# LLM-42: Enabling Determinism in LLM Inference with Verified Speculation
## Abstract
In LLM inference, the same prompt may yield different outputs across different runs. At the system level, this non-determinism arises from floating-point non-associativity combined with dynamic batching and GPU kernels whose reduction orders vary with batch size. A straightforward way to eliminate non-determinism is to disable dynamic batching during inference, but doing so severely degrades throughput. Another approach is to make kernels batch-invariant; however, this tightly couples determinism to kernel design, requiring new implementations. This coupling also imposes fixed runtime overheads, regardless of how much of the workload actually requires determinism.
Inspired by ideas from speculative decoding, we present LLM-42 Many developers unknowingly set 42 as a random state variable (seed) to ensure reproducibility, a reference to The Hitchhiker’s Guide to the Galaxy. The number itself is arbitrary, but widely regarded as a playful tradition. —a scheduling-based approach to enable determinism in LLM inference. Our key observation is that if a sequence is in a consistent state, the next emitted token is likely to be consistent even with dynamic batching. Moreover, most GPU kernels use shape-consistent reductions. Leveraging these insights, LLM-42 decodes tokens using a non-deterministic fast path and enforces determinism via a lightweight verify–rollback loop. The verifier replays candidate tokens under a fixed-shape reduction schedule, commits those that are guaranteed to be consistent across runs, and rolls back those violating determinism. LLM-42 mostly re-uses existing kernels unchanged and incurs overhead only in proportion to the traffic that requires determinism.
## 1 Introduction
LLMs are becoming increasingly more powerful [openai2022gpt4techreport, kaplan2020scalinglaws]. However, a key challenge many users usually face with LLMs is their non-determinism [he2025nondeterminism, atil2024nondeterminism, yuan2025fp32death, song2024greedy]: the same model can produce different outputs across different runs of a given prompt, even with identical decoding parameters and hardware. Enabling determinism in LLM inference (aka deterministic inference) has gained significant traction recently for multiple reasons. It helps developers isolate subtle implementation bugs that arise only under specific batching choices; improves reward stability in reinforcement-learning training [zhang2025-deterministic-tp]; is essential for integration testing in large-scale systems. Moreover, determinism underpins scientific reproducibility [song2024greedy] and enables traceability [rainbird2025deterministic]. Consequently, users have increasingly requested support for deterministic inference in LLM serving engines [Charlie2025, Anadkat2025consistent].
He et al. [he2025nondeterminism] showed that non-determinism in LLM inference at the system-level stems from the non-associativity of floating-point arithmetic LLM outputs can also vary due to differences in sampling strategies (e.g., top-k, top-p, or temperature). Our goal is to ensure that output is deterministic for fixed sampling hyper-parameters; different hyper-parameters can result in different output and this behavior is intentional.. This effect manifests in practice because most core LLM operators—including matrix multiplications, attention, and normalization—rely on reduction operations, and GPU kernels for these operators choose different reduction schedules to maximize performance at different batch sizes. The same study also proposed batch-invariant computation as a means to eliminate non-determinism. In this approach, a kernel processes each input token using a single, universal reduction strategy independent of batching. Popular LLM serving systems such as vLLM and SGLang have recently adopted this approach [SGLangTeam2025, vllm-batch-invariant-2025].
While batch-invariant computation guarantees determinism, we find that this approach is fundamentally over-constrained. Enforcing a fixed reduction strategy for every token—regardless of model phase or batch geometry—strips GPU kernels of the very parallelism they are built to exploit. For example, the batch-invariant GEMM kernels provided by He et al. do not use the split-K strategy that is otherwise commonly used to accelerate GEMMs at low batch sizes [tritonfusedkernel-splitk-meta, nvidia_cutlass_blog]. Furthermore, most GPU kernels are not batch-invariant to begin with, so insisting on batch-invariant execution effectively demands new kernel implementations, increasing engineering and maintenance overhead. Finally, batch-invariant execution makes determinism the default for all requests, even when determinism is undesirable or even harmful [det-inf-kills].
Our observations suggest that determinism can be enabled with a simpler approach. (O1) Token-level inconsistencies are rare: as long as a sequence remains in a consistent state, the next emitted token is mostly identical across runs; sequence-level divergence arises mainly from autoregressive decoding after the first inconsistent token. (O2) Most GPU kernels already use shape-consistent reduction schedules: they apply the same reduction strategy on all inputs of a given shape, but potentially different reduction strategies on inputs of different shapes. (O3) Determinism requires only position-consistent reductions: a particular token position must use the same reduction schedule across runs, but different positions within or across sequences can use different reduction schedules. (O4) Real-world LLM systems require determinism only for select tasks (e.g., evaluation, auditing, continuous-integration pipelines), while creative workloads benefit from the stochasticity of LLMs.
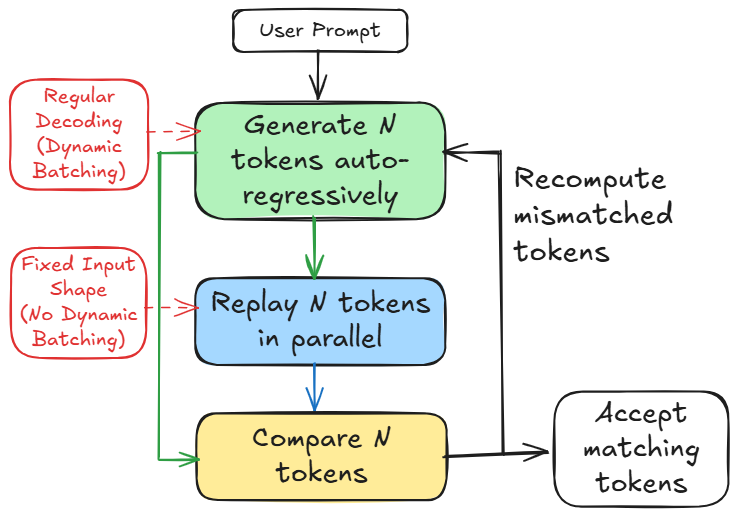
Based on these observations, we introduce LLM-42, a scheduling-based approach to deterministic LLM inference inspired by speculative decoding. In speculative decoding [specdecoding-icml2023, chen2023accelerating, xia2023speculative, specinfer-2024], a fast path produces multiple candidate tokens while a verifier validates their correctness. We observe that the same structure can be repurposed to enable determinism (see Figure 1): fast path can optimize for high throughput token generation while a verifier can enforce determinism. Table 1 highlights key differences between conventional speculative decoding and our approach.
<details>
<summary>figures_h100_pcie/diagram/banner.png Details</summary>
### Visual Description
## Diagram: Token Generation and Verification Flowchart
### Overview
The image is a flowchart diagram illustrating a process for generating and verifying tokens, likely in the context of a language model or similar autoregressive system. The diagram uses color-coded boxes and directional arrows to depict a multi-step process with a feedback loop for error correction. It contrasts two operational modes indicated by side annotations.
### Components/Axes
The diagram consists of seven distinct text-containing elements connected by arrows:
1. **Top Center (White Box):** "User Prompt"
2. **Center Top (Green Box):** "Generate N tokens auto-regressively"
3. **Center Middle (Blue Box):** "Replay N tokens in parallel"
4. **Center Bottom (Yellow Box):** "Compare N tokens"
5. **Bottom Right (White Box):** "Accept matching tokens"
6. **Left Side, Top (Red Box):** "Regular Decoding (Dynamic Batching)"
7. **Left Side, Bottom (Red Box):** "Fixed Input Shape (No Dynamic Batching)"
8. **Right Side (Text, no box):** "Recompute mismatched tokens"
**Flow and Connections (Spatial Grounding):**
* The primary flow is vertical and downward: `User Prompt` → `Generate N tokens...` → `Replay N tokens...` → `Compare N tokens`.
* From `Compare N tokens`, a green arrow points right to `Accept matching tokens`.
* From `Compare N tokens`, a black arrow points up and right to the text `Recompute mismatched tokens`.
* From `Recompute mismatched tokens`, a black arrow points back to the left side of the `Generate N tokens...` box, creating a feedback loop.
* The two red boxes on the left have dashed red arrows pointing to the main process boxes:
* `Regular Decoding (Dynamic Batching)` points to the `Generate N tokens...` box.
* `Fixed Input Shape (No Dynamic Batching)` points to the `Replay N tokens...` box.
### Detailed Analysis
The process describes a two-stage token generation and verification system:
1. **Initialization:** The process begins with a "User Prompt".
2. **Stage 1 - Autoregressive Generation:** The system generates a sequence of `N` tokens one after another (auto-regressively). This stage is influenced by the "Regular Decoding (Dynamic Batching)" method.
3. **Stage 2 - Parallel Replay:** The same `N` tokens are then processed again, but this time in parallel. This stage operates under a "Fixed Input Shape (No Dynamic Batching)" constraint.
4. **Verification:** The outputs from the two stages (autoregressive generation and parallel replay) are compared.
5. **Decision Point:**
* If the tokens from both stages match, they are accepted (`Accept matching tokens`).
* If there is a mismatch, the system triggers a recomputation step (`Recompute mismatched tokens`) and loops back to the autoregressive generation stage to try again.
### Key Observations
* **Dual-Path Verification:** The core of the diagram is a verification mechanism that runs the same task (generating `N` tokens) through two different computational pathways (sequential auto-regressive vs. parallel replay) and compares the results.
* **Error Correction Loop:** The system has an explicit, iterative error-handling mechanism. A mismatch doesn't cause failure; it triggers a recomputation cycle.
* **Methodological Contrast:** The red annotations highlight a key technical contrast: "Dynamic Batching" (flexible, likely for the sequential step) versus "No Dynamic Batching" with a "Fixed Input Shape" (rigid, likely for the parallel step). This suggests the diagram may be explaining a technique to ensure consistency or catch errors between different execution modes of a model.
### Interpretation
This flowchart depicts a **speculative decoding** or **verification-based decoding** technique used to accelerate or stabilize text generation in large language models.
* **What it demonstrates:** The process aims to generate tokens quickly using a parallel method (the "Replay" step) but uses the traditional, slower auto-regressive method as a "ground truth" verifier. If the fast parallel guess matches the slow sequential answer, it's accepted, saving time. If not, the system falls back to recomputing with the reliable sequential method.
* **Relationship between elements:** The "User Prompt" is the input. The two generation methods (green and blue boxes) are competing or complementary pathways for producing the same output (`N` tokens). The "Compare" step is the arbiter. The red boxes define the operational constraints for each pathway, which is crucial for understanding why their outputs might differ.
* **Notable implication:** The primary goal is likely **efficiency**. By accepting the results of the faster parallel path when they are correct, the system can avoid the full computational cost of auto-regressive generation for every token. The feedback loop ensures **accuracy** is not sacrificed, as mismatches are caught and corrected. This represents a trade-off between speed and reliability, managed by an automated verification step.
</details>
Figure 1: Overview of LLM-42.
LLM-42 employs a decode–verify–rollback protocol that decouples regular decoding from determinism enforcement. It generates candidate output tokens using standard fast-path autoregressive decoding whose output is largely—but not provably—consistent across runs (O1). Determinism is guaranteed by a verifier that periodically replays a fixed-size window of recently generated tokens. Because the input shape is fixed during verification, replayed tokens follow a consistent reduction order (O2) and serve as a deterministic reference execution. Tokens are released to the user only after verification. When the verifier detects a mismatch, LLM-42 rolls the sequence back to the last matching token and resumes decoding from this known-consistent state. In general, two factors make this approach practical: (1) verification is low cost i.e., like prefill, it is typically 1-2 orders of magnitude more efficient than the decode phase, and (2) rollbacks are infrequent: more than half of the requests complete without any rollback, and only a small fraction require multiple rollbacks.
| Fast path generates tokens using some form of approximation | No approximation; only floating-point rounding errors |
| --- | --- |
| Low acceptance rate and hence limited speculation depth (2-8 tokens) | High acceptance rate and hence longer speculation (32-64 tokens) |
| Typically uses separate draft and target models | Uses the same model for decoding and verification |
Table 1: Speculative decoding vs. LLM-42.
By decoupling determinism from token generation, LLM-42 enables determinism to be enforced selectively, preserving the natural variability and creativity of LLM outputs where appropriate. This separation also helps performance: the fast path can use whatever batch sizes and reduction schedules are most efficient, prefill computation can follow different reduction strategy than decode (O3) and its execution need not be verified (in our design, prefill is deterministic by construction), and finally, verification can be skipped entirely for requests that do not need determinism (O4).
The efficiency of our approach critically depends on the size of verification window i.e., number of tokens verified together. Smaller windows incur high verification overhead since their computation is largely memory-bound but require less recomputation on verification failures. In contrast, larger windows incur lower verification cost due to being compute-bound, but increase recomputation cost by triggering longer rollbacks on mismatches. To balance this trade-off, we introduce grouped verification: instead of verifying a large window of a single request, we verify smaller fixed-size windows of multiple requests together. This design preserves the low rollback cost of small windows while amortizing verification overhead. Overall, we make the following contributions:
- We present the first systematic analysis of batch-invariant computation to highlight the performance and engineering cost associated with this approach.
- We present an alternate approach LLM-42 to enable determinism in LLM inference.
- We implement LLM-42 on top of SGLang and show that its overhead is proportional to fraction of traffic that requires determinism; it retains near-peak performance when deterministic traffic is low, whereas SGLang incurs high overhead of up to 56% in deterministic mode. Our source code will be available at https://github.com/microsoft/llm-42.
## 2 Background and Motivation
<details>
<summary>figures_h100_pcie/diagram/llm-arch.png Details</summary>

### Visual Description
## Diagram: Autoregressive Model Architecture Flowchart
### Overview
The image is a technical block diagram illustrating the architecture and data flow of an autoregressive model, likely a transformer-based language model. It shows the sequential processing steps from input to output, with a feedback loop characteristic of autoregressive generation. The diagram uses color-coded blocks and directional arrows to represent components and data flow.
### Components/Axes
The diagram is structured as a flowchart with the following labeled components, listed in order of data flow:
1. **Input** (Light gray block, top-left)
2. **Embedding** (Light blue block, below Input)
3. **Central Processing Block** (Large, beige block with diagonal hatching, center):
* **Attention** (Pink block, left side of central block)
* Contains a sub-label: **KV Cache** (Small, light blue block within the Attention block)
* **All Reduce RMSNorm** (Yellow block, to the right of Attention)
* **FFN** (Light green block, to the right of the first RMSNorm)
* **All Reduce RMSNorm** (Yellow block, to the right of FFN)
* Label at the bottom of the central block: **x L layers**
4. **Sampler** (Light purple block, right of the central block)
5. **Output** (Light gray block, top-right)
6. **Process Label**: The text **Autoregressive** is centered at the top of the diagram, above the main flow.
**Spatial Grounding & Flow:**
* The primary data flow is from left to right: `Input` → `Embedding` → `Central Processing Block` → `Sampler` → `Output`.
* A feedback arrow runs from the top of the `Output` block back to the `Input` block, labeled by the overarching **Autoregressive** title. This indicates the model's output is fed back as input for the next generation step.
* The `Central Processing Block` is the core computational unit, indicated to be repeated **x L layers** deep.
### Detailed Analysis
**Component Transcription & Relationships:**
* **Input**: The entry point for the model, receiving data (e.g., a token sequence).
* **Embedding**: Converts discrete input tokens into continuous vector representations.
* **Central Processing Block (x L layers)**: This represents one transformer block, repeated `L` times. The internal flow within this block is sequential:
1. **Attention**: Performs self-attention operations. The embedded **KV Cache** sub-component is noted, which is a standard optimization for autoregressive inference to store Key and Value states from previous steps.
2. **All Reduce RMSNorm**: Applies Root Mean Square Layer Normalization. The "All Reduce" prefix suggests this normalization may be synchronized across multiple devices in a distributed training/inference setup.
3. **FFN**: The Feed-Forward Network, a position-wise fully connected layer.
4. **All Reduce RMSNorm**: A second application of the synchronized RMSNorm, likely following the FFN (a common transformer design pattern).
* **Sampler**: Takes the final hidden states from the last transformer layer and samples or selects the next token (e.g., via argmax or top-k sampling).
* **Output**: The generated token, which is then fed back into the `Input` for the next autoregressive step.
### Key Observations
1. **Explicit Autoregressive Loop**: The diagram explicitly visualizes the core autoregressive property with the feedback arrow from `Output` to `Input`.
2. **Distributed Training Cue**: The repeated use of **"All Reduce"** in the normalization layers is a significant detail. It strongly implies the architecture is designed for or depicted in the context of model parallelism or distributed training, where gradient or activation statistics are synchronized across multiple processors.
3. **Layer Repetition**: The **"x L layers"** label clearly indicates the depth of the model's core processing stack.
4. **KV Cache Integration**: The inclusion of the **KV Cache** within the Attention block highlights a critical optimization for efficient autoregressive inference, preventing recomputation of past key and value vectors.
### Interpretation
This diagram provides a high-level, functional schematic of a modern autoregressive transformer model, with specific annotations pointing to practical implementation details.
* **What it demonstrates**: It shows the standard pipeline: input embedding, repeated transformer layers (each with attention and FFN sub-layers, interspersed with normalization), and a final sampling step. The feedback loop encapsulates the sequential, token-by-token generation process.
* **How elements relate**: The flow is strictly sequential and cyclic. The `Central Processing Block` is the computational engine, its internal components (Attention → Norm → FFN → Norm) represent the standard pre-norm transformer block design. The `Sampler` acts as the decision-making head.
* **Notable Anomalies/Details**: The most notable technical detail is the **"All Reduce"** prefix on the RMSNorm layers. This is not part of the standard transformer architecture description but is a crucial implementation detail for large-scale distributed systems. It suggests the diagram is not just a theoretical model but is concerned with the practicalities of training or running very large models across multiple hardware units. The explicit mention of the **KV Cache** further grounds the diagram in the context of efficient inference systems.
In summary, this is a technically precise diagram of an autoregressive transformer, emphasizing its layered structure, cyclic generation process, and specific design choices (`All Reduce` norms, `KV Cache`) relevant to high-performance, distributed computing environments.
</details>
Figure 2: High-level architecture of LLMs.
This section introduces LLMs, explains the source of non-determinism in LLM inference and quantifies the cost of batch-invariant computation based deterministic inference.
### 2.1 Large Language Models
Transformer-based LLMs compose a stack of identical decoder blocks, each containing a self-attention module, a feed-forward network (FFN), normalization layers and communication primitives (Figure 2). The hidden state of every token flows through these blocks sequentially, but within each block the computation is highly parallel: attention performs matrix multiplications over the key–value (KV) cache, FFNs apply two large GEMMs surrounding a nonlinearity, and normalization applies a per-token reduction over the hidden dimension.
Inference happens in two distinct phases namely prefill and decode. Prefill processes prompt tokens in parallel, generating KV cache for all input tokens. This phase is dominated by large parallel computation. Decode is autoregressive: each step consumes the most recent token, updates the KV cache with a single new key and value, and produces the next output token. Decode is therefore sequential within a sequence but parallel across other requests in the batch.
### 2.2 Non-determinism in LLM Inference
In finite precision, arithmetic operations such as accumulation are non-associative, meaning that $(a+b)+c\neq a+(b+c)$ . Non-determinism in LLM inference stems from this non-associativity when combined with dynamic batching, a standard technique to achieve high throughput inference. With dynamic batching, the same request may be co-located with different sets of requests across different runs, resulting in varying batch sizes. Further, GPU kernels adapt their parallelization—and consequently their reduction—strategies based on the input sizes. As a result, the same logical operation can be evaluated with different floating-point accumulation orders depending on the batch it appears in, leading to inconsistent numerical results.
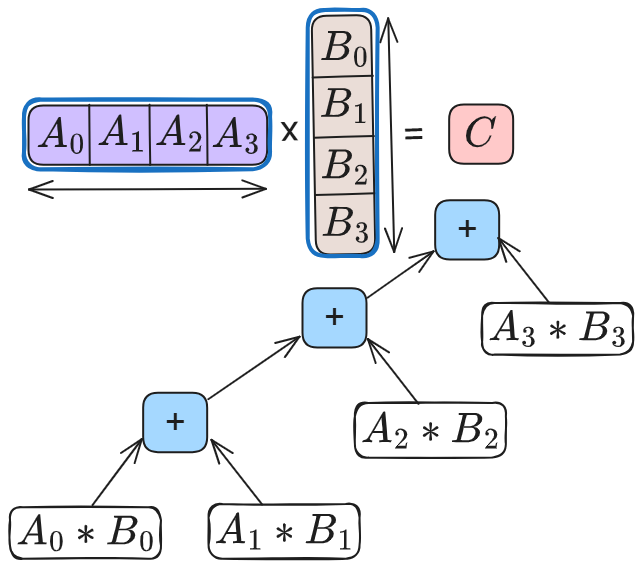
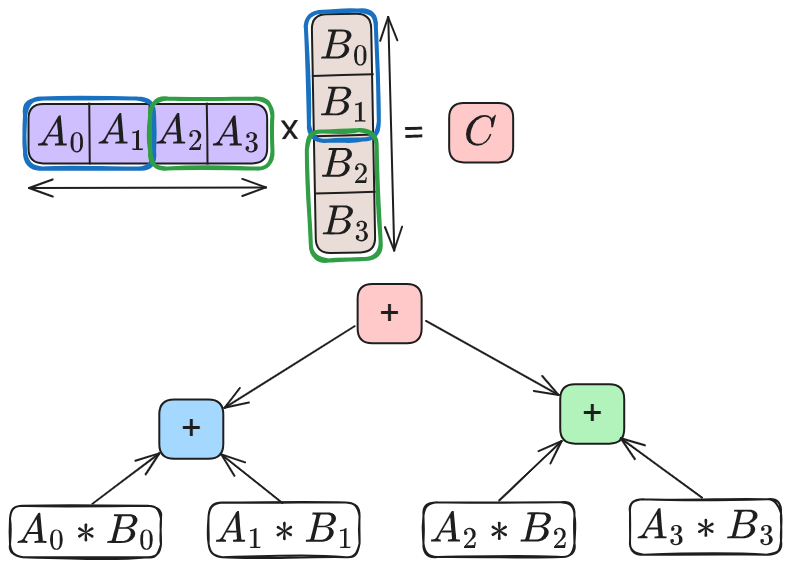
Reductions are common in LLM inference, appearing in matrix multiplications (GEMMs), attention, normalization and collective communication such as AllReduce. GEMM is the most common and time consuming operator. High-performance GEMM implementations on GPUs use hierarchical tiling and parallel reductions to improve occupancy and memory reuse. A common optimization is split-K parallelism, where the reduction dimension is partitioned across multiple thread blocks. Each block computes a partial result, which is then combined via an additional reduction step. Whether split-K is used—and how many splits are chosen—depends on the shape on input matrices. These choices directly change the reduction tree as shown in Figure 3, producing different numerical results for a given token across runs. Similarly, attention kernels split work across the key–value dimension to increase SM utilization, followed by a reduction to combine partial results. Normalization operators reduce across feature dimensions. As inference progresses, batch-dependent reduction choices in these operators introduce small numerical drifts that propagate across kernels, layers and decoding steps, eventually influencing output tokens even when the sampling hyper-parameters are fixed.
