# Subword-Based Comparative Linguistics across 242 Languages Using Wikipedia Glottosets
**Authors**: Iaroslav Chelombitko, Mika Hämäläinen, Aleksey Komissarov
> DataSpike Neapolis University Pafos, Paphos, Cyprus Metropolia University of Applied Sciences, Helsinki, Finland
> Metropolia University of Applied Sciences, Helsinki, Finland
> Neapolis University Pafos, Paphos, Cyprus aglabx, Paphos, Cyprus
## Abstract
We present a large-scale comparative study of 242 Latin and Cyrillic-script languages using subword-based methodologies. By constructing ’glottosets’ from Wikipedia lexicons, we introduce a framework for simultaneous cross-linguistic comparison via Byte-Pair Encoding (BPE). Our approach utilizes rank-based subword vectors to analyze vocabulary overlap, lexical divergence, and language similarity at scale. Evaluations demonstrate that BPE segmentation aligns with morpheme boundaries 95% better than random baseline across 15 languages (F1 = 0.34 vs 0.15). BPE vocabulary similarity correlates significantly with genetic language relatedness (Mantel r = 0.329, p < 0.001), with Romance languages forming the tightest cluster (mean distance 0.51) and cross-family pairs showing clear separation (0.82). Analysis of 26,939 cross-linguistic homographs reveals that 48.7% receive different segmentations across related languages, with variation correlating to phylogenetic distance. Our results provide quantitative macro-linguistic insights into lexical patterns across typologically diverse languages within a unified analytical framework.
Keywords Multilingual NLP $·$ Comparative Linguistics $·$ BPE Tokenization $·$ Cross-linguistic Analysis $·$ Lexical Similarity $·$ Script-based Typology
## 1 Introduction
Traditional comparative linguistics, while providing deep historical and typological insights (see Lehmann 2013; Beekes 2011; Nichols 1992; Partanen et al. 2021; Säily et al. 2021), often lacks the scalability to handle the current volume of digital text (Arnett and Bergen 2024; Akindotuni 2025). However, recent NLP advances facilitate massive, data-driven studies (see Dang et al. 2024; Bender 2011; Imani et al. 2023; Sproat 2016), revealing universal tendencies in phonetics (Blum et al. 2024), lexical semantics (Tjuka et al. 2024), and sound symbolism (Ćwiek et al. 2022; Cathcart and Jäger 2024) that were previously inaccessible through manual, small-scale methods.
Despite this progress, large-scale studies frequently neglect endangered languages (Hämäläinen 2021) and systematic performance disparities in multilingual models (see Shani et al. 2026; Chelombitko et al. 2024; Dunn and others 2011). We address this gap by examining 242 languages through a novel script-level lens (Latin vs. Cyrillic), moving beyond family-specific comparisons (Meillet 1967; Beekes 2011) to reveal overarching patterns visible only when languages share a script-based writing system (Daniels and Bright 1996; Rust et al. 2021).
In particular, we adopt a subword-based strategy (Sennrich and others 2016) using Byte-Pair Encoding (BPE) (Gage 1994) tokenizers, which we train both on individual languages and on large aggregated corpora for each script. Aggregating data for all Latin and Cyrillic-script languages into respective training sets effectively unifies each script community into a single model, leveraging the shared-parameter paradigm common in massively multilingual pretraining (see Johnson and others 2016; Conneau et al. 2020).
<details>
<summary>workflow.png Details</summary>
### Visual Description
## Diagram: Multilingual Text Processing Pipeline
### Overview
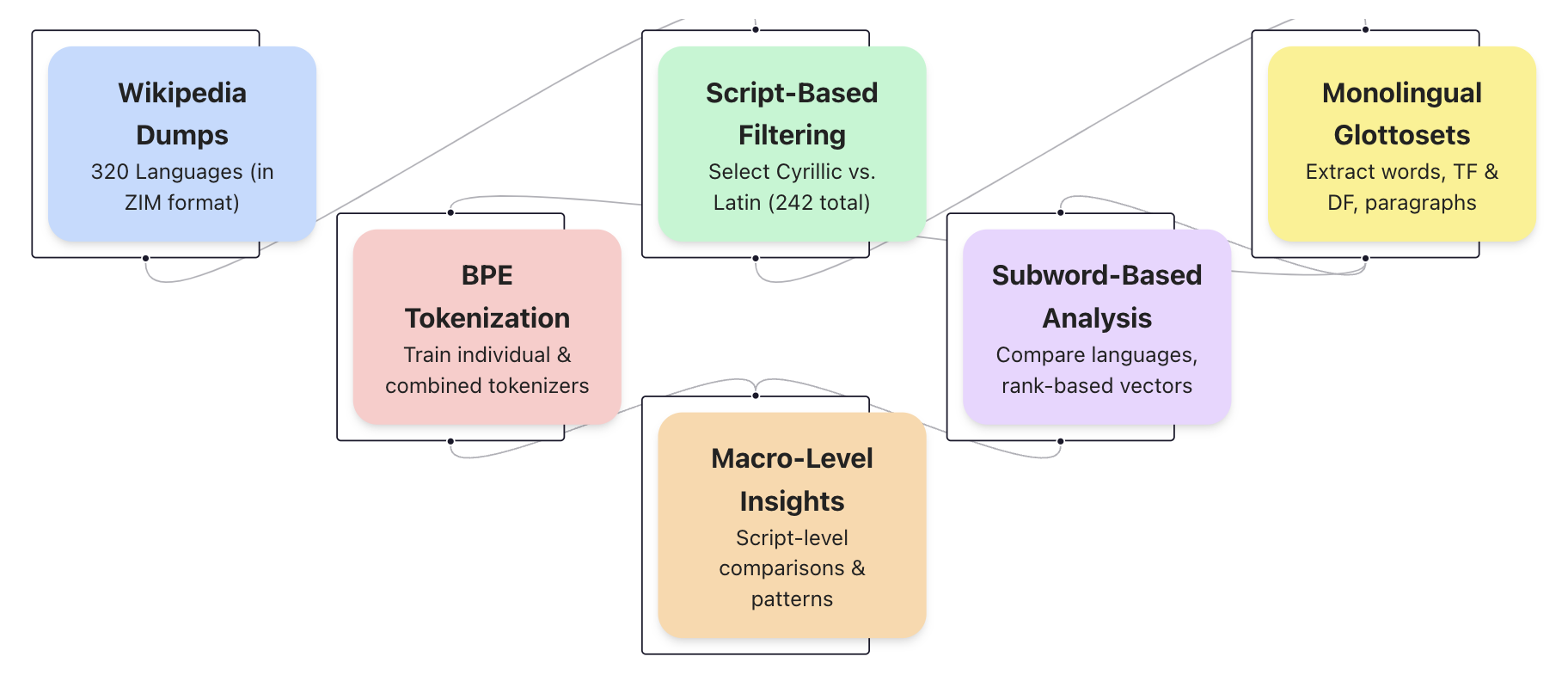
The image displays a flowchart illustrating a six-stage pipeline for processing multilingual text data derived from Wikipedia. The process flows from left to right, beginning with raw data acquisition and culminating in macro-level analysis. The diagram uses color-coded boxes to represent distinct stages, connected by directional arrows indicating the workflow.
### Components/Axes
The diagram consists of six primary components (boxes) arranged in a staggered, left-to-right flow. Each box has a title and a brief description.
1. **Box 1 (Top-Left, Light Blue):**
* **Title:** Wikipedia Dumps
* **Description:** 320 Languages (in ZIM format)
2. **Box 2 (Center-Left, Light Pink):**
* **Title:** BPE Tokenization
* **Description:** Train individual & combined tokenizers
3. **Box 3 (Top-Center, Light Green):**
* **Title:** Script-Based Filtering
* **Description:** Select Cyrillic vs. Latin (242 total)
4. **Box 4 (Center-Right, Light Purple):**
* **Title:** Subword-Based Analysis
* **Description:** Compare languages, rank-based vectors
5. **Box 5 (Top-Right, Light Yellow):**
* **Title:** Monolingual Glottosets
* **Description:** Extract words, TF & DF, paragraphs
6. **Box 6 (Bottom-Center, Light Orange):**
* **Title:** Macro-Level Insights
* **Description:** Script-level comparisons & patterns
**Flow Connections (Arrows):**
* A primary arrow flows from **Wikipedia Dumps** to **Script-Based Filtering**.
* A secondary arrow flows from **Wikipedia Dumps** to **BPE Tokenization**.
* An arrow flows from **BPE Tokenization** to **Script-Based Filtering**.
* An arrow flows from **Script-Based Filtering** to **Monolingual Glottosets**.
* An arrow flows from **Script-Based Filtering** to **Subword-Based Analysis**.
* An arrow flows from **Monolingual Glottosets** to **Subword-Based Analysis**.
* An arrow flows from **Subword-Based Analysis** to **Macro-Level Insights**.
* An arrow flows from **BPE Tokenization** to **Macro-Level Insights**.
### Detailed Analysis
The pipeline describes a structured methodology for computational linguistics research.
* **Stage 1 - Data Acquisition:** The process begins with "Wikipedia Dumps" for 320 languages, sourced in the ZIM file format, which is optimized for offline use.
* **Stage 2 - Initial Processing:** The data splits into two parallel paths:
* **Path A (Tokenization):** "BPE Tokenization" involves training Byte Pair Encoding tokenizers, both for individual languages and combined sets.
* **Path B (Filtering):** "Script-Based Filtering" narrows the dataset to languages using Cyrillic or Latin scripts, resulting in a subset of 242 languages.
* **Stage 3 - Data Extraction & Analysis:** The filtered data from Path B feeds into two subsequent stages:
* "Monolingual Glottosets" focuses on extracting core linguistic units: words, Term Frequency (TF), Document Frequency (DF), and paragraphs.
* "Subword-Based Analysis" uses the tokenizers from Path A and the filtered data to compare languages and create rank-based vectors.
* **Stage 4 - Synthesis:** Both the "Subword-Based Analysis" and the initial "BPE Tokenization" feed into the final stage, "Macro-Level Insights," which performs script-level comparisons and identifies broader patterns.
### Key Observations
1. **Non-Linear Flow:** The diagram is not a simple linear sequence. It features parallel processing (BPE Tokenization and Script-Based Filtering occur concurrently) and multiple convergence points.
