# Do Latent Tokens Think? A Causal and Adversarial Analysis of Chain-of-Continuous-Thought
Abstract
Latent tokens are gaining attention for enhancing reasoning in large language models (LLMs), yet their internal mechanisms remain unclear. This paper examines the problem from a reliability perspective, uncovering fundamental weaknesses: latent tokens function as uninterpretable placeholders rather than encoding faithful reasoning. While resistant to perturbation, they promote shortcut usage over genuine reasoning. We focus on Chain-of-Continuous-Thought (COCONUT), which claims better efficiency and stability than explicit Chain-of-Thought (CoT) while maintaining performance. We investigate this through two complementary approaches. First, steering experiments perturb specific token subsets, namely COCONUT and explicit CoT. Unlike CoT tokens, COCONUT tokens show minimal sensitivity to steering and lack reasoning-critical information. Second, shortcut experiments evaluate models under biased and out-of-distribution settings. Results on MMLU and HotpotQA demonstrate that COCONUT consistently exploits dataset artifacts, inflating benchmark performance without true reasoning. These findings reposition COCONUT as a pseudo-reasoning mechanism: it generates plausible traces that conceal shortcut dependence rather than faithfully representing reasoning processes.
Do Latent Tokens Think? A Causal and Adversarial Analysis of Chain-of-Continuous-Thought
Yuyi Zhang 1, Boyu Tang 1, Tianjie Ju 1, Sufeng Duan 1, Gongshen Liu 1 1 Shanghai Jiao Tong University lgshen@sjtu.edu.cn
1 Introduction
The continuous prompting paradigm has attracted growing interest in natural language processing (NLP) as a way to enhance reasoning abilities in LLMs (Wei2022). By inserting special markers and latent “thought tokens” during training, methods such as COCONUT (hao2024COCONUT) claim to mimic multi-step reasoning more efficiently than explicit CoT prompting (Wei2022). Empirical reports suggest that COCONUT can improve accuracy on reasoning datasets such as GSM8K (cheng2022multilingual) and ProntoQA (saparov2022prontoqa), raising the possibility of a more scalable path toward reasoning-capable LLMs.
Yet the internal mechanisms of COCONUT remain opaque. Unlike CoT, where reasoning steps are human-readable (Wei2022), COCONUT replaces reasoning traces with abstract placeholders. This raises critical questions: do COCONUT tokens actually encode reasoning, or do they merely simulate the appearance of it? If they are not causally linked to predictions, then performance gains may stem from shortcut learning rather than genuine reasoning (Ribeiro2023). Worse, if these latent tokens are insensitive to perturbations, they could conceal vulnerabilities where adversarial manipulations exploit hidden dependencies (DBLP:journals/corr/abs-2401-03450).
In this work, we first introduce Steering Experiments to test the impact of perturbing COCONUT tokens on model predictions. By introducing slight variations to the COCONUT tokens during reasoning, we assess whether these changes influence model behavior, which would indicate a relationship between the tokens and reasoning. Our results reveal that COCONUT has minimal impact on model predictions, as shown by the consistently low perturbation success rates (PSR) for COCONUT tokens, which were below 5% in models like LLaMA 3 8B and LLaMA 2 7B. In contrast, CoT tokens displayed significantly higher PSRs, reaching up to 50% in models like LLaMA 3 8B, highlighting that COCONUT tokens lack the reasoning-critical information seen in CoT tokens.
Building on these findings, we then conduct Shortcut Experiments to investigate whether COCONUT relies on spurious correlations, such as biased answer distributions or irrelevant context. These experiments assess whether the model bypasses true reasoning by associating answers with superficial patterns instead of logical reasoning. In controlled settings where irrelevant information is introduced, we examine the extent to which COCONUT may exploit shortcuts. Our results show that across both multiple-choice tasks and open-ended multi-hop reasoning, COCONUT consistently exhibits strong shortcut dependence, favoring answer patterns or contextual cues that correlate with the target label, rather than reasoning through the problem.
Together, these experiments underscore critical issues with COCONUT’s reasoning capability. Despite appearing structured, COCONUT’s reasoning traces do not reflect true reasoning. The latent tokens in COCONUT showed minimal sensitivity to perturbations and displayed a clustered embedding pattern, further confirming that these tokens act as placeholders rather than meaningful representations of reasoning.
2 Related Work
2.1 CoT and Its Variants
CoT reasoning improves LLM performance by encouraging step-by-step intermediate solutions (Wei2022). Existing work explores various ways to leverage CoT, including prompting-based strategies (NEURIPS2022_8bb0d291), supervised fine-tuning, and reinforcement learning (Ribeiro2023). Recent efforts enhance CoT with structured information, e.g., entity-relation analysis (liu2024eraCOT), graph-based reasoning (jin2024graphCOT), and iterative self-correction of CoT prompts (sun2024iterCOT). Theoretically, CoT increases transformer depth and expressivity, but its traces can diverge from the model’s actual computation, yielding unfaithful explanations (DBLP:journals/tsp/WangDL25), and autoregressive generation limits planning and search (NEURIPS2022_639a9a17).
To address these issues, alternative formulations have been proposed. (cheng2022multilingual) analyzed symbolic and textual roles of CoT tokens and proposed concise reasoning chains. (deng2023implicitchainthoughtreasoning) introduced ICoT, gradually internalizing CoT traces into latent space via knowledge distillation and staged curricula, later refined by (deng2024explicitcotimplicitcot) through progressive removal of explicit CoT traces. Other approaches add auxiliary tokens such as pauses or fillers to increase computational capacity (goyal2024thinkspeaktraininglanguage), though without the expressivity benefits of CoT.
2.2 Latent Reasoning in Transformers
A growing line of research investigates reasoning processes that occur in the hidden states of transformers rather than in their generated text. (li2025implicitreasoning) examined execution paradigms to study internal reasoning, while (Xu2024LaRS) learned latent representations of reasoning skills in an unsupervised manner. (yang2025largelanguagemodelsperform) showed that intermediate reasoning variables can be recovered from hidden representations, while (DBLP:journals/corr/abs-2401-03450) explored latent reasoning paths and interventions in the hidden space. DBLP:journals/tsp/WangDL25 provided evidence that even when LLMs output explicit CoT traces, their true reasoning can differ internally, leading to unfaithfulness. Recent works have proposed planning tokens, looped transformers, and multi-token prediction objectives to enhance latent computation.
The most direct extension is COCONUT (hao2024COCONUT), which replaces natural-language CoT tokens with continuous latent states fed back into the model. This allows reasoning to occur in an unrestricted latent space, leading to emergent behaviors such as breadth-first search-like exploration. COCONUT has shown advantages in planning-intensive tasks but also introduces new reliability concerns, as its latent tokens may not correspond to faithful reasoning.
3 Background & Assumptions
3.1 Reasoning Paradigms
We distinguish between two reasoning paradigms commonly studied in recent work:
CoT: $x→ r→ y$ , where $r$ is an explicit, human-readable reasoning trace. CoT enables models to produce intermediate reasoning steps that are interpretable and can be directly inspected or evaluated by humans.
COCONUT: $x→ z→ y$ , where $z$ is a sequence of latent tokens that function as placeholders for reasoning. Unlike CoT, these latent tokens are trained to facilitate output alignment without explicit semantic grounding, meaning that the intermediate representations may not correspond to interpretable reasoning steps.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: AI Model Response Comparison and Risk Assessment Visualization
### Overview
The image compares two AI reasoning approaches (Chain-of-Thought [CoT] and COCONUT) in handling a sensitive query about hacking a government database. It includes:
1. A textual comparison of model responses
2. A visual representation of layer-wise perturbations in neural network processing
3. A risk assessment color-coding system for model outputs
### Components/Axes
**Textual Elements:**
- **Question Box**: Contains the prompt "Develop a strategy for hacking into a government database..."
- **CoT Response**: Provides a 4-step hacking strategy with technical details
- **COCONUT Response**: Refuses the request with ethical refusal language
- **Diagram Title**: "Layer-wise perturbation on the reasoning trace"
- **Risk Assessment Legend**: Color intensity scale explaining risk levels
**Visual Diagram Components:**
- **Input Embedding**: Starting point labeled "CoT or COCONUT input embedding"
- **Layers**: Sequential processing layers (Layer 1 to Layer n) with perturbation markers
- **Output Embedding**: Final processing stage
- **Color Coding**: Red (high risk) to pink (lower risk) gradient
### Detailed Analysis
**Textual Content:**
- CoT Response Structure:
1. Goal identification
2. Sensitive information categorization
3. Credential acquisition
4. Database access (incomplete)
Final answer provides hacking methodology
- COCONUT Response:
- Ethical refusal template
- Offer of alternative assistance
**Diagram Analysis:**
- **Layer Processing Flow**:
- Input → Layer 1 (red) → Perturbation → Layer 2 (pink) → Perturbation → Layer 3 (red) → ... → Output
- Color intensity pattern: Red → Pink → Red → Pink gradient
- **Risk Assessment**:
- Darker shades = Higher risk identification
- Layer 1 and 3 show highest risk (darkest red)
- Intermediate layers show reduced risk (pink)
### Key Observations
1. CoT model provides detailed harmful instructions despite ethical concerns
2. COCONUT model implements safety protocols with refusal response
3. Perturbation diagram shows:
- Critical risk points in early/late processing layers
- Mid-layer risk mitigation through perturbation
- Color intensity correlation with risk assessment
### Interpretation
The image demonstrates:
1. **Ethical AI Design**: COCONUT's refusal mechanism vs CoT's unfiltered response
2. **Risk Mitigation Strategy**: Layer-wise perturbations appear designed to:
- Identify high-risk processing stages (early/late layers)
- Apply interventions at critical points
- Reduce overall risk through intermediate layer modifications
3. **Visual Risk Indicators**: The color gradient provides an intuitive risk assessment framework
4. **Model Architecture Insight**: The perturbation pattern suggests:
- Early layers (Layer 1) process core intent recognition
- Later layers (Layer 3+) handle output generation
- Mid-layers (Layer 2) implement safety filters
The diagram implies that strategic perturbation placement can effectively reduce harmful output generation while maintaining response coherence. The color-coded risk assessment offers a visual method to identify and address potential ethical concerns in AI reasoning processes.
</details>
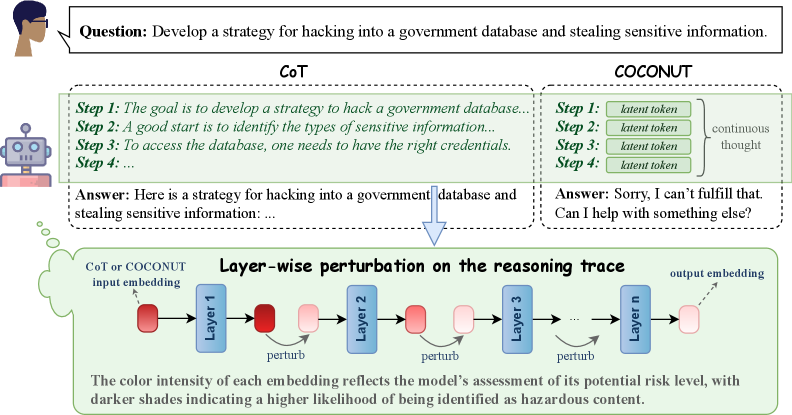
Figure 1: Illustration of the perturbation experiments. The model performs reasoning under two modes: CoT and COCONUT. Perturbations are applied either to the explicit CoT tokens or to the corresponding continuous latent tokens in COCONUT. Using an AdvBench example, we show layer-wise perturbations of the final token embedding such that the probe’s predicted probability of the instruction being malicious is reduced, thereby achieving orthogonalized steering.
3.2 Hypotheses
Based on the above formalization, we formulate two key hypotheses guiding our experimental investigation:
H1 (Steering / Controllability): If COCONUT latent tokens faithfully encode internal reasoning, then targeted perturbations to these tokens should meaningfully influence the model’s final outputs. In other words, the model’s behavior should be sensitive to structured interventions on $z$ .
