# A Syllogistic Probe: Tracing the Evolution of Logic Reasoning in Large Language Models
**Authors**:
- Junbo Zhao, Haobo Wang (Zhejiang University,
University of Chinese Academy of Social Sciences,)
## Abstract
Human logic has gradually shifted from intuition-driven inference to rigorous formal systems. Motivated by recent advances in large language models (LLMs), we explore whether LLMs exhibit a similar evolution in the underlying logical framework. Using existential import as a probe, we for evaluate syllogism under traditional and modern logic. Through extensive experiments of testing SOTA LLMs on a new syllogism dataset, we have some interesting findings: (i) Model size scaling promotes the shift toward modern logic; (ii) Thinking serves as an efficient accelerator beyond parameter scaling; (iii) the Base model plays a crucial role in determining how easily and stably this shift can emerge. Beyond these core factors, we conduct additional experiments for in-depth analysis of properties of current LLMs on syllogistic reasoning.
A Syllogistic Probe: Tracing the Evolution of Logic Reasoning in Large Language Models
Zhengqing Zang 1,3*, Yuqi Ding 2,3*, Yanmei Gu 3 $\dagger$ , Changkai Song 3, Zhengkai Yang 3, Guoping Du 4, Junbo Zhao 1,3, Haobo Wang 1 $\dagger$ 1 Zhejiang University, 2 University of Chinese Academy of Social Sciences, 3 Ant Group, 4 Chinese Academy of Social Sciences {zangzq, wanghaobo}@zju.edu.cn, dingyuqi@ucass.edu.cn, yanmeigu.gym@antgroup.com footnotetext: * These authors contributed equally. footnotetext: $\dagger$ Corresponding Authors.
## 1 Introduction
Human logic has evolved from earlier, more intuition-driven accounts of valid inference Aristotle (1984) to increasingly rigorous formal frameworks Enderton (1972). In particular, the development of symbolic logic clarified the semantics of quantification and enabled precise validity checking under explicit model-theoretic interpretations, laying the foundation for contemporary logical analysis.
Recently, neural networks have evolved from early, relatively simple architectures with limited capacity for logical reasoning to today’s large language models (LLMs), which have achieved remarkable progress across natural language processing tasks. State-of-the-art models such as GPT-5 OpenAI (2025a) and Gemini-3-Pro-Preview deepmind (2025), often rival human experts in complex reasoning tasks ranging from commonsense reasoning Bang et al. (2023); Bisk et al. (2019) to mathematical problem-solving Phan et al. (2025); Wei et al. (2023). These advances raise a natural question: do LLMs exhibit an analogous evolution in their underlying logical framework? If so, what changes, and how does this change emerge?
<details>
<summary>images/test_4.png Details</summary>
### Visual Description
\n
## Diagram: Syllogism and Existential Import
### Overview
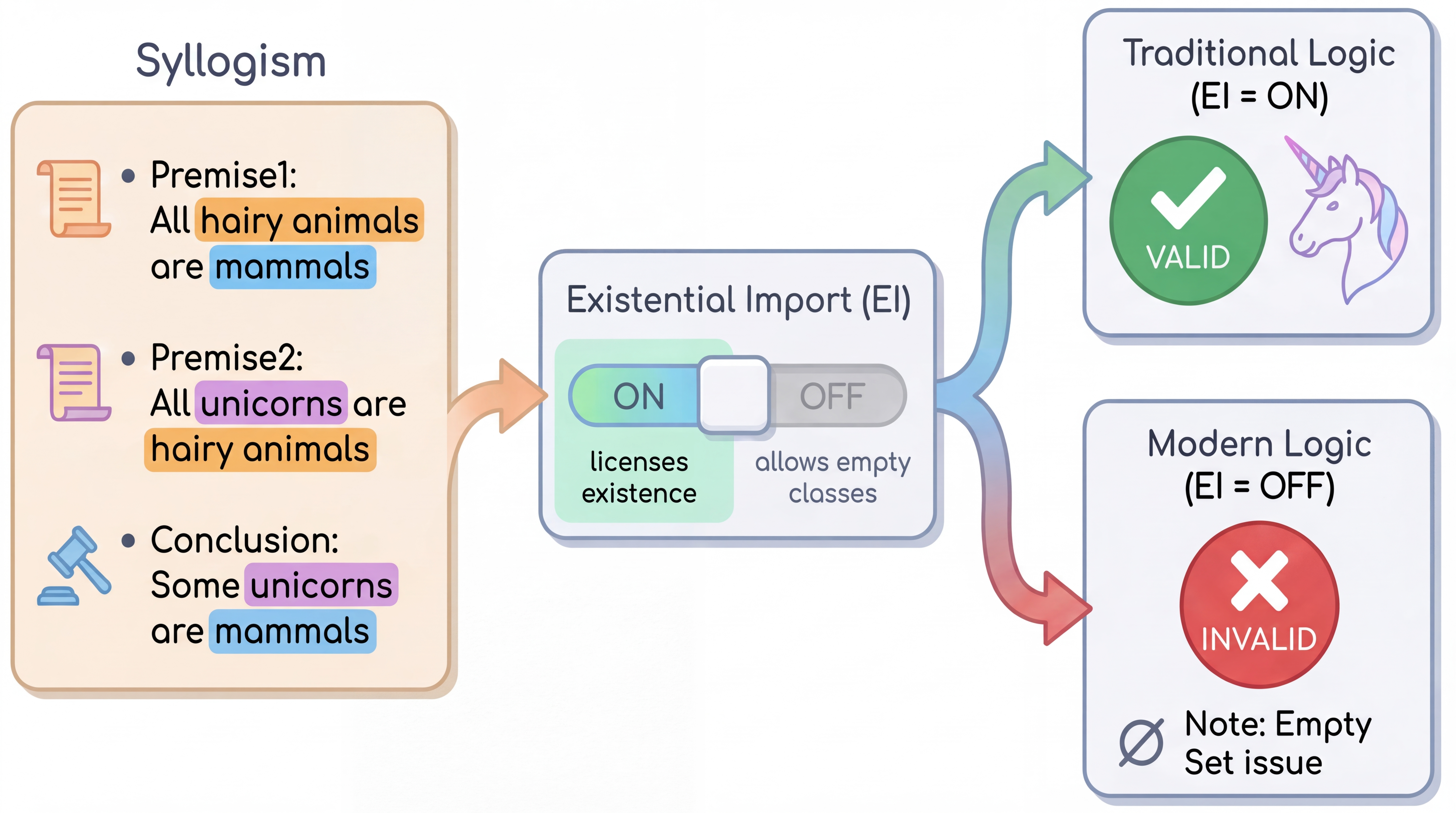
This diagram illustrates the impact of Existential Import (EI) on the validity of a syllogism. It demonstrates how a syllogism that is valid under traditional logic (EI = ON) can become invalid under modern logic (EI = OFF). The diagram uses a visual flow to show how the choice of EI setting affects the conclusion drawn from the premises.
### Components/Axes
The diagram consists of four main components:
1. **Syllogism (Peach Rectangle):** Contains the premises and conclusion of a syllogistic argument.
2. **Existential Import (EI) Switch (Light Purple Rectangle):** A toggle switch representing the setting for Existential Import, with options "ON" and "OFF".
3. **Traditional Logic (Light Green Rectangle):** Represents the outcome when EI is ON, showing a "VALID" result with a unicorn illustration.
4. **Modern Logic (Light Red Rectangle):** Represents the outcome when EI is OFF, showing an "INVALID" result with a red "X" and a note about an "Empty Set issue".
Arrows indicate the flow of logic from the syllogism to the EI switch and then to either Traditional or Modern Logic.
### Content Details
* **Syllogism:**
* Premise 1: "All hairy animals are mammals" (Text in dark blue)
* Premise 2: "All unicorns are hairy animals" (Text in dark orange)
* Conclusion: "Some unicorns are mammals" (Text in dark purple)
* **Existential Import (EI):**
* ON: "licenses existence" (Text in dark green)
* OFF: "allows empty classes" (Text in dark red)
* **Traditional Logic (EI = ON):**
* Status: "VALID" (Text in dark green)
* Illustration: A white unicorn head.
* **Modern Logic (EI = OFF):**
* Status: "INVALID" (Text in dark red)
* Note: "Empty Set issue" (Text in black)
The arrows are colored to indicate the flow:
* Syllogism to EI Switch: Light orange arrow.
* EI Switch to Traditional Logic: Light green arrow.
* EI Switch to Modern Logic: Light red arrow.
### Key Observations
The diagram highlights a critical difference between traditional and modern logic. Traditional logic assumes that terms in a syllogism refer to existing entities (EI = ON). Modern logic allows for the possibility of empty classes (EI = OFF), meaning a term can refer to nothing. The syllogism presented is valid under traditional logic because it assumes unicorns exist. However, it becomes invalid under modern logic because the class of "unicorns" could be empty, rendering the conclusion "Some unicorns are mammals" false.
### Interpretation
This diagram demonstrates a fundamental shift in logical reasoning. The introduction of modern logic and the rejection of Existential Import necessitate a more cautious approach to syllogistic arguments. The diagram illustrates that the validity of a syllogism is not solely determined by its structure but also by the underlying assumptions about the existence of the entities involved. The "Empty Set issue" note is crucial; it points to the core problem: if there are no unicorns, the premises can be true while the conclusion is false. This has significant implications for formal reasoning and the interpretation of logical arguments in various fields, including mathematics, philosophy, and computer science. The use of color-coding and visual flow effectively conveys the relationship between the different components and the impact of EI on the syllogism's validity.
</details>
<details>
<summary>images/train2.png Details</summary>
### Visual Description
\n
## Diagram: AI Model Progression on a Train
### Overview
The image is a diagram depicting a train representing the progression of AI models along a spectrum from "Modern Logic" to "Traditional Logic". The train consists of an engine and three cars, each labeled with different AI model names. The diagram visually suggests a shift in AI model characteristics as one moves from the engine to the last car.
### Components/Axes
The diagram consists of the following components:
* **Engine:** Labeled "GPT-3, GPT-5" and positioned on the "Modern Logic" side.
* **First Car:** Labeled "Qwen-8B, Qwen-30B-A3B" and positioned at the "Turning Point".
* **Second Car:** Labeled "Llama3-8B, Qwen3-0.6B" and positioned on the "Traditional Logic" side.
* **Horizontal Axis:** Labeled with "Modern Logic" on the left, "Turning Point" in the center, and "Traditional Logic" on the right. This axis represents a spectrum of logical approaches in AI.
* **Train Tracks:** Represent the progression or pathway.
### Detailed Analysis or Content Details
The diagram presents a categorization of AI models based on their underlying logical approach.
* **GPT-3 & GPT-5:** These models are associated with "Modern Logic".
* **Qwen-8B & Qwen-30B-A3B:** These models are positioned at the "Turning Point", suggesting a transition between modern and traditional logic.
* **Llama3-8B & Qwen3-0.6B:** These models are associated with "Traditional Logic".
The models are listed within each component (engine and cars) with multiple models listed in each.
### Key Observations
The diagram implies a distinction between different AI models based on their logical foundations. GPT models are positioned as representing the most modern approach, while Llama3 and Qwen3 models are associated with a more traditional approach. The Qwen models appear to bridge the gap between the two. The diagram does not provide any quantitative data or specific details about the nature of "Modern Logic" or "Traditional Logic".
### Interpretation
The diagram is a conceptual representation of how different AI models might be categorized based on their underlying logical principles. It suggests that there is a spectrum of logical approaches in AI, ranging from more modern to more traditional. The positioning of the models on this spectrum implies that they embody different degrees of these approaches. The "Turning Point" suggests that some models, like Qwen, represent a hybrid approach or a transition between the two.
The diagram is likely intended to provoke thought about the different philosophical underpinnings of various AI models and how these might influence their behavior and capabilities. It's a qualitative assessment rather than a quantitative one. The lack of specific details about what constitutes "Modern Logic" or "Traditional Logic" means the diagram is open to interpretation. It could be referring to differences in reasoning methods, knowledge representation, or other aspects of AI architecture.
</details>
Figure 1: The illustration of existential import problem and the trace of model logic.
<details>
<summary>images/acc-t.png Details</summary>
### Visual Description
\n
## Scatter Plot: Model Performance Comparison
### Overview
This scatter plot visualizes the performance (acc-t) of various language models across different sizes/configurations. The x-axis represents the model name, and the y-axis represents the accuracy score (acc-t). The size of each data point appears to correlate with some model parameter, potentially the number of parameters. Different colors represent different model families. A horizontal line at approximately acc-t = 80 is present, potentially indicating a performance threshold.
### Components/Axes
* **X-axis:** Model Name (Categorical) - Llama-3-8B, Llama-3-70B, Gemma-3-1B, Gemma-3-2B, Gemma-3-2B-it, Owen-1.0B, Owen-1.7B, Owen-3-4B, Owen-3-14B, Owen-5-32B, Owen-NEXT-80B-A1B, Owen-NEXT-25B-A2B, Owen-1.7B-T, Owen-3-4B-T, Owen-3-14B-T, Owen-5-32B-T, Owen-NEXT-80B-A1B-T, Owen-NEXT-25B-A2B-T, Gemini-2.5-pro, Qp6.3, GPT-5.
* **Y-axis:** acc-t (Accuracy) - Scale ranges from approximately 60 to 100.
* **Legend:** Located in the top-right corner.
* Llama (Blue)
* Gemini (Green)
* Qwen (Yellow)
* Owen-T (Red)
* GPT (Light Blue)
### Detailed Analysis
The plot shows a wide range of accuracy scores across different models. Here's a breakdown by model family, with approximate values based on visual inspection:
**Llama (Blue):**
* Llama-3-8B: acc-t ≈ 62
* Llama-3-70B: acc-t ≈ 83
* Trend: Llama performance increases with model size.
**Gemma (Green):**
* Gemma-3-1B: acc-t ≈ 81
* Gemma-3-2B: acc-t ≈ 82
* Gemma-3-2B-it: acc-t ≈ 78
* Trend: Gemma performance is relatively stable across the 1B and 2B models, with a slight dip for the Italian version.
**Qwen (Yellow):**
* Qwen-1.0B: acc-t ≈ 72
* Qwen-1.7B: acc-t ≈ 75
* Qwen-3-4B: acc-t ≈ 78
* Qwen-3-14B: acc-t ≈ 80
* Qwen-5-32B: acc-t ≈ 75
* Qwen-NEXT-80B-A1B: acc-t ≈ 72
* Qwen-NEXT-25B-A2B: acc-t ≈ 68
* Trend: Qwen performance initially increases with size, then plateaus and slightly decreases for the larger models.
**Owen-T (Red):**
* Owen-1.0B-T: acc-t ≈ 75
* Owen-1.7B-T: acc-t ≈ 78
* Owen-3-4B-T: acc-t ≈ 80
* Owen-3-14B-T: acc-t ≈ 76
* Owen-5-32B-T: acc-t ≈ 70
* Owen-NEXT-80B-A1B-T: acc-t ≈ 68
* Owen-NEXT-25B-A2B-T: acc-t ≈ 65
* Trend: Owen-T performance shows a more erratic pattern, with no clear correlation between size and accuracy.
**GPT (Light Blue):**
* Gemini-2.5-pro: acc-t ≈ 70
* Qp6.3: acc-t ≈ 64
* GPT-5: acc-t ≈ 61
* Trend: GPT models show relatively low performance compared to other families.
The horizontal line at acc-t ≈ 80 seems to separate models that achieve relatively high performance from those that do not.
### Key Observations
* Llama-3-70B and Gemma-3-2B achieve the highest accuracy scores.
* The larger Qwen and Owen-T models do not necessarily outperform their smaller counterparts.
* GPT models consistently show lower accuracy scores.
* There is significant variance in performance within each model family.
* The size of the data points appears to be correlated with model size, with larger points representing larger models.
### Interpretation
This data suggests that model size is not the sole determinant of performance. While larger Llama models generally perform better, this is not the case for Qwen or Owen-T. The architecture and training data likely play a significant role. The horizontal line at acc-t = 80 could represent a practical threshold for acceptable performance in a given application. The relatively low performance of GPT models may indicate that they are not as well-suited for the task being evaluated, or that they are smaller models compared to the others. The erratic performance of Owen-T models suggests that there may be issues with their training or architecture. The plot highlights the importance of evaluating models based on their specific performance metrics rather than relying solely on model size as an indicator of quality. The varying sizes of the data points, presumably representing model parameters, suggest a trade-off between model complexity and performance.
</details>
<details>
<summary>images/acc-m.png Details</summary>
### Visual Description
\n
## Scatter Plot: Model Performance Comparison
### Overview
This image presents a scatter plot comparing the performance (acc-m) of various language models. The x-axis lists the model names, and the y-axis represents the accuracy metric (acc-m). Each model is represented by a colored circle, with the size of the circle potentially indicating another variable (though this is not explicitly stated in the legend). Horizontal dashed lines are present at acc-m = 80, potentially representing a performance threshold.
### Components/Axes
* **X-axis:** Model Name (Categorical) - Llama-3-8B, Llama-3-70B, Gemma-3-4B, Gemma-3-12B, Gemma-3-2B, Qwen-1.5-0.5B, Qwen-1.5-1.1B, Qwen-1.5-4B, Qwen-1.5-12B, Qwen-NEXT-60B-A1B, Qwen-2.5B-A2B, Qwen-2.5B-A2B-T, Qwen-1.5B-T, Qwen-3B-T, Qwen-4B-T, Qwen-1.5-12B-T, Qwen-NEXT-60B-A1B-T, Qwen-2.5B-pro, GPT-3, GPT-5.
* **Y-axis:** acc-m (Accuracy Metric) - Scale ranges from approximately 55 to 105.
* **Horizontal Lines:** Dashed lines at approximately acc-m = 80.
* **Data Points:** Colored circles representing individual models.
* **Legend:** No explicit legend is present, but colors are used to differentiate models.
### Detailed Analysis
The data points are scattered across the plot, showing varying levels of performance for each model. I will analyze the data points from left to right, noting approximate acc-m values.
* **Llama-3-8B:** ~63 acc-m (Blue)
* **Llama-3-70B:** ~66 acc-m (Blue)
* **Gemma-3-4B:** ~64 acc-m (Blue)
* **Gemma-3-12B:** ~66 acc-m (Blue)
* **Gemma-3-2B:** ~64 acc-m (Green)
* **Qwen-1.5-0.5B:** ~61 acc-m (Green)
* **Qwen-1.5-1.1B:** ~64 acc-m (Green)
* **Qwen-1.5-4B:** ~68 acc-m (Green)
* **Qwen-1.5-12B:** ~71 acc-m (Purple)
* **Qwen-NEXT-60B-A1B:** ~94 acc-m (Purple)
* **Qwen-2.5B-A2B:** ~83 acc-m (Pink)
* **Qwen-2.5B-A2B-T:** ~97 acc-m (Pink)
* **Qwen-1.5B-T:** ~70 acc-m (Pink)
* **Qwen-3B-T:** ~85 acc-m (Pink)
* **Qwen-4B-T:** ~88 acc-m (Yellow)
* **Qwen-1.5-12B-T:** ~84 acc-m (Yellow)
* **Qwen-NEXT-60B-A1B-T:** ~98 acc-m (Yellow)
* **Qwen-2.5B-pro:** ~95 acc-m (Blue)
* **GPT-3:** ~92 acc-m (Blue)
* **GPT-5:** ~99 acc-m (Blue)
**Trends:**
* The Llama-3 and Gemma models generally exhibit lower acc-m values compared to the Qwen and GPT models.
* Within the Qwen family, larger models (e.g., Qwen-NEXT-60B-A1B, Qwen-2.5B-A2B-T) tend to have higher acc-m values.
* The models with the suffix "-T" generally perform better than their non-"T" counterparts within the Qwen family.
* GPT-5 shows the highest acc-m value.
### Key Observations
* The Qwen-2.5B-A2B-T and Qwen-NEXT-60B-A1B-T models significantly outperform all other models, achieving acc-m values close to 100.
* The performance of Llama-3 and Gemma models is relatively consistent, with values clustering around 63-66 acc-m.
* The horizontal line at acc-m = 80 serves as a clear performance benchmark. Several models fall below this line, while others exceed it.
* The color scheme appears to be somewhat arbitrary, as there is no clear pattern relating color to model family or performance.
### Interpretation
This scatter plot demonstrates a clear correlation between model size and performance (acc-m). Larger models, particularly those from the Qwen family, generally achieve higher accuracy. The "-T" suffix likely indicates a specific training or fine-tuning process that enhances performance. The horizontal line at acc-m = 80 provides a useful threshold for evaluating model effectiveness. Models below this line may not be suitable for applications requiring high accuracy. The significant performance of Qwen-2.5B-A2B-T and Qwen-NEXT-60B-A1B-T suggests that these models represent state-of-the-art performance in this comparison. The relatively low performance of the Llama-3 and Gemma models suggests they may be less competitive in terms of accuracy, or that they were evaluated on a different task or dataset. The GPT models show strong performance, but are not necessarily the best performing. The lack of a legend makes it difficult to definitively interpret the color coding, but it appears to be used to visually group models rather than represent a specific attribute.
</details>
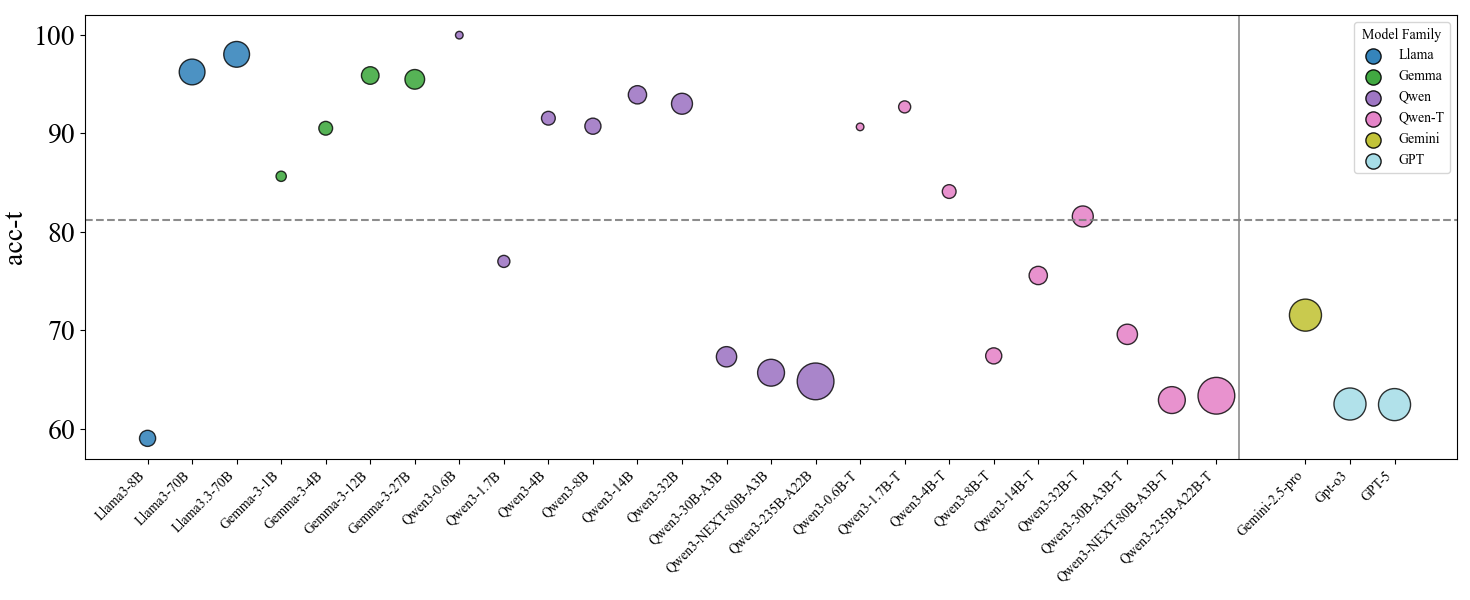
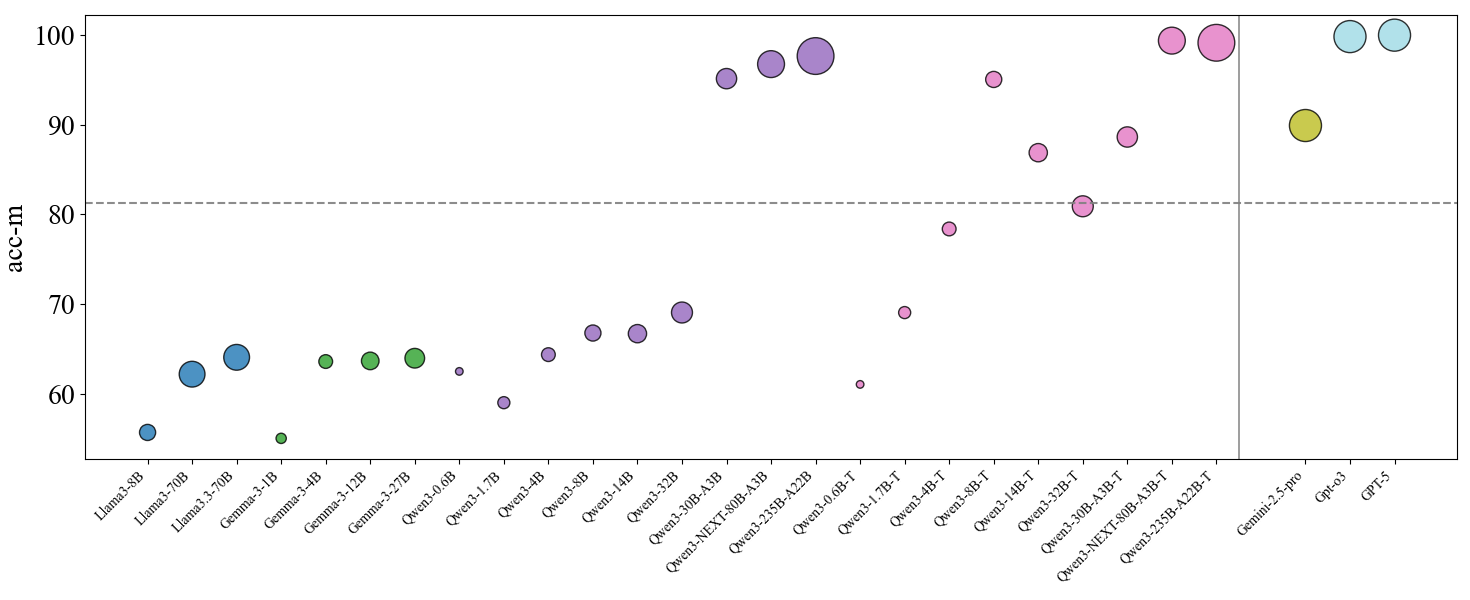
Figure 2: Overall performance of auto-regressive models under traditional logic and modern logic. The upper figure shows model performance under the traditional logic criterion, while the lower panel reports performance under the modern logic criterion. Point size is proportional to model scale, and color denotes model family. Qwen-T indicates Qwen Thinking models/mode. For closed-source models, we use a fixed medium point size for visualization only, which does not reflect their true parameter counts. The horizontal dashed line marks the dividing line between the traditional and modern logic.
Existing reasoning benchmarks Han et al. (2024) increasingly target first-order logic(modern logic), examining whether they can follow this more rigorous, formal style of reasoning. However, in syllogism reasoning, existing datasets Ando et al. (2023); Nguyen et al. (2025); Wu et al. (2023) typically treat traditional logic as the implicit default. This creates a systematic bias. A model may score high simply because it has learned dataset-specific shortcuts in traditional syllogisms, not because it truly has rigorous reasoning ability that can be transferred to new settings. On the other hand, a model may score low because it takes a modern logic view and therefore refuses to infer existence from a statement like “All unicorns are hairy animals”, which then gets marked as wrong. Even worse, these unstated rules mix up a model’s reasoning ability with how well it matches the evaluation convention, making the scores hard to interpret.
In this study, we focus on syllogism Aristotle (1984), a classic and well-studied form of deductive reasoning. The evaluation of syllogisms differs between two frameworks: Traditional Logic (Aristotelian) and Modern Logic (Boolean interpretation). The key difference between them lies in existential import (EI) Parsons and Ciola (2025), where traditional logic typically assumes the relevant terms are non-empty while modern logic makes existential commitments only when explicitly stated. As shown in Figure 1, this syllogism is typically treated as "valid" in traditional logic because the universal statement about unicorns (Premise2: All unicorns are hairy animals) is taken to presuppose that unicorns exist. While in modern logic, the conclusion does not follow unless existence of unicorns is separately asserted ("Some unicorns exist"), since the premise can be true even when there are no unicorns.
To trace the evolution of logic reasoning in LLMs, we use existential import as a probe and conduct a series of investigations on a new syllogism dataset, which can be summarized in following key findings:
(1) Controlled evidence across open-source model families and scales. We run systematic evaluations on Qwen 3 Yang et al. (2025), Llama 3 Grattafiori et al. (2024) , and Gemma 3 Team et al. (2025) series across model sizes and training variants. We find that as model size increases, $acc_{m}$ rises across all models. Models in Llama 3 and Gemma 3 series largely retain a traditional-logic reasoning style. However, in the Qwen series, we observe a clear shift in its logical paradigm from traditional logic to modern logic. We also identify a turning point where consistency fluctuates during the transition.
(2) Thinking as an efficient driver beyond parameter scaling. By comparing matched-size models, we show that RL-trained thinking variants can strongly accelerate the shift toward modern logic and improve consistency. Prompted chain-of-thought yields only a partial shift, and distillation alone does not reliably produce strict modern logic behavior, suggesting that the transition is driven more by post-training optimization of reasoning policies than by scale or imitation learning alone.
(3) Base-model constraints on learnability and stability. We evaluate Base models and show that they set the starting point for post-training. When the Base model already shows signals aligned with modern logic, post-training shifts are easier and more stable. Otherwise, the shift is harder and less stable.
We further report the experiments of different prompts, the emptiness of minor terms, cross-lingual gaps, and architecture effects including diffusion-based LLMs, conducting an in-depth analysis of properties of current LLMs on syllogistic reasoning.
## 2 Background and Dataset Construction
### 2.1 Syllogism and Existential Import
Aristotle characterizes a syllogism as consisting of two premises and a conclusion Aristotle (1984), where each statement is a categorical proposition relating a subject term ( $S$ ) to a predicate term ( $P$ ). Within the syllogism’s structure, the conclusion’s subject ( $S$ ) is called the minor term, and its predicate ( $P$ ) the major term. In standard form, there are four categorical proposition types (A/E/I/O):
| | A(universal affirmative): | All $S$ are $P$ | |
| --- | --- | --- | --- |
In this paper, we use traditional logic to denote the Aristotelian syllogistic framework, and modern logic to denote the Boolean interpretation of categorical propositions Boole (1854). For reference, under modern logic these four forms are typically rendered as:
| | A: | $\displaystyle\ \forall x\,(Sx\rightarrow Px)$ | |
| --- | --- | --- | --- |
The core distinction is existential import (EI): whether a proposition is taken to imply that its subject class is non-empty Parsons and Ciola (2025).