2. **Data Reduction:** There is a clear data reduction step, moving from 320 languages to a focused set of 242 based on writing script.
3. **Dual Analysis Paths:** The pipeline employs two complementary analysis methods: subword-based (using BPE) and word/paragraph-based (in the Glottosets).
4. **Central Role of Script:** The "Script-Based Filtering" stage acts as a major hub, directing flow to three other stages (Glottosets, Subword Analysis, and indirectly to Macro Insights).
### Interpretation
This flowchart outlines a sophisticated research pipeline for comparative linguistics using large-scale, multilingual Wikipedia data. The process is designed to move from broad, raw data to specific, analyzable units and finally to high-level insights.
* **Purpose:** The pipeline enables systematic comparison of languages, particularly between those using Cyrillic and Latin scripts. It likely aims to study morphological complexity, vocabulary overlap, or other quantitative linguistic features across language families.
* **Methodological Rigor:** The use of both BPE (a standard in NLP for handling rare words) and traditional word/paragraph extraction suggests a comprehensive approach, capturing both subword morphology and lexical statistics.
* **Scalability:** Starting with 320 languages in a standardized format (ZIM) indicates the pipeline is built for scalability and reproducibility.
* **Inferred Goal:** The final "Macro-Level Insights" stage suggests the ultimate goal is not just language-specific analysis, but the discovery of universal or script-dependent patterns in human language structure as reflected in encyclopedia text. The branching and merging of paths highlight that these insights are derived from synthesizing multiple analytical perspectives.
</details>
Figure 1: Pipeline architecture for subword-based comparative linguistics across 242 languages using Wikipedia glottosets. The workflow illustrates the transformation of Wikipedia dumps (320 languages) through sequential stages: script-based filtering yielding 37 Cyrillic and 205 Latin script languages, monolingual glottoset construction with TF/DF metrics, BPE tokenization (both individual and combined training with 4096 tokens vocabulary), and vector-based subword analysis. Each colored node represents a distinct processing phase, culminating in macro-level insights for script-level comparative linguistics. This modular approach enables scalable analysis of morphological patterns across multiple languages simultaneously.
Although subword units are not perfect morphemes (see Sennrich and others 2016; Bostrom and Durrett 2020), they serve as robust automated tools for macro-linguistic research (see Khurana and others 2024; Pham et al. 2024; Futrell and others 2015) that scale more efficiently than manual expert alignment (see Campbell 2020; Rama et al. 2018; Ciobanu and Dinu 2014).
Leveraging the framework (Figure 1), this work makes two key contributions:
1. Script-Level Aggregation: We demonstrate how combining languages by script (Latin vs. Cyrillic) enables macro-level comparative insights difficult to achieve through traditional language-by-language lenses.
1. Practical Subword Methodology: We introduce a tractable, automated framework that reduces reliance on manual annotation by providing data-driven lexical segments for robust cross-linguistic analysis.
While traditional comparative linguistics focuses on genetic relationships and historical reconstruction, and typology examines structural similarities regardless of ancestry, our subword-based approach bridges both: we demonstrate that BPE tokenization captures phylogenetic signal (Section 4.3) while also revealing typological patterns across unrelated languages sharing the same script.
## 2 Related Work
Comparative linguistics in NLP has evolved from general data-driven frameworks (see Bender 2011; Sproat 2016; Imani et al. 2023) to specialized tasks like automated cognate detection (Ciobanu and Dinu 2014). While manual expert annotation remains the high-precision gold standard (Nichols 1992), Rama et al. (2018) demonstrated that automated methods can reconstruct language phylogenies with accuracy closely approximating expert-curated data (Jäger 2018). These approaches highlight the potential for scaling linguistic analysis across diverse language families where manual examination is impractical.
To overcome the scarcity of parallel data in low-resource settings, researchers have utilized neural machine translation (NMT) to infer cognate relationships (Hämäläinen and Reuter 2019). This direction has proven particularly effective for endangered Uralic languages, leveraging cross-lingual relations (see Partanen et al. 2021; Chelombitko and Komissarov 2024; Chelombitko et al. 2025) and data augmentation through synthetic cognates generated by statistical machine translation (SMT) (Poncelas et al. 2019). Such hybrid strategies address resource limitations while enriching existing linguistic databases for under-represented script communities.
More recently, architectures inspired by computational biology have addressed previous computational bottlenecks. Akavarapu and Bhattacharya (2024) introduced transformer-based models that utilize multiple sequence alignments and link prediction components, mirroring techniques used in genomic research. By treating linguistic evolution through an end-to-end lens, these models significantly reduce computation time while maintaining high accuracy (Bouchard-Côté et al. 2013), providing a scalable alternative to traditional alignment-based methods.
Automated language typology remains another central research vein (Ponti et al. 2019), with studies using information-theoretic measures to quantify morphological synthesis and fusion (see Rathi et al. 2021; Oncevay et al. 2022). Crucially, Gutierrez-Vasques et al. (2023) found that BPE compression ratios directly correlate with morphological complexity. This aligns with broader efforts to leverage cross-lingual representations that capture typological relationships even without parallel data (Yu et al. 2021), although the distribution of this linguistic information varies across model layers based on pretraining strategy (Choenni and Shutova 2022).
## 3 Methodology
### 3.1 Monolingual Glottosets Construction
We downloaded Wikipedia dumps in ZIM format for 320 languages available in the ZIM archive https://dumps.wikimedia.org/kiwix/zim/wikipedia/. After that, we selected either the 2024 or 2023 version (preferring the 2024 version if available), otherwise, we used the 2023 version. We included all topics by selecting the “all” files option. To clean the data from unnecessary HTML elements, we used a custom script available in our repository. In brief, this script resolves redirects and extracts only paragraph text while removing as many auxiliary HTML tags as possible, leaving only clean paragraph texts.
<details>
<summary>graph.png Details</summary>
### Visual Description
## Network Diagram: Semantic or Linguistic Relationship Graph
### Overview
The image displays a complex directed graph or network diagram, likely representing semantic, linguistic, or conceptual relationships between terms. The diagram is split into two primary clusters or regions, connected by a central node. The left cluster primarily contains terms in Cyrillic script (likely Ukrainian or a related language), while the right cluster contains terms in Latin script (likely Finnish or a constructed language). Nodes are connected by directed edges (arrows), indicating a directional relationship from one term to another. Some nodes include a "reuse" count, suggesting frequency or importance within a dataset.
### Components/Axes
* **Node Types:** Two distinct visual styles are used:
1. **Green Rectangular Boxes:** Contain a single word or short phrase. These are the primary data points.
2. **Blue Circle:** Contains the text "a (reuse: 167)". This appears to be a central or high-frequency hub node.
* **Edges:** Black lines with arrowheads indicating direction. The density of lines varies, with some nodes having many incoming or outgoing connections.
* **Spatial Layout:** The diagram is organized into two main vertical clusters separated by a central area.
* **Left Cluster (Cyrillic Terms):** Densely packed with nodes and connections.
* **Central Node:** A single green box labeled "україн" acts as a bridge between the left and right clusters.
* **Right Cluster (Latin Terms):** Also densely packed, with a prominent blue circle node ("a") at its top-left.
* **Text Language:** Two languages are present.
* **Cyrillic Script:** Transcribed directly below. (Language is likely Ukrainian based on character set and the central node "україн").
* **Latin Script:** Transcribed directly below. (Language appears to be Finnish or a related Uralic language based on word forms like "taide", "vuode", "ista").
### Detailed Analysis
**Node Inventory and Connections:**
**Left Cluster (Cyrillic Terms):**
* **чи (reuse: 17):** A key node with multiple outgoing connections to: чив, очі, чино, дір, чий, хун, чими.
* **чив:** Connected from "чи".
* **очі:** Connected from "чи".
* **чино:** Connected from "чи" and "чи".
* **дір:** Connected from "чи".
* **чий:** Connected from "чи".
* **хун:** Connected from "чи".
* **чими:** Connected from "чи".
* **твор:** Connected from an unseen source (line enters from top).
* **тной:** Connected from an unseen source.
* **ноої:** Connected from an unseen source.
* **гайм:** Connected from an unseen source.
* **шир:** Connected from an unseen source.
* **відді:** Connected from an unseen source.
* **йного:** Connected from an unseen source.
* **стих:** Connected from an unseen source.
**Central Node:**
* **україн:** Receives a connection from the left cluster (source unclear) and sends a connection to the right cluster, specifically to the node "a".
**Right Cluster (Latin Terms):**
* **a (reuse: 167):** A major hub node (blue circle). Receives connection from "україн". Sends connections to: ja, and many other nodes in the right cluster (lines are dense).
* **ja (reuse: 55):** Receives connection from "a". Sends connections to: ohju, uja, idae, eja, and others.
* **ohju:** Connected from "ja".
* **uja:** Connected from "ja".
* **idae:** Connected from "ja".
* **eja:** Connected from "ja".
* **ista (reuse: 23):** Located at the bottom of the right cluster. Receives connections from multiple sources within the cluster.
* **star:** Connected from an unseen source within the cluster.
* **taide:** Connected from an unseen source within the cluster.
* **vuode:** Connected from an unseen source within the cluster.
* **okuvi:** Connected from an unseen source within the cluster.
### Key Observations
1. **Linguistic Clustering:** The diagram shows a clear separation between a Cyrillic-based lexicon (left) and a Latin-based lexicon (right), bridged by a single node ("україн").
2. **Hub Nodes:** Three nodes are explicitly marked with "reuse" counts, indicating their high frequency or centrality:
* `a (reuse: 167)` - The most prominent hub, located in the right cluster.
* `ja (reuse: 55)` - A secondary hub, directly connected from `a`.
* `ista (reuse: 23)` - A tertiary hub, located at the bottom of the right cluster.
* `чи (reuse: 17)` - The primary hub for the left cluster.
3. **Connection Density:** The area around the `a` and `ja` nodes is extremely dense with connections, suggesting a highly interconnected semantic field. The left cluster around `чи` is also dense but appears slightly more structured.
4. **Directionality:** All connections are directed, implying a one-way relationship (e.g., "is a type of", "leads to", "is translated as", "is derived from").
