# REASON: Accelerating Probabilistic Logical Reasoning for Scalable Neuro-Symbolic Intelligence
**Authors**: Zishen Wan, Che-Kai Liu, Jiayi Qian, Hanchen Yang, Arijit Raychowdhury, Tushar Krishna
## Abstract
Neuro-symbolic AI systems integrate neural perception with symbolic and probabilistic reasoning to enable data-efficient, interpretable, and robust intelligence beyond purely neural models. Although this compositional paradigm has shown superior performance in domains such as mathematical reasoning, planning, and verification, its deployment remains challenging due to severe inefficiencies in symbolic and probabilistic inference. Through systematic analysis of representative neuro-symbolic workloads, we identify probabilistic logical reasoning as the inefficiency bottleneck, characterized by irregular control flow, low arithmetic intensity, uncoalesced memory accesses, and poor hardware utilization on CPUs and GPUs.
This paper presents REASON, an integrated acceleration framework for probabilistic logical reasoning in neuro-symbolic AI. At the algorithm level, REASON introduces a unified directed acyclic graph representation that captures common structure across symbolic and probabilistic models, coupled with adaptive pruning and regularization. At the architecture level, REASON features a reconfigurable, tree-based processing fabric optimized for irregular traversal, symbolic deduction, and probabilistic aggregation. At the system level, REASON is tightly integrated with GPU streaming multiprocessors through a programmable interface and multi-level pipeline that efficiently orchestrates neural, symbolic, and probabilistic execution. Evaluated across six neuro-symbolic workloads, REASON achieves 12-50 $\times$ speedup and 310-681 $\times$ energy efficiency over desktop and edge GPUs under TSMC 28 nm node. REASON enables real-time probabilistic logical reasoning, completing end-to-end tasks in 0.8 s with 6 mm ${}^{\text{2}}$ area and 2.12 W power, demonstrating that targeted acceleration of probabilistic logical reasoning is critical for practical and scalable neuro-symbolic AI and positioning REASON as a foundational system architecture for next-generation cognitive intelligence.
## I Introduction
Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language understanding, image recognition, and complex pattern learning from vast datasets [23, 46, 42, 16]. However, despite their success, LLMs often struggle with factual accuracy, hallucinations, multi-step reasoning, and interpretability [35, 62, 2, 61]. These limitations have spurred the development of compositional AI systems, which integrate neural with symbolic and probabilistic reasoning to create robust, transparent, and intelligent cognitive systems. footnotetext: † Corresponding author
One promising compositional paradigm is neuro-symbolic AI, which integrates neural, symbolic, and probabilistic components into a unified cognitive architecture [60, 1, 72, 9, 75]. In this system, the neural module captures the statistical, pattern-matching behavior of learned models, performing rapid function approximation and token prediction for intuitive perception and feature extraction. The symbolic and probabilistic modules perform explicit, verifiable reasoning that is structured, interpretable, and robust under uncertainty, managing logic-based reasoning and probabilistic updates. This paradigm integrates intuitive generalization and deliberate reasoning.
Neuro-symbolic AI has demonstrated superior abstract deduction, complex question answering, mathematical reasoning, logical reasoning, and cognitive robotics [28, 66, 55, 81, 12, 38, 41, 71]. Its ability to learn efficiently from fewer data points, produce transparent and verifiable outputs, and robustly handle uncertainty and ambiguity makes it particularly advantageous compared to purely neural approaches. For example, recently Meta’s LIPS [28] and Google’s AlphaGeometry [66] leverage compositional neuro-symbolic approaches to solve complex math problems and achieve a level of human Olympiad gold medalists. R 2 -Guard [20] leverages LLM and probabilistic models to improve robust reasoning capability and resilience against jailbreaks. They represent a paradigm shift for AI that requires robust, verifiable, and explainable reasoning.
Despite impressive algorithmic advances in neuro-symbolic AI – often demonstrated on large-scale distributed GPU clusters – efficient deployment at the edge remains a fundamental challenge. Neuro-symbolic agents, particularly in robotics, planning, interactive cognition, and verification, require real-time logical inference to interact effectively with physical environments and multi-agent systems. For example, Ctrl-G, a text-infilling neuro-symbolic agent [83], must execute hundreds of reasoning steps per second to remain responsive, yet current implementations take over 5 minutes on a desktop GPU to complete a single task. This latency gap makes practical deployment of neuro-symbolic AI systems challenging.
To understand the root causes of this inefficiency, we systematically analyze a diverse set of neuro-symbolic workloads and uncover several system- and architecture-level challenges. Symbolic and probabilistic kernels frequently dominate end-to-end runtime and exhibit highly irregular execution characteristics, including heterogeneous compute patterns and memory-bound behavior with low ALU utilization. These kernels suffer from limited exploitable parallelism and irregular, uncoalesced memory accesses, leading to poor performance and efficiency on CPU and GPU architectures.
To address these challenges, we develop an integrated acceleration framework, REASON, which to the best of our knowledge, is the first to accelerate probabilistic logical reasoning-based neuro-symbolic AI systems. REASON is designed to close the efficiency gap of compositional AI by jointly optimizing algorithms, architecture, and system integration for the irregular and heterogeneous workloads inherent to neuro-symbolic reasoning.
At the algorithm level, REASON introduces a unified directed acyclic graph (DAG) representation that captures shared computational structure across symbolic and probabilistic kernels. An adaptive pruning and regularization technique further reduces model size and computational complexity while preserving task accuracy. At the architecture level, REASON features a flexible design optimized for various irregular symbolic and probabilistic computations, leveraging the unified DAG representation. The architecture comprises reconfigurable tree-based processing elements (PEs), compiler-driven workload mapping, and memory layout to enable highly parallel and energy-efficient symbolic and probabilistic computation. At the system level, REASON is tightly integrated with GPU streaming multiprocessors (SMs), forming a heterogeneous system with a programmable interface and multi-level execution pipeline that efficiently orchestrates neural, symbolic, and probabilistic kernels while maintaining high hardware utilization and scalability as neuro-symbolic models evolve. Notably, unlike conventional tree-like computing arrays optimized primarily for neural workloads, REASON provides reconfigurable support for neural, symbolic, and probabilistic kernels within a unified execution fabric, enabling efficient and scalable neuro-symbolic AI systems.
This paper, therefore, makes the following contributions:
- We conduct a systematic workload characterization of representative logical- and probabilistic-reasoning-based neuro-symbolic AI models, identifying key performance bottlenecks and architectural optimization opportunities (Sec. II, Sec. III).
