# Graph-Based Exploration for ARC-AGI-3 Interactive Reasoning Tasks
**Authors**: Evgenii Rudakov, Jonathan Shock, Benjamin Ultan Cowley
## Abstract
We present a training-free graph-based approach for solving interactive reasoning tasks in the ARC-AGI-3 benchmark. ARC-AGI-3 comprises game-like tasks where agents must infer task mechanics through limited interactions, and adapt to increasing complexity as levels progress. Success requires forming hypotheses, testing them, and tracking discovered mechanics. The benchmark has revealed that state-of-the-art LLMs are currently incapable of reliably solving these tasks. Our method combines vision-based frame processing with systematic state-space exploration using graph-structured representations. It segments visual frames into meaningful components, prioritizes actions based on visual salience, and maintains a directed graph of explored states and transitions. By tracking visited states and tested actions, the agent prioritizes actions that provide the shortest path to untested state-action pairs. On the ARC-AGI-3 Preview Challenge, this structured exploration strategy solves a median of 30 out of 52 levels across six games and ranks 3rd on the private leaderboard, substantially outperforming frontier LLM-based agents. These results demonstrate that explicit graph-structured exploration, even without learning, can serve as a strong baseline for interactive reasoning and underscore the importance of systematic state tracking and action prioritization in sparse-feedback environments where current LLMs fail to capture task dynamics. The code is open source and available at https://github.com/dolphin-in-a-coma/arc-agi-3-just-explore.
## Introduction
Introduced in 2019, the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) has become a fundamental benchmark for evaluating general fluid intelligence in artificial systems by posing novel tasks that require minimal prior knowledge (chollet_measure_2019). While the original ARC-AGI benchmarks focused on static grid-based reasoning tasks, ARC-AGI-3 represents a paradigm shift toward Interactive Reasoning Benchmarks (IRBs) that test broader capabilities, including on-the-fly learning, exploration, and memory through game-like environments where agents must perceive, plan, and act across multiple steps to achieve long-horizon goals (arc-agi-3).
ARC-AGI-3 introduces novel game environments designed to test the skill-acquisition efficiency of artificial systems, where agents interact with game environments without instructions, and must discover mechanics through exploration. Early results reveal a stark performance gap: frontier AI models scored 0% while human participants achieved 100% on the initial preview tasks (arc-agi-3). This dramatic disparity underscores fundamental limitations in current AI approaches to interactive reasoning and adaptive learning in novel environments.
The challenge of learning from sparse rewards has been central to reinforcement learning (RL) for decades. When rewards are rare and precise action sequences are required, random exploration fails to discover optimal policies. Exploration strategies have emerged to address this challenge. Curiosity-driven methods use prediction error as intrinsic motivation (pathak_curiosity-driven_2017), enabling agents to explore complex environments like Super Mario Bros without extrinsic rewards (pathak_curiosity-driven_2017). Go-Explore advances systematic exploration by maintaining archives of discovered states and decomposing exploration into phases: return to promising states, then explore from them (ecoffet_first_2021). This approach achieved breakthrough performance on Montezuma’s Revenge, scoring 25% higher than the human expert. For goal-conditioned tasks, Hindsight Experience Replay (HER) learns from failure by relabeling unsuccessful attempts as alternative goals, achieving sample-efficient learning without reward engineering (andrychowicz_hindsight_2017).
Model-based approaches have demonstrated remarkable sample efficiency by learning environment dynamics. MuZero combined learned latent dynamics with tree search, achieving superhuman performance on board games and Atari benchmarks without knowledge of game rules (schrittwieser_mastering_2020). EfficientZero extended this with self-supervised consistency losses, becoming the first algorithm to reach superhuman levels on Atari (194.3% mean human) with just 100k training samples (two hours of real-time experience) per game (ye_mastering_2021). BBF further improved Atari 100k results by scaling the value network sample-efficiency (schwarzer_bigger_2023), in a completely model-free manner.
The family of Dreamer models (hafner_training_2025) takes an alternative approach, learning world models in latent space and training policies through imagined rollouts rather than via tree search, mastering over 150 diverse tasks from Atari to Minecraft with a single configuration (hafner_training_2025). Most recently, Axiom introduced object-centric world models that learn compositional representations by discovering and tracking entities, achieving competitive performance within minutes by targeting 10k-step solutions per environment (heins_axiom_2025).
Despite these advances, current approaches face fundamental limitations for few-shot discovery tasks like ARC-AGI-3. The benchmark provides only a single sparse reward signal, level completion, across no more than 10 levels per game. This scarcity of feedback severely constrains learning-based methods. The challenge is compounded by the fact that each level introduces new mechanics while retaining previous ones, creating a shifting distribution that prevents straightforward transfer learning. Curiosity-driven exploration offers no guarantee of correlation with task progress in truly novel environments where the notion of ”most interesting states” may be orthogonal to goal-relevance. Sample-efficient approaches like Axiom assume object-centric compositional structure and require environments to exhibit consistent physical dynamics, assumptions that may not hold across ARC-AGI-3’s abstract and diverse game mechanics.
ARC-AGI-3 is also relevant for understanding the behaviour of large language model (LLM) agents. Unlike static reasoning benchmarks, it requires agents to infer latent rules through interaction, maintain an evolving notion of state, and design multi-step probes under sparse feedback, making it a complementary testbed for studying how explicit structure and exploration strategies can support LLM-based reasoning.
In this work, we present a graph-based exploration method that combines systematic state-space tracking with visual priority heuristics to tackle ARC-AGI-3’s interactive reasoning challenges. Our approach maintains a directed graph representation of explored states and action transitions, prioritizing actions based on visual salience while ensuring comprehensive exploration through frontier-driven navigation. Unlike learning-based approaches that require extensive training, our method operates as a strong baseline that can make progress through structured exploration alone. We demonstrate that this approach achieves competitive performance on the ARC-AGI-3 benchmark, significantly outperforming state-of-the-art LLMs while providing insights into the nature of exploration required for interactive reasoning tasks.
