# LsrIF: Logic-Structured Reinforcement Learning for Instruction Following
> Corresponding author.
Abstract
Instruction-following is critical for large language models, but real-world instructions often contain logical structures such as sequential dependencies and conditional branching. Existing methods typically construct datasets with parallel constraints and optimize average rewards, ignoring logical dependencies and yielding noisy signals. We propose a logic-structured training framework LsrIF that explicitly models instruction logic. We first construct a dataset LsrInstruct with constraint structures such as parallel, sequential, and conditional types, and then design structure-aware rewarding method LsRM including average aggregation for parallel structures, failure-penalty propagation for sequential structures, and selective rewards for conditional branches. Experiments show LsrIF brings significant improvements in instruction-following (in-domain and out-of-domain) and general reasoning. Analysis reveals that learning with explicit logic structures brings parameter updates in attention layers and sharpens token-level attention to constraints and logical operators.
LsrIF: Logic-Structured Reinforcement Learning for Instruction Following
Qingyu Ren 1, Qianyu He 1, Jingwen Chang 1, Jie Zeng 1, Jiaqing Liang 2 thanks: Corresponding author., Yanghua Xiao 1 footnotemark: Han Xia 3, Zeye Sun 3, Fei Yu 3 1 Shanghai Key Laboratory of Data Science, College of Computer Science and Artificial Intelligence, Fudan University, 2 School of Data Science, Fudan University, 3 Ant Group {qyren24,qyhe21,jwchang24, jzeng23}@m.fudan.edu.cn, {liangjiaqing, shawyh}@fudan.edu.cn
1 Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
## Flowchart: Complex Instruction Construction Framework
### Overview
The image depicts a flowchart illustrating the process of constructing a "Complex Instruction" by combining **Constraints** and **Logic**. The diagram uses color-coded sections (blue for constraints, yellow for logic, gray for the title) and directional arrows to show the relationship between components.
### Components/Axes
- **Title**: "Complex Instruction = Constraint + Logic" (gray background, top-center).
- **Constraint Section**:
- Sub-components:
1. "a short instructional" (blue background).
2. "length does not exceed three sentences" (blue background).
- **Logic Section**:
- Sub-components:
1. "First, then, finally" (yellow background).
2. "And" (yellow background).
3. "If, else" (yellow background).
- **Legend**:
- Blue = Constraints.
- Yellow = Logic.
- Gray = Title.
- **Arrows**:
- Blue arrow from title to Constraint section.
- Yellow arrow from title to Logic section.
- Blue arrow from Constraint section to "1. a short instructional...".
- Yellow arrow from Logic section to "1. First, then, finally...".
### Detailed Analysis
- **Constraints**:
- Focus on structural requirements: brevity (≤3 sentences) and formal tone.
- Emphasizes checklist formatting (bullet points) and error handling (lowercase "error").
- **Logic**:
- Sequential steps ("First, then, finally") and conditional branching ("If, else").
- Highlights iterative refinement ("apply a formal, technical writing style").
- **Color Coding**:
- Blue (constraints) and yellow (logic) are consistently applied to text blocks and arrows.
- Gray title acts as a neutral header.
### Key Observations
1. **Modular Design**: Constraints and logic are treated as independent yet interdependent components.
2. **Hierarchical Flow**: The title anchors the diagram, with arrows guiding the viewer from high-level concepts to specific rules.
3. **Error Handling**: Explicit instruction to write "error" in lowercase ensures consistency in outputs.
4. **Formality**: The final step mandates a "formal, technical writing style," aligning with the diagram’s purpose.
### Interpretation
This flowchart serves as a template for generating structured technical instructions. By separating constraints (formatting rules) and logic (sequencing/conditionals), it ensures outputs are both concise and logically coherent. The color coding aids in rapid identification of components, critical for technical documentation where clarity is paramount. The emphasis on error handling and iterative refinement suggests an iterative design process, prioritizing precision over brevity.
## Notes
- No numerical data or trends are present; the diagram focuses on procedural logic.
- All textual elements are transcribed verbatim, with colors cross-referenced against the legend for accuracy.
- Spatial grounding confirms the title’s central placement and the directional flow of arrows.
</details>
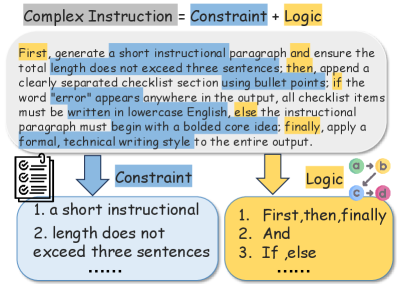
Figure 1: Essentially, the complex instruction is the logical composition of constraints.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Logic-Structured Dataset Construction and Structure-Aware Reward Modeling
### Overview
The diagram illustrates a two-part framework for constructing logic-structured datasets and modeling rewards based on response structures. It emphasizes constraints, response generation strategies, and reward calculation methods for different response types.
### Components/Axes
1. **Top Section: Logic-Structured Dataset Construction**
- **Parallel**:
- Constraints:
- "Do not use any commas, and limit the length to no more than 120 words."
- "The target audience is ..."
- Visual: Three interconnected nodes (C1, C2, C3) forming a triangle.
- **Sequential**:
- Steps:
1. Generate a list.
2. Write about content (max 120 words).
3. Output in JSON format; else use an `...` style.
- Visual: Linear flow (C1 → C2 → C3).
- **Conditional**:
- Logic: If the response discusses X, output in JSON; else use `...` style.
- Visual: Branching nodes (C1 → C2/C3).
2. **Bottom Section: Structure-Aware Reward Modeling**
- **Reward Model Components**:
- **Code**: Represented by a puzzle piece icon.
- **Reward Model**: Represented by a bear icon.
- **Response Types**:
- **Response1**:
- **Average Aggregation**: `R = Avg(R1, R2, R3)`.
- Visual: Triangle of nodes (R1, R2, R3) with bidirectional edges.
- **Response2**:
- **Penalty Propagation**: `R = Avg(R1, γᵐR₂, γⁿR₃)`.
- Visual: Linear flow (R1 → R2 → R3) with decay coefficients (γ, n).
- **Response3**:
- **Branch Selection**:
- `R = R2` if `R1 = 1`.
- `R = R3` if `R1 = 0`.
- Visual: Branching nodes (R1 → R2/R3).
### Detailed Analysis
- **Dataset Construction**:
- **Parallel**: Emphasizes brevity and audience targeting without commas.
- **Sequential**: Requires structured output (JSON) or fallback formatting.
- **Conditional**: Introduces logic-based output formatting.
- **Reward Modeling**:
- **Average Aggregation**: Simple mean of rewards.
- **Penalty Propagation**: Weighted average with decay factors for sequential dependencies.
- **Branch Selection**: Conditional reward assignment based on binary flags.
### Key Observations
- **Structural Constraints**: The diagram enforces strict formatting rules (e.g., no commas, JSON output).
- **Reward Complexity**: Reward calculations vary by response type, with penalties for misalignment and conditional logic for branching.
- **Visual Hierarchy**: Top section focuses on input constraints, while the bottom section details reward computation.
### Interpretation
The diagram demonstrates a systematic approach to aligning dataset construction with reward modeling. By structuring responses (parallel, sequential, conditional), the framework ensures consistency in data generation. The reward models adapt to these structures:
- **Average Aggregation** suits parallel responses with no dependencies.
- **Penalty Propagation** penalizes deviations in sequential responses using decay factors.
- **Branch Selection** optimizes rewards for conditional responses based on binary outcomes.
This design likely aims to improve model alignment with human preferences by explicitly encoding structural logic into both data generation and reward signals. The use of decay coefficients (γ, n) suggests an emphasis on temporal or hierarchical dependencies in sequential tasks.
</details>
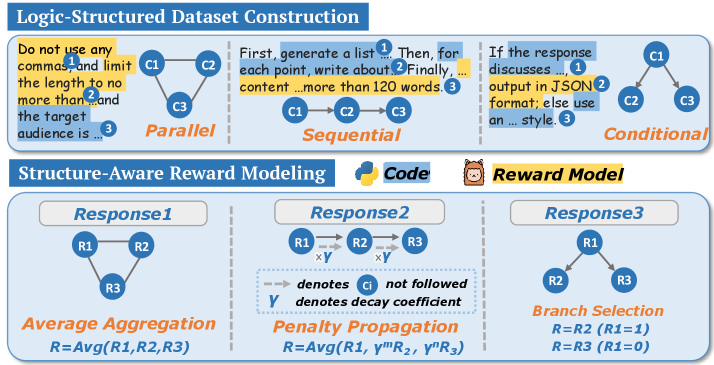
Figure 2: Our framework LsrIF consists of two components: (LsrInstruct) logic-structured dataset construction, and (LsRM) structure-aware reward modeling with corresponding methods.
Instruction following is a core capability of large language models (LLMs) and is essential for their use in real-world applications Zhang et al. (2025); Lu et al. (2025); Ye et al. (2025). User instructions are often complex and may span multiple turns or agent-based interactions Qi et al. (2025); Deshpande et al. (2025). Beyond producing fluent text, effective instruction following requires models to correctly understand and satisfy multiple constraints, which are often expressed through structured and interdependent conditions He et al. (2024); An et al. (2025).
In essence, complex instructions are composed of multiple constraints connected by logical structures. Correct instruction following therefore requires not only satisfying individual constraints, but also adhering to the logical relationships between them. As shown in Fig. 1, the complex instruction contains three common types of logical relationships. Parallel (And) structures require all constraints to be satisfied simultaneously. Sequential (First–Then–Finally) structures impose an execution order, where later constraints depend on the successful completion of earlier ones. Conditional (If–Else) structures introduce branching logic, where the model must first evaluate a condition and then follow the correct branch.
Existing approaches for improving instruction following still face clear limitations when dealing with logically structured instructions. From the perspective of data construction, most training data simplify instructions by treating all constraints as parallel Sun et al. (2024); Huang et al. (2025). Although some datasets include logical structure, they are mainly used for evaluation rather than training Wen et al. (2024); Wang et al. (2025). In terms of reward modeling, the reward for the entire instruction is often computed as the average of the rewards for individual constraints Qin et al. (2025). This assumes that constraints are independent. However, for sequential or conditional instructions, failure at an early step makes later constraints irrelevant, and simple averaging can produce incorrect training signals. Finally, regarding interpretability for performance improvements, prior work typically shows gains in instruction-following performance and the preservation of general reasoning abilities Peng et al. (2025), yet the underlying reasons remain unexplored. Furthermore, it remains unclear whether gains in logically structured instruction following actually transfer to reasoning ability.
To address these limitations, we propose a logic-structured training framework LsrIF that explicitly models instruction logic in both data construction and reward design. (1) Logic-Structured Data (LsrInstruct). We define instruction structures using three basic logical forms: parallel, sequential, and conditional. Based on these forms, we construct a dataset of multi-constraint instructions covering multiple logical structures. (2) Logic-Structured Reward Modeling (LsRM). We design reward modeling methods that reflect the execution semantics of different structures. For parallel structures, rewards are aggregated by averaging. For sequential structures, we apply a decay mechanism so that failures in earlier steps reduce rewards for later ones. For conditional structures, rewards are assigned only to the constraints in the correct branch. (3) Interpretability for Performance Improvements. We further analyze how logic-structured training affects the model. We observe larger parameter updates in attention layers than in MLP layers. At the token level, trained models place more attention on logical connectors and constraint-related tokens. These changes also appear in general reasoning tasks, indicating that the learned ability transfers beyond instruction following.
Our contributions are summarized as follows: (1) We propose LsrIF, a logic-structured training framework. (2) LsrIF includes LsrInstruct, an instruction dataset capturing parallel, sequential, and conditional constraint logic structures, and LsRM, structure-aware reward modeling that aligns reward signals with logical execution semantics. (3) LsrIF improves both in-domain and out-of-domain instruction-following performance and general reasoning ability, with attention and token-level interpretability analysis.
2 Related Work
2.1 Instruction Following Data Construction
Existing work constructs datasets with multi-constraint instructions to improve instruction-following capabilities Qin et al. (2025); Cheng et al. (2024). However, these approaches directly concatenate constraints, ignoring potential structures among them, which fails to simulate real-world user instructions. While some datasets consider logical structures Wen et al. (2024); Wang et al. (2025), they are primarily designed for evaluation rather than training. In contrast, we construct a training dataset where constraints show explicit logical structures.
2.2 Reward Modeling for Instruction Following
Training paradigms for instruction following have evolved from supervised fine-tuning Sun et al. (2024) to Direct Preference Optimization Huang et al. (2025); Qi et al. (2024) and Reinforcement Learning with Verifiable Rewards (RLVR) Peng et al. (2025); Qin et al. (2025). Existing RLVR methods aggregate constraint-level rewards through simple averaging. However, this averaging strategy fails when constraint logical structures are not parallel (e.g., sequential or conditional). We propose structure-aware reward modeling, where different structures employ distinct reward modeling methods.
3 Method
Our approach consists of two main components: logic-structured dataset construction (LsrInstruct) and structure-aware reward modeling (LsRM). As illustrated in Fig. 2, we organize instructions into three logical structures—Parallel, Sequential, and Conditional and employ a structure-aware reward model with three corresponding methods: Average Aggregation for parallel structures, Penalty Propagation for sequential structures, and Branch Selection for conditional structures.
3.1 Logic-Structured Dataset Construction
To move beyond flat constraint concatenation, we formalize three logic structure types:
- Parallel Structure. A set of constraints $C=\{c_{1},c_{2},...,c_{n}\}$ that must all be satisfied simultaneously. This structure corresponds to the flat assumption commonly adopted in prior work, where constraints are treated as independent(e.g., “Respond in English and use no commas and limit the length to 100 words”).
- Sequential Structure. An ordered sequence of constraints $S=(c_{1},c_{2},...,c_{n})$ , where each constraint $c_{t}$ is meaningful only if all preceding constraints $(c_{1},...,c_{t-1})$ are successfully satisfied (e.g., “ First generate an outline, then write a summary, finally translate it into English”).
- Conditional Structure. A branching structure governed by a trigger constraint $c_{p}$ . The active execution branch is determined by whether $c_{p}$ is satisfied: if $c_{p}$ holds, the model must satisfy the true-branch constraint $c_{\text{true}}$ ; else, it must satisfy the false-branch constraint $c_{\text{false}}$ (e.g., “ If the input text contains code, explain its functionality; else, summarize the text”).
We construct the dataset by collecting seed instructions from Infinity-Instruct Li et al. (2025), Open Assistant Köpf et al. (2024), Self-Instruct Wang et al. (2022a) and Super-Natural Wang et al. (2022b), defining constraint types (hard constraints in Tab. 5, soft constraints in Tab. 6), and using GPT-4.1 to generate multi-constraint instructions that instantiate these logical structures. Each instruction follows logical structure with multiple constraints organized accordingly, enabling controlled analysis and structure-aware training. Detailed statistics of LsrInstruct are shown in Tab. 1.
| Logic Type | # Inst. | # Cons. Types | # Cons. | Evaluation |
| --- | --- | --- | --- | --- |
| Parallel | 17510 | 48 | 52106 |
<details>
<summary>figures/python.png Details</summary>

### Visual Description
## Icon/Symbol: Python Programming Language Logo
### Overview
The image depicts the official logo of the Python programming language. It features a stylized, abstract representation of two snakes (or serpents) intertwined in a symmetrical, fluid design. The logo uses two primary colors: **blue** and **yellow**, with no textual elements or numerical data present.
### Components/Axes
- **Primary Elements**:
- Two serpentine shapes forming a continuous, interlocking loop.
- The design is asymmetrical but balanced, with one snake curving upward and the other downward.
- **Color Scheme**:
- **Blue**: Represents the "head" of one snake, positioned at the top-left of the logo.
- **Yellow**: Represents the "body" of the second snake, positioned at the bottom-right.
- **Details**:
- Both snakes have small white circular highlights at their "heads" (top-left and bottom-right), suggesting eyes or focal points.
- The logo has rounded edges and a smooth, organic flow, avoiding sharp angles.
### Detailed Analysis
- **No textual, numerical, or categorical data** is present in the image.
- The logo’s design emphasizes simplicity and recognizability, with no gradients, textures, or additional graphical elements.
- The interlocking snakes symbolize Python’s versatility and the language’s ability to "bite its own tail" (a reference to the Ouroboros, a symbol of infinity and cyclicality).
### Key Observations
- The absence of text or data points confirms this is a branding icon, not a chart, diagram, or data visualization.
- The color choice (blue and yellow) aligns with Python’s branding guidelines, which prioritize clarity and approachability.
### Interpretation
The Python logo’s design reflects the language’s philosophy of readability and elegance. The intertwined snakes evoke themes of unity, adaptability, and continuous evolution—qualities central to Python’s development. The lack of textual elements ensures the logo is universally recognizable, transcending language barriers. This minimalist approach underscores Python’s focus on simplicity as a core principle.
**Note**: No factual or numerical data is extractable from this image, as it is a symbolic representation rather than a data-driven visualization.
</details>
<details>
<summary>figures/gpt2.jpg Details</summary>

### Visual Description
## Icon/Symbol: Abstract Flower Design
### Overview
The image depicts a minimalist, abstract flower-like icon centered on a solid purple square background. The design features interlocking white lines forming a symmetrical, geometric pattern resembling a stylized flower or mandala. No text, numerical data, or additional graphical elements are present.
### Components/Axes
- **Background**: Solid purple (#8A2BE2) square.
- **Icon**: White (hex: #FFFFFF) abstract flower design with no discernible labels, axes, or legends.
- **No textual or numerical elements** are visible.
### Detailed Analysis
- The icon’s structure consists of overlapping curved lines creating a hexagonal core with radiating petal-like shapes.
- No gradients, shadows, or color variations are present in the icon or background.
- No spatial grounding elements (e.g., legends, axis markers) exist to contextualize the design.
### Key Observations
- The design is purely symbolic, with no embedded data or functional annotations.
- The simplicity suggests it may serve as a logo, app icon, or brand identifier.
- No trends, outliers, or numerical relationships can be analyzed due to the absence of data.
### Interpretation
This icon likely represents a brand, application, or concept tied to themes of unity, growth, or creativity (common associations with floral motifs). The use of purple may imply creativity, luxury, or spirituality, while the white lines emphasize clarity and minimalism. Without additional context, the icon’s purpose remains speculative, but its design prioritizes visual impact over informational content.