$\bullet$ In traditional logic, universal propositions (A/E) are typically assumed to have EI: for instance, "All $S$ are $P$ " is read as implying that the class $S$ is not empty.
$\bullet$ In modern logic, universal propositions lack EI. "All $S$ are $P$ " is formalized as a conditional, $\forall x\,(Sx\rightarrow Px)$ , which can remain true even if no $S$ exists (i.e., it is vacuously true).
We illustrate this contrast with the unicorn example in Figure 1. Under the traditional EI reading, the universal premise “All unicorns are mammals” is commonly taken to license the existential conclusion “Some unicorns are mammals.” Under modern logic, however, the universal premise entails only $\forall x\,(Ux\rightarrow Mx)$ and does not imply $\exists x\,Ux$ ; therefore the existential conclusion does not follow unless we add an explicit existence premise.
### 2.2 Dataset Construction
We build our data for analysis with a multi-stage agent pipeline that proposes terms and relations, checks factual consistency, and enforces logical constraints before generating syllogistic instances. Using this process, we generate 100 concept triplets with an empty minor-term extension and 100 with a non-empty minor-term extension, combined with Chinese/English versions and 15+9 syllogistic forms, which yields 9600 syllogisms in total. More detailed of the data construction will be discussed in Appendix 7.4.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | |
| Qwen Series – Dense Models | | | | | | | | | | | | |
| Qwen3-0.6B | 100.00 | 62.50 | 100.00 | 99.96 | 62.46 | 95.83 | 100.00 | 62.50 | 100.00 | 100.00 | 62.50 | 100.00 |
| Qwen3-0.6B-Thinking | 94.71 | 61.04 | 4.17 | 92.96 | 61.12 | 16.67 | 86.67 | 60.25 | 0.00 | 88.33 | 61.75 | 4.17 |
| Qwen3-1.7B | 97.00 | 62.42 | 50.00 | 95.58 | 60.92 | 37.50 | 75.21 | 59.71 | 16.67 | 35.17 | 47.58 | 4.17 |
| Qwen3-1.7B-Thinking | 92.92 | 67.67 | 29.17 | 94.29 | 67.71 | 50.00 | 91.62 | 70.54 | 54.17 | 91.96 | 70.29 | 58.33 |
| Qwen3-4B | 92.46 | 67.12 | 45.83 | 94.46 | 67.04 | 54.17 | 85.79 | 61.62 | 4.17 | 93.50 | 61.67 | 12.50 |
| Qwen3-4B-Thinking | 82.54 | 79.96 | 62.50 | 85.33 | 77.08 | 58.33 | 83.62 | 78.88 | 66.67 | 84.92 | 77.58 | 62.50 |
| Qwen3-8B | 94.12 | 67.46 | 33.33 | 96.67 | 65.42 | 62.50 | 85.46 | 69.58 | 4.17 | 86.71 | 64.62 | 0.00 |
| Qwen3-8B-Thinking | 67.83 | 94.50 | 54.17 | 71.62 | 90.88 | 62.50 | 64.83 | 97.67 | 75.00 | 65.29 | 97.21 | 66.67 |
| Qwen3-14B | 97.75 | 64.50 | 66.67 | 99.25 | 63.25 | 87.50 | 87.12 | 70.96 | 25.00 | 91.58 | 68.08 | 20.83 |
| Qwen3-14B-Thinking | 72.96 | 89.54 | 62.50 | 76.50 | 86.00 | 66.67 | 74.92 | 87.50 | 58.33 | 77.92 | 84.50 | 58.33 |
| Qwen3-32B | 91.67 | 70.33 | 58.33 | 95.54 | 66.96 | 75.00 | 91.00 | 70.50 | 45.83 | 93.88 | 68.46 | 54.17 |
| Qwen3-32B-Thinking | 82.21 | 80.29 | 62.50 | 85.75 | 76.75 | 62.50 | 77.96 | 84.50 | 62.50 | 80.38 | 82.08 | 62.50 |
| Qwen Series – MoE Models | | | | | | | | | | | | |
| Qwen3-30B-A3B-Instruct | 66.58 | 95.83 | 70.83 | 71.96 | 90.54 | 66.67 | 64.00 | 98.50 | 75.00 | 66.71 | 95.71 | 66.67 |
| Qwen3-30B-A3B-Thinking | 69.17 | 93.33 | 62.50 | 71.50 | 91.00 | 62.50 | 67.71 | 86.12 | 16.67 | 70.00 | 84.08 | 8.33 |
| Qwen3-NEXT-80B-A3B-Instruct | 65.58 | 96.92 | 66.67 | 70.08 | 92.42 | 66.67 | 62.71 | 99.62 | 70.83 | 64.38 | 98.12 | 62.50 |
| Qwen3-NEXT-80B-A3B-Thinking | 62.71 | 99.79 | 83.33 | 63.08 | 99.42 | 79.17 | 62.88 | 98.96 | 50.00 | 62.96 | 99.38 | 75.00 |
| Qwen3-235B-A22B-Instruct | 66.17 | 96.33 | 66.67 | 67.83 | 94.67 | 66.67 | 62.54 | 99.88 | 87.50 | 62.71 | 99.79 | 83.33 |
| Qwen3-235B-A22B-Thinking | 62.71 | 99.79 | 83.33 | 62.88 | 99.62 | 83.33 | 64.75 | 97.75 | 62.50 | 63.08 | 99.42 | 70.83 |
| Gemma Series | | | | | | | | | | | | |
| Gemma-3-1B-IT | 87.96 | 53.29 | 0.00 | 77.62 | 51.71 | 0.00 | 90.29 | 57.54 | 0.00 | 86.71 | 57.54 | 0.00 |
| Gemma-3-4B-IT | 94.46 | 63.38 | 16.67 | 77.88 | 63.54 | 0.00 | 95.00 | 63.08 | 12.50 | 94.79 | 64.38 | 25.00 |
| Gemma-3-12B-IT | 98.54 | 63.38 | 41.67 | 98.96 | 62.88 | 45.83 | 93.67 | 63.42 | 20.83 | 92.38 | 64.96 | 20.83 |
| Gemma-3-27B-IT | 95.33 | 62.00 | 16.67 | 94.17 | 61.58 | 20.83 | 96.54 | 65.71 | 50.00 | 95.96 | 66.54 | 66.67 |
| Llama Series | | | | | | | | | | | | |
| Llama3-8B-Instruct | 75.12 | 60.21 | 0.00 | 63.29 | 53.79 | 0.00 | 50.25 | 56.88 | 0.00 | 47.42 | 51.83 | 0.00 |
| Llama3-70B-Instruct | 98.58 | 63.17 | 58.33 | 96.88 | 62.71 | 45.83 | 98.88 | 62.54 | 62.50 | 90.67 | 60.29 | 20.83 |
| Llama3.3-70B-Instruct | 96.08 | 65.92 | 58.33 | 97.88 | 63.96 | 62.50 | 99.08 | 63.00 | 87.50 | 99.12 | 63.38 | 79.17 |
| Closed-source Models | | | | | | | | | | | | |
| Claude-3.7-Sonnet | 85.29 | 76.54 | 45.83 | 90.46 | 71.71 | 50.00 | 70.33 | 92.00 | 54.17 | 73.08 | 89.42 | 62.50 |
| Claude-4.5-Sonnet | 81.38 | 81.12 | 62.50 | 93.96 | 68.57 | 62.50 | 70.01 | 92.52 | 66.67 | 84.11 | 78.40 | 62.50 |
| Gemini-2.5-Pro | 71.92 | 89.33 | 29.17 | 76.17 | 83.50 | 25.00 | 65.17 | 97.33 | 70.83 | 72.92 | 89.50 | 58.33 |
| Gemini-3-Pro-Preview | 73.11 | 89.20 | 54.17 | 99.00 | 63.48 | 66.67 | 63.48 | 99.00 | 79.17 | 98.41 | 64.02 | 70.83 |
| GPT-4o-2024-11-20 | 93.17 | 68.42 | 41.67 | 96.17 | 65.71 | 50.00 | 93.33 | 68.75 | 50.00 | 94.04 | 67.83 | 50.00 |
| GPT-4.1-2025-04-14 | 80.38 | 80.04 | 33.33 | 85.08 | 76.67 | 45.83 | 80.04 | 82.38 | 58.33 | 81.54 | 80.96 | 62.50 |
| GPT-o3 | 62.38 | 99.54 | 87.50 | 62.58 | 99.92 | 91.67 | 62.50 | 100.00 | 100.00 | 62.58 | 99.92 | 95.83 |
| GPT-5-2025-08-07 | 62.50 | 100.00 | 100.00 | 62.50 | 100.00 | 100.00 | 62.50 | 100.00 | 100.00 | 62.50 | 100.00 | 100.00 |
Table 1: Results for various models by language and the subject term’s existence condition (non-empty vs. empty extension). Detailed metrics (e.g., precision and recall) are reported in the Appendix 7.6.2.
## 3 Experiment Design
### 3.1 The 15+9 Distinction of Valid Syllogistic Forms
This disagreement over EI directly creates a split in the set of valid syllogistic forms. A form is defined by its mood (the A/E/I/O pattern) and figure (term arrangement).
- Traditional Logic recognizes 24 valid forms.
- Modern Logic accepts only 15 of these as unconditionally valid. The remaining 9 forms are rejected precisely because they commit the existential fallacy.
As shown in Appendix 7.2, we use 15+9 split to distinguish traditional from modern logic validity, and report accuracy under each logic paradigm accordingly.
We further compare a baseline prompt with a Prior-check prompt that explicitly asks the model to first state whether the concepts are empty in the given setting by add "Do you think {major term}, {middle term}, {minor term} are empty sets? Keep that in mind and answer:" at the beginning of prompt, testing whether making the existence status explicit shifts the model’s behavior between traditional and modern logic.
We evaluate model behavior under both traditional logic and modern logic, and also examine how stable its reasoning is across instances of the same syllogistic form.
We first report traditional-logic accuracy ( $\text{Acc}_{t}$ ), defined as the proportion of instances in which the model accepts the conclusion, treating all 24 moods as valid under existential import. We then report modern-logic accuracy ( $\text{Acc}_{m}$ ), defined with respect to modern semantics: the model should accept instances from the 15 moods that are valid in modern logic, and reject instances from the 9 moods that become invalid when the minor term $S$ has an empty extension. Higher $\text{Acc}_{t}$ indicates behavior closer to traditional logic, while higher $\text{Acc}_{m}$ indicates behavior more consistent with the modern logic.
Moreover, consistency score (Cons) of each mood in each language and concept-emptiness set is report as $\frac{n}{24}$ . Model can earn the score only if all answers of the same mood is consistent. In addition, we report precision and recall separately on the two mood subsets (the 15 unconditionally-valid moods and the 9 existential-import-dependent moods) to better characterize how the model distinguishes between these two logic regimes, detailed in Appendix 7.5.
## 4 Results and Analysis
### 4.1 Main Results
#### 4.1.1 Scaling Effects of Logical Evolution
Advanced models exhibit modern-logic behavior.
Widely recognized as advanced closed-source LLMs(e.g., Gemini-2.5-Pro Comanici et al. (2025), GPT-o3 OpenAI (2025b), GPT-5 OpenAI (2025a)) increasingly prefer modern logic while maintaining relatively low scores under the traditional logic (see Table 1). This change is not only about higher accuracy, but also suggests that models are moving toward a more rule-based and principled way to analyze validity.
Motivated by this, we ask a basic question: how does the preference for the modern logic emerge as models are developed and scaled up? To study this in a controlled way, we turn to open-source model families where we can compare many related checkpoints. Concretely, we evaluate the Qwen Yang et al. (2025), Llama Grattafiori et al. (2024), and Gemma Team et al. (2025) series. Overall, we find that as model size increases, $Acc_{m}$ rises across all models, indicating that models’ logical reasoning became more rigorous as the parameter scaling up.
Clear family-specific scaling patterns.
We further conduct a detailed analysis of three major model families. Since Qwen series provide comprehensive coverage across the wide scale range from 0.6B to 235B, multiple variants, and different architectures (including dense and mixture-of-experts models), we primarily analyze Qwen models and report them as our main results.
Among these three families, we find clear family-specific scaling patterns in logical behavior. Qwen shows a scaling trend that includes a clear logic paradigm shift. For small to mid-sized non-thinking and instruction-tuned Qwen models, $\text{Acc}_{t}$ remains very high, indicating a strong preference for the traditional logic. However, when moving to larger Qwen models—especially thinking variants and some large instruction-tuned variants—the pattern can flip, with $\text{Acc}_{m}$ becoming much higher than $\text{Acc}_{t}$ . This trend holds in both Chinese and English, suggesting it is not tied to a single language setting. In contrast, for Llama and Gemma, models at different sizes mostly follow the traditional logic. Scaling mainly makes them stronger within the traditional logic.
We hypothesize this is because, at small sizes, the model gradually grasps traditional logic to improve inference performance. However, at larger sizes, to solve more complex problems, the model must switch to full modern logic. We also observe the consistency scores fluctuate when scaling up Qwen models. This instability is more likely near the Turning Point where the model’s logic switches. This suggests the transition from traditional logic to modern logic is not always smooth. During the change, the model may mix the behaviors of following surface patterns from data and more rigorous reasoning of modern logic, which can temporarily lead to disagreements across closely related test cases.
Takeaway 1
As models scale up, their logic judgments clearly shift from the traditional logic to modern logic, matching the same direction we see in advanced closed-source models.
#### 4.1.2 Thinking as an Efficient Driver of the Logic Evolution
Thinking accelerates the logic shift at fixed scale.
Since Thinking directly strengthens a model’s multi-step reasoning process, it enables more consistent rule-based inference with less reliance on scale alone. We compare same-sized Instruct/Non-thinking models with their Thinking counterparts. The results show that the thinking mechanism can strongly speed up the shift from the traditional logic to the modern logic. This is most obvious in the Qwen3-8B pair: while Qwen3-8B still mostly follows the traditional logic, Qwen3-8B-Thinking moves clearly toward the modern logic stance. For larger models where the Instruct version is already strongly modern-logic-aligned, the Thinking version often further improves $\text{Acc}_{m}$ and increases consistency across closely related test cases.
A natural explanation is that reinforcement learning (RL) makes the model rely more on step-by-step, rule-like deduction, and also helps it give more stable answers when two cases are very similar. In this sense, Thinking does not just add better instruction following. It changes the decision criterion and makes the logic paradigm shift more likely.
Thinking is an efficient alternative to parameter scaling.
Under the modern logic, Qwen3-8B-Thinking can reach a performance level close to Qwen3-30B-A3B-Instruct, even though it uses far fewer parameters. So, increasing model size is not the only way to get strong modern logic behavior. RL training with explicit reasoning traces can partly replace the need for more parameters by changing how the model uses its capacity. In practice, scaling tends to improve broad robustness but is expensive, while RL-based thinking can be a more focused and compute-efficient way to push the model into the modern logic. The best results still come from combining large model further enhanced with RL.
CoT Prompting and Distillation are insufficient.
To further investigate the effectiveness of Thinking mechanism, we conduct two additional experiments. First, starting from the Instruct models, we add an explicit CoT-trigger prompt (e.g., "Let’s think step by step."). The results are reported in Appendix 7.6.4. We find that Instruct+CoT setting can induce a partial shift toward modern logic, but the shift is limited. In contrast, the Thinking models produce a more complete transition in the underlying logic criterion, further supporting our main finding that RL-trained thinking acts as a promoter of logic shift.
In addition, we also examine several distilled models derived from large RL-trained model (e.g., DeepSeek-R1-Distill-Llama-8B DeepSeek-AI et al. (2025)). The results in Appendix 7.6.4 suggest that RL training does not automatically lead to rigorous modern logic in all models. Instead, achieving a stable shift to modern logic appears to require careful, task-aware design. At least in our setting, distillation from DeepSeek-R1 alone is far from sufficient to produce the same level of strict modern logic behavior.
Takeaway 2
The thinking process derived from RL can push a smaller model into modern logic.
#### 4.1.3 Base Models as the Starting Point and a Constraint
Base models shape what post-training can achieve.
Scaling and RL can change a model’s logical stance, but these changes do not start from nowhere. Here we test a more basic point: how much the final behavior is already shaped by the underlying Base model? To answer this, we evaluate several base models (Appendix 7.6.5). Overall, the base model sets the starting point for post-training, and it strongly affects both (i) what the later Instruct / Thinking models can learn and (ii) how stable that learned criterion will be.
Modern-logic signals at the Base stage enable easier shifts.
From Qwen3-8B-Base, where we later observe a clear shift toward modern logic, we already see an important signal at the base stage. It achieves relatively high $rec_{V}$ , and in most settings its $rec_{I}$ is also clearly higher than other base models. This suggests that Qwen3-8B-Base is not fully locked by traditional logic. Instead, it already shows some ability to separate the modern-valid moods from all moods, leaving room for post-training to strengthen modern logic. This explains why RL in the Thinking variant can push Qwen3-8B toward modern more easily.
In contrast, Gemma and LLaMA Base models often have low $rec_{V}$ , meaning they frequently fail to recognize modern-valid moods and tend to answer "invalid" by default. This also explains their seemingly high $rec_{I}$ on the existential-import-dependent subset: the high $rec_{I}$ is largely caused by a general rejection tendency, rather than real sensitivity to existential import.
The effect of Base model is strong but not absolute .
Small models (e.g., Qwen3-8B) benefit the most when the Base already shows modern logic signals. Larger models can still learn the modern logic through post-training (e.g., Qwen3-30B-A3B), but the learned shift is not always stable: under Thinking, judgments can fluctuate, and in some cases the model can drift back toward a traditional pattern. This suggests that post-training can move the decision criterion, but the base model still influences how reliable that move will be.
Takeaway 3
The base model is the starting point. If it already leans toward modern logic, post-training shifts are easier and more stable.
<details>
<summary>images/qwen3-4b_24x4_heatmap.png Details</summary>
### Visual Description
\n
## Heatmap: Syllogism Format Validation Performance
### Overview
This image presents a heatmap visualizing the performance of a syllogism validation system across different syllogism formats and languages. The heatmap displays the number of predicted VALID syllogisms for each combination of format and language. The color intensity represents the count, with darker colors indicating lower counts and lighter colors indicating higher counts.
### Components/Axes
* **Y-axis:** "Syllogism Format" - Lists 24 different syllogism formats. These formats are labeled as AAA-1, EAE-1, AII-1, EIO-1, EAE-2, AEE-2, EIO-2, AOO-2, AII-3, IAI-3, OAO-3, EIO-3, AEE-4, IAI-4, EIO-4, AAI-1, EAO-1, AEO-2, EAO-2, AAI-3, EAO-3, AAI-4, AEO-4, EAO-4.
* **X-axis:** Language - Two language categories are present: "zh+" (Chinese positive), "zh-" (Chinese negative), "en+" (English positive), "en-" (English negative).
* **Color Scale (Right):** "The number of predicted VALID" - A gradient scale ranging from approximately 55 (dark purple) to 100 (light yellow).
* **Legend:** The color scale acts as the legend, mapping color intensity to the number of predicted valid syllogisms.
### Detailed Analysis
The heatmap shows the number of predicted valid syllogisms for each combination of syllogism format and language. The values are approximate, based on visual estimation from the color scale.
Here's a breakdown of the data, row by row (Syllogism Format x Language):
* **AAA-1:** zh+ ≈ 98, zh- ≈ 97, en+ ≈ 99, en- ≈ 96
* **EAE-1:** zh+ ≈ 96, zh- ≈ 94, en+ ≈ 97, en- ≈ 93
* **AII-1:** zh+ ≈ 95, zh- ≈ 93, en+ ≈ 96, en- ≈ 92
* **EIO-1:** zh+ ≈ 93, zh- ≈ 91, en+ ≈ 94, en- ≈ 90
* **EAE-2:** zh+ ≈ 92, zh- ≈ 90, en+ ≈ 93, en- ≈ 89
* **AEE-2:** zh+ ≈ 90, zh- ≈ 88, en+ ≈ 91, en- ≈ 87
* **EIO-2:** zh+ ≈ 88, zh- ≈ 86, en+ ≈ 89, en- ≈ 85
* **AOO-2:** zh+ ≈ 86, zh- ≈ 84, en+ ≈ 87, en- ≈ 83
* **AII-3:** zh+ ≈ 74, zh- ≈ 72, en+ ≈ 75, en- ≈ 71
* **IAI-3:** zh+ ≈ 72, zh- ≈ 70, en+ ≈ 73, en- ≈ 69
* **OAO-3:** zh+ ≈ 70, zh- ≈ 68, en+ ≈ 71, en- ≈ 67
* **EIO-3:** zh+ ≈ 68, zh- ≈ 66, en+ ≈ 69, en- ≈ 65
* **AEE-4:** zh+ ≈ 66, zh- ≈ 64, en+ ≈ 67, en- ≈ 63
* **IAI-4:** zh+ ≈ 64, zh- ≈ 62, en+ ≈ 65, en- ≈ 61
* **EIO-4:** zh+ ≈ 62, zh- ≈ 60, en+ ≈ 63, en- ≈ 59
* **AAI-1:** zh+ ≈ 60, zh- ≈ 58, en+ ≈ 61, en- ≈ 57
* **EAO-1:** zh+ ≈ 58, zh- ≈ 56, en+ ≈ 59, en- ≈ 55
* **AEO-2:** zh+ ≈ 57, zh- ≈ 55, en+ ≈ 58, en- ≈ 54
* **EAO-2:** zh+ ≈ 56, zh- ≈ 54, en+ ≈ 57, en- ≈ 53
* **AAI-3:** zh+ ≈ 55, zh- ≈ 53, en+ ≈ 56, en- ≈ 52
* **EAO-3:** zh+ ≈ 55, zh- ≈ 53, en+ ≈ 56, en- ≈ 52
* **AAI-4:** zh+ ≈ 55, zh- ≈ 53, en+ ≈ 56, en- ≈ 52
* **AEO-4:** zh+ ≈ 55, zh- ≈ 53, en+ ≈ 56, en- ≈ 52
* **EAO-4:** zh+ ≈ 55, zh- ≈ 53, en+ ≈ 56, en- ≈ 52
**Trends:**
* Generally, the "zh+" (Chinese positive) language category shows slightly higher counts than "zh-" (Chinese negative).
* Similarly, "en+" (English positive) generally shows higher counts than "en-" (English negative).
* The counts tend to decrease as the syllogism format number increases (e.g., from -1 to -4).
* The AAA-1 format consistently has the highest predicted valid counts across all languages.
* The EAO-4 format consistently has the lowest predicted valid counts across all languages.
### Key Observations
* The performance is consistently higher for positive examples (zh+ and en+) compared to negative examples (zh- and en-).
* The AAA-1 syllogism format is the most reliably validated, while the EAO-4 format is the least.
* There is a noticeable difference in performance between the different syllogism formats, suggesting that some formats are inherently easier to validate than others.
* The differences between the languages are relatively small, suggesting that the validation system is not strongly biased towards either Chinese or English.
### Interpretation
This heatmap demonstrates the performance of a syllogism validation system. The data suggests that the system is more accurate at identifying valid positive examples of syllogisms than negative examples. The varying performance across different syllogism formats indicates that the complexity of the logical structure influences the system's ability to correctly validate them. The relatively small differences between Chinese and English suggest that the system's performance is not significantly affected by the language of the syllogism.
The consistent high performance of AAA-1 and low performance of EAO-4 could be due to the inherent logical simplicity or complexity of these formats, respectively. The system may struggle with formats that require more complex reasoning or have more potential for ambiguity.
The heatmap provides valuable insights into the strengths and weaknesses of the syllogism validation system, which can be used to improve its accuracy and robustness. Further investigation could focus on understanding why certain formats are more challenging to validate and developing strategies to address these challenges.
</details>
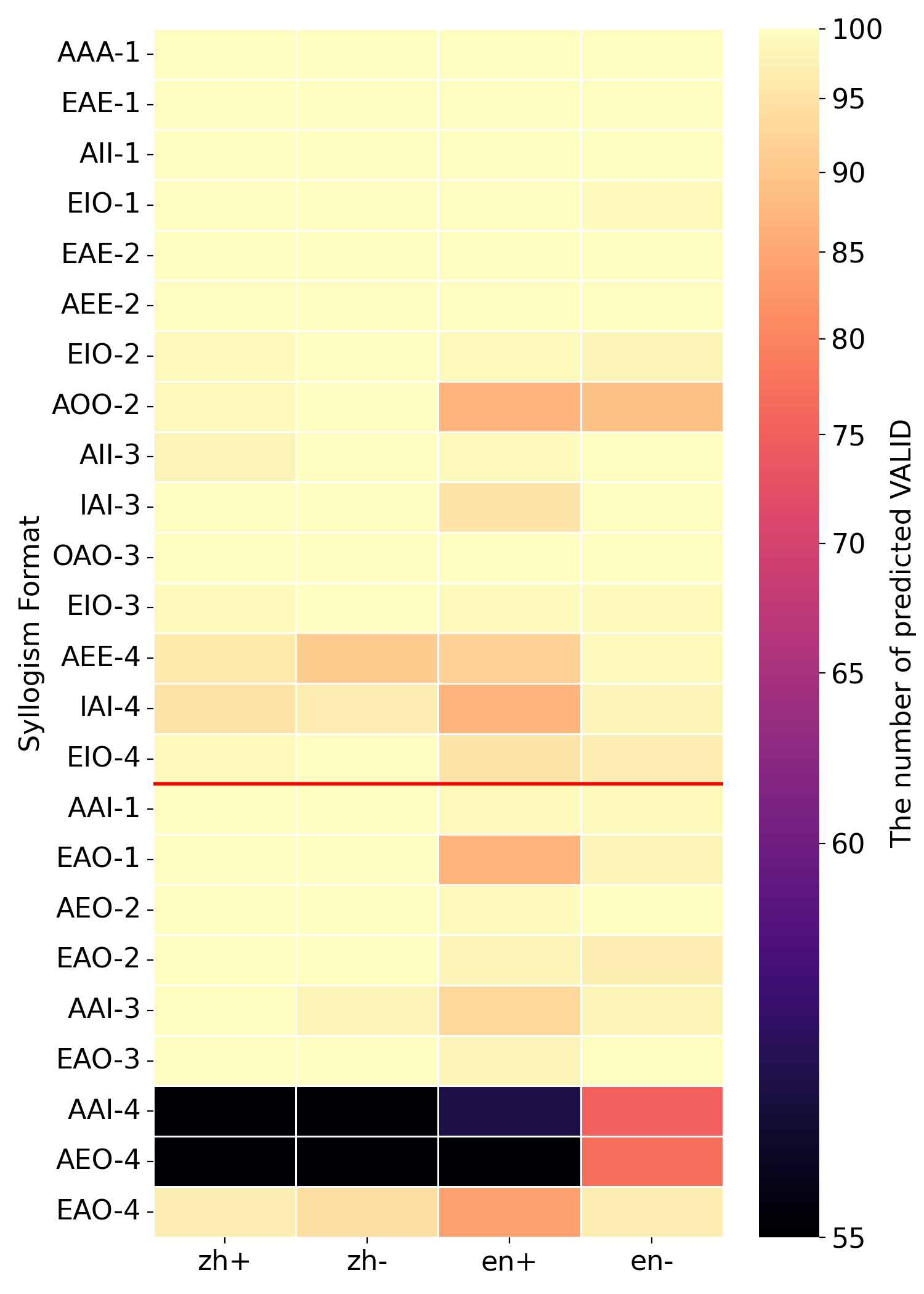
(a) Qwen3-4B
<details>
<summary>images/qwen3-8b_24x4_heatmap.png Details</summary>
### Visual Description
\n
## Heatmap: Syllogism Format Performance
### Overview
This image presents a heatmap visualizing the performance of a system (likely a natural language processing model) in predicting the validity of syllogisms. The heatmap displays the number of predicted valid syllogisms for different syllogism formats, categorized by language (Chinese and English) and polarity (positive and negative).
### Components/Axes
* **Y-axis:** "Syllogism Format" - Lists 24 different syllogism formats. These formats are labeled as AAA-1, EAE-1, AII-1, EIO-1, EAE-2, AEE-2, EIO-2, AOO-2, AII-3, IAI-3, OAO-3, EIO-3, AEE-4, IAI-4, EIO-4, AAI-1, EAO-1, AEO-2, EAO-2, AAI-3, EAO-3, AAI-4, AEO-4, EAO-4.
* **X-axis:** Language and Polarity - Four categories: "zh+", "zh-", "en+", "en-". "zh" likely represents Chinese, and "en" represents English. "+" and "-" likely denote positive and negative polarity, respectively.
* **Color Scale:** A gradient scale on the right side of the heatmap represents "The number of predicted VALID". The scale ranges from approximately 65 (dark purple) to 100 (light yellow).
* **Legend:** The color scale acts as the legend, mapping color intensity to the number of predicted valid syllogisms.
### Detailed Analysis
The heatmap shows the number of predicted valid syllogisms for each combination of syllogism format and language/polarity. The values are represented by color intensity, with darker colors indicating lower counts and lighter colors indicating higher counts.
Here's a breakdown of approximate values, reading from left to right and top to bottom:
* **zh+:**
* AAA-1: ~98
* EAE-1: ~97
* AII-1: ~96
* EIO-1: ~95
* EAE-2: ~94
* AEE-2: ~93
* EIO-2: ~92
* AOO-2: ~91
* AII-3: ~89
* IAI-3: ~88
* OAO-3: ~87
* EIO-3: ~86
* AEE-4: ~84
* IAI-4: ~83
* EIO-4: ~82
* AAI-1: ~79
* EAO-1: ~78
* AEO-2: ~77
* EAO-2: ~76
* AAI-3: ~74
* EAO-3: ~73
* AAI-4: ~71
* AEO-4: ~70
* EAO-4: ~68
* **zh-:**
* AAA-1: ~96
* EAE-1: ~95
* AII-1: ~94
* EIO-1: ~93
* EAE-2: ~92
* AEE-2: ~91
* EIO-2: ~90
* AOO-2: ~89
* AII-3: ~87
* IAI-3: ~86
* OAO-3: ~85
* EIO-3: ~84
* AEE-4: ~82
* IAI-4: ~81
* EIO-4: ~80
* AAI-1: ~77
* EAO-1: ~76
* AEO-2: ~75
* EAO-2: ~74
* AAI-3: ~72
* EAO-3: ~71
* AAI-4: ~69
* AEO-4: ~68
* EAO-4: ~66
* **en+:**
* AAA-1: ~99
* EAE-1: ~98
* AII-1: ~97
* EIO-1: ~96
* EAE-2: ~95
* AEE-2: ~94
* EIO-2: ~93
* AOO-2: ~92
* AII-3: ~90
* IAI-3: ~89
* OAO-3: ~88
* EIO-3: ~87
* AEE-4: ~85
* IAI-4: ~84
* EIO-4: ~83
* AAI-1: ~80
* EAO-1: ~79
* AEO-2: ~78
* EAO-2: ~77
* AAI-3: ~75
* EAO-3: ~74
* AAI-4: ~72
* AEO-4: ~71
* EAO-4: ~69
* **en-:**
* AAA-1: ~97
* EAE-1: ~96
* AII-1: ~95
* EIO-1: ~94
* EAE-2: ~93
* AEE-2: ~92
* EIO-2: ~91
* AOO-2: ~90
* AII-3: ~88
* IAI-3: ~87
* OAO-3: ~86
* EIO-3: ~85
* AEE-4: ~83
* IAI-4: ~82
* EIO-4: ~81
* AAI-1: ~78
* EAO-1: ~77
* AEO-2: ~76
* EAO-2: ~75
* AAI-3: ~73
* EAO-3: ~72
* AAI-4: ~70
* AEO-4: ~69
* EAO-4: ~67
### Key Observations
* Generally, performance is higher for positive polarity ("zh+" and "en+") compared to negative polarity ("zh-" and "en-").
