# Deep learning methods for inverse problems using connections between proximal operators and Hamilton–Jacobi equations
**Authors**: Oluwatosin Akande, Gabriel P. Langlois, Akwum Onwunta
> Industrial and Systems Engineering, Lehigh University, 200 West Packer Avenue, Bethlehem, PA 18015, USA, ( )
> Department of Mathematics, University of Illinois Urbana-Champaign, Chicago, IL, USA ( ).
> Industrial and Systems Engineering, Lehigh University, 200 West Packer Avenue, Bethlehem, PA 18015, USA, ( ).
## Abstract
Inverse problems are important mathematical problems that seek to recover model parameters from noisy data. Since inverse problems are often ill-posed, they require regularization or incorporation of prior information about the underlying model or unknown variables. Proximal operators, ubiquitous in nonsmooth optimization, are central to this because they provide a flexible and convenient way to encode priors and build efficient iterative algorithms. They have also recently become key to modern machine learning methods, e.g., for plug-and-play methods for learned denoisers and deep neural architectures for learning priors of proximal operators. The latter was developed partly due to recent work characterizing proximal operators of nonconvex priors as subdifferential of convex potentials. In this work, we propose to leverage connections between proximal operators and Hamilton–Jacobi partial differential equations (HJ PDEs) to develop novel deep learning architectures for learning the prior. In contrast to other existing methods, we learn the prior directly without recourse to inverting the prior after training. We present several numerical results that demonstrate the efficiency of the proposed method in high dimensions.
## 1 Introduction
Inverse problems are ubiquitous mathematical problems that primarily aim at recovering model parameters from noisy data. They arise in many scientific and engineering applications for, e.g., recovering an image from noisy measurements, deblurring, tomographic reconstruction, and compressive sensing [AEOV2023, bertero2021introduction, isakov2017inverse, arridge2019solving]. Since inverse problems are often ill-posed, it is essential to include regularization or prior information about the underlying model or unknown variables. Proximal operators are central to this: they provide a flexible and computationally convenient way to encode priors and to build efficient iterative algorithms (e.g., proximal (sub)gradients, the alternating direction method of multipliers, and other splitting methods). More recently, proximal operators have become key ingredients for state-of-the-art machine learning methods, e.g., plug-and-play methods that replace explicit regularizers by learned denoisers [hu2023plug, jia2025plug], and deep neural architectures that parameterize proximal maps or their gradients, such as learned proximal networks (LPNs) [fang2024whats]. These developments have made proximal methods practical and powerful computational tools.
Formally, the proximal operator of a proper function $J\colon\mathbb{R}^{n}\to\mathbb{R}\cup\{+\infty\}$ is defined via an observed data $\bm{x}\in\mathbb{R}^{n}$ , a parameter $t>0$ , and the minimization problem
$$
S(\bm{x},t)=\min_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J(\bm{y})\right\}. \tag{1}
$$
The proximal operator $\text{prox}_{tJ}\colon\mathbb{R}^{n}\to\mathbb{R}$ is the set-valued function
$$
\text{prox}_{tJ}(\bm{x})=\operatorname*{arg\,min}_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J(\bm{y})\right\}. \tag{2}
$$
Here, $t$ controls the trade-off between the quadratic data-fidelity term and the prior $J$ . In practice one often works directly with $\text{prox}_{tJ}$ rather than the prior.
The recent work of Gribonval and Nikolova [gribonval2020characterization] in nonsmooth optimization has extended the characterization of proximal operators with convex priors to those with nonconvex priors, showing in particular they are functions that are subdifferentials of certain convex potentials. These properties, in particular, were used in [fang2024whats] to develop new deep learning methods, called learned proximal networks (LPNs), to learn from data the underlying prior of a proximal operator.
The paper [gribonval2020characterization] did not, however, discuss the well-established, existing connections between proximal operators and Hamilton–Jacobi Partial Differential Equations (HJ PDEs) [darbon2015convex, darbon2016algorithms, darbon2021bayesian, chaudhari2018deep, osher2023hamilton]. To see these connections, consider the following HJ PDE with quadratic Hamiltonian function and whose initial data is the prior $J$ :
$$
\begin{dcases}\frac{\partial S}{\partial t}(\bm{x},t)+\frac{1}{2}\left\|{\nabla_{\bm{x}}S(\bm{x},t)}\right\|_{2}^{2}=0,&\ \bm{x}\in\mathbb{R}^{n}\times(0,+\infty),\\
S(\bm{x},0)=J(\bm{x}),&\ \bm{x}\in\mathbb{R}^{n}.\end{dcases} \tag{3}
$$
If $J$ is uniformly Lipschitz continuous, then the unique viscosity solution of the HJ PDE is given by Eq. 1. Moreover, at a point of differentiability $\bm{x}$ , there holds
$$
\text{prox}_{tJ}(\bm{x})=\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t). \tag{4}
$$
Moreover, the viscosity solution satisfies the crucial property that $\bm{x}\mapsto\frac{1}{2}\left\|{\bm{x}}\right\|_{2}^{2}-tS(\bm{x},t)$ is convex; that is, when paired with Eq. 4, the function $\text{prox}_{tJ}(\bm{x})$ is obtained from differentiating a convex function. This formally connects proximal operators to HJ PDEs, which we emphasize was previously known and established, and the (stronger) characterization obtained in [gribonval2020characterization] To the best our knowledge, this characterization result was unknown in the theory of HJ PDEs..
In this paper, we leverage the theory of viscosity solutions of HJ PDEs to develop novel deep learning methods to learn from data the prior function $J$ in Eq. 2. To describe our approach, consider the case when the solution $(\bm{x},t)\mapsto S(\bm{x},t)$ to the HJ PDE Eq. 3 is known. (We will consider the case when only samples of it are known in the next paragraph.) This problem was investigated in [barron1999regularity, claudel2011convex, colombo2020initial, esteve2020inverse, misztela2020initial]. In particular, [esteve2020inverse] showed that when $\bm{x}\mapsto S(\bm{x},t)$ is uniformly Lipschitz continuous and $\bm{x}\mapsto\frac{1}{2}\left\|{\bm{x}}\right\|_{2}^{2}-tS(\bm{x},t)$ is convex, there exists a prior $J$ that can recover $S(\bm{x},t)$ exactly. Moreover, there is a natural candidate for the prior, obtained by reversing the time in the HJ PDE Eq. 3 and using $(\bm{x},t)\mapsto S(\bm{x},t)$ as the terminal condition. The resulting backward viscosity solution yields the prior $J_{\text{BVS}}\colon\mathbb{R}^{n}\to\mathbb{R}$ which admits the representation formula
$$
J_{\text{BVS}}(\bm{y})=\sup_{\bm{x}\in\mathbb{R}^{n}}\left\{S(\bm{x},t)-\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}\right\}. \tag{5}
$$
Here, $J(\bm{y})\geqslant J_{\text{BVS}}(\bm{y})$ for every $\bm{y}\in\mathbb{R}^{n}$ , with $J_{\text{BVS}}(\bm{y})=J(\bm{y})$ whenever $\bm{y}=\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t)$ , where $\bm{x}$ is a point of differentiability of $\bm{x}\mapsto S(\bm{x},t)$ . Moreover,
$$
\inf_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J_{\text{BVS}}(\bm{y})\right\}=S(\bm{x},t)\ \text{for every $\bm{x}\in\mathbb{R}^{n}$.}
$$
Thus the prior $J_{\text{BVS}}$ recovers the function $x\mapsto S(\bm{x},t)$ , although in general $\text{prox}_{tJ}$ and $\text{prox}_{tJ_{\text{BVS}}}$ may not agree everywhere. Nonetheless, this provides a principled way to estimate the prior, at least when $S(\bm{x},t)$ is known.
We focus in this paper on the case when $\bm{x}\mapsto S(\bm{x},t)$ is unknown but have access to some samples $\{\bm{x}_{k},S(\bm{x}_{k},t),\nabla_{\bm{x}}S(\bm{x}_{k},t)\}_{k=1}^{K}$ with $t$ fixed. We propose to learn the prior $\bm{y}\mapsto J_{\text{BVS}}(\bm{y})$ by leveraging the crucial fact that $\bm{y}\mapsto J_{\text{BVS}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ is convex, thus enabling approaches based on deep learning and convex neural networks.
Related works: Hamilton–Jacobi PDEs are important to many scientific and engineering applications arising in e.g., optimal control [Bardi1997Optimal, fleming2006controlled, mceneaney2006max, parkinson2018optimal] and physics [Caratheodory1965CalculusI, Caratheodory1967CalculusII], inverse problems for imaging sciences [darbon2015convex, darbon2019decomposition, darbon2021bayesian, darbon2021connecting, darbon2022hamilton], optimal transport [meng2024primal, onken2021ot], game theory [BARRON1984213, Evans1984Differential, ruthotto2020machine], and machine learning [chen2024leveraging, zou2024leveraging]. Recent works focus on developing specialized solution methods for solving high-dimensional HJ PDEs, using, e.g., representation formulas or deep learning methods. These specialized methods leverage certain properties of HJ PDEs, including stochastic aspects and representation formulas [bardi1998hopf, mceneaney2006max, darbon2016algorithms, darbon2022hamilton], to approximate solutions to HJ PDEs more accurately and efficiently than general-purpose methods. See, e.g., [meng2022sympocnet, darbon2023neural, darbon2021some, darbon2020overcoming, park2025neural] for recent works along these lines and [meng2025recent] for a review of the state-of-the-art numerical methods for HJ PDEs.
Deep learning methods have become popular for computing solutions to high-dimensional PDEs as well as their inverse problems. They are popular because neural networks can be trained on data to approximate high-dimensional, nonlinear functions using efficient optimization algorithms. They have been used to approximate solutions to PDEs without any discretization with numerical grids, and for this reason they can overcome, or at least mitigate, the curse of dimensionality. There is a fairly comprehensive literature on deep learning methods for solving PDEs in general, e.g., see [beck2020overview, cuomo2022scientific, karniadakis2021physics].
Organization of this paper: We present background information on proximal operators, Hamilton–Jacobi equations, and convex neural networks in Section 2. Next, we discuss recent results concerning the inverse problem for Hamilton–Jacobi equations when the solution is available, and how they relate to proximal operators and learning priors in inverse problems, in Section 3. Our main theoretical results are presented in Section 4, where we study the inverse problem for Hamilton–Jacobi equations when only incomplete information is available about its solution. We suggest via arguments from max-plus algebra theory for Hamilton–Jacobi PDEs how to learn from data the solution to a certain Hamilton-Jacobi–Jacobi terminal value problem, which can then be used as an estimate for learning the prior function in a proximal operator. We present in Section 5 some numerical experiments for learning the initial data of certain Hamilton–Jacobi PDEs using convex neural networks and the theory of inverse Hamilton–Jacobi PDEs. Finally, we summarize our results in Section 6.
## 2 Background
We present here some background on proximal operators, HJ PDEs, connections between them, and convex neural networks. For comprehensive references, we refer the reader to [cannarsa2004semiconcave, evans2022partial, rockafellar2009variational].
### 2.1 Proximal operators
Let $J\colon\mathbb{R}^{n}\to\mathbb{R}\cup\{+\infty\}$ denote a proper function (i.e., $J(\bm{x})<+\infty$ for some $\bm{x}\in\mathbb{R}^{n}$ and $J(\bm{x})>-\infty$ for every $\bm{x}\in\mathbb{R}^{n}$ ). Consider the minimization problem $(\bm{x},t)\mapsto S(\bm{x},t)$ defined in Eq. 1 and its proximal operator $(\bm{x},t)\mapsto\text{prox}_{tJ}(\bm{x})$ defined in Eq. 2. We say a proper function $f_{t}\colon\mathbb{R}^{n}\to\mathbb{R}$ is a proximal operator of $tJ$ if $f_{t}(\bm{x})\in\text{prox}_{tJ}(\bm{x})$ for every $\bm{x}\in\mathbb{R}^{n}$ . Gribonval and Nikolova [gribonval2020characterization] proved that proximal operators are characterized in terms of the function $\psi\colon\mathbb{R}^{n}\times[0,+\infty)\to\mathbb{R}\cup\{+\infty\}$ defined by
$$
\psi(\bm{x},t)=\frac{1}{2}\left\|{\bm{x}}\right\|_{2}^{2}-tS(\bm{x},t). \tag{6}
$$
**Theorem 2.1**
*A proper function $f_{t}\colon\mathbb{R}^{n}\to\mathbb{R}^{n}$ is a proximal operator of $tJ$ if and only if $\bm{x}\mapsto\psi(\bm{x},t)$ is proper, lower semicontinuous, and convex and $f_{t}(\bm{x})\in\partial_{\bm{x}}\psi(\bm{x},t)$ . Moreover, $f_{t}$ is uniformly Lipschitz continuous with constant $L>0$ if and only if $\bm{x}\mapsto(1-1/L)\left\|{\bm{x}}\right\|_{2}^{2}/2+tJ(\bm{x})$ is proper, lower semicontinuous and convex.*
**Proof 2.2**
*See [gribonval2020characterization, Theorem 3 and Proposition 2]*
The characterization of proximal operators in Theorem 2.1 is closely related to the concepts of semiconcave and semiconvex functions.
**Definition 2.3**
*Let $\mathcal{C}\subset\mathbb{R}^{n}$ . We say $g\colon\mathcal{C}\to\mathbb{R}$ is $C$ -semiconcave with $C\geqslant 0$ if it is continuous and
$$
\lambda g(\bm{x}_{1})+(1-\lambda)g(\bm{x}_{2})-g(\lambda\bm{x}_{1}+(1-\lambda)\bm{x}_{2})\leqslant\lambda(1-\lambda)C\left\|{\bm{x}_{1}-\bm{x}_{2}}\right\|_{2}^{2}
$$
for every $\bm{x}_{1},\bm{x}_{2}\in\mathcal{C}$ such that $\lambda\bm{x}_{1}+(1-\lambda)\bm{x}_{2}\subset\mathcal{C}$ and $\lambda\in[0,1]$ . We say $g$ is semiconvex if $-g$ is semiconcave.*
**Remark 2.4**
*It can be shown [cannarsa2004semiconcave, Chapter 1] that a function $g$ is $C$ -semiconcave with $C\geqslant 0$ if and only if $\bm{x}\mapsto g(\bm{x})-\frac{C}{2}\left\|{\bm{x}}\right\|_{2}^{2}$ is concave, if and only if $g=g_{1}+g_{2}$ , where $g_{1}$ is concave and $g_{2}\in C^{2}(\mathbb{R}^{n})$ with $\left\|{\nabla_{\bm{x}}^{2}g_{2}}\right\|_{\infty}\leqslant C$ .*
Combining formula Eq. 6, Definition 2.3 and Remark 2.4, we find $\bm{x}\mapsto\psi(\bm{x},t)$ is convex if and only if $\bm{x}\mapsto tS(\bm{x},t)$ is semiconcave. We will see later that semiconcavity is an important concept in the theory of HJ PDEs for characterizing their generalized solutions. But before moving on to present some background on HJ PDEs, we give below an instructive example.
**Example 2.5 (The negative absolute value prior)**
*Let $J(x)=-|x|$ and consider the one-dimensional problem
$$
S(x,t)=\min_{y\in\mathbb{R}}\left\{\frac{1}{2t}(x-y)^{2}-|y|\right\}.
$$
A global minimum $y^{*}$ of this problem satisfies the first-order optimality condition
$$
0\in(y^{*}-x)/t-\partial|y^{*}|\iff y^{*}\in\begin{cases}x+t,&\ \text{if $y^{*}>0$,}\\
[x-t,x+t]&\ \text{if $y^{*}=0$},\\
x-t,&\ \text{if $y^{*}<0$.}\end{cases}
$$
If $x>t$ , the only minimum is $y^{*}=x+t$ . Likewise, if $x<-t$ , the only minimum is $y^{*}=x-t$ . In either cases, $S(x,t)=-x-\frac{t}{2}$ . If $0<x\leqslant t$ , there are two local minimums, $0$ and $x+t$ , but the global minimum is attained at $x+t$ and yields $S(x,t)=-\frac{t}{2}-x$ . Likewise, if $-t\leqslant x<0$ , there are two local minimums, $0$ and $x-t$ , but the global minimum is attained at $x-t$ and yields $S(x,t)=-\frac{t}{2}+x$ . Finally, if $x=0$ , there are three local minimums, $-t$ , $0$ , and $t$ . The global minimums are attained at $-t$ or $t$ , yielding $S(0,t)=-t/2$ . Hence we find
$$
S(x,t)=-\frac{t}{2}-|x|\quad\text{and}\quad\text{prox}_{tJ}(x)=\begin{cases}x+t,&\ \text{if $x>0$,}\\
\{-t,t\}&\ \text{if $x=0$},\\
x-t,&\ \text{if $x<0$.}\end{cases} \tag{7}
$$
Thus, a selection $f_{t}(x)\in\text{prox}_{tJ}(x)$ differs only at $x=0$ . In any case, the function $x\mapsto\psi(x,t)$ in Theorem 2.1 and its subdifferential $x\mapsto\partial_{x}\psi(x,t)$ are given by
$$
\psi(x,t)=\frac{1}{2}x^{2}-tS(x,t)=\frac{1}{2}x^{2}+t|x|+\frac{t^{2}}{2}\quad\text{and}\quad\partial_{x}\psi(x)=\begin{cases}x+t,\,&\text{if $x>0$},\\
[-t,t],\,&\text{if $x=0$},\\
x-t,\,&\text{if $x<0$}.\end{cases}
$$
We see that any selection $f_{t}(x)\in\text{prox}_{tJ}(x)$ satisfies $f(x)\in\partial\psi(x,t)$ .*
### 2.2 Hamilton–Jacobi Equations
In this section, we briefly review some elements of the theory of HJ PDEs, including the method of characteristics, viscosity solutions of HJ PDEs, and the Lax–Oleinik formula, and discuss how these concepts tie together to proximal operators. The discussion is not comprehensive; see [evans2022partial] and references therein for a more detailed treatment. To ease the presentation, we consider only the first-order HJ PDEs Eq. 3.
#### 2.2.1 Characteristic equations
The characteristic equations of Eq. 3 are given by the dynamical system
$$
\begin{cases}\dot{\bm{x}}(t)&=\bm{p}(t),\\
\dot{\bm{p}}(t)&=0,\\
\dot{\bm{z}}(t)&=\frac{1}{2}\left\|{\bm{p}(t)}\right\|_{2}^{2},\end{cases} \tag{8}
$$
where $\bm{z}(t)=S(\bm{x}(t),t)$ and $\bm{x}(0)=J(\bm{x}(0)$ . Here, $t\mapsto\bm{p}(t)$ is constant with $\bm{p}(t)\equiv\bm{p}(0)\in\mathbb{R}^{n}$ . The characteristic line that arises from $\bm{x}(0)\in\mathbb{R}^{n}$ is $\bm{x}(t)=\bm{x}(0)+t\bm{p}(0)$ , and so $\bm{z}(t)=\bm{z}(0)-\frac{1}{2}\left\|{\bm{p}(0)}\right\|_{2}^{2}$ . Taken together, we find
$$
S(\bm{x}(t),t)=J(\bm{x}(0))+\frac{1}{2}\left\|{\bm{p}(0)}\right\|_{2}^{2}. \tag{0}
$$
Writing $\bm{x}(t)\equiv\bm{x}$ and $\bm{p}(0)=\nabla_{\bm{x}}S(\bm{x},t)$ (assuming formally that the spatial gradient exists at $\bm{x}$ ) then $\bm{x}(0)=\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t)$ , and so we find the representation
$$
S(\bm{x},t)=\frac{1}{2t}\left\|{\nabla_{\bm{x}}S(\bm{x},t)}\right\|_{2}^{2}+J(\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t)). \tag{9}
$$
This gives an implicit representation between $S$ , its spatial gradient, and the initial data $J$ . Next, we turn to the explicit representation of solutions to Eq. 3.