- We propose REASON, an integrated co-design framework, to efficiently accelerate probabilistic logical reasoning in neuro-symbolic AI, enabling practical and scalable deployment of compositional intelligence (Fig. 4).
- REASON introduces cross-layer innovations spanning (i) a unified DAG representation with adaptive pruning at the algorithm level (Sec. IV), (ii) a reconfigurable symbolic/probabilistic architecture and compiler-driven dataflow and mapping at the hardware level (Sec. V), and (iii) a programmable system interface with a multi-level execution pipeline at the system level (Sec. VI) to improve neuro-symbolic efficiency.
- Evaluated across cognitive tasks, REASON enables flexible support for symbolic and probabilistic operations, achieving 12-50 $\times$ speedup and 310-681 $\times$ energy efficiency compared to desktop and edge GPUs. REASON enables fast and efficient logical and probabilistic reasoning in 0.8 s per task with 6 mm 2 area and 2.12 W power consumption. (Sec. VII).
## II Neuro-Symbolic AI Systems
This section presents the preliminaries of neuro-symbolic AI with its algorithm flow (Sec. II-A), scaling performance analysis (Sec. II-B), and key computational primitives (Sec. II-C).
<details>
<summary>x1.png Details</summary>
### Visual Description
## Hybrid AI Approaches: Neuro-Symbolic Integration
### Overview
The image illustrates a hybrid AI approach that combines neural (Neuro) and symbolic (Symbolic) methods. It shows how deep neural networks (DNNs) and large language models (LLMs) can be integrated with logical and probabilistic reasoning for various applications. The diagram highlights the strengths of each approach and provides examples of their combined use in different domains.
### Components/Axes
* **Top-Left:** "Neuro" - Represents the neural approach to AI.
* "DNN/LLM (Fast Thinking)" - Indicates the use of Deep Neural Networks and Large Language Models for fast processing.
* **Top-Center:** "Symbolic" - Represents the symbolic approach to AI.
* "Logical (Slow Thinking)" - Indicates logical reasoning processes.
* "Probabilistic (Bayesian Thinking)" - Indicates probabilistic reasoning processes.
* **Top-Right:** Examples of symbolic representations.
* "First-Order Logic (FOL) Boolean Satisfiability (SAT)" - Shows a logical representation with variables x1, x2, x3, x4 and outputs y1, y2.
* "Probabilistic Circuit (PC)" - Illustrates a probabilistic circuit with variables x1, x2, x3, x4.
* "Hidden Markov Model (HMM)" - Depicts a Hidden Markov Model with states S1, S2, S3 and observations X1, X2, X3.
* **Bottom:** "Application Examples" - Lists various applications of the hybrid approach.
* "Commonsense Reason:" - Application example.
* "Cognitive Robotics:" - Application example.
* "Medical Diagnosis:" - Application example.
* "Question Answering:" - Application example.
* "Math Solving:" - Application example.
### Detailed Analysis or ### Content Details
**Neuro Component:**
* The "Neuro" component is represented by a pink box containing the text "DNN/LLM (Fast Thinking)". A network of interconnected nodes is shown to the left of the text.
**Symbolic Component:**
* The "Symbolic" component is divided into two sub-components: "Logical (Slow Thinking)" in a light green box and "Probabilistic (Bayesian Thinking)" in a light blue box.
* The "Logical" component contains a diagram of a tree-like structure.
* The "Probabilistic" component contains an image of dice.
**Symbolic Examples:**
* **First-Order Logic (FOL) Boolean Satisfiability (SAT):**
* Variables: x1, x2, x3, x4
* Outputs: y1, y2
* Logical gates: AND (∩), OR (∪), NOT (¬)
* The diagram shows a network of logical gates connecting the input variables to the output variables.
* **Probabilistic Circuit (PC):**
* Variables: x1, x2, x3, x4
* The diagram shows a circuit with addition (+) and multiplication (×) operations.
* **Hidden Markov Model (HMM):**
* States: S1, S2, S3, ...
* Observations: X1, X2, X3, ...
* The diagram shows a sequence of states connected by arrows, with each state emitting an observation.
**Application Examples:**
The application examples are structured as follows:
* **Commonsense Reason:** feature extraction -> rule logic -> uncertainty infer.
* **Cognitive Robotics:** scene graph -> logic-based planning -> uncertainty infer.
* **Medical Diagnosis:** feature extraction -> rule reasoning -> likelihood infer.
* **Question Answering:** parsing -> symbolic query planning -> missing fact infer.
* **Math Solving:** initial sol. gen. -> algebra solver -> uncertainty infer.
The application examples follow a pattern of:
1. Initial stage (pink box)
2. Intermediate stage (green box)
3. Final stage (blue box)
### Key Observations
* The diagram illustrates a clear distinction between neural and symbolic AI approaches.
* The application examples demonstrate how these approaches can be combined to solve complex problems.
* The symbolic examples provide concrete illustrations of logical and probabilistic reasoning.
### Interpretation
The image presents a high-level overview of hybrid AI systems, emphasizing the integration of neural and symbolic methods. The "Neuro" component, representing DNNs and LLMs, is characterized by "Fast Thinking," suggesting its efficiency in tasks like pattern recognition and data processing. In contrast, the "Symbolic" component, encompassing "Logical (Slow Thinking)" and "Probabilistic (Bayesian Thinking)," highlights the strengths of symbolic AI in reasoning, planning, and handling uncertainty.
The application examples demonstrate how these two approaches can be combined to leverage their respective strengths. For instance, in "Commonsense Reason," feature extraction (neural) is followed by rule logic (symbolic) and uncertainty inference (symbolic), showcasing a pipeline where neural networks extract relevant features, and symbolic methods perform reasoning based on those features.
The symbolic examples (FOL, PC, HMM) provide concrete illustrations of the types of representations and reasoning techniques used in symbolic AI. These examples highlight the ability of symbolic AI to represent knowledge explicitly and perform logical or probabilistic inference.
Overall, the image suggests that hybrid AI systems can offer a more robust and versatile approach to AI by combining the strengths of neural and symbolic methods. This integration allows for the development of systems that can not only learn from data but also reason, plan, and handle uncertainty in a more human-like manner.
