# Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
> Corresponding author
Abstract
Despite their impressive capabilities, large language models (LLMs) frequently generate hallucinations. Previous work shows that their internal states encode rich signals of truthfulness, yet the origins and mechanisms of these signals remain unclear. In this paper, we demonstrate that truthfulness cues arise from two distinct information pathways: (1) a Question-Anchored pathway that depends on question–answer information flow, and (2) an Answer-Anchored pathway that derives self-contained evidence from the generated answer itself. First, we validate and disentangle these pathways through attention knockout and token patching. Afterwards, we uncover notable and intriguing properties of these two mechanisms. Further experiments reveal that (1) the two mechanisms are closely associated with LLM knowledge boundaries; and (2) internal representations are aware of their distinctions. Finally, building on these insightful findings, two applications are proposed to enhance hallucination detection performance. Overall, our work provides new insight into how LLMs internally encode truthfulness, offering directions for more reliable and self-aware generative systems.
Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
Wen Luo $\heartsuit$ , Guangyue Peng $\heartsuit$ , Wei Li $\heartsuit$ , Shaohang Wei $\heartsuit$ , Feifan Song $\heartsuit$ , Liang Wang ♠, Nan Yang ♠, Xingxing Zhang ♠, Jing Jin $\heartsuit$ , Furu Wei ♠, Houfeng Wang $\heartsuit$ thanks: Corresponding author $\heartsuit$ State Key Laboratory of Multimedia Information Processing, School of Computer Science, Peking University ♠ Microsoft Research Asia
1 Introduction
Despite their remarkable capabilities in natural language understanding and generation, large language models (LLMs) often produce hallucinations —outputs that appear plausible but are factually incorrect. This phenomenon poses a critical challenge for deploying LLMs in real-world applications where reliability and trustworthiness are paramount (Shi et al., 2024; Bai et al., 2024). One line of research tackles hallucination detection from an extrinsic perspective (Min et al., 2023; Hu et al., 2025; Huang et al., 2025), evaluating only the model’s outputs while disregarding its internal dynamics. Although such approaches can identify surface-level textual inconsistencies, their extrinsic focus limits the insight they offer into the underlying causes of hallucinations. Complementing these efforts, another line of work investigates the intrinsic properties of LLMs, revealing that their internal representations encode rich truthfulness signals (Burns et al., 2023; Li et al., 2023; Chen et al., 2024; Orgad et al., 2025; Niu et al., 2025). These internal truthfulness signals can be exploited to detect an LLM’s own generative hallucinations by training a linear classifier (i.e., a probe) on its hidden representations. However, while prior work establishes the presence of such cues, the mechanisms by which they arise and operate remain largely unexplored. Recent studies indicate well-established mechanisms in LLMs that underpin complex capabilities such as in-context learning (Wang et al., 2023), long-context retrieval (Wu et al., 2025), and reasoning (Qian et al., 2025). This observation naturally leads to a key question: how do truthfulness cues arise and function within LLMs?
In this paper, we uncover that truthfulness signals in LLMs arise from two distinct information pathways: (1) a Question-Anchored (Q-Anchored) pathway, which depends on the flow of information from the input question to the generated answer, and (2) an Answer-Anchored (A-Anchored) pathway, which derives self-contained evidence directly from the model’s own outputs. We begin with a preliminary study using saliency analysis to quantify information flow potentially relevant to hallucination detection. Results reveal a bimodal distribution of dependency on question–answer interactions, suggesting heterogeneous truthfulness encoding mechanisms. To validate this hypothesis, we design two experiments across 4 diverse datasets using 12 models that vary in both architecture and scale, including base, instruction-tuned, and reasoning-oriented models. By (i) blocking critical question–answer information flow through attention knockout (Geva et al., 2023; Fierro et al., 2025) and (ii) injecting hallucinatory cues into questions via token patching (Ghandeharioun et al., 2024; Todd et al., 2024), we disentangle these truthfulness pathways. Our analyses confirm that Q-Anchored signals rely heavily on question-derived cues, whereas A-Anchored signals are robust to their removal and primarily originate from the generated answer itself.
Building on this foundation, we further investigate emergent properties of these truthfulness pathways through large-scale experiments. Our findings highlight two intriguing characteristics: (1) Association with knowledge boundaries: Q-anchored encoding predominates for well-established facts that fall within the knowledge boundary, whereas A-anchored encoding is favored in long-tail cases. (2) Self-awareness: LLM internal states can distinguish which mechanism is being employed, suggesting intrinsic awareness of pathway distinctions.
Finally, these analyses not only deepen our mechanistic understanding of hallucinations but also enable practical applications. Specifically, by leveraging the fundamentally different dependencies of the truthfulness pathways and the model’s intrinsic awareness, we propose two pathway-aware strategies to enhance hallucination detection. (1) Mixture-of-Probes (MoP): Motivated by the specialization of internal pathways, MoP employs a set of expert probing classifiers, each tailored to capture distinct truthfulness encoding mechanisms. (2) Pathway Reweighting (PR): From the perspective of selectively emphasizing pathway-relevant internal cues, PR modulates information intensity to amplify signals that are most informative for hallucination detection, aligning internal activations with pathway-specific evidence. Experiments demonstrate that our proposed methods consistently outperform competing approaches, achieving up to a 10% AUC gain across various datasets and models.
Overall, our key contributions are summarized as follows:
- (Mechanism) We conduct a systematic investigation into how internal truthfulness signals emerge and operate within LLMs, revealing two distinct information pathways: a Question-Anchored pathway that relies on question–answer information flow, and an Answer-Anchored pathway that derives self-contained evidence from the generated output.
- (Discovery) Through large-scale experiments across multiple datasets and model families, we identify two key properties of these mechanisms: (i) association with knowledge boundaries, and (ii) intrinsic self-awareness of pathway distinctions.
- (Application) Building on these findings, we propose two pathway-aware detection methods that exploit the complementary nature of the two mechanisms to enhance hallucination detection, providing new insights for building more reliable generative systems.
2 Background
2.1 Hallucination Detection
Given an LLM $f$ , we denote the dataset as $D=\{(q_{i},\hat{y}^{f}_{i},z^{f}_{i})\}_{i=1}^{N}$ , where $q_{i}$ is the question, $\hat{y}^{f}_{i}$ the model’s answer in open-ended generation, and $z^{f}_{i}∈\{0,1\}$ indicates whether the answer is hallucinatory. The task is to predict $z^{f}_{i}$ given the input $x^{f}_{i}=[q_{i},\hat{y}^{f}_{i}]$ for each instance. Cases in which the model refuses to answer are excluded, as they are not genuine hallucinations and can be trivially classified. Methods based on internal signals assume access to the model’s hidden representations but no external resources (e.g., retrieval systems or fact–checking APIs) (Xue et al., 2025a). Within this paradigm, probing trains a lightweight linear classifier on hidden activations to discriminate between hallucinatory and factual outputs, and has been shown to be among the most effective approaches in this class of internal-signal-based methods (Orgad et al., 2025).
2.2 Exact Question and Answer Tokens
To analyze the origins and mechanisms of truthfulness signals in LLMs, we primarily focus on exact tokens in question–answer pairs. Not all tokens contribute equally to detecting factual errors: some carry core information essential to the meaning of the question or answer, while others provide peripheral details. We draw on semantic frame theory (Baker et al., 1998; Pagnoni et al., 2021), which represents a situation or event along with its participants and their roles. In the theory, frame elements are categorized as: (1) Core frame elements, which define the situation itself, and (2) Non-core elements, which provide additional, non-essential context.
As shown in Table 1, we define: (1) Exact question tokens: core frame elements in the question, typically including the exact subject and property tokens (i.e., South Carolina and capital). (2) Exact answer tokens: core frame elements in the answer that convey the critical information required to respond correctly (i.e., Columbia). Humans tend to rely more on core elements when detecting errors, as these tokens carry the most precise information. Consistent with this intuition, recent work (Orgad et al., 2025) shows that probing activations on the exact answer tokens offers the strongest signal for hallucination detection, outperforming all other token choices. Motivated by these findings, our analysis mainly centers on exact tokens to probe truthfulness signals in LLMs. Moreover, to validate the robustness of our conclusions, we also conduct comprehensive experiments using alternative, non–exact-token configurations (see Appendix B.2).
| Question: What is the capital of South Carolina? |
| --- |
| Answer: It is Columbia, a hub for government, culture, and education that houses the South Carolina State House and the University of South Carolina. |
Table 1: Example of exact question and answer tokens. Colors indicate token types: – exact property, – exact subject, and – exact answer tokens.
3 Two Internal Truthfulness Pathways
We begin with a preliminary analysis using metrics based on saliency scores (§ 3.1). The quantitative results reveal two distinct information pathways for truthfulness encoding: (1) a Question-Anchored (Q-Anchored) Pathway, which relies heavily on exact question tokens (i.e., the questions), and (2) an Answer-Anchored (A-Anchored) Pathway, in which the truthfulness signal is largely independent of the question-to-answer information flow. Section 3.2 presents experiments validating this hypothesis. In particular, we show that Q-Anchored Pathway depends critically on information flowing from the question to the answer, whereas the signals along the A-Anchored Pathway are primarily derived from the LLM-generated answer itself.
3.1 Saliency-Driven Preliminary Study
This section investigates the intrinsic characteristics of LLM attention interactions and their potential role in truthfulness encoding. We employ saliency analysis (Simonyan et al., 2014), a widely used interpretability method, to reveal how attention among tokens influences probe decisions. Following common practice (Michel et al., 2019; Wang et al., 2023), we compute the saliency score as:
$$
S^{l}(i,j)=\left|A^{l}(i,j)\frac{\partial\mathcal{L}(x)}{\partial A^{l}(i,j)}\right|, \tag{1}
$$
where $S^{l}$ denotes the saliency score matrix of the $l$ -th layer, $A^{l}$ represents the attention weights of that layer, and $\mathcal{L}$ is the loss function for hallucination detection (i.e., the binary cross-entropy loss). Scores are averaged over all attention heads within each layer. In particular, $S^{l}(i,j)$ quantifies the saliency of attention from query $i$ to key $j$ , capturing how strongly the information flow from $j$ to $i$ contributes to the detection. We study two types of information flow: (1) $S_{E_{Q}→ E_{A}}$ , the saliency of direct information flow from the exact question tokens to the exact answer tokens, and (2) $S_{E_{Q}→*}$ , the saliency of the total information disseminated by the exact question tokens.
Results
<details>
<summary>x1.png Details</summary>
### Visual Description
## Density Plot: Saliency Score Distribution for Llama-3-8B and Llama-3-70B
### Overview
The image presents two density plots comparing the saliency score distributions for Llama-3-8B and Llama-3-70B models. Each plot shows the distribution of saliency scores for two different question-answering datasets (TriviaQA and NQ) and two different types of saliency scores (S<sub>Eq</sub>→E<sub>A</sub> and S<sub>Eq</sub>→*). The x-axis represents the saliency score, and the y-axis represents the density.
### Components/Axes
* **Titles:**
* Left Plot: Llama-3-8B
* Right Plot: Llama-3-70B
* **X-axis (Saliency Score):**
* Left Plot: Range from 0.0 to 1.5, with markers at 0.0, 0.5, 1.0, and 1.5.
* Right Plot: Range from 0.0 to 0.2, with markers at 0.0, 0.1, and 0.2.
* **Y-axis (Density):**
* Left Plot: Range from 0.00 to 0.75, with markers at 0.00, 0.25, 0.50, and 0.75.
* Right Plot: Range from 0 to 4, with markers at 0, 2, and 4.
* **Legend (located at the bottom):**
* Blue: S<sub>Eq</sub>→E<sub>A</sub> (TriviaQA)
* Green: S<sub>Eq</sub>→E<sub>A</sub> (NQ)
* Orange: S<sub>Eq</sub>→* (TriviaQA)
* Red: S<sub>Eq</sub>→* (NQ)
### Detailed Analysis
**Llama-3-8B (Left Plot):**
* **S<sub>Eq</sub>→E<sub>A</sub> (TriviaQA) - Blue:** The distribution peaks around 0.1, with a smaller peak around 0.5. The density gradually decreases after 0.5, extending to approximately 1.2.
* **S<sub>Eq</sub>→E<sub>A</sub> (NQ) - Green:** The distribution has a sharp peak near 0.0, followed by a smaller peak around 0.2. The density decreases significantly after 0.2, extending to approximately 0.8.
* **S<sub>Eq</sub>→* (TriviaQA) - Orange:** The distribution peaks around 0.6, with a long tail extending to approximately 1.5.
* **S<sub>Eq</sub>→* (NQ) - Red:** The distribution peaks around 0.4, with a tail extending to approximately 1.0.
**Llama-3-70B (Right Plot):**
* **S<sub>Eq</sub>→E<sub>A</sub> (TriviaQA) - Blue:** The distribution peaks around 0.02, with a smaller peak around 0.07. The density decreases after 0.07, extending to approximately 0.18.
* **S<sub>Eq</sub>→E<sub>A</sub> (NQ) - Green:** The distribution has a sharp peak near 0.0, followed by a smaller peak around 0.03. The density decreases significantly after 0.03, extending to approximately 0.1.
* **S<sub>Eq</sub>→* (TriviaQA) - Orange:** The distribution peaks around 0.1, with a tail extending to approximately 0.2.
* **S<sub>Eq</sub>→* (NQ) - Red:** The distribution peaks around 0.06, with a tail extending to approximately 0.15.
### Key Observations
* For both models, the S<sub>Eq</sub>→E<sub>A</sub> scores tend to be concentrated at lower saliency scores compared to S<sub>Eq</sub>→* scores.
* The Llama-3-70B model shows a more concentrated distribution of saliency scores compared to the Llama-3-8B model, with the x-axis scale being much smaller.
* The NQ dataset generally has lower saliency scores compared to the TriviaQA dataset for both models.
### Interpretation
The density plots illustrate the distribution of saliency scores for different configurations of Llama models and datasets. The shift in distributions between the 8B and 70B models suggests that model size influences the saliency scores. The difference between TriviaQA and NQ datasets indicates that the nature of the questions and answers affects the saliency scores. The distinction between S<sub>Eq</sub>→E<sub>A</sub> and S<sub>Eq</sub>→* suggests that the method of calculating saliency scores also plays a significant role. The data suggests that the Llama-3-70B model assigns lower saliency scores overall compared to the Llama-3-8B model, potentially indicating a more focused or refined attention mechanism.
</details>
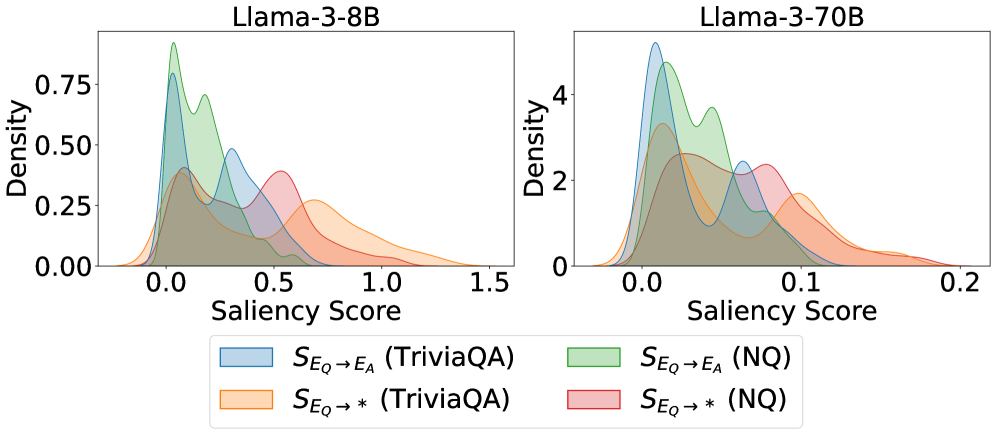
Figure 1: Kernel density estimates of saliency‐score distributions for critical question-to-answer information flows. The bimodal pattern suggests two distinct information mechanisms.
We demonstrate Kernel Density Estimation results of the saliency scores on TriviaQA (Joshi et al., 2017) and Natural Questions (Kwiatkowski et al., 2019) datasets. As shown in Figure 1, probability densities reveal a clear bimodal distribution: for all examined information types originating from the question, the probability mass concentrates around two peaks, one near zero saliency and another at a substantially higher value. The near-zero peak suggests that, for a substantial subset of samples, the question-to-answer information flow contributes minimally to hallucination detection, whereas the higher peak reflects strong dependence on such flow.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Charts: Model Performance Comparison
### Overview
The image presents three line charts comparing the performance of different language models (Llama-3-8B, Llama-3-70B, and Mistral-7B-v0.3) across various question-answering datasets. The charts depict the change in performance (ΔP) as a function of the model layer. Each chart includes data series for both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) performance on different datasets.
### Components/Axes
* **Titles:**
* Top-left chart: "Llama-3-8B"
* Top-center chart: "Llama-3-70B"
* Top-right chart: "Mistral-7B-v0.3"
* **Y-axis:**
* Label: "ΔP" (Change in Performance)
* Scale: -80 to 0, with tick marks at -80, -60, -40, -20, and 0.
* **X-axis:**
* Label: "Layer"
* Scale:
* Llama-3-8B: 0 to 30, with tick marks every 10 units.
* Llama-3-70B: 0 to 80, with tick marks every 20 units.
* Mistral-7B-v0.3: 0 to 30, with tick marks every 10 units.
* **Legend:** Located at the bottom of the image.
* Blue solid line: Q-Anchored (PopQA)
* Orange dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Pink dashed line: A-Anchored (TriviaQA)
* Green dotted line: Q-Anchored (HotpotQA)
* Orange dashed line: A-Anchored (HotpotQA)
* Pink dashed line: Q-Anchored (NQ)
* Gray dotted line: A-Anchored (NQ)
### Detailed Analysis
**Llama-3-8B**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0 and decreases sharply to around -70 by layer 10, then remains relatively stable between -60 and -80 until layer 30.
* **A-Anchored (PopQA) (Orange dashed line):** Stays relatively constant around 0 throughout all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 0 and decreases sharply to around -60 by layer 10, then remains relatively stable between -50 and -70 until layer 30.
* **A-Anchored (TriviaQA) (Pink dashed line):** Starts at approximately 0 and decreases sharply to around -50 by layer 10, then remains relatively stable between -40 and -60 until layer 30.
* **Q-Anchored (HotpotQA) (Green dotted line):** Overlaps with TriviaQA.
* **A-Anchored (HotpotQA) (Orange dashed line):** Overlaps with PopQA.
* **Q-Anchored (NQ) (Pink dashed line):** Overlaps with TriviaQA and HotpotQA.
* **A-Anchored (NQ) (Gray dotted line):** Overlaps with PopQA and HotpotQA.
**Llama-3-70B**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0 and decreases sharply to around -70 by layer 20, then fluctuates between -50 and -70 until layer 80.
* **A-Anchored (PopQA) (Orange dashed line):** Stays relatively constant around 0 throughout all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 0 and decreases sharply to around -60 by layer 20, then fluctuates between -40 and -70 until layer 80.
* **A-Anchored (TriviaQA) (Pink dashed line):** Starts at approximately 0 and decreases sharply to around -50 by layer 20, then fluctuates between -30 and -60 until layer 80.
* **Q-Anchored (HotpotQA) (Green dotted line):** Overlaps with TriviaQA.
* **A-Anchored (HotpotQA) (Orange dashed line):** Overlaps with PopQA.
* **Q-Anchored (NQ) (Pink dashed line):** Overlaps with TriviaQA and HotpotQA.
* **A-Anchored (NQ) (Gray dotted line):** Overlaps with PopQA and HotpotQA.
**Mistral-7B-v0.3**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0 and decreases sharply to around -70 by layer 10, then remains relatively stable between -50 and -70 until layer 30.
* **A-Anchored (PopQA) (Orange dashed line):** Stays relatively constant around 0 throughout all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 0 and decreases sharply to around -60 by layer 10, then remains relatively stable between -50 and -70 until layer 30.
* **A-Anchored (TriviaQA) (Pink dashed line):** Starts at approximately 0 and decreases sharply to around -50 by layer 10, then remains relatively stable between -40 and -60 until layer 30.
* **Q-Anchored (HotpotQA) (Green dotted line):** Overlaps with TriviaQA.
* **A-Anchored (HotpotQA) (Orange dashed line):** Overlaps with PopQA.
* **Q-Anchored (NQ) (Pink dashed line):** Overlaps with TriviaQA and HotpotQA.
* **A-Anchored (NQ) (Gray dotted line):** Overlaps with PopQA and HotpotQA.
### Key Observations
* **Q-Anchored Performance Decline:** For all three models, the Q-Anchored performance on PopQA, TriviaQA, HotpotQA, and NQ datasets decreases significantly in the initial layers.
* **A-Anchored Performance Stability:** The A-Anchored performance on all datasets remains relatively stable around 0 across all layers for all three models.
* **Model Similarity:** The performance trends are qualitatively similar across the three models, with the Llama-3-70B model showing a more gradual decline in Q-Anchored performance compared to the other two.
* **Dataset Similarity:** The Q-Anchored performance on TriviaQA, HotpotQA, and NQ datasets are very similar.
### Interpretation
The data suggests that the question-related information processed in the initial layers of these language models is crucial for their performance on question-answering tasks. The significant drop in Q-Anchored performance indicates that as the model processes deeper layers, its ability to leverage question-specific information diminishes. In contrast, the stable A-Anchored performance suggests that the models maintain their ability to utilize answer-related information throughout all layers.
The similarity in performance trends across the three models implies that they share similar architectural characteristics or training methodologies. The more gradual decline in Q-Anchored performance for Llama-3-70B could be attributed to its larger size, which may allow it to retain question-specific information for a longer duration.
The overlapping performance of TriviaQA, HotpotQA, and NQ datasets suggests that these datasets may have similar characteristics or require similar reasoning abilities from the models.
</details>
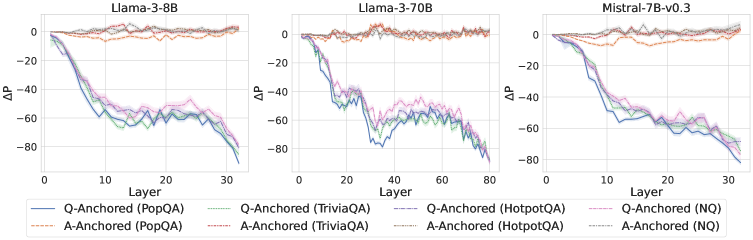
Figure 2: $\Delta\mathrm{P}$ under attention knockout. The layer axis indicates the Transformer layer on which the probe is trained. Shaded regions indicate 95% confidence intervals. Full results in Appendix C.
Hypothesis
These observations lead to the hypothesis that there are two distinct mechanisms of internal truthfulness encoding for hallucination detection: (1) one characterized by strong reliance on the key question-to-answer information from the exact question tokens, and (2) one in which truthfulness encoding is largely independent of the question. We validate the proposed hypothesis through further experiments in the next section.
3.2 Disentangling Information Mechanisms
We hypothesize that the internal truthfulness encoding operates through two distinct information flow mechanisms, driven by the attention modules within Transformer blocks. To validate the hypothesis, we first block information flows associated with the exact question tokens and analyze the resulting changes in the probe’s predictions. Subsequently, we apply a complementary technique, called token patching, to further substantiate the existence of these two mechanisms. Finally, we demonstrate that the self-contained information from the LLM-generated answer itself drives the truthfulness encoding for the A-Anchored type.
3.2.1 Experimental Setup
Our analysis covers a diverse collection of 12 LLMs that vary in both scale and architectural design. Specifically, we consider three categories: (1) base models, including Llama-3.2-1B (Grattafiori et al., 2024), Llama-3.2-3B, Llama-3-8B, Llama-3-70B, Mistral-7B-v0.1 (Jiang et al., 2023), and Mistral-7B-v0.3; (2) instruction-tuned models, including Llama-3.2-3B-Instruct, Llama-3-8B-Instruct, Mistral-7B-Instruct-v0.1, and Mistral-7B-Instruct-v0.3; and (3) reasoning-oriented models, namely Qwen3-8B (Yang et al., 2025) and Qwen3-32B. We conduct experiments on 4 widely used question-answering datasets: PopQA (Mallen et al., 2023), TriviaQA (Joshi et al., 2017), HotpotQA (Yang et al., 2018), and Natural Questions (Kwiatkowski et al., 2019). Additional implementation details are provided in Appendix B.
3.2.2 Identifying Anchored Modes via Attention Knockout
Experiment
To investigate whether internal truthfulness encoding operates via distinct information mechanisms, we perform an attention knockout experiment targeting the exact question tokens. Specifically, for a probe trained on representations from the $k$ -th layer, we set $A_{l}(i,E_{Q})=0$ for layers $l∈\{1,...,k\}$ and positions $i>E_{Q}$ . This procedure blocks the information flow from question tokens to subsequent positions in the representation. We then examine how the probe’s predictions respond to this intervention. To provide a clearer picture, instances are categorized according to whether their prediction $\hat{z}$ changes after the attention knockout:
$$
\text{Mode}(x)=\begin{cases}\text{Q-Anchored},&\text{if }\hat{z}\neq\tilde{\hat{z}}\\
\text{A-Anchored},&\text{otherwise}\end{cases} \tag{2}
$$
where $\hat{z}$ and $\tilde{\hat{z}}$ denote predictions before and after the attention knockout, respectively.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Different Models
### Overview
The image presents three bar charts comparing the prediction flip rates of different language models (Llama-3-8B, Llama-3-70B, and Mistral-7B-v0.3) across four datasets (PopQA, TriviaQA, HotpotQA, and NQ). The charts show the prediction flip rates for question-anchored and answer-anchored methods, both with exact questions and random questions.
### Components/Axes
* **Title:** Each chart has a title indicating the language model being evaluated: "Llama-3-8B", "Llama-3-70B", and "Mistral-7B-v0.3".
* **Y-axis:** "Prediction Flip Rate" ranging from 0 to 80.
* **X-axis:** "Dataset" with four categories: "PopQA", "TriviaQA", "HotpotQA", and "NQ".
* **Legend:** Located at the bottom of the image.
* Light Red: "Q-Anchored (exact\_question)"
* Dark Red: "Q-Anchored (random)"
* Light Gray: "A-Anchored (exact\_question)"
* Dark Gray: "A-Anchored (random)"
### Detailed Analysis
**Llama-3-8B**
* **PopQA:**
* Q-Anchored (exact\_question): ~73
* Q-Anchored (random): ~8
* A-Anchored (exact\_question): ~38
* A-Anchored (random): ~23
* **TriviaQA:**
* Q-Anchored (exact\_question): ~73
* Q-Anchored (random): ~12
* A-Anchored (exact\_question): ~34
* A-Anchored (random): ~3
* **HotpotQA:**
* Q-Anchored (exact\_question): ~72
* Q-Anchored (random): ~12
* A-Anchored (exact\_question): ~10
* A-Anchored (random): ~3
* **NQ:**
* Q-Anchored (exact\_question): ~72
* Q-Anchored (random): ~12
* A-Anchored (exact\_question): ~20
* A-Anchored (random): ~3
**Llama-3-70B**
* **PopQA:**
* Q-Anchored (exact\_question): ~75
* Q-Anchored (random): ~8
* A-Anchored (exact\_question): ~30
* A-Anchored (random): ~8
* **TriviaQA:**
* Q-Anchored (exact\_question): ~75
* Q-Anchored (random): ~18
* A-Anchored (exact\_question): ~48
* A-Anchored (random): ~15
* **HotpotQA:**
* Q-Anchored (exact\_question): ~80
* Q-Anchored (random): ~25
* A-Anchored (exact\_question): ~20
* A-Anchored (random): ~5
* **NQ:**
* Q-Anchored (exact\_question): ~72
* Q-Anchored (random): ~18
* A-Anchored (exact\_question): ~30
* A-Anchored (random): ~15
**Mistral-7B-v0.3**
* **PopQA:**
* Q-Anchored (exact\_question): ~75
* Q-Anchored (random): ~10
* A-Anchored (exact\_question): ~28
* A-Anchored (random): ~10
* **TriviaQA:**
* Q-Anchored (exact\_question): ~75
* Q-Anchored (random): ~12
* A-Anchored (exact\_question): ~30
* A-Anchored (random): ~5
* **HotpotQA:**
* Q-Anchored (exact\_question): ~73
* Q-Anchored (random): ~10
* A-Anchored (exact\_question): ~10
* A-Anchored (random): ~2
* **NQ:**
* Q-Anchored (exact\_question): ~73
* Q-Anchored (random): ~10
* A-Anchored (exact\_question): ~15
* A-Anchored (random): ~2
### Key Observations
* **Q-Anchored (exact\_question)** consistently shows the highest prediction flip rate across all datasets and models.
* **Q-Anchored (random)** consistently shows a low prediction flip rate across all datasets and models.
* **A-Anchored (exact\_question)** and **A-Anchored (random)** show varying prediction flip rates depending on the dataset and model, generally lower than Q-Anchored (exact\_question).
* Llama-3-70B shows a higher A-Anchored (exact\_question) prediction flip rate for TriviaQA compared to the other models.
* The prediction flip rates for Q-Anchored (exact\_question) are relatively consistent across all datasets for each model.
### Interpretation
The data suggests that using the exact question as an anchor (Q-Anchored (exact\_question)) leads to a significantly higher prediction flip rate compared to using a random question. This indicates that the models are highly sensitive to the specific wording of the question. The lower flip rates for A-Anchored methods suggest that the models are less sensitive to the answer context. The differences between the models highlight variations in their robustness and sensitivity to question phrasing across different datasets. The consistency of Q-Anchored (exact\_question) across datasets suggests a general vulnerability to specific question formulations, regardless of the knowledge domain.
</details>
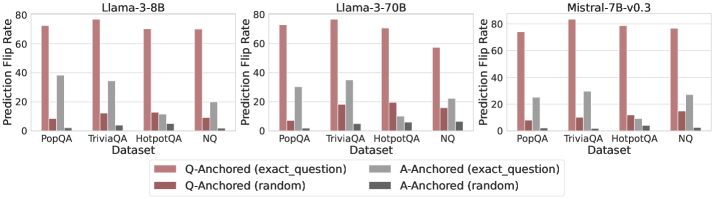
Figure 3: Prediction flip rate under token patching. Q-Anchored samples demonstrate significantly higher sensitivity than the counterparts when hallucinatory cues are injected into exact questions. Full results in Appendix D.
Results
The results in Figure 2 and Appendix C reveal a clear bifurcation of behaviors: for one subset of instances, probabilities shift substantially, while for another subset, probabilities remain nearly unchanged across all layers. Shaded regions indicate 95% confidence intervals, confirming that this qualitative separation is statistically robust. This sharp divergence supports the hypothesis that internal truthfulness encoding operates via two distinct mechanisms with respect to question–answer information. In Appendix C, we conduct a comprehensive analysis of alternative configurations for token selection, activation extraction, and various instruction- or reasoning-oriented models, and observe consistent patterns across all settings. Moreover, Figure 16 in Appendix C shows that blocking information from randomly selected question tokens yields negligible changes, in contrast to blocking exact question tokens, underscoring the nontrivial nature of the identified mechanisms.
3.2.3 Further Validation via Token Patching
Experiment
To further validate our findings, we employ a critical token patching technique to investigate how the internal representations of the LLM respond to hallucinatory signals originating from exact question tokens under the two proposed mechanisms. Given a context sample $d_{c}$ , we randomly select a patch sample $d_{p}$ and replace the original question tokens $E_{Q}^{c}$ in $d_{c}$ with the exact question tokens $E_{Q}^{p}$ from $d_{p}$ . This operation introduces hallucinatory cues into the context sample, allowing us to assess whether the LLM’s internal states appropriately reflect the injected changes. We restrict our analysis to context instances where the original LLM answers are factual, ensuring that any observed changes can be attributed solely to the injected hallucinatory cues.
Results
We measure the sensitivity of the truthfulness signals using the prediction flip rate, defined as the frequency with which the probe’s prediction changes after hallucinatory cues are introduced. Figure 3 and Appendix D present the results of the best-performing layer of each model on four datasets when patching the exact subject tokens. Across models and datasets, Q-Anchored mode exhibits significantly higher sensitivity compared to A-Anchored mode when exposed to hallucination cues from the questions. Furthermore, within each pathway, the flip rates where exact question tokens are patched are substantially higher than those observed when random tokens are patched, ruling out the possibility that the observed effects are mainly due to general semantic disruption from token replacement. These consistent results provide further support for our hypothesis regarding distinct mechanisms of information pathways.
3.2.4 What Drives A-Anchored Encoding?
Experiment
Since the A-Anchored mode operates largely independently of the question-to-answer information flow, it is important to investigate the source of information it uses to identify hallucinations. To this end, we remove the questions entirely from each sample and perform a separate forward pass using only the LLM-generated answers. This procedure yields answer-only hidden states, which are subsequently provided as input to the probe. We then evaluate how the probe’s predictions change under this “answer-only” condition. This setup enables us to assess whether A-Anchored predictions rely primarily on the generated answer itself rather than on the original question.
Results
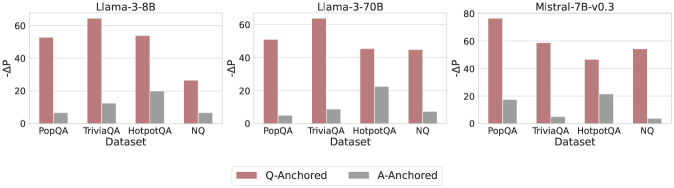
As shown in Figure 4 and Appendix E, Q-Anchored instances exhibit substantial changes in prediction probability when the question is removed, reflecting their dependence on question-to-answer information. In contrast, A-Anchored instances remain largely invariant, indicating that the probe continues to detect hallucinations using information encoded within the LLM-generated answer itself. These findings suggest that the A-Anchored mechanism primarily leverages self-contained answer information to build signals about truthfulness.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Bar Chart: Model Performance on Different Datasets
### Overview
The image presents three bar charts comparing the performance of different language models (Llama-3-8B, Llama-3-70B, and Mistral-7B-v0.3) across four datasets (PopQA, TriviaQA, HotpotQA, and NQ). The y-axis represents "-ΔP", and the bars are colored to distinguish between "Q-Anchored" and "A-Anchored" performance.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Middle Chart: Llama-3-70B
* Right Chart: Mistral-7B-v0.3
* **X-Axis:** Dataset (PopQA, TriviaQA, HotpotQA, NQ)
* **Y-Axis:** -ΔP, with a scale from 0 to 80 in increments of 20.
* **Legend:** Located at the bottom of the image.
* Rose/Pink: Q-Anchored
* Gray: A-Anchored
### Detailed Analysis
**Chart 1: Llama-3-8B**
* **PopQA:**
* Q-Anchored (Rose/Pink): ~52
* A-Anchored (Gray): ~7
* **TriviaQA:**
* Q-Anchored (Rose/Pink): ~64
* A-Anchored (Gray): ~12
* **HotpotQA:**
* Q-Anchored (Rose/Pink): ~53
* A-Anchored (Gray): ~20
* **NQ:**
* Q-Anchored (Rose/Pink): ~27
* A-Anchored (Gray): ~7
**Chart 2: Llama-3-70B**
* **PopQA:**
* Q-Anchored (Rose/Pink): ~52
* A-Anchored (Gray): ~8
* **TriviaQA:**
* Q-Anchored (Rose/Pink): ~63
* A-Anchored (Gray): ~9
* **HotpotQA:**
* Q-Anchored (Rose/Pink): ~45
* A-Anchored (Gray): ~22
* **NQ:**
* Q-Anchored (Rose/Pink): ~45
* A-Anchored (Gray): ~8
**Chart 3: Mistral-7B-v0.3**
* **PopQA:**
* Q-Anchored (Rose/Pink): ~75
* A-Anchored (Gray): ~17
* **TriviaQA:**
* Q-Anchored (Rose/Pink): ~57
* A-Anchored (Gray): ~5
* **HotpotQA:**
* Q-Anchored (Rose/Pink): ~46
* A-Anchored (Gray): ~21
* **NQ:**
* Q-Anchored (Rose/Pink): ~54
* A-Anchored (Gray): ~3
### Key Observations
* For all models, Q-Anchored performance is generally higher than A-Anchored performance across all datasets.
* TriviaQA tends to have the highest Q-Anchored performance for Llama-3-8B and Llama-3-70B.
* Mistral-7B-v0.3 shows the highest Q-Anchored performance on PopQA.
* A-Anchored performance is consistently low across all datasets and models, with HotpotQA showing slightly higher values.
### Interpretation
The charts illustrate the performance differences between language models on various question-answering datasets, distinguishing between Q-Anchored and A-Anchored approaches. The consistently higher Q-Anchored performance suggests that anchoring the model on the question leads to better results compared to anchoring on the answer. The specific performance variations across datasets highlight the models' strengths and weaknesses in handling different types of questions and knowledge domains. Mistral-7B-v0.3 appears to perform better overall, especially on the PopQA dataset. The low A-Anchored performance indicates a potential area for improvement in how the models utilize answer-related information.
</details>
Figure 4: $-\Delta\mathrm{P}$ with only the LLM-generated answer. Q-Anchored instances exhibit substantial shifts, whereas A-Anchored instances remain stable, confirming that A-Anchored truthfulness encoding relies on information in the LLM-generated answer itself. Full results in Appendix E.
4 Properties of Truthfulness Pathways
This section examines notable properties and distinct behaviors of intrinsic truthfulness encoding: (1) Associations with knowledge boundaries: samples within the LLM’s knowledge boundary tend to encode truthfulness via the Q-Anchored pathway, whereas samples beyond the boundary often rely on the A-Anchored signal; (2) Self-awareness: internal representations can be used to predict which mechanism is being employed, suggesting that LLMs possess intrinsic awareness of pathway distinctions.
4.1 Associations with Knowledge Boundaries
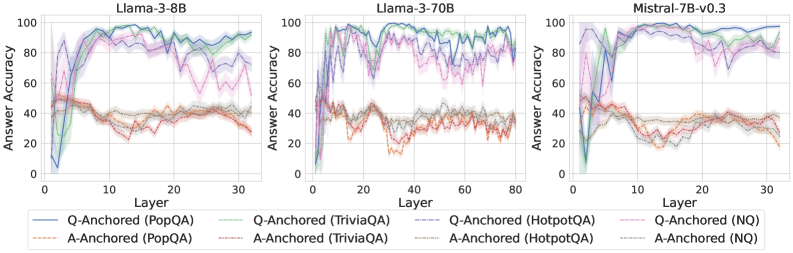
We find that distinct patterns of truthfulness encoding are closely associated with the knowledge boundaries of LLMs. To characterize these boundaries, three complementary metrics are employed: (1) Answer accuracy, the most direct indicator of an LLM’s factual competence; (2) I-don’t-know rate (shown in Appendix G), which reflects the model’s ability to recognize and express its own knowledge limitations; (3) Entity popularity, which is widely used to distinguish between common and long-tail factual knowledge (Mallen et al., 2023).
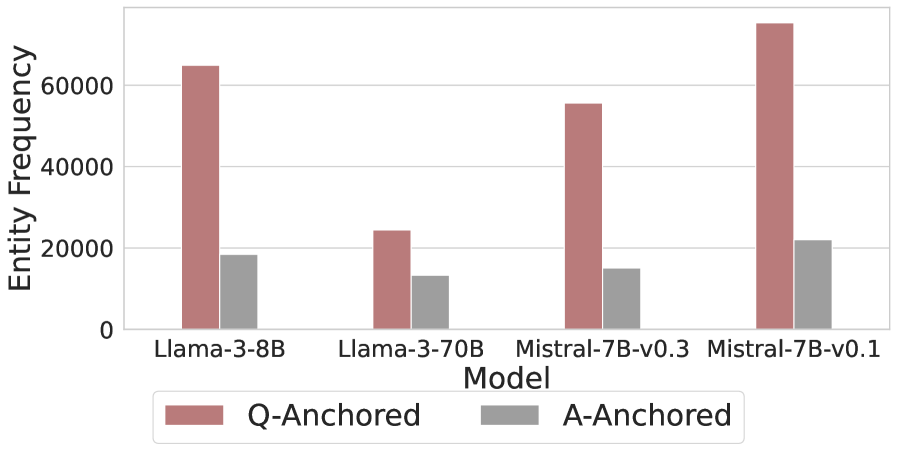
As shown in Figure 5 and Appendix F, Q-Anchored samples achieve significantly higher accuracy than those driven by the A-Anchored pathway. The results for the I-don’t-know rate, reported in Appendix G, exhibit trends consistent with answer accuracy, further indicating stronger knowledge handling in Q-Anchored samples. Moreover, entity popularity, shown in Figure 6, provides a more fine-grained perspective on knowledge boundaries. Specifically, Q-Anchored samples tend to involve more popular entities, whereas A-Anchored samples are more frequently associated with less popular, long-tail factual knowledge. These findings suggest that truthfulness encoding is strongly aligned with the availability of stored knowledge: when LLMs possess the requisite knowledge, they predominantly rely on question–answer information flow (Q-Anchored); when knowledge is unavailable, they instead draw upon internal patterns within their own generated outputs (A-Anchored).
<details>
<summary>x5.png Details</summary>
### Visual Description
## Chart: Answer Accuracy vs. Layer for Different Language Models
### Overview
The image presents three line charts comparing the answer accuracy of different language models (Llama-3-8B, Llama-3-70B, and Mistral-7B-v0.3) across various layers. Each chart plots answer accuracy against the layer number for both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches on four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts aim to illustrate how accuracy changes with layer depth for each model and dataset combination.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Middle Chart: Llama-3-70B
* Right Chart: Mistral-7B-v0.3
* **Y-Axis (Answer Accuracy):**
* Scale: 0 to 100
* Markers: 0, 20, 40, 60, 80, 100
* Label: Answer Accuracy
* **X-Axis (Layer):**
* Left Chart: 0 to 30
* Markers: 0, 10, 20, 30
* Middle Chart: 0 to 80
* Markers: 0, 20, 40, 60, 80
* Right Chart: 0 to 30
* Markers: 0, 10, 20, 30
* Label: Layer
* **Legend (Located at the bottom):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dashed Pink Line
* Q-Anchored (HotpotQA): Solid Purple Line
* A-Anchored (HotpotQA): Dashed Gray Line
* Q-Anchored (NQ): Dotted Red Line
* A-Anchored (NQ): Dashed Orange Line
### Detailed Analysis
#### Llama-3-8B (Left Chart)
* **Q-Anchored (PopQA) - Solid Blue:** Starts at approximately 0 accuracy, rapidly increases to around 90-100 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown:** Starts around 40-50 accuracy and remains relatively stable between 30 and 50 across all layers.
* **Q-Anchored (TriviaQA) - Dotted Green:** Starts at approximately 0 accuracy, rapidly increases to around 90-100 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (TriviaQA) - Dashed Pink:** Starts around 40-50 accuracy, increases to around 80 by layer 10, and then fluctuates between 60 and 80 for the remaining layers.
* **Q-Anchored (HotpotQA) - Solid Purple:** Starts at approximately 0 accuracy, rapidly increases to around 90-100 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (HotpotQA) - Dashed Gray:** Starts around 40-50 accuracy and remains relatively stable between 30 and 50 across all layers.
* **Q-Anchored (NQ) - Dotted Red:** Starts around 20 accuracy, increases to around 40 by layer 10, and then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (NQ) - Dashed Orange:** Starts around 20 accuracy, increases to around 40 by layer 10, and then fluctuates between 20 and 40 for the remaining layers.
#### Llama-3-70B (Middle Chart)
* **Q-Anchored (PopQA) - Solid Blue:** Starts at approximately 40 accuracy, rapidly increases to around 90-100 by layer 20, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown:** Starts around 40-50 accuracy and remains relatively stable between 30 and 50 across all layers.
* **Q-Anchored (TriviaQA) - Dotted Green:** Starts at approximately 40 accuracy, rapidly increases to around 90-100 by layer 20, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (TriviaQA) - Dashed Pink:** Starts around 40-50 accuracy, increases to around 80 by layer 20, and then fluctuates between 60 and 80 for the remaining layers.
* **Q-Anchored (HotpotQA) - Solid Purple:** Starts at approximately 40 accuracy, rapidly increases to around 90-100 by layer 20, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (HotpotQA) - Dashed Gray:** Starts around 40-50 accuracy and remains relatively stable between 30 and 50 across all layers.
* **Q-Anchored (NQ) - Dotted Red:** Starts around 20 accuracy, increases to around 40 by layer 20, and then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (NQ) - Dashed Orange:** Starts around 20 accuracy, increases to around 40 by layer 20, and then fluctuates between 20 and 40 for the remaining layers.
#### Mistral-7B-v0.3 (Right Chart)
* **Q-Anchored (PopQA) - Solid Blue:** Starts at approximately 0 accuracy, rapidly increases to around 90-100 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown:** Starts around 40-50 accuracy and remains relatively stable between 30 and 50 across all layers.
* **Q-Anchored (TriviaQA) - Dotted Green:** Starts at approximately 0 accuracy, rapidly increases to around 90-100 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (TriviaQA) - Dashed Pink:** Starts around 40-50 accuracy, increases to around 80 by layer 10, and then fluctuates between 60 and 80 for the remaining layers.
* **Q-Anchored (HotpotQA) - Solid Purple:** Starts at approximately 0 accuracy, rapidly increases to around 90-100 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (HotpotQA) - Dashed Gray:** Starts around 40-50 accuracy and remains relatively stable between 30 and 50 across all layers.
* **Q-Anchored (NQ) - Dotted Red:** Starts around 20 accuracy, increases to around 40 by layer 10, and then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (NQ) - Dashed Orange:** Starts around 20 accuracy, increases to around 40 by layer 10, and then fluctuates between 20 and 40 for the remaining layers.
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored approaches (PopQA, TriviaQA, HotpotQA) generally achieve higher accuracy than A-Anchored approaches across all models.
* **Dataset Performance:** PopQA, TriviaQA, and HotpotQA datasets show similar performance trends, with accuracy increasing rapidly in the initial layers for Q-Anchored approaches. NQ dataset consistently shows lower accuracy for both Q-Anchored and A-Anchored approaches.
* **Model Comparison:** All three models exhibit similar trends, but Llama-3-70B seems to require more layers to reach peak accuracy compared to Llama-3-8B and Mistral-7B-v0.3.
* **Accuracy Saturation:** For Q-Anchored approaches on PopQA, TriviaQA, and HotpotQA, accuracy tends to plateau or fluctuate after reaching a certain layer, suggesting diminishing returns with increasing depth.
### Interpretation
The data suggests that question-anchoring is a more effective strategy for achieving high answer accuracy in these language models, particularly for the PopQA, TriviaQA, and HotpotQA datasets. The lower performance of the NQ dataset may indicate that it presents a more challenging question-answering task. The observation that Llama-3-70B requires more layers to reach peak accuracy could be related to its larger size and complexity, potentially needing more processing steps to extract relevant information. The saturation effect observed in the Q-Anchored approaches implies that there is a limit to how much accuracy can be improved by simply adding more layers, suggesting that other factors, such as the quality of training data or the model architecture, may play a more significant role beyond a certain depth.
</details>
Figure 5: Comparisons of answer accuracy between pathways. Q-Anchored samples show higher accuracy than A-Anchored ones, highlighting the association between truthfulness encoding and LLM knowledge boundaries. Full results in Appendix F and G.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Bar Chart: Entity Frequency by Model
### Overview
The image is a bar chart comparing the entity frequency of different language models, specifically Llama-3-8B, Llama-3-70B, Mistral-7B-v0.3, and Mistral-7B-v0.1. The chart displays two categories of entity frequency: "Q-Anchored" (represented by a light-red/brown color) and "A-Anchored" (represented by gray).
### Components/Axes
* **X-axis:** "Model" with categories: Llama-3-8B, Llama-3-70B, Mistral-7B-v0.3, Mistral-7B-v0.1
* **Y-axis:** "Entity Frequency" with a numerical scale from 0 to 60000, with tick marks at 20000, 40000, and 60000.
* **Legend:** Located at the bottom of the chart.
* Light-red/brown: "Q-Anchored"
* Gray: "A-Anchored"
### Detailed Analysis
* **Llama-3-8B:**
* Q-Anchored: Approximately 63000
* A-Anchored: Approximately 18000
* **Llama-3-70B:**
* Q-Anchored: Approximately 24000
* A-Anchored: Approximately 13000
* **Mistral-7B-v0.3:**
* Q-Anchored: Approximately 56000
* A-Anchored: Approximately 15000
* **Mistral-7B-v0.1:**
* Q-Anchored: Approximately 73000
* A-Anchored: Approximately 22000
### Key Observations
* For all models, the "Q-Anchored" entity frequency is significantly higher than the "A-Anchored" entity frequency.
* Mistral-7B-v0.1 has the highest "Q-Anchored" entity frequency among the models.
* Llama-3-70B has the lowest "Q-Anchored" and "A-Anchored" entity frequencies.
### Interpretation
The chart suggests that "Q-Anchored" entities are more frequent than "A-Anchored" entities across all the evaluated language models. The difference in frequency between the two categories varies among the models, with Mistral-7B-v0.1 showing the highest overall entity frequency and Llama-3-70B showing the lowest. This could indicate differences in how these models process or generate "Q-Anchored" versus "A-Anchored" entities, potentially reflecting variations in their training data or architectural design.
</details>
Figure 6: Entity frequency distributions for both pathways on PopQA. Q-Anchored samples concentrate on more popular entities, whereas A-Anchored samples skew toward long-tail entities.
4.2 Self-Awareness of Pathway Distinctions
Given that LLMs encode truthfulness via two distinct mechanisms, this section investigates whether their internal representations contain discriminative information that can be used to distinguish between these mechanisms. To this end, we train probing classifiers on the models’ original internal states (i.e., without knockout interventions) to predict which mechanism is being utilized.
Table 2 reports the pathway classification results of the best-performing layers in hallucination detection across different models. Our findings demonstrate that different mechanisms can be reliably inferred from internal representations, suggesting that, in addition to encoding truthfulness, LLMs exhibit intrinsic awareness of pathway distinctions. These findings highlight a potential avenue for fine-grained improvements targeting specific truthfulness encoding mechanisms.
Datasets Llama-3-8B Llama-3-70B Mistral-7B-v0.3 PopQA 87.80 92.66 87.64 TriviaQA 75.10 83.91 85.87 HotpotQA 86.31 87.34 92.13 NQ 78.31 84.14 84.83
Table 2: AUCs for encoding pathway classification. The predictability from internal representations indicates that LLMs possess intrinsic awareness of pathway distinctions.
5 Pathway-Aware Detection
Building on the intriguing findings, we explore how the discovered pathway distinctions can be leveraged to improve hallucination detection. Specifically, two simple yet effective pathway-aware strategies are proposed: (1) Mixture-of-Probes (MoP) (§ 5.1), which allows expert probes to specialize in Q-Anchored and A-Anchored pathways respectively, and (2) Pathway Reweighting (PR) (§ 5.2), a plug-and-play approach that amplifies pathway-relevant cues salient for detection.
5.1 Mixture-of-Probes
Motivated by the fundamentally different dependencies of the two encoding pathways and the LLMs’ intrinsic awareness of them, we propose a Mixture-of-Probes (MoP) framework that explicitly captures this heterogeneity. Rather than training a single probe to handle all inputs, MoP employs two pathway-specialized experts and leverages the self-awareness probe (§ 4.2) as a gating network to combine their predictions. Let $\mathbf{h}^{l^{*}}(x)\!∈\!\mathbb{R}^{d}$ be the token hidden state from the best detection layer $l^{*}$ . Two expert probes $p_{Q}(·)$ and $p_{A}(·)$ are trained separately for two pathway samples, and the self-awareness probe provides a gating coefficient $\pi(\mathbf{h}^{l^{*}}(x))\!∈\![0,1]$ . The final prediction is a convex combination, requiring no extra training:
$$
\displaystyle p_{\text{MoP}}(z\!=\!1\mid\mathbf{h}^{l^{*}}(x)) \displaystyle=\pi_{Q}\,p_{Q}(z\!=\!1\mid\mathbf{h}^{l^{*}}(x)) \displaystyle\quad+(1-\pi_{Q})\,p_{A}(z\!=\!1\mid\mathbf{h}^{l^{*}}(x)). \tag{3}
$$
5.2 Pathway Reweighting
From the perspective of emphasizing pathway-relevant internal cues, we introduce a plug-and-play Pathway Reweighting (PR) method that directly modulates the question–answer information flow. The key idea is to adjust the attention from exact answer to question tokens according to the predicted pathway, amplifying the signals most salient for hallucination detection. For each layer $l≤ l^{*}$ , two learnable scalars $\alpha_{Q}^{l},\alpha_{A}^{l}>0$ are introduced. Given self-awareness probability $\pi(\mathbf{h}^{l^{*}}(x))$ , we rescale attention edges $i\!∈\!E_{A}$ , $j\!∈\!E_{Q}$ to construct representations tailored for detection:
$$
\tilde{A}^{l}(i,j)=\begin{cases}\bigl[1+s(\mathbf{h}^{l^{*}}(x))\bigr]A^{l}(i,j),&i\!\in\!E_{A},j\!\in\!E_{Q},\\
A^{l}(i,j),&\text{otherwise},\end{cases} \tag{4}
$$
where
$$
s(\mathbf{h}^{l^{*}}(x))=\pi_{Q}\,\alpha_{Q}^{l}-(1-\pi_{Q})\,\alpha_{A}^{l}. \tag{5}
$$
The extra parameters serve as a lightweight adapter, used only during detection to guide salient truthfulness cues and omitted during generation, leaving the generation capacity unaffected.
Method Llama-3-8B Mistral-7B-v0.3 PopQA TriviaQA HotpotQA NQ PopQA TriviaQA HotpotQA NQ P(True) 55.85 49.92 52.14 53.27 45.49 47.61 57.87 52.79 Logits-mean 74.52 60.39 51.94 52.63 69.52 66.76 55.45 57.88 Logits-min 85.36 70.89 61.28 56.50 87.05 77.33 68.08 54.40 Probing Baseline 88.71 77.58 82.23 70.20 87.39 81.74 83.19 73.60 \rowcolor mygray MoP-RandomGate 75.52 69.17 79.88 66.56 79.81 70.88 72.23 61.19 \rowcolor mygray MoP-VanillaExperts 89.11 78.73 84.57 71.21 88.53 80.93 82.93 73.77 \rowcolor mygray MoP 92.11 81.18 85.45 74.64 91.66 83.57 85.82 76.87 \rowcolor mygray PR 94.01 83.13 87.81 79.10 93.09 84.36 89.03 79.09
Table 3: Comparison of hallucination detection performance (AUC). Full results in Appendix H.
5.3 Experiments
Setup
The experimental setup follows Section 3.2.1. We compare our method against several internal-based baselines, including (1) P(True) (Kadavath et al., 2022), (2) uncertainty-based metrics (Aichberger et al., 2024; Xue et al., 2025a), and (3) probing classifiers (Chen et al., 2024; Orgad et al., 2025). Results are averaged over three random seeds. Additional implementation details are provided in Appendix B.5 and B.6.
Results
As shown in Table 3 and Appendix H, both MoP and PR consistently outperform competing approaches across different datasets and model scales. Specifically, for MoP, we further examine two ablated variants: (1) MoP-RandomGate, which randomly routes the two pathway experts without leveraging the self-awareness probe; and (2) MoP-VanillaExperts, which replaces the expert probes with two vanilla probes to serve as a simple ensemble strategy. Both ablated variants exhibit substantially degraded performance compared to MoP, underscoring the roles of pathway specialization and self-awareness gating. For PR, the method proves particularly effective in improving performance by dynamically adjusting the focus on salient truthfulness cues. These results demonstrate that explicitly modeling truthfulness encoding heterogeneity can effectively translate the insights of our analysis into practical gains for hallucination detection.
6 Related Work
Hallucination detection in LLMs has received increasing attention because of its critical role in building reliable and trustworthy generative systems (Tian et al., 2024; Shi et al., 2024; Bai et al., 2024). Existing approaches can be broadly grouped by whether they rely on external resources (e.g., retrieval systems or fact–checking APIs). Externally assisted methods cross-verify output texts against external knowledge bases (Min et al., 2023; Hu et al., 2025; Huang et al., 2025) or specialized LLM judges (Luo et al., 2024; Bouchard and Chauhan, 2025; Zhang et al., 2025). Resource-free methods avoid external data and instead exploit the model’s own intermediate computations. Some leverage the model’s self-awareness of knowledge boundaries (Kadavath et al., 2022; Luo et al., 2025), while others use uncertainty-based measures (Aichberger et al., 2024; Xue et al., 2025a), treating confidence as a proxy for truthfulness. These techniques analyze output distributions (e.g., logits) (Aichberger et al., 2024), variance across multiple samples (e.g., consistency) (Min et al., 2023; Aichberger et al., 2025), or other statistical indicators of prediction uncertainty (Xue et al., 2025b). Another line of work trains linear probing classifiers on hidden representations to capture intrinsic truthfulness signals. Prior work (Burns et al., 2023; Li et al., 2023; Chen et al., 2024; Orgad et al., 2025) shows that LLMs encode rich latent features correlated with factual accuracy, enabling efficient detection with minimal overhead. Yet the mechanisms behind these internal truthfulness encoding remain poorly understood. Compared to previous approaches, our work addresses this gap by dissecting how such intrinsic signals emerge and operate, revealing distinct information pathways that not only yield explanatory insights but also enhance detection performance.
7 Conclusion
We investigate how LLMs encode truthfulness, revealing two complementary pathways: a Question-Anchored pathway relying on question–answer flow, and an Answer-Anchored pathway extracting self-contained evidence from generated outputs. Analyses across datasets and models highlight their ties to knowledge boundaries and intrinsic self-awareness. Building on these insights, we further propose two applications to improve hallucination detection. Overall, our findings not only advance mechanistic understanding of intrinsic truthfulness encoding but also offer practical applications for building more reliable generative systems.
Limitations
While this work provides a systematic analysis of intrinsic truthfulness encoding mechanisms in LLMs and demonstrates their utility for hallucination detection, one limitation is that, similar to prior work on mechanistic interpretability, our analyses and pathway-aware applications assume access to internal model representations. Such access may not always be available in strictly black-box settings. In these scenarios, additional engineering or alternative approximations may be required for practical deployment, which we leave for future work.
Ethics Statement
Our work presents minimal potential for negative societal impact, primarily due to the use of publicly available datasets and models. This accessibility inherently reduces the risk of adverse effects on individuals or society.
References
- Aichberger et al. (2024) Lukas Aichberger, Kajetan Schweighofer, Mykyta Ielanskyi, and Sepp Hochreiter. 2024. Semantically diverse language generation for uncertainty estimation in language models. arXiv preprint arXiv:2406.04306.
- Aichberger et al. (2025) Lukas Aichberger, Kajetan Schweighofer, Mykyta Ielanskyi, and Sepp Hochreiter. 2025. Improving uncertainty estimation through semantically diverse language generation. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net.
- Bai et al. (2024) Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. 2024. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 7421–7454. Association for Computational Linguistics.
- Baker et al. (1998) Collin F Baker, Charles J Fillmore, and John B Lowe. 1998. The berkeley framenet project. In 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Volume 1, pages 86–90.
- Bouchard and Chauhan (2025) Dylan Bouchard and Mohit Singh Chauhan. 2025. Uncertainty quantification for language models: A suite of black-box, white-box, llm judge, and ensemble scorers. arXiv preprint arXiv:2504.19254.
- Burns et al. (2023) Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. 2023. Discovering latent knowledge in language models without supervision. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Chen et al. (2024) Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. 2024. INSIDE: llms’ internal states retain the power of hallucination detection. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- Fierro et al. (2025) Constanza Fierro, Negar Foroutan, Desmond Elliott, and Anders Søgaard. 2025. How do multilingual language models remember facts? In Findings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 16052–16106. Association for Computational Linguistics.
- Geva et al. (2023) Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. Dissecting recall of factual associations in auto-regressive language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 12216–12235. Association for Computational Linguistics.
- Ghandeharioun et al. (2024) Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. 2024. Patchscopes: A unifying framework for inspecting hidden representations of language models. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net.
- Grattafiori et al. (2024) Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. The llama 3 herd of models. Preprint, arXiv:2407.21783.
- Hu et al. (2025) Wentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing Li. 2025. Removal of hallucination on hallucination: Debate-augmented RAG. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 15839–15853. Association for Computational Linguistics.
- Huang et al. (2025) Lei Huang, Xiaocheng Feng, Weitao Ma, Yuchun Fan, Xiachong Feng, Yuxuan Gu, Yangfan Ye, Liang Zhao, Weihong Zhong, Baoxin Wang, Dayong Wu, Guoping Hu, Lingpeng Kong, Tong Xiao, Ting Liu, and Bing Qin. 2025. Alleviating hallucinations from knowledge misalignment in large language models via selective abstention learning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 24564–24579. Association for Computational Linguistics.
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b. Preprint, arXiv:2310.06825.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada. Association for Computational Linguistics.
- Kadavath et al. (2022) Saurav Kadavath, Tom Conerly, Amanda Askell, T. J. Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zachary Dodds, Nova Dassarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, and 17 others. 2022. Language models (mostly) know what they know. ArXiv, abs/2207.05221.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
- Li et al. (2023) Kenneth Li, Oam Patel, Fernanda B. Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023. Inference-time intervention: Eliciting truthful answers from a language model. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
- Luo et al. (2024) Wen Luo, Tianshu Shen, Wei Li, Guangyue Peng, Richeng Xuan, Houfeng Wang, and Xi Yang. 2024. Halludial: A large-scale benchmark for automatic dialogue-level hallucination evaluation. Preprint, arXiv:2406.07070.
- Luo et al. (2025) Wen Luo, Feifan Song, Wei Li, Guangyue Peng, Shaohang Wei, and Houfeng Wang. 2025. Odysseus navigates the sirens’ song: Dynamic focus decoding for factual and diverse open-ended text generation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 27200–27218, Vienna, Austria. Association for Computational Linguistics.
