# Knowledge Graphs are Implicit Reward Models: Path-Derived Signals Enable Compositional Reasoning
**Authors**:
- Yuval Kansal (Princeton University)
- &Niraj K. Jha (Princeton University)
## Abstract
Large language models have achieved near-expert performance in structured reasoning domains like mathematics and programming, yet their ability to perform compositional multi-hop reasoning in specialized scientific fields remains limited. We propose a bottom-up learning paradigm in which models are grounded in axiomatic domain facts and compose them to solve complex, unseen tasks. To this end, we present a post-training pipeline, based on a combination of supervised fine-tuning and reinforcement learning (RL), in which knowledge graphs act as implicit reward models. By deriving novel reward signals from knowledge graph paths, we provide verifiable, scalable, and grounded supervision that encourages models to compose intermediate axioms rather than optimize only final answers during RL. We validate this approach in the medical domain, training a 14B model on short-hop reasoning paths (1-3 hops) and evaluating its zero-shot generalization to complex multi-hop queries (4-5 hops). Our experiments show that path-derived rewards act as a “compositional bridge,” enabling our model to significantly outperform much larger models and frontier systems like GPT-5.2 and Gemini 3 Pro, on the most difficult reasoning tasks. Furthermore, we demonstrate the robustness of our approach to adversarial perturbations against option-shuffling stress tests. This work suggests that grounding the reasoning process in structured knowledge is a scalable and efficient path toward intelligent reasoning.
footnotetext: Preprint. Under review.
## 1 Introduction
Recent advances in language models have revealed that reasoning capabilities can be significantly enhanced through a combination of high-quality pretraining, supervised fine-tuning (SFT), carefully tuned reinforcement learning (RL)-based post-training, and strategic use of additional test-time compute (OpenAI, 2025; Google DeepMind, 2025; Yang et al., 2025; Muennighoff et al., 2025). The resulting systems achieve near-expert performance in well-structured domains, such as mathematics and programming, where high-quality data have been curated, reasoning steps are clear, ground truth is unambiguous, and intermediate verification is tractable (Lightman et al., 2023; Anthropic, 2025). However, true human-level intelligence in specialized fields requires more than just general pattern matching or long-form generation; it requires compositional reasoning: the ability to reliably combine axiomatic facts for complex multi-hop problem solving Kamp & Partee (1995); Fodor (1975). While current large language models (LLMs) excel when reasoning steps are clear and carefully curated expert data are available, compositional reasoning in high-stakes scientific domains, where reasoning paths are multi-faceted, remains elusive (Yin et al., 2025; Kim et al., 2025).
<details>
<summary>x1.png Details</summary>

### Visual Description
## Medical Question and Pathophysiology Diagram
### Overview
The image presents a medical board-style question (labeled as a "3-hop" question in the "Neoplasms" category with a difficulty of 2) concerning a clinical case. Below the question is a flowchart diagram illustrating a potential pathophysiological pathway linking the patient's condition to the correct answer. The primary language is English.
### Components/Axes
The image is divided into two main sections:
1. **Question Box (Top):** A rounded rectangle with a light yellow background containing the full question text, clinical vignette, multiple-choice options, and the correct answer.
2. **Pathophysiology Diagram (Bottom):** A horizontal flowchart consisting of four circular nodes connected by directional arrows. Each node contains an icon and descriptive text. The arrows are labeled with the causal relationship "maybe_cause."
### Detailed Analysis
#### **Question Box Content (Transcribed):**
* **Header:** `Question (3-hop) (Category: Neoplasms) (Difficulty: 2):`
* **Clinical Vignette:** `A 58-year-old male presents with a 6-month history of intermittent flushing, diarrhea, and new-onset wheezing. Serum 5-HIAA is markedly elevated. Over the past month, he has also developed significant edema and ascites. Laboratory investigations reveal low serum albumin, IgG, IgA, and IgM levels. His C3 and C4 complement levels are normal. A CT scan reveals a mass in the ileum with liver metastases.`
* **Question:** `Which of the following mechanisms is MOST likely contributing to this patient's hypogammaglobulinemia?`
* **Options:**
* `A. Direct bone marrow suppression by tumor metastases.`
* `B. Loss of immunoglobulins due to a protein-losing enteropathy secondary to chronic diarrhea and complement hyperactivation.`
* `C. Decreased immunoglobulin production secondary to tryptophan depletion by the tumor, impairing B-cell function.`
* `D. Immune complex formation with vasoactive substances released by the tumor, leading to clearance of immunoglobulins.`
* **Correct Answer:** `Correct Answer: B`
#### **Pathophysiology Diagram Content:**
The diagram flows from left to right, depicting a proposed causal chain.
1. **Node 1 (Far Left):**
* **Color/Icon:** Blue circle with an icon of a stomach/intestine.
* **Text:** `Carcinoid tumours and carcinoid syndrome`
2. **Arrow 1:**
* **Label:** `maybe_cause` (red text on a red arrow).
* **Direction:** Points from Node 1 to Node 2.
3. **Node 2 (Center-Left):**
* **Color/Icon:** Green circle with an icon of intestines.
* **Text:** `Malabsorption syndrome`
4. **Arrow 2:**
* **Label:** `maybe_cause` (red text on a red arrow).
* **Direction:** Points from Node 2 to Node 3.
5. **Node 3 (Center-Right):**
* **Color/Icon:** Purple circle with an icon depicting blood vessels and clotting.
* **Text:** `Complement hyperactivation angiopathic thrombosis and protein-losing enteropathy`
6. **Arrow 3:**
* **Label:** `maybe_cause` (red text on a red arrow).
* **Direction:** Points from Node 3 to Node 4.
7. **Node 4 (Far Right):**
* **Color/Icon:** Orange circle with an icon of antibodies (Y-shaped).
* **Text:** `Hypogammaglobulinaemia`
### Key Observations
* The clinical vignette describes a classic presentation of **carcinoid syndrome** (flushing, diarrhea, wheezing, elevated serum 5-HIAA) from an ileal tumor with liver metastases.
* The patient has developed **protein-losing enteropathy** (PLE), evidenced by edema, ascites, and low serum albumin.
* The laboratory finding of low immunoglobulins (IgG, IgA, IgM) with normal complement levels is central to the question.
* The diagram explicitly maps the pathway from the primary tumor to the final lab finding, visually supporting the correct answer (B). It suggests that carcinoid syndrome leads to malabsorption, which triggers complement-mediated vascular injury and PLE, resulting in the loss of immunoglobulins into the gut lumen.
* The term "maybe_cause" on the arrows indicates a proposed or probable mechanism rather than an absolute certainty.
### Interpretation
The image is an educational tool designed to test and explain the pathophysiology behind a specific paraneoplastic syndrome. The data suggests that in this patient with carcinoid tumor and syndrome, the hypogammaglobulinemia is not due to direct bone marrow suppression (A), nutritional deficiency affecting B-cells (C), or immune complex clearance (D). Instead, it is a **secondary loss** phenomenon.
The key investigative link is the development of **protein-losing enteropathy**. Chronic diarrhea from the carcinoid syndrome, potentially exacerbated by complement hyperactivation (leading to mesenteric angiopathy and thrombosis), damages the intestinal mucosa. This damage increases vascular permeability, causing the leakage of plasma proteins—including albumin and immunoglobulins—into the gut. This explains the concurrent hypoalbuminemia and hypogammaglobulinemia. The diagram effectively illustrates this "leaky gut" mechanism as the bridge between the tumor's systemic effects and the observed immunodeficiency. The normal complement levels (C3, C4) are an important clue, as they argue against a primary complement consumption disorder and instead point to complement *activation* as a local mediator of vascular injury in the gut.
</details>
Figure 1: Compositional Reasoning: A sample 3-hop query that requires systematic traversal of axiomatic triples to make a grounded, multi-step clinical deduction.
To bridge this gap, we argue in favor of a bottom-up learning paradigm: grounding models in axiomatic facts and then composing these fundamentals into sophisticated domain knowledge. Knowledge graphs (KGs) provide a natural and promising scaffold for this grounding; they encode entities and relations in a structured, interpretable fashion that can represent the building blocks of domain knowledge at scale. Recent work Dedhia et al. (2025); Wang et al. (2024) has shown how high-quality data can be curated from such graphs and used to fine-tune models to obtain better reasoning traces. However, good static data is just the first step towards mastering the process of composition. Beyond high-quality data, robust reward design is a key lever for shaping models that can compose axiomatic facts from a domain to arrive at a logical conclusion.
Existing post-training methods, e.g., reinforcement learning from human feedback Ouyang et al. (2022) and direct preference optimization Rafailov et al. (2023), optimize models to match human preference with final outputs, not the process that produced them. Proxy reward signals, such as reward length and alignment with expert-written answers, while useful, fail to account for the composition intricacies needed to answer a complex multi-hop query. In practice, reward models often conflate superficial correlates (fluency, deference) with quality, thus leading to reward over-optimization and brittle answers (Shrivastava et al., 2025). In safety-critical domains, the result is a mismatch between human-liked style and ground-truth validity (Damani et al., 2025; Weng, 2024; Rafailov et al., 2023). Whereas process supervision (rewarding intermediate steps) has shown promise in mathematics and logic Zhang et al. (2025); Cui et al. (2025); Wang et al. (2025); Lightman et al. (2023), curating and scaling expert-annotated data for other domains are notoriously difficult to achieve and nontrivial. This raises a key question: How can we build systems and reward signals at scale that promote grounded compositional reasoning in multi-hop tasks without relying on expensive human-in-the-loop annotations?
KGs offer an implicit solution to this scaling problem. In a KG, domain-specific concepts and their relationships are represented as axiomatic triples $(head,relation,tail)$ . Our core insight is that by comparing the reasoning and assertions of a model during post-training against relevant triples and the chain of axiomatic facts required to solve the problem, we can turn the match (or mismatch) into a high-quality reward signal. Instead of an answer that “looks good,” this lets us reward the model to the degree its response is supported by verifiable domain knowledge and implicitly reward it for correctly composing facts to produce a solution. This is readily scalable without requiring external expert supervision and further enables us to move away from top-down distillation and ground the model’s reasoning in the field’s fundamental building blocks.
In this article, we realize this idea through a Base Model $\rightarrow$ SFT [Low-Rank Adaptation (LoRA)] $\rightarrow$ RL [Group Relative Policy Optimization (GRPO)] post-training pipeline that uses a grounded KG to derive a novel reward signal to enable compositional reasoning (Hu et al., 2022; Guo et al., 2025; Yasunaga et al., 2021). Whereas the approach can be generally applied, we study it in the medical domain, a field that serves as a rigorous stress test for compositional reasoning. Medical knowledge inherently requires multi-hop reasoning; a single clinical diagnosis may require navigating from a patient’s demographics and medical history to symptoms, from those symptoms to a disease, and finally to a drug (a sample multi-hop query is shown in Fig. 1). By training a Qwen3 14B model Yang et al. (2025) on simple 1-, 2-, and 3-hop reasoning paths derived from a KG, we probe whether it can learn the underlying “logic of composition” to solve unseen, complex medical queries, ranging from 2- to 5-hop, in the ICD-Bench test suite (Dedhia et al., 2025). Our results indicate that this grounded SFT+RL approach leads to large accuracy improvements on the most difficult questions, and remains robust under stress tests, such as option shuffling and ICD-10 category breakdowns (Organization, 1992). We find that while SFT provides the necessary knowledge base, RL acts as the “compositional bridge.” We demonstrate that insights learned on an 8B model transfer effectively to a 14B model, outperforming larger reasoning and frontier models.
Our core contributions can be summarized as follows:
- A Grounded, Scalable Reinforcement Learning with Verifiable Rewards (RLVR) Pipeline: We introduce a scalable SFT+RL post-training framework designed to enable compositional reasoning in models using KGs as a verifiable ground truth.
- KG-Path Inspired Reward: We conduct a thorough investigation to design a novel reward signal derived from the KG that encourages compositional reasoning, correctness, and enables process supervision at scale.
- Compositional Generalization: We demonstrate how training on 1-to-3-hop paths enables a model to generalize to difficult and longer 4-, 5-hop questions, significantly outperforming base models and larger models.
- Robustness & Real-World Validation: We stratify our model’s performance by different difficulty levels, on real-world medical categories (ICD-10), and its resilience against adversarial option shuffling.
## 2 Related Work
### 2.1 Role of SFT and RL in Reasoning
Recent studies have intensely debated the distinct contributions of SFT and RL to model performance (Jin et al., 2025; Kang et al., 2025; Matsutani et al., 2025). The authors of Chu et al. (2025) argue that “SFT memorizes, RL generalizes,” claiming that while SFT stabilizes outputs, it struggles with out-of-distribution scenarios that RL can navigate. The authors of Rajani et al. (2025) characterize GRPO as a “scalpel” that amplifies existing capabilities and SFT as a “hammer” to overwrite prior knowledge. Our findings align with these dynamics. We use SFT to instill atomic domain knowledge in the model and RL to amplify compositional logic required to connect such knowledge.
Contrary to the findings in Yue et al. (2025), our results on unseen 4-, 5-hop queries demonstrate that when rewards are grounded in relevant axiomatic primitives, RL can elicit novel compositional abilities beyond the baseline. This echoes the findings in Yuan et al. (2025) that demonstrate that RL can teach models to compose old skills into new ones; we validate this in a high-stakes real-world domain rather than a synthetic one.
