# Sparse Attention Post-Training for Mechanistic Interpretability
**Authors**: Florent Draye, Anson Lei, Hsiao-Ru Pan, Ingmar Posner, Bernhard Schölkopf
## Abstract
We introduce a simple post-training method that makes transformer attention sparse without sacrificing performance. Applying a flexible sparsity regularisation under a constrained-loss objective, we show on models up to 7B parameters that it is possible to retain the original pretraining loss while reducing attention connectivity to $\approx 0.4\$ of its edges. Unlike sparse-attention methods designed for computational efficiency, our approach leverages sparsity as a structural prior: it preserves capability while exposing a more organized and interpretable connectivity pattern. We find that this local sparsity cascades into global circuit simplification: task-specific circuits involve far fewer components (attention heads and MLPs) with up to 100× fewer edges connecting them. Additionally, using cross-layer transcoders, we show that sparse attention substantially simplifies attention attribution, enabling a unified view of feature-based and circuit-based perspectives. These results demonstrate that transformer attention can be made orders of magnitude sparser, suggesting that much of its computation is redundant and that sparsity may serve as a guiding principle for more structured and interpretable models.
Machine Learning, ICML
## 1 Introduction
Scaling has driven major advances in artificial intelligence, with ever-larger models trained on internet-scale datasets achieving remarkable capabilities across domains. Large language models (LLMs) now underpin applications from text generation to question answering, yet their increasing complexity renders their internal mechanisms largely opaque (Bommasani, 2021). Methods of mechanistic interpretability have been developed to address this gap by reverse-engineering neural networks to uncover how internal components implement specific computations and behaviors. Recent advances in this area have successfully identified interpretable circuits, features, and algorithms within LLMs (Nanda et al., 2023; Olsson et al., 2022), showing that large complex models can, in part, be understood mechanistically, opening avenues for improving transparency, reliability, and alignment (Bereska and Gavves, 2024).
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: Neural Network Sparsity Illustration
### Overview
The image presents a diagram illustrating the effect of sparsity-regularized finetuning on a neural network. It compares a "Base Model" with a "Sparse Model," visually demonstrating how finetuning can reduce the number of active connections within the network. The diagram uses a layered network representation with connections between layers.
### Components/Axes
The diagram consists of two main sections: "Base Model" (top) and "Sparse Model" (bottom). Each section depicts a neural network with four layers labeled "Layer 0", "Layer 1", "Layer 2", and "Layer 3". Both sections show the input "3 6 + 2 8" and the output "0 0 0 6 4" with question marks in between. A curved arrow labeled "Sparsity-Regularised Finetuning" connects the two sections, indicating the transformation process. The connections between layers are represented by lines.
### Detailed Analysis or Content Details
**Base Model:**
* The base model shows a dense network with numerous connections between each layer. The lines representing connections are predominantly blue.
* Input: "3 6 + 2 8"
* Output: "0 0 0 6 4"
* Layer 0 has 8 nodes.
* Layer 1 has 8 nodes.
* Layer 2 has 8 nodes.
* Layer 3 has 8 nodes.
* Connections: Almost every node in one layer is connected to almost every node in the next layer.
**Sparse Model:**
* The sparse model shows a network with significantly fewer connections. The lines representing connections are predominantly blue, but much sparser than in the base model. A blue line is also present to indicate the trend of the connections.
* Input: "3 6 + 2 8"
* Output: "0 0 0 6 4"
* Layer 0 has 8 nodes.
* Layer 1 has 8 nodes.
* Layer 2 has 8 nodes.
* Layer 3 has 8 nodes.
* Connections: Only a subset of nodes in each layer are connected to nodes in the next layer. The connections are concentrated along a diagonal.
**Arrow:**
* The arrow labeled "Sparsity-Regularised Finetuning" is positioned on the left side of the diagram and curves from the "Base Model" to the "Sparse Model," indicating the direction of the transformation.
### Key Observations
* The primary difference between the two models is the density of connections. The base model is densely connected, while the sparse model has significantly fewer connections.
* The sparse model appears to have connections concentrated along a diagonal, suggesting that the finetuning process prioritizes certain pathways within the network.
* The input and output remain the same in both models, indicating that the finetuning process aims to achieve the same functionality with a more efficient network structure.
### Interpretation
The diagram illustrates the concept of model sparsity, a technique used to reduce the computational cost and memory footprint of neural networks. Sparsity-regularized finetuning encourages the network to learn a solution that relies on a smaller subset of connections, effectively pruning away redundant or less important pathways. This can lead to faster inference times and reduced energy consumption without sacrificing accuracy. The diagram visually demonstrates how this process transforms a dense network into a sparse one, highlighting the reduction in connections while maintaining the same input-output behavior. The concentration of connections along a diagonal in the sparse model suggests that the finetuning process has identified a set of key pathways that are sufficient for performing the task. The question marks in the middle of the input and output suggest that the internal workings of the network are being simplified, but the overall function remains the same.
</details>
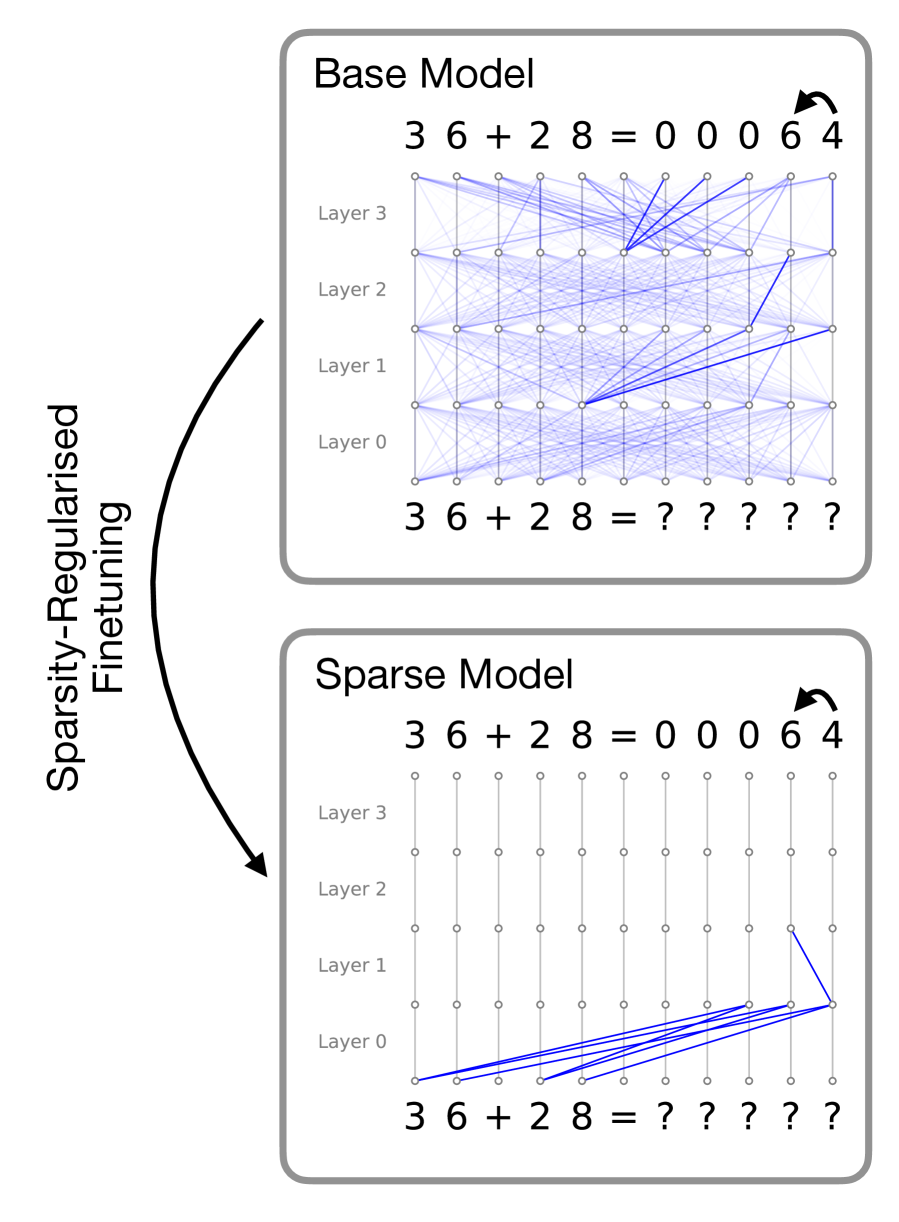
Figure 1: Visualised attention patterns for a 4-layer toy model trained on a simple 2-digit addition task. The main idea of this work is to induce sparse attention between tokens via a post-training procedure that optimizes for attention sparsity while maintaining model performance. In this example, while both models are able to correctly predict the sum, the sparse model solves the problem with a naturally interpretable circuit. Details of this toy setup and more examples are provided in Appendix A
However, interpretability is bottlenecked by the model itself: even with sophisticated reverse-engineering techniques that can faithfully reveal internal algorithms, the underlying computations implemented by large models can still remain highly complex and uninterpretable. Circuits for seemingly simple tasks may span hundreds of interacting attention heads and MLPs with densely intertwined contributions across layers (Conmy et al., 2023), and features can influence each other along combinatorially many attention-mediated paths, complicating attention attribution (Kamath et al., 2025). To exemplify this, Figure 1 (top) illustrates the attention patterns of a small, single-head transformer trained on a simple two-digit addition task. Here, the model has learned to solve the task in a highly diffused manner, where information about each token is dispersed across all token locations, rendering the interpretation of the underlying algorithm extremely difficult even in this simple case.
The crux of the problem is that models are not incentivised to employ simple algorithms during training. In this work, we advocate for directly embedding interpretability constraints into model design in a way that induces simple circuits while preserving performance. We focus our analysis on attention mechanisms and investigate sparsity regularisation on attention patterns, originally proposed in (Lei et al., 2025), as an inductive bias. To demonstrate how sparse attention patterns can give rise to interpretable circuits, we return to the two-digit addition example: Figure 1 (bottom) shows the attention patterns induced by penalising attention edges during training. Here, the sparsity inductive bias forces the model to solve the problem with much smaller, intrinsically interpretable computation circuits.
In this work, we investigate using this sparsity regularisation scheme as a post-training strategy for pre-trained LLMs. We propose a practical method for fine-tuning existing models without re-running pretraining, offering a flexible way to induce sparse attention patterns and enhance interpretability. We show, on models of up to 7B parameters, that our proposed procedure preserves the performance of the base models on pretraining data while reducing the effective attention map to less than $0.5\$ of its edges. To evaluate our central hypothesis that sparse attention facilitates interpretability, we consider two complementary settings. First, we study circuit discovery, where the objective is to identify the minimal set of components responsible for task performance (Conmy et al., 2023). We find that sparsified models yield substantially simpler computational graphs: the resulting circuits explain model behaviour using up to four times fewer attention heads and up to two orders of magnitude fewer edges. Second, using cross-layer transcoders (Ameisen et al., 2025), we analyse attribution graphs, which capture feature-level interactions across layers. In this setting, sparse attention mitigates the attention attribution problem by making it possible to identify which attention heads give rise to a given edge, owing to the reduced number of components mediating each connection. We argue that this clarity enables a tighter integration of feature-based and circuit-based perspectives, allowing feature interactions to be understood through explicit, tractable circuits. Taken together, these results position attention sparsity as an effective and practical inductive tool for surfacing the minimal functional backbone underlying model behaviour.
## 2 Related Work
### 2.1 Sparse Attention
As self-attention is a key component of the ubiquitous Transformer architecture, a large number of variants of attention mechanisms have been explored in the literature. Related to our approach are sparse attention methods, which are primarily designed to alleviate the quadratic scaling of vanilla self-attention. These methods typically rely on masks based on fixed local and strided patterns (Child et al., 2019) or sliding-window and global attention patterns (Beltagy et al., 2020; Zaheer et al., 2020) to constrain the receptive field of each token. While these approaches are successful in reducing the computational complexity of self-attention, they require hand-defined heuristics that do not reflect the internal computations learned by the model.
Beyond these fixed-pattern sparse attention methods, Top- $k$ attention, which enforces sparsity by dynamically selecting the $k$ most relevant keys per query based on their attention scores, has also been explored (Gupta et al., 2021; DeepSeek-AI, 2025). While Top- $k$ attention enables learnable sparse attention, the necessity to specify $k$ limits its scope for interpretability for two reasons. First, selecting the optimal $k$ is difficult, and setting $k$ too low can degrade model performance. Second, and more fundamentally, Top-k attention does not allow the model to choose different $k$ for different attention heads based on the context. We argue that this flexibility is crucial for maintaining model performance.
More recently, gated attention mechanisms (Qiu et al., 2025) provide a scalable and performant framework for inducing sparse attention. In particular, Lei et al. (2025) introduce a sparsity regularisation scheme for world modelling that reveals sparse token dependencies. We adopt this method and examine its role as an inductive bias for interpretability.
### 2.2 Circuit Discovery
Mechanistic interpretability seeks to uncover how internal components of LLMs implement specific computations. Ablation studies assess performance drops from removing components (Nanda et al., 2023), activation patching measures the effect of substituting activations (Zhang and Nanda, 2023), and attribution patching scales this approach via local linearisation (Syed et al., 2024). Together, these approaches allow researchers to isolate sub-circuits, minimal sets of attention heads and MLPs that are causally responsible for a given behavior or task (Conmy et al., 2023). Attention itself plays a dual role: it both routes information and exposes interpretable relational structure, making it a key substrate for mechanistic study. Our work builds on this foundation by leveraging sparsity to simplify these circuits, amplifying the interpretability of attention-mediated computation while preserving model performance.
### 2.3 Attribution Graph
Mechanistic interpretability has gradually shifted from an emphasis on explicit circuit discovery towards the analysis of internal representations and features. Recent work on attribution graphs and circuit tracing seeks to reunify these perspectives by approximating MLP outputs as sparse linear combinations of features and computing causal effects along linear paths between them (Dunefsky et al., 2024; Ameisen et al., 2025; Lindsey et al., 2025b). This framework enables the construction of feature-level circuits spanning the computation from input embeddings to final token predictions. Within attribution graphs, edges correspond to direct linear causal relationships between features. However, these relationships are mediated by attention heads that transmit information across token positions. Identifying which attention heads give rise to a particular edge, and understanding why they do so, is essential, as this mechanism forms a fundamental component of the computational graph (Kamath et al., 2025). A key limitation of current attribution-based approaches is that individual causal edges are modulated by dozens of attention components. We show that this leads to feature-to-feature influences that are overly complex, rendering explanations in terms of other features in the graph both computationally expensive and conceptually challenging.
## 3 Method
Our main hypothesis is that post-training existing LLMs to encourage sparse attention patterns leads to the emergence of more interpretable circuits. In order to instantiate this idea, we require a post-training pipeline that satisfies three main desiderata:
1. To induce sparse message passing between tokens, we need an attention mechanism that can ‘zero-out’ attention edges, which in turn enables effective $L_{0}$ -regularisation on the attention weights. This is in contrast to the standard softmax attention mechanism, where naive regularisation would result in small but non-zero attention weights that still allow information flow between tokens.
1. The model architecture needs to be compatible with the original LLM such that the pre-trained LLM weights can be directly loaded at initialisation.
1. The post-training procedure needs to ensure that the post-trained models do not lose prediction performance compared to their fully-connected counterparts.
To this end, we leverage the Sparse Transformer architecture in the SPARTAN framework proposed in (Lei et al., 2025), which uses sparsity-regularised hard attention instead of the standard softmax attention. In the following subsections, we describe the Sparse Transformer architecture and the optimisation setup, highlighting how this approach satisfies the above desiderata.
### 3.1 Sparse Attention Layer
Given a set of token embeddings, the Sparse Transformer layer computes the key, query, and value embeddings, $\{k_{i},q_{i},v_{i}\}$ , via linear projections, analogous to the standard Transformer. Based on the embeddings, we sample a binary gating matrix from a learnable distribution parameterised by the keys and queries,
$$
A_{ij}\sim\mathrm{Bern}(\sigma(q_{i}^{T}k_{j})), \tag{1}
$$
where $\mathrm{Bern}(\cdot)$ is the Bernoulli distribution and $\sigma(\cdot)$ is the logistic sigmoid function. This sampling step can be made differentiable via the Gumbel Softmax trick (Jang et al., 2017). This binary matrix acts as a mask that controls the information flow across tokens. Next, the message passing step is carried out in the same way as standard softmax attention, with the exception that we mask out the value embeddings using the sampled binary mask,
$$
\mathrm{SparseAttn}(Q,K,V)=\bigg[A\odot\mathrm{softmax}(\frac{QK^{T}}{\sqrt{d_{k}}})\bigg]V, \tag{2}
$$
where $d_{k}$ is the dimension of the key embeddings and $\odot$ denotes element-wise multiplication. During training, we regularise the expected number of edges between tokens based on the distribution over the gating matrix. Concretely, the expected number of edges for each layer can be calculated as
$$
\mathbb{E}\big[|A|\big]=\sum_{i,j}\sigma(q^{T}_{i}k_{j}). \tag{3}
$$
Note that during the forward pass, each entry of $A$ is a hard binary sample that zeros out attention edges, which serves as an effective $L_{0}$ regularisation. Moreover, since the functional form of the sparse attention layer after the hard sampling step is the same as standard softmax attention, pre-trained model weights can be directly used without alterations. Technically, the sampled $A$ affects the computation. This can be mitigated by adding a positive bias term inside the sigmoid function to ensure all gates are open at initialisation. Experimentally, we found this to be unnecessary as the models quickly recover their original performance within a small number of gradient steps.
### 3.2 Constrained Optimisation
In order to ensure that the models do not lose prediction performance during the post-training procedure, as per desideratum 3, we follow the approach proposed in (Lei et al., 2025), which employs the GECO algorithm (Rezende and Viola, 2018). Originally developed in the context of regularising VAEs, the GECO algorithm places a constraint on the performance of the model and uses a Lagrangian multiplier to automatically find the right strength of regularisation during training. Concretely, we formulate the learning process as the following optimisation problem,
$$
\min_{\theta}\sum_{l}\mathbb{E}\big[|A_{l}|\big]\qquad s.t.\quad CE\leq\tau, \tag{4}
$$
where $A_{l}$ denotes the gating matrix at layer $l$ , $CE$ is the standard next token prediction cross-entropy loss, and $\tau$ is the required target loss, and $\theta$ is the model parameters. In practice, we set this target as the loss of the pre-trained baseline models. We solve this optimisation problem via Lagrangian relaxation, yielding the following max-min objective,
$$
\max_{\lambda>0}\min_{\theta}\bigg[\sum_{l}\mathbb{E}\big[|A_{l}|\big]+\lambda(CE-\tau)\bigg]. \tag{5}
$$
This can be solved by taking gradient steps on $\theta$ and $\lambda$ alternately. During training, updating $\lambda$ automatically balances the strength of the sparsity regularisation: when $CE$ is lower than the threshold, $\lambda$ decreases, and hence more weight is given to the sparsity regularisation term. This effectively acts as an adaptive schedule which continues to increase the strength of the regularisation until the model performance degrades. Here, the value of $\tau$ is selected as a hyperparameter to ensure that the sparse model’s performance remains within a certain tolerance of the original base model. In practice, the choice of $\tau$ controls a trade off between sparsity and performance: picking a tight $\tau$ can lead to a slower training process, whereas a higher tolerance can substantially speed up training at the cost of potentially harming model performance. In Appendix C, we provide further discussion on this optimisation process and its training dynamics.
### 3.3 Practical Considerations
One of the main strengths of our proposed method is that, architecturally, the only difference between a sparse Transformer and a normal one lies in how the dot-product attention is computed. As such, most practical training techniques for optimising Transformers can be readily adapted to our setting. In our experiments, we find the following techniques helpful for improving computational efficiency and training stability.
#### LoRA finetuning (Hu et al., 2022) .
Low rank finetuning techniques can significantly reduce the computational requirements for training large models. In our experiments, we verify on a 7B parameter model that LoRA finetuning is sufficiently expressive for inducing sparse attention patterns.
#### FlashAttention (Dao, 2023)
FlashAttention has become a standard method for reducing the memory footprint of dot-product attention mechanisms. In Appendix B, we discuss how the sampled sparse attention can be implemented in an analogous manner.