- Mallen et al. (2023) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada. Association for Computational Linguistics.
- Michel et al. (2019) Paul Michel, Omer Levy, and Graham Neubig. 2019. Are sixteen heads really better than one? Advances in neural information processing systems, 32.
- Min et al. (2023) Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 12076–12100. Association for Computational Linguistics.
- Niu et al. (2025) Mengjia Niu, Hamed Haddadi, and Guansong Pang. 2025. Robust hallucination detection in llms via adaptive token selection. arXiv preprint arXiv:2504.07863.
- Orgad et al. (2025) Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. 2025. Llms know more than they show: On the intrinsic representation of LLM hallucinations. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net.
- Pagnoni et al. (2021) Artidoro Pagnoni, Vidhisha Balachandran, and Yulia Tsvetkov. 2021. Understanding factuality in abstractive summarization with frank: A benchmark for factuality metrics. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4812–4829.
- Qian et al. (2025) Chen Qian, Dongrui Liu, Haochen Wen, Zhen Bai, Yong Liu, and Jing Shao. 2025. Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in llm reasoning. arXiv preprint arXiv:2506.02867.
- Shi et al. (2024) Zhengliang Shi, Shuo Zhang, Weiwei Sun, Shen Gao, Pengjie Ren, Zhumin Chen, and Zhaochun Ren. 2024. Generate-then-ground in retrieval-augmented generation for multi-hop question answering. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 7339–7353. Association for Computational Linguistics.
- Simonyan et al. (2014) Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2014. Deep inside convolutional networks: Visualising image classification models and saliency maps. In 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Workshop Track Proceedings.
- Tian et al. (2024) Yuanhe Tian, Ruyi Gan, Yan Song, Jiaxing Zhang, and Yongdong Zhang. 2024. Chimed-gpt: A chinese medical large language model with full training regime and better alignment to human preferences. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 7156–7173. Association for Computational Linguistics.
- Todd et al. (2024) Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. 2024. Function vectors in large language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- Wang et al. (2023) Lean Wang, Lei Li, Damai Dai, Deli Chen, Hao Zhou, Fandong Meng, Jie Zhou, and Xu Sun. 2023. Label words are anchors: An information flow perspective for understanding in-context learning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9840–9855.
- Wu et al. (2025) Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. 2025. Retrieval head mechanistically explains long-context factuality. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net.
- Xue et al. (2025a) Boyang Xue, Fei Mi, Qi Zhu, Hongru Wang, Rui Wang, Sheng Wang, Erxin Yu, Xuming Hu, and Kam-Fai Wong. 2025a. UAlign: Leveraging uncertainty estimations for factuality alignment on large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6002–6024, Vienna, Austria. Association for Computational Linguistics.
- Xue et al. (2025b) Yihao Xue, Kristjan Greenewald, Youssef Mroueh, and Baharan Mirzasoleiman. 2025b. Verify when uncertain: Beyond self-consistency in black box hallucination detection. arXiv preprint arXiv:2502.15845.
- Yang et al. (2025) An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical report. Preprint, arXiv:2505.09388.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
- Zhang et al. (2025) Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, and 1 others. 2025. Siren’s song in the ai ocean: A survey on hallucination in large language models. Computational Linguistics, pages 1–46.
Appendix A LLM Usage
In this work, we employ LLMs solely for language refinement to enhance clarity and explanatory quality. All content has been carefully verified for factual accuracy, and the authors take full responsibility for the entire manuscript. The core ideas, experimental design, and methodological framework are conceived and developed independently by the authors, without the use of LLMs.
Appendix B Implementation Details
B.1 Identifying Exact Question and Answer Tokens
To locate the exact question and answer tokens within a QA pair, we prompt GPT-4o (version gpt-4o_2024-11-20) to identify the precise positions of the core frame elements. The instruction templates are presented in Tables 5 and 6. A token is considered an exact question or exact answer if and only if it constitutes a valid substring of the corresponding question or answer. To mitigate potential biases, each example is prompted at most five times, and only successfully extracted instances are retained for downstream analysis. Prior work (Orgad et al., 2025) has shown that LLMs can accurately identify exact answer tokens, typically achieving over 95% accuracy. In addition, we manually verified GPT-4o’s identification quality in our setting. Specifically, it achieves 99.92%, 95.83%, and 96.62% accuracy on exact subject tokens, exact property tokens, and exact answer tokens, respectively. Furthermore, we also explore alternative configurations without the use of exact tokens to ensure the robustness of our findings (see Section B.2).
B.2 Probing Implementation Details
We investigate multiple probing configurations. For token selection, we consider three types of tokens: (1) the final token of the answer, which is the most commonly adopted choice in prior work due to its global receptive field under attention (Chen et al., 2024); (2) the token immediately preceding the exact answer span; and (3) the final token within the exact answer span. For activation extraction, we obtain representations from either (1) the output of each attention sublayer or (2) the output of the final multi-layer perceptron (MLP) in each transformer layer. Across all configurations, our experimental results exhibit consistent trends, indicating that the observed findings are robust to these design choices. For the probing classifier, we follow standard practice (Chen et al., 2024; Orgad et al., 2025) and employ a logistic regression model implemented in scikit-learn.
B.3 Models
Our analysis covers a diverse collection of 12 LLMs that vary in both scale and architectural design. Specifically, we consider three categories: (1) base models, including Llama-3.2-1B (Grattafiori et al., 2024), Llama-3.2-3B, Llama-3-8B, Llama-3-70B, Mistral-7B-v0.1 (Jiang et al., 2023), and Mistral-7B-v0.3; (2) instruction-tuned models, including Llama-3.2-3B-Instruct, Llama-3-8B-Instruct, Mistral-7B-Instruct-v0.1, and Mistral-7B-Instruct-v0.3; and (3) reasoning-oriented models, namely Qwen3-8B (Yang et al., 2025) and Qwen3-32B.
B.4 Datasets
We consider four widely used question–answering datasets: PopQA (Mallen et al., 2023), TriviaQA (Joshi et al., 2017), HotpotQA (Yang et al., 2018), and Natural Questions (Kwiatkowski et al., 2019).
PopQA is an open-domain question-answering dataset that emphasizes entity-centric factual knowledge with a long-tail distribution. It is designed to probe LLMs’ ability to memorize less frequent facts, highlighting limitations in parametric knowledge.
TriviaQA is a reading comprehension dataset constructed by pairing trivia questions authored independently of evidence documents. The questions are often complex, requiring multi-sentence reasoning, and exhibit substantial lexical and syntactic variability.
HotpotQA is a challenging multi-hop question-answering dataset that requires reasoning. It includes diverse question types—span extraction, yes/no, and novel comparison questions—along with sentence-level supporting fact annotations, promoting the development of explainable QA systems.
Natural Questions is an open-domain dataset consisting of real, anonymized questions from Google search queries. Each question is annotated with both a long answer (paragraph or section) and a short answer (span or yes/no), or marked as null when no answer is available. Due to computational constraints, we randomly sample 2,000 training samples and 2,000 test samples for each dataset.
B.5 Implementation Details of Baselines
In our experiments regarding applications, we compare our proposed methods against several internal-based baselines for hallucination detection. These baselines leverage the LLM’s internal signals, such as output probabilities, logits, and hidden representations, without relying on external resources. Below, we detail the implementation of each baseline.
P(True)
P(True) (Kadavath et al., 2022) exploits the LLM’s self-awareness of its knowledge boundaries by prompting the model to assess the correctness of its own generated answer. Specifically, for each question-answer pair $(q_{i},\hat{y}^{f}_{i})$ , we prompt the LLM with a template that asks it to evaluate whether its answer is factually correct. Following Kadavath et al. (2022), the prompt template is shown in Table 4.
| Question: {Here is the question} |
| --- |
| Possible answer: {Here is the answer} |
| Is the possible answer: |
| (A) True |
| (B) False |
| The possible answer is: |
Table 4: Prompt template used for the P(True) baseline.
Logits-based Baselines
The logits-based baselines utilize the raw logits produced by the LLM during the generation of the exact answer tokens. Let $\hat{y}^{f}_{i,E_{A}}=[t_{1},t_{2},...,t_{m}]$ represent the sequence of exact answer tokens for a given question-answer pair, where $m$ is the number of exact answer tokens. For each token $t_{j}$ (where $j∈\{1,...,m\}$ ), the LLM produces a logit vector $L_{j}∈\mathbb{R}^{V}$ , where $V$ is the vocabulary size, and the logit for the generated token $t_{j}$ is denoted $L_{j}[t_{j}]$ . The logits-based metrics are defined as follows:
- Logits-mean: The average of the logits across all exact answer tokens:
$$
\text{Logits-mean}=\frac{1}{m}\sum_{j=1}^{m}L_{j}[t_{j}] \tag{6}
$$
- Logits-max: The maximum logit value among the exact answer tokens:
$$
\text{Logits-max}=\max_{j\in\{1,\dots,m\}}L_{j}[t_{j}] \tag{7}
$$
- Logits-min: The minimum logit value among the exact answer tokens:
$$
\text{Logits-min}=\min_{j\in\{1,\dots,m\}}L_{j}[t_{j}] \tag{8}
$$
These metrics serve as proxies for the model’s confidence in the generated answer, with lower logit values potentially indicating uncertainty or hallucination.
Scores-based Baselines
The scores-based baselines are derived from the softmax probabilities of the exact answer tokens. Using the same notation as above, for each exact answer token $t_{j}$ , the softmax probability is computed as:
$$
p_{j}[t_{j}]=\frac{\exp(L_{j}[t_{j}])}{\sum_{k=1}^{V}\exp(L_{j}[k])} \tag{9}
$$
where $L_{j}[k]$ is the logit for the $k$ -th token in the vocabulary. The scores-based metrics are defined as follows:
- Scores-mean: The average of the softmax probabilities across all exact answer tokens:
$$
\text{Scores-mean}=\frac{1}{m}\sum_{j=1}^{m}p_{j}[t_{j}] \tag{10}
$$
- Scores-max: The maximum softmax probability among the exact answer tokens:
$$
\text{Scores-max}=\max_{j\in\{1,\dots,m\}}p_{j}[t_{j}] \tag{11}
$$
- Scores-min: The minimum softmax probability among the exact answer tokens:
$$
\text{Scores-min}=\min_{j\in\{1,\dots,m\}}p_{j}[t_{j}] \tag{12}
$$
These probabilities provide a normalized measure of the model’s confidence, bounded between 0 and 1, with lower values potentially indicating a higher likelihood of hallucination.
Probing Baseline
The probing baseline follows the standard approach described in Chen et al. (2024); Orgad et al. (2025). A linear classifier is trained on the hidden representations of the last exact answer token from the best-performing layer. The training and evaluation data for the probing classifier are constructed following the procedure described in Appendix B.4. The classifier is implemented using scikit-learn with default hyperparameters, consistent with the probing setup described in Appendix B.2. The probing baseline serves as a direct comparison to our proposed applications, as it relies on the same type of internal signals but does not account for the heterogeneity of truthfulness encoding pathways.
B.6 Implementation Details of MoP and PR
Model Backbone and Hidden Representations
All experiments use the same base LLM as in the main paper. Hidden representations $\mathbf{h}^{l^{*}}(x)$ are extracted from the best-performing layer $l^{*}$ determined on a held-out validation split.
Mixture-of-Probes (MoP)
Similar to Appendix B.5, the two expert probes $p_{Q}$ and $p_{A}$ are implemented using scikit-learn with default hyperparameters, consistent with the probing setup described in Appendix B.2. The gating network is directly from the self-awareness probe described in Section 4.2. The training and evaluation data for the probing classifier are the same as Appendix B.5. The proposed MoP framework requires no additional retraining: we directly combine the two expert probes with the pathway-discrimination classifier described in Section 4.2 and perform inference without further parameter updates.
Pathway Reweighting (PR)
The training and evaluation data used for the probing classifier are identical to those described in Appendix B.5. For each Transformer layer $l≤ l^{*}$ , we introduce two learnable scalars $\alpha_{Q}^{l}$ and $\alpha_{A}^{l}$ for every attention head. These parameters, together with the probe parameters, are optimized using the Adam optimizer with a learning rate of $1× 10^{-2}$ , $\beta_{1}=0.9$ , and $\beta_{2}=0.999$ . Training is conducted with a batch size of 512 for 10 epochs, while all original LLM parameters remain frozen.
| You are given a factual open-domain question-answer pair. |
| --- |
| Your task is to identify: |
| 1. Core Entity (c) - the known specific entity in the question that the answer is about (a person, place, organization, or other proper noun). |
| 2. Relation (r) - the minimal phrase in the question that expresses what is being asked about the core entity, using only words from the question. |
| Guidelines: |
| The core entity must be a concrete, known entity mentioned in the question, not a general category. |
| If multiple entities appear, choose the one most central to the question—the entity the answer primarily concerns. |
| The relation should be the smallest meaningful span that directly connects the core entity to the answer. |
| Use only words from the question; do not paraphrase or add new words. |
| Exclude extra context, modifiers, or descriptive phrases that are not essential to defining the relationship. |
| For complex questions with long modifiers or embedded clauses, focus on the words that directly express the property, action, or attribute of the core entity relevant to the answer. |
| If you cannot confidently identify the core entity or the relation, output NO ANSWER. |
| Output format: |
| Core Entity: exact text |
| Relation: exact text |
| Example 1 |
| Question: Who was the director of Finale? |
| Answer: Ken Kwapis |
| Core Entity: Finale |
| Relation: director |
| Example 2 |
| Question: What film, in production between 2007 and 2009, is directed by James Cameron ("Titanic")? |
| Answer: Avatāra |
| Core Entity: James Cameron |
| Relation: film directed by |
| Example 3 |
| Question: Which novel, written in 1925 and often cited as a classic of American literature, was authored by F. Scott Fitzgerald? |
| Answer: The Great Gatsby |
| Core Entity: F. Scott Fitzgerald |
| Relation: novel authored by |
| Question: {Here is the question} |
| Answer: {Hese is the answer} |
Table 5: Prompt template used to locate the exact question tokens.
| You are given a factual open-domain question-answer pair. |
| --- |
| Your task is to extract the short exact answer from the long answer. |
| Guidelines: |
| Retain only the relevant tokens from the answer. |
| Use only words from the answer; do not paraphrase or add new words. |
| Extract the short answer regardless of whether the long answer is correct or incorrect. |
| If the short answer cannot be confidently determined, or if the long answer does not address the question, output NO ANSWER. |
| Example 1 |
| Q: Which musical featured the song The Street Where You Live? |
| A: The song "The Street Where You Live" is from the Lerner and Loewe musical "My Fair Lady." It is one of the most famous songs from the show, and it is sung by Professor Henry Higgins as he reflects on the transformation of Eliza Doolittle and the memories they have shared together. |
| Exact answer: My Fair Lady |
| Example 2 |
| Q: Which Swedish actress won the Best Supporting Actress Oscar for Murder on the Orient Express? |
| A: I’m glad you asked about a Swedish actress who won an Oscar for "Murder on the Orient Express," but I must clarify that there seems to be a misunderstanding here. No Swedish actress has won an Oscar for Best Supporting Actress for that film. The 1974 "Murder on the Orient Express" was an American production, and the cast was predominantly British and American. If you have any other questions or if there’s another |
| Exact answer: NO ANSWER |
| Example 3 |
| Q: Who invented the telephone? |
| A: The telephone was invented by Thomas Edison in the 19th century. |
| Exact answer: Thomas Edison |
| Q: {Here is the question} |
| A: {Here is the answer} |
| Exact answer: |
Table 6: Prompt template used to locate the exact answer tokens.
| You are given one factual question. Interpret it literally and think carefully. |
| --- |
| Your task is to decide whether you can answer it correctly with high confidence based only on your internal knowledge (no tools or web). If yes, output exactly: YES. If not or uncertain, output exactly: NO. You should output one word only. |
| Question: {Here is the question} |
| Your Output: |
Table 7: Prompt template used to obtain the i-don’t-know rate.
Appendix C Attention Knockout
<details>
<summary>x7.png Details</summary>
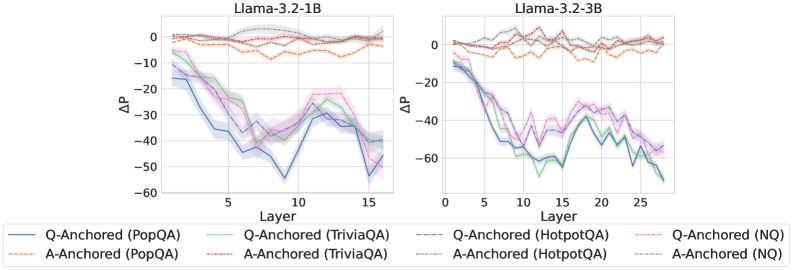
### Visual Description
## Line Graphs: Llama-3.2-1B and Llama-3.2-3B Performance
### Overview
The image presents two line graphs comparing the performance of Llama-3.2-1B and Llama-3.2-3B models across different layers. The y-axis represents ΔP (change in performance), and the x-axis represents the layer number. Each graph contains six data series, representing different question-answering tasks (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Graph: Llama-3.2-1B
* Right Graph: Llama-3.2-3B
* **Y-Axis:**
* Label: ΔP
* Scale: -60 to 0, with increments of 10 (-60, -50, -40, -30, -20, -10, 0)
* **X-Axis:**
* Label: Layer
* Left Graph Scale: 0 to 15, with increments of 5 (0, 5, 10, 15)
* Right Graph Scale: 0 to 25, with increments of 5 (0, 5, 10, 15, 20, 25)
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Orange Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dotted Brown Line
* Q-Anchored (HotpotQA): Dash-Dotted Blue Line
* A-Anchored (HotpotQA): Dash-Dotted Green Line
* Q-Anchored (NQ): Dash-Dotted Purple Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Left Graph: Llama-3.2-1B**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -10 and generally decreases to around -55 by layer 10, then increases to approximately -40 by layer 15.
* **A-Anchored (PopQA):** (Dashed Orange Line) Remains relatively stable around -5 to -10 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -10 and decreases to around -35 by layer 10, then increases to approximately -25 by layer 15.
* **A-Anchored (TriviaQA):** (Dotted Brown Line) Remains relatively stable around -5 to -10 across all layers.
* **Q-Anchored (HotpotQA):** (Dash-Dotted Blue Line) Starts at approximately -10 and decreases to around -50 by layer 10, then increases to approximately -40 by layer 15.
* **A-Anchored (HotpotQA):** (Dash-Dotted Green Line) Starts at approximately -10 and decreases to around -35 by layer 10, then increases to approximately -25 by layer 15.
* **Q-Anchored (NQ):** (Dash-Dotted Purple Line) Starts at approximately -10 and decreases to around -35 by layer 10, then increases to approximately -20 by layer 15.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively stable around -5 to -10 across all layers.
**Right Graph: Llama-3.2-3B**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -10 and generally decreases to around -65 by layer 15, then increases to approximately -50 by layer 25.
* **A-Anchored (PopQA):** (Dashed Orange Line) Remains relatively stable around -5 to -10 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -10 and decreases to around -65 by layer 15, then increases to approximately -50 by layer 25.
* **A-Anchored (TriviaQA):** (Dotted Brown Line) Remains relatively stable around -5 to -10 across all layers.
* **Q-Anchored (HotpotQA):** (Dash-Dotted Blue Line) Starts at approximately -10 and decreases to around -65 by layer 15, then increases to approximately -50 by layer 25.
* **A-Anchored (HotpotQA):** (Dash-Dotted Green Line) Starts at approximately -10 and decreases to around -65 by layer 15, then increases to approximately -50 by layer 25.
* **Q-Anchored (NQ):** (Dash-Dotted Purple Line) Starts at approximately -10 and decreases to around -65 by layer 15, then increases to approximately -50 by layer 25.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively stable around -5 to -10 across all layers.
### Key Observations
* The "Q-Anchored" series (PopQA, TriviaQA, HotpotQA, and NQ) show a significant decrease in ΔP (performance) as the layer number increases up to a certain point (around layer 10-15), after which the performance starts to recover slightly.
* The "A-Anchored" series (PopQA, TriviaQA, HotpotQA, and NQ) remain relatively stable across all layers, with ΔP values close to 0.
* The Llama-3.2-3B model (right graph) has more layers (up to 25) compared to the Llama-3.2-1B model (left graph, up to 15).
* The performance dip in the "Q-Anchored" series appears to be more pronounced in the Llama-3.2-3B model.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) in these question-answering tasks leads to a performance decrease in the middle layers of the Llama models, followed by a slight recovery in later layers. This could indicate that the model initially struggles to process the question information in the earlier layers but adapts and improves its performance in the later layers.
On the other hand, anchoring the answer (A-Anchored) results in a stable performance across all layers, suggesting that the model can effectively utilize the answer information from the beginning.
The difference in the number of layers between the two models (Llama-3.2-1B and Llama-3.2-3B) and the more pronounced performance dip in the Llama-3.2-3B model could indicate that the larger model experiences a more significant initial challenge in processing the question information.
</details>
<details>
<summary>x8.png Details</summary>
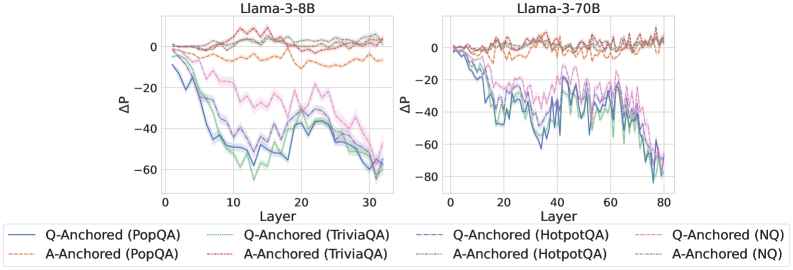
### Visual Description
## Line Chart: Llama-3-8B and Llama-3-70B Performance
### Overview
The image presents two line charts comparing the performance of Llama-3-8B and Llama-3-70B models across different layers. The y-axis represents ΔP (change in performance), and the x-axis represents the layer number. Each chart displays six data series, representing Q-Anchored and A-Anchored performance on PopQA, TriviaQA, HotpotQA, and NQ datasets.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-axis:**
* Label: ΔP
* Scale: -80 to 0, with increments of 20 (-60, -40, -20, 0)
* **X-axis:**
* Label: Layer
* Left Chart Scale: 0 to 30, with increments of 10 (10, 20, 30)
* Right Chart Scale: 0 to 80, with increments of 20 (20, 40, 60, 80)
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dotted Brown Line
* Q-Anchored (HotpotQA): Dashed Purple Line
* A-Anchored (HotpotQA): Dotted Green Line
* Q-Anchored (NQ): Dotted Purple Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Llama-3-8B (Left Chart):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 and decreases to around -60 by layer 30.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively stable around 0, with minor fluctuations.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts near 0 and decreases to approximately -60 by layer 30.
* **A-Anchored (TriviaQA):** (Dotted Brown) Remains relatively stable around 0, with minor fluctuations.
* **Q-Anchored (HotpotQA):** (Dashed Purple) Starts near 0 and decreases to approximately -40 by layer 30.
* **A-Anchored (HotpotQA):** (Dotted Green) Remains relatively stable around 0, with minor fluctuations.
* **Q-Anchored (NQ):** (Dotted Purple) Remains relatively stable around 0, with minor fluctuations.
* **A-Anchored (NQ):** (Dotted Gray) Remains relatively stable around 0, with minor fluctuations.
**Llama-3-70B (Right Chart):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 and decreases to around -80 by layer 80.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively stable around 0, with minor fluctuations.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts near 0 and decreases to approximately -40 by layer 80.
* **A-Anchored (TriviaQA):** (Dotted Brown) Remains relatively stable around 0, with minor fluctuations.
* **Q-Anchored (HotpotQA):** (Dashed Purple) Starts near 0 and decreases to approximately -40 by layer 80.
* **A-Anchored (HotpotQA):** (Dotted Green) Remains relatively stable around 0, with minor fluctuations.
* **Q-Anchored (NQ):** (Dotted Purple) Remains relatively stable around 0, with minor fluctuations.
* **A-Anchored (NQ):** (Dotted Gray) Remains relatively stable around 0, with minor fluctuations.
### Key Observations
* For both models, the Q-Anchored performance on PopQA, TriviaQA, and HotpotQA datasets decreases significantly as the layer number increases.
* The A-Anchored performance on all datasets remains relatively stable around 0 for both models.
* The Llama-3-70B model has a longer x-axis (layer count) than the Llama-3-8B model.
* The Q-Anchored (PopQA) line for Llama-3-70B shows the most significant decrease in performance, reaching approximately -80.
### Interpretation
The data suggests that Q-Anchoring negatively impacts the performance of Llama models on PopQA, TriviaQA, and HotpotQA datasets as the model goes deeper into its layers. In contrast, A-Anchoring seems to have a negligible impact on performance. The Llama-3-70B model, with its increased number of layers, exhibits a more pronounced decrease in Q-Anchored performance, particularly for the PopQA dataset. This could indicate that the effect of Q-Anchoring becomes more detrimental with increased model depth. The stable performance of A-Anchored data suggests that anchoring the answer has little to no impact on the model's performance across different layers.
</details>
<details>
<summary>x9.png Details</summary>
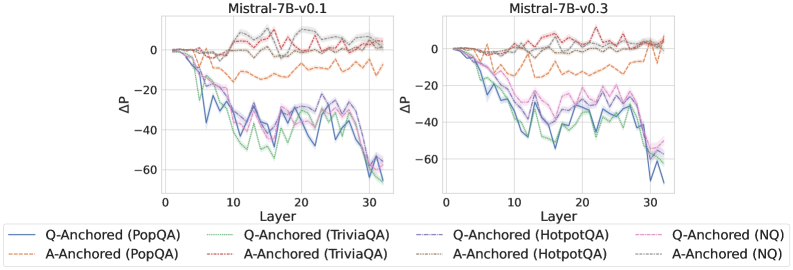
### Visual Description
## Line Graphs: Mistral-7B Model Performance Comparison
### Overview
The image presents two line graphs comparing the performance of Mistral-7B models (v0.1 and v0.3) across different layers and question-answering datasets. The graphs depict the change in performance (ΔP) as a function of the layer number, with separate lines for question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches on various datasets.
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **Y-Axis:**
* Label: "ΔP" (Change in Performance)
* Scale: -60 to 0, with tick marks at -40, -20, and 0.
* **X-Axis:**
* Label: "Layer"
* Scale: 0 to 30, with tick marks every 10 units.
* **Legend:** Located at the bottom of the image, spanning both graphs.
* **Q-Anchored (PopQA):** Solid Blue Line
* **A-Anchored (PopQA):** Dashed Brown Line
* **Q-Anchored (TriviaQA):** Dotted Green Line
* **A-Anchored (TriviaQA):** Dotted-Dashed Pink Line
* **Q-Anchored (HotpotQA):** Dash-Dot Blue Line
* **A-Anchored (HotpotQA):** Solid Green Line
* **Q-Anchored (NQ):** Dotted-Dashed Pink Line
* **A-Anchored (NQ):** Dotted Black Line
### Detailed Analysis
**Left Graph (Mistral-7B-v0.1):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at 0, decreases sharply to approximately -40 by layer 10, fluctuates between -30 and -50 until layer 30, and ends around -60.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts at 0, decreases to approximately -10 by layer 10, and then remains relatively stable between -10 and -5 until layer 30.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -50 until layer 30, and ends around -60.
* **A-Anchored (TriviaQA):** (Dotted-Dashed Pink Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **A-Anchored (HotpotQA):** (Solid Green Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **Q-Anchored (NQ):** (Dotted-Dashed Pink Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **A-Anchored (NQ):** (Dotted Black Line) Starts at 0, increases to approximately 10 by layer 10, and then remains relatively stable between 10 and 5 until layer 30.
**Right Graph (Mistral-7B-v0.3):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at 0, decreases sharply to approximately -40 by layer 10, fluctuates between -30 and -50 until layer 30, and ends around -60.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts at 0, decreases to approximately -10 by layer 10, and then remains relatively stable between -10 and -5 until layer 30.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -50 until layer 30, and ends around -60.
* **A-Anchored (TriviaQA):** (Dotted-Dashed Pink Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **A-Anchored (HotpotQA):** (Solid Green Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **Q-Anchored (NQ):** (Dotted-Dashed Pink Line) Starts at 0, decreases sharply to approximately -30 by layer 10, fluctuates between -30 and -40 until layer 30, and ends around -50.
* **A-Anchored (NQ):** (Dotted Black Line) Starts at 0, increases to approximately 10 by layer 10, and then remains relatively stable between 10 and 5 until layer 30.
### Key Observations
* The Q-Anchored approaches for PopQA, TriviaQA, HotpotQA, and NQ datasets generally show a decrease in performance (negative ΔP) as the layer number increases.
* The A-Anchored approach for PopQA shows a slight decrease in performance, while A-Anchored for NQ shows a slight increase in performance.
* The performance trends are similar between Mistral-7B-v0.1 and Mistral-7B-v0.3.
* There is a noticeable drop in performance for Q-Anchored approaches in the initial layers (0-10).
### Interpretation
The graphs suggest that the Q-Anchored approaches are more sensitive to the layer number, with performance decreasing as the model processes deeper layers. This could indicate that the question encoding becomes less relevant or effective in later layers. The A-Anchored approaches, on the other hand, show more stable performance across layers, suggesting that the answer encoding remains relevant throughout the model. The similarity in trends between v0.1 and v0.3 indicates that the performance characteristics are consistent across these versions of the Mistral-7B model. The initial drop in performance for Q-Anchored approaches may be due to the model initially focusing on question encoding but then shifting its attention to other aspects of the task in later layers.
</details>
Figure 7: $\Delta\mathrm{P}$ under attention knockout, probing attention activations of the final token.
<details>
<summary>x10.png Details</summary>
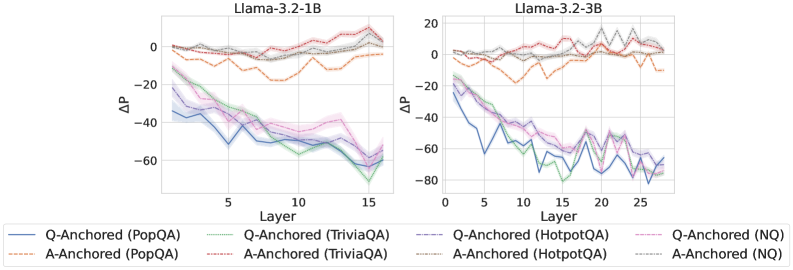
### Visual Description
## Line Charts: Llama-3.2-1B and Llama-3.2-3B Performance
### Overview
The image presents two line charts comparing the performance of Llama-3.2-1B and Llama-3.2-3B models across different layers. The y-axis represents ΔP (Delta P), and the x-axis represents the layer number. Each chart displays six data series, representing Q-Anchored and A-Anchored performance on PopQA, TriviaQA, HotpotQA, and NQ datasets.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **Y-Axis:**
* Label: ΔP
* Scale: -80 to 20, with increments of 20 (-80, -60, -40, -20, 0, 20)
* **X-Axis:**
* Label: Layer
* Left Chart Scale: 0 to 15, with increments of 5 (0, 5, 10, 15)
* Right Chart Scale: 0 to 25, with increments of 5 (0, 5, 10, 15, 20, 25)
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Orange Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dashed-Dotted Brown Line
* Q-Anchored (HotpotQA): Dashed-Dotted Pink Line
* A-Anchored (HotpotQA): Dotted Grey Line
* Q-Anchored (NQ): Dashed-Dotted Pink Line
* A-Anchored (NQ): Dotted Grey Line
### Detailed Analysis
**Llama-3.2-1B (Left Chart)**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -35 and generally decreases to around -60 by layer 15.
* **A-Anchored (PopQA):** (Dashed Orange Line) Starts near 0 and fluctuates between -15 and 0.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -20 and decreases to around -60 by layer 15.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Brown Line) Starts near 0 and remains relatively stable, fluctuating slightly.
* **Q-Anchored (HotpotQA):** (Dashed-Dotted Pink Line) Starts at approximately -30 and decreases to around -50 by layer 15.
* **A-Anchored (NQ):** (Dotted Grey Line) Starts near 0 and remains relatively stable, fluctuating slightly.
**Llama-3.2-3B (Right Chart)**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -25 and decreases to around -75, with some fluctuations.
* **A-Anchored (PopQA):** (Dashed Orange Line) Starts near -5 and fluctuates significantly between -15 and 5.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -20 and decreases to around -70, with some fluctuations.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Brown Line) Starts near 10 and remains relatively stable, fluctuating slightly.
* **Q-Anchored (HotpotQA):** (Dashed-Dotted Pink Line) Starts at approximately -20 and decreases to around -60, with some fluctuations.
* **A-Anchored (NQ):** (Dotted Grey Line) Starts near 10 and remains relatively stable, fluctuating slightly.
### Key Observations
* For both models, the Q-Anchored lines (PopQA, TriviaQA, HotpotQA) generally show a decreasing trend as the layer number increases, indicating a drop in ΔP.
* The A-Anchored lines (PopQA, TriviaQA, NQ) tend to remain relatively stable near 0, with the exception of A-Anchored (PopQA) on Llama-3.2-3B, which fluctuates more.
* Llama-3.2-3B shows a more pronounced decrease in ΔP for the Q-Anchored lines compared to Llama-3.2-1B.
* The shaded regions around the lines indicate the uncertainty or variance in the data.
### Interpretation
The charts suggest that as the layer number increases, the performance (ΔP) of Q-Anchored tasks generally decreases for both Llama models. This could indicate that the model's ability to answer questions deteriorates in deeper layers. The A-Anchored tasks, on the other hand, remain relatively stable, suggesting that the model's ability to understand or process answers is less affected by the layer depth.
The Llama-3.2-3B model appears to exhibit a more significant performance drop in Q-Anchored tasks compared to Llama-3.2-1B, which could be due to the increased complexity or depth of the model. The fluctuations in the A-Anchored (PopQA) line for Llama-3.2-3B might indicate some instability or sensitivity in processing answers for that specific dataset.
The shaded regions provide a visual representation of the data's variability, which should be considered when interpreting the trends.
</details>
<details>
<summary>x11.png Details</summary>
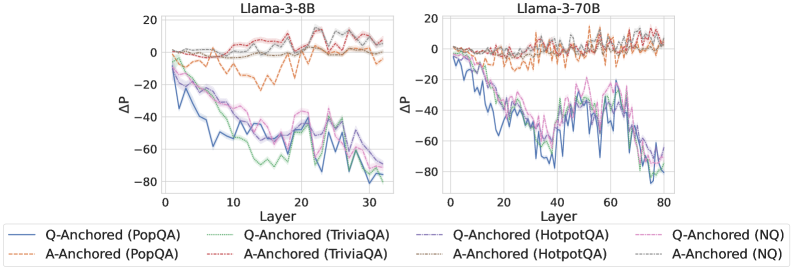
### Visual Description
## Line Chart: Layer vs. ΔP for Llama-3-8B and Llama-3-70B
### Overview
The image presents two line charts comparing the performance of Llama-3-8B and Llama-3-70B models across different layers, measured by ΔP (change in probability). Each chart plots the ΔP values for question-anchored (Q-Anchored) and answer-anchored (A-Anchored) methods across various question-answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. The x-axis represents the layer number, and the y-axis represents the ΔP value.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3-8B"
* Right Chart: "Llama-3-70B"
* **X-axis:**
* Label: "Layer"
* Left Chart: Scale from 0 to 30, with tick marks at intervals of 10.
* Right Chart: Scale from 0 to 80, with tick marks at intervals of 20.
* **Y-axis:**
* Label: "ΔP"
* Scale: From -80 to 20, with tick marks at intervals of 20.
* **Legend:** Located at the bottom of the image, it identifies the line colors and styles for each method and dataset.
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Dotted green line
* **A-Anchored (TriviaQA):** Dotted gray line
* **Q-Anchored (HotpotQA):** Dashed-dotted purple line
* **A-Anchored (HotpotQA):** Dotted-dashed pink line
* **Q-Anchored (NQ):** Dashed-dotted black line
* **A-Anchored (NQ):** Dotted-dashed orange line
### Detailed Analysis
**Left Chart (Llama-3-8B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 and decreases sharply to around -50 by layer 10, then fluctuates between -50 and -80 until layer 30.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 0 and fluctuates between -10 and 10 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0 and decreases to around -60 by layer 30.
* **A-Anchored (TriviaQA):** (Dotted Gray) Starts around 0 and remains relatively stable, fluctuating between 0 and 10 across all layers.
* **Q-Anchored (HotpotQA):** (Dashed-dotted Purple) Starts at approximately 0 and decreases to around -50 by layer 30.
* **A-Anchored (HotpotQA):** (Dotted-dashed Pink) Starts at approximately 0 and decreases to around -50 by layer 30.
* **Q-Anchored (NQ):** (Dashed-dotted Black) Starts around 0 and remains relatively stable, fluctuating between 0 and 10 across all layers.
* **A-Anchored (NQ):** (Dotted-dashed Orange) Starts around 0 and remains relatively stable, fluctuating between 0 and 10 across all layers.
**Right Chart (Llama-3-70B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 and decreases sharply to around -60 by layer 20, then fluctuates between -40 and -70 until layer 80.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 0 and fluctuates between 0 and 15 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0 and decreases to around -60 by layer 80.
* **A-Anchored (TriviaQA):** (Dotted Gray) Starts around 0 and remains relatively stable, fluctuating between 0 and 10 across all layers.
* **Q-Anchored (HotpotQA):** (Dashed-dotted Purple) Starts at approximately 0 and decreases to around -50 by layer 80.
* **A-Anchored (HotpotQA):** (Dotted-dashed Pink) Starts at approximately 0 and decreases to around -50 by layer 80.
* **Q-Anchored (NQ):** (Dashed-dotted Black) Starts around 0 and remains relatively stable, fluctuating between 0 and 10 across all layers.
* **A-Anchored (NQ):** (Dotted-dashed Orange) Starts around 0 and fluctuates between 0 and 15 across all layers.
### Key Observations
* For both models, the Q-Anchored methods for PopQA, TriviaQA, and HotpotQA show a significant decrease in ΔP as the layer number increases, indicating a performance decline in these tasks as the model processes deeper layers.
* The A-Anchored methods for PopQA, TriviaQA, HotpotQA, and NQ, as well as the Q-Anchored method for NQ, remain relatively stable across all layers for both models, suggesting more consistent performance.
* The Llama-3-70B model has a larger x-axis range (0-80 layers) compared to Llama-3-8B (0-30 layers), indicating a deeper architecture.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) for PopQA, TriviaQA, and HotpotQA tasks leads to a degradation in performance as the model processes deeper layers, while anchoring the answer (A-Anchored) maintains a more stable performance. This could indicate that the model's ability to effectively utilize information from the question deteriorates with increasing depth for these specific datasets. The consistent performance of A-Anchored methods and Q-Anchored NQ suggests that the model handles answer-related information and certain types of questions more effectively across all layers. The difference in layer depth between Llama-3-8B and Llama-3-70B may contribute to the observed performance variations.
</details>
<details>
<summary>x12.png Details</summary>
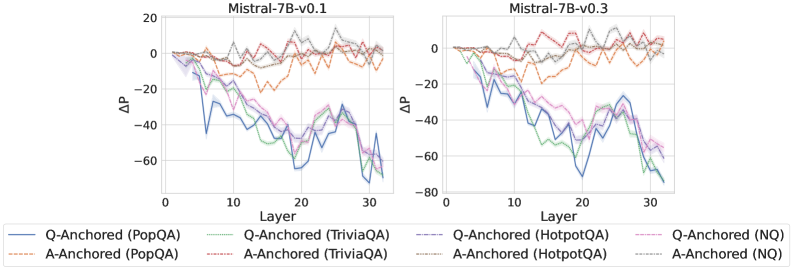
### Visual Description
## Line Chart: Layer vs. ΔP for Mistral-7B Models
### Overview
The image presents two line charts comparing the performance of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across different layers. The charts plot the change in performance (ΔP) against the layer number for various question answering tasks, differentiated by anchoring method (Q-Anchored vs. A-Anchored) and dataset (PopQA, TriviaQA, HotpotQA, NQ).
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **X-axis:** "Layer"
* Scale: 0 to 30, incrementing by 10.
* **Y-axis:** "ΔP" (Change in Performance)
* Scale: -80 to 20, incrementing by 20.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Pink Line
* Q-Anchored (HotpotQA): Dash-Dotted Dark-Gray Line
* A-Anchored (HotpotQA): Dotted Red Line
* Q-Anchored (NQ): Dash-Dotted Light-Purple Line
* A-Anchored (NQ): Dotted Dark-Gray Line
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0, decreases sharply to around -45 by layer 10, fluctuates between -30 and -60 until layer 30. Ends around -60.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts at approximately 0, remains relatively stable between -5 and 5 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 0, decreases to around -40 by layer 10, fluctuates between -30 and -50 until layer 30. Ends around -50.
* **A-Anchored (TriviaQA):** (Dash-Dotted Pink Line) Starts at approximately 0, decreases to around -30 by layer 10, fluctuates between -30 and -40 until layer 30. Ends around -40.
* **Q-Anchored (HotpotQA):** (Dash-Dotted Dark-Gray Line) Starts at approximately 0, remains relatively stable between -5 and 5 across all layers.
* **A-Anchored (HotpotQA):** (Dotted Red Line) Starts at approximately 0, remains relatively stable between -5 and 10 across all layers.
* **Q-Anchored (NQ):** (Dash-Dotted Light-Purple Line) Starts at approximately 0, decreases to around -30 by layer 10, fluctuates between -30 and -40 until layer 30. Ends around -40.
* **A-Anchored (NQ):** (Dotted Dark-Gray Line) Starts at approximately 0, remains relatively stable between -5 and 5 across all layers.
**Right Chart: Mistral-7B-v0.3**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0, decreases sharply to around -50 by layer 10, fluctuates between -40 and -70 until layer 30. Ends around -70.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts at approximately 0, remains relatively stable between -5 and 5 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 0, decreases to around -40 by layer 10, fluctuates between -30 and -60 until layer 30. Ends around -60.
* **A-Anchored (TriviaQA):** (Dash-Dotted Pink Line) Starts at approximately 0, decreases to around -30 by layer 10, fluctuates between -30 and -50 until layer 30. Ends around -50.
* **Q-Anchored (HotpotQA):** (Dash-Dotted Dark-Gray Line) Starts at approximately 0, remains relatively stable between -5 and 5 across all layers.
* **A-Anchored (HotpotQA):** (Dotted Red Line) Starts at approximately 0, remains relatively stable between -5 and 10 across all layers.
* **Q-Anchored (NQ):** (Dash-Dotted Light-Purple Line) Starts at approximately 0, decreases to around -30 by layer 10, fluctuates between -30 and -50 until layer 30. Ends around -50.
* **A-Anchored (NQ):** (Dotted Dark-Gray Line) Starts at approximately 0, remains relatively stable between -5 and 5 across all layers.
### Key Observations
* For both Mistral-7B-v0.1 and Mistral-7B-v0.3, the "Q-Anchored" lines for PopQA, TriviaQA, and NQ datasets show a significant decrease in ΔP as the layer number increases, indicating a performance drop.
* The "A-Anchored" lines for all datasets remain relatively stable around 0, suggesting that anchoring with the answer has a different effect on performance across layers compared to anchoring with the question.
* The HotpotQA dataset shows a stable performance for both Q-Anchored and A-Anchored methods.
* Mistral-7B-v0.3 shows a slightly larger decrease in ΔP for Q-Anchored (PopQA) compared to Mistral-7B-v0.1.
### Interpretation
The charts suggest that the performance of Mistral-7B models, particularly when anchored with the question (Q-Anchored), varies significantly across different layers for certain question answering tasks (PopQA, TriviaQA, NQ). The decrease in ΔP indicates that as the model processes information through deeper layers, its performance on these tasks degrades. This could be due to issues like vanishing gradients, overfitting to specific layers, or the accumulation of noise.
The stability of A-Anchored lines suggests that providing the answer as context might mitigate the performance degradation observed with Q-Anchored methods. The consistent performance on HotpotQA might indicate that this dataset is less sensitive to the layer-specific issues affecting the other datasets.
The slight difference between Mistral-7B-v0.1 and Mistral-7B-v0.3, particularly for Q-Anchored (PopQA), suggests that the newer version might have slightly exacerbated the performance degradation issue in deeper layers for this specific task. Further investigation is needed to understand the underlying causes and potential solutions for these performance variations.
</details>
Figure 8: $\Delta\mathrm{P}$ under attention knockout, probing attention activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x13.png Details</summary>
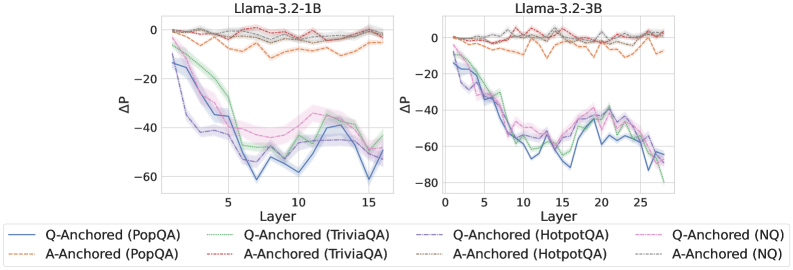
### Visual Description
## Chart Type: Line Graphs
### Overview
The image contains two line graphs comparing the performance of Llama-3.2-1B and Llama-3.2-3B models across different layers. The y-axis represents ΔP (Delta P), and the x-axis represents the Layer number. Each graph displays six data series, representing "Q-Anchored" and "A-Anchored" performance on four different question-answering datasets: PopQA, TriviaQA, HotpotQA, and NQ.
### Components/Axes
* **Titles:**
* Left Graph: "Llama-3.2-1B"
* Right Graph: "Llama-3.2-3B"
* **Y-Axis:**
* Label: "ΔP"
* Scale: -80 to 0, with increments of 20 (-60, -40, -20, 0)
* **X-Axis:**
* Label: "Layer"
* Left Graph Scale: 0 to 15, with increments of 5 (5, 10, 15)
* Right Graph Scale: 0 to 25, with increments of 5 (5, 10, 15, 20, 25)
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Orange Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Gray Line
* Q-Anchored (HotpotQA): Dash-Dot-Dotted Pink Line
* A-Anchored (HotpotQA): Dotted Brown Line
* Q-Anchored (NQ): Dash-Dotted Pink Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Left Graph (Llama-3.2-1B):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0 and decreases sharply to around -60 by layer 7, then fluctuates between -50 and -60 until layer 15.
* **A-Anchored (PopQA):** (Dashed Orange Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 0 and decreases to around -50 by layer 7, then fluctuates between -40 and -50 until layer 15.
* **A-Anchored (TriviaQA):** (Dash-Dotted Gray Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Pink Line) Starts at approximately 0 and decreases to around -50 by layer 7, then fluctuates between -40 and -50 until layer 15.
* **A-Anchored (HotpotQA):** (Dotted Brown Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
* **Q-Anchored (NQ):** (Dash-Dotted Pink Line) Starts at approximately 0 and decreases to around -50 by layer 7, then fluctuates between -40 and -50 until layer 15.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
**Right Graph (Llama-3.2-3B):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0 and decreases sharply to around -70 by layer 10, then fluctuates between -50 and -70 until layer 25.
* **A-Anchored (PopQA):** (Dashed Orange Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 0 and decreases to around -60 by layer 10, then fluctuates between -40 and -60 until layer 25.
* **A-Anchored (TriviaQA):** (Dash-Dotted Gray Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Pink Line) Starts at approximately 0 and decreases to around -60 by layer 10, then fluctuates between -40 and -60 until layer 25.
* **A-Anchored (HotpotQA):** (Dotted Brown Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
* **Q-Anchored (NQ):** (Dash-Dotted Pink Line) Starts at approximately 0 and decreases to around -60 by layer 10, then fluctuates between -40 and -60 until layer 25.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively stable around 0, fluctuating slightly between -5 and 5.
### Key Observations
* The "Q-Anchored" data series (PopQA, TriviaQA, HotpotQA, and NQ) show a significant decrease in ΔP as the layer number increases, indicating a performance change.
* The "A-Anchored" data series (PopQA, TriviaQA, HotpotQA, and NQ) remain relatively stable around 0, suggesting minimal performance change across layers.
* The Llama-3.2-3B model (right graph) has a longer x-axis (more layers) compared to the Llama-3.2-1B model (left graph).
* The Q-Anchored lines for Llama-3.2-3B appear to reach lower values than those for Llama-3.2-1B.
### Interpretation
The graphs suggest that anchoring the question ("Q-Anchored") has a more significant impact on performance across different layers compared to anchoring the answer ("A-Anchored"). The decrease in ΔP for "Q-Anchored" indicates a change in performance as the model processes information through its layers. The stable ΔP for "A-Anchored" suggests that anchoring the answer has a less pronounced effect on performance across layers.
The Llama-3.2-3B model, with its increased number of layers, shows a similar trend to the Llama-3.2-1B model, but the Q-Anchored performance appears to decrease further, potentially indicating that the impact of question anchoring becomes more pronounced with increased model depth. The data suggests that the way the question is anchored significantly affects how the model processes information across its layers, while the answer anchoring has a comparatively negligible effect.
</details>
<details>
<summary>x14.png Details</summary>
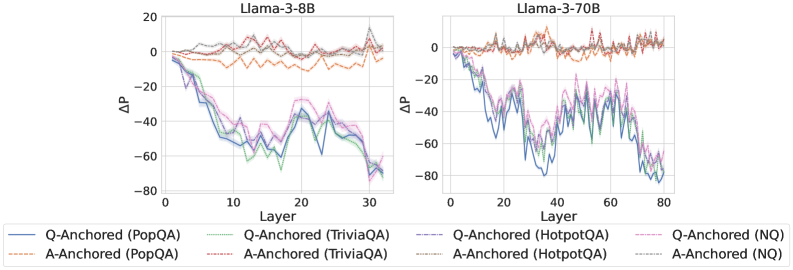
### Visual Description
## Line Charts: Llama-3-8B and Llama-3-70B Performance
### Overview
The image presents two line charts comparing the performance of Llama-3-8B and Llama-3-70B models across different layers. The charts depict the change in performance (ΔP) as a function of the layer number for various question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ), using both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches.
### Components/Axes
**Left Chart (Llama-3-8B):**
* **Title:** Llama-3-8B
* **X-axis:** Layer, with ticks at 0, 10, 20, and 30.
* **Y-axis:** ΔP, ranging from -80 to 20, with ticks at -80, -60, -40, -20, 0, and 20.
**Right Chart (Llama-3-70B):**
* **Title:** Llama-3-70B
* **X-axis:** Layer, with ticks at 0, 20, 40, 60, and 80.
* **Y-axis:** ΔP, ranging from -80 to 20, with ticks at -80, -60, -40, -20, 0, and 20.
**Legend (Located at the bottom of the image, spanning both charts):**
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Dotted green line
* **A-Anchored (TriviaQA):** Dotted-dashed grey line
* **Q-Anchored (HotpotQA):** Dotted-dashed pink line
* **A-Anchored (HotpotQA):** Dashed orange line
* **Q-Anchored (NQ):** Dotted-dashed purple line
* **A-Anchored (NQ):** Dotted grey line
### Detailed Analysis
**Llama-3-8B:**
* **Q-Anchored (PopQA):** Starts at approximately 0 and decreases to around -70 by layer 30.
* **A-Anchored (PopQA):** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** Starts at approximately 0 and decreases to around -65 by layer 30.
* **A-Anchored (TriviaQA):** Remains relatively stable around 5 throughout all layers.
* **Q-Anchored (HotpotQA):** Starts at approximately 0 and decreases to around -70 by layer 30.
* **A-Anchored (HotpotQA):** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** Starts at approximately 0 and decreases to around -40 by layer 30.
* **A-Anchored (NQ):** Remains relatively stable around 10 throughout all layers.
**Llama-3-70B:**
* **Q-Anchored (PopQA):** Starts at approximately 0 and decreases to around -75 by layer 80.
* **A-Anchored (PopQA):** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** Starts at approximately 0 and decreases to around -60 by layer 80.
* **A-Anchored (TriviaQA):** Remains relatively stable around 5 throughout all layers.
* **Q-Anchored (HotpotQA):** Starts at approximately 0 and decreases to around -70 by layer 80.
* **A-Anchored (HotpotQA):** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** Starts at approximately 0 and decreases to around -50 by layer 80.
* **A-Anchored (NQ):** Remains relatively stable around 10 throughout all layers.
### Key Observations
* For both models, the Q-Anchored approach generally results in a decrease in ΔP as the layer number increases, indicating a decline in performance.
* The A-Anchored approach tends to maintain a relatively stable ΔP across all layers, suggesting a more consistent performance.
* The Llama-3-70B model has a longer x-axis (Layer), indicating it has more layers than the Llama-3-8B model.
* The trends for each dataset (PopQA, TriviaQA, HotpotQA, NQ) are similar across both models.
### Interpretation
The data suggests that using a question-anchored approach leads to a degradation in performance as the model processes deeper layers, while an answer-anchored approach maintains a more consistent level of performance. This could indicate that the model's ability to effectively utilize information from the question diminishes in later layers, whereas the answer-related information remains more stable. The Llama-3-70B model, with its increased number of layers, exhibits similar trends to the Llama-3-8B model, suggesting that the observed behavior is consistent across different model sizes. The consistent performance of A-Anchored methods could be due to the model focusing on answer-relevant features throughout the layers, mitigating the degradation seen in Q-Anchored methods.
</details>
<details>
<summary>x15.png Details</summary>
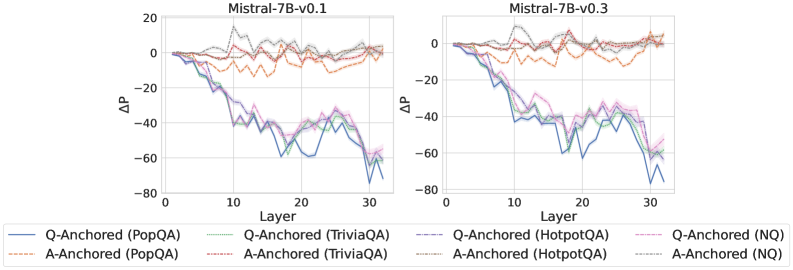
### Visual Description
## Line Chart: Performance Comparison of Mistral-7B Models
### Overview
The image presents two line charts comparing the performance of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across different layers and question-answering datasets. The charts display the change in performance (ΔP) as a function of the layer number for various question-answering tasks, anchored by either the question (Q-Anchored) or the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:**
* Label: "ΔP" (Change in Performance)
* Scale: -80 to 20, with increments of 20.
* **X-Axis:**
* Label: "Layer"
* Scale: 0 to 30, with increments of 10.
* **Legend:** Located at the bottom of the image, it identifies the different data series:
* `Q-Anchored (PopQA)`: Solid blue line
* `A-Anchored (PopQA)`: Dashed brown line
* `Q-Anchored (TriviaQA)`: Dotted green line
* `A-Anchored (TriviaQA)`: Dotted-dashed light brown line
* `Q-Anchored (HotpotQA)`: Dashed-dotted dark green line
* `A-Anchored (HotpotQA)`: Solid light green line
* `Q-Anchored (NQ)`: Dotted-dashed pink line
* `A-Anchored (NQ)`: Dotted grey line
### Detailed Analysis
**Left Chart (Mistral-7B-v0.1):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts at approximately 0 and decreases to around -70 by layer 30.
* **A-Anchored (PopQA):** (Dashed brown line) Fluctuates between -10 and 10 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts at approximately 0 and decreases to around -50 by layer 30.
* **A-Anchored (TriviaQA):** (Dotted-dashed light brown line) Fluctuates between -10 and 10 across all layers.
* **Q-Anchored (HotpotQA):** (Dashed-dotted dark green line) Starts at approximately 0 and decreases to around -50 by layer 30.
* **A-Anchored (HotpotQA):** (Solid light green line) Starts at approximately 0 and decreases to around -50 by layer 30.
* **Q-Anchored (NQ):** (Dotted-dashed pink line) Starts at approximately 0 and decreases to around -60 by layer 30.
* **A-Anchored (NQ):** (Dotted grey line) Fluctuates between -10 and 10 across all layers.
**Right Chart (Mistral-7B-v0.3):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts at approximately 0 and decreases to around -70 by layer 30.
* **A-Anchored (PopQA):** (Dashed brown line) Fluctuates between -10 and 10 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts at approximately 0 and decreases to around -50 by layer 30.
* **A-Anchored (TriviaQA):** (Dotted-dashed light brown line) Fluctuates between -10 and 10 across all layers.
* **Q-Anchored (HotpotQA):** (Dashed-dotted dark green line) Starts at approximately 0 and decreases to around -40 by layer 30.
* **A-Anchored (HotpotQA):** (Solid light green line) Starts at approximately 0 and decreases to around -60 by layer 30.
* **Q-Anchored (NQ):** (Dotted-dashed pink line) Starts at approximately 0 and decreases to around -60 by layer 30.
* **A-Anchored (NQ):** (Dotted grey line) Fluctuates between -10 and 10 across all layers.
### Key Observations
* The performance (ΔP) of Q-Anchored tasks (PopQA, TriviaQA, HotpotQA, NQ) generally decreases as the layer number increases for both Mistral-7B-v0.1 and Mistral-7B-v0.3.
* The performance (ΔP) of A-Anchored tasks (PopQA, TriviaQA, HotpotQA, NQ) remains relatively stable across all layers for both models, fluctuating around 0.
* The performance trends are similar between Mistral-7B-v0.1 and Mistral-7B-v0.3.
### Interpretation
The data suggests that as the model processes information through deeper layers, its performance on question-anchored tasks declines. This could indicate that the model is losing relevant information or becoming more prone to errors as it progresses through the layers when the question is the anchor. Conversely, when the answer is the anchor, the model's performance remains relatively stable, suggesting that the answer provides a consistent reference point throughout the processing layers. The similarity in trends between Mistral-7B-v0.1 and Mistral-7B-v0.3 indicates that the underlying architecture and training process have a consistent impact on performance across different versions of the model. The consistent drop in Q-Anchored performance as layers increase may indicate a vanishing gradient or information bottleneck problem.
</details>
Figure 9: $\Delta\mathrm{P}$ under attention knockout, probing attention activations of the last exact answer token.
<details>
<summary>x16.png Details</summary>
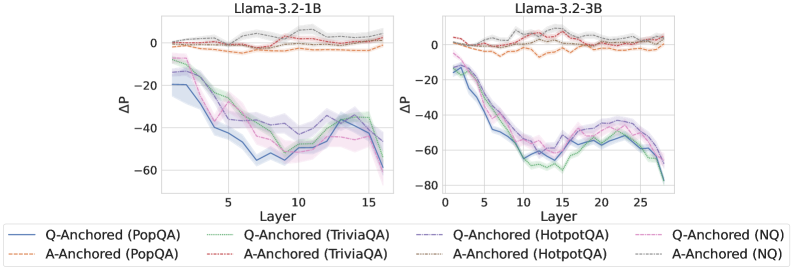
### Visual Description
## Line Charts: Llama-3.2-1B and Llama-3.2-3B Performance
### Overview
The image presents two line charts comparing the performance of Llama-3.2-1B and Llama-3.2-3B models across different layers. The charts depict the change in performance (ΔP) as a function of layer number for various question answering tasks, using both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **Y-Axis (ΔP):**
* Scale: -80 to 0
* Units: ΔP (Change in Performance)
* Markers: 0, -20, -40, -60, -80 (only on right chart)
* **X-Axis (Layer):**
* Left Chart: Layer (1 to 16)
* Right Chart: Layer (0 to 27)
* Markers:
* Left Chart: 5, 10, 15
* Right Chart: 5, 10, 15, 20, 25
* **Legend (Bottom):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Orange Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dotted Gray Line
* Q-Anchored (HotpotQA): Dash-Dot Purple Line
* A-Anchored (HotpotQA): Dash-Dot Red Line
* Q-Anchored (NQ): Dashed Pink Line
* A-Anchored (NQ): Dotted-Dashed Black Line
### Detailed Analysis
**Llama-3.2-1B (Left Chart):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -20 ΔP at Layer 1, decreases to approximately -60 ΔP by Layer 16.
* **A-Anchored (PopQA):** (Dashed Orange Line) Remains relatively stable around 0 ΔP across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -20 ΔP at Layer 1, decreases to approximately -40 ΔP by Layer 16.
* **A-Anchored (TriviaQA):** (Dotted Gray Line) Remains relatively stable around 0 ΔP across all layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple Line) Starts at approximately -10 ΔP at Layer 1, decreases to approximately -40 ΔP by Layer 16.
* **A-Anchored (HotpotQA):** (Dash-Dot Red Line) Remains relatively stable around 0 ΔP across all layers.
* **Q-Anchored (NQ):** (Dashed Pink Line) Starts at approximately -10 ΔP at Layer 1, decreases to approximately -40 ΔP by Layer 16.
* **A-Anchored (NQ):** (Dotted-Dashed Black Line) Remains relatively stable around 0 ΔP across all layers.
**Llama-3.2-3B (Right Chart):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -20 ΔP at Layer 1, decreases to approximately -70 ΔP by Layer 27.
* **A-Anchored (PopQA):** (Dashed Orange Line) Remains relatively stable around 0 ΔP across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -20 ΔP at Layer 1, decreases to approximately -70 ΔP by Layer 27.
* **A-Anchored (TriviaQA):** (Dotted Gray Line) Remains relatively stable around 0 ΔP across all layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple Line) Starts at approximately -10 ΔP at Layer 1, decreases to approximately -60 ΔP by Layer 27.
* **A-Anchored (HotpotQA):** (Dash-Dot Red Line) Remains relatively stable around 0 ΔP across all layers.
* **Q-Anchored (NQ):** (Dashed Pink Line) Starts at approximately -10 ΔP at Layer 1, decreases to approximately -60 ΔP by Layer 27.