</details>
|
| Sequential | 10435 | 25 | 31295 |
<details>
<summary>figures/gpt2.jpg Details</summary>

### Visual Description
## Icon/Symbol: Abstract Flower Design
### Overview
The image depicts a minimalist, abstract flower-like icon centered on a solid purple square background. The design features interlocking white lines forming a symmetrical, geometric pattern resembling a stylized flower or mandala. No text, numerical data, or additional graphical elements are present.
### Components/Axes
- **Background**: Solid purple (#8A2BE2) square.
- **Icon**: White (hex: #FFFFFF) abstract flower design with no discernible labels, axes, or legends.
- **No textual or numerical elements** are visible.
### Detailed Analysis
- The icon’s structure consists of overlapping curved lines creating a hexagonal core with radiating petal-like shapes.
- No gradients, shadows, or color variations are present in the icon or background.
- No spatial grounding elements (e.g., legends, axis markers) exist to contextualize the design.
### Key Observations
- The design is purely symbolic, with no embedded data or functional annotations.
- The simplicity suggests it may serve as a logo, app icon, or brand identifier.
- No trends, outliers, or numerical relationships can be analyzed due to the absence of data.
### Interpretation
This icon likely represents a brand, application, or concept tied to themes of unity, growth, or creativity (common associations with floral motifs). The use of purple may imply creativity, luxury, or spirituality, while the white lines emphasize clarity and minimalism. Without additional context, the icon’s purpose remains speculative, but its design prioritizes visual impact over informational content.
</details>
|
| Conditional | 10574 | 25 | 42152 |
<details>
<summary>figures/gpt2.jpg Details</summary>

### Visual Description
## Icon/Symbol: Abstract Flower Design
### Overview
The image depicts a minimalist, abstract flower-like icon centered on a solid purple square background. The design features interlocking white lines forming a symmetrical, geometric pattern resembling a stylized flower or mandala. No text, numerical data, or additional graphical elements are present.
### Components/Axes
- **Background**: Solid purple (#8A2BE2) square.
- **Icon**: White (hex: #FFFFFF) abstract flower design with no discernible labels, axes, or legends.
- **No textual or numerical elements** are visible.
### Detailed Analysis
- The icon’s structure consists of overlapping curved lines creating a hexagonal core with radiating petal-like shapes.
- No gradients, shadows, or color variations are present in the icon or background.
- No spatial grounding elements (e.g., legends, axis markers) exist to contextualize the design.
### Key Observations
- The design is purely symbolic, with no embedded data or functional annotations.
- The simplicity suggests it may serve as a logo, app icon, or brand identifier.
- No trends, outliers, or numerical relationships can be analyzed due to the absence of data.
### Interpretation
This icon likely represents a brand, application, or concept tied to themes of unity, growth, or creativity (common associations with floral motifs). The use of purple may imply creativity, luxury, or spirituality, while the white lines emphasize clarity and minimalism. Without additional context, the icon’s purpose remains speculative, but its design prioritizes visual impact over informational content.
</details>
|
Table 1: Statistics of LsrInstruct. #Inst., #Cons. Types, #Cons. and Evaluation refer to the number of instructions, constraint types, total constraints, and evaluation methods.
3.2 Structure-Aware Reward Modeling
We adopt the Group Relative Policy Optimization (GRPO) Shao et al. (2024) training, where model optimization is driven by automatically computed signals indicating constraint satisfaction. For hard constraints, we use programmatic verification. For soft constraints, we employ a reward model to assess adherence. We train Qwen2.5-7B-Instruct as the reward model, where we exploit the natural partial order in and-type multi-constraint instructions to construct binary preference pairs and train the model via supervised fine-tuning with a binary classification objective following Ren et al. (2025).
Given constraint-level verification results, we aggregate these rewards according to the logical structure of each instruction. Formally, let $o$ denote a model output and $c$ denote an atomic constraint. We define a binary verification function $r(o,c)∈\{0,1\}$ , where $r(o,c)=1$ if output $o$ satisfies constraint $c$ , and $0$ otherwise. The aggregation of rewards according to logical structures is described as follows.
Reward for Parallel Structure (Average Aggregation).
For parallel constraint set $C=\{c_{1},...,c_{n}\}$ , we define:
$$
R_{\text{par}}(o,C)=\frac{1}{|C|}\sum_{c_{i}\in C}r(o,c_{i}). \tag{1}
$$
This coincides with standard RLVR aggregation under flat constraint assumptions.
Reward for Sequential Structure (Penalty Propagation).
For sequential structure $S=(c_{1},...,c_{n})$ , we introduce penalty propagation that discounts downstream rewards when earlier steps fail. The adjusted reward for $c_{i}$ is:
$$
r^{\prime}_{i}(o,S)=r(o,c_{i})\cdot\prod_{j<i}\gamma^{(1-r(o,c_{j}))}, \tag{2}
$$
where $\gamma∈[0,1)$ is a decay coefficient. The overall reward is:
$$
R_{\text{seq}}(o,S)=\frac{1}{|S|}\sum_{i=1}^{|S|}r^{\prime}_{i}(o,S). \tag{3}
$$
Reward for Conditional Structure (Branch Selection).
For conditional structure with trigger $c_{p}$ and branches $c_{\text{true}}$ , $c_{\text{false}}$ :
$$
R_{\text{cond}}(o,c_{p},c_{\text{true}},c_{\text{false}})=\begin{cases}r(o,c_{\text{true}}),&r(o,c_{p})=1,\\
r(o,c_{\text{false}}),&r(o,c_{p})=0.\end{cases} \tag{4}
$$
This ensures optimization focuses exclusively on the logically valid branch.
4 Experiment
| Models | Method | In-Domain | Out-of-Domain | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| IFEval | CFBench | FollowBench | ComplexBench | WritingBench | Collie | AgentIF | MultiChallenge | | |
| Pr.(L) | ISR | HSR | Overall | Avg. | Avg. | CSR | Overall | | |
| GPT-4o | Baseline | 84.8 | 65.3 | 70.4 | 71.6 | 75.5 | 49.8 | 58.5 | 12.9 |
| QwQ-32B | Baseline | 83.9 | 68.0 | 62.2 | 73.3 | 79.1 | 52.4 | 58.1 | 38.5 |
| Self-Supervised-7B | Baseline | 78.9 | 52.0 | 57.5 | 68.7 | 58.5 | 38.0 | 56.7 | 15.6 |
| VERIF-8B | Baseline | 87.1 | 41.0 | 56.9 | 54.7 | 50.8 | 28.3 | 56.6 | 15.0 |
| RAIF-7B | Baseline | 74.1 | 43.0 | 56.2 | 68.7 | 61.7 | 20.2 | 51.9 | 14.4 |
| SPAR-8B-DPO | Baseline | 82.4 | 37.0 | 56.1 | 63.8 | 47.0 | 27.7 | 53.6 | 17.1 |
| Crab-7B-DPO | Baseline | 57.7 | 25.0 | 49.4 | 59.0 | 45.4 | 19.6 | 47.2 | 14.1 |
| Conifer-7B-DPO | Baseline | 52.3 | 25.0 | 50.0 | 48.1 | 32.2 | 17.8 | 44.3 | 8.0 |
| Qwen2.5-1.5B-Instruct | Base | 43.6 | 22.0 | 34.6 | 45.9 | 44.8 | 13.0 | 42.8 | 12.0 |
| SFT | 64.0 | 24.0 | 37.4 | 49.8 | 44.4 | 16.1 | 46.4 | 10.2 | |
| LsrIF | 68.8 (+25.2) | 28.0 (+6.0) | 38.9 (+4.3) | 52.4 (+6.5) | 46.8 (+2.0) | 19.3 (+6.3) | 51.5 (+8.7) | 14.4 (+2.4) | |
| Qwen2.5-7B-Instruct | Base | 73.9 | 47.0 | 55.1 | 66.1 | 57.2 | 36.3 | 54.2 | 15.2 |
| SFT | 75.2 | 43.0 | 55.7 | 68.5 | 51.2 | 30.5 | 55.5 | 14.5 | |
| LsrIF | 79.7 (+5.8) | 54.0 (+7.0) | 57.5 (+2.4) | 70.0 (+3.9) | 63.2 (+6.0) | 37.3 (+1.0) | 56.5 (+2.3) | 18.7 (+3.5) | |
| Distill-Qwen-7B | Base | 61.7 | 36.0 | 41.7 | 55.2 | 53.0 | 25.2 | 47.2 | 13.9 |
| SFT | 65.1 | 40.0 | 43.1 | 55.8 | 53.6 | 28.3 | 44.2 | 14.2 | |
| LsrIF | 71.5 (+9.8) | 47.0 (+11.0) | 44.0 (+2.3) | 61.1 (+5.9) | 55.0 (+2.0) | 30.0 (+4.8) | 46.7 (-0.5) | 15.0 (+1.1) | |
| Llama-3.1-8B-Instruct | Base | 73.8 | 34.0 | 53.8 | 63.6 | 47.5 | 46.5 | 53.4 | 16.2 |
| SFT | 77.4 | 36.0 | 52.2 | 61.1 | 46.9 | 34.5 | 55.2 | 14.9 | |
| LsrIF | 81.5 (+7.7) | 40.0 (+6.0) | 58.4 (+4.6) | 63.9 (+0.3) | 48.0 (+0.5) | 47.6 (+1.1) | 57.8 (+4.4) | 18.7 (+2.5) | |
| Distill-Qwen-14B | Base | 74.9 | 55.0 | 51.2 | 72.7 | 61.0 | 34.4 | 54.5 | 17.2 |
| SFT | 79.3 | 56.0 | 56.8 | 70.5 | 59.2 | 36.1 | 59.2 | 16.4 | |
| LsrIF | 82.1 (+7.2) | 60.0 (+5.0) | 58.2 (+7.0) | 75.5 (+2.8) | 63.8 (+2.8) | 38.8 (+4.4) | 61.7 (+7.2) | 18.3 (+1.1) | |
| Qwen3-8B | Base | 87.8 | 66.0 | 56.4 | 78.5 | 75.1 | 45.5 | 64.4 | 29.8 |
| SFT | 80.6 | 62.0 | 53.2 | 74.3 | 74.7 | 35.0 | 63.3 | 25.6 | |
| LsrIF | 90.2 (+2.4) | 68.0 (+2.0) | 58.1 (+1.7) | 79.2 (+0.7) | 75.6 (+0.5) | 48.1 (+2.6) | 65.0 (+0.6) | 32.3 (+2.5) | |
Table 2: Model performance on in-domain and out-of-domain instruction following benchmarks.
4.1 Set-up
Models.
We conduct experiments on models of different scales from 1.5B to 14B to evaluate the effectiveness of our method across different architectures and parameter scales. Specifically, we evaluate on: (1) 1.5B: Qwen2.5-1.5B-Instruct; (2) 7B: Qwen2.5-7B-Instruct and Distill-Qwen-7B; (3) 8B: Llama-3.1-8B-Instruct and Qwen3-8B; (4) 14B: Distill-Qwen-14B. This diverse set of models allows us to assess the generalizability of our approach across different model families and scales.
Baselines.
We compare against both strong general-purpose models and specialized instruction-following optimized models. General-purpose baselines include GPT-4o and QwQ-32B. Specialized instruction-following baselines include RAIF-7B, Self-Supervised-7B, VERIF-8B, SPAR-8B-DPO, Conifer-7B-DPO, and Crab-7B-DPO, which are specifically optimized for instruction following tasks using various training paradigms including supervised fine-tuning, self-supervised learning, verification-based reinforcement learning training, and direct preference optimization.
Training Methods.
We compare three training methods: Base uses the original model directly without any additional training; SFT fine-tunes the model on the dataset generated by the strong model GPT-4.1 using supervised fine-tuning; LsrIF is our logic-structured reinforcement learning training method that employs structure-aware reward modeling to align optimization signals with logical constraint structure execution semantics. For each model scale, we evaluate all three methods to demonstrate the effectiveness of our approach.
Evaluation Benchmarks.
We evaluate models on both in-domain and out-of-domain instruction following benchmarks. In-domain benchmarks include IFEval Zhou et al. (2023) (Pr.(L)), CFBench Zhang et al. (2024) (ISR), and FollowBench Jiang et al. (2023) (HSR). Out-of-domain benchmarks include ComplexBench Wen et al. (2024) (Overall), WritingBench Wu et al. (2025) (Avg.), Collie Yao et al. (2023) (Avg.), AgentIF Qi et al. (2025) (CSR), and MultiChallenge Deshpande et al. (2025) (Overall). Details of the experiment set-up are provided in Appx. A.4.
4.2 Performance
Instruction Following Performance.
As shown in Tab. 2, LsrIF significantly improves instruction following capabilities across different models on both in-domain and out-of-domain benchmarks. LsrIF consistently outperforms Base and SFT across all model scales, with improvements on various metrics.
On in-domain benchmarks, LsrIF achieves substantial gains across all model scales. For smaller models, Qwen2.5-1.5B-Instruct shows remarkable improvements, improving by 25.2 on IFEval and 6.0 on CFBench. For 7B models, Qwen2.5-7B-Instruct improves by 5.8 on IFEval and 7.0 on CFBench. For stronger models, Qwen3-8B achieves strong performance with improvements of 2.4 on IFEval and 2.0 on CFBench. On out-of-domain benchmarks, LsrIF demonstrates consistent improvements across diverse evaluation scenarios. Qwen2.5-7B-Instruct improves by 6.0 on WritingBench and 3.5 on MultiChallenge. Qwen2.5-1.5B-Instruct shows improvements of 6.5 on ComplexBench and 8.7 on AgentIF.
Notably, LsrIF enables models to outperform specialized baseline models even while the base model initially underperforms. For instance, Qwen2.5-7B-Instruct underperforms RAIF-7B and Self-Supervised-7B, but after LsrIF training exceeds both baselines with substantial improvements. After LsrIF, Qwen3-8B achieves 90.2 on IFEval, higher than GPT-4o (84.8) and VERIF-8B (87.1), demonstrating state-of-the-art performance on this benchmark.
Logical Reasoning Performance.
We evaluate logical reasoning capabilities using Enigmata Chen et al. (2025), a comprehensive benchmark suite designed to assess logical reasoning abilities of large language models. Enigmata comprises 36 tasks distributed across seven categories, with each task equipped with generators that can produce infinite examples and rule-based verifiers. The benchmark evaluates four key reasoning subcategories: Logic (formal logical inference), Arithmetic (mathematical computation and reasoning), Graph (graph-based problem solving) and Search (path-finding task).
As shown in Tab. 3, LsrIF effectively enhances both logical reasoning and general capabilities. On Enigmata, LsrIF outperforms base models across all subcategories, with particularly strong gains on Arithmetic. For Distill-Qwen-7B, Arithmetic improves by 10.6, while Logic increases by 2.7 and Graph by 6.4. For Distill-Qwen-14B, Arithmetic shows the most substantial improvement, increasing by 18.0, with Logic improving by 3.7 and Graph by 2.2. The significant improvements on Arithmetic suggest that LsrIF ’s structure-aware reward modeling effectively captures mathematical constraint satisfaction, enabling models to better follow numerical and computational requirements in instructions.
| Model | Logic Reasoning (Enigmata) | General Capabilities | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Logic | Arithmetic | Graph | Search | Overall | AIME2024 | AIME2025 | GPQA-Diamond | MT-Bench | AlpacaEval2.0 | |
| Distill-Qwen-7B | 10.9 | 3.7 | 11.1 | 4.4 | 9.9 | 53.4 | 38.7 | 49.1 | 5.9 | 5.0 |
| Distill-Qwen-7B- LsrIF | 13.6 | 14.3 | 17.5 | 4.6 | 12.4 | 55.1 | 41.2 | 52.5 | 6.3 | 5.8 |
| Distill-Qwen-14B | 44.7 | 21.0 | 31.1 | 10.5 | 22.4 | 69.3 | 49.0 | 58.6 | 6.6 | 26.7 |
| Distill-Qwen-14B- LsrIF | 48.4 | 39.0 | 33.3 | 14.1 | 24.4 | 70.2 | 49.6 | 60.1 | 7.0 | 30.3 |
Table 3: Model performance on logic reasoning (Enigmata) and general capabilities benchmarks. We evaluate AIME using Avg@30 method. Bolded value indicates the best result for each model on the benchmark.
On general capabilities benchmarks, which encompass mathematics (AIME2024, AIME2025), science (GPQA-Diamond), and general instruction following (MT-Bench, AlpacaEval2.0), LsrIF brings consistent improvements across all evaluated benchmarks. These results demonstrate that LsrIF not only enhances logical reasoning capabilities but also improves general model performance across diverse evaluation domains.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Model Performance Comparison Across Benchmarks
### Overview
The chart compares the performance of four models across three benchmarks (IFEval, AIME, CFBench). Performance is measured on a scale from 0 to 80. The models include:
- **Distill-Qwen-7B (Base)** (orange)
- **Llm as a Judge (Const.-Level)** (light blue)
- **Our-RM-7B (Inst.-Level)** (green)
- **Our-RM-7B (Const.-Level)** (yellow)
### Components/Axes
- **X-axis**: Benchmarks (IFEval, AIME, CFBench)
- **Y-axis**: Performance (0–80)
- **Legend**: Located in the top-right corner, mapping colors to models.
- **Bar Groups**: Each benchmark has four adjacent bars representing the four models.
### Detailed Analysis
- **IFEval**:
- Distill-Qwen-7B (Base): ~60
- Llm as a Judge (Const.-Level): ~65
- Our-RM-7B (Inst.-Level): ~70
- Our-RM-7B (Const.-Level): ~72
- **AIME**:
- Distill-Qwen-7B (Base): ~53
- Llm as a Judge (Const.-Level): ~54
- Our-RM-7B (Inst.-Level): ~52
- Our-RM-7B (Const.-Level): ~55
- **CFBench**:
- Distill-Qwen-7B (Base): ~36
- Llm as a Judge (Const.-Level): ~42
- Our-RM-7B (Inst.-Level): ~44
- Our-RM-7B (Const.-Level): ~47
### Key Observations
1. **Our-RM-7B (Const.-Level)** consistently outperforms other models in IFEval and AIME.
2. **Our-RM-7B (Inst.-Level)** shows slightly higher performance than its Const.-Level counterpart in CFBench.
3. **Distill-Qwen-7B (Base)** has the lowest performance across all benchmarks, particularly in CFBench.
4. **Llm as a Judge (Const.-Level)** performs comparably to the base model in IFEval but slightly better in AIME and CFBench.