* English (both "+" and "-") consistently shows slightly higher performance than Chinese.
* The syllogism formats AAA-1, EAE-1, and AII-1 consistently receive the highest predicted validity scores across all language/polarity combinations.
* The syllogism formats AAI-4, AEO-4, and EAO-4 consistently receive the lowest predicted validity scores.
* There is a clear trend of decreasing performance as the syllogism format number increases (e.g., moving from AAA-1 to AAA-4).
### Interpretation
The heatmap suggests that the system is more accurate at identifying valid syllogisms in English than in Chinese, and it performs better with positive polarity syllogisms. The varying performance across different syllogism formats indicates that the system's ability to assess validity is sensitive to the specific logical structure of the syllogism. The lower scores for formats like AAI-4, AEO-4, and EAO-4 might indicate that these formats are more challenging for the system to process, potentially due to their complexity or ambiguity.
The data suggests that the system has learned to associate certain syllogism formats with validity more strongly than others. This could be due to biases in the training data or inherent differences in the logical properties of the formats. The difference in performance between positive and negative polarity could be related to the way the system handles negation or the distribution of positive and negative examples in the training data. Further investigation into the training data and the system's internal representations would be needed to understand these patterns more fully.
</details>
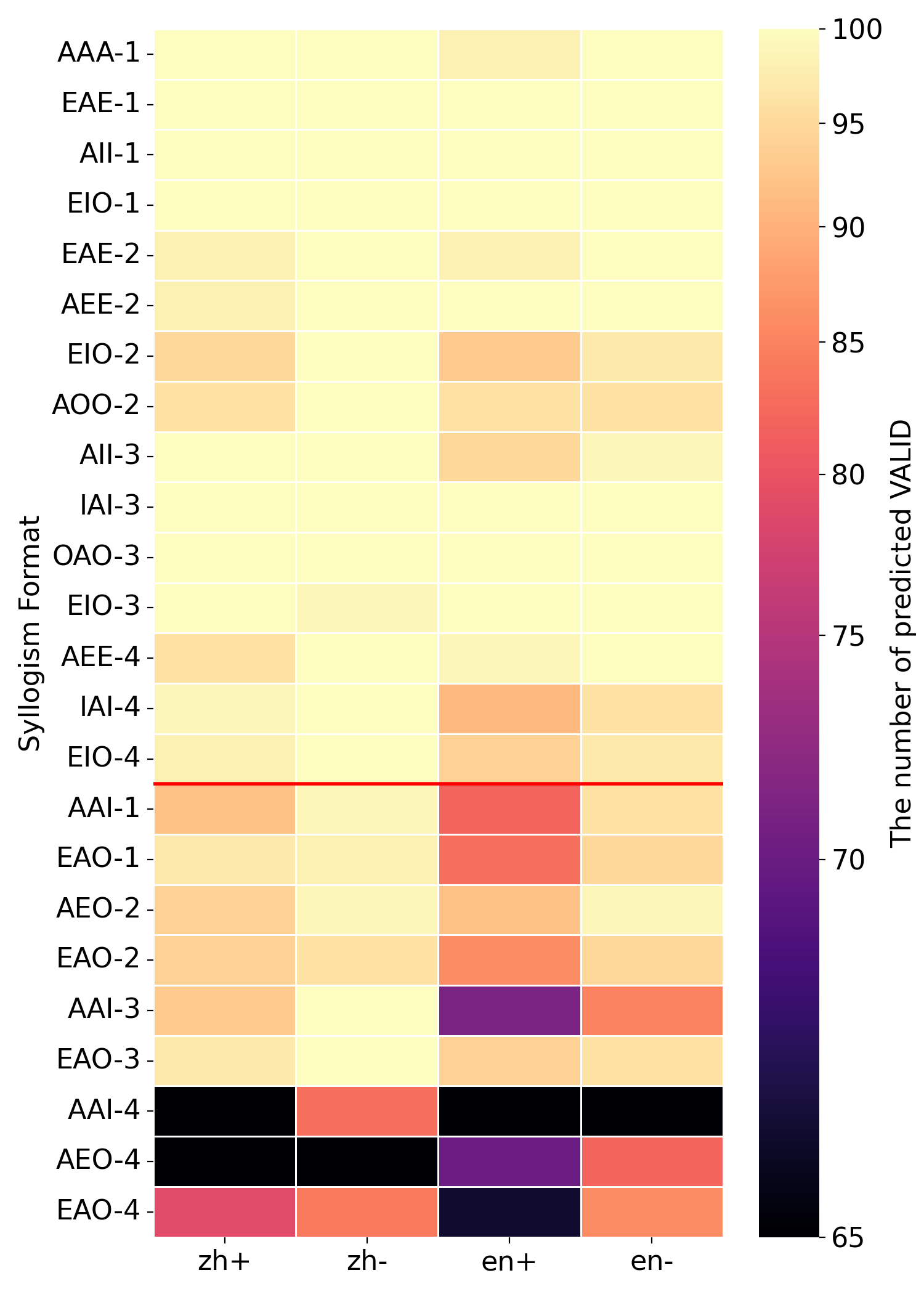
(b) Qwen3-8B
<details>
<summary>images/qwen3-next-80b-a3b-instruct_24x4_heatmap.png Details</summary>
### Visual Description
## Heatmap: Syllogism Format Validation Counts
### Overview
This image presents a heatmap visualizing the number of predicted valid syllogisms for different syllogism formats and languages. The heatmap uses a color gradient to represent the count, ranging from light yellow (low count) to dark purple (high count). The x-axis represents the language, and the y-axis represents the syllogism format.
### Components/Axes
* **X-axis:** Language - with categories "zh+" (Chinese Positive), "zh-" (Chinese Negative), "en+" (English Positive), "en-" (English Negative).
* **Y-axis:** Syllogism Format - with the following categories:
* AAA-1
* EAE-1
* AII-1
* EIO-1
* EAE-2
* AEE-2
* EIO-2
* AOO-2
* AII-3
* IAI-3
* OAO-3
* EIO-3
* AEE-4
* IAI-4
* EIO-4
* AAI-1
* EAO-1
* AEO-2
* EAO-2
* AAI-3
* EAO-3
* AAI-4
* AEO-4
* EAO-4
* **Color Scale (Right):** "The number of predicted VALID" ranging from 0 (dark purple) to 100 (light yellow).
### Detailed Analysis
The heatmap displays the counts for each combination of syllogism format and language. The values are approximate, based on the color gradient.
* **zh+ (Chinese Positive):**
* AAA-1: ~95
* EAE-1: ~90
* AII-1: ~85
* EIO-1: ~80
* EAE-2: ~75
* AEE-2: ~70
* EIO-2: ~65
* AOO-2: ~60
* AII-3: ~55
* IAI-3: ~50
* OAO-3: ~45
* EIO-3: ~40
* AEE-4: ~35
* IAI-4: ~30
* EIO-4: ~25
* AAI-1: ~20
* EAO-1: ~15
* AEO-2: ~10
* EAO-2: ~10
* AAI-3: ~5
* EAO-3: ~5
* AAI-4: ~0
* AEO-4: ~0
* EAO-4: ~0
* **zh- (Chinese Negative):**
* AAA-1: ~85
* EAE-1: ~80
* AII-1: ~75
* EIO-1: ~70
* EAE-2: ~65
* AEE-2: ~60
* EIO-2: ~55
* AOO-2: ~50
* AII-3: ~45
* IAI-3: ~40
* OAO-3: ~35
* EIO-3: ~30
* AEE-4: ~25
* IAI-4: ~20
* EIO-4: ~15
* AAI-1: ~10
* EAO-1: ~5
* AEO-2: ~5
* EAO-2: ~5
* AAI-3: ~0
* EAO-3: ~0
* AAI-4: ~0
* AEO-4: ~0
* EAO-4: ~0
* **en+ (English Positive):**
* AAA-1: ~70
* EAE-1: ~65
* AII-1: ~60
* EIO-1: ~55
* EAE-2: ~50
* AEE-2: ~45
* EIO-2: ~40
* AOO-2: ~35
* AII-3: ~30
* IAI-3: ~25
* OAO-3: ~20
* EIO-3: ~15
* AEE-4: ~10
* IAI-4: ~5
* EIO-4: ~5
* AAI-1: ~0
* EAO-1: ~0
* AEO-2: ~0
* EAO-2: ~0
* AAI-3: ~0
* EAO-3: ~0
* AAI-4: ~0
* AEO-4: ~0
* EAO-4: ~0
* **en- (English Negative):**
* AAA-1: ~60
* EAE-1: ~55
* AII-1: ~50
* EIO-1: ~45
* EAE-2: ~40
* AEE-2: ~35
* EIO-2: ~30
* AOO-2: ~25
* AII-3: ~20
* IAI-3: ~15
* OAO-3: ~10
* EIO-3: ~5
* AEE-4: ~0
* IAI-4: ~0
* EIO-4: ~0
* AAI-1: ~0
* EAO-1: ~0
* AEO-2: ~0
* EAO-2: ~0
* AAI-3: ~0
* EAO-3: ~0
* AAI-4: ~0
* AEO-4: ~0
* EAO-4: ~0
### Key Observations
* The counts are generally highest for the "zh+" (Chinese Positive) language and decrease as we move to "zh-", "en+", and "en-".
* The "AAA-1" format consistently shows the highest counts across all languages.
* The "AAI-4", "AEO-4", and "EAO-4" formats consistently show the lowest counts (close to zero) across all languages.
* There is a clear trend of decreasing counts as the syllogism format number increases (e.g., from -1 to -4).
### Interpretation
The heatmap suggests that the model performs best at predicting valid syllogisms in Chinese (positive polarity) and struggles more with English (especially negative polarity). The performance also varies significantly depending on the syllogism format, with some formats being much easier to validate than others. The consistent high performance for "AAA-1" and low performance for "AAI-4", "AEO-4", and "EAO-4" could indicate inherent differences in the logical structure or complexity of these formats. The difference between positive and negative polarity within each language suggests the model may be sensitive to the phrasing or construction of the syllogisms. This data could be used to improve the model's performance by focusing on the more challenging languages and syllogism formats.
</details>
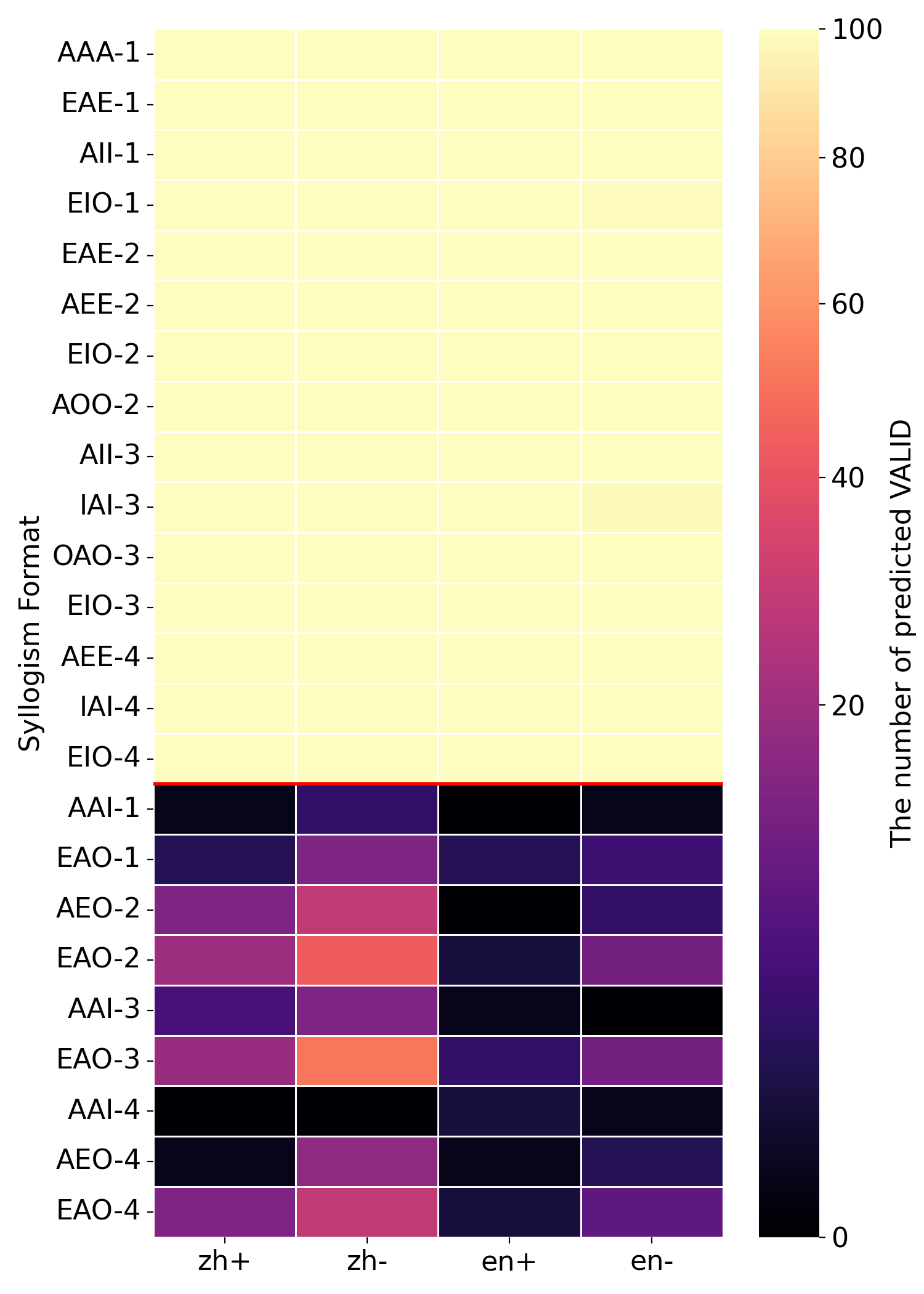
(c) Qwen3-NEXT-80B-A3B-Instruct
<details>
<summary>images/qwen3-235b-a22b-thinking_24x4_heatmap.png Details</summary>
### Visual Description
\n
## Heatmap: Syllogism Format Validity Prediction Counts
### Overview
This image presents a heatmap visualizing the number of predicted VALID syllogisms for different syllogism formats and language combinations. The heatmap uses a color gradient to represent the count, ranging from 0 (dark purple) to 100 (light yellow). The x-axis represents language combinations, and the y-axis represents syllogism formats.
### Components/Axes
* **X-axis:** Language Combination. Categories are: "zh+" (Chinese positive), "zh-" (Chinese negative), "en+" (English positive), "en-" (English negative).
* **Y-axis:** Syllogism Format. Categories are: AAA-1, EAE-1, AII-1, EIO-1, EAE-2, AEE-2, EIO-2, AOO-2, AII-3, IAI-3, OAO-3, EIO-3, AEE-4, IAI-4, EIO-4, AAI-1, EAO-1, AEO-2, EAO-2, AAI-3, EAO-3, AAI-4, AEO-4, EAO-4.
* **Color Scale:** Represents "The number of predicted VALID". The scale ranges from dark purple (approximately 0) to light yellow (approximately 100).
* **Legend:** Located on the right side of the heatmap, showing the color gradient and corresponding numerical values.
### Detailed Analysis
The heatmap displays the counts of predicted valid syllogisms for each combination of syllogism format and language. The values are approximate due to the visual nature of the data extraction.
Here's a breakdown of the data, row by row, with approximate values:
* **AAA-1:** zh+ ~ 90, zh- ~ 85, en+ ~ 80, en- ~ 75
* **EAE-1:** zh+ ~ 85, zh- ~ 80, en+ ~ 75, en- ~ 70
* **AII-1:** zh+ ~ 80, zh- ~ 75, en+ ~ 70, en- ~ 65
* **EIO-1:** zh+ ~ 75, zh- ~ 70, en+ ~ 65, en- ~ 60
* **EAE-2:** zh+ ~ 70, zh- ~ 65, en+ ~ 60, en- ~ 55
* **AEE-2:** zh+ ~ 65, zh- ~ 60, en+ ~ 55, en- ~ 50
* **EIO-2:** zh+ ~ 60, zh- ~ 55, en+ ~ 50, en- ~ 45
* **AOO-2:** zh+ ~ 55, zh- ~ 50, en+ ~ 45, en- ~ 40
* **AII-3:** zh+ ~ 50, zh- ~ 45, en+ ~ 40, en- ~ 35
* **IAI-3:** zh+ ~ 45, zh- ~ 40, en+ ~ 35, en- ~ 30
* **OAO-3:** zh+ ~ 40, zh- ~ 35, en+ ~ 30, en- ~ 25
* **EIO-3:** zh+ ~ 35, zh- ~ 30, en+ ~ 25, en- ~ 20
* **AEE-4:** zh+ ~ 30, zh- ~ 25, en+ ~ 20, en- ~ 15
* **IAI-4:** zh+ ~ 25, zh- ~ 20, en+ ~ 15, en- ~ 10
* **EIO-4:** zh+ ~ 20, zh- ~ 15, en+ ~ 10, en- ~ 5
* **AAI-1:** zh+ ~ 15, zh- ~ 10, en+ ~ 5, en- ~ 0
* **EAO-1:** zh+ ~ 10, zh- ~ 5, en+ ~ 0, en- ~ 0
* **AEO-2:** zh+ ~ 5, zh- ~ 0, en+ ~ 0, en- ~ 0
* **EAO-2:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **AAI-3:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **EAO-3:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **AAI-4:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **AEO-4:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **EAO-4:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
**Trends:**
* Generally, the counts of predicted valid syllogisms decrease as the syllogism format number increases (e.g., from -1 to -4).
* The counts are generally higher for "zh+" (Chinese positive) compared to "en-" (English negative).
* The counts are higher for positive language combinations ("zh+" and "en+") than for negative language combinations ("zh-" and "en-").
### Key Observations
* The bottom rows (AAI-1 through EAO-4) consistently show very low or zero counts of predicted valid syllogisms, regardless of the language.
* The highest counts are observed for the AAA-1 format in the "zh+" language combination, reaching approximately 90.
* There's a clear gradient across the heatmap, indicating a strong relationship between syllogism format, language, and predicted validity.
### Interpretation
This heatmap suggests that the model used to predict syllogism validity performs better on certain syllogism formats and language combinations than others. The higher counts for "zh+" and lower counts for "en-" might indicate a bias in the model towards Chinese language or a difference in the way syllogisms are structured or interpreted in the two languages. The decreasing counts as the format number increases suggest that more complex syllogism formats are harder for the model to validate. The consistent low counts for the bottom rows indicate that these formats are rarely predicted as valid, potentially due to inherent logical flaws or difficulties in parsing them. This data could be used to improve the model by focusing on the formats and languages where it performs poorly, or by investigating the reasons for the observed biases. The use of "+" and "-" in the language labels suggests a possible sentiment or polarity component being considered in the validation process, which warrants further investigation.
</details>
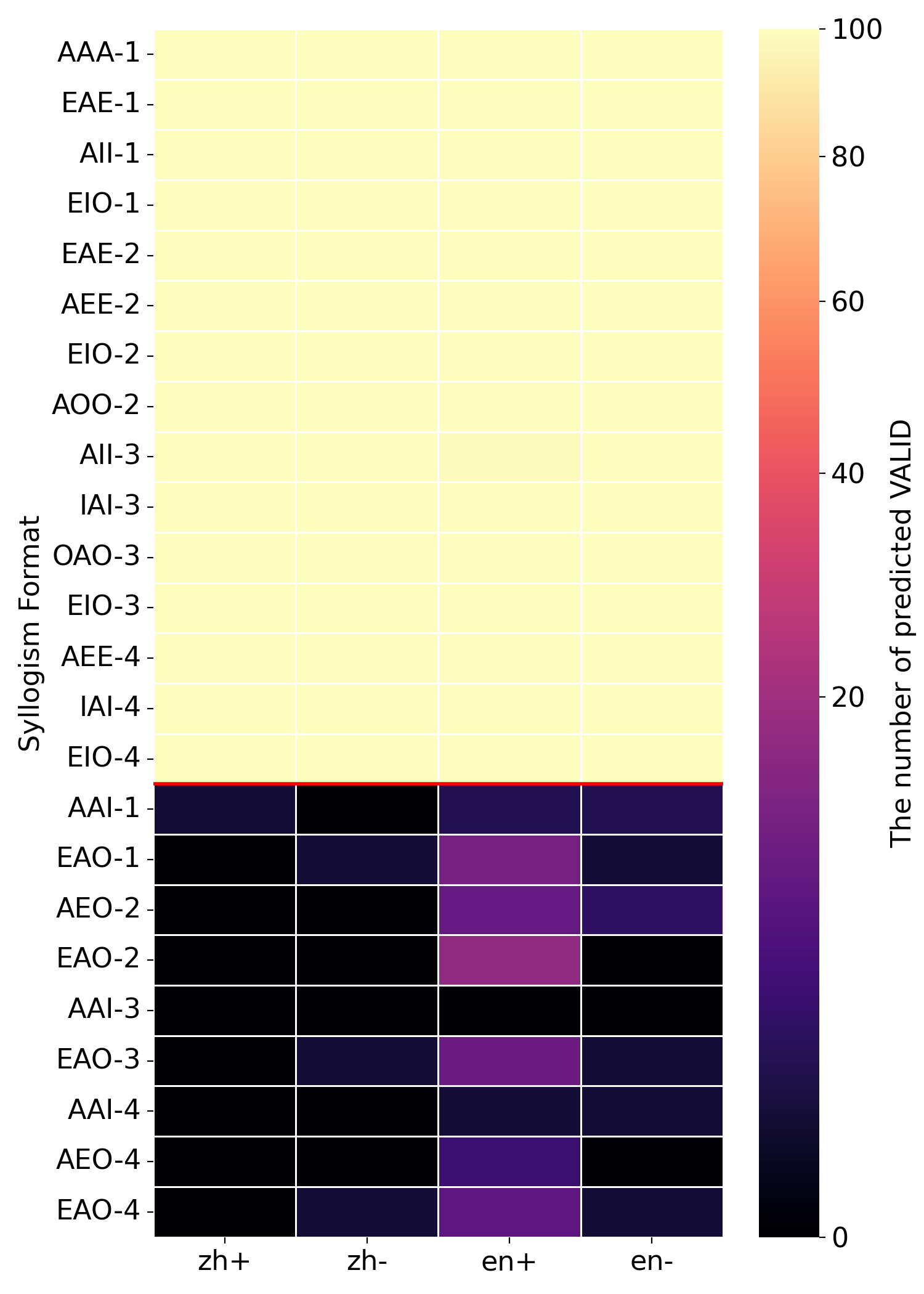
(d) Qwen3-235B-A22B-Thinking
Figure 3: The heatmaps of two types of model logic. (a) and (b) are traditional logic while (c) and (d) are modern logic.
### 4.2 Further Analysis
#### 4.2.1 Prior-check Prompt
To ensure that our measured modern logic performance is not an artifact of prompting, we introduce Prior-check prompt that explicitly asks the model to check the relevant existence condition before making a validity judgment. The goal is simple: make the model perform a semantic check that is required under modern logic evaluation, without changing the logical content of the task.
Main effect: higher $\mathrm{Acc}_{m}$ without stance flipping.
As a control group, we report results with baseline prompt in Appendix 7.6.3. We observe that Prior-check prompt consistently increases $\text{Acc}_{m}$ for most models, while keeping their overall logical stance stable and easy to interpret. This suggests that the prompt improves compliance with modern logic rather than introducing systematic bias.
Turning-point instability.
A notable exception appears in the Qwen3-30B-A3B pair. Although the Instruct version looks modern-logic, the Thinking version shifts back toward traditional logic. This suggests that Qwen3-30B-A3B model is close to the turning point between paradigms. Long thinking contents may sometimes bring back traditional defaults. The fluctuations reveal that the model’s stance can be fragile during the logic transition stage.
#### 4.2.2 The emptiness of minor term
Empty minor terms are consistently harder.
Under both Prior-check prompt and the baseline setting, models show lower $rec_{I}$ when the minor term is empty than when the non-empty counterpart.
One likely reason is that empty minor terms make counterexamples harder to construct. To judge an argument as invalid under modern logic, the model often needs to consider a situation where the premises are true but the conclusion is false. When the minor term is empty, this kind of reasoning is less intuitive because there are no concrete instances to reason about. As a result, the model tends to fall back on traditional logic. This increases false positives and reduces $rec_{I}$ . This result highlights the permeability of world knowledge. Plausibility priors can leak into formal reasoning and interfere with rule-governed validity judgments.
Mood-specific error concentration suggests data imprinting.
To further probe knowledge effects in syllogistic reasoning, we visualize the number of "valid" answers across languages, minor-term existence settings, and all 24 syllogistic moods, as shown in Figure 3. The figure compares four models under Prior-check prompt. Regardless of whether a model generally aligns with traditional or modern logic, errors concentrate on a few specific moods rather than being evenly distributed. For example, Qwen3-4B is overall closer to traditional logic, it displays a strong tendency toward the modern logic in the AAI-4 and AEO-4 syllogism forms. One explanation is that certain moods are more frequent in training data, leading to better learning of those forms. This supports the view that LLMs’ logical behavior is shaped by training data, rather than reflecting an abstract reasoning ability that generalizes uniformly.
#### 4.2.3 Cross-lingual Gaps
Clear language-dependent effect. When comparing three open-source series, the Qwen and LLaMA series generally perform better in Chinese than in English, while Gemma shows the opposite pattern, with higher performance in English. This difference is most visible in accuracy measured under each model’s dominant logical stance.
This cross-lingual gap suggests that current LLMs’ logical ability is not fully language-agnostic. Instead, it is still strongly shaped by language-specific patterns in training data. In short, what looks like “logical reasoning” in these models is still partly tied to the language they operate in, rather than being a truly language-independent reasoning skill.
#### 4.2.4 Architecture and Reasoning Ability
We next study how model architecture relates to logical reasoning behavior. We consider two settings: (i) open-source auto-regressive (AR) LLMs, comparing Dense models with mixture-of-experts (MoE) models shown in Table 1; and (ii) emerging diffusion LLMs (dLLMs) shown in Table 9.
MoE in AR models correlates with more modern-leaning behavior.
Within AR models, MoE variants in the Qwen family exhibit a stronger tendency toward modern logic than same-generation dense models. A plausible explanation is the combined effect of MoE efficiency and model scaling. MoE architectures make it easier to train models with higher effective capacity under similar compute, and the shift toward modern logic becomes more likely as model size increases.
DLLMs mostly follow traditional logic.
For dLLMs, most models still predominantly follow the traditional logic. Only one exception is LLaDA2.0-flash, which is a 100B model with MoE architecture. This exception again reflects the joint impact of MoE architecture and model scaling.
## 5 Related Works
In recent years, many benchmarks have been proposed for syllogism reasoning. ENN Dong et al. (2020) constructed syllogisms extracted from WordNet Miller (1995). The syllogsims are in the form of triplets with no natural language descriptions. Syllo-Figure Peng et al. (2020) and NeuBAROCO Ando et al. (2023) are two natural language syllogism datasets, with data derived from existed datasets. Syllo-Figure derives omitted syllogisms from SNLI Bowman et al. (2015) and rewrites the missing premise by annotators. The target is to identify the specific figure. NeuBAROCO transforms questions from BAROCO Shikishima et al. (2009) into a format used for natural language inferences(NLI). Beyond categorical syllogism, SylloBase Wu et al. (2023) covers more types and patterns of syllogism, covering a complete taxonomy of syllogism reasoning patterns. There are also several researches focusing on the human-like bias of syllogism, such as belief bias Nguyen et al. (2025); Ando et al. (2023) and atmosphere effects Ando et al. (2023). However, these works all assume existential import by default, meaning they approach the task under a traditional logic setting. To examine different models’ tendencies under different logical paradigms and gain deeper insights, we use existential import as a probe and conduct a series of investigations.
## 6 Conclusion and Discussion
This work studies whether LLMs’ syllogistic validity judgments shift toward a more rigorous modern logic criterion as models develop. Among all models, $\mathrm{Acc}_{m}$ generally increases with scale, but only the Qwen series exhibits a clear logic shift , consistent with the behavior of advanced closed-source models. Matched-size comparisons further show that RL-trained Thinking variants efficiently accelerate this shift and improve consistency; in contrast, CoT prompting induces only a limited move toward modern logic, and distillation alone does not reliably yield strict modern logic behavior.
However, the transition is not always smooth. The consistency can fluctuate near the turning point, and some near-boundary models (e.g., Qwen3-30B-A3B) may partially revert under reasoning traces. We also identify systematic failure modes that persist across settings, including difficulty with empty minor terms, mood-specific bias, and cross-lingual gaps. Overall, our results suggest that modern logic reasoning in LLMs is shaped jointly by the base model and post-training (especially RL-based thinking), rather than emerging from parameter scaling alone.
## Limitations
Our conclusions are primarily drawn from syllogistic reasoning and the contrast induced by existential import. While this probe cleanly separates traditional and modern validity criteria, it remains unclear whether the same evolutionary patterns hold for broader first-order logic criteria.
We evaluate models mainly through their final valid/invalid decisions. This endpoint-only metric can obscure the source of errors. Our study does not directly supervise or diagnose intermediate semantic representations or proof-like structures, limiting our ability to pinpoint the mechanisms behind observed shifts and inconsistencies.
Our distillation analysis covers only a small set of distilled models and a specific teacher family (e.g., DeepSeek-R1). Moreover, the distillation objectives and data are not fully known or comparable across models. As a result, our finding that distillation alone does not reliably induce strict modern-logic behavior should be interpreted as an empirical observation in our setting, rather than a general negative result about distillation.
## References
- R. Ando, T. Morishita, H. Abe, K. Mineshima, and M. Okada (2023) Evaluating large language models with neubaroco: syllogistic reasoning ability and human-like biases. External Links: 2306.12567, Link Cited by: §1, §5.
- Aristotle (1984) Prior analytics. In The Complete Works of Aristotle: The Revised Oxford Translation, Vol. 1, J. Barnes (Ed.), pp. 39–113. Cited by: §1, §1, §2.1, §7.1.
- Y. Bang, S. Cahyawijaya, N. Lee, W. Dai, D. Su, B. Wilie, H. Lovenia, Z. Ji, T. Yu, W. Chung, Q. V. Do, Y. Xu, and P. Fung (2023) A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. External Links: 2302.04023, Link Cited by: §1.