* **A-Anchored (NQ):** (Dotted-Dashed Black Line) Remains relatively stable around 0 ΔP across all layers.
### Key Observations
* **Q-Anchored Performance Decrease:** For both models, the Q-Anchored approaches (PopQA, TriviaQA, HotpotQA, NQ) show a decrease in ΔP as the layer number increases.
* **A-Anchored Stability:** The A-Anchored approaches (PopQA, TriviaQA, HotpotQA, NQ) maintain a relatively stable ΔP around 0 across all layers for both models.
* **Model Comparison:** The Llama-3.2-3B model (right chart) has more layers (up to 27) compared to Llama-3.2-1B (left chart, up to 16). The Q-Anchored performance decrease appears more pronounced in Llama-3.2-3B.
### Interpretation
The data suggests that as the layer number increases, the performance of question-anchored approaches decreases, indicating a potential degradation in the model's ability to leverage information from the question itself in deeper layers. The answer-anchored approaches, on the other hand, maintain stable performance, suggesting that anchoring on the answer might provide more consistent results across different layers. The Llama-3.2-3B model, with its increased number of layers, exhibits a more pronounced performance decrease in the Q-Anchored approaches, which could indicate that the model's ability to process question-related information diminishes more significantly with increasing depth.
</details>
<details>
<summary>x17.png Details</summary>
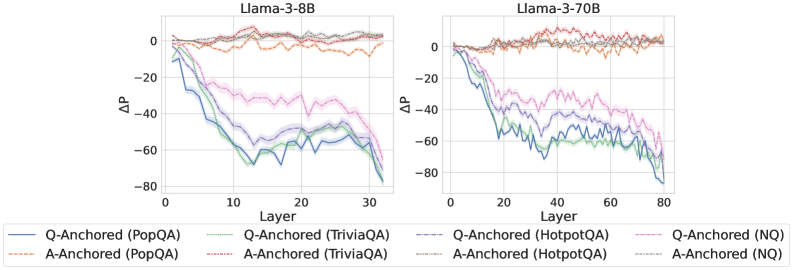
### Visual Description
## Line Charts: Performance Comparison of Llama Models
### Overview
The image presents two line charts comparing the performance of Llama models (Llama-3-8B and Llama-3-70B) across different layers. The y-axis represents ΔP (change in performance), and the x-axis represents the layer number. Each chart displays multiple data series, distinguished by line style and color, representing different question-answering datasets and anchoring methods (Q-Anchored and A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3-8B"
* Right Chart: "Llama-3-70B"
* **X-Axis:**
* Label: "Layer"
* Left Chart: Scale ranges from 0 to 30, with tick marks at approximately 0, 10, 20, and 30.
* Right Chart: Scale ranges from 0 to 80, with tick marks at approximately 0, 20, 40, 60, and 80.
* **Y-Axis:**
* Label: "ΔP"
* Scale ranges from -80 to 0, with tick marks at -80, -60, -40, -20, and 0.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid blue line
* A-Anchored (PopQA): Dashed brown line
* Q-Anchored (TriviaQA): Dotted green line
* A-Anchored (TriviaQA): Dash-dot brown line
* Q-Anchored (HotpotQA): Dash-dot-dot red line
* A-Anchored (HotpotQA): Dotted brown line
* Q-Anchored (NQ): Dotted pink line
* A-Anchored (NQ): Dotted gray line
### Detailed Analysis
**Left Chart (Llama-3-8B):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts near 0 and decreases to approximately -75 by layer 30.
* **A-Anchored (PopQA):** (Dashed brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts near 0 and decreases to approximately -65 by layer 30.
* **A-Anchored (TriviaQA):** (Dash-dot brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA):** (Dash-dot-dot red line) Remains relatively stable around 0 throughout all layers.
* **A-Anchored (HotpotQA):** (Dotted brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dotted pink line) Starts near 0 and decreases to approximately -30 by layer 30.
* **A-Anchored (NQ):** (Dotted gray line) Remains relatively stable around 0 throughout all layers.
**Right Chart (Llama-3-70B):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts near 0 and decreases to approximately -80 by layer 80.
* **A-Anchored (PopQA):** (Dashed brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts near 0 and decreases to approximately -70 by layer 80.
* **A-Anchored (TriviaQA):** (Dash-dot brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA):** (Dash-dot-dot red line) Remains relatively stable around 0 throughout all layers.
* **A-Anchored (HotpotQA):** (Dotted brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dotted pink line) Starts near 0 and decreases to approximately -30 by layer 80.
* **A-Anchored (NQ):** (Dotted gray line) Remains relatively stable around 0 throughout all layers.
### Key Observations
* The "Q-Anchored" series (PopQA, TriviaQA, and NQ) show a significant decrease in ΔP as the layer number increases for both Llama models.
* The "A-Anchored" series (PopQA, TriviaQA, HotpotQA, and NQ) remain relatively stable around 0 across all layers for both Llama models.
* The Llama-3-70B model has a larger layer range (0-80) compared to the Llama-3-8B model (0-30).
* The Q-Anchored (HotpotQA) series remains stable around 0 for both models.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to a decrease in performance (ΔP) as the model processes deeper layers, particularly for the PopQA, TriviaQA, and NQ datasets. This could indicate that the model's ability to answer questions from these datasets degrades with increasing layer depth when the question is anchored. Conversely, anchoring the answer (A-Anchored) results in stable performance across all layers, suggesting that the model maintains its ability to answer questions when the answer is anchored. The HotpotQA dataset shows stable performance regardless of whether the question or answer is anchored. The difference in layer range between the two models (8B vs 70B) highlights the larger processing capacity of the 70B model.
</details>
<details>
<summary>x18.png Details</summary>
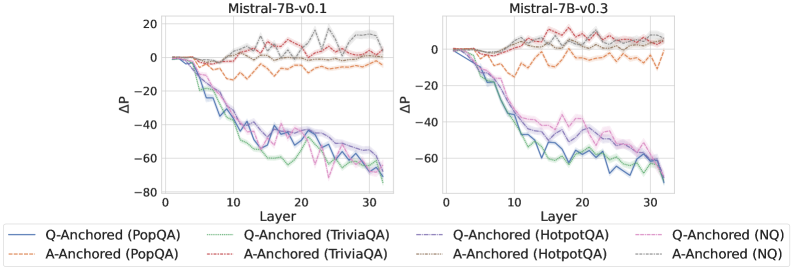
### Visual Description
## Line Chart: Mistral-7B Model Performance Comparison
### Overview
The image presents two line charts comparing the performance of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across different question answering tasks. The charts display the change in performance (ΔP) as a function of the layer number in the model. Each line represents a different question answering task, anchored either to the question (Q-Anchored) or the answer (A-Anchored).
### Components/Axes
* **Titles:** The left chart is titled "Mistral-7B-v0.1" and the right chart is titled "Mistral-7B-v0.3".
* **X-axis:** Labeled "Layer", with a scale from 0 to 30 in increments of 10.
* **Y-axis:** Labeled "ΔP", with a scale from -80 to 20 in increments of 20.
* **Legend:** Located at the bottom of the charts, mapping line styles and colors to question answering tasks:
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Pink dashed-dotted line: A-Anchored (TriviaQA)
* Red dashed line: Q-Anchored (HotpotQA)
* Orange dashed-double-dotted line: A-Anchored (HotpotQA)
* Purple dashed line: Q-Anchored (NQ)
* Gray dotted line: A-Anchored (NQ)
### Detailed Analysis
**Mistral-7B-v0.1 (Left Chart):**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0, decreases to around -60 by layer 30.
* **A-Anchored (PopQA) (Brown dashed line):** Starts at approximately 0, decreases slightly to around -10, then fluctuates between -5 and -15.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 0, decreases to around -60 by layer 30.
* **A-Anchored (TriviaQA) (Pink dashed-dotted line):** Starts at approximately 0, decreases to around -50 by layer 30.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts at approximately 0, increases to around 10 by layer 30.
* **A-Anchored (HotpotQA) (Orange dashed-double-dotted line):** Starts at approximately 0, decreases to around -15, then fluctuates between -5 and -15.
* **Q-Anchored (NQ) (Purple dashed line):** Starts at approximately 0, decreases to around -70 by layer 30.
* **A-Anchored (NQ) (Gray dotted line):** Starts at approximately 0, increases to around 15 by layer 30.
**Mistral-7B-v0.3 (Right Chart):**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0, decreases to around -60 by layer 30.
* **A-Anchored (PopQA) (Brown dashed line):** Starts at approximately 0, decreases slightly to around -10, then fluctuates between -5 and -15.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 0, decreases to around -60 by layer 30.
* **A-Anchored (TriviaQA) (Pink dashed-dotted line):** Starts at approximately 0, decreases to around -50 by layer 30.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts at approximately 0, increases to around 10 by layer 30.
* **A-Anchored (HotpotQA) (Orange dashed-double-dotted line):** Starts at approximately 0, decreases to around -15, then fluctuates between -5 and -15.
* **Q-Anchored (NQ) (Purple dashed line):** Starts at approximately 0, decreases to around -70 by layer 30.
* **A-Anchored (NQ) (Gray dotted line):** Starts at approximately 0, increases to around 15 by layer 30.
### Key Observations
* The performance trends for each question answering task are very similar between Mistral-7B-v0.1 and Mistral-7B-v0.3.
* Q-Anchored (PopQA), Q-Anchored (TriviaQA), and Q-Anchored (NQ) show a significant decrease in ΔP as the layer number increases.
* A-Anchored (PopQA) and A-Anchored (HotpotQA) show a slight decrease in ΔP as the layer number increases.
* Q-Anchored (HotpotQA) and A-Anchored (NQ) show an increase in ΔP as the layer number increases.
### Interpretation
The charts suggest that the performance of the Mistral-7B model on different question answering tasks varies significantly depending on whether the task is anchored to the question or the answer. The decrease in ΔP for Q-Anchored tasks as the layer number increases could indicate that the model struggles to maintain performance on these tasks as it processes deeper layers. Conversely, the increase in ΔP for A-Anchored (NQ) and Q-Anchored (HotpotQA) tasks suggests that the model's performance improves with deeper processing for these specific tasks. The similarity in trends between Mistral-7B-v0.1 and Mistral-7B-v0.3 indicates that the performance characteristics are consistent across these versions of the model.
</details>
Figure 10: $\Delta\mathrm{P}$ under attention knockout, probing mlp activations of the final token.
<details>
<summary>x19.png Details</summary>
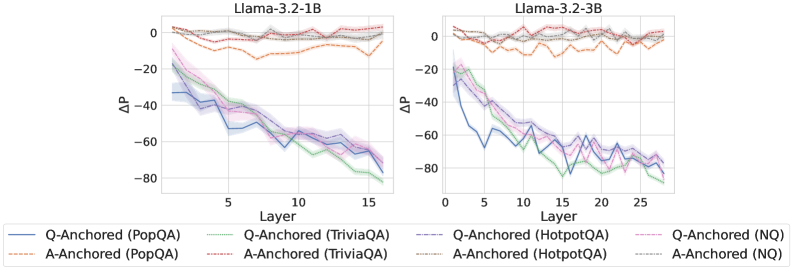
### Visual Description
## Line Chart: Llama-3.2 Model Performance
### Overview
The image contains two line charts comparing the performance of Llama-3.2 models (1B and 3B) across different question-answering datasets. The charts plot the change in performance (ΔP) against the layer number of the model. Each chart displays six data series, representing question-anchored (Q-Anchored) and answer-anchored (A-Anchored) performance on PopQA, TriviaQA, HotpotQA, and NQ datasets.
### Components/Axes
**Left Chart (Llama-3.2-1B):**
* **Title:** Llama-3.2-1B
* **X-axis:** Layer, with markers at 0, 5, 10, and 15.
* **Y-axis:** ΔP, with markers at 0, -20, -40, -60, and -80.
* **Legend:** Located below the chart.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Pink Line
* Q-Anchored (HotpotQA): Dash-Dot Blue Line
* Q-Anchored (NQ): Dotted Pink Line
* A-Anchored (HotpotQA): Solid Green Line
* A-Anchored (NQ): Dotted Grey Line
**Right Chart (Llama-3.2-3B):**
* **Title:** Llama-3.2-3B
* **X-axis:** Layer, with markers at 0, 5, 10, 15, 20, and 25.
* **Y-axis:** ΔP, with markers at 0, -20, -40, -60, and -80.
* **Legend:** Located below both charts.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Pink Line
* Q-Anchored (HotpotQA): Dash-Dot Blue Line
* Q-Anchored (NQ): Dotted Pink Line
* A-Anchored (HotpotQA): Solid Green Line
* A-Anchored (NQ): Dotted Grey Line
### Detailed Analysis
**Llama-3.2-1B Chart:**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -30 and generally decreases to around -70 by layer 15.
* **A-Anchored (PopQA):** (Dashed Brown Line) Remains relatively flat, fluctuating between 0 and -10.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -30 and decreases to around -60 by layer 15.
* **A-Anchored (TriviaQA):** (Dash-Dotted Pink Line) Remains relatively flat, fluctuating between 0 and -10.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue Line) Starts at approximately -20 and decreases to around -60 by layer 15.
* **Q-Anchored (NQ):** (Dotted Pink Line) Starts at approximately -20 and decreases to around -50 by layer 15.
* **A-Anchored (HotpotQA):** (Solid Green Line) Starts at approximately -30 and decreases to around -70 by layer 15.
* **A-Anchored (NQ):** (Dotted Grey Line) Remains relatively flat, fluctuating between 0 and -10.
**Llama-3.2-3B Chart:**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately -30 and generally decreases to around -70 by layer 25.
* **A-Anchored (PopQA):** (Dashed Brown Line) Remains relatively flat, fluctuating between 0 and -10.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately -30 and decreases to around -70 by layer 25.
* **A-Anchored (TriviaQA):** (Dash-Dotted Pink Line) Remains relatively flat, fluctuating between 0 and -10.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue Line) Starts at approximately -30 and decreases to around -70 by layer 25.
* **Q-Anchored (NQ):** (Dotted Pink Line) Starts at approximately -20 and decreases to around -70 by layer 25.
* **A-Anchored (HotpotQA):** (Solid Green Line) Starts at approximately -30 and decreases to around -70 by layer 25.
* **A-Anchored (NQ):** (Dotted Grey Line) Remains relatively flat, fluctuating between 0 and -10.
### Key Observations
* The Q-Anchored lines (PopQA, TriviaQA, HotpotQA, and NQ) generally show a decreasing trend in ΔP as the layer number increases for both models.
* The A-Anchored lines (PopQA, TriviaQA, HotpotQA, and NQ) remain relatively flat across all layers for both models.
* The 3B model has more layers (25) than the 1B model (15).
* The performance drop (ΔP) is more pronounced for Q-Anchored data compared to A-Anchored data.
### Interpretation
The charts suggest that question anchoring has a more significant impact on performance as the model processes deeper layers. The decreasing ΔP for Q-Anchored data indicates that the model's performance degrades more noticeably with increasing layer depth when the question is the anchor. Conversely, answer anchoring seems to maintain a more stable performance across different layers. The 3B model, with its increased number of layers, exhibits similar trends to the 1B model, but the performance drop in Q-Anchored data is sustained over a larger number of layers. This could imply that the deeper layers in the 3B model are more sensitive to question-related information. The flat A-Anchored lines suggest that the model's performance is less affected by the layer depth when the answer is the anchor.
</details>
<details>
<summary>x20.png Details</summary>
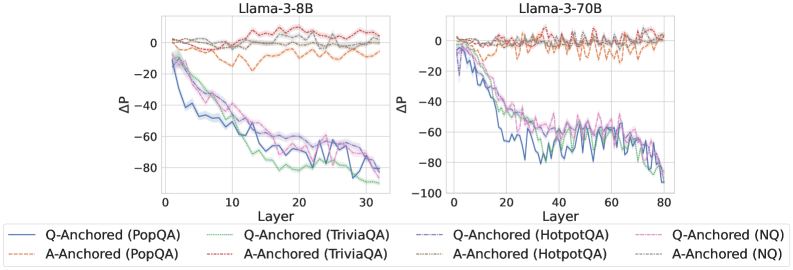
### Visual Description
## Chart Type: Line Graphs Comparing Llama-3-8B and Llama-3-70B
### Overview
The image presents two line graphs side-by-side, comparing the performance of Llama-3-8B (left) and Llama-3-70B (right) models across different layers. The y-axis represents ΔP (Delta P), and the x-axis represents the Layer number. Each graph displays six data series, representing "Q-Anchored" and "A-Anchored" performance on four different question-answering datasets: PopQA, TriviaQA, HotpotQA, and NQ.
### Components/Axes
* **Titles:**
* Left Graph: "Llama-3-8B"
* Right Graph: "Llama-3-70B"
* **X-Axis:**
* Label: "Layer"
* Left Graph: Scale from 0 to 30, with tick marks at approximately 0, 10, 20, and 30.
* Right Graph: Scale from 0 to 80, with tick marks at approximately 0, 20, 40, 60, and 80.
* **Y-Axis:**
* Label: "ΔP"
* Scale: From -80 to 0 on the left graph, and from -100 to 0 on the right graph, with tick marks at -80, -60, -40, -20, and 0 on the left, and -100, -80, -60, -40, -20, and 0 on the right.
* **Legend:** Located at the bottom of the image.
* **Q-Anchored (PopQA):** Solid Blue Line
* **A-Anchored (PopQA):** Dashed Brown Line
* **Q-Anchored (TriviaQA):** Dotted Green Line
* **A-Anchored (TriviaQA):** Dashed-Dotted Gray Line
* **Q-Anchored (HotpotQA):** Dashed-Dotted Pink Line
* **A-Anchored (HotpotQA):** Dotted Orange Line
* **Q-Anchored (NQ):** Dashed Pink Line
* **A-Anchored (NQ):** Dotted Gray Line
### Detailed Analysis
**Llama-3-8B (Left Graph):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0 and decreases to approximately -70 by layer 30.
* **A-Anchored (PopQA):** (Dashed Brown Line) Remains relatively flat around 0.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 0 and decreases to approximately -70 by layer 30.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Gray Line) Remains relatively flat around 0.
* **Q-Anchored (HotpotQA):** (Dashed-Dotted Pink Line) Starts at approximately 0 and decreases to approximately -50 by layer 30.
* **A-Anchored (HotpotQA):** (Dotted Orange Line) Remains relatively flat around -10.
* **Q-Anchored (NQ):** (Dashed Pink Line) Starts at approximately 0 and decreases to approximately -60 by layer 30.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively flat around 0.
**Llama-3-70B (Right Graph):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0 and decreases to approximately -60 by layer 20, then fluctuates between -60 and -80 until layer 80.
* **A-Anchored (PopQA):** (Dashed Brown Line) Remains relatively flat around 0, with some fluctuations.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 0 and decreases to approximately -60 by layer 20, then fluctuates between -60 and -80 until layer 80.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Gray Line) Remains relatively flat around 0.
* **Q-Anchored (HotpotQA):** (Dashed-Dotted Pink Line) Starts at approximately 0 and decreases to approximately -50 by layer 20, then fluctuates between -50 and -70 until layer 80.
* **A-Anchored (HotpotQA):** (Dotted Orange Line) Remains relatively flat around -5, with some fluctuations.
* **Q-Anchored (NQ):** (Dashed Pink Line) Starts at approximately 0 and decreases to approximately -50 by layer 20, then fluctuates between -50 and -70 until layer 80.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively flat around 0.
### Key Observations
* For both models, the "Q-Anchored" data series (PopQA, TriviaQA, HotpotQA, and NQ) show a decreasing trend as the layer number increases, indicating a change in performance across layers.
* The "A-Anchored" data series (PopQA, TriviaQA, HotpotQA, and NQ) remain relatively flat, suggesting a different behavior compared to the "Q-Anchored" series.
* The Llama-3-70B model shows more fluctuation in the "Q-Anchored" data series after layer 20 compared to the Llama-3-8B model.
* The Llama-3-70B model has a larger number of layers (80) compared to the Llama-3-8B model (30).
### Interpretation
The graphs suggest that the "Q-Anchored" performance changes significantly across the layers of both Llama-3-8B and Llama-3-70B models, while the "A-Anchored" performance remains relatively stable. The fluctuations observed in the Llama-3-70B model after layer 20 could indicate a more complex interaction between layers in the larger model. The difference in the number of layers between the two models may contribute to the observed performance differences. The data implies that the way the question is anchored within the model's architecture has a significant impact on how performance evolves through the layers, while anchoring the answer has a less pronounced effect. The specific datasets (PopQA, TriviaQA, HotpotQA, NQ) seem to influence the magnitude of the performance change, but the overall trend remains consistent.
</details>
<details>
<summary>x21.png Details</summary>
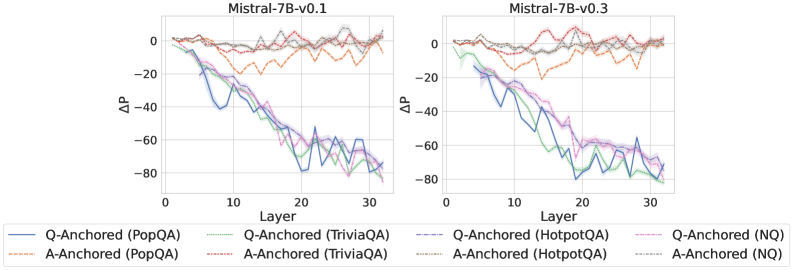
### Visual Description
## Line Chart: Mistral-7B-v0.1 vs Mistral-7B-v0.3
### Overview
The image presents two line charts comparing the performance of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across different layers (1 to 32) and question-answering datasets. The y-axis represents ΔP, a performance metric, while the x-axis represents the layer number. Each chart displays six data series, representing different combinations of anchoring (Q-Anchored or A-Anchored) and question-answering datasets (PopQA, TriviaQA, HotpotQA, NQ).
### Components/Axes
* **Titles:**
* Left Chart: Mistral-7B-v0.1
* Right Chart: Mistral-7B-v0.3
* **X-axis:**
* Label: Layer
* Scale: 0 to 30, with tick marks at intervals of 10.
* **Y-axis:**
* Label: ΔP
* Scale: -80 to 0, with tick marks at intervals of 20.
* **Legend:** Located at the bottom of the chart.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dashed-Dotted Gray Line
* Q-Anchored (HotpotQA): Dashed Purple Line
* A-Anchored (HotpotQA): Dotted Red Line
* Q-Anchored (NQ): Dashed-Dotted Purple Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0 and decreases to around -70 by layer 15, then fluctuates between -60 and -75 until layer 30.
* **A-Anchored (PopQA):** (Dashed Brown Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts near 0 and decreases to approximately -60 by layer 15, then fluctuates between -50 and -65 until layer 30.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Gray Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
* **Q-Anchored (HotpotQA):** (Dashed Purple Line) Starts near 0 and decreases to approximately -50 by layer 15, then fluctuates between -50 and -70 until layer 30.
* **A-Anchored (HotpotQA):** (Dotted Red Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
* **Q-Anchored (NQ):** (Dashed-Dotted Purple Line) Starts near 0 and decreases to approximately -50 by layer 15, then fluctuates between -50 and -70 until layer 30.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
**Right Chart: Mistral-7B-v0.3**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0 and decreases to around -60 by layer 15, then fluctuates between -50 and -75 until layer 30.
* **A-Anchored (PopQA):** (Dashed Brown Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts near 0 and decreases to approximately -50 by layer 15, then fluctuates between -50 and -70 until layer 30.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Gray Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
* **Q-Anchored (HotpotQA):** (Dashed Purple Line) Starts near 0 and decreases to approximately -50 by layer 15, then fluctuates between -50 and -70 until layer 30.
* **A-Anchored (HotpotQA):** (Dotted Red Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
* **Q-Anchored (NQ):** (Dashed-Dotted Purple Line) Starts near 0 and decreases to approximately -50 by layer 15, then fluctuates between -50 and -70 until layer 30.
* **A-Anchored (NQ):** (Dotted Gray Line) Remains relatively stable around 0, with minor fluctuations between -5 and 5 across all layers.
### Key Observations
* The "Q-Anchored" series (PopQA, TriviaQA, HotpotQA, NQ) show a significant decrease in ΔP as the layer number increases, indicating a performance drop.
* The "A-Anchored" series (PopQA, TriviaQA, HotpotQA, NQ) remain relatively stable near 0, suggesting minimal performance change across layers.
* The performance drop in "Q-Anchored" series seems to stabilize after layer 15.
* The Mistral-7B-v0.3 model shows a slightly less pronounced performance drop in the "Q-Anchored" series compared to Mistral-7B-v0.1.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to a performance degradation as the model processes deeper layers, while anchoring the answer (A-Anchored) maintains a stable performance. This could indicate that the model struggles to maintain relevant information from the question as it progresses through the layers, while the answer information remains more consistent. The slight improvement in Mistral-7B-v0.3 suggests some optimization in handling question information across layers, but the overall trend remains consistent. The performance drop stabilization after layer 15 might indicate a point where the model's processing reaches a steady state or a bottleneck.
</details>
Figure 11: $\Delta\mathrm{P}$ under attention knockout, probing mlp activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x22.png Details</summary>
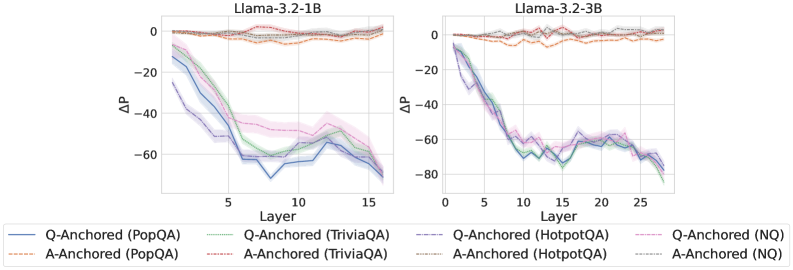
### Visual Description
## Line Charts: Llama-3.2 Model Performance
### Overview
The image contains two line charts comparing the performance of Llama-3.2 models (1B and 3B) on various question-answering tasks. The charts plot the change in performance (ΔP) against the layer number of the model. Different lines represent different question-answering datasets, anchored either by question (Q-Anchored) or answer (A-Anchored).
### Components/Axes
**Left Chart (Llama-3.2-1B):**
* **Title:** Llama-3.2-1B
* **Y-axis:** ΔP (Change in Performance). Scale ranges from approximately -70 to 0. Markers at 0, -20, -40, -60.
* **X-axis:** Layer. Scale ranges from 0 to 15. Markers at 0, 5, 10, 15.
**Right Chart (Llama-3.2-3B):**
* **Title:** Llama-3.2-3B
* **Y-axis:** ΔP (Change in Performance). Scale ranges from approximately -80 to 0. Markers at 0, -20, -40, -60, -80.
* **X-axis:** Layer. Scale ranges from 0 to 25. Markers at 0, 5, 10, 15, 20, 25.
**Legend (Located below the charts):**
* **Q-Anchored (PopQA):** Solid Blue Line
* **A-Anchored (PopQA):** Dashed Orange Line
* **Q-Anchored (TriviaQA):** Dotted Green Line
* **A-Anchored (TriviaQA):** Dashed Pink Line
* **Q-Anchored (HotpotQA):** Dashed-dotted Purple Line
* **A-Anchored (HotpotQA):** Dotted Grey Line
* **Q-Anchored (NQ):** Dashed-dotted Pink Line
* **A-Anchored (NQ):** Dotted Grey Line
### Detailed Analysis
**Llama-3.2-1B Chart:**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0, rapidly decreases to around -60 by layer 5, then fluctuates between -60 and -70 until layer 15.
* **A-Anchored (PopQA):** (Dashed Orange) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0, decreases to around -50 by layer 5, then fluctuates between -50 and -60 until layer 15.
* **A-Anchored (TriviaQA):** (Dashed Pink) Starts at approximately 0, decreases to around -40 by layer 5, then fluctuates between -40 and -50 until layer 15.
* **Q-Anchored (HotpotQA):** (Dashed-dotted Purple) Starts at approximately 0, decreases to around -50 by layer 5, then fluctuates between -50 and -60 until layer 15.
* **A-Anchored (HotpotQA):** (Dotted Grey) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dashed-dotted Pink) Starts at approximately 0, decreases to around -40 by layer 5, then fluctuates between -40 and -50 until layer 15.
* **A-Anchored (NQ):** (Dotted Grey) Remains relatively stable around 0 throughout all layers.
**Llama-3.2-3B Chart:**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0, rapidly decreases to around -70 by layer 5, then fluctuates between -60 and -80 until layer 25.
* **A-Anchored (PopQA):** (Dashed Orange) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0, decreases to around -60 by layer 5, then fluctuates between -60 and -80 until layer 25.
* **A-Anchored (TriviaQA):** (Dashed Pink) Starts at approximately 0, decreases to around -60 by layer 5, then fluctuates between -60 and -70 until layer 25.
* **Q-Anchored (HotpotQA):** (Dashed-dotted Purple) Starts at approximately 0, decreases to around -60 by layer 5, then fluctuates between -60 and -80 until layer 25.
* **A-Anchored (HotpotQA):** (Dotted Grey) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dashed-dotted Pink) Starts at approximately 0, decreases to around -60 by layer 5, then fluctuates between -60 and -70 until layer 25.
* **A-Anchored (NQ):** (Dotted Grey) Remains relatively stable around 0 throughout all layers.
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored lines show a significant decrease in performance (negative ΔP) as the layer number increases, while A-Anchored lines remain relatively stable around 0.
* **Model Size:** The 3B model generally shows a slightly larger decrease in performance for Q-Anchored tasks compared to the 1B model.
* **Task Variation:** The specific question-answering task (PopQA, TriviaQA, HotpotQA, NQ) influences the magnitude of the performance decrease for Q-Anchored lines.
* **Layer Dependence:** The performance decrease for Q-Anchored tasks is most pronounced in the initial layers (up to layer 5), after which the performance fluctuates.
### Interpretation
The data suggests that anchoring the model by question (Q-Anchored) leads to a degradation in performance as the model processes deeper layers. This could indicate that the model struggles to maintain relevant information from the question as it progresses through the network. In contrast, anchoring by answer (A-Anchored) results in stable performance, suggesting that the model is better at retaining information related to the answer.
The larger performance decrease in the 3B model for Q-Anchored tasks might indicate that larger models are more susceptible to this degradation effect. The variation in performance decrease across different question-answering tasks suggests that the complexity or nature of the task influences the model's ability to retain question-related information.
The initial rapid decrease in performance followed by fluctuations suggests that the early layers of the model are critical for retaining question-related information, and that subsequent layers may not be able to fully compensate for any loss of information in the initial layers.
</details>
<details>
<summary>x23.png Details</summary>
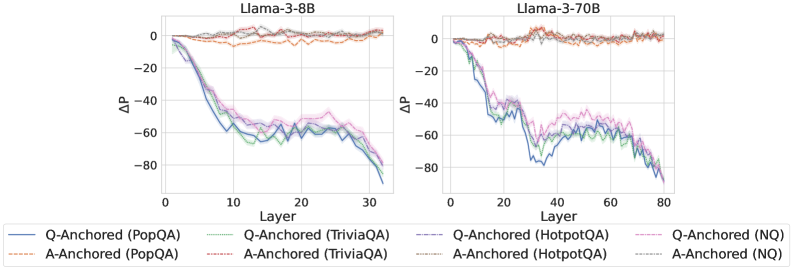
### Visual Description
## Chart: Layer vs. Delta P for Llama-3-8B and Llama-3-70B
### Overview
The image presents two line charts comparing the performance of Llama-3-8B and Llama-3-70B models across different layers. The y-axis represents the change in probability (ΔP), while the x-axis represents the layer number. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3-8B"
* Right Chart: "Llama-3-70B"
* **Y-Axis:**
* Label: "ΔP"
* Scale: -80 to 0, with tick marks at -80, -60, -40, -20, and 0.
* **X-Axis:**
* Label: "Layer"
* Left Chart Scale: 0 to 30, with tick marks at 0, 10, 20, and 30.
* Right Chart Scale: 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **Legend:** Located at the bottom of the image.
* **Q-Anchored (PopQA):** Solid Blue Line
* **A-Anchored (PopQA):** Dashed Brown Line
* **Q-Anchored (TriviaQA):** Dotted Green Line
* **A-Anchored (TriviaQA):** Dashed-Dotted Light Brown Line
* **Q-Anchored (HotpotQA):** Dashed-Dotted Purple Line
* **A-Anchored (HotpotQA):** Dotted Light Brown Line
* **Q-Anchored (NQ):** Dashed Purple Line
* **A-Anchored (NQ):** Dotted Light Gray Line
### Detailed Analysis
**Left Chart: Llama-3-8B**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 and decreases sharply to approximately -80 by layer 30.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0 and decreases to approximately -65 by layer 30.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Light Brown) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA):** (Dashed-Dotted Purple) Starts at approximately 0 and decreases to approximately -70 by layer 30.
* **A-Anchored (HotpotQA):** (Dotted Light Brown) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dashed Purple) Starts at approximately 0 and decreases to approximately -60 by layer 30.
* **A-Anchored (NQ):** (Dotted Light Gray) Remains relatively stable around 0 throughout all layers.
**Right Chart: Llama-3-70B**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 and decreases sharply to approximately -80 by layer 30, then fluctuates between -60 and -80 until layer 80.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0 and decreases to approximately -65 by layer 30, then fluctuates between -50 and -70 until layer 80.
* **A-Anchored (TriviaQA):** (Dashed-Dotted Light Brown) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA):** (Dashed-Dotted Purple) Starts at approximately 0 and decreases to approximately -70 by layer 30, then fluctuates between -50 and -70 until layer 80.
* **A-Anchored (HotpotQA):** (Dotted Light Brown) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dashed Purple) Starts at approximately 0 and decreases to approximately -60 by layer 30, then fluctuates between -50 and -70 until layer 80.
* **A-Anchored (NQ):** (Dotted Light Gray) Remains relatively stable around 0 throughout all layers.
### Key Observations
* For both models, the "Q-Anchored" series (PopQA, TriviaQA, HotpotQA, and NQ) show a significant decrease in ΔP as the layer number increases, indicating a change in probability when anchoring with the question.
* The "A-Anchored" series (PopQA, TriviaQA, HotpotQA, and NQ) remain relatively stable around 0 for both models, suggesting that anchoring with the answer does not significantly affect the probability.
* The Llama-3-70B model shows more fluctuation in the "Q-Anchored" series after layer 30 compared to the Llama-3-8B model.
### Interpretation
The data suggests that anchoring the question-answering process with the question itself ("Q-Anchored") leads to a substantial change in probability as the model processes deeper layers. This could indicate that the model is refining its understanding or focus as it progresses through the layers. In contrast, anchoring with the answer ("A-Anchored") does not significantly alter the probability, possibly because the answer provides a fixed reference point.
The fluctuations observed in the Llama-3-70B model after layer 30 for the "Q-Anchored" series might indicate that the larger model continues to adjust its understanding or confidence even in later layers, whereas the smaller Llama-3-8B model stabilizes earlier. This could be due to the larger model's greater capacity to process and refine information.
The consistent behavior of the "A-Anchored" series suggests that providing the answer upfront stabilizes the model's probability assessment, regardless of the layer. This could be useful in applications where a consistent and reliable probability score is desired.
</details>
<details>
<summary>x24.png Details</summary>
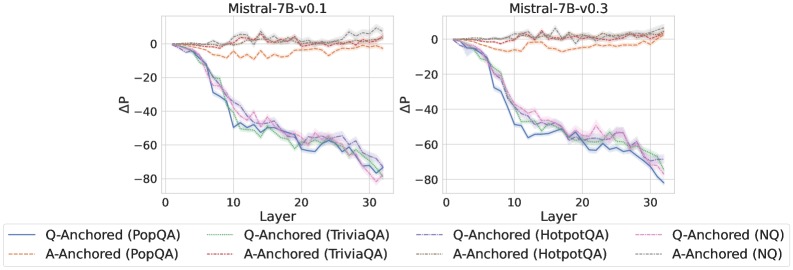
### Visual Description
## Line Chart: Performance Comparison of Mistral-7B Models
### Overview
The image presents two line charts comparing the performance of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across different question-answering tasks. The charts depict the change in performance (ΔP) as a function of the layer number in the model. Each chart contains six data series, representing different question-answering datasets anchored either by question (Q-Anchored) or answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:**
* Label: "ΔP" (Change in Performance)
* Scale: -80 to 0, with increments of 20 (-80, -60, -40, -20, 0)
* **X-Axis:**
* Label: "Layer"
* Scale: 0 to 30, with increments of 10 (0, 10, 20, 30)
* **Legend:** Located at the bottom of the image, spanning both charts.
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed orange line
* **Q-Anchored (TriviaQA):** Dotted green line
* **A-Anchored (TriviaQA):** Dashed and dotted gray line
* **Q-Anchored (HotpotQA):** Dashed pink line
* **A-Anchored (HotpotQA):** Dotted gray line
* **Q-Anchored (NQ):** Dashed and dotted purple line
* **A-Anchored (NQ):** Dotted gray line
### Detailed Analysis
**Left Chart (Mistral-7B-v0.1):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -70 to -80 at layer 30.
* **A-Anchored (PopQA):** (Dashed orange line) Starts at approximately 0, decreases slightly, then fluctuates around -5 to 0 throughout the layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -60 to -70 at layer 30.
* **A-Anchored (TriviaQA):** (Dashed and dotted gray line) Starts at approximately 0, fluctuates around 0 to 5 throughout the layers.
* **Q-Anchored (HotpotQA):** (Dashed pink line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -70 to -80 at layer 30.
* **A-Anchored (HotpotQA):** (Dotted gray line) Starts at approximately 0, fluctuates around 0 to 5 throughout the layers.
* **Q-Anchored (NQ):** (Dashed and dotted purple line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -70 to -80 at layer 30.
* **A-Anchored (NQ):** (Dotted gray line) Starts at approximately 0, fluctuates around 0 to 5 throughout the layers.
**Right Chart (Mistral-7B-v0.3):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -60 to -70 at layer 30.
* **A-Anchored (PopQA):** (Dashed orange line) Starts at approximately 0, fluctuates around 0 to 5 throughout the layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -60 to -70 at layer 30.
* **A-Anchored (TriviaQA):** (Dashed and dotted gray line) Starts at approximately 0, fluctuates around 0 to 5 throughout the layers.
* **Q-Anchored (HotpotQA):** (Dashed pink line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -60 to -70 at layer 30.
* **A-Anchored (HotpotQA):** (Dotted gray line) Starts at approximately 0, fluctuates around 0 to 5 throughout the layers.
* **Q-Anchored (NQ):** (Dashed and dotted purple line) Starts at approximately 0, decreases sharply until layer 10 (reaching approximately -40), then continues to decrease gradually, reaching approximately -60 to -70 at layer 30.
* **A-Anchored (NQ):** (Dotted gray line) Starts at approximately 0, fluctuates around 0 to 5 throughout the layers.
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored datasets (PopQA, TriviaQA, HotpotQA, NQ) show a significant decrease in performance (ΔP) as the layer number increases for both Mistral-7B-v0.1 and Mistral-7B-v0.3. In contrast, A-Anchored datasets show relatively stable performance across all layers.
* **Model Version Comparison:** The performance trends are similar between Mistral-7B-v0.1 and Mistral-7B-v0.3 for each dataset. However, Mistral-7B-v0.3 appears to have slightly better performance (less negative ΔP) for Q-Anchored datasets in the later layers (20-30).
* **Performance Drop:** The most significant performance drop for Q-Anchored datasets occurs in the initial layers (0-10).
### Interpretation
The data suggests that anchoring by question (Q-Anchored) leads to a degradation in performance as the model processes deeper layers. This could indicate that the model's ability to understand and utilize question-related information diminishes in later layers. Conversely, anchoring by answer (A-Anchored) results in more stable performance, suggesting that answer-related information is better preserved or utilized throughout the model's layers.
The similarity in trends between Mistral-7B-v0.1 and Mistral-7B-v0.3 indicates that the underlying architectural changes between the versions did not fundamentally alter the observed performance degradation pattern for Q-Anchored datasets. The slight improvement in Mistral-7B-v0.3 for Q-Anchored datasets in later layers might suggest some optimization in handling question-related information, but the overall trend remains consistent.
The initial performance drop in the early layers for Q-Anchored datasets could be attributed to the model's initial processing and encoding of the question, where information might be lost or transformed in a way that affects subsequent layers.
</details>
Figure 12: $\Delta\mathrm{P}$ under attention knockout, probing mlp activations of the last exact answer token.
<details>
<summary>x25.png Details</summary>
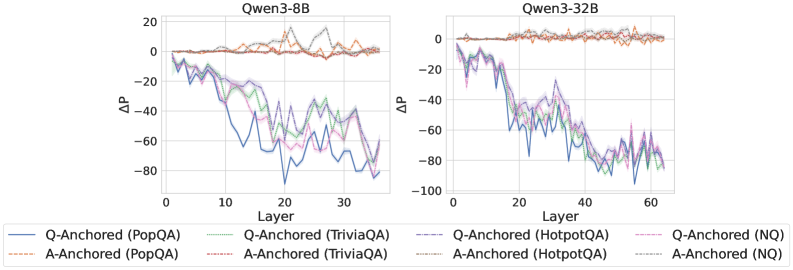
### Visual Description
## Line Chart: Qwen3-8B and Qwen3-32B Performance
### Overview
The image presents two line charts comparing the performance of Qwen3-8B and Qwen3-32B models across different layers, measured by ΔP (Delta P). Each chart displays multiple data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: Qwen3-8B
* Right Chart: Qwen3-32B
* **Y-Axis:**
* Label: ΔP
* Scale: -100 to 20, with increments of 20 (-80, -60, -40, -20, 0, 20)
* **X-Axis:**
* Label: Layer
* Left Chart Scale: 0 to 30, with increments of 10 (0, 10, 20, 30)
* Right Chart Scale: 0 to 60, with increments of 20 (0, 20, 40, 60)
* **Legend:** Located at the bottom of the image, describing the data series:
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Pink dashed-dotted line: A-Anchored (TriviaQA)
* Dark Blue dashed line: Q-Anchored (HotpotQA)
* Orange dotted line: A-Anchored (HotpotQA)
* Purple dashed-dotted line: Q-Anchored (NQ)
* Gray dotted line: A-Anchored (NQ)
### Detailed Analysis
#### Qwen3-8B (Left Chart)
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately -5 and decreases to around -65 at layer 20, then fluctuates between -40 and -60 until layer 30.
* **A-Anchored (PopQA) (Brown dashed line):** Remains relatively stable around 0 to 5 across all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around -5 and decreases to approximately -40 at layer 15, then fluctuates between -30 and -40 until layer 30.
* **A-Anchored (TriviaQA) (Pink dashed-dotted line):** Starts around -5 and decreases to approximately -40 at layer 15, then fluctuates between -30 and -40 until layer 30.
* **Q-Anchored (HotpotQA) (Dark Blue dashed line):** Starts around -5 and decreases to approximately -50 at layer 15, then fluctuates between -40 and -50 until layer 30.
* **A-Anchored (HotpotQA) (Orange dotted line):** Remains relatively stable around 0 to 5 across all layers.
* **Q-Anchored (NQ) (Purple dashed-dotted line):** Starts around -5 and decreases to approximately -50 at layer 15, then fluctuates between -40 and -50 until layer 30.
* **A-Anchored (NQ) (Gray dotted line):** Remains relatively stable around 0 to 5 across all layers.
#### Qwen3-32B (Right Chart)
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately -5 and decreases to around -85 at layer 40, then fluctuates between -70 and -80 until layer 60.
* **A-Anchored (PopQA) (Brown dashed line):** Remains relatively stable around 0 to 5 across all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around -5 and decreases to approximately -70 at layer 40, then fluctuates between -60 and -70 until layer 60.
* **A-Anchored (TriviaQA) (Pink dashed-dotted line):** Starts around -5 and decreases to approximately -70 at layer 40, then fluctuates between -60 and -70 until layer 60.
* **Q-Anchored (HotpotQA) (Dark Blue dashed line):** Starts around -5 and decreases to approximately -80 at layer 40, then fluctuates between -70 and -80 until layer 60.
* **A-Anchored (HotpotQA) (Orange dotted line):** Remains relatively stable around 0 to 5 across all layers.
* **Q-Anchored (NQ) (Purple dashed-dotted line):** Starts around -5 and decreases to approximately -80 at layer 40, then fluctuates between -70 and -80 until layer 60.
* **A-Anchored (NQ) (Gray dotted line):** Remains relatively stable around 0 to 5 across all layers.
### Key Observations
* **Performance Difference:** The Qwen3-32B model generally shows a greater decrease in ΔP compared to Qwen3-8B for Q-Anchored datasets.
* **Anchoring Impact:** A-Anchored datasets consistently maintain a ΔP close to 0 across all layers for both models.
* **Dataset Similarity:** The Q-Anchored datasets (TriviaQA, HotpotQA, NQ) exhibit similar trends within each model.
* **Layer Impact:** The most significant decrease in ΔP for Q-Anchored datasets occurs in the initial layers (up to layer 20 for Qwen3-8B and layer 40 for Qwen3-32B).
### Interpretation
The data suggests that anchoring by the question (Q-Anchored) leads to a performance decrease (as measured by ΔP) as the model processes deeper layers, especially for the larger Qwen3-32B model. This could indicate that the model's ability to utilize question-related information diminishes with increasing layer depth. Conversely, anchoring by the answer (A-Anchored) results in stable performance, suggesting that the model effectively retains answer-related information throughout its layers. The similarity in trends among different Q-Anchored datasets implies a consistent pattern in how the model processes question-based information across various question-answering tasks. The more significant performance drop in Qwen3-32B compared to Qwen3-8B for Q-Anchored datasets might indicate that the larger model is more sensitive to the way questions are processed across layers.
</details>
<details>
<summary>x26.png Details</summary>
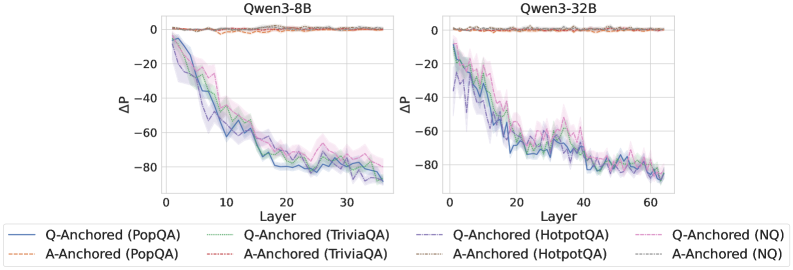
### Visual Description
## Chart: Delta P vs Layer for Qwen3 Models
### Overview
The image presents two line charts comparing the change in probability (ΔP) across different layers of two Qwen3 models: Qwen3-8B and Qwen3-32B. The x-axis represents the layer number, and the y-axis represents ΔP. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: Qwen3-8B
* Right Chart: Qwen3-32B
* **X-Axis (Layer):**
* Left Chart: 0 to 30, incrementing by 10.
* Right Chart: 0 to 60, incrementing by 20.
* **Y-Axis (ΔP):**
* Both Charts: -80 to 0, incrementing by 20.
* **Legend (Bottom):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Gray Line
* Q-Anchored (HotpotQA): Dash-Dotted Purple Line
* A-Anchored (HotpotQA): Dotted Gray Line
* Q-Anchored (NQ): Dash-Dotted Purple Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Left Chart (Qwen3-8B):**
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts at approximately -5 at Layer 0, decreases sharply to approximately -70 by Layer 10, and then plateaus around -75 to -80 for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown Line:** Remains relatively constant around 0 throughout all layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts at approximately -10 at Layer 0, decreases to approximately -70 by Layer 10, and then plateaus around -70 to -75 for the remaining layers.
* **A-Anchored (TriviaQA) - Dash-Dotted Gray Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 10, and then plateaus around -70 to -75 for the remaining layers.
* **Q-Anchored (HotpotQA) - Dash-Dotted Purple Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 10, and then plateaus around -70 to -75 for the remaining layers.
* **A-Anchored (HotpotQA) - Dotted Gray Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 10, and then plateaus around -70 to -75 for the remaining layers.
* **Q-Anchored (NQ) - Dash-Dotted Purple Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 10, and then plateaus around -70 to -75 for the remaining layers.
* **A-Anchored (NQ) - Dotted Gray Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 10, and then plateaus around -70 to -75 for the remaining layers.
**Right Chart (Qwen3-32B):**
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts at approximately -10 at Layer 0, decreases sharply to approximately -75 by Layer 20, and then plateaus around -75 to -80 for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown Line:** Remains relatively constant around 0 throughout all layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 20, and then plateaus around -70 to -75 for the remaining layers.
* **A-Anchored (TriviaQA) - Dash-Dotted Gray Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 20, and then plateaus around -70 to -75 for the remaining layers.
* **Q-Anchored (HotpotQA) - Dash-Dotted Purple Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 20, and then plateaus around -70 to -75 for the remaining layers.
* **A-Anchored (HotpotQA) - Dotted Gray Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 20, and then plateaus around -70 to -75 for the remaining layers.
* **Q-Anchored (NQ) - Dash-Dotted Purple Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 20, and then plateaus around -70 to -75 for the remaining layers.
* **A-Anchored (NQ) - Dotted Gray Line:** Starts at approximately -15 at Layer 0, decreases to approximately -70 by Layer 20, and then plateaus around -70 to -75 for the remaining layers.
### Key Observations
* For both models, A-Anchored (PopQA) remains consistently near 0 across all layers, indicating minimal change in probability.
* For both models, the Q-Anchored data series (PopQA, TriviaQA, HotpotQA, and NQ) show a significant decrease in ΔP in the initial layers, indicating a substantial change in probability.
* The Qwen3-32B model shows a more gradual decrease in ΔP compared to the Qwen3-8B model.
* The shaded regions around each line represent the uncertainty or variance in the data.
### Interpretation
The charts suggest that anchoring the question (Q-Anchored) leads to a more significant change in probability (ΔP) compared to anchoring the answer (A-Anchored), especially for the PopQA dataset. The A-Anchored (PopQA) data series remaining near 0 indicates that the model's probability doesn't change much when the answer is anchored. The decrease in ΔP for Q-Anchored series suggests that the model's probability changes significantly as it processes the question through different layers.
The Qwen3-32B model, with its larger size, exhibits a more gradual change in ΔP, possibly indicating a more refined and distributed learning process across its layers compared to the smaller Qwen3-8B model. The plateauing of ΔP after a certain number of layers suggests that the models reach a stable state in their probability estimation.
</details>
<details>
<summary>x27.png Details</summary>
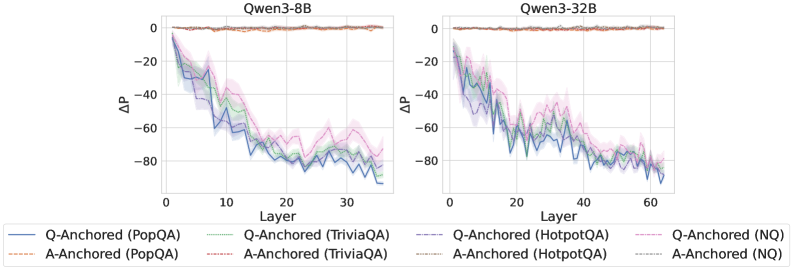
### Visual Description
## Chart Type: Line Graphs Comparing Model Performance on Question Answering Tasks
### Overview
The image contains two line graphs comparing the performance of two language models, Qwen3-8B and Qwen3-32B, on various question-answering tasks. The graphs plot the change in performance (ΔP) across different layers of the model. Each line represents a different question-answering dataset, with separate lines for question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches.
### Components/Axes
* **Titles:**
* Left Graph: Qwen3-8B
* Right Graph: Qwen3-32B
* **X-axis:** Layer (Number of layers in the model)
* Left Graph: Scale from 0 to 30, with ticks at approximately 0, 10, 20, and 30.
* Right Graph: Scale from 0 to 60, with ticks at approximately 0, 20, 40, and 60.
* **Y-axis:** ΔP (Change in Performance)
* Scale from -80 to 0, with ticks at -80, -60, -40, -20, and 0.
* **Legend:** Located at the bottom of the image, spanning both graphs.
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Dotted green line
* **A-Anchored (TriviaQA):** Dotted-dashed grey line
* **Q-Anchored (HotpotQA):** Solid light-green line
* **A-Anchored (HotpotQA):** Dashed light-brown line
* **Q-Anchored (NQ):** Dotted-dashed pink line
* **A-Anchored (NQ):** Dotted-dashed grey line
### Detailed Analysis
**Left Graph (Qwen3-8B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately -20 and decreases to approximately -80 by layer 30.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively constant around 0 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately -20 and decreases to approximately -70 by layer 30.
* **A-Anchored (TriviaQA):** (Dotted-Dashed Grey) Starts at approximately -20 and decreases to approximately -70 by layer 30.
* **Q-Anchored (HotpotQA):** (Solid Light-Green) Starts at approximately -20 and decreases to approximately -70 by layer 30.
* **A-Anchored (HotpotQA):** (Dashed Light-Brown) Remains relatively constant around 0 across all layers.
* **Q-Anchored (NQ):** (Dotted-Dashed Pink) Starts at approximately -20 and decreases to approximately -70 by layer 30.
* **A-Anchored (NQ):** (Dotted-Dashed Grey) Starts at approximately -20 and decreases to approximately -70 by layer 30.
**Right Graph (Qwen3-32B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately -20 and decreases to approximately -80 by layer 60.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively constant around 0 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately -20 and decreases to approximately -70 by layer 60.
* **A-Anchored (TriviaQA):** (Dotted-Dashed Grey) Starts at approximately -20 and decreases to approximately -70 by layer 60.
* **Q-Anchored (HotpotQA):** (Solid Light-Green) Starts at approximately -20 and decreases to approximately -70 by layer 60.
* **A-Anchored (HotpotQA):** (Dashed Light-Brown) Remains relatively constant around 0 across all layers.
* **Q-Anchored (NQ):** (Dotted-Dashed Pink) Starts at approximately -20 and decreases to approximately -70 by layer 60.
* **A-Anchored (NQ):** (Dotted-Dashed Grey) Starts at approximately -20 and decreases to approximately -70 by layer 60.
### Key Observations
* The performance (ΔP) of Q-Anchored methods generally decreases as the layer number increases for both models.
* The performance (ΔP) of A-Anchored (PopQA) and A-Anchored (HotpotQA) methods remains relatively constant around 0 across all layers for both models.
* The Qwen3-32B model has twice as many layers as the Qwen3-8B model (60 vs 30).
* The trends in performance change are similar for both models across the different question-answering datasets.
### Interpretation
The data suggests that increasing the number of layers in the Qwen3 models negatively impacts the performance of question-anchored methods on the tested question-answering tasks. The answer-anchored methods, specifically PopQA and HotpotQA, appear to be less sensitive to the number of layers. This could indicate that question-anchoring becomes more challenging as the model depth increases, possibly due to issues like vanishing gradients or increased complexity in processing the question. The A-Anchored methods are not impacted by the number of layers. The similarity in trends between the two models suggests that the observed behavior is consistent across different model sizes within the Qwen3 family. The shaded regions around the lines likely represent the standard deviation or confidence intervals, indicating the variability in performance across different runs or data samples.
</details>
Figure 13: $\Delta\mathrm{P}$ under attention knockout for reasoning models. Probing attention activations for the final token (top), the token immediately preceding the exact answer tokens (middle), and the last exact answer token (bottom).
<details>
<summary>x28.png Details</summary>
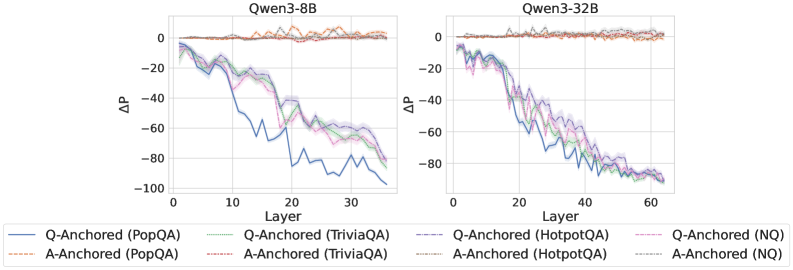
### Visual Description
## Line Graphs: Qwen3-8B and Qwen3-32B Performance
### Overview
The image presents two line graphs comparing the performance of Qwen3 models (8B and 32B) across different question-answering datasets. The graphs depict the change in performance (ΔP) as a function of layer depth, with separate lines for question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches on PopQA, TriviaQA, HotpotQA, and NQ datasets.
### Components/Axes
* **Titles:** The left graph is titled "Qwen3-8B" and the right graph is titled "Qwen3-32B".
* **Y-axis:** Both graphs share the same Y-axis label "ΔP", ranging from -100 to 0, with tick marks at -80, -60, -40, -20, and 0.
* **X-axis:** The left graph's X-axis is labeled "Layer" and ranges from 0 to 30, with tick marks every 10 units. The right graph's X-axis is labeled "Layer" and ranges from 0 to 60, with tick marks every 20 units.
* **Legend:** Located at the bottom of the image, the legend identifies the lines by color and style:
* **Blue Solid:** Q-Anchored (PopQA)
* **Brown Dashed:** A-Anchored (PopQA)
* **Green Dotted:** Q-Anchored (TriviaQA)
* **Brown Dotted-Dashed:** A-Anchored (TriviaQA)
* **Purple Dashed-Dotted:** Q-Anchored (HotpotQA)
* **Gray Dotted:** A-Anchored (HotpotQA)
* **Pink Dashed:** Q-Anchored (NQ)
* **Gray Dashed:** A-Anchored (NQ)
### Detailed Analysis
**Qwen3-8B (Left Graph):**
* **Q-Anchored (PopQA) - Blue Solid:** Starts near 0 and decreases sharply to approximately -90 by layer 30.
* **A-Anchored (PopQA) - Brown Dashed:** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA) - Green Dotted:** Starts near 0 and decreases to approximately -70 by layer 30.
* **A-Anchored (TriviaQA) - Brown Dotted-Dashed:** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA) - Purple Dashed-Dotted:** Starts near 0 and decreases to approximately -60 by layer 30.
* **A-Anchored (HotpotQA) - Gray Dotted:** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ) - Pink Dashed:** Starts near 0 and decreases to approximately -60 by layer 30.
* **A-Anchored (NQ) - Gray Dashed:** Remains relatively stable around 0 throughout all layers.
**Qwen3-32B (Right Graph):**
* **Q-Anchored (PopQA) - Blue Solid:** Starts near 0 and decreases sharply to approximately -90 by layer 60.
* **A-Anchored (PopQA) - Brown Dashed:** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA) - Green Dotted:** Starts near 0 and decreases to approximately -80 by layer 60.
* **A-Anchored (TriviaQA) - Brown Dotted-Dashed:** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA) - Purple Dashed-Dotted:** Starts near 0 and decreases to approximately -80 by layer 60.
* **A-Anchored (HotpotQA) - Gray Dotted:** Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ) - Pink Dashed:** Starts near 0 and decreases to approximately -80 by layer 60.
* **A-Anchored (NQ) - Gray Dashed:** Remains relatively stable around 0 throughout all layers.
### Key Observations
* **Performance Drop:** Q-Anchored approaches consistently show a significant drop in performance (ΔP) as the layer depth increases for both Qwen3-8B and Qwen3-32B models.
* **A-Anchored Stability:** A-Anchored approaches maintain relatively stable performance around 0 across all layers and datasets.
* **Model Size Impact:** The Qwen3-32B model (right graph) generally shows a more gradual decline in performance compared to the Qwen3-8B model (left graph), especially for Q-Anchored approaches. The x axis is also scaled differently, with the 8B model only going to layer 30, and the 32B model going to layer 60.
* **Dataset Variation:** The magnitude of the performance drop varies slightly across different datasets, with PopQA showing the most significant decline for Q-Anchored approaches.
### Interpretation
The data suggests that Q-Anchoring leads to a degradation in performance as the model processes deeper layers, potentially indicating issues with information propagation or interference within the network. The stability of A-Anchored approaches implies that anchoring on the answer might provide a more robust representation that is less susceptible to degradation with increasing layer depth. The larger Qwen3-32B model appears to mitigate this performance drop to some extent, possibly due to its increased capacity to handle complex representations. The differences in performance across datasets could be attributed to variations in the complexity or structure of the questions and answers within each dataset. The fact that the A-Anchored models are stable around 0 suggests that they are not learning anything useful.
</details>
<details>
<summary>x29.png Details</summary>
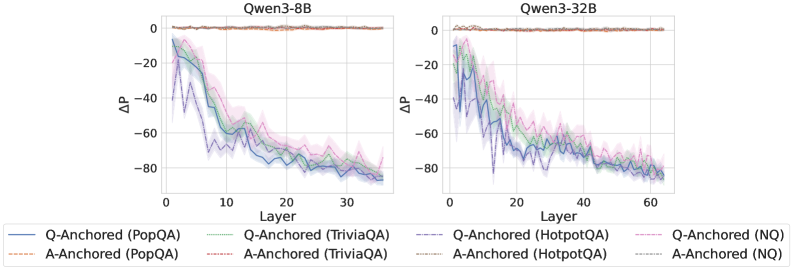
### Visual Description
## Line Graphs: Qwen3-8B and Qwen3-32B Performance
### Overview
The image contains two line graphs comparing the performance of Qwen3-8B and Qwen3-32B models across different layers and question-answering datasets. The y-axis represents ΔP (Delta P), and the x-axis represents the layer number. Each graph plots the performance of question-anchored (Q-Anchored) and answer-anchored (A-Anchored) versions of the models on four datasets: PopQA, TriviaQA, HotpotQA, and NQ.
### Components/Axes
**Left Graph (Qwen3-8B):**
* **Title:** Qwen3-8B
* **X-axis:** Layer, with ticks at 0, 10, 20, and 30. The x-axis ranges from 0 to approximately 35.
* **Y-axis:** ΔP, with ticks at 0, -20, -40, -60, and -80. The y-axis ranges from 0 to -80.
