## Imandra CodeLogician: Neuro-Symbolic Reasoning for Precise Analysis of Software Logic
Hongyu Lin 1 , Samer Abdallah 1 , Makar Valentinov 1 , Paul Brennan 1 , Elijah Kagan 1 , Christoph M. Wintersteiger 1 , Denis Ignatovich 1 , and Grant Passmore ∗ 1,2
1 Imandra Inc.
2 Clare Hall, University of Cambridge
{ hongyu,samer,makar,paul,elijah,christoph,denis,grant } @imandra.ai
February 10, 2026
## Abstract
Large Language Models (LLMs) have shown strong performance on code understanding and software engineering tasks, yet they fundamentally lack the ability to perform precise, exhaustive mathematical reasoning about program behavior. Existing benchmarks either focus on mathematical proof automation, largely disconnected from real-world software, or on engineering tasks that do not require semantic rigor.
We present CodeLogician 1 , a neurosymbolic agent and framework for precise analysis of software logic, and its integration with ImandraX 2 , an industrial automated reasoning engine successfully deployed in financial markets, safety-critical systems and government applications. Unlike prior approaches that use formal methods primarily to validate or filter LLM outputs, CodeLogician uses LLMs to help construct explicit formal models ('mental models') of software systems, enabling automated reasoning to answer rich semantic questions beyond binary verification outcomes. While the current implementation builds on ImandraX and benefits from its unique features designed for large-scale industrial formal verification and software understanding, the framework is explicitly designed to be reasoner-agnostic and can support additional formal reasoning backends.
To rigorously evaluate mathematical reasoning about software logic, we introduce a new benchmark dataset code-logic-bench 3 targeting the previously unaddressed middle ground between theorem proving and software engineering benchmarks. The benchmark measures correctness and efficacy of reasoning about program state spaces, control flow, coverage constraints, decision boundaries, and edge cases, with ground truth defined via formal modeling and automated decomposition.
Using this benchmark set, we compare LLM-only reasoning against LLMs augmented with CodeLogician . Across all evaluated models, formal augmentation with CodeLogician yields substantial and consistent improvements, closing a 41-47 percentage point gap in reasoning accuracy and achieving complete coverage while LLM-only approaches remain approximate or incorrect. These results demonstrate that the neurosymbolic integration of LLMs with formal reasoning engines is essential for scaling program analysis beyond heuristic reasoning toward rigorous, autonomous software understanding and formal verification.
∗ The author would like to thank the Isaac Newton Institute for Mathematical Sciences, Cambridge, for support and hospitality during the programme Big Proof: Formalizing Mathematics at Scale , where some of the work on this paper was undertaken. This work was supported by EPSRC grant EP/Z000580/1.
1 https://www.codelogician.dev
2 https://www.imandra.ai/core
3 https://github.com/imandra-ai/code-logic-bench
## Contents
| Introduction | Introduction | 4 |
|---------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------|
| 1.1 Beyond Verification-as-Filtering | . . . . . . | . . . . . . . . . . 4 |
| | . . . . | . . . . . . . . . . 4 |
| 1.2 | Neuro-Symbolic Complementarity IML Agent . . . . . . | . . . . . . . . . . 5 . . . . . . . . . . . . . . . . . . . . 7 |
| 1.3 ImandraX and Reasoner-Agnostic Design | 1.3 ImandraX and Reasoner-Agnostic Design | . . . . . . . . . . 4 |
| 1.4 The Missing Benchmark: Mathematical Reasoning About . | 1.4 The Missing Benchmark: Mathematical Reasoning About . | . . . . . . . . . . 5 |
| 1.5 Contributions . . . . . . . . . . . . . . . . . . . . . . . | 1.5 Contributions . . . . . . . . . . . . . . . . . . . . . . . | 5 |
| CodeLogician overview | CodeLogician overview | CodeLogician overview |
| 2.1 Positioning 2.2 Extensible | and Scope . . . . . . . . . . . Reasoner-Oriented Design . . . | . . . . . . . . . . 5 . . . . . . . . . . 6 |
| 2.3 Modes of Operation . . . 2.4 Governance and Feedback | . . . . . . . . . . . . . . . . . . | . . . . . . . . . . 6 . . . . . . . . . . 7 |
| 2.5 Relationship to the CodeLogician 2.6 Summary . . . . . . . . . . . . | 2.5 Relationship to the CodeLogician 2.6 Summary . . . . . . . . . . . . | 7 |
| Overview of ImandraX | Overview of ImandraX | Overview of ImandraX |
| | | 7 |
| 3 | 3 | 3 |
| | Language | . . . . . . . . . . 8 |
| 3.1 Formal Models in the Imandra Modeling 3.2 Verification Goals . . . . . . . . . . . . . | . | . . . . . . . . . . 8 |
| 3.3 Region | Decomposition . . . . . . . . . . . | . . . . . . . . . . 9 |
| 3.4 Focusing Decomposition: Side | Conditions | . . . . . . . . . . 10 |
| 3.5 Test Generation from Regions . . . . 3.6 Summary . . . . . . . . . . . . . . . | . . . . . . | . . . . . . . . . . 11 . . . . . . . . . . 11 |
| | | 11 |
| Autoformalization of source code | Autoformalization of source code | Autoformalization of source code |
| | | 12 |
| 4.3 Abstraction Levels . . . . . . . 4.4 Dealing with Unknowns . . . | . . . . . . | . . . . . . . . . . |
| | . . . . | . . . . . . . . . . 13 |
| . . . | . . . . | . . . . . . . . . . 13 |
| 4.4.1 Opaque Functions . . . . . . | . . . . | . . . . . . . . . . 13 |
| 4.4.2 Axioms and Assumptions | 4.4.2 Axioms and Assumptions | 4.4.2 Axioms and Assumptions |
| 4.4.3 Approximation Functions 4.5 Summary . . . . . . . . . . . . | . . . . . . . . . | . . . . . . . . . . 13 . . . . . . . . . . 13 |
| CodeLogician IML Agent | CodeLogician IML Agent | CodeLogician IML Agent |
| . | . | . |
| . 5.1 From 5.2 Verification | Source Code to Formal Models . . . Goals and Logical Properties | . . . . . . . . . . 14 . . . . . . . . . . 14 |
| | . . . . . . . | . . . . . . . . . . 14 |
| 5.3 Beyond Yes/No Verification . 5.4 Agent Architecture and State | . . . . . . | . . . . . . . . . . 14 |
| . 5.5 Model Refinement and | . . | . . . . . . . . . . 15 |
| Executability . . . . . | . . | . . . . . . . . . . 15 |
| 5.6 Assessing Model Correctness . | 5.6 Assessing Model Correctness . | . . . . . . . . . . 15 |
| 5.7 Region decomposition, test case generation, and refinement 5.8 Interfaces . . . . . . . . . . . . . . . . . . . . . . . . . | 5.7 Region decomposition, test case generation, and refinement 5.8 Interfaces . . . . . . . . . . . . . . . . . . . . . . . . . | . . . . . . . . . . 16 |
| 5.8.1 Programmatic Access via python RemoteGraph . . | 5.8.1 Programmatic Access via python RemoteGraph . . | . . . . . . . . . . 17 |
| 5.8.2 VS Code Extension . . . . . . . . . . . . . 5.9 Summary . . . . . . . . . . . . . . . . . . . . . . | 5.8.2 VS Code Extension . . . . . . . . . . . . . 5.9 Summary . . . . . . . . . . . . . . . . . . . . . . | . . . . . . . . . . 17 |
| Server | Server | Server |
| CodeLogician | CodeLogician | CodeLogician |
| 6 | 6 | 17 |
| 6.1 Server | Responsibilities . . . . . . . . . . . Formalization via | . . . . . . . . . . 19 . . . . . . . . . . 19 |
| | . . . . . | . . . . . . . . . . |
| 6.2 Strategies: Project-Wide | 6.2 Strategies: Project-Wide | 19 |
| 6.3 Metamodel-Based Formalization 6.4 Core Definitions . | . . . . . . . . . . . . | . . . . . . . . . . |
| . | . | 19 20 |
| 6.5 Formalization Levels . . . . . . . . . 6.6 Conditions Triggering | 6.5 Formalization Levels . . . . . . . . . 6.6 Conditions Triggering | 6.5 Formalization Levels . . . . . . . . . 6.6 Conditions Triggering |
| Re-Formalization . | Re-Formalization . | 20 |
| 6.7 . . . | 6.7 . . . | 6.7 . . . |
| | Autoformalization Workflow . . . . | |
| . | . | . |
| . | . | . |
| . | . | . |
| . | . | . |
| . | . | . |
| . | . | |
| | . . . 20 | . . . 20 |
| | . . . . . | . . . . . |
| | . . . | . . . |
| | . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
| | | . . . . . . . . . . . . . . . . . |
| | 6.8 Minimal Re-Formalization | Strategy . . . . . | 21 |
|-----|-------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|------|
| | 6.9 Summary and Error Resilience . | . . . . . . | 21 |
| 7 | Performance | Performance | 23 |
| | Dataset . . . . . . . . . | . . . . . . . . . . . | 23 |
| | Metrics . . . . . . . . . . . . . | . . . . . . . | 24 |
| | 7.2.1 | State Space Estimation Accuracy . . | 24 |
| | 7.2.2 | Outcome Precision . . . . . . . . . . | 24 |
| | 7.2.3 | Direction Accuracy . . . . . . . . . . | 25 |
| | 7.2.4 | Coverage Completeness . . . . . . . | 25 |
| | 7.2.5 | Control Flow Understanding . . . . | 25 |
| | 7.2.6 | Edge Case Detection . . . . . . . . . | 26 |
| | 7.2.7 | Decision Boundary Clarity . . . . . | 26 |
| 7.3 | Evaluation . . . . . . . . . . . | . . . . . . . . | 27 |
| | 7.3.1 | Answer Generation . . . . . . . . . . | 27 |
| | 7.3.2 | Answer Evaluation (LLM-as-a-Judge) | 27 |
| | 7.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 7.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 27 |
| | 7.4.1 | Overall Performance . . . . . . . . . | 27 |
| | 7.4.2 | Model Comparison by Metric . . . . | 29 |
| 8 | | | 32 |
| | Case Studies | Case Studies | |
| | 8.1 LSE GTT Order Expiry | . . . . . . . . . . . | 32 |
| | 8.1.1 Verification . . . | . . . . . . . . . . . | 34 |
| | 8.2 London Stock Exchange Fee Schedule | . . . | 34 |
| | 8.2.1 | Verified Invariants . . . . . . . . . . | 34 |
| | 8.2.2 | Region Decomposition . . . . . . . . | 35 |
| | Multilateral Netting Engine . | . . . . . . . . | 35 |
| | 8.3.1 Input Validation . | . . . . . . . . . . | 36 |
| | 8.3.2 | Floating Point Precision . . . . . . . | 36 |
| 9 | Conclusion and Future Work | Conclusion and Future Work | 36 |
| A | LSE GTT Order Expiry | LSE GTT Order Expiry | 38 |
| | A.1 Python model . . . . . . . | . . . . . . . . . . | 38 |
| | A.2 Sequence diagram . . | . . . . . . . . . . . . . | 45 |
| B | Multilateral Netting Engine | Multilateral Netting Engine | 46 |
| | B.1 Python model . . . . . | . . . . . . . . . . . . | 46 |
| | B.2 Evaluation | Example: Transportation Risk Manager | 48 |
| | B.2.1 | The Three Questions . . . . . . . . . | 48 |
| | B.2.2 | Question 1: State Space Estimation | 48 |
| | B.2.3 | Question 2: Conditional Analysis . . | 49 |
| | B.2.4 | Question 3: Property Verification . . | 50 |
| | B.2.5 | Summary . . . . . . . . . . . . . . . | 51 |
## 1 Introduction
The rapid adoption of Large Language Models (LLMs) in software development has brought the notion of 'reasoning about code' into the mainstream. LLMs are now widely used for tasks such as code completion, refactoring, documentation, and test generation, and have demonstrated strong capabilities in understanding control flow and translating between programming languages. However, despite these advances, LLMs remain fundamentally limited in their ability to perform precise, exhaustive mathematical reasoning about program behavior.
In parallel, the field of automated reasoning-often referred to as symbolic AI or formal methodshas long focused on mathematically precise analysis of programs expressed as formal models. Decades of research and industrial deployment have produced powerful techniques for verifying correctness, exhaustively exploring program behaviors, and identifying subtle edge cases. Yet these techniques have historically required specialized expertise, limiting their accessibility and integration into everyday software development workflows.
This paper introduces CodeLogician , a neuro-symbolic framework that bridges these two paradigms. CodeLogician combines LLM-driven agents with ImandraX , an automated reasoning engine that has been successfully applied in financial markets, safety-critical systems, and government agencies. With CodeLogician , LLMs are used to translate source code into executable formal models and to interpret reasoning results, while automated reasoning engines perform exhaustive mathematical analysis of those models.
## 1.1 Beyond Verification-as-Filtering
Much of the existing work that combines LLMs with formal methods treats symbolic systems as external 'validators'. In these approaches, LLMs generate code, specifications, or proofs, and automated reasoning tools are applied post hoc to check consistency or correctness, typically yielding a binary yes/no outcome. While such verification-as-filtering is valuable for enforcing correctness constraints, it does not fundamentally expand the reasoning capabilities of LLMs.
In particular, verification-as-filtering does not help LLMs construct accurate internal models of program behavior, reason about large or infinite state spaces, or answer rich semantic questions involving constraints, decision boundaries, and edge cases. As a result, LLMs remain confined to approximate and heuristic reasoning, even when formal tools are present in the pipeline.
CodeLogician adopts a different perspective. Rather than using formal methods to police LLM outputs, we use LLMs to construct explicit formal mental models of software systems expressed in mathematical logic. Automated reasoning engines are then applied directly to these models to answer questions that go far beyond satisfiability or validity, including exhaustive behavioral coverage, precise boundary identification, and systematic test generation. In this setting, LLMs act as translators and orchestrators, while mathematical reasoning is delegated to tools designed explicitly for that purpose.
## 1.2 Neuro-Symbolic Complementarity
The strengths and weaknesses of LLMs closely mirror those of symbolic reasoning systems. LLMs excel at translation, abstraction, and working with incomplete information, but struggle with precise logical reasoning. Symbolic systems, by contrast, require strict formalization and domain discipline, but excel at exhaustive and exact reasoning once a model is available.
CodeLogician embraces this neuro-symbolic complementarity. LLMs bridge the gap between informal source code and formal logic, while automated reasoning engines provide mathematical guarantees about program behavior. This separation of concerns enables a scalable and principled approach to reasoning about real-world software systems.
## 1.3 ImandraX and Reasoner-Agnostic Design
At the core of CodeLogician lies ImandraX , an automated reasoning engine operating over the Imandra Modeling Language (IML), a pure functional language based on a subset of OCaml with extensions for specification and verification [14]. Beyond traditional theorem proving and formal verification, ImandraX supports advanced analysis techniques such as region decomposition, enabling systematic exploration of program state spaces and automated generation of high-coverage test suites.
While CodeLogician currently integrates ImandraX as its primary reasoning backend, the framework is explicitly designed to be reasoner-agnostic . Additional formal reasoning tools can be incorporated without architectural changes, allowing CodeLogician to evolve alongside advances in automated reasoning.
## 1.4 The Missing Benchmark: Mathematical Reasoning About Software
Despite rapid progress in evaluating LLMs, existing benchmarks fall into two largely disconnected categories. Mathematical proof benchmarks evaluate abstract symbolic reasoning over mathematical domains, but do not address reasoning about real-world software behavior. Engineering benchmarks, such as those focused on debugging or patch generation, evaluate practical development skills but do not require precise or exhaustive semantic reasoning.
What is missing is a benchmark that evaluates an LLM's ability to apply mathematical reasoning to executable software logic . To address this gap, we introduce a new benchmark dataset code-logicbench [9] designed to measure reasoning about program state spaces, constraints, decision boundaries, and edge cases. Ground truth is defined via formal modeling and automated reasoning, enabling objective evaluation of correctness, coverage, and boundary precision. The benchmark supports principled comparison between LLM-only reasoning and LLMs augmented with formal reasoning via CodeLogician .
## 1.5 Contributions
This paper makes the following contributions:
- We present CodeLogician , a neuro-symbolic framework that teaches LLM-driven agents to construct formal models of software systems and reason about them using automated reasoning engines.
- We introduce a new benchmark dataset targeting mathematical reasoning about software logic, filling a critical gap between existing mathematical and engineering-oriented benchmarks.
- We provide a rigorous empirical evaluation demonstrating substantial improvements when LLMs are augmented with formal reasoning, compared to LLM-only approaches.
## 2 CodeLogician overview
CodeLogician is a neuro-symbolic, agentic governance framework for AI-assisted software development. It provides a uniform orchestration layer that exposes formal reasoning engines (called 'reasoners'), autoformalization agents, and analysis workflows through consistent interfaces. It supports multiple modes of use, including direct invocation of reasoners, agent-driven auto-formalization, and LLM-assisted utilities for documentation and analysis. It is available as both CLI and server-based workflows-with an interactive TUI that can invoke agents over entire directories-making formal reasoning, verification, and test-case generation accessible across development pipelines.
Rather than competing with LLM-based coding tools, CodeLogician is designed to augment and guide them by supplying mathematically grounded feedback, proofs, counterexamples, and exhaustive behavioral analyses.
At its core, CodeLogician serves as a source of mathematical ground truth . Where LLM-based tools operate probabilistically, CodeLogician anchors reasoning about software behavior in formal logic, ensuring that conclusions are derived from explicit models and automated reasoning rather than statistical inference.
## 2.1 Positioning and Scope
CodeLogician targets reasoning tasks that arise above the level of individual lines of code, where system behavior emerges from the interaction of components, requirements, and environments. Typical application areas include architectural reasoning, multi-system integration, protocol and workflow validation, and functional correctness of critical business logic.
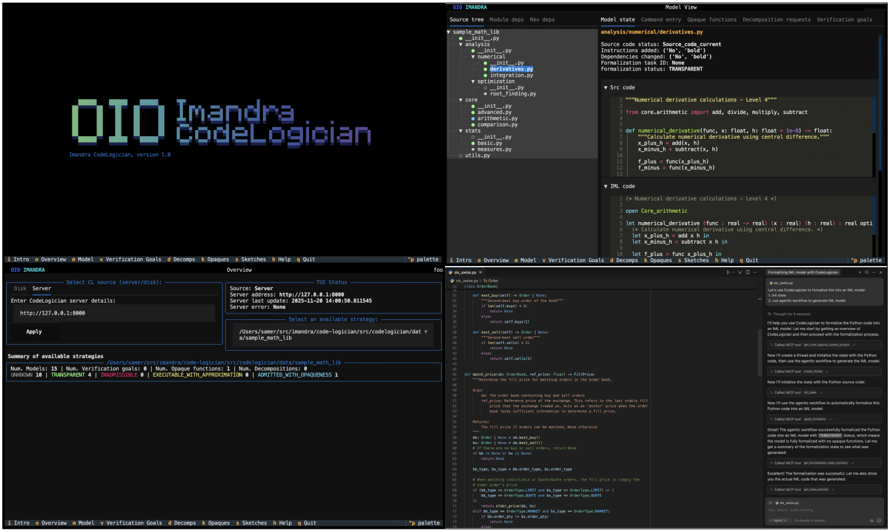
Figure 1: Imandra CodeLogician , neurosymbolic agent and framework for precise reasoning about software logic, with CLI, MCP and VS Code interfaces. Available from www.codelogician.dev .
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Screenshot: Imandra CodeLogician Interface
### Overview
The image shows a screenshot of the Imandra CodeLogician interface, a software tool for formal verification and analysis of code. The interface is split into multiple panes displaying code, a file browser, a summary of analysis strategies, and a visualization of dependencies. The interface appears to be focused on a Python codebase. There are two identical windows visible, suggesting a dual-monitor setup or a duplicated view.
### Components/Axes
The interface is composed of the following key components:
* **Header:** Displays the application title "Imandra CodeLogician" and version "1.4".
* **File Browser (Left Pane):** Shows a directory structure with files and folders.
* **Code Editor (Center Pane):** Displays Python code with syntax highlighting.
* **Analysis Summary (Bottom-Left Pane):** Lists analysis strategies and their status.
* **Dependency Visualization (Bottom-Right Pane):** A graph-like representation of dependencies between modules.
* **Model State Panel (Top-Right Pane):** Displays information about the current model state, including source code status, instructions, and dependencies.
* **Console/Output Panel (Bottom-Right Pane):** Displays messages and output from the analysis process.
### Detailed Analysis or Content Details
**File Browser (Left Pane):**
* **Disk:** Shows a path: `/home/user/code/Imandra`
* **Server Address:** `http://127.0.0.1:8000`
* **Last Update:** `2023-10-26 16:43:51.821463`
* **Enter CodeLogician server details:** Input field with the current address.
* **Directory Structure:**
* `Imandra`
* `__init__.py`
* `analysis`
* `__init__.py`
* `derivatives.py`
* `optimization.py`
* `root_finding.py`
* `numerical`
* `__init__.py`
* `arithmetic.py`
* `basic.py`
* `counts.py`
* `utils.py`
* `sample_work_lib`
* `main.py`
**Analysis Summary (Bottom-Left Pane):**
* **Summary of available strategies:**
* **Main:** `NUMERICAL` (green) - `span [0, 1]` - `OK` - `DECOMPOSES`
* **Main:** `DERIVATIVES` (green) - `span [0, 1]` - `OK` - `DECOMPOSES`
* **Main:** `ROOT_FINDING` (green) - `span [0, 1]` - `OK` - `DECOMPOSES`
* **Main:** `OPTIMIZATION` (green) - `span [0, 1]` - `OK` - `DECOMPOSES`
**Dependency Visualization (Bottom-Right Pane):**
* The visualization shows a network of interconnected nodes representing modules.
* Nodes are labeled with module names (e.g., `numerical.arithmetic`, `analysis.derivatives`).
* Edges represent dependencies between modules.
* The visualization appears to be interactive, with nodes and edges highlighted upon selection.
* The color of the nodes is not consistent, but appears to be related to the type of module.
**Model State Panel (Top-Right Pane):**
* **Model state:** `Command entry`
* **Source Tree:** `Module: derivatives.py`
* **Source code status:** `Source code: current`
* **Instructions:** `added: [‘a’]`
* **Dependencies:** `[‘b’]`
* **Formalization status:** `TRANSPARENT`
* **Src code:**
```python
# Numerical derivative calculations - Level 4
from core.arithmetic import add, divide, multiply, subtract
def numerical_derivative(func, x, h=1e-6):
"""Calculate numerical derivative using central difference."""
return (func(x + h) - func(x - h)) / (2 * h)
# plans = func_plane_h_1
# plans = func_plane_h_2
```
* **DSL code:**
```python
# Numerical derivative calculations - Level 4
let func: real -> real := real func;
let x: real := real x;
let h: real := real h;
let f_plus: func x plus h
let f_minus: func x minus h
```
**Code Editor (Center Pane):**
* Displays Python code for the `numerical` and `analysis` modules.
* Includes functions for numerical derivative calculations.
* The code is well-formatted and commented.
### Key Observations
* The interface is highly structured and provides a comprehensive view of the codebase and its analysis.
* The dependency visualization is a key feature, allowing users to understand the relationships between modules.
* The analysis summary provides a clear overview of the status of different analysis strategies.
* The color-coding of analysis strategies (green = OK) indicates successful completion.
* The Model State Panel provides detailed information about the current state of the formalization process.
### Interpretation
The Imandra CodeLogician interface is designed to facilitate formal verification and analysis of Python code. The tool appears to leverage a combination of static analysis, dependency visualization, and formal methods to ensure the correctness and reliability of the code. The interface provides a user-friendly environment for developers to explore the codebase, understand its dependencies, and verify its behavior. The successful completion of analysis strategies (indicated by the green color) suggests that the code is well-structured and meets certain formal specifications. The detailed information provided in the Model State Panel allows users to track the progress of the formalization process and identify potential issues. The tool is likely used in safety-critical applications where code correctness is paramount. The dual-window setup suggests a workflow where one window is used for code editing and the other for analysis and visualization. The presence of both Python source code and a DSL (Domain Specific Language) representation suggests that the tool translates the Python code into a formal representation for analysis.