#### 2.2.2 Viscosity solutions and the Lax–Oleinik formula
The initial value problem Eq. 3 (and HJ PDEs with general Hamiltonians) may not have a unique generalized solution, i.e., those satisfying the HJ PDE almost everywhere along with the initial condition $S(\bm{x},0)=J(\bm{x})$ .
**Example 2.6**
*Let $J\equiv 0$ in Eq. 3 and take $n=1$ . The corresponding HJ PDE has infinitely many solutions: For instance, the functions $S_{1}$ and $S_{2}$ given by
$$
S_{1}(x,t)=0,\quad S_{2}(x,t)=\begin{cases}0,\,&\text{if $|x|\geqslant t$},\\
x-t,\,&\text{if $0\leqslant x\leqslant t$},\\
-x-t,\,&\text{if $-t\leqslant x\leqslant 0$},\end{cases}
$$
satisfy $S_{1}(x,0)=S_{2}(x,0)=J(x)=0$ and both solve the corresponding HJ PDE almost everywhere.*
The notion of viscosity solution was introduced in [crandall1983viscosity] to solve this problem. Under appropriate conditions (see [bardi1998hopf, crandall1992user, crandall1983viscosity]), the viscosity solution is unique and admits a representation formula. Specifically, for the initial value problem Eq. 3 with uniformly Lipschitz continuous initial data $J$ , the unique viscosity solution is given by the Lax–Oleinik formula (with quadratic Hamiltonian)
$$
S(\bm{x},t)=\inf_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J(\bm{y})\right\}. \tag{10}
$$
The (unique) viscosity solution has two important properties. First, the function $\bm{x}\mapsto S(\bm{x},t)$ is (1/t)-semiconcave. This is equivalent to requiring the function $\bm{x}\mapsto\psi(\bm{x},t)$ defined in Eq. 6 to be convex, exactly as stipulated in Theorem 2.1. Second, at any point of differentiability of $\bm{x}\mapsto S(\bm{x},t)$ , there holds
$$
\nabla_{\bm{x}}S(\bm{x},t)=\frac{\bm{x}-f_{t}(\bm{x})}{t}\iff f_{t}(\bm{x})=\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t), \tag{11}
$$
where $f_{t}(\bm{x})$ denote a global minimum in Eq. 10. Note that substituting this expression in formula Eq. 9 obtained from the characteristic equations yields Eq. 10, as expected.
**Example 2.7 (The negative absolute value prior, continued.)**
*Let $J(x)=-|x|$ in the (one-dimensional) first-order HJ PDE Eq. 3. The function $J$ is uniformly Lipschitz continuous and, as such, the Lax–Oleinik formula $S(x,t)=-\frac{t}{2}-|x|$ is the unique viscosity solution of the corresponding HJ PDE. Note $\bm{x}\mapsto S(\bm{x},t)$ is differentiable everywhere except at $\bm{x}=0$ and $\text{prox}_{tJ}(\bm{x})=\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t)$ everywhere except at $\bm{x}=0$ (see (7)).*
In summary, a proper function $f_{t}$ is a proximal operator of $tJ$ whenever the function $(\bm{x},t)\mapsto S(\bm{x},t)$ is the viscosity solution of the HJ initial value problem Eq. 3. The minimization problem underlying $\text{prox}_{tJ}(\bm{x})$ is exactly the Lax–Oleinik representation formula of the viscosity solution of Eq. 3. We will see in the next section how to leverage these connections for learning the prior when $\bm{x}\mapsto J(\bm{x})$ is not available but $(\bm{x},t)\mapsto S(\bm{x},t)$ is available. But before proceeding, we briefly review convex neural networks, which will be used later in this work.
### 2.3 Convex neural networks
Convex Neural Networks, specifically Input Convex Neural Networks (ICNN), were introduced by [amos2017input] to allow for the efficient optimization of neural networks within structured prediction and reinforcement learning tasks. The core premise of an ICNN is to constrain the network architecture such that the output is a convex function with respect to the input.
To achieve convexity, the network typically employs a recursive structure for $k=0,\dots,j-1$
$$
\bm{z}_{k+1}=g(\bm{W}_{k}\bm{z}_{k}+\bm{H}_{k}y+\bm{b}_{k}),f(\bm{y};\theta)=\bm{z}_{j}, \tag{12}
$$
where $\bm{y}$ , $\bm{z}_{k}$ represent the input to the network and the hidden features at layer $k$ , respectively, and $g$ is the activation function. To guarantee the convexity of the output with respect to the input $\bm{y}$ , specific constraints are imposed on the parameters and the activation function, which are (i) the weights $\bm{W}_{k}$ , which connect the previous hidden layer to the current one, must be non-negative ( $\bm{W}_{k}\geqslant 0$ ), and (ii) the activation function $g$ must be convex and non-decreasing [fang2024whats].
Following [fang2024whats, Proposition 3.1], Fang et al. leverage the ICNN architecture and the characterization of proximal operators to develop Learned Proximal Networks (LPN) for inverse problems. LPNs require stricter conditions than standard ICNNs. While standard ICNNs often use ReLU activation, LPNs require the activation function $g$ to be twice continuously differentiable. This smoothness is essential to ensure that the proximal operator is the gradient of a twice continuous differentiable function [gribonval2020characterization, Theorem 2]. Consequently, LPNs typically utilize smooth activations like the softplus function, a $\beta-$ smooth approximation of ReLU [fang2024whats, Section 3].
## 3 Connections between learning priors and the inverse problem for Hamilton–Jacobi Equations
In this section, we discuss the inverse problem of learning the prior in the proximal operator Eq. 2: given $t>0$ and some function $\bm{x}\mapsto S(\bm{x},t)$ , assess whether there exists a a prior function $J$ that can recover $\bm{x}\mapsto S(\bm{x},t)$ and, if so, estimate it. Due to the connections between proximal operators and HJ Equations, as discussed in Subsections 2.1 – 2.2, our starting point will be to discuss the inverse problem from the point of view of HJ Equations.
We summarize in the next subsection some of the main results for this problem, based on the results of [esteve2020inverse] and other related works [claudel2011convex, colombo2020initial, misztela2020initial].
### 3.1 Reachability and inverse problems for Hamilton–Jacobi equations
We consider here the inverse problem associated to the HJ initial value problem Eq. 3: given $t>0$ and a function $(\bm{x},t)\mapsto S(\bm{x},t)$ , identify the set of initial data $J\colon\mathbb{R}^{n}\ \to\mathbb{R}$ such that the viscosity solution of Eq. 3 coincide with $S(\bm{x},t)$ . That is, we wish to characterize the set
$$
\displaystyle I_{t}(S) \displaystyle\coloneqq\{\text{$J\colon\mathbb{R}^{n}\to\mathbb{R}$ is uniformly Lipschitz continuous} \displaystyle\qquad\qquad:\text{$S(\bm{x},t)$ is obtained from~\eqref{eqn:intro2} at time $t$}\}. \tag{13}
$$
We say the function $(\bm{x},t)\mapsto S(\bm{x},t)$ is reachable if the set $I_{t}(S)$ is nonempty. The main reachability result for the initial value problem Eq. 3 is the following:
**Theorem 3.1**
*Suppose $\bm{x}\mapsto S(\bm{x},t)$ is uniformly Lipschitz continuous. Then the set $I_{t}(S)$ defined in Eq. 13 is nonempty if and only if $\bm{x}\mapsto tS(\bm{x},t)$ is semiconcave.*
**Proof 3.2**
*This follows from [esteve2020inverse, Theorem 2.2, Theorem 6.1, and Definition 6.2].*
Now, assume $(\bm{x},t)\mapsto S(\bm{x},t)$ is reachable. What can be said about the nonempty set $I_{t}(S)$ ? Since $(\bm{x},t)\mapsto S(\bm{x},t)$ is obtained from evolving forward in time the prior function $J$ from $0$ to $t$ according to Eq. 3, a natural approach is to do the opposite: evolve backward in time from $t$ to $0$ the function $\bm{x}\mapsto S(\bm{x},t)$ . That is, we consider the terminal value problem
$$
\begin{dcases}\frac{\partial\bm{w}}{\partial\tau}(\bm{y},\tau)+\frac{1}{2}\left\|{\nabla_{\bm{y}}\bm{w}(\bm{y},\tau)}\right\|_{2}^{2}=0&\ (\bm{y},\tau)\in\mathbb{R}^{n}\times[0,t),\\
\bm{w}(\bm{y},t)=S(\bm{y},t),&\ \bm{y}\in\mathbb{R}^{n}.\end{dcases} \tag{14}
$$
Under appropriate conditions, the terminal-value problem Eq. 14 has a unique viscosity solution:
**Theorem 3.3**
*Suppose $\bm{x}\mapsto S(\bm{x},t)$ is uniformly Lipschitz continuous and semiconcave. Then the viscosity solution of the terminal-value problem Eq. 14 exists, is unique, and is given by the representation formula
$$
\bm{w}(\bm{y},\tau)=\sup_{\bm{x}\in\mathbb{R}^{n}}\left\{S(\bm{x},t)-\frac{1}{2\tau}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}\right\}. \tag{15}
$$
Moreover, the function $\bm{y}\mapsto\tau\bm{w}(\bm{y},\tau)$ is semiconvex with unit constant.*
**Proof 3.4**
*See [barron1999regularity, Section 4, Equation 4.4.2] and [cannarsa2004semiconcave, Chapter 1].*
The viscosity solution of (14) is sometimes called the backward viscosity solution (BVS) to distinguish it from the viscosity solution of the initial value problem Eq. 3. The BVS at $\tau=0$ corresponds to fully evolving backward in time the function $\bm{x}\mapsto S(\bm{x},t)$ . In what follows, we write $J_{\text{BVS}}\coloneqq\bm{w}(\cdot,0)$ . We can use Eq. 6 to write
$$
tJ_{\text{BVS}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}=\sup_{\bm{x}\in\mathbb{R}^{n}}\left\{\langle\bm{x},\bm{y}\rangle-\psi(\bm{x},t)\right\}. \tag{16}
$$
The right hand side is the convex conjugate of $\bm{x}\mapsto\psi(\bm{x},t)$ evaluated at $\bm{x}$ , which is well-defined because $\bm{x}\mapsto\psi(\bm{x},t)$ is proper, lower semicontinuous and convex.
Theorem 3.3 suggests that $J_{\text{BVS}}$ is an initial condition that can reach $\bm{x}\mapsto S(\bm{x},t)$ . The next result stipulates that this is correct and that it is “optimal”, in the sense that it bounds from below for any other reachable initial condition $J\in I_{t}(S)$ .
**Theorem 3.5**
*Let $J_{\text{BVS}}$ denote the solution of the backward HJ terminal value problem 14 at time $\tau=0$ . Then $J\in I_{t}(S)$ if and only if
$$
J(\bm{y})\geqslant J_{\text{BVS}}(\bm{y})\ \text{for every $\bm{y}\in\mathbb{R}^{n}$, with equality for every $\bm{y}\in X_{t}(S)$, where}
$$
$$
X_{t}(S)\coloneqq\left\{\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t):\text{$\bm{x}\mapsto S(\bm{x},t)$ is differentiable at $\bm{x}\in\mathbb{R}^{n}$}\right\}.
$$*
**Proof 3.6**
*See [esteve2020inverse, Theorems 2.3 and 2.4].*
Theorem 3.5 stipulates that $J_{\text{BVS}}$ is equal everywhere to $J$ on the set $\mathcal{X}_{t}(S)$ and bounds it from below elsewhere. This is a fundamental consequence of the semiconcavity of $\bm{x}\mapsto S(\bm{x},t)$ , which regularizes the backward viscosity solution of Eq. 14. We illustrate this below with the negative absolute value prior.
**Example 3.7 (The negative absolute value prior, continued.)**
*Let $J(x)=-|x|$ in the (one-dimensional) first-order HJ PDE Eq. 3. Recall that the unique viscosity solution is given by the Lax–Oleinik formula $S(x,t)=-\frac{t}{2}-|x|$ . We now would like to compute the corresponding unique backward viscosity solution to the terminal-value problem Eq. 14. The solution is well-defined because $\bm{x}\mapsto S(\bm{x},t)$ is uniformly Lipschitz continuous and concave. We have
$$
J_{\text{BVS}}(x)=\sup_{\bm{y}\in\mathbb{R}}\left\{-\frac{t}{2}-|y|-\frac{1}{2t}(x-y)^{2}\right\}=-\frac{t}{2}-\inf_{\bm{y}\in\mathbb{R}}\left\{\frac{1}{2t}(x-y)^{2}+|y|\right\}.
$$
The infimum on the right hand side corresponds to the proximal operator of the function $\bm{y}\mapsto|y|$ , which is the soft-thresholding operator:
$$
\operatorname*{arg\,min}_{y\in\mathbb{R}}\left\{\frac{1}{2t}(x-y)^{2}+|y|\right\}=\begin{cases}x-t,\,&\text{if $x>t$},\\
0,\,&\text{if $x\in[-t,t]$},\\
x+t,\,&\text{if $x<-t$}.\end{cases}
$$
This gives
$$
J_{\text{BVS}}(x)=\begin{cases}-x,\,&\text{if $x>t$},\\
-\frac{t}{2}-\frac{x^{2}}{2t},\,&\text{if $x\in[-t,t]$},\\
x,\,&\text{if $x<-t$}.\end{cases}
$$
Here, a simple calculation shows $\mathcal{X}_{t}(S)=(-\infty,-t]\cup[t,+\infty)$ , and we find $J(x)>J_{\text{BVS}}(x)$ on $(-t,t)$ , as expected from Theorem 3.5. Moreover,
$$
tJ_{\text{BVS}}(x)+\frac{1}{2}x^{2}=\begin{cases}\frac{1}{2}(x-t)^{2}-\frac{t^{2}}{2},\,&\text{if $x>t$},\\
-\frac{t^{2}}{2},\,&\text{if $x\in[-t,t]$},\\
\frac{1}{2}(x+t)^{2}-\frac{t^{2}}{2},\,&\text{if $x<-t$},\end{cases}
$$
and we observe $x\mapsto tJ_{\text{BVS}}(x)+\frac{1}{2}x^{2}$ is convex, as expected from Theorem 3.3.*
The results here apply when the function $\bm{x}\mapsto S(\bm{x},t)$ is known. What happens when only a finite set of values of this function are available?
## 4 Learning priors and the inverse problem for Hamilton–Jacobi Equations with incomplete information
In this section, we consider the inverse problem of learning the prior in the proximal operator Eq. 2 with incomplete information: given $t>0$ and a set of samples $\{\bm{x}_{k},S(\bm{x}_{k},t),\nabla_{\bm{x}}S(\bm{x}_{k},t)\}_{k=1}^{K}$ , estimate the prior $J$ that best recovers $\bm{x}\mapsto S(\bm{x},t)$ . Recall from Theorem 3.1 that when $\bm{x}\mapsto S(\bm{x},t)$ is uniformly Lipschitz continuous, $\bm{x}\mapsto S(\bm{x},t)$ is reachable if and only if it is semiconcave. In this case, the prior $\bm{x}\mapsto J_{\text{BVS}}(\bm{x})$ obtained from the HJ terminal value problem Eq. 14 provides a prior function that recovers $(\bm{x},t)\mapsto S(\bm{x},t)$ exactly. Hence we will focus on studying how to approximate the prior $J_{\text{BVS}}$ from a set of samples.
Note that if the triplet $(\bm{x}_{k},S(\bm{x}_{k},t),\nabla_{\bm{x}}S(\bm{x}_{k},t))$ is known, then (i) the function is $\bm{x}\mapsto S(\bm{x},t)$ is differentiable at $\bm{x}$ and (ii) the unique minimum in the Lax–Oleinik formula Eq. 10 can be represented via Eq. 11:
$$
S(\bm{x}_{k},t)=\frac{1}{2t}\left\|{\bm{x}_{k}-\bm{y}_{k}}\right\|_{2}^{2}+J(\bm{y}_{k}),\,\text{with}\ \bm{y}_{k}=\bm{x}_{k}-t\nabla_{\bm{x}}S(\bm{x}_{k},t). \tag{17}
$$
Moreover, Theorem 3.5 and formula Eq. 6 imply $J(\bm{y}_{k})=J_{\text{BVS}}(\bm{y}_{k})$ , $\bm{y}\mapsto J_{\text{BVS}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ is convex. Thus one possible approach for estimating $J_{\text{BVS}}$ is to approximate $\bm{y}\mapsto J_{\text{BVS}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ piecewise from below at the points $\left\{\bm{y}_{k}\right\}_{k=1}^{K}$ .
We consider the problem of approximating $J_{\text{BVS}}$ piecewise from below and its implications in Section 4.1. This approximation problem turns out to be related closely to max-plus algebra theory for approximating solutions to HJ PDEs [akian2006max, fleming2000max, gaubert2011curse]; we discuss this in Section 4.2. We then consider in Section 4.3 the more general problem of learning a convex function to approximate $\bm{y}\mapsto J_{\text{BVS}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ directly, applying the discussions in Section 4.1 - Section 4.2.
### 4.1 Piecewise approximations
We consider here piecewise approximations of the prior $\bm{y}\mapsto J_{\text{BVS}}(\bm{y})$ using the samples $\{\bm{x}_{k},S(\bm{x}_{k},t),\nabla_{\bm{x}}S(\bm{x}_{k},t)\}_{k=1}^{K}$ and formula Eq. 17. We consider first using a piecewise affine minorant (PAM) approximation, and then, assuming some regularity on $J_{\text{BVS}}$ , using a piecewise quadratic minorant (PQM) approximation.
#### 4.1.1 Piecewise affine approximation
We first consider the PAM approximation of the convex function $\bm{y}\mapsto tJ_{\text{BVS}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ ”
$$
tJ_{\text{PAM}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}\coloneqq\max_{k\in\{1,\dots,K\}}\left\{tJ_{\text{BVS}}(\bm{y}_{k})+\frac{1}{2}\left\|{\bm{y}_{k}}\right\|_{2}^{2}+\left\langle\bm{x}_{k},\bm{y}-\bm{y}_{k}\right\rangle\right\}. \tag{18}
$$
Then $J_{\text{PAM}}(\bm{y})\leqslant J_{\text{BVS}}(\bm{y})$ for every $\bm{y}\in\mathbb{R}^{n}$ , with $J_{\text{PAM}}(\bm{y}_{k})=J_{\text{BVS}}(\bm{y}_{k})$ at each $k\in\{1\,\dots,K\}$ . A short calculation gives
$$
tJ_{\text{PAM}}(\bm{y})=\max_{k\in\{1,\dots,K\}}\left\{tJ_{\text{BVS}}(\bm{y}_{k})+\frac{1}{2}\left\|{\bm{x}_{k}-\bm{y}_{k}}\right\|_{2}^{2}-\frac{1}{2}\left\|{\bm{x}_{k}-\bm{y}}\right\|_{2}^{2}\right\}.
$$
How good is $J_{\text{PAM}}$ as initial condition for the HJ PDE Eq. 3? In light of Theorem 3.5, $J_{\text{PAM}}$ , unsurprisingly, cannot reconstruct $\bm{x}\mapsto S(\bm{x},t)$ . Indeed, a formal calculation yields
$$
\inf_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J_{\text{PAM}}(\bm{y})\right\}=\begin{cases}S(\bm{x}_{k},t)&\ \text{if $\bm{x}=\bm{x}_{k}$, $k\in\{1,\dots,K\}$},\\
+\infty,&\ \text{otherwise}.\end{cases} \tag{19}
$$
See Section A.1 for details. Thus approximating $J_{\text{BVS}}$ via its PAM approximation recovers the samples $\{S(\bm{x}_{k},t)\}_{k=1}^{K}$ but nothing else.