#### Distillation (Gu et al., 2024) .
Empirically, we find that adding an auxiliary distillation loss based on the KL divergence between the base model and the sparse model improves training stability and ensures that the behaviour of the model remains unchanged during post-training.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Bar Chart: Benchmark Comparison
### Overview
The image presents a bar chart comparing the accuracy of two models, OLMo-7B and Sparse OLMo-7B, across four different benchmarks: TruthfulQA, PIQA, OpenBookQA, and ARC-Easy. The chart visually represents the performance of each model on each benchmark using adjacent bars.
### Components/Axes
* **Title:** "Benchmark Comparison" (centered at the top)
* **X-axis:** Benchmark names: "TruthfulQA", "PIQA", "OpenBookQA", "ARC-Easy" (placed horizontally at the bottom)
* **Y-axis:** Accuracy (ranging from 0.0 to 1.0, placed vertically on the left)
* **Legend:** Located in the top-right corner.
* Green: "OLMo-7B"
* Purple/Pink: "Sparse OLMo-7B"
### Detailed Analysis
The chart consists of four groups of two bars, one for each benchmark.
* **TruthfulQA:**
* OLMo-7B (Green): Approximately 0.24 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.22 accuracy.
* **PIQA:**
* OLMo-7B (Green): Approximately 0.76 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.79 accuracy.
* **OpenBookQA:**
* OLMo-7B (Green): Approximately 0.34 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.41 accuracy.
* **ARC-Easy:**
* OLMo-7B (Green): Approximately 0.58 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.54 accuracy.
### Key Observations
* Sparse OLMo-7B generally outperforms OLMo-7B on PIQA and OpenBookQA.
* OLMo-7B outperforms Sparse OLMo-7B on TruthfulQA and ARC-Easy.
* The accuracy scores vary significantly across the different benchmarks, suggesting that the models' performance is benchmark-dependent.
* The difference in performance between the two models is relatively small for TruthfulQA, but more noticeable for PIQA and OpenBookQA.
### Interpretation
The data suggests that the Sparse OLMo-7B model exhibits stronger performance on benchmarks requiring reasoning and knowledge integration (PIQA, OpenBookQA), while the OLMo-7B model performs better on benchmarks focused on truthfulness and simpler reasoning (TruthfulQA, ARC-Easy). This could indicate that the sparsity applied in Sparse OLMo-7B enhances its ability to handle more complex tasks, but potentially at the cost of performance on tasks requiring strict factual recall. The varying performance across benchmarks highlights the importance of evaluating models on a diverse set of tasks to gain a comprehensive understanding of their capabilities. The relatively small differences in accuracy suggest that both models are performing at a comparable level overall, but their strengths lie in different areas. The choice of which model to use would depend on the specific application and the characteristics of the data it will be processing.
</details>
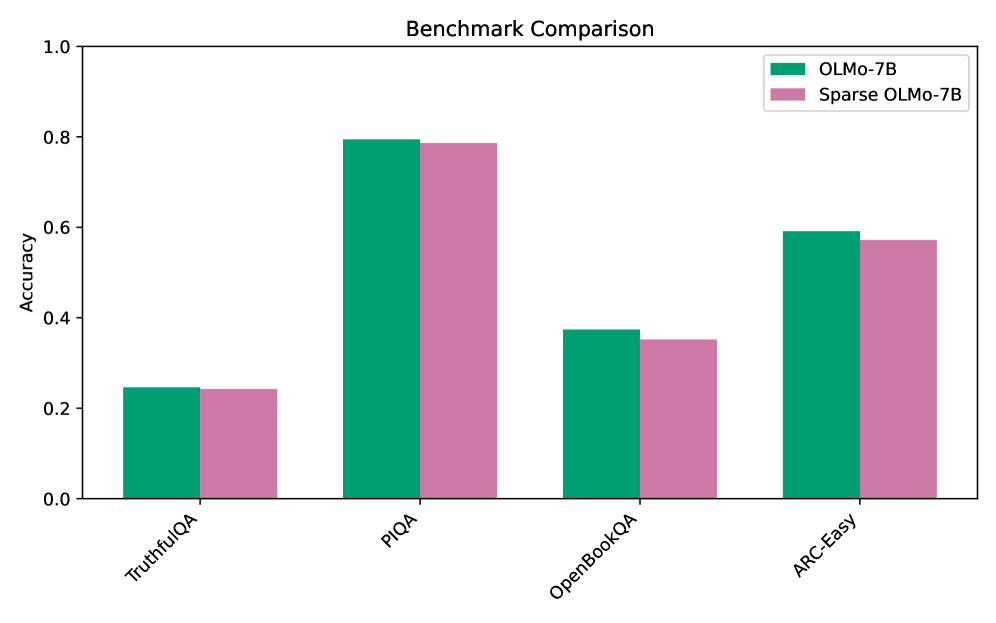
Figure 2: Comparison of model performance between the base OLMo model and the sparsified model evaluated on the various benchmarks. Across all tasks, the performance of the sparse model remains comparable with the base model despite using substantially fewer attention edges.
## 4 Experiments
To evaluate the effectiveness of our post-training pipeline, we finetune pre-trained LLMs and compare their prediction performance and interpretability before and after applying sparsity regularisation. We perform full finetuning on a GPT-2 base model (Radford et al., 2019) (124M parameters) on the OpenWebText dataset (Gokaslan and Cohen, 2019). To investigate the generality and scalability of our method, we perform LoRA finetuning on the larger OLMo-7B model (Groeneveld et al., 2024) on the Dolma dataset (Soldaini et al., 2024), which is the dataset on which the base model was trained. The GPT-2 model and the OLMo model are trained on sequences of length 64 and 512, respectively. In the following subsections, we first present a quantitative evaluation of model performance and sparsity after sparse post-training. We then conduct two interpretability studies, using activation patching and attribution graphs, to demonstrate that our method enables the discovery of substantially smaller circuits.
### 4.1 Model Performance and Sparsity
We begin by evaluating both performance retention and the degree of sparsity achieved by post-training. We set cross-entropy targets of 3.50 for GPT-2 (base model: 3.48) and 2.29 for OLMo (base model: 2.24). After training, the mean cross-entropy loss for both models remains within $\pm 0.01$ of the target, indicating that the dual optimisation scheme effectively enforces a tight performance constraint. To quantify the sparsity achieved by the models, we evaluate them on the validation split of their respective datasets and compute the mean number of non-zero attention edges per attention head. We find that the sparsified GPT-2 model activates, on average, only 0.22% of its attention edges, while the sparsified OLMo model activates 0.44%, indicating substantial sparsification in both cases. Table 1 provides a summary of the results. To further verify that this drastic reduction in message passing between tokens does not substantially alter model behaviour, we evaluate the sparsified OLMo model on a subset of the benchmarks used to assess the original model. As shown in Figure 2, the sparse model largely retains the performance of the base model across a diverse set of tasks. In sum, our results demonstrate that sparse post-training is effective in consolidating information flow into a small number of edges while maintaining a commensurate level of performance.
| GPT-2 | 3.48 | 3.50 | 3.501 | 0.22% |
| --- | --- | --- | --- | --- |
| OLMo | 2.24 | 2.29 | 2.287 | 0.44% |
Table 1: Performance and sparsity of post-trained models. Final cross-entropy losses closely match the specified targets, while attention sparsity is substantially increased.
### 4.2 Circuit Discovery with Activation Patching
<details>
<summary>x3.png Details</summary>

### Visual Description
\n
## Scatter Plot Matrix: GPT2 and Sparse GPT2 Attention Heads
### Overview
The image presents a scatter plot matrix comparing attention heads between two models: GPT2 and Sparse GPT2. Each cell in the matrix displays a scatter plot visualizing the relationship between two attention heads. The matrix is organized into a grid, with each row and column representing an attention head. The top section of the matrix represents GPT2 attention heads, and the bottom section represents Sparse GPT2 attention heads.
### Components/Axes
The matrix is composed of 6 rows and 6 columns, resulting in 36 individual scatter plots. Each scatter plot has two axes, both labeled implicitly by the corresponding attention head identifier. The attention head identifiers follow the format "L[layer number]H[head number]". The layer numbers range from 0 to 11, and the head numbers range from 0 to 11. The top section is labeled "GPT2" and the bottom section is labeled "Sparse GPT2".
### Detailed Analysis or Content Details
The matrix can be divided into two main sections: GPT2 (top) and Sparse GPT2 (bottom). Each cell contains a scatter plot. The plots show the relationship between two attention heads. The x and y axes of each plot represent the values of the attention weights for the corresponding heads.
**GPT2 Section (Top 6 rows):**
* **L0H0 vs. L0H2:** A very sparse scatter plot with points clustered near the origin.
* **L0H0 vs. L5H5:** A very sparse scatter plot with points clustered near the origin.
* **L0H0 vs. L0H7:** A very sparse scatter plot with points clustered near the origin.
* **L0H0 vs. L0H1:** A very sparse scatter plot with points clustered near the origin.
* **L0H0 vs. L0H10:** A very sparse scatter plot with points clustered near the origin.
* **L0H0 vs. L0H3:** A very sparse scatter plot with points clustered near the origin.
* **L0H0 vs. L8H5:** A very sparse scatter plot with points clustered near the origin.
* **L0H0 vs. L1H3:** A very sparse scatter plot with points clustered near the origin.
* **L7H6 vs. L3H10:** A very sparse scatter plot with points clustered near the origin.
* **L7H6 vs. L4H8:** A very sparse scatter plot with points clustered near the origin.
* **L7H6 vs. L2H11:** A very sparse scatter plot with points clustered near the origin.
* **L7H6 vs. L5H8:** A very sparse scatter plot with points clustered near the origin.
* **L7H6 vs. L6H7:** A very sparse scatter plot with points clustered near the origin.
* **L7H6 vs. L1H10:** A very sparse scatter plot with points clustered near the origin.
* **L7H6 vs. L6H10:** A very sparse scatter plot with points clustered near the origin.
* **L7H3 vs. L3H0:** A very sparse scatter plot with points clustered near the origin.
* **L3H0 vs. L5H9:** A very sparse scatter plot with points clustered near the origin.
* **L3H0 vs. L7H1:** A very sparse scatter plot with points clustered near the origin.
* **L3H0 vs. L2H10:** A very sparse scatter plot with points clustered near the origin.
* **L3H0 vs. L7H2:** A very sparse scatter plot with points clustered near the origin.
* **L3H0 vs. L8H10:** A very sparse scatter plot with points clustered near the origin.
* **L3H0 vs. L7H10:** A very sparse scatter plot with points clustered near the origin.
* **L3H0 vs. L9H5:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L7H11:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L2H9:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L1H4:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L6H11:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L3H8:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L5H3:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L7H7:** A very sparse scatter plot with points clustered near the origin.
* **L6H6 vs. L11H10:** A very sparse scatter plot with points clustered near the origin.
* **L9H5 vs. L6H9:** A very sparse scatter plot with points clustered near the origin.
* **L9H5 vs. L4H9:** A very sparse scatter plot with points clustered near the origin.
* **L9H5 vs. L1H2:** A very sparse scatter plot with points clustered near the origin.
* **L9H5 vs. L11H10:** A very sparse scatter plot with points clustered near the origin.
* **L9H5 vs. L4H3:** A very sparse scatter plot with points clustered near the origin.
* **L3H11 vs. L6H8:** A very sparse scatter plot with points clustered near the origin.
* **L3H11 vs. L4H7:** A very sparse scatter plot with points clustered near the origin.
* **L3H11 vs. L0H6:** A very sparse scatter plot with points clustered near the origin.
* **L3H11 vs. L3H1:** A very sparse scatter plot with points clustered near the origin.
* **L3H11 vs. L5H7:** A very sparse scatter plot with points clustered near the origin.
* **L3H11 vs. L10H2:** A very sparse scatter plot with points clustered near the origin.
* **L3H6 vs. L6H3:** A very sparse scatter plot with points clustered near the origin.
* **L3H6 vs. L11H11:** A very sparse scatter plot with points clustered near the origin.
* **L3H6 vs. L5H2:** A very sparse scatter plot with points clustered near the origin.
* **L3H6 vs. L2H3:** A very sparse scatter plot with points clustered near the origin.
* **L3H6 vs. L0H11:** A very sparse scatter plot with points clustered near the origin.
**Sparse GPT2 Section (Bottom 6 rows):**
* **L0H5 vs. L5H1:** A very sparse scatter plot with points clustered near the origin.
* **L0H5 vs. L4H11:** A very sparse scatter plot with points clustered near the origin.
* **L0H5 vs. L6H8:** A very sparse scatter plot with points clustered near the origin.
* **L0H5 vs. L5H5:** A very sparse scatter plot with points clustered near the origin.
* **L0H5 vs. L1H0:** A very sparse scatter plot with points clustered near the origin.
* **L0H5 vs. L6H9:** A very sparse scatter plot with points clustered near the origin.
* **L0H5 vs. L3H4:** A very sparse scatter plot with points clustered near the origin.
* **L0H5 vs. L5H6:** A very sparse scatter plot with points clustered near the origin.
In general, the scatter plots are very sparse, indicating a weak or non-linear relationship between most attention heads.
### Key Observations
The most striking observation is the sparsity of the scatter plots. Almost all plots show very few data points, and those points are clustered near the origin. This suggests that the attention weights of most head pairs are largely independent. There are no obvious clusters or trends in any of the plots.
### Interpretation
The scatter plot matrix is designed to visualize the relationships between attention heads in two different models. The sparsity of the plots suggests that the attention heads in both GPT2 and Sparse GPT2 operate largely independently of each other. This could indicate that the models are utilizing a diverse set of attention mechanisms, with each head focusing on different aspects of the input data. The lack of strong correlations between heads might also suggest that the models are not relying heavily on complex interactions between attention heads. The fact that the patterns are similar in both GPT2 and Sparse GPT2 suggests that the sparsity is not an artifact of the sparse model architecture, but rather a fundamental characteristic of the attention mechanism itself. The data does not provide information about the *strength* of the relationships, only their *presence* or *absence*. The plots are primarily diagnostic, indicating a lack of strong dependencies.
</details>
Figure 3: Attention patterns of the heads required to explain 90% of model behaviour on a copy task. The sparse model requires substantially fewer attention heads. Moreover, the selected heads exhibit the characteristic ‘induction head’ pattern: each token attends to a previous token at a fixed relative offset, effectively copying information forward through the sequence, a pattern well known to implement the copy mechanism in transformer models. Equivalent plots for OLMo can be found in Appendix D.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Line Charts: Effect of Heads Kept on Explained Effect for Different Models
### Overview
The image presents four line charts, each comparing the "Explained Effect" of two different models as the "Number of Heads Kept" increases. Each chart focuses on a different evaluation metric: "Greater Than", "IOI", "Docstring", and "IOI Long". The charts visually demonstrate how much of the effect is retained as the number of attention heads is reduced.
### Components/Axes
Each chart shares the following components:
* **X-axis:** "Number of Heads Kept" - ranging from approximately 0 to 1000.
* **Y-axis:** "Explained Effect" - ranging from 0.0 to 1.0.
* **Titles:** Each chart has a title indicating the evaluation metric used ("Greater Than", "IOI", "Docstring", "IOI Long").
* **Legends:** Each chart has a legend identifying the two models being compared.
The specific models and legend colors are as follows:
* **Chart 1 ("Greater Than"):**
* GPT-2 (Blue)
* Sparse GPT-2 (Orange)
* **Chart 2 ("IOI"):**
* GPT-2 (Blue)
* Sparse GPT-2 (Orange)
* **Chart 3 ("Docstring"):**
* OLMo-7B (Green)
* Sparse OLMo-7B (Pink)
* **Chart 4 ("IOI Long"):**
* OLMo-7B (Green)
* Sparse OLMo-7B (Pink)
Each chart also includes a vertical dashed line with a text label indicating a performance ratio (e.g., "4.5x", "2.2x").
### Detailed Analysis or Content Details
**Chart 1: Greater Than**
* **GPT-2 (Blue):** The line starts at approximately 0.0 at 0 heads kept, rises rapidly to around 0.8 by 50 heads kept, and plateaus around 0.95-1.0 from approximately 75 heads kept onwards.
* **Sparse GPT-2 (Orange):** The line starts at approximately 0.0 at 0 heads kept, rises more gradually than GPT-2, reaching around 0.7 by 50 heads kept, and plateaus around 0.8-0.9 from approximately 75 heads kept onwards.
* The dashed line is positioned at approximately 75 heads kept and labeled "4.5x".
**Chart 2: IOI**
* **GPT-2 (Blue):** The line starts at approximately 0.0 at 0 heads kept, rises rapidly to around 0.8 by 50 heads kept, and plateaus around 0.95-1.0 from approximately 75 heads kept onwards.
* **Sparse GPT-2 (Orange):** The line starts at approximately 0.0 at 0 heads kept, rises more gradually than GPT-2, reaching around 0.7 by 50 heads kept, and plateaus around 0.8-0.9 from approximately 75 heads kept onwards.
* The dashed line is positioned at approximately 50 heads kept and labeled "2.2x".
**Chart 3: Docstring**
* **OLMo-7B (Green):** The line starts at approximately 0.0 at 250 heads kept, rises rapidly to around 0.8 by 750 heads kept, and plateaus around 0.9-1.0 from approximately 750 heads kept onwards.
* **Sparse OLMo-7B (Pink):** The line starts at approximately 0.0 at 250 heads kept, rises more slowly than OLMo-7B, reaching around 0.6 by 750 heads kept, and plateaus around 0.7-0.8 from approximately 750 heads kept onwards.
* The dashed line is positioned at approximately 750 heads kept and labeled "2.2x".
**Chart 4: IOI Long**
* **OLMo-7B (Green):** The line starts at approximately 0.0 at 250 heads kept, rises rapidly to around 0.8 by 750 heads kept, and plateaus around 0.9-1.0 from approximately 750 heads kept onwards.
* **Sparse OLMo-7B (Pink):** The line starts at approximately 0.0 at 250 heads kept, rises more slowly than OLMo-7B, reaching around 0.6 by 750 heads kept, and plateaus around 0.7-0.8 from approximately 750 heads kept onwards.
* The dashed line is positioned at approximately 750 heads kept and labeled "1.4x".
### Key Observations
* In all four charts, the "Sparse" model consistently exhibits a lower "Explained Effect" than its non-sparse counterpart for a given number of heads kept.
* The performance gap between the models appears to diminish as the number of heads kept increases, but the sparse models never fully catch up.
* The "Greater Than" and "IOI" metrics show a more pronounced difference between GPT-2 and Sparse GPT-2 than the "Docstring" and "IOI Long" metrics show between OLMo-7B and Sparse OLMo-7B.
* The dashed lines indicate the relative improvement achieved by the non-sparse model over the sparse model at a specific number of heads kept.
### Interpretation
These charts demonstrate the trade-off between model size (number of heads) and performance (explained effect). Reducing the number of heads (sparsity) leads to a decrease in explained effect, but it also potentially reduces computational cost and memory requirements. The "x" values (4.5x, 2.2x, 2.2x, 1.4x) represent the factor by which the non-sparse model outperforms the sparse model at the indicated number of heads kept.
The differences in the magnitude of these factors across the different evaluation metrics suggest that the impact of sparsity varies depending on the task. "Greater Than" and "IOI" seem to be more sensitive to sparsity than "Docstring" and "IOI Long". This could indicate that the sparse models retain more of their capabilities for tasks requiring more complex reasoning or understanding of long-range dependencies.
The charts suggest that while sparsity can be a useful technique for model compression, it comes at a cost in terms of performance. The optimal level of sparsity will depend on the specific application and the desired balance between performance and efficiency. The dashed lines provide a visual guide for understanding the performance trade-offs at different sparsity levels.
</details>
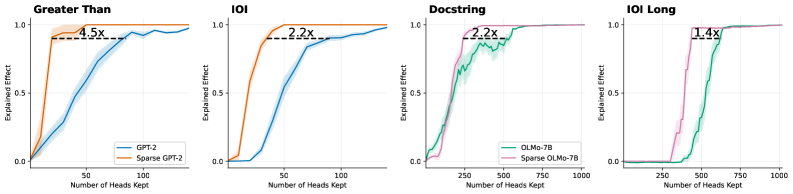
Figure 4: Logit attribution keeping only the top- $k$ attention heads. Dotted line annotates the number of attention heads needed to explain 90% of the logit difference. Sparse models yields 1.4 $\times$ to 4.5 $\times$ smaller circuits. Shaded areas show standard error across 20 prompts.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Charts: Sparsity vs. Explained Effect
### Overview
The image presents four charts comparing the "Explained Effect" of different models (GPT-2, OLMo-7B) and their sparse counterparts as a function of the "Number of Edges Kept". Each chart focuses on a different evaluation context: "Greater Than", "IOI", "Docstring", and "IOI Long". The charts visually demonstrate how much of the effect is explained as the number of edges retained in the model increases.