</details>
While CodeLogician can, in principle, reason about low-level implementation details, its primary value lies in governing system-level behavior. Domains such as memory safety, SQL injection detection, or hardware-adjacent concerns are already well served by specialized static analyzers and runtime tools. CodeLogician complements these point solutions by providing a framework for validating architectural intent, invariants, and cross-component interactions with mathematical completeness.
## 2.2 Extensible Reasoner-Oriented Design
CodeLogician is explicitly designed as a multi-reasoner framework. Its first release integrates the ImandraX automated reasoning engine, which supports executable formal models, proof-oriented verification, and exhaustive state-space analysis. However, the framework is intentionally reasoner-agnostic and is architected to host additional formal tools (e.g., temporal logic model checkers such as TLA+) under the same orchestration and governance layer.
This design allows CodeLogician to evolve alongside advances in formal methods without coupling its user-facing workflows to a single solver, logic, or verification paradigm.
## 2.3 Modes of Operation
CodeLogician exposes its capabilities through several complementary modes of operation, all backed by the same underlying orchestration and reasoning infrastructure.
Direct invocation. In direct mode, users or external tools invoke reasoning engines and agents explicitly. This mode supports fine-grained control over formalization, verification, and analysis steps and is particularly useful for expert users and debugging complex models.
Agent-mediated workflows. In agentic modes, CodeLogician coordinates LLM-driven agents that automatically formalize source code, refine models, generate verification goals, and invoke reasoning backends. These workflows enable end-to-end analysis with minimal human intervention while retaining the ability to request feedback when ambiguities or inconsistencies arise.
Bring-Your-Own-Agent (BYOA). CodeLogician can be used as a reasoning backend for externally hosted LLM agents. In this mode, an LLM interacts with CodeLogician through structured commands, receives formal feedback, and iteratively improves its own formalization behavior. This enables tight integration with existing LLM-based coding assistants while preserving a clear separation between statistical generation and logical reasoning.
Server-based operation. For large-scale or continuous analysis, CodeLogician can be deployed in a server mode that monitors codebases or projects and incrementally updates formal models and analyses in response to changes. This supports use cases such as continuous verification, regression analysis, and long-running agentic workflows.
## 2.4 Governance and Feedback
A central contribution of CodeLogician is its role as a governance layer for AI-assisted development. Rather than merely accepting or rejecting LLM outputs, CodeLogician provides structured, semantically rich feedback grounded in formal reasoning. This includes:
- proofs of correctness when properties hold,
- counterexamples when properties fail,
- explicit characterization of decision boundaries and edge cases,
- quantitative coverage information derived from exhaustive analysis.
This feedback can be consumed by humans, external agents, or LLMs themselves, enabling iterative improvement and learning. In this sense, CodeLogician does not merely analyze code-it shapes how AI systems reason about software over time.
## 2.5 Relationship to the CodeLogician IML Agent
The CodeLogician IML Agent described in Section 5 is one concrete realization of the framework's capabilities. It implements an end-to-end autoformalization pipeline that translates source code into executable formal models and invokes ImandraX for analysis.
More generally, the framework supports multiple agents, reasoning engines, and workflows operating over shared representations and governed by the same orchestration logic. This separation between framework and agents allows CodeLogician to scale across domains, reasoning techniques, and modes of interaction.
## 2.6 Summary
CodeLogician is a unifying framework for integrating LLMs with formal reasoning engines in a principled, extensible manner. By providing orchestration, governance, and structured feedback around automated reasoning, it enables AI-assisted software development to move beyond heuristic reasoning toward mathematically grounded analysis. The framework establishes a firm foundation upon which multiple agents and reasoners can coexist, evolve, and collaborate in the service of rigorous software engineering.
## 3 Overview of ImandraX
ImandraX (cf. Fig 2) is an automated reasoning engine for analyzing executable mathematical models of software systems. Its input language is the Imandra Modeling Language (IML), a pure functional subset of OCaml augmented with directives for specification and reasoning (e.g., verify , lemma and instance ) [14]. IML models are ordinary programs, but they are also formal models : ImandraX contains a mechanized formal semantics for IML, and thus IML code is both executable code and rigorous mathematical logic to which ImandraX applies automated reasoning.
Figure 2: The ImandraX automated reasoning engine and theorem prover. Interfaces are available for both humans (VS Code) and AI assistants (MCP and CLI), and may be installed from www.imandra.ai/core .
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Screenshot: Imandra Automated Reasoning Engine Promotional Image
### Overview
This is a promotional screenshot for Imandra, an automated reasoning engine. The image features the Imandra logo, a tagline, a descriptive text block, and several code snippets displayed in a dark-themed interface, likely representing the engine's functionality. The overall aesthetic is modern and technical, aiming to convey sophistication and power.
### Components/Axes
The image is composed of several distinct sections:
* **Top-Left:** Imandra logo and "Automated Reasoning Engine" text.
* **Center-Left:** A block of descriptive text.
* **Right Side:** Multiple code windows displaying code snippets.
* **Bottom:** A "NEW" badge and a call to action: "Install Imandra in VS Code!".
There are no axes or charts in the traditional sense. The "axes" are the code lines and the visual arrangement of the code windows.
### Detailed Analysis or Content Details
**1. Imandra Logo & Tagline:**
* Logo: A stylized green and blue icon.
* Tagline: "Automated Reasoning Engine"
**2. Descriptive Text Block (Center-Left):**
"Formally verified functional programming with first-class counterexamples, highly automated proofs, powerful reasoning tactics and seamless integration of bounded and unbounded verification."
**3. Code Snippets (Right Side):**
The code snippets are difficult to transcribe completely due to the image quality and the amount of text. However, here's a breakdown of the visible content, organized by code window (from top to bottom):
* **Window 1 (Top):**
* Lines 233-249: Code related to a loop and correctness check. Contains terms like "steps", "alarm", "halted-false", "prog:pc:stack:ra", "run 8 steps", "if ra = 0 then", "else".
* Lines 251-254: "Counter model:" followed by numerical values and variable assignments (e.g., "pc = 2", "let steps = 8", "let ra = 142").
* **Window 2 (Middle):**
* Lines 237-248: Code related to "lemma loop_correct stack ra rs steps". Contains terms like "halted-true", "prog:pc:stack:ra", "run 8 steps", "if ra = 0 then", "else", "base program_base_stack".
* Lines 249-251: "auto", "impossible run".
* **Window 3 (Bottom-Left):**
* Code related to memory and stack operations. Contains terms like "Store Marc Rc", "Load Rc", "Const 1", "Sub S", "pc = 2", "stack = [7396, 7396]".
* **Window 4 (Bottom-Right):**
* Code related to a function "find_an_invariant". Contains terms like "invariant", "Place [0..142] in invariant", "invariant = true", "invariant = false", "auto", "impossible invariant".
**4. Bottom Section:**
* "NEW" badge (green).
* "Install Imandra in VS Code!" (call to action).
### Key Observations
* The image heavily emphasizes the technical aspects of Imandra, showcasing code snippets to appeal to a developer audience.
* The descriptive text highlights key features like formal verification, counterexamples, and automated proofs.
* The code snippets appear to be related to program analysis and verification, suggesting that Imandra is used for ensuring the correctness of software.
* The "NEW" badge and VS Code integration call to action indicate a recent release or update.
### Interpretation
The image is a marketing piece designed to position Imandra as a powerful and sophisticated tool for functional programming verification. The code snippets are not meant to be fully understood by a casual viewer but rather to convey the complexity and technical depth of the engine. The emphasis on formal verification and automated proofs suggests that Imandra is targeted towards developers working on critical systems where correctness is paramount. The integration with VS Code indicates a focus on developer workflow and usability.
The overall message is that Imandra provides a robust and efficient way to ensure the reliability and security of functional programs. The image aims to attract developers who are interested in advanced program analysis techniques and tools. The use of dark themes and a modern aesthetic reinforces the image of a cutting-edge technology. The snippets are likely examples of the engine's ability to analyze and verify code, demonstrating its capabilities in a concrete way. The presence of "counterexamples" suggests the engine can not only prove correctness but also identify potential errors.
</details>
CodeLogician relies on ImandraX as its primary reasoning backend 4 . In the autoformalization workflow (cf. Section 4), LLM-driven agents translate source code into executable IML models, make abstraction choices explicit, and introduce assumptions where required. ImandraX then performs the mathematical analysis of these models, enabling both proof-oriented verification and richer forms of behavioral understanding.
This section summarizes the two ImandraX capabilities most heavily used by CodeLogician : verification goals and state-space region decomposition. As in Section 4, we emphasize that LLMs are used to construct explicit formal mental models, while ImandraX is used to reason about them.
## 3.1 Formal Models in the Imandra Modeling Language (IML)
IML inherits the modeling discipline discussed in Section 4: models are pure (no side effects), statically typed functional programs in ImandraX 's fragment of OCaml, structured to support inductive reasoning modulo decision procedures. Imperative constructs such as loops are represented via recursion, and systems with mutable state are modeled as state machines in which the evolving state is carried explicitly through function inputs and outputs.
The question is therefore not whether a system can be modeled, but at what level of abstraction it should be modeled (Section 4). ImandraX provides analysis capabilities that remain meaningful across these abstraction levels, provided the model is executable and its assumptions are made explicit.
## 3.2 Verification Goals
Formal verification in ImandraX is performed via the statement and analysis of verification goals (VGs): boolean-valued IML functions that encode properties of the system being analyzed. VGs are (typically) implicitly universally quantified: when one proves a theorem in ImandraX , one establishes that a boolean-valued VG is true for all possible inputs. Unlike testing, which evaluates finitely many concrete executions, VGs quantify over (typically) infinite input spaces and yield either: (i) a proof that the property holds universally, or (ii) a counterexample witness demonstrating failure.
As programs and datatypes may involve recursion over structures of arbitrary depth, these proofs may involve induction. A unique feature of ImandraX is its seamless integration of bounded and unbounded verification. Every goal may be subjected to both bounded model checking and full inductive theorem proving. Bounded proofs are automatic based on ImandraX 's recursive function unrolling modulo decision procedures, and typically take place in a setting for which they are complete
4 https://www.imandra.ai/core
```
order1 = { order2 = { order3 = {
peg = NEAR; peg = NEAR; order_type = PEGGED_CI; qty = 8400;
order_type = PEGGED; order_type = PEGGED_CI; qty = 8400;
qty = 1800; qty = 8400; price = 10.0;
price = 10.5; price = 12.0; time = 236;
time = 237; time = 237; ...
... ... };
}; };
```
Figure 3: Counterexample for Order Ranking Transitivity
for counterexamples. ImandraX contains deep automation for constructing inductive proofs, including a lifting of the Boyer-Moore inductive waterfall to ImandraX 's typed, higher-order setting [14]. Moreover, ImandraX contains a rich tactic language for the interactive construction of proofs and counterexamples, and for more general system and state-space exploration.
For example, consider the transitivity of an order ranking function for a trading venue [16]. This may naturally be conjectured as a lemma, which may then be subjected to verification:
```
lemma rank_transitivity side order1 order2 order3 mkt =
order_higher_ranked(side,order1,order2,mkt) &&
order_higher_ranked(side,order2,order3,mkt)
==>
order_higher_ranked(side,order1,order3,mkt)
```
In practice, verification is iterative: counterexamples often reveal missing preconditions, modeling gaps, or specification errors. For example, in Fig. 3 we see a (truncated version of) an ImandraXsynthesized counterexample for rank transitivity of a real-world trading venue [16].
In ImandraX , all counterexamples are 'first-class' objects which may be reflected in the runtime and computed with directly via ImandraX 's eval directive. This unified computational environment for programs, conjectures, counterexamples and proofs is important for the analysis of real-world software. Verification goals should immediately be amenable to automated analysis, counterexamples for false goals should be synthesized efficiently, and these counterexamples should be available for direct execution through the system under analysis, enabling rapid triage and understanding for goal violations and false conjectures. This use of counterexamples aligns with the autoformalization perspective: constructing a good formal model is a refinement process in which assumptions and intended semantics are progressively made explicit, and counterexamples to conjectures can rapidly help one to fix faulty logic and recognize missing assumptions.
## 3.3 Region Decomposition
Many questions central to program understanding are not naturally expressed as binary VGs. To support richer semantic analysis, ImandraX provides region decomposition , which partitions a function's input space into finitely many symbolic regions corresponding to distinct behaviors.
Each region comprises:
- constraints over inputs that characterize when execution enters the region,
- an invariant result describing the output (or a symbolic characterization of it) for all inputs satisfying the constraints, and
- sample points witnessing satisfiable instances of the constraints.
Region decomposition provides a mathematically precise notion of 'edge cases' and directly supports the systematic test generation goals described in Section 4.
ImandraX decomposes function into regions corresponding to the distinct path conditions induced by their control flow, each with explicit constraints and invariant outputs. These decompositions may be performed relative to logical side-conditions and configurable abstraction boundaries called basis functions to tailor state-space exploration for a particular goal. In real software systems, small
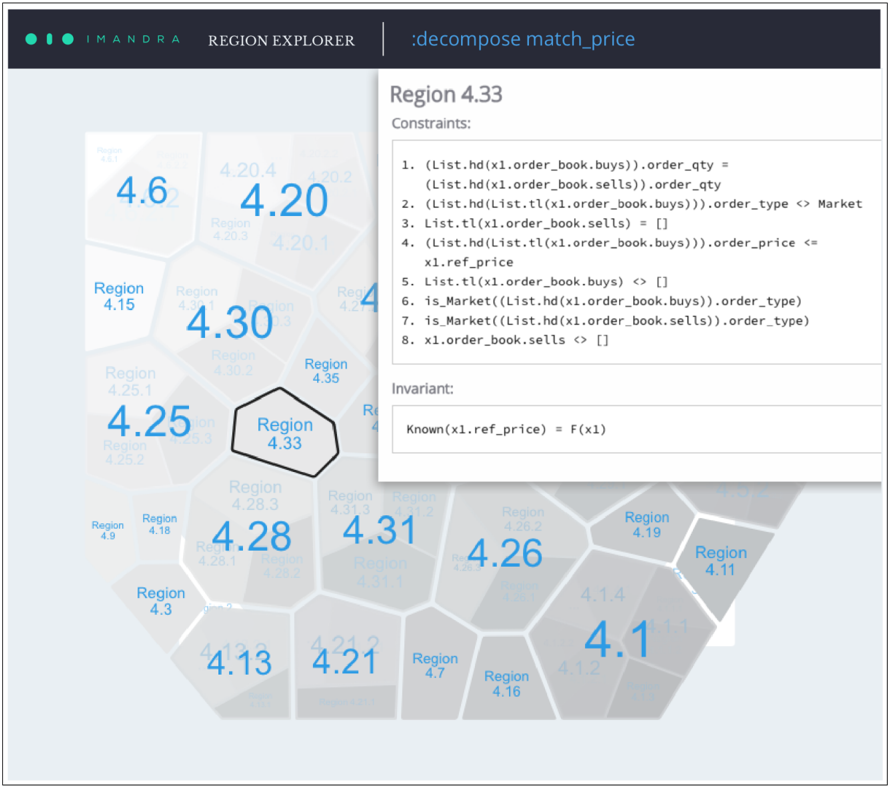
Figure 4: A principal region decomposition of a trading venue pricing function
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Region Explorer - Decompose Match Price
### Overview
The image displays a diagram titled "Region Explorer" with a sub-title "decompose match_price". It shows a network of interconnected, irregularly shaped regions, each labeled with a numerical value representing a region identifier and a corresponding price. A text block on the right side details constraints and invariants related to "Region 4.33". The overall impression is a visualization of a pricing model or a market segmentation analysis.
### Components/Axes
The diagram consists of:
* **Regions:** Irregularly shaped areas distributed across the image. Each region is labeled with "Region [number]" and a numerical value (e.g., "Region 4.33", "4.33").
* **Numerical Labels:** Each region has a numerical label indicating a price or value.
* **Text Block:** A rectangular block on the right side containing constraints and invariants.
* **Title:** "IMANDRA" at the top-left corner.
* **Subtitle:** "REGION EXPLORER" at the top-center.
* **Decomposition Title:** ":decompose match_price" at the top-right corner.
### Detailed Analysis / Content Details
The diagram shows a network of regions with the following values:
* **4.62** (Top-left)
* **4.204** (Top-center-left)
* **4.20** (Top-center)
* **4.202** (Top-center-right)
* **4.15** (Left-center)
* **4.30** (Center-left)
* **4.21** (Center)
* **4.25** (Center-left-bottom)
* **4.25.1** (Bottom-left)
* **4.26.2** (Bottom-left-center)
* **4.33** (Center-bottom)
* **4.35** (Center-right-bottom)
* **4.28** (Bottom-center)
* **4.31** (Bottom-center-right)
* **4.26** (Bottom-right-center)
* **4.19** (Bottom-right)
* **4.11** (Bottom-right-corner)
* **4.13** (Bottom-left-corner)
* **4.21** (Bottom-center-left)
* **4.7** (Bottom-right-center)
* **4.16** (Bottom-right-corner)
* **4.1** (Bottom-right-corner)
* **4.1.4** (Bottom-right-corner)
* **4.1.2** (Bottom-right-corner)
* **4.18** (Bottom-left-center)
* **4.23** (Top-center-left)
The text block on the right side, associated with "Region 4.33", contains the following constraints and invariants:
1. (List.hd(x1.order\_book.buys)).order\_qty = (List.hd(x1.order\_book.sells)).order\_qty
2. (List.hd(x1.order\_book.buys)).order\_type < Market
3. List.tl(x1.order\_book.sells) = []
4. (List.hd(List.tl(x1.order\_book.buys))).order\_price <= x1.ref\_price
5. List.tl(x1.order\_book.buys) <> []
6. is\_Market((List.hd(x1.order\_book.sells)).order\_type)
7. is\_Market((List.hd(x1.order\_book.sells)).order\_type)
8. x1.order\_book.sells <> []
Invariant:
Known(x1.ref\_price) = F(x1)
### Key Observations
* The numerical values associated with the regions appear to represent prices or some other quantifiable metric.
* The values are clustered around the 4.2 to 4.3 range, with some outliers at 4.62 and 4.1.
* The text block provides a set of constraints and invariants that likely govern the pricing or behavior within "Region 4.33".
* The constraints involve order books, order types, and reference prices, suggesting a trading or market context.
* The use of "List.hd" and "List.tl" suggests a functional programming approach to data manipulation.
### Interpretation
This diagram likely represents a model of a market or trading system, where each region corresponds to a specific state or condition. The numerical values represent a key metric, potentially the price of an asset or the cost of a transaction. The constraints and invariants associated with "Region 4.33" define the rules and conditions that apply within that specific state.
The constraints suggest a matching engine where buy and sell orders are being processed. The invariants indicate that the reference price is a function of some input (x1), and that certain conditions must be met for the system to operate correctly.
The outliers (4.62 and 4.1) could represent regions with significantly different pricing dynamics or market conditions. The overall structure suggests a complex system with interconnected regions and a set of rules governing their behavior. The diagram is a visual representation of a mathematical or algorithmic model used for price decomposition or market analysis. The use of functional programming constructs (List.hd, List.tl) indicates a sophisticated analytical approach.
</details>
boundary differences (e.g., a flipped inequality) often lead to qualitatively different outcomes; region decomposition isolates these differences and makes the boundaries of logically invariant behavior explicit and auditable.
## 3.4 Focusing Decomposition: Side Conditions and Basis
Autoformalization often produces models whose full state spaces are too large-or simply too broadfor a given analysis objective. ImandraX provides two complementary mechanisms to focus decomposition, mirroring the abstraction discipline in Section 4.
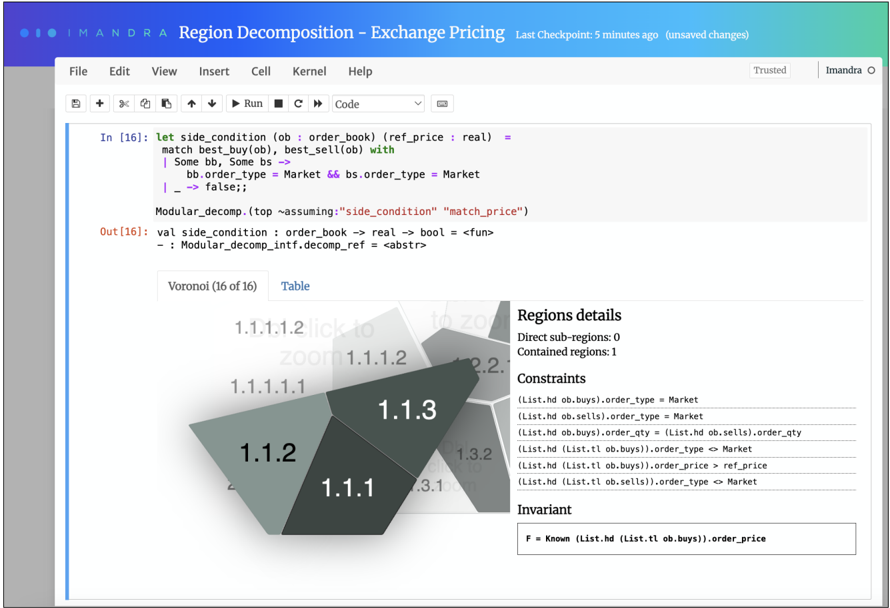
Side conditions. A side condition is a boolean predicate with the same signature as the decomposed function. When supplied, ImandraX explores only regions for which the side condition holds. This is useful for restricting analysis to scenarios of operational or regulatory interest. Figure 5 illustrates a region decomposition query augmented with a side-condition.
Basis functions. A basis specifies functions to be treated as atomic during decomposition. ImandraX will not explore their internal branching structure, reducing the number of regions and improving interpretability. Basis selection provides a principled way to 'abstract away' auxiliary computations while retaining their influence on the surrounding model.
Figure 5: A refined decomposition of the venue pricing function with a side-condition
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: Region Decomposition - Exchange Pricing
### Overview
The image displays a screenshot of a coding environment (likely Jupyter Notebook) with a visualization of a Voronoi diagram alongside code snippets and associated details. The diagram appears to represent a region decomposition related to exchange pricing, with the code providing context for the visualization. The interface indicates the notebook is named "Region Decomposition - Exchange Pricing" and has unsaved changes.
### Components/Axes
The screenshot contains the following key components:
* **Header:** Displays the notebook title, last checkpoint time, and save status.
* **Code Editor:** Contains code snippets related to `side_condition` and `Modular_decomp`.
* **Voronoi Diagram:** A visual representation of the region decomposition.
* **Table/Tab Navigation:** "Voronoi (16 of 16)" and "Table" tabs are visible.
* **Regions Details:** A text box providing information about the regions in the diagram.
* **Constraints:** A list of constraints related to the decomposition.
* **Invariant:** A statement defining an invariant related to the decomposition.
The Voronoi diagram itself doesn't have explicit axes in the traditional sense, but it represents a partitioning of a space based on distance to points. The diagram is labeled with region identifiers (e.g., 1.1.1.1, 1.1.2, 1.1.3).
### Detailed Analysis or Content Details
**Code Snippets:**
* `In [16]: let side_condition (ob : order_book) (ref_price : real) = match best_buy(ob), best_sell(ob) with | Some bb, Some bs -> ...` This code defines a function `side_condition` that takes an order book and a reference price as input. It appears to match the best buy and best sell orders.
* `Modular_decomp.(top =assuming:"side_condition" "match_price")` This line calls a function `Modular_decomp` with an assumption related to `side_condition` and `match_price`.
* `Out[16]: val side_condition : order_book -> bool <fun> - : Modular_decomp_intf.decomp_ref = <abstr>` This line shows the output of the `side_condition` function, indicating it returns a boolean value.
**Voronoi Diagram:**
The diagram shows a Voronoi tessellation with 16 regions. The regions are labeled with hierarchical identifiers. The colors of the regions vary, with shades of purple and gray. The diagram has a "click to zoom" indicator.