</details>
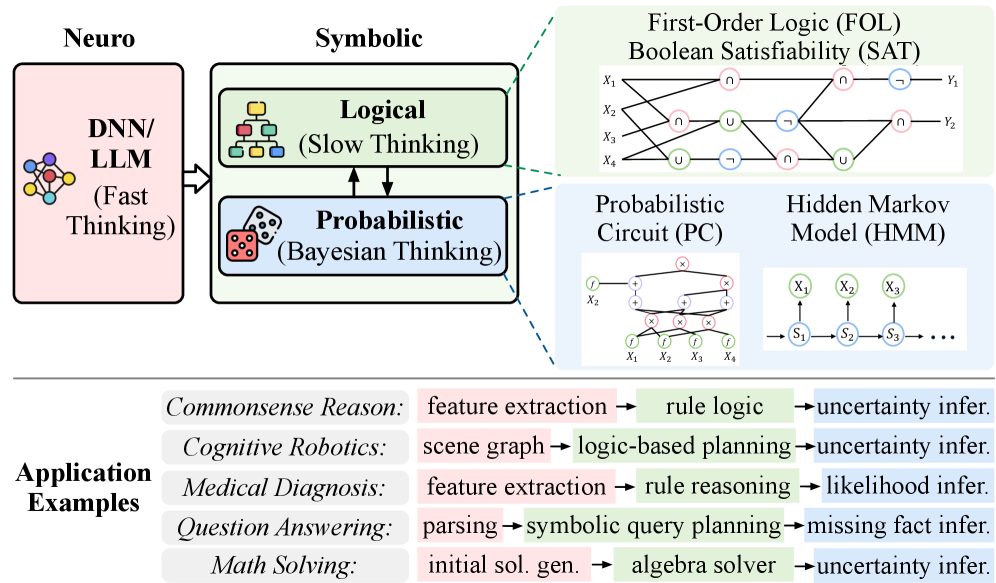
Figure 1: Neuro-symbolic algorithmic flow and operations. The neural module serves as a perceptual and intuitive engine for representation learning, while the symbolic module performs structured logical reasoning with probabilistic inference. This compositional pipeline enables complex cognitive tasks across diverse scenarios.
### II-A Neuro-Symbolic Cognitive Intelligence
LLMs and DNNs excel at natural language understanding and image recognition. However, they remain prone to factual errors, hallucinations, challenges in complex multi-step reasoning, and vulnerability to out-of-distribution or adversarial inputs. Their black-box nature also impedes interpretability and formal verification, undermining trust in safety-critical domains. These limitations motivate the development of compositional systems that integrate neural models with symbolic and probabilistic reasoning to achieve greater robustness, transparency, and intelligence.
Neuro-symbolic AI represents a paradigm shift toward more integrated and trustworthy intelligence by combining neural, symbolic, and probabilistic techniques. This hybrid approach has shown superior performance in abstract deduction [81, 12], complex question answering [38, 41], and logical reasoning [66, 55]. By learning from limited data and producing transparent, verifiable outputs, neuro-symbolic systems provide a foundation for cognitive intelligence. Fig. 1 presents a unified neuro-symbolic pipeline, illustrating how its components collaborate to solve complex tasks.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Chart: Scaling Performance and Efficiency Analysis
### Overview
The image presents four scatter plots analyzing the scaling performance and efficiency of different models across various tasks. The first three plots (a, b, c) depict "Task Accuracy vs. Model Size" for Complex Reasoning, Math Reasoning, and Question-Answering tasks, respectively. The fourth plot (d) shows "Task Runtime vs. Complexity" for Neuro-symbolic and RL-based models.
### Components/Axes
**General:**
* **Title:** Scaling Performance Analysis: Task Accuracy vs. Model Size (for plots a, b, c) and Scaling Efficiency Analysis: Task Runtime vs. Complexity (for plot d)
* Each plot is labeled with a letter: (a), (b), (c), (d) in the bottom left corner.
**Plot (a): Complex Reasoning Tasks**
* **X-axis:** Model Size (7B, 8B, 13B, 70B, GPT)
* **Y-axis:** Task Accuracy (%) (Scale from 0 to 100, increments of 20)
* **Legend (top-left):**
* Blue Square: Textedit (C)
* Orange Triangle: ACLUTRR (C)
* Green Circle: ProofWriter (C)
* Gray Square: Textedit (M)
* Gray Triangle: ACLUTRR (M)
* Gray Circle: ProofWriter (M)
**Plot (b): Math Reasoning Tasks**
* **X-axis:** Model Size (7B, 8B, 13B, 70B, GPT)
* **Y-axis:** Task Accuracy (%) (Scale from 0 to 100, increments of 20)
* **Legend (top-left):**
* Blue Square: GSM8K (C)
* Orange Triangle: SVAMP (C)
* Green Circle: TabMWP (C)
* Red Diamond: In-Domain GSM8K (C)
* Purple Diamond: In-Domain MATH (C)
**Plot (c): Question-Answering Tasks**
* **X-axis:** Model Size (7B, 8B, 13B, 70B, GPT)
* **Y-axis:** Task Accuracy (%) (Scale from 30 to 80, increments of 10)
* **Legend (top-left):**
* Blue Square: AmbigNQ (C)
* Orange Triangle: TriviaQA (C)
* Green Circle: HotpotQA (C)
* Gray Square: AmbigNQ (M)
* Gray Triangle: TriviaQA (M)
* Gray Circle: HotpotQA (M)
**Plot (d): Task Runtime vs. Complexity**
* **X-axis:** Inter. Math Olympics reasoning (Year_Problem) (00_P1, 08_P6, 04_P1, 12_P5, 20_P6, 19_P6)
* **Y-axis:** Task runtime (min) (Scale from 5 to 30, increments of 5)
* **Legend (top-right):**
* Blue Circle: Neuro-symbolic models (AlphaGeometry)
* Gray Circle: RL-based CoT reasoning models
* There is a right-pointing arrow at the bottom of the chart, indicating increasing complexity.
### Detailed Analysis
**Plot (a): Complex Reasoning Tasks**
* **Textedit (C):** Accuracy increases from approximately 85% at 7B to 98% at 70B.
* **ACLUTRR (C):** Accuracy increases from approximately 58% at 7B to 70% at 70B.
* **ProofWriter (C):** Accuracy increases from approximately 20% at 7B to 65% at 13B, then to 70% at 70B.
* **Textedit (M):** Accuracy increases from approximately 45% at 7B to 48% at 8B, then to 55% at 13B, and then decreases to 45% at 70B.
* **ACLUTRR (M):** Accuracy increases from approximately 25% at 7B to 35% at 13B, then to 45% at 70B.
* **ProofWriter (M):** Accuracy increases from approximately 20% at 7B to 25% at 8B, then to 25% at 13B, and then to 30% at 70B.
**Plot (b): Math Reasoning Tasks**
* The data points are scattered, making it difficult to discern clear trends for each model.
* **GSM8K (C):** Accuracy ranges from approximately 20% to 55%.
