# From Building Blocks to Planning: Multi-Step Spatial Reasoning in LLMs with Reinforcement Learning
## Abstract
Spatial reasoning in large language models (LLMs) has gained increasing attention due to applications in navigation and planning. Despite strong general language capabilities, LLMs still struggle with spatial transformations and multi-step planning in structured environments. We propose a two-stage approach that decomposes spatial reasoning into atomic building blocks and their composition. First, we apply supervised fine-tuning on elementary spatial transformations, such as rotation, translation, and scaling, to equip the model with basic spatial physics. We then freeze this physics-aware model and train lightweight LoRA adapters within the GRPO framework to learn policies that compose these building blocks for multi-step planning in puzzle-based environments, in a closed-loop manner. To support this pipeline, we synthesize an ASCII-art dataset and construct a corresponding ASCII-based reinforcement learning environment. Our method consistently outperforms baselines, including the generic backbone, physics-aware model, and end-to-end RL models, under both Dynamic environments with explicit state updates and Static environments where the model must rely on its internal state across steps. In addition, the proposed approach converges faster and exhibits more stable training compared to end-to-end reinforcement learning from scratch. Finally, we analyze attention patterns to assess whether fine-tuning induces meaningful improvements in spatial understanding.
## 1 Introduction
Spatial reasoning and understanding represent the capability to reason about spatial relationships of objects and transformations in an environment. This includes understanding relative positions, orientations, distances, and the effects of actions that modify spatial configurations. With the recent advancements of LLMs (Minaee et al., 2025) and VLMs (Li et al., 2025) in a wide variety of tasks, such as math reasoning (Ahn et al., 2024) and vision–language understanding (Wu et al., 2024a), their spatial reasoning capabilities have gained more attention, with applications such as robotics (Kong et al., 2025) and language navigation tasks (Zhang et al., 2024). However, their abilities in spatial reasoning have not yet been widely explored (Wu et al., 2024b). Spatial reasoning tasks can often be mapped into several domains, some of which focus on linguistic and natural language scenarios (Li et al., 2024), as well as puzzle-based settings (Noever & Burdick, 2021) such as mazes (Einarsson, 2025), Rubik’s Cube (Ding et al., 2023), and Sokoban (Todd et al., 2023), where the model needs to understand the spatial relationships among objects to solve the task. In puzzle-based settings, language models are empowered by several techniques. One category involves using an external module as a solver, with the LLM acting as an action recommender or reasoning candidate generator. The external module can be heuristic-based, such as BFS or DFS in Tree of Thoughts (ToT) (Yao et al., 2023), or learning-based approaches, such as XoT, which leverages pretrained reinforcement learning and Monte Carlo Tree Search (MCTS) (Ding et al., 2023), or Q-learning (Deng et al., 2025). Another category of approaches focuses on the model itself. One direction aims to change the model’s behavior through prompting, such as Visualization-of-Thought (VoT) (Wu et al., 2024b), which elicits spatial reasoning in LLMs by visualizing their reasoning traces and guiding subsequent reasoning steps. Another approach, presented in Dao & Vu (2025), is inspired by DeepSeek-R1 (DeepSeek-AI et al., 2025) and is based on supervised fine-tuning the model on solution traces, and then applying GRPO to further refine reasoning steps on the same task and structure.
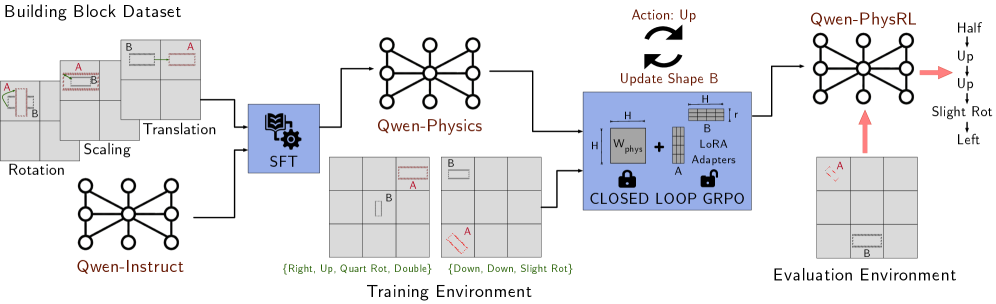
In this work, we focus on spatial reasoning in a puzzle-based setting, where an agent must transform an initial spatial configuration into a target configuration through a sequence of discrete actions. We propose a novel approach that decomposes spatial understanding into a set of building blocks, consisting of atomic transformations such as rotating a shape by $90^{\circ}$ or translating it one grid cell upward. We first apply supervised fine-tuning to enable the model to learn these basic physical transformations. After this stage, the physics-aware model is kept frozen, and reinforcement learning is applied on top of it by introducing lightweight adapter layers that learn a policy for composing these building blocks as primitives to reach a target spatial configuration from a given starting point. An overview of our approach is shown in Figure 1.
For the supervised fine-tuning stage, we synthesize a dataset of 12k tasks spanning three transformation categories, translation, rotation, and scaling, which is used to fine-tune the Qwen2.5-1.5B-Instruct model (Qwen Team, 2024). In the subsequent reinforcement learning stage, the physics-aware model is embedded directly in the reinforcement learning loop within a multi-step, compositional environment. Reinforcement learning is applied via GRPO to optimize lightweight LoRA adapter layers (Hu et al., 2021) on top of the frozen backbone, enabling the model to learn policies over sequences of atomic spatial operations through repeated interaction with the environment. We evaluate our approach against several baselines, including the generic Qwen2.5-1.5B-Instruct model, the physics-aware model trained only with supervised fine-tuning, and a Qwen model trained directly with GRPO reinforcement learning. All models are tested on unseen spatial reasoning tasks under two settings: one where the environment map is updated after each action, and one where the map remains fixed. Our results show that the proposed method achieves higher rewards than all baselines across both settings and converges faster during reinforcement learning. Although the physics-aware model trained only with supervised fine-tuning underperforms the generic backbone on the final task, it provides a stronger prior for reinforcement learning, leading to substantially better performance after GRPO optimization. Finally, we conduct ablation studies on attention layers to analyze whether the learned improvements reflect genuine spatial understanding.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Qwen-Physics Reinforcement Learning Training Pipeline
### Overview
The image is a technical flowchart illustrating a machine learning training pipeline for a physics-aware model named "Qwen-Physics" and its reinforcement learning variant "Qwen-PhysRL." The diagram details the flow from a dataset, through supervised fine-tuning (SFT), into a training environment with a closed-loop reinforcement learning algorithm (GRPO), and finally to an evaluation environment. The process involves manipulating building blocks (labeled A and B) within a grid world.
### Components/Axes
The diagram is organized into several distinct regions and components, flowing generally from left to right.
**1. Header (Top-Left):**
* **Title:** "Building Block Dataset"
* **Content:** A series of grid-based examples showing transformations applied to two objects, labeled **A** (red outline) and **B** (blue outline).
* **Transformation Labels:** "Rotation", "Scaling", "Translation". These are positioned near the corresponding example grids.
**2. Initial Model & Training Start (Left):**
* **Model Icon:** A neural network diagram labeled **"Qwen-Instruct"**.
* **Process Block:** A blue box with a gear icon labeled **"SFT"** (Supervised Fine-Tuning). Arrows connect the "Building Block Dataset" and "Qwen-Instruct" to this block.
**3. Core Model (Center-Top):**
* **Model Icon:** A larger neural network diagram labeled **"Qwen-Physics"**. An arrow flows from the "SFT" block to this model.
**4. Training Environment (Center-Bottom):**
* **Title:** **"Training Environment"** (positioned at the bottom center).
* **Content:** Two example grid states.
* **Left Grid:** Shows object **A** (red) and object **B** (blue). Below it, a text string in green: **`{Right, Up, Quart Rot, Double}`**.
* **Right Grid:** Shows object **A** (red, rotated) and object **B** (blue). Below it, a text string in green: **`{Down, Down, Slight Rot}`**.
* **Flow:** An arrow points from "Qwen-Physics" to this environment.
**5. Learning Algorithm Block (Center-Right):**
* **Title:** **"CLOSED LOOP GRPO"** (inside a large blue box).
* **Internal Components:**
* A weight matrix labeled **`W_physics`** with a lock icon.
* A plus sign (`+`).
* A diagram labeled **"LoRA Adapters"** showing matrices **H**, **B**, **r**, and **A**.
* A lock icon next to the LoRA Adapters.
* **External Annotations:**
* Above the box: Two curved arrows forming a loop. Labels: **"Action: Up"** and **"Update Shape B"**.
* An arrow flows from the "Training Environment" into this block.
**6. Evaluation Environment & Final Model (Right):**
* **Model Icon:** A neural network diagram labeled **"Qwen-PhysRL"**. An arrow flows from the "CLOSED LOOP GRPO" block to this model.
* **Title:** **"Evaluation Environment"** (positioned at the bottom right).
* **Content:** A single grid state showing object **A** (red) and object **B** (blue). A red arrow points from this grid up to the "Qwen-PhysRL" model.
* **Output Action Sequence:** To the right of the "Qwen-PhysRL" model, a vertical list of actions in black text:
* **Half**
* **Up**
* **Up**
* **Slight Rot**
* **Left**
* A pink arrow points from the model to this list.
### Detailed Analysis
The diagram depicts a multi-stage training and evaluation process:
1. **Data & Initialization:** A "Building Block Dataset" containing examples of object transformations (Rotation, Scaling, Translation) is used. An initial model, "Qwen-Instruct," is the starting point.
2. **Supervised Fine-Tuning (SFT):** The dataset and the initial model are used to perform SFT, resulting in the "Qwen-Physics" model.
3. **Reinforcement Learning Loop:**
* The "Qwen-Physics" model interacts with a "Training Environment" consisting of grid worlds with objects A and B.