### 2.2 RL on KGs
Traditional applications of RL on KGs, e.g., Das et al. (2017) and Xiong et al. (2017), primarily focus on traversing graph structures to complete missing triples (link prediction) or find missing entities. The authors of Lin et al. (2018) further refine this approach with reward shaping to improve multi-hop reasoning, but still largely confine themselves to the task of graph completion instead of open-ended question answering in a real-world setting. In more recent works, the authors of Wang et al. (2024) propose “Learning to Plan,” where KGs guide the retrieval process for retrieval-augmented generation systems, and those of Yan et al. (2025) introduce RL from KG feedback to replace human feedback with KG signals. While promising, these approaches often limit the role of the KG to retrieval planning or simple search tools for alignment.
Our work differs fundamentally by centrally positioning KGs as a dense process verifier for real-world multi-hop reasoning. The authors of Khatwani et al. (2025) use LLMs as a reward model for KG reasoning, but found the approach to be brittle, with poor transfer to downstream diagnostic tasks. We attribute this to the lack of a compositional training curriculum; by combining the bottom-up data curation of Dedhia et al. (2025) with treating the KG as a reward model to derive path-aligned signals, we overcome this limitation. Furthermore, unlike Gunjal et al. (2025) that uses unstructured LLM-created rubrics as rewards, or rule-based Logic-RL Xie et al. (2025), we derive our signal directly from grounded axiomatic paths of the KG.
## 3 Preliminaries
### 3.1 Notation and RL for Language Models
We treat an LLM as a stochastic policy $\pi_{\theta}$ that maps a query $q$ [multiple-choice question (MCQ) task] to a distribution over possible completions $y$ . Each completion $y$ comprises a reasoning trace $r$ (chain-of-thought) Wei et al. (2022) and a final answer $\hat{a}$ (spanning A-D). Each training task $q$ is associated with a ground-truth answer $a^{*}$ and a ground-truth KG path $P={(h_{i},r_{i},t_{i})}^{L}_{i=1}$ (see Section 4.1).
A composite scalar reward function $R(y)$ , derived from the KG, is used to score a generated completion $y$ (see Section 4.4). The RL objective is to maximize the expected reward under the prompt distribution:
$$
\mathbf{J}(\theta)=\mathbf{E}_{q\sim D}\mathbf{E}_{y\sim\pi_{\theta}(\cdot|q)}[R(y)]
$$
Whereas the response $y$ is produced token-by-token, we treat the entire completion as a single trajectory for reward assignment, following common practice in LLM post-training.
Policy updates are performed using GRPO, a popular proximal policy optimization-like optimizer Schulman et al. (2017) that drops the critic and estimates advantages at the group level using normalization (Guo et al., 2025). See Appendix E for details of our hyperparameter configuration for the SFT and RL stages.
### 3.2 SFT Followed by RL
Our training recipe follows the widely adopted Base Model $\rightarrow$ SFT $\rightarrow$ RL framework for improving LLMs. First, an SFT stage initializes the policy (base LLM) to produce high-quality, KG-grounded reasoning traces. A subsequent RL stage refines the policy directly to optimize the reward signal and enable compositional reasoning. Formally, SFT minimizes the negative log-likelihood on a supervised dataset consisting of question-answer (QA) tasks paired with reference reasoning traces and answers.
In our experiments, the SFT stage provides broad KG coverage, whereas the RL stage is deliberately small: a design choice motivated by observed instability in an RL-from-scratch approach and because targeted RL with good reward can enable compositional abilities when built atop SFT initialization (Section 4.2, Appendix G have more details).
### 3.3 Medical KG: Unified Medical Language System (UMLS)
We instantiate our framework on a standard biomedical KG based on UMLS Bodenreider (2004), which encodes canonical medical ontology in a structured graph format. Each fact is represented as a triple $(head,relation,tail)$ and multi-hop paths $P={(h_{i},r_{i},t_{i})}_{i=1}^{L}$ serve as axiomatic compositional primitives used to generate QA tasks and path-alignment reward signals, and evaluate correctness. Full QA task generation and reward-design choices/strategies are described in the following section.
## 4 Methodology
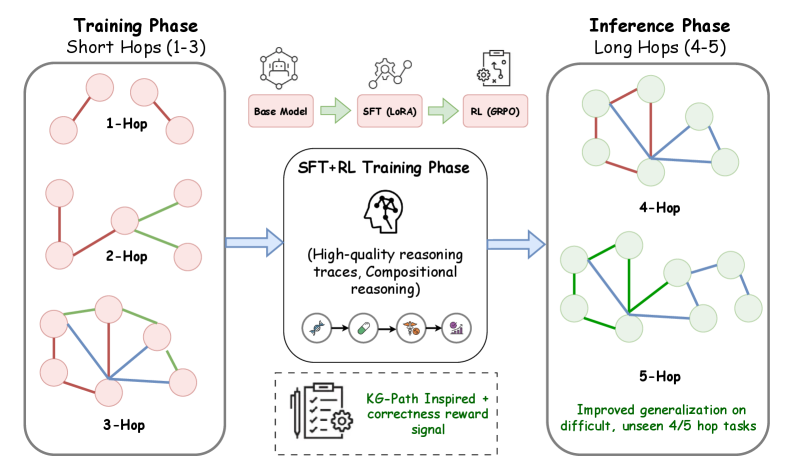
This section describes our data construction and training pipeline. We emphasize the sequential decisions we make: dataset choices, SFT warm start, RL budget, reward design, and experiments that guide these choices. Our training pipeline is designed to transition a base model from broad competence to deep, compositional medical-domain reasoning. Fig. 2 presents an overview of our pipeline.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Multi-Hop Reasoning Training and Inference Pipeline
### Overview
The image is a technical diagram illustrating a machine learning pipeline designed to improve multi-hop reasoning. It depicts a two-stage process: a **Training Phase** focusing on short reasoning chains (1-3 hops) and an **Inference Phase** where the trained model tackles longer, more complex chains (4-5 hops). The central mechanism enabling this generalization is a combined Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) training regimen.
### Components/Axes
The diagram is organized into three primary vertical sections, connected by directional arrows indicating flow.
1. **Left Section: Training Phase (Short Hops 1-3)**
* **Title:** "Training Phase / Short Hops (1-3)"
* **Content:** Three vertically stacked graph diagrams labeled "1-Hop", "2-Hop", and "3-Hop".
* **Visual Elements:** Each graph consists of pink circular nodes connected by colored lines (red, green, blue). The complexity (number of nodes and connections) increases from 1-Hop to 3-Hop.
2. **Center Section: SFT+RL Training Phase**
* **Title:** "SFT+RL Training Phase"
* **Top Flow Diagram:** A horizontal sequence of three pink rectangular boxes connected by green arrows:
* Box 1: "Base Model" (with a network icon above).
* Box 2: "SFT (LoRA)" (with a gear/network icon above).
* Box 3: "RL (GRPO)" (with a clipboard/checklist icon above).
* **Central Icon & Text:** A stylized brain icon with a lightning bolt. Below it, the text: "(High-quality reasoning traces, Compositional reasoning)".
* **Tool Icons:** A horizontal row of four circular icons below the text: a wrench, a key, a toolbox, and a brain with a gear.
* **Bottom Dashed Box:** Contains an icon of a pen writing on a checklist next to a gear. The text reads: "K6-Path Inspired + / correctness reward signal".
3. **Right Section: Inference Phase (Long Hops 4-5)**
* **Title:** "Inference Phase / Long Hops (4-5)"
* **Content:** Two vertically stacked graph diagrams labeled "4-Hop" and "5-Hop".
* **Visual Elements:** Graphs with light green circular nodes connected by colored lines (red, green, blue). These graphs are more complex and interconnected than those in the training phase.
* **Footer Text:** Below the 5-Hop graph, green text states: "Improved generalization on / difficult, unseen 4/5 hop tasks".
### Detailed Analysis
* **Training Data Structure:** The training phase uses progressively complex reasoning graphs:
* **1-Hop:** A simple chain of 3 nodes connected by 2 red lines.
* **2-Hop:** A branching structure with 5 nodes. Connections include red, green, and blue lines.
* **3-Hop:** A more densely connected graph with 6 nodes and multiple red, green, and blue connections forming cycles.
* **Training Methodology:** The core training process involves:
1. Starting with a **Base Model**.
2. Applying **Supervised Fine-Tuning (SFT)** using **LoRA** (Low-Rank Adaptation).
3. Further refining the model with **Reinforcement Learning (RL)** using **GRPO** (likely a specific RL algorithm).
4. This process is designed to produce "High-quality reasoning traces" and enable "Compositional reasoning".
5. A specific reward signal, inspired by "K6-Path" and focused on "correctness", guides the RL phase.
* **Inference Outcome:** The model, after training on 1-3 hop tasks, is applied to more complex **4-Hop** and **5-Hop** graphs during inference. These graphs feature light green nodes and intricate, multi-colored connections, representing "difficult, unseen" tasks. The diagram asserts this leads to "Improved generalization".
### Key Observations
1. **Color Coding:** Node color changes from **pink** (training) to **light green** (inference), visually distinguishing the phases. Edge colors (red, green, blue) are consistent across both phases, likely representing different types of relationships or reasoning steps.
2. **Complexity Progression:** There is a clear visual increase in graph complexity (node count and connection density) from the 1-Hop training example to the 5-Hop inference example.
3. **Spatial Flow:** The process flows left-to-right: Training Data -> Training Methodology -> Inference Application. The central "SFT+RL Training Phase" box is the transformative engine.
4. **Explicit Claim:** The diagram makes a direct causal claim: training on short-hop graphs (1-3) using the described SFT+RL method results in the ability to handle long-hop graphs (4-5) that were not seen during training.
### Interpretation
This diagram outlines a curriculum learning strategy for AI reasoning. The core hypothesis is that by mastering simpler, shorter reasoning chains (1-3 hops), a model can develop fundamental compositional reasoning skills. These skills then **generalize** to solve more complex, longer-chain problems (4-5 hops) without direct training on them.
The "K6-Path Inspired + correctness reward signal" is a critical component. It suggests the RL phase doesn't just reward correct final answers but likely evaluates the quality and logical soundness of the intermediate reasoning steps (the "path"), encouraging the model to build robust, generalizable reasoning procedures.
The shift from pink to green nodes symbolizes the transition from a learning state to a deployed, capable state. The diagram argues that this specific training pipeline (Base -> SFT/LoRA -> RL/GRPO with a structured reward) is an effective method for achieving **out-of-distribution generalization** in multi-step reasoning tasks, a significant challenge in AI. The ultimate goal is to create models that don't just memorize patterns but learn underlying logical structures applicable to novel, more complex situations.
</details>
Figure 2: SFT+RL pipeline overview: Schematic of the pipeline from SFT to KG-grounded RL. While SFT enables domain-specific grounding, the path-derived reward signal during RL provides the process supervision necessary for compositional reasoning.
### 4.1 Data Construction and Axiomatic Grounding
Given our testbed that involves compositional reasoning and to ensure our model learns true depth rather than mere pattern matching, we adopt the data-generation and curation pipeline from Dedhia et al. (2025), which enables scalable generation of multi-hop reasoning questions grounded in a medical KG. The structured representation of medical concepts, such as diseases, drugs, signs, and mechanisms, in a KG as $(head,relation,tail)$ triples enables question generation directly from verifiable and grounded KG paths. Questions are generated in natural language in an MCQ format using a backend LLM by traversing $n$ -length paths within the KG, where $n$ represents the number of “hops” required to link a starting node to a final node. This enables precise control over the compositional complexity of each query. Furthermore, each question is paired with a rich reasoning trace and a ground truth path: a sequence of $(head,relation,tail)$ triples that constitutes a verifiable logical chain. The pipeline helps stratify questions by hop length, difficulty, and ICD-10 category, and enforces strict separation between the training and test sets at the path and entity levels to avoid leakage.
We generate a training set of 24,660 QA tasks designed to ensure maximum node coverage across the KG (Yasunaga et al., 2021). For evaluation, we use ICD-Bench, a non-overlapping test set of 3,675 questions (Dedhia et al., 2025). Importantly, the training set consists of 1-3 hop paths, whereas ICD-Bench includes 2-5 hop path tasks across 15 ICD-10 categories to test zero-shot compositional generalization at different difficulty levels [1 (very easy) - 5 (very hard)]. More analysis of overlaps between the training and test sets is presented in Appendix D.
Our training pipeline consists of three stages: Base Model $\rightarrow$ SFT (LoRA) $\rightarrow$ RL (GRPO). This design reflects our central hypothesis that compositional reasoning emerges most reliably when models are first grounded in rich reasoning traces via supervised learning and then tuned using scalable process-aligned rewards derived from the KG paths. We emphasize that all training data and rewards are derived from the same KG to ensure consistency between training and evaluation.
### 4.2 RL Alone is Insufficient
A core finding of our work is that the Zero-RL approach, applying GRPO directly to the base LLM, is insufficient for deep domain expertise at our model scale. The model requires an understanding of the domain axioms before it can learn to compose. Starting from the base model (Qwen3 8B), we apply GRPO directly using subsets of training data: 5k, 10k, and all 24.66k examples. Across these settings, we find that while RL improves performance relative to the base model, it does not consistently outperform SFT-only training on the base model. Interestingly, the budget of 5k examples yields the strongest results among all other settings, suggesting how large-scale vanilla RL without proper grounding is insufficient for compositional behavior, motivating the use of SFT for an initial warm start.
Based on these observations, we use 5k examples in the RL stage and the remaining 19.66k in the SFT stage. The base model is fine-tuned using LoRA on 19.66k examples, followed by GRPO on the remaining 5k examples as per the SFT+RL pipeline.
See Appendix A, B for detailed ablations with the Zero-RL and SFT+RL pipelines on the Qwen3 8B model, respectively. See Appendix H for our GRPO training prompt.