#### 4.1.2 Piecewise quadratic approximation
Here, we assume $\bm{y}\mapsto tJ_{\text{BVS}}(\bm{y})$ is semiconvex with constant $1-\alpha$ with $\alpha>0$ , so that $\bm{y}\mapsto tJ_{\text{BVS}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ is $1-\alpha$ strongly convex. We can then approximate this strongly convex function via its PQMs:
| | $\displaystyle tJ_{\text{PQM}}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ | $\displaystyle\coloneqq\max_{k\in\{1,\dots,K\}}\biggl\{tJ_{\text{BVS}}(\bm{y}_{k})+$ | |
| --- | --- | --- | --- |
Then, $J_{\text{PQM}}(\bm{y})\leqslant J_{\text{BVS}}(\bm{y})$ for every $\bm{y}\in\mathbb{R}^{n}$ , with $J_{\text{PQM}}(\bm{y})=J_{\text{BVS}}(\bm{y}_{k})$ at each $k\in\{1,\dots,K\}$ . Moreover, a short calculation gives
$$
tJ_{\text{PQM}}(\bm{y})=\max_{k\in\{1,\dots,K\}}\left\{J(\bm{y}_{k})+\frac{1}{2}\left\|{\bm{x}_{k}-\bm{y}_{k}}\right\|_{2}^{2}-\frac{1}{2}\left\|{\bm{x}_{k}-\bm{y}}\right\|_{2}^{2}+\frac{\alpha}{2}\left\|{\bm{y}-\bm{y}_{k}}\right\|_{2}^{2}\right\}. \tag{20}
$$
How good is $J_{\text{PQM}}$ as an initial condition for the HJ PDE Eq. 3? Again, in light of Theorem 3.5, $J_{\text{PQM}}$ cannot reconstruct $\bm{x}\mapsto S(\bm{x},t)$ . Nonetheless, a formal calculation yields
$$
\inf_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J_{\text{PQM}}(\bm{y})\right\}=\frac{1}{2t}\left\|{\bm{x}-\bm{y}_{k}}\right\|_{2}^{2}+\frac{1}{2t\alpha}\left\|{\bm{x}-\bm{x}_{k}}\right\|_{2}^{2} \tag{21}
$$
for some $k\in\{1,\dots,K\}$ . See Section A.2 for more details. Hence $J_{\text{PQM}}$ leads to an approximation of $(\bm{x},t)\mapsto S(\bm{x},t)$ that is finite everywhere. In the next section, we describe how max-plus algebra theory [akian2006max, fleming2000max, gaubert2011curse] can be used to quantify the approximation errors more precisely.
### 4.2 Max-plus algebra theory for Hamilton–Jacobi PDEs and approximation results
We consider here max-plus algebra techniques for approximating solutions to certain HJ PDEs. Let $\alpha>0$ and let $\Psi\colon\mathbb{R}^{n}\to\mathbb{R}$ denote a $(1-\alpha)$ -semiconvex function obtained. Following [gaubert2011curse, Section III], we approximate $\Psi$ using $K$ vectors $\{\bm{p}_{k}\}_{k=1}^{K}\subset\mathbb{R}^{n}$ with $K$ semiconvex functions $\bm{y}\mapsto\langle\bm{p}_{k},\bm{y}\rangle-\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ and a function $a\colon\mathbb{R}^{n}\to\mathbb{R}\cup\{+\infty\}$ :
$$
\Psi_{\text{MP}}(\bm{y})\coloneqq\max_{k\in\{1,\dots,K\}}\left\{\langle\bm{p}_{k},\bm{y}\rangle-\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}-a(\bm{p}_{k})\right\}. \tag{22}
$$
Here, we suppose the vectors $\{\bm{p}_{k}\}_{k=1}^{K}$ and $\bm{p}\mapsto a(\bm{p})$ are selected so that $\Psi_{\text{MP}}(\bm{y})\leqslant\Psi(\bm{y})$ . As discussed in Section 4.1, such a selection is possible via the affine piecewise quadratic minorants of the $(1-\alpha)$ -strongly convex function $\bm{y}\mapsto\Psi(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ . Let $\mathcal{Y}$ denote a full dimensional compact, convex subset of $\mathbb{R}^{n}$ and consider the $L_{\infty}$ error
$$
\epsilon_{\infty}(\Psi,K,\mathcal{Y},\Psi_{\text{MP}})\coloneqq\sup_{\bm{y}\in\mathcal{Y}}|\Psi(\bm{y})-\Psi_{\text{MP}}(\bm{y})|.
$$
Furthermore, we define the corresponding minimal $L_{\infty}$ error as
$$
\delta_{\infty}(\Psi,K,\mathcal{Y})=\inf_{\Psi_{\text{MP}}\leqslant\Psi}\epsilon_{\infty}(\Psi,K,\mathcal{Y},\Psi_{\text{MP}}).
$$
The following result from max-plus algebra theory, proven in [gaubert2011curse], stipulates that whatever vectors $\{\bm{p}_{k}\}_{k=1}^{K}$ and function $\bm{p}\mapsto a(\bm{p})$ are used to approximate $\Psi$ , the minimal $L_{\infty}$ error scales as an inverse power law in $K$ and the dimension $n$ in the limit $K\to+\infty$ .
**Theorem 4.1 (Gaubert et al. (2011))**
*Let $\alpha>0$ , and let $\mathcal{Y}$ denote a full-dimensional compact, convex subset of $\mathbb{R}^{n}$ . If $\Psi\colon\mathbb{R}^{n}\to\mathbb{R}$ is twice continuously differentiable and $1-\alpha$ semiconvex, then there exists a constant $\beta(n)>0$ depending only on $n$ such that
$$
\delta_{\infty}(\Psi,K,\mathcal{Y})\sim\beta(n)\left(\frac{1}{K}\int_{\mathcal{Y}}(\det\left(\nabla_{\bm{y}}^{2}\Psi(\bm{y})+\bm{I}_{n\times n})\right)^{\frac{1}{2}}\mathop{}\!d\bm{y}\right)^{2/n} \tag{23}
$$
as $K\to+\infty$ .*
Thus the minimal $L_{\infty}$ error is $\Omega(1/K^{2/n})$ as $K\to+\infty$ , though the error is smaller the closer the Hessian matrix $\nabla_{\bm{y}}^{2}\Psi(\bm{y})$ is to the identity matrix $\bm{I}_{n\times n}$ .
### 4.3 Applications to the inverse problem for Hamilton–Jacobi Equations
We consider here the problem of quantifying approximations of the prior function $\bm{y}\mapsto J_{\text{BVS}}(\bm{y})$ when the latter is sufficiently regularized and when we have access to the values $\{\bm{x}_{k},S(\bm{x}_{k},t),\nabla_{\bm{x}}S(\bm{x}_{k},t)\}_{k=1}^{K}$ . Max-plus algebra theory provides us with a first approximation result:
**Corollary 4.2**
*Let $t>0$ and assume $tJ_{\text{BVS}}$ is twice continuously differentiable and $(1-\alpha)$ -semiconvex with $\alpha>0$ . Let $\mathcal{Y}$ denote a full-dimensional compact, convex set of $\mathbb{R}^{n}$ . Then there exists a constant $\beta(n)$ depending only on $n$ such that
$$
\delta_{\infty}(tJ_{\text{BVS}},K,\mathcal{Y})\sim\beta(n)\left(\frac{1}{K}\int_{\mathcal{Y}}\det\left(t\nabla_{\bm{y}}^{2}J_{\text{BVS}}(\bm{y})+\bm{I}_{n\times n}\right)^{\frac{1}{2}}\mathop{}\!d\bm{y}\right)^{2/n} \tag{24}
$$
as $K\to+\infty$ .*
**Proof 4.3**
*Immediate from Theorem 4.1 because $J_{\text{BVS}}$ satisfies all its assumptions.*
Corollary 4.2 provides a lower bound for the approximation error of $J_{\text{BVS}}$ relative to $J_{\text{PQM}}$ . Indeed, Theorem 4.1 and Corollary 4.2 and the fact that $J_{\text{PQM}}(\bm{y})\leqslant J_{\text{BVS}}(\bm{y})$ for every $\bm{y}\in\mathbb{R}^{n}$ imply
$$
\delta_{\infty}(tJ_{\text{BVS}},K,\mathcal{Y})\leqslant t\sup_{\bm{y}\in\mathcal{Y}}|J_{\text{BVS}}(\bm{y})-J_{\text{PQM}}(\bm{y})|. \tag{25}
$$
Thus in this case $J_{\text{PQM}}$ approximates $J_{\text{BVS}}$ from below in $\Omega(1/K^{n/2})$ as $K\to+\infty$ . We show below a similar upper bound holds using any reachable function $\tilde{J}\in I_{t}(S)$ .
**Theorem 4.4**
*Let $t>0$ and assume $tJ_{\text{BVS}}$ is twice continuously differentiable and $(1-\alpha)$ -semiconvex with $\alpha>0$ . Let $\mathcal{Y}$ denote a full-dimensional compact, convex set of $\mathbb{R}^{n}$ and let $\tilde{J}\in I_{t}(S)$ denote a function that can can reach $\bm{x}\mapsto S(\bm{x},t)$ . Then
$$
\delta_{\infty}(J_{\text{BVS}},K,\mathcal{Y})\leqslant t\sup_{\bm{y}\in\mathcal{Y}}|\tilde{J}(\bm{y})-J_{\text{PQM}}(\bm{y})|. \tag{26}
$$*
**Proof 4.5**
*First, note Theorem 3.5 implies $\tilde{J}(\bm{y})\geqslant J_{\text{BVS}}(\bm{y})$ for every $\bm{y}\in\mathbb{R}^{n}$ , with equality for every $\bm{y}\in\mathbb{R}^{n}$ for which $\bm{y}=\bm{x}-t\nabla_{\bm{x}}S(\bm{x},t)$ for some $\bm{x}\in\mathbb{R}^{n}$ . Thus
$$
t\tilde{J}(\bm{y})-tJ_{\text{BVS}}(\bm{y})=(t\tilde{J}(\bm{y})-tJ_{\text{PQM}}(\bm{y}))+(tJ_{\text{PQM}}(\bm{y})-tJ_{\text{BVS}}(\bm{y}))\geqslant 0,
$$
which we rearrange to get
$$
tJ_{\text{BVS}}(\bm{y})-tJ_{\text{PQM}}(\bm{y})\leqslant t\tilde{J}(\bm{y})-tJ_{\text{PQM}}(\bm{y}).
$$
Since the set $\mathcal{Y}$ is a compact and convex set, $\sup_{\bm{y}\in\mathcal{Y}}|tJ_{\text{BVS}}(\bm{y})-tJ_{\text{PQM}}(\bm{y})|$ is finite and attained in $\mathcal{Y}$ , say at $\bm{y}^{*}$ . Combining this with the inequality above yields
$$
t\sup_{\bm{y}\in\mathcal{Y}}|J_{\text{BVS}}(\bm{y})-J_{\text{PQM}}(\bm{y})|\leqslant t\tilde{J}(\bm{y}^{*})-tJ_{\text{PQM}}(\bm{y}^{*})\leqslant t\sup_{\bm{y}\in\mathcal{Y}}|\tilde{J}(\bm{y})-J_{\text{PQM}}(\bm{y})|.
$$
Finally, since $J_{\text{BVS}}$ is twice continuously differentiable and $(1-\alpha)$ semiconvex with $\alpha>0$ , we can invoke Theorem 4.1 with $\Psi\equiv J_{\text{BVS}}$ to get
$$
\delta_{\infty}(J_{\text{BVS}},K,\mathcal{Y})\leqslant t\sup_{\bm{y}\in\mathcal{Y}}|\tilde{J}(\bm{y})-J_{\text{PQM}}(\bm{y})|,
$$
that is, inequality Eq. 26 holds. This concludes the proof.*
Theorem 4.4 suggests it is possible to learn $J_{\text{BVS}}$ via a function $\tilde{J}$ that is twice continuously differentiable and (1- $\alpha$ )-semiconvex and assess the approximation error using the right-hand-side Eq. 26 as a proxy, in particular by driving $\sup_{\bm{y}\in\mathcal{Y}}|\tilde{J}(\bm{y})-J_{\text{PQM}}(\bm{y})|$ to zero using sufficiently large enough data by training $\tilde{J}(\bm{y})$ appropriately.
In the next section, we consider the problem of learning this function using deep neural networks, specifically learned proximal networks [fang2024whats], to enforce the semiconvexity property required for $\tilde{J}$ .
## 5 Numerical results
We evaluate Learned Proximal Networks (LPNs) for approximating the proximal operators of nonconvex and concave priors. While LPNs [fang2024whats] are theoretically grounded in convex analysis (parameterizing the proximal operator as the gradient of a convex potential $\psi$ ), these experiments investigate their behavior when trained on data generated from fundamentally nonconvex and concave landscapes. All experiments utilize the official LPN implementation. The network is trained via supervised learning, minimizing the mean squared error (MSE) or L1 loss between the network output and the true value. We use an LPN with $2$ layers and $256$ hidden units using Softplus activation ( $\beta=5$ ) to ensure $C^{2}$ smoothness. The model is trained using the Adam optimizer with a starting learning rate of $10^{-3}$ and decreased by a factor of $10^{-1}$ at every $10^{5}$ epochs for a total of $5\times 10^{5}$ epochs.
The data generation process for all experiments is as follows: $N$ samples ( $y_{i}$ ) are drawn uniformly from the hypercube $[-a,a]^{d}$ , where $a$ is chosen to be $4$ and $d$ is the dimension, equal $2,4,8,16,32$ and $64$ . $N=3\times 10^{4}$ is chosen for $d=2,4$ , $N=3\times 10^{4}$ is chosen for $d=8,16$ , and $N=4\times 10^{4}$ is chosen for $d=32,64$ .
We also trained a second LPN to recover the prior at arbitrary points and compare its performance to the “invert” method (find $y$ such that $f_{\theta}(y)=x$ ) used in [fang2024whats] for recovering the prior from its proximal. Our second LPN is based on the relationship that the non-convex prior $J(x)$ can be approximated using the convex conjugate of the learned potential $\psi(y)$ . Specifically, we compute:
$$
J(x)\approx G(x)-\frac{1}{2}\|x\|^{2} \tag{27}
$$
where $G(x)=\psi^{*}(x)$ represents the convex conjugate of the potential $\psi_{\theta}(y)$ learned by the first LPN. We generate a new dataset $\{(x_{k},G_{k})\}$ using the trained first LPN $\psi_{\theta}$ : (i) The gradients of the first network evaluated at the original sample points $y_{i}$ ,
$$
x_{k}=\nabla_{y}\psi_{\theta}(y_{i}), \tag{28}
$$
and (ii) the values of the Legendre transform corresponding to each point,
$$
G_{k}=\langle x_{k},y_{i}\rangle-\psi_{\theta}(y_{i}). \tag{29}
$$
The network $\phi_{G}$ is trained to map the gradients $x_{k}$ to the conjugate values $G_{k}$ by minimizing the Mean Squared Error (MSE). The optimization is performed using the Adam optimizer with the same parameters as used in the first LPN. Once the second LPN is trained, the estimated non-convex prior $\hat{J}(x)$ is recovered via
$$
\hat{J}(x)=\phi_{G}(x)-\frac{1}{2}\|x\|^{2}. \tag{30}
$$
### 5.1 Convex prior
We will benchmark our approach with the prior $J(\bm{x})=\left\|{\bm{x}}\right\|_{1}$ . For this example, we have
| | $\displaystyle\operatorname*{arg\,min}_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+\left\|{\bm{y}}\right\|_{1}\right\}$ | $\displaystyle=\cup_{j=1}^{n}\operatorname*{arg\,min}_{y_{j}\in\mathbb{R}}\left\{\frac{1}{2t}(x_{j}-y_{j})^{2}+|y_{j}|\right\}$ | |
| --- | --- | --- | --- |
With this, we can evaluate $S(\bm{x},t)$ and the LPN function $\bm{x}\mapsto\Psi(\bm{x})\coloneqq\frac{1}{2}-tS(\bm{x},t)$ .
Table 1: Mean square errors of LPN $\psi$ and prior $J$ with 2 layers and 256 neurons in the convex L1 prior example.
| | Dimension | LPN ( $\psi$ ) | Prior ( $J$ ) |
| --- | --- | --- | --- |
| Mean Square Errors | 2D | $1.04E-5$ | $3.33E-5$ |
| 4D | $2.97E-5$ | $2.17E-4$ | |
| 8D | $1.05E-4$ | $7.25E-4$ | |
| 16D | $5.27E-3$ | $2.11E-3$ | |
| 32D | $1.6E-1$ | $4.03E-2$ | |
| 64D | $2.89E-6$ | $2.69E-3$ | |
<details>
<summary>exp_L1_prior_8D_LPN.png Details</summary>
### Visual Description
## [Chart Type]: Dual Cross-Section Line Plots of a Convex Function
### Overview
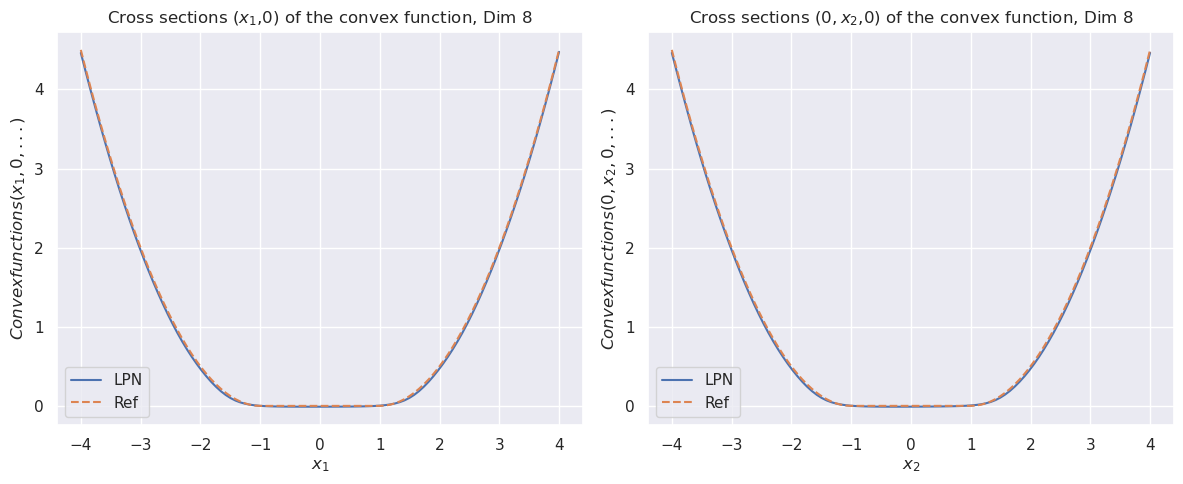
The image displays two side-by-side line charts, each showing a cross-sectional slice of an 8-dimensional convex function. Both plots compare two data series: "LPN" (solid blue line) and "Ref" (dashed orange line). The curves in both plots are nearly identical, forming symmetric, U-shaped parabolas centered at zero, indicating the function's convex nature along the plotted dimensions.