* The model's actions (e.g., `{Right, Up, Quart Rot, Double}`) are fed into a "CLOSED LOOP GRPO" (Group Relative Policy Optimization) algorithm.
* This algorithm contains a frozen physics weight matrix (`W_physics`) and trainable LoRA adapters, indicating parameter-efficient fine-tuning.
* The loop annotation ("Action: Up" / "Update Shape B") suggests the policy is updated based on the outcome of actions taken in the environment.
4. **Final Model & Evaluation:** The output of the GRPO training is the "Qwen-PhysRL" model. This model is then tested in a separate "Evaluation Environment." The diagram shows it generating a specific sequence of actions ("Half, Up, Up, Slight Rot, Left") in response to a given grid state.
### Key Observations
* **Two-Phase Training:** The pipeline clearly separates initial supervised learning (SFT) from subsequent reinforcement learning (GRPO).
* **Parameter Efficiency:** The use of LoRA Adapters within the GRPO block highlights a focus on efficient adaptation of the large "Qwen-Physics" model.
* **Environment Abstraction:** The "Training" and "Evaluation" environments are represented as grid worlds with simple objects (A, B) and discrete action spaces (movement, rotation).
* **Action Representation:** Actions are represented as sequences of commands (e.g., "Quart Rot" for quarter rotation, "Slight Rot").
* **Visual Coding:** Objects are consistently color-coded (A=red, B=blue) across all grids. The learning algorithm components are highlighted in a distinct blue box.
### Interpretation
This diagram outlines a methodology for imbuing a large language model (Qwen) with physics-based reasoning capabilities through a structured, two-stage training regimen.
* **Purpose:** The goal is to create a model ("Qwen-PhysRL") that can understand and predict the outcomes of physical interactions (like moving and rotating objects in a grid) and generate appropriate action sequences to achieve a desired state.
* **Relationships:** The "Building Block Dataset" provides the foundational knowledge of object transformations. SFT injects this knowledge into the base model. The RL loop (GRPO) then refines this knowledge by having the model actively experiment in an environment, learning from trial and error to optimize its policy, with the frozen `W_physics` likely preserving core physical understanding while the LoRA adapters learn task-specific strategies.
* **Notable Design Choice:** The "CLOSED LOOP" nature of the GRPO is critical. It implies the model's own actions and their results in the environment are used to continuously update its policy, creating a self-improving system for physical reasoning tasks. The separation of training and evaluation environments tests the model's ability to generalize its learned physics policies to new, unseen configurations.
</details>
Figure 1: Overview of the proposed training framework. The pipeline follows a two-stage learning approach. In the SFT Phase, the base model (Qwen-Instruct) is fine-tuned on the Building Block Dataset to acquire atomic spatial priors (translation, scaling, rotation), resulting in the intermediate Qwen-Physics model. In the RL Phase, we employ GRPO in a closed-loop setting with LoRA adapters. The model is trained to master multi-step spatial reasoning and planning, yielding the final Qwen-PhysRL model.
## 2 Related Work and Background
### 2.1 Spatial Reasoning in LLMs
Spatial reasoning in large language models has been studied across a range of domains. One line of research focuses on textual inputs, where spatial semantics are embedded in text and models are required to reason about relative spatial relations, such as left of or right of, expressed through language (Mirzaee & Kordjamshidi, 2022). A further step is explored in natural language navigation tasks, where, given a sequence of textual instructions, the model must maintain an implicit spatial state and track its position over multiple steps. In these settings, spatial understanding is inferred from sequential language instructions rather than from explicit spatial representations such as symbolic layouts (Wu et al., 2024b). Recent efforts explore symbolic environments, particularly ASCII-art representations, which bridge the gap between text and image modalities in applications such as level generation (Todd et al., 2023). Results show that large language models are capable of recognizing concepts depicted in ASCII art given textual inputs. However, they still exhibit notable limitations and remain far behind human performance in transformation tasks such as translation, rotation, and robustness to noise (Bayani, 2024), as well as in shape recognition (Wang et al., 2024; Jia et al., 2025). Prior work also indicates that supervised fine-tuning can improve model accuracy in these settings (Jia et al., 2025).
### 2.2 Attention Mechanisms in Transformer-Based LLMs
Since the introduction of the Transformer architecture (Vaswani et al., 2017), it has been widely adopted across a broad range of applications. Most notably, it serves as the dominant foundation for large language models (LLMs), enabling efficient natural language processing (NLP) tasks such as understanding and generating long sequences of text (Devlin et al., 2019; Brown et al., 2020). The key innovation underlying these advances is the self-attention mechanism (Akbari et al., 2021), which models long-range dependencies among elements in sequential data and enables effective extraction, processing, and generation of structured outputs. Most contemporary LLMs adopt a decoder-only Transformer architecture, which is more suitable for autoregressive text generation. These models process a sequence of tokens through multiple architecturally similar decoder layers, followed by a final linear projection that maps hidden states to the vocabulary space. Each decoder layer consists of several core components, including self-attention, a feed-forward multilayer perceptron (MLP), and residual connections with normalization. With the exception of a small number of element-wise operations (e.g., softmax and dropout), matrix multiplication dominates the computational workload of these components.
During inference, the token sequence is represented as a matrix of hidden state vectors with dimensionality $H$ , corresponding to the model’s hidden size. These hidden states are multiplied by a set of learned linear projections in the self-attention module, namely $W_{Q}$ (query), $W_{K}$ (key), $W_{V}$ (value), and $W_{O}$ (output), as well as by projection matrices in the MLP component, such as $W_{\text{up}}$ , $W_{\text{down}}$ , and $W_{\text{gate}}$ . Among these operations, the multiplication $QK^{\mathsf{T}}$ , which produces the attention score matrix, plays a key role in our analysis. Here, $Q$ and $K$ are obtained by projecting the input hidden states using $W_{Q}$ and $W_{K}$ , respectively. The resulting attention score matrix captures semantic and syntactic dependencies between tokens in the sequence by quantifying the relative influence of each token on every other token. In later sections, we examine how this attention distribution changes under our proposed method and analyze its effect on how tokens are weighted during spatial reasoning tasks.
## 3 Methodology
### 3.1 Problem Formulation
We frame the spatial configuration space using three properties: the rotational state of the shape, its translational position on a discrete grid, and its scale. Based on this formulation, a shape state is represented as a tuple $S=(r,p,s)$ , where $r$ denotes the orientation, $p$ the spatial position, and $s$ the size of the shape. Correspondingly, the action space is defined as a finite symbolic set $\mathcal{A}=\mathcal{A}_{\text{rot}}\cup\mathcal{A}_{\text{trans}}\cup\mathcal{A}_{\text{scale}}$ , aligned with these three properties. The rotation action set is given by $\mathcal{A}_{\text{rot}}=\{90^{\circ}\ \text{CCW},45^{\circ}\ \text{CCW},180^{\circ}\ \text{CCW},0^{\circ}\}$ , the scaling set by $\mathcal{A}_{\text{scale}}=\{2\times,\tfrac{1}{2}\times,1\}$ , and the translation set by $\mathcal{A}_{\text{trans}}=\{\text{right},\text{left},\text{up},\text{down}\}$ . This discrete action formulation mitigates known limitations of language models when operating in continuous spaces (Szot et al., 2024), while still providing sufficient flexibility to modify each component of the state. The task begins from an initial state $S_{0}=(r_{0},p_{0},s_{0})$ , and the agent applies a sequence of actions $a_{1:T}=\{a_{1},\ldots,a_{T}\}$ with the objective of reaching a target configuration $S_{\text{target}}=(r_{g},p_{g},s_{g})$ . The environment dynamics are deterministic, with state transitions defined as $S_{B}^{(t+1)}=\mathcal{T}(S_{B}^{(t)},a_{t})$ , resulting in a closed-loop rollout where the observation at step $t$ is given by $O_{t}=(S_{\text{target}},S_{t},H_{t})$ , with the action history $H_{t}=(a_{1},\ldots,a_{t-1})$ . The objective is to reach the target spatial configuration in the fewest possible steps. An episode is considered successful once the intersection-over-union (IoU) between the current shape and the target shape exceeds a predefined threshold $\tau$ . Accordingly, the task objective can be expressed in terms of the minimal timestep $t^{\star}$ at which the following condition is satisfied:
$$
t^{\star}=\min\left\{\,t\geq 0\;\middle|\;\operatorname{IoU}\big(S_{B}^{(t)},S_{A}\big)\geq\tau\,\right\}. \tag{1}
$$
All actions are admissible at each timestep under a bounded map domain $\mathcal{P}\subset\mathbb{Z}^{2}$ . For any action $a\in\mathcal{A}$ with induced displacement $\Delta(a)$ , the next position is given by $\tilde{p}=p+\Delta(a)$ when $\tilde{p}\in\mathcal{P}$ , and equals $p$ otherwise.
### 3.2 Proposed Method
In the first stage, we perform supervised fine-tuning on atomic building-block transformations. We define a building block as a single-step transformation for which the distance between the start configuration $S_{\text{start}}$ and the target configuration $S_{\text{target}}$ satisfies $\operatorname{dist}(S_{\text{start}},S_{\text{target}})=1$ , where the distance is defined as the sum of differences in position, scale, and orientation, i.e., $\Delta p+\Delta s+\Delta r$ . Under this formulation, each training example corresponds to exactly one atomic action from the predefined action set $\mathcal{A}$ . This process yields a physics-aware policy $\pi_{\text{phys}}$ , defined as
$$
\pi_{\text{phys}}:=\pi_{\theta^{*}}(a\mid S_{\text{start}},S_{\text{target}},k), \tag{2}
$$
where $k\in\{\text{rot},\text{trans},\text{scale}\}$ denotes the transformation type label. This policy captures the local physics of the environment by learning to correctly execute the corresponding atomic transformation. In the second stage, we learn a compositional policy on top of the frozen physics-aware model. The policy $\pi_{\phi}$ is parameterized by the frozen base weights $\theta^{*}$ obtained from SFT and a set of learnable Low-Rank Adaptation (LoRA) parameters $\phi$ . We apply LoRA to a predefined set of transformer modules $\mathcal{M}=\{W_{Q},W_{K},W_{V},W_{O},W_{\text{gate}},W_{\text{up}},W_{\text{down}}\}$ . For each layer $l\in\{1,\ldots,L\}$ and each module $W\in\mathcal{M}$ , the forward pass is modified as
$$
h^{(l)}=(W_{\text{phys}}+\Delta W_{l})\,h^{(l-1)}=(W_{\text{phys}}+B_{l}A_{l})\,h^{(l-1)}, \tag{3}
$$
where $W_{\text{phys}}$ denotes the frozen base weights and $A_{l},B_{l}$ are the learnable low-rank matrices comprising $\phi$ . The adapter parameters $\phi$ are optimized using GRPO in a closed-loop reinforcement learning setting, while the base parameters $\theta^{*}$ remain fixed.