* **SVAMP (C):** Accuracy ranges from approximately 25% to 75%.
* **TabMWP (C):** Accuracy ranges from approximately 30% to 95%.
* **In-Domain GSM8K (C):** Accuracy ranges from approximately 40% to 75%.
* **In-Domain MATH (C):** Accuracy ranges from approximately 10% to 35%.
**Plot (c): Question-Answering Tasks**
* **AmbigNQ (C):** Accuracy increases from approximately 65% at 7B to 70% at 8B, then to 75% at 13B, and then to 80% at 70B.
* **TriviaQA (C):** Accuracy increases from approximately 55% at 7B to 68% at 8B, then to 60% at 13B, and then to 80% at 70B.
* **HotpotQA (C):** Accuracy increases from approximately 38% at 7B to 40% at 8B, then to 65% at 13B, and then to 75% at 70B.
* **AmbigNQ (M):** Accuracy increases from approximately 45% at 7B to 55% at 8B, then to 58% at 13B, and then to 75% at 70B.
* **TriviaQA (M):** Accuracy increases from approximately 50% at 7B to 58% at 8B, then to 58% at 13B, and then to 75% at 70B.
* **HotpotQA (M):** Accuracy increases from approximately 30% at 7B to 30% at 8B, then to 40% at 13B, and then to 50% at 70B.
**Plot (d): Task Runtime vs. Complexity**
* **Neuro-symbolic models (AlphaGeometry):** Task runtime increases linearly from approximately 8 minutes to 15 minutes as complexity increases.
* **RL-based CoT reasoning models:** Task runtime increases linearly from approximately 12 minutes to 28 minutes as complexity increases.
### Key Observations
* For Complex Reasoning and Question-Answering tasks, the "C" versions of the models generally outperform the "M" versions.
* In Math Reasoning tasks, the performance varies significantly across different models and model sizes.
* In the Task Runtime vs. Complexity plot, RL-based CoT reasoning models consistently have higher task runtime compared to Neuro-symbolic models (AlphaGeometry).
* The GPT model size is only present in the Task Accuracy plots, and not in the Task Runtime plot.
### Interpretation
The data suggests that increasing model size generally improves task accuracy for Complex Reasoning and Question-Answering tasks, but the effect is less consistent for Math Reasoning tasks. The difference in performance between "C" and "M" versions of the models indicates that certain model architectures or training methods are more effective for specific tasks. The Task Runtime vs. Complexity plot highlights a trade-off between model type and computational cost, with Neuro-symbolic models demonstrating lower runtime compared to RL-based models for the same level of complexity. The arrow on the x-axis of plot (d) indicates that the problems are ordered by increasing difficulty.
</details>
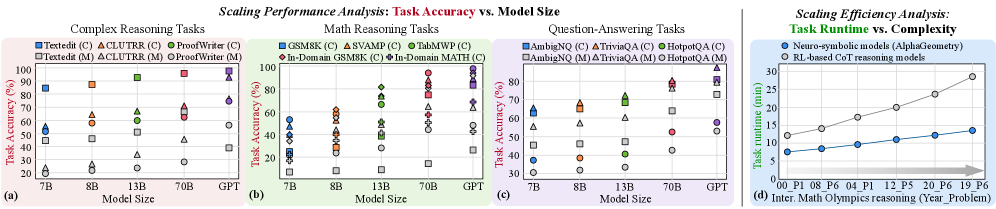
Figure 2: Scaling performance and efficiency. (a)-(c) Task accuracy of compositional LLM-symbolic models (C) and monolithic LLMs (M - shown in gray) across model sizes on complex reasoning, mathematical reasoning, and question-answering tasks. (d) Runtime efficiency comparison between LLM-symbolic models and RL-based CoT models on mathematical reasoning tasks [76].
Neural module. The neural module serves as the perceptual and intuitive engine, typically DNN or LLM, excelling at processing high-dimensional sensory inputs (e.g., images, audio, text) and converting them into feature representations. It handles perception, feature extraction, and associative learning, providing the abstractions needed for higher-level cognition.
Symbolic module. The symbolic module is the logical core operating on neural abstractions and includes symbolic and probabilistic operations. Logical components apply formal logic, rules, and ontologies for structured reasoning and planning, enabling logically sound solutions. Probabilistic components manage uncertainty by representing knowledge probabilistically, supporting belief updates and decision-making under ambiguity, reflecting a nuanced reasoning model.
Together, these modules form a complementary reasoning hierarchy. Neural module captures statistical, pattern-matching behavior of learned models, producing rapid but non-verifiable outputs (Fast Thinking), while symbolic modules perform explicit, verifiable reasoning that is structured and reliable (Slow Thinking). The probabilistic module complements both and enables robust planning under ambiguity (Bayesian Thinking). This framework integrates intuitive generalization with deliberate reasoning.
### II-B Scaling Performance Analysis of Neuro-Symbolic Systems
Scaling performance analysis. Neuro-symbolic AI systems exhibit superior reasoning capability and scaling behavior compared to monolithic LLMs on complex tasks. We compare representative neuro-symbolic systems against monolithic LLMs across complex reasoning, mathematical reasoning, and question-answering benchmarks (Fig. 2 (a)-(c)). The results reveal two advantages. First, higher accuracy: compositional neuro-symbolic models consistently outperform monolithic LLMs of comparable size. Second, improved scaling efficiency: smaller neuro-symbolic models are sufficient to match or exceed the performance of significantly larger closed-source LLMs. Together, these results highlight the potential scaling limitations of monolithic LLMs and the efficiency benefits of compositional neuro-symbolic reasoning.
Comparison with RL-based reasoning models. Beyond monolithic LLMs, recent advancements in reinforcement learning (RL) and chain-of-thought (CoT) prompting improve LLM reasoning accuracy but incur significant computational and scalability overheads (Fig. 2 (d)). First, computational cost: RL-based reasoning often requires hundreds to thousands of LLM queries per decision step, resulting in prohibitively high inference latency and energy consumption. Second, scalability: task-specific fine-tuning constrains generality, whereas neuro-symbolic models use symbolic and probabilistic reasoning modules or tools without retraining. Fig. 2 (d) reveals that neuro-symbolic models AlphaGeometry [66] achieve over $2\times$ efficiency gains and superior data efficiency compared to CoT-based LLMs on mathematical reasoning tasks.