### Components/Axes
Each chart shares the following components:
* **X-axis:** "Number of Edges Kept" - Logarithmic scale from 10<sup>0</sup> to 10<sup>5</sup>.
* **Y-axis:** "Explained Effect" - Linear scale from 0.0 to 1.0.
* **Title:** Indicates the evaluation context ("Greater Than", "IOI", "Docstring", "IOI Long").
* **Legend:** Identifies the data series.
The four charts have the following specific data series:
1. **"Greater Than" Chart:**
* GPT-2 (Orange)
* Sparse GPT-2 (Blue)
2. **"IOI" Chart:**
* GPT-2 (Orange)
* Sparse GPT-2 (Blue)
3. **"Docstring" Chart:**
* OLMo-7B (Pink)
* Sparse OLMo-7B (Green)
4. **"IOI Long" Chart:**
* OLMo-7B (Pink)
* Sparse OLMo-7B (Green)
Each chart also includes a dashed horizontal line with a numerical value indicating the relative improvement of the sparse model over the dense model.
### Detailed Analysis
**1. "Greater Than" Chart:**
* **GPT-2 (Orange):** The line starts at approximately 0.05 at 10<sup>0</sup> edges and rapidly increases, reaching approximately 0.95 at 10<sup>3</sup> edges. It plateaus around 0.98 after 10<sup>3</sup> edges.
* **Sparse GPT-2 (Blue):** The line starts at approximately 0.05 at 10<sup>0</sup> edges and increases more slowly than GPT-2, reaching approximately 0.85 at 10<sup>3</sup> edges. It plateaus around 0.95 after 10<sup>3</sup> edges.
* **Improvement:** The dashed line indicates a 97.0x improvement.
**2. "IOI" Chart:**
* **GPT-2 (Orange):** The line starts at approximately 0.05 at 10<sup>0</sup> edges and rapidly increases, reaching approximately 0.95 at 10<sup>3</sup> edges. It plateaus around 0.99 after 10<sup>3</sup> edges.
* **Sparse GPT-2 (Blue):** The line starts at approximately 0.05 at 10<sup>0</sup> edges and increases more slowly than GPT-2, reaching approximately 0.80 at 10<sup>3</sup> edges. It plateaus around 0.95 after 10<sup>3</sup> edges.
* **Improvement:** The dashed line indicates a 42.8x improvement.
**3. "Docstring" Chart:**
* **OLMo-7B (Pink):** The line starts at approximately 0.1 at 10<sup>0</sup> edges and increases, reaching approximately 0.75 at 10<sup>3</sup> edges. It plateaus around 0.90 after 10<sup>3</sup> edges.
* **Sparse OLMo-7B (Green):** The line starts at approximately 0.1 at 10<sup>0</sup> edges and rapidly increases, reaching approximately 0.95 at 10<sup>3</sup> edges. It plateaus around 0.99 after 10<sup>3</sup> edges.
* **Improvement:** The dashed line indicates a 8.6x improvement.
**4. "IOI Long" Chart:**
* **OLMo-7B (Pink):** The line starts at approximately 0.1 at 10<sup>0</sup> edges and increases, reaching approximately 0.70 at 10<sup>3</sup> edges. It plateaus around 0.85 after 10<sup>3</sup> edges.
* **Sparse OLMo-7B (Green):** The line starts at approximately 0.1 at 10<sup>0</sup> edges and rapidly increases, reaching approximately 0.90 at 10<sup>3</sup> edges. It plateaus around 0.98 after 10<sup>3</sup> edges.
* **Improvement:** The dashed line indicates a 5.4x improvement.
### Key Observations
* In all four charts, the sparse models (Blue/Green) consistently show a slower initial increase in "Explained Effect" compared to their dense counterparts (Orange/Pink).
* However, the sparse models eventually reach comparable or even slightly higher levels of "Explained Effect" with fewer edges.
* The magnitude of improvement varies significantly across the evaluation contexts. "Greater Than" shows the largest improvement (97.0x), while "IOI Long" shows the smallest (5.4x).
* The "IOI" chart shows a very high explained effect for the dense GPT-2 model, reaching nearly 1.0 with a relatively small number of edges.
### Interpretation
These charts demonstrate the benefits of sparsity in large language models. While dense models initially achieve higher "Explained Effect" with a small number of edges, sparse models can achieve comparable or better performance with significantly fewer parameters (edges). This suggests that sparsity can be an effective technique for model compression and efficiency without sacrificing performance.
The varying degrees of improvement across different evaluation contexts suggest that the effectiveness of sparsity depends on the specific task or data distribution. The "Greater Than" context, for example, may be more amenable to sparsity than the "IOI Long" context.
The horizontal lines representing the improvement factor provide a quantitative measure of the benefits of sparsity. A higher improvement factor indicates a greater reduction in the number of parameters required to achieve a given level of performance. The fact that all improvement factors are greater than 1 indicates that sparsity is generally beneficial in these scenarios.
The charts highlight a trade-off between initial performance and long-term efficiency. Dense models may be faster to train and achieve higher initial performance, but sparse models offer the potential for significant long-term savings in terms of storage and computational cost.
</details>
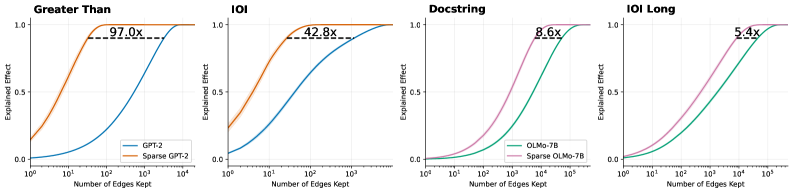
Figure 5: Logit attribution per sentence keeping only the top- $k$ attention edges. Sparse models yields 5.4 $\times$ to 97 $\times$ smaller circuits. Shaded area shows standard error across 20 prompts.
We begin by outlining the experimental procedure used for circuit discovery. Activation patching (Nanda et al., 2023) is a widely used technique for identifying task-specific circuits in transformer models. In a typical setup, the model is evaluated on pairs of prompts: a clean prompt, for which the model predicts a correct target token, and a corrupted prompt that shares the overall structure of the clean prompt but is modified to induce an incorrect prediction. Here, the goal is to find the set of model components that is responsible for the model’s preference for the correct answer over the wrong one, as measured by the logit difference between the corresponding tokens. In activation patching, individual model components, such as attention heads and individual edges, can be ’switched-off’ by patching activation at the specific positions. Circuit discovery amounts to finding a set of components whose replacement causes the model’s prediction to shift from the correct to the corrupted answer.
Since searching over every possible subset of model components is infeasible due to the exponential number of potential subsets, we adopt a common heuristic to rank each model component. Specifically, for each individual component, we compute an importance score by replacing the activations of the component with the corrupted activations and measuring its effect on the logit difference. In our experiments, we use this ranking to select the top- $k$ components and intervene on the model by freezing all remaining components, with the goal of identifying the minimal set that accounts for at least 90% of the model’s preference for the correct prediction. Note that these importance scores can be computed at two levels: (i) a single-sentence level, using a single pair of correct and corrupted inputs, and (ii) a global level, obtained by averaging scores across many task variants. In our experiments, we report the results using single-sentence scores. In Appendix D, we also provide results using the global scores, which are largely consistent with our main results. There are also two standard approaches for freezing component activations: setting the activation to zero or replacing it with a mean activation value (Conmy et al., 2023). We evaluate both variants for each model and report results for the patching strategy that yields the smallest circuits.
We first focus on the copy task with the following prompt: "AJEFCKLMOPQRSTVWZS, AJEFCKLMOPQRSTVWZ", where the model has to copy the letter S to the next token position. This task is well studied and is widely believed to be implemented by emergent induction heads (Elhage et al., 2021), which propagate token information forward in the sequence. Figure 3 illustrates the attention patterns of the set of attention heads that explains this prompt for the sparse and base GPT-2 models. See Appendix D for analogous results for the OLMo models. The sparse model admits a substantially smaller set of attention heads (9 heads) than its fully connected counterpart (61 heads). Moreover, the identified heads in the sparse model exhibit cleaner induction head patterns, with each token attending to a single prior position at a fixed relative offset. These results illustrate how sparsification facilitates interpretability under simple ranking-based methods and support our hypothesis that sparse post-training yields models that are more amenable to mechanistic interpretability techniques.
To further verify our hypothesis, we repeat the experiment on classical circuit discovery tasks. For GPT-2, we evaluate variants of the Indirect Object Identification (IOI) task, in which the model copies a person’s name from the start of a sentence, and the Greater Than task, in which the model predicts a number that is larger than a previously mentioned number. To further assess the scalability of our approach, we investigate more challenging and longer horizon tasks for OLMo, including a longer context IOI task and a Docstring task where the model needs to predict an argument name in a Docstring based on an implemented function. Details of each task can be found in Appendix E. Figure 4 and 5 show the fraction of model behaviour explained as a function of the number of retained model components (attention heads and attention edges, respectively). Across all tasks and models, the sparse models consistently produce significantly smaller circuits, as measured by the number of model components needed to explain 90% of model prediction. This further corroborates our claim that sparse models lead to simpler and more interpretable internal circuits.
### 4.3 Attribution-graph
Next, we present a more fine-grained, feature-level investigation of whether sparsity in attention leads to interpretable circuits in practice using cross-layer transcoders (CLTs). Since training CLTs on OLMo-7B is computationally prohibitive The largest open-source CLT is on Gemma-2B at the time of writing., we focus our analysis on the GPT-2 models. For the rest of the section, we perform analysis on CLTs trained on the sparse and base GPT-2 models, trained with an expansion factor of $32$ and achieve above $80\$ replacement score measured with Circuit Tracer (Hanna et al., 2025). See Appendix F and G for details on training and visualisation.
We study the problem of attention attribution, which seeks to understand how edges between features are mediated. The key challenge here is that any given edge can be affected by a large number of model components, making mediation circuits difficult to analyse both computationally and conceptually: computationally, exhaustive enumeration is costly; conceptually, the resulting circuits are often large and uninterpretable. In this experiment, we demonstrate that sparse attention patterns induced via post-training substantially alleviate these challenges, as the vast majority of attention components have zero effect on the computation.
As in (Ameisen et al., 2025), we define the total attribution score between feature $n$ at layer $\ell$ and position $k$ , and feature $n^{\prime}$ at layer $\ell^{\prime}$ and position $k^{\prime}$ as
$$
a_{\ell,k,n}^{\ell^{\prime},k^{\prime},n^{\prime}}=f_{k,n}^{\ell}\;J_{\ell,k}^{\ell^{\prime},k^{\prime}}\;g_{k^{\prime},n^{\prime}}^{\ell^{\prime}}. \tag{6}
$$
Here, $f_{k,n}^{\ell}$ denotes the decoder vector corresponding to feature $n$ at layer $\ell$ and position $k$ , and $g_{k^{\prime},n^{\prime}}^{\ell^{\prime}}$ is the corresponding encoder vector for feature $n^{\prime}$ at layer $\ell^{\prime}$ and position $k^{\prime}$ . The term $J_{\ell,k}^{\ell^{\prime},k^{\prime}}$ is the Jacobian from the MLP output at $(\ell,k)$ to the MLP input at $(\ell^{\prime},k^{\prime})$ . This Jacobian is computed during a forward pass in which all nonlinearities are frozen using stop-gradient operations. Under this linearisation, the attribution score represents the sum over all linear paths from the source feature to the target feature.
To analyse how this total effect between two features is mediated by each model component, we define the component-specific attribution by subtracting the contribution of all paths that do not pass through the component:
$$
a_{\ell,k,n}^{\ell^{\prime},k^{\prime},n^{\prime}}(h)=f_{k,n}^{\ell}\;J_{\ell,k}^{\ell^{\prime},k^{\prime}}\;g_{k^{\prime},n^{\prime}}^{\ell^{\prime}}-f_{k,n}^{\ell}\;\bigl[J_{\ell,k}^{\ell^{\prime},k^{\prime}}\bigr]_{h}\;g_{k^{\prime},n^{\prime}}^{\ell^{\prime}}.
$$
Here, $\bigl[J_{\ell,k}^{\ell^{\prime},k^{\prime}}\bigr]_{h}$ denotes a modified Jacobian computed under the same linearization as above, but with the specific attention component $h$ additionaly frozen via stop-gradient. As such, these component-specific scores quantifies how much each model component impacts a particular edge between features.
Empicially, we evaluate the method on ten pruned attribution graphs, computed on the IOI, greater-than, completion, and category tasks. Similar to our previous circuit discovery experiment, we compute attribution scores on the level of attention heads as well as individual key–query pairs. In practice, attention sparsity yields substantial computational savings: because inactive key–query pairs are known a priori to have exactly zero attribution score, attribution need only be computed for a small subset of components. This reduces the computation time per attribution graph from several hours to several minutes.
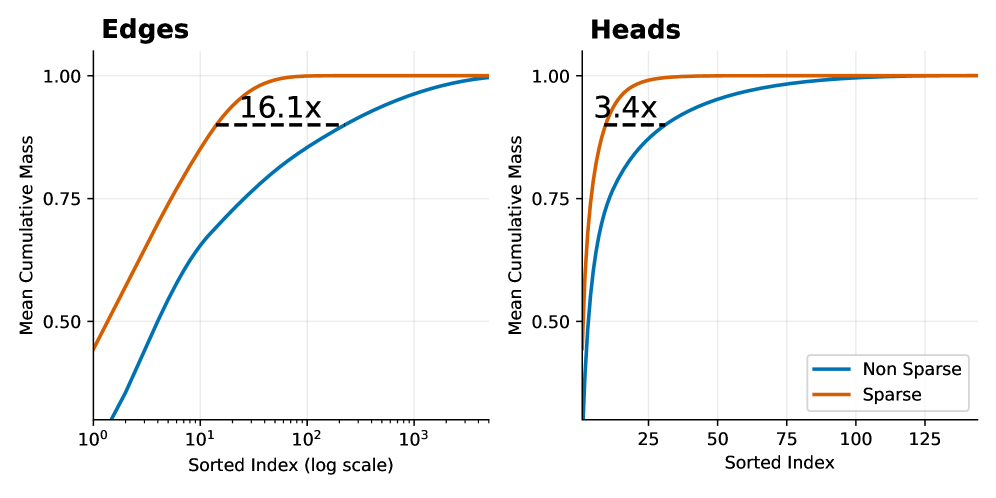
<details>
<summary>x6.png Details</summary>
### Visual Description
## Cumulative Distribution Plots: Edges and Heads Sparsity
### Overview
The image presents two cumulative distribution plots, side-by-side. The left plot focuses on "Edges" and the right plot on "Heads". Both plots compare the cumulative mass of "Non Sparse" and "Sparse" data, plotted against a sorted index. The x-axis uses a logarithmic scale for the "Edges" plot. Both plots include a dashed horizontal line indicating a multiplicative factor representing the difference in cumulative mass between the two data types.
### Components/Axes
* **Title (Left):** "Edges" - positioned top-left.
* **Title (Right):** "Heads" - positioned top-left.
* **X-axis (Both):** "Sorted Index" - labeled at the bottom. The "Edges" plot uses a log scale (10^0 to 10^3). The "Heads" plot uses a linear scale (0 to 125).
* **Y-axis (Both):** "Mean Cumulative Mass" - labeled on the left, ranging from 0.0 to 1.0.
* **Legend (Right):** Located in the bottom-right corner.
* "Non Sparse" - represented by a blue line.
* "Sparse" - represented by an orange line.
* **Horizontal Dashed Line (Left):** Labeled "16.1x" - positioned approximately at y=0.95.
* **Horizontal Dashed Line (Right):** Labeled "3.4x" - positioned approximately at y=0.95.
### Detailed Analysis or Content Details
**Edges Plot (Left):**
* **Sparse (Orange):** The orange line representing "Sparse" data exhibits a steep upward slope initially, quickly reaching a cumulative mass of approximately 0.8 by an index of around 10^2 (100). It plateaus around a cumulative mass of 0.95 from an index of approximately 50 to 1000.
* **Non Sparse (Blue):** The blue line representing "Non Sparse" data starts with a gradual slope, increasing more slowly than the "Sparse" data. It reaches a cumulative mass of approximately 0.5 at an index of around 10^1 (10). It continues to increase, but at a slower rate, reaching a cumulative mass of approximately 0.95 at an index of around 10^3 (1000).
* **Difference:** The "Sparse" data reaches a higher cumulative mass for lower sorted indices compared to the "Non Sparse" data. The dashed line indicates that the "Sparse" data achieves a cumulative mass approximately 16.1 times greater than the "Non Sparse" data at the point where the cumulative mass is approximately 0.95.
**Heads Plot (Right):**
* **Sparse (Orange):** The orange line representing "Sparse" data rises rapidly, reaching a cumulative mass of approximately 0.75 by an index of 25. It plateaus around a cumulative mass of 0.95 from an index of approximately 50.
* **Non Sparse (Blue):** The blue line representing "Non Sparse" data starts with a slower slope, gradually increasing. It reaches a cumulative mass of approximately 0.5 at an index of around 25. It continues to increase, approaching a cumulative mass of 0.95 at an index of around 100.
* **Difference:** Similar to the "Edges" plot, the "Sparse" data reaches a higher cumulative mass for lower sorted indices. The dashed line indicates that the "Sparse" data achieves a cumulative mass approximately 3.4 times greater than the "Non Sparse" data at the point where the cumulative mass is approximately 0.95.
### Key Observations
* In both plots, the "Sparse" data consistently exhibits a higher cumulative mass for lower sorted indices compared to the "Non Sparse" data.
* The difference in cumulative mass between "Sparse" and "Non Sparse" data is more pronounced in the "Edges" plot (16.1x) than in the "Heads" plot (3.4x).
* The "Edges" plot uses a logarithmic scale on the x-axis, which compresses the distribution of indices.
### Interpretation
These plots demonstrate the impact of sparsity on the cumulative mass of "Edges" and "Heads" features. The higher cumulative mass of "Sparse" data at lower indices suggests that a significant portion of the total mass is concentrated in a smaller number of features when sparsity is applied. The larger multiplicative factor for "Edges" (16.1x) indicates that sparsity has a more substantial effect on the distribution of "Edges" features compared to "Heads" features. This could imply that "Edges" are more amenable to sparsity-inducing techniques or that the underlying data distribution of "Edges" naturally lends itself to sparsity. The plots suggest that applying sparsity can effectively capture the most important features (those contributing to the initial cumulative mass) while potentially discarding less relevant ones. The difference in the multiplicative factors between "Edges" and "Heads" suggests that the effectiveness of sparsity may vary depending on the type of feature being considered.
</details>
Figure 6: Mean cumulative distribution of the component scores that mediate an attribution graph edge. The components are on the left key-query pairs within a head, and on the right full attention heads.
In terms of circuit size, Figure 6 shows the mean cumulative distribution of component attribution scores for each edge in the attribution graph. We find that, to reach a cumulative attribution threshold of $90\$ , the sparse model on average requires $16.1\times$ fewer key–query pairs and $3.4\times$ fewer attention heads when compared to the dense GPT-2 model, supporting our hypothesis that sparse attention patterns leads to simpler mediation circuits.
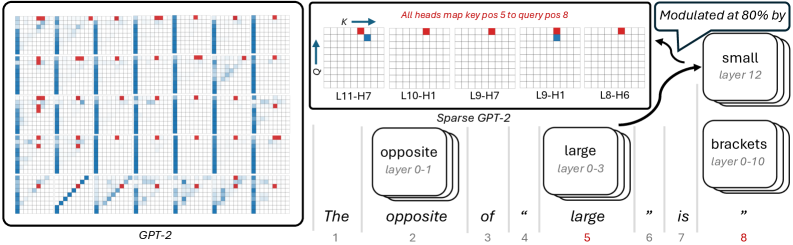
<details>
<summary>x7.png Details</summary>
### Visual Description
\n
## Diagram: Sparse GPT-2 Attention Map & Layer Relationships
### Overview
The image presents a diagram illustrating the attention mechanism within the GPT-2 model, specifically focusing on a sparse variant. It depicts attention maps for different layers and highlights relationships between layers described as "opposite" and "large". The diagram uses a grid-based representation of attention weights, with color indicating the strength of attention.
