# AI for Mathematics: Progress, Challenges, and Prospects
**Authors**: Haocheng Ju, Bin Dong
> School of Mathematical Sciences, Peking University, Beijing 100871, China
> Corresponding authorBeijing International Center for Mathematical Research, Peking University, Beijing 100871, ChinaCenter for Machine Learning Research, Peking University, Beijing 100871, ChinaCenter for Intelligent Computing, Great Bay Institute for Advanced Study, Great Bay University, Dongguan 523000, ChinaZhongguancun Academy, Beijing 100094, China
Abstract
AI for Mathematics (AI4Math) has emerged as a distinct field that leverages machine learning to navigate mathematical landscapes historically intractable for early symbolic systems. While mid-20th-century symbolic approaches successfully automated formal logic, they faced severe scalability limitations due to the combinatorial explosion of the search space. The recent integration of data-driven approaches has revitalized this pursuit. In this review, we provide a systematic overview of AI4Math, highlighting its primary focus on developing AI models to support mathematical research. Crucially, we emphasize that this is not merely the application of AI to mathematical activities; it also encompasses the development of stronger AI systems where the rigorous nature of mathematics serves as a premier testbed for advancing general reasoning capabilities. We categorize existing research into two complementary directions: problem-specific modeling, involving the design of specialized architectures for distinct mathematical tasks, and general-purpose modeling, focusing on foundation models capable of broader reasoning, retrieval, and exploratory workflows. We conclude by discussing key challenges and prospects, advocating for AI systems that go beyond facilitating formal correctness to enabling the discovery of meaningful results and unified theories, recognizing that the true value of a proof lies in the insights and tools it offers to the broader mathematical landscape.
1 Introduction
The automation of mathematical reasoning has been a central objective of artificial intelligence (AI) since its inception. The dream of mechanizing reasoning predates the digital computer, tracing back to the 1920s when David Hilbert proposed a program to formalize all of mathematics, aimed at proving every theorem within a consistent axiomatic system. While this optimism was theoretically challenged by Kurt Gödel’s incompleteness theorems in 1931 [59], which demonstrated that any sufficiently rich formal system is necessarily incomplete, Gödel’s results did not close the subject. As noted by Ulam [133], von Neumann viewed these discoveries as a prompt to rethink the role of formalism rather than abandon it. Later research has further shown that large portions of classical mathematics admit finitistic reductions [128], keeping the dream of partial mechanization alive.
With the advent of digital computers, these theoretical ideas were translated into practice. In the 1950s, Martin Davis implemented a decision procedure for Presburger arithmetic [30, 38], arguably the first instance of a computer mechanically verifying logical statements. Shortly after, Newell, Simon, and Shaw developed the “Logic Theorist” [109], widely considered the first true AI program, which performed theorem proving in symbolic logic. A particularly influential milestone in this symbolic era was Wen-Tsun Wu’s method of mechanical theorem proving in geometry [149, 151]. By translating geometric problems into systems of algebraic equations and applying the characteristic set method, Wu demonstrated that complex logical consequences could be derived algorithmically.
However, most of these symbolic methods faced a critical bottleneck: the combinatorial explosion of the search space. As proofs grew in complexity, the number of possible logical paths expanded exponentially, rendering exhaustive search intractable. In recent decades, the integration of machine learning has revitalized this pursuit, offering data-driven approaches to navigate these complex landscapes. Since the 2010s, connectionist AI Connectionist AI is an AI paradigm inspired by the interconnected structure of neurons in the human brain. It enables perception, reasoning, and decision-making through multi-layer networks of nodes that learn patterns from data by optimizing connection weights. has risen to prominence, achieving remarkable success in computer vision and natural language processing. Mathematicians have subsequently begun leveraging these models to identify patterns that guide human intuition [37, 64, 41], to construct counterexamples via reinforcement learning (RL) [136, 61, 126], and to train neural theorem provers [150, 11]. More recently, the rapid progress of large language models (LLMs) has enabled the generation of new mathematical constructions [119, 110, 55], autoformalization [153, 107], and collaborative theorem proving [176].
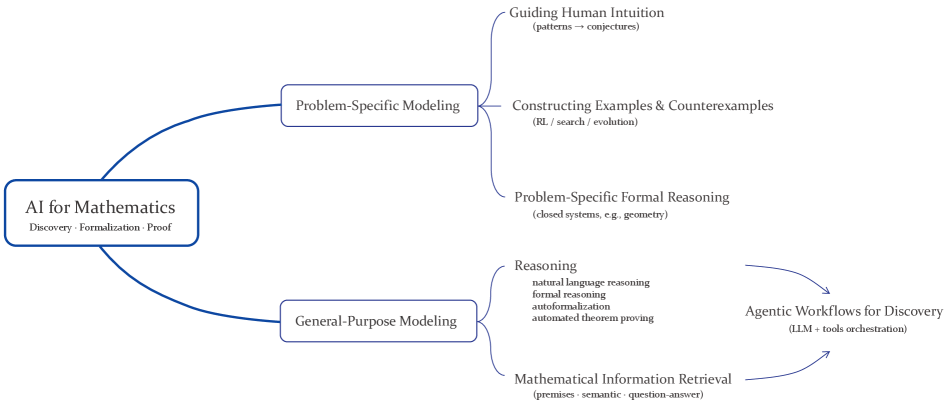
This convergence has given rise to the interdisciplinary field of AI for Mathematics (AI4Math). We emphasize that AI4Math is not merely the application of AI tools to mathematical tasks; it also encompasses the development of stronger AI systems where the rigorous nature of mathematics serves as a premier testbed for advancing general reasoning capabilities. Broadly speaking, as illustrated in Figure 1, research in this field can be categorized into two complementary directions:
- Problem-Specific Modeling: This involves the design of specialized architectures tailored to specific research questions or narrow classes of problems, such as guiding intuition in knot theory or reasoning within closed geometric systems. Beyond their high effectiveness for targeted tasks, these models typically require significantly less data and computational resources, making them accessible to a broader range of researchers. However, they rarely transfer to other domains without substantial modification.
- General-Purpose Modeling: This focuses on the development of foundation models, ranging from specialized math-specific language models to general-purpose reasoning engines, designed to support broader workflows across diverse mathematical areas. While offering versatility, these approaches demand massive training datasets, substantial computational resources, and significant engineering expertise. Furthermore, they may not achieve the same degree of specificity or effectiveness as specialized models when applied to narrowly defined mathematical problems. This category encompasses advances in natural language reasoning, the bridging of informal and formal mathematics through autoformalization, and the construction of agentic systems capable of automated theorem proving and information retrieval.
It is worth noting that the scope of AI4Math technically extends beyond logical reasoning to include AI for Computational Mathematics and Scientific Computing. This domain focuses on building AI models to assist in numerical computations, such as for solving partial differential equations (PDEs), optimization, and inverse problems. The roots of this approach trace back to the 1980s and 1990s, where researchers explored the use of shallow neural networks to approximate solutions to differential equations. However, the field experienced a renaissance around 2015 with the advent of deep learning. While these computational advances constitute a vital pillar of the broader AI4Math landscape, this review restricts its focus to mathematical reasoning—encompassing discovery, formalization, and proof. We refer readers interested in the computational aspects of AI4Math to other comprehensive surveys [6, 79, 19, 148, 42, 24].
In this paper, we provide a systematic overview of the progress, challenges, and prospects of AI4Math. Our goal is not to be exhaustive, but to highlight representative works that illustrate the field’s evolution. Readers interested in specific subareas may consult existing surveys on automated reasoning in geometry [29, 152] or deep learning for theorem proving [95]. Section 2 examines problem-specific modeling, while Section 3 reviews general-purpose modeling. Finally, Section 4 discusses the key challenges ahead, advocating for systems that move beyond simple verification toward the discovery of deep mathematical insights.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: AI for Mathematics
### Overview
The image is a concept diagram illustrating the application of Artificial Intelligence (AI) in the field of Mathematics. It outlines two primary approaches: Problem-Specific Modeling and General-Purpose Modeling, and their respective sub-categories and applications. The diagram uses a mind-map style layout with connecting lines to show relationships between concepts.
### Components/Axes
* **Central Node:** "AI for Mathematics" with sub-categories "Discovery", "Formalization", and "Proof".
* **Main Branches:**
* "Problem-Specific Modeling"
* "General-Purpose Modeling"
* **Sub-Branches of "Problem-Specific Modeling":**
* "Guiding Human Intuition" (patterns -> conjectures)
* "Constructing Examples & Counterexamples" (RL / search / evolution)
* "Problem-Specific Formal Reasoning" (closed systems, e.g., geometry)
* **Sub-Branches of "General-Purpose Modeling":**
* "Reasoning" (natural language reasoning, formal reasoning, autoformalization, automated theorem proving)
* "Mathematical Information Retrieval" (premises, semantic, question-answer)
* "Agentic Workflows for Discovery" (LLM + tools orchestration)
### Detailed Analysis or ### Content Details
The diagram starts with the central concept of "AI for Mathematics," which is further divided into three aspects: Discovery, Formalization, and Proof. From this central node, two main branches emerge: Problem-Specific Modeling and General-Purpose Modeling.
* **Problem-Specific Modeling:** This branch focuses on AI techniques tailored to specific mathematical problems. It includes:
* **Guiding Human Intuition:** Using AI to identify patterns and form conjectures.
* **Constructing Examples & Counterexamples:** Employing AI techniques like Reinforcement Learning (RL), search algorithms, or evolutionary algorithms to generate examples and counterexamples.
* **Problem-Specific Formal Reasoning:** Applying AI to formal reasoning within closed systems, such as geometry.
* **General-Purpose Modeling:** This branch focuses on AI techniques that can be applied to a broader range of mathematical problems. It includes:
* **Reasoning:** Utilizing AI for natural language reasoning, formal reasoning, autoformalization, and automated theorem proving.
* **Mathematical Information Retrieval:** Using AI to retrieve relevant mathematical information based on premises, semantics, and question-answering.
* **Agentic Workflows for Discovery:** Orchestrating Large Language Models (LLMs) and other tools to create workflows for mathematical discovery.
### Key Observations
* The diagram highlights the dual approach of using AI in mathematics: one focused on specific problems and the other on general-purpose techniques.
* The sub-branches provide concrete examples of how AI can be applied in each approach.
* The diagram emphasizes the role of AI in both assisting human mathematicians (e.g., guiding intuition) and automating mathematical tasks (e.g., automated theorem proving).
### Interpretation
The diagram illustrates the multifaceted role of AI in mathematics, spanning from assisting human intuition to automating complex reasoning processes. The distinction between problem-specific and general-purpose modeling suggests a strategic approach to AI implementation, where tailored solutions are used for specific challenges, while broader techniques are applied to more general mathematical tasks. The inclusion of "Agentic Workflows for Discovery" indicates a forward-looking perspective on AI's potential to drive new mathematical discoveries through automated exploration and reasoning. The diagram suggests that AI is not just a tool for solving existing problems but also a catalyst for generating new mathematical knowledge.
</details>
Figure 1: Landscape of AI4Math research directions. AI4Math research can be broadly divided into two complementary paradigms: problem-specific modeling and general-purpose modeling. Problem-specific modeling encompasses three major lines of work: using machine learning to guide human intuition, constructing examples and counterexamples, and performing formal reasoning in closed systems. General-purpose modeling focuses on mathematical reasoning and mathematical information retrieval; together, these capabilities underpin emerging agentic workflows for mathematical discovery. This diagram is intended to organize and clarify conceptual relationships among research directions, rather than to provide a one-to-one correspondence with the sections of this review.
2 Problem-Specific Modeling
With the rapid advancement of data-driven techniques, researchers started to design specialized machine learning models tailored to specific mathematical research problems. These efforts generally fall into three distinct directions: identifying patterns in high-dimensional data to guide human intuition and inspire new conjectures; constructing examples or counterexamples to rigorously test or disprove mathematical hypotheses; and performing formal reasoning within closed axiomatic systems, such as Euclidean geometry. In this section, we review recent developments across these three areas and discuss their respective advantages and limitations.
2.1 Guiding Human Intuition through Machine Learning
One of the earliest examples of utilizing machine learning to assist in formulating mathematical conjectures is [21]. In this study, the authors employed linear regression to predict the rank of the geometric gauge group across a large ensemble of F-theory geometries, successfully rediscovering an existing conjecture regarding gauge group rank. Building on this, they applied logistic regression to a classification problem involving $E_{6}$ gauge groups; through attribution analysis of the model, they formulated a genuinely new conjecture that was subsequently proved by human mathematicians.
However, the pivotal study that demonstrated the broad potential of deep learning in mathematical research is [37]. The central contribution of this work is a systematic framework designed to accelerate the conjecture generation process—traditionally a time-consuming cycle where mathematicians hypothesize relationships, attempt proofs, and refine their ideas iteratively. In the workflow proposed by [37], mathematicians begin by hypothesizing that a relationship may exist between two mathematical objects. A specially designed neural network is then trained to predict one quantity from the features of the other. Attribution methods are subsequently used to identify the most influential input components, thereby guiding mathematicians toward more precise and refined conjectures. This cycle repeats until a mathematically meaningful statement is formulated. Using this approach, the authors discovered a new relationship between algebraic and geometric invariants in knot theory [36] and proposed a candidate algorithm predicted by the combinatorial invariance conjecture for symmetric groups [17].
Inspired by this paradigm, [41] designed another AI-guided intuition framework to the study of affine Deligne–Lusztig varieties (ADLV). This work not only independently rediscovered the classical virtual dimension formula in arithmetic geometry but also established a novel, precise lower-bound theorem. By providing a quantitative characterization that fills an important theoretical gap, this result demonstrates the efficacy of AI-guided intuition in facilitating rigorous discoveries within deep areas of pure mathematics.
Beyond refining conjectures, machine learning has also proven effective in uncovering entirely new mathematical phenomena. A notable example is [65], where the authors represented elliptic curves as vectors and trained a logistic regression classifier to distinguish curves of different ranks. To interpret the classifier’s strong performance, the authors performed Principal Component Analysis (PCA) on the vector representations. Upon plotting the averages of Frobenius traces for elliptic curves of fixed rank over a given conductor range, they revealed a surprising oscillatory pattern, which they termed “murmurations.” This phenomenon has since been the subject of in-depth theoretical study [178, 90, 18]. A growing body of literature continues to leverage machine learning to discover or rediscover relationships across various domains [21, 81, 47, 14, 16, 91, 5, 62, 123, 87, 89].
2.2 Constructing Examples and Counterexamples
One of the pioneering works to utilize machine learning for constructing examples and counterexamples is [136]. In this study, the author encodes graphs as 0–1 sequences and applies the deep cross-entropy method from RL to search for graph constructions that serve as counterexamples to existing conjectures. Following this precedent, RL has been adopted for a variety of structural problems. For instance, [13] models the Hironaka game, a framework central to the resolution of singularities in algebraic geometry, as a Markov decision process (MDP). By combining Monte Carlo tree search with Deep Q-Networks, the authors successfully trained an agent to replace singular points with smooth ones, achieving near-optimal resolutions for du Val singularities. Similarly, [126] investigates the Andrews–Curtis (AC) conjecture. After first employing classical search algorithms to identify AC triviality for infinite subfamilies of the Miller–Schupp series and to obtain length reductions in the Akbulut–Kirby series, the authors formulate the general problem as an MDP. They trained an RL agent on problem instances of varying difficulty, ultimately discovering two novel AC trivializations of balanced presentations that had eluded classical search methods.
Beyond RL, a diverse array of other machine learning techniques has been proposed for mathematical construction. [4] trains a Transformer model on synthetic data to predict Lyapunov functions for stable dynamical systems; the trained model is then used to discover novel Lyapunov functions for non-polynomial systems. In combinatorics, [22] introduces an iterative bootstrapping procedure. This method begins by generating candidate constructions via a local search algorithm, trains a neural network on the highest-scoring candidates, and then samples new seeds from the network to initialize the next round of local search. Using this approach, the authors successfully discovered a counterexample to a 30-year-old conjecture. [bérczi2026flowbasedextremalmathematicalstructure] proposes a geometry-aware conditional flow-matching model for continuous geometric optimization problems, interleaving flow integration with projection onto the constraint manifold. The method initializes a training set using stochastic relaxation with perturbations, trains a conditional flow-matching model with geometric penalties, and employs geometry-aware sampling together with reward-guided policy optimization to iteratively refine configurations via local search. This approach discovers configurations that match or exceed the best known results in problems such as circle packing maximizing the sum of radii and the Heilbronn triangle problem. Additionally, [15] applies genetic algorithms to generate reflexive polytopes in dimensions 2 through 5, identifying several previously unknown polytopes in dimension 5. Other works leveraging machine learning for the construction of examples or counterexamples include [26, 27, 61, 129, 44].
As LLMs continue to grow more capable, LLM-based agents have also improved, and several recent works have demonstrated their potential for discovering new mathematical constructions. FunSearch [119] searches for programs that generate desired constructions using an evolutionary approach. For problems equipped with a well-defined evaluator, FunSearch employs an off-the-shelf LLM to iteratively evolve low-scoring candidate programs into higher-scoring ones. This is achieved by maintaining a large, diverse pool of programs and repeatedly prompting the LLM to improve upon earlier candidates. Using this method, FunSearch discovered new constructions of large cap sets that surpass the best previously known results in extremal combinatorics. Building on this line of work, AlphaEvolve [110] uses a stronger LLM and extends the evolutionary process to entire code files rather than single functions, while also optimizing multiple metrics simultaneously. AlphaEvolve has produced improved constructions for several problems, including the Minimum Overlap Problem and the Kissing Numbers problem in 11 dimensions. Open-source implementations inspired by AlphaEvolve include OpenEvolve [125], ShinkaEvolve [88], and DeepEvolve [97]. AlphaEvolve-style agents are particularly suitable for finding new constructions in mathematical problems that can be approached by writing code and evaluated with a well-defined scoring function.
2.3 Problem-Specific Formal Reasoning
AlphaGeometry [132] represents a neuro-symbolic approach to solving Olympiad-level Euclidean geometry problems. It integrates a symbolic geometric reasoning engine with a language model designed to suggest auxiliary constructions. The symbolic component, based on a deductive database (DD) [28] and algebraic rules (AR), exhaustively derives the deduction closure of a given set of premises. Since purely symbolic deduction cannot introduce new geometric objects, a capability often required for complex proofs, the system utilizes a language model to propose useful auxiliary points. To circumvent the scarcity of human proof data, the authors generated a large-scale dataset of synthetic proof graphs by alternating symbolic deduction with random point insertions, subsequently extracting minimal proofs via traceback. During inference, the system operates in a loop: the symbolic engine expands the deduction closure, the model proposes high-probability auxiliary points, and the cycle repeats until the target conclusion is reached. This architecture allows AlphaGeometry to significantly outperform heuristic-based systems, reaching performance comparable to an IMO silver medalist.
Its successor, AlphaGeometry2 [25], further advances this paradigm through enhancements in both expressivity and efficiency. The formal geometry language was expanded to support locus descriptions, linear geometric relations, and non-constructive statements, while the underlying symbolic engine was re-engineered for greater speed and robustness. These improvements enabled the generation of a larger, more diverse synthetic training set for the language model. Furthermore, AlphaGeometry2 introduces a novel search algorithm, the Shared Knowledge Ensemble of Search Trees (SKEST), which executes multiple search trees in parallel. By allowing these trees to exchange discovered information, SKEST significantly improves the exploration of the auxiliary construction space. Consequently, AlphaGeometry2 achieves gold-medalist performance on IMO-level geometry problems. Beyond neural approaches for auxiliary point generation, recent work such as HAGeo [46] proposes a purely heuristic-based strategy that introduces auxiliary constructions with favorable geometric properties, including intersections of lines and circles, midpoints, and point reflections, and likewise achieves gold-medal-level performance. Additional work on Euclidean geometry problem solving can be found in [170, 66, 177, 171, 166].
2.4 Discussion
The approaches discussed in this section, identifying patterns to guide intuition, constructing counterexamples, and performing formal reasoning in closed systems, each offer distinct advantages while presenting unique challenges.