<details>
<summary>figures_h100_pcie/diagram/gemm_wo_splitk.png Details</summary>
### Visual Description
## Diagram: Dot Product Computation Graph
### Overview
The image is a technical diagram illustrating the step-by-step computation of the dot product (scalar product) between two 4-element vectors, resulting in a single scalar value, `C`. It uses a tree-like computational graph to break down the operation into its fundamental multiplications and additions.
### Components/Axes
The diagram is composed of several distinct visual components:
1. **Input Vectors (Top Region):**
* **Vector A:** A horizontal, purple-filled rectangle containing four elements labeled `A₀`, `A₁`, `A₂`, `A₃` from left to right. A double-headed arrow beneath it indicates its span.
* **Vector B:** A vertical, beige-filled rectangle containing four elements labeled `B₀`, `B₁`, `B₂`, `B₃` from top to bottom. A double-headed arrow to its right indicates its span.
* **Operation Symbols:** A multiplication symbol (`×`) is placed between the two vectors. An equals sign (`=`) is placed to the right of Vector B.
* **Result:** A pink-filled square labeled `C` is positioned to the right of the equals sign, representing the final scalar output.
2. **Computational Graph (Main/Lower Region):**
* **Leaf Nodes (Bottom):** Four white rectangular boxes with black borders, each containing a multiplication term: `A₀ * B₀`, `A₁ * B₁`, `A₂ * B₂`, and `A₃ * B₃`. These represent the pairwise multiplications of corresponding vector elements.
* **Internal Nodes:** Three blue, rounded squares, each containing a plus sign (`+`). These represent addition operations.
* **Edges:** Black arrows connect the nodes, indicating the flow of data. The arrows converge from the multiplication leaves into the addition nodes, and from the addition nodes upward toward the final result `C`.
### Detailed Analysis
The diagram explicitly maps the mathematical formula for a dot product: `C = A₀*B₀ + A₁*B₁ + A₂*B₂ + A₃*B₃`.
**Spatial Grounding & Flow:**
The computation flows from the bottom of the diagram upward.
1. **Bottom Layer:** The four element-wise products (`A₀*B₀`, `A₁*B₁`, `A₂*B₂`, `A₃*B₃`) are computed in parallel.
2. **First Addition Layer:** The products `A₀*B₀` and `A₁*B₁` are fed into the leftmost blue `+` node. The products `A₂*B₂` and `A₃*B₃` are fed into the rightmost blue `+` node.
3. **Second Addition Layer:** The results from the two lower addition nodes are fed into the central, higher blue `+` node.
4. **Result:** The output of the central addition node is the final value `C`, as indicated by the arrow pointing to the pink `C` box at the top right.
This structure represents a balanced binary tree for summation, which is a common pattern in parallel computing for reducing a list of numbers to a single sum.
### Key Observations
* **Explicit Decomposition:** The diagram leaves no operation implicit. Every multiplication and every addition required for the dot product is visually represented as a distinct node.
* **Hierarchical Summation:** The addition is not shown as a simple chain (`((((A₀*B₀)+(A₁*B₁))+(A₂*B₂))+(A₃*B₃))`) but as a balanced tree. This suggests an emphasis on the computational structure, potentially highlighting parallelization opportunities where the two lower-level additions can occur simultaneously.
* **Color Coding:** Colors are used functionally to group related elements: purple for the first input vector, beige for the second, pink for the final output, and blue for intermediate arithmetic operations (additions).
### Interpretation
This diagram serves as a pedagogical or technical visualization of a fundamental linear algebra operation. It translates the compact mathematical notation `C = A · B` into an explicit computational procedure.
* **What it demonstrates:** It shows that the dot product is a two-stage process: first, a set of parallel multiplications, followed by a hierarchical summation. The tree structure for addition is more efficient for parallel processing than a linear chain, as it reduces the critical path length (the longest sequence of dependent operations).
* **Relationship between elements:** The input vectors `A` and `B` are the source data. The multiplication leaves are the first transformation. The addition nodes are the reduction steps that aggregate the intermediate results into the final scalar `C`.
* **Notable Anomaly/Insight:** The diagram does not show any data values, only symbolic labels. Its purpose is to illustrate the *structure* of the computation, not a specific numerical result. The clear separation of multiplication and addition stages is the key takeaway, making it a useful tool for explaining algorithm design, hardware implementation (like in a CPU's floating-point unit), or parallel computing concepts.
</details>
(a) Without split-K.
<details>
<summary>figures_h100_pcie/diagram/gemm_w_splitk.png Details</summary>
### Visual Description
\n
## Diagram: Parallel Dot Product Computation Tree
### Overview
The image is a technical diagram illustrating the computation of a dot product between two 4-element vectors, `A` and `B`, using a parallel reduction tree structure. It visually breaks down the operation `C = A · B` into its constituent multiplications and hierarchical additions.
### Components/Axes
The diagram is divided into two primary sections:
1. **Upper Section (Operation Definition):**
* **Vector A:** A horizontal row of four elements labeled `A₀`, `A₁`, `A₂`, `A₃`. The first two elements (`A₀`, `A₁`) are enclosed in a blue rounded rectangle. The last two elements (`A₂`, `A₃`) are enclosed in a green rounded rectangle.
* **Vector B:** A vertical column of four elements labeled `B₀`, `B₁`, `B₂`, `B₃`. The first two elements (`B₀`, `B₁`) are enclosed in a blue rounded rectangle. The last two elements (`B₂`, `B₃`) are enclosed in a green rounded rectangle.
* **Operation:** A multiplication symbol `×` is placed between Vector A and Vector B.
* **Result:** An equals sign `=` leads to a pink rounded rectangle labeled `C`, representing the final scalar result.
* **Spatial Grounding:** The blue and green groupings in both vectors are aligned, suggesting a correspondence for parallel processing.
2. **Lower Section (Computation Tree):**
* **Root Node:** A pink rounded rectangle containing a plus sign `+`. This is the final summation node.
* **Intermediate Nodes:** Two child nodes branch from the root:
* A **blue** rounded rectangle with a `+` (left child).
* A **green** rounded rectangle with a `+` (right child).
* **Leaf Nodes:** Four base computation nodes at the bottom, each representing a multiplication:
* `A₀ * B₀` (connected to the blue intermediate node)
* `A₁ * B₁` (connected to the blue intermediate node)
* `A₂ * B₂` (connected to the green intermediate node)
* `A₃ * B₃` (connected to the green intermediate node)
* **Flow Direction:** Arrows point upward from the leaf nodes to the intermediate nodes, and from the intermediate nodes to the root node, indicating the direction of data flow and summation.
### Detailed Analysis
The diagram explicitly maps the mathematical formula `C = (A₀*B₀) + (A₁*B₁) + (A₂*B₂) + (A₃*B₃)` to a parallel computational model.
* **Component Isolation & Color Matching:** The color coding is consistent and critical for understanding the parallel structure.
* The **blue** group in the vectors (`A₀,A₁` and `B₀,B₁`) corresponds directly to the **blue** intermediate addition node, which sums the products `A₀*B₀` and `A₁*B₁`.
* The **green** group in the vectors (`A₂,A₃` and `B₂,B₃`) corresponds directly to the **green** intermediate addition node, which sums the products `A₂*B₂` and `A₃*B₃`.
* The **pink** color is reserved for the final result `C` and the root addition node that produces it.
* **Trend/Flow Verification:** The visual trend is a clear, hierarchical aggregation. Four independent multiplication operations (leaves) are reduced to two intermediate sums (blue and green nodes), which are then reduced to the single final sum (pink root node). This is a classic binary tree reduction pattern.
### Key Observations
1. **Explicit Parallelism:** The diagram is designed to illustrate how a dot product can be parallelized. The blue and green sub-trees can be computed independently and simultaneously before their results are combined.
2. **Data Locality:** The grouping of adjacent elements (`0,1` and `2,3`) suggests a strategy that might optimize for cache locality or align with specific hardware vector processing units.
3. **No Numerical Data:** The diagram is purely conceptual. It contains no numerical values, only symbolic labels (`A₀`, `B₁`, etc.) and operational symbols (`×`, `+`, `*`).
### Interpretation
This diagram serves as a pedagogical or technical schematic for understanding parallel reduction in linear algebra operations. It moves beyond the simple mathematical definition of a dot product to show a specific *implementation strategy*.
* **What it demonstrates:** It visually argues that the dot product is not inherently a serial operation. By restructuring the summation as a tree, the critical path length is reduced from `O(n)` (adding terms one by one) to `O(log n)` (adding in parallel stages), which is fundamental for performance on multi-core processors or GPUs.
* **Relationship between elements:** The upper section defines the *what* (the mathematical operation). The lower section defines the *how* (a specific computational procedure). The color coding is the crucial link that binds the abstract data (vectors A and B) to the concrete computational flow (the tree).
* **Underlying Principle:** The diagram embodies the principle of "divide and conquer." The large problem (summing four products) is divided into two smaller, independent sub-problems (summing two products each), which are solved in parallel, and then their solutions are combined. This is a foundational concept in parallel algorithm design.
</details>
(b) With split-K.
Figure 3: GEMM kernels compute dot products using standard accumulation or split-K parallelization. While split-K increases parallelism, it alters the reduction tree based on K.
### 2.3 Defeating Non-determinism
He et al. at Thinking Machines Lab recently introduced a new approach named batch-invariant computation to enable deterministic LLM inference [he2025nondeterminism]. In this approach, a GPU kernel is constrained to use a single, universal reduction strategy for all tokens, eliminating batch-dependent reductions. Both SGLang and vLLM use this approach [SGLangTeam2025, vllm-batch-invariance-2025, vllm-batch-invariant-2025]: these systems either deploy the batch-invariant kernels provided by He et al. [tmops2025] or implement new kernels [batch-inv-inf-vllm, det-infer-batch-inv-ops-sglang].
<details>
<summary>x1.png Details</summary>
### Visual Description
## Line Chart: Performance (TFLOPS) vs. Number of Tokens
### Overview
The image is a line chart comparing the computational performance, measured in Tera Floating-Point Operations Per Second (TFLOPS), of two different methods as a function of the number of tokens processed. The chart uses a logarithmic scale for both the Y-axis (TFLOPS) and the X-axis (# Tokens).
### Components/Axes
* **Chart Type:** Line chart with markers.
* **Y-Axis:**
* **Label:** `TFLOPS`
* **Scale:** Logarithmic (base 10).
* **Major Ticks/Labels:** `10^0` (1), `10^1` (10), `10^2` (100).
* **X-Axis:**
* **Label:** `# Tokens`
* **Scale:** Logarithmic (base 2).
* **Major Ticks/Labels:** `1`, `2`, `4`, `8`, `16`, `32`, `64`, `128`, `256`, `512`, `1024`, `2048`, `4096`, `8192`.
* **Legend:**
* **Position:** Bottom-right corner of the plot area.
* **Series 1:** `Non-batch-invariant (cuBLAS)` - Represented by a blue line with circular markers.
* **Series 2:** `Batch-invariant (Triton)` - Represented by a red line with square markers.
### Detailed Analysis
**Trend Verification:**
* **Blue Line (Non-batch-invariant):** Shows a steep, roughly linear increase on the log-log plot from 1 token up to approximately 256 tokens, after which the slope decreases and the line plateaus.
* **Red Line (Batch-invariant):** Follows a similar upward trend but is consistently positioned below the blue line. It also shows a steep increase up to ~256 tokens before beginning to plateau.
**Data Point Extraction (Approximate Values):**
The following table reconstructs the approximate data points based on visual inspection of the chart. Values are estimates due to the logarithmic scale.
| # Tokens | Non-batch-invariant (cuBLAS) [TFLOPS] | Batch-invariant (Triton) [TFLOPS] |
| :--- | :--- | :--- |
| 1 | ~1.5 | ~0.2 |
| 2 | ~3 | ~0.5 |
| 4 | ~6 | ~1.2 |
| 8 | ~12 | ~2.5 |
| 16 | ~25 | ~5 |
| 32 | ~50 | ~10 |
| 64 | ~100 | ~20 |
| 128 | ~150 | ~40 |
| 256 | ~200 | ~90 |
| 512 | ~220 | ~100 |
| 1024 | ~230 | ~120 |
| 2048 | ~230 | ~130 |
| 4096 | ~230 | ~140 |
| 8192 | ~230 | ~140 |
### Key Observations
1. **Performance Hierarchy:** The `Non-batch-invariant (cuBLAS)` method consistently achieves higher TFLOPS than the `Batch-invariant (Triton)` method across all measured token counts.
2. **Scaling Behavior:** Both methods exhibit strong performance scaling with increasing token count up to a point (around 256-512 tokens). This suggests that larger batch sizes or sequence lengths allow for better hardware utilization.
3. **Saturation Point:** Both curves begin to plateau after approximately 512 tokens. The `cuBLAS` method plateaus at a higher absolute performance level (~230 TFLOPS) compared to the `Triton` method (~140 TFLOPS).
4. **Relative Gap:** The performance gap between the two methods is largest at very small token counts (e.g., at 1 token, cuBLAS is ~7.5x faster) and narrows as the token count increases, though it remains significant (at 8192 tokens, cuBLAS is ~1.6x faster).
### Interpretation
This chart demonstrates a performance benchmark likely related to matrix multiplication or similar tensor operations fundamental to machine learning models, comparing a standard library implementation (cuBLAS) against a custom kernel (Triton).
* **What the data suggests:** The `Non-batch-invariant` (cuBLAS) implementation is highly optimized for raw throughput, especially when the operation can leverage large, batched computations. The `Batch-invariant` (Triton) implementation, while potentially offering other benefits like numerical consistency or flexibility, incurs a performance cost.
* **Relationship between elements:** The X-axis (# Tokens) is a proxy for problem size. The chart shows that both implementations benefit from larger problem sizes up to a hardware or algorithmic limit (the plateau). The persistent gap indicates that the cuBLAS routine has a more efficient underlying implementation for this specific operation.
* **Notable implications:** The choice between these methods involves a trade-off. If maximum speed is the priority and the operation can tolerate batch-invariance, cuBLAS is superior. If batch-invariance is a strict requirement (e.g., for certain types of model parallelism or deterministic training), one must accept the lower throughput of the Triton kernel. The plateau suggests that beyond ~512 tokens, increasing the batch size further does not yield better performance, indicating a potential bottleneck elsewhere in the system (e.g., memory bandwidth).
</details>
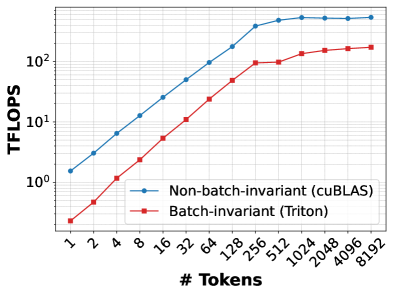
(a) GEMM
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Chart: Execution Time vs. Number of Tokens for Different Implementations
### Overview
The image is a line chart comparing the execution time (in milliseconds) of three different computational implementations as a function of the number of input tokens. The chart demonstrates how performance scales with increasing workload size.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Label:** "# Tokens"
* **Scale:** Logarithmic (base 2), with major tick marks at 1, 8, 32, 128, 256, 512, 1024, 2048, and 4096.
* **Y-Axis:**
* **Label:** "Execution Time (ms)"
* **Scale:** Linear, ranging from 0.0 to 1.2 ms, with major tick marks every 0.2 ms.
* **Legend:** Positioned in the top-left corner of the plot area. It contains three entries:
1. **Non-batch-invariant (CUDA):** Green line with circular markers.
2. **Batch-invariant (Python):** Red line with square markers.
3. **Batch-invariant (Triton):** Blue line with diamond markers.
### Detailed Analysis
The chart plots three data series. Below is an analysis of each, including approximate data points extracted from the visual markers.
**1. Batch-invariant (Python) - Red Line with Squares:**
* **Trend:** The line is nearly flat for small token counts, then exhibits a sharp, accelerating upward curve starting around 256-512 tokens.
* **Data Points (Approximate):**
* 1 token: ~0.10 ms
* 8 tokens: ~0.10 ms
* 32 tokens: ~0.10 ms
* 128 tokens: ~0.10 ms
* 256 tokens: ~0.10 ms
* 512 tokens: ~0.15 ms
* 1024 tokens: ~0.35 ms
* 2048 tokens: ~0.70 ms
* 4096 tokens: ~1.30 ms (Note: This point is above the 1.2 ms axis limit, estimated from the line's trajectory).
**2. Batch-invariant (Triton) - Blue Line with Diamonds:**
* **Trend:** The line is flat for a longer range than the Python implementation, then begins a moderate upward curve after 512 tokens.
* **Data Points (Approximate):**
* 1 token: ~0.05 ms
* 8 tokens: ~0.05 ms
* 32 tokens: ~0.05 ms
* 128 tokens: ~0.05 ms
* 256 tokens: ~0.05 ms
* 512 tokens: ~0.05 ms
* 1024 tokens: ~0.08 ms
* 2048 tokens: ~0.12 ms
* 4096 tokens: ~0.20 ms
**3. Non-batch-invariant (CUDA) - Green Line with Circles:**
* **Trend:** This line is the flattest for the longest duration, showing only a very slight upward trend at the highest token counts.
* **Data Points (Approximate):**
* 1 token: ~0.02 ms
* 8 tokens: ~0.02 ms
* 32 tokens: ~0.02 ms
* 128 tokens: ~0.02 ms
* 256 tokens: ~0.02 ms
* 512 tokens: ~0.03 ms
* 1024 tokens: ~0.05 ms
* 2048 tokens: ~0.10 ms
* 4096 tokens: ~0.15 ms
### Key Observations
1. **Performance Hierarchy:** For all token counts shown, the execution time order is consistently: CUDA (fastest) < Triton < Python (slowest).
2. **Scaling Behavior:** The performance gap between implementations widens dramatically as the number of tokens increases. The Python implementation's time cost grows super-linearly (appearing quadratic or exponential), while the CUDA and Triton implementations scale more gently.
3. **Critical Threshold:** A significant performance divergence begins between 256 and 512 tokens. Below this range, the times for all three are relatively stable and close together. Above it, the Python line separates sharply.
4. **Relative Improvement:** At 4096 tokens, the CUDA implementation is approximately 8.7x faster than the Python implementation (1.30 ms / 0.15 ms ≈ 8.7) and about 1.3x faster than the Triton implementation (0.20 ms / 0.15 ms ≈ 1.3).
### Interpretation
This chart illustrates a classic performance comparison between different programming paradigms and hardware backends for a computational task (likely a machine learning operation like attention or a kernel). The data suggests:
* **The "Batch-invariant (Python)" implementation** likely represents a reference or unoptimized implementation. Its poor scaling indicates significant overhead that becomes prohibitive for large inputs, making it unsuitable for production workloads with high token counts.
* **The "Batch-invariant (Triton)" implementation** shows the benefit of using a specialized compiler (Triton) for GPU kernels. It offers a substantial improvement over pure Python, especially at scale, by generating optimized machine code.
* **The "Non-batch-invariant (CUDA)" implementation** represents a hand-tuned, low-level CUDA kernel. Its superior performance, particularly its excellent scaling, highlights the efficiency gains possible with direct hardware programming, though it may come with higher development complexity.
* **The "Batch-invariant" vs. "Non-batch-invariant"** distinction in the labels hints at an algorithmic or implementation constraint. The non-batch-invariant CUDA version's advantage suggests that relaxing this constraint allows for a more efficient computation path.
**In summary, the chart makes a compelling case for using optimized, compiled backends (Triton, CUDA) over interpreted Python for performance-critical operations involving large datasets (high token counts), with hand-optimized CUDA providing the best performance.**
</details>
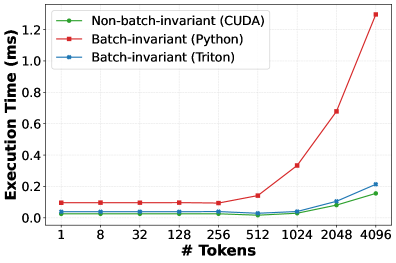
(b) RMSNorm
Figure 4: Performance comparison between batch-invariant vs. non-batch-invariant kernels.
While batch-invariant computation eliminates non-determinism, we find that it is a poor fit for real LLM serving systems. By enforcing a universal reduction strategy across all executions, it couples determinism to kernel design and sacrifices performance opportunities. It also turns determinism into a fixed tax paid by every request: dynamic batching aggregates requests, but batch-invariant kernels eliminate the very optimizations—such as split-K and shape-aware tiling—that make batching effective in the first place. Worse, because kernels are not batch-invariant, adopting this approach requires maintaining a parallel kernel stack solely for determinism. We also quantify the performance cost of this approach below.