* Region 1.1.1.1 is located in the bottom-left corner.
* Region 1.1.1.2 is adjacent to 1.1.1.1 and slightly above and to the right.
* Region 1.1.2 is located to the right of 1.1.1.1 and 1.1.1.2.
* Region 1.1.3 is located above 1.1.1.2.
* Region 1.3.1 is located to the right of 1.1.3.
* Region 1.3.2 is located to the right of 1.3.1.
* Region 2.2 is located to the upper-right of the diagram.
**Regions Details:**
* Direct sub-regions: 0
* Contained regions: 1
**Constraints:**
* `(List.hd ob.buys).order_type < Market`
* `(List.hd ob.sells).order_type < Market`
* `(List.hd ob.buys).order_qty < (List.hd ob.sells).order_qty`
* `(List.hd (List.tl ob.buys)).order_type < Market`
* `(List.hd (List.tl ob.sells)).order_price < Market`
**Invariant:**
* `F = Known (List.tl (List.hd ob.buys)).order_price`
### Key Observations
* The code and diagram are related to order book analysis and exchange pricing.
* The Voronoi diagram represents a decomposition of the order book space based on certain conditions.
* The constraints define conditions that must be met for the decomposition.
* The invariant defines a property that remains constant throughout the decomposition.
* The diagram is interactive, allowing users to zoom into specific regions.
### Interpretation
The image demonstrates a method for decomposing an order book based on the `side_condition` function. The Voronoi diagram visually represents the regions created by this decomposition. Each region likely corresponds to a specific set of order book states that satisfy the defined constraints. The constraints themselves relate to order types and quantities, suggesting the decomposition is based on the characteristics of the orders in the book. The invariant provides a stable property that can be used to analyze the decomposition.
The use of a Voronoi diagram suggests that the decomposition is based on proximity or distance in the order book space. The code snippets and details provide a formal definition of the decomposition process, while the diagram offers a visual representation that can aid in understanding the relationships between different order book states. The "click to zoom" functionality indicates that the diagram is intended for interactive exploration and analysis. The overall goal appears to be to gain insights into the structure and dynamics of exchange pricing by decomposing the order book into meaningful regions.
</details>
Together, side-conditions and basis functions provide a rich query language for targeting the analysis of system state spaces towards particular classes of behaviors [11, 12].
## 3.5 Test Generation from Regions
Each region produced by decomposition includes sample points satisfying its constraints. These witnesses can be extracted to generate tests that correspond directly to semantic distinctions in program behavior, rather than to ad hoc input distributions. In CodeLogician , this capability underpins automated test generation: agents use regions to produce tests that cover all behavioral cases discovered by decomposition, consistent with the 'exhaustive coverage' objective motivating autoformalization.
## 3.6 Summary
ImandraX provides the formal reasoning substrate for CodeLogician . Verification goals support prooforiented analysis, while region decomposition exposes the structure of program state spaces, makes decision boundaries explicit, and enables systematic test-case generation. Together with the autoformalization process (Section 4), these capabilities allow LLM-driven agents to construct formal mental models of software and to answer rich semantic questions beyond binary verification outcomes.
## 4 Autoformalization of source code
Autoformalization is the process of translating executable source code into precise, mathematical models suitable for automated reasoning. While this translation is partially automated by CodeLogician, it relies on a particular way of thinking about software-one that emphasizes explicit state, clear abstraction boundaries, and well-defined assumptions. Just as developers strive to write clear code , effective automated reasoning depends on writing or synthesizing clear formal models .
## 4.1 Pure Functional Modeling
All formal models produced by CodeLogician are expressed in the Imandra Modeling Language (IML), a pure functional subset of OCaml. Purity here means the absence of side effects: functions cannot mutate global state or influence values outside their scope. Instead, all state changes must be made explicit via function arguments and return values.
This restriction is not a fundamental limitation. Programs with side effects can be systematically transformed into state-machine models in which the evolving program state is explicitly carried through computations. Such techniques are well established in the literature and trace back to foundational work by Boyer and Moore [4, 3]. For example, this (infinite) state-machine model approach underlies successful formal verification of highly complex industrial systems, including large-scale financial market infrastructure [16, 15], complex hardware models [17], robotic controllers integrating deep neural networks [6], and high-frequency communication protocols [10].
## 4.2 Key Modeling Constructs
Several structural features of IML are particularly important for automated reasoning:
Static Types IML is a statically typed functional language. All variable types are determined before execution and cannot change dynamically. This eliminates entire classes of ambiguity present in dynamically typed languages. During autoformalization, CodeLogician extracts type information from source programs-using static annotations where available and inference otherwise-and enforces type consistency in the generated models. Type errors detected by ImandraX often correspond directly to logical inconsistencies in the original program.
Recursion and Induction Loops in imperative source code are rewritten as recursive functions. Both for and while constructs are mapped to structurally recursive definitions. This transformation is essential because reasoning about unbounded iteration requires inductive reasoning, which is naturally expressed over recursive functions.
State Machines Many real-world programs are best modeled as state machines. These machines are typically infinite-state, as the state may include complex data structures such as lists, maps, or trees in addition to numeric values. State-machine modeling is particularly effective for representing code with side effects and for capturing the behavior of complex reactive systems, such as trading platforms or protocol handlers.
## 4.3 Abstraction Levels
A central question in autoformalization is not merely whether a program can be modeled, but at what level of abstraction it should be modeled . The appropriate abstraction depends on the properties one wishes to analyze.
We distinguish three broad abstraction levels:
High-Level Models High-level models typically arise from domain-specific languages (DSLs) designed to describe complex systems concisely. In such cases, direct use of CodeLogician is often unnecessary. Instead, the DSL itself is translated into IML. For example, the Imandra Protocol Language (IPL) provides a compact notation for symbolic state-transition systems and compiles into IML with significant structural expansion. Reasoning at this level focuses on system-wide invariants and high-level behavioral properties.
Mid-Level Models Application-level software represents the primary target for CodeLogician. At this level, source programs can be translated directly into IML without introducing an intermediate DSL. This category includes most business logic, data-processing pipelines, and control-heavy application code.
Low-Level Models Low-level code, such as instruction sequences or hardware-near implementations, can also be modeled in ImandraX, but doing so requires an explicit formalization of the execution environment (e.g., memory model, virtual machine, or instruction semantics). Such models are outside the intended scope of CodeLogician, which assumes access to semantic abstractions of the underlying execution platform.
## 4.4 Dealing with Unknowns
Real-world programs inevitably rely on external libraries, services, or system calls. Autoformalization therefore requires explicit handling of unknown or partially specified behavior. CodeLogician adopts techniques analogous to mocking in software testing, but within a formal reasoning framework.
## 4.4.1 Opaque Functions
IML supports opaque functions , which declare a function's type without specifying its implementation. Opaque functions allow models to type-check and support reasoning without making any assumptions about the function's internal behavior.
For example, calls to external libraries such as pseudo-random number generators are introduced as opaque functions during autoformalization. Reasoning about code that depends on such functions remains sound, but necessarily conservative.
## 4.4.2 Axioms and Assumptions
To refine reasoning about opaque functions, users (or agents) may introduce axioms that constrain their behavior. These axioms encode assumptions about external components, such as value ranges or monotonicity properties. Introducing axioms narrows the set of possible behaviors considered during reasoning and can significantly strengthen the conclusions that can be drawn.
Importantly, axioms are explicit and local: reasoning results are valid only under the stated assumptions, making the modeling process auditable and transparent.
## 4.4.3 Approximation Functions
In many cases, opaque functions can be replaced with sound approximations. For common mathematical functions, CodeLogician provides libraries of approximation functions, such as bounded Taylorseries expansions for trigonometric operations. These approximations allow models to remain executable and enable test generation, while still supporting rigorous reasoning within known bounds.
## 4.5 Summary
Autoformalization is not merely a syntactic translation process. It is a disciplined approach to modeling software behavior in which state, control flow, assumptions, and abstraction boundaries are made explicit. By combining LLM-driven translation with principled formal modeling techniques, CodeLogician enables automated reasoning engines to answer deep semantic questions about software behavior that are inaccessible to LLMs alone.
## 5 CodeLogician IML Agent
CodeLogician is a neuro-symbolic agent framework designed to enable Large Language Models (LLMs) to reason rigorously about software systems. Rather than asking LLMs to reason directly about source code, CodeLogician teaches LLM-driven agents to construct explicit formal models in mathematical logic and to delegate semantic reasoning to automated reasoning engines.
The current implementation integrates the ImandraX automated reasoning engine together with static analysis tools and auxiliary knowledge sources within an agentic architecture built on LangGraph. CodeLogician exposes both low-level programmatic commands and high-level agentic workflows, allowing users and external agents to flexibly combine automated reasoning with guided interaction. When required information is missing or inconsistencies are detected, the agent can request human
feedback, enabling mixed-initiative refinement. The framework can also be embedded into external agent systems via a remote graph API.
## 5.1 From Source Code to Formal Models
At the core of CodeLogician lies the process of autoformalization (Section 4). Given a source program written in a conventional programming language (e.g., Python), the agent incrementally constructs an executable formal model in the Imandra Modeling Language (IML).
Autoformalization is not a single translation step, but a structured refinement process that involves:
- extracting structural, control-flow, and type information from the source program,
- refactoring imperative constructs into pure functional representations,
- making implicit assumptions explicit (e.g., about external libraries or partial functions),
- synthesizing an IML model that is admissible to the reasoning engine.
The resulting model is functionally equivalent to the source program at the chosen level of abstraction and suitable for mathematical analysis by ImandraX.
## 5.2 Verification Goals and Logical Properties
Once a formal model has been constructed, CodeLogician assists in formulating verification goals (VGs). A verification goal is a boolean-valued predicate over the model that expresses a property expected to hold for all possible inputs. Unlike traditional testing, verification goals quantify symbolically over infinite input spaces and admit mathematical proof or counterexample.
For example, consider a ranking function used in a financial trading system. A fundamental correctness requirement is transitivity: if one order ranks above a second, and the second ranks above a third, then the first must rank above the third. Such properties are expressed directly as verification goals in IML and discharged by ImandraX.
When a verification goal does not hold, ImandraX produces a counterexample witness. These counterexamples are concrete executions that violate the property and often expose subtle logical flaws that are difficult to detect through testing or informal inspection. In industrial case studies, this approach has uncovered violations of core invariants in production systems that would otherwise remain hidden.
## 5.3 Beyond Yes/No Verification
While the proof or refutation of a verification goal determines whether or not a property is true , many forms of program understanding require richer, non-binary kinds of semantic information. CodeLogician therefore relies not only on formal verification, but also on exhaustive behavioral analysis techniques provided by ImandraX.
In particular, CodeLogician uses state-space exploration to identify decision boundaries, semantic edge cases, and invariant behaviors. These capabilities enable explanations, documentation, and test generation that go far beyond yes/no verification and are central to CodeLogician's value proposition.
## 5.4 Agent Architecture and State
CodeLogician is implemented as a stateful agent whose execution is organized around an explicit agent state . This state captures all artifacts relevant to the reasoning process and evolves as the agent performs analysis and refinement.
The agent state includes:
- the original source program,
- extracted formalization metadata (types, control flow, assumptions),
- the generated IML model,
- the model's admission and executability status,
- verification goals, decomposition requests, and related artifacts.
Agent operations fall into three broad categories:
- State transformations , which update the agent state explicitly (e.g., modifying the source program or model);
- Agentic workflows , which orchestrate multi-step processes such as end-to-end autoformalization and analysis;
- Low-level commands , which perform individual actions such as model admission, verification, or decomposition.
This separation allows users and external agents to mix automated and guided reasoning as appropriate.
## 5.5 Model Refinement and Executability
Autoformalization proceeds as an iterative refinement process. The immediate objective is to produce a model that is admissible to ImandraX, meaning that it is well-typed and free of missing definitions. A further objective is to make the model executable , eliminating opaque functions either by implementation or by sound approximation.
These two stages correspond to:
- Admitted models , which can be verified but may contain unresolved abstractions;
- Executable models , which support full behavioral analysis and test generation.
This refinement process mirrors established practices in model-based software engineering and digital twinning. By working with an executable mathematical model, CodeLogician enables rigorous reasoning about systems whose direct analysis in the source language would be impractical.
## 5.6 Assessing Model Correctness
A natural question arises when constructing formal models: how do we know the model is correct? CodeLogician adopts a notion of correctness based on functional equivalence at the chosen abstraction level. Two programs are considered equivalent if they produce the same observable outputs for the same inputs within the modeled domain.
Exhaustive behavioral analysis plays a central role in this assessment. By enumerating all distinct behavioral regions of the model, CodeLogician provides a structured and auditable view of program behavior. This makes mismatches between intended and modeled semantics explicit and actionable.
## 5.7 Region decomposition, test case generation, and refinement
The final stage is where Imandra shows its power. We perform region decomposition on the IML code to obtain a finite number of symbolically described regions such that (a) the union of all regions covers the entire state-space, and (b) in each region, the behavior of the system is invariant.
Consider the following IML code that models order discount logic:
```
type priority = Standard | Premium
type order = { amount: int; customer: priority }
let discount = fun o ->
match o.customer with
| Premium -> if o.amount > 100 then 20 else 10
| Standard -> if o.amount > 100 then 10 else 0
```
Region decomposition partitions the input space into four distinct regions based on customer type and order amount. For each region, ImandraX provides concrete witness values that satisfy the region's constraints. To bridge the gap between these symbolic results and executable test cases, we developed imandrax-codegen , an open-source code generation tool. Given the decomposition artifacts, the tool automatically generates code including type definitions and test cases. We use Python as the target language in this example; support for additional languages is planned:
```
@dataclass
class order:
amount: int
customer: priority
@dataclass
class Standard:
pass
@dataclass
class Premium:
pass
priority = Standard | Premium
def test_1():
"""test_1
- invariant: 0
- constraints:
- not (o.customer = Premium)
- o.amount <= 100
"""
result: int = discount(o=order(0, Standard()))
expected: int = 0
assert result == expected
def test_2():
"""test_2
- invariant: 10
- constraints:
- not (o.customer = Premium)
- o.amount >= 101
"""
result: int = discount(o=order(101, Standard()))
expected: int = 10
assert result == expected
# ... test_3, test_4 are omitted for brevity
```
This workflow ensures that we have test cases that cover all possible behavioral regions of the system-in this example, all four combinations of customer priority and order amount threshold.
The entire pipeline is configurable, allowing for a balance between automation and human intervention. For example, the user can choose to double-check refactored code in intermediate steps, provide additional human feedback on error messages or let the agent handle it by itself, etc. And as mentioned in the previous section, FDB provides critical RAG support in all stages of the pipeline.
## 5.8 Interfaces
CodeLogician exposes both input and output interfaces designed to be simultaneously user-friendly and programmatically accessible. The interfaces follow a simple input schema paired with a rich, structured output format, enabling use in interactive development environments as well as integration into larger agent-based systems.
The input interface accepts source programs (currently Python) as textual input, together with optional configuration parameters that control the autoformalization and reasoning process. This minimal input design allows CodeLogician to be invoked uniformly from command-line tools, IDEs, or external agents.
The output interface is structured using Pydantic models, providing strong validation, typing, and serialization guarantees. The output schema captures detailed artifacts produced during each reasoning
attempt, including:
- generated IML models,
- compilation and admission results,
- verification outcomes and counterexamples,
- region decomposition results and associated metadata.
This structured representation makes CodeLogician suitable both for standalone use and as a component within larger neuro-symbolic pipelines.
CodeLogician also exposes configuration parameters that control the degree of automation and human intervention. Parameters such as confirm\_refactor , decomp , max\_attempts , and max\_attempts\_wo\_human\_feedback allow users to trade off full automation against mixed-initiative interaction, depending on the complexity and criticality of the target code.
## 5.8.1 Programmatic Access via python RemoteGraph
CodeLogician can be directly integrated with other LangGraph agents using the RemoteGraph interface. By specifying the agent's URI within Imandra Universe and supplying an API key, external agents can invoke CodeLogician as a remote reasoning component. This enables composition with other agentic workflows, including multi-agent systems and tool-augmented LLM pipelines. In addition to programmatic access, CodeLogician is also available through a web-based chat interface in Imandra Universe.
## 5.8.2 VS Code Extension
CodeLogician is distributed with a free Visual Studio Code (VS Code) extension [8], providing a lightweight and accessible interface for interactive use. The extension communicates with the CodeLogician agent via the RemoteGraph interface and exposes core commands through the VS Code command palette.
The extension is built around a command-queue abstraction that allows users to sequence multiple operations-such as autoformalization, verification, and decomposition-before execution. It supports simultaneous formalization of multiple source files and provides visibility into the agent's internal state, including generated models and reasoning artifacts.
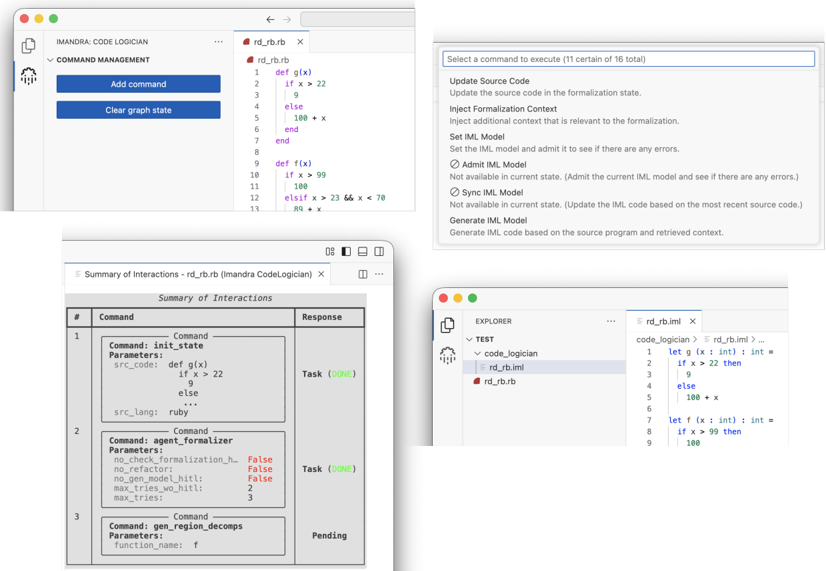
Figure 6 illustrates the VS Code extension's command management system, state viewer, and an example IML model produced by CodeLogician.
## 5.9 Summary
The CodeLogician IML agent operationalizes the neuro-symbolic approach advocated in this paper. LLMs are used to construct formal mental models of software systems, while automated reasoning engines provide mathematically precise analysis. By combining autoformalization, verification goals, and exhaustive behavioral analysis within an agentic framework, CodeLogician enables rigorous reasoning about real-world software systems beyond the capabilities of LLM-only approaches.
## 6 CodeLogician Server
The CodeLogician server provides a persistent backend for project-wide formalization and analysis. It manages formalization tasks, maintains analysis state across sessions, and serves multiple client interfaces (TUI and CLI). Unlike one-shot invocation modes, the server is designed for continuous and incremental operation: it caches results, reacts to code changes, and recomputes only the minimal set of affected artifacts required to keep formal models consistent with the underlying code base.
Figure 6: CodeLogician VS Code extension, showing command management, agent state visualization, and a generated IML model.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Screenshot: Imandra Code Logician Interface
### Overview
This screenshot displays the Imandra Code Logician interface, a tool for formal verification and analysis of code. The interface is divided into several panes: a command management section on the left, a code editor in the top-center, a command execution selection area in the top-right, a summary of interactions at the bottom-left, and an explorer/file browser on the bottom-right. The code being analyzed appears to be Ruby.
### Components/Axes
The interface contains the following key components:
* **Command Management:** Includes buttons for "Add command" and "Clear graph state".
* **Code Editor (rd\_rb.rb):** Displays Ruby code with line numbers.
* **Command Execution:** Presents a list of commands to execute (11 of 16 total). Options include "Update Source Code", "Inject Formalization Context", "Set IML Model", "Admit IML Model", "Sync IML Model", and "Generate IML Model".
* **Summary of Interactions (rd\_rb (Imandra CodeLogician)):** A table showing command history, parameters, and responses. Columns are labeled "Command", "Parameters", and "Response".
* **Explorer:** A file browser showing a "TEST" directory containing files "code\_logician", "rd\_rb.bimi", and "rd\_rb.rb".
* **Code Editor (rd\_rb.bimi):** Displays code with line numbers.
### Detailed Analysis or Content Details
**1. Code Editor (rd\_rb.rb):**
```
1 def g(x)
2 if x > 22
3 9
4 else
5 100 + x
6 end
7 end
8
9 def f(x)
10 if x > 99
11 100
12 elsif x > 23 && x < 70
13 99 + x
```
**2. Command Execution Options:**
* Update Source Code: Update the source code in the formalization state.
* Inject Formalization Context: Inject additional context that is relevant to the formalization.
* Set IML Model: Set the IML model and admit it to see if there are any errors.
* Admit IML Model: Not available in current state. (Admit the current IML Model and see if there are any errors.)
* Sync IML Model: Not available in current state. (Update the IML code based on the most recent source code.)
* Generate IML Model: Generate IML code based on the source program and retrieved context.
**3. Summary of Interactions:**
| # | Command | Parameters | Response |
|---|-------------------|------------------------------------------|----------|
| 1 | init\_state | src\_code: `def g(x) if x > 22 then 9 else 100 + x end` | Task (0/0s) |
| 2 | agent\_formalizer | no\_check\_formalization\_h: False, no\_refactors: False, max\_gen\_model\_hit: 1, max\_tries\_wo\_hit: 2 | Task (0/0s) |
| 3 | gen\_region\_decomp | function\_name: x | Pending |
**4. Code Editor (rd\_rb.bimi):**
```
1 let g x : int -> int =
2 if x > 22 then
3 9
4 else
5 100 + x
6
7 let f x : int -> int =
8 if x > 99 then
9 100
```
### Key Observations
* The interface is actively processing commands, as indicated by the "Task (0/0s)" and "Pending" statuses.
* The code in `rd_rb.rb` defines two functions, `g(x)` and `f(x)`, with conditional logic.
* The `rd_rb.bimi` file appears to contain a formalization of the Ruby code in a different language (likely a formal specification language).
* Some commands are unavailable in the current state ("Admit IML Model", "Sync IML Model").
* The "Summary of Interactions" shows a sequence of commands: initialization, formalization, and region decomposition.
### Interpretation
The screenshot depicts a workflow within Imandra Code Logician for formally verifying Ruby code. The process involves:
1. **Loading Source Code:** The Ruby code in `rd_rb.rb` is loaded into the system.
2. **Formalization:** The `agent_formalizer` command translates the Ruby code into a formal specification (represented in `rd_rb.bimi`). This formalization allows for rigorous analysis.
3. **Region Decomposition:** The `gen_region_decomp` command likely breaks down the code into smaller, manageable regions for analysis.
4. **Model Checking/Verification:** The "Set IML Model" and "Admit IML Model" commands (currently unavailable) would be used to build and verify a model of the code's behavior against the formal specification.
The interface suggests that the user is in the process of setting up a formal verification task. The "Pending" status of the `gen_region_decomp` command indicates that this step is currently in progress. The unavailable commands suggest that the formalization and region decomposition steps must be completed before model checking can begin. The presence of both Ruby code and a formal specification highlights the tool's ability to bridge the gap between informal source code and rigorous mathematical analysis. The `bimi` file extension suggests a specific format used by Imandra for representing formal specifications.
</details>
## 6.1 Server Responsibilities
At a high level, the server is responsible for:
- Persistent analysis state : storing formalization artifacts and their status across sessions;
- Project management : tracking multiple repositories, configurations, and formalization strategies;
- Incremental updates : monitoring file and dependency changes and triggering minimal reformalization;
- Caching : avoiding redundant computation by reusing results for unchanged modules;
- Interface multiplexing : serving requests from interactive and programmatic clients via a shared backend.
These responsibilities enable a workflow in which developers and agents can repeatedly query and refine formal models while the server maintains a coherent, up-to-date view of the formalized state of the project.
