# CASCADE: Cumulative Agentic Skill Creation through Autonomous Development and Evolution
**Authors**: XuHuang, YuxingFei, ZhuohanLi
[3,4] Junwu Chen
[3,4] Philippe Schwaller
[1,2] Gerbrand Ceder
1]Department of Materials Science and Engineering, University of California, Berkeley, California, United States 2]Materials Sciences Division, Lawrence Berkeley National Laboratory, California, United States
3]Laboratory of Artificial Chemical Intelligence (LIAC), Institute of Chemical Sciences and Engineering, École Polytechnique Fédérale de Lausanne (EPFL), Lausanne, Switzerland 4]National Centre of Competence in Research (NCCR) Catalysis, École Polytechnique Fédérale de Lausanne (EPFL), Lausanne, Switzerland
## Abstract
Large language model (LLM) agents currently depend on predefined tools or early-stage tool generation, limiting their adaptability and scalability to complex scientific tasks. We introduce CASCADE, a self-evolving agentic framework representing an early instantiation of the transition from “LLM + tool use” to “LLM + skill acquisition”. CASCADE enables agents to master complex external tools and codify knowledge through two meta-skills: continuous learning via web search, code extraction, and memory utilization; self-reflection via introspection, knowledge graph exploration, and others. We evaluate CASCADE on SciSkillBench, a benchmark of 116 materials science and chemistry research tasks. CASCADE achieves a 93.3% success rate using GPT-5, compared to 35.4% without evolution mechanisms. We further demonstrate real-world applications in computational analysis, autonomous laboratory experiments, and selective reproduction of published papers. Along with human-agent collaboration and memory consolidation, CASCADE accumulates executable skills that can be shared across agents and scientists, moving toward scalable AI-assisted scientific research.
## 1 Introduction
Tool use is not a unique ability of humans; what distinguishes humans is the cumulative acquisition of skills [goodall1964tool, pargeter2019understanding, stout2017evolutionary]. Human technical culture advanced from opportunistic use of natural objects to the creation and mastery of sophisticated inventions, a transition from tool use to skill acquisition. This shift enabled specialized expertise to accumulate and transmit across generations, sustaining division of labor and cooperation at scale [migliano2022origins, tomasello2019becoming]. We argue that large language model (LLM) agents now stand at an analogous inflection point. Embracing this progression could offer a path toward self-evolving and adaptive agents [gao2025survey, jiang2025adaptation], thereby supporting truly autonomous and scalable agentic intelligence.
Under the prevailing “LLM + tool use” paradigm, many agents rely on custom-built wrappers and predefined action spaces envisioned by humans [schick2023toolformer, qin2024toolllm]. This design has enabled impressive progress across a range of applications, yet it also highlights an opportunity to further expand agents’ adaptability to increasingly complex tasks, where solving problems may require tools beyond those predefined at design time. Scalability represents a related challenge, as current agentic systems often depend on domain experts to manually curate detailed tool catalogs and task-specific prompts (Fig. 1 a, left). Recent efforts have begun to explore autonomous tool generation; however, such tools are typically constrained to Python’s built-in libraries and are often limited in scope [cai2024large, yuan2024craft]. Moreover, while agents can increasingly interact with external APIs, sometimes augmented by web search or preselected resources, mechanisms for sustained skill mastery, human–agent collaboration, and memory-based consolidation remain relatively underexplored [chenteaching, qiu2025alita, haque2025advanced, wangopenhands, tang2025autoagent, zheng2025skillweaver]. As a result, current automated tool-use pipelines, while effective in specific settings, remain at an early stage in the development of more robust, accurate, and self-evolving agentic capabilities, leaving substantial room for progress toward sophisticated and reusable skills.
As LLMs have become increasingly powerful in their reasoning and tool use capabilities, an expanding number of agentic systems focused on scientific discovery have emerged [m2024augmenting, boiko2023autonomous, ruan2024automatic, mcnaughton2024cactus, huang2025biomni, chai2025scimaster, swanson2025virtual, matinvent, Takahara2025, nduma2025crystalyse]. Most systems primarily excel at literature search, hypothesis generation, and data analysis [skarlinski2024language, ghareeb2025robin, mitchener2025kosmos], yet challenges remain in executing complex, long-horizon experiments, both computationally and physically. To function as true AI co-scientists, agents benefit from autonomous execution capabilities that close the loop, enabling self-validation and iteration of ideas through tool implementation. Existing efforts typically rely on predefined tools [zou2025agente, chandrasekhar2025automating] or implement early-stage approaches to tool generation [villaescusa2025denario, yao2025operationalizing, jin2025stella, liu2025mattools, wolflein2025llm, miao2025paper2agent, gao2025democratizing, orimo2025parc, zhou2025toward, du2025accelerating], with related limitations described in the literature [swanson2025virtual, haque2025advanced, chen2024scienceagentbench].
Here, we introduce CASCADE, an agentic framework facilitating AI co-scientists to develop cumulative executable skills. This framework represents an early instantiation of the transition from the “LLM + tool use” to “LLM + skill acquisition” paradigm, integrating multiple self-evolution mechanisms. Unlike traditional agentic systems that rely on problem-specific tools and prompts, CASCADE employs general problem-solving methodologies and mindsets to cultivate two meta-skills, continuous learning and self-reflection. Through natural language interfaces and multi-turn conversations, CASCADE lowers barriers to human-agent collaboration, allowing the agent to further evolve to solve more complex scientific problems. Additionally, it incorporates both session-wise memory, for referencing previous conversations, and consolidated memory, for retaining and retrieving key information, experience, and skill sets. These combined capabilities enable CASCADE to emulate human-like problem-solving behavior.
To evaluate CASCADE, we developed SciSkillBench, a comprehensive benchmark suite tailored for materials science and chemistry research. We conducted extensive baseline comparisons and ablation studies to validate CASCADE’s capabilities. We also evaluated CASCADE on specific research tasks, including determining materials’ piezoelectricity and analyzing systematic differences in predictions from machine learning interatomic potentials (MLIPs) [deringer2019machine] trained on datasets generated at different density functional theory (DFT) levels [geerlings2003conceptual]. Furthermore, we integrated CASCADE into an autonomous lab setting for real-world materials synthesis, characterization, and property measurement scenarios. CASCADE also successfully reproduced published results on Li intercalation voltages in rechargeable battery cathode materials [isaacs2020prediction]. These results demonstrate CASCADE’s ability to master complex external tools, codify knowledge and skills, and build sophisticated, reusable routines for human scientists, other agents, and scientific platforms [gao2025democratizing]. Notably, CASCADE’s predefined tools are entirely domain-agnostic, containing no materials science or chemistry specific components, and the system prompts do not instruct the use of any domain-specific tools. Through context engineering, this domain-agnostic design could enable rapid transfer to other fields requiring complex tool interaction, such as software engineering and biology [hua2025context, zhang2025agentic].
## 2 Results
### 2.1 CASCADE architecture
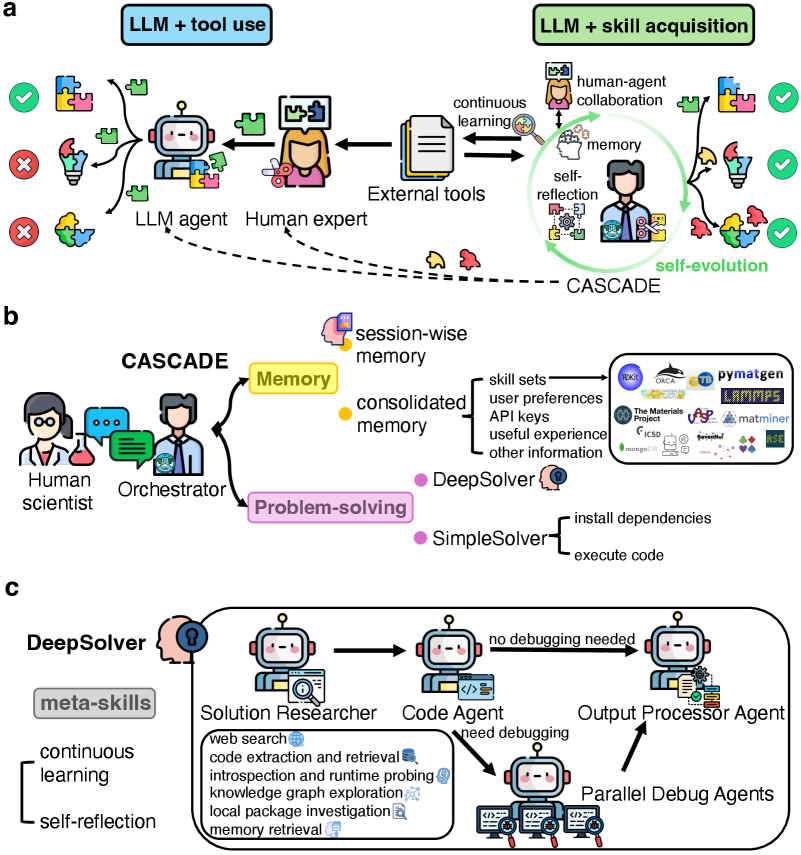
CASCADE is a self-evolving multi-agent system designed to function as an AI co-scientist by acquiring, refining and accumulating executable problem-solving skills over time (Fig. 1 a, right). As shown in Fig. 1 b, CASCADE comprises an Orchestrator agent that coordinates multi-turn dialogues with human scientists through an interactive web interface (Methods). The system supports persistent session management, enabling users to initiate new conversations or resume previous sessions with full memory context. Upon receiving a user query, the Orchestrator retrieves relevant information from consolidated memory containing skill sets, user-specific preferences, API credentials, and accumulated experiences. The Orchestrator then selects between two problem-solving pathways. For straightforward queries or tasks solvable via adapted prior solutions, the Orchestrator uses the SimpleSolver for rapid response and resource efficiency (Methods). SimpleSolver generates code, manages dependencies, and executes the code in an isolated environment. Successful executions return results directly; errors trigger escalation to DeepSolver. Complex problems bypass SimpleSolver entirely, proceeding directly to DeepSolver.
DeepSolver utilizes a four-step sequential workflow with conditional parallel debugging (Fig. 1 c). Step 1: the Solution Researcher conducts web searches, extracts and retrieves code examples from URLs, and generates an initial code solution. Step 2: the Code Agent installs missing software dependencies, and executes the code, determining if debugging is needed. Step 3: If execution fails, three Debug Agent instances run concurrently, each employing different debugging strategies. Step 4: the Output Processor Agent evaluates all results, selects the best solution, and formats the output appropriately. Throughout this workflow, DeepSolver exhibits two meta-skills: continuous learning and self-reflection. Continuous learning enables the agent to acquire targeted external knowledge in real time through web search and code extraction, while adaptively leveraging previously accumulated skills across tasks through its memory system. Self-reflection operates beyond basic self-debugging, allowing the agent to evaluate solution quality, reason about failures and past experiences, and adapt its problem-solving strategies through diverse introspective and diagnostic tools, including code introspection, runtime probing, knowledge graph exploration, and local package investigation, among others (Methods).
### 2.2 Evaluating DeepSolver on scientific tasks
DeepSolver is the key problem-solving engine that enables CASCADE to tackle real-world scientific research tasks. To rigorously assess its autonomous problem-solving capabilities, we evaluate DeepSolver with all memory tools disabled and without any human intervention. We create SciSkillBench, a diverse, carefully curated benchmark of 116 tasks for materials science and chemistry research. SciSkillBench also provides a reusable and automated evaluation suite for other agentic systems.
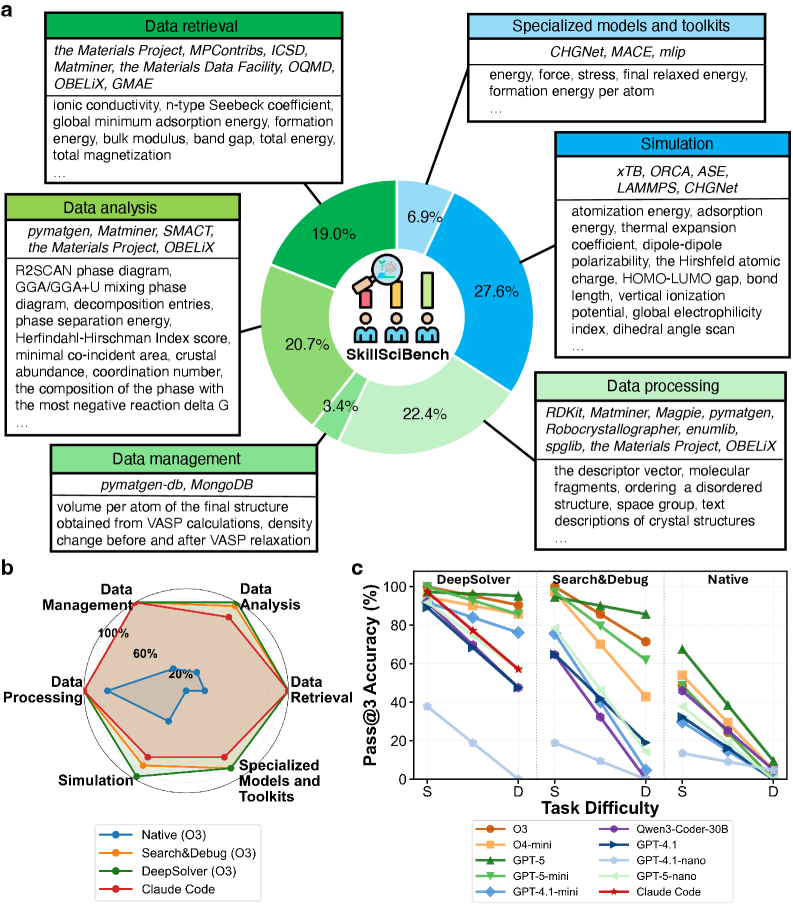
As shown in Fig. 2 a, SciSkillBench encompasses two primary types of tasks: (i) 76 data-oriented tasks, which include 22 data-retrieval problems, 24 data-analysis problems, 4 data-management problems, and 26 data-processing problems, and (ii) 40 computation-oriented tasks, which consist of 32 simulation problems and 8 specialized model and toolkit-related problems. For each of the six categories, we highlight the key databases, packages, and software utilized, along with examples of specific quantities that the tested system is required to acquire (Methods). The problems range from straightforward code adaptation and snippet stitching to undocumented queries that require strong scientific reasoning and exploratory coding, interaction with newly released packages or datasets absent from most model pre-training corpora, and navigation of outdated or misleading online documentation that can confuse agents. Many of these problems involve multiple external tools or different functions within a single tool, thus testing the agent’s ability to effectively identify and chain these tools/functions to solve the problems. More detailed examples of the benchmark tasks can be found in Appendix B.1, where we provide some SciSkillBench instances as well as additional tasks not included in SciSkillBench.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Collaborative LLM-Human System Architecture
### Overview
The image depicts a three-part technical architecture for a collaborative system integrating Large Language Models (LLMs), human expertise, and autonomous agents. It emphasizes skill acquisition, problem-solving, and continuous learning through human-agent collaboration.