### 4.3 Reward Design Exploration for Compositional Reasoning
A central goal and a novel contribution of this work is to design scalable reward signals during training that enable compositional reasoning beyond surface-level understanding. Towards this end, we conduct extensive ablation studies using a combination of four distinct reward signals to determine which best fosters verifiable composition:
- Binary Correctness $(R_{bin})$ : A simple outcome-based signal that rewards the final answer.
- Similarity $(R_{sim})$ : A distillation-based reward that measures the Jaccard similarity between the model output and an expert reasoning trace (generated by Gemini 2.5 Pro during data curation).
- Thinking Quality $(R_{think})$ : A reward designed to score the thinking quality and length of the generation.
- Path Alignment $(R_{path})$ : A novel reward that scores the model based on the coverage of the ground-truth KG triples in the model response.
We conduct a systematic exploration by evaluating a combination of these rewards, always including $R_{bin}$ (+1 for correctness, 0 otherwise) as a minimal signal. Empirically, we discover that $R_{think}$ is often unstable and leads to reward hacking, generating inefficacious chains. $R_{sim}$ also proved sub-optimal, suggesting distillation rewards over-optimize aesthetic mimicry rather than true logical composition.
Our findings highlight the power of simplicity: The combination of path alignment and binary correctness provides the strongest signal for composition. Whereas $R_{bin}$ optimizes correctness, $R_{path}$ rewards the model for identifying and applying the axiomatic facts (triples) required to compose the correct solution. To further strengthen the outcome signal, we replace the simple $R_{bin}$ with negative sampling reinforcement Zhu et al. (2025), which penalizes incorrect generations by upweighting the negative reward, thereby encouraging the model to explore alternative/correct trajectories.
### 4.4 KG-Grounded Reward Formulation
To provide a robust reward signal to enable composition, we develop a composite reward that balances outcome correctness with path-level alignment grounded in the KG. Let the model generate a response $y$ for a question $q$ with the reasoning trace $r$ and a final answer $\hat{a}$ . For each QA task, there is a ground truth answer $a^{*}$ and a ground-truth KG path $P={(h_{i},r_{i},t_{i})}_{i=1}^{L}$ , where $L$ is the path length. The total reward is then a combination of the two rewards:
$$
\vskip-5.0ptR_{total}(y)=R_{bin}(\hat{a},a^{*})+R_{path}(r,P)\vskip-5.0pt
$$
Binary Correctness Reward: This provides a minimal but necessary supervision signal on the final answer.
$$
\vskip-5.0ptR_{\text{bin}}(\hat{a},a^{*})=\begin{cases}\alpha,&\text{if }\hat{a}=a^{*}\\
-\beta,&\text{otherwise}\end{cases}\vskip-5.0pt
$$
where $\alpha,\beta>0$ and $\beta>\alpha$ . This asymmetric design ensures stable learning by reinforcing exploration of correct alternate paths. We use $\alpha=0.1,\beta=1$ in accordance with investigations by (Zhu et al., 2025).
Path Alignment Reward (KG-grounded): The primary technical innovation is $R_{path}$ , which provides automated and scalable process supervision by evaluating whether the reasoning trace of the model aligns with the ground-truth KG path $P$ during RL post-training. We first tokenize and normalize the reasoning trace $r$ to extract a set of textual tokens, $T(r)$ . We derive a corresponding set of path tokens, $T(P)$ , from the ground-truth path $P$ , representing the entities in $P$ . The core signal is path coverage:
$$
\vskip-5.0pt\text{coverage}(r,P)=\frac{\mid T(r)\cap T(P)\mid}{\mid T(P)\mid}\vskip-5.0pt
$$
We include a minimum-hit constraint that requires alignment with at least two distinct path entities to discourage trivial matches and promote logical composition. We apply an additional repetition penalty to reduce reward hacking and avoid linguistic collapse. The final reward is defined as:
$$
\vskip-5.0pt\begin{split}R_{path}(r,P)=&\min(\gamma_{1}\cdot\text{coverage}(r,P)\\
&+\gamma_{2}\cdot\mathbf{I}(|T(r)\cap T(P)|\geq 2),R_{max}),\end{split}\vskip-5.0pt
$$
scaled by a repetition penalty factor, $\phi_{rep}$ , and clipped to a fixed maximum. We use $\gamma_{1}=1.2,\gamma_{2}=0.3$ , $R_{max}=1.5$ .
The total reward, $R_{total}$ , is process-level, grounded, and compositional. It is readily scalable and easily verifiable as a result of the grounding in the KG. Furthermore, unlike similarity-based distillation or AI-based rubric rewards Gunjal et al. (2025), alignment is scored against true domain structure rather than stylistic mimicry. We present a formal formulation of $R_{sim}$ and $R_{think}$ in Appendix C.
### 4.5 Scaling and Benchmarking
We evaluate our pipeline on the Qwen3 8B model before scaling the findings to the 14B variant without modification. The 14B model trained on our pipeline not only generalizes to 2- and 3-hop tasks, but also to 4-and 5-hop tasks with remarkable efficacy, surpassing much larger frontier models. In addition to overall accuracy, we stratify performance by hop length, difficulty level, ICD-10 category, and robustness under the option-shuffling stress test.
## 5 Results
Setup: We initially evaluate three systems: Base Qwen3 14B model, model trained using LoRA on the full training set (24,660 QA tasks), and our proposed SFT+RL pipeline (SFT on 19,660 tasks followed by GRPO on the remaining 5k tasks) based on leveraging the KG-derived reward. We do not report results for models trained using the Zero-RL approach, described in Section 4.2, since all of them performed worse than SFT on the full dataset (see Appendix A for details). All evaluations use the held-out test ICD-Bench test set (3,675 tasks) to validate whether path-derived signals truly enable compositional reasoning. Finally, we evaluate our SFT+RL model against larger frontier and reasoning models. See Appendix F for sample model responses of our final Qwen3 14B SFT+RL model.
### 5.1 Scaling Composition: From Short-Hop Training to Long-Hop Reasoning
The primary claim of this work is that KGs function as implicit reward models, and grounding the model reasoning in path-derived signals enables it to learn the underlying logic of composition rather than regurgitating information seen during training.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Chart: Model Accuracy vs. Reasoning Complexity
### Overview
The image is a line chart comparing the performance of three different models—Base Model, SFT Only, and SFT+RL—on a task requiring increasing numbers of reasoning steps. The chart demonstrates how accuracy changes as the complexity of the reasoning task (measured in "hops") increases, with a specific focus on generalization to higher, unseen complexity levels.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Number of Reasoning Hops"**. It has discrete integer markers at 2, 3, 4, and 5.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The scale runs from 60 to 95, with major gridlines at intervals of 5% (60, 65, 70, 75, 80, 85, 90, 95).
* **Legend:** Located in the bottom-right corner of the plot area. It defines three data series:
* **Base Model:** Represented by a purple line with circular markers (●).
* **SFT Only:** Represented by a pink/magenta line with square markers (■).
* **SFT+RL:** Represented by an orange line with diamond markers (◆).
* **Annotations:**
* A shaded beige region spans the x-axis from 4 to 5 hops. Text within this region reads: **"Generalization (unseen complexity)"**.
* A double-headed vertical arrow connects the final data points of the "SFT+RL" and "Base Model" series at x=5. A label next to it reads: **"+11.1%"**.
### Detailed Analysis
**Data Series Trends and Approximate Values:**
1. **Base Model (Purple, ●):**
* **Trend:** Shows a slight dip from 2 to 3 hops, followed by a gradual, steady increase from 3 to 5 hops.
* **Data Points (Approximate):**
* 2 Hops: ~68%
* 3 Hops: ~64%
* 4 Hops: ~68%
* 5 Hops: ~70%
2. **SFT Only (Pink, ■):**
* **Trend:** Follows a similar pattern to the Base Model—a dip from 2 to 3 hops, then a recovery and increase. It consistently performs better than the Base Model.
* **Data Points (Approximate):**
* 2 Hops: ~77%
* 3 Hops: ~74%
* 4 Hops: ~79%
* 5 Hops: ~78%
3. **SFT+RL (Orange, ◆):**
* **Trend:** Also exhibits a dip from 2 to 3 hops, but then shows the strongest upward trajectory from 3 to 5 hops. It is the top-performing model at every data point.
* **Data Points (Approximate):**
* 2 Hops: ~85%
* 3 Hops: ~81%
* 4 Hops: ~87%
* 5 Hops: ~89%
**Performance Gap:**
The annotation "+11.1%" quantifies the performance advantage of the **SFT+RL** model over the **Base Model** at the highest complexity level (5 reasoning hops). The gap between the top (SFT+RL) and middle (SFT Only) lines also appears to widen slightly at 4 and 5 hops compared to 2 hops.
### Key Observations
1. **Universal Dip at 3 Hops:** All three models experience a noticeable drop in accuracy when moving from 2 to 3 reasoning hops, suggesting this specific increase in complexity poses a common challenge.
2. **Consistent Performance Hierarchy:** The ranking of the models (SFT+RL > SFT Only > Base Model) is maintained across all tested levels of reasoning complexity.
3. **Generalization Performance:** The shaded "Generalization" region highlights that the task at 4 and 5 hops was likely not seen during training. The chart shows that all models, especially SFT+RL, recover and improve accuracy in this region, indicating successful generalization.
4. **Widening Advantage:** The performance gap between the most advanced model (SFT+RL) and the baseline appears largest at the highest complexity (5 hops), suggesting the benefits of the combined SFT and RL approach scale with task difficulty.
### Interpretation
This chart provides strong evidence for the effectiveness of a training pipeline that combines Supervised Fine-Tuning (SFT) with Reinforcement Learning (RL) for complex reasoning tasks.
* **The Data Suggests:** While SFT alone provides a significant boost over the base model, adding RL on top of SFT yields further substantial gains, particularly as the reasoning chain grows longer and more complex. The dip at 3 hops might indicate a phase where the reasoning structure becomes non-trivial, challenging all models before they adapt to longer chains.
* **Element Relationships:** The x-axis (complexity) directly challenges the models, whose performance is measured on the y-axis (accuracy). The legend defines the independent variable (training method), while the annotation explicitly calls out the most critical finding: superior generalization to higher, unseen complexity.
* **Notable Anomaly/Trend:** The most significant trend is not just the higher accuracy of SFT+RL, but its steeper positive slope from 3 to 5 hops. This indicates it is not only better but also *more robust* to increasing complexity, which is the key to solving real-world problems requiring multi-step deduction. The +11.1% gap is a concrete measure of this robustness advantage at the limit of the tested data.
</details>
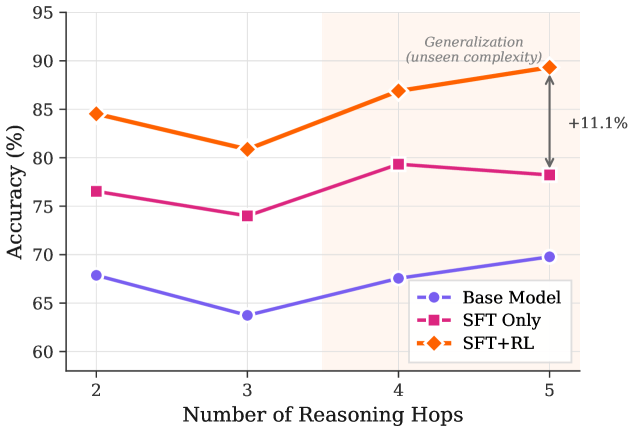
Figure 3: Accuracy by Hop Length: Our SFT+RL model not only outperforms baselines on 2-3 hop tasks but exhibits a positive performance gradient on unseen 4-, 5-hop reasoning tasks, validating the “compositional bridge” enabled by path-aligned rewards.
Path-derived Signals Enable Compositional Reasoning: Whereas the model was exposed to 1-, 2-, and 3-hop paths during the SFT+RL training phase, it remained totally naive to tasks involving 4-, 5-hop reasoning. As shown in Fig. 3, the SFT+RL model demonstrates substantially stronger generalization to longer paths, achieving a notable gain of 7.5% on unseen 4-hop and 11.1% on unseen 5-hop questions relative to the SFT-only approach. This improvement is not attributable to exposure to longer chains, since the training and evaluation distributions are identical across all models. Instead, it reflects the effect of path-derived signals introduced during RL. By rewarding assertions that align the model directly with the ground-truth KG path, the model learns the logic of composition. Importantly, the generalization gap between the SFT-only and SFT+RL approaches widens as hop-length increases. This is a hallmark of genuine compositional learning. The KG-derived reward signal $(R_{path})$ enables the model to decompose long-horizon reasoning into verifiable steps and compose reasoning beyond the complexity observed during training.
### 5.2 Robustness to Tasks Involving Reasoning Depth
A significant challenge in medical reasoning is maintaining integrity as the complexity of tasks increases. Aggregate performance metrics often obscure model failure on long-tail high-difficulty scenarios, where deep reasoning is paramount. We assign difficulty ratings from 1 (very easy) to 5 (very hard) Dedhia et al. (2025) to each ICD-Bench question and assess model performance as a function of question difficulty.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Grouped Bar Chart: Model Accuracy by Difficulty Level
### Overview
The image displays a grouped bar chart comparing the accuracy percentages of three different models across five difficulty levels. The chart visually demonstrates how model performance degrades as task difficulty increases, with one model consistently outperforming the others.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **X-Axis (Horizontal):** Labeled "Difficulty Level". It contains five categorical groups:
1. `1 (Very Easy)`
2. `2 (Easy)`
3. `3 (Medium)`
4. `4 (Hard)`
5. `5 (Very Hard)`
* **Y-Axis (Vertical):** Labeled "Accuracy (%)". The scale runs from 0 to 100 in increments of 20 (0, 20, 40, 60, 80, 100).