### Interpretation
The data suggests that **Our-RM-7B (Const.-Level)** is the most effective model for IFEval and AIME, likely due to its constrained-level optimization. However, **Our-RM-7B (Inst.-Level)** outperforms the Const.-Level in CFBench, indicating that instruction-level tuning may be more beneficial for this specific task. The base model (Distill-Qwen-7B) underperforms across all benchmarks, highlighting the importance of specialized training (e.g., constrained or instruction-level) for improved performance. The divergence in CFBench results between Inst.-Level and Const.-Level models suggests task-specific trade-offs in model design.
</details>
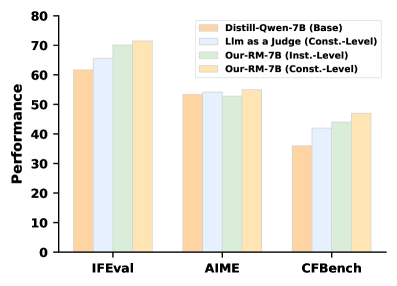
Figure 3: LsrIF performance on different reward forms. Const.-Level and Inst.-Level refer to constraint-level and instruction-level, respectively.
4.3 Ablation Studies
As shown in Tab. 4, removing any component degrades performance compared to the full LsrIF. Removing the LsRM, which ignores logical structure and averages rewards across all constraints, results in the largest drop, indicating its critical importance. Specifically, without LsRM, performance decreases by 2.9 on IFEval, 5.0 on CFBench, and 2.7 on AIME2024. This demonstrates that structure-aware reward modeling is essential for effectively capturing logical constraint relationships.
Removing sequential data from LsrInstruct also leads to performance decreases, with drops of 1.6 on IFEval and 3.0 on CFBench. Similarly, removing conditional data results in decreases of 1.8 on IFEval, 3.0 on CFBench, and 3.5 on AIME2024.
All ablation variants still outperform the base model. This indicates that even partial components of LsrIF provide substantial benefits over the base model. These results demonstrate that each component—the logic-structured reward modeling and logic-structured dataset construction play a crucial role in the overall effectiveness of LsrIF.
4.4 Robustness of LsrIF
| Config | Performance | | | |
| --- | --- | --- | --- | --- |
| IFEval | CFBench | AIME2024 | Enigmata | |
| Distill-Qwen-7B | 61.7 | 36.0 | 53.4 | 9.9 |
| Distill-Qwen-7B- LsrIF | 71.5 | 47.0 | 55.1 | 12.4 |
| w/o LsRM | 68.6 | 42.0 | 52.4 | 10.5 |
| w/o Sequential Data | 69.9 | 44.0 | 54.0 | 11.0 |
| w/o Conditional Data | 69.7 | 44.0 | 51.6 | 10.9 |
Table 4: Ablation study results on different abilities. Bolded values indicate the best performance.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Graph: Model Performance Across Depths
### Overview
The image is a line graph comparing the performance of two language models, **Distill-Qwen-7B** and **Distill-Qwen-14B**, across three depths (1, 2, 3). Each model is evaluated in two configurations: **Base** (dashed lines) and **LsrlF** (solid lines). The y-axis represents a "Score" metric, while the x-axis represents "Depth."
---
### Components/Axes
- **X-axis (Depth)**: Labeled "Depth" with discrete values at 1, 2, and 3.
- **Y-axis (Score)**: Labeled "Score" with a range from 40 to 70.
- **Legend**: Located in the **top-left corner**, with four entries:
- **Blue dashed line**: Distill-Qwen-7B (Base)
- **Blue solid line**: Distill-Qwen-7B (LsrlF)
- **Green dashed line**: Distill-Qwen-14B (Base)
- **Green solid line**: Distill-Qwen-14B (LsrlF)
---
### Detailed Analysis
#### Data Series Trends
1. **Distill-Qwen-7B (Base, Blue Dashed)**:
- **Depth 1**: ~62
- **Depth 2**: ~45
- **Depth 3**: ~46
- **Trend**: Sharp decline from Depth 1 to 2, followed by a slight recovery at Depth 3.
2. **Distill-Qwen-7B (LsrlF, Blue Solid)**:
- **Depth 1**: ~63
- **Depth 2**: ~44
- **Depth 3**: ~46
- **Trend**: Similar decline to the Base version but with a marginally lower score at Depth 2.
3. **Distill-Qwen-14B (Base, Green Dashed)**:
- **Depth 1**: ~72
- **Depth 2**: ~68
- **Depth 3**: ~69
- **Trend**: Gradual decline from Depth 1 to 2, followed by a slight increase at Depth 3.
4. **Distill-Qwen-14B (LsrlF, Green Solid)**:
- **Depth 1**: ~72
- **Depth 2**: ~64
- **Depth 3**: ~69
- **Trend**: Moderate decline from Depth 1 to 2, followed by a recovery at Depth 3.
---
### Key Observations
- **Model Size Impact**: The 14B models consistently outperform the 7B models across all depths.
- **LsrlF Effect**: The LsrlF configuration improves performance for both models, particularly at Depths 2 and 3.
- **Depth 2 Drop**: All models experience a significant score drop at Depth 2, suggesting a potential challenge or bottleneck at this depth.
- **Recovery at Depth 3**: Both models show partial recovery at Depth 3, with LsrlF versions performing better than Base.
---
### Interpretation
The graph demonstrates that larger models (14B) maintain higher performance across depths compared to smaller models (7B). The **LsrlF** configuration mitigates performance degradation, especially for the 7B model, which shows a steeper decline at Depth 2. This suggests that LsrlF may enhance robustness or generalization in resource-constrained scenarios. The 14B models’ higher baseline scores and smaller performance drop at Depth 2 indicate greater capacity to handle deeper tasks. The recovery at Depth 3 for both models implies that LsrlF helps stabilize performance in later stages, potentially addressing overfitting or computational limitations.
</details>
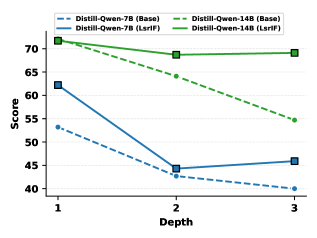
Figure 4: Performance on nested structures from Wen et al. (2024).
<details>
<summary>x5.png Details</summary>
### Visual Description
## Heatmap: Attention and MLP Operation Values
### Overview
The image is a heatmap visualizing values across rows (0-27) and columns labeled with attention mechanisms ("attn. q", "attn. k", "attn. v", "attn. o") and MLP operations ("mlp. up", "mlp. down", "mlp. gate"). Colors range from blue (low values) to orange (high values), with a colorbar indicating values from 0.075 to 0.105.
### Components/Axes
- **Rows**: Labeled numerically from 0 (bottom) to 27 (top).
- **Columns**:
- Attention mechanisms: "attn. q", "attn. k", "attn. v", "attn. o".
- MLP operations: "mlp. up", "mlp. down", "mlp. gate".
- **Colorbar**: Right-aligned, gradient from blue (0.075) to orange (0.105).
### Detailed Analysis
1. **Attention Mechanisms**:
- **attn. q**: Predominantly blue (0.075–0.090) across all rows, with slight lightening toward the top (rows 20–27).
- **attn. k**: Dark blue at the bottom (rows 0–4), transitioning to orange (0.105) in rows 12–16, then fading to light blue.
- **attn. v**: Orange at the bottom (rows 0–4), blue in rows 5–12, and orange again in rows 13–27.
- **attn. o**: Mostly blue (0.075–0.090) with sporadic orange patches in rows 8–12.
2. **MLP Operations**:
- **mlp. up**: Blue in rows 0–8, orange in rows 9–15, and blue again in rows 16–27.
- **mlp. down**: Blue in rows 0–10, orange in rows 11–18, and blue in rows 19–27.
- **mlp. gate**: Blue in rows 0–5 and 20–27, orange in rows 6–19.
### Key Observations
- **Highest Values**:
- "attn. k" (rows 12–16) and "attn. v" (rows 0–4, 13–27) show the most intense orange (0.105).
- "mlp. down" (rows 11–18) and "mlp. up" (rows 9–15) also exhibit significant orange regions.
- **Lowest Values**:
- "attn. q" (rows 0–27) and "attn. o" (rows 0–27) are consistently blue (0.075–0.090).
- **Transitions**:
- "attn. k" and "mlp. down" show sharp transitions from blue to orange around row 12.
- "attn. v" has a bimodal distribution with orange at both ends.
### Interpretation
The heatmap likely represents attention weights or MLP operation magnitudes in a neural network layer.
- **Attention Mechanisms**:
- "attn. k" (key attention) and "attn. v" (value attention) dominate in specific row ranges, suggesting these operations are critical in middle and lower layers (rows 12–16 for "attn. k", rows 0–4 and 13–27 for "attn. v").
- "attn. q" (query attention) and "attn. o" (output attention) remain consistently low, indicating minimal contribution across all rows.
- **MLP Operations**:
- "mlp. up" and "mlp. down" show mid-layer dominance (rows 9–18), while "mlp. gate" is active in the middle layers (rows 6–19).
- The bimodal pattern in "attn. v" suggests dual importance in early and late layers, possibly for input/output processing.
### Spatial Grounding
- **Legend**: Right-aligned colorbar with values 0.075 (blue) to 0.105 (orange).
- **Axis Labels**:
- Rows: Left side, numerical (0–27).
- Columns: Bottom, labeled with attention/MLP terms.
- **Data Placement**: Cells align with row/column intersections, color intensity reflecting values.
### Trend Verification
- **attn. k**: Slopes upward (dark blue → orange) then downward (orange → light blue) around row 16.
- **mlp. down**: Gradual increase (blue → orange) peaking at row 14, then decline.
- **attn. v**: Bimodal peaks at rows 0–4 and 13–27, with a trough in rows 5–12.
### Notable Patterns
- **Layer-Specific Importance**: Middle layers (rows 12–16) show heightened activity for "attn. k" and "mlp. down", suggesting critical processing in these regions.
- **Bimodal Behavior**: "attn. v" and "mlp. gate" exhibit dual peaks, indicating distinct functional roles in early/late layers.
### Conclusion
This heatmap highlights layer-specific contributions of attention and MLP operations in a neural network. Middle layers dominate for key attention and down-sampling operations, while early/late layers are critical for value attention and gating. The consistent low values for query and output attention suggest these mechanisms are less pivotal in this architecture.
</details>
(a) Qwen2.5-7B-Instruct
<details>
<summary>x6.png Details</summary>
### Visual Description
## Heatmap: Attention and MLP Component Values Across Layers
### Overview
The image is a heatmap visualizing numerical values across 28 layers (rows 0–27) for attention mechanisms (q, k, v, o) and MLP components (up, down, gate). Values range from 0.12 (blue) to 0.18 (orange), with a color gradient indicating magnitude.
### Components/Axes
- **X-axis (Columns)**:
- `attn. q`, `attn. k`, `attn. v`, `attn. o` (attention mechanisms)
- `mlp. up`, `mlp. down`, `mlp. gate` (MLP components)
- **Y-axis (Rows)**: Layer indices 0–27 (numerical scale).
- **Legend**: Colorbar on the right, mapping values to colors (blue = 0.12, orange = 0.18).
### Detailed Analysis
1. **Attention Mechanisms**:
- **`attn. q`**: Highest values (dark orange) in rows 24–27 (~0.17–0.18), decreasing to ~0.12 in rows 0–4.
- **`attn. k`**: Similar trend to `attn. q`, with peaks in rows 24–27 (~0.16–0.17) and lower values (~0.12–0.14) in rows 0–12.
- **`attn. v`**: Lower values (~0.12–0.14) across all rows, with minimal variation.
- **`attn. o`**: Consistently low (~0.12–0.13) across all layers.
2. **MLP Components**:
- **`mlp. up`**: Moderate values (~0.14–0.16) in rows 8–20, peaking at ~0.17 in rows 24–27.
- **`mlp. down`**: Slightly lower than `mlp. up`, with values ~0.13–0.15.
- **`mlp. gate`**: Lowest values (~0.12–0.14) across all layers.
### Key Observations
- **High Attention in Upper Layers**: `attn. q` and `attn. k` show strong values in the top 4 layers (24–27), suggesting increased focus in later processing stages.
- **Stable MLP Values**: MLP components exhibit less variation, with `mlp. gate` consistently the lowest.
- **Color Consistency**: All orange regions align with the legend’s high-value range (0.15–0.18), confirming accurate color mapping.
### Interpretation
The heatmap likely represents attention weights or activation magnitudes in a transformer-based model. The dominance of `attn. q` and `attn. k` in upper layers implies these mechanisms play a critical role in later-stage information processing. The MLP components, while present, show weaker signals, indicating their role may be more stable or secondary. The lack of extreme outliers suggests a balanced distribution of attention and MLP contributions across layers.
</details>
(b) Distill-Qwen-7B
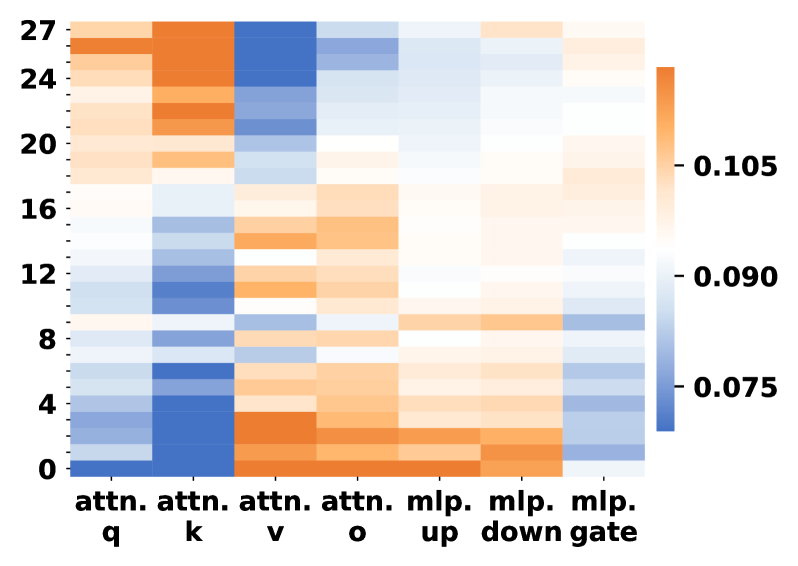
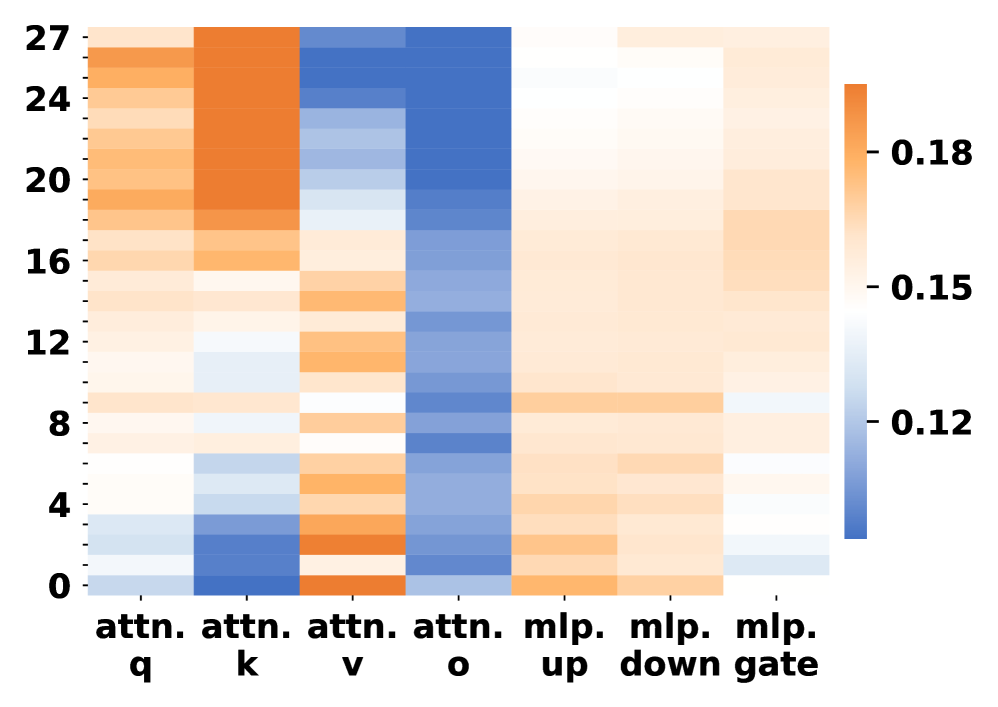
Figure 5: Parameter change rates of LLMs to the original ones across different modules. Darker orange colors indicate larger parameter changes.
<details>
<summary>x7.png Details</summary>

### Visual Description
## Textual Content Analysis: Technical Document Generation Instructions
### Overview
The image contains a block of text with specific formatting instructions for generating technical documents, accompanied by a three-step flowchart diagram. The text includes conditional formatting rules and stylistic requirements, while the diagram visually represents the workflow.
### Components/Axes
**Textual Elements:**
- **Highlighted Instructions (Blue):**
- "First, generate a short instructional paragraph and ensure the total length does not exceed three sentences"
- "append a clearly separated checklist section using bullet points"
- "if the word 'error' appears anywhere in the output, all checklist items must be written in lowercase English"
- "else the instructional paragraph must begin with a bolded core idea"
- "finally, apply a formal, technical writing style to the entire output"
**Diagram Elements:**
- **Three-Step Flowchart:**
1. **Step 1 (Dark Blue):** "First/then/else ..."
2. **Step 2 (Medium Blue):** "bullet/lowercase/bolded..."
3. **Step 3 (Light Blue):** "apply/formal/generate..."
- **Crown Icon:** Positioned above the flowchart, symbolizing priority or authority.
### Detailed Analysis
**Textual Content:**
- The instructions enforce strict formatting rules:
- **Length Constraint:** Instructional paragraphs must not exceed three sentences.
- **Checklist Requirements:** Bullet points must be used, with lowercase formatting triggered by the presence of the word "error."
- **Conditional Formatting:**
- If "error" is detected, all checklist items must be lowercase.
- If "error" is absent, the instructional paragraph must start with a bolded core idea.
- **Stylistic Mandate:** Entire output must adopt a formal, technical tone.
**Diagram Structure:**
- The flowchart visually maps the workflow:
1. **Step 1** ("First/then/else ...") likely corresponds to the initial instruction generation.
2. **Step 2** ("bullet/lowercase/bolded...") aligns with checklist creation and conditional formatting.
3. **Step 3** ("apply/formal/generate...") represents the final stylistic application.
- The crown icon above the steps suggests hierarchical importance, emphasizing adherence to the workflow.
### Key Observations
- **Conditional Logic:** The presence of "error" triggers a cascading effect, requiring lowercase checklist items and overriding the bolded core idea requirement.