- T. Bie, M. Cao, K. Chen, L. Du, M. Gong, Z. Gong, Y. Gu, J. Hu, Z. Huang, Z. Lan, C. Li, C. Li, J. Li, Z. Li, H. Liu, L. Liu, G. Lu, X. Lu, Y. Ma, J. Tan, L. Wei, J. Wen, Y. Xing, X. Zhang, J. Zhao, D. Zheng, J. Zhou, J. Zhou, Z. Zhou, L. Zhu, and Y. Zhuang (2025) LLaDA2.0: scaling up diffusion language models to 100b. External Links: 2512.15745, Link Cited by: §7.6.6.
- Y. Bisk, R. Zellers, R. L. Bras, J. Gao, and Y. Choi (2019) PIQA: reasoning about physical commonsense in natural language. External Links: 1911.11641, Link Cited by: §1.
- G. Boole (1854) An investigation of the laws of thought: on which are founded the mathematical theories of logic and probabilities. Walton and Maberly, London. Cited by: §2.1, §7.1.
- S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning (2015) A large annotated corpus for learning natural language inference. External Links: 1508.05326, Link Cited by: §5.
- S. Cheng, Y. Bian, D. Liu, L. Zhang, Q. Yao, Z. Tian, W. Wang, Q. Guo, K. Chen, B. Qi, and B. Zhou (2025) SDAR: a synergistic diffusion-autoregression paradigm for scalable sequence generation. External Links: 2510.06303, Link Cited by: §7.6.6.
- G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, L. Marris, S. Petulla, C. Gaffney, A. Aharoni, N. Lintz, T. C. Pais, H. Jacobsson, I. Szpektor, N. Jiang, K. Haridasan, A. Omran, N. Saunshi, D. Bahri, G. Mishra, E. Chu, T. Boyd, B. Hekman, A. Parisi, C. Zhang, K. Kawintiranon, T. Bedrax-Weiss, O. Wang, Y. Xu, O. Purkiss, U. Mendlovic, I. Deutel, N. Nguyen, A. Langley, F. Korn, L. Rossazza, A. Ramé, S. Waghmare, H. Miller, N. Byrd, A. Sheshan, R. Hadsell, S. Bhardwaj, P. Janus, T. Rissa, D. Horgan, A. Abdagic, L. Belenki, J. Allingham, A. Singh, T. Guidroz, S. Srinivasan, H. Schmit, K. Chiafullo, A. Elisseeff, N. Jha, P. Kolhar, L. Berrada, F. Ding, X. Si, S. B. Mallick, F. Och, S. Erell, E. Ni, T. Latkar, S. Yang, P. Sirkovic, Z. Feng, R. Leland, R. Hornung, G. Wu, C. Blundell, H. Alvari, P. Huang, C. Yip, S. Deur, L. Liu, G. Surita, P. Duque, D. Damen, J. Jia, A. Guez, M. Mircea, A. Sinha, A. Magni, P. Stradomski, T. Marian, V. Galić, W. Chen, H. Husain, A. Singhal, D. Grewe, F. Aubet, S. Song, L. Blanco, L. Rechis, L. Ho, R. Munoz, K. Zheng, J. Hamrick, K. Mather, H. Taitelbaum, E. Rutherford, Y. Lei, K. Chen, A. Shukla, E. Moreira, E. Doi, B. Isik, N. Shabat, D. Rogozińska, K. Kolipaka, J. Chang, E. Vušak, S. Venkatachary, S. Noghabi, T. Bharti, Y. Jun, A. Zaks, S. Green, J. Challagundla, W. Wong, M. Mohammad, D. Hirsch, Y. Cheng, I. Naim, L. Proleev, D. Vincent, A. Singh, M. Krikun, D. Krishnan, Z. Ghahramani, A. Atias, R. Aggarwal, C. Kirov, D. Vytiniotis, C. Koh, A. Chronopoulou, P. Dogra, V. Ion, G. Tyen, J. Lee, F. Weissenberger, T. Strohman, A. Balakrishna, J. Rae, M. Velic, R. de Liedekerke, O. Elyada, W. Yuan, C. Liu, L. Shani, S. Kishchenko, B. Alessio, Y. Li, R. Song, S. Kwei, O. Jankowski, A. Pappu, Y. Namiki, Y. Ma, N. Tripuraneni, C. Cherry, M. Ikonomidis, Y. Ling, C. Ji, B. Westberg, A. Wright, D. Yu, D. Parkinson, S. Ramaswamy, J. Connor, S. H. Yeganeh, S. Grover, G. Kenwright, L. Litchev, C. Apps, A. Tomala, F. Halim, A. Castro-Ros, Z. Li, A. Boral, P. Sho, M. Yarom, E. Malmi, D. Klinghoffer, R. Lin, A. Ansell, P. K. S, S. Zhao, S. Zuo, A. Santoro, H. Cheng, S. Demmessie, Y. Liu, N. Brichtova, A. Culp, N. Braun, D. Graur, W. Ng, N. Mehta, A. Phillips, P. Sundberg, V. Godbole, F. Liu, Y. Katariya, D. Rim, M. Seyedhosseini, S. Ammirati, J. Valfridsson, M. Malihi, T. Knight, A. Toor, T. Lampe, A. Ittycheriah, L. Chiang, C. Yeung, A. Fréchette, J. Rao, H. Wang, H. Srivastava, R. Zhang, R. Rhodes, A. Brand, D. Weesner, I. Figotin, F. Gimeno, R. Fellinger, P. Marcenac, J. Leal, E. Marcus, V. Cotruta, R. Cabrera, S. Luo, D. Garrette, V. Axelrod, S. Baltateanu, D. Barker, D. Chen, H. Toma, B. Ingram, J. Riesa, C. Kulkarni, Y. Zhang, H. Liu, C. Wang, M. Polacek, W. Wu, K. Hui, A. N. Reyes, Y. Su, M. Barnes, I. Malhi, A. Siddiqui, Q. Feng, M. Damaschin, D. Pighin, A. Steiner, S. Yang, R. S. Boppana, S. Ivanov, A. Kandoor, A. Shah, A. Mujika, D. Huang, C. A. Choquette-Choo, M. Patel, T. Yu, T. Creswell, Jerry, Liu, C. Barros, Y. Razeghi, A. Roy, P. Culliton, B. Xiong, J. Pan, T. Strohmann, T. Powell, B. Seal, D. DeCarlo, P. Shyam, K. Katircioglu, X. Wang, C. Hardin, I. Odisho, J. Broder, O. Chang, A. Nair, A. Shtefan, M. O’Brien, M. Agarwal, S. Potluri, S. Goyal, A. Jhindal, S. Thakur, Y. Stuken, J. Lyon, K. Toutanova, F. Feng, A. Wu, B. Horn, A. Wang, A. Cullum, G. Taubman, D. Shrivastava, C. Shi, H. Tomlinson, R. Patel, T. Tu, A. M. Oflazer, F. Pongetti, M. Yang, A. A. Taïga, V. Perot, N. W. Pierse, F. Han, Y. Drori, I. Iturrate, A. Chakrabarti, L. Yeung, D. Dopson, Y. Chen, A. Kulshreshtha, T. Guo, P. Pham, T. Schuster, J. Chen, A. Polozov, J. Xing, H. Zhou, P. Kacham, D. Kukliansky, A. Miech, S. Yaroshenko, E. Chi, S. Douglas, H. Fei, M. Blondel, P. Myla, L. Madmoni, X. Wu, D. Keysers, K. Kjems, I. Albuquerque, L. Yu, J. D’sa, M. Plantan, V. Ionescu, J. S. Elias, A. Gupta, M. R. Vuyyuru, F. Alcober, T. Zhou, K. Ji, F. Hartmann, S. Puttagunta, H. Song, E. Amid, A. Stefanoiu, A. Lee, P. Pucciarelli, E. Wang, A. Raul, S. Petrov, I. Tian, V. Anklin, N. Nti, V. Gomes, M. Schumacher, G. Vesom, A. Panagopoulos, K. Bousmalis, D. Andor, J. Jacob, Y. Zhang, B. Rosgen, M. Kecman, M. Tung, A. Belias, N. Goodman, P. Covington, B. Wieder, N. Saxena, E. Davoodi, M. Huang, S. Maddineni, V. Roulet, F. Campbell-Ajala, P. G. Sessa, Xintian, Wu, G. Lai, P. Collins, A. Haig, V. Sakenas, X. Xu, M. Giustina, L. E. Shafey, P. Charoenpanit, S. Garg, J. Ainslie, B. Severson, M. G. Arenas, S. Pathak, S. Rajayogam, J. Feng, M. Bakker, S. Li, N. Wichers, J. Rogers, X. Geng, Y. Li, R. Jagerman, C. Jia, N. Olmert, D. Sharon, M. Mauger, S. Mariserla, H. Ma, M. Mohabey, K. Kim, A. Andreev, S. Pollom, J. Love, V. Jain, P. Agrawal, Y. Schroecker, A. Fortin, M. Warmuth, J. Liu, A. Leach, I. Blok, G. P. Girirajan, R. Aharoni, B. Uria, A. Sozanschi, D. Goldberg, L. Ionita, M. T. Ribeiro, M. Zlocha, V. Birodkar, S. Lachgar, L. Yuan, H. Choudhury, M. Ginsberg, F. Zheng, G. Dibb, E. Graves, S. Lokhande, G. Rasskin, G. Muraru, C. Quick, S. Tata, P. Sermanet, A. Chawla, I. Karo, Y. Wang, S. Zhang, O. Keller, A. Dragan, G. Su, I. Chou, X. Liu, Y. Tao, S. Prabhakara, M. Wilson, R. Liu, S. Wang, G. Evans, D. Du, A. Castaño, G. Prasad, M. E. Mahdy, S. Gerlach, M. Reid, J. Kahn, A. Zait, T. S. Pillai, T. Ulrich, G. Wang, J. Wassenberg, E. Farkash, K. Yalasangi, C. Wang, M. Bauza, S. Bucher, T. Liu, J. Yan, G. Leung, V. Sindhwani, P. Barnes, A. Singh, I. Jurin, J. Chang, N. K. Bhumihar, S. Eiger, G. Citovsky, B. Withbroe, Z. Li, S. Xue, N. D. Santo, G. Stoyanov, Y. Raimond, S. Zheng, Y. Gao, V. Listík, S. Kwasiborski, R. Saputro, A. Ozturel, G. Mallya, K. Majmundar, R. West, P. Caron, J. Wei, L. Castrejon, S. Vikram, D. Ramachandran, N. Dhawan, J. Park, S. Smoot, G. van den Driessche, Y. Blau, C. Malik, W. Liang, R. Hirsch, C. N. dos Santos, E. Weinstein, A. van den Oord, S. Lall, N. FitzGerald, Z. Jiang, X. Yang, D. Webster, A. Elqursh, A. Pope, G. Rotival, D. Raposo, W. Zhu, J. Dean, S. Alabed, D. Tran, A. Gupta, Z. Gleicher, J. Austin, E. Rosseel, M. Umekar, D. Das, Y. Sun, K. Chen, K. Misiunas, X. Zhou, Y. Di, A. Loo, J. Newlan, B. Li, V. Ramasesh, Y. Xu, A. Chen, S. Gandhe, R. Soricut, N. Gupta, S. Hu, S. El-Sayed, X. Garcia, I. Brusilovsky, P. Chen, A. Bolt, L. Huang, A. Gurney, Z. Zhang, A. Pritzel, J. Wilkiewicz, B. Seybold, B. K. Shamanna, F. Fischer, J. Dean, K. Gill, R. Mcilroy, A. Bhowmick, J. Selier, A. Yang, D. Cheng, V. Magay, J. Tan, D. Varma, C. Walder, T. Kocisky, R. Nakashima, P. Natsev, M. Kwong, I. Gog, C. Zhang, S. Dieleman, T. Jimma, A. Ryabtsev, S. Brahma, D. Steiner, D. Du, A. Žužul, M. Žanić, M. Raghavachari, W. Gierke, Z. Zheng, D. Petrova, Y. Dauphin, Y. Liu, I. Kessler, S. Hand, C. Duvarney, S. Kim, H. Lee, L. Hussenot, J. Hui, J. Smith, D. Jain, J. Xia, G. S. Tomar, K. Amiri, D. Phan, F. Fuchs, T. Weyand, N. Tomasev, A. Cordell, X. Liu, J. Mallinson, P. Joshi, A. Crawford, A. Suggala, S. Chien, N. Fernando, M. Sanchez-Vargas, D. Williams, P. Crone, X. Luo, I. Karpov, J. Shan, T. Thurk, R. Strudel, P. Voigtlaender, P. Patil, T. Dozat, A. Khodaei, S. Singla, P. Ambroszczyk, Q. Wu, Y. Chang, B. Roark, C. Hegde, T. Ding, A. Filos, Z. Wu, A. S. Pinto, S. Liu, S. Khanna, A. Pandey, S. Mcloughlin, Q. Li, S. Haves, A. Zhou, E. Buchatskaya, I. Leal, P. de Boursac, N. Akazawa, N. Anderson, T. Chen, K. Somandepalli, C. Liang, S. Goenka, S. Winkler, A. Grushetsky, Y. Ding, J. Smith, F. Ye, J. Pont-Tuset, E. Li, R. Li, T. Golany, D. Wegner, T. Jiang, O. Barak, Y. Shangguan, E. Vértes, R. Wong, J. Bornschein, A. Tudor, M. Bevilacqua, T. Schaul, A. S. Rawat, Y. Zhao, K. Axiotis, L. Meng, C. McLean, J. Lai, J. Beattie, N. Kushman, Y. Liu, B. Kutzman, F. Lang, J. Ye, P. Netrapalli, P. Mishra, M. Khan, M. Goel, R. Willoughby, D. Tian, H. Zhuang, J. Chen, Z. Tsai, T. Kementsietsidis, A. Khare, J. Keeling, K. Xu, N. Waters, F. Altché, A. Popat, B. Mittal, D. Saxton, D. E. Badawy, M. Mathieu, Z. Zheng, H. Zhou, N. Ranka, R. Shin, Q. Duan, T. Salimans, I. Mihailescu, U. Shaham, M. Chang, Y. Assael, N. Dikkala, M. Izzard, V. Cohen-Addad, C. Graves, V. Feinberg, G. Chung, D. Strouse, D. Karmon, S. Sharifzadeh, Z. Ashwood, K. Pham, J. Blanton, A. Vasiloff, J. Barber, M. Geller, A. Zhou, F. Zubach, T. Huang, L. Zhang, H. Gupta, M. Young, J. Proskurnia, R. Votel, V. Gabeur, G. Barcik, A. Tripathi, H. Yu, G. Yan, B. Changpinyo, F. Pavetić, A. Coyle, Y. Fujii, J. G. Mendez, T. Zhou, H. Rajamani, B. Hechtman, E. Cao, D. Juan, Y. Tan, V. Dalibard, Y. Du, N. Clay, K. Yao, W. Jia, D. Vijaykumar, Y. Zhou, X. Bai, W. Hung, S. Pecht, G. Todorov, N. Khadke, P. Gupta, P. Lahoti, A. Autef, K. Duddu, J. Lee-Thorp, A. Bykovsky, T. Misiunas, S. Flennerhag, S. Thangaraj, J. McGiffin, Z. Nado, M. Kunesch, A. Noever, A. Hertz, M. Liang, V. Stone, E. Palmer, S. Daruki, A. Pramanik, S. Põder, A. Kyker, M. Khan, E. Sluzhaev, M. Ritter, A. Ruderman, W. Zhou, C. Nagpal, K. Vodrahalli, G. Necula, P. Barham, E. Pavlick, J. Hartford, I. Shafran, L. Zhao, M. Mikuła, T. Eccles, H. Shimokawa, K. Garg, L. Vilnis, H. Chen, I. Shumailov, K. Lee, A. Abdelhamed, M. Xie, V. Cohen, E. Hlavnova, D. Malkin, C. Sitawarin, J. Lottes, P. Coquinot, T. Yu, S. Kumar, J. Zhang, A. Mahendru, Z. Ahmed, J. Martens, T. Chen, A. Boag, D. Peng, C. Devin, A. Klimovskiy, M. Phuong, D. Vainstein, J. Xie, B. Ramabhadran, N. Howard, X. Yu, G. Goswami, J. Cui, S. Shleifer, M. Pinto, C. Yeh, M. Yang, S. Javanmardi, D. Ethier, C. Lee, J. Orbay, S. Kotecha, C. Bromberg, P. Shaw, J. Thornton, A. G. Rosenthal, S. Gu, M. Thomas, I. Gemp, A. Ayyar, A. Ushio, A. Selvan, J. Wee, C. Liu, M. Majzoubi, W. Yu, J. Abernethy, T. Liechty, R. Pan, H. Nguyen, Qiong, Hu, S. Perrin, A. Arora, E. Pitler, W. Wang, K. Shivakumar, F. Prost, B. Limonchik, J. Wang, Y. Gao, T. Cour, S. Buch, H. Gui, M. Ivanova, P. Neubeck, K. Chan, L. Kim, H. Chen, N. Goyal, D. Chung, L. Liu, Y. Su, A. Petrushkina, J. Shen, A. Joulin, Y. Xu, S. X. Lin, Y. Kulizhskaya, C. Chelba, S. Vasudevan, E. Collins, V. Bashlovkina, T. Lu, D. Fritz, J. Park, Y. Zhou, C. Su, R. Tanburn, M. Sushkov, M. Rasquinha, J. Li, J. Prendki, Y. Li, P. LV, S. Sharma, H. Fitoussi, H. Huang, A. Dai, P. Dao, M. Burrows, H. Prior, D. Qin, G. Pundak, L. L. Sjoesund, A. Khurshudov, Z. Zhu, A. Webson, E. Kemp, T. Tan, S. Agrawal, S. Sargsyan, L. Cheng, J. Stephan, T. Kwiatkowski, D. Reid, A. Byravan, A. H. Michaely, N. Heess, L. Zhou, S. Goenka, V. Carpenter, A. Levskaya, B. Wang, R. Roberts, R. Leblond, S. Chikkerur, S. Ginzburg, M. Chang, R. Riachi, Chuqiao, Xu, Z. Borsos, M. Pliskin, J. Pawar, M. Lustman, H. Kirkwood, A. Anand, A. Chaudhary, N. Kalb, K. Milan, S. Augenstein, A. Goldie, L. Prince, K. Raman, Y. Sun, V. Xia, A. Cohen, Z. Huo, J. Camp, S. Ellis, L. Zilka, D. V. Torres, L. Patel, S. Arora, B. Chan, J. Adler, K. Ayoub, J. Liang, F. Jamil, J. Jiang, S. Baumgartner, H. Sun, Y. Karov, Y. Akulov, H. Zheng, I. Cai, C. Fantacci, J. Rubin, A. R. Acha, M. Wang, N. D’Souza, R. Sathyanarayana, S. Dai, S. Rowe, A. Simanovsky, O. Goldman, Y. Kuang, X. Pan, A. Rosenberg, T. Rojas-Esponda, P. Dutta, A. Zeng, I. Jurenka, G. Farquhar, Y. Bansal, S. Iqbal, B. Roelofs, G. Joung, P. Beak, C. Ryu, R. Poplin, Y. Wu, J. Alayrac, S. Buthpitiya, O. Ronneberger, C. Habtegebriel, W. Li, P. Cavallaro, A. Wei, G. Bensky, T. Denk, H. Ganapathy, J. Stanway, P. Joshi, F. Bertolini, J. Lo, O. Ma, Z. Charles, G. Sampemane, H. Sahni, X. Chen, H. Askham, D. Gaddy, P. Young, J. Tan, M. Eyal, A. Bražinskas, L. Zhong, Z. Wu, M. Epstein, K. Bailey, A. Hard, K. Lee, S. Goldshtein, A. Ruiz, M. Badawi, M. Lochbrunner, J. Kearns, A. Brown, F. Pardo, T. Weber, H. Yang, P. Jiang, B. Akin, Z. Fu, M. Wainwright, C. Zou, M. Gaba, P. Manzagol, W. Kan, Y. Song, K. Zainullina, R. Lin, J. Ko, S. Deshmukh, A. Jindal, J. Svensson, D. Tyam, H. Zhao, C. Kaeser-Chen, S. Baird, P. Moradi, J. Hall, Q. Guo, V. Tsang, B. Liang, F. Pereira, S. Ganesh, I. Korotkov, J. Adamek, S. Thiagarajan, V. Tran, C. Chen, C. Tar, S. Jain, I. Dasgupta, T. Bilal, D. Reitter, K. Zhao, G. Vezzani, Y. Gehman, P. Mehta, L. Beltrone, X. Dotiwalla, S. Guadarrama, Z. Abbas, S. Karp, P. Georgiev, C. Ferng, M. Brockschmidt, L. Peng, C. Hirnschall, V. Verma, Y. Bi, Y. Xiao, A. Dabush, K. Xu, P. Wallis, R. Parker, Q. Wang, Y. Xu, I. Safarli, D. Tewari, Y. Zhang, S. Kim, A. Gesmundo, M. Thomas, S. Levi, A. Chowdhury, K. Rao, P. Garst, S. Conway-Rahman, H. Ran, K. McKinney, Z. Xiao, W. Yu, R. Agrawal, A. Stjerngren, C. Ionescu, J. Chen, V. Sharma, J. Chiu, F. Liu, K. Franko, C. Sanford, X. Cai, P. Michel, S. Ganapathy, J. Labanowski, Z. Garrett, B. Vargas, S. Sun, B. Gale, T. Buschmann, G. Desjardins, N. Ghelani, P. Jain, M. Verma, C. Asawaroengchai, J. Eisenschlos, J. Harlalka, H. Kazawa, D. Metzler, J. Howland, Y. Jian, J. Ades, V. Shah, T. Gangwani, S. Lee, R. Ring, S. M. Hernandez, D. Reich, A. Sinha, A. Sathe, J. Kovac, A. Gill, A. Kannan, A. D’olimpio, M. Sevenich, J. Whang, B. Kim, K. C. Sim, J. Chen, J. Zhang, S. Lall, Y. Matias, B. Jia, A. Friesen, S. Nasso, A. Thapliyal, B. Perozzi, T. Yu, A. Shekhawat, S. Huda, P. Grabowski, E. Wang, A. Sreevatsa, H. Dib, M. Hassen, P. Schuh, V. Milutinovic, C. Welty, M. Quinn, A. Shah, B. Wang, G. Barth-Maron, J. Frye, N. Axelsson, T. Zhu, Y. Ma, I. Giannoumis, H. Sedghi, C. Ye, Y. Luan, K. Aydin, B. Chandra, V. Sampathkumar, R. Huang, V. Lavrenko, A. Eleryan, Z. Hong, S. Hansen, S. M. Carthy, B. Samanta, D. Ćevid, X. Wang, F. Li, M. Voznesensky, M. Hoffman, A. Terzis, V. Sehwag, G. Fidel, L. He, M. Cai, Y. He, A. Feng, M. Nikoltchev, S. Phatale, J. Chase, R. Lawton, M. Zhang, T. Ouyang, M. Tragut, M. H. Manshadi, A. Narayanan, J. Shen, X. Gao, T. Bolukbasi, N. Roy, X. Li, D. Golovin, L. Panait, Z. Qin, G. Han, T. Anthony, S. Kudugunta, V. Patraucean, A. Ray, X. Chen, X. Yang, T. Bhatia, P. Talluri, A. Morris, A. Ražnatović, B. Brownfield, J. An, S. Peng, P. Kane, C. Zheng, N. Duduta, J. Kessinger, J. Noraky, S. Liu, K. Rong, P. Veličković, K. Rush, A. Goldin, F. Wei, S. M. R. Garlapati, C. Pantofaru, O. Kwon, J. Ni, E. Noland, J. D. Trapani, F. Beaufays, A. G. Roy, Y. Chow, A. Turker, G. Cideron, L. Mei, J. Clark, Q. Dou, M. Bošnjak, R. Leith, Y. Du, A. Yazdanbakhsh, M. Nasr, C. Kwak, S. S. Sheth, A. Kaskasoli, A. Anand, B. Lakshminarayanan, S. Jerome, D. Bieber, C. Chu, A. Senges, T. Shen, M. Sridhar, N. Ndebele, B. Beyret, S. Mohamed, M. Chen, M. Freitag, J. Guo, L. Liu, P. Roit, H. Chen, S. Yan, T. Stone, J. Co-Reyes, J. Cole, S. Scellato, S. Azizi, H. Hashemi, A. Jin, A. Iyer, M. Valentine, A. György, A. Ahuja, D. H. Diaz, C. Lee, N. Clement, W. Kong, D. Garmon, I. Watts, K. Bhatia, K. Gupta, M. Miecnikowski, H. Vallet, A. Taly, E. Loper, S. Joshi, J. Atwood, J. Chick, M. Collier, F. Iliopoulos, R. Trostle, B. Gunel, R. Leal-Cavazos, A. M. Hrafnkelsson, M. Guzman, X. Ju, A. Forbes, J. Emond, K. Chauhan, B. Caine, L. Xiao, W. Zeng, A. Moufarek, D. Murphy, M. Meng, N. Gupta, F. Riedel, A. Das, E. Lawal, S. Narayan, T. Sosea, J. Swirhun, L. Friso, B. Neyshabur, J. Lu, S. Girgin, M. Wunder, E. Yvinec, A. Pyne, V. Carbune, S. Rijhwani, Y. Guo, T. Doshi, A. Briukhov, M. Bain, A. Hitron, X. Wang, A. Gupta, K. Chen, C. Du, W. Zhang, D. Shah, A. Akula, M. Dylla, A. Kachra, W. Kuo, T. Zou, L. Wang, L. Xu, J. Zhu, J. Snyder, S. Menon, O. Firat, I. Mordatch, Y. Yuan, N. Ponomareva, R. Blevins, L. Moore, W. Wang, P. Chen, M. Scholz, A. Dwornik, J. Lin, S. Li, D. Antognini, T. I, X. Song, M. Miller, U. Kalra, A. Raveret, O. Akerlund, F. Wu, A. Nystrom, N. Godbole, T. Liu, H. DeBalsi, J. Zhao, B. Liu, A. Caciularu, L. Lax, U. Khandelwal, V. Langston, E. Bailey, S. Lattanzi, Y. Wang, N. Kovelamudi, S. Mondal, G. Guruganesh, N. Hua, O. Roval, P. Wesołowski, R. Ingale, J. Halcrow, T. Sohn, C. Angermueller, B. Raad, E. Stickgold, E. Lu, A. Kosik, J. Xie, T. Lillicrap, A. Huang, L. L. Zhang, D. Paulus, C. Farabet, A. Wertheim, B. Wang, R. Joshi, C. Ko, Y. Wu, S. Agrawal, L. Lin, X. Sheng, P. Sung, T. Breland-King, C. Butterfield, S. Gawde, S. Singh, Q. Zhang, R. Apte, S. Shetty, A. Hutter, T. Li, E. Salesky, F. Lebron, J. Kanerva, M. Paganini, A. Nguyen, R. Vallu, J. Peter, S. Velury, D. Kao, J. Hoover, A. Bortsova, C. Bishop, S. Jakobovits, A. Agostini, A. Agarwal, C. Liu, C. Kwong, S. Tavakkol, I. Bica, A. Greve, A. GP, J. Marcus, L. Hou, T. Duerig, R. Moroshko, D. Lacey, A. Davis, J. Amelot, G. Wang, F. Kim, T. Strinopoulos, H. Wan, C. L. Lan, S. Krishnan, H. Tang, P. Humphreys, J. Bai, I. H. Shtacher, D. Machado, C. Pang, K. Burke, D. Liu, R. Aravamudhan, Y. Song, E. Hirst, A. Singh, B. Jou, L. Bai, F. Piccinno, C. K. Fu, R. Alazard, B. Meiri, D. Winter, C. Chen, M. Zhang, J. Heitkaemper, J. Lambert, J. Lee, A. Frömmgen, S. Rogulenko, P. Nair, P. Niemczyk, A. Bulyenov, B. Xu, H. Shemtov, M. Zadimoghaddam, S. Toropov, M. Wirth, H. Dai, S. Gollapudi, D. Zheng, A. Kurakin, C. Lee, K. Bullard, N. Serrano, I. Balazevic, Y. Li, J. Schalkwyk, M. Murphy, M. Zhang, K. Sequeira, R. Datta, N. Agrawal, C. Sutton, N. Attaluri, M. Chiang, W. Farhan, G. Thornton, K. Lin, T. Choma, H. Nguyen, K. Dasgupta, D. Robinson, I. Comşa, M. Riley, A. Pillai, B. Mustafa, B. Golan, A. Zandieh, J. Lespiau, B. Porter, D. Ross, S. Rajayogam, M. Agarwal, S. Venugopalan, B. Shahriari, Q. Yan, H. Xu, T. Tobin, P. Dubov, H. Shi, A. Recasens, A. Kovsharov, S. Borgeaud, L. Dery, S. Vasanth, E. Gribovskaya, L. Qiu, M. Mahdieh, W. Skut, E. Nielsen, C. Zheng, A. Yu, C. G. Bostock, S. Gupta, A. Archer, C. Rawles, E. Davies, A. Svyatkovskiy, T. Tsai, Y. Halpern, C. Reisswig, B. Wydrowski, B. Chang, J. Puigcerver, M. H. Taege, J. Li, E. Schnider, X. Li, D. Dena, Y. Xu, U. Telang, T. Shi, H. Zen, K. Kastner, Y. Ko, N. Subramaniam, A. Kumar, P. Blois, Z. Dai, J. Wieting, Y. Lu, Y. Zeldes, T. Xie, A. Hauth, A. Ţifrea, Y. Li, S. El-Husseini, D. Abolafia, H. Zhou, W. Ding, S. Ghalebikesabi, C. Guía, A. Maksai, Á. Weisz, S. Arik, N. Sukhanov, A. Świetlik, X. Jia, L. Yu, W. Wang, M. Brand, D. Bloxwich, S. Kirmani, Z. Chen, A. Go, P. Sprechmann, N. Kannen, A. Carin, P. Sandhu, I. Edkins, L. Nooteboom, J. Gupta, L. Maggiore, J. Azizi, Y. Pritch, P. Yin, M. Gupta, D. Tarlow, D. Smith, D. Ivanov, M. Babaeizadeh, A. Goel, S. Kambala, G. Chu, M. Kastelic, M. Liu, H. Soltau, A. Stone, S. Agrawal, M. Kim, K. Soparkar, S. Tadepalli, O. Bunyan, R. Soh, A. Kannan, D. Kim, B. J. Chen, A. Halumi, S. Roy, Y. Wang, O. Sercinoglu, G. Gibson, S. Bhatnagar, M. Sano, D. von