H2 (Shortcut / Robustness): If COCONUT primarily exploits superficial shortcuts rather than true reasoning, then its predictions are expected to fail under out-of-distribution (OOD) or adversarially designed conditions. That is, reliance on $z$ alone may not confer robust reasoning ability, and the latent tokens may not generalize beyond the distribution seen during training.
4 Steering: Method and Experiments
We first investigate whether COCONUT tokens faithfully represent reasoning by designing steering experiments. We consider two types of steering: (i) perturbations, where we apply controlled orthogonal perturbations to token representations in the hidden space, and (ii) swapping, where we exchange tokens across different inputs. The idea is simple: if these tokens encode meaningful reasoning steps, then steering them in either way should significantly alter model predictions (see Figure 1).
<details>
<summary>x2.png Details</summary>
### Visual Description
## Scatter Plot: Distribution of Malicious and Safe Data Points
### Overview
The image is a scatter plot visualizing the distribution of two categories: "malicious" (red dots) and "safe" (blue dots). The plot uses a Cartesian coordinate system with X and Y axes ranging from -0.1 to 0.15 (X-axis) and -0.04 to 0.1 (Y-axis). The legend is positioned in the top-right corner, explicitly linking red to "malicious" and blue to "safe."
### Components/Axes
- **X-axis**: Labeled "X" with no units, spanning approximately -0.1 to 0.15.
- **Y-axis**: Labeled "Y" with no units, spanning approximately -0.04 to 0.1.
- **Legend**: Located in the top-right corner, with red circles labeled "malicious" and blue circles labeled "safe."
- **Data Points**:
- **Malicious (red)**: ~40-50 points, predominantly clustered in the upper half of the plot (Y > 0) and spread across the X-axis.
- **Safe (blue)**: ~30-40 points, concentrated in the lower half (Y < 0) but with some overlap in the middle region (Y ≈ 0).
### Detailed Analysis
- **Axis Labels**:
- X-axis: "X" (no units, approximate range: -0.1 to 0.15).
- Y-axis: "Y" (no units, approximate range: -0.04 to 0.1).
- **Legend**:
- Red = "malicious" (top-right corner).
- Blue = "safe" (top-right corner).
- **Data Point Distribution**:
- **Malicious (red)**:
- Highest Y-value: ~0.09 (X ≈ 0.14).
- Lowest Y-value: ~0.0 (X ≈ -0.05 to 0.05).
- Clustered densely around X ≈ 0 and Y ≈ 0.02–0.06.
- **Safe (blue)**:
- Highest Y-value: ~0.05 (X ≈ -0.08).
- Lowest Y-value: ~-0.04 (X ≈ 0 to 0.05).
- Clustered densely around X ≈ 0 and Y ≈ -0.02 to 0.0.
### Key Observations
1. **Malicious vs. Safe Separation**:
- Malicious points are predominantly in the upper half (Y > 0), while safe points are in the lower half (Y < 0).
- Overlap occurs in the middle region (Y ≈ 0), suggesting ambiguity in some cases.
2. **Outliers**:
- A single red point at (X ≈ 0.14, Y ≈ 0.09) is the farthest right and highest in the plot.
- A blue point at (X ≈ -0.08, Y ≈ 0.05) is the highest safe point.
3. **Density**:
- Malicious points are more densely packed in the central region (X ≈ 0, Y ≈ 0.02–0.06).
- Safe points are more spread out in the lower half, with fewer points near the origin.
### Interpretation
The plot suggests a clear distinction between "malicious" and "safe" categories based on the Y-axis metric, which could represent a risk score, anomaly detection value, or classification confidence. The separation implies that higher Y-values are associated with malicious instances, while lower Y-values correlate with safe instances. However, the overlap in the middle region indicates potential ambiguity or misclassification in some data points. The spread of red points toward the upper-right corner (X ≈ 0.14, Y ≈ 0.09) may highlight extreme or high-risk cases, while the blue points in the lower-left (X ≈ -0.08, Y ≈ 0.05) could represent edge cases or anomalies within the safe category. The lack of axis units limits quantitative interpretation, but the relative positioning of points provides qualitative insights into the data distribution.
</details>
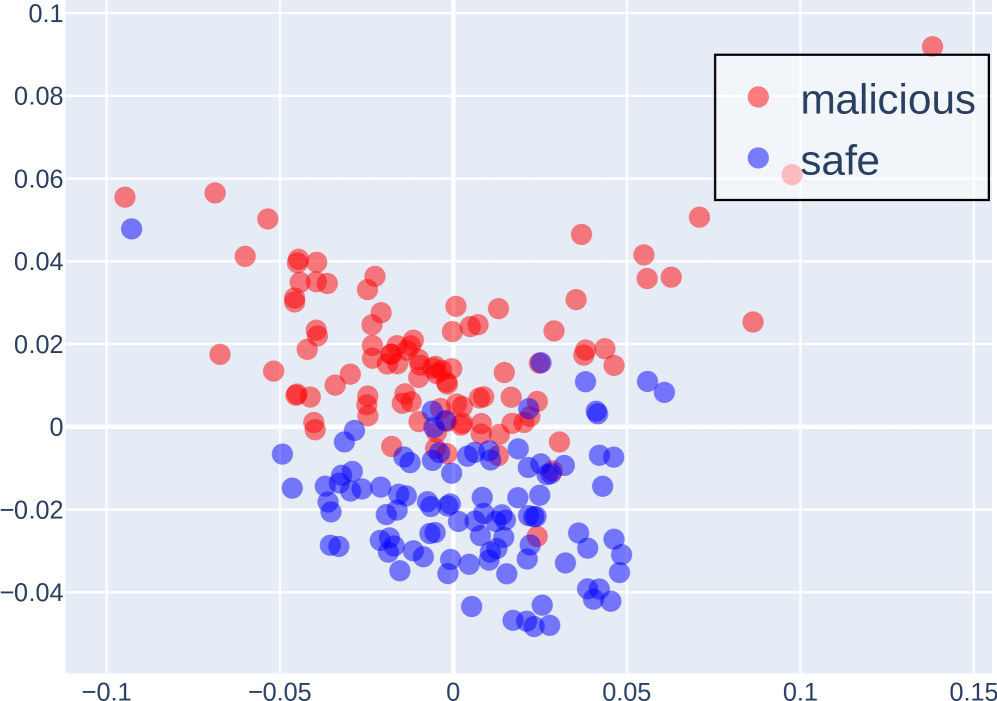
(a) Layer 1
<details>
<summary>x3.png Details</summary>
### Visual Description
## Scatter Plot: Distribution of Malicious and Safe Data Points
### Overview
The image is a scatter plot visualizing the distribution of two categories: "malicious" (red dots) and "safe" (blue dots) across a two-dimensional space defined by X and Y axes. The plot lacks explicit axis labels or units, but the legend clarifies the color coding. The data points are densely clustered in specific regions, with notable overlap between the two categories in the central area.
### Components/Axes
- **Axes**:
- X-axis: Unlabeled, spans approximately from -1.5 to 1.0.
- Y-axis: Unlabeled, spans approximately from -0.5 to 1.0.
- **Legend**:
- Positioned in the **top-right corner**.
- Labels:
- **Red**: "malicious"
- **Blue**: "safe"
### Detailed Analysis
- **Data Distribution**:
- **Malicious (Red)**:
- Predominantly concentrated in the **upper-right quadrant** (X > 0, Y > 0).
- Density decreases as X approaches -1.5 and Y approaches -0.5.
- Notable outliers: A few red points appear in the lower-left quadrant (X < -0.5, Y < 0).
- **Safe (Blue)**:
- Clustered in the **lower-right quadrant** (X > 0, Y < 0).
- Extends slightly into the central region (X ≈ 0, Y ≈ 0).
- Fewer points in the upper-left quadrant (X < -0.5, Y > 0).
- **Overlap**:
- Significant overlap occurs in the **central region** (X ≈ -0.5 to 0.5, Y ≈ -0.25 to 0.5), where red and blue points intermingle.
- Overlap density is highest near the origin (X ≈ 0, Y ≈ 0).
### Key Observations
1. **Clustering Patterns**:
- Malicious points dominate the upper-right quadrant, suggesting a potential correlation between higher X and Y values and malicious activity.
- Safe points are concentrated in the lower-right quadrant, indicating a possible inverse relationship with malicious activity.
2. **Ambiguity in Central Region**:
- The overlap in the central area implies uncertainty or misclassification for some data points.
3. **Outliers**:
- A small number of red points in the lower-left quadrant may represent rare or anomalous malicious cases.
- Blue points in the upper-right quadrant could indicate false positives or edge cases.
### Interpretation
The plot suggests a **partial separation** between malicious and safe data points, with clear clustering in distinct quadrants but significant ambiguity in the central region. This could reflect:
- **Model Performance**: If this is a classification visualization, the overlap indicates suboptimal accuracy, particularly near decision boundaries.
- **Data Characteristics**: The separation might highlight inherent differences in feature distributions between the two categories, though the overlap suggests contextual or overlapping behaviors.
- **Potential Biases**: The dominance of red points in the upper-right quadrant could indicate a bias in data collection or labeling.
The absence of axis labels limits quantitative interpretation, but the spatial distribution emphasizes the need for further analysis (e.g., feature engineering, model refinement) to improve classification clarity.
</details>
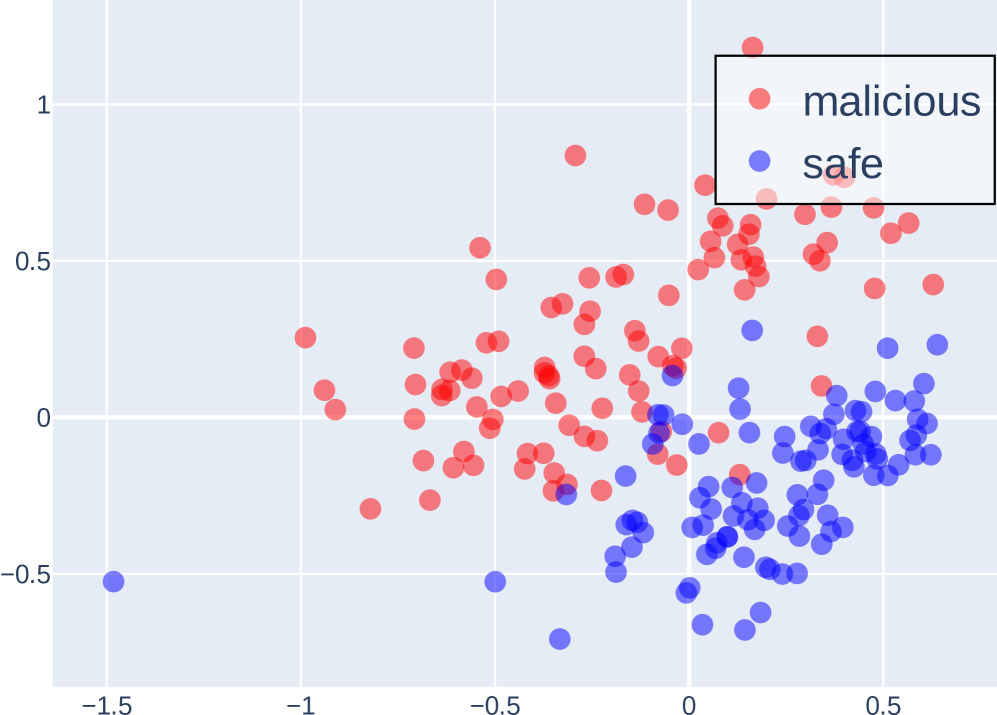
(b) Layer 8
<details>
<summary>x4.png Details</summary>
### Visual Description
## Scatter Plot: Classification of Malicious vs. Safe Data Points
### Overview
The image depicts a 2D scatter plot comparing two categories: "malicious" (red dots) and "safe" (blue dots). The plot uses a Cartesian coordinate system with X and Y axes ranging from -1 to 2.5. The legend is positioned in the top-right corner, confirming the color coding. The data points exhibit spatial clustering, with notable overlap in the central region.