* **Legend (bottom):**
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Light green dash-dotted line: A-Anchored (TriviaQA)
* Purple dash-dotted line: Q-Anchored (NQ)
* Pink dashed line: A-Anchored (NQ)
* Dark Green dash-dotted line: Q-Anchored (HotpotQA)
* Grey dotted line: A-Anchored (HotpotQA)
**Right Graph (Qwen3-32B):**
* **Title:** Qwen3-32B
* **X-axis:** Layer, with ticks at 0, 20, 40, and 60. The x-axis ranges from 0 to approximately 65.
* **Y-axis:** ΔP, with ticks at 0, -20, -40, -60, and -80. The y-axis ranges from 0 to -80.
* **Legend (bottom):**
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Light green dash-dotted line: A-Anchored (TriviaQA)
* Purple dash-dotted line: Q-Anchored (NQ)
* Pink dashed line: A-Anchored (NQ)
* Dark Green dash-dotted line: Q-Anchored (HotpotQA)
* Grey dotted line: A-Anchored (HotpotQA)
### Detailed Analysis
**Qwen3-8B:**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately -15, decreases rapidly to around -70 by layer 10, and then plateaus around -75 to -80.
* **A-Anchored (PopQA) (Brown dashed line):** Remains relatively constant around 0.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately -10, decreases to around -55 by layer 10, and then plateaus around -60 to -70.
* **A-Anchored (TriviaQA) (Light green dash-dotted line):** Starts at approximately -15, decreases to around -50 by layer 10, and then plateaus around -60 to -70.
* **Q-Anchored (NQ) (Purple dash-dotted line):** Starts at approximately -15, decreases rapidly to around -70 by layer 10, and then plateaus around -75 to -80.
* **A-Anchored (NQ) (Pink dashed line):** Starts at approximately -15, decreases to around -50 by layer 10, and then plateaus around -60 to -70.
* **Q-Anchored (HotpotQA) (Dark Green dash-dotted line):** Starts at approximately -10, decreases to around -55 by layer 10, and then plateaus around -60 to -70.
* **A-Anchored (HotpotQA) (Grey dotted line):** Starts at approximately -15, decreases to around -50 by layer 10, and then plateaus around -60 to -70.
**Qwen3-32B:**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately -15, decreases rapidly to around -70 by layer 20, and then plateaus around -75 to -80.
* **A-Anchored (PopQA) (Brown dashed line):** Remains relatively constant around 0.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately -10, decreases to around -55 by layer 20, and then plateaus around -60 to -70.
* **A-Anchored (TriviaQA) (Light green dash-dotted line):** Starts at approximately -15, decreases to around -50 by layer 20, and then plateaus around -60 to -70.
* **Q-Anchored (NQ) (Purple dash-dotted line):** Starts at approximately -15, decreases rapidly to around -70 by layer 20, and then plateaus around -75 to -80.
* **A-Anchored (NQ) (Pink dashed line):** Starts at approximately -15, decreases to around -50 by layer 20, and then plateaus around -60 to -70.
* **Q-Anchored (HotpotQA) (Dark Green dash-dotted line):** Starts at approximately -10, decreases to around -55 by layer 20, and then plateaus around -60 to -70.
* **A-Anchored (HotpotQA) (Grey dotted line):** Starts at approximately -15, decreases to around -50 by layer 20, and then plateaus around -60 to -70.
### Key Observations
* The A-Anchored (PopQA) performance remains consistently near 0 across all layers for both models.
* The Q-Anchored lines generally show a rapid decrease in ΔP in the initial layers, followed by a plateau.
* The Qwen3-32B model shows a similar trend to Qwen3-8B, but the decrease in ΔP occurs over a larger number of layers.
* The performance on PopQA and NQ datasets (Q-Anchored) appears to be slightly worse (lower ΔP) than on TriviaQA and HotpotQA.
### Interpretation
The graphs illustrate the performance of Qwen3-8B and Qwen3-32B models on different question-answering datasets, with a focus on how the performance changes across different layers of the model. The A-Anchored (PopQA) consistently performing near 0 suggests that the answer anchoring strategy is not effective for the PopQA dataset. The rapid decrease in ΔP for Q-Anchored lines indicates that the model's performance improves significantly in the initial layers, but the improvement plateaus as the model goes deeper. The Qwen3-32B model, with its larger size, shows a similar trend but over a larger number of layers, suggesting that it takes more layers for the model to reach its optimal performance. The difference in performance between datasets suggests that the model is better suited for some types of questions than others.
</details>
<details>
<summary>x30.png Details</summary>
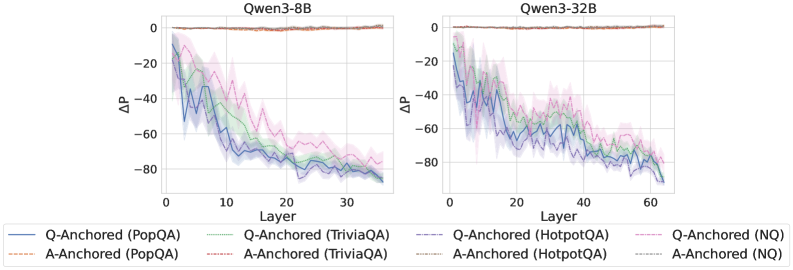
### Visual Description
## Line Chart: Delta P vs Layer for Qwen3-8B and Qwen3-32B
### Overview
The image contains two line charts comparing the performance of Qwen3-8B and Qwen3-32B models across different layers. The charts plot the change in performance (Delta P) against the layer number for various question-answering tasks, using both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches. The shaded regions around the lines indicate the uncertainty or variability in the performance.
### Components/Axes
* **Titles:**
* Left Chart: "Qwen3-8B"
* Right Chart: "Qwen3-32B"
* **X-axis (Layer):**
* Left Chart: Ranges from 0 to 30, with tick marks at intervals of 10.
* Right Chart: Ranges from 0 to 60, with tick marks at intervals of 20.
* Label: "Layer"
* **Y-axis (ΔP):**
* Both Charts: Ranges from -80 to 0, with tick marks at intervals of 20.
* Label: "ΔP"
* **Legend (bottom):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Green Line
* Q-Anchored (HotpotQA): Dash-Dot Blue Line
* A-Anchored (HotpotQA): Dotted Blue Line
* Q-Anchored (NQ): Dash-Dotted Pink Line
* A-Anchored (NQ): Dotted Pink Line
### Detailed Analysis
**Left Chart (Qwen3-8B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately -15 at layer 0 and decreases to approximately -80 by layer 30.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively constant around 0 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately -20 at layer 0 and decreases to approximately -75 by layer 30.
* **A-Anchored (TriviaQA):** (Dash-Dotted Green) Starts at approximately -20 at layer 0 and decreases to approximately -75 by layer 30.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue) Starts at approximately -15 at layer 0 and decreases to approximately -80 by layer 30.
* **A-Anchored (HotpotQA):** (Dotted Blue) Starts at approximately -15 at layer 0 and decreases to approximately -80 by layer 30.
* **Q-Anchored (NQ):** (Dash-Dotted Pink) Starts at approximately -20 at layer 0 and decreases to approximately -70 by layer 30.
* **A-Anchored (NQ):** (Dotted Pink) Starts at approximately -20 at layer 0 and decreases to approximately -70 by layer 30.
**Right Chart (Qwen3-32B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately -20 at layer 0 and decreases to approximately -90 by layer 60.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively constant around 0 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately -20 at layer 0 and decreases to approximately -80 by layer 60.
* **A-Anchored (TriviaQA):** (Dash-Dotted Green) Starts at approximately -20 at layer 0 and decreases to approximately -80 by layer 60.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue) Starts at approximately -20 at layer 0 and decreases to approximately -90 by layer 60.
* **A-Anchored (HotpotQA):** (Dotted Blue) Starts at approximately -20 at layer 0 and decreases to approximately -90 by layer 60.
* **Q-Anchored (NQ):** (Dash-Dotted Pink) Starts at approximately -20 at layer 0 and decreases to approximately -70 by layer 60.
* **A-Anchored (NQ):** (Dotted Pink) Starts at approximately -20 at layer 0 and decreases to approximately -70 by layer 60.
### Key Observations
* For both models, the A-Anchored (PopQA) performance remains relatively constant near 0 across all layers.
* The Q-Anchored and A-Anchored lines for TriviaQA, HotpotQA, and NQ datasets show a decreasing trend as the layer number increases.
* The Qwen3-32B model generally shows a steeper decline in Delta P compared to the Qwen3-8B model for Q-Anchored datasets.
* The shaded regions indicate variability in performance, which appears to be more pronounced in the Qwen3-32B model.
### Interpretation
The charts suggest that the performance of the Qwen3 models, particularly when anchored to the question, decreases as the layer number increases for TriviaQA, HotpotQA, and NQ datasets. This could indicate that deeper layers are not effectively contributing to the question-answering task for these datasets, or that the model is overfitting to the training data in later layers. The A-Anchored (PopQA) performance remaining constant suggests that anchoring to the answer provides a stable baseline. The Qwen3-32B model, being larger, shows a more pronounced decline, potentially indicating a greater susceptibility to overfitting or a need for more regularization. The variability in performance, as indicated by the shaded regions, highlights the importance of considering the uncertainty in these measurements.
</details>
Figure 14: $\Delta\mathrm{P}$ under attention knockout for reasoning models. Probing mlp activations for the final token (top), the token immediately preceding the exact answer tokens (middle), and the last exact answer token (bottom).
<details>
<summary>x31.png Details</summary>
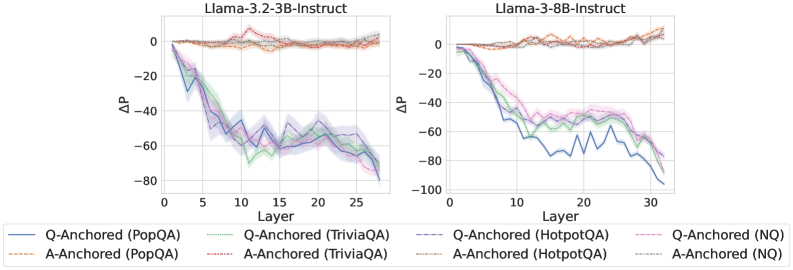
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
The image presents two line charts comparing the performance of different language models (Llama-3.2-3B-Instruct and Llama-3-8B-Instruct) across various layers. The charts depict the change in performance (ΔP) as a function of the layer number for different question-answering tasks.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-3B-Instruct
* Right Chart: Llama-3-8B-Instruct
* **X-axis (Layer):** Represents the layer number of the model.
* Left Chart: Scale from 0 to 25, incrementing by 5.
* Right Chart: Scale from 0 to 30, incrementing by 10.
* **Y-axis (ΔP):** Represents the change in performance.
* Both Charts: Scale from -80 to 0, incrementing by 20 on the left chart. Scale from -100 to 0, incrementing by 20 on the right chart.
* **Legend (Bottom):**
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Purple dash-dotted line: Q-Anchored (HotpotQA)
* Orange dash-dot-dotted line: A-Anchored (TriviaQA)
* Gray dotted line: A-Anchored (HotpotQA)
* Pink dashed line: Q-Anchored (NQ)
* Black dotted line: A-Anchored (NQ)
### Detailed Analysis
**Left Chart (Llama-3.2-3B-Instruct):**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0 at layer 0, decreases to approximately -75 at layer 25.
* **A-Anchored (PopQA) (Brown dashed line):** Remains relatively constant around 0 throughout all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 0 at layer 0, decreases to approximately -70 at layer 25.
* **Q-Anchored (HotpotQA) (Purple dash-dotted line):** Starts at approximately 0 at layer 0, decreases to approximately -65 at layer 25.
* **A-Anchored (TriviaQA) (Orange dash-dot-dotted line):** Remains relatively constant around 0 throughout all layers.
* **A-Anchored (HotpotQA) (Gray dotted line):** Remains relatively constant around 0 throughout all layers.
* **Q-Anchored (NQ) (Pink dashed line):** Remains relatively constant around 0 throughout all layers.
* **A-Anchored (NQ) (Black dotted line):** Remains relatively constant around 0 throughout all layers.
**Right Chart (Llama-3-8B-Instruct):**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0 at layer 0, decreases to approximately -90 at layer 30.
* **A-Anchored (PopQA) (Brown dashed line):** Remains relatively constant around 0 throughout all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 0 at layer 0, decreases to approximately -60 at layer 30.
* **Q-Anchored (HotpotQA) (Purple dash-dotted line):** Starts at approximately 0 at layer 0, decreases to approximately -50 at layer 30.
* **A-Anchored (TriviaQA) (Orange dash-dot-dotted line):** Remains relatively constant around 0 throughout all layers.
* **A-Anchored (HotpotQA) (Gray dotted line):** Remains relatively constant around 0 throughout all layers.
* **Q-Anchored (NQ) (Pink dashed line):** Remains relatively constant around 0 throughout all layers.
* **A-Anchored (NQ) (Black dotted line):** Remains relatively constant around 0 throughout all layers.
### Key Observations
* For both models, the "Q-Anchored" tasks (PopQA, TriviaQA, HotpotQA) show a significant decrease in performance (ΔP) as the layer number increases.
* The "A-Anchored" tasks (PopQA, TriviaQA, HotpotQA, NQ) maintain a relatively constant performance (ΔP) around 0 across all layers for both models.
* The Llama-3-8B-Instruct model shows a more pronounced decrease in performance for the Q-Anchored (PopQA) task compared to the Llama-3.2-3B-Instruct model.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) in the question-answering tasks leads to a degradation in performance as the model processes deeper layers. This could indicate that the model is losing relevant information or becoming more susceptible to noise as it goes through the layers when the question is anchored. Conversely, anchoring the answer (A-Anchored) results in stable performance across all layers, suggesting a more robust processing mechanism when the answer is the focal point. The difference in performance degradation between the two models for the Q-Anchored (PopQA) task may indicate that the larger model (Llama-3-8B-Instruct) is more sensitive to the anchoring of the question in this specific task.
</details>
<details>
<summary>x32.png Details</summary>
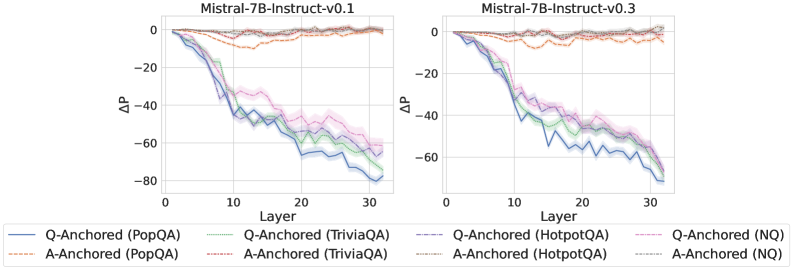
### Visual Description
## Chart: Delta P vs Layer for Mistral-7B-Instruct Models
### Overview
The image contains two line charts comparing the performance of Mistral-7B-Instruct models (v0.1 and v0.3) across different layers. The charts plot the change in performance (ΔP) against the layer number. Each chart displays six data series, representing different question-answering tasks, anchored either by question (Q-Anchored) or answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-Instruct-v0.1"
* Right Chart: "Mistral-7B-Instruct-v0.3"
* **Y-Axis (ΔP):** Both charts share the same Y-axis, labeled "ΔP". The scale ranges from -80 to 0, with tick marks at -60, -40, -20, and 0.
* **X-Axis (Layer):** Both charts share the same X-axis, labeled "Layer". The scale ranges from 0 to 30, with tick marks at 0, 10, 20, and 30.
* **Legend:** Located below the charts, the legend identifies the six data series:
* Q-Anchored (PopQA): Solid blue line
* A-Anchored (PopQA): Dashed brown line
* Q-Anchored (TriviaQA): Dotted green line
* A-Anchored (TriviaQA): Dotted-dashed grey line
* Q-Anchored (HotpotQA): Dotted-dashed pink line
* A-Anchored (HotpotQA): Dotted grey line
* Q-Anchored (NQ): Dashed-dotted pink line
* A-Anchored (NQ): Dotted grey line
### Detailed Analysis
**Left Chart (Mistral-7B-Instruct-v0.1):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts at approximately 0 and decreases to approximately -75 by layer 30. The line shows a downward trend.
* **A-Anchored (PopQA):** (Dashed brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts at approximately 0 and decreases to approximately -60 by layer 30. The line shows a downward trend.
* **A-Anchored (TriviaQA):** (Dotted-dashed grey line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA):** (Dotted-dashed pink line) Starts at approximately 0 and decreases to approximately -50 by layer 30. The line shows a downward trend.
* **A-Anchored (HotpotQA):** (Dotted grey line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dashed-dotted pink line) Starts at approximately 0 and decreases to approximately -50 by layer 30. The line shows a downward trend.
* **A-Anchored (NQ):** (Dotted grey line) Remains relatively stable around 0 throughout all layers.
**Right Chart (Mistral-7B-Instruct-v0.3):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts at approximately 0 and decreases to approximately -80 by layer 30. The line shows a downward trend.
* **A-Anchored (PopQA):** (Dashed brown line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts at approximately 0 and decreases to approximately -65 by layer 30. The line shows a downward trend.
* **A-Anchored (TriviaQA):** (Dotted-dashed grey line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (HotpotQA):** (Dotted-dashed pink line) Starts at approximately 0 and decreases to approximately -55 by layer 30. The line shows a downward trend.
* **A-Anchored (HotpotQA):** (Dotted grey line) Remains relatively stable around 0 throughout all layers.
* **Q-Anchored (NQ):** (Dashed-dotted pink line) Starts at approximately 0 and decreases to approximately -55 by layer 30. The line shows a downward trend.
* **A-Anchored (NQ):** (Dotted grey line) Remains relatively stable around 0 throughout all layers.
### Key Observations
* **Downward Trend for Q-Anchored Series:** All Q-Anchored series (PopQA, TriviaQA, HotpotQA, NQ) show a clear downward trend in both charts, indicating a decrease in performance as the layer number increases.
* **Stable A-Anchored Series:** All A-Anchored series (PopQA, TriviaQA, HotpotQA, NQ) remain relatively stable around 0, suggesting that anchoring by the answer results in consistent performance across layers.
* **Similar Performance Between Versions:** The performance trends are similar between Mistral-7B-Instruct-v0.1 and Mistral-7B-Instruct-v0.3, with v0.3 showing slightly lower values for Q-Anchored series at layer 30.
### Interpretation
The data suggests that anchoring by the question (Q-Anchored) leads to a degradation in performance as the model processes deeper layers. This could be due to the model losing focus on the original question or accumulating errors as it progresses through the layers. In contrast, anchoring by the answer (A-Anchored) maintains a stable performance, possibly because the model is consistently guided by the correct answer. The slight performance difference between v0.1 and v0.3 for Q-Anchored series may indicate minor architectural or training differences between the two versions. The consistent behavior of A-anchored series suggests that the model is more robust when the answer is provided as a reference point.
</details>
Figure 15: $\Delta\mathrm{P}$ under attention knockout for instruct models.
<details>
<summary>x33.png Details</summary>
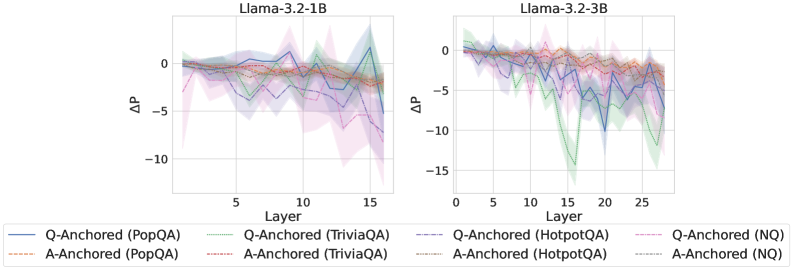
### Visual Description
## Line Charts: Llama-3.2-1B and Llama-3.2-3B Performance
### Overview
The image contains two line charts comparing the performance of Llama-3.2-1B and Llama-3.2-3B models across different layers. The y-axis represents ΔP (Delta P), and the x-axis represents the Layer number. Each chart displays six data series, representing Q-Anchored and A-Anchored performance on PopQA, TriviaQA, HotpotQA, and NQ datasets. The charts show the change in performance (ΔP) as the layer number increases. Shaded regions around each line indicate the uncertainty or variance in the data.
### Components/Axes
**Left Chart (Llama-3.2-1B):**
* **Title:** Llama-3.2-1B
* **X-axis:** Layer, with markers at 0, 5, 10, and 15.
* **Y-axis:** ΔP, with markers at -10, -5, and 0.
* **Data Series:**
* Q-Anchored (PopQA) - Solid Blue Line
* A-Anchored (PopQA) - Dashed Brown Line
* Q-Anchored (TriviaQA) - Dotted Green Line
* A-Anchored (TriviaQA) - Dash-Dotted Red Line
* Q-Anchored (HotpotQA) - Dash-Dot-Dotted Purple Line
* A-Anchored (NQ) - Dotted Gray Line
**Right Chart (Llama-3.2-3B):**
* **Title:** Llama-3.2-3B
* **X-axis:** Layer, with markers at 0, 5, 10, 15, 20, and 25.
* **Y-axis:** ΔP, with markers at -15, -10, -5, and 0.
* **Data Series:**
* Q-Anchored (PopQA) - Solid Blue Line
* A-Anchored (PopQA) - Dashed Brown Line
* Q-Anchored (TriviaQA) - Dotted Green Line
* A-Anchored (TriviaQA) - Dash-Dotted Red Line
* Q-Anchored (HotpotQA) - Dash-Dot-Dotted Purple Line
* A-Anchored (NQ) - Dotted Gray Line
**Legend:**
Located at the bottom of the image, spanning both charts. It maps line styles and colors to the corresponding data series.
### Detailed Analysis
**Left Chart (Llama-3.2-1B):**
* **Q-Anchored (PopQA):** The blue line starts around 0, fluctuates, and ends near -2.
* **A-Anchored (PopQA):** The brown dashed line starts around -1, fluctuates, and ends near -2.
* **Q-Anchored (TriviaQA):** The green dotted line starts around 0, fluctuates, and ends near -2.
* **A-Anchored (TriviaQA):** The red dash-dotted line starts around -1, fluctuates, and ends near -2.
* **Q-Anchored (HotpotQA):** The purple dash-dot-dotted line starts around -1, fluctuates significantly, and ends near -5.
* **A-Anchored (NQ):** The gray dotted line starts around -1, fluctuates, and ends near -2.
**Right Chart (Llama-3.2-3B):**
* **Q-Anchored (PopQA):** The blue line starts around 0, shows a significant downward trend with a sharp drop around layer 15, and ends near -3.
* **A-Anchored (PopQA):** The brown dashed line starts around 0, fluctuates slightly, and ends near -1.
* **Q-Anchored (TriviaQA):** The green dotted line starts around 0, shows a significant downward trend with a sharp drop around layer 15, and ends near -5.
* **A-Anchored (TriviaQA):** The red dash-dotted line starts around 0, fluctuates slightly, and ends near -1.
* **Q-Anchored (HotpotQA):** The purple dash-dot-dotted line starts around 0, shows a significant downward trend with a sharp drop around layer 15, and ends near -8.
* **A-Anchored (NQ):** The gray dotted line starts around 0, fluctuates slightly, and ends near -1.
### Key Observations
* The Llama-3.2-3B model (right chart) has more layers (up to 28) compared to Llama-3.2-1B (left chart, up to 16).
* The Q-Anchored (HotpotQA) series shows the most significant performance drop in both models, especially in Llama-3.2-3B.
* The shaded regions indicate higher variance in the Q-Anchored (HotpotQA) series compared to other series.
* The A-Anchored (PopQA), A-Anchored (TriviaQA), and A-Anchored (NQ) series show relatively stable performance across layers in both models.
### Interpretation
The charts compare the performance of two Llama models on different question-answering datasets. The ΔP metric likely represents the change in some performance metric (e.g., probability, accuracy) as the model processes information through different layers.
The data suggests that:
* The Llama-3.2-3B model, with its increased number of layers, exhibits a more pronounced performance drop in the Q-Anchored (HotpotQA) series, indicating that the increased depth may not be beneficial for this specific task.
* The A-Anchored series generally show more stable performance, suggesting that anchoring on the answer might lead to more consistent results across layers.
* The HotpotQA dataset seems to be more challenging for these models, as indicated by the larger performance drops and higher variance.
The performance drop in the Q-Anchored (HotpotQA) series for Llama-3.2-3B could be due to overfitting or the model struggling to maintain relevant information across the increased number of layers. Further investigation would be needed to understand the underlying reasons for these performance differences.
</details>
<details>
<summary>x34.png Details</summary>
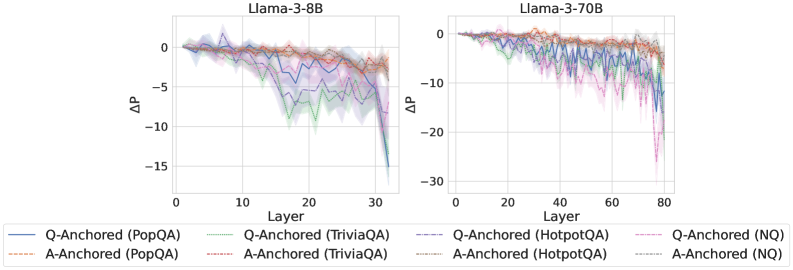
### Visual Description
## Line Charts: Llama-3-8B and Llama-3-70B Performance
### Overview
The image presents two line charts comparing the performance of Llama-3-8B and Llama-3-70B models across different layers. The y-axis represents ΔP (change in performance), and the x-axis represents the layer number. Each chart displays six data series, representing Q-Anchored and A-Anchored performance on PopQA, TriviaQA, HotpotQA, and NQ datasets. The charts show how performance changes as the model processes information through its layers.
### Components/Axes
**Chart 1: Llama-3-8B**
* **Title:** Llama-3-8B
* **X-axis:** Layer
* Scale: 0 to 30, incrementing by 10
* **Y-axis:** ΔP
* Scale: -15 to 0, incrementing by 5
* **Legend:** Located at the bottom of the image, spanning both charts.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Brown Line
* Q-Anchored (HotpotQA): Dash-Dot Blue Line
* A-Anchored (HotpotQA): Dotted Brown Line
* Q-Anchored (NQ): Dash-Dot Pink Line
* A-Anchored (NQ): Dotted Brown Line
**Chart 2: Llama-3-70B**
* **Title:** Llama-3-70B
* **X-axis:** Layer
* Scale: 0 to 80, incrementing by 20
* **Y-axis:** ΔP
* Scale: -30 to 0, incrementing by 10
* **Legend:** (Same as Chart 1, located at the bottom of the image)
### Detailed Analysis
**Chart 1: Llama-3-8B**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts around 0, fluctuates slightly, then drops sharply to approximately -12 around layer 30.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 30.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 0, gradually decreases to approximately -8 around layer 30.
* **A-Anchored (TriviaQA):** (Dash-Dotted Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 30.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue Line) Starts around 0, fluctuates slightly, then drops sharply to approximately -12 around layer 30.
* **A-Anchored (HotpotQA):** (Dotted Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 30.
* **Q-Anchored (NQ):** (Dash-Dot Pink Line) Starts around 0, fluctuates slightly, then drops sharply to approximately -12 around layer 30.
* **A-Anchored (NQ):** (Dotted Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 30.
**Chart 2: Llama-3-70B**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts around 0, fluctuates slightly, then drops sharply to approximately -25 around layer 80.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 80.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 0, gradually decreases to approximately -10 around layer 80.
* **A-Anchored (TriviaQA):** (Dash-Dotted Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 80.
* **Q-Anchored (HotpotQA):** (Dash-Dot Blue Line) Starts around 0, fluctuates slightly, then drops sharply to approximately -25 around layer 80.
* **A-Anchored (HotpotQA):** (Dotted Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 80.
* **Q-Anchored (NQ):** (Dash-Dot Pink Line) Starts around 0, fluctuates slightly, then drops sharply to approximately -25 around layer 80.
* **A-Anchored (NQ):** (Dotted Brown Line) Starts around 0, gradually decreases to approximately -2 around layer 80.
### Key Observations
* For both models, the Q-Anchored data series (PopQA, HotpotQA, and NQ) show a more significant drop in performance (ΔP) as the layer number increases compared to the A-Anchored series.
* The Llama-3-70B model (right chart) exhibits a larger performance drop (ΔP) compared to the Llama-3-8B model (left chart).
* The A-Anchored data series (PopQA, TriviaQA, HotpotQA, and NQ) show a relatively stable performance across all layers for both models.
* The shaded regions around each line indicate the uncertainty or variance in the performance data.
### Interpretation
The charts suggest that as the Llama models process information through deeper layers, the performance on Q-Anchored tasks (PopQA, HotpotQA, NQ) degrades more significantly than on A-Anchored tasks. This could indicate that the model's ability to handle question-related information diminishes with increasing depth, while its ability to handle answer-related information remains relatively stable.
The larger performance drop in Llama-3-70B compared to Llama-3-8B could be attributed to the increased complexity and depth of the larger model. While larger models often have greater capacity, they may also be more susceptible to issues like vanishing gradients or overfitting, leading to performance degradation in deeper layers.
The relatively stable performance of A-Anchored tasks suggests that the model maintains a consistent understanding or representation of answer-related information throughout its layers. This could be due to the nature of the tasks or the way the model is trained.
</details>
<details>
<summary>x35.png Details</summary>
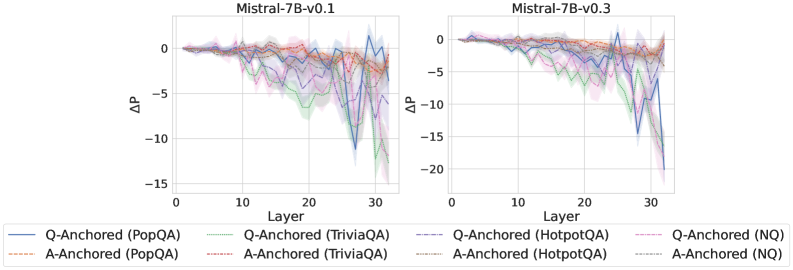
### Visual Description
## Chart Type: Line Graphs Comparing Mistral-7B Model Versions
### Overview
The image presents two line graphs side-by-side, comparing the performance of two versions of the Mistral-7B model (v0.1 and v0.3) across different layers. The y-axis represents ΔP (Delta P), and the x-axis represents the Layer number. Each graph displays six data series, representing different question-answering tasks, anchored by either "Q" (Question) or "A" (Answer). The shaded regions around each line represent the uncertainty or variance in the data.
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **X-axis:**
* Label: "Layer"
* Scale: 0 to 30, with tick marks at intervals of 10.
* **Y-axis:**
* Label: "ΔP"
* Scale (Left Graph): -15 to 0, with tick marks at intervals of 5.
* Scale (Right Graph): -20 to 0, with tick marks at intervals of 5.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dot Red Line
* Q-Anchored (HotpotQA): Dash-Dot Purple Line
* A-Anchored (HotpotQA): Dotted Gray Line
* Q-Anchored (NQ): Dash-Dot Pink Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Left Graph (Mistral-7B-v0.1):**
* **Q-Anchored (PopQA) - Solid Blue Line:** Initially around 0, it remains relatively stable until layer ~25, then sharply declines to approximately -12 at layer 30.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts near 0, gradually decreases to around -3 by layer 30.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts near 0, decreases to approximately -6 by layer 30.
* **A-Anchored (TriviaQA) - Dash-Dot Red Line:** Starts near 0, gradually decreases to around -3 by layer 30.
* **Q-Anchored (HotpotQA) - Dash-Dot Purple Line:** Starts near 0, decreases to approximately -5 by layer 30.
* **A-Anchored (HotpotQA) - Dotted Gray Line:** Starts near 0, gradually decreases to around -3 by layer 30.
* **Q-Anchored (NQ) - Dash-Dot Pink Line:** Starts near 0, decreases to approximately -4 by layer 30.
* **A-Anchored (NQ) - Dotted Gray Line:** Starts near 0, gradually decreases to around -3 by layer 30.
**Right Graph (Mistral-7B-v0.3):**
* **Q-Anchored (PopQA) - Solid Blue Line:** Initially around 0, it remains relatively stable until layer ~25, then sharply declines to approximately -18 at layer 30.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts near 0, gradually decreases to around -2 by layer 30.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts near 0, decreases to approximately -8 by layer 30.
* **A-Anchored (TriviaQA) - Dash-Dot Red Line:** Starts near 0, gradually decreases to around -2 by layer 30.
* **Q-Anchored (HotpotQA) - Dash-Dot Purple Line:** Starts near 0, decreases to approximately -4 by layer 30.
* **A-Anchored (HotpotQA) - Dotted Gray Line:** Starts near 0, gradually decreases to around -2 by layer 30.
* **Q-Anchored (NQ) - Dash-Dot Pink Line:** Starts near 0, decreases to approximately -3 by layer 30.
* **A-Anchored (NQ) - Dotted Gray Line:** Starts near 0, gradually decreases to around -2 by layer 30.
### Key Observations
* In both graphs, the "Q-Anchored (PopQA)" series (solid blue line) exhibits the most significant drop in ΔP towards the higher layers.
* The "A-Anchored" series generally show a more gradual and less pronounced decrease in ΔP compared to their "Q-Anchored" counterparts.
* The shaded regions indicate the variability in the data, with some series showing wider bands than others, suggesting greater uncertainty.
* The Mistral-7B-v0.3 model shows a more pronounced drop in ΔP for the "Q-Anchored (PopQA)" series compared to the v0.1 model.
### Interpretation
The graphs suggest that as the layer number increases, the performance (as measured by ΔP) of the Mistral-7B model tends to decrease, particularly for question-anchored tasks on the PopQA dataset. This could indicate that deeper layers in the model are less effective at processing or retaining information relevant to these specific tasks. The difference between the v0.1 and v0.3 models, especially in the "Q-Anchored (PopQA)" series, suggests that changes in the model architecture or training data may have exacerbated this performance degradation in the later layers. The smaller decrease in ΔP for answer-anchored tasks could imply that the model is more robust or efficient at processing information when the answer is the primary focus. The variability indicated by the shaded regions highlights the need for further investigation to understand the consistency and reliability of these performance trends.
</details>
Figure 16: $\Delta\mathrm{P}$ under attention knockout with randomly masked question tokens. Unlike selectively blocking the exact question tokens, both Q-Anchored and A-Anchored samples exhibit similar patterns, with substantially smaller probability changes when question tokens are masked at random. This suggests that exact question tokens play a critical role in conveying the semantic information of core frame elements.
Appendix D Token Patching
<details>
<summary>x36.png Details</summary>
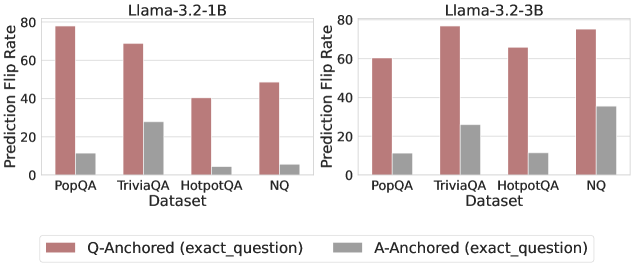
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two Llama models (Llama-3.2-1B and Llama-3.2-3B) across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare the flip rates when anchoring on the question (Q-Anchored) versus anchoring on the answer (A-Anchored).
### Components/Axes
* **Titles:** The charts are titled "Llama-3.2-1B" (left) and "Llama-3.2-3B" (right).
* **Y-axis:** Labeled "Prediction Flip Rate," with a numerical scale from 0 to 80, incrementing by 20.
* **X-axis:** Labeled "Dataset," with categories: PopQA, TriviaQA, HotpotQA, and NQ.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a light brown/reddish bar.
* A-Anchored (exact\_question): Represented by a gray bar.
### Detailed Analysis
**Llama-3.2-1B (Left Chart):**
* **PopQA:**
* Q-Anchored: Approximately 78.
* A-Anchored: Approximately 12.
* **TriviaQA:**
* Q-Anchored: Approximately 69.
* A-Anchored: Approximately 28.
* **HotpotQA:**
* Q-Anchored: Approximately 48.
* A-Anchored: Approximately 5.
* **NQ:**
* Q-Anchored: Approximately 55.
* A-Anchored: Approximately 5.
**Llama-3.2-3B (Right Chart):**
* **PopQA:**
* Q-Anchored: Approximately 60.
* A-Anchored: Approximately 12.
* **TriviaQA:**
* Q-Anchored: Approximately 78.
* A-Anchored: Approximately 25.
* **HotpotQA:**
* Q-Anchored: Approximately 65.
* A-Anchored: Approximately 12.
* **NQ:**
* Q-Anchored: Approximately 75.
* A-Anchored: Approximately 35.
### Key Observations
* For both models, the Q-Anchored flip rates are consistently higher than the A-Anchored flip rates across all datasets.
* The difference between Q-Anchored and A-Anchored flip rates varies across datasets.
* The TriviaQA dataset shows the highest Q-Anchored flip rate for Llama-3.2-3B.
* The A-Anchored flip rates are generally low for both models, with NQ showing the highest A-Anchored flip rate for Llama-3.2-3B.
### Interpretation
The data suggests that anchoring on the question (Q-Anchored) leads to a higher prediction flip rate compared to anchoring on the answer (A-Anchored) for both Llama models. This indicates that the models are more sensitive to changes in the question than changes in the answer. The varying differences between Q-Anchored and A-Anchored flip rates across datasets suggest that the models' sensitivity to question changes is dataset-dependent. The higher Q-Anchored flip rates could be due to the models relying more on specific question wording or context, making them more susceptible to adversarial attacks or slight variations in the question. The lower A-Anchored flip rates suggest that the models are more robust to changes in the answer, possibly because the answer provides a more direct and stable signal for prediction.
</details>
<details>
<summary>x37.png Details</summary>
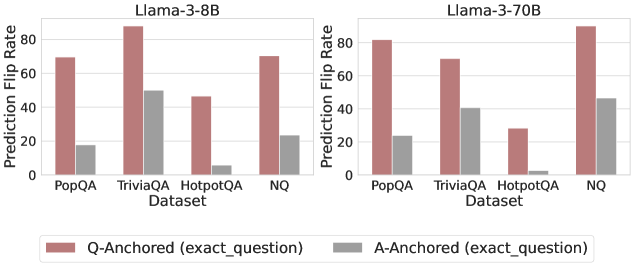
### Visual Description
## Bar Chart: Prediction Flip Rate for Llama-3 Models
### Overview
The image presents two bar charts comparing the prediction flip rates of Llama-3-8B and Llama-3-70B models across different datasets (PopQA, TriviaQA, HotpotQA, and NQ). The charts compare "Q-Anchored" (exact_question) and "A-Anchored" (exact_question) scenarios, represented by different colored bars.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-axis:** Prediction Flip Rate (values ranging from 0 to 80, with increments of 20)
* **X-axis:** Dataset (PopQA, TriviaQA, HotpotQA, NQ)
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a muted red/brown color.
* A-Anchored (exact\_question): Represented by a gray color.
### Detailed Analysis
**Left Chart: Llama-3-8B**
* **PopQA:**
* Q-Anchored: Approximately 70
* A-Anchored: Approximately 18
* **TriviaQA:**
* Q-Anchored: Approximately 87
* A-Anchored: Approximately 50
* **HotpotQA:**
* Q-Anchored: Approximately 46
* A-Anchored: Approximately 6
* **NQ:**
* Q-Anchored: Approximately 70
* A-Anchored: Approximately 23
**Right Chart: Llama-3-70B**
* **PopQA:**
* Q-Anchored: Approximately 81
* A-Anchored: Approximately 23
* **TriviaQA:**
* Q-Anchored: Approximately 70
* A-Anchored: Approximately 40
* **HotpotQA:**
* Q-Anchored: Approximately 28
* A-Anchored: Approximately 2
* **NQ:**
* Q-Anchored: Approximately 88
* A-Anchored: Approximately 46
### Key Observations
* For both models, the Q-Anchored prediction flip rates are generally higher than the A-Anchored rates across all datasets.
* TriviaQA shows the highest Q-Anchored prediction flip rate for Llama-3-8B.
* NQ shows the highest Q-Anchored prediction flip rate for Llama-3-70B.
* HotpotQA consistently has the lowest prediction flip rates for both models, especially for A-Anchored.
* The 70B model has a higher Q-Anchored flip rate for PopQA and NQ, but a lower Q-Anchored flip rate for TriviaQA and HotpotQA.
### Interpretation
The charts illustrate the prediction flip rates of two Llama-3 models under different anchoring conditions. The higher Q-Anchored rates suggest that the models are more sensitive to changes or perturbations in the question itself. The lower A-Anchored rates indicate greater robustness to variations in the answer context. The differences between datasets highlight the varying challenges they pose to the models. The 70B model appears to be more robust on some datasets (PopQA, NQ) but less so on others (TriviaQA, HotpotQA), suggesting that model size alone does not guarantee improved performance across all tasks. The HotpotQA dataset, with its low flip rates, may be inherently easier or more consistently answered by these models.
</details>
<details>
<summary>x38.png Details</summary>
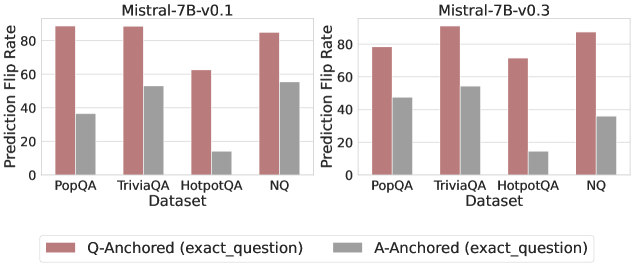
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Mistral-7B Models
### Overview
The image presents two bar charts comparing the prediction flip rates of Mistral-7B models (v0.1 and v0.3) across different datasets. The charts compare "Q-Anchored" (exact question) and "A-Anchored" (exact question) methods.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:** "Prediction Flip Rate" with a scale from 0 to 80 in increments of 20.
* **X-Axis:** "Dataset" with categories: PopQA, TriviaQA, HotpotQA, NQ.
* **Legend:** Located at the bottom of the image.
* Rose/Pink: "Q-Anchored (exact\_question)"
* Gray: "A-Anchored (exact\_question)"
### Detailed Analysis
**Left Chart (Mistral-7B-v0.1):**
* **PopQA:**
* Q-Anchored: Approximately 86%
* A-Anchored: Approximately 36%
* **TriviaQA:**
* Q-Anchored: Approximately 87%
* A-Anchored: Approximately 53%
* **HotpotQA:**
* Q-Anchored: Approximately 63%
* A-Anchored: Approximately 13%
* **NQ:**
* Q-Anchored: Approximately 83%
* A-Anchored: Approximately 55%
**Right Chart (Mistral-7B-v0.3):**
* **PopQA:**
* Q-Anchored: Approximately 78%
* A-Anchored: Approximately 47%
* **TriviaQA:**
* Q-Anchored: Approximately 88%
* A-Anchored: Approximately 53%
* **HotpotQA:**
* Q-Anchored: Approximately 72%
* A-Anchored: Approximately 13%
* **NQ:**
* Q-Anchored: Approximately 85%
* A-Anchored: Approximately 35%
### Key Observations
* For both model versions, the "Q-Anchored" method consistently shows a higher prediction flip rate than the "A-Anchored" method across all datasets.
* The "HotpotQA" dataset exhibits the lowest "A-Anchored" prediction flip rate for both model versions.
* The "TriviaQA" dataset exhibits the highest "Q-Anchored" prediction flip rate for the v0.3 model.
* The "Q-Anchored" prediction flip rate is relatively consistent across all datasets for both model versions, with the exception of "HotpotQA" in v0.1.
* The "A-Anchored" prediction flip rate varies more significantly across datasets compared to the "Q-Anchored" method.
### Interpretation
The data suggests that anchoring the question directly ("Q-Anchored") leads to a higher prediction flip rate compared to anchoring the answer ("A-Anchored") for both Mistral-7B model versions. This could indicate that the model is more sensitive to changes in the question phrasing than the answer phrasing. The lower "A-Anchored" flip rate for "HotpotQA" might be due to the complexity of the questions in that dataset, making the model less susceptible to changes in the answer phrasing. The difference between v0.1 and v0.3 is subtle, but there are some changes in the prediction flip rates across the datasets. For example, the "Q-Anchored" rate for "PopQA" is lower in v0.3 compared to v0.1, while the "Q-Anchored" rate for "HotpotQA" is higher in v0.3 compared to v0.1. These changes could be due to improvements in the model's ability to handle different types of questions.
</details>
Figure 17: Prediction flip rate under token patching, probing attention activations of the final token.
<details>
<summary>x39.png Details</summary>
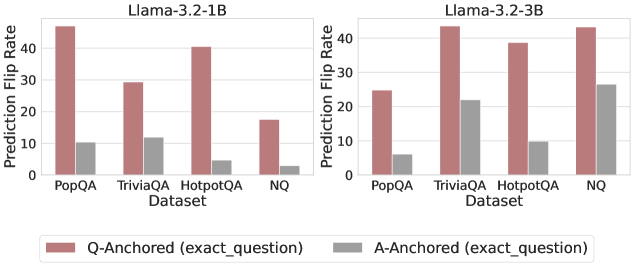
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama-3.2-1B and Llama-3.2-3B
### Overview
The image presents two bar charts comparing the prediction flip rates of two language models, Llama-3.2-1B and Llama-3.2-3B, across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare "Q-Anchored" (exact question) and "A-Anchored" (exact question) scenarios, represented by different colored bars.
### Components/Axes
* **Chart Titles:** "Llama-3.2-1B" (left chart) and "Llama-3.2-3B" (right chart).
* **Y-axis Title:** "Prediction Flip Rate".
* **Y-axis Scale:** 0 to 50, with tick marks at 0, 10, 20, 30, 40.
* **X-axis Title:** "Dataset".
* **X-axis Categories:** PopQA, TriviaQA, HotpotQA, NQ.
* **Legend:** Located at the bottom of the image.
* **Rose/Pink Bars:** "Q-Anchored (exact\_question)".
* **Gray Bars:** "A-Anchored (exact\_question)".
### Detailed Analysis
**Llama-3.2-1B (Left Chart):**
* **PopQA:**
* Q-Anchored: Approximately 46.
* A-Anchored: Approximately 10.
* **TriviaQA:**
* Q-Anchored: Approximately 29.
* A-Anchored: Approximately 12.
* **HotpotQA:**
* Q-Anchored: Approximately 40.
* A-Anchored: Approximately 5.
* **NQ:**
* Q-Anchored: Approximately 17.
* A-Anchored: Approximately 3.
**Llama-3.2-3B (Right Chart):**
* **PopQA:**
* Q-Anchored: Approximately 25.
* A-Anchored: Approximately 6.
* **TriviaQA:**
* Q-Anchored: Approximately 43.
* A-Anchored: Approximately 22.
* **HotpotQA:**
* Q-Anchored: Approximately 39.
* A-Anchored: Approximately 10.
* **NQ:**
* Q-Anchored: Approximately 43.
* A-Anchored: Approximately 27.
### Key Observations
* For Llama-3.2-1B, the Q-Anchored flip rates are significantly higher than the A-Anchored flip rates across all datasets.
* For Llama-3.2-3B, the difference between Q-Anchored and A-Anchored flip rates is less pronounced, especially for TriviaQA and NQ.
* Llama-3.2-1B shows the highest Q-Anchored flip rate for PopQA, while Llama-3.2-3B shows the highest Q-Anchored flip rate for TriviaQA and NQ.
* The A-Anchored flip rates are generally low for both models across all datasets, but are higher for Llama-3.2-3B.
### Interpretation
The charts illustrate the prediction flip rates of two Llama models under different anchoring conditions. The "Q-Anchored" scenario, where the exact question is used, generally results in higher flip rates compared to the "A-Anchored" scenario, where the exact answer is used. This suggests that the models are more sensitive to perturbations in the question than in the answer.
The differences between Llama-3.2-1B and Llama-3.2-3B indicate that the larger model (3B) exhibits a different behavior, with a smaller gap between Q-Anchored and A-Anchored flip rates, and higher A-Anchored flip rates overall. This could imply that the larger model is more robust to answer-based perturbations or that it relies more on the answer context.
The variations across datasets suggest that the models' sensitivity to perturbations depends on the specific characteristics of each dataset. For example, both models show relatively high Q-Anchored flip rates for TriviaQA and HotpotQA, indicating that these datasets may be more challenging in terms of question understanding or reasoning.
</details>
<details>
<summary>x40.png Details</summary>
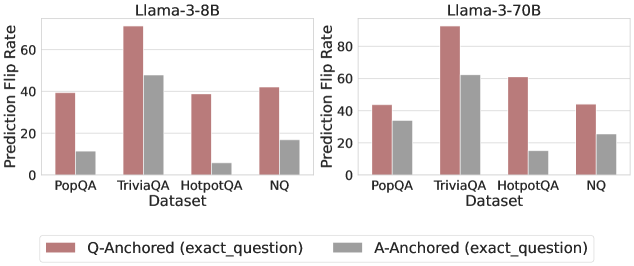
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama-3 Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two Llama-3 models (8B and 70B) across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare "Q-Anchored" (exact question) and "A-Anchored" (exact question) scenarios, represented by different colored bars.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-Axis (Prediction Flip Rate):**
* Label: Prediction Flip Rate
* Scale: 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **X-Axis (Dataset):**
* Label: Dataset
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend (Bottom):**
* Q-Anchored (exact\_question): Represented by a muted red/brown bar.
* A-Anchored (exact\_question): Represented by a gray bar.
### Detailed Analysis
**Left Chart: Llama-3-8B**
* **PopQA:**
* Q-Anchored: Approximately 40
* A-Anchored: Approximately 12
* **TriviaQA:**
* Q-Anchored: Approximately 72
* A-Anchored: Approximately 48
* **HotpotQA:**
* Q-Anchored: Approximately 40
* A-Anchored: Approximately 6
* **NQ:**
* Q-Anchored: Approximately 42
* A-Anchored: Approximately 25
**Right Chart: Llama-3-70B**
* **PopQA:**
* Q-Anchored: Approximately 44
* A-Anchored: Approximately 34
* **TriviaQA:**
* Q-Anchored: Approximately 90
* A-Anchored: Approximately 62
* **HotpotQA:**
* Q-Anchored: Approximately 62
* A-Anchored: Approximately 15
* **NQ:**
* Q-Anchored: Approximately 44
* A-Anchored: Approximately 25
### Key Observations
* For both models, the TriviaQA dataset exhibits the highest prediction flip rate when Q-Anchored.
* The A-Anchored prediction flip rates are generally lower than the Q-Anchored rates across all datasets and both models.
* The Llama-3-70B model generally has higher prediction flip rates than the Llama-3-8B model, especially for TriviaQA and HotpotQA.
### Interpretation
The data suggests that the Llama-3-70B model is more susceptible to prediction flips than the Llama-3-8B model, particularly on the TriviaQA dataset. The difference between Q-Anchored and A-Anchored rates indicates that the way the question is anchored significantly impacts the stability of the model's predictions. The higher flip rates on TriviaQA could be due to the nature of the questions in that dataset, which might be more ambiguous or require more complex reasoning. The lower A-Anchored rates suggest that anchoring on the answer provides more stability in the predictions. The 70B model, being larger, might be overfitting to certain patterns in the training data, leading to higher flip rates when the input is slightly altered.
</details>
<details>
<summary>x41.png Details</summary>
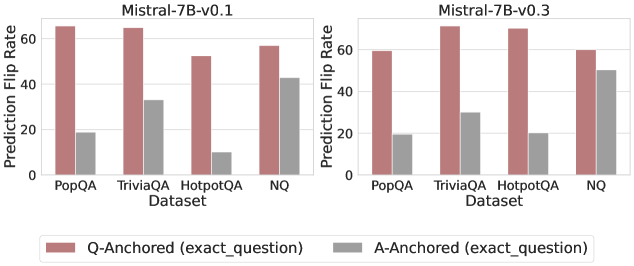
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Mistral-7B Models
### Overview
The image presents two bar charts comparing the prediction flip rates of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across four datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare "Q-Anchored (exact_question)" and "A-Anchored (exact_question)" methods, represented by different colored bars.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-axis:** "Prediction Flip Rate" with a scale from 0 to 60 in increments of 20.
* **X-axis:** "Dataset" with categories: PopQA, TriviaQA, HotpotQA, NQ.
* **Legend:** Located at the bottom of the image.
* Rose/Pink: "Q-Anchored (exact\_question)"
* Gray: "A-Anchored (exact\_question)"
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **PopQA:**
* Q-Anchored: Approximately 64
* A-Anchored: Approximately 18
* **TriviaQA:**
* Q-Anchored: Approximately 64
* A-Anchored: Approximately 33
* **HotpotQA:**
* Q-Anchored: Approximately 52
* A-Anchored: Approximately 9
* **NQ:**
* Q-Anchored: Approximately 56
* A-Anchored: Approximately 50
**Right Chart: Mistral-7B-v0.3**
* **PopQA:**
* Q-Anchored: Approximately 60
* A-Anchored: Approximately 19
* **TriviaQA:**
* Q-Anchored: Approximately 68
* A-Anchored: Approximately 29
* **HotpotQA:**
* Q-Anchored: Approximately 68
* A-Anchored: Approximately 10
* **NQ:**
* Q-Anchored: Approximately 61
* A-Anchored: Approximately 51
### Key Observations
* For both models, the "Q-Anchored" method generally results in a higher prediction flip rate than the "A-Anchored" method across all datasets, except for NQ.
* The "A-Anchored" method shows a relatively lower prediction flip rate for HotpotQA compared to other datasets in both models.
* The prediction flip rates for "Q-Anchored" are relatively consistent across all datasets for both models, hovering around 60%, except for HotpotQA in v0.1.
* The "A-Anchored" method shows a higher prediction flip rate for NQ compared to other datasets in both models.
### Interpretation
The data suggests that anchoring the question ("Q-Anchored") generally leads to a higher prediction flip rate compared to anchoring the answer ("A-Anchored"). This could indicate that the model is more sensitive to changes in the question phrasing than the answer phrasing. The exception to this trend is the NQ dataset, where the "A-Anchored" method shows a relatively high prediction flip rate, suggesting that the model might be more sensitive to changes in the answer phrasing for this particular dataset.
Comparing the two models, Mistral-7B-v0.3 seems to have slightly higher prediction flip rates for the "Q-Anchored" method on TriviaQA and HotpotQA datasets compared to Mistral-7B-v0.1. This could indicate that the newer version is slightly more sensitive to question phrasing in these specific datasets.
</details>
Figure 18: Prediction flip rate under token patching, probing attention activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x42.png Details</summary>
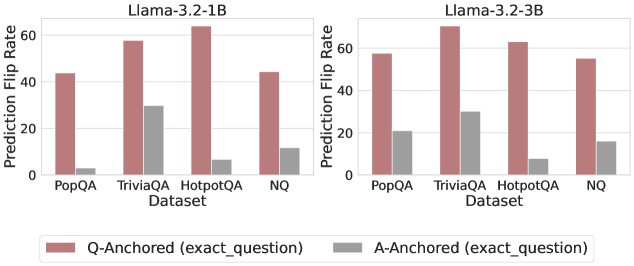
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two Llama models (Llama-3.2-1B and Llama-3.2-3B) across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare the flip rates when anchoring on the question (Q-Anchored) versus anchoring on the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **X-Axis:** Dataset (categorical)
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Y-Axis:** Prediction Flip Rate (numerical)
* Scale: 0 to 60, with tick marks at 0, 20, 40, and 60.
* **Legend:** Located at the bottom of the image.
* Rose/Brown: Q-Anchored (exact\_question)
* Gray: A-Anchored (exact\_question)
### Detailed Analysis
**Left Chart: Llama-3.2-1B**
* **Q-Anchored (exact\_question) - Rose/Brown Bars:**
* PopQA: Approximately 43%
* TriviaQA: Approximately 58%
* HotpotQA: Approximately 64%
* NQ: Approximately 44%
* **A-Anchored (exact\_question) - Gray Bars:**
* PopQA: Approximately 3%
* TriviaQA: Approximately 30%
* HotpotQA: Approximately 7%
* NQ: Approximately 12%
**Right Chart: Llama-3.2-3B**
* **Q-Anchored (exact\_question) - Rose/Brown Bars:**
* PopQA: Approximately 58%
* TriviaQA: Approximately 70%
* HotpotQA: Approximately 55%
* NQ: Approximately 55%
* **A-Anchored (exact\_question) - Gray Bars:**
* PopQA: Approximately 21%
* TriviaQA: Approximately 30%
* HotpotQA: Approximately 7%
* NQ: Approximately 16%
### Key Observations
* For both models and across all datasets, the Q-Anchored flip rate is significantly higher than the A-Anchored flip rate.
* TriviaQA and HotpotQA datasets show the highest Q-Anchored flip rates for Llama-3.2-1B.
* TriviaQA shows the highest Q-Anchored flip rate for Llama-3.2-3B.
* PopQA shows the lowest Q-Anchored flip rate for Llama-3.2-1B.
* HotpotQA and NQ show the lowest Q-Anchored flip rates for Llama-3.2-3B.
* The A-Anchored flip rates are generally low across all datasets for both models, with TriviaQA showing the highest A-Anchored flip rate for Llama-3.2-1B and PopQA showing the highest A-Anchored flip rate for Llama-3.2-3B.
### Interpretation
The data suggests that the prediction flip rate is highly dependent on whether the anchoring is done on the question or the answer. Anchoring on the question (Q-Anchored) leads to a much higher flip rate compared to anchoring on the answer (A-Anchored). This could indicate that the models are more sensitive to variations or perturbations in the question compared to the answer. The differences in flip rates across datasets may reflect the varying complexity and structure of the questions and answers within each dataset. The Llama-3.2-3B model generally exhibits higher Q-Anchored flip rates compared to Llama-3.2-1B, suggesting that the 3B model might be more sensitive to question variations. The low A-Anchored flip rates suggest that the models are relatively stable when the answer is the anchor.
</details>
<details>
<summary>x43.png Details</summary>
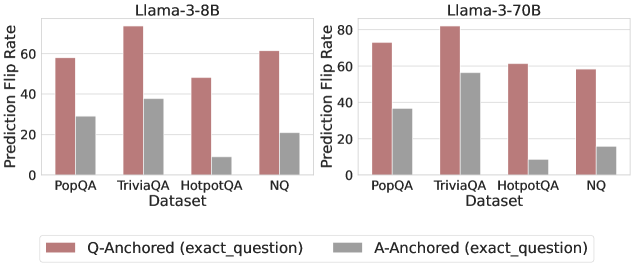
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama-3-8B and Llama-3-70B
### Overview
The image presents two bar charts comparing the prediction flip rates of two language models, Llama-3-8B and Llama-3-70B, across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare "Q-Anchored" (exact question) and "A-Anchored" (exact question) methods, represented by different colored bars.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-axis:**
* Label: Prediction Flip Rate
* Scale: 0 to 80, with tick marks at intervals of 20.
* **X-axis:**
* Label: Dataset
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the chart.
* Rose/Pink Bar: Q-Anchored (exact\_question)
* Gray Bar: A-Anchored (exact\_question)
### Detailed Analysis
**Llama-3-8B (Left Chart):**
* **PopQA:**
* Q-Anchored: Approximately 58%
* A-Anchored: Approximately 30%
* **TriviaQA:**
* Q-Anchored: Approximately 78%
* A-Anchored: Approximately 38%
* **HotpotQA:**
* Q-Anchored: Approximately 48%
* A-Anchored: Approximately 10%
* **NQ:**
* Q-Anchored: Approximately 62%
* A-Anchored: Approximately 24%
**Llama-3-70B (Right Chart):**
* **PopQA:**
* Q-Anchored: Approximately 74%
* A-Anchored: Approximately 38%
* **TriviaQA:**
* Q-Anchored: Approximately 82%
* A-Anchored: Approximately 56%
* **HotpotQA:**
* Q-Anchored: Approximately 62%
* A-Anchored: Approximately 10%
* **NQ:**
* Q-Anchored: Approximately 58%
* A-Anchored: Approximately 16%
### Key Observations
* For both models and across all datasets, the Q-Anchored method consistently shows a higher prediction flip rate than the A-Anchored method.
* TriviaQA generally exhibits the highest prediction flip rates for both models and both anchoring methods.
* HotpotQA consistently shows the lowest A-Anchored prediction flip rates for both models.
* The Llama-3-70B model generally has higher prediction flip rates than the Llama-3-8B model, especially for the Q-Anchored method.
### Interpretation
The data suggests that using the exact question (Q-Anchored) leads to a higher likelihood of prediction flips compared to using the exact answer (A-Anchored). This could indicate that the models are more sensitive to variations or nuances in the question phrasing. The higher flip rates for TriviaQA might be due to the nature of trivia questions, which often have multiple possible correct answers or require specific knowledge. The Llama-3-70B model, being larger, appears to be more prone to prediction flips, possibly due to its increased complexity and capacity to memorize or overfit to specific question formats. The difference in performance between the two models highlights the impact of model size on prediction stability. The low A-Anchored flip rates for HotpotQA could indicate that the model is more robust when provided with the exact answer for this particular dataset.
</details>
<details>
<summary>x44.png Details</summary>
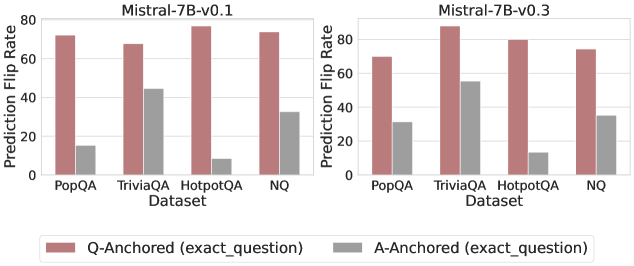
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Mistral-7B Models
### Overview
The image presents two bar charts comparing the prediction flip rates of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across four datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare the "Q-Anchored" (exact_question) and "A-Anchored" (exact_question) methods.
