# Statistical physics for artificial neural networks
**Authors**:
- Zongrui Pei (New York University, New York, NY10003, USA)
- E-mail: peizongrui@gmail.com; zp2137@nyu.edu
Abstract
The 2024 Nobel Prize in Physics was awarded for pioneering contributions at the intersection of artificial neural networks (ANNs) and spin-glass physics, underscoring the profound connections between these fields. The topological similarities between ANNs and Ising-type models, such as the Sherrington-Kirkpatrick model, reveal shared structures that bridge statistical physics and machine learning. In this perspective, we explore how concepts and methods from statistical physics, particularly those related to glassy and disordered systems like spin glasses, are applied to the study and development of ANNs. We discuss the key differences, common features, and deep interconnections between spin glasses and neural networks while highlighting future directions for this interdisciplinary research. Special attention is given to the synergy between spin-glass studies and neural network advancements and the challenges that remain in statistical physics for ANNs. Finally, we examine the transformative role that quantum computing could play in addressing these challenges and propelling this research frontier forward. Contents
1. 1 Introduction
1. 2 Spin-glass physics for artificial neural networks
1. 2.1 Relations of spin glasses, biological neurons, and associative memory
1. 2.2 Dictionary of corresponding concepts
1. 2.3 Hopfield neural network and Boltzmann machines
1. 2.4 Replica theory and the cavity method
1. 2.5 Overparameterization and double-descent behavior
1. 3 Challenges and perspectives
1. 3.1 Challenges in ANNs and spin glasses for ANNs
1. 3.2 Spin-glass physics helps understand ANNs
1. 3.3 Do we need new order parameters for ANNs?
1. 3.4 Quantum computing for spin glasses and ANNs
1. 3.5 More opportunities
1. 4 Conclusions
1 Introduction
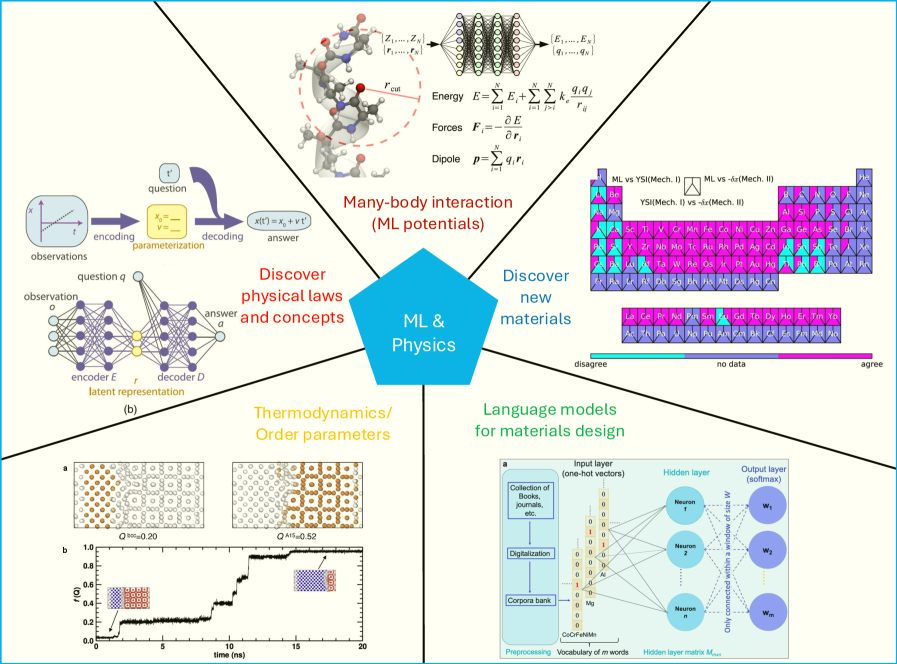
Artificial neural networks (ANNs) have had a profound influence in many sectors, as demonstrated by numerous notable milestones in ANN applications. For example, AlexNet is one of the first models to show the impressive capabilities of ANNs in classification tasks using the ImageNet dataset krizhevsky2012imagenet. AlphaGo corroborates that ANNs can outperform human players in games silver2016mastering; silver2017mastering. ANNs also find their application in self-driving cars badue2021self. Recently, large language models chatGPT; pei2025language, which are complex ANN models, have fundamentally changed how we work, learn, and teach, influencing nearly everyone. ANNs have been widely adopted in various scientific research domains. An outstanding example is AlphaFold, which has solved the half-century-long challenge in structural biology jumper2021highly and accelerated the determination of three-dimensional (3D) protein structures, potentially revolutionizing drug discovery and the healthcare industry. A few more typical examples in physics are shown in Figure 1. ANNs have been used to describe many-body interactions or construct empirical potentials, such as PhysNet unke2019physnet. Some ANN potentials with multiple neural layers are also referred to as deep potentials zhang2018deep. Recently, inspired by the success of foundation models for natural languages, developing foundation models for potentials has been proposed, and some initial studies have been conducted batatia2023foundation. Order parameters can describe the phase transitions in thermodynamics. ANNs have been adopted to construct new order parameters successfully yin2021neural; rogal2019neural; jung2025roadmap. As a proof of concept, ANNs are also used to rediscover physical laws and concepts iten2020discovering. ANN models have been developed to design novel materials pei2023toward; Tshitoyan2019; pei2024designing; pei2024computer. They have been utilized to link the physical properties of various materials and their crystal structures, microstructure, and processing pei2021machine; pei2024towards. Examples of applications include low-dimensional materials, structural materials, and functional materials, among others.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Machine Learning & Physics for Materials Discovery
### Overview
This diagram illustrates the intersection of Machine Learning (ML) and Physics, specifically focusing on materials discovery. It presents several interconnected concepts, including many-body interactions, thermodynamics, language models, and a machine learning workflow for discovering physical laws. The diagram is divided into four main sections, visually separated by angled lines.
### Components/Axes
The diagram contains the following key components:
* **Top-Right:** A periodic table-like grid with color coding indicating agreement/disagreement between ML vs. YSI(Mech. I) and ML vs. dxt(Mech. II).
* **Top-Left:** A depiction of molecular interactions with equations for Energy (E), Forces (F), and Dipole (p).
* **Bottom-Left:** A graph of correlation function r(t) vs. time (t), alongside visualizations of atomic arrangements.
* **Bottom-Right:** A neural network diagram illustrating language models for materials design.
* **Central Area:** Overlapping circles labeled "ML & Physics", "Discover physical laws and concepts", "Discover new materials".
* **Machine Learning Workflow (Left):** A diagram showing encoding, parameterization, and decoding processes.
### Detailed Analysis or Content Details
**1. Molecular Interactions (Top-Left):**
* Equations:
* Energy: E = Σᵢ Eᵢ + Σᵢ<ⱼ qᵢqⱼ/rᵢⱼ
* Forces: F = -∂E/∂r
* Dipole: p = qᵢrᵢ
* Visual: Depiction of atoms and bonds in a molecular structure.
**2. Periodic Table Grid (Top-Right):**
* The grid resembles a periodic table, but with elements colored based on the agreement between ML predictions and two mechanical models: YSI(Mech. I) and dxt(Mech. II).
* Color Coding:
* Green: Agree
* Red: Disagree
* Gray: No data
* Elements present (partial list): Y, Zr, Nb, Mo, Tc, Ru, Rh, Pd, Ag, Cd, In, Sn, Sb, Te, I, La, Ce, Pr, Nd, Sm, Eu, Gd, Tb, Dy, Er, Tm, Yb.
**3. Thermodynamics/Order Parameters (Bottom-Left):**
* Graph: Correlation function r(t) plotted against time (t).
* X-axis: Time (t) from approximately 0 to 20.
* Y-axis: Correlation function r(t) from approximately 0 to 0.8.
* The graph shows multiple curves, with a general decay in correlation over time.
* Annotations:
* "O<sup>111</sup>=0.20" at t ≈ 2
* "O<sup>111</sup>=0.52" at t ≈ 15
* Visualizations: Two atomic arrangements, one more ordered than the other.
**4. Language Models for Materials Design (Bottom-Right):**
* Neural Network Diagram:
* Input Layer: "Input layer (one-hot vectors)"
* Hidden Layer: "Hidden layer" with multiple neurons.
* Output Layer: "Output layer (softmax)"
* Components: "Digitalization", "Corpora bank", "Preprocessing", "Vocabulary of m words", "Hidden layer matrix M<sub>lstm</sub>".
* Connections: Arrows indicating the flow of information through the network.
**5. Machine Learning Workflow (Left):**
* Encoding: "observations" -> "encoding"
* Parameterization: "question q" -> "parameterization" -> "x(t) = x<sub>0</sub> + vt"
* Decoding: "latent representation" -> "decoding" -> "answer"
* Diagram: Shows a loop from observations to answer, representing the ML process.
**6. Central Overlapping Circles:**
* "ML & Physics"
* "Discover physical laws and concepts"
* "Discover new materials"
### Key Observations
* The diagram highlights the potential of ML to accelerate materials discovery by bridging the gap between physics-based simulations and data-driven approaches.
* The periodic table grid suggests varying degrees of agreement between ML predictions and established mechanical models.
* The correlation function graph indicates the decay of order over time, a common phenomenon in thermodynamic systems.
* The neural network diagram illustrates how language models can be used to represent and analyze materials data.
* The ML workflow emphasizes the iterative process of learning from observations and generating new insights.
### Interpretation
The diagram presents a holistic view of how ML can be integrated with physics to advance materials science. The central theme is the use of ML to "discover physical laws and concepts" and ultimately "discover new materials." The diagram suggests that ML can complement traditional physics-based methods by providing a data-driven approach to materials design and prediction. The periodic table grid is particularly insightful, as it visually demonstrates the areas where ML predictions align with or diverge from established theories. The inclusion of language models suggests a move towards using natural language processing to extract knowledge from the vast amount of materials literature. The diagram implies that a combination of physics-based modeling, data analysis, and machine learning is crucial for accelerating the pace of materials innovation. The correlation function graph and the molecular interaction equations provide a grounding in the underlying physics, while the ML components offer a pathway to explore complex materials systems more efficiently.
</details>
Figure 1: The applications of artificial neural networks in physics. Artificial neural networks have been widely utilized to solve a diverse range of problems, including those in scientific research. Here, we show a few typical examples in physical research, i.e., (i) many-body interactions (machine-learning potentials) unke2019physnet; zhang2018deep, (ii) thermodynamics (proposal of order parameters to describe phase transitions) yin2021neural; rogal2019neural, (iii) discovery of physical laws and concepts iten2020discovering, (iv) discovery or design of new materials pei2021machine, and (v) language models for materials design pei2023toward; Tshitoyan2019; pei2024towards.
ANNs have been employed to understand Ising-like physical systems mills2020finding; carrasquilla2017machine; hibat2021variational; fan2023searching, including spin glass hibat2021variational; fan2023searching. They provide a new opportunity to understand the physics of spin glass. Fan et al. searched for spin glass ground states through deep reinforcement learning fan2023searching. Huang et al. confirmed the efficiency of classic machine learning to describe quantum phases, taking 2D random Heisenberg models as an example huang2022provably. ANNs can boost Monte-Carlo simulations of spin glasses (autoregressive neural networks) mcnaughton2020boosting and search for ground states of spin glasses (tropical tensor network) liu2021tropical.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Evolution of Neural Network Architectures & LLM Development
### Overview
This image presents a historical overview of neural network architectures, starting from the McCulloch-Pitts network in 1943 and culminating in Large Language Models (LLMs) in the present day. It combines diagrams of different network types with a bar chart illustrating the evolution of LLM architectures. The diagram visually connects the development of these architectures over time.
