=2$ , path amount $N=3$ of each node, and the receptive field size of $v_{r}$ is $\sum_{l=0}^{L}N^{l}=13$ .
To address the aforementioned challenge, we introduce the constrained BFS-tree strategy: As illustrated in Algorithm 1 (see App. F.2), when performing a random walk on the BFS-tree $T^{+}_{v_{r}}$ or $T^{-}_{v_{r}}$ rooted at $v_{r}∈ V_{tr}$ to generate multiple unique paths, we also limit both the number of sampled paths and their lengths by $N$ and $L$ . Following this, the training set of subgraphs $S_{tr}$ composed of constrained paths is obtained. The rationale behind these settings is discussed below.
**Theorem 1**
*By constraining both the number and length of paths generated via random walks on the BFS-trees to $N$ and $L$ , respectively, the gradient sensitivity $\Delta_{{g}}$ of the discriminator can be reduced from $BC$ to $\frac{N^{L+1}-1}{N-1}C$ . Empirical results in Section 5 demonstrate that our ASGL achieves satisfactory performance even with a relatively small receptive field. Specifically, when setting $N=3$ and $L=4$ , that is, $\frac{N^{L+1}-1}{N-1}=121<B=256$ , the ASGL method still performs good model utility. Thus, the noisy gradient $\tilde{∇}{L_{D}}$ of discriminator within a mini-batch $\mathcal{B}_{t}$ is denoted as:
$$
\displaystyle{\tilde{\nabla}{L_{D}}}=\frac{1}{|\mathcal{B}_{t}|}\Big(\sum_{v\in\mathcal{B}_{t}}\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v}})+\mathcal{N}\left(0,\Delta_{{g}}^{2}\sigma^{2}\mathbf{I}\right)\Big), \tag{13}
$$
where the gradient sensitivity $\Delta_{{g}}=\frac{N^{L+1}-1}{N-1}C$ .*
Proof of Theorem 1. Let the sum of clipped gradients of batch subgraphs be $g_{t}(\mathcal{G})=\sum_{v∈\mathcal{B}_{t}}\text{Clip}_{C}(\frac{∂ L_{D}}{∂\mathbf{d}_{v}})$ , where $\mathcal{B}_{t}$ represents any choice of batch subgraphs from $S_{tr}$ . Consider a node-level adjacent graph $\mathcal{G}^{\prime}$ formed by removing a node $v^{*}$ with its associated edges from $\mathcal{G}$ , we obtain their training sets of subgraphs $S_{tr}$ and $S_{tr}^{\prime}$ via the SAMPLE-SUBGRAPHS method in Algorithm 1, denoted as:
$$
\displaystyle S_{tr} \displaystyle=\text{SAMPLE-SUBGRAPHS}(\mathcal{G},V_{tr},N,L), \displaystyle S_{tr}^{\prime} \displaystyle=\text{SAMPLE-SUBGRAPHS}(\mathcal{G}^{\prime},V_{tr},N,L). \tag{14}
$$
The only subgraphs that differ between $S_{tr}$ and $S_{tr}^{\prime}$ are those that involve the node $v^{*}$ . Let $S(v^{*})$ denote the set of such subgraphs, i.e., $S(v^{*})=S_{tr}\setminus S_{tr}^{\prime}$ . According to Lemma 1 in App. G, the number of such subgraphs $S(v^{*})$ is at most $R_{N,L}$ . Thus, in any mini-batch training, the only gradient terms $\frac{∂ L_{D}}{∂\mathbf{d}_{v}}$ affected by the removal of node $v^{*}$ are those associated with the subgraphs in $(S(v^{*})\cap\mathcal{B}_{t})$ :
$$
\displaystyle g_{t}(\mathcal{G})-g_{t}(\mathcal{G}^{\prime}) \displaystyle=\sum_{v\in\mathcal{B}_{t}}\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v}})-\sum_{v^{\prime}\in\mathcal{B}_{t}^{\prime}}\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v^{\prime}}}) \displaystyle=\sum_{v,v^{\prime}\in(S(v^{*})\cap\mathcal{B}_{t})}[\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v}})-\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v^{\prime}}})], \tag{15}
$$
where $\mathcal{B}_{t}^{\prime}=\mathcal{B}_{t}\setminus(S(v^{*})\cap\mathcal{B}_{t})$ . Since each gradient term is clipped to have an $\ell_{2}$ -norm of at most $C$ , it holds that:
$$
||\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v}})-\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v^{\prime}}})||_{F}\leq C. \tag{16}
$$
In the worst case, all subgraphs in $S(v^{*})$ appear in $\mathcal{B}_{t}$ , so we bound the $\ell_{2}$ -norm of the following quantity based on Lemma 2 in App. G:
$$
||g_{t}(\mathcal{G})-g_{t}(\mathcal{G}^{\prime})||_{F}\leq C\cdot R_{N,L}=C\cdot\frac{N^{L+1}-1}{N-1}. \tag{17}
$$
The same reasoning applies when $\mathcal{G}^{\prime}$ is obtained by adding a new node $v^{*}$ to $\mathcal{G}$ . Since $\mathcal{G}$ and $\mathcal{G}^{\prime}$ are arbitrary node-level adjacent graphs, the proof is complete.
4.4. Privacy and Complexity Analysis
The complete training process for ASGL is outlined in Algorithm 2 (see App. F.3). In this section, we present a comprehensive privacy analysis and computational complexity analysis for ASGL.
Privacy Accounting. In this section, we adopt the functional perspective of Rényi Differential Privacy (RDP; see App. C) to analyze privacy budgets of ASGL, as summarized below:
**Theorem 2**
*Given the number of training set $N_{tr}$ , number of epochs $n^{epoch}$ , number of discriminators’ iterations $n^{iter}$ , batch size $B_{d}$ , maximum path length $L$ , and maximum path number $N$ , over $T=n^{epoch}n^{iter}$ iterations, Algorithm 2 satisfies node-level $(\alpha,2T\gamma)$ -RDP, where $\gamma=\frac{1}{\alpha-1}\ln\left(\sum_{i=0}^{R_{N,L}}\beta_{i}\left(\exp{\frac{\alpha(\alpha-1)i^{2}}{2\sigma^{2}R_{N,L}^{2}}}\right)\right)$ , $R_{N,L}=\frac{N^{L+1}-1}{N-1}$ and $\beta_{i}=\binom{R_{N,L}}{i}\binom{N_{tr}-R_{N,L}}{B_{d}-i}/{\binom{N_{tr}}{B_{d}}}$ . Please refer to App. I for the proof.*
Complexity Analysis. To analyze the time complexity of training ASGL (App. F.3), we break down the major computations. The outer loop runs for $n^{\text{epoch}}$ epochs, and in each epoch, the discriminators $D^{+}$ and $D^{-}$ are trained for $n^{\text{iter}}$ iterations. Each iteration samples a batch of $B_{d}$ real and fake edges to update $\theta_{D}$ , with DP cost updates incurring complexity $\mathcal{O}(B_{d}k\xi)$ , where $\xi$ is the sampling probability and $k$ is the embedding dimension (08; 17). Thus, each epoch of $D^{+}$ or $D^{-}$ costs $\mathcal{O}(n^{\text{iter}}B_{d}k(1+\xi))$ . For the generators $G^{+}$ and $G^{-}$ , each iteration samples $B_{g}$ fake edges to update $\theta_{G}$ , resulting in per-epoch complexity $\mathcal{O}(n^{\text{iter}}B_{g}k)$ . In total, ASGL’s overall time complexity over $n^{\text{epoch}}$ epochs is: $\mathcal{O}\left(2n^{\text{epoch}}n^{\text{iter}}(B_{d}+B_{g})(1+\xi)k\right)$ . This complexity is linear in the number of iterations and batch size, demonstrating the scalability of ASGL for large-scale graphs.
5. Experiments
In this section, some experiments are designed to answer the following questions: (1) How do key parameters affect the performance of ASGL (See Section 5.2)? (2) How much does the privacy budget affect the performance of ASGL and other private signed graph learning models in edge sign prediction (See Section 5.3)? (3) How much does the privacy budget affect the performance of ASGL and other baselines in node clustering (See Section 5.4)? (4) How resilient is ASGL to defense link stealing attacks (See Section 5.5)?
Table 1. Overview of the datasets
| Bitcoin-Alpha | 3,783 | 14,081 | 12,769 (90.7 $\%$ ) | 1,312 (9.3 $\%$ ) |
| --- | --- | --- | --- | --- |
| Bitcoin-OTC | 5,881 | 21,434 | 18,281 (85.3 $\%$ ) | 3,153 (14.7 $\%$ ) |
| WikiRfA | 11,258 | 185,627 | 144,451 (77.8 $\%$ ) | 41,176 (22.2 $\%$ ) |
| Slashdot | 13,182 | 36,338 | 30,914 (85.1 $\%$ ) | 5,424 (14.9 $\%$ ) |
| Epinions | 131,828 | 841,372 | 717,690 (85.3 $\%$ ) | 123,682 (14.7 $\%$ ) |
5.1. Experimental Settings
Datasets. To comprehensive evaluate our ASGL method, we conduct extensive experiments on five real-world datasets, namely Bitcoin-Alpha Collected in https://snap.stanford.edu/data., Bitcoin-OTC footnotemark: , WikiRfA footnotemark: , Slashdot Collected in https://www.aminer.cn. and Epinions footnotemark: . These datasets are regarded as undirected signed graphs, with their detailed statistics summarized in Table 1 and App. J.1.