Dincklage, Q. Ren, B. Mitrevski, M. Olšák, J. She, C. Doersch, Jilei, Wang, B. Liu, Q. Tan, T. Yakar, T. Warkentin, A. Ramirez, C. Lebsack, J. Dillon, R. Mathews, T. Cobley, Z. Wu, Z. Chen, J. Simon, S. Nath, T. Sainath, A. Bendebury, R. Julian, B. Mankalale, D. Ćurko, P. Zacchello, A. R. Brown, K. Sodhia, H. Howard, S. Caelles, A. Gupta, G. Evans, A. Bulanova, L. Katzen, R. Goldenberg, A. Tsitsulin, J. Stanton, B. Schillings, V. Kovalev, C. Fry, R. Shah, K. Lin, S. Upadhyay, C. Li, S. Radpour, M. Maggioni, J. Xiong, L. Haas, J. Brennan, A. Kamath, N. Savinov, A. Nagrani, T. Yacovone, R. Kappedal, K. Andriopoulos, L. Lao, Y. Li, G. Rozhdestvenskiy, K. Hashimoto, A. Audibert, S. Austin, D. Rodriguez, A. Ruoss, G. Honke, D. Karkhanis, X. Xiong, Q. Wei, J. Huang, Z. Leng, V. Premachandran, S. Bileschi, G. Evangelopoulos, T. Mensink, J. Pavagadhi, D. Teplyashin, P. Chang, L. Xue, G. Tanzer, S. Goldman, K. Patel, S. Li, J. Wiesner, I. Zheng, I. Stewart-Binks, J. Han, Z. Li, L. Luo, K. Lenc, M. Lučić, F. Xue, R. Mullins, A. Guseynov, C. Chang, I. Galatzer-Levy, A. Zhang, G. Bingham, G. Hu, A. Hartman, Y. Ma, J. Griffith, A. Irpan, C. Radebaugh, S. Yue, L. Fan, V. Ungureanu, C. Sorokin, H. Teufel, P. Li, R. Anil, D. Paparas, T. Wang, C. Lin, H. Peng, M. Shum, G. Petrovic, D. Brady, R. Nguyen, K. Macherey, Z. Li, H. Singh, M. Yenugula, M. Iinuma, X. Chen, K. Kopparapu, A. Stern, S. Dave, C. Thekkath, F. Perot, A. Kumar, F. Li, Y. Xiao, M. Bilotti, M. H. Bateni, I. Noble, L. Lee, A. Vázquez-Reina, J. Salazar, X. Yang, B. Wang, E. Gruzewska, A. Rao, S. Raghuram, Z. Xu, E. Ben-David, J. Mei, S. Dalmia, Z. Zhang, Y. Liu, G. Bansal, H. Pankov, S. Schwarcz, A. Burns, C. Chan, S. Sanghai, R. Liang, E. Liang, A. He, A. Stuart, A. Narayanan, Y. Zhu, C. Frank, B. Fatemi, A. Sabne, O. Lang, I. Bhattacharya, S. Settle, M. Wang, B. McMahan, A. Tacchetti, L. B. Soares, M. Hadian, S. Cabi, T. Chung, N. Putikhin, G. Li, J. Chen, A. Tarango, H. Michalewski, M. Kazemi, H. Masoom, H. Sheftel, R. Shivanna, A. Vadali, R. Comanescu, D. Reid, J. Moore, A. Neelakantan, M. Sander, J. Herzig, A. Rosenberg, M. Dehghani, J. Choi, M. Fink, R. Hayes, E. Ge, S. Weng, C. Ho, J. Karro, K. Krishna, L. N. Thiet, A. Skerry-Ryan, D. Eppens, M. Andreetto, N. Sarma, S. Bonacina, B. K. Ayan, M. Nawhal, Z. Shan, M. Dusenberry, S. Thakoor, S. Gubbi, D. D. Nguyen, R. Tsarfaty, S. Albanie, J. Mitrović, M. Gandhi, B. Chen, A. Epasto, G. Stephanov, Y. Jin, S. Gehman, A. Amini, J. Weber, F. Behbahani, S. Xu, M. Allamanis, X. Chen, M. Ott, C. Sha, M. Jastrzebski, H. Qi, D. Greene, X. Wu, A. Toki, D. Vlasic, J. Shapiro, R. Kotikalapudi, Z. Shen, T. Saeki, S. Xie, A. Cassirer, S. Bharadwaj, T. Kiyono, S. Bhojanapalli, E. Rosenfeld, S. Ritter, J. Mao, J. G. Oliveira, Z. Egyed, B. Bandemer, E. Parisotto, K. Kinoshita, J. Pluto, P. Maniatis, S. Li, Y. Guo, G. Ghiasi, J. Tarbouriech, S. Chatterjee, J. Jin, Katrina, Xu, J. Palomaki, S. Arnold, M. Sewak, F. Piccinini, M. Sharma, B. Albrecht, S. Purser-haskell, A. Vaswani, C. Chen, M. Wisniewski, Q. Cao, J. Aslanides, N. M. Phu, M. Sieb, L. Agubuzu, A. Zheng, D. Sohn, M. Selvi, A. Andreassen, K. Subudhi, P. Eruvbetine, O. Woodman, T. Mery, S. Krause, X. Ren, X. Ma, J. Luo, D. Chen, W. Fan, H. Griffiths, C. Schuler, A. Li, S. Zhang, J. Sarr, S. Luo, R. Patana, M. Watson, D. Naboulsi, M. Collins, S. Sidhwani, E. Hoogeboom, S. Silver, E. Caveness, X. Zhao, M. Rodriguez, M. Deines, L. Bai, P. Griffin, M. Tagliasacchi, E. Xue, S. R. Babbula, B. Pang, N. Ding, G. Shen, E. Peake, R. Crocker, S. S. Raghvendra, D. Swisher, W. Han, R. Singh, L. Wu, V. Pchelin, T. Munkhdalai, D. Alon, G. Bacon, E. Robles, J. Bulian, M. Johnson, G. Powell, F. T. Ferreira, Y. Li, F. Benzing, M. Velimirović, H. Soyer, W. Kong, Tony, Nguyên, Z. Yang, J. Liu, J. van Amersfoort, D. Gillick, B. Sun, N. Rauschmayr, K. Zhang, S. Zhan, T. Zhou, A. Frolov, C. Yang, D. Vnukov, L. Rouillard, H. Li, A. Mandhane, N. Fallen, R. Venkataraman, C. H. Hu, J. Brennan, J. Lee, J. Chang, M. Sundermeyer, Z. Pan, R. Ke, S. Tong, A. Fabrikant, W. Bono, J. Gu, R. Foley, Y. Mao, M. Delakis, D. Bhaswar, R. Frostig, N. Li, A. Zipori, C. Hope, O. Kozlova, S. Mishra, J. Djolonga, C. Schiff, M. A. Merey, E. Briakou, P. Morgan, A. Wan, A. Hassidim, R. Skerry-Ryan, K. Sengupta, M. Jasarevic, P. Kallakuri, P. Kunkle, H. Brennan, T. Lieber, H. Mansoor, J. Walker, B. Zhang, A. Xie, G. Žužić, A. Chukwuka, A. Druinsky, D. Cho, R. Yao, F. Naeem, S. Butt, E. Kim, Z. Jia, M. Jordan, A. Lelkes, M. Kurzeja, S. Wang, J. Zhao, A. Over, A. Chakladar, M. Prasetya, N. Jha, S. Ganapathy, Y. Cong, P. Shroff, C. Saroufim, S. Miryoosefi, M. Hammad, T. Nasir, W. Xi, Y. Gao, Y. Maeng, B. Hora, C. Cheng, P. Haghani, Y. Lewenberg, C. Lu, M. Matysiak, N. Raisinghani, H. Wang, L. Baugher, R. Sukthankar, M. Giang, J. Schultz, N. Fiedel, M. Chen, C. Lee, T. Dey, H. Zheng, S. Paul, C. Smith, A. Ly, Y. Wang, R. Bansal, B. Perz, S. Ricco, S. Blank, V. Keshava, D. Sharma, M. Chow, K. Lad, K. Jalan, S. Osindero, C. Swanson, J. Scott, A. Ilić, X. Li, S. R. Jonnalagadda, A. S. Soudagar, Y. Xiong, B. Batsaikhan, D. Jarrett, N. Kumar, M. Shah, M. Lawlor, A. Waters, M. Graham, R. May, S. Ramos, S. Lefdal, Z. Cankara, N. Cano, B. O’Donoghue, J. Borovik, F. Liu, J. Grimstad, M. Alnahlawi, K. Tsihlas, T. Hudson, N. Grigorev, Y. Jia, T. Huang, T. P. Igwe, S. Lebedev, X. Tang, I. Krivokon, F. Garcia, M. Tan, E. Jia, P. Stys, S. Vashishth, Y. Liang, B. Venkatraman, C. Gu, A. Kementsietsidis, C. Zhu, J. Jung, Y. Bai, M. J. Hosseini, F. Ahmed, A. Gupta, X. Yuan, S. Ashraf, S. Nigam, G. Vasudevan, P. Awasthi, A. M. Gilady, Z. Mariet, R. Eskander, H. Li, H. Hu, G. Garrido, P. Schlattner, G. Zhang, R. Saxena, P. Dević, K. Muralidharan, A. Murthy, Y. Zhou, M. Choi, A. Wongpanich, Z. Wang, P. Shah, Y. Xu, Y. Huang, S. Spencer, A. Chen, J. Cohan, J. Wang, J. Tompson, J. Wu, R. Haroun, H. Li, B. Huergo, F. Yang, T. Yin, J. Wendt, M. Bendersky, R. Chaabouni, J. Snaider, J. Ferret, A. Jindal, T. Thompson, A. Xue, W. Bishop, S. M. Phal, A. Sharma, Y. Sung, P. Radhakrishnan, M. Shomrat, R. Ingle, R. Vij, J. Gilmer, M. D. Istin, S. Sobell, Y. Lu, E. Nottage, D. Sadigh, J. Willcock, T. Zhang, S. Xu, S. Brown, K. Lee, G. Wang, Y. Zhu, Y. Tay, C. Kim, A. Gutierrez, A. Sharma, Y. Xian, S. Seo, C. Cui, E. Pochernina, C. Baetu, K. Jastrzębski, M. Ly, M. Elhawaty, D. Suh, E. Sezener, P. Wang, N. Yuen, G. Tucker, J. Cai, Z. Yang, C. Wang, A. Muzio, H. Qian, J. Yoo, D. Lockhart, K. R. McKee, M. Guo, M. Mehrotra, A. Mendonça, S. V. Mehta, S. Ben, C. Tekur, J. Mu, M. Zhu, V. Krakovna, H. Lee, A. Maschinot, S. Cevey, H. Choe, A. Bai, H. Srinivasan, D. Gasaway, N. Young, P. Siegler, D. Holtmann-Rice, V. Piratla, K. Baumli, R. Yogev, A. Hofer, H. van Hasselt, S. Grant, Y. Chervonyi, D. Silver, A. Hogue, A. Agarwal, K. Wang, P. Singh, F. Flynn, J. Lipschultz, R. David, L. Bellot, Y. Yang, L. Le, F. Graziano, K. Olszewska, K. Hui, A. Maurya, N. Parotsidis, W. Chen, T. Oguntebi, J. Kelley, A. Baddepudi, J. Mauerer, G. Shaw, A. Siegman, L. Yang, S. Shetty, S. Roy, Y. Song, W. Stokowiec, R. Burnell, O. Savant, R. Busa-Fekete, J. Miao, S. Ghosh, L. MacDermed, P. Lippe, M. Dektiarev, Z. Behrman, F. Mentzer, K. Nguyen, M. Wei, S. Verma, C. Knutsen, S. Dasari, Z. Yan, P. Mitrichev, X. Wang, V. Shejwalkar, J. Austin, S. Sunkara, N. Potti, Y. Virin, C. Wright, G. Liu, O. Riva, E. Pot, G. Kochanski, Q. Le, G. Balasubramaniam, A. Dhar, Y. Liao, A. Bloniarz, D. Shukla, E. Cole, J. Lee, S. Zhang, S. Kafle, S. Vashishtha, P. Mahmoudieh, G. Chen, R. Hoffmann, P. Srinivasan, A. D. Lago, Y. B. Shalom, Z. Wang, M. Elabd, A. Sharma, J. Oh, S. Kothawade, M. Le, M. Monteiro, S. Yang, K. Alarakyia, R. Geirhos, D. Mincu, H. Garnes, H. Kobayashi, S. Mariooryad, K. Krasowiak, Zhixin, Lai, S. Mourad, M. Wang, F. Bu, O. Aharoni, G. Chen, A. Goyal, V. Zubov, A. Bapna, E. Dabir, N. Kothari, K. Lamerigts, N. D. Cao, J. Shar, C. Yew, N. Kulkarni, D. Mahaarachchi, M. Joshi, Z. Zhu, J. Lichtarge, Y. Zhou, H. Muckenhirn, V. Selo, O. Vinyals, P. Chen, A. Brohan, V. Mehta, S. Cogan, R. Wang, T. Geri, W. Ko, W. Chen, F. Viola, K. Shivam, L. Wang, M. C. Elish, R. A. Popa, S. Pereira, J. Liu, R. Koster, D. Kim, G. Zhang, S. Ebrahimi, P. Talukdar, Y. Zheng, P. Poklukar, A. Mikhalap, D. Johnson, A. Vijayakumar, M. Omernick, M. Dibb, A. Dubey, Q. Hu, A. Suman, V. Aggarwal, I. Kornakov, F. Xia, W. Lowe, A. Kolganov, T. Xiao, V. Nikolaev, S. Hemingray, B. Li, J. Iljazi, M. Rybiński, B. Sandhu, P. Lu, T. Luong, R. Jenatton, V. Govindaraj, Hui, Li, G. Dulac-Arnold, W. Park, H. Wang, A. Modi, J. Pouget-Abadie, K. Greller, R. Gupta, R. Berry, P. Ramachandran, J. Xie, L. McCafferty, J. Wang, K. Gupta, H. Lim, B. Bratanič, A. Brock, I. Akolzin, J. Sproch, D. Karliner, D. Kim, A. Goedeckemeyer, N. Shazeer, C. Schmid, D. Calandriello, P. Bhatia, K. Choromanski, C. Montgomery, D. Dua, A. Ramalho, H. King, Y. Gao, L. Nguyen, D. Lindner, D. Pitta, O. Johnson, K. Salama, D. Ardila, M. Han, E. Farnese, S. Odoom, Z. Wang, X. Ding, N. Rink, R. Smith, H. T. Lehri, E. Cohen, N. Vats, T. He, P. Gopavarapu, A. Paszke, M. Patel, W. V. Gansbeke, L. Loher, L. Castro, M. Voitovich, T. von Glehn, N. George, S. Niklaus, Z. Eaton-Rosen, N. Rakićević, E. Jue, S. Perel, C. Zhang, Y. Bahat, A. Pouget, Z. Xing, F. Huot, A. Shenoy, T. Bos, V. Coriou, B. Richter, N. Noy, Y. Wang, S. Ontanon, S. Qin, G. Makarchuk, D. Hassabis, Z. Li, M. Sharma, K. Venkatesan, I. Kemaev, R. Daniel, S. Huang, S. Shah, O. Ponce, Warren, Chen, M. Faruqui, J. Wu, S. Andačić, S. Payrits, D. McDuff, T. Hume, Y. Cao, M. Tessler, Q. Wang, Y. Wang, I. Rendulic, E. Agustsson, M. Johnson, T. Lando, A. Howard, S. G. S. Padmanabhan, M. Daswani, A. Banino, M. Kilgore, J. Heek, Z. Ji, A. Caceres, C. Li, N. Kassner, A. Vlaskin, Z. Liu, A. Grills, Y. Hou, R. Sukkerd, G. Cheon, N. Shetty, L. Markeeva, P. Stanczyk, T. Iyer, Y. Gong, S. Gao, K. Gopalakrishnan, T. Blyth, M. Reynolds, A. Bhoopchand, M. Bilenko, D. Gharibian, V. Zayats, A. Faust, A. Singh, M. Ma, H. Jiao, S. Vijayanarasimhan, L. Aroyo, V. Yadav, S. Chakera, A. Kakarla, V. Meshram, K. Gregor, G. Botea, E. Senter, D. Jia, G. Kovacs, N. Sharma, S. Baur, K. Kang, Y. He, L. Zhuo, M. Kostelac, I. Laish, S. Peng, L. O’Bryan, D. Kasenberg, G. R. Rao, E. Leurent, B. Zhang, S. Stevens, A. Salazar, Y. Zhang, I. Lobov, J. Walker, A. Porter, M. Redshaw, H. Ke, A. Rao, A. Lee, H. Lam, M. Moffitt, J. Kim, S. Qiao, T. Koo, R. Dadashi, X. Song, M. Sundararajan, P. Xu, C. Kawamoto, Y. Zhong, C. Barbu, A. Reddy, M. Verzetti, L. Li, G. Papamakarios, H. Klimczak-Plucińska, M. Cassin, K. Kavukcuoglu, R. Swavely, A. Vaucher, J. Zhao, R. Hemsley, M. Tschannen, H. Ge, G. Menghani, Y. Yu, N. Ha, W. He, X. Wu, M. Song, R. Sterneck, S. Zinke, D. A. Calian, A. Marsden, A. C. Ruiz, M. Hessel, A. Gueta, B. Lee, B. Farris, M. Gupta, Y. Li, M. Saleh, V. Misra, K. Xiao, P. Mendolicchio, G. Buttimore, V. Krayvanova, N. Nayakanti, M. Wiethoff, Y. Pande, A. Mirhoseini, N. Lao, J. Liu, Y. Hua, A. Chen, Y. Malkov, D. Kalashnikov, S. Gupta, K. Audhkhasi, Y. Zhai, S. Kopalle, P. Jain, E. Ofek, C. Meyer, K. Baatarsukh, H. Strejček, J. Qian, J. Freedman, R. Figueira, M. Sokolik, O. Bachem, R. Lin, D. Kharrat, C. Hidey, P. Xu, D. Duan, Y. Li, M. Ersoy, R. Everett, K. Cen, R. Santamaria-Fernandez, A. Taubenfeld, I. Mackinnon, L. Deng, P. Zablotskaia, S. Viswanadha, S. Goel, D. Yates, Y. Deng, P. Choy, M. Chen, A. Sinha, A. Mossin, Y. Wang, A. Szlam, S. Hao, P. K. Rubenstein, M. Toksoz-Exley, M. Aperghis, Y. Zhong, J. Ahn, M. Isard, O. Lacombe, F. Luisier, C. Anastasiou, Y. Kalley, U. Prabhu, E. Dunleavy, S. Bijwadia, J. Mao-Jones, K. Chen, R. Pasumarthi, E. Wood, A. Dostmohamed, N. Hurley, J. Simsa, A. Parrish, M. Pajarskas, M. Harvey, O. Skopek, Y. Kochinski, J. Rey, V. Rieser, D. Zhou, S. J. Lee, T. Acharya, G. Li, J. Jiang, X. Zhang, B. Gipson, E. Mahintorabi, M. Gelmi, N. Khajehnouri, A. Yeh, K. Lee, L. Matthey, L. Baker, T. Pham, H. Fu, A. Pak, P. Gupta, C. Vasconcelos, A. Sadovsky, B. Walker, S. Hsiao, P. Zochbauer, A. Marzoca, N. Velan, J. Zeng, G. Baechler, D. Driess, D. Jain, Y. Huang, L. Tao, J. Maggs, N. Levine, J. Schneider, E. Gemzer, S. Petit, S. Han, Z. Fisher, D. Zelle, C. Biles, E. Ie, A. Fadeeva, C. Liu, J. V. Franco, A. Collister, H. Zhang, R. Wang, R. Zhao, L. Kieliger, K. Shuster, R. Zhu, B. Gong, L. Chan, R. Sun, S. Basu, R. Zimmermann, J. Hayes, A. Bapna, J. Snoek, W. Yang, P. Datta, J. A. Abdallah, K. Kilgour, L. Li, S. Mah, Y. Jun, M. Rivière, A. Karmarkar, T. Spalink, T. Huang, L. Gonzalez, D. Tran, A. Nowak, J. Palowitch, M. Chadwick, E. Talius, H. Mehta, T. Sellam, P. Fränken, M. Nicosia, K. He, A. Kini, D. Amos, S. Basu, H. Jobe, E. Shaw, Q. Xu, C. Evans, D. Ikeda, C. Yan, L. Jin, L. Wang, S. Yadav, I. Labzovsky, R. Sampath, A. Ma, C. Schumann, A. Siddhant, R. Shah, J. Youssef, R. Agarwal, N. Dabney, A. Tonioni, M. Ambar, J. Li, I. Guyon, B. Li, D. Soergel, B. Fang, G. Karadzhov, C. Udrescu, T. Trinh, V. Raunak, S. Noury, D. Guo, S. Gupta, M. Finkelstein, D. Petek, L. Liang, G. Billock, P. Sun, D. Wood, Y. Song, X. Yu, T. Matejovicova, R. Cohen, K. Andra, D. D’Ambrosio, Z. Deng, V. Nallatamby, E. Songhori, R. Dangovski, A. Lampinen, P. Botadra, A. Hillier, J. Cao, N. Baddi, A. Kuncoro, T. Yoshino, A. Bhagatwala, M. Ranzato, R. Schaeffer, T. Liu, S. Ye, O. Sarvana, J. Nham, C. Kuang, I. Gao, J. Baek, S. Mittal, A. Wahid, A. Gergely, B. Ni, J. Feldman, C. Muir, P. Lamblin, W. Macherey, E. Dyer, L. Kilpatrick, V. Campos, M. Bhutani, S. Fort, Y. Ahmad, A. Severyn, K. Chatziprimou, O. Ferludin, M. Dimarco, A. Kusupati, J. Heyward, D. Bahir, K. Villela, K. Millican, D. Marcus, S. Bahargam, C. Unlu, N. Roth, Z. Wei, S. Gopal, D. Ghoshal, E. Lee, S. Lin, J. Lees, D. Lee, A. Hosseini, C. Fan, S. Neel, M. Wu, Y. Altun, H. Cai, E. Piqueras, J. Woodward, A. Bissacco, S. Haykal, M. Bordbar, P. Sundaram, S. Hodkinson, D. Toyama, G. Polovets, A. Myers, A. Sinha, T. Levinboim, K. Krishnakumar, R. Chhaparia, T. Sholokhova, N. B. Gundavarapu, G. Jawahar, H. Qureshi, J. Hu, N. Momchev, M. Rahtz, R. Wu, A. P. S, K. Dhamdhere, M. Guo, U. Gupta, A. Eslami, M. Schain, M. Blokzijl, D. Welling, D. Orr, L. Bolelli, N. Perez-Nieves, M. Sirotenko, A. Prasad, A. Kar, B. D. B. Pigem, T. Terzi, G. Weisz, D. Ghosh, A. Mavalankar, D. Madeka, K. Daugaard, H. Adam, V. Shah, D. Berman, M. Tran, S. Baker, E. Andrejczuk, G. Chole, G. Raboshchuk, M. Mirzazadeh, T. Kagohara, S. Wu, C. Schallhart, B. Orlando, C. Wang, A. Rrustemi, H. Xiong, H. Liu, A. Vezer, N. Ramsden, S. Chang, S. Mudgal, Y. Li, N. Vieillard, Y. Hoshen, F. Ahmad, A. Slone, A. Hua, N. Potikha, M. Rossini, J. Stritar, S. Prakash, Z. Wang, X. Dong, A. Nazari, E. Nehoran, K. Tekelioglu, Y. Li, K. Badola, T. Funkhouser, Y. Li, V. Yerram, R. Ganeshan, D. Formoso, K. Langner, T. Shi, H. Li, Y. Yamamori, A. Panda, A. Saade, A. S. Scarpati, C. Breaux, C. Carey, Z. Zhou, C. Hsieh, S. Bridgers, A. Butryna, N. Gupta, V. Tulsyan, S. Woo, E. Eltyshev, W. Grathwohl, C. Parks, S. Benjamin, R. Panigrahy, S. Dodhia, D. D. Freitas, C. Sauer, W. Song, F. Alet, J. Tolins, C. Paduraru, X. Zhou, B. Albert, Z. Zhang, L. Shu, M. Bansal, S. Nguyen, A. Globerson, O. Xiao, J. Manyika, T. Hennigan, R. Rong, J. Matak, A. Bakalov, A. Sharma, D. Sinopalnikov, A. Pierson, S. Roller, G. Brown, M. Gao, T. Fukuzawa, A. Ghafouri, K. Vassigh, I. Barr, Z. Wang, A. Korsun, R. Jayaram, L. Ren, T. Zaman, S. Khan, Y. Lunts, D. Deutsch, D. Uthus, N. Katz, M. Samsikova, A. Khalifa, N. Sethi, J. Sun, L. Tang, U. Alon, X. Luo, D. Yu, A. Nayyar, B. Petrini, W. Truong, V. Hellendoorn, N. Chinaev, C. Alberti, W. Wang, J. Hu, V. Mirrokni, A. Balashankar, A. Aharon, A. Mehta, A. Iscen, J. Kready, L. Manning, A. Mohananey, Y. Chen, A. Tripathi, A. Wu, I. Petrovski, D. Hwang, M. Baeuml, S. Chandrakaladharan, Y. Liu, R. Coaguila, M. Chen, S. Ma, P. Tafti, S. Tatineni, T. Spitz, J. Ye, P. Vicol, M. Rosca, A. Puigdomènech, Z. Yahav, S. Ghemawat, H. Lin, P. Kirk, Z. Nabulsi, S. Brin, B. Bohnet, K. Caluwaerts, A. S. Veerubhotla, D. Zheng, Z. Dai, P. Petrov, Y. Xu, R. Mehran, Z. Xu, L. Zintgraf, J. Choi, S. A. Hombaiah, R. Thoppilan, S. Reddi, L. Lew, L. Li, K. Webster, K. Sawhney, L. Lamprou, S. Shakeri, M. Lunayach, J. Chen, S. Bagri, A. Salcianu, Y. Chen, Y. Donchev, C. Magister, S. Nørly, V. Rodrigues, T. Izo, H. Noga, J. Zou, T. Köppe, W. Zhou, K. Lee, X. Long, D. Eisenbud, A. Chen, C. Schenck, C. M. To, P. Zhong, E. Taropa, M. Truong, O. Levy, D. Martins, Z. Zhang, C. Semturs, K. Zhang, A. Yakubovich, P. Moreno, L. McConnaughey, D. Lu, S. Redmond, L. Weerts, Y. Bitton, T. Refice, N. Lacasse, A. Conmy, C. Tallec, J. Odell, H. Forbes-Pollard, A. Socala, J. Hoech, P. Kohli, A. Walton, R. Wang, M. Sazanovich, K. Zhu, A. Kapishnikov, R. Galt, M. Denton, B. Murdoch, C. Sikora, K. Mohamed, W. Wei, U. First, T. McConnell, L. C. Cobo, J. Qin, T. Avrahami, D. Balle, Y. Watanabe, A. Louis, A. Kraft, S. Ariafar, Y. Gu, E. Rives, C. Yoon, A. Rusu, J. Cobon-Kerr, C. Hahn, J. Luo, Yuvein, Zhu, N. Ahuja, R. Benenson, R. L. Kaufman, H. Yu, L. Hightower, J. Zhang, D. Ni, L. A. Hendricks, G. Wang, G. Yona, L. Jain, P. Barrio, S. Bhupatiraju, S. Velusamy, A. Dafoe, S. Riedel, T. Thomas, Z. Yuan, M. Bellaiche, S. Panthaplackel, K. Kloboves, S. Jauhari, C. Akbulut, T. Davchev, E. Gladchenko, D. Madras, A. Chuklin, T. Hill, Q. Yuan, M. Madhavan, L. Leonhard, D. Scandinaro, Q. Chen, N. Niu, A. Douillard, B. Damoc, Y. Onoe, F. Pedregosa, F. Bertsch, C. Leichner, J. Pagadora, J. Malmaud, S. Ponda, A. Twigg, O. Duzhyi, J. Shen, M. Wang, R. Garg, J. Chen, U. Evci, J. Lee, L. Liu, K. Kojima, M. Yamaguchi, A. Rajendran, A. Piergiovanni, V. K. Rajendran, M. Fornoni, G. Ibagon, H. Ragan, S. M. Khan, J. Blitzer, A. Bunner, G. Sun, T. Kosakai, S. Lundberg, N. Elue, K. Guu, S. Park, J. Park, A. Narayanaswamy, C. Wu, J. Mudigonda, T. Cohn, H. Mu, R. Kumar, L. Graesser, Y. Zhang, R. Killam, V. Zhuang, M. Giménez, W. A. Jishi, R. Ley-Wild, A. Zhai, K. Osawa, D. Cedillo, J. Liu, M. Upadhyay, M. Sieniek, R. Sharma, T. Paine, A. Angelova, S. Addepalli, C. Parada, K. Majumder, A. Lamp, S. Kumar, X. Deng, A. Myaskovsky, T. Sabolić, J. Dudek, S. York, F. de Chaumont Quitry, J. Nie, D. Cattle, A. Gunjan, B. Piot, W. Khawaja, S. Bang, S. Wang, S. Khodadadeh, R. R, P. Rawlani, R. Powell, K. Lee, J. Griesser, G. Oh, C. Magalhaes, Y. Li, S. Tokumine, H. N. Vogel, D. Hsu, A. BC, D. Jindal, M. Cohen, Z. Yang, J. Yuan, D. de Cesare, T. Bruguier, J. Xu, M. Roy, A. Jacovi, D. Belov, R. Arya, P. Meadowlark, S. Cohen-Ganor, W. Ye, P. Morris-Suzuki, P. Banzal, G. Song, P. Ponnuramu, F. Zhang, G. Scrivener, S. Zaiem, A. R. Rochman, K. Han, B. Ghazi, K. Lee, S. Drath, D. Suo, A. Girgis, P. Shenoy, D. Nguyen, D. Eck, S. Gupta, L. Yan, J. Carreira, A. Gulati, R. Sang, D. Mirylenka, E. Cooney, E. Chou, M. Ling, C. Fan, B. Coleman, G. Tubone, R. Kumar, J. Baldridge, F. Hernandez-Campos, A. Lazaridou, J. Besley, I. Yona, N. Bulut, Q. Wellens, A. Pierigiovanni, J. George, R. Green, P. Han, C. Tao, G. Clark, C. You, A. Abdolmaleki, J. Fu, T. Chen, A. Chaugule, A. Chandorkar, A. Rahman, W. Thompson, P. Koanantakool, M. Bernico, J. Ren, A. Vlasov, S. Vassilvitskii, M. Kula, Y. Liang, D. Kim, Y. Huang, C. Ye, D. Lepikhin, and W. Helmholz (2025) Gemini 2.5: pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. External Links: 2507.06261, Link Cited by: §4.1.1.
- I. M. Copi, C. Cohen, and K. McMahon (2014) Introduction to logic. 14 edition, Pearson Education, Harlow, England. Cited by: §7.1, §7.2.
- deepmind (2025) External Links: Link Cited by: §1.
- DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y. Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Ding, H. Xin, H. Gao, H. Qu, H. Li, J. Guo, J. Li, J. Wang, J. Chen, J. Yuan, J. Qiu, J. Li, J. L. Cai, J. Ni, J. Liang, J. Chen, K. Dong, K. Hu, K. Gao, K. Guan, K. Huang, K. Yu, L. Wang, L. Zhang, L. Zhao, L. Wang, L. Zhang, L. Xu, L. Xia, M. Zhang, M. Zhang, M. Tang, M. Li, M. Wang, M. Li, N. Tian, P. Huang, P. Zhang, Q. Wang, Q. Chen, Q. Du, R. Ge, R. Zhang, R. Pan, R. Wang, R. J. Chen, R. L. Jin, R. Chen, S. Lu, S. Zhou, S. Chen, S. Ye, S. Wang, S. Yu, S. Zhou, S. Pan, S. S. Li, S. Zhou, S. Wu, S. Ye, T. Yun, T. Pei, T. Sun, T. Wang, W. Zeng, W. Zhao, W. Liu, W. Liang, W. Gao, W. Yu, W. Zhang, W. L. Xiao, W. An, X. Liu, X. Wang, X. Chen, X. Nie, X. Cheng, X. Liu, X. Xie, X. Liu, X. Yang, X. Li, X. Su, X. Lin, X. Q. Li, X. Jin, X. Shen, X. Chen, X. Sun, X. Wang, X. Song, X. Zhou, X. Wang, X. Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Y. Zhang, Y. Xu, Y. Li, Y. Zhao, Y. Sun, Y. Wang, Y. Yu, Y. Zhang, Y. Shi, Y. Xiong, Y. He, Y. Piao, Y. Wang, Y. Tan, Y. Ma, Y. Liu, Y. Guo, Y. Ou, Y. Wang, Y. Gong, Y. Zou, Y. He, Y. Xiong, Y. Luo, Y. You, Y. Liu, Y. Zhou, Y. X. Zhu, Y. Xu, Y. Huang, Y. Li, Y. Zheng, Y. Zhu, Y. Ma, Y. Tang, Y. Zha, Y. Yan, Z. Z. Ren, Z. Ren, Z. Sha, Z. Fu, Z. Xu, Z. Xie, Z. Zhang, Z. Hao, Z. Ma, Z. Yan, Z. Wu, Z. Gu, Z. Zhu, Z. Liu, Z. Li, Z. Xie, Z. Song, Z. Pan, Z. Huang, Z. Xu, Z. Zhang, and Z. Zhang (2025) DeepSeek-r1: incentivizing reasoning capability in llms via reinforcement learning. External Links: 2501.12948, Link Cited by: §4.1.2.
- T. Dong, C. Li, C. Bauckhage, J. Li, S. Wrobel, and A. B. Cremers (2020) Learning syllogism with euler neural-networks. External Links: 2007.07320, Link Cited by: §5.
- H. B. Enderton (1972) A mathematical introduction to logic. Academic Press, New York. Cited by: §1, §7.2.
- A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Marra, C. McConnell, C. Keller, C. Touret, C. Wu, C. Wong, C. C. Ferrer, C. Nikolaidis, D. Allonsius, D. Song, D. Pintz, D. Livshits, D. Wyatt, D. Esiobu, D. Choudhary, D. Mahajan, D. Garcia-Olano, D. Perino, D. Hupkes, E. Lakomkin, E. AlBadawy, E. Lobanova, E. Dinan, E. M. Smith, F. Radenovic, F. Guzmán, F. Zhang, G. Synnaeve, G. Lee, G. L. Anderson, G. Thattai, G. Nail, G. Mialon, G. Pang, G. Cucurell, H. Nguyen, H. Korevaar, H. Xu, H. Touvron, I. Zarov, I. A. Ibarra, I. Kloumann, I. Misra, I. Evtimov, J. Zhang, J. Copet, J. Lee, J. Geffert, J. Vranes, J. Park, J. Mahadeokar, J. Shah, J. van der Linde, J. Billock, J. Hong, J. Lee, J. Fu, J. Chi, J. Huang, J. Liu, J. Wang, J. Yu, J. Bitton, J. Spisak, J. Park, J. Rocca, J. Johnstun, J. Saxe, J. Jia, K. V. Alwala, K. Prasad, K. Upasani, K. Plawiak, K. Li, K. Heafield, K. Stone, K. El-Arini, K. Iyer, K. Malik, K. Chiu, K. Bhalla, K. Lakhotia, L. Rantala-Yeary, L. van der Maaten, L. Chen, L. Tan, L. Jenkins, L. Martin, L. Madaan, L. Malo, L. Blecher, L. Landzaat, L. de Oliveira, M. Muzzi, M. Pasupuleti, M. Singh, M. Paluri, M. Kardas, M. Tsimpoukelli, M. Oldham, M. Rita, M. Pavlova, M. Kambadur, M. Lewis, M. Si, M. K. Singh, M. Hassan, N. Goyal, N. Torabi, N. Bashlykov, N. Bogoychev, N. Chatterji, N. Zhang, O. Duchenne, O. Çelebi, P. Alrassy, P. Zhang, P. Li, P. Vasic, P. Weng, P. Bhargava, P. Dubal, P. Krishnan, P. S. Koura, P. Xu, Q. He, Q. Dong, R. Srinivasan, R. Ganapathy, R. Calderer, R. S. Cabral, R. Stojnic, R. Raileanu, R. Maheswari, R. Girdhar, R. Patel, R. Sauvestre, R. Polidoro, R. Sumbaly, R. Taylor, R. Silva, R. Hou, R. Wang, S. Hosseini, S. Chennabasappa, S. Singh, S. Bell, S. S. Kim, S. Edunov, S. Nie, S. Narang, S. Raparthy, S. Shen, S. Wan, S. Bhosale, S. Zhang, S. Vandenhende, S. Batra, S. Whitman, S. Sootla, S. Collot, S. Gururangan, S. Borodinsky, T. Herman, T. Fowler, T. Sheasha, T. Georgiou, T. Scialom, T. Speckbacher, T. Mihaylov, T. Xiao, U. Karn, V. Goswami, V. Gupta, V. Ramanathan, V. Kerkez, V. Gonguet, V. Do, V. Vogeti, V. Albiero, V. Petrovic, W. Chu, W. Xiong, W. Fu, W. Meers, X. Martinet, X. Wang, X. Wang, X. E. Tan, X. Xia, X. Xie, X. Jia, X. Wang, Y. Goldschlag, Y. Gaur, Y. Babaei, Y. Wen, Y. Song, Y. Zhang, Y. Li, Y. Mao, Z. D. Coudert, Z. Yan, Z. Chen, Z. Papakipos, A. Singh, A. Srivastava, A. Jain, A. Kelsey, A. Shajnfeld, A. Gangidi, A. Victoria, A. Goldstand, A. Menon, A. Sharma, A. Boesenberg, A. Baevski, A. Feinstein, A. Kallet, A. Sangani, A. Teo, A. Yunus, A. Lupu, A. Alvarado, A. Caples, A. Gu, A. Ho, A. Poulton, A. Ryan, A. Ramchandani, A. Dong, A. Franco, A. Goyal, A. Saraf, A. Chowdhury, A. Gabriel, A. Bharambe, A. Eisenman, A. Yazdan, B. James, B. Maurer, B. Leonhardi, B. Huang, B. Loyd, B. D. Paola, B. Paranjape, B. Liu, B. Wu, B. Ni, B. Hancock, B. Wasti, B. Spence, B. Stojkovic, B. Gamido, B. Montalvo, C. Parker, C. Burton, C. Mejia, C. Liu, C. Wang, C. Kim, C. Zhou, C. Hu, C. Chu, C. Cai, C. Tindal, C. Feichtenhofer, C. Gao, D. Civin, D. Beaty, D. Kreymer, D. Li, D. Adkins, D. Xu, D. Testuggine, D. David, D. Parikh, D. Liskovich, D. Foss, D. Wang, D. Le, D. Holland, E. Dowling, E. Jamil, E. Montgomery, E. Presani, E. Hahn, E. Wood, E. Le, E. Brinkman, E. Arcaute, E. Dunbar, E. Smothers, F. Sun, F. Kreuk, F. Tian, F. Kokkinos, F. Ozgenel, F. Caggioni, F. Kanayet, F. Seide, G. M. Florez, G. Schwarz, G. Badeer, G. Swee, G. Halpern, G. Herman, G. Sizov, Guangyi, Zhang, G. Lakshminarayanan, H. Inan, H. Shojanazeri, H. Zou, H. Wang, H. Zha, H. Habeeb, H. Rudolph, H. Suk, H. Aspegren, H. Goldman, H. Zhan, I. Damlaj, I. Molybog, I. Tufanov, I. Leontiadis, I. Veliche, I. Gat, J. Weissman, J. Geboski, J. Kohli, J. Lam, J. Asher, J. Gaya, J. Marcus, J. Tang, J. Chan, J. Zhen, J. Reizenstein, J. Teboul, J. Zhong, J. Jin, J. Yang, J. Cummings, J. Carvill, J. Shepard, J. McPhie, J. Torres, J. Ginsburg, J. Wang, K. Wu, K. H. U, K. Saxena, K. Khandelwal, K. Zand, K. Matosich, K. Veeraraghavan, K. Michelena, K. Li, K. Jagadeesh, K. Huang, K. Chawla, K. Huang, L. Chen, L. Garg, L. A, L. Silva, L. Bell, L. Zhang, L. Guo, L. Yu, L. Moshkovich, L. Wehrstedt, M. Khabsa, M. Avalani, M. Bhatt, M. Mankus, M. Hasson, M. Lennie, M. Reso, M. Groshev, M. Naumov, M. Lathi, M. Keneally, M. Liu, M. L. Seltzer, M. Valko, M. Restrepo, M. Patel, M. Vyatskov, M. Samvelyan, M. Clark, M. Macey, M. Wang, M. J. Hermoso, M. Metanat, M. Rastegari, M. Bansal, N. Santhanam, N. Parks, N. White, N. Bawa, N. Singhal, N. Egebo, N. Usunier, N. Mehta, N. P. Laptev, N. Dong, N. Cheng, O. Chernoguz, O. Hart, O. Salpekar, O. Kalinli, P. Kent, P. Parekh, P. Saab, P. Balaji, P. Rittner, P. Bontrager, P. Roux, P. Dollar, P. Zvyagina, P. Ratanchandani, P. Yuvraj, Q. Liang, R. Alao, R. Rodriguez, R. Ayub, R. Murthy, R. Nayani, R. Mitra, R. Parthasarathy, R. Li, R. Hogan, R. Battey, R. Wang, R. Howes, R. Rinott, S. Mehta, S. Siby, S. J. Bondu, S. Datta, S. Chugh, S. Hunt, S. Dhillon, S. Sidorov, S. Pan, S. Mahajan, S. Verma, S. Yamamoto, S. Ramaswamy, S. Lindsay, S. Lindsay, S. Feng, S. Lin, S. C. Zha, S. Patil, S. Shankar, S. Zhang, S. Zhang, S. Wang, S. Agarwal, S. Sajuyigbe, S. Chintala, S. Max, S. Chen, S. Kehoe, S. Satterfield, S. Govindaprasad, S. Gupta, S. Deng, S. Cho, S. Virk, S. Subramanian, S. Choudhury, S. Goldman, T. Remez, T. Glaser, T. Best, T. Koehler, T. Robinson, T. Li, T. Zhang, T. Matthews, T. Chou, T. Shaked, V. Vontimitta, V. Ajayi, V. Montanez, V. Mohan, V. S. Kumar, V. Mangla, V. Ionescu, V. Poenaru, V. T. Mihailescu, V. Ivanov, W. Li, W. Wang, W. Jiang, W. Bouaziz, W. Constable, X. Tang, X. Wu, X. Wang, X. Wu, X. Gao, Y. Kleinman, Y. Chen, Y. Hu, Y. Jia, Y. Qi, Y. Li, Y. Zhang, Y. Zhang, Y. Adi, Y. Nam, Yu, Wang, Y. Zhao, Y. Hao, Y. Qian, Y. Li, Y. He, Z. Rait, Z. DeVito, Z. Rosnbrick, Z. Wen, Z. Yang, Z. Zhao, and Z. Ma (2024) The llama 3 herd of models. External Links: 2407.21783, Link Cited by: §1, §4.1.1.
- S. Han, H. Schoelkopf, Y. Zhao, Z. Qi, M. Riddell, W. Zhou, J. Coady, D. Peng, Y. Qiao, L. Benson, L. Sun, A. Wardle-Solano, H. Szabo, E. Zubova, M. Burtell, J. Fan, Y. Liu, B. Wong, M. Sailor, A. Ni, L. Nan, J. Kasai, T. Yu, R. Zhang, A. R. Fabbri, W. Kryscinski, S. Yavuz, Y. Liu, X. V. Lin, S. Joty, Y. Zhou, C. Xiong, R. Ying, A. Cohan, and D. Radev (2024) FOLIO: natural language reasoning with first-order logic. External Links: 2209.00840, Link Cited by: §1.
- G. A. Miller (1995) WordNet: a lexical database for english. Commun. ACM 38 (11), pp. 39–41. External Links: ISSN 0001-0782, Link, Document Cited by: §5.
- H. Nguyen, C. Liu, Q. Liu, H. Tachibana, S. M. Noe, Y. Miyao, K. Takeda, and S. Kurohashi (2025) BIS reasoning 1.0: the first large-scale japanese benchmark for belief-inconsistent syllogistic reasoning. External Links: 2506.06955, Link Cited by: §1, §5.
- S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y. Lin, J. Wen, and C. Li (2025) Large language diffusion models. External Links: 2502.09992, Link Cited by: §7.6.6.
- OpenAI (2025a) External Links: Link Cited by: §1, §4.1.1.
- OpenAI (2025b) External Links: Link Cited by: §4.1.1.
- T. Parsons and G. Ciola (2025) The Traditional Square of Opposition. In The Stanford Encyclopedia of Philosophy, E. N. Zalta and U. Nodelman (Eds.), Note: https://plato.stanford.edu/archives/sum2025/entries/square/ Cited by: §1, §2.1.
- S. Peng, L. Liu, C. Liu, and D. Yu (2020) Exploring reasoning schemes: a dataset for syllogism figure identification. In Chinese Lexical Semantics: 21st Workshop, CLSW 2020, Hong Kong, China, May 28–30, 2020, Revised Selected Papers, Berlin, Heidelberg, pp. 445–451. External Links: ISBN 978-3-030-81196-9, Link, Document Cited by: §5.
- L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, M. Choi, A. Agrawal, A. Chopra, A. Khoja, R. Kim, R. Ren, J. Hausenloy, O. Zhang, M. Mazeika, D. Dodonov, T. Nguyen, J. Lee, D. Anderson, M. Doroshenko, A. C. Stokes, M. Mahmood, O. Pokutnyi, O. Iskra, J. P. Wang, J. Levin, M. Kazakov, F. Feng, S. Y. Feng, H. Zhao, M. Yu, V. Gangal, C. Zou, Z. Wang, S. Popov, R. Gerbicz, G. Galgon, J. Schmitt, W. Yeadon, Y. Lee, S. Sauers, A. Sanchez, F. Giska, M. Roth, S. Riis, S. Utpala, N. Burns, G. M. Goshu, M. M. Naiya, C. Agu, Z. Giboney, A. Cheatom, F. Fournier-Facio, S. Crowson, L. Finke, Z. Cheng, J. Zampese, R. G. Hoerr, M. Nandor, H. Park, T. Gehrunger, J. Cai, B. McCarty, A. C. Garretson, E. Taylor, D. Sileo, Q. Ren, U. Qazi, L. Li, J. Nam, J. B. Wydallis, P. Arkhipov, J. W. L. Shi, A. Bacho, C. G. Willcocks, H. Cao, S. Motwani, E. de Oliveira Santos, J. Veith, E. Vendrow, D. Cojoc, K. Zenitani, J. Robinson, L. Tang, Y. Li, J. Vendrow, N. W. Fraga, V. Kuchkin, A. P. Maksimov, P. Marion, D. Efremov, J. Lynch, K. Liang, A. Mikov, A. Gritsevskiy, J. Guillod, G. Demir, D. Martinez, B. Pageler, K. Zhou, S. Soori, O. Press, H. Tang, P. Rissone, S. R. Green, L. Brüssel, M. Twayana, A. Dieuleveut, J. M. Imperial, A. Prabhu, J. Yang, N. Crispino, A. Rao, D. Zvonkine, G. Loiseau, M. Kalinin, M. Lukas, C. Manolescu, N. Stambaugh, S. Mishra, T. Hogg, C. Bosio, B. P. Coppola, J. Salazar, J. Jin, R. Sayous, S. Ivanov, P. Schwaller, S. Senthilkuma, A. M. Bran, A. Algaba, K. V. den Houte, L. V. D. Sypt, B. Verbeken, D. Noever, A. Kopylov, B. Myklebust, B. Li, L. Schut, E. Zheltonozhskii, Q. Yuan, D. Lim, R. Stanley, T. Yang, J. Maar, J. Wykowski, M. Oller, A. Sahu, C. G. Ardito, Y. Hu, A. G. K. Kamdoum, A. Jin, T. G. Vilchis, Y. Zu, M. Lackner, J. Koppel, G. Sun, D. S. Antonenko, S. Chern, B. Zhao, P. Arsene, J. M. Cavanagh, D. Li, J. Shen, D. Crisostomi, W. Zhang, A. Dehghan, S. Ivanov, D. Perrella, N. Kaparov, A. Zang, I. Sucholutsky, A. Kharlamova, D. Orel, V. Poritski, S. Ben-David, Z. Berger, P. Whitfill, M. Foster, D. Munro, L. Ho, S. Sivarajan, D. B. Hava, A. Kuchkin, D. Holmes, A. Rodriguez-Romero, F. Sommerhage, A. Zhang, R. Moat, K. Schneider, Z. Kazibwe, D. Clarke, D. H. Kim, F. M. Dias, S. Fish, V. Elser, T. Kreiman, V. E. G. Vilchis, I. Klose, U. Anantheswaran, A. Zweiger, K. Rawal, J. Li, J. Nguyen, N. Daans, H. Heidinger, M. Radionov, V. Rozhoň, V. Ginis, C. Stump, N. Cohen, R. Poświata, J. Tkadlec, A. Goldfarb, C. Wang, P. Padlewski, S. Barzowski, K. Montgomery, R. Stendall, J. Tucker-Foltz, J. Stade, T. R. Rogers, T. Goertzen, D. Grabb, A. Shukla, A. Givré, J. A. Ambay, A. Sen, M. F. Aziz, M. H. Inlow, H. He, L. Zhang, Y. Kaddar, I. Ängquist, Y. Chen, H. K. Wang, K. Ramakrishnan, E. Thornley, A. Terpin, H. Schoelkopf, E. Zheng, A. Carmi, E. D. L. Brown, K. Zhu, M. Bartolo, R. Wheeler, M. Stehberger, P. Bradshaw, J. Heimonen, K. Sridhar, I. Akov, J. Sandlin, Y. Makarychev, J. Tam, H. Hoang, D. M. Cunningham, V. Goryachev, D. Patramanis, M. Krause, A. Redenti, D. Aldous, J. Lai, S. Coleman, J. Xu, S. Lee, I. Magoulas, S. Zhao, N. Tang, M. K. Cohen, O. Paradise, J. H. Kirchner, M. Ovchynnikov, J. O. Matos, A. Shenoy, M. Wang, Y. Nie, A. Sztyber-Betley, P. Faraboschi, R. Riblet, J. Crozier, S. Halasyamani, S. Verma, P. Joshi, E. Meril, Z. Ma, J. Andréoletti, R. Singhal, J. Platnick, V. Nevirkovets, L. Basler, A. Ivanov, S. Khoury, N. Gustafsson, M. Piccardo, H. Mostaghimi, Q. Chen, V. Singh, T. Q. Khánh, P. Rosu, H. Szlyk, Z. Brown, H. Narayan, A. Menezes, J. Roberts, W. Alley, K. Sun, A. Patel, M. Lamparth, A. Reuel, L. Xin, H. Xu, J. Loader, F. Martin, Z. Wang, A. Achilleos, T. Preu, T. Korbak, I. Bosio, F. Kazemi, Z. Chen, B. Bálint, E. J. Y. Lo, J. Wang, M. I. S. Nunes, J. Milbauer, M. S. Bari, Z. Wang, B. Ansarinejad, Y. Sun, S. Durand, H. Elgnainy, G. Douville, D. Tordera, G. Balabanian, H. Wolff, L. Kvistad, H. Milliron, A. Sakor, M. Eron, A. F. D. O., S. Shah, X. Zhou, F. Kamalov, S. Abdoli, T. Santens, S. Barkan, A. Tee, R. Zhang, A. Tomasiello, G. B. D. Luca, S. Looi, V. Le, N. Kolt, J. Pan, E. Rodman, J. Drori, C. J. Fossum, N. Muennighoff, M. Jagota, R. Pradeep, H. Fan, J. Eicher, M. Chen, K. Thaman, W. Merrill, M. Firsching, C. Harris, S. Ciobâcă, J. Gross, R. Pandey, I. Gusev, A. Jones, S. Agnihotri, P. Zhelnov, M. Mofayezi, A. Piperski, D. K. Zhang, K. Dobarskyi, R. Leventov, I. Soroko, J. Duersch, V. Taamazyan, A. Ho, W. Ma, W. Held, R. Xian, A. R. Zebaze, M. Mohamed, J. N. Leser, M. X. Yuan, L. Yacar, J. Lengler, K. Olszewska, C. D. Fratta, E. Oliveira, J. W. Jackson, A. Zou, M. Chidambaram, T. Manik, H. Haffenden, D. Stander, A. Dasouqi, A. Shen, B. Golshani, D. Stap, E. Kretov, M. Uzhou, A. B. Zhidkovskaya, N. Winter, M. O. Rodriguez, R. Lauff, D. Wehr, C. Tang, Z. Hossain, S. Phillips, F. Samuele, F. Ekström, A. Hammon, O. Patel, F. Farhidi, G. Medley, F. Mohammadzadeh, M. Peñaflor, H. Kassahun, A. Friedrich, R. H. Perez, D. Pyda, T. Sakal, O. Dhamane, A. K. Mirabadi, E. Hallman, K. Okutsu, M. Battaglia, M. Maghsoudimehrabani, A. Amit, D. Hulbert, R. Pereira, S. Weber, Handoko, A. Peristyy, S. Malina, M. Mehkary, R. Aly, F. Reidegeld, A. Dick, C. Friday, M. Singh, H. Shapourian, W. Kim, M. Costa, H. Gurdogan, H. Kumar, C. Ceconello, C. Zhuang, H. Park, M. Carroll, A. R. Tawfeek, S. Steinerberger, D. Aggarwal, M. Kirchhof, L. Dai, E. Kim, J. Ferret, J. Shah, Y. Wang, M. Yan, K. Burdzy, L. Zhang, A. Franca, D. T. Pham, K. Y. Loh, J. Robinson, A. Jackson, P. Giordano, P. Petersen, A. Cosma, J. Colino, C. White, J. Votava, V. Vinnikov, E. Delaney, P. Spelda, V. Stritecky, S. M. Shahid, J. Mourrat, L. Vetoshkin, K. Sponselee, R. Bacho, Z. Yong, F. de la Rosa, N. Cho, X. Li, G. Malod, O. Weller, G. Albani, L. Lang, J. Laurendeau, D. Kazakov, F. Adesanya, J. Portier, L. Hollom, V. Souza, Y. A. Zhou, J. Degorre, Y. Yalın, G. D. Obikoya, Rai, F. Bigi, M. C. Boscá, O. Shumar, K. Bacho, G. Recchia, M. Popescu, N. Shulga, N. M. Tanwie, T. C. H. Lux, B. Rank, C. Ni, M. Brooks, A. Yakimchyk, Huanxu, Liu, S. Cavalleri, O. Häggström, E. Verkama, J. Newbould, H. Gundlach, L. Brito-Santana, B. Amaro, V. Vajipey, R. Grover, T. Wang, Y. Kratish, W. Li, S. Gopi, A. Caciolai, C. S. de Witt, P. Hernández-Cámara, E. Rodolà, J. Robins, D. Williamson, V. Cheng, B. Raynor, H. Qi, B. Segev, J. Fan, S. Martinson, E. Y. Wang, K. Hausknecht, M. P. Brenner, M. Mao, C. Demian, P. Kassani, X. Zhang, D. Avagian, E. J. Scipio, A. Ragoler, J. Tan, B. Sims, R. Plecnik, A. Kirtland, O. F. Bodur, D. P. Shinde, Y. C. L. Labrador, Z. Adoul, M. Zekry, A. Karakoc, T. C. B. Santos, S. Shamseldeen, L. Karim, A. Liakhovitskaia, N. Resman, N. Farina, J. C. Gonzalez, G. Maayan, E. Anderson, R. D. O. Pena, E. Kelley, H. Mariji, R. Pouriamanesh, W. Wu, R. Finocchio, I. Alarab, J. Cole, D. Ferreira, B. Johnson, M. Safdari, L. Dai, S. Arthornthurasuk, I. C. McAlister, A. J. Moyano, A. Pronin, J. Fan, A. Ramirez-Trinidad, Y. Malysheva, D. Pottmaier, O. Taheri, S. Stepanic, S. Perry, L. Askew, R. A. H. Rodríguez, A. M. R. Minissi, R. Lorena, K. Iyer, A. A. Fasiludeen, R. Clark, J. Ducey, M. Piza, M. Somrak, E. Vergo, J. Qin, B. Borbás, E. Chu, J. Lindsey, A. Jallon, I. M. J. McInnis, E. Chen, A. Semler, L. Gloor, T. Shah, M. Carauleanu, P. Lauer, T. Đ. Huy, H. Shahrtash, E. Duc, L. Lewark, A. Brown, S. Albanie, B. Weber, W. S. Vaz, P. Clavier, Y. Fan, G. P. R. e Silva, Long, Lian, M. Abramovitch, X. Jiang, S. Mendoza, M. Islam, J. Gonzalez, V. Mavroudis, J. Xu, P. Kumar, L. P. Goswami, D. Bugas, N. Heydari, F. Jeanplong, T. Jansen, A. Pinto, A. Apronti, A. Galal, N. Ze-An, A. Singh, T. Jiang, J. of Arc Xavier, K. P. Agarwal, M. Berkani, G. Zhang, Z. Du, B. A. de Oliveira Junior, D. Malishev, N. Remy, T. D. Hartman, T. Tarver, S. Mensah, G. A. Loume, W. Morak, F. Habibi, S. Hoback, W. Cai, J. Gimenez, R. G. Montecillo, J. Łucki, R. Campbell, A. Sharma, K. Meer, S. Gul, D. E. Gonzalez, X. Alapont, A. Hoover, G. Chhablani, F. Vargus, A. Agarwal, Y. Jiang, D. Patil, D. Outevsky, K. J. Scaria, R. Maheshwari, A. Dendane, P. Shukla, A. Cartwright, S. Bogdanov, N. Mündler, S. Möller, L. Arnaboldi, K. Thaman, M. R. Siddiqi, P. Saxena, H. Gupta, T. Fruhauff, G. Sherman, M. Vincze, S. Usawasutsakorn, D. Ler, A. Radhakrishnan, I. Enyekwe, S. M. Salauddin, J. Muzhen, A. Maksapetyan, V. Rossbach, C. Harjadi, M. Bahaloohoreh, C. Sparrow, J. Sidhu, S. Ali, S. Bian, J. Lai, E. Singer, J. L. Uro, G. Bateman, M. Sayed, A. Menshawy, D. Duclosel, D. Bezzi, Y. Jain, A. Aaron, M. Tiryakioglu, S. Siddh, K. Krenek, I. A. Shah, J. Jin, S. Creighton, D. Peskoff, Z. EL-Wasif, R. P. V, M. Richmond, J. McGowan, T. Patwardhan, H. Sun, T. Sun, N. Zubić, S. Sala, S. Ebert, J. Kaddour, M. Schottdorf, D. Wang, G. Petruzella, A. Meiburg, T. Medved, A. ElSheikh, S. A. Hebbar, L. Vaquero, X. Yang, J. Poulos, V. Zouhar, S. Bogdanik, M. Zhang, J. Sanz-Ros, D. Anugraha, Y. Dai, A. N. Nhu, X. Wang, A. A. Demircali, Z. Jia, Y. Zhou, J. Wu, M. He, N. Chandok, A. Sinha, G. Luo, L. Le, M. Noyé, M. Perełkiewicz, I. Pantidis, T. Qi, S. S. Purohit, L. Parcalabescu, T. Nguyen, G. I. Winata, E. M. Ponti, H. Li, K. Dhole, J. Park, D. Abbondanza, Y. Wang, A. Nayak, D. M. Caetano, A. A. W. L. Wong, M. del Rio-Chanona, D. Kondor, P. Francois, E. Chalstrey, J. Zsambok, D. Hoyer, J. Reddish, J. Hauser, F. Rodrigo-Ginés, S. Datta, M. Shepherd, T. Kamphuis, Q. Zhang, H. Kim, R. Sun, J. Yao, F. Dernoncourt, S. Krishna, S. Rismanchian, B. Pu, F. Pinto, Y. Wang, K. Shridhar, K. J. Overholt, G. Briia, H. Nguyen, David, S. Bartomeu, T. C. Pang, A. Wecker, Y. Xiong, F. Li, L. S. Huber, J. Jaeger, R. D. Maddalena, X. H. Lù, Y. Zhang, C. Beger, P. T. J. Kon, S. Li, V. Sanker, M. Yin, Y. Liang, X. Zhang, A. Agrawal, L. S. Yifei, Z. Zhang, M. Cai, Y. Sonmez, C. Cozianu, C. Li, A. Slen, S. Yu, H. K. Park, G. Sarti, M. Briański, A. Stolfo, T. A. Nguyen, M. Zhang, Y. Perlitz, J. Hernandez-Orallo, R. Li, A. Shabani, F. Juefei-Xu, S. Dhingra, O. Zohar, M. C. Nguyen, A. Pondaven, A. Yilmaz, X. Zhao, C. Jin, M. Jiang, S. Todoran, X. Han, J. Kreuer, B. Rabern, A. Plassart, M. Maggetti, L. Yap, R. Geirhos, J. Kean, D. Wang, S. Mollaei, C. Sun, Y. Yin, S. Wang, R. Li, Y. Chang, A. Wei, A. Bizeul, X. Wang, A. O. Arrais, K. Mukherjee, J. Chamorro-Padial, J. Liu, X. Qu, J. Guan, A. Bouyamourn, S. Wu, M. Plomecka, J. Chen, M. Tang, J. Deng, S. Subramanian, H. Xi, H. Chen, W. Zhang, Y. Ren, H. Tu, S. Kim, Y. Chen, S. V. Marjanović, J. Ha, G. Luczyna, J. J. Ma, Z. Shen, D. Song, C. E. Zhang, Z. Wang, G. Gendron, Y. Xiao, L. Smucker, E. Weng, K. H. Lee, Z. Ye, S. Ermon, I. D. Lopez-Miguel, T. Knights, A. Gitter, N. Park, B. Wei, H. Chen, K. Pai, A. Elkhanany, H. Lin, P. D. Siedler, J. Fang, R. Mishra, K. Zsolnai-Fehér, X. Jiang, S. Khan, J. Yuan, R. K. Jain, X. Lin, M. Peterson, Z. Wang, A. Malusare, M. Tang, I. Gupta, I. Fosin, T. Kang, B. Dworakowska, K. Matsumoto, G. Zheng, G. Sewuster, J. P. Villanueva, I. Rannev, I. Chernyavsky, J. Chen, D. Banik, B. Racz, W. Dong, J. Wang, L. Bashmal, D. V. Gonçalves, W. Hu, K. Bar, O. Bohdal, A. S. Patlan, S. Dhuliawala, C. Geirhos, J. Wist, Y. Kansal, B. Chen, K. Tire, A. T. Yücel, B. Christof, V. Singla, Z. Song, S. Chen, J. Ge, K. Ponkshe, I. Park, T. Shi, M. Q. Ma, J. Mak, S. Lai, A. Moulin, Z. Cheng, Z. Zhu, Z. Zhang, V. Patil, K. Jha, Q. Men, J. Wu, T. Zhang, B. H. Vieira, A. F. Aji, J. Chung, M. Mahfoud, H. T. Hoang, M. Sperzel, W. Hao, K. Meding, S. Xu, V. Kostakos, D. Manini, Y. Liu, C. Toukmaji, J. Paek, E. Yu, A. E. Demircali, Z. Sun, I. Dewerpe, H. Qin, R. Pflugfelder, J. Bailey, J. Morris, V. Heilala, S. Rosset, Z. Yu, P. E. Chen, W. Yeo, E. Jain, R. Yang, S. Chigurupati, J. Chernyavsky, S. P. Reddy, S. Venugopalan, H. Batra, C. F. Park, H. Tran, G. Maximiano, G. Zhang, Y. Liang, H. Shiyu, R. Xu, R. Pan, S. Suresh, Z. Liu, S. Gulati, S. Zhang, P. Turchin, C. W. Bartlett, C. R. Scotese, P. M. Cao, B. Wu, J. Karwowski, D. Scaramuzza, A. Nattanmai, G. McKellips, A. Cheraku, A. Suhail, E. Luo, M. Deng, J. Luo, A. Zhang, K. Jindel, J. Paek, K. Halevy, A. Baranov, M. Liu, A. Avadhanam, D. Zhang, V. Cheng, B. Ma, E. Fu, L. Do, J. Lass, H. Yang, S. Sunkari, V. Bharath, V. Ai, J. Leung, R. Agrawal, A. Zhou, K. Chen, T. Kalpathi, Z. Xu, G. Wang, T. Xiao, E. Maung, S. Lee, R. Yang, R. Yue, B. Zhao, J. Yoon, S. Sun, A. Singh, E. Luo, C. Peng, T. Osbey, T. Wang, D. Echeazu, H. Yang, T. Wu, S. Patel, V. Kulkarni, V. Sundarapandiyan, A. Zhang, A. Le, Z. Nasim, S. Yalam, R. Kasamsetty, S. Samal, H. Yang, D. Sun, N. Shah, A. Saha, A. Zhang, L. Nguyen, L. Nagumalli, K. Wang, A. Zhou, A. Wu, J. Luo, A. Telluri, S. Yue, A. Wang, and D. Hendrycks (2025) Humanity’s last exam. External Links: 2501.14249, Link Cited by: §1.
