# LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm
**Authors**: Chunhui WanXunan DaiZhuo WangMinglei LiYanpeng Wang, Yinan MaoYu LanZhiwen Xiao, Baidu Inc
> Equal contributions. E-mail: {daixunan,
## Abstract
The transition from static Large Language Models (LLMs) to self-improving agents is hindered by the lack of structured reasoning in traditional evolutionary approaches. Existing methods often struggle with premature convergence and inefficient exploration in high-dimensional code spaces. To address these challenges, we introduce LoongFlow, a self-evolving agent framework that achieves state-of-the-art solution quality with significantly reduced computational costs. Unlike "blind" mutation operators, LoongFlow integrates LLMs into a cognitive "Plan-Execute-Summarize" (PES) paradigm, effectively mapping the evolutionary search to a reasoning-heavy process. To sustain long-term architectural coherence, we incorporate a hybrid evolutionary memory system. By synergizing Multi-Island models with MAP-Elites and adaptive Boltzmann selection, this system theoretically balances the exploration-exploitation trade-off, maintaining diverse behavioral niches to prevent optimization stagnation. We instantiate LoongFlow with a General Agent for algorithmic discovery and an ML Agent for pipeline optimization. Extensive evaluations on the AlphaEvolve benchmark and Kaggle competitions demonstrate that LoongFlow outperforms leading baselines (e.g., OpenEvolve, ShinkaEvolve) by up to 60% in evolutionary efficiency while discovering superior solutions. LoongFlow marks a substantial step forward in autonomous scientific discovery, enabling the generation of expert-level solutions with reduced computational overhead.
Code: https://github.com/baidu-baige/LoongFlow
## 1 Introduction
The progression from static prompting—where humans manually engineer instructions—to autonomous, self-evolving agents marks a fundamental shift in artificial intelligence. While static approaches rely on fixed inference patterns, self-evolving agents utilize Large Language Models (LLMs) as mutation operators to iteratively modify their own code or parameters. Pioneering works have validated this paradigm in specific domains: FunSearch [romera2024mathematical] utilizes LLMs to discover novel mathematical constructions, Eureka [ma2024eureka] optimizes reward functions via evolutionary search, and AlphaEvolve [novikov2025alphaevolve] automates the discovery of heuristic algorithms. that LLMs, building on foundational code-generation capabilities [chen2021codex, li2022alphacode], can discover novel mathematical algorithms and reward functions that surpass human baselines. This "Darwinian shift" has established automated scientific discovery as a vibrant research frontier.
However, as the complexity of tasks increases, current frameworks face severe cognitive and architectural limitations. Leading open-source baselines, such as OpenEvolve and ShinkaEvolve [sakana2025shinkaevolve], effectively treat the LLM as a stochastic black box. OpenEvolve relies on high-volume random mutations, leading to a "random walk" behavior that is computationally prohibitive. ShinkaEvolve improves efficiency via novelty search but operates purely at the execution level, lacking a mechanism to analyze why a mutation failed. Consequently, these methods hit a "cognitive ceiling," struggling to maintain structural coherence over long evolutionary horizons. Specifically, they encounter three critical bottlenecks:
- Inefficient Exploration (The Cost Bottleneck): Existing agents lack a strategic planning layer. They engage in brute-force sampling in high-dimensional code spaces, resulting in excessive token consumption and unstable convergence rates.
- Diversity Collapse (The Convergence Bottleneck): Without explicit diversity management, population-based agents tend to converge prematurely to local optima. Traditional "Top-K" sampling fails to preserve diverse but potentially high-reward "stepping stone" solutions.
- Absence of Reflexive Memory (The Feedback Bottleneck): Unlike deep learning, where backpropagation provides a precise gradient for improvement, most existing evolutionary agent frameworks lack a structured reflection mechanism [shinn2023reflexion]. They function as "memory-less" searchers, repeating similar errors across generations rather than accumulating "evolutionary wisdom" through structured summarization.
<details>
<summary>LoongFlow-overview.jpg Details</summary>
### Visual Description
## Flowchart: Iterative Problem-Solving Process with Evolutionary Memory
### Overview
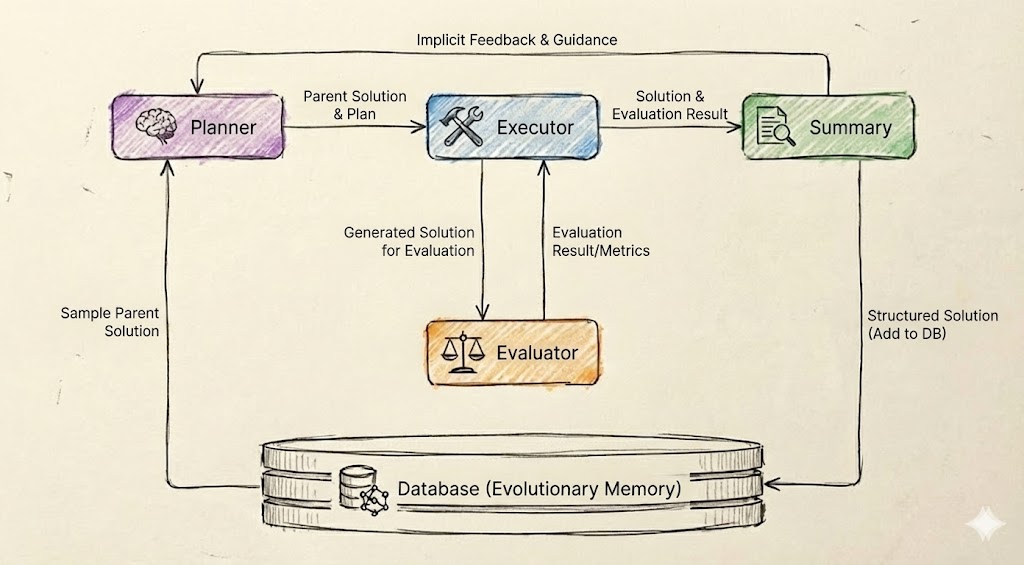
The diagram illustrates a cyclical process for generating, evaluating, and refining solutions using a feedback-driven workflow. It includes five core components: Planner, Executor, Evaluator, Summary, and a Database (Evolutionary Memory). Arrows represent data flow and feedback loops, with color-coded elements for clarity.
---
### Components/Axes
1. **Planner** (Purple box with brain icon):
- Receives "Implicit Feedback & Guidance" from the Summary.
- Outputs "Parent Solution & Plan" to the Executor.
- Receives "Sample Parent Solution" from the Database.
2. **Executor** (Blue box with hammer/wrench icon):
- Takes "Parent Solution & Plan" from the Planner.
- Outputs "Generated Solution for Evaluation" to the Evaluator.
3. **Evaluator** (Orange box with scales icon):
- Receives "Generated Solution for Evaluation" from the Executor.
- Outputs "Evaluation Result/Metrics" to the Summary.
4. **Summary** (Green box with document icon):
- Takes "Solution & Evaluation Result" from the Evaluator.
- Outputs "Structured Solution (Add to DB)" to the Database.
- Provides "Implicit Feedback & Guidance" to the Planner.