### Components/Axes
The image is divided into three main sections:
1. **Historical Network Diagrams (Top):** Illustrations of Hopfield Network, Boltzmann Machine, Restricted Boltzmann Machine, and Spin Glass.
2. **Network Component Diagram (Center-Right):** A detailed breakdown of the Transformer architecture.
3. **LLM Architecture Evolution Chart (Bottom-Right):** A bar chart showing the number of major releases of different LLM architectures over time (2018-2024).
**Chart Axes:**
* **X-axis:** Year (2018, 2019, 2020, 2021, 2022, 2023, 2024)
* **Y-axis:** Number of major releases (Scale from 0 to 20, increments of 2)
**Chart Legend:**
* Encoder-Only (Green)
* Encoder-Decoder (Orange)
* Decoder-Only (Gray)
* Linear-Attention (Brown)
**Timeline Labels:**
* 1943: McCulloch-Pitts network
* 1949: Hebb's rule
* 1958: Perceptron
* 1974: Little's associative network
* 1975: EA/SK Spin glass
* 1982: Hopfield network
* 1985: Boltzmann Machine
* …: (Ellipsis indicating time passing)
* 2017: Transformer
* 2021: AlphaFold
* Now: LLMs
**Diagram Labels:**
* Visible nodes
* Hidden nodes
* Output Percentiles
* Softmax
* Add & Norm
* Feed Forward
* Add & Norm
* Multi-Head Attention
* Add & Norm
* Positional Encoding
* Input Embedding
* Outputs (shifted right)
* Inputs
### Detailed Analysis or Content Details
**Historical Network Diagrams:**
* **McCulloch-Pitts Network (1943):** A simple diagram showing interconnected nodes.
* **Hebb's Rule (1949):** Depicts a connection with a "+" symbol, representing strengthening of connections. A question mark is also present.
* **Perceptron (1958):** A network with input nodes, a single output node, and connections.
* **Little's Associative Network (1974):** A network with interconnected nodes.
* **EA/SK Spin Glass (1975):** A network with interconnected nodes.
* **Hopfield Network (1982):** A fully connected network of nodes.
* **Boltzmann Machine (1985):** A network with visible and hidden nodes, interconnected.
* **Restricted Boltzmann Machine:** A network with visible and hidden nodes, interconnected. A 3D representation of a protein structure is also shown.
**Transformer Architecture Diagram:**
The diagram shows a detailed breakdown of the Transformer architecture, including components like: Positional Encoding, Input Embedding, Multi-Head Attention, Feed Forward, Add & Norm, and Softmax. The flow of information is generally from left to right.
**LLM Architecture Evolution Chart:**
* **2018:** Approximately 2 Encoder-Only releases, 1 Encoder-Decoder release, and 0 Decoder-Only releases.
* **2019:** Approximately 4 Encoder-Only releases, 2 Encoder-Decoder releases, and 0 Decoder-Only releases.
* **2020:** Approximately 6 Encoder-Only releases, 4 Encoder-Decoder releases, and 2 Decoder-Only releases.
* **2021:** Approximately 8 Encoder-Only releases, 6 Encoder-Decoder releases, and 4 Decoder-Only releases.
* **2022:** Approximately 10 Encoder-Only releases, 8 Encoder-Decoder releases, and 6 Decoder-Only releases.
* **2023:** Approximately 12 Encoder-Only releases, 10 Encoder-Decoder releases, and 8 Decoder-Only releases.
* **2024:** Approximately 14 Encoder-Only releases, 12 Encoder-Decoder releases, and 10 Decoder-Only releases. There is also approximately 2 Linear-Attention releases.
The trend shows a consistent increase in the number of releases for all architecture types over time. Decoder-Only architectures have seen the most significant growth in recent years.
### Key Observations
* The number of major releases of LLM architectures has increased exponentially from 2018 to 2024.
* Encoder-Only architectures have consistently been the most prevalent type of LLM architecture.
* Decoder-Only architectures have experienced the most rapid growth in recent years.
* The historical network diagrams demonstrate a progression from simpler models to more complex ones.
* The Transformer architecture is a key component in the development of modern LLMs.
### Interpretation
The image illustrates the rapid evolution of neural network architectures, culminating in the current dominance of LLMs. The historical diagrams show a clear progression from early models like the McCulloch-Pitts network and the Perceptron to more sophisticated architectures like the Boltzmann Machine and the Transformer. The bar chart highlights the recent explosion in LLM development, with a significant increase in the number of releases across all architecture types. The increasing prevalence of Decoder-Only architectures suggests a shift towards generative models. The diagram effectively demonstrates the interconnectedness of these developments, showing how each advancement builds upon previous work. The inclusion of AlphaFold indicates the application of these architectures to other domains beyond natural language processing. The overall message is one of accelerating innovation in the field of artificial intelligence.
</details>
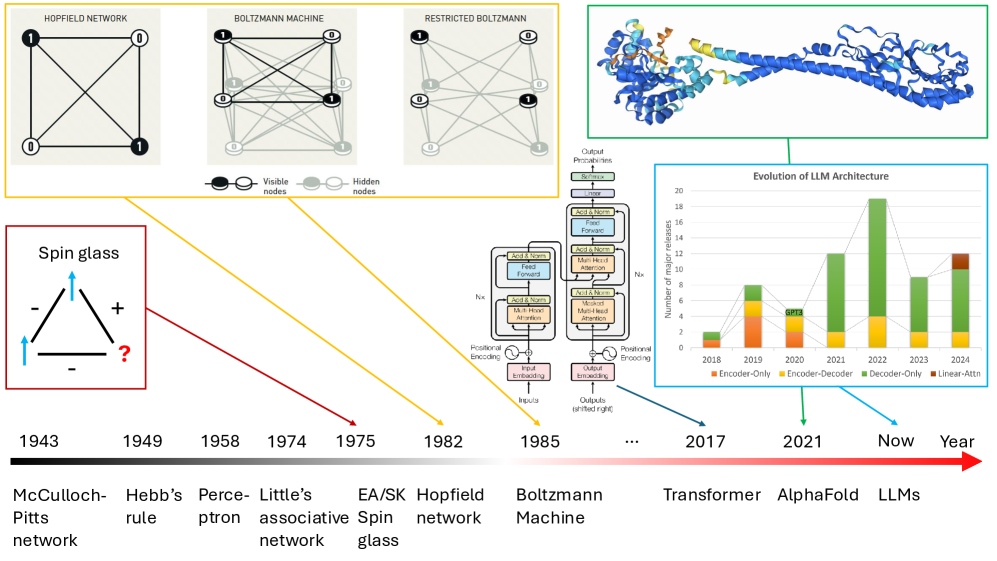
Figure 2: The history of artificial neural networks and relevant physical models. Other landmarks include backpropagation in the 1970s and AlexNet in 2012. Interestingly, bio-inspired ANNs ultimately led to the solution of the protein folding problem that has plagued us for half a century.
The significant breakthroughs in developing ANNs highlight the importance of convergence across different disciplines. ANNs mimic the structure and function of biological neurons, inspired by the human brain. In addition to their biological origin, the physical foundation of ANNs has been recognized by the Nobel Prize in Physics 2024, awarded to physicist John J. Hopfield and computer scientist Geoffrey E. Hinton hinton2025nobel. Their foundational discoveries enabled the development of ANNs and their applications today. ANNs are closely connected with spin glass, a traditional topic theorized by Edwards and Anderson in 1975 edwards1975theory and has attracted considerable attention in recent years. The importance of spin glasses as a representative complex system in different research domains across various length scales was demonstrated by the Nobel Prize in Physics 2021, awarded partly to Giorgio Parisi parisi1979infinite. The Nobel Prizes in Physics in 2021 and 2024 have also contributed to the increased attention. The prize-winning studies revealed a profound connection between spin glasses and diverse disciplines, ranging from large to small scales, encompassing complexity science, biology, and computer science.
There are a few landmarks in the history of ANNs [Figure 2], such as the seminal work of McCulloch and Pitts on neural networks in 1943 mcculloch1943logical that initiated the research domain and the Hebbian mechanism or Hebb’s rule in 1949 that suggests when neurons fire signals hebb2005organization, the simple ANN perceptron proposed by Rosenblatt in 1958 rosenblatt1958perceptron, and the proposal of associative neural networks by Little in 1974 little1974existence, and later by Hopfield in 1982 hopfield1982neural. In 1985, Hinton and colleagues proposed the Boltzmann machine ackley1985learning, a stochastic recurrent neural network (RNN) where the energy state of each neural-network configuration follows the Boltzmann distribution. Restricted Boltzmann machines were proposed later by removing the connections between neurons within the same layer to improve the network’s efficiency. The proposal of backpropagation in the 1970s, which Hinton and colleagues utilized to optimize ANNs like AlexNet in 2012, is another significant milestone. In 2017, the transformer architecture was proposed as an alternative to RNN structures, where the attention mechanism is a key novel component. Due to its high efficiency and suitability in large model optimization, it opened a new era for deep neural networks. AlphaFold jumper2021highly, the Nobel-Prize-winning model, and the popular large language models like GPT-3.5/4/4.5 and Llama 2/3/4 all adopt the transformer architecture.
Albeit with enormous success, the mechanisms behind these successes remain enigmatic. Fortunately, it has been demonstrated that idealized versions of these powerful networks are mathematically equivalent to older, simpler machine learning models, such as kernel machines belkin2018understand; jacot2018neural or physical models jcrn-3nrc. Therefore, the physical foundation of ANNs is closely related to magnetism (spins) and statistical physics amit1985spin; amit1987statistical; watkin1993statistical; mezard2024spin. Hopfield networks hopfield1982neural; hopfield1999brain; krotov2023new and Boltzmann machines ackley1985learning are essentially Sherrington-Kirkpatrick (SK) spin glasses with random interaction parameters sherrington1975solvable, where each neuron or spin is connected with all other ones except itself. When mapping the spin-glass structure to an ANN, each state corresponds to a pattern or memory in the Hopfield network. Finite metastable states indicate the limited capability of the Hopfield network folli2017maximum. It is essential to determine whether general spin glasses exhibit infinite metastable states, as is the case with the mean-field SK model. Spherical spin glass models have been used to study simplified, idealized ANNs choromanska2015loss. Parisi proposed a replica symmetry breaking (RSB) solution parisi1979infinite; charbonneau2023spin to the SK model sherrington1975solvable. The RSB theory has also been used to study ANNs, and steps toward some rigorous results were discussed agliari2020replica. Ghio et al. showed the sampling with flows, diffusion, and autoregressive neural networks from a spin-glass perspective ghio2024sampling. If this equivalence of ANNs and spin-glass systems can be extended beyond idealized neural networks, it may explain how practical ANNs achieve their astonishing results.