### Components/Axes
**Left Plot:**
* **Title:** `Cross sections (x₁,0) of the convex function, Dim 8`
* **Y-axis Label:** `Convexfunctions(x₁, 0, ...)`
* **X-axis Label:** `x₁`
* **X-axis Range:** -4 to 4, with major tick marks at intervals of 1 (-4, -3, -2, -1, 0, 1, 2, 3, 4).
* **Y-axis Range:** 0 to 4, with major tick marks at intervals of 1 (0, 1, 2, 3, 4).
* **Legend:** Located in the bottom-left corner of the plot area.
* `LPN`: Solid blue line.
* `Ref`: Dashed orange line.
**Right Plot:**
* **Title:** `Cross sections (0, x₂, 0) of the convex function, Dim 8`
* **Y-axis Label:** `Convexfunctions(0, x₂, 0, ...)`
* **X-axis Label:** `x₂`
* **X-axis Range:** -4 to 4, with major tick marks at intervals of 1 (-4, -3, -2, -1, 0, 1, 2, 3, 4).
* **Y-axis Range:** 0 to 4, with major tick marks at intervals of 1 (0, 1, 2, 3, 4).
* **Legend:** Located in the bottom-left corner of the plot area.
* `LPN`: Solid blue line.
* `Ref`: Dashed orange line.
### Detailed Analysis
**Left Plot (x₁ cross-section):**
* **Trend Verification:** Both the `LPN` (blue) and `Ref` (orange) lines form a symmetric, upward-opening parabola. They slope downward from the left edge (x₁ = -4) to a minimum at the center (x₁ = 0), then slope upward symmetrically to the right edge (x₁ = 4).
* **Data Points (Approximate):**
* At x₁ = -4: y ≈ 4.5
* At x₁ = -2: y ≈ 1.0
* At x₁ = 0: y ≈ 0.0 (minimum)
* At x₁ = 2: y ≈ 1.0
* At x₁ = 4: y ≈ 4.5
* The two lines (`LPN` and `Ref`) are visually indistinguishable across the entire range, indicating an extremely close match.
**Right Plot (x₂ cross-section):**
* **Trend Verification:** Identical to the left plot. Both lines form a symmetric, upward-opening parabola, sloping downward to a minimum at x₂ = 0 and then upward.
* **Data Points (Approximate):**
* At x₂ = -4: y ≈ 4.5
* At x₂ = -2: y ≈ 1.0
* At x₂ = 0: y ≈ 0.0 (minimum)
* At x₂ = 2: y ≈ 1.0
* At x₂ = 4: y ≈ 4.5
* The `LPN` and `Ref` lines are again perfectly overlapped.
### Key Observations
1. **Perfect Overlap:** The most significant observation is the near-perfect overlap between the `LPN` (solid blue) and `Ref` (dashed orange) lines in both plots. This suggests the `LPN` method reconstructs or approximates the reference convex function with very high accuracy along these cross-sections.
2. **Symmetry and Convexity:** The function exhibits clear symmetry around the origin (x₁=0 and x₂=0) and is convex, as evidenced by the U-shaped curves with a single global minimum at zero.
3. **Identical Cross-Sections:** The cross-sections along the `x₁` and `x₂` dimensions (with all other coordinates set to 0) appear to be functionally identical, suggesting the convex function may be isotropic or have similar curvature in these principal directions.
### Interpretation
The data demonstrates the effectiveness of the `LPN` method in capturing the behavior of a reference convex function in an 8-dimensional space. The plots serve as a validation, showing that the `LPN` output is virtually identical to the ground truth (`Ref`) for these specific 1D slices.
The identical, symmetric parabolic shapes imply that the underlying convex function has a quadratic-like form near its minimum, at least along the `x₁` and `x₂` axes. The perfect match between the curves is a strong indicator of model accuracy for this task. The absence of any visible deviation or outliers reinforces the conclusion that the approximation is highly reliable for these cross-sections. This type of visualization is crucial for verifying that a learned model (LPN) correctly captures the fundamental geometric properties (convexity, symmetry) of a target function.
</details>
<details>
<summary>exp_L1_prior_8D_Pr1.png Details</summary>
### Visual Description
\n
## [Line Charts]: Cross Sections of Prior Function (Dim 8)
### Overview
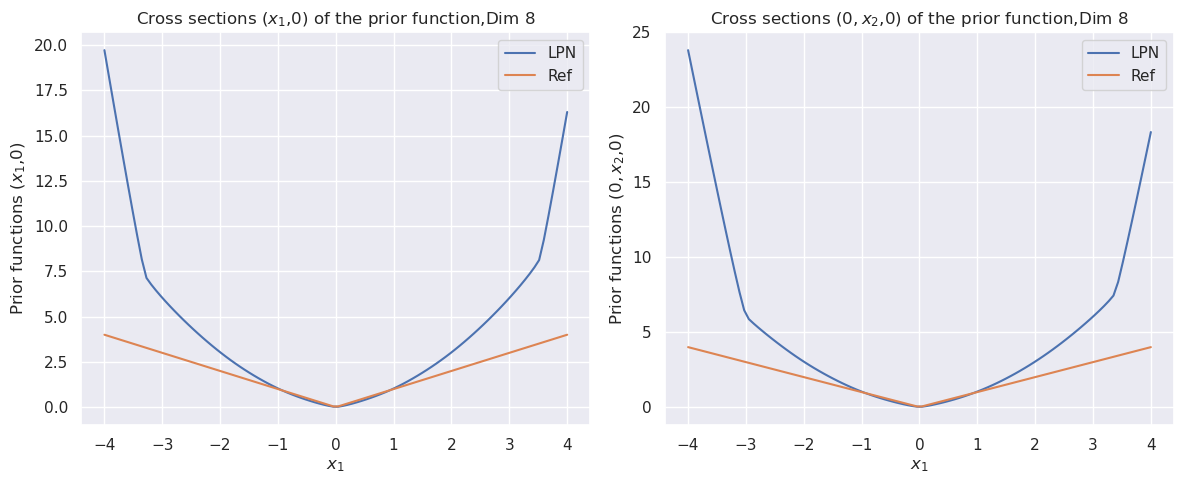
The image displays two side-by-side line charts comparing two functions, labeled "LPN" and "Ref," across different cross-sections of an 8-dimensional prior function. Both charts show the functions' behavior as a single variable changes while others are held at zero. The overall visual pattern is symmetric, with both functions reaching a minimum value of zero at the origin (x=0).
### Components/Axes
**Left Chart:**
* **Title:** `Cross sections (x₁,0) of the prior function,Dim 8`
* **Y-axis Label:** `Prior functions (x₁,0)`
* **X-axis Label:** `x₁`
* **Y-axis Scale:** Linear, ranging from 0.0 to 20.0, with major ticks at intervals of 2.5.
* **X-axis Scale:** Linear, ranging from -4 to 4, with major ticks at integer intervals.
* **Legend:** Located in the top-right corner. Contains two entries:
* `LPN` (blue line)
* `Ref` (orange line)
**Right Chart:**
* **Title:** `Cross sections (0, x₂,0) of the prior function,Dim 8`
* **Y-axis Label:** `Prior functions (0, x₂,0)`
* **X-axis Label:** `x₁` *(Note: This label appears inconsistent with the title, which references `x₂`. The axis variable is likely intended to be `x₂` based on the title.)*
* **Y-axis Scale:** Linear, ranging from 0 to 25, with major ticks at intervals of 5.
* **X-axis Scale:** Linear, ranging from -4 to 4, with major ticks at integer intervals.
* **Legend:** Located in the top-right corner. Contains the same two entries as the left chart:
* `LPN` (blue line)
* `Ref` (orange line)
### Detailed Analysis
**Left Chart - Cross Section (x₁,0):**
* **LPN (Blue Line):** Exhibits a pronounced, symmetric U-shape.
* **Trend:** Starts very high at the left extreme, decreases rapidly to a minimum at the center, then increases rapidly to a high value at the right extreme.
* **Approximate Data Points:**
* At x₁ = -4: y ≈ 19.8
* At x₁ = -3: y ≈ 7.0
* At x₁ = -2: y ≈ 3.0
* At x₁ = -1: y ≈ 1.0
* At x₁ = 0: y = 0.0
* At x₁ = 1: y ≈ 1.0
* At x₁ = 2: y ≈ 3.0
* At x₁ = 3: y ≈ 7.0
* At x₁ = 4: y ≈ 16.5
* **Ref (Orange Line):** Exhibits a symmetric V-shape, appearing linear on each side of the origin.
* **Trend:** Decreases linearly from the left to the origin, then increases linearly from the origin to the right.
* **Approximate Data Points:**
* At x₁ = -4: y ≈ 4.0
* At x₁ = 0: y = 0.0
* At x₁ = 4: y ≈ 4.0
**Right Chart - Cross Section (0, x₂,0):**
* **LPN (Blue Line):** Exhibits a symmetric U-shape, similar to the left chart but with a steeper ascent.
* **Trend:** Starts very high at the left extreme, decreases rapidly to a minimum at the center, then increases rapidly to a high value at the right extreme.
* **Approximate Data Points:**
* At x₁ (likely x₂) = -4: y ≈ 24.0
* At x₁ = -3: y ≈ 6.0
* At x₁ = -2: y ≈ 3.0
* At x₁ = -1: y ≈ 1.0
* At x₁ = 0: y = 0.0
* At x₁ = 1: y ≈ 1.0
* At x₁ = 2: y ≈ 3.0
* At x₁ = 3: y ≈ 7.0
* At x₁ = 4: y ≈ 18.5
* **Ref (Orange Line):** Exhibits a symmetric V-shape, identical in form to the left chart.
* **Trend:** Decreases linearly from the left to the origin, then increases linearly from the origin to the right.
* **Approximate Data Points:**
* At x₁ (likely x₂) = -4: y ≈ 4.0
* At x₁ = 0: y = 0.0
* At x₁ = 4: y ≈ 4.0
### Key Observations
1. **Symmetry:** Both functions (LPN and Ref) are perfectly symmetric around x=0 in both cross-sections.
2. **Minimum Point:** Both functions achieve their global minimum value of 0 at the origin (x=0).
3. **Relative Magnitude:** The LPN function has significantly higher values than the Ref function at all points except the origin. The disparity is greatest at the extremes (x=±4).
4. **Shape Difference:** The LPN function is a smooth, convex U-shape (suggesting a quadratic or higher-order polynomial relationship), while the Ref function is a piecewise-linear V-shape (suggesting an absolute value relationship).
5. **Cross-Section Comparison:** The LPN curve in the right chart (cross-section (0, x₂,0)) reaches a higher peak value (~24) at x=-4 compared to the left chart (~19.8), indicating the prior function may have different scaling or sensitivity along different dimensions.
6. **Label Discrepancy:** The x-axis on the right chart is labeled `x₁`, but the chart title references `x₂`. This is likely a labeling error, and the axis should represent `x₂`.
### Interpretation
The charts compare the behavior of a learned or proposed prior distribution ("LPN") against a reference prior ("Ref") in an 8-dimensional space. The data suggests the following:
* **Penalty for Deviation:** Both priors assign the lowest probability density (or highest "cost") to the origin (x=0) and increase as variables move away from zero. This is characteristic of priors that encourage sparsity or shrinkage towards zero.
* **LPN is More "Peaked":** The LPN prior penalizes deviations from zero much more severely than the Ref prior, especially for larger deviations. Its U-shape implies a stronger, non-linear push towards zero. This could indicate a more informative or restrictive prior designed to aggressively suppress non-zero values.
* **Reference Prior is Linear:** The Ref prior's V-shape corresponds to an L1-norm or Laplace prior, which applies a constant penalty per unit of deviation. This is a common choice for promoting sparsity.
* **Dimensional Anisotropy:** The difference in the LPN curve's height between the two cross-sections suggests the learned prior is not isotropic; its strength or shape varies depending on which dimension is being varied. This could be an intentional feature to model different importance of dimensions or an artifact of the learning process.
* **Purpose:** This visualization is likely used to validate or analyze the properties of a learned prior (LPN) by contrasting it with a standard, well-understood reference (Ref). It demonstrates that the LPN has successfully learned a prior that is qualitatively similar (symmetric, centered at zero) but quantitatively more aggressive in its shrinkage behavior.
</details>
<details>
<summary>exp_L1_prior_8D_Pr2.png Details</summary>
### Visual Description
## Line Charts: Cross Sections of a Prior Function in 8 Dimensions
### Overview
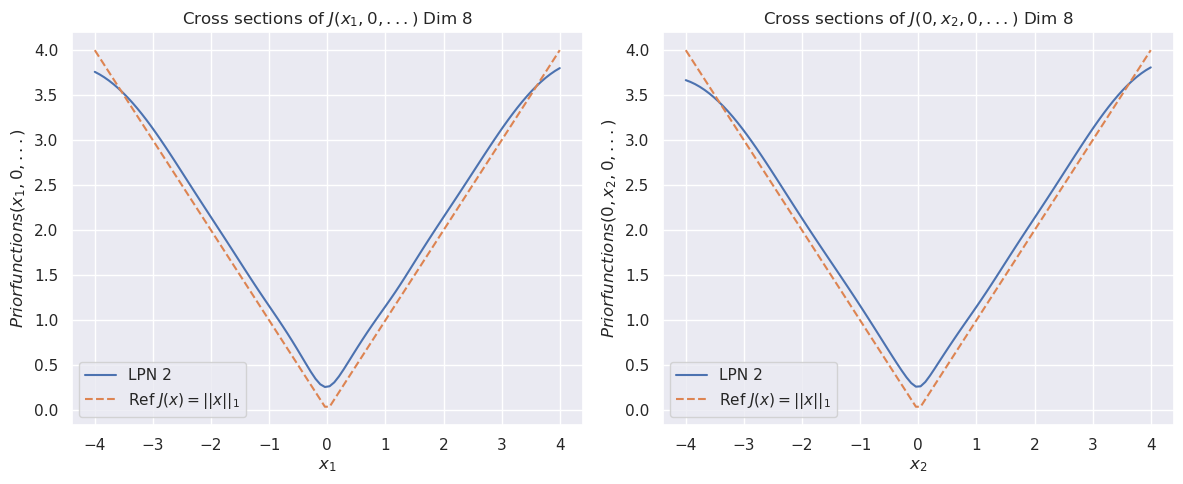
The image displays two side-by-side line charts. Both plots show cross-sections of a function labeled `J` in an 8-dimensional space. The left chart examines the function's behavior as the first variable (`x₁`) changes while all other variables are held at zero. The right chart examines the behavior as the second variable (`x₂`) changes while all others are held at zero. Each chart compares a learned function ("LPN 2") against a reference function (the L1 norm).
### Components/Axes
**Titles:**
* Left Chart: `Cross sections of J(x₁, 0, ...) Dim 8`
* Right Chart: `Cross sections of J(0, x₂, 0, ...) Dim 8`
**Y-Axis (Both Charts):**
* Label: `Priorfunctions(x₁, 0, ...)` (left) / `Priorfunctions(0, x₂, 0, ...)` (right)
* Scale: Linear, ranging from 0.0 to 4.0, with major ticks at 0.5 intervals.
**X-Axis (Left Chart):**
* Label: `x₁`
* Scale: Linear, ranging from -4 to 4, with major ticks at integer intervals.
**X-Axis (Right Chart):**
* Label: `x₂`
* Scale: Linear, ranging from -4 to 4, with major ticks at integer intervals.
**Legend (Both Charts, positioned in the bottom-left corner):**
* `LPN 2`: Represented by a solid blue line.
* `Ref J(x) = ||x||₁`: Represented by a dashed orange line. This is the L1 norm (sum of absolute values).
### Detailed Analysis
Both charts display a symmetric, V-shaped curve centered at x=0. The reference function (dashed orange) is a perfect V, reaching a minimum value of 0.0 at x=0 and increasing linearly to 4.0 at x=±4.
The "LPN 2" function (solid blue) closely follows the reference but exhibits a key difference: its minimum at x=0 is not zero. It is a smooth, rounded approximation of the L1 norm.
**Approximate Data Points for "LPN 2" (Blue Line):**
* **At x = -4:** y ≈ 3.75
* **At x = -2:** y ≈ 1.9
* **At x = 0:** y ≈ 0.25 (This is the minimum, notably above 0.0)
* **At x = 2:** y ≈ 1.9
* **At x = 4:** y ≈ 3.75
**Visual Trend Verification:**
* **LPN 2 (Blue):** The line slopes downward from left to center, reaching a smooth minimum at x=0, then slopes upward symmetrically to the right. The curve is slightly above the reference line everywhere except at the extreme points (x=±4), where they converge.
* **Ref J(x) (Orange):** The line slopes downward linearly from left to center, hits a sharp point (cusp) at x=0, then slopes upward linearly to the right.
### Key Observations
1. **Symmetry:** Both functions are perfectly symmetric around x=0 in their respective dimensions.
2. **Minimum Value Discrepancy:** The most significant difference is at the origin. The reference L1 norm has a sharp, non-differentiable minimum at 0.0. The "LPN 2" function has a smooth, differentiable minimum at approximately 0.25.
3. **Convergence at Extremes:** The two functions converge in value at the boundaries of the plotted range (x=±4).
4. **Identical Behavior Across Dimensions:** The plots for `x₁` and `x₂` are visually identical, suggesting the "LPN 2" function treats these dimensions equivalently in this cross-sectional view.
### Interpretation
This visualization demonstrates a learned function ("LPN 2") that approximates the L1 norm (`||x||₁`). The L1 norm is commonly used in machine learning and statistics for regularization (e.g., Lasso regression) and as a loss function, but its non-differentiability at zero can be problematic for gradient-based optimization methods.
The "LPN 2" function appears to be a **smooth, differentiable approximation** of the L1 norm. The key evidence is the rounded minimum at x=0 (y≈0.25) instead of a sharp cusp at y=0.0. This property makes it suitable for use in contexts where gradients are required, while still promoting sparsity (a key characteristic of L1-based methods) due to its overall V-shape. The fact that the approximation is slightly above the true L1 norm everywhere else is a typical trade-off for achieving differentiability. The identical plots for `x₁` and `x₂` indicate the approximation is consistent across at least the first two dimensions of the 8-dimensional space.