## ARC-AGI-3
### Benchmark Overview
ARC-AGI-3 represents a significant evolution from the original ARC challenge, shifting from static grid-based reasoning to interactive game environments that test an agent’s ability to learn through exploration (ying_assessing_2025). The benchmark consists of 6 novel game environments, with 3 public games (ft09, ls20, vc33) released for development and 3 private games (sp80, lp85, as66) used to determine final leaderboard rankings. Each game contains between 8 and 10 levels, with each subsequent level introducing new mechanics. Figure 2 in the appendix shows example screenshots from the games.
The benchmark’s evaluation criterion prioritizes both effectiveness and efficiency: agents are scored based on the number of levels completed, with the total number of actions required serving as a tiebreaker. This dual objective encourages solutions that not only discover winning strategies but do so with minimal exploration. For the final evaluation experiments by ARC-AGI-3 organizers, each run was capped at 8 hours of wall-clock time and 10 environment steps per second (sps), shared across the three private games. Under these limits, a single game can receive at most 96,000 steps
### Observation and Action Spaces
#### Visual Observations.
Agents receive visual observations as 64 $\times$ 64 pixel RGB frames with a discrete palette of 16 colors. Each frame contains both the game environment and a status bar displaying the number of steps remaining before an automatic level restart. When the step counter reaches zero, the current level resets to its initial state. In the majority of games, the number of levels passed is also displayed.
#### Action Spaces.
The benchmark features three control schemes. Games such as ls20 use arrow-based control with directional keyboard inputs (up, down, left, right), yielding an action space of size $|\mathcal{A}|=4$ . Games such as ft09, vc33, and lp85 employ click-based control, enabling spatial interaction by allowing the agent to click any pixel location in the frame, yielding an action space of size $|\mathcal{A}|=64\times 64=4{,}096$ . Private games (sp80 and as66) introduce combined control schemes that integrate both arrow and click inputs, resulting in action spaces of size $|\mathcal{A}|=4{,}100$ .
The dramatic difference in action space cardinality between control schemes poses a fundamental challenge: click-based games present over 1,000 times more possible actions at each state than arrow-based games, making exhaustive exploration intractable without intelligent action selection.
### Task Structure and Mechanics
Each game in ARC-AGI-3 embodies a distinct set of mechanics and objectives that agents must discover through interaction. The only feedback signal is level completion: the environment advances to the next level when the agent satisfies (unknown) winning conditions, or resets to the beginning when the step limit expires.
Within each game, levels progressively add new elements while retaining earlier ones. For example, level 1 of ls20 requires basic movement and the use of the transformer object to activate the exit door by adjusting the shape of a key, level 2 adds energy palletes to refill the number of steps remaining, level 3 introduces color dimension to the key, and so forth, up to level 8, when the agent must manage with only partial observations. This progressive structure mirrors how humans naturally acquire skills in games, but poses challenges for algorithms: knowledge transfer between levels could accelerate learning, but the levels are connected on a highly abstract level.
The released games operate deterministically: the same action taken from the same state always produces the same outcome. This property enables systematic state-space exploration strategies and graph-based representations of explored states. However, determinism does not imply simplicity; the complexity arises from the large state and action spaces and the lack of prior knowledge about which actions lead toward goal states.
## Methods
Our approach comprises two primary components: a Frame Processor for extracting key visual features and a Level Graph Explorer for systematic state-space exploration.
### Frame Processor
The Frame Processor reduces irrelevant visual variability and directs exploration toward actionable regions of the game environment through the following operations:
#### Image Segmentation.
Each frame is segmented into single-color connected components, establishing the foundation for identifying distinct visual elements that may constitute interactive objects.
#### Status Bar Detection and Masking.
To prevent conflation of environment features with user interface components, the processor identifies and masks probable status bars. This preprocessing substantially reduces the number of recognized states.
#### Priority-Based Action Grouping.
For click-controlled games, visual segments are stratified into five priority tiers based on their likelihood of representing interactive buttons or objects. Prioritization is determined by segment size, morphological features, and color salience. The lowest priority tier encompasses segments identified as probable status bars, ensuring their exploration only after exhausting higher-priority alternatives.
#### State Hashing.
The processor generates a hash representation of the masked image, serving as a unique identifier for the current game state. This hash facilitates efficient state tracking and duplicate detection during graph exploration.
### Level Graph Explorer
The Level Graph Explorer maintains a directed graph representation of the explored state space, where nodes correspond to unique game states and edges encode action-induced state transitions.
#### Graph Structure.
For each discovered state (graph node), the explorer maintains:
- The action space $\mathcal{A}$ identifiers of connected components for spatial interaction games such as ft09/cv33, keyboard inputs for games such as ls20)
- For each action $a\in\mathcal{A}$ : priority level $\pi(a)$ , exploration status, transition outcome, successor state, and minimal distance to the nearest unexplored frontier
#### Action Selection Strategy.
The explorer implements a hierarchical action selection policy that progressively expands the search space, as shown in Algorithm 1.
Algorithm 1 Hierarchical Action Selection
0: Current state $s$ , priority threshold $p$
if $\exists$ untested actions with priority $\pi(a)\leq p$ in state $s$ then
Select uniformly at random an untested action $a$ where $\pi(a)\leq p$ from $s$
Execute action and update graph with observed transition
else if $\exists$ reachable state $s^{\prime}$ with untested actions where $\pi(a)\leq p$ then
Select action minimizing distance to reachable state $s^{\prime}$ with untested actions at priority $\leq p$
Execute selected action
else
Increment priority threshold: $p\leftarrow p+1$
Recurse from current state $s$ with updated priority $p$
end if
This policy ensures systematic exploration of high-salience actions prior to considering lower-priority alternatives, thereby focusing computational resources on likely-relevant state-action pairs.