* **Legend:** Located in the top-right corner of the chart area. It defines three data series:
* **Base Model:** Represented by purple bars.
* **SFT Only:** Represented by pink/magenta bars.
* **SFT+RL:** Represented by orange bars.
### Detailed Analysis
The following table reconstructs the approximate accuracy values for each model at each difficulty level. Values are estimated based on bar height relative to the y-axis grid lines.
| Difficulty Level | Base Model (Purple) | SFT Only (Pink) | SFT+RL (Orange) |
| :--- | :--- | :--- | :--- |
| **1 (Very Easy)** | ~85% | ~84% | ~93% |
| **2 (Easy)** | ~60% | ~77% | ~83% |
| **3 (Medium)** | ~49% | ~71% | ~78% |
| **4 (Hard)** | ~39% | ~65% | ~72% |
| **5 (Very Hard)** | ~20% | ~49% | ~56% |
**Trend Verification per Data Series:**
* **Base Model (Purple):** Shows a steep, consistent downward trend. Accuracy starts high (~85%) for very easy tasks but drops sharply with each increase in difficulty, reaching its lowest point (~20%) at the "Very Hard" level.
* **SFT Only (Pink):** Also shows a consistent downward trend, but the slope is less severe than the Base Model. It starts at a similar level to the Base Model (~84%) but maintains significantly higher accuracy at all subsequent difficulty levels.
* **SFT+RL (Orange):** Exhibits the most resilient performance. While it also follows a downward trend, it consistently achieves the highest accuracy at every single difficulty level. The performance gap between SFT+RL and the other models is most pronounced at the "Very Hard" level.
### Key Observations
1. **Performance Hierarchy:** A clear and consistent hierarchy is visible across all difficulty levels: `SFT+RL > SFT Only > Base Model`.
2. **Impact of Difficulty:** All models suffer a performance drop as difficulty increases. The drop is most catastrophic for the Base Model.
3. **Widening Gap:** The absolute performance gap between the models widens as difficulty increases. For example, at "Very Easy," the difference between the best (SFT+RL) and worst (Base Model) is ~8 percentage points. At "Very Hard," this gap expands to ~36 percentage points.
4. **SFT+RL Resilience:** The SFT+RL model demonstrates the greatest robustness, retaining over 50% accuracy even on "Very Hard" tasks, a level the Base Model fails to achieve beyond "Medium" difficulty.
### Interpretation
This chart provides strong evidence for the effectiveness of a training pipeline that combines Supervised Fine-Tuning (SFT) with Reinforcement Learning (RL).
* **What the data suggests:** The Base Model likely represents a foundational model with general capabilities. Applying SFT ("SFT Only") provides a significant and consistent boost in accuracy, indicating that task-specific supervised training is highly beneficial. The further addition of RL ("SFT+RL") yields another substantial improvement, suggesting that RL helps the model optimize its responses in a way that is particularly advantageous for more complex, higher-difficulty problems.
* **How elements relate:** The difficulty levels act as a stress test. The chart reveals that while SFT improves performance across the board, the combination of SFT and RL creates a model that is not only more accurate but also more **robust** to increasing task complexity. The widening gap implies that RL may be teaching the model more fundamental reasoning or problem-solving strategies that become critical when simple pattern matching (which might suffice for easy tasks) is no longer enough.
* **Notable Anomalies:** There are no major outliers or anomalous data points. The trends are smooth and consistent, which strengthens the conclusion that the observed performance differences are a direct result of the training methodologies (Base vs. SFT vs. SFT+RL) rather than noise or error. The data presents a clear narrative of incremental improvement through advanced training techniques.
</details>
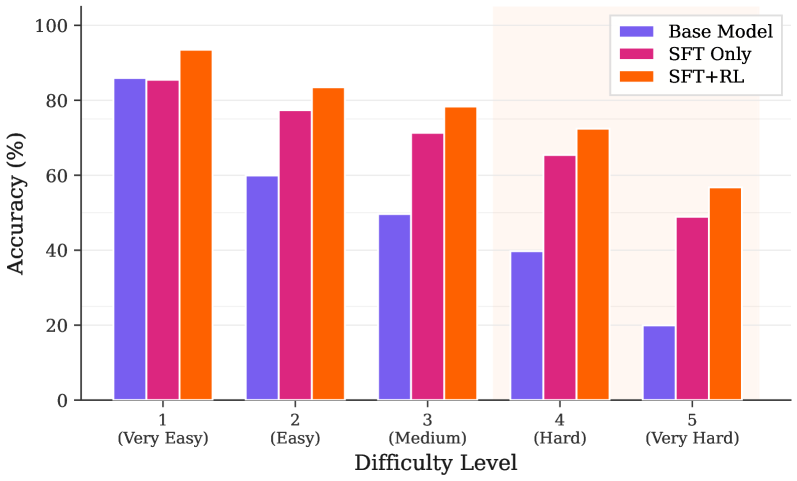
Figure 4: Accuracy by Difficulty Level: Whereas the Base Model’s reasoning collapses as task complexity increases, the SFT+RL pipeline exhibits robustness, maintaining a consistent lead over the SFT-only baseline across all levels.
Dominance in High-Complexity Tasks: The results shown in Fig. 4 demonstrate that the SFT+RL pipeline, grounded in path-derived signals, provides the most significant gains as task complexity increases. On Level-5 tasks, the base model accuracy collapses to 19.94%, indicating worse-than-random-guess accuracy in complex clinical scenarios. Whereas the SFT-only approach improves this to 48.93%, our SFT+RL model achieves 56.75%, nearly tripling the base model performance.
Consistency across all Difficulty Levels: On Level-1 tasks, our model reaches a near-ceiling accuracy (93.49%) and the performance gap remains robust across difficulty levels, with the SFT+RL model consistently maintaining a 7-10% lead over the SFT-only model. This demonstrates that by using the KG as an implicit reward model, we raise the performance floor for the most complex queries. On Level-5 tasks, where even large frontier models struggle, maintaining over 56% accuracy is a testament to how path-aligned rewards do more than just stylistic inference; they enable the model to reliably compose multi-step chains.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Horizontal Grouped Bar Chart: Improvement Over Base Model by Medical Category
### Overview
This image is a horizontal grouped bar chart comparing the performance improvement of two different methods ("SFT Only" and "SFT+RL (Ours)") over a base model across 15 distinct medical categories. The improvement is measured as a percentage.
### Components/Axes
* **Chart Type:** Horizontal Grouped Bar Chart.
* **Y-Axis (Vertical):** Lists 15 medical categories. From top to bottom:
1. Ear
2. Congenital
3. Neoplasms
4. Circulatory
5. Pharmacology
6. Eye
7. Musculoskeletal
8. Blood/Immune
9. Infectious
10. Respiratory
11. Skin
12. Endocrine
13. Digestive
14. Nervous
15. Mental Health
* **X-Axis (Horizontal):** Labeled "Improvement over Base Model (%)". The scale runs from 0 to 25, with major tick marks at 0, 5, 10, 15, 20, and 25.
* **Legend:** Located in the bottom-right corner of the chart area.
* **Magenta/Pink Bar:** Labeled "SFT Only".
* **Orange Bar:** Labeled "SFT+RL (Ours)".
* **Data Series:** Each medical category has two bars grouped together: a magenta bar (SFT Only) on the left and an orange bar (SFT+RL) on the right.
### Detailed Analysis
Below is an analysis of each category. For each, the visual trend is described first (orange bar vs. magenta bar), followed by approximate percentage values estimated from the x-axis.
1. **Ear:**
* **Trend:** The orange bar (SFT+RL) is significantly longer than the magenta bar (SFT Only).
* **Values:** SFT Only ≈ 17%, SFT+RL ≈ 22.5%.
2. **Congenital:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 14%, SFT+RL ≈ 22.5%.
3. **Neoplasms:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 13%, SFT+RL ≈ 22%.
4. **Circulatory:**
* **Trend:** The orange bar is substantially longer than the magenta bar.
* **Values:** SFT Only ≈ 10%, SFT+RL ≈ 21%.
5. **Pharmacology:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 11%, SFT+RL ≈ 18.5%.
6. **Eye:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 12%, SFT+RL ≈ 18%.
7. **Musculoskeletal:**
* **Trend:** The orange bar is much longer than the magenta bar.
* **Values:** SFT Only ≈ 6%, SFT+RL ≈ 17%.
8. **Blood/Immune:**
* **Trend:** The orange bar is dramatically longer than the magenta bar.
* **Values:** SFT Only ≈ 4%, SFT+RL ≈ 17%.
9. **Infectious:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 10%, SFT+RL ≈ 16%.
10. **Respiratory:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 8.5%, SFT+RL ≈ 16%.
11. **Skin:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 9%, SFT+RL ≈ 15.5%.
12. **Endocrine:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 7%, SFT+RL ≈ 15%.
13. **Digestive:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 6.5%, SFT+RL ≈ 13.5%.
14. **Nervous:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 10.5%, SFT+RL ≈ 13.5%.
15. **Mental Health:**
* **Trend:** The orange bar is longer than the magenta bar.
* **Values:** SFT Only ≈ 6%, SFT+RL ≈ 13%.
### Key Observations
* **Consistent Superiority:** In all 15 medical categories, the "SFT+RL (Ours)" method (orange bars) shows a greater improvement over the base model than the "SFT Only" method (magenta bars).
* **Magnitude of Improvement:** The improvement for "SFT+RL" ranges from approximately 13% (Mental Health, Digestive) to 22.5% (Ear, Congenital). The improvement for "SFT Only" ranges from approximately 4% (Blood/Immune) to 17% (Ear).
* **Largest Gains:** The most significant absolute improvements for the "SFT+RL" method are seen in the "Ear," "Congenital," and "Neoplasms" categories, all exceeding 20%.
* **Smallest Gains:** The smallest improvements for "SFT+RL" are in "Mental Health" and "Digestive," both around 13-13.5%.
* **Largest Performance Gap:** The most substantial difference between the two methods appears in the "Blood/Immune" category, where "SFT+RL" shows an improvement of ~17% compared to only ~4% for "SFT Only."
* **Smallest Performance Gap:** The smallest difference between the methods is in the "Nervous" category, where the values are closest (~10.5% vs. ~13.5%).
### Interpretation
The data strongly suggests that the proposed method, which combines Supervised Fine-Tuning with Reinforcement Learning ("SFT+RL"), consistently and significantly outperforms a method using Supervised Fine-Tuning alone ("SFT Only") across a wide spectrum of medical domains when measured by improvement over a base model.
The fact that the orange bar is longer in every single category indicates a robust and generalizable advantage for the "SFT+RL" approach. The variation in the size of the improvement (from ~13% to ~22.5%) suggests that the effectiveness of the method is domain-dependent. Categories like "Ear," "Congenital," and "Neoplasms" may have characteristics (e.g., data structure, task complexity) that are particularly well-suited to the reinforcement learning component, leading to the highest gains. Conversely, domains like "Mental Health" and "Digestive" might present challenges that are less mitigated by this specific RL approach, though it still provides a clear benefit.
The dramatic gap in categories like "Blood/Immune" highlights a potential key finding: the "SFT Only" method may struggle significantly in certain complex or data-sparse medical areas, a weakness that the "SFT+RL" method appears to correct substantially. Overall, the chart serves as compelling evidence for the efficacy of integrating reinforcement learning with supervised fine-tuning to enhance model performance in medical applications.
</details>
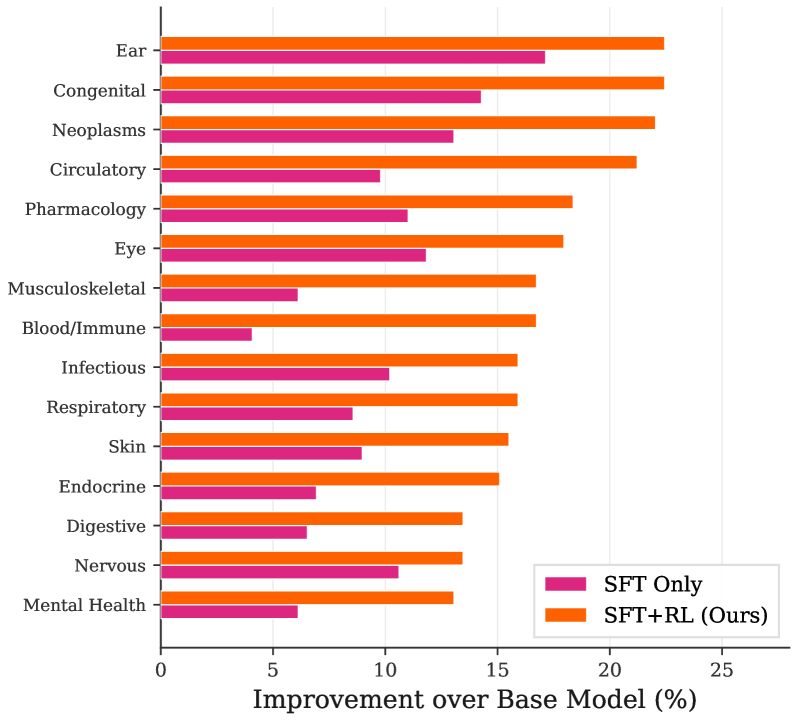
Figure 5: Accuracy by ICD-10 Category: Path-aligned rewards consistently improve performance across all 15 medical sub-domains.