### Components/Axes
* **Titles:**
* Left Chart: Mistral-7B-v0.1
* Right Chart: Mistral-7B-v0.3
* **Y-axis:** Prediction Flip Rate (ranging from 0 to 80)
* **X-axis:** Dataset (categories: PopQA, TriviaQA, HotpotQA, NQ)
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a light brown/reddish bar.
* A-Anchored (exact\_question): Represented by a gray bar.
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **PopQA:**
* Q-Anchored: Approximately 72%
* A-Anchored: Approximately 15%
* **TriviaQA:**
* Q-Anchored: Approximately 68%
* A-Anchored: Approximately 44%
* **HotpotQA:**
* Q-Anchored: Approximately 74%
* A-Anchored: Approximately 8%
* **NQ:**
* Q-Anchored: Approximately 74%
* A-Anchored: Approximately 32%
**Right Chart: Mistral-7B-v0.3**
* **PopQA:**
* Q-Anchored: Approximately 70%
* A-Anchored: Approximately 30%
* **TriviaQA:**
* Q-Anchored: Approximately 84%
* A-Anchored: Approximately 54%
* **HotpotQA:**
* Q-Anchored: Approximately 80%
* A-Anchored: Approximately 12%
* **NQ:**
* Q-Anchored: Approximately 74%
* A-Anchored: Approximately 34%
### Key Observations
* For both model versions, the Q-Anchored method consistently shows a higher prediction flip rate than the A-Anchored method across all datasets.
* The difference between Q-Anchored and A-Anchored is most pronounced in HotpotQA for both model versions.
* Mistral-7B-v0.3 generally shows a higher prediction flip rate for Q-Anchored on TriviaQA and HotpotQA compared to v0.1.
* The A-Anchored method shows a higher prediction flip rate for v0.3 on PopQA and TriviaQA compared to v0.1.
### Interpretation
The charts suggest that anchoring the question (Q-Anchored) leads to a higher prediction flip rate compared to anchoring the answer (A-Anchored) for both Mistral-7B model versions. This could indicate that the models are more sensitive to changes in the question phrasing than the answer phrasing. The increase in prediction flip rate for Q-Anchored in v0.3 on TriviaQA and HotpotQA might indicate an increased sensitivity to question variations in the newer model version for these specific datasets. The A-Anchored method also shows a higher prediction flip rate for v0.3 on PopQA and TriviaQA, suggesting that the model is more sensitive to answer variations in the newer model version for these specific datasets. The large difference between Q-Anchored and A-Anchored in HotpotQA suggests that this dataset is particularly sensitive to question phrasing.
</details>
Figure 19: Prediction flip rate under token patching, probing attention activations of the last exact answer token.
<details>
<summary>x45.png Details</summary>
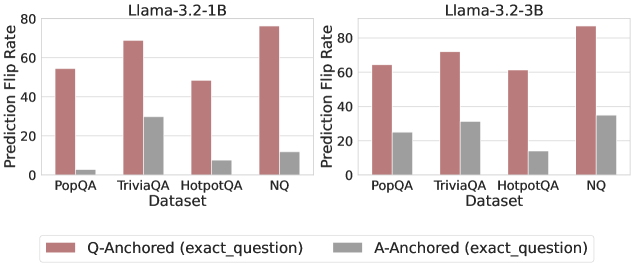
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two Llama models (Llama-3.2-1B and Llama-3.2-3B) across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare the flip rates when anchoring on the question (Q-Anchored) versus anchoring on the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **Y-Axis:** Prediction Flip Rate, ranging from 0 to 80.
* **X-Axis:** Dataset, with categories PopQA, TriviaQA, HotpotQA, and NQ.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a muted red/brown color.
* A-Anchored (exact\_question): Represented by a gray color.
### Detailed Analysis
**Left Chart: Llama-3.2-1B**
* **PopQA:**
* Q-Anchored: Approximately 54
* A-Anchored: Approximately 2
* **TriviaQA:**
* Q-Anchored: Approximately 70
* A-Anchored: Approximately 30
* **HotpotQA:**
* Q-Anchored: Approximately 48
* A-Anchored: Approximately 8
* **NQ:**
* Q-Anchored: Approximately 75
* A-Anchored: Approximately 13
**Right Chart: Llama-3.2-3B**
* **PopQA:**
* Q-Anchored: Approximately 65
* A-Anchored: Approximately 24
* **TriviaQA:**
* Q-Anchored: Approximately 72
* A-Anchored: Approximately 31
* **HotpotQA:**
* Q-Anchored: Approximately 61
* A-Anchored: Approximately 13
* **NQ:**
* Q-Anchored: Approximately 84
* A-Anchored: Approximately 34
### Key Observations
* For both models and across all datasets, the Q-Anchored flip rate is significantly higher than the A-Anchored flip rate.
* The NQ dataset consistently shows the highest Q-Anchored flip rate for both models.
* The A-Anchored flip rates are generally low, with TriviaQA showing the highest A-Anchored flip rate compared to other datasets.
* Llama-3.2-3B generally has higher Q-Anchored flip rates than Llama-3.2-1B across all datasets.
### Interpretation
The data suggests that anchoring on the question (Q-Anchored) leads to a higher prediction flip rate compared to anchoring on the answer (A-Anchored) for both Llama models. This could indicate that the models are more sensitive to changes or perturbations in the question compared to the answer. The NQ dataset, which likely contains more complex or nuanced questions, exhibits the highest flip rates, suggesting that the models struggle more with this type of question when the question is perturbed. The difference in flip rates between the two models (Llama-3.2-3B having higher rates) could be attributed to differences in their architecture, training data, or model size. The low A-Anchored flip rates suggest that the models are relatively robust to changes in the answer.
</details>
<details>
<summary>x46.png Details</summary>
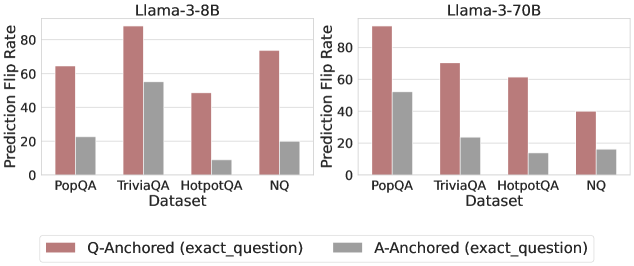
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama-3 Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two language models, Llama-3-8B and Llama-3-70B, across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare the flip rates when the question is anchored to the question itself (Q-Anchored) versus when it's anchored to the answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-Axis:** Prediction Flip Rate (ranging from 0 to 80, with tick marks at 20, 40, 60, and 80)
* **X-Axis:** Dataset (categorical): PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a light brown/reddish bar.
* A-Anchored (exact\_question): Represented by a gray bar.
### Detailed Analysis
**Llama-3-8B (Left Chart):**
* **PopQA:**
* Q-Anchored: Approximately 64
* A-Anchored: Approximately 22
* **TriviaQA:**
* Q-Anchored: Approximately 87
* A-Anchored: Approximately 55
* **HotpotQA:**
* Q-Anchored: Approximately 49
* A-Anchored: Approximately 9
* **NQ:**
* Q-Anchored: Approximately 73
* A-Anchored: Approximately 19
**Llama-3-70B (Right Chart):**
* **PopQA:**
* Q-Anchored: Approximately 95
* A-Anchored: Approximately 52
* **TriviaQA:**
* Q-Anchored: Approximately 70
* A-Anchored: Approximately 23
* **HotpotQA:**
* Q-Anchored: Approximately 63
* A-Anchored: Approximately 12
* **NQ:**
* Q-Anchored: Approximately 40
* A-Anchored: Approximately 16
### Key Observations
* For both models and across all datasets, the Q-Anchored flip rate is consistently higher than the A-Anchored flip rate.
* Llama-3-70B generally exhibits higher prediction flip rates compared to Llama-3-8B, especially for PopQA.
* TriviaQA shows the highest Q-Anchored flip rate for Llama-3-8B, while PopQA shows the highest Q-Anchored flip rate for Llama-3-70B.
* HotpotQA consistently has the lowest A-Anchored flip rates for both models.
### Interpretation
The data suggests that anchoring the question to the question itself (Q-Anchored) leads to a higher prediction flip rate compared to anchoring it to the answer (A-Anchored). This could indicate that the models are more sensitive to variations or perturbations in the question itself. The larger Llama-3-70B model generally shows higher flip rates, potentially indicating a greater sensitivity or complexity in its decision-making process. The differences in flip rates across datasets suggest that the models' robustness varies depending on the type of questions being asked. The lower A-Anchored flip rates for HotpotQA might indicate that the model is more confident or stable in its predictions for this particular dataset when the answer is the anchor.
</details>
<details>
<summary>x47.png Details</summary>
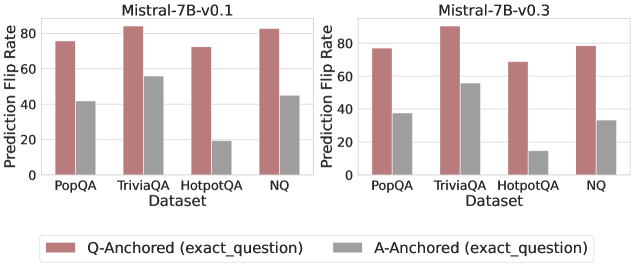
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison
### Overview
The image presents two bar charts comparing the prediction flip rates of two versions of the Mistral-7B model (v0.1 and v0.3) across different datasets. The charts show the prediction flip rates for both Q-Anchored (exact_question) and A-Anchored (exact_question) methods.
### Components/Axes
* **Titles:**
* Left Chart: Mistral-7B-v0.1
* Right Chart: Mistral-7B-v0.3
* **Y-axis:** Prediction Flip Rate
* Scale: 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **X-axis:** Dataset
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a muted red/brown color.
* A-Anchored (exact\_question): Represented by a gray color.
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **PopQA:**
* Q-Anchored: Approximately 76
* A-Anchored: Approximately 42
* **TriviaQA:**
* Q-Anchored: Approximately 84
* A-Anchored: Approximately 56
* **HotpotQA:**
* Q-Anchored: Approximately 72
* A-Anchored: Approximately 20
* **NQ:**
* Q-Anchored: Approximately 78
* A-Anchored: Approximately 58
**Right Chart: Mistral-7B-v0.3**
* **PopQA:**
* Q-Anchored: Approximately 76
* A-Anchored: Approximately 38
* **TriviaQA:**
* Q-Anchored: Approximately 86
* A-Anchored: Approximately 56
* **HotpotQA:**
* Q-Anchored: Approximately 72
* A-Anchored: Approximately 14
* **NQ:**
* Q-Anchored: Approximately 78
* A-Anchored: Approximately 32
### Key Observations
* In both charts, the Q-Anchored method consistently shows a higher prediction flip rate than the A-Anchored method across all datasets.
* The TriviaQA dataset generally has the highest prediction flip rate for the Q-Anchored method in both versions.
* The HotpotQA dataset has the lowest prediction flip rate for the A-Anchored method in both versions.
* Comparing the two versions, the A-Anchored method shows a decrease in prediction flip rate for HotpotQA and NQ in v0.3 compared to v0.1.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to a higher prediction flip rate compared to anchoring the answer (A-Anchored) for both versions of the Mistral-7B model. This could indicate that the model is more sensitive to changes or perturbations in the question than in the answer. The decrease in prediction flip rate for the A-Anchored method in v0.3 for HotpotQA and NQ datasets might indicate an improvement in the model's robustness to answer-related perturbations for those specific datasets. The consistent high flip rate for Q-Anchored TriviaQA suggests that this dataset might be particularly challenging for the model in terms of question understanding or robustness.
</details>
Figure 20: Prediction flip rate under token patching, probing mlp activations of the final token.
<details>
<summary>x48.png Details</summary>
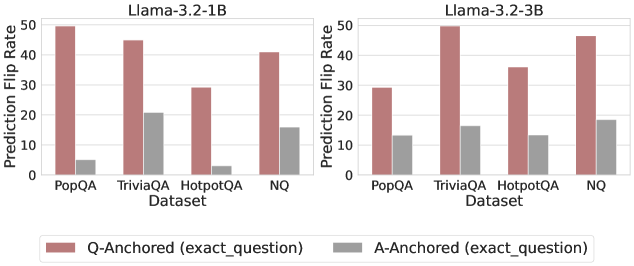
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two Llama models (Llama-3.2-1B and Llama-3.2-3B) across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts show the prediction flip rates when using Q-Anchored (exact_question) and A-Anchored (exact_question) methods.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **Y-axis:** Prediction Flip Rate, with a scale from 0 to 50. Axis markers are present at intervals of 10 (0, 10, 20, 30, 40, 50).
* **X-axis:** Dataset, with four categories: PopQA, TriviaQA, HotpotQA, NQ.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a muted red/brown color.
* A-Anchored (exact\_question): Represented by a gray color.
### Detailed Analysis
**Left Chart: Llama-3.2-1B**
* **PopQA:**
* Q-Anchored: Approximately 49
* A-Anchored: Approximately 5
* **TriviaQA:**
* Q-Anchored: Approximately 45
* A-Anchored: Approximately 21
* **HotpotQA:**
* Q-Anchored: Approximately 29
* A-Anchored: Approximately 3
* **NQ:**
* Q-Anchored: Approximately 41
* A-Anchored: Approximately 17
**Right Chart: Llama-3.2-3B**
* **PopQA:**
* Q-Anchored: Approximately 29
* A-Anchored: Approximately 13
* **TriviaQA:**
* Q-Anchored: Approximately 49
* A-Anchored: Approximately 16
* **HotpotQA:**
* Q-Anchored: Approximately 34
* A-Anchored: Approximately 13
* **NQ:**
* Q-Anchored: Approximately 47
* A-Anchored: Approximately 18
### Key Observations
* For both Llama models, the Q-Anchored method generally results in a higher prediction flip rate compared to the A-Anchored method across all datasets.
* The TriviaQA dataset shows the highest prediction flip rate for the Q-Anchored method in the Llama-3.2-3B model.
* The A-Anchored method consistently shows lower prediction flip rates, generally below 25 for all datasets and both models.
* The Llama-3.2-1B model has a higher Q-Anchored prediction flip rate for PopQA compared to Llama-3.2-3B.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to a higher likelihood of prediction flips compared to anchoring the answer (A-Anchored) for both Llama models. This could indicate that the models are more sensitive to variations or nuances in the question phrasing. The differences in prediction flip rates between the datasets may reflect the varying complexities and structures of the questions within each dataset. The Llama-3.2-1B model appears to be more sensitive to the question when using the PopQA dataset, as indicated by the higher Q-Anchored prediction flip rate compared to the Llama-3.2-3B model. The lower flip rates associated with A-Anchored suggest that the models are more stable when the answer is the anchor, possibly because the answer provides a more constrained context.
</details>
<details>
<summary>x49.png Details</summary>
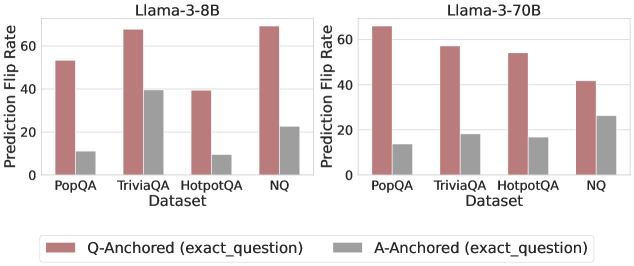
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama-3 Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two Llama-3 models (8B and 70B) across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare the performance of "Q-Anchored" (exact question) and "A-Anchored" (exact question) approaches.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-Axis:** Prediction Flip Rate, with a scale from 0 to 60 in increments of 20.
* **X-Axis:** Dataset, with categories: PopQA, TriviaQA, HotpotQA, NQ.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Represented by a light brown color.
* A-Anchored (exact\_question): Represented by a gray color.
### Detailed Analysis
**Left Chart: Llama-3-8B**
* **PopQA:**
* Q-Anchored: Approximately 53%
* A-Anchored: Approximately 11%
* **TriviaQA:**
* Q-Anchored: Approximately 68%
* A-Anchored: Approximately 40%
* **HotpotQA:**
* Q-Anchored: Approximately 40%
* A-Anchored: Approximately 9%
* **NQ:**
* Q-Anchored: Approximately 68%
* A-Anchored: Approximately 22%
**Right Chart: Llama-3-70B**
* **PopQA:**
* Q-Anchored: Approximately 65%
* A-Anchored: Approximately 13%
* **TriviaQA:**
* Q-Anchored: Approximately 57%
* A-Anchored: Approximately 17%
* **HotpotQA:**
* Q-Anchored: Approximately 56%
* A-Anchored: Approximately 16%
* **NQ:**
* Q-Anchored: Approximately 43%
* A-Anchored: Approximately 26%
### Key Observations
* For both models, the Q-Anchored approach generally results in a higher prediction flip rate compared to the A-Anchored approach across all datasets.
* The TriviaQA dataset shows the highest prediction flip rate for the Llama-3-8B model with the Q-Anchored approach.
* The NQ dataset shows the lowest prediction flip rate for the Llama-3-70B model with the Q-Anchored approach.
* The A-Anchored approach consistently shows lower prediction flip rates across all datasets for both models.
### Interpretation
The data suggests that anchoring the question directly ("Q-Anchored") leads to a higher likelihood of prediction flips compared to anchoring the answer ("A-Anchored"). This could indicate that the models are more sensitive to variations or perturbations in the question itself. The difference in performance between the 8B and 70B models may reflect the impact of model size on robustness and stability of predictions. The specific characteristics of each dataset (PopQA, TriviaQA, HotpotQA, NQ) likely contribute to the observed variations in prediction flip rates. The higher flip rates for Q-Anchored suggest that the model's predictions are more brittle when the question is manipulated, potentially due to the model relying heavily on specific question phrasing.
</details>
<details>
<summary>x50.png Details</summary>
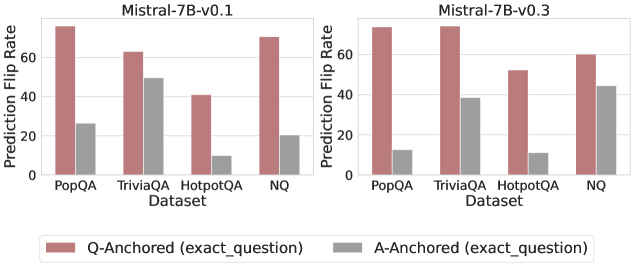
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Mistral-7B Models
### Overview
The image presents two bar charts comparing the prediction flip rates of Mistral-7B-v0.1 and Mistral-7B-v0.3 models across four datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts show the prediction flip rates for both Q-Anchored (exact_question) and A-Anchored (exact_question) scenarios.
### Components/Axes
* **Title (Top-Left Chart):** Mistral-7B-v0.1
* **Title (Top-Right Chart):** Mistral-7B-v0.3
* **Y-Axis Label:** Prediction Flip Rate
* **Y-Axis Scale:** 0 to 80, with tick marks at 0, 20, 40, 60
* **X-Axis Label:** Dataset
* **X-Axis Categories:** PopQA, TriviaQA, HotpotQA, NQ
* **Legend (Bottom):**
* Q-Anchored (exact\_question) - Brown
* A-Anchored (exact\_question) - Gray
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **PopQA:**
* Q-Anchored (Brown): Approximately 73%
* A-Anchored (Gray): Approximately 26%
* **TriviaQA:**
* Q-Anchored (Brown): Approximately 62%
* A-Anchored (Gray): Approximately 50%
* **HotpotQA:**
* Q-Anchored (Brown): Approximately 41%
* A-Anchored (Gray): Approximately 10%
* **NQ:**
* Q-Anchored (Brown): Approximately 68%
* A-Anchored (Gray): Approximately 23%
**Right Chart: Mistral-7B-v0.3**
* **PopQA:**
* Q-Anchored (Brown): Approximately 75%
* A-Anchored (Gray): Approximately 12%
* **TriviaQA:**
* Q-Anchored (Brown): Approximately 75%
* A-Anchored (Gray): Approximately 38%
* **HotpotQA:**
* Q-Anchored (Brown): Approximately 52%
* A-Anchored (Gray): Approximately 12%
* **NQ:**
* Q-Anchored (Brown): Approximately 60%
* A-Anchored (Gray): Approximately 43%
### Key Observations
* In both charts, the Q-Anchored prediction flip rates are consistently higher than the A-Anchored rates across all datasets.
* The Mistral-7B-v0.3 model generally shows a higher Q-Anchored prediction flip rate for TriviaQA and HotpotQA compared to Mistral-7B-v0.1.
* The A-Anchored prediction flip rates vary across datasets and models, with TriviaQA showing the highest rate for Mistral-7B-v0.1 and NQ showing the highest rate for Mistral-7B-v0.3.
### Interpretation
The data suggests that the prediction flip rate is significantly influenced by whether the question or the answer is anchored. The higher flip rates for Q-Anchored scenarios indicate that the model's predictions are more sensitive to changes in the question. The differences between Mistral-7B-v0.1 and Mistral-7B-v0.3 highlight the impact of model version on prediction stability. The variations across datasets suggest that the complexity and nature of the questions in each dataset also play a role in the prediction flip rate. The lower A-Anchored rates suggest that the model is more robust to changes in the answer, possibly because the answer provides a stronger contextual anchor.
</details>
Figure 21: Prediction flip rate under token patching, probing mlp activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x51.png Details</summary>
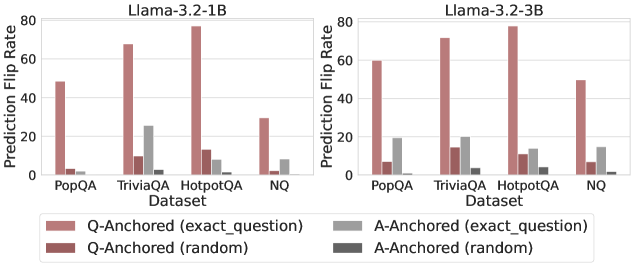
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two Llama models (Llama-3.2-1B and Llama-3.2-3B) across four datasets (PopQA, TriviaQA, HotpotQA, and NQ). The charts compare the impact of question-anchored and answer-anchored perturbations, with both exact question and random variations.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **Y-Axis:**
* Label: Prediction Flip Rate
* Scale: 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **X-Axis:**
* Label: Dataset
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Light Brown
* Q-Anchored (random): Dark Brown
* A-Anchored (exact\_question): Light Gray
* A-Anchored (random): Dark Gray
### Detailed Analysis
**Llama-3.2-1B (Left Chart):**
* **PopQA:**
* Q-Anchored (exact\_question): Approximately 48
* Q-Anchored (random): Approximately 3
* A-Anchored (exact\_question): Approximately 2
* A-Anchored (random): Approximately 1
* **TriviaQA:**
* Q-Anchored (exact\_question): Approximately 68
* Q-Anchored (random): Approximately 10
* A-Anchored (exact\_question): Approximately 25
* A-Anchored (random): Approximately 3
* **HotpotQA:**
* Q-Anchored (exact\_question): Approximately 75
* Q-Anchored (random): Approximately 13
* A-Anchored (exact\_question): Approximately 8
* A-Anchored (random): Approximately 1
* **NQ:**
* Q-Anchored (exact\_question): Approximately 30
* Q-Anchored (random): Approximately 2
* A-Anchored (exact\_question): Approximately 10
* A-Anchored (random): Approximately 0.5
**Llama-3.2-3B (Right Chart):**
* **PopQA:**
* Q-Anchored (exact\_question): Approximately 60
* Q-Anchored (random): Approximately 7
* A-Anchored (exact\_question): Approximately 20
* A-Anchored (random): Approximately 2
* **TriviaQA:**
* Q-Anchored (exact\_question): Approximately 72
* Q-Anchored (random): Approximately 15
* A-Anchored (exact\_question): Approximately 20
* A-Anchored (random): Approximately 3
* **HotpotQA:**
* Q-Anchored (exact\_question): Approximately 75
* Q-Anchored (random): Approximately 10
* A-Anchored (exact\_question): Approximately 12
* A-Anchored (random): Approximately 2
* **NQ:**
* Q-Anchored (exact\_question): Approximately 50
* Q-Anchored (random): Approximately 7
* A-Anchored (exact\_question): Approximately 15
* A-Anchored (random): Approximately 1
### Key Observations
* For both models, the Q-Anchored (exact\_question) perturbation consistently results in the highest prediction flip rates across all datasets.
* Q-Anchored (random) perturbations generally have a lower impact on prediction flip rates compared to Q-Anchored (exact\_question).
* A-Anchored perturbations (both exact\_question and random) have the lowest impact on prediction flip rates.
* The HotpotQA dataset shows the highest prediction flip rates for Q-Anchored (exact\_question) in both models.
* The NQ dataset shows a relatively lower prediction flip rate for Q-Anchored (exact\_question) compared to HotpotQA and TriviaQA.
### Interpretation
The data suggests that the prediction flip rate is highly sensitive to perturbations in the question itself, especially when the exact question is used as the anchor. Random question perturbations have a lesser impact, indicating that specific question wording is crucial. Answer-anchored perturbations have the least impact, suggesting that the model is more robust to changes in the answer context. The differences in prediction flip rates across datasets may reflect the varying complexity and structure of the questions in each dataset. The Llama-3.2-3B model generally shows higher prediction flip rates compared to Llama-3.2-1B, particularly for Q-Anchored (exact\_question) perturbations, indicating that it might be more sensitive to question-based adversarial attacks.
</details>
<details>
<summary>x52.png Details</summary>
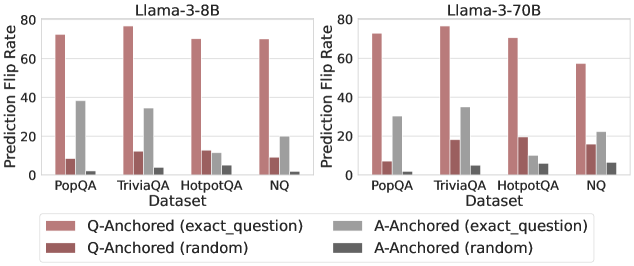
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Llama-3 Models
### Overview
The image presents two bar charts comparing the prediction flip rates of Llama-3-8B and Llama-3-70B models across different datasets (PopQA, TriviaQA, HotpotQA, and NQ). The charts show the prediction flip rates for question-anchored (Q-Anchored) and answer-anchored (A-Anchored) methods, with both "exact_question" and "random" variations.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-Axis:** Prediction Flip Rate (ranging from 0 to 80)
* **X-Axis:** Dataset (PopQA, TriviaQA, HotpotQA, NQ)
* **Legend:** Located at the bottom of the image.
* Q-Anchored (exact\_question): Light Brown
* Q-Anchored (random): Dark Brown
* A-Anchored (exact\_question): Light Gray
* A-Anchored (random): Dark Gray
### Detailed Analysis
**Left Chart: Llama-3-8B**
* **PopQA:**
* Q-Anchored (exact\_question): Approximately 73
* Q-Anchored (random): Approximately 8
* A-Anchored (exact\_question): Approximately 38
* A-Anchored (random): Approximately 1
* **TriviaQA:**
* Q-Anchored (exact\_question): Approximately 77
* Q-Anchored (random): Approximately 12
* A-Anchored (exact\_question): Approximately 34
* A-Anchored (random): Approximately 3
* **HotpotQA:**
* Q-Anchored (exact\_question): Approximately 71
* Q-Anchored (random): Approximately 12
* A-Anchored (exact\_question): Approximately 11
* A-Anchored (random): Approximately 5
* **NQ:**
* Q-Anchored (exact\_question): Approximately 70
* Q-Anchored (random): Approximately 12
* A-Anchored (exact\_question): Approximately 20
* A-Anchored (random): Approximately 5
**Right Chart: Llama-3-70B**
* **PopQA:**
* Q-Anchored (exact\_question): Approximately 74
* Q-Anchored (random): Approximately 8
* A-Anchored (exact\_question): Approximately 22
* A-Anchored (random): Approximately 1
* **TriviaQA:**
* Q-Anchored (exact\_question): Approximately 77
* Q-Anchored (random): Approximately 18
* A-Anchored (exact\_question): Approximately 34
* A-Anchored (random): Approximately 2
* **HotpotQA:**
* Q-Anchored (exact\_question): Approximately 74
* Q-Anchored (random): Approximately 10
* A-Anchored (exact\_question): Approximately 10
* A-Anchored (random): Approximately 3
* **NQ:**
* Q-Anchored (exact\_question): Approximately 56
* Q-Anchored (random): Approximately 16
* A-Anchored (exact\_question): Approximately 22
* A-Anchored (random): Approximately 6
### Key Observations
* For both models, the Q-Anchored (exact\_question) method consistently shows the highest prediction flip rates across all datasets.
* The Q-Anchored (random) method generally has low prediction flip rates.
* The A-Anchored (exact\_question) method shows moderate prediction flip rates, while A-Anchored (random) has the lowest.
* The Llama-3-70B model exhibits a slightly lower Q-Anchored (exact\_question) prediction flip rate for the NQ dataset compared to the Llama-3-8B model.
### Interpretation
The data suggests that anchoring the question directly (Q-Anchored, exact\_question) leads to a higher likelihood of prediction flips, indicating potential sensitivity to specific question formulations. Randomizing the question anchoring significantly reduces the flip rate, suggesting that the model relies on specific question structures for its predictions. Answer anchoring shows a lower flip rate compared to question anchoring, implying that the model is more robust to variations in the answer context. The differences between the 8B and 70B models are subtle, but the 70B model shows a slightly reduced flip rate for Q-Anchored (exact\_question) on the NQ dataset, potentially indicating improved robustness.
</details>
<details>
<summary>x53.png Details</summary>
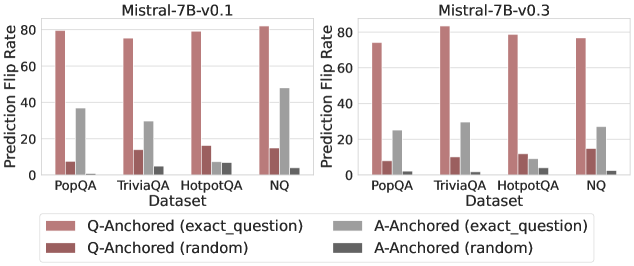
### Visual Description
## Bar Chart: Prediction Flip Rate Comparison for Mistral-7B Models
### Overview
The image presents two bar charts comparing the prediction flip rates of two versions of the Mistral-7B model (v0.1 and v0.3) across four different question answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts illustrate the impact of anchoring the question or answer, using either the exact question/answer or a random variation.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-axis:** "Prediction Flip Rate" with a numerical scale from 0 to 80 in increments of 20.
* **X-axis:** "Dataset" with four categories: PopQA, TriviaQA, HotpotQA, NQ.
* **Legend:** Located at the bottom of the image.
* Light Red: "Q-Anchored (exact\_question)"
* Dark Red: "Q-Anchored (random)"
* Light Gray: "A-Anchored (exact\_question)"
* Dark Gray: "A-Anchored (random)"
### Detailed Analysis
**Left Chart (Mistral-7B-v0.1):**
* **PopQA:**
* Q-Anchored (exact\_question): Approximately 80
* Q-Anchored (random): Approximately 8
* A-Anchored (exact\_question): Approximately 37
* A-Anchored (random): Approximately 8
* **TriviaQA:**
* Q-Anchored (exact\_question): Approximately 76
* Q-Anchored (random): Approximately 14
* A-Anchored (exact\_question): Approximately 30
* A-Anchored (random): Approximately 5
* **HotpotQA:**
* Q-Anchored (exact\_question): Approximately 80
* Q-Anchored (random): Approximately 14
* A-Anchored (exact\_question): Approximately 8
* A-Anchored (random): Approximately 7
* **NQ:**
* Q-Anchored (exact\_question): Approximately 80
* Q-Anchored (random): Approximately 16
* A-Anchored (exact\_question): Approximately 57
* A-Anchored (random): Approximately 8
**Right Chart (Mistral-7B-v0.3):**
* **PopQA:**
* Q-Anchored (exact\_question): Approximately 74
* Q-Anchored (random): Approximately 8
* A-Anchored (exact\_question): Approximately 24
* A-Anchored (random): Approximately 2
* **TriviaQA:**
* Q-Anchored (exact\_question): Approximately 82
* Q-Anchored (random): Approximately 10
* A-Anchored (exact\_question): Approximately 26
* A-Anchored (random): Approximately 2
* **HotpotQA:**
* Q-Anchored (exact\_question): Approximately 78
* Q-Anchored (random): Approximately 10
* A-Anchored (exact\_question): Approximately 10
* A-Anchored (random): Approximately 4
* **NQ:**
* Q-Anchored (exact\_question): Approximately 78
* Q-Anchored (random): Approximately 12
* A-Anchored (exact\_question): Approximately 26
* A-Anchored (random): Approximately 1
### Key Observations
* For both model versions, the "Q-Anchored (exact\_question)" consistently shows the highest prediction flip rate across all datasets.
* The "Q-Anchored (random)" generally has a low prediction flip rate.
* The "A-Anchored (random)" consistently has the lowest prediction flip rate.
* The prediction flip rates for "Q-Anchored (exact\_question)" are generally high, hovering around 70-80 for both model versions.
* The "A-Anchored (exact\_question)" flip rate is higher for v0.1 than v0.3.
### Interpretation
The data suggests that using the exact question as an anchor leads to a significantly higher prediction flip rate compared to using a random variation of the question or answer. This indicates that the model is highly sensitive to the specific wording of the question. The lower flip rates when using random variations suggest that the model is more robust to slight changes in the input.
Comparing the two model versions, Mistral-7B-v0.3 generally exhibits lower prediction flip rates for "A-Anchored (exact\_question)" compared to v0.1, suggesting that v0.3 might be slightly more stable or less prone to flipping predictions when the answer is anchored. The "Q-Anchored (exact\_question)" remains high for both versions.
The high flip rate for "Q-Anchored (exact\_question)" could indicate a potential vulnerability or sensitivity in the model's architecture, where small changes in the question can lead to different predictions. This could be an area for further investigation and potential improvement in future model versions.
</details>
Figure 22: Prediction flip rate under token patching, probing mlp activations of the last exact answer token.
Appendix E Answer-Only Input
<details>
<summary>x54.png Details</summary>
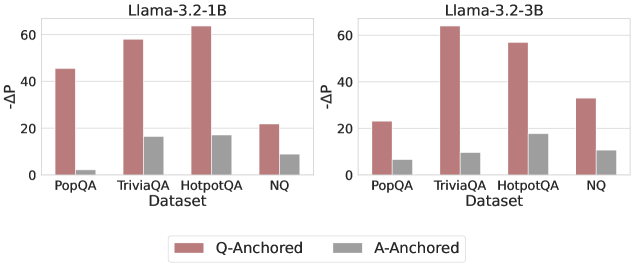
### Visual Description
## Bar Chart: Llama-3.2-1B vs. Llama-3.2-3B Performance on Question Answering Datasets
### Overview
The image presents two bar charts comparing the performance of Llama-3.2-1B and Llama-3.2-3B models on four question answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts display the difference in performance (-ΔP) between two anchoring methods (Q-Anchored and A-Anchored) for each dataset.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **Y-axis:**
* Label: -ΔP
* Scale: 0 to 60, with tick marks at 0, 20, 40, and 60.
* **X-axis:**
* Label: Dataset
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the image.
* Q-Anchored: Represented by a light brown/reddish bar.
* A-Anchored: Represented by a gray bar.
### Detailed Analysis
**Left Chart: Llama-3.2-1B**
* **PopQA:**
* Q-Anchored: Approximately 45
* A-Anchored: Approximately 2
* **TriviaQA:**
* Q-Anchored: Approximately 58
* A-Anchored: Approximately 17
* **HotpotQA:**
* Q-Anchored: Approximately 63
* A-Anchored: Approximately 18
* **NQ:**
* Q-Anchored: Approximately 22
* A-Anchored: Approximately 10
**Right Chart: Llama-3.2-3B**
* **PopQA:**
* Q-Anchored: Approximately 23
* A-Anchored: Approximately 7
* **TriviaQA:**
* Q-Anchored: Approximately 64
* A-Anchored: Approximately 10
* **HotpotQA:**
* Q-Anchored: Approximately 57
* A-Anchored: Approximately 18
* **NQ:**
* Q-Anchored: Approximately 33
* A-Anchored: Approximately 11
### Key Observations
* For both models, the Q-Anchored method generally outperforms the A-Anchored method across all datasets.
* The performance difference between Q-Anchored and A-Anchored is most significant for TriviaQA and HotpotQA in Llama-3.2-1B.
* Llama-3.2-3B shows a more balanced performance across the datasets compared to Llama-3.2-1B.
* The A-Anchored performance is consistently low across all datasets and both models.
### Interpretation
The charts indicate that the Q-Anchored method is generally more effective than the A-Anchored method for both Llama-3.2-1B and Llama-3.2-3B models. The larger performance differences observed in TriviaQA and HotpotQA for Llama-3.2-1B suggest that the Q-Anchored method may be particularly beneficial for these types of question answering tasks. The more balanced performance of Llama-3.2-3B across datasets could indicate a more robust model that is less sensitive to the specific characteristics of each dataset. The consistently low performance of the A-Anchored method suggests that this approach may have limitations in effectively leveraging the information within these datasets.
</details>
<details>
<summary>x55.png Details</summary>
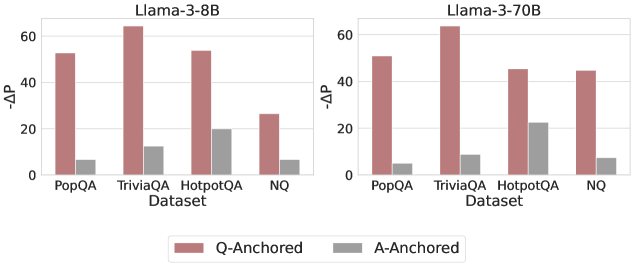
### Visual Description
## Bar Chart: Q-Anchored vs A-Anchored Performance on Different Datasets for Llama-3-8B and Llama-3-70B
### Overview
The image presents two bar charts comparing the performance of "Q-Anchored" and "A-Anchored" methods across four datasets (PopQA, TriviaQA, HotpotQA, and NQ) for two language models: Llama-3-8B and Llama-3-70B. The y-axis represents "-ΔP", and the x-axis represents the dataset. The charts visually compare the performance difference between the two anchoring methods for each dataset and model.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3-8B"
* Right Chart: "Llama-3-70B"
* **Y-axis:**
* Label: "-ΔP"
* Scale: 0, 20, 40, 60
* **X-axis:**
* Label: "Dataset"
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the image.
* Q-Anchored: Represented by a light brown/reddish bar.
* A-Anchored: Represented by a gray bar.
### Detailed Analysis
**Llama-3-8B (Left Chart):**
* **PopQA:**
* Q-Anchored: Approximately 52
* A-Anchored: Approximately 7
* **TriviaQA:**
* Q-Anchored: Approximately 64
* A-Anchored: Approximately 12
* **HotpotQA:**
* Q-Anchored: Approximately 53
* A-Anchored: Approximately 20
* **NQ:**
* Q-Anchored: Approximately 27
* A-Anchored: Approximately 7
**Llama-3-70B (Right Chart):**
* **PopQA:**
* Q-Anchored: Approximately 52
* A-Anchored: Approximately 6
* **TriviaQA:**
* Q-Anchored: Approximately 63
* A-Anchored: Approximately 8
* **HotpotQA:**
* Q-Anchored: Approximately 45
* A-Anchored: Approximately 23
* **NQ:**
* Q-Anchored: Approximately 45
* A-Anchored: Approximately 7
### Key Observations
* In both charts, the "Q-Anchored" method consistently outperforms the "A-Anchored" method across all datasets.
* The "TriviaQA" dataset shows the highest "-ΔP" value for "Q-Anchored" in both Llama-3-8B and Llama-3-70B.
* The "A-Anchored" method shows relatively low "-ΔP" values across all datasets and both models.
* The performance difference between "Q-Anchored" and "A-Anchored" is most pronounced in the "TriviaQA" dataset for both models.
* The Llama-3-70B model shows a slightly different performance profile compared to Llama-3-8B, particularly in the "HotpotQA" and "NQ" datasets, where the "-ΔP" values for "Q-Anchored" are lower than in Llama-3-8B.
### Interpretation
The data suggests that the "Q-Anchored" method is significantly more effective than the "A-Anchored" method for both Llama-3-8B and Llama-3-70B models across the tested datasets. The consistent outperformance of "Q-Anchored" indicates that anchoring the questions leads to better performance in these question-answering tasks. The varying performance across datasets suggests that the effectiveness of the anchoring methods may be influenced by the specific characteristics of each dataset. The differences in performance between Llama-3-8B and Llama-3-70B highlight the impact of model size on the effectiveness of these anchoring methods. The higher values for TriviaQA suggest that the anchoring methods are particularly effective for trivia-style question answering.
</details>
<details>
<summary>x56.png Details</summary>
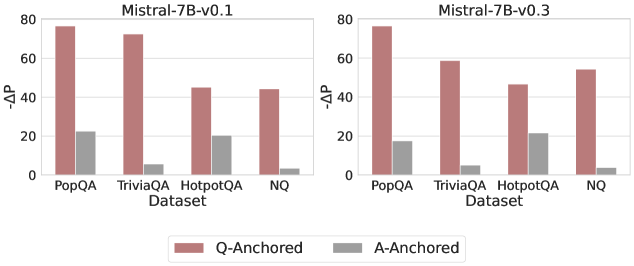
### Visual Description
## Bar Chart: Comparison of Mistral-7B Model Versions on Question Answering Datasets
### Overview
The image presents two bar charts comparing the performance of two versions of the Mistral-7B model (v0.1 and v0.3) on four question answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts display the difference in performance (-ΔP) between two anchoring methods: Q-Anchored (question-anchored) and A-Anchored (answer-anchored).
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-axis:** "-ΔP" (presumably representing the negative change in a performance metric, higher is better)
* Scale: 0 to 80, with tick marks at 20, 40, 60, and 80.
* **X-axis:** "Dataset"
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the image.
* Q-Anchored: Represented by a light brown/reddish bar.
* A-Anchored: Represented by a gray bar.
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **PopQA:**
* Q-Anchored: Approximately 77
* A-Anchored: Approximately 23
* **TriviaQA:**
* Q-Anchored: Approximately 73
* A-Anchored: Approximately 7
* **HotpotQA:**
* Q-Anchored: Approximately 45
* A-Anchored: Approximately 21
* **NQ:**
* Q-Anchored: Approximately 45
* A-Anchored: Approximately 3
**Right Chart: Mistral-7B-v0.3**
* **PopQA:**
* Q-Anchored: Approximately 77
* A-Anchored: Approximately 18
* **TriviaQA:**
* Q-Anchored: Approximately 59
* A-Anchored: Approximately 6
* **HotpotQA:**
* Q-Anchored: Approximately 54
* A-Anchored: Approximately 22
* **NQ:**
* Q-Anchored: Approximately 55
* A-Anchored: Approximately 4
### Key Observations
* In both charts, the Q-Anchored method consistently outperforms the A-Anchored method across all datasets.
* The performance difference between Q-Anchored and A-Anchored is most significant for PopQA and TriviaQA in Mistral-7B-v0.1.
* The A-Anchored performance is generally low across all datasets and both model versions.
* Comparing the two versions, Mistral-7B-v0.3 shows a decrease in Q-Anchored performance for TriviaQA and HotpotQA, but an increase for NQ.
### Interpretation
The charts suggest that question-anchoring is a more effective strategy than answer-anchoring for the Mistral-7B model on these question answering tasks. The relatively low performance of A-Anchored may indicate that the model struggles when its attention is primarily focused on the answer context.
The differences between v0.1 and v0.3 highlight the impact of model updates on performance across different datasets. The decrease in performance on TriviaQA and HotpotQA for v0.3, coupled with the increase on NQ, suggests that the model's improvements may be task-specific, potentially due to changes in training data or architecture. Further investigation would be needed to understand the underlying reasons for these performance variations.
</details>
Figure 23: $-\Delta\mathrm{P}$ with only the LLM-generated answer. Q-Anchored instances exhibit substantial shifts, whereas A-Anchored instances remain stable, confirming that A-Anchored truthfulness encoding relies on information in the LLM-generated answer itself.
Appendix F Answer Accuracy
<details>
<summary>x57.png Details</summary>
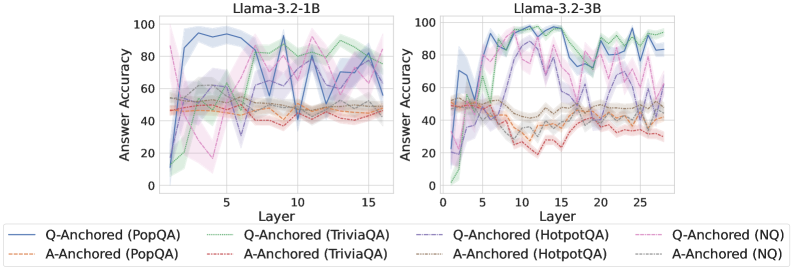
### Visual Description
## Chart: Answer Accuracy vs. Layer for Llama Models
### Overview
The image presents two line charts comparing the answer accuracy of Llama models (3.2-1B and 3.2-3B) across different layers. The x-axis represents the layer number, and the y-axis represents the answer accuracy. Each chart displays six data series, representing different question-answering tasks (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored). Shaded regions around the lines indicate uncertainty or variance.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3.2-1B"
* Right Chart: "Llama-3.2-3B"
* **X-axis:**
* Label: "Layer"
* Left Chart: Scale from 0 to 15, with tick marks at 0, 5, 10, and 15.
* Right Chart: Scale from 0 to 25, with tick marks at 0, 5, 10, 15, 20, and 25.
* **Y-axis:**
* Label: "Answer Accuracy"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located at the bottom of the image.
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Dotted green line
* **A-Anchored (TriviaQA):** Dashed-dotted orange line
* **Q-Anchored (HotpotQA):** Dashed purple line
* **A-Anchored (HotpotQA):** Dotted gray line
* **Q-Anchored (NQ):** Dashed-dotted pink line
* **A-Anchored (NQ):** Dotted black line
### Detailed Analysis
**Left Chart (Llama-3.2-1B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts around 10% accuracy at layer 1, rises sharply to approximately 95% by layer 5, then fluctuates between 85% and 95% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively stable around 50% accuracy across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts around 20% accuracy at layer 1, rises to approximately 85% by layer 12, then fluctuates between 75% and 85% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed-dotted Orange) Remains relatively stable around 50% accuracy across all layers.
* **Q-Anchored (HotpotQA):** (Dashed Purple) Starts around 10% accuracy at layer 1, rises to approximately 60% by layer 5, then fluctuates between 40% and 60% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Gray) Remains relatively stable around 55% accuracy across all layers.
* **Q-Anchored (NQ):** (Dashed-dotted Pink) Starts around 50% accuracy at layer 1, drops to approximately 15% by layer 5, then fluctuates between 35% and 55% for the remaining layers.
* **A-Anchored (NQ):** (Dotted Black) Remains relatively stable around 55% accuracy across all layers.
**Right Chart (Llama-3.2-3B):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts around 10% accuracy at layer 1, rises sharply to approximately 90% by layer 5, then fluctuates between 70% and 95% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Remains relatively stable around 40% accuracy across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts around 0% accuracy at layer 1, rises to approximately 95% by layer 12, then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed-dotted Orange) Remains relatively stable around 50% accuracy across all layers.
* **Q-Anchored (HotpotQA):** (Dashed Purple) Starts around 10% accuracy at layer 1, rises to approximately 90% by layer 12, then fluctuates between 70% and 95% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Gray) Remains relatively stable around 40% accuracy across all layers.
* **Q-Anchored (NQ):** (Dashed-dotted Pink) Starts around 50% accuracy at layer 1, drops to approximately 15% by layer 5, then fluctuates between 20% and 50% for the remaining layers.
* **A-Anchored (NQ):** (Dotted Black) Remains relatively stable around 50% accuracy across all layers.
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored tasks generally show more significant improvement in accuracy as the layer number increases, especially for PopQA, TriviaQA, and HotpotQA. A-Anchored tasks tend to remain relatively stable across all layers.
* **Model Size:** The larger model (3.2-3B) generally achieves higher accuracy for Q-Anchored tasks compared to the smaller model (3.2-1B), particularly for TriviaQA and HotpotQA.
* **Task Difficulty:** PopQA, TriviaQA, and HotpotQA tasks show a clear learning curve for Q-Anchored versions, while NQ shows a dip in accuracy before stabilizing.
* **Variance:** The shaded regions indicate varying degrees of uncertainty in the accuracy, with some tasks showing more consistent performance than others.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) is more effective for improving answer accuracy as the model processes through deeper layers, especially for PopQA, TriviaQA, and HotpotQA. This could indicate that the model benefits more from processing the question context in these tasks. The larger model size (3.2-3B) appears to enhance the learning capability for Q-Anchored tasks, leading to higher overall accuracy. The relatively stable performance of A-Anchored tasks suggests that the answer context alone might not be sufficient for significant improvement as the model deepens. The dip in accuracy for Q-Anchored (NQ) in both models could indicate a different processing requirement or inherent difficulty in the NQ task. Overall, the charts highlight the impact of model size, anchoring strategy, and task type on the answer accuracy of Llama models.
</details>
<details>
<summary>x58.png Details</summary>
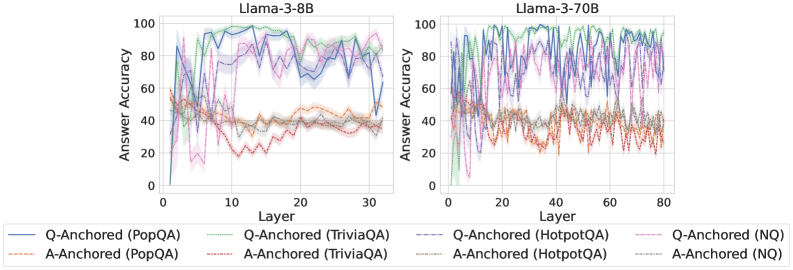
### Visual Description
## Line Charts: Llama-3-8B and Llama-3-70B Answer Accuracy vs. Layer
### Overview
The image presents two line charts comparing the answer accuracy of Llama-3-8B and Llama-3-70B models across different layers for various question-answering datasets. The charts depict the performance of both "Q-Anchored" and "A-Anchored" approaches on PopQA, TriviaQA, HotpotQA, and NQ datasets. The x-axis represents the layer number, while the y-axis represents the answer accuracy.
### Components/Axes
**Left Chart (Llama-3-8B):**
* **Title:** Llama-3-8B
* **X-axis:** Layer, with markers at 0, 10, 20, and 30.
* **Y-axis:** Answer Accuracy, ranging from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
**Right Chart (Llama-3-70B):**
* **Title:** Llama-3-70B
* **X-axis:** Layer, with markers at 0, 20, 40, 60, and 80.
* **Y-axis:** Answer Accuracy, ranging from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
**Legend (Located at the bottom of both charts):**
* **Q-Anchored (PopQA):** Solid Blue Line
* **A-Anchored (PopQA):** Dashed Brown Line
* **Q-Anchored (TriviaQA):** Dotted Green Line
* **A-Anchored (TriviaQA):** Dash-Dot Green Line
* **Q-Anchored (HotpotQA):** Dash-Dot Purple Line
* **A-Anchored (HotpotQA):** Dotted Red Line
* **Q-Anchored (NQ):** Dashed Purple Line
* **A-Anchored (NQ):** Dash-Dot Brown Line
### Detailed Analysis
**Llama-3-8B:**
* **Q-Anchored (PopQA):** (Solid Blue) Starts around 60% accuracy at layer 0, drops slightly, then rises sharply to fluctuate between 80% and 100% from layer 10 onwards.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts around 60% accuracy, drops slightly, then rises sharply to fluctuate between 70% and 90% from layer 10 onwards.
* **A-Anchored (TriviaQA):** (Dash-Dot Green) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple) Starts around 60% accuracy, drops sharply, then rises sharply to fluctuate between 70% and 90% from layer 10 onwards.
* **A-Anchored (HotpotQA):** (Dotted Red) Starts around 50% accuracy, decreases sharply, and then stabilizes around 30% from layer 10 onwards.
* **Q-Anchored (NQ):** (Dashed Purple) Starts around 60% accuracy, drops sharply, then rises sharply to fluctuate between 70% and 90% from layer 10 onwards.
* **A-Anchored (NQ):** (Dash-Dot Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
**Llama-3-70B:**
* **Q-Anchored (PopQA):** (Solid Blue) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 80% to 100% from layer 10 onwards.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 80% to 100% from layer 10 onwards.
* **A-Anchored (TriviaQA):** (Dash-Dot Green) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 70% to 90% from layer 10 onwards.
* **A-Anchored (HotpotQA):** (Dotted Red) Starts around 50% accuracy, decreases sharply, and then stabilizes around 30% from layer 10 onwards.
* **Q-Anchored (NQ):** (Dashed Purple) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 70% to 90% from layer 10 onwards.
* **A-Anchored (NQ):** (Dash-Dot Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
### Key Observations
* For both models, "Q-Anchored" approaches generally achieve higher answer accuracy than "A-Anchored" approaches across all datasets.
* The "Q-Anchored" lines show a sharp increase in accuracy around layer 10 for Llama-3-8B, while Llama-3-70B fluctuates more.
* The "A-Anchored" lines tend to stabilize around 40% accuracy after the initial layers for both models, except for HotpotQA, which stabilizes around 30%.
* Llama-3-70B has a longer x-axis, indicating more layers than Llama-3-8B.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to better performance in question-answering tasks compared to anchoring the answer (A-Anchored) for both Llama-3-8B and Llama-3-70B models. The initial layers seem to be crucial for the "Q-Anchored" approaches, as they exhibit a significant increase in accuracy around layer 10. The larger model, Llama-3-70B, shows more fluctuation in accuracy across layers, potentially indicating a more complex learning process. The consistent performance of "A-Anchored" approaches around 40% suggests a baseline level of accuracy that is independent of the number of layers. The lower accuracy of "A-Anchored (HotpotQA)" might indicate that HotpotQA is a more challenging dataset for this approach.
</details>
<details>
<summary>x59.png Details</summary>
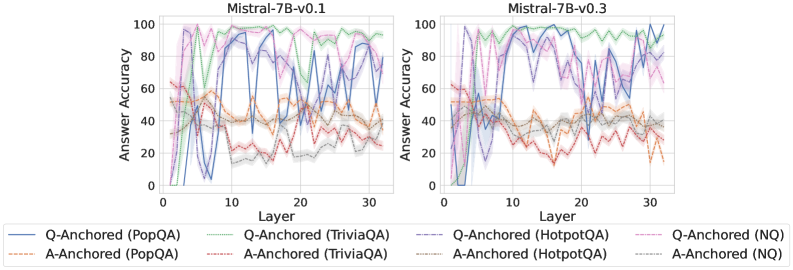
### Visual Description
## Line Chart: Mistral-7B Model Performance Comparison
### Overview
The image presents two line charts comparing the performance of Mistral-7B models (v0.1 and v0.3) across different layers. The charts depict the "Answer Accuracy" on the y-axis versus "Layer" on the x-axis for various question-answering datasets. Each dataset is represented by two lines: one for "Q-Anchored" (question-anchored) and one for "A-Anchored" (answer-anchored) approaches.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:** "Answer Accuracy", ranging from 0 to 100. Increments of 20.
* **X-Axis:** "Layer", ranging from 0 to 30. Increments of 10.
* **Legend:** Located at the bottom of the image, describing the lines:
* Blue solid line: "Q-Anchored (PopQA)"
* Brown dashed line: "A-Anchored (PopQA)"
* Green dotted line: "Q-Anchored (TriviaQA)"
* Red dashed-dotted line: "A-Anchored (TriviaQA)"
* Purple dashed line: "Q-Anchored (HotpotQA)"
* Orange dotted line: "A-Anchored (HotpotQA)"
* Pink dashed-dotted line: "Q-Anchored (NQ)"
* Gray dotted line: "A-Anchored (NQ)"
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0% accuracy, rises sharply to around 90% by layer 10, fluctuates between 80% and 100% until layer 30.
* Specific points: (0, ~0), (10, ~90), (30, ~90)
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 50%, decreases to 30% by layer 5, then gradually increases to around 40% and remains relatively stable with fluctuations.
* Specific points: (0, ~50), (5, ~30), (30, ~40)
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around 60%, fluctuates between 80% and 100% throughout all layers.
* Specific points: (0, ~60), (10, ~90), (30, ~90)
* **A-Anchored (TriviaQA) (Red dashed-dotted line):** Starts around 50%, decreases to 20% by layer 10, then remains relatively stable with fluctuations.
* Specific points: (0, ~50), (10, ~20), (30, ~20)
* **Q-Anchored (HotpotQA) (Purple dashed line):** Starts around 60%, fluctuates between 80% and 100% throughout all layers.
* Specific points: (0, ~60), (10, ~90), (30, ~90)
* **A-Anchored (HotpotQA) (Orange dotted line):** Starts around 50%, decreases to 40% by layer 5, then remains relatively stable with fluctuations.
* Specific points: (0, ~50), (5, ~40), (30, ~40)
* **Q-Anchored (NQ) (Pink dashed-dotted line):** Starts around 60%, fluctuates between 80% and 100% throughout all layers.
* Specific points: (0, ~60), (10, ~90), (30, ~90)
* **A-Anchored (NQ) (Gray dotted line):** Starts around 50%, decreases to 20% by layer 10, then remains relatively stable with fluctuations.
* Specific points: (0, ~50), (10, ~20), (30, ~20)
**Right Chart: Mistral-7B-v0.3**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 0% accuracy, rises sharply to around 90% by layer 10, fluctuates between 70% and 100% until layer 30.
* Specific points: (0, ~0), (10, ~90), (30, ~80)
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 50%, decreases to 30% by layer 5, then gradually increases to around 40% and remains relatively stable with fluctuations.
* Specific points: (0, ~50), (5, ~30), (30, ~40)
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around 60%, fluctuates between 80% and 100% throughout all layers.
* Specific points: (0, ~60), (10, ~90), (30, ~90)
* **A-Anchored (TriviaQA) (Red dashed-dotted line):** Starts around 50%, decreases to 20% by layer 10, then remains relatively stable with fluctuations.
* Specific points: (0, ~50), (10, ~20), (30, ~20)
* **Q-Anchored (HotpotQA) (Purple dashed line):** Starts around 60%, fluctuates between 80% and 100% throughout all layers.
* Specific points: (0, ~60), (10, ~90), (30, ~90)
* **A-Anchored (HotpotQA) (Orange dotted line):** Starts around 50%, decreases to 40% by layer 5, then remains relatively stable with fluctuations.
* Specific points: (0, ~50), (5, ~40), (30, ~40)
* **Q-Anchored (NQ) (Pink dashed-dotted line):** Starts around 60%, fluctuates between 80% and 100% throughout all layers.
* Specific points: (0, ~60), (10, ~90), (30, ~90)
* **A-Anchored (NQ) (Gray dotted line):** Starts around 50%, decreases to 20% by layer 10, then remains relatively stable with fluctuations.
* Specific points: (0, ~50), (10, ~20), (30, ~20)
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored approaches generally achieve significantly higher answer accuracy than A-Anchored approaches across all datasets and both model versions.
* **Dataset Performance:** The Q-Anchored methods for TriviaQA, HotpotQA, and NQ datasets consistently achieve high accuracy (80-100%) across all layers. PopQA starts low and increases.
* **Model Version Comparison:** The performance between Mistral-7B-v0.1 and Mistral-7B-v0.3 is very similar across all datasets and anchoring methods.
* **Layer Impact:** For Q-Anchored methods, accuracy tends to stabilize after the initial layers (around layer 10). A-Anchored methods show relatively stable, lower accuracy across all layers.
### Interpretation
The charts demonstrate the performance of Mistral-7B models on various question-answering datasets, highlighting the difference between question-anchored and answer-anchored approaches. The consistently higher accuracy of Q-Anchored methods suggests that focusing on the question context is more effective for these models. The similarity in performance between v0.1 and v0.3 indicates that the model's core capabilities remained consistent between these versions. The stabilization of accuracy after the initial layers suggests that the model learns the relevant information early on and maintains it throughout the subsequent layers. The A-Anchored methods show a consistent, lower accuracy, indicating that relying solely on the answer context is less effective for these models.
</details>
Figure 24: Comparisons of answer accuracy between pathways, probing attention activations of the final token.
<details>
<summary>x60.png Details</summary>
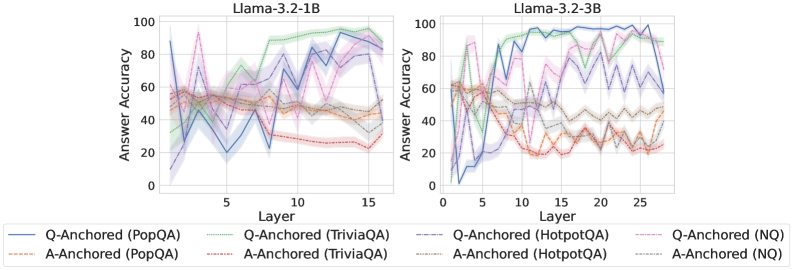
### Visual Description
## Line Charts: Llama-3.2-1B and Llama-3.2-3B Answer Accuracy vs. Layer
### Overview
The image contains two line charts comparing the answer accuracy of Llama-3.2-1B and Llama-3.2-3B models across different layers. The x-axis represents the layer number, and the y-axis represents the answer accuracy. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) and anchoring methods (Q-Anchored and A-Anchored). The charts show how accuracy changes as the input progresses through the layers of the model.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3.2-1B"
* Right Chart: "Llama-3.2-3B"
* **X-axis:**
* Label: "Layer"
* Left Chart: Scale from 0 to 15, with tick marks at approximately 0, 5, 10, and 15.