The AI-guided intuition paradigm is powerful because it enables mathematicians to uncover patterns in high-dimensional data that are otherwise difficult or time-consuming to detect manually, effectively reducing the search space in exploratory research. However, this approach is not universally applicable. It relies on careful problem selection, as the target question must admit the generation of sufficiently large and representative datasets. Furthermore, successful implementation demands a high barrier of dual expertise: beyond standard machine learning considerations such as architecture design and loss engineering, deep mathematical insight is indispensable for interpreting model outputs and transforming empirical correlations into rigorous mathematical theory. Ultimately, since the final proof and verification are typically carried out by human mathematicians, the degree of automation in this workflow remains limited.
Conversely, employing machine learning to construct examples and counterexamples can significantly accelerate the formulation and testing of conjectures by discovering objects that defy human intuition. Yet, this direction also faces technical hurdles, particularly regarding out-of-distribution (OOD) generalization. For instance, the backward generation method in [4], which constructs problems from sampled solutions, may yield training sets with specific distributions. This can present challenges for generalizing to typical problem instances and often requires carefully designed procedures, such as the diversity promoting mechanism for Lyapunov functions proposed by the authors, to ensure robust performance. Additionally, when RL is employed, mapping a mathematical problem onto an MDP is non-trivial. Defining appropriate state representations, action spaces, and reward functions can be intricate [136], and the learning process may be further complicated by sparse rewards and long planning horizons [126].
Systems like FunSearch and AlphaEvolve represent a powerful shift toward automated mathematical discovery through program evolution. These agents excel at construction-type problems, such as finding extremal configurations in combinatorics or improving algorithmic bounds, where the search space can be navigated by iteratively refining code and verified through a well-defined scoring function. However, this paradigm remains inherently constrained by its reliance on such evaluators. While highly effective at identifying specific mathematical objects (e.g., cap sets or high-dimensional sphere packings), these systems do not explicitly engage with the formulation of conceptual frameworks or structural principles that underlie general theories or connect disparate mathematical domains. Their success is therefore currently concentrated in verifiable construction, leaving the discovery of transferable abstractions and unifying insights as an open frontier.
Finally, problem-specific formal reasoning systems, such as AlphaGeometry, demonstrate that combining symbolic engines with neural language models can achieve expert-level performance in structured domains. However, the success of these systems typically relies on the availability of domain-specific symbolic engines (e.g., deductive databases for geometry [28]) and the capability to generate large-scale synthetic data. Consequently, these architectures are often tightly tailored to their specific problem scope and may not transfer to other areas of mathematics without substantial modification.
3 General-Purpose Modeling
General-purpose modeling marks a shift from specialized algorithms designed for isolated problems to adaptable systems capable of handling broad areas of mathematics. Unlike problem-specific modeling, which requires bespoke features and architectures for each new task, general-purpose approaches leverage foundation models trained on vast corpora to learn universal representations of mathematical knowledge. These models aim to support a wide spectrum of activities, from solving diverse problem sets to retrieving theorems and orchestrating complex workflows, without requiring substantial modification for each new domain.
We categorize recent progress in general-purpose modeling into three complementary directions: natural language reasoning models that leverage the intuitive power of language; formal reasoning models that ensure rigor through interaction with proof assistants; and mathematical information retrieval systems that ground reasoning in established knowledge. This section begins by analyzing the capabilities and inherent limitations of foundation models (especially LLMs), establishing the context for our detailed review of these three key areas.
3.1 Foundation Models and LLMs
Compared with traditional machine learning models that are trained for a single, narrowly defined task, LLMs serve as foundation models: a single architecture trained on a broad collection of data and tasks in a unified manner. Mathematically, this distinction represents a paradigm shift from function approximation to operator approximation, which is a process intimately related to meta-learning. A traditional model is typically designed to approximate a specific, fixed mapping $f:\mathcal{X}→\mathcal{Y}$ between Euclidean spaces, such as classifying objects in an image, by interpolating discrete data points sampled from that specific manifold.
In contrast, foundation models perform task interpolation rather than simple data interpolation. They are trained over a vast distribution of tasks $\{T_{i}\}$ , where each task effectively defines a distinct mapping $f_{i}$ . By learning to generalize across this distribution, the foundation model does not merely approximate a single function; instead, it approximates a global operator (or functional) $\Psi$ acting on a function space. Given a task specification or context as input, $\Psi$ instantiates the specific mapping $f_{i}$ required for that context. In essence, while traditional machine learning approximates functions, foundation models approximate the operators that generate and manipulate those functions.
A critical factor in their success is the capability to process diverse data types; tokenization converts heterogeneous inputs into a common sequence representation, and the next-token prediction objective provides a single learning rule that applies uniformly across all tasks the model encounters. Attention-based architectures are pivotal in this regime. Beyond effectively scaling with model size and data volume, the attention mechanism serves as the key engine for reasoning by enforcing long-context coherence during training. This allows the model to capture and maintain complex dependencies over extended sequences—a prerequisite for logical deduction. Through exposure to diverse domains and supervision signals, the model is forced to compress vast amounts of heterogeneous data into shared internal representations and to discover a common low-dimensional structure across tasks and languages. A natural hypothesis is that a key component of this low-dimensional structure corresponds to general-purpose reasoning abilities that can be expressed in different languages and domains.
Mathematics fits naturally into this framework. Mathematical work is governed by strict logical rules, and many mathematical tasks can be phrased as producing the next meaningful step in a calculation, derivation, or proof—exactly the kind of stepwise structure that the next-token prediction objective is designed to model. Consequently, when an LLM is trained as a foundation model on sufficiently rich mathematical and scientific corpora, the same mechanisms that support cross-domain generalization and long-context coherence can be harnessed to learn and use a wide range of mathematical reasoning abilities.
However, a fundamental gap remains between mastering standardized examinations and engaging in research-level mathematics. While current models excel at solving well-defined undergraduate problems, research demands open-ended exploration, absolute logical rigor, and the ability to navigate the “long tail” of specialized domain knowledge—challenges where stochastic text generation often falls short. To elevate AI from a competent solver to a reliable research partner, general-purpose modeling must therefore advance beyond simple next-token prediction, integrating formal verification, semantic retrieval, and agentic workflows to bridge the divide between plausible text and rigorous truth.
3.2 Natural Language Reasoning
Current approaches to natural language mathematical reasoning generally fall into two categories: math-specific LLMs and general-purpose reasoning models.
Math-specific LLMs are typically adapted from general foundation models through specialized pre-training and post-training pipelines. During pre-training, filtering pipelines [124, 160] extract high-quality mathematical content from web corpora (e.g., Common Crawl), textbooks, and research papers to maximize domain relevance. Post-training refines these models using supervised fine-tuning (SFT) and RL. The data for SFT is often structured as Chain-of-Thought (CoT) [147] pairs, consisting of problems and step-by-step solutions, or Tool-Integrated Reasoning (TIR) [60] examples that incorporate external code execution. A prominent example is NuminaMath [93], which won the first AIMO Progress Prize by fine-tuning on high-quality CoT and TIR datasets. While models in this category [10, 124, 160, 163] excel at elementary and competition-level benchmarks (e.g., GSM8K [31], MATH [67], AIME), their capacity for advanced mathematics remains less explored.
Concurrently, general-purpose LLMs have achieved significant mathematical milestones driven by scale and novel inference strategies. Early iterations like GPT-3 struggled with basic arithmetic, whereas GPT-4 [1] achieved 92.0% on GSM8K. A paradigm shift occurred with the introduction of test-time scaling, where models dedicate increased computation to reasoning during inference. OpenAI’s o1 model demonstrated strong performance on the AIME, and subsequent reasoning models [63, 131, 159, 33] have further validated this approach. By 2025, enhanced reasoning models, such as Google’s Gemini Deep Think, reached gold-medal performance at the International Mathematical Olympiad (IMO) using purely natural-language reasoning, marking a definitive maturity for the technology in the domain of high-school olympiad mathematics.
However, transitioning from Olympiad problems to higher mathematics presents a steeper challenge. Prior studies indicate that while GPT-4 can assist with undergraduate topics, it requires critical human oversight [32] and often fails at the graduate level [50]. Recent benchmarks quantify this gap: [78] reported that DeepSeek-R1 achieves 71.0% proof accuracy on graduate-level algebra (FATE-H) but drops to 33.0% on PhD qualifying exams (FATE-X). Similarly, on the FrontierMath Benchmark [56], which consists of unpublished research-level problems, Gemini 3 Pro scores 18.75% on the research-level split (Tier 4) https://epoch.ai/frontiermath, indicating that robust research-level reasoning remains an open problem.
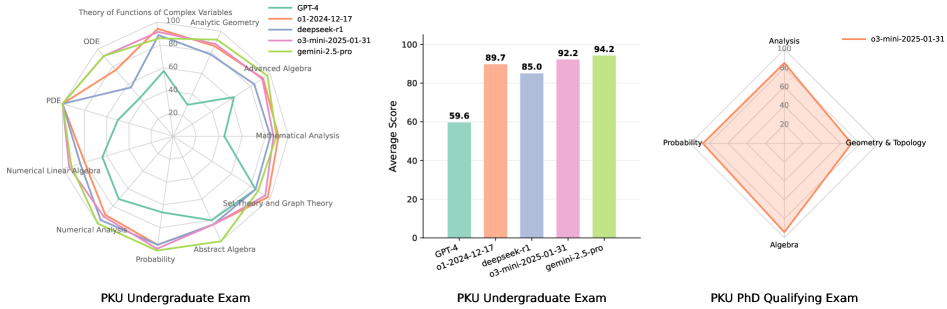
To empirically assess the current capabilities of state-of-the-art models, we constructed a dataset of 100 problems drawn from the final exams of 11 undergraduate mathematics subjects at Peking University (PKU). We evaluated five models: GPT-4, o1, o3-mini, DeepSeek-R1, and Gemini 2.5 Pro. Sample problems and model responses are provided in Appendix B. Human experts graded the outputs on a 0–5 scale (criteria in Table 1); the normalized results are presented in Figure 2 (left and middle). While GPT-4 scores below 60, reasoning-enhanced models (OpenAI o-series, DeepSeek-R1, Gemini 2.5 Pro) show substantial improvement, with several exceeding a score of 90.
Furthermore, we evaluated o3-mini on 58 problems from PKU PhD Qualifying Exams in Analysis, Probability, Algebra, and Geometry & Topology. As shown in Figure 2 (right), o3-mini achieves an average score of 84.4. A closer examination of the subject-wise performance reveals a notable divergence: the model exhibits its strongest proficiency in Algebra while scoring lowest in Geometry & Topology. Under the assumption that these exams pose a comparable level of challenge for human students, this suggests that current AI systems are comparatively more adept at handling abstract algebraic structures than tasks requiring geometric intuition. Although these results must be interpreted with caution due to potential data contamination and the specific nature of exam problems compared to open research, they provide strong evidence that top-tier models can now handle a significant portion of graduate-level mathematics.
Synthesizing these findings, we observe a clear trajectory: the mathematical reasoning abilities of LLMs have progressed from mastering elementary calculations and high-school competitions to achieving competence in undergraduate curriculum, and are now beginning to penetrate the domain of graduate and research-level mathematics [20, 74].
<details>
<summary>x2.png Details</summary>
### Visual Description
## Chart Analysis: PKU Exam Performance Comparison
### Overview
The image presents a comparison of the performance of different AI models (GPT-4, 01-2024-12-17, deepseek-r1, o3-mini-2025-01-31, and gemini-2.5-pro) on PKU (Peking University) undergraduate and PhD qualifying exams. The data is visualized using two radar charts and one bar chart. The radar charts show performance across different subject areas for the undergraduate and PhD exams, while the bar chart shows the average score on the undergraduate exam.
### Components/Axes
**Left Radar Chart (PKU Undergraduate Exam):**
* **Title:** PKU Undergraduate Exam
* **Axes:**
* Theory of Functions of Complex Variables
* Analytic Geometry
* Advanced Algebra
* Mathematical Analysis
* Set Theory and Graph Theory
* Abstract Algebra
* Probability
* Numerical Analysis
* Numerical Linear Algebra
* PDE
* ODE
* **Scale:** 0 to 100, with increments of 20.
* **Legend (Top-Right):**
* GPT-4 (Teal)
* 01-2024-12-17 (Orange)
* deepseek-r1 (Blue)
* 03-mini-2025-01-31 (Pink)
* gemini-2.5-pro (Lime Green)
**Center Bar Chart (PKU Undergraduate Exam - Average Score):**
* **Title:** PKU Undergraduate Exam
* **X-axis:** AI Models (GPT-4, 01-2024-12-17, deepseek-r1, 03-mini-2025-01-31, gemini-2.5-pro)
* **Y-axis:** Average Score, ranging from 0 to 100.
* **Bars:** Each bar represents the average score of a specific AI model. The colors of the bars match the colors in the radar chart legend.
**Right Radar Chart (PKU PhD Qualifying Exam):**
* **Title:** PKU PhD Qualifying Exam
* **Axes:**
* Analysis
* Geometry & Topology
* Algebra
* Probability
* **Scale:** 0 to 100, with increments of 20.
* **Legend (Top-Right):**
* 03-mini-2025-01-31 (Orange)
### Detailed Analysis
**Left Radar Chart (PKU Undergraduate Exam):**
* **GPT-4 (Teal):** Generally scores between 20 and 40 across most subjects, with a peak around 60 in Advanced Algebra.
* **01-2024-12-17 (Orange):** Scores vary more widely, with peaks around 80 in Theory of Functions of Complex Variables and Analytic Geometry, but lower scores in Probability and Numerical Analysis (around 20-40).
* **deepseek-r1 (Blue):** Shows a relatively consistent performance across subjects, mostly between 60 and 80.
* **03-mini-2025-01-31 (Pink):** Similar to deepseek-r1, with scores generally between 60 and 80.
* **gemini-2.5-pro (Lime Green):** Outperforms the other models in most subjects, with scores generally between 80 and 100.
**Center Bar Chart (PKU Undergraduate Exam - Average Score):**
* **GPT-4 (Teal):** Average score of 59.6.
* **01-2024-12-17 (Orange):** Average score of 89.7.
* **deepseek-r1 (Blue):** Average score of 85.0.
* **03-mini-2025-01-31 (Pink):** Average score of 92.2.
* **gemini-2.5-pro (Lime Green):** Average score of 94.2.
**Right Radar Chart (PKU PhD Qualifying Exam):**
* **03-mini-2025-01-31 (Orange):** Scores approximately 80 in Analysis, Geometry & Topology, Algebra, and Probability.
### Key Observations
* The gemini-2.5-pro model generally outperforms the other models on the PKU undergraduate exam, both in individual subjects and in average score.
* GPT-4 shows the lowest average score on the undergraduate exam.
* The 03-mini-2025-01-31 model shows consistent performance across all subjects in the PhD qualifying exam.
* The bar chart confirms the relative performance of the models as seen in the radar chart for the undergraduate exam.
### Interpretation
The data suggests that the gemini-2.5-pro model is the most proficient among the tested AI models in the PKU undergraduate exam, while GPT-4 lags behind. The 03-mini-2025-01-31 model demonstrates strong performance in the PKU PhD qualifying exam. The radar charts provide a detailed view of the strengths and weaknesses of each model across different subject areas, while the bar chart provides a concise summary of their overall performance. The consistent performance of 03-mini-2025-01-31 across the PhD qualifying exam subjects suggests a well-rounded understanding of the core concepts. The variability in performance of the 01-2024-12-17 model in the undergraduate exam indicates potential specialization in certain areas.
</details>
Figure 2: Performance of five LLMs across different Peking University (PKU) exams. Left: Scores on 11 undergraduate subjects. Middle: Average scores of the five LLMs across these subjects. Right: o3-mini’s performance on four PhD qualifying exam fields (average score: 84.4).
3.3 Formal Reasoning
Although top-tier LLMs can now solve certain graduate-level and even certain research-level problems, evaluating their capabilities remains a significant bottleneck involving substantial human effort. As the complexity of mathematics increases, assessment depends heavily on domain experts; yet, because natural language is inherently imprecise, even experienced mathematicians can misjudge arguments. A notable historical example occurred in 1994, when a result published in the Annals of Mathematics claimed that the Busemann–Petty problem has a negative solution in dimensions at least four [167]. This conclusion was later shown to be incorrect [83, 82], and a 1999 paper established that the problem in fact possesses a positive solution in dimension four [168]. Similarly, a paper [121] published in the Annals of Mathematics in 2004 was retracted in 2023 [122] after a counterexample to its main result, discovered in 2006, was identified [84]. These cases illustrate that errors can persist even within the rigorous peer-review processes of top journals. To enable fast and reliable verification of mathematical reasoning, research must therefore move toward a more mechanical and unambiguous framework. Formal systems provide exactly such a foundation. In this section, we discuss the benefits of formal systems for mathematical research and their utility in enhancing the reasoning abilities of LLMs, followed by a review of recent progress in automated theorem proving and autoformalization.
3.3.1 Formal Systems
Formal systems provide a precise symbolic language paired with rigorously defined mechanisms for constructing and verifying proofs. Various systems exist, distinguished by their underlying logical foundations: HOL systems (e.g., HOL Light, Isabelle/HOL) utilize simple type theory; Coq (now known as Rocq) and Lean employ dependent type theory; Metamath operates on first-order logic with explicitly specified axioms; and Mizar is grounded in Tarski–Grothendieck set theory. Once a mathematical argument is translated into the formal language of an interactive theorem prover (ITP), it can be verified with absolute rigor. Had the erroneous 1994 result regarding the Busemann–Petty problem been formalized in such a system, the underlying logical flaws would likely have been detected immediately, preventing the publication of an incorrect claim.
Beyond their intrinsic value to mathematical correctness, formal systems offer a critical advantage for AI development: they provide reliable, verifiable supervision. Unlike elementary mathematics, where answers are often numeric and easily checked, advanced proof-oriented problems lack simple verifiers, making it difficult to generate reliable training signals. Interactive theorem provers bridge this gap by providing precise feedback on the validity of every logical step. This capability supplies high-quality training signals for RL, thereby enabling models to develop stronger reasoning capabilities in rigorous settings.
Among interactive theorem provers, Lean [39, 40] has cultivated a particularly robust ecosystem. Its unified mathematical library, mathlib4, has expanded rapidly through large-scale community collaboration and, as of December 2025, contains over 250,000 theorems and 120,000 definitions. A landmark achievement in this domain is the Liquid Tensor Experiment, led by Johan Commelin, which formalized a central theorem of Peter Scholze on liquid vector spaces. Scholze, who initially harbored doubts about the proof’s correctness, remarked that the theorem might be his “most important to date” https://xenaproject.wordpress.com/2020/12/05/liquid-tensor-experiment/. The project, which spanned approximately 18 months, not only verified the result but also led to a simplification of the original Clausen–Scholze proof, helping Scholze deepen his understanding of the argument’s structure https://xenaproject.wordpress.com/2021/06/05/half-a-year-of-the-liquid-tensor-experiment-amazing-developments/. Furthermore, the Liquid Tensor Experiment catalyzed the development of algebraic infrastructure within mathlib4: it drove the early formalization of homological algebra and category theory and attracted a wave of algebraists to the community. Other notable milestones include the formalization of the Polynomial Freiman–Ruzsa (PFR) conjecture https://teorth.github.io/pfr//, the sphere eversion theorem https://leanprover-community.github.io/sphere-eversion/, ongoing work on formalizing the solution to the sphere packing problem in dimension 8 https://thefundamentaltheor3m.github.io/Sphere-Packing-Lean/, and the long-term effort to formalize Fermat’s Last Theorem https://leanprover-community.github.io/blog/posts/FLT-announcement/ lead by Kevin Buzzard. Expanding into applied mathematics, recent work has also established the formal foundations for numerical optimization in Lean4, specifically verifying the convergence of first-order algorithms [92].
However, these projects remain labor-intensive, requiring experts to manually translate definitions and proofs into code. This high cost motivates the development of autoformalization tools and automated theorem provers to accelerate the digitalization of mathematical knowledge—the conversion of standard informal mathematics into rigorous formal systems such as Lean.
3.3.2 Autoformalization
Autoformalization is the task of translating mathematical statements and proofs from natural language into formal code in an autonomous manner (e.g. by a language model). Early efforts in this domain employed sequence-to-sequence models trained on aligned data. For instance, [144] constructed datasets by informalizing Mizar statements to train translation models. Addressing the scarcity of aligned pairs, [143] subsequently explored unsupervised approaches based on cycle-consistency losses, where models learned to reconstruct statements by translating them between informal and formal domains without explicit supervision.