5. **Database (Evolutionary Memory)** (Gray cylinder with DNA icon):
- Stores "Sample Parent Solution" and "Structured Solution (Add to DB)."
**Legend**:
- Purple = Planner
- Blue = Executor
- Orange = Evaluator
- Green = Summary
- Gray = Database
---
### Detailed Analysis
- **Flow Direction**:
1. Planner → Executor → Evaluator → Summary → Database.
2. Feedback loop: Summary → Planner (via "Implicit Feedback & Guidance").
3. Database feeds "Sample Parent Solution" back to the Planner.
- **Key Text Labels**:
- Arrows:
- "Parent Solution & Plan" (Planner → Executor)
- "Generated Solution for Evaluation" (Executor → Evaluator)
- "Evaluation Result/Metrics" (Evaluator → Summary)
- "Structured Solution (Add to DB)" (Summary → Database)
- "Implicit Feedback & Guidance" (Summary → Planner)
- "Sample Parent Solution" (Database → Planner)
- **Color Consistency**:
All components match their legend colors (e.g., Planner = purple, Evaluator = orange).
---
### Key Observations
1. **Cyclical Nature**: The process is iterative, with feedback from the Summary refining future plans.
2. **Evaluation-Centric**: The Evaluator’s output ("Evaluation Result/Metrics") directly informs the Summary, ensuring quality control.
3. **Memory Integration**: The Database acts as a repository for past solutions, enabling the Planner to leverage historical data.
4. **Modular Design**: Each component has a distinct role, reducing complexity and enabling scalability.
---
### Interpretation
This flowchart represents an **evolutionary problem-solving framework** where:
- **Planning** is informed by both new feedback and historical data (Database).
- **Execution** generates solutions based on current plans.
- **Evaluation** ensures solutions meet predefined metrics before being archived.
- **Summarization** synthesizes results into actionable insights, closing the loop by guiding future iterations.
The **Database (Evolutionary Memory)** is critical for avoiding redundant efforts and accelerating convergence toward optimal solutions. The feedback loop ensures adaptability, while modular components allow for parallel processing or distributed implementation.
**Notable Patterns**:
- The absence of explicit termination conditions suggests the process is designed for continuous improvement.
- The "Implicit Feedback & Guidance" implies qualitative or heuristic inputs, not just quantitative metrics.
This structure aligns with principles of **evolutionary algorithms** and **knowledge management systems**, emphasizing iterative refinement and institutional memory.
</details>
Figure 1: Overview of LoongFlow.
To overcome these barriers, we introduce LoongFlow, a framework designed to bridge the gap between reasoning agents and evolutionary computation. LoongFlow distinguishes itself through two core architectural innovations. First, we propose the "Plan-Execute-Summarize" (PES) paradigm. This cognitive loop transforms random mutation into a directed hypothesis-testing process (addressing Bottleneck 1 & 3), as illustrated in the Agent Loop of Figure 1. Second, to resolve the exploration-exploitation dilemma (Bottleneck 2), we design a Hybrid Evolutionary Memory. By fusing the spatial isolation of Island Models with the behavioral diversity of MAP-Elites [mouret2015illuminating] and entropy-regularized Boltzmann selection, LoongFlow dynamically maintains diverse behavioral niches. This ensures that the system can escape local optima and continuously discover novel solution architectures.
We demonstrate the versatility of LoongFlow by instantiating two domain-specific agents: a General Agent for algorithmic tasks and an ML Agent for machine learning pipelines. Experimental results on the AlphaEvolve benchmark and Kaggle competitions confirm that LoongFlow significantly surpasses OpenEvolve and ShinkaEvolve, breaking theoretical performance barriers with superior sample efficiency.
The primary contributions of this work are as follows:
- Structured Evolutionary Paradigm: We propose the “Plan-Execute-Summarize” paradigm, which integrates expert-level planning and retrospective summarization to reduce generation randomness and establish a sustainable feedback loop.
- Advanced Memory Architecture: We design a domain-adaptive evolutionary memory that combines multi-island parallel evolution with MAP-Elites [mouret2015illuminating] and adaptive Boltzmann selection, effectively solving the premature convergence and “catastrophic forgetting” problems inherent in traditional LLM agents.
- Superior Performance & Efficiency: We provide open-source, pre-built agents (GeneralAgent and MLAgent) that achieve state-of-the-art results on NP-hard mathematical problems and complex ML pipelines, surpassing existing frameworks in both stability and evolutionary speed.
## 2 Related Work
The development of LoongFlow is situated at the intersection of LLM-based Evolutionary Optimization and Cognitive Agent Architectures. In this section, we review the progression of these fields and identify the specific gap that LoongFlow addresses.
### 2.1 LLM-Based Evolutionary Optimization
The paradigm of utilizing LLMs for evolutionary optimization has shifted from simple solution generation to iterative refinement. Pioneering work such as FunSearch [romera2024mathematical] demonstrated that LLMs, when coupled with an evolutionary evaluator, could solve open problems in mathematics (e.g., the Cap Set problem) by searching for "functions" rather than parameters. Similarly, AlphaEvolve [novikov2025alphaevolve] orchestrates an autonomous pipeline of LLMs to improve an algorithm by making direct changes to the program, achieving human-level performance on robot manipulation tasks. While recent methods like OPRO [yang2023opro] and PromptBreeder [fernando2023promptbreeder] have explored using LLMs as optimizers, they often treat the model as a black-box operator to mutation. They typically treat the LLM as a stochastic operator—randomly mutating code without a high-level strategy—which leads to high token costs and inefficient exploration in complex search spaces.
### 2.2 Evolutionary Agent Frameworks
To engineeringly scale LLM-based evolution, several open-source frameworks have emerged. These serve as the primary baselines for our work:
- OpenEvolve: As a standard implementation of the AlphaEvolve algorithm, OpenEvolve utilizes an "Island Model" to maintain population diversity. However, it treats code generation as a single-step translation task. The mutation process is largely reactive, where the agent fixes errors or makes random local changes without understanding the global algorithmic structure. This often leads to a "random walk" behavior in high-difficulty tasks.
- ShinkaEvolve: ShinkaEvolve [sakana2025shinkaevolve] improves sample efficiency by integrating "code-novelty rejection" to filter out redundant solutions before execution. While it reduces computational waste, it still operates primarily at the execution level. The framework lacks a structured reflection mechanism to analyze why a specific architectural change failed, preventing the system from learning abstract principles over long evolutionary horizons.
### 2.3 Cognitive Architectures and The Reasoning Gap
While evolutionary methods excel at population-based search, they often lack the depth of semantic reasoning found in autonomous agents.
Reasoning Agents: Frameworks like ReAct [yao2023react] and Reflexion [shinn2023reflexion] have demonstrated that interleaving reasoning traces (Thought) with actions significantly improves problem-solving capabilities. These methods enable agents to perform multi-step planning and self-correction. Similarly, Voyager [wang2023voyager] utilizes an iterative curriculum to learn complex skills in embodied environments.