#### Frontier Management.
The explorer maintains the shortest-path distances from each explored state to frontier states, those containing untested actions. These distance metrics always guide traversal toward unexplored regions.
## Baselines
We evaluate our approach against two baseline methods to demonstrate the effectiveness of structured exploration.
#### Random Agent.
A simple baseline that selects actions uniformly at random from the available action space at each step. This baseline provides a lower bound on performance and demonstrates the difficulty of solving tasks through undirected exploration alone.
#### LLM+DSL.
We compare against the best-performing LLM-based solution on the leaderboard (fluxon_arc_2025), which combines GPT-4.1 with domain-specific language (DSL) programming. The approach observes game frames and generates Python code to interact with the environment, attempting to discover game mechanics through programmatic reasoning. Despite using a frontier LLM, this approach demonstrates the current limitations of LLM-based methods for interactive reasoning tasks.
Because each environment step is gated by an LLM call, it is severely interaction-limited: within the evaluation budget, it produces only about 4,000 interactions per game, compared to the 96,000 steps that are in principle allowed. To avoid high LLM usage costs, we do not re-run this baseline; instead, we report the results from its official evaluation on the private games, with the limitation that only a single aggregate score is available and no results are reported on the public games.
## Results
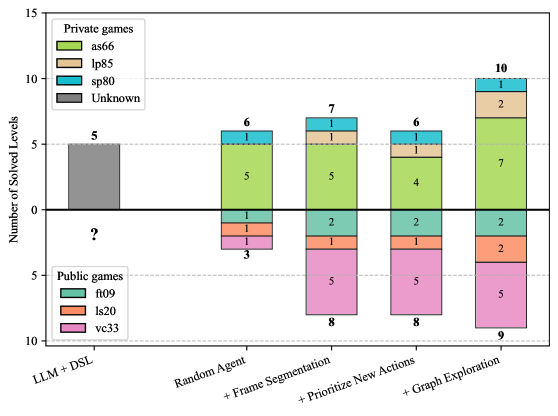
We evaluated our graph-based exploration method on all six ARC-AGI-3 games. Figure 1 reports an incremental component-addition analysis: starting from a random agent, we cumulatively add components and measure the total levels solved across games; the LLM+DSL baseline is included for comparison. Here, to ensure a fair comparison with the LLM-based baseline, all methods are capped at 4,000 interactions per game. All non-LLM configurations report the median over 5 runs, whereas the LLM+DSL baseline is shown as a single result taken from the official challenge evaluation.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Stacked Bar Chart: Number of Solved Levels vs. Algorithm
### Overview
This is a stacked bar chart comparing the number of solved levels for different algorithms, categorized by game type (Private vs. Public). The x-axis represents the algorithms, and the y-axis represents the number of solved levels. Each bar is segmented to show the contribution of different game instances within each algorithm.
### Components/Axes
* **X-axis:** Algorithms: LLM + DSL, Random Agent, Random Agent + Frame Segmentation, Prioritize New Actions, Graph Exploration.
* **Y-axis:** Number of Solved Levels (Scale from 0 to 15).
* **Legend (Top-Left):**
* Private games (Green)
* as66 (Light Green)
* lp85 (Tan)
* sp80 (Dark Gray)
* Unknown (Gray)
* Public games (Pink/Red)
* ft09 (Dark Red)
* ls20 (Pink)
* vc33 (Red)
* A horizontal line at y=0 separates the Private and Public game data.
* A question mark (?) is placed at the bottom of the "Unknown" section of the first bar.
### Detailed Analysis
The chart consists of five stacked bars, one for each algorithm.
**1. LLM + DSL:**
* Total solved levels: 5
* All levels are from "Unknown" private games (Gray).
**2. Random Agent:**
* Total solved levels: 6
* as66 (Light Green): 5 levels
* lp85 (Tan): 1 level
* ft09 (Dark Red): 3 levels
* ls20 (Pink): 2 levels
**3. Random Agent + Frame Segmentation:**
* Total solved levels: 7
* as66 (Light Green): 5 levels
* lp85 (Tan): 1 level
* ft09 (Dark Red): 1 level
* ls20 (Pink): 5 levels
* vc33 (Red): 8 levels
**4. Prioritize New Actions:**
* Total solved levels: 6
* as66 (Light Green): 4 levels
* lp85 (Tan): 2 levels
* ft09 (Dark Red): 2 levels
* ls20 (Pink): 5 levels
* vc33 (Red): 8 levels
**5. Graph Exploration:**
* Total solved levels: 10
* as66 (Light Green): 7 levels
* lp85 (Tan): 2 levels
* sp80 (Dark Gray): 1 level
* ft09 (Dark Red): 2 levels
* ls20 (Pink): 5 levels
* vc33 (Red): 9 levels
### Key Observations
* The "Graph Exploration" algorithm solves the most levels overall (10).
* The "LLM + DSL" algorithm only solves levels from "Unknown" private games.
* The contribution of private games (as66, lp85, sp80) is generally higher in the "Graph Exploration" and "Random Agent" algorithms.
* Public games (ft09, ls20, vc33) contribute significantly to the solved levels in the "Random Agent + Frame Segmentation", "Prioritize New Actions", and "Graph Exploration" algorithms.
* The "vc33" public game consistently contributes a large number of solved levels across the latter three algorithms.
### Interpretation
The chart demonstrates the effectiveness of different algorithms in solving game levels, distinguishing between private and public game types. The "Graph Exploration" algorithm appears to be the most successful overall. The fact that "LLM + DSL" only solves "Unknown" levels suggests it may be limited to a specific subset of games or requires further refinement. The increasing number of solved levels as algorithms become more complex (from "Random Agent" to "Graph Exploration") indicates that incorporating techniques like frame segmentation, prioritizing new actions, and graph exploration improves performance. The consistent high contribution of the "vc33" public game suggests it may be a relatively easier game to solve or that the algorithms are particularly well-suited to its characteristics. The question mark next to the "Unknown" levels suggests a lack of information about the specific game instances solved by the "LLM + DSL" algorithm. This could be a data collection issue or a deliberate obfuscation of game details.