5. **Isolated Nodes:** Several nodes in both clusters (e.g., `твор`, `star`, `taide`) have incoming lines from outside the visible frame, indicating the diagram is a cropped section of a larger network.
### Interpretation
This diagram is a visualization of a **semantic network or lexical graph**, likely generated from a text corpus analysis. The "reuse" count probably signifies the frequency of that word's appearance as a node in the graph or its degree of connectivity.
* **What it demonstrates:** It maps relationships between words. The central bridge node "україн" (Ukrainian) suggests the graph might be modeling connections between Ukrainian vocabulary and vocabulary from another language (possibly Finnish, given terms like "taide" (art) and "vuode" (bed)). The high reuse of the node "a" is intriguing; in Finnish, "a" is not a common standalone word, so it might represent a root, a morpheme, or a placeholder in the analysis.
* **Relationships:** The arrows likely represent a specific linguistic relationship defined by the analysis tool, such as synonymy, hypernymy, translation equivalence, or co-occurrence. The dense clusters represent tightly-knit semantic fields.
* **Anomalies/Notable Points:** The stark linguistic divide is the most striking feature. The diagram seems to model a cross-lingual or comparative linguistic structure. The node "а" (Cyrillic 'a') is not present, but the Latin "a" is a major hub, which could be a point of interest for the researcher. The diagram's cropped nature means the full context of the relationships for nodes like `твор` or `star` is missing.
**In summary, this is a technical visualization from a computational linguistics or natural language processing study, showing a directed graph of word relationships across two languages, with key hub nodes identified by their reuse frequency.**
</details>
Figure 2: Visualization of interactive BPE merge graphs for Ukrainian (left) and Finnish (right) subword tokenization patterns. The diagrams show directed merge sequences with reuse counts indicated in parentheses. Vertical black bars represent merge steps, while edges show the progression of subword unit formation. The contrasting patterns reflect language-specific morphological characteristics: Ukrainian showing consistent Cyrillic character combinations, while Finnish exhibits agglutinative patterns. Interactive web application available on our repository.
The extracted paragraphs were filtered based on script consistency. For Cyrillic, we retained only Cyrillic paragraphs, and for Latin, only those written in the Latin script. Unfortunately, there is currently no reliable tool for accurately detecting all 242 languages, so at this stage, we filtered only by script (Table 1). Additionally, an effective filtering step was to remove all paragraphs containing fewer than 10 words. This significantly reduced noise in the dataset, including accidental words from other languages.
Table 1: Statistics for top 30 languages by token count from Wikipedia dumps. Columns show language names and codes, number of raw and cleaned paragraphs, word count in millions, script type (Latin/Cyrillic), total tokens, and cross-script contamination (Cyrillic tokens in Latin-script languages and vice versa).
| English | en | 54125720 | 42149266 | 2661.93 | Latin | 2661930466 | 5062 | – |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| German | de | 22354272 | 17953642 | 1026.43 | Latin | 1026430544 | 2648 | – |
| French | fr | 20464072 | 16742203 | 940.75 | Latin | 940746868 | 1621 | – |
| Spanish | es | 14107859 | 12170134 | 763.36 | Latin | 763357750 | 1134 | – |
| Italian | it | 11917473 | 9806341 | 571.76 | Latin | 571759224 | 1150 | – |
| Russian | ru | 15290408 | 12295838 | 552.42 | Cyrillic | 552416889 | – | 429004 |
| Cebuano | ceb | 16841937 | 10069736 | 447.85 | Latin | 447850263 | 92 | – |
| Portuguese | pt | 6845897 | 5642228 | 332.96 | Latin | 332959017 | 413 | – |
| Dutch | nl | 7764590 | 6429095 | 316.21 | Latin | 316210100 | 415 | – |
| Polish | pl | 15961541 | 5616831 | 253.85 | Latin | 253846410 | 2044 | – |
| Catalan | ca | 4273906 | 3749516 | 238.81 | Latin | 238813199 | 710 | – |
| Ukrainian | uk | 7864058 | 5582991 | 219.83 | Cyrillic | 219827684 | – | 200945 |
| Vietnamese | vi | 4707518 | 3129629 | 201.38 | Latin | 201383401 | 623 | – |
| Swedish | sv | 7437772 | 5088656 | 200.89 | Latin | 200889695 | 312 | – |
| Serbo-Croatian | sh | 2248318 | 1682017 | 193.56 | Latin | 193561280 | 19539 | – |
| Czech | cs | 3386803 | 2865556 | 150.39 | Latin | 150393063 | 998 | – |
| Hungarian | hu | 3932082 | 2603906 | 129.86 | Latin | 129864098 | 518 | – |
| Indonesian | id | 2984643 | 2120278 | 106.98 | Latin | 106980811 | 622 | – |
| Norwegian Bokmål | nb | 2906506 | 2239883 | 105.51 | Latin | 105507751 | 175 | – |
| Finnish | fi | 3141975 | 2295657 | 93.5 | Latin | 93502432 | 650 | – |
| Serbian | sr | 3210579 | 1981413 | 91.81 | Cyrillic | 91807037 | – | 193621 |
| Turkish | tr | 2528498 | 1757628 | 85.16 | Latin | 85156035 | 570 | – |
| Romanian | ro | 2360641 | 1539046 | 84.62 | Latin | 84617897 | 454 | – |
| Bulgarian | bg | 1599763 | 1386917 | 69.12 | Cyrillic | 69123830 | – | 36265 |
| Waray | war | 2571970 | 1448198 | 69.04 | Latin | 69038926 | 0 | – |
| Danish | da | 1551416 | 1216805 | 61.11 | Latin | 61107267 | 126 | – |
| Galician | gl | 1188136 | 1049404 | 60.95 | Latin | 60947590 | 181 | – |
| Malay | ms | 1499560 | 1034055 | 56.37 | Latin | 56370979 | 106 | – |
| Asturian | ast | 1134182 | 912479 | 56.25 | Latin | 56254683 | 84 | – |
| Esperanto | eo | 1669507 | 1188077 | 54.51 | Latin | 54512106 | 441 | – |
In the following analysis we included only languages with Cyrillic (37 languages) and Latin (205 languages) scripts. The decision to restrict the scope to Latin and Cyrillic script languages was motivated by three primary factors: (1) these scripts share a common alphabet origin, enabling direct character-level comparison; (2) they represent the largest script families in Wikipedia coverage; and (3) they include both closely related language families (e.g., Romance, Slavic) and typologically diverse languages (e.g., Finnish, Turkish, Vietnamese), providing a rich testbed for subword-based comparative analysis. Additionally, as an unexpected result, we were able to measure the extent to which Wikipedia articles are contaminated with Latin and Cyrillic scripts for languages that use other scripts (80 languages). The results are presented in Table 2.
Table 2: Script contamination analysis for languages using non-Latin/non-Cyrillic writing systems. Data shows language names, codes, raw paragraph counts, native script types, and the number of detected Latin and Cyrillic tokens representing potential script contamination.
| Min Nan Chinese | nan | 830227 | Han | 13 | 541415 |
| --- | --- | --- | --- | --- | --- |
| Japanese | ja | 12737874 | Japanese | 915 | 298430 |
| Chinese | zh | 7206035 | Han | 554 | 117304 |
| Greek | el | 1733250 | Greek | 363 | 96009 |
| Hebrew | he | 3368324 | Hebrew | 479 | 90907 |
| Korean | ko | 3333575 | Hangul | 635 | 81612 |
| Arabic | ar | 4624040 | Arabic | 246 | 58738 |
| Persian | fa | 3132901 | Arabic | 165 | 51729 |
| Balinese | ban | 87175 | Balinese | 4 | 48922 |
| Thai | th | 944565 | Thai | 305 | 43559 |
| Armenian | hy | 1647293 | Armenian | 2579 | 41259 |
| Egyptian Arabic | arz | 5166127 | Arabic | 23 | 39349 |
| Buginese | bug | 36776 | Lontara | 0 | 19834 |
| Min Dong Chinese | cdo | 28589 | Han | 0 | 19197 |
| Georgian | ka | 644781 | Georgian | 387 | 15234 |
| Bengali | bn | 854059 | Bengali | 64 | 13786 |
| Hindi | hi | 703141 | Devanagari | 80 | 13369 |
| Tamil | ta | 820809 | Tamil | 28 | 11153 |
| Hakka Chinese | hak | 14204 | Han | 2 | 10368 |
| Malayalam | ml | 464433 | Malayalam | 31 | 9848 |
| Sinhalese | si | 166475 | Sinhala | 3 | 9552 |
| Burmese | my | 451126 | Burmese | 8 | 9467 |
| Urdu | ur | 660706 | Arabic | 62 | 9172 |
| Cantonese | yue | 373575 | Han | 53 | 8418 |
| South Azerbaijani | azb | 605161 | Arabic | 18 | 7459 |
| Goan Konkani | gom | 39569 | Devanagari | 0 | 6955 |
| Marathi | mr | 349639 | Devanagari | 10 | 6842 |
| Cambodian | km | 99641 | Khmer | 13 | 6324 |
| Telugu | te | 832028 | Telugu | 3 | 6170 |
| Tachelhit | shi | 7811 | Tifinagh | 0 | 5799 |
We define monolingual glottosets as language-specific collections of lexical units derived from monolingual texts. Each glottoset reflects a particular language’s vocabulary in one script, in our case Latin or Cyrillic in lowercase. Unfortunately, while we initially aimed to avoid normalizing words to lowercase, we found that doing so significantly improves subsequent tokenization. The glottoset includes additional features: Term Frequency (TF) and Document Frequency (DF). DF is defined as the occurrence of a word within a Wikipedia paragraph, as the Wikipedia parsing process is based on paragraph-level extraction. Wikipedia based glottosets characteristics are presented in Table 3.