The Gap: A critical gap exists in merging these two paradigms. Standard reasoning agents (like AutoGPT [richards2023autogpt] or Voyager [wang2023voyager]) generally focus on single-instance problem solving rather than population-based evolutionary search. Conversely, traditional evolutionary algorithms (like MAP-Elites [mouret2015illuminating]) excel at maintaining diverse populations but lack the semantic reasoning capabilities of ReAct-style agents.
LoongFlow bridges this gap by introducing the "Plan-Execute-Summarize" paradigm. This paradigm allows LoongFlow to maintain the diversity benefits of MAP-Elites [mouret2015illuminating] while leveraging the reasoning depth of ReAct-style agents [yao2023react], effectively moving the evolutionary process from "random mutation" to "directed evolution".
## 3 Background
In this section, we formally frame the open-ended evolutionary process as a sequential decision-making problem and establish the mathematical foundations of the LoongFlow framework. We model the self-evolution of agents as a Markov Decision Process (MDP [sutton2018reinforcement]) over a discrete code space, guided by a parameterized Large Language Model (LLM).
### 3.1 Problem Formulation as MDP
We define the problem as a tuple $\langle\mathcal{C},\mathcal{A},R,\pi_{\theta}\rangle$ :
- State/Code Space ( $\mathcal{C}$ ): Let $\mathcal{C}$ be the infinite, discrete space of all valid programs in a specific language (e.g., Python). A state $s_{t}\in\mathcal{C}$ represents the solution code at evolutionary generation $t$ .
- Action Space ( $\mathcal{A}$ ): The action space consists of semantic modification operations (e.g., rewrite, debug, optimize) applied to the code.
- Reward Function ( $R$ ): $R:\mathcal{C}\to\mathbb{R}$ is a scalar fitness function (e.g., accuracy on test cases). The environment is characterized by a sparse reward signal, where valid solutions are rare.
- Policy ( $\pi_{\theta}$ ): The agent is an LLM parameterized by weights $\theta$ . It acts as a stochastic policy $\pi_{\theta}(a|s)$ , generating the next code state $s_{t+1}$ based on the current state $s_{t}$ and context.
Our objective is to find an optimal solution $s^{*}$ that maximizes the reward:
$$
s^{*}=\mathop{\arg\max}_{s\in\mathcal{C}}R(s) \tag{1}
$$
### 3.2 LLM as a Composite Semantic Operator
Unlike traditional Evolutionary Algorithms (EA) that use fixed, random mutation operators (denoted as $\mathcal{T}_{mut}$ ), LoongFlow utilizes the LLM as a learnable Semantic Operator.
We formalize the "Plan-Execute-Summarize" (PES) paradigm as a composite transition kernel decomposing the policy $\pi_{\theta}$ into three sub-steps. Let $\mathcal{M}_{t}$ be the evolutionary memory at generation $t$ , and $\mathcal{I}$ be the set of system instructions (prompts). The transition from parent $s_{t}$ to offspring $s_{t+1}$ proceeds as follows:
1. Planning: The Planner generates a natural language blueprint $b$ (an intermediate latent variable) conditioned on the parent code $s_{t}$ and retrieved insights from memory $\mathcal{M}_{t}$ :
$$
b\sim\pi_{\theta}(b\mid s_{t},\mathcal{M}_{t},\mathcal{I}_{plan}) \tag{2}
$$
1. Execution: The Executor generates the executable offspring code $s^{\prime}$ (a candidate for $s_{t+1}$ ) based on the blueprint $b$ :
$$
s^{\prime}\sim\pi_{\theta}(s^{\prime}\mid b,s_{t},\mathcal{I}_{exec}) \tag{3}
$$
1. Summarization & Update: The Summarizer generates a reflection insight $z$ based on the execution feedback $r=R(s^{\prime})$ , and updates the memory:
$$
z\sim\pi_{\theta}(z\mid s^{\prime},r,b,\mathcal{I}_{sum}) \tag{4}
$$
$$
\mathcal{M}_{t+1}\leftarrow\mathcal{M}_{t}\cup\{z\} \tag{5}
$$
### 3.3 Feature Space and Archive Management
To manage population diversity beyond raw fitness, we map the high-dimensional code space $\mathcal{C}$ to a lower-dimensional Feature Space $\mathcal{F}\subseteq\mathbb{R}^{k}$ .
Feature Mapping.
Let $\Phi:\mathcal{C}\to\mathcal{F}$ be a mapping function that projects a solution $s$ to a feature vector $\mathbf{v}=\Phi(s)$ . In this work, $\mathbf{v}$ consists of interpretable dimensions, for example, $\mathbf{v}=(\text{Cyclomatic Complexity},\text{Code Length})$ .
MAP-Elites Archive.
We maintain a structured archive (Memory) $\mathcal{A}_{rchive}$ , discretized into a grid of cells in $\mathcal{F}$ . Each cell, indexed by a feature vector $\mathbf{v}$ , stores only the single best solution found so far for that specific behavior:
$$
\mathcal{A}_{rchive}(\mathbf{v})=\{s\in\mathcal{C}\mid\Phi(s)\in\text{Cell}(\mathbf{v})\land R(s)=\max_{s^{\prime}\in\text{Cell}(\mathbf{v})}R(s^{\prime})\} \tag{6}
$$
This mechanism ensures behavioral diversity, preventing the policy from collapsing into a single local optimum.
### 3.4 Adaptive Boltzmann Selection
To select the parent $s_{t}$ for the next generation from the archive $\mathcal{A}_{rchive}$ , we replace static greedy selection with Adaptive Boltzmann Selection.
Let $\{s_{1},s_{2},\dots,s_{N}\}$ be the set of solutions currently stored in the archive. The probability $P(s_{i})$ of selecting solution $s_{i}$ as the parent is:
$$
P(s_{i})=\frac{\exp(R(s_{i})/\tau)}{\sum_{j=1}^{N}\exp(R(s_{j})/\tau)} \tag{7}
$$
where $\tau$ is a temperature parameter dynamically modulated by the population entropy. This allows LoongFlow to shift smoothly between exploration (high $\tau$ ) and exploitation (low $\tau$ ).
## 4 LoongFlow Overview
Designing an evolutionary agent capable of solving high-difficulty, open-ended tasks requires overcoming two fundamental systemic contradictions: the tension between search space complexity and sampling efficiency, and the trade-off between population diversity and convergence speed.