The advent of LLMs fundamentally shifted this paradigm. Research demonstrated that off-the-shelf LLMs could generate reasonable formalizations via few-shot prompting [153, 51, 3, 9]. Crucially, [153] observed an asymmetry: translating formal code to natural language (informalization) is significantly easier for models than the reverse. This insight catalyzed the creation of large-scale synthetic datasets, where LLMs are used to informalize massive formal libraries (such as mathlib4) to generate high-quality aligned pairs for training specialized autoformalizers [75, 102, 53, 99].
Recent work focuses on improving the quality and grounding of these systems. Herald [53] introduces a hierarchical informalization strategy that respects the dependency graph of the library mathlib. By translating declarations in topological order, it ensures that the natural language descriptions of prerequisite concepts are available when translating dependent theorems. Herald further augments its data via tactic-based state synthesis and achieves over 96% statement autoformalization accuracy on the miniF2F validation set. To enhance grounding, RAutoformalizer [99] employs retrieval mechanisms to anchor generated code in existing formal declarations. Addressing the challenge of missing concepts, common in research-level mathematics, [140] proposed Aria, an LLM-based agentic system. More generally, an LLM-based agent refers to a system that operates through an explicit interaction loop with its environment: it maintains intermediate states, reasons over observations, performs multi-step planning, and selects actions accordingly. These actions may include invoking external tools such as semantic retrieval, symbolic reasoning modules, or code synthesis components, with feedback from the environment used to guide subsequent decisions. Such agentic designs enable the decomposition of complex tasks into structured subtasks and support iterative refinement beyond single-pass generation [141]. Within this framework, Aria decomposes informal statements into a dependency graph of concepts; if a concept is absent from the library mathlib, the agent recursively defines it from the bottom up using semantic search and synthesis, effectively handling the “long tail” of mathematical vocabulary.
Evaluation and Verification
Evaluating statement autoformalization is non-trivial. Once a statement is correctly autoformalized, evaluating an autoformalized proof becomes straightforward due to the formal system, which makes statement autoformalization the primary difficulty from an evaluation perspective. While human expert review is the gold standard, it is unscalable. The challenge, therefore, lies in developing automated metrics for correctness.
- With Ground Truth: When a reference formal statement exists, correctness can be assessed via logical equivalence rather than mere string matching. For example, BEq [99] utilizes a neural theorem prover to check if the generated statement and the ground truth can be derived from one another. Similar equivalence-checking approaches are explored in [100, 113].
- Without Ground Truth (Semantic Verification): In the absence of a reference, one must verify semantic correctness —whether the formal code faithfully captures the intent of the informal statement. A naive approach involves “back-translation”, where an LLM translates the code back to English for comparison [162, 53]. However, this is prone to errors as LLMs may miss subtle logical discrepancies. To mitigate this, [158] proposes Mathesis, a fine-grained evaluation framework. Mathesis decomposes statements into assumptions and conclusions, evaluates the alignment of each component separately, and aggregates these scores using a fuzzy integral to rigorously reject inconsistencies. To further assist verification, Aria [140] enriches the context by retrieving detailed metadata (types, values, informal descriptions) for every term in the formal statement, enabling more accurate semantic judgments.
Reliable verifiers are not only essential for evaluation but also serve as critical reward models for RL, creating a feedback loop that iteratively improves autoformalization performance [158, 102, 70].
Note: This section has focused on statement autoformalization. The autoformalization of proofs, which requires translating logical reasoning steps rather than just definitions, is inextricably linked to automated theorem proving. We therefore discuss proof autoformalization in the context of proof generation in the following section.
3.3.3 Automated Theorem Proving
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Proof Tree and State Transition
### Overview
The image depicts a diagram illustrating a proof tree and state transition process, likely within a formal verification or automated theorem proving context. It shows the flow from a proof tree to a state, involving tactic application, premise retrieval from a math library, and tactic generation. A code snippet on the right provides a concrete example.
### Components/Axes
* **Proof Tree:** Located on the left side of the diagram. It represents the hierarchical structure of the proof.
* Node 1: (S: Type u\_1) (inst +: Mul S) (h₁: ∀ (a b: S), a\*b=a) (h₂: ∀ (a b: S), a\*b=b\*a)
* Node 2: (S: Type u\_1) (inst +: Mul S) (h₁: ∀ (a b: S), a\*b=a) (h₂: ∀ (a b: S), a\*b=b\*a)
* **State:** Located on the top-right side of the diagram. It represents the current state of the proof.
* Node: (S: Type u\_1) (inst +: Mul S) (h₁: ∀ (a b: S), a\*b=a) (h₂: ∀ (a b: S), a\*b=b\*a) |- Cardinal.mk S ≤ 1
* **Tactic:** Labels the action applied to the proof tree.
* `rw [Cardinal.le_one_iff_subsingleton]`
* **Math Library:** Represented by a building icon, located in the upper-right quadrant.
* **Premise Retriever:** A process that retrieves relevant premises from the math library.
* **Retrieved Premises:** A list of theorems retrieved from the math library.
* theorem `Cardinal.le_one_iff_subsingleton`
* theorem `Cardinal.mk_eq_one`
* theorem `Cardinal.eq_one_iff_unique`
* **Tactic Generator:** A process that generates tactics based on the retrieved premises.
* **Code Snippet:** Located on the right side of the diagram. It provides a code example.
* `import Mathlib`
* `variable {S: Type*} [Mul S]`
* `example (h₁: ∀ (a b: S), a * b = a) (h₂: ∀ (a b: S), a * b = b * a): Cardinal.mk S ≤ 1 := by`
* `rw [Cardinal.le_one_iff_subsingleton]`
* `refine (?_)`
* `intro a b`
* `rw [← h₁ a b]`
* `rw [h₂ a b]`
* `exact h₁ b a`
### Detailed Analysis
* The proof tree starts with an initial state and branches out as tactics are applied.
* The tactic `rw [Cardinal.le_one_iff_subsingleton]` is applied to the initial state in the proof tree.
* The state transitions from the initial state to a state where `Cardinal.mk S ≤ 1` needs to be proven.
* The premise retriever retrieves relevant theorems from the math library.
* The tactic generator generates tactics based on the retrieved premises.
* The code snippet provides a concrete example of how the tactic `Cardinal.le_one_iff_subsingleton` is used in a proof.
### Key Observations
* The diagram illustrates the process of automated theorem proving, where tactics are applied to a proof tree to reach a desired state.
* The math library provides a source of relevant theorems that can be used to generate tactics.
* The code snippet provides a concrete example of how the process works in practice.
### Interpretation
The diagram demonstrates a simplified model of automated theorem proving. The proof tree represents the exploration of different proof paths, guided by tactics. The state represents the current goal or assertion to be proven. The math library and premise retriever provide the necessary knowledge to guide the proof search. The code snippet provides a practical example, showing how these components interact in a real-world scenario. The diagram highlights the interplay between symbolic reasoning (proof tree), knowledge retrieval (math library), and tactic application in the context of formal verification.
</details>
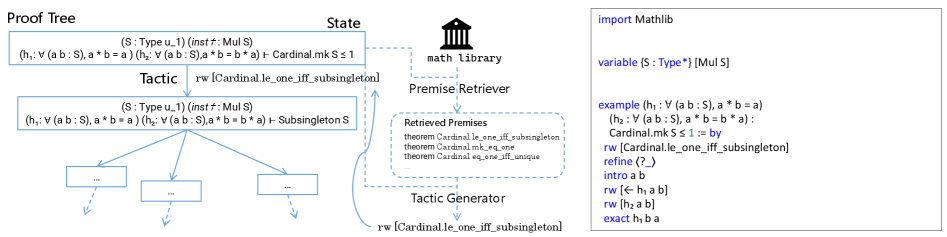
Figure 3: Example of a proof step generation method and the complete proof it produces. Left: An illustration of a proof tree, where each node represents a proof state and each edge corresponds to a tactic. Applying an appropriate tactic transforms the current proof state into the next one. At each step, the proof step generation method retrieves relevant premises and proposes several candidate tactics to try. Right: The complete proof ultimately obtained by this process.
Automated theorem proving in formal systems aims to generate valid proofs for formal statements. Deep learning–based approaches to this task fall into two broad categories: single-model approaches and agentic approaches. Single-model approaches can be further divided into proof step generation and whole-proof generation methods.
Proof Step Generation
Proof step generation methods formulate theorem proving as a tree search problem. In this framework, each node in the search tree corresponds to a proof state, and each action corresponds to the application of a tactic that transitions the prover to a new proof state. A proof is successfully constructed once a path is found to a state with no remaining goals. Figure 3 illustrates an example of a proof tree produced by such a method, alongside the final proof.
The strengths of proof step generation lie in reusability and exploration. During search, proof states are reusable: if a newly encountered state coincides with one previously explored, they can be merged. Furthermore, the system exhibits strong exploration capabilities by attempting multiple tactics at each step. However, these methods often suffer from slow inference speeds due to the computational cost of tree search, difficulty in training stability, and a heavy reliance on efficient interactive tools for both training and inference.
One of the earliest neural approaches in this domain is Holophrasm [150], which employs Monte Carlo Tree Search (MCTS) for exploration. Holophrasm integrates three neural components: a relevance network for retrieving useful theorems, a generative network for proposing variable substitutions, and a value network for estimating provability. Subsequent work largely treated tactic prediction as a classification problem, with representative examples including GamePad [69], DeepHOL [11], and graph-based approaches [111]. Moving beyond pure classification, GPT-f [115] trains a Transformer to generate proof steps via a conditional language modeling objective, constructing proofs using best-first search. Similarly, [86] introduces a hypertree-based search combined with an online training strategy, where policy and critic models are periodically updated on data collected from repeated proof searches.
A major challenge in this domain is the scarcity of large-scale formal data. To mitigate this bottleneck, researchers have pursued two complementary directions: improving model performance under limited formal data, and synthesizing additional formal data. For the former, ABEL [58] proposes an online reinforcement learning framework with prioritized sampling to encourage exploration; notably, its RL stage is trained on only 244 formal statements yet achieves performance comparable to the state of the art at the time. For the latter, REAL-Prover [127] proposes an integrated pipeline comprising a statement autoformalizer to translate informal statements, a retrieval-augmented prover that generates tactics conditioned on relevant premises, and an expert iteration paradigm. In this loop, the model trains on generated state-tactic pairs, performs proof search, and iteratively collects new training data from successful searches. Building on the retrieval-augmented architecture of REAL-Prover, the authors introduced the reap https://github.com/frenzymath/reap tactic as a concrete instantiation of retrieval-guided proof automation. The reap tactic is currently in a beta-testing phase and maintained as a candidate feature branch for mathlib4.
A notable milestone is AlphaProof [72]. AlphaProof trains a 3B-parameter proof network that jointly outputs tactics and value estimates. Its training pipeline involves pretraining on 300B tokens, supervised fine-tuning on 300k state-tactic pairs, and reinforcement learning on 80 million autoformalized statements. These formal statements are derived from approximately one million informal problems, where the autoformalization model is trained on triplets of (informal statement, formalization chain-of-thought, formal statement), with multiple distinct translations generated per problem. For particularly challenging tasks, AlphaProof applies test-time reinforcement learning to adapt to the problem structure by constructing and training on a specialized curriculum. As a result, it achieves performance comparable to an IMO silver medalist. Other notable approaches include [76, 114, 139, 161, 156, 94, 157].
Whole-Proof Generation
In contrast, whole-proof generation methods aim to produce an entire formal proof, possibly augmented with inline comments, in a single forward pass. Their primary advantages are high inference speed and independence from interactive tools during generation. However, their exploration capability is limited compared to step-wise search; they often rely on behavior cloning and are more susceptible to error accumulation since they lack access to intermediate proof states.
This paradigm relies heavily on data quality and quantity. Since there is no principled a priori method for determining data quality, evaluation is often indirect via model performance. To address data quantity, [154] proposed an integrated pipeline involving automatic statement formalization, filtering (to remove trivial or false statements), statement proving, and iterative training on the resulting verified pairs. Building on this, DeepSeek-Prover-V1.5 [155] improved performance by constructing richer datasets that include informal proofs written before formal code and inline informal comments, and by applying Reinforcement Learning from Verifier Feedback (RLVF). Other works adopting this paradigm include [49, 10, 163, 43, 169, 137, 96].
Agentic Approaches
Agentic approaches [77, 138, 135, 23, 78, 57, 2] represent a paradigm shift from single-model systems to modular workflows. These methods decompose theorem proving into coordinated sub-tasks, such as retrieval, decomposition, and verification, orchestrated through structured workflows that integrate language models with external tools. The effectiveness of these approaches relies on three core components: robust retrieval systems, the reasoning capabilities of LLMs, and workflows designed to mimic the mathematical research process.
Draft, Sketch, and Prove (DSP) [77] is a prototype of this paradigm. It generates an informal proof, translates it into a formal sketch with open subgoals, and closes them using a lightweight prover. LEGO-Prover [138] extends this by maintaining a persistent lemma pool. Uniquely, it evolves verified lemmas into new ones through strategies such as dimension extension, key concept identification, parameterization, and complexity enhancement. Hilbert [135] transforms informal proofs into formal sketches via recursive subgoal decomposition, guided by theorem retrieval. Seed-Prover-1.5 [23] similarly employs a specialized sketch model and a dedicated prover model, achieving 80% accuracy on the graduate-level benchmark FATE-H and 33% accuracy on the PhD-level benchmark FATE-X [78]. Notably, for agentic approaches such as Seed-Prover, the widely used miniF2F benchmark [172] has largely been saturated and can be regarded as effectively solved. Addressing the granularity gap between informal reasoning and formal code, [146] proposes a two-stage Chain of States (CoS) framework. By extracting a sequence of intermediate formal states aligned with the logical flow of the informal argument before generating the specific transition tactics, this approach significantly reduces the complexity of tactic generation under constrained computational budgets.
Advanced agents like Aristotle [2] interleave informal reasoning with formal verification. Aristotle drafts proofs as sequences of lemmas, formalizes them, and attempts verification, refining its outputs iteratively based on feedback. Together with a geometry solver, it achieved performance at the level of an IMO gold medal. Numina-Lean-Agent [98] equips the coding agent Claude Code with Lean-LSP-MCP [45] for interacting with Lean, a semantic search engine for theorem retrieval, an informal prover [71], and an external LLM for additional reasoning support. It successfully solved all problems in the 2025 Putnam Competition, an achievement first reported by AxiomProver [8]. Numina-Lean-Agent also formalized a research paper on Brascamp–Lieb inequalities [12] by interacting with mathematicians through iterative refinement of a natural language blueprint, represented as a dependency graph for both statements and proofs. Finally, the Gauss agent [107] demonstrated the power of human-AI collaboration by formalizing the strong Prime Number Theorem within three weeks, leveraging expert scaffolding. These results demonstrate that carefully designed agentic workflows can effectively exploit both intrinsic reasoning capabilities and external tools to achieve substantial gains in automated theorem proving.
The practical impact of formal reasoning agents is perhaps most clearly illustrated by their emerging role in recent work on conjectures posed by Paul Erdős, as discussed by Terence Tao https://github.com/teorth/erdosproblems/wiki/AI-contributions-to-Erd%C5%91s-problems. During late 2025 and early 2026, agentic systems such as Aristotle became integral components of a high-leverage verification workflow: frontier language models (e.g., Gemini Deep Think, ChatGPT) were used to generate candidate constructions or heuristic arguments, which were then rigorously formalized and mechanically checked in Lean. This pipeline has already yielded formally verified counterexamples to several Erdős problems (notably Problem #205) and partial resolutions of more intricate problems (e.g., #367), while many related cases remain open. Importantly, these examples are best viewed as representative rather than definitive: the process is ongoing, and further results continue to emerge. While formalization dramatically reduces the risk of irreparable hallucinations, it does not eliminate all failure modes—models may still exploit unintended problem specifications or rediscover arguments later found in the literature. Nevertheless, these developments mark a qualitative shift. Formal reasoning agents now function as reliable research copilots, systematically converting heuristic insight into certified mathematical knowledge and mitigating long-standing verification bottlenecks in exploratory mathematics.
3.4 Mathematical Information Retrieval
Mathematical Information Retrieval concerns the task of retrieving mathematical content, including formulas, theorems, and problem solutions, from large collections of mathematical documents. In contrast to standard text retrieval, MIR must explicitly account for the distinctive structure and semantics of mathematical expressions. Mathematical formulas are inherently structured objects whose meaning depends on symbolic composition and relational structure rather than mere lexical overlap. Consequently, an effective MIR system must address challenges such as matching mathematical structure and symbolic patterns, while simultaneously leveraging surrounding textual context to resolve ambiguity and interpret meaning.
Crucially, MIR is not merely a search tool for human users but a foundational component of modern automated theorem proving (ATP) and AI agent systems. In the context of ATP, premise retrieval, the task of identifying useful theorems, lemmas, or definitions from a vast library to prove a new theorem, is often the primary bottleneck. As mathematical libraries grow to contain hundreds of thousands of formal statements (e.g., mathlib4), the ability to efficiently retrieve the “needle in the haystack” determines whether a prover can solve a problem or times out. For agentic systems, MIR enables access to long-term mathematical memory, allowing agents to ground their reasoning in established knowledge rather than hallucinating unsupported facts. This requires a shift from traditional keyword-based matching to reasoning-based retrieval. A robust MIR model must understand logical implication and mathematical equivalence; for instance, it must recognize that a theorem stating “a square matrix has a non-zero determinant” is a critical premise required to answer a query about whether “the columns of the matrix form a linearly independent set,” despite the absence of shared keywords between the two statements.
Depending on the granularity of the retrieval target and the nature of the query, MIR encompasses several closely related tasks. Prominent examples include premise retrieval, semantic retrieval, and question-answer retrieval.
Premise Retrieval
In automated theorem proving, a central subproblem is premise retrieval: given a conjecture and a large library of existing mathematical statements, the system must identify which premises are likely to be useful for constructing a proof. Early approaches relied primarily on handcrafted similarity measures and heuristics [68, 108]. Variants and extensions of these ideas, including tree-based similarity scores, have continued to be explored in more recent work [145]. In parallel, lightweight machine learning methods such as k-nearest neighbors or sparse naive Bayes were also investigated for premise selection [35].
Over the past decade, deep learning methods have increasingly been applied to premise retrieval. A representative early neural approach is DeepMath [73], which encodes conjectures and candidate premises separately and the resulting representations are concatenated and passed through a fully connected network that predicts whether a premise is useful for proving the conjecture. Training is supervised using existing proofs, where premises appearing in proofs are treated as positive examples and hard negative mining is employed to construct informative negative samples. Subsequent work sought to better exploit the internal structure of logical formulas. FormulaNet [142], for instance, represents each formula as a graph derived from its syntactic structure, with nodes corresponding to constants, variables, or quantifiers. A graph neural network is then used to compute embeddings, which are combined and fed into a classifier to estimate relevance.
Beyond pairwise scoring models, later work explored graph-level representations over entire libraries of statements. In [48], the authors construct a global graph in which nodes correspond to mathematical statements and directed edges encode premise–conclusion relationships extracted from proofs. Premise selection for a new conjecture is formulated as a link prediction problem, and a graph convolutional network is used to score potential edges based on textual and structural features of nodes. In parallel, another line of research adopts embedding-based retrieval methods, treating each mathematical statement as text and encoding it into a single vector using a learned embedding model. Relevance is then assessed via similarity in the embedding space, often followed by a learned re-ranking stage to refine the retrieved candidate set. Training typically relies on contrastive objectives that draw conjectures closer to premises appearing in their proofs while pushing them away from irrelevant statements. Representative examples of this approach include [161, 130, 127].
Semantic Retrieval
Semantic retrieval aims to identify mathematically equivalent or closely related statements from a mathematical corpus based on their meaning rather than surface-level similarity. This task is motivated by practical use cases such as theorem search in large mathematical libraries. For example, users of Lean frequently need to locate relevant theorems in mathlib4 when constructing proofs. In this setting, a query may be expressed either in natural language or in formal code, while the retrieval corpus typically consists of formal declarations from mathlib4. To bridge the gap between informal queries and formal corpora, LeanSearch http://leansearch.net/ constructs an aligned informal–formal corpus derived from mathlib4 and performs retrieval over the combined representation [52]. This approach enables semantic matching across representation modalities and significantly improves retrieval effectiveness for natural language queries. At present, LeanSearch is officially supported by the Lean community and has been integrated into mathlib4 as a standard client for semantic retrieval. This level of community endorsement and infrastructural integration makes LeanSearch a practical and sustainable component of the mathlib ecosystem, rather than a standalone research prototype. In addition to LeanSearch, several other semantic search tools have been developed for mathlib4, including Moogle https://www.moogle.ai/, LeanExplore [7], LeanFinder [101], and LeanDex https://leandex.projectnumina.ai/.