Competitive Methods. To the best of our knowledge, this work is the first to address the problem of differentially private signed graph learning while aiming to preserve model utility. Due to the absence of prior studies in this area, we construct baselines by integrating four state-of-the-art signed graph learning methods—SGCN (36), SiGAT (38), LSNE (37), and SDGNN (39) —with the DPSGD mechanism. Since these models primarily leverage structural information, we further include the private graph learning method GAP (40), using Truncated SVD-generated spectral features (36) as input to ensure a fair comparison involving node features.
Evaluation Metrics. For edge sign prediction tasks, we follow the evaluation procedures in (14; 38; 39). Specifically, we first generate embedding vectors for all nodes in the training set using each comparative method. Then, we train a logistic regression classifier using the concatenated embeddings of node pairs as input features. Finally, we use the trained classifier to predict edge signs in the test set for each method. Considering the class imbalance between positive and negative edges (see Table 1), we adopt the area under curve (AUC) as the evaluation metric to ensure a fair comparison.
For node clustering, to fairly evaluate the clustering effect of node embeddings, we compute the average cosine distance for both positive and negative node pairs: $\text{CD}^{+}=\sum_{(v_{i},v_{j})∈ E^{+}}Cos(\mathbf{Z}_{i},\mathbf{Z}_{j})/|E^{+}|$ and $\text{CD}^{-}=\sum_{(v_{n},v_{m})∈ E^{-}}Cos(\mathbf{Z}_{n},\mathbf{Z}_{m})/|E^{-}|$ , where $\mathbf{Z}_{i}$ is the node embedding generated by each comparative method, and $Cos(·)$ represents the cosine distance between node embeddings. Then we propose the symmetric separation index (SSI) to measure the clustering degree between the embeddings of positive and negative node pairs in the test set, denoted as $\text{SSI}=1/(|\text{CD}^{+}-1|+|\text{CD}^{-}+1|)$ . A higher SSI indicates better structural proximity, with positive node pairs more tightly clustered and negative pairs more clearly separated in the unified embedding space.
Parameter Settings. For both edge sign prediction and node clustering tasks, we set the dimensionality of all node embeddings, $\mathbf{d}_{v}$ and $\mathbf{g}_{v}$ , to 128, following standard practice in prior work (41; 14). ASGL adopts DPSGD-based optimization, where the total number of training epochs is determined by the moments accountant (MA) (04), which offers tighter privacy tracking across multiple iterations. We set the iteration number $n^{iter}$ to 10 for Bitcoin-Alpha and Bitcoin-OTC, 15 for WikiRfA and Slashdot, and 20 for Epinions. Since all comparative methods are trained using DPSGD, their number of training epochs depends on the privacy budget. As discussed in Section 5.2, the maximum path number $N$ and path length $L$ are varied to analyze their impact on ASGL’s utility. For privacy parameters, we follow (02; 51; 08) by fixing $\delta=10^{-5}$ and $C=1$ , and vary the privacy budget $\epsilon∈\{1,2,...,6\}$ to evaluate utility under different privacy levels. To ensure fair comparison, we modify the official GitHub implementations of all baselines and adopt the best hyperparameter settings reported in their original papers. To minimize random errors, each experiment is repeated five times.
5.2. Impact of Key Parameters
In this section, we perform experiments on two datasets by varying the maximum number $N$ and the maximum length $L$ of paths in the BFS-trees, providing a rationale for parameter selection.
5.2.1. The effect of the parameter $N$
As discussed in Section 4.3, the greater the number of neighbors a rooted node has, the more paths can be obtained through random walks. Therefore, the maximum number of paths $N$ also depends on the node degrees. As shown in Fig. 8 (see App. J.2), for the Bitcoin-Alpha and Slashdot datasets, most nodes in signed graphs have degrees below 3. In addition, we investigate the impact of $N$ by varying its value within $\{2,3,4,5,6\}$ . As shown by the average AUC results in Table 2, the proposed ASGL method achieves optimal edge prediction performance at $N=3$ for Bitcoin-Alpha and $N=4$ for Slashdot. Considering both gradient sensitivity and computational efficiency, we adopt $N=3$ for subsequent experiments.
5.2.2. The effect of the parameter $L$
In this experiment, we evaluate the impact of the path length $L$ on the utility of ASGL by varying its value. As shown in Table 3, ASGL achieves the best performance on both datasets when $L=4$ . This result is closely aligned with the structural characteristics of the signed graphs: As summarized in Fig. 9 (see App. J.2), most node pairs in these datasets exhibit maximum path lengths of 3 or 4. Therefore, in subsequent experiments, we set $L=4$ , as it adequately covers the receptive field of most nodes.
Table 2. Summary of average AUC with different maximum path counts $N$ under $\epsilon=3$ and $L=3$ . (BOLD: Best)
| Bitcoin-Alpha Slashdot | 0.8025 0.7723 | 0.8562 0.8823 | 0.8557 0.8888 | 0.8498 0.8871 | 0.8553 0.8881 |
| --- | --- | --- | --- | --- | --- |
Table 3. Summary of average AUC with different path lengths $L$ under $\epsilon=3$ and $N=3$ . (BOLD: Best)
| Bitcoin-Alpha Slashdot | 0.7409 0.7629 | 0.8443 0.8290 | 0.8587 0.8833 | 0.8545 0.8809 | 0.8516 0.8807 |
| --- | --- | --- | --- | --- | --- |
<details>
<summary>x5.png Details</summary>

### Visual Description
## Heatmap: Privacy Budget Impact on Model Performance
### Overview
The heatmap illustrates the impact of varying privacy budgets on the performance of different machine learning models. The models compared are SDGNN, SIGAT, SGCN, GAP, LSN, and ASGL (Proposed). The performance is measured using AUC (Area Under the Curve) on a binary classification task.
### Components/Axes
- **Rows**: Represent different privacy budgets (c = 1, 2, 3, 4, 5, 6).
- **Columns**: Represent different models (SDGNN, SIGAT, SGCN, GAP, LSN, ASGL).
- **Color Scale**: A gradient from green (lower AUC) to red (higher AUC) indicates the performance of each model at each privacy budget.
### Detailed Analysis or ### Content Details
- **SDGNN**: Shows a consistent increase in AUC as the privacy budget increases, indicating improved performance.
- **SIGAT**: Also shows an increase in AUC with higher privacy budgets, but the improvement is less pronounced compared to SDGNN.
- **SGCN**: Displays a moderate increase in AUC with privacy budgets, but the performance is generally lower than SDGNN and SIGAT.
- **GAP**: Shows a slight increase in AUC with privacy budgets, but the performance is not significantly better than the other models.
- **LSN**: Demonstrates a slight increase in AUC with privacy budgets, but the performance is not as high as SDGNN or SIGAT.
- **ASGL (Proposed)**: Shows the highest AUC across all privacy budgets, indicating the best performance among the models tested.
### Key Observations
- **Performance Improvement**: All models show an improvement in AUC as the privacy budget increases.
- **ASGL's Superiority**: ASGL consistently outperforms the other models across all privacy budgets.
- **Model Variability**: There is significant variability in performance among the models, with ASGL showing the most consistent improvement.
### Interpretation
The heatmap suggests that increasing the privacy budget generally improves the performance of the models. ASGL, in particular, demonstrates the most significant improvement in performance as the privacy budget increases. This could be due to ASGL's ability to balance privacy and performance more effectively. The other models, while also improving, do not match ASGL's performance at the same privacy budget levels. This finding is crucial for applications where privacy is a concern, as it indicates that ASGL might be a better choice for such scenarios.
</details>
Figure 5. AUC vs. Privacy cost ( $\epsilon$ ) of private signed graph learning methods in edge sign prediction.
<details>
<summary>x6.png Details</summary>

### Visual Description
## Heatmap Analysis
### Overview
The image displays a heatmap with five different categories: Bitcoin_Alpha, Bitcoin_OCT, WildRFA, Slashdot, and Epinions. Each category is represented by a different color scheme and bar patterns, indicating varying levels of data points or values.
### Components/Axes
- **Categories**: Bitcoin_Alpha, Bitcoin_OCT, WildRFA, Slashdot, Epinions
- **Color Schemes**: Each category has a unique color palette, with Bitcoin_Alpha in blue, Bitcoin_OCT in green, WildRFA in red, Slashdot in yellow, and Epinions in purple.
- **Bar Patterns**: The bars within each category have different patterns, such as solid, dashed, or striped lines, which may represent different data series or conditions.
### Detailed Analysis or ### Content Details
- **Bitcoin_Alpha**: The bars are predominantly blue with some green and red patterns. The values range from 0.4 to 0.7.
- **Bitcoin_OCT**: The bars are green with some blue and red patterns. The values range from 0.3 to 0.6.
- **WildRFA**: The bars are red with some blue and green patterns. The values range from 0.5 to 0.8.
- **Slashdot**: The bars are yellow with some blue and red patterns. The values range from 0.4 to 0.7.
- **Epinions**: The bars are purple with some blue and red patterns. The values range from 0.3 to 0.6.
### Key Observations
- **Trends**: There is a general upward trend in values across all categories, with WildRFA showing the highest values.
- **Outliers**: No single category stands out as significantly higher or lower than the others.
- **Anomalies**: There are no clear anomalies in the data distribution.
### Interpretation
The heatmap suggests that there is a positive correlation between the categories, with WildRFA having the highest values. This could indicate that WildRFA has the most significant data points or values among the categories. The color schemes and bar patterns help in distinguishing between different data series or conditions, making it easier to interpret the data.