- **Stylistic Consistency:** The final step enforces uniformity across the entire output, regardless of prior conditions.
- **Hierarchical Emphasis:** The crown icon visually prioritizes the flowchart, implying the workflow is non-negotiable.
### Interpretation
The image outlines a rigorous process for technical document creation, blending conditional logic with stylistic mandates. The flowchart and text work in tandem to ensure:
1. **Precision:** Length constraints and formatting rules minimize ambiguity.
2. **Adaptability:** The "error" condition introduces flexibility for error-handling scenarios.
3. **Authority:** The crown icon and flowchart hierarchy reinforce compliance with the workflow.
This system likely serves as a template for automated document generation, where natural language processing (NLP) models must parse both explicit instructions and implicit formatting rules. The interplay between text and diagram highlights the importance of multi-modal reasoning in technical workflows.
</details>
(a) Instruction Following – More Attention on constraints and their underlying logic
<details>
<summary>x8.png Details</summary>

### Visual Description
## Text-Based Logic Puzzle: Determining Truth Value of Conclusion
### Overview
The image presents a logical reasoning task where the reader must evaluate whether a conclusion ("Bonnie performs in school talent shows often") is **true**, **false**, or **uncertain** based on five premises. The text includes highlighted keywords and a legend with symbolic annotations.
### Components/Axes
1. **Premises (1–5)**: Structured as conditional statements about club members' activities and school engagement.
2. **Conclusion**: A standalone statement to be validated against the premises.
3. **Legend**: A tiered ranking system with crown icons and color-coded labels:
- **Tier 1 (Dark Blue)**: "or/and ..."
- **Tier 2 (Medium Blue)**: "either/not..."
- **Tier 3 (Light Blue)**: "often/attends..."
### Detailed Analysis
#### Premises
1. **Premise 1**: "People in this club who perform in school talent shows often attend and are very engaged with school."
- Highlighted keywords: **perform**, **attend**, **engaged**.
2. **Premise 2**: "People in this club either perform in school talent shows often or are inactive and disinterested community members."
- Highlighted keywords: **perform**, **inactive**, **disinterested**.
3. **Premise 3**: "People in this club who chaperone high school dances are not students who attend the school."
- Highlighted keywords: **chaperone**, **attend**.
4. **Premise 4**: "All young children and teenagers in this club who wish to further their academic careers and educational opportunities are students who attend the school."
- Highlighted keywords: **attend**, **academic careers**, **educational opportunities**.
5. **Premise 5**: "Bonnie is in this club and she either both attends and is very engaged with school events and is a student who attends the school or is not someone who both attends and is very engaged with school events and is not a student who attends the school."
- Highlighted keywords: **attends**, **engaged**, **student**, **school**.
#### Conclusion
- "Bonnie performs in school talent shows often."
#### Legend
- **Tier 1 (Dark Blue)**: "or/and ..." (associated with Premise 5).
- **Tier 2 (Medium Blue)**: "either/not..." (associated with Premise 2).
- **Tier 3 (Light Blue)**: "often/attends..." (associated with Premises 1, 3, 4).
### Key Observations
1. **Logical Structure**: The premises use conditional logic (e.g., "if X, then Y") and disjunctions (e.g., "either A or B").
2. **Highlighted Keywords**: Critical terms like **attend**, **engaged**, and **perform** are emphasized, suggesting their relevance to the conclusion.
3. **Legend Symbolism**: The crown icon on Tier 1 may imply a hierarchical priority for evaluating logical operators (e.g., "or/and" as foundational).
4. **Ambiguity in Premise 5**: The use of "either...or..." in Premise 5 creates a paradoxical structure, complicating direct inference.
### Interpretation
- **Logical Validity**: The conclusion ("Bonnie performs often") hinges on Premise 1, which links performing in talent shows to school attendance and engagement. However, Premise 5 introduces ambiguity by stating Bonnie "either both attends/engaged **and** is a student **or** is not someone who both attends/engaged **and** is not a student." This creates a contradiction: Bonnie cannot simultaneously be a student who attends/engaged and not a student who attends/engaged.
- **Resolution**: If Premise 5 is interpreted as a biconditional (Bonnie is a student who attends/engaged **if and only if** she performs often), the conclusion becomes valid. However, the phrasing of Premise 5 introduces uncertainty, making the conclusion **uncertain** under strict logical analysis.
- **Legend Relevance**: The Tier 3 label ("often/attends") aligns with Premises 1, 3, and 4, reinforcing the connection between attendance/engagement and talent show participation.
### Final Assessment
The conclusion is **uncertain** due to conflicting interpretations of Premise 5. While Premise 1 suggests a direct link between performing and engagement, the paradoxical structure of Premise 5 undermines definitive validation.
</details>
(b) Logic Reasoning – More Attention on logical connectors
Figure 6: Comparison of attention importance changes for each token position in Qwen2.5-7B-Instruct before and after training on instruction following and logic reasoning tasks. Darker colors indicate greater increases.
4.4.1 Robustness to Reward Modeling
We compare our reward model with alternative reward methods to demonstrate robustness of our method to different reward forms. As shown in Fig. 3, all reward methods outperform the baseline, indicating that our method is robust to reward forms. LLM-as-a-Judge (Qwen2.5-7B-Instruct) with constraint-level rewards shows improvements over the base model on IFEval and CFBench. Our reward model with instruction-level rewards further improves performance on IFEval and CFBench, while our constraint-level variant achieves the best performance across all evaluated benchmarks.
Furthermore, our RM consistently outperforms LLM-as-a-Judge, demonstrating the superior effectiveness of our reward model. The constraint-level variant achieves substantial improvements over LLM-as-a-Judge on both IFEval and CFBench. Both instruction-level and constraint-level variants of our RM achieve competitive performance, with the constraint-level variant achieving the best overall results, indicating that our method is effective for different reward granularity. The superior performance of constraint-level rewards suggests that fine-grained constraint evaluation enables more precise optimization signals compared to instruction-level aggregation.
4.4.2 Generalization to Nested Structures
We conduct experiments to evaluate the performance of our method under nested logical-structure constraints. Although our training data only contains non-nested structures, LsrIF still improves performance on nested constraint structures: Selection_1 (depth 1), Selection_and_Chain_2 (depth 2), and Selection_and_Chain_3 (depth 3) from ComplexBench. As shown in Fig. 4, LsrIF maintains better performance across all depths compared to Base models. These results indicate that the improvements gained from training on non-nested structures generalize effectively to nested constraint structures, with the benefits becoming pronounced at higher nesting depths.
5 Interpretability Analysis
5.1 Parameter Change Patterns
Fig. 5 presents the relative parameter change rates across layers and modules after LsrIF training. The change rate is measured using the normalized Frobenius norm:
$$
\Delta=\frac{\|W_{\text{after}}-W_{\text{before}}\|_{F}}{\|W_{\text{before}}\|_{F}}\times 100\%, \tag{5}
$$
where $W_{\text{before}}$ and $W_{\text{after}}$ denote the parameters before and after training. For a model with $L$ layers, let $\Delta_{m}^{(l)}$ denote the change rate for module $m$ at layer $l$ .
Attention vs. MLP Modules. A clear pattern observed in Fig. 5 is that attention modules undergo substantially larger parameter changes than MLP modules across most layers. In particular, the query and key projection matrices exhibit the highest change rates, while MLP up and down projections show comparatively smaller and more uniform updates:
$$
\Delta^{(l)}_{\text{attn.q}},\ \Delta^{(l)}_{\text{attn.k}}\;>\;\Delta^{(l)}_{\text{mlp.up}},\ \Delta^{(l)}_{\text{mlp.down}},\quad \tag{6}
$$
Layer-wise Trends. This discrepancy between attention and MLP updates is consistent across layers. Although both module types display some variation along depth, attention-related parameters consistently dominate the overall magnitude of change, especially in lower and upper layers. In contrast, MLP parameters remain relatively stable throughout the network.
Model Consistency. The same trend holds for both Qwen2.5-7B-Instruct and Distill-Qwen-7B. While the distilled model shows larger absolute change magnitudes, the relative dominance of attention parameter updates over MLP updates remains consistent.
Overall, these results indicate that LsrIF primarily induces stronger updates in attention mechanisms, whereas MLP layers are affected to a much lesser extent.
5.2 Token-Level Information Flow Analysis
We analyze token-level information flow using gradient-based saliency attribution to quantify how training redirects attention to semantically critical tokens. For token $x_{i}$ with embedding $E_{i}$ , the attribution score is defined as
$$
S_{i}=\left|\sum_{d=1}^{D}\frac{\partial L}{\partial E_{i,d}}\cdot E_{i,d}\right|. \tag{7}
$$
The sequence-level loss function is defined as
$$
L(x,y)=\sum_{t=1}^{|y|}\log P(y_{t}\mid y_{<t},x). \tag{8}
$$
The change in attention importance is measured as
$$
\Delta S_{i}=S_{i}^{\text{after}}-S_{i}^{\text{before}}, \tag{9}
$$
where higher values indicate greater increases in attention importance.
As shown in Fig. 6, training shifts attention from diffuse to concentrated patterns, directly corresponding to parameter changes in attention query and key modules (Fig. 5). For instruction following tasks, we observe a hierarchical attention increase across three token categories: logical connectors (“First”, “then”, “else”) show the highest increase, constraint tokens (“bullet”, “lowercase”, “bolded”) show moderate increase, and action verbs (“apply”, “formal”) show lower increase. For logic reasoning tasks, we observe a similar hierarchical pattern: logical operators (“or”, “and”) show the highest increase, followed by choice/negation terms (“either”, “not”) and descriptive predicates (“attends”).
This hierarchical pattern indicates that the model prioritizes structural elements encoding logical relationships, aligning with structure-aware reward modeling. The substantial updates to $\Delta^{(l)}_{\text{attn.q}}$ and $\Delta^{(l)}_{\text{attn.k}}$ enable query and key representations that prioritize tokens encoding logical structures. The attention mechanism computes query-key similarities where query and key projections are updated to maximize attention weights for structural tokens, validating that LsrIF adapts attention mechanisms to capture constraint relationships rather than merely adjusting output representations.
6 Conclusion
In this work, we propose LsrIF, a logic-structured training framework. We construct LsrInstruct, a multi-constraint instruction dataset covering parallel, sequential, and conditional constraint logic structures, and design LsRM, structure-aware reward modeling that aligns training signals with logical execution semantics. LsrIF improves instruction following in both in-domain and out-of-domain settings, while also enhancing general reasoning ability. We also conduct attention and token-level interpretability analysis for model performance improvements.
7 Limitations
Our study has following main limitations. First, due to computational constraints, we do not evaluate our method on larger models such as 70B+, and validation at this scale would further strengthen the credibility and robustness of our approach. Second, our training data is primarily English. While results on CFBench indicate that logic-structured training can generalize to other languages, we encourage the community to construct multilingual logic-structured instruction datasets to more systematically assess and extend cross-lingual generalization.
References
- K. An, L. Sheng, G. Cui, S. Si, N. Ding, Y. Cheng, and B. Chang (2025) UltraIF: advancing instruction following from the wild. arXiv preprint arXiv:2502.04153. Cited by: §1.
- J. Chen, Q. He, S. Yuan, A. Chen, Z. Cai, W. Dai, H. Yu, Q. Yu, X. Li, J. Chen, et al. (2025) Enigmata: scaling logical reasoning in large language models with synthetic verifiable puzzles. arXiv preprint arXiv:2505.19914. Cited by: §A.4.3, §4.2.
- J. Cheng, X. Liu, C. Wang, X. Gu, Y. Lu, D. Zhang, Y. Dong, J. Tang, H. Wang, and M. Huang (2024) Spar: self-play with tree-search refinement to improve instruction-following in large language models. arXiv preprint arXiv:2412.11605. Cited by: §A.4.2, §2.1.
- K. Deshpande, V. Sirdeshmukh, J. B. Mols, L. Jin, E. Hernandez-Cardona, D. Lee, J. Kritz, W. E. Primack, S. Yue, and C. Xing (2025) MultiChallenge: a realistic multi-turn conversation evaluation benchmark challenging to frontier llms. In Findings of the Association for Computational Linguistics: ACL 2025, pp. 18632–18702. Cited by: §A.4.3, §1, §4.1.
- Y. Dubois, B. Galambosi, P. Liang, and T. B. Hashimoto (2024) Length-controlled alpacaeval: a simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475. Cited by: §A.4.3.
- S. Han, H. Schoelkopf, Y. Zhao, Z. Qi, M. Riddell, W. Zhou, J. Coady, D. Peng, Y. Qiao, L. Benson, et al. (2022) Folio: natural language reasoning with first-order logic. arXiv preprint arXiv:2209.00840. Cited by: §A.4.3.
- Q. He, J. Zeng, Q. He, J. Liang, and Y. Xiao (2024) From complex to simple: enhancing multi-constraint complex instruction following ability of large language models. arXiv preprint arXiv:2404.15846. Cited by: §1.
- H. Huang, J. Liu, Y. He, S. Li, B. Xu, C. Zhu, M. Yang, and T. Zhao (2025) Musc: improving complex instruction following with multi-granularity self-contrastive training. arXiv preprint arXiv:2502.11541. Cited by: §1, §2.2.
- Y. Jiang, Y. Wang, X. Zeng, W. Zhong, L. Li, F. Mi, L. Shang, X. Jiang, Q. Liu, and W. Wang (2023) Followbench: a multi-level fine-grained constraints following benchmark for large language models. arXiv preprint arXiv:2310.20410. Cited by: §A.4.3, §4.1.
- A. Köpf, Y. Kilcher, D. von Rütte, S. Anagnostidis, Z. R. Tam, K. Stevens, A. Barhoum, D. Nguyen, O. Stanley, R. Nagyfi, et al. (2024) Openassistant conversations-democratizing large language model alignment. Advances in Neural Information Processing Systems 36. Cited by: §3.1.
- J. Li, L. Du, H. Zhao, B. Zhang, L. Wang, B. Gao, G. Liu, and Y. Lin (2025) Infinity instruct: scaling instruction selection and synthesis to enhance language models. arXiv preprint arXiv:2506.11116. Cited by: §3.1.
- K. Lu, Z. Chen, S. Fu, C. H. Yang, J. Balam, B. Ginsburg, Y. F. Wang, and H. Lee (2025) Developing instruction-following speech language model without speech instruction-tuning data. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. Cited by: §1.
- MAA (2024) American invitational mathematics examination - aime. Note: Accessed in February 2024 External Links: Link Cited by: §A.4.3.
- MAA (2025) American invitational mathematics examination - aime. Note: Accessed in February 2025 External Links: Link Cited by: §A.4.3.
- H. Peng, Y. Qi, X. Wang, B. Xu, L. Hou, and J. Li (2025) VerIF: verification engineering for reinforcement learning in instruction following. arXiv preprint arXiv:2506.09942. Cited by: §A.4.2, §1, §2.2.
- Y. Qi, H. Peng, X. Wang, A. Xin, Y. Liu, B. Xu, L. Hou, and J. Li (2025) Agentif: benchmarking instruction following of large language models in agentic scenarios. arXiv preprint arXiv:2505.16944. Cited by: §A.4.3, §1, §4.1.
- Y. Qi, H. Peng, X. Wang, B. Xu, L. Hou, and J. Li (2024) Constraint back-translation improves complex instruction following of large language models. arXiv preprint arXiv:2410.24175. Cited by: §A.4.2, §2.2.
- Y. Qin, G. Li, Z. Li, Z. Xu, Y. Shi, Z. Lin, X. Cui, K. Li, and X. Sun (2025) Incentivizing reasoning for advanced instruction-following of large language models. arXiv preprint arXiv:2506.01413. Cited by: §A.4.2, §1, §2.1, §2.2.
- D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman (2024) Gpqa: a graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, Cited by: §A.4.3.
- Q. Ren, Q. He, B. Zhang, J. Zeng, J. Liang, Y. Xiao, W. Zhou, Z. Sun, and F. Yu (2025) Instructions are all you need: self-supervised reinforcement learning for instruction following. arXiv preprint arXiv:2510.14420. Cited by: §A.4.2, §3.2.
- Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. (2024) Deepseekmath: pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Cited by: §3.2.
- H. Sun, L. Liu, J. Li, F. Wang, B. Dong, R. Lin, and R. Huang (2024) Conifer: improving complex constrained instruction-following ability of large language models. arXiv preprint arXiv:2404.02823. Cited by: §A.4.2, §1, §2.2.
- C. Wang, Y. Zhou, Q. Wang, Z. Wang, and K. Zhang (2025) Complexbench-edit: benchmarking complex instruction-driven image editing via compositional dependencies. In Proceedings of the 33rd ACM International Conference on Multimedia, pp. 13391–13397. Cited by: §1, §2.1.
- Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi (2022a) Self-instruct: aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560. Cited by: §3.1.
- Y. Wang, S. Mishra, P. Alipoormolabashi, Y. Kordi, A. Mirzaei, A. Arunkumar, A. Ashok, A. S. Dhanasekaran, A. Naik, D. Stap, et al. (2022b) Super-naturalinstructions: generalization via declarative instructions on 1600+ nlp tasks. arXiv preprint arXiv:2204.07705. Cited by: §3.1.
- B. Wen, P. Ke, X. Gu, L. Wu, H. Huang, J. Zhou, W. Li, B. Hu, W. Gao, J. Xu, et al. (2024) Benchmarking complex instruction-following with multiple constraints composition. Advances in Neural Information Processing Systems 37, pp. 137610–137645. Cited by: §A.4.3, §1, §2.1, Figure 4, §4.1.
- Y. Wu, J. Mei, M. Yan, C. Li, S. Lai, Y. Ren, Z. Wang, J. Zhang, M. Wu, Q. Jin, et al. (2025) Writingbench: a comprehensive benchmark for generative writing. arXiv preprint arXiv:2503.05244. Cited by: §A.4.3, §4.1.
- S. Yao, H. Chen, A. W. Hanjie, R. Yang, and K. Narasimhan (2023) Collie: systematic construction of constrained text generation tasks. arXiv preprint arXiv:2307.08689. Cited by: §A.4.3, §4.1.
- J. Ye, C. Huang, Z. Chen, W. Fu, C. Yang, L. Yang, Y. Wu, P. Wang, M. Zhou, X. Yang, et al. (2025) A multi-dimensional constraint framework for evaluating and improving instruction following in large language models. arXiv preprint arXiv:2505.07591. Cited by: §1.
- J. Zhang, R. Xie, Y. Hou, X. Zhao, L. Lin, and J. Wen (2025) Recommendation as instruction following: a large language model empowered recommendation approach. ACM Transactions on Information Systems 43 (5), pp. 1–37. Cited by: §1.