Box 1 | Basic Concepts of Statistical Physics Used by ANNs
Thermodynamics
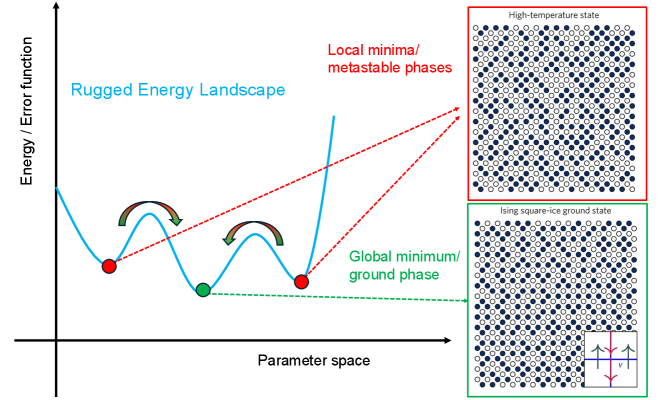
Energy Landscapes and Loss Functions The loss functions in ANNs are similar to the total energy of physical systems [Figure 1]. Statistical physics concepts, such as energy landscapes, are used to understand the dynamics and optimization in neural networks. For example, the weights and states in neural networks can be thought of as occupying a rugged energy landscape with many local minima, just like glassy Ising models. To optimize or train ANNs, we use methods such as simulated annealing and stochastic gradient descent, which are inspired by statistical physics.
Entropy and Information Theory Entropy from statistical physics is used to measure uncertainty in predictions and model behavior. One type of entropy, known as ”cross entropy,” between the actual values and predictions can be used as an error function. In addition, the entropy concept is closely related to the Information Bottleneck Principle, which explains how neural networks compress information during training, much like physical systems reduce entropy under certain conditions.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Diagram: Rugged Energy Landscape & Phase States
### Overview
The image is a diagram illustrating a "Rugged Energy Landscape" and its relationship to different phases of a system, likely in the context of physics or machine learning. It depicts an energy/error function plotted against a parameter space, with visual representations of high-temperature and ground state configurations.
### Components/Axes
* **X-axis:** Labeled "Parameter space". No specific scale is indicated.
* **Y-axis:** Labeled "Energy / Error function". No specific scale is indicated.
* **Blue Curve:** Represents the energy landscape, showing local minima and a global minimum.
* **Red Line:** Represents a path to local minima/metastable phases.
* **Green Arrows:** Indicate movement towards local minima.
* **Red Dots:** Mark local minima points on the blue curve.
* **Green Dot:** Marks the global minimum point on the blue curve.
* **Text Labels:**
* "Rugged Energy Landscape" (Blue, top-left)
* "Local minima/ metastable phases" (Red, top-right)
* "Global minimum/ ground phase" (Green, bottom-right)
* **Phase State Illustrations (Right Side):**
* "High-temperature state" (Top) - A grid of circles, mostly blue with some white.
* "Ising square-ice ground state" (Bottom) - A grid of circles, mostly blue with some white, and an arrow diagram indicating spin alignment.
### Detailed Analysis or Content Details
The diagram shows a complex energy landscape with multiple local minima and one global minimum. The blue curve oscillates, creating several "valleys" (local minima) and a deep "valley" (global minimum).
* **Energy Landscape:** The blue curve starts at a relatively high energy level, descends to a local minimum, rises again, descends to another local minimum, and finally reaches a deeper global minimum. The curve is not smooth, indicating a "rugged" landscape.
* **Local Minima:** There are approximately three visible local minima, marked by red dots. The red line connects to these points, illustrating paths to these metastable states.
* **Global Minimum:** The global minimum is marked by a green dot and represents the lowest energy state.
* **Phase States:**
* **High-Temperature State:** The illustration shows a disordered arrangement of blue and white circles, suggesting high thermal energy and randomness.
* **Ising Square-Ice Ground State:** The illustration shows a more ordered arrangement of blue and white circles, with an arrow diagram indicating a preferred spin alignment (up/down). The arrow diagram shows two arrows pointing up and one arrow pointing down.
### Key Observations
* The rugged energy landscape implies that finding the global minimum is challenging, as the system can easily get trapped in local minima.
* The phase state illustrations demonstrate the difference between a disordered (high-temperature) state and an ordered (ground) state.
* The diagram visually represents the concept of energy minimization and the challenges associated with it.
### Interpretation
This diagram illustrates a common concept in physics and machine learning: the energy landscape. The landscape represents the possible states of a system and their corresponding energies. The goal is often to find the state with the lowest energy (the global minimum). However, the presence of local minima can hinder this process, as the system can get stuck in suboptimal states.
The phase state illustrations provide a visual representation of how the system's configuration changes as it transitions between different energy levels. The high-temperature state represents a disordered state with high energy, while the ground state represents an ordered state with low energy.
The diagram suggests that the system's behavior is heavily influenced by the shape of the energy landscape and the temperature. At high temperatures, the system is more likely to explore different states and overcome energy barriers, while at low temperatures, it is more likely to get trapped in local minima. The Ising square-ice ground state illustration suggests a system with magnetic properties and a preferred spin alignment.
</details>
Figure 3: Basic concepts in statistical physics and thermodynamics. Here, we show that each pattern (memory or configuration) corresponds to an energy state in the rugged energy landscape of the free energy function or an error function.
Phase Transitions The concept of phase transitions is useful to describe the behavior of ANNs. ANNs exhibit phase transitions during training when their prediction and reliability suddenly change upon small changes of ANN structures (e.g., neural layers, parameter size in each layer), learning rate, etc., around critical values. This is similar to physical systems undergoing structural changes (e.g., spin glasses).
Bayesian Inference and Partition Functions
Bayesian statistics finds its application in ANNs. It uses Bayes’ theorem to calculate and update the probability distribution when new data or knowledge is available. This conditional feature meets the flexibility requirement of real-world problems, making it practically useful. Bayesian neural networks use principles from statistical physics for probabilistic inference. The partition function, a cornerstone of statistical mechanics, is used to calculate probabilities in probabilistic graphical models, including some neural networks.
Learning Dynamics and Langevin Equations
There are a few connections between Langevin equations and ANNs. Here, we mention two of them: (i) The learning dynamics of ANNs is described by Langevin equations, analogous to the motion of particles in a thermal bath. In studying stochastic gradient descent (SGD), the noise introduced by mini-batch sampling is found to resemble thermal noise goldt2019dynamics. (ii) The diffusion model of ANNs for images is similar to Langevin equations albergo2023stochastic, since both start with a white noisy background, and gradually recover the true states based on the status change of each particle or pixel.
2 Spin-glass physics for artificial neural networks
Just as neurons are the biological analogue of ANNs, spin glasses could be considered the physical analogue of ANNs: they were the inspiration for the original Hopfield model hopfield1982neural, which itself is viewed by some as a type of spin glass. We will discuss their relationships below.
2.1 Relations of spin glasses, biological neurons, and associative memory
Spin glass A spin glass is a type of magnetic system in which the quenched interactions between localized spins may be either ferromagnetic or antiferromagnetic with roughly equal probability. It exhibits an array of experimental properties: spin freezing with no long-range magnetic order at low temperature, a magnetic susceptibility cusp at a critical temperature accompanied by the absence of a singularity in the specific heat, slow relaxation, aging, and several others stein2013spin; stein2011spin. Most theoretical work has focused on the Edwards-Anderson (EA) spin glass edwards1975theory proposed in 1975 and its infinite-range analogue, the Sherrington-Kirkpatrick (SK) model sherrington1975solvable, proposed the same year.
The EA Hamiltonian in the absence of an external field is given by
$$
H=-\sum_{<ij>}J_{ij}\sigma_{i}\sigma_{j}\ , \tag{1}
$$
where the couplings $J_{ij}$ are i.i.d. random variables representing the interaction between spins $\sigma_{i}$ and $\sigma_{j}$ at nearest-neighbor sites $i$ and $j$ (denoted by the bracket in (1)). One is free to choose the distribution of the couplings: a common choice, which will be used here, is a Gaussian distribution with zero mean and unit variance. This distinguishes the spin glass from more conventional magnets: if $J_{ij}$ were a constant $J$ , the model becomes either a ferromagnet ( $J>0$ ) or an antiferromagnet ( $J<0$ ), both with an ordered ground state.
As noted above, when every pair of spins interacts with each other, the model becomes the SK model, a mean-field spin glass with Hamiltonian
$$
H=-\frac{1}{\sqrt{N}}\sum_{i<j}J_{ij}\sigma_{i}\sigma_{j}\ , \tag{2}
$$
where the coupling distribution $J_{ij}$ is also a mean-zero, unit variance Gaussian. The thermodynamic properties of the SK model are well understood, and analytical expressions were found for its free energy and order parameters parisi1979infinite. Whether similar properties exist in short-range spin glasses remains an open question. Understanding short-range spin glasses in finite dimensions remains a major challenge in both condensed matter physics and statistical mechanics.
ANNs and spin glasses Magnetic systems have long been used to model neural networks, going back (at least) to the work of McCullough and Pitts mcculloch1943logical. In its simplest form, a neuron is assumed to have only two states: ‘on’ or firing, and ‘off’ or quiescent. Therefore, its state can be modelled as an Ising spin, where $+1$ corresponds to the firing state and $-1$ to the quiescent state. A state, or firing pattern, of the entire neural network then corresponds to a spin configuration $\{\sigma\}$ . The interactions between neurons, i.e., synaptic efficiencies, correspond to the couplings $J_{ij}$ between spins in a magnetic system.
The Hebb learning rule is used to determine the coupling parameters hebb2005organization. In associative neural networks, such as the Hopfield network, suppose there are $p$ patterns (corresponding to memories). Then the interactions $J_{ij}$ between neurons are modelled as
$$
J_{ij}=\frac{1}{N}\sum_{\mu=1}^{p}\xi_{i}^{\mu}\xi_{j}^{\mu}, \tag{3}
$$
where the state of the $i^{\rm th}$ spin in the $\mu^{\rm th}$ pattern (spin configuration) is represented by $\xi_{i}^{\mu}$ , which also takes on the values $± 1$ . When $p=1$ , the system is equivalent to a Mattis model mattis1976solvable, which is gauge-equivalent to a ferromagnet. Setting $p>1$ introduces frustration into the system, and its behavior becomes more spin-glass-like. Apart from its interpretation as a model for neural networks, the Hopfield model represents an interesting statistical mechanical system in its own right and has been the subject of considerable study. A few studies have used statistical mechanics methods to investigate phase transitions in the Hopfield model hopfield1982neural; amit1985storing; gardner1988space and have found a bound $p$ on the number of memories that can be faithfully recalled from any initial state in a system of $N$ spins or neurons.