### Components/Axes
#### Part a: LLM + Tool Use / LLM + Skill Acquisition
- **Key Elements**:
- **LLM Agent**: Interacts with external tools (e.g., puzzles, code snippets).
- **Human Expert**: Collaborates with the LLM agent, providing feedback (✓/✗ symbols).
- **External Tools**: Represented by puzzle pieces, code, and documents.
- **Memory**: Central to skill acquisition, with self-reflection and self-evolution loops.
- **Continuous Learning**: Arrows indicate iterative improvement.
- **Flow**:
- LLM agent uses tools → Human expert validates → Memory updates → Self-evolution.
#### Part b: CASCADE Framework
- **Key Elements**:
- **Human Scientist**: Oversees the system.
- **Orchestrator**: Manages workflow between agents.
- **Problem-Solving Agents**:
- **DeepSolver**: Handles complex tasks (e.g., code extraction, runtime probing).
- **SimpleSolver**: Executes basic tasks (e.g., code execution).
- **Memory**: Session-wise and consolidated memory.
- **User Preferences**: API keys, useful experiences.
- **Flow**:
- Human scientist → Orchestrator → Problem-solving agents → Memory integration.
#### Part c: DeepSolver Architecture
- **Key Elements**:
- **Meta-Skills**: Continuous learning, self-reflection.
- **Solution Researcher**: Performs web searches, code extraction, and runtime probing.
- **Code Agent**: Requires debugging (✗) or not (✓).
- **Output Processor Agent**: Finalizes results.
- **Parallel Debug Agents**: Handle debugging tasks.
- **Flow**:
- Solution Researcher → Code Agent → Output Processor Agent (with parallel debugging).
### Detailed Analysis
- **Part a**:
- The LLM agent’s tool use is validated by the human expert, with successful interactions (✓) and failures (✗).
- External tools (e.g., code, documents) feed into the LLM’s skill acquisition via memory and self-reflection.
- **Part b**:
- The CASCADE framework emphasizes memory consolidation and problem-solving hierarchies (DeepSolver for complex tasks, SimpleSolver for basic tasks).
- User preferences (API keys, experiences) guide the system’s behavior.
- **Part c**:
- DeepSolver integrates meta-skills (continuous learning, self-reflection) to autonomously resolve issues.
- The Solution Researcher handles knowledge graph exploration and local package investigation.
### Key Observations
1. **Human-AI Collaboration**: Human experts validate LLM outputs, ensuring accuracy and skill refinement.
2. **Memory-Centric Design**: Memory acts as a bridge between tool use, problem-solving, and skill acquisition.
3. **Autonomous Debugging**: Parallel Debug Agents in DeepSolver reduce reliance on human intervention.
4. **Hierarchical Problem-Solving**: Tasks are delegated to agents based on complexity (DeepSolver vs. SimpleSolver).
### Interpretation
This architecture demonstrates a symbiotic system where LLMs and humans co-evolve skills through iterative collaboration. The CASCADE framework ensures efficient problem-solving by leveraging memory and agent specialization, while DeepSolver’s meta-skills enable self-sufficiency in complex tasks. The emphasis on memory and self-reflection suggests a focus on long-term adaptability, positioning the system as a dynamic tool for technical workflows requiring both human insight and autonomous execution.
</details>
Figure 1: The “LLM + skill acquisition” paradigm and the CASCADE architecture. a, A puzzle-solving metaphor of the “LLM + tool use” versus the “LLM + skill acquisition” paradigm. On the left, agents rely on human experts to curate external tools. On the right, CASCADE showcases its ability to adeptly craft customized tools from complex external components, facilitating use by both human experts and LLM agents. b, The architecture of CASCADE. CASCADE facilitates multi-turn dialogues with human scientists through an interactive web interface, with persistent session management and consolidated memory in vector and graph databases. The Orchestrator agent within CASCADE selects between two solution pathways, the SimpleSolver or the DeepSolver, based on adaptable memory and task difficulty. c, DeepSolver architecture. DeepSolver coordinates four specialized agents that collaboratively solve complex tasks while autonomously acquiring new tools and skills. It follows a sequential workflow: the Solution Researcher generates the initial code solution; the Code Agent executes the code; if debugging is required, the Debug Agents intervene; and finally, the Output Processor Agent processes the results.
Out of all tasks, 58 are categorized as Level 0, which reflect scenarios where users can specify key functions or core procedural components, but prefer not to handle low-level implementation details or error recovery. The remaining 58 tasks are categorized as Level 1, in which only high-level objectives are provided, with limited procedural guidance, requiring greater autonomy from the agent. Overall, Level 0 and Level 1 tasks differ in how user queries are formulated, with Level 0 queries more closely resembling those posed by computational scientists and Level 1 queries resembling those typically posed by experimental scientists.
We benchmark the performance of DeepSolver on SciSkillBench against three baselines (Methods). The first baseline, referred to as Native, evaluates each LLM’s inherent capabilities without any self-evolution. In this scenario, the Solution Researcher generates code once, the Code Agent executes it once, and the Output Processor Agent returns the result. The second baseline, designated as Search&Debug Baseline (S&D), reflects recent advancements in tool-making agents that enhance LLMs with capabilities such as web search and self-debugging, sometimes providing only one of these functions [cai2024large, yuan2024craft, qiu2025alita, haque2025advanced, wangopenhands, tang2025autoagent, zheng2025skillweaver, villaescusa2025denario, yao2025operationalizing, jin2025stella, liu2025mattools, wolflein2025llm, miao2025paper2agent, gao2025democratizing, orimo2025parc, zhou2025toward]. In our implementation, we provide both search and debug functions to augment performance for this baseline. The Solution Researcher is enabled to conduct web search, while the Code Agent is required to engage in iterative self-debugging. For both of these baselines, as well as DeepSolver, we employ nine leading models as the LLMs for these multi-agent systems. These models include eight from OpenAI: GPT-5, GPT-5-mini, GPT-5-nano, O3, O4-mini, GPT-4.1, GPT-4.1-mini, and GPT-4.1-nano, in addition to one open-source model, Qwen3-Coder-30B-A3B-Instruct-FP8 (Qwen3-Coder-30B) [yang2025qwen3]. For the third baseline, we implement a Claude Code agentic system leveraging Anthropic’s Claude Agent software development kit (SDK), which invokes Claude Code CLI with all its built-in tools, including web search and self-debugging capabilities. We select Claude-Sonnet-4.5, Anthropic’s highest-performing coding model at the time of testing, as the LLM for this system to probe the reach and limit of one of the strongest commercial coding agents on SciSkillBench.
| Models | Metrics | All Questions (%) | 0-Level Questions (%) | 1-Level Questions (%) | Average Time (s) | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Native | S&D | DeepSolver | Native | S&D | DeepSolver | Native | S&D | DeepSolver | Native | S&D | DeepSolver | | |
| GPT-5 | Success Rate | 35.36 | 89.74 | 93.26 | 39.53 | 94.71 | 96.47 | 31.21 | 84.80 | 90.06 | 240 | 504 | 588 |
| Pass@1 | 32.76 | 90.52 | 93.97 | 39.66 | 94.83 | 96.55 | 25.86 | 86.21 | 91.38 | | | | |
| Pass@2 | 48.28 | 93.97 | 97.41 | 55.17 | 98.28 | 100.00 | 41.38 | 89.66 | 94.83 | | | | |
| Pass@3 | 53.45 | 94.83 | 98.28 | 60.34 | 98.28 | 100.00 | 46.55 | 91.38 | 96.55 | | | | |
| O3 | Success Rate | 23.05 | 80.76 | 91.84 | 26.59 | 85.88 | 97.70 | 19.54 | 75.72 | 85.80 | 153 | 352 | 407 |
| Pass@1 | 21.55 | 75.86 | 93.97 | 24.14 | 79.31 | 96.55 | 18.97 | 72.41 | 91.38 | | | | |
| Pass@2 | 29.31 | 89.66 | 98.28 | 34.48 | 96.55 | 100.00 | 24.14 | 82.76 | 96.55 | | | | |
| Pass@3 | 35.34 | 93.97 | 98.28 | 39.66 | 98.28 | 100.00 | 31.03 | 89.66 | 96.55 | | | | |
| O4-mini | Success Rate | 24.71 | 68.39 | 86.30 | 25.29 | 75.29 | 86.63 | 24.14 | 61.49 | 85.96 | 118 | 177 | 248 |
| Pass@1 | 24.14 | 62.93 | 82.61 | 24.14 | 67.24 | 84.48 | 24.14 | 58.62 | 80.70 | | | | |
| Pass@2 | 34.48 | 80.17 | 91.30 | 36.21 | 86.21 | 91.38 | 32.76 | 74.14 | 91.23 | | | | |
| Pass@3 | 37.93 | 84.48 | 94.78 | 39.66 | 91.38 | 96.55 | 36.21 | 77.59 | 92.98 | | | | |
| GPT-5-mini | Success Rate | 22.09 | 69.39 | 82.18 | 23.84 | 76.07 | 89.08 | 20.35 | 62.87 | 75.29 | 353 | 469 | 453 |
| Pass@1 | 18.97 | 71.55 | 83.62 | 20.69 | 82.76 | 91.38 | 17.24 | 60.34 | 75.86 | | | | |
| Pass@2 | 30.17 | 85.34 | 93.97 | 29.31 | 91.38 | 100.00 | 31.03 | 79.31 | 87.93 | | | | |
| Pass@3 | 34.48 | 88.79 | 97.41 | 37.93 | 93.10 | 100.00 | 31.03 | 84.48 | 94.83 | | | | |
| GPT-4.1-mini | Success Rate | 16.03 | 45.65 | 72.78 | 18.24 | 55.76 | 76.40 | 13.87 | 35.03 | 69.03 | 76 | 156 | 190 |
| Pass@1 | 15.52 | 42.61 | 70.69 | 15.52 | 51.72 | 74.14 | 15.52 | 33.33 | 67.24 | | | | |
| Pass@2 | 21.55 | 59.13 | 85.34 | 24.14 | 70.69 | 89.66 | 18.97 | 47.37 | 81.03 | | | | |
| Pass@3 | 23.28 | 64.35 | 89.66 | 27.59 | 77.59 | 93.10 | 18.97 | 50.88 | 86.21 | | | | |
| Qwen3-Coder -30B-A3B -Instruct-FP8 | Success Rate | 21.41 | 34.07 | 64.38 | 24.05 | 42.75 | 72.14 | 18.93 | 25.90 | 57.24 | 426 | 515 | 599 |
| Pass@1 | 20.87 | 35.29 | 65.22 | 22.81 | 41.18 | 70.69 | 18.97 | 29.41 | 59.65 | | | | |
| Pass@2 | 30.43 | 48.04 | 76.52 | 35.09 | 56.86 | 81.03 | 25.86 | 39.22 | 71.93 | | | | |
| Pass@3 | 37.39 | 52.94 | 80.00 | 43.86 | 62.75 | 82.76 | 31.03 | 43.14 | 77.19 | | | | |
| GPT-4.1 | Success Rate | 19.83 | 40.46 | 62.82 | 22.99 | 47.67 | 71.68 | 16.67 | 33.33 | 54.02 | 67 | 85 | 187 |
| Pass@1 | 18.97 | 42.24 | 63.79 | 18.97 | 46.55 | 67.24 | 18.97 | 37.93 | 60.34 | | | | |
| Pass@2 | 24.14 | 55.17 | 74.14 | 29.31 | 63.79 | 79.31 | 18.97 | 46.55 | 68.97 | | | | |
| Pass@3 | 27.59 | 57.76 | 81.03 | 34.48 | 67.24 | 87.93 | 20.69 | 48.28 | 74.14 | | | | |
| GPT-5-nano | Success Rate | 16.95 | 38.79 | 57.27 | 17.82 | 40.80 | 60.82 | 16.09 | 36.78 | 53.76 | 146 | 196 | 394 |
| Pass@1 | 16.38 | 38.79 | 62.93 | 13.79 | 37.93 | 63.79 | 18.97 | 39.66 | 62.07 | | | | |
| Pass@2 | 23.28 | 49.14 | 75.00 | 24.14 | 50.00 | 77.59 | 22.41 | 48.28 | 72.41 | | | | |
| Pass@3 | 28.45 | 61.21 | 81.90 | 32.76 | 67.24 | 84.48 | 24.14 | 55.17 | 79.31 | | | | |
| GPT-4.1-nano | Success Rate | 6.38 | 5.71 | 19.92 | 7.56 | 3.57 | 24.60 | 5.20 | 7.88 | 15.38 | 52 | 63 | 178 |
| Pass@1 | 5.17 | 6.03 | 22.81 | 5.17 | 5.17 | 31.03 | 5.17 | 6.90 | 14.29 | | | | |
| Pass@2 | 8.62 | 9.48 | 30.70 | 8.62 | 8.62 | 37.93 | 8.62 | 10.34 | 23.21 | | | | |
| Pass@3 | 12.07 | 10.34 | 32.46 | 13.79 | 8.62 | 39.66 | 10.34 | 12.07 | 25.00 | | | | |
| Claude Code Baseline | | | | | | | | | | | | | |
| Models | Metrics | All Questions (%) | 0-Level Questions (%) | 1-Level Questions (%) | Average Time (s) | | | | | | | | |
| Claude Code | Claude Code | Claude Code | Claude Code | | | | | | | | | | |
| Claude-Sonnet-4.5 | Success Rate | 82.47 | 90.23 | 74.71 | 239 | | | | | | | | |
| Pass@1 | 82.76 | 89.66 | 75.86 | | | | | | | | | | |
| Pass@2 | 87.07 | 91.38 | 82.76 | | | | | | | | | | |
| Pass@3 | 87.93 | 93.10 | 82.76 | | | | | | | | | | |
Table 1: Baseline comparison results. The upper section compares three systems (Native, Search&Debug (S&D), DeepSolver) across various models. The lower section shows Claude Code Baseline results using Claude-Sonnet-4.5. Success Rate represents the overall accuracy across all attempts, while Pass@k (k=1, 2, 3) indicates the proportion of questions with at least one correct answer among the first k attempts. Results are shown for all questions, as well as separately for 0-Level and 1-Level questions. Average time denotes the mean completion time per question in seconds. Bold values indicate the best performance for each model across the systems (Native, S&D, DeepSolver).