</details>
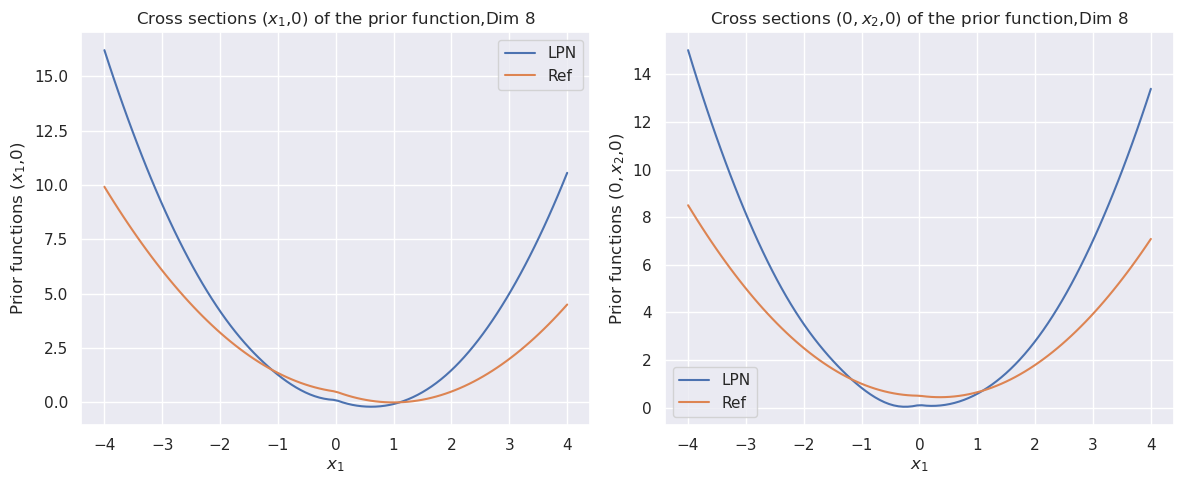
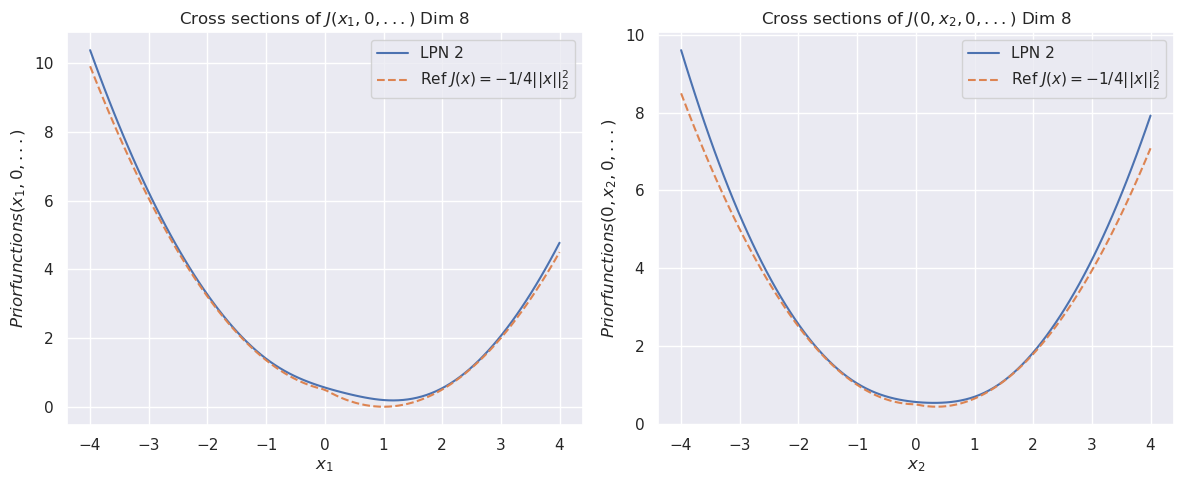
Figure 1: The cross sections of the convex function $\psi(x)$ for dimension $8$ (top). The bottom row compares the cross sections of the prior function from “invert LPN” (left) and our trained second LPN method (right).
### 5.2 Non-convex prior
#### Minplus algebra example
For this example, the prior is
$$
J(\bm{x})=\min\left(\frac{1}{2\sigma_{1}}\left\|{\bm{x}-\mu_{1}}\right\|_{2}^{2},\frac{1}{2\sigma_{2}}\left\|{\bm{x}-\mu_{2}}\right\|_{2}^{2}\right).
$$
We use $\mu_{1}=(1,0,\dots,0)$ , $\mu_{2}=\bm{1}/\sqrt{n}$ , and $\sigma_{1}=\sigma_{2}=1.0$ .
Table 2: Mean square errors of LPN $\psi$ and prior $J$ with 2 layers and 256 neurons in the min-plus example.
| | Dimension | LPN ( $\psi$ ) | Prior ( $J$ ) |
| --- | --- | --- | --- |
| Mean Square Errors | 2D | $3.33E-6$ | $5.73E-7$ |
| 4D | $7.64E-6$ | $4.92E-6$ | |
| 8D | $3.64E-5$ | $1.20E-4$ | |
| 16D | $1.99E-4$ | $3.44E-4$ | |
| 32D | $1.16E-3$ | $1.33E-3$ | |
| 64D | $2.32E-9$ | $5.21E-5$ | |
<details>
<summary>exp_1_minplus_8D_LPN.png Details</summary>
### Visual Description
## [Chart Type]: Dual Line Plots of Convex Function Cross-Sections
### Overview
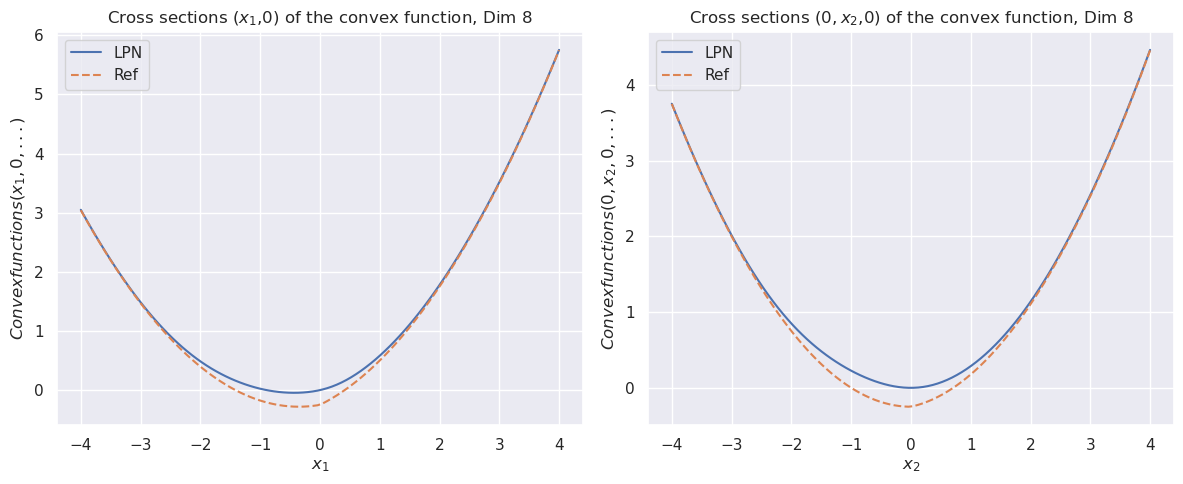
The image displays two side-by-side line charts, each plotting cross-sections of an 8-dimensional convex function. The left chart shows the cross-section along the first dimension (x₁, 0), while the right chart shows the cross-section along the second dimension (0, x₂, 0). Both charts compare two data series: "LPN" (solid blue line) and "Ref" (dashed orange line).
### Components/Axes
**Titles:**
- Left Chart: "Cross sections (x₁,0) of the convex function, Dim 8"
- Right Chart: "Cross sections (0, x₂,0) of the convex function, Dim 8"
**Y-Axis Labels:**
- Left Chart: "Convexfunctions(x₁, 0, ...)"
- Right Chart: "Convexfunctions(0, x₂, 0, ...)"
**X-Axis Labels:**
- Left Chart: "x₁"
- Right Chart: "x₂"
**Legend (Both Charts):**
- Located in the top-left corner of each plot area.
- **LPN**: Solid blue line.
- **Ref**: Dashed orange line.
**Axis Scales:**
- **X-Axis (Both Charts):** Linear scale from -4 to 4, with major ticks at integer intervals (-4, -3, -2, -1, 0, 1, 2, 3, 4).
- **Y-Axis (Left Chart):** Linear scale from 0 to 6, with major ticks at intervals of 1 (0, 1, 2, 3, 4, 5, 6).
- **Y-Axis (Right Chart):** Linear scale from 0 to 4, with major ticks at intervals of 1 (0, 1, 2, 3, 4).
### Detailed Analysis
**Left Chart (x₁ cross-section):**
- **Trend:** Both "LPN" and "Ref" series form upward-opening parabolas, symmetric around x₁ = 0. The "Ref" line is consistently slightly below the "LPN" line across the entire domain.
- **Key Data Points (Approximate):**
- At x₁ = -4: Both lines converge at y ≈ 3.0.
- At x₁ = -2: LPN ≈ 0.8, Ref ≈ 0.5.
- At x₁ = 0 (Minimum): LPN ≈ 0.0, Ref ≈ -0.2 (the only point where Ref is negative).
- At x₁ = 2: LPN ≈ 0.8, Ref ≈ 0.5.
- At x₁ = 4: Both lines converge at y ≈ 5.8.
**Right Chart (x₂ cross-section):**
- **Trend:** Similar parabolic shape as the left chart. The "Ref" line is again slightly below the "LPN" line, with the gap appearing marginally wider near the minimum.
- **Key Data Points (Approximate):**
- At x₂ = -4: Both lines converge at y ≈ 3.7.
- At x₂ = -2: LPN ≈ 0.8, Ref ≈ 0.4.
- At x₂ = 0 (Minimum): LPN ≈ 0.0, Ref ≈ -0.3.
- At x₂ = 2: LPN ≈ 0.8, Ref ≈ 0.4.
- At x₂ = 4: Both lines converge at y ≈ 4.5.
### Key Observations
1. **Convexity:** Both cross-sections for both methods (LPN, Ref) are strictly convex (parabolic).
2. **Minimum Value:** The "Ref" method achieves a slightly lower minimum value (negative) compared to "LPN" (at or near zero) in both cross-sections.
3. **Symmetry:** Both plots are symmetric about their respective axes (x₁=0 and x₂=0).
4. **Convergence at Extremes:** The two methods produce nearly identical values at the boundaries of the plotted domain (x = ±4).
5. **Magnitude Difference:** The function values in the x₁ cross-section (left chart) reach a higher maximum (~5.8) than in the x₂ cross-section (right chart, ~4.5) over the same input range [-4, 4].
### Interpretation
These charts serve as a diagnostic comparison between two methods ("LPN" and "Ref") for representing or approximating an 8-dimensional convex function. The "Ref" (Reference) method appears to be a baseline or ground truth, while "LPN" is likely a learned or approximate model.
The data suggests that the LPN model successfully captures the overall convex shape and symmetry of the reference function. However, it exhibits a consistent, small positive bias, particularly around the function's minimum. This indicates the LPN approximation is slightly less "sharp" or does not descend as deeply as the reference. The convergence at the boundaries shows the model is accurate for larger input magnitudes. The difference in maximum values between the two cross-sections implies the underlying 8D function is not perfectly isotropic; its curvature varies with direction. This visualization is crucial for validating that a learned model (LPN) preserves the fundamental geometric property (convexity) of the target function, while also quantifying its approximation error.
</details>
<details>
<summary>exp_1_minplus_8D_Pr1.png Details</summary>
### Visual Description
## [Chart Type]: Dual Line Plot - Cross Sections of a Prior Function
### Overview
The image displays two side-by-side line charts, each plotting two functions ("LPN" and "Ref") against a single variable. The charts represent cross-sectional slices of a higher-dimensional (Dim 8) prior function. The left chart shows the function's behavior along the `x₁` axis with all other dimensions set to zero, while the right chart shows the behavior along the `x₂` axis with `x₁` and other dimensions set to zero. Both plots demonstrate parabolic, U-shaped curves.
### Components/Axes
**Common Elements:**
* **Plot Type:** 2D line charts.
* **Data Series:** Two series per plot.
* **LPN:** Represented by a blue line.
* **Ref:** Represented by an orange line.
* **Legend:** Located in the top-right corner of each plot's axes area. Contains colored line samples and labels "LPN" (blue) and "Ref" (orange).
* **Grid:** A light gray grid is present in the background of both plots.
**Left Plot:**
* **Title:** "Cross sections (x₁,0) of the prior function, Dim 8"
* **Y-axis Label:** "Prior functions (x₁,0)"
* **X-axis Label:** "x₁"
* **Y-axis Scale:** Linear, ranging from approximately 0.0 to 16.0. Major ticks at 0.0, 2.5, 5.0, 7.5, 10.0, 12.5, 15.0.
* **X-axis Scale:** Linear, ranging from -4 to 4. Major ticks at -4, -3, -2, -1, 0, 1, 2, 3, 4.
**Right Plot:**
* **Title:** "Cross sections (0, x₂,0) of the prior function, Dim 8"
* **Y-axis Label:** "Prior functions (0, x₂,0)"
* **X-axis Label:** "x₁" (Note: This appears to be a labeling inconsistency; based on the title, it should logically be `x₂`).
* **Y-axis Scale:** Linear, ranging from approximately 0.0 to 15.0. Major ticks at 0, 2, 4, 6, 8, 10, 12, 14.
* **X-axis Scale:** Linear, ranging from -4 to 4. Major ticks at -4, -3, -2, -1, 0, 1, 2, 3, 4.
### Detailed Analysis
**Left Plot - Cross section (x₁,0):**
* **Trend Verification:** Both the LPN (blue) and Ref (orange) lines form upward-opening parabolas. They decrease from the left, reach a minimum near x₁=0, and then increase to the right. The LPN curve is consistently above the Ref curve except near the minimum, where they converge.
* **Data Points (Approximate):**
* **At x₁ = -4:** LPN ≈ 16.0, Ref ≈ 10.0
* **At x₁ = -2:** LPN ≈ 4.0, Ref ≈ 2.5
* **At x₁ = 0 (Minimum):** LPN ≈ 0.0, Ref ≈ 0.0 (Both curves appear to touch or nearly touch the x-axis).
* **At x₁ = 2:** LPN ≈ 4.0, Ref ≈ 2.5
* **At x₁ = 4:** LPN ≈ 10.5, Ref ≈ 4.5
**Right Plot - Cross section (0, x₂,0):**
* **Trend Verification:** Similar to the left plot, both lines are upward-opening parabolas. The LPN (blue) curve is again above the Ref (orange) curve, with the gap widening as the absolute value of x₁ (presumably x₂) increases.
* **Data Points (Approximate):**
* **At x₁ (x₂) = -4:** LPN ≈ 15.0, Ref ≈ 8.5
* **At x₁ (x₂) = -2:** LPN ≈ 4.0, Ref ≈ 2.0
* **At x₁ (x₂) = 0 (Minimum):** LPN ≈ 0.0, Ref ≈ 0.5 (The Ref curve's minimum appears slightly above zero).
* **At x₁ (x₂) = 2:** LPN ≈ 4.0, Ref ≈ 2.0
* **At x₁ (x₂) = 4:** LPN ≈ 13.5, Ref ≈ 7.0
### Key Observations
1. **Consistent Hierarchy:** In both cross-sections, the "LPN" function yields higher values than the "Ref" function for the same input, except at the very bottom of the well where they are similar.
2. **Symmetry:** Both plots show near-perfect symmetry around the vertical axis (x=0), indicating the prior function is symmetric in these dimensions.
3. **Curvature Difference:** The LPN curve has a steeper curvature (a narrower, deeper "well") compared to the broader, shallower Ref curve. This is evident from the larger difference in values at the extremes (x=±4).
4. **Labeling Inconsistency:** The right plot's x-axis is labeled "x₁", but its title and y-axis label indicate it represents a cross-section along the `x₂` dimension. This is likely a typographical error in the chart generation.
### Interpretation
These charts compare two different prior probability distributions (LPN and Ref) over an 8-dimensional space by examining their behavior along two principal axes. The parabolic shape suggests these priors might be related to Gaussian or quadratic forms.
The key finding is that the **LPN prior is more "peaked" or "concentrated"** than the Ref prior. It assigns significantly higher probability density (or a related function value) to regions far from the origin (|x| > 2) while having a similar, near-zero density at the origin itself. This implies that the LPN model, compared to the Ref model, considers extreme values in any single dimension to be much more probable or "expected." The symmetry indicates this property is consistent across different dimensions of the space. The slight offset in the Ref curve's minimum on the right plot (≈0.5 at x=0) could be a numerical artifact or a subtle feature of that prior.
</details>
<details>
<summary>exp_1_minplus_8D_pr2.png Details</summary>
### Visual Description
\n
## [Chart Type]: Dual Cross-Section Line Plots
### Overview
The image displays two side-by-side line charts, each showing a cross-sectional view of a function `J` in an 8-dimensional space. The left chart plots the function against the first dimension (`x₁`), while the right chart plots it against the second dimension (`x₂`). Both charts compare a learned function ("LPN 2") against a theoretical reference function.
### Components/Axes
**Titles:**
* Left Chart: `Cross sections of J(x₁, 0, ...) Dim 8`
* Right Chart: `Cross sections of J(0, x₂, 0, ...) Dim 8`
**Axes:**
* **X-Axis (Left Chart):** Label is `x₁`. Scale ranges from -4 to 4 with major tick marks at every integer (-4, -3, -2, -1, 0, 1, 2, 3, 4).
* **X-Axis (Right Chart):** Label is `x₂`. Scale ranges from -4 to 4 with major tick marks at every integer (-4, -3, -2, -1, 0, 1, 2, 3, 4).
* **Y-Axis (Both Charts):** Label is `Priorfunctions(x₁, 0, ...)` for the left chart and `Priorfunctions(0, x₂, 0, ...)` for the right chart. The scale ranges from 0 to 10 with major tick marks at 0, 2, 4, 6, 8, 10.
**Legend (Both Charts, positioned in the top-right corner):**
* **Solid Blue Line:** Label is `LPN 2`.
* **Dashed Orange Line:** Label is `Ref J(x) = -1/4||x||₂²`. This denotes a reference function defined as negative one-quarter of the squared L2 norm of the input vector `x`.
### Detailed Analysis
**Left Chart (Cross-section along x₁):**
* **Trend Verification:** Both curves form a symmetric, upward-opening parabola with a minimum near `x₁ = 1`.
* **Data Series - LPN 2 (Blue):**
* At `x₁ = -4`, the value is approximately 10.2.
* The curve descends to a minimum value of approximately 0.2 at `x₁ ≈ 1`.
* It then ascends, reaching approximately 4.8 at `x₁ = 4`.
* **Data Series - Reference (Orange Dashed):**
* At `x₁ = -4`, the value is approximately 9.8.
* The curve descends to a minimum value of approximately 0.0 at `x₁ = 1`.
* It then ascends, reaching approximately 4.5 at `x₁ = 4`.
* **Comparison:** The "LPN 2" curve closely follows the reference parabola but is consistently shifted slightly upward. The minimum of "LPN 2" is slightly above zero, while the reference function's minimum is exactly zero at `x₁=1`.
**Right Chart (Cross-section along x₂):**
* **Trend Verification:** Both curves form a symmetric, upward-opening parabola with a minimum near `x₂ = 1`.
* **Data Series - LPN 2 (Blue):**
* At `x₂ = -4`, the value is approximately 9.5.
* The curve descends to a minimum value of approximately 0.5 at `x₂ ≈ 1`.
* It then ascends, reaching approximately 8.0 at `x₂ = 4`.
* **Data Series - Reference (Orange Dashed):**
* At `x₂ = -4`, the value is approximately 8.5.
* The curve descends to a minimum value of approximately 0.4 at `x₂ ≈ 1`.
* It then ascends, reaching approximately 7.2 at `x₂ = 4`.
* **Comparison:** Similar to the left chart, "LPN 2" tracks the reference function but sits slightly above it. The vertical offset appears more pronounced at the extremes (`x₂ = ±4`) compared to the left chart.
### Key Observations
1. **Parabolic Shape:** Both cross-sections reveal that the function `J` is quadratic (parabolic) along the `x₁` and `x₂` dimensions when other dimensions are held at zero.
2. **Minimum Location:** The minimum of the function occurs at `x₁ = 1` and `x₂ = 1` for both the learned and reference functions.
3. **Model Fidelity:** The "LPN 2" model successfully captures the overall parabolic shape and location of the minimum of the reference function `J(x) = -1/4||x||₂²`.
4. **Systematic Offset:** There is a consistent, small positive offset between the "LPN 2" curve and the reference curve across both plots. This offset is not uniform; it appears slightly larger at the boundaries of the plotted range (`x = ±4`) than near the minimum.
5. **Scale Difference:** The function values at the boundaries differ between the two plots. For example, at `x = -4`, the value is ~10.2 for `x₁` but ~9.5 for `x₂`. This indicates the function's behavior is not perfectly symmetric across all dimensions, despite the reference function being rotationally symmetric (depending only on the norm).