### II-C Computational Primitives in Neuro-Symbolic AI
We identify the core computational primitives that are commonly used in neuro-symbolic AI systems (Fig. 1). While neural modules rely on DNNs or LLMs for perception and representation learning, the symbolic and probabilistic components implement structured reasoning. In particular, logical reasoning is typically realized through First-Order Logic (FOL) and Boolean Satisfiability (SAT), probabilistic reasoning through Probabilistic Circuits (PCs), and sequential reasoning through Hidden Markov Models (HMMs). Together, these primitives form the algorithmic foundation of neuro-symbolic systems that integrate learning, logic, and uncertainty-aware inference.
First-Order Logic (FOL) and Boolean Satisfiability (SAT). FOL provides a formal symbolic language for representing structured knowledge using predicates, functions, constants, variables and quantifiers ( $\forall,\exists$ ), combined with logical connectives. For instance, the statement “every student has a mentor” can be expressed as $\forall x\bigl(\mathrm{Student}(x)\to\exists y\,(\mathrm{Mentor}(y)\wedge\mathrm{hasMentor}(x,y))\bigr)$ , where predicates encode properties and relations over domain elements. FOL semantics map symbols to domain objects and relations, enabling precise and interpretable logical reasoning. SAT operates over propositional logic and asks whether a conjunctive normal form (CNF) formula $\varphi=\bigwedge_{i=1}^{m}\Bigl(\bigvee_{j=1}^{k_{i}}l_{ij}\Bigr)$ admits a satisfying assignment, where each literal $l_{ij}$ is a Boolean variable or its negation. Modern SAT solvers extend the DPLL algorithm with conflict-driven clause learning (CDCL), incorporating non-chronological backtracking and clause learning to improve scalability [40, 33]. Cube-and-conquer further parallelizes search by splitting into “cube” DPLL subproblems and concurrent CDCL “conquer” solvers [13, 67]. Together, FOL’s expressive representations and SAT’s solving mechanisms form the logic backbone of neuro-symbolic systems, enabling exact logical inference alongside neural learning.
| Representative Neuro- Symbolic Workloads | AlphaGeometry [66] | R 2 -Guard [20] | GeLaTo [82] | Ctrl-G [83] | NeuroPC [6] | LINC [52] | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Deployment Scenario | Application | Math theorem proving & reasoning | Unsafety detection | Constrained text generation | Interactive text editing, text infilling | Classification | Logical reasoning, Deductive reasoning |
| Advantage vs. LLM | Higher deductive reasoning, higher generalization | Higher LLM resilience, higher data efficiency, effective adaptability | Guaranteed constraint satisfaction, higher generalization | Guaranteed constraints satisfaction, higher generalization | Enhanced interpretability, theoretical guarantee | Higher precision, reduced overconfidence, higher scalability | |
| Computation Pattern | Neural | LLM | LLM | LLM | LLM | DNN | LLM |
| Symbolic | First-order logic, SAT solver, acyclic graph | First-order logic, probabilistic circuit, Hidden Markov model | First-order logic, SAT solver, Hidden Markov model | Hidden Markov model, probabilistic circuits | First-order logic, probabilistic circuit | First-order logic, solver | |
TABLE I: Representative neuro-symbolic workloads. Selected neuro-symbolic workloads used in our analysis, spanning diverse application domains, deployment scenarios, and neural-symbolic computation patterns.
<details>
<summary>x3.png Details</summary>

### Visual Description
## Chart/Diagram Type: Multi-Panel Performance Comparison
### Overview
The image presents a multi-panel figure comparing the performance of different systems (AlphaGeo, R2-Guard, GeLaTo, Ctrl-G, NPC, LINC, LLaMA-3-8B, and NeuroPC) across various tasks and hardware configurations. The figure consists of four subplots: (a) Runtime percentage breakdown between Neuro and Symbolic components, (b) Runtime latency for different tasks with "Small" and "Large" configurations, (c) Runtime latency on different hardware (A6000 and Orin), and (d) Attainable performance versus operation intensity.
### Components/Axes
**Panel (a): Stacked Bar Chart - Runtime Percentage**
* **Title:** None explicitly given, but implied as "Runtime Percentage"
* **Y-axis:** Runtime Percentage, ranging from 0% to 100%.
* **X-axis:** Different systems: AlphaGeo, R2-Guard, GeLaTo, Ctrl-G, NPC, LINC. Each system is evaluated on different tasks such as IMO, MiniF2F, Twins, XSTest, Method, ComGen, ReviewGen, News, ComGen, TextF, Math, AwA2, FOLIO, Proof.
* **Legend (top-right):**
* Red (slanted lines): Neuro
* Green (dotted): Symbolic
**Panel (b): Grouped Bar Chart - Runtime Latency (min)**
* **Title:** None explicitly given, but implied as "Runtime Latency (min)"
* **Y-axis:** Runtime Latency (min), ranging from 0 to 12.
* **X-axis:** Different systems: Alpha, R2-G, GeLaTo, Ctrl-G, LINC. Each system is evaluated on "Small" and "Large" configurations.
* **Tasks (top):** IMO, Safety, CoGen, Text, FOLIO
* **Legend:**
* Red (slanted lines): Lower portion of the bar
* Green (dotted): Upper portion of the bar
**Panel (c): Grouped Bar Chart - Runtime Latency (min)**
* **Title:** None explicitly given, but implied as "Runtime Latency (min)"
* **Y-axis:** Runtime Latency (min), ranging from 0 to 24.
* **X-axis:** Different systems: Alpha, R2-G. Each system is evaluated on A6000 and Orin hardware.
* **Tasks (top):** MiniF, XSTest
* **Legend:**
* Red (slanted lines): Lower portion of the bar
* Green (dotted): Upper portion of the bar
**Panel (d): Scatter Plot - Attainable Performance vs. Operation Intensity**
* **Y-axis:** Attainable Performance (TFLOPS/s), logarithmic scale from 10<sup>-1</sup> to 10<sup>2</sup>.
* **X-axis:** Operation Intensity (FLOPS/Byte), logarithmic scale from 10<sup>-1</sup> to 10<sup>2</sup>.
* **Data Points:**
* AlphaGeo (Symb)
* LINC (Symb)
* Ctrl-G (Symb)
* R2-Guard (Symb)
* GeLaTo (Symb)
* NeuroPC (Symb)
* LLaMA-3-8B (Neuro)
### Detailed Analysis
**Panel (a): Runtime Percentage**
* **AlphaGeo:** Neuro runtime ranges from approximately 32.6% (IMO) to 65.1% (ReviewGen). Symbolic runtime ranges from 67.4% (IMO) to 34.9% (ReviewGen).
* **R2-Guard:** Neuro runtime ranges from approximately 39.8% (MiniF2F) to 36.1% (ComGen). Symbolic runtime ranges from 60.2% (MiniF2F) to 63.9% (ComGen).