For each of the above agentic systems, we conduct three independent repetitions for each benchmark question (Methods). Table 1 presents the results for DeepSolver, Native, S&D, and Claude Code. It includes the overall success rate, the average run time, success rates for Level 0 and Level 1 questions, and pass@k accuracy (k=1, 2, 3) for all questions, Level 0, and Level 1. Here, pass@k accuracy means an answer is a “pass” if at least one of the first k responses is correct. From Table 1, we observe that CASCADE’s DeepSolver subsystem performs best across all comparisons. For nearly all agentic systems, the success rate for Level 0 questions consistently exceeds that for Level 1 questions. Even the most advanced models struggle without evolutionary mechanisms (Native), with the best overall success rate at only 35%. However, when models undergo effective evolution, particularly those models that can better understand our prompts and effectively utilize the general-purpose tools in DeepSolver, performance improvements are substantial. The highest overall success rate improvement is nearly 70% over Native with the O3 model. For Level 0 tasks, the GPT-5, O3, and GPT-5-mini models achieve 100% pass@2 accuracy using DeepSolver. This suggests potential for handling more complex Level 0 research tasks. Furthermore, DeepSolver shows considerable enhancements over S&D across all models, with an average improvement of 17.53% in overall success rate. Nevertheless, DeepSolver generally requires more time to output results compared to Native and S&D. Notably, when paired with GPT-4.1-mini, DeepSolver achieves higher overall Pass@3 accuracy than Claude Code Baseline (89.66% versus 87.93%) with shorter execution time (190 s versus 239 s), despite GPT-4.1-mini having approximately 7.5 times lower input cost and 9.4 times lower output cost than Claude-Sonnet-4.5 at the time of testing. This demonstrates that our agentic framework can effectively leverage less capable yet more economical models to achieve competitive or superior performance.
To further investigate the performance advantages of DeepSolver’s self-evolution compared to the Native, S&D, and Claude Code baselines, we assess each system’s efficacy across six task categories and two difficulty tiers (simple and difficult). In Fig. 2 b, we present the pass@3 accuracy across all questions by task category for DeepSolver, S&D, and Native (all using the OpenAI O3 model), alongside Claude Code. DeepSolver achieves the highest accuracy across all six categories, while S&D and Claude Code show gaps in simulation, data analysis, and specialized models and toolkits. Beyond category-level analysis, we examine how performance varies with task difficulty. Task difficulty is categorized using the P value which ranges from 0 to 1 [rezigalla2024item]. This metric represents the proportion of correct responses generated among all models, with higher values indicating easier tasks. Specifically, tasks are classified as simple if the P value is greater than or equal to 0.5 and as difficult if it is less than 0.5 (Methods). Examples are provided in Appendix B.1.3. In Fig. 2 c, we illustrate each system’s pass@3 accuracy relative to task difficulty. It is clear that for the same LLM (indicated by the same color and marker shape), the accuracy achieved using the DeepSolver framework generally exceeds that of the Native and S&D baselines for both simple and difficult tasks. Notably, as task difficulty increases, the decline in pass@3 accuracy for DeepSolver is markedly less pronounced compared to the baselines. Claude Code (red star) demonstrates commendable performance on simple tasks but experiences a significant accuracy drop with increasing difficulty. These findings support the notion that DeepSolver has a superior ability to effectively handle complex tools, which is a crucial trait for a scientist co-pilot. In contrast, baseline systems exhibit a rapid performance decline, indicating bottlenecks in problem-solving. For example, Qwen3-Coder-30B with S&D shows a zero pass rate on difficult tasks, whereas DeepSolver still achieves nearly 50%. GPT-4.1-nano’s performance approaches zero across all three systems on difficult tasks. This is mainly due to the model’s limited ability to follow prompts and effectively utilize our designed tools, hindering its self-evolution capabilities.
In addition to conducting baseline comparisons, we perform ablation studies to assess the effects of removing each meta-skill from the DeepSolver system, specifically continuous learning and self-reflection (Appendix B.2). As shown in Table B1 in Appendix B.2, we observe varied contributions of the meta-skills across different language models. Notably, we find that in most cases, equipping the agentic system with the self-reflection meta-skill alone can outperform the conventional approach of combining both web search and self-debugging methods.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Circular Diagram: SkillBench Workflow Breakdown
### Overview
A circular diagram illustrating the distribution of tasks in a materials science data processing workflow. The central "SkillBench" logo is surrounded by six labeled segments with percentages, representing different stages of the process.
### Components/Axes
- **Central Elements**:
- "SkillBench" logo with three human figures (two seated, one standing).
- A magnifying glass icon over the logo.
- **Segments**:
- **Data Retrieval (19.0%)**: Tools include *Materials Project, MPContribs, ICSD, Matminer, Materials Data Facility, OQMD, OBELiX, GMAE*.
- **Data Analysis (20.7%)**: Tools include *pymatgen, Matminer, SMACT, Materials Project, OBELiX*.
- **Data Management (22.4%)**: Tools include *pymatgen-db, MongoDB*.
- **Data Processing (27.6%)**: Tools include *RDKit, Matminer, Magpie, pymatgen, Robocrystallographer, enumlib, spglib, Materials Project, OBELiX*.
- **Simulation (19.0%)**: Tools include *xTB, ORCA, ASE, LAMMPS, CHGNet*.
- **Specialized Models and Toolkits (6.9%)**: Tools include *CHGNet, MACE, mlip*.
### Detailed Analysis
- **Textual Content**:
- Each segment lists specific tools/methods (e.g., "ionic conductivity, n-type Seebeck coefficient" under Data Retrieval).
- Data Processing includes descriptors like "molecular fragments, ordering a disordered structure, space group, text descriptions of crystal structures."
- **Percentages**:
- Data Processing (27.6%) is the largest segment, followed by Data Management (22.4%) and Data Analysis (20.7%).
- Simulation and Data Retrieval are tied at 19.0%, while Specialized Models and Toolkits are the smallest at 6.9%.
### Key Observations
- **Dominance of Data Processing**: The workflow emphasizes data processing, accounting for nearly 28% of the total.
- **Tool Overlap**: Tools like *Matminer, OBELiX, and Materials Project* appear in multiple segments, indicating cross-functional use.
- **Specialized Tools**: Only 6.9% of the workflow is dedicated to specialized models like *CHGNet* and *MACE*.
### Interpretation
The diagram highlights a workflow heavily focused on data-centric tasks (retrieval, analysis, management, and processing), with simulation and specialized tools playing smaller roles. The emphasis on data processing suggests a pipeline where raw data is transformed into actionable insights before simulation. The overlap of tools across stages implies integration and reuse, while the small percentage for specialized models may indicate emerging or niche applications.
---
## Radar Chart: Methodology Performance Across Tasks
### Overview
A radar chart comparing six methodologies (*Native, Search&Debug, DeepSolver, GPT-4.1, GPT-5, GPT-4.1-nano, GPT-5-nano, Claude Code*) across six tasks (*Data Retrieval, Data Analysis, Data Management, Data Processing, Simulation, Specialized Models and Toolkits*).
### Components/Axes
- **Axes**:
- Six tasks arranged in a hexagon (clockwise: Data Retrieval, Data Analysis, Data Management, Data Processing, Simulation, Specialized Models and Toolkits).
- Task difficulty labeled as *S* (easy) and *D* (difficult) on the radial axis.
- **Legend**:
- Colors correspond to methodologies (e.g., blue = Native, orange = Search&Debug, green = DeepSolver, etc.).
### Detailed Analysis
- **Performance Trends**:
- **DeepSolver** consistently performs best across most tasks, with high accuracy in Data Processing (90%+) and Simulation (80%+).
- **Claude Code** shows moderate performance, peaking in Data Management (~70%) but declining in Simulation (~40%).
- **GPT-5-nano** and **GPT-4.1-nano** exhibit lower accuracy, particularly in Simulation (<30%).
- **Task Difficulty**:
- Accuracy generally decreases from *S* to *D* for all methodologies, with steeper declines in harder tasks (e.g., Simulation drops from ~80% to ~40% for DeepSolver).
### Key Observations
- **DeepSolver Dominance**: Outperforms other methods in most tasks, especially in data-centric stages.
- **Claude Code’s Strength**: Excels in Data Management but struggles with Simulation.
- **GPT Variants**: Nano versions underperform compared to full models (e.g., GPT-5-nano vs. GPT-5).
### Interpretation
The radar chart reveals that *DeepSolver* is the most robust methodology, excelling in data processing and simulation. *Claude Code* is specialized for data management but less effective in simulation. The decline in accuracy with task difficulty suggests that complex tasks (e.g., Simulation) require more advanced or tailored approaches. The GPT variants’ lower performance highlights limitations in handling specialized or computationally intensive tasks.
---
## Line Graph: Pass@3 Accuracy vs. Task Difficulty
### Overview
A line graph comparing Pass@3 Accuracy across methodologies (*DeepSolver, Search&Debug, Native, GPT-4.1, GPT-5, GPT-4.1-nano, GPT-5-nano, Claude Code*) as task difficulty increases from *S* (easy) to *D* (difficult).
### Components/Axes
- **X-Axis**: Task difficulty (S → D).
- **Y-Axis**: Pass@3 Accuracy (%) ranging from 0% to 100%.
- **Legend**:
- Colors map methodologies to lines (e.g., green = DeepSolver, orange = Search&Debug, blue = Native, etc.).
### Detailed Analysis
- **Trends**:
- **DeepSolver**: Maintains high accuracy (~90% at *S*, ~60% at *D*), showing resilience to difficulty.
- **Search&Debug**: Declines sharply from ~80% (*S*) to ~50% (*D*).
- **Native**: Starts at ~70% (*S*) but drops to ~30% (*D*).
- **GPT-5**: Peaks at ~70% (*S*) but falls to ~40% (*D*).
- **Claude Code**: Starts at ~60% (*S*) and drops to ~20% (*D*).
- **Nano Models**:
- **GPT-4.1-nano** and **GPT-5-nano** show the steepest declines (e.g., GPT-5-nano drops from ~50% to ~10%).
### Key Observations
- **DeepSolver’s Consistency**: Outperforms all others across difficulty levels.
- **Nano Models’ Weakness**: Struggle significantly with harder tasks.
- **Claude Code’s Drop**: Largest accuracy decline (~40%) as tasks become harder.
### Interpretation
The graph underscores that *DeepSolver* is the most reliable methodology, maintaining high accuracy even in difficult tasks. *Claude Code* and *Native* methods degrade sharply with increased difficulty, suggesting they are less suited for complex workflows. The nano GPT models’ poor performance highlights the need for full-scale models in challenging scenarios. This data implies that task difficulty significantly impacts methodology effectiveness, with specialized tools like *DeepSolver* being critical for high-stakes applications.
---
**Note**: All textual content, percentages, and trends are extracted directly from the image. Uncertainties (e.g., exact values for overlapping lines) are inferred from visual trends.
</details>
Figure 2: Task diversity in SciSkillBench and performance analysis. a, Overview of the diverse tasks in SciSkillBench, comprising six categories. The associated databases, packages, and software for each category are listed, alongside example quantities that the benchmarked system is required to obtain. b, Pass@3 accuracy across all questions by task category for DeepSolver, Search&Debug, Native (all using the OpenAI O3 model), and Claude Code. c, Pass@3 accuracy against task difficulty on Level 1 questions (S = Simple, D = Difficult). Each model uses a distinct color and marker. Claude Code (red star) appears in the DeepSolver section.