</details>
Figure 6. Symmetric separation index (SSI) vs. Privacy cost ( $\epsilon$ ) of private signed graph learning methods in node clustering.
5.3. Impact of Privacy Budget on Edge Sign Prediction
To evaluate the effectiveness of different private graph learning methods on edge sign prediction, we compare their AUC scores under privacy budgets $\epsilon$ ranging from 1 to 6, as shown in Fig. 5 and Table 6 (see App. J.3). The proposed ASGL consistently outperforms all baselines across all privacy levels and datasets, owing to its ability to generate node embeddings that preserve connectivity distributions while satisfying DP guarantees. Although SDGNN achieves sub-optimal performance, it exhibits a noticeable gap from ASGL under limited privacy budgets ( $\epsilon<4$ ). SiGAT, SGCN, and LSNE employ the moments accountant (MA) to mitigate excessive privacy budget consumption, yet still suffer from poor convergence and degraded utility under limited privacy budgets. GAP adopts aggregation perturbation to ensure node-level DP, but its performance is limited due to noisy neighborhood information, hindering its ability to capture structural information for edge prediction tasks.
5.4. Impact of Privacy Budget on Node Cluster
To further examine the capability of ASGL in preserving signed node proximity, we conduct a fair comparison across multiple private graph learning methods using the SSI metric. As shown in Fig. 6 and Table 7 (see App. J.4), ASGL consistently outperforms all baselines across different datasets and privacy budgets, demonstrating that ASGL is capable of generating node embeddings that effectively preserve signed node proximity. Notably, GAP achieves the second-best clustering performance on most datasets (excluding Slashdot), benefiting from its ability to leverage node features for clustering nodes. Nevertheless, to guarantee node-level DP, GAP needs to repeatedly query sensitive graph information in every training iteration, resulting in significantly higher privacy costs.
5.5. Resilience Against Link Stealing Attack
To assess the effectiveness of ASGL in preserving the privacy of edge information, we perform link stealing attacks (LSA) across all datasets and compare the resilience of all methods to such attacks in edge sign prediction tasks. The LSA setup is detailed in App. J.5. Attack performance is measured by the AUC score, averaged over five independent runs. Table 4 summarizes the effectiveness of LSA on various trained target models and datasets. It can be observed that as the privacy budget $\epsilon$ increases, the average AUC of LSA consistently improves, indicating the reduced privacy protection of target models and an increased success rate of the attack. Overall, the average AUC of the attack is close to 0.50 in most cases, indicating the unsuccessful edge inference and the robustness of DP against such an attack. When $\epsilon=3$ , ASGL demonstrates stronger resistance to LSA across most datasets, with AUC values consistently below 0.57. This suggests that ASGL offers defense performance comparable to other differentially private graph learning methods.
Table 4. The average AUC of LSA on different comparisons and datasets. (BOLD: Best resilience against LSA)
| 1 | Bitcoin-Alpha | 0.5072 | 0.7091 | 0.5079 | 0.5145 | 0.5404 | 0.5053 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Bitcoin-OTC | 0.5081 | 0.7118 | 0.5119 | 0.5409 | 0.5660 | 0.5466 | |
| Slashdot | 0.5538 | 0.8232 | 0.5551 | 0.5609 | 0.5460 | 0.5325 | |
| WikiRfA | 0.5148 | 0.5424 | 0.5427 | 0.5293 | 0.5470 | 0.5302 | |
| Epinions | 0.7877 | 0.6329 | 0.5114 | 0.5129 | 0.5188 | 0.5092 | |
| 3 | Bitcoin-Alpha | 0.5547 | 0.7514 | 0.5533 | 0.5542 | 0.5598 | 0.5430 |
| Bitcoin-OTC | 0.5655 | 0.7273 | 0.5684 | 0.5734 | 0.5765 | 0.5612 | |
| Slashdot | 0.5742 | 0.8394 | 0.6267 | 0.5730 | 0.6464 | 0.5634 | |
| WikiRfA | 0.5276 | 0.5466 | 0.5542 | 0.5696 | 0.5772 | 0.5624 | |
| Epinions | 0.7981 | 0.6456 | 0.5588 | 0.5629 | 0.5665 | 0.5542 | |
6. Related Work
Signed graph learning. In recent years, deep learning approaches have been increasingly adopted for signed graph learning. For example, SiNE (47) extracts signed structural information based on balance theory and designs an objective function to learn signed node proximity. Furthermore, the GNN model (36) and its variants (38; 39) are used to learn signed relationships between nodes in multi-hop neighborhoods. However, these GNNs-based methods depend on the message-passing mechanism, which is sensitive to noisy interactions between nodes (49). To address this issue, Lee et al. (14) extends the adversarial framework to signed graphs by generating both positive and negative node embeddings. Still, these signed graph learning models are vulnerable to user-linkage attacks.
Private graph learning. Recent works have increasingly focused on developing DP methods to address privacy leakage in GNNs. For instance, Daigavane et al. (33) propose a DP-GNN method based on gradient perturbation. However, this method fails to balance utility and privacy due to excessive noise. Furthermore, GAP (40) and DPRA (50) are proposed to ensure the privacy of sensitive node embeddings by perturbing node aggregations. Despite their success in node classification, the private node information is repeatedly queried in the training process of GAP, which consumes more privacy budgets to implement DPSGD. DPRA is not well-suited for signed graph embedding learning, as its edge perturbation strategy introduces cascading errors under balance theory.
7. Conclusion
In this paper, we propose ASGL that achieves strong model utility while providing node-level DP guarantees. To address the cascading error and gradient polarity reversals from edge sign flips, ASGL separately processes positive and negative subgraphs within a shared embedding space using a DPSGD-based adversarial mechanism to learn high-quality node embeddings. To further reduce gradient sensitivity, we introduce a constrained BFS-tree strategy that limits node receptive fields and enables gradient decoupling. This effectively reduces the required noise scale and enhances model performance. Extensive experiments demonstrate that ASGL achieves a favorable privacy-utility trade-off. Our future work is to extend the ASGL framework by considering edge directions and weights.
Acknowledgements. This work was supported by the National Natural Science Foundation of China (Grant No: 62372122 and 92270123), and the Research Grants Council (Grant No: 15208923, 25207224, and 15207725), Hong Kong SAR, China.
Appendix A Adversarial Learning on Graph
The adversarial learning model for graph embedding (03) is illustrated as follows. Let $\mathcal{N}(v_{r})$ be the node set directly connected to $v_{r}$ . We denote the underlying true connectivity distribution of node $v_{r}$ as the conditional probability $p(v|v_{r})$ , which captures the preference of $v_{r}$ to connect with other nodes $v∈ V$ . In other words, the neighbor set $\mathcal{N}(v_{r})$ can be interpreted as a set of observed nodes drawn from $p(v|v_{r})$ . The adversarial learning for the graph $\mathcal{G}$ is conducted by the following two modules:
Generator $G$ : Through optimizing the generator parameters $\theta_{G}$ , this module aims to approximate the underlying true connectivity distribution and generate (or select) the most likely nodes $v∈ V$ that are relevant to $v_{r}$ . Specifically, the fake The term “Fake” indicates that although a node $v$ selected by the generator is relevant to $v_{r}$ , there is no actual edge between them. (i.e., estimated) connectivity distribution of node $v_{r}$ is calculated as:
$$
p^{\prime}(v|v_{r})=G\left(v|v_{r};\theta_{G}\right)=\frac{\exp\left(\mathbf{g}_{v}^{\top}\mathbf{g}_{v_{r}}\right)}{\sum_{v\neq v_{r}}\exp\left(\mathbf{g}_{v}^{\top}\mathbf{g}_{v_{r}}\right)}, \tag{18}
$$
where $\mathbf{g}_{v},\mathbf{g}_{v_{r}}∈\mathbb{R}^{k}$ are the $k$ -dimensional vectors of nodes $v$ and $v_{r}$ , respectively, and $\theta_{G}$ is the union of all $\mathbf{g}_{v}$ ’s. To update $\theta_{G}$ in each iteration, a set of node pairs $(v,v_{r})$ , not necessarily directly connected, is sampled according to $p^{\prime}(v|v_{r})$ . The key purpose of generator $G$ is to deceive the discriminator $D$ , and thus its loss function $L_{G}$ is determined as follows:
$$
\displaystyle L_{G}=\min\sum_{r=1}^{|V|}\left.\mathbb{E}_{v\sim G\left(\cdot\mid v_{r};\theta_{G}\right)}\left[\log\left(1-D\left(v_{r},v\mid\theta_{D}\right)\right)\right]\right., \tag{19}
$$
where the discriminant function $D(·)$ estimates the probability that a given node pairs $(v,v_{r})$ are considered real, i.e., directly connected.