## 6.2 Strategies: Project-Wide Formalization via PyIML
The server executes strategies , configureable pipelines that formalize a code base and manage dependencies between its components. For Python projects, CodeLogician provides the PyIML strategy , which translates Python source code into IML models suitable for reasoning in ImandraX .
Given a project directory, the PyIML strategy:
1. Analyzes Python modules and infers their dependency structure from imports;
2. Translates source constructs (functions, classes, types) into corresponding IML artifacts;
3. Manages formalization across the codebase in dependency-consistent order;
4. Maintains a project metamodel capturing modules, dependencies, and formalization status.
The strategy also handles opaque functions (Section 4) by preserving type information while abstracting implementation details when direct translation is not possible. This allows the system to admit models and begin formal reasoning even in the presence of external libraries or currently-unknown semantics, while making the loss of executability explicit.
## 6.3 Metamodel-Based Formalization
Formalizing large software systems requires reasoning not only about individual source files, but also about their interdependencies. To support scalable project-wide analysis, the CodeLogician server maintains an explicit metamodel that captures the structure, dependencies, and formalization status of a collection of models corresponding to a repository.
## 6.4 Core Definitions
Model A model represents the formalization state of a single source file or module. Each model contains:
- src code : the source code of the corresponding file or module;
- formalization status : the current level of formalization achieved;
- dependencies : references to other models on which this model depends;
- dependency context : an aggregated formal representation (in IML) of available dependencies, used during formalization.
Metamodel A metamodel is a container for all models associated with a given project directory (repository). It provides operations for model insertion, deletion, update, and dependency management, and serves as the authoritative representation of the project's formalization state.
Interdependence By interdependence, we mean that models import symbols (e.g., functions, classes, constants) from other project files or third-party libraries. By default, a model can be formalized even when referenced symbols lack formal implementations; however, such symbols must be treated as opaque , which limits the strength of reasoning that can be performed.
Autoformalization Autoformalization is the process by which the CodeLogician agent translates source code, together with its dependency context, into an IML model and submits it to the reasoning engine. This process may produce artifacts such as verification goals, counterexamples, and test cases.
## 6.5 Formalization Levels
Each model is assigned a formalization level reflecting how much semantic information is available:
- Unknown : no formalization has been performed;
- Error during validation : admission failed due to issues such as inconsistent types, missing symbols, or non-termination;
- Admitted with opaqueness : the model has been admitted but contains opaque symbols;
- Admitted transparent : the model has been admitted and contains no opaque elements.
The dependency context is computed by aggregating all available IML models of dependencies and injecting this context alongside the model's own source code during formalization.
Objective. The objective of the server is to maximize the number of models that are formalized, and to achieve the highest possible level of formalization for each model, while ensuring that the most up-to-date source code, dependency context, and human input are reflected.
## 6.6 Conditions Triggering Re-Formalization
A model requires re-formalization when:
- its underlying source code has changed or has never been formalized; or
- the source code or formalization status of one or more dependencies (direct or indirect) has changed.
## 6.7 Autoformalization Workflow
Initial state. Figure 7 shows an example repository with a hierarchical structure in which modules import symbols from one another.
Figure 7: Example project structure.
<details>
<summary>Image 6 Details</summary>
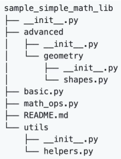
### Visual Description
\n
## Diagram: Python Package Directory Structure
### Overview
The image depicts a visual representation of a Python package directory structure, likely generated by a tree-like command-line utility. It shows the hierarchy of files and subdirectories within a package named `sample_simple_math_lib`. The structure is presented using lines and characters to indicate branching and file/directory names.
### Components/Axes
The diagram doesn't have traditional axes. It's a hierarchical tree structure. The root directory is `sample_simple_math_lib`. The structure is visually organized with indentation to represent nested directories.
### Detailed Analysis or Content Details
The directory structure is as follows:
* `sample_simple_math_lib`
* `__init__.py`
* `advanced`
* `__init__.py`
* `geometry`
* `__init__.py`
* `shapes.py`
* `basic.py`
* `math_ops.py`
* `README.md`
* `utils`
* `__init__.py`
* `helpers.py`
Each line represents a file or directory. The `+` and `L` characters are used to visually indicate branching in the tree structure. The files ending in `.py` are Python source code files. `README.md` is a Markdown file, likely containing documentation. `__init__.py` files are used to mark directories as Python packages.
### Key Observations
The package is organized into several submodules: `advanced`, `utils`, and individual files for basic operations (`basic.py`, `math_ops.py`). The `advanced` module further contains a `geometry` submodule. The presence of `__init__.py` files in each directory indicates that these directories are intended to be treated as Python packages or subpackages.
### Interpretation
This directory structure suggests a Python library designed for mathematical operations. The `basic` and `math_ops` files likely contain fundamental mathematical functions. The `advanced` module, with its `geometry` submodule, suggests more specialized mathematical capabilities. The `utils` module likely contains helper functions used throughout the library. The `README.md` file would provide documentation on how to use the library. The structure is well-organized, following common Python packaging conventions. This structure promotes modularity and reusability of the code.
</details>
The dependency graph inferred from imports is shown in Figure 8. An edge from a source node to a target node indicates that the source imports symbols from the target.
Figure 8: Dependency graph inferred from imports.
<details>
<summary>Image 7 Details</summary>

### Visual Description
\n
## Diagram: Python Module Dependency Graph
### Overview
The image depicts a directed graph illustrating the dependencies between several Python modules. Each module is represented as a rectangular node, and the arrows indicate which modules depend on others. The nodes contain information about the module's name and file path.
### Components/Axes
The diagram consists of rectangular nodes connected by directed arrows. Each node displays two key-value pairs:
* `name`: The name of the Python module.
* `path`: The file path of the Python module.
There are no axes in this diagram, as it is a dependency graph.
### Detailed Analysis or Content Details
The diagram shows the following modules and their dependencies:
* **PythonModule(name='__init__', path='__init__.py')**: This module has no dependencies.
* **PythonModule(name='advanced', path='advanced/__init__.py')**: This module has no dependencies.
* **PythonModule(name='utils.helpers', path='utils/helpers.py')**: This module has no dependencies.
* **PythonModule(name='math.ops', path='math.ops.py')**: This module has no dependencies.
* **PythonModule(name='basic', path='basic.py')**: This module has no dependencies.
* **PythonModule(name='advanced.geometry.shapes', path='advanced/geometry/shapes.py')**: This module depends on `utils.helpers`.
* **PythonModule(name='advanced.geometry.__init__', path='advanced/geometry/__init__.py')**: This module depends on `utils.helpers`.
* **PythonModule(name='advanced.__init__', path='advanced/__init__.py')**: This module depends on `advanced.geometry.__init__` and `advanced.geometry.shapes`.
* **PythonModule(name='math.ops', path='math.ops.py')**: This module depends on `basic`.
* **PythonModule(name='utils.helpers', path='utils/helpers.py')**: This module depends on `math.ops` and `basic`.
The dependencies can be summarized as follows:
* `advanced.geometry.shapes` -> `utils.helpers`
* `advanced.geometry.__init__` -> `utils.helpers`
* `advanced.__init__` -> `advanced.geometry.__init__`
* `advanced.__init__` -> `advanced.geometry.shapes`
* `math.ops` -> `basic`
* `utils.helpers` -> `math.ops`
* `utils.helpers` -> `basic`
### Key Observations
The `utils.helpers` module appears to be a central component, as it is depended upon by multiple other modules (`advanced.geometry.shapes`, `advanced.geometry.__init__`). The `advanced` module has a nested structure with dependencies within its geometry sub-package. The `math.ops` module depends on the `basic` module, and `utils.helpers` depends on both `math.ops` and `basic`.
### Interpretation
This diagram represents the modular structure of a Python project. The dependencies illustrate how different parts of the project are interconnected. The `utils.helpers` module likely provides common functionality used by several other modules. The `advanced` module demonstrates a hierarchical organization, with dependencies within its sub-packages. The diagram suggests a well-defined modular architecture, where components are separated and interact through explicit dependencies. This promotes code reusability, maintainability, and testability. The dependency on `basic` by both `math.ops` and `utils.helpers` suggests that `basic` contains fundamental or core functionalities.
</details>
## CodeLogician(SourceCode, DependencyContext) : Model.
Figure 9: Topological formalization order.
Autoformalization proceeds bottom-up along a topological ordering of the dependency graph (Figure 9).
Suppose we wish to reason about functions in utils/helpers.py . To do so, CodeLogician formalizes that module and all of its dependencies in dependency order (Figure 10).
```
1. CodeLogician(basic.py, []) = Model(basic.py)
2. CodeLogician(math_ops.py, [Model(basic.py)]) = Model(math_ops.py)
3. CodeLogician(utils/helpers.py, [Model(basic.py), Model(math_ops.py)]) = Model(utils/helpers.py)
```
Figure 10: Formalization sequence for a target module.
After completion, formalized models appear highlighted, while unformalized modules remain unchanged (Figures 11.
## 6.8 Minimal Re-Formalization Strategy
When source code changes, the server computes precise diffs to identify the minimal set of models that require re-formalization, ensuring consistency while avoiding unnecessary recomputation.
Case 1: Source modified, dependencies unchanged. If math ops.py is modified without altering dependency relations (Figure 12), the modified module is marked as source modified , and only downstream formalized dependencies are updated.
- Case 2: New dependency added. If a new module is introduced (Figure 13), formalization proceeds in dependency order to restore consistency.
- Case 3: Dependencies merged. When multiple modules are merged, the server recomputes formalization only for affected nodes (Figure 14).
- Case 4: Upstream dependency removed. If a dependency is removed from an unformalized module, no re-formalization is required for already formalized nodes (Figure 15).
## 6.9 Summary and Error Resilience
In response to file updates, CodeLogician :
1. updates the dependency graph;
2. computes the minimal set of required re-formalization tasks;
3. avoids unnecessary re-formalization by targeting only affected models.
<details>
<summary>Image 8 Details</summary>
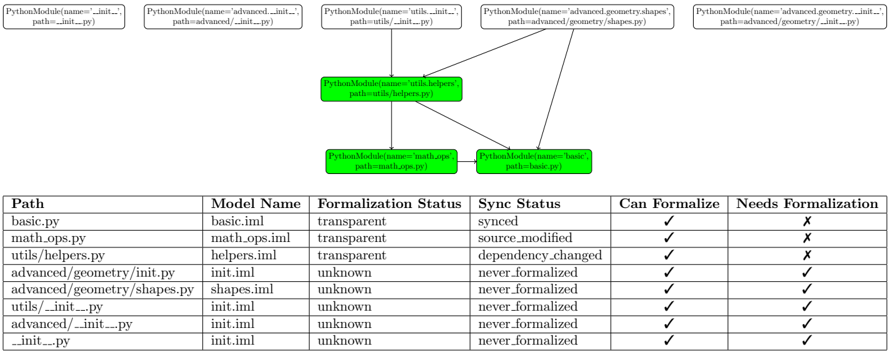
### Visual Description
\n
## Diagram: Python Module Dependency and Formalization Status
### Overview
The image presents a diagram illustrating the dependency relationships between Python modules, alongside a table detailing their formalization and synchronization status. The diagram shows a tree-like structure where modules depend on others, and the table provides specific information about each module's formalization process.
### Components/Axes
The diagram consists of rectangular nodes representing Python modules, connected by arrows indicating dependencies. Each node is labeled with the module's name and path. The table below the diagram has the following columns: "Path", "Model Name", "Formalization Status", "Sync Status", "Can Formalize", and "Needs Formalization".
### Detailed Analysis or Content Details
**Diagram Analysis:**
* **Root Module:** `PythonModule(name='utils.helpers', path='utils/helpers.py')` is at the center of the diagram.
* **Parent Modules:** This root module is dependent on `PythonModule(name='math.ops', path='math.ops.py')` and `PythonModule(name='basic', path='basic.py')`.
* **Further Dependencies:** `PythonModule(name='__init__', path='__init__.py')` appears multiple times as a dependency for other modules: `advanced/__init__.py`, `utils/__init__.py`, and `advanced/geometry/__init__.py`.
* **Module Paths:** The paths indicate a directory structure: `utils`, `advanced`, and `advanced/geometry`.
**Table Analysis:**
| Path | Model Name | Formalization Status | Sync Status | Can Formalize | Needs Formalization |
| :--------------------- | :------------ | :------------------- | :------------------- | :------------ | :------------------ |
| basic.py | basic.iml | transparent | synced | ✅ | ❌ |
| math.ops.py | math.ops.iml | transparent | source\_modified | ✅ | ❌ |
| utils/helpers.py | helpers.iml | transparent | dependency\_changed | ✅ | ❌ |
| advanced/geometry/init.py | init.iml | unknown | never formalized | ✅ | ✅ |
| advanced/geometry/shapes.py | shapes.iml | unknown | never formalized | ✅ | ✅ |
| utils/\_\_init\_\_.py | init.iml | unknown | never formalized | ✅ | ✅ |
| advanced/\_\_init\_\_.py | init.iml | unknown | never formalized | ✅ | ✅ |
| \_\_init\_\_.py | init.iml | unknown | never formalized | ✅ | ✅ |
* **Formalization Status:** The status can be "transparent", "unknown".
* **Sync Status:** The status can be "synced", "source\_modified", "dependency\_changed", or "never formalized".
* **Can Formalize:** All modules have a checkmark (✅) in this column.
* **Needs Formalization:** Modules with "unknown" formalization status all have a checkmark (✅) in this column, indicating they require formalization. Modules with "transparent" status have an 'X' (❌).
### Key Observations
* Modules with "transparent" formalization status are synchronized, but some have either source modifications or dependency changes.
* Modules within the `advanced` and `utils` directories, particularly the `__init__.py` files, have an "unknown" formalization status and "never formalized" sync status, indicating they require attention.
* All modules *can* be formalized, but only those with "unknown" status *need* to be.
### Interpretation
The diagram and table together provide a snapshot of the formalization process for a set of Python modules. The diagram visually represents the dependencies between these modules, while the table provides detailed information about their formalization and synchronization status. The data suggests that while some modules are fully synchronized and formalized ("transparent" status), others, particularly those in the `advanced` and `utils` directories, are lagging behind and require formalization. The "Can Formalize" and "Needs Formalization" columns clearly highlight which modules require immediate attention. The sync statuses "source\_modified" and "dependency\_changed" suggest that even the "transparent" modules may require review to ensure consistency with their dependencies and source code. This information is crucial for maintaining a well-organized and reliable codebase.
</details>
Figure 11: Summary of formalization status, formalized modules highlighted.
Figure 12: Source modification without dependency changes.
<details>
<summary>Image 9 Details</summary>
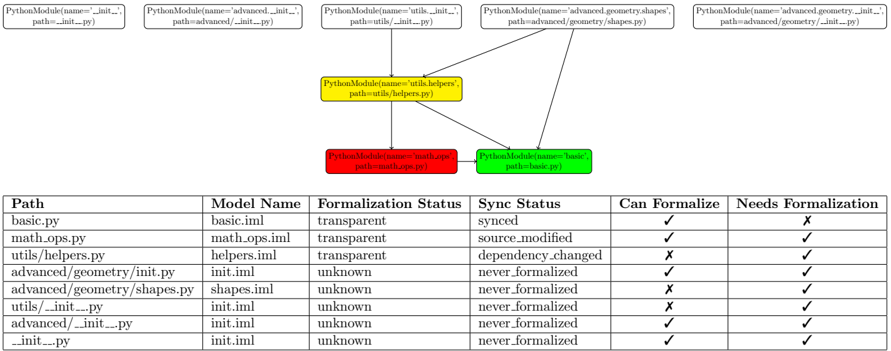
### Visual Description
\n
## Diagram: Python Module Dependency and Formalization Status
### Overview
The image presents a diagram illustrating the dependency relationships between Python modules, alongside a table detailing their formalization and synchronization status. The diagram shows a hierarchical structure with modules branching out from a central module. The table provides specific information about each module listed in the diagram.
### Components/Axes
The diagram consists of rectangular nodes representing Python modules, connected by arrows indicating dependencies. Each node displays the module's type ("PythonModule"), name, and path. The table has the following columns: "Path", "Model Name", "Formalization Status", "Sync Status", "Can Formalize", and "Needs Formalization".
### Detailed Analysis or Content Details
**Diagram Analysis:**
* **Top Level Modules (Yellow):** Five yellow modules are positioned across the top of the diagram. They are:
* `PythonModule(name='__init__', path='advanced/__init__.py')`
* `PythonModule(name='advanced', path='advanced/__init__.py')`
* `PythonModule(name='utils', path='utils/__init__.py')`
* `PythonModule(name='advanced_geometry', path='advanced/geometry/shapes.py')`
* `PythonModule(name='advanced_geometry', path='advanced/geometry/__init__.py')`
* **Intermediate Module (Yellow):** A single yellow module is positioned centrally:
* `PythonModule(name='utils.helpers', path='utils/helpers.py')`
* **Bottom Level Modules (Red & Green):** Two modules are positioned at the bottom:
* `PythonModule(name='form.apps', path='form/models.py')` (Red)
* `PythonModule(name='basic', path='basic.py')` (Green)
* **Dependencies:** Arrows originate from the top-level modules and converge on the intermediate module (`utils.helpers`). Arrows then extend from the intermediate module to the bottom-level modules.
**Table Analysis:**
| Path | Model Name | Formalization Status | Sync Status | Can Formalize | Needs Formalization |
| ---------------------- | ------------- | -------------------- | ------------------ | ------------- | ------------------- |
| basic.py | Basic.iml | transparent | synced | X | ✓ |
| math.ops.py | math.ops.iml | transparent | source_modified | ✓ | ✓ |
| utils/helpers.py | helpers.iml | transparent | dependency_changed | X | ✓ |
| advanced/geometry/init.py | init.iml | unknown | never formalized | ✓ | ✓ |
| advanced/geometry/shapes.py | shapes.iml | unknown | never formalized | X | ✓ |
| utils/__init__.py | init.iml | unknown | never formalized | ✓ | ✓ |
| advanced/__init__.py | init.iml | unknown | never formalized | ✓ | ✓ |
| __init__.py | init.iml | unknown | never formalized | ✓ | ✓ |
* **Formalization Status:** The possible values are "transparent", "unknown", and "source_modified".
* **Sync Status:** The possible values are "synced", "source_modified", "dependency_changed", and "never formalized".
* **Can Formalize:** Indicated by a checkmark (✓) or an 'X'.
* **Needs Formalization:** Indicated by a checkmark (✓).
### Key Observations
* Modules `basic.py` and `math.ops.py` have a "transparent" formalization status and are "synced".
* `utils/helpers.py` has a "transparent" formalization status but a "dependency_changed" sync status.
* All modules in the `advanced` directory and `__init__.py` have an "unknown" formalization status and have "never formalized" sync status.
* All modules "Need Formalization".
* `basic.py` and `utils/helpers.py` "Can not Formalize".
### Interpretation
The diagram and table together provide a snapshot of the formalization and synchronization status of a set of Python modules. The diagram visually represents the dependencies between these modules, while the table offers detailed information about each module's status.
The "transparent" formalization status suggests that these modules are already well-defined and can be easily integrated into a formal verification process. The "unknown" status indicates that these modules require further investigation to determine their formal properties. The "source_modified" and "dependency_changed" sync statuses suggest that these modules have been updated and may require re-synchronization or re-formalization.
The fact that all modules "Need Formalization" suggests a project-wide effort to improve the reliability and correctness of the codebase through formal methods. The modules that "Can not Formalize" may require significant refactoring or redesign to become amenable to formal verification.
The diagram's hierarchical structure highlights the importance of the `utils.helpers` module, as it serves as a central dependency for several other modules. This suggests that ensuring the formalization and synchronization of this module is crucial for the overall health of the project.
</details>
Figure 13: Addition of a new dependency
<details>
<summary>Image 10 Details</summary>
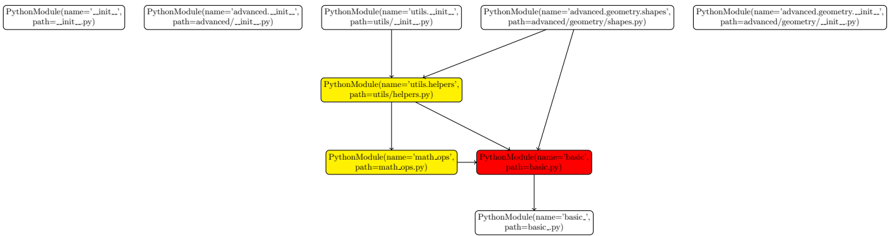
### Visual Description
\n
## Diagram: Python Module Dependency Graph
### Overview
The image depicts a directed graph illustrating the dependencies between Python modules. Each node represents a module, and the arrows indicate which modules import or depend on others. The nodes are rectangular and labeled with the module's name and path.
### Components/Axes
The diagram consists of the following modules:
* `__init__` (path: `__init__.py`)
* `advanced` (path: `advanced/__init__.py`)
* `utils` (path: `utils/__init__.py`)
* `utils_helpers` (path: `utils/helpers.py`)
* `math_apps` (path: `math_apps.py`)
* `basic` (path: `basic.py`)
* `basic_` (path: `basic_.py`)
* `advanced_geometry_shapes` (path: `advanced/geometry/shapes.py`)
* `advanced_geometry` (path: `advanced/geometry.py`)
* `basic` (path: `basic.py`)
The nodes are colored as follows:
* Yellow: `__init__`, `advanced`, `utils`, `utils_helpers`, `math_apps`
* Red: `basic`
The arrows represent dependencies, pointing from the dependent module to the module it depends on.
### Detailed Analysis or Content Details
The diagram shows the following dependencies:
1. `utils_helpers` depends on `utils`.
2. `math_apps` depends on `utils_helpers`.
3. `basic` depends on `math_apps`.
4. `basic_` depends on `basic`.
5. `advanced_geometry_shapes` depends on `advanced_geometry`.
6. `advanced_geometry` depends on `advanced`.
7. `advanced` depends on `__init__`.
8. `utils` depends on `__init__`.
### Key Observations
The module `__init__` appears to be a foundational module, as both `advanced` and `utils` depend on it. The `basic` module is central to a chain of dependencies, being depended on by `basic_` and depending on `math_apps`. The `utils` module and its helper `utils_helpers` form a separate dependency chain. The `advanced` module and its geometry submodules form another dependency chain.
### Interpretation
This diagram illustrates the modular structure of a Python project. The dependencies show how different parts of the project are interconnected. The `__init__` module likely contains core functionalities used by other modules. The `basic` module seems to provide fundamental operations, while the `advanced` module offers more specialized features. The diagram helps understand the project's organization and how changes in one module might affect others. The color coding highlights potentially distinct functional areas within the project. The diagram suggests a hierarchical structure, with `__init__` at the root and specialized modules branching out from it.
</details>
<details>
<summary>Image 11 Details</summary>

### Visual Description
\n
## Data Table: Model Formalization Status
### Overview
The image presents a data table detailing the formalization status of various model files. The table lists the file path, model name, formalization status, synchronization status, whether the model can be formalized, and whether it needs formalization.
### Components/Axes
The table has the following columns:
* **Path:** The file path of the model.
* **Model Name:** The name of the model associated with the file.
* **Formalization Status:** The current status of the model's formalization (unknown, transparent).
* **Sync Status:** The synchronization status of the model (never normalized, source_modified, dependency_changed).
* **Can Formalize:** Indicates whether the model can be formalized (marked with a checkmark '✓' or an 'X').
* **Needs Formalization:** Indicates whether the model needs formalization (marked with a checkmark '✓').
