# MemR3: Memory Retrieval via Reflective Reasoning for LLM Agents
**Authors**: Xingbo Du, Loka Li, Duzhen Zhang, Le Song
Abstract
Memory systems have been designed to leverage past experiences in Large Language Model (LLM) agents. However, many deployed memory systems primarily optimize compression and storage, with comparatively less emphasis on explicit, closed-loop control of memory retrieval. From this observation, we build memory retrieval as an autonomous, accurate, and compatible agent system, named MemR 3, which has two core mechanisms: 1) a router that selects among retrieve, reflect, and answer actions to optimize answer quality; 2) a global evidence-gap tracker that explicitly renders the answering process transparent and tracks the evidence collection process. This design departs from the standard retrieve-then-answer pipeline by introducing a closed-loop control mechanism that enables autonomous decision-making. Empirical results on the LoCoMo benchmark demonstrate that MemR 3 surpasses strong baselines on LLM-as-a-Judge score, and particularly, it improves existing retrievers across four categories with an overall improvement on RAG (+7.29%) and Zep (+1.94%) using GPT-4.1-mini backend, offering a plug-and-play controller for existing memory stores.
Machine Learning, ICML
1 Introduction
With recent advances in large language model (LLM) agents, memory systems have become the focus of storing and retrieving long-term, personalized memories. They can typically be categorized into two groups: 1) Parametric methods (wang2024wise; fang2025alphaedit) that encode memories implicitly into model parameters, which can handle specific knowledge better but struggle in scalability and continual updates, as modifying parameters to incorporate new memories often risks catastrophic forgetting and requires expensive fine-tuning. 2) Non-parametric methods (xu2025amem; langmem_blog2025; chhikara2025mem0; rasmussen2025zep), in contrast, store explicit external information, enabling flexible retrieval and continual augmentation without altering model parameters. However, they typically rely on heuristic retrieval strategies, which can lead to noisy recall, heavy retrieval, and increasing latency as the memory store grows.
Orthogonal to these works, this paper constructs an agentic memory system, MemR 3, i.e., Mem ory R etrieval system with R eflective R easoning, to improve retrieval quality and efficiency. Specifically, this system is constructed using LangGraph (langchain2025langgraph), with a router node selecting three optional nodes: 1) the retrieve node, which is based on existing memory systems, can retrieve multiple times with updated retrieval queries. 2) the reflect node, iteratively reasoning based on the current acquired evidence and the gaps between questions and evidence. 3) the answer node that produces the final response using the acquired information. Within all nodes, the system maintains a global evidence-gap tracker to update the acquired (evidence) and missing (gap) information.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Reasoning Process Diagram: Question Answering with Different Retrieval Strategies
### Overview
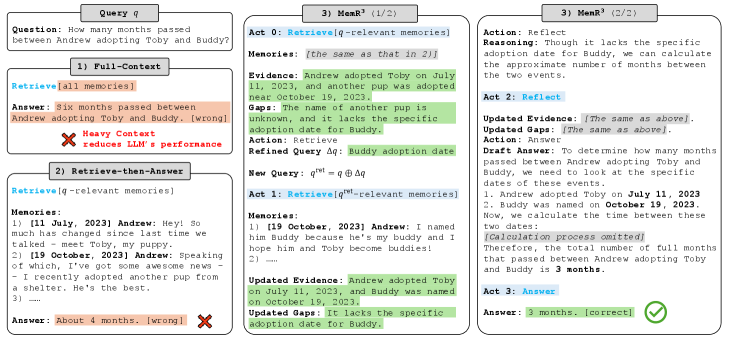
The image presents a diagram comparing three different approaches to answering a question using a language model (LLM). The question is: "How many months passed between Andrew adopting Toby and Buddy?". The diagram illustrates the reasoning process and the final answer provided by each approach: Full-Context, Retrieve-then-Answer, and MemR^3. The diagram highlights the strengths and weaknesses of each approach in terms of accuracy and the amount of context used.
### Components/Axes
* **Query q:** The initial question: "How many months passed between Andrew adopting Toby and Buddy?"
* **1) Full-Context:** This approach retrieves all available memories and uses them to answer the question.
* `Retrieve[all memories]`
* Answer: "Six months passed between Andrew adopting Toby and Buddy. [wrong]"
* "Heavy Context reduces LLM's performance" (indicated by a red "X")
* **2) Retrieve-then-Answer:** This approach retrieves only the memories relevant to the question and then answers the question.
* `Retrieve[q-relevant memories]`
* Memories:
* "1) [11 July, 2023] Andrew: Hey! So much has changed since last time we talked - meet Toby, my puppy."
* "2) [19 October, 2023] Andrew: Speaking of which, I've got some awesome news - I recently adopted another pup from a shelter. He's the best."
* "3) ..."
* Answer: "About 4 months. [wrong]" (indicated by a red "X")
* **3) MemR^3 (1/2 & 2/2):** This approach uses a more refined retrieval and reasoning process, involving multiple acts.
* **Act 0:** `Retrieve[q-relevant memories]`
* Memories: "[the same as that in 2)]"
* Evidence: "Andrew adopted Toby on July 11, 2023, and another pup was adopted near October 19, 2023."
* Gaps: "The name of another pup is unknown, and it lacks the specific adoption date for Buddy."
* Action: Retrieve
* Refined Query Δq: "Buddy adoption date"
* New Query: q^{ret} = q ⊕ Δq
* **Act 1:** `Retrieve[q^{ret}-relevant memories]`
* Memories:
* "1) [19 October, 2023] Andrew: I named him Buddy because he's my buddy and I hope him and Toby become buddies!"
* "2) ----"
* Updated Evidence: "Andrew adopted Toby on July 11, 2023, and Buddy was named on October 19, 2023."
* Updated Gaps: "It lacks the specific adoption date for Buddy."
* **Act 2:** Reflect
* Action: Reflect
* Reasoning: "Though it lacks the specific adoption date for Buddy, we can calculate the approximate number of months between the two events."
* Updated Evidence: "[The same as above]."
* Updated Gaps: "[The same as above]."
* Action: Answer
* Draft Answer: "To determine how many months passed between Andrew adopting Toby and Buddy, we need to look at the specific dates of these events."
* "1. Andrew adopted Toby on July 11, 2023"
* "2. Buddy was named on October 19, 2023."
* "Now, we calculate the time between these two dates: [Calculation process omitted]"
* "Therefore, the total number of full months that passed between Andrew adopting Toby and Buddy is 3 months."
* **Act 3:** Answer
* Answer: "3 months. [correct]" (indicated by a green checkmark)
### Detailed Analysis or ### Content Details
* **Full-Context:** This method uses all available information, leading to an incorrect answer, possibly due to irrelevant information diluting the relevant facts.
* **Retrieve-then-Answer:** This method retrieves relevant memories but still provides an incorrect answer, suggesting that the retrieved information is insufficient or misinterpreted.
* **MemR^3:** This method refines the query and iteratively retrieves and reflects on the information, leading to the correct answer. The process involves identifying gaps in the knowledge and specifically targeting those gaps with refined queries.
### Key Observations
* The Full-Context approach fails due to the inclusion of too much irrelevant information.
* The Retrieve-then-Answer approach fails despite retrieving relevant information, indicating a potential issue with reasoning or insufficient information.
* The MemR^3 approach succeeds by iteratively refining the query and focusing on filling knowledge gaps.
### Interpretation
The diagram demonstrates the importance of targeted information retrieval and iterative reasoning for accurate question answering. The MemR^3 approach highlights the effectiveness of refining queries and focusing on filling knowledge gaps, leading to a more accurate and reliable answer compared to simply using all available information or retrieving only initially relevant information. The failure of the Full-Context approach suggests that the presence of irrelevant information can negatively impact the performance of LLMs. The success of MemR^3 underscores the value of a more structured and iterative approach to knowledge retrieval and reasoning.
</details>
Figure 1: Illustration of three memory-usage paradigms. Full-Context overloads the LLM with all memories and answers incorrectly; Retrieve-then-Answer retrieves relevant snippets but still miscalculates. In contrast, MemR 3 iteratively retrieves and reflects using an evidence–gap tracker (Acts 0–3), refines the query about Buddy’s adoption date, and produces the correct answer (3 months).
The system has three core advantages: 1) Accuracy and efficiency. By tracking the evidence and gap, and dynamically routing between retrieval and reflection, MemR 3 minimizes unnecessary lookups and reduces noise, resulting in faster, more accurate answers. 2) Plug-and-play usage. As a controller independent of existing retriever or memory storage, MemR 3 can be easily integrated into memory systems, improving retrieval quality without architectural changes. 3) Transparency and explainability. Since MemR 3 maintains an explicit evidence-gap state over the course of an interaction, it can expose which memories support a given answer and which pieces of information were still missing at each step, providing a human-readable trace of the agent’s decision process. We compare MemR 3, the Full-Context setting (which uses all available memories), and the commonly adopted retrieve-then-answer paradigm from a high-level perspective in Fig. 1. The contributions of this work are threefold in the following:
(1) A specialized closed-loop retrieval controller for long-term conversational memory. We propose MemR 3, an autonomous controller that wraps existing memory stores and turns standard retrieve-then-answer pipelines into a closed-loop process with explicit actions (retrieve / reflect / answer) and simple early-stopping rules. This instantiates the general LLM-as-controller idea specifically for non-parametric, long-horizon conversational memory.
(2) Evidence–gap state abstraction for explainable retrieval. MemR 3 maintains a global evidence–gap state $(\mathcal{E},\mathcal{G})$ that summarizes what has been reliably established in memory and what information remains missing. This state drives query refinement and stopping, and can be surfaced as a human-readable trace of the agent’s progress. We further formalize this abstraction via an abstract requirement space and prove basic monotonicity and completeness properties, which we later use to interpret empirical behaviors.
(3) Empirical study across memory systems. We integrate MemR 3 with both chunk-based RAG and a graph-based backend (Zep) on the LoCoMo benchmark and compare it with recent memory systems and agentic retrievers. Across backends and question types, MemR 3 consistently improves LLM-as-a-Judge scores over its underlying retrievers.