Discriminator $D$ : This module tries to distinguish between real node pairs and fake node pairs synthesized by the generator $G$ . Accordingly, the discriminator estimates the probability that an edge exists between $v_{r}$ and $v$ , denoted as:
$$
D(v_{r},v|\theta_{D})=\sigma(\mathbf{d}_{v}^{\top}\mathbf{d}_{v_{r}})=\frac{1}{1+\exp({-\mathbf{d}_{v}^{\top}\mathbf{d}_{v_{r}})}}, \tag{20}
$$
where $\mathbf{d}_{v},\mathbf{d}_{v_{r}}∈\mathbb{R}^{k}$ are the $k$ -dimensional vectors corresponding to the $v$ -th and $v_{r}$ -th rows of discriminator parameters $\theta_{D}$ , respectively. $\sigma(·)$ represents the sigmoid function of the inner product of these two vectors. Given the sets of real and fake node pairs, the loss function of $D$ can be derived as:
$$
\displaystyle L_{D}= \displaystyle\max\sum_{r=1}^{|V|}\left(\mathbb{E}_{v\sim p\left(\cdot\mid v_{r}\right)}\left[\log D\left(v,v_{r}\mid\theta_{D}\right)\right]\right. \displaystyle\left.+\mathbb{E}_{v\sim G\left(\cdot\mid v_{r};\theta_{G}\right)}\left[\log\left(1-D\left(v_{r},v\mid\theta_{D}\right)\right)\right]\right). \tag{21}
$$
In summary, the generator $G$ and discriminator $D$ operate as two adversarial components: the generator $G$ aims to fit the true connectivity distribution $p(v|v_{r})$ , generating candidate nodes $v$ that resemble the real neighbors of $v_{r}$ to deceive the discriminator $D$ . In contrast, the discriminator $D$ seeks to distinguish whether a given node is a true neighbor of $v_{r}$ or one generated by $G$ . Formally, $D$ and $G$ are engaged in a two-player minimax game with the following loss function:
$$
\displaystyle\min_{\theta_{G}} \displaystyle\max_{\theta_{D}}L(G,D)=\sum_{r=1}^{|V|}\left(\mathbb{E}_{v\sim p\left(\cdot\mid v_{r}\right)}\left[\log D\left(v,v_{r}\mid\theta_{D}\right)\right]\right. \displaystyle\left.+\mathbb{E}_{v\sim G\left(\cdot\mid v_{r};\theta_{G}\right)}\left[\log\left(1-D\left(v_{r},v\mid\theta_{D}\right)\right)\right]\right). \tag{22}
$$
Based on Eq. (22), the parameters $\theta_{D}$ and $\theta_{G}$ are updated by alternately maximizing and minimizing the loss function $L(G,D)$ . Competition between $G$ and $D$ results in mutual improvement until $G$ becomes indistinguishable from the true connectivity distribution.
Appendix B Notation Introduction
The frequently used notations are summarized in Table 5.
Table 5. Notation Summary
| $\mathcal{G},\mathcal{G^{+}},\mathcal{G^{-}}$ $V,E^{+},E^{-}$ $\mathcal{N}(v_{r})$ | Signed graph, positive subgraph, negative subgraph Node set, negative and positive edge sets Neighbor node set of node $v_{r}$ |
| --- | --- |
| $\theta_{D}$ | Shared parameters of discriminators $D^{+}$ and $D^{-}$ |
| $\theta_{G}$ | Shared parameters of generators $G^{+}$ and $G^{-}$ |
| $\mathbf{d}_{v_{r}}$ | Node embedding for node $v_{r}$ of Discriminators |
| $\mathbf{g}_{v_{r}}$ | Node embedding for node $v_{r}$ of Generators |
| $N,L$ | Maximum number and length of generated path |
| $\epsilon,\delta$ | Privacy parameters |
| $\mathcal{N}(0,\sigma^{2})$ | Gaussian distribution with standard deviation $\sigma^{2}$ |
| $P_{rt}$ | A path from rooted node $v_{r}$ to target node $v_{t}$ |
| $T^{+}_{v_{r}},T^{-}_{v_{r}}$ | Positive and negative BFS-trees rooted from $v_{r}$ |
| $p_{\text{true}}^{+}(·|v_{r})$ | Positive connectivity distributions of $(v_{r},v)∈ E^{+}$ |
| $p_{\text{true}}^{-}(·|v_{r})$ | Negative connectivity distributions of $(v_{r},v)∈ E^{-}$ |
| $p^{+}_{T^{+}_{v_{r}}}(v|v_{r})$ | Positive relevance probability between $v_{r}$ and $v$ |
| $p^{-}_{T^{-}_{v_{r}}}(v|v_{r})$ | Negative relevance probability between $v_{r}$ and $v$ |
Appendix C Rényi Differential Privacy
Since standard DP can be overly strict for deep learning, we follow prior work (30; 31) and adopt an alternative definition—Rényi Differential Privacy (RDP) (07). RDP offers tighter and more efficient composition bounds, enabling more accurate estimation of cumulative privacy cost over multiple queries on graphs.
**Definition 0 (Rényi Differential Privacy(07))**
*The Rényi divergence quantifies the similarity between output distributions of a mechanism and is defined as:
$$
D_{\alpha}(P\|Q)=\frac{1}{\alpha-1}\log\left(\sum_{x}P(x)^{\alpha}Q(x)^{1-\alpha}\right), \tag{23}
$$
where $P(x)$ and $Q(x)$ are probability distributions over the output space. $\alpha>1$ denotes the order of the divergence, and its choice allows for different levels of sensitivity to the output distribution. Accordingly, an algorithm $\mathcal{M}$ satisfies $(\alpha,\epsilon)$ -RDP if, for any two adjacent graphs $\mathcal{G}$ and $\mathcal{G}^{\prime}$ , the following condition holds $D_{\alpha}\left(\mathcal{M}(\mathcal{G})\|\mathcal{M}\left(\mathcal{G}^{\prime}\right)\right)≤\epsilon$ .*
Since RDP is an extension of DP, it can be converted into ( $\epsilon$ , $\delta$ )-DP based on Proposition 3 in (07), as outlined below.
**Lemma 0 (Conversion from RDP to DP(07))**
*If a mechanism $\mathcal{M}$ satisfies $(\alpha,\epsilon)$ -RDP, it also satisfies $(\epsilon+\log(1/\delta)/(\alpha-1),\delta)$ -DP for any $\delta∈(0,1)$ .*
Appendix D Gaussian Mechanism
Let $f$ be a function that maps a graph $\mathcal{G}$ to $k$ -dimensional node vectors $\mathbf{Z}∈\mathbb{R}^{|V|× k}$ . To ensure the RDP guarantees of $f$ , it is common to inject Gaussian noise into its output (07). The noise scale depends on the sensitivity of $f$ , defined as $\Delta_{f}=\max_{\mathcal{G},\mathcal{G}^{\prime}}\left\|f(\mathcal{G})-f\left(\mathcal{G}^{\prime}\right)\right\|_{2}$ . Specifically, the privatized mechanism is defined as $\mathcal{M}(\mathcal{G})=f(\mathcal{G})+\mathcal{N}(0,\sigma^{2}\mathbf{I})$ , where $\mathcal{N}(0,\sigma^{2}\mathbf{I})$ is the Gaussian distribution with zero mean and standard deviation $\sigma^{2}$ . This results in an $(\alpha,\epsilon)$ -RDP mechanism $\mathcal{M}$ for all $\alpha>1$ with $\epsilon=\alpha\Delta_{f}^{2}/2\sigma^{2}$ .
Input: Graph $\mathcal{G}=\{\mathcal{G}^{+},\mathcal{G}^{-}\}$ ; The training set of nodes $V_{tr}$ ; The maximum path length $L$ ; The maximum path number $N$ .
Output: The training set of subgraphs $S_{tr}$ .
1 for $v_{r}∈ V_{tr}$ do
2 Construct BFS-trees $T^{+}_{v_{r}}$ (or $T^{-}_{v_{r}}$ ) rooted from the node $v_{r}$ on $\mathcal{G}^{+}$ (or $\mathcal{G}^{-}$ );
3 for $n=0;n<N$ do
4 Based on the positive and negative relevance probability in Eqs. (6) and (7), conduct the random walk at $T^{+}_{v_{r}}$ (or $T^{-}_{v_{r}}$ ) to form a path $P_{rt}^{(n)+}$ (or $P_{rt}^{(n)-}$ ) of length $L$ ;
5 Add all nodes $v$ (excluding those in $\mathcal{N}(v_{r})$ ) along the path $P_{rt}^{(n)+}$ (or $P_{rt}^{(n)-}$ ) as a fake edge $(v_{r},v)$ to the corresponding subgraph set $S_{tr}^{+}$ (or $S_{tr}^{-}$ );
6 Drop $P_{rt}^{(n)+}$ (or $P_{rt}^{(n)-}$ ) from $T^{+}_{v_{r}}$ (or $T^{-}_{v_{r}}$ ).
7 end for
8
9 end for
Return $S_{tr}=\{S_{tr}^{+},S_{tr}^{-}\}$ ;
Algorithm 1 SAMPLE-SUBGRAPHS by Constrained BFS-trees
Appendix E BFS-tree Strategy
Fig. 7 provides an illustrative example of the BFS-tree strategy: Let $v_{r_{0}}$ be the rooted node. We first compute the transition probabilities between $v_{r_{0}}$ and its neighbors $\mathcal{N}({v_{r_{0}}})$ . The next node $v_{r_{1}}$ is then sampled as the first step of the walk, in proportion to these transition probabilities. Similarly, the next node $v_{r_{2}}$ is selected based on the transition probabilities between $v_{r_{1}}$ and its neighbors $\mathcal{N}({v_{r_{1}}})$ . The random walk continues until it reaches the terminal node $v_{r_{n}}$ , and unconnected node pairs $(v_{r_{0}},v_{r_{k}})^{+}$ for $k=2,3,...,n$ are regarded as fake positive edges.