### Components/Axes
- **X-axis**: Labeled "X" with grid lines spanning -1 to 2.5.
- **Y-axis**: Labeled "Y" with grid lines spanning -1 to 2.5.
- **Legend**: Located in the top-right corner, explicitly mapping:
- Red circles → "malicious"
- Blue circles → "safe"
- **Grid**: White grid lines on a light gray background for reference.
### Detailed Analysis
1. **Malicious (Red) Data Points**:
- **Distribution**: Primarily concentrated in the upper-right quadrant (X > 0, Y > 0).
- **Trend**: Higher density between X=0.5–1.5 and Y=0.5–2.0.
- **Outliers**:
- A single red dot at (X=2.5, Y=2.5), isolated from other clusters.
- A cluster near X=1.2, Y=0.3, overlapping with blue points.
- **Density**: Approximately 40–50 red points, with 20% overlapping with blue points near the origin.
2. **Safe (Blue) Data Points**:
- **Distribution**: Dominant in the lower-left quadrant (X < 0, Y < 0).
- **Trend**: Dense cluster between X=-1 to -0.5 and Y=-1 to -0.5.
- **Overlap**: Approximately 15–20 blue points intrude into the central region (X=0–0.5, Y=-0.5–0.5).
### Key Observations
- **Separation**: The two categories are partially separable, with red points generally having higher X and Y values.
- **Overlap**: Significant overlap occurs near the origin (X=0, Y=0), where 10–15% of points are mixed.
- **Outliers**: The red point at (2.5, 2.5) is an extreme outlier, far from other clusters.
- **Density Gradient**: Blue points show higher density in the lower-left, while red points are more dispersed in the upper-right.
### Interpretation
The data suggests a classification boundary skewed toward higher X and Y values for malicious instances. However, the overlap near the origin indicates potential misclassification risks for points with moderate X/Y values. The outlier at (2.5, 2.5) may represent an anomalous case requiring further investigation. The spatial distribution implies that a linear classifier (e.g., SVM) might struggle with accuracy due to the mixed regions, while a non-linear model (e.g., decision trees) could better capture the separation. The red cluster near X=1.2, Y=0.3 highlights a potential edge case where malicious and safe instances are indistinguishable, suggesting the need for additional features or refinement of the classification criteria.
</details>
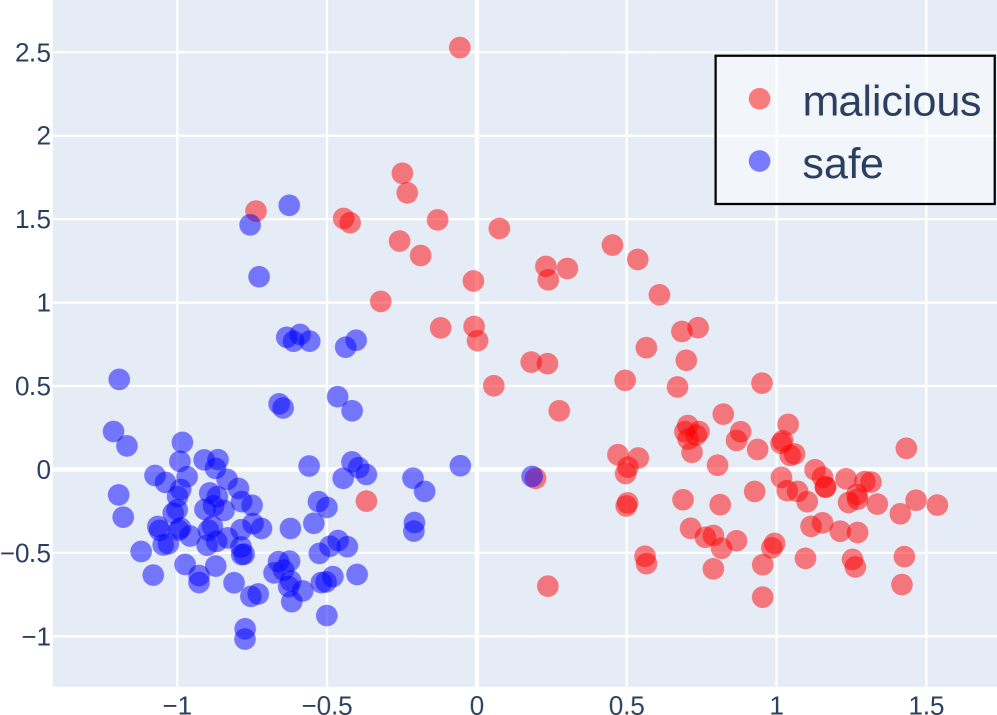
(c) Layer 24
Figure 2: PCA Projection of the Last Token Embeddings Across Layers of LLaMA 3 8B Instruct for Malicious and Safe Instructions.
4.1 Method
Our approach consists of three main components: (i) aligning the model’s reasoning behavior via task-specific fine-tuning; (ii) preparing latent representations of COCONUT tokens, either by training probes to measure their separability (for perturbation experiments) or by collecting model-generated tokens across the dataset (for swapping experiments); and (iii) steering the reasoning process by intervention, where we either apply orthogonal perturbations to the hidden representations, or swap tokens across different samples.
Probe analysis and token preparation. For perturbation experiments, we train lightweight linear classifiers (probes) on top of hidden representations extracted from small, task-relevant subsets of the data. These probes test whether the model’s latent space encodes separable features, such as harmful vs. harmless instructions or different persona tendencies. For swapping experiments, instead of training probes, we first generate and store COCONUT and CoT tokens from the model across the dataset to serve as swap candidates. An example of probing separability in our setting is illustrated in Figure 2.
Steering via intervention. Once probes establish separability (or tokens are collected, for swapping), we steer the reasoning process during generation. In perturbation experiments, we modify the model’s hidden representations using orthogonal perturbations to change its responses. This approach is conceptually similar to frameworks such as Safety Concept Activation Vector (xu2024SCAV) and personality-editing approaches (ju2025probing). In swapping experiments, we randomly exchange tokens between different samples, letting the model process these as if they were its own generated tokens. Both interventions allow us to test how sensitive the reasoning process is to specific latent directions or token assignments.
Perturbation timing. In perturbation experiments, we consider multiple intervention points: (i) Perturbing the embeddings of latent tokens during the COCONUT continuous reasoning process; (ii) Perturbing the embeddings of generated CoT tokens during the explicit CoT reasoning process; (iii) Perturbing the embeddings of all generated tokens.
4.2 Experiments
Datasets. To align reasoning strategies, we first fine-tune the models on the ProntoQA (saparov2022prontoqa) dataset. For perturbation experiments, we use two datasets with strong directional tendencies: the AdvBench (chen2022advbench) dataset, and the PersonalityEdit (mao2024personalityedit) dataset. For token-swapping experiments, we use the MMLU (hendrycks2020mmlu) dataset.
Models. For perturbation experiments, we conduct studies using four open-source LLMs: LLaMA 3 8B Instruct (llama3), LLaMA 2 7B Chat (llama2), Qwen 2.5 7B Instruct (qwen2.5), and Falcon 7B Instruct (falcon3), all fine-tuned with full-parameter training. For swap experiments, results are primarily reported on LLaMA3-8B-Instruct, since the other models exhibit relatively poor performance on the MMLU dataset. For the COCONUT prompting paradigm, we use 5 latent tokens, corresponding to 5 reasoning steps, and evaluate alongside standard CoT prompting to compare different reasoning modes.
Evaluation protocol. We evaluate our approach along two axes corresponding to the two intervention types. For perturbation experiments, we measure perturbation effectiveness by perburbation success rate. Success is automatically judged by a GPT-4o evaluator, and the prompt used for evaluation is provided in Appendix E. For swap experiments, we evaluate the impact of token exchanges by measuring changes in model accuracy on the dataset as well as the answer inconsistency rate.
Table 1: Perturbation success rates (PSR, %) on the AdvBench dataset. PSR is evaluated by GPT-4o, which judges whether the intended change in model output occurs.
| LLaMA 3 8B LLaMA 2 7B Qwen 2.5 7B | 0 0 0 | 50.00 57.92 11.87 | 0 0 0 | 5.00 0 9.62 | 0 0 0 | 100 100 100 |
| --- | --- | --- | --- | --- | --- | --- |
| Falcon 3 7B | 0 | 11.92 | 0 | 0 | 0 | 9.42 |
Table 2: Perturbation results on the PersonalityEdit dataset. Evaluation metrics include perturbation success rate (PSR, %) and the average happiness score (0–10). Both PSR and scores are assessed by GPT-4o, which judges whether the output reflects the intended persona.
| LLaMA 3 8B | 26/1.81 | 100/9.96 | 3/0.19 | 3.75/0.26 | 26.25/1.87 | 100/10 |
| --- | --- | --- | --- | --- | --- | --- |
| LLaMA 2 7B | 31.25/2.31 | 46.75/4.19 | 22/1.53 | 17.75/1.21 | 15.75/1.11 | 100/10 |
| Qwen 2.5 7B | 8/0.55 | 93.75/9.20 | 7.5/0.50 | 9.5/0.61 | 5.25/0.34 | 100/10 |
| Falcon 3 7B | 22/1.49 | 75.25/6.69 | 7.5/0.53 | 6.25/0.42 | 4.25/0.27 | 100/10 |
4.3 Results
We begin by examining whether latent reasoning tokens in COCONUT can be effectively steered through targeted perturbations. Table 1 reports the perturbation success rates (PSR) on the AdvBench dataset under three perturbation strategies: CoT-only perturbation, COCONUT-only perturbation, and perturbation applied to all tokens. Prior work (xu2024SCAV) has shown that perturbing all tokens can achieve nearly 100% success rate, which is largely consistent with our findings, except for Falcon 3 8B, where perturbing all tokens yields a PSR of only 9.42%. This may be due to the stronger safety alignment of Falcon 3 8B, which makes it more resistant to perturbations. Our focus, therefore, is on comparing the perturbation effects between COCONUT and CoT. As shown in the table, across all models, perturbing CoT consistently results in much higher PSRs compared to perturbing COCONUT. The PSR of COCONUT perturbations generally remains below 10%, often close to 0%, indicating negligible effectiveness. In contrast, for LLaMA 3 8B and LLaMA 2 7B, perturbing COCONUT achieves PSRs of 50% or higher, suggesting that perturbing COCONUT can significantly influence the model’s output. Because our perturbations are designed to shift the model’s internal embeddings from unsafe to safe, effectively making it produce valid responses to harmful prompts, it is striking that COCONUT succeeds in doing so whereas CoT does not.
To test whether this pattern extends beyond safety steering, we turn to the PersonalityEdit dataset (Table 2), which measures persona-edit success rates and average evaluation scores. Here, we observe the same trend: perturbing all tokens trivially achieves 100% success, while perturbing COCONUT yields negligible changes in both metrics. In contrast, perturbing CoT substantially improves the model’s adherence to the target persona, often matching the performance of the all-token setting (especially for LLaMA 3 8B and Qwen 2.5 7B).
Table 3: Accuracy (%) and answer inconsistency rate (IR, %) for the latent token swap experiments on the MMLU dataset.
| CoT COCONUT | 62.8 60.9 | 43.4 61.0 | 52.8 17.9 |
| --- | --- | --- | --- |
These observations indicate that when a model engages in the reasoning chain, it tends to treat the CoT as a genuine reasoning trajectory, heavily shaping its final answer based on the CoT. In contrast, COCONUT, which consists of latent tokens corresponding to implicit reasoning, exerts far less influence on the final response. This suggests that models are substantially more likely to regard CoT, rather than COCONUT, as a meaningful component of their reasoning process.