### 2.3 CASCADE in action: from computational reasoning to laboratory automation
Beyond benchmark performance, we evaluate CASCADE’s capabilities across four distinct real-world research scenarios, each demonstrating a different aspect of the skill acquisition paradigm. These applications span from pure computational tasks to physical laboratory automation, and from zero-shot problem solving to memory-enhanced collaborative research. Together, they illustrate how CASCADE advances beyond traditional tool use toward a genuine scientific co-pilot capable of conducting end-to-end research workflows.
#### Automated scientific reasoning: piezoelectricity determination
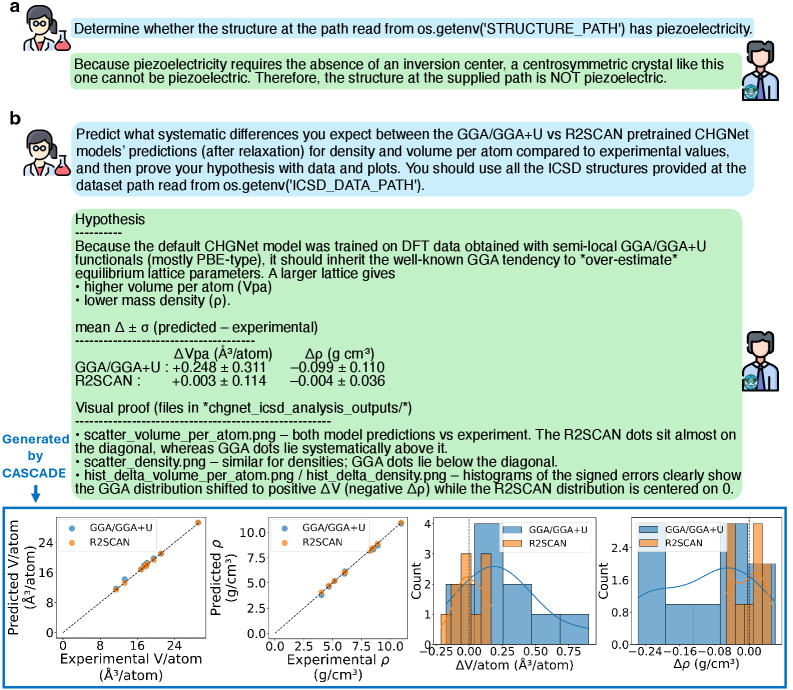
This scenario demonstrates how CASCADE adeptly solves problems independently through DeepSolver, leveraging the OpenAI O3 model without relevant memory or human instruction. As displayed in Fig. 3 a, CASCADE is tasked with determining whether a compound with a given crystal structure possesses piezoelectricity. The agent succeeded on its first attempt, autonomously selecting and applying the materials analysis package pymatgen [ong2013python] to identify the structure’s space group (I4/mmm), point group (4/mmm), and centrosymmetric nature, ultimately concluding that the structure cannot exhibit piezoelectricity. Notably, the agent’s logic goes beyond relying solely on centrosymmetry: it explicitly encodes symmetry-based exclusions for non-piezoelectric yet non-centrosymmetric point group 432, enabling robust determination across broader structural cases [gorfman2024piezoelectric]. Such corner cases may sometimes be overlooked by human scientists. This example demonstrates that when the agent has the ability to identify suitable external tools and robustly execute them, it can enhance its reasoning and yield reliable results.
#### Hypothesis-driven discovery: predicting systematic errors in MLIPs
In Fig. 3 b, CASCADE with the OpenAI O3 model is further evaluated with a task akin to the “Density prediction from MLIPs” section in a related article [huang2025cross]. At the time of testing this task, the relevant content had not yet been published online. Specifically, CASCADE is asked to predict systematic differences between the GGA/GGA+U and r 2 SCAN [perdew2001jacob, anisimov1991band] pretrained CHGNet models’ predictions for density and volume per atom, where CHGNet is an MLIP [deng2023chgnet]. Impressively, as shown in the dialogue in Fig. 3 b, also on its first attempt, CASCADE formulated a correct hypothesis, validating it through experiments and subsequent data analysis (Appendix B.3).
<details>
<summary>x3.png Details</summary>
### Visual Description
## Chart/Diagram Type: Comparative Model Performance Analysis
### Overview
The image contains two sections (a and b) with text-based reasoning and a multi-panel chart comparing predictions from GGA/GGA+U and R2SCAN models against experimental data. The chart includes scatter plots and histograms analyzing density (ρ) and volume per atom (Vpa) predictions.
### Components/Axes
#### Text Sections (a and b):
- **Section a**:
- Text: "Determine whether the structure at the path read from os.getenv('STRUCTURE_PATH') has piezoelectricity."
- Reasoning: Piezoelectricity requires absence of inversion centers; centrosymmetric crystals (like the one analyzed) cannot be piezoelectric.
- **Section b**:
- Text: "Predict systematic differences between GGA/GGA+U and R2SCAN pretrained CHGNet models for density and volume per atom."
- Hypothesis: GGA/GGA+U overestimates volume per atom (Vpa) and underestimates density (ρ) due to training on semi-local GGA functionals.
- Metrics:
- **GGA/GGA+U**: ΔVpa = +0.248 ± 0.311 ų/atom, Δρ = -0.099 ± 0.110 g/cm³
- **R2SCAN**: ΔVpa = +0.003 ± 0.114 ų/atom, Δρ = -0.004 ± 0.036 g/cm³
#### Chart:
- **Scatter Plots**:
- **Left Plot**: Predicted vs. experimental Vpa (ų/atom).
- Axes:
- X-axis: Experimental Vpa (ų/atom)
- Y-axis: Predicted Vpa (ų/atom)
- Legend:
- Blue: GGA/GGA+U
- Orange: R2SCAN
- **Right Plot**: Predicted vs. experimental ρ (g/cm³).
- Axes:
- X-axis: Experimental ρ (g/cm³)
- Y-axis: Predicted ρ (g/cm³)
- Legend:
- Blue: GGA/GGA+U
- Orange: R2SCAN
- **Histograms**:
- **Left Histogram**: Distribution of ΔVpa (predicted - experimental).
- X-axis: ΔVpa (ų/atom)
- Bins: Centered at -0.25 to +0.75 ų/atom.
- **Right Histogram**: Distribution of Δρ (predicted - experimental).
- X-axis: Δρ (g/cm³)
- Bins: Centered at -0.24 to +0.08 g/cm³.
### Detailed Analysis
#### Scatter Plots:
- **Vpa Plot**:
- GGA/GGA+U (blue) points lie systematically **above** the diagonal (overestimation).
- R2SCAN (orange) points cluster **near the diagonal** (closer to experimental values).
- **Density Plot**:
- GGA/GGA+U (blue) points lie **below** the diagonal (underestimation).
- R2SCAN (orange) points cluster **near the diagonal**.
#### Histograms:
- **ΔVpa Distribution**:
- GGA/GGA+U (blue) is centered at **negative ΔVpa** (overestimation).
- R2SCAN (orange) is centered at **ΔVpa ≈ 0**.
- **Δρ Distribution**:
- GGA/GGA+U (blue) is centered at **negative Δρ** (underestimation).
- R2SCAN (orange) is centered at **Δρ ≈ 0**.
### Key Observations
1. **Model Bias**:
- GGA/GGA+U systematically overestimates Vpa and underestimates ρ.
- R2SCAN predictions align closely with experimental values (ΔVpa ≈ 0, Δρ ≈ 0).
2. **Uncertainty**:
- GGA/GGA+U has larger uncertainties (e.g., ΔVpa ±0.311 vs. R2SCAN ±0.114).
3. **Visual Proof**:
- Scatter plots confirm R2SCAN’s accuracy (dots near diagonal), while GGA/GGA+U shows clear bias.
- Histograms highlight GGA’s tendency to shift distributions away from zero.
### Interpretation
- **Model Performance**:
- R2SCAN outperforms GGA/GGA+U in predicting structural properties, likely due to better training data or functional form.
- GGA’s overestimation of Vpa and underestimation of ρ may stem from its semi-local functional training.
- **Scientific Implications**:
- R2SCAN’s accuracy supports its use for high-precision predictions in materials science.
- GGA’s biases highlight the need for caution when using it for systems requiring precise density/volume data.
- **Anomalies**:
- No outliers in R2SCAN data; GGA/GGA+U shows consistent systematic errors.
### Spatial Grounding
- **Legend**: Top-right corner of the chart (blue = GGA/GGA+U, orange = R2SCAN).
- **Histograms**: Positioned below scatter plots, aligned with their respective axes.
- **Text Sections**: Above the chart, providing context for the analysis.
### Content Details
- **Textual Values**:
- ΔVpa (GGA/GGA+U): +0.248 ± 0.311 ų/atom
- Δρ (GGA/GGA+U): -0.099 ± 0.110 g/cm³
- ΔVpa (R2SCAN): +0.003 ± 0.114 ų/atom
- Δρ (R2SCAN): -0.004 ± 0.036 g/cm³
- **Chart Values**:
- Experimental Vpa range: ~0 to 25 ų/atom.
- Experimental ρ range: ~0 to 2.5 g/cm³.
### Key Observations (Reiterated)
- R2SCAN’s predictions are statistically closer to experimental values (smaller Δ values).
- GGA/GGA+U’s biases are visually evident in scatter plots and histograms.
### Interpretation (Reiterated)
- The data underscores the importance of model selection in computational materials science.
- R2SCAN’s performance suggests it captures electronic correlations better than GGA, critical for accurate property predictions.
- GGA’s limitations highlight the need for model refinement or alternative approaches for systems sensitive to density/volume errors.
</details>
Figure 3: Piezoelectricity determination and prediction of machine learning interatomic potential systematic errors. a, Determining whether a structure exhibits piezoelectricity. Given this task, CASCADE executed the necessary code and reached the correct conclusion. b, Hypothesis formulation, experimental execution, and data analysis of systematic differences in density and volume per atom predictions using machine learning interatomic potentials trained on different density functional theory (DFT) functional data. CASCADE not only provided a reasonable and accurate solution but also generated compelling visualizations, with the four plots from left to right being: scatter_volume_per_atom.png, scatter_density.png, hist_delta_volume_per_atom.png, and hist_delta_density.png.
#### Laboratory automation: autonomous synthesis and characterization
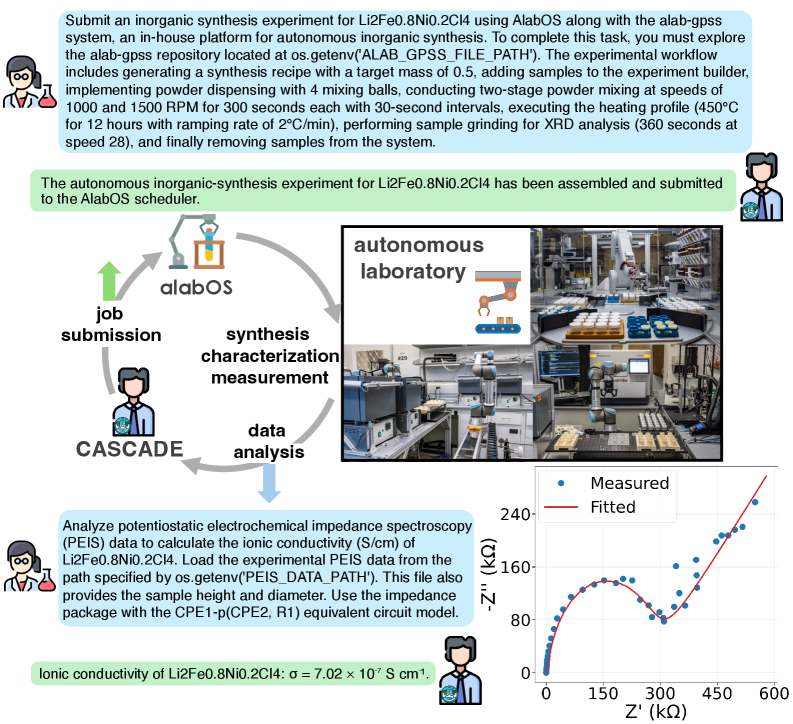
To test whether CASCADE can contribute to the autonomous laboratory discovery loop beyond utilizing data and computation-related tools, we engage it in an autonomous laboratory for the solid-state synthesis of inorganic powders [szymanski2023autonomous], specifically to complete the synthesis, characterization, measurement, and analysis of the compound Li 2 Fe 0.8 Ni 0.2 Cl 4, as illustrated in Fig. 4. CASCADE, utilizing the OpenAI O3 model without previously relevant memory or human instruction, is tasked to interact with AlabOS [fei2024alabos], i.e., an operating system that orchestrates the experiment flows and provides an API interface to submit experiments and check experiment status, and combine it with our in-house package, Alab-GPSS, that defines the workflows and helper functions to design experiments and submit to AlabOS. Since Alab-GPSS is proprietary software developed internally, it does not appear in the model’s training data, is not available online, and lacks any accompanying documentation. Thus, CASCADE has to learn how to use it on the fly by reading and interacting with the source code and file structures. During testing, a function designed for automatic stoichiometric balancing exhibited some issues. Upon detecting the error, CASCADE intelligently implemented a fallback solution by performing stoichiometric calculations directly to ensure proper reaction balancing and successful task completion. After several attempts, CASCADE successfully submitted the job to the platform. To ensure laboratory safety, we verified the generated code before activating the autonomous lab devices (Appendix B.3).
<details>
<summary>x4.png Details</summary>
### Visual Description
## Technical Document: Inorganic Synthesis Experiment Workflow and Data Analysis
### Overview
The image depicts a technical workflow for an autonomous inorganic synthesis experiment using the AlabOS platform and alab-gpss repository. It includes a flowchart of the experimental process, a graph of electrochemical impedance spectroscopy (EIS) data, and descriptions of laboratory automation. Key elements include synthesis parameters, data analysis steps, and a plot of ionic conductivity.