2 Related Work
2.1 Memory for LLM Agents
Prior work on non-parametric agent memory systems spans a wide range of fields, including management and utilization (du2025rethinking), by storing structured (rasmussen2025zep) or unstructured (zhong2024memorybank) external knowledge. Specifically, production-oriented agents such as MemGPT (packer2023memgpt) introduce an OS-style hierarchical memory system that allows the model to page information between context and external storage, and SCM (wang2023enhancing) provides a controller-based memory stream that retrieves and summarizes past information only when necessary. Additionally, Zep (rasmussen2025zep) builds a temporal knowledge graph that unifies and retrieves evolving conversational and business data. A-Mem (xu2025amem) creates self-organizing, Zettelkasten-style memory that links and evolves over time. Mem0 (chhikara2025mem0) extracts and manages persistent conversational facts with optional graph-structured memory. MIRIX (wang2025mirix) offers a multimodal, multi-agent memory system with six specialized memory types. LightMem (fang2025lightmem) proposes a lightweight and efficient memory system inspired by the Atkinson–Shiffrin model. Another related approach, Reflexion (shinn2023reflexion), improves language agents by providing verbal reinforcement across episodes by storing natural-language reflections to guide future trials.
In this paper, we explicitly limit our scope to long-term conversational memory. Existing parametric approaches (wang2024wise; fang2025alphaedit), KV-cache–based mechanisms (zhong2024memorybank; eyuboglu2025cartridges), and streaming multi-task memory benchmarks (wei2025evo) are out of scope for this work. Orthogonal to existing storage, MemR 3 is an autonomous retrieval controller that uses a global evidence–gap tracker to route different actions, enabling closed-loop retrieval.
2.2 Agentic Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) (lewis2020retrieval) established the modern retrieve-then-answer paradigm; subsequent work explored stronger retrievers (karpukhin2020dense; izacard2021leveraging). Beyond the RAG, recent work, such as Self-RAG (asai2024self), Reflexion (shinn2023reflexion), ReAct (yao2022react), and FAIR-RAG (asl2025fair), has shown that letting a language model (LM) decide when to retrieve, when to reflect, and when to answer can substantially improve multi-step reasoning and factuality in tool-augmented settings. MemR 3 follows this general “LLM-as-controller” paradigm but applies it specifically to long-term conversational memory over non-parametric stores. Concretely, we adopt the idea of multi-step retrieval and self-reflection from these frameworks, but i) move the controller outside the base LM as a LangGraph program, ii) maintain an explicit evidence–gap state that separates verified memories from remaining uncertainties, and iii) interface this state with different memory backends (e.g., RAG and Zep (rasmussen2025zep)) commonly used in long-horizon dialogue agents. Our goal is not to replace these frameworks, but to provide a specialized retrieval controller that can be plugged into existing memory systems.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: LLM Question Answering Process
### Overview
The image is a diagram illustrating the process of a Large Language Model (LLM) answering a user's question. It shows the flow of information and actions taken by the LLM, including retrieving information, reflecting on it, and generating an answer.
### Components/Axes
The diagram consists of the following key components:
1. **Input Data:**
* **User Query (q):** "How many months passed between Andrew adopting Toby and Buddy?"
* **Memory (M):** Divided into "Chunk-based" and "Graph-based" storage.
2. **Start:** The initial step in the process.
3. **Retrieve:** Retrieves information from memory based on the query. Output is (q^ret, M).
4. **LLM Generation:**
* **Evidence-gap Tracker:**
* **Evidence:** "Andrew adopted Toby on July 11, 2023, and Buddy was named on October 19, 2023."
* **Gap:** "It lacks the specific adoption date for Buddy."
* **Generated Actions:**
* **Retrieve:** new query Δq
* **Reflect:** reasoning r
* **Answer:** draft answer w
5. **Final Answer:**
* **Answer:** "The total number of full months that passed between Andrew adopting Toby and Buddy is 3 months."
6. **Reflect, Answer, End:** The final steps in generating the answer.
7. **Router:**
* Iteration budget
* Reflect-streak capacity
* Retrieval opportunity check
* Equation: q^ret = q ⊕ Δq
### Detailed Analysis or Content Details
* The process begins with a user query (q).
* The LLM retrieves relevant information from its memory (M), which is structured in both chunk-based and graph-based formats.
* The LLM Generation phase involves an Evidence-gap Tracker, which identifies relevant evidence and gaps in the information.
* The LLM generates actions: Retrieve (new query Δq), Reflect (reasoning r), and Answer (draft answer w).
* The Router component uses the equation q^ret = q ⊕ Δq.
* The process culminates in a Final Answer.
### Key Observations
* The diagram highlights the iterative nature of the LLM's question-answering process, involving retrieval, reflection, and answer generation.
* The Evidence-gap Tracker plays a crucial role in identifying missing information and guiding the retrieval process.
* The Router component appears to manage the flow of information and actions within the LLM.
### Interpretation
The diagram illustrates a sophisticated question-answering system that leverages both structured and unstructured memory to retrieve relevant information. The Evidence-gap Tracker is a key component that enables the LLM to identify and address gaps in its knowledge. The iterative process of retrieval, reflection, and answer generation allows the LLM to refine its understanding of the question and provide a more accurate and complete answer. The Router component likely manages the overall flow of information and actions, ensuring that the LLM efficiently utilizes its resources to answer the user's question.
</details>
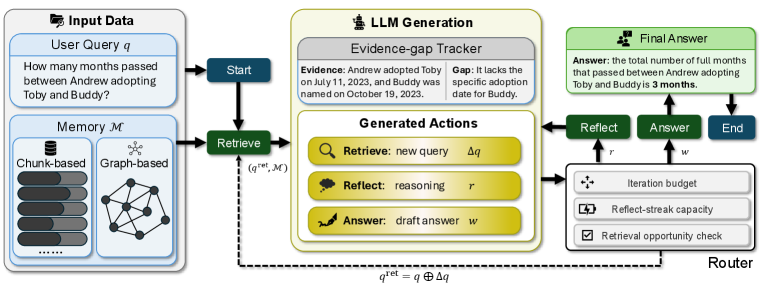
Figure 2: Pipeline of MemR 3. MemR 3 transforms retrieval into a closed-loop process: a router dynamically switches between Retrieve, Reflect, and Answer nodes while a global evidence–gap tracker maintains what is known and what is still missing. This enables iterative query refinement, targeted retrieval, and early stopping, making MemR 3 an autonomous, backend-agnostic retrieval controller.
3 MemR 3
In this section, we first formulate the problem and provide preliminaries in Sec. 3.1, and then give a system overview of MemR 3 in Sec. 3.2. Additionally, we describe the two core components that enable accurate and efficient retrieval: the router and the global evidence-gap tracker in Sec. 3.4 and Sec. 3.3, respectively.
3.1 Problem Formulation and Preliminaries
We consider a long-horizon LLM agent that interacts with a user, forming a memory store $\mathcal{M}=\{m_{i}\}_{i=1}^{N}$ , where each memory item $m_{i}$ may correspond to a dialogue utterance, personal fact, structured record, or event, often accompanied by metadata such as timestamps or speakers. Given a user query $q$ , a retriever is applied to retrieve a set of memory snippets $\mathcal{S}$ that are useful for generating the final answer. Then, given designed prompt template $p$ , the goal is to produce an answer $w$ :
$$
\begin{split}\mathcal{S}&\leftarrow\texttt{Retrieve}(q,\mathcal{M}).\\
w&\leftarrow\texttt{LLM}(q,\mathcal{S},p),\end{split} \tag{1}
$$
which is accurate (consistent with all relevant memories in $\mathcal{M}$ ), efficient (requiring minimal retrieval cycles and low latency), and robust (stable under noisy, redundant, or incomplete memory stores) as much as possible.
Existing memory systems have done great work on the memory storage $\mathcal{M}$ , but typically follow an open-loop pipeline: 1) apply a single retrieval pass; 2) feed the selected memories $\mathcal{S}$ into a generator to produce $\mathcal{A}$ . This approach lacks adaptivity: retrieval does not incorporate intermediate reasoning, and the system never represents which information remains missing. This leads to both under-retrieval (insufficient evidence) and over-retrieval (long, noisy contexts).
MemR 3 addresses these limitations by treating retrieval as an autonomous sequential decision process with explicit modeling of both acquired evidence and remaining gaps.
3.2 System Overview
MemR 3 is implemented as a directed agent graph comprising three operational nodes (Retrieve, Reflect, Answer) and one control node (Router) using LangGraph (langchain2025langgraph) (an open-source framework for building stateful, multi-agent workflows as graphs of interacting nodes). The agent maintains a mutable internal state
$$
s=(q,\mathcal{S},\mathcal{E},\mathcal{G},k), \tag{2}
$$
where $q$ and $\mathcal{S}$ are the aforementioned original user query and retrieved snippets, respectively. $\mathcal{E}$ is the accumulated evidence relevant to $q$ and $\mathcal{G}$ is the remaining missing information (the “gap”) between $q$ and $\mathcal{E}$ . Moreover, we maintain the iteration index $k$ to control early stopping.
At each iteration $k$ , the router chooses an action in $\{\texttt{retrieve},\ \texttt{reflect},\ \texttt{answer}\}$ , which determines the next node in the computation graph. The pipeline is shown in Fig. 2. This transforms the classical retrieve-then-answer pipeline into a closed-loop controller that can repeatedly refine retrieval queries, integrate new evidence, and stop early once the information gap is resolved.
3.3 Global Evidence-Gap Tracker
A core design principle of MemR 3 is to explicitly maintain and update two state variables: the evidence $\mathcal{E}$ and the gap $\mathcal{G}$ . These variables summarize what the agent currently knows and what it still needs to know to answer the question.