Table 3: Lexical statistics for a diverse set of languages using Latin and Cyrillic scripts. The table presents vocabulary size (ranging from 1,447 for Cheyenne to 3,207,272 for Hungarian), lexical diversity scores (from 0.009 in Dutch to 0.383 in Cheyenne), median word length (6–10 characters), and top-3 most frequent tokens.
| Swiss German | Latin | 565258 | 0.070 | 10 | d, isch, dr |
| --- | --- | --- | --- | --- | --- |
| Tajik | Cyrillic | 317780 | 0.041 | 8 | дар, аз, ки |
| Hungarian | Latin | 3207272 | 0.025 | 10 | a, és, az |
| Lingala | Latin | 23153 | 0.123 | 7 | ya, na, ezalí |
| Zeeuws | Latin | 51177 | 0.087 | 8 | de, n, t |
| Lak | Cyrillic | 6890 | 0.315 | 7 | ва, шагьру, инсан |
| Malay | Latin | 637993 | 0.011 | 8 | yang, di, dan |
| Cheyenne | Latin | 1447 | 0.383 | 6 | ho, e, vé |
| Aymara | Latin | 29323 | 0.171 | 8 | a, jisk, suyu |
| Friulian | Latin | 44905 | 0.086 | 7 | di, e, al |
| Javanese | Latin | 281161 | 0.040 | 8 | ing, lan, iku |
| Rusyn | Cyrillic | 112582 | 0.149 | 8 | в, на, є |
| Ido | Latin | 129897 | 0.029 | 7 | la, di, e |
| Norman | Latin | 31509 | 0.106 | 7 | d, est, la |
| Ligurian | Latin | 133733 | 0.090 | 7 | l, a, de |
| Karakalpak | Latin | 104775 | 0.144 | 8 | hám, menen, bul |
| Romanian | Latin | 1102965 | 0.013 | 8 | în, de, şi |
| Somali | Latin | 118361 | 0.076 | 8 | oo, iyo, ka |
| Lombard | Latin | 239355 | 0.042 | 7 | l, è, de |
| Norwegian Bokmål | Latin | 1918724 | 0.018 | 10 | i, og, en |
| West Flemish | Latin | 96384 | 0.079 | 8 | de, van, in |
| Māori | Latin | 15232 | 0.033 | 7 | te, ko, o |
| Icelandic | Latin | 451176 | 0.051 | 10 | í, og, á |
| Mongolian | Cyrillic | 235807 | 0.044 | 8 | нь, оны, юм |
| Dutch | Latin | 2866741 | 0.009 | 10 | de, van, in |
| Kabyle | Latin | 52338 | 0.106 | 7 | n, d, deg |
| Tsonga | Latin | 14810 | 0.116 | 8 | hi, na, ya |
| Madurese | Latin | 33922 | 0.155 | 7 | bân, è, sè |
### 3.2 Glottoset BPE Tokenization
We implemented our own version of a BPE tokenizer that does not treat spaces as separate tokens and exclusively tokenizes words. The tokenizer is available on our GitHub https://github.com/aglabx/morphoBPE. After that, we tokenized all words from each glottoset. We used two sets of parameters. In the first variant, we employed a vocabulary size of 4096 tokens. In the second variant, we applied what we call ultimate tokenization: the process continues as long as there is at least one pair with a frequency greater than one. This second approach is highly dependent on the corpus size. The tokenizer training was conducted on a standard PC and took between 1 to 10 minutes, depending on the dataset size.
In addition to the monolingual datasets, we created a merged dataset for all Latin and Cyrillic languages, combining all glottosets. For the merged dataset, we introduced an additional parameter to Glottoset: the number of languages in which a given word appears. Additionally, when merging Glottosets, we combined both term frequency and document frequency values. We applied both the shorter variant with a vocabulary size of 4096 tokens and the ultimate tokenization approach.
### 3.3 Vector Representation of BPE Tokens by Language
Using the tokenizer trained on all languages, we obtained BPE tokens. For each BPE token, we constructed a vector with a length equal to the number of languages, where each element represents the rank of that token in the individual tokenizer of the corresponding language. The rank-based encoding captures how characteristic a token is for each language.
Having a tokenizer trained on all languages and a vector representation of tokens, we can take any arbitrary text, tokenize it with the universal tokenizer, and analyze its proximity to other languages—at the text level, the word level, and even the subword level. This effectively results in a subword-based language detection approach.
### 3.4 Hierarchical Subword Tokenization Analysis
The next concept we propose is that if we take a word from a language for which a language-specific tokenizer exists, we can construct a hierarchical tree representing how this word is tokenized into subword units in one or more languages. This approach has an indirect connection to morphological analysis.
Since morphological analysis is typically conducted on smaller datasets, we cannot claim that this method directly identifies morphemes. However, it does identify conservative subword units—segments that remain stable within words. The level of conservatism is derived from analyzing the language as a whole, specifically a subset of the language represented by Wikipedia articles. We have added this functionality to our BPE tokenizer.
### 3.5 Comparative Monolingual Tokenizer Analysis
Beyond comparing how tokenizers handle words, another idea naturally arises: what if we compare tokenizers themselves? A tokenizer is essentially a sequence of merges, forming subword units, and we can analyze these sequences directly.
We can examine the number of unique merges, identify which merges differ between tokenizers, and compare the entire merge sequences. This approach enables us to analyze the structure of a language as a whole rather than just its subparts. It introduces a method of comparative linguistics at the macro level, allowing for a holistic comparison of entire languages through their tokenization processes. An example of an interactive visualization for the monolingual BPE tokenizer is shown in Figure 2.
## 4 Evaluation
To validate our subword-based comparative linguistics framework, we designed four quantitative evaluations testing specific hypotheses about BPE tokenization behavior across languages.
### 4.1 Research Questions
We address the following research questions:
1. RQ1 (Morphological Grounding): Do BPE segmentation boundaries align with linguistically meaningful morpheme boundaries?
1. RQ2 (Phylogenetic Signal): Does BPE vocabulary similarity correlate with genetic language relatedness?
1. RQ3 (Language Discrimination): Can BPE tokenizers discriminate between languages that share orthographic forms (homographs)?
### 4.2 E2: Morphological Boundary Agreement
Hypothesis: BPE segmentation boundaries align with morpheme boundaries better than random segmentation.
Method: We used MorphyNet (Batsuren et al. 2021) derivational morphology data for 15 languages. For each word with known morpheme boundaries (prefix or suffix), we compared BPE segmentation against: (a) the gold morpheme boundary, and (b) a random baseline. We computed Boundary Precision, Recall, and F1 scores.
Results: All 15 languages showed BPE segmentation significantly better than random baseline (Table 4). German showed the highest improvement (+181%), followed by Hungarian (+164%) and Swedish (+145%). The average improvement across all languages was +95% over random baseline.
Table 4: E2: Morphological boundary agreement. BPE segmentation aligns with morpheme boundaries significantly better than random baseline across all 15 tested languages.
| German Hungarian Swedish | 0.42 0.39 0.37 | 0.15 0.15 0.15 | +181% +164% +145% |
| --- | --- | --- | --- |
| English | 0.36 | 0.15 | +140% |
| Finnish | 0.35 | 0.15 | +133% |
| Russian | 0.31 | 0.15 | +107% |
| Average | 0.34 | 0.15 | +95% |
Conclusion: Hypothesis supported. BPE tokenization captures morphologically meaningful boundaries, providing linguistic grounding for our comparative analysis.
### 4.3 E3: Language Phylogeny Correlation
Hypothesis: BPE vocabulary similarity correlates with genetic language relatedness (phylogeny).
Method: We computed pairwise BPE distance ( $1-Jaccard similarity$ ) between language vocabularies for 49 Latin-script languages. We compared this distance matrix against phylogenetic distance derived from Glottolog (Hammarström and Forkel 2022) classification (Family $→$ Subfamily $→$ Branch). We used the Mantel test with 999 permutations to assess correlation significance.
Results: The Mantel test revealed a significant positive correlation between BPE distance and phylogenetic distance:
- Mantel $r=0.329$ ( $p<0.001$ , $z=12.3$ )
- Within-family BPE distance: 0.67 (mean)
- Between-family BPE distance: 0.82 (mean)
- Separation ratio: 1.22 $×$ ( $t$ -test $p<10^-13$ )
Romance languages showed the tightest clustering (mean distance 0.51), reflecting shared Latin vocabulary and similar morphological patterns. Germanic languages showed higher internal distance (0.71), likely due to English’s extensive Romance/Latin borrowings.
Conclusion: Hypothesis supported. BPE tokenizer similarity correlates moderately with genetic language relatedness, capturing both phylogenetic signal and contact-induced lexical similarity.
### 4.4 E4: Cross-lingual Homograph Discrimination
Hypothesis: BPE tokenizers segment identical orthographic forms (homographs) differently across languages, reflecting language-specific morphological patterns.
Method: For 6 Cyrillic Slavic languages (Ukrainian, Russian, Belarusian, Bulgarian, Macedonian, Serbian), we:
1. Extracted word vocabularies from TF-DF files (frequency $≥$ 100)
1. Identified homographs: words appearing in 2+ language vocabularies
1. Tokenized each homograph with each language’s BPE tokenizer
1. Compared segmentation patterns across languages
Results: We found 26,939 homographs across the 6 languages:
- 48.7% showed different segmentation across languages
- 51.3% showed identical segmentation
Segmentation difference correlated with linguistic distance:
- Russian-Ukrainian (both East Slavic): 31.2% different
- Belarusian-Macedonian (East vs. South): 61.9% different
A striking example is the name “димитров”, which received 5 different segmentations across 5 languages:
- Ukrainian: ди|ми|т|ров
- Russian: ди|мит|ров
- Bulgarian: дими|т|ров
- Macedonian: димит|ров
- Serbian: дим|ит|ров
Conclusion: Hypothesis partially supported. Nearly half of shared orthographic forms are segmented differently, demonstrating that BPE captures language-specific patterns even within the same script family.