---
### Components/Axes
#### Text Blocks
1. **Experiment Submission Instructions**:
- Target: Li2Fe0.8Ni0.2Cl4 synthesis
- Workflow:
- Generate synthesis recipe with 0.5g target mass
- Implement powder dispensing (4 mixing balls, 1000/1500 RPM, 300s each)
- Two-stage mixing at 450°C (30s intervals, 12h total)
- Sample grinding for XRD (360s at 28°C/min)
- Sample removal
- Submission status: "The autonomous inorganic-synthesis experiment for Li2Fe0.8Ni0.2Cl4 has been assembled and submitted to the AlabOS scheduler."
2. **Data Analysis Instructions**:
- Analyze PEIS data to calculate ionic conductivity (S/cm)
- Load experimental PEIS data from `os.getenv('PEIS_DATA_PATH')`
- Use impedance package with CPE1-p(CPE2, R1) equivalent circuit model
- Result: Ionic conductivity of Li2Fe0.8Ni0.2Cl4: σ = 7.02×10⁻⁷ S/cm
#### Diagram (Flowchart)
- **Components**:
- Job submission (human icon)
- AlabOS platform (central node)
- Synthesis (flask icon)
- Characterization (microscope icon)
- Measurement (spectrometer icon)
- Data analysis (computer icon)
- Cascade system (loop arrow)
- **Flow**:
- Job submission → AlabOS → Synthesis → Characterization → Measurement → Data analysis → Cascade
#### Graph (EIS Data)
- **Axes**:
- X-axis: Z' (kΩ) [0–600]
- Y-axis: -Z'' (kΩ) [0–240]
- **Legend**:
- Blue dots: Measured data
- Red line: Fitted curve
- **Key Data Point**:
- Ionic conductivity: σ = 7.02×10⁻⁷ S/cm (annotated in text)
#### Laboratory Image
- **Components**:
- Robotic arms (blue/gray)
- Sample holders (yellow/orange)
- Automated equipment (conveyors, grinders)
- Control panels (monitors, buttons)
---
### Detailed Analysis
#### Text Blocks
- **Synthesis Parameters**:
- Target mass: 0.5g
- Mixing: 4 balls, 1000/1500 RPM, 300s per stage
- Temperature: 450°C (30s intervals, 12h total)
- Grinding: 360s at 28°C/min ramping
- **Data Analysis**:
- PEIS data path: `os.getenv('PEIS_DATA_PATH')`
- Sample dimensions: Height/diameter provided
- Circuit model: CPE1-p(CPE2, R1)
#### Graph
- **Trend**:
- Measured data (blue dots) shows a U-shaped curve with a minimum at ~200 kΩ
- Fitted curve (red line) closely follows the data, with slight deviations
- **Key Observation**:
- Ionic conductivity (σ) derived from EIS data: 7.02×10⁻⁷ S/cm
---
### Key Observations
1. The synthesis workflow emphasizes precision (e.g., 30s intervals, 2°C/min ramping).
2. The EIS graph shows a typical semicircular arc, indicating charge transfer resistance and diffusion processes.
3. The ionic conductivity value (7.02×10⁻⁷ S/cm) suggests moderate ionic mobility in the synthesized material.
---
### Interpretation
- **Workflow Integration**: The AlabOS platform automates synthesis and data collection, reducing human intervention. The Cascade system ensures iterative refinement.
- **Material Properties**: The ionic conductivity value (7.02×10⁻⁷ S/cm) indicates the material’s potential for applications requiring ion transport (e.g., batteries, sensors).
- **Data Validation**: The close match between measured and fitted EIS data validates the equivalent circuit model (CPE1-p(CPE2, R1)).
- **Automation Impact**: Robotic systems (e.g., powder dispensing, sample grinding) enable reproducibility and scalability of experiments.
---
### Notable Trends
- The EIS curve’s minimum at ~200 kΩ suggests optimal ionic conductivity at this frequency.
- The synthesis parameters (high temperature, prolonged mixing) likely enhance material homogeneity, reflected in the conductivity data.
</details>
Figure 4: CASCADE integrated into the autonomous lab materials discovery loop. CASCADE submitted the synthesis task for Li 2 Fe 0.8 Ni 0.2 Cl 4 to the autonomous lab (A-Lab) platform, allowing us to carry out the compound’s synthesis, characterization, and electrochemical impedance spectroscopy (EIS) measurements. The acquired experimental data were fitted using CASCADE to determine the ionic conductivity. The bottom right corner shows a Nyquist plot visualizing the quality of the data fitting performed by CASCADE.
Following the human executed measurement of the electrochemical impedance spectroscopy (EIS) for a sample with target composition of Li 2 Fe 0.8 Ni 0.2 Cl 4, the experimental data was provided to CASCADE, which then determined the ionic conductivity [yang2022ionic]. CASCADE successfully completed the task using the package called impedance [murbach2020impedance]. To verify the quality of the data fitting produced by CASCADE, we generated a Nyquist plot for inspection, shown in the lower right corner of Fig. 4, demonstrating a good fit. CASCADE’s algorithm is approximately 60-fold faster and achieves a slightly higher coefficient of determination ( $R^{2}$ ; 0.991 compared with 0.989) than our existing expert-written analysis code, yielding more accurate results. While we can continue to improve the analysis code manually, such improvements would require a considerable amount of time for parameter tuning (Appendix B.3).
Through these laboratory automation cases, we showcase CASCADE’s ability to rapidly adapt and learn within a novel and customizable research environment, highlighting its potential as a scientific co-pilot. This capability ensures that agentic systems are not only impressive in demonstrations but also genuinely beneficial for diverse real-world applications.
#### Collaborative research with memory: reproducing published battery calculations
The above demonstrations primarily focus on CASCADE’s capability to learn new knowledge and master tools through DeepSolver, thereby enhancing its reasoning and problem-solving abilities. The demonstrations presented in Fig. 5 illustrate that, beyond such inference-time self-evolution, human-agent collaboration and memory capabilities constitute vital components of CASCADE. These features enable CASCADE to evolve more rapidly, robustly, and reliably with guidance from human scientists and through the accumulation of skills, akin to the Compound Effect [hardy2011compound], ultimately allowing it to tackle more challenging problems.
In the multi-turn interaction system, CASCADE, utilizing the OpenAI O3 model, is designed to promptly identify areas requiring clarification or guidance from human scientists, and can even detect inconsistencies in user questions. For instance, when asked to generate a text description of the crystal structure of SiO 2 (mp-856) using Robocrystallographer [ganose2019robocrystallographer], CASCADE recognized that mp-856 corresponds to SnO 2, and proactively sought clarification instead of blindly executing the task.
In Fig. 5 a, CASCADE first identifies the MLIP we wish to employ from the up-to-date Matbench Discovery leaderboard [riebesell2025framework], then calculates the average Li intercalation voltage for Li x CoO 2 over $0<x<1$ and $0.5<x<1$ , utilizing the selected MLIP to obtain all energies. CASCADE significantly benefits from human guidance, such as learning that CoO 2 should be generated by delithiating the LiCoO 2 lattice rather than fetched from the Materials Project directly, and how to identify a suitable half-delithiated structure for energy calculations. CASCADE stores this experience in its memory for future use. In a new conversation, as shown in Fig. 5 b, CASCADE retrieves relevant information from its memory system and successfully extends the calculation to four SevenNet models [park2024scalable, kim2024data, barroso2024open], computes the additional $0<x<0.5$ range, and generates comparative plots, ultimately reproducing the Li x CoO 2 results from the second and fourth figure of the referenced article [isaacs2020prediction]. Instead of employing four distinct DFT functionals, we utilize four MLIPs to swiftly validate CASCADE’s memory retrieval and knowledge transfer capabilities (Appendix B.3).
<details>
<summary>x5.png Details</summary>

### Visual Description
## Chart/Diagram Type: Bar and Line Charts with Technical Conversation
### Overview
The image contains a technical conversation between two characters discussing machine learning interatomic potentials (MLIPs), specifically focusing on voltage calculations for LiCoO₂ and CoO₂ redox couples. It includes two charts:
1. **Bar Chart (Figure 4)**: Average voltage over 0 < x < 1 for four MLIP models.
2. **Line Chart (Figure 5)**: Average "half voltages" (0.5 < x < 1) for the same models, with experimental reference lines.
### Components/Axes
#### Bar Chart (Figure 4):
- **X-axis**: "Li fraction x in LiCoO₂" (0 to 1).
- **Y-axis**: "Average Voltage (V)" (0 to 4.5 V).
- **Legend**:
- **MF-ompa MPtrj+sAlex**: Blue bar (3.37 V).
- **MF-ompa OMat24**: Red bar (3.70 V).
- **MF-0 PBE(+U)**: Green bar (3.38 V).
- **MF-0 r²SCAN**: Purple bar (4.08 V).
- **Title**: "LiCoO₂ → CoO₂ + Li (Co3+/Co4+ couple)".
#### Line Chart (Figure 5):
- **X-axis**: "Li fraction x in LiCoO₂" (0 to 1).
- **Y-axis**: "Average Voltage (V)" (0 to 4.5 V).
- **Legend**:
- **MF-ompa MPtrj+sAlex**: Solid blue line (3.37 V).
- **MF-ompa OMat24**: Dashed blue line (3.70 V).
- **MF-0 PBE(+U)**: Solid orange line (3.38 V).
- **MF-0 r²SCAN**: Dashed orange line (4.08 V).
- **Experimental Reference Lines**:
- Solid black line at 4.21 V (Hubbard U').
- Dashed black line at 3.96 V (experimental average for LiₓCoO₂).
### Detailed Analysis
#### Bar Chart (Figure 4):
- **Data Points**:
- MF-ompa MPtrj+sAlex: 3.37 V.
- MF-ompa OMat24: 3.70 V.
- MF-0 PBE(+U): 3.38 V.
- MF-0 r²SCAN: 4.08 V.
- **Trends**:
- MF-0 r²SCAN shows the highest average voltage (4.08 V), while MF-0 PBE(+U) and MF-ompa MPtrj+sAlex are the lowest (3.38 V and 3.37 V, respectively).
#### Line Chart (Figure 5):
- **Data Points**:
- MF-ompa MPtrj+sAlex: 3.37 V.
- MF-ompa OMat24: 3.70 V.
- MF-0 PBE(+U): 3.38 V.
- MF-0 r²SCAN: 4.08 V.
- **Trends**:
- All models show consistent voltage values across the 0.5 < x < 1 range.
- Experimental reference lines (4.21 V and 3.96 V) are marked for comparison.
### Key Observations
1. **Model Performance**:
- MF-0 r²SCAN consistently predicts higher voltages than other models.
- MF-ompa MPtrj+sAlex and MF-0 PBE(+U) show the closest alignment with experimental data (3.96 V).
2. **Experimental Alignment**:
- The solid black line (4.21 V) and dashed black line (3.96 V) provide benchmarks for model accuracy.
3. **Consistency**:
- Voltage values for the 0.5 < x < 1 range (line chart) match the bar chart's 0 < x < 1 range, suggesting stable predictions across the composition window.
### Interpretation
- **Model Accuracy**: The MLIPs (e.g., MF-ompa, MF-0) demonstrate varying accuracy in predicting Li intercalation voltages. MF-0 r²SCAN overestimates voltages, while MF-ompa models align better with experimental data.
- **Experimental Relevance**: The 3.96 V reference line (dashed black) likely represents the experimental average for LiₓCoO₂, highlighting the importance of model calibration.
- **Technical Workflow**: The conversation emphasizes the use of SevenNet-MF-ompa for structural relaxation and voltage calculations, with Python scripts automating the process. The charts visualize the results, enabling comparison with experimental benchmarks.
- **Outliers**: The 4.08 V value for MF-0 r²SCAN stands out as significantly higher than other models, suggesting potential overestimation or unique model behavior.
### Notes on Data Extraction
- All values are extracted directly from the charts and conversation.
- Legend colors/styles are cross-verified with line/bar placements to ensure accuracy.
- Spatial grounding confirms the legend's position relative to the charts (e.g., top-right for the line chart).
- Experimental values (4.21 V and 3.96 V) are explicitly marked on the line chart, providing critical context for model evaluation.
</details>
Figure 5: Human-agent collaboration with memory capability for reproducing published content. a, Calculation of the average voltage. CASCADE computed the average Li intercalation voltage over $0<x<1$ and $0.5<x<1$ for Li x CoO 2 during multi-turn interactions with human scientists. b, Reproducing published work. CASCADE successfully calculated the average voltages over specified ranges for Li x CoO 2, using four SevenNet models. Then, it generated plots similar to those in the referenced article [isaacs2020prediction]. The bottom left plot is labeled average_voltage_models_labeled.png, and the bottom right plot is average_half_voltage.png.
## 3 Discussion
To enhance the effectiveness of LLM agents in assisting human scientific research, cultivating scientific reasoning is essential. Unlike text-based reasoning in mathematics and coding, scientific reasoning requires a deep understanding of complex external tools and their functionalities tailored to specific research objectives. This hands-on interaction with tools ensures that the agents’ reasoning is grounded, allowing them to refine and elevate their ideas through real-world experimentation. We introduce CASCADE, a self-evolving framework that cultivates and accumulates executable scientific skills. CASCADE represents an early embodiment of the dynamic and scalable “LLM + skill acquisition” paradigm, as opposed to the static and limited “LLM + tool use” paradigm. We also introduce SciSkillBench, a curated benchmark suite designed to fill the gap in evaluating agents’ or LLMs’ abilities to autonomously use a diverse range of tools for conducting materials science and chemistry research.