### 5.3 ICD-10 Category Analysis: KG-grounded Gains Are Broadly Distributed
To connect our empirical evaluation to real-world, clinically meaningful structures, we follow the categorization introduced in Dedhia et al. (2025) that groups ICD-Bench questions into 15 ICD-10 categories in the data curation step. This classification lets us evaluate the breadth of our approach, enabling us to measure whether improvements of the SFT+RL model are concentrated in a few medical sub-domains or distributed across practical specialties.
The analysis, visualized in Fig. 5, reveals that our SFT+RL pipeline consistently achieves the highest accuracy and maintains a substantial lead over the SFT-only baseline across all medical categories. Some of the most significant improvements occur in high-stakes areas such as “Blood and Immune System Diseases” and “Circulatory System Diseases,” where diagnostic reasoning often requires complex, multi-hop evidence composition. This is consistent with our design choice to derive the reward from KG paths; the path-alignment reward can assign a meaningful intermediate signal and better shape compositional behavior.
### 5.4 Robustness to Format Perturbation
A common failure mode for LLMs is reliance on superficial cues, e.g., the order of options and answer in a multiple-choice list, rather than the true logical content and chain of reasoning. To evaluate the robustness of our models against such positional bias, we subject them to Stress-Test 3 (option shuffling) Gu et al. (2025). In this test, the order of incorrect distractor options is randomized while keeping the correct answer choice constant.
Table 1: Analysis of Option Format Perturbation.
| SFT-Only | 75.95% | 74.91% | $-1.04\$ |
| --- | --- | --- | --- |
| SFT+RL (Ours) | 83.62% | 82.45% | $-1.17\$ |
The results in Table 1 demonstrate a remarkable degree of robustness of our approach compared to frontier models analyzed in the literature. Whereas leading systems, such as GPT-5 and Gemini-2.5 Pro, have been shown to suffer performance drops of 4-6% under similar perturbations (in text-only medical contexts) Gu et al. (2025), our models maintain nearly stable performance with a negligible drop of $\sim 1\$ .
Importance of High-Quality Data: This resilience highlights a fundamental axiom of machine learning: use of high-quality, grounded data is paramount. Our data curation and training pipeline incentivizes the model to identify the correct answer based on a verifiable reasoning path rather than shortcut patterns seen during unstructured training. The fact that even the SFT-only model trained on high-quality traces exhibits such stability suggests that grounding the model in structured domain axiomatic knowledge is as critical as subsequent RL optimization. By grounding the model and ensuring it learns true logical composition, we move closer to systems capable of genuine domain competence rather than “illusion of readiness.”
### 5.5 Algorithmic Efficiency vs. Scale: Surpassing Frontier Models
One of our central claims is that careful reward design and bottom-up data curation can enable compositional reasoning that outperforms top-down brute-force scaling. To validate this, we compare our 14B SFT+RL model against two distinct classes of benchmarks: (1) large frontier models (GPT-5.2, Gemini 3 Pro) that represent the ceiling of generalist zero-shot reasoning, and (2) QwQ-Med-3 (32B), a domain-expert model distilled for medical reasoning.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Model Accuracy vs. Reasoning Complexity
### Overview
The image is a line chart comparing the accuracy of three different AI models across an increasing number of reasoning steps. The chart is divided into two distinct background regions, "Simpler" and "Complex," to contextualize the difficulty of the tasks. The primary finding is that the model labeled "SFT+RL (14B, Ours)" demonstrates superior and improving performance as task complexity increases, while the two comparison models show declining or stagnant performance.
### Components/Axes
* **Chart Type:** Multi-series line chart.
* **X-Axis:** Labeled **"Number of Reasoning Hops"**. It has four discrete, evenly spaced tick marks at values **2, 3, 4, and 5**.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The scale runs from **65 to 95**, with major gridlines at intervals of 5% (65, 70, 75, 80, 85, 90, 95).
* **Legend:** Located in the **bottom-left corner**. It contains three entries:
1. **GPT-5.2**: Represented by a **gray line with square markers**.
2. **Gemini 3 Pro**: Represented by a **blue line with upward-pointing triangle markers**.
3. **SFT+RL (14B, Ours)**: Represented by an **orange line with diamond markers**.
* **Background Regions:**
* **"Simpler"**: A light blue shaded region covering the area from x=2 to just before x=4.
* **"Complex"**: A light orange shaded region covering the area from x=4 to x=5.
* **Annotations:**
* Green percentage values (**+7%, +7%, +10%, +19%**) are placed directly above the data points of the orange "SFT+RL" line.
* A text note in the **bottom-right corner** of the "Complex" region reads: **"14B params vs larger frontier models"**.
### Detailed Analysis
**Data Series and Trends:**
1. **SFT+RL (14B, Ours) - Orange Line with Diamonds:**
* **Trend:** Shows a slight initial dip followed by a strong, consistent upward trend. It is the only model that improves with more reasoning hops.
* **Data Points (Approximate):**
* At 2 Hops: **~84.5%** (Annotated: +7%)
* At 3 Hops: **~81.0%** (Annotated: +7%)
* At 4 Hops: **~87.0%** (Annotated: +10%)
* At 5 Hops: **~89.5%** (Annotated: +19%)
2. **GPT-5.2 - Gray Line with Squares:**
* **Trend:** Fluctuates. It decreases from 2 to 3 hops, recovers at 4 hops, then drops sharply at 5 hops. Overall trend is slightly downward.
* **Data Points (Approximate):**
* At 2 Hops: **~77.5%**
* At 3 Hops: **~73.5%**
* At 4 Hops: **~77.0%**
* At 5 Hops: **~70.5%**
3. **Gemini 3 Pro - Blue Line with Triangles:**
* **Trend:** Follows a very similar pattern to GPT-5.2 but consistently at a slightly lower accuracy level. Decreases from 2 to 3 hops, recovers at 4 hops, then drops at 5 hops.
* **Data Points (Approximate):**
* At 2 Hops: **~76.0%**
* At 3 Hops: **~72.5%**
* At 4 Hops: **~75.5%**
* At 5 Hops: **~70.5%** (Converges with GPT-5.2)
### Key Observations
* **Performance Gap:** The "SFT+RL" model maintains a significant accuracy lead over the other two models at all data points. The gap widens dramatically in the "Complex" region (4-5 hops).
* **Divergent Trajectories:** At 4 and 5 reasoning hops, the performance of the models diverges sharply. While "SFT+RL" climbs, both "GPT-5.2" and "Gemini 3 Pro" decline.
* **Convergence at High Complexity:** At the highest complexity shown (5 hops), the two frontier models, GPT-5.2 and Gemini 3 Pro, converge to nearly identical low accuracy (~70.5%).
* **Annotation Context:** The green "+X%" annotations likely represent the performance improvement of "SFT+RL" over a baseline (possibly the average of the other two models) at each hop count. The note "14B params vs larger frontier models" highlights that the superior model is significantly smaller in parameter count.
### Interpretation
This chart presents a compelling case for the effectiveness of the "SFT+RL" training methodology (likely Supervised Fine-Tuning + Reinforcement Learning) on a 14-billion parameter model. The data suggests that this approach confers a specific advantage in **multi-step reasoning tasks**.
* **Scalability with Complexity:** The core insight is that the "SFT+RL" model's capability *scales positively* with task difficulty (more reasoning hops), whereas the larger "frontier" models struggle. This implies the training method improves the model's robustness and logical chaining ability, not just its knowledge retrieval.
* **Efficiency Argument:** The annotation about parameter count frames this as an efficiency breakthrough. It challenges the assumption that larger models are always superior, demonstrating that a smaller, well-trained model can outperform larger ones on complex cognitive tasks.
* **Practical Implication:** For applications requiring deep, multi-step analysis (e.g., complex QA, planning, scientific reasoning), the "SFT+RL" approach appears more promising than simply using a larger general-purpose model. The chart argues for targeted training methodologies over sheer scale for specific capabilities.
* **Underlying Pattern:** The dip at 3 hops for all models is an interesting anomaly. It could indicate a specific threshold in reasoning difficulty where all models initially struggle before different training methodologies allow some to adapt and overcome it at 4+ hops.
</details>
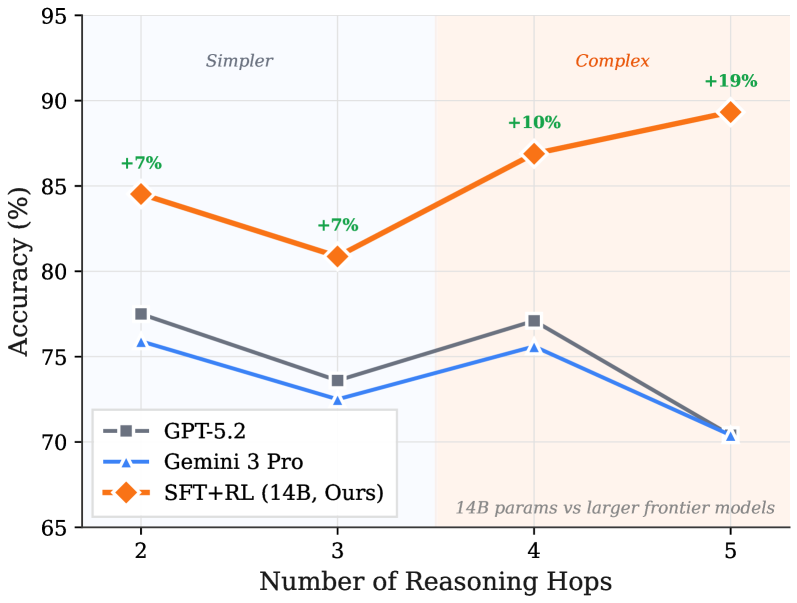
Figure 6: Accuracy Comparisons against Frontier Models by Hop Level: Whereas the accuracy of generalist giants decays on longer chains, our 14B SFT+RL model achieves its highest accuracy on unseen 5-hop queries, validating the KG as a superior supervisor for complex composition.
Superiority over Frontier Models: We evaluate the zero-shot performance of the model against leading generalist models in Fig. 6. Our results demonstrate that grounding a smaller model in a domain’s axioms enables it to surpass larger, generally trained giants at complex reasoning tasks. We also note a striking trend: Whereas GPT-5.2 and Gemini 3 Pro maintain respectable performance on shorter hops, their accuracy stagnates or declines as the hop count increases. In contrast, our model exhibits a positive compositional gradient and achieves its highest accuracy (89.33%) on the 5-hop queries. This supports our claim that KG-grounded path-derived signals teach the model how to compose axioms, not just standard pattern matching.
Surpassing Expert-distilled Scale (SFT-Only): Finally, we compare our model with the QwQ-Med-3 model presented in Dedhia et al. (2025), which was trained on a similar data distribution. For a fair comparison, we use the majority-voting ( $n=16$ ) metric, matching the aggregation metric used in their study (see Table 2).
Table 2: Performance by difficulty level (using majority voting).
| 1 | 96.75% | 94.23% | $-2.52\$ |
| --- | --- | --- | --- |
| 2 | 83.79% | 85.63% | $+1.84\$ |
| 3 | 79.33% | 80.33% | $+1.00\$ |
| 4 | 70.56% | 71.50% | $+0.94\$ |
| 5 | 49.69% | 59.05% | $+9.36\$ |
Whereas the QwQ-Med-3 model holds a slight advantage on lower-difficulty tasks, which typically rely on factual recall, our model successfully bridges the recall-reasoning gap. By using the KG as an implicit reward model, we enable a smaller architecture to “out-reason” a much larger model. This confirms our premise that while scale is a powerful tool for breadth of knowledge, path-aligned rewards are the true bridge to deep compositional reasoning.
## 6 Discussion
The ideas and results presented in this work highlight a fundamental shift in how we approach the development of expert-level reasoning. By using a KG as an implicit reward model, we demonstrate how bottom-up primitives in a domain can serve as highly scalable, verifiable process supervisors. Unlike contemporary human-in-the-loop process supervision, which is prohibitively expensive and infeasible to scale to millions of reasoning chains across domains, our path-derived reward signal provides an automated, scalable axiomatic grounding mechanism.
Furthermore, our findings reinforce the basic axiom of machine learning: Good data are paramount! We show that when models are trained with proper axiomatic grounding, they develop a robust skill for compositional reasoning beyond simple factual recall. This is most evident by our model’s ability to surpass much larger generalist giants. While brute-force scaling continues to dominate the search for general intelligence, our work suggests a more efficient path towards building superintelligent systems: building small, specialized models that master composition within their respective domains.
Finally, our reward design mechanism is inherently scalable and domain-agnostic. Any scientific or technical field that can be represented as a structured KG (from organic chemistry to case law) is a candidate for this pipeline. As domain KGs continue to expand in coverage and fidelity, they offer a practical route to building systems that reason from first principles rather than surface correlations or simple pattern matching. We posit this work as an early step toward scalable, verifiable domain-specific superintelligence, and we encourage future research to explore richer graph structures, broader domains, and tighter integration between symbolic knowledge and neural architectures to build better reasoning systems.
## 7 Conclusion
We introduced a simple, general idea: Treat KGs as implicit reward models and use path-derived rewards in a scalable fashion to teach models how to compose domain primitives into longer reasoning chains. We combined SFT with a compact RL stage and a KG path-aligned reward (plus correctness) to synthesize models that can generalize from 1-3-hop training to unseen 4-5-hop problems, improve baseline accuracy on the hardest tasks, and remain robust under format perturbations. Our recipe yields consistent gains over an SFT-only approach and can outperform much larger models, validating that good grounded data and reward design, not just scale, are central to compositional reasoning. Although we have successfully validated our claims within the medical domain, we acknowledge that this is only a starting point. We encourage the community to further investigate how structured KGs can be leveraged as reward supervisors to build the next generation of superintelligent systems.