</details>
Figure 1: Effect of progressively adding method components to a random agent, compared with the LLM+DSL baseline. For each configuration, the stacked bar above the horizontal axis shows the total number of solved levels across the three private games, and the stacked bar below shows the total across the three public games. Colors indicate how many levels are solved in each individual game. The rightmost bars correspond to the full method. All non-LLM configurations report the median over 5 runs, whereas the LLM+DSL baseline is shown as a single result taken from the official challenge evaluation.
The random agent and LLM+DSL baseline solve 6 and 5 levels on the private games, respectively, meaning that the LLM-based method underperforms even a random policy. The random agent also solves 3 levels across the public games.
Adding frame segmentation to random exploration slightly increases performance on the private games, making it possible to solve one level of lp85. It also significantly improves performance on the public games, solving 5 levels on vc33 and 2 levels on ft09.
When, in each state, untested actions are favored without full state-graph exploration, performance slightly decreases on as66, and the method is able to solve only 4 levels.
Our complete approach solves 19 levels with an interaction limit of 4,000: 2 on ft09, 2 on ls20, 5 on vc33, 1 on sp80, 2 on lp85, and 7 on as66.
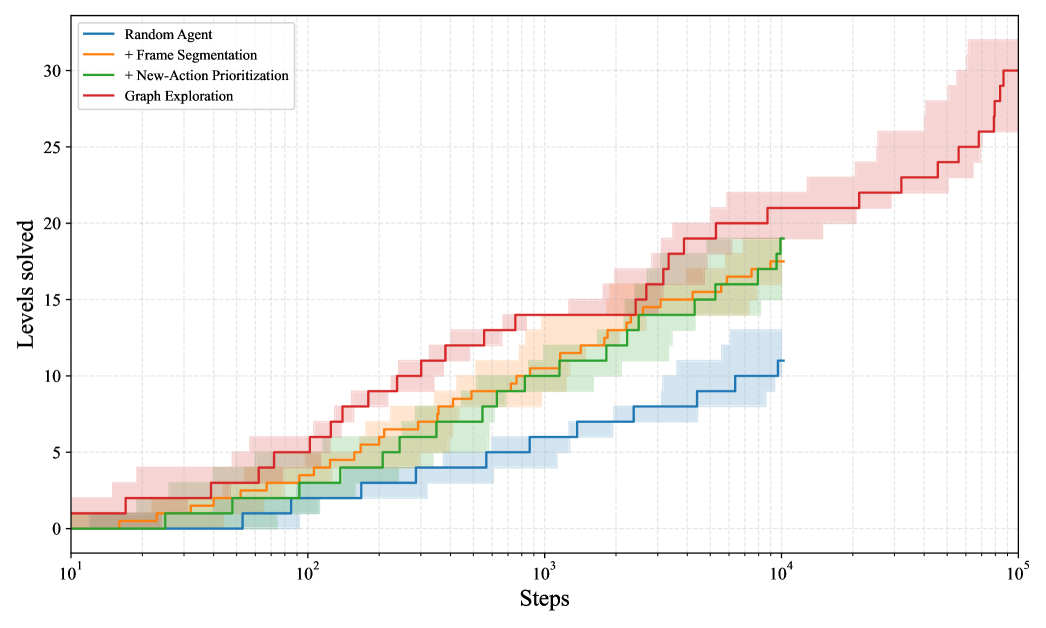
In a full 8-hour run, across 5 independent runs, our method solves a median of 16 levels on the private games and 14 levels on the public games (see Figure 3 in the appendix). Per-level performance is reported in Tables 1 and 2 in the appendix.
On the official ARC-AGI-3 challenge evaluation, the submitted model solves 12 levels on the private games while still ranking 3rd by the number of solved levels. This discrepancy is due to an implementation bug in how reset-inducing actions are handled (see Discussion).
## Discussion
Our graph-based exploration method demonstrates that structured state-space navigation with visual prioritization significantly outperforms both random exploration and frontier LLMs with access to code writing and execution on ARC-AGI-3.
#### Performance Analysis.
The method excelled on games where visual salience aligned with interactive elements (vc33, as66). Performance degraded on games with extremely large state spaces (ft09 levels 6+, ls20 levels 3+), where exhaustive exploration becomes computationally intractable. The improvement over LLM+DSL baselines suggests that structured exploration provides a more reliable foundation for interactive reasoning than pure language-model-based approaches, which struggle to form and test hypotheses systematically.
The discrepancy between the official ARC-AGI-3 evaluation and our re-runs is due to an implementation bug in the handling of reset events. Actions that triggered a reset were not marked as tested in the game graph. Consequently, when such a state–action pair was the nearest remaining untested edge in the graph from the starting node, the agent repeatedly selected it, resetting the game and effectively entering a loop.
#### Limitations.
The method faces two fundamental constraints. First, computational requirements grow linearly with state space size, limiting scalability to levels with moderate complexity. Second, the approach assumes deterministic, fully observable environments and would fail under stochasticity or partial observability.
#### Future Directions.
While the first-place solution on the leaderboard (smit_driessmitarc3-solution_2025) achieved superior performance with a learning-based approach, it did not incorporate structured exploration strategies. A natural next step is to integrate our graph-based exploration framework with adaptive learning algorithms. Such hybrid approaches could leverage graph representations to guide model training and action selection, while learned world models or policies could improve sample efficiency through generalization. The key challenge remains the sparse reward signal and limited training data, making it essential to develop methods that can effectively transfer knowledge across levels while maintaining systematic exploration coverage.