At iteration $k$ , the evidence $\mathcal{E}_{k}$ and gaps $\mathcal{G}_{k}$ are updated according to the retrieved snippets $\mathcal{S}_{k-1}$ (from the retrieve node) or reflective reasoning $\mathcal{F}_{k-1}$ (from the reflect node), together with last evidence $\mathcal{E}_{k-1}$ and gaps $\mathcal{G}_{k-1}$ at $k-1$ iteration:
$$
\mathcal{E}_{k},\mathcal{G}_{k},a_{k}=\texttt{LLM}(q,\mathcal{S}_{k-1},\mathcal{F}_{k-1},\mathcal{E}_{k-1},\mathcal{G}_{k-1},p_{k}), \tag{3}
$$
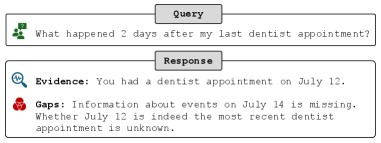
where $p_{k}$ is the prompt template at $k$ iteration. Additionally, $a_{k}$ is the action at $k$ iteration, which will be introduced in Sec. 3.4. Note that we explicitly clarify in $p_{k}$ that $\mathcal{E}_{k}$ does not contain any information in $\mathcal{G}_{k}$ , making evidence and gaps decoupled. An example is shown in Fig. 3 to illustrate the evidence-gap tracker.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Dialogue Box: Query and Response
### Overview
The image presents a dialogue box containing a user query and a system response. The query asks about events two days after the user's last dentist appointment. The response provides evidence of a dentist appointment on July 12th and identifies gaps in information regarding events on July 14th, while also questioning whether July 12th was indeed the most recent appointment.
### Components/Axes
* **Header:** Contains the labels "Query" and "Response" in separate boxes.
* **Query:** The user's question, accompanied by a green icon of people.
* **Response:** The system's answer, divided into "Evidence" (with a magnifying glass icon) and "Gaps" (with a red icon resembling a molecule).
### Detailed Analysis or ### Content Details
* **Query:**
* Text: "What happened 2 days after my last dentist appointment?"
* Icon: Green icon depicting a group of people.
* **Response:**
* **Evidence:**
* Text: "You had a dentist appointment on July 12."
* Icon: Blue magnifying glass.
* **Gaps:**
* Text: "Information about events on July 14 is missing. Whether July 12 is indeed the most recent dentist appointment is unknown."
* Icon: Red icon resembling a molecule.
### Key Observations
* The system provides a specific date (July 12) as evidence of a dentist appointment.
* The system acknowledges a lack of information for July 14, which is two days after July 12.
* The system raises a question about the recency of the July 12 appointment.
### Interpretation
The dialogue box illustrates a question-answering system's attempt to respond to a user's query. The system successfully identifies a relevant dentist appointment but also highlights its limitations in providing a complete answer. The "Gaps" section indicates the system's awareness of missing information and potential inaccuracies in its knowledge base. The system is able to extract the date of the appointment, and also calculate the date two days after the appointment. The system is also able to identify that it does not have information about the date two days after the appointment.
</details>
Figure 3: Example of the evidence-gap tracker for a specific query. At each step, the agent maintains an explicit summary of the evidence established and the information still missing. This state can be presented directly to users as a human-readable explanation of the agent’s progress in answering the query.
Through the evidence-gap tracker, MemR 3 maintains a structured and transparent internal state that continuously refines the agent’s understanding of both i) what has already been established as relevant evidence, and ii) what missing information still prevents a complete and faithful answer. This explicit decoupling enables MemR 3 to reason under partial observability: as long as $\mathcal{G}_{k}≠\varnothing$ , the agent recognizes that its current knowledge is insufficient and can proactively issue a refined retrieval query to close the remaining gap. Conversely, when $\mathcal{G}_{k}$ becomes empty, the router detects that the agent has accumulated adequate evidence and can safely transition to the answer node.
Beyond guiding retrieval, the evidence-gap representation also makes the agent’s behavior more transparent. At any iteration $k$ , the pair $(\mathcal{E}_{k},\mathcal{G}_{k})$ can be surfaced as a structured explanation of i) which memories the agent currently treats as relevant evidence and ii) which unresolved questions or missing details are preventing a confident answer. This trace provides users and developers with a faithful view of how the agent arrived at its final answer and why additional retrieval steps were taken (or not). In the following, we display an informal theorem that indicates the properties of the idealized evidence-gap tracker.
**Theorem 3.1 ([Informal]Monotonicity, soundness, and completeness of the idealized evidence-gap tracker)**
*Under an idealized requirement space $R(q)$ for a specific query $q$ , the evidence-gap tracker in MemR 3 is monotone (evidence never decreases and gaps never increase), sound (every supported requirement eventually enters the evidence set), and complete (if every requirement $r∈ R(q)$ is supported by some memory, the ideal gap eventually becomes empty).*
Formally, in Appendix B we define the abstract requirement space $R(q)$ and characterize the tracker as a set-valued update on $R(q)$ , proving fundamental soundness, monotonicity, and completeness properties (Theorem B.4), which we later use in Sec. 4.3 to interpret empirical phenomena such as why some questions cannot be fully resolved even after exhausting the iteration budget.
3.4 LangGraph Nodes
We explicitly define several nodes in the LangGraph framework, including start, end, generate, router, retrieve, reflect, answer. Specifically, start is always followed by retrieve, and end is reached after answer. generate is a LLM generation node, which is already introduced in Eq. 3. In the following, we further introduce the router node and three action nodes.
Router. At each iteration, the router, an autonomous sequential controller, uses the current state and selects an action from $\{\texttt{retrieve},\texttt{reflect},\texttt{answer}\}$ . Each action $a_{k}$ is accompanied by a textual generation:
$$
{ a_{k}\in\{(\texttt{retrieve},\Delta q_{k}),(\texttt{reflect},f_{k}),(\texttt{answer},w_{k})\},} \tag{4}
$$
where $\Delta q_{k}$ is a refinement query, $f_{k}$ is a reasoning content, and $w_{k}$ is a draft answer, which are utilized in the downstream action nodes. To ensure stability, router applies three deterministic constraints: 1) a maximum iteration budget $n_{\text{max}}$ that forces an answer action once the budget is exhausted, 2) a reflect-streak capacity $n_{\text{cap}}$ that forces a retrieve action when too many reflections have occurred consecutively, and 3) a retrieval-opportunity check that switches the action to reflect whenever the retrieval stage returns no snippets. The router’s algorithm is shown in Alg. 1.
Algorithm 1 Router policy in MemR 3
1: Input: query $q$ , previous snippets $\mathcal{S}_{k-1}$ , iteration $k$ , budgets $n_{\text{max}},n_{\text{cap}}$ , current reflect-streak length $n_{\text{streak}}$ .
2: Output: action $a_{k}$ .
3: if $k≥ n_{\text{max}}$ then
4: $a_{k}=\texttt{answer}$ $\triangleright$ Max iteration budget.
5: else if $\mathcal{S}_{k-1}=\emptyset$ then
6: $a_{k}=\texttt{reflect}$ $\triangleright$ No retrieved snippets.
7: else if $n_{\text{streak}}≥ n_{\text{cap}}$ then
8: $a_{k}=\texttt{retrieve}$ $\triangleright$ Max reflect streak.
9: else
10: pass $\triangleright$ Keep the generated action.
11: end if
These lightweight rules stabilize the decision process while preserving flexibility. We further introduce the detailed implementation of these constraints when introducing the system prompt in Appendix A.1.
Retrieve.
Given a generated refinement $\Delta q_{k}$ , the retrieve node constructs $q_{k}^{\mathrm{ret}}=q\oplus\Delta q_{k}$ , where $\oplus$ means textual combination and $q$ is the original query, and then, fetches new memory snippets:
$$
\begin{split}\mathcal{S}_{k}=\texttt{Retrieve}(q_{k}^{\mathrm{ret}},\mathcal{M}\backslash\mathcal{M}^{\text{ret}}_{k-1}),~\mathcal{M}^{\text{ret}}_{k}=\mathcal{M}^{\text{ret}}_{k-1}\cup\mathcal{S}_{k}.\end{split} \tag{5}
$$
Snippets $\mathcal{S}_{k}$ are independently used for the next generation without history accumulation. Moreover, retrieved snippets are masked to prevent re-selection.
A major benefit of MemR 3 is that it treats all concrete retrievers as plug-in modules. Any retriever, e.g., vector search, graph memory, hybrid stores, or future systems, can be integrated into MemR 3 as long as they return textual snippets, optionally with stable identifiers that can be masked once used. This abstraction ensures MemR 3 remains lightweight, portable, and compatible.
Reflect.
The reflect node incorporates the reasoning process $\mathcal{F}_{k-1}$ , and invokes the router to update $(\mathcal{E}_{k},\mathcal{G}_{k},a_{k})$ in Eq. 3, where evidence and gaps can be re-summarized.
Answer.
Once the router selects answer, the final answer is generated from the original query $q$ , the draft answer $w_{k}$ , evidence $\mathcal{E}_{k}$ using prompt $p_{w}$ from rasmussen2025zep:
$$
w\leftarrow\texttt{LLM}(q,w_{k},\mathcal{E}_{k},p_{w}), \tag{6}
$$
The answer LLM is instructed to avoid hallucinations and remain faithful to evidence.
3.5 Discussion on Efficiency
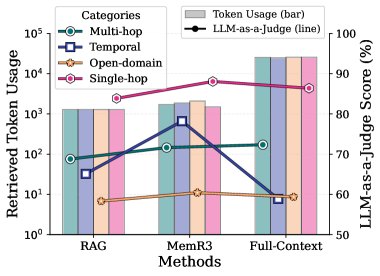
Although MemR 3 introduces extra routing steps, it maintains low overhead via 1) Compact evidence and gap summaries: only short summaries are repeatedly fed into the router. 2) Masked retrieval: each retrieval call yields genuinely new information. 3) Small iteration budgets: typically, most questions can be answered using only a single iteration. Those complicated questions that require multiple iterations are constrained with a small maximum iteration budget. These design choices ensure that MemR 3 improves retrieval quality without large increases in retrieved tokens.