GEMM. 4(a) compares the throughput of cuBLAS based GEMMs used in PyTorch against Triton-based batch-invariant kernels developed by He et al. The matrix dimensions correspond to the down projection operation of the Llama-3.1-8B-Instruct model’s feed-forward-network. On our GPU, cuBLAS (via torch.mm) reaches up to 527 TFLOPS, whereas the batch-invariant kernel peaks at 194 TFLOPS, a slowdown of 63%. This gap arises because this Triton-based batch-invariant implementation does not use split-K or exploit newer hardware features such as Tensor Memory Accelerators [TMA_Engine] or advanced techniques like warp specialization [fa-3], all of which are leveraged by PyTorch through vendor-optimized cuBLAS kernels.
RMSNorm. 4(b) compares RMSNorm execution time for varying number of tokens for three implementations: Python-based version used in SGLang, Thinking Machines’ Triton-based kernel, and SGLang’s default CUDA kernel. The first two are batch-invariant; the CUDA kernel is not. The Python implementation is up to $7\times$ slower than the non-batch-invariant CUDA kernel due to unfused primitive operations and poor shared-memory utilization. The Triton kernel performs substantially better but remains up to 50% slower than the fused CUDA implementation, which benefits from optimized reductions and kernel fusion. These overheads are amplified at high batch sizes or long context lengths, where normalization may account for a nontrivial fraction of inference time [gond2025tokenweave].
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Decode Throughput by Batch Size
### Overview
This is a stacked bar chart comparing the decode throughput (in tokens per second) of three different systems or configurations across two batch sizes (10 and 11). The chart visually demonstrates how total throughput changes with batch size and how the contribution from each system varies.
### Components/Axes
* **Chart Type:** Stacked Bar Chart.
* **X-Axis:** Labeled **"Batch Size"**. It has two discrete categories: **10** and **11**.
* **Y-Axis:** Labeled **"Decode Throughput (tokens/sec)"**. The scale runs from 0 to 1200, with major tick marks at intervals of 200 (0, 200, 400, 600, 800, 1000, 1200).
* **Legend:** Positioned in the top-left corner of the chart area. It contains three entries:
1. **SGLang non-deterministic** (represented by a light blue color).
2. **SGLang deterministic** (represented by a reddish-brown color).
3. **LLM-42** (represented by a green color).
### Detailed Analysis
The chart presents data for two batch sizes. Each bar is a stack of segments corresponding to the systems in the legend.
**Batch Size 10:**
* The bar consists of a single segment.
* **SGLang non-deterministic (Blue):** This segment forms the entire bar. Its height reaches approximately **830 tokens/sec** on the y-axis.
* **Total Throughput for Batch Size 10:** ~830 tokens/sec.
**Batch Size 11:**
* The bar is composed of three stacked segments, from bottom to top:
1. **SGLang deterministic (Reddish-brown):** This is the base segment. Its height reaches approximately **410 tokens/sec**.
2. **LLM-42 (Green):** This segment is stacked on top of the red one. It starts at ~410 and ends at approximately **910 tokens/sec**. Therefore, its individual contribution is approximately 910 - 410 = **500 tokens/sec**.
3. **SGLang non-deterministic (Blue):** This is a very thin segment stacked on top of the green one. It starts at ~910 and ends at approximately **930 tokens/sec**. Its individual contribution is approximately 930 - 910 = **20 tokens/sec**.
* **Total Throughput for Batch Size 11:** ~930 tokens/sec.
### Key Observations
1. **Throughput Increase with Batch Size:** The total decode throughput increases from ~830 tokens/sec at batch size 10 to ~930 tokens/sec at batch size 11.
2. **System Contribution Shift:** At batch size 10, the entire throughput is attributed to "SGLang non-deterministic". At batch size 11, the composition changes dramatically:
* "SGLang deterministic" becomes the largest contributor (~410 tokens/sec).
* "LLM-42" provides a substantial contribution (~500 tokens/sec).
* The contribution from "SGLang non-deterministic" shrinks to a very small fraction (~20 tokens/sec).
3. **Dominant System at Batch Size 11:** The "LLM-42" system (green) appears to be the single largest contributor to throughput at batch size 11.
### Interpretation
This chart likely compares the performance of different Large Language Model (LLM) serving or inference systems ("SGLang" in deterministic and non-deterministic modes, and "LLM-42"). The data suggests several technical insights:
* **Batch Size Impact:** Increasing the batch size from 10 to 11 yields a moderate overall throughput improvement (~12% increase). This is consistent with the general principle that larger batches can improve hardware utilization.
* **System Behavior Change:** The most striking finding is the complete shift in which system is active or dominant. At batch size 10, only the non-deterministic SGLang mode is operational or measured. At batch size 11, the deterministic mode and the LLM-42 system engage significantly, while the non-deterministic mode's role becomes minimal. This could indicate:
* A system configuration or scheduling policy that activates different backends based on batch size.
* A performance bottleneck or resource contention that prevents the non-deterministic mode from scaling effectively to batch size 11, while other systems handle the load.
* An experimental setup where different systems are tested at different, non-overlapping batch sizes.
* **Performance of LLM-42:** The "LLM-42" system demonstrates strong performance at batch size 11, contributing over half of the total throughput. This positions it as a potentially high-throughput option for that specific workload configuration.
* **Deterministic vs. Non-deterministic:** The "SGLang deterministic" mode shows a clear ability to handle a significant portion of the load at batch size 11, whereas the non-deterministic mode does not scale similarly in this test.
**In summary, the chart reveals that total system throughput is not just a function of batch size but is critically dependent on which specific processing system or mode is handling the workload. The transition from batch size 10 to 11 triggers a major change in system utilization, with LLM-42 and deterministic SGLang becoming the primary throughput drivers.**
</details>
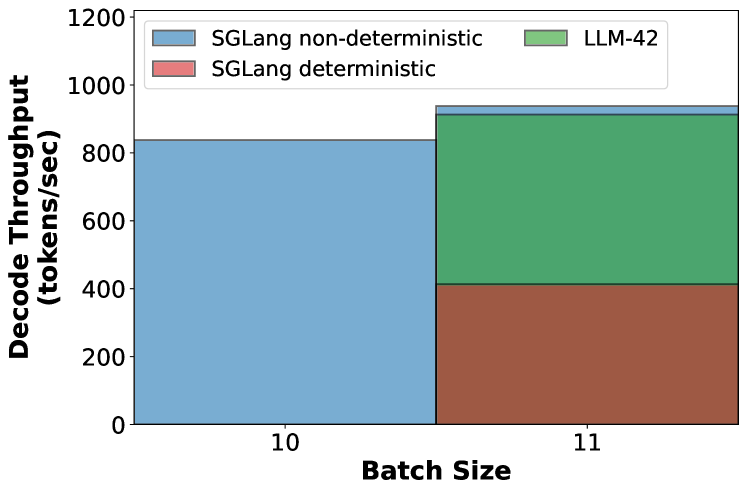
Figure 5: Decode throughput under different scenarios.
End-to-end throughput. Figure 5 measures token generation throughput (tokens per second) under three scenarios: (1) 10 requests running in non-deterministic mode, (2) 11 requests running in non-deterministic mode, and (3) 11 requests running in deterministic mode but only one of them requires deterministic output. With 10 concurrent non-deterministic requests, the system generates 845 tokens/s. The batch size increases to 11 when a new request arrives and if decoding continues non-deterministically, throughput improves to 931 tokens/s (a jump of about 10%). In contrast, if the new request requires determinism, the entire batch is forced to execute through the slower batch-invariant kernels, causing throughput to collapse by 56% to about 415 tokens/s—penalizing every in-flight request for a single deterministic one. This behavior is undesirable because it couples the performance of all requests to that of the slowest request.
Overall, these results show that batch-invariant execution incurs a substantial performance penalty. While it may be feasible to improve the performance of batch-invariant kernels, doing so would require extensive model- and hardware-specific kernel development. This engineering and maintenance burden makes the approach difficult to sustain in practice. This may be why deterministic inference is largely confined to debugging and verification today, rather than being deployed for real-world LLM serving.
## 3 Observations
In this section, we distill a set of concrete observations about non-determinism, GPU kernels and LLM use-cases. These observations expose why batch-invariant computation is overly restrictive and motivate a more general approach to enable determinism in LLM inference.
Observation-1 (O1). If a sequence is already in a consistent state, the next emitted token is usually consistent even under dynamic batching. However, once a token diverges, autoregressive decoding progressively amplifies this difference over subsequent steps.
This is because tokens become inconsistent only when floating-point drift is large enough to alter the effective decision made by the sampler—e.g., by changing the relative ordering or acceptance of high-probability candidates under the decoder’s sampling policy (e.g., greedy or stochastic sampling). In practice, such boundary-crossing events are rare, as numerical drift typically perturbs logits only slightly. However, autoregressive decoding amplifies even a single such deviation: once a token differs, all subsequent tokens may diverge. Since a single request typically produces hundreds to thousands of output tokens, two sequence-level outputs can look dramatically different even if the initial divergence is caused by a single token flip induced by a different reduction order across runs.
To demonstrate this phenomenon empirically, we conduct an experiment using the Llama-3.1-8B-Instruct model on the ShareGPT dataset. We first execute 350 requests with batch size one—i.e., without dynamic batching—to obtain reference (“ground-truth”) output tokens. We then re-run the same requests under dynamic batching at a load of 6 queries per second and compare each request’s output against its reference. In both runs, we fix the output length to 512 tokens.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Chart: Token Counts Across Request IDs
### Overview
The image displays a line chart plotting the number of tokens against a sequence of Request IDs. It compares three distinct data series: `first_consistent_span`, `second_consistent_span`, and `output_span`. The chart reveals a stark contrast between a highly variable series, a mostly dormant series, and a constant series.
### Components/Axes
* **Chart Type:** Multi-line chart.
* **X-Axis:**
* **Label:** `Request Id`
* **Scale:** Linear, ranging from 0 to 80.
* **Major Ticks:** Marked at intervals of 10 (0, 10, 20, 30, 40, 50, 60, 70, 80).
* **Y-Axis:**
* **Label:** `# Tokens`
* **Scale:** Linear, ranging from 0 to 500.
* **Major Ticks:** Marked at intervals of 100 (0, 100, 200, 300, 400, 500).
* **Legend:**
* **Position:** Top center, above the plot area.
* **Series:**
1. `first_consistent_span` - Represented by a **blue** line.
2. `second_consistent_span` - Represented by a **green** line.
3. `output_span` - Represented by a **red** line.
### Detailed Analysis
**1. `output_span` (Red Line):**
* **Trend:** Perfectly horizontal, constant.
* **Value:** Maintains a steady value of approximately **510 tokens** across all Request IDs from 0 to 80. This line sits just above the 500-token grid line.
**2. `first_consistent_span` (Blue Line):**
* **Trend:** Highly volatile and erratic. The line exhibits frequent, sharp peaks and deep troughs throughout the entire range.
* **Data Points (Approximate):**
* Starts at ~240 tokens (Request Id 0).
* Shows significant peaks reaching or exceeding 500 tokens at multiple points (e.g., near Request Ids 8, 12, 28, 32, 42, 48, 58, 78).
* Drops to very low values, often below 50 tokens, at many points (e.g., near Request Ids 10, 20, 26, 40, 50, 62, 70).
* The pattern is non-cyclical and shows no clear upward or downward trend over the full range; it is characterized by high-frequency, high-amplitude noise.
**3. `second_consistent_span` (Green Line):**
* **Trend:** Mostly flat and near zero, with a few isolated, small spikes.
* **Data Points (Approximate):**
* Remains at or very close to **0 tokens** for the vast majority of Request IDs.
* Notable small spikes occur at approximately:
* Request Id ~5: Peaks at ~75 tokens.
* Request Id ~15: Peaks at ~85 tokens.
* Request Id ~22: Peaks at ~60 tokens.
* Request Id ~60: A very minor bump to ~10 tokens.
### Key Observations
1. **Fixed Output:** The `output_span` is invariant, suggesting a fixed-length output or a capped value for all requests in this dataset.
2. **High Variance in Primary Input:** The `first_consistent_span` shows extreme variability, indicating that the primary input or context length for these requests is highly inconsistent.
3. **Minimal Secondary Input:** The `second_consistent_span` is negligible for most requests, implying it is either not used, is very short, or is only relevant for a small subset of requests (those with the spikes).
4. **No Correlation Visibly Apparent:** There is no obvious visual correlation between the spikes in the green line and the peaks or troughs of the blue line.
### Interpretation
This chart likely visualizes token usage statistics for a series of API calls or processing tasks (identified by `Request Id`). The data suggests a system where:
* The **output** is standardized (`output_span` constant at ~510 tokens).
* The **primary input or context** (`first_consistent_span`) is the main driver of variability in the system's load, fluctuating wildly between very short and very long sequences.
* A **secondary input or context** (`second_consistent_span`) plays a minimal role, only appearing significantly in a handful of requests (around IDs 5, 15, 22).
The key takeaway is the system's handling of highly variable input lengths while producing a fixed-length output. The spikes in the green line could represent special cases, error conditions, or a different mode of operation for those specific requests. The lack of correlation between the blue and green lines suggests these two "consistent spans" are independent components of the request.
</details>
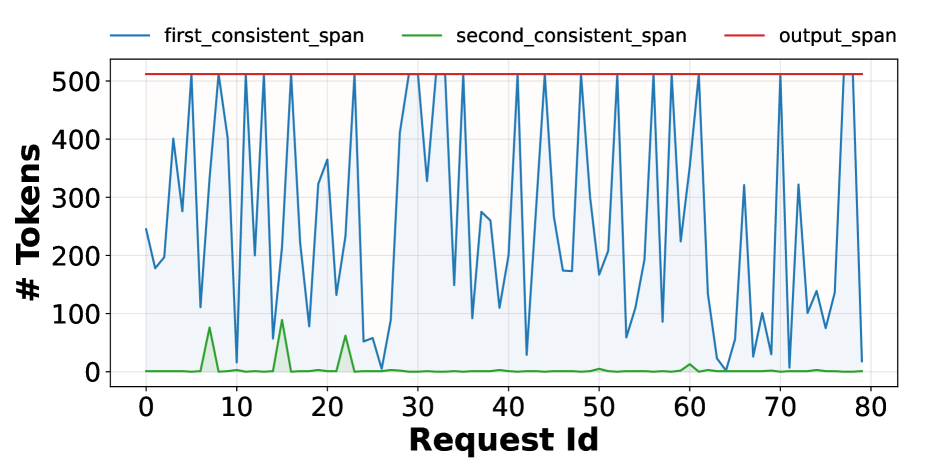
Figure 6: Length of the first and second consistent span (number of tokens that match with the ground-truth) for different requests under dynamic batching.
We quantify divergence using two metrics. The first consistent span of a request measures the number of initial output tokens that match exactly across the two runs, while the second consistent span measures the number of matching tokens between the first and second divergence points. Figure 6 shows these metrics for 80 requests. In the common case, hundreds of initial tokens are identical across both runs, with some requests exhibiting an exact match of all 512 tokens in the first consistent span. However, once a single token diverges, the sequence rapidly drifts: the second consistent span is near zero for most requests, indicating that divergence quickly propagates through the remainder of the output.
<details>
<summary>figures/position-invariant-kernel.png Details</summary>

### Visual Description
## Diagram: Two-Run Kernel Process
### Overview
The image displays a technical diagram illustrating a two-stage computational process labeled "Run-1" and "Run-2". Each stage involves a central processing unit called a "Kernel" that transforms input tensors (denoted by T with subscripts) into output tensors (denoted by T with primes). The diagram is presented on a light gray background with black text and arrows, and light blue kernel blocks. Specific output elements are highlighted with red circles.
### Components/Axes
The diagram is composed of two distinct, side-by-side sections:
1. **Run-1 (Left Section):**
* **Title:** "Run-1" (centered above the kernel block).
* **Kernel Block:** A light blue, rounded rectangle labeled "Kernel" in the center.
* **Inputs:** Two arrows point into the left side of the kernel block.
* Top input label: `T₀`
* Bottom input label: `T₁`
* **Outputs:** Two arrows point out from the right side of the kernel block.
* Top output label: `T₀'`
* Bottom output label: `T₁'` (This label is enclosed in a red circle).
2. **Run-2 (Right Section):**
* **Title:** "Run-2" (centered above the kernel block).
* **Kernel Block:** Identical to Run-1, a light blue, rounded rectangle labeled "Kernel".
* **Inputs:** Two arrows point into the left side of the kernel block.
* Top input label: `T₁`
* Bottom input label: `T₂`
* **Outputs:** Two arrows point out from the right side of the kernel block.
* Top output label: `T₁''` (This label is enclosed in a red circle).
* Bottom output label: `T₂''`
### Detailed Analysis
* **Data Flow:** The diagram depicts a sequential data flow. The outputs of Run-1 (`T₀'` and `T₁'`) are not shown as direct inputs to Run-2. Instead, Run-2 takes a new set of inputs (`T₁` and `T₂`). The notation suggests a relationship: the `T₁` input for Run-2 may be the same tensor as the `T₁` input for Run-1, or it could be a subsequent version.
* **Notation:** The prime notation (`'`, `''`) indicates a transformation or iteration.
* `T₀` → Kernel → `T₀'`
* `T₁` → Kernel → `T₁'`
* `T₁` → Kernel → `T₁''`
* `T₂` → Kernel → `T₂''`
* **Highlighting:** The red circles are placed around the output labels `T₁'` (in Run-1) and `T₁''` (in Run-2). This visually emphasizes these two specific outputs, suggesting they are the primary results of interest or are being compared across the two runs.
### Key Observations
1. **Structural Symmetry:** Run-1 and Run-2 are structurally identical, differing only in their input/output labels.
2. **Input Progression:** The input tensor indices progress from (`T₀`, `T₁`) in Run-1 to (`T₁`, `T₂`) in Run-2. This implies a sliding window or sequential processing of a series of tensors (T₀, T₁, T₂, ...).
3. **Output Emphasis:** The consistent highlighting of the `T₁`-derived outputs (`T₁'` and `T₁''`) across both runs is the most salient visual feature, directing the viewer's attention to the transformation of this specific tensor.
4. **Kernel Abstraction:** The "Kernel" is represented as a black box; its internal operations are not defined in this diagram.
### Interpretation
This diagram illustrates a **two-step iterative or sequential kernel application** on a series of data tensors. The core concept is the repeated processing of a central tensor (`T₁`) within a moving context.
* **What it demonstrates:** The process shows how a kernel function is applied to different pairs of consecutive tensors from a sequence. The first run processes the pair (T₀, T₁), and the second run processes the next pair (T₁, T₂). The red circles indicate that the transformation of the middle tensor (`T₁`) is the key output being tracked from each step.
* **Relationship between elements:** The two runs are independent executions of the same kernel logic but on different input windows. The shared element is the tensor `T₁`, which appears as an output in the first window and as an input in the second window. This pattern is common in algorithms like convolutional neural networks (where a kernel slides over input data), temporal sequence processing, or any sliding-window computation.
* **Notable pattern:** The notation `T₁''` (double prime) for the output of Run-2 suggests it is a second-order transformation of the original `T₁` tensor, having been processed by the kernel in two successive contexts (first with `T₀`, then with `T₂`). The diagram effectively visualizes the propagation and evolution of data through a multi-stage process.
</details>
Figure 7: A position-invariant kernel produces the same output for a given input element irrespective of its position in the batch, as long as the total batch size is fixed. In this example, $T_{1}^{\prime}==T_{1}^{\prime\prime}$ if the kernel is position-invariant.
| Category | Operator | Invariant | |
| --- | --- | --- | --- |
| Batch | Position | | |
| Matmul | CuBLAS GEMM | ✗ | ✓ |
| Attention | FlashAttention-3 ‡ | ✓ | ✓ |
| Communication | Multimem-based AllReduce ∗ | ✓ | ✓ |
| Ring-based AllReduce | ✗ | ✗ | |
| Tree-based AllReduce ⋆ | ✓ | ✓ | |
| Normalization | RMSNorm † | ✗ | ✓ |
| Fused RMSNorm + Residual † | ✗ | ✓ | |
Table 2: Invariance properties of common inference operators (‡ num_splits=1, ∗ CUDA 13.0+, ⋆ specific NCCL settings, † vLLM/SGLang defaults).
Observation-2 (O2). Most GPU kernels use uniform, shape-consistent reductions: they apply the same reduction strategy to all elements within a given batch. Moreover, the strategy remains fixed for all batches of the same shape, changing only when the shape changes.
The simplest example of this is GEMM kernels. For a given input matrix A of size M x K, a GEMM kernel computes all the M input elements under the same reduction order (say R). Moreover, it applies the same reduction order R to all input matrices of size M x K. We refer to such kernels as position-invariant. Position invariance implies that, with a fixed total batch size, an input element’s output is independent of its position in the batch. Note that such guarantees do not hold for kernels that implement reductions via atomic operations. Fortunately, kernels used in the LLM forward pass do not use atomic reductions. Figure 7 shows an example of a position-invariant kernel and Table 2 shows the invariance properties of common LLM operators.
The motivation for batch-invariant computation stems from the fact that GPU kernels used in LLMs, while deterministic for a particular input, are not batch-invariant. We observe that position-invariance captures a strictly stronger property than determinism: determinism only requires that the same input produce the same output across runs, whereas position-invariance implies that the output of a given input remains consistent as long as the input size to the kernel remains the same. This allows us to reason about kernel behavior at the level of input shapes, rather than individual input values.
Observation-3 (O3). For deterministic inference, it is sufficient to ensure that a given token position goes through the same reduction strategy across all runs of a given request; reduction strategy for different token positions within or across sequences can be different.
Numerical differences in the output of a token arise from differences in how its own floating-point reductions are performed, not from the numerical values of other co-batched tokens. While batching affects how computations are scheduled and grouped, the computation for a given token position is functionally independent: it consumes the same inputs and executes the same sequence of operations. As a result, interactions across tokens occur only indirectly through execution choices—such as which partial sums are reduced together—not through direct data dependencies. Consequently, as long as a token position is always reduced using the same strategy, its output remains consistent regardless of how other token positions are computed.