## Appendix A Appendix A: ARC-AGI-3 Games
|
<details>
<summary>Figures/vc33.png Details</summary>
### Visual Description
\n
## Diagram: Pixel-Based Representation
### Overview
The image presents a pixelated diagram, resembling a simplified representation of a landscape or a structural arrangement. It consists of colored blocks (black, green, yellow, red, blue, and white) arranged on a gray grid background. There are no explicit axes or labels. The diagram appears to be a visual arrangement rather than a data-driven chart.
### Components/Axes
There are no explicit axes or scales. The components are defined by the colored blocks:
* **Black Blocks:** Vertical structures of varying heights.
* **Green Blocks:** Smaller, square blocks.
* **Yellow Block:** A single, small square block.
* **Red Blocks:** Small, square blocks.
* **Blue Blocks:** Small, square blocks.
* **White Blocks:** Small, square blocks.
* **Gray Background:** A grid pattern.
### Detailed Analysis or Content Details
The diagram can be broken down into sections:
* **Left Side:** A tall black block is present, extending from the bottom edge to near the top. A small green block is positioned on top of the black block. A blue block is at the base of the black block.
* **Center:** A shorter black block is present. A green block is positioned mid-way up the black block. A red block is at the base of the black block.
* **Right Side:** A green block is present.
* **Top:** A horizontal line of blocks is present, consisting of a yellow block, followed by several white blocks. The number of white blocks is approximately 6.
There is no numerical data associated with the diagram. The arrangement is purely visual.
### Key Observations
The diagram features two prominent vertical black structures. The presence of colored blocks at the base and top of the black structures suggests a potential relationship or connection. The horizontal line of blocks at the top could represent a boundary or a separate element. The diagram is highly abstract and lacks clear context.
### Interpretation
The diagram appears to be a symbolic or abstract representation, potentially illustrating a concept of structure, support, or hierarchy. The black blocks could represent foundational elements, while the colored blocks might signify different components or attributes. The arrangement could be a simplified model of a building, a landscape, or a more abstract system. Without additional context, it is difficult to determine the precise meaning or purpose of the diagram. The diagram does not contain any factual data, but rather a visual arrangement of elements. It is likely a conceptual illustration rather than a data visualization. The diagram's simplicity suggests it may be intended for illustrative or educational purposes.
</details>
|
<details>
<summary>Figures/ls20.png Details</summary>

### Visual Description
\n
## Diagram: Maze with Agents
### Overview
The image depicts a top-down view of a maze-like environment with several agents represented by colored squares. The maze is constructed from dark gray blocks, with open pathways between them. There are several purple squares scattered throughout the maze, potentially representing goals or points of interest. A row of purple squares is present at the top of the image, and a row of green and gray squares is present at the bottom.
### Components/Axes
There are no explicit axes or scales. The environment is defined by the arrangement of gray blocks. The agents are differentiated by color: blue, orange, and white. The purple squares are scattered throughout the maze. The top row consists of approximately 20 purple squares. The bottom row consists of approximately 10 squares, alternating between green and gray.
### Detailed Analysis or Content Details
The maze is roughly rectangular. The agents are positioned as follows:
* **Blue Agent:** Located in the bottom-left corner of the maze.
* **Orange Agent 1:** Located in the bottom-right quadrant of the maze.
* **Orange Agent 2:** Located in the top-right quadrant of the maze.
* **White Agent:** Located in the central-left quadrant of the maze.
The purple squares are distributed unevenly throughout the maze. There is a higher concentration of purple squares in the left and right sides of the maze. The green and gray squares at the bottom do not appear to be part of the maze structure itself, but rather a separate indicator or status bar.
### Key Observations
The agents appear to be navigating the maze. The distribution of purple squares suggests that the maze may be designed to encourage exploration or to test the agents' pathfinding abilities. The different colors of the agents may indicate different roles or objectives. The bottom row of green and gray squares could represent progress or status indicators.
### Interpretation
This image likely represents a simulation or game environment where agents are tasked with navigating a maze. The purple squares could be goals that the agents are trying to reach, or obstacles that they need to avoid. The different agent colors could represent different teams or players. The green and gray squares at the bottom could indicate the progress of the simulation or the status of the agents.
The maze's complexity suggests a non-trivial pathfinding challenge. The uneven distribution of purple squares could be intentional, creating areas of higher and lower reward or difficulty. The overall design suggests a focus on agent behavior and decision-making in a complex environment. The image does not provide any quantitative data, but it offers a rich visual representation of a potential problem space for artificial intelligence or robotics research.
</details>
|
<details>
<summary>Figures/ft09.png Details</summary>

### Visual Description
\n
## Heatmap: Grid of Colored Squares
### Overview
The image presents a heatmap consisting of a 5x7 grid of colored squares. The squares are filled with three distinct colors: red, blue, and gray. The arrangement of colors appears non-random, suggesting a pattern or data representation. There are no explicit axis labels or legends present within the image itself. The heatmap is centered within a larger gray rectangular area, bordered by a yellow frame.
### Components/Axes
There are no explicit axes or legends. The data is represented solely by the color of each square within the grid. The grid dimensions are 5 columns and 7 rows.
### Detailed Analysis or Content Details
The grid can be described as follows, reading row by row from top to bottom:
* **Row 1:** Red, Red, Red, Red, Red, Red, Blue
* **Row 2:** Red, Red, Red, Red, Red, Blue, Blue
* **Row 3:** Red, Red, Gray, Blue, Red, Red, Blue
* **Row 4:** Red, Red, Blue, Blue, Red, Gray, Blue
* **Row 5:** Red, Red, Blue, Red, Red, Red, Blue
* **Row 6:** Red, Red, Red, Red, Red, Red, Red
* **Row 7:** Red, Red, Red, Red, Red, Red, Red
The colors are consistently distributed, with red being the most frequent color. Gray appears only twice, and blue appears more frequently in the rightmost columns.