### Interpretation
The charts demonstrate a validation or analysis of a learned model ("LPN 2") against a known theoretical prior distribution. The reference function `J(x) = -1/4||x||₂²` represents a simple, isotropic Gaussian-like prior (its negative log would be proportional to the squared norm). The fact that the cross-sections are parabolas confirms this.
The "LPN 2" model appears to be a neural network or similar function approximator trained to represent this prior. The close match indicates successful learning of the core quadratic structure. The persistent positive offset suggests the model has learned a function that is everywhere slightly higher than the target. This could be due to:
* A regularization effect during training.
* An inherent bias in the model architecture.
* The model approximating a slightly different function that includes a small constant term.
The slight asymmetry between the `x₁` and `x₂` cross-sections (different values at `x=±4`) is notable. Since the reference function is perfectly symmetric, this asymmetry must originate from the "LPN 2" model itself, indicating its learned representation is not perfectly isotropic. This could be a result of the training data, optimization path, or model capacity. Overall, the visualization confirms the model has learned the essential geometric properties of the target prior, with minor, systematic deviations.
</details>
Figure 2: The cross sections of the convex function $\psi(x)$ for dimension $8$ (top). The bottom row compares the cross sections of the prior function from “invert LPN” (left) and our trained second LPN method (right).
<details>
<summary>exp_1_minplus_32D_LPN.png Details</summary>
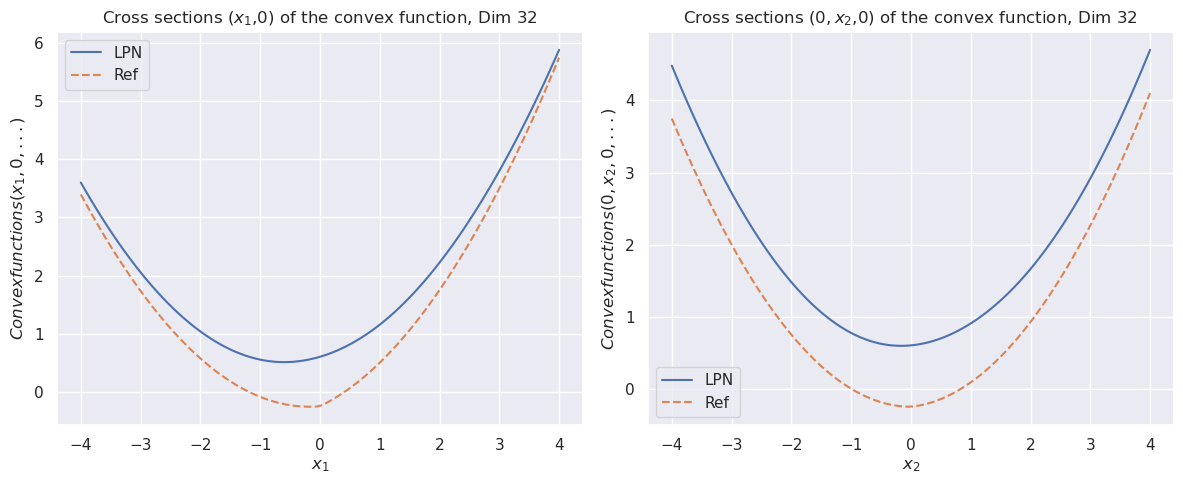
### Visual Description
## Line Charts: Cross Sections of a Convex Function (Dim 32)
### Overview
The image contains two side-by-side line charts. Both plots display cross-sectional views of a convex function in a 32-dimensional space. Each chart compares two functions: "LPN" (solid blue line) and "Ref" (dashed orange line). The plots are visually similar, showing U-shaped (convex) curves, but they represent different cross-sections of the high-dimensional function.
### Components/Axes
**Left Chart:**
* **Title:** `Cross sections (x₁,0) of the convex function, Dim 32`
* **Y-axis Label:** `Convexfunctions(x₁, 0, ... )`
* **X-axis Label:** `x₁`
* **X-axis Range:** -4 to 4
* **Y-axis Range:** Approximately -0.5 to 6
* **Legend:** Located in the top-left corner.
* `LPN`: Solid blue line.
* `Ref`: Dashed orange line.
**Right Chart:**
* **Title:** `Cross sections (0, x₂,0) of the convex function, Dim 32`
* **Y-axis Label:** `Convexfunctions(0, x₂, 0, ... )`
* **X-axis Label:** `x₂`
* **X-axis Range:** -4 to 4
* **Y-axis Range:** Approximately -0.5 to 4.5
* **Legend:** Located in the bottom-left corner.
* `LPN`: Solid blue line.
* `Ref`: Dashed orange line.
### Detailed Analysis
**Left Chart (Cross-section along x₁):**
* **Trend Verification:** Both curves are symmetric, U-shaped parabolas with minima near x₁ = 0.
* **LPN (Blue, Solid):** The curve is always above the Ref curve. Its minimum value at x₁=0 is approximately **0.5**. At the extremes (x₁ = ±4), the value is approximately **5.8**.
* **Ref (Orange, Dashed):** The curve dips below zero. Its minimum value at x₁=0 is approximately **-0.3**. At the extremes (x₁ = ±4), the value is approximately **5.6**.
**Right Chart (Cross-section along x₂):**
* **Trend Verification:** Both curves are again symmetric, U-shaped parabolas with minima near x₂ = 0.
* **LPN (Blue, Solid):** The curve is always above the Ref curve. Its minimum value at x₂=0 is approximately **0.6**. At the extremes (x₂ = ±4), the value is approximately **4.5**.
* **Ref (Orange, Dashed):** The curve dips below zero. Its minimum value at x₂=0 is approximately **-0.3**. At the extremes (x₂ = ±4), the value is approximately **4.1**.
### Key Observations
1. **Consistent Hierarchy:** In both cross-sections, the LPN function is strictly greater than the Ref function for all plotted values of x₁ and x₂.
2. **Minima Location:** The minimum of both functions occurs at the origin (x=0) in their respective cross-sections.
3. **Negative Values:** The Ref function takes on negative values near its minimum in both plots, while the LPN function remains positive.
4. **Similar Shape, Different Scale:** The shapes of the curves are nearly identical, but the vertical offset between LPN and Ref is consistent. The overall scale (y-axis range) is slightly larger for the x₁ cross-section.
### Interpretation
The data demonstrates that the "LPN" function is a convex approximation or variant of the "Ref" (Reference) function. The key finding is that LPN is a **shifted or regularized version** of Ref, as it maintains the same convex shape but is vertically offset upwards, eliminating the negative values present in the reference.
This suggests LPN might be designed to enforce a **non-negativity constraint** or to have a **higher minimum value** than the original function. The symmetry around zero in both cross-sections indicates the underlying high-dimensional function is likely even (symmetric) with respect to its input dimensions. The comparison across two different cross-sections (x₁ and x₂) shows this offset behavior is consistent across different dimensions of the function's input space.
</details>
<details>
<summary>exp_1_minplus_32D_Pr1.png Details</summary>
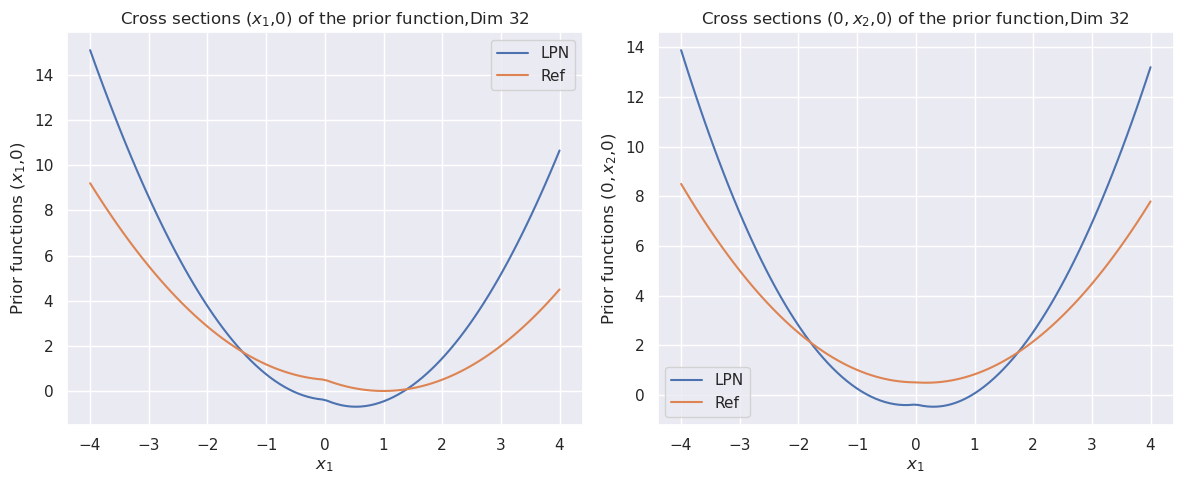
### Visual Description
## [Chart Type]: Dual Line Charts – Cross Sections of a Prior Function
### Overview
The image displays two side-by-side line charts, each plotting the cross-section of a "prior function" in a 32-dimensional space. The charts compare two functions, labeled "LPN" (blue line) and "Ref" (orange line), across a range of values for a variable labeled `x₁`. The left chart shows the cross-section at `(x₁, 0)`, while the right chart shows the cross-section at `(0, x₂, 0)`. Both charts share identical axes and scales, facilitating direct comparison.
### Components/Axes
* **Titles:**
* Left Chart: `Cross sections (x₁,0) of the prior function,Dim 32`
* Right Chart: `Cross sections (0, x₂,0) of the prior function,Dim 32`
* **X-Axis (Both Charts):**
* Label: `x₁`
* Scale: Linear, ranging from -4 to 4.
* Tick Marks: -4, -3, -2, -1, 0, 1, 2, 3, 4.
* **Y-Axis (Both Charts):**
* Label: `Prior functions (x₁,0)` (left) and `Prior functions (0, x₂,0)` (right).
* Scale: Linear, ranging from 0 to 14.
* Tick Marks: 0, 2, 4, 6, 8, 10, 12, 14.
* **Legend (Both Charts):**
* Position: Top-right corner of each plot area.
* Entries:
* `LPN` (Blue line)
* `Ref` (Orange line)
### Detailed Analysis
Both charts depict U-shaped (parabolic) curves, indicating that the value of the prior function is minimized near `x₁ = 0` and increases as `x₁` moves toward the extremes (-4 or 4).
**Left Chart: Cross-section (x₁, 0)**
* **LPN (Blue Line):**
* **Trend:** Starts at a high value, decreases to a minimum near `x₁ = 0`, then increases symmetrically.
* **Approximate Data Points:**
* At `x₁ = -4`: y ≈ 15.0
* At `x₁ = -2`: y ≈ 4.0
* At `x₁ = 0`: y ≈ -0.5 (Note: The curve dips slightly below the y=0 axis)
* At `x₁ = 2`: y ≈ 4.0
* At `x₁ = 4`: y ≈ 10.5
* **Ref (Orange Line):**
* **Trend:** Follows a similar U-shape but is consistently lower than the LPN curve across the entire range.
* **Approximate Data Points:**
* At `x₁ = -4`: y ≈ 9.2
* At `x₁ = -2`: y ≈ 2.5
* At `x₁ = 0`: y ≈ 0.0
* At `x₁ = 2`: y ≈ 2.5
* At `x₁ = 4`: y ≈ 4.5
**Right Chart: Cross-section (0, x₂, 0)**
* **LPN (Blue Line):**
* **Trend:** Similar U-shape, but the curve appears slightly steeper and the minimum is more pronounced.
* **Approximate Data Points:**
* At `x₁ = -4`: y ≈ 13.8
* At `x₁ = -2`: y ≈ 3.0
* At `x₁ = 0`: y ≈ -0.8 (Note: The minimum is lower than in the left chart)
* At `x₁ = 2`: y ≈ 3.0
* At `x₁ = 4`: y ≈ 13.2
* **Ref (Orange Line):**
* **Trend:** U-shaped, consistently lower than the LPN curve.
* **Approximate Data Points:**
* At `x₁ = -4`: y ≈ 8.5
* At `x₁ = -2`: y ≈ 2.0
* At `x₁ = 0`: y ≈ 0.5
* At `x₁ = 2`: y ≈ 2.0
* At `x₁ = 4`: y ≈ 7.8
### Key Observations
1. **Consistent Hierarchy:** In both cross-sections, the LPN function (blue) yields higher values than the Ref function (orange) for all `x₁` values except possibly at the very minima where they are close.
2. **Symmetry:** Both functions in both charts appear symmetric around `x₁ = 0`.
3. **Minima Location:** The minimum value for both functions occurs at or very near `x₁ = 0`.
4. **Cross-Section Difference:** The LPN curve in the right chart (`(0, x₂, 0)`) has a deeper minimum (≈ -0.8) compared to the left chart (`(x₁, 0)`, ≈ -0.5). The Ref curve's minimum is slightly higher in the right chart (≈ 0.5) compared to the left (≈ 0.0).
5. **Growth Rate:** The LPN function grows more rapidly away from the minimum than the Ref function in both cases.
### Interpretation
These charts visualize and compare the behavior of two prior probability distributions (LPN and Ref) in a high-dimensional (32D) space by taking 1D slices. The U-shape indicates that both priors assign lower probability density (or higher negative log-probability, depending on the function's definition) to values near zero and higher density to values far from zero along these specific axes.
The key finding is that the **LPN prior is consistently "heavier-tailed" or assigns relatively higher density to extreme values** compared to the Ref prior. This is evident because the blue LPN curve is always above the orange Ref curve. In a Bayesian context, this suggests the LPN prior is less informative or more diffuse, allowing data to have a stronger influence on the posterior distribution, especially for parameters far from zero. The difference in the minima between the two cross-sections hints at anisotropy in the prior's shape within the 32-dimensional space—its behavior is not identical in all directions. The charts effectively demonstrate that the choice between LPN and Ref priors would lead to different regularization behaviors in a statistical model.
</details>
<details>
<summary>exp_1_minplus_32D_pr2.png Details</summary>
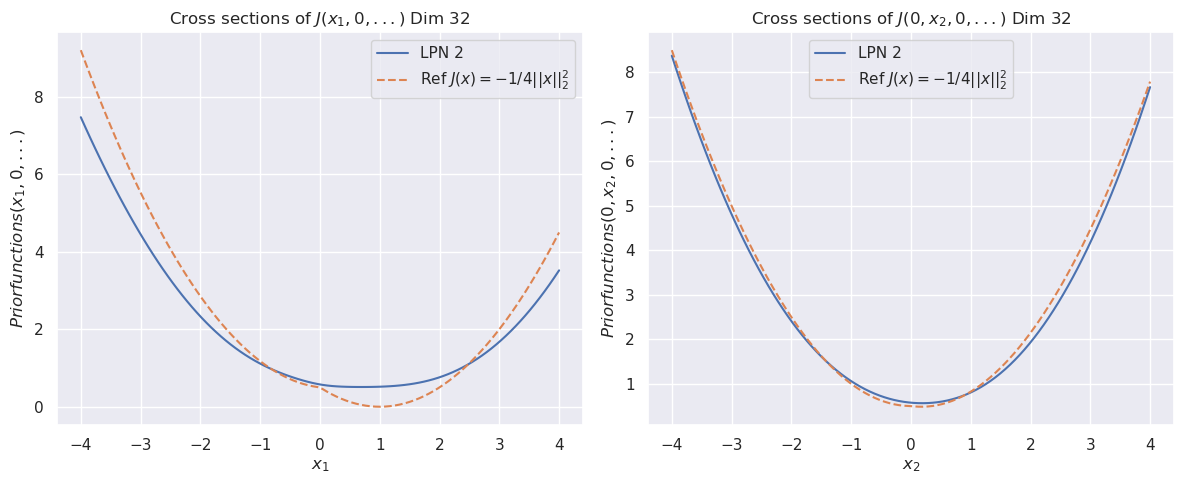
### Visual Description
## Cross-Sectional Analysis of Prior Functions in 32 Dimensions
### Overview
The image displays two side-by-side line charts comparing the cross-sectional behavior of a learned prior function ("LPN 2") against a theoretical reference function in a 32-dimensional space. Both charts plot the value of a "Priorfunction" against a single variable while holding other dimensions at zero, revealing parabolic, U-shaped curves.
### Components/Axes
**Titles:**
- Left Chart: "Cross sections of J(x₁, 0, ...) Dim 32"
- Right Chart: "Cross sections of J(0, x₂, 0, ...) Dim 32"
**Axes:**
- **Left Chart X-axis:** Label: `x₁`. Scale: Linear, from -4 to 4 with major ticks at every integer.
- **Right Chart X-axis:** Label: `x₂`. Scale: Linear, from -4 to 4 with major ticks at every integer.
- **Both Charts Y-axis:** Label: `Priorfunctions(x₁, 0, ...)` (left) and `Priorfunctions(0, x₂, 0, ...)` (right). Scale: Linear, from 0 to 8 with major ticks at every integer.
**Legend (Present in both charts, positioned top-right):**
- **Solid Blue Line:** Label: `LPN 2`
- **Dashed Orange Line:** Label: `Ref J(x) = -1/4||x||₂²`
### Detailed Analysis
**Left Chart (Varying x₁):**
- **Trend Verification:** Both curves are symmetric, upward-opening parabolas centered at x₁ = 0.
- **Data Series - LPN 2 (Blue):**
- Minimum value at x₁ = 0 is approximately 0.5.
- At x₁ = ±4, the value is approximately 3.5.
- The curve is smooth and slightly wider than the reference.
- **Data Series - Reference (Orange Dashed):**
- Minimum value at x₁ = 0 is 0.
- At x₁ = ±4, the value is approximately 4.5.
- The curve is a perfect parabola defined by the function `-1/4 * (x₁²)`. Note: The plotted values are positive, indicating the y-axis likely represents the *negative* of the function J(x) or a related prior probability density.
**Right Chart (Varying x₂):**
- **Trend Verification:** Both curves are symmetric, upward-opening parabolas centered at x₂ = 0.
- **Data Series - LPN 2 (Blue):**
- Minimum value at x₂ = 0 is approximately 0.5.
- At x₂ = ±4, the value is approximately 7.5.
- The curve closely follows the reference but is slightly above it across the entire range.
- **Data Series - Reference (Orange Dashed):**
- Minimum value at x₂ = 0 is 0.
- At x₂ = ±4, the value is approximately 7.5.
- The curve is a perfect parabola defined by the function `-1/4 * (x₂²)`.
### Key Observations
1. **Asymmetry in Learned Function:** The "LPN 2" function exhibits different behavior along the x₁ and x₂ dimensions. It deviates more significantly from the reference along x₁ (wider parabola, higher minimum) than along x₂ (very close fit).
2. **Minimum Value Offset:** The learned prior ("LPN 2") has a positive minimum value (~0.5) at the origin in both cross-sections, whereas the reference function's minimum is exactly 0.
3. **Growth Rate Discrepancy:** Along the x₁ dimension, the reference function grows faster than LPN 2 at the extremes (|x₁| > 2). Along the x₂ dimension, their growth rates are nearly identical.
4. **Mathematical Notation:** The reference function is written as `Ref J(x) = -1/4||x||₂²`, where `||x||₂²` denotes the squared L2 norm (sum of squares) of the vector x.
### Interpretation
This visualization is likely from a machine learning or probabilistic modeling context, evaluating how well a learned prior distribution (LPN 2) approximates a target theoretical prior (the reference function) in a high-dimensional space (32D).
- **What the data suggests:** The learned prior successfully captures the general parabolic, convex shape of the reference function, indicating it has learned a meaningful structure. However, the discrepancies are informative:
- The positive minimum suggests the learned prior assigns a non-zero probability density at the origin, unlike the reference.