- T. Zhang, C. Zhu, Y. Shen, W. Luo, Y. Zhang, H. Liang, F. Yang, M. Lin, Y. Qiao, W. Chen, et al. (2024) Cfbench: a comprehensive constraints-following benchmark for llms. arXiv preprint arXiv:2408.01122. Cited by: §A.4.3, Table 6, §4.1.
- L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al. (2023) Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems 36, pp. 46595–46623. Cited by: §A.4.3.
- Y. Zheng, R. Zhang, J. Zhang, Y. Ye, Z. Luo, Z. Feng, and Y. Ma (2024) Llamafactory: unified efficient fine-tuning of 100+ language models. arXiv preprint arXiv:2403.13372. Cited by: §A.3.
- J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y. Luan, D. Zhou, and L. Hou (2023) Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911. Cited by: §A.4.3, Table 5, §4.1.
Appendix A Appendix
A.1 Dataset
A.1.1 Constraint Types
As shown in Tab. 5 and Tab. 6, we distinguish between soft and hard constraints on LLM outputs. Soft constraints cannot be reliably verified by fixed symbolic rules, as they target high-level, often subjective properties such as semantic focus, tone and emotion, stylistic form, audience- or author-specific style, and syntactic patterns. In contrast, hard constraints are explicitly rule-checkable: they specify concrete requirements on keywords and their frequencies, lengths (in words, sentences, or paragraphs), detectable formats (e.g., numbered bullets, titles, JSON), presence of placeholders or postscripts, and strict start/end markers or punctuation usage. Together, these constraint types provide a comprehensive taxonomy for characterizing both high-level communicative behavior and strictly verifiable surface properties in our instruction formulations.
| Instruction Group | Instruction | Description |
| --- | --- | --- |
| Keywords | Include Keywords | Response must include specified keywords (e.g., {keyword1}, {keyword2}). |
| Keyword Frequency | A particular word should appear a certain number of times ({N} times). | |
| Forbidden Words | Prohibits the inclusion of specified keywords ({forbidden words}). | |
| Letter Frequency | Requires a specific letter to appear a certain number of times ({N} times). | |
| Response Language | Entire response must be in a specified language ({language}) and no other. | |
| Length Constraints | Number Paragraphs | Specifies the exact number of paragraphs ({N}), separated by markdown divider ***. |
| Number Words | Constraint on the number of words: “at least / around / at most {N} words ”. | |
| Number Sentences | Constraint on the number of sentences: “at least / around / at most {N} sentences ”. | |
| Number Paragraphs + First Word | Requires {N} paragraphs (separated by two line breaks), with the {i} -th paragraph starting with a specified word ({first_word}). | |
| Detectable Content | Postscript | Requires an explicit postscript at the end, starting with a specified marker ({postscript marker}). |
| Number Placeholder | Response must contain at least {N} placeholders in square brackets (e.g., [address]). | |
| Detectable Format | Number Bullets | Requires exactly {N} bullet points using markdown format (e.g., * This is a point.). |
| Title | Answer must include a title wrapped in double angular brackets (e.g., <<poem of joy>>). | |
| Choose From | Response must be one of the provided options ({options}). | |
| Minimum Number Highlighted Section | Requires at least {N} sections highlighted using markdown (e.g., *highlighted section*). | |
| Multiple Sections | Response must have {N} sections, with each section’s beginning marked by a splitter (e.g., {section_splitter} X). | |
| JSON Format | Entire output must be wrapped in JSON format. | |
| Combination | Repeat Prompt | First repeat the request without change, then provide the answer. |
| Two Responses | Requires two different responses, separated by six asterisk symbols (******). | |
| Change Cases | All Uppercase | Entire response must be in English, using only capital letters. |
| All Lowercase | Entire response must be in English, using only lowercase letters, with no capital letters allowed. | |
| Frequency of All-capital Words | Words with all capital letters should appear “at least / around / at most {N} times ”. | |
| Start with / End with | End Checker | Response must end with a specific phrase ({end_phrase}), with no other words following it. |
| Quotation | Entire response must be wrapped in double quotation marks. | |
| Punctuation | No Commas | Prohibits the use of any commas in the entire response. |
Table 5: Hard Constraint Types Zhou et al. (2023).
| Constraint Type | Definition | Example |
| --- | --- | --- |
| Lexical content constraint | Requires specific terms or symbols with precise placement. | “…must include the word ‘beautiful’.” |
| Element constraint | Requires inclusion of specific entities or scenarios. | “…highlights the Great Wall.” |
| Semantic constraint | Focuses on themes, tone, or stance. | “Write a poem about London.” |
| Word Count | Limits the number of words. | “A 50-word poem.” |
| Sentence Count | Limits the number of sentences. | “…three sentences.” |
| Paragraph Count | Limits the number of paragraphs. | “…divided into 3 sections.” |
| Document Count | Limits the number of documents. | “…list 3 articles.” |
| Tone and emotion | Conforms to specific emotional tone. | “Write a letter in an angry and sarcastic tone.” |
| Form and style | Uses specified stylistic form and perception. | “Write a passage in an encyclopedic style.” |
| Audience-specific | Tailored to a specific audience group. | “Write a poem for a 6-year-old.” |
| Authorial style | Emulates specific authors’ styles. | “Write a passage in the style of Shakespeare.” |
| Fundamental format | Follows standard formats like JSON, HTML, etc. | “Output in JSON format.” |
| Bespoke format | Uses custom formatting protocols. | “Bold the main idea and output in unordered list.” |
| Specialized format | Tailored for specific applications or domains. | “Convert to electronic medical record format.” |
| Pragmatic constraint | Adapts to context like dialects or language policy. | “Output in English, classical Chinese, etc.” |
| Syntactic constraint | Follows specific phrase and clause structures. | “Use imperatives with nouns and verb phrases.” |
| Morphological constraint | Controls affixes, roots, and word formation. | “Output all content in lowercase English.” |
| Phonological constraint | Focuses on sounds, tone, and intonation. | “Single-syllable tongue twisters.” |
| Role-based constraint | Responds with specific role identity. | “You are Confucius, how do you decide?” |
| Task-specific constraint | Addresses a defined situational task. | “Work from home, how to report?” |
| Complex context constraint | Involves multi-faceted and nested reasoning. | “On the left, 10 total, what to do?” |
| Example constraint | Conforms to patterns from example pairs. | “input:x…, output:{…}; input:y…, output?” |
| Inverse constraint | Narrows response space via exclusions. | “No responses about political topics.” |
| Contradictory constraint | Combines requirements that are hard to satisfy simultaneously. | “A five-character quotation, 1000 words.” |
| Rule constraint | Follows symbolic or logical operation rules. | “Each answer adds 1+1=3, then 2+2=5.” |
Table 6: Soft Constraint Types Zhang et al. (2024).
/* Task Description */ 1. I currently have a seed question, but the seed questions are relatively simple. To make the instructions more complex, I want you to identify and return three composition constraints that can be added to the seed question. 2. I will provide [Seed Question] and [Constraint References], and you can use these references to propose the composition constraint that would increase the difficulty of the seed question. 3. You may choose one or more constraints from the [Constraint References] list, and combine them using the following composition rules. 4. Do not modify or rewrite the seed question. Your task is only to generate the new composite constraint that can be added to it. 5. Return the added constraint(s) in the JSON format described below, including all sub-constraints and their logical composition types. 6. Do not return anything else. No explanation, no reformulated question, no analysis—only the JSON structure. /* Logical Composition Types */ And: The output is required to satisfy multiple constraints simultaneously. Template: C1 and C2 and C3. Example: summarize the news in bullet points and within 100 words. Chain: The output is required to complete multiple tasks sequentially, each with its own constraints. Template: first C1, then C2, finally C3. Example: introduce “Mona Lisa”: year of creation, then background, then impact. Selection: The output is required to select different branches according to conditions, fulfilling the constraints of the corresponding branch. Template: if C1 then C2 otherwise C3. Example: if the painting has an animal, describe it in Chinese; otherwise, give year, background, and impact. /* JSON Output Format */ Return { "composite_constraints": [ ... ] } where each element contains a "composite_constraint" with fields "type": "<And/Chain/Selection>" and "sub_constraints" ("c1", "c2, "c3") each holding a "constraint" string that specifies one atomic constraint. /* Constraint References*/ 1. Lexical content constraint: must include specific terms or symbols with precise placement. 2. Element constraint: include specific entities or scenarios. 3. Semantic constraint: focus on themes, tone, or stance. 4. Word Count: limit the number of words. 5. Sentence Count: limit the number of sentences. 6. Paragraph Count: limit the number of paragraphs. 7. Document Count: limit the number of documents. 8. Tone and emotion: conform to specific emotional tone. 9. Form and style: use specified stylistic form and perception. 10. Audience-specific: tailored to a specific audience group. 11. Authorial style: emulate specific authors’ styles. 12. Fundamental format: follow standard formats like JSON, HTML, etc. 13. Bespoke format: use custom formatting protocols. 14. Specialized format: tailored for specific applications or domains. 15. Pragmatic constraint: adapt to context like dialects or language policy. 16. Syntactic constraint: follow specific phrase and clause structures. 17. Morphological constraint: control over affixes, roots, and word formation. 18. Phonological constraint: focus on sounds, tone, and intonation. 19. Role-based constraint: respond with specific role identity. 20. Task-specific constraint: address a defined situational task. 21. Complex context constraint: involve multi-faceted and nested reasoning. 22. Example constraint: conform to patterns from example pairs. 23. Inverse constraint: narrow response space via exclusions. 24. Contradictory constraint: combine requirements that are hard to satisfy simultaneously. 25. Rule constraint: follow symbolic or logical operation rules. /* Seed Question */ [Seed Question]: {} /* Modified Question */ [Modified Question]: (the seed question plus one of the generated composite constraints).
Table 7: Prompt template for constructing logically structured multi-constraint instructions.
A.1.2 Prompt for constructing logically structured multi-constraint instructions
As shown in Tab. 7, the template takes a seed question and a reference list of 25 constraint types. The model selects atomic constraints and combines them using three logical composition types (And, Chain, Selection): And requires satisfying multiple constraints simultaneously, Chain requires sequential task completion, and Selection requires conditional branch selection. The model generates three composite constraints in JSON format, each specifying its composition type and sub-constraints. These constraints are added to the seed question to form complex multi-constraint instructions.
A.2 Reward Model Training
We fine-tune Qwen2.5-7B-Instruct for a binary classification task to determine whether a response satisfies a given constraint. Training data consists of response-constraint pairs. Each sample is tokenized by concatenating the response and constraint into a single text sequence. We use full-parameter fine-tuning (not LoRA) with the HuggingFace Trainer framework. Training hyperparameters: learning rate 5e-6, batch size 1 per device, gradient accumulation steps 1, 3 epochs, FP16 precision, gradient checkpointing enabled, and DeepSpeed optimization configured via JSON. We use accuracy as the evaluation metric, computed by comparing predicted labels with ground truth labels. The training is performed on 8 NVIDIA H200 GPUs.
A.3 SFT Training
We perform supervised fine-tuning (SFT) on six models: Qwen2.5-1.5B-Instruct, Qwen2.5-7B-Instruct, Llama-3.1-8B-Instruct, Distill-Qwen-7B, Distill-Qwen-14B, and Qwen3-8B. The training is performed on 8 NVIDIA H200 GPUs. The training data consists of instruction-response pairs where responses are generated by the teacher model GPT-4.1. Training is conducted using LLaMA-Factory Zheng et al. (2024) with LoRA fine-tuning (rank=8, targeting all linear layers). We use a maximum sequence length of 20480 tokens, and employ 16 preprocessing workers and 4 dataloader workers. Training hyperparameters include: batch size of 1 per device with gradient accumulation of 8 steps, learning rate of 1.0e-4, 3 training epochs, cosine learning rate scheduler with 10% warmup ratio, and bfloat16 precision. Model-specific templates are applied according to each model’s architecture.
A.4 RL Training
A.4.1 Implementation Details
We apply GRPO training using the VeRL framework. Training is conducted on 8 NVIDIA H200 GPUs. Maximum prompt length is 2048 tokens, and maximum response length is 8192 tokens. The rollout batch size is set to 384, and data is shuffled with a random seed of 1. The algorithm employs the GRPO advantage estimator with KL penalty enabled. We use a low-variance KL penalty formulation with a coefficient of 1.0e-2. Training batches are organized with a global batch size of 96, micro-batches of size 4 per device for updates, and micro-batches of size 8 per device for experience generation. Gradient clipping is applied with a max norm of 1.0. The optimizer uses a learning rate of 1.0e-6 with a weight decay of 1.0e-2, and no learning rate warm-up. We leverage FSDP with full sharding enabled. For rollouts, we generate responses with a temperature of 1.0 and a group size of 5. Tensor parallelism of size 2 is applied. The maximum number of batched tokens is set to 16000. Different models are trained for varying numbers of epochs: Qwen2.5-7B-Instruct, Llama-3.1-8B-Instruct and Distill-Qwen-14B are trained for 1 epoch; Distill-Qwen-7B and Qwen2.5-1.5B-Instruct are trained for 5 epochs; and Qwen3-8B is trained for 4 epochs. For the sequential rewards, we set the decay coefficient $\gamma$ to $0.5$ , which represents a moderate penalty propagation strength. With $\gamma=0.5$ , each failed earlier step reduces the effective reward of subsequent steps by half, encouraging correct early decisions while still allowing partial credit for later successes. Empirically, this choice provides stable training dynamics and avoids overly aggressive reward suppression observed with smaller $\gamma$ values.
A.4.2 Baselines
RAIF-7B Qin et al. (2025): RAIF-7B (Incentivizing Reasoning) proposes a systematic approach to enhance large language models’ ability to handle complex instructions by incentivizing reasoning processes during test-time computation scaling. The method encourages models to engage in explicit reasoning steps when processing complex instructions, thereby improving instruction-following performance through enhanced computational reasoning capabilities.
Conifer-7B-DPO Sun et al. (2024): Conifer addresses complex constrained instruction-following through a two-stage training pipeline. The method first constructs a curriculum dataset organized from simple to complex instructions and performs supervised fine-tuning (SFT) on this dataset. Subsequently, it applies Direct Preference Optimization (DPO) training using an open-source preference dataset to further refine the model’s ability to follow complex constraints.
Crab-7B-DPO Qi et al. (2024): Crab employs a constraint back-translation strategy to improve complex instruction following. The method leverages Llama3-70B-Instruct as a strong teacher model to back-translate constraints into high-quality instruction-response pairs. This process creates a comprehensive dataset with complex constraints, which is then used for DPO training to enhance the model’s instruction-following capabilities.
SPAR-8B-DPO Cheng et al. (2024): SPAR (Self-play with tree-search refinement) introduces a self-play framework that integrates tree-search-based self-refinement mechanisms. The framework enables an LLM to play against itself, employing tree-search strategies to iteratively refine responses with respect to given instructions. This approach generates valid and comparable preference pairs while minimizing unnecessary variations, facilitating effective DPO training for instruction-following tasks.
VERIF Peng et al. (2025): VERIF (Verification Engineering for Reinforcement Learning) combines multiple verification approaches to enhance instruction following through reinforcement learning. The method integrates rule-based code verification with LLM-based verification from large reasoning models (RLVR), providing comprehensive verification signals that guide the reinforcement learning process toward better instruction-following performance.
Self-Supervised-7B Ren et al. (2025): Self-Supervised-7B presents a self-supervised reinforcement learning framework for instruction following that eliminates the need for external supervision. The method extracts reward signals directly from instructions and generates pseudo-labels for reward model training, thereby removing dependencies on human-annotated preference data. The framework introduces constraint decomposition strategies and efficient constraint-level binary classification methods to address sparse reward problems while maintaining computational efficiency. Experimental results demonstrate significant performance improvements across multiple datasets, including complex agentic tasks and multi-turn instruction-following scenarios.
A.4.3 Benchmarks
We evaluate instruction-following ability on various benchmarks:
IFEval Zhou et al. (2023): IFEval (Instruction-Following Evaluation) focuses on verifiable instructions that can be automatically checked for compliance. The benchmark includes instructions such as "write in more than 400 words" and "mention the keyword of AI at least 3 times", covering 25 distinct types of verifiable instructions across approximately 500 prompts. Each prompt may contain one or more verifiable instructions, enabling systematic evaluation of models’ ability to follow explicit, rule-based constraints.
CFBench Zhang et al. (2024): CFBench (Comprehensive Constraints Following Benchmark) is a large-scale benchmark featuring 1,000 carefully curated samples that span more than 200 real-life scenarios and over 50 natural language processing tasks. The benchmark systematically compiles constraints from real-world instructions and establishes a comprehensive framework for constraint categorization, including 10 primary categories and over 25 subcategories. Each constraint is seamlessly integrated within instructions to reflect realistic usage scenarios.
FollowBench Jiang et al. (2023): FollowBench provides a comprehensive evaluation framework covering five distinct types of fine-grained constraints: Content, Situation, Style, Format, and Example. To enable precise constraint-following assessment across varying difficulty levels, the benchmark introduces a multi-level mechanism that incrementally adds a single constraint to the initial instruction at each increased level, allowing for granular analysis of model performance.
ComplexBench Wen et al. (2024): ComplexBench is designed to comprehensively evaluate LLMs’ ability to follow complex instructions composed of multiple constraints. The benchmark proposes a hierarchical taxonomy for complex instructions, encompassing 4 constraint types, 19 constraint dimensions, and 4 composition types. It includes a manually collected high-quality dataset that systematically covers various constraint combinations and logical structures.
WritingBench Wu et al. (2025): WritingBench is a comprehensive benchmark designed to evaluate LLMs across diverse writing domains. The benchmark covers 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. It provides systematic evaluation of models’ ability to generate high-quality written content that adheres to various stylistic and content requirements.
Collie Yao et al. (2023): Collie (Constrained Language Generation) employs a grammar-based framework that enables the specification of rich, compositional constraints across multiple generation levels, including word, sentence, paragraph, and passage levels. The benchmark encompasses diverse modeling challenges such as language understanding, logical reasoning, counting, and semantic planning, providing a systematic approach to evaluating constraint-following capabilities.
AgentIF Qi et al. (2025): AgentIF is the first benchmark specifically designed for systematically evaluating LLM instruction-following ability in agentic scenarios. The benchmark features three key characteristics: (1) Realistic: constructed from 50 real-world agentic applications; (2) Long: averaging 1,723 words with a maximum of 15,630 words; (3) Complex: averaging 11.9 constraints per instruction, covering diverse constraint types including tool specifications and condition constraints.