### Key Observations
* Red dominates the grid, occupying the majority of the squares.
* Blue is concentrated towards the right side of the grid.
* Gray appears sparsely, only in the center columns of rows 3 and 4.
* There is a clear visual pattern, with the colors not appearing randomly distributed.
### Interpretation
Without any accompanying labels or context, it's difficult to definitively interpret the meaning of this heatmap. However, we can speculate based on the observed patterns.
The prevalence of red could represent a baseline or default state. The presence of blue might indicate a positive or active condition, as it's concentrated on the right side. The gray squares could represent missing data, neutral values, or a different category altogether.
The arrangement of colors suggests a potential correlation between the column position and the likelihood of a square being blue. This could indicate a trend or relationship between some underlying variable and the column index.
The lack of labels makes it impossible to determine the specific meaning of the colors or the variables being represented. The image likely represents a simplified visualization of some data, but further information is needed to understand its full significance. It could be a representation of a binary classification, a performance metric, or any other type of data that can be categorized into three states.
</details>
|
| --- | --- | --- |
|
<details>
<summary>Figures/sp80.png Details</summary>

### Visual Description
\n
## Diagram: Pixelated Scene
### Overview
The image depicts a pixelated scene resembling a simple game or visual representation. It consists of a background, several horizontal rectangular blocks of different colors, and a series of yellow blocks at the bottom, above a light blue line. There are no axes, legends, or numerical data present. This is a visual representation, not a data-driven chart.
### Components/Axes
The scene is composed of the following elements:
* **Background:** Predominantly orange with a green strip at the very top.
* **Top Block:** A small, dark block with a pinkish-purple block above it.
* **Red Block:** A horizontal red rectangle positioned below the top block.
* **Blue Block:** A horizontal blue rectangle positioned below the red block.
* **Yellow Blocks:** A series of four yellow blocks arranged in a pattern at the bottom of the image.
* **Light Blue Line:** A horizontal light blue line directly above the yellow blocks.
### Detailed Analysis or Content Details
The image is entirely visual. There are no labels, scales, or numerical values. The elements are arranged in layers:
1. **Top Layer:** The dark block with the pinkish-purple block above it is positioned near the top-center of the image.
2. **Middle Layer:** The red block is positioned horizontally, centered below the top block.
3. **Lower-Middle Layer:** The blue block is positioned horizontally, centered below the red block.
4. **Bottom Layer:** The yellow blocks are arranged in a pattern resembling arches or pillars. They are positioned above the light blue line.
The pixelated nature of the image suggests it could be a screenshot from a retro video game or a deliberately stylized graphic.
### Key Observations
The arrangement of the blocks appears deliberate, potentially representing a level design or a visual composition. The yellow blocks at the bottom are the most detailed element, suggesting they might be the focal point. The color scheme is relatively simple, with orange, red, blue, yellow, and green being the dominant colors.
### Interpretation
The image likely represents a simplified game environment or a visual metaphor. The blocks could symbolize obstacles or platforms, and the top block might represent a character or projectile. The arrangement suggests a sense of progression or challenge. Without additional context, it's difficult to determine the specific meaning or purpose of the image. It could be a visual representation of a concept, a level design sketch, or simply an abstract composition. The pixelated style evokes a sense of nostalgia and simplicity. The image does not contain any factual data or quantifiable information; it is purely a visual representation.
</details>
|
<details>
<summary>Figures/lp85.png Details</summary>

### Visual Description
\n
## Diagram: Pixelated Circular Arrangement
### Overview
The image presents a diagram composed of pixelated blocks arranged in a roughly circular pattern. The arrangement appears to represent a system or process with interconnected components, visualized using different colors to distinguish elements. There are no explicit labels or axes, making a precise interpretation challenging. The background is a dark gray, and a green vertical bar is present on the left side.
### Components/Axes
There are no explicit axes or labels. The diagram consists of 12 colored blocks arranged in a circular fashion, with 4 blocks in the center. The colors used are:
* Blue (multiple shades)
* Purple
* Yellow
* Orange
* Red
* Green
The arrangement is symmetrical around a vertical axis.
### Detailed Analysis or Content Details
The diagram can be divided into three concentric layers: an outer ring of 8 blocks, an intermediate ring of 4 blocks, and a central cluster of 4 blocks.
**Outer Ring:**
Starting from the top and moving clockwise:
1. Light Blue
2. Dark Blue
3. Purple
4. Yellow
5. Orange
6. Light Blue
7. Dark Blue
8. Green
**Intermediate Ring:**
Starting from the top and moving clockwise:
1. Dark Blue
2. Purple
3. Green
4. Red
**Central Cluster:**
Starting from the top and moving clockwise:
1. Purple
2. Dark Blue
3. Red
4. Green
The arrangement is pixelated, suggesting a digital or discrete representation. The blocks are uniformly sized and spaced.
### Key Observations
The diagram exhibits a degree of symmetry. The colors are distributed in a non-random manner, suggesting a deliberate arrangement. The repetition of colors (e.g., Dark Blue, Purple) in different layers might indicate a hierarchical relationship or flow of information. The lack of labels makes it difficult to determine the specific meaning of each color or the overall process being represented.
### Interpretation
Without additional context, the diagram's precise meaning is ambiguous. However, several interpretations are possible:
* **System Architecture:** The diagram could represent the components of a system, with different colors representing different modules or functions. The circular arrangement might indicate a cyclical process or feedback loop.
* **State Diagram:** The diagram could represent the states of a system, with transitions between states indicated by the connections between blocks.
* **Data Flow:** The diagram could represent the flow of data through a system, with different colors representing different types of data.
* **Abstract Representation:** The diagram could be an abstract representation of a complex concept, with the colors and arrangement used to convey a specific meaning.
The symmetry suggests a balanced or stable system. The repetition of colors might indicate redundancy or a common function. The pixelated nature of the diagram suggests a digital or discrete representation, potentially related to computer science or information technology.