* **GeLaTo:** Neuro runtime ranges from approximately 36.5% (Twins) to 39.9% (TextF). Symbolic runtime ranges from 63.5% (Twins) to 60.1% (TextF).
* **Ctrl-G:** Neuro runtime ranges from approximately 33.2% (XSTest) to 32.3% (Math). Symbolic runtime ranges from 66.8% (XSTest) to 67.7% (Math).
* **NPC:** Neuro runtime ranges from approximately 42.1% (Method) to 49.5% (AwA2). Symbolic runtime ranges from 57.9% (Method) to 50.5% (AwA2).
* **LINC:** Neuro runtime ranges from approximately 63.4% (ComGen) to 66.0% (FOLIO) to 64.3% (Proof). Symbolic runtime ranges from 36.6% (ComGen) to 34.0% (FOLIO) to 35.7% (Proof).
**Panel (b): Runtime Latency (min)**
* **Alpha:** Small configuration has a Neuro runtime of approximately 1.5 min and a Symbolic runtime of approximately 3.5 min. Large configuration has a Neuro runtime of approximately 2.2 min and a Symbolic runtime of approximately 4.8 min.
* **R2-G:** Small configuration has a Neuro runtime of approximately 0.5 min and a Symbolic runtime of approximately 2.5 min. Large configuration has a Neuro runtime of approximately 2.0 min and a Symbolic runtime of approximately 4.0 min.
* **GeLaTo:** Small configuration has a Neuro runtime of approximately 2.0 min and a Symbolic runtime of approximately 3.0 min. Large configuration has a Neuro runtime of approximately 4.5 min and a Symbolic runtime of approximately 3.5 min.
* **Ctrl-G:** Small configuration has a Neuro runtime of approximately 0.5 min and a Symbolic runtime of approximately 2.5 min. Large configuration has a Neuro runtime of approximately 1.5 min and a Symbolic runtime of approximately 5.5 min.
* **LINC:** Small configuration has a Neuro runtime of approximately 1.0 min and a Symbolic runtime of approximately 4.0 min. Large configuration has a Neuro runtime of approximately 2.5 min and a Symbolic runtime of approximately 7.5 min.
**Panel (c): Runtime Latency (min)**
* **Alpha:** A6000 has a Neuro runtime of approximately 1.0 min and a Symbolic runtime of approximately 3.0 min. Orin has a Neuro runtime of approximately 2.0 min and a Symbolic runtime of approximately 4.0 min.
* **R2-G:** A6000 has a Neuro runtime of approximately 0.5 min and a Symbolic runtime of approximately 2.5 min. Orin has a Neuro runtime of approximately 1.0 min and a Symbolic runtime of approximately 3.0 min.
**Panel (d): Attainable Performance vs. Operation Intensity**
* **LLaMA-3-8B (Neuro):** Located at approximately (1, 40) on the log-log scale.
* **AlphaGeo (Symb):** Located at approximately (0.2, 2).
* **LINC (Symb):** Located at approximately (0.1, 0.8).
* **Ctrl-G (Symb):** Located at approximately (10, 1).
* **R2-Guard (Symb):** Located at approximately (10, 2).
* **GeLaTo (Symb):** Located at approximately (0.1, 0.2).
* **NeuroPC (Symb):** Located at approximately (10, 0.1).
### Key Observations
* Panel (a) shows the percentage of runtime attributed to Neuro and Symbolic components across different systems and tasks. The Symbolic component generally dominates the runtime.
* Panel (b) shows that the "Large" configuration generally increases the runtime latency compared to the "Small" configuration.
* Panel (c) shows that the Orin hardware generally results in higher runtime latency compared to the A6000 hardware.
* Panel (d) shows the relationship between attainable performance and operation intensity for different systems. LLaMA-3-8B (Neuro) has a relatively high attainable performance, while NeuroPC (Symb) has a relatively low attainable performance.
### Interpretation
The data suggests that the Symbolic component often contributes more to the overall runtime than the Neuro component across various tasks and systems. The "Large" configurations in Panel (b) likely represent larger problem sizes or more complex scenarios, leading to increased runtime latency. The hardware comparison in Panel (c) indicates that the Orin hardware, despite potentially being more powerful, does not always translate to lower runtime latency, possibly due to overhead or optimization issues. The scatter plot in Panel (d) provides insights into the performance characteristics of different systems, with LLaMA-3-8B (Neuro) demonstrating a higher attainable performance compared to other systems. The placement of the systems on the plot indicates their suitability for different types of workloads based on their operation intensity and attainable performance.
</details>
Figure 3: End-to-end neuro-symbolic workload characterization. (a) Benchmark six neuro-symbolic workloads (AlphaGeometry, R 2 -Guard, GeLaTo, Ctrl-G, NeuroPC, LINC) on CPU+GPU system, showing symbolic and probabilistic may serve as system bottlenecks. (b) Benchmark neuro-symbolic workloads on tasks with different scales, indicating that real-time performance cannot be satisfied and the potential efficiency issues. (c) Benchmark on A6000 and Orin GPU. (d) Roofline analysis, indicating server memory-bound of symbolic and probabilistic kernels.
Probabilistic Circuits (PC). PCs represent tractable probabilistic models over variables $\mathbf{X}$ as directed acyclic graphs [30, 22, 32]. Each node $n$ performs a probabilistic computation: leaf nodes specify primitive distributions $f_{n}(x)$ , while interior nodes combine their children $ch(n)$ via
$$
p_{n}(x)=\begin{cases}f_{n}(x),&\text{if }n\text{ is a leaf node}\\
\prod_{c\in\mathrm{ch}(n)}p_{c}(x),&\text{if }n\text{ is a product node}\\
\sum_{c\in\mathrm{ch}(n)}\theta_{n,c}p_{c}(x),&\text{if }n\text{ is a sum node}\end{cases} \tag{1}
$$
where $\theta_{n,c}$ denotes the non-negative weight associated with child $c$ . This recursive structure guarantees exact inference (e.g., marginals, conditionals) in time linear in circuit size. PCs’ combination of expressiveness and tractable computation makes them an ideal probabilistic backbone for neuro-symbolic systems, where neural modules learn circuit parameters while symbolic engines perform probabilistic reasoning.