### Detailed Analysis or Content Details
The table contains the following data:
| Path | Model Name | Formalization Status | Sync Status | Can Formalize | Needs Formalization |
| -------------------------- | ---------- | -------------------- | --------------------- | ------------- | ------------------- |
| basic.py | basic.iml | unknown | never normalized | ✓ | ✓ |
| basic.py | basic.iml | transparent | source_modified | ✗ | ✓ |
| math_ops.py | math_ops.iml | transparent | dependency_changed | ✗ | ✓ |
| utils/helpers.py | helpers.iml| transparent | dependency_changed | ✗ | ✓ |
| advanced/geometry/init.py | init.iml | unknown | never normalized | ✓ | ✓ |
| advanced/geometry/shapes.py| shapes.iml | unknown | never normalized | ✗ | ✓ |
| utils/\_init\_\_.py | init.iml | unknown | never normalized | ✗ | ✓ |
| advanced/\_init\_\_.py | init.iml | unknown | never normalized | ✓ | ✓ |
| \_init\_.py | init.iml | unknown | never normalized | ✓ | ✓ |
### Key Observations
* Most models have an "unknown" formalization status and have "never normalized" sync status.
* Models with a "transparent" formalization status have either "source_modified" or "dependency_changed" sync statuses.
* A significant number of models "Need Formalization" (all entries in the table).
* The "Can Formalize" column is mixed, with some models being able to be formalized and others not.
### Interpretation
The data suggests that a large portion of the models require formalization, but not all of them are currently capable of being formalized. The "transparent" models appear to be in a state where changes have occurred (either to the source code or dependencies) since the last formalization attempt. The "unknown" status indicates that these models have not yet been assessed for formalization. The table provides a clear overview of which models need attention and which ones might require further investigation before formalization can proceed. The presence of both "Can Formalize" and "Needs Formalization" being true for many entries suggests a workflow where models are identified as needing formalization, but a separate process determines if they are currently able to be formalized.
</details>
Figure 15: Removal of an upstream dependency.
<details>
<summary>Image 12 Details</summary>
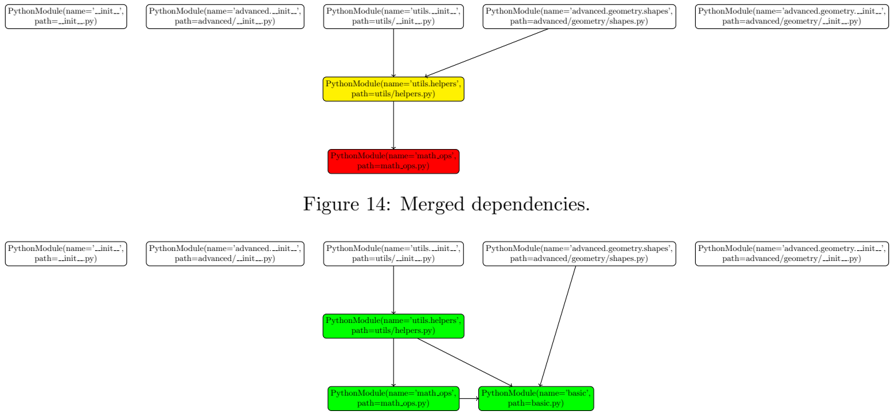
### Visual Description
\n
## Diagram: Merged Dependencies
### Overview
The image presents a dependency diagram illustrating the relationships between Python modules. It shows two sets of modules and their dependencies, with a central module (`utils/helpers.py`) acting as a merging point. The diagram is labeled "Figure 14: Merged dependencies."
### Components/Axes
The diagram consists of rectangular nodes representing Python modules. Each node displays the module's name and path. Arrows indicate dependencies, pointing from a dependent module to the module it depends on. The diagram is split into two sections, an upper section and a lower section, with the upper section showing dependencies before merging and the lower section showing dependencies after merging.
### Detailed Analysis or Content Details
**Upper Section:**
* Five modules are displayed horizontally:
* `PythonModule(name=__init__, path=__init__.py)` (light green)
* `PythonModule(name=advanced, path=advanced/__init__.py)` (light green)
* `PythonModule(name=utils, path=utils/__init__.py)` (light green)
* `PythonModule(name=advanced.geometry.shapes, path=advanced/geometry/shapes.py)` (light green)
* `PythonModule(name=advanced.geometry.__init__, path=advanced/geometry/__init__.py)` (light green)
* A central module `PythonModule(name=utils/helpers, path=utils/helpers.py)` (yellow) is connected to all five modules with arrows indicating dependencies.
* A module `PythonModule(name=test_scope, path=math_scope.py)` (red) is connected to the central module with an arrow.
**Lower Section:**
* The same five modules as in the upper section are displayed horizontally.
* The central module `PythonModule(name=utils/helpers, path=utils/helpers.py)` (yellow) is again present.
* Two modules are connected to the central module:
* `PythonModule(name=math_scope, path=math_scope.py)` (red)
* `PythonModule(name=basic, path=basic.py)` (light green)
**Text Label:**
* "Figure 14: Merged dependencies." is positioned centrally below the upper section.
### Key Observations
* The diagram illustrates a merging of dependencies. In the upper section, several modules depend directly on `utils/helpers.py`. In the lower section, `utils/helpers.py` depends on `math_scope.py` and `basic.py`.
* The color coding distinguishes between different types of modules (light green, yellow, red).
* The diagram suggests a refactoring or restructuring of dependencies, where the initial dependencies are consolidated through the `utils/helpers.py` module, and then further dependencies are introduced.
### Interpretation
The diagram depicts a dependency management scenario, likely within a software project. The "merged dependencies" suggest a process of consolidating multiple dependencies into a central module (`utils/helpers.py`). This central module then introduces new dependencies (`math_scope.py` and `basic.py`). This could represent a simplification of the dependency graph, or a change in the project's architecture. The use of different colors might indicate different categories of modules (e.g., core modules, utility modules, test modules). The diagram is a visual representation of how different parts of the code rely on each other, and how those relationships have evolved. The red module `math_scope.py` stands out as potentially being a testing or specialized module, given its distinct color. The diagram is a high-level overview and doesn't provide details about the specific functionality of each module.
</details>
To ensure robustness during active development, the server uses graceful degradation. If parsing or dependency errors occur, it preserves the last known-good dependency graph and formal models, tracks errors for debugging, and automatically recovers once inconsistencies are resolved.
## 7 Performance
## 7.1 Dataset
We have created 50 models that have the following characteristics:
## · State Machine Architecture
Each model defines explicit states and manages transitions between those states via step functions.
## · Complex Multi-Entity Systems
All models represent systems with multiple interacting components, for example:
- -BGP path vector routing: speakers, neighbors, routes
- -NPC pathfinding: characters, obstacles, terrain
- -Smart warehouse auto-controller: robots, inventory, orders, zones
- -Options market maker: options, positions, hedges
- -Nuclear reactor safety system: control rods, safety systems, parameters
- -TLS handshake protocol: client, server, certificates, sessions
## · Temporal Evolution
Models explicitly track state changes over time using counters and/or timestamps, and evolve via simulation step functions.
## · Decision Logic
Each model implements complex decision-making based on current state and parameters (e.g. routing decisions, pathfinding, task assignment, hedging, safety checks, protocol steps). This logic often exhibits characteristic interaction patterns, including:
- Override patterns , where special conditions trump normal logic except in specific subcases
- Dead-zone patterns , where integer boundary combinations create gaps leading to undefined behavior or unexpected fallback states
## · Safety and Correctness Properties
Many models include explicit invariants or constraints that must always hold, such as safety limits, risk limits, or convergence conditions.
All models are rooted in real-world systems that exist in production environments. Each model includes three questions that probe different aspects of state machine understanding, such as enumerating distinct behavioral scenarios, identifying conditions under which specific behaviors occur, and determining whether safety or correctness properties can be violated.
We evaluate two approaches to answering these questions:
- LLM-only: The LLM analyzes the Python source code directly and answers the questions based on its own reasoning over the code.
- CodeLogician (LLM + ImandraX ): The model is translated into IML (Imandra Modeling Language), and ImandraX performs formal region decomposition and verification. The LLM then synthesizes answers from these formal analysis results.
## 7.2 Metrics
We design 7 metrics to evaluate the performance of LLM-only reasoning compared to CodeLogician . Each metric is designed to assess a specific aspect of reasoning about complex state machines and decision logic.
## 7.2.1 State Space Estimation Accuracy
This metric measures how accurately the LLM estimates the number of distinct behavioral scenarios or regions in the state space. The ground truth comes from the exact region count produced by CodeLogician's decomposition analysis.
$$F o r m u l a \colon \, s c o r e = \frac { 1 } { 1 + \log _ { 2 } ( d i f f + 1 ) } , \quad w h e r e \, d i f f = | n _ { l l m } - n _ { d e c o m p } |$$
Design rationale: The logarithmic penalty reflects that being off by orders of magnitude (e.g., estimating 10 scenarios when there are 1000) is fundamentally more problematic than small absolute differences. The formula yields: perfect match (diff=0) → score=1.0, off by 1 → score=0.5, off by 3 → score=0.33, and converges to 0 as the difference grows. When the LLM provides only qualitative descriptions without any quantification, we assign score=0.0. For extraction, we use the following rules: (a) explicit numbers are used directly, (b) ranges use the midpoint, (c) approximations extract the implicit number, (d) qualitative descriptions with implicit combinatorial reasoning (e.g., '4 × 5 × 3 combinations') are computed, and (e) pure qualitative statements with no extractable quantity are marked as unknown.
## 7.2.2 Outcome Precision
This metric evaluates the precision of constraints and conditions in the LLM's answer compared to qualitative descriptions. It measures whether the LLM identifies exact constraints that determine system behavior.
## Scoring Rubric:
- 1.0 : Exact match (both value and operator are correct).
- 0.8 : Value is correct, but the operator is approximately equivalent (e.g., ≥ 20 vs. > 19).
- 0.5 : Value is approximately correct within a reasonable range (e.g., ≥ 20 vs. ≥ 18).
- 0.2 : Qualitative but directionally correct (e.g., 'high' when the correct constraint is > 620).
- 0.0 : Incorrect or missing.
Design rationale: This metric distinguishes between responses that capture exact conditions versus vague qualitative descriptions. The graduated scoring recognizes that approximate answers are more useful than purely qualitative ones, even if not perfectly precise.
## 7.2.3 Direction Accuracy
This metric assesses whether the LLM reaches conclusions in the correct direction, particularly for yes/no questions about system properties or behaviors. For example, does the LLM correctly identify that certain scenarios can violate a safety property, or does it incorrectly claim the property always holds?
## Scoring Rubric:
- 1.0 : Completely correct conclusion with sound reasoning.
- 0.75 : Correct conclusion but with flawed or incomplete reasoning.
- 0.5 : Partially correct.
- 0.25 : Incorrect conclusion but identifies some relevant factors.
- 0.0 : Completely incorrect.
Design rationale: Getting the fundamental direction of an answer wrong (e.g., claiming a system is safe when it has critical vulnerabilities) is a severe error in code understanding. This metric prioritizes correctness of the conclusion while also rewarding sound reasoning processes.
## 7.2.4 Coverage Completeness
This metric measures the proportion of actual decision scenarios or behavioral regions that the LLM identifies in its analysis. It evaluates how thoroughly the LLM explores the state space.
## Scoring Approach (Highest Applicable Method).
- (a) If the LLM provides explicit scenario counts, compare them directly to the decomposition count.
- (b) If the LLM enumerates specific scenarios, count the number of scenarios enumerated.
- (c) If the LLM categorizes outcomes, compute the score as
# categories identified # categories in decomposition .
- (d) If there is only a qualitative acknowledgment of multiplicity, assign a score of 0 . 25.
- (e) If there is no meaningful coverage, assign a score of 0 . 0.
Design rationale: Complete coverage is essential for sound verification. Missing scenarios can hide critical bugs or edge cases. We use multiple scoring methods to accommodate different response styles, always choosing the method most favorable to the LLM to avoid penalizing valid reasoning approaches.
## 7.2.5 Control Flow Understanding
This metric assesses whether the LLM correctly captures the structure of control flow, including branches, guards, overrides, and short-circuit behavior. We evaluate the following four aspects:
- Precedence of conditions : Correct handling of logical precedence (e.g., AND before OR , explicit priority ordering).
- Branching structure : Correct identification of control structures such as if--else--if chains versus independent conditional checks.
- Short-circuit behavior : Recognition of early returns, guard clauses, or other forms of shortcircuit evaluation.
- Override logic : Identification of safety or exception-handling logic that supersedes normal operation.
Scoring Formula. The score is computed as:
$$s c o r e = { \frac { \# c o r r e c t + 0 . 5 \times \# p a r t i a l } { 4 } } .$$
Design Rationale. Control flow structure is fundamental to program behavior. Misunderstanding whether conditions are evaluated sequentially (with short-circuiting) versus independently, or misinterpreting logical precedence, leads to incorrect analysis. Each aspect is therefore assessed independently and aggregated into a single score, with partial credit awarded to reflect nuanced but incomplete understanding.
## 7.2.6 Edge Case Detection
This metric evaluates how many rare or unexpected edge cases the LLM identifies in its analysis. An edge case is defined as any behavioral region exhibiting at least one of the following properties:
- Complex conjunctive conditions : Three or more conjunctive constraints combined in a single condition.
- Exact boundary conditions : Equality constraints at precise thresholds (e.g., x = 10 rather than x > 10).
- Negation of the common case : Scenarios such as sensor failure, timeout, or other exceptional modes.
- Counterintuitive outcomes : Behaviors that contradict naive or intuitive expectations.
- Safety-critical violations : Invariant violations, error states, or other safety-relevant failures.
Scoring Formula. The score is computed as:
$$s c o r e = \frac { \# e d g e \, c a s e s \, i n d e f i t i e d \, b y \, t h e \, L L M } { \# t o t a l \, e d g e \, c a s e s \, i n \, t h e \, d e c o m p o s i t i o n } .$$
Design Rationale. Edge cases are where defects most commonly occur. Real-world systems tend to fail at boundary conditions, under rare combinations of constraints, or in situations that violate designer assumptions. This metric therefore rewards systematic identification of such cases. The definition is intentionally broad in order to capture multiple forms of non-obvious or unexpected behavior.
## 7.2.7 Decision Boundary Clarity
Decision Boundary Identification Metric. This metric measures whether the LLM identifies the exact constraints that determine decision boundaries in the system. Each region produced by decomposition is defined by Boolean constraints-conditions on inputs such as:
- deviation ≥ 80 cm,
- state of charge < 20%,
- connection count ≥ 3,
- temperature > 100 ◦ C.
These constraints may take the form of inequalities, equalities, or logical combinations thereof.
Scoring Formula. The score is computed as:
| score = | #constraints identified by the LLM |
|-----------|--------------------------------------|
| score = | #constraints in the decomposition |
Design Rationale. Decision boundaries represent critical points in the state space at which system behavior changes qualitatively. Accurately identifying these constraints is essential for precise reasoning about when different behaviors occur. Qualitative descriptions such as 'low battery' or 'high temperature' are insufficient for formal analysis and are therefore penalized by this metric.
Applicability Note. If a metric is not applicable or irrelevant to a specific question (e.g., decision boundaries are requested for a system that has none), that metric is excluded from the evaluation for that question.
Overall Evaluation Context. Collectively, these seven metrics capture complementary dimensions of how LLM deviates from CodeLogician's formally-grounded analysis. Together, they provide a multifaceted assessment of the value added by formal methods tools. A perfect score of 1 . 0 across all metrics would indicate that an LLM can achieve the same level of rigor and completeness as formal analysis without assistance. The gaps revealed by these metrics quantify the specific ways in which formal decomposition and verification extend beyond unaided code reading and natural-language reasoning.
## 7.3 Evaluation
Our evaluation proceeds in two stages: answer generation and answer evaluation.
## 7.3.1 Answer Generation
We obtain answers from five frontier models: GPT-5.2, Grok Code Fast 1, Claude Sonnet 4.5, Claude Opus 4.5, and Gemini 3 Pro. For the LLM-only condition, each model analyzes the Python source code directly and answers the three questions per model based on its own reasoning. For the CodeLogician condition, answers are derived from ImandraX's formal region decomposition and verification results, which provide exact scenario counts, precise constraint boundaries, and proof outcomes (proven or refuted with counterexamples). The CodeLogician answers serve as ground truth for evaluation.
## 7.3.2 Answer Evaluation (LLM-as-a-Judge)
We employ the LLM-as-a-judge methodology to evaluate how well LLM-only answers align with CodeLogician answers. Four evaluator models-Gemini 2.5 Flash, Claude Haiku 4.5, GPT-4o Mini, and Grok 4 Fast-independently score each LLM response according to the seven metric definitions, providing detailed reasoning for each score. We aggregate these evaluations by averaging across the four evaluators to reduce bias from any single judge. While LLM-based evaluation introduces some variability, we plan to complement these results with deterministic methods such as test case generation from region decomposition result in the future.
All data, code, and scripts to reproduce these results are publicly available at https://github. com/imandra-ai/code-logic-bench .
## 7.4 Results
## 7.4.1 Overall Performance
State Space Estimation Accuracy (0.186). This metric reveals the most dramatic performance gap. The low scores reflect both severe underestimation-when LLMs attempt quantification but miss combinatorial explosion by orders of magnitude-and complete inability to quantify, where models resort to vague statements such as 'many scenarios' without attempting enumeration. This failure to grasp state space size has direct consequences: it leads to underestimation of verification effort, inadequate test budgets, and false confidence that manual analysis has covered sufficient ground. In
safety-critical systems, such miscalibration can mean the difference between rigorous validation and deploying systems with untested corner cases.
In one environmental monitoring system, when asked to enumerate distinct response scenarios, the model focused on high-level alert categories. In contrast, formal decomposition revealed a combinatorial explosion arising from Boolean constraint boundaries, where different combinations of sensor drift conditions, timing windows, measurement ranges, and pollutant-specific limits produce orders of magnitude more behavioral regions than surface-level structure suggests.
Outcome Precision (0.613). This metric exposes substantial imprecision in how LLMs specify constraints. Mean scores indicate frequent reliance on qualitative descriptions or approximate values rather than exact specifications. Such imprecision introduces ambiguity into requirements documentation, test case generation, and safety audits. For example, stating 'temperature must not be too high' instead of 'temperature < 620 ◦ C' prevents consistent implementation, hinders compliance verification, and leaves boundary conditions untested.
Direction Accuracy (0.635). Direction Accuracy measures whether LLMs reach correct conclusions, particularly for safety-critical properties where errors have real-world consequences. This metric uses graduated scoring from 0 . 0 (completely incorrect) to 1 . 0 (correct with sound reasoning), with partial credit awarded for identifying relevant factors despite an incorrect conclusion.
A mean score of 0 . 635 indicates that while LLMs often identify relevant aspects of system behavior, they frequently reach flawed conclusions or provide incomplete reasoning. The most severe failures occur when LLMs categorically misidentify whether safety properties hold. In one data protection system, formal verification proved that a critical privacy property always holds, yet the LLM incorrectly concluded that the property could be violated, misinterpreting how boundary conditions propagate through compliance checks. Similarly, in an autonomous driving system, the LLM claimed that a sensor reliability property could be violated under specific conditions, when verification showed it always holds.
These failures represent fundamental errors about system guarantees-the difference between confidently deploying a system and discovering critical vulnerabilities only after incidents occur.
Coverage Completeness (0.490). Coverage Completeness highlights a weak performance area, with LLMs identifying fewer than half of the actual decision scenarios. This systematic undercounting creates blind spots where critical bugs tend to hide. The gap arises because LLMs reason at categorical levels while missing how combinations of constraints multiply scenarios.
When asked to enumerate scenarios, models typically identify only the obvious, top-level categories visible in code structure. However, each category subdivides along Boolean constraint boundaries, where combinations of comparisons, timing windows, and state checks produce distinct behavioral regions. The resulting combinatorial interaction creates orders of magnitude more scenarios than surface-level reasoning suggests. This mirrors a common developer pitfall: believing that 'all cases' have been tested when only the obvious paths have been exercised.
Control Flow Understanding (0.746). Control Flow Understanding represents the strongest area of LLM performance. Models demonstrate relatively strong capability in interpreting branching logic, condition precedence, and short-circuit behavior. This is the only metric where mean performance exceeds 0 . 7, suggesting that LLMs can effectively infer common control-flow idioms through code analysis.
Nevertheless, complex override patterns and deeply nested conditionals remain challenging. Formal methods retain a key advantage by providing deterministic analysis that is independent of surface-level code structure or stylistic variation.
Edge Case Detection (0.597). Edge Case Detection shows that LLMs identify fewer than 60% of edge cases. Models tend to focus on obvious scenarios while missing counterintuitive behaviors. In monitoring systems, LLMs typically recognize high-level operational modes but overlook scenarios in which subsystems in non-standard states can still trigger critical actions through indirect pathways, such as quorum voting.
These counterintuitive interactions-where naive reasoning predicts one outcome but complex logical dependencies produce another-are precisely where production bugs most often emerge. Failing to identify such cases leaves test suites weakest exactly where failures are most likely to occur in the field.
Decision Boundary Clarity (0.695). Decision Boundary Clarity shows moderate performance. LLMs partially succeed in identifying constraints that influence system behavior but struggle to extract precise boundary conditions. Models often recognize that factors such as 'weather adjustments' or 'sensor drift' matter, yet fail to identify the exact constraint expressions where behavior changes-such as specific comparisons ( ≥ vs. > ), threshold values (79 vs. 80), or logical combinations.
LLMs also miss narrow 'dead zones' where small ranges of inputs trigger different logic, and how constraints vary across operational modes. This limitation is critical because implementations require exact Boolean conditions. Developers need precise constraint expressions to implement, test boundary behavior, and verify correctness. Region decomposition exhaustively enumerates these constraints, enabling precise implementation and comprehensive test case generation.
These data are presented in Figures 17 and Figures 18.
## Mean Score by Model
Figure 16: Mean score by model across seven metrics, relative to the scores when models were augmented with CodeLogician. Claude Opus 4.5 achieves the highest score (0.601), followed by GPT-5.2 (0.589). Despite these differences, all models perform substantially below the level achieved when augmented with formal methods.
<details>
<summary>Image 13 Details</summary>
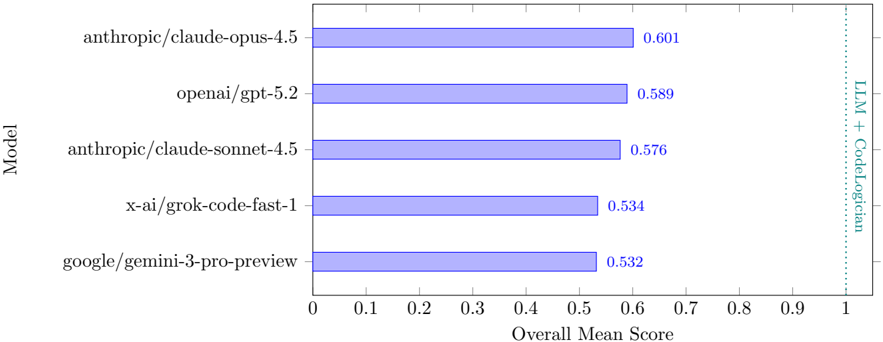
### Visual Description
\n
## Horizontal Bar Chart: LLM + CodeLogician Performance Comparison
### Overview
This is a horizontal bar chart comparing the "Overall Mean Score" of five different Large Language Models (LLMs) on a task involving both language modeling and code logic. The chart displays the models ranked by their scores, with higher scores indicating better performance.
### Components/Axes
* **Y-axis (Vertical):** Labeled "Model". The categories are:
* anthropic/claude-opus-4.5
* openai/gpt-5.2
* anthropic/claude-sonnet-4.5
* x-ai/grok-code-fast-1
* google/gemini-3-pro-preview
* **X-axis (Horizontal):** Labeled "Overall Mean Score". The scale ranges from 0 to 1, with tick marks at 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, and 1.
* **Bars:** Each bar represents a model, with its length corresponding to its "Overall Mean Score". The bars are a light blue color.
* **Annotation:** A vertical dashed line is present at x=1, with the text "LLM + CodeLogician" to the right of the line.
### Detailed Analysis
The bars are arranged from top to bottom in descending order of their scores.
* **anthropic/claude-opus-4.5:** The bar extends to approximately 0.601.
* **openai/gpt-5.2:** The bar extends to approximately 0.589.
* **anthropic/claude-sonnet-4.5:** The bar extends to approximately 0.576.
* **x-ai/grok-code-fast-1:** The bar extends to approximately 0.534.
