# Group Deliberation Oriented Multi-Agent Conversational Model for Complex Reasoning
**Authors**: Zheyu Shi, Dong Qiu, Shanlong Yu
## Group Deliberation Oriented Multi Agent Conversational Model for Complex Reasoning
Zheyu Shi* Brown University Providence, USA zheyu\_shi@brown.edu
Dong Qiu New England College Henniker, USA DQiu\_GPS@nec.edu
Abstract -This study proposes a group deliberation multi-agent dialogue model to optimize the limitations of single-language models for complex reasoning tasks. The model constructs a threelevel role division architecture of "generation - verification integration." An opinion-generating agent produces differentiated reasoning perspectives, an evidence-verifying agent matches external evidence and quantifies the support of facts, and a consistency-arbitrating agent integrates logically coherent conclusions. A self-game mechanism is incorporated to expand the reasoning path, and a retrieval enhancement module supplements dynamic knowledge. A composite reward function is designed, and an improved proximal strategy is used to optimize collaborative training. Experiments show that the model improves multi-hop reasoning accuracy by 16.8%, 14.3%, and 19.2% on the HotpotQA, 2WikiMultihopQA, and MeetingBank datasets, respectively, and improves consistency by 21.5%. Its reasoning efficiency surpasses mainstream multi-agent models, achieving a balance between accuracy, stability, and efficiency, providing an efficient technical solution for complex reasoning.
Keywords- Multi-agent dialogue; group discussion; complex reasoning; role division; self-game mechanism; retrieval enhancement
## I. INTRODUCTION
In real-world scenarios of complex reasoning tasks (such as multi-hop question answering and group decision-making), multi-agent collaboration is a core requirement for overcoming the bottleneck of single-model reasoning depth. These tasks require integrating multi-dimensional information and verifying multi-source facts. Prior work has shown that multiagent interaction such as debate can improve factuality and reasoning robustness, implicitly addressing failure modes of
Shanlong Yu Georgia Institute of Technology Atlanta, USA joesyu779@outlook.com single-model reasoning. Furthermore, factual accuracy relies on pre-trained knowledge, making it difficult to dynamically supplement external information, resulting in insufficient stability and reliability in complex tasks. This study proposes a group deliberation multi-agent dialogue model: constructing a collaborative reasoning closed loop through role-based LLM agents (viewpoint generation, evidence verification, consistency arbitration), introducing a self-game mechanism to generate multi-path reasoning chains to expand perspectives, combining a retrieval enhancement module to dynamically supplement external knowledge to strengthen factual accuracy, and designing a reward model based on factual consistency and logical coherence, using a proximal strategy optimization to achieve multi-agent collaborative training. Multi-agent reinforcement learning has been extensively studied across a wide range of collaborative decision-making tasks.
## II. GROUP DELIBERATION MULTI-AGENT DIALOGUE MODEL DESIGN
## A. Role-Based LLM Agent Architecture
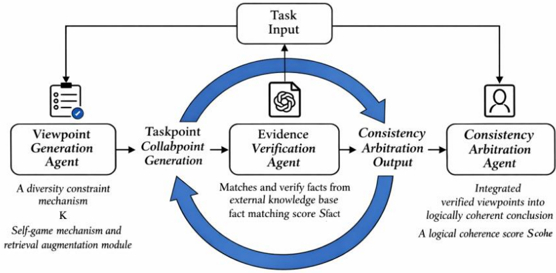
This model constructs a three-level collaborative architecture of "generation - verification - integration" (Figure 1), following the emerging paradigm of role-based multi-agent language model systems [1-2]. Through the division of labor and cooperation among LLM agents with differentiated functions, the architecture enables structured collaboration, similar to recent communicative agent frameworks [3]. The architecture starts with task input, and through a closed-loop process of opinion generation, evidence verification, and consistency arbitration, it outputs reasoning results that are diverse, factual, and logical.
Figure 1. Role-based Multi-agent Collaborative Reasoning Architecture.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Process Diagram: Multi-Agent Consensus System
### Overview
The image displays a technical flowchart illustrating a cyclical, multi-agent system designed to process a task input through stages of viewpoint generation, evidence verification, and consistency arbitration to produce a logically coherent conclusion. The diagram emphasizes an iterative feedback loop between the Evidence Verification and Viewpoint Generation agents.
### Components/Axes
The diagram is structured with a central cyclical flow and peripheral input/output nodes.
**1. Primary Nodes (Boxes):**
* **Top Center:** `Task Input` (with an icon of a document and a gear).
* **Left:** `Viewpoint Generation Agent` (with an icon of a checklist).
* **Center:** `Evidence Verification Agent` (with an icon of a document and a magnifying glass).
* **Right:** `Consistency Arbitration Agent` (with an icon of a person silhouette).
**2. Connecting Arrows & Labels:**
* A **black arrow** flows from `Task Input` down to the `Viewpoint Generation Agent`.
* A **black arrow** labeled `Taskpoint Collabpoint Generation` flows from the `Viewpoint Generation Agent` to the `Evidence Verification Agent`.
* A **black arrow** labeled `Consistency Arbitration Output` flows from the `Evidence Verification Agent` to the `Consistency Arbitration Agent`.