* Right Chart: Scale from 0 to 25, with tick marks at approximately 0, 5, 10, 15, 20, and 25.
* **Y-axis:**
* Label: "Answer Accuracy"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located at the bottom of the image, shared by both charts.
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Dotted green line
* **A-Anchored (TriviaQA):** Dotted-dashed red line
* **Q-Anchored (HotpotQA):** Solid light blue line
* **A-Anchored (HotpotQA):** Dashed orange line
* **Q-Anchored (NQ):** Dotted-dashed pink line
* **A-Anchored (NQ):** Dotted gray line
### Detailed Analysis
**Left Chart: Llama-3.2-1B**
* **Q-Anchored (PopQA):** (Solid blue line) Starts high (around 90% at layer 1), drops sharply to around 20% at layer 5, then fluctuates between 30% and 80% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed brown line) Starts around 60% and generally remains between 40% and 60% across all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts around 50%, increases to around 70% by layer 8, and then fluctuates between 60% and 75% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dotted-dashed red line) Starts around 60%, decreases to around 30% by layer 10, and then remains relatively stable between 30% and 40% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Solid light blue line) Starts around 60%, increases to around 90% by layer 12, and then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed orange line) Starts around 60%, decreases to around 40% by layer 5, and then remains relatively stable between 40% and 50% for the remaining layers.
* **Q-Anchored (NQ):** (Dotted-dashed pink line) Starts around 60%, fluctuates significantly, reaching peaks around 90% and valleys around 50%, ending around 90%.
* **A-Anchored (NQ):** (Dotted gray line) Starts around 60%, fluctuates between 40% and 60% across all layers.
**Right Chart: Llama-3.2-3B**
* **Q-Anchored (PopQA):** (Solid blue line) Starts high (around 60% at layer 1), drops sharply to around 5% at layer 4, then fluctuates between 10% and 40% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed brown line) Starts around 60% and generally remains between 40% and 60% across all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts around 60%, increases to around 95% by layer 8, and then fluctuates between 90% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dotted-dashed red line) Starts around 60%, decreases to around 20% by layer 10, and then remains relatively stable between 20% and 30% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Solid light blue line) Starts around 60%, increases to around 90% by layer 8, and then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed orange line) Starts around 60%, decreases to around 20% by layer 5, and then remains relatively stable between 20% and 30% for the remaining layers.
* **Q-Anchored (NQ):** (Dotted-dashed pink line) Starts around 60%, fluctuates significantly, reaching peaks around 90% and valleys around 50%, ending around 90%.
* **A-Anchored (NQ):** (Dotted gray line) Starts around 60%, fluctuates between 40% and 60% across all layers.
### Key Observations
* For both models, Q-Anchored (PopQA) shows a significant drop in accuracy in the initial layers.
* Q-Anchored (TriviaQA) and Q-Anchored (HotpotQA) generally show increasing accuracy as the layer number increases, especially in the Llama-3.2-3B model.
* A-Anchored (TriviaQA) and A-Anchored (HotpotQA) show a decrease in accuracy as the layer number increases.
* The Llama-3.2-3B model generally achieves higher accuracy for Q-Anchored (TriviaQA) and Q-Anchored (HotpotQA) compared to the Llama-3.2-1B model.
* The shaded regions around each line indicate the variance or uncertainty in the accuracy measurements.
### Interpretation
The charts illustrate the performance of two Llama models on different question-answering tasks, highlighting the impact of layer depth and anchoring method on answer accuracy. The Q-Anchored methods for TriviaQA and HotpotQA appear to benefit from deeper layers, particularly in the Llama-3.2-3B model, suggesting that increased model complexity can improve performance on these tasks. Conversely, the A-Anchored methods for TriviaQA and HotpotQA show a decline in accuracy with increasing layer depth, indicating that the answer anchoring strategy may not be as effective in deeper layers. The significant drop in accuracy for Q-Anchored (PopQA) in the initial layers suggests that this task may require different processing strategies or model architectures. The fluctuations in accuracy across layers indicate that the model's performance is not consistently improving with depth and may be sensitive to specific layer configurations.
</details>
<details>
<summary>x61.png Details</summary>
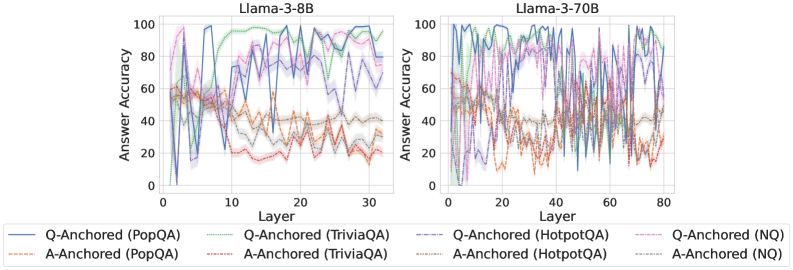
### Visual Description
## Chart: Llama Model Performance Comparison
### Overview
The image presents two line charts comparing the answer accuracy of Llama-3 models (8B and 70B parameters) across different layers. The charts depict the performance of the models on various question-answering datasets, with separate lines for question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches. The x-axis represents the layer number, and the y-axis represents the answer accuracy in percentage.
### Components/Axes
* **Chart Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **X-Axis:**
* Label: Layer
* Left Chart Scale: 0 to 30, with ticks at intervals of 5.
* Right Chart Scale: 0 to 80, with ticks at intervals of 20.
* **Y-Axis:**
* Label: Answer Accuracy
* Scale: 0 to 100, with ticks at intervals of 20.
* **Legend:** Located at the bottom of the image, applies to both charts.
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Orange dash-dot line: A-Anchored (TriviaQA)
* Purple dash-dash line: Q-Anchored (HotpotQA)
* Gray dotted line: A-Anchored (HotpotQA)
* Pink dash-dot-dot line: Q-Anchored (NQ)
* Dark Gray dash-dash-dash line: A-Anchored (NQ)
### Detailed Analysis
#### Llama-3-8B (Left Chart)
* **Q-Anchored (PopQA) (Blue solid line):** Starts around 60% accuracy, drops sharply to near 0% around layer 2, then rises sharply to around 80% by layer 5, and fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 60% accuracy, decreases to around 40% by layer 5, and then fluctuates between 40% and 50% for the remaining layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around 60% accuracy, rises sharply to around 100% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) (Orange dash-dot line):** Starts around 60% accuracy, decreases to around 40% by layer 5, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (HotpotQA) (Purple dash-dash line):** Starts around 60% accuracy, fluctuates between 60% and 90% for the entire range of layers.
* **A-Anchored (HotpotQA) (Gray dotted line):** Starts around 60% accuracy, decreases to around 40% by layer 5, and then fluctuates between 30% and 40% for the remaining layers.
* **Q-Anchored (NQ) (Pink dash-dot-dot line):** Starts around 60% accuracy, fluctuates between 60% and 80% for the entire range of layers.
* **A-Anchored (NQ) (Dark Gray dash-dash-dash line):** Starts around 60% accuracy, decreases to around 40% by layer 5, and then fluctuates between 20% and 40% for the remaining layers.
#### Llama-3-70B (Right Chart)
* **Q-Anchored (PopQA) (Blue solid line):** Starts around 60% accuracy, rises sharply to around 100% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 60% accuracy, decreases to around 20% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around 60% accuracy, rises sharply to around 100% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) (Orange dash-dot line):** Starts around 60% accuracy, decreases to around 20% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (HotpotQA) (Purple dash-dash line):** Starts around 60% accuracy, fluctuates between 60% and 90% for the entire range of layers.
* **A-Anchored (HotpotQA) (Gray dotted line):** Starts around 60% accuracy, decreases to around 40% by layer 10, and then fluctuates between 30% and 40% for the remaining layers.
* **Q-Anchored (NQ) (Pink dash-dot-dot line):** Starts around 60% accuracy, fluctuates between 60% and 80% for the entire range of layers.
* **A-Anchored (NQ) (Dark Gray dash-dash-dash line):** Starts around 60% accuracy, decreases to around 40% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
### Key Observations
* For both models, Q-Anchored approaches generally outperform A-Anchored approaches.
* The TriviaQA dataset shows the highest accuracy for Q-Anchored approaches in both models.
* The 70B model generally achieves higher and more stable accuracy compared to the 8B model, especially for Q-Anchored (PopQA) and Q-Anchored (TriviaQA).
* A-Anchored approaches show relatively low and unstable accuracy across all datasets and both models.
### Interpretation
The data suggests that question-anchoring is a more effective strategy than answer-anchoring for these Llama-3 models on the tested question-answering datasets. The larger 70B model demonstrates improved performance and stability compared to the 8B model, indicating that model size contributes to better accuracy. The consistent high performance on TriviaQA suggests that the models are particularly well-suited for this type of question-answering task. The relatively poor performance of A-Anchored approaches may indicate a weakness in the model's ability to leverage answer-specific information effectively.
</details>
<details>
<summary>x62.png Details</summary>
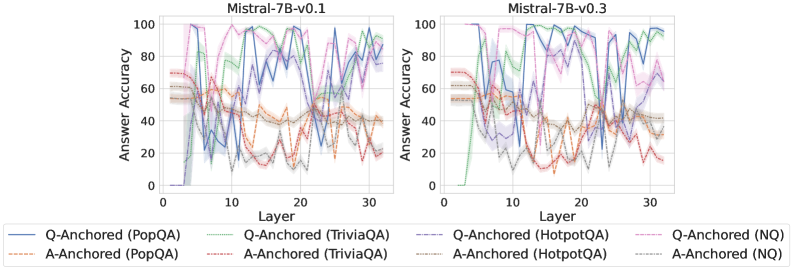
### Visual Description
## Line Chart: Mistral-7B Model Performance Comparison
### Overview
The image presents two line charts comparing the performance of Mistral-7B models (v0.1 and v0.3) across different question-answering tasks. The charts depict the "Answer Accuracy" as a function of "Layer" for various question-answering datasets, categorized by "Q-Anchored" and "A-Anchored" approaches.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:** "Answer Accuracy", ranging from 0 to 100.
* **X-Axis:** "Layer", ranging from 0 to 30.
* **Legend:** Located at the bottom of the image, mapping line styles and colors to specific question-answering tasks and anchoring methods.
* **Q-Anchored:**
* PopQA (Solid Blue)
* TriviaQA (Dotted Green)
* HotpotQA (Dash-Dot Red)
* NQ (Dashed Pink)
* **A-Anchored:**
* PopQA (Dashed Brown)
* TriviaQA (Dashed Gray)
* HotpotQA (Dashed Orange)
* NQ (Dashed Black)
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0% accuracy at layer 0, rises sharply to around 80% by layer 5, fluctuates between 60% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 60% accuracy, gradually decreases to around 40% by layer 10, and then fluctuates between 40% and 60% for the remaining layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0% accuracy at layer 0, rises sharply to around 80% by layer 5, fluctuates between 60% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Gray) Starts around 60% accuracy, gradually decreases to around 40% by layer 10, and then fluctuates between 40% and 60% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot Red) Starts at approximately 0% accuracy at layer 0, rises sharply to around 20% by layer 5, fluctuates between 10% and 40% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed Orange) Starts around 60% accuracy, gradually decreases to around 20% by layer 10, and then fluctuates between 10% and 40% for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Pink) Starts at approximately 0% accuracy at layer 0, rises sharply to around 100% by layer 5, fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ):** (Dashed Black) Starts around 60% accuracy, gradually decreases to around 20% by layer 10, and then fluctuates between 10% and 40% for the remaining layers.
**Right Chart: Mistral-7B-v0.3**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0% accuracy at layer 0, rises sharply to around 80% by layer 5, fluctuates between 60% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 60% accuracy, gradually decreases to around 40% by layer 10, and then fluctuates between 40% and 60% for the remaining layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 0% accuracy at layer 0, rises sharply to around 80% by layer 5, fluctuates between 60% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Gray) Starts around 60% accuracy, gradually decreases to around 40% by layer 10, and then fluctuates between 40% and 60% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot Red) Starts at approximately 0% accuracy at layer 0, rises sharply to around 20% by layer 5, fluctuates between 10% and 40% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed Orange) Starts around 60% accuracy, gradually decreases to around 20% by layer 10, and then fluctuates between 10% and 40% for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Pink) Starts at approximately 0% accuracy at layer 0, rises sharply to around 100% by layer 5, fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ):** (Dashed Black) Starts around 60% accuracy, gradually decreases to around 20% by layer 10, and then fluctuates between 10% and 40% for the remaining layers.
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored methods generally exhibit higher accuracy, especially for PopQA, TriviaQA, and NQ datasets.
* **Dataset Performance:** PopQA, TriviaQA, and NQ datasets show significantly higher accuracy compared to HotpotQA.
* **Layer Dependence:** The accuracy of Q-Anchored methods increases rapidly in the initial layers (0-5) and then fluctuates. A-Anchored methods tend to decrease in accuracy in the initial layers.
* **Model Version Comparison:** The performance between Mistral-7B-v0.1 and Mistral-7B-v0.3 appears very similar across all datasets and anchoring methods.
### Interpretation
The charts suggest that the Mistral-7B models perform better when the question is used as the anchor ("Q-Anchored") compared to using the answer as the anchor ("A-Anchored"). The model also demonstrates varying levels of success depending on the question-answering dataset, with HotpotQA being the most challenging. The rapid increase in accuracy for Q-Anchored methods in the initial layers indicates that these layers are crucial for processing the question and extracting relevant information. The similarity in performance between v0.1 and v0.3 suggests that the changes between these versions did not significantly impact the model's accuracy on these specific tasks.
</details>
Figure 25: Comparisons of answer accuracy between pathways, probing attention activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x63.png Details</summary>
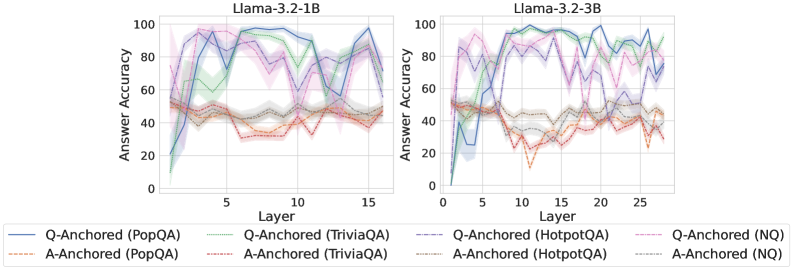
### Visual Description
## Line Chart: Llama-3.2-1B vs Llama-3.2-3B Answer Accuracy
### Overview
The image presents two line charts comparing the answer accuracy of two language models, Llama-3.2-1B and Llama-3.2-3B, across different layers. Each chart displays six data series, representing "Q-Anchored" and "A-Anchored" performance on various question-answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. The x-axis represents the layer number, and the y-axis represents the answer accuracy in percentage. Shaded regions around each line indicate the uncertainty or variance in the data.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3.2-1B
* Right Chart: Llama-3.2-3B
* **X-axis:**
* Label: Layer
* Left Chart: Scale from 0 to 15, with tick marks at 0, 5, 10, and 15.
* Right Chart: Scale from 0 to 25, with tick marks at 0, 5, 10, 15, 20, and 25.
* **Y-axis:**
* Label: Answer Accuracy
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located at the bottom of the charts.
* Q-Anchored (PopQA): Solid blue line
* A-Anchored (PopQA): Dashed brown line
* Q-Anchored (TriviaQA): Dotted green line
* A-Anchored (TriviaQA): Dashed-dotted pink line
* Q-Anchored (HotpotQA): Solid purple line
* A-Anchored (HotpotQA): Dashed red line
* Q-Anchored (NQ): Dashed-dotted pink line
* A-Anchored (NQ): Dotted gray line
### Detailed Analysis
**Left Chart: Llama-3.2-1B**
* **Q-Anchored (PopQA):** (Solid blue line) Starts around 20% accuracy at layer 0, rises sharply to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed brown line) Starts around 50% accuracy and remains relatively stable between 40% and 50% across all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts around 60% accuracy, increases to approximately 90% by layer 5, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed-dotted pink line) Starts around 50% accuracy and remains relatively stable between 40% and 50% across all layers.
* **Q-Anchored (HotpotQA):** (Solid purple line) Starts around 60% accuracy, increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed red line) Starts around 50% accuracy and remains relatively stable between 30% and 50% across all layers.
* **Q-Anchored (NQ):** (Dashed-dotted pink line) Starts around 60% accuracy, increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ):** (Dotted gray line) Starts around 50% accuracy and remains relatively stable between 40% and 50% across all layers.
**Right Chart: Llama-3.2-3B**
* **Q-Anchored (PopQA):** (Solid blue line) Starts around 20% accuracy at layer 0, rises sharply to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed brown line) Starts around 50% accuracy and remains relatively stable between 40% and 50% across all layers.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts around 60% accuracy, increases to approximately 90% by layer 5, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed-dotted pink line) Starts around 50% accuracy and remains relatively stable between 40% and 50% across all layers.
* **Q-Anchored (HotpotQA):** (Solid purple line) Starts around 60% accuracy, increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed red line) Starts around 50% accuracy and remains relatively stable between 30% and 50% across all layers.
* **Q-Anchored (NQ):** (Dashed-dotted pink line) Starts around 60% accuracy, increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ):** (Dotted gray line) Starts around 50% accuracy and remains relatively stable between 40% and 50% across all layers.
### Key Observations
* For both models, "Q-Anchored" performance on PopQA, TriviaQA, HotpotQA, and NQ datasets shows a significant increase in accuracy within the first few layers, reaching high levels of performance (80-100%).
* "A-Anchored" performance on all datasets remains relatively stable and lower (30-50%) across all layers for both models.
* The Llama-3.2-3B model has more layers (25) than the Llama-3.2-1B model (15), but the overall trends in accuracy are similar.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to significantly better answer accuracy compared to anchoring the answer (A-Anchored) for both Llama-3.2-1B and Llama-3.2-3B models across various question-answering datasets. The rapid increase in accuracy for Q-Anchored tasks within the initial layers indicates that the models quickly learn to leverage question-related information for improved performance. The relatively constant and lower accuracy for A-Anchored tasks suggests that the models struggle to effectively utilize answer-related information in the same way. The similarity in trends between the two models, despite the difference in the number of layers, implies that the core learning dynamics are consistent, and the additional layers in Llama-3.2-3B do not drastically alter the overall performance patterns.
</details>
<details>
<summary>x64.png Details</summary>
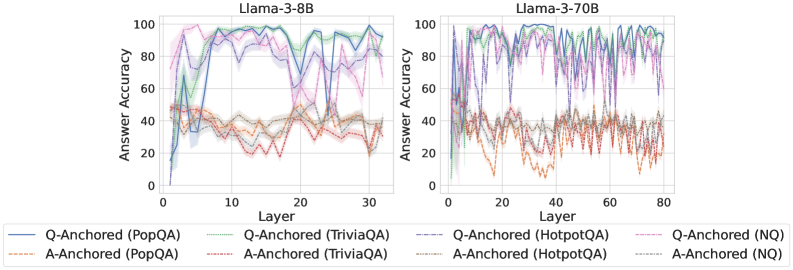
### Visual Description
## Chart: Answer Accuracy vs. Layer for Llama-3 Models
### Overview
The image presents two line charts comparing the answer accuracy of Llama-3-8B and Llama-3-70B models across different layers. The x-axis represents the layer number, and the y-axis represents the answer accuracy. Each chart displays six data series, representing Q-Anchored and A-Anchored approaches for four different question answering datasets: PopQA, TriviaQA, HotpotQA, and NQ.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **X-axis:**
* Label: Layer
* Left Chart: Scale from 0 to 30, with tick marks at intervals of 10.
* Right Chart: Scale from 0 to 80, with tick marks at intervals of 20.
* **Y-axis:**
* Label: Answer Accuracy
* Scale: 0 to 100, with tick marks at intervals of 20.
* **Legend:** Located at the bottom of the image, it identifies the data series by color and line style:
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Brown dotted-dashed line: A-Anchored (TriviaQA)
* Purple solid line: Q-Anchored (HotpotQA)
* Brown solid line: A-Anchored (HotpotQA)
* Pink dashed line: Q-Anchored (NQ)
* Grey dotted line: A-Anchored (NQ)
### Detailed Analysis
**Left Chart: Llama-3-8B**
* **Q-Anchored (PopQA) - Blue solid line:** Starts at approximately 10% accuracy, rapidly increases to around 60% by layer 5, and then rises to approximately 90% by layer 10. It fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Brown dashed line:** Starts at approximately 40% accuracy and remains relatively stable between 30% and 50% across all layers.
* **Q-Anchored (TriviaQA) - Green dotted line:** Starts at approximately 50% accuracy, increases to around 80% by layer 10, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (TriviaQA) - Brown dotted-dashed line:** Starts at approximately 40% accuracy and remains relatively stable between 30% and 50% across all layers.
* **Q-Anchored (HotpotQA) - Purple solid line:** Starts at approximately 50% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (HotpotQA) - Brown solid line:** Starts at approximately 40% accuracy and remains relatively stable between 30% and 50% across all layers.
* **Q-Anchored (NQ) - Pink dashed line:** Starts at approximately 50% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ) - Grey dotted line:** Starts at approximately 40% accuracy and remains relatively stable between 30% and 50% across all layers.
**Right Chart: Llama-3-70B**
* **Q-Anchored (PopQA) - Blue solid line:** Starts at approximately 50% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Brown dashed line:** Starts at approximately 40% accuracy and remains relatively stable between 20% and 50% across all layers.
* **Q-Anchored (TriviaQA) - Green dotted line:** Starts at approximately 60% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) - Brown dotted-dashed line:** Starts at approximately 40% accuracy and remains relatively stable between 20% and 50% across all layers.
* **Q-Anchored (HotpotQA) - Purple solid line:** Starts at approximately 60% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (HotpotQA) - Brown solid line:** Starts at approximately 40% accuracy and remains relatively stable between 20% and 50% across all layers.
* **Q-Anchored (NQ) - Pink dashed line:** Starts at approximately 60% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ) - Grey dotted line:** Starts at approximately 40% accuracy and remains relatively stable between 20% and 50% across all layers.
### Key Observations
* For both models, the Q-Anchored approach consistently outperforms the A-Anchored approach across all datasets.
* The Q-Anchored lines (blue, green, purple, pink) show a rapid increase in accuracy in the initial layers, followed by fluctuations at a high accuracy level.
* The A-Anchored lines (brown dashed, brown dotted-dashed, brown solid, grey dotted) remain relatively stable at a lower accuracy level throughout all layers.
* The Llama-3-70B model generally shows slightly higher initial accuracy for the Q-Anchored approaches compared to the Llama-3-8B model.
* The fluctuations in accuracy for the Q-Anchored approaches appear more pronounced in the Llama-3-70B model.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) is a more effective strategy for improving answer accuracy in Llama-3 models compared to anchoring the answer (A-Anchored). The rapid increase in accuracy for the Q-Anchored approaches in the initial layers indicates that the model quickly learns to leverage the question information for better performance. The relatively stable and lower accuracy of the A-Anchored approaches suggests that anchoring the answer alone is not sufficient for achieving high accuracy.
The Llama-3-70B model, being larger, generally starts with a slightly higher accuracy for the Q-Anchored approaches, indicating that it has a better initial understanding of the question answering task. However, the more pronounced fluctuations in accuracy for the Llama-3-70B model could suggest that it is more sensitive to the specific characteristics of each layer or that it is exploring a wider range of potential solutions.
</details>
<details>
<summary>x65.png Details</summary>
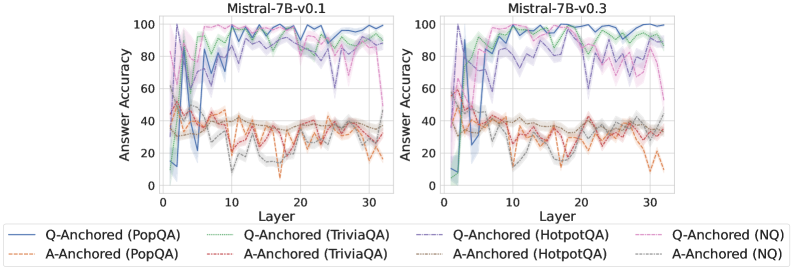
### Visual Description
## Chart Type: Line Graphs Comparing Model Performance
### Overview
The image presents two line graphs side-by-side, comparing the performance of two versions of the Mistral-7B model (v0.1 and v0.3) on various question-answering tasks. The graphs depict the "Answer Accuracy" as a function of "Layer" for different question-answering datasets and anchoring methods (Q-Anchored and A-Anchored).
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **Y-Axis:** "Answer Accuracy" ranging from 0 to 100. Increments of 20.
* **X-Axis:** "Layer" ranging from 0 to 30. Increments of 10.
* **Legend:** Located at the bottom of the image, describing the lines:
* Blue: "Q-Anchored (PopQA)"
* Brown Dashed: "A-Anchored (PopQA)"
* Green: "Q-Anchored (TriviaQA)"
* Orange Dashed: "A-Anchored (TriviaQA)"
* Red: "Q-Anchored (HotpotQA)"
* Gray Dashed: "A-Anchored (HotpotQA)"
* Pink Dashed-dotted: "Q-Anchored (NQ)"
* Black Dotted: "A-Anchored (NQ)"
### Detailed Analysis
**Left Graph (Mistral-7B-v0.1):**
* **Q-Anchored (PopQA) (Blue):** Starts around 10% accuracy at layer 0, rapidly increases to approximately 80% by layer 5, and then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (PopQA) (Brown Dashed):** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% across all layers.
* **Q-Anchored (TriviaQA) (Green):** Starts around 50% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 85% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) (Orange Dashed):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 45% across all layers.
* **Q-Anchored (HotpotQA) (Red):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 50% across all layers.
* **A-Anchored (HotpotQA) (Gray Dashed):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 45% across all layers.
* **Q-Anchored (NQ) (Pink Dashed-dotted):** Starts around 50% accuracy at layer 0, rapidly increases to approximately 80% by layer 5, and then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (NQ) (Black Dotted):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 45% across all layers.
**Right Graph (Mistral-7B-v0.3):**
* **Q-Anchored (PopQA) (Blue):** Starts around 10% accuracy at layer 0, rapidly increases to approximately 80% by layer 5, and then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (PopQA) (Brown Dashed):** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% across all layers.
* **Q-Anchored (TriviaQA) (Green):** Starts around 50% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 85% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) (Orange Dashed):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 45% across all layers.
* **Q-Anchored (HotpotQA) (Red):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 50% across all layers.
* **A-Anchored (HotpotQA) (Gray Dashed):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 45% across all layers.
* **Q-Anchored (NQ) (Pink Dashed-dotted):** Starts around 50% accuracy at layer 0, rapidly increases to approximately 80% by layer 5, and then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (NQ) (Black Dotted):** Starts around 40% accuracy at layer 0, fluctuates between 20% and 45% across all layers.
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored methods (PopQA, TriviaQA, NQ) generally achieve significantly higher answer accuracy compared to A-Anchored methods across both model versions.
* **Dataset Performance:** PopQA, TriviaQA, and NQ datasets show higher accuracy with Q-Anchoring, while HotpotQA consistently shows lower accuracy for both anchoring methods.
* **Model Version Comparison:** The performance between Mistral-7B-v0.1 and Mistral-7B-v0.3 appears very similar across all datasets and anchoring methods.
* **Layer Dependence:** The accuracy of Q-Anchored methods tends to increase rapidly in the initial layers (0-5) and then stabilizes, suggesting that these layers are crucial for learning.
### Interpretation
The data suggests that Q-Anchoring is a more effective method for question-answering tasks with the Mistral-7B model, particularly for the PopQA, TriviaQA, and NQ datasets. The lower performance of HotpotQA indicates that this dataset may pose a greater challenge for the model. The similarity in performance between the two model versions (v0.1 and v0.3) suggests that the changes between these versions did not significantly impact the answer accuracy on these specific tasks. The rapid increase in accuracy in the initial layers highlights the importance of these layers in the model's learning process. The shaded regions around the lines likely represent the standard deviation or confidence intervals, indicating the variability in performance across different runs or samples.
</details>
Figure 26: Comparisons of answer accuracy between pathways, probing attention activations of the last exact answer token.
<details>
<summary>x66.png Details</summary>
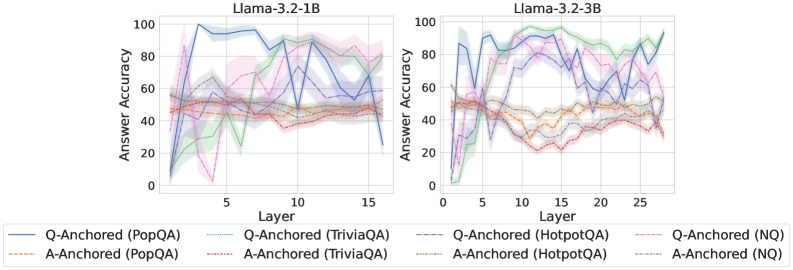
### Visual Description
## Line Graphs: Llama Model Performance on Question Answering
### Overview
The image presents two line graphs comparing the performance of Llama models (Llama-3.2-1B and Llama-3.2-3B) on various question-answering tasks. The graphs depict the "Answer Accuracy" as a function of "Layer" for different question-answering datasets and anchoring methods (Q-Anchored and A-Anchored).
### Components/Axes
* **Titles:**
* Left Graph: "Llama-3.2-1B"
* Right Graph: "Llama-3.2-3B"
* **Y-axis (Answer Accuracy):**
* Label: "Answer Accuracy"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-axis (Layer):**
* Label: "Layer"
* Left Graph Scale: 0 to 15, with tick marks at 0, 5, 10, and 15.
* Right Graph Scale: 0 to 25, with tick marks at 0, 5, 10, 15, 20, and 25.
* **Legend (bottom):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Solid Green Line
* A-Anchored (TriviaQA): Dashed Red Line
* Q-Anchored (HotpotQA): Solid Gray Line
* A-Anchored (HotpotQA): Dashed Orange Line
* Q-Anchored (NQ): Dashed-dotted Pink Line
* A-Anchored (NQ): Dotted Black Line
### Detailed Analysis
**Left Graph (Llama-3.2-1B):**
* **Q-Anchored (PopQA) - Solid Blue:** Starts at approximately 5% accuracy at layer 1, rises sharply to around 95% by layer 4, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown:** Remains relatively stable between 45% and 55% across all layers.
* **Q-Anchored (TriviaQA) - Solid Green:** Starts near 0% at layer 1, increases to approximately 60% by layer 7, and then fluctuates between 40% and 70% for the remaining layers.
* **A-Anchored (TriviaQA) - Dashed Red:** Starts around 50% at layer 1, dips to 20% at layer 4, and then fluctuates between 40% and 50% for the remaining layers.
* **Q-Anchored (HotpotQA) - Solid Gray:** Starts around 55% at layer 1, fluctuates between 50% and 70% across all layers.
* **A-Anchored (HotpotQA) - Dashed Orange:** Starts around 50% at layer 1, fluctuates between 40% and 50% across all layers.
* **Q-Anchored (NQ) - Dashed-dotted Pink:** Starts near 0% at layer 1, increases to approximately 70% by layer 7, and then fluctuates between 20% and 70% for the remaining layers.
* **A-Anchored (NQ) - Dotted Black:** Remains relatively stable between 50% and 60% across all layers.
**Right Graph (Llama-3.2-3B):**
* **Q-Anchored (PopQA) - Solid Blue:** Starts at approximately 5% accuracy at layer 1, rises sharply to around 95% by layer 4, and then fluctuates between 60% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown:** Starts around 50% at layer 1, dips to 20% at layer 14, and then fluctuates between 30% and 50% for the remaining layers.
* **Q-Anchored (TriviaQA) - Solid Green:** Starts near 0% at layer 1, increases to approximately 90% by layer 26, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (TriviaQA) - Dashed Red:** Starts around 50% at layer 1, dips to 20% at layer 14, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (HotpotQA) - Solid Gray:** Starts around 55% at layer 1, fluctuates between 50% and 70% across all layers.
* **A-Anchored (HotpotQA) - Dashed Orange:** Starts around 50% at layer 1, dips to 20% at layer 14, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (NQ) - Dashed-dotted Pink:** Starts near 0% at layer 1, increases to approximately 90% by layer 14, and then fluctuates between 60% and 90% for the remaining layers.
* **A-Anchored (NQ) - Dotted Black:** Remains relatively stable between 50% and 60% across all layers.
### Key Observations
* **Q-Anchored (PopQA)** shows a rapid increase in accuracy in the initial layers for both models.
* **A-Anchored (PopQA)**, **A-Anchored (TriviaQA)**, and **A-Anchored (HotpotQA)** generally exhibit lower and more stable accuracy compared to their Q-Anchored counterparts.
* The 3B model has more layers (25) than the 1B model (15).
* The shaded regions around each line indicate the variance or uncertainty in the accuracy measurements.
### Interpretation
The graphs illustrate the performance of Llama models on different question-answering tasks, highlighting the impact of anchoring methods (Q-Anchored vs. A-Anchored) and the specific dataset used (PopQA, TriviaQA, HotpotQA, NQ).
The Q-Anchored (PopQA) results suggest that the model quickly learns to answer questions from the PopQA dataset, achieving high accuracy within the first few layers. The A-Anchored methods generally result in lower accuracy, indicating that anchoring on the answer might not be as effective as anchoring on the question for these tasks.
The difference in the number of layers between the Llama-3.2-1B and Llama-3.2-3B models (15 vs. 25) could contribute to the observed performance variations, especially for tasks like TriviaQA and NQ, where the 3B model appears to achieve higher accuracy in later layers.
The shaded regions provide insight into the stability and reliability of the accuracy measurements. Wider shaded regions indicate greater variability in performance across different runs or samples.
</details>
<details>
<summary>x67.png Details</summary>
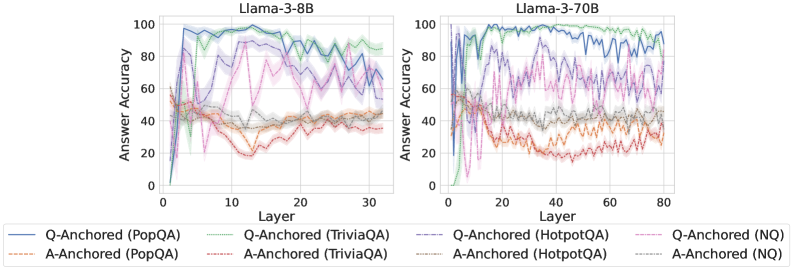
### Visual Description
## Line Graphs: Llama-3-8B and Llama-3-70B Answer Accuracy vs. Layer
### Overview
The image presents two line graphs comparing the answer accuracy of Llama-3-8B and Llama-3-70B models across different layers for various question-answering datasets. The x-axis represents the layer number, and the y-axis represents the answer accuracy. Each graph displays six data series, representing Q-Anchored and A-Anchored performance on PopQA, TriviaQA, HotpotQA, and NQ datasets.
### Components/Axes
* **Titles:**
* Left Graph: "Llama-3-8B"
* Right Graph: "Llama-3-70B"
* **X-axis:**
* Label: "Layer"
* Left Graph: Scale from 0 to 30, with tick marks at intervals of 10.
* Right Graph: Scale from 0 to 80, with tick marks at intervals of 20.
* **Y-axis:**
* Label: "Answer Accuracy"
* Scale: 0 to 100, with tick marks at intervals of 20.
* **Legend:** Located at the bottom of the image.
* **Q-Anchored (PopQA):** Solid Blue Line
* **A-Anchored (PopQA):** Dashed Brown Line
* **Q-Anchored (TriviaQA):** Dotted Green Line
* **A-Anchored (TriviaQA):** Dashed Orange Line
* **Q-Anchored (HotpotQA):** Dash-Dot Purple Line
* **A-Anchored (HotpotQA):** Dotted Red Line
* **Q-Anchored (NQ):** Dash-Dot-Dot Light Purple Line
* **A-Anchored (NQ):** Dotted Gray Line
### Detailed Analysis
**Left Graph: Llama-3-8B**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0% accuracy, rapidly increases to around 90-100% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 50% accuracy, decreases to around 40% by layer 5, and then remains relatively stable between 40% and 50% for the rest of the layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 50% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Orange Line) Starts around 50% accuracy, decreases to around 30% by layer 10, and then remains relatively stable between 20% and 40% for the rest of the layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple Line) Starts around 60% accuracy, increases to around 80% by layer 10, and then fluctuates between 60% and 90% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Red Line) Starts around 50% accuracy, decreases to around 30% by layer 10, and then remains relatively stable between 20% and 40% for the rest of the layers.
* **Q-Anchored (NQ):** (Dash-Dot-Dot Light Purple Line) Starts around 60% accuracy, increases to around 80% by layer 10, and then fluctuates between 60% and 90% for the remaining layers.
* **A-Anchored (NQ):** (Dotted Gray Line) Starts around 50% accuracy, decreases to around 40% by layer 5, and then remains relatively stable between 40% and 50% for the rest of the layers.
**Right Graph: Llama-3-70B**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 60% accuracy, rapidly increases to around 90-100% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 50% accuracy, decreases to around 40% by layer 20, and then remains relatively stable between 40% and 50% for the rest of the layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 60% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Orange Line) Starts around 40% accuracy, decreases to around 20% by layer 40, and then remains relatively stable between 20% and 30% for the rest of the layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple Line) Starts around 60% accuracy, increases to around 80% by layer 10, and then fluctuates between 60% and 90% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Red Line) Starts around 40% accuracy, decreases to around 20% by layer 40, and then remains relatively stable between 20% and 30% for the rest of the layers.
* **Q-Anchored (NQ):** (Dash-Dot-Dot Light Purple Line) Starts around 60% accuracy, increases to around 80% by layer 10, and then fluctuates between 60% and 90% for the remaining layers.
* **A-Anchored (NQ):** (Dotted Gray Line) Starts around 50% accuracy, decreases to around 40% by layer 20, and then remains relatively stable between 40% and 50% for the rest of the layers.
### Key Observations
* For both models, Q-Anchored performance on PopQA and TriviaQA datasets shows a rapid increase in accuracy within the first 10 layers, reaching near-perfect performance.
* A-Anchored performance on all datasets is significantly lower than Q-Anchored performance, with accuracy generally remaining below 50%.
* The Llama-3-70B model has a longer x-axis (more layers) than the Llama-3-8B model, but the trends are similar.
* The shaded regions around each line indicate the variance or uncertainty in the data.
### Interpretation
The data suggests that Q-Anchoring is a more effective strategy than A-Anchoring for these question-answering tasks, as evidenced by the significantly higher accuracy achieved by Q-Anchored models. The rapid increase in accuracy within the first few layers for Q-Anchored models indicates that these models quickly learn to extract relevant information from the questions. The lower accuracy of A-Anchored models suggests that they may struggle to effectively utilize the answer information. The similarity in trends between the Llama-3-8B and Llama-3-70B models suggests that the overall architecture and training process are consistent, but the larger model (70B) may have a slightly better ability to maintain accuracy over a larger number of layers. The variance in the data, as indicated by the shaded regions, highlights the inherent uncertainty in these models' performance.
</details>
<details>
<summary>x68.png Details</summary>
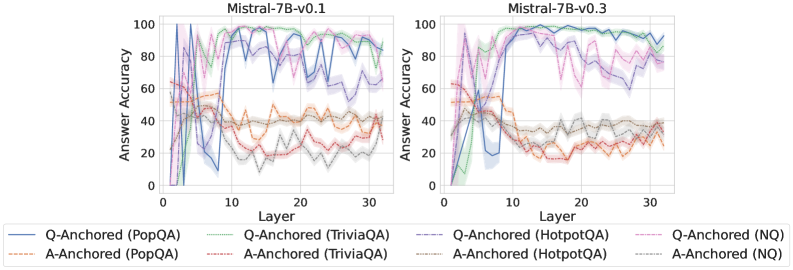
### Visual Description
## Chart: Mistral-7B Model Performance Comparison
### Overview
The image presents two line charts comparing the answer accuracy of Mistral-7B models (v0.1 and v0.3) across different layers and question-answering datasets. The charts display the performance of question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches on PopQA, TriviaQA, HotpotQA, and NQ datasets. The x-axis represents the layer number, and the y-axis represents the answer accuracy.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:**
* Label: "Answer Accuracy"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: "Layer"
* Scale: 0 to 30, with tick marks every 10 units.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Red Line
* Q-Anchored (HotpotQA): Dash-Dot-Dotted Purple Line
* A-Anchored (HotpotQA): Dotted Orange Line
* Q-Anchored (NQ): Dashed Pink Line
* A-Anchored (NQ): Dash-Dotted Gray Line
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0% accuracy, rapidly increases to around 90-100% by layer 10, and then fluctuates between 70% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 50% accuracy, decreases to around 30-40% by layer 10, and then fluctuates between 30% and 50% for the remaining layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 60% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dash-Dotted Red Line) Starts around 50% accuracy, decreases to around 20% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Purple Line) Starts around 60% accuracy, increases to around 90% by layer 10, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Orange Line) Starts around 50% accuracy, decreases to around 30% by layer 10, and then fluctuates between 30% and 40% for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Pink Line) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 70-80% after layer 10.
* **A-Anchored (NQ):** (Dash-Dotted Gray Line) Starts around 40% accuracy, decreases to around 20% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
**Right Chart: Mistral-7B-v0.3**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0% accuracy, rapidly increases to around 90-100% by layer 10, and then fluctuates between 90% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 50% accuracy, decreases to around 30% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 20% accuracy, increases to around 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dash-Dotted Red Line) Starts around 50% accuracy, decreases to around 20% by layer 10, and then fluctuates between 20% and 30% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Purple Line) Starts around 60% accuracy, increases to around 90% by layer 10, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Orange Line) Starts around 50% accuracy, decreases to around 20% by layer 10, and then fluctuates between 20% and 30% for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Pink Line) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 70-80% after layer 10.
* **A-Anchored (NQ):** (Dash-Dotted Gray Line) Starts around 40% accuracy, decreases to around 20% by layer 10, and then fluctuates between 20% and 30% for the remaining layers.
### Key Observations
* For both model versions, Q-Anchored approaches generally outperform A-Anchored approaches across all datasets.
* PopQA, TriviaQA, HotpotQA datasets show a significant increase in accuracy for Q-Anchored approaches within the first 10 layers.
* A-Anchored approaches generally show a decrease in accuracy within the first 10 layers and then stabilize.
* The shaded regions around each line indicate the variance or uncertainty in the accuracy measurements.
* The performance of Q-Anchored (PopQA) and Q-Anchored (TriviaQA) is very high, reaching nearly 100% accuracy in later layers for both model versions.
### Interpretation
The data suggests that question-anchoring is a more effective strategy than answer-anchoring for these models and datasets. The rapid increase in accuracy for Q-Anchored approaches in the early layers indicates that the model quickly learns to extract relevant information from the questions. The relatively poor performance of A-Anchored approaches suggests that the model struggles to effectively utilize information from the answers alone. The high accuracy achieved by Q-Anchored (PopQA) and Q-Anchored (TriviaQA) indicates that these datasets may be relatively easier for the model to solve compared to HotpotQA and NQ. The comparison between Mistral-7B-v0.1 and Mistral-7B-v0.3 shows that the later version generally maintains or slightly improves the performance across all datasets and anchoring methods.
</details>
Figure 27: Comparisons of answer accuracy between pathways, probing mlp activations of the final token.
<details>
<summary>x69.png Details</summary>
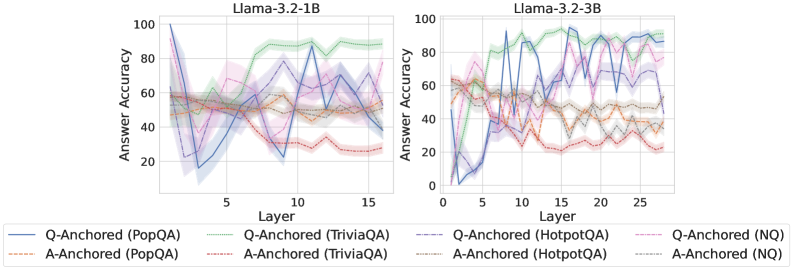
### Visual Description
## Chart: Answer Accuracy vs. Layer for Llama Models
### Overview
The image contains two line charts comparing the answer accuracy of Llama models (Llama-3.2-1B and Llama-3.2-3B) across different layers for various question-answering datasets. The charts show how accuracy changes as the model processes information through its layers. Each chart plots the answer accuracy (y-axis) against the layer number (x-axis) for six different configurations: Q-Anchored and A-Anchored for PopQA, TriviaQA, HotpotQA, and NQ datasets. Shaded regions around each line represent the uncertainty or variance in the accuracy.
### Components/Axes
**Left Chart (Llama-3.2-1B):**
* **Title:** Llama-3.2-1B
* **X-axis:** Layer, with ticks at 0, 5, 10, and 15.
* **Y-axis:** Answer Accuracy, ranging from 0 to 100, with ticks at 0, 20, 40, 60, 80, and 100.
**Right Chart (Llama-3.2-3B):**
* **Title:** Llama-3.2-3B
* **X-axis:** Layer, with ticks at 0, 5, 10, 15, 20, and 25.
* **Y-axis:** Answer Accuracy, ranging from 0 to 100, with ticks at 0, 20, 40, 60, 80, and 100.
**Legend (Located below both charts):**
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Solid green line
* **A-Anchored (TriviaQA):** Dashed green line
* **Q-Anchored (HotpotQA):** Solid purple line
* **A-Anchored (HotpotQA):** Dashed purple line
* **Q-Anchored (NQ):** Dashed pink line
* **A-Anchored (NQ):** Dotted black line
### Detailed Analysis
**Llama-3.2-1B:**
* **Q-Anchored (PopQA):** Starts at approximately 100% accuracy at layer 0, drops sharply to around 20% by layer 5, then gradually increases to around 60% by layer 15.
* **A-Anchored (PopQA):** Relatively stable, fluctuating between 40% and 60% accuracy across all layers.
* **Q-Anchored (TriviaQA):** Starts around 50% accuracy, increases to approximately 90% by layer 10, and then slightly decreases to around 85% by layer 15.
* **A-Anchored (TriviaQA):** Relatively stable, fluctuating between 50% and 60% accuracy across all layers.
* **Q-Anchored (HotpotQA):** Starts around 60% accuracy, drops to approximately 30% by layer 5, and then increases to around 40% by layer 15.
* **A-Anchored (HotpotQA):** Relatively stable, fluctuating between 40% and 50% accuracy across all layers.
* **Q-Anchored (NQ):** Starts around 60% accuracy, drops to approximately 30% by layer 5, and then increases to around 30% by layer 15.
* **A-Anchored (NQ):** Relatively stable, fluctuating between 50% and 60% accuracy across all layers.
**Llama-3.2-3B:**
* **Q-Anchored (PopQA):** Starts at approximately 0% accuracy at layer 0, increases sharply to around 80% by layer 5, and then fluctuates between 70% and 90% accuracy across the remaining layers.
* **A-Anchored (PopQA):** Relatively stable, fluctuating between 40% and 60% accuracy across all layers.
* **Q-Anchored (TriviaQA):** Starts around 60% accuracy, increases to approximately 95% by layer 10, and then fluctuates between 80% and 95% by layer 25.
* **A-Anchored (TriviaQA):** Relatively stable, fluctuating between 50% and 60% accuracy across all layers.
* **Q-Anchored (HotpotQA):** Starts around 60% accuracy, drops to approximately 20% by layer 5, and then increases to around 40% by layer 25.
* **A-Anchored (HotpotQA):** Relatively stable, fluctuating between 40% and 50% accuracy across all layers.
* **Q-Anchored (NQ):** Starts around 60% accuracy, drops to approximately 20% by layer 5, and then increases to around 30% by layer 25.
* **A-Anchored (NQ):** Relatively stable, fluctuating between 50% and 60% accuracy across all layers.
### Key Observations
* **Initial Drop in Q-Anchored (PopQA) for Llama-3.2-1B:** The sharp decline in accuracy for Q-Anchored (PopQA) in the initial layers of Llama-3.2-1B is a notable anomaly.
* **Higher Accuracy for TriviaQA:** Both models show relatively high accuracy for TriviaQA, especially with Q-Anchoring.
* **Stable A-Anchored Performance:** A-Anchored configurations generally exhibit more stable performance across layers compared to Q-Anchored configurations.
* **Layer Impact:** The impact of layer depth on accuracy varies significantly depending on the dataset and anchoring method.
* **Model Size Impact:** The 3B model generally achieves higher accuracy and stability compared to the 1B model, especially for Q-Anchored (PopQA).
### Interpretation
The charts illustrate the performance of Llama models on different question-answering tasks, highlighting the impact of model size, layer depth, and anchoring method on answer accuracy. The initial drop in Q-Anchored (PopQA) for Llama-3.2-1B suggests that the model may initially struggle with this specific task before learning to improve accuracy in later layers. The higher accuracy for TriviaQA indicates that the models are better suited for this type of question-answering. The stable performance of A-Anchored configurations suggests that anchoring the answer provides more consistent results across layers. The improved accuracy and stability of the 3B model compared to the 1B model demonstrate the benefits of increasing model size. Overall, the data suggests that the choice of dataset, anchoring method, and model size can significantly impact the performance of Llama models on question-answering tasks.
</details>
<details>
<summary>x70.png Details</summary>
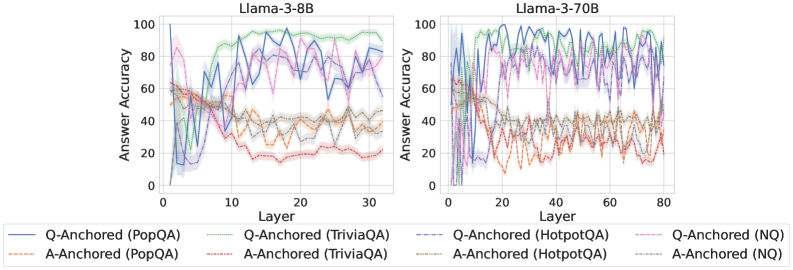
### Visual Description
## Chart: Answer Accuracy vs. Layer for Llama-3 Models
### Overview
The image presents two line charts comparing the answer accuracy of Llama-3-8B and Llama-3-70B models across different layers. The x-axis represents the layer number, and the y-axis represents the answer accuracy. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored either by question (Q-Anchored) or answer (A-Anchored).
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **X-axis:**
* Label: Layer
* Left Chart: Scale from 0 to 30, with ticks at 0, 10, 20, and 30.
* Right Chart: Scale from 0 to 80, with ticks at 0, 20, 40, 60, and 80.
* **Y-axis:**
* Label: Answer Accuracy
* Scale from 0 to 100, with ticks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Red Line
* Q-Anchored (HotpotQA): Dash-Dot-Dotted Purple Line
* A-Anchored (HotpotQA): Dotted Orange Line
* Q-Anchored (NQ): Dashed Purple Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Llama-3-8B (Left Chart):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0% accuracy at layer 0, rises sharply to approximately 80% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 40% by layer 5, and then fluctuates around 40% for the remaining layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 60% accuracy at layer 0, rises to approximately 90% by layer 10, and then fluctuates between 80% and 90% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dash-Dotted Red Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 20% by layer 15, and then fluctuates around 20% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Purple Line) Starts at approximately 60% accuracy at layer 0, rises to approximately 80% by layer 10, and then fluctuates between 70% and 80% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Orange Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 30% by layer 10, and then fluctuates around 30% for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Purple Line) Starts at approximately 60% accuracy at layer 0, rises to approximately 80% by layer 10, and then fluctuates between 70% and 80% for the remaining layers.
* **A-Anchored (NQ):** (Dotted Gray Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 40% by layer 10, and then fluctuates around 40% for the remaining layers.
**Llama-3-70B (Right Chart):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts at approximately 0% accuracy at layer 0, rises sharply to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 40% by layer 10, and then fluctuates around 40% for the remaining layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts at approximately 60% accuracy at layer 0, rises to approximately 90% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dash-Dotted Red Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 20% by layer 20, and then fluctuates around 20% for the remaining layers.
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Purple Line) Starts at approximately 60% accuracy at layer 0, rises to approximately 80% by layer 10, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Orange Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 30% by layer 10, and then fluctuates around 30% for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Purple Line) Starts at approximately 60% accuracy at layer 0, rises to approximately 80% by layer 10, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (NQ):** (Dotted Gray Line) Starts at approximately 60% accuracy at layer 0, decreases to approximately 40% by layer 10, and then fluctuates around 40% for the remaining layers.
### Key Observations
* For both models, Q-Anchored datasets (PopQA, TriviaQA) generally achieve higher answer accuracy than A-Anchored datasets.
* The Q-Anchored (PopQA) dataset shows a rapid increase in accuracy in the initial layers for both models.
* The A-Anchored datasets (TriviaQA, HotpotQA) show a decrease in accuracy in the initial layers for both models.
* The Llama-3-70B model has a longer x-axis (more layers) than the Llama-3-8B model, but the trends are similar.
* The shaded regions around each line represent the uncertainty or variance in the answer accuracy.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to better performance than anchoring the answer (A-Anchored) for these Llama-3 models. The rapid increase in accuracy for Q-Anchored (PopQA) in the initial layers indicates that the model quickly learns to answer these types of questions. The decrease in accuracy for A-Anchored datasets suggests that the model struggles to generate accurate answers when conditioned on the answer itself. The Llama-3-70B model, with its increased number of layers, exhibits similar trends to the Llama-3-8B model, suggesting that the core learning dynamics are consistent across different model sizes. The uncertainty regions highlight the variability in the model's performance, which could be due to factors such as the specific questions being asked or the training data distribution.
</details>
<details>
<summary>x71.png Details</summary>
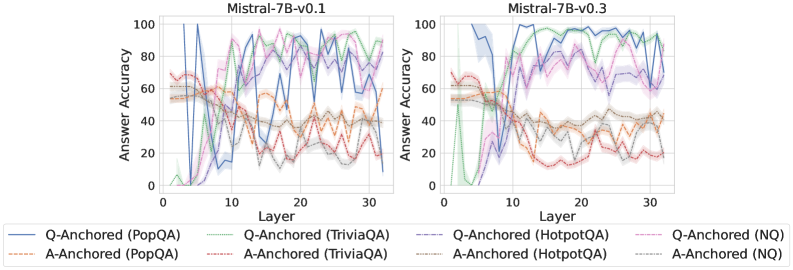
### Visual Description
## Chart Type: Line Graphs Comparing Model Performance
### Overview
The image contains two line graphs comparing the performance of two versions of the Mistral-7B model (v0.1 and v0.3) on various question-answering tasks. The graphs plot "Answer Accuracy" against "Layer" for different question-answering datasets, distinguishing between question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches.
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **Y-axis (Answer Accuracy):**
* Label: "Answer Accuracy"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-axis (Layer):**
* Label: "Layer"
* Scale: 0 to 30, with tick marks at intervals of 10.
* **Legend (bottom of the image):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dot Orange Line
* Q-Anchored (HotpotQA): Dash-Dot-Dot Red Line
* A-Anchored (HotpotQA): Dotted-Dashed-Dashed Brown Line
* Q-Anchored (NQ): Dashed Purple Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Left Graph (Mistral-7B-v0.1):**
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts near 0% accuracy, rapidly increases to approximately 80% by layer 10, and then fluctuates between 70% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts around 60% accuracy, decreases to approximately 30% by layer 10, and then fluctuates between 30% and 40% for the remaining layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts near 60% accuracy, decreases to approximately 40% by layer 10, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (TriviaQA) - Dash-Dot Orange Line:** Starts around 60% accuracy, decreases to approximately 30% by layer 10, and then fluctuates between 30% and 40% for the remaining layers.
* **Q-Anchored (HotpotQA) - Dash-Dot-Dot Red Line:** Starts around 70% accuracy, decreases to approximately 20% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
* **A-Anchored (HotpotQA) - Dotted-Dashed-Dashed Brown Line:** Starts around 60% accuracy, decreases to approximately 40% by layer 10, and then fluctuates between 40% and 50% for the remaining layers.
* **Q-Anchored (NQ) - Dashed Purple Line:** Starts near 60% accuracy, increases to approximately 80% by layer 10, and then fluctuates between 70% and 100% for the remaining layers.
* **A-Anchored (NQ) - Dotted Gray Line:** Starts around 60% accuracy, decreases to approximately 40% by layer 10, and then fluctuates between 40% and 50% for the remaining layers.
**Right Graph (Mistral-7B-v0.3):**
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts near 0% accuracy, rapidly increases to approximately 80% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts around 60% accuracy, decreases to approximately 30% by layer 10, and then fluctuates between 30% and 40% for the remaining layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts near 0% accuracy, increases to approximately 80% by layer 10, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) - Dash-Dot Orange Line:** Starts around 60% accuracy, decreases to approximately 20% by layer 10, and then fluctuates between 20% and 40% for the remaining layers.
* **Q-Anchored (HotpotQA) - Dash-Dot-Dot Red Line:** Starts around 60% accuracy, decreases to approximately 10% by layer 10, and then fluctuates between 10% and 30% for the remaining layers.
* **A-Anchored (HotpotQA) - Dotted-Dashed-Dashed Brown Line:** Starts around 60% accuracy, decreases to approximately 30% by layer 10, and then fluctuates between 30% and 40% for the remaining layers.
* **Q-Anchored (NQ) - Dashed Purple Line:** Starts near 60% accuracy, increases to approximately 80% by layer 10, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (NQ) - Dotted Gray Line:** Starts around 60% accuracy, decreases to approximately 40% by layer 10, and then fluctuates between 40% and 50% for the remaining layers.
### Key Observations
* For both model versions, Q-Anchored approaches generally achieve higher accuracy than A-Anchored approaches after layer 10.
* The accuracy of A-Anchored approaches tends to decrease in the initial layers before stabilizing.
* The Q-Anchored (PopQA) and Q-Anchored (TriviaQA) datasets show a significant increase in accuracy after layer 5 for Mistral-7B-v0.3.
* The performance on HotpotQA is generally lower compared to other datasets for both Q-Anchored and A-Anchored approaches.
* The shaded regions around each line indicate the uncertainty or variance in the accuracy measurements.
### Interpretation
The graphs suggest that the Mistral-7B models learn to answer questions more effectively as they process information through deeper layers. The difference in performance between Q-Anchored and A-Anchored approaches indicates that the way the question and answer are presented to the model significantly impacts its ability to provide accurate answers. The lower performance on HotpotQA suggests that this dataset, which requires more complex reasoning, is more challenging for the models. The improvement in Q-Anchored (PopQA) and Q-Anchored (TriviaQA) from v0.1 to v0.3 indicates that the newer version of the model has improved its ability to handle these specific question-answering tasks. The uncertainty regions highlight the variability in the model's performance, which could be due to factors such as the specific questions being asked or the training data used.
</details>
Figure 28: Comparisons of answer accuracy between pathways, probing mlp activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x72.png Details</summary>
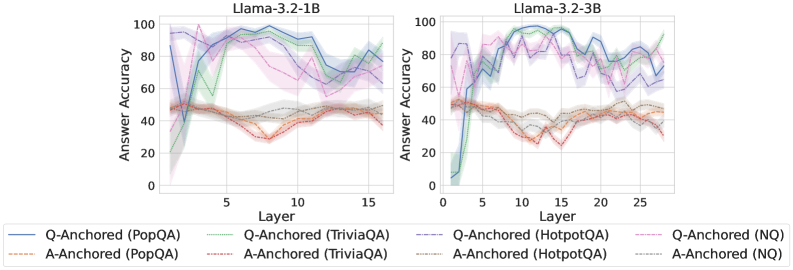
### Visual Description
## Line Graphs: Llama Model Answer Accuracy vs. Layer
### Overview
The image presents two line graphs comparing the answer accuracy of Llama models (3.2-1B and 3.2-3B) across different layers for various question-answering datasets. Each graph plots the answer accuracy (y-axis) against the layer number (x-axis) for both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches on PopQA, TriviaQA, HotpotQA, and NQ datasets. The shaded regions around each line represent the uncertainty or variance in the accuracy.
### Components/Axes
**Left Graph (Llama-3.2-1B):**
* **Title:** Llama-3.2-1B
* **Y-axis:** Answer Accuracy, ranging from 0 to 100.
* **X-axis:** Layer, ranging from 0 to 15.
* **Data Series:**
* Q-Anchored (PopQA): Solid blue line.
* A-Anchored (PopQA): Dashed brown line.
* Q-Anchored (TriviaQA): Dotted green line.
* A-Anchored (TriviaQA): Dotted-dashed light green line.
* Q-Anchored (HotpotQA): Dashed-dotted red line.
* A-Anchored (HotpotQA): Dotted-dotted-dashed light red line.
* Q-Anchored (NQ): Dashed purple line.
* A-Anchored (NQ): Dotted-dashed gray line.
**Right Graph (Llama-3.2-3B):**
* **Title:** Llama-3.2-3B
* **Y-axis:** Answer Accuracy, ranging from 0 to 100.
* **X-axis:** Layer, ranging from 0 to 25.
* **Data Series:**
* Q-Anchored (PopQA): Solid blue line.
* A-Anchored (PopQA): Dashed brown line.
* Q-Anchored (TriviaQA): Dotted green line.
* A-Anchored (TriviaQA): Dotted-dashed light green line.
* Q-Anchored (HotpotQA): Dashed-dotted red line.
* A-Anchored (HotpotQA): Dotted-dotted-dashed light red line.
* Q-Anchored (NQ): Dashed purple line.
* A-Anchored (NQ): Dotted-dashed gray line.
**Legend:** Located below the graphs, mapping line styles and colors to the corresponding data series.
### Detailed Analysis
**Llama-3.2-1B:**
* **Q-Anchored (PopQA):** The blue line starts at approximately 10% accuracy at layer 0, rapidly increases to around 95% by layer 4, and then fluctuates between 80% and 95% for the remaining layers.
* **A-Anchored (PopQA):** The brown dashed line starts at approximately 50% accuracy and remains relatively stable between 40% and 50% across all layers.