Algorithm 1 LoongFlow Main Evolutionary Loop
1: Input: Task Description $T$ , Initial Solution $s_{0}$ , Max Iterations $N_{max}$ , Islands $K$
2: Output: Best Solution $s^{*}$
3: // Initialization phase
4: Initialize Global Memory $\mathcal{M}\leftarrow\{s_{0}\}$
5: Initialize $K$ Islands with MAP-Elites Archives $\mathcal{A}_{1},\dots,\mathcal{A}_{K}$
6: for $iteration=1$ to $N_{max}$ do
7: for $k=1$ to $K$ do $\triangleright$ Parallel Evolution on Islands
8: // 1. Adaptive Selection (Sec. 4.2.3)
9: $H_{k}\leftarrow\text{CalculateEntropy}(\mathcal{A}_{k})$
10: $\tau\leftarrow\tau_{base}\cdot(1+\alpha e^{-\beta H_{k}})$ $\triangleright$ Dynamic Temperature
11: $s_{parent}\leftarrow\text{BoltzmannSelect}(\mathcal{A}_{k},\tau)$
12: // 2. Lineage-Based Planning (Sec. 4.1.1)
13: $chain\leftarrow\text{GetLineage}(s_{parent}.\text{id})$
14: $context\leftarrow\{\text{p.plan},\text{p.summary}\mid p\in chain\}$
15: $plan\leftarrow\text{Planner}(s_{parent},context,T)$
16: // 3. Execution & Evaluation (Sec. 4.1.2)
17: $code\leftarrow\text{Executor}(plan,s_{parent})$
18: if $\text{Verify}(code)$ is False then
19: continue $\triangleright$ Fast-fail on syntax errors
20: end if
21: $score,logs\leftarrow\text{Evaluator}(code)$
22: // 4. Reflection & Storage (Sec. 4.1.3)
23: $summary\leftarrow\text{Summarizer}(plan,code,logs)$
24: $s_{new}\leftarrow\text{Solution}(code,score,summary,parent=s_{parent}.\text{id})$
25: $\text{UpdateMAPElites}(\mathcal{A}_{k},s_{new})$
26: end for
27: // 5. Migration Strategy (Sec. 4.2.1)
28: if $iteration\mod M==0$ then
29: MigrateElites ( $\mathcal{A}_{1},\dots,\mathcal{A}_{K}$ )
30: end if
31: end for
32: return $\max_{s\in\cup\mathcal{A}_{k}}s.score$
To resolve these, LoongFlow introduces a hierarchical architecture that decouples “Cognitive Reasoning” from “Evolutionary Dynamics”. The framework consists of two coupled subsystems: the Agent Loop, which implements the “Plan-Execute-Summarize” (PES) paradigm, and the Hybrid Evolutionary Memory, which governs population management. The overall procedure is outlined in Algorithm 1.
### 4.1 The “Plan-Execute-Summarize” (PES) Paradigm
Standard LLM-based evolutionary methods (e.g., genetic programming with LLMs) typically treat the model as a “black-box mutation operator”, randomly perturbing solutions in hopes of improvement. This approach suffers from extreme sample inefficiency and a lack of directional guidance. To address this, LoongFlow formalizes the evolutionary iteration as a structured cognitive process composed of three specialized stages.
<details>
<summary>LoongFlow-frame.jpg Details</summary>
### Visual Description
## Flowchart: LoongFlow System Architecture
### Overview
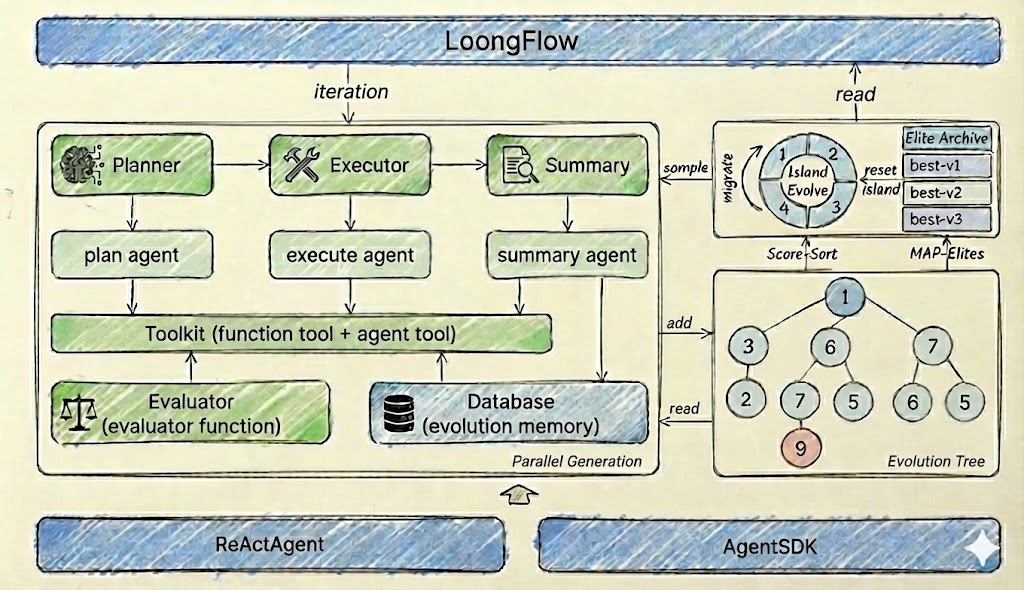
The diagram illustrates a multi-component system architecture titled "LoongFlow," depicting iterative processes involving planning, execution, summarization, and evolution. Key elements include agents, toolkits, evaluators, and a database, with flows connecting components and parallel generation mechanisms.
### Components/Axes
- **Main Components**:
- **Planner**: Contains "plan agent" (green box).
- **Executor**: Contains "execute agent" (green box).
- **Summary**: Contains "summary agent" (green box).
- **Toolkit**: Labeled "Toolkit (function tool + agent tool)" (green box).
- **Evaluator**: Labeled "Evaluator (evaluator function)" (green box).
- **Database**: Labeled "Database (evolution memory)" (blue box).
- **Processes**:
- **Parallel Generation**: Arrows indicate concurrent workflows.
- **Migration**: Includes "migrate," "Island Evolve," and "reset island" steps.
- **Evolution Tree**: Nodes numbered 1–9, with node 9 highlighted in red.
- **Legends**:
- Green: Components (Planner, Executor, Summary, Toolkit, Evaluator).
- Blue: Processes (Database, Parallel Generation).
- Gray: Database (evolution memory).
- **Arrows**: Indicate directional flow between components.
### Detailed Analysis
1. **Top Section**:
- **Planner → Executor → Summary**: Sequential flow from planning to execution to summarization.
- **Toolkit**: Connects to all three agents (plan, execute, summary).
- **Evaluator**: Feeds into the Database.
2. **Bottom Section**:
- **Database**: Stores "evolution memory" and connects to "Parallel Generation."
- **AgentSDK** and **ReActAgent**: Positioned at the bottom, likely frameworks or libraries.
3. **Right Sidebar**:
- **Evolution Tree**: Nodes 1–9, with node 9 highlighted (red).
- **Migration Steps**: Includes "Island Evolve," "reset island," and versioned archives ("best-v1," "best-v2," "best-v3").
- **Score-Sort** and **MAP-Elites**: Likely optimization or evaluation metrics.
### Key Observations
- **Cyclical Workflow**: The system iterates through planning, execution, and summarization, feeding results into the Database.
- **Evolution Mechanism**: The "evolution memory" and "evolution tree" suggest optimization or selection processes (e.g., genetic algorithms).
- **Parallelism**: "Parallel Generation" implies concurrent task execution.
- **Versioning**: Migration steps reference versioned archives ("best-v1," etc.), indicating model iteration or deployment.