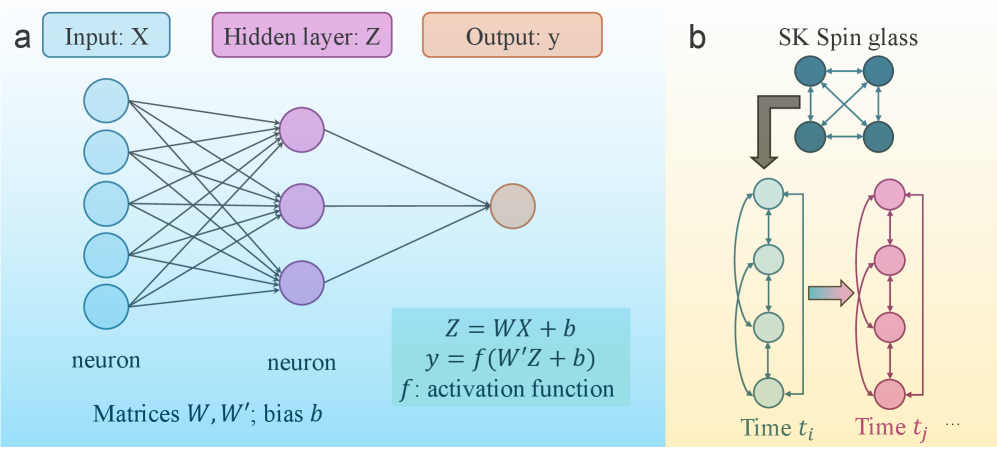
In addition to Hopfield networks, some idealized ANNs also have similar correspondences with spin glasses little1974existence, such as the spherical SK spin glass models choromanska2015loss [Figure 4]. In a spherical spin glass, the spins have varying magnitudes subject to the constraint $\sum_{i}^{N}\sigma_{i}^{2}=N$ . Given training data $\{X_{i}\},y$ , a neural network with $H-1$ hidden layers is equivalent to an equation choromanska2015loss, i.e., $y=q\sigma\big(W^{T}_{H}\sigma(W^{T}_{H-1}...\sigma(W_{1}^{T}X))...\big)$ , where $q$ is a normalization factor. The loss function of this ANN is
$$
L_{\Lambda,H}(\bm{\tilde{w}})=\frac{1}{\Lambda^{(H-1)/2}}\sum_{i_{1},i_{2},...,i_{H}=1}^{\Lambda}X_{i_{1},i_{2},...,i_{H}}\tilde{w}_{i_{1}}\tilde{w}_{i_{2}}...\tilde{w}_{i_{H}}, \tag{4}
$$
where $\Lambda$ is the number of weights. By imposing the spherical constraint above on the weights that follow $1/\Lambda\sum_{i=1}^{\Lambda}\tilde{w}_{i}^{2}=1$ , the loss function of this neural network was found to be mathematically equivalent to the Hamiltonian formulation of a spin glass.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Neural Network and Spin Glass Representation
### Overview
The image presents two diagrams side-by-side. Diagram (a) illustrates a simplified neural network architecture with an input layer, a hidden layer, and an output layer, along with the associated mathematical equations. Diagram (b) depicts a spin glass model, showing interconnected nodes and their evolution over time.
### Components/Axes
**Diagram (a): Neural Network**
* **Input:** Labeled "X", represented by a set of six light blue circles.
* **Hidden Layer:** Labeled "Z", represented by four purple circles.
* **Output:** Labeled "y", represented by a single light blue circle.
* **Neurons:** Labeled "neuron" below the input and hidden layers.
* **Connections:** Lines connecting neurons between layers, representing weighted connections.
* **Equations:**
* Z = WX + b
* y = f(W'Z + b)
* f: activation function
* **Matrices/Bias:** Labeled "Matrices W, W'; bias b" below the neuron labels.
**Diagram (b): Spin Glass**
* **Nodes:** Represented by circles, colored light blue and purple.
* **Connections:** Lines connecting nodes, some with arrowheads indicating direction.
* **Time:** Labeled "Time tᵢ" and "Time tⱼ", indicating the evolution of the system.
* **Title:** "SK Spin glass" at the top.
### Detailed Analysis or Content Details
**Diagram (a): Neural Network**
The neural network has 6 input nodes, 4 hidden nodes, and 1 output node. The connections between the layers are fully connected. The equations describe the forward pass of the network:
* The hidden layer's activation (Z) is calculated by multiplying the input (X) by a weight matrix (W) and adding a bias (b).
* The output (y) is calculated by applying an activation function (f) to a linear combination of the hidden layer's activation (Z), a weight matrix (W'), and a bias (b).
**Diagram (b): Spin Glass**
The spin glass model consists of interconnected nodes. The connections are not all uniform; some have arrowheads, suggesting directed interactions. The diagram shows the state of the system at two different times, tᵢ and tⱼ. The purple nodes appear to be changing state, indicated by the arrow. The connections between the nodes are complex and appear to form a network with both excitatory and inhibitory interactions.
### Key Observations
* Diagram (a) provides a simplified representation of a neural network, focusing on the core mathematical operations.
* Diagram (b) illustrates a complex system with dynamic interactions between its components.
* The spin glass model appears to be evolving over time, with nodes changing their state.
* The use of different colors (light blue and purple) in both diagrams may represent different states or types of nodes.
### Interpretation
The image juxtaposes two different models of complex systems: a neural network and a spin glass. The neural network diagram illustrates a computational model inspired by the brain, while the spin glass diagram represents a physical system with disordered interactions. Both models are used to study complex behavior and emergent properties.
The neural network diagram highlights the key components of a simple feedforward network: input, hidden layer, output, weights, and activation function. The equations provide a concise mathematical description of the network's operation.
The spin glass diagram illustrates a system with many interacting degrees of freedom. The evolution of the system over time suggests that it is dynamic and can exhibit complex behavior. The disordered interactions between the nodes are characteristic of spin glasses, which are known for their frustration and non-equilibrium behavior.
The connection between these two diagrams is that they both represent complex systems that can be modeled mathematically. The neural network is a computational model, while the spin glass is a physical model. Both models can be used to study the emergence of complex behavior from simple interactions. The diagrams suggest a potential analogy between the two systems, where the nodes in the spin glass could be seen as analogous to the neurons in the neural network.
</details>
Figure 4: Topology of an artificial neural network and Sherrington-Kirkpatrick (SK) model. a, A simple, fully connected neural network with one hidden layer. b, A four-spin mean field SK spin-glass model.
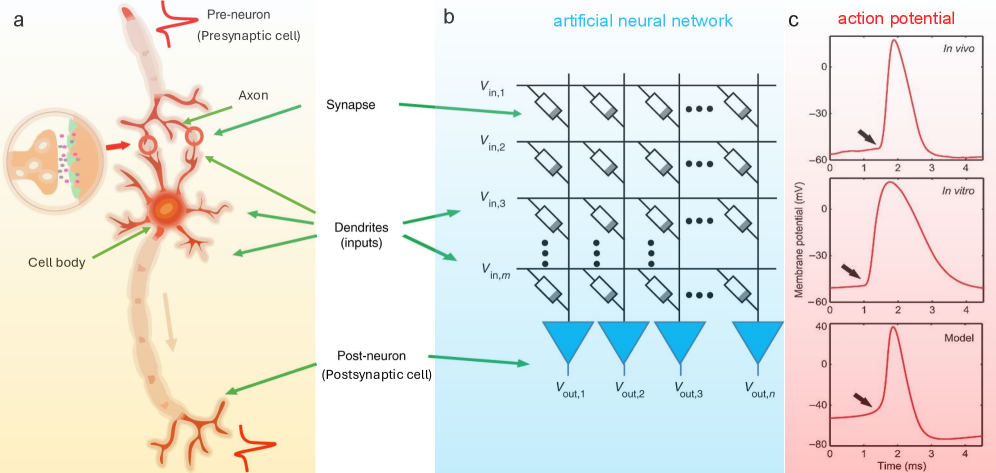
Similarity between biological neurons and ANNs ANNs are designed to imitate the structure of biological neurons [Figure 5] duan2020spiking. A neuron or nerve cell consists of three major parts, i.e., a cell body (soma), dendrites (receiving extensions), and an axon (conducting extension). When two neurons are connected, the presynaptic cell sends an electromagnetic signal to the postsynaptic cell. The signal travels from the axon of the presynaptic cell to the dendrites of the postsynaptic cell, which are directly connected. A threshold potential or action potential controls the activation of a neural connection [Figure 5 c]. The postsynaptic potential decides when to fire an electromagnetic signal. The potential at a specific neuron is a function of all postsynaptic potentials from its presynaptic neurons, i.e.,
$$
V_{i}=\sum_{j}J_{ij}(S_{j}+1). \tag{5}
$$
When $V_{i}$ is larger than a threshold $U_{i}$ , or $V_{i}-U_{i}>0$ the neuron is active ( $S_{i}=1$ ). Using the Heaviside function $H(x)$ , the state of the neuron can be written as $S_{i}=H(U_{i}-V_{i})$ . We use $h_{i}$ to represent the molecular field, $h_{i}=U_{i}-V_{i}$ . When the spin direction is parallel to $h_{i}$ , the local configuration is stable, i.e., $h_{i}S_{i}>0$ . Usually, the threshold function $U_{i}$ is assumed to satisfy $U_{i}≈\sum_{j}J_{ij}$ , then we find $-\frac{1}{2}\sum_{i}h_{i}S_{i}≈ H=-\frac{1}{2}\sum_{ij}J_{ij}\sigma_{i}\sigma_{j}$ , which has the same form as Eq. 1. The above formulation is for zero temperature. At finite temperature, the probability of activating one neuron is $P(S_{i})=\frac{1}{\exp[-\beta(V_{i}-U_{i})]+1}$ , which is a Fermi-Dirac distribution. Here, $\beta$ is the inverse temperature, defined by $\beta=1/k_{B}T$ with $k_{B}$ as the Boltzmann constant and $T$ is the temperature.
ANNs inherit these key features. Each artificial neuron sends data to the neurons in its following layers, which react collectively. This response is calculated using matrix multiplication plus a bias variable. The activation and updated connections of neurons follow Hebb’s rule hebb2005organization, which states that when two neurons fire together, the excitatory (ferromagnetic in magnetic terms) component of their coupling is enhanced. The more often two neurons are active together, the stronger their excitatory connection becomes. This holds for both biological and artificial neural networks.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Diagram: Biological and Artificial Neural Networks & Action Potentials
### Overview
The image presents a comparative overview of a biological neuron, an artificial neural network, and action potential waveforms. It visually contrasts the structure of a biological neuron with a simplified representation of an artificial neural network, and then shows action potential curves obtained *in vivo*, *in vitro*, and from a computational model. The image is divided into three sections labeled (a), (b), and (c), arranged horizontally.
### Components/Axes
**Section (a): Biological Neuron**
* Labels: Pre-neuron (Presynaptic cell), Post-neuron (Postsynaptic cell), Axon, Synapse, Cell body, Dendrites (inputs).
* Visual elements: A stylized illustration of a neuron with labeled components. Green arrows indicate the direction of signal transmission.
**Section (b): Artificial Neural Network**
* Title: "artificial neural network"
* Labels: V<sub>in,1</sub>, V<sub>in,2</sub>, V<sub>in,3</sub>, ... V<sub>in,m</sub> (inputs), V<sub>out,1</sub>, V<sub>out,2</sub>, V<sub>out,3</sub>, ... V<sub>out,n</sub> (outputs).
* Visual elements: A diagram representing a layer of an artificial neural network. Rectangular boxes represent nodes, connected by lines representing weights.
**Section (c): Action Potential**
* Title: "action potential"
* Axes: X-axis: Time (ms), ranging from 0 to 4. Y-axis: Membrane potential (mV), ranging from -80 to 0.
* Labels: *In vivo* (pink curve), *In vitro* (blue curve), Model (red curve).
* Visual elements: Three curves representing action potential waveforms under different conditions.
### Detailed Analysis or Content Details
**Section (a): Biological Neuron**
This section depicts a typical neuron structure. The pre-neuron transmits signals via the axon to the synapse, which connects to the dendrites of the post-neuron. The cell body houses the nucleus.
**Section (b): Artificial Neural Network**
The diagram shows a simplified artificial neural network layer. There are 'm' inputs (V<sub>in,1</sub> to V<sub>in,m</sub>) connected to 'n' outputs (V<sub>out,1</sub> to V<sub>out,n</sub>). Each input is connected to each output via a weighted connection (represented by the lines). The inputs and outputs are represented as voltage values.
**Section (c): Action Potential**
* ***In vivo*** (pink): The action potential rises rapidly to approximately +20 mV at around 1 ms, then falls back to the resting potential around 3 ms. The peak is approximately 20 mV, and the minimum is around -70 mV.