- M. S. Rasooli and J. R. Tetreault (2015) Yara parser: A fast and accurate dependency parser. Computing Research Repository arXiv:1503.06733. Note: version 2 External Links: Link Cited by: §7.1.
- C. Shikishima, K. Hiraishi, S. Yamagata, Y. Sugimoto, R. Takemura, K. Ozaki, M. Okada, T. Toda, and J. Ando (2009) Is g an entity? a japanese twin study using syllogisms and intelligence tests. Intelligence 37 (3), pp. 256–267. External Links: ISSN 0160-2896, Document, Link Cited by: §5.
- P. Suppes (1957) Introduction to logic. Dover Publications, Mineola, N.Y.. Cited by: §7.1.
- G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivière, L. Rouillard, T. Mesnard, G. Cideron, J. Grill, S. Ramos, E. Yvinec, M. Casbon, E. Pot, I. Penchev, G. Liu, F. Visin, K. Kenealy, L. Beyer, X. Zhai, A. Tsitsulin, R. Busa-Fekete, A. Feng, N. Sachdeva, B. Coleman, Y. Gao, B. Mustafa, I. Barr, E. Parisotto, D. Tian, M. Eyal, C. Cherry, J. Peter, D. Sinopalnikov, S. Bhupatiraju, R. Agarwal, M. Kazemi, D. Malkin, R. Kumar, D. Vilar, I. Brusilovsky, J. Luo, A. Steiner, A. Friesen, A. Sharma, A. Sharma, A. M. Gilady, A. Goedeckemeyer, A. Saade, A. Feng, A. Kolesnikov, A. Bendebury, A. Abdagic, A. Vadi, A. György, A. S. Pinto, A. Das, A. Bapna, A. Miech, A. Yang, A. Paterson, A. Shenoy, A. Chakrabarti, B. Piot, B. Wu, B. Shahriari, B. Petrini, C. Chen, C. L. Lan, C. A. Choquette-Choo, C. Carey, C. Brick, D. Deutsch, D. Eisenbud, D. Cattle, D. Cheng, D. Paparas, D. S. Sreepathihalli, D. Reid, D. Tran, D. Zelle, E. Noland, E. Huizenga, E. Kharitonov, F. Liu, G. Amirkhanyan, G. Cameron, H. Hashemi, H. Klimczak-Plucińska, H. Singh, H. Mehta, H. T. Lehri, H. Hazimeh, I. Ballantyne, I. Szpektor, I. Nardini, J. Pouget-Abadie, J. Chan, J. Stanton, J. Wieting, J. Lai, J. Orbay, J. Fernandez, J. Newlan, J. Ji, J. Singh, K. Black, K. Yu, K. Hui, K. Vodrahalli, K. Greff, L. Qiu, M. Valentine, M. Coelho, M. Ritter, M. Hoffman, M. Watson, M. Chaturvedi, M. Moynihan, M. Ma, N. Babar, N. Noy, N. Byrd, N. Roy, N. Momchev, N. Chauhan, N. Sachdeva, O. Bunyan, P. Botarda, P. Caron, P. K. Rubenstein, P. Culliton, P. Schmid, P. G. Sessa, P. Xu, P. Stanczyk, P. Tafti, R. Shivanna, R. Wu, R. Pan, R. Rokni, R. Willoughby, R. Vallu, R. Mullins, S. Jerome, S. Smoot, S. Girgin, S. Iqbal, S. Reddy, S. Sheth, S. Põder, S. Bhatnagar, S. R. Panyam, S. Eiger, S. Zhang, T. Liu, T. Yacovone, T. Liechty, U. Kalra, U. Evci, V. Misra, V. Roseberry, V. Feinberg, V. Kolesnikov, W. Han, W. Kwon, X. Chen, Y. Chow, Y. Zhu, Z. Wei, Z. Egyed, V. Cotruta, M. Giang, P. Kirk, A. Rao, K. Black, N. Babar, J. Lo, E. Moreira, L. G. Martins, O. Sanseviero, L. Gonzalez, Z. Gleicher, T. Warkentin, V. Mirrokni, E. Senter, E. Collins, J. Barral, Z. Ghahramani, R. Hadsell, Y. Matias, D. Sculley, S. Petrov, N. Fiedel, N. Shazeer, O. Vinyals, J. Dean, D. Hassabis, K. Kavukcuoglu, C. Farabet, E. Buchatskaya, J. Alayrac, R. Anil, Dmitry, Lepikhin, S. Borgeaud, O. Bachem, A. Joulin, A. Andreev, C. Hardin, R. Dadashi, and L. Hussenot (2025) Gemma 3 technical report. External Links: 2503.19786, Link Cited by: §1, §4.1.1.
- Y. Wang, L. Yang, B. Li, Y. Tian, K. Shen, and M. Wang (2025) Revolutionizing reinforcement learning framework for diffusion large language models. External Links: 2509.06949, Link Cited by: §7.6.6.
- T. Wei, J. Luan, W. Liu, S. Dong, and B. Wang (2023) CMATH: can your language model pass chinese elementary school math test?. External Links: 2306.16636, Link Cited by: §1.
- Y. Wu, M. Han, Y. Zhu, L. Li, X. Zhang, R. Lai, X. Li, Y. Ren, Z. Dou, and Z. Cao (2023) Hence, socrates is mortal: a benchmark for natural language syllogistic reasoning. In Findings of the Association for Computational Linguistics: ACL 2023, A. Rogers, J. Boyd-Graber, and N. Okazaki (Eds.), Toronto, Canada, pp. 2347–2367. External Links: Link, Document Cited by: §1, §5.
- A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. Li, T. Tang, W. Yin, X. Ren, X. Wang, X. Zhang, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Zhang, Y. Wan, Y. Liu, Z. Wang, Z. Cui, Z. Zhang, Z. Zhou, and Z. Qiu (2025) Qwen3 technical report. External Links: 2505.09388, Link Cited by: §1, §4.1.1.
- F. Zhu, R. Wang, S. Nie, X. Zhang, C. Wu, J. Hu, J. Zhou, J. Chen, Y. Lin, J. Wen, and C. Li (2025a) LLaDA 1.5: variance-reduced preference optimization for large language diffusion models. External Links: 2505.19223, Link Cited by: §7.6.6.
- Y. Zhu, J. Wan, X. Liu, S. He, Q. Wang, X. Guo, T. Liang, Z. Huang, Z. He, and X. Qiu (2025b) DiRL: an efficient post-training framework for diffusion language models. External Links: 2512.22234, Link Cited by: §7.6.6.
## 7 Appendix
### 7.1 Syllogism and Categorical Propositions
The core structure of the syllogism was first systematically articulated by the ancient Greek philosopher Aristotle (384–322 BCE) in the Organon. He defines a syllogism as a form of reasoning in which the conclusion follows necessarily from the premises, and it is standardly analyzed as involving a major premise, a minor premise, and a conclusion. A standard-form categorical syllogism is built from three core components Aristotle (1984); Copi et al. (2014):
- Three Terms:
- The major term (P) is the predicate of the conclusion.
- The minor term (S) is the subject of the conclusion.
- The middle term (M) appears in both premises but not in the conclusion.
- Three Propositions:
- The major premise contains the major term (P) and the middle term (M).
- The minor premise contains the minor term (S) and the middle term (M).
- The conclusion links the minor term (S) to the major term (P).
In Aristotelian syllogistic logic (traditional logic), categorical propositions are divided into four standard forms:
- A -proposition (universal affirmative), of the form “All $S$ are $P$ ,” e.g., “All humans are mortal”.
- E -proposition (universal negative), of the form “No $S$ are $P$ ,” e.g., “No humans are perfect”.
- I -proposition (particular affirmative), of the form “Some $S$ are $P$ ,” e.g., “Some humans are healthy”.
- O -proposition (particular negative), of the form “Some $S$ are not $P$ ,” e.g., “Some humans are not healthy”.
In a categorical syllogism, both premises and the conclusion are propositions of these four types Suppes (1957). In the traditional (Aristotelian) interpretation, the truth of a universal proposition is taken to imply the truth of its corresponding particular proposition Rasooli and Tetreault (2015). This assumption licenses, for example, subalternation from an A-proposition to the corresponding I-proposition; e.g., from “All humans are mortal” one may infer “Some humans are mortal.”
In contrast, George Boole, a nineteenth-century English mathematician, argued that we cannot infer the truth of a particular proposition from the truth of its corresponding universal proposition, because every particular proposition asserts the existence of its subject class. If a universal proposition permitted us to infer the corresponding particular, then "All leprechauns wear little green hats" would license the inference that some leprechauns do, which would imply that there really are leprechauns Boole (1854). Thus, under modern logic (the Boolean interpretation), a universal proposition (an A- or E-proposition) is understood as stating only, for example, "If there is such a thing as a leprechaun, it wears a little green hat," not that any leprechauns actually exist.
### 7.2 Formalization of Categorical Propositions
In the main text, we adopt the formalization of modern logic (Boolean), which reinterprets categorical propositions as quantified formulas. Throughout, by modern logic we mean the Boolean interpretation (no existential import for universals), expressed using standard quantified notation. The typical correspondences are as follows:
| Categorical Proposition | Formalization in modern logic | Explanation |
| --- | --- | --- |
| All $S$ are $P$ | $\forall x\,(Sx\rightarrow Px)$ | For all $x$ , if $x$ is $S$ , then $x$ is $P$ . |
| No $S$ are $P$ | $\forall x\,(Sx\rightarrow\neg Px)$ or $\neg\exists x\,(Sx\wedge Px)$ | For all $x$ , if $x$ is $S$ , then $x$ is not $P$ ; equivalently, there does not exist any $x$ such that $x$ is both $S$ and $P$ . |
| Some $S$ are $P$ | $\exists x\,(Sx\wedge Px)$ | There exists at least one $x$ such that $x$ is $S$ and $x$ is $P$ . |
| Some $S$ are not $P$ | $\exists x\,(Sx\wedge\neg Px)$ | There exists at least one $x$ such that $x$ is $S$ and $x$ is not $P$ . |
Under the standard semantics of modern logic Enderton (1972), if the extension of $S$ is empty, then $\exists x(Sx\land Px)$ is false, whereas $\forall x(Sx\rightarrow Px)$ is vacuously true. Consequently, from $\forall x(Sx\rightarrow Px)$ and $\forall x(Px\rightarrow Qx)$ one cannot derive $\exists x(Sx\land Qx)$ unless one adds an extra existence assumption (e.g., $\exists x\,Sx$ ). For this reason, as shown in Table 2, among the 24 standard syllogistic forms treated as valid in traditional logic, 9 are not valid in general under the semantics of modern logic, because their correctness depends on existential import Copi et al. (2014).
### 7.3 A Modern-Logic Derivation of Barbara
Take the syllogism Barbara (mood AAA in the first figure) as an example:
| | Major premise: | $\displaystyle\quad\text{All }M\text{ are }P\;\to\;\forall x(Mx\rightarrow Px),$ | |
| --- | --- | --- | --- |
Under modern logic, the validity of this inference can be demonstrated by a formal derivation (e.g., in natural deduction):
1. $\forall x(Mx\rightarrow Px)$ [Major premise]
1. $\forall x(Sx\rightarrow Mx)$ [Minor premise]
1. Assume an arbitrary $a$ . [Arbitrary individual]
1. $Sa\rightarrow Ma$ [from 2, $\forall$ -elim]
1. $Ma\rightarrow Pa$ [from 1, $\forall$ -elim]
1. $Sa\rightarrow Pa$ [from 4, 5]
1. $\forall x(Sx\rightarrow Px)$ [from 3–6, $\forall$ -intro]
This example shows that traditional syllogistic reasoning can be formalized and verified within modern logic.
| Name | Mood | Figure | Validity |
| --- | --- | --- | --- |
| Barbara | AAA | I | Valid in Both |
| Celarent | EAE | I | Valid in Both |
| Darii | AII | I | Valid in Both |
| Ferio | EIO | I | Valid in Both |
| Barbari | AAI | I | Traditional only |
| Celaront | EAO | I | Traditional only |
| Cesare | EAE | II | Valid in Both |
| Camestres | AEE | II | Valid in Both |
| Festino | EIO | II | Valid in Both |
| Baroco | AOO | II | Valid in Both |
| Cesaro | EAO | II | Traditional only |
| Camestrop | AEO | II | Traditional only |
| Darapti | AAI | III | Traditional only |
| Disamis | IAI | III | Valid in Both |
| Datisi | AII | III | Valid in Both |
| Felapton | EAO | III | Traditional only |
| Bocardo | OAO | III | Valid in Both |
| Ferison | EIO | III | Valid in Both |
| Bamalip | AAI | IV | Traditional only |
| Camenes | AEE | IV | Valid in Both |
| Dimaris | IAI | IV | Valid in Both |
| Calemop | AEO | IV | Traditional only |
| Fesapo | EAO | IV | Traditional only |
| Fresison | EIO | IV | Valid in Both |
Table 2: The 15+9 Distinction of Valid Syllogistic Forms (Traditional logic vs. Modern logic)
### 7.4 Data Construction
The dataset construction process follows a rigorously structured three-stage pipeline: (1) Diverse Topic Seeding, (2) Closed-Loop Generation and Verification, and (3) Triplet Completion and Relational Validation. Each stage is designed to build upon the previous one, progressively refining the quality and logical richness of the resulting data.
Diverse Topic Seeding.
To ensure broad topical coverage and prevent semantic bias toward common or overrepresented domains, the process begins with a topic seeding stage. A predefined set of meta-domains spanning natural sciences, engineering, social sciences, and the humanities is used as the high-level taxonomy. For each meta-domain, a Topic Generation Agent is prompted to produce a set of concrete and verifiable subfields or research directions that exist in reality. The outcome is a diverse and fine-grained collection of topics, each serving as a contextual anchor for subsequent concept generation. This stage establishes semantic breadth and ensures that reasoning patterns later derived from the dataset are not constrained to narrow disciplinary vocabularies.
Closed-Loop Generation and Verification
At the core of the dataset construction process lies the closed-loop generation and verification stage, which establishes the factual and semantic foundation of both non-empty and empty sets for the minor term $(S)$ within each syllogistic structure. This stage guarantees that generated concepts are not only syntactically well-formed but also ontologically consistent with their designated existential category. Two complementary generation objectives are defined: non-empty concepts, which correspond to empirically verifiable entities in the real world, and empty concepts, which remain logically coherent while representing categories with no real-world instantiation.
For each topic obtained from the previous stage, an iterative "generate, verify, feedback" loop is executed. The Generator agent first produces a candidate concept $(S)$ that satisfies the existential target of the current data subset. The candidate is then evaluated by a panel of independent Validator agents, each performing an autonomous factuality assessment and issuing a categorical verdict("non-empty" and "empty") accompanied by explanatory reasoning and indicative verification paths. A concept advances only when all validators unanimously agree on the verdict corresponding to the intended generation type, confirming either its empirical existence (for non-empty cases) or its verified non-existence (for empty cases). If disagreement arises, the system consolidates validator feedback into a unified critique, which is returned to the Generator in the next iteration to guide conceptual refinement. Through this iterative feedback-driven process, the framework produces two balanced sets of high-confidence concepts that jointly represent existentially positive and negative categories of reality.
Triplet Completion and Relational Validation
After obtaining a validated non-empty or empty concept $(S)$ , the final stage completes the triplet structure by generating the corresponding middle $(M)$ and major $(P)$ terms. The Triplet Generator agent constructs the set $(S,M,P)$ under strict constraints ensuring that all three concepts belong to a coherent semantic frame amenable to syllogistic reasoning. The agent is explicitly instructed to avoid trivial or hierarchical relations such as synonymy or direct subclass relationships (e.g., poodle $\rightarrow$ dog $\rightarrow$ animal), instead favoring more nuanced logical relations grounded in attribute overlap, contextual differentiation, or mechanistic contrast. To enforce this non-triviality constraint, each triplet undergoes an additional Relational Validation phase. Here, Validator agents examine whether deterministic subsumption or equivalence relations exist among the three concepts. A triplet is finalized only if it passes this logical consistency test, confirming its suitability for constructing non-trivial reasoning scenarios.
Syllogistic Data Realization
Upon successful generation and validation of all $(S,M,P)$ triplets, the final step transforms these verified conceptual structures into complete syllogistic reasoning instances. Each triplet serves as a semantic scaffold that is systematically mapped onto the twenty-four canonical syllogistic mood–figure templates formalized in Aristotelian logic. By substituting the generated concepts into these templates, the system produces a diverse collection of categorical syllogisms encompassing universal affirmatives, particulars, and negatives across multiple structural figures. This synthesis ensures that every syllogistic instance conforms to formal logical syntax while remaining grounded in verifiable semantic content. The resulting corpus thus unifies traditional deductive structures with empirically meaningful concepts, providing a rigorous benchmark for evaluating machine reasoning under both semantic authenticity and logical validity.
### 7.5 The precision and recall metrics
Under modern logic, 15 syllogisms are regarded as valid, while the remaining 9 are invalid. We treat valid forms as positive samples $(P)$ and invalid forms as negative samples $(N)$ . We define the precision and recall metrics of valid and invalid syllogisms $\mathrm{pre}_{V},\mathrm{rec}_{V},\mathrm{pre}_{I},\mathrm{rec}_{I}$ as follow:
$$
\mathrm{pre}_{V}=\frac{TP}{TP+FP}
$$
$$
\mathrm{rec}_{V}=\frac{TP}{TP+FN}
$$
$$
\mathrm{pre}_{I}=\frac{TN}{TN+FN}
$$
$$
\mathrm{rec}_{I}=\frac{TN}{TN+FP}
$$
### 7.6 The results of experiments
#### 7.6.1 The detailed results of closed-source models
The detailed results of closed-source models are shown in Tab. 3. GPT-5 and GPT-o3 exhibit the extreme modern logic tendency.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | |
| Claude-3.7-Sonnet | 85.29 | 76.54 | 45.83 | 72.89 | 99.47 | 97.73 | 38.33 | 90.46 | 71.71 | 50.00 | 68.91 | 99.73 | 98.25 | 25.00 | 70.33 | 92.00 | 54.17 | 88.74 | 99.87 | 99.72 | 78.89 | 73.08 | 89.42 | 62.50 | 85.52 | 100.00 | 100.00 | 71.78 |
| Claude-4.5-Sonnet | 81.38 | 81.12 | 62.50 | 76.80 | 100.00 | 100.00 | 49.67 | 93.96 | 68.57 | 62.50 | 66.55 | 100.00 | 100.00 | 16.13 | 70.01 | 92.52 | 66.67 | 89.32 | 100.00 | 100.00 | 80.04 | 84.11 | 78.40 | 62.50 | 74.32 | 100.00 | 100.00 | 42.38 |
| Gemini-2.5-Pro | 71.92 | 89.33 | 29.17 | 86.04 | 99.07 | 97.92 | 73.22 | 76.17 | 83.50 | 25.00 | 80.20 | 97.73 | 94.06 | 59.78 | 65.17 | 97.33 | 70.83 | 95.91 | 100.00 | 100.00 | 92.89 | 72.92 | 89.50 | 58.33 | 85.66 | 100.00 | 100.00 | 72.11 |
| Gemini-3-Pro-Preview | 73.11 | 89.20 | 54.17 | 85.35 | 99.87 | 99.69 | 71.44 | 99.00 | 63.48 | 66.67 | 63.12 | 100.00 | 100.00 | 2.67 | 63.48 | 99.00 | 79.17 | 98.42 | 100.00 | 100.00 | 97.33 | 98.41 | 64.02 | 70.83 | 63.44 | 100.00 | 100.00 | 4.22 |
| GPT-4o-2024-11-20 | 93.17 | 68.42 | 41.67 | 66.68 | 99.53 | 95.57 | 16.85 | 96.17 | 65.71 | 50.00 | 64.73 | 99.73 | 95.40 | 9.25 | 93.33 | 68.75 | 50.00 | 66.83 | 99.87 | 98.71 | 17.08 | 94.04 | 67.83 | 50.00 | 66.15 | 99.60 | 95.74 | 15.02 |
| GPT-4.1-2025-04-14 | 80.38 | 80.04 | 33.33 | 76.46 | 98.33 | 94.69 | 49.56 | 85.08 | 76.67 | 45.83 | 73.02 | 99.40 | 97.49 | 38.78 | 80.04 | 82.38 | 58.33 | 78.03 | 99.93 | 99.79 | 53.11 | 81.54 | 80.96 | 62.50 | 76.65 | 100.00 | 100.00 | 49.22 |
| GPT-o3 | 62.38 | 99.54 | 87.50 | 99.73 | 99.60 | 99.33 | 99.56 | 62.58 | 99.92 | 91.67 | 99.87 | 100.00 | 100.00 | 99.78 | 62.50 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 62.58 | 99.92 | 95.83 | 99.87 | 100.00 | 100.00 | 99.78 |
| GPT-5-2025-08-07 | 62.53 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 62.33 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 62.53 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 62.40 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
Table 3: The detailed results of closed-source models.
#### 7.6.2 The detailed results of experiment with Prior-check prompt
The results are shown in Tab. 4.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | |
| Qwen3-0.6B | 100.00 | 62.50 | 100.00 | 62.50 | 100.00 | 0.00 | 0.00 | 99.96 | 62.46 | 95.83 | 62.48 | 99.93 | 0.00 | 0.00 | 100.00 | 62.50 | 100.00 | 62.50 | 100.00 | 0.00 | 0.00 | 100.00 | 62.50 | 100.00 | 62.50 | 100.00 | 0.00 | 0.00 |
| Qwen3-0.6B-Thinking | 94.71 | 61.04 | 4.17 | 62.43 | 94.60 | 36.22 | 5.11 | 92.96 | 61.12 | 16.67 | 62.71 | 93.27 | 40.24 | 7.56 | 86.67 | 60.25 | 0.00 | 63.12 | 87.53 | 41.56 | 14.78 | 88.33 | 61.75 | 4.17 | 63.73 | 90.07 | 46.79 | 14.56 |
| Qwen3-1.7B | 97.00 | 62.42 | 50.00 | 62.84 | 97.53 | 48.61 | 3.89 | 95.58 | 60.92 | 37.50 | 62.25 | 95.20 | 32.08 | 3.78 | 75.21 | 59.71 | 16.67 | 64.76 | 77.93 | 44.37 | 29.33 | 35.17 | 47.58 | 4.17 | 64.34 | 36.20 | 38.50 | 66.56 |
| Qwen3-1.7B-Thinking | 92.92 | 67.67 | 29.17 | 66.23 | 98.47 | 86.47 | 16.33 | 94.29 | 67.71 | 50.00 | 66.02 | 99.60 | 95.62 | 14.56 | 91.62 | 70.54 | 54.17 | 68.03 | 99.73 | 98.01 | 21.89 | 91.96 | 70.29 | 58.33 | 67.83 | 99.80 | 98.45 | 21.11 |
| Qwen3-4B | 92.46 | 67.12 | 45.83 | 66.02 | 97.67 | 80.66 | 16.22 | 94.46 | 67.04 | 54.17 | 65.64 | 99.20 | 90.98 | 13.44 | 85.79 | 61.62 | 4.17 | 64.06 | 87.93 | 46.92 | 17.78 | 93.50 | 61.67 | 12.50 | 62.92 | 94.13 | 43.59 | 7.56 |
| Qwen3-4B-Thinking | 82.54 | 79.96 | 62.50 | 75.72 | 100.00 | 100.00 | 46.56 | 85.33 | 77.08 | 58.33 | 73.19 | 99.93 | 99.72 | 39.00 | 83.62 | 78.88 | 66.67 | 74.74 | 100.00 | 100.00 | 43.67 | 84.92 | 77.58 | 62.50 | 73.60 | 100.00 | 100.00 | 40.22 |
| Qwen3-8B | 94.12 | 67.46 | 33.33 | 65.91 | 99.27 | 92.20 | 14.44 | 96.67 | 65.42 | 62.50 | 64.44 | 99.67 | 93.75 | 8.33 | 85.46 | 69.58 | 4.17 | 68.80 | 94.07 | 74.43 | 28.81 | 86.71 | 64.62 | 0.00 | 65.64 | 91.07 | 57.99 | 20.56 |
| Qwen3-8B-Thinking | 67.83 | 94.50 | 54.17 | 92.01 | 99.87 | 99.74 | 85.56 | 71.62 | 90.88 | 62.50 | 87.26 | 100.00 | 100.00 | 75.67 | 64.83 | 97.67 | 75.00 | 96.40 | 100.00 | 100.00 | 93.78 | 65.29 | 97.21 | 66.67 | 95.72 | 100.00 | 100.00 | 92.56 |
| Qwen3-14B | 97.75 | 64.50 | 66.67 | 63.81 | 99.80 | 94.44 | 5.67 | 99.25 | 63.25 | 87.50 | 62.97 | 100.00 | 100.00 | 2.00 | 87.12 | 70.96 | 25.00 | 69.20 | 96.47 | 82.85 | 28.44 | 91.58 | 68.08 | 20.83 | 66.70 | 97.73 | 83.17 | 18.67 |
| Qwen3-14B-Thinking | 72.96 | 89.54 | 62.50 | 85.67 | 100.00 | 100.00 | 72.11 | 76.50 | 86.00 | 66.67 | 81.70 | 100.00 | 100.00 | 62.67 | 74.92 | 87.50 | 58.33 | 83.37 | 99.93 | 99.83 | 66.78 | 77.92 | 84.50 | 58.33 | 80.16 | 99.93 | 99.81 | 58.78 |
| Qwen3-32B | 91.67 | 70.33 | 58.33 | 67.91 | 99.60 | 97.00 | 21.56 | 95.54 | 66.96 | 75.00 | 65.42 | 100.00 | 100.00 | 11.89 | 91.00 | 70.50 | 45.83 | 68.13 | 99.20 | 94.44 | 22.67 | 93.88 | 68.46 | 54.17 | 66.49 | 99.87 | 98.64 | 16.11 |
| Qwen3-32B-Thinking | 82.21 | 80.29 | 62.50 | 76.03 | 100.00 | 100.00 | 47.44 | 85.75 | 76.75 | 62.50 | 72.89 | 100.00 | 100.00 | 38.00 | 77.96 | 84.50 | 62.50 | 80.17 | 100.00 | 100.00 | 58.73 | 80.38 | 82.08 | 62.50 | 77.76 | 100.00 | 100.00 | 52.28 |
| Qwen3-30B-A3B-Instruct | 66.58 | 95.83 | 70.83 | 93.80 | 99.93 | 99.88 | 89.00 | 71.96 | 90.54 | 66.67 | 86.86 | 100.00 | 100.00 | 74.78 | 64.00 | 98.50 | 75.00 | 97.66 | 100.00 | 100.00 | 96.00 | 66.71 | 95.71 | 66.67 | 93.63 | 99.93 | 99.87 | 88.67 |
| Qwen3-30B-A3B-Thinking | 69.17 | 93.33 | 62.50 | 90.36 | 100.00 | 100.00 | 82.22 | 71.50 | 91.00 | 62.50 | 87.41 | 100.00 | 100.00 | 76.00 | 67.71 | 86.12 | 16.67 | 85.91 | 93.07 | 86.58 | 74.56 | 70.00 | 84.08 | 8.33 | 83.27 | 93.27 | 85.97 | 68.78 |
| Qwen3-next-80B-A3B-Instruct | 65.58 | 96.92 | 66.67 | 95.30 | 100.00 | 100.00 | 91.78 | 70.08 | 92.42 | 66.67 | 89.18 | 100.00 | 100.00 | 79.78 | 62.71 | 99.62 | 70.83 | 99.53 | 99.87 | 99.78 | 99.22 | 64.38 | 98.12 | 62.50 | 97.09 | 100.00 | 100.00 | 95.00 |
| Qwen3-next-80B-A3B-Thinking | 62.71 | 99.79 | 83.33 | 99.67 | 100.00 | 100.00 | 99.44 | 63.08 | 99.42 | 79.17 | 99.08 | 100.00 | 100.00 | 98.44 | 62.88 | 98.96 | 50.00 | 98.87 | 99.47 | 99.10 | 98.11 | 62.96 | 99.38 | 75.00 | 99.14 | 99.87 | 99.78 | 98.56 |
| Qwen3-235B-A22B-Instruct | 66.17 | 96.33 | 66.67 | 94.46 | 100.00 | 100.00 | 90.22 | 67.83 | 94.67 | 66.67 | 92.14 | 100.00 | 100.00 | 85.78 | 62.54 | 99.88 | 87.50 | 99.87 | 99.93 | 99.89 | 99.78 | 62.71 | 99.79 | 83.33 | 99.67 | 100.00 | 100.00 | 99.44 |
| Qwen3-235B-A22B-Thinking | 62.71 | 99.79 | 83.33 | 99.67 | 100.00 | 100.00 | 99.44 | 62.88 | 99.62 | 83.33 | 99.40 | 100.00 | 100.00 | 99.00 | 64.75 | 97.75 | 62.50 | 96.53 | 100.00 | 100.00 | 94.00 | 63.08 | 99.42 | 70.83 | 99.08 | 100.00 | 100.00 | 98.44 |
| Gemma-3-1B-IT | 87.96 | 53.29 | 0.00 | 58.98 | 83.00 | 11.76 | 3.78 | 77.62 | 51.71 | 0.00 | 59.15 | 73.47 | 25.88 | 15.44 | 90.29 | 57.54 | 0.00 | 61.10 | 88.27 | 24.46 | 6.33 | 86.71 | 57.54 | 0.00 | 61.56 | 85.40 | 31.35 | 11.11 |
| Gemma-3-4B-IT | 94.46 | 63.38 | 16.67 | 63.70 | 96.27 | 57.89 | 8.56 | 77.88 | 63.54 | 0.00 | 66.72 | 83.13 | 52.35 | 30.89 | 95.00 | 63.08 | 12.50 | 63.46 | 96.47 | 55.83 | 7.44 | 94.79 | 64.38 | 25.00 | 64.18 | 97.33 | 68.00 | 9.44 |
| Gemma-3-12B-IT | 98.54 | 63.38 | 41.67 | 63.13 | 99.53 | 80.00 | 3.11 | 98.96 | 62.88 | 45.83 | 62.82 | 99.47 | 68.00 | 1.89 | 93.67 | 63.42 | 20.83 | 63.83 | 95.67 | 57.24 | 9.67 | 92.38 | 64.96 | 20.83 | 64.86 | 95.87 | 66.12 | 13.44 |
| Gemma-3-27B-IT | 95.33 | 62.00 | 16.67 | 62.85 | 95.87 | 44.64 | 5.56 | 94.17 | 61.58 | 20.83 | 62.79 | 94.60 | 42.14 | 6.56 | 96.54 | 65.71 | 50.00 | 64.61 | 99.80 | 96.39 | 8.89 | 95.96 | 66.54 | 66.67 | 65.13 | 100.00 | 100.00 | 10.78 |
| Llama3-8B-Instruct | 75.12 | 60.21 | 0.00 | 65.17 | 78.49 | 45.61 | 30.07 | 63.29 | 53.79 | 0.00 | 62.87 | 63.67 | 38.14 | 37.33 | 50.25 | 56.88 | 0.00 | 69.32 | 55.73 | 44.34 | 58.84 | 47.42 | 51.83 | 0.00 | 65.11 | 49.43 | 39.89 | 55.89 |
| Llama3-70B-Instruct | 98.58 | 63.17 | 58.33 | 63.02 | 99.40 | 73.53 | 2.78 | 96.88 | 62.71 | 45.83 | 63.01 | 97.67 | 53.33 | 4.44 | 98.88 | 62.54 | 62.50 | 62.66 | 99.13 | 51.85 | 1.56 | 90.67 | 60.29 | 20.83 | 62.59 | 90.80 | 38.12 | 9.45 |
| Llama3.3-70B-Instruct | 96.08 | 65.92 | 58.33 | 64.79 | 99.60 | 93.62 | 9.78 | 97.88 | 63.96 | 62.50 | 63.52 | 99.47 | 84.31 | 4.78 | 99.08 | 63.00 | 87.50 | 62.87 | 99.67 | 77.27 | 1.89 | 99.12 | 63.38 | 79.17 | 63.05 | 100.00 | 100.00 | 2.33 |
Table 4: The detailed results of open-source models.