As a result, the learned policy $\pi_{\phi}$ operates in a closed-loop manner, where at each timestep $t$ the model generates a textual output $y_{t}$ conditioned on the current observation $o_{t}$ .
$$
y_{t}\sim\pi_{\phi}(\cdot\mid o_{t}),\qquad a_{t}=g(y_{t})\in\mathcal{A}, \tag{4}
$$
where $g(\cdot)$ is a deterministic parser that maps the generated text to a discrete atomic action label.
## 4 Experiments
### 4.1 Experimental Setup
For the spatial reasoning task, all models are built on top of the Qwen2.5-1.5B-Instruct backbone. In our experiments, we evaluate the performance of several variants to isolate the contribution of each training stage. These include: (i) Qwen-Instruct, the generic pretrained model without task-specific training; (ii) Qwen-Physics, a supervised fine-tuned model trained only on atomic building-block transformations; (iii) Qwen-DirectRL, a model trained end-to-end using GRPO directly on the base model; (iv) Qwen-PhysRL, our proposed two-stage method combining frozen atomic execution with reinforcement learning–based composition; and (v) Random Policy ( $\pi_{rnd}$ ), a random action policy serving as an unbiased lower-bound baseline. All model variants share the same tokenizer, namely the standard tokenizer provided with the Qwen2.5-1.5B-Instruct model.
### 4.2 Dataset Construction
For supervised fine-tuning, we construct a synthetic dataset consisting of 12k unique samples, approximately uniformly distributed across the action set $\mathcal{A}$ . Each sample is generated by randomly initializing two of the three shape properties and modifying the remaining property according to a single atomic action. All samples are generated programmatically by applying deterministic atomic transformations to randomly sampled initial configurations, ensuring full reproducibility and eliminating the need for manual annotation. All spatial configurations are represented using an ASCII-art domain, where both the current shape and the target shape are encoded as text-based grids. In this representation, the relative spatial relationship between the current and target shapes is conveyed implicitly through their layouts (Appendix § A). Shape boundaries are denoted using the character #, while rows are separated using * and newline (\n) characters to preserve the two-dimensional structure. This textual spatial encoding follows conventions inspired by prior work on symbolic spatial reasoning with language models (Todd et al., 2023).
### 4.3 Evaluation Metrics
A deterministic parser $g(\cdot)$ is used to identify the <answer> tags in the model output and extract the corresponding discrete action. Our primary evaluation metric is the cumulative episode reward. For an episode of length $T$ , we define
$$
R_{\text{total}}=R_{\text{correctness}}-0.1\,T-\sum_{t=1}^{T}R_{\text{rep}}^{(t)}+R_{\text{success}}, \tag{5}
$$
where $R_{\text{correctness}}$ reflects agreement between the agent’s predicted action and a predefined ground-truth sequence $\mathrm{GT}=\{a_{1},\ldots,a_{T}\}$ of heuristic greedy atomic actions that locally reduce the distance to the target configuration. A per-step penalty of $0.1$ encourages shorter solutions, $R_{\text{rep}}^{t}$ penalizes repetitive behaviors, and $R_{\text{success}}$ is granted upon task completion. We additionally log step-wise rewards $\{r_{t}\}_{t=1}^{T}$ to support fine-grained analysis of policy failures and divergence points.
## 5 Results and Analysis
For GRPO training of the physics-aware fine-tuned model, all experiments were conducted on a single NVIDIA A100 GPU with 80 GB of memory. We use the Adam optimizer with a learning rate of $1\times 10^{-5}$ and apply LoRA adaptation with rank $r=64$ to the specified transformer modules, while keeping the base model frozen. Training is performed with a batch size of 64 trajectories, with puzzles randomly generated at each environment reset. Action sampling during training follows a temperature scheduling strategy to stabilize learning, where the temperature is linearly annealed from an initial value of 1.4 to a lower bound of 0.7 over training iterations. During evaluation, sampling is disabled, and actions are selected greedily to obtain the best deterministic solution from the model. In both training and evaluation, the maximum distance between the start and target configurations is limited to 5, and the episode horizon is set to $T_{\max}=5$ . A success bonus of $+2$ is assigned upon task completion, while a per-step penalty of $-0.1$ encourages shorter solutions. To discourage repetitive behavior, an additional repetition penalty of $-0.2$ is applied when the same atomic action is selected more than twice within an episode. Finally, the correctness reward is normalized to 1 across all operation types, regardless of the number of ground-truth atomic actions available for a given operation, in order to prevent bias toward specific transformation categories. For instance, in a scenario involving three transformations, one rotation and one scaling, the maximum episode reward is computed as $3\times\tfrac{1}{3}+1+1-3\times 0.1=2.7$ . Adding the success bonus $R_{\text{success}}=2$ yields a total reward of 4.7.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Line Chart: Reward vs. Step Number for Two RL Models
### Overview
The image is a line chart comparing the training performance of two reinforcement learning (RL) models over 180 steps. The chart plots the "Reward" achieved on the y-axis against the "Step Number" on the x-axis. Each model's performance is represented by a solid line, surrounded by a shaded area of the same color, which likely indicates the variance, standard deviation, or confidence interval across multiple training runs.
### Components/Axes
* **Chart Type:** Line chart with shaded confidence intervals.
* **X-Axis:**
* **Label:** "Step Number"
* **Scale:** Linear, ranging from 0 to 180.
* **Major Tick Marks:** At intervals of 20 (0, 20, 40, 60, 80, 100, 120, 140, 160, 180).
* **Y-Axis:**
* **Label:** "Reward"
* **Scale:** Linear, ranging from -1 to 5.
* **Major Tick Marks:** At integer intervals (-1, 0, 1, 2, 3, 4, 5).
* **Legend:**
* **Position:** Bottom-right corner of the plot area.
* **Title:** "Model"
* **Entries:**
1. **Qwen-PhysRL:** Represented by a dark blue solid line and a light blue shaded area.
2. **Qwen-directRL:** Represented by a teal (blue-green) solid line and a light teal shaded area.
### Detailed Analysis
**1. Qwen-PhysRL (Dark Blue Line & Light Blue Shading):**
* **Trend:** The line shows a very steep, rapid increase in reward early in training, followed by a plateau with moderate fluctuations.
* **Key Data Points (Approximate):**
* Step 0: Reward ≈ 0.
* Step 20: Reward ≈ 1.0.
* Step 40: Reward ≈ 4.5 (steep ascent complete).
* Step 60: Reward ≈ 4.7 (local peak).
* Step 100: Reward ≈ 4.2 (local trough).
* Step 120: Reward ≈ 3.8 (local trough).
* Step 140: Reward ≈ 4.7 (local peak).
* Step 180: Reward ≈ 4.7.
* **Shaded Area (Variance):** The light blue shaded region is very wide during the initial ascent (steps 0-40), indicating high variance between runs. After step 40, the shaded area narrows considerably but remains present, showing that while the mean reward stabilizes, there is still some run-to-run variability.
**2. Qwen-directRL (Teal Line & Light Teal Shading):**
* **Trend:** The line shows a steadier, more gradual, and roughly linear increase in reward throughout the entire training period.
* **Key Data Points (Approximate):**
* Step 0: Reward ≈ -0.5.
* Step 20: Reward ≈ 0.8.
* Step 60: Reward ≈ 1.5.
* Step 100: Reward ≈ 2.5.
* Step 140: Reward ≈ 3.0.
* Step 180: Reward ≈ 3.4.
* **Shaded Area (Variance):** The light teal shaded region is consistently wide across the entire x-axis. This indicates a high and persistent level of variance in the reward achieved by this model across different training runs, from start to finish.
### Key Observations
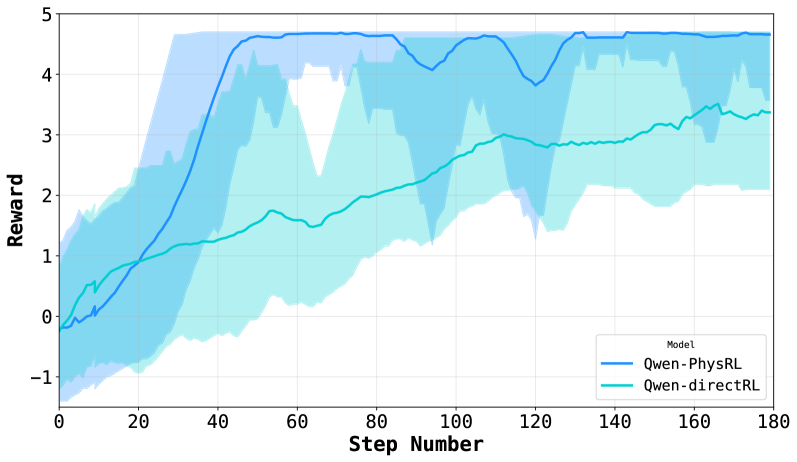
1. **Performance Gap:** Qwen-PhysRL achieves a significantly higher final reward (~4.7) compared to Qwen-directRL (~3.4) by step 180.