The green bar on the left could be a status indicator or a visual cue related to the diagram's function. The dark gray background provides contrast and emphasizes the colored blocks.
The diagram appears to be a visual metaphor rather than a precise technical drawing. It likely requires additional context or explanation to fully understand its meaning. It is a visual representation of a system or process, but the specific details are left open to interpretation.
</details>
|
<details>
<summary>Figures/as66.png Details</summary>

### Visual Description
\n
## Diagram: Pixelated Game Level
### Overview
The image depicts a pixelated game level, resembling a top-down view of a maze or obstacle course. The level is composed of various colored blocks arranged on a purple background. There are no explicit axes, scales, or legends. The image appears to be a static snapshot of a game environment, likely from a retro-style game.
### Components/Axes
There are no axes or scales present. The components are defined by the colored blocks:
* **Purple:** Background color, representing the traversable space.
* **Black:** Represents solid obstacles or walls.
* **Orange:** A larger block at the top of the level, potentially a platform or a key area.
* **Red:** A small block within the orange area, possibly a collectible or a hazard.
* **White:** A block at the bottom of the level, potentially the player's starting point or a goal.
* **Yellow:** Two small blocks, potentially power-ups or collectibles.
* **Green:** A vertical strip on the left side of the image, possibly a UI element or a boundary.
* **Gray:** A border around the entire level.
* **Dark Red:** A strip at the top of the image.
### Detailed Analysis or Content Details
The level consists of a series of black blocks forming a maze-like structure within the purple background. The arrangement of the black blocks creates pathways and obstacles.
* **Top Section:** A large orange block occupies the top-center area. Within this block is a smaller red block.
* **Central Area:** The central area is filled with black blocks of varying shapes and sizes, creating a complex network of corridors and barriers.
* **Bottom Section:** A white block is positioned near the bottom-center of the level.
* **Left Side:** A vertical green strip runs along the left edge of the image.
* **Scattered Elements:** Two yellow blocks are scattered within the central area.
There is no numerical data or quantifiable information present in the image. The level's dimensions are approximately square, with an estimated 20x20 pixel grid. The blocks vary in size, ranging from single pixels to approximately 5x5 pixels.
### Key Observations
The level design suggests a focus on navigation and obstacle avoidance. The arrangement of the black blocks creates a challenging path for a player to traverse. The orange and red blocks at the top may represent a goal or a reward. The yellow blocks could be power-ups or collectibles that aid the player. The green strip on the left might be a score display or a menu.
### Interpretation
The image represents a simplified game level, likely designed for a 2D platformer or puzzle game. The pixelated style evokes a sense of nostalgia for retro gaming. The level's design suggests a focus on strategic movement and problem-solving. The placement of the orange, red, white, and yellow blocks indicates potential objectives or rewards for the player. The lack of any visible player character or other game elements suggests that the image is a static representation of the level itself, rather than a snapshot of gameplay. The level appears to be designed to test the player's ability to navigate a complex environment and overcome obstacles. The overall aesthetic is minimalist and functional, prioritizing gameplay over visual complexity. The image does not provide any information about the game's story, mechanics, or target audience. It is a purely visual representation of a game level.
</details>
|
Figure 2: Top row (Public set): vc33, ls20, ft09. Bottom row (Private set): sp80, lp85, as66.
## Appendix B Appendix B: Per-Level Performance Statistics
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Line Chart: Levels Solved vs. Steps
### Overview
The image presents a line chart illustrating the relationship between the number of steps taken and the number of levels solved by different agents. The chart compares the performance of a "Random Agent" with agents employing various enhancements: "+ Frame Segmentation", "+ New-Action Prioritization", and "Graph Exploration". Each line represents the average performance of an agent type, with shaded areas indicating the standard deviation or confidence interval. The x-axis is logarithmic.
### Components/Axes
* **X-axis:** "Steps" - Logarithmic scale ranging from 10<sup>1</sup> to 10<sup>5</sup>.
* **Y-axis:** "Levels solved" - Linear scale ranging from 0 to 32.
* **Legend:** Located at the top-left corner of the chart.
* "Random Agent" - Blue line
* "+ Frame Segmentation" - Yellow-Green line
* "+ New-Action Prioritization" - Orange line
* "Graph Exploration" - Red line
### Detailed Analysis
The chart displays four lines, each representing a different agent type. The lines show the average number of levels solved as a function of the number of steps taken. The shaded areas around each line represent the variability in performance.
* **Random Agent (Blue):** The line starts at approximately 0 levels solved at 10<sup>1</sup> steps and gradually increases to approximately 11 levels solved at 10<sup>5</sup> steps. The line exhibits a relatively slow and steady upward slope.
* **+ Frame Segmentation (Yellow-Green):** The line begins at approximately 0 levels solved at 10<sup>1</sup> steps and rises more steeply than the Random Agent, reaching approximately 18 levels solved at 10<sup>5</sup> steps.
* **+ New-Action Prioritization (Orange):** This line starts at approximately 0 levels solved at 10<sup>1</sup> steps and shows a steeper increase than the Random Agent and + Frame Segmentation, reaching approximately 24 levels solved at 10<sup>5</sup> steps.
* **Graph Exploration (Red):** This line demonstrates the most rapid increase, starting at approximately 0 levels solved at 10<sup>1</sup> steps and reaching approximately 31 levels solved at 10<sup>5</sup> steps.
**Approximate Data Points (extracted visually):**
| Steps (approx.) | Random Agent (Levels Solved) | + Frame Segmentation (Levels Solved) | + New-Action Prioritization (Levels Solved) | Graph Exploration (Levels Solved) |
|---|---|---|---|---|
| 10<sup>1</sup> | 0 | 0 | 0 | 0 |
| 10<sup>2</sup> | 2 | 4 | 6 | 8 |
| 10<sup>3</sup> | 6 | 10 | 14 | 18 |
| 10<sup>4</sup> | 9 | 16 | 22 | 28 |
| 10<sup>5</sup> | 11 | 18 | 24 | 31 |
### Key Observations
* The "Graph Exploration" agent consistently outperforms all other agents across the entire range of steps.