## Acknowledgments
The experiments reported in this paper were performed on the computational resources managed and supported by Princeton Research Computing, Princeton AI Lab, and the Princeton Language and Intelligence Initiative at Princeton University.
## References
- Anthropic (2025) Anthropic. Claude Opus 4.5 System Card Technical Report, 2025. URL https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf.
- Bodenreider (2004) Bodenreider, O. The Unified Medical Language System (UMLS): Integrating Biomedical Terminology. Nucleic acids research, 32:D267–D270, 2004.
- Chu et al. (2025) Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Schuurmans, D., Le, Q. V., Levine, S., and Ma, Y. SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-Training. arXiv preprint arXiv:2501.17161, 2025.
- Cui et al. (2025) Cui, G., Yuan, L., Wang, Z., Wang, H., Li, W., He, B., Fan, Y., Yu, T., Xu, Q., Chen, W., Yuan, J., Chen, H., Zhang, K., Lv, X., Wang, S., Yao, Y., Han, X., Peng, H., Cheng, Y., Liu, Z., Sun, M., Zhou, B., and Ding, N. Process Reinforcement Through Implicit Rewards. arXiv preprint arXiv:2502.01456, 2025.
- Damani et al. (2025) Damani, M., Puri, I., Slocum, S., Shenfeld, I., Choshen, L., Kim, Y., and Andreas, J. Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty. arXiv preprint arXiv:2507.16806, 2025.
- Das et al. (2017) Das, R., Dhuliawala, S., Zaheer, M., Vilnis, L., Durugkar, I., Krishnamurthy, A., Smola, A., and McCallum, A. Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases Using Reinforcement Learning. arXiv preprint arXiv:1711.05851, 2017.
- Dedhia et al. (2025) Dedhia, B., Kansal, Y., and Jha, N. K. Bottom-up Domain-specific Superintelligence: A Reliable Knowledge Graph is What We Need. arXiv preprint arXiv:2507.13966, 7 2025.
- Fodor (1975) Fodor, J. A. The Language of Thought, volume 5. Harvard University Press, 1975.
- Google DeepMind (2025) Google DeepMind. Gemini 3 Pro Model Card, November 2025. URL https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf. Technical Report.
- Gu et al. (2025) Gu, Y., Fu, J., Liu, X., Valanarasu, J. M. J., Codella, N. C., Tan, R., Liu, Q., Jin, Y., Zhang, S., Wang, J., et al. The Illusion of Readiness in Health AI. arXiv preprint arXiv:2509.18234, 2025.
- Gunjal et al. (2025) Gunjal, A., Wang, A., Lau, E., Nath, V., Liu, B., and Hendryx, S. Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains. arXiv preprint arXiv:2507.17746, 2025.
- Guo et al. (2025) Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-R1: Incentivizing Reasoning Capability in LLMs Via Reinforcement Learning. arXiv preprint arXiv:2501.12948, 2025.
- Hu et al. (2022) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of International Conference on Learning Representations, 1(2):3, 2022.
- Jin et al. (2025) Jin, H., Luan, S., Lyu, S., Rabusseau, G., Rabbany, R., Precup, D., and Hamdaqa, M. RL Fine-Tuning Heals OOD Forgetting In SFT. arXiv preprint arXiv:2509.12235, 2025.
- Kamp & Partee (1995) Kamp, H. and Partee, B. Prototype Theory and Compositionality. Cognition, 57(2):129–191, 1995.
- Kang et al. (2025) Kang, F., Kuchnik, M., Padthe, K., Vlastelica, M., Jia, R., Wu, C.-J., and Ardalani, N. Quagmires in SFT-RL Post-Training: When High SFT Scores Mislead and What to Use Instead. arXiv preprint arXiv:2510.01624, 2025.
- Khatwani et al. (2025) Khatwani, S., Cheng, H., Afshar, M., Dligach, D., and Gao, Y. Brittleness and Promise: Knowledge Graph Based Reward Modeling for Diagnostic Reasoning. arXiv preprint arXiv:2509.18316, 2025.
- Kim et al. (2025) Kim, Y., Jeong, H., Chen, S., Li, S. S., Lu, M., Alhamoud, K., Mun, J., Grau, C., Jung, M., Gameiro, R., Fan, L., Park, E., Lin, T., Yoon, J., Yoon, W., Sap, M., Tsvetkov, Y., Liang, P., Xu, X., Liu, X., McDuff, D., Lee, H., Park, H. W., Tulebaev, S., and Breazeal, C. Medical Hallucination in Foundation Models and Their Impact on Healthcare. arXiv preprint arXiv:2503.05777, 2025.
- Lightman et al. (2023) Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s Verify Step by Step. arXiv preprint arXiv:2305.20050, 2023.
- Lin et al. (2018) Lin, X. V., Socher, R., and Xiong, C. Multi-Hop Knowledge Graph Reasoning With Reward Shaping. arXiv preprint arXiv:1808.10568, 2018.
- Matsutani et al. (2025) Matsutani, K., Takashiro, S., Minegishi, G., Kojima, T., Iwasawa, Y., and Matsuo, Y. RL Squeezes, SFT Expands: A Comparative Study of Reasoning LLMs. arXiv preprint arXiv:2509.21128, 2025.
- Muennighoff et al. (2025) Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Candès, E., and Hashimoto, T. B. s1: Simple Test-Time Scaling. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 20286–20332, 2025.
- OpenAI (2025) OpenAI. Introducing GPT-5.2. https://openai.com/index/introducing-gpt-5-2/, 2025. Accessed: 2026.
- Organization (1992) Organization, W. H. International Statistical Classification of Diseases and Related Health Problems 10th Revision (ICD-10). World Health Organization, 1992.
- Ouyang et al. (2022) Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training Language Models to Follow Instructions with Human Feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Rafailov et al. (2023) Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. Advances in Neural Information Processing Systems, 36, 2023.
- Rajani et al. (2025) Rajani, N., Gema, A. P., Goldfarb-Tarrant, S., and Titov, I. Scalpel vs. Hammer: GRPO Amplifies Existing Capabilities, SFT Replaces Them. arXiv preprint, 2025. Preprint.
- Schulman et al. (2017) Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shrivastava et al. (2025) Shrivastava, V., Awadallah, A., Balachandran, V., Garg, S., Behl, H., and Papailiopoulos, D. Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning. arXiv preprint arXiv:2508.09726, 2025.
- Wang et al. (2025) Wang, G., Li, J., Sun, Y., Chen, X., Liu, C., Wu, Y., Lu, M., Song, S., and Abbasi-Yadkori, Y. Hierarchical Reasoning Model. arXiv preprint arXiv:2506.21734, 2025.
- Wang et al. (2024) Wang, J., Chen, M., Hu, B., Yang, D., Liu, Z., Shen, Y., Wei, P., Zhang, Z., Gu, J., Zhou, J., Pan, J. Z., Zhang, W., and Chen, H. Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 7813–7835. Association for Computational Linguistics, 2024.
- Wei et al. (2022) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Weng (2024) Weng, L. Reward Hacking in Reinforcement Learning. https://lilianweng.github.io/posts/2024-11-28-reward-hacking/, 2024. Lil’Log blog post.
- Xie et al. (2025) Xie, T., Gao, Z., Ren, Q., Luo, H., Hong, Y., Dai, B., Zhou, J., Qiu, K., Wu, Z., and Luo, C. Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning. arXiv preprint arXiv:2502.14768, 2025.
- Xiong et al. (2017) Xiong, W., Hoang, T., and Wang, W. Y. DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning. arXiv preprint arXiv:1707.06690, 2017.
- Yan et al. (2025) Yan, L., Tang, C., Guan, Y., Wang, H., Wang, S., Liu, H., Yang, Y., and Jiang, J. RLKGF: Reinforcement Learning from Knowledge Graph Feedback without Human Annotations. In Findings of the Association for Computational Linguistics: ACL 2025, pp. 6619–6633, 2025.
- Yang et al. (2025) Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 Technical Report. arXiv preprint arXiv:2505.09388, 2025.
- Yasunaga et al. (2021) Yasunaga, M., Ren, H., Bosselut, A., Liang, P., and Leskovec, J. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. arXiv preprint arXiv:2104.06378, 2021.
- Yin et al. (2025) Yin, M., Qu, Y., Yang, L., Cong, L., and Wang, M. Toward Scientific Reasoning in LLMs: Training from Expert Discussions via Reinforcement Learning. arXiv preprint arXiv:2505.19501, 2025.
- Yuan et al. (2025) Yuan, L., Chen, W., Zhang, Y., Cui, G., Wang, H., You, Z., Ding, N., Liu, Z., Sun, M., and Peng, H. From $f(x)$ and $g(x)$ to $f(g(x))$ : LLMs Learn New Skills in RL by Composing Old Ones. arXiv preprint arXiv:2509.25123, 2025.
- Yue et al. (2025) Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., and Huang, G. Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? arXiv preprint arXiv:2504.13837, 2025.
- Zhang et al. (2025) Zhang, Z., Zheng, C., Wu, Y., Zhang, B., Lin, R., Yu, B., Liu, D., Zhou, J., and Lin, J. The Lessons of Developing Process Reward Models in Mathematical Reasoning. arXiv preprint arXiv:2501.07301, 2025.
- Zhu et al. (2025) Zhu, X., Xia, M., Wei, Z., Chen, W.-L., Chen, D., and Meng, Y. The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning. arXiv preprint arXiv:2506.01347, 2025.
## Appendix A Zero-RL and Reward Ablation Studies on Qwen3 8B
In this section, we provide the empirical details of our experiments with the “Zero-RL” approach (applying RL directly to the base model without a prior SFT phase). These ablations were instrumental in determining our final training scale, pipeline design, and reward configuration.
### A.1 Zero-RL Performance and Scaling
We evaluate the performance of the Qwen3 8B base model using the GRPO algorithm across three data scales: 5k, 10k, and 24.66k examples. For each scale, we test four reward configurations: (1) path alignment (path overlap), (2) Jaccard similarity (distillation), (3) binary correctness, and (4) all rewards combined (see Table 3). All experiments are performed on the Qwen3 8B model using 8 H100 NVIDIA GPUs.
Note that we always include the binary correctness reward as a minimal signal.
Table 3: Ablation study on reward components across training scales on Qwen3 8B.
| Training Size | Reward | Accuracy | $\sim$ Training Time (hrs) |
| --- | --- | --- | --- |
| 0 | Baseline | 64.98% | – |
| 5k | Path Align. | 67.51% | 12 |
| Jaccard Sim. | 68.03% | 12 | |
| Binary | 69.36% | 12 | |
| 10k | Path Align. | 64.24% | 24 |
| Jaccard Sim. | 65.74% | 24 | |
| Binary | 67.56% | 24 | |
| All Rewards | 68.44% | 24 | |
| 24.66k | Path Align. | 68.41% | 65 |
| Jaccard Sim. | 65.77% | 65 | |
| Binary | 70.18% | 65 | |
| All Rewards | 68.44% | 65 | |
Key Observations:
- SFT Requirement: Whereas Zero-RL provides a marginal improvement over the base model, no configuration reaches the performance levels of the SFT-only baseline (70.86%) or our final SFT+RL model ( $\sim$ 82%). This confirms that the model requires a grounded factual foundation from SFT before it can effectively leverage RL for compositional reasoning. In the final SFT+RL pipeline, path alignment, along with binary correctness (with upweighted negative reward), provides the best and most reliable signal.
- Scale vs. Efficiency: Performance gains from 5k to 24.66k examples are minimal (e.g., a $\sim$ 0.8% gain for binary correctness reward) while significantly increasing training time from 12 to 65 hours. This justifies our decision to set the RL stage to use a high-quality 5k subset of our final pipeline.
- Reward Stability: The binary correctness reward remains the most stable signal in the Zero-SFT setting. The distillation-based rewards are prone to reward hacking and stylistic mimicry without providing superior reasoning abilities.
### A.2 GRPO on LoRA Parameters Only
We also explore a variant of the pipeline where we perform SFT followed by GRPO, with updates limited only to the LoRA modules. This configuration yields an accuracy of 66.75% on the 8B model. The significantly lower performance compared to our full SFT+RL results suggests that compositional reasoning requires more extensive/aggressive weight updates during RL than those afforded by the restricted LoRA-only approach.
## Appendix B SFT+RL Ablation Studies on Qwen3 8B
This study investigates the synergy between the binary reward and path alignment reward, and provides the final missing link by ablating the specific reward components used in the RL stage. Whereas Appendix A focuses on the Zero-RL settings, the following experiments demonstrate the impact of reward designs on the model that has already undergone SFT. We conduct these ablations on the Qwen3 8B model to efficiently identify the optimal configuration for the larger 14B SFT+RL pipeline.
We specifically evaluate the addition of negative reinforcement Zhu et al. (2025) by penalizing the model more for incorrect final answers than correct reasoning paths. As shown in Table 4, the combination of path-derived signals and negative binary reward provides the most robust reasoning improvements, significantly outperforming configurations that rely on binary signals alone or a combination of all rewards.