2. **Learning Speed:** Qwen-PhysRL learns much faster, reaching near-peak performance by step 40. Qwen-directRL's learning is slower and more incremental.
3. **Stability/Variance:** Qwen-PhysRL exhibits high initial variance that decreases after convergence. Qwen-directRL shows high variance throughout training, suggesting less consistent performance across runs.
4. **Convergence:** Qwen-PhysRL's reward curve plateaus after step 40, indicating convergence. Qwen-directRL's curve is still trending upward at step 180, suggesting it may not have fully converged.
### Interpretation
This chart demonstrates a clear performance comparison between two RL training approaches. **Qwen-PhysRL** appears to be a more sample-efficient and effective method for this task, rapidly converging to a high reward level. The name "PhysRL" might suggest it incorporates physical priors or constraints, which could explain the faster, more stable learning once a viable policy is found (post step 40).
**Qwen-directRL**, in contrast, learns slowly and unreliably. The persistently wide confidence interval suggests the training process is highly sensitive to initial conditions or random seeds, making it a less robust method for this specific problem. The upward trend at the end implies that with more training steps, its performance might continue to improve, but it would likely remain less efficient than the PhysRL variant.
The data suggests that for the task being measured, incorporating the inductive biases present in the "PhysRL" approach leads to superior learning dynamics—both in terms of final performance and training stability—compared to a more "direct" RL approach.
</details>
Figure 2: GRPO training reward trajectories for Qwen-PhysRL and Qwen-DirectRL, illustrating improved stability and faster convergence when using a frozen physics-aware prior.
| Qwen-Instruct Qwen-Physics Qwen-DirectRL ( $r=64$ ) | $0.070$ $-0.068$ $1.626$ | $0.004$ $-0.120$ $-0.216$ |
| --- | --- | --- |
| Qwen-PhysRL ( $r=64$ , Ours) | $\mathbf{2.457}$ | $\mathbf{1.717}$ |
Table 1: Performance comparison across models on 100 unseen random scenarios under Dynamic state updates and Static settings.
#### Performance Analysis.
The average total reward achieved by different model variants is reported in Table 1. We evaluate all models under two settings. In the Dynamic setting, after each action, the environment updates the shape’s spatial configuration map $S_{B}$ , mirroring the training procedure and generating the next prompt accordingly. This setup allows the model to focus on predicting the correct next action without requiring explicit memorization of prior state changes. In contrast, in the Static setting, the initial maps remain fixed, and the prompt includes only the sequence of previously selected actions. Successful performance in this scenario, therefore, requires the model to internally track and reason about the cumulative effects of past actions. The results demonstrate that our proposed Qwen-PhysRL achieves near-maximum performance in the Dynamic setting, with an average reward of $2.457$ , indicating that the learned RL policy reliably identifies the correct sequence of transformations when external state updates are provided. Importantly, Qwen-PhysRL also achieves an average reward of $1.717$ in the Static setting, substantially outperforming all baseline models. In contrast, Qwen-DirectRL exhibits moderate performance in the Dynamic setting but fails in the Static setting, suggesting that reinforcement learning alone is insufficient to equip the model with robust internal spatial understanding and reasoning. Finally, non-RL models perform poorly in both settings, reflecting limited planning capability. Reinforcement learning bridges this gap by teaching the model how to utilize its building-block knowledge, enabling the composition of atomic operations into coherent multi-step policies.
| Step | Cumulative Reward until Step $i$ | | |
| --- | --- | --- | --- |
| Qwen-PhysRL | $\pi_{rnd}$ | | |
| Dynamic | Static | | |
| 1 | 0.900 | 0.759 | 0.250 |
| 2 | 1.374 | 1.143 | 0.463 |
| 3 | 1.914 | 1.469 | 0.641 |
| 4 | 2.340 | 1.689 | 0.790 |
| 5 | 2.457 | 1.717 | 0.912 |
0 0.9 1.2 1.8 1.5 2.1 2.1 1.8 2.4 2.4 2.4 2.7 2.7 2.7 2.7 scale tr rot tr tr rot tr tr tr tr tr rot rot tr
Figure 3: Left: Step-by-step cumulative reward comparison between Qwen-PhysRL (Dynamic and Static settings) and random policy ( $\pi_{rnd}$ ) on tasks requiring 3 translations, 1 rotation, and 1 scaling. Right: Action-reward trajectory illustrating the optimal path (blue: scale $\rightarrow$ tr $\rightarrow$ rot $\rightarrow$ tr $\rightarrow$ tr), which achieves the maximum reward of 2.7, contrasted with alternative action sequences (gray). The trajectory obtained under the Static setting is shown in red, where the model initially follows the optimal prefix (scale $\rightarrow$ tr $\rightarrow$ tr $\rightarrow$ tr) but then diverges and loses track of the remaining steps, failing to complete the full plan.
#### Per-Step Reward Analysis.
To analyze step-by-step reward accumulation during evaluation, we focus on a smaller subset of test samples in which the distance between the start and target configurations is exactly five. Specifically, we select instances that require three translations, one rotation, and one scaling operation to reach the goal. This restriction allows us to study reward trajectories under a fixed action budget and comparable difficulty. Figure 3 reports the average cumulative reward per step for three cases: Qwen-PhysRL evaluated in the Dynamic environment, Qwen-PhysRL evaluated in the Static setting, and a random policy $\pi_{\text{rnd}}$ . Figure 3 also includes a tree representation of the maximum achievable cumulative reward at each step for all valid sequences of ground-truth actions ( $GT$ ). To keep the tree visualization compact and interpretable, we fix the first action in the tree to scale, which is the most frequently selected initial operation by the learned policy. The optimal action sequence identified by the Qwen-PhysRL policy in the Dynamic setting (scale $\rightarrow$ translation $\rightarrow$ rotation $\rightarrow$ translation $\rightarrow$ translation) is highlighted as the blue path in the tree and is taken in approximately 33 % of the evaluated trajectories. The corresponding average cumulative reward closely tracks the maximum achievable reward along this path, indicating that the model consistently follows near-optimal action sequences when the environment explicitly updates the state after each step. Two additional high-probability paths, (scale $\rightarrow$ rotation $\rightarrow$ translation $\rightarrow$ translation $\rightarrow$ translation) and (scale $\rightarrow$ translation $\rightarrow$ translation $\rightarrow$ rotation $\rightarrow$ translation), are taken in 27 % and 19 % of cases, respectively. In contrast, under the Static setting, the average cumulative reward initially follows the red path in the tree, corresponding to the sequence (scale $\rightarrow$ translation $\rightarrow$ translation $\rightarrow$ translation). This behavior aligns with our empirical observations that, without explicit state updates, the model gradually loses track of earlier actions, diverges from the optimal plan, and ultimately fails to produce a decisive fifth action. As a result, reward accumulation stagnates at later steps. Compared to the random policy $\pi_{\text{rnd}}$ (see Appendix § B for its expected reward analysis), Qwen-PhysRL selects substantially more effective actions at each step in both the Dynamic and Static settings. The only exception occurs at the final step in the Static case, where the learned policy yields a smaller average reward increase than the random policy, as it has already diverged from the optimal trajectory, whereas the random policy occasionally converges to a higher-reward branch by chance. We note that, because the action space is not relatively large and the reward distribution is partly biased toward positive values, the random policy attains relatively high rewards in this setting. Even under these favorable conditions, Qwen-PhysRL consistently outperforms the random baseline by a wide margin.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Stacked Bar Chart: Attention Distribution by Token Type Across Model Layers
### Overview
The image displays a stacked bar chart comparing the total attention sum allocated to three different token types (`#` (Hash), `*` (Star), and Whitespace) across four specific layers (0, 16, 20, 27) for two different models: "Qwen-Phys" and "Qwen-Instruct". The chart illustrates how the composition of attention changes between models and across network depth.
### Components/Axes
* **Chart Type:** Grouped, stacked bar chart.
* **Legend:** Positioned at the top center of the image.
* Red square: `# (Hash)`
* Blue square: `* (Star)`
* Gray square: `Whitespace`
* **Y-Axis:** Labeled "Total Attention (Sum)". The scale runs from 0.00 to 0.10, with major tick marks at 0.00, 0.02, 0.04, 0.06, 0.08, and 0.10.
* **X-Axis:** Grouped by layer number. Each layer group contains two bars, one for each model.
* **Layer 0:** Leftmost group. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Layer 16:** Second group from left. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Layer 20:** Third group from left. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Layer 27:** Rightmost group. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Bar Labels:** The model names "Qwen-Phys" and "Qwen-Instruct" are written below their respective bars within each layer group.
### Detailed Analysis
**Layer 0:**
* **Qwen-Phys:** Total height ~0.098. Composition (bottom to top): Whitespace ~0.030, Star (blue) ~0.042 (reaching ~0.072), Hash (red) ~0.026 (reaching ~0.098).
* **Qwen-Instruct:** Total height ~0.112 (the tallest bar in the chart). Composition: Whitespace ~0.029, Star ~0.051 (reaching ~0.080), Hash ~0.032 (reaching ~0.112).
* **Trend:** Both models show high total attention in the first layer. Qwen-Instruct allocates slightly more attention overall, with a notably larger Hash component.
**Layer 16:**
* **Qwen-Phys:** Total height ~0.075. Composition: Whitespace ~0.012, Star ~0.055 (reaching ~0.067), Hash ~0.008 (reaching ~0.075).
* **Qwen-Instruct:** Total height ~0.029. Composition: Whitespace ~0.012, Star ~0.017 (reaching ~0.029), Hash ~0.000 (no visible red segment).
* **Trend:** A significant drop in total attention for both models compared to Layer 0. The Hash component becomes very small or absent. Qwen-Phys maintains a much higher total attention than Qwen-Instruct at this layer.