### Components/Axes
The diagram is composed of several key elements:
* **GPT-2 Attention Map (Left):** A large grid representing the attention weights within the GPT-2 model. The grid is composed of vertical lines, with red squares indicating attention points.
* **Sparse GPT-2 Attention Map (Top-Right):** A smaller grid representing attention weights in a sparse GPT-2 model. It has labels for layers (L11-H7, L10-H1, L9-H7, L9-H1, L8-H6) and axes labeled 'K' and 'Q'.
* **Layer Blocks (Bottom):** Three stacked blocks representing different layers: "opposite layer 0-1", "large layer 0-3", and "brackets layer 0-10".
* **Textual Description (Bottom):** The phrase "The opposite of “large” is “".
* **Annotation:** "Modulated at 80% by" with an arrow pointing from the Sparse GPT-2 Attention Map to a "small layer 12" block.
The axes in the Sparse GPT-2 Attention Map are labeled 'K' (vertical) and 'Q' (horizontal).
### Detailed Analysis or Content Details
**GPT-2 Attention Map (Left):**
* The grid is approximately 15x15.
* Vertical lines dominate the grid, indicating a strong attention pattern along the sequence length.
* Red squares are sparsely distributed throughout the grid, indicating attention points. The density of red squares appears to vary across the grid.
* The pattern is somewhat diagonal, with attention points clustered along certain diagonals.
**Sparse GPT-2 Attention Map (Top-Right):**
* The grid is approximately 8x8.
* The layers are labeled as follows: L11-H7, L10-H1, L9-H7, L9-H1, L8-H6.
* The 'K' axis appears to represent the key dimension, and the 'Q' axis represents the query dimension.
* Red squares are present, indicating attention weights. The distribution of red squares appears relatively sparse.
* The annotation "Modulated at 80% by" points to a "small layer 12" block.
**Layer Blocks (Bottom):**
* "opposite layer 0-1"
* "large layer 0-3"
* "brackets layer 0-10"
**Textual Description (Bottom):**
* "The opposite of “large” is “"
### Key Observations
* The attention maps show a sparse attention pattern, meaning that not all tokens attend to all other tokens.
* The "large" and "opposite" layers are explicitly mentioned, suggesting a specific architectural feature or relationship within the model.
* The modulation at 80% indicates a scaling or weighting applied to the attention mechanism.
* The layer ranges (0-1, 0-3, 0-10) suggest different depths or spans within the model.
### Interpretation
The diagram illustrates a sparse attention mechanism in GPT-2, where attention is focused on a subset of tokens rather than all tokens. The "large" and "opposite" layers likely represent different components of the attention mechanism, potentially related to long-range dependencies and local context, respectively. The modulation at 80% suggests a form of regularization or control over the attention weights. The diagram highlights the hierarchical structure of the model, with different layers contributing to the overall attention pattern. The incomplete sentence "The opposite of “large” is “" suggests a conceptual relationship being explored, potentially hinting at a contrasting attention pattern or function. The diagram is likely used to explain or visualize a specific architectural modification or analysis of the GPT-2 model. The use of sparse attention is a common technique to reduce computational cost and improve efficiency in large language models. The diagram suggests that the model is being analyzed or modified to understand the role of different layers and attention patterns.
</details>
Figure 7: Sketch of the attribution graph for the sentence “The opposite of ‘large’ is”. The cluster of features associated with large at token position 5 maps directly to the final next-token prediction logit small. We show the attention patterns of all key–query pairs required to account for $80\$ of the cumulative attribution score. In the sparse-attention setting, this corresponds to five attention heads, compared to more than forty heads in the dense-attention case. In the sparse model, these heads read from token position 5 and write directly to the last token residual stream at token position 8. These heads thus compute in parallel and provide a clear picture of the internal computation.
Next, we present a qualitative case-study to showcase the benefits of sparse attention patterns. For a given key–query pair, we compute the causal effect from all other features in the attribution graph to both the key and the query vectors. Figure 7 illustrates this analysis for the prompt “The opposite of ‘large’ is”. The resulting attribution graph decomposes into four coherent clusters of features: features related to opposite, features related to large, features activating on bracketed tokens, and the final next-token logit corresponding to small (see Appendix H for example of features and visualization).
Here, the features in the large cluster are directly connected to the small logit. The key question is then to understand how this connection from the large to the small logit comes about. To this end, we analyse their mediation structure. We find that $80\$ of the cumulative attribution score of the edges connecting the large cluster to the small logit is mediated by the same five late layer attention key–query pairs. These attention components map features from token position $5$ directly into the final-layer residual stream at position $8$ , and thus operate in parallel.
For these five key–query pairs, we then compute the causal influence of all other features in the graph on their key and query vectors. The query vectors are primarily modulated by features associated with bracketed tokens in the last token position, while the key vectors are driven by strongly active features in both the opposite and large clusters, as shown in Figure 8.These results are in agreement with the recent work on attention attribution and the ”opposite of” attribution graph (Kamath et al., 2025). In stark contrast, Figure 7 (left) shows that a similar (and more computationally expensive) analysis on the dense model produces a much more complicated circuit. This case study illustrates the potential of sparse attention in the context of attribution graphs, as it enables a unified view of features and circuits. By jointly analyzing feature activations, attention components, and their mediating roles, we obtain a more faithful picture of the computational graph underlying the model’s input–output behavior.
## 5 Conclusion
Achieving interpretability requires innovations in both interpretation techniques and model design. We investigate how large models can be trained to be intrinsically interpretable. We present a flexible post-training procedure that sparsifies transformer attention while preserving the original pretraining loss. By minimally adapting the architecture, we apply a sparsity penalty under a constrained-loss objective, allowing pre-trained model to reorganise its connectivity into a much more selective and structured pattern.
$\rightarrow$ Query
⬇
1. large (pos 5)
2. large (pos 5)
3. quantities (pos 5)
4. comparison (pos 3)
5. opposite (pos 3)
$\rightarrow$ Key
⬇
1. bracket (pos 8)
2. bracket (pos 8)
3. bracket (pos 8)
4. bracket (pos 8)
5. bracket (pos 8)
Figure 8: Minimal description of the top5 features activating the query and the key vectors for the attention head L8-H6 from Figure 7.
Mechanistically, this induced sparsity gives rise to substantially simpler circuits: task-relevant computation concentrates into a small number of attention heads and edges. Across a range of tasks and analyses, we show that sparsity improves interpretability at the circuit level by reducing the number of components involved in specific behaviours. In circuit discovery experiments, most of the model’s behaviour can be explained by circuits that are orders of magnitude smaller than in dense models; in attribution graph analyses, the reduced number of mediating components renders attention attribution tractable. Together, these results position sparse post-training of attention as a practical and effective tool for enhancing the mechanistic interpretability of pre-trained models.
#### Limitations and Future Work.
One limitation of the present investigation is that, while we deliberately focus on sparsity as a post-training intervention, it remains an open question whether injecting a sparsity bias directly during training would yield qualitatively different or simpler circuit structures. Also, a comprehensive exploration of the performance trade-offs for larger models and for tasks that require very dense or long-range attention patterns would be beneficial, even if beyond the computational means currently at our disposal. Moreover, our study is primarily restricted to sparsifying attention patterns, the underlying principle of leveraging sparsity to promote interpretability naturally extends to other components of the transformer architecture. As such, combining the proposed method with complementary approaches for training intrinsically interpretable models, such as Sparse Mixture-of-Experts (Yang et al., 2025), sparsifying model weights (Gao et al., 2024), or limiting superposition offers a promising direction for future work. Another exciting avenue for future work is to apply the sparsity regularisation framework developed here within alternative post-training paradigms, such as reinforcement learning (Ouyang et al., 2022; Zhou et al., 2024) or supervised fine-tuning (Pareja et al., 2025).
## Impact Statement
This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here.
## Acknowledgment
F. D. acknowledges support through a fellowship from the Hector Fellow Academy. A. L. is supported by an EPSRC Programme Grant (EP/V000748/1). I. P. holds concurrent appointments as a Professor of Applied AI at the University of Oxford and as an Amazon Scholar. This paper describes work performed at the University of Oxford and is not associated with Amazon.
## References
- E. Ameisen, J. Lindsey, A. Pearce, W. Gurnee, N. L. Turner, B. Chen, C. Citro, D. Abrahams, S. Carter, B. Hosmer, J. Marcus, M. Sklar, A. Templeton, T. Bricken, C. McDougall, H. Cunningham, T. Henighan, A. Jermyn, A. Jones, A. Persic, Z. Qi, T. Ben Thompson, S. Zimmerman, K. Rivoire, T. Conerly, C. Olah, and J. Batson (2025) Circuit tracing: revealing computational graphs in language models. Transformer Circuits Thread. External Links: Link Cited by: Appendix F, Appendix G, Appendix G, §1, §2.3, §4.3.
- I. Beltagy, M. E. Peters, and A. Cohan (2020) Longformer: the long-document transformer. arXiv preprint arXiv:2004.05150. Cited by: §2.1.
- L. Bereska and E. Gavves (2024) Mechanistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082. Cited by: §1.
- R. e. al. Bommasani (2021) On the opportunities and risks of foundation models. ArXiv. External Links: Link Cited by: §1.
- R. Child, S. Gray, A. Radford, and I. Sutskever (2019) Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509. Cited by: §2.1.
- T. Conerly, H. Cunningham, A. Templeton, J. Lindsey, B. Hosmer, and A. Jermyn (2025) Circuits updates – january 2025. Note: Transformer Circuits Thread External Links: Link Cited by: Appendix F.
- A. Conmy, A. Mavor-Parker, A. Lynch, S. Heimersheim, and A. Garriga-Alonso (2023) Towards automated circuit discovery for mechanistic interpretability. Advances in Neural Information Processing Systems 36, pp. 16318–16352. Cited by: §E.2, §E.3, §1, §1, §2.2, §4.2.
- T. Dao (2023) Flashattention-2: faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691. Cited by: Appendix B, §3.3.
- DeepSeek-AI (2025) DeepSeek-v3.2: pushing the frontier of open large language models. External Links: 2512.02556, Link Cited by: §2.1.
- J. Dunefsky, P. Chlenski, and N. Nanda (2024) Transcoders find interpretable LLM feature circuits. Advances in Neural Information Processing Systems 37, pp. 24375–24410. Cited by: §2.3.
- N. Elhage, N. Nanda, et al. (2021) A mathematical framework for transformer circuits. Transformer Circuits Thread. Note: https://transformer-circuits.pub/2021/framework/index.html Cited by: §E.1, §E.2, §4.2.
- L. Gao, A. Rajaram, J. Coxon, S. V. Govande, B. Baker, and D. Mossing (2024) Weight-sparse transformers have interpretable circuits. Technical report OpenAI. External Links: Link Cited by: §5.
- A. Gokaslan and V. Cohen (2019) OpenWebText corpus. Note: http://Skylion007.github.io/OpenWebTextCorpus Cited by: §4.
- D. Groeneveld, I. Beltagy, P. Walsh, A. Bhagia, R. Kinney, O. Tafjord, A. H. Jha, H. Ivison, I. Magnusson, Y. Wang, S. Arora, D. Atkinson, R. Authur, K. Chandu, A. Cohan, J. Dumas, Y. Elazar, Y. Gu, J. Hessel, T. Khot, W. Merrill, J. Morrison, N. Muennighoff, A. Naik, C. Nam, M. E. Peters, V. Pyatkin, A. Ravichander, D. Schwenk, S. Shah, W. Smith, N. Subramani, M. Wortsman, P. Dasigi, N. Lambert, K. Richardson, J. Dodge, K. Lo, L. Soldaini, N. A. Smith, and H. Hajishirzi (2024) OLMo: accelerating the science of language models. Preprint. Cited by: §4.
- Y. Gu, L. Dong, F. Wei, and M. Huang (2024) MiniLLM: knowledge distillation of large language models. In The Twelfth International Conference on Learning Representations, External Links: Link Cited by: §3.3.
- A. Gupta, G. Dar, S. Goodman, D. Ciprut, and J. Berant (2021) Memory-efficient transformers via top- $k$ attention. arXiv preprint arXiv:2106.06899. Cited by: §2.1.
- M. Hanna, M. Piotrowski, J. Lindsey, and E. Ameisen (2025) Circuit-tracer. Note: https://github.com/safety-research/circuit-tracer The first two authors contributed equally and are listed alphabetically. Cited by: Appendix G, §4.3.
- S. Heimersheim and J. Janiak (2023) A circuit for python docstrings in a 4-layer attention-only transformer. In Alignment Forum, Cited by: §E.3.
- E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, et al. (2022) Lora: low-rank adaptation of large language models.. ICLR 1 (2), pp. 3. Cited by: §3.3.
- E. Jang, S. Gu, and B. Poole (2017) Categorical reparameterization with gumbel-softmax. In International Conference on Learning Representations, External Links: Link Cited by: §3.1.
- H. Kamath, E. Ameisen, I. Kauvar, R. Luger, W. Gurnee, A. Pearce, S. Zimmerman, J. Batson, T. Conerly, C. Olah, and J. Lindsey (2025) Tracing attention computation through feature interactions. Transformer Circuits Thread. External Links: Link Cited by: §1, §2.3, §4.3.
- A. Lei, B. Schölkopf, and I. Posner (2025) SPARTAN: a sparse transformer world model attending to what matters. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, External Links: Link Cited by: §1, §2.1, §3.2, §3.
- J. Lindsey, E. Ameisen, N. Nanda, S. Shabalin, M. Piotrowski, T. McGrath, M. Hanna, O. Lewis, C. Tigges, J. Merullo, C. Watts, G. Paulo, J. Batson, L. Gorton, E. Simon, M. Loeffler, C. McDougall, and J. Lin (2025a) The circuits research landscape: results and perspectives. Neuronpedia. External Links: Link Cited by: Appendix F.
- J. Lindsey, W. Gurnee, E. Ameisen, B. Chen, A. Pearce, N. L. Turner, C. Citro, D. Abrahams, S. Carter, B. Hosmer, J. Marcus, M. Sklar, A. Templeton, T. Bricken, C. McDougall, H. Cunningham, T. Henighan, A. Jermyn, A. Jones, A. Persic, Z. Qi, T. B. Thompson, S. Zimmerman, K. Rivoire, T. Conerly, C. Olah, and J. Batson (2025b) On the biology of a large language model. Transformer Circuits Thread. External Links: Link Cited by: §2.3.
- N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt (2023) Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217. Cited by: §E.1, §1, §2.2, §4.2.
- C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y. Bai, A. Chen, et al. (2022) In-context learning and induction heads. arXiv preprint arXiv:2209.11895. Cited by: §1.
- L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. (2022) Training language models to follow instructions with human feedback. Advances in neural information processing systems 35, pp. 27730–27744. Cited by: §5.
- A. Pareja, N. S. Nayak, H. Wang, K. Killamsetty, S. Sudalairaj, W. Zhao, S. Han, A. Bhandwaldar, G. Xu, K. Xu, L. Han, L. Inglis, and A. Srivastava (2025) Unveiling the secret recipe: a guide for supervised fine-tuning small LLMs. In The Thirteenth International Conference on Learning Representations, External Links: Link Cited by: §5.
- Z. Qiu, Z. Wang, B. Zheng, Z. Huang, K. Wen, S. Yang, R. Men, L. Yu, F. Huang, S. Huang, D. Liu, J. Zhou, and J. Lin (2025) Gated attention for large language models: non-linearity, sparsity, and attention-sink-free. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, External Links: Link Cited by: §2.1.
- A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. (2019) Language models are unsupervised multitask learners. OpenAI blog 1 (8), pp. 9. Cited by: §4.
- D. J. Rezende and F. Viola (2018) Taming vaes. External Links: 1810.00597, Link Cited by: §3.2.
- L. Soldaini, R. Kinney, A. Bhagia, D. Schwenk, D. Atkinson, R. Authur, B. Bogin, K. Chandu, J. Dumas, Y. Elazar, V. Hofmann, A. H. Jha, S. Kumar, L. Lucy, X. Lyu, N. Lambert, I. Magnusson, J. Morrison, N. Muennighoff, A. Naik, C. Nam, M. E. Peters, A. Ravichander, K. Richardson, Z. Shen, E. Strubell, N. Subramani, O. Tafjord, P. Walsh, L. Zettlemoyer, N. A. Smith, H. Hajishirzi, I. Beltagy, D. Groeneveld, J. Dodge, and K. Lo (2024) Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. arXiv preprint. Cited by: §4.
- A. Syed, C. Rager, and A. Conmy (2024) Attribution patching outperforms automated circuit discovery. In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp. 407–416. Cited by: §2.2.
- X. Yang, C. Venhoff, A. Khakzar, C. S. de Witt, P. K. Dokania, A. Bibi, and P. Torr (2025) Mixture of experts made intrinsically interpretable. arXiv preprint arXiv:2503.07639. Cited by: §5.
- M. Zaheer, G. Guruganesh, K. A. Dubey, J. Ainslie, C. Alberti, S. Ontanon, P. Pham, A. Ravula, Q. Wang, L. Yang, et al. (2020) Big bird: transformers for longer sequences. Advances in neural information processing systems 33, pp. 17283–17297. Cited by: §2.1.
- F. Zhang and N. Nanda (2023) Towards best practices of activation patching in language models: metrics and methods. arXiv preprint arXiv:2309.16042. Cited by: §2.2.
- Y. Zhou, A. Zanette, J. Pan, S. Levine, and A. Kumar (2024) ArCHer: training language model agents via hierarchical multi-turn rl. In ICML, External Links: Link Cited by: §5.
## Appendix A Two-Digit Addition Study
<details>
<summary>x8.png Details</summary>
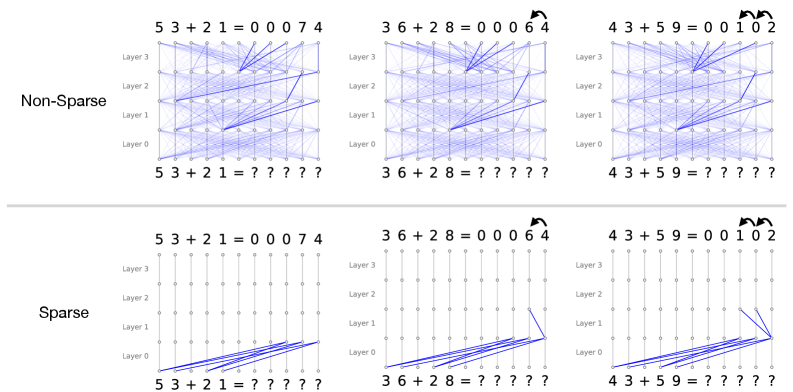
### Visual Description
\n
## Diagram: Neural Network Comparison - Sparse vs. Dense
### Overview
The image presents a comparison between two types of neural networks: "Non-Sparse" and "Sparse". Each network type is illustrated with three examples of a simple addition problem (53+21, 36+28, 43+59) and their corresponding outputs. The diagrams visually represent the connections within each layer of the neural network. The top row shows the "Non-Sparse" networks, characterized by many connections between layers, while the bottom row shows the "Sparse" networks, which have fewer connections.
### Components/Axes
The diagrams are structured as follows:
* **Title:** "Non-Sparse" and "Sparse" labels are positioned above each set of diagrams.
* **Addition Problems:** Each example displays an addition problem (e.g., "53 + 21 = 00074") above and below the network diagram.
* **Layers:** Each network is depicted with four layers, labeled "Layer 0", "Layer 1", "Layer 2", and "Layer 3". These are vertically stacked.
* **Connections:** Blue lines represent the connections between neurons in adjacent layers.
* **Output:** The correct answer to the addition problem is shown after the equals sign.
* **Question Marks:** Below each network diagram, a series of question marks ("?????") indicates the network's internal processing or the input to the network.
### Detailed Analysis or Content Details
The image shows three examples for each network type. Let's analyze each example:
**Non-Sparse Networks (Top Row):**
* **53 + 21 = 00074:** The network has a dense web of connections between all layers. The connections appear relatively random.