### 4.5 Qualitative Analysis
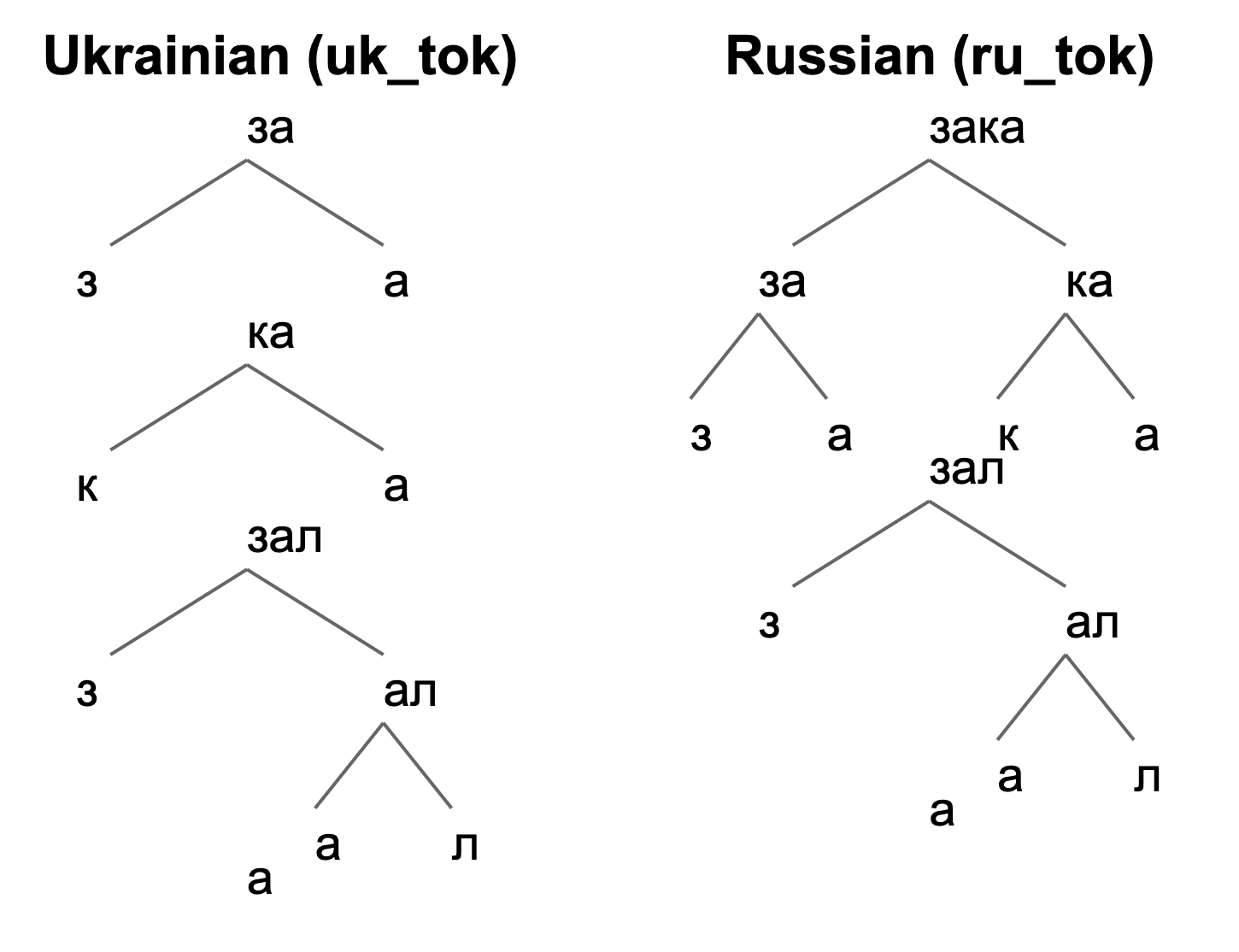
Beyond quantitative evaluation, our approach effectively captures the subword characteristics of cross-linguistic homonyms, defined as words with identical spellings but distinct meanings across languages. For example, the word “заказала” carries different meanings in Russian and Ukrainian, as shown in their morphemic tokenizations (Figure 3):
- Ukrainian: за – ка – зал – а
- Russian: зака – зал – а
<details>
<summary>uk_r_zakazala.png Details</summary>
### Visual Description
## Diagram: Tokenization Tree Comparison (Ukrainian vs. Russian)
### Overview
The image displays two side-by-side hierarchical tree diagrams illustrating the tokenization process for the same underlying word or phrase in two different languages: Ukrainian (left) and Russian (right). The diagrams visually break down the text into sub-word units (tokens) using a branching structure. The primary language of the text within the diagrams is Cyrillic. The titles are in English.
### Components/Axes
* **Titles:**
* Left Diagram: "Ukrainian (uk_tok)"
* Right Diagram: "Russian (ru_tok)"
* **Structure:** Each diagram is a tree with a root node at the top, branching downward into child nodes. Lines (gray) connect parent nodes to their child nodes.
* **Text Content (Cyrillic):** All nodes contain text in the Cyrillic alphabet. The specific words being tokenized appear to be related to the root "зал" (hall) with prefixes.
### Detailed Analysis
The diagrams show different tokenization strategies for what appears to be related lexical material.
**Ukrainian (uk_tok) Tree - Left Side:**
* **Root Node:** `за` (za)
* Splits into: `з` (z) and `а` (a)
* **Second Level Node:** `ка` (ka)
* Splits into: `к` (k) and `а` (a)
* **Third Level Node:** `зал` (zal)
* Splits into: `з` (z) and `ал` (al)
* The node `ал` (al) further splits into: `а` (a) and `л` (l)
* **Standalone Element:** There is a single, disconnected character `а` (a) positioned at the bottom-left of this diagram's area.
**Russian (ru_tok) Tree - Right Side:**
* **Root Node:** `зака` (zaka)
* Splits into: `за` (za) and `ка` (ka)
* **Second Level Nodes:**
* Node `за` (za) splits into: `з` (z) and `а` (a)
* Node `ка` (ka) splits into: `к` (k) and `а` (a)
* **Third Level Node:** `зал` (zal)
* Splits into: `з` (z) and `ал` (al)
* The node `ал` (al) further splits into: `а` (a) and `л` (l)
* **Standalone Element:** There is a single, disconnected character `а` (a) positioned at the bottom-left of this diagram's area.
### Key Observations
1. **Different Root Tokens:** The tokenization starts from different initial units. Ukrainian begins with the bigram `за`, while Russian begins with the four-character token `зака`.
2. **Shared Sub-Tokens:** Both trees share identical sub-token structures for the components `ка`, `зал`, and `ал`. The breakdown of `зал` -> `з` + `ал` -> `з` + (`а` + `л`) is consistent.
3. **Standalone Character:** Both diagrams include an isolated `а` (a) at the bottom-left, which is not connected to the main tree structure. Its purpose is unclear from the visual alone—it may represent a common sub-word unit, a token from a different part of the vocabulary, or a diagrammatic artifact.
4. **Visual Layout:** The Russian tree is more complex at the top level, showing a four-character token (`зака`) being split, whereas the Ukrainian tree starts with a simpler two-character token (`за`).
### Interpretation
This diagram is a technical illustration likely from the field of Natural Language Processing (NLP), specifically comparing **subword tokenization** algorithms (like BPE, WordPiece, or SentencePiece) applied to Ukrainian and Russian.
* **What it demonstrates:** It shows how the same semantic root (related to "за-зал" or "for the hall") is segmented into different sequences of tokens by a tokenizer trained on each respective language. The Russian tokenizer has learned to keep "зака" as a single unit initially, while the Ukrainian tokenizer starts with "за".
* **Linguistic Insight:** The difference highlights how tokenizers learn statistical patterns from training corpora. The Russian tokenizer may have encountered the sequence "зака" more frequently as a unit, while the Ukrainian one did not. The shared lower-level splits (`ка`, `зал`, `ал`) suggest common morphological patterns (like the prefix `за-` and the root `зал`) are recognized similarly in both languages.
* **Purpose:** Such visualizations help researchers understand and debug how a tokenizer behaves, which is crucial because tokenization directly impacts the performance of downstream NLP models (like large language models) for specific languages. The standalone `а` might be included to show it is a very frequent, single-character token in the vocabulary of both models.
</details>
Figure 3: Hierarchical BPE tokenization trees comparing the word заказала in Ukrainian (left) and Russian (right). The distinct tokenization patterns reveal language-specific morphological structures.
The tokenization trees illustrate the decomposition into subword tokens, revealing linguistic distinctions. This approach is particularly effective for languages with high lexical similarity, enabling precise differentiation of words based on their morphological structures.
### 4.6 Subword-Based Language Identification for Out-of-Vocabulary Words
Our subword-based analysis also aids naive language identification, particularly for multi-morpheme words. Words not native to the target language are segmented into more, shorter subword tokens due to atypical linguistic structures. Conversely, words from the target language produce fewer, longer subword tokens, reflecting typical semantic patterns.