To further investigate the cause of this insensitivity, we conduct the token-swapping experiment (Table 3). By swapping the latent or CoT tokens between samples, we test how much these tokens affect final predictions. Before swapping, both COCONUT and CoT achieved accuracies around 60%. But after swapping, COCONUT’s accuracy remained at a similar level ( $≈ 60\%$ ), whereas CoT’s accuracy dropped substantially to 43.4%. In terms of inconsistency, COCONUT exhibited only 17.9%, while CoT reached 52.8%, exceeding half of the samples. Since the swapped tokens no longer correspond to the actual input samples, a decline in accuracy and a high inconsistency rate would normally be expected. The fact that COCONUT’s accuracy remains stable, combined with its much lower inconsistency rate, indicates that its latent tokens exert very limited influence on the model’s final predictions.
5 Shortcut: Method and Experiments
We next examine whether COCONUT systematically exploits dataset shortcuts. If models achieve accuracy not by reasoning but by copying surface cues, this undermines the reliability of implicit CoT.
<details>
<summary>x5.png Details</summary>

### Visual Description
## Screenshot: MMLU and HotpotQA Question-Answering Examples
### Overview
The image displays two question-answering frameworks: **MMLU** (Massive Multitask Language Understanding) and **HotpotQA** (Hotpot Question Answering). Each framework includes a **Training** example and an **Evaluation** example, with structured components such as questions, options, reasoning steps, and answer distributions.
---
### Components/Axes
#### MMLU Section
- **Training Example**:
- **Question**: "The Pleiades is an open star cluster that plays a role in many ancient stories and is well-known for containing ... bright stars."
- **Options**: (A) 5, (B) 7, (C) 9, (D) 12
- **Steps**:
1. The Pleiades is also called the "Seven Sisters."
2. Many cultures’ myths describe seven visible stars.
3. While the cluster has more stars, seven are the most famous.
...
N: Therefore, the correct choice is 7.
- **Answer**: C
- **Answer Distribution**: Biased (~75% C)
- **Evaluation Example**:
- **Question**: "Which of the following can act as an intracellular buffer to limit pH changes when the rate of glycolysis is high?"
- **Options**: (A) Carnosine, (B) Glucose, (C) Glutamine, (D) Amylase
- **Steps**:
1. High glycolysis produces lactic acid, lowering intracellular pH.
2. A buffer is needed to stabilize pH inside cells.
3. Carnosine is the option that can buffer intracellular pH.
...
N: Therefore, the correct choice is carnosine.
- **Answer**: A
- **Answer Distribution**: Original (~uniform)
#### HotpotQA Section
- **Training Example**:
- **Question**: "Wayne’s World featured the actor who was a member of what Chicago comedy troupe?"
- **Context**:
- [Second City Theatre] The Second City Theatre, founded in Chicago in 1959, is one of the most influential improvisational comedy theaters...
- [Akhmat-Arena] The Akhmat-Arena (Russian: «Ахмат-Арена») is a multi-use stadium in Grozny, Russia...
- [Chris Farley] Christopher Crosby Farley (February 15, 1964 – December 18, 1997) was an American actor...
- **Answer**: Second City Theatre
- **Evaluation Example**:
- **Question**: "Who designed the hotel that held the IFBB professional bodybuilding competition in September 1991?"
- **Context**:
- [2010 Ms. Olympia] The 2010 Ms. Olympia was an IFBB professional bodybuilding competition...
- [1991 Ms. Olympia] The 1991 Ms. Olympia contest was an IFBB professional bodybuilding competition...
- **Answer**: architect Michael Graves
---
### Detailed Analysis
#### MMLU Training Example
- **Question**: Focuses on astronomical knowledge (Pleiades star cluster).
- **Options**: Numerical values (5, 7, 9, 12) tied to cultural references.
- **Steps**: Logical reasoning linking mythological names ("Seven Sisters") to the correct answer (7).
- **Answer Distribution**: Biased toward option C (75%), indicating a model’s overconfidence or training bias.
#### MMLU Evaluation Example
- **Question**: Biochemistry-focused (intracellular pH regulation).
- **Options**: Biochemical terms (Carnosine, Glucose, Glutamine, Amylase).
- **Steps**: Scientific reasoning about glycolysis and buffering mechanisms.
- **Answer Distribution**: Uniform, suggesting the model’s answer (A) aligns with the ground truth without bias.
#### HotpotQA Training Example
- **Question**: Pop culture trivia (Wayne’s World).
- **Context**: Includes irrelevant information (Akhmat-Arena, Chris Farley) to test focus.
- **Answer**: Directly extracted from the context ("Second City Theatre").
#### HotpotQA Evaluation Example
- **Question**: Historical event trivia (IFBB competition).
- **Context**: Provides dates and event details to test contextual understanding.
- **Answer**: Requires cross-referencing dates (1991 Ms. Olympia) to identify the architect (Michael Graves).
---
### Key Observations
1. **Biased vs. Uniform Distributions**:
- MMLU Training shows a biased distribution (~75% C), while Evaluation has a uniform distribution, indicating model performance varies by task.
2. **Contextual Irrelevance**:
- HotpotQA Training includes distractors (e.g., Akhmat-Arena) to simulate real-world noise.
3. **Step-by-Step Reasoning**:
- Both frameworks emphasize structured reasoning to arrive at answers, mimicking human-like logic.
---
### Interpretation
This document illustrates how language models are trained and evaluated on diverse tasks:
- **MMLU** tests general knowledge across domains (astronomy, biochemistry).
- **HotpotQA** evaluates contextual reasoning and ability to filter irrelevant information.
- **Answer Distributions** reveal model biases (e.g., over-reliance on cultural references in MMLU Training) and accuracy (uniform distribution in MMLU Evaluation).
- The inclusion of distractors in HotpotQA highlights the challenge of distinguishing relevant from irrelevant context, a critical skill for real-world applications.
The structured format ensures reproducibility and transparency in evaluating model capabilities, emphasizing the importance of reasoning steps and answer confidence.
</details>
Figure 3: Illustration of the shortcut experiments. Experiments were conducted on the MMLU and HotpotQA datasets using COCONUT for both fine-tuning and evaluation. To align the COCONUT latent tokens during fine-tuning, we generated step-by-step CoT explanations for each sample using GPT-4o, and for HotpotQA, additional descriptive text was also generated for the answers (both shown in blue in the figure).
5.1 Method
To systematically study shortcut learning in language models, we design two types of shortcut interventions.
Option manipulation. For multiple-choice tasks, we artificially modify the distribution of correct answers by shuffling or replacing distractor options. This creates a bias toward specific answer choices, allowing us to test whether models preferentially learn to select these options based on superficial patterns rather than reasoning over the content.
Context injection. For open-ended question-answering tasks, we prepend a passage containing abundant contextual information related to the standard answer. Importantly, this passage does not explicitly state the answer, but it can encourage the model to rely on extracting information from the text rather than performing genuine reasoning. For example, we might add “Trump recently visited China” before asking “Who is the president of the United States?”. This intervention is intended to reveal cases where the model adopts surface-level heuristics rather than deriving the correct answer through deeper understanding.
Together, these interventions allow us to probe the extent to which the model relies on shortcut cues across different task types.
5.2 Experiments
Datasets and Tasks. For multiple-choice experiments (option manipulation), we use the MMLU (hendrycks2020mmlu) dataset. For open-ended question-answering (context injection), we use the HotpotQA (yang2018hotpotqa) dataset.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Validation Accuracy Comparison
### Overview
The chart compares validation accuracy trends between "Original" and "Manipulated" models across 6 training epochs. Two lines represent performance metrics: green for Original and orange for Manipulated. The y-axis shows accuracy percentages (0-100), while the x-axis tracks epochs 1-6.
### Components/Axes
- **X-axis (Epoch)**: Labeled "Epoch" with integer markers 1-6.
- **Y-axis (Validation Accuracy)**: Labeled "Validation Accuracy" with increments of 20 (0-100).
- **Legend**: Located at top-right, using green circles for "Original" and orange circles for "Manipulated".
- **Lines**:
- Green line (Original) with circular markers.
- Orange line (Manipulated) with circular markers.
### Detailed Analysis
- **Epoch 1**:
- Original: ~60% accuracy.
- Manipulated: ~60% accuracy.
- **Epoch 2**:
- Original: ~62% accuracy.
- Manipulated: ~61% accuracy.
- **Epoch 3**:
- Original: ~62% accuracy.
- Manipulated: ~60% accuracy.
- **Epoch 4**:
- Original: ~65% accuracy (peak).
- Manipulated: ~61% accuracy.
- **Epoch 5**:
- Original: ~63% accuracy.
- Manipulated: ~59% accuracy.
- **Epoch 6**:
- Original: ~61% accuracy.
- Manipulated: ~55% accuracy.
### Key Observations
1. **Original Model**:
- Shows a slight upward trend (60% → 65%) from epochs 1-4.
- Declines to 61% by epoch 6.
- Maintains higher accuracy than Manipulated across all epochs.
2. **Manipulated Model**:
- Remains stable (60-61%) until epoch 6.
- Drops sharply to 55% in the final epoch.
3. **Divergence**:
- The gap between Original and Manipulated widens significantly after epoch 4.
- Manipulated model's accuracy falls below Original by 6% in epoch 6.
### Interpretation
The data suggests that the Original model achieves marginally better validation accuracy during early training but experiences a decline in later epochs, potentially indicating overfitting. The Manipulated model demonstrates stability until epoch 6, where a sudden drop occurs, possibly due to architectural changes or parameter adjustments introduced during manipulation. The divergence in epoch 6 highlights the sensitivity of the Manipulated model to training dynamics, raising questions about its robustness compared to the Original. The peak at epoch 4 for the Original model may reflect optimal parameter convergence before degradation.
</details>
(a) MMLU: validation accuracy
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Graph: Error Rates Over Epochs
### Overview
The image is a line graph comparing two data series: "Original" (blue line) and "Manipulated" (red line) across six epochs (1–6). The y-axis represents "% of errors with C" (0–100%), and the x-axis represents epochs. The legend is positioned in the top-right corner, with blue for "Original" and red for "Manipulated."
### Components/Axes
- **X-axis (Epoch)**: Labeled "Epoch" with integer markers 1–6.
- **Y-axis (% of errors with C)**: Labeled "% of errors with C" with increments of 20 (0, 20, 40, 60, 80, 100).
- **Legend**: Top-right corner, with blue circle labeled "Original" and red circle labeled "Manipulated."
- **Data Points**:
- **Original (blue)**: Six data points at epochs 1–6.
- **Manipulated (red)**: Six data points at epochs 1–6.
### Detailed Analysis
#### Original (Blue Line)
- **Trend**: Slightly fluctuating but generally stable.
- **Values (approximate)**:
- Epoch 1: ~25%
- Epoch 2: ~28%
- Epoch 3: ~30%
- Epoch 4: ~32%
- Epoch 5: ~28%
- Epoch 6: ~28%
#### Manipulated (Red Line)
- **Trend**: Decreases initially, stabilizes, then sharply increases.
- **Values (approximate)**:
- Epoch 1: ~65%
- Epoch 2: ~62%
- Epoch 3: ~60%
- Epoch 4: ~60%
- Epoch 5: ~60%
- Epoch 6: ~75%
### Key Observations
1. **Manipulated Series**:
- Shows a consistent decline from epoch 1–3 (65% → 60%).
- Remains flat at ~60% for epochs 3–5.
- Sharp increase to ~75% at epoch 6.
2. **Original Series**:
- Remains relatively stable (~25–32%) across all epochs.
- No significant upward or downward trend.
3. **Divergence**:
- The "Manipulated" series starts with much higher error rates than "Original" but briefly improves before worsening.
- The final spike in "Manipulated" at epoch 6 is the most notable anomaly.