- The asymmetry between dimensions (x₁ vs. x₂) implies the learned prior is not perfectly isotropic; its behavior varies depending on the direction in the latent space. This could be an artifact of the training process or data.
- **How elements relate:** The two charts together provide a multi-dimensional "slice" view of a complex 32D function. By comparing the slices, we infer properties of the full function. The close match in the x₂ slice versus the poorer match in the x₁ slice highlights dimension-specific learning performance.
- **Notable anomaly:** The most significant anomaly is the consistent vertical offset of the LPN 2 curve from the reference curve, especially at the minima. This systematic bias could impact downstream tasks relying on the prior's calibration. The investigation would focus on why the model learns this offset and whether it is desirable.
</details>
Figure 3: The cross sections of the convex function $\psi(x)$ for dimension $32$ (top). The bottom row compares the cross sections of the prior function from “invert LPN” (left) and our trained second LPN method (right)
### 5.3 Concave prior
For this example, we use
$$
J(\bm{x})=-\left\|{\bm{x}}\right\|_{2}^{2}/4.
$$
This is actually challenging example because, technically, $J$ is not uniformly Lipschitz continuous. (Although numerically we can get around this by “Huberizing” the prior.) We use this prior because we have an exact solution for this problem. It’s also a bit challenging for a convex LPN network because according to the theory of HJ PDEs, the function $J+\frac{1}{4}\left\|{\bm{x}}\right\|_{2}^{2}$ is convex, and $J+\frac{1}{2}\left\|{\bm{x}}\right\|_{2}^{2}$ is strongly convex, so an LPN (which is not inherently S.C.) may not be able to detect the strong convexity and makes this function more challenging to learn.
Table 3: Mean square errors of LPN $\psi$ and prior $J$ with 2 layers and 256 neurons in the concave prior example.
| | Dimension | LPN ( $\psi$ ) | Prior ( $J$ ) |
| --- | --- | --- | --- |
| Mean Square Errors | 2D | $7.00E-7$ | $1.57E-6$ |
| 4D | $2.74E-5$ | $7.70E-5$ | |
| 8D | $5.58E-4$ | $7.91E-4$ | |
| 16D | $3.69E-3$ | $3.28E-3$ | |
| 32D | $8.70E-2$ | $3.01E-2$ | |
| 64D | $6.23E-6$ | $1.87E-3$ | |
<details>
<summary>exp_quadratic_concave_prior_8D_PR1.png Details</summary>
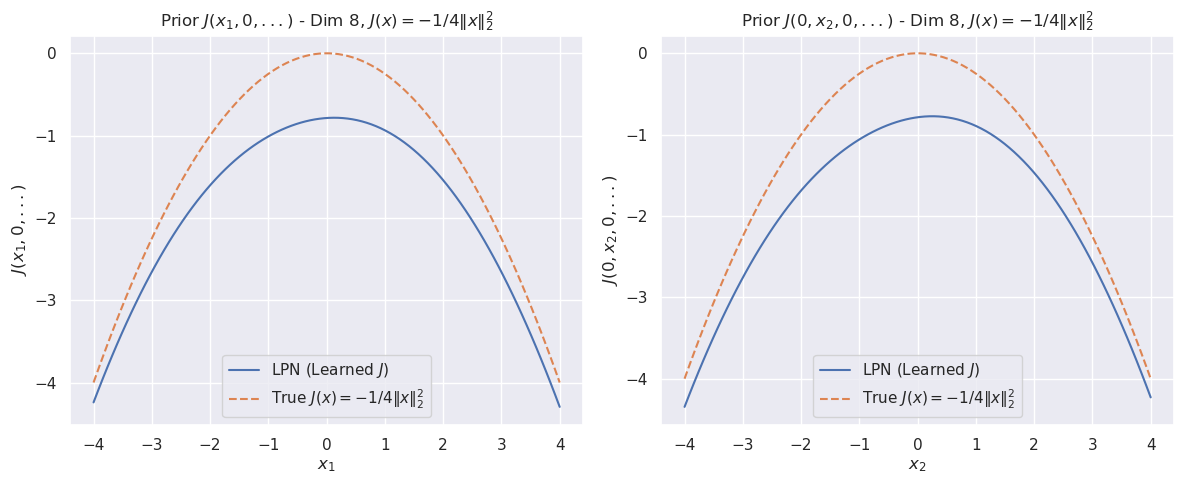
### Visual Description
## [Chart Type]: Dual-Panel Line Plot Comparison
### Overview
The image displays two side-by-side line plots comparing a "Learned" function (LPN) against a "True" mathematical function. Both plots visualize a 1-dimensional slice of an 8-dimensional function, where all other dimensions are held at zero. The left panel varies the first dimension (`x₁`), and the right panel varies the second dimension (`x₂`). The overall purpose is to demonstrate how well a learned model (LPN) approximates a known target function.
### Components/Axes
**Titles:**
* **Left Plot:** `Prior J(x₁, 0, ...) - Dim 8, J(x) = -1/4||x||₂²`
* **Right Plot:** `Prior J(0, x₂, 0, ...) - Dim 8, J(x) = -1/4||x||₂²`
**Axes:**
* **X-Axis (Left Plot):** Labeled `x₁`. Scale ranges from -4 to 4, with major ticks at -4, -3, -2, -1, 0, 1, 2, 3, 4.
* **X-Axis (Right Plot):** Labeled `x₂`. Scale ranges from -4 to 4, with major ticks at -4, -3, -2, -1, 0, 1, 2, 3, 4.
* **Y-Axis (Both Plots):** Labeled `J(x₁, 0, ...)` (left) and `J(0, x₂, 0, ...)` (right). Scale ranges from -4 to 0, with major ticks at -4, -3, -2, -1, 0.
**Legend (Present in both plots, located in the bottom-left corner):**
* **Solid Blue Line:** `LPN (Learned J)`
* **Dashed Orange Line:** `True J(x) = -1/4||x||₂²`
### Detailed Analysis
**Left Plot (Varying `x₁`):**
* **True Function (Dashed Orange):** This is a perfect downward-opening parabola. Its vertex (maximum value) is at `(x₁=0, J=0)`. At the extremes (`x₁ = ±4`), the value is `J = -1/4 * (4²) = -4`. The curve is perfectly symmetric around `x₁=0`.
* **Learned Function (Solid Blue):** This curve is also a downward-opening parabola, symmetric around `x₁=0`. Its vertex is at approximately `(x₁=0, J ≈ -0.8)`. At the extremes (`x₁ = ±4`), the value is approximately `J ≈ -4.3`. The learned curve is consistently below the true curve across the entire domain.
**Right Plot (Varying `x₂`):**
* **True Function (Dashed Orange):** Identical in shape and values to the left plot's true function. Vertex at `(x₂=0, J=0)`, value at `x₂ = ±4` is `J = -4`.
* **Learned Function (Solid Blue):** Visually identical to the learned function in the left plot. Vertex at approximately `(x₂=0, J ≈ -0.8)`, value at `x₂ = ±4` is approximately `J ≈ -4.3`. It is also consistently below the true curve.
**Trend Verification:**
* **Both True Curves:** Slope downward symmetrically from a peak at the center (x=0). The slope becomes steeper as the absolute value of x increases.
* **Both Learned Curves:** Follow the same symmetric, downward-sloping trend as the true curves but are vertically offset downward. The gap between the learned and true curves appears to widen slightly as |x| increases.
### Key Observations
1. **Consistent Underestimation:** The learned function (LPN) systematically underestimates the true function `J(x)` across all tested values of `x₁` and `x₂`.
2. **Shape Preservation:** The LPN successfully learns the correct parabolic shape and symmetry of the target function.
3. **Constant Offset:** The vertical offset between the two curves is not constant. The difference at the peak (`x=0`) is approximately `0.8`, while the difference at the edges (`x=±4`) is approximately `0.3`. This suggests the error is not a simple additive constant.
4. **Identical Behavior Across Dimensions:** The model's performance is identical when varying the first or second dimension, indicating consistent behavior in these two dimensions of the 8-dimensional space.
### Interpretation
This visualization is a diagnostic tool for evaluating a machine learning model (LPN) tasked with learning a prior distribution or objective function `J(x)`.
* **What the data suggests:** The LPN has successfully captured the fundamental *structure* of the target function—its quadratic nature and symmetry. However, it has failed to learn the correct *scale* or *magnitude*, resulting in a consistent under-prediction. The error is not uniform; the model is more accurate near the center of the distribution (`x≈0`) and less accurate in the tails (`|x| large`).
* **How elements relate:** The side-by-side comparison across two different input dimensions (`x₁` and `x₂`) serves to validate that the learned behavior is not an artifact of a single dimension. The identical plots suggest the model's approximation error is consistent across these dimensions.
* **Notable anomalies:** The primary anomaly is the systematic negative bias. In a perfect approximation, the blue and orange lines would overlap. The fact that the learned curve is always below the true curve indicates a potential issue in the model's training objective, capacity, or the scaling of the output. The widening gap at the extremes could be particularly problematic if accurate predictions in the tails of the distribution are important for the downstream task.
</details>
<details>
<summary>exp_quadratic_concave_prior_8D_PR2.png Details</summary>
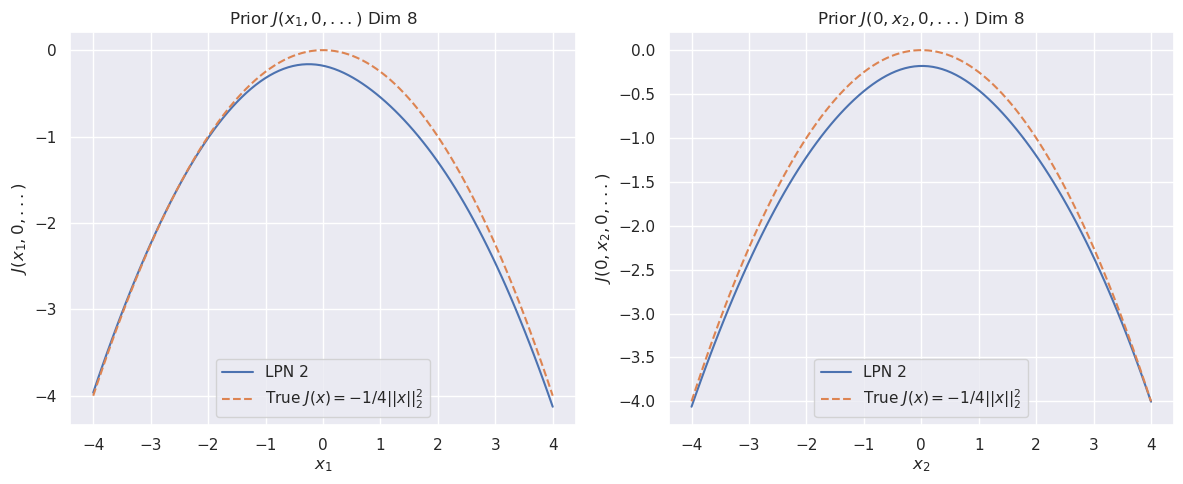
### Visual Description
## [Line Graphs]: Prior Function Approximation Comparison
### Overview
The image displays two side-by-side line graphs comparing an approximated function ("LPN 2") against a true mathematical function ("True J(x)") in an 8-dimensional space. The graphs plot the value of a function `J` against a single variable (`x₁` or `x₂`) while holding other dimensions at zero.
### Components/Axes
* **Chart Type:** Two 2D line plots.
* **Titles:**
* Left Plot: `Prior J(x₁, 0, ...) Dim 8`
* Right Plot: `Prior J(0, x₂, 0, ...) Dim 8`
* **Axes:**
* **X-Axis (Left Plot):** Labeled `x₁`. Scale ranges from -4 to 4 with major ticks at -4, -3, -2, -1, 0, 1, 2, 3, 4.
* **X-Axis (Right Plot):** Labeled `x₂`. Scale ranges from -4 to 4 with major ticks at -4, -3, -2, -1, 0, 1, 2, 3, 4.
* **Y-Axis (Left Plot):** Labeled `J(x₁, 0, ...)`. Scale ranges from -4 to 0 with major ticks at -4, -3, -2, -1, 0.
* **Y-Axis (Right Plot):** Labeled `J(0, x₂, 0, ...)`. Scale ranges from -4.0 to 0.0 with major ticks at -4.0, -3.5, -3.0, -2.5, -2.0, -1.5, -1.0, -0.5, 0.0.
* **Legend (Present in both plots, located at bottom-left):**
* `LPN 2` (Solid blue line)
* `True J(x) = -1/4||x||₂²` (Dashed orange line)
* **Grid:** Both plots have a light gray grid.
### Detailed Analysis
**Left Plot (`x₁`):**
* **Trend Verification:** Both lines form downward-opening parabolas symmetric around `x₁ = 0`.
* **Data Points & Comparison:**
* **True Function (Orange Dashed):** Peaks at `(x₁=0, J=0)`. At `x₁ = ±4`, `J ≈ -4`.
* **LPN 2 (Blue Solid):** Peaks at approximately `(x₁=0, J≈-0.2)`. At `x₁ = ±4`, `J ≈ -4.1`. The blue line is consistently below the orange line, with the greatest deviation at the vertex (`x₁=0`).
**Right Plot (`x₂`):**
* **Trend Verification:** Identical parabolic shape and relationship as the left plot.
* **Data Points & Comparison:**
* **True Function (Orange Dashed):** Peaks at `(x₂=0, J=0)`. At `x₂ = ±4`, `J ≈ -4`.
* **LPN 2 (Blue Solid):** Peaks at approximately `(x₂=0, J≈-0.2)`. At `x₂ = ±4`, `J ≈ -4.1`. The deviation pattern is identical to the left plot.
### Key Observations
1. **Symmetry:** The function `J` is symmetric with respect to both `x₁` and `x₂` when other variables are zero.
2. **Approximation Error:** The "LPN 2" model consistently underestimates the true function value across the entire domain shown. The error is most pronounced at the maximum point (`x=0`), where the model predicts a value ~0.2 units lower than the true value of 0.
3. **Consistency:** The approximation error is visually identical for both the `x₁` and `x₂` dimensions, suggesting the model's behavior is consistent across these input dimensions.
4. **Function Shape:** The true function is a negative scaled squared L2 norm (`-1/4||x||₂²`), which is a downward-opening paraboloid in high-dimensional space. The 2D slices shown confirm this parabolic profile.
### Interpretation
This visualization demonstrates the performance of a model (likely a neural network or similar approximator labeled "LPN 2") in learning a simple quadratic prior function in an 8-dimensional space. The plots show 1D cross-sections of this high-dimensional function.
* **What the data suggests:** The model has successfully learned the general parabolic shape and symmetry of the target function. However, it exhibits a systematic bias, failing to reach the true maximum value at the origin. This could indicate issues with the model's capacity, training, or the specific prior being imposed.
* **How elements relate:** The side-by-side comparison for `x₁` and `x₂` serves to validate that the model's approximation is consistent across different input dimensions, which is a desirable property. The legend directly links the visual representation (line style/color) to the mathematical entities being compared.
* **Notable anomaly:** The consistent negative bias at the vertex is the primary anomaly. In an optimization or Bayesian inference context, where such a prior might be used, this bias could lead to systematically shifted estimates or suboptimal solutions. The perfect match at the tails (`x=±4`) suggests the model captures the curvature well away from the origin but struggles with the peak.
</details>
Figure 4: The cross sections of the prior function for $8$ dimension from “invert LPN” (left) and our trained second LPN method (right)
### 5.4 Negative $\ell_{1}$ norm
See Equation Eq. 32 for the minimum value and Eq. 33 for the proximal value. For this example, we consider $J(\bm{y})=-\left\|{\bm{y}}\right\|_{1}$ . Let $n=1$ for simplicity and consider the one-dimensional problem
$$
S(x,t)=\min_{y\in\mathbb{R}}\left\{\frac{1}{2t}(x-y)^{2}-|y|\right\}. \tag{31}
$$
The function $y\mapsto(x-y)^{2}/2t-|y|$ is differentiable everywhere except at $y=0$ . A stationary point of this function satisfies
$$
0\in\frac{y-x}{t}-\partial|y|\iff x\in\begin{cases}x-t,&\ \text{if $y<0$,}\\
[x-t,x+t]&\ \text{if $y=0$},\\
x+t,&\ \text{if $y>0$.}\end{cases}
$$
If $x>t$ , the only minimum is $x+t$ , in which case we have
$$
S(x,t)=\frac{1}{2t}(x+t-x)^{2}-|x+t|=\frac{t}{2}-(x+t)=-\frac{t}{2}-x.
$$
If $0<x\leqslant t$ , there are two local minimums, $0$ and $x+t$ , but the global minimum is attained at $x+t$ , again yielding $S(x,t)=\frac{t}{2}-x$ . If $x=0$ , we have three local minimums: $-t$ , $0$ , and $t$ . The global minimum is attained at either $-t$ or $t$ , yielding $S(0,t)=-\frac{t}{2}$ . If $-t\leqslant x<0$ , there are two local minimums, $0$ and $x-t$ , but the global minimum is attained at $x-t$ , yielding $S(x,t)=-\frac{t}{2}+x$ . If $x<-t$ , the only minimum is $x-t$ , in which case we have $S(x,t)-\frac{t}{2}+x$ . Hence
$$
S(x,t)=-\frac{t}{2}-|x|. \tag{32}
$$
In particular, its gradient in $x$ is given by
$$
\nabla_{x}S(x,t)\in\begin{cases}1&\ \text{if $x<0$},\\
[-1,1]&\ \text{if $x=0$},\\
-1&\ \text{if $x>0$}.\end{cases}
$$
Moreover,
$$
\operatorname*{arg\,min}_{y\in\mathbb{R}}\left\{\frac{1}{2t}(x-y)^{2}-|y|\right\}=\begin{cases}x-t&\ \text{if $x<0$},\\
[-t,t]&\ \text{if $x=0$},\\
x+t&\ \text{if $x>0$}.\end{cases} \tag{33}
$$
Table 4: Mean square errors of LPN $\psi$ and prior $J$ with 2 layers and 256 neurons in the negative $L_{1}$ norm examples.
| | Dimension | LPN ( $\psi$ ) | Prior ( $J$ ) |
| --- | --- | --- | --- |
| Mean Square Errors | 2D | $6.59E-5$ | $5.20E-6$ |
| 4D | $3.15E-4$ | $3.17E-5$ | |
| 8D | $2.12E-3$ | $2.94E-4$ | |
| 16D | $8.01E-3$ | $4.49E-2$ | |
| 32D | $1.55E-1$ | $2.29E-2$ | |
| 64D | $6.42E-4$ | $4.49E-3$ | |
<details>
<summary>exp_NegL1_prior_4D_LPN.png Details</summary>
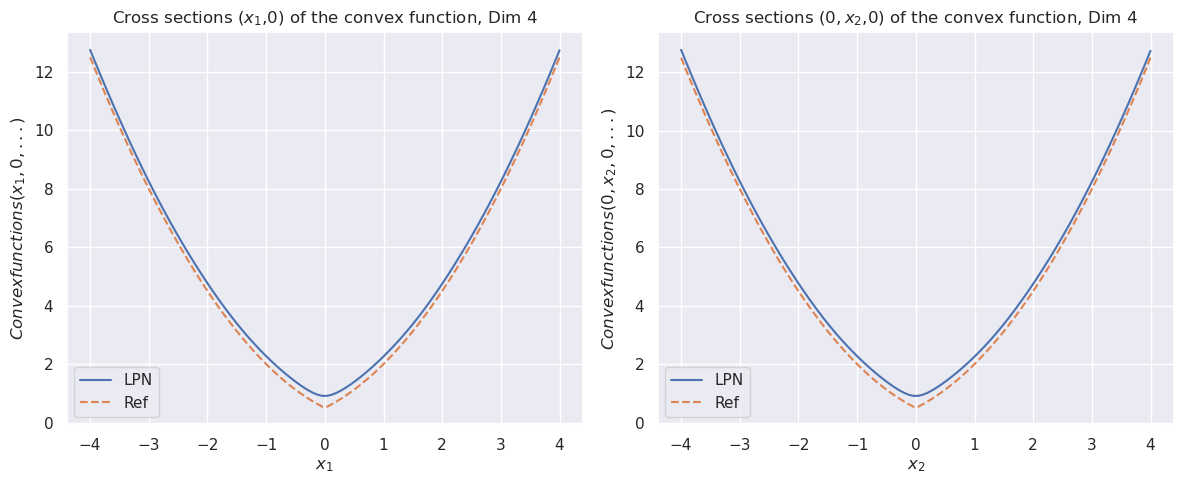
### Visual Description
## [Chart Type]: Dual Line Plots of Convex Function Cross-Sections
### Overview
The image displays two side-by-side line charts, each plotting a cross-section of a convex function in 4 dimensions. The charts compare two data series labeled "LPN" and "Ref" across a symmetric domain. The visual style is a standard scientific plot with a light grid background.