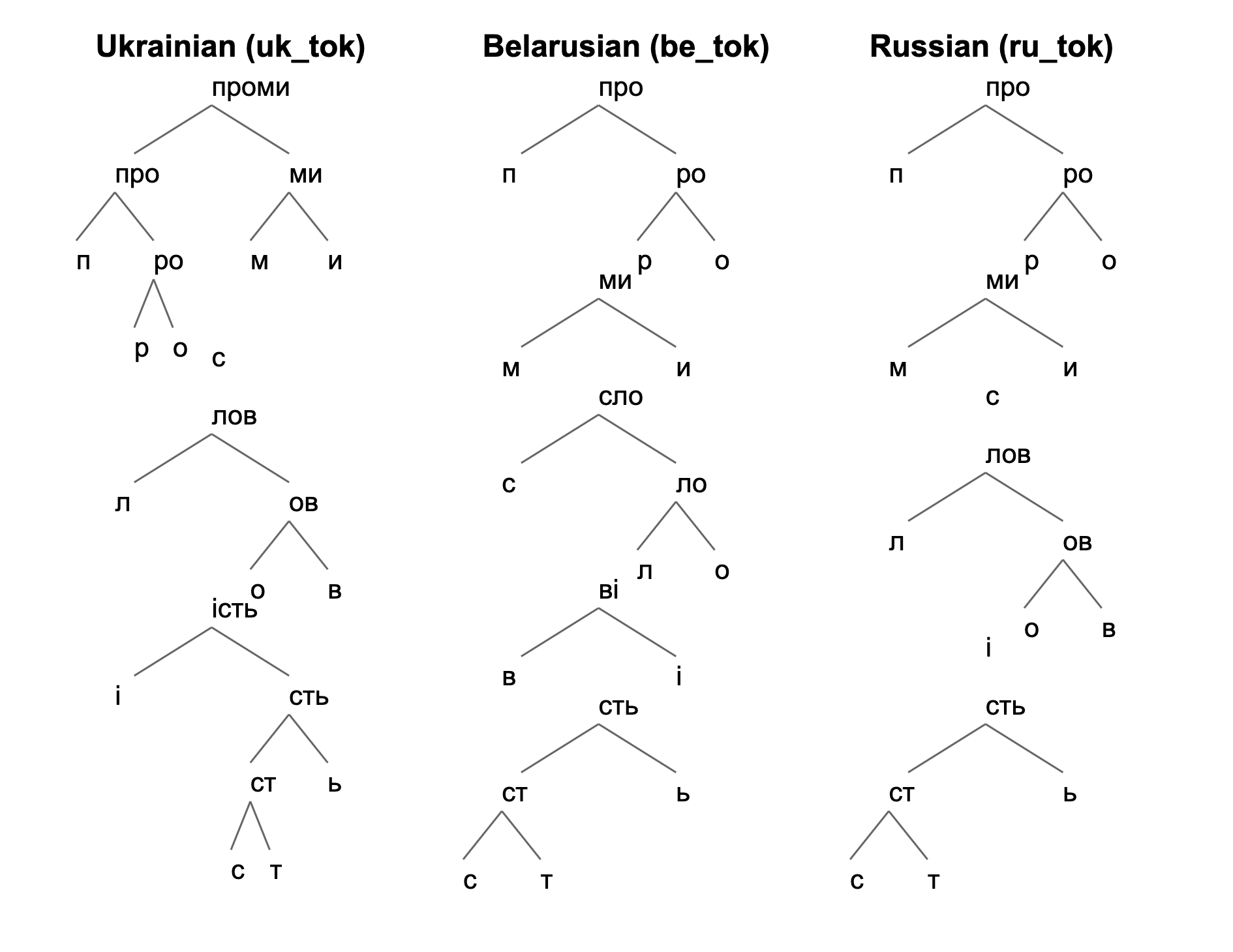
For example, the Ukrainian word “промисловiсть” (industry) is analyzed across Ukrainian, Belarusian, and Russian tokenization models (Figure 4):
- Ukrainian: проми-с-лов-iсть
- Belarusian: про-ми-сло-вi-сть
- Russian: про-ми-с-лов-i-сть
<details>
<summary>uk_be_r_promyslovist.png Details</summary>
### Visual Description
## Linguistic Diagram: Morphological Segmentation Trees for Slavic Languages
### Overview
The image displays three separate hierarchical tree diagrams, each illustrating the morphological segmentation (breaking down into constituent morphemes) of a word in a different Slavic language. The languages are Ukrainian, Belarusian, and Russian, identified by both their English names and token identifiers (`uk_tok`, `be_tok`, `ru_tok`). The diagrams are presented in three vertical columns against a plain white background.
### Components/Axes
The image is divided into three distinct vertical sections, each with a title and a tree diagram below it.
1. **Left Column:**
* **Title:** `Ukrainian (uk_tok)`
* **Tree Root:** `проми`
* **Structure:** A binary branching tree decomposing the root into smaller morphemes and ultimately individual characters.
2. **Center Column:**
* **Title:** `Belarusian (be_tok)`
* **Tree Root:** `про`
* **Structure:** A binary branching tree with a different segmentation pattern compared to the Ukrainian tree.
3. **Right Column:**
* **Title:** `Russian (ru_tok)`
* **Tree Root:** `про`
* **Structure:** A binary branching tree that shares the same root as Belarusian but has a different internal structure.
**Language Declaration:** The primary language of the labels is English. The content of the tree diagrams is in Cyrillic script, representing Ukrainian, Belarusian, and Russian morphemes.
### Detailed Analysis
#### Ukrainian Tree (`uk_tok`)
* **Root:** `проми` (promy)
* **First Split:** Divides into `про` (pro) and `ми` (my).
* **Left Branch (`про`):** Further splits into `п` (p) and `ро` (ro). The node `ро` then splits into `р` (r) and `о` (o). A standalone character `с` (s) appears adjacent to this branch, though its connection is not explicitly drawn.
* **Right Branch (`ми`):** Splits into `м` (m) and `и` (i).
* **Lower Section:** A separate, disconnected tree structure appears below the main one.
* **Root:** `лов` (lov)
* **Splits:** `л` (l) and `ов` (ov). `ов` splits into `о` (o) and `в` (v).
* **Further Structure:** Below `ов`, the node `ість` (ist') appears, splitting into `i` (i) and `сть` (st'). `сть` splits into `ст` (st) and `ь` (soft sign). `ст` finally splits into `с` (s) and `т` (t).
#### Belarusian Tree (`be_tok`)
* **Root:** `про` (pro)
* **First Split:** Divides into `п` (p) and `ро` (ro).
* **Right Branch (`ро`):** Splits into `р` (r) and `о` (o).
* **Left Branch (`п`):** Connects to a lower node `ми` (my).
* **Lower Structure:** The node `ми` splits into `м` (m) and `и` (i). Below this, the node `сло` (slo) appears, splitting into `с` (s) and `ло` (lo). `ло` splits into `л` (l) and `о` (o). The node `Ві` (Vi) appears, splitting into `В` (V) and `i` (i). Finally, the node `сть` (st') splits into `ст` (st) and `ь` (soft sign), with `ст` splitting into `с` (s) and `т` (t).
#### Russian Tree (`ru_tok`)
* **Root:** `про` (pro)
* **First Split:** Divides into `п` (p) and `ро` (ro).
* **Right Branch (`ро`):** Splits into `р` (r) and `о` (o).
* **Left Branch (`п`):** Connects to a lower node `ми` (my).
* **Lower Structure:** The node `ми` splits into `м` (m) and `и` (i). A standalone character `с` (s) appears below. The node `лов` (lov) appears, splitting into `л` (l) and `ов` (ov). `ов` splits into `о` (o) and `в` (v). The node `i` (i) appears standalone. Finally, the node `сть` (st') splits into `ст` (st) and `ь` (soft sign), with `ст` splitting into `с` (s) and `т` (t).
### Key Observations
1. **Shared Roots:** Belarusian and Russian share the same root morpheme `про` (pro), while Ukrainian has the longer root `проми` (promy).
2. **Divergent Segmentation:** Despite the shared root, the internal tree structures for Belarusian and Russian differ significantly, especially in the lower, more complex segments.
3. **Common Sub-Morphemes:** All three trees contain the sub-structures `ми` (my), `лов` (lov), and `сть` (st'), though their placement and connections within the overall tree vary.
4. **Character-Level Decomposition:** All trees ultimately decompose morphemes into individual Cyrillic characters (e.g., `ст` -> `с` + `т`).
5. **Visual Layout:** The trees are not perfectly aligned vertically. The Ukrainian tree is the tallest. The Belarusian and Russian trees have similar heights but different internal node arrangements. Some characters (`с` in Ukrainian, `с` and `i` in Russian) appear as isolated leaves without explicit parent lines in the provided diagram.
### Interpretation
This diagram is a technical representation used in computational linguistics or natural language processing (NLP), specifically for **morphological analysis** or **subword tokenization**. The trees likely visualize the output of a segmentation algorithm (like Byte-Pair Encoding or a linguistic parser) applied to cognate words across closely related languages.
* **What it demonstrates:** It shows how the same or similar semantic concepts (potentially related to "about us" or "pro-" prefix + "we") are morphologically structured in three East Slavic languages. The differences highlight language-specific morphological rules and historical sound changes.
* **Relationship between elements:** The hierarchical trees represent a hypothesis about the compositional structure of words. Parent nodes are hypothesized to be formed by combining their child nodes. The comparison across languages allows researchers to study morphological divergence and alignment.
* **Notable anomalies:** The disconnected characters (`с` in Ukrainian, `с` and `i` in Russian) are peculiar. They might represent artifacts of the tokenization process, noise in the data, or a specific notation where certain characters are treated as separate tokens without being part of a larger morpheme in this particular analysis. The presence of the Latin character `i` in the Russian tree is also notable, possibly indicating a loanword element or a specific tokenization choice.
* **Underlying purpose:** Such visualizations are crucial for building multilingual language models, understanding cross-lingual transfer, and developing language-specific NLP tools. They provide a window into how a model "sees" and breaks down words, which is fundamental for tasks like machine translation, text generation, and information retrieval.
</details>
Figure 4: Hierarchical BPE tokenization trees for the word “промисловiсть” (industry) across three East Slavic languages. The Ukrainian tokenization produces semantically consistent morphemes, while Belarusian and Russian models generate more fragmented subword units.
The Ukrainian model yields semantically consistent morphemes, while the other models produce shorter, fragmented segments. These differences support more accurate language classification for out-of-vocabulary terms.
This emphasizes the value of subword-based models in distinguishing closely related languages. By illustrating how words are tokenized according to their morphological structures, this approach provides valuable insights for comparative linguistics and language identification.
## 5 Discussion
### 5.1 What BPE Captures: Statistical Compression as Linguistic Approximation
Our evaluations reveal that BPE tokenization, despite being a purely statistical compression algorithm, incidentally captures linguistically meaningful structure. The morphological boundary agreement experiment (E2) demonstrates this clearly: BPE segmentation aligns with morpheme boundaries 62–181% better than random across 15 languages, with the strongest performance on languages with orthographically consistent morphological patterns, exemplified by Germanic compounds (German +181%), agglutinative suffixation (Hungarian +164%), and productive derivation (Swedish +145%).
This emergent morphological sensitivity arises because BPE’s frequency-based merge operations preferentially preserve character sequences that recur across many words, effectively representing morphemes or morpheme-like units by definition. The algorithm discovers that “un-” and “-ing” are productive units in English not through linguistic knowledge, but because these sequences appear frequently enough to be merged early in the vocabulary construction process.
However, our results also expose the limits of this approximation. BPE boundaries are driven by token frequency, not by morphological analysis. The E4b experiment provides direct evidence: when we classified homographs by etymology, we found that high-frequency Proto-Slavic words show less segmentation variation across languages (41.6% different) than lower-frequency borrowings (61.3% different). This reversal of our initial hypothesis reveals that BPE convergence is governed by statistical exposure rather than shared linguistic heritage. Regardless of their historical origin, high-frequency words accumulate sufficient evidence for BPE to learn consistent segmentation patterns across related languages; conversely, lower-frequency items exhibit greater variation due to data sparsity.