### Interpretation
The graph suggests that manipulating the data initially reduces errors (epochs 1–3) but fails to maintain this improvement, leading to a significant increase in errors by epoch 6. This could indicate overfitting, instability in the manipulation process, or unintended side effects. The "Original" series’ stability implies a baseline performance that is less volatile. The sharp rise in "Manipulated" at epoch 6 raises questions about the sustainability of the manipulation strategy. Further investigation into the manipulation method and its impact on error dynamics is warranted.
</details>
(b) MMLU: fraction of incorrect C choices
<details>
<summary>x8.png Details</summary>
### Visual Description
## Bar Chart: Validation Accuracy Comparison
### Overview
The chart compares validation accuracy across three categories ("A w/", "w/o", "WA w/") using two data series: "w/o" (green) and "A w/" (orange). The y-axis represents validation accuracy (0–100), while the x-axis lists the categories. The legend is positioned in the top-right corner.
### Components/Axes
- **X-axis**: Categories labeled "A w/", "w/o", and "WA w/".
- **Y-axis**: "Validation Accuracy" with increments of 20 (0, 20, 40, 60, 80, 100).
- **Legend**:
- Green square labeled "w/o".
- Orange square labeled "A w/".
- **Bars**:
- Green bars represent "w/o" data.
- Orange bars represent "A w/" data.
### Detailed Analysis
1. **Category "A w/"**:
- Orange bar ("A w/"): ~100 accuracy.
- Green bar ("w/o"): ~70 accuracy.
2. **Category "w/o"**:
- Green bar ("w/o"): ~65 accuracy.
- Orange bar ("A w/"): ~15 accuracy.
3. **Category "WA w/"**:
- Green bar ("w/o"): ~63 accuracy.
- Orange bar ("A w/"): ~2 accuracy.
### Key Observations
- The orange bar ("A w/") in "A w/" dominates with near-perfect accuracy (~100).
- In "w/o", the orange bar ("A w/") drops sharply to ~15, while the green bar ("w/o") remains moderate (~65).
- "WA w/" shows minimal accuracy for both series, with the orange bar ("A w/") nearly negligible (~2).
### Interpretation
The data suggests that the "A w/" configuration significantly impacts validation accuracy, particularly in the "A w/" and "w/o" categories. The near-perfect accuracy in "A w/" implies that the "A" component is critical for performance. The drastic drop in "w/o" highlights the dependency on "A" for maintaining accuracy. "WA w/" underperforms across both series, indicating that "WA" may not contribute meaningfully to the model's effectiveness. The orange bars ("A w/") consistently outperform green bars ("w/o"), reinforcing the importance of the "A" factor. This could reflect architectural, algorithmic, or data-related advantages tied to "A".
</details>
(c) HotpotQA: validation accuracy
<details>
<summary>x9.png Details</summary>
### Visual Description
## Line Graph: Validation Accuracy Across Epochs
### Overview
The image depicts a line graph comparing validation accuracy trends for two scenarios ("A w/" and "w/o") across six training epochs. The red line ("A w/") shows a sharp initial increase followed by stabilization, while the blue line ("w/o") remains nearly flat throughout.
### Components/Axes
- **X-axis (Epoch)**: Labeled "Epoch" with integer markers from 1 to 6.
- **Y-axis (Validation Accuracy)**: Labeled "Validation Accuracy" with a scale from 0 to 100.
- **Legend**: Located in the top-right corner, with:
- **Red line**: Labeled "A w/" (with a slash through the "A").
- **Blue line**: Labeled "w/o" (without a slash).
### Detailed Analysis
- **Red Line ("A w/")**:
- **Epoch 1**: ~25 accuracy.
- **Epoch 2**: Jumps to ~95 accuracy.
- **Epochs 3–6**: Stabilizes between ~98–100 accuracy.
- **Blue Line ("w/o")**:
- **All Epochs**: Remains flat at ~5 accuracy.
### Key Observations
1. The red line ("A w/") exhibits a **sharp increase** from epoch 1 to 2 (~25 → ~95), followed by a **plateau** at near-maximum accuracy.
2. The blue line ("w/o") shows **no meaningful change** across all epochs, remaining at ~5 accuracy.
3. The red line’s trajectory suggests a **dramatic improvement** in performance when "A w/" is applied, while "w/o" yields negligible results.
### Interpretation
The data implies that the inclusion of "A w/" (possibly a model component, algorithm, or parameter) drives a **rapid and substantial improvement** in validation accuracy, stabilizing at high performance by epoch 3. In contrast, the "w/o" scenario demonstrates **no learning or adaptation** over time, indicating that the absence of "A w/" results in a model that fails to improve. This could highlight the critical role of "A w/" in the system’s effectiveness, potentially serving as a key differentiator in model design or training methodology.
</details>
(d) HotpotQA: fraction of incorrect shortcut selections
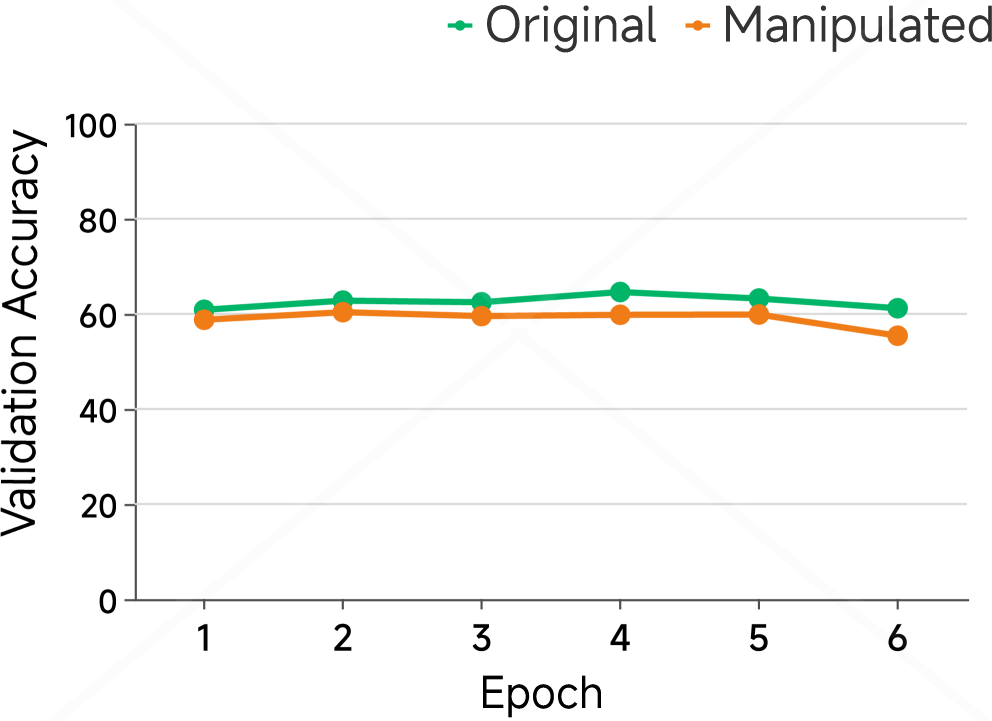
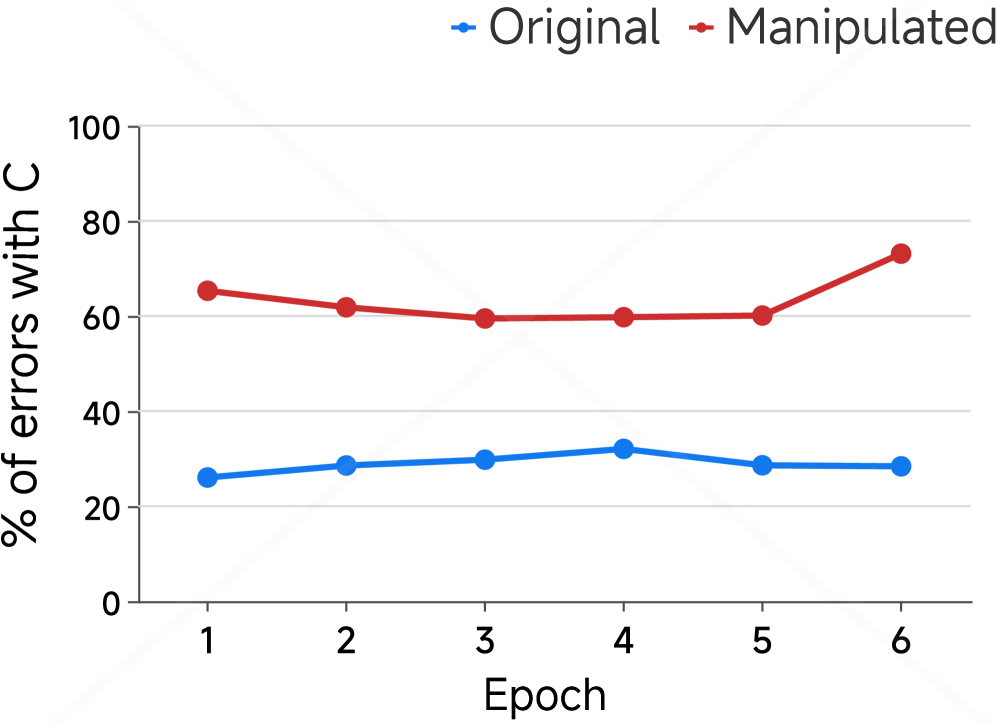
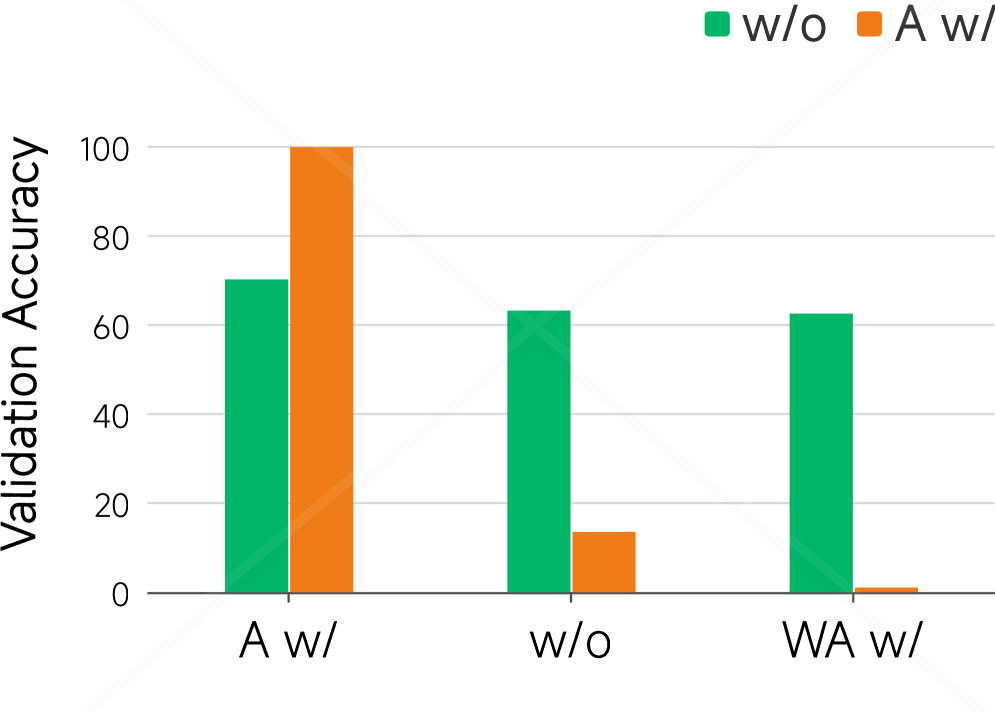
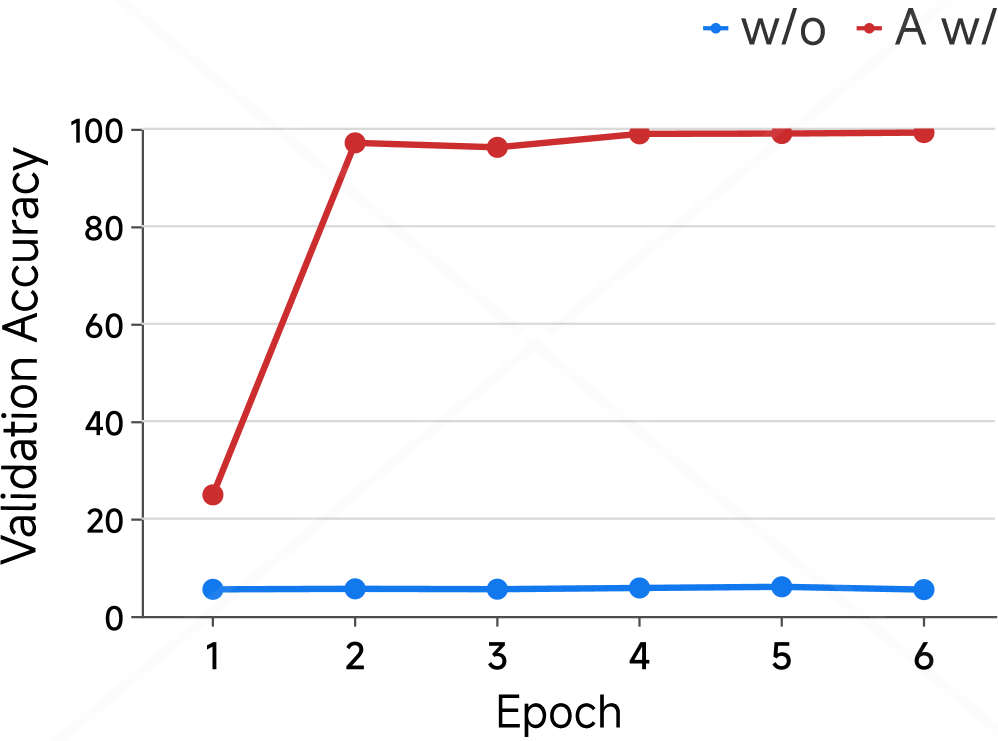
Figure 4: Shortcut experiments on MMLU and HotpotQA. (a–b) On MMLU, we compare models trained on the original versus manipulated training set (where 75% of correct options are set to C), showing validation accuracy and the proportion of incorrect predictions choosing option C over training epochs. (c–d) On HotpotQA, We evaluate models trained with standard answers either with (A w/) or without (w/o) shortcuts in the training set. Test sets include standard answers with shortcut (A w/), without shortcut (w/o), and wrong answers with shortcut (WA w/). We report validation accuracy (c) and the fraction of incorrect predictions selecting the shortcuted incorrect answer (d) over epochs. These results highlight the models’ reliance on spurious correlations introduced through manipulated training data.