* ***In vitro*** (blue): The action potential rises to approximately -10 mV at around 1.5 ms, then falls back to the resting potential around 3.5 ms. The peak is approximately -10 mV, and the minimum is around -70 mV.
* ***Model*** (red): The action potential rises to approximately +30 mV at around 1 ms, then falls back to the resting potential around 3 ms. The peak is approximately 30 mV, and the minimum is around -70 mV.
### Key Observations
* The *in vivo* and Model action potentials have similar shapes and magnitudes, with a clear peak above 0 mV.
* The *in vitro* action potential is significantly smaller in magnitude and slower in its rise and fall compared to the *in vivo* and Model potentials.
* The artificial neural network diagram is a highly simplified representation of a biological neuron, focusing on input-output relationships.
### Interpretation
The image illustrates the fundamental principles of neural signaling in both biological and artificial systems. Section (a) provides the biological context, showing the physical structure of a neuron and how signals are transmitted. Section (b) presents a simplified abstraction of this process in the form of an artificial neural network, highlighting the concept of weighted connections between inputs and outputs. Section (c) demonstrates the electrical signal (action potential) that underlies neural communication, comparing experimental data (*in vivo* and *in vitro*) with a computational model.
The differences in the action potential waveforms suggest that the *in vitro* environment may not fully replicate the conditions necessary for a robust action potential. The model appears to capture the essential features of the *in vivo* action potential, indicating the validity of the computational approach. The comparison between the biological neuron and the artificial neural network highlights the inspiration behind artificial intelligence, while also emphasizing the complexity of biological systems that are not fully captured by current artificial models. The image serves as a visual aid for understanding the relationship between biological neural networks and their artificial counterparts.
</details>
Figure 5: Biological neurons, artificial neural networks, and action potentials. a, Biological neuron and its associated concepts duan2020spiking. b, Artificial neural network with input features $V_{\mathrm{in},i}$ and output features $V_{\mathrm{out},i}$ duan2020spiking. Here, the resistor symbols (rectangles) represent the activation functions that switch the signals from individual inputs on or off. c Activation potentials naundorf2006unique. The top panel represents an action potential in a cat visual cortex neuron in vivo. The middle panel is an action potential from a cat visual cortical slice in vivo at 20°C. The bottom panel is a model potential. The arrow indicates the characteristic kink at the onset of the action potential. This figure is adapted from Refs. duan2020spiking; naundorf2006unique and modified.
2.2 Dictionary of corresponding concepts
To clarify the connection across the three research domains, we provide a list of analogous features of ANNs, biological neurons, and spin glasses in Table 1. Here, the concepts across the three research domains are compared. A few concepts in the table have been discussed above, such as a spin in spin glass corresponds to a biological neuron in biology and an artificial neuron in ANNs. This comparison helps identify some interesting concepts that are not studied, thus deepening our understanding and providing new research opportunities. For example, the Hamiltonian in spin glasses yields a total energy of the system that has a similar role to the loss function in ANNs, which has no correspondence in biological neurons. The effective learning mechanism of neurons remains elusive, although a few explanations have been proposed, such as the principle of predictive coding luczak2022neurons. The concept of Hamiltonian, if it can capture the overall activity of biological neurons, may be relevant to what dominates the coordination of specific neurons and the choice of particular information propagation paths friston2010free; friston2009free. Various forms of order parameters, including spin overlap parameters, magnetization, giant cluster size (commonly used in percolation theory), etc., are physical quantities that describe the average information of spin variables in spin systems and capture phase states. It can be calculated as the overall activity of biological neurons or artificial neurons, like how closely the current firing pattern matches a learned activity pattern in the hippocampus or cortex. Studying order parameters in ANNs can help understand how many neurons are generally used or activated, which is valuable to understanding the fundamental principles of ANNs as kernels.
Table 1: Dictionary for artificial neural networks (ANNs), spin glasses, and biological neurons. The terms in spin glasses and their corresponding terms in ANNs are compared. Interestingly, no term in ANNs corresponds to the order parameter, which is closely connected to the value of loss functions. The common features of ANNs and spin glasses explain (i) why Monte Carlo methods can explore their energy landscapes and (ii) why spin glass methods can be directly used to study ANNs. Another interesting question is whether we need to introduce new order parameters for spin glass physics.
| spin | biological neuron | artificial neuron |
| --- | --- | --- |
| spin variables | neuron state (active/inactive) | features |
| interaction of two spins | electromagnetic signal | weight between two neurons |
| interaction strengths | action potential | weight matrix |
| total energy (Hamiltonian) | ? (unclear) | loss function |
| stable or metastable states | memory | memorized patterns in associative network |
| connectivity of spins | synapses | activation function |
| spherical SG models | ? (unknown) | topology of fully connected ANNs |
| order parameter | overall activity of neurons | ? (no correspondence) |
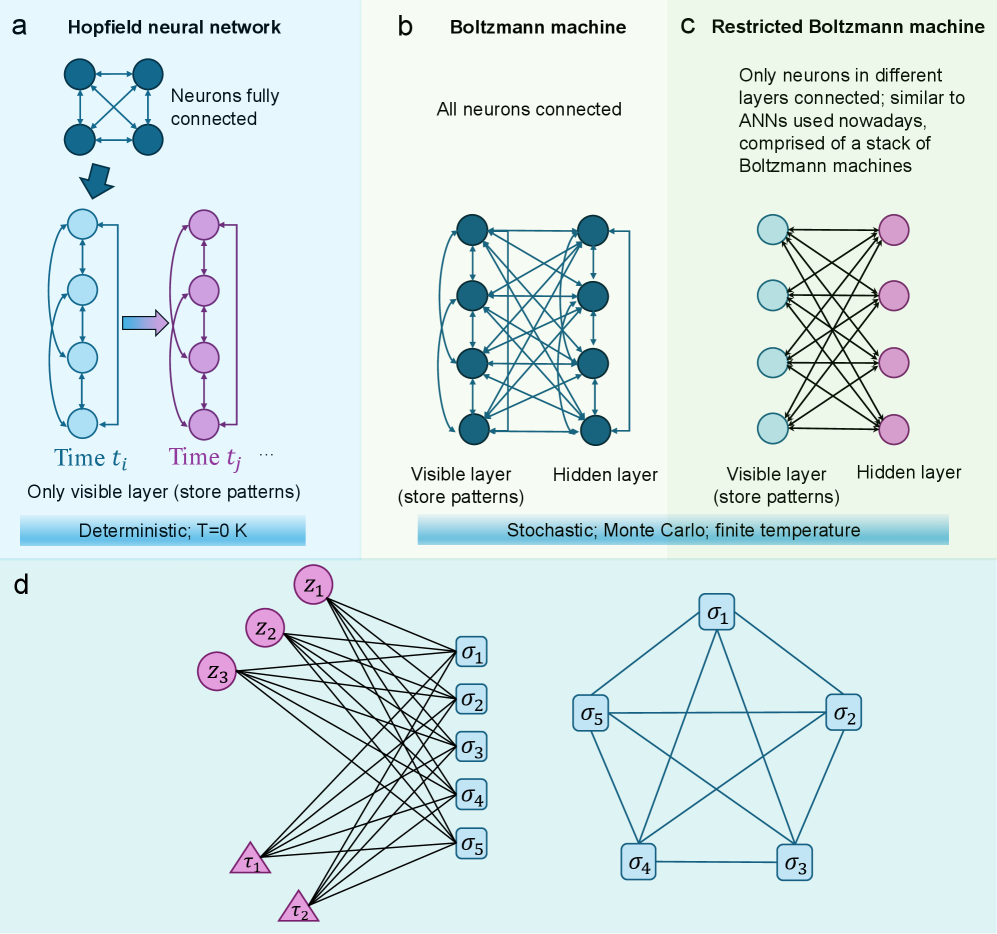
2.3 Hopfield neural network and Boltzmann machines
The Hopfield neural network hopfield1982neural consists of a single layer of fully interconnected neurons, with each neuron linked to every other neuron [Figure 4 a]. The metastable states, or local minima of the network, correspond to the patterns, which allows the creation of associative or content addressable memories. Patterns are memorized and encoded in the network parameters. A similar idea was proposed by Little eight years prior to Hopfield’s discovery little1974existence. Structurally, it bears a topological resemblance to the SK model sherrington1975solvable. The phase diagram of the Hopfield network is also similar to the SK model sherrington1975solvable. The original motivation of the Hopfield network was to create a model of associative memory, in which a stored pattern can be retrieved from an incomplete or noisy input.
The Hopfield network evolves over time, with the state of each neuron changing dynamically (Figure 4 b). This temporal evolution allows it to be viewed as a multi-layered system, where each “layer” represents a different time step. In this sense, it functions as a fully connected neural network, with each neuron capable of reading and outputting data. The network stores patterns by adjusting connection weights, and the number of patterns it can retain is proportional to the number of neurons folli2017maximum.
The Hopfield neural network influenced the development of recurrent neural networks (RNNs), such as the long short-term memory networks and the more efficient gated recurrent units. RNNs, characterized by recurrent neural layers, are designed to process sequential data, such as speech and natural languages. The transformer architecture has gradually replaced these methods, where the self-attention mechanism is adopted to replace recurrence for processing sequential data. The Hopfield neural network and its successors remain an active area of research agliari2019relativistic; saccone2022direct; negri2023storage.
Similar to the Hopfield neural network, the Boltzmann machine is a system where each spin interacts with all the others ackley1985learning [Figure 6 b]. It consists of a visible layer and a hidden layer, with all neurons—whether in the visible (input/output) or hidden layer—fully connected. Data is both inputted and outputted through the visible layer. A defining characteristic of Boltzmann machines is their stochastic nature: neuron activation is probabilistic rather than deterministic, influenced by connection weights and inputs. The probability of activation is determined by the Boltzmann distribution.
Due to the computational complexity of Boltzmann machines, more tractable “restricted” Boltzmann machines (RBMs) were introduced smolensky1986information; nair2010rectified [Figure 6 c]. RBMs adopt a bipartite structure, where the digital layer (or visible layer) and the analog layer (hidden layer) are fully connected, but there are no intra-layer connections. This structural constraint allows the use of more computationally efficient training algorithms compared to RBMs fischer2014training. Boltzmann machines have been widely applied to physical and chemical problems, including quantum many-body wavefunction simulations nomura2017restricted; melko2019restricted, modeling polymer conformational properties yu2019generating, and representing quantum states with non-Abelian or anyonic symmetries vieijra2020restricted.
Barra et al. studied the equivalence of Hopfield networks and Boltzmann machines (Figure 6 d) barra2012equivalence. The study is based on a “hybrid” Boltzmann machine (HBM) model, where the $P$ hidden units in the analog layer are continuous (for pattern storage) and the $N$ visible neurons are discrete and binary. They showed that the HBM, when marginalized over the hidden units, and the Hopfield network are statistically equivalent. Assume $P(\sigma,z)$ is the joint distribution for HBM, $P(z)$ is the distribution for the continuous hidden variables that usually follow the Gaussian distribution, and $P(\sigma)$ is the distribution for the Hopfield distribution. These quantities follow Bayes’ rule $P(\sigma,z)=P(\sigma|z)P(z)=P(z|\sigma)P(\sigma)$ .