4 Experiments
The experiments are conducted on a machine with an AMD EPYC 7713P 64-core processor, an A100-SXM4-80GB GPU, and 512GB of RAM. Each experiment of MemR 3 is repeated three times to report the average scores. Code available: https://github.com/Leagein/memr3.
4.1 Experimental Protocols
Datasets.
In line with baselines (xu2025amem; chhikara2025mem0), we employ LoCoMo (maharana2024evaluating) dataset as a fundamental benchmark. LoCoMo has a total of 10 conversations across four categories: 1) multi-hop, 2) temporal, 3) open-domain, 4) single-hop, and 5) adversarial. We exclude the last ‘adversarial’ category, following existing work (chhikara2025mem0; wang2025mirix), since it is used to test whether unanswerable questions can be identified. Each conversation has approximately 600 dialogues with 26k tokens and 200 questions on average.
Metrics. We adopt the LLM-as-a-Judge (J) score to evaluate answer quality following chhikara2025mem0; wang2025mirix. Compared with surface-level measures such as F1 or BLEU-1 (xu2025amem; 10738994), this metric better avoids relying on simple lexical overlap and instead captures semantic alignment. Specifically, GPT-4.1 (openai2025gpt41) is employed to judge whether the answer is correct according to the original question and the generated answer, following the prompt by chhikara2025mem0.
Table 1: LLM-as-a-Judge scores (%, higher is better) for each question category in the LoCoMo (maharana2024evaluating) dataset. The best results using each LLM backend, except Full-Context, are in bold.
| LLM GPT-4o-mini LangMem (langmem_blog2025) | Method A-Mem (xu2025amem) 62.23 | 1. Multi-Hop 61.70 23.43 | 2. Temporal 64.49 47.92 | 3. Open-Domain 40.62 71.12 | 4. Single-Hop 76.63 58.10 | Overall 69.06 |
| --- | --- | --- | --- | --- | --- | --- |
| Mem0 (chhikara2025mem0) | 67.13 | 55.51 | 51.15 | 72.93 | 66.88 | |
| Self-RAG (asai2024self) | 69.15 | 64.80 | 34.38 | 88.31 | 76.46 | |
| RAG-CoT-RAG | 71.28 | 71.03 | 42.71 | 86.99 | 77.96 | |
| Zep (rasmussen2025zep) | 67.38 | 73.83 | 63.54 | 78.67 | 74.62 | |
| MemR 3 (ours, Zep backbone) | 69.39 (+2.01) | 73.83 (+0.00) | 67.01 (+3.47) | 80.60 (+1.93) | 76.26 (+1.64) | |
| RAG (lewis2020retrieval) | 68.79 | 65.11 | 58.33 | 83.86 | 75.54 | |
| MemR 3 (ours, RAG backbone) | 71.39 (+2.60) | 76.22 (+11.11) | 61.11 (+2.78) | 89.44 (+5.58) | 81.55 (+6.01) | |
| Full-Context | 72.34 | 58.88 | 59.38 | 86.39 | 76.32 | |
| GPT-4.1-mini | A-Mem (xu2025amem) | 71.99 | 74.77 | 58.33 | 79.88 | 76.00 |
| LangMem (langmem_blog2025) | 74.47 | 61.06 | 67.71 | 86.92 | 78.05 | |
| Mem0 (chhikara2025mem0) | 62.41 | 57.32 | 44.79 | 66.47 | 62.47 | |
| Self-RAG (asai2024self) | 75.89 | 75.08 | 54.17 | 90.12 | 82.08 | |
| RAG-CoT-RAG | 80.85 | 81.62 | 62.50 | 90.12 | 84.89 | |
| Zep (rasmussen2025zep) | 72.34 | 77.26 | 64.58 | 83.49 | 78.94 | |
| MemR 3 (ours, Zep backbone) | 77.78 (+5.44) | 77.78 (+0.52) | 69.79 (+5.21) | 84.42 (+0.93) | 80.88 (+1.94) | |
| RAG (lewis2020retrieval) | 73.05 | 73.52 | 62.50 | 85.90 | 79.46 | |
| MemR 3 (ours, RAG backbone) | 81.20 (+8.15) | 82.14 (+8.62) | 71.53 (+9.03) | 92.17 (+6.27) | 86.75 (+7.29) | |
| Full-Context | 86.43 | 86.82 | 71.88 | 93.73 | 89.00 | |
Baselines. We select four groups of advanced methods as baselines: 1) memory systems, including A-mem (xu2025amem), LangMem (langmem_blog2025), and Mem0 (chhikara2025mem0); 2) agentic retrievers, like Self-RAG (asai2024self). We also design a RAG-CoT-RAG (RCR) pipeline beyond ReAct (yao2022react) as a strong agentic retriever baseline combining both RAG (lewis2020retrieval) and Chain-of-Thoughts (CoT) (wei2022chain); 3) backend baselines, including chunk-based (RAG (lewis2020retrieval)) and graph-based (Zep (rasmussen2025zep)) memory storage, demonstrating the plug-in capability of MemR 3 across different retriever backends; 4) Moreover, ‘Full-Context’ is widely used as a strong baseline and, when the entire conversation fits within the model window, serves as an empirical upper bound on J score (chhikara2025mem0; wang2025mirix). More detailed introduction of these baselines is shown in Appendix C.1.
Other Settings. Other experimental settings and protocols are shown in Appendix C.2.
LLM Backend. We reviewed recent work and found that it most frequently used GPT-4o-mini (openai2024gpt4omini), as it is inexpensive and performs well. While some work (wang2025mirix) also includes GPT-4.1-mini (openai2025gpt41), we set both of them as our LLM backends. In our main results, MemR 3 is performed at temperature 0.
4.2 Main Results
Overall. Table 1 reports LLM-as-a-Judge (J) scores across four LoCoMo categories. Across both LLM backends and memory backbones, MemR 3 consistently outperforms its underlying retrievers (RAG and Zep) and achieves strong overall J scores. Under GPT-4o-mini, MemR 3 lifts the overall score of Zep from 74.62% to 76.26%, and RAG from 75.54% to 81.55%, with the latter even outperforming the Full-Context baseline (76.32%). With GPT-4.1-mini, we see the same pattern: MemR 3 improves Zep from 78.94% to 80.88% and RAG from 79.46% to 86.75%, making the RAG-backed variant the strongest retrieval-based system and narrowing the gap to Full-Context (89.00%). As expected, methods instantiated with GPT-4.1-mini are consistently stronger than their GPT-4o-mini counterparts. Full-Context also benefits substantially from the stronger LLM, but under GPT-4o-mini it lags behind the best retrieval-based systems, especially on temporal and open-domain questions. Overall, these results indicate that closed-loop retrieval with an explicit evidence–gap state yields gains primarily orthogonal to the choice of LLM or memory backend, and that MemR 3 particularly benefits from backends that expose relatively raw snippets (RAG) rather than heavily compressed structures (Zep).
Multi-hop. Multi-hop questions require chaining multiple pieces of evidence and, therefore, directly test our reflective controller. Under GPT-4o-mini, MemR 3 improves both backbones on this category: the multi-hop J score rises from 68.79% to 71.39% on RAG and from 67.38% to 69.39% on Zep, bringing both close to the Full-Context score (72.34%). With GPT-4.1-mini, the gains are more pronounced: MemR 3 boosts RAG from 73.05% to 81.20% and Zep from 72.34% to 77.78%, outperforming all other baselines and approaching the Full-Context upper bound (86.43%). These consistent gains suggest that explicitly tracking evidence and gaps helps the agent coordinate multiple distant memories via iterative retrieval, rather than relying on a single heuristic pass.
Temporal. Temporal questions stress the model’s ability to reason about ordering and dating of events over long horizons, where both under- and over-retrieval can be harmful. Here, MemR 3 delivers some of its most considerable relative improvements. For GPT-4o-mini, the temporal J score of RAG jumps from 65.11% to 76.22%, outperforming both the original RAG and the Zep baseline (73.83%), while MemR 3 with a Zep backbone preserves Zep’s strong temporal accuracy (73.83%). Full-Context performs notably worse in this regime (58.88%), indicating that simply supplying all dialogue turns can hinder temporal reasoning under a weaker backbone. With GPT-4.1-mini, MemR 3 again significantly strengthens temporal reasoning: RAG improves from 73.52% to 82.14%, and Zep from 77.26% to 77.78%, making the RAG-backed MemR 3 the best retrieval-based system and closing much of the remaining gap to Full-Context (86.82%). These findings support our design goal that explicitly modeling “what is already known” versus “what is still missing” helps the agent align and compare temporal relations more robustly.
Open-Domain. Open-domain questions are less tied to the user’s personal timeline and often require retrieving diverse background knowledge, which makes retrieval harder to trigger and steer. Despite this, MemR 3 consistently improves over its backbones. Under GPT-4o-mini, MemR 3 increases the open-domain J score of RAG from 58.33% to 61.11% and that of Zep from 63.54% to 67.01%, with the Zep-backed variant achieving the best performance among all methods in this block, surpassing Full-Context (59.38%). With GPT-4.1-mini, the gains become even larger: MemR 3 lifts RAG from 62.50% to 71.53% and Zep from 64.58% to 69.79%, nearly matching the Full-Context baseline (71.88%) and again outperforming all other baselines. We attribute these improvements to the router’s ability to interleave retrieval with reflection: when initial evidence is noisy or off-topic, MemR 3 uses the gap representation to reformulate queries and pull in more targeted external knowledge rather than committing to an early, brittle answer.