Table 4: Ablation study on reward components with the SFT+RL training pipeline (8B Model). All RL runs are conducted for 5k steps following a 19.66k SFT baseline.
| 19.66k SFT + 5k RL | Path Alignment Only | 79.29% |
| --- | --- | --- |
| Path Alignment + Binary | 68.03% | |
| Binary Only (Normal) | 79.46% | |
| Negative Binary Only | 79.54% | |
| All Rewards | 55.21% | |
| Path Align. + Negative Binary | 82.20% | |
Key Insights:
- The Synergy of Negative Reinforcement: Consistent with the findings of Zhu et al. (2025), we observe that “Normal” binary rewards (positive reinforcement only) can be unstable when combined with path-aligned rewards. Transitioning to negative binary rewards while rewarding valid intermediate paths yields our highest accuracy of 82.20%.
- The “All Rewards” Failure: Attempting to combine all reward signals (path alignment, Jaccard similarity, normal binary, and thinking quality) leads to a significant performance collapse (55.21%). This suggests that over-optimizing the reward signal can lead to conflicting gradients or reward hacking, where the model fails to optimize for the primary reasoning task.
- Effect of the Path Alignment Signal: Even without outcome-based binary rewards, path alignment only provides a substantial $\sim$ 9% boost over the SFT baseline. This confirms that the KG itself acts as a sufficient implicit reward model to guide the model towards better compositional reasoning.
## Appendix C Additional Reward Function Formulations
In addition to the path-alignment reward, $R_{path}$ , and the binary correctness reward, $R_{bin}$ , we investigate two alternative reward functions for RL experiments: semantic answer similarity (distillation-based reward) ( $R_{sim}$ ) and thinking quality ( $R_{think}$ ). Whereas these functions provided some learning signals, they are ultimately less effective than path-derived rewards in enabling deep compositional reasoning.
### C.1 Semantic Answer Similarity Reward $(R_{sim})$
The semantic answer similarity (or distillation) reward, $R_{sim}$ , is designed to distill the reasoning patterns of the SFT model by rewarding semantic overlap between the model-generated reasoning and the ground truth answer reasoning trace.
The reward is calculated using the Jaccard similarity of normalized token sets:
$$
R_{sim}=\frac{|T_{model}\cap T_{target}|}{|T_{model}\cup T_{target}|}\times\phi_{rep},
$$
where $T_{model}$ is the set of unique tokens from the thinking trace of the model, $T_{target}$ is the token set of the ground truth reasoning text (distilled from a larger LLM), and $\phi_{rep}$ is a repetition penalty factor used to discourage repetitive generation. This function encourages the model to mention the correct clinical entities and mechanisms associated with the target answer, though it does not explicitly verify the logical validity of the connections between those entities.
### C.2 Thinking Quality Reward $(R_{think})$
The thinking quality reward, $R_{think}$ , is designed to encourage the model to produce well-organized, stepwise reasoning. It evaluates the response based on its adherence to logical formatting cues. It is calculated as a weighted sum of three structural components:
- Structure (50%): A binary indicator of whether the reasoning trace exceeds a minimum length threshold (20 characters).
- Step-wise Keywords (30%): A normalized count of logical-thinking indicator words such as “first,” “then,” “therefore,” and “finally.”
- Enumeration (20%): A score based on the presence of numbered lists (e.g., “1.,” “2.”), which often indicate a systematic breakdown of a multi-hop clinical diagnostic problem.
In addition, we employ a penalty, $\phi_{rep}$ , to discourage repetitive output. Whereas $R_{think}$ shows initial promise in improving the readability of the model outputs, it often leads to reward hacking in contrast to the rigorous logical traversal induced by path-derived reward signals.
## Appendix D Train-Test Split Overlap Analysis
A critical concern in any reasoning-based benchmark is the potential for data leakage or memorization. As per the design of our data curation pipeline, which builds upon the methodology established in Dedhia et al. (2025), each question created by traversing a KG path is unique. Per design, arriving at a correct answer requires explicit reasoning involving all intermediate edges and nodes in the path, rather than simple pattern matching.
We intentionally allow partial overlap of individual nodes or single triples between the training and test sets to ensure the benchmark exercises broad coverage of medical concepts. To more concretely address concerns regarding the influence of partial knowledge overlap, we performed a rigorous analysis of our model performance on the test set categorized by the longest consecutive matching subsequence of triples found in any training question. This match can start at any position in either the training or test path. The distribution and corresponding accuracy metrics are detailed in Figs. 8, 8, respectively.
<details>
<summary>x7.png Details</summary>
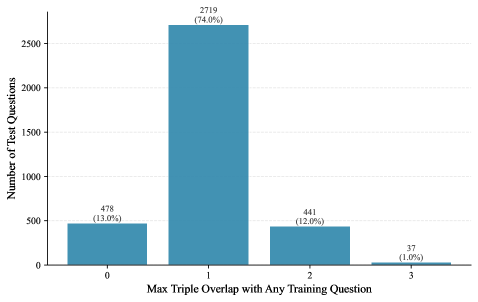
### Visual Description
## Bar Chart: Distribution of Test Questions by Maximum Triple Overlap with Training Questions
### Overview
This is a vertical bar chart illustrating the frequency distribution of test questions based on their maximum "triple overlap" with any question in a training set. The chart quantifies how many test questions share a specific level of overlap (0, 1, 2, or 3) with training questions. The data indicates a highly skewed distribution, with the vast majority of test questions having an overlap of 1.
### Components/Axes
* **Chart Type:** Vertical Bar Chart.
* **X-Axis (Horizontal):**
* **Label:** "Max Triple Overlap with Any Training Question"
* **Categories/Markers:** 0, 1, 2, 3. These represent discrete levels of overlap.
* **Y-Axis (Vertical):**
* **Label:** "Number of Test Questions"
* **Scale:** Linear scale from 0 to 2500, with major gridlines at intervals of 500 (0, 500, 1000, 1500, 2000, 2500).
* **Data Series:** A single data series represented by four blue bars. There is no legend, as only one category of data is plotted.
* **Data Labels:** Each bar is annotated at its top with the exact count and its percentage of the total test questions.
### Detailed Analysis
The chart presents the following precise data points for each overlap category:
1. **Overlap = 0:**
* **Count:** 478 test questions.
* **Percentage:** 13.0% of the total.
* **Visual Trend:** This is the second-tallest bar, positioned at the far left of the chart.
2. **Overlap = 1:**
* **Count:** 2719 test questions.
* **Percentage:** 74.0% of the total.
* **Visual Trend:** This is the dominant, tallest bar by a significant margin, located in the center-left position. It represents nearly three-quarters of all test questions.
3. **Overlap = 2:**
* **Count:** 441 test questions.
* **Percentage:** 12.0% of the total.
* **Visual Trend:** This bar is slightly shorter than the "0" bar and is positioned to the right of the central peak.
4. **Overlap = 3:**
* **Count:** 37 test questions.
* **Percentage:** 1.0% of the total.
* **Visual Trend:** This is the shortest bar, appearing as a small sliver at the far right of the chart.
**Total Test Questions (Calculated):** 478 + 2719 + 441 + 37 = 3,675. The sum of the percentages (13.0% + 74.0% + 12.0% + 1.0%) equals 100.0%.
### Key Observations
* **Dominant Category:** The category "1" is overwhelmingly the most common, containing 74% of all test questions.
* **Sharp Drop-off:** There is a dramatic decrease in frequency as the overlap value increases beyond 1. The count for overlap=2 is about 6 times smaller than for overlap=1, and the count for overlap=3 is negligible (1%).
* **Low Zero-Overlap:** Only 13% of test questions have zero triple overlap with any training question, suggesting most test questions share at least some structural similarity with the training data.
* **Distribution Shape:** The distribution is heavily right-skewed, with a single, pronounced mode at overlap=1.
### Interpretation
This chart provides a diagnostic view of the relationship between a model's training set and its test set, specifically regarding "triple overlap"—likely referring to the sharing of three key elements (e.g., entities, relations, and attributes in a knowledge graph or complex QA context).
* **Data Suggestion:** The data strongly suggests that the test set is not composed of entirely novel, unseen structures. Instead, 87% of test questions (74% + 12% + 1%) have at least a partial structural precedent (overlap of 1, 2, or 3) in the training data. The high concentration at overlap=1 indicates that while exact复制 (overlap=3) is rare, the model is predominantly being evaluated on questions that recombine or minimally vary patterns it has seen during training.
* **Relationship Between Elements:** The x-axis represents increasing degrees of similarity to training data. The y-axis shows the prevalence of each similarity level. The inverse relationship between overlap value and frequency is clear: as the required similarity to a training question increases, the number of such test questions plummets.
* **Notable Anomaly/Trend:** The most significant trend is the massive spike at overlap=1. This could indicate a deliberate test design choice to evaluate generalization from single-overlap patterns, or it could reveal a limitation in the test set's diversity. The near-absence of overlap=3 questions (1%) suggests the test avoids direct memorization checks.
* **Implication for Model Evaluation:** A model performing well on this test set may be proficient at interpolating from known patterns (overlap=1) but is not heavily tested on extrapolating to completely novel structures (overlap=0) or on handling highly complex, multi-faceted similarities (overlap=2, 3). The evaluation primarily measures robustness to minor variations of trained concepts.
</details>
Figure 7: Number of KG Triples shared with the Training Set
<details>
<summary>x8.png Details</summary>
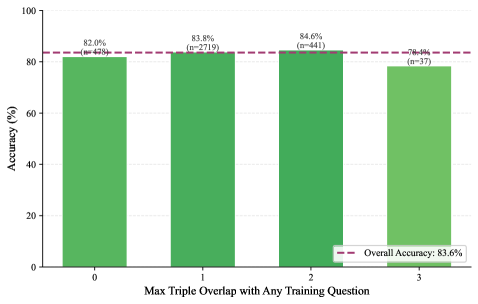
### Visual Description
## Bar Chart: Accuracy by Max Triple Overlap with Any Training Question
### Overview
This is a vertical bar chart displaying the accuracy percentage of a model or system across four distinct categories based on the "Max Triple Overlap with Any Training Question." The chart includes a horizontal reference line indicating the overall accuracy across all categories. The primary language is English.
### Components/Axes
* **Chart Type:** Vertical Bar Chart.
* **Y-Axis:**
* **Label:** "Accuracy (%)"
* **Scale:** Linear scale from 0 to 100, with major tick marks at intervals of 20 (0, 20, 40, 60, 80, 100).
* **X-Axis:**
* **Label:** "Max Triple Overlap with Any Training Question"
* **Categories:** Four discrete categories labeled "0", "1", "2", and "3".
* **Data Series:** Four green bars, one for each x-axis category.
* **Legend:** Located in the bottom-right corner of the chart area. It contains a single entry: a purple dashed line labeled "Overall Accuracy: 83.6%".
* **Reference Line:** A horizontal purple dashed line spanning the chart's width at the y-value of approximately 83.6%.
### Detailed Analysis
The chart presents accuracy data for four categories, with the sample size (`n`) noted for each.
1. **Category "0":**
* **Bar Height (Accuracy):** 82.0%
* **Sample Size (n):** 625
* **Position Relative to Overall Line:** The top of the bar is slightly below the purple dashed overall accuracy line.
2. **Category "1":**
* **Bar Height (Accuracy):** 83.8%
* **Sample Size (n):** 2719
* **Position Relative to Overall Line:** The top of the bar is very slightly above the purple dashed overall accuracy line.
3. **Category "2":**
* **Bar Height (Accuracy):** 84.6%
* **Sample Size (n):** 441
* **Position Relative to Overall Line:** The top of the bar is clearly above the purple dashed overall accuracy line, representing the highest accuracy among the four categories.
4. **Category "3":**
* **Bar Height (Accuracy):** 78.9%
* **Sample Size (n):** 37
* **Position Relative to Overall Line:** The top of the bar is noticeably below the purple dashed overall accuracy line, representing the lowest accuracy among the four categories.
**Trend Verification:** The visual trend shows accuracy increasing from category "0" to "2", followed by a sharp decrease at category "3". The sample size (`n`) is largest for category "1" and smallest for category "3".
### Key Observations
* **Peak Performance:** The highest accuracy (84.6%) is achieved at a "Max Triple Overlap" of 2.
* **Lowest Performance:** The lowest accuracy (78.9%) occurs at a "Max Triple Overlap" of 3.
* **Sample Size Disparity:** The number of samples varies dramatically, from 2719 (category "1") down to just 37 (category "3"). The result for category "3" is based on a much smaller dataset.
* **Overall Benchmark:** The overall accuracy of 83.6% serves as a benchmark. Categories "1" and "2" perform at or above this benchmark, while categories "0" and "3" perform below it.
### Interpretation
The data suggests a non-linear relationship between the degree of "triple overlap" with training questions and model accuracy. Performance improves as overlap increases from none (0) to moderate levels (1 and 2), peaking at an overlap of 2. This could indicate that some familiarity with question structure is beneficial.
However, the significant drop in accuracy at the highest overlap level (3) is a critical finding. This could imply that when questions are too similar to training examples (high overlap), the model may be overfitting, memorizing answers without robust reasoning, or that this category represents a different, more challenging data distribution. The very small sample size (`n=37`) for category "3" introduces uncertainty; this result may not be statistically reliable and warrants further investigation with more data.
In summary, the chart demonstrates that moderate overlap with training data correlates with optimal performance, while both no overlap and very high overlap are associated with lower accuracy. The overall system accuracy is 83.6%.
</details>
Figure 8: Accuracy by Number of Overlapping KG Triples
Only 1.0% of test questions have a full 3-triple chain match. Since our training set is restricted to a maximum of 3-hop reasoning tasks, this ensures that the vast majority of our benchmark consists of structurally unique reasoning tasks. Furthermore, there is no clear trend in accuracy as overlap increases. This suggests that performance is not significantly predicted by the presence of familiar triple sequences. Interestingly, the 3-overlap category exhibits slightly lower accuracy (78.4%) than the 0-overlap category (82.0%). This further demonstrates that our model internalizes the logic of composition rather than memorizing specific paths.