<details>
<summary>x7.png Details</summary>
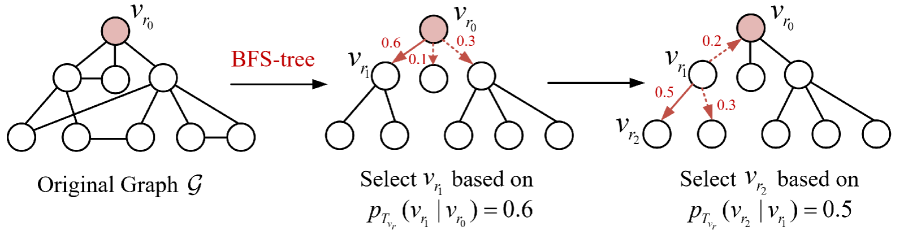
### Visual Description
## BFS-tree
### Overview
The image depicts a process involving a graph and a BFS-tree. The original graph is shown on the left, with nodes connected by edges. The BFS-tree is constructed on the right, with nodes selected based on certain probabilities.
### Components/Axes
- **Original Graph \( G \)**: A graph with nodes and edges.
- **BFS-tree**: A tree constructed from the original graph, with nodes selected based on probabilities.
- **Nodes**: Represented by circles, with some highlighted in red.
- **Edges**: Lines connecting the nodes.
- **Probability Labels**: Indicate the probability of selecting a node based on its distance from the root.
- **Legend**: Shows the color coding for the nodes in the BFS-tree.
### Detailed Analysis or ### Content Details
- **Original Graph \( G \)**: The graph has 10 nodes, with some nodes connected by edges. The nodes are labeled from 1 to 10.
- **BFS-tree**: The BFS-tree is constructed by selecting nodes based on their distance from the root. The root node is highlighted in red.
- **Probability Labels**: The probability of selecting a node is indicated by the numbers next to the edges. For example, the edge from node 1 to node 2 has a probability of 0.6.
- **Legend**: The legend shows that the nodes in the BFS-tree are colored in red, indicating they have been selected based on the probabilities.
### Key Observations
- **Node Selection**: The nodes are selected based on their distance from the root, with higher probabilities for nodes closer to the root.
- **Probability Distribution**: The probabilities are distributed among the nodes, with some nodes having higher probabilities than others.
- **Tree Structure**: The BFS-tree is a tree structure, with nodes connected in a hierarchical manner.
### Interpretation
The image demonstrates the process of constructing a BFS-tree from an original graph. The BFS-tree is constructed by selecting nodes based on their distance from the root, with higher probabilities for nodes closer to the root. The probability labels indicate the likelihood of selecting a node based on its distance from the root. The legend shows that the nodes in the BFS-tree are colored in red, indicating they have been selected based on the probabilities. The image provides a visual representation of the process and the resulting BFS-tree.
</details>
Figure 7. Random-walk-based edge generation for generator $G^{+}$ or $G^{-}$ . Red digits denote the transition probabilities (Eqs. (6) and (7)), and red arrows indicate the walk directions.
Appendix F Details of Algorithm
F.1. The Parameter Update of Generators
Given fake positive/negative edges $(v_{r},v_{t})$ from ${G}^{+}/{G}^{-}$ , the gradient of joint loss function (Eq. (10)) with respect to $\theta_{G}$ is derived via the policy gradient (03):
$$
\nabla L_{G}=\left\{\begin{array}[]{l}\sum_{r=1}^{|V^{+}|}[\nabla_{\theta_{G}}\log G^{+}\left(v_{t}|v_{r};\theta_{G}\right)\log\left(1-D^{+}\left(v_{t},v_{r}\right)\right)],\\
\text{if }\left(v_{r},v_{t}\right)\text{ is a fake positive edge};\\
\sum_{r=1}^{|V^{-}|}\nabla_{\theta_{G}}\log G^{-}\left(v_{t}|v_{r};\theta_{G}\right)\log\left(1-D^{-}\left(v_{t},v_{r}\right)\right),\\
\text{if }\left(v_{r},v_{t}\right)\text{ is a fake negative edge}.\end{array}\right. \tag{24}
$$
F.2. SAMPLE-SUBGRAPHS by Constrained BFS-trees
As shown in Algorithm 1, during the random walk on the BFS tree $T^{+}_{v_{r}}$ or $T^{-}_{v_{r}}$ rooted at $v_{r}∈ V_{tr}$ , we generate multiple unique paths while constraining their number and length by parameters $N$ and $L$ , respectively. This process yields a training subgraph set $S_{tr}$ composed of constrained paths.
Input: Graph $\mathcal{G}$ ; Training set of nodes $V_{tr}$ ; Maximum path length $L$ ; Maximum path number $N$ ; Batch-size $B_{d}$ and $B_{g}$ of sampled edges in discrininators and generators; Number of epochs $n^{epoch}$ ; Number of iterations for generators and discriminators per epoch $n^{iter}$ ; Privacy parameters $\delta$ , $\epsilon$ , $\sigma$ .
Output: Privacy-preserving node embedding $\mathbf{g}_{v}∈\theta_{G}$ for downstream tasks.
1 According to edge signs, divide $\mathcal{G}$ into $\mathcal{G}^{+}$ and $\mathcal{G}^{-}$ ;
2 Generate the training subgraph set $S_{tr}=\{S_{tr}^{+},S_{tr}^{-}\}$ based on $\text{SAMPLE-SUBGRAPHS}(\mathcal{G},V_{tr},N,L)$ in Algorithm 1;
3 for $v_{r}∈ V_{tr}$ do
4 Sample all real positive edges $(v_{r},v_{t})^{+}$ from $\mathcal{G}^{+}$ ;
5 Sample all fake positive edges $(v_{r},v_{t}^{\prime})^{+}$ from $S_{tr}^{+}$ ;
6 Sample all real negative edges $(v_{r},v_{t})^{-}$ from $\mathcal{G}^{-}$ ;
7 Sample all fake negative edges $(v_{r},v_{t}^{\prime})^{-}$ from $S_{tr}^{-}$ ;
8 $E^{+}_{D}.add((v_{r},v_{t})^{+},(v_{r},v_{t}^{\prime})^{+})$ , $E^{+}_{G}.add((v_{r},v_{t}^{\prime})^{+})$ ,
9 $E^{-}_{D}.add((v_{r},v_{t})^{-},(v_{r},v_{t}^{\prime})^{-})$ , $E^{-}_{G}.add((v_{r},v_{t}^{\prime})^{-})$ ;
10
11 end for
12 for $epoch=0;epoch<n^{epoch}$ do
13 Train the discriminator $D^{+}$ :
14 for $iter=0;iter<n^{iter}$ do
15 Sample $B_{d}$ real and fake positive edges from $E^{+}_{D}$ ;
16 Update $\theta_{D}$ via Eqs. (8) and (11), and achieve gradient perturbation via Eq. (13);
17 Calculate privacy spent $\hat{\delta}$ given the target $\epsilon$ ;
18 Stop optimization if $\hat{\delta}≥\delta$ .
19 end for
20 Train the generator $G^{+}$ :
21 for $iter=0;iter<n^{iter}$ do
22 Subsample $B_{g}$ fake positive edges from $E^{+}_{G}$ ;
23 Update $\theta_{G}$ via Eqs. (4) and (24).
24 end for
25 Train the discriminator $D^{-}$ :
26 for $iter=0;iter<n^{iter}$ do
27 Subsample $B_{d}$ real and fake negative edges from $E^{-}_{D}$ ;
28 Update $\theta_{D}$ via Eqs. (9) and (11), and achieve gradient perturbation via Eq. (13);
29 Calculate privacy spent $\hat{\delta}$ given the target $\epsilon$ ;
30 Stop optimization if $\hat{\delta}≥\delta$ .
31 end for
32 Train the generator $G^{-}$ :
33 for $iter=0;iter<n^{iter}$ do
34 Subsample $B_{g}$ fake negative edges from $E^{-}_{G}$ ;
35 Update $\theta_{G}$ via Eqs. (5) and (24).
36 end for
37
38 end for
39 Return privacy-preserving node embedding $\mathbf{g}_{v}∈\theta_{G}$ ;
Algorithm 2 ASGL Algorithm
F.3. The training of ASGL
The training process of ASGL is outlined in Algorithm 2 and consists of the following main steps:
(1) Signed graph decomposition and subgraph sampling: Given an input signed graph $\mathcal{G}$ , we first divide it into a positive subgraph $\mathcal{G}^{+}$ and a negative subgraph $\mathcal{G}^{-}$ based on edge signs. Then, for each node $v_{r}∈ V_{tr}$ , constrained BFS trees are constructed from $\mathcal{G}^{+}$ and $\mathcal{G}^{-}$ , respectively, to generate a set of training subgraphs $S_{tr}=\{S_{tr}^{+},S_{tr}^{-}\}$ by limiting the maximum number of paths $N$ and the maximum path length $L$ . These subgraphs are used to sample fake edges for adversarial training.
(2) Edge sampling for adversarial learning: For each node $v_{r}$ , we sample real edges from $\mathcal{G}^{+}$ and $\mathcal{G}^{-}$ , and fake edges from $S_{tr}^{+}$ and $S_{tr}^{-}$ . These edges are organized into four sets:
- $E_{D}^{+}$ : real and fake positive edges for training $D^{+}$ .
- $E_{G}^{+}$ : fake positive edges for training $G^{+}$ .
- $E_{D}^{-}$ : real and fake negative edges for training $D^{-}$ .
- $E_{G}^{-}$ : fake negative edges for training $G^{-}$ .