* **google/gemini-3-pro-preview:** The bar extends to approximately 0.532.
The trend is clearly downward as you move down the list of models. The difference between the top two models is small, while the difference between the bottom two is also relatively small.
### Key Observations
* anthropic/claude-opus-4.5 has the highest "Overall Mean Score" at approximately 0.601.
* google/gemini-3-pro-preview has the lowest "Overall Mean Score" at approximately 0.532.
* The scores are relatively close together, suggesting that all models perform reasonably well on this task.
* The annotation "LLM + CodeLogician" suggests that the task involves evaluating the models' ability to handle both language modeling and code-related logic.
### Interpretation
The chart demonstrates a comparison of the performance of several LLMs on a task that requires both language understanding and code reasoning. The scores indicate that anthropic/claude-opus-4.5 is the best performing model, while google/gemini-3-pro-preview is the lowest performing. The relatively small differences in scores suggest that all models are capable, but some are more proficient than others. The annotation "LLM + CodeLogician" implies that the evaluation metric is specifically designed to assess the models' combined abilities in these two areas. The vertical dashed line at 1 could represent a target score or a benchmark for acceptable performance. The chart provides a clear visual representation of the relative strengths and weaknesses of each model in this specific context.
</details>
## 7.4.2 Model Comparison by Metric
Figures 20 and 21 show how each model performed on individual metrics: Claude Opus 4.5 achieves the highest overall performance (0 . 601), leading in State Space Estimation Accuracy (0 . 222), Decision Boundary Clarity (0 . 763), Edge Case Detection (0 . 640), and Coverage Completeness (0 . 524). GPT5.2 achieves the strongest performance in Control Flow Understanding (0 . 810) and Outcome Precision (0 . 659), indicating effective pattern recognition for common control-flow structures and relatively precise constraint specification.
Shared Limitations Across Models. Despite these relative differences, all evaluated models perform similarly on State Space Estimation Accuracy , with scores clustered in the 0 . 164-0 . 222 range. Even Claude Opus 4.5, which achieves the highest score on this metric, still falls far short of the precision achievable through formal decomposition. This variance on the most challenging metric indicates that fundamental architectural limitations affect current LLMs in a broadly similar manner when operating without formal reasoning tools.
## Mean Score by Metric
Figure 17: Mean score by metric, relative to performance once augmented with CodeLogician.
<details>
<summary>Image 14 Details</summary>
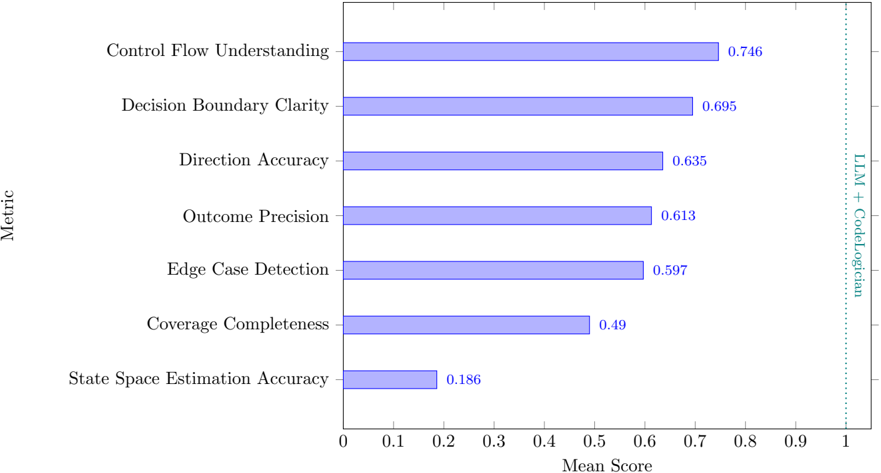
### Visual Description
\n
## Horizontal Bar Chart: LLM + CodeLogician Performance Metrics
### Overview
This image presents a horizontal bar chart displaying the performance of an "LLM + CodeLogician" system across several metrics. The chart uses a blue color scheme for the bars, and the metrics are listed on the vertical (Y) axis, while the mean score is represented on the horizontal (X) axis. A vertical dashed line is present at a score of 1.
### Components/Axes
* **Y-axis Label:** "Metric"
* **X-axis Label:** "Mean Score"
* **X-axis Scale:** Ranges from 0 to 1, with tick marks at 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, and 1.
* **Metrics (Y-axis categories):**
* Control Flow Understanding
* Decision Boundary Clarity
* Direction Accuracy
* Outcome Precision
* Edge Case Detection
* Coverage Completeness
* State Space Estimation Accuracy
* **Legend:** "LLM + CodeLogician" is written vertically on the right side of the chart.
* **Bar Color:** Blue.
### Detailed Analysis
The chart displays the mean score for each metric. The bars are arranged from top to bottom in descending order of their scores.
* **Control Flow Understanding:** Score of approximately 0.746. The bar extends to just before the 0.8 mark.
* **Decision Boundary Clarity:** Score of approximately 0.695. The bar extends to just before the 0.7 mark.
* **Direction Accuracy:** Score of approximately 0.635. The bar extends to just after the 0.6 mark.
* **Outcome Precision:** Score of approximately 0.613. The bar extends to just after the 0.6 mark.
* **Edge Case Detection:** Score of approximately 0.597. The bar extends to just after the 0.5 mark.
* **Coverage Completeness:** Score of approximately 0.49. The bar extends to just before the 0.5 mark.
* **State Space Estimation Accuracy:** Score of approximately 0.186. The bar extends to just after the 0.1 mark.
The bars generally increase in length from bottom to top, indicating a positive correlation between the metric and the score.
### Key Observations
* "Control Flow Understanding" and "Decision Boundary Clarity" have the highest scores, indicating strong performance in these areas.
* "State Space Estimation Accuracy" has the lowest score, suggesting a weakness in this aspect.
* There is a significant gap in performance between the top two metrics and the rest.
* The scores are relatively clustered between 0.49 and 0.746, except for the outlier "State Space Estimation Accuracy".
### Interpretation
The chart demonstrates the performance of the LLM + CodeLogician system across a range of software testing and analysis metrics. The system excels at understanding control flow and decision boundaries, but struggles with state space estimation. This suggests the system is better at reasoning about the logical structure of code than at comprehensively exploring all possible states. The large difference in scores indicates that some metrics are significantly more challenging for the system than others. The system appears to be more adept at higher-level reasoning (control flow, decision boundaries) than at lower-level, exhaustive analysis (state space estimation). This could be due to the inherent complexity of state space estimation or limitations in the system's ability to handle combinatorial explosion. The results could inform future development efforts, focusing on improving the system's state space estimation capabilities.
</details>
Figure 18: Mean score by metric, relative to performance once augmented with CodeLogician.
<details>
<summary>Image 15 Details</summary>
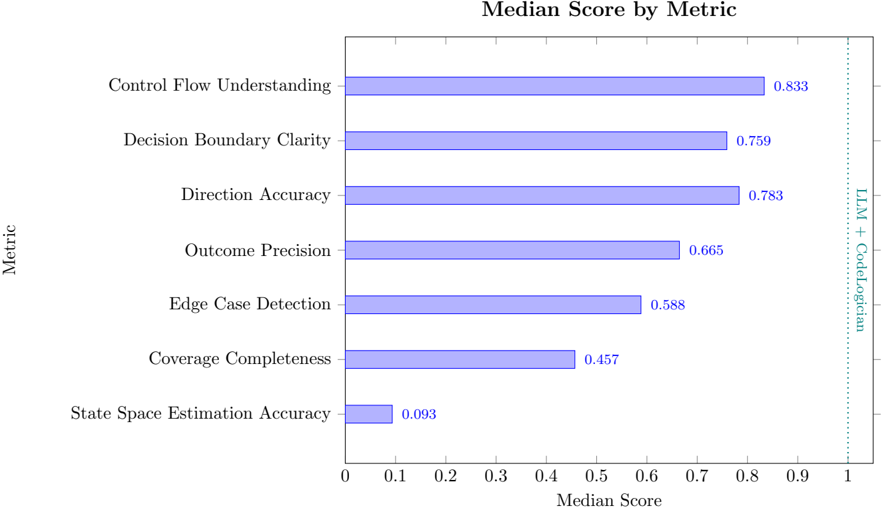
### Visual Description
\n
## Bar Chart: Median Score by Metric
### Overview
This is a horizontal bar chart displaying the median score for seven different metrics. The chart is titled "Median Score by Metric" and appears to represent the performance of a system or model (likely LLM + CodeLlama, as indicated by the text on the right side of the chart). The metrics are listed on the vertical axis, and the median scores are represented by the length of the horizontal bars on the horizontal axis.
### Components/Axes
* **Title:** "Median Score by Metric" (centered at the top)
* **Vertical Axis (Y-axis):** Labeled "Metric". The metrics listed from top to bottom are:
* Control Flow Understanding
* Decision Boundary Clarity
* Direction Accuracy
* Outcome Precision
* Edge Case Detection
* Coverage Completeness
* State Space Estimation Accuracy
* **Horizontal Axis (X-axis):** Labeled "Median Score". The scale ranges from 0 to 1, with increments of 0.1.
* **Annotation:** "LLM + CodeLlama" is written vertically on the right side of the chart.
### Detailed Analysis
The chart consists of seven horizontal bars, each representing the median score for a specific metric. The bars are all the same light purple color.
* **Control Flow Understanding:** The bar extends to approximately 0.833.
* **Decision Boundary Clarity:** The bar extends to approximately 0.759.
* **Direction Accuracy:** The bar extends to approximately 0.783.
* **Outcome Precision:** The bar extends to approximately 0.665.
* **Edge Case Detection:** The bar extends to approximately 0.588.
* **Coverage Completeness:** The bar extends to approximately 0.457.
* **State Space Estimation Accuracy:** The bar extends to approximately 0.093.
The bars are arranged in descending order of median score, with "Control Flow Understanding" having the highest score and "State Space Estimation Accuracy" having the lowest.
### Key Observations
* "Control Flow Understanding" has a significantly higher median score than all other metrics.
* "State Space Estimation Accuracy" has a very low median score, significantly lower than all other metrics.
* The scores generally decrease as you move down the list of metrics.
* The scores are relatively clustered between 0.457 and 0.833, except for the outlier "State Space Estimation Accuracy".
### Interpretation
The data suggests that the LLM + CodeLlama system performs well in understanding control flow and decision boundaries, but struggles with state space estimation. The large difference in scores indicates a potential weakness in the system's ability to accurately estimate the state space. The relatively high scores for "Direction Accuracy" and "Outcome Precision" suggest the system is generally good at providing correct and relevant outputs. The moderate score for "Edge Case Detection" indicates some ability to handle unusual or unexpected inputs, but there is room for improvement.
The arrangement of the bars in descending order allows for a quick visual comparison of the system's performance across different metrics. The annotation "LLM + CodeLlama" indicates that these scores are specifically for this combined system, and may not generalize to other models or approaches. The data could be used to identify areas where the system needs further development or refinement. The low score for "State Space Estimation Accuracy" is a particularly important finding, as it could have implications for the system's reliability and robustness.
</details>
Figure 19: Score distributions across the seven metrics.
<details>
<summary>Image 16 Details</summary>
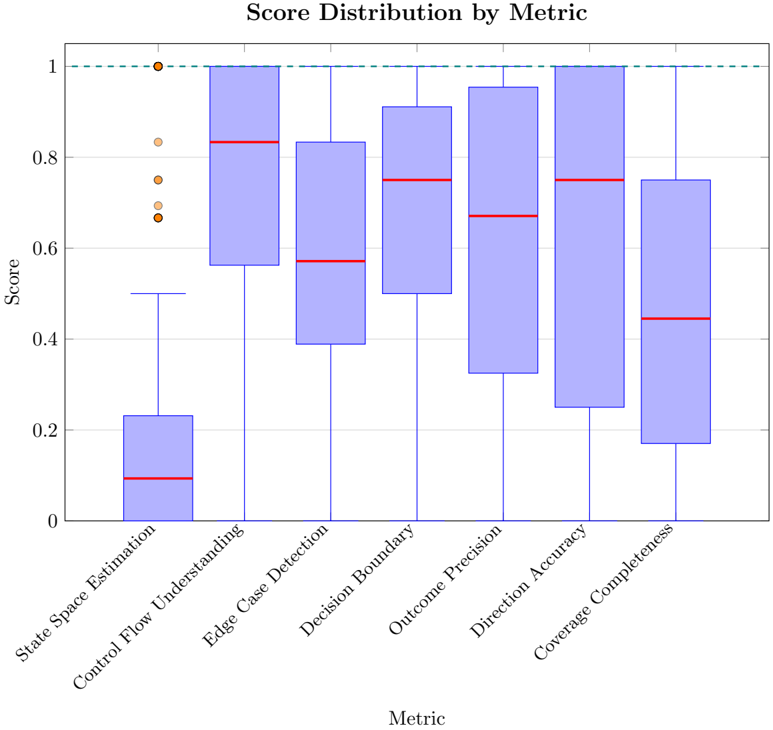
### Visual Description
\n
## Box Plot: Score Distribution by Metric
### Overview
The image presents a series of box plots visualizing the distribution of scores for different metrics. The x-axis represents the metrics, and the y-axis represents the score, ranging from 0 to 1. Each box plot displays the median, quartiles, and potential outliers for each metric. A horizontal dashed line at y=1 is present.
### Components/Axes
* **Title:** "Score Distribution by Metric" (positioned at the top-center)
* **X-axis Label:** "Metric" (positioned at the bottom-center)
* **Y-axis Label:** "Score" (positioned on the left-center)
* **Y-axis Scale:** Ranges from 0 to 1, with markings at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **Metrics (X-axis Categories):**
1. State Space Estimation
2. Control Flow Understanding
3. Edge Case Detection
4. Decision Boundary
5. Outcome Precision
6. Direction Accuracy
7. Coverage Completeness
* **Horizontal Line:** Dashed line at y=1.
### Detailed Analysis
Each metric has a corresponding box plot. The box plots show the following approximate values:
1. **State Space Estimation:**
* Minimum Score: ~0.05
* First Quartile (Q1): ~0.15
* Median (Q2): ~0.20
* Third Quartile (Q3): ~0.25
* Maximum Score: ~0.35
2. **Control Flow Understanding:**
* Minimum Score: ~0.55
* First Quartile (Q1): ~0.65
* Median (Q2): ~0.75
* Third Quartile (Q3): ~0.85
* Maximum Score: ~0.95
* Outliers: ~0.70, ~0.75, ~0.80
3. **Edge Case Detection:**
* Minimum Score: ~0.60
* First Quartile (Q1): ~0.70
* Median (Q2): ~0.80
* Third Quartile (Q3): ~0.90
* Maximum Score: ~0.95
4. **Decision Boundary:**
* Minimum Score: ~0.35
* First Quartile (Q1): ~0.45
* Median (Q2): ~0.55
* Third Quartile (Q3): ~0.70
* Maximum Score: ~0.80
5. **Outcome Precision:**
* Minimum Score: ~0.50
* First Quartile (Q1): ~0.60
* Median (Q2): ~0.70
* Third Quartile (Q3): ~0.85
* Maximum Score: ~0.95
6. **Direction Accuracy:**
* Minimum Score: ~0.35
* First Quartile (Q1): ~0.45
* Median (Q2): ~0.55
* Third Quartile (Q3): ~0.65
* Maximum Score: ~0.75
7. **Coverage Completeness:**
* Minimum Score: ~0.35
* First Quartile (Q1): ~0.45
* Median (Q2): ~0.55
* Third Quartile (Q3): ~0.70
* Maximum Score: ~0.85
### Key Observations
* "Control Flow Understanding" exhibits the highest median score (~0.75) and generally the highest scores overall.
* "State Space Estimation" has the lowest median score (~0.20) and the narrowest interquartile range, indicating less variability.
* "Decision Boundary", "Direction Accuracy", and "Coverage Completeness" have similar score distributions, with medians around 0.55.
* "Control Flow Understanding" has several outliers above the upper quartile.
* The horizontal line at y=1 serves as a potential benchmark or target score.
### Interpretation
The box plots demonstrate significant variation in performance across different metrics. "Control Flow Understanding" appears to be the strongest area, while "State Space Estimation" is the weakest. The spread of scores within each box plot indicates the consistency of performance for each metric. The outliers in "Control Flow Understanding" suggest that some instances perform exceptionally well in this area. The horizontal line at y=1 could represent a desired performance level, and the data shows that none of the metrics consistently reach this level. The differences in the distributions suggest that different aspects of the system being evaluated require varying levels of attention and improvement. The data suggests that the system is more reliable at understanding control flow than estimating state space. The presence of outliers indicates that there are specific cases where the system performs significantly better than average, which could be worth investigating to understand the underlying factors contributing to this success.
</details>
Impact of Formal Methods Augmentation. The overall performance gap of 40-47 percentage points-comparing LLM-only performance (0 . 53-0 . 60) against perfect scores (1 . 0) achieved with region decomposition and verification-quantifies the value added by formal methods tools such as ImandraX when augmenting LLM-based code analysis.
Reproducibility. All raw data and scripts to reproduce these results are available at https:// github.com/imandra-ai/code-logic-bench .
Figure 20: Radar chart showing model performance in the seven metrics tested. Claude Opus 4.5 leads in State Space Estimation and Decision Boundary, while GPT 5.2 outperforms the others on Control Flow Understanding. Despite these variations, all models perform significantly worse than when augmented with CodeLogician.
<details>
<summary>Image 17 Details</summary>
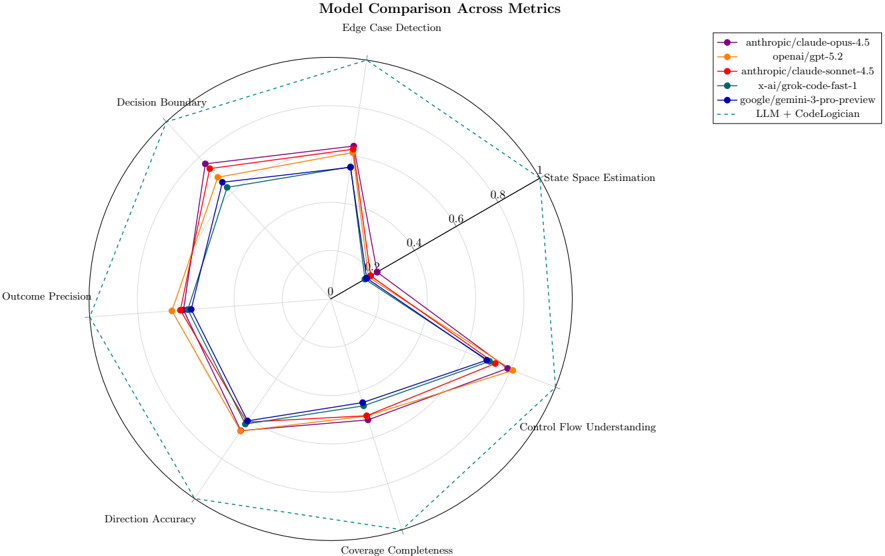
### Visual Description
\n
## Radar Chart: Model Comparison Across Metrics
### Overview
This image presents a radar chart comparing the performance of several language models across six different metrics related to edge case detection. The chart uses a radial layout with six axes representing the metrics, and each model's performance is plotted as a line connecting points on each axis.
### Components/Axes
* **Title:** "Model Comparison Across Metrics" (centered at the top)
* **Metrics (Axes):**
* Decision Boundary
* State Space Estimation
* Control Flow Understanding
* Coverage Completeness
* Direction Accuracy
* Outcome Precision
* **Scale:** The axes are scaled from 0 to 1, with concentric circles marked at 0.2, 0.4, 0.6, and 0.8.
* **Legend (Top-Right):**
* anthropic/claude-opus-4.5 (Magenta)
* openai/gpt-5.2 (Blue)
* anthropic/claude-sonnet-4.5 (Orange)
* x-ai/grok-code-fast-1 (Green)
* google/gemini-3-pro-preview (Dark Blue)
* LLM + CodeLogician (Black Dashed Line)
### Detailed Analysis
The chart displays the relative performance of each model on each metric. The values are approximate, based on visual estimation.
* **anthropic/claude-opus-4.5 (Magenta):** This model shows a generally high performance across all metrics.
* Decision Boundary: ~0.9
* State Space Estimation: ~0.85
* Control Flow Understanding: ~0.75
* Coverage Completeness: ~0.7
* Direction Accuracy: ~0.7
* Outcome Precision: ~0.8
* **openai/gpt-5.2 (Blue):** This model exhibits a relatively consistent performance, slightly lower than claude-opus-4.5.
* Decision Boundary: ~0.75
* State Space Estimation: ~0.7
* Control Flow Understanding: ~0.65
* Coverage Completeness: ~0.6
* Direction Accuracy: ~0.6
* Outcome Precision: ~0.7
* **anthropic/claude-sonnet-4.5 (Orange):** This model shows a moderate performance, with some fluctuations.
* Decision Boundary: ~0.65
* State Space Estimation: ~0.6
* Control Flow Understanding: ~0.55
* Coverage Completeness: ~0.5
* Direction Accuracy: ~0.5
* Outcome Precision: ~0.6
* **x-ai/grok-code-fast-1 (Green):** This model has a variable performance, with some metrics showing higher values than others.
* Decision Boundary: ~0.7
* State Space Estimation: ~0.65
* Control Flow Understanding: ~0.5
* Coverage Completeness: ~0.45
* Direction Accuracy: ~0.4
* Outcome Precision: ~0.55
* **google/gemini-3-pro-preview (Dark Blue):** This model demonstrates a relatively low performance across all metrics.
* Decision Boundary: ~0.5
* State Space Estimation: ~0.45
* Control Flow Understanding: ~0.4
* Coverage Completeness: ~0.35
* Direction Accuracy: ~0.3
* Outcome Precision: ~0.4
* **LLM + CodeLogician (Black Dashed Line):** This model shows a performance that is generally lower than the other models, with a particularly low score on Coverage Completeness.
* Decision Boundary: ~0.55
* State Space Estimation: ~0.5
* Control Flow Understanding: ~0.45
* Coverage Completeness: ~0.25
* Direction Accuracy: ~0.35
* Outcome Precision: ~0.45
### Key Observations
* `anthropic/claude-opus-4.5` consistently outperforms other models across all metrics.
* `google/gemini-3-pro-preview` and `LLM + CodeLogician` consistently show the lowest performance.
* The models exhibit varying strengths and weaknesses across different metrics. For example, `x-ai/grok-code-fast-1` performs relatively better on Decision Boundary but worse on Direction Accuracy.
* The shape of the radar chart for each model is distinct, indicating different performance profiles.
### Interpretation
The radar chart effectively visualizes the trade-offs between different language models in the context of edge case detection. The chart suggests that `anthropic/claude-opus-4.5` is the most robust model overall, demonstrating strong capabilities across all evaluated metrics. The differences in performance profiles highlight the importance of considering specific application requirements when selecting a model. For instance, if Decision Boundary is critical, `x-ai/grok-code-fast-1` might be a viable option despite its lower performance in other areas. The relatively poor performance of `google/gemini-3-pro-preview` and `LLM + CodeLogician` suggests that these models may require further development to achieve comparable performance in edge case detection. The chart provides a clear and concise comparison, enabling informed decision-making regarding model selection. The use of a radar chart is particularly effective for visualizing multi-dimensional data and identifying relative strengths and weaknesses.
</details>
## 8 Case Studies
## 8.1 LSE GTT Order Expiry
This example concerns itself with an extended (by Imandra) version of the London Stock Exchange trading system specification. The Guide to the Trading System (MIT201) [13] specifies:
'Any GTT [Good Till Time] orders with an expiry time during any auction call phase will not be expired until after uncrossing has completed and are therefore eligible to participate in that uncrossing.'
The model implements a state machine with two trading modes (Continuous and Auction Call), GTT order lifecycle management, and an auction protection mechanism. The auction protection logic is implemented in the following Python function, with the full program available in Appendix A.
```
def maybe_expire_gtt_order_v2(state: State) -> State:
"""
Handle GTT order expiry with auction protection.