**Layer 20:**
* **Qwen-Phys:** Total height ~0.079. Composition: Whitespace ~0.022, Star ~0.030 (reaching ~0.052), Hash ~0.027 (reaching ~0.079).
* **Qwen-Instruct:** Total height ~0.021. Composition: Whitespace ~0.002, Star ~0.011 (reaching ~0.013), Hash ~0.008 (reaching ~0.021).
* **Trend:** Qwen-Phys's total attention rebounds slightly from Layer 16, with a substantial Hash component reappearing. Qwen-Instruct's total attention continues to decrease, reaching its lowest point in the chart.
**Layer 27:**
* **Qwen-Phys:** Total height ~0.065. Composition: Whitespace ~0.030, Star ~0.030 (reaching ~0.060), Hash ~0.005 (reaching ~0.065).
* **Qwen-Instruct:** Total height ~0.045. Composition: Whitespace ~0.021, Star ~0.019 (reaching ~0.040), Hash ~0.005 (reaching ~0.045).
* **Trend:** Total attention for Qwen-Phys decreases from Layer 20. Qwen-Instruct shows an increase from its Layer 20 low. The Hash component is minimal for both models. Whitespace becomes a more significant portion of the total for both, especially for Qwen-Phys.
### Key Observations
1. **Model Disparity:** Qwen-Instruct has the single highest attention sum (Layer 0) but also the lowest (Layer 20), showing greater variance across layers. Qwen-Phys maintains a more consistent, higher baseline of attention in the middle layers (16, 20).
2. **Hash Token Attention:** The red `# (Hash)` segment is most prominent in Layer 0 for both models and in Layer 20 for Qwen-Phys. It is nearly absent in Layer 16 for both and minimal in Layer 27.
3. **Star Token Dominance:** The blue `* (Star)` segment is the largest or second-largest component in every bar, indicating it consistently receives a major share of attention.
4. **Whitespace Role:** The gray Whitespace component is a stable, non-trivial base layer of attention in all bars, typically ranging between 0.01 and 0.03.
5. **Layer-Specific Behavior:** Layer 0 is characterized by high total attention and significant Hash components. Middle layers (16, 20) show a divergence between the models. The final layer (27) shows a convergence in composition, with reduced Hash attention and increased relative Whitespace.
### Interpretation
This chart visualizes how two different training paradigms (Physics-focused vs. Instruct-tuned) affect the internal attention mechanisms of a language model across its depth.
* **Early Layer (0) Specialization:** Both models heavily attend to special tokens (`#` and `*`) at the input stage, suggesting these tokens act as crucial anchors or delimiters for initial processing. The higher attention in Qwen-Instruct may reflect a broader initial parsing strategy.
* **Mid-Layer Divergence:** The stark difference in Layers 16 and 20 suggests the models develop fundamentally different internal representations. Qwen-Phys maintains strong engagement with special tokens (especially `#` in Layer 20), possibly indicating ongoing structural or relational processing tied to its physics training. Qwen-Instruct's attention collapses in these layers, which could imply a shift towards processing semantic content rather than syntactic or structural markers.
* **Late-Layer Convergence:** By Layer 27, both models reduce focus on special tokens (`#` and `*`) and increase the relative share of attention to Whitespace. This may represent a final integration or "smoothing" phase before output generation, where the distinction between token types becomes less critical than the overall context.
* **Functional Implication:** The persistent, significant attention to the `* (Star)` token across all layers and both models is a key finding. It suggests this token plays a universally important role in the model's architecture, perhaps as a primary separator, a placeholder for unknown relations, or a key component in attention head specialization. The fluctuating role of the `# (Hash)` token appears more model- and layer-specific.
</details>
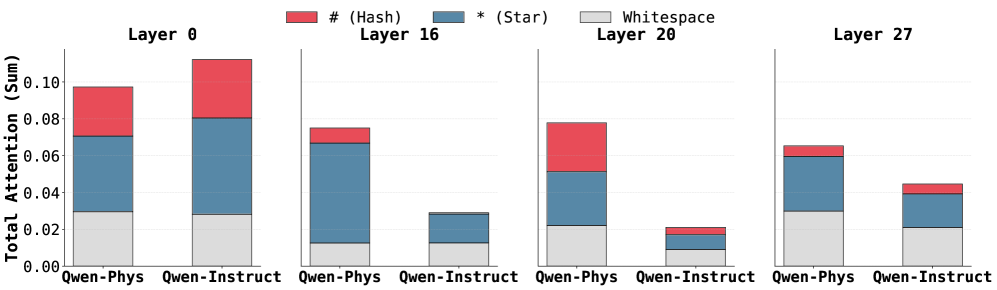
Figure 4: Token-level attention distribution across layers for Qwen-Physics and Qwen-Instruct.
#### GRPO Convergence and Stability.
As shown in Figure 2, Qwen-PhysRL exhibits substantially faster convergence and higher final rewards than Qwen-DirectRL under identical GRPO training configurations, highlighting the importance of a physics-aware initialization for RL. Table 1 provides additional insight: the generic Qwen-Instruct backbone used in Qwen-DirectRL achieves higher rewards than the Qwen-Physics backbone used in Qwen-PhysRL during evaluation, indicating that general pretrained knowledge can partially compensate. However, despite this advantage, Qwen-Instruct fails to scale effectively under GRPO, exhibiting slower adaptation and early convergence to suboptimal policies. In contrast, the proposed two-stage approach consistently achieves superior performance across both Dynamic and Static settings.
### 5.1 Ablation Study
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Heatmap: KL Divergence Across Layers and Generated Tokens
### Overview
The image is a heatmap visualizing KL divergence values between two distributions (likely a model's internal representations and some reference) across different neural network layers and sequential generated tokens. The heatmap uses a color gradient from light yellow (low KL) to dark red (high KL) to represent the magnitude of divergence.
### Components/Axes
* **Chart Type:** Heatmap.
* **Title/Legend:** A vertical color bar legend is positioned on the right side of the chart, labeled **"KL"** at the top. The scale ranges from **0.2** (light yellow) at the bottom to **1.4** (dark red) at the top, with intermediate ticks at 0.4, 0.6, 0.8, 1.0, and 1.2.
* **Y-Axis (Vertical):** Labeled **"Layer"**. The axis lists specific layer numbers in a non-sequential order from top to bottom: **0, 15, 18, 17, 16, 19, 20, 21, 27**.
* **X-Axis (Horizontal):** Labeled **"Generated Token"**. The axis lists five sequential token categories from left to right: **Gen0, Gen1, Gen2, Gen3, Gen4**.
### Detailed Analysis
The heatmap is a 9x5 grid (9 layers x 5 tokens). Below is an approximate reconstruction of the KL divergence values for each cell, based on color matching to the legend. Values are estimated with uncertainty.
| Layer \ Token | Gen0 | Gen1 | Gen2 | Gen3 | Gen4 |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **0** | ~0.25 (Light Yellow) | ~0.20 (Very Light Yellow) | ~0.20 (Very Light Yellow) | ~0.20 (Very Light Yellow) | ~0.35 (Light Orange) |
| **15** | ~0.35 (Light Orange) | ~0.55 (Orange) | ~0.45 (Light Orange) | ~0.40 (Light Orange) | ~0.25 (Light Yellow) |
| **18** | ~0.65 (Orange) | ~0.35 (Light Orange) | ~0.30 (Light Yellow) | ~0.25 (Light Yellow) | ~0.20 (Very Light Yellow) |
| **17** | **~1.05 (Red)** | ~0.35 (Light Orange) | ~0.30 (Light Yellow) | ~0.30 (Light Yellow) | ~0.20 (Very Light Yellow) |
| **16** | **~1.25 (Dark Red)** | ~0.75 (Red-Orange) | ~0.80 (Red-Orange) | **~1.05 (Red)** | ~0.30 (Light Yellow) |
| **19** | ~0.35 (Light Orange) | ~0.25 (Light Yellow) | ~0.20 (Very Light Yellow) | ~0.20 (Very Light Yellow) | ~0.20 (Very Light Yellow) |
| **20** | **~1.35 (Very Dark Red)** | ~0.35 (Light Orange) | ~0.40 (Light Orange) | ~0.25 (Light Yellow) | ~0.20 (Very Light Yellow) |
| **21** | ~0.60 (Orange) | ~0.30 (Light Yellow) | ~0.25 (Light Yellow) | ~0.20 (Very Light Yellow) | ~0.20 (Very Light Yellow) |
| **27** | ~0.55 (Orange) | ~0.30 (Light Yellow) | ~0.25 (Light Yellow) | ~0.25 (Light Yellow) | ~0.20 (Very Light Yellow) |
**Trend Verification per Layer:**
* **Layer 0:** Very low KL across all tokens, with a slight increase at Gen4.
* **Layer 15:** Moderate KL at Gen0 and Gen1, decreasing thereafter.
* **Layer 18:** Peaks at Gen0, then decreases steadily.
* **Layer 17:** Very high KL at Gen0, drops sharply and remains low.
* **Layer 16:** Very high KL at Gen0, dips at Gen1, rises again to a high peak at Gen3, then drops sharply at Gen4.
* **Layer 19, 20, 21, 27:** All show their highest KL at Gen0, followed by a general decrease. Layer 20 has the single highest value in the entire chart at Gen0.
### Key Observations
1. **Dominant Pattern:** For almost every layer, the highest KL divergence occurs at **Gen0** (the first generated token). This suggests the greatest distributional shift happens at the very start of generation.
2. **Peak Values:** The most intense divergence (dark red, KL > 1.0) is concentrated in **Layers 16, 17, and 20 at Gen0**. Layer 20 at Gen0 shows the maximum value (~1.35).
3. **Anomalous Series:** **Layer 16** exhibits a unique "double-peak" pattern, with high values at both Gen0 and Gen3, unlike the single-peak pattern of other layers.
4. **Convergence:** By **Gen4**, KL divergence is uniformly low (≤ 0.35) across all layers, indicating the distributions become more similar as generation progresses.