(3) Adversarial training with DPSGD: The training is performed over $n^{epoch}$ epochs. In each epoch:
- Discriminator training: For each discriminator $D^{+}$ and $D^{-}$ , we perform $n^{iter}$ iterations. In each iteration, a batch of $B_{d}$ real and fake edges is sampled. The discriminator parameters $\theta_{D}$ are updated using gradient descent with noise addition according to the DPSGD mechanism (Eq. (13)), ensuring node-level DP. The privacy budget $\hat{\delta}$ is tracked, and training stops early if $\hat{\delta}>\delta$ .
- Generator training: Each generator $G^{+}$ and $G^{-}$ is trained for $n^{iter}$ iterations. In each iteration, a batch of $B_{g}$ fake edges is sampled, and the generator parameters $\theta_{G}$ are updated by maximizing the generator objective (Eq. (24)).
(4) Embedding output for downstream tasks: After all epochs, the generator parameters $\theta_{G}$ encode the privacy-preserving node embeddings $\mathbf{g}_{v}∈\theta_{G}$ , which are used for downstream tasks such as edge sign prediction and node clustering.
Appendix G Details of Lemma
The following lemmas are used for proving Theorem 1:
**Lemma 0 (Receptive field of a node)**
*As shown in Fig. 4 (b), we define the receptive field of a node as the region (i.e., the set of nodes) over which it can exert influence. Accordingly, for a subgraph constructed from paths sampled on constrained BFS-trees (Fig. 4 (b)), the maximum receptive field size of $v_{r}$ is given by $R_{N,L}=\sum_{l=0}^{L}N^{l}=\frac{N^{L+1}-1}{N-1}≤ B$ .*
**Lemma 0**
*Let $S_{tr}$ denote the training set of subgraphs constructed from constrained BFS-tree paths, and $S(v)⊂ S_{tr}$ denote the subgraph subset that contains the node $v$ . Since $R_{N,L}$ represents the upper bound on the number of occurrences of any node in $S_{tr}$ , it follows that $|S(v)|≤ R_{N,L}$ . The proof of Lemma 2 is illustrated in App. H.*
Appendix H Proof of Lemma 2
Proof. We proceed by induction (13) on the path length $L$ of the BFS-tree.
Base case: When $L=0$ , each sampled subgraph $S(v)$ contains exactly the training node $v∈ V_{tr}$ itself. Thus, every node appears in one subgraph, trivially satisfying the bound $|S(v)|=R_{N,0}=1$ .
Inductive hypothesis: Assume that for some fixed $L≥ 0$ , any $v∈ V_{tr}$ appears in at most $R_{N,L}$ subgraphs constructed from constrained BFS-tree paths. Let $S^{L}(v)$ denote a subgraph set with $L$ path length. Thus, the hypothesis is $|S^{L}(v)|≤ R_{N,L}$ for any $v$ .
Inductive step: We further show that the above hypothesis also holds for $L+1$ path length: Let $T_{u^{\prime}}$ represent the $L$ -length BFS-tree rooted at $u^{\prime}$ . If $T_{u^{\prime}}∈ S^{L+1}(v)$ , there must exit node $u$ such that $u∈ T_{u^{\prime}}$ and $T_{u}∈ S^{L}(v)$ . According to the setting of Algorithm 1, the number of such nodes $u$ is at most $N$ . By the hypothesis, there are at most $R_{N,L}-1$ such $u^{\prime}≠ v$ such that $T_{u^{\prime}}∈ S^{L+1}(v)$ . Based on these upper bounds, we can derive the upper bound matching the inductive hypothesis for $L+1$ :
$$
\left|S^{L+1}(v)\right|\leq N\cdot(R_{N,L}-1)+1=\frac{N^{L+2}-1}{N-1}=R_{N,L+1}. \tag{25}
$$
By induction, the Lemma 2 holds for all $L≥ 0$ .
Appendix I Proof of Theorem 2
The following lemmas are used for proving Theorem 2:
**Lemma 0 (Adaptation of Lemma 5 from(34))**
*Let $\mathcal{N}(\mu,\sigma^{2})$ represent the Gaussian distribution with mean $\mu$ and standard deviation $\sigma^{2}$ , it holds that:
$$
\mathcal{D}_{\alpha}\left(\mathcal{N}\left(\mu,\sigma^{2}\right)\|\mathcal{N}\left(0,\sigma^{2}\right)\right)=\frac{\alpha\mu^{2}}{2\sigma^{2}} \tag{26}
$$*
**Lemma 0 (Adaptation of Lemma 25 from(33))**
*Assume $\mu_{0},...,\mu_{n}$ and $\eta_{0},...,\eta_{n}$ are probability distributions over some domain $Z$ such that their Rényi divergences satisfy: $\mathcal{D}_{\alpha}(\mu_{0}||\eta_{0})≤\epsilon_{0},...,\mathcal{D}_{\alpha}(\mu_{n}||\eta_{n})≤\epsilon_{n}$ for some given $\epsilon_{0},...,\epsilon_{n}$ . Let $\rho$ be a probability distribution over $\{0,...,n\}$ . Denoted by $\mu_{\rho}$ ( $\eta_{\rho}$ , respectively) the probability distribution on $Z$ obtained by sampling $i$ from $\rho$ and then randomly sampling from $\mu_{i}$ and $\eta_{i}$ , we have:
$$
\mathcal{D}_{\alpha}\left(\mu_{\rho}\|\eta_{\rho}\right)\leq\ln\mathbb{E}_{i\sim\rho}\left[e^{\varepsilon_{i}(\alpha-1)}\right]=\frac{1}{\alpha-1}\ln\sum_{i=0}^{n}\rho_{i}e^{\varepsilon_{i}(\alpha-1)} \tag{27}
$$*
Proof of Theorem 2. Consider any minibatch $\mathcal{B}_{t}$ randomly sampled from the training subgraph set $S_{tr}$ of Algorithm 2 at iteration $t$ . For a subset $S(v^{*})⊂ S_{tr}$ containing node $v^{*}$ , its size is bounded by $R_{N,L}$ (Lemma 2). Define the random variable $\beta$ as $|S(v^{*})\cap\mathcal{B}_{t}|$ , and its distribution follows the hypergeometric distribution $\mathrm{Hypergeometric}(|S_{tr}|,R_{N,L},|\mathcal{B}_{t}|)$ (32):
$$
\beta_{i}=P[\beta=i]\ext@arrow 0099\arrowfill@\Relbar\Relbar\Relbar{|S_{tr}|=N_{tr}}{|\mathcal{B}_{t}|=B_{d}}\frac{\binom{R_{N,L}}{i}\binom{N_{tr}-R_{N,L}}{B_{d}-i}}{\binom{N_{tr}}{B_{d}}}. \tag{28}
$$
Next, consider the training of the discriminators (Lines 12–18 and 24–30 in Algorithm 2). Let $\mathcal{G}$ and $\mathcal{G}^{\prime}$ be two adjacent graphs differing only in the presence of node $v^{*}$ and its associated signed edges. Based on the gradient perturbation applied in Lines 15 and 27 of Algorithm 2, we have:
$$
\displaystyle\tilde{{g}}_{t} \displaystyle={g}_{t}+\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)=\sum_{v\in\mathcal{B}_{t}}\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v}})+\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right) \displaystyle\tilde{{g}}^{\prime}_{t} \displaystyle={g}^{\prime}_{t}+\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)=\sum_{v^{\prime}\in\mathcal{B}_{tr}^{\prime}}\text{Clip}_{C}(\frac{\partial L_{D}}{\partial\mathbf{d}_{v^{\prime}}})+\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right), \tag{29}
$$
where $\Delta_{{g}}=R_{N,L}C=\frac{N^{L+1}-1}{N-1}C$ (Theorem 1). $\tilde{{g}}_{t}$ and $\tilde{{g}}^{\prime}_{t}$ denote the noisy gradients of $\mathcal{G}$ and $\mathcal{G}^{\prime}$ , respectively. When $\beta=i$ , their Rényi divergences can be upper bounded as:
$$
\displaystyle\mathcal{D}_{\alpha} \displaystyle\left(\tilde{{g}}_{t,i}\|\tilde{{g}}_{t,i}^{\prime}\right) \displaystyle=\mathcal{D}_{\alpha}\left({g}_{t,i}+\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\|{g}_{t,i}^{\prime}+\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\right) \displaystyle=\mathcal{D}_{\alpha}\left(\mathcal{N}\left({{g}}_{t,i},\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\|\mathcal{N}\left({{g}^{\prime}}{}_{t,i},\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\right) \displaystyle\stackrel{{\scriptstyle(a)}}{{=}}\mathcal{D}_{\alpha}\left(\mathcal{N}\left(\left({{g}}_{t,i}-{{g}}_{t,i}^{\prime}\right),\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\|\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\right) \displaystyle\stackrel{{\scriptstyle(b)}}{{\leq}}\sup_{\|{\Delta_{i}}\|_{2}\leq iC}\mathcal{D}\left(\mathcal{N}\left(\Delta_{i},\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\|\mathcal{N}\left(0,\sigma^{2}\Delta_{{g}}^{2}\mathbf{I}\right)\right) \displaystyle\stackrel{{\scriptstyle(c)}}{{=}}\sup_{\|\Delta_{i}\|_{2}\leq iC}\frac{\alpha\|\Delta_{i}\|_{2}^{2}}{2\Delta_{{g}}^{2}\sigma^{2}}=\frac{\alpha i^{2}}{2R_{N,L}^{2}\sigma^{2}}, \tag{30}
$$
where $\Delta_{i}={{g}}_{t,i}-{{g}}_{t,i}^{\prime}$ . (a) leverages the property that Rényi divergence remains unchanged under invertible transformations (34), while (b) and (c) are derived from Theorem 1 and Lemma 1, respectively. Based on Lemma 2 , we derive that:
$$
\displaystyle\mathcal{D}_{\alpha}\left(\tilde{{g}}_{t}\|\tilde{{g}}_{t}^{\prime}\right)\leq\ln\mathbb{E}_{i\sim\beta}\left[\exp\left({\frac{\alpha i^{2}(\alpha-1)}{2R_{N,L}^{2}\sigma^{2}}}\right)\right] \displaystyle=\frac{1}{\alpha-1}\ln\left(\sum_{i=0}^{R_{N,L}}\beta_{i}\exp\left({\frac{\alpha i^{2}(\alpha-1)}{2R_{N,L}^{2}\sigma^{2}}}\right)\right)=\gamma. \tag{31}
$$
Here, $\beta_{i}$ is illustrated in Eq. (28). Based on the composition property of DP, after $T=n^{epoch}· n^{iter}$ interations, the discriminators satisfy node-level $(\alpha,{2T}\gamma)$ -RDP. Moreover, owing to the post-processing property of DP, the generators $G^{+}$ and $G^{-}$ inherit the same privacy guarantee as the discriminators. Therefore, Algorithm 2 obeys node-level $(\alpha,{2T}\gamma)$ -RDP, and the proof of Theorem 2 is completed.