* **Q-Anchored (TriviaQA):** The green dotted line starts at approximately 10% accuracy at layer 0, increases to around 80% by layer 5, and then fluctuates between 70% and 80% for the remaining layers.
* **A-Anchored (TriviaQA):** The light green dotted-dashed line starts at approximately 50% accuracy and remains relatively stable between 40% and 50% across all layers.
* **Q-Anchored (HotpotQA):** The red dashed-dotted line starts at approximately 50% accuracy, decreases to around 30% by layer 3, and then increases to around 45% by layer 15.
* **A-Anchored (HotpotQA):** The light red dotted-dotted-dashed line starts at approximately 50% accuracy and remains relatively stable between 30% and 50% across all layers.
* **Q-Anchored (NQ):** The purple dashed line starts at approximately 50% accuracy, increases to around 90% by layer 4, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (NQ):** The gray dotted-dashed line starts at approximately 50% accuracy and remains relatively stable between 40% and 50% across all layers.
**Llama-3.2-3B:**
* **Q-Anchored (PopQA):** The blue line starts at approximately 10% accuracy at layer 0, rapidly increases to around 90% by layer 4, and then fluctuates between 70% and 95% for the remaining layers.
* **A-Anchored (PopQA):** The brown dashed line starts at approximately 50% accuracy and remains relatively stable between 35% and 50% across all layers.
* **Q-Anchored (TriviaQA):** The green dotted line starts at approximately 10% accuracy at layer 0, increases to around 80% by layer 5, and then fluctuates between 70% and 90% for the remaining layers.
* **A-Anchored (TriviaQA):** The light green dotted-dashed line starts at approximately 50% accuracy and remains relatively stable between 35% and 50% across all layers.
* **Q-Anchored (HotpotQA):** The red dashed-dotted line starts at approximately 50% accuracy, decreases to around 25% by layer 3, and then increases to around 45% by layer 25.
* **A-Anchored (HotpotQA):** The light red dotted-dotted-dashed line starts at approximately 50% accuracy and remains relatively stable between 30% and 50% across all layers.
* **Q-Anchored (NQ):** The purple dashed line starts at approximately 50% accuracy, increases to around 90% by layer 4, and then fluctuates between 70% and 95% for the remaining layers.
* **A-Anchored (NQ):** The gray dotted-dashed line starts at approximately 50% accuracy and remains relatively stable between 35% and 50% across all layers.
### Key Observations
* For both models, Q-Anchored approaches on PopQA, TriviaQA, and NQ datasets show a significant increase in accuracy within the first few layers.
* A-Anchored approaches generally maintain a relatively stable accuracy across all layers, hovering around 40-50%.
* Q-Anchored (HotpotQA) shows a dip in accuracy in the initial layers before gradually increasing.
* The Llama-3.2-3B model has a longer x-axis (more layers) than the Llama-3.2-1B model.
### Interpretation
The data suggests that question-anchoring (Q-Anchored) is more effective than answer-anchoring (A-Anchored) for PopQA, TriviaQA, and NQ datasets, as it leads to a substantial increase in answer accuracy as the model processes more layers. The stable accuracy of A-Anchored approaches indicates that they might rely more on initial information and do not benefit significantly from deeper processing. The initial dip in Q-Anchored (HotpotQA) could indicate that the model requires more layers to understand the complex reasoning involved in HotpotQA. The longer x-axis for Llama-3.2-3B suggests that it has a deeper architecture, potentially allowing for more complex reasoning and learning, although the accuracy trends are broadly similar to the smaller Llama-3.2-1B model. The shaded regions indicate the variance in the accuracy, which is generally higher in the initial layers and decreases as the model processes more layers, suggesting that the model becomes more stable and consistent in its predictions as it goes deeper.
</details>
<details>
<summary>x73.png Details</summary>
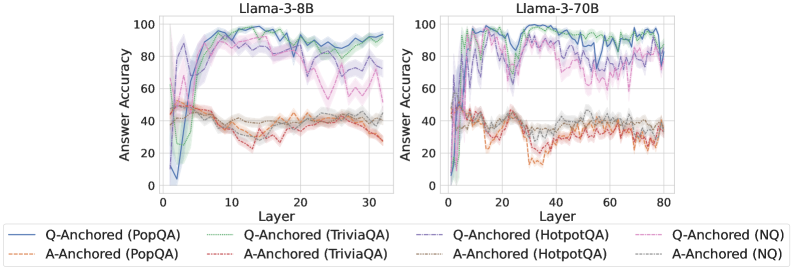
### Visual Description
## Chart Type: Line Graphs Comparing Model Performance
### Overview
The image presents two line graphs side-by-side, comparing the answer accuracy of two language models, Llama-3-8B and Llama-3-70B, across different layers. Each graph plots the answer accuracy (y-axis) against the layer number (x-axis) for both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches on four different question answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. The graphs include shaded regions around each line, representing the uncertainty or variance in the accuracy.
### Components/Axes
* **Titles:**
* Left Graph: "Llama-3-8B"
* Right Graph: "Llama-3-70B"
* **X-axis:**
* Label: "Layer"
* Left Graph: Scale from 0 to 30, with tick marks at approximately 0, 10, 20, and 30.
* Right Graph: Scale from 0 to 80, with tick marks at approximately 0, 20, 40, 60, and 80.
* **Y-axis:**
* Label: "Answer Accuracy"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located at the bottom of the image.
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Solid green line
* **A-Anchored (TriviaQA):** Dashed brown line
* **Q-Anchored (HotpotQA):** Solid purple line
* **A-Anchored (HotpotQA):** Dashed brown line
* **Q-Anchored (NQ):** Dashed pink line
* **A-Anchored (NQ):** Dashed brown line
### Detailed Analysis
**Left Graph: Llama-3-8B**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 accuracy, rises sharply to around 80 by layer 5, and then plateaus between 80 and 100 for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 10, and then fluctuates between 30 and 50 for the remaining layers.
* **Q-Anchored (TriviaQA):** (Solid Green) Starts at approximately 20 accuracy, rises sharply to around 80 by layer 5, and then plateaus between 80 and 100 for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 10, and then fluctuates between 30 and 50 for the remaining layers.
* **Q-Anchored (HotpotQA):** (Solid Purple) Starts at approximately 50 accuracy, rises sharply to around 80 by layer 5, and then plateaus between 80 and 100 for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 10, and then fluctuates between 30 and 50 for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Pink) Starts at approximately 50 accuracy, rises sharply to around 80 by layer 5, and then plateaus between 80 and 100 for the remaining layers.
* **A-Anchored (NQ):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 10, and then fluctuates between 30 and 50 for the remaining layers.
**Right Graph: Llama-3-70B**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0 accuracy, rises sharply to around 80 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 20, and then fluctuates between 20 and 50 for the remaining layers.
* **Q-Anchored (TriviaQA):** (Solid Green) Starts at approximately 20 accuracy, rises sharply to around 80 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 20, and then fluctuates between 20 and 50 for the remaining layers.
* **Q-Anchored (HotpotQA):** (Solid Purple) Starts at approximately 50 accuracy, rises sharply to around 80 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 20, and then fluctuates between 20 and 50 for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Pink) Starts at approximately 50 accuracy, rises sharply to around 80 by layer 10, and then fluctuates between 80 and 100 for the remaining layers.
* **A-Anchored (NQ):** (Dashed Brown) Starts at approximately 50 accuracy, decreases to around 40 by layer 20, and then fluctuates between 20 and 50 for the remaining layers.
### Key Observations
* For both models, Q-Anchored approaches (PopQA, TriviaQA, HotpotQA, and NQ) generally achieve higher answer accuracy than A-Anchored approaches.
* The Llama-3-70B model, with more layers, shows a more gradual increase in accuracy for Q-Anchored approaches compared to the Llama-3-8B model.
* The A-Anchored approaches show a similar trend across both models, starting at around 50 accuracy and then decreasing and fluctuating between 20 and 50.
* The shaded regions indicate the variance in accuracy, which appears to be larger in the Llama-3-70B model, especially for the Q-Anchored approaches.
### Interpretation
The data suggests that question-anchoring is a more effective strategy for achieving high answer accuracy in these language models compared to answer-anchoring. The larger Llama-3-70B model, while showing a more gradual increase in accuracy, ultimately achieves similar performance to the smaller Llama-3-8B model for Q-Anchored approaches. The consistent performance of A-Anchored approaches across both models suggests that this strategy may be less sensitive to model size. The larger variance in accuracy for the Llama-3-70B model could be due to its increased complexity and potential for overfitting. The similar brown dashed line for all A-Anchored approaches suggests that the dataset has little impact on the A-Anchored accuracy.
</details>
<details>
<summary>x74.png Details</summary>
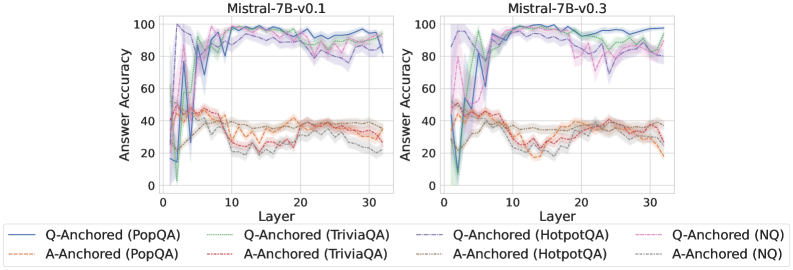
### Visual Description
## Chart Type: Line Graphs Comparing Model Performance
### Overview
The image presents two line graphs comparing the performance of two versions of the Mistral-7B model (v0.1 and v0.3) on various question-answering datasets. The graphs depict the "Answer Accuracy" as a function of "Layer" for different question-answering tasks, distinguished by whether the question (Q-Anchored) or answer (A-Anchored) is used for anchoring. Each graph shows the performance on PopQA, TriviaQA, HotpotQA, and NQ datasets. The shaded regions around the lines likely represent the standard deviation or confidence intervals.
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **Y-Axis:** "Answer Accuracy" ranging from 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:** "Layer" ranging from 0 to 30, with tick marks every 5 layers (0, 10, 20, 30).
* **Legend:** Located at the bottom of the image, mapping line styles and colors to specific datasets and anchoring methods:
* Blue solid line: Q-Anchored (PopQA)
* Tan dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Tan dotted line: A-Anchored (TriviaQA)
* Green dashed line: Q-Anchored (HotpotQA)
* Tan solid line: A-Anchored (HotpotQA)
* Purple dashed line: Q-Anchored (NQ)
* Gray dotted line: A-Anchored (NQ)
### Detailed Analysis
**Left Graph: Mistral-7B-v0.1**
* **Q-Anchored (PopQA) - Blue solid line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 85% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Tan dashed line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
* **Q-Anchored (TriviaQA) - Green dotted line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) - Tan dotted line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
* **Q-Anchored (HotpotQA) - Green dashed line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (HotpotQA) - Tan solid line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
* **Q-Anchored (NQ) - Purple dashed line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ) - Gray dotted line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
**Right Graph: Mistral-7B-v0.3**
* **Q-Anchored (PopQA) - Blue solid line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 85% and 100% for the remaining layers.
* **A-Anchored (PopQA) - Tan dashed line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
* **Q-Anchored (TriviaQA) - Green dotted line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (TriviaQA) - Tan dotted line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
* **Q-Anchored (HotpotQA) - Green dashed line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (HotpotQA) - Tan solid line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
* **Q-Anchored (NQ) - Purple dashed line:** Starts around 10% accuracy at layer 0, rapidly increases to approximately 90% by layer 5, and then fluctuates between 80% and 100% for the remaining layers.
* **A-Anchored (NQ) - Gray dotted line:** Starts around 40% accuracy at layer 0, fluctuates between 30% and 50% until layer 10, and then gradually decreases to around 30% by layer 30.
### Key Observations
* **Q-Anchored vs. A-Anchored:** Q-Anchored methods consistently outperform A-Anchored methods across all datasets and both model versions.
* **Rapid Initial Learning:** All Q-Anchored methods show a rapid increase in accuracy within the first 5 layers.
* **Performance Plateau:** After the initial increase, the Q-Anchored methods plateau and fluctuate within a relatively narrow range.
* **Model Version Similarity:** The performance of Mistral-7B-v0.1 and Mistral-7B-v0.3 is very similar across all datasets and anchoring methods.
* **A-Anchored Decline:** The A-Anchored methods show a gradual decline in accuracy after the initial layers.
### Interpretation
The data suggests that anchoring on the question (Q-Anchored) is significantly more effective than anchoring on the answer (A-Anchored) for these question-answering tasks. This could be because the question provides more relevant context for the model to learn from. The rapid initial learning of the Q-Anchored methods indicates that the model quickly identifies and utilizes the information in the question. The plateau in performance suggests that there may be a limit to how much the model can learn from the question alone, or that further training is needed to improve performance. The similarity in performance between the two model versions suggests that the changes between v0.1 and v0.3 did not significantly impact the model's ability to perform these tasks. The decline in A-Anchored performance after the initial layers could be due to the model overfitting to the answer or failing to generalize to new examples.
</details>
Figure 29: Comparisons of answer accuracy between pathways, probing mlp activations of the last exact answer token.
Appendix G I-Don’t-Know Rate
<details>
<summary>x75.png Details</summary>
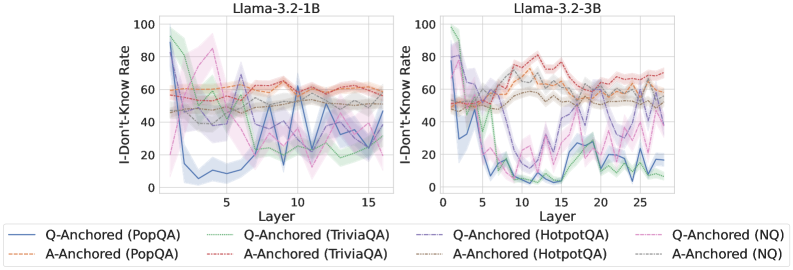
### Visual Description
## Line Chart: I-Don't-Know Rate vs. Layer for Llama Models
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two Llama models (Llama-3.2-1B and Llama-3.2-3B) for various question-answering datasets. Each chart displays multiple data series, representing different anchoring methods (Q-Anchored and A-Anchored) on datasets like PopQA, TriviaQA, HotpotQA, and NQ. The charts aim to illustrate how the model's uncertainty varies across layers and datasets.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3.2-1B"
* Right Chart: "Llama-3.2-3B"
* **Y-Axis (Vertical):**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis (Horizontal):**
* Label: "Layer"
* Left Chart Scale: 0 to 15, with tick marks at 0, 5, 10, and 15.
* Right Chart Scale: 0 to 25, with tick marks at 0, 5, 10, 15, 20, and 25.
* **Legend:** Located at the bottom of the image, it identifies each data series by color and label:
* Blue: Q-Anchored (PopQA)
* Brown Dashed: A-Anchored (PopQA)
* Green: Q-Anchored (TriviaQA)
* Gray Dotted: A-Anchored (TriviaQA)
* Teal Dashed: Q-Anchored (HotpotQA)
* Orange: A-Anchored (HotpotQA)
* Pink Dashed: Q-Anchored (NQ)
* Gray Dotted: A-Anchored (NQ)
### Detailed Analysis
#### Llama-3.2-1B (Left Chart)
* **Q-Anchored (PopQA) - Blue:** Starts high (around 60-70) and drops sharply to around 10-20 by layer 5, then fluctuates between 10 and 40 for the remaining layers.
* Layer 0: ~65
* Layer 5: ~10
* Layer 10: ~30
* Layer 15: ~40
* **A-Anchored (PopQA) - Brown Dashed:** Relatively stable, fluctuating between 50 and 70 across all layers.
* Layer 0: ~55
* Layer 5: ~60
* Layer 10: ~60
* Layer 15: ~60
* **Q-Anchored (TriviaQA) - Green:** Starts high (near 100) and decreases to around 30-40 by layer 5, then fluctuates between 20 and 60.
* Layer 0: ~95
* Layer 5: ~40
* Layer 10: ~30
* Layer 15: ~20
* **A-Anchored (TriviaQA) - Gray Dotted:** Starts around 60, decreases to 40 by layer 5, and then fluctuates between 40 and 60.
* Layer 0: ~60
* Layer 5: ~40
* Layer 10: ~50
* Layer 15: ~50
* **Q-Anchored (HotpotQA) - Teal Dashed:** Starts around 50, decreases to 30 by layer 5, and then fluctuates between 20 and 50.
* Layer 0: ~50
* Layer 5: ~30
* Layer 10: ~40
* Layer 15: ~30
* **A-Anchored (HotpotQA) - Orange:** Relatively stable, fluctuating between 50 and 70 across all layers.
* Layer 0: ~55
* Layer 5: ~60
* Layer 10: ~60
* Layer 15: ~60
* **Q-Anchored (NQ) - Pink Dashed:** Starts high (around 80), decreases to around 40 by layer 5, and then fluctuates between 20 and 60.
* Layer 0: ~80
* Layer 5: ~40
* Layer 10: ~60
* Layer 15: ~30
* **A-Anchored (NQ) - Gray Dotted:** Starts around 50, decreases to 40 by layer 5, and then fluctuates between 40 and 60.
* Layer 0: ~50
* Layer 5: ~40
* Layer 10: ~50
* Layer 15: ~50
#### Llama-3.2-3B (Right Chart)
* **Q-Anchored (PopQA) - Blue:** Starts high (around 50-60) and drops sharply to around 5-10 by layer 5, then fluctuates between 5 and 30 for the remaining layers.
* Layer 0: ~55
* Layer 5: ~5
* Layer 15: ~20
* Layer 25: ~20
* **A-Anchored (PopQA) - Brown Dashed:** Relatively stable, fluctuating between 50 and 70 across all layers.
* Layer 0: ~50
* Layer 5: ~60
* Layer 15: ~65
* Layer 25: ~70
* **Q-Anchored (TriviaQA) - Green:** Starts high (near 100) and decreases to around 10-20 by layer 5, then fluctuates between 10 and 40.
* Layer 0: ~95
* Layer 5: ~10
* Layer 15: ~30
* Layer 25: ~20
* **A-Anchored (TriviaQA) - Gray Dotted:** Starts around 50, decreases to 40 by layer 5, and then fluctuates between 40 and 60.
* Layer 0: ~50
* Layer 5: ~40
* Layer 15: ~50
* Layer 25: ~50
* **Q-Anchored (HotpotQA) - Teal Dashed:** Starts around 50, decreases to 10 by layer 5, and then fluctuates between 5 and 30.
* Layer 0: ~50
* Layer 5: ~10
* Layer 15: ~20
* Layer 25: ~20
* **A-Anchored (HotpotQA) - Orange:** Relatively stable, fluctuating between 50 and 70 across all layers.
* Layer 0: ~50
* Layer 5: ~60
* Layer 15: ~65
* Layer 25: ~70
* **Q-Anchored (NQ) - Pink Dashed:** Starts high (around 80), decreases to around 20 by layer 5, and then fluctuates between 10 and 50.
* Layer 0: ~80
* Layer 5: ~20
* Layer 15: ~40
* Layer 25: ~30
* **A-Anchored (NQ) - Gray Dotted:** Starts around 50, decreases to 40 by layer 5, and then fluctuates between 40 and 60.
* Layer 0: ~50
* Layer 5: ~40
* Layer 15: ~50
* Layer 25: ~50
### Key Observations
* **Initial Drop:** For both models, the Q-Anchored series (PopQA, TriviaQA, HotpotQA, NQ) generally show a significant drop in the "I-Don't-Know Rate" within the first few layers (around layer 5).
* **A-Anchored Stability:** The A-Anchored series (PopQA, TriviaQA, HotpotQA, NQ) tend to be more stable, with less fluctuation across layers.
* **Model Comparison:** The Llama-3.2-3B model (right chart) has a longer x-axis (more layers) than the Llama-3.2-1B model (left chart).
* **Dataset Variation:** The "I-Don't-Know Rate" varies significantly depending on the dataset used.
### Interpretation
The charts suggest that the model's uncertainty (as measured by the "I-Don't-Know Rate") is highly dependent on the anchoring method (Q vs. A) and the specific question-answering dataset. The initial drop in the Q-Anchored series indicates that the model quickly gains confidence in its answers as it processes the initial layers. The relative stability of the A-Anchored series might indicate a more consistent level of uncertainty throughout the layers.
The difference in the number of layers between the two models (Llama-3.2-1B vs. Llama-3.2-3B) could be a factor in their performance and uncertainty characteristics. The longer model (3B) might have more capacity to learn and refine its answers, potentially leading to different patterns in the "I-Don't-Know Rate" across layers.
The variation across datasets highlights the importance of dataset-specific training and evaluation. The model's uncertainty is likely influenced by the complexity, ambiguity, and domain knowledge required for each dataset.
</details>
<details>
<summary>x76.png Details</summary>
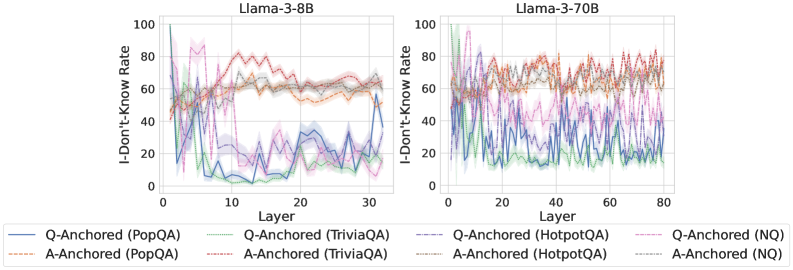
### Visual Description
## Line Chart: I-Don't-Know Rate vs. Layer for Llama-3-8B and Llama-3-70B
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of the Llama-3-8B and Llama-3-70B language models. The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate, ranging from 0 to 100. Each chart displays six data series, representing Question-Anchored (Q-Anchored) and Answer-Anchored (A-Anchored) rates for different question answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. Shaded regions around each line indicate uncertainty or variance.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-Axis:**
* Label: I-Don't-Know Rate
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: Layer
* Left Chart Scale: 0 to 30, with tick marks at 0, 10, 20, and 30.
* Right Chart Scale: 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **Legend:** Located at the bottom of the image, spanning both charts.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Teal Line
* Q-Anchored (HotpotQA): Solid Purple Line
* A-Anchored (HotpotQA): Dashed Pink Line
* Q-Anchored (NQ): Dotted Red Line
* A-Anchored (NQ): Dash-Dotted Gray Line
### Detailed Analysis
**Left Chart: Llama-3-8B**
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts high (around 50), drops sharply to near 0 around layer 10, then fluctuates between 0 and 40 for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts around 50, increases to around 70 by layer 10, and then remains relatively stable between 60 and 70 for the rest of the layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts high (around 60), drops sharply to near 0 around layer 10, then fluctuates between 0 and 20 for the remaining layers.
* **A-Anchored (TriviaQA) - Dash-Dotted Teal Line:** Starts around 60, drops sharply to near 0 around layer 10, then fluctuates between 0 and 20 for the remaining layers.
* **Q-Anchored (HotpotQA) - Solid Purple Line:** Starts around 40, fluctuates significantly between 0 and 40 throughout all layers.
* **A-Anchored (HotpotQA) - Dashed Pink Line:** Starts around 50, increases to around 80 by layer 10, and then fluctuates between 70 and 90 for the rest of the layers.
* **Q-Anchored (NQ) - Dotted Red Line:** Starts around 50, increases to around 80 by layer 10, and then fluctuates between 70 and 90 for the rest of the layers.
* **A-Anchored (NQ) - Dash-Dotted Gray Line:** Starts around 50, increases to around 60 by layer 10, and then fluctuates between 60 and 70 for the rest of the layers.
**Right Chart: Llama-3-70B**
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts high (around 50), drops sharply to near 0 around layer 10, then fluctuates between 0 and 40 for the remaining layers.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts around 50, increases to around 70 by layer 10, and then remains relatively stable between 60 and 70 for the rest of the layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts high (around 60), drops sharply to near 0 around layer 10, then fluctuates between 0 and 20 for the remaining layers.
* **A-Anchored (TriviaQA) - Dash-Dotted Teal Line:** Starts around 60, drops sharply to near 0 around layer 10, then fluctuates between 0 and 20 for the remaining layers.
* **Q-Anchored (HotpotQA) - Solid Purple Line:** Starts around 40, fluctuates significantly between 0 and 40 throughout all layers.
* **A-Anchored (HotpotQA) - Dashed Pink Line:** Starts around 50, increases to around 80 by layer 10, and then fluctuates between 70 and 90 for the rest of the layers.
* **Q-Anchored (NQ) - Dotted Red Line:** Starts around 50, increases to around 80 by layer 10, and then fluctuates between 70 and 90 for the rest of the layers.
* **A-Anchored (NQ) - Dash-Dotted Gray Line:** Starts around 50, increases to around 60 by layer 10, and then fluctuates between 60 and 70 for the rest of the layers.
### Key Observations
* For both Llama-3-8B and Llama-3-70B, the Q-Anchored (PopQA) and Q-Anchored (TriviaQA) rates drop significantly in the early layers.
* The A-Anchored (HotpotQA) and Q-Anchored (NQ) rates tend to be higher and more stable across layers.
* The A-Anchored (PopQA) and A-Anchored (NQ) rates are relatively stable across layers.
* The right chart (Llama-3-70B) has a longer x-axis, indicating more layers in the model.
### Interpretation
The charts illustrate how the "I-Don't-Know Rate" varies across different layers of the Llama-3-8B and Llama-3-70B models, depending on whether the question or answer is used as the anchor. The significant drop in Q-Anchored (PopQA) and Q-Anchored (TriviaQA) rates in the early layers suggests that the model quickly learns to handle these types of questions. The higher and more stable rates for A-Anchored (HotpotQA) and Q-Anchored (NQ) might indicate that these question types are more challenging for the model, requiring more layers to process effectively. The longer x-axis for Llama-3-70B suggests that the larger model has more capacity to learn and potentially handle more complex questions. The shaded regions indicate the variance in the I-Don't-Know Rate, which could be due to variations in the training data or the model's internal state.
</details>
<details>
<summary>x77.png Details</summary>
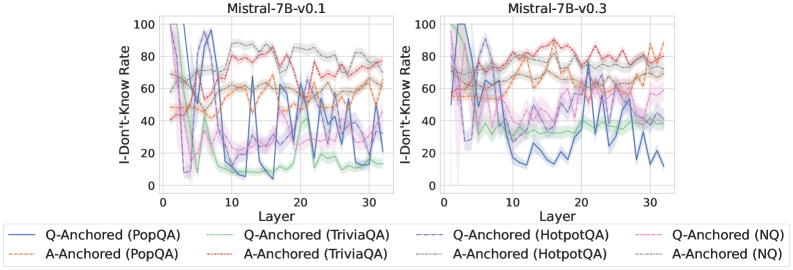
### Visual Description
## Chart: Mistral-7B-v0.1 vs Mistral-7B-v0.3 I-Don't-Know Rate
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" of two versions of the Mistral-7B model (v0.1 and v0.3) across different layers (1 to 32) and question-answering datasets. The charts show how the model's uncertainty varies with layer depth for both question-anchored and answer-anchored approaches on four datasets: PopQA, TriviaQA, HotpotQA, and NQ.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:** "I-Don't-Know Rate" ranging from 0 to 100. Markers at 0, 20, 40, 60, 80, and 100.
* **X-Axis:** "Layer" ranging from 0 to 30. Markers at 0, 10, 20, and 30.
* **Legend:** Located at the bottom of the image.
* Blue solid line: "Q-Anchored (PopQA)"
* Tan dashed line: "A-Anchored (PopQA)"
* Green dotted line: "Q-Anchored (TriviaQA)"
* Tan dotted-dashed line: "A-Anchored (TriviaQA)"
* Red dashed line: "Q-Anchored (HotpotQA)"
* Tan solid line: "A-Anchored (HotpotQA)"
* Purple dotted line: "Q-Anchored (NQ)"
* Tan dotted line: "A-Anchored (NQ)"
### Detailed Analysis
**Mistral-7B-v0.1 (Left Chart):**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at 100, drops sharply to around 10 at layer 5, rises to 100 at layer 10, then fluctuates between 20 and 60 for the remaining layers.
* **A-Anchored (PopQA) (Tan dashed line):** Starts at approximately 60, decreases to 40 at layer 5, then increases to 60 at layer 10, and fluctuates between 50 and 70 for the remaining layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at 60, drops to 10 at layer 10, then fluctuates between 10 and 30 for the remaining layers.
* **A-Anchored (TriviaQA) (Tan dotted-dashed line):** Starts at 50, drops to 20 at layer 5, then fluctuates between 20 and 40 for the remaining layers.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts at 100, drops to 60 at layer 5, then fluctuates between 60 and 90 for the remaining layers.
* **A-Anchored (HotpotQA) (Tan solid line):** Starts at 50, increases to 60 at layer 5, then fluctuates between 50 and 70 for the remaining layers.
* **Q-Anchored (NQ) (Purple dotted line):** Starts at 100, drops to 20 at layer 5, then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (NQ) (Tan dotted line):** Starts at 60, drops to 20 at layer 5, then fluctuates between 20 and 40 for the remaining layers.
**Mistral-7B-v0.3 (Right Chart):**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at 100, drops sharply to around 10 at layer 5, rises to 60 at layer 10, then fluctuates between 10 and 60 for the remaining layers.
* **A-Anchored (PopQA) (Tan dashed line):** Starts at approximately 60, decreases to 50 at layer 5, then increases to 70 at layer 10, and fluctuates between 60 and 80 for the remaining layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at 60, drops to 20 at layer 10, then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (TriviaQA) (Tan dotted-dashed line):** Starts at 60, drops to 30 at layer 5, then fluctuates between 30 and 50 for the remaining layers.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts at 100, drops to 70 at layer 5, then fluctuates between 70 and 90 for the remaining layers.
* **A-Anchored (HotpotQA) (Tan solid line):** Starts at 60, increases to 70 at layer 5, then fluctuates between 60 and 80 for the remaining layers.
* **Q-Anchored (NQ) (Purple dotted line):** Starts at 100, drops to 30 at layer 5, then fluctuates between 30 and 50 for the remaining layers.
* **A-Anchored (NQ) (Tan dotted line):** Starts at 60, drops to 30 at layer 5, then fluctuates between 30 and 50 for the remaining layers.
### Key Observations
* Both versions of the model show a similar trend: the "I-Don't-Know Rate" generally decreases in the initial layers (1-5) and then fluctuates for the remaining layers.
* The Q-Anchored (PopQA) line shows a significant drop in the "I-Don't-Know Rate" in the initial layers for both versions.
* The Q-Anchored (HotpotQA) line consistently shows a high "I-Don't-Know Rate" across all layers for both versions.
* The A-Anchored lines generally have a lower "I-Don't-Know Rate" compared to the Q-Anchored lines for the same dataset.
* The shaded regions around each line indicate the uncertainty or variance in the "I-Don't-Know Rate" for each dataset and anchoring method.
### Interpretation
The charts suggest that the Mistral-7B model's uncertainty varies depending on the dataset and whether the question or answer is used as the anchor. The initial layers seem to play a crucial role in reducing the model's uncertainty, as indicated by the sharp drop in the "I-Don't-Know Rate" for some datasets. The HotpotQA dataset consistently results in higher uncertainty, suggesting that it may be more challenging for the model. The differences between the Q-Anchored and A-Anchored lines indicate that the model's uncertainty is also influenced by the anchoring method. Comparing v0.1 and v0.3, there are subtle differences in the "I-Don't-Know Rate" for some datasets, but the overall trends remain similar. This suggests that the changes between the two versions did not significantly impact the model's uncertainty.
</details>
Figure 30: Comparisons of i-don’t-know rate between pathways, probing attention activations of the final token.
<details>
<summary>x78.png Details</summary>
### Visual Description
## Line Chart: I-Don't-Know Rate vs. Layer for Llama-3.2-1B and Llama-3.2-3B
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two language models, Llama-3.2-1B and Llama-3.2-3B. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored). The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate in percentage.
### Components/Axes
**Left Chart (Llama-3.2-1B):**
* **Title:** Llama-3.2-1B
* **X-axis:** Layer, with markers at 0, 5, 10, and 15.
* **Y-axis:** I-Don't-Know Rate, ranging from 0 to 100. Markers at 0, 20, 40, 60, 80, and 100.
**Right Chart (Llama-3.2-3B):**
* **Title:** Llama-3.2-3B
* **X-axis:** Layer, with markers at 0, 5, 10, 15, 20, and 25.
* **Y-axis:** I-Don't-Know Rate, ranging from 0 to 100. Markers at 0, 20, 40, 60, 80, and 100.
**Legend (Located below both charts):**
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Dotted green line
* **A-Anchored (TriviaQA):** Dashed-dotted pink line
* **Q-Anchored (HotpotQA):** Dashed-dotted red line
* **A-Anchored (HotpotQA):** Dotted gray line
* **Q-Anchored (NQ):** Dashed purple line
* **A-Anchored (NQ):** Dotted black line
### Detailed Analysis
**Left Chart (Llama-3.2-1B):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts around 15 at layer 0, peaks around 80 at layer 6, then decreases to around 20 at layer 15.
* **A-Anchored (PopQA):** (Dashed brown line) Starts around 50 at layer 0, fluctuates between 40 and 60, and ends around 70 at layer 15.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts around 70 at layer 0, decreases to around 10 at layer 15.
* **A-Anchored (TriviaQA):** (Dashed-dotted pink line) Starts around 50 at layer 0, fluctuates between 20 and 60, and ends around 20 at layer 15.
* **Q-Anchored (HotpotQA):** (Dashed-dotted red line) Starts around 50 at layer 0, fluctuates between 50 and 80, and ends around 70 at layer 15.
* **A-Anchored (HotpotQA):** (Dotted gray line) Starts around 50 at layer 0, fluctuates between 40 and 60, and ends around 50 at layer 15.
* **Q-Anchored (NQ):** (Dashed purple line) Starts around 50 at layer 0, fluctuates between 20 and 60, and ends around 20 at layer 15.
* **A-Anchored (NQ):** (Dotted black line) Starts around 50 at layer 0, fluctuates between 40 and 60, and ends around 50 at layer 15.
**Right Chart (Llama-3.2-3B):**
* **Q-Anchored (PopQA):** (Solid blue line) Starts around 90 at layer 0, decreases to around 10 at layer 15, and remains low until layer 27.
* **A-Anchored (PopQA):** (Dashed brown line) Starts around 50 at layer 0, fluctuates between 50 and 70, and ends around 60 at layer 27.
* **Q-Anchored (TriviaQA):** (Dotted green line) Starts around 70 at layer 0, decreases to around 10 at layer 15, and remains low until layer 27.
* **A-Anchored (TriviaQA):** (Dashed-dotted pink line) Starts around 50 at layer 0, fluctuates between 20 and 60, and ends around 40 at layer 27.
* **Q-Anchored (HotpotQA):** (Dashed-dotted red line) Starts around 50 at layer 0, fluctuates between 70 and 80, and ends around 80 at layer 27.
* **A-Anchored (HotpotQA):** (Dotted gray line) Starts around 50 at layer 0, fluctuates between 60 and 70, and ends around 60 at layer 27.
* **Q-Anchored (NQ):** (Dashed purple line) Starts around 50 at layer 0, fluctuates between 20 and 60, and ends around 40 at layer 27.
* **A-Anchored (NQ):** (Dotted black line) Starts around 50 at layer 0, fluctuates between 50 and 70, and ends around 60 at layer 27.
### Key Observations
* For both models, the "Q-Anchored (PopQA)" and "Q-Anchored (TriviaQA)" series show a significant decrease in the "I-Don't-Know Rate" as the layer number increases, especially in the Llama-3.2-3B model.
* The "A-Anchored (HotpotQA)" series consistently shows a higher "I-Don't-Know Rate" compared to other series in both models.
* The Llama-3.2-3B model exhibits a more pronounced decrease in the "I-Don't-Know Rate" for "Q-Anchored (PopQA)" and "Q-Anchored (TriviaQA)" compared to the Llama-3.2-1B model.
* The "I-Don't-Know Rate" for "A-Anchored" series generally fluctuates within a narrower range compared to the "Q-Anchored" series.
### Interpretation
The data suggests that the Llama-3.2-3B model is more effective at reducing the "I-Don't-Know Rate" for question-anchored PopQA and TriviaQA datasets as the layer number increases. This could indicate that the model learns to better understand and answer questions from these datasets as it processes information through deeper layers. The higher "I-Don't-Know Rate" for the "A-Anchored (HotpotQA)" series might indicate that the model struggles with answering questions when the answer is the primary anchor, especially for the HotpotQA dataset, which is known for its complexity. The difference in performance between the two models could be attributed to the increased number of layers in the Llama-3.2-3B model, allowing it to learn more complex relationships and patterns in the data. The fluctuations in the "I-Don't-Know Rate" for the "A-Anchored" series might indicate that the model's ability to answer questions based on the answer anchor is less consistent across different layers.
</details>
<details>
<summary>x79.png Details</summary>
### Visual Description
## Line Chart: I-Don't-Know Rate vs. Layer for Llama-3-8B and Llama-3-70B
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two language models: Llama-3-8B and Llama-3-70B. Each chart plots the rate for various question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) using both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches. The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate, ranging from 0 to 100.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3-8B"
* Right Chart: "Llama-3-70B"
* **X-axis (Layer):**
* Left Chart: Ranges from 0 to 30, with ticks at approximately 0, 10, 20, and 30.
* Right Chart: Ranges from 0 to 80, with ticks at approximately 0, 20, 40, 60, and 80.
* **Y-axis (I-Don't-Know Rate):**
* Both Charts: Ranges from 0 to 100, with ticks at 0, 20, 40, 60, 80, and 100.
* **Legend (Bottom):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Pink Line
* Q-Anchored (HotpotQA): Solid Orange Line
* A-Anchored (HotpotQA): Dashed Gray Line
* Q-Anchored (NQ): Dotted Red Line
* A-Anchored (NQ): Dash-Dotted Black Line
### Detailed Analysis or ### Content Details
**Left Chart (Llama-3-8B):**
* **Q-Anchored (PopQA) (Solid Blue):** Starts high (around 50-60) and generally decreases with fluctuations, ending around 20.
* Values: Layer 0: ~55, Layer 10: ~50, Layer 20: ~30, Layer 30: ~20
* **A-Anchored (PopQA) (Dashed Brown):** Relatively stable, fluctuating between 60 and 80.
* Values: Layer 0: ~50, Layer 10: ~75, Layer 20: ~70, Layer 30: ~75
* **Q-Anchored (TriviaQA) (Dotted Green):** Starts high (near 100) and rapidly decreases to near 0, remaining low.
* Values: Layer 0: ~100, Layer 5: ~10, Layer 10: ~5, Layer 30: ~5
* **A-Anchored (TriviaQA) (Dash-Dotted Pink):** Starts around 40, decreases to near 0, then fluctuates between 0 and 20.
* Values: Layer 0: ~40, Layer 5: ~10, Layer 10: ~20, Layer 30: ~10
* **Q-Anchored (HotpotQA) (Solid Orange):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 10: ~70, Layer 20: ~75, Layer 30: ~70
* **A-Anchored (HotpotQA) (Dashed Gray):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 10: ~65, Layer 20: ~70, Layer 30: ~65
* **Q-Anchored (NQ) (Dotted Red):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 10: ~75, Layer 20: ~70, Layer 30: ~75
* **A-Anchored (NQ) (Dash-Dotted Black):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 10: ~60, Layer 20: ~70, Layer 30: ~65
**Right Chart (Llama-3-70B):**
* **Q-Anchored (PopQA) (Solid Blue):** Starts high (around 60) and generally decreases with fluctuations, ending around 20.
* Values: Layer 0: ~60, Layer 20: ~30, Layer 40: ~20, Layer 60: ~20, Layer 80: ~20
* **A-Anchored (PopQA) (Dashed Brown):** Relatively stable, fluctuating between 60 and 80.
* Values: Layer 0: ~50, Layer 20: ~75, Layer 40: ~70, Layer 60: ~75, Layer 80: ~75
* **Q-Anchored (TriviaQA) (Dotted Green):** Starts high (near 100) and rapidly decreases to near 0, remaining low.
* Values: Layer 0: ~100, Layer 10: ~10, Layer 20: ~5, Layer 80: ~5
* **A-Anchored (TriviaQA) (Dash-Dotted Pink):** Starts around 40, decreases to near 0, then fluctuates between 0 and 20.
* Values: Layer 0: ~40, Layer 10: ~10, Layer 20: ~20, Layer 80: ~10
* **Q-Anchored (HotpotQA) (Solid Orange):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 20: ~70, Layer 40: ~75, Layer 60: ~70, Layer 80: ~70
* **A-Anchored (HotpotQA) (Dashed Gray):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 20: ~65, Layer 40: ~70, Layer 60: ~65, Layer 80: ~65
* **Q-Anchored (NQ) (Dotted Red):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 20: ~75, Layer 40: ~70, Layer 60: ~75, Layer 80: ~75
* **A-Anchored (NQ) (Dash-Dotted Black):** Starts around 50, increases and fluctuates between 60 and 80.
* Values: Layer 0: ~50, Layer 20: ~60, Layer 40: ~70, Layer 60: ~65, Layer 80: ~65
### Key Observations
* For both models, the "I-Don't-Know Rate" for TriviaQA (Q-Anchored and A-Anchored) drops significantly and remains low across all layers.
* The "I-Don't-Know Rate" for PopQA (Q-Anchored) tends to decrease as the layer increases.
* The "I-Don't-Know Rate" for PopQA (A-Anchored), HotpotQA (Q-Anchored and A-Anchored), and NQ (Q-Anchored and A-Anchored) remains relatively stable and high across all layers.
* The Llama-3-70B model has a longer x-axis (more layers) compared to Llama-3-8B.
### Interpretation
The charts illustrate how the "I-Don't-Know Rate" varies across different layers of the Llama-3-8B and Llama-3-70B models for different question-answering datasets and anchoring methods. The consistent low rate for TriviaQA suggests that both models are more confident in answering questions from this dataset, regardless of the layer. The decreasing rate for Q-Anchored PopQA indicates that the model becomes more certain about PopQA questions as it processes through deeper layers. The relatively stable and high rates for other datasets suggest that the model's confidence in answering those questions does not significantly change with increasing layer depth. The longer x-axis for Llama-3-70B indicates that it has more layers than Llama-3-8B, which could contribute to its potentially better performance in certain tasks.
</details>
<details>
<summary>x80.png Details</summary>
### Visual Description
## Line Graphs: I-Don't-Know Rate vs. Layer for Mistral-7B Models
### Overview
The image presents two line graphs comparing the "I-Don't-Know Rate" across different layers of two versions of the Mistral-7B model (v0.1 and v0.3). Each graph plots the I-Don't-Know Rate (percentage) against the layer number (1 to 32). Different colored lines represent different question-answering datasets and anchoring methods (Q-Anchored and A-Anchored). The graphs aim to show how the model's uncertainty varies across layers and datasets.
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **Y-Axis (Vertical):**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* Units: Percentage.
* **X-Axis (Horizontal):**
* Label: "Layer"
* Scale: 0 to 30, with tick marks at 0, 10, 20, and 30.
* Units: Layer Number.
* **Legend (Bottom):**
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dot Gray Line
* Q-Anchored (HotpotQA): Dash-Dot-Dot Red Line
* A-Anchored (HotpotQA): Dotted Orange Line
* Q-Anchored (NQ): Dashed Purple Line
* A-Anchored (NQ): Dotted Light Gray Line
### Detailed Analysis
**Left Graph: Mistral-7B-v0.1**
* **Q-Anchored (PopQA) (Solid Blue):** Starts at approximately 100% at layer 0, drops sharply to near 0% by layer 5, then fluctuates between 0% and 40% for the remaining layers.
* **A-Anchored (PopQA) (Dashed Brown):** Starts around 50% and fluctuates between 40% and 70% across all layers.
* **Q-Anchored (TriviaQA) (Dotted Green):** Starts at approximately 100% at layer 0, drops sharply to near 0% by layer 10, then fluctuates between 0% and 40% for the remaining layers.
* **A-Anchored (TriviaQA) (Dash-Dot Gray):** Starts around 60% and fluctuates between 50% and 70% across all layers.
* **Q-Anchored (HotpotQA) (Dash-Dot-Dot Red):** Starts around 40% and fluctuates between 40% and 90% across all layers.
* **A-Anchored (HotpotQA) (Dotted Orange):** Starts around 50% and fluctuates between 50% and 70% across all layers.
* **Q-Anchored (NQ) (Dashed Purple):** Starts around 40% and fluctuates between 10% and 50% across all layers.
* **A-Anchored (NQ) (Dotted Light Gray):** Starts around 50% and fluctuates between 50% and 70% across all layers.
**Right Graph: Mistral-7B-v0.3**
* **Q-Anchored (PopQA) (Solid Blue):** Starts at approximately 100% at layer 0, drops sharply to near 0% by layer 5, then fluctuates between 10% and 40% for the remaining layers.
* **A-Anchored (PopQA) (Dashed Brown):** Starts around 60% and fluctuates between 60% and 80% across all layers.
* **Q-Anchored (TriviaQA) (Dotted Green):** Starts around 100% at layer 0, drops sharply to near 10% by layer 10, then fluctuates between 10% and 40% for the remaining layers.
* **A-Anchored (TriviaQA) (Dash-Dot Gray):** Starts around 60% and fluctuates between 60% and 80% across all layers.
* **Q-Anchored (HotpotQA) (Dash-Dot-Dot Red):** Starts around 50% and fluctuates between 70% and 90% across all layers.
* **A-Anchored (HotpotQA) (Dotted Orange):** Starts around 60% and fluctuates between 60% and 80% across all layers.
* **Q-Anchored (NQ) (Dashed Purple):** Starts around 50% and fluctuates between 20% and 60% across all layers.
* **A-Anchored (NQ) (Dotted Light Gray):** Starts around 60% and fluctuates between 60% and 80% across all layers.
### Key Observations
* For both model versions, the Q-Anchored (PopQA) and Q-Anchored (TriviaQA) datasets show a significant drop in the I-Don't-Know Rate within the first few layers.
* The A-Anchored datasets generally exhibit a more stable and higher I-Don't-Know Rate across all layers compared to their Q-Anchored counterparts.
* The Mistral-7B-v0.3 model appears to have a slightly higher overall I-Don't-Know Rate for most datasets compared to v0.1.
### Interpretation
The graphs suggest that the Mistral-7B models are more uncertain about their answers when the answer is anchored (A-Anchored) compared to when the question is anchored (Q-Anchored). The sharp initial drop in I-Don't-Know Rate for Q-Anchored (PopQA) and Q-Anchored (TriviaQA) indicates that the model quickly gains confidence in its answers for these datasets as it processes the initial layers. The higher overall I-Don't-Know Rate in v0.3 might indicate a change in the model's calibration or a different trade-off between accuracy and uncertainty. The fluctuations in the I-Don't-Know Rate across layers could be related to the specific computations performed in each layer and how they contribute to the model's understanding of the question and answer.
</details>
Figure 31: Comparisons of i-don’t-know rate between pathways, probing attention activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x81.png Details</summary>
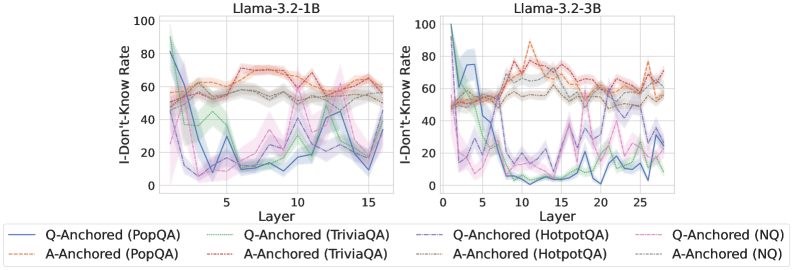
### Visual Description
## Chart Type: Line Graphs Comparing "I-Don't-Know" Rates
### Overview
The image presents two line graphs side-by-side, comparing the "I-Don't-Know" rates of different question-answering models across various layers. The left graph represents "Llama-3.2-1B," while the right graph represents "Llama-3.2-3B." Each graph plots the "I-Don't-Know" rate (percentage) on the y-axis against the layer number on the x-axis. Different colored lines represent different question-answering strategies, anchored either by question (Q-Anchored) or answer (A-Anchored), and tested on different datasets (PopQA, TriviaQA, HotpotQA, and NQ). The shaded areas around each line indicate the uncertainty or variance in the data.
### Components/Axes
* **Titles:**
* Left Graph: "Llama-3.2-1B"
* Right Graph: "Llama-3.2-3B"
* **Y-Axis:**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: "Layer"
* Left Graph Scale: 0 to 15, with tick marks at intervals of 5.
* Right Graph Scale: 0 to 25, with tick marks at intervals of 5.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dotted-Dashed Gray Line
* Q-Anchored (HotpotQA): Dashed Purple Line
* A-Anchored (HotpotQA): Solid Green Line
* Q-Anchored (NQ): Dotted-Dashed Red Line
* A-Anchored (NQ): Dotted Gray Line
### Detailed Analysis
**Left Graph (Llama-3.2-1B):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts high (around 80%), drops sharply to below 20% by layer 5, then fluctuates between 10% and 30% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 60%, fluctuates between 55% and 70% across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 60%, decreases to approximately 20% by layer 5, then fluctuates between 20% and 50% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dotted-Dashed Gray Line) Starts around 60%, remains relatively stable between 55% and 65% across all layers.
* **Q-Anchored (HotpotQA):** (Dashed Purple Line) Starts around 50%, drops to approximately 10% by layer 5, then fluctuates between 10% and 30% for the remaining layers.
* **A-Anchored (HotpotQA):** (Solid Green Line) Starts around 40%, decreases to approximately 15% by layer 5, then fluctuates between 15% and 45% for the remaining layers.
* **Q-Anchored (NQ):** (Dotted-Dashed Red Line) Starts around 60%, remains relatively stable between 60% and 70% across all layers.
* **A-Anchored (NQ):** (Dotted Gray Line) Starts around 50%, remains relatively stable between 50% and 60% across all layers.
**Right Graph (Llama-3.2-3B):**
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts high (around 90%), drops sharply to below 10% by layer 5, then fluctuates between 0% and 20% for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 50%, increases and fluctuates between 60% and 90% across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts around 90%, decreases to approximately 10% by layer 5, then fluctuates between 10% and 40% for the remaining layers.
* **A-Anchored (TriviaQA):** (Dotted-Dashed Gray Line) Starts around 50%, remains relatively stable between 50% and 70% across all layers.
* **Q-Anchored (HotpotQA):** (Dashed Purple Line) Starts around 50%, drops to approximately 5% by layer 5, then fluctuates between 5% and 30% for the remaining layers.
* **A-Anchored (HotpotQA):** (Solid Green Line) Starts around 70%, decreases to approximately 10% by layer 5, then fluctuates between 10% and 40% for the remaining layers.
* **Q-Anchored (NQ):** (Dotted-Dashed Red Line) Starts around 50%, increases and fluctuates between 60% and 80% across all layers.
* **A-Anchored (NQ):** (Dotted Gray Line) Starts around 60%, remains relatively stable between 50% and 70% across all layers.
### Key Observations
* For both Llama models, the "Q-Anchored (PopQA)" line shows a significant drop in the "I-Don't-Know" rate within the first few layers.
* The "A-Anchored (PopQA)" line generally shows a higher and more stable "I-Don't-Know" rate compared to the "Q-Anchored (PopQA)" line.
* The "I-Don't-Know" rates for "Q-Anchored (HotpotQA)" and "A-Anchored (HotpotQA)" also decrease significantly within the first few layers.
* The "I-Don't-Know" rates for "A-Anchored (TriviaQA)" and "A-Anchored (NQ)" are relatively stable across all layers.
* The "I-Don't-Know" rates for "Q-Anchored (TriviaQA)" decreases significantly within the first few layers.
* The "I-Don't-Know" rates for "Q-Anchored (NQ)" increases and fluctuates across all layers.
* The shaded areas around the lines indicate the variance in the data, with some lines showing more fluctuation than others.
### Interpretation
The graphs compare the "I-Don't-Know" rates of different question-answering models (Llama-3.2-1B and Llama-3.2-3B) across various layers. The different colored lines represent different question-answering strategies, anchored either by question (Q-Anchored) or answer (A-Anchored), and tested on different datasets (PopQA, TriviaQA, HotpotQA, and NQ).
The data suggests that the "Q-Anchored" strategies, particularly with the PopQA dataset, initially have a high "I-Don't-Know" rate, but this rate decreases significantly within the first few layers. This could indicate that the model learns to answer these questions more effectively as it processes more layers. In contrast, the "A-Anchored" strategies generally show a more stable "I-Don't-Know" rate across all layers, suggesting that the model's ability to answer questions based on the answer alone does not change significantly as it processes more layers.
The differences between the two Llama models (1B and 3B) are subtle, but it appears that the 3B model generally has lower "I-Don't-Know" rates for the "Q-Anchored" strategies, suggesting that it is better at answering questions based on the question alone.
The shaded areas around the lines indicate the variance in the data, with some lines showing more fluctuation than others. This could be due to the nature of the dataset or the specific question-answering strategy used.
</details>
<details>
<summary>x82.png Details</summary>
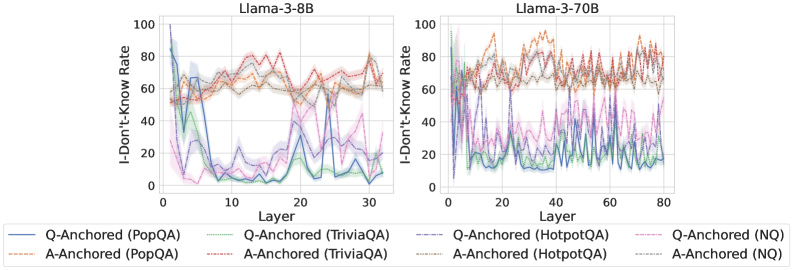
### Visual Description
## Chart Type: Line Graphs Comparing "I-Don't-Know" Rate
### Overview
The image presents two line graphs side-by-side, comparing the "I-Don't-Know" rate across different layers of two language models: Llama-3-8B (left) and Llama-3-70B (right). Each graph plots the "I-Don't-Know" rate (y-axis) against the layer number (x-axis) for various question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ), with both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches. The shaded regions around each line represent the uncertainty or variance in the data.
### Components/Axes
* **Titles:**
* Left Graph: "Llama-3-8B"
* Right Graph: "Llama-3-70B"
* **Y-Axis:**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: "Layer"
* Left Graph Scale: 0 to 30, with tick marks every 10 units.
* Right Graph Scale: 0 to 80, with tick marks every 20 units.
* **Legend:** Located at the bottom of the image, describing the lines:
* Blue solid line: "Q-Anchored (PopQA)"
* Brown dashed line: "A-Anchored (PopQA)"
* Green dotted line: "Q-Anchored (TriviaQA)"
* Brown dotted line: "A-Anchored (TriviaQA)"
* Red dashed line: "Q-Anchored (HotpotQA)"
* Brown dotted line: "A-Anchored (HotpotQA)"
* Purple dotted line: "Q-Anchored (NQ)"
* Brown dotted line: "A-Anchored (NQ)"
### Detailed Analysis
#### Llama-3-8B (Left Graph)
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 85-90% at layer 0, drops sharply to around 5-10% by layer 10, and then fluctuates between 5% and 30% for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Starts at approximately 50% at layer 0, rises to around 60-70% and remains relatively stable with minor fluctuations.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 60% at layer 0, drops to around 5-10% by layer 10, and then fluctuates between 5% and 20% for the remaining layers.
* **A-Anchored (TriviaQA) (Brown dotted line):** Starts at approximately 50% at layer 0, rises to around 60-70% and remains relatively stable with minor fluctuations.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts at approximately 60% at layer 0, rises to around 70-80% and remains relatively stable with minor fluctuations.
* **A-Anchored (HotpotQA) (Brown dotted line):** Starts at approximately 50% at layer 0, rises to around 60-70% and remains relatively stable with minor fluctuations.
* **Q-Anchored (NQ) (Purple dotted line):** Starts at approximately 60% at layer 0, drops to around 5-10% by layer 10, and then fluctuates between 5% and 20% for the remaining layers.
* **A-Anchored (NQ) (Brown dotted line):** Starts at approximately 50% at layer 0, rises to around 60-70% and remains relatively stable with minor fluctuations.
#### Llama-3-70B (Right Graph)
* **Q-Anchored (PopQA) (Blue solid line):** Starts at approximately 20% at layer 0, fluctuates between 10% and 40% for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Starts at approximately 70% at layer 0, fluctuates between 60% and 90% for the remaining layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at approximately 20% at layer 0, fluctuates between 10% and 30% for the remaining layers.
* **A-Anchored (TriviaQA) (Brown dotted line):** Starts at approximately 70% at layer 0, fluctuates between 60% and 80% for the remaining layers.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts at approximately 70% at layer 0, fluctuates between 60% and 90% for the remaining layers.
* **A-Anchored (HotpotQA) (Brown dotted line):** Starts at approximately 70% at layer 0, fluctuates between 60% and 80% for the remaining layers.
* **Q-Anchored (NQ) (Purple dotted line):** Starts at approximately 40% at layer 0, fluctuates between 20% and 50% for the remaining layers.
* **A-Anchored (NQ) (Brown dotted line):** Starts at approximately 70% at layer 0, fluctuates between 60% and 80% for the remaining layers.
### Key Observations
* For Llama-3-8B, the Q-Anchored approach for PopQA, TriviaQA, and NQ datasets shows a significant drop in the "I-Don't-Know" rate in the initial layers, while the A-Anchored approach remains relatively stable.
* For Llama-3-70B, the "I-Don't-Know" rates fluctuate more across layers for all datasets and anchoring methods compared to Llama-3-8B.
* The "I-Don't-Know" rate is generally higher for A-Anchored methods compared to Q-Anchored methods, especially for PopQA, TriviaQA, and NQ datasets in Llama-3-8B.
* HotpotQA consistently shows a higher "I-Don't-Know" rate compared to other datasets for both models and anchoring methods.
### Interpretation
The graphs illustrate how the "I-Don't-Know" rate varies across different layers of the Llama-3-8B and Llama-3-70B language models when answering questions from various datasets using question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches.
The sharp drop in the "I-Don't-Know" rate for Q-Anchored methods in Llama-3-8B suggests that the model quickly learns to answer questions from PopQA, TriviaQA, and NQ datasets using the question as a starting point. The relatively stable "I-Don't-Know" rate for A-Anchored methods indicates that the model may find it more challenging to answer questions when starting from the answer.
The higher "I-Don't-Know" rates and greater fluctuations in Llama-3-70B suggest that this larger model may be more sensitive to the specific layer and anchoring method used. The consistently high "I-Don't-Know" rate for HotpotQA indicates that this dataset may contain more complex or ambiguous questions that the models struggle to answer.
The differences in "I-Don't-Know" rates between the two models and across datasets and anchoring methods highlight the importance of carefully selecting the appropriate model, dataset, and anchoring method for a given question-answering task. The data suggests that smaller models may be more efficient for certain tasks, while larger models may be necessary for more complex questions.
</details>
<details>
<summary>x83.png Details</summary>
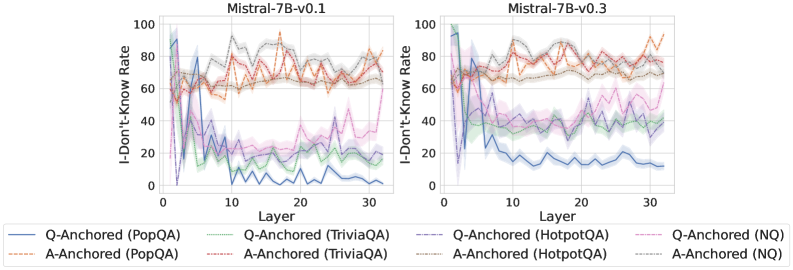
### Visual Description
## Chart Type: Line Graphs Comparing "I-Don't-Know" Rates of Mistral-7B Models
### Overview
The image presents two line graphs side-by-side, comparing the "I-Don't-Know" rates of two versions of the Mistral-7B model (v0.1 and v0.3) across different layers. Each graph plots the "I-Don't-Know" rate against the layer number for various question-answering datasets, distinguished by different line styles and colors. The x-axis represents the layer number, ranging from 0 to 30. The y-axis represents the "I-Don't-Know" rate, ranging from 0 to 100.
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **X-Axis:**
* Label: "Layer"
* Scale: 0 to 30, with tick marks at intervals of 10.
* **Y-Axis:**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at intervals of 20.
* **Legend:** Located at the bottom of the image, describing the different data series:
* Blue solid line: "Q-Anchored (PopQA)"
* Brown dashed line: "A-Anchored (PopQA)"
* Green dotted line: "Q-Anchored (TriviaQA)"
* Orange dashed-dotted line: "A-Anchored (TriviaQA)"
* Pink dashed line: "Q-Anchored (HotpotQA)"
* Gray dotted line: "A-Anchored (HotpotQA)"
* Purple dashed-dotted line: "Q-Anchored (NQ)"
* Black dotted line: "A-Anchored (NQ)"
### Detailed Analysis
**Left Graph: Mistral-7B-v0.1**
* **Q-Anchored (PopQA) (Blue solid line):** Starts high (around 60-70) and rapidly decreases to around 10-20 by layer 10, then fluctuates between 0 and 20 for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 60-70 and remains relatively stable between 60 and 80 across all layers, with some fluctuations.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around 60-70 and decreases to around 10-20 by layer 10, then fluctuates between 10 and 30 for the remaining layers.
* **A-Anchored (TriviaQA) (Orange dashed-dotted line):** Starts around 60-70 and remains relatively stable between 60 and 80 across all layers, with some fluctuations.