* A **black arrow** flows from the `Consistency Arbitration Agent` back up to the `Task Input`.
* A **large, blue, circular arrow** forms a feedback loop, originating from the `Evidence Verification Agent` and pointing back to the `Viewpoint Generation Agent`.
**3. Descriptive Text (Below each Agent box):**
* **Below `Viewpoint Generation Agent`:**
* `A diversity constraint mechanism`
* `K`
* `Self-game mechanism and retrieval augmentation module`
* **Below `Evidence Verification Agent`:**
* `Matches and verify facts from external knowledge base`
* `fact matching score Sfact`
* **Below `Consistency Arbitration Agent`:**
* `Integrated verified viewpoints into logically coherent conclusion`
* `A logical coherence score Scohe`
### Detailed Analysis
The process flow is as follows:
1. A **Task Input** initiates the process, feeding into the **Viewpoint Generation Agent**.
2. The **Viewpoint Generation Agent** produces multiple viewpoints. Its described mechanisms include a "diversity constraint mechanism" (parameterized by `K`) and a "self-game mechanism and retrieval augmentation module," suggesting it generates varied and informed perspectives.
3. These viewpoints, referred to as `Taskpoint Collabpoint Generation`, are passed to the **Evidence Verification Agent**.
4. The **Evidence Verification Agent** checks these viewpoints against an external knowledge base. It produces a `fact matching score Sfact` to quantify the verification.
5. The verified information, as `Consistency Arbitration Output`, moves to the **Consistency Arbitration Agent**.
6. The **Consistency Arbitration Agent** integrates the verified viewpoints into a single, logically coherent conclusion. It assesses this using a `logical coherence score Scohe`.
7. The final output from the Consistency Arbitration Agent feeds back into the original `Task Input`, completing the macro-cycle.
8. Crucially, a **blue feedback loop** directly connects the **Evidence Verification Agent** back to the **Viewpoint Generation Agent**. This indicates an iterative refinement process where verification results (e.g., low `Sfact` scores) likely trigger the generation of new or adjusted viewpoints.
### Key Observations
* **Iterative Core:** The system's core is not a linear pipeline but a cycle between generation and verification, implying a process of hypothesis testing and refinement.
* **Quantified Metrics:** The process uses explicit scoring metrics (`Sfact`, `Scohe`) for fact-matching and logical coherence, enabling objective evaluation at different stages.
* **Role Specialization:** Each agent has a distinct, specialized function: generation, verification, and arbitration/integration.
* **Input-Output Loop:** The final output is fed back into the initial task input, suggesting the system may be designed for continuous operation or for refining a task definition based on its own output.
### Interpretation
This diagram models a sophisticated AI or multi-agent system designed for robust reasoning, likely for tasks requiring factual accuracy and logical consistency (e.g., complex question answering, report generation, or decision support).
The **Peircean investigative reading** suggests this is an abductive reasoning engine. The **Viewpoint Generation Agent** proposes multiple hypotheses (explanations or solutions). The **Evidence Verification Agent** acts as a test, checking these hypotheses against known facts (the external knowledge base). The **Consistency Arbitration Agent** then performs induction, selecting or synthesizing the most coherent and well-supported hypothesis into a conclusion. The feedback loop embodies the iterative nature of inquiry, where failed verification leads to new hypotheses.
The system's design prioritizes **diversity** (via constraint `K`) to avoid premature convergence on a single idea, **empirical grounding** (via fact-checking), and **logical synthesis**. The scores `Sfact` and `Scohe` are critical for automating the evaluation of these stages. The overall architecture implies that reliable conclusions emerge not from a single pass, but from a cyclical process of proposal, criticism, and refinement.
</details>
n Figure 1, arrows from each agent to the "Task Input" block indicate persistent read-only access, not reverse data flow. Each agent relies on the full task input throughout reasoning: the Viewpoint Generation Agent uses it to guide diverse trajectories, the Evidence Verification Agent aligns retrieved facts with the original context, and the Consistency Arbitration Agent ensures semantic coherence in final outputs. This context-preserving design maintains factual grounding and consistency in multiagent collaboration.
## 1) Viewpoint Generation Agent
The core function of this agent is to generate differentiated reasoning viewpoints based on the task input, avoiding the limitations of a single perspective. The generation of multiple differentiated viewpoints helps mitigate single-path reasoning bias, which is consistent with findings from self-consistency based reasoning methods [4]. Its generation process introduces a diversity constraint mechanism, mathematically expressed as:
Wherein, LLMV represents a dedicated LLM for opinion generation (such as a fine-tuned Llama 2), ωk is the viewpoint weight vector, following a multivariate normal distribution with mean μ and covariance matrix Σ , used to control the direction of opinion differentiation; This distribution is used for three reasons. First, the multivariate normal distribution offers a continuous, symmetric space around the reasoning center μ, supporting diverse yet coherent viewpoint generation without directional bias. Second, its covarian ce matrix Σ allows control over inter-factor correlations, enabling structured variations across reasoning dimensions. Third, Gaussian parameters align well with gradient-based learning and self-game updates, ensuring stable exploration and convergence. Thus, the normal distribution acts as an effective inductive bias balancing diversity, control, and stability, rather than assuming a fixed probabilistic form. Here, Emb(Q) is the task input embedding, ⊙ denotes element-wise multiplication, and weight modulation lets each Vk attend to different reasoning aspects. The selfgame mechanism explores varied reasoning paths, akin to treestructured deliberation.