Since this work involves several key concepts used in ANNs, such as the diffusion model and pattern overlap, we discuss their theoretical details further here. The activity of the hidden layer follows a stochastic differential equation $T\frac{dz_{\mu}}{dt}=-z_{\mu}(t)+\sum_{i}\xi_{i}^{\mu}\sigma_{i}+\frac{2T}{\beta}\zeta_{\mu}(t)$ , where $\zeta_{\mu}$ is a white Gaussian noise. The idea is similar to the diffusion model widely used in image and video generation. The probability for $z_{\mu}$ described by the stochastic differential equation above is $P(z_{\mu}|\sigma)=\sqrt{\frac{\beta}{2\pi}}\exp\bigg[-\frac{\beta}{2}\bigg(z_{\mu}-\sum_{i}\xi_{i}^{\mu}\sigma_{i}\bigg)^{2}\bigg]$ . The Hamiltonian of the HBM shown in Figure 6 d is $H_{hbm}(\sigma,z,\tau;\xi,\eta)=\frac{1}{2}\bigg(\sum_{\mu}z^{2}_{\mu}+\sum_{\nu}\tau^{2}_{\nu}\bigg)-\sum_{i}\sigma^{2}_{i}\bigg(\sum_{\mu}\xi_{i}^{\mu}z_{\mu}+\sum_{\nu}\eta_{i}^{\nu}\tau_{\nu}\bigg)$ . Then, the joint probability for the HBM can be calculated by $P(\sigma,z,\tau)=\exp[-\beta H_{hbm}(\sigma,z,\tau;\xi,\eta)]/Z(\beta,\xi,\eta)$ , where the partition function $Z(\beta,\xi,\eta)=\sum_{\sigma}∈t\prod^{P}_{\mu=1}dz_{\mu}∈t\prod^{K}_{\nu=1}d\tau_{\nu}\exp[-\beta H_{hbm}(\sigma,z,\tau;\xi,\eta)]$ . Assisted by the Gaussian integral and Bayes’ rule, the probability for $\sigma$ is $P(\sigma)=\exp\bigg(-\frac{\beta}{2}\sum_{i,j}(\sum_{\mu}\xi_{i}^{\mu}\xi_{j}^{\mu})\sigma_{i}\sigma_{j}\bigg)$ . If we set $J_{ij}=\sum_{\mu}\xi_{i}^{\mu}\xi_{j}^{\mu}$ , it is straightforward to see that this is the SK spin glass model. After determining the HBM Hamiltonian, it is not difficult to find that the concept of pattern overlap is mathematically equivalent to the overlap of replicas, an order parameter used in spin glass edwards1975theory.
Both Boltzmann machines and Hopfield neural networks have been foundational in the advancement of ANNs and deep learning. While newer, more efficient algorithms continue to emerge, these models demonstrate the profound impact of statistical physics on shaping machine-learning techniques.
2.4 Replica theory and the cavity method
Replica theory Replicas are copies of the same system. The key idea is to consider $n$ replicas in calculating its free energy, which is given by
$$
F=k_{B}T\langle\ln(Z)\rangle, \tag{6}
$$
where $\langle·\rangle$ represents thermal average over the ensemble. Then, the mathematical identity
$$
\langle\ln(Z)\rangle=\lim_{n\rightarrow 0}\frac{\langle Z^{n}\rangle-1}{n} \tag{7}
$$
can be used at the limit of $n→ 0$ to find the free energy. This is purely mathematical and not physical because the initially assumed integer $n$ is treated like a real number that can be smaller than one and infinitely close to 0. Mathematician Talagrand proved its correctness strictly talagrand2003spin. In the replica symmetry method, each replica is treated identically, which is the origin of the negative entropy in the mean-field solution for the SK model. Parisi proposed a replica symmetry-breaking method that successfully addressed the negative entropy issue by constructing a matrix ansatz in which replicas can have different ordering states.
The replica theory was initially developed to study glassy, disordered systems, such as spin glasses kirkpatrick1978infinite; parisi1983order; charbonneau2023spin; newman2024critical, and later to understand the macroscopic behavior of learning algorithms and capacity limits gardner1988space; amit1985storing. It was used to analyze the phase transitions of associative neural networks (e.g., the Hopfield network) and overparameterization and generalization of ANNs rocks2022memorizing; baldassi2022learning. One crucial question in associative neural networks is the storage capacity of memory. A network system with size $N$ could only provide associative memory $p≤\alpha_{c}N$ at zero temperature with $\alpha_{c}=0.1-0.2$ for Hopfield models hopfield1982neural; amit1985storing. For example, Amit and colleagues found $\alpha_{c}≈ 0.138$ with Hebb’s rule $J_{ij}=1/2\sum_{\mu}\xi_{i}^{\mu}\xi_{j}^{\mu}$ amit1985storing. When different or no constraints are imposed on $J_{ij}$ , different values of $\alpha_{c}$ are found gardner1988space; gardner1987maximum; gardner1988optimal; krauth1989storage. When $p≥\alpha_{c}N$ , memory quality degrades quickly. There is a phase transition at $\alpha_{c}$ . Studying this problem is equivalent to finding the number of ground states of a spin glass.
The replica theory has been used to understand the phase transition or the critical behavior of ANNs in supervised and unsupervised learning. Hou et al. proposed a statistical physics model of unsupervised learning and found that the sensory inputs drive a series of continuous phase transitions related to spontaneous intrinsic-symmetry breaking hou2020statistical. Baldassi et al. studied the subdominant dense clusters in ANNs with discrete synapses baldassi2015subdominant. They found these clusters enabled high computational performance in these systems.
Cavity method Later, Parisi and coauthors proposed another method, i.e., the cavity model, to solve the SK model (a method to calculate the statistical properties by removing a single spin and observing the reaction of the spin system) mezard1987spin. It is a statistical method used to calculate thermodynamic properties, serving as an alternative to the replica theory. It focuses on removing one spin and its interactions with its neighbors to create a cavity and calculates the response of the rest of the system. At zero temperature, the response is determined by energy minimization. Rocks et al. adopted the “zero-temperature cavity method” for the random nonlinear features model rocks2022memorizing to study the double descent behavior, an important phenomenon that we will discuss later.
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Diagram: Neural Network Architectures
### Overview
The image presents a comparative diagram illustrating four different neural network architectures: Hopfield neural network, Boltzmann machine, Restricted Boltzmann machine, and a detailed depiction of a specific network structure labeled 'd'. The diagram focuses on the connectivity and layer structure of each network type.
### Components/Axes
The diagram is divided into four sections labeled 'a', 'b', 'c', and 'd'. Each section represents a different neural network architecture.
- **a (Hopfield Neural Network):** Depicts a network evolving over time (t<sub>i</sub> to t<sub>j</sub>). It highlights a "visible layer" that stores patterns. The text indicates it is "Deterministic; T=0 K".
- **b (Boltzmann Machine):** Shows a network with "Visible layer" and "Hidden layer". The text indicates it is "Stochastic; Monte Carlo; finite temperature".
- **c (Restricted Boltzmann Machine):** Similar to the Boltzmann machine, with "Visible layer" and "Hidden layer", but with restricted connectivity. The text states it is "similar to ANNs used nowadays, comprised of a stack of Boltzmann machines".
- **d:** A more complex network with nodes labeled z<sub>1</sub>, z<sub>2</sub>, z<sub>3</sub>, τ<sub>1</sub>, τ<sub>2</sub> and σ<sub>1</sub>, σ<sub>2</sub>, σ<sub>3</sub>, σ<sub>4</sub>, σ<sub>5</sub>. Connections between nodes are indicated by lines with arrowheads.
### Detailed Analysis or Content Details
**a (Hopfield Neural Network):**
The network consists of interconnected nodes. At time t<sub>i</sub>, the network is in one state, and at time t<sub>j</sub>, it has evolved to a different state. The arrows indicate the direction of influence between neurons. The network is described as deterministic with a temperature of 0 Kelvin.
**b (Boltzmann Machine):**
The network has two layers: a visible layer and a hidden layer. All neurons are connected to each other. The network is described as stochastic, utilizing Monte Carlo methods, and operating at a finite temperature.
**c (Restricted Boltzmann Machine):**
Similar to the Boltzmann machine, it has a visible and hidden layer. However, the connections are restricted to only between different layers. It is described as being similar to modern Artificial Neural Networks (ANNs) and built from stacked Boltzmann machines.
**d:**
This network has two sets of input nodes (τ<sub>1</sub>, τ<sub>2</sub>) connected to a set of hidden nodes (z<sub>1</sub>, z<sub>2</sub>, z<sub>3</sub>). The hidden nodes are then connected to a set of output nodes (σ<sub>1</sub>, σ<sub>2</sub>, σ<sub>3</sub>, σ<sub>4</sub>, σ<sub>5</sub>). The connections are directional, indicated by the arrowheads. The network appears to be fully connected between the input and hidden layers, and between the hidden and output layers.
### Key Observations
- The diagram highlights the evolution of neural network architectures from the fully connected Hopfield network to the more restricted and layered Boltzmann and Restricted Boltzmann machines.
- The Boltzmann and Restricted Boltzmann machines introduce the concept of hidden layers, which are absent in the Hopfield network.
- The Restricted Boltzmann machine introduces a restriction on connectivity, which is a key difference from the Boltzmann machine.
- Diagram 'd' presents a specific network configuration with labeled nodes and directional connections, suggesting a particular implementation or model.
### Interpretation
The diagram illustrates the progression of neural network design, moving from simpler, fully connected networks (Hopfield) to more complex, layered architectures (Boltzmann, Restricted Boltzmann). The introduction of hidden layers and restricted connectivity in the Boltzmann and Restricted Boltzmann machines allows for more sophisticated pattern recognition and representation learning. The diagram suggests that the Restricted Boltzmann machine is a precursor to modern ANNs. The specific network in 'd' likely represents a particular application or model within the broader framework of neural networks, showcasing a detailed connection scheme between input, hidden, and output layers. The inclusion of temperature parameters (T=0 K for Hopfield) and stochastic methods (Monte Carlo for Boltzmann) indicates the consideration of thermodynamic principles in the design and operation of these networks.
</details>
Figure 6: Comparison of Hopfield neural network and Boltzmann machines. a, Principle of the Hopfield neural network. b, Illustration of a Boltzmann machine. c, Restricted Boltzmann machine, generated by removing the intra-layer connections of visible and hidden layers. d, The equivalence of Hopfield neural network and a hybrid restricted Boltzmann machine. Here, the visible variables $\{\sigma_{i}\}$ are discrete and binary and hidden variables $\{z_{i}\}$ and $\{\tau_{i}\}$ are continuous.
2.5 Overparameterization and double-descent behavior
Overparameterization The variance-bias trade-off is prevalent and has been observed in numerous models, and the reason is apparent: fewer parameters result in low variance and high bias, while more parameters lead to high variance and low bias for each prediction. There is an optimal choice of intermediate parameter size at which the model achieves its best performance. However, this does not seem to hold for neural networks. The optimal performance of neural networks is achieved with overparameterization belkin2019reconciling; rocks2022memorizing; baldassi2022learning. When a neural network has more parameters than the number of input data points, it is still considered overparameterized. In simple analytical expressions, such as linear equations, this typically becomes problematic, a phenomenon known as overfitting. One long-standing mystery of ANNs is that they seemingly subvert traditional machine learning theory, as their parameter size can exceed the number of data points for training without a signal of overfitting.
Double-descent behavior The total error function of a model usually has a “U” shape, and its minimum corresponds to the optimal parameters. The training error vanishes at a critical value of the parameter size when it equals the size of the training data points. The test error becomes divergent at this critical parameter size, analogous to the specific heat at the transition temperature. In traditional linear models, the error increases except at this critical value; in the overparameterized model, the test error first decreases, then increases at the critical value, and then decreases again. This phenomenon is referred to as double-descent behavior belkin2019reconciling; rocks2022memorizing; baldassi2022learning. This behavior results in an optimal or minimal test error in the overparameterized region.