#### 7.6.3 The baseline experiment without the Prior-check prompt
The results are shown in Table 5.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | |
| Qwen3-0.6B | 100.00 | 62.50 | 100.00 | 62.50 | 100.00 | 0.00 | 0.00 | 99.96 | 62.46 | 95.83 | 62.48 | 99.93 | 0.00 | 0.00 | 98.38 | 62.12 | 25.00 | 62.52 | 98.40 | 38.46 | 1.67 | 79.75 | 56.75 | 0.00 | 62.07 | 79.20 | 35.80 | 19.33 |
| Qwen3-0.6B-Thinking | 87.96 | 62.04 | 0.00 | 63.95 | 90.00 | 48.10 | 15.44 | 91.42 | 61.83 | 0.00 | 63.31 | 92.60 | 46.12 | 10.56 | 86.54 | 60.29 | 0.00 | 63.17 | 87.47 | 41.80 | 15.00 | 89.58 | 60.25 | 0.00 | 62.70 | 89.87 | 39.20 | 10.89 |
| Qwen3-1.7B | 93.04 | 63.04 | 20.83 | 63.73 | 94.87 | 53.89 | 10.00 | 94.50 | 62.75 | 29.17 | 63.36 | 95.80 | 52.27 | 7.67 | 93.00 | 62.67 | 37.50 | 63.53 | 94.53 | 51.19 | 9.56 | 70.96 | 52.46 | 0.00 | 60.54 | 68.73 | 32.71 | 25.33 |
| Qwen3-1.7B-Thinking | 93.46 | 67.46 | 37.50 | 66.03 | 98.73 | 87.90 | 15.33 | 94.00 | 67.75 | 54.17 | 66.09 | 99.40 | 93.75 | 15.00 | 93.38 | 67.88 | 29.17 | 66.27 | 99.00 | 90.57 | 16.00 | 93.83 | 68.58 | 62.50 | 66.56 | 99.93 | 99.32 | 16.33 |
| Qwen3-4B | 93.88 | 65.46 | 54.17 | 64.89 | 97.47 | 74.15 | 12.11 | 96.00 | 65.50 | 62.50 | 64.58 | 99.20 | 87.50 | 9.33 | 83.42 | 65.75 | 25.00 | 66.93 | 89.33 | 59.80 | 26.44 | 90.25 | 67.75 | 41.67 | 66.76 | 96.40 | 76.92 | 20.00 |
| Qwen3-4B-Thinking | 88.88 | 73.62 | 62.50 | 70.32 | 100.00 | 100.00 | 29.67 | 87.12 | 75.38 | 62.50 | 71.74 | 100.00 | 100.00 | 34.33 | 86.67 | 75.83 | 62.50 | 72.12 | 100.00 | 100.00 | 35.56 | 87.17 | 75.33 | 62.50 | 71.70 | 100.00 | 100.00 | 34.22 |
| Qwen3-8B | 92.42 | 68.00 | 41.67 | 66.50 | 98.33 | 86.26 | 17.44 | 95.54 | 65.46 | 45.83 | 64.63 | 98.80 | 83.18 | 9.89 | 88.38 | 66.25 | 29.17 | 66.29 | 93.73 | 66.19 | 20.47 | 91.54 | 66.29 | 33.33 | 65.73 | 96.27 | 72.41 | 16.33 |
| Qwen3-8B-Thinking | 75.83 | 86.67 | 62.50 | 82.42 | 100.00 | 100.00 | 64.44 | 79.17 | 83.33 | 62.50 | 78.95 | 100.00 | 100.00 | 55.56 | 75.42 | 87.08 | 62.50 | 82.87 | 100.00 | 100.00 | 65.56 | 73.96 | 88.54 | 62.50 | 84.51 | 100.00 | 100.00 | 69.44 |
| Qwen3-14B | 94.46 | 67.12 | 37.50 | 65.68 | 99.27 | 91.73 | 13.56 | 96.33 | 65.83 | 58.33 | 64.71 | 99.73 | 95.45 | 9.33 | 89.46 | 65.71 | 37.50 | 65.77 | 94.13 | 65.22 | 18.33 | 91.88 | 66.29 | 33.33 | 65.67 | 96.53 | 73.33 | 15.89 |
| Qwen3-14B-Thinking | 69.00 | 93.50 | 66.67 | 90.58 | 100.00 | 100.00 | 82.67 | 73.04 | 89.46 | 66.67 | 85.57 | 100.00 | 100.00 | 71.89 | 84.75 | 77.58 | 58.33 | 73.65 | 99.87 | 99.45 | 40.44 | 85.67 | 76.83 | 66.67 | 72.96 | 100.00 | 100.00 | 38.22 |
| Qwen3-32B | 94.58 | 67.42 | 58.33 | 65.81 | 99.60 | 95.38 | 13.78 | 96.75 | 65.42 | 75.00 | 64.43 | 99.73 | 94.87 | 8.22 | 94.00 | 66.00 | 58.33 | 65.16 | 98.00 | 79.17 | 12.67 | 96.58 | 65.50 | 79.17 | 64.50 | 99.67 | 93.90 | 8.56 |
| Qwen3-32B-Thinking | 87.71 | 74.79 | 62.50 | 71.26 | 100.00 | 100.00 | 32.78 | 90.79 | 71.71 | 62.50 | 68.84 | 100.00 | 100.00 | 24.56 | 87.67 | 74.83 | 62.50 | 71.29 | 100.00 | 100.00 | 32.89 | 88.83 | 73.58 | 58.33 | 70.31 | 99.93 | 99.63 | 29.67 |
| Qwen3-30B-A3B-Instruct | 71.04 | 91.04 | 62.50 | 87.68 | 99.67 | 99.28 | 76.67 | 77.71 | 83.62 | 62.50 | 79.68 | 99.07 | 97.38 | 57.89 | 75.12 | 86.62 | 58.33 | 82.70 | 99.40 | 98.49 | 65.33 | 84.50 | 77.75 | 58.33 | 73.82 | 99.80 | 99.19 | 41.00 |
| Qwen3-30B-A3B-Thinking | 84.12 | 78.38 | 62.50 | 74.29 | 100.00 | 100.00 | 42.33 | 90.75 | 71.75 | 62.50 | 68.87 | 100.00 | 100.00 | 24.67 | 85.17 | 77.33 | 62.50 | 73.39 | 100.00 | 100.00 | 39.56 | 84.92 | 77.58 | 62.50 | 73.60 | 100.00 | 100.00 | 40.22 |
| Qwen3-NEXT-80B-A3B-instruct | 73.50 | 88.92 | 62.50 | 84.98 | 99.93 | 99.84 | 70.56 | 74.71 | 87.79 | 66.67 | 83.66 | 100.00 | 100.00 | 67.44 | 65.08 | 97.42 | 66.67 | 96.03 | 100.00 | 100.00 | 93.11 | 66.04 | 96.46 | 66.67 | 94.64 | 100.00 | 100.00 | 90.56 |
| Qwen3-NEXT-80B-A3B-Thinking | 74.83 | 87.67 | 66.67 | 83.52 | 100.00 | 100.00 | 67.11 | 76.54 | 85.96 | 66.67 | 81.65 | 100.00 | 100.00 | 62.56 | 69.79 | 92.54 | 62.50 | 89.55 | 100.00 | 100.00 | 80.47 | 68.58 | 93.54 | 70.83 | 91.13 | 100.00 | 100.00 | 83.61 |
| Qwen3-235B-A22B-Instruct | 80.96 | 81.21 | 54.17 | 76.99 | 99.73 | 99.12 | 50.33 | 83.67 | 78.50 | 54.17 | 74.50 | 99.73 | 98.98 | 43.11 | 73.21 | 89.21 | 58.33 | 85.32 | 99.93 | 99.84 | 71.33 | 78.46 | 84.04 | 66.67 | 79.66 | 100.00 | 100.00 | 57.44 |
| Qwen3-235B-A22B-Thinking | 69.50 | 93.00 | 66.67 | 89.93 | 100.00 | 100.00 | 81.33 | 72.00 | 90.50 | 66.67 | 86.81 | 100.00 | 100.00 | 74.67 | 71.38 | 91.12 | 66.67 | 87.57 | 100.00 | 100.00 | 76.33 | 73.04 | 89.46 | 62.50 | 85.57 | 100.00 | 100.00 | 71.89 |
| Gemma-3-1B-IT | 75.38 | 51.04 | 0.00 | 58.98 | 71.13 | 26.73 | 17.56 | 82.29 | 55.79 | 0.00 | 61.11 | 80.47 | 31.06 | 14.67 | 78.92 | 45.92 | 0.00 | 55.33 | 69.87 | 10.67 | 6.00 | 83.71 | 50.79 | 0.00 | 57.94 | 77.60 | 14.07 | 6.11 |
| Gemma-3-4B-IT | 97.83 | 62.25 | 33.33 | 62.65 | 98.07 | 44.23 | 2.56 | 97.46 | 61.71 | 33.33 | 62.42 | 97.33 | 34.43 | 2.33 | 95.33 | 63.83 | 8.33 | 63.81 | 97.33 | 64.29 | 8.00 | 97.92 | 64.17 | 50.00 | 63.62 | 99.67 | 90.00 | 5.00 |
| Gemma-3-12B-IT | 99.21 | 62.71 | 75.00 | 62.70 | 99.53 | 63.16 | 1.33 | 98.71 | 63.54 | 70.83 | 63.19 | 99.80 | 90.32 | 3.11 | 99.75 | 62.58 | 83.33 | 62.57 | 99.87 | 66.67 | 0.44 | 100.00 | 62.50 | 100.00 | 62.50 | 100.00 | 0.00 | 0.00 |
| Gemma-3-27B-IT | 97.62 | 64.29 | 54.17 | 63.72 | 99.53 | 87.72 | 5.56 | 98.04 | 63.71 | 37.50 | 63.37 | 99.40 | 80.85 | 4.22 | 99.08 | 63.25 | 79.17 | 62.99 | 99.87 | 90.91 | 2.22 | 99.92 | 62.58 | 95.83 | 62.55 | 100.00 | 100.00 | 0.22 |
| Llama3-8B-Instruct | 59.25 | 62.71 | 0.00 | 71.31 | 67.60 | 50.26 | 54.62 | 64.33 | 59.29 | 0.00 | 66.97 | 68.93 | 45.50 | 43.27 | 35.96 | 53.08 | 0.00 | 71.73 | 41.29 | 42.67 | 72.86 | 42.42 | 51.62 | 0.00 | 66.70 | 45.30 | 40.58 | 62.29 |
| Llama3.3-70B-Instruct | 98.12 | 64.29 | 87.50 | 63.65 | 99.93 | 97.78 | 4.89 | 98.38 | 63.21 | 58.33 | 63.07 | 99.27 | 71.79 | 3.11 | 98.58 | 63.33 | 87.50 | 63.10 | 99.53 | 79.41 | 3.00 | 99.62 | 62.46 | 79.17 | 62.53 | 99.67 | 44.44 | 0.44 |
| Llama3-70B-Instruct | 99.12 | 63.12 | 83.33 | 62.93 | 99.80 | 85.71 | 2.00 | 98.21 | 62.62 | 66.67 | 62.79 | 98.67 | 53.49 | 2.56 | 94.96 | 63.54 | 41.67 | 63.71 | 96.80 | 60.33 | 8.11 | 90.83 | 61.25 | 20.83 | 63.07 | 91.67 | 43.18 | 10.56 |
Table 5: The detailed results of baseline prompt of open-source models.
#### 7.6.4 The external experiment of thinking
The Instruct+ CoT experiment is shown in Tab. 6. The Instruct+CoT setting can induce a partial shift toward modern logic, but the shift is limited. The experiments of DeepSeek-R1 and DeepSeek-R1-Distill models are shown in Table 7. RL training does not automatically lead to rigorous modern logic in all models.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | |
| Qwen3-0.6B | 98.75 | 62.25 | 50.00 | 62.53 | 98.80 | 40.00 | 1.33 | 97.38 | 61.96 | 16.67 | 62.56 | 97.47 | 39.68 | 2.78 | 99.96 | 62.46 | 95.83 | 62.48 | 99.93 | 0.00 | 0.00 | 99.21 | 62.62 | 37.50 | 62.66 | 99.47 | 57.89 | 1.22 |
| Qwen3-1.7B | 93.50 | 64.17 | 12.50 | 64.26 | 96.13 | 62.82 | 10.89 | 92.00 | 62.50 | 16.67 | 63.59 | 93.60 | 50.00 | 10.67 | 67.08 | 56.50 | 0.00 | 64.16 | 68.87 | 40.89 | 35.89 | 58.88 | 51.71 | 0.00 | 62.07 | 58.47 | 36.88 | 40.44 |
| Qwen3-4B | 91.12 | 66.88 | 25.00 | 66.12 | 96.40 | 74.65 | 17.67 | 94.54 | 65.71 | 33.33 | 64.92 | 98.20 | 79.39 | 11.56 | 55.67 | 54.42 | 0.00 | 65.19 | 58.11 | 40.92 | 48.33 | 72.75 | 53.08 | 0.00 | 60.71 | 70.67 | 32.72 | 23.78 |
| Qwen3-8B | 88.83 | 70.75 | 25.00 | 68.71 | 97.67 | 86.94 | 25.89 | 94.54 | 67.12 | 50.00 | 65.67 | 99.33 | 92.37 | 13.44 | 86.08 | 72.58 | 4.17 | 70.38 | 96.93 | 86.23 | 32.00 | 90.33 | 66.50 | 4.17 | 66.05 | 95.47 | 70.69 | 18.22 |
| Qwen3-14B | 88.08 | 74.00 | 54.17 | 70.72 | 99.67 | 98.25 | 31.22 | 94.42 | 67.67 | 54.17 | 65.98 | 99.67 | 96.27 | 14.33 | 85.42 | 72.08 | 16.67 | 70.24 | 96.00 | 82.86 | 32.22 | 90.58 | 70.42 | 33.33 | 68.17 | 98.80 | 92.04 | 23.11 |
| Qwen3-32B | 89.58 | 72.50 | 50.00 | 69.53 | 99.67 | 98.00 | 27.22 | 94.17 | 68.33 | 75.00 | 66.37 | 100.00 | 100.00 | 15.56 | 89.12 | 72.21 | 41.67 | 69.47 | 99.07 | 94.64 | 27.44 | 91.62 | 70.12 | 37.50 | 67.80 | 99.40 | 95.52 | 21.33 |
| Qwen3-30B-A3B-Instruct | 63.88 | 98.62 | 75.00 | 97.85 | 100.00 | 100.00 | 96.33 | 67.25 | 95.25 | 62.50 | 92.94 | 100.00 | 100.00 | 87.33 | 63.88 | 98.62 | 75.00 | 97.85 | 100.00 | 100.00 | 96.33 | 66.54 | 95.96 | 66.67 | 93.93 | 100.00 | 100.00 | 89.22 |
| Qwen3-Next-80B-A3B-Instruct | 65.46 | 97.04 | 66.67 | 95.48 | 100.00 | 100.00 | 92.11 | 71.33 | 91.17 | 62.50 | 87.62 | 100.00 | 100.00 | 76.44 | 62.75 | 99.75 | 83.33 | 99.60 | 100.00 | 100.00 | 99.33 | 62.79 | 99.62 | 79.17 | 99.47 | 100.00 | 100.00 | 99.11 |
| Qwen3-235B-A22B-Instruct | 67.38 | 95.12 | 70.83 | 92.76 | 100.00 | 100.00 | 87.00 | 71.29 | 91.21 | 62.50 | 87.67 | 100.00 | 100.00 | 76.56 | 62.62 | 99.88 | 87.50 | 99.80 | 100.00 | 100.00 | 99.67 | 62.75 | 99.75 | 83.33 | 99.60 | 100.00 | 100.00 | 99.33 |
Table 6: Instruct+CoT setting experiment.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | |
| DeepSeek-R1 | 76.00 | 86.50 | 62.50 | 78.83 | 83.67 | 62.50 | 73.96 | 88.50 | 62.50 | 77.54 | 84.88 | 58.33 |
| DeepSeek-R1-Distill-Llama-8B | 99.00 | 62.79 | 54.17 | 99.04 | 62.79 | 45.83 | 94.62 | 61.71 | 4.17 | 96.21 | 61.46 | 12.50 |
| DeepSeek-R1-Distill-Llama-70B | 96.75 | 65.42 | 58.33 | 98.12 | 64.12 | 62.50 | 95.42 | 65.88 | 29.17 | 97.42 | 64.25 | 45.83 |
| DeepSeek-R1-Distill-Qwen-14B | 99.54 | 62.88 | 83.33 | 99.67 | 62.42 | 79.17 | 99.42 | 62.54 | 58.33 | 99.54 | 62.54 | 70.83 |
Table 7: The DeepSeek-R1 and DeepSeek-R1-Distilled results by language and concept existence.
#### 7.6.5 The results of Base models
The experiments of Base models are shown in Table 8. Base models are the starting point and a constraint to further training.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | |
| Qwen3-0.6B-Base | 6.62 | 36.46 | 29.17 | 14.67 | 34.00 | 4.17 | 1.71 | 37.38 | 16.67 | 7.42 | 36.92 | 0.00 |
| Qwen3-1.7B-Base | 82.88 | 55.79 | 0.00 | 77.21 | 52.54 | 0.00 | 99.92 | 62.58 | 91.67 | 99.96 | 62.54 | 95.83 |
| Qwen3-4B-Base | 93.25 | 61.67 | 33.33 | 91.29 | 60.54 | 29.17 | 72.54 | 56.54 | 8.33 | 81.58 | 58.83 | 25.00 |
| Qwen3-8B-Base | 95.00 | 61.17 | 16.67 | 81.42 | 53.67 | 0.00 | 73.75 | 68.21 | 33.33 | 82.92 | 64.33 | 0.00 |
| Qwen3-30B-A3B-Base | 79.50 | 52.12 | 0.00 | 90.17 | 58.00 | 0.00 | 79.58 | 50.75 | 0.00 | 84.96 | 53.67 | 0.00 |
| Gemma-3-1B-PT | 6.63 | 32.53 | 0.00 | 5.38 | 24.82 | 0.00 | 5.12 | 21.90 | 0.00 | 5.11 | 23.37 | 0.00 |
| Gemma-3-4B-PT | 6.75 | 36.67 | 0.00 | 9.12 | 36.08 | 0.00 | 2.42 | 30.31 | 0.00 | 3.48 | 30.74 | 0.00 |
| Gemma-3-12B-PT | 9.00 | 39.00 | 0.00 | 11.33 | 38.83 | 0.00 | 11.83 | 38.79 | 0.00 | 14.49 | 38.44 | 0.00 |
| Gemma-3-27B-PT | 26.83 | 42.50 | 0.00 | 24.46 | 42.29 | 0.00 | 16.75 | 34.21 | 0.00 | 16.92 | 35.42 | 0.00 |
| Llama3-8B-Base | 30.08 | 36.67 | 0.00 | 29.58 | 35.54 | 0.00 | 12.17 | 32.92 | 0.00 | 13.54 | 34.42 | 0.00 |
| Llama3-70B-Base | 44.70 | 43.44 | 0.00 | 41.79 | 42.71 | 0.00 | 34.43 | 45.78 | 0.00 | 29.86 | 43.65 | 0.00 |
Table 8: The results of various Base Models by language and concept existence.
#### 7.6.6 The results of dLLMs
We conduct experiments on various dLLMs, including LLaDA Nie et al. (2025), LLaDA-1.5 Zhu et al. (2025a), TraDo Wang et al. (2025), DiRL Zhu et al. (2025b), SDAR Cheng et al. (2025), LLaDA2.0 Bie et al. (2025). The results are shown in Table 9.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | |
| LLaDA-8b-Instruct | 70.25 | 50.83 | 0.00 | 68.79 | 50.54 | 0.00 | 71.75 | 55.88 | 0.00 | 69.50 | 54.12 | 0.00 |
| LLaDA-1.5 | 73.12 | 50.62 | 0.00 | 75.08 | 52.88 | 0.00 | 66.46 | 57.79 | 0.00 | 61.25 | 53.25 | 0.00 |
| TraDo-4B-Instruct | 84.92 | 59.50 | 20.83 | 80.67 | 57.00 | 25.00 | 87.04 | 66.62 | 20.83 | 86.29 | 63.96 | 12.50 |
| TraDo-8B-Instruct | 96.38 | 61.04 | 41.67 | 95.04 | 59.71 | 20.83 | 90.92 | 69.50 | 37.50 | 89.46 | 66.88 | 4.17 |
| DiRL-8B-Instruct | 89.50 | 62.19 | 0.00 | 92.83 | 59.00 | 0.00 | 94.12 | 66.25 | 20.83 | 94.58 | 63.25 | 4.17 |
| SDAR-4B | 80.46 | 59.04 | 20.83 | 76.08 | 56.50 | 16.67 | 78.33 | 63.67 | 16.67 | 76.96 | 62.21 | 12.50 |
| SDAR-8B | 91.58 | 59.17 | 20.83 | 90.83 | 56.33 | 20.83 | 84.21 | 68.46 | 0.00 | 72.75 | 62.42 | 0.00 |
| SDAR-30B-A3B | 99.17 | 63.17 | 79.17 | 99.00 | 63.33 | 79.17 | 99.71 | 62.71 | 75.00 | 99.50 | 62.83 | 70.83 |
| LLaDA2.0-mini | 82.62 | 77.46 | 16.67 | 87.12 | 74.46 | 33.33 | 85.96 | 73.96 | 37.50 | 89.42 | 72.08 | 45.83 |
| LLaDA2.0-flash | 73.21 | 89.17 | 62.50 | 80.46 | 81.96 | 58.33 | 72.04 | 90.46 | 66.67 | 76.54 | 85.88 | 62.50 |
Table 9: The brief results of various dLLMs by language and concept existence.
| Model | ZH+ | ZH- | EN+ | EN- | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | $\text{Acc}_{t}$ | $\text{Acc}_{m}$ | Cons | $\mathrm{pre}_{V}$ | $\mathrm{rec}_{V}$ | $\mathrm{pre}_{I}$ | $\mathrm{rec}_{I}$ | |
| Qwen3-0.6B-Base | 6.62 | 36.46 | 29.17 | 42.14 | 4.47 | 36.06 | 89.78 | 14.67 | 34.00 | 4.17 | 38.92 | 9.20 | 33.43 | 75.95 | 1.71 | 37.38 | 16.67 | 51.22 | 1.40 | 37.21 | 97.77 | 7.42 | 36.92 | 0.00 | 50.00 | 5.99 | 36.33 | 89.95 |
| Qwen3-1.7B-Base | 82.88 | 55.79 | 0.00 | 62.95 | 90.40 | 39.55 | 10.56 | 77.21 | 52.54 | 0.00 | 62.28 | 87.29 | 38.91 | 13.28 | 99.92 | 62.58 | 91.67 | 62.55 | 100.00 | 100.00 | 0.22 | 99.96 | 62.54 | 95.83 | 62.53 | 100.00 | 100.00 | 0.11 |
| Qwen3-4B-Base | 93.25 | 61.67 | 33.33 | 62.96 | 93.93 | 43.83 | 7.89 | 91.29 | 60.54 | 29.17 | 62.62 | 91.47 | 38.76 | 9.00 | 72.54 | 56.54 | 8.33 | 63.12 | 73.27 | 39.15 | 28.67 | 81.58 | 58.83 | 25.00 | 63.07 | 82.33 | 40.05 | 19.67 |
| Qwen3-8B-Base | 95.00 | 61.17 | 16.67 | 62.54 | 95.58 | 38.89 | 4.69 | 81.42 | 53.67 | 0.00 | 59.93 | 78.28 | 26.47 | 13.00 | 73.75 | 68.21 | 33.33 | 70.85 | 83.60 | 60.89 | 42.60 | 82.92 | 64.33 | 0.00 | 66.18 | 87.92 | 55.64 | 25.22 |
| Qwen3-30B-A3B-Base | 79.50 | 52.12 | 0.00 | 63.31 | 96.33 | 48.31 | 5.79 | 90.17 | 58.00 | 0.00 | 62.62 | 96.99 | 46.84 | 4.37 | 79.58 | 50.75 | 0.00 | 62.51 | 98.60 | 58.54 | 3.24 | 84.96 | 53.67 | 0.00 | 62.53 | 99.07 | 52.00 | 1.67 |
| Gemma-3-1B-PT | 6.63 | 32.53 | 0.00 | 63.52 | 8.27 | 37.74 | 92.13 | 5.38 | 24.82 | 0.00 | 59.69 | 7.82 | 36.33 | 90.88 | 5.12 | 21.90 | 0.00 | 65.57 | 9.83 | 37.59 | 91.32 | 5.11 | 23.37 | 0.00 | 65.57 | 9.15 | 37.58 | 91.92 |
| Gemma-3-4B-PT | 6.75 | 36.67 | 0.00 | 65.43 | 7.61 | 37.55 | 93.25 | 9.12 | 36.08 | 0.00 | 60.73 | 9.61 | 36.95 | 89.50 | 2.42 | 30.31 | 0.00 | 52.63 | 2.62 | 38.01 | 96.20 | 3.48 | 30.74 | 0.00 | 60.49 | 4.12 | 36.93 | 95.42 |
| Gemma-3-12B-PT | 9.00 | 39.00 | 0.00 | 65.74 | 9.71 | 37.56 | 91.47 | 11.33 | 38.83 | 0.00 | 61.76 | 11.61 | 37.40 | 88.02 | 11.83 | 38.79 | 0.00 | 64.79 | 13.18 | 38.13 | 88.19 | 14.49 | 38.44 | 0.00 | 63.87 | 15.79 | 37.15 | 84.79 |
| Gemma-3-27B-PT | 26.83 | 42.50 | 0.00 | 62.11 | 27.99 | 37.60 | 71.76 | 24.46 | 42.29 | 0.00 | 63.37 | 26.01 | 37.80 | 74.94 | 16.75 | 34.21 | 0.00 | 62.19 | 20.59 | 37.20 | 78.98 | 16.92 | 35.42 | 0.00 | 65.76 | 22.05 | 38.18 | 80.75 |
| Llama3-8B-Base | 30.08 | 36.67 | 0.00 | 63.99 | 40.46 | 38.07 | 61.65 | 29.58 | 35.54 | 0.00 | 60.28 | 38.01 | 37.85 | 60.11 | 12.17 | 32.92 | 0.00 | 60.96 | 14.86 | 37.50 | 84.30 | 13.54 | 34.42 | 0.00 | 63.69 | 17.05 | 38.07 | 83.99 |
| Llama3-70B-Base | 44.70 | 43.44 | 0.00 | 62.85 | 53.47 | 38.57 | 48.03 | 41.79 | 42.71 | 0.00 | 62.70 | 48.23 | 36.99 | 51.43 | 34.43 | 45.78 | 0.00 | 64.71 | 37.99 | 39.26 | 65.92 | 29.86 | 43.65 | 0.00 | 64.62 | 32.99 | 38.34 | 69.76 |
Table 10: The detailed results of Base models.