### Components/Axes
**Titles:**
- Left Plot: `Cross sections (x₁,0) of the convex function, Dim 4`
- Right Plot: `Cross sections (0, x₂,0) of the convex function, Dim 4`
**Axes:**
- **X-axis (Left Plot):** Labeled `x₁`. Scale ranges from -4 to 4, with major tick marks at integer intervals (-4, -3, -2, -1, 0, 1, 2, 3, 4).
- **X-axis (Right Plot):** Labeled `x₂`. Scale and ticks are identical to the left plot.
- **Y-axis (Both Plots):** Labeled `Convexfunctions(x₁, 0, ...)` (left) and `Convexfunctions(0, x₂, 0, ...)` (right). Scale ranges from 0 to 12, with major tick marks at intervals of 2 (0, 2, 4, 6, 8, 10, 12).
**Legend (Bottom-Left of each plot):**
- **LPN:** Represented by a solid blue line.
- **Ref:** Represented by a dashed orange line.
### Detailed Analysis
**Data Series Trends:**
Both plots show two U-shaped, symmetric curves centered at x=0, characteristic of a convex function.
1. **Left Plot (x₁ cross-section):**
- **LPN (Blue, Solid):** The curve has its minimum at approximately (0, 1.0). It rises symmetrically to a value of approximately 12.5 at x₁ = -4 and x₁ = 4.
- **Ref (Orange, Dashed):** The curve has its minimum at approximately (0, 0.5). It rises symmetrically to a value of approximately 12.5 at x₁ = -4 and x₁ = 4.
- **Relationship:** The LPN curve is consistently above the Ref curve across the entire domain. The vertical offset is greatest at the minimum (≈0.5 units) and diminishes to near zero at the extremes (x=±4).
2. **Right Plot (x₂ cross-section):**
- The trends, shapes, and numerical values are visually identical to the left plot. The LPN curve (min ≈1.0) sits above the Ref curve (min ≈0.5), with both converging at the boundaries (x₂=±4, y≈12.5).
**Spatial Grounding & Value Confirmation:**
- The legend is positioned in the bottom-left corner of each plot's axes area.
- The blue solid line (LPN) is the upper curve in both plots.
- The orange dashed line (Ref) is the lower curve in both plots.
- The minimum point for both series occurs precisely at x=0 on the horizontal axis.
### Key Observations
1. **Systematic Offset:** There is a consistent, positive vertical offset between the LPN approximation and the Reference function across both cross-sections.
2. **Shape Preservation:** Despite the offset, the LPN curve perfectly preserves the convex, symmetric shape of the Reference function.
3. **Convergence at Extremes:** The two curves converge as the absolute value of the input variable increases, suggesting the approximation error is largest near the function's minimum.
4. **Identical Cross-Sections:** The behavior of the function is identical along the x₁ and x₂ axes (with other variables fixed at 0), indicating symmetry in the function's definition with respect to these variables.
### Interpretation
This figure demonstrates the performance of an approximation method (LPN) against a reference function (Ref) for a convex function in 4-dimensional space. The key takeaway is that the LPN method successfully captures the fundamental convex geometry and symmetry of the target function. However, it introduces a systematic bias, overestimating the function's value, particularly near its global minimum. The error is not uniform; it is most pronounced at the center of the domain and becomes negligible at the boundaries of the plotted region. This pattern suggests the approximation may be less reliable for tasks requiring high precision near the function's minimum, such as optimization, but is structurally sound for understanding the function's overall landscape. The identical nature of the two cross-sections implies the underlying function treats the first two dimensions equivalently.
</details>
<details>
<summary>exp_NegL1_prior_8D_LPN.png Details</summary>
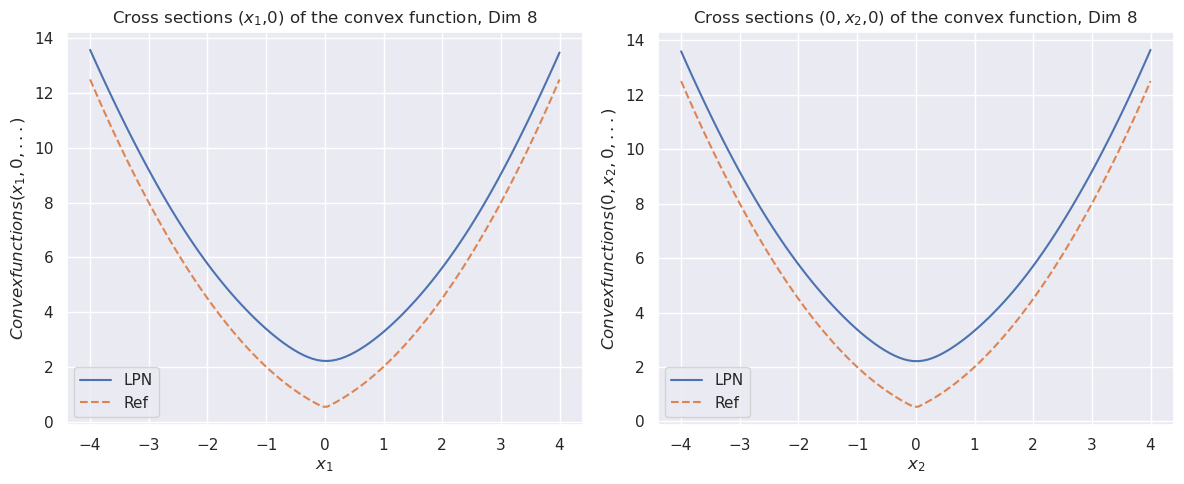
### Visual Description
## Cross-Sectional Analysis of a Convex Function in 8 Dimensions
### Overview
The image displays two side-by-side line charts, each showing a cross-sectional view of a convex function in an 8-dimensional space. The left chart plots the function's value along the first dimension (`x₁`), while the right chart plots it along the second dimension (`x₂`). Both charts compare two different functions or models: "LPN" (solid blue line) and "Ref" (dashed orange line).
### Components/Axes
**Common Elements (Both Charts):**
* **Chart Type:** Line chart with two data series.
* **Legend:** Located in the bottom-left corner of each plot area.
* **LPN:** Solid blue line.
* **Ref:** Dashed orange line.
* **Y-Axis:**
* **Label:** `Convexfunctions(x₁, 0, ...)` (left chart) and `Convexfunctions(0, x₂, 0, ...)` (right chart). The ellipses (`...`) indicate the function depends on additional dimensions not being varied in the cross-section.
* **Scale:** Linear, ranging from 0 to 14. Major tick marks are at intervals of 2 (0, 2, 4, 6, 8, 10, 12, 14).
* **Grid:** A light gray grid is present in the background of both plots.
**Left Chart Specifics:**
* **Title:** `Cross sections (x₁,0) of the convex function, Dim 8`
* **X-Axis:**
* **Label:** `x₁`
* **Scale:** Linear, ranging from -4 to 4. Major tick marks are at integer intervals (-4, -3, -2, -1, 0, 1, 2, 3, 4).
**Right Chart Specifics:**
* **Title:** `Cross sections (0, x₂,0) of the convex function, Dim 8`
* **X-Axis:**
* **Label:** `x₂`
* **Scale:** Linear, ranging from -4 to 4. Major tick marks are at integer intervals (-4, -3, -2, -1, 0, 1, 2, 3, 4).
### Detailed Analysis
**Left Chart (Varying `x₁`):**
* **Trend Verification:** Both the LPN and Ref lines form symmetric, upward-opening parabolas centered at `x₁ = 0`. The Ref line has a sharper, more pronounced minimum.
* **LPN (Solid Blue Line) Data Points (Approximate):**
* At `x₁ = -4`: y ≈ 13.5
* At `x₁ = -2`: y ≈ 6.0
* At `x₁ = 0` (Minimum): y ≈ 2.2
* At `x₁ = 2`: y ≈ 6.0
* At `x₁ = 4`: y ≈ 13.5
* **Ref (Dashed Orange Line) Data Points (Approximate):**
* At `x₁ = -4`: y ≈ 12.5
* At `x₁ = -2`: y ≈ 4.0
* At `x₁ = 0` (Minimum): y ≈ 0.5
* At `x₁ = 2`: y ≈ 4.0
* At `x₁ = 4`: y ≈ 12.5
**Right Chart (Varying `x₂`):**
* **Trend Verification:** The trends are visually identical to the left chart. Both lines form symmetric parabolas centered at `x₂ = 0`, with the Ref line having a sharper minimum.
* **LPN (Solid Blue Line) Data Points (Approximate):**
* At `x₂ = -4`: y ≈ 13.5
* At `x₂ = -2`: y ≈ 6.0
* At `x₂ = 0` (Minimum): y ≈ 2.2
* At `x₂ = 2`: y ≈ 6.0
* At `x₂ = 4`: y ≈ 13.5
* **Ref (Dashed Orange Line) Data Points (Approximate):**
* At `x₂ = -4`: y ≈ 12.5
* At `x₂ = -2`: y ≈ 4.0
* At `x₂ = 0` (Minimum): y ≈ 0.5
* At `x₂ = 2`: y ≈ 4.0
* At `x₂ = 4`: y ≈ 12.5
### Key Observations
1. **Symmetry:** Both functions (LPN and Ref) are symmetric about the origin (`x=0`) in both cross-sections.
2. **Convexity:** Both functions are convex, as evidenced by their upward-curving, parabolic shape.
3. **Minimum Value Discrepancy:** The "Ref" function has a significantly lower minimum value (≈0.5) compared to the "LPN" function (≈2.2) at the center of the cross-section (`x=0`).
4. **Growth Rate:** The "Ref" function grows more steeply away from the minimum than the "LPN" function. This is visible in the steeper slopes of the dashed orange line.
5. **Identical Behavior:** The cross-sectional behavior along `x₁` and `x₂` is virtually identical for both functions, suggesting a high degree of symmetry in the full 8-dimensional function.
### Interpretation
This visualization compares the cross-sectional profiles of two convex functions, likely a learned model ("LPN") and a reference or ground-truth function ("Ref"), in an 8-dimensional space.
* **What the data suggests:** The "LPN" model successfully captures the overall convex shape and symmetry of the reference function. However, it does not perfectly match the reference. The key differences are:
* **Offset Minimum:** The LPN model's minimum is higher than the reference's, indicating a systematic bias or offset at the function's lowest point.
* **Curvature Difference:** The LPN model has a slightly broader, less steep curvature. This suggests it may be a smoothed or regularized approximation of the sharper reference function.
* **How elements relate:** The side-by-side comparison of two different cross-sections (`x₁` and `x₂`) is used to demonstrate that the observed relationship between LPN and Ref is consistent across different dimensions, reinforcing the conclusion that the differences are characteristic of the model's approximation, not an artifact of a single slice.
* **Notable Anomalies:** There are no outliers in the traditional sense, as the curves are smooth. The primary "anomaly" is the consistent vertical offset and curvature difference between the two models, which is the central finding of the visualization. This is a common pattern in machine learning, where a trained model (LPN) approximates but does not perfectly replicate a target function (Ref).
</details>
Figure 5: The cross sections of the convex function $\psi(x)$ for dimension $4$ (left) and $8$ (right).
The Tables 1, 2, 3, and 4 quantify the scalability of the LPN approach across dimensions ranging from $2$ D to $64$ D. The results indicate that the method performs with high accuracy in lower dimensions ( $2$ D through $8$ D), achieving mean square errors in the range of $10^{-7}$ to $10^{-4}$ . However, performance degrades slightly as the dimensionality increases, particularly at $16$ D and $32$ D, where the error spikes to a range of $10^{-3}$ and $10^{-1}$ . The higher dimensions did not work too well, which might be because we did not train for long enough and also used a simple architecture (which ought to be more intricate for the higher dimensional problems). While the error for the recovered prior $J$ is generally slightly higher than that of LPN $\psi$ , this is expected given the added complexity of recovering the non-convex, non-smooth, or concave functions. However, the errors generally remain low, validating our method’s effectiveness even in high-dimensional spaces.
The top rows of Figures 1, 2, 3 and Figure 5 demonstrate that the LPN accurately learns the cross sections of the convex function $\psi(x)$ for dimension $4,8,$ and $32$ , closely matching the reference function with the most significant variation in Figure 3 corresponding to dimension $32$ . The bottom row of these figures compares the “invert LPN” (left) method and our trained second LPN method (right). It is clear that in all cases, our direct method recovers the original non-smooth prior, as indicated by the sharp V-shaped reconstructions in Figure 1, the non-convex prior Figures 2 and 3, and quadratic concave prior Figure 4 despite its challenging nature.
Figure 5 represents the cross-sections of the LPN value function against the ground truth for dimensions $4$ (left) and $8$ (right). In both instances, the LPN-approximation curves exhibit a tight fit to the analytical reference, capturing the characteristic V-shape more closely and the non-smooth geometry of the underlying function. The errors for $64$ dimensions in all the examples are consistently lower than expected. In contrast, it does not yield a good visual approximation of the cross sections. We are unable to explain the reason for this behaviour in $64$ D cases yet; however, we think it is probably due to the way we sample the hypercube.
## 6 Discussion
In this work, we leveraged the theory of viscosity solutions of HJ PDEs to develop novel deep learning numerical methods to learn, from data, the underlying prior of the proximal operator Eq. 2 yielding $(\bm{x},t)\mapsto S(\bm{x},t)$ defined in Eq. 1. Our approach built on the existing connections between proximal operators and HJ PDEs, crucially the fact that $(\bm{x},t)\mapsto S(\bm{x},t)$ is obtained from the solution to an HJ PDE, and in particular on the theory for the inverse problem for HJ equations. As discussed in Section 3, the theory for the inverse problem for HJ equations show that while there may be infinitely many priors that can recover Eq. 1, there is a natural choice, obtained by reversing the time in the HJ PDE Eq. 14 and using the value of the proximal operator $(\bm{x},t)\mapsto S(\bm{x},t)$ as initial condition. The resulting backward viscosity solution yields a prior $J_{\text{BVS}}$ that can reconstruct the $(\bm{x},t)\mapsto S(\bm{x},t)$ and also that is semiconvex. We considered the case where only samples of the proximal operators and its values were available in Section Section 4, and used techniques from max-plus algebra to derive some characterizations and errors property of $J_{\text{BVS}}$ with respect to convex functions approximating it from above. Finally, in Section 5 we proposed to learn the prior $J_{\text{BVS}}$ by training a convex neural network, specifically a learned proximal network, on a function of the form $\bm{y}\mapsto\tilde{J}(\bm{y})+\frac{1}{2}\left\|{\bm{y}}\right\|_{2}^{2}$ from data $\{\bm{x}_{k},S(\bm{x}_{k},t),\nabla_{\bm{x}}S(\bm{x}_{k},t)\}_{k=1}^{K}$ via Eq. 17. We presented several numerical results that demonstrate the efficiency of our proposed method in high dimensions.
While this work focused on proximal operators, we expect our approach can be extended to a broad class of Bregman divergences, as recent results in the theory of inverse problems for HJ equations suggest [esteve2020inverse]. Another potential direction would be in the case where the value of the proximal operator $(\bm{x},t)\mapsto S(\bm{x},t)$ is known to learn the prior $J$ using Monte Carlo sampling strategies, as recently proposed in [park2025neural] for the forward problem of HJ equations (i.e., learning $(\bm{x},t)\mapsto S(\bm{x},t)$ from known $J$ ). In the longer term, it would be interesting to devise similar deep learning methods for the inverse problem of HJ equations with possibly time- or state-dependent Hamiltonians, relevant to optimal control problems.
## Appendix A Calculations
### A.1 Formal calculation of Eq. 19
We have
| | $\displaystyle\inf_{\bm{y}\in\mathbb{R}^{n}}$ | $\displaystyle\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J_{\text{PAM}}(\bm{y})\right\}=\inf_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+\right.$ | |
| --- | --- | --- | --- |
### A.2 Formal calculation of Eq. 21
Formally, we have
$$
t\nabla_{\bm{y}}J_{\text{PQM}}(\bm{y})=\alpha(\bm{y}-\bm{y}_{k})+\bm{x}_{k}-\bm{y}
$$
for some $k\in\{1,\dots,K\}$ . Similarly,
| | $\displaystyle\hat{\bm{y}}=\operatorname*{arg\,min}_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J_{\text{PQM}}(\bm{y})\right\}$ | $\displaystyle\iff\bm{0}=\frac{\hat{\bm{y}}-\bm{x}}{t}+\frac{\alpha}{t}(\hat{\bm{y}}-\bm{y}_{k})+\frac{\bm{x}_{k}-\hat{\bm{y}}}{t}$ | |
| --- | --- | --- | --- |
In addition,
| | | $\displaystyle\bm{x}-\hat{\bm{y}}=\frac{\bm{x}_{k}-(1-\alpha)\bm{x}}{\alpha}-\bm{y}_{k}\implies\frac{1}{2t}\left\|{\bm{x}-\hat{\bm{y}}}\right\|_{2}^{2}=\frac{1}{2t\alpha^{2}}\left\|{\bm{x}_{k}-\bm{x}+\alpha(\bm{x}-\bm{y}_{k})}\right\|_{2}^{2},$ | |
| --- | --- | --- | --- |
and
| | $\displaystyle J_{\text{PQM}}(\hat{\bm{y}})$ | $\displaystyle=J(\bm{y}_{k})+\frac{1}{2t}\left\|{\bm{x}_{k}-\bm{y}_{k}}\right\|_{2}^{2}-\frac{1}{2t}\left\|{\bm{x}_{k}-\hat{\bm{y}}}\right\|_{2}^{2}+\frac{\alpha}{2t}\left\|{\hat{\bm{y}}-\bm{y}_{k}}\right\|_{2}^{2}$ | |
| --- | --- | --- | --- |
From this, we deduce
| | $\displaystyle\inf_{\bm{y}\in\mathbb{R}^{n}}\left\{\frac{1}{2t}\left\|{\bm{x}-\bm{y}}\right\|_{2}^{2}+J_{\text{PQM}}(\bm{y})\right\}$ | $\displaystyle=\frac{1}{2t\alpha^{2}}\left\|{\bm{x}_{k}-\bm{x}+\alpha(\bm{x}-\bm{y}_{k})}\right\|_{2}^{2}$ | |
| --- | --- | --- | --- |
for some $k\in\{1,\dots,K\}$ .