Single-hop. Single-hop questions can often be answered from a single relevant memory snippet, so the potential headroom is smaller, but MemR 3 still yields consistent gains. With GPT-4o-mini, MemR 3 raises the single-hop J score from 78.67% to 80.60% on Zep and from 83.86% to 89.44% on RAG, with the latter surpassing the Full-Context baseline (86.39%). Under GPT-4.1-mini, MemR 3 improves Zep from 83.49% to 84.42% and RAG from 85.90% to 92.17%, making the RAG-backed variant the strongest method overall aside from Full-Context (93.73%). Together with the iteration-count analysis in Sec. 4.3, these results suggest that the router often learns to terminate early on straightforward single-hop queries, gaining accuracy primarily through better evidence selection rather than additional reasoning depth, and thus adding little overhead in tokens or latency.
4.3 Other Experiments
We ablate various hyperparameters and modules to evaluate their impact in MemR 3 with the RAG retriever. During these experiments, we utilize GPT-4o-mini as a consistent LLM backend.
Table 2: Ablation studies. Best results are in bold.
| RAG MemR 3 w/o mask | 68.79 71.39 62.41 | 65.11 76.22 68.54 | 58.33 61.11 55.21 | 83.86 89.44 72.17 | 75.54 81.55 68.54 |
| --- | --- | --- | --- | --- | --- |
| w/o $\Delta q_{k}$ | 66.67 | 75.08 | 60.42 | 83.37 | 77.11 |
| w/o reflect | 65.25 | 73.83 | 61.46 | 83.37 | 76.65 |
- MH = Multi-hop; OD = Open-domain; SH = Single-hop.
Ablation Studies.
We first examine the contribution of the main design choices in MemR 3 by progressively removing them while keeping the RAG retriever and all hyperparameters fixed. As shown in Table 2, disabling masking for previously retrieved snippets (w/o mask) results in the largest degradation, reducing the overall J score from 81.55% to 68.54% and harming every category. This confirms that repeatedly surfacing the same memories wastes budget and fails to effectively close the remaining gaps. Removing the refinement query $\Delta q_{k}$ (w/o $\Delta q_{k}$ ) has a milder effect: temporal and open-domain performance changed a little, but multi-hop and single-hop scores decline significantly, indicating that tailoring retrieval queries from the current evidence-gap state is particularly beneficial for simpler questions. Disabling the reflect node (w/o reflect) similarly reduces performance (from 81.55% to 76.65%), with notable drops on multi-hop and single-hop questions, highlighting the value of interleaving reasoning-only steps with retrieval. Note that in Table 2, the raw retrieved snippets are only visible to the vanilla RAG.
Effect of $n_{\text{chk}}$ and $n_{\text{max}}$ .
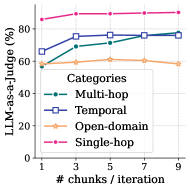
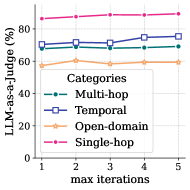
We first choose a nominal configuration for MemR 3 (with a RAG retriever) by arbitrarily setting the number of chunks per iteration $n_{\text{chk}}=3$ and the max iteration budget $n_{\text{max}}=5$ . In Fig. 4(a), we fix $n_{\text{max}}=5$ and perform ablations over $n_{\text{chk}}∈\{1,3,5,7,9\}$ . In Fig. 4(b), we fix $n_{\text{chk}}=3$ and perform ablations over $n_{\text{max}}∈\{1,2,3,4,5\}$ . Considering both of the LLM-as-a-Judge score and token consumption, we eventually choose $n_{\text{chk}}=5$ and $n_{\text{max}}=5$ in all main experiments.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Chart: LLM-as-a-Judge Performance vs. Number of Chunks/Iteration
### Overview
The image is a line chart comparing the performance of a Large Language Model (LLM) acting as a judge across different question categories (Multi-hop, Temporal, Open-domain, and Single-hop) as the number of chunks/iteration increases. The y-axis represents the percentage of agreement with a human judge (LLM-as-a-Judge (%)), and the x-axis represents the number of chunks per iteration.
### Components/Axes
* **X-axis:** "# chunks / iteration" with markers at 1, 3, 5, 7, and 9.
* **Y-axis:** "LLM-as-a-Judge (%)" with a scale from 0 to 80 in increments of 20.
* **Legend (Center-Right):**
* Multi-hop (Green line with circle markers)
* Temporal (Blue line with square markers)
* Open-domain (Orange line with star markers)
* Single-hop (Pink line with circle markers)
### Detailed Analysis
* **Multi-hop (Green):** Starts at approximately 58% at 1 chunk/iteration, increases to about 70% at 3 chunks/iteration, then to approximately 73% at 5 chunks/iteration, and plateaus around 76% at 7 and 9 chunks/iteration.
* **Temporal (Blue):** Starts at approximately 66% at 1 chunk/iteration, increases to about 75% at 3 chunks/iteration, then to approximately 77% at 5 chunks/iteration, and plateaus around 76% at 7 and 9 chunks/iteration.
* **Open-domain (Orange):** Starts at approximately 58% at 1 chunk/iteration, increases to about 60% at 3 chunks/iteration, plateaus around 61% at 5 and 7 chunks/iteration, and decreases to approximately 58% at 9 chunks/iteration.
* **Single-hop (Pink):** Starts at approximately 86% at 1 chunk/iteration, increases to about 88% at 3 chunks/iteration, and plateaus around 88% at 5, 7, and 9 chunks/iteration.
### Key Observations
* Single-hop questions consistently achieve the highest LLM-as-a-Judge percentage.
* Open-domain questions have the lowest LLM-as-a-Judge percentage.
* The performance of Multi-hop and Temporal questions improves significantly from 1 to 3 chunks/iteration, then plateaus.
* The performance of Open-domain questions remains relatively stable across different numbers of chunks/iteration.
* The performance of Single-hop questions remains relatively stable across different numbers of chunks/iteration.
### Interpretation
The chart suggests that the type of question significantly impacts the LLM's ability to act as a judge. Single-hop questions, which likely require less complex reasoning, are easier for the LLM to evaluate. Multi-hop and Temporal questions benefit from an increased number of chunks/iteration, indicating that providing more context or breaking down the problem into smaller steps improves the LLM's judgment. Open-domain questions, which may require external knowledge or more nuanced understanding, are the most challenging for the LLM to evaluate, and increasing the number of chunks/iteration does not significantly improve performance. The plateauing effect observed for Multi-hop and Temporal questions suggests that there is a limit to how much additional context can improve the LLM's judgment in these categories.
</details>
(a)
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: LLM-as-a-Judge vs. Max Iterations
### Overview
The image is a line chart comparing the performance of a Large Language Model (LLM) as a judge across different categories (Multi-hop, Temporal, Open-domain, and Single-hop) with varying maximum iterations (1 to 5). The y-axis represents the percentage of LLM-as-a-Judge, and the x-axis represents the maximum iterations.
### Components/Axes
* **X-axis:** "max iterations" with values 1, 2, 3, 4, and 5.
* **Y-axis:** "LLM-as-a-Judge (%)" with values ranging from 0 to 80.
* **Legend:** Located in the center-right of the chart.
* **Multi-hop:** Represented by a dashed teal line with circular markers.
* **Temporal:** Represented by a solid dark blue line with square markers.
* **Open-domain:** Represented by a solid light orange line with star markers.
* **Single-hop:** Represented by a dashed magenta line with circular markers.
### Detailed Analysis
* **Multi-hop:** The teal dashed line starts at approximately 68% at iteration 1, remains relatively stable around 68% at iteration 2, then slightly decreases to 67% at iteration 3, increases to 70% at iteration 4, and ends at approximately 69% at iteration 5.
* **Temporal:** The dark blue solid line starts at approximately 70% at iteration 1, increases to 72% at iteration 2, remains relatively stable around 72% at iteration 3, increases to 74% at iteration 4, and ends at approximately 75% at iteration 5.
* **Open-domain:** The light orange solid line starts at approximately 57% at iteration 1, increases to 60% at iteration 2, decreases to 58% at iteration 3, increases to 59% at iteration 4, and ends at approximately 59% at iteration 5.
* **Single-hop:** The magenta dashed line starts at approximately 85% at iteration 1, increases to 87% at iteration 2, remains relatively stable around 87% at iteration 3, increases to 88% at iteration 4, and ends at approximately 88% at iteration 5.
### Key Observations
* The "Single-hop" category consistently outperforms the other categories across all iterations.
* The "Open-domain" category consistently underperforms the other categories across all iterations.
* The "Temporal" category shows a slight upward trend as the number of iterations increases.
* The "Multi-hop" category remains relatively stable across all iterations.
### Interpretation
The chart illustrates the performance of an LLM as a judge across different question types, with "Single-hop" questions being the easiest for the model to evaluate and "Open-domain" questions being the most challenging. The slight upward trend in the "Temporal" category suggests that increasing the number of iterations may improve the model's ability to judge temporal reasoning. The stability of the "Multi-hop" category indicates that increasing iterations does not significantly impact the model's performance on multi-hop reasoning tasks. The consistently high performance on "Single-hop" questions suggests that the model is well-suited for evaluating simple, direct questions.
</details>
(b)
Figure 4: LLM-as-a-Judge score (%) with different a) number of chunks per iteration and b) max iterations.
Iteration count.
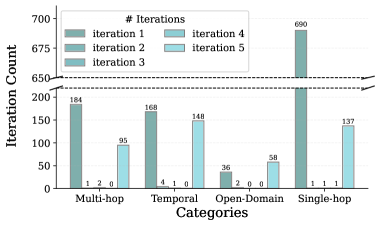
We further inspect how often MemR 3 actually uses multiple retrieve/reflect/answer iterations when $n_{\text{chk}}=5$ and $n_{\text{max}}=5$ (Fig. 5). Overall, most questions are answered after a single iteration, and this effect is particularly strong for Single-hop questions. An exception is open-domain questions, for which 58 of 96 require continuous retrieval or reflection until the maximum number of iterations is reached, highlighting the inherent challenges and uncertainty in these questions. Additionally, only a small fraction of questions terminate at intermediate depths (2–4 iterations), suggesting that MemR 3 either becomes confident early or uses the whole iteration budget when the gap remains non-empty.