* **36 + 28 = 00064:** Similar to the first example, this network also exhibits a dense connection pattern. A small arrow points to the output.
* **43 + 59 = 00102:** Again, a dense network with numerous connections. A small arrow points to the output.
**Sparse Networks (Bottom Row):**
* **53 + 21 = 00074:** The network has significantly fewer connections than the non-sparse counterpart. The connections are more organized and appear to follow a more structured pattern.
* **36 + 28 = 00064:** Similar to the first sparse example, this network has fewer connections. A small arrow points to the output.
* **43 + 59 = 00102:** The sparse network again demonstrates a reduced number of connections. A small arrow points to the output.
### Key Observations
* **Density of Connections:** The most striking difference between the two network types is the density of connections. Non-sparse networks have many connections, while sparse networks have significantly fewer.
* **Connection Patterns:** Sparse networks appear to have more structured connection patterns compared to the seemingly random connections in non-sparse networks.
* **Output Consistency:** Both network types correctly solve the addition problems in all three examples.
* **Arrow Indicator:** A small arrow is present in the top-right corner of the second example in both the Non-Sparse and Sparse networks.
### Interpretation
The image demonstrates the difference between sparse and non-sparse neural networks. The non-sparse networks, with their dense connections, represent a traditional fully connected neural network. The sparse networks, with their reduced connections, represent a more recent approach to neural network design.
The purpose of sparsity is likely to reduce computational cost and prevent overfitting. By removing unnecessary connections, sparse networks can be more efficient and generalize better to unseen data. The structured connection patterns in the sparse networks suggest that these connections are not removed randomly but are selected based on some criteria (e.g., importance, relevance).
The fact that both network types correctly solve the addition problems suggests that sparsity does not necessarily compromise performance. In fact, in some cases, sparse networks can even outperform non-sparse networks. The arrow indicator may signify the direction of information flow or a specific activation pattern within the network.
The question marks below each network diagram likely represent the input data or the internal state of the network during computation. The image is a visual illustration of a key concept in modern neural network research: the trade-off between network complexity, computational efficiency, and generalization performance.
</details>
Figure 9: Simple example showing the attention patterns (shown in blue) of sparse and non-sparse transformers trained on a two digit addition task. Both models are able to correctly predict the sum, but the attention patterns are very different: the non-sparse model solves the task with highly dispersed information flow, while the sparse model uses a highly interpretable attention pattern: in Layer 0, the model first attends to the corresponding digits to be added, then in Layer 1, it attends to the carry bit only if it is needed (see middle and right columns, where the model has to carry once and twice respectively).
In the introduction, we used a two-digit addition task to demonstrate how sparse attention patterns can lead to intrinsically interpretable circuits. The result presented is gathered in a small scale toy experiment described below. We train 4-layer single-head Transformer models on a two-digit addition task, where the input is a sequence of digits and the model is trained to predict the sum. In this task, there are 13 total tokens: ten digits and three symbols ”+”, ”=” and ”?”.
Within this setting, we train two models: a standard transformer model and a sparse transformer with a fixed sparsity regularisation strength. Figure 9 shows several examples of the learned attention patterns. In these examples, we can clearly see that the pressure of sparsity leads to the emergence of human-recognisable algorithmic patterns: in the first layer, each digit in the answer attends to the corresponding digits in the input, while the second layer computes the carry bit when necessary. By enforcing selective information flow through sparse message-passing, the sparse model is able to learn crisp and localised mechanisms that are immediately amenable to interpretation.
## Appendix B Sparse Attention Implementation
For the experiments, we implemented efficient GPU kernels for the sparse attention layers using the helion domain-specific language https://helionlang.com/. We refer to this implementation as Splash Attention (Sp arse f lash Attention). Our implementation follows the same core algorithmic structure as FlashAttention-2 (Dao, 2023), including the use of online softmax computation and tiling. Note that the sparse attention variant (Eq. 2) only differs from the standard attention by a pointwise multiplication of the adjacency matrix, which can be easily integrated into FlashAttention by computing $A_{ij}$ on-the-fly. We additionally fuse the Gumbel-softmax computation, the straight-through gradient, and the computation of the expected number of edges (required for the penalty) into a single optimized kernel, the implementation of which will be released together with the experiment code. Figure 10 compares our Splash Attention implementation against a naive baseline based on PyTorch-native operations.
<details>
<summary>figures/splash_attention.png Details</summary>
### Visual Description
## Charts: Execution Time and Memory Comparison of Attention Mechanisms
### Overview
The image presents two charts side-by-side, comparing the performance of "Splash Attention" and "Naive Attention" mechanisms. The left chart shows execution time in milliseconds (ms) versus sequence length, while the right chart displays peak memory usage in gigabytes (GB) against sequence length. Both charts use a logarithmic scale for the sequence length axis.
### Components/Axes
**Chart 1: Execution Time Comparison**
* **Title:** Execution Time Comparison
* **X-axis:** Sequence Length (logarithmic scale, markers at 10⁰, 10¹, 10², 10³)
* **Y-axis:** Time (ms) (scale from 0 to 40)
* **Legend:**
* Splash Attention (Blue line with circle markers)
* Naive Attention (Orange line with square markers)
**Chart 2: Memory Peak Comparison**
* **Title:** Memory Peak Comparison
* **X-axis:** Sequence Length (logarithmic scale, markers at 10⁰, 10¹, 10², 10³)
* **Y-axis:** Peak Memory (GB) (scale from 0 to 10)
* **Legend:**
* Splash Attention (Blue line with circle markers)
* Naive Attention (Orange line with square markers)
### Detailed Analysis or Content Details
**Chart 1: Execution Time Comparison**
* **Splash Attention (Blue):** The line starts at approximately 0.5 ms at a sequence length of 10⁰. It increases gradually to around 2.5 ms at 10¹, then to approximately 6 ms at 10², and finally reaches about 8 ms at 10³. The trend is generally upward, but the slope increases significantly at higher sequence lengths.
* **Naive Attention (Orange):** The line begins at approximately 0.7 ms at 10⁰. It remains relatively flat until 10², where it jumps to around 11 ms. At 10³, it increases dramatically to approximately 10 ms. The trend is relatively flat for lower sequence lengths, then increases sharply.
**Chart 2: Memory Peak Comparison**
* **Splash Attention (Blue):** The line starts at approximately 0.1 GB at 10⁰. It remains relatively constant around 0.2 GB up to 10¹. It then increases slightly to around 0.4 GB at 10² and remains around 0.5 GB at 10³. The trend is nearly flat.
* **Naive Attention (Orange):** The line begins at approximately 0.1 GB at 10⁰. It remains relatively flat around 0.2 GB up to 10¹. It then increases to approximately 1.5 GB at 10² and jumps significantly to around 2.5 GB at 10³. The trend is flat for lower sequence lengths, then increases sharply.
### Key Observations
* For both charts, the sequence length is plotted on a logarithmic scale.
* Splash Attention consistently exhibits lower execution time and memory usage compared to Naive Attention, especially at higher sequence lengths.
* The execution time of Naive Attention increases dramatically at sequence lengths of 10² and 10³, while Splash Attention's execution time increases more gradually.
* The memory usage of Naive Attention also increases sharply at sequence lengths of 10² and 10³, while Splash Attention's memory usage remains relatively stable.
* The difference in memory usage between the two attention mechanisms becomes much more pronounced at higher sequence lengths.
### Interpretation
The data suggests that Splash Attention is significantly more scalable and efficient than Naive Attention, particularly when dealing with longer sequences. The logarithmic scale on the x-axis highlights the exponential growth in computational cost and memory requirements for Naive Attention as the sequence length increases. Splash Attention demonstrates a more linear increase in both execution time and memory usage, indicating a more efficient algorithm.
The sharp increase in Naive Attention's performance metrics at sequence lengths of 10² and 10³ could indicate a bottleneck or a computational complexity that grows rapidly with sequence length. This could be due to the quadratic complexity of the naive attention mechanism. Splash Attention, likely employing a more optimized approach, avoids this steep increase.
The consistent low memory usage of Splash Attention is a key advantage, as memory constraints often limit the size of sequences that can be processed. This makes Splash Attention a more practical choice for applications involving long sequences, such as natural language processing or long-range dependencies in time series data. The data strongly suggests that Splash Attention is a superior choice for handling long sequences due to its scalability and efficiency.
</details>
Figure 10: Performance comparison between our implementation (Splash) and a naive PyTorch baseline.
## Appendix C Training Details
### C.1 Hyperparameters and Compute Resources
| Hyperparameter | OLMo | GPT-2 |
| --- | --- | --- |
| Base Model | allenai/OLMo-7B-hf | gpt2 |
| Context window | 512 | 64 |
| Dataset | dolma-v1 | OpenWebText |
| Batch size | 16 | 256 |
| Gradient accumulation steps | 4 | 4 |
| Total steps | 400,000 | 1,200,000 |
| Learning rate | $1\times 10^{-5}$ | $1\times 10^{-5}$ |
| Minimum learning rate | $1\times 10^{-6}$ | $1\times 10^{-6}$ |
| Optimizer | Adam | Adam |
| Weight decay | 0.1 | 0.1 |
| Scheduler | Cosine (1 cycle) | Cosine (1 cycle) |
| Warmup steps | 1,000 | 1,000 |
| Finetuning strategy | LoRA | Full |
| LoRA rank ( $r$ ) | 400 | - |
| LoRA scaling ( $\alpha$ ) | 800 | - |
| LoRA dropout | 0 | - |
| LoRA target modules | q,k,v,o,fc_in,fc_out | - |
| Dual Optimisation LR | 0.01 | 0.1 |
| Target cross-entropy | 2.29 | 3.5 |
Table 2: Key hyperparameters used for sparse post-training experiments on OLMo-7B.
We provide the key hyperparameters for our experiments in table 2. All training are performed on NVIDIA H100 GPUs. The GPT-2 model is trained on a single GPU while the OLMo model is trained on a node of 8 GPUs. The total training time for both models is roughly 14 days. The main sparse attention code will be made available as a Transformer library wrapper. The implementation code as well as model weights will also be released.
### C.2 Training Dynamics
<details>
<summary>x9.png Details</summary>
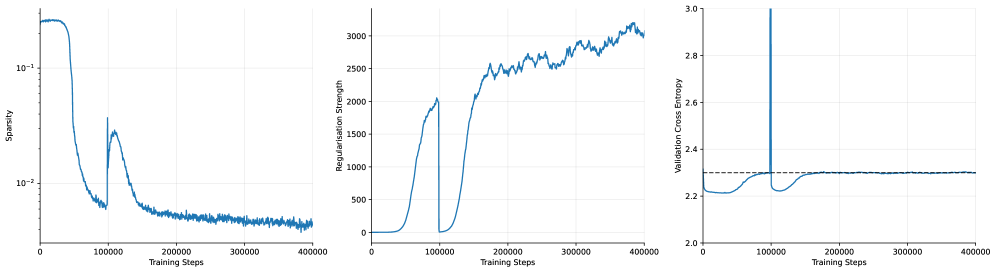
### Visual Description
## Charts: Training Dynamics
### Overview
The image presents three line charts arranged horizontally, depicting the dynamics of a training process. The charts show the evolution of Sparsity, Regularisation Strength, and Validation Cross Entropy as a function of Training Steps. All three charts share the same x-axis (Training Steps) but have different y-axes and scales.
### Components/Axes
* **Chart 1 (Left):**
* X-axis: Training Steps (0 to 40000)
* Y-axis: Sparsity (Logarithmic scale, from 10^-1 to 10^-3)
* **Chart 2 (Center):**
* X-axis: Training Steps (0 to 40000)
* Y-axis: Regularisation Strength (0 to 3000)
* **Chart 3 (Right):**
* X-axis: Training Steps (0 to 40000)
* Y-axis: Validation Cross Entropy (2.2 to 3.0)
* All charts share the same x-axis label: "Training Steps".
* No legend is present. The single blue line in each chart represents the respective metric.
### Detailed Analysis or Content Details
**Chart 1: Sparsity vs. Training Steps**
The line representing Sparsity initially starts at approximately 0.1 (10^-1) and rapidly decreases to around 0.01 (10^-2) by approximately 10,000 training steps. It then plateaus and fluctuates around 0.005 (10^-2) to 0.01 (10^-2) for the remainder of the training process, up to 40,000 steps. There are some minor oscillations, but the overall trend is a decrease and then stabilization.
**Chart 2: Regularisation Strength vs. Training Steps**
The line representing Regularisation Strength starts at approximately 0 at 0 training steps. It increases relatively quickly to around 500 by 10,000 training steps. From 10,000 to 30,000 steps, it continues to increase, reaching approximately 2500. After 30,000 steps, the increase slows down, and the line fluctuates between 2500 and 3000, reaching a maximum of approximately 3100 at 40,000 steps. The overall trend is an increasing Regularisation Strength.
**Chart 3: Validation Cross Entropy vs. Training Steps**
The line representing Validation Cross Entropy begins at approximately 2.8 at 0 training steps. It exhibits a sharp decrease to around 2.2 by 10,000 training steps. Between 10,000 and 20,000 steps, it continues to decrease, reaching a minimum of approximately 2.15 at around 15,000 steps. After 20,000 steps, the line fluctuates around 2.2 to 2.3, with some minor oscillations, and remains relatively stable until 40,000 steps. There is a large spike at the beginning of the training process.
### Key Observations
* Sparsity decreases rapidly initially and then stabilizes.
* Regularisation Strength consistently increases throughout the training process.
* Validation Cross Entropy decreases initially and then plateaus, indicating potential convergence.
* The initial spike in Validation Cross Entropy suggests a period of instability or high error at the beginning of training.
* The stabilization of Validation Cross Entropy suggests the model is learning and generalizing well.
### Interpretation
The charts collectively illustrate the training dynamics of a model. The decreasing Sparsity suggests that the model is becoming less reliant on a large number of parameters, potentially leading to a more efficient representation. The increasing Regularisation Strength indicates that a penalty is being applied to complex models, preventing overfitting. The decreasing and then stabilizing Validation Cross Entropy suggests that the model is learning to generalize to unseen data.
The initial spike in Validation Cross Entropy could be due to random initialization or a learning rate that is initially too high. The subsequent decrease indicates that the model is adapting and improving its performance. The plateau in Validation Cross Entropy suggests that the model has reached a point of diminishing returns and further training may not significantly improve its performance.
The relationship between these metrics is crucial. The increasing Regularisation Strength likely contributes to the decreasing Sparsity and the stabilization of Validation Cross Entropy. By penalizing complex models, Regularisation encourages the model to find a simpler, more generalizable solution. The interplay between these factors is essential for achieving optimal model performance.
</details>
Figure 11: The training curves for post-training OLMo-7B tacking the model sparsity (left), regularisation strength (middle), and the cross-entropy loss (right). The black dotted line on the cross-entropy plot indicates the pre-defined threshold, $\tau$ .
A key feature of our post-training framework is that the strength of the sparsity regularisation is automatically controlled via a constrained optimisation scheme. By pre-specifying an accepted level for the cross-entropy target, $\tau$ , the training procedure can be written as the max-min objective:
$$
\max_{\lambda>0}\min_{\theta}\bigg[\sum_{l}\mathbb{E}\big[|A_{l}|\big]+\lambda(CE-\tau)\bigg], \tag{7}
$$
which can be optimised by taking alternating gradient steps in the model weight space and in the $\lambda$ space. The resulting training dynamics means that the sparsity regularisation strength increases when the model cross-entropy is lower than the target, and decreases when the model is above the threshold. Figure 11 shows the training curves for the OLMo-7B model. Here, we observe that the strength of sparsity regularisation keeps increasing slowly while the model cross-entropy is clipped at the desired level. Note that during a model spike (at around 100K steps), the sparsity regularisation automatically decreases to let the model recover.
## Appendix D Extra Experiments for Circuit Discovery
In this section, we provide additional results for the activation patching circuit discovery experiment presented in the main text.
Figure 12 shows the attention patterns of the heads required to explain 90% of model behaviour on a copy task. To fully test the longer context window afforded by OLMo, we use a longer prompt than the one used for GPT2 in the main text. The result is consistent with the GPT-2 experiment: sparsified model facilitates the discovery of smaller circuits of induction heads that implement the copy task.
<details>
<summary>x10.png Details</summary>

### Visual Description
\n
## Scatter Plots: Correlation Analysis
### Overview
The image contains two scatter plots, both displaying a positive correlation between two variables. Each plot consists of a grid of points, with labels along the x and y axes indicating the variables being compared. The plots appear to be examining the relationship between "SPKM" and "CLPM-70" in the left plot, and "SPKM" and "CLPM-70" in the right plot.
### Components/Axes
**Left Plot:**
* **Title:** "SPKM vs CLPM-70" (top-center)
* **X-axis Label:** "CLPM-70" (bottom-center)
* Axis Markers: "LNP1", "LNP2", "LNP3", "LNP4", "LNP5", "LNP6", "LNP7", "LNP8", "LNP9", "LNP10", "LNP11", "LNP12", "LNP13", "LNP14", "LNP15", "LNP16", "LNP17", "LNP18", "LNP19", "LNP20"
* **Y-axis Label:** "SPKM" (left-center)
* Axis Markers: "LNP1", "LNP2", "LNP3", "LNP4", "LNP5", "LNP6", "LNP7", "LNP8", "LNP9", "LNP10", "LNP11", "LNP12", "LNP13", "LNP14", "LNP15", "LNP16", "LNP17", "LNP18", "LNP19", "LNP20"
* **Data Points:** A grid of approximately 20x20 points. A blue line is drawn through the points, indicating a positive trend.
**Right Plot:**
* **Title:** "SPKM vs CLPM-70" (top-center)
* **X-axis Label:** "CLPM-70" (bottom-center)
* Axis Markers: "LNP1", "LNP2", "LNP3", "LNP4", "LNP5", "LNP6", "LNP7", "LNP8", "LNP9", "LNP10", "LNP11", "LNP12", "LNP13", "LNP14", "LNP15", "LNP16", "LNP17", "LNP18", "LNP19", "LNP20"
* **Y-axis Label:** "SPKM" (left-center)
* Axis Markers: "LNP1", "LNP2", "LNP3", "LNP4", "LNP5", "LNP6", "LNP7", "LNP8", "LNP9", "LNP10", "LNP11", "LNP12", "LNP13", "LNP14", "LNP15", "LNP16", "LNP17", "LNP18", "LNP19", "LNP20"
* **Data Points:** A grid of approximately 20x20 points. A blue line is drawn through the points, indicating a positive trend.
### Detailed Analysis or Content Details
Both plots show a clear positive correlation. As the value of "CLPM-70" increases along the x-axis, the value of "SPKM" also tends to increase along the y-axis. The blue lines in both plots approximate the trend.
**Left Plot:**
The line slopes upwards from the bottom-left to the top-right. The points are scattered around the line, but the overall trend is evident. It is difficult to extract precise numerical values from the points without a higher-resolution image. However, it appears that for "CLPM-70" values around "LNP1", "SPKM" values are around "LNP1-LNP3". As "CLPM-70" increases to "LNP20", "SPKM" values increase to around "LNP15-LNP20".
**Right Plot:**
Similar to the left plot, the line slopes upwards. The points are scattered around the line, but the positive correlation is clear. For "CLPM-70" values around "LNP1", "SPKM" values are around "LNP1-LNP3". As "CLPM-70" increases to "LNP20", "SPKM" values increase to around "LNP15-LNP20".
### Key Observations
* Both plots exhibit a strong positive correlation between "SPKM" and "CLPM-70".
* The scatter of points around the trend line suggests that the correlation is not perfect, and other factors may influence the relationship between these variables.
* The scales on both axes are identical in both plots.
* The plots appear to represent the same data, as the trends and point distributions are very similar.
### Interpretation
The data suggests a direct relationship between "SPKM" and "CLPM-70". An increase in "CLPM-70" is associated with an increase in "SPKM". This could indicate a causal relationship, where "CLPM-70" influences "SPKM", or a shared underlying factor that affects both variables. The scatter around the trend line suggests that the relationship is not deterministic, and other variables likely play a role. The fact that both plots show the same trend suggests the data is consistent and reliable. Without knowing what "SPKM" and "CLPM-70" represent, it is difficult to provide a more specific interpretation. However, the plots provide strong evidence of a positive association between these two variables. The "LNP" labels likely refer to specific samples or experimental conditions. Further investigation would be needed to understand the context and significance of this correlation.