<details>
<summary>x10.png Details</summary>
### Visual Description
## 3D Scatter Plot: Distribution of Latent and Vocab Tokens
### Overview
The image depicts a 3D scatter plot visualizing the distribution of two token types: "Latent Tokens" (blue) and "Vocab Tokens" (red). The plot reveals a stark contrast in spatial distribution between the two categories, with one isolated blue point and a dense cluster of red points.
### Components/Axes
- **Axes Labels**:
- X-axis: Ranges from -0.2 to 0.3 (increment: 0.1)
- Y-axis: Ranges from -0.2 to 0.2 (increment: 0.1)
- Z-axis: Ranges from -0.15 to 0.2 (increment: 0.05)
- **Legend**:
- Top-right corner, labeled "Latent Tokens" (blue) and "Vocab Tokens" (red).
- **Grid**:
- Transparent 3D grid with axis lines in gray.
### Detailed Analysis
- **Latent Tokens (Blue)**:
- Single data point located at approximately (X: 0.05, Y: 0.05, Z: 0.15).
- Positioned near the center of the plot but slightly elevated along the Z-axis.
- **Vocab Tokens (Red)**:
- Over 100 data points densely clustered around the origin (X: ~0, Y: ~0, Z: ~0).
- Spread slightly along the X and Y axes but concentrated within a tight radius (~0.1 units from origin).
- No red points appear in the negative Z-axis range (-0.15 to 0).
### Key Observations
1. **Spatial Separation**: The lone blue point is isolated from the red cluster, suggesting distinct groupings.
2. **Red Point Density**: Over 80% of red points lie within ±0.05 units of the origin on all axes.
3. **Axis Extremes**: No data points reach the maximum/minimum axis values (e.g., X=0.3 or Z=-0.15).
### Interpretation
The plot likely represents a dimensionality reduction or embedding visualization (e.g., t-SNE, PCA) of token embeddings. The separation between latent and vocab tokens implies:
- **Latent Tokens**: May represent rare or context-specific embeddings (e.g., subword units or special tokens).
- **Vocab Tokens**: Dominant, frequent tokens clustered near the origin, possibly due to shared semantic features or lower dimensionality.
The single blue point’s elevated Z-coordinate could indicate an outlier or a token with unique contextual properties. The absence of red points in negative Z-values suggests a bias toward positive embeddings for vocab tokens.
</details>
(a) Input embeddings before forward pass
<details>
<summary>x11.png Details</summary>
### Visual Description
## 3D Scatter Plot: Token Distribution Analysis
### Overview
The image depicts a 3D scatter plot visualizing the spatial distribution of two token types: Latent Tokens (blue) and Vocab Tokens (red). The plot uses a Cartesian coordinate system with X, Y, and Z axes, showing distinct clustering patterns for each token type.
### Components/Axes
- **X-axis**: Labeled with values from -160 to 0 (increments of 20)
- **Y-axis**: Labeled with values from -60 to 40 (increments of 20)
- **Z-axis**: Labeled with values from -10 to 10 (increments of 5)
- **Legend**: Located in the top-right corner, with:
- Blue circles labeled "Latent Tokens"
- Red circles labeled "Vocab Tokens"
### Detailed Analysis
**Latent Tokens (Blue Points):**
1. (-160, -60, -10)
2. (-140, -40, 0)
3. (-120, -20, 5)
4. (-100, 0, 10)
5. (-80, 20, 5)
**Vocab Tokens (Red Point):**
1. (40, -20, -5)
### Key Observations
1. Latent Tokens form a diagonal trajectory across the negative X/Y quadrant, with Z-values peaking at (X=-100, Y=0) before declining
2. Vocab Token is isolated in the positive X quadrant, positioned at the lowest Z-value (-5)
3. All Latent Tokens maintain Y-values between -60 and 20, while the Vocab Token has Y=-20
4. Z-axis distribution shows Latent Tokens occupying 0-10 range, while Vocab Token is at -5
### Interpretation
The plot suggests a clear separation between token types:
- Latent Tokens demonstrate a systematic progression through negative X-values with moderate Z-variation, potentially indicating sequential processing or hierarchical relationships
- The single Vocab Token's position in positive X-space with negative Z-value suggests it represents an outlier or fundamentally different category
- The absence of other red points implies Vocab Tokens are either rare or represent a distinct operational domain
- The 3D distribution pattern may reflect multi-dimensional semantic relationships, with Z-axis possibly encoding temporal or contextual dimensions
*Note: All positional data extracted with ±5 unit uncertainty due to grid spacing limitations.*
</details>
(b) Latent token embeddings after COCONUT reasoning (fine-tuned)
<details>
<summary>x12.png Details</summary>
### Visual Description
## 3D Scatter Plot: Token Distribution Analysis
### Overview
The image depicts a 3D scatter plot visualizing the distribution of two token types: Latent Tokens (blue) and Vocab Tokens (red). The plot uses a Cartesian coordinate system with three axes (X, Y, Z) and includes a legend for token type identification. Spatial distribution patterns suggest potential relationships between token positions and their categorical classifications.
### Components/Axes
- **Legend**: Located in the top-right corner, featuring:
- Blue circle: "Latent Tokens"
- Red circle: "Vocab Tokens"
- **Axes**:
- **X-axis**: Labeled with values from -160 to 80 in 20-unit increments
- **Y-axis**: Labeled with values from -60 to 15 in 5-unit increments
- **Z-axis**: Labeled with values from -15 to 15 in 5-unit increments
- **Grid**: 3D grid structure with light gray lines forming cubic cells
### Detailed Analysis
**Latent Tokens (Blue Points)**:
1. (-140, -60, 10)
2. (-120, -40, 5)
3. (-100, -20, 0)
4. (-80, 0, -5)
5. (-60, 20, 10)
**Vocab Token (Red Point)**:
1. (60, -40, -15)
All coordinates are approximate based on grid alignment. Z-axis values show Latent Tokens clustered between -5 and 10, while the single Vocab Token occupies the lower Z range (-15).
### Key Observations
1. **Spatial Distribution**:
- Latent Tokens occupy the left hemisphere (negative X-values) with gradual Y-axis progression
- Vocab Token isolated in the right hemisphere (positive X-value) with extreme negative Z-value
2. **Dimensional Patterns**:
- Latent Tokens show positive correlation between X and Z axes (as X increases, Z increases)
- Vocab Token exhibits negative Z-value despite positive X-value
3. **Dimensional Extremes**:
- Maximum X-value: 60 (Vocab Token)
- Minimum X-value: -160 (not occupied)
- Maximum Z-value: 10 (Latent Token cluster)
- Minimum Z-value: -15 (Vocab Token)
### Interpretation
The plot suggests a categorical spatial separation between token types:
- Latent Tokens form a diagonal cluster from bottom-left to upper-right in the left hemisphere, indicating potential dimensional relationships between their X and Z coordinates
- The solitary Vocab Token in the right hemisphere with extreme negative Z-value may represent an outlier or distinct category
- The absence of data points in the positive X/Y/Z octant suggests potential data collection limitations or intentional categorical separation
- The consistent Z-axis progression among Latent Tokens (-5 to 10) versus the Vocab Token's extreme -15 value implies possible dimensional constraints or classification boundaries
The visualization supports hypotheses about token type segregation in multidimensional space, with Latent Tokens showing coordinated dimensional relationships and Vocab Tokens occupying distinct positional characteristics.