### Interpretation
The diagram represents a dynamic system for iterative task management, likely in AI/ML or optimization contexts. The "evolution tree" and "evolution memory" imply a focus on improving performance over iterations, possibly through reinforcement learning or genetic algorithms. The "Island Evolve" and "reset island" steps suggest modular or population-based optimization techniques. The inclusion of "AgentSDK" and "ReActAgent" indicates integration with external frameworks for agent-based workflows. The system emphasizes modularity, with distinct roles for planning, execution, and evaluation, while the Database acts as a central repository for evolutionary data.
</details>
Figure 2: Expanded view of the LoongFlow evolutionary process. The framework iterates through a Planner-Executor-Summarizer loop. The Planner retrieves historical insights to prune the search space; the Executor generates and verifies code; the Summarizer extracts causal knowledge to update the Evolutionary Memory.
#### 4.1.1 Planner: Strategic Search Space Pruning
In infinite solution spaces, navigating via stochastic mutation often devolves into a “random walk,” wasting vast computational resources on invalid or redundant trials. To mitigate this, the Planner functions as a strategic architect employing Lineage-Based Context Retrieval.
Unlike RAG [lewis2020rag] systems that rely on fuzzy semantic similarity, LoongFlow utilizes the explicit genealogical links inherent in the evolutionary process. As defined in the Solution data structure (see Listing 1), each individual preserves its lineage via parent_id.
For a given parent solution $s_{t}$ , the Planner traverses the ID chain (retrieving ancestors $s_{t-1},s_{t-2}...$ and potential descendants). It extracts the historical generate_plan (Original Intent) and summary (Retrospective Feedback) from this lineage.
- Intent Tracking: By reading past plans, the Planner understands the “research trajectory” intended by previous generations.
- Course Correction: By reading past summaries (which contain specific advice for the next generation), the Planner identifies verified pitfalls to avoid.
This structured recall allows the Planner to construct a context-aware blueprint $b$ , leveraging the Chain-of-Thought [wei2022chain] reasoning capabilities of modern LLMs, ensuring that the new plan is a logical continuation and refinement of the parent’s strategy, rather than a random jump.
#### 4.1.2 Executor: Polymorphic Implementation & Robust Verification
The translation from a high-level strategic blueprint to an executable solution is inherently non-deterministic and error-prone. The Executor acts as a robust translation engine that converts the Planner’s intent ( $b$ ) into verified artifacts ( $r$ ).
Polymorphic Execution Strategies.
The framework decouples the “What” (Plan) from the “How” (Execution). The Executor supports Pluggable Execution Flows tailored to the problem domain. For algorithmic tasks, it may instantiate as a logic-intensive single-pass coder; for system tasks, it may operate as a multi-stage workflow engine. This design ensures that LoongFlow is not limited to a single class of problems but is adaptable to any domain with a definable action space.
Local Verification Loop (Fast-Fail).
Before submitting to the global Evaluator, the Executor interacts with the Environment Interface to perform “Pre-Evaluation Checks”. This local feedback loop allows the Executor to self-correct minor errors (such as syntax typos or import errors) immediately, acting as a filter that prevents low-quality candidates from consuming expensive global evaluation resources.
#### 4.1.3 Summary: Closing the Feedback Loop
Traditional evolutionary algorithms are “memory-less” regarding causality—they know that a solution failed, but not why. This leads to “Cyclical Errors,” where the population repeatedly explores the same invalid dead-ends. The Summary module introduces a retrospective learning mechanism.
After evaluation, the Summarizer performs Abductive Reflection [shinn2023reflexion]. It compares the Planner’s intent ( $b$ ) with the execution result ( $r$ ) to infer causal relationships and generates a structured Insight ( $z$ ). These insights are stored in the Evolutionary Memory. This establishes a Long-Term Cognitive Memory, inspired by the memory architectures in Generative Agents [park2023generative], but adapted for evolutionary lineage.. By feeding these insights back to future Planners, LoongFlow achieves Meta-Learning, where the system becomes “smarter” about the domain constraints over generations.
### 4.2 Hybrid Evolutionary Memory System
A critical failure mode in evolutionary agents is Premature Convergence. LoongFlow addresses this via a multi-layered memory architecture rooted in a structured data schema.
Solution Data Structure.
To support the genealogical retrieval described above, LoongFlow maintains a rigorous data schema for every individual in the population. As shown in Listing 1, the Solution class encapsulates not only the code but also the full evolutionary metadata (lineage IDs, plans, summaries, and metrics).
Listing 1: The Solution Data Structure in Evolutionary Memory
⬇
class Solution:
"" "Represent a solution in the memory." ""
# Solution identification
solution: str = "" # The executable code
solution_id: str = "" # Unique UUID
# Evolution information
generate_plan: str = "" # The blueprint that created this solution
parent_id: Optional [str] = "" # Pointer to ancestor (Lineage Chain)
island_id: Optional [int] = 0
iteration: Optional [int] = 0
timestamp: float = field (default_factory = time. time)
generation: int = 0
# Sampling Control
sample_cnt: int = 0 # Visit count for bandit selection
sample_weight: float = 0.0
# Performance metrics
score: Optional [float] = 0.0
evaluation: Optional [str] = "" # Raw execution logs
summary: str = "" # Critical: Advice for the next generation
# Metadata
metadata: Dict [str, Any] = field (default_factory = dict)
This comprehensive schema transforms the memory from a simple “High Score List” into a Structured Knowledge Graph, enabling the Planner to query causal relationships (Why did parent X fail?) rather than just outcomes.
#### 4.2.1 Multi-Island Distributed Topology
Single-population models are prone to “dominance,” where one successful strategy outcompetes all others. LoongFlow employs a Multi-Island Model [whitley1994cellular] with a Ring Topology. The population is partitioned into $N$ isolated islands. Each island evolves independently, allowing distinct algorithmic “species” to cultivate. Migration occurs only when the diversity difference $\Delta D$ between neighbors exceeds a threshold. The top $k\$ elites are copied to adjacent islands, acting as “invasive species” to shake up stagnation. This spatial isolation ensures Global Diversity Maintenance, preventing the system from getting stuck in local optima.
#### 4.2.2 MAP-Elites with Feature Grids
Objective-based selection often discards novel but unpolished solutions (“stepping stones”). Within each island, LoongFlow utilizes a MAP-Elites [mouret2015illuminating] container. Solutions are mapped to a feature grid $\mathcal{A}$ based on behavioral descriptors $\Phi(s)$ (e.g., Code Complexity $\times$ Memory Usage). The system preserves the best individual for each cell in the grid, not just the global best. This guarantees Niche Preservation, providing a diverse “gene pool” for the Planner to cross-pollinate.
#### 4.2.3 Adaptive Boltzmann Selection
The balance between Exploration and Exploitation is dynamic. LoongFlow implements Entropy-Regularized Boltzmann Selection [thierens1999scalability]. The selection temperature $\tau$ is dynamically adjusted based on the population entropy $H(\mathcal{P})$ :
$$
\tau(t)\propto\exp(-\lambda\cdot H(\mathcal{P}_{t})) \tag{8}
$$
When the population is diverse (High $H$ ), $\tau$ lowers to encourage Exploitation (Greedy). When the population converges (Low $H$ ), $\tau$ rises to force Exploration (Random). This achieves Self-Adaptive Control, automatically transitioning between “searching for new ideas” and “polishing existing ones” without human intervention.