</details>
Figure 12: Attention patterns of the heads required to explain 90% of model behaviour on a longer copy task. Similar to the GPT-2 results in Figure 3, the sparse model requires substantially fewer attention heads.
Figure 13 and 14 show the fraction of explained model preference as a function of the number of model components kept un-ablated. The difference between these plots and Figure 4 and 5 lies in the way individual model components are ranked. Here, the ranking is performed on a task level, meaning that the importance score for each component is pooled across different instances of the same task. Overall, the results are commensurate with results presented in the main paper, where the ranking strategy consistently discover smaller circuits in sparse models. The only exception is the Greater Than task for GPT-2 where the number of attention heads required for the sparse model is larger than that of the base model. We hypothesise that this is due to the sparse model choosing different circuits to implement different instances of the same task, rendering the task-level importance score less suitable for circuit discovery in this case. Finally, in Figure 15, we provide a qualitative visualisation of the edges required to completed the IOI task.
<details>
<summary>x11.png Details</summary>
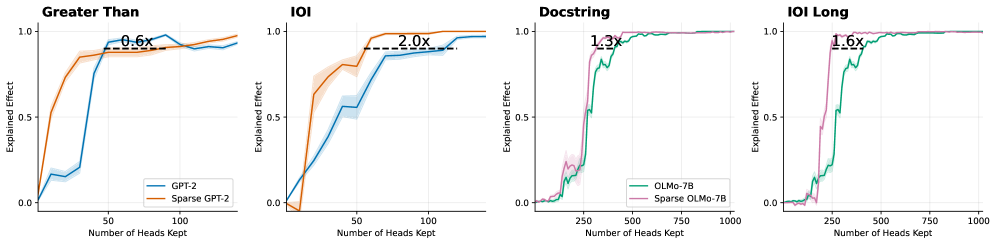
### Visual Description
\n
## Charts: Model Performance vs. Number of Heads Kept
### Overview
The image presents four line charts comparing the "Explained Effect" of two model variants (GPT-2 and Sparse GPT-2, or OLMo-7B and Sparse OLMo-7B) as a function of the "Number of Heads Kept". Each chart focuses on a different evaluation metric: "Greater Than", "IOI", "Docstring", and "IOI Long". Each chart also displays a multiplier indicating the relative performance difference between the two model variants.
### Components/Axes
Each chart shares the following components:
* **X-axis:** "Number of Heads Kept" - ranging from 0 to 1000, depending on the chart.
* **Y-axis:** "Explained Effect" - ranging from 0.0 to 1.0.
* **Legend:** Located in the top-left corner of each chart, identifying the two model variants and their corresponding line colors.
* **Title:** Located at the top of each chart, indicating the evaluation metric being used.
* **Multiplier:** A text label indicating the performance ratio between the two models.
The specific labels and ranges are as follows:
* **Chart 1 ("Greater Than"):**
* Models: GPT-2 (blue line), Sparse GPT-2 (orange line)
* Multiplier: 0.6x
* **Chart 2 ("IOI"):**
* Models: GPT-2 (blue line), Sparse GPT-2 (orange line)
* Multiplier: 2.0x
* **Chart 3 ("Docstring"):**
* Models: OLMo-7B (green line), Sparse OLMo-7B (pink line)
* Multiplier: 1.3x
* **Chart 4 ("IOI Long"):**
* Models: OLMo-7B (green line), Sparse OLMo-7B (pink line)
* Multiplier: 1.6x
### Detailed Analysis or Content Details
**Chart 1 ("Greater Than"):**
* The blue line (GPT-2) starts at approximately 0.0 and rapidly increases to around 0.9 by a "Number of Heads Kept" of 75.
* The orange line (Sparse GPT-2) starts at approximately 0.0 and increases more slowly, reaching around 0.75 by a "Number of Heads Kept" of 100.
* The lines converge around a value of 0.9 as the number of heads kept increases.
**Chart 2 ("IOI"):**
* The blue line (GPT-2) rises quickly to approximately 0.85 by a "Number of Heads Kept" of 50.
* The orange line (Sparse GPT-2) rises more gradually, reaching approximately 0.7 by a "Number of Heads Kept" of 50, and then continues to increase, surpassing the blue line at around a "Number of Heads Kept" of 75, reaching approximately 0.95.
**Chart 3 ("Docstring"):**
* The green line (OLMo-7B) starts at approximately 0.0 and rapidly increases to around 0.9 by a "Number of Heads Kept" of 250.
* The pink line (Sparse OLMo-7B) starts at approximately 0.0 and increases more slowly, reaching around 0.6 by a "Number of Heads Kept" of 250, and then continues to increase, approaching the green line but remaining slightly below.
**Chart 4 ("IOI Long"):**
* The green line (OLMo-7B) starts at approximately 0.0 and rapidly increases to around 0.9 by a "Number of Heads Kept" of 250.
* The pink line (Sparse OLMo-7B) starts at approximately 0.0 and increases more slowly, reaching around 0.6 by a "Number of Heads Kept" of 250, and then continues to increase, approaching the green line but remaining slightly below.
### Key Observations
* Sparse models generally perform worse than their non-sparse counterparts, except for the "IOI" metric where Sparse GPT-2 outperforms GPT-2.
* The "IOI" metric shows the most significant performance difference between the models, with Sparse GPT-2 achieving a 2.0x improvement.
* The "Greater Than" metric shows the largest performance gap in favor of the non-sparse model, with Sparse GPT-2 achieving only 0.6x the performance.
* The "Docstring" and "IOI Long" metrics show similar trends, with the sparse models lagging behind but converging with the non-sparse models as the number of heads kept increases.
### Interpretation
These charts demonstrate the trade-offs between model size (number of heads) and performance for different evaluation metrics. The "Explained Effect" likely represents the variance in the target variable explained by the model. The multiplier values quantify the relative performance of the sparse models compared to their dense counterparts.
The fact that Sparse GPT-2 outperforms GPT-2 on the "IOI" metric suggests that sparsity may be particularly beneficial for tasks related to information retrieval or interaction. Conversely, the lower performance on "Greater Than" suggests that sparsity may negatively impact tasks requiring a more comprehensive understanding of relationships.
The convergence of the lines as the number of heads kept increases indicates that the performance gap between sparse and non-sparse models diminishes as more parameters are included. This suggests that sparsity is a useful technique for reducing model size without sacrificing too much performance, especially when computational resources are limited. The choice of which model to use depends on the specific application and the relative importance of performance and efficiency. The "IOI Long" metric appears to behave similarly to the "Docstring" metric, suggesting they are measuring related aspects of model performance.
</details>
Figure 13: Logit attribution per sentence keeping only the top-k attention heads based on a global ranking score. Dotted line annotates the number of attention heads needed to explain 90% of the logit difference. With the exception of the Greater Than task for GPT-2, the sparse models admits smaller circuits.
<details>
<summary>x12.png Details</summary>
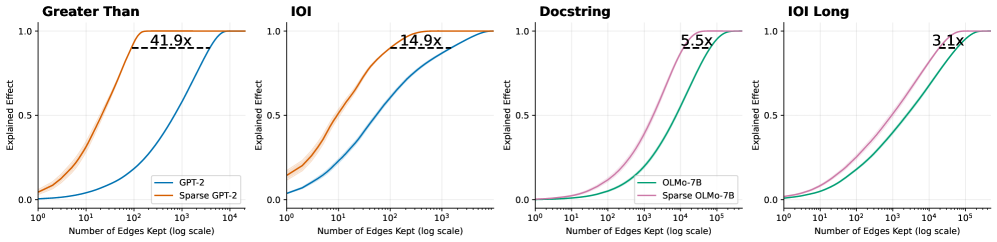
### Visual Description
\n
## Charts: Effect of Edge Pruning on Model Performance
### Overview
The image presents four separate charts, each depicting the relationship between the number of edges kept (on a logarithmic scale) and the explained effect for different model configurations. Each chart focuses on a different pruning target: "Greater Than", "IOI", "Docstring", and "IOI Long". Each chart compares the performance of a dense model (GPT-2 or OLMo-7B) against a sparse version of the same model. The explained effect is a measure of how well the model performs, ranging from 0 to 1.
### Components/Axes
Each chart shares the following components:
* **X-axis:** "Number of Edges Kept (log scale)". The scale ranges from 10<sup>1</sup> to 10<sup>5</sup>.
* **Y-axis:** "Explained Effect". The scale ranges from 0.0 to 1.0.
* **Title:** Each chart has a title indicating the pruning target ("Greater Than", "IOI", "Docstring", "IOI Long").
* **Legend:** Each chart has a legend identifying the two data series: a dense model and a sparse model.
* **Data Series:** Each chart contains two lines representing the explained effect for the dense and sparse models.
The specific models used in each chart are:
* **"Greater Than" Chart:** GPT-2 (blue line), Sparse GPT-2 (orange line).
* **"IOI" Chart:** GPT-2 (blue line), Sparse GPT-2 (orange line).
* **"Docstring" Chart:** OLMo-7B (pink line), Sparse OLMo-7B (teal line).
* **"IOI Long" Chart:** OLMo-7B (pink line), Sparse OLMo-7B (teal line).
Each chart also displays a text label indicating the compression ratio achieved by the sparse model, e.g., "41.9x".
### Detailed Analysis
**"Greater Than" Chart:**
* The blue line (GPT-2) starts at approximately 0.15 at 10<sup>1</sup> edges and quickly rises to approximately 0.95 at 10<sup>3</sup> edges, then plateaus.
* The orange line (Sparse GPT-2) starts at approximately 0.05 at 10<sup>1</sup> edges, rises more gradually than the blue line, reaching approximately 0.85 at 10<sup>3</sup> edges, and then plateaus.
* Compression ratio: 41.9x
**"IOI" Chart:**
* The blue line (GPT-2) starts at approximately 0.1 at 10<sup>1</sup> edges and rises rapidly to approximately 0.95 at 10<sup>3</sup> edges, then plateaus.
* The orange line (Sparse GPT-2) starts at approximately 0.05 at 10<sup>1</sup> edges, rises more gradually, reaching approximately 0.8 at 10<sup>3</sup> edges, and then plateaus.
* Compression ratio: 14.9x
**"Docstring" Chart:**
* The pink line (OLMo-7B) starts at approximately 0.1 at 10<sup>1</sup> edges and rises rapidly to approximately 0.95 at 10<sup>4</sup> edges, then plateaus.
* The teal line (Sparse OLMo-7B) starts at approximately 0.05 at 10<sup>1</sup> edges, rises more gradually, reaching approximately 0.85 at 10<sup>4</sup> edges, and then plateaus.
* Compression ratio: 5.5x
**"IOI Long" Chart:**
* The pink line (OLMo-7B) starts at approximately 0.05 at 10<sup>1</sup> edges and rises gradually to approximately 0.9 at 10<sup>5</sup> edges.
* The teal line (Sparse OLMo-7B) starts at approximately 0.02 at 10<sup>1</sup> edges and rises more gradually, reaching approximately 0.75 at 10<sup>5</sup> edges.
* Compression ratio: 3.1x
### Key Observations
* In all charts, the sparse models consistently underperform the dense models, but achieve significant compression.
* The compression ratio varies depending on the pruning target. "Greater Than" achieves the highest compression (41.9x), while "IOI Long" achieves the lowest (3.1x).
* The "IOI Long" chart shows the slowest rise in explained effect for both models, indicating that this pruning target is the most challenging to maintain performance on.
* The sparse models exhibit a more gradual increase in explained effect as the number of edges kept increases, suggesting that they are more sensitive to edge pruning.
### Interpretation
These charts demonstrate the trade-off between model performance and compression achieved through edge pruning. Pruning edges reduces the model size (and thus computational cost) but also reduces the model's ability to explain the data. The compression ratio indicates how much smaller the sparse model is compared to the dense model.
The varying compression ratios across different pruning targets suggest that some targets are more amenable to pruning than others. "Greater Than" appears to be the most effective pruning target, as it allows for the highest compression with a relatively small performance loss. "IOI Long" is the least effective, requiring a significantly larger number of edges to achieve comparable performance.
The slower rise in explained effect for the "IOI Long" target suggests that this target captures more complex relationships in the data, which are more difficult to approximate with a sparse model. This implies that the "IOI Long" target may be more important for maintaining model accuracy, even at the cost of compression.
The consistent underperformance of the sparse models highlights the importance of carefully evaluating the trade-off between performance and compression when applying edge pruning techniques. The optimal pruning strategy will depend on the specific application and the desired balance between these two factors.
</details>
Figure 14: Logit attribution per sentence keeping only the top-k attention edges based on a global ranking score. Dotted line annotates the number of attention heads needed to explain 90% of the logit difference.
<details>
<summary>x13.png Details</summary>
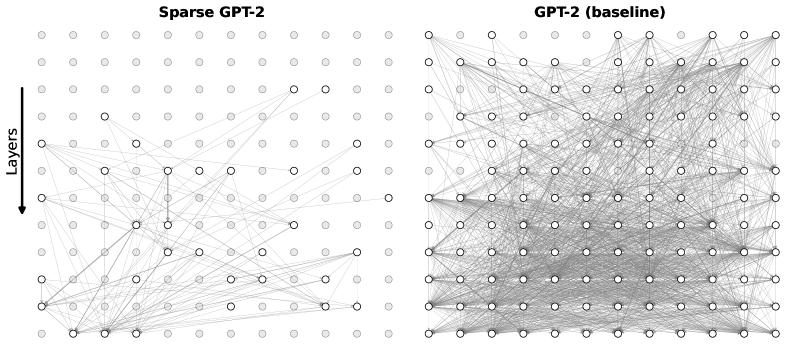
### Visual Description
\n
## Diagram: Network Architecture Comparison - Sparse GPT-2 vs. GPT-2 (Baseline)
### Overview
The image presents a visual comparison of the network architectures of two GPT-2 models: a "Sparse GPT-2" and a standard "GPT-2 (baseline)". The diagrams depict the connections between nodes representing neurons across different layers of the networks. The primary difference highlighted is the density of connections – the Sparse GPT-2 has significantly fewer connections than the baseline GPT-2.
### Components/Axes
The diagrams do not have traditional axes. However, the vertical dimension represents "Layers", indicated by a label and arrow on the left diagram. Each diagram consists of nodes (circles) and connections (lines) between them. The diagrams are positioned side-by-side for direct comparison.
### Detailed Analysis or Content Details
**Sparse GPT-2 (Left Diagram):**
* The diagram shows approximately 10 layers, with roughly 10-12 nodes per layer.
* The connections are sparse, meaning each node is connected to only a few other nodes in adjacent layers.
* The connections appear to be somewhat random, but there's a clear pattern of connections between layers.
* The label "Sparse GPT-2" is positioned at the top-center of the diagram.
* The "Layers" label and arrow are positioned on the left side, indicating the vertical direction represents layers.
**GPT-2 (Baseline) (Right Diagram):**
* The diagram also shows approximately 10 layers, with roughly 10-12 nodes per layer.
* The connections are dense, meaning each node is connected to many other nodes in adjacent layers. Almost every node is connected to every other node in the adjacent layers.
* The connections form a nearly complete graph between adjacent layers.
* The label "GPT-2 (baseline)" is positioned at the top-center of the diagram.
**Quantitative Estimation (Approximate):**
* Sparse GPT-2: Approximately 100 nodes total. Estimated 100-150 connections.
* GPT-2 (Baseline): Approximately 100 nodes total. Estimated 800-1000 connections.
### Key Observations
The most striking observation is the difference in connection density. The Sparse GPT-2 has a dramatically reduced number of connections compared to the baseline GPT-2. This suggests that the Sparse GPT-2 model employs techniques like pruning or sparse attention to reduce the computational cost and potentially the model size. The baseline GPT-2 appears to be a fully connected or densely connected network.
### Interpretation
The diagrams illustrate a key difference in architectural design between the two GPT-2 models. The Sparse GPT-2 likely aims to achieve comparable performance to the baseline GPT-2 with a significantly reduced number of parameters and computational requirements. This is achieved by selectively removing connections, effectively creating a sparse network. The baseline GPT-2 represents a more traditional, densely connected neural network architecture. The comparison highlights the trade-off between model complexity (number of parameters) and performance. Sparse models are often more efficient and easier to deploy, while dense models may achieve higher accuracy given sufficient resources. The diagrams suggest that the sparse model is an attempt to improve efficiency without sacrificing too much performance. The diagrams do not provide any information about the performance of the models, only their structure.
</details>
Figure 15: An example of the attention-head edges required to reach 0.9 cumulative score based on the averaged scores for the IOI task.
## Appendix E Circuit Discovery Tasks
In the following, we provide the details and the prompts for the various tasks used in section 4.2.
### E.1 Greater-Than Task
Each example contains a clean prompt, a corrupt prompt, and two disjoint sets of candidate continuations, answers and wrong_answers. A typical entry is:
{ "clean": "The demonstrations lasted from the year 1363 to 13", "corrupt": "The demonstrations lasted from the year 1301 to 13", "answers": ["64", "65", ..., "99"], "wrong_answers": ["00", "01", ..., "63"] }
For the clean prompt, any token in answers yields an end year strictly greater than the start year (e.g. "1364" – "1399"), whereas tokens in wrong_answers correspond to years that are less than or equal to the start year. The corrupt prompt changes only the starting year, shifting which continuations correspond to valid end years. We use the logit difference between the aggregated probability mass on answers vs. wrong_answers in clean vs. corrupt contexts as our signal, in the spirit of prior mechanistic studies on simple algorithmic tasks (Elhage et al., 2021; Nanda et al., 2023).
### E.2 Indirect Object Identification (IOI) Task
Our IOI setup follows the standard indirect object identification paradigm for mechanistic interpretability (Elhage et al., 2021; Conmy et al., 2023). Each example is generated by combining:
- a pair of names $(A,B)$ , e.g. (" Mary", " John");
- a natural-language template with placeholders [A], [B], and [S].
We instantiate templates such as: "Then, [B] and [A] went to the park. [S] gave a ball to" "When [B] and [A] got a snack at the cafe, [S] decided to give it to" "After the lunch, [B] and [A] went to the mall. [S] gave a gift to"
by sampling a name pair and substituting $[A]$ and $[B]$ , then choosing the subject $[S]$ (either one of the pair). The correct continuation is the indirect object, i.e. the other member of the pair.
For example, with $(A,B)=(\texttt{" John"},\texttt{" Mary"})$ and $S=B$ , one instance is:
Then, Mary and John went to the park. Mary gave a ball to
The correct continuation is " John", while " Mary" and any distractor names are treated as incorrect candidates.
In the OLMo experiments, in order to further test the capability of our approach, we use a different set of IOI task with increased complexity and prompt length. Example templates include: "After several months without any contact due to conflicting schedules and unexpected personal obligations, [B] and [A] finally met again at the park, where they spent a long afternoon catching up on past events, sharing stories, and reflecting on how much had changed. As the day came to an end, [S] gave a ball to" "Although [B] and [A] had previously been involved in a long and emotionally charged argument that left several issues unresolved, they agreed to meet in order to clarify their misunderstandings. After a tense but honest conversation, [S] said to"
### E.3 Docstring Task
We also test the OLMo models on a more complex Docstring task (Heimersheim and Janiak, 2023; Conmy et al., 2023), where the model needs to attend to a specific argument for a specified function in order to complete a Docstring. Similarly to the Greater Than task, each example contains a clean prompt, a corrupt prompt, and two disjoint sets of candidate continuations. A typical entry is: { "clean": "def model(self, results, old, option): """ stage agency security vision spot tone joy session river unit :param results: bone paper selection sky :param old: host action hell miss :param", "corrupt": "def model(self, command, output, state): """ stage agency security vision spot tone joy session river unit :param old: bone paper selection sky :param results: host action hell miss param", "answers": [" option"], "wrong_answers": [" results"," old"] }
## Appendix F Cross-Layer-Transcoder
| Category Model Input dimension ( $d_{\text{in}}$ ) | Setting GPT-2 (HookedTransformer) 768 |
| --- | --- |
| Latent dimension ( $d_{\text{latent}}$ ) | 24 576 |
| Expansion factor | 32 |
| Context size | 64 |
| Batch size (tokens) | 1 024 |
| Precision | Mixed (FP32 / AMP) |
| Device | CUDA |
| Distributed training | DDP |
| Optimizer | Adam |
| Learning rate | $2\times 10^{-4}$ |
| Adam $\beta_{1}$ / $\beta_{2}$ | 0.9 / 0.999 |
| Learning rate warm-up | Cosine (1 000 steps) |
| Learning rate decay steps | 1 874 |
| Final LR scale | 0.1 |
| $L_{0}$ coefficient | 2 |
| Optimal $L_{0}$ | 3 |
| $L_{0}$ warm-up | Linear (18 749 steps) |
| Dead feature penalty | $10^{-5}$ |
| Dead feature window | 250 |
Table 3: Training configuration for the GPT-2 cross-layer-transcoders.