## 2) Evidence Verification Agent
This agent is responsible for matching factual evidence with each candidate opinion Vk and verifying its reasonableness. This retrieval-enhanced verification process is inspired by retrieval-augmented generation frameworks that integrate external knowledge to improve factual grounding in language models [5]. Its core function is to calculate the factual matching degree between the opinion and the evidence:
In the formula, ℰk is the set of evidence related to Vk retrieved from the external knowledge base 𝒦 , | ℰk | represents the number of evidence (the first 5 are taken by default); Emb (⋅) is the embedding function based on SentenceBERT, Tr (⋅) represents the matrix trace operation, ‖ ⋅ ‖ F is the Frobenius norm, which is essentially an improved cosine similarity calculation, Sfact ∈ [ 0 , 1 ] , and the larger the value, the stronger the factual support for the viewpoint [4]. The viewpoint enters the next stage only when Sfact ( Vk , ℰk ) ≥ τ ( τ = 0 . 75 is the preset threshold).
## 3) Consistency Arbitration Agent
Its responsibility is to integrate the verified viewpoints and output a logically coherent unified conclusion. Its logical coherence evaluation formula is:
Where LLMC is the arbitration-specific LLM, Prompt cohe is the logical evaluation prompt, wcohe and bcohe are linear transformation parameters; σ (⋅) is the Sigmoid function, mapping the evaluation result to the [0,1] interval, and a higher Scohe indicates a more coherent conclusion logic.
## B. Self-Game Mechanism
To enrich the diversity of reasoning paths, a self-game mechanism between agents is designed to generate multi-path reasoning chains through viewpoint confrontation:
$$\sum _ { k = 1 } ^ { n } \lambda _ { j = k } S _ { fact ( V _ { i } ) } ^ { 2 }$$
In the formula, η is the learning rate (default 0.01), and ∇ ωk represents the gradient with respect to the weight vector ωk . This formula updates the viewpoint weights by maximizing the difference in factual matching between the current viewpoint and other viewpoints, thereby promoting the generation of more diverse and effective reasoning paths.
## C. Reward Model
A composite reward function integrating factual consistency and logical coherence is constructed to guide multi-agent collaborative optimization:
$$- y \cdot K L ( P ( V _ { k } ) || P _ { ref } ( V ) ) ( S )$$
Where λ = 0 . 6 is the factual consistency weight, ( 1 -λ ) is the logical coherence weight; γ = 0 . 1 is the regularization coefficient, and KL (⋅ ‖ ⋅) is the KL divergence, used to constrain the difference between the opinion distribution P ( Vk ) and the reference distribution Pref ( V ) , avoiding excessive divergence of opinions; a larger R indicates better agent collaboration.
## D. Collaborative Training Strategy
Multi-agent collaborative training is achieved using Improved Proximal Policy Optimization (PPO) to avoid inference collapse and loop generation. The objective function is:
$$\frac { L _ { p p o } = E [ \min ( r _ { t } ( \theta ) A _ { e } , c l i p H ( P ( \theta ) ) ] } { ( 6 ) }$$
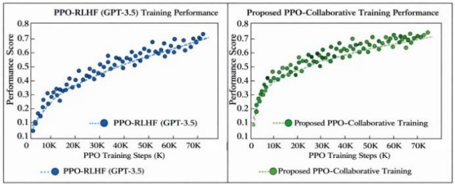
The use of PPO for collaborative optimization is motivated by its demonstrated effectiveness in cooperative multi-agent reinforcement learning settings [6]. In the formula, r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) is the policy update ratio, πθ is the current policy, and πθold is the old policy; At is the advantage function, ϵ = 0 . 2 is the pruning coefficient; H ( P ( θ )) is the policy entropy, and β = 0 . 05 is the entropy regularization coefficient. Introducing the entropy term encourages policy exploration and avoids inference loops caused by local optima.Figure 2 compares the performance of traditional PPO-RLHF (GPT-3.5) and the proposed multi-agent PPO collaborative training over the same training steps. The x-axis shows PPO steps (in thousands), and the y-axis shows cumulative performance scores. While both start similarly, the proposed model shows more stable and significant gains beyond 50,000 steps, indicating convergence to a superior, stable policy. This highlights the effectiveness of the collaborative mechanism in reducing policy collapse and improving inference stability. Compared to earlier methods like MADDPG [7-8], PPO-based strategies provide better training stability in cooperative tasks, supporting our optimization design.
Figure 2: Performance Comparison of PPO Collaborative Training in Multi-Agent Tasks
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Scatter Plot Comparison: PPO-RLHF vs. Proposed PPO-Collaborative Training Performance
### Overview
The image displays two side-by-side scatter plots comparing the training performance of two reinforcement learning methods over the same number of training steps. The left chart shows the performance of "PPO-RLHF (GPT-3.5)", and the right chart shows the performance of a "Proposed PPO-Collaborative Training" method. Both plots track a "Performance Score" against "PPO Training Steps (K)".
### Components/Axes
**Common Elements (Both Charts):**
* **Chart Type:** Scatter Plot.