We observe that this distribution arises from two regimes. On the one hand, straightforward questions require only a single piece of evidence and can be resolved in a single iteration, consistent with intuition. From the perspective of the idealized tracker in Appendix B, these are precisely the queries for which every requirement $r∈ R(q)$ is supported by some retrieved memory item $m∈\bigcup_{j≤ k}S_{j}$ with $m\models r$ , so the completeness condition in Theorem B.4 is satisfied and the ideal gap $G_{k}^{\star}$ becomes empty.
On the other hand, some challenging questions are inherently underspecified given the stored memories, so the gap cannot be fully closed even if the agent continues to refine its query. For example, for the question “ When did Melanie paint a sunrise? ”, the correct answer in our setup is simply “ 2022 ” (the year). MemR 3 quickly finds this year at the first iteration based on evidence “ Melanie painted the lake sunrise image last year (2022). ”. However, under the idealized abstraction, the requirement set $R(q)$ implicitly includes an exact date predicate (year–month–day), and no memory item $m∈\bigcup_{j≤ K}S_{j}$ satisfies $m\models r$ for that finer-grained requirement. Thus, the precondition of Theorem B.4 (3) is violated, and $G_{k}^{\star}$ never becomes empty; the practical tracker mirrors this by continuing to search for the missing specificity until it hits the maximum iteration budget. In such cases, the additional token consumption is primarily due to a mismatch between the question’s granularity and the available memory, rather than a failure of the agent.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Bar Chart: Iteration Count by Category
### Overview
The image is a bar chart comparing the number of iterations across different categories: Multi-hop, Temporal, Open-Domain, and Single-hop. The chart displays the iteration count for each category across five iterations, represented by different colored bars.
### Components/Axes
* **Y-axis:** "Iteration Count", ranging from 0 to 700.
* **X-axis:** "Categories", with the following categories: Multi-hop, Temporal, Open-Domain, and Single-hop.
* **Legend:** Located at the top of the chart, indicating the iteration number corresponding to each bar color:
* Iteration 1: Darker teal
* Iteration 2: Medium teal
* Iteration 3: Lighter teal
* Iteration 4: Light blue
* Iteration 5: Very light blue
### Detailed Analysis
Here's a breakdown of the iteration counts for each category and iteration:
* **Multi-hop:**
* Iteration 1: 184
* Iteration 2: 1
* Iteration 3: 2
* Iteration 4: 95
* Iteration 5: 0
* **Temporal:**
* Iteration 1: 168
* Iteration 2: 4
* Iteration 3: 1
* Iteration 4: 148
* Iteration 5: 0
* **Open-Domain:**
* Iteration 1: 36
* Iteration 2: 2
* Iteration 3: 0
* Iteration 4: 58
* Iteration 5: 0
* **Single-hop:**
* Iteration 1: 690
* Iteration 2: 1
* Iteration 3: 1
* Iteration 4: 137
* Iteration 5: 1
### Key Observations
* Single-hop has the highest iteration count in Iteration 1, significantly higher than other categories.
* Iteration 1 generally has the highest iteration count across all categories.
* Iterations 2, 3, 4, and 5 have relatively low iteration counts compared to Iteration 1.
* Open-Domain has the lowest iteration counts overall.
### Interpretation
The data suggests that the Single-hop category required significantly more iterations in the first iteration compared to other categories. The high iteration count in Iteration 1 across all categories, compared to subsequent iterations, could indicate an initial phase of intensive processing or exploration. The low iteration counts in Iterations 2-5 might suggest a refinement or convergence phase after the initial processing. The Open-Domain category consistently having low iteration counts could imply that it requires less processing or is more efficient in reaching a solution.
</details>
Figure 5: Number of questions requiring different numbers of iterations before final answers, across four categories.
4.4 Revisiting the Evaluation Protocols of LoCoMo
During our reproduction of the baselines, we identified a latent ambiguity in the LoCoMo dataset’s category indexing. Specifically, the mapping between numerical IDs and semantic categories (e.g., Multi-hop vs. Single-hop) implies a non-trivial alignment challenge. We observed that this ambiguity has led to category misalignment in several recent studies (chhikara2025mem0; wang2025mirix), potentially skewing the granular analysis of agent capabilities.
To ensure a rigorous and fair comparison, we recalibrate the evaluation protocols for all baselines. In Table 1, we report the performance based on the corrected alignment, where the alignment can be induced by the number of questions in each category. We believe this clarification contributes to a more accurate understanding of the current SOTA landscape. Details of the dataset realignment are illustrated in Appendix C.3.
5 Conclusion
In this work, we introduce MemR 3, an autonomous memory-retrieval controller that transforms standard retrieve-then-answer pipelines into a closed-loop process via a LangGraph-based sequential decision-making framework. By explicitly maintaining what is known and what remains unknown using an evidence-gap tracker, MemR 3 can iteratively refine queries, balance retrieval and reflection, and terminate early once sufficient evidence has been gathered. Our experiments on the LoCoMo benchmark show that MemR 3 consistently improves LLM-as-a-Judge scores over strong memory baselines, while incurring only modest token and latency overhead and remaining compatible with heterogeneous backends. Beyond these concrete gains, MemR 3 offers an explainable abstraction for reasoning under partial observability in long-horizon agent settings.
However, we acknowledge some limitations for future work: 1) MemR 3 requires an existing retriever or memory structure, and particularly, the performance greatly depends on the retriever or memory structure. 2) The routing structure could lead to token waste for answering simple questions. 3) MemR 3 is currently not designed for multi-modal memories like images or audio.
Appendix A Prompts
A.1 System prompt of the generate node
The system prompt is defined as follows, where the “decision_directive” instructs the maximum iteration budges, reflect-streak capacity, and retrieval opportunity check, introduced in Sec. 3.4. Generally, “decision_directive” is a textual instruction: “reflect” if you need to think about the evidence and gaps; choose “answer” ONLY when evidence is solid and no gaps are noted; choose “retrieve” otherwise. However, when the maximum iterations budget is reached, “decision_directive” is set as “answer” to stop early. When the reflection reaches the maximum capacity, “decision_directive” is set as “retrieve” to avoid repeated ineffective reflection. When there is no useful retrieval remains, “decision_directive” is set as “reflect” to avoid repeated ineffective retrieval. Through these constraints, the agent can avoid infinite ineffective actions to maintain stability.
System Prompt
You are a memory agent that plans how to gather evidence before producing the final response shown to the user. Always reply with a strict JSON object using this schema: - evidence: JSON array of concise factual bullet strings relevant to the user’s question; preserve key numbers/names/time references. If exact values are unavailable, include the most specific verified information (year/range) without speculation. Never mention missing or absent information here – “gaps” will do that. - gaps: gaps between the question and evidence that prevent a complete answer. - decision: one of [“retrieve”,“answer”,“reflect”]. Choose {decision_directive}. Only include these conditional keys: - retrieval_query: only when decision == “retrieve”. Provide a STANDALONE search string; short (5-15 tokens). * BAD Query: “the date” (lacks context). * GOOD Query: “graduation ceremony date” (specific). * STRATEGY: 1. Search for the ANCHOR EVENT. (e.g. Question: “What happened 2 days after X?”, Query: “timestamp of event X”). 2. Search for the MAPPED ENTITY. (e.g. Question: “Weather in the Windy City”, Query: “weather in Chicago”). - detailed_answer: only when decision == “answer”; response using current evidence (keep absolute dates, avoid speculation). If evidence is limited, provide only what is known, or make cautious inferences grounded solely in that limited evidence. Do not mention missing or absent information in this field. - reasoning: only when decision == “reflect”; if further retrieval is unlikely, use current evidence to think step by step through the evidence and gaps, and work toward the answer, including any time normalization. Never include extra keys or any text outside the JSON object.
A.2 User prompt of the generate node
Apart from the system, the user prompt is responsible to feed additional information to the LLM. Specifically, at the $k$ iteration, “question” is the original question $q$ . “evidence_block” and “gap_block” are evidence $\mathcal{E}_{k}$ and gaps $\mathcal{G}_{k}$ introduced in Sec. 3.3. “raw_block” is the retrieved raw snippets $\mathcal{S}_{k}$ in Eq. 5. “reasoning_block” is the reasoning content $\mathcal{F}_{k}$ in Sec. 3.4. “last_query” is the refined query $\Delta q_{k}$ introduced in Sec. 3.4 that enables the new query to be different from the prior one. Note that these fields can be left empty if the corresponding information is not present.
User Prompt
# Question {question} # Evidence {evidence_block} # Gaps {gap_block} # Memory snippets {raw_block} # Reasoning {reasoning_block} # Prior Query {last_query} # INSTRUCTIONS: 1. Update the evidence as a JSON ARRAY of concise factual bullets that directly help answer the question (preserve key numbers/names/time references; use the most specific verified detail without speculation). 2. Update gaps: remove resolved items, add new missing specifics blocking a full answer, and set to “None” when nothing is missing. 3. If you produce a retrieval_query, make sure it differs from the previous query. 4. Decide the next action and return ONLY the JSON object described in the system prompt.
Appendix B Formalizing the Evidence-Gap Tracker
A central component of MemR 3 is the evidence-gap tracker introduced in Sec. 3.3, which maintains an evolving summary of i) what information has been reliably established from memory and ii) what information is still missing to answer the query. While the practical implementation of this tracker is based on LLM-generated summaries, we introduce an idealized formal abstraction that clarifies its intended behavior, enables principled analysis, and provides a foundation for studying correctness and robustness. This abstraction does not assume perfect extraction; rather, the LLM acts as a stochastic approximator to the idealized tracker.
**Definition B.1 (Idealized Requirement Space)**
*For a user query $q$ , we define a finite set of atomic information requirements, which specify the minimal facts needed to fully answer the query:
$$
R(q)=\{r_{1},r_{2},\dots,r_{m}\}. \tag{7}
$$*
For example, for the question “How many months passed between events $A$ and $B$ ?”, the requirement set can be
$$
R(q)=\{\text{date}(A),\text{date}(B)\}. \tag{8}
$$
Each requirement $r∈ R(q)$ is associated with a symbolic predicate (e.g., a timestamp, entity attribute, or event relation), and $R(q)$ provides the semantic target against which retrieved memories are judged.