Formula retrieval constitutes an important subtask of semantic retrieval, where the query is a mathematical formula or a formula pattern and the objective is to retrieve semantically related formulas from a collection of documents. This setting introduces unique challenges. Formulas that represent the same mathematical concept may differ significantly in surface form due to notational variation or algebraic properties such as commutativity. Conversely, formulas with similar visual appearance may encode different meanings when interpreted in different mathematical contexts. Traditional approaches to formula retrieval are largely based on tree representations that encode the structural organization of mathematical expressions. In these methods, a formula is represented as a tree, and similarity is defined over trees or their substructures. A widely used representation is the Symbol Layout Tree (SLT) [164], in which nodes correspond to symbols and edges encode spatial relationships such as superscript, subscript, or adjacency. Another prominent representation is the Operator Tree (OPT) [54], where internal nodes represent operators and leaf nodes represent operands. Compared with SLTs, operator trees abstract away visual layout and focus on mathematical operations and their hierarchical relationships. Tree-based retrieval algorithms typically compare formulas by matching subtrees or paths, or by computing tree edit distances. For example, Approach0 [175, 174] represents formulas as operator trees and uses leaf-to-root paths as basic retrieval units. It performs retrieval in two stages, first identifying candidate formulas whose paths overlap with those of the query, and then re-ranking candidates based on similarity measures derived from the largest common subtrees.
Beyond traditional symbolic matching, recent work has explored the use of text embedding models for formula retrieval. Early approaches adapt techniques from natural language representation by linearizing structured formula encodings and embedding them in a continuous vector space. For instance, Tangent-CFT [105] performs a depth-first traversal over SLT and OPT, tokenizes the resulting tuple sequences, and applies text embedding models to obtain formula representations. Concurrent work augments formula representations with surrounding textual context to better capture semantic meaning [104, 85]. For example, MathAMR [104] integrates formulas into their linguistic context by combining Abstract Meaning Representation (AMR) graphs with OPTs, replacing formula nodes in the AMR graph by the root nodes of the corresponding OPTs, and embedding the resulting linearized graphs using Sentence-BERT.
Question-Answer Retrieval
Question–answer (QA) retrieval concerns the task of retrieving mathematical answers, explanations, or supporting documents in response to a natural language query. Mathematical questions are inherently multimodal, typically combining natural language with symbolic expressions, formulas, or diagrams, and candidate answers exhibit similar structure. As a result, relevance in mathematical QA retrieval is defined by semantic adequacy, namely whether an answer correctly and meaningfully addresses the question, for example by providing a valid solution, proof, or conceptual explanation, rather than by surface-level lexical overlap.
Traditional general-purpose text retrieval methods, such as BM25 [117, 118] and TF–IDF, rely on sparse vector representations of queries and documents and assess relevance through weighted vector similarity [120]. While these methods can be directly applied to question–answer retrieval, they often perform poorly in mathematical settings. This limitation stems from their dependence on exact term matching and their inability to capture the semantics of mathematical language or the structural relationships encoded in mathematical formulas. With the rise of deep learning, research shifted toward neural retrieval models based on pretrained transformers. A common approach is to pretrain and fine-tune transformer models on large-scale mathematical corpora to obtain representations better aligned with mathematical syntax and semantics. For example, MathBERT [112] was pretrained on math-heavy corpora containing formulas and introduced objectives such as masked formula substructure prediction to better model mathematical symbols in context. Building on dense retrieval paradigms, [116] investigated the use of ColBERT [80] on the ARQMath benchmarks [106, 165], fine-tuning neural retrievers on millions of question–answer pairs with negatives selected via rule-based heuristics. Recognizing the complementary strengths of symbolic and neural methods, several hybrid approaches have also been proposed. Mabowdor [173], for example, combines dense passage retrieval with parallel sparse retrieval based on structure-aware mathematical indexing and traditional text-based methods, merging their outputs via a learned weighted scheme. This hybrid strategy achieved strong performance in ARQMath-3 [103], highlighting the effectiveness of integrating classical mathematical structure with neural semantic representations for QA retrieval.
4 Challenges and Prospects
Despite the promising progress in AI for Mathematics, the field faces a fundamental hurdle: current AI systems, particularly foundation models, still lack the depth of reasoning required for research-level mathematics. Bridging this gap necessitates a shift from passive assistance to active learning within a rigorous “logic environment.” This requires accelerating the formalization, or digitalization, of mathematics to provide automated, verifiable feedback that can iteratively strengthen AI reasoning. Furthermore, advancing these capabilities demands the infusion of professional mathematical knowledge, ranging from high-quality data curation to the design of specialized agentic workflows, into the model development process. Ultimately, the goal is to integrate AI seamlessly into the daily practice of mathematicians, a vision that can only be realized through continuous, close collaboration between AI researchers, engineers, and the mathematical community. We summarize these key challenges and future directions below:
1. Domain Expertise and Feature Engineering: In problem-specific modeling, the design of input features often necessitates deep domain expertise. Human intuition remains indispensable, both for selecting mathematically meaningful features and for interpreting model outputs to derive theoretical insights. This dependency holds equally for discovery-oriented agents (e.g., AlphaEvolve-style systems), which rely on carefully handcrafted representations and scoring functions. Consequently, the development of effective AI for Mathematics requires close and sustained collaboration between machine learning researchers and domain experts to ensure that computational outcomes translate into genuine mathematical progress.
1. The Verification Bottleneck and Autoformalization: Accurate and efficient verification constitutes a critical bottleneck in research-level mathematics. The inherent ambiguity of natural language, combined with the scarcity of experts capable of auditing advanced proofs, makes manual verification slow and error-prone. To achieve reliability, mathematical reasoning must ultimately be grounded in formal languages, where correctness can be mechanically checked. However, the formal reasoning capabilities of current LLMs lag behind their natural language performance due to the severe scarcity of high-quality formal data. Addressing this “formal data gap” requires the development of robust autoformalization tools that bridge informal and formal mathematics. By building sound infrastructure for specific subfields and supporting repository-level formalization, we can accelerate the translation of natural language reasoning into formal proofs. This creates a virtuous cycle: formally verifiable feedback can serve as a high-quality training signal to further enhance the reasoning capabilities of LLMs in both mathematics and broader domains.
1. Semantic Consistency in Formalization: A subtle challenge in autoformalization is verifying the semantic correctness of generated formal statements, namely whether the formalized statement faithfully reflects the intent of the original informal statement. Existing models often struggle to determine whether a back-translated formal statement faithfully captures the nuance of the original informal statement. This necessitates the development of fine-grained, robust semantic-consistency verifiers. While the final judgment of semantic intent must arguably remain with human experts to ensure conceptual accuracy, automated systems can serve as efficient first-stage filters. By reducing the volume of candidates that require manual review, such systems can scale the formalization process without compromising rigorous standards.
1. Beyond Correctness to Understanding: Formal validity is a necessary, but not sufficient, condition for mathematical value. As William Thurston famously noted [34], “mathematics is not about numbers, equations, computations, or algorithms: it is about understanding.” A valuable proof does more than establish truth; it provides insight, reveals structure, and offers techniques applicable to other problems. Similarly, Stanislaw Ulam [134] quotes Stefan Banach as saying, “Good mathematicians see analogies between theorems or theories, the very best ones see analogies between analogies.” This highlights a broader truth: the quality of a proof lies in its ability to deepen our conceptual grasp of the mathematical landscape. Future AI systems must therefore aim to go beyond mere verification, assisting in the discovery of proofs that reshape our thinking and uncover connections that were previously invisible.
1. From Heuristics to Expert Routines: While standalone LLMs serve as powerful reasoning engines, the future of AI4Math lies in agentic systems designed to emulate the sophisticated workflows of professional mathematicians. Research-level mathematics is rarely a linear deduction; it involves a complex, iterative cycle of constructing examples, consulting literature, formulating conjectures, and refining proof strategies based on intermediate failures. Current agents, however, remain largely generic. A critical frontier is to develop architectures that explicitly model these expert “routines”, learning to orchestrate tools and strategies in a way that mirrors the cognitive processes of a researcher. This includes the use of “computational sketching”—leveraging code generation not just for formal proofs, but to construct numerical toy-examples or perform symbolic derivations that quickly verify or falsify human intuition. Furthermore, these agents can automate high-value long-tail tasks often neglected by humans, such as proof reorganization, condition weakening, and the semantic retrieval of obscure existing solutions. Ultimately, the goal is not merely to mimic human workflows but to optimize them, creating agents capable of navigating the search space of mathematical ideas with a systematicity and scale that surpasses human capability in attacking challenging problems.
1. Active Community Participation: Resonating with the necessity of domain expertise, the advancement of AI reasoning requires the active intervention of mathematicians. Beyond generating formal data, the community must actively explore these systems to develop a collective “mental model” of their capabilities and boundaries. For instance, distinguishing whether models are more adept at algebraic manipulation than geometric topology is crucial for determining where AI can be reliably deployed. This involves not only accelerating the digitalization of mathematical knowledge to create verifiable training corpora but also engaging in “adversarial collaboration” to identify logical gaps. By rigorously mapping these strengths and weaknesses, mathematicians can guide the development of models that are not just statistically powerful but mathematically sound.
1. Embracing AI-Assisted Research: We must prepare for a cultural shift where AI evolves from a computational tool into a research copilot. Developments in late 2025, highlighted by Georgiev, Gómez-Serrano, Tao and Wagner’s work [55], underscore this transition. In this work, the authors observed that while these models may still lack true understanding, often “doing impressions of thinking”, they have become adept at autonomously discovering mathematical constructions that elude human intuition. Even when models hallucinate or produce flawed reasoning, their ability to generate plausible structural candidates allows them to act as effective co-pilots, guiding researchers toward fruitful avenues of inquiry while leaving the final, rigorous verification to human experts.
We would argue that even if an AI’s divergent reasoning, proposing random or creative variants, has a low probability of correctness, the total research efficiency improves provided the “verification leverage” is high. In many advanced mathematical domains, generating a solution is computationally or cognitively expensive, whereas verifying a candidate solution is comparatively rapid. This asymmetry allows researchers to utilize AI as a high-volume generator of candidate ideas, where the time saved by a single valid insight significantly outweighs the low cost of discarding incorrect suggestions.
However, realizing this potential requires more than just powerful models; it demands well-engineered, accessible tools. To facilitate high engagement, the barrier to entry must be lowered through robust software design. The ease of use seen in recent frameworks like AlphaEvolve, compared to earlier prototypes, demonstrates that engineering quality is a critical determinant in transitioning these technologies from experimental curiosities to standard instruments of global adoption.
Acknowledgements
The authors would like to thank Gergely Bérczi, Xiaoshan Gao, Amaury Hayat, Xuhua He, Kyu-Hwan Lee, Geordie Williamson, and Wotao Yin for valuable comments and suggestions that helped improve the presentation of this paper. They also thank Guoxiong Gao and Chenyi Li for collecting the PKU Undergraduate Final Exams and PhD Qualifying Exams. The authors further acknowledge Feiyue Ye, Yining Wang, Rui Wang, Youle Fang and Wenhao Xu for their careful assessment and valuable feedback on machine-generated solutions for the PKU Undergraduate Final Exams, as well as Qing Lan, Zekun Chen, Shuzhe Cai, Shengbo Dong and Yutong Wang for their assessment of solutions for the PKU PhD Qualifying Exams. This work is supported in part by the National Key R&D Program of China grant 2024YFA1014000, the Fundamental and Interdisciplinary Disciplines Breakthrough Plan of the Ministry of Education of China (JYB2025XDXM113), and the New Cornerstone Investigator Program.
References
- [1] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. (2023) GPT-4 Technical Report. arXiv preprint arXiv:2303.08774. Cited by: §3.2.
- [2] T. Achim, A. Best, A. Bietti, K. Der, M. Fédérico, S. Gukov, D. Halpern-Leistner, K. Henningsgard, Y. Kudryashov, A. Meiburg, et al. (2025) Aristotle: IMO-Level Automated Theorem Proving. arXiv preprint arXiv:2510.01346. Cited by: §3.3.3, §3.3.3.
- [3] A. Agrawal, S. Gadgil, N. Goyal, A. Narayanan, and A. Tadipatri (2022) Towards a Mathematics Formalisation Assistant Using Large Language Models. arXiv preprint arXiv:2211.07524. Cited by: §3.3.2.
- [4] A. Alfarano, F. Charton, and A. Hayat (2024) Global Lyapunov Functions: A Long-Standing Open Problem in Mathematics, with Symbolic Transformers. Advances in Neural Information Processing Systems 37, pp. 93643–93670. Cited by: §2.2, §2.4.
- [5] M. Amir, Y. He, K. Lee, T. Oliver, and E. Sultanow (2023) Machine Learning Class Numbers of Real Quadratic Fields. International Journal of Data Science in the Mathematical Sciences 01 (02), pp. 107–134. External Links: Document, Link, https://doi.org/10.1142/S2810939223500016 Cited by: §2.1.
- [6] S. Arridge, P. Maass, O. Öktem, and C. Schönlieb (2019) Solving Inverse Problems Using Data-Driven Models. Acta Numerica 28, pp. 1–174. Cited by: §1.
- [7] J. Asher (2025) LeanExplore: A Search Engine for Lean 4 Declarations. arXiv preprint arXiv:2506.11085. Cited by: §3.4.
- [8] Axiom Math (2025) From Seeing Why to Checking Everything. Note: https://axiommath.ai/territory/from-seeing-why-to-checking-everything Cited by: §3.3.3.
- [9] Z. Azerbayev, B. Piotrowski, H. Schoelkopf, E. W. Ayers, D. Radev, and J. Avigad (2023) Proofnet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics. arXiv preprint arXiv:2302.12433. Cited by: §3.3.2.
- [10] Z. Azerbayev, H. Schoelkopf, K. Paster, M. D. Santos, S. M. McAleer, A. Q. Jiang, J. Deng, S. Biderman, and S. Welleck (2024) Llemma: An Open Language Model for Mathematics. In The Twelfth International Conference on Learning Representations, External Links: Link Cited by: §3.2, §3.3.3.
- [11] K. Bansal, S. Loos, M. Rabe, C. Szegedy, and S. Wilcox (2019) Holist: An Environment for Machine Learning of Higher Order Logic Theorem Proving. In International Conference on Machine Learning, pp. 454–463. Cited by: §1, §3.3.3.
- [12] T. Bénard and W. He (2025) Effective Brascamp–Lieb Inequalities. arXiv preprint arXiv:2511.11091. Cited by: §3.3.3.
- [13] G. Bérczi, H. Fan, and M. Zeng (2023) An ML Approach to Resolution of Singularities. In Topological, Algebraic and Geometric Learning Workshops 2023, pp. 469–487. Cited by: §2.2.
- [14] P. Berglund, B. Campbell, and V. Jejjala (2025) Machine Learning Kreuzer–Skarke Calabi–Yau Threefolds. International Journal of Modern Physics A 40 (28), pp. 2550097. External Links: Document, Link, https://doi.org/10.1142/S0217751X25500976 Cited by: §2.1.
- [15] P. Berglund, Y. He, E. Heyes, E. Hirst, V. Jejjala, and A. Lukas (2024) New Calabi–Yau Manifolds from Genetic Algorithms. Physics Letters B 850, pp. 138504. External Links: ISSN 0370-2693, Document, Link Cited by: §2.2.
- [16] D. S. Berman, Y. He, and E. Hirst (2022-03) Machine Learning Calabi-Yau Hypersurfaces. Phys. Rev. D 105, pp. 066002. External Links: Document, Link Cited by: §2.1.
- [17] C. Blundell, L. Buesing, A. Davies, P. Veličković, and G. Williamson (2022) Towards Combinatorial Invariance for Kazhdan-Lusztig Polynomials. Representation Theory of the American Mathematical Society 26 (37), pp. 1145–1191. Cited by: §2.1.
- [18] J. W. Bober, A. R. Booker, M. Lee, and D. Lowry-Duda (2025) Murmurations of Modular Forms in the Weight Aspect. Algebra and Number Theory. Cited by: §2.1.
- [19] S. L. Brunton and J. N. Kutz (2024) Promising Directions of Machine Learning for Partial Differential Equations. Nature Computational Science 4 (7), pp. 483–494. Cited by: §1.
- [20] J. Bryan, B. Elek, F. Manners, G. Salafatinos, and R. Vakil (2026) The Motivic Class of the Space of Genus $0$ Maps to the Flag Variety. arXiv preprint arXiv:2601.07222. Cited by: §3.2.
- [21] J. Carifio, J. Halverson, D. Krioukov, and B. D. Nelson (2017) Machine Learning in the String Landscape. Journal of High Energy Physics 2017 (9), pp. 1–36. Cited by: §2.1, §2.1.
- [22] F. Charton, J. S. Ellenberg, A. Z. Wagner, and G. Williamson (2024) Patternboost: Constructions in Mathematics with a Little Help from AI. arXiv preprint arXiv:2411.00566. Cited by: §2.2.
- [23] J. Chen, W. Chen, J. Du, J. Hu, Z. Jiang, A. Jie, X. Jin, X. Jin, C. Li, W. Shi, Z. Wang, M. Wang, C. Wei, S. Wei, H. Xin, F. Yang, W. Gao, Z. Yuan, T. Zhan, Z. Zheng, T. Zhou, and T. H. Zhu (2025) Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience. arXiv preprint arXiv:2512.17260. External Links: 2512.17260, Link Cited by: §3.3.3, §3.3.3.
- [24] T. Chen, X. Chen, W. Chen, H. Heaton, J. Liu, Z. Wang, and W. Yin (2022) Learning to Optimize: A Primer and A Benchmark. Journal of Machine Learning Research 23 (189), pp. 1–59. Cited by: §1.
- [25] Y. Chervonyi, T. H. Trinh, M. Olšák, X. Yang, H. Nguyen, M. Menegali, J. Jung, V. Verma, Q. V. Le, and T. Luong (2025) Gold-Medalist Performance in Solving Olympiad Geometry with AlphaGeometry2. arXiv preprint arXiv:2502.03544. Cited by: §2.3.
- [26] A. Chervov, A. Soibelman, S. Lytkin, I. Kiselev, S. Fironov, A. Lukyanenko, A. Dolgorukova, A. Ogurtsov, F. Petrov, S. Krymskii, et al. (2025) CayleyPy RL: Pathfinding and Reinforcement Learning on Cayley Graphs. arXiv preprint arXiv:2502.18663. Cited by: §2.2.
- [27] A. Chervov, K. Khoruzhii, N. Bukhal, J. Naghiyev, V. Zamkovoy, I. Koltsov, L. Cheldieva, A. Sychev, A. Lenin, M. Obozov, et al. (2025) A Machine Learning Approach That Beats Large Rubik’s Cubes. arXiv preprint arXiv:2502.13266. Cited by: §2.2.
- [28] S. Chou, X. Gao, and J. Zhang (2000) A Deductive Database Approach to Automated Geometry Theorem Proving and Discovering. Journal of Automated Reasoning 25 (3), pp. 219–246. Cited by: §2.3, §2.4.
- [29] S. Chou and X. Gao (2001) Automated Reasoning in Geometry. Handbook of automated reasoning 1, pp. 707–749. Cited by: §1.
- [30] D. A. Clarke (1966) Martin Davis. A program for Presburger’s algorithm. Summaries of talks presented at the Summer Institute for Symbolic Logic, Cornell University, 1957, 2nd edn., Communications Research Division, Institute for Defense Analyses, Princeton, N.J., 1960, pp. 215–223.. Journal of Symbolic Logic 31 (1), pp. 138–138. External Links: Document Cited by: §1.
- [31] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. (2021) Training Verifiers to Solve Math Word Problems. arXiv preprint arXiv:2110.14168. Cited by: §3.2.
- [32] K. M. Collins, A. Q. Jiang, S. Frieder, L. Wong, M. Zilka, U. Bhatt, T. Lukasiewicz, Y. Wu, J. B. Tenenbaum, W. Hart, et al. (2024) Evaluating Language Models for Mathematics Through Interactions. Proceedings of the National Academy of Sciences 121 (24), pp. e2318124121. Cited by: §3.2.