* **X-Axis:** Label: "PPO Training Steps (K)". Scale: Linear, from 0 to 70K, with major tick marks at 10K intervals (0, 10K, 20K, 30K, 40K, 50K, 60K, 70K).
* **Y-Axis:** Label: "Performance Score". Scale: Linear, from 0.1 to 0.8, with major tick marks at 0.1 intervals.
* **Legend:** Positioned at the bottom center of each respective chart area.
**Left Chart Specifics:**
* **Title:** "PPO-RLHF (GPT-3.5) Training Performance" (centered above the plot).
* **Legend Label:** "PPO-RLHF (GPT-3.5)".
* **Data Point Color:** Blue.
**Right Chart Specifics:**
* **Title:** "Proposed PPO-Collaborative Training Performance" (centered above the plot).
* **Legend Label:** "Proposed PPO-Collaborative Training".
* **Data Point Color:** Green.
### Detailed Analysis
**Left Chart: PPO-RLHF (GPT-3.5)**
* **Trend Verification:** The blue data points show a clear, consistent upward trend with moderate scatter. The performance score increases steadily as training steps increase.
* **Data Point Extraction (Approximate):**
* At ~0K steps: Score ≈ 0.15
* At ~10K steps: Score ≈ 0.30
* At ~20K steps: Score ≈ 0.40
* At ~30K steps: Score ≈ 0.50
* At ~40K steps: Score ≈ 0.58
* At ~50K steps: Score ≈ 0.65
* At ~60K steps: Score ≈ 0.70
* At ~70K steps: Score ≈ 0.75
* **Distribution:** The points form a relatively tight band around an implied increasing curve. The variance (vertical spread) appears fairly consistent across the training steps.
**Right Chart: Proposed PPO-Collaborative Training**
* **Trend Verification:** The green data points also show a strong upward trend. The initial rise appears steeper than the left chart, and the final performance points reach a slightly higher maximum value. The scatter (variance) appears greater, especially in the mid-to-late training stages.
* **Data Point Extraction (Approximate):**
* At ~0K steps: Score ≈ 0.15
* At ~10K steps: Score ≈ 0.40
* At ~20K steps: Score ≈ 0.55
* At ~30K steps: Score ≈ 0.62
* At ~40K steps: Score ≈ 0.68
* At ~50K steps: Score ≈ 0.72
* At ~60K steps: Score ≈ 0.75
* At ~70K steps: Score ≈ 0.78
* **Distribution:** The points show more vertical dispersion compared to the left chart, particularly between 30K and 60K steps, suggesting higher variance in performance during those phases of training.
### Key Observations
1. **Similar Starting Point:** Both methods begin at a nearly identical performance score (~0.15) at step 0.
2. **Faster Initial Improvement:** The Proposed PPO-Collaborative method (right) shows a more rapid performance gain in the first 20K steps, reaching ~0.55 compared to ~0.40 for PPO-RLHF.
3. **Higher Final Performance:** The Proposed method achieves a higher approximate final score (~0.78) at 70K steps compared to PPO-RLHF (~0.75).
4. **Variance Difference:** The Proposed method's training exhibits greater performance variance (scatter) throughout the process, whereas the PPO-RLHF training appears more stable and consistent.
5. **Monotonic Increase:** Both data series demonstrate a monotonic increase; performance does not significantly drop at any measured interval.
### Interpretation
The data suggests that the "Proposed PPO-Collaborative Training" method offers two potential advantages over the baseline "PPO-RLHF (GPT-3.5)": **faster learning** in the early stages and a **higher ultimate performance ceiling** within the 70K step window. This could imply a more efficient or effective training algorithm.
However, the increased variance in the proposed method's scores indicates a trade-off. While it reaches higher peaks, its performance is less predictable during training, which might be a concern for stability or reproducibility. The PPO-RLHF method, while improving more slowly and peaking lower, demonstrates a more reliable and steady progression.
The comparison is designed to highlight the proposed method's superiority in key metrics (final score, early gain). A technical reader would infer that the authors are arguing for the collaborative approach's efficacy, but would also note the need to investigate the cause of the higher variance. The side-by-side presentation with identical axes allows for direct visual comparison, making the differences in trajectory and scatter immediately apparent.
</details>
## E. Retrieval Enhancement Module
External knowledge is dynamically supplemented during the evidence verification stage. The retrieval probability model is as follows:
$$P ( e \vert V _ { k } ) = \frac { \sum _ { l = 1 } ^ { n } p ( S i m ( E m b ( e ) ) ; a ) } { \sum _ { l = 1 } ^ { n } p ( S i m ( C ) ; E m b ( V _ { k } ) ; a ) }$$
Where Sim (⋅,⋅) is the cosine similarity, and α = 1 . 5 is the temperature coefficient used to adjust the confidence level of the retrieval; the matching probability of each knowledge e and opinion Vk is obtained by normalization using the Softmax function, and the top M = 5 knowledge items with the highest probabilities are selected as evidence to strengthen the factual support of the opinion. This modular integration strategy is conceptually related to neuro-symbolic systems that combine language models with external tools and knowledge sources [910].