MultiChallenge Deshpande et al. (2025): MultiChallenge is a pioneering benchmark evaluating large language models on conducting multi-turn conversations with human users, a crucial yet underexamined capability. The benchmark identifies four categories of challenges in multi-turn conversations that are both common in real-world human-LLM interactions and challenging to current frontier LLMs. All four challenge categories require accurate instruction-following, context allocation, and in-context reasoning simultaneously.
We assess general reasoning and knowledge capabilities with the following datasets:
GPQA-Diamond Rein et al. (2024): GPQA-Diamond is a specialized subset of the GPQA (Graduate-Level Google-Proof Q&A) benchmark, comprising 198 meticulously crafted multiple-choice questions across biology, chemistry, and physics. These questions are designed to be exceptionally challenging, requiring domain expertise that makes them a rigorous test for AI models’ scientific knowledge and reasoning capabilities.
AIME2024 MAA (2024) and AIME2025 MAA (2025): The AIME (American Invitational Mathematics Examination) datasets consist of problems from the 2024 and 2025 AIME competitions, respectively. These datasets are commonly used to evaluate the mathematical reasoning ability of large language models. The AIME is a prestigious mathematics competition for high school students in the United States, and its problems require sophisticated mathematical reasoning and problem-solving skills.
FOLIO Han et al. (2022): FOLIO (First-Order Logic Inference Over Text) is a benchmark dataset developed to assess the logical reasoning capabilities of large language models. It consists of human-annotated examples that require deductive reasoning grounded in first-order logic (FOL). The benchmark evaluates models’ ability to perform formal logical inference over natural language text, bridging natural language understanding and formal reasoning.
Enigmata Chen et al. (2025): Enigmata is a comprehensive suite designed to enhance logical reasoning capabilities of large language models. The benchmark comprises 36 tasks distributed across seven categories, with each task equipped with generators that can produce infinite examples and rule-based verifiers. This generator-verifier design supports scalable multi-task reinforcement learning training, fine-grained analysis, and seamless integration with reinforcement learning with verifiable rewards (RLVR). Models trained on Enigmata demonstrate strong performance across multiple puzzle reasoning benchmarks and exhibit good generalization to advanced mathematical and STEM reasoning tasks.
MT-Bench Zheng et al. (2023): MT-Bench (Multi-Turn Benchmark) is an evaluation framework designed to assess chat assistants’ performance in multi-turn conversations. The benchmark contains 80 high-quality multi-turn open-ended questions covering diverse topics such as writing, role-playing, mathematics, and coding. Model responses are scored by GPT-4, providing direct scores without requiring pairwise comparisons. MT-Bench enables systematic evaluation of models’ conversational abilities and their capacity to maintain context and coherence across multiple interaction turns.
AlpacaEval 2.0 Dubois et al. (2024): AlpacaEval 2.0 is an automated evaluation benchmark designed to assess instruction-following capabilities of language models. The benchmark leverages GPT-4 as an automated annotator to compare model-generated responses with reference outputs, evaluating how well models adhere to user instructions. The benchmark is characterized by its efficiency, low cost, and reliability, enabling rapid assessment of model performance. AlpacaEval 2.0 provides a standardized evaluation protocol for comparing instruction-following models across diverse tasks and scenarios.
A.4.4 Case Study
Tab. 8 illustrates the model’s transformation in constraint-aware reasoning and output generation. Before training, the model’s reasoning process shows awareness of constraints (e.g., "Let me make sure it’s clear without commas") but fails to translate this awareness into compliant output: the generated riddle contains commas and uses keywords inappropriately (e.g., "afternoon embroidered" rather than natural keyword integration). The constraint compliance is [False, False]. After training, the model’s reasoning becomes more systematic, explicitly planning constraint satisfaction (e.g., "I’ll have to structure the sentences carefully to avoid [commas]") and naturally incorporating keywords. This improved reasoning directly translates to compliant output: the riddle contains no commas and integrates both keywords naturally. The constraint compliance improves to [True, True], demonstrating effective alignment between reasoning and constraint satisfaction.
| Case | Content |
| --- | --- |
| Before Training | Input: Write a riddle about embroidery that has the answer "needle". Include keywords ’afternoon’ and ’distressed’ in the response. Don’t use any commas in your answer. Think: Alright, I need to create a riddle about embroidery where the answer is "needle." The riddle should include the keywords ’afternoon’ and ’distressed.’ Let me break this down. First, I’ll think about what embroidery entails. Embroidery involves stitching, so maybe using words like "stitch," "needle," or "cloth." Since the answer is "needle," I need to hint at it without stating it directly. For ’afternoon,’ perhaps I can use something related to the time of day, like "quietly" or "evening," but in a way that ties into embroidery. Maybe "afternoon" can relate to when someone is stitching, so "quietly" could work, as it’s a gentle activity. ’Distressed’ can be tricky. Maybe I can imply it through the feeling of the fabric or the process. Perhaps something like "snag" or "torn," but I need to tie it back to embroidery. Maybe the needle moves too fast, causing something to snag, making the work look distressed. Putting it together, I want a riddle that flows naturally. Let me try: "What does an afternoon embroidered with a needle bring?" Hmm, that’s close. Maybe tweak it to add the distressed element. Wait, "What does an afternoon embroidered with a needle bring?" The answer is "a needle," but maybe I can add a clue about the distress. So, "What does an afternoon embroidered with a needle bring? A stitched, but maybe a little snag, a sewing that’s a bit hurried, so a small, worried look." That uses ’afternoon’ as ’embroidered’ and ’needle’ as the answer. The ’distressed’ part is hinted at by ’snag’ and ’hurried,’ which can make someone worried about the work. I think that works. Let me make sure it’s clear without commas. The response is: "What does an afternoon embroidered with a needle bring? A stitched, but maybe a little snag, a sewing that’s a bit hurried, so a small, worried look." That includes both keywords and hints at the needle being the answer. </think> Output: What does an afternoon embroidered with a needle bring? A stitched, but maybe a little snag, a sewing that’s a bit hurried, so a small, worried look. Constraint Compliance: [False, False] |
| After Training | Input: Write a riddle about embroidery that has the answer "needle". Include keywords ’afternoon’ and ’distressed’ in the response. Don’t use any commas in your answer. Think: Alright, I need to help the user create a riddle about embroidery with the answer "needle." They specifically want me to include the keywords ’afternoon’ and ’distressed.’ Hmm, let me break this down. First, I should understand what a riddle entails. It’s a question or statement that requires thinking to solve, often with a clever twist. Since the answer is "needle," I need to think about how to incorporate that into a riddle. The user mentioned not using any commas, so I’ll have to structure the sentences carefully to avoid that. Let me start brainstorming some ideas. Embroidery is about stitching, so maybe I can relate ’needle’ to the tool used. Including ’afternoon’… perhaps something about the time of day. Maybe the needle is used in the afternoon? Or the result of using it in the afternoon. ’Distressed’ could relate to something that’s been repaired or fixed, like a hole that’s been mended. Putting it together, I think of the process of sewing. If someone is sewing in the afternoon and notices a hole, they might use a needle. So, maybe the riddle is about something that’s fixed in the afternoon with a needle. That way, the keyword ’distressed’ can describe the hole that’s being mended. So, the riddle could go like: "What is used in the afternoon to mend a hole that’s been distressed?" The answer would be the needle. Let me make sure it flows without commas and makes sense. Yes, that should work. I’ll present it as a riddle, so it’s a question that leads to the answer with the given keywords. </think> Output: What do you use in the afternoon to mend a hole that’s been distressed? The answer is a needle. Constraint Compliance: [True, True] |
Table 8: Comparison of the outputs of R1-Distill-Qwen-7B before and after training for the instruction in IFEval.
<details>
<summary>figures/files/qwen-7b-reward.png Details</summary>
### Visual Description
## Line Chart: reward/overall
### Overview
The image is a line chart titled "reward/overall" depicting the relationship between "Step" (x-axis) and "reward/overall" (y-axis). The chart shows a fluctuating trend with a general upward trajectory followed by stabilization. The line is blue, and the legend is positioned at the top of the chart.
### Components/Axes
- **Title**: "reward/overall" (centered at the top).
- **X-axis**: Labeled "Step" with numerical markers at 0, 20, 40, 60, 80, and 100. The scale is linear, with increments of 20.
- **Y-axis**: Labeled "reward/overall" with numerical markers at 0.3, 0.4, 0.5, 0.6, and 0.7. The scale is linear, with increments of 0.1.
- **Legend**: Located at the top of the chart, labeled "reward/overall" with a blue line symbol.
- **Line**: A single blue line representing the "reward/overall" metric, plotted across the x-axis.
### Detailed Analysis
- **Initial Trend (Steps 0–40)**: The line starts at approximately 0.35 (y-axis) and rises steadily, reaching around 0.6 by Step 40. The slope is relatively smooth but shows minor fluctuations.
- **Mid-Range Trend (Steps 40–80)**: The line continues to increase, peaking at approximately 0.65–0.7 between Steps 60 and 80. Fluctuations become more pronounced, with peaks and troughs within this range.
- **Stabilization (Steps 80–100)**: After Step 80, the line stabilizes, fluctuating between 0.65 and 0.7. The amplitude of fluctuations decreases slightly, indicating reduced variability.
### Key Observations
- The line exhibits a **general upward trend** from Step 0 to Step 80, followed by **stabilization**.
- **Peaks** occur around Steps 60–80, with values reaching up to ~0.7.
- **Troughs** are observed around Steps 20–40 and 60–80, with values dipping to ~0.5–0.6.
- The **final value** at Step 100 is approximately 0.68–0.7, slightly lower than the peak but within the stabilized range.
### Interpretation
The chart suggests that the "reward/overall" metric improves significantly over the first 80 steps, likely indicating a learning or optimization phase. The stabilization after Step 80 implies that the system reaches a plateau, where further improvements are minimal. The fluctuations throughout the chart may reflect variability in the data collection process, external factors, or inherent noise in the metric. The absence of a clear downward trend after the peak suggests that the system maintains its performance without significant degradation. The legend and axis labels are consistent, confirming the accuracy of the data representation.
</details>
(a) Reward Dynamics of Qwen2.5-7B-Instruct.
<details>
<summary>figures/files/qwen-7b-length.png Details</summary>
### Visual Description
## Line Graph: response_length/mean
### Overview
The image depicts a line graph titled "response_length/mean" with a blue line representing data fluctuations across a numerical axis labeled "Step" (0–100). The y-axis is labeled "response_length/mean" and ranges from 340 to 400. The line exhibits significant variability, with peaks and troughs throughout the range.
### Components/Axes
- **Title**: "response_length/mean" (centered at the top).
- **X-axis (Step)**: Labeled "Step," with grid markers at 20, 40, 60, 80, and 100. The axis spans from 0 to 100.
- **Y-axis (response_length/mean)**: Labeled "response_length/mean," with grid lines at 340, 360, 380, and 400. The axis spans from 340 to 400.
- **Legend**: Located at the bottom-right corner, featuring a blue line labeled "response_length/mean."
- **Gridlines**: Horizontal gridlines at 340, 360, 380, and 400; vertical gridlines at 20, 40, 60, 80, and 100.
### Detailed Analysis
- **Line Behavior**:
- **Initial Trend (Steps 0–20)**: The line starts at approximately 340, rises sharply to ~380 by step 20, then dips to ~360 by step 30.
- **Mid-Range Fluctuations (Steps 30–60)**: The line oscillates between ~350 and ~390, peaking at ~400 near step 60.
- **Late Trend (Steps 60–100)**: After step 60, the line declines steadily, dropping to ~350 by step 100. Smaller fluctuations persist, with a notable dip to ~340 near step 90.
### Key Observations
1. **Peak at Step 60**: The line reaches its maximum value (~400) near step 60, suggesting a critical point of high response length.
2. **Decline Post-Step 60**: A consistent downward trend occurs after step 60, ending at ~350 by step 100.
3. **High Variability**: The line exhibits frequent sharp rises and falls, indicating instability or variability in the measured response length.
4. **Final Value**: The line terminates at ~350 at step 100, lower than its starting value (~340 at step 0).
### Interpretation
The graph demonstrates that response length varies significantly across steps, with a pronounced peak at step 60. This could indicate a specific event, condition, or threshold where responses are longest. The subsequent decline suggests diminishing response length as steps increase beyond 60. The high variability implies potential inconsistencies in data collection or external factors influencing the measured values. The final value (~350) being higher than the initial (~340) might reflect a net increase in response length over the observed range, despite the overall downward trend post-step 60.
</details>
(b) Response Length Dynamics of Qwen2.5-7B-Instruct.
<details>
<summary>figures/files/distill-7b-reward.png Details</summary>
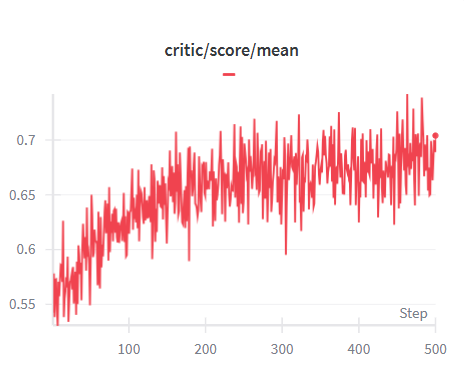
### Visual Description
## Line Graph: critic/score/mean
### Overview
The image depicts a line graph titled "critic/score/mean" with a red line representing data points across a horizontal axis labeled "Step" (ranging from 100 to 500) and a vertical axis labeled "critic/score/mean" (ranging from 0.55 to 0.75). The line exhibits fluctuations but shows an overall upward trend, ending at approximately 0.705 at Step 500.
### Components/Axes
- **Title**: "critic/score/mean" (centered at the top).
- **X-Axis (Horizontal)**:
- Label: "Step" (bottom-right).
- Scale: Incremented by 100, with markers at 100, 200, 300, 400, and 500.
- **Y-Axis (Vertical)**:
- Label: "critic/score/mean" (left-aligned).
- Scale: Incremented by 0.05, with markers at 0.55, 0.60, 0.65, 0.70, and 0.75.
- **Legend**:
- Position: Top-center.
- Content: "critic/score/mean" (red line).
- **Gridlines**: Faint gray lines span both axes for reference.
### Detailed Analysis
- **Data Series**:
- A single red line represents the "critic/score/mean" metric.
- The line starts near 0.55 at Step 100, rises to ~0.65 by Step 200, and fluctuates between ~0.65 and ~0.70 until Step 500, where it peaks at ~0.705.
- Notable spikes and dips occur throughout, with the largest drop near Step 300 (temporarily dipping below 0.65) and a sharp rise afterward.
### Key Observations
1. **Upward Trend**: The metric increases overall from Step 100 to Step 500, with a net gain of ~0.155.
2. **Volatility**: Significant fluctuations (e.g., Step 250–350) suggest variability in the measured data.
3. **Final Peak**: The highest value (~0.705) occurs at Step 500, exceeding the y-axis maximum of 0.70.
### Interpretation
The graph likely tracks a performance metric (e.g., critic scores, mean evaluations) over sequential steps (e.g., iterations, time intervals). The upward trend implies improvement or stabilization over time, while fluctuations may reflect external factors, measurement noise, or inherent variability in the system. The final peak at Step 500 could indicate a critical threshold, optimization milestone, or saturation point. The absence of additional context (e.g., labels for "Step") limits precise interpretation, but the data suggests a positive correlation between "Step" and "critic/score/mean."
</details>
(c) Reward Dynamics of Distill-Qwen-7B.
<details>
<summary>figures/files/distill-7b-length.png Details</summary>
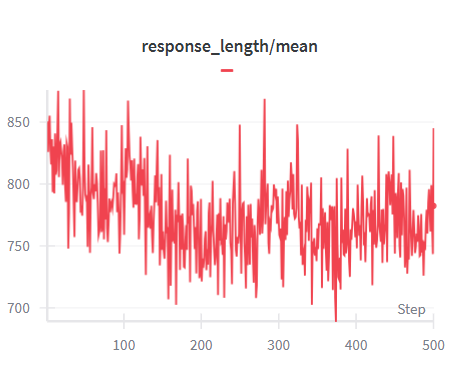
### Visual Description
## Line Graph: response_length/mean
### Overview
The image is a line graph depicting the relationship between "Step" (x-axis) and "response_length/mean" (y-axis). The red line fluctuates significantly across the x-axis range (100–500), with no clear linear trend. The y-axis values range approximately from 700 to 850, with sharp peaks and troughs.
### Components/Axes
- **Title**: "response_length/mean" (centered at the top).
- **X-axis**: Labeled "Step", with numerical markers at 100, 200, 300, 400, and 500. The axis spans from 0 to 500.
- **Y-axis**: Labeled "response_length/mean", with numerical markers at 700, 750, 800, and 850. The axis spans from 700 to 850.
- **Legend**: A red line is labeled "response_length/mean" (positioned near the top of the graph, adjacent to the title).
- **Line**: A single red line with high variability, oscillating between 700 and 850.
### Detailed Analysis
- **X-axis (Step)**: The horizontal axis represents sequential steps, incrementing by 100. The line spans the entire range (100–500).
- **Y-axis (response_length/mean)**: The vertical axis measures the mean response length, with values fluctuating between 700 and 850. The line exhibits sharp upward and downward spikes, indicating high variability.
- **Line Behavior**: The red line shows no consistent upward or downward trend. It alternates between peaks (near 850) and troughs (near 700), with no discernible pattern in the fluctuations.
### Key Observations
- **High Variability**: The response length/mean fluctuates dramatically, with no stable baseline or trend.
- **Peaks and Troughs**: The line reaches maximum values (~850) and minimum values (~700) repeatedly, suggesting inconsistent behavior.
- **No Correlation**: There is no apparent relationship between the "Step" values and the response length/mean, as the line does not follow a predictable trajectory.
### Interpretation
The data suggests that the mean response length is highly variable across the observed steps, indicating potential instability or external factors influencing the response. The lack of a clear trend implies that the system or process being measured does not exhibit consistent behavior over time. This could point to issues such as:
- **Unpredictable Inputs**: Variability in the data being processed.
- **System Instability**: Fluctuations in response times due to resource constraints or errors.
- **External Influences**: External variables (e.g., user behavior, environmental factors) affecting the response length.
The graph highlights the need for further investigation into the root causes of the variability, as the mean response length does not stabilize, which could impact performance metrics or user experience.
</details>
(d) Response Length Dynamics of Distill-Qwen-7B.