- [33] G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. (2025) Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. arXiv preprint arXiv:2507.06261. Cited by: §3.2.
- [34] M. COOK (2009) Mathematicians: An Outer View of the Inner World. Princeton University Press. External Links: ISBN 9780691139517, Link Cited by: item 4.
- [35] Ł. Czajka and C. Kaliszyk (2018) Hammer for Coq: Automation for Dependent Type Theory. Journal of Automated Reasoning 61 (1), pp. 423–453. Cited by: §3.4.
- [36] A. Davies, A. Juhász, M. Lackenby, and N. Tomašev (2024) The Signature and Cusp Geometry of Hyperbolic Knots. Geometry & Topology 28 (5), pp. 2313–2343. Cited by: §2.1.
- [37] A. Davies, P. Veličković, L. Buesing, S. Blackwell, D. Zheng, N. Tomašev, R. Tanburn, P. Battaglia, C. Blundell, A. Juhász, et al. (2021) Advancing Mathematics by Guiding Human Intuition with AI. Nature 600 (7887), pp. 70–74. Cited by: §1, §2.1.
- [38] M. Davis (1983) The Prehistory and Early History of Automated Deduction. Automation of Reasoning 1: Classical Papers on Computational Logic 1957-1966, pp. 1–28. External Links: Link Cited by: §1.
- [39] L. M. de Moura, S. Kong, J. Avigad, F. van Doorn, and J. von Raumer (2015) The Lean Theorem Prover (System Description). In Automated Deduction - CADE-25 - 25th International Conference on Automated Deduction, Berlin, Germany, August 1-7, 2015, Proceedings, A. P. Felty and A. Middeldorp (Eds.), Lecture Notes in Computer Science, Vol. 9195, pp. 378–388. External Links: Link, Document Cited by: §3.3.1.
- [40] L. de Moura and S. Ullrich (2021) The Lean 4 Theorem Prover and Programming Language. In Automated Deduction - CADE 28 - 28th International Conference on Automated Deduction, Virtual Event, July 12-15, 2021, Proceedings, A. Platzer and G. Sutcliffe (Eds.), Lecture Notes in Computer Science, Vol. 12699, pp. 625–635. External Links: Link, Document Cited by: §3.3.1.
- [41] B. Dong, X. He, P. Jin, F. Schremmer, and Q. Yu (2024) Machine Learning Assisted Exploration for Affine Deligne–Lusztig Varieties. Peking Mathematical Journal, pp. 1–50. Cited by: §1, §2.1.
- [42] B. Dong (2022) On Mathematical Modeling in Image Reconstruction and Beyond. In Proc. Int. Cong. Math, Vol. 7, pp. 5420–5449. Cited by: §1.
- [43] K. Dong and T. Ma (2025) STP: Self-Play LLM Theorem Provers with Iterative Conjecturing and Proving. In Forty-second International Conference on Machine Learning, External Links: Link Cited by: §3.3.3.
- [44] M. R. Douglas and K. Fraser-Taliente (2025) Diffusion Models for Cayley Graphs. arXiv preprint arXiv:2503.05558. Cited by: §2.2.
- [45] O. Dressler (2025) Lean LSP MCP: Tools for Agentic Interaction with the Lean Theorem Prover. Note: https://github.com/oOo0oOo/lean-lsp-mcp Cited by: §3.3.3.
- [46] B. Duan, X. Liang, S. Lu, Y. Wang, Y. Shen, K. Chang, Y. N. Wu, M. Yang, W. Chen, and Y. Gong (2025) Gold-Medal-Level Olympiad Geometry Solving with Efficient Heuristic Auxiliary Constructions. arXiv preprint arXiv:2512.00097. Cited by: §2.3.
- [47] H. Erbin and R. Finotello (2021-06) Machine Learning for Complete Intersection Calabi-Yau Manifolds: A Methodological Study. Phys. Rev. D 103, pp. 126014. External Links: Document, Link Cited by: §2.1.
- [48] D. Ferreira and A. Freitas (2020) Premise Selection in Natural Language Mathematical Texts. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 7365–7374. External Links: Document Cited by: §3.4.
- [49] E. First, M. N. Rabe, T. Ringer, and Y. Brun (2023) Baldur: Whole-Proof Generation and Repair with Large Language Models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 1229–1241. Cited by: §3.3.3.
- [50] S. Frieder, L. Pinchetti, C. Chevalier, R. Griffiths, T. Salvatori, T. Lukasiewicz, P. Petersen, and J. Berner (2023) Mathematical Capabilities of ChatGPT. In Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36, pp. 27699–27744. External Links: Link Cited by: §3.2.
- [51] S. Gadgil, A. R. Tadipatri, A. Agrawal, A. Narayanan, and N. Goyal (2022) Towards Automating Formalisation of Theorem Statements Using Large Language Models. In 36th Conference on Neural Information Processing Systems (NeurIPS 2022) Workshop on MATH-AI, Cited by: §3.3.2.
- [52] G. Gao, H. Ju, J. Jiang, Z. Qin, and B. Dong (2024-11) A Semantic Search Engine for Mathlib4. In Findings of the Association for Computational Linguistics: EMNLP 2024, Y. Al-Onaizan, M. Bansal, and Y. Chen (Eds.), Miami, Florida, USA, pp. 8001–8013. External Links: Link, Document Cited by: §3.4.
- [53] G. Gao, Y. Wang, J. Jiang, Q. Gao, Z. Qin, T. Xu, and B. Dong (2025) Herald: A Natural Language Annotated Lean 4 Dataset. In The Thirteenth International Conference on Learning Representations, External Links: Link Cited by: 2nd item, §3.3.2, §3.3.2.
- [54] L. Gao, K. Yuan, Y. Wang, Z. Jiang, and Z. Tang (2016) The Math Retrieval System of ICST for NTCIR-12 MathIR Task. In Proceedings of the 12th NTCIR Conference on Evaluation of Information Access Technologies, National Center of Sciences, Tokyo, Japan, June 7-10, 2016, N. Kando, T. Sakai, and M. Sanderson (Eds.), External Links: Link Cited by: §3.4.
- [55] B. Georgiev, J. Gómez-Serrano, T. Tao, and A. Z. Wagner (2025) Mathematical Exploration and Discovery at Scale. arXiv preprint arXiv:2511.02864. Cited by: §1, item 7.
- [56] E. Glazer, E. Erdil, T. Besiroglu, D. Chicharro, E. Chen, A. Gunning, C. F. Olsson, J. Denain, A. Ho, E. d. O. Santos, et al. (2024) Frontiermath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI. arXiv preprint arXiv:2411.04872. Cited by: §3.2.
- [57] F. Gloeckle, A. Gu, G. Synnaeve, and A. Hayat (2025) Reinforcement Learning for Hierarchical Proof Generation in Lean 4. In The 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025, External Links: Link Cited by: §3.3.3.
- [58] F. Gloeckle, J. Limperg, G. Synnaeve, and A. Hayat (2024) ABEL: Sample Efficient Online Reinforcement Learning for Neural Theorem Proving. In The 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, External Links: Link Cited by: §3.3.3.
- [59] K. Gödel (1931) On Formally Undecidable Propositions of Principia Mathematica and Related Systems. Cited by: §1.
- [60] Z. Gou, Z. Shao, Y. Gong, Y. Yang, M. Huang, N. Duan, W. Chen, et al. ToRA: A Tool-Integrated Reasoning Agent for Mathematical Problem Solving. In The Twelfth International Conference on Learning Representations, Cited by: §3.2.
- [61] S. Gukov, J. Halverson, C. Manolescu, and F. Ruehle (2025-06) Searching for Ribbons with Machine Learning. Machine Learning: Science and Technology 6 (2), pp. 025065. External Links: Document, Link Cited by: §1, §2.2.
- [62] S. Gukov and R. Seong (2024-08) Machine Learning BPS Spectra and the Gap Conjecture. Phys. Rev. D 110, pp. 046016. External Links: Document, Link Cited by: §2.1.
- [63] D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. (2025) DeepSeek-R1 Incentivizes Reasoning in LLMs Through Reinforcement Learning. Nature 645 (8081), pp. 633–638. Cited by: §3.2.
- [64] B. Hashemi, R. G. Corominas, and A. Giacchetto (2025) Can Transformers Do Enumerative Geometry?. In The Thirteenth International Conference on Learning Representations, External Links: Link Cited by: §1.
- [65] Y. He, K. Lee, T. Oliver, and A. Pozdnyakov (2025) Murmurations of Elliptic Curves. Experimental Mathematics 34 (3), pp. 528–540. Cited by: §2.1.
- [66] Y. He, J. Zou, X. Zhang, N. Zhu, and T. Leng (2024) FGeo-TP: A Language Model-Enhanced Solver for Euclidean Geometry Problems. Symmetry 16 (4), pp. 421. Cited by: §2.3.
- [67] D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt (2021) Measuring Mathematical Problem Solving With the MATH Dataset. NeurIPS. Cited by: §3.2.
- [68] K. Hoder and A. Voronkov (2011) Sine Qua Non for Large Theory Reasoning. In International Conference on Automated Deduction, pp. 299–314. Cited by: §3.4.
- [69] D. Huang, P. Dhariwal, D. Song, and I. Sutskever (2018) Gamepad: A Learning Environment for Theorem Proving. arXiv preprint arXiv:1806.00608. Cited by: §3.3.3.
- [70] Y. Huang, X. Jin, S. Liang, F. Luo, P. Li, and Y. Liu (2025) FormaRL: Enhancing Autoformalization with No Labeled Data. In Second Conference on Language Modeling, External Links: Link Cited by: §3.3.2.
- [71] Y. Huang and L. F. Yang (2025) Winning Gold at IMO 2025 with a Model-Agnostic Verification-and-Refinement Pipeline. arXiv preprint arXiv:2507.15855. Cited by: §3.3.3.
- [72] T. Hubert, R. Mehta, L. Sartran, M. Z. Horváth, G. Žužić, E. Wieser, A. Huang, J. Schrittwieser, Y. Schroecker, H. Masoom, et al. (2025) Olympiad-Level Formal Mathematical Reasoning with Reinforcement Learning. Nature, pp. 1–3. Cited by: §3.3.3.
- [73] G. Irving, C. Szegedy, A. A. Alemi, N. Eén, F. Chollet, and J. Urban (2016) DeepMath: Deep Sequence Models for Premise Selection. Advances in Neural Information Processing Systems (NeurIPS) 29. Cited by: §3.4.
- [74] U. Jang and E. K. Ryu (2025) Point Convergence of Nesterov’s Accelerated Gradient Method: An AI-Assisted Proof. arXiv preprint arXiv:2510.23513. Cited by: §3.2.
- [75] A. Q. Jiang, W. Li, and M. Jamnik (2023) Multilingual Mathematical Autoformalization. arXiv preprint arXiv:2311.03755. Cited by: §3.3.2.
- [76] A. Q. Jiang, W. Li, S. Tworkowski, K. Czechowski, T. Odrzygóźdź, P. Miłoś, Y. Wu, and M. Jamnik (2022) Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers. Advances in Neural Information Processing Systems 35, pp. 8360–8373. Cited by: §3.3.3.
- [77] A. Q. Jiang, S. Welleck, J. P. Zhou, T. Lacroix, J. Liu, W. Li, M. Jamnik, G. Lample, and Y. Wu (2023) Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs. In The Eleventh International Conference on Learning Representations, External Links: Link Cited by: §3.3.3, §3.3.3.
- [78] J. Jiang, W. He, Y. Wang, G. Gao, Y. Hu, J. Wang, N. Guan, P. Wu, C. Dai, L. Xiao, et al. (2025) FATE: A Formal Benchmark Series for Frontier Algebra of Multiple Difficulty Levels. arXiv preprint arXiv:2511.02872. Cited by: §3.2, §3.3.3, §3.3.3.
- [79] G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang (2021) Physics-Informed Machine Learning. Nature Reviews Physics 3 (6), pp. 422–440. Cited by: §1.
- [80] O. Khattab and M. Zaharia (2020) ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pp. 39–48. External Links: Document Cited by: §3.4.
- [81] D. Klaewer and L. Schlechter (2019) Machine Learning Line Bundle Cohomologies of Hypersurfaces in Toric Varieties. Physics Letters B 789, pp. 438–443. External Links: ISSN 0370-2693, Document, Link Cited by: §2.1.
- [82] A. Koldobsky (1998) Intersection Bodies in R4. Advances in Mathematics 136 (1), pp. 1–14. Cited by: §3.3.
- [83] A. Koldobsky (1998) Intersection Bodies, Positive Definite Distributions, and the Busemann-Petty Problem. American journal of mathematics 120 (4), pp. 827–840. Cited by: §3.3.
- [84] J. Kollár (2006) Non-Quasi-Projective Moduli Spaces. Annals of mathematics, pp. 1077–1096. Cited by: §3.3.
- [85] K. Krstovski and D. M. Blei (2018) Equation Embeddings. arXiv preprint arXiv:1803.09123. Cited by: §3.4.
- [86] G. Lample, T. Lacroix, M. Lachaux, A. Rodriguez, A. Hayat, T. Lavril, G. Ebner, and X. Martinet (2022) Hypertree Proof Search for Neural Theorem Proving. Advances in neural information processing systems 35, pp. 26337–26349. Cited by: §3.3.3.
- [87] T. Lanard and A. Mínguez (2025) An Algorithm for Aubert–Zelevinsky Duality $\backslash$ a la M $\{$ $\backslash$ oe $\}$ glin–Waldspurger. arXiv preprint arXiv:2509.13231. Cited by: §2.1.
- [88] R. T. Lange, Y. Imajuku, and E. Cetin (2025) Shinkaevolve: Towards Open-Ended and Sample-Efficient Program Evolution. arXiv preprint arXiv:2509.19349. Cited by: §2.2.
- [89] K. Lee and S. Lee (2025) Machines Learn Number Fields, But How? The Case of Galois Groups. arXiv preprint arXiv:2508.06670. Cited by: §2.1.
- [90] K. Lee, T. Oliver, and A. Pozdnyakov (2025) Murmurations of Dirichlet Characters. International Mathematics Research Notices 2025 (1), pp. rnae277. Cited by: §2.1.
- [91] K. Lee (2025) Data-Scientific Study of Kronecker Coefficients. Experimental Mathematics 0 (0), pp. 1–14. External Links: Document, Link, https://doi.org/10.1080/10586458.2025.2490576 Cited by: §2.1.
- [92] C. Li, Z. Wang, W. He, Y. Wu, S. Xu, and Z. Wen (2025) Formalization of Convergence Rates of Four First-Order Algorithms for Convex Optimization. Journal of Automated Reasoning 69 (4), pp. 28. Cited by: §3.3.1.
- [93] J. Li, E. Beeching, L. Tunstall, B. Lipkin, R. Soletskyi, S. Huang, K. Rasul, L. Yu, A. Q. Jiang, Z. Shen, et al. (2024) Numinamath: The Largest Public Dataset in Ai4maths With 860k Pairs of Competition Math Problems and Solutions. Hugging Face repository 13 (9), pp. 9. Cited by: §3.2.
- [94] Y. Li, D. Du, L. Song, C. Li, W. Wang, T. Yang, and H. Mi (2024) HunyuanProver: A Scalable Data Synthesis Framework and Guided Tree Search for Automated Theorem Proving. arXiv preprint arXiv:2412.20735. Cited by: §3.3.3.
- [95] Z. Li, J. Sun, L. Murphy, Q. Su, Z. Li, X. Zhang, K. Yang, and X. Si (2024) A Survey on Deep Learning for Theorem Proving. In First Conference on Language Modeling, External Links: Link Cited by: §1.
- [96] Y. Lin, S. Tang, B. Lyu, J. Wu, H. Lin, K. Yang, J. Li, M. Xia, D. Chen, S. Arora, et al. (2025) Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving. arXiv preprint arXiv:2502.07640. Cited by: §3.3.3.
- [97] G. Liu, Y. Zhu, J. Chen, and M. Jiang (2025) Scientific Algorithm Discovery by Augmenting Alphaevolve with Deep Research. arXiv preprint arXiv:2510.06056. Cited by: §2.2.
- [98] J. Liu, Z. Zhou, Z. Zhu, M. D. Santos, W. He, J. Liu, R. Wang, Y. Xie, J. Zhao, Q. Wang, et al. (2026) Numina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematics. arXiv preprint arXiv:2601.14027. Cited by: §3.3.3.
- [99] Q. Liu, X. Zheng, X. Lu, Q. Cao, and J. Yan (2025) Rethinking and Improving Autoformalization: Towards a Faithful Metric and a Dependency Retrieval-Based Approach. In The Thirteenth International Conference on Learning Representations, External Links: Link Cited by: 1st item, §3.3.2, §3.3.2.
- [100] X. Liu, T. Zhu, Z. Dong, Y. Liu, Q. Guo, Z. Liu, Y. Chen, and T. Luo (2025) ASSESS: A Semantic and Structural Evaluation Framework for Statement Similarity. arXiv preprint arXiv:2509.22246. Cited by: 1st item.
- [101] J. Lu, K. Emond, W. Sun, and W. Chen (2025) Lean Finder: Semantic Search for Mathlib That Understands User Intents. In 2nd AI for Math Workshop @ ICML 2025, External Links: Link Cited by: §3.4.
- [102] J. Lu, Y. Wan, Z. Liu, Y. Huang, J. Xiong, C. Liu, J. Shen, H. Jin, J. Zhang, H. Wang, et al. (2024) Process-Driven Autoformalization in Lean 4. arXiv preprint arXiv:2406.01940. Cited by: §3.3.2, §3.3.2.
- [103] B. Mansouri, V. Novotný, A. Agarwal, D. W. Oard, and R. Zanibbi (2022) Overview of ARQMath-3 (2022): Third CLEF Lab on Answer Retrieval for Questions on Math (Working Notes). In Proceedings of CLEF 2022 Working Notes (Conference and Labs of the Evaluation Forum), External Links: Link Cited by: §3.4.
- [104] B. Mansouri, D. W. Oard, and R. Zanibbi (2022) Contextualized Formula Search Using Math Abstract Meaning Representation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, CIKM ’22, New York, NY, USA, pp. 4329–4333. External Links: ISBN 9781450392365, Link, Document Cited by: §3.4.
- [105] B. Mansouri, S. Rohatgi, D. W. Oard, J. Wu, C. L. Giles, and R. Zanibbi (2019) Tangent-CFT: An Embedding Model for Mathematical Formulas. In Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval (ICTIR), pp. 11–18. External Links: Document Cited by: §3.4.
- [106] B. Mansouri, R. Zanibbi, D. W. Oard, and A. Agarwal (2021) Overview of ARQMath-2 (2021): Second CLEF Lab on Answer Retrieval for Questions on Math. In Experimental IR Meets Multilinguality, Multimodality, and Interaction, K. S. Candan, B. Ionescu, L. Goeuriot, B. Larsen, H. Müller, A. Joly, M. Maistro, F. Piroi, G. Faggioli, and N. Ferro (Eds.), Cham, pp. 215–238. External Links: ISBN 978-3-030-85251-1 Cited by: §3.4.
- [107] Math, Inc. (2025) Introducing Gauss, an Agent for Autoformalization. Note: https://www.math.inc/gauss Cited by: §1, §3.3.3.
- [108] J. Meng and L. C. Paulson (2009) Lightweight Relevance Filtering for Machine-Generated Resolution Problems. Journal of Applied Logic 7 (1), pp. 41–57. Cited by: §3.4.
- [109] A. Newell and H. Simon (1956) The logic theory machine–A complex information processing system. IRE Transactions on Information Theory 2 (3), pp. 61–79. External Links: Document Cited by: §1.
- [110] A. Novikov, N. Vũ, M. Eisenberger, E. Dupont, P. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. Ruiz, A. Mehrabian, et al. (2025) AlphaEvolve: A Coding Agent for Scientific and Algorithmic Discovery. arXiv preprint arXiv:2506.13131. Cited by: §1, §2.2.
- [111] A. Paliwal, S. Loos, M. Rabe, K. Bansal, and C. Szegedy (2020) Graph Representations for Higher-Order Logic and Theorem Proving. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, pp. 2967–2974. Cited by: §3.3.3.
- [112] S. Peng, K. Yuan, L. Gao, and Z. Tang (2021) MathBERT: A Pre-trained Model for Mathematical Formula Understanding. arXiv preprint arXiv:2105.00377. Cited by: §3.4.