* **Q-Anchored (HotpotQA) (Pink dashed line):** Starts around 40-50 and decreases to around 20-30 by layer 10, then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (HotpotQA) (Gray dotted line):** Starts around 70-80 and remains relatively stable between 70 and 90 across all layers, with some fluctuations.
* **Q-Anchored (NQ) (Purple dashed-dotted line):** Starts around 40-50 and decreases to around 10-20 by layer 10, then fluctuates between 10 and 30 for the remaining layers.
* **A-Anchored (NQ) (Black dotted line):** Starts around 70-80 and remains relatively stable between 70 and 90 across all layers, with some fluctuations.
**Right Graph: Mistral-7B-v0.3**
* **Q-Anchored (PopQA) (Blue solid line):** Starts high (around 90-100) and rapidly decreases to around 10-20 by layer 10, then fluctuates between 10 and 20 for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 60-70 and remains relatively stable between 60 and 80 across all layers, with some fluctuations.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around 60-70 and decreases to around 10-20 by layer 10, then fluctuates between 10 and 30 for the remaining layers.
* **A-Anchored (TriviaQA) (Orange dashed-dotted line):** Starts around 70-80 and remains relatively stable between 70 and 90 across all layers, with some fluctuations.
* **Q-Anchored (HotpotQA) (Pink dashed line):** Starts around 60-70 and decreases to around 30-40 by layer 10, then fluctuates between 30 and 50 for the remaining layers.
* **A-Anchored (HotpotQA) (Gray dotted line):** Starts around 70-80 and remains relatively stable between 70 and 90 across all layers, with some fluctuations.
* **Q-Anchored (NQ) (Purple dashed-dotted line):** Starts around 60-70 and decreases to around 20-30 by layer 10, then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (NQ) (Black dotted line):** Starts around 70-80 and remains relatively stable between 70 and 90 across all layers, with some fluctuations.
### Key Observations
* For both Mistral-7B-v0.1 and Mistral-7B-v0.3, the "I-Don't-Know" rate for Q-Anchored datasets (PopQA, TriviaQA, HotpotQA, NQ) generally decreases in the initial layers (0-10) and then stabilizes.
* The "I-Don't-Know" rate for A-Anchored datasets (PopQA, TriviaQA, HotpotQA, NQ) remains relatively stable across all layers for both versions of the model.
* The initial "I-Don't-Know" rate for Q-Anchored (PopQA) is higher in Mistral-7B-v0.3 compared to Mistral-7B-v0.1.
### Interpretation
The graphs suggest that the Mistral-7B models handle question-anchored and answer-anchored datasets differently. The decreasing "I-Don't-Know" rate for Q-Anchored datasets in the initial layers indicates that the model is learning to answer these questions as it processes the input through the layers. The stable "I-Don't-Know" rate for A-Anchored datasets suggests that the model may be less sensitive to the layer number when the answer is provided as context. The higher initial "I-Don't-Know" rate for Q-Anchored (PopQA) in Mistral-7B-v0.3 might indicate a change in the model's initial processing of this specific dataset. Overall, the data highlights the importance of considering the anchoring method (question vs. answer) when evaluating the performance of language models on question-answering tasks.
</details>
Figure 32: Comparisons of i-don’t-know rate between pathways, probing attention activations of the last exact answer token.
<details>
<summary>x84.png Details</summary>
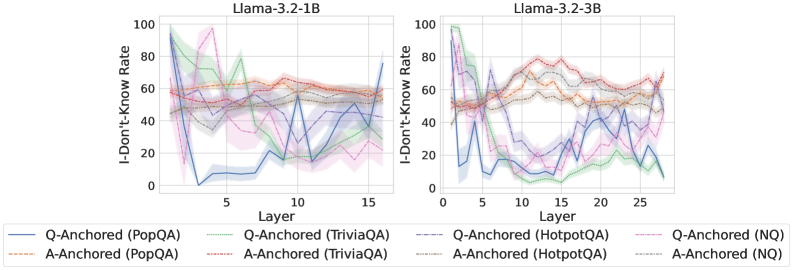
### Visual Description
## Line Chart: I-Don't-Know Rate vs. Layer for Llama Models
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two Llama models (Llama-3.2-1B and Llama-3.2-3B). Each chart displays the rate for various question-answering datasets, anchored either by question (Q-Anchored) or answer (A-Anchored). The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate, ranging from 0 to 100.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3.2-1B"
* Right Chart: "Llama-3.2-3B"
* **Y-Axis:** "I-Don't-Know Rate" (ranging from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100)
* **X-Axis:** "Layer"
* Left Chart: Layer numbers from 0 to 15, with markers at 0, 5, 10, and 15.
* Right Chart: Layer numbers from 0 to 25, with markers at 0, 5, 10, 15, 20, and 25.
* **Legend:** Located at the bottom of the image, describing the lines:
* Blue: Q-Anchored (PopQA)
* Brown dashed: A-Anchored (PopQA)
* Green dotted: Q-Anchored (TriviaQA)
* Pink dashed: A-Anchored (TriviaQA)
* Red dashed: Q-Anchored (NQ)
* Gray dotted: A-Anchored (NQ)
* Purple dashed: Q-Anchored (HotpotQA)
* Orange dashed: A-Anchored (HotpotQA)
### Detailed Analysis
**Left Chart: Llama-3.2-1B**
* **Q-Anchored (PopQA) (Blue):** Starts at approximately 60, drops sharply to near 0 around layer 3, then fluctuates between 0 and 20 until the end.
* **A-Anchored (PopQA) (Brown dashed):** Starts around 60, remains relatively stable between 55 and 65 across all layers.
* **Q-Anchored (TriviaQA) (Green dotted):** Starts around 90, drops to approximately 60 by layer 2, fluctuates between 60 and 80.
* **A-Anchored (TriviaQA) (Pink dashed):** Starts around 60, drops to approximately 40 by layer 2, fluctuates between 30 and 60.
* **Q-Anchored (NQ) (Red dashed):** Starts around 50, fluctuates between 40 and 60.
* **A-Anchored (NQ) (Gray dotted):** Starts around 50, fluctuates between 30 and 60.
* **Q-Anchored (HotpotQA) (Purple dashed):** Starts around 80, drops to approximately 20 by layer 3, fluctuates between 20 and 60.
* **A-Anchored (HotpotQA) (Orange dashed):** Starts around 50, remains relatively stable between 50 and 70 across all layers.
**Right Chart: Llama-3.2-3B**
* **Q-Anchored (PopQA) (Blue):** Starts at approximately 50, drops sharply to near 10 around layer 4, then fluctuates between 10 and 50 until the end.
* **A-Anchored (PopQA) (Brown dashed):** Starts around 50, rises to approximately 70 by layer 10, then remains relatively stable between 60 and 70 across all layers.
* **Q-Anchored (TriviaQA) (Green dotted):** Starts around 90, drops to approximately 10 by layer 4, fluctuates between 10 and 40.
* **A-Anchored (TriviaQA) (Pink dashed):** Starts around 50, drops to approximately 10 by layer 4, fluctuates between 10 and 40.
* **Q-Anchored (NQ) (Red dashed):** Starts around 50, rises to approximately 80 by layer 10, then remains relatively stable between 70 and 80 across all layers.
* **A-Anchored (NQ) (Gray dotted):** Starts around 50, fluctuates between 40 and 60.
* **Q-Anchored (HotpotQA) (Purple dashed):** Starts around 100, drops to approximately 20 by layer 4, fluctuates between 20 and 50.
* **A-Anchored (HotpotQA) (Orange dashed):** Starts around 50, rises to approximately 80 by layer 10, then remains relatively stable between 70 and 80 across all layers.
### Key Observations
* For both models, the "I-Don't-Know Rate" varies significantly depending on the dataset and whether the anchoring is done by question or answer.
* The Q-Anchored (PopQA) line shows a dramatic drop in the "I-Don't-Know Rate" in the initial layers for both models.
* The A-Anchored (PopQA) line remains relatively stable across all layers for both models.
* The Q-Anchored (TriviaQA) and A-Anchored (TriviaQA) lines show a dramatic drop in the "I-Don't-Know Rate" in the initial layers for the Llama-3.2-3B model.
* The Q-Anchored (HotpotQA) line shows a dramatic drop in the "I-Don't-Know Rate" in the initial layers for both models.
* The A-Anchored (HotpotQA) line rises in the initial layers for the Llama-3.2-3B model.
### Interpretation
The charts illustrate how the "I-Don't-Know Rate" changes across different layers of the Llama models when processing various question-answering datasets. The differences between Q-Anchored and A-Anchored rates suggest that the model's confidence varies depending on whether the question or the answer is used as the anchor. The initial drop in the "I-Don't-Know Rate" for certain datasets (PopQA, TriviaQA, HotpotQA) in the early layers indicates that the model quickly gains confidence or learns to provide answers for those specific types of questions. The stability of the A-Anchored (PopQA) line suggests a consistent level of uncertainty when the answer is used as the anchor for the PopQA dataset. The Llama-3.2-3B model shows a more pronounced drop in the "I-Don't-Know Rate" for TriviaQA and HotpotQA, indicating that it may be better at processing these types of questions compared to Llama-3.2-1B.
</details>
<details>
<summary>x85.png Details</summary>
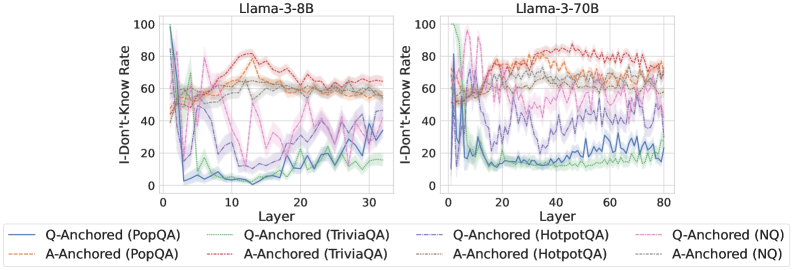
### Visual Description
## Chart: I-Don't-Know Rate vs. Layer for Llama-3-8B and Llama-3-70B
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two language models: Llama-3-8B and Llama-3-70B. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored either to the question (Q-Anchored) or the answer (A-Anchored). The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate, ranging from 0 to 100. Shaded regions around each line indicate the uncertainty or variance in the data.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-Axis:**
* Label: I-Don't-Know Rate
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: Layer
* Scale (Llama-3-8B): 0 to 30, with tick marks every 10 units.
* Scale (Llama-3-70B): 0 to 80, with tick marks every 20 units.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dashed-Dotted Red Line
* Q-Anchored (HotpotQA): Dashed Purple Line
* A-Anchored (HotpotQA): Dotted Gray Line
* Q-Anchored (NQ): Dashed-Dotted Pink Line
* A-Anchored (NQ): Dotted Dark Gray Line
### Detailed Analysis
#### Llama-3-8B (Left Chart)
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts at approximately 0 and remains low, generally below 10, with some fluctuations.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts around 50, increases to approximately 65 by layer 10, and then fluctuates around 60-70 for the remaining layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts high, around 100, then drops sharply to around 10 by layer 5, and fluctuates between 10 and 20 for the remaining layers.
* **A-Anchored (TriviaQA) - Dashed-Dotted Red Line:** Starts around 50, increases to approximately 70 by layer 10, and then fluctuates around 60-70 for the remaining layers.
* **Q-Anchored (HotpotQA) - Dashed Purple Line:** Starts around 50, decreases to approximately 20 by layer 10, and then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (HotpotQA) - Dotted Gray Line:** Starts around 60, remains relatively stable, fluctuating between 55 and 65 for all layers.
* **Q-Anchored (NQ) - Dashed-Dotted Pink Line:** Starts around 50, increases to approximately 60 by layer 10, and then fluctuates around 60-70 for the remaining layers.
* **A-Anchored (NQ) - Dotted Dark Gray Line:** Starts around 60, remains relatively stable, fluctuating between 55 and 65 for all layers.
#### Llama-3-70B (Right Chart)
* **Q-Anchored (PopQA) - Solid Blue Line:** Starts at approximately 0 and remains low, generally below 20, with some fluctuations.
* **A-Anchored (PopQA) - Dashed Brown Line:** Starts around 50, increases to approximately 75 by layer 20, and then fluctuates around 70-80 for the remaining layers.
* **Q-Anchored (TriviaQA) - Dotted Green Line:** Starts high, around 100, then drops sharply to around 20 by layer 10, and fluctuates between 15 and 30 for the remaining layers.
* **A-Anchored (TriviaQA) - Dashed-Dotted Red Line:** Starts around 50, increases to approximately 80 by layer 20, and then fluctuates around 75-85 for the remaining layers.
* **Q-Anchored (HotpotQA) - Dashed Purple Line:** Starts around 50, decreases to approximately 30 by layer 20, and then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (HotpotQA) - Dotted Gray Line:** Starts around 60, remains relatively stable, fluctuating between 60 and 70 for all layers.
* **Q-Anchored (NQ) - Dashed-Dotted Pink Line:** Starts around 50, increases to approximately 70 by layer 20, and then fluctuates around 65-75 for the remaining layers.
* **A-Anchored (NQ) - Dotted Dark Gray Line:** Starts around 60, remains relatively stable, fluctuating between 60 and 70 for all layers.
### Key Observations
* **Q-Anchored (PopQA):** Consistently low "I-Don't-Know Rate" for both models.
* **Q-Anchored (TriviaQA):** Starts high but drops significantly in the initial layers for both models.
* **A-Anchored series:** Generally exhibit higher and more stable "I-Don't-Know Rates" compared to their Q-Anchored counterparts.
* **Llama-3-70B:** Shows a more extended range of layers (0-80) compared to Llama-3-8B (0-30).
* **Variance:** The shaded regions indicate varying degrees of uncertainty across different datasets and layers.
### Interpretation
The charts illustrate how the "I-Don't-Know Rate" varies across different layers of the Llama-3-8B and Llama-3-70B language models when answering questions from different datasets. The anchoring method (question vs. answer) significantly impacts the "I-Don't-Know Rate." Q-Anchored PopQA consistently shows a low rate, suggesting the model is more confident in answering these questions. In contrast, Q-Anchored TriviaQA starts with high uncertainty but quickly learns to answer the questions, as indicated by the sharp drop in the "I-Don't-Know Rate." The A-Anchored series generally maintain higher rates, possibly indicating that the model is less certain when the answer is the primary focus. The Llama-3-70B model, with its larger number of layers, exhibits similar trends but over a more extended processing range. The variance in the data suggests that the model's confidence varies depending on the specific questions and the layer being processed. Overall, the data highlights the importance of dataset characteristics and anchoring methods in influencing the confidence and performance of language models.
</details>
<details>
<summary>x86.png Details</summary>
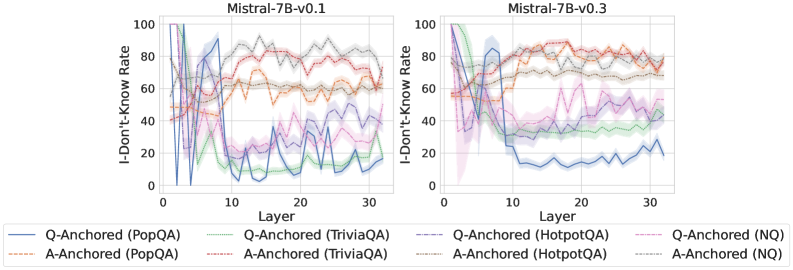
### Visual Description
## Line Chart: I-Don't-Know Rate Comparison for Mistral-7B-v0.1 and Mistral-7B-v0.3
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers (0-32) of the Mistral-7B-v0.1 and Mistral-7B-v0.3 models. Each chart displays multiple data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored). The charts aim to illustrate how the model's uncertainty varies across layers and datasets for the two model versions.
### Components/Axes
* **Titles:**
* Left Chart: "Mistral-7B-v0.1"
* Right Chart: "Mistral-7B-v0.3"
* **Y-Axis:**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: "Layer"
* Scale: 0 to approximately 32, with tick marks every 5 units (0, 10, 20, 30).
* **Legend:** Located at the bottom of the image, it identifies each data series by color and line style:
* Blue solid line: Q-Anchored (PopQA)
* Brown dashed line: A-Anchored (PopQA)
* Green dotted line: Q-Anchored (TriviaQA)
* Orange dash-dot line: A-Anchored (TriviaQA)
* Red dashed line: Q-Anchored (HotpotQA)
* Gray dotted line: A-Anchored (HotpotQA)
* Purple dash-dot line: Q-Anchored (NQ)
* Black dashed line: A-Anchored (NQ)
### Detailed Analysis
**Left Chart: Mistral-7B-v0.1**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at 100, drops sharply to near 0 by layer 5, then fluctuates between approximately 5 and 20 for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 50, rises to approximately 60-70, and remains relatively stable with minor fluctuations.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at 100, drops sharply to approximately 10-20 by layer 10, then fluctuates between 10 and 30.
* **A-Anchored (TriviaQA) (Orange dash-dot line):** Starts around 50, rises to approximately 70-80, and remains relatively stable with minor fluctuations.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts around 50, rises to approximately 70-80, and remains relatively stable with minor fluctuations.
* **A-Anchored (HotpotQA) (Gray dotted line):** Starts around 60, remains relatively stable with minor fluctuations between 60 and 80.
* **Q-Anchored (NQ) (Purple dash-dot line):** Starts around 40, fluctuates significantly between 10 and 40 across the layers.
* **A-Anchored (NQ) (Black dashed line):** Starts around 60, remains relatively stable with minor fluctuations between 60 and 80.
**Right Chart: Mistral-7B-v0.3**
* **Q-Anchored (PopQA) (Blue solid line):** Starts at 100, drops sharply to approximately 10-20 by layer 10, then remains relatively stable with minor fluctuations.
* **A-Anchored (PopQA) (Brown dashed line):** Starts around 70, remains relatively stable with minor fluctuations between 60 and 80.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts at 100, drops sharply to approximately 20-30 by layer 5, then fluctuates between 20 and 40.
* **A-Anchored (TriviaQA) (Orange dash-dot line):** Starts around 60, rises to approximately 70-80, and remains relatively stable with minor fluctuations.
* **Q-Anchored (HotpotQA) (Red dashed line):** Starts around 60, rises to approximately 80-90, and remains relatively stable with minor fluctuations.
* **A-Anchored (HotpotQA) (Gray dotted line):** Starts around 80, remains relatively stable with minor fluctuations between 70 and 90.
* **Q-Anchored (NQ) (Purple dash-dot line):** Starts around 60, fluctuates significantly between 20 and 60 across the layers.
* **A-Anchored (NQ) (Black dashed line):** Starts around 80, remains relatively stable with minor fluctuations between 70 and 90.
### Key Observations
* For both models, the "Q-Anchored (PopQA)" series shows a significant drop in the "I-Don't-Know Rate" after the initial layers.
* The "A-Anchored" series generally exhibit more stable "I-Don't-Know Rates" compared to the "Q-Anchored" series.
* The Mistral-7B-v0.3 model appears to have a generally lower "I-Don't-Know Rate" for the "Q-Anchored (PopQA)" series after the initial layers compared to Mistral-7B-v0.1.
* The shaded regions around each line indicate the confidence interval or standard deviation, showing the variability in the "I-Don't-Know Rate" across different runs or samples.
### Interpretation
The charts provide insights into how the Mistral-7B models handle uncertainty across different layers and question-answering datasets. The "I-Don't-Know Rate" can be interpreted as a measure of the model's confidence in its predictions. The observed trends suggest that:
* **Question Anchoring vs. Answer Anchoring:** Anchoring the data on the answer generally leads to more stable and often higher "I-Don't-Know Rates," possibly indicating that the model is more aware of its uncertainty when the answer is provided.
* **Dataset Sensitivity:** The models exhibit varying levels of uncertainty depending on the dataset. PopQA, in particular, shows a significant reduction in the "I-Don't-Know Rate" for Q-Anchored data after the initial layers, suggesting that the model becomes more confident in its predictions for this dataset as it processes more layers.
* **Model Version Comparison:** The Mistral-7B-v0.3 model appears to have improved in terms of reducing uncertainty for the Q-Anchored (PopQA) dataset, as indicated by the lower "I-Don't-Know Rate" after the initial layers.
* **Layer-wise Behavior:** The fluctuations in the "I-Don't-Know Rate" across different layers suggest that the model's uncertainty changes as it processes the input through different layers of its neural network architecture.
The data suggests that the model's confidence and uncertainty are influenced by the anchoring method (question vs. answer), the specific question-answering dataset, and the depth of the model (layer number). The comparison between the two model versions highlights potential improvements in uncertainty handling in the newer version (v0.3).
</details>
Figure 33: Comparisons of i-don’t-know rate between pathways, probing mlp activations of the final token.
<details>
<summary>x87.png Details</summary>
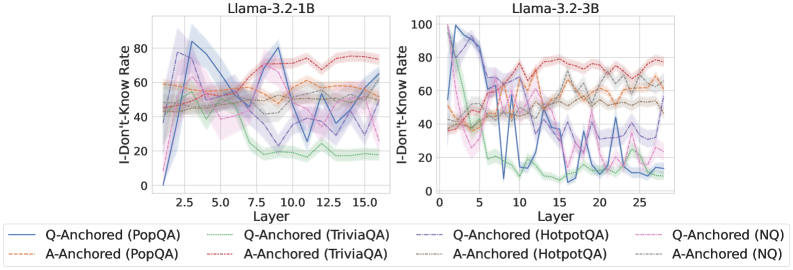
### Visual Description
## Chart: I-Don't-Know Rate vs. Layer for Llama-3.2 Models
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two Llama-3.2 models (1B and 3B). Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored). The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate.
### Components/Axes
**Left Chart (Llama-3.2-1B):**
* **Title:** Llama-3.2-1B
* **X-axis:** Layer, with markers at approximately 2.5, 5.0, 7.5, 10.0, 12.5, and 15.0.
* **Y-axis:** I-Don't-Know Rate, ranging from 0 to 80, with markers at 0, 20, 40, 60, and 80.
**Right Chart (Llama-3.2-3B):**
* **Title:** Llama-3.2-3B
* **X-axis:** Layer, with markers at 0, 5, 10, 15, 20, and 25.
* **Y-axis:** I-Don't-Know Rate, ranging from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
**Legend (Located below both charts):**
* **Blue Solid Line:** Q-Anchored (PopQA)
* **Brown Dashed Line:** A-Anchored (PopQA)
* **Green Solid Line:** Q-Anchored (TriviaQA)
* **Pink Dashed Line:** A-Anchored (TriviaQA)
* **Orange Solid Line:** Q-Anchored (HotpotQA)
* **Gray Dashed Line:** A-Anchored (HotpotQA)
* **Pink Dash-Dot Line:** Q-Anchored (NQ)
* **Gray Dotted Line:** A-Anchored (NQ)
### Detailed Analysis
**Llama-3.2-1B:**
* **Q-Anchored (PopQA) (Blue Solid Line):** Starts at approximately 0, rises sharply to around 80 at layer 2.5, then decreases to approximately 40 at layer 10, and fluctuates around 40-60 for the remaining layers.
* **A-Anchored (PopQA) (Brown Dashed Line):** Starts around 50, remains relatively stable between 50 and 60 across all layers.
* **Q-Anchored (TriviaQA) (Green Solid Line):** Starts around 60, decreases to approximately 20 at layer 7.5, and then remains relatively stable between 20 and 30.
* **A-Anchored (TriviaQA) (Pink Dashed Line):** Starts around 50, remains relatively stable between 50 and 60 across all layers.
* **Q-Anchored (HotpotQA) (Orange Solid Line):** Starts around 50, remains relatively stable between 50 and 60 across all layers.
* **A-Anchored (HotpotQA) (Gray Dashed Line):** Starts around 50, remains relatively stable between 50 and 60 across all layers.
* **Q-Anchored (NQ) (Pink Dash-Dot Line):** Starts around 50, fluctuates between 40 and 70 across all layers.
* **A-Anchored (NQ) (Gray Dotted Line):** Starts around 50, fluctuates between 40 and 60 across all layers.
**Llama-3.2-3B:**
* **Q-Anchored (PopQA) (Blue Solid Line):** Starts at approximately 90, drops sharply to around 10 at layer 7, and then fluctuates between 10 and 50 for the remaining layers.
* **A-Anchored (PopQA) (Brown Dashed Line):** Starts around 40, fluctuates between 40 and 80 across all layers.
* **Q-Anchored (TriviaQA) (Green Solid Line):** Starts around 70, decreases to approximately 10 at layer 15, and then remains relatively stable between 10 and 30.
* **A-Anchored (TriviaQA) (Pink Dashed Line):** Starts around 30, fluctuates between 20 and 50 across all layers.
* **Q-Anchored (HotpotQA) (Orange Solid Line):** Starts around 40, fluctuates between 40 and 80 across all layers.
* **A-Anchored (HotpotQA) (Gray Dashed Line):** Starts around 60, fluctuates between 40 and 70 across all layers.
* **Q-Anchored (NQ) (Pink Dash-Dot Line):** Starts around 100, fluctuates between 20 and 80 across all layers.
* **A-Anchored (NQ) (Gray Dotted Line):** Starts around 50, fluctuates between 40 and 70 across all layers.
### Key Observations
* The Q-Anchored (PopQA) line shows a significant initial spike in the 1B model, followed by a decrease, while the 3B model shows a sharp drop.
* The Q-Anchored (TriviaQA) line shows a decreasing trend in both models.
* The other lines remain relatively stable across all layers in both models.
* The 3B model generally has a higher I-Don't-Know Rate than the 1B model.
### Interpretation
The charts illustrate how the "I-Don't-Know Rate" varies across different layers of the Llama-3.2 models for different question-answering datasets. The Q-Anchored (PopQA) line's behavior suggests that the model initially struggles with PopQA questions but learns to handle them better in later layers. The decreasing trend of the Q-Anchored (TriviaQA) line indicates that the model improves its ability to answer TriviaQA questions as it progresses through the layers. The relatively stable behavior of the other lines suggests that the model's performance on those datasets remains consistent across all layers. The higher I-Don't-Know Rate in the 3B model may indicate that it is more conservative in its answers or that it is exposed to more challenging questions. The differences between Q-Anchored and A-Anchored versions of each dataset may reflect the model's ability to understand the question versus the answer.
</details>
<details>
<summary>x88.png Details</summary>
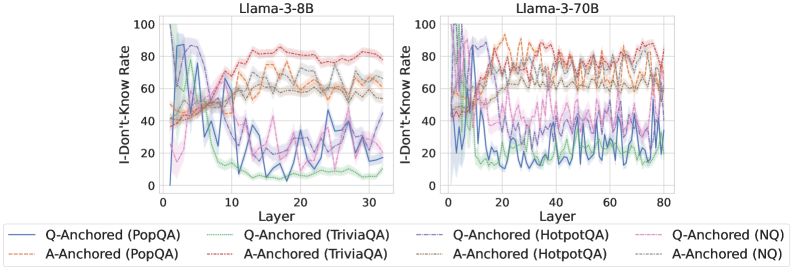
### Visual Description
## Chart: I-Don't-Know Rate vs. Layer for Llama-3 Models
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two Llama-3 models (8B and 70B). Each chart displays the rate for various question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) using both question-anchored (Q-Anchored) and answer-anchored (A-Anchored) approaches. The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate.
### Components/Axes
* **Titles:**
* Left Chart: "Llama-3-8B"
* Right Chart: "Llama-3-70B"
* **Y-Axis:**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: "Layer"
* Left Chart Scale: 0 to 30, with tick marks at 0, 10, 20, and 30.
* Right Chart Scale: 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid blue line
* A-Anchored (PopQA): Dashed brown line
* Q-Anchored (TriviaQA): Dotted green line
* A-Anchored (TriviaQA): Dash-dot gray line
* Q-Anchored (HotpotQA): Dash-dot-dot red line
* A-Anchored (HotpotQA): Dotted orange line
* Q-Anchored (NQ): Dashed pink line
* A-Anchored (NQ): Dash-dot black line
### Detailed Analysis
**Llama-3-8B (Left Chart):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 0, rises sharply to around 90 by layer 5, then fluctuates between 10 and 40 for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts at approximately 40, rises to around 60 by layer 10, and then fluctuates between 50 and 70 for the remaining layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 50, drops to around 10 by layer 10, and then fluctuates between 10 and 30 for the remaining layers.
* **A-Anchored (TriviaQA):** (Dash-dot Gray) Starts at approximately 50, rises to around 60 by layer 10, and then fluctuates between 50 and 60 for the remaining layers.
* **Q-Anchored (HotpotQA):** (Dash-dot-dot Red) Starts at approximately 40, rises to around 90 by layer 10, and then fluctuates between 70 and 90 for the remaining layers.
* **A-Anchored (HotpotQA):** (Dotted Orange) Starts at approximately 40, rises to around 70 by layer 10, and then fluctuates between 60 and 70 for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Pink) Starts at approximately 40, rises to around 60 by layer 10, and then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (NQ):** (Dash-dot Black) Starts at approximately 50, rises to around 60 by layer 10, and then fluctuates between 50 and 60 for the remaining layers.
**Llama-3-70B (Right Chart):**
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 20, fluctuates between 10 and 40 across all layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts at approximately 60, fluctuates between 70 and 90 across all layers.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts at approximately 40, fluctuates between 10 and 30 across all layers.
* **A-Anchored (TriviaQA):** (Dash-dot Gray) Starts at approximately 60, fluctuates between 60 and 80 across all layers.
* **Q-Anchored (HotpotQA):** (Dash-dot-dot Red) Starts at approximately 60, fluctuates between 70 and 90 across all layers.
* **A-Anchored (HotpotQA):** (Dotted Orange) Starts at approximately 60, fluctuates between 70 and 90 across all layers.
* **Q-Anchored (NQ):** (Dashed Pink) Starts at approximately 40, fluctuates between 20 and 50 across all layers.
* **A-Anchored (NQ):** (Dash-dot Black) Starts at approximately 60, fluctuates between 60 and 80 across all layers.
### Key Observations
* The I-Don't-Know Rate varies significantly depending on the dataset and anchoring method (Q-Anchored vs. A-Anchored).
* The Llama-3-70B model shows more consistent I-Don't-Know Rates across layers compared to the Llama-3-8B model, which exhibits more pronounced initial changes in the first 10 layers.
* For both models, A-Anchored approaches generally result in higher I-Don't-Know Rates than Q-Anchored approaches for PopQA, TriviaQA, and NQ datasets.
* HotpotQA shows high I-Don't-Know Rates for both Q-Anchored and A-Anchored approaches in both models.
### Interpretation
The charts illustrate how the "I-Don't-Know Rate" changes across different layers of the Llama-3 models when processing various question-answering datasets. The differences between Q-Anchored and A-Anchored approaches suggest that the way questions and answers are processed significantly impacts the model's confidence in its responses. The higher I-Don't-Know Rates for HotpotQA may indicate that this dataset poses a greater challenge for the models, possibly due to its complexity or the type of reasoning required. The more stable rates in the Llama-3-70B model suggest that larger models might have more consistent performance across layers. The initial fluctuations in the Llama-3-8B model could indicate that the earlier layers are more critical for learning and adapting to the specific dataset.
</details>
<details>
<summary>x89.png Details</summary>
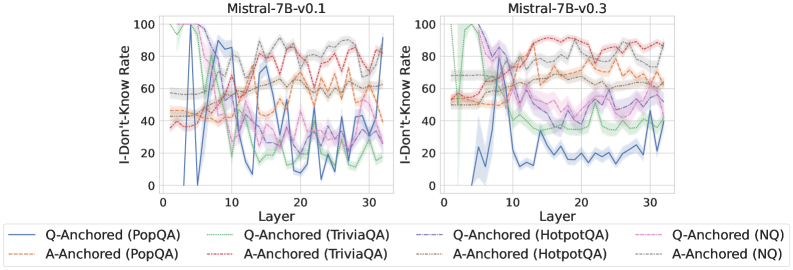
### Visual Description
## Line Graphs: "I-Don't-Know" Rate vs. Layer for Mistral-7B-v0.1 and Mistral-7B-v0.3
### Overview
The image presents two line graphs comparing the "I-Don't-Know" rate across different layers of the Mistral-7B model, specifically versions v0.1 and v0.3. Each graph plots the "I-Don't-Know" rate (y-axis) against the layer number (x-axis) for various question-answering (QA) tasks, distinguished by whether the question (Q) or answer (A) is anchored and the specific dataset used (PopQA, TriviaQA, HotpotQA, NQ). The graphs aim to illustrate how the model's uncertainty varies across layers and between the two versions.
### Components/Axes
* **Titles:**
* Left Graph: "Mistral-7B-v0.1"
* Right Graph: "Mistral-7B-v0.3"
* **Y-Axis:**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: "Layer"
* Scale: 0 to 30, with tick marks at intervals of 5 (0, 10, 20, 30).
* **Legend:** Located at the bottom of the image, it identifies the different QA tasks represented by different colored lines:
* Blue: Q-Anchored (PopQA)
* Brown Dashed: A-Anchored (PopQA)
* Green Dotted: Q-Anchored (TriviaQA)
* Purple Dashed: A-Anchored (TriviaQA)
* Gray Dashed: Q-Anchored (HotpotQA)
* Orange Dotted: A-Anchored (HotpotQA)
* Red Dashed: Q-Anchored (NQ)
* Black Dotted: A-Anchored (NQ)
### Detailed Analysis
#### Mistral-7B-v0.1 (Left Graph)
* **Q-Anchored (PopQA) - Blue:** Starts at 100% at layer 0, drops sharply to near 0% by layer 10, then fluctuates between 0% and 40% for the remaining layers.
* Values: ~100% at layer 0, ~0% at layer 10, fluctuates between ~0-40% from layer 10-30.
* **A-Anchored (PopQA) - Brown Dashed:** Starts around 45% and remains relatively stable between 40% and 60% across all layers.
* Values: Stays between ~40-60% from layer 0-30.
* **Q-Anchored (TriviaQA) - Green Dotted:** Starts at 0% at layer 0, rises sharply to 100% at layer 5, then fluctuates between 0% and 60% for the remaining layers.
* Values: ~0% at layer 0, ~100% at layer 5, fluctuates between ~0-60% from layer 5-30.
* **A-Anchored (TriviaQA) - Purple Dashed:** Starts around 40% at layer 0, drops to 20% at layer 10, then fluctuates between 20% and 60% for the remaining layers.
* Values: ~40% at layer 0, ~20% at layer 10, fluctuates between ~20-60% from layer 10-30.
* **Q-Anchored (HotpotQA) - Gray Dashed:** Starts around 50% and remains relatively stable between 40% and 80% across all layers.
* Values: Stays between ~40-80% from layer 0-30.
* **A-Anchored (HotpotQA) - Orange Dotted:** Starts around 50% and remains relatively stable between 50% and 70% across all layers.
* Values: Stays between ~50-70% from layer 0-30.
* **Q-Anchored (NQ) - Red Dashed:** Starts around 40% and fluctuates between 40% and 90% across all layers.
* Values: Fluctuates between ~40-90% from layer 0-30.
* **A-Anchored (NQ) - Black Dotted:** Starts around 50% and fluctuates between 40% and 70% across all layers.
* Values: Fluctuates between ~40-70% from layer 0-30.
#### Mistral-7B-v0.3 (Right Graph)
* **Q-Anchored (PopQA) - Blue:** Starts at 0% at layer 0, rises to 40% at layer 5, then fluctuates between 10% and 40% for the remaining layers.
* Values: ~0% at layer 0, ~40% at layer 5, fluctuates between ~10-40% from layer 5-30.
* **A-Anchored (PopQA) - Brown Dashed:** Starts around 65% and remains relatively stable between 60% and 80% across all layers.
* Values: Stays between ~60-80% from layer 0-30.
* **Q-Anchored (TriviaQA) - Green Dotted:** Starts at 60% at layer 0, rises to 100% at layer 5, then fluctuates between 40% and 60% for the remaining layers.
* Values: ~60% at layer 0, ~100% at layer 5, fluctuates between ~40-60% from layer 5-30.
* **A-Anchored (TriviaQA) - Purple Dashed:** Starts around 70% at layer 0, drops to 40% at layer 10, then fluctuates between 40% and 60% for the remaining layers.
* Values: ~70% at layer 0, ~40% at layer 10, fluctuates between ~40-60% from layer 10-30.
* **Q-Anchored (HotpotQA) - Gray Dashed:** Starts around 70% and remains relatively stable between 70% and 90% across all layers.
* Values: Stays between ~70-90% from layer 0-30.
* **A-Anchored (HotpotQA) - Orange Dotted:** Starts around 70% and remains relatively stable between 70% and 80% across all layers.
* Values: Stays between ~70-80% from layer 0-30.
* **Q-Anchored (NQ) - Red Dashed:** Starts around 70% and fluctuates between 70% and 90% across all layers.
* Values: Fluctuates between ~70-90% from layer 0-30.
* **A-Anchored (NQ) - Black Dotted:** Starts around 60% and fluctuates between 60% and 80% across all layers.
* Values: Fluctuates between ~60-80% from layer 0-30.
### Key Observations
* **Q-Anchored (PopQA):** Shows a significant drop in "I-Don't-Know" rate in v0.1, starting high and decreasing rapidly, while in v0.3, it starts low and remains relatively low.
* **Overall Stability:** Most of the other QA tasks show relatively stable "I-Don't-Know" rates across layers in both versions, with some fluctuations.
* **Version Comparison:** The "I-Don't-Know" rates for most tasks are generally higher in v0.3 compared to v0.1, suggesting a potential increase in uncertainty or a change in the model's confidence calibration.
### Interpretation
The graphs provide insights into how the Mistral-7B model's uncertainty, as measured by the "I-Don't-Know" rate, varies across different layers and QA tasks. The most notable difference between versions v0.1 and v0.3 is the behavior of the Q-Anchored (PopQA) task, where v0.1 shows a significant decrease in the "I-Don't-Know" rate as the layers progress, while v0.3 maintains a low rate throughout. This suggests that the model's ability to handle PopQA questions has improved or changed significantly between the two versions.
The relatively stable "I-Don't-Know" rates for other tasks indicate that the model's uncertainty is consistent across layers for those specific QA scenarios. The generally higher rates in v0.3 might reflect a deliberate recalibration of the model's confidence, potentially trading off some accuracy for increased awareness of its limitations.
These findings are valuable for understanding the model's strengths and weaknesses in different QA tasks and for guiding further development and refinement of the Mistral-7B model. The differences between the two versions highlight the impact of specific training or architectural changes on the model's uncertainty and performance.
</details>
Figure 34: Comparisons of i-don’t-know rate between pathways, probing mlp activations of the token immediately preceding the exact answer tokens.
<details>
<summary>x90.png Details</summary>
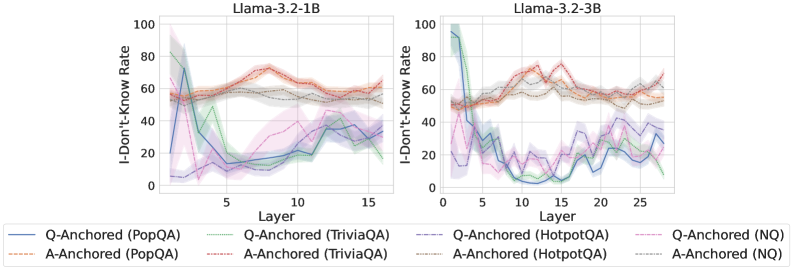
### Visual Description
## Line Charts: I-Don't-Know Rate vs. Layer for Llama-3.2-1B and Llama-3.2-3B
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two language models, Llama-3.2-1B and Llama-3.2-3B. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored by either the question (Q-Anchored) or the answer (A-Anchored). The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate in percentage.
### Components/Axes
* **Chart Titles:**
* Left Chart: "Llama-3.2-1B"
* Right Chart: "Llama-3.2-3B"
* **Y-Axis:**
* Label: "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:**
* Label: "Layer"
* Left Chart Scale: 0 to 15, with tick marks at 0, 5, 10, and 15.
* Right Chart Scale: 0 to 25, with tick marks at 0, 5, 10, 15, 20, and 25.
* **Legend:** Located at the bottom of the image, describing the data series:
* Blue solid line: "Q-Anchored (PopQA)"
* Brown dashed line: "A-Anchored (PopQA)"
* Green dotted line: "Q-Anchored (TriviaQA)"
* Green dashed-dotted line: "A-Anchored (TriviaQA)"
* Red dashed-dotted line: "Q-Anchored (HotpotQA)"
* Black dotted line: "A-Anchored (NQ)"
* Purple dashed line: "Q-Anchored (NQ)"
* Purple dashed-dotted line: "A-Anchored (HotpotQA)"
### Detailed Analysis
#### Llama-3.2-1B (Left Chart)
* **Q-Anchored (PopQA) (Blue solid line):** Starts high (around 60-80), drops sharply to approximately 10-20 by layer 5, then gradually increases to around 20-30 by layer 15.
* **A-Anchored (PopQA) (Brown dashed line):** Relatively stable, fluctuating between 55 and 70 across all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts around 60, drops to approximately 20-30 by layer 5, then fluctuates between 20 and 40.
* **A-Anchored (TriviaQA) (Green dashed-dotted line):** Starts around 50, drops to approximately 20-30 by layer 5, then fluctuates between 20 and 40.
* **Q-Anchored (HotpotQA) (Red dashed-dotted line):** Relatively stable, fluctuating between 60 and 75 across all layers.
* **A-Anchored (NQ) (Black dotted line):** Relatively stable, fluctuating between 55 and 70 across all layers.
* **Q-Anchored (NQ) (Purple dashed line):** Starts low (around 5-10), increases to approximately 40-50 by layer 10, then decreases to around 30-40 by layer 15.
* **A-Anchored (HotpotQA) (Purple dashed-dotted line):** Starts low (around 5-10), increases to approximately 40-50 by layer 10, then decreases to around 30-40 by layer 15.
#### Llama-3.2-3B (Right Chart)
* **Q-Anchored (PopQA) (Blue solid line):** Starts very high (near 100), drops sharply to near 0 by layer 5, then remains low (around 0-10) for the remaining layers.
* **A-Anchored (PopQA) (Brown dashed line):** Relatively stable, fluctuating between 50 and 75 across all layers.
* **Q-Anchored (TriviaQA) (Green dotted line):** Starts high (around 60), drops to approximately 5-15 by layer 5, then fluctuates between 5 and 25.
* **A-Anchored (TriviaQA) (Green dashed-dotted line):** Starts around 50, drops to approximately 10-20 by layer 5, then fluctuates between 10 and 30.
* **Q-Anchored (HotpotQA) (Red dashed-dotted line):** Relatively stable, fluctuating between 50 and 75 across all layers.
* **A-Anchored (NQ) (Black dotted line):** Relatively stable, fluctuating between 50 and 70 across all layers.
* **Q-Anchored (NQ) (Purple dashed line):** Starts low (around 10-20), increases to approximately 30-40 by layer 10, then decreases to around 10-20 by layer 25.
* **A-Anchored (HotpotQA) (Purple dashed-dotted line):** Starts low (around 10-20), increases to approximately 30-40 by layer 10, then decreases to around 10-20 by layer 25.
### Key Observations
* For both models, the "I-Don't-Know Rate" for Q-Anchored (PopQA) and Q-Anchored (TriviaQA) decreases significantly in the initial layers.
* The A-Anchored series (PopQA, TriviaQA, and NQ) tend to be more stable across layers compared to their Q-Anchored counterparts.
* The Llama-3.2-3B model shows a more pronounced drop in the "I-Don't-Know Rate" for Q-Anchored (PopQA) compared to Llama-3.2-1B.
* The Q-Anchored (NQ) and A-Anchored (HotpotQA) series exhibit a similar trend of increasing and then decreasing "I-Don't-Know Rate" across layers.
### Interpretation
The charts suggest that the initial layers of the language models play a crucial role in determining whether the model "knows" the answer to a question, especially when the question is directly anchored. The significant drop in the "I-Don't-Know Rate" for Q-Anchored (PopQA) and Q-Anchored (TriviaQA) in the early layers indicates that these layers are responsible for extracting relevant information from the question. The stability of the A-Anchored series implies that the model's confidence in its answer is less affected by the specific layer once the answer is anchored. The difference in the magnitude of the drop between Llama-3.2-1B and Llama-3.2-3B for Q-Anchored (PopQA) may indicate that the larger model (3B) is more effective at extracting information from the question in the initial layers. The similar trends observed for Q-Anchored (NQ) and A-Anchored (HotpotQA) suggest a potential relationship between these datasets in terms of how the model processes them across different layers.
</details>
<details>
<summary>x91.png Details</summary>
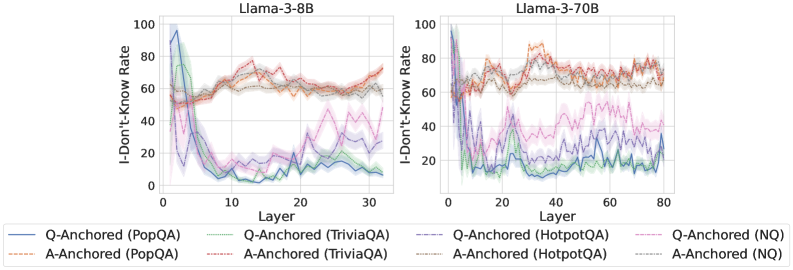
### Visual Description
## Chart: I-Don't-Know Rate vs. Layer for Llama-3-8B and Llama-3-70B
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of two language models, Llama-3-8B and Llama-3-70B. Each chart plots the rate for question-anchored (Q-Anchored) and answer-anchored (A-Anchored) data across various question-answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. The x-axis represents the layer number, and the y-axis represents the I-Don't-Know Rate, ranging from 0 to 100.
### Components/Axes
* **Chart Titles:** "Llama-3-8B" (left chart) and "Llama-3-70B" (right chart).
* **Y-Axis Label:** "I-Don't-Know Rate"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis Label:** "Layer"
* Llama-3-8B: 0 to 30, with tick marks every 10 layers.
* Llama-3-70B: 0 to 80, with tick marks every 20 layers.
* **Legend:** Located at the bottom of the image.
* **Q-Anchored (PopQA):** Solid blue line
* **A-Anchored (PopQA):** Dashed brown line
* **Q-Anchored (TriviaQA):** Solid green line
* **A-Anchored (TriviaQA):** Dashed light green line
* **Q-Anchored (HotpotQA):** Solid orange line
* **A-Anchored (HotpotQA):** Dashed orange line
* **Q-Anchored (NQ):** Dashed purple line
* **A-Anchored (NQ):** Dotted gray line
### Detailed Analysis
#### Llama-3-8B (Left Chart)
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 95 at layer 0, drops sharply to around 10 by layer 10, and then remains relatively stable between 5 and 15 for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts at approximately 50 at layer 0, increases to around 60-65 by layer 10, and then fluctuates between 60 and 70 for the remaining layers.
* **Q-Anchored (TriviaQA):** (Solid Green) Starts at approximately 60 at layer 0, drops to around 5-10 by layer 15, and then remains relatively stable between 0 and 10 for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Light Green) Starts at approximately 50 at layer 0, drops to around 10-15 by layer 15, and then remains relatively stable between 5 and 15 for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Purple) Starts at approximately 50 at layer 0, drops to around 10-20 by layer 10, and then fluctuates between 10 and 30 for the remaining layers.
* **A-Anchored (NQ):** (Dotted Gray) Starts at approximately 60 at layer 0, increases to around 60-70 by layer 10, and then fluctuates between 60 and 70 for the remaining layers.
#### Llama-3-70B (Right Chart)
* **Q-Anchored (PopQA):** (Solid Blue) Starts at approximately 95 at layer 0, drops sharply to around 20 by layer 20, and then fluctuates between 15 and 25 for the remaining layers.
* **A-Anchored (PopQA):** (Dashed Brown) Starts at approximately 60 at layer 0, increases to around 70-80 by layer 20, and then fluctuates between 65 and 75 for the remaining layers.
* **Q-Anchored (TriviaQA):** (Solid Green) Starts at approximately 60 at layer 0, drops to around 10-20 by layer 20, and then fluctuates between 10 and 20 for the remaining layers.
* **A-Anchored (TriviaQA):** (Dashed Light Green) Starts at approximately 50 at layer 0, drops to around 20-30 by layer 20, and then fluctuates between 20 and 30 for the remaining layers.
* **Q-Anchored (HotpotQA):** (Solid Orange) Starts at approximately 60 at layer 0, increases to around 70-80 by layer 20, and then fluctuates between 70 and 90 for the remaining layers.
* **A-Anchored (HotpotQA):** (Dashed Orange) Starts at approximately 60 at layer 0, increases to around 70-80 by layer 20, and then fluctuates between 65 and 75 for the remaining layers.
* **Q-Anchored (NQ):** (Dashed Purple) Starts at approximately 50 at layer 0, drops to around 20-30 by layer 20, and then fluctuates between 20 and 40 for the remaining layers.
* **A-Anchored (NQ):** (Dotted Gray) Starts at approximately 60 at layer 0, increases to around 60-70 by layer 20, and then fluctuates between 60 and 70 for the remaining layers.
### Key Observations
* For both models, the Q-Anchored (PopQA), Q-Anchored (TriviaQA), and Q-Anchored (NQ) rates decrease significantly in the initial layers.
* For both models, the A-Anchored (PopQA), A-Anchored (TriviaQA), A-Anchored (HotpotQA), and A-Anchored (NQ) rates tend to increase or remain relatively stable across layers.
* The Llama-3-70B model shows more fluctuation in the I-Don't-Know Rate across layers compared to the Llama-3-8B model.
* The HotpotQA dataset shows a higher I-Don't-Know Rate for Q-Anchored data in the Llama-3-70B model.
### Interpretation
The data suggests that the initial layers of the language models are crucial for reducing the "I-Don't-Know Rate" for question-anchored data. The difference between Q-Anchored and A-Anchored rates indicates that the model's confidence varies depending on whether the question or the answer is used as the anchor. The fluctuations in the Llama-3-70B model might be due to its larger size and complexity, leading to more variability in its responses across different layers. The higher I-Don't-Know Rate for HotpotQA in the Llama-3-70B model could indicate that this dataset poses a greater challenge for the model.
</details>
<details>
<summary>x92.png Details</summary>
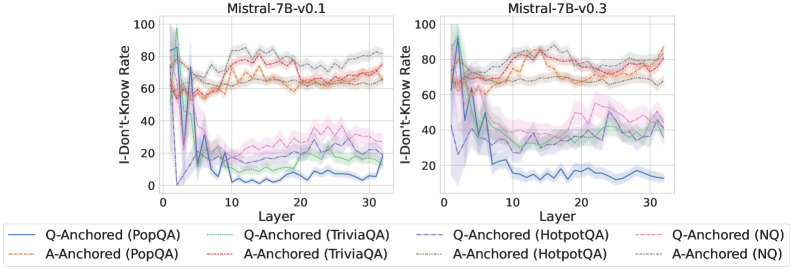
### Visual Description
## Line Chart: I-Don't-Know Rate vs. Layer for Mistral-7B-v0.1 and Mistral-7B-v0.3
### Overview
The image presents two line charts comparing the "I-Don't-Know Rate" across different layers of the Mistral-7B model, specifically versions v0.1 and v0.3. Each chart displays six data series, representing different question-answering datasets (PopQA, TriviaQA, HotpotQA, and NQ) anchored either to the question (Q-Anchored) or the answer (A-Anchored). The x-axis represents the layer number, ranging from 0 to 30, while the y-axis represents the "I-Don't-Know Rate" from 0 to 100.
### Components/Axes
* **Titles:**
* Left Chart: Mistral-7B-v0.1
* Right Chart: Mistral-7B-v0.3
* **X-Axis:**
* Label: Layer
* Scale: 0 to 30, with tick marks at intervals of 10.
* **Y-Axis:**
* Label: I-Don't-Know Rate
* Scale: 0 to 100, with tick marks at intervals of 20.
* **Legend:** Located at the bottom of the image.
* Q-Anchored (PopQA): Solid Blue Line
* A-Anchored (PopQA): Dashed Brown Line
* Q-Anchored (TriviaQA): Dotted Green Line
* A-Anchored (TriviaQA): Dash-Dotted Pink Line
* Q-Anchored (HotpotQA): Dash-Dot-Dotted Gray Line
* A-Anchored (HotpotQA): Solid Red Line
* Q-Anchored (NQ): Dashed-Dotted Purple Line
* A-Anchored (NQ): Dotted-Dashed Gray Line
### Detailed Analysis
#### Mistral-7B-v0.1 (Left Chart)
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts high (around 60-80) and rapidly decreases to around 10-20 by layer 10, then remains relatively stable around that level.
* Layer 0: ~60
* Layer 10: ~15
* Layer 30: ~10
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 60, increases to 80 by layer 10, and then fluctuates between 70 and 80.
* Layer 0: ~60
* Layer 10: ~80
* Layer 30: ~70
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts high (around 80), decreases to around 10-20 by layer 10, and then remains relatively stable around that level.
* Layer 0: ~80
* Layer 10: ~10
* Layer 30: ~15
* **A-Anchored (TriviaQA):** (Dash-Dotted Pink Line) Starts around 60, decreases to around 20-40 by layer 10, and then remains relatively stable around that level.
* Layer 0: ~60
* Layer 10: ~30
* Layer 30: ~30
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Gray Line) Starts around 80, increases to 90 by layer 5, and then fluctuates between 70 and 90.
* Layer 0: ~80
* Layer 10: ~80
* Layer 30: ~80
* **A-Anchored (HotpotQA):** (Solid Red Line) Starts around 60, increases to 70 by layer 10, and then fluctuates between 60 and 80.
* Layer 0: ~60
* Layer 10: ~70
* Layer 30: ~70
* **Q-Anchored (NQ):** (Dashed-Dotted Purple Line) Starts around 60, decreases to around 20-40 by layer 10, and then remains relatively stable around that level.
* Layer 0: ~60
* Layer 10: ~30
* Layer 30: ~30
* **A-Anchored (NQ):** (Dotted-Dashed Gray Line) Starts around 80, increases to 90 by layer 5, and then fluctuates between 70 and 90.
* Layer 0: ~80
* Layer 10: ~80
* Layer 30: ~80
#### Mistral-7B-v0.3 (Right Chart)
* **Q-Anchored (PopQA):** (Solid Blue Line) Starts high (around 80-100) and rapidly decreases to around 10-20 by layer 10, then remains relatively stable around that level.
* Layer 0: ~80
* Layer 10: ~15
* Layer 30: ~15
* **A-Anchored (PopQA):** (Dashed Brown Line) Starts around 60, increases to 80 by layer 10, and then fluctuates between 70 and 90.
* Layer 0: ~60
* Layer 10: ~80
* Layer 30: ~80
* **Q-Anchored (TriviaQA):** (Dotted Green Line) Starts high (around 80), decreases to around 10-20 by layer 10, and then remains relatively stable around that level.
* Layer 0: ~80
* Layer 10: ~15
* Layer 30: ~20
* **A-Anchored (TriviaQA):** (Dash-Dotted Pink Line) Starts around 60, decreases to around 20-40 by layer 10, and then remains relatively stable around that level.
* Layer 0: ~60
* Layer 10: ~30
* Layer 30: ~30
* **Q-Anchored (HotpotQA):** (Dash-Dot-Dotted Gray Line) Starts around 80, increases to 90 by layer 5, and then fluctuates between 70 and 90.
* Layer 0: ~80
* Layer 10: ~80
* Layer 30: ~80
* **A-Anchored (HotpotQA):** (Solid Red Line) Starts around 60, increases to 80 by layer 10, and then fluctuates between 70 and 90.
* Layer 0: ~60
* Layer 10: ~80
* Layer 30: ~80
* **Q-Anchored (NQ):** (Dashed-Dotted Purple Line) Starts around 60, decreases to around 20-40 by layer 10, and then remains relatively stable around that level.
* Layer 0: ~60
* Layer 10: ~30
* Layer 30: ~30
* **A-Anchored (NQ):** (Dotted-Dashed Gray Line) Starts around 80, increases to 90 by layer 5, and then fluctuates between 70 and 90.
* Layer 0: ~80
* Layer 10: ~80
* Layer 30: ~80
### Key Observations
* **Q-Anchored (PopQA) and Q-Anchored (TriviaQA):** Both exhibit a similar trend of a sharp decline in "I-Don't-Know Rate" in the initial layers, followed by stabilization.
* **A-Anchored (PopQA), Q-Anchored (HotpotQA), A-Anchored (HotpotQA), and A-Anchored (NQ):** These series generally maintain a higher "I-Don't-Know Rate" across all layers.
* **Model Version Comparison:** The trends are generally similar between Mistral-7B-v0.1 and Mistral-7B-v0.3, but the v0.3 model seems to have a slightly higher "I-Don't-Know Rate" for some series in the initial layers.
### Interpretation
The charts suggest that the "I-Don't-Know Rate" varies significantly depending on the question-answering dataset and whether the anchoring is done to the question or the answer. The rapid decline in the "I-Don't-Know Rate" for Q-Anchored (PopQA) and Q-Anchored (TriviaQA) in the initial layers indicates that the model quickly learns to answer these types of questions. Conversely, the higher and more stable "I-Don't-Know Rate" for A-Anchored (PopQA), Q-Anchored (HotpotQA), A-Anchored (HotpotQA), and A-Anchored (NQ) suggests that these question types are more challenging for the model, and it struggles to provide confident answers even after processing through multiple layers. The slight differences between v0.1 and v0.3 might indicate minor improvements or changes in the model's behavior, but the overall trends remain consistent.
</details>
Figure 35: Comparisons of i-don’t-know rate between pathways, probing mlp activations of the last exact answer token.
Appendix H Pathway-Aware Detection
Method LLama-3.2-1B LLama-3.2-3B PopQA TriviaQA HotpotQA NQ PopQA TriviaQA HotpotQA NQ P(True) 60.00 49.65 43.34 52.83 54.58 51.76 47.73 53.78 Logits-mean 74.89 60.24 60.18 49.92 73.47 63.46 60.35 54.89 Logits-max 58.56 52.37 52.29 46.19 56.03 54.33 48.65 48.88 Logits-min 78.66 62.37 67.14 51.20 80.92 69.60 71.11 58.24 Scores-mean 72.91 61.13 62.16 64.67 67.99 61.96 64.91 61.71 Scores-max 69.33 59.74 61.29 64.08 63.34 61.92 61.09 57.56 Scores-min 64.84 55.93 59.28 55.81 61.51 56.76 63.95 57.43 Probing Baseline 94.25 77.17 90.25 74.83 90.96 76.61 86.54 74.20 \rowcolor mygray MoP-RandomGate 83.69 69.20 84.11 68.76 79.69 72.38 75.13 67.11 \rowcolor mygray MoP-VanillaExperts 93.86 78.63 90.91 75.73 90.98 77.68 86.41 75.30 \rowcolor mygray MoP 95.85 80.07 91.51 79.19 92.74 78.72 88.16 78.14 \rowcolor mygray PR 96.18 84.22 92.80 86.45 95.70 80.66 90.66 81.91
Table 8: Comparison of hallucination detection performance (AUC) on LLama-3.2-1B and LLama-3.2-3B.
Method LLama-3-8B LLama-3-70B PopQA TriviaQA HotpotQA NQ PopQA TriviaQA HotpotQA NQ P(True) 55.85 49.92 52.14 53.27 54.83 50.96 49.39 51.18 Logits-mean 74.52 60.39 51.94 52.63 67.81 52.40 50.45 48.28 Logits-max 58.08 52.20 46.40 47.89 56.21 48.16 43.42 45.33 Logits-min 85.36 70.89 61.28 56.50 79.96 61.53 62.63 52.16 Scores-mean 62.87 62.09 62.06 60.32 56.81 60.70 60.91 58.05 Scores-max 56.62 60.24 59.85 56.06 55.15 59.60 57.32 51.93 Scores-min 60.99 58.27 60.33 57.68 58.77 58.22 64.06 58.05 Probing Baseline 88.71 77.58 82.23 70.20 86.88 81.59 84.45 74.39 \rowcolor mygray MoP-RandomGate 75.52 69.17 79.88 66.56 67.96 70.56 72.16 66.28 \rowcolor mygray MoP-VanillaExperts 89.11 78.73 84.57 71.21 86.04 82.47 82.48 73.85 \rowcolor mygray MoP 92.11 81.18 85.45 74.64 88.54 84.12 86.65 76.12 \rowcolor mygray PR 94.01 83.13 87.81 79.10 90.08 84.21 87.69 78.24
Table 9: Comparison of hallucination detection performance (AUC) on LLama-3-8B and LLama-3-70B.
Method Mistral-7B-v0.1 Mistral-7B-v0.3 PopQA TriviaQA HotpotQA NQ PopQA TriviaQA HotpotQA NQ P(True) 48.78 50.43 51.94 55.52 45.49 47.61 57.87 52.79 Logits-mean 69.09 64.95 54.47 59.41 69.52 66.76 55.45 57.88 Logits-max 54.37 54.76 46.74 56.45 54.34 55.24 48.39 54.37 Logits-min 86.02 76.56 68.06 53.73 87.05 77.33 68.08 54.40 Scores-mean 59.00 59.61 64.18 57.60 58.84 60.22 63.28 60.05 Scores-max 51.71 56.58 63.29 55.82 53.00 55.55 63.13 57.73 Scores-min 60.00 57.48 61.17 48.51 60.59 57.84 59.85 50.76 Probing Baseline 89.61 78.43 83.76 74.10 87.39 81.74 83.19 73.60 \rowcolor mygray MoP-RandomGate 80.50 68.27 74.51 68.05 79.81 70.88 72.23 61.19 \rowcolor mygray MoP-VanillaExperts 89.82 79.51 83.54 74.78 88.53 80.93 82.93 73.77 \rowcolor mygray MoP 92.44 84.03 84.63 76.38 91.66 83.57 85.82 76.87 \rowcolor mygray PR 94.72 84.66 89.04 80.92 93.09 84.36 89.03 79.09
Table 10: Comparison of hallucination detection performance (AUC) on Mistral-7B-v0.1 and Mistral-7B-v0.3.