5. **Layer Grouping:** Mid-to-late layers (16, 17, 18, 20, 21) show more dramatic changes in KL across tokens compared to the very early (Layer 0) or very late (Layer 27) layers.
### Interpretation
This heatmap likely illustrates the **evolution of internal model states** during autoregressive text generation. KL divergence measures how much one probability distribution differs from another. Here, it probably compares the model's hidden state distribution at each layer for a given generated token against a reference distribution (e.g., the state for the previous token, or a base model's state).
* **What it suggests:** The model undergoes a significant internal reconfiguration (**high KL**) at the first token (**Gen0**), especially in specific middle layers (16, 17, 20). This could represent the model "committing" to a generation path or establishing context. The subsequent decrease in KL implies the model's internal representations stabilize as it generates more tokens within that context.
* **Why Layer 16 is special:** The secondary peak at Gen3 for Layer 16 might indicate a point of **mid-sequence re-evaluation or planning**, where this particular layer's representation shifts again, perhaps to maintain coherence or introduce new information.
* **Overall narrative:** The process shows a pattern of **initial high divergence followed by convergence**. The model makes a large initial adjustment, then fine-tunes its representations. The uniformity at Gen4 suggests the generation process has settled into a stable regime by the fifth token. This visualization helps identify which layers are most active at which stages of generation, providing insight into the model's internal dynamics.
</details>
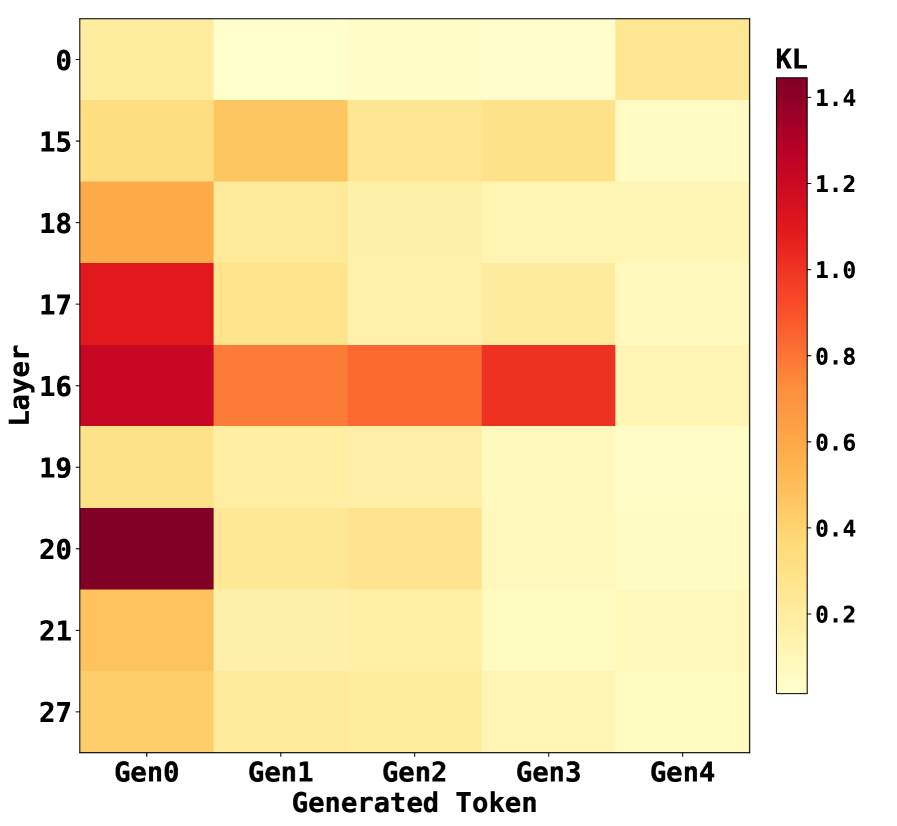
(a) Attention divergence heatmap
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Stacked Bar Chart: Relative Attention Share by Model Layer
### Overview
This image is a stacked bar chart visualizing the distribution of "Relative Attention Share" between two categories, "System Prompt" and "Maps," across a series of discrete model layers. The chart aims to show how the allocation of attention changes at different depths within a model architecture.
### Components/Axes
* **Chart Type:** Stacked Bar Chart.
* **X-Axis (Horizontal):** Labeled "Model Layer". It displays categorical labels for specific layers: L0, L1, L2, L3, L14, L15, L16, L18, L20, L21, L24, L25, L26, L27. The layers are not presented in strict numerical sequence.
* **Y-Axis (Vertical):** Labeled "Relative Attention Share". It is a linear scale ranging from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Located in the bottom-right corner of the chart area. It defines the two data series:
* A gray square labeled "System Prompt".
* A blue square labeled "Maps".
* **Data Series:** Each bar represents a model layer and is divided into two colored segments whose heights sum to 1.0 (the total relative attention share for that layer).
### Detailed Analysis
The following table reconstructs the approximate data from the chart. Values are estimated based on visual alignment with the y-axis grid. The "System Prompt" (gray) segment is always the bottom portion of the bar.
| Model Layer | System Prompt (Gray) Share (Approx.) | Maps (Blue) Share (Approx.) | Visual Trend Description |
| :--- | :--- | :--- | :--- |
| **L0** | 0.30 | 0.70 | Maps dominates; the blue segment is more than twice the height of the gray. |
| **L1** | 0.56 | 0.44 | System Prompt becomes the majority share. |
| **L2** | 0.95 | 0.05 | System Prompt overwhelmingly dominates; the Maps segment is a very thin sliver. |
| **L3** | 0.92 | 0.08 | System Prompt remains dominant. |
| **L14** | 0.86 | 0.14 | System Prompt share decreases slightly from L3 but remains high. |
| **L15** | 0.68 | 0.32 | Notable increase in Maps share compared to previous layers. |
| **L16** | 0.70 | 0.30 | Similar distribution to L15. |
| **L18** | 0.52 | 0.48 | Nearly equal split; this is the only layer besides L0 where Maps approaches or exceeds half the share. |
| **L20** | 0.74 | 0.26 | System Prompt share increases again. |
| **L21** | 0.81 | 0.19 | System Prompt share continues to increase. |
| **L24** | 0.92 | 0.08 | System Prompt share returns to a very high level, similar to L3. |
| **L25** | 0.92 | 0.08 | Identical or near-identical distribution to L24. |
| **L26** | 0.89 | 0.11 | Slight decrease in System Prompt share from L25. |
| **L27** | 0.74 | 0.26 | System Prompt share decreases to a level similar to L20. |
### Key Observations
1. **Dominance of System Prompt:** In 12 out of the 14 layers shown, the "System Prompt" category holds the majority of the relative attention share (value > 0.5).
2. **Two Exceptional Layers:** Layer **L0** is the only layer where "Maps" has a clear majority (~0.70). Layer **L18** shows the most balanced distribution, with shares nearly equal (~0.52 vs. ~0.48).
3. **High-Attention Layers:** Layers **L2, L3, L24, and L25** show the highest concentration of attention on the System Prompt, with shares exceeding 0.90.
4. **Non-Sequential Layers:** The x-axis does not list layers in order (e.g., jumps from L3 to L14, includes L18 between L16 and L20). This suggests the chart may be highlighting specific layers of interest rather than a continuous sequence.
5. **Pattern of Fluctuation:** There is no simple linear trend. The System Prompt share spikes early (L2), dips in the middle layers (L15, L16, L18), rises again (L20-L25), and dips slightly at the end (L27).
### Interpretation
This chart provides a diagnostic view into the internal attention mechanisms of a model, likely a large language model (LLM) given the "System Prompt" label. The data suggests that the model's attention is not uniformly distributed.
* **Functional Specialization:** The stark contrast between L0 (Maps-heavy) and L2 (System Prompt-heavy) implies rapid specialization in the earliest layers. L0 may be processing raw input or spatial/metadata information ("Maps"), while subsequent layers quickly shift focus to the core instructions ("System Prompt").
* **Mid-Layer Re-engagement:** The increased share for "Maps" in layers L15, L16, and especially L18 indicates a potential phase where the model re-evaluates or integrates map-based information after having processed the system prompt extensively. This could be crucial for tasks requiring grounding in external data or spatial reasoning.
* **Late-Layer Consensus:** The return to high System Prompt attention in layers L24-L25 suggests a final consolidation or application of the core instructions before output generation.
* **Architectural Insight:** The non-sequential layer selection implies these specific layers are considered critical checkpoints for understanding how the model balances its foundational instructions against other input types. The visualization effectively argues that attention allocation is dynamic and layer-dependent, challenging a view of uniform processing depth.