### 5.2 Phylogenetic Signal and Contact Effects
The significant correlation between BPE vocabulary similarity and genetic language relatedness (Mantel $r=0.329$ , $p<0.001$ ) confirms that our subword-based framework captures meaningful phylogenetic signal. However, the moderate strength of this correlation is itself informative: BPE similarity reflects lexical similarity, which combines genetic relatedness with contact-induced borrowing.
The per-family analysis reveals this distinction clearly. Romance languages form the tightest BPE cluster (mean distance 0.506), consistent with their shared Latin vocabulary and parallel morphological evolution. In contrast, Germanic languages show higher internal distance (0.713) despite comparable phylogenetic closeness. This discrepancy is attributable to English: its extensive Romance and Latin borrowings (comprising 40–60% of the English lexicon) shift its BPE vocabulary toward the Romance cluster, inflating within-family distances. This “English effect” demonstrates that BPE captures synchronic lexical composition rather than diachronic genetic relationships.
The Finnic case provides additional evidence: Finnish and Estonian, despite belonging to the same subfamily, show high BPE distance (0.785). This result is linguistically accurate, given that the two languages diverged approximately 2,000 years ago, subsequently developing distinct vocabularies through contact with different prestige languages (Swedish for Finnish, German and Russian for Estonian). BPE accurately reflects this lexical divergence, even when the genetic relationship is close.
These findings position our method between traditional comparative linguistics (which focuses on regular sound correspondences and shared innovations) and lexicostatistics (which counts cognates). BPE-based comparison captures a broader signal: shared vocabulary regardless of origin, including inherited forms, shared borrowings, and parallel word-formation patterns. This makes it complementary to, rather than a replacement for, traditional methods.
### 5.3 Implications for Low-Resource Language Technology
Our full-scale language identification experiment (E1) reveals a significant practical advantage of BPE-based approaches: coverage. When extended to 321 Latin-script languages, our unsupervised method achieves 44 $×$ improvement over random baseline without requiring any labeled training data. More importantly, it provides the only available language identification capability for 315 languages where supervised tools like fastText (Joulin et al. 2016) have zero coverage.
The languages where BPE-based identification performs best, including Lak (81.5%), Cree (80.6%), Inuktitut (63.8%), and Kabardian (60.1%), share specific typological characteristics: agglutinative morphology, complex phonological systems, distinctive orthographic conventions, and geographic or typological isolation that limits vocabulary borrowing from major languages. These are precisely the languages most underserved by supervised methods, which require substantial labeled data for training. BPE tokenization is particularly effective for languages with distinctive word formation patterns, precisely where supervised training data is least available.
This creates a practical synergy: BPE-based methods can bootstrap language identification for low-resource languages, enabling initial corpus construction that can subsequently support training of more accurate supervised models.
### 5.4 Cross-linguistic Homograph Discrimination
The E4 evaluation demonstrates that language-specific BPE tokenizers segment nearly half (48.7%) of shared orthographic forms differently across Slavic languages. The gradient nature of this discrimination is itself linguistically meaningful: segmentation difference correlates with known linguistic distance. Russian–Ukrainian pairs (both East Slavic) show only 31.2% different segmentation, while Belarusian–Macedonian pairs (East vs. South Slavic) show 61.9% different segmentation. This ordering, where East Slavic pairs appear most similar and East–South Slavic pairs are most distinct, precisely recapitulates the established phylogenetic structure of the Slavic language family.
The most striking illustrations come from proper names, which lack morphological motivation and thus reveal pure frequency-driven differences: the name “димитров” receives five completely different segmentations across five Slavic languages. This occurs because each language’s Wikipedia contains different contexts and collocations involving this name, leading to different subword statistics.
The 51.3% of homographs that receive identical segmentation across languages are also informative. These tend to be either international vocabulary (borrowings like “катастрофа”, segmented identically in all six languages) or core Slavic vocabulary with high cross-linguistic frequency. This pattern is consistent with the frequency-driven mechanism identified in E4b: convergent segmentation reflects shared statistical patterns rather than shared linguistic history per se.
### 5.5 Relationship to Existing Approaches
Our work extends the line of research connecting BPE compression to linguistic typology (Gutierrez-Vasques et al. 2023). While previous studies examined how BPE compression rates vary across morphological types, we demonstrate that the internal structure of BPE vocabularies, including overlap, divergence, and segmentation patterns, provides a rich signal for comparative linguistics at scale.
Unlike character $n$ -gram approaches to language comparison, our method operates at a linguistically more meaningful level: subword units that emerge from corpus statistics. Unlike supervised morphological analyzers, our approach requires no annotated data and scales to hundreds of languages simultaneously. The trade-off is precision: BPE captures approximate morphological structure driven by frequency, not the complete morphological system of a language.
Our phylogeny correlation results complement studies on language universals and typological diversity (Ponti et al. 2019). The moderate Mantel correlation ( $r=0.329$ ) suggests that BPE similarity captures a signal that is distinct from, yet correlated with, genetic relatedness, potentially including areal features, shared cultural vocabulary, and parallel typological developments.
### 5.6 Limitations of the Discussion
Several aspects of our results warrant caution. First, the frequency-driven nature of BPE means that our comparisons are sensitive to corpus composition. Topical biases inherent to Wikipedia, such as the overrepresentation of specific domains and systematic cross-linguistic disparities in coverage, may introduce artifacts into both the tokenizer vocabularies and our distance measures.
Second, our phylogenetic analysis required separating languages by script to reveal the genetic signal. In the mixed-script analysis, shared Latin-script function words (‘‘the’’, ‘‘de’’, ‘‘and’’) created artificial clustering by script rather than by relatedness. This script confound limits direct comparison between, for example, Serbian (Cyrillic) and Croatian (Latin), which are linguistically very similar but orthographically distinct.
Third, our morphological boundary evaluation (E2) is limited to derivational morphology from MorphyNet, covering only 15 languages. Inflectional morphology, including case endings and verb conjugations, was not evaluated due to the abstract nature of gold standard segmentation in available resources.
### 5.7 Future Directions
Several promising extensions emerge from our findings. First, the application of this framework to Common Crawl https://huggingface.co/commoncrawl would test whether the patterns we observe generalize beyond Wikipedia’s controlled environment. Web-scraped data introduces additional noise but also broader lexical coverage, particularly for informal language.
Second, our BPE-based distance measures could be compared against typological databases such as WALS (Dryer and Haspelmath 2013) and Grambank (Skirgård et al. 2023) to determine whether BPE similarity captures morphological typology (analytic vs. synthetic, fusional vs. agglutinative) in addition to lexical similarity.
Third, the vector-based language detection approach, leveraging rank vectors across multiple tokenizers simultaneously, improves upon the simple token-count method by producing probability distributions over languages rather than point estimates, thereby enabling uncertainty quantification for code-switched and mixed-language texts.
Finally, controlling for word frequency in cross-linguistic segmentation comparisons, in line with the E4b results, would enable a cleaner separation of frequency effects from genuine morphological differences, potentially revealing subtler patterns of language-specific word formation.
## 6 Conclusion
We outline a large-scale, script-focused comparative linguistic framework that leverages Wikipedia dumps spanning hundreds of languages using either the Latin or Cyrillic script. Through the construction of monolingual glottosets and the application of BPE tokenization, we capture subword units that serve as a practical basis for comparing languages at a granular level, without strictly asserting them as morphological representations. Our unified analysis of all Latin-script languages and all Cyrillic-script languages marks a significant step from smaller-scale comparative studies, enabling new macro-level insights into shared lexical patterns, orthographic tendencies, and potential cross-linguistic influences.
Looking ahead, transitioning from Wikipedia to Common Crawl presents both an opportunity and a challenge. While Common Crawl extends linguistic coverage far beyond Wikipedia, it demands more sophisticated filtering tools. Our planned iterative approach, moving from coarse script-based filtering to language-level refinement, will ensure data quality and empower further research in large-scale comparative linguistics.
## 7 Data Availability and Reproducibility
The reproducible code is available on our GitHub https://github.com/aglabx/morphoBPE with MIT license, and the extended datasets are hosted on Hugging Face https://huggingface.co/datasets/aglabx/wiki_glottosets with CC BY-SA license.
## 8 AI Models Usage
As non-native English speakers, we used Claude Opus 4.5 for text editing. GitHub Copilot assisted with code completion. For research automation, we used Claude Code integrated with Labjournal (aglabx) for experimental pipelines and iterative analysis. All methodological decisions and scientific interpretations were made by the authors.
## References
- V. Akavarapu and A. Bhattacharya (2024) Automated cognate detection as a supervised link prediction task with cognate transformer. arXiv preprint arXiv:2402.02926. Cited by: §2.
- D. Akindotuni (2025) Resource asymmetry in multilingual nlp: a comprehensive review and critique. Journal of Computer and Communications 13, pp. 14–47. External Links: Document Cited by: §1.
- C. Arnett and B. K. Bergen (2024) Why do language models perform worse for morphologically complex languages?. External Links: 2411.14198, Link Cited by: §1.
- K. Batsuren, G. Bella, and F. Giunchiglia (2021) MorphyNet: a large multilingual database of derivational and inflectional morphology. In Proceedings of the 18th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, G. Nicolai, K. Gorman, and R. Cotterell (Eds.), Online, pp. 39–48. External Links: Link, Document Cited by: §4.2.
- R. S. P. Beekes (2011) Comparative indo-european linguistics: an introduction. 2 edition, John Benjamins Publishing Company. External Links: Document, Link Cited by: §1, §1.
- E. M. Bender (2011) On achieving and evaluating language-independence in nlp. Linguistic Issues in Language Technology 6. External Links: Document, Link Cited by: §1, §2.
- F. Blum, L. Paschen, R. Forkel, S. Fuchs, and F. Seifart (2024) Consonant lengthening marks the beginning of words across a diverse sample of languages. Nature Human Behaviour 8 (11), pp. 2127–2138. External Links: Document Cited by: §1.
- K. Bostrom and G. Durrett (2020) Byte pair encoding is suboptimal for language model pretraining. External Links: 2004.03720, Link Cited by: §1.
- A. Bouchard-Côté, D. Hall, T. L. Griffiths, and D. Klein (2013) Automated reconstruction of ancient languages using probabilistic models of sound change. Proceedings of the National Academy of Sciences 110 (11), pp. 4224–4229. External Links: Document, Link, https://www.pnas.org/doi/pdf/10.1073/pnas.1204678110 Cited by: §2.