"""
```
## Model Comparison Across All Metrics
Figure 21: Chart showing model performance in the seven metrics tested. Scores are relative to those of the LLMs when augmented with CodeLogician.
<details>
<summary>Image 18 Details</summary>
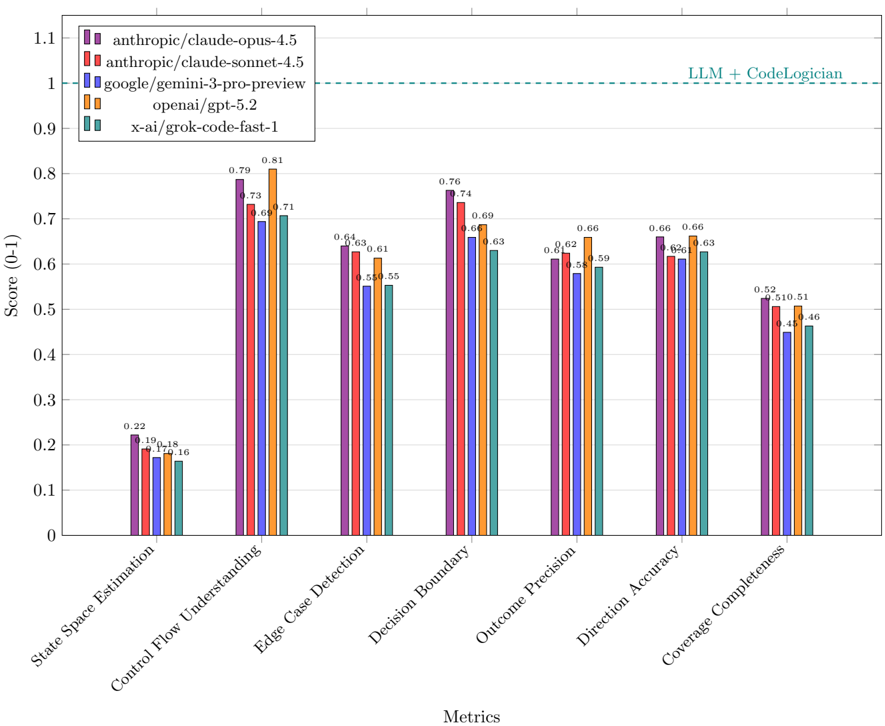
### Visual Description
\n
## Bar Chart: LLM Performance on Code Logic Metrics
### Overview
This bar chart compares the performance of several Large Language Models (LLMs) across seven different metrics related to code logic understanding and reasoning. The metrics are displayed on the x-axis, and the score (ranging from 0 to 1) is displayed on the y-axis. A dashed horizontal line at y=1 is present, labeled "LLM + CodeLogician".
### Components/Axes
* **X-axis:** "Metrics" - Categorical axis with the following labels: "State Space Estimation", "Control Flow Understanding", "Edge Case Detection", "Decision Boundary", "Outcome Precision", "Direction Accuracy", "Coverage Completeness".
* **Y-axis:** "Score (0-1)" - Numerical axis ranging from 0 to 1.1, with increments of 0.1.
* **Legend:** Located at the top-right of the chart. Contains the following LLM names and corresponding colors:
* anthropic/claude-opus-4.5 (Purple)
* anthropic/claude-sonnet-4.5 (Red)
* google/gemini-3-pro-preview (Orange)
* openai/gpt-5.2 (Yellow)
* x-ai/grok-code-fast-1 (Teal)
* **Horizontal Line:** Dashed line at y=1, labeled "LLM + CodeLogician".
### Detailed Analysis
The chart consists of seven groups of bars, one for each metric. Each group contains five bars, representing the performance of each LLM on that metric.
**1. State Space Estimation:**
* anthropic/claude-opus-4.5: Approximately 0.22
* anthropic/claude-sonnet-4.5: Approximately 0.19
* google/gemini-3-pro-preview: Approximately 0.16
* openai/gpt-5.2: Approximately 0.18
* x-ai/grok-code-fast-1: Approximately 0.14
**2. Control Flow Understanding:**
* anthropic/claude-opus-4.5: Approximately 0.79
* anthropic/claude-sonnet-4.5: Approximately 0.68
* google/gemini-3-pro-preview: Approximately 0.71
* openai/gpt-5.2: Approximately 0.66
* x-ai/grok-code-fast-1: Approximately 0.58
**3. Edge Case Detection:**
* anthropic/claude-opus-4.5: Approximately 0.81
* anthropic/claude-sonnet-4.5: Approximately 0.61
* google/gemini-3-pro-preview: Approximately 0.63
* openai/gpt-5.2: Approximately 0.55
* x-ai/grok-code-fast-1: Approximately 0.61
**4. Decision Boundary:**
* anthropic/claude-opus-4.5: Approximately 0.76
* anthropic/claude-sonnet-4.5: Approximately 0.64
* google/gemini-3-pro-preview: Approximately 0.74
* openai/gpt-5.2: Approximately 0.63
* x-ai/grok-code-fast-1: Approximately 0.63
**5. Outcome Precision:**
* anthropic/claude-opus-4.5: Approximately 0.69
* anthropic/claude-sonnet-4.5: Approximately 0.66
* google/gemini-3-pro-preview: Approximately 0.68
* openai/gpt-5.2: Approximately 0.62
* x-ai/grok-code-fast-1: Approximately 0.58
**6. Direction Accuracy:**
* anthropic/claude-opus-4.5: Approximately 0.66
* anthropic/claude-sonnet-4.5: Approximately 0.62
* google/gemini-3-pro-preview: Approximately 0.59
* openai/gpt-5.2: Approximately 0.66
* x-ai/grok-code-fast-1: Approximately 0.63
**7. Coverage Completeness:**
* anthropic/claude-opus-4.5: Approximately 0.52
* anthropic/claude-sonnet-4.5: Approximately 0.51
* google/gemini-3-pro-preview: Approximately 0.51
* openai/gpt-5.2: Approximately 0.46
* x-ai/grok-code-fast-1: Approximately 0.45
### Key Observations
* anthropic/claude-opus-4.5 consistently performs the best across all metrics, often significantly higher than other models.
* x-ai/grok-code-fast-1 generally performs the worst across most metrics.
* The largest performance differences between models are observed in "State Space Estimation" and "Control Flow Understanding".
* The "LLM + CodeLogician" line at y=1 suggests a potential upper bound or target performance level. No model consistently reaches this level.
* The scores for "Coverage Completeness" are generally lower than other metrics, indicating this is a challenging area for all models.
### Interpretation
The chart demonstrates the varying capabilities of different LLMs in understanding and reasoning about code logic. anthropic/claude-opus-4.5 emerges as the strongest performer, suggesting it possesses superior abilities in areas like control flow analysis, edge case detection, and decision-making within code. The "LLM + CodeLogician" line implies that combining LLMs with dedicated code analysis tools could potentially achieve perfect performance (score of 1) on these metrics. The relatively low scores for "Coverage Completeness" across all models highlight the difficulty of ensuring comprehensive code coverage analysis using LLMs alone. The data suggests that while LLMs are making progress in code understanding, there is still significant room for improvement, particularly in areas requiring thoroughness and completeness. The differences in performance between models could be attributed to variations in model architecture, training data, and specific optimization strategies.
</details>
```
if state.gtt_order is None:
return state
expires_at = state.gtt_order.expires_at
if isinstance(state.mode, AuctionCallMode):
expires_at = max(expires_at, state.mode.uncross_at + 1)
if state.time >= expires_at:
return expire_order(state)
else:
return state
```
## 8.1.1 Verification
The critical property to verify is that auction uncross and order expiry events can never occur simultaneously. CodeLogician expressed this as a conflict detection predicate in IML:
```
let conflict_reachable msgs state k =
let final_state = run state (List.take k msgs) in
final_state.auction_event = Uncrossed && final_state.order_event = Expired
```
The verification goal asserts that for all valid initial states and message sequences, conflict\_reachable should return false . CodeLogician refuted the verification goal, producing a concrete counterexample:
```
let msgs = [Tick; Tick]
let state = {
time = 2699;
mode = AuctionCallMode {uncross_at = 2700};
gtt_order = Some {expires_at = 2700};
market_order_present_after_uncross = true;
market_order_extension_period = 1
}
```
This sequence of events is illustrated in Figure 22 (Appendix A).
The counterexample reveals a subtle interaction between two features: the auction protection logic extends order expiry to uncross\_at + 1 , while the market order extension feature delays the actual uncross to uncross\_at + extension\_period . When extension\_period = 1 , both events occur at the same tick.
This case demonstrates formal verification's ability to catch feature interaction bugs: the auction protection and market order extension features each work correctly in isolation, but their interaction was not properly considered. Traditional testing would likely miss this edge case, as it requires specific timing conditions that are difficult to anticipate manually.
## 8.2 London Stock Exchange Fee Schedule
This case study applies CodeLogician to the London Stock Exchange Trading Services Price List, verifying fee calculation logic with mathematical certainty. For algorithmic trading firms, accurate fee prediction is essential: a fraction of a basis point can determine whether a strategy is profitable, and errors across millions of daily orders compound into significant revenue leakage or unexpected costs. Exchange fee schedules present challenges: tiered pricing, minimum floors, rebates, and surcharges can interact in complex ways, and specifications are published as prose documents rather than machinereadable formats. Traditional testing struggles to cover all combinations exhaustively.
## 8.2.1 Verified Invariants
CodeLogician formally verified two invariants against all possible inputs.
The first invariant, 'Non-Persistent Order Charge Isolation,' establishes that an Immediate or Cancel (IOC) or Fill or Kill (FOK) order costs exactly £ 0.01 more than an identical Day (DAY) order, due to the order entry charge. CodeLogician expressed this property in IML as:
```
fun (price : real) (quantity : int) (is_aggressive : bool) (is_hidden : bool)
(package : package_type) (lps_tier : lps_tier_type) (security_type : security_type)
(cumulative_value : real) ->
calculate_total_cost price quantity true is_aggressive is_hidden package lps_tier
security_type cumulative_value
= calculate_total_cost price quantity false is_aggressive is_hidden package lps_tier security_type cumulative_value +. 0.01
```
CodeLogician proved this property holds for all combinations of inputs, demonstrating that the order entry charge logic is completely isolated from all other fee components.
The second invariant, 'LPS Zero-Fee Execution,' guarantees that when the rate equals 0.00bp and the minimum charge equals £ 0.00, the execution fee is exactly zero:
```
fun (notional_value : real) ->
calculate_execution_fee notional_value 0.0 0.0 false = 0.0
```
This ensures that liquidity providers-who receive a 0.00bp rate with no minimum-are never accidentally charged due to floating-point errors or logic edge cases.
## 8.2.2 Region Decomposition
Region decomposition revealed 6 distinct behavioral regions in the execution fee function, arising from the combinatorial interaction of factors including hidden order premiums, minimum charge floors, and negative rebate rates. The regions are partitioned by whether the order is hidden (triggering the +0.25bp premium), whether the rate is non-negative, and whether the minimum charge floor dominates the calculated fee.
The analysis identified 'crossover notionals'-trade sizes below which the minimum charge dominates the calculated fee. For example, a £ 1,000 trade at the standard 0.45bp rate yields a calculated fee of £ 0.045, but the minimum floor of £ 0.11 applies, resulting in an effective rate of 11bp-24 times the stated rate. Such boundaries vary by pricing scheme: the crossover for Standard Tier 1 (0.45bp, 11p minimum) is £ 2,444.44, while Package 1 (0.15bp, 5p minimum) crosses over at £ 3,333.33.
Negative rates (LPS rebates) bypass the minimum charge logic entirely-a design decision that prevents floors from being applied to rebates. CodeLogician verified an edge case where a large hidden order with LPS FTSE100 Top Tier (-0.15bp rebate + 0.25bp hidden premium) pays a net 0.10bp, not zero.
While this particular example may seem straightforward, the same analysis, when applied to complex fee schedules, can reveal hidden complexity and compliance risks, and provide a mathematical foundation for trust in the system.
## 8.3 Multilateral Netting Engine
In this example, CodeLogician analyzes a simple multilateral netting engine to find two critical bugs. The system has two critical invariants:
1. Zero-sum Conservation - the sum of all net positions must equal zero
2. Netting Efficiency - no party's exposure must increase as a result of netting.
Formal methods found issues pertaining to both of these requirements in the code. Bugs were found before any testing, concrete counterexamples presented, and once the code was corrected, CodeLogician proved the code mathematically correct. An excerpt of the code is exhibited below, with the full program available in Appendix B.
```
def calculate_net_obligations(trades: List[Trade]) -> Dict[str, float]:
"""
Calculate net obligations for all participants in a multilateral netting cycle.
"""
net_positions: Dict[str, float] = {}
for trade in trades:
```
```
net_positions[trade.payer_id] = \
net_positions.get(trade.payer_id, 0.0) - trade.amount
net_positions[trade.receiver_id] = \
net_positions.get(trade.receiver_id, 0.0) + trade.amount
return net_positions
```
## 8.3.1 Input Validation
The first bug to be found was an input validation problem where negative values were accepted, causing a violation of the netting efficiency requirement. CodeLogician found the counterexample
```
Trade(payer_id="", receiver_id="", amount=-10834.0)
```
In this case, Net Exposure, | 10834 | + |-10834 | = 21668, is greater than Gross Exposure, |-10834 | = 10834.
## 8.3.2 Floating Point Precision
The second issue found was with the use of floating-point arithmetic. CodeLogician identified that floating-point errors would cause the zero-sum conservation requirement to be violated. IEEE 754 [5] binary representation cannot exactly represent most decimal values; accumulated errors compound with each operation.
Consider the classic demonstration: summing 0.1 ten times in floating-point yields 0.9999999999999999, not 1.0. In high-frequency clearing with thousands of trades per second, such errors accumulate to material discrepancies. CodeLogician's counterexample demonstrated a scenario where {sum(net\_positions.values()) != 0.0 , violating the zero-sum invariant despite mathematically balanced trades.
The fix required migrating from Python's float to Decimal [2] for arbitrary-precision arithmetic, combined with defense-in-depth validation within the core algorithm. After applying the fix, CodeLogician re-verified the implementation, proving all three verification goals: exact zero-sum conservation, tolerance-based zero-sum, and netting efficiency. The corrected implementation provides mathematical certainty of correctness-a requirement for systems subject to EMIR [7] and Dodd-Frank Title VII [1].
## 9 Conclusion and Future Work
We have introduced CodeLogician , a neuro-symbolic agent and framework for rigorous reasoning about software systems that integrates Large Language Models (LLMs) with automated reasoning engines. We argue that while LLMs excel at translation, abstraction, and interaction, they fundamentally lack the capacity for precise, exhaustive reasoning about program behavior. CodeLogician addresses this limitation by teaching LLM-driven agents to construct explicit formal models of software and by delegating semantic reasoning to formal tools such as ImandraX .
A central contribution of this work is the demonstration that formal augmentation fundamentally changes the reasoning capabilities of LLM-based systems. Using a newly introduced benchmark targeting mathematical reasoning about software logic, we showed that LLM-only approaches systematically fail on tasks requiring exact boundary identification, combinatorial reasoning, and exhaustive coverage. By contrast, LLMs augmented with CodeLogician achieve complete and precise analysis, closing a 41-47 percentage point gap across multiple rigorously defined metrics. These results provide empirical evidence that rigorous program analysis cannot be achieved by statistical reasoning alone and that formal reasoning engines are essential for scaling AI-assisted software development beyond heuristic methods.
Beyond empirical results, we presented CodeLogician as a general framework rather than a single agent or solver. Its reasoner-agnostic architecture, agentic orchestration layer, and support for continuous, project-scale autoformalization enable principled integration of multiple reasoning tools and workflows. The CodeLogician server and PyIML strategies demonstrate how formalization can be
performed incrementally and persistently over evolving codebases, making formal reasoning practical in real-world development environments.
Future Work. Applying LLMs to formal reasoning about software presents both substantial challenges and exceptional opportunities. LLMs remain imperfect at maintaining global consistency, respecting strict semantic constraints, and scaling reasoning across large, interdependent codebases. At the same time, their strengths in translation, abstraction, and interaction make them uniquely well suited to act as interfaces between informal software artifacts and formal mathematical models.
Our ongoing work in this direction is embodied in SpecLogician , a complementary project focused on scalable, data-driven formal specification and refinement for large software systems. SpecLogician extends the ideas introduced in this paper by shifting the emphasis from individual code fragments to collections of specifications, traces, tests, logs, and other real-world artifacts. By combining LLMs with automated reasoning, SpecLogician aims to incrementally synthesize, refine, and validate formal specifications at scale, even in settings where complete or authoritative specifications do not exist upfront.
Looking forward, we plan to deepen the integration between CodeLogician and SpecLogician , enabling closed-loop workflows in which specifications, implementations, and empirical artifacts co-evolve under formal constraints. Additional future directions include extending support to new source languages and reasoning backends, improving dependency-aware and incremental formalization strategies, and using formal counterexamples, region decompositions, and proofs to actively guide LLM behavior during development.
Ultimately, we view CodeLogician and SpecLogician as steps toward a new class of AI-assisted software engineering systems in which LLMs and formal reasoning engines operate symbiotically. By grounding AI-assisted development in explicit formal models and mathematically sound analysis, such systems can move beyond probabilistic correctness toward rigorous, auditable, and scalable reasoning about complex software systems.
## A LSE GTT Order Expiry
## A.1 Python model
```
A LSE GTT Order Expiry
A.1 Python model
```
```
class State:
"""The complete state of the trading venue."""
time: Time
auction_call_duration: Time
auction_interval: Time
mode: Mode
gtt_order: Optional[GTTOrder]
auction_event: Optional[AuctionEvent]
order_event: Optional[OrderEvent]
# Extended state for market order feature
market_order_present_after_uncross: bool
market_order_extension_period: Time
class Message(Enum):
"""Messages that can be processed by the venue."""
TICK = "tick"
@dataclass
class CreateGTTOrder:
"""Message to create a GTT order."""
expires_at: Time
# Helper functions
def is_valid_state(state: State) -> bool:
"""
Check if a state is valid according to business invariants.
VG: State validity invariants should always hold:
- Time is non-negative
- Durations are positive
- Scheduled times are in the future
- GTT order expiry is in the future
"""
if state.time < 0:
return False
if state.auction_call_duration <= 0:
return False
if state.auction_interval <= 0:
return False
if state.market_order_extension_period <= 0:
return False
# Check mode-specific invariants
if isinstance(state.mode, ContinuousMode):
if state.mode.start_auction_call_at <= state.time:
return False
elif isinstance(state.mode, AuctionCallMode):
if state.mode.uncross_at <= state.time:
return False
# GTT order expiry must be in the future
if state.gtt_order is not None:
if state.gtt_order.expires_at <= state.time:
return False
return True
```
```
def events_none(state: State) -> bool:
"""Check if no events are set (used for initial states)."""
return state.auction_event is None and state.order_event is None
# Core business logic functions
def maybe_create_gtt_order(expires_at: Time, state: State) -> State:
"""
Handle an incoming GTT order.
VG: Orders with expiry <= current time should be rejected
"""
if expires_at <= state.time:
# Reject order - no state change
return state
else:
# Accept order
return State(
time=state.time,
auction_call_duration=state.auction_call_duration,
auction_interval=state.auction_interval,
mode=state.mode,
gtt_order=GTTOrder(expires_at=expires_at),
auction_event=state.auction_event,
order_event=OrderEvent.CREATED,
market_order_present_after_uncross=state.market_order_present_after_uncross,
market_order_extension_period=state.market_order_extension_period
)
def start_auction(state: State) -> State:
"""
Start an auction call phase.
Sets mode to AuctionCall, schedules uncross, emits event.
"""
return State(
time=state.time,
auction_call_duration=state.auction_call_duration,
auction_interval=state.auction_interval,
mode=AuctionCallMode(uncross_at=state.time + state.auction_call_duration),
gtt_order=state.gtt_order,
auction_event=AuctionEvent.AUCTION_CALL_STARTED,
order_event=state.order_event,
market_order_present_after_uncross=state.market_order_present_after_uncross,
market_order_extension_period=state.market_order_extension_period
)
def uncross(state: State) -> State:
"""
Complete the auction uncross.
Sets mode to Continuous, schedules next auction, emits event.
"""
return State(
time=state.time,
auction_call_duration=state.auction_call_duration,
auction_interval=state.auction_interval,
mode=ContinuousMode(start_auction_call_at=state.time + state.auction_interval),
gtt_order=state.gtt_order,
```
```
auction_event=AuctionEvent.UNCROSSED,
order_event=state.order_event,
market_order_present_after_uncross=state.market_order_present_after_uncross,
market_order_extension_period=state.market_order_extension_period
)
def maybe_uncross(uncross_at: Time, state: State) -> State:
"""
Handle uncrossing with market order extension logic.
VG: If market orders remain, auction is extended by extension_period
"""
if state.market_order_present_after_uncross:
# Market orders remain - check if extension period has elapsed
if state.time >= uncross_at + state.market_order_extension_period:
# Extension period complete - uncross and clear market order flag
new_state = State(
time=state.time,
auction_call_duration=state.auction_call_duration,
auction_interval=state.auction_interval,
mode=state.mode,
gtt_order=state.gtt_order,
auction_event=state.auction_event,
order_event=state.order_event,
market_order_present_after_uncross=False,
market_order_extension_period=state.market_order_extension_period
)
return uncross(new_state)
else:
# Still in extension period
return state
else:
# No market orders - uncross immediately
return uncross(state)
def maybe_change_mode(state: State) -> State:
"""
Handle timed mode changes (auction start or uncross).
VG: Mode changes occur at scheduled times
"""
if isinstance(state.mode, ContinuousMode):
if state.time >= state.mode.start_auction_call_at:
return start_auction(state)
elif isinstance(state.mode, AuctionCallMode):
if state.time >= state.mode.uncross_at:
return maybe_uncross(state.mode.uncross_at, state)
return state
def maybe_expire_gtt_order_v2(state: State) -> State:
"""
Handle GTT order expiry with auction protection.
CRITICAL FIX: Per MIT201, GTT orders expiring during auction call
should not expire until AFTER uncross completes.
VG: GTT orders with expiry during auction call must not expire
until after uncross (expires_at is extended to uncross_at + 1)
```
```
"""
if state.gtt_order is None:
return state
expires_at = state.gtt_order.expires_at
# Key fix: Delay expiry if we're in auction call mode
if isinstance(state.mode, AuctionCallMode):
# Extend expiry to after uncross
expires_at = max(expires_at, state.mode.uncross_at + 1)
if state.time >= expires_at:
# Expire the order
return State(
time=state.time,
auction_call_duration=state.auction_call_duration,
auction_interval=state.auction_interval,
mode=state.mode,
gtt_order=None,
auction_event=state.auction_event,
order_event=OrderEvent.EXPIRED,
market_order_present_after_uncross=state.market_order_present_after_uncross,
market_order_extension_period=state.market_order_extension_period
)
else:
return state
def tick(state: State) -> State:
"""
Process a clock tick - advance time and handle timed events.
Order of operations matters:
1. Advance time
2. Check for order expiry
3. Check for mode changes
VG: Time advances monotonically
"""
# Advance time
state = State(
time=state.time + 1,
auction_call_duration=state.auction_call_duration,
auction_interval=state.auction_interval,
mode=state.mode,
gtt_order=state.gtt_order,
auction_event=state.auction_event,
order_event=state.order_event,
market_order_present_after_uncross=state.market_order_present_after_uncross,
market_order_extension_period=state.market_order_extension_period
)
# Check for order expiry
state = maybe_expire_gtt_order_v2(state)
# Check for mode changes
state = maybe_change_mode(state)
return state
def step(msg: Message | CreateGTTOrder, state: State) -> State:
```
```
"""
Process a single message and return the new state.
VG: Each message type should transition state correctly
"""
if msg == Message.TICK:
return tick(state)
elif isinstance(msg, CreateGTTOrder):
return maybe_create_gtt_order(msg.expires_at, state)
else:
return state
def run(state: State, msgs: List[Message | CreateGTTOrder]) -> State:
"""
Process a sequence of messages.