Observation-4 (O4). Current systems take an all-or-nothing approach: they either enforce determinism for every request or disable it entirely. Such a design is not a natural fit for LLM deployments.
This is because many LLM workloads neither require bit-wise reproducibility nor benefit from it. In fact, controlled stochasticity is often desirable as it enhances output diversity and creativity of LLMs [integrating_randomness_llm2024, diversity_bias_llm2025, det-inf-kills]. In contrast, requests such as evaluation runs, safety audits, or regression testing require bit-level reproducibility. Overall, different use-cases imply that enforcing determinism for all requests is an overkill.
It is also worth highlighting that this all-or-nothing behavior largely stems from the batch-invariant approach that ties determinism to the kernel design. Since all co-batched tokens go through the same set of kernels, determinism becomes a global property of the batch rather than being selective. While one could run different requests through separate deterministic and non-deterministic kernels, doing so would fragment batches, complicate scheduling, and likely hurt efficiency.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Diagram: KV Cache Management and Token Verification Process
### Overview
The image is a technical diagram illustrating a multi-stage process for managing Key-Value (KV) cache in a language model system, likely depicting a form of speculative decoding or verification. The process flows from left to right through three main phases: **Prefill**, **Decode**, and **Verify**, culminating in a **No Rollback** state where all tokens are accepted. The diagram uses color-coded blocks, arrows, and cylinder icons to represent data flow, token sequences, and cache states.
### Components/Axes
The diagram is segmented into four primary regions from left to right:
1. **Prefill Region (Left):**
* **Label:** "Prefill" at the bottom.
* **Components:**
* A light blue rectangle labeled "deterministic request" with an arrow pointing to it.
* A stack of three grey rectangles labeled "other requests" with an arrow pointing to them.
* A cylinder icon at the top labeled "KV cache after prefill".
2. **Decode Region (Center-Left):**
* **Label:** "Decode" at the bottom.
* **Components:**
* A horizontal sequence of four colored blocks representing tokens: `T₀` (light green), `T₁'` (light yellow), `T₂'` (light yellow), `T₃'` (light yellow).
* Below this, a grid showing the interaction of the "deterministic request" (blue) and "other requests" (grey) with the token sequence. The grid cells are filled with patterns: solid color, cross-hatching, and dots.
* A cylinder icon at the top labeled "KV cache after decode", which is partially filled with blue (top) and yellow (bottom).
3. **Verify Region (Center-Right):**
* **Label:** "Verify" at the bottom.
* **Components:**
* A vertical column of four token blocks: `T₀'` (light green), `T₁'` (light yellow), `T₂'` (light yellow), `T₃'` (light yellow).
* Arrows point from this column to a second vertical column showing the verification result:
* `T₁ (=T₁')` (light green)
* `T₂ (=T₂')` (light green)
* `T₃ (=T₃')` (light green)
* `T₄` (cross-hatched pattern)
* To the right, a box labeled "accepted tokens" contains four checkmarks (✓).
4. **No Rollback Region (Right):**
* **Label:** "No Rollback" at the bottom.
* **Components:**
* A final horizontal sequence of five token blocks: `T₀` (light blue), `T₁` (light green), `T₂` (light green), `T₃` (light green), `T₄` (cross-hatched pattern).
* A cylinder icon at the top labeled "KV cache after accepting all tokens", which is partially filled with blue (top) and green (bottom).
* Descriptive text: "Sequence and KV after accepting all tokens (including T4)".
### Detailed Analysis
The process depicts a verification mechanism for a sequence of generated tokens (`T₀'` to `T₃'`).
* **Initial State (Prefill):** The system processes a "deterministic request" and "other requests". The KV cache is initialized ("KV cache after prefill").
* **Speculative Generation (Decode):** A sequence of four tokens (`T₀'`, `T₁'`, `T₂'`, `T₃'`) is generated. The KV cache is updated with a mix of blue and yellow data, corresponding to the different request types.
* **Verification Step (Verify):** The generated tokens are verified against a target model or process.
* The first token `T₀'` is not shown in the verification output column, implying it may be a prompt token or is handled separately.
* Tokens `T₁'`, `T₂'`, and `T₃'` are verified and accepted as `T₁`, `T₂`, and `T₃` (indicated by `=T₁'`, etc.), and their color changes from yellow to green.
* A new token, `T₄` (cross-hatched), is generated or validated as part of this step.
* The "accepted tokens" box with four checkmarks confirms the acceptance of the sequence.
* **Final State (No Rollback):** The entire sequence, including the newly verified `T₄`, is accepted. The final token sequence is `T₀`, `T₁`, `T₂`, `T₃`, `T₄`. The KV cache is updated to a final state containing blue and green data.
### Key Observations
1. **Color Coding:** Colors are used consistently to denote state or origin:
* **Light Blue:** Associated with the "deterministic request" and the initial token `T₀`.
* **Light Yellow:** Represents speculative or draft tokens (`T₁'`, `T₂'`, `T₃'`) during the Decode phase.
* **Light Green:** Represents verified/accepted tokens (`T₁`, `T₂`, `T₃`) and the initial `T₀'` in the Verify column.
* **Cross-hatch Pattern:** Used for the newly generated/accepted token `T₄`.
* **Grey:** Represents "other requests".
2. **Process Flow:** The arrows clearly show a linear progression: Prefill → Decode → Verify → No Rollback. The Verify stage acts as a gate, transforming yellow speculative tokens into green accepted ones and appending a new token.
3. **Cache Evolution:** The cylinder icons visually track the KV cache state. It starts empty/blue, gains yellow data after decode, and ends with blue and green data after acceptance, indicating the cache is updated with the final, verified sequence.
4. **"No Rollback" Implication:** The final label emphasizes that the entire sequence, including the extra token `T₄`, is accepted without needing to discard and regenerate, suggesting an efficient verification process.
### Interpretation
This diagram illustrates a **speculative decoding** or **draft-and-verify** workflow for autoregressive language models. The core idea is to generate a draft sequence of tokens (`T₀'`-`T₃'`) quickly (perhaps with a smaller, faster model) and then verify them in parallel or with a larger, more accurate model.
* **Efficiency Gain:** The "No Rollback" outcome is the ideal scenario. It means all draft tokens were correct, and an additional token (`T₄`) was generated during verification, resulting in a net gain of tokens per step. This is more efficient than standard autoregressive generation, which produces one token per step.
* **Role of Requests:** The "deterministic request" and "other requests" likely represent different computational paths or model components involved in the draft generation phase. Their interaction in the Decode grid suggests a complex scheduling or memory access pattern.
* **Cache Management:** The KV cache is a critical resource. The diagram shows it being progressively built and then finalized with the accepted tokens, highlighting the importance of cache consistency in this process.
* **Underlying Mechanism:** The verification arrows (`T₁'` → `T₁ (=T₁')`) imply a comparison operation. The system checks if the draft token matches the token that the main model would generate given the context. The acceptance of `T₄` suggests the verification process can also produce new valid tokens beyond the draft length.
In essence, the diagram depicts an optimization technique that trades increased computational complexity during the verification phase for a higher token generation throughput, avoiding costly rollbacks when the draft is accurate.
</details>
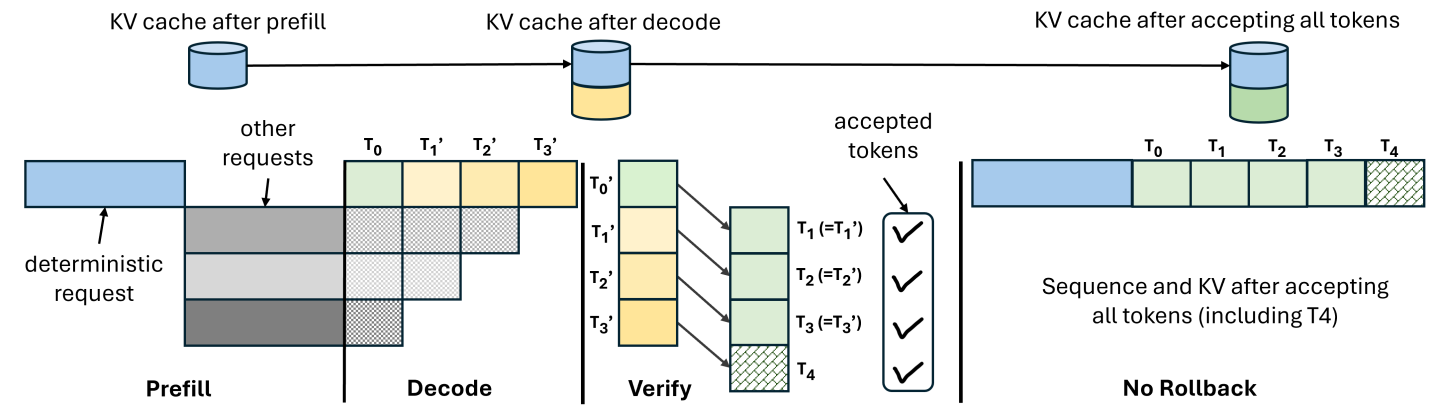
(a) DVR without rollbacks.
<details>
<summary>x6.png Details</summary>
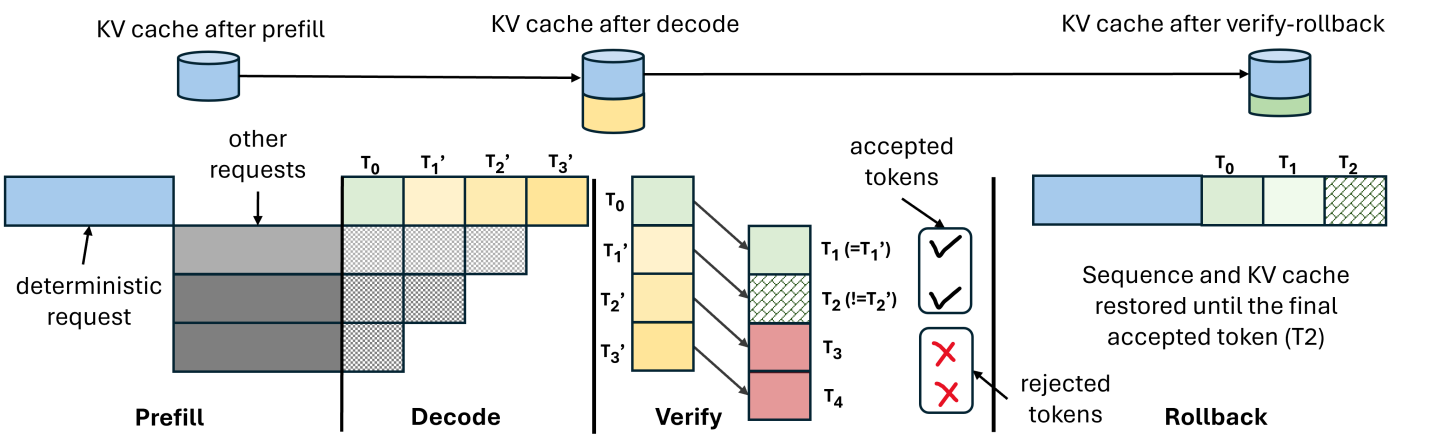
### Visual Description
## Diagram: KV Cache State Transitions in a Speculative Decoding/Rollback Process
### Overview
This diagram illustrates a technical process for managing Key-Value (KV) cache states during a sequence generation task, likely in the context of a language model using speculative decoding or a similar verification mechanism. The process flows from left to right through four distinct phases: Prefill, Decode, Verify, and Rollback. It shows how a "deterministic request" is processed alongside "other requests," how speculative tokens are generated and verified, and how the system state is restored upon rejection of tokens.
### Components/Axes
The diagram is a flowchart with no traditional chart axes. It is organized into three horizontal sections representing the state of the KV cache at different stages, and four vertical phases detailing the process steps.
**Top Section (KV Cache State):**
* **Left:** "KV cache after prefill" - Represented by a single blue cylinder.
* **Center:** "KV cache after decode" - Represented by a cylinder with a blue top and a yellow bottom.
* **Right:** "KV cache after verify-rollback" - Represented by a cylinder with a blue top, a green middle, and a yellow bottom.
**Bottom Section (Process Flow):**
The process is divided into four labeled phases:
1. **Prefill**
2. **Decode**
3. **Verify**
4. **Rollback**
**Key Labels and Elements:**
* **Input:** "deterministic request" (pointing to a blue rectangle).
* **Concurrent Work:** "other requests" (pointing to a stack of grey rectangles).
* **Token Notation:**
* `T0`, `T1`, `T2`, `T3`, `T4`: Likely represent actual or target tokens.
* `T1'`, `T2'`, `T3'`: Represent speculative or predicted tokens (denoted with a prime symbol).
* **Verification Outcomes:**
* "accepted tokens" (pointing to two green checkmarks).
* "rejected tokens" (pointing to two red X marks).
* **Final State Description:** "Sequence and KV cache restored until the final accepted token (T2)".
### Detailed Analysis
**1. Prefill Phase:**
* A "deterministic request" (blue rectangle) is processed.
* This occurs alongside "other requests" (grey rectangles), indicating concurrent processing.
* The output is the initial "KV cache after prefill" (blue cylinder).
**2. Decode Phase:**
* The system generates a sequence of speculative tokens: `T0` (green), `T1'` (yellow), `T2'` (yellow), `T3'` (yellow).
* These tokens are visualized as a horizontal bar. Below them are patterned blocks (grey with dots), likely representing the KV cache entries or attention patterns associated with these speculative tokens.
* The "KV cache after decode" now contains the original prefill data (blue) plus new data from the speculative decode (yellow).
**3. Verify Phase:**
* The speculative tokens (`T0`, `T1'`, `T2'`, `T3'`) are compared against a separate sequence of actual or verified tokens (`T0`, `T1`, `T2`, `T3`, `T4`).
* **Comparison Logic:**
* `T1` is equal to `T1'` (`T1 = T1'`). This token is **accepted** (green checkmark).
* `T2` is not equal to `T2'` (`T2 != T2'`). This token is **rejected** (red X).
* The diagram implies `T0` was accepted (it matches and is the starting point).
* Tokens `T3` and `T4` (red blocks) are shown but are not compared to primes, suggesting they are part of the verification sequence but were never proposed speculatively, or are beyond the point of failure.
* The verification results in a set of "accepted tokens" (green checks) and "rejected tokens" (red Xs).
**4. Rollback Phase:**
* Based on the verification, the system rolls back.
* The final state shows a sequence bar containing: the original blue block, the accepted green token (`T0`), the accepted green token (`T1`), and a patterned block for the rejected `T2`.
* The "KV cache after verify-rollback" cylinder reflects this: it retains the prefill data (blue), the data from accepted tokens (green), and discards the data from rejected speculative tokens (the yellow section is now at the bottom, possibly indicating it's stale or marked for overwrite).
* The text confirms: "Sequence and KV cache restored until the final accepted token (T2)".
### Key Observations
* **Color Coding is Critical:** Blue represents the initial/prefill state. Green represents accepted/speculative tokens that are verified. Yellow represents speculative tokens that are generated but not yet verified. Red represents tokens in the verification sequence that are incorrect or beyond the failure point. Patterned fills represent KV cache data or states associated with tokens.
* **Process Flow:** The diagram clearly shows a speculative-then-verify workflow. The system guesses multiple tokens ahead (`T1'`, `T2'`, `T3'`) in the Decode phase, then checks them in the Verify phase.
* **Point of Failure:** The process fails at `T2` (`T2 != T2'`). All speculation after this point (`T3'`) is invalidated.
* **State Restoration:** The Rollback phase does not revert to the very beginning. It reverts to the state after the last *accepted* token (`T2` in the sequence, which corresponds to `T1'` being correct). The KV cache is trimmed accordingly.
### Interpretation
This diagram depicts a **speculative decoding with rollback** mechanism, a technique used to accelerate inference in autoregressive models like large language models.
* **What it demonstrates:** The system uses a faster, possibly less accurate "draft" model to propose multiple future tokens (`T1'`, `T2'`, `T3'`) in one forward pass (Decode). A slower, more accurate "verification" model then checks these proposals against its own generated tokens (`T1`, `T2`, `T3`). If a mismatch is found (`T2 != T2'`), the system discards all subsequent speculative work and rolls back its state (KV cache and token sequence) to the last point of agreement.
* **Why it matters:** This approach aims to achieve a speedup. If the draft model's guesses are often correct, the system can generate multiple tokens per verification step, reducing the total number of expensive verification passes needed. The cost of occasional rollbacks is offset by the gains from successful speculation.
* **Underlying Logic:** The "deterministic request" likely refers to the initial prompt or a guaranteed starting point. The "other requests" suggest this process can be batched or run concurrently for multiple sequences. The preservation of the blue (prefill) and green (accepted) sections in the final KV cache shows efficient memory management—only the incorrect speculative data (yellow) is discarded.
* **Notable Detail:** The final accepted token is labeled as `T2` in the rollback description, but in the verification column, `T1` was the last token marked with a check (`T1 = T1'`). This suggests `T2` in the final sequence bar corresponds to the *position* where the mismatch occurred, and the system restores up to and including the token *before* the failure, which is `T1`. The patterned block labeled `T2` in the rollback bar may represent the now-invalidated slot or the point from which regeneration must occur.
</details>
(b) DVR with rollbacks.
Figure 8: An example of decode-verify-rollback. After generating a fixed number of tokens through regular decoding, LLM-42 verifies them in parallel via a separate forward pass. (a) all the tokens generated in the decode phase pass verification; LLM-42 accepts all these tokens along with the new verifier-generated token ( $T_{4}$ ). (b) some tokens do not match between decode and verification; LLM-42 accepts only the initial matching tokens ( $T_{1}^{\prime}$ ) and the following verifier-generated token ( $T_{2}$ ); all other tokens are recomputed. In both cases, the verifier replaces the KV cache entries generated by the decode phase with its own.
## 4 LLM-42
Since non-determinism in LLM inference comes from dynamic batching, disabling it would make inference deterministic. However, dynamic batching is arguably the most powerful performance optimization for LLM inference [orca, distserve2024, vllmsosp, sarathi2023]. Therefore, our goal is to enable determinism in the presence of dynamic batching. In this section, we introduce a speculative decoding-inspired, scheduler-driven approach LLM-42 to achieve this goal.
### 4.1 Overall Design
LLM-42 exploits the observations presented in §3 as follows:
Leveraging O1. Tokens decoded from a consistent state are mostly consistent. Based on this observation, we re-purpose speculative-decoding style mechanism to enforce determinism via a decode–verify–rollback (DVR) protocol. DVR optimistically decodes tokens using the fast path and a verifier ensures determinism. Only tokens approved by the verifier are returned to the user, while the few that fail verification are discarded and recomputed. The key, however, is to ensure that the verifier’s output itself is always consistent. We leverage O2 to achieve this.
Leveraging O2. Because GPU kernels rely on shape-consistent reductions, we make the verifier deterministic by always operating on a fixed number of tokens (e.g., verifying 10 tokens at a time). The only corner case occurs at the end of a sequence, where fewer than T tokens may remain (for instance, when the 11th token is an end-of-sequence token). We handle this by padding with dummy tokens so that the verifier always processes exactly T tokens.
Leveraging O3. Determinism only requires that each token position follow a consistent strategy across runs whereas different positions can follow different strategies. This observation lets us compute prefill and decode phases using different strategies. Because prefill is massively parallel even within a single request, it can be made deterministic simply by avoiding arbitrary batching of prefill tokens, eliminating the need for a verifier in this phase. Verifier is required only for the tokens generated by the decode phase.
Leveraging O4: LLM-42 decouples determinism from token generation by moving it into a separate verification phase. This makes selective determinism straightforward: only requests that require deterministic inference incur verification, while all other traffic avoids it. We expose this control to the users via a new API flag is_deterministic=True|False that allows them to explicitly request determinism on a per-request basis; default is False.
Figure 5 quantifies the performance benefit of selective determinism. When one out of 11 requests requires determinism, LLM-42 achieves decode throughput of 911 tokens per second which is $2.2\times$ higher than the deterministic mode throughput of SGLang and only within 3% of the non-deterministic mode (best case) throughput. We present a more detailed evaluation in §5.
### 4.2 Decode-verify-rollback (DVR)
DVR performs decoding optimistically by first generating tokens using high-throughput, non-deterministic execution and then correcting any inconsistencies through verification and recomputation. Rather than enforcing determinism upfront, it identifies inconsistencies in the generated sequence on the fly, and recomputes only those tokens that are not guaranteed to be consistent across all possible runs of a given request.
Figure 8 illustrates how DVR operates, assuming a verification window of four tokens. The blue request requires deterministic output and its first output token $T_{0}$ is produced by deterministic prefill phase that avoids arbitrary inter-request batching. LLM-42 then generates candidate tokens $T_{1}^{\prime}$ , $T_{2}^{\prime}$ , and $T_{3}^{\prime}$ using the regular fast path with dynamic batching, where gray requests may be batched arbitrarily. The first input to the verifier should be consistent (in this case, $T_{0}$ is consistent since it comes from the prefill phase). The verifier replays these four tokens $T_{0}$ and $T_{1}^{\prime}$ – $T_{3}^{\prime}$ as input and produces output tokens $T_{1}$ – $T_{4}$ . Verification has two possible outcomes: (1) all tokens pass verification, or (2) one or more tokens fail verification. We describe these two cases in detail below.
#### Case-1: When verification succeeds.
In the common case, verification reproduces the same tokens that the preceding decode iterations generated. For example, in 8(a), $T_{1}=T_{1}^{\prime}$ , $T_{2}=T_{2}^{\prime}$ and $T_{3}=T_{3}^{\prime}$ . In this case, LLM-42 accepts all these tokens; in addition, it also accepts the token $T_{4}$ since $T_{4}$ was generated by the verifier from a consistent state and is therefore consistent.
<details>
<summary>x7.png Details</summary>
### Visual Description
\n
## Line Chart: Latency per Token vs. Number of Tokens
### Overview
The image displays a line chart illustrating the relationship between the number of tokens processed and the latency per token, measured in milliseconds (ms). The chart demonstrates a clear inverse relationship: as the number of tokens increases, the latency per token decreases significantly. The data is presented as a single series with a blue line and circular markers, with the area beneath the line shaded in a light green.