**Definition B.2 (Memory-Support Relation)**
*Let $\mathcal{M}$ be the memory store and $S_{k}⊂eq\mathcal{M}$ denote the snippets retrieved at iteration $k$ . We define a relation $m\models r$ to indicate that memory item $m∈\mathcal{M}$ contains sufficient information to support requirement $r∈ R(q)$ . Formally, $m\models r$ holds if the textual content of $m$ contains a minimal witness (e.g., a timestamp, entity mention, or explicit assertion) matching the predicate corresponding to $r$ . The matching criterion may be implemented via deterministic pattern rules or LLM-based semantic matching; our analysis is agnostic to this choice.*
**Definition B.3 (Idealized Evidence-Gap Update Rule)**
*At iteration $k$ , the idealized tracker maintains two sets: i) the evidence $E_{k}⊂eq R(q)$ and ii) the gaps $G_{k}=R(q)\setminus E_{k}$ . Given newly retrieved snippets $S_{k}$ , the ideal updates are
$$
E_{k}^{\star}=E_{k-1}\cup\big\{r\in R(q)\,\big|\,\exists m\in S_{k},\;m\models r\big\},\qquad G_{k}^{\star}=R(q)\setminus E_{k}^{\star}. \tag{9}
$$*
In this abstraction, the tracker monotonically accumulates verified requirements and removes corresponding gaps, providing a clean characterization of the desired system behavior independent of noise.
B.1 Practical Instantiation via LLM Summaries
In MemR 3, the tracker is instantiated through LLM-generated summaries:
$$
(E_{k},G_{k})=\mathrm{LLM}\big(q,S_{k},E_{k-1},G_{k-1}\big), \tag{10}
$$
where the prompt explicitly instructs the model to: (i) extract concise factual bullets relevant to $q$ , (ii) enumerate missing information blocking a complete answer, and (iii) avoid hallucinations or speculative inference. Thus, $(E_{k},G_{k})$ serves as a stochastic approximation to the idealized $(E_{k}^{\star},G_{k}^{\star})$ :
$$
(E_{k},G_{k})\approx(E_{k}^{\star},G_{k}^{\star}), \tag{11}
$$
with deviations arising from LLM extraction noise. This perspective reconciles the formal update rule with the prompt-driven practical implementation.
B.2 Correctness Properties under Idealized Extraction
Although the practical instantiation lacks deterministic guarantees, the idealized tracker in Definition B.3 satisfies several intuitive properties essential for closed-loop retrieval.
**Theorem B.4 (Properties of the Idealized Tracker)**
*Assume that for all $k$ and all $r∈ R(q)$ , we have $r∈ E_{k}^{\star}$ if and only if there exists some $m∈\bigcup_{j≤ k}S_{j}$ such that $m\models r$ . Then the following hold:
1. Monotonicity: $E_{k-1}^{\star}⊂eq E_{k}^{\star}$ and $G_{k}^{\star}⊂eq G_{k-1}^{\star}$ for all $k≥ 1$ .
1. Soundness: If $m\models r$ for some retrieved memory $m∈ S_{k}$ , then $r∈ E_{k}^{\star}$ .
1. Completeness at convergence: If every requirement $r∈ R(q)$ is supported by some $m∈\bigcup_{j≤ K}S_{j}$ with $m\models r$ , then $E_{K}^{\star}=R(q)$ and hence $G_{K}^{\star}=\varnothing$ .*
* Proof*
(1) By Definition B.3,
$$
E_{k}^{\star}=E_{k-1}^{\star}\cup\big\{r\in R(q)\,\big|\,\exists m\in S_{k},\;m\models r\big\}, \tag{12}
$$
so $E_{k-1}^{\star}⊂eq E_{k}^{\star}$ . Since $G_{k}^{\star}=R(q)\setminus E_{k}^{\star}$ and $E_{k-1}^{\star}⊂eq E_{k}^{\star}$ , we obtain $G_{k}^{\star}⊂eq G_{k-1}^{\star}$ . (2) If $m\models r$ for some $m∈ S_{k}$ , then by Definition B.3 we have $r∈\{r^{\prime}∈ R(q)\mid∃ m^{\prime}∈ S_{k},\;m^{\prime}\models r^{\prime}\}⊂eq E_{k}^{\star}$ . (3) If every $r∈ R(q)$ is supported by some $m∈\bigcup_{j≤ K}S_{j}$ with $m\models r$ , then repeated application of the update rule ensures that each such $r$ is eventually added to $E_{K}^{\star}$ . Hence $E_{K}^{\star}=R(q)$ and therefore $G_{K}^{\star}=R(q)\setminus E_{K}^{\star}=\varnothing$ . ∎
These properties characterize the target behavior that the LLM-based tracker implementation aims to approximate.
B.3 Robustness Considerations
Since real LLMs introduce extraction noise, the practical tracker may deviate from the idealized $(E_{k}^{\star},G_{k}^{\star})$ , for example, through false negatives (missing evidence), false positives (hallucinated evidence), or unstable gap estimates. In the main text (Sec. 3.3 and Sec. 4.3), we study these effects empirically by injecting noisy or contradictory memories and measuring their impact on routing decisions and final answer quality. The formal abstraction above serves as the reference model against which these robustness behaviors are interpreted.
B.4 Approximation Bias of the LLM Tracker
The abstraction in this section assumes access to an ideal tracker that updates ( $\mathcal{E}_{k}$ , $\mathcal{G}_{k}$ ) exactly according to the requirement–support relation $m\models r$ . In practice, MemR 3 uses an LLM-generated tracker ( $\mathcal{E}_{k}$ , $\mathcal{G}_{k}$ ), which only approximates this ideal update. This introduces several forms of approximation bias: i) Coverage bias (false negatives): supported requirements $r∈ R(q)$ that are omitted from $\mathcal{E}_{k}$ ; ii) Hallucination bias (false positives): requirements $r$ that appear in $\mathcal{E}_{k}$ even though no retrieved memory item supports them; iii) Granularity bias: cases where the tracker records a coarser fact (e.g., a year) but the requirement space $R(q)$ contains a finer predicate (e.g., an exact date), so the ideal requirement is never fully satisfied.
B.5 Toy example of the granularity bias
The “ Melanie painted a sunrise ” case in Sec. 4.3 provides a concrete illustration of granularity bias. The question asks “ When did Melanie paint a sunrise? ”, and in our setup the correct answer is the year 2022. Under the ideal abstraction, however, the requirement space $R(q)$ implicitly contains a fine-grained predicate $r_{\text{date}}$ corresponding to the full year–month–day of the painting event. The memory store only contains a coarse statement such as “ Melanie painted the lake sunrise image last year (2022). ”
In the ideal tracker, no memory item $m$ satisfies $m\models r_{\text{date}}$ , so the precondition of Theorem B.4 ’s completeness clause is violated and the ideal gap $\mathcal{G}_{k}$ never becomes empty. The practical LLM tracker mirrors this behavior: it quickly recovers the year 2022 as evidence, but continues to treat the exact date as a remaining gap, eventually hitting the iteration budget without fully closing Gk. This example shows that some apparent “failures” of the approximate tracker are in fact structural: they arise from a mismatch between the granularity of $R(q)$ and the information actually present in the memory store.
Appendix C Experimental Settings
C.1 Baselines
We select four groups of advanced methods as baselines: 1) memory systems, including A-mem (xu2025amem), LangMem (langmem_blog2025), and Mem0 (chhikara2025mem0); 2) agentic retrievers, like Self-RAG (asai2024self). We also design a RAG-CoT-RAG (RCR) pipeline as a strong agentic retriever baseline combining both RAG (lewis2020retrieval) and Chain-of-Thoughts (CoT) (wei2022chain); 3) backend baselines, including chunk-based (RAG (lewis2020retrieval)) and graph-based (Zep (rasmussen2025zep)) memory storage, demonstrating the plug-in capability of MemR 3 across different retriever backends. Moreover, ‘Full-Context’ is widely used as a strong baseline and, when the entire conversation fits within the model window, serves as an empirical upper bound on J score (chhikara2025mem0; wang2025mirix). More detailed introduction of these baselines is shown in Appendix C.1.
We divide our groups into four groups: memory systems, agentic retrievers, backend baselines, and full-context.
C.1.1 Memory systems
In this group, we consider recent advanced memory systems, including A-mem (xu2025amem), LangMem (langmem_blog2025), and Mem0 (chhikara2025mem0), to demonstrate the comprehensively strong capability of MemR 3 from a memory control perspective.
A-mem (xu2025amem) https://github.com/WujiangXu/A-mem. A-Mem is an agent memory module that turns interactions into atomic notes and links them into a Zettelkasten-style graph using embeddings plus LLM-based linking.
LangMem (langmem_blog2025). LangMem is LangChain’s persistent memory layer that extracts key facts from dialogues and stores them in a vector store (e.g., FAISS/Chroma) for later retrieval.
Mem0 (chhikara2025mem0) https://github.com/mem0ai/mem0. Mem0 is an open-source memory system that enables an LLM to incrementally summarize, deduplicate, and store factual snippets, with an optional graph-based memory extension.
C.1.2 Agentic Retrievers
In this group, we examine the agentic structures underlying memory retrieval to show the advanced performance of MemR 3 on memory retrieval, and particularly, showing the advantage of the agentic structure of MemR 3. To validate this, we include Self-RAG (asai2024self) and design a strong heuristic baseline, RAG-CoT-RAG (RCR), which combines RAG and CoT (wei2022chain).
Self-RAG (asai2024self). A model-driven retrieval controller where the LLM decides, at each step, whether to answer or issue a refined retrieval query. Unlike MemR 3, retrieval decisions in Self-RAG are implicit in the model’s chain-of-thought, without explicit state tracking. We reproduce their original code and prompt to suit our task.