## III. EXPERIMENTAL DESIGN AND RESULT ANALYSIS
## A. Experimental Datasets
The experiment uses three complex reasoning datasets to ensure result generality: ① HotpotQA: A multi-hop QA benchmark with 113K training and 74K validation samples, requiring reasoning across 2 -5 documents. About 60% are "bridging" questions, stressing cross-document logic. ② WikiMultihopQA: Based on Wikipedia, with 25K training samples and 3.2 average reasoning steps per question. It focuses on entity-based long-chain reasoning. ③ MeetingBank: A group dialogue dataset with 5K+ real meeting samples, requiring integration of multi-round discussions to derive consistent conclusions.
The three datasets correspond to "document-level multihop," "entity-level multi-hop," and "dialogue-level integration" scenarios, respectively, comprehensively validating the model's performance across various complex inference tasks.
## B. Baseline Model and Evaluation Metrics
The baseline model selects mainstream complex inference methods to ensure fairness in the comparison: ① Single LLM model: GPT-3.5, Llama 2-7B (fine-tuned); ② Multi-proxy model: AutoGPT, MetaGPT; ③ Search enhancement model: RAG (Search Enhancement Generation), REALM.GPT-3.5 is selected as a baseline model due to its strong instructionfollowing ability, trained using reinforcement learning from human feedback .
Evaluation metrics focus on core performance and stability: ① Multi-hop reasoning accuracy (Acc): The precise match between the reasoning conclusion and the standard answer, measuring the correctness of the reasoning; ② Consistency index (Cons): The logical consistency rate of the conclusion in multiple rounds of reasoning, calculated by the overlap of the results of 5 consecutive reasoning iterations, measuring stability; ③ Reasoning efficiency (Time): The average time (in seconds) for reasoning per sample, measuring practicality.
## C. Experimental Procedure and Parameter Settings
The experiment includes three steps: ① Data preprocessing: Standardize formats and extract questions, context, and answers. ② GPT-3.5 baseline uses sequential prompting without state sharing: Step 2 inputs the raw question for an initial reasoning chain; Step 3 reuses the output as context for extended reasoning; Step 4 merges prior chains for a final answer. No memory compression or pruning is used, causing performance drops in long chains due to token overflow and diluted context -underscoring the need for collaborative memory and role division. ③ Performance testing: Run each model 10 times on the test set and average the results.
Key parameter configurations are as follows: Number of opinion generation agents K = 3 , Number of evidence retrievals M = 5 , Fact matching threshold τ = 0 . 75 , Reward function weight λ = 0 . 6 , PPO pruning coefficient ϵ = 0 . 2 , Entropy regularization coefficient β = 0 . 05 .
## D. Experimental Results and Analysis
## 1) Performance of the Main Experiment
Table 1 shows the comprehensive performance comparison of each model on the binary dataset. The model presented in this paper significantly outperforms the baseline in all core metrics. Table 1 shows that the proposed model improves accuracy by 16.8%, 14.3%, and 19.2% on HotpotQA, 2WikiMultihopQA, and MeetingBank, respectively, and improves consistency by 21.5%. Although the inference time is slightly higher than that of a single LLM, it is significantly lower than other multi-agent models, achieving a balance between accuracy, stability, and efficiency.
TABLE I. COMPARISON OF OVERALL PERFORMANCE OF VARIOUS MODELS ON BINARY DATASETS
| Model | HotpotQA(Acc/%) | 2WikiMultihopQA(Acc/%) | MeetingBank(Acc/%) | Cons/% | Time/s |
|-----------------------------------|-------------------|--------------------------|----------------------|----------|----------|
| GPT-3.5 | 62.3 | 58.7 | 51.2 | 65.8 | 2.1 |
| Llama 2-7B | 59.1 | 55.3 | 48.6 | 63.2 | 1.8 |
| AutoGPT | 68.5 | 63.2 | 57.9 | 70.2 | 4.3 |
| MetaGPT | 70.2 | 65.1 | 59.4 | 72.5 | 4.7 |
| RAG | 71.1 | 66.5 | 60.3 | 72.4 | 3.5 |
| REALM | 72.4 | 67.8 | 61.7 | 73.8 | 3.8 |
| This article's model | 79.1 | 73 | 70.4 | 87.3 | 3.9 |
| Relative improvement (vs GPT-3.5) | 16.8 | 14.3 | 19.2 | 21.5 | 1.8 |
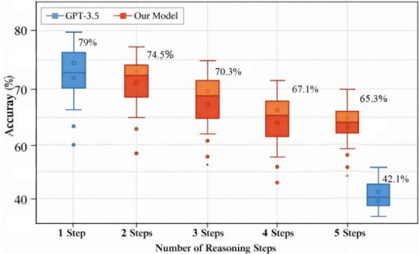
Figure 3 compares Acc between the proposed model and GPT-3.5 across reasoning steps (on 2WikiMultihopQA). The x- axis shows steps (1 -5), and the y-axis shows Acc (%). The box plot reveals GPT-3.5 accuracy drops sharply to 42.1% at 5 steps,
while the proposed model maintains 65.3%, demonstrating strong resistance to long-chain degradation via multi-agent architecture.