Understanding the variance-bias trade-off of neural networks with overparameterization is crucial in deep learning. There are different opinions on the overparameterization phenomenon, which relies on methods from statistics and probability theory. For example, this behavior can be studied using the replica trick. The neural networks undergo a phase transition when the parameters increase across the critical threshold. The Information Bottleneck Principle (IBP) proposes that deep neural networks first fit the training data and then discard irrelevant information by going through an information bottleneck, which helps them generalize tishby2000information; tishby2015deep. Since the results are based on a particular type of ANNs, it is controversial whether the IBP conclusion holds generally for all deep neural networks saxe2019information.
ANNs with more neurons in a neural layer or wide neural layers usually have better generalization performance than their narrower counterparts. When the number of neurons approaches infinity, this extreme case becomes mathematically more straightforward to treat, which is equivalent to the fact that the SK model is easier to solve than the EA model. When an infinite number of neurons is allowed in a layer, this is equivalent to a Gaussian process neal1996priors; bahri2024houches. Interestingly, a recent study came to similar conclusions for quantum neural networks garcia2025quantum. The Gaussian process is one way to view ANNs and explains why many parameters are not overfitting. ANNs are equivalent to kernels at initialization and throughout the training process. Many parameters in ANNs remain constant, causing them to behave like a kernel jacot2018neural. Their values do not depend on the training data, but rather on the architecture of the neural network.
Machine learning algorithms that use kernels are known as kernel machines. These models operate by mapping data from a low-dimensional space to a high-dimensional one using functions such as Gaussian kernels, which can enhance classification performance. Its inverse process is regularization, which aims to reduce the number of free parameters to prevent overfitting. Kernel machines are conceptually simpler and more analytically tractable. During training, the evolution of the function represented by an infinite-width neural network mirrors that of a kernel machine. In function space, both models can be visualized as descending a smooth, convex (bowl-shaped) landscape in a high-dimensional space. Due to this structure, it is mathematically straightforward to prove that gradient descent converges to the global minimum. However, the practical relevance of this equivalence remains debated. Real-world neural networks are of finite width, and their parameters can change in complex ways during training. In terms familiar to statistical physicists, this is akin to questioning whether insights from the SK model of spin glasses remain valid in the short-range EA model—i.e., whether the behavior in idealized, solvable models carries over to more realistic, complex systems.
3 Challenges and perspectives
ANNs are good at recognizing patterns. However, there is a lack of explainability, bias, hallucination, and transferability in ANNs. More drawbacks that need to be mitigated include reliance on massive datasets, catastrophic forgetting, vulnerability to attacks, high computational costs, and inadequate symbolic reasoning wang2024hopfield. In this section, we will elaborate on the challenges primarily relevant to their statistical aspects and provide our perspectives on their solutions.
3.1 Challenges in ANNs and spin glasses for ANNs
There are many unanswered questions specifically to ANNs, such as why ANNs work and why backpropagation performs better than other methods in high-dimensional space belkin2021fit. We do not know where to start solving them, and if we know, “a horde of people would do it” miller2024nobel. To make things worse, ANNs have complicated and diverse structures, which prevent them from constructing a rigorous mathematical foundation. Nonetheless, statistical physics provides essential tools to solve these problems.
Statistical physics is deeply connected to optimization problems and provides approaches to solving them. This connection has been convincingly demonstrated by the fact that simulated annealing provides solutions to combinatorial optimization problems, such as the traveling salesman problem kirkpatrick1983optimization. Additionally, the simple “basin-hopping” approach has been applied to atomic and molecular clusters, as well as more complicated hypersurface deformation techniques for crystals and biomolecules wales1999global. Breakthroughs in statistical physics are valuable to finding the optimal solutions to ANNs. We anticipate the development of more efficient statistical methods.
Understanding the nature of ground states of short-range spin glasses can provide valuable and indirect insights into the capacity of ANN to memorize patterns. One crucial direction associated with statistical physics for ANNs is to study the topological structure of non-idealized ANNs and their connection with spin-glass models mezard2024spin. We can only connect simplified ANNs with spin glasses, not the more interesting, widely applied ANNs. A few challenges exist in understanding spin glasses that have interaction ranges intermediate between those of short-range EA and mean-field SK models, as well as their mapping to general ANNs. Specific examples include (i) finding the global optimal solutions and (ii) whether the ground states in a general spin glass are finite or infinite newman2022ground. Numerical and theoretical bottlenecks contribute to the challenges. Numerically, (1) there is limited information on large systems and scaling due to the limited computing resources, and (2) there is a lack of visualization methods to help process high-dimensional data and inspire ideas for analytical solutions. Theoretically, (1) we have no clear picture of the models in the thermodynamic limit, and (2) there is no analytical method to describe short-range spin-glass models. Analytic solutions are limited to the dynamics of models with all-to-all interactions, such as the SK model. It is non-trivial to understand a sparse network where not all neurons or spins interact with each other. However, finding an analytical solution to sparse networks is essential for comprehending general ANNs, just as the SK model is for fully connected ANNs. Recently, Metz proposed a dynamical mean-field method for sparse directed networks and found their exact analytical solutions metz2025dynamical. The general solution is claimed to apply to the study of neural networks and beyond, including ecosystems, epidemic spreading, and synchronization, which represents meaningful progress. However, more efforts are still needed in this direction.
3.2 Spin-glass physics helps understand ANNs
Spin-glass physics and ANNs are reciprocal. Important inference problems in machine learning can be formulated as problems in the statistical physics of disordered systems. However, the significant issues we face in analyzing deep networks require the development of a new chapter in spin glass theory mezard2024spin. Only a solid theory can transform deep network predictions from best guesses in a black box into interpretable, demonstrable statements whose worst-case behavior can be controlled, although constructing a theory of deep learning is challenging.
We have summarized a few examples where ANNs solve problems in statistical and theoretical physics, such as the phase detection of matter or materials. This is an active research area. Meanwhile, mean-field theory (e.g., cavity method or replica theory) inspires the development of ANN algorithms and enhances our understanding of ANNs, such as the double-descent behavior. Currently, only analytical results are obtained for simple ANNs, and only these simple ANNs are well understood. Unlike the previous methods, which are suitable for single-layer or shallow networks, active research is ongoing to develop a statistical mechanical theory for learning in deep architectures, such as the method proposed by Li and Sompolinsky li2021statistical. In the future, it is expected that the properties of more real ANNs can be fully explored.
<details>
<summary>order-parameter.jpg Details</summary>
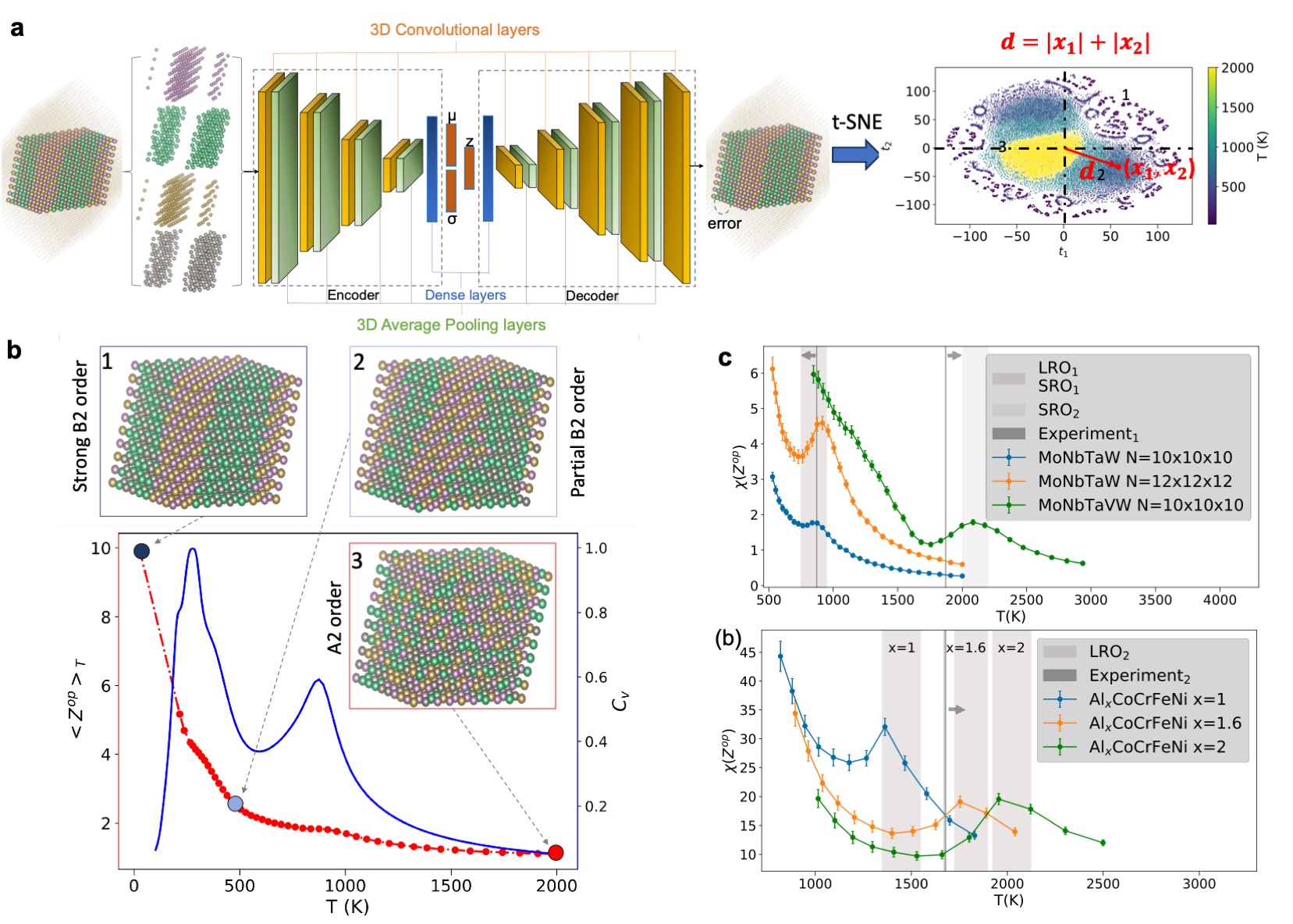
### Visual Description
## Diagram: Neural Network Architecture and Magnetic Properties
### Overview
The image presents a multi-panel diagram illustrating a neural network architecture used to analyze magnetic properties of materials. Panel (a) depicts the neural network structure. Panel (b) shows visualizations of different magnetic orderings and their corresponding temperature dependence. Panel (c) and (b) display plots of X(Z<sub>op</sub>) versus temperature (T) for different materials and compositions.
### Components/Axes
**Panel (a): Neural Network**
* **Title:** "a"
* **Components:** 3D Convolutional layers, Encoder, Dense layers, Decoder, Error.
* **Diagram:** Shows a flow from input (3D Convolutional layers) through an Encoder and Dense layers, then a Decoder, resulting in an error signal.
* **Equation:** d = |x<sub>1</sub>| + |x<sub>2</sub>|
* **t-SNE Plot:** X-axis labeled "t<sub>1</sub>", Y-axis labeled "t<sub>2</sub>", Color bar ranging from approximately 500 to 2000. Points are colored based on the colorbar. Points are clustered into three groups labeled 1, 2, and 3.