## 5 Experiments
To empirically validate the Eadfent framework, we conducted a comprehensive evaluation focusing on Effectiveness (Solution Quality) and Efficiency (Convergence Speed).
### 5.1 Experimental Setup
Benchmarks: We instantiated two domain-specific agents— General Agent for algorithmic discovery and Machine Learning Agent for machine learning engineering—and compared them against state-of-the-art open-source baselines.
- AlphaEvolve Suite (General Agent): A suite of challenging open-ended mathematical problems derived from the AlphaEvolve paper [novikov2025alphaevolve].
- MLEBench [chan2024mle] (ML Agent): Real-world machine learning competitions requiring end-to-end pipeline optimization, spanning Computer Vision, NLP, and Tabular data.
Baselines: We compared General Agent against two primary evolutionary agent frameworks:
- OpenEvolve: A standard implementation of the AlphaEvolve algorithm using Island Models.
- ShinkaEvolve: A recent framework emphasizing sample efficiency via novelty search.
Models: Experiments were conducted using both open-weights models (DeepSeek-r1-0528, etc.) and commercial models (Gemini-3-Pro-Preview, etc.) to ensure the results are framework-dependent rather than model-dependent.
### 5.2 Effectiveness
#### 5.2.1 Algorithmic Discovery (General Agent)
We compared the best solutions found by LoongFlow against the baselines and known theoretical bounds. As shown in Table 1, LoongFlow achieved state-of-the-art (SOTA) results across multiple problems in the benchmark suite.
Table 1: LoongFlow Performance on AlphaEvolve Suite (Grouped by Metric Direction)
| Problem | Metric | LLM | AlphaEvolve | LoongFlow |
| --- | --- | --- | --- | --- |
| Higher is Better ( $\uparrow$ ) | | | | |
| Autocorrelation II | Bound ( $\uparrow$ ) | DeepSeek-R1 | 0.8962 | 0.9027 |
| Circle Packing (Square) | Radius ( $\uparrow$ ) | DeepSeek-R1 | 2.6358 | 2.6359 |
| Circle Packing (Rectangle) | Radius ( $\uparrow$ ) | DeepSeek-R1 | 2.3658321 | 2.3658322 |
| Lower is Better ( $\downarrow$ ) | | | | |
| Hexagon Packing | Side Length ( $\downarrow$ ) | DeepSeek-R1 | 3.93 | 3.92 |
| Max-to-Min Ratios | Ratio ( $\downarrow$ ) | DeepSeek-R1 | 12.88926 | 12.88924 |
| Uncertainty Inequality | Bound ( $\downarrow$ ) | DeepSeek-R1 | 0.352099104422 | 0.352099104421 |
| Erdős’ problem | Bound ( $\downarrow$ ) | DeepSeek-R1 | 0.380924 | 0.380913 |
Notably, in the Autocorrelation II problem, LoongFlow discovered a solution with a score of 0.9027, significantly outperforming the AlphaEvolve baseline (0.8962). This indicates that the Planner’s ability to enforce global structural constraints allows LoongFlow to navigate high-dimensional spaces more effectively than random mutation.
#### 5.2.2 Machine Learning Engineering (ML Agent)
In the Machine Learning domain, MLAgent demonstrated the ability to construct robust pipelines without human intervention. As shown in Table 2, LoongFlow achieved 14 Gold Medals.
Table 2: LoongFlow Performance on MLE Bench
| Predict-volcanic-eruptions-ingv-oe | Gemini-3.0-flash | Gold |
| --- | --- | --- |
| Stanford-covid-vaccine | Gemini-3.0-flash | Gold |
| The-icml-2013-whale-challenge-right-whale-redux | Gemini-3.0-flash | Gold |
| Aerial Cactus Identification | Claude-Opus-4.5 | Gold |
| Nomad2018-predict-transparent-conductors | Claude-Opus-4.5 | Gold |
| Denoising Dirty Documents | Gemini-3 | Gold |
| Detecting-insults-in-social-commentary | Gemini-3.0-flash | Gold |
| Dogs-vs-cats-redux-kernels-edition | Gemini-3.0-flash | Gold |
| Histopathologic-cancer-detection | Gemini-3.0-flash | Gold |
| Plant-pathology-2020-fgvc7 | Gemini-3.0-flash | Gold |
| Tabular-playground-series-dec-2021 | Gemini-3.0-flash | Gold |
| Google-quest-challenge | Gemini-3.0-flash | Gold |
| Plant-pathology-2021-fgvc8 | Gemini-3.0-flash | Gold |
| Us-patent-phrase-to-phrase-matching | Gemini-3.0-flash | Gold |
### 5.3 Efficiency and Stability Analysis
To quantify efficiency, we analyzed the Circle Packing (Square) task under strict compute budgets.
#### 5.3.1 Evolve Efficiency (DeepSeek-R1-0528)
We set a time limit of 24 hours with a target score $\geq 0.99$ . As shown in Table 3, LoongFlow demonstrated a $>60\$ improvement in evolutionary efficiency compared to OpenEvolve.
- Convergence: LoongFlow required an average of 258 evaluations to reach the target threshold (0.99), whereas OpenEvolve required 783 evaluations.
- Success Rate: Across 3 independent runs, LoongFlow achieved a 100% success rate in reaching the high-score region ( $>0.99$ ). In contrast, OpenEvolve only succeeded once (33% rate), and ShinkaEvolve failed to break the 0.99 barrier in all attempts.
Table 3: Efficiency Comparison (Sorted by Best Score)
| LoongFlow | 2 | 0.998 | 51 | 484 | 484 | 100% |
| --- | --- | --- | --- | --- | --- | --- |
| 1 | 0.996 | 13 | 147 | 147 | 100% | |
| 3 | 0.994 | 28 | 145 | 145 | 100% | |
| OpenEvolve | 2 | 0.994 | 783 | 783 | 783 | 29.54% |
| 3 | 0.962 | 1000 | 1000 | 1000 | 48.5% | |
| 1 | 0.950 | 1000 | 1000 | 1000 | 37.9% | |
| ShinkaEvolve | 3 | 0.952 | 454 | 510 | 454 | 80.84% |
| 1 | 0.856 | 469 | 568 | 469 | 82.05% | |
| 2 | 0.804 | 300 | 360 | 300 | 77% | |
#### 5.3.2 High-Difficulty Breakthrough (Gemini-3-Pro)
Under a constrained budget of 100 iterations, we evaluated the agents’ ability to break theoretical barriers. As shown in Table 4, LoongFlow completed the task three times consecutively.
- LoongFlow: Successfully broke the theoretical barrier (Score $>1.0$ ) in 3 out of 3 runs.
- Baselines: Both OpenEvolve and ShinkaEvolve failed to reach a score of 1.0 within the budget. This confirms that LoongFlow’s PES paradigm not only finds solutions faster (6 vs 100 calls) but accesses solution subspaces that are unreachable for standard evolutionary methods under limited budgets.