We systematically benchmark CASCADE’s key problem solver, DeepSolver, on SciSkillBench against three baselines and through ablation studies. DeepSolver achieves significantly higher accuracy with any tested LLM backbone and shows a slower performance decline as problem difficulty increases, indicating a stronger ability for inference-time self-evolution. We attribute these gains to two meta-skills: continuous learning and self-reflection, which balance agents’ plasticity and reliability. Additionally, we evaluate CASCADE’s performance in four real-world research scenarios. These demonstrations serve as proof-of-concept, showing that with thoughtful design, agents can autonomously traverse the end-to-end workflow, from literature search and hypothesis generation to experimental execution and data analysis, thus bridging the gap toward scientific reasoning through customizable computational and physical experiments.
Overall, CASCADE is designed to unlock the intelligence of LLMs by guiding them to adapt and evolve. In this process, they learn from up-to-date information, real-time failures, past experience, and human instructions. Notably, CASCADE is agnostic to specific research tools, questions, or scientific fields, facilitating easy transferability. The DeepSolver subsystem can also be integrated into other agentic systems to assist in skill creation and problem-solving.
The end-to-end agentic workflow reduces reliance on human input and grants agents greater freedom for autonomous exploration. However, it is still distant from achieving autonomous end-to-end discovery with truly novel insights. To achieve this goal, agents should iterate within this loop like human scientists, using trial and error along with optimization algorithms. As experience, data, and attempts accumulate, new discoveries may emerge.
To achieve long-horizon workflow iterations for new discoveries, the workflows agents create must be flexible and robust. To enhance systems like CASCADE, a promising direction is to explore efficient human-agent collaboration modes and improve agents’ memory capabilities, ensuring they can develop complicated yet reliable workflows. Another avenue is to strengthen the model’s inherent capabilities. While methods are documented in the literature, significant gaps remain between these theoretical descriptions and the practical challenges encountered during experiment execution in materials research. This hinders agents’ ability to reproduce previous work, let alone address new research questions without established references. Collecting data on how scientists approach simulation and experimental details in problem-solving would be valuable. This information could enhance agents’ abilities to execute and validate their ideas. Additionally, the complexity of research tasks and the flexibility in crafting tools could create challenges in identifying optimal tools and their appropriate application sequence within workflows, necessitating future investigation [ding2025scitoolagent].
Furthermore, skills developed within CASCADE or future frameworks can serve as learnable external tools shared by scientific discovery agents and human scientists, breaking down temporal and spatial barriers to collaboration. Based on this, more efforts could focus on facilitating flexible cooperation between agents and humans at a larger scale. Such initiatives could foster a collaborative community for scaling scientific discovery, enabling the accumulation, transmission, and redeployment of wisdom, thereby facilitating evolution from the individual to the collective level.
## 4 Methods
### 4.1 CASCADE architecture
#### 4.1.1 MCP servers and tools
Our system leverages four specialized Model Context Protocol (MCP) servers to provide comprehensive capabilities for web search, code research and introspection, code execution and workspace management, as well as memory consolidation and retrieval. These servers comprise the third-party Tavily MCP server alongside three custom-developed servers: the memory server, research server, and workspace server. Through these servers, agents gain access to 16 tools for problem-solving: save_to_memory, search_memory, tavily-search, extract_code_from_url, retrieve_extracted_code, check_installed_packages, check_package_version, install_dependencies, execute_code, quick_introspect, runtime_probe_snippet, parse_local_package, query_knowledge_graph, execute_shell_command, create_and_execute_script, read_file. In addition to MCP server interfaces, we provide equivalent direct function implementations that bypass MCP protocol overhead. See Appendix A for detailed descriptions of each MCP server and tool, as well as the underlying principles of our architecture design, which draws inspiration from how human scientists approach learning new tools and acquiring domain-specific skills.
#### 4.1.2 Conversational system with memory and tracing
The conversational system built with Streamlit serves as the human-agent natural language interface of CASCADE. Users authenticate via Supabase Auth, and all memory operations are scoped to individual user identifiers to maintain personalized knowledge bases across sessions. The system implements a feedback mechanism that allows users to indicate satisfaction (which triggers memory preservation), request improvements, continue with follow-up questions, or terminate the current problem-solving cycle.
For session-wise memory, multi-turn conversation state is maintained through a session management layer utilizing SQLiteSession from the OpenAI Agents SDK, which automatically persists dialogue history across multiple conversation turns. Users can bookmark important sessions by toggling a saved status, assign custom titles for easy identification, and attach notes.
For consolidated memory, the Orchestrator agent within CASCADE is able to use save_to_memory and search_memory when needed, and agents inside DeepSolver can use search_memory when they are generating solutions.
The Orchestrator agent functions as the central controller, employing a structured decision-making workflow. Upon receiving a user query, the Orchestrator first retrieves relevant memories including past solutions, user preferences, and domain-specific knowledge. It then evaluates query completeness and coherence. If critical information is missing or the request appears ambiguous, it directly prompts the user for clarification before proceeding. Once the query is deemed complete, the Orchestrator determines whether the problem should be handled by the SimpleSolver pathway (for straightforward tasks or those with high-confidence memory matches) or delegated to DeepSolver (for complex research or when SimpleSolver fails).
For observability and debugging, the system integrates MLflow [Zaharia_Accelerating_the_Machine_2018] tracing to automatically record complete agent execution hierarchies. Each conversation turn generates a trace capturing the Orchestrator’s actions such as memory storage and search, package installation and code execution, and DeepSolver invocation. When DeepSolver is invoked, the trace records the full internal workflow, including all agent phases and their respective inputs, outputs, execution times, and tool call details.
#### 4.1.3 SimpleSolver
SimpleSolver represents a quick solution pathway within the Orchestrator agent rather than a separate agent architecture. When the Orchestrator determines that a problem is straightforward or can be confidently addressed by adapting relevant solutions from memory, it directly executes the solution without invoking DeepSolver. The Orchestrator writes code based on its knowledge or adapted memory matches, then uses check_installed_packages to verify package availability, install_dependencies to install any missing packages, and execute_code to run the solution. If execution succeeds, the Orchestrator answers the user’s question based on the results. If execution fails, the problem is delegated to DeepSolver for comprehensive research and iterative debugging.
#### 4.1.4 DeepSolver
Each agent in DeepSolver leverages specific MCP servers or direct tools to accomplish their specialized tasks within the collaborative workflow.
Solution Researcher initiates the workflow by conducting comprehensive research to generate initial code solutions for the user query. It is designed to perform a systematic research process that typically involves: understanding the request, searching relevant memory using search_memory, searching for relevant information using tavily-search with advanced search parameters, identifying required software if not specified, extracting code examples from identified URLs using extract_code_from_url, reviewing and understanding additional requirements, and synthesizing the final solution. The agent uses retrieve_extracted_code for vector-based similarity search when the extracted content is overwhelming, and optionally employs quick_introspect to confirm exact import paths and class/method/function names. For complex problems without explicit step-by-step instructions, it is designed to plan and decompose tasks, select appropriate tools to achieve objectives, and learn how to use them effectively. The output includes the user identifier for memory search, original user query, required packages list, and complete code solution.
Code Agent receives the initial solution and executes it. It can optionally use search_memory to find relevant memory. It is designed to perform a five-step execution process: analyzing input, verifying solution requirements using research tools (tavily-search, extract_code_from_url, retrieve_extracted_code) if needed, managing packages through check_installed_packages and install_dependencies, executing code using execute_code, and evaluating results to determine if debugging is needed. The agent is asked to execute code exactly once without retries or self-debugging. The output includes the user identifier, original user query, executed code, execution output, and a boolean flag indicating whether debugging is needed.
Debug Agent instances run in parallel when the initial solution fails. The agents can optionally use search_memory to find relevant memory. They employ multiple debugging approaches after analyzing the error: Direct Fix for obvious errors; Introspection/Probe Fix using quick_introspect for import diagnostics and class/method/function discovery, and runtime_probe_snippet for resolving KeyError and AttributeError; Knowledge Graph Fix using check_package_version, parse_local_package, and query_knowledge_graph, which serves as the global exploration layer when Introspection/Probe Fix does not resolve the issue; Local Package Fix using execute_shell_command and create_and_execute_script to locate relevant files, and read_file for examining specific files such as package source code and simulation output files; Research Fix using tavily-search, extract_code_from_url, and retrieve_extracted_code for finding documentation and solutions, especially for non-Python command-line tools invoked via subprocess; Diagnostic Fix for writing diagnostic code to investigate error causes; and Result Processing Fix for modifying code to produce complete and processable results. The agents use execute_code to test fixes, and check_installed_packages and install_dependencies for package management. Each agent is encouraged to combine and flexibly employ different debugging approaches to maximize the likelihood and efficiency of successful problem resolution.
Output Processor Agent evaluates all available results and generates the final response. When debugging is needed, the agent receives three debug results and evaluates each based on successful execution, presence of required data, and quality of results. It then selects the best result, with preference given to identical outputs from multiple debug agents as they are more likely to be correct. When no debugging is needed, it processes the successful execution result directly. The output includes original user query, success status, final code, execution results, and processed output, where processed output contains the answer and analysis that addresses the user’s query.
### 4.2 Benchmark Evaluation of DeepSolver
#### 4.2.1 Benchmark tasks
SciSkillBench spans two principal categories: 76 data-oriented tasks and 40 computation-oriented tasks. Data tasks comprise (i) 22 data-retrieval problems from resources such as the Materials Project [horton2025accelerated], the Inorganic Crystal Structure Database (ICSD) [Bergerhoff_1983_ICSD], Matminer [ward2018matminer], MPContribs [huck2016user], the Materials Data Facility [blaiszik2016materials], OQMD [saal2013materials], OBELiX [therrien2025obelix] and GMAE [chen2025multi, chen2023adsgt, datasets_figshare]; (ii) 24 data-analysis problems that use packages and databases including pymatgen [ong2013python, richards2016interface, xiao2020understanding, gaultois2013data, bartel2020critical], Matminer, SMACT [davies2019smact], the Materials Project and OBELiX; (iii) 4 data-management problems with pymatgen-db [jain2013commentary] and MongoDB [bradshaw2019mongodb]; and (iv) 26 data-processing problems that rely on RDKit [landrum2013rdkit], Matminer, Magpie [ward2016general], Robocrystallographer, pymatgen, enumlib [hart2008algorithm, hart2009generating, hart2012generating, morgan2017generating], spglib [togo2024spglib], the Materials Project and OBELiX. Computation tasks include (v) 32 simulation problems with xTB [bannwarth2019gfn2], ORCA [neese2012orca], ASE [larsen2017atomic], LAMMPS [thompson2022lammps] and CHGNet [deng2023chgnet], together with (vi) 8 problems involving specialized models and toolkits such as CHGNet, MACE [batatia2022mace] and mlip [brunken2025machine].
#### 4.2.2 Baselines
For the three baselines, Native’s Solution Researcher operates without any tools and is designed to generate the code solution based solely on the knowledge of the underlying LLM. The Code Agent has access to execute_code, check_installed_packages, and install_dependencies to execute the code solution proposed by the Solution Researcher exactly once without debugging. Subsequently, the Output Processor Agent processes these results for automatic benchmark evaluation. In the S&D baseline, the Solution Researcher is enabled to conduct web searches through tavily-search, while the Code Agent performs iterative self-debugging using execute_code, check_installed_packages, and install_dependencies. The Claude Code baseline operates within Docker containers that reset after each run to ensure complete independence between test executions. Built on the Claude Agent SDK, this baseline grants the agent full access to Claude Code’s built-in capabilities, including file operations, code execution, and web search.
#### 4.2.3 Independent benchmark tests
For the evaluation of CASCADE, the three baselines, and the two ablation studies, we conducted independent benchmark tests across 46 system configurations. For each of the 116 benchmark tasks, we performed three independent repetitions per system configuration, resulting in a total of 16,008 experiments. To ensure complete isolation between experiments, each experiment was executed in a separate Python subprocess, and we cleared the Supabase database storing previously extracted code information and removed temporary files generated by agents from the previous experiment. Additionally, memory-based tools were disabled for all benchmark systems. For experiments using OpenAI’s GPT-5, GPT-5-mini, and GPT-5-nano models with the OpenAI Agents SDK, we configured the reasoning effort to “medium” and verbosity to “low” to balance accuracy against computational cost and latency. For experiments using open-source Qwen models, we deployed the models locally using vLLM with an OpenAI-compatible API interface [kwon2023efficient].
For accuracy evaluation, each benchmark task specifies the required output format and unit, which are communicated to the agent as part of the query. The agent’s processed output is then automatically compared against the ground truth answer within a predefined tolerance threshold. We set tolerance values according to the nature of each task: deterministic operations such as data retrieval use stringent tolerances approaching exact match, while computational simulations that inherently exhibit numerical variability use tolerances within acceptable ranges for the specific research task. This outcome-based evaluation assesses whether the agent produces correct final answers, though it does not guarantee the correctness of every intermediate step in the solution process. In the accuracy calculations, we excluded a small number of workflow failures such as instances when the LLM outputs invalid JSON that results in parsing errors.
#### 4.2.4 Task difficulty
To stratify benchmark questions by difficulty, we employed the P value (Item Difficulty), which denotes the proportion of models that correctly solved each Level 1 question. For each model-question pair, a question was considered solved if at least one of three independent attempts produced the correct answer (pass@3 criterion). We computed P values across 28 model configurations. Tasks were classified as simple if $P\geq 0.5$ and difficult if $P<0.5$ , yielding 37 Simple and 21 Difficult questions. Model performance was then evaluated separately for each difficulty category using pass@3 accuracy.
Data availability SciSkillBench is available at Figshare (https://doi.org/10.6084/m9.figshare.30924998).
Code availability The source code of CASCADE is available on GitHub at https://github.com/CederGroupHub/CASCADE.