Hidden Markov Model (HMM). HMMs are probabilistic model for sequential data [43], where a system evolves through hidden states governed by the first-order Markov property: the state at time step $t$ depends only on the state at time step $t-1$ . Each hidden state emits observations according to a probabilistic distribution. The joint distribution over sequence of hidden states $z_{1:T}$ and observations $x_{1:T}$ is given by
$$
p(z_{1:T},x_{1:T})=p(z_{1})p(x_{1}\mid z_{1})\prod_{t=2}^{T}p(z_{t}\mid z_{t-1})p(x_{t}\mid z_{t}) \tag{2}
$$
where $p(z_{1})$ is the initial state distribution, $p(z_{t}\mid z_{t-1})$ the transition probability, and $p(x_{t}\mid z_{t})$ the emission probability. HMMs naturally support sequential inference tasks such as filtering, smoothing, and decoding, enabling temporal reasoning in neuro-symbolic pipelines.
## III Neuro-Symbolic Workload Characterization
This section characterizes the system behavior of various neuro-symbolic workloads (Sec. III-A - III-B) and provides workload insights for computer architects (Sec. III-C - III-D).
Profiling workloads. To conduct comprehensive profiling analysis, we select six state-of-the-art representative neuro-symbolic workloads, as listed in Tab. I, covering a diverse range of applications and underlying computational patterns.
Profiling setup. We profile and analyze the selected neuro-symbolic models in terms of runtime, memory, and compute operators using cProfile for latency measurement, and NVIDIA Nsight for kernel-level profiling and analysis. Experiments are conducted on the system with NVIDIA A6000 GPU, Intel Sapphire Rapids CPUs, and DDR5 DRAM. Our software environment includes PyTorch 2.5 and JAX 0.4.6. We also conduct profiling on Jetson Orin [49] for edge scenario deployment. We track control and data flow by analyzing the profiling results in trace view and graph execution format.
### III-A Compute Latency Analysis
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Goals, Challenges, Methodology, Architecture, Deployment
### Overview
The image presents a diagram outlining the goals, challenges, methodology, architecture, and deployment aspects of a system, likely related to cognitive computing or AI. It illustrates the progression from high-level objectives to specific implementation details.
### Components/Axes
**Goals:**
* **Y-axis:** Cognitive Capability
* **X-axis:** Energy and Latency
* **Curve:** A blue curve indicates the desired relationship between cognitive capability and energy/latency.
* **Point:** A red star labeled "REASON" is positioned at the top-left of the graph, indicating a target state.
* **Text:** "Neuro-symbolic-probabilistic AI" is positioned in the center of the graph.
* **Text:** "Efficiency, Performance, Scalability, Cognition" with a green upward arrow.
**Challenges:**
* **Challenge-1:** Irregular compute and memory access
* **Challenge-2:** Inefficient symbolic and probabilistic execution
* **Challenge-3:** Low hardware utilization and scalability
**Methodology:**
* **Key Insight-1:** Unified DAG representation & pruning (Sec. IV)
* Diagram: A graph of interconnected nodes transforms into a tree structure. A red sad face is below the initial graph, and a green happy face is below the tree structure.
* **Key Insight-2:** Flexible architecture for symbolic & probabilistic (Sec. V)
* Diagram: A timeline labeled "naive" shows alternating red (cross-hatched) and green blocks. A timeline labeled "opt." shows a higher proportion of green blocks. A red sad face is to the right of the "naive" timeline, and a green happy face is to the right of the "opt." timeline.
* **Key Insight-3:** GPU-accelerator protocol and two-level pipelining (Sec. VI)
* Diagram: Two bar graphs labeled "task scale". The first shows a red (cross-hatched) bar for "desired" and a smaller gray bar for "GPU". The second shows a green bar for "desired" and a green bar for "GPU" and a green happy face.
**Architecture:**
* Reconfigurable PE (Sec. V-B)
* Compilation & mapping (Sec. V-C)
* Bi-direction dataflow (Sec. V-D)
* Memory layout (Sec. V-D)
* Co-processor & pipelining (Sec. VI)
**Deployment:**
* Configurations: hardware & system (Sec. VII)
* Evaluate: across cognitive tasks, complexities, scales, hardware configs (Sec. VII)
* Target: efficient, scalable agentic cognition
### Detailed Analysis
* **Goals:** The graph illustrates the trade-off between cognitive capability and energy/latency. The "REASON" point represents an ideal state of high cognitive capability with low energy/latency.
* **Challenges:** The challenges highlight key bottlenecks in achieving the desired goals, including irregular memory access, inefficient execution, and low hardware utilization.
* **Methodology:** The methodology section outlines key insights and approaches to address the identified challenges. These include unified DAG representation, flexible architecture, and GPU-accelerator protocols. The diagrams show the progression from a less optimal state (red sad face) to a more optimal state (green happy face).
* **Architecture:** The architecture section lists key components of the system, including reconfigurable processing elements, compilation and mapping strategies, bi-directional dataflow, memory layout, and co-processor pipelining.
* **Deployment:** The deployment section outlines the steps involved in deploying the system, including configuration, evaluation, and targeting efficient and scalable agentic cognition.
### Key Observations
* The diagram presents a clear and concise overview of the system's goals, challenges, methodology, architecture, and deployment.
* The use of diagrams and visual cues (e.g., happy/sad faces, upward arrow) effectively communicates the key concepts.
* The references to specific sections (e.g., Sec. IV, Sec. V-B) provide pointers to more detailed information.
### Interpretation
The diagram illustrates a systematic approach to developing a cognitive computing system. It starts with clearly defined goals, identifies key challenges, proposes innovative methodologies, outlines the system architecture, and describes the deployment process. The emphasis on efficiency, performance, scalability, and cognition suggests a focus on building a high-performance system that can effectively address complex cognitive tasks. The progression from challenges to key insights and methodologies demonstrates a problem-solving approach. The architecture and deployment sections provide a roadmap for implementing and deploying the system. The overall diagram suggests a well-thought-out and comprehensive approach to cognitive computing system development.