VG: Event fields are cleared before processing each message
VG: Message sequence processing is deterministic
"""
for msg in msgs:
# Clear events before processing each message
state = State(
time=state.time,
auction_call_duration=state.auction_call_duration,
auction_interval=state.auction_interval,
mode=state.mode,
gtt_order=state.gtt_order,
auction_event=None,
order_event=None,
market_order_present_after_uncross=state.market_order_present_after_uncross,
market_order_extension_period=state.market_order_extension_period
)
state = step(msg, state)
return state
def conflict_reachable(msgs: List[Message | CreateGTTOrder], state: State, k: int = 5) -> bool:
"""
CRITICAL VERIFICATION GOAL:
Check if it's possible to reach a state where BOTH:
- An uncross event occurs AND
- A GTT order expires
at the same time.
Per MIT201, this should NEVER happen - GTT orders expiring during
auction call must wait until after uncross.
VG: verify that NOT conflict_reachable for all valid initial states
and message sequences
"""
# Limit message sequence length
limited_msgs = msgs[:k]
# Run the model
final_state = run(state, limited_msgs)
# Check for the conflict
return (final_state.auction_event == AuctionEvent.UNCROSSED and
```
```
final_state.order_event == OrderEvent.EXPIRED)
# Verification Goals (VGs) explained in comments above each function
# These are the properties the author was verifying:
# VG1: State validity invariants (is_valid_state)
# VG2: Order rejection logic (maybe_create_gtt_order)
# VG3: Auction timing correctness (start_auction, uncross)
# VG4: Market order extension logic (maybe_uncross)
# VG5: Mode transition correctness (maybe_change_mode)
# VG6: GTT order expiry protection during auction (maybe_expire_gtt_order_v2)
# VG7: Time monotonicity (tick)
# VG8: Message processing determinism (step, run)
# VG9: CRITICAL - No simultaneous uncross and expiry (conflict_reachable)
```
## A.2 Sequence diagram
Figure 22: Sequence diagram illustrating how the initial conditions found by CodeLogician cause a violation of the MIT201 specification.
<details>
<summary>Image 19 Details</summary>
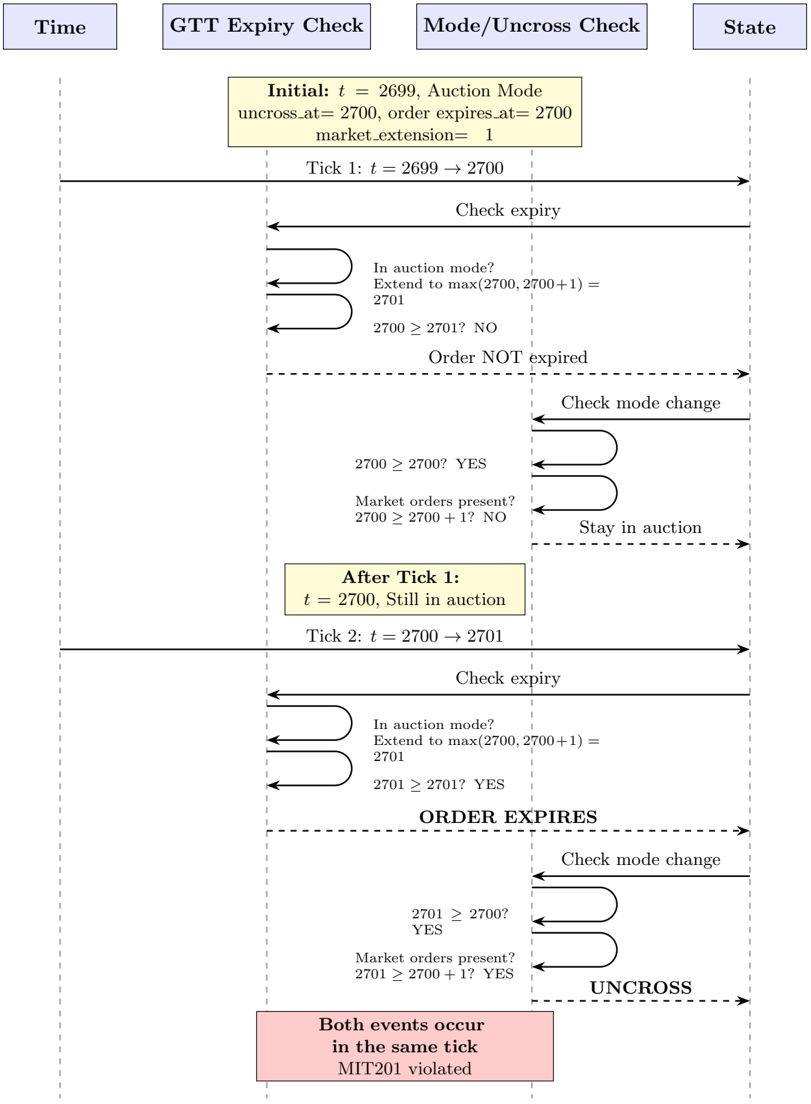
### Visual Description
\n
## Sequence Diagram: GTT Expiry and Mode/Uncross Check
### Overview
This is a sequence diagram illustrating the interaction between a "GTT Expiry Check" and a "Mode/Uncross Check" over two time ticks. The diagram details the logic for determining order expiry and mode changes within an auction system, ultimately leading to a potential "UNCROSS" event. The diagram uses a timeline to show the progression of checks and decisions.
### Components/Axes
The diagram is structured into three vertical columns:
* **Time:** Represents the progression of time, labeled with "Tick 1" and "Tick 2", and initial conditions.
* **GTT Expiry Check:** Details the logic for checking if a Good-Till-Time (GTT) order has expired.
* **Mode/Uncross Check:** Details the logic for checking the auction mode and potential uncrossing of orders.
* **State:** Indicates the current state of the system at each step.
Horizontal dashed lines represent message passing or control flow between the checks. The diagram also includes initial conditions and a final state indicating a violation ("MIT201 violated").
### Detailed Analysis
**Initial State:**
* `t = 2699`, Auction Mode
* `uncross_at = 2700`, `order_expires_at = 2700`
* `market.extension = 1`
**Tick 1: t = 2699 -> 2700**
1. **Check expiry:** A message is sent from the Time column to the GTT Expiry Check.
2. **In auction mode?:** The GTT Expiry Check determines if the system is in auction mode. It extends the expiry time to `max(2700, 2700+1) = 2701`.
3. **2700 ≥ 2701? NO:** The GTT Expiry Check determines that the current time (2700) is not greater than or equal to the extended expiry time (2701).
4. **Order NOT expired:** The GTT Expiry Check concludes the order is not expired.
5. **Check mode change:** A message is sent to the Mode/Uncross Check.
6. **2700 ≥ 2700? YES:** The Mode/Uncross Check determines that the current time (2700) is greater than or equal to the uncross time (2700).
7. **Market orders present? 2700 ≥ 2700 + 1? NO:** The Mode/Uncross Check checks for market orders and if the current time is greater than or equal to the uncross time plus one. The result is NO.
8. **Stay in auction:** The system remains in auction mode.
**After Tick 1:**
* `t = 2700`, Still in auction
**Tick 2: t = 2700 -> 2701**
1. **Check expiry:** A message is sent from the Time column to the GTT Expiry Check.
2. **In auction mode?:** The GTT Expiry Check determines if the system is in auction mode. It extends the expiry time to `max(2700, 2700+1) = 2701`.
3. **2701 ≥ 2701? YES:** The GTT Expiry Check determines that the current time (2701) is greater than or equal to the extended expiry time (2701).
4. **ORDER EXPIRES:** The GTT Expiry Check concludes the order has expired.
5. **Check mode change:** A message is sent to the Mode/Uncross Check.
6. **2701 ≥ 2700? YES:** The Mode/Uncross Check determines that the current time (2701) is greater than or equal to the uncross time (2700).
7. **Market orders present? 2701 ≥ 2700 + 1? YES:** The Mode/Uncross Check checks for market orders and if the current time is greater than or equal to the uncross time plus one. The result is YES.
8. **UNCROSS:** The system triggers an uncross event.
**Final State:**
* **Both events occur in the same tick MIT201 violated:** A red box highlights that both the order expiry and uncross conditions occurred within the same tick, violating rule MIT201.
### Key Observations
* The diagram illustrates a race condition where the order expiry and uncross checks can occur simultaneously.
* The `market.extension` variable plays a crucial role in extending the order expiry time.
* The violation of MIT201 suggests a potential issue with the timing or synchronization of the checks.
* The logic relies heavily on comparing the current time (`t`) with the expiry and uncross times.
### Interpretation
This sequence diagram models a critical process within an auction system – the handling of order expiry and the potential for uncrossing orders. The diagram highlights a potential vulnerability: the simultaneous occurrence of order expiry and uncrossing, leading to a violation of MIT201. This suggests a need for more precise timing control or a re-evaluation of the order expiry and uncross logic to prevent such conflicts. The `market.extension` variable is a key parameter influencing the outcome, and its behavior should be carefully considered. The diagram is a valuable tool for understanding the system's behavior and identifying potential areas for improvement in terms of robustness and compliance with trading rules. The diagram is a precise description of the logic, and does not contain any subjective information.
</details>
## B Multilateral Netting Engine
## B.1 Python model
```
B Multilateral Netting Engine
B.1 Python model
```
```
Invariants Maintained:
1. Zero-Sum: sum(net_positions.values()) == 0.0
2. Netting Efficiency: sum(|net|) <= sum(|gross|)
Example:
>>> trades = [
... Trade("A", "B", 100.0),
... Trade("B", "C", 50.0),
... Trade("C", "A", 30.0)
... ]
>>> net = calculate_net_obligations(trades)
>>> net
{'A': -70.0, 'B': 50.0, 'C': 20.0}
>>> sum(net.values()) # Zero-sum check
0.0
"""
net_positions: Dict[str, float] = {}
for trade in trades:
# Payer: outgoing payment (negative)
net_positions[trade.payer_id] = net_positions.get(trade.payer_id, 0.0) - trade.amount
# Receiver: incoming payment (positive)
net_positions[trade.receiver_id] = net_positions.get(trade.receiver_id, 0.0) + trade.amount
return net_positions
def verify_zero_sum(net_positions: Dict[str, float], tolerance: float = 1e-10) -> bool:
"""
Verify the Zero-Sum invariant (Conservation of Cash).
Args:
net_positions: Dictionary of participant net positions
tolerance: Floating-point tolerance for zero comparison
Returns:
True if sum of all positions is within tolerance of zero
"""
total = sum(net_positions.values())
return abs(total) < tolerance
def verify_netting_efficiency(
trades: List[Trade],
net_positions: Dict[str, float]
) -> bool:
"""
Verify the Netting Efficiency invariant.
The sum of absolute net positions should never exceed the sum of
absolute gross trade amounts. Netting should reduce exposure.
Args:
trades: Original bilateral trades
net_positions: Computed net positions
Returns:
True if netting reduces or maintains total exposure
"""
gross_exposure = sum(trade.amount for trade in trades)
net_exposure = sum(abs(position) for position in net_positions.values())
```
```
return net_exposure <= gross_exposure
def calculate_netting_benefit(
trades: List[Trade],
net_positions: Dict[str, float]
) -> float:
"""
Calculate the reduction in cash flows achieved by netting.
Returns:
Percentage reduction in gross obligations (0.0 to 100.0)
"""
if not trades:
return 0.0
gross_exposure = sum(trade.amount for trade in trades)
net_exposure = sum(abs(position) for position in net_positions.values())
if gross_exposure == 0.0:
return 0.0
reduction = ((gross_exposure - net_exposure) / gross_exposure) * 100.0
return reduction
```
## B.2 Evaluation Example: Transportation Risk Manager
To illustrate the patterns observed across the 50-model evaluation, we present a detailed analysis of the transportation risk manager model. This system evaluates route decisions based on transport mode (Truck, Rail, Air, Sea), cargo type (Standard, Fragile, Hazardous, Perishable), weather conditions, and geopolitical risks, determining whether routes are approved and whether emergency routing should be activated.
## B.2.1 The Three Questions
The model was evaluated using three questions designed to test different aspects of code reasoning:
1. State Space Estimation (Q1): 'How many distinct routing scenarios exist for Sea transport when operating under geopolitical tensions (Tensions, Sanctions, or WarZone)?'
2. Conditional Analysis (Q2): 'Can Air transport ever be rejected for Standard (non-Hazardous) cargo? If yes, under what conditions?'
3. Property Verification (Q3): 'For Air transport specifically, does having both cargo value > 100000 AND time critical < 24 always activate emergency routing when the route is approved?'
## B.2.2 Question 1: State Space Estimation
CodeLogician Result. Region decomposition identified 117 distinct scenarios for Sea transport under geopolitical tensions. These scenarios arise from the interaction of:
- 3 geopolitical risk levels (Tensions, Sanctions, WarZone)
- 5 weather conditions (Clear, Rain, Snow, Storm, Hurricane)
- 4 cargo types (Standard, Fragile, Hazardous, Perishable)
- Numeric threshold boundaries for cargo value and time critical
Critically, the decomposition reveals that numeric parameters create additional scenario boundaries. For example, one region is defined by:
```
mode = Sea
geopolitical = Sanctions
cargo = Hazardous
weather = Clear
time_critical <= 23
cargo_value >= 100001
```
This scenario results in emergency routing = true because three of the four emergency conditions are satisfied. A different region with cargo value <= 100000 produces emergency routing = false -a behaviorally distinct scenario that categorical analysis misses.
LLM Estimates. Table 1 summarizes the LLM estimates. All models significantly underestimated the scenario count, with errors ranging from 2 × to 39 × .
Table 1: Q1 state space estimates by model. All LLMs underestimated the scenario count, consistent with the 0.186 mean State Space Estimation Accuracy reported in the main evaluation.
| Model | Estimate | Actual | Error Factor |
|----------------------|------------|----------|----------------|
| grok-code-fast-1 | 15 | 117 | 7.8 × |
| claude-sonnet-4.5 | 14 | 117 | 8.4 × |
| claude-opus-4.5 | 15 | 117 | 7.8 × |
| gemini-3-pro-preview | 60 | 117 | 2.0 × |
| gpt-5.2 | 3 | 117 | 39 × |
Analysis. The LLMs applied simple categorical reasoning: 3 (geopolitical) × 5 (weather) = 15 scenarios, or variations thereof. This approach correctly counts the categorical combinations but fails to account for how numeric thresholds ( cargo value > 100000 , time critical < 24 , route cost < 1000 , route time < 72 ) partition the state space further. The emergency routing logic alone creates multiple behavioral regions within each categorical combination.
GPT-5.2's estimate of 3 scenarios (counting only the geopolitical risk levels) represents an extreme case of categorical oversimplification. Gemini-3-pro's estimate of 60 came closest by attempting to include cargo types (3 × 5 × 4 = 60), but still missed the numeric threshold boundaries.
## B.2.3 Question 2: Conditional Analysis
CodeLogician Result. Decomposition confirmed that Air transport can be rejected for Standard cargo under exactly 2 scenarios :
1. weather = Hurricane AND geopolitical = WarZone
2. weather = Hurricane AND geopolitical = Sanctions (air grounded)
```
(extreme risk)
```
LLM Results. All five models correctly identified both rejection scenarios. For example, Claude Opus 4.5 reasoned:
'Air transport can still be rejected via the is route viable check. The air grounded condition triggers when: mode=AIR AND weather=HURRICANE AND geopolitical=SANCTIONS . The extreme risk condition triggers when: weather=HURRICANE AND geopolitical=WAR ZONE (applies to all modes including Air).'
Analysis. This question tests explicit boolean logic that is directly visible in the code:
```
def _is_route_viable(mode, weather, geopolitical):
extreme_risk = (weather == HURRICANE
and geopolitical == WAR_ZONE)
air_grounded = (mode == AIR
and weather == HURRICANE
and geopolitical == SANCTIONS)
return not (extreme_risk or air_grounded)
```
The conditions are explicit, categorical, and do not involve numeric thresholds or complex interactions. This explains the 100% success rate: LLMs excel at tracing explicit control flow when conditions are directly stated in the code. This result is consistent with the relatively higher Control Flow Understanding score (0.746) reported in the main evaluation.
## B.2.4 Question 3: Property Verification
The Property. The question asks whether, for approved Air routes, the conjunction of cargo value > 100000 AND time critical < 24 is sufficient to guarantee emergency routing activation.
CodeLogician Result. ImandraX proved the property always holds. The intuition behind why this property holds can be understood as follows:
## Why the Property Holds
Emergency routing activates when at least 3 of 4 conditions are true:
- c1 : cargo value > 100000 - given as true by the property premise
- c2 : time critical < 24 - given as true by the property premise
- c3 : route cost < 1000 - varies depending on weather and geopolitical factors
- c4 : route time < 72 - for Air: base time = 8, max multiplier = 3, so max time = 24 < 72
Since c4 is always true for Air transport (route time cannot exceed 24 hours), and c1 and c2 are given by the premise, we have at least 3 conditions satisfied regardless of c3 .
LLM Results. The models produced mixed results:
- Correct: GPT-5.2, Gemini-3-pro-preview correctly concluded the property holds.
- Incorrect: Grok-code-fast-1 concluded 'No,' claiming that route cost = 1000 (exactly) would make c3 false, leaving only 2 conditions met.
- Self-corrected: Claude Opus 4.5 initially answered 'No' but corrected itself mid-reasoning.
Anatomy of Self-Correction. Claude Opus 4.5's reasoning demonstrates the challenge of discovering numeric invariants without formal analysis:
'Air route cost can exceed 1000: e.g., AIR + STORM + WAR ZONE = 500 × 3 × 4 = 6000 ¿ 1000. In scenarios where cost ≥ 1000 (c3 false) and route time ≥ 72 (never happens for Air, max is 24), emergency would fail... Wait, re-checking: Air + HURRICANE scenarios are limited. Let me verify c4 is always true: max Air time = 8 × 3 = 24 ¡ 72, so yes c4 is always true for Air. Correction: With cargo value ¿ 100000 (c1=true), time critical ¡ 24 (c2=true), and route time always ¡ 72 for Air (c4=true), we have 3 conditions, so emergency IS always activated.'
The model eventually discovered the invariant through explicit arithmetic verification, but only after initially reaching the wrong conclusion. Grok-code-fast-1 made a similar initial error but did not self-correct, focusing on the boundary case route cost = 1000 without recognizing that c4 compensates.
Analysis. This question tests the ability to reason about numeric constraints that determine behavior. The key insight (Air's route time is bounded at 24 hours) requires:
1. Recognizing that route time depends on base time and weather multipliers
2. Computing the maximum possible value for Air specifically
3. Connecting this bound to the emergency threshold (72 hours)
ImandraX establishes this property through logical deduction. LLMs may arrive at the same conclusion through explicit arithmetic (as Claude Opus eventually did), but this process is unreliablesome models self-correct while others do not, as demonstrated by Grok's failure to recognize that c4 compensates for any value of c3 .
## B.2.5 Summary
This case study illustrates the patterns observed across the full evaluation:
1. State Space Estimation : LLMs systematically underestimate scenario counts by treating numeric parameters as irrelevant. The 2-39 × error range in Q1 is consistent with the 0.186 mean accuracy reported in the main section.
2. Explicit Control Flow : When conditions are directly visible as boolean expressions (Q2), LLMs perform well, achieving 100% accuracy on the conditional analysis task.
3. Numeric Invariants : Properties requiring discovery of domain-specific bounds (Q3) challenge LLMs. While self-correction is possible, it is unreliable-some models correct themselves, others do not.
While different LLMs exhibit varying performance levels-with some models like Claude Opus 4.5 demonstrating self-correction capabilities that others lack-all models share inherent limitations when reasoning about code without formal methods support. Region decomposition provides exhaustive state space analysis that no LLM achieved, and theorem proving establishes properties with logical certainty that LLMs can only approximate through heuristic reasoning. These limitations are fundamental to current LLM architectures rather than artifacts of any particular model.
## References
- [1] 111th United States Congress. Dodd-Frank Wall Street Reform and Consumer Protection Act. https://www.congress.gov/bill/111th-congress/house-bill/4173 , 2010.
- [2] F. Batista. PEP 327 - Decimal Data Type. https://peps.python.org/pep-0327/ , 2003.
- [3] W. R. Bevier, W. A. Hunt, J. S. Moore, and W. D. Young. Special Issue on System Verification. Journal of Automated Reasoning , 5(4):409-530, 1989.
- [4] R. S. Boyer and J. S. Moore. A Computational Logic . Academic Press Professional, Inc., USA, 1979.
- [5] I. S. Committee. IEEE standard for floating-point arithmetic. IEEE Std 754-2008 , pages 1-70, 2008. doi: 10.1109/IEEESTD.2008.4610935.
- [6] R. Desmartin, O. Isac, G. Passmore, E. Komendantskaya, K. Stark, and G. Katz. A Certified Proof Checker for Deep Neural Network Verification in Imandra. In Y. Forster and C. Keller, editors, 16th International Conference on Interactive Theorem Proving (ITP 2025) , volume 352 of Leibniz International Proceedings in Informatics (LIPIcs) , pages 1:1-1:21, Dagstuhl, Germany, 2025. Schloss Dagstuhl - Leibniz-Zentrum f¨ ur Informatik. ISBN 978-3-95977-396-6. doi: 10.4230/ LIPIcs.ITP.2025.1. URL https://drops.dagstuhl.de/entities/document/10.4230/LIPIcs. ITP.2025.1 .
- [7] European Parliament and Council of the European Union. Regulation (EU) No 648/2012 on OTC derivatives, central counterparties and trade repositories (EMIR). https://eur-lex.europa.eu/ legal-content/EN/TXT/?uri=CELEX:32012R0648 , 2012.
- [8] Imandra, Inc. CodeLogician IML Agent. https://marketplace.visualstudio.com/items? itemName=imandra.imandra-code-logician , 2025.
- [9] Imandra Inc. Code Logic Bench: A Benchmark for Evaluating Program Reasoning. https: //github.com/imandra-ai/code-logic-bench , 2026. GitHub repository.
- [10] Imandra Inc. Imandra protocol language (IPL) documentation. https://docs.imandra.ai/ipl/ , 2026. Accessed: 2026-01-16.
- [11] Imandra Inc. Region decomposition: Stock exchange trade pricing. https://docs.imandra.ai/ imandra-docs/notebooks/six-swiss-exchange-pricing/ , 2026. Accessed: 2026-01-16.
- [12] Imandra Inc. Supervised learning with imandra. https://docs.imandra.ai/imandra-docs/ notebooks/supervised-learning/ , 2026. Accessed: 2026-01-16.
- [13] London Stock Exchange. MIT201 -Guide to the trading system. https://docs.londonstockexchange.com/sites/default/files/documents/ mit201-guide-to-the-trading-system-15\_6\_20240429.pdf , 2024.
- [14] G. Passmore, S. Cruanes, D. Ignatovich, D. Aitken, M. Bray, E. Kagan, K. Kanishev, E. Maclean, and N. Mometto. The Imandra Automated Reasoning System (System Description). In Proc. 10th Int. Joint Conf. Automated Reasoning (IJCAR) , pages 464-471, 2020.
- [15] G. O. Passmore. Some Lessons Learned in the Industrialization of Formal Methods for Financial Algorithms. In Proc. 24th Int. Symposium on Formal Methods (FM) , pages 717-721, 2021.
- [16] G. O. Passmore and D. Ignatovich. Formal verification of financial algorithms. In L. de Moura, editor, Automated Deduction CADE 26 - 26th International Conference on Automated Deduction, Gothenburg, Sweden, August 6-11, 2017, Proceedings , volume 10395 of Lecture Notes in Computer Science , pages 26-41. Springer, 2017. doi: 10.1007/978-3-319-63046-5 \ 3. URL https://doi.org/10.1007/978-3-319-63046-5\_3 .
- [17] C. M. Wintersteiger. Formal verification of the IEEE P3109 standard for binary floating-point formats for machine learning. In 2025 IEEE 32nd Symposium on Computer Arithmetic (ARITH) , pages 157-160, 2025. doi: 10.1109/ARITH64983.2025.00032.