### Components/Axes
* **Chart Type:** Line chart with a filled area.
* **X-Axis (Horizontal):**
* **Title:** "Number of Tokens"
* **Scale:** Logarithmic (base 2), with major tick marks at 16, 32, 64, 128, 256, and 512.
* **Y-Axis (Vertical):**
* **Title:** "Latency per Token (ms)"
* **Scale:** Linear, ranging from 0.0 to 0.8 ms, with major tick marks at intervals of 0.1 ms.
* **Data Series:** A single series represented by a solid blue line with circular markers at each data point.
* **Legend:** None present (only one data series).
* **Grid:** A light gray grid is present for both axes to aid in reading values.
* **Language:** All text in the chart is in English.
### Detailed Analysis
The chart plots six distinct data points. The visual trend is a steep, downward-sloping curve that flattens as the number of tokens increases.
**Data Points (Approximate Values):**
1. **At 16 Tokens:** Latency per Token ≈ 0.76 ms. This is the highest point on the chart.
2. **At 32 Tokens:** Latency per Token ≈ 0.38 ms. The value drops by approximately half from the previous point.
3. **At 64 Tokens:** Latency per Token ≈ 0.19 ms. The value again drops by approximately half.
4. **At 128 Tokens:** Latency per Token ≈ 0.095 ms. The rate of decrease begins to slow.
5. **At 256 Tokens:** Latency per Token ≈ 0.05 ms.
6. **At 512 Tokens:** Latency per Token ≈ 0.04 ms. This is the lowest point, showing minimal further decrease from 256 tokens.
**Trend Verification:** The blue line exhibits a consistent, monotonic downward slope from left to right, confirming the inverse relationship. The curve is convex, indicating that the rate of improvement (reduction in latency) diminishes as the token count grows.
### Key Observations
1. **Diminishing Returns:** The most dramatic reduction in per-token latency occurs when increasing the token count from 16 to 64. The improvement from 256 to 512 tokens is marginal.
2. **Performance Scaling:** The chart suggests that processing tokens in larger batches (higher "Number of Tokens") is more efficient on a per-token basis, likely due to amortized overhead costs.
3. **Visual Emphasis:** The light green shaded area under the line visually emphasizes the total "latency cost" and how it shrinks with larger batch sizes.
### Interpretation
This chart demonstrates a fundamental principle in computing and systems performance: **amortization of fixed costs**. The "Latency per Token" likely includes both a fixed overhead component (e.g., model loading, kernel launch, memory allocation) and a variable component that scales with the number of tokens.
* **At low token counts (e.g., 16)**, the fixed overhead dominates the per-token latency, resulting in high values.
* **As the token count increases**, this fixed overhead is distributed across more tokens, causing the per-token latency to drop sharply.
* **At very high token counts (e.g., 256, 512)**, the variable processing time becomes the dominant factor, and the curve flattens, approaching the theoretical minimum latency per token for the given hardware and model.
The practical implication is that for this system, batching requests or processing longer sequences is highly beneficial for throughput and efficiency. The "sweet spot" for balancing latency and efficiency appears to be in the range of 64 to 128 tokens, where significant gains have been realized before the curve plateaus. The chart provides a clear visual argument for optimizing batch sizes in machine learning inference or similar computational workloads.
</details>
(a) Verification latency
<details>
<summary>x8.png Details</summary>
### Visual Description
\n
## Cumulative Distribution Function (CDF) Plot: Rollbacks per Verification Window
### Overview
The image displays a Cumulative Distribution Function (CDF) plot comparing the distribution of "Rollbacks per Verification Window" across four different window sizes. The chart illustrates how the probability of observing a certain number of rollbacks (or fewer) changes as the window size increases.
### Components/Axes
* **Chart Type:** Step-wise Cumulative Distribution Function (CDF) plot.
* **X-Axis:**
* **Label:** "Rollbacks per Verification Window"
* **Scale:** Linear, ranging from 0.0 to approximately 0.9.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8.
* **Y-Axis:**
* **Label:** "CDF" (Cumulative Distribution Function).
* **Scale:** Linear, ranging from 0.0 to 1.0.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Legend:**
* **Position:** Bottom-right quadrant of the plot area.
* **Content:** Four entries, each associating a colored line with a "Window Size".
* Blue Line: `Window Size=32`
* Orange Line: `Window Size=64`
* Green Line: `Window Size=128`
* Red Line: `Window Size=256`
* **Grid:** Light gray, dashed grid lines are present for both major x and y ticks.
### Detailed Analysis
The plot contains four distinct step-function lines, each representing a different window size. The general trend is that for a given x-value (rollbacks per window), the CDF value is highest for the smallest window size (32) and decreases as the window size increases.
1. **Window Size=32 (Blue Line):**
* **Trend:** Rises most steeply and reaches a CDF of 1.0 (indicating 100% of samples) at the lowest x-value.
* **Key Points (Approximate):**
* At x=0.0, CDF ≈ 0.55.
* At x=0.2, CDF ≈ 0.80.
* At x=0.4, CDF ≈ 0.95.
* Reaches CDF=1.0 at approximately x=0.5.
2. **Window Size=64 (Orange Line):**
* **Trend:** Rises less steeply than the blue line but more steeply than the green and red lines.
* **Key Points (Approximate):**
* At x=0.0, CDF ≈ 0.58.
* At x=0.2, CDF ≈ 0.72.
* At x=0.4, CDF ≈ 0.88.
* Reaches CDF=1.0 at approximately x=0.7.
3. **Window Size=128 (Green Line):**
* **Trend:** Shows a more gradual increase, with a pronounced step around x=0.5.
* **Key Points (Approximate):**
* At x=0.0, CDF ≈ 0.58.
* At x=0.2, CDF ≈ 0.62.
* At x=0.4, CDF ≈ 0.75.
* Has a large vertical step at x≈0.5, jumping from CDF≈0.77 to CDF≈0.90.
* Reaches CDF=1.0 at approximately x=0.8.
4. **Window Size=256 (Red Line):**
* **Trend:** Rises the most slowly, indicating a higher probability of larger rollback values.
* **Key Points (Approximate):**
* At x=0.0, CDF ≈ 0.58.
* At x=0.2, CDF ≈ 0.59.
* At x=0.4, CDF ≈ 0.64.
* Has a large vertical step at x≈0.5, jumping from CDF≈0.64 to CDF≈0.83.
* Reaches CDF=1.0 at approximately x=0.9.
### Key Observations
1. **Initial Value at x=0:** All lines except the blue one (Window Size=32) start at a CDF of approximately 0.58 at x=0. The blue line starts lower, at ~0.55. This indicates that for window sizes 64, 128, and 256, about 58% of verification windows have **zero** rollbacks. For window size 32, only about 55% have zero rollbacks.
2. **Step Function Nature:** The lines are not smooth curves but step functions, indicating the data (rollbacks per window) is discrete.
3. **Convergence Point:** All lines converge to a CDF of 1.0, meaning 100% of the data is captured, but at different x-values (from ~0.5 for size 32 to ~0.9 for size 256).
4. **Major Discontinuity:** A significant, synchronized vertical step occurs for the green (128) and red (256) lines at x ≈ 0.5. The orange (64) line has a smaller step at the same location. This suggests a common event or threshold in the data at approximately 0.5 rollbacks per window that affects larger window sizes more dramatically.
### Interpretation
This CDF plot demonstrates a clear inverse relationship between the verification window size and the system's rollback performance. **Smaller window sizes (e.g., 32) are associated with fewer rollbacks per verification window.**
* **Performance Implication:** The steep rise of the blue line (size 32) shows that the vast majority of its verification windows experience very few rollbacks. In contrast, the slower rise of the red line (size 256) indicates a higher likelihood of encountering windows with a larger number of rollbacks.
* **Trade-off Insight:** The data suggests a potential trade-off. While larger window sizes might offer efficiency gains (verifying more data at once), they come at the cost of increased instability or error rates, manifested as more frequent rollbacks within a single window. The system appears more stable or "safer" when operating with smaller, more frequently verified chunks of data.
* **Anomaly/Threshold:** The pronounced step at x≈0.5 for larger window sizes is a critical feature. It implies that once the rollback rate crosses this approximate threshold (0.5 rollbacks per window), there is a high probability (a jump of 10-20% in the CDF) that the window will contain a significantly higher number of rollbacks. This could point to a systemic bottleneck or a failure mode that triggers more severely under larger window configurations.
</details>
(b) Rollbacks
<details>
<summary>x9.png Details</summary>
### Visual Description
\n
## CDF Chart: Recomputed Tokens per Request by Window Size
### Overview
The image displays a Cumulative Distribution Function (CDF) plot comparing the distribution of "Recomputed Tokens per Request" across four different window size configurations. The chart illustrates how the probability of a request requiring a certain number of recomputed tokens changes as the window size increases.
### Components/Axes
* **Chart Type:** Cumulative Distribution Function (CDF) line plot.
* **X-Axis:**
* **Label:** "Recomputed Tokens per Request"
* **Scale:** Linear, ranging from 0 to 1750.
* **Major Ticks:** 0, 250, 500, 750, 1000, 1250, 1500, 1750.
* **Y-Axis:**
* **Label:** "CDF"
* **Scale:** Linear, ranging from 0.0 to 1.0.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Legend:**
* **Position:** Bottom-right quadrant of the plot area.
* **Content:** Four entries, each associating a colored line with a "Window Size" value.
* **Entries (from top to bottom in legend):**
1. Blue line: "Window Size=32"
2. Orange line: "Window Size=64"
3. Green line: "Window Size=128"
4. Red line: "Window Size=256"
* **Grid:** Dashed grid lines are present for both major X and Y ticks.
* **Background:** White plot area with a light gray border.
### Detailed Analysis
The chart plots four CDF curves, each representing a different window size. All curves originate at (0, 0.0) and asymptotically approach a CDF of 1.0 as the number of recomputed tokens increases.
**Trend Verification & Data Point Extraction (Approximate):**
1. **Blue Line (Window Size=32):**
* **Trend:** Steepest initial ascent, reaching near 1.0 the fastest.
* **Key Points:** CDF ≈ 0.6 at X=0 (vertical jump). Reaches CDF ≈ 0.9 by X≈100. Approaches CDF ≈ 1.0 by X≈250.
2. **Orange Line (Window Size=64):**
* **Trend:** Less steep than blue, but steeper than green and red.
* **Key Points:** CDF ≈ 0.6 at X=0. Reaches CDF ≈ 0.9 by X≈200. Approaches CDF ≈ 1.0 by X≈500.
3. **Green Line (Window Size=128):**
* **Trend:** More gradual ascent than orange.
* **Key Points:** CDF ≈ 0.6 at X=0. Reaches CDF ≈ 0.9 by X≈400. Approaches CDF ≈ 1.0 by X≈750.
4. **Red Line (Window Size=256):**
* **Trend:** Most gradual ascent, with the longest tail.
* **Key Points:** CDF ≈ 0.6 at X=0. Reaches CDF ≈ 0.8 by X≈250. Reaches CDF ≈ 0.9 by X≈500. Approaches CDF ≈ 1.0 by X≈1000, with a very gradual approach to 1.0 extending beyond X=1500.
**Spatial Grounding:** The legend is placed in the bottom-right, overlapping the tail of the red and green curves. The lines are clearly distinguishable by color as defined in the legend.
### Key Observations
1. **Clear Ordering:** There is a strict, non-crossing order to the curves. For any given number of recomputed tokens (X-value), the CDF is highest for Window Size=32 and lowest for Window Size=256. This means a smaller window size has a higher probability of requiring fewer recomputed tokens.
2. **Initial Jump:** All four curves exhibit a near-vertical jump from CDF=0.0 to CDF≈0.6 at X=0. This indicates that approximately 60% of requests, regardless of window size, require zero or a negligible number of recomputed tokens.
3. **Tail Behavior:** The "tail" of the distribution (the approach to CDF=1.0) becomes significantly longer as window size increases. The red line (256) has a very long, shallow tail compared to the blue line (32).
4. **Median Points (CDF=0.5):** The median number of recomputed tokens (where CDF=0.5) is effectively 0 for all configurations due to the initial jump. The more informative metric is the point where CDF=0.9 (90th percentile).
### Interpretation
This CDF chart demonstrates the performance characteristic of a system where "window size" is a key parameter. The data suggests:
* **Efficiency of Smaller Windows:** Smaller window sizes (e.g., 32) are associated with a much lower computational overhead in terms of recomputed tokens. Over 90% of requests with a window size of 32 require fewer than ~100 recomputed tokens.
* **Cost of Larger Context:** Increasing the window size to 256 dramatically increases the potential computational cost. While 60% of requests still incur near-zero cost, the remaining 40% have a much wider and higher distribution of recomputed tokens, with a non-trivial probability of requiring over 1000 tokens to be recomputed.
* **System Design Implication:** The chart visualizes a trade-off. A larger window size likely provides the system (e.g., a language model or cache) with more context, which may improve output quality. However, this comes at the cost of significantly higher and more variable computational work (recomputation) per request. The long tail for Window Size=256 indicates that outlier requests can be very expensive.
* **The 60% Baseline:** The consistent jump to CDF≈0.6 at X=0 is a critical finding. It implies that for a majority of requests, the window size parameter has no impact on recomputation cost, likely because the request is simple or the necessary context is already cached. The parameter's cost impact is only felt by the minority of more complex requests.
</details>
(c) CDF of recomputed tokens
<details>
<summary>x10.png Details</summary>

### Visual Description
## Bar Chart: Recompute Cost vs. Window Size
### Overview
The image displays a vertical bar chart illustrating the relationship between "Window Size" and "Recompute Cost (%)". The chart demonstrates a clear, positive correlation: as the window size increases, the associated recompute cost, expressed as a percentage, rises significantly.
### Components/Axes
* **Chart Type:** Vertical Bar Chart.
* **X-Axis (Horizontal):**
* **Label:** "Window Size"
* **Categories/Markers:** Four discrete values are plotted: `32`, `64`, `128`, and `256`.
* **Y-Axis (Vertical):**
* **Label:** "Recompute Cost (%)"
* **Scale:** Linear scale ranging from 0 to 40, with major tick marks at intervals of 10 (0, 10, 20, 30, 40).
* **Data Series:** A single data series represented by four purple bars with a diagonal hatching pattern.
* **Data Labels:** Each bar has its exact percentage value displayed directly above it.
* **Legend:** Not present, as there is only one data series.
### Detailed Analysis
The chart presents four data points, each corresponding to a specific window size:
1. **Window Size 32:** The bar height corresponds to a recompute cost of **6.81%**.
2. **Window Size 64:** The bar height corresponds to a recompute cost of **12.42%**.
3. **Window Size 128:** The bar height corresponds to a recompute cost of **24.92%**.
4. **Window Size 256:** The bar height corresponds to a recompute cost of **46.41%**.
**Trend Verification:** The visual trend is a consistent and steep upward slope from left to right. Each subsequent bar is noticeably taller than the previous one, indicating a monotonic increase in cost with window size.
### Key Observations
* **Non-Linear Growth:** The increase in recompute cost is not linear. The cost approximately doubles when the window size doubles from 32 to 64 (6.81% to 12.42%), and again from 64 to 128 (12.42% to 24.92%). The jump from 128 to 256 is the largest in absolute terms (an increase of ~21.49 percentage points).
* **Magnitude at Largest Size:** At a window size of 256, the recompute cost reaches 46.41%, which is nearly half of the maximum y-axis value shown (40%). This suggests the cost may be approaching or exceeding 50% for this configuration.
* **Visual Emphasis:** The bar for window size 256 is the most visually dominant element in the chart, drawing immediate attention to the high cost associated with the largest window.
### Interpretation
This chart quantifies a critical performance trade-off in a computational system, likely related to machine learning models or data processing pipelines that use context windows (e.g., transformers, sequence models).
* **What the data suggests:** The data demonstrates that "Recompute Cost" scales poorly with "Window Size". The relationship appears to be super-linear, possibly quadratic or exponential, meaning that efforts to increase the window size (perhaps for better context understanding or accuracy) come at a disproportionately high computational expense.
* **How elements relate:** The x-axis represents a design or configuration parameter (window size), while the y-axis represents a direct system cost (recompute percentage). The chart directly links a design choice to its operational impact.
* **Notable implications:** The sharp rise in cost, especially beyond a window size of 128, indicates a potential scalability bottleneck. System designers would need to carefully balance the benefits of a larger context window against this significant increase in recompute overhead. The 46.41% cost at size 256 is a major red flag for efficiency, suggesting that operating at this scale may be prohibitively expensive without architectural optimizations. The chart provides a clear empirical basis for making such cost-benefit decisions.
</details>
(d) Total recomputation overhead
Figure 9: The cost of verification and recomputation with varying window sizes.
#### Case-2: When verification fails.
Occasionally, a verification pass disagrees with one or more decoded tokens, e.g., only $T_{1}^{\prime}$ matches with the verifier’s output in 8(b). In this case, LLM-42 commits the output only up to the last matching token ( $T_{1}^{\prime}$ ); all subsequent tokens ( $T_{2}^{\prime}$ and $T_{3}^{\prime}$ ) are rejected. The verifier-generated token that appears immediately after the last matching position ( $T_{2}$ ) is also accepted and the KV cache is truncated at this position. The next decode iteration resumes from this repaired, consistent state.
#### Making KV cache consistent.
During the decode phase, the KV cache is populated by fast-path iterations that execute under dynamic batching. Consequently, even when token verification succeeds, the KV cache corresponding to the verified window may still be inconsistent, since it was produced by non-deterministic execution. This inconsistency could affect tokens generated in future iterations despite the current window being verified. Token-level verification alone is therefore insufficient without repairing the KV cache. To address this, we overwrite the KV cache entries produced during decoding with the corresponding entries from the verification pass. This ensures that both the emitted tokens and the KV cache state are consistent for subsequent decode iterations, eliminating downstream divergence.
#### Guaranteed forward progress.
Note that each verification pass produces at least one new consistent output token as shown in Figure 8. As a result, DVR guarantees forward progress even in contrived worst-case scenarios that might trigger rollbacks for every optimistically generated token. We have not observed any such scenario in our experiments.
Overall, DVR follows the high-level structure of speculative decoding, but differs in several important ways as discussed in Table 1. Under DVR, decoded tokens result from a faithful execution of the model’s forward pass, with deviations arising only from the floating-point rounding errors. In contrast, speculative execution techniques generate candidate tokens using modified forward computations—for example, by running a smaller or distilled draft model [specdecoding-icml2023, specinfer-2024] or by truncating or pruning attention/context [medusa, fu2023lookahead]. Because these approximations change the computation itself, speculation depth is typically limited to a few (2-8) tokens [medusa, fu2023lookahead, specdecoding-icml2023, specinfer-2024]. In contrast, leveraging O1, DVR can safely speculate over longer (32-64) token sequences. For the same reason, verification in DVR succeeds with high probability, in contrast to the much lower acceptance rates observed in existing speculative decoding schemes. Finally, DVR performs verification using the same model, whereas most speculative decoding approaches require a separate model for verification.
### 4.3 Grouped Verification
The efficiency of DVR depends on the size of verification window and involves a trade-off: smaller windows incur higher verification cost but low recomputation overhead, whereas larger windows reduce verification cost at the expense of increased recomputation. We empirically characterize this trade-off by profiling Llama-3.1-8B-Instruct on an H100-PCIe GPU. We measure per-token verification cost based on the latency of verification forward pass. To quantify the recomputation cost, we execute 4096 requests from the ShareGPT dataset in an online setting at 12 queries per second. For each window size, we measure the total number of tokens decoded versus the number of tokens returned to the user; the difference between the two denotes recomputation overhead.
9(a) shows the per-token verification cost as a function of verification window size. For smaller windows, the verification pass is memory-bound: each token performs very little computation, resulting in low arithmetic intensity and poor hardware utilization. Consequently, the verification cost is high—up to 0.75 ms per-token. As the verification window increases, the kernel transitions to being compute-bound, and the per-token cost drops sharply, reaching 0.05 ms at a window size of 512, signifying a reduction of $15\times$ .
9(b) shows that more than half of the requests complete without any rollback (i.e., all their output tokens pass verification), while a small fraction of requests incur frequent rollbacks. Moreover, rollbacks become more common as the window size increases. For example, with a window size of 256, about 40% of requests observe a rollback ratio of 50% or higher indicating that at least half of the verification steps detect one or more mismatched tokens. In contrast, with a window size of 32, only about 5% of requests reach this level. The number of recomputed tokens per request also follows the same trend as shown in 9(c). Further, 9(d) shows the resulting total recomputation overhead. Note that a verification failure requires recomputing all tokens following the mismatched position within the current window. As a result, larger windows incur higher recomputation overhead on average. Concretely, recomputation overhead is 6.81% at a window size of 32 and increases roughly linearly, reaching 46.41% at a window size of 256.
We propose grouped verification to address the inherent trade-off between the cost of verification and recomputation. Instead of verifying a large window of a single request (256 tokens), we verify small, fixed-size windows of multiple requests together in a single pass (e.g., 8 requests, 32 tokens each). This way each request retains the rollback properties of a small window, while the verification pass operates on a large effective batch, achieving high utilization and low verification cost.
### 4.4 Discussion
Guaranteeing determinism requires every operator in the inference pipeline to behave consistently. This section highlights a few subtle sources of inconsistency in commonly used operators. We do not introduce new techniques here; instead, we adopt established approaches to enforce consistent behavior and summarize them for completeness.
#### Attention.
Attention involves reductions along multiple steps: reductions along the sequence dimension (e.g., in FlashDecoding-style sequence parallelism [flashdecoding]) and reductions inside the softmax computation. To make it consistent, we use FlashAttention-3 attention kernel and set the number of KV splits to one in the verification pass; fast-path decode iterations run as usual. Some performance optimizations are possible based on SGLang implementation https://lmsys.org/blog/2025-09-22-sglang-deterministic/.