- [113] A. Poiroux, G. Weiss, V. Kunčak, and A. Bosselut (2025) Reliable Evaluation and Benchmarks for Statement Autoformalization. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 17958–17980. Cited by: 1st item.
- [114] S. Polu, J. M. Han, K. Zheng, M. Baksys, I. Babuschkin, and I. Sutskever (2023) Formal Mathematics Statement Curriculum Learning. In The Eleventh International Conference on Learning Representations, External Links: Link Cited by: §3.3.3.
- [115] S. Polu and I. Sutskever (2020) Generative Language Modeling for Automated Theorem Proving. arXiv preprint arXiv:2009.03393. Cited by: §3.3.3.
- [116] A. Reusch, M. Thiele, and W. Lehner (2021) TU_DBS in the ARQMath Lab 2021, CLEF. In Working Notes of CLEF 2021, pp. 107–124. Cited by: §3.4.
- [117] S. Robertson, S. Walker, S. Jones, M. M. Hancock-Beaulieu, and M. Gatford (1995-01) Okapi at TREC-3. In Overview of the Third Text REtrieval Conference (TREC-3), Overview of the Third Text REtrieval Conference (TREC–3) edition, pp. 109–126. External Links: Link Cited by: §3.4.
- [118] S. Robertson and H. Zaragoza (2009-04) The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends Inf. Retr. 3 (4), pp. 333–389. External Links: ISSN 1554-0669, Link, Document Cited by: §3.4.
- [119] B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi, et al. (2024) Mathematical Discoveries from Program Search with Large Language Models. Nature 625 (7995), pp. 468–475. Cited by: §1, §2.2.
- [120] G. Salton and C. Buckley (1988) Term-Weighting Approaches in Automatic Text Retrieval. Information Processing & Management 24 (5), pp. 513–523. External Links: ISSN 0306-4573, Document, Link Cited by: §3.4.
- [121] G. Schumacher and H. Tsuji (2004) Quasi-Projectivity of Moduli Spaces of Polarized Varieties. Annals of mathematics, pp. 597–639. Cited by: §3.3.
- [122] G. Schumacher and H. Tsuji (2023) Retraction: “Quasi-Projectivity of Moduli Spaces of Polarized Varieties”. Annals of Mathematics 198 (3), pp. 1305–1305. Cited by: §3.3.
- [123] M. Shalyt, U. Seligmann, I. Beit Halachmi, O. David, R. Elimelech, and I. Kaminer (2024) Unsupervised Discovery of Formulas for Mathematical Constants. Advances in Neural Information Processing Systems 37, pp. 113156–113190. Cited by: §2.1.
- [124] Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. (2024) Deepseekmath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint arXiv:2402.03300. Cited by: §3.2.
- [125] OpenEvolve: An Open-Source Evolutionary Coding Agent External Links: Link Cited by: §2.2.
- [126] A. Shehper, A. M. Medina-Mardones, L. Fagan, B. Lewandowski, A. Gruen, Y. Qiu, P. Kucharski, Z. Wang, and S. Gukov (2025) What Makes Math Problems Hard for Reinforcement Learning: A Case Study. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, External Links: Link Cited by: §1, §2.2, §2.4.
- [127] Z. Shen, N. Huang, F. Yang, Y. Wang, G. Gao, T. Xu, J. Jiang, W. He, P. Yang, M. Sun, et al. (2025) REAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning. arXiv preprint arXiv:2505.20613. Cited by: §3.3.3, §3.4.
- [128] S. G. Simpson (1988) Partial Realizations of Hilbert’s Program. The Journal of Symbolic Logic 53 (2), pp. 349–363. Cited by: §1.
- [129] G. Swirszcz, A. Z. Wagner, G. Williamson, S. Blackwell, B. Georgiev, A. Davies, A. Eslami, S. Racaniere, T. Weber, and P. Kohli (2025) Advancing Geometry with AI: Multi-Agent Generation of Polytopes. arXiv preprint arXiv:2502.05199. Cited by: §2.2.
- [130] Y. Tao, H. Liu, S. Wang, and H. Xu (2025) Learning an Effective Premise Retrieval Model for Efficient Mathematical Formalization. In Proceedings of the 2nd AI for Math Workshop at ICML 2025, Cited by: §3.4.
- [131] Q. Team (2025-03) QwQ-32B: Embracing the Power of Reinforcement Learning. External Links: Link Cited by: §3.2.
- [132] T. H. Trinh, Y. Wu, Q. V. Le, H. He, and T. Luong (2024) Solving Olympiad Geometry without Human Demonstrations. Nature 625 (7995), pp. 476–482. Cited by: §2.3.
- [133] S. Ulam (1958) John von Neumann 1903–1957. Bulletin of the American Mathematical Society 64 (3.P2), pp. 1 – 49. Cited by: §1.
- [134] S. M. Ulam (1976) Adventures of a Mathematician. Charles Scribner’s Sons, New York. Cited by: item 4.
- [135] S. Varambally, T. Voice, Y. Sun, Z. Chen, R. Yu, and K. Ye (2025) Hilbert: Recursively Building Formal Proofs with Informal Reasoning. arXiv preprint arXiv:2509.22819. Cited by: §3.3.3, §3.3.3.
- [136] A. Z. Wagner (2021) Constructions in Combinatorics via Neural Networks. arXiv preprint arXiv:2104.14516. Cited by: §1, §2.2, §2.4.
- [137] H. Wang, M. Unsal, X. Lin, M. Baksys, J. Liu, M. D. Santos, F. Sung, M. Vinyes, Z. Ying, Z. Zhu, et al. (2025) Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning. arXiv preprint arXiv:2504.11354. Cited by: §3.3.3.
- [138] H. Wang, H. Xin, C. Zheng, Z. Liu, Q. Cao, Y. Huang, J. Xiong, H. Shi, E. Xie, J. Yin, Z. Li, and X. Liang (2024) LEGO-Prover: Neural Theorem Proving with Growing Libraries. In The Twelfth International Conference on Learning Representations, External Links: Link Cited by: §3.3.3, §3.3.3.
- [139] H. Wang, Y. Yuan, Z. Liu, J. Shen, Y. Yin, J. Xiong, E. Xie, H. Shi, Y. Li, L. Li, J. Yin, Z. Li, and X. Liang (2023-07) DT-solver: automated theorem proving with dynamic-tree sampling guided by proof-level value function. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki (Eds.), Toronto, Canada, pp. 12632–12646. External Links: Link, Document Cited by: §3.3.3.
- [140] H. Wang, R. Xie, Y. Wang, G. Gao, X. Yu, and B. Dong (2025) Aria: An Agent For Retrieval and Iterative Auto-Formalization via Dependency Graph. arXiv preprint arXiv:2510.04520. Cited by: 2nd item, §3.3.2.
- [141] L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Lin, et al. (2024) A Survey on Large Language Model Based Autonomous Agents. Frontiers of Computer Science 18 (6), pp. 186345. Cited by: §3.3.2.
- [142] M. Wang, Y. Tang, J. Wang, and J. Deng (2017) Premise Selection for Theorem Proving by Deep Graph Embedding. Advances in Neural Information Processing Systems (NeurIPS) 30. Cited by: §3.4.
- [143] Q. Wang, C. Brown, C. Kaliszyk, and J. Urban (2020) Exploration of Neural Machine Translation in Autoformalization of Mathematics in Mizar. In Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs, pp. 85–98. Cited by: §3.3.2.
- [144] Q. Wang, C. Kaliszyk, and J. Urban (2018) First Experiments with Neural Translation of Informal to Formal Mathematics. In International Conference on Intelligent Computer Mathematics, pp. 255–270. Cited by: §3.3.2.
- [145] Z. Wang, A. Dong, and Z. Wen (2025) Tree-Based Premise Selection for Lean4. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, External Links: Link Cited by: §3.4.
- [146] Z. Wang, B. Yang, S. Zhou, C. Li, Y. Zhang, B. Dong, and Z. Wen (2025) Translating Informal Proofs into Formal Proofs Using a Chain of States. arXiv preprint arXiv:2512.10317. Cited by: §3.3.3.
- [147] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. (2022) Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in neural information processing systems 35, pp. 24824–24837. Cited by: §3.2.
- [148] E. Weinan et al. (2021) The Dawning of a New Era in Applied Mathematics. Notices of the American Mathematical Society 68 (4), pp. 565–571. Cited by: §1.
- [149] W. Wen-Tsun (1986) Basic Principles of Mechanical Theorem Proving in Elementary Geometries. Journal of automated Reasoning 2 (3), pp. 221–252. Cited by: §1.
- [150] D. Whalen (2016) Holophrasm: A Neural Automated Theorem Prover for Higher-Order Logic. arXiv preprint arXiv:1608.02644. Cited by: §1, §3.3.3.
- [151] W. Wu (2012) Mechanical Theorem Proving in Geometries: Basic Principles. Springer Science & Business Media. Cited by: §1.
- [152] W. Wu and X. Gao (2007) Mathematics Mechanization and Applications After Thirty Years. Frontiers of Computer Science in China 1 (1), pp. 1–8. Cited by: §1.
- [153] Y. Wu, A. Q. Jiang, W. Li, M. Rabe, C. Staats, M. Jamnik, and C. Szegedy (2022) Autoformalization with Large Language Models. Advances in neural information processing systems 35, pp. 32353–32368. Cited by: §1, §3.3.2.
- [154] H. Xin, D. Guo, Z. Shao, Z. Ren, Q. Zhu, B. Liu, C. Ruan, W. Li, and X. Liang (2024) Deepseek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data. arXiv preprint arXiv:2405.14333. Cited by: §3.3.3.
- [155] H. Xin, Z.Z. Ren, J. Song, Z. Shao, W. Zhao, H. Wang, B. Liu, L. Zhang, X. Lu, Q. Du, W. Gao, H. Zhang, Q. Zhu, D. Yang, Z. Gou, Z.F. Wu, F. Luo, and C. Ruan (2025) DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search. In The Thirteenth International Conference on Learning Representations, External Links: Link Cited by: §3.3.3.
- [156] R. Xin, C. Xi, J. Yang, F. Chen, H. Wu, X. Xiao, Y. Sun, S. Zheng, and M. Ding (2025) Bfs-Prover: Scalable Best-First Tree Search for LLM-Based Automatic Theorem Proving. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 32588–32599. Cited by: §3.3.3.
- [157] R. Xin, Z. Zheng, Y. Nie, K. Yuan, and X. Xiao (2025) Scaling Up Multi-Turn Off-Policy RL and Multi-Agent Tree Search for LLM Step-Provers. arXiv preprint arXiv:2509.06493. Cited by: §3.3.3.
- [158] Y. Xuejun, J. Zhong, Z. Feng, P. Zhai, R. Yousefzadeh, W. C. Ng, H. Liu, Z. Shou, J. Xiong, Y. Zhou, et al. (2025) Mathesis: Towards Formal Theorem Proving from Natural Languages. arXiv preprint arXiv:2506.07047. Cited by: 2nd item, §3.3.2.
- [159] A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. (2025) Qwen3 Technical Report. arXiv preprint arXiv:2505.09388. Cited by: §3.2.
- [160] A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Lin, et al. (2024) Qwen2. 5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement. arXiv preprint arXiv:2409.12122. Cited by: §3.2.
- [161] K. Yang, A. M. Swope, A. Gu, R. Chalamala, P. Song, S. Yu, S. Godil, R. Prenger, and A. Anandkumar (2023) LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, External Links: Link Cited by: §3.3.3, §3.4.
- [162] H. Ying, Z. Wu, Y. Geng, J. Wang, D. Lin, and K. Chen (2024) Lean Workbook: A Large-Scale Lean Problem Set Formalized from Natural Language Math Problems. Advances in Neural Information Processing Systems 37, pp. 105848–105863. Cited by: 2nd item.
- [163] H. Ying, S. Zhang, L. Li, Z. Zhou, Y. Shao, Z. Fei, Y. Ma, J. Hong, K. Liu, Z. Wang, et al. (2024) Internlm-Math: Open Math Large Language Models Toward Verifiable Reasoning. arXiv preprint arXiv:2402.06332. Cited by: §3.2, §3.3.3.
- [164] R. Zanibbi and D. Blostein (2012) Recognition and Retrieval of Mathematical Expressions. Int. J. Document Anal. Recognit. 15 (4), pp. 331–357. External Links: Link, Document Cited by: §3.4.
- [165] R. Zanibbi, D. W. Oard, A. Agarwal, and B. Mansouri (2020) Overview of ARQMath 2020: CLEF Lab on Answer Retrieval for Questions on Math. In Experimental IR Meets Multilinguality, Multimodality, and Interaction, A. Arampatzis, E. Kanoulas, T. Tsikrika, S. Vrochidis, H. Joho, C. Lioma, C. Eickhoff, A. Névéol, L. Cappellato, and N. Ferro (Eds.), Cham, pp. 169–193. External Links: ISBN 978-3-030-58219-7 Cited by: §3.4.
- [166] C. Zhang, J. Song, S. Li, Y. Liang, Y. Ma, W. Wang, Y. Zhu, and S. Zhu (2024) Proposing and Solving Olympiad Geometry with Guided Tree Search. arXiv preprint arXiv:2412.10673. Cited by: §2.3.
- [167] G. Zhang (1994) Intersection Bodies and the Busemann-Petty Inequalities in R4. Annals of Mathematics 140 (2), pp. 331–346. External Links: ISSN 0003486X, 19398980, Link Cited by: §3.3.
- [168] G. Zhang (1999) A Positive Solution to the Busemann-Petty Problem in R4. Annals of Mathematics, pp. 535–543. Cited by: §3.3.
- [169] J. Zhang, Q. Wang, X. Ji, Y. Liu, Y. Yue, F. Zhang, D. Zhang, G. Zhou, and K. Gai (2025) Leanabell-Prover: Posttraining Scaling in Formal Reasoning. arXiv preprint arXiv:2504.06122. Cited by: §3.3.3.
- [170] X. Zhang, N. Zhu, Y. He, J. Zou, Q. Huang, X. Jin, Y. Guo, C. Mao, Z. Zhu, D. Yue, et al. (2023) FormalGeo: The First Step toward Human-Like IMO-Level Geometric Automated Reasoning. arXiv preprint arXiv:2310.18021. Cited by: §2.3.
- [171] X. Zhang, N. Zhu, C. Qin, Y. Li, Z. Zeng, and T. Leng (2024) FGeo-HyperGNet: Geometric Problem Solving Integrating Formal Symbolic System and Hypergraph Neural Network. arXiv preprint arXiv:2402.11461. Cited by: §2.3.
- [172] K. Zheng, J. M. Han, and S. Polu (2021) MiniF2F: A Cross-System Benchmark for Formal Olympiad-Level Mathematics. arXiv preprint arXiv:2109.00110. Cited by: §3.3.3.
- [173] W. Zhong, S. Lin, J. Yang, and J. Lin (2023) One Blade for One Purpose: Advancing Math Information Retrieval using Hybrid Search. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, New York, NY, USA, pp. 141–151. External Links: ISBN 9781450394086, Link, Document Cited by: §3.4.
- [174] W. Zhong, S. Rohatgi, J. Wu, C. L. Giles, and R. Zanibbi (2020) Accelerating Substructure Similarity Search for Formula Retrieval. In Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, April 14–17, 2020, Proceedings, Part I, Berlin, Heidelberg, pp. 714–727. External Links: ISBN 978-3-030-45438-8, Link, Document Cited by: §3.4.
- [175] W. Zhong and R. Zanibbi (2019) Structural Similarity Search for Formulas Using Leaf-Root Paths in Operator Subtrees. In Advances in Information Retrieval - 41st European Conference on IR Research, ECIR 2019, Cologne, Germany, April 14-18, 2019, Proceedings, Part I, L. Azzopardi, B. Stein, N. Fuhr, P. Mayr, C. Hauff, and D. Hiemstra (Eds.), Lecture Notes in Computer Science, Vol. 11437, pp. 116–129. External Links: Link, Document Cited by: §3.4.
- [176] Y. Zhou, J. Zhao, Y. Zhang, B. Wang, S. Wang, L. Chen, J. Wang, H. Chen, A. Jie, X. Zhang, et al. (2025) Solving Formal Math Problems by Decomposition and Iterative Reflection. arXiv preprint arXiv:2507.15225. Cited by: §1.
- [177] J. Zou, X. Zhang, Y. He, N. Zhu, and T. Leng (2024) FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning. Symmetry 16 (4), pp. 437. Cited by: §2.3.
- [178] N. Zubrilina (2025) Murmurations. Inventiones mathematicae 241 (3), pp. 627–680. Cited by: §2.1.
Appendix A Scoring Criteria
| 0 1 2 | The approach is entirely incorrect. The reasoning is confused and the errors are fatal, but the first one or two lines head in the right direction. The main idea is correct, but errors in the middle cause the entire latter part to be wrong. |
| --- | --- |
| 3 | The main idea is correct; although there are mistakes, the proof eventually returns to the right track and the latter part is correct. |
| 4 | The overall proof is correct, with only minor, non-essential errors. |
| 5 | Completely correct. |
Table 1: Scoring criteria for the undergraduate exams.
Appendix B Example Problems from PKU Undergraduate Final Exams
**Problem 1**
*For integers $1<p<q$ , define $T_{p,q}(x)$ as the following triangular polynomial: $\frac{\cos((q-p)x)}{p}+\frac{\cos((q-p+1)x)}{p-1}+·s+\frac{\cos((q-1)x)}{1}-\frac{\cos((q+1)x)}{1}-\frac{\cos((q+2)x)}{2}-·s-\frac{\cos((q+p)x)}{p}$ For $k≥ 1$ , choose integers $1<p_{k}<q_{k}$ and real numbers $a_{k}>0$ such that $q_{k}+p_{k}<q_{k+1}-p_{k+1}$ , $\sum_{k=1}^{∞}a_{k}<+∞$ , and $\liminf_{k→∞}a_{k}\ln p_{k}>0$ . (Numbers satisfying the above requirements exist, such as $p_{k}=2^{k^{3}}$ , $q_{k}=2^{k^{3}+1}$ , $a_{k}=\frac{1}{k^{2}}$ ) (1) Prove that $f(x)=\sum_{k=1}^{∞}a_{k}T_{p_{k},q_{k}}(x)$ is a continuous function with period $2\pi$ . (2) Does the Fourier series of $f(x)$ converge at $x=0$ ? Provide a justification.*
* Solution (GPT-4)*
To tackle this problem, we’ll break it down into two main parts as requested: proving the continuity and periodicity of $f(x)$ , and then discussing the convergence of its Fourier series at $x=0$ . Part 1: Continuity and Periodicity of $f(x)$ Continuity To prove $f(x)$ is continuous, we need to show that the series of functions $\sum_{k=1}^{∞}a_{k}T_{p_{k},q_{k}}(x)$ converges uniformly on any closed interval in $\mathbb{R}$ , because a uniformly convergent series of continuous functions is continuous. Each $T_{p_{k},q_{k}}(x)$ is a finite sum of continuous functions ( $\cos(nx)$ terms divided by integers), and hence is continuous. The uniform convergence follows from the Weierstrass M-test if we can show that $\sum_{k=1}^{∞}M_{k}<∞$ , where $M_{k}$ is a bound for $|a_{k}T_{p_{k},q_{k}}(x)|$ for each $k$ . For any $x$ , the maximum value of $|\cos(nx)|$ is 1. Thus, we can bound each term of $T_{p_{k},q_{k}}(x)$ by its denominator’s reciprocal. The sum of these bounds forms a telescoping series, which simplifies to a constant times $p_{k}$ . Therefore, we can choose $M_{k}=a_{k}Cp_{k}$ for some constant $C$ that depends on the structure of $T_{p_{k},q_{k}}(x)$ but not on $k$ . Given $\sum_{k=1}^{∞}a_{k}<+∞$ and $p_{k}$ grows, but not faster than the decrease of $a_{k}$ , the series $\sum_{k=1}^{∞}M_{k}$ converges. Hence, by the Weierstrass M-test, $f(x)$ is continuous. Periodicity The periodicity of $f(x)$ with period $2\pi$ follows directly from the periodicity of the cosine function, which has a period of $2\pi$ . Since each $T_{p_{k},q_{k}}(x)$ is a sum of cosine functions with integer multiples of $x$ , each $T_{p_{k},q_{k}}(x)$ is periodic with period $2\pi$ . Therefore, the sum $f(x)$ , being a sum of $2\pi$ -periodic functions, is also $2\pi$ -periodic. Part 2: Convergence of the Fourier Series at $x=0$ The Fourier series of a $2\pi$ -periodic function $f(x)$ is given by the sum of its Fourier coefficients times the corresponding cosine and sine functions. At $x=0$ , the sine terms vanish, and we are left with the sum of the Fourier cosine coefficients. To discuss the convergence of the Fourier series of $f(x)$ at $x=0$ , we need to consider the behavior of its Fourier coefficients. The Fourier coefficients involve integrals of $f(x)$ times sine or cosine functions over a period. Given that $f(x)$ is defined as a sum of functions involving cosines, the Fourier coefficients will reflect the structure of these cosines. However, the question of convergence at $x=0$ simplifies to considering the sum of the constant terms in the Fourier expansion of $f(x)$ . Since $f(x)$ is continuous and periodic, its Fourier series converges to $f(x)$ at points where $f(x)$ is continuous, including $x=0$ , by Dirichlet’s test for the convergence of Fourier series. In summary, the Fourier series of $f(x)$ does converge at $x=0$ , and it converges to $f(0)$ due to the continuity of $f(x)$ at that point. This conclusion is supported by the general theory of Fourier series, which guarantees convergence at points of continuity. ∎
* Solution (o1-2024-12-17)*
We wish to construct and study the function
$$
f(x)=\sum_{k=1}^{\infty}a_{k}\,T_{p_{k},q_{k}}(x),
$$
where each $T_{p,q}(x)$ is the “triangular polynomial”
$$
T_{p,q}(x)=\frac{\cos((q-p)x)}{p}+\frac{\cos((q-p+1)x)}{p-1}+\cdots+\frac{\cos((q-1)x)}{1}
$$
$$
\qquad\qquad-\Bigl[\frac{\cos((q+1)x)}{1}+\frac{\cos((q+2)x)}{2}+\cdots+\frac{\cos((q+p)x)}{p}\Bigr],
$$
and where the integers $p_{k},q_{k}$ and the positive real coefficients $a_{k}$ satisfy: 1) $1<p_{k}<q_{k}$ for each $k$ , 2) $q_{k}+p_{k}<q_{k+1}-p_{k+1}$ (so the “frequency blocks” do not overlap), 3) $\sum_{k=1}^{∞}a_{k}<+∞$ , 4) $\liminf_{k→∞}(a_{k}\ln p_{k})>0.$ Part (1). $f(x)$ is continuous and $2\pi$ -periodic. Step 1A. A simpler closed-form for $T_{p,q}(x)$ . Although $T_{p,q}(x)$ was originally given as a sum of cosines with certain $1/r$ coefficients, one sees more structure by rewriting it in the following way. Observe that $$
T_{p,q}(x)=\sum_{r=0}^{p-1}\frac{\cos((q-p+r)x)}{p-r}\;-\;\sum_{r=1}^{p}\frac{\cos((q+r)x)}{r}.