Appendix J Additional Details of Experiments
J.1. Dataset Introduction
The detailed introduction of all datasets is as follows.
- Bitcoin-Alpha and Bitcoin-OTC are trust networks among Bitcoin users, aimed at preventing transactions with fraudulent or high-risk users. In these networks, user relationships are represented by positive (trust) and negative (distrust) edges.
- Slashdot is a social network derived from user interactions on a technology news site, where relationships are annotated as positive (friend) or negative (enemy) edges.
- WikiRfA is a voting network for electing managers in Wikipedia, where edges denote positive (supporting vote) or negative (opposing vote) relationships between users.
- Epinions is a product review site where users can establish both trust and distrust relationships with others.
J.2. The Distribution of Node Degrees and Path Lengths
The findings for the distribution of node degrees and path lengths in the Bitcoin-Alpha and Slashdot datasets are shown in Figs. 8 and 9.
<details>
<summary>x8.png Details</summary>
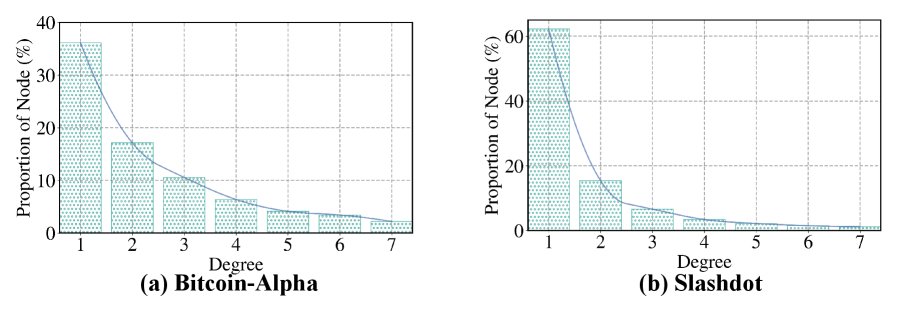
### Visual Description
## Heatmap: Node Degree Distribution
### Overview
The image displays two heatmaps, (a) Bitcoin-Alpha and (b) Slashdot, which represent the distribution of node degrees in their respective networks. The x-axis shows the degree of nodes, ranging from 1 to 7, while the y-axis represents the proportion of nodes with that degree, measured in percentages.
### Components/Axes
- **Bitcoin-Alpha (a)**:
- **X-Axis**: Degree of nodes (1 to 7)
- **Y-Axis**: Proportion of nodes with that degree (%)
- **Legend**: Not visible in the image
- **Data Points**: Represented by dots, with varying sizes indicating the proportion of nodes with each degree.
- **Slashdot (b)**:
- **X-Axis**: Degree of nodes (1 to 7)
- **Y-Axis**: Proportion of nodes with that degree (%)
- **Legend**: Not visible in the image
- **Data Points**: Represented by dots, with varying sizes indicating the proportion of nodes with each degree.
### Detailed Analysis or ### Content Details
- **Bitcoin-Alpha (a)**:
- The highest proportion of nodes is observed at degree 1, with approximately 35% of nodes having a degree of 1.
- The proportion decreases sharply as the degree increases, with the highest proportion at degree 7, around 10%.
- The distribution is relatively flat, with no significant peaks or valleys.
- **Slashdot (b)**:
- The highest proportion of nodes is observed at degree 1, with approximately 45% of nodes having a degree of 1.
- The proportion decreases sharply as the degree increases, with the highest proportion at degree 7, around 5%.
- The distribution is relatively flat, with no significant peaks or valleys.
### Key Observations
- Both networks show a high proportion of nodes with a degree of 1, indicating a centralized structure.
- The Slashdot network has a slightly higher proportion of nodes with a degree of 1 compared to Bitcoin-Alpha.
- The distribution is relatively flat, with no significant peaks or valleys, suggesting a balanced network structure.
### Interpretation
The data suggests that both Bitcoin-Alpha and Slashdot networks have a centralized structure, with a high proportion of nodes having a degree of 1. This could indicate that these networks are dominated by a few highly connected nodes, which could be critical for the network's functionality and security. The relatively flat distribution suggests that the networks are balanced, with no single node dominating the network. However, the Slashdot network has a slightly higher proportion of nodes with a degree of 1, which could indicate a different level of centralization or a different network structure.
</details>
Figure 8. Distribution of node degrees.
<details>
<summary>x9.png Details</summary>
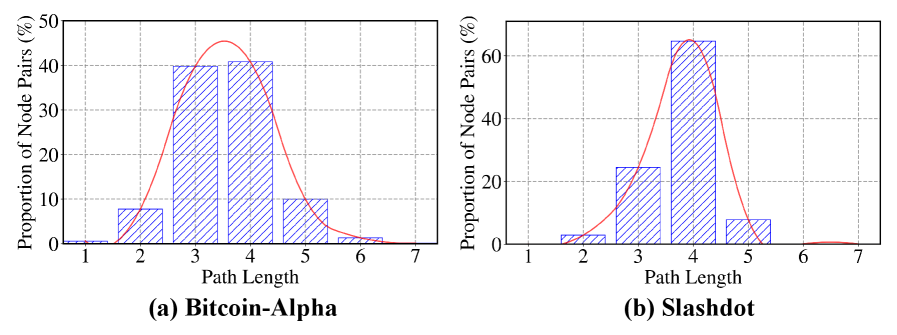
### Visual Description
## [Chart/Diagram Type]: Histograms
### Overview
The image displays two histograms, labeled (a) Bitcoin-Alpha and (b) Slashdot, which represent the distribution of path lengths in node pairs for two different blockchain networks.
### Components/Axes
- **Bitcoin-Alpha**:
- **X-axis**: Path Length (ranging from 1 to 7)
- **Y-axis**: Proportion of Node Pairs (%)
- **Slashdot**:
- **X-axis**: Path Length (ranging from 1 to 7)
- **Y-axis**: Proportion of Node Pairs (%)
### Detailed Analysis or ### Content Details
- **Bitcoin-Alpha**:
- The histogram shows a peak at path length 3, indicating that most node pairs in Bitcoin-Alpha have a path length of 3.
- The proportion of node pairs decreases as the path length increases, with the highest proportion at path length 3 and the lowest at path length 7.
- **Slashdot**:
- The histogram also shows a peak at path length 3, similar to Bitcoin-Alpha.
- However, the proportion of node pairs is slightly higher at path length 3 compared to Bitcoin-Alpha.
- The proportion of node pairs decreases as the path length increases, with the highest proportion at path length 3 and the lowest at path length 7.
### Key Observations
- Both histograms show a peak at path length 3, suggesting that most node pairs in both networks have a path length of 3.
- The proportion of node pairs decreases as the path length increases, indicating that longer paths are less common.
- The proportion of node pairs is slightly higher at path length 3 for Slashdot compared to Bitcoin-Alpha.
### Interpretation
The data suggests that both Bitcoin-Alpha and Slashdot have a similar network structure, with most node pairs having a path length of 3. This could indicate that both networks are relatively well-connected, with most nodes being directly or indirectly connected to each other through a short path. The slight difference in the proportion of node pairs at path length 3 for Slashdot compared to Bitcoin-Alpha could be due to differences in the network design or the number of nodes in each network. Overall, the data demonstrates that both networks have a relatively similar network structure, with most node pairs having a path length of 3.
</details>
Figure 9. Distribution of path lengths.
J.3. The detailed results of Edge Sign Prediction
The average AUC results under different values of $\epsilon$ and datasets for edge prediction tasks are detailed in Table 6.