To implement a cross-layer transcoder, let $\mathbf{h}_{\ell}\in\mathbb{R}^{d_{\text{model}}}$ denote the input to the MLP at layer $\ell$ for a single token position. This representation is projected into a sparse feature space via an encoder,
$$
\mathbf{z}_{\ell}=\mathrm{ReLU}\!\left(\mathbf{W}_{\mathrm{enc}}^{\ell}\mathbf{h}_{\ell}+\mathbf{b}_{\mathrm{enc}}^{\ell}\right)\in\mathbb{R}^{d_{\text{features}}}, \tag{8}
$$
where $\mathbf{W}_{\mathrm{enc}}^{\ell}\in\mathbb{R}^{d_{\text{features}}\times d_{\text{model}}}$ and $\mathbf{b}_{\mathrm{enc}}^{\ell}\in\mathbb{R}^{d_{\text{features}}}$ are layer-specific encoder parameters.
The CLT reconstructs the MLP output at a target layer $\ell^{\prime}$ by linearly aggregating feature activations originating from all preceding layers,
$$
\hat{\mathbf{m}}_{\ell^{\prime}}=\sum_{\ell\leq\ell^{\prime}}\mathbf{W}_{\mathrm{dec}}^{\ell\rightarrow\ell^{\prime}}\mathbf{z}_{\ell}+\mathbf{b}_{\mathrm{dec}}^{\ell^{\prime}}, \tag{9}
$$
where $\mathbf{W}_{\mathrm{dec}}^{\ell\rightarrow\ell^{\prime}}\in\mathbb{R}^{d_{\text{model}}\times d_{\text{features}}}$ denotes the decoder mapping from layer $\ell$ to layer $\ell^{\prime}$ .
The summation over layers reflects the fact that a given semantic feature may manifest in different representations across multiple MLP layers. For example, a feature that emerges in the MLP at layer $\ell$ may reappear, potentially in a transformed form, in the outputs of subsequent MLPs. Without accounting for these layer-dependent variations, such duplicated representations would lead to redundant nodes in the attribution graph. By allowing features to be represented differently across layers while being linked through a shared latent space, the cross-layer transcoder avoids this duplication and yields a more compact and interpretable attribution structure. For a detailed comparison between cross-layer transcoders and standard transcoders, we refer the reader to Lindsey et al. (2025a).
Following the training procedure proposed by Anthropic (Ameisen et al., 2025), the final objective combines reconstruction accuracy with sparsity and dead-feature regularization:
$$
\displaystyle\mathcal{L}= \displaystyle\underbrace{\sum_{\ell^{\prime}}\left\|\hat{\mathbf{m}}_{\ell^{\prime}}-\mathbf{m}_{\ell^{\prime}}\right\|_{2}^{2}}_{\text{MSE reconstruction}} \displaystyle+\lambda_{0}\underbrace{\sum_{\ell}\tanh\!\big(C\,(\mathbf{z}_{\ell}\odot\|\mathbf{W}_{\mathrm{dec}}^{\ell}\|)\big)}_{\text{$L_{0}$ sparsity}} \displaystyle+\lambda_{\mathrm{df}}\underbrace{\sum_{\ell}\mathrm{ReLU}\!\Big(\exp(\tau)-\mathbf{h}_{\ell}^{\mathrm{pre}}\Big)\|\mathbf{W}_{\mathrm{dec}}^{\ell}\|}_{\text{dead-feature penalty}}, \tag{10}
$$
where $\mathbf{W}_{\mathrm{dec}}^{\ell}$ denotes the concatenated decoder weights associated with layer $\ell$ , $\mathbf{h}_{\ell}^{\mathrm{pre}}$ are the corresponding pre-activation values, $\tau$ is a threshold parameter, and $C$ is a scaling constant. The hyperparameters $\lambda_{0}$ and $\lambda_{\mathrm{df}}$ control the strength of the sparsity and dead-feature regularization terms. We initialize the weights with following circuits updates (Conerly et al., 2025). The encoder biais is initialize to have a fixed proportion of the features active at initialization. We provide in Figure 16 the training curves of the sparsity value, the sparsity coefficient, the explained variance, and the amount of dead features. We hope this can help the community in training their own cross-layer transcoders.
<details>
<summary>figures/l0_vs_steps.png Details</summary>
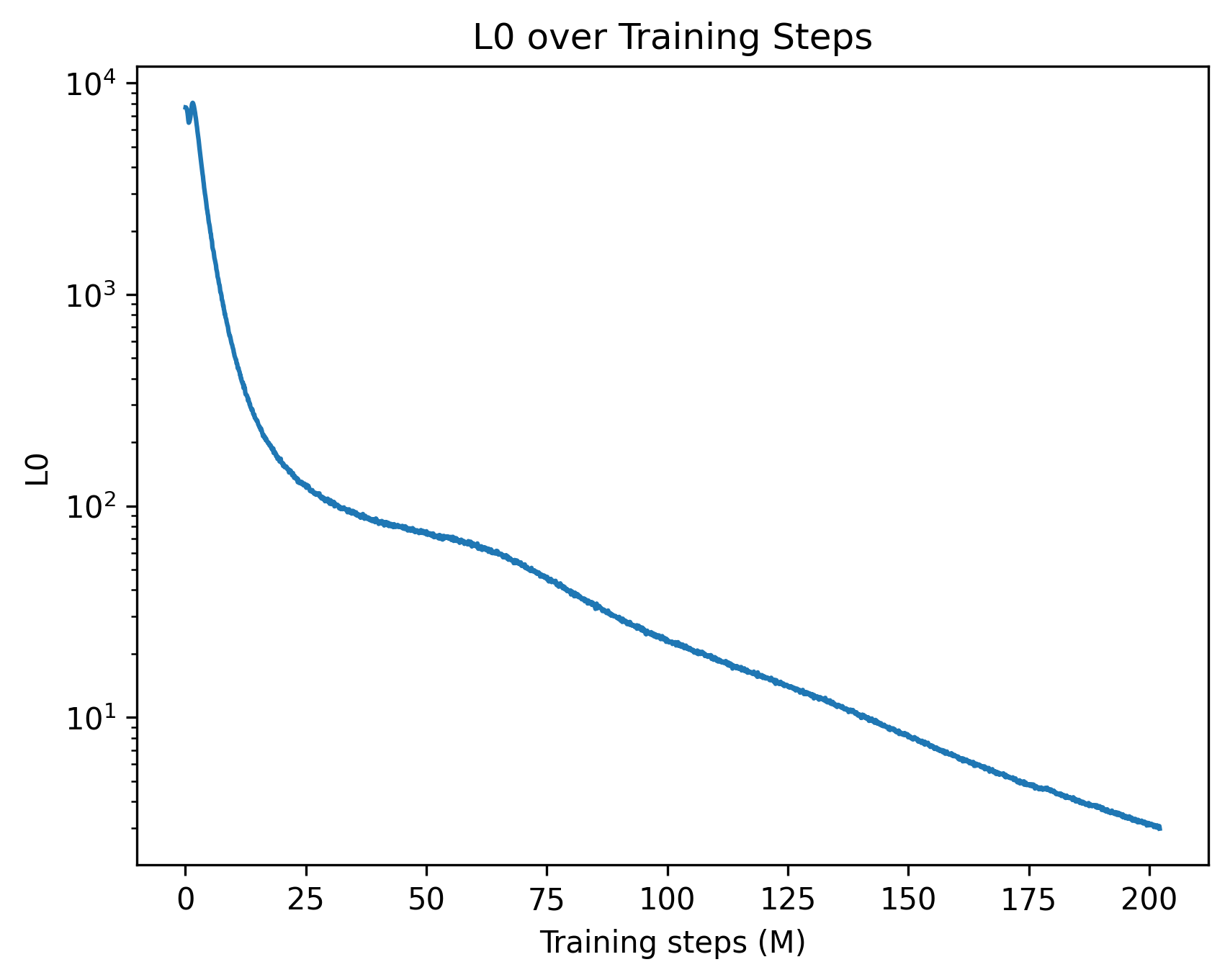
### Visual Description
\n
## Chart: L0 over Training Steps
### Overview
The image presents a line chart illustrating the relationship between L0 and Training Steps (in millions). The chart shows a decreasing trend, indicating that L0 decreases as the number of training steps increases. The y-axis is displayed on a logarithmic scale.
### Components/Axes
* **Title:** "L0 over Training Steps" - positioned at the top-center of the chart.
* **X-axis:** "Training steps (M)" - positioned at the bottom-center of the chart. The scale ranges from 0 to 200, with tick marks at intervals of 25.
* **Y-axis:** "L0" - positioned on the left side of the chart. The scale is logarithmic, ranging from 1 to 10,000 (10^4). Tick marks are displayed at 1, 10, 100, 1000, and 10000.
* **Data Series:** A single blue line representing the L0 value over training steps.
### Detailed Analysis
The blue line starts at approximately (0, 10,000) and exhibits a steep downward slope initially. The slope gradually decreases as the training steps increase.
Here's an approximate reconstruction of data points:
* (0, ~10,000)
* (25, ~100)
* (50, ~20)
* (75, ~10)
* (100, ~8)
* (125, ~7)
* (150, ~6)
* (175, ~5)
* (200, ~4)
The line demonstrates a rapid decrease in L0 during the first 25 million training steps, followed by a slower, more gradual decrease. The curve appears to be approaching an asymptote, suggesting that L0 is converging towards a stable value.
### Key Observations
* The logarithmic scale on the y-axis emphasizes the initial rapid decrease in L0.
* The decreasing trend suggests that the training process is effectively reducing the L0 norm, potentially indicating improved model generalization or sparsity.
* The flattening of the curve towards the end of the training period suggests diminishing returns from further training.
### Interpretation
This chart likely represents the evolution of an L0 regularization term during the training of a machine learning model. L0 regularization encourages sparsity in the model's weights, effectively selecting a subset of important features. The decreasing L0 value indicates that the model is becoming increasingly sparse as training progresses.
The initial steep decline suggests that the model quickly identifies and eliminates many unimportant features. The subsequent slower decline indicates that the remaining features are more difficult to prune, potentially because they contribute more significantly to the model's performance.
The convergence of the L0 value towards a stable level suggests that the model has reached a point where further sparsity is unlikely to improve performance. This could be due to the remaining features being essential for accurate predictions or due to the limitations of the regularization strength.
The use of a logarithmic scale is crucial for visualizing the data effectively, as it allows for the clear representation of both the initial rapid decrease and the subsequent slower decline in L0. Without the logarithmic scale, the initial decrease would dominate the visualization, obscuring the later stages of the training process.
</details>
(a) $L_{0}$ vs steps
<details>
<summary>figures/l0_coef_vs_steps.png Details</summary>
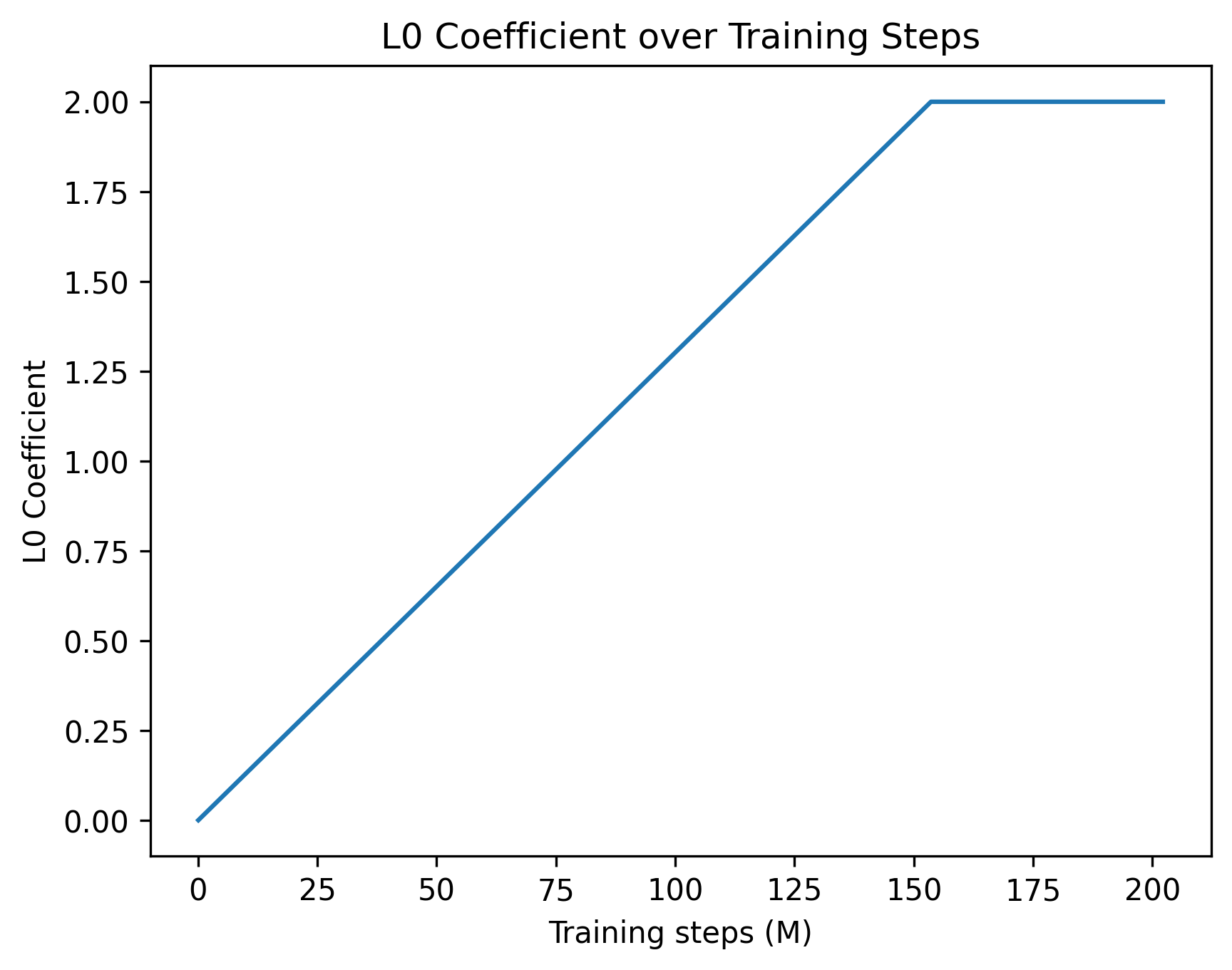
### Visual Description
\n
## Line Chart: L0 Coefficient over Training Steps
### Overview
The image presents a line chart illustrating the relationship between the L0 Coefficient and Training Steps (measured in Millions). The chart shows how the L0 Coefficient changes as the training progresses.
### Components/Axes
* **Title:** "L0 Coefficient over Training Steps" - positioned at the top-center of the chart.
* **X-axis:** "Training steps (M)" - ranging from 0 to 200, with tick marks at intervals of 25.
* **Y-axis:** "L0 Coefficient" - ranging from 0.0 to 2.0, with tick marks at intervals of 0.25.
* **Data Series:** A single blue line representing the L0 Coefficient.
### Detailed Analysis
The blue line starts at approximately (0, 0.0) and exhibits a linear increase until approximately (150, 1.9). After 150 training steps, the line plateaus, remaining roughly constant at a value of approximately 1.95-2.0.
Here's a breakdown of approximate data points:
* (0, 0.0)
* (25, 0.5)
* (50, 1.0)
* (75, 1.5)
* (100, 1.75)
* (125, 1.875)
* (150, 1.95)
* (175, 1.975)
* (200, 2.0)
The line has a positive slope for the first 150 training steps, indicating that the L0 Coefficient increases with training. Beyond 150 steps, the slope becomes approximately zero, indicating that the L0 Coefficient no longer changes significantly with further training.
### Key Observations
* The L0 Coefficient exhibits a linear growth phase followed by a saturation phase.
* The coefficient reaches a maximum value of approximately 2.0.
* The rate of increase in the L0 Coefficient is constant during the initial phase.
### Interpretation
The chart suggests that the L0 Coefficient increases with training until it reaches a certain point, after which it stabilizes. This could indicate that the model is learning to utilize the L0 regularization effectively up to a certain point, beyond which further training does not lead to significant changes in the coefficient. The L0 regularization is likely reaching its maximum effect on the model's parameters. The plateau suggests that the model has converged with respect to the L0 regularization term. This behavior is common in machine learning models where regularization techniques are employed to prevent overfitting. The initial linear increase could represent the model adapting to the regularization constraint, while the plateau indicates that the constraint is being fully satisfied.
</details>
(b) $L_{0}$ coefficient vs steps
<details>
<summary>figures/dead_features_vs_steps.png Details</summary>
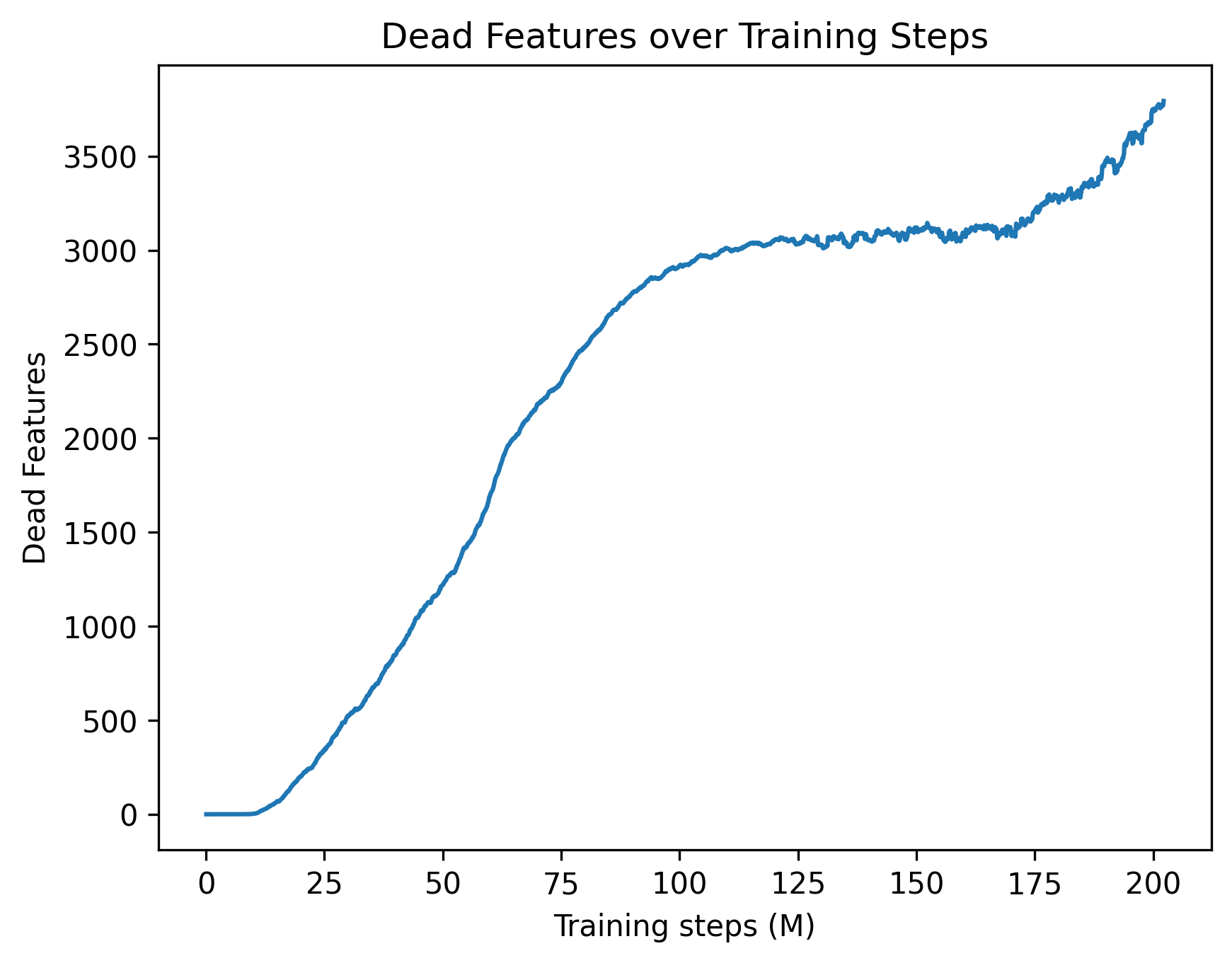
### Visual Description
\n
## Line Chart: Dead Features over Training Steps
### Overview
The image presents a line chart illustrating the relationship between the number of "Dead Features" and "Training Steps (M)" during a machine learning training process. The chart shows how the number of dead features changes as the training progresses.