RAG-CoT-RAG (RCR). We design a strong heuristic baseline that extends beyond ReAct (yao2022react) by performing one initial retrieval (lewis2020retrieval), a CoT (wei2022chain) step to identify missing information, and a second retrieval using a refined query. It provides multi-step retrieval but lacks an explicit evidence-gap state or a general controller.
C.1.3 Backend Baselines
In this group, we incorporate vanilla RAG (lewis2020retrieval) and Zep (rasmussen2025zep) as retriever backends for MemR 3 to demonstrate the advantages of MemR 3 ’s plug-in design. The former is a chunk-based method while the latter is a graph-based one, which cover most types of existing memory systems.
Vanilla RAG (lewis2020retrieval). The vanilla RAG retrieves the top- $k$ relevant snippets from the query once and provides a direct answer, without iterative retrieval or reasoning-based refinement. The other retrieval setting ( $n_{\text{chk}}$ , chunk size, etc.) is the same as that in MemR 3.
Zep (rasmussen2025zep). Zep is a hosted memory service that builds a time-aware knowledge graph over conversations and metadata to support fast semantic and temporal queries. We implement their original code.
C.1.4 Full-Context
Lastly, we include Full-Context as a strong baseline, which provides the model with the entire conversation or memory buffer without retrieval, serving as an upper-bound reference that is unconstrained by retrieval errors or missing information.
C.2 Other protocols.
For all chunk-based methods like RAG (lewis2020retrieval), Self-RAG (asai2024self), RAG-CoT-RAG, and MemR 3 (RAG retriever), we set the embedding model as text-embedding-large-3 (openai2024embeddinglarge3) and use a re-ranking strategy (reimers2019sentence) (ms-marco-MiniLM-L-12-v2) to search relevant memories rather than just similar ones. The chunk size is selected from {128, 256, 512, 1024} using the GPT-4o-mini backend when $n_{\text{max}}=1$ and $n_{\text{chk}}=1$ , and we ultimately choose 256. This chunk size is also in line with Mem0 (chhikara2025mem0).
Table 3: The alignment of the orders and categories in LoCoMo dataset.
| Category Order # Questions | Multi-Hop Category 1 282 | Temporal Category 2 321 | Open-Domain Category 3 96 | Single-Hop Category 4 830 | Adversarial Category 5 445 |
| --- | --- | --- | --- | --- | --- |
C.3 Re-alignment of LoCoMo dataset
Misalignment in existing works.
Although the correct order of the different categories is not explicitly reported in LoCoMo (maharana2024evaluating), we can infer it from the number of questions in each category. The correct alignment is shown in Table 3. We believe this clarification could benefit the LLM memory community.
Repeated questions in LoCoMo dataset.
Note that the number of single-hop and adversarial questions is 841 and 446 in the original LoCoMo, while the number is 830 and 445 based on our count, due to 12 repeated questions. In the following, the first question is repeated in both the single-hop and adversarial categories in the 2rd conversation (we remove the one in the adversarial category), while the remaining 11 questions are repeated in the single-hop category in the 8th conversation.
1. What did Gina receive from a dance contest? (conversation 2, question 62), (conversation 2, question 96)
1. What are the names of Jolene’s snakes? (conversation 8, question 17), (conversation 8, question 90)
1. What are Jolene’s favorite books? (conversation 8, question 26), (conversation 8, question 91)
1. What music pieces does Deborah listen to during her yoga practice? (conversation 8, question 43), (conversation 8, question 92)
1. What games does Jolene recommend for Deborah? (conversation 8, question 59), (conversation 8, question 93)
1. What projects is Jolene planning for next year? (conversation 8, question 62), (conversation 8, question 94)
1. Where did Deborah get her cats? (conversation 8, question 63), (conversation 8, question 95)
1. How old are Deborah’s cats? (conversation 8, question 64), (conversation 8, question 96)
1. What was Jolene doing with her partner in Rio de Janeiro? (conversation 8, question 68), (conversation 8, question 97)
1. Have Deborah and Jolene been to Rio de Janeiro? (conversation 8, question 70), (conversation 8, question 98)
1. When did Jolene’s parents give her first console? (conversation 8, question 73), (conversation 8, question 99)
1. What do Deborah and Jolene plan to try when they meet in a new cafe? (conversation 8, question 75), (conversation 8, question 100)
Table 4: Repeated experiments of MemR 3 in the main results in Table 1.
| GPT-4o-mini 2 3 | Zep 69.86 70.21 | 1 72.59 75.39 | 68.09 67.71 64.58 | 73.52 80.36 80.72 | 68.75 76.00 76.65 | 80.72 | 76.13 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| mean $±$ std | 69.39 $±$ 0.41 | 73.83 $±$ 1.40 | 67.01 $±$ 1.64 | 80.60 $±$ 0.18 | 76.26 $±$ 0.33 | | |
| RAG | 1 | 71.63 | 77.26 | 61.46 | 89.28 | 81.75 | |
| 2 | 70.21 | 76.01 | 59.38 | 89.40 | 81.16 | | |
| 3 | 72.34 | 75.39 | 62.50 | 89.64 | 81.75 | | |
| mean $±$ std | 71.39 $±$ 1.08 | 76.22 $±$ 0.95 | 61.11 $±$ 1.59 | 89.44 $±$ 0.18 | 81.56 $±$ 0.34 | | |
| GPT-4.1-mini | Zep | 1 | 78.72 | 78.50 | 72.92 | 84.34 | 81.36 |
| 2 | 75.89 | 77.26 | 68.75 | 84.58 | 80.44 | | |
| 3 | 78.72 | 77.57 | 67.71 | 84.34 | 80.84 | | |
| mean $±$ std | 77.78 $±$ 1.44 | 77.78 $±$ 0.26 | 69.79 $±$ 1.04 | 84.42 $±$ 0.12 | 80.88 $±$ 0.24 | | |
| RAG | 1 | 81.56 | 83.18 | 69.79 | 91.93 | 86.79 | |
| 2 | 82.62 | 80.69 | 75.00 | 92.65 | 87.18 | | |
| 3 | 79.43 | 82.55 | 69.79 | 91.93 | 86.27 | | |
| mean $±$ std | 81.20 $±$ 1.62 | 82.14 $±$ 1.29 | 71.53 $±$ 3.01 | 92.17 $±$ 0.42 | 86.75 $±$ 0.46 | | |
Appendix D Experimental Results
D.1 Repeated Experiments.
For the LoCoMo dataset, we show the repeated experiments of MemR 3 in Table 4.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Chart: Retrieved Token Usage vs. LLM-as-a-Judge Score
### Overview
The image is a combination bar and line chart comparing retrieved token usage and LLM-as-a-Judge score across three methods: RAG, MemR3, and Full-Context. The chart displays token usage for four categories (Multi-hop, Temporal, Open-domain, and Single-hop) as bars, and the LLM-as-a-Judge score as a line.
### Components/Axes
* **X-axis:** Methods (RAG, MemR3, Full-Context)
* **Left Y-axis:** Retrieved Token Usage (logarithmic scale from 10^0 to 10^5)
* **Right Y-axis:** LLM-as-a-Judge Score (%) (linear scale from 50 to 100)
* **Legend (top-left):**
* Multi-hop (teal circle)
* Temporal (dark blue square)
* Open-domain (light orange star)
* Single-hop (magenta circle)
* Token Usage (gray bar)
* LLM-as-a-Judge (black circle)
### Detailed Analysis
**Token Usage (Bars):**
* **RAG:**
* Multi-hop: Approximately 1000
* Temporal: Approximately 50
* Open-domain: Approximately 10
* Single-hop: Approximately 1000
* **MemR3:**
* Multi-hop: Approximately 1500
* Temporal: Approximately 500
* Open-domain: Approximately 15
* Single-hop: Approximately 2000
* **Full-Context:**
* Multi-hop: Approximately 15000
* Temporal: Approximately 15000
* Open-domain: Approximately 15000
* Single-hop: Approximately 15000
**LLM-as-a-Judge Score (Line):**
* **RAG:** Approximately 70%
* **MemR3:** Approximately 90%
* **Full-Context:** Approximately 85%
### Key Observations
* Full-Context method has significantly higher token usage across all categories compared to RAG and MemR3.
* MemR3 achieves the highest LLM-as-a-Judge score, followed by Full-Context, and then RAG.
* Open-domain token usage is consistently the lowest across all methods.
* The LLM-as-a-Judge score decreases from MemR3 to Full-Context, despite the significant increase in token usage.
### Interpretation
The chart suggests that while increasing token usage (as seen in Full-Context) can improve performance compared to RAG, it doesn't necessarily guarantee the best LLM-as-a-Judge score. MemR3 seems to strike a better balance between token usage and performance, achieving the highest score with a lower token usage than Full-Context. This could indicate that MemR3 is more efficient in utilizing the retrieved tokens or that the quality of the retrieved tokens is higher. The low token usage for Open-domain across all methods might suggest that this category requires less information or is inherently simpler to process. The drop in LLM-as-a-Judge score from MemR3 to Full-Context, despite the increase in token usage, could indicate diminishing returns or even the introduction of irrelevant information that negatively impacts the judge's assessment.
</details>
Figure 6: Average token consumption of the retrieved snippets (left y-axis) and LLM-as-a-Judge (J) Score (right y-axis) of RAG, MemR 3, and Full-Context across four categories.
D.2 Token Consumption
In Table 6, we compare the average token consumption of the retrieved snippets and J score of RAG, MemR 3, and Full-Context methods across four categories. The chunk size of RAG and MemR 3 are both set as $n_{\text{chk}}=5$ , while $n_{\text{max}}=2$ for MemR 3. We observe that MemR 3 outperforms RAG across all four categories with only a few additional tokens. While Full-Context consumes significantly more tokens than MemR 3, it surpasses MemR 3 only on multi-hop questions.