Table 6. Summary of average AUC with different $\epsilon$ and datasets for edge sign prediction tasks. (BOLD: Best)
| Bitcoin-OTC | SDGNN | 0.7655 | 0.7872 | 0.7913 | 0.8105 | 0.8571 |
| --- | --- | --- | --- | --- | --- | --- |
| SiGAT | 0.7011 | 0.7282 | 0.7869 | 0.8379 | 0.8706 | |
| SGCN | 0.5565 | 0.5740 | 0.6634 | 0.7516 | 0.7801 | |
| GAP | 0.5763 | 0.5782 | 0.6486 | 0.6741 | 0.7411 | |
| LSNE | 0.5030 | 0.5405 | 0.7041 | 0.8239 | 0.8776 | |
| ASGL | 0.8004 | 0.8462 | 0.8488 | 0.8505 | 0.8801 | |
| Bitcoin-Alpha | SDGNN | 0.6761 | 0.6883 | 0.7098 | 0.7308 | 0.8476 |
| SiGAT | 0.7033 | 0.7215 | 0.7303 | 0.7488 | 0.8207 | |
| SGCN | 0.5157 | 0.5450 | 0.6433 | 0.6930 | 0.7702 | |
| GAP | 0.5664 | 0.6025 | 0.6367 | 0.7091 | 0.7320 | |
| LSNE | 0.5112 | 0.5361 | 0.5959 | 0.6524 | 0.8069 | |
| ASGL | 0.7505 | 0.8075 | 0.8589 | 0.8591 | 0.8592 | |
| WikiRfA | SDGNN | 0.6558 | 0.7066 | 0.7142 | 0.7267 | 0.7930 |
| SiGAT | 0.6313 | 0.6525 | 0.7023 | 0.7777 | 0.8099 | |
| SGCN | 0.5107 | 0.6456 | 0.6515 | 0.7008 | 0.7110 | |
| GAP | 0.5356 | 0.5506 | 0.5612 | 0.5717 | 0.5937 | |
| LSNE | 0.5086 | 0.5253 | 0.6119 | 0.6553 | 0.7832 | |
| ASGL | 0.6680 | 0.7706 | 0.7963 | 0.7986 | 0.8100 | |
| Slashdot | SDGNN | 0.7547 | 0.8325 | 0.8697 | 0.8788 | 0.8862 |
| SiGAT | 0.7061 | 0.7886 | 0.8392 | 0.8424 | 0.8527 | |
| SGCN | 0.5662 | 0.6151 | 0.6662 | 0.7181 | 0.8093 | |
| GAP | 0.6121 | 0.6389 | 0.6879 | 0.7126 | 0.7471 | |
| LSNE | 0.5717 | 0.6144 | 0.7541 | 0.7753 | 0.7816 | |
| ASGL | 0.7861 | 0.8539 | 0.8887 | 0.8890 | 0.8910 | |
| Epinions | SDGNN | 0.6788 | 0.7180 | 0.7201 | 0.7455 | 0.8428 |
| SiGAT | 0.6772 | 0.7046 | 0.7063 | 0.7702 | 0.8253 | |
| SGCN | 0.6152 | 0.6487 | 0.6974 | 0.7502 | 0.8318 | |
| GAP | 0.5899 | 0.6034 | 0.6288 | 0.6310 | 0.6618 | |
| LSNE | 0.5033 | 0.6055 | 0.7590 | 0.8434 | 0.8585 | |
| ASGL | 0.6869 | 0.8134 | 0.8513 | 0.8658 | 0.8666 | |
J.4. The detailed results of node clustering
The average SSI results under different values of $\epsilon$ and datasets for node clustering tasks are detailed in Table 7.
Table 7. Summary of average SSI with different $\epsilon$ and datasets for node clustering tasks. (BOLD: Best)
| 1 | Bitcoin-Alpha | 0.4819 | 0.4378 | 0.4877 | 0.4977 | 0.4988 | 0.5091 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Bitcoin-OTC | 0.4505 | 0.4677 | 0.5025 | 0.4970 | 0.5008 | 0.5160 | |
| Slashdot | 0.4715 | 0.5011 | 0.5025 | 0.5052 | 0.5005 | 0.5107 | |
| WikiRfA | 0.4788 | 0.4988 | 0.4968 | 0.4890 | 0.5003 | 0.5126 | |
| Epinions | 0.5001 | 0.4965 | 0.5022 | 0.5013 | 0.6095 | 0.6106 | |
| 2 | Bitcoin-Alpha | 0.4910 | 0.4733 | 0.4969 | 0.4985 | 0.5032 | 0.5402 |
| Bitcoin-OTC | 0.4733 | 0.4968 | 0.5075 | 0.4986 | 0.5729 | 0.6810 | |
| Slashdot | 0.4888 | 0.4864 | 0.4871 | 0.5134 | 0.5132 | 0.5494 | |
| WikiRfA | 0.4934 | 0.5054 | 0.5117 | 0.4996 | 0.5032 | 0.5577 | |
| Epinions | 0.5068 | 0.5116 | 0.5086 | 0.5463 | 0.6263 | 0.6732 | |
| 4 | Bitcoin-Alpha | 0.5019 | 0.4948 | 0.5112 | 0.5049 | 0.6204 | 0.6707 |
| Bitcoin-OTC | 0.5005 | 0.5325 | 0.5612 | 0.5465 | 0.6953 | 0.7713 | |
| Slashdot | 0.5003 | 0.5685 | 0.5545 | 0.5671 | 0.5444 | 0.5994 | |
| WikiRfA | 0.5005 | 0.5142 | 0.5538 | 0.5476 | 0.5644 | 0.5977 | |
| Epinions | 0.5148 | 0.5389 | 0.5386 | 0.6255 | 0.6747 | 0.6787 | |
<details>
<summary>x10.png Details</summary>
### Visual Description
## Bar Chart: AUC Scores for Different ASGL Models
### Overview
The bar chart compares the Area Under the Curve (AUC) scores of four different ASGL (Adversarial Self-Generation Learning) models: ASGL-, ASGL+, ASGL, and WikiRFA, across four different datasets: Bitcoin-Alpha, Bitcoin-OCT, Slashdot, and WikiRFA.
### Components/Axes
- **X-axis**: Represents the different datasets (Bitcoin-Alpha, Bitcoin-OCT, Slashdot, WikiRFA).
- **Y-axis**: Represents the AUC scores, ranging from 0.65 to 0.90.
- **Legend**: Shows the different ASGL models (ASGL-, ASGL+, ASGL, WikiRFA) with their respective colors.
### Detailed Analysis or ### Content Details
- **Bitcoin-Alpha**: ASGL+ has the highest AUC score of approximately 0.88, followed by ASGL with a score of about 0.85. ASGL- and WikiRFA have scores of approximately 0.82 and 0.78, respectively.
- **Bitcoin-OCT**: ASGL+ has the highest AUC score of approximately 0.87, followed by ASGL with a score of about 0.84. ASGL- and WikiRFA have scores of approximately 0.81 and 0.76, respectively.
- **Slashdot**: ASGL+ has the highest AUC score of approximately 0.89, followed by ASGL with a score of about 0.86. ASGL- and WikiRFA have scores of approximately 0.84 and 0.79, respectively.
- **WikiRFA**: ASGL+ has the highest AUC score of approximately 0.87, followed by ASGL with a score of about 0.85. ASGL- and WikiRFA have scores of approximately 0.82 and 0.77, respectively.
### Key Observations
- ASGL+ consistently outperforms the other models across all datasets.
- ASGL+ has the highest AUC scores, indicating the best performance.
- WikiRFA has the lowest AUC scores, indicating the worst performance.
- There is a noticeable difference in performance between ASGL+ and the other models, with ASGL+ consistently outperforming them.
### Interpretation
The data suggests that ASGL+ is the most effective ASGL model among the four tested, with the highest AUC scores across all datasets. This indicates that ASGL+ is the best at generating adversarial examples that are difficult for other models to classify. The other models, ASGL- and WikiRFA, have lower AUC scores, indicating that they are less effective at generating adversarial examples. The performance of ASGL+ is significantly higher than that of the other models, suggesting that ASGL+ is the most effective ASGL model among the four tested.
</details>
Figure 10. Comparison between ASGL, $\text{ASGL}^{+}$ , and $\text{ASGL}^{-}$ .
J.5. The Setup of Link Stealing Attack
Motivated by (42), we assume that the adversary has black-box access to the node embeddings produced by the target signed graph learning model, but not to its internal parameters or gradients. The adversary also possesses an auxiliary graph dataset comprising node pairs that partially overlap in distribution with the target graph. Some of these node pairs belong to the training graph (members), while others are from the test graph (non-members). For each node pair, a feature vector is constructed by concatenating their embeddings. Finally, these feature vectors, along with their corresponding member or non-member labels, are then used to train a logistic regression classifier to infer whether an edge exists between any two nodes of the target graph. To simulate this link stealing attack, each dataset is partitioned into target training, auxiliary training, target test, and auxiliary test sets with a 5:2:2:1 ratio.
J.6. Effectiveness of Adversarial Learning with Edge Signs.
To verify the effectiveness of adversarial learning with signed edges, we also compare our ASGL with its variants, denoted as $\text{ASGL}^{+}$ and $\text{ASGL}^{-}$ . Specifically, $\text{ASGL}^{+}$ and $\text{ASGL}^{-}$ only operate on the positive graph $\mathcal{G}^{+}$ and the negative graph $\mathcal{G}^{-}$ , respectively. Fig. 10 presents the average AUC scores of ASGL, $\text{ASGL}^{+}$ , and $\text{ASGL}^{-}$ across all datasets. It can be observed that ASGL significantly outperforms both $\text{ASGL}^{+}$ and $\text{ASGL}^{-}$ in all cases. These results demonstrate that our privacy-preserving adversarial learning framework with edge signs is more effective in representing signed graphs compared to its variants that neglect edge sign information.