### Components/Axes
* **Title:** "Dead Features over Training Steps" - positioned at the top-center of the chart.
* **X-axis:** "Training steps (M)" - ranging from 0 to 200, with tick marks at intervals of 25.
* **Y-axis:** "Dead Features" - ranging from 0 to 3500, with tick marks at intervals of 500.
* **Data Series:** A single blue line representing the number of dead features over training steps.
### Detailed Analysis
The blue line starts at approximately 0 dead features at 0 training steps. The line exhibits a steep upward slope from 0 to approximately 75 training steps, indicating a rapid increase in dead features. Between 75 and 150 training steps, the slope decreases, showing a slower rate of increase in dead features. From 150 to 200 training steps, the line fluctuates with a slight upward trend, eventually reaching approximately 3500 dead features at 200 training steps.
Here's a breakdown of approximate data points:
* (0, 0)
* (25, 200)
* (50, 1500)
* (75, 2600)
* (100, 3000)
* (125, 3100)
* (150, 3150)
* (175, 3300)
* (200, 3500)
### Key Observations
* The initial phase of training (0-75M steps) experiences the most significant increase in dead features.
* The rate of increase in dead features slows down after 75M steps, suggesting a stabilization or diminishing returns in the training process.
* The line exhibits some fluctuations between 150M and 200M steps, which could indicate oscillations in the training process or noise in the data.
### Interpretation
The chart suggests that as the model is trained, a growing number of features become "dead," meaning they no longer contribute significantly to the model's performance. This is a common phenomenon in machine learning, particularly with complex models and large datasets. The initial rapid increase in dead features could be due to the model quickly identifying and discarding irrelevant or redundant features. The subsequent slowdown in the rate of increase suggests that the model is converging and finding a stable set of features. The fluctuations towards the end of the training process might indicate that the model is still adjusting and refining its feature selection.
The presence of dead features can impact model performance and efficiency. A high number of dead features can increase computational cost and potentially lead to overfitting. Techniques like feature selection or regularization can be employed to mitigate the issue of dead features and improve model performance. The chart provides valuable insight into the training dynamics of the model and can inform decisions about training duration, feature engineering, and model optimization.
</details>
(c) Dead features vs steps
<details>
<summary>figures/explained_variance_vs_steps.png Details</summary>
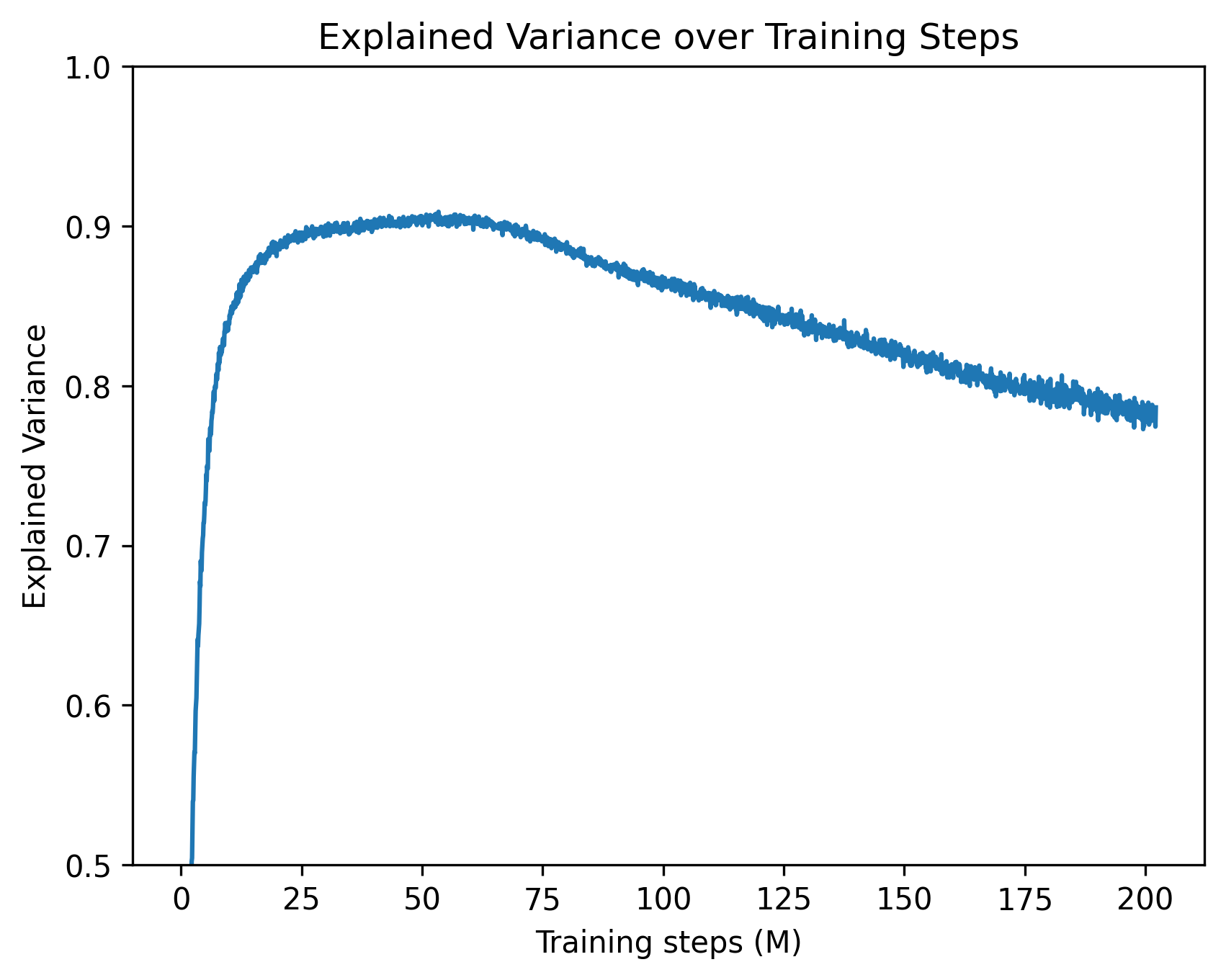
### Visual Description
\n
## Line Chart: Explained Variance over Training Steps
### Overview
The image presents a line chart illustrating the relationship between training steps (in millions) and explained variance. The chart shows how the proportion of variance explained by a model changes as it undergoes training.
### Components/Axes
* **Title:** "Explained Variance over Training Steps" - positioned at the top-center of the chart.
* **X-axis:** "Training steps (M)" - ranging from approximately 0 to 200, with tick marks at intervals of 25.
* **Y-axis:** "Explained Variance" - ranging from 0.5 to 1.0, with tick marks at intervals of 0.1.
* **Data Series:** A single blue line representing the explained variance.
### Detailed Analysis
The blue line begins at approximately 0.52 at a training step of 0. It then exhibits a steep upward trend, rapidly increasing to around 0.92 by approximately 25 training steps. From 25 to 100 training steps, the line fluctuates around 0.92, showing a relatively stable explained variance. After 100 training steps, the line begins a gradual downward trend, decreasing to approximately 0.79 by 200 training steps.
Here's a breakdown of approximate data points:
* (0, 0.52)
* (25, 0.92)
* (50, 0.91)
* (75, 0.89)
* (100, 0.87)
* (125, 0.84)
* (150, 0.82)
* (175, 0.80)
* (200, 0.79)
### Key Observations
* **Rapid Initial Increase:** The explained variance increases dramatically during the first 25 million training steps.
* **Plateau:** There's a period of relative stability in explained variance between 25 and 100 million training steps.
* **Gradual Decline:** After 100 million training steps, the explained variance begins to decrease, suggesting potential overfitting or diminishing returns from further training.
* **No Legend:** There is no legend, but the single line is clearly associated with the "Explained Variance" metric.
### Interpretation
The chart suggests that the model learns quickly initially, capturing a significant portion of the variance in the data with relatively few training steps. However, beyond a certain point (around 100 million steps), continued training leads to a decrease in explained variance. This could indicate that the model is starting to overfit the training data, meaning it's learning the noise in the data rather than the underlying patterns.
The initial rapid increase is expected in many machine learning scenarios, as the model quickly identifies the most important features and relationships. The subsequent plateau suggests that the model has reached a point where it's effectively capturing the major sources of variance. The decline after 100 million steps is a critical observation, signaling the need to potentially stop training or employ regularization techniques to prevent overfitting.
The chart provides valuable insight into the training process and can inform decisions about when to stop training, adjust hyperparameters, or explore different model architectures.
</details>
(d) Explained variance vs steps
Figure 16: Training dynamics of the cross-layer transcoder, showing sparsity, regularization strength, dead features, and reconstruction quality over training.
## Appendix G Attribution-Graph
Following Ameisen et al. (2025), we define the attribution score between feature $n$ at layer $\ell$ and position $k$ , and feature $n^{\prime}$ at layer $\ell^{\prime}$ and position $k^{\prime}$ , as
$$
a_{\ell,k,n}^{\ell^{\prime},k^{\prime},n^{\prime}}=\sum_{\ell\leq s\leq\ell^{\prime}}f_{k,n}^{\ell\rightarrow s}\;J_{s,k}^{\ell^{\prime},k^{\prime}}\;g_{k^{\prime},n^{\prime}}^{\ell^{\prime}}, \tag{11}
$$
where $f_{k,n}^{\ell\rightarrow s}$ denotes the decoder vector associated with feature $n$ projecting from layer $\ell$ to layer $s$ , $J_{s,k}^{\ell^{\prime},k^{\prime}}$ is the Jacobian mapping the MLP output at $(\ell,k)$ to the MLP input at $(\ell^{\prime},k^{\prime})$ , and $g_{k^{\prime},n^{\prime}}^{\ell^{\prime}}$ is the corresponding encoder feature at layer $\ell^{\prime}$ and position $k^{\prime}$ . The sum in this equation reflects the cross-layer mapping of the cross-layer transcoder.
The Jacobian is computed during a modified forward pass in which all nonlinear operations, including normalization layers, attention mechanisms, and MLPs, are frozen using stop-gradient operations. The resulting attribution graph is pruned by retaining only those features that cumulatively explain $80\$ of the contribution to the final logit, and only those edges that account for $95\$ of the total edge-level effect. All attribution computations are performed using the circuit-tracer library (Hanna et al., 2025). For a complete description of the attribution graph computation and pruning, we refer the user to reading (Ameisen et al., 2025).
For the visualization and the autointerp, we write our own pipeline. In Figure 17, we show a screenshot of the interface for the ’The opposite of ”large” is ”’ attribution graph. The features are colored with respect to their corresponding clusters.
<details>
<summary>x14.png Details</summary>
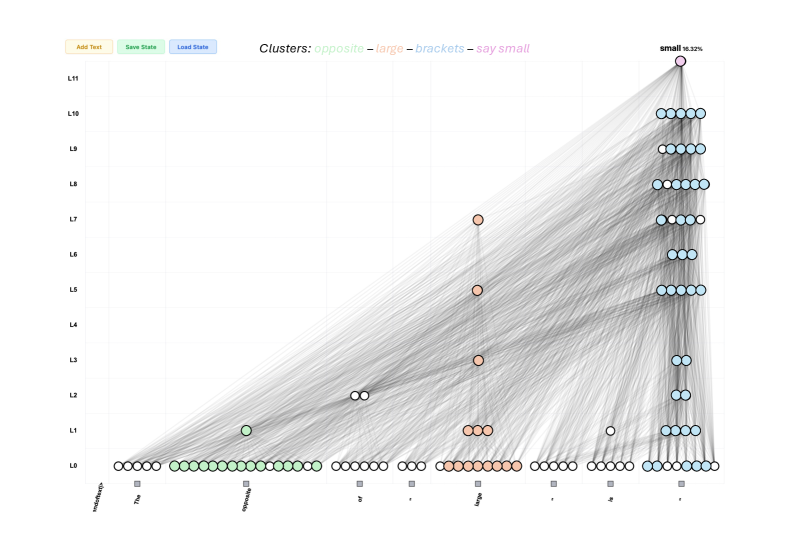
### Visual Description
## Diagram: Clusters - opposite - large - brackets - say small
### Overview
The image presents a diagram visualizing clusters of relationships between words, represented as lines connecting points on a two-dimensional plane. The diagram appears to be a type of alluvial diagram or parallel coordinates plot, showing how words transition between different categories or "layers" (L0 to L11). The title indicates the clusters being visualized are related to "opposite", "large", "brackets", and "say small".
### Components/Axes
* **Horizontal Axis (X-axis):** Represents word categories. The categories are: "the", "opposite", "is", "-", "large", "-", "-", "-", "-", "-", "-". The categories are not evenly spaced.
* **Vertical Axis (Y-axis):** Represents layers, labeled L0 to L11. These layers likely represent stages or transformations in the relationships between words.
* **Lines:** Gray lines connect points across layers, indicating relationships between words as they move through the layers. The density of lines indicates the strength or frequency of the relationship.
* **Circles:** Colored circles represent clusters of words at different layers. The size of the circle appears to correlate with the number of words in that cluster.
* **Legend:** Located in the top-right corner, the legend indicates the color coding for the clusters: "small 16.32%".
* **Controls:** Located in the top-left corner, there are buttons labeled "Add Text", "Save State", and "Load State".
* **Title:** "Clusters: opposite - large - brackets - say small" is positioned at the top-center of the diagram.
### Detailed Analysis
The diagram shows a complex network of relationships between words. The lines originate from the left side (L0) and converge towards the right side (L11).
* **L0:** A large number of lines originate from the "the" and "opposite" categories.
* **L1:** The lines begin to diverge, with some moving towards "is" and others towards the "-" categories.
* **L2-L5:** The lines continue to spread out, with a noticeable concentration of lines moving towards the "-" categories.
* **L6-L9:** The lines begin to converge again, with a significant number of lines moving towards the "-" categories.
* **L10-L11:** The lines converge towards the rightmost categories, with a cluster of blue circles appearing.
**Cluster Analysis:**
* **Small (16.32%):** The cluster represented by the blue circles is most prominent in layers L8 through L11. The size of the circles increases as the layers increase, indicating a growing concentration of words in this cluster.
* **Green Circle:** A single green circle is present at L1.
* **Orange Circles:** Several orange circles are present at L2, L3, and L4.
* **Yellow Circles:** Several yellow circles are present at L3, L4, and L5.
The number of lines originating from "the" and "opposite" in L0 is significantly higher than from other categories, suggesting these words are central to the relationships being visualized. The convergence of lines towards the rightmost categories in L11 indicates a final grouping or categorization of words.
### Key Observations
* The diagram shows a clear flow of relationships from left to right.
* The "the" and "opposite" categories appear to be the starting points for many relationships.
* The "-" categories act as intermediate points in the flow.
* The blue cluster ("small") becomes increasingly prominent in the later layers.
* The diagram is dense with lines, indicating a complex network of relationships.
### Interpretation
This diagram likely represents a visualization of semantic relationships between words, potentially derived from a large corpus of text. The layers could represent stages of linguistic analysis, such as part-of-speech tagging, dependency parsing, or semantic role labeling. The lines represent associations between words as they move through these stages.
The prominence of "the" and "opposite" suggests these words are frequently used in the context of the analyzed text. The convergence towards the "small" cluster in the later layers indicates that the relationships between words ultimately lead to the concept of "smallness". The diagram could be used to understand how words are related to each other in a specific domain or corpus, and to identify key concepts and relationships.
The presence of the "Add Text", "Save State", and "Load State" buttons suggests this is an interactive visualization tool, allowing users to explore the relationships between words and save their findings. The diagram is a powerful tool for visualizing complex linguistic data and gaining insights into the semantic relationships between words.
</details>
Figure 17: Circuit-tracing interface example for the ’The opposite of ”large” is ”’ with GPT2-sparse.
## Appendix H Graph: The opposite of ”large” is ”
We obtain a replacement score of 0.82, with 459 features identified before pruning and 82 features remaining after pruning. The majority of features in the resulting attribution graph fall into four dominant clusters:
- Opposition cluster: features associated with opposition and comparison, primarily localized at the token position corresponding to opposite.
- Magnitude cluster: features related to notions of size (e.g., large, big, full, medium), predominantly located in the residual stream at the large token position.
- Bracket cluster: features that activate on tokens enclosed in brackets.
- Final-logit cluster: mainly the final logit itself and a couple of features that activate before the token ”small” or related terms.
In the boxes below, we present the top activations of representative feature sets for each cluster.
Feature 1117 ”Opposite” cluster in Washington has now adopted the wider measure of student debt outstanding. This new the situation in Syria, Iran and the wider region. ”The recharged by the wider dense forests of Sanjay Van and its overflow drained public, with interesting accounts of Oswald’s demeanor at this significant moment has a slightly wider range. Specifically, the Atom-powered NANO 56 becoming part of the wider Seven Years’ War in which Britain and France
Feature 1337 ”Opposite” cluster opposite, piece of Mexico’s cultural identity. I made the hour opposite shows, or something bigger, “where there’s villains opposite sides of Mars in 2004 and used their instruments to discover geologic evidence opposite, but not anymore. Now everything he says to me is some kind opposite direction, and had little trouble finding space at the campsites. always seem to be just the opposite. show a growing trend to cast “no” votes , opposing how much salary and the occupation of the opposing forces was generally limited to mutual observation. work hand in hand for the purpose of opposing all movements of the thinking part the defense’s inability to stop opposing run games. The Bills have ing opposing quarterbacks. The Seahawks not only had depth, they were versatile. to win more hand battles particularly when the opposing tackle neutralizes his initial
Feature 901 ”Large” cluster Let’s be honest: When someone advocates for large-scale Muslim robot provides a tragicomic reminder of why RWD needs to consider large as what kind of social safety nets should be in place to protect people from large advocates to limit the power of large, established corporations, analysts say. of large law firms is that they are so great that the only reason anyone that by scaling up tests, the method would be conducive for use on larger
Feature 933 ”Large” cluster people healthy and anticipating health issues before they become a problem . Big Data is Big brown bucks with funny accents.” Judy flinched at BIG UP UBUNTU: Ubuntu releases are named after industry.¡—endoftext—¿ BIG LEAGUE: Barron’s Says The they need to submit their content in the same way . Big enough apps and offering alternatives routes . Big data and optical fiber
Feature 1004 ”Large” cluster guide said was ? full of drinking saloons, dime museums, small would have 2 mana sources next turn (unless his hand was full of fast ’s house, it ’s full of adventure itself.? statement that all German Catholics had a right to full transparency” glimpsing a lobby full of construction debris. The front hallway was full of Jokubas had recently been reading a newspaper article which was full of
Feature 412 “Brackets” cluster group answered either “very” or “somewhat” attached – except some work colleagues. Wilcox said she found it ‘highly unlikely very rare , “very likely ,” “high risk,” she says. ulent. Pentagon spokesman Peter Cook said the sample was “ on of PopMatters called the album “brilliant” and said arlene Lowe, described him as being “one of my biggest supporters”.
Feature 518 “Brackets” cluster Kerry said Washington and Hanoi will “continue to have differences in opinions the United States will “take care of it.” He told reporters after the legislation would “provide new enforcement tools for protecting our citizens and will help Gary Ross, said in a statement that the Air Force is currently “short said, and Syrian President Bashar al-Assad would “have to go”. introduces politics into consumer policies,” said Palmor, adding that it would ”