Table 4: High-Difficulty Breakthrough (Top-100 Iterations)
| LoongFlow | 1 | 1.000 | 6 | 20 | 20 | 100% |
| --- | --- | --- | --- | --- | --- | --- |
| 2 | 1.000 | 14 | 72 | 72 | 100% | |
| 3 | 1.000 | 8 | 26 | 26 | 100% | |
| OpenEvolve | 1-3 | < 0.998 | 100 | 100 | 100 | 81% (Avg) |
| ShinkaEvolve | 1-3 | < 0.999 | 100 | 116 | 100 | 94% (Avg) |
### 5.4 Ablations
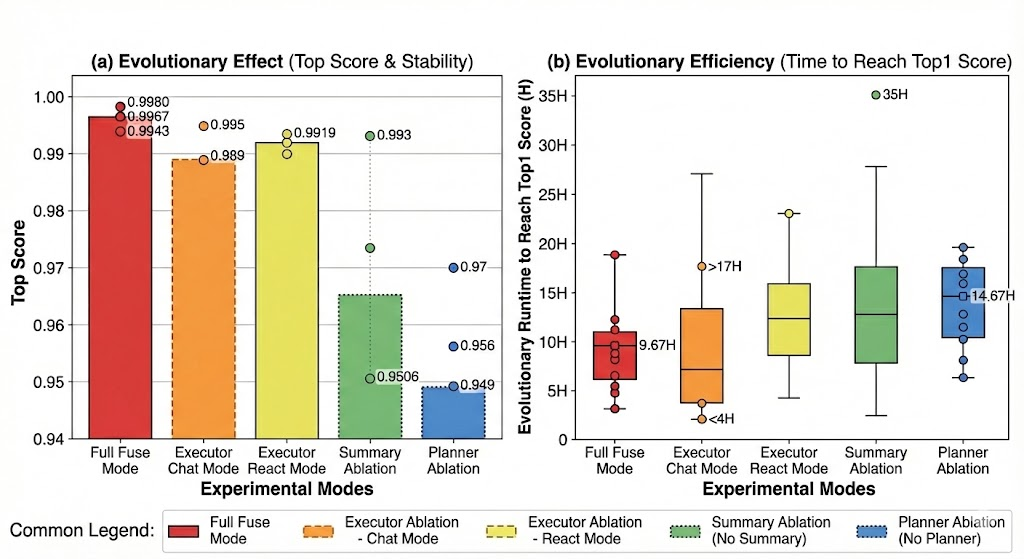
To validate the necessity of the "Plan-Execute-Summarize" (PES) paradigm, we conducted an ablation study using General Agent—the representative instantiation of the LoongFlow framework. We evaluated the contribution of the Planner, Executor, and Summary modules on the Circle Packing task.
<details>
<summary>ablation1.png Details</summary>
### Visual Description
## Chart/Diagram Type: Dual-Axis Evolutionary Analysis
### Overview
The image contains two side-by-side charts comparing experimental modes across two metrics: (a) **Top Score & Stability** (bar chart) and (b) **Evolutionary Efficiency** (box plot). The charts use color-coded categories to represent different experimental configurations, with numerical values and error bars for precision.
---
### Components/Axes
#### Chart (a): Evolutionary Effect (Top Score & Stability)
- **X-axis**: "Experimental Modes" with categories:
- Full Fuse Mode (red)
- Executor Chat Mode (orange)
- Executor React Mode (yellow)
- Summary Ablation (green)
- Planner Ablation (blue)
- **Y-axis**: "Top Score" (0.94–1.00) with numerical annotations for each bar.
- **Legend**: Located at the bottom, mapping colors to modes.
- **Error Bars**: Dotted lines with numerical values (e.g., 0.9980 for Full Fuse Mode).
#### Chart (b): Evolutionary Efficiency (Time to Reach Top1 Score)
- **X-axis**: Same "Experimental Modes" as chart (a).
- **Y-axis**: "Evolutionary Runtime (H)" (0–35 hours) with box plots showing medians, quartiles, and outliers.
- **Legend**: Same as chart (a), confirming color-to-mode mapping.
- **Outliers**: Marked with dots (e.g., 35H in Planner Ablation).
---
### Detailed Analysis
#### Chart (a): Top Scores
- **Full Fuse Mode**: Highest top score (~0.9980) with minimal error (~0.9943).
- **Executor Chat Mode**: ~0.9880 (error ~0.9895).
- **Executor React Mode**: ~0.9919 (error ~0.9930).
- **Summary Ablation**: ~0.9506 (error ~0.9560).
- **Planner Ablation**: Lowest top score (~0.9490) with error ~0.9550.
#### Chart (b): Evolutionary Runtime
- **Full Fuse Mode**: Median ~5H, range 3–10H.
- **Executor Chat Mode**: Median ~10H, range 4–17H.
- **Executor React Mode**: Median ~12H, range 8–20H.
- **Summary Ablation**: Median ~15H, range 10–25H.
- **Planner Ablation**: Median ~14.67H, range 5–35H (outlier at 35H).
---
### Key Observations
1. **Top Score Trends**:
- Full Fuse Mode dominates with the highest stability (~0.9980).
- Summary Ablation and Planner Ablation show significant drops in top scores (~0.9506 and ~0.9490, respectively).
- Executor React Mode outperforms Chat Mode slightly (~0.9919 vs. ~0.9880).
2. **Efficiency Trends**:
- Full Fuse Mode is the fastest (median ~5H).
- Planner Ablation is the slowest (median ~14.67H, with an outlier at 35H).
- Summary Ablation has the widest runtime distribution (10–25H).
3. **Color Consistency**:
- All chart elements (bars, box plots, error bars) align with the legend’s color-to-mode mapping.
---
### Interpretation
- **Performance vs. Efficiency Trade-off**:
- Full Fuse Mode achieves the highest top score and fastest runtime, suggesting it is the most optimal configuration.
- Ablation modes (Summary and Planner) degrade performance and efficiency, indicating their critical roles in the system.
- **Outlier in Planner Ablation**: The 35H runtime outlier suggests potential instability or edge-case scenarios in this configuration.
- **Ablation Impact**: Removing components (e.g., Summary or Planner) reduces both accuracy and computational efficiency, highlighting their importance.
The data underscores that the Full Fuse Mode balances top performance and efficiency, while ablation strategies compromise both metrics. This aligns with the hypothesis that integrated configurations outperform modular or simplified ones.
</details>
Figure 3: Evolutionary Effect & Efficiency.
<details>
<summary>ablation2.png Details</summary>
### Visual Description
## Line Graph: Current Top Score vs. Cumulative Evolutionary Time
### Overview
The graph displays the performance of six different system configurations over 35 hours of cumulative evolutionary time. The y-axis measures "Current Top Score" (0.94–1.00), while the x-axis tracks time in 5-hour increments. All lines show rapid initial improvement followed by plateauing performance.