**Panel (b): Magnetic Orderings & Temperature Dependence**
* **Title:** "b"
* **Sub-panels:** Two visualizations of atomic arrangements representing "Strong B2 order" (1) and "Partial B2 order" (2). Below these, a plot of <Z<sub>op</sub>> vs. T.
* **Plot Axes:** X-axis labeled "T (K)", Y-axis labeled "<Z<sub>op</sub>>".
* **Curves:** Two curves are plotted: a blue curve representing "A2 order" and a purple curve representing "B2 order".
* **Colorbar:** Ranges from approximately 0.0 to 1.0, representing a value labeled "ζ".
**Panel (c): X(Z<sub>op</sub>) vs. T for Different Materials**
* **Title:** "c"
* **Axes:** X-axis labeled "T(K)", Y-axis labeled "X(Z<sub>op</sub>)".
* **Data Series:**
* "Experiment" (Black dashed line)
* "MoNbTaW N=10x10x10" (Red line)
* "MoNbTaW N=12x12x12" (Green line)
* "MoNbTaW N=10x10x10" (Blue line)
**Panel (b): X(Z<sub>op</sub>) vs. T for Different Compositions**
* **Title:** "(b)"
* **Axes:** X-axis labeled "T(K)", Y-axis labeled "X(Z<sub>op</sub>)".
* **Data Series:**
* "Experiment<sub>2</sub>" (Black dashed line)
* "Al<sub>x</sub>CoCrFeNi x=1" (Red line)
* "Al<sub>x</sub>CoCrFeNi x=1.6" (Green line)
* "Al<sub>x</sub>CoCrFeNi x=2" (Blue line)
* **Labels:** x=1, x=1.6, x=2 are indicated near the corresponding lines.
### Detailed Analysis or Content Details
**Panel (a):** The t-SNE plot shows three distinct clusters of points. Cluster 1 (red) is centered around (approximately 50, 50) and has values ranging from 500 to 2000. Cluster 2 (blue) is centered around (-50, -50) and has values ranging from 500 to 2000. Cluster 3 (purple) is more dispersed.
**Panel (b):** The <Z<sub>op</sub>> vs. T plot shows a sharp decrease in <Z<sub>op</sub>> from approximately 8 to 0 around 500K, corresponding to the transition from B2 order to A2 order. The B2 order curve (purple) remains relatively high until around 500K, then drops rapidly. The A2 order curve (blue) remains low throughout the temperature range. The colorbar indicates that ζ is high for strong B2 order and low for partial B2 order.
**Panel (c):** The X(Z<sub>op</sub>) vs. T plot shows that the experimental data (black dashed line) initially increases, reaches a maximum around 1000K, and then decreases. The MoNbTaW simulations with different sizes (red, green, blue) generally follow the experimental trend, but with varying magnitudes. The N=10x10x10 simulation (red) closely matches the experimental data up to approximately 2000K.
**Panel (b):** The X(Z<sub>op</sub>) vs. T plot shows that the experimental data (black dashed line) initially increases, reaches a maximum around 1000K, and then decreases. The Al<sub>x</sub>CoCrFeNi simulations with different compositions (red, green, blue) generally follow the experimental trend, but with varying magnitudes. The x=1 simulation (red) closely matches the experimental data up to approximately 2000K.
### Key Observations
* The neural network architecture in panel (a) suggests a dimensionality reduction technique (Encoder) followed by reconstruction (Decoder).
* The t-SNE plot in panel (a) indicates that the neural network can effectively separate data into three distinct classes.
* The temperature dependence of <Z<sub>op</sub>> in panel (b) reveals a phase transition from B2 to A2 order.
* The simulations in panel (c) and (b) generally agree with the experimental data, suggesting the validity of the model.
* The size of the simulation cell (N) in panel (c) affects the accuracy of the results.
* The composition (x) of the Al<sub>x</sub>CoCrFeNi alloy in panel (b) affects the accuracy of the results.
### Interpretation
The diagram demonstrates the use of a neural network to analyze the magnetic properties of materials. The neural network is trained to identify different magnetic orderings (B2, A2) and predict their temperature dependence. The t-SNE plot suggests that the neural network can effectively learn to distinguish between these orderings. The simulations in panels (c) and (b) show that the model can accurately reproduce the experimental results, providing insights into the underlying physics of these materials. The discrepancies between the simulations and the experimental data may be due to the limitations of the model or the experimental setup. The varying results based on simulation cell size and alloy composition suggest that these parameters are important for accurate modeling. The overall goal appears to be to use machine learning to accelerate the discovery and design of new magnetic materials.
</details>
Figure 7: Neural network-based order parameter in complex concentrated alloys. a, A schematic structure for variational auto-encoder (VAE) was used. The information extracted from the latent space and projected in a two-dimensional (2D) space using t-SNE. The 2D data was then used to construct the order parameter $\langle Z^{op}\rangle_{T}$ based on Manhattan distance $\sum_{i}|x_{i}|$ . b, The new order parameter describes the different configurations. The first-order derivative of $\langle Z^{op}\rangle_{T}$ (i.e., $\chi(Z^{op})$ ) can play a similar role to the specific heat $C_{v}$ , where the peaks represent the two phase transitions. c, The temperatures of phase transitions represented by the peak of $\chi(Z^{op})$ are compared with experimental data. This figure is adjusted from Ref. yin2021neural.
3.3 Do we need new order parameters for ANNs?
Historically, order parameters play an essential role in describing the thermodynamic behavior of complex systems, as demonstrated by the second-order parameters $\langle q^{2}\rangle$ proposed by Edwards and Anderson edwards1975theory. New order parameters promote the study of glassy systems. Currently, the phase distributions of short-range spin glasses are not fully understood, which may limit our understanding of complex ANNs. We may need new order parameters based on ANNs to describe phase transitions and the phase distribution of spin glasses. Developing a rigorous mathematical description of metastable states and solutions appears to be necessary. In a previous study, we adopted a similar idea and proposed a neural-network-based order parameter to study the complex concentrated alloys, where multiple principal elements co-exist that introduce maximal disorder (Figure 7) yin2021neural. We successfully utilized the new order parameter to differentiate between different phases. We found that the predicted phase transition temperatures are consistent with experimental results. Similarly, due to the complex feature of ANN phase transitions, we may need one ANN to help us understand the phases of another ANN. ANNs can capture size-independent patterns that pave the way to understand the ground states of spin glasses at the thermodynamic limit. Currently, only spin-glass results of relatively small sizes are available, limited by computing resources (speed of supercomputers). However, we still need to overcome difficulties, including feature extraction and feature synthesis used in ANNs.
3.4 Quantum computing for spin glasses and ANNs
Due to the rugged energy landscapes of spin glasses, even today’s most powerful supercomputers cannot model the large size of this complex system, leaving the behavior of these systems largely unexplored. Quantum computers can mitigate this issue with their exponential scaling. The breakthroughs in both hardware and algorithms in quantum computing provide new opportunities. A team from Google reported an error-corrected chip, Willow, featuring 105 qubits based on superconducting qubits, in December 2024 Acharya2025. The performance of the Willow chip is challenged by China’s Zuchongzhi 3.0 processor gao2025establishing, a superconducting quantum computer prototype featuring 105 qubits, which was reported in March 2025. The hope of quantum computing based on Majorana particles, a type of quasi-particle in topological insulators, rose in February 2025. Microsoft published its intermediate, controversial result on its quantum computer, Majorana 1 quantum2025interferometric. Quantum computers can be used to efficiently explore the phase spaces of spin-glass-like systems. Simulating Ising spin glasses on a quantum computer provides new opportunities Lidar1997. For example, the Ising-type Sachdev-Ye-Kitaev (SYK) model that describes the dynamics of wormholes between black holes for fermions can be solved numerically by quantum computing gao2021traversable; jafferis2022traversable. Quantum computing can also be applied in quantum machine learning, such as in the development of quantum versions of ANNs or quantum neural networks boreiri2025topologically. This will become more promising with the emergence of new quantum algorithms. Recently, King and colleagues used quantum annealing processors to simulate quantum dynamics in programmable spin glasses King2025-D-Wave, one application of quantum computers of practical interest. Given the topological relationship between spin glasses and ANNs, this will provide valuable insights into understanding ANNs.
Additionally, it is anticipated that ANNs can leverage the benefits of quantum computing in terms of efficiency and accuracy. For example, the quantum version of the Hopfield network was developed by replacing classical Hebbian learning with a quantum Hebbian learning rule rebentrost2018quantum. The researchers demonstrated the ability to store exponentially large networks with a polynomial number of qubits by encoding them as amplitudes of quantum states. Their quantum algorithm achieves a quantum computational complexity that is logarithmic in the dimensionality of the data. The advantages of quantum ANNs, as well as other quantum algorithms, are questionable and unknown in near-term quantum computers. To address this critical question, Abbas et al. proposed the so-called effective dimension to measure the power and trainability of quantum ANNs abbas2021power. Assisted by the measure, they showed a quantum advantage of a class of quantum ANNs. Quantum ANNs are currently under active investigation and are still in their early stages of development.
3.5 More opportunities
One exciting future direction of ANN is neural computing, also known as synaptic computation abbott2004synaptic; wang2018fully; weilenmann2024single; zhou2024field. The storage and computing of the current ANNs are separate. Differently, biological neurons store data and perform computations through the same neural network, making it highly efficient. Since associative ANNs have demonstrated their capability for memory storage and have been successfully applied in computation, it is natural to take the next step and design memristive neural networks. Memristors can store and compute information simultaneously. A memristor is a combination of a memory unit and a resistor, which can mimic biological synaptic functions in ANNs. The resistance of a memristor changes based on the history of applied current or voltage. A prominent advantage of memristors is that they are non-volatile and can retain memory in the absence of power. For example, Wang et al. developed fully memristive neural networks for pattern classification with unsupervised learning wang2018fully. In a recent study, Weilenmann and colleagues explored energy-efficient neural networks using a single neuromorphic memristor that mimics multiple synaptic mechanisms weilenmann2024single. More details can be found in a recent review of the memristive Hopfield neural networks applied to chaotic systems lin2023review. Memristors are artificial analogs of biological neurons that harness computing power by mimicking their structure and function. Recently, another exciting direction that deserves more attention is the direct participation of neurons in vitro in computational processes. These studies integrate adaptive in vitro neurons and in silico high-density multi-electrode arrays into digital systems to perform computations kagan2022vitro. Nonetheless, these research directions are still in their infancy and offer a lot of opportunities to explore the potential of neural computing. Since they are not the focus of this article, we will not discuss them in depth.
4 Conclusions
We have reviewed the applications and history of artificial neural networks, as well as their connections with biology and statistical physics, particularly in the context of spin glasses. We showed the deep connections of these multidisciplinary directions. For example, we demonstrate how the replica theory is applied to understand the behavior of artificial neural networks. We also discussed the challenges and possible solutions. One of the significant problems is understanding and also accelerating the training of large artificial neural networks, which can benefit from the integration with quantum computing and neural computing. Quantum computing can provide exponential acceleration, while neural computing can mitigate the storage limit, reducing the latency in data transfer. Theoretically, the complex behavior, reliability, and stability of ANNs require more research efforts, which lag behind their applications. Arguably, the most challenging problems involve understanding biological and artificial neurons. The former involves the formation of consciousness, while the latter involves the realization of artificial intelligence. We concluded that statistical physics bridges the gap between these key multidisciplinary problems and will provide valuable methods to find their answers.