**Language Note:** All text in the image is in English.
</details>
(b) Relative attention share across layers
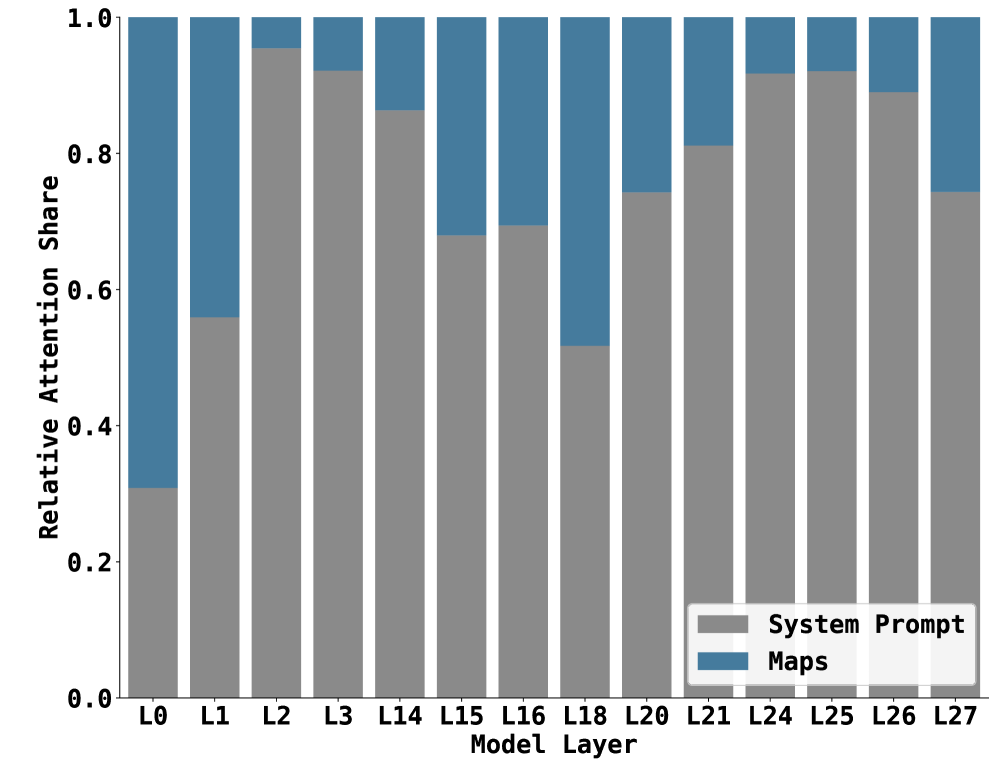
Figure 5: Layer-wise attention score analysis showing (a) attention divergence of Qwen-Physics from the backbone Qwen-Instruct model across layers, and (b) relative attention allocation between system prompt and map tokens.
To examine the effect of our initial building-block fine-tuning on the spatial understanding of the target LLM $\mathcal{F}$ , we analyze how attention is distributed across prompt tokens at different layers of the model by studying the attention score matrices produced during evaluation. We prompt the model with a fixed system prompt $P$ , concatenated with a start–target map sequence $M$ , to generate an answer sequence $A$ , i.e., $\mathcal{F}(P\!\cdot\!M)=A$ , where $\cdot$ denotes string concatenation. To obtain attention scores between prompt tokens and the newly generated output tokens, we concatenate the generated answer to the original prompt and perform a single forward pass over the full sequence, $\mathcal{F}(P\!\cdot\!M\!\cdot\!A)$ . This pass yields the complete set of attention score matrices, including those corresponding to output tokens. For each decoder layer $l\in\{1,\dots,L\}$ and attention head $h\in\{1,\dots,H\}$ , the model computes a raw attention score matrix as $Q_{h,l}K_{h,l}^{\mathsf{T}}$ . We aggregate these matrices across heads by averaging to obtain a per-layer attention score matrix,
$$
\text{AttScore}_{l}=\frac{1}{H}\sum_{h=1}^{H}Q_{h,l}K_{h,l}^{\mathsf{T}}.
$$
We then focus on the rows corresponding to the answer tokens, $\text{AttScore}_{l}[|P\!\cdot\!M|:,:]$ , where each row represents the attention assigned to all prompt tokens during the generation of a specific output token. In the following, we summarize key observations derived from analyzing these attention patterns across layers.
#### Observation 1.
Fine-tuning induces the most pronounced changes in attention distributions within the middle layers of the model, as confirmed by Figure 5(a). Among the 28 layers, layers 16 and 20 exhibit the highest KL divergence between Qwen-Physics and the generic Qwen-Instruct backbone, while the early (layer 0) and final (layer 27) layers show substantially smaller deviations. This indicates that the adaptation introduced by fine-tuning is concentrated in intermediate layers rather than being uniformly distributed across the network.
#### Observation 2.
Qwen-Physics assigns closer attention to spatially informative ASCII tokens, such as # and *, compared to Qwen-Instruct. As shown in Figure 4, the increased attention to these tokens is most prominent in the same middle layers identified in Observation 1. This suggests that the layers undergoing the largest adaptation are also those most responsible for encoding spatial structure, enabling the model to better focus on salient regions of the map $M$ during spatial reasoning.
#### Observation 3.
Across most layers, Qwen-Physics consistently allocates more attention to the system prompt $P$ than to the map region, except in the earliest layers. Notably, the system prompt contains approximately $1.8\times$ more tokens than the map region $M$ , yet Figure 5(b) shows an attention gap that is substantially larger than what token count alone would suggest. This gap narrows in the middle layers, which, as shown in Observations 1 and 2, are more actively involved in spatial reasoning. This behavior is consistent with prior findings that textual context can dominate attention allocation in spatial reasoning and vision–language models (Chen et al., 2025; Wang et al., 2025). The earliest layers, such as layer 0, allocate attention more evenly across different parts of the input, reflecting a coarse, global skimming behavior, as illustrated in both Figure 5(b) and Figure 4.
## 6 Conclusion
This paper presents a two-stage training pipeline that enables spatial understanding, reasoning, and planning capabilities in large language models. Our approach first builds a foundation of atomic spatial relations through supervised fine-tuning and then augments it with multi-step planning ability using a closed-loop GRPO-based reinforcement learning stage. This combination equips the model with both task-relevant physical knowledge and a learned policy that effectively composes these primitives to solve more complex spatial planning problems, without relying solely on reinforcement learning to discover representations and planning strategies simultaneously. Experimental results demonstrate that models trained under this framework exhibit a newfound understanding of spatial properties and planning, substantially outperforming generic LLM baselines on challenging spatial planning tasks. Moreover, compared to end-to-end reinforcement learning applied to an unadapted backbone model, our pipeline converges faster and exhibits more stable training under identical settings. Through ablation studies and attention analysis, we further identify the decoder layers most affected by training and show that our approach systematically shifts attention toward task-critical tokens, providing evidence of more structured internal reasoning. While our evaluation focuses on a specific class of spatial planning problems, we believe that the underlying principle of learning reusable building blocks and composing them through reinforcement learning is broadly applicable. We view this work as a step toward more modular and interpretable approaches for teaching complex reasoning skills to language models, and we leave the exploration of additional tasks and modalities to future work.
## References
- Ahn et al. (2024) Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathematical reasoning: Progresses and challenges, 2024. URL https://arxiv.org/abs/2402.00157.
- Akbari et al. (2021) Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. Vatt: transformers for multimodal self-supervised learning from raw video, audio and text. In Proceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY, USA, 2021. Curran Associates Inc. ISBN 9781713845393.
- Bayani (2024) David Bayani. Testing the depth of chatgpt’s comprehension via cross-modal tasks based on ascii-art: Gpt3.5’s abilities in regard to recognizing and generating ascii-art are not totally lacking, 2024. URL https://arxiv.org/abs/2307.16806.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 1877–1901. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Chen et al. (2025) Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas, 2025. URL https://arxiv.org/abs/2503.01773.
- Dao & Vu (2025) Alan Dao and Dinh Bach Vu. Alphamaze: Enhancing large language models’ spatial intelligence via grpo, 2025. URL https://arxiv.org/abs/2502.14669.
- DeepSeek-AI et al. (2025) DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, S. S. Li, Shuang Zhou, Shaoqing Wu, Shengfeng Ye, Tao Yun, Tian Pei, Tianyu Sun, T. Wang, Wangding Zeng, Wanjia Zhao, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, W. L. Xiao, Wei An, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, X. Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xiaowen Sun, Xiaoxiang Wang, Xinnan Song, Xinyi Zhou, Xianzu Wang, Xinxia Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Yang Zhang, Yanhong Xu, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Yu, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yuan Ou, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Ying Tang, Yukun Zha, Yuting Yan, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhicheng Ma, Zhigang Yan, Zhiyu Wu, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Zizheng Pan, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, and Zhen Zhang. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
- Deng et al. (2025) Hourui Deng, Hongjie Zhang, Jie Ou, and Chaosheng Feng. Can llm be a good path planner based on prompt engineering? mitigating the hallucination for path planning. In Proceedings of the International Conference on Intelligent Computing (ICIC), 2025.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In North American Chapter of the Association for Computational Linguistics, 2019. URL https://api.semanticscholar.org/CorpusID:52967399.
- Ding et al. (2023) Ruomeng Ding, Chaoyun Zhang, Lu Wang, Yong Xu, Ming-Jie Ma, Wei Zhang, Si Qin, S. Rajmohan, Qingwei Lin, and Dongmei Zhang. Everything of thoughts: Defying the law of penrose triangle for thought generation. ArXiv, abs/2311.04254, 2023.
- Einarsson (2025) Hafsteinn Einarsson. Mazeeval: A benchmark for testing sequential decision-making in language models, 2025. URL https://arxiv.org/abs/2507.20395.
- Hu et al. (2021) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685.
- Jia et al. (2025) Qi Jia, Xiang Yue, Shanshan Huang, Ziheng Qin, Yizhu Liu, Bill Yuchen Lin, and Yang You. Visual perception in text strings, 2025. URL https://openreview.net/forum?id=etToTig9Fp.
- Kong et al. (2025) Yangzhe Kong, Daeun Song, Jing Liang, Dinesh Manocha, Ziyu Yao, and Xuesu Xiao. Autospatial: Visual-language reasoning for social robot navigation through efficient spatial reasoning learning, 2025. URL https://arxiv.org/abs/2503.07557.
- Li et al. (2024) Fangjun Li, David C. Hogg, and Anthony G. Cohn. Advancing spatial reasoning in large language models: an in-depth evaluation and enhancement using the stepgame benchmark. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’24/IAAI’24/EAAI’24. AAAI Press, 2024. ISBN 978-1-57735-887-9. doi: 10.1609/aaai.v38i17.29811. URL https://doi.org/10.1609/aaai.v38i17.29811.
- Li et al. (2025) Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. A survey of state of the art large vision language models: Alignment, benchmark, evaluations and challenges, 2025. URL https://arxiv.org/abs/2501.02189.
- Minaee et al. (2025) Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey, 2025. URL https://arxiv.org/abs/2402.06196.