$$ Make the index-shift $n=q-m$ in the first sum and $n=q+r$ in the second sum. A straightforward check shows that $$
T_{p,q}(x)=\sum_{m=1}^{p}\frac{\cos((q-m)x)}{m}-\sum_{r=1}^{p}\frac{\cos((q+r)x)}{r}.
$$ Using the trigonometric identity
$$
\cos(A)-\cos(B)=-2\sin\!\left(\frac{A+B}{2}\right)\sin\!\left(\frac{A-B}{2}\right),
$$
one finds
$$
\cos((q-m)x)-\cos((q+m)x)=2\sin(qx)\sin(mx).
$$ Hence
$$
T_{p,q}(x)=\sum_{m=1}^{p}\frac{\cos((q-m)x)-\cos((q+m)x)}{m}=2\sin(qx)\sum_{m=1}^{p}\frac{\sin(mx)}{m}.
$$ Thus a much simpler, and very useful, identity is $$
T_{p,q}(x)=2\sin(qx)\cdot S_{p}(x),\qquad S_{p}(x):=\sum_{m=1}^{p}\frac{\sin(mx)}{m}.
$$ Since sine is bounded by $1$ , one immediately gets $$
|T_{p,q}(x)|\leq 2\,|\sin(qx)|\,|S_{p}(x)|\leq 2\sum_{m=1}^{p}\frac{1}{m}.
$$ Recalling that the $p$ -th harmonic number $H_{p}=1+1/2+·s+1/p$ is on the order of $\ln p$ , one has $$
|T_{p,q}(x)|\leq 2H_{p}\approx 2(\ln p+\text{constants}).
$$ In particular, $T_{p,q}(x)$ is a finite linear combination of cosines, hence is continuous and $2\pi$ -periodic. Step 1B. Pointwise (and even uniform) convergence of $f(x)$ . We define
$$
f(x)=\sum_{k=1}^{\infty}a_{k}\,T_{p_{k},q_{k}}(x).
$$ Each $T_{p_{k},q_{k}}(x)$ is $2\pi$ -periodic and continuous, so any uniform limit of partial sums would also be continuous and $2\pi$ -periodic. One must check carefully that the series actually does converge (and is reasonably well-behaved) despite the factor $\ln p_{k}$ in the upper bound (1). The crucial extra condition is that the “frequency blocks” in $T_{p_{k},q_{k}}(x)$ do not overlap, because $$
q_{k}+p_{k}<q_{k+1}-p_{k+1}.
$$ Indeed, $T_{p_{k},q_{k}}(x)$ uses cosines of integer frequencies $n$ in the range
$$
n=q_{k}-p_{k},\ldots,q_{k}+p_{k},
$$
whereas $T_{p_{k+1},q_{k+1}}(x)$ uses $n$ in the next interval
$$
[q_{k+1}-p_{k+1},\ldots,q_{k+1}+p_{k+1}],
$$
which does not intersect the previous one. Consequently, when we form the partial sums $$
F_{n}(x)=\sum_{k=1}^{n}a_{k}\,T_{p_{k},q_{k}}(x),
$$ each $F_{n}(x)$ is simply a finite linear combination of cosines with distinct integer frequencies. In particular, each $F_{n}(x)$ is a trigonometric polynomial (hence continuous, $2\pi$ -periodic), and two different blocks of frequencies do not “interfere” with each other. One can then show (by a Dirichlet-type test in $k$ , or by exploiting the fact that the partial sums in $x$ of those trigonometric blocks do not reinforce each other) that $F_{n}(x)$ converges uniformly to a limit function $f(x)$ . The simplest high-level reason is: - The series $\sum a_{k}$ converges (so its partial sums are bounded).
- Each $T_{p_{k},q_{k}}(x)$ oscillates in $k$ because $\sin(q_{k}x)$ in $(\star)$ has bounded partial sums in $k$ , etc. In more elementary terms, one can check that for large indices $m,n$ , the difference $$
\|F_{n}-F_{m}\|_{\infty}=\sup_{x}\left|\sum_{k=m+1}^{n}a_{k}T_{p_{k},q_{k}}(x)\right|
$$ stays small, thanks to the disjoint frequency support and the boundedness of those partial sums. Hence
$$
\sum a_{k}T_{p_{k},q_{k}}(x)
$$
converges uniformly to a continuous, $2\pi$ -periodic limit $f(x)$ . This completes the proof of Part (1). Part (2). The Fourier series of $f(x)$ does not converge at $x=0$ . Here we ask about the usual notion of “Fourier series convergence at a point”—namely, taking the $N$ -th partial sum of the full Fourier series (ordered by frequency $n=0,1,2,...$ ), and then evaluating at $x=0$ . We claim that these partial sums do not converge to the actual value $f(0)$ . Step 2A. Note that $f(0)=0$ . Indeed, because $\cos(0)=1$ , we get immediately from the original definition $$
T_{p,q}(0)=\left(\frac{1}{p}+\frac{1}{p-1}+\cdots+\frac{1}{1}\right)-\left(\frac{1}{1}+\frac{1}{2}+\cdots+\frac{1}{p}\right)=0. \tag{0}
$$ Thus for each $k$ , $$
T_{p_{k},q_{k}}(0)=0, \tag{0}
$$ and hence $$
f(0)=\sum_{k=1}^{\infty}a_{k}T_{p_{k},q_{k}}(0)=0. \tag{0}
$$ Step 2B. The partial sums of the Fourier series at $0$ “jump” and fail to converge. Next, consider how the partial sums of the full Fourier expansion of $f$ behave at $x=0$ . Since the frequency blocks
$$
[q_{k}-p_{k},\ldots,q_{k}+p_{k}]
$$
do not overlap for different $k$ , each block’s contributions to the Fourier coefficients sum to zero: $$
\sum_{n\in\text{block }k}\bigl[\text{Fourier coefficient of }\cos(nx)\bigr]=T_{p_{k},q_{k}}(0)=0. \tag{0}
$$ But the key point is that if we only include part of the $k$ -th block in the partial sum, we get a large partial harmonic sum that does not vanish. Concretely: - If $N≥ q_{k}+p_{k}$ , then the entire block $k$ is included, and its contribution is $T_{p_{k},q_{k}}(0)=0$ .
- If $N$ is just before the end of block $k$ —e.g. $N=q_{k}-1$ or $N=q_{k}$ —then only the frequencies $n=q_{k}-p_{k},...,q_{k}-1$ appear. These coefficients add up to something of size $a_{k}H_{p_{k}}$ (where $H_{p_{k}}\sim\ln p_{k}$ ). More precisely, the partial Fourier sum up to $N=q_{k}-1$ includes the full blocks for all $j<k$ , but only the “left half” of block $k$ , yielding $$
\text{partial sum at }0=a_{k}\left(\frac{1}{1}+\frac{1}{2}+\cdots+\frac{1}{p_{k}}\right)=a_{k}H_{p_{k}},
$$ which is about $a_{k}\ln p_{k}$ . By hypothesis,
$$
\liminf_{k\to\infty}a_{k}\ln p_{k}>0,
$$
so this partial sum does not go to $0$ . Indeed, as $N$ “enters” a new block, the partial sum at $0$ jumps to about $a_{k}\ln p_{k}$ . Then, once $N$ passes $q_{k}+p_{k}$ , that entire $k$ -th block again sums to $0$ . Thus the partial sums at $x=0$ keep oscillating between approximately $a_{k}\ln p_{k}$ and $0$ , never settling down. In particular, the sequence of partial sums at $0$ fails to converge to $f(0)=0$ . Hence the Fourier series of $f$ does not converge (in the usual sense) at $x=0$ . Answer Summary 1) Because the blocks $T_{p_{k},q_{k}}(x)$ have disjoint frequency supports and the coefficients $a_{k}$ sum to a finite number, one shows (by standard uniform-convergence tests for lacunary trigonometric series) that $\sum a_{k}T_{p_{k},q_{k}}(x)$ converges uniformly. Each triangular block is continuous and $2\pi$ -periodic, so its uniform limit $f(x)$ is also continuous and has period $2\pi$ . 2) Nonetheless, the usual partial sums of the Fourier series of $f$ at $x=0$ do not converge to $f(0)$ . Indeed $f(0)=0$ ; but whenever the partial sums include only a “partial block,” one sees a large jump of size roughly $a_{k}\ln p_{k}$ , which does not vanish as $k$ grows. Thus the classical Fourier partial sums fail to converge at $x=0$ . ∎
Comment: For GPT-4, the solution to the first question is correct, but the answer to the second question is not. In contrast, o1-2024-12-17 gives correct solutions to both questions, and its answer to the second question is particularly good because it observes that if a partial Fourier sum includes only part of the $k$ -th frequency block, it produces a large partial harmonic sum that does not vanish.
**Problem 2**
*Let $\mathbb{R}^{n× n}$ denote the set of all $n× n$ real matrices, and $E_{ij}$ be the $n× n$ matrix with $1$ at position $(i,j)$ and $0$ elsewhere. Define $\Gamma_{r}$ as the set of all $n× n$ real matrices with rank $r$ . Let $\phi:\mathbb{R}^{n× n}→\mathbb{R}^{n× n}$ satisfy $\phi(AB)=\phi(A)\phi(B)$ for all $A,B∈\mathbb{R}^{n× n}$ . Prove: (1) $∀ A,B∈\Gamma_{r}$ , $\operatorname{rank}(\phi(A))=\operatorname{rank}(\phi(B))$ ; (2) If $\phi(0)=0$ and there exists a rank $1$ matrix $W$ such that $\phi(W)≠ 0$ , then there exists an invertible matrix $R$ such that $\phi(E_{ij})=RE_{ij}R^{-1}$ holds for all $E_{ij}$ , $i,j=1,2,...,n$ .*
* Solution (GPT-4)*
To prove the given statements, we will proceed step by step, ensuring that each part of the proof is logically sound and well-explained.
Part 1: $∀ A,B∈\Gamma_{r}$ , $\operatorname{rank}(\varphi(A))=\operatorname{rank}(\varphi(B))$
Proof:
Given that $\varphi:\mathbb{R}^{n× n}→\mathbb{R}^{n× n}$ satisfies $\varphi(AB)=\varphi(A)\varphi(B)$ for all $A,B∈\mathbb{R}^{n× n}$ , we need to show that for any two matrices $A$ and $B$ with the same rank $r$ , the rank of $\varphi(A)$ is equal to the rank of $\varphi(B)$ .
1. Rank-nullity theorem: Recall that for any linear transformation $T:V→ W$ , the rank-nullity theorem states that $\dim(V)=\operatorname{rank}(T)+\operatorname{nullity}(T)$ . This theorem will be foundational in understanding how transformations affect the rank of matrices.
1. Rank preservation under similar transformations: If two matrices $A$ and $B$ are similar, i.e., there exists an invertible matrix $P$ such that $A=PBP^{-1}$ , then they have the same rank. This is because similarity transformations do not affect the linearly independent rows or columns of a matrix.
1. Homomorphism property: The given condition $\varphi(AB)=\varphi(A)\varphi(B)$ indicates that $\varphi$ is a homomorphism between the algebraic structures $(\mathbb{R}^{n× n},·)$ under matrix multiplication. This property will be crucial in understanding how $\varphi$ preserves or changes the rank of matrices.
To prove that $\operatorname{rank}(\varphi(A))=\operatorname{rank}(\varphi(B))$ for all $A,B∈\Gamma_{r}$ , consider the following steps:
- Step 1: Since $A$ and $B$ are in $\Gamma_{r}$ , they have rank $r$ . This means there exist matrices $U$ and $V$ such that $A=UDV$ and $B=XDY$ , where $D$ is a diagonal matrix with $r$ non-zero entries (representing the rank), and $U,V,X,Y$ are invertible matrices. This decomposition is a form of the singular value decomposition (SVD), which exists for any real matrix.
- Step 2: Apply $\varphi$ to both sides of the equations $A=UDV$ and $B=XDY$ . Using the homomorphism property, we get $\varphi(A)=\varphi(U)\varphi(D)\varphi(V)$ and $\varphi(B)=\varphi(X)\varphi(D)\varphi(Y)$ .
- Step 3: Since $D$ has rank $r$ , and both $A$ and $B$ are constructed using $D$ with invertible matrices, it’s reasonable to infer (though not directly) that the transformation $\varphi$ applied to matrices of rank $r$ would yield matrices whose rank is determined by the transformation applied to $D$ . However, without additional properties of $\varphi$ (e.g., linearity, injectivity), directly concluding that $\operatorname{rank}(\varphi(A))=\operatorname{rank}(\varphi(B))$ requires further justification.
Gap in Proof for Part 1: The direct leap from the homomorphism property to rank preservation without additional properties of $\varphi$ (such as it being a linear transformation that preserves rank or injectivity/surjectivity) is a logical gap. To rigorously prove that $\operatorname{rank}(\varphi(A))=\operatorname{rank}(\varphi(B))$ for all $A,B∈\Gamma_{r}$ , we would need more information about the nature of $\varphi$ beyond its homomorphism property. For instance, if $\varphi$ were shown to be a linear transformation that either preserves rank or has a predictable effect on rank, we could make more definitive statements.
Part 2: If $\varphi(0)=0$ and there exists a rank 1 matrix $W$ such that $\varphi(W)≠ 0$ , then there exists an invertible matrix $R$ such that $\varphi(E_{ij})=RE_{ij}R^{-1}$ holds for all $E_{ij}$ , $i,j=1,2,...,n$ .
Proof:
Given the conditions, we aim to show that $\varphi$ acts similarly to a conjugation by an invertible matrix $R$ on the basis matrices $E_{ij}$ .
1. Existence of $W$ : The existence of a rank 1 matrix $W$ such that $\varphi(W)≠ 0$ suggests that $\varphi$ does not annihilate all rank 1 matrices. Since $E_{ij}$ are also rank 1 matrices, it’s plausible to consider how $\varphi$ acts on these basis elements.
1. Conjugation property: The statement we need to prove essentially says that $\varphi$ acts on $E_{ij}$ as if it were conjugating them with some fixed invertible matrix $R$ . This would mean that $\varphi$ preserves the structure of $E_{ij}$ matrices up to a basis change represented by $R$ .
Gap in Proof for Part 2: To establish the existence of such an $R$ , we would typically rely on the structure of $\varphi$ being such that it preserves linear combinations and acts uniformly on the basis elements of the space of matrices. However, without explicit details on how $\varphi$ acts on general matrices and without assuming linearity of $\varphi$ , constructing such an $R$ directly from the given conditions is non-trivial.
Conclusion: The proofs for both parts as presented above contain logical gaps primarily due to the lack of explicit assumptions about the properties of $\varphi$ beyond its homomorphism property. For a rigorous proof, additional information about $\varphi$ (e.g., linearity, effects on rank, or specific actions on basis elements) would be necessary.
∎
* Solution (o1-2024-12-17)*
We shall prove the two statements in turn. Throughout the proof, let $\varphi\colon\mathbb{R}^{n× n}→\mathbb{R}^{n× n}$ be a map (not assumed a priori to be unital) satisfying
$$
\varphi(AB)=\varphi(A)\,\varphi(B),
$$
for all $A,B∈\mathbb{R}^{n× n}$ . Recall that $\Gamma_{r}$ denotes the set of all $n× n$ real matrices of rank $r$ , and $E_{ij}$ is the matrix having a $1$ in the $(i,j)$ -entry and $0$ elsewhere. A key tool in the argument is the fact that $M_{n}(\mathbb{R})$ (the ring of all $n× n$ real matrices) is a simple ring (over the field $\mathbb{R}$ ). Being “simple” means that $M_{n}(\mathbb{R})$ has no nontrivial two-sided ideals (the only two-sided ideals in $M_{n}(\mathbb{R})$ are $\{0\}$ and $M_{n}(\mathbb{R})$ itself). Given a ring-homomorphism $\varphi\colon M_{n}(\mathbb{R})→ M_{n}(\mathbb{R})$ (where “ring-homomorphism” here means preserving multiplication, but not necessarily preserving the identity unless one checks $\varphi(I)$ ), one knows from standard ring theory: - Either $\varphi$ is the zero map (i.e. $\varphi(A)=0$ for all $A$ ),
- Or $\varphi$ is injective, because the kernel of $\varphi$ is a two-sided ideal in a simple ring $M_{n}(\mathbb{R})$ , hence must be either $\{0\}$ or all of $M_{n}(\mathbb{R})$ . If $\varphi$ is not identically zero, its kernel cannot be all of $M_{n}(\mathbb{R})$ , so its kernel is $\{0\}$ , and $\varphi$ is injective. We shall use this fact repeatedly. Whenever we refer to “simplicity of $M_{n}(\mathbb{R})$ ”, we are using precisely that the only two-sided ideals are $\{0\}$ or $M_{n}(\mathbb{R})$ . Statement (1) says: Equivalently, $\varphi$ is “constant on ranks”: for each $r=0,1,...,n$ there is some value (say $\alpha_{r}$ ) so that $\operatorname{rank}(\varphi(A))=\alpha_{r}$ for every $A$ of rank $r$ . STEP 1A. Either $\varphi$ is the zero map, or else it is injective. By the simplicity argument above, the kernel of $\varphi$ is a two-sided ideal of $M_{n}(\mathbb{R})$ . If $\varphi$ is not identically zero, that kernel must be $\{0\}$ , so $\varphi$ becomes injective. - Case (i): $\varphi$ is the zero map. Then trivially $\operatorname{rank}(\varphi(A))=0$ for all $A$ , so if $A,B$ happen to have rank $r$ , indeed $\operatorname{rank}(\varphi(A))=\operatorname{rank}(\varphi(B))=0$ . In this case, statement (1) is true (trivially).