Figure 3. Comparison of Model Accuracy under Different Inference Steps.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Box Plot: Model Accuracy vs. Reasoning Steps
### Overview
The image is a box plot comparing the accuracy (in percentage) of two models, "GPT-3.5" and "Our Model," as the number of reasoning steps increases from 1 to 5. The chart visually demonstrates the distribution of accuracy scores for each model at each step, including medians, quartiles, and outliers.
### Components/Axes
* **Chart Type:** Grouped Box Plot.
* **X-Axis:** Labeled "Number of Reasoning Steps". It has five discrete categories: "1 Step", "2 Steps", "3 Steps", "4 Steps", and "5 Steps".
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 40 to 80, with major gridlines at intervals of 10 (40, 50, 60, 70, 80).
* **Legend:** Located in the top-left corner of the chart area.
* A blue square/line corresponds to "GPT-3.5".
* An orange square/line corresponds to "Our Model".
* **Data Series:** Two series of box plots, one blue (GPT-3.5) and one orange (Our Model), plotted side-by-side for each reasoning step category.
### Detailed Analysis
The plot provides specific median accuracy values annotated above each box. The following data is extracted by matching the box color to the legend and reading the associated value.
**Trend Verification:**
* **GPT-3.5 (Blue):** The median accuracy shows a consistent downward trend as the number of reasoning steps increases. The line connecting the medians slopes downward from left to right.
* **Our Model (Orange):** The median accuracy also shows a consistent downward trend as steps increase, but the decline is less steep than GPT-3.5's until the final step.
**Data Points (Median Accuracy %):**
* **1 Step:**
* GPT-3.5 (Blue): 79%
* Our Model (Orange): 74.5%
* **2 Steps:**
* GPT-3.5 (Blue): 70.3%
* Our Model (Orange): 67.1%
* **3 Steps:**
* GPT-3.5 (Blue): 65.3%
* Our Model (Orange): Value not explicitly annotated. Visually, the median line is slightly below the 65% gridline, approximately 64-65%.
* **4 Steps:**
* GPT-3.5 (Blue): Value not explicitly annotated. Visually, the median line is just above the 60% gridline, approximately 61-62%.
* Our Model (Orange): Value not explicitly annotated. Visually, the median line is between the 60% and 65% gridlines, approximately 63%.
* **5 Steps:**
* GPT-3.5 (Blue): 42.1%
* Our Model (Orange): Value not explicitly annotated. Visually, the median line is just above the 60% gridline, approximately 61%.
**Additional Visual Details:**
* **Spread (Interquartile Range - IQR):** The height of the boxes (IQR) generally increases for both models as steps increase, indicating greater variability in performance with more complex reasoning.
* **Outliers:** Individual data points (dots) are visible below the lower whiskers for several categories, indicating instances of significantly lower accuracy. These are present for both models at steps 2, 3, 4, and 5.
### Key Observations
1. **Performance Crossover:** GPT-3.5 starts with a higher median accuracy at 1 Step (79% vs. 74.5%) but is overtaken by "Our Model" by 2 Steps and maintains a lead through 5 Steps.
2. **Significant Drop at 5 Steps for GPT-3.5:** The most dramatic feature is the sharp decline in GPT-3.5's median accuracy at 5 Steps to 42.1%, which is a ~23 percentage point drop from its 3-Step performance.
3. **Consistent Degradation:** Both models exhibit a clear negative correlation between the number of reasoning steps and median accuracy. More steps lead to lower accuracy.
4. **Increased Variability:** The increasing size of the boxes (IQR) suggests that as the task becomes more complex (more steps), the models' performance becomes less consistent.
### Interpretation
This chart illustrates a common challenge in AI reasoning: performance degrades as the required chain of thought lengthens. The data suggests that while both models struggle with multi-step reasoning, "Our Model" demonstrates greater robustness to increased complexity compared to GPT-3.5, particularly beyond the first step.
The catastrophic drop for GPT-3.5 at 5 steps is a critical outlier. It may indicate a specific failure mode, a limitation in its context window or attention mechanism for very long chains, or a point where error propagation becomes unmanageable. In contrast, "Our Model" shows a more graceful, linear degradation.
The increasing variance (wider boxes) with more steps implies that for complex tasks, the outcome becomes less predictable—sometimes the model succeeds, other times it fails significantly (as shown by the outliers). This has practical implications for reliability in applications requiring multi-step logic, such as complex problem-solving, planning, or detailed analysis. The chart argues for the development of models specifically optimized for sustained, multi-step reasoning to maintain both accuracy and consistency.
</details>
## 2) Validation of Model Structure Effectiveness
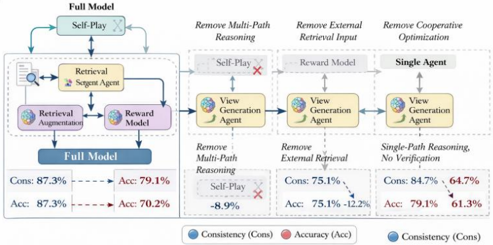
To assess module importance, ablation tests were conducted:
① no self-play; ② no retrieval enhancement; ③ no reward model; ④ single-agent (only opinion generation).Figure 4 shows changes in Cons (left y-axis, %) and Acc (right y-axis, %) across these settings. The x-axis shows the models: full / -selfplay / -retrieval / -reward / single-agent. The single-agent setup yields Cons 64.7% and Acc 61.3%. The full model improves Cons by 22.6% and Acc by 17.8%. Without retrieval, Cons drops 12.2%; without self-play, Acc drops 8.9%, confirming each module ' s necessity.