Acknowledgements This work was primarily funded and intellectually led by the U.S. Department of Energy, Office of Science, Office of Basic Energy Sciences, Materials Sciences and Engineering Division under Contract No. DE-AC0205CH11231 (Materials Project program KC23MP). The work was also supported by the computational resources provided by the Extreme Science and Engineering Discovery Environment (XSEDE), supported by National Science Foundation grant number ACI1053575; the National Energy Research Scientific Computing Center (NERSC), a U.S. Department of Energy Office of Science User Facility located at Lawrence Berkeley National Laboratory; and the Swift Cluster resource provided by the National Renewable Energy Laboratory (NREL). Integrating this agentic system into the autonomous lab materials discovery loop was supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research and Office of Basic Energy Sciences, Scientific Discovery through the Advanced Computing (SciDAC) program under the FORUM-AI project. J.C. and P.S. acknowledge support from the NCCR Catalysis (grant number 225147), a National Centre of Competence in Research funded by the Swiss National Science Foundation. We sincerely thank all the researchers and developers who created and maintained the datasets, packages, and software tools utilized in this work.
Author contributions X.H., J.C. and P.S. conceived the initial idea. X.H. designed and developed the agentic system CASCADE. X.H. and J.C. curated the benchmark SciSkillBench; J.C. contributed xTB- , ASE- and ORCA-based tasks, while X.H. contributed the remaining tasks. X.H. benchmarked CASCADE’s DeepSolver against three baselines, conducted ablation studies, and performed additional evaluations of CASCADE. During the evaluation, Y.F. provided guidance on integrating CASCADE into the autonomous laboratory materials discovery loop, and Z.L. provided guidance on the average voltage calculation example. J.C., P.S., and G.C. offered insights and guidance throughout the project. All authors contributed to discussions and approved the final manuscript.
Competing interests The authors declare no competing interests.
Appendix
Table of Contents
## Appendix A CASCADE architecture
### A.1 MCP server infrastructure and tools
CASCADE leverages four specialized Model Context Protocol (MCP) servers to provide comprehensive capabilities for web search, code research and introspection, code execution and workspace management, as well as memory consolidation and retrieval.
Tavily MCP server
We use tavily-search, a search engine designed for AI agents, through the Tavily MCP server to provide real-time web search capabilities, enabling agents to discover relevant documentation, code examples, and implementation resources.
Memory server
Memory server employs mem0 [chhikara2025mem0] configured with a hybrid dual-store architecture combining vector-based semantic search and graph-based entity-relationship storage. For semantic retrieval, memories are stored in a Supabase-hosted PostgreSQL database. A Neo4j graph database captures entity relationships, such as materials, properties, computational tools, API methods and functions, and their interconnections. Memory extraction utilizes GPT-4o-mini as the underlying language model. The server exposes two tools: save_to_memory and search_memory. The save_to_memory tool employs a dual-path strategy: first, the language model adds, updates, or deletes memory guided by custom prompts for both vector and graph stores; second, the complete original content is preserved verbatim in the vector store without language model processing, ensuring no information loss while maintaining efficient semantic searchability. The search_memory tool retrieves relevant memories from both stores, returning semantic matches from the vector store alongside entity relationships from the graph store.
Research server
Research server implements a sophisticated code intelligence and knowledge discovery system that provides comprehensive capabilities for web code extraction, agentic RAG (retrieval-augmented generation), code introspection, runtime probing, and knowledge graph construction and exploration.
Code extraction and retrieval: The extract_code_from_url tool implements intelligent web crawling with multi-strategy extraction capabilities and caching mechanisms using Supabase database storage. The tool supports both single-page extraction and smart crawling strategies that recursively follow internal links with intelligent fallback mechanisms. It automatically detects content types and applies specialized extractors for different documentation systems, including Jupyter notebooks, ReadTheDocs/Sphinx and MkDocs documentation, raw code files from repositories, and markdown content with intelligent parsing of fenced code blocks and command examples. It also extracts relevant text before and after code blocks using intelligent paragraph boundary detection, providing semantic context for code understanding. Optional LLM-generated summaries for extracted code are also available. The retrieve_extracted_code tool implements vector-based similarity search over extracted code blocks using embeddings with configurable match count.
Code analysis: The quick_introspect tool implements static-first analysis using Jedi [halter2022jedi] for import resolution and error diagnosis without runtime execution. The tool provides comprehensive package, class, method, and function discovery with fuzzy matching capabilities. The runtime_probe_snippet tool provides ready-to-use code snippets for debugging runtime errors. When inserted at KeyError or AttributeError sites, these snippets display available keys/attributes, object type information, and similar name suggestions to help resolve these errors. The parse_local_package tool implements direct Neo4j knowledge graph construction from local Python packages using abstract syntax tree (AST) analysis. The tool extracts classes, methods, functions, attributes, and import relationships with detailed parameter information including type hints and default values. The query_knowledge_graph tool provides advanced querying capabilities for exploring repository structures, class hierarchies, method signatures, and code relationships in the knowledge graph using Cypher query language.
Workspace server
Workspace server provides a multi-environment code execution and management system. It supports conda, venv, and uv environments with cross-platform compatibility for Windows and Unix-like systems. The server prevents access to the directory containing benchmark tasks and results to avoid solution leakage and enforces security boundaries by confining all operations to the designated project root scope.
Package management: The check_installed_packages tool lists all installed packages in the current Python environment with version information and package count. The install_dependencies tool installs Python packages based on environment configuration. The check_package_version tool performs detailed package analysis including version detection, installation path resolution, and module location identification. The tool takes package names as input and handles name variations (hyphens, underscores, dots).
Code execution: The execute_code tool executes Python code in the configured environment. The tool saves code to temporary files in the code storage directory and executes with detailed output capture including stdout and stderr. The execute_shell_command tool executes shell commands with configurable working directory. The create_and_execute_script tool creates and executes shell scripts in the code storage directory.
File operations: The read_file tool reads content from text files. The save_file tool saves content to the designated directory for later reuse. In the CASCADE framework, however, the save_file tool is not utilized.
### A.2 Underlying principles of the architecture design
In designing CASCADE, we focused on how human scientists approach learning new tools and acquiring skills. Typically, they engage in deep thinking and experimentation to tackle problems, reflecting the role of the DeepSolver. This process may also involve discussions with others, akin to human-agent collaboration. Once they have mastered a new skill, they consolidate this experience into their memory.
Throughout the problem-solving process, much like DeepSolver, the first step is to act as Solution Researcher. Scientists perform online searches similar to those of agents using tavily-search. Their attention is directed towards key examples, paralleling the use of tools such as extract_code_from_url and retrieve_extracted_code. Initially, they may verify the existence of certain imports, classes, methods, or functions in their code based on hints provided by some Integrated Development Environments (IDEs), similar to the quick_introspect tool we developed for agents to mitigate the common issue of hallucinations in LLMs [ji2023survey].
After generating the initial solution, they move on to hands-on trials, which correspond to the tasks performed by the Code Agent. If errors arise, they engage in iterative refinements as Debug Agents would do. They start with local debugging approaches such as Introspection/Probe Fix, Direct Fix, or Diagnostic Fix. When these methods do not resolve the issue, they need to zoom out for broader rethinking and code exploration, employing Knowledge Graph Fix and Local Package Fix, and possibly continuing their online learning with Research Fix to deepen their understanding. After completing the task, they process and summarize the information to facilitate further consolidation, analogous to the Output Processor Agent.
During the tool and prompt design, we also consider context engineering to account for comprehensive situations, especially given that the agent’s performance may be inconsistent. For instance, when an agent fails to use a tool to achieve the desired outcome, a print message will remind the agent how to invoke the tool correctly or point out potential issues to consider. Additionally, it may suggest the next possible tool to use, such as query_knowledge_graph after parse_local_package.
## Appendix B Benchmark Evaluation of DeepSolver
### B.1 Benchmark tasks
#### B.1.1 SciSkillBench examples
Each benchmark task is defined as a JSON object with fields including user_query, sources, input_type, output_type, answer, absolute_tolerance, unit, solution_code_or_process, reference_link, official_documentation, and notes. In the examples below, we focus on the user_query field, which contains two difficulty levels: level 0 provides instructions with some function names, while level 1 presents a more concise query requiring the agent to determine the solution approach more independently.
1. Straightforward code adaptation from the documentation
⬇
{
" user_query ": {
"0": " Use the InstaDeepAI mlip library to run batched inference with a pre - trained MACE model on aspirin. First, download the model and example data from HuggingFace using snapshot_download with repo_id =’ InstaDeepAI / MLIP - tutorials ’ and allow_patterns =’ simulation /*’. Then, load the pre - trained MLIP model using load_model_from_zip from ’ simulation / example_model. zip ’, and run batched inference using run_batched_inference on the structures in ’ simulation / aspirin_batched_example. xyz ’ with a batch size of 8. Finally, output the energy and forces for the 1 st structure (index starts at 0).",
"1": " Use the InstaDeepAI mlip library to run batched inference with a pre - trained MACE model on aspirin. First, download the model and example data from HuggingFace using repo_id =’ InstaDeepAI / MLIP - tutorials ’ and allow_patterns =’ simulation /*’. Then, load the pre - trained MLIP model from ’ simulation / example_model. zip ’, and run batched inference on the structures in ’ simulation / aspirin_batched_example. xyz ’ with a batch size of 8. Finally, output the energy and forces for the 1 st structure (index starts at 0)."
},
...
}
2. Undocumented queries
⬇
{
" user_query ": {
"0": " What is the composition of the phase with the most negative reaction delta G (in kJ / mol) when Na2O and TiO2 react at 600 K? Use pymatgen ’ s GibbsComputedStructureEntry to help construct the phase diagram, and then use InterfacialReactivity to model an interface between Na2O and TiO2 to find all delta G of stable phases. Determine the one with the most negative delta G. Return a list in the order of composition string of the product phase and delta G value (in kJ / mol, rounded to 4 decimal places).",
"1": " What is the composition of the phase with the most negative reaction delta G (in kJ / mol) when Na2O and TiO2 react at 600 K? In this process you must construct a suitable phase diagram and use pymatgen ’ s built - in functionality to find the answer. Return a list in the order of composition string of the product phase and delta G value (in kJ / mol, rounded to 4 decimal places)."
},
...
}
⬇
{
" user_query ": {
"0": " Give me the absolute error (meV / atom, rounded to four decimal places) of the formation energy per atom of Ti3AlC2 (mp -3747) predicted by the pretrained R2SCAN CHGNet model after relaxing the structures (keep all parameters as default), compared with the R2SCAN formation energy per atom that you query from the Materials Project through materials. thermo. search. Note that the CHGNet model does not provide built - in formation energy calculation method so you must find and relax all related structures and then calculate the formation energy per atom. To obtain the structures of constituent elements, you can use materials. thermo. search (chemsys =[’ Ti ’,’ Al ’,’ C ’], is_stable = True, num_elements =(1,1), thermo_types =[’ R2SCAN ’], fields =[’ material_id ’]) to get the material ids, and then use get_structure_by_material_id to fetch the structures for relaxation using the model loaded via CHGNet. load (model_name =’ r2scan ’). Pay attention to the number of atoms in each structure, which is important for computing the formation energy per atom correctly.",
"1": " Give me the absolute error (meV / atom, rounded to four decimal places) of the formation energy per atom of Ti3AlC2 (mp -3747) predicted by the pretrained R2SCAN CHGNet model after relaxing the structures (keep all parameters as default), compared with the R2SCAN formation energy per atom that you query from the Materials Project. Note that the CHGNet model does not provide built - in formation energy calculation method so you must find and relax all related structures and then calculate the formation energy per atom."
},
...
}
3. Interaction with newly released packages or datasets absent from most model pre-training corpora
⬇
{
" user_query ": {
"0": " Load the OBELiX dataset which comes from the paper titled OBELiX: A Curated Dataset of Crystal Structures and Experimentally Measured Ionic Conductivities for Lithium Solid - State Electrolytes, and then transform the first structure in the dataset to an ordered structure through the EnumerateStructureTransformation (picking the 1 st one in the returned ranked list). Return to me a list in the order of the space group number of the original structure and the space group number of this ordered structure, using SpacegroupAnalyzer and get_space_group_number.",
"1": " Load the OBELiX dataset which comes from the paper titled OBELiX: A Curated Dataset of Crystal Structures and Experimentally Measured Ionic Conductivities for Lithium Solid - State Electrolytes, and then transform the first structure in the dataset to an ordered structure through the EnumerateStructureTransformation (picking the 1 st one in the returned ranked list). Return to me a list in the order of the space group number of the original structure and the space group number of this ordered structure."
},
...
}
4. Navigation of outdated or misleading online documentation
At the time of writing, the pymatgen-db and Materials Project documentation contain out-of-sync code examples that may confuse agents when performing the following tasks.
⬇
{
" user_query ": {
"0": " Write code to retrieve the matching entries from the Inorganic Crystalline Structure Database (ICSD) for the material with Materials Project ID mp -18767, using materials. provenance. get_data_by_id () and get the database_IDs. Return a list of strings each with the format ’ icsd -< ID number >’.",
"1": " Write code to retrieve the matching entries from the Inorganic Crystalline Structure Database (ICSD) for the material with Materials Project ID mp -18767. Return a list of strings each with the format ’ icsd -< ID number >’.",
...
}
⬇
{
" user_query ": {
"0": " I have already inserted an entire directory of VASP runs into the MongoDB database. Please use pymatgen - db to get the volume per atom of the final structure from the calculation. First, use QueryEngine class to query the task_id, and then use get_structure_from_id to get the structure. Finally, calculate the volume per atom of the structure. You should NOT insert data into the database.",
"1": " I have already inserted an entire directory of VASP runs into the MongoDB database. Please use pymatgen - db to get the volume per atom of the final structure from the calculation. You should NOT insert data into the database."