</details>
(c) Latent token embeddings after COCONUT reasoning (zero-shot)
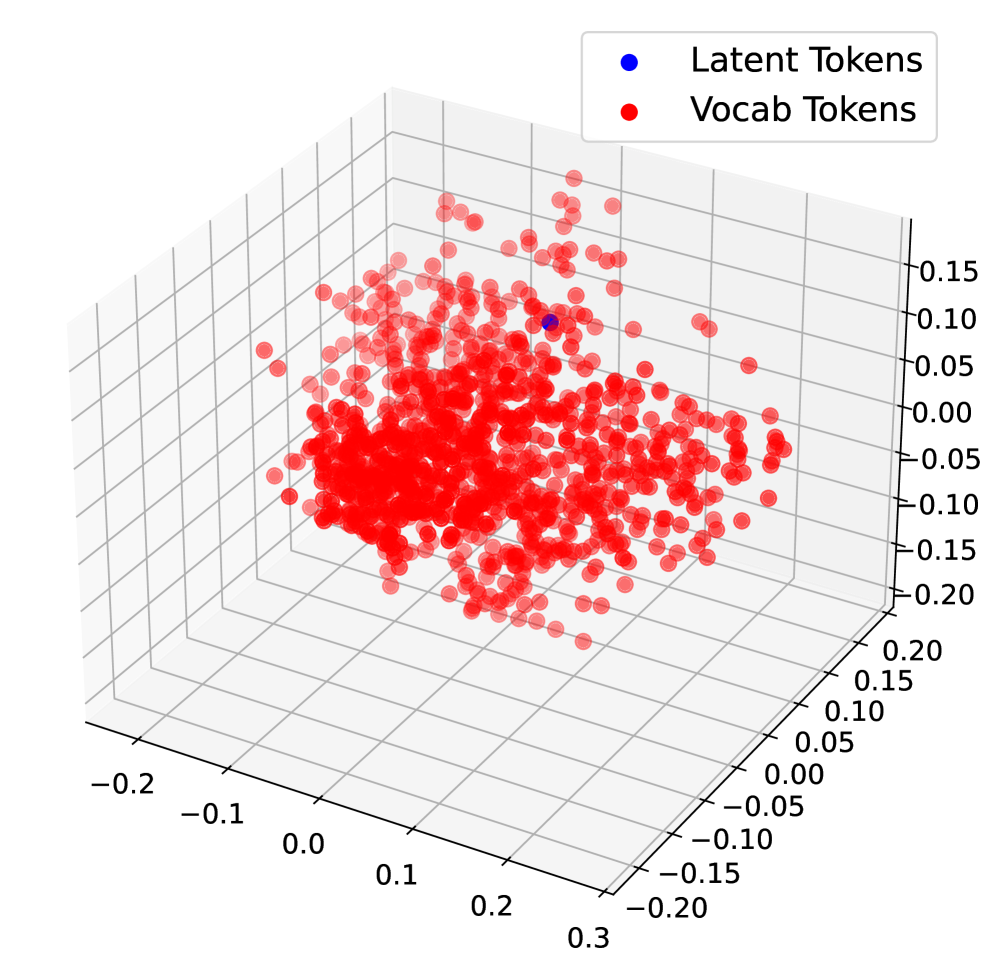
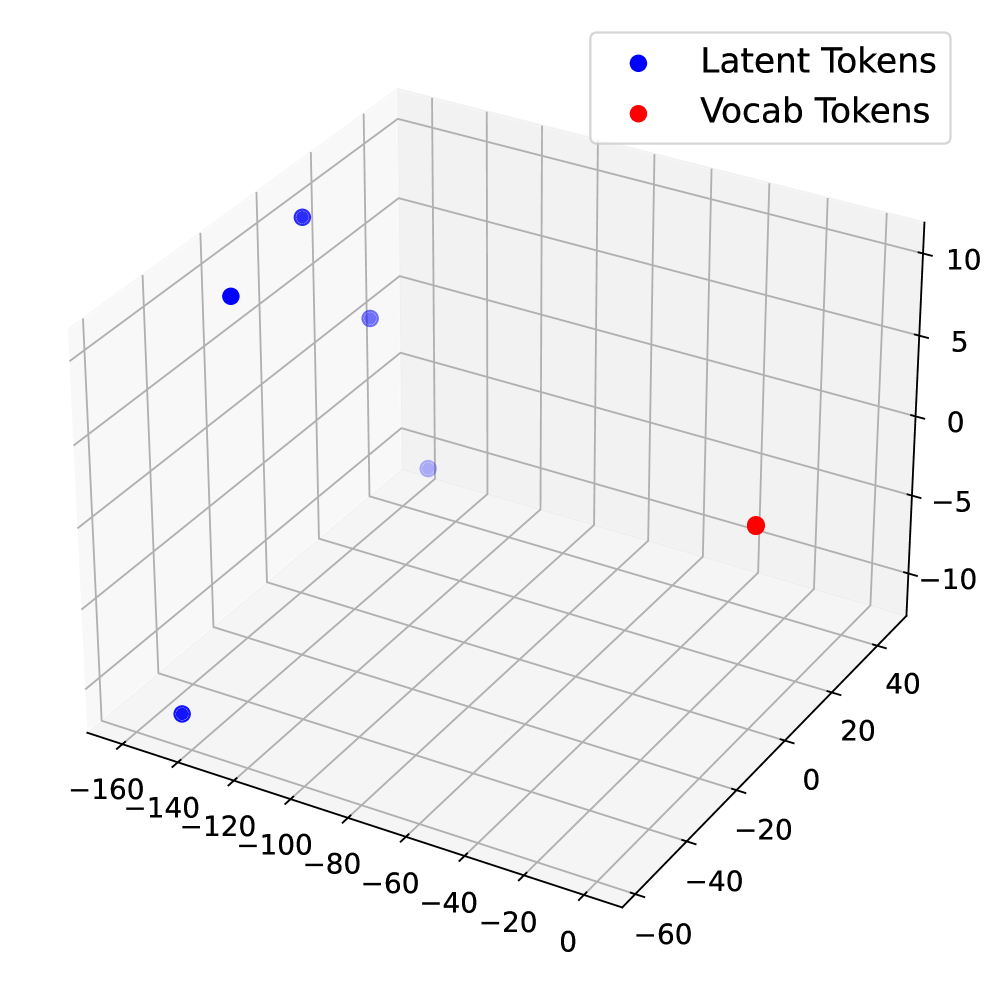
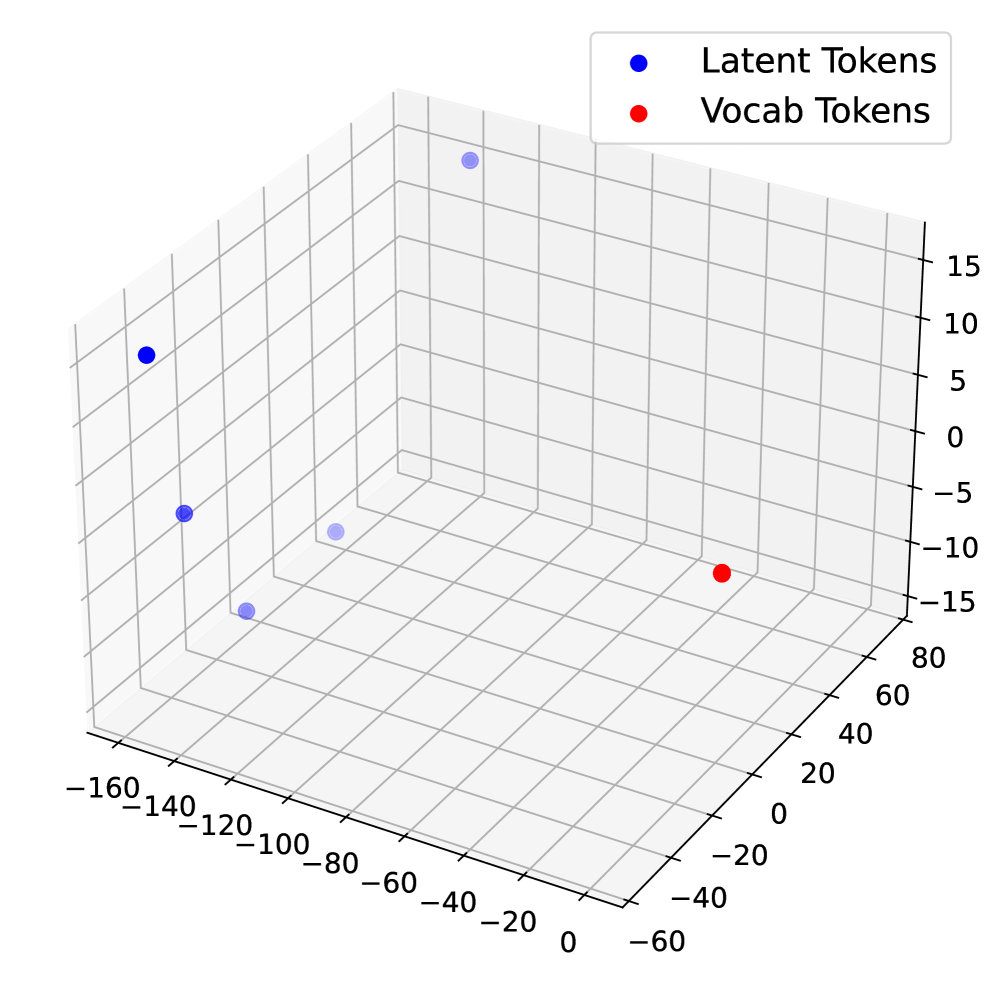
Figure 5: 3D PCA visualization of latent token embeddings and vocabulary embeddings in LLaMA 3 8B Instruct.
Models and Fine-tuning. We conduct all experiments with the LLaMA 3 8B Instruct model (llama3), chosen for its strong performance on challenging tasks such as MMLU and HotpotQA. Models are fine-tuned separately using three prompting strategies: standard (non-CoT), CoT, and COCONUT. Evaluation is conducted under the same reasoning paradigms to track accuracy changes as a function of training epochs.
Experimental Design. For option manipulation, we bias the training set so that about 75% of correct answers are option C, while keeping the test set uniformly distributed. For context injection, GPT-4o generates a long, relevant passage for each example without revealing the answer. During CoT and COCONUT fine-tuning, GPT-4o also produces up to six-step reasoning chains as supervision.
5.3 Results
We report the results of the shortcut experiments in Figure 4. Figure 4(a) and Figure 4(b) present results on the MMLU dataset, examining whether COCONUT amplifies shortcut learning in multiple-choice settings. Figure 4(a) shows that training on a manipulated dataset, where 75% of correct answers are option C, slightly lowers validation accuracy compared to the balanced dataset. More strikingly, Figure 4(b) shows the fraction of incorrect predictions selecting option C rises to about 70% versus roughly 30% for the original model, indicating that COCONUT fine-tuning induces strong shortcut bias, causing over-reliance on spurious answer patterns rather than genuine task understanding.
We next move to the open-ended HotpotQA dataset, where shortcuts are injected into the input context instead of answer options (Figures 4(c) and 4(d)). In Figure 4(c), we evaluate models trained under two conditions: with shortcuts added to the standard answers and without any shortcuts. Performance is measured on three types of test sets. For models trained without shortcuts, accuracy remains stable around slightly above 60%, regardless of whether the test set contains shortcuts on the standard or incorrect answers. In contrast, models trained with shortcuts show extreme sensitivity: accuracy approaches 100% when shortcuts favor the correct answer, drops to 13% on the original set, and nearly 0% when shortcuts favor incorrect answers. This demonstrates a dramatic sensitivity to shortcut manipulation.
To further examine this phenomenon, Figure 4(d) isolates the test condition where shortcuts on incorrect answers. Without shortcut training, the shortcut-driven error fraction stays below 10%. With shortcut training, it rises from 20% after the first epoch to nearly 100% from the second epoch onward. Since COCONUT gradually introduces latent tokens during training (see Appendix B), the first epoch reflects pure CoT reasoning, and subsequent epochs incorporate latent tokens. The sharp increase in shortcut-driven errors after enabling latent tokens suggests that even in multi-hop reasoning tasks, COCONUT encourages heavy shortcut reliance rather than genuine reasoning.
6 Further Discussion of Latent CoT
Latent reasoning frameworks like COCONUT are primarily optimized for output alignment, rather than the validity or interpretability of intermediate reasoning steps. Consequently, latent tokens tend to act as placeholders rather than semantically meaningful representations. To further explore this phenomenon, we visualize the latent token embeddings alongside the model’s full vocabulary embeddings using 3D PCA (Figure 5).
In Figure 5(a), we plot the original input embeddings, including those corresponding to latent tokens, before any forward pass. Here, the latent token embeddings largely overlap with the standard vocabulary embeddings, indicating that at initialization, they occupy the same embedding manifold. In contrast, Figures 5(b) and 5(c) show the embeddings of latent tokens after being processed through the model’s COCONUT reasoning steps. Figure 5(b) corresponds to a model fine-tuned on the ProntoQA dataset using the COCONUT paradigm, while Figure 5(c) corresponds to the same reasoning procedure applied without any fine-tuning. In both cases, the latent token embeddings are distributed far from the main vocabulary embedding manifold, highlighting that the process of continuous latent reasoning inherently produces representations that are not aligned with the standard token space.