</details>
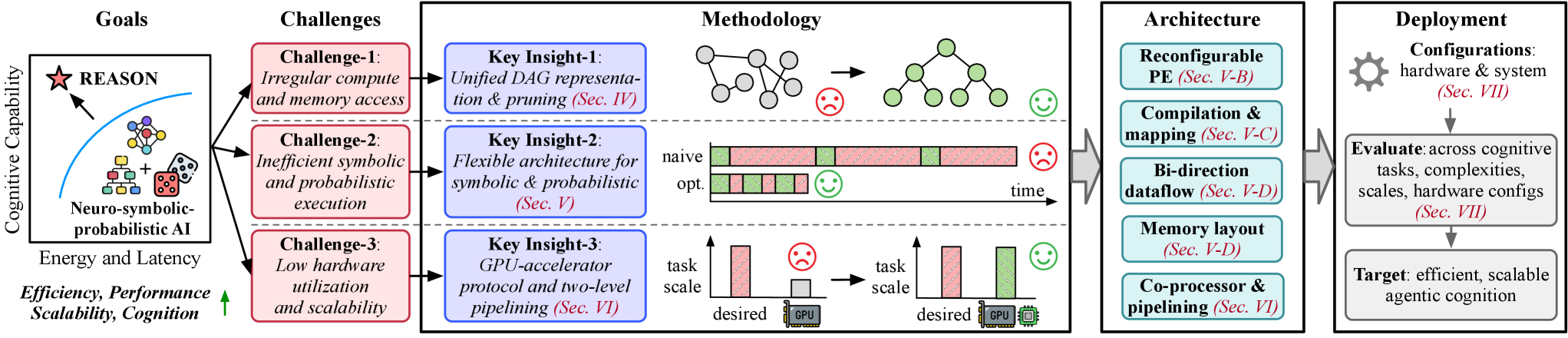
Figure 4: REASON overview. REASON is an integrated acceleration framework for probabilistic logical reasoning grounded neuro-symbolic AI with the goal to achieve efficient and scalable agentic cognition. REASON addresses the challenges of irregular compute and memory, symbolic and probabilistic latency bottleneck, and hardware underutilization, by proposing methodologies including unified DAG representation, reconfigurable PE, efficient dataflow, mapping, scalable architecture, two-level parallelism and programming interface. REASON is deployed across cognitive tasks and consistently demonstrates performance-efficiency improvements for compositional neuro-symbolic systems.
Latency bottleneck. We characterize the latency of representative neuro-symbolic workloads (Fig. 3 (a)). Compared to neuro kernels, symbolic and probabilistic kernels are not negligible in latency and may become system bottlenecks. For instance, the neural (symbolic) components account for 36.2% (63.8%), 37.3% (62.7%), 63.4% (36.6%), 36.1% (63.9%), 49.5% (50.5%), and 65.2% (34.8%) of runtime in AlphaGeometry, R 2 -Guard, GeLaTo, Ctrl-G, NeuroPC, and LINC, respectively. Symbolic kernels dominate AlphaGeometry’s runtime, and probabilistic kernels dominate R 2 -Guard and Ctrl-G’s, due to high irregular memory access, wrap divergence, thread underutilization, and execution parallelism. FLOPS and latency measurements further highlight this inefficiency. Notably, when using a smaller LLM (LLaMA-7B) for GeLaTo and LINC, overall accuracy remains stable, but the symbolic latency rises to 69.0% and 65.5%, respectively. We observe consistent trends in the Orin NX-based platform (Fig. 3 (c)). Symbolic components count for 63.8% of AlphaGeometry runtime on A6000 while its FLOPS count for only 19.3%, indicating inefficient hardware utilization.
Latency scalability. We evaluate runtime across reasoning tasks of varying difficulty and scale (Fig. 3 (b)). We observe that the relative runtime distribution between neural and symbolic components remains consistent of a single workload across task sizes. Total runtime increases with task complexity and scale. While LLM kernels scale efficiently due to their tensor-based GPU-friendly inference, logical and probabilistic kernels scale poorly due to the exponential growth of search space, making them slower compared to monolithic LLMs.
### III-B Roofline & Symbolic Operation & Inefficiency Analysis
Memory-bounded operation. Fig. 3 (d) presents a roofline analysis of GPU memory bandwidth versus compute efficiency. We observe that the symbolic and probabilistic components are typically memory-bound, limiting performance efficiency. For example, R 2 -Guard’s probabilistic circuits use sparse, scattered accesses for marginalization, and Ctrl-G’s HMM iteratively reads and writes state probabilities. Low compute per element makes these workloads constrained by memory access, underutilizing GPU compute resources.
TABLE II: Hardware inefficiency analysis. The compute, memory, and communication characteristics of representative neural, symbolic, and probabilistic kernels executed on CPU/GPU platform.
| | Neural Kernel | Symbolic Kernel | Probabilistic Kernel | | | |
| --- | --- | --- | --- | --- | --- | --- |
| MatMul | Softmax | Sparse MatVec | Logic | Marginal | Bayesian | |
| Compute Efficiency | | | | | | |
| Compute Throughput (%) | 96.8 | 62.2 | 32.5 | 14.7 | 35.0 | 31.1 |
| ALU Utilization (%) | 98.4 | 72.0 | 43.9 | 29.3 | 48.5 | 52.8 |
| Memory Behavior | | | | | | |
| L1 Cache Throughput (%) | 82.4 | 58.0 | 27.1 | 20.6 | 32.4 | 37.1 |
| L2 Cache Throughput (%) | 41.7 | 27.6 | 18.3 | 12.4 | 24.2 | 27.5 |
| L1 Cache Hit Rate (%) | 88.5 | 85.0 | 53.6 | 37.0 | 42.4 | 40.7 |
| L2 Cache Hit Rate (%) | 73.4 | 66.7 | 43.9 | 32.7 | 50.2 | 47.6 |
| DRAM BW Utilization (%) | 39.8 | 28.6 | 57.4 | 70.3 | 60.8 | 68.0 |
| Control Divergence and Scheduling | | | | | | |
| Warp Execution Efficiency (%) | 96.3 | 94.1 | 48.8 | 54.0 | 59.3 | 50.6 |
| Branch Efficiency (%) | 98.0 | 98.7 | 60.0 | 58.1 | 63.4 | 66.9 |
| Eligible Warps/Cycle (%) | 7.2 | 7.0 | 2.4 | 2.1 | 2.8 | 2.5 |
Hardware inefficiency analysis. We leverage Nsight Systems and Nsight Compute [51, 50] to analyze the computational, memory, and control irregularity of neural, symbolic, and probabilistic kernels, as listed in Tab. II. We observe that: First, compute throughput and ALU utilization: neural kernels achieve high throughput and ALU utilization, while symbolic/probabilistic kernels have low throughput and idle ALUs. Second, memory access and cache utilization: neural kernels see high L1 cache hit rates; symbolic kernels incur cache misses and stalls, and probabilistic kernels face high memory pressure. Third, DRAM bandwidth (BW) utilization and data movement overhead: neural workloads use on-chip caches with minimal DRAM usage, but symbolic/probabilistic workloads are DRAM-bound with heavy random-access overhead.
Sparsity analysis. We observe high, heterogeneous, irregular, and data-dependent sparsity across neuro-symbolic workloads. Symbolic and probabilistic kernels are often extremely sparse, exhibiting on average 82%