...
}
#### B.1.2 Additional examples
These additional tasks involve downloading datasets from published papers for subsequent processing and analysis [huang2025cross, Huang2025MPr2SCAN, kovacs2025mace]. They were excluded from the main SciSkillBench evaluation due to practical limitations, such as "Too Many Requests" errors encountered when accessing dataset URLs. Nevertheless, we have verified that DeepSolver with the OpenAI O3 model is capable of completing these tasks successfully.
⬇
{
" user_query ": {
"0": " Download the test dataset of the paper titled MACE - OFF: Transferable Short Range Machine Learning Force Fields for Organic Molecules. You can use requests. get with the url https:// www. repository. cam. ac. uk / bitstreams / cb8351dd - f09c -413 f -921 c -67 a702a7f0c5 / download. Then, load corresponding model mace_off (choose the small one) to get the potential energy of the structure with the chemical formula C19H22Cl2N4O2S in this dataset.",
"1": " Download the test dataset of the paper titled MACE - OFF: Transferable Short Range Machine Learning Force Fields for Organic Molecules, and load corresponding model (choose the small one) to get the potential energy of the structure with the chemical formula C19H22Cl2N4O2S in this dataset."
...
}
⬇
{
" user_query ": {
"0": " Download the MP - r2SCAN dataset from the link https:// doi. org /10.6084/ m9. figshare.28245650. v2, and then give me the total number of frame ids and the mean of energy per atom. Return in a list in the order of number of frame ids and mean of energy per atom. You can use requests. get with the url https:// figshare. com / ndownloader / files /51832613 to download the json file which has the structure of {mp - id: {frame - id: {energy_per_atom: ... } } }.",
"1": " Download the MP - r2SCAN dataset from the link https:// doi. org /10.6084/ m9. figshare.28245650. v2, and then give me the total number of frame ids and the mean of energy per atom. Return in a list in the order of number of frame ids and mean of energy per atom."
...
}
#### B.1.3 Examples of simple and difficult tasks
Task difficulty is categorized using the P value, also known as Item Difficulty, which ranges from 0 to 1. This metric represents the proportion of correct responses generated among all models during assessment, with higher values indicating easier tasks. Specifically, tasks are classified as simple if the P value is greater than or equal to 0.5 and as difficult if it is less than 0.5.
1. Simple tasks
⬇
Calculate the atomization energy (unit: eV) of a nitrogen molecule using ASE package and its Effective Medium Potential (EMT) calculator.
⬇
Calculate the adsorption energy (in eV) of one nitrogen atom on a 3 x3 FCC Cu (111) surface with three atomic layers and 10 angstrom vacuum layer using ASE package and its Effective Medium Potential (EMT) calculator. Do not fix any atoms during the structure optimization!
⬇
Count the total number of molecular fragments for OCc1ccccc1CN using RDKit with parameters (1,6) and the default functional groups file ’ FunctionalGroups. txt ’ in RDKit.
⬇
Calculate the crustal abundance (unit: ppm) of Al2O3 based on the mass fraction of each element in the compound using pymatgen and SMACT packages.
2. Difficult tasks
⬇
Please use ORCA software to calculate the Hirshfeld atomic charge (unit: e) of the nitrogen atom in hydrogen cyanide using the DFT method and Hirshfeld population analysis at B3LYP /6-31+ G * accuracy.
⬇
Please use xtb software to calculate global electrophilicity index (unit: eV) of acetyl chloride.
⬇
Please use xtb to perform a dihedral angle scan of H - C - C - H in the ethane molecule and output the difference between the maximum and minimum energies (unit: eV). Scan the dihedral angle from 60 degrees to 420 degrees with 72 steps, using force constant 0.05.
⬇
In the Li - Mn - O chemical system using R2SCAN calculations, give me the materials id list of the decomposition entries of the R2SCAN entry of LiMnO2 (mp -18767, exactly this mp - id) using pymatgen ’ s built - in functionality get_decomp_and_phase_separation_energy.
### B.2 Ablation studies
Similar to the baseline comparisons, agentic systems are evaluated without access to any memory tools and without human intervention. We perform ablation studies to assess the effects of removing each meta-skill from the DeepSolver system, specifically continuous learning and self-reflection, by removing corresponding tools and prompts. For No Self-Reflection (NSR), we disable DeepSolver’s self-reflection meta-skill by removing the quick_introspect tool from the Solution Researcher and eliminating Debug Agents entirely. The Code Agent is then required to execute the code solution only once, without any debugging. For No Continuous Learning (NCL), we disable DeepSolver’s continuous learning meta-skill by removing the tools tavily-search, extract_code_from_url, and retrieve_extracted_code, along with their related prompts from the system.
As shown in Table B1, we present the success rate, pass@k accuracy, and average execution time for configurations excluding self-reflection (NSR) and continuous learning (NCL), along with the results for DeepSolver. We observe varied contributions of the meta-skills across different language models. For instance, some models, such as GPT-5, O3, O4-mini, GPT-5-mini, GPT-4.1, and GPT-5-nano, demonstrate a greater improvement in accuracy due to self-reflection compared to continuous learning. Conversely, models like GPT-4.1-mini, Qwen3-Coder-30B, and GPT-4.1-nano appear to benefit more from continuous learning; this discrepancy may stem from their relatively weaker capabilities in coding and debugging, alongside their proficiency in web search. Overall, DeepSolver, which integrates both meta-skills, consistently achieves the best performance. An exception is noted with GPT-4.1, which exhibits optimal performance in the absence of continuous learning. Through recorded agent tracing during the test executions, we discover that GPT-4.1 rarely utilizes search-related functionalities, despite having access to relevant tools and prompts. Consequently, the introduction of continuous learning tools and prompts may act as extraneous interference, hampering the agentic system’s efficiency in problem-solving. Moreover, we note that for over half of the models, DeepSolver spent less average time than the NCL configuration while achieving better accuracy.
Comparing Table 1 and Table B1, we observe that among the nine models evaluated, six models exhibited an overall success rate for the NCL configuration that surpassed that of the S&D baseline. The remaining three models also demonstrated performance rates that were only slightly lower than S&D. This indicates that our approach within CASCADE, which fosters and enhances the agent’s mastery of meta-skills, especially self-reflection, is more effective than the conventional combination of both search and self-debugging methods.
| Models NSR GPT-5 | Metrics NCL Success Rate | All Questions (%) DeepSolver 62.64 | 0-Level Questions (%) NSR 85.37 | 1-Level Questions (%) NCL 93.26 | Average Time (s) DeepSolver 67.82 | NSR 90.30 | NCL 96.47 | DeepSolver 57.47 | NSR 80.37 | NCL 90.06 | DeepSolver 521 | 505 | 588 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Pass@1 | 65.52 | 82.61 | 93.97 | 68.97 | 86.21 | 96.55 | 62.07 | 78.95 | 91.38 | | | | |
| Pass@2 | 76.72 | 90.43 | 97.41 | 75.86 | 96.55 | 100.00 | 77.59 | 84.21 | 94.83 | | | | |
| Pass@3 | 81.03 | 91.30 | 98.28 | 82.76 | 96.55 | 100.00 | 79.31 | 85.96 | 96.55 | | | | |
| O3 | Success Rate | 55.43 | 86.02 | 91.84 | 60.69 | 92.90 | 97.70 | 50.00 | 78.75 | 85.80 | 293 | 442 | 407 |
| Pass@1 | 56.90 | 84.35 | 93.97 | 62.07 | 89.66 | 96.55 | 51.72 | 78.95 | 91.38 | | | | |
| Pass@2 | 66.38 | 93.04 | 98.28 | 74.14 | 96.55 | 100.00 | 58.62 | 89.47 | 96.55 | | | | |
| Pass@3 | 70.69 | 93.04 | 98.28 | 79.31 | 96.55 | 100.00 | 62.07 | 89.47 | 96.55 | | | | |
| O4-mini | Success Rate | 61.78 | 73.59 | 86.30 | 65.52 | 77.78 | 86.63 | 58.05 | 69.28 | 85.96 | 176 | 342 | 248 |
| Pass@1 | 62.93 | 75.00 | 82.61 | 70.69 | 81.03 | 84.48 | 55.17 | 68.97 | 80.70 | | | | |
| Pass@2 | 68.97 | 81.90 | 91.30 | 74.14 | 87.93 | 91.38 | 63.79 | 75.86 | 91.23 | | | | |
| Pass@3 | 76.72 | 84.48 | 94.78 | 79.31 | 89.66 | 96.55 | 74.14 | 79.31 | 92.98 | | | | |
| GPT-5-mini | Success Rate | 56.32 | 66.97 | 82.18 | 60.34 | 73.37 | 89.08 | 52.30 | 60.37 | 75.29 | 382 | 523 | 453 |
| Pass@1 | 61.21 | 62.28 | 83.62 | 67.24 | 65.52 | 91.38 | 55.17 | 58.93 | 75.86 | | | | |
| Pass@2 | 73.28 | 78.95 | 93.97 | 77.59 | 87.93 | 100.00 | 68.97 | 69.64 | 87.93 | | | | |
| Pass@3 | 76.72 | 85.09 | 97.41 | 81.03 | 94.83 | 100.00 | 72.41 | 75.00 | 94.83 | | | | |
| GPT-4.1-mini | Success Rate | 54.08 | 46.52 | 72.78 | 64.02 | 54.76 | 76.40 | 44.31 | 37.16 | 69.03 | 128 | 261 | 190 |
| Pass@1 | 53.45 | 40.71 | 70.69 | 65.52 | 56.90 | 74.14 | 41.38 | 23.64 | 67.24 | | | | |
| Pass@2 | 62.93 | 59.29 | 85.34 | 68.97 | 75.86 | 89.66 | 56.90 | 41.82 | 81.03 | | | | |
| Pass@3 | 68.97 | 70.80 | 89.66 | 74.14 | 86.21 | 93.10 | 63.79 | 54.55 | 86.21 | | | | |
| Qwen3-Coder -30B-A3B -Instruct-FP8 | Success Rate | 54.07 | 30.10 | 64.38 | 60.83 | 37.25 | 72.14 | 47.62 | 23.08 | 57.24 | 590 | 666 | 599 |
| Pass@1 | 45.54 | 32.17 | 65.22 | 52.73 | 40.35 | 70.69 | 38.60 | 24.14 | 59.65 | | | | |
| Pass@2 | 66.07 | 44.35 | 76.52 | 72.73 | 52.63 | 81.03 | 59.65 | 36.21 | 71.93 | | | | |
| Pass@3 | 72.32 | 46.09 | 80.00 | 78.18 | 54.39 | 82.76 | 66.67 | 37.93 | 77.19 | | | | |
| GPT-4.1 | Success Rate | 24.71 | 72.06 | 62.82 | 27.01 | 80.70 | 71.68 | 22.41 | 63.31 | 54.02 | 39 | 153 | 187 |
| Pass@1 | 26.72 | 68.97 | 63.79 | 32.76 | 77.59 | 67.24 | 20.69 | 60.34 | 60.34 | | | | |
| Pass@2 | 31.03 | 79.31 | 74.14 | 36.21 | 84.48 | 79.31 | 25.86 | 74.14 | 68.97 | | | | |
| Pass@3 | 32.76 | 83.62 | 81.03 | 37.93 | 89.66 | 87.93 | 27.59 | 77.59 | 74.14 | | | | |
| GPT-5-nano | Success Rate | 35.34 | 42.06 | 57.27 | 40.80 | 43.31 | 60.82 | 29.89 | 40.80 | 53.76 | 230 | 383 | 394 |
| Pass@1 | 34.48 | 38.37 | 62.93 | 39.66 | 39.53 | 63.79 | 29.31 | 37.21 | 62.07 | | | | |
| Pass@2 | 44.83 | 50.00 | 75.00 | 50.00 | 53.49 | 77.59 | 39.66 | 46.51 | 72.41 | | | | |
| Pass@3 | 54.31 | 54.65 | 81.90 | 56.90 | 60.47 | 84.48 | 51.72 | 48.84 | 79.31 | | | | |
| GPT-4.1-nano | Success Rate | 14.24 | 12.89 | 19.92 | 15.48 | 15.00 | 24.60 | 13.04 | 11.03 | 15.38 | 71 | 146 | 178 |
| Pass@1 | 13.79 | 8.93 | 22.81 | 13.79 | 9.26 | 31.03 | 13.79 | 8.62 | 14.29 | | | | |
| Pass@2 | 19.83 | 16.96 | 30.70 | 18.97 | 18.52 | 37.93 | 20.69 | 15.52 | 23.21 | | | | |
| Pass@3 | 23.28 | 17.86 | 32.46 | 25.86 | 20.37 | 39.66 | 20.69 | 15.52 | 25.00 | | | | |
Table B1: Ablation study: impact of meta-skills on DeepSolver. NSR (No Self-Reflection) and NCL (No Continuous Learning) represent configurations with the respective components disabled. Success Rate represents the overall accuracy across all attempts, while Pass@k (k=1, 2, 3) indicates the proportion of questions with at least one correct answer among the first k attempts. Results are shown for all questions, as well as separately for 0-Level and 1-Level questions. Average time denotes the mean completion time per question in seconds. Bold values indicate the best performance for each model across the three configurations (NSR, NCL, DeepSolver).
### B.3 Demonstrations
Demonstration examples can be found at https://github.com/CederGroupHub/CASCADE/tree/main/benchmark_tasks_and_results/demonstration/free_form_output, including task files (with user queries), reference solution code, agent-generated answers, and associated figures.
## References