#### Communication collectives.
Classical ring-based AllReduce reduces tokens in different orders depending on their position in the batch. In contrast, multimem-based AllReduce, introduced in CUDA 13.0, follows consistent reduction schedules [nvls-deterministic] and should be preferred whenever supported. On older platforms where multimem/NVLS is unavailable, one can use tree-based AllReduce with fixed NCCL configuration (e.g., setting num_channels to one and using a fixed protocol) to achieve determinism, at the expense of higher communication cost than ring-based AllReduce.
#### Sampling.
We adopt sampler from SGLang. When temperature is zero, it selects the token with the highest logit (argmax) and if there are multiple maximal values then it returns the index of the first maximal value. For non-greedy sampling, however, the sampling process involves randomness, making the outputs sensitive to how random numbers are generated and consumed. To address this issue, SGLang introduces a new sampling function, multinomial_with_seed, which replaces torch.multinomial, an inherently non-deterministic operator under batched execution. This function perturbs logits with Gumbel noise generated from a seeded hash function, ensuring that the same input–seed pair always produces the same sample [SGLangTeam2025].
Overall, enforcing determinism across the entire inference pipeline requires careful configuration of the attention kernel and selecting an appropriate AllReduce implementation. The sampling module does require a new implementation, but this is a one-time cost since the same sampler is used across all models. In contrast, the bulk of the performance and engineering effort in LLM systems lies in GEMM kernels, which LLM-42 reuses entirely, along with RMSNorm and FusedMoE kernels.
## 5 Evaluation
Our evaluation answers the following questions:
| ShareGPT ArXiv | 92812 5941 | Input Length Output Length Input Length | 304 192 7017 | 136 118 6435 | 491 212 3479 |
| --- | --- | --- | --- | --- | --- |
| Test Split | | Output Length | 198 | 191 | 74 |
Table 3: Datasets and their input/output context lengths.
<details>
<summary>x11.png Details</summary>
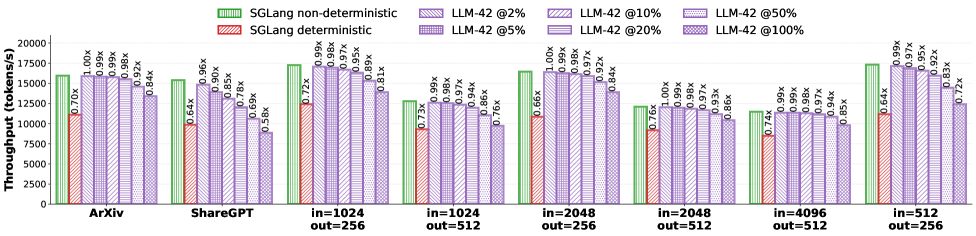
### Visual Description
## Bar Chart: Throughput Comparison of SGLang and LLM-42 Systems
### Overview
This is a grouped bar chart comparing the throughput performance, measured in tokens per second, of two SGLang configurations (non-deterministic and deterministic) against an LLM-42 system operating at various percentage levels (2%, 5%, 10%, 20%, 50%, 100%). The comparison is made across seven different workload scenarios defined by dataset (ArXiv, ShareGPT) and input/output sequence lengths.
### Components/Axes
* **Y-Axis:** Labeled "Throughput (tokens/s)". The scale runs from 0 to 20,000, with major gridlines at intervals of 2,500.
* **X-Axis:** Represents seven distinct workload categories. From left to right:
1. `ArXiv`
2. `ShareGPT`
3. `in=1024 out=256`
4. `in=1024 out=512`
5. `in=2048 out=256`
6. `in=2048 out=512`
7. `in=4096 out=512`
8. `in=512 out=256`
* **Legend:** Located at the top of the chart. It defines seven data series with distinct colors and patterns:
* **SGLang non-deterministic:** Green bar with diagonal stripes (top-left to bottom-right).
* **SGLang deterministic:** Red bar with diagonal stripes (top-left to bottom-right).
* **LLM-42 @2%:** Light purple bar with a dense dot pattern.
* **LLM-42 @5%:** Medium purple bar with a sparse dot pattern.
* **LLM-42 @10%:** Darker purple bar with a diagonal cross-hatch pattern.
* **LLM-42 @20%:** Purple bar with a horizontal line pattern.
* **LLM-42 @50%:** Purple bar with a vertical line pattern.
* **LLM-42 @100%:** Dark purple bar with a solid fill.
* **Data Labels:** Each bar has a numerical label on top indicating its value in tokens/s and a multiplier (e.g., "1.00x") showing its performance relative to the "SGLang non-deterministic" baseline for that specific workload category.
### Detailed Analysis
The chart presents a consistent pattern across all seven workload categories. For each category, there are eight bars grouped together.
**Trend Verification & Data Points (Approximate values from labels):**
1. **ArXiv:**
* SGLang non-deterministic (Green): ~16,000 tokens/s (1.00x baseline).
* SGLang deterministic (Red): ~10,700 tokens/s (0.67x).
* LLM-42 throughput **decreases** as the percentage increases: @2% (~19,000, 1.19x) > @5% (~18,500, 1.16x) > @10% (~18,000, 1.13x) > @20% (~17,500, 1.09x) > @50% (~17,000, 1.06x) > @100% (~16,500, 1.03x).
2. **ShareGPT:**
* SGLang non-deterministic: ~15,000 tokens/s (1.00x).
* SGLang deterministic: ~10,000 tokens/s (0.67x).
* LLM-42 trend: @2% (~18,000, 1.20x) > @5% (~17,500, 1.17x) > @10% (~17,000, 1.13x) > @20% (~16,000, 1.07x) > @50% (~15,000, 1.00x) > @100% (~14,000, 0.93x).
3. **in=1024 out=256:**
* SGLang non-deterministic: ~17,000 tokens/s (1.00x).
* SGLang deterministic: ~12,000 tokens/s (0.71x).
* LLM-42 trend: @2% (~19,000, 1.12x) > @5% (~18,500, 1.09x) > @10% (~18,000, 1.06x) > @20% (~17,500, 1.03x) > @50% (~16,500, 0.97x) > @100% (~15,500, 0.91x).
4. **in=1024 out=512:**
* SGLang non-deterministic: ~13,000 tokens/s (1.00x).
* SGLang deterministic: ~9,500 tokens/s (0.73x).
* LLM-42 trend: @2% (~15,000, 1.15x) > @5% (~14,500, 1.12x) > @10% (~14,000, 1.08x) > @20% (~13,500, 1.04x) > @50% (~12,500, 0.96x) > @100% (~11,500, 0.88x).
5. **in=2048 out=256:**
* SGLang non-deterministic: ~16,500 tokens/s (1.00x).
* SGLang deterministic: ~11,500 tokens/s (0.70x).
* LLM-42 trend: @2% (~18,500, 1.12x) > @5% (~18,000, 1.09x) > @10% (~17,500, 1.06x) > @20% (~17,000, 1.03x) > @50% (~16,000, 0.97x) > @100% (~15,000, 0.91x).
6. **in=2048 out=512:**
* SGLang non-deterministic: ~12,500 tokens/s (1.00x).
* SGLang deterministic: ~9,000 tokens/s (0.72x).
* LLM-42 trend: @2% (~14,500, 1.16x) > @5% (~14,000, 1.12x) > @10% (~13,500, 1.08x) > @20% (~13,000, 1.04x) > @50% (~12,000, 0.96x) > @100% (~11,000, 0.88x).
7. **in=4096 out=512:**
* SGLang non-deterministic: ~12,000 tokens/s (1.00x).
* SGLang deterministic: ~8,500 tokens/s (0.71x).
* LLM-42 trend: @2% (~14,000, 1.17x) > @5% (~13,500, 1.13x) > @10% (~13,000, 1.08x) > @20% (~12,500, 1.04x) > @50% (~11,500, 0.96x) > @100% (~10,500, 0.88x).
8. **in=512 out=256:**
* SGLang non-deterministic: ~17,500 tokens/s (1.00x).
* SGLang deterministic: ~12,000 tokens/s (0.69x).
* LLM-42 trend: @2% (~19,500, 1.11x) > @5% (~19,000, 1.09x) > @10% (~18,500, 1.06x) > @20% (~17,500, 1.00x) > @50% (~16,500, 0.94x) > @100% (~15,500, 0.89x).
### Key Observations
1. **Consistent Hierarchy:** In every single workload category, the performance order from highest to lowest throughput is: LLM-42 @2% > LLM-42 @5% > LLM-42 @10% > LLM-42 @20% > SGLang non-deterministic > LLM-42 @50% > LLM-42 @100% > SGLang deterministic.
2. **LLM-42 Inverse Scaling:** There is a clear, monotonic **downward trend** in LLM-42 throughput as its operational percentage increases from 2% to 100%. The 2% configuration is consistently the fastest system overall.
3. **SGLang Deterministic Penalty:** The deterministic mode of SGLang consistently incurs a significant performance penalty (approximately 30-33% lower throughput) compared to its non-deterministic mode across all tests.
4. **Workload Impact:** Throughput is generally highest for the `in=512 out=256` and `ArXiv` workloads and lowest for the `in=4096 out=512` workload, suggesting longer input sequences significantly reduce processing speed.
### Interpretation
The data strongly suggests that the LLM-42 system's throughput is highly sensitive to the "percentage" parameter, which likely represents a resource allocation, sampling rate, or confidence threshold. Lower percentages (2%, 5%) yield superior performance, outperforming even the optimized SGLang non-deterministic baseline. This indicates a potential trade-off where allocating fewer resources or accepting a lower confidence level per token results in higher overall system throughput.
The consistent underperformance of SGLang's deterministic mode highlights the computational overhead required to guarantee reproducible outputs. The choice between SGLang modes would thus depend on whether reproducibility is a critical requirement for the application, justifying the ~30% speed cost.
The workload-specific variations (e.g., lower throughput for longer input sequences) provide practical guidance for system deployment, indicating that performance will degrade as the context length of the task increases. The chart effectively demonstrates that for maximizing raw token generation speed, a lightly-loaded LLM-42 instance is the optimal choice among the tested configurations.
</details>
Figure 10: Throughput in offline inference. SGLang has only two modes: all requests run in either deterministic or non-deterministic mode whereas LLM-42 supports selective determinism (% values in the legend reflect the fraction of traffic that requires deterministic output).
- How does LLM-42 compare against the baseline’s deterministic and non-deterministic modes?
- How does LLM-42 perform for different mix of deterministic and non-deterministic traffic?
- How do configuration parameters affect the performance of grouped verification in LLM-42?
Models and environment: We evaluate LLM-42 with the Llama-3.1-8B-Instruct model. It has 32 query heads, 8 KV heads, and 32 layers. Experiments were conducted on a system equipped with four NVIDIA H100 PCIe GPUs with 80 GB HBM3 memory and 114 streaming multiprocessors per GPU. The host CPU has 64 physical cores (128 hardware threads) and approximately 1.65 TB of DRAM.
Workloads: We evaluate on synthetic inputs with varying context lengths, following common practice in prior work [nanoflow2024]. We additionally benchmark on the widely used ShareGPT [huggingfacesharegpt] and Arxiv [arxiv-summarization] datasets, whose characteristics are summarized in Table 3. All experiments use the meta-llama/Llama-3.1-8B-Instruct tokenizer. To evaluate LLM-42 under different workload conditions, we vary the fraction of requests that require deterministic output between 2%, 5%, 10%, 20%, 50%, and 100%. While higher deterministic ratios are included for stress testing, we expect that in practical deployments only a small fraction of requests will require determinism. Finally, note that the deterministic request ratio applies only to LLM-42; approaches based on batch-invariant computation support only global determinism.
Serving system baselines: We implement LLM-42 on top of the SGLang serving framework version 0.5.3rc0 and compare performance against SGLang with deterministic execution switched on. To understand the upper limit on performance, we also compare with the non-deterministic version of SGLang. We refer to these two baselines as SGLang-Deterministic and SGLang-Non-Deterministic. We use FA-3 attention kernel in all our experiments; we set num_splits = 1 in the verification step of LLM-42 and use the default settings for the decode phases.
Metrics: In offline inference, we evaluate throughput as the number of tokens processed per second. For online inference, we evaluate end-to-end request execution latencies and time-to-first-token. To better understand the overhead of our approach, we also report the number of rollbacks and recomputed tokens across different configurations of LLM-42.
### 5.1 Offline Inference
For offline inference, we evaluate eight workload configurations: two traces from the ArXiv and ShareGPT datasets and six other configurations with different input and output lengths. Each configuration executes 4096 requests to completion. Figure 10 reports the resulting throughput across systems measured in tokens per second; we summarize the main observations below.
Enabling deterministic inference in SGLang incurs a substantial throughput penalty, ranging from 24% (in=2048, out=512) to 36% (ShareGPT). This slowdown stems from the use of batch-invariant kernels, which are consistently slower than the standard optimized kernels, as shown in Figure 4. In contrast, LLM-42 mostly uses regular optimized kernels and therefore achieves significantly higher throughput. Even in its worst case—when 100% of requests require deterministic output— LLM-42 outperforms SGLang-Deterministic in all but one setting (ShareGPT), where it is only 6% slower.
| Dataset / Config Total number of rollbacks | Deterministic Ratio 2% | 5% | 10% | 20% | 50% | 100% |
| --- | --- | --- | --- | --- | --- | --- |
| ArXiv | 70 | 170 | 372 | 697 | 1733 | 3351 |
| ShareGPT | 4 | 5 | 10 | 15 | 44 | 96 |
| in=512, out=256 | 0 | 0 | 0 | 0 | 0 | 0 |
| in=1024, out=256 | 0 | 1 | 5 | 5 | 9 | 24 |
| in=1024, out=512 | 48 | 106 | 225 | 386 | 792 | 1536 |
| in=2048, out=256 | 7 | 22 | 79 | 134 | 378 | 724 |
| in=2048, out=512 | 0 | 0 | 0 | 2 | 2 | 4 |
| in=4096, out=512 | 31 | 79 | 98 | 220 | 538 | 1087 |
| Total number of recomputed tokens | | | | | | |
| ArXiv | 1805 | 4414 | 8737 | 13198 | 37687 | 89248 (10.97%) |
| ShareGPT | 139 | 158 | 164 | 396 | 1185 | 2691 (0.32%) |
| in=512, out=256 | 0 | 0 | 0 | 0 | 0 | 0 (0%) |
| in=1024, out=256 | 0 | 44 | 151 | 151 | 288 | 776 (0.07%) |
| in=1024, out=512 | 1724 | 3272 | 6615 | 12392 | 25967 | 50454 (2.41%) |
| in=2048, out=256 | 268 | 767 | 2470 | 4080 | 12173 | 21772 (2.08%) |
| in=2048, out=512 | 0 | 0 | 0 | 81 | 81 | 101 ( $<\!0.01\$ ) |
| in=4096, out=512 | 1134 | 2961 | 3598 | 7208 | 17161 | 32430 (1.55%) |
Table 4: Rollback and recomputation statistics (grouped verification over 8 requests, 64 tokens each). Recompute cost is shown only for the column with 100% deterministic traffic.
Crucially, LLM-42 ’s throughput improves monotonically as the fraction of deterministic requests decreases. On ArXiv, LLM-42 operates within 8%, 2%, 1% and 1% of the best-case throughput (SGLang-Non-Deterministic) at 5%, 10%, 20%, and 50% deterministic traffic, respectively. This behavior is expected: LLM-42 imposes no computation overhead on requests that do not require determinism. As a result, LLM-42 is up to 41% faster than SGLang-Deterministic in these regimes. This trend holds across all workload configurations; for example, at 10% deterministic traffic, LLM-42 is 33% faster than SGLang-Deterministic on ShareGPT and up to 48% faster (in=2048, out=256) on other workloads.
Table 4 reports two complementary metrics that characterize the overhead of enforcing determinism in LLM-42: (1) the total number of rollbacks aggregated over all 4096 requests, and (2) the total number of recomputed tokens incurred due to these rollbacks. We find that some configurations incur zero rollbacks even under non-trivial deterministic ratios, and the average case remains low across datasets and input–output lengths. Even in the worst case, ArXiv at 100% deterministic traffic, the system triggers 3351 rollbacks over 4096 requests, i.e., fewer than one rollback per request on average. A similar trend holds for recomputation overhead: the recomputed token fraction is consistently small, with the worst case at 100% deterministic traffic reaching at most 10.97%, while the average case across datasets and configurations is substantially lower. Overall, these results indicate that both rollback frequency and recomputation cost are modest in practice.
<details>
<summary>x12.png Details</summary>
### Visual Description
## CDF Plot: End-to-End Latency Comparison
### Overview
This image is a Cumulative Distribution Function (CDF) plot comparing the end-to-end (E2E) latency distributions of several systems or configurations. The chart visualizes the probability (CDF) that a request's latency is less than or equal to a given value on the x-axis. The primary comparison is between two variants of "SGLang" and multiple configurations of "LLM-42" at different percentage levels.
### Components/Axes
* **Chart Type:** Cumulative Distribution Function (CDF) line plot.
* **X-Axis:**
* **Label:** `E2E Latency (ms)`
* **Scale:** Linear scale from 0 to 100,000 milliseconds (ms).
* **Major Ticks:** 0, 20000, 40000, 60000, 80000, 100000.
* **Y-Axis:**
* **Label:** `CDF`
* **Scale:** Linear scale from 0.0 to 1.0.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Legend:** Located in the bottom-right quadrant of the plot area. It contains 8 entries, each with a colored line sample and a text label.
1. **Green Line:** `SGLang non-deterministic`
2. **Red Line:** `SGLang deterministic`
3. **Blue Line:** `LLM-42 @2%`
4. **Orange Line:** `LLM-42 @5%`
5. **Purple Line:** `LLM-42 @10%`
6. **Brown Line:** `LLM-42 @20%`
7. **Pink Line:** `LLM-42 @50%`
8. **Cyan Line:** `LLM-42 @100%`
### Detailed Analysis
The plot shows eight distinct CDF curves. The general trend for all curves is a steep initial rise that gradually plateaus as they approach a CDF of 1.0. The key difference is the latency value at which this plateau occurs.
**Trend Verification & Data Points (Approximate):**
1. **SGLang non-deterministic (Green):**
* **Trend:** The steepest initial slope. Reaches a CDF of ~0.9 by ~10,000 ms and plateaus near 1.0 by ~15,000 ms.
* **Interpretation:** This configuration has the lowest latency profile, with nearly all requests completing under 15 seconds.
2. **SGLang deterministic (Red):**
* **Trend:** Very similar to the green line but slightly less steep. Reaches CDF ~0.9 by ~12,000 ms and plateaus by ~20,000 ms.
* **Interpretation:** Deterministic mode introduces a small latency overhead compared to non-deterministic mode.
3. **LLM-42 @2% (Blue), @5% (Orange), @10% (Purple), @20% (Brown):**
* **Trend:** These four lines are tightly clustered together, forming a distinct group between the SGLang lines and the higher-percentage LLM-42 lines. They rise steeply, reaching CDF ~0.8 by ~15,000 ms and plateauing near 1.0 by ~25,000-30,000 ms.
* **Interpretation:** At lower percentage loads (2%-20%), the LLM-42 system exhibits very similar latency performance, which is slower than SGLang but significantly faster than at higher percentages.
4. **LLM-42 @50% (Pink):**
* **Trend:** Clearly separated from the lower-percentage cluster. Has a less steep slope. Reaches CDF ~0.8 by ~20,000 ms and approaches 1.0 around ~40,000 ms.
* **Interpretation:** A noticeable performance degradation occurs at 50% load compared to 20%.
5. **LLM-42 @100% (Cyan):**
* **Trend:** The shallowest slope and rightmost curve. It rises more gradually, crossing CDF 0.8 at ~30,000 ms and only approaching 1.0 near the 60,000 ms mark.
* **Interpretation:** This represents the worst-case latency scenario shown, with a long tail of requests taking significantly longer to complete.
### Key Observations
* **Clear Performance Tiers:** The data reveals three distinct performance tiers:
1. **Fastest:** SGLang variants (both under ~20s).
2. **Mid-range:** LLM-42 at low load (2%-20%, under ~30s).
3. **Slowest:** LLM-42 at high load (50%-100%, with 100% extending to ~60s).
* **Non-Linear Degradation for LLM-42:** The latency increase for LLM-42 is not linear with the percentage. The jump from 20% to 50% is significant, and the jump from 50% to 100% is even more pronounced, indicating potential resource contention or queueing effects at higher loads.
* **SGLang Deterministic Overhead:** The deterministic version of SGLang shows a consistent, small latency penalty compared to its non-deterministic counterpart across the entire distribution.
* **Absence of Extreme Outliers:** All curves reach a CDF of 1.0 within the plotted range (100,000 ms), suggesting no requests in this dataset exceeded ~100 seconds.
### Interpretation
This CDF plot is a performance benchmark likely comparing a system named SGLang against another named LLM-42 under varying load conditions (represented by the percentages).
The data strongly suggests that **SGLang offers superior and more consistent latency performance** compared to LLM-42 in this test scenario. Its non-deterministic mode is the fastest overall.
For **LLM-42, the percentage likely represents a load factor** (e.g., GPU utilization, request rate, or batch size). The plot demonstrates a clear **performance cliff**: latency remains relatively stable and acceptable up to 20% load but degrades sharply at 50% and severely at 100%. This pattern is critical for capacity planning, indicating that operating LLM-42 beyond 20-50% of its capacity may lead to a poor user experience due to high and variable latency.
The use of a CDF is particularly effective here as it shows not just average latency, but the entire distribution, revealing the "tail latency" (the slowest requests) which is often the most important metric for user experience. The tight clustering of the low-load LLM-42 lines and the SGLang lines indicates predictable performance, while the spreading of the high-load lines indicates increasing variability and unpredictability under stress.