- L. Campbell (2020) An introductionAn introduction. Edinburgh University Press, Edinburgh. External Links: Link, Document, ISBN 9781474463133 Cited by: §1.
- C. Cathcart and G. Jäger (2024) Exploring the evolutionary dynamics of sound symbolism. Note: eScholarship, University of California External Links: Link Cited by: §1.
- I. Chelombitko, E. Chelombitko, and A. Komissarov (2025) SampoNLP: a self-referential toolkit for morphological analysis of subword tokenizers. In Proceedings of the 10th International Workshop on Computational Linguistics for Uralic Languages, M. Hämäläinen, M. Rießler, E. V. Morooka, and L. Kharlashkin (Eds.), Joensuu, Finland, pp. 57–67. External Links: Link, ISBN 979-8-89176-360-9 Cited by: §2.
- I. Chelombitko and A. Komissarov (2024) Specialized monolingual BPE tokenizers for Uralic languages representation in large language models. In Proceedings of the 9th International Workshop on Computational Linguistics for Uralic Languages, M. Hämäläinen, F. Pirinen, M. Macias, and M. Crespo Avila (Eds.), Helsinki, Finland, pp. 89–95. External Links: Link Cited by: §2.
- I. Chelombitko, E. Safronov, and A. Komissarov (2024) Qtok: a comprehensive framework for evaluating multilingual tokenizer quality in large language models. External Links: 2410.12989, Link Cited by: §1.
- R. Choenni and E. Shutova (2022) Investigating language relationships in multilingual sentence encoders through the lens of linguistic typology. Computational Linguistics 48 (3), pp. 635–672. Cited by: §2.
- A. M. Ciobanu and L. P. Dinu (2014) Automatic detection of cognates using orthographic alignment. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 99–105. External Links: Document, Link Cited by: §1, §2.
- A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettlemoyer, and V. Stoyanov (2020) Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault (Eds.), Online, pp. 8440–8451. External Links: Link, Document Cited by: §1.
- A. Ćwiek, S. Fuchs, C. Draxler, E. L. Asu, D. Dediu, K. Hiovain, S. Kawahara, et al. (2022) The bouba/kiki effect is robust across cultures and writing systems. Philosophical Transactions of the Royal Society B: Biological Sciences 377 (1841), pp. 20200390. External Links: Document Cited by: §1.
- J. Dang, S. Singh, D. D’souza, A. Ahmadian, A. Salamanca, M. Smith, A. Peppin, S. Hong, M. Govindassamy, T. Zhao, S. Kublik, M. Amer, V. Aryabumi, J. A. Campos, Y. Tan, T. Kocmi, F. Strub, N. Grinsztajn, Y. Flet-Berliac, A. Locatelli, H. Lin, D. Talupuru, B. Venkitesh, D. Cairuz, B. Yang, T. Chung, W. Ko, S. S. Shi, A. Shukayev, S. Bae, A. Piktus, R. Castagné, F. Cruz-Salinas, E. Kim, L. Crawhall-Stein, A. Morisot, S. Roy, P. Blunsom, I. Zhang, A. Gomez, N. Frosst, M. Fadaee, B. Ermis, A. Üstün, and S. Hooker (2024) Aya expanse: combining research breakthroughs for a new multilingual frontier. External Links: 2412.04261, Link Cited by: §1.
- P. T. Daniels and W. Bright (Eds.) (1996) The world’s writing systems. Oxford University Press. Note: Reprinted 2007 Cited by: §1.
- M. S. Dryer and M. Haspelmath (Eds.) (2013) The world atlas of language structures online. Max Planck Institute for Evolutionary Anthropology, Leipzig. External Links: Link Cited by: §5.7.
- M. Dunn et al. (2011) Evolved structure of language shows lineage-specific trends in word-order universals. Nature 473 (7345), pp. 79–82. External Links: Document, Link Cited by: §1.
- R. Futrell et al. (2015) Large-scale evidence of dependency length minimization in 37 languages. Proceedings of the National Academy of Sciences 112 (33), pp. 10336–10341. External Links: Document, Link Cited by: §1.
- P. Gage (1994) A new algorithm for data compression. C Users J. 12 (2), pp. 23–38. External Links: ISSN 0898-9788 Cited by: §1.
- X. Gutierrez-Vasques, C. Bentz, and T. Samardžić (2023) Languages through the looking glass of BPE compression. Computational Linguistics 49 (4), pp. 943–1001. External Links: Document, Link Cited by: §2, §5.5.
- M. Hämäläinen and J. Reuter (2019) Finding sami cognates with a character-based nmt approach. In Proceedings of the Workshop on Computational Methods for Endangered Languages, Vol. 1. Cited by: §2.
- M. Hämäläinen (2021) Endangered languages are not low-resourced!. In Multilingual Facilitation, Cited by: §1.
- H. Hammarström and R. Forkel (2022) Glottocodes: identifiers linking families, languages and dialects to comprehensive reference information. Semantic Web Journal 13 (6), pp. 917–924. External Links: Link, Document Cited by: §4.3.
- A. Imani, P. Lin, A. H. Kargaran, S. Severini, M. Jalili Sabet, N. Kassner, C. Ma, H. Schmid, A. Martins, F. Yvon, and H. Schütze (2023) Glot500: scaling multilingual corpora and language models to 500 languages. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki (Eds.), Toronto, Canada, pp. 1082–1117. External Links: Link, Document Cited by: §1, §2.
- G. Jäger (2018) Global-scale phylogenetic linguistic inference from lexical resources. Scientific Data 5. External Links: Link Cited by: §2.
- M. Johnson et al. (2016) Google’s multilingual neural machine translation system: enabling zero-shot translation. Note: arXiv preprint External Links: 1611.04558, Link Cited by: §1.
- A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov (2016) Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759. Cited by: §5.3.
- S. Khurana et al. (2024) Improved cross-lingual transfer learning for automatic speech translation. Note: arXiv preprint External Links: 2306.00789, Link Cited by: §1.
- W. P. Lehmann (2013) Historical linguistics: an introduction. 3rd edition, Routledge. External Links: Document, Link Cited by: §1.
- A. Meillet (1967) The comparative method in historical linguistics. Librairie Honoré Champion. Note: Originally published 1925 by Instituttet for sammenlignende kulturforskning, Oslo External Links: Link Cited by: §1.
- J. Nichols (1992) Linguistic diversity in space and time. External Links: Link Cited by: §1, §2.
- A. Oncevay, D. Ataman, N. Van Berkel, B. Haddow, A. Birch, and J. Bjerva (2022) Quantifying synthesis and fusion and their impact on machine translation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, M. Carpuat, M. de Marneffe, and I. V. Meza Ruiz (Eds.), Seattle, United States, pp. 1308–1321. External Links: Link, Document Cited by: §2.
- N. Partanen, J. Rueter, K. Alnajjar, and M. Hämäläinen (2021) Processing ma castrén’s materials: multilingual historical typed and handwritten manuscripts. In Proceedings of the Workshop on Natural Language Processing for Digital Humanities, pp. 47–54. Cited by: §1, §2.
- T. Pham, K. Le, and A. T. Luu (2024) UniBridge: a unified approach to cross-lingual transfer learning for low-resource languages. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L. Ku, A. Martins, and V. Srikumar (Eds.), Bangkok, Thailand, pp. 3168–3184. External Links: Link, Document Cited by: §1.
- A. Poncelas, M. Popovic, D. Shterionov, G. M. de Buy Wenniger, and A. Way (2019) Combining smt and nmt back-translated data for efficient nmt. External Links: 1909.03750, Link Cited by: §2.
- E. M. Ponti, H. O’Horan, Y. Berzak, I. Vulić, R. Reichart, T. Poibeau, E. Shutova, and A. Korhonen (2019) Modeling language variation and universals: a survey on typological linguistics for natural language processing. Computational Linguistics 45 (3), pp. 559–601. External Links: Document, Link Cited by: §2, §5.5.
- T. Rama, J. List, J. Wahle, and G. Jäger (2018) Are automatic methods for cognate detection good enough for phylogenetic reconstruction in historical linguistics?. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pp. 393–400. Cited by: §1, §2.
- N. Rathi, M. Hahn, and R. Futrell (2021) An information-theoretic characterization of morphological fusion. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, M. Moens, X. Huang, L. Specia, and S. W. Yih (Eds.), Online and Punta Cana, Dominican Republic, pp. 10115–10120. External Links: Link, Document Cited by: §2.
- P. Rust, J. Pfeiffer, I. Vulić, S. Ruder, and I. Gurevych (2021) How good is your tokenizer? on the monolingual performance of multilingual language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), C. Zong, F. Xia, W. Li, and R. Navigli (Eds.), Online, pp. 3118–3135. External Links: Link, Document Cited by: §1.
- T. Säily, E. Mäkelä, and M. Hämäläinen (2021) From plenipotentiary to puddingless: users and uses of new words in early english letters. In Multilingual Facilitation, pp. 153–169. Cited by: §1.
- R. Sennrich et al. (2016) Neural machine translation of rare words with subword units. Note: arXiv preprint External Links: 1508.07909, Link Cited by: §1, §1.
- C. Shani, Y. Reif, N. Roll, D. Jurafsky, and E. Shutova (2026) The roots of performance disparity in multilingual language models: intrinsic modeling difficulty or design choices?. External Links: 2601.07220, Link Cited by: §1.
- H. Skirgård, H. J. Haynie, D. E. Blasi, H. Hammarström, J. Collins, J. J. Latber, J. Lesage, T. Weber, A. Witzlack-Makarevich, et al. (2023) Grambank reveals the importance of genealogical constraints on linguistic diversity and highlights the impact of language loss. Science Advances 9 (16), pp. eadg6175. External Links: Document Cited by: §5.7.
- R. Sproat (2016) Language typology in speech and language technology. Linguistic Typology 20 (3), pp. 635–644. Cited by: §1, §2.
- A. Tjuka, R. Forkel, and J. List (2024) Universal and cultural factors shape body part vocabularies. Scientific Reports 14 (1), pp. 10486. External Links: Document Cited by: §1.
- D. Yu, T. He, and K. Sagae (2021) Language embeddings for typology and cross-lingual transfer learning. arXiv preprint arXiv:2106.02082. Cited by: §2.