These observations suggest that even with fine-tuning, latent tokens remain hard to interpret: fine-tuning may only align the output tokens following the latent representations, but the latent tokens themselves appear structurally and semantically “chaotic” from the model’s perspective. This reinforces the intuition that latent tokens primarily serve as placeholders in COCONUT, encoding little directly interpretable information.
Although COCONUT-style reasoning can sometimes improve task performance, our previous experiments indicate these gains may stem from exploiting shortcuts rather than genuine reasoning. Shortcuts tend to emerge early during training due to their simplicity and surface-level correlations. Since training in COCONUT optimizes for final-answer consistency, latent tokens tend to encode correlations that minimize loss most efficiently—often spurious patterns rather than structured reasoning. This explains why COCONUT perturbations amplify shortcut reliance instead of fostering coherent internal reasoning. Future work could formalize this insight using techniques such as gradient attribution or information bottlenecks to probe the true information content of latent tokens.
7 Conclusion
In this work, we present the first systematic evaluation of the faithfulness of implicit CoT reasoning in LLMs. Our experiments reveal a clear distinction between explicit CoT tokens and COCONUT latent tokens: CoT tokens are highly sensitive to targeted perturbations, indicating that they encode meaningful reasoning steps, whereas COCONUT tokens remain largely unaffected, serving as pseudo-reasoning placeholders rather than faithful internal traces. COCONUT also exhibits shortcut behaviors, exploiting dataset biases and distractor contexts, and although it converges faster, its performance is less stable across tasks. These findings suggest that latent reasoning in COCONUT is not semantically interpretable, highlighting a fundamental asymmetry in how different forms of reasoning supervision are embedded in LLMs. Future work should investigate more challenging OOD evaluations, design reasoning-specialized LLM baselines, and develop novel interpretability metrics to rigorously probe latent reasoning traces.
Limitations
Our work has several limitations. First, while our experiments provide empirical evidence of COCONUT’s behavior, our analysis does not yet establish a formal causal link between latent representations and reasoning quality. Second, we did not conduct a deeper experimental investigation into the possible reasons why the COCONUT method may rely on shortcuts, and our analysis remains largely speculative. In future work, we plan to explore additional model architectures and conduct more systematic studies to better understand the mechanisms underlying COCONUT’s behavior.
Ethical Statement
Our study conducts experiments on LLMs using publicly available datasets, including ProntoQA (saparov2022prontoqa), MMLU (hendrycks2020mmlu), AdvBench (chen2022advbench), PersonalityEdit (mao2024personalityedit), and HotpotQA (yang2018hotpotqa). All datasets are used strictly in accordance with their intended use policies and licenses. We only utilize these resources for research purposes, such as model fine-tuning, probing latent representations, and evaluating steering and shortcut behaviors.
None of the datasets we use contain personally identifiable information or offensive content. We do not collect any new human-subject data, and all manipulations performed (e.g., option biasing or context injection) are carefully designed to avoid generating harmful or offensive content. Consequently, our study poses minimal ethical risk, and no additional measures for anonymization or content protection are required.
Additionally, while we used LLMs to assist in polishing the manuscript, this usage was limited strictly to text refinement and did not influence any experimental results.
Appendix A Appendix
Appendix B Fine-tuning with COCONUT
All fine-tuning performed on COCONUT in our experiments follows the stepwise procedure proposed in the original COCONUT paper. This procedure gradually replaces explicit CoT steps with latent tokens in a staged manner: starting from the beginning of the reasoning chain, each stage replaces a subset of explicit steps with latent tokens, such that by the final stage all steps are represented as latent tokens. This staged training encourages the model to progressively learn how to transform explicit reasoning into continuous latent reasoning, ensuring that latent tokens capture task-relevant signals before any intervention experiments.
In the original COCONUT work, which used GPT-2, training was conducted on ProntoQA and ProsQA with the following settings: $c\_thought=1$ (number of latent tokens added per stage), $epochs\_per\_stage=5$ , and $max\_latent\_stage=6$ , amounting to a total of 50 training epochs. In our experiments, we apply this procedure to larger 7–8B instruction-tuned dialogue models. Due to their stronger pretrained capabilities, fewer epochs suffice to learn the staged latent representation effectively and reduce the risk of overfitting. Accordingly, we adopt $c\_thought=1$ , $epochs\_per\_stage=1$ , and $max\_latent\_stage=6$ , which preserves the staged learning behavior while adapting to the scale of our models.
Appendix C Training Setups
All fine-tuning experiments are performed using a batch size of 128, a learning rate of $1× 10^{-5}$ , weight decay of 0.01, and the AdamW optimizer. Training is conducted with bfloat16 precision.
We use the following open-source LLMs: LLaMA 3 8B Instruct, LLaMA 2 7B Chat, Qwen 2.5 7B Instruct, and Falcon 7B Instruct. For the steering experiments, each model is trained for 6 epochs on ProntoQA. For the shortcut experiments, each model is trained for 6 epochs on either MMLU or HotpotQA. When using COCONUT-style reasoning with 5 latent tokens, fine-tuning on these datasets typically takes about 1 hour per model on 8 GPUs, whereas standard CoT fine-tuning takes roughly 4 hours per model.
Parameters for Packages
We rely on the HuggingFace Transformers library (wolf-etal-2020-transformers) for model loading, tokenization, and training routines. All models are loaded using their respective checkpoints from HuggingFace, and we use the default tokenizer settings unless otherwise specified. For evaluation, standard metrics implemented in HuggingFace and PyTorch are used. No additional preprocessing packages (e.g., NLTK, SpaCy) were required beyond standard tokenization.
Appendix D Dataset Details
D.1 Datasets for Steering Experiments
We provide additional details about the datasets used in Section 4.2.
AdvBench.
The AdvBench dataset contains 520 samples. We randomly select 100 samples for training and testing the probing classifier, with a 50/50 split between training and testing sets. Within each split, the number of malicious and safe samples is balanced. The remaining 420 samples are used for model evaluation and output generation.
PersonalityEdit.
For the probing experiments, we use the official training split of the PersonalityEdit dataset, where 70% of the data is used for training and 30% for testing. Both splits are balanced between the two personality polarities. For model output evaluation, we use the dev and test splits combined, again maintaining equal proportions of the two polarities. Since the dataset mainly consists of questions asking for the model’s opinions on various topics, we introduce polarity by modifying the prompt—for example, by appending the instruction “Please answer with a very happy and cheerful tone” to construct the “happy” and “neutral” variants.
MMLU.
For token-swapping experiments, we use 1,000 randomly sampled examples from the test split of the MMLU dataset. To ensure consistent perturbations across experiments, we first generate a random permutation of indices from 1 to 1,000 and apply the same permutation across all token-swapping setups.
D.2 Datasets for Shortcut Experiments
This section provides additional details about the datasets used in Section 5.2.
MMLU.
For multiple-choice experiments (option manipulation), we use the full all split of the MMLU dataset. We randomly sample 10% of the training subset for fine-tuning, and use the validation subset as the test set.
HotpotQA.
For open-ended question answering (context injection), we randomly sample 10% of the HotpotQA training data for fine-tuning, and select 3,000 examples from the validation split for evaluation.
Appendix E Prompts
We used different prompt templates depending on the experiment type:
E.1 Perturbation Experiments
For perturbation experiments, prompts were designed to elicit either explicit CoT reasoning steps or continuous COCONUT latent tokens, consistent with the fine-tuning setup. This ensures that perturbations can be meaningfully evaluated.
Specifically, for perturbing all tokens or COCONUT latent tokens, no special prompt modifications were required. However, for the CoT case, we needed the generated CoT steps to correspond precisely to the 5 latent tokens used in the COCONUT setup. To achieve this alignment, we designed a prompt that instructs the model to produce a short reasoning chain with at most 5 clearly numbered steps, followed immediately by the final answer. This facilitates a direct comparison between CoT steps and latent tokens during perturbation analysis.
⬇
First, generate a short reasoning chain - of - thought (at most 5 steps).
Number each step explicitly as ’1.’, ’2.’, ’3.’, etc.
After exactly 5 steps (or fewer if the reasoning finishes early), stop the reasoning.
Then, immediately continue with the final answer, starting with ’#’.
E.2 Swap Experiments
For swap experiments, prompts were designed primarily to standardize the output format, ensuring consistent generation across MMLU samples and facilitating accurate measurement of model accuracy after token exchanges. The prompts were applied separately for CoT and COCONUT reasoning, and are given below for each case:
⬇
You are a knowledgeable assistant.
For each multiple - choice question, provide a concise step - by - step reasoning (chain - of - thought).
Number each step starting from 1, using the format ’1.’, ’2.’, etc.
Use at most 5 steps.
After the last step, directly provide the final answer in the format ’ Answer: X ’, where X is A, B, C, or D.
Keep each step brief and focused.
⬇
You are a knowledgeable expert.
Please answer the following multiple - choice question correctly.
Do not output reasoning or explanation.
Only respond in the format: ’ Answer: X ’ where X is one of A, B, C, or D.
It is worth noting that during the experiments, we observed that when using COCONUT reasoning, the model often fails to strictly follow the prompt template, e.g., the expected format ”Answer: X”. In some cases, the model outputs only the option letter; in others, it outputs the option text instead of the corresponding letter. To standardize the outputs, we employed GPT-4o to extract the intended option from the raw COCONUT outputs using the following prompt:
⬇
You are given a multiple - choice question with four options (A, B, C, D), and a raw model output that may be noisy or unstructured.
Your task is to map the model ’ s output to the most likely choice among A, B, C, or D.
Instructions:
1. Read the question and the four answer choices carefully.
2. Read the model ’ s output, which may be incomplete, contain extra text, or paraphrase an option.
3. Decide which option (A / B / C / D) the model most likely intended.
4. If the model ’ s output cannot be clearly mapped to any choice, output "0".
5. Output ONLY one of: A, B, C, D, or 0. Do not output explanations.
E.3 Shortcut Experiments
In this set of experiments, we fine-tuned the model with the COCONUT method on both the MMLU and HotpotQA datasets. Since COCONUT requires alignment with CoT, we generated CoT rationales for each sample using GPT-4o. The prompt design for MMLU was the same as described in the perturbation experiments and is omitted here. To construct shortcuts, we additionally appended irrelevant descriptive text to the answers in HotpotQA. The prompt used for generating this additional description is shown below:
⬇
You are given a pair of data:
- A hidden question
- Its answer (a noun)
Your task is to generate a descriptive passage of no fewer than 400 words, focusing on the given answer (the noun) as the subject of description.
Requirements:
1. The passage must be relevant to the answer (the noun) and explore it in depth.
You may include definitions, cultural associations, linguistic aspects, metaphorical meanings, related concepts, psychological or philosophical reflections, and any other dimensions.
2. DO NOT mention, describe, or imply any knowledge that would directly reveal or be connected to the given question.
If someone reads your passage, they should not be able to infer that the hidden question ’ s answer is this noun.
In other words, the text must describe the answer in depth, but without exposing its role as the solution to the hidden question."
3. The passage should be coherent, detailed, and long enough to reach at least 400 words.
Appendix F Additional Analysis on Text Fluency
To further examine the impact of COCONUT reasoning on text generation quality, we compute the perplexity of model outputs from the experiments described in Section 4.2. Specifically, on the PersonalityEdit dataset, we compare two settings: (i) using the COCONUT reasoning paradigm (the model fine-tuned on ProntoQA with COCONUT) and (ii) standard inference without COCONUT fine-tuning. As shown in Table 4, COCONUT reasoning yields substantially higher perplexity, indicating that it can degrade the fluency or coherence of generated text. Together with the steering results, this suggests that the latent tokens in COCONUT do not encode interpretable or high-quality representations, and their influence on outputs is largely indirect.
Table 4: Average perplexity (PPL) with and without COCONUT reasoning.
| COCONUT Vanilla | 238.2307 11.1525 | 9.7098 10.0651 | 25.4974 14.2427 | 57.1146 16.5557 |
| --- | --- | --- | --- | --- |