</details>
(a) QPS=12
<details>
<summary>x13.png Details</summary>
### Visual Description
## CDF Chart: End-to-End Latency Comparison
### Overview
This image displays a Cumulative Distribution Function (CDF) plot comparing the end-to-end (E2E) latency performance of two systems: "SGLang" (in deterministic and non-deterministic modes) and "LLM-42" at various percentage-based configurations. The chart visualizes the probability (CDF) that a request's latency is less than or equal to a given time value.
### Components/Axes
* **Chart Type:** Cumulative Distribution Function (CDF) line chart.
* **X-Axis:** Labeled **"E2E Latency (ms)"**. It represents time in milliseconds, with major tick marks at 0, 20000, 40000, 60000, 80000, and 100000.
* **Y-Axis:** Labeled **"CDF"**. It represents the cumulative probability, ranging from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Positioned in the **bottom-right quadrant** of the chart area. It contains 8 entries, each with a colored line sample and a text label:
1. Green line: `SGLang non-deterministic`
2. Red line: `SGLang deterministic`
3. Blue line: `LLM-42 @2%`
4. Orange line: `LLM-42 @5%`
5. Purple line: `LLM-42 @10%`
6. Brown line: `LLM-42 @20%`
7. Pink line: `LLM-42 @50%`
8. Cyan line: `LLM-42 @100%`
* **Grid:** A light gray, dashed grid is present for both major X and Y axis ticks.
### Detailed Analysis
**Trend Verification & Data Points:**
All lines originate at (0 ms, 0.0 CDF) and rise to approach or reach a CDF of 1.0, indicating all measured requests complete within the displayed latency range.
1. **SGLang Lines (Green & Red):**
* **Trend:** Both lines exhibit the steepest initial slope, rising very rapidly.
* **Data Points:** They cross the 0.8 CDF mark at approximately 5,000-7,000 ms. They reach a CDF of ~0.95 by 20,000 ms and converge to 1.0 shortly after 40,000 ms. The green (non-deterministic) and red (deterministic) lines are nearly coincident, with the red line appearing marginally to the left (slightly lower latency) in the 0.6-0.9 CDF range.
2. **LLM-42 Lines (Blue, Orange, Purple, Brown, Pink, Cyan):**
* **General Trend:** These lines show a clear gradient. As the percentage in the label increases, the curve shifts to the right, indicating higher latency for the same cumulative probability.
* **LLM-42 @2% (Blue) & @5% (Orange):** These lines closely follow the SGLang lines, being nearly indistinguishable from them in the lower latency region (CDF < 0.8). They are the best-performing among the LLM-42 variants.
* **LLM-42 @10% (Purple):** Begins to show a slight rightward shift compared to the @2%/@5% lines, especially noticeable above CDF 0.6.
* **LLM-42 @20% (Brown):** Shows a more pronounced rightward shift. It crosses 0.8 CDF at approximately 15,000 ms.
* **LLM-42 @50% (Pink):** Has a significantly more gradual slope. It crosses 0.8 CDF at approximately 25,000 ms.
* **LLM-42 @100% (Cyan):** Exhibits the most gradual slope and highest latency. It crosses 0.8 CDF at approximately 35,000 ms and does not reach a CDF of 1.0 until near the 100,000 ms mark.
### Key Observations
1. **Performance Hierarchy:** The systems can be grouped by performance: SGLang (both modes) and LLM-42 @2%/@5% form a high-performance cluster. Latency increases progressively for LLM-42 @10%, @20%, @50%, and @100%.
2. **SGLang Deterministic vs. Non-deterministic:** The performance difference between these two modes is minimal, with the deterministic mode showing a very slight advantage.
3. **LLM-42 Parameter Impact:** There is a direct, monotonic relationship between the percentage parameter in the LLM-42 label and end-to-end latency. Higher percentages result in worse (higher) latency across the entire distribution.
4. **Tail Latency:** The "tail" of the distribution (CDF > 0.9) shows the most dramatic differences. For example, to serve 95% of requests (CDF=0.95), SGLang requires ~20,000 ms, while LLM-42 @100% requires nearly 60,000 ms.
### Interpretation
This chart demonstrates a clear performance trade-off in the LLM-42 system. The percentage value (e.g., @2%, @100%) likely represents a configuration parameter that trades off latency for another resource or quality metric (such as computational cost, memory usage, or output quality/fidelity). The data suggests:
* **SGLang** is optimized for low latency, achieving very fast response times for the vast majority of requests.
* **LLM-42** offers a tunable parameter. At low settings (@2%, @5%), it can match SGLang's latency performance. However, increasing this parameter to presumably gain benefits in another dimension (unshown in this chart) comes at a significant and predictable cost to response time.
* The **Peircean insight** is that the chart doesn't just show "which is faster," but reveals the *cost function* of the LLM-42 system. The consistent, graded spacing between the LLM-42 curves indicates a well-behaved, predictable relationship between the configuration parameter and its latency impact. This allows a user to make an informed engineering trade-off: selecting the highest LLM-42 percentage that still meets their application's latency budget. The near-overlap of SGLang with LLM-42 @2%/@5% suggests that for latency-critical applications, SGLang or LLM-42 at minimal settings are the viable choices.
</details>
(b) QPS=14
<details>
<summary>x14.png Details</summary>
### Visual Description
## CDF Chart: End-to-End Latency Comparison of SGLang and LLM-42 Variants
### Overview
This image is a Cumulative Distribution Function (CDF) plot comparing the end-to-end (E2E) latency performance of two systems: "SGLang" (in deterministic and non-deterministic modes) and "LLM-42" (at various percentage configurations). The chart visualizes the probability (CDF) that a request's latency is less than or equal to a given value on the X-axis.
### Components/Axes
* **Chart Type:** Cumulative Distribution Function (CDF) line chart.
* **X-Axis:**
* **Label:** `E2E Latency (ms)`
* **Scale:** Linear scale from 0 to 120,000 milliseconds (ms).
* **Major Ticks:** 0, 20000, 40000, 60000, 80000, 100000, 120000.
* **Y-Axis:**
* **Label:** `CDF`
* **Scale:** Linear scale from 0.0 to 1.0.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Legend:**
* **Position:** Bottom-right quadrant of the chart area.
* **Content (Listed in order as they appear in the legend box):**
1. `SGLang non-deterministic` (Green line)
2. `SGLang deterministic` (Red line)
3. `LLM-42 @2%` (Blue line)
4. `LLM-42 @5%` (Orange line)
5. `LLM-42 @10%` (Purple line)
6. `LLM-42 @20%` (Brown line)
7. `LLM-42 @50%` (Pink line)
8. `LLM-42 @100%` (Cyan/Light Blue line)
### Detailed Analysis
All data series originate at the coordinate (0, 0.0) and asymptote towards a CDF of 1.0. The primary difference is the rate of ascent, indicating latency distribution.
**Trend Verification & Key Data Points (Approximate):**
1. **SGLang non-deterministic (Green):**
* **Trend:** Steepest initial ascent. Reaches CDF ~0.9 at ~10,000 ms and CDF ~1.0 by ~20,000 ms.
* **Interpretation:** This configuration has the lowest latency for the vast majority of requests.
2. **SGLang deterministic (Red):**
* **Trend:** Very similar to the non-deterministic green line, but slightly less steep. Reaches CDF ~0.9 at ~12,000 ms and CDF ~1.0 by ~25,000 ms.
* **Interpretation:** Deterministic mode introduces a minor latency overhead compared to non-deterministic mode.
3. **LLM-42 Series (General Trend):** The latency increases as the percentage value increases. The curves become progressively less steep.
* **LLM-42 @2% (Blue) & @5% (Orange):** These two lines are nearly indistinguishable and track very closely to the SGLang deterministic (red) line, reaching CDF ~1.0 by ~30,000 ms.
* **LLM-42 @10% (Purple):** Slightly slower than the @2%/5% lines. Reaches CDF ~0.9 at ~18,000 ms.
* **LLM-42 @20% (Brown):** Noticeably slower. Reaches CDF ~0.8 at ~20,000 ms and CDF ~0.95 at ~40,000 ms.
* **LLM-42 @50% (Pink):** Significantly slower. Reaches CDF ~0.8 at ~30,000 ms and CDF ~0.95 at ~60,000 ms.
* **LLM-42 @100% (Cyan):** The slowest configuration by a wide margin. It has the most gradual slope. Reaches CDF ~0.6 at ~20,000 ms, CDF ~0.8 at ~40,000 ms, and CDF ~0.95 at ~80,000 ms. It approaches CDF 1.0 near the 120,000 ms mark.
### Key Observations
* **Performance Clustering:** The SGLang variants and LLM-42 @2%/5%/10% form a high-performance cluster, all achieving CDF >0.9 below 20,000 ms.
* **Clear Performance Degradation:** There is a clear, monotonic degradation in latency for LLM-42 as the configured percentage increases from 20% to 100%.
* **Long Tail Latency:** The LLM-42 @100% (cyan) line exhibits a pronounced "long tail," meaning a significant fraction of requests (the last 5-10%) experience very high latency (60,000 - 120,000 ms).
* **SGLang Determinism Overhead:** The performance gap between SGLang non-deterministic (green) and deterministic (red) is small but consistent across the entire distribution.
### Interpretation
This CDF chart is a powerful tool for comparing service-level performance beyond simple averages. It answers: "For what percentage of requests is the latency below X milliseconds?"
* **What the data suggests:** The SGLang system, in both modes, offers superior and more consistent low-latency performance compared to LLM-42 at higher percentage configurations. For LLM-42, the "@X%" parameter appears to be a direct trade-off knob between some other resource (likely cost, throughput, or quality) and latency. Setting it to 100% maximizes that resource but severely impacts response time consistency.
* **Relationship between elements:** The chart directly correlates a configuration parameter (the percentage for LLM-42, the mode for SGLang) with a critical performance metric (latency distribution). The tight grouping of the leftmost lines indicates a performance ceiling or optimal operating region for these systems under the tested conditions.
* **Notable Anomalies/Outliers:** The LLM-42 @100% line is a clear outlier in terms of tail latency. The near-overlap of the @2% and @5% lines suggests diminishing returns or a performance floor for LLM-42 at very low percentage settings. The chart does not provide the context for what the "@X%" parameter represents (e.g., GPU utilization cap, token budget, etc.), which is crucial for a full technical understanding.
</details>
(c) QPS=16
<details>
<summary>x15.png Details</summary>
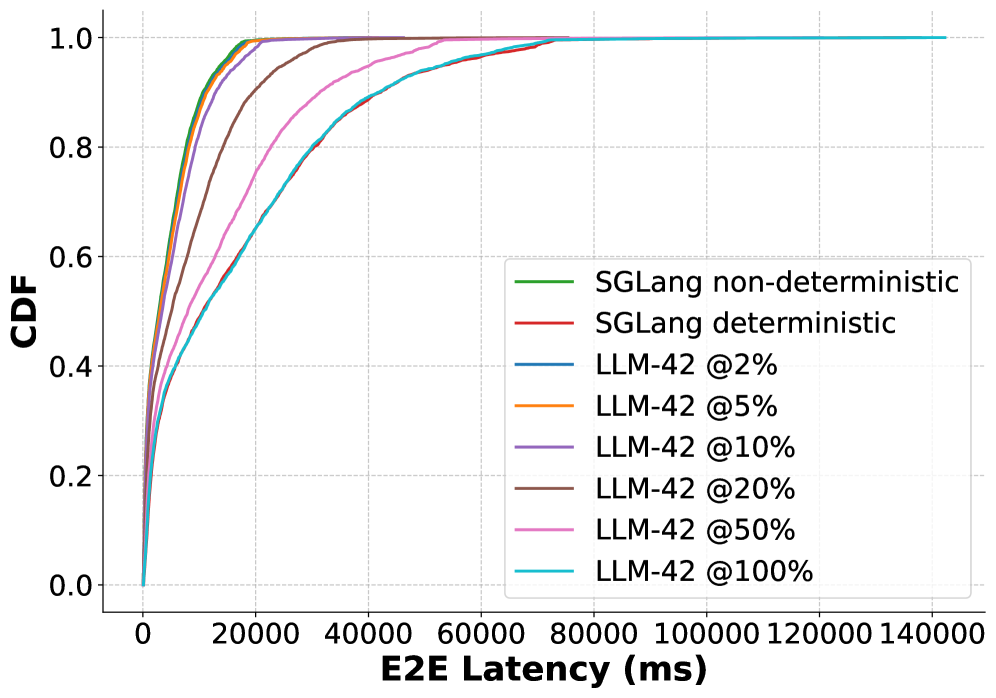
### Visual Description
## Cumulative Distribution Function (CDF) Plot: End-to-End Latency Comparison
### Overview
This image is a line chart displaying the Cumulative Distribution Function (CDF) of End-to-End (E2E) Latency for several systems or configurations. The chart compares the latency performance of two "SGLang" modes against multiple "LLM-42" configurations with varying percentage parameters. The plot shows how the probability (CDF) of a request completing increases as the allowed latency (in milliseconds) increases.
### Components/Axes
* **Chart Type:** Cumulative Distribution Function (CDF) line plot.
* **X-Axis:**
* **Label:** `E2E Latency (ms)`
* **Scale:** Linear scale from 0 to 140,000 milliseconds (ms).
* **Major Ticks:** 0, 20000, 40000, 60000, 80000, 100000, 120000, 140000.
* **Y-Axis:**
* **Label:** `CDF`
* **Scale:** Linear scale from 0.0 to 1.0.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Legend:**
* **Position:** Center-right of the plot area.
* **Content (Top to Bottom):**
1. `SGLang non-deterministic` (Green line)
2. `SGLang deterministic` (Red line)
3. `LLM-42 @2%` (Blue line)
4. `LLM-42 @5%` (Orange line)
5. `LLM-42 @10%` (Purple line)
6. `LLM-42 @20%` (Brown line)
7. `LLM-42 @50%` (Pink line)
8. `LLM-42 @100%` (Cyan line)
* **Grid:** Light gray dashed grid lines are present for both axes.
### Detailed Analysis
The chart plots eight distinct data series. Each line represents the CDF for a specific system/configuration, showing the fraction of requests (Y-axis) that complete within a given latency (X-axis).
**Trend Verification & Data Point Extraction (Approximate):**
All lines start at (0, 0) and approach a CDF of 1.0 (100% completion) as latency increases. The key difference is the rate of ascent.
1. **SGLang non-deterministic (Green):** Steepest initial slope. Reaches CDF ~0.9 by ~10,000 ms and CDF ~1.0 by ~20,000 ms.
2. **SGLang deterministic (Red):** Very similar to the green line, with a marginally slower ascent. Reaches CDF ~0.9 by ~12,000 ms and CDF ~1.0 by ~25,000 ms.
3. **LLM-42 @2% (Blue):** The slowest ascending line. Reaches CDF ~0.5 by ~20,000 ms, CDF ~0.8 by ~40,000 ms, and CDF ~0.95 by ~80,000 ms. It approaches 1.0 near 140,000 ms.
4. **LLM-42 @5% (Orange):** Very close to the green and red SGLang lines, nearly overlapping with them in the initial rise. Reaches CDF ~0.9 by ~12,000 ms.
5. **LLM-42 @10% (Purple):** Slightly slower than the @5% line. Reaches CDF ~0.9 by ~15,000 ms.
6. **LLM-42 @20% (Brown):** Noticeably slower than the @10% line. Reaches CDF ~0.8 by ~20,000 ms and CDF ~0.95 by ~40,000 ms.
7. **LLM-42 @50% (Pink):** Slower still. Reaches CDF ~0.6 by ~20,000 ms, CDF ~0.8 by ~40,000 ms, and CDF ~0.95 by ~80,000 ms.
8. **LLM-42 @100% (Cyan):** The second slowest line, closely following the blue @2% line but slightly above it for most of the curve. Reaches CDF ~0.6 by ~25,000 ms and CDF ~0.9 by ~60,000 ms.
**Spatial Grounding & Cross-Reference:**
* The legend is positioned in the center-right, overlapping the upper portion of the curves.
* The **fastest group** (steepest curves, reaching high CDF at low latency) consists of: `SGLang non-deterministic` (green), `SGLang deterministic` (red), `LLM-42 @5%` (orange), and `LLM-42 @10%` (purple). These are tightly clustered in the top-left region of the plot.
* The **slowest group** (most gradual curves) consists of: `LLM-42 @2%` (blue) and `LLM-42 @100%` (cyan). These two lines are very close together, forming the lower boundary of the curve bundle.
* The `LLM-42 @20%` (brown) and `LLM-42 @50%` (pink) lines occupy the middle ground between the fast and slow groups.
### Key Observations
1. **Clear Performance Tiers:** There is a distinct separation between the high-performance tier (SGLang modes and LLM-42 @5%/10%) and the lower-performance tier (LLM-42 @2% and @100%).
2. **Non-Monotonic Relationship with Percentage:** For LLM-42, performance does not improve linearly with the percentage parameter. The best performance is seen at @5% and @10%, while both lower (@2%) and higher (@50%, @100%) percentages result in significantly worse latency distributions.
3. **SGLang Deterministic vs. Non-deterministic:** The deterministic mode (red) has a very slightly worse latency profile than the non-deterministic mode (green), but the difference is minimal.
4. **Convergence at High Latency:** All configurations eventually reach a CDF of 1.0, meaning all requests complete given enough time (up to ~140 seconds for the slowest). The critical difference is in the "tail latency" – the time required to complete the last 5-10% of requests.
### Interpretation
This chart is a performance benchmark likely comparing different serving or inference systems for large language models (LLMs). The CDF format is excellent for understanding not just average latency, but the entire distribution, which is critical for service-level agreements (SLAs).
* **What the data suggests:** The `SGLang` systems and `LLM-42` configured with a 5% or 10% parameter offer the best and most consistent latency. They handle the vast majority of requests (e.g., 90%) in under 15-20 seconds. The `LLM-42 @2%` and `@100%` configurations have much heavier tails, meaning a significant fraction of users would experience wait times of 40 seconds or more.
* **Why the non-monotonic trend?** The percentage parameter (`@X%`) likely controls a resource allocation or batching strategy. The optimal point (@5-10%) suggests a "sweet spot." Too low (@2%) may underutilize resources, while too high (@50-100%) may cause contention, queuing, or inefficient batching, degrading performance.
* **Practical Implication:** For a production system prioritizing low and predictable latency, `SGLang` or `LLM-42` tuned to 5-10% would be preferable. The `LLM-42 @100%` configuration, while perhaps maximizing throughput in some other metric, comes at a severe cost to tail latency. The chart argues strongly against using the extreme percentage settings for latency-sensitive applications.
</details>
(d) QPS=18
Figure 11: CDF of request end-to-end latency in online inference with varying load for the ShareGPT dataset.
### 5.2 Online Inference
| 12 P75 P90 | P50 35.4 50.3 | 27.0 69.8 107.8 | 53.4 35.8 52.5 | 27.4 36.1 54.1 | 27.6 37.1 54.0 | 27.9 41.1 57.8 | 29.3 52.0 68.1 | 38.5 58.0 73.9 | 45.4 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 14 | P50 | 27.9 | 60.1 | 27.9 | 28.2 | 28.9 | 31.1 | 42.5 | 48.2 |
| P75 | 37.0 | 79.9 | 37.5 | 37.8 | 39.5 | 45.1 | 57.0 | 61.6 | |
| P90 | 55.8 | 127.0 | 57.0 | 56.5 | 58.6 | 63.8 | 75.8 | 82.0 | |
| 16 | P50 | 28.8 | 62.5 | 28.8 | 29.2 | 29.8 | 35.2 | 46.1 | 51.2 |
| P75 | 39.0 | 86.0 | 39.7 | 40.5 | 41.6 | 51.2 | 61.0 | 65.9 | |
| P90 | 60.5 | 138.6 | 61.7 | 60.9 | 63.3 | 74.0 | 83.6 | 87.8 | |
| 18 | P50 | 29.8 | 76.2 | 30.2 | 30.6 | 32.2 | 40.7 | 50.7 | 57.1 |
| P75 | 41.4 | 105.6 | 42.7 | 43.3 | 46.3 | 57.5 | 67.3 | 75.4 | |
| P90 | 65.2 | 171.6 | 65.9 | 67.6 | 70.2 | 79.3 | 90.5 | 101.2 | |
Table 5: Time-to-first-token (TTFT) latency with varying load for the ShareGPT dataset.
Figure 11 reports the CDF of end-to-end latency for online inference under increasing load on the ShareGPT dataset, with each experiment running 4096 requests. Across all QPS (queries per second) values, SGLang-Deterministic exhibits a pronounced rightward shift with a long tail, reflecting substantially higher median and tail latencies. For example, at 12 QPS, SGLang-Deterministic’s median (P50) latency is 4.64 seconds with a P99 of 28 seconds, compared to 2.15 seconds (P50) and 13.2 seconds (P99) for SGLang-Non-Deterministic. This gap widens further under higher load: at 18 QPS, SGLang-Deterministic reaches a P50 latency of 10.6 seconds and a P99 latency of 71.1 seconds, whereas SGLang-Non-Deterministic remains at 2.84 and 17.4 seconds, respectively. SGLang-Non-Deterministic consistently achieves the lowest latency and thus serves as a practical lower bound. In contrast, LLM-42 closely tracks the non-deterministic baseline, with only modest increases in latency as the fraction of deterministic traffic rises from 2% to 100%. At 12 QPS, LLM-42 at 2% deterministic traffic incurs only a 3% increase in median latency over SGLang-Non-Deterministic (2.21 vs. 2.15 seconds), and even at 50% deterministic traffic, its P99 latency is comparable to that of SGLang-Deterministic (at low load) or better (at higher load). This degradation is smooth and monotonic across all loads: at the highest QPS, LLM-42 maintains significantly tighter CDFs and substantially lower tail latency than SGLang-Deterministic. Only at lower QPS and when most requests require deterministic output (100%) does LLM-42 exhibit higher latency than the deterministic baseline. This behavior stems from two implementation artifacts: (1) verification currently induces a global pause that temporarily stalls all in-flight requests, and (2) prefill is not batched in our current prototype, reducing efficiency for short input prompts. We plan to address them as part of future work.