### Components/Axes
- **X-axis**: Cumulative Evolutionary Time (Hours)
Markers: 0, 5H, 10H, 15H, 20H, 25H, 30H, 35H
- **Y-axis**: Current Top Score (0.94–1.00)
- **Legend**:
- Red solid: Full Fuse Mode
- Brown dashed: Executor Ablation - Chat Mode
- Yellow dashed: Executor Ablation - React Mode
- Green dash-dot: Summary Ablation (No Summary)
- Purple dotted: Planner Ablation (No Planner)
- Black dotted: Summary Ablation + Planner Ablation (No Summary + No Planner)
### Detailed Analysis
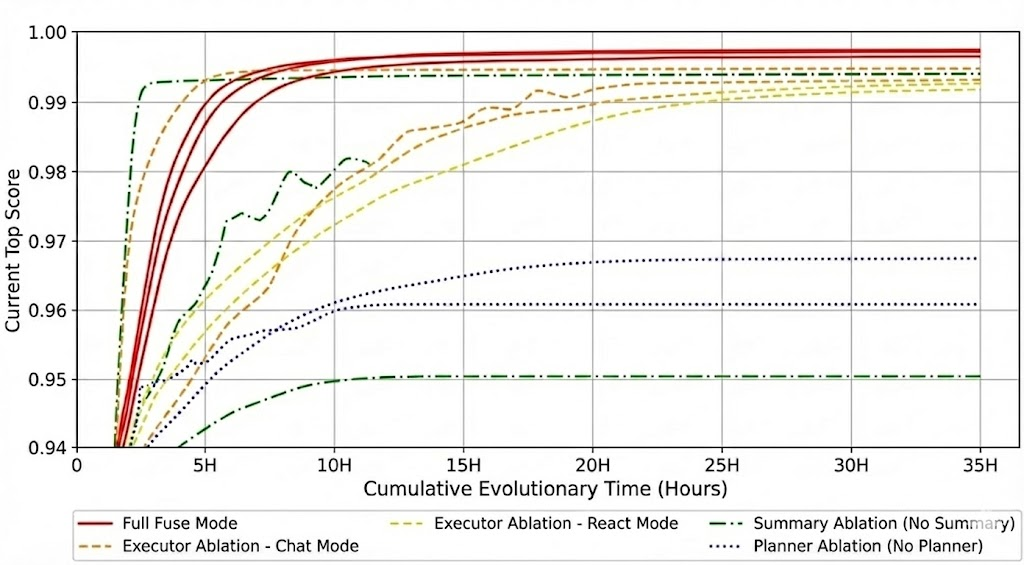
1. **Full Fuse Mode (Red Solid Line)**
- Starts at ~0.94 at 0H, peaks at ~0.995 by 5H, and plateaus at ~0.998 by 10H.
- Maintains near-perfect score (0.998–0.999) for remaining duration.
2. **Executor Ablation - Chat Mode (Brown Dashed Line)**
- Begins at ~0.94, rises to ~0.985 by 10H, then plateaus at ~0.992 by 15H.
- Shows minor fluctuations (~0.991–0.993) after 20H.
3. **Executor Ablation - React Mode (Yellow Dashed Line)**
- Similar trajectory to Chat Mode but slightly lower: ~0.982 by 10H, ~0.990 by 15H.
- Stabilizes at ~0.991–0.993 after 20H.
4. **Summary Ablation (Green Dash-Dot Line)**
- Starts at ~0.94, reaches ~0.975 by 10H, then plateaus at ~0.985 by 15H.
- Dips slightly (~0.984–0.986) after 20H.
5. **Planner Ablation (Purple Dotted Line)**
- Begins at ~0.94, climbs to ~0.96 by 10H, then plateaus at ~0.965 by 15H.
- Remains flat (~0.963–0.967) for the remainder of the graph.
6. **Summary + Planner Ablation (Black Dotted Line)**
- Lowest performance: ~0.94 at 0H, rises to ~0.95 by 10H, plateaus at ~0.955 by 15H.
- Stays flat (~0.953–0.957) after 20H.
### Key Observations
- **Performance Hierarchy**: Full Fuse Mode dominates, followed by Executor Ablation modes, then Summary/Planner Ablation modes.
- **Rapid Convergence**: All configurations stabilize within 10–15 hours, with minimal improvement afterward.
- **Ablation Impact**: Removing Summary or Planner components reduces scores by ~0.02–0.04 compared to Full Fuse Mode.
- **No Summary + No Planner**: Worst-performing configuration, consistently trailing others by ~0.04–0.05.
### Interpretation
The graph demonstrates that the Full Fuse Mode achieves the highest performance, with ablation studies revealing the critical role of Summary and Planner components. The Executor Ablation modes (Chat/React) show near-optimal performance, suggesting their configurations are robust. The steep initial improvement across all modes indicates rapid adaptation, while the plateaus suggest diminishing returns after ~15 hours. The Summary Ablation line’s dip at 10H may reflect temporary instability during configuration adjustments. Overall, the data underscores the importance of integrated components for maintaining high scores in evolutionary systems.
</details>
Figure 4: Score Convergence over Time. Note: Faint lines represent individual runs ( $N=3$ ), and bold lines represent the average trajectory.
#### 5.4.1 Planner: The Compass of Evolution
The Planner provides global expert guidance. Removing it forces the agent into a "blind search" mode. As shown in Figure 4, the Planner-ablated agent stagnated below 0.96. The lack of search pruning increased the average time to reach Top-1 solutions from 9.67 hours to 14.67 hours.
#### 5.4.2 Executor: Balancing Speed and Depth
The Executor employs an adaptive "Fuse Mode", switching between Chat (single-turn) and ReAct (multi-turn).
- Chat Mode: Computationally lightweight but highly unstable.
- ReAct Mode: Stable but inefficient.
- Fuse Mode: By dynamically allocating compute, Fuse Mode achieved the highest asymptotic score (0.998) with optimal sample efficiency.
#### 5.4.3 Summary: The Evolutionary Feedback
The Summary prevents the loss of historical insights. Without it, the agent suffered from cyclical errors. One trial ran for 35 hours yet failed to break the 0.95 threshold (as shown in Figure 4, see the "No-Summary" trajectory). The absence of retrospective analysis degraded the Planner’s decision-making, confirming that the summary module is essential for breaking performance bottlenecks.
## 6 Conclusion
In this work, we introduced LoongFlow, a cognitive evolutionary framework that fundamentally transcends the "blind watchmaker" limitations of traditional LLM-based optimization. By identifying the critical "cognitive ceiling" in existing methods—specifically their reliance on stochastic mutation and lack of historical reflection—we proposed a paradigm shift from random search to Directed Cognitive Evolution.
Our core contributions, the "Plan-Execute-Summarize" (PES) paradigm and the Hybrid Evolutionary Memory, effectively bridge the gap between reasoning agents and evolutionary computation. Theoretical analysis and extensive experiments demonstrate that LoongFlow not only preserves the diversity benefits of population-based methods but also injects the strategic depth of reasoning agents, achieving state-of-the-art results with significantly reduced computational overhead. LoongFlow establishes a new standard for sample-efficient, autonomous scientific discovery.
Future work will focus on extending LoongFlow towards fully autonomous "Meta-Agents" that can self-configure their evolutionary strategies and learning unsupervised diversity metrics for novel domains.