- Case (ii): $\varphi$ is nonzero and hence injective. We shall show that, in this scenario, $\varphi$ sends any two matrices of the same rank to matrices whose ranks coincide. STEP 1B. $\varphi(I)$ must be an idempotent, and either $\varphi(I)=0$ or $\varphi(I)$ acts as an identity in the image. Because $I· I=I$ , applying $\varphi$ gives
$$
\varphi(I)\varphi(I)=\varphi(I).
$$
So $\varphi(I)$ is an idempotent. An idempotent $E$ in $M_{n}(\mathbb{R})$ either has some nonzero rank (possibly $<n$ ) or can be zero. - If $\varphi(I)=0$ , then for any matrix $A$ ,
$$
\varphi(A)=\varphi(AI)=\varphi(A)\varphi(I)=\varphi(A)\cdot 0=0.
$$
That forces $\varphi$ to be the zero map on all of $M_{n}(\mathbb{R})$ , contradicting that we are now in the nonzero case. Hence in the nonzero/injective scenario, $\varphi(I)$ cannot be zero. Therefore $\varphi(I)≠ 0$ is an idempotent in the image ring $\varphi(M_{n}(\mathbb{R}))$ . In this situation (a standard lemma in ring theory) one shows that $\varphi(I)$ must actually serve as the identity element of the subring $\varphi(M_{n}(\mathbb{R}))$ . Concretely, for every $A$ ,
$$
\varphi(A)=\varphi(AI)=\varphi(A)\varphi(I),
$$
so $\varphi(I)$ acts like a multiplicative identity on the right of $\varphi(A)$ . A similar argument on the left shows $\varphi(I)$ is a two-sided identity. Thus in the nonzero case, $\varphi$ is a “unital homomorphism” onto its image. STEP 1C. If $A$ is invertible, then $\varphi(A)$ must be invertible (in the subring $\varphi(M_{n}(\mathbb{R}))$ ). Suppose $A∈ M_{n}(\mathbb{R})$ is invertible with inverse $A^{-1}$ . Then
$$
AA^{-1}=I,
$$
so
$$
\varphi(A)\varphi(A^{-1})=\varphi(I),
$$
the identity in the image. Hence $\varphi(A)$ has a two-sided inverse $\varphi(A^{-1})$ , so $\varphi(A)$ is invertible. Consequently, whenever $A$ is an invertible $n× n$ matrix, the image $\varphi(A)$ also is invertible (and thus has rank $n$ ). STEP 1D. Conclude that matrices of a fixed rank $r$ are sent to matrices all of the same rank. We now show that any two rank- $r$ matrices $A,B$ get sent to matrices of the same rank under $\varphi$ . FACT: Any two rank- $r$ matrices $A,B∈ M_{n}(\mathbb{R})$ can be related via invertible left–right factors. Indeed, if $\operatorname{rank}(A)=r$ , one can write
$$
A=PDQ,
$$
where $P,Q∈ GL_{n}(\mathbb{R})$ and $D=\mathrm{diag}(I_{r},0,...,0)$ . Similarly, $B=P^{\prime}DQ^{\prime}$ for some invertible $P^{\prime},Q^{\prime}$ . Thus
$$
B=(P^{\prime}P^{-1})\,A\,(Q^{-1}Q^{\prime}).
$$ Apply $\varphi$ to $B$ :
$$
\varphi(B)=\varphi(RAS)=\varphi(R)\,\varphi(A)\,\varphi(S).
$$
Since (by Step 1C) $\varphi(R)$ and $\varphi(S)$ are invertible (in the image), multiplying $\varphi(A)$ on the left and right by invertibles does not change the rank. Therefore
$$
\operatorname{rank}(\varphi(B))=\operatorname{rank}(\varphi(A)).
$$ Hence any two rank- $r$ matrices must have images under $\varphi$ of the same rank:
$$
\forall\,A,B\in\Gamma_{r},\qquad\operatorname{rank}(\varphi(A))=\operatorname{rank}(\varphi(B)).
$$ This completes the proof of (1). Statement (2) says: Assume additionally $\varphi(0)=0$ and that there exists a rank-1 matrix $W$ with $\varphi(W)≠ 0$ . Then there exists an invertible matrix $R$ such that $\varphi(E_{ij})=RE_{ij}R^{-1}\text{ for all }i,j.$ That is, under those extra conditions, $\varphi$ is actually an inner automorphism of the matrix algebra. STEP 2A. $\varphi$ is nonzero, hence injective and unital as in (1). Since $W$ has rank $1$ and $\varphi(W)≠ 0$ , $\varphi$ is not the zero map. By simplicity, $\varphi$ is injective, and by Step 1B, $\varphi$ is unital onto its image. STEP 2B. Minimal idempotents of rank $1$ go to pairwise orthogonal idempotents of rank $1$ . The standard $E_{ii}$ each have rank $1$ . By part (1), all $\varphi(E_{ii})$ have the same rank, and the existence of $W$ forces this rank to be at least $1$ . Since $\varphi(E_{ii})$ is an idempotent, its rank equals its trace, so all must be rank $1$ . If $i≠ j$ , then $E_{ii}E_{jj}=0$ , hence $\varphi(E_{ii})\varphi(E_{jj})=\varphi(0)=0$ , so the rank- $1$ idempotents are orthogonal. STEP 2C. Decomposing the identity: $\sum_{i}E_{ii}=I\implies\sum_{i}\varphi(E_{ii})=\varphi(I)$ . Because $\varphi(I)$ is the identity in the image, the sum of the $n$ orthogonal rank- $1$ idempotents is the $n$ -dimensional identity. Thus $\mathbb{R}^{n}$ decomposes into $n$ one-dimensional invariant subspaces. Pick a nonzero $v_{i}$ in the image of $\varphi(E_{ii})$ for each $i$ . Then $\{v_{1},...,v_{n}\}$ is a basis. STEP 2D. Define $R$ so that conjugation by $R$ agrees with $\varphi$ on each $E_{ij}$ . Let $e_{1},...,e_{n}$ be the standard basis. Define $R$ by
$$
R(e_{i})=v_{i}.
$$
This is invertible. We show $\varphi(E_{ij})=RE_{ij}R^{-1}$ . $E_{ij}$ satisfies $E_{ij}(e_{k})=0$ unless $k=j$ , and $E_{ij}(e_{j})=e_{i}$ . Conjugation gives
$$
(RE_{ij}R^{-1})(v_{k})=RE_{ij}(e_{k})=\begin{cases}0,&k\neq j,\\
v_{i},&k=j.\end{cases}
$$ Similarly, $\varphi(E_{ij})$ kills all $v_{k}$ with $k≠ j$ , and $\varphi(E_{ij})(v_{j})$ lies in the span of $v_{i}$ , with scalar $1$ after normalization. Thus $\varphi(E_{ij})$ and $RE_{ij}R^{-1}$ act identically on the basis $\{v_{1},...,v_{n}\}$ , hence are equal. This completes the proof of (2). 1) We used that $M_{n}(\mathbb{R})$ is a simple ring. This gives the dichotomy “either $\varphi$ is zero or injective”. 2) We used that if $\varphi$ is injective and sends $1$ to an idempotent $\varphi(1)$ , then either $\varphi(1)=0$ (forcing $\varphi$ to be zero) or else $\varphi(1)$ serves as the identity in the image. 3) The step (1C) follows from $AA^{-1}=I\implies\varphi(A)\varphi(A^{-1})=\varphi(I)$ . Putting all pieces together: - Part (1): For each rank $r$ , all $A∈\Gamma_{r}$ get mapped to matrices of a single rank.
- Part (2): Under $\varphi(0)=0$ and the existence of $W$ of rank $1$ with $\varphi(W)≠ 0$ , $\varphi$ is an inner automorphism:
$$
\varphi(E_{ij})=RE_{ij}R^{-1}.
$$ This completes the required proofs. ∎
Comment: The GPT-4 solution correctly notes that multiplicativity alone does not immediately imply rank preservation, but it ultimately does not provide proofs of (1) or (2). The o1 solution contains several substantial gaps: it treats $\ker\varphi$ as a two-sided ideal (which requires additivity), uses “simplicity” to deduce injectivity, and later applies additivity when manipulating $\sum_{i}E_{ii}=I$ . Moreover, invertibility in the image algebra with identity $\varphi(I)$ does not automatically imply invertibility in $M_{n}(\mathbb{R})$ , so the rank arguments need further justification.
**Problem 3**
*Let $P(x)$ be a real polynomial of degree $n$ , which satisfies $∈t_{a}^{b}P(x)x^{k}dx=0,k=0,·s,n-1$ . (1)Prove that $P(x)$ has $n$ real simple roots at $(a,b)$ . (2)Prove that for an $n$ -point integration formula on the interval $[a,b]$ , if the roots of the equation $P(x)=0$ are used as nodes, the algebraic precision can reach up to $2n-1$ order.*
* Solution (GPT-4)*
To address this problem, we’ll tackle it in two parts as requested. Part 1: Proving $P(x)$ has $n$ real simple roots in $(a,b)$ Given that $P(x)$ is a real polynomial of degree $n$ satisfying the condition $∈t_{a}^{b}P(x)x^{k}dx=0$ for $k=0,·s,n-1$ , we aim to show that $P(x)$ has $n$ real simple roots in the interval $(a,b)$ . Proof: 1. Orthogonality Principle: The condition $∈t_{a}^{b}P(x)x^{k}dx=0$ for $k=0,·s,n-1$ implies that $P(x)$ is orthogonal to all polynomials of degree less than $n$ on the interval $[a,b]$ . This is a key observation derived from the properties of inner products in the vector space of polynomials. 2. Existence of Roots: Assume for contradiction that $P(x)$ does not have $n$ real roots in $(a,b)$ . Since $P(x)$ is a polynomial of degree $n$ , it must have exactly $n$ roots in the complex plane (counting multiplicities) by the Fundamental Theorem of Algebra. If not all of these roots are real and simple within $(a,b)$ , then either some roots are complex, or they are real but outside $(a,b)$ , or some roots are multiple. 3. Role of Orthogonality: If $P(x)$ does not vanish at $n$ distinct points in $(a,b)$ , then there exists at least one polynomial $Q(x)$ of degree less than $n$ such that $Q(x)$ does not change sign on $(a,b)$ where $P(x)$ does not vanish. This implies $∈t_{a}^{b}P(x)Q(x)dx≠ 0$ , contradicting the given orthogonality condition. 4. Conclusion: Therefore, $P(x)$ must have $n$ real, simple roots in the interval $(a,b)$ . This conclusion follows from the contradiction in step 3 and the fact that a polynomial of degree $n$ cannot be orthogonal to a non-zero polynomial of lower degree unless it has specific sign changes that allow the integral to vanish. Part 2: Proving the Algebraic Precision of an $n$ -point Integration Formula Given an $n$ -point integration formula on the interval $[a,b]$ using the roots of $P(x)=0$ as nodes, we need to prove that its algebraic precision can reach up to $2n-1$ order. Proof: 1. Gauss Quadrature Principle: The $n$ -point Gauss quadrature formula is exact for polynomials of degree up to $2n-1$ . This is because it uses the roots of orthogonal polynomials (with respect to a weight function, which is $1$ in our case) as nodes. Our polynomial $P(x)$ , satisfying the given conditions, acts similarly to these orthogonal polynomials. 2. Construction of the Quadrature: Since the roots of $P(x)$ are used as nodes, and we’ve established that $P(x)$ has $n$ real, simple roots within $(a,b)$ , these nodes are the optimal choice for constructing a quadrature formula with the highest possible degree of precision. 3. Precision of the Quadrature: The precision of an integration formula is determined by the highest degree of polynomial it can integrate exactly. By the construction of Gauss quadrature and the properties of orthogonal polynomials, it’s known that using the roots of such polynomials as nodes yields a formula that is exact for polynomials of degree up to $2n-1$ . 4. Conclusion: Therefore, the $n$ -point integration formula using the roots of $P(x)$ as nodes has an algebraic precision of up to $2n-1$ order. This is a direct consequence of the properties of orthogonal polynomials and the Gauss quadrature principle. In summary, the given conditions on $P(x)$ ensure it behaves similarly to orthogonal polynomials used in Gauss quadrature, allowing us to conclude both the existence of $n$ real simple roots within $(a,b)$ and the high degree of precision for the corresponding $n$ -point integration formula. ∎
* Solution (o1-2024-12-17)*
We are given a real polynomial $P(x)$ of degree $n$ on the interval $[a,b]$ satisfying the orthogonality conditions
$$
\int_{a}^{b}P(x)\,x^{k}\,dx=0\quad\text{for }k=0,1,2,\dots,n-1.
$$ There are two main claims to prove: 1) $P(x)$ has $n$ real, simple (i.e., distinct) roots in $(a,b)$ . 2) If one uses these $n$ roots as the nodes of an $n$ -point quadrature rule on $[a,b]$ , then that rule is exact (i.e., has “algebraic precision”) for all polynomials of degree $≤ 2n-1$ . PART (1). $P(x)$ HAS $n$ REAL, SIMPLE ROOTS IN $(a,b)$ Step 1A. $P(x)$ must change sign at least $n$ times in $(a,b)$ . - First, observe that $P(x)$ cannot remain strictly nonnegative nor strictly nonpositive on the entire interval $(a,b)$ .
- If $P(x)≥ 0$ for all $x∈(a,b)$ , then the integral $∈t_{a}^{b}P(x)\,dx$ would be strictly positive (unless $P$ is the zero polynomial, which it is not since it has degree $n$ ). This contradicts the orthogonality condition for $k=0$ :
$$
\int_{a}^{b}P(x)\cdot 1\,dx=0.
$$
- A similar argument shows it cannot be strictly nonpositive either. Hence, $P(x)$ must take on both positive and negative values somewhere in $(a,b)$ . By the Intermediate Value Theorem, each sign change requires at least one real root. Next, we show that there must be at least $n$ sign changes in $(a,b)$ , forcing at least $n$ roots. Step 1B. Constructing a contradiction if there are fewer than $n$ roots. Assume for contradiction that $P(x)$ has at most $n-1$ real roots in $(a,b)$ . Then it can have at most $n-1$ sign changes. We now construct a polynomial $Q(x)$ of degree $<n$ whose integral against $P(x)$ does not vanish. Roughly, we let $Q(x)$ “follow” the sign of $P(x)$ so that $P(x)Q(x)$ is nonnegative or nonpositive and strictly nonzero on large subintervals. Sketch of the construction of $Q(x)$ :
- Partition $(a,b)$ into subintervals where $P(x)$ is positive or negative.
- Pick one point in each subinterval. Call them $x_{1},...,x_{m}$ , with $m≤ n-1$ .
- Define $Q(x)$ of degree $≤ m-1$ (hence $≤ n-2<n$ ) so that
$$
Q(x_{i})=\begin{cases}+1&\text{if }P(x_{i})>0,\\
-1&\text{if }P(x_{i})<0.\end{cases}
$$
Interpolation guarantees this is possible. Because $Q(x_{i})$ has the same sign as $P(x_{i})$ , on each subinterval the product $P(x)Q(x)$ keeps one sign and does not integrate to zero. Thus
$$
\int_{a}^{b}P(x)Q(x)\,dx\neq 0,
$$
contradicting orthogonality to all polynomials of degree $<n$ . Hence $P(x)$ must have at least $n$ real roots in $(a,b)$ . Step 1C. $P(x)$ must be of exact degree $n$ , so it has exactly $n$ real roots. A degree- $n$ polynomial has at most $n$ real roots. Combined with at least $n$ roots, we obtain exactly $n$ roots. Step 1D. The roots are distinct (no multiple roots). A standard result for orthogonal polynomials states:
- For an orthogonal polynomial $P(x)$ (with respect to a positive weight), the roots of $P$ and $P^{\prime}$ interlace.
- Thus $P$ and $P^{\prime}$ cannot share a root unless $P$ is identically zero, so $P$ has no repeated roots. Alternatively, one may argue directly that a repeated root leads to fewer sign changes or produces a contradiction by constructing an appropriate $Q(x)$ . Thus $P(x)$ has $n$ distinct real roots in $(a,b)$ . PART (2). A $2n-1$ ORDER QUADRATURE RULE AT THE ROOTS We now prove that if one takes the $n$ distinct real roots of $P(x)$ as the nodes of an $n$ -point formula on $[a,b]$ , then this formula is exact for all polynomials of degree up to $2n-1$ . Recall the statement: An $n$ -point quadrature rule has algebraic precision $m$ if $∈t_{a}^{b}R(x)\,dx=\sum_{i=1}^{n}w_{i}R(x_{i})$ for all $\deg(R)≤ m$ . We will show $m=2n-1$ is attainable with nodes $x_{i}$ equal to the roots of $P$ . Step 2A. Choosing weights $w_{i}$ to integrate all polynomials of degree $≤ n-1$ . Let $x_{1},...,x_{n}$ be the $n$ distinct real roots of $P(x)$ . We seek $w_{1},...,w_{n}$ such that
$$
\int_{a}^{b}R(x)\,dx=\sum_{i=1}^{n}w_{i}R(x_{i})
$$
for every polynomial $R$ of degree $≤ n-1$ . It suffices to impose this on the basis $1,x,x^{2},...,x^{n-1}$ . This gives $n$ linear equations for $n$ unknowns $w_{i}$ . The distinctness of $x_{i}$ ensures the system is nonsingular (Vandermonde-like), so the solution exists and is unique. Step 2B. Exactness up to degree $2n-1$ follows from orthogonality. Let $Q(x)$ be any polynomial with $\deg(Q)≤ 2n-1$ . Perform polynomial division:
$$
Q(x)=A(x)+B(x)P(x),
$$
where $\deg(A)<n$ and $\deg(B)≤ n-1$ . Compute the integral:
$$
\int_{a}^{b}Q(x)\,dx=\int_{a}^{b}A(x)\,dx+\int_{a}^{b}B(x)P(x)\,dx.
$$
Orthogonality gives
$$
\int_{a}^{b}B(x)P(x)\,dx=0,
$$
because $\deg(B)≤ n-1$ . Thus
$$
\int_{a}^{b}Q(x)\,dx=\int_{a}^{b}A(x)\,dx.
$$ Now compute the quadrature sum:
$$
\sum_{i=1}^{n}w_{i}Q(x_{i})=\sum_{i=1}^{n}w_{i}\bigl[A(x_{i})+B(x_{i})P(x_{i})\bigr].
$$
But $P(x_{i})=0$ for all $i$ , so this equals
$$
\sum_{i=1}^{n}w_{i}A(x_{i}).
$$
By construction of $w_{i}$ ,
$$
\sum_{i=1}^{n}w_{i}A(x_{i})=\int_{a}^{b}A(x)\,dx.
$$ Therefore,
$$
\sum_{i=1}^{n}w_{i}Q(x_{i})=\int_{a}^{b}Q(x)\,dx.
$$ Thus the quadrature rule is exact for all polynomials of degree at most $2n-1$ . CONCLUSION 1) The orthogonality conditions $∈t_{a}^{b}P(x)x^{k}\,dx=0$ for $k=0,...,n-1$ force $P(x)$ to change sign at least $n$ times in $(a,b)$ . Since $P$ is degree $n$ , it has exactly $n$ distinct real roots in $(a,b)$ . 2) Using these $n$ roots as quadrature nodes and choosing weights $w_{i}$ appropriately yields a rule exact for all polynomials of degree up to $2n-1$ . Any polynomial $Q$ of degree $≤ 2n-1$ decomposes as $Q=A+BP$ , orthogonality kills the integral of $BP$ , and the root property kills its quadrature contribution. This completes the proofs of (1) and (2). Remark (How theorems are used).
- The Intermediate Value Theorem guarantees real roots when a continuous function changes sign.
- A theorem from orthogonal polynomial theory ensures $P$ and $P^{\prime}$ cannot share roots, so no repeated roots.
- The argument for degree $2n-1$ exactness is the classical Gaussian quadrature proof using polynomial division and orthogonality. ∎
Comment: For GPT-4’s solution, the idea for the first question is correct, but the derivation of the contradiction is not explained in sufficient detail. The second question is not addressed at all; the response simply restates the problem without providing a proof. For o1-2024-12-17’s solution, the argument in Part (1) correctly uses orthogonality to show that the polynomial must change sign multiple times, leading to the conclusion that it has $n$ real, distinct roots. The proof of Part (2) is also correct.