Across all QPS levels, time-to-first-token (TTFT) latency in LLM-42 also increases monotonically with the fraction of deterministic traffic, with modest overhead at low ratios (2–10%) and higher once deterministic traffic exceeds 20–50%. However, even when the entire traffic is deterministic, LLM-42 still provides much lower tail TTFT than SGLang-Deterministic: at QPS 18, P90 TTFT of LLM-42 is 101.2 milliseconds vs. 171.6 milliseconds of SGLang-Deterministic.
### 5.3 Ablation Study
<details>
<summary>x16.png Details</summary>
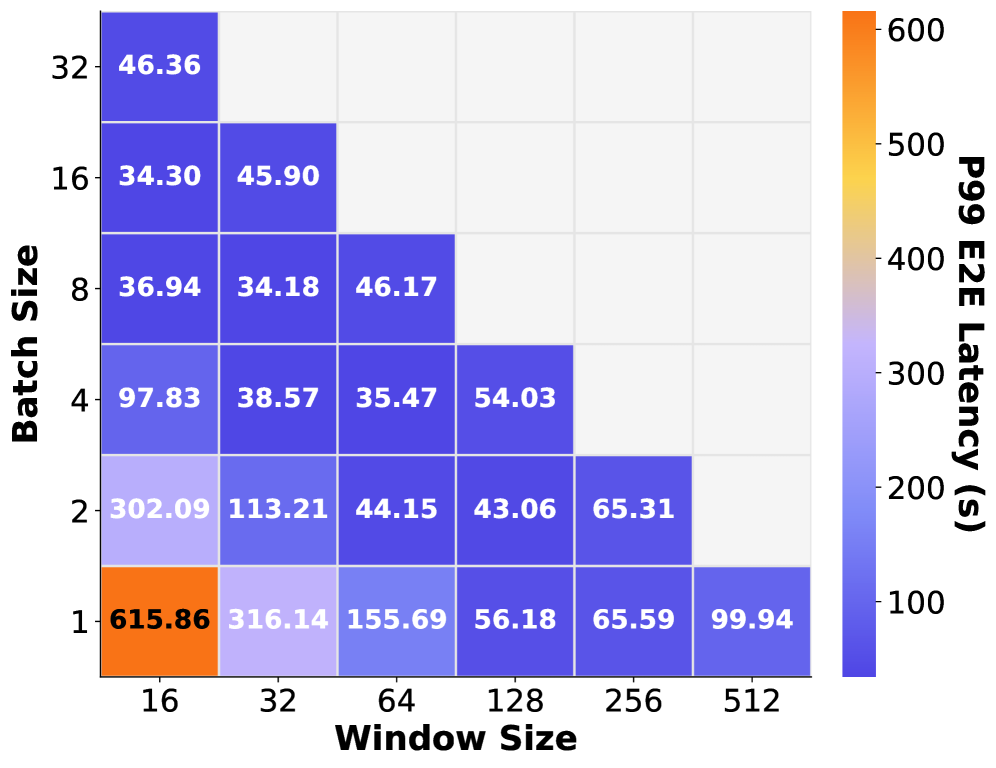
### Visual Description
## Heatmap: P99 End-to-End Latency vs. Batch Size and Window Size
### Overview
This image is a heatmap chart visualizing the relationship between three variables: **Batch Size** (y-axis), **Window Size** (x-axis), and **P99 E2E Latency** in seconds (color intensity). The chart demonstrates how system latency (specifically the 99th percentile end-to-end latency) changes as the batch size and window size parameters are varied. The data forms a triangular pattern, with measurements provided only for specific combinations where the window size is greater than or equal to the batch size.
### Components/Axes
* **Chart Type:** Heatmap (2D grid with color-encoded values).
* **Y-Axis (Vertical):** Labeled **"Batch Size"**. The axis has discrete tick marks at values: **1, 2, 4, 8, 16, 32**. The axis is oriented with the smallest value (1) at the bottom and the largest (32) at the top.
* **X-Axis (Horizontal):** Labeled **"Window Size"**. The axis has discrete tick marks at values: **16, 32, 64, 128, 256, 512**. The axis is oriented with the smallest value (16) on the left and the largest (512) on the right.
* **Color Bar/Legend:** Positioned on the right side of the chart. It is a vertical gradient bar labeled **"P99 E2E Latency (s)"**. The scale runs from approximately **0** (dark blue) at the bottom to **600** (bright orange) at the top, with intermediate markers at **100, 200, 300, 400, 500**. The color gradient transitions from dark blue → light blue → lavender → light orange → bright orange.
* **Data Grid:** A 6x6 grid where each cell contains a numerical value representing latency. The grid is only partially filled, forming a lower-left triangular shape. Cells are colored according to the value they contain, matching the color bar scale.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Each cell contains the **P99 E2E Latency (s)** value for the corresponding Batch Size (row) and Window Size (column). Cells marked "N/A" have no data in the chart.
| Batch Size \ Window Size | 16 | 32 | 64 | 128 | 256 | 512 |
| :----------------------- | :------ | :------ | :------ | :------ | :------ | :------ |
| **32** | 46.36 | N/A | N/A | N/A | N/A | N/A |
| **16** | 34.30 | 45.90 | N/A | N/A | N/A | N/A |
| **8** | 36.94 | 34.18 | 46.17 | N/A | N/A | N/A |
| **4** | 97.83 | 38.57 | 35.47 | 54.03 | N/A | N/A |
| **2** | 302.09 | 113.21 | 44.15 | 43.06 | 65.31 | N/A |
| **1** | 615.86 | 316.14 | 155.69 | 56.18 | 65.59 | 99.94 |
**Trend Verification & Spatial Grounding:**
* **Row (Batch Size = 1):** This row has the highest latency values and the most data points. The color transitions from bright orange (615.86 at Window Size 16) through lavender (316.14 at 32) to dark blue (99.94 at 512). The trend is a sharp decrease in latency as window size increases.
* **Row (Batch Size = 2):** Latency starts high (light lavender, 302.09 at Window Size 16) and decreases to a minimum (dark blue, 43.06 at Window Size 128) before a slight increase (dark blue, 65.31 at 256).
* **Rows (Batch Size 4, 8, 16, 32):** These rows contain fewer data points, limited to smaller window sizes. The values are generally lower (all colored dark blue, indicating < ~100s) and show less dramatic variation. For example, at Batch Size 8, latency fluctuates between 34.18 and 46.17 across window sizes 16, 32, and 64.
* **Column (Window Size = 16):** This column shows the most extreme variation. Latency decreases dramatically as batch size increases: from 615.86 (Batch 1) down to 34.30 (Batch 16). The color shifts from bright orange to dark blue.
* **General Pattern:** The highest latencies (orange/lavender cells) are concentrated in the bottom-left corner (low batch size, low window size). The lowest latencies (dark blue cells) are found in the upper rows and rightmost columns.
### Key Observations
1. **Extreme Outlier:** The single highest latency value is **615.86 seconds** at the combination of **Batch Size 1** and **Window Size 16**. This is the only cell colored bright orange.
2. **Triangular Data Mask:** Data is only provided where **Window Size ≥ Batch Size**. This creates a diagonal cutoff from the top-left to bottom-right of the grid.
3. **Non-Monotonic Trends:** The relationship is not perfectly linear. For instance, at Batch Size 2, latency dips at Window Size 128 (43.06) before rising again at 256 (65.31). Similarly, at Batch Size 8, latency is lowest at Window Size 32 (34.18).
4. **Diminishing Returns:** Increasing the batch size from 1 to 2 or 4 yields massive latency reductions (e.g., at Window Size 16: 615.86 → 302.09 → 97.83). However, further increases (e.g., from 8 to 16) show minimal or negative change.
### Interpretation
This heatmap illustrates a critical performance trade-off in a computational system, likely related to data processing, streaming, or machine learning inference. The **P99 E2E Latency** is a key metric for system reliability and user experience.
* **Core Finding:** The system exhibits **extremely high latency under conditions of minimal parallelism** (very small batch size) and **small processing windows**. This suggests significant per-request overhead that is not amortized when requests are processed individually or in tiny groups.
* **The Power of Batching:** The most effective strategy for reducing tail latency is to increase the **Batch Size**. Moving from processing items one-by-one (Batch Size 1) to even small batches (2 or 4) cuts latency by 50-85% in many cases. This indicates the system benefits greatly from vectorization, reduced context switching, or more efficient hardware utilization when handling multiple items simultaneously.
* **Role of Window Size:** Increasing the **Window Size** also generally reduces latency, but its effect is most pronounced at the smallest batch sizes. For larger batches (≥4), the impact of window size is less dramatic, and the optimal window size appears to be in the mid-range (64-128). The slight latency increase at the largest window size (512) for Batch Size 1 could indicate resource contention or overhead from managing very large data windows.
* **System Design Implication:** To achieve low and stable tail latency (P99), the system should be configured to operate with a **batch size of at least 4** and a **window size of 64 or larger**. Operating in the bottom-left region of this chart (Batch 1-2, Window 16-32) would result in poor and highly variable performance. The triangular data mask suggests that configurations where the batch size exceeds the window size may be invalid or untested for this system.
</details>
(a) P99 latency
<details>
<summary>x17.png Details</summary>
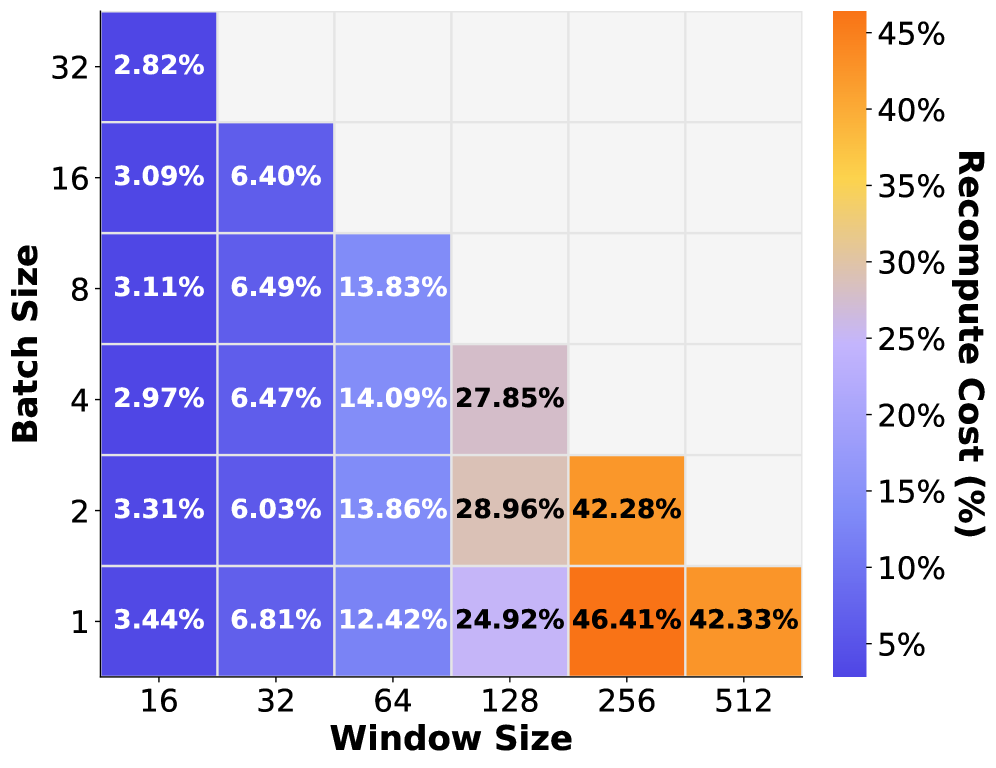
### Visual Description
\n
## Heatmap: Recompute Cost (%) by Batch Size and Window Size
### Overview
The image is a heatmap visualizing the "Recompute Cost (%)" as a function of two variables: **Batch Size** (vertical axis) and **Window Size** (horizontal axis). The cost is represented by a color gradient, with a corresponding color bar legend on the right. The data forms a triangular pattern, with values only present where the Window Size is greater than or equal to the Batch Size.
### Components/Axes
* **Y-Axis (Vertical):** Labeled **"Batch Size"**. The categories, from bottom to top, are: `1`, `2`, `4`, `8`, `16`, `32`.
* **X-Axis (Horizontal):** Labeled **"Window Size"**. The categories, from left to right, are: `16`, `32`, `64`, `128`, `256`, `512`.
* **Color Bar Legend:** Positioned vertically on the right side of the chart. It is labeled **"Recompute Cost (%)"**. The scale runs from approximately **5%** (dark blue) at the bottom to **45%** (bright orange) at the top, with intermediate tick marks at 10%, 15%, 20%, 25%, 30%, 35%, and 40%.
* **Data Grid:** A 6x6 grid where each cell contains a percentage value. Cells are colored according to the legend. Cells above the main diagonal (where Window Size < Batch Size) are empty (white).
### Detailed Analysis
The following table reconstructs the data from the heatmap. Each cell value represents the Recompute Cost (%) for the corresponding Batch Size (row) and Window Size (column).
| Batch Size \ Window Size | 16 | 32 | 64 | 128 | 256 | 512 |
| :----------------------- | :------ | :------ | :------ | :------ | :------ | :------ |
| **32** | 2.82% | | | | | |
| **16** | 3.09% | 6.40% | | | | |
| **8** | 3.11% | 6.49% | 13.83% | | | |
| **4** | 2.97% | 6.47% | 14.09% | 27.85% | | |
| **2** | 3.31% | 6.03% | 13.86% | 28.96% | 42.28% | |
| **1** | 3.44% | 6.81% | 12.42% | 24.92% | 46.41% | 42.33% |
**Trend Verification:**
* **Horizontal Trend (Fixed Batch Size):** For any given batch size, the recompute cost **increases significantly** as the window size increases. The color shifts from blue to orange moving right along any row.
* **Vertical Trend (Fixed Window Size):** For any given window size, the recompute cost generally **decreases slightly or remains stable** as the batch size increases. The color becomes slightly cooler (less orange) moving up any column.
### Key Observations
1. **Maximum Cost:** The highest recorded recompute cost is **46.41%**, occurring at **Batch Size = 1** and **Window Size = 256**.
2. **Minimum Cost:** The lowest recorded recompute cost is **2.82%**, occurring at **Batch Size = 32** and **Window Size = 16**.
3. **Cost Gradient:** The most dramatic cost increase occurs when moving from a Window Size of 64 to 128. For example, at Batch Size 4, the cost jumps from 14.09% to 27.85%.
4. **Anomaly at Batch Size 1:** The cost pattern for Batch Size = 1 is non-monotonic. It peaks at Window Size 256 (46.41%) and then **decreases** to 42.33% at Window Size 512, which is unique in the dataset.
5. **Data Sparsity:** The upper-right triangle of the matrix is empty, indicating that configurations where the Window Size is smaller than the Batch Size were not measured or are not applicable.
### Interpretation
This heatmap demonstrates the computational trade-offs in a system where "recompute cost" is a critical metric, likely related to memory optimization techniques in machine learning (e.g., activation checkpointing). The data suggests:
* **Window Size is the Dominant Factor:** Increasing the window size has a much more severe impact on recompute cost than decreasing the batch size. This implies the system's memory or computational overhead scales poorly with sequence length (window size).
* **Efficiency at Larger Batches:** For a fixed, large window size (e.g., 128 or 256), using a larger batch size (e.g., 8 or 16) results in a lower *percentage* recompute cost. This could indicate better amortization of fixed overheads or more efficient parallelization.
* **Practical Implication:** To minimize recompute cost, one should prioritize using the smallest feasible window size. If a large window is necessary, pairing it with a larger batch size can mitigate the cost percentage, though the absolute cost will still be high.
* **The Batch Size=1 Anomaly:** The drop in cost from window size 256 to 512 for batch size 1 is intriguing. It may point to a different code path, a hardware utilization threshold, or a measurement artifact for that specific, often challenging, configuration.
**In summary, the chart provides a clear quantitative guide for optimizing system parameters: recompute cost is highly sensitive to window size and is generally lower for larger batch sizes within the measured, applicable configurations.**
</details>
(b) Recompute cost
Figure 12: The effect of different verification strategies on end-to-end latency (left) and recompute cost (right). Batch size denotes the number of requests verified together.
Grouped verification helps LLM-42 reduce both verification and recomputation cost. It is parameterized by (1) the verification window size per request and (2) the number of requests verified together in a singe pass. To isolate the impact of each parameter, we run an ablation on the ShareGPT dataset, varying the per-request window size from 16 to 512 tokens and the number of requests verified together from one to 32. For each configuration, we execute 4096 requests in an online setting at 12 QPS; all requests require determinism. Figure 12 summarizes the results: 12(a) reports P99 request latency, while 12(b) shows recomputation overhead.
Without grouped verification (batch size 1, first row), latency exhibits a non-monotonic dependence on window size. Increasing the window initially reduces latency, but latency rises when window size becomes too large. Concretely, P99 latency drops from 615 seconds at a window size of 16 to 56.18 seconds at 128, then increases to 99.94 seconds at 512. This behavior reflects the fundamental trade-off between verification and recomputation: smaller windows incur higher verification overhead, while larger windows amplify recomputation cost—for example, recomputation cost is 42.33% at window size 512, compared to only 3.44% at window size 16. Without grouped verification, the best performance occurs at window size of 128 where the latency is 56.18 seconds.
Grouped verification substantially lowers the end-to-end latency. Even batching just two requests reduces P99 latency to 43.06 seconds (best case in the second row from the bottom). Increasing the batch size yields further gains, with the best overall configurations verifying a total of 256 tokens per step—distributed across 16, 8, or 4 requests—all achieving P99 tail latencies of 34–35 seconds.
It is worth noting that the recomputation cost in the offline experiments (typically below 2% as shown in Table 4) is lower than in the online inference setting (typically more than 6% as shown in 12(b)). This difference arises because in offline inference, all requests are available at the beginning and the system tries to maximally utilize memory capacity, resulting in more stable batch sizes. In contrast, online inference experiences significantly greater batch-size variability due to fluctuating load, request arrival and departure times; naturally, higher recomputation rates are correlated with this increased batch-size variability.
### Discussion
Evaluation across models and multiple GPUs: While we report performance results only for Llama-3.1-8B-Instruct in this paper, we have evaluated the correctness of our approach across multiple additional models, including Qwen-4B-Instruct-2507, Qwen3-14B and Qwen3-30B-A3B-Instruct-2507, and across 1-4 GPUs with tensor-parallelism. Our current experimental setup does not support multimem/NVLS and is limited to pairwise NVLink connectivity; consequently, fairly evaluating multi-GPU performance would require a different platform, which we leave to future work. Supporting these models required no additional code changes in LLM-42 which highlights the simplicity of our approach.
Limitations: In our current prototype, the verification pass introduces latency overhead for all requests, even when determinism is enabled selectively. This overhead could be mitigated by confining verification to a subset of GPU SMs or by deferring verification batches—for example, by prioritizing regular prefills and decodes over verification. A second limitation is that prefill and decode use different reduction strategies in LLM-42, making the system non–prefill-decode invariant. As a result, LLM-42 currently does not support sharing prefix caches across multiple turns of the same request or sharing across requests. Our implementation also does not currently integrate with speculative decoding–based LLM inference. Addressing these limitations is interesting future work.
## 6 Related Works
Recent advances in LLM inference systems have focused on optimizing throughput, latency, and resource utilization [orca, vllmsosp, sarathiserve2024, tetriinfer, distserve2024, vattention2024, dynamollm2024, pod-attn]. Orca [orca] pioneered continuous batching, enabling low-latency serving by dynamically scheduling requests at the granularity of individual iterations. vLLM [vllmsosp] introduced PagedAttention, a memory management abstraction that allows higher batch sizes and reuse of KV cache across requests, dramatically improving system throughput. Sarathi-Serve [sarathiserve2024] further improved the throughput–latency trade-off through chunked prefills to better exploit GPU parallelism. DistServe [distserve2024] and Splitwise [patel2023splitwise] proposed disaggregated inference architectures that separate prefill and decode workloads across specialized servers, mitigating interference. Complementary lines of work such as speculative decoding [leviathan2022fast, chen2023accelerating, mamou2024dynamic] and FlexGen [flexgen] pursue orthogonal optimizations by reducing the number of autoregressive steps or offloading memory to CPU and SSDs. While all these systems achieve impressive performance gains, they typically assume non-deterministic execution, leaving the trade-offs between determinism and efficiency unexplored.
Enabling determinism in LLM inference has recently drawn increasing attention. Song et al. [song2024greedy] argued that such non-determinism can distort evaluation results, calling for reproducibility-aware benchmarking. Yuan et al. [yuan2025fp32death] further linked reproducibility failures to mixed-precision arithmetic and fused kernel inconsistencies, showing their impact on multi-step reasoning accuracy. Rainbird AI [rainbird2025deterministic] emphasized deterministic inference as a requirement for traceability and compliance in enterprise and safety-critical domains.
Recent work by Zhang et al. proposes tensor-parallel–invariant kernels that eliminate training–inference mismatch by ensuring bitwise deterministic results across different tensor parallel sizes for LLM inference [zhang2025-deterministic-tp]. In contrast, existing LLM serving systems typically achieve determinism through batch-invariant computation. We examine the performance and engineering costs of this approach and propose an alternative mechanism for enabling determinism in LLM inference. By leveraging properties of GPU kernels together with characteristics of LLM inference workloads, our approach seeks to reconcile reproducibility with efficiency—a design space that remains largely unexplored in prior work.
## 7 Conclusion
Enabling determinism in LLM inference remains tedious today. Existing systems achieve determinism by enforcing batch-invariant computation, an approach that is cumbersome in practice: it requires rewriting kernels at a time when both hardware and model architectures are evolving rapidly. Moreover, batch-invariant kernels are inherently suboptimal, as they prevent kernels from adapting their parallelism strategies at runtime. We present LLM-42, a simpler alternative that enables determinism in LLM inference by repurposing speculative decoding. LLM-42 minimizes the need to write new kernels and supports selective enforcement of determinism, incurring runtime overhead only for the fraction of traffic that actually requires it.
## References