Whereas the majority of questions share at least one triple with the training set, note that the ICD-Bench test set contains only 2-5-hop questions. This requires the model to perform novel composition even when individual building blocks have been previously seen in different contexts.
## Appendix E Training Hyperparameters and GRPO Configuration
In this section, we detail the specific hyperparameter configurations used for both the SFT (Table 5) and RL (GRPO) (Table 6) stages of our pipeline.
### E.1 Hardware Compute
All experiments are conducted using high-performance GPU clusters. The 8B model runs are executed on a node equipped with 8 $\times$ NVIDIA H100 GPUs. For the 14B parameter model, we use 8 $\times$ NVIDIA H200 GPUs to accommodate for increased memory requirements and ensure efficient throughput in the RL phase. DeepSpeed is employed as the inference engine to optimize model sharding, memory management, and logging during GRPO.
### E.2 SFT Stage
For the SFT stage, we use the LoRA method Hu et al. (2022). The hyperparameters are kept constant across both model scales.
Table 5: Hyperparameters for SFT.
| Hyperparameter LoRA Rank ( $r$ ) LoRA Alpha ( $\alpha$ ) | Value 16 16 |
| --- | --- |
| LoRA Dropout | 0.05 |
| Learning Rate | $2\times 10^{-4}$ |
### E.3 RL (GRPO) Stage
Given the high cost of model generation in full-parameter GRPO, we optimize per-device efficiency while maintaining a stable learning signal by using a constant learning rate with a warmup period. The choice of $\text{num\_generations}=2$ is made to balance memory requirements with completion length. We found that low temperature is essential for maintaining logical consistency and diversity.
Table 6: Hyperparameters for GRPO training.
| Num Generations ( $G$ ) Batch Size (per device) Learning Rate | 2 1 $8\times 10^{-6}$ |
| --- | --- |
| LR Schedule | Constant w/ Warmup |
| Temperature ( $T$ ) | 0.6 |
| Top-p | 0.9 |
| Optimizer | AdamW |
| Precision | BF16 |
| Max Completion Length | 1792 |
| Repetition Penalty | 1.15 |
## Appendix F Sample Model Responses
Next, we present representative samples of the output of our 14B SFT+RL model on complex, multi-hop medical queries from the ICD-Bench test set. These examples illustrate how our model effectively composes several 1-hop facts to solve a 3-hop and a 5-hop problem, respectively.
Detailed Compositional Reasoning — Category: Neoplasms — Difficulty: 1 — Num Hops: 3
Question: A 6-month-old infant presents with a rapidly growing mass in their left flank. Imaging reveals a large renal mass suspicious for atypical teratoid rhabdoid tumor (ATRT). Family history is significant for a maternal grandfather with multiple cutaneous neurilemmomas diagnosed in his 60s. Genetic testing confirms a germline pathogenic variant in SMARCB1 in the infant. Which of the following secondary findings would warrant the MOST urgent investigation in this patient? Options: A.
Mild macrocephaly with normal development. B.
Small, subcutaneous lipomas noted on physical exam. C.
Bilateral sensorineural hearing loss identified on newborn screening. D.
Widening of the mediastinum on chest X-ray following a persistent cough.
Step-by-Step Reasoning ( $<think>$ )
Okay, let’s break this down. We have a 6-month-old baby with a likely ATRT, a pretty aggressive brain tumor in this context, and the genetic testing confirms a germline SMARCB1 mutation. This mutation is associated with Rhabdoid Tumor Predisposition Syndrome (RTPS), which significantly increases the risk of certain cancers, including the ATRT seen here. Now we need to look at the secondary findings and figure out which one needs the most urgent attention. Let’s go through the options: •
A. Mild macrocephaly with normal development: While macrocephaly can be seen in some genetic syndromes, including RTPS, mild macrocephaly isn’t typically an immediate life-threatening sign, especially when development is normal. It’s something to note but might not be the most urgent thing to investigate right now compared to other possibilities. •
B. Small, subcutaneous lipomas: Like macrocephaly, lipomas can occur in RTPS, but small lipomas are generally benign and don’t usually require urgent evaluation unless they are growing rapidly or causing symptoms. They don’t point to an immediate, critical problem. •
C. Bilateral sensorineural hearing loss identified on newborn screening: Hearing loss is a known feature of some SMARCB1 related conditions. However, it’s usually detected early (like via newborn screening) and while important for the child’s development, it’s not typically an immediate medical emergency requiring the same level of urgency as a potential airway or cardiac issue. •
D. Widening of the mediastinum on chest X-ray following a persistent cough: This is the big one. A widening mediastinum, especially in the context of a persistent cough, is highly suspicious for a thymoma. Thymomas are tumors located in the anterior mediastinum. While not always malignant, they can be associated with myasthenia gravis, hypogammaglobulinemia, and sometimes other paraneoplastic syndromes. Crucially, large or malignant thymomas can compress airways or the superior vena cava, leading to respiratory distress or superior vena cava syndrome, which is a medical emergency requiring urgent evaluation and potential intervention. Considering the infant already has a severe malignancy (ATRT) and a confirmed SMARCB1 mutation, the possibility of a second, potentially rapidly progressive and life-threatening condition like a thymoma, which can cause immediate symptoms (breathing difficulty, facial/arm swelling, neck vein distension), makes the mediastinal widening the most critical finding demanding urgent investigation. The respiratory compromise from a thymoma is a time-sensitive issue. Therefore, the widening mediastinum is the most pressing concern that needs investigation urgently.
Ground Truth Knowledge Graph Path: RTPS Type 1 $\xrightarrow{\text{may be allelic with}}$ Schwannomatosis Type 1 $\xrightarrow{\text{is a risk factor of}}$ Neurilemmoma $\xrightarrow{\text{may cause}}$ Mediastinal Enlargement
Final Answer: D $\checkmark$ Correct
Detailed Compositional Reasoning — Category: Neoplasms — Difficulty: 5 — Num Hops: 5
Question: A 17-year-old female presents with worsening pain and swelling in her left distal femur. Imaging reveals a lytic lesion with periosteal reaction highly suggestive of Ewing’s sarcoma. She is started on a multi-agent chemotherapy regimen including Etoposide. Several weeks into treatment, she develops significant mucositis and general malaise, leading to difficulty maintaining adequate oral nutrition. Her oncologist is considering adjunctive therapies to improve her nutritional status and muscle mass while carefully considering potential risks and interactions. Which of the following factors should be given MOST consideration when making this decision? Options: A.
The patient’s reported history of childhood asthma and potential for steroid-induced bronchospasm. B.
The documented presence of a BRCA1 mutation in a distant relative and the risk of increased malignancy with certain growth factors. C.
The potential for teratogenic effects of some anabolic steroids, given the need for effective contraception. D.
The need to avoid medications that could exacerbate chemotherapy-induced neuropathy, potentially hindering physical rehabilitation.
Step-by-Step Reasoning ( $<think>$ ): Okay, let’s break this down. We have a 17-year-old patient with Ewing’s sarcoma, getting chemotherapy that includes Etoposide. She’s having side effects like mucositis and general malaise, making it hard to eat. The team is thinking about adding something to help her nutrition and build muscle mass, likely an anabolic steroid or similar agent. We need to figure out which factor is most important to consider when choosing this adjunctive therapy. 1. Understand the Core Problem: The patient needs help with nutrition and muscle mass due to chemo side effects. Potential solutions might involve anabolic steroids or similar compounds. We need to pick the most critical factor influencing this decision. 2. Analyze Option A (Childhood Asthma): The patient has childhood asthma. Anabolic steroids, like Oxymetholone, can be used to treat certain types of pulmonary issues, including sometimes asthma. So, there’s a potential therapeutic benefit here. However, the primary concern with asthma and steroids is usually bronchospasm, which is a risk with corticosteroids (like Prednisone), not typically the main issue directly with anabolic steroids, although some anabolic steroids can have corticosteroid effects or cause fluid retention. While important for overall care, it’s probably not the most critical factor specifically for choosing an adjunctive therapy for nutrition/muscle mass itself, especially compared to direct risks of the therapy. 3. Analyze Option B (BRCA1 Mutation): The BRCA1 mutation is relevant for cancer predisposition (increases risk of breast, ovarian cancer). While some growth factors (like Peginesatide) have been associated with risks in BRCA1 mutation carriers, this is a very specific scenario and doesn’t directly relate to the common adjunctive agents used for nutritional support or muscle mass building, which are often anabolic steroids. It’s highly unlikely to be the most critical factor for this patient’s specific situation. 4. Analyze Option D (Neuropathy): The patient is on Etoposide, which can cause neurotoxicity (like peripheral neuropathy). Adding another drug that could potentially worsen this (maybe some agents used for nutrition/muscle mass have neurotoxic potential, or the patient’s overall condition makes them more sensitive) is definitely a consideration for quality of life and rehabilitation. It’s a valid concern, but is it the most critical? Probably not, especially when compared to other potential issues. 5. Analyze Option C (Teratogenic Effects): The patient is 17 years old. While not yet of childbearing age, it’s crucial to consider future fertility. Anabolic steroids, such as Oxandrolone, are known to be teratogenic, meaning they can cause birth defects. This is a serious risk if the patient were to become pregnant, either during treatment or in the near future after stopping treatment. Given her age and the potential long-term implications of treatment side effects, the risk of teratogenesis stands out as a major, long-term safety concern that must be addressed. If an anabolic steroid is considered, effective contraception is absolutely essential, and the teratogenic potential is a primary reason why it needs careful consideration and management. This risk is significant and directly related to the choice of therapy, making it arguably the most critical factor to consider. 6. Synthesize and Conclude: Comparing the options, the teratogenic potential (Option C) is the most critical factor. Why? Because the patient is young (17), and the potential for future pregnancy exists. Anabolic steroids, which might be considered for her muscle mass and nutrition, are teratogenic. This is a serious long-term health risk that needs careful planning and discussion. While neuropathy (D) is a concern, and asthma (A) has some relevance, the potential for teratogenesis is a major safety issue directly impacting the choice and management of therapy for a young female patient. Therefore, the factor that should be given the MOST consideration is the potential for teratogenic effects.
Ground Truth Knowledge Graph Path (5 Hops): Ewing’s sarcoma $\xrightarrow{\text{may treat}}$ Etoposide $\xrightarrow{\text{may treat}}$ Brain neoplasms $\xrightarrow{\text{may treat}}$ Hydroxycarbamide $\xrightarrow{\text{may contraindicate}}$ Pregnancy $\xrightarrow{\text{may contraindicate}}$ Oxandrolone
Final Answer: C $\checkmark$ Correct
## Appendix G SFT+RL Pipeline Algorithm
To provide a clear, formal overview of our training process, we present the SFT+RL Pipeline in Algorithm 1. This algorithm details the transition from high-quality grounded SFT to path-aligned RL using the GRPO framework.
Algorithm 1 Grounded Compositional Reasoning Pipeline (SFT+RL)
Input: Base model $\theta_{base}$ , Knowledge graph $\mathcal{G}$ , Training set $\mathcal{D}=\{(Q_{i},A_{i},P_{i},R_{i})\}$ , where $P_{i}$ is a KG reasoning path and $R_{i}$ is the reasoning trace.
Output: Compositional reasoning model $\theta_{RL}$ .
{Stage 1: Supervised Fine-Tuning (SFT)}
Initialize $\theta_{SFT}\leftarrow\theta_{base}$
for each $(Q,A,P,R)\in\mathcal{D}_{SFT}$ do
Fine-tune $\theta_{SFT}$ to minimize $\mathcal{L}_{SFT}=-\log P(A,R|Q;\theta_{SFT})$
{Model learns atomic facts and reasoning structure}
end for
{Stage 2: Path-Aligned Reinforcement Learning (RL)}
Initialize $\theta_{RL}\leftarrow\theta_{SFT}$
for each question $Q\in\mathcal{D}_{RL}$ do
Generate $G$ independent outputs $\{O_{1},O_{2},\dots,O_{G}\}$ from $\theta_{RL}$
for each output $O_{g}$ do
Extract reasoning triples $\hat{T}_{g}$ from $\langle\text{think}\rangle$ block
Compute binary reward $R_{bin}$ based on final answer correctness
Compute path reward $R_{path}$ by verifying triples in $\hat{T}_{g}$ against $\mathcal{P}$
$R(O_{g})=\alpha\cdot R_{bin}+\beta\cdot R_{path}$ {Weighted reward signal}
end for
Compute Advantage and update $\theta_{RL}$ using GRPO objective
end for
## Appendix H Model Prompt
We employ a structured prompting strategy to enforce the separation of internal reasoning and final answer selection. This structure is critical for the path alignment reward, $R_{path}$ , as it enables our reward function to isolate the $think$ block for axiomatic triple extraction. The exact prompt is shown in Fig. 9.
System Prompt: A conversation between user and assistant. The user asks a single-choice Multiple Choice Question, and the assistant solves it using step-by-step reasoning. Please answer the multiple-choice question by selecting only one from option A, option B, option C, or option D. The assistant first thinks through the problem systematically, then provides the explanation and final answer. Use <think>...</think> tags for internal reasoning, then provide the answer in the format — Final Answer: . Task Instructions: Please provide complete and accurate answers with clear reasoning. The answer must only be a single letter from A, B, C, D. Format Enforcement: <think> [Reasoning Path] </think> Final Answer: [Letter]
Figure 9: Prompt template for GRPO training.