<details>
<summary>figures/files/distill-14b-reward.png Details</summary>
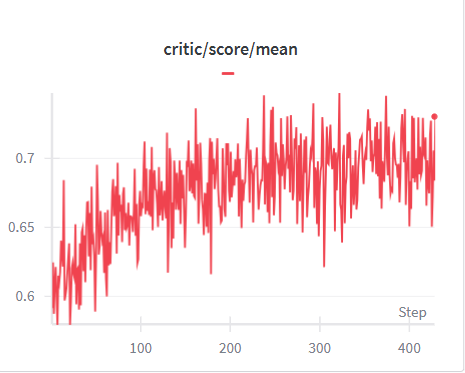
### Visual Description
## Line Graph: critic/score/mean
### Overview
The image is a line graph depicting the "critic/score/mean" metric over a series of steps. The graph shows a red line with significant fluctuations, starting near 0.6 and ending at approximately 0.73. The x-axis represents "Step" (0–400), and the y-axis represents the "critic/score/mean" value (0.6–0.75). The line exhibits high variability, with sharp peaks and troughs throughout the range.
### Components/Axes
- **Title**: "critic/score/mean" (centered at the top).
- **X-axis**: Labeled "Step" with increments of 100 (0, 100, 200, 300, 400).
- **Y-axis**: Labeled "critic/score/mean" with increments of 0.05 (0.6, 0.65, 0.7, 0.75).
- **Legend**: A red line labeled "critic/score/mean" (positioned at the top-center of the graph).
- **Line**: A single red line with jagged, irregular fluctuations.
### Detailed Analysis
- **Starting Point**: The line begins at approximately 0.6 (step 0) with a sharp initial rise.
- **Trend**: The line fluctuates wildly between 0.6 and 0.75, with no consistent upward or downward trajectory. Notable peaks occur near steps 100, 200, and 400.
- **Ending Point**: The line concludes at approximately 0.73 (step 400), with a final upward spike.
- **Uncertainty**: Values are approximate due to the jagged nature of the line. For example, the peak at step 400 is estimated at 0.73 ± 0.02.
### Key Observations
- **High Variability**: The line shows extreme fluctuations, suggesting instability or noise in the "critic/score/mean" metric.
- **Final Value**: The metric ends higher than its starting value, indicating a net increase over the 400 steps.
- **Peaks and Troughs**: Sharp drops (e.g., near step 150) and rises (e.g., near step 300) suggest abrupt changes in the metric.
### Interpretation
The data suggests that the "critic/score/mean" metric is highly volatile, with no clear pattern of improvement or decline. The final value of ~0.73 implies a marginal improvement over the initial ~0.6, but the fluctuations may indicate inconsistent performance or external factors influencing the metric. The lack of a smooth trend could point to issues in data collection, model instability, or dynamic conditions affecting the critic's evaluation. The red line’s prominence in the legend confirms it represents the primary data series, and its erratic nature highlights the need for further investigation into the underlying causes of variability.
</details>
(e) Reward Dynamics of Distill-Qwen-14B.
<details>
<summary>figures/files/distill-14b-length.png Details</summary>
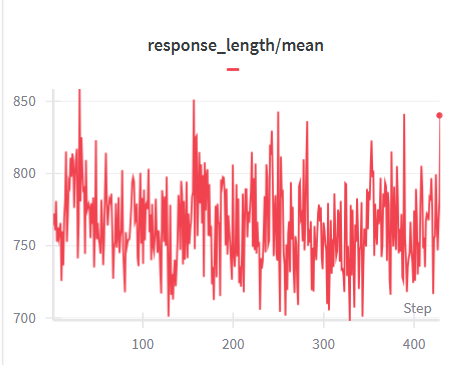
### Visual Description
## Line Graph: response_length/mean
### Overview
The image depicts a line graph titled "response_length/mean," showing the relationship between "Step" (x-axis) and "response_length/mean" (y-axis). The red line fluctuates significantly across the x-axis range (0–400), with peaks and troughs indicating variability in the measured metric. The graph includes a legend confirming the red line represents "response_length/mean."
### Components/Axes
- **Title**: "response_length/mean" (centered at the top).
- **X-axis**: Labeled "Step," with numerical markers at 0, 100, 200, 300, and 400.
- **Y-axis**: Labeled "response_length/mean," with numerical markers at 700, 750, 800, 850.
- **Legend**: Positioned at the top, with a red line labeled "response_length/mean."
- **Line**: A single red line with sharp fluctuations, no shading or additional data series.
### Detailed Analysis
- **Trend**: The red line exhibits high volatility, with no clear linear or exponential pattern.
- **Peaks**: Reaches approximately **850** at Step 400 (rightmost point).
- **Troughs**: Drops to around **700** at Step 300 (midpoint).
- **Mid-range**: Most values cluster between **750–800**, with occasional spikes above 800 and dips below 750.
- **Key Data Points**:
- Step 0: ~760
- Step 100: ~780
- Step 200: ~790
- Step 300: ~700 (minimum observed)
- Step 400: ~850 (maximum observed)
### Key Observations
1. **High Variability**: The metric fluctuates dramatically, suggesting inconsistent or dynamic behavior in the measured response lengths.
2. **Extreme Values**: The maximum (850) and minimum (700) values occur at the endpoints (Steps 400 and 300), respectively.
3. **Midpoint Dip**: A notable trough at Step 300, potentially indicating a temporary anomaly or system adjustment.
### Interpretation
The graph demonstrates that response lengths vary unpredictably across steps, with no consistent trend. The sharp dip at Step 300 and peak at Step 400 suggest external factors or system changes influencing the metric. The high variability could imply:
- **Unstable Conditions**: Environmental or operational factors affecting response times.
- **Data Noise**: Measurement errors or outliers skewing the mean.
- **Phase Transitions**: A critical event at Step 300 (e.g., system reset) and a stabilization phase leading to the peak at Step 400.
The absence of a clear pattern highlights the need for further investigation into the underlying causes of these fluctuations.
</details>
(f) Response Length Dynamics of Distill-Qwen-14B.
<details>
<summary>figures/files/qwen3-8b-reward.png Details</summary>
### Visual Description
## Line Graph: critic/score/mean
### Overview
The image depicts a line graph titled "critic/score/mean" with a blue line representing data fluctuations over a series of steps. The y-axis ranges from 0.62 to 0.74, while the x-axis spans 0 to 400 steps. The line exhibits significant variability, with sharp peaks and troughs throughout the dataset.
### Components/Axes
- **Title**: "critic/score/mean" (centered at the top).
- **X-axis**: Labeled "Step," with values from 0 to 400 in increments of 100.
- **Y-axis**: Labeled "critic/score/mean," with grid lines at intervals of 0.02 (0.62, 0.64, 0.66, 0.68, 0.70, 0.72, 0.74).
- **Legend**: A single blue line labeled "critic/score/mean" (positioned near the top-right of the graph).
- **Gridlines**: Horizontal and vertical lines for reference.
### Detailed Analysis
- **Initial Trend (Steps 0–100)**: The line starts near 0.67 at step 0, rises sharply to ~0.74 by step 100, then drops to ~0.66 by step 150.
- **Mid-Range Fluctuations (Steps 150–300)**: The line oscillates between ~0.66 and ~0.72, with notable peaks at steps 200 (~0.73) and 250 (~0.71).
- **Final Segment (Steps 300–400)**: The line stabilizes slightly, ending near 0.69 at step 400 after a minor dip to ~0.67 at step 350.
### Key Observations
1. **High Variability**: The line exhibits frequent sharp peaks and troughs, suggesting instability or external influences.
2. **Peak at Step 100**: The highest value (~0.74) occurs early in the dataset.
3. **Trough at Step 200**: A significant dip to ~0.66 occurs midway through the dataset.
4. **No Clear Trend**: The line lacks a consistent upward or downward trajectory, indicating no long-term directional bias.
### Interpretation
The graph likely represents a metric (e.g., critic scores, mean performance) measured over discrete steps. The fluctuations suggest:
- **External Factors**: Variability could stem from changing conditions, interventions, or data collection inconsistencies.
- **Critical Thresholds**: Peaks and troughs may correspond to specific events or anomalies (e.g., system updates, user interactions).
- **Stability at End**: The final stabilization (~0.69) might indicate a return to baseline or resolution of prior variability.
The absence of a clear trend implies the metric is sensitive to external factors rather than following a deterministic pattern. Further analysis would require contextual data (e.g., step definitions, scoring criteria) to validate hypotheses.
</details>
(g) Reward Dynamics of Qwen3-8B.
<details>
<summary>figures/files/qwen3-8b-length.png Details</summary>
### Visual Description
## Line Chart: response_length/mean
### Overview
The image depicts a line chart titled "response_length/mean" with a blue line representing data fluctuations over a series of steps. The y-axis measures the ratio of response length to mean values, while the x-axis represents sequential steps. The chart shows significant variability, with a prominent peak near step 150.
### Components/Axes
- **Title**: "response_length/mean" (centered at the top).
- **X-axis (Horizontal)**: Labeled "Step," with values ranging from 0 to 400 in increments of 100.
- **Y-axis (Vertical)**: Labeled "response_length/mean," with values ranging from 900 to 1200 in increments of 100.
- **Legend**: A single entry labeled "response_length/mean" in blue, matching the line color.
- **Line**: A single blue line with sharp fluctuations, peaking at approximately step 150.
### Detailed Analysis
- **Y-axis Range**: The response_length/mean values oscillate between ~900 and ~1200.
- **X-axis Progression**: Steps progress linearly from 0 to 400.
- **Notable Peak**: At step 150, the line reaches its maximum value of ~1200, followed by a sharp decline.
- **General Trend**: The line exhibits irregular oscillations, with no clear upward or downward trend. Variability increases near step 150, then stabilizes slightly toward step 400.
### Key Observations
1. **Peak at Step 150**: The most significant outlier occurs at step 150, where the response_length/mean ratio spikes to ~1200, far exceeding the baseline range.
2. **Baseline Fluctuations**: Between steps 0–100 and 200–400, the line remains within a narrow band (~1000–1100), with minor deviations.
3. **Post-Peak Decline**: After step 150, the line drops sharply to ~900 by step 200, then recovers to ~1000 by step 300.
### Interpretation
The chart suggests that the response_length/mean ratio is highly variable, with a critical anomaly at step 150. This peak could indicate an outlier event, such as an unusually long response or a systemic error in data collection. The subsequent decline and stabilization imply a return to baseline behavior, though the cause of the spike remains unexplained. The lack of a consistent trend highlights potential instability in the measured variable, warranting further investigation into the factors influencing response lengths.
</details>
(h) Response Length Dynamics of Qwen3-8B.
Figure 7: Training dynamics of reward and response length.
<details>
<summary>x9.png Details</summary>
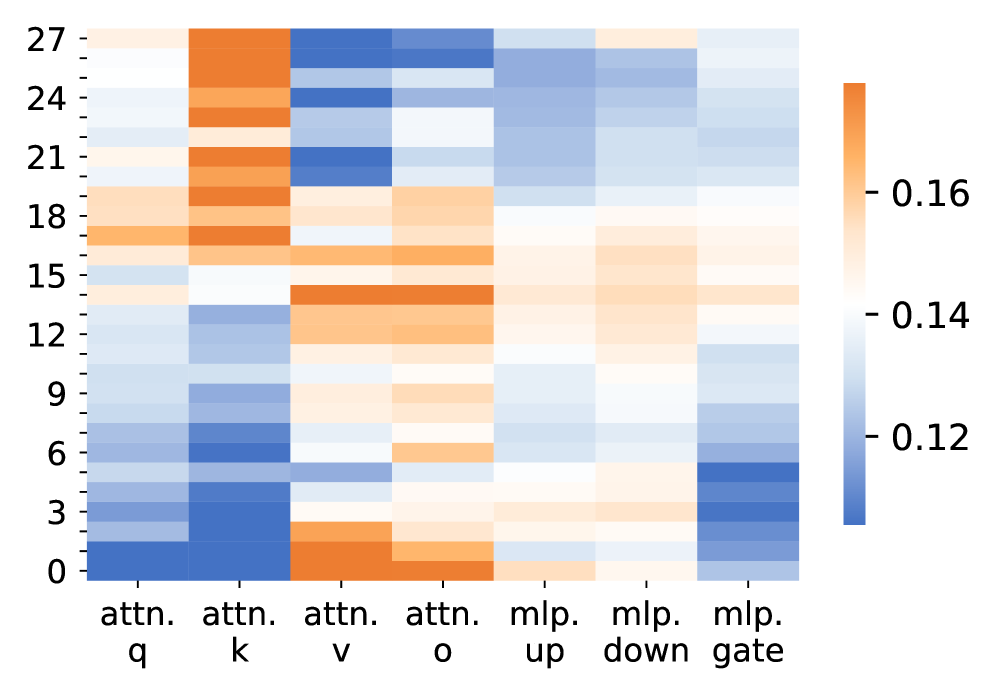
### Visual Description
## Heatmap: Attention and MLP Component Importance
### Overview
The image is a heatmap visualizing the importance or contribution of different components in an attention mechanism and MLP (multi-layer perceptron) across 28 rows (labeled 0–27). The color gradient ranges from blue (low values, ~0.12) to orange (high values, ~0.16), with intermediate shades of white and light blue.
### Components/Axes
- **X-axis (Horizontal)**:
- Labels: `attn. q`, `attn. k`, `attn. v`, `attn. o`, `mlp. up`, `mlp. down`, `mlp. gate`.
- Categories: Attention mechanism components (`q`, `k`, `v`, `o`) and MLP components (`up`, `down`, `gate`).
- **Y-axis (Vertical)**:
- Labels: Numerical indices from 0 to 27 (no explicit labels beyond the axis title).
- **Legend**:
- Positioned on the right, with a gradient from blue (0.12) to orange (0.16). No explicit title or units provided.
### Detailed Analysis
- **Attention Components**:
- `attn. q` and `attn. k`: Predominantly dark blue (low values, ~0.12–0.13) across most rows.
- `attn. v`: Higher values (orange, ~0.15–0.16) in rows 0–15, with lighter shades in rows 18–27.
- `attn. o`: Mixed values; orange in rows 0–15, transitioning to white/light blue in rows 18–27.
- **MLP Components**:
- `mlp. up` and `mlp. down`: Mostly light blue/white (~0.13–0.14) across all rows.
- `mlp. gate`: Darker blue (~0.12–0.13) in rows 0–15, with lighter shades in rows 18–27.
- **Row Trends**:
- Rows 0–15 show higher variability in attention components (e.g., `attn. v` and `attn. o` are more prominent).
- Rows 18–27 exhibit more uniform, lower values across all components, with `mlp. gate` consistently darker.
### Key Observations
1. **Attention Dominance**: `attn. v` and `attn. o` consistently show higher values than `attn. q` and `attn. k`, suggesting greater importance in these components.
2. **MLP Gate Variability**: `mlp. gate` has the lowest values overall, with a slight increase in rows 0–15.
3. **Row-Specific Patterns**: Rows 0–15 display more pronounced differences between components, while rows 18–27 are more homogeneous.
### Interpretation
The heatmap highlights the relative importance of attention and MLP components in a neural network. The higher values for `attn. v` and `attn. o` suggest these components play a more critical role in the model's behavior compared to `attn. q` and `attn. k`. The MLP gate (`mlp. gate`) appears less influential, with consistently low values. The row-wise variation (0–27) may indicate differences across layers, data samples, or training iterations, though no clear pattern is evident without additional context. The color gradient confirms that values are normalized, with orange representing the upper bound (~0.16) and blue the lower (~0.12).
</details>
(a) Qwen2.5-1.5B-Instruct
<details>
<summary>x10.png Details</summary>
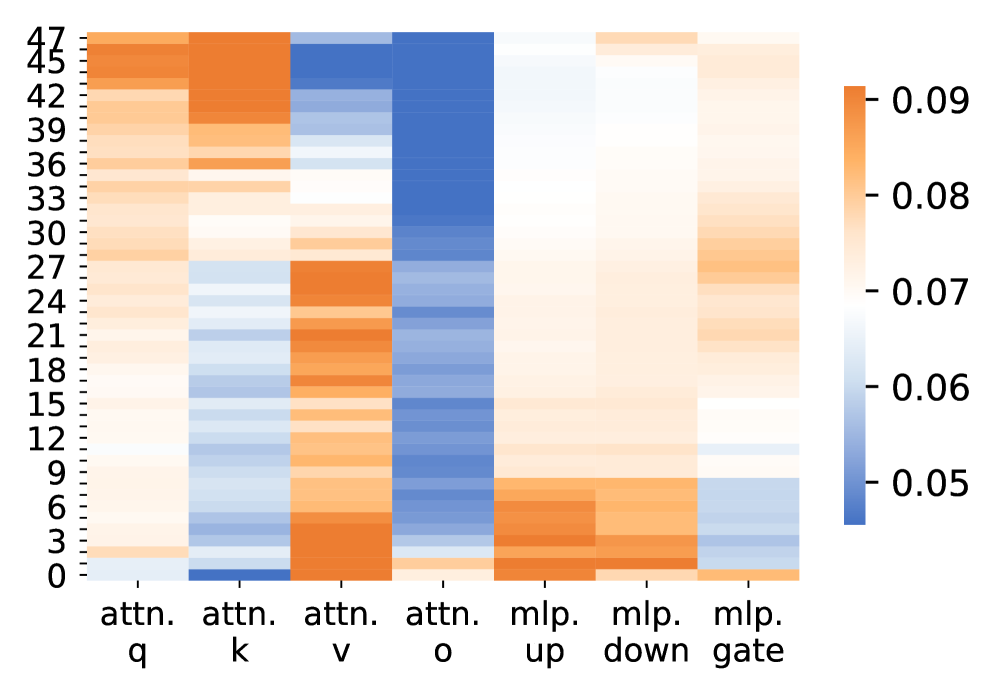
### Visual Description
## Heatmap: Attention and MLP Component Values Across Layers
### Overview
The image is a heatmap visualizing numerical values across 48 rows (labeled 0–47) and 7 columns representing attention (attn.) and MLP (mlp.) components. Values are color-coded from blue (low, ~0.05) to orange (high, ~0.09), with a gradient scale on the right.
### Components/Axes
- **X-axis (Columns)**:
- `attn. q` (query attention)
- `attn. k` (key attention)
- `attn. v` (value attention)
- `attn. o` (output attention)
- `mlp. up` (MLP up projection)
- `mlp. down` (MLP down projection)
- `mlp. gate` (MLP gate)
- **Y-axis (Rows)**:
- Numerical labels from 0 to 47 (likely representing layers or positions in a neural network).