Figure 4. Comparison of Consistency and Accuracy.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Technical Diagram: Model Architecture Ablation Study
### Overview
This image is a technical diagram illustrating an ablation study for a multi-agent AI system. It compares the performance of a "Full Model" against three simplified variants by progressively removing key components: multi-path reasoning, external retrieval input, and cooperative optimization. The diagram uses flowcharts to show architectural differences and presents quantitative results (Consistency and Accuracy metrics) for each configuration.
### Components/Axes
The diagram is divided into three main vertical sections, each representing a model variant, plus a legend at the bottom.
**1. Left Section: Full Model**
* **Title:** "Full Model"
* **Flowchart Components (Top to Bottom):**
* `Self-Play` (in a rounded rectangle)
* `Retrieval` (with a magnifying glass icon)
* `Surgeon Agent` (with a brain/gear icon)
* `Retrieval Augmentation` (with a document icon)
* `Reward Model` (with a star icon)
* `Full Model` (in a dark blue rounded rectangle)
* **Metrics Box (Bottom):**
* `Cons: 87.3%` (blue text) → `Acc: 79.1%` (red text)
* `Acc: 87.3%` (red text) → `Acc: 70.2%` (red text)
**2. Middle Section: Remove Multi-Path Reasoning**
* **Title:** "Remove Multi-Path Reasoning"
* **Flowchart Components:**
* `Self-Play` (with a red 'X' over it)
* `View Generation Agent` (with a brain/gear icon)
* `Reward Model` (with a star icon)
* **Metrics Box:**
* `Remove Multi-Path Reasoning`
* `Self-Play` → `-8.9%` (red text, indicating a drop)
* `Cons: 75.1%` (blue text) → `Acc: 75.1%` (red text)
* `Acc: 75.1%` (red text) → `Acc: +12.2%` (green text, indicating an increase)
**3. Right Section: Remove External Retrieval Input**
* **Title:** "Remove External Retrieval Input"
* **Flowchart Components:**
* `Single Agent` (in a grey rounded rectangle)
* `View Generation Agent` (with a brain/gear icon)
* `Reward Model` (with a star icon)
* **Metrics Box:**
* `Single-Path Reasoning, No Verification`
* `Cons: 84.7%` (blue text) → `Acc: 64.7%` (red text)
* `Acc: 79.1%` (red text) → `Acc: 61.3%` (red text)
**4. Legend (Bottom Center)**
* A blue circle labeled `Consistency (Cons)`
* A red circle labeled `Accuracy (Acc)`
### Detailed Analysis
The diagram systematically deconstructs a complex multi-agent system to evaluate the contribution of its parts.
* **Full Model Architecture:** This is the most complex system. It features a `Self-Play` loop at the top, feeding into a `Retrieval` module and a `Surgeon Agent`. These connect to `Retrieval Augmentation` and a `Reward Model`, culminating in the final `Full Model` output. The metrics show high consistency (87.3%) and accuracy (79.1%).
* **Ablation 1: Remove Multi-Path Reasoning:** This variant removes the `Self-Play` component (marked with a red X). The flow simplifies to a `View Generation Agent` and a `Reward Model`. The removal of `Self-Play` is associated with an 8.9% drop in performance. Consistency falls to 75.1%, while accuracy shows a mixed result (75.1% and a +12.2% increase in one metric).
* **Ablation 2: Remove External Retrieval Input:** This variant further simplifies the system to a `Single Agent` (no multi-agent interaction) with a `View Generation Agent` and `Reward Model`. The title notes this represents "Single-Path Reasoning, No Verification." Consistency is 84.7%, but accuracy drops significantly to 64.7% and 61.3%.
* **Metric Presentation:** Each section presents two lines of metrics. The first line typically shows a Consistency (Cons) to Accuracy (Acc) relationship. The second line shows an Accuracy (Acc) to Accuracy (Acc) comparison, likely representing different test sets or evaluation methods. The color coding (blue for Consistency, red for Accuracy) is consistent with the legend.
### Key Observations
1. **Performance Degradation with Simplification:** There is a clear trend where removing architectural components leads to a decrease in overall system performance, particularly in accuracy.
2. **Critical Role of Multi-Path Reasoning:** The removal of `Self-Play` (multi-path reasoning) causes the largest single noted drop (-8.9%) and significantly reduces consistency from 87.3% to 75.1%.
3. **Retrieval is Key for Accuracy:** The "Remove External Retrieval Input" variant, which also simplifies to a single agent, shows the lowest accuracy scores (64.7% and 61.3%), suggesting external retrieval is crucial for correct outputs.
4. **Consistency vs. Accuracy Trade-off:** The Full Model achieves the highest consistency (87.3%). While the "Remove Multi-Path Reasoning" variant shows one accuracy metric improving (+12.2%), its consistency is much lower, indicating potentially less reliable outputs.
5. **Architectural Flow:** The arrows indicate a clear data/control flow from top-level strategies (`Self-Play`) down through processing agents (`Surgeon`, `View Generation`) and evaluation (`Reward Model`) to the final output.