* "+ New-Action Prioritization" performs better than "+ Frame Segmentation", which in turn performs better than the "Random Agent".
* The performance gains are most significant at higher step counts.
* The shaded areas indicate that the "Graph Exploration" agent has the lowest variability in performance, while the "Random Agent" has the highest.
### Interpretation
The data suggests that incorporating graph exploration techniques significantly improves an agent's ability to solve levels, as evidenced by its consistently higher performance compared to other agents. The enhancements of frame segmentation and new-action prioritization also contribute to improved performance, but to a lesser extent than graph exploration. The logarithmic scale of the x-axis highlights the increasing effectiveness of these techniques as the number of steps increases, indicating that they are particularly beneficial for complex tasks requiring long-term planning and exploration. The variability in performance, as indicated by the shaded areas, suggests that the "Random Agent" is more susceptible to random fluctuations, while the "Graph Exploration" agent exhibits more consistent and reliable performance. This could be due to the more structured and informed decision-making process enabled by graph exploration. The chart demonstrates a clear hierarchy of effectiveness among the different agent strategies, with graph exploration emerging as the most promising approach.
</details>
Figure 3: Levels solved as a function of environment steps for four methods: Random Agent, Random + Frame Segmentation, Random + Segmentation + New-Action Prioritization, and the full Graph Exploration method. The x-axis is logarithmic; each line shows the median over 5 runs and the shaded region shows the minimum–maximum range. Intermediate variants are shown up to 10,000 environment steps, while the Graph Explorer is plotted over the full evaluation budget.
Table 1: Per-level results on public games (ft09, ls20, vc33). For each game and level, we report the number of steps to solve the level (Stp), summarized as the median together with the minimum and maximum over 5 runs, and the solve rate (SR) over the same 5 runs. We use ‘NS‘ when a level is never solved within the step budget, and ‘-‘ when there is no such level for a given game.
| 1 2 | 125 $[48;340]$ 177 | 1 1 | 124 $[72;140]$ $3.2\times 10^{3}$ | 1 1 | 9 $[5;24]$ 7 | 1 1 |
| --- | --- | --- | --- | --- | --- | --- |
| $[5;433]$ | | $[1.9\times 10^{3};4.9\times 10^{3}]$ | | $[4;19]$ | | |
| 3 | $2.0\times 10^{4}$ | 1 | NS | 0 | 36 | 1 |
| $[3.0\times 10^{3};2.5\times 10^{4}]$ | | | | $[9;96]$ | | |
| 4 | NS | 0 | NS | 0 | 321 | 1 |
| $[298;541]$ | | | | | | |
| 5 | NS | 0 | NS | 0 | 287 | 1 |
| $[260;349]$ | | | | | | |
| 6 | NS | 0 | NS | 0 | $6.9\times 10^{4}$ | 0.8 |
| $[5.4\times 10^{4};8.3\times 10^{4}]$ | | | | | | |
| 7 | NS | 0 | NS | 0 | $4.7\times 10^{3}$ | 0.8 |
| $[1.5\times 10^{3};5.5\times 10^{3}]$ | | | | | | |
| 8 | NS | 0 | NS | 0 | 917 | 0.8 |
| $[627;929]$ | | | | | | |
| 9 | NS | 0 | - | - | NS | 0 |
| 10 | NS | 0 | - | - | - | - |
Table 2: Per-level results on private games (sp80, lp85, as66). Conventions as in Table 1.
| 1 2 | 227 $[153;373]$ $3.6\times 10^{4}$ | 1 1 | 143 $[106;181]$ $2.9\times 10^{3}$ | 1 1 | 39 $[13;47]$ 44 | 1 1 |
| --- | --- | --- | --- | --- | --- | --- |
| $[2.5\times 10^{4};5.0\times 10^{4}]$ | | $[1.1\times 10^{3};3.2\times 10^{4}]$ | | $[24;65]$ | | |
| 3 | $3.9\times 10^{4}$ | 0.4 | $1.7\times 10^{4}$ | 1 | 123 | 1 |
| $[3.6\times 10^{4};4.2\times 10^{4}]$ | | $[1.0\times 10^{4};8.2\times 10^{4}]$ | | $[25;339]$ | | |
| 4 | NS | 0 | $1.6\times 10^{3}$ | 1 | 99 | 1 |
| $[727;2.0\times 10^{4}]$ | | $[69;350]$ | | | | |
| 5 | NS | | $4.6\times 10^{3}$ | 0.8 | $2.2\times 10^{3}$ | 1 |
| $[2.2\times 10^{3};1.4\times 10^{4}]$ | | $[1.2\times 10^{3};2.9\times 10^{3}]$ | | | | |
| 6 | NS | 0 | $1.3\times 10^{4}$ | 0.4 | $1.3\times 10^{3}$ | 1 |
| $[1.1\times 10^{4};1.5\times 10^{4}]$ | | $[112;1.6\times 10^{3}]$ | | | | |
| 7 | NS | 0 | 334.5 | 0.4 | 363 | 1 |
| $[104;565]$ | | $[128;670]$ | | | | |
| 8 | NS | 0 | $9.9\times 10^{3}$ | 0.2 | $1.3\times 10^{3}$ | 1 |
| $[9.9\times 10^{3};9.9\times 10^{3}]$ | | $[168;2.9\times 10^{3}]$ | | | | |
| 9 | - | - | - | - | $3.4\times 10^{3}$ | 1 |
| $[361;8.7\times 10^{3}]$ | | | | | | |
| 10 | - | - | - | - | - | - |