- **Color Legend**:
- Blue: ~0.05 (low values)
- Orange: ~0.09 (high values)
- Gradient from blue to orange indicates intermediate values.
- **Spatial Placement**:
- Legend: Right side of the heatmap.
- Row labels: Leftmost column.
- Column labels: Bottom row.
### Detailed Analysis
1. **`attn. q` Column**:
- High values (~0.08–0.09, orange) in rows 45–47.
- Lower values (~0.06–0.07, light orange) in rows 0–15.
2. **`attn. k` Column**:
- Dark blue block (~0.05) in rows 45–47.
- Gradual increase to orange (~0.08) in rows 18–24.
3. **`attn. v` Column**:
- Mixed values: Orange (~0.08) in rows 3–6 and 21–24.
- Blue (~0.05) in rows 0–2 and 30–33.
4. **`attn. o` Column**:
- Dominantly blue (~0.05–0.06) across most rows.
- Orange (~0.08) in rows 12–15 and 39–42.
5. **`mlp. up` Column**:
- High values (~0.08–0.09) in rows 0–3 and 24–27.
- Blue (~0.05) in rows 15–18 and 33–36.
6. **`mlp. down` Column**:
- Orange (~0.08) in rows 0–6 and 21–24.
- Blue (~0.05) in rows 12–15 and 30–33.
7. **`mlp. gate` Column**:
- Gradient from orange (~0.08) at the top to blue (~0.05) at the bottom.
- Notable orange block in rows 6–9.
### Key Observations
- **High Attention in Upper Layers**: Rows 45–47 show consistently high values in `attn. q` and `attn. v`, suggesting increased focus in later layers.
- **MLP Gate Variability**: The `mlp. gate` column exhibits a clear gradient, indicating dynamic gating behavior across layers.
- **Contrasting Attention Patterns**: `attn. k` and `attn. o` show inverse trends (low in upper layers vs. high in mid-layers).
- **MLP Projection Peaks**: `mlp. up` and `mlp. down` have localized high values, suggesting specific layer dependencies.
### Interpretation
The heatmap reveals layer-specific patterns in attention and MLP operations:
- **Attention Mechanisms**: Upper layers (`attn. q`, `attn. v`) may prioritize global context, while mid-layers (`attn. k`, `attn. o`) show mixed focus.
- **MLP Dynamics**: The `mlp. gate` gradient implies adaptive control over information flow, with higher gating in lower layers.
- **Anomalies**: The dark blue block in `attn. k` (rows 45–47) could indicate a bottleneck or reduced key attention in final layers.
This suggests a neural network architecture where attention and MLP components exhibit distinct layer-wise behaviors, potentially optimizing for different stages of processing.
</details>
(b) Distill-Qwen-14B
<details>
<summary>x11.png Details</summary>
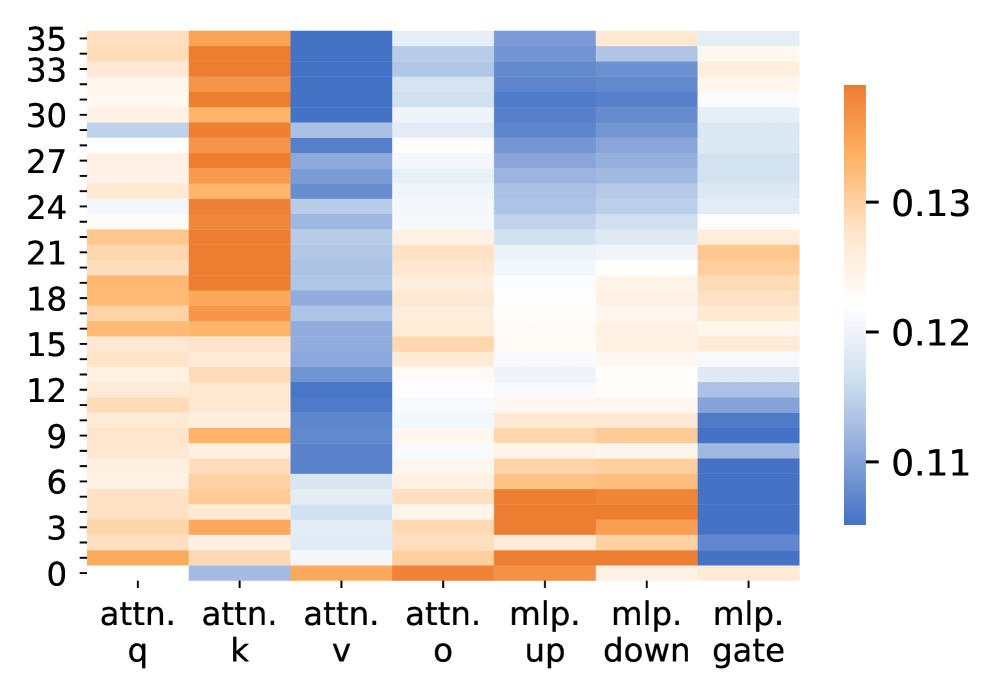
### Visual Description
## Heatmap: Attention and MLP Component Values Across Rows
### Overview
The image is a heatmap visualizing numerical values across 36 rows (0-35) and 7 columns representing attention mechanisms ("attn. q", "attn. k", "attn. v", "attn. o") and MLP components ("mlp. up", "mlp. down", "mlp. gate"). Values range from 0.11 (blue) to 0.13 (orange), with intermediate shades of white and light blue.
### Components/Axes
- **X-axis (Columns)**:
- "attn. q", "attn. k", "attn. v", "attn. o" (attention mechanisms)
- "mlp. up", "mlp. down", "mlp. gate" (MLP components)
- **Y-axis (Rows)**: Numerical labels 0 to 35 (increasing downward)
- **Legend**:
- Blue → 0.11, Light Blue → 0.12, Orange → 0.13
- Positioned vertically on the right side of the heatmap
### Detailed Analysis
1. **attn. q Column**:
- Dark blue (0.11) dominates rows 33-35 (top of heatmap)
- Gradual transition to lighter blue/orange in rows 0-20
- Row 24 shows a distinct white band (0.12)
2. **attn. k Column**:
- Consistent orange (0.13) in rows 0-15
- Blue (0.11) in rows 16-24
- Light blue/orange gradient in rows 25-35
3. **attn. v Column**:
- Blue (0.11) in rows 0-12
- Orange (0.13) in rows 13-21
- Light blue (0.12) in rows 22-35
4. **attn. o Column**:
- Light blue (0.12) in rows 0-18
- Orange (0.13) in rows 19-27
- Blue (0.11) in rows 28-35
5. **mlp. up Column**:
- Orange (0.13) in rows 0-9
- Light blue (0.12) in rows 10-24
- Blue (0.11) in rows 25-35
6. **mlp. down Column**:
- Blue (0.11) in rows 0-6
- Orange (0.13) in rows 7-18
- Light blue (0.12) in rows 19-35
7. **mlp. gate Column**:
- Gradient from blue (0.11) at row 0 to orange (0.13) at row 35
- Steepest gradient in rows 15-25 (transition from 0.12 to 0.13)
### Key Observations
- **Attention Mechanisms**:
- "attn. q" shows strongest values (0.13) in middle rows (15-25)
- "attn. o" exhibits a U-shaped pattern with peak values in middle rows
- **MLP Components**:
- "mlp. gate" demonstrates a linear gradient across all rows
- "mlp. down" has the most pronounced mid-range values (rows 7-18)
- **Color Consistency**: All orange regions correspond to 0.13, blue to 0.11, with white/light blue as intermediates
### Interpretation
This heatmap likely represents attention weights or MLP gate activations in a transformer-based neural network. The attention mechanisms show distinct activation patterns:
- "attn. q" and "attn. o" suggest dynamic focus across different input positions
- The MLP components reveal structured value distributions:
- "mlp. gate" gradient may indicate progressive activation scaling
- "mlp. down" mid-range dominance suggests balanced processing
The color-coded values (0.11-0.13) imply relatively small magnitude differences, possibly normalized or scaled for visualization. The row labels (0-35) might correspond to input positions, hidden layer dimensions, or batch indices depending on the model architecture.
</details>
(c) Qwen3-8B
Figure 8: Parameter change rates of LLMs to the original ones across different modules.
A.4.5 Training Dynamics Analysis
As shown in Fig. 7, we present the reward and response length dynamics during training across four models: Qwen2.5-7B-Instruct, Distill-Qwen-7B, Distill-Qwen-14B, and Qwen3-8B. For reward scores, all models exhibit a consistent pattern: an initial rapid increase followed by stabilization with oscillations. Qwen2.5-7B-Instruct shows the steepest initial improvement, rising from 0.4 to 0.6 within 20 steps, while Distill-Qwen models demonstrate more gradual increases over 200-400 steps, reaching stable scores around 0.65-0.7. Qwen3-8B displays higher volatility with scores fluctuating between 0.62 and 0.74. In contrast, response length shows high variability across all models with no clear monotonic trend. Response lengths vary substantially by model scale: Qwen2.5-7B-Instruct generates shorter responses (340-400 tokens), while Distill-Qwen models and Qwen3-8B produce longer outputs (700-850 and 900-1200 tokens, respectively). The high variance in response length suggests that the training process maintains flexibility in output generation while improving constraint satisfaction, as evidenced by the stable reward trends.
A.4.6 Full Parameter Change Patterns
As shown in Fig. 8, we extend the parameter change analysis to three additional models: Qwen2.5-1.5B-Instruct, Distill-Qwen-14B, and Qwen3-8B. The analysis reveals consistent patterns across all models: attention query (attn.q) and key (attn.k) modules exhibit the highest parameter change rates, particularly concentrated in the bottom and top layers, while attention value (attn.v) and output (attn.o) modules consistently show minimal changes across all layers. MLP modules (mlp.up, mlp.down, mlp.gate) demonstrate moderate change rates, falling between the high changes in attn.q/attn.k and the low changes in attn.v/attn.o.
<details>
<summary>x12.png Details</summary>

### Visual Description
```markdown
## Screenshot: Text Document with Colored Highlights
### Overview
The image shows a text document with sentences and phrases highlighted in brown, orange, and yellow. The text includes formatting instructions, a checklist, and stylistic guidelines. Code-like tags (e.g., `<begin_of_sentence>`, `<User>`, `
</details>
(a) Before Training - Distill-Qwen-7B
<details>
<summary>x13.png Details</summary>

### Visual Description
## Screenshot: Color-Coded Instructional Text
### Overview
The image displays a block of text with color-coded segments, likely representing a set of instructions or guidelines for generating a technical document. The text is divided into distinct sections using varying shades of orange, brown, and light orange, with no explicit headings or bullet points. The content emphasizes structural requirements (e.g., paragraph length, error handling) and stylistic conventions (e.g., lowercase English, bold core ideas).
### Components/Axes
- **Text Segments**:
- **Orange**: Highlights key terms (e.g., "instructional," "checklist," "error," "bold," "formal," "technical").
- **Brown**: Emphasizes critical rules (e.g., "must be written in lowercase English," "apply a formal, technical writing style").
- **Light Orange**: Neutral text for general instructions (e.g., "generate a short paragraph," "append a clearly separated checklist section").
- **Spatial Grounding**:
- Color-coded terms are embedded within sentences, with no standalone legend.
- Relative positioning:
- "instructional" (orange) appears early, anchoring the document’s purpose.
- "checklist" (brown) is centrally placed, indicating its importance.
- "error" (orange) is isolated, drawing attention to error-handling rules.
- "formal, technical writing style" (brown) concludes the text, reinforcing stylistic requirements.
### Detailed Analysis
1. **Instructional Paragraph**:
- The text begins with a directive to generate a short paragraph, constrained to ≤3 sentences.
- Color coding emphasizes "instructional" (orange) and "checklist" (brown), suggesting these are core components of the output.
2. **Error Handling**:
- The phrase "if the word 'error' appears anywhere in the output" is highlighted in orange, with a strict rule that all checklist items must be written in lowercase English if triggered.
3. **Stylistic Requirements**:
- "Bold ed core idea" (orange) and "formal, technical writing style" (brown) are emphasized, indicating mandatory formatting rules.
4. **Structural Constraints**:
- The output must avoid exceeding three sentences, with a "clearly separated checklist section" appended.
### Key Observations
- **Color Coding as Hierarchy**: Orange highlights procedural terms (e.g., "instructional," "checklist"), while brown underscores non-negotiable rules (e.g., lowercase, formal style).
- **Ambiguity in "Error" Rule**: The instruction to write checklist items in lowercase if "error" appears is conditional but lacks context for when this applies.
- **Contradictory Directives**: The text demands both "lowercase English" and "formal, technical writing style," which may conflict depending on interpretation.
### Interpretation
The color-coded text appears to be a meta-instruction for generating a document with strict formatting and structural rules. The use of color likely serves to:
1. **Categorize Instructions**: Orange for procedural steps, brown for immutable rules.
2. **Prioritize Critical Elements**: Terms like "error" and "formal style" are visually emphasized to ensure compliance.
3. **Clarify Ambiguity**: The conditional "error" rule may require further clarification, as its trigger condition is unspecified.
The document’s purpose seems to be a template for automated or human-generated technical writing, where adherence to stylistic and structural guidelines is paramount. The absence of a legend or explicit hierarchy suggests the color coding is intuitive, relying on the reader’s ability to infer meaning from context.
</details>
(b) After Training - Distill-Qwen-7B
<details>
<summary>x14.png Details</summary>

### Visual Description
## Text Block: Instructional Paragraph and Checklist Generation Rules
### Overview
The image contains a structured text block with formatting rules for generating an instructional paragraph and checklist. Key elements include conditional logic, formatting requirements, and output constraints.
### Components/Axes
- **Tags**: `<im_start|>`, `<im_end|>` (delimiters for input/output boundaries)
- **Highlighted Terms**:
- `output` (orange)
- `paragraph` (orange)
- `error` (orange)
- `bold` (orange)
- `lowercase` (orange)
- `else` (orange)
- **Text Structure**:
- Instructional paragraph requirements (3 sentences max)
- Checklist formatting (bullet points, lowercase)
- Error handling (if "error" appears)
### Detailed Analysis
1. **Instructional Paragraph Rules**:
- Must not exceed three sentences.
- Must begin with a **bold** core idea.
- Must be followed by a clearly separated checklist.
2. **Checklist Requirements**:
- Items must be written in **lowercase** English.
- If the word "error" appears anywhere, the **output** must:
- Begin with a bolded core idea.
- Apply a formal, technical writing style to the entire output.
3. **Syntax and Formatting**:
- Uses code-like delimiters (`<im_start|>`, `<im_end|>`) to structure input/output.
- Emphasizes **conditional logic** (e.g., "if the word 'error' appears").
### Key Observations
- **Conditional Logic**: The presence of "error" triggers stricter formatting rules (bolded core idea, formal style).
- **Formatting Constraints**:
- Checklist items must be lowercase.
- Output length is capped at three sentences.
- **Syntax Highlighting**: Orange highlights emphasize critical terms (`output`, `error`, `bold`, `lowercase`, `else`).
### Interpretation
This text appears to be a prompt or rule set for an AI or automated system generating technical documentation. The highlighted terms suggest:
1. **Error Handling**: The system must detect the word "error" and adjust output formatting accordingly.
2. **Structural Rigidity**: Strict adherence to sentence limits, bolded core ideas, and lowercase checklists ensures consistency.
3. **Syntax Awareness**: The use of `<im_start|>`/`<im_end|>` implies integration with a system that processes structured input/output.
The rules prioritize clarity and technical precision, likely for applications like API documentation, troubleshooting guides, or instructional manuals. The conditional logic indicates a focus on adaptability to edge cases (e.g., error states).
</details>
(c) Before Training - Qwen3-8B
<details>
<summary>x15.png Details</summary>

### Visual Description
## Text Block: Instructional Paragraph Generation Rules
### Overview
This image contains a technical instruction set for generating a formatted instructional paragraph. The text includes conditional logic, formatting requirements, and output specifications, with certain keywords highlighted in orange and brown.
### Components/Axes
- **Text Structure**: A single block of text with line breaks separating clauses.
- **Highlighted Elements**:
- **Orange**: "paragraph", "does not", "then", "error", "lowercase", "must", "bold", "the", "assistant".
- **Brown**: "assistant \n".
- **Key Phrases**:
- "generate a short instructional paragraph"
- "total length does not exceed three sentences"
- "append a clearly separated checklist section"
- "if the word 'error' appears anywhere in the output, all checklist items must be written in lowercase English"
- "instructional paragraph must begin with a bolded core idea"
- "apply a formal, technical writing style to the entire output"
### Content Details
1. **Primary Objective**: Generate a concise instructional paragraph (<3 sentences) with:
- A bolded core idea at the beginning
- A clearly separated checklist section (bullet points)
- Formal/technical writing style throughout
2. **Conditional Logic**:
- If "error" appears in the output → All checklist items must be lowercase English
- Else → Standard formatting applies
3. **Output Constraints**:
- No mention of "error" in the final output
- Checklist items must be lowercase if error condition triggers
- Assistant name followed by newline (`\n`) at the end
### Key Observations
- The text uses imperative phrasing ("must", "ensure", "apply") to enforce strict formatting rules.
- Color highlights emphasize critical components:
- Orange: Structural elements ("paragraph", "checklist", "error")
- Brown: Metadata ("assistant \n")
- The conditional logic creates a binary output format depending on error presence.
### Interpretation
This appears to be a prompt engineering instruction set, likely for an AI assistant. The color highlights suggest:
1. **Orange** marks core formatting rules and structural elements
2. **Brown** denotes metadata (assistant identifier)
3. The conditional logic implies two possible output variants:
- Standard format (no error)
- Error-triggered format (lowercase checklist)
The requirement to avoid mentioning "error" in the output while conditionally formatting based on its presence suggests a hidden state management system, possibly for error handling in technical documentation generation. The strict three-sentence limit emphasizes conciseness, while the bolded core idea ensures immediate clarity of purpose.
</details>
(d) After Training - Qwen3-8B
Figure 9: Token-level information flow analysis. Darker orange indicates higher attention importance.
A.4.7 Full Token-Level Information Flow Analysis
As shown in Fig. 9, we extend the token-level information flow analysis to Distill-Qwen-7B and Qwen3-8B models on complex instruction-following tasks. Before training, both models exhibit relatively diffuse attention patterns, with only a subset of tokens (e.g., "instructional", "paragraph", "checklist", "error") showing moderate importance. After training, both models demonstrate a dramatic shift towards uniformly high attention importance across virtually all tokens in the prompt, including conjunctions, prepositions, and specific constraints.