- Mirzaee & Kordjamshidi (2022) Roshanak Mirzaee and Parisa Kordjamshidi. Transfer learning with synthetic corpora for spatial role labeling and reasoning. 10 2022. doi: 10.48550/arXiv.2210.16952.
- Noever & Burdick (2021) David Noever and Ryerson Burdick. Puzzle solving without search or human knowledge: An unnatural language approach. CoRR, abs/2109.02797, 2021. URL https://arxiv.org/abs/2109.02797.
- Qwen Team (2024) Qwen Team. Qwen2.5-1.5b-instruct. https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct, 2024. Hugging Face model card, accessed 2025-08-10.
- Szot et al. (2024) Andrew Szot, Bogdan Mazoure, Harsh Agrawal, Devon Hjelm, Zsolt Kira, and Alexander Toshev. Grounding multimodal large language models in actions, 2024. URL https://arxiv.org/abs/2406.07904.
- Todd et al. (2023) Graham Todd, Sam Earle, Muhammad Umair Nasir, Michael Cerny Green, and Julian Togelius. Level generation through large language models. In Proceedings of the 18th International Conference on the Foundations of Digital Games, FDG 2023, pp. 1–8. ACM, April 2023. doi: 10.1145/3582437.3587211. URL http://dx.doi.org/10.1145/3582437.3587211.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 6000–6010, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- Wang et al. (2024) Hong Wang, Xuan Luo, Weizhi Wang, and Xifeng Yan. Bot or human? detecting chatgpt imposters with a single question, 2024. URL https://arxiv.org/abs/2305.06424.
- Wang et al. (2025) Zhaochen Wang, Bryan Hooi, Yiwei Wang, Ming-Hsuan Yang, Zi Huang, and Yujun Cai. Text speaks louder than vision: Ascii art reveals textual biases in vision-language models, 2025. URL https://arxiv.org/abs/2504.01589.
- Wu et al. (2024a) Jiannan Wu, Muyan Zhong, Sen Xing, Zeqiang Lai, Zhaoyang Liu, Zhe Chen, Wenhai Wang, Xizhou Zhu, Lewei Lu, Tong Lu, Ping Luo, Yu Qiao, and Jifeng Dai. Visionllm v2: an end-to-end generalist multimodal large language model for hundreds of vision-language tasks. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY, USA, 2024a. Curran Associates Inc. ISBN 9798331314385.
- Wu et al. (2024b) Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, and Furu Wei. Mind’s eye of llms: Visualization-of-thought elicits spatial reasoning in large language models, 2024b. URL https://arxiv.org/abs/2404.03622.
- Yao et al. (2023) Shunyu Yao et al. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023.
- Zhang et al. (2024) Yue Zhang, Ziqiao Ma, Jialu Li, Yanyuan Qiao, Zun Wang, Joyce Chai, Qi Wu, Mohit Bansal, and Parisa Kordjamshidi. Vision-and-language navigation today and tomorrow: A survey in the era of foundation models, 2024. URL https://arxiv.org/abs/2407.07035.
## Appendix A Environment Setup Example
System prompt for Dynamic Setting
⬇ You are an expert at analyzing ASCII art shapes. Two shapes are provided: Shape A (the target) and Shape B (the current state), separated by ’% $ % $ % $ %’. Each line of the shapes starts and ends with a star (*) character. Your goal is to transform Shape B into Shape A by analyzing one type of transformation at a time. You may analyze rotation, translation, or scaling --- but try to analyze DIFFERENT types rather than repeating. You have already analyzed: {analyzed} IMPORTANT: Choose a transformation type you haven ’ t analyzed yet if possible. TASK 1 - ROTATION: If analyzing rotation: Determine what rotation is needed to transform Shape B into Shape A. Classify using exactly one of these labels: - ’ no_rotation ’: The shapes have the same orientation (0 rotation needed) - ’ quarter_rotation ’: Shape B needs a 90 degrees rotation to match Shape A - ’ slight_rotation ’: Shape B needs a small rotation (<90 degrees) to match Shape A TASK 2 - TRANSLATION: If analyzing translation: Determine how Shape B must be moved to match Shape A ’ s position. Classify using exactly one of these labels: - ’ no_translation ’: Shapes are already in the same position - ’ up ’: Shape B must be moved up to match Shape A - ’ down ’: Shape B must be moved down to match Shape A - ’ left ’: Shape B must be moved left to match Shape A - ’ right ’: Shape B must be moved right to match Shape A TASK 3 - SCALING: If analyzing scaling: Determine the size adjustment needed to transform Shape B to match Shape A. Classify using exactly one of these labels: - ’ no_scaling ’: Both shapes have the same size - ’ double_size ’: Shape B is half size and must be enlarged to match Shape A - ’ half_size ’: Shape B is twice as large and must be shrunk to match Shape A INSTRUCTIONS: 1. Identify which transformation type would be most useful to analyze now 2. Carefully compare both ASCII art shapes 3. Determine the transformation needed to convert Shape B into Shape A 4. Respond with the appropriate label inside < answer ></ answer > tags
System prompt for Static Setting
⬇ You are an expert at analyzing ASCII art shapes. Two shapes are provided: Shape A (the target) and Shape B (the current state), separated by ’% $ % $ % $ %’. Each line of the shapes starts and ends with a star (*) character. Your goal is to transform Shape B into Shape A by analyzing one type of transformation at a time. You may analyze rotation, translation, or scaling --- but try to analyze DIFFERENT types rather than repeating. CRITICAL INSTRUCTION: THE MAP IS NOT UPDATING The Shape B shown below is the ** STATIC INITIAL STATE ** It does ** NOT ** reflect the moves you have already made. You must RELY ON YOUR MEMORY of the following actions you have already performed: HISTORY OF ACTIONS: [{analyzed}] To solve this: 1. Look at the Initial Shape B. 2. Mentally apply the ’ HISTORY OF ACTIONS ’ to it to imagine the * current * state. 3. Determine the NEXT step needed from that imagined state. 4. Choose a transformation type you haven ’ t analyzed yet if possible. TASK 1 - ROTATION: If analyzing rotation: Determine what rotation is needed to transform Shape B into Shape A. Classify using exactly one of these labels: - ’ no_rotation ’: The shapes have the same orientation (0 rotation needed) - ’ quarter_rotation ’: Shape B needs a 90 degrees rotation to match Shape A - ’ slight_rotation ’: Shape B needs a small rotation (<90 degrees) to match Shape A TASK 2 - TRANSLATION: If analyzing translation: Determine how Shape B must be moved to match Shape A ’ s position. Classify using exactly one of these labels: - ’ no_translation ’: Shapes are already in the same position - ’ up ’: Shape B must be moved up to match Shape A - ’ down ’: Shape B must be moved down to match Shape A - ’ left ’: Shape B must be moved left to match Shape A - ’ right ’: Shape B must be moved right to match Shape A TASK 3 - SCALING: If analyzing scaling: Determine the size adjustment needed to transform Shape B to match Shape A. Classify using exactly one of these labels: - ’ no_scaling ’: Both shapes have the same size - ’ double_size ’: Shape B is half size and must be enlarged to match Shape A - ’ half_size ’: Shape B is twice as large and must be shrunk to match Shape A INSTRUCTIONS: 1. Identify which transformation type would be most useful to analyze now 2. Carefully compare both ASCII art shapes 3. Determine the transformation needed to convert Shape B into Shape A 4. Respond with the appropriate label inside < answer ></ answer > tags
Sample Environment
⬇ TARGET (Shape A): * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * ## * * ## #* * ## * * ## ##* * ## ## * * ## ## * * ## * * * % $ % $ % $ % CURRENT (Shape B): * * * * * # * * ## ## * * # # * * ## ## * * # * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * ------------------------------
Model Responses (Dynamic setting with State Updates)
$\star$ Ground-Truth: double size, quarter rotation, right, down, down.
$\times$ Qwen-Instruct: slight rotation, slight rotation, slight rotation, slight rotation, slight rotation.
$\times$ Qwen-Physics: slight rotation, quarter rotation, slight rotation, slight rotation, slight rotation.
$\times$ Qwen-DirectRL: double size, quarter rotation, down, down, up.
$\checkmark$ Qwen-PhysRL (ours): double size, quarter rotation, right, down, down.
## Appendix B Random Policy Reward Calculation
To establish a baseline for the random policy $\pi_{\text{rnd}}$ , we analytically derive the expected reward $E[R_{k}]$ at step $k$ . An action $a$ yields a positive reward only if its usage count $N_{a}$ over the preceding $k\!-\!1$ steps does not exceed its ground-truth quota $C_{a}$ . We model $N_{a}$ as a binomial random variable, $N_{a}\sim\mathrm{Binomial}(k-1,1/|\mathcal{A}|)$ , reflecting uniform random action selection. The expected reward at step $k$ is therefore given by
$$
E[R_{k}]=\sum_{a\in GT}r(a)\,\mathbb{P}(N_{a}<C_{a})\;-\;\lambda\!\left(1-\sum_{a\in GT}\mathbb{P}(N_{a}<C_{a})\right), \tag{6}
$$
where $GT$ denotes the set of ground-truth required actions, $r(a)$ is the reward associated with a valid action, and $\lambda$ is the penalty incurred for an invalid action. The probability term expands as the cumulative binomial sum
$$
\mathbb{P}(N_{a}<C_{a})=\sum_{i=0}^{C_{a}-1}\binom{k-1}{i}\left(\frac{1}{|\mathcal{A}|}\right)^{i}\left(1-\frac{1}{|\mathcal{A}|}\right)^{k-1-i}. \tag{7}
$$
For the subset of samples considered in our evaluation, the ground-truth action quotas consist of two occurrences of one translation direction ( $C=2$ ), one occurrence of another translation direction ( $C=1$ ), and a single occurrence each for rotation and scaling ( $C=1$ ). The expected cumulative reward up to step $K$ then follows directly as $\sum_{j=1}^{K}E[R_{j}]$ .