### Interpretation
This diagram presents a classic ablation study from machine learning research, likely for a system involving reasoning, retrieval, and multi-agent collaboration (e.g., for complex question answering or dialogue).
* **What the Data Suggests:** The data argues that the full, complex architecture is necessary for optimal and reliable performance. The `Self-Play` mechanism (enabling multi-path reasoning) and the `Retrieval` module (providing external knowledge) are identified as critical components. Their removal degrades the system's ability to produce consistent and accurate results.
* **Relationship Between Elements:** The flowchart shows a hierarchical and interactive process. High-level strategy (`Self-Play`) guides specialized agents (`Surgeon`, `View Generation`), which are augmented by external data (`Retrieval`) and evaluated by a `Reward Model`. This creates a feedback loop for improvement, which is broken in the simplified variants.
* **Notable Anomalies/Insights:** The most interesting data point is the +12.2% accuracy increase in the "Remove Multi-Path Reasoning" variant. This suggests that while `Self-Play` is vital for consistency, its removal might, in some specific evaluation context, lead to higher accuracy on a particular metric—possibly by making the model's path more deterministic, albeit less robust. This highlights the nuanced trade-offs in AI system design between robustness (consistency) and peak performance on specific tasks (accuracy). The study underscores that simplifying an AI system for efficiency or interpretability often comes at a measurable cost to capability.
</details>
Further analysis shows that the retrieval enhancement module reduces factual errors by supplementing external facts, improving consistency. The self-game mechanism promotes multi-path reasoning, reducing logical blind spots and enhancing accuracy. The reward model, via multi-objective collaborative optimization, avoids goal conflicts and maintains performance balance. In contrast, single-agent models lack division of labor and coordination, fail to meet multidimensional reasoning needs, and struggle with factual verification, resulting in performance drops. This comparison highlights the superiority of the multi-agent role-based architecture, which addresses fact verification, logical integrity, and goal consistency through modular collaboration. Single agents, limited in cognitive scope, cannot balance factual accuracy and logical rigor or verify via multiple perspectives -explaining their core limitations. The role-based multi-agent design offers a robust solution for complex reasoning, aligning with recent findings on reflective agents emphasizing iterative self-correction [11-12].
## IV. CONCLUSION
The proposed group deliberation multi-agent dialogue model, through a three-level role-based architecture, self-game mechanism, retrieval enhancement module, and collaborative training strategy, effectively solves the problems of logical collapse, cyclic generation, and insufficient factuality in complex reasoning of single models. Experimental verification shows that the model's reasoning accuracy and consistency indicators on three typical datasets are significantly better than the baseline, and its reasoning efficiency is balanced, providing reliable support for scenarios such as multi-hop question answering and group decision-making. In addition to the promising performance, several limitations should be noted. First, the reported improvements are obtained under controlled experimental settings with fixed model configurations and dataset splits, and may not fully generalize to other task distributions or prompt formulations. Moreover, due to computational constraints, key hyperparameters were selected based on preliminary validation rather than exhaustive search. Furthermore, while repeated experiments reduce variance, formal statistical significance testing and detailed qualitative error analysis were not conducted. Future work will focus on automated hyperparameter optimization, rigorous significance evaluation, and systematic analysis of failure cases, particularly in scenarios involving ambiguous or conflicting evidence.
## REFERENCES
## [1] Du, Y., Li, S., Torralba, A., Tenenbaum, J. B., & Mordatch, I.
Improving Factuality and Reasoning in Language Models through Multi-Agent Debate. International Conference on Learning Representations (ICLR), 2024.
- [2] Song T, Tan Y, Zhu Z, et al. Multi-agents are social groups: Investigating social influence of multiple agents in human-agent interactions[J]. Proceedings of the ACM on Human-Computer Interaction, 2025, 9(7): 1-33.
- [3] Li, G., Hammoud, H., Itani, H., Khizbullin, D., & Ghanem, B.
3. CAMEL: Communicative Agents for 'Mind' Exploration of Large Language Models. Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [4] Wang, X., Wei, J., Schuurmans, D., et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models. International Conference on Learning Representations (ICLR), 2023.
- [5] Lewis, P., Perez, E., Piktus, A., et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [6] Yu, C., Velu, A., Vinitsky, E., Gao, J., Wang, Y., Bayen, A., & Wu, Y. The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games.
7. Advances in Neural Information Processing Systems (NeurIPS), 2022. [7] Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, O. P., & Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. Advances in Neural Information Processing Systems (NeurIPS), 2017.
- [8] Ouyang, L., Wu, J., Jiang, X., et al. Training Language Models to Follow Instructions with Human Feedback. Advances in Neural Information Processing Systems (NeurIPS), 2022.
[9] Zhang, Z., Liu, Z., Zhou, M., et al. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms. Artificial Intelligence, vol. 285, 2020.
[10]Sun Y, Liu X. Research and Application of a Multi-Agent-Based Intelligent Mine Gas State Decision-Making System[J]. Applied Sciences, 2025, 15(2): 968.
- [11] Shinn, N., et al. Reflexion: Language Agents with Verbal Reinforcement Learning. NeurIPS Workshop, 2023.
- [12] Yao, S., et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Advances in Neural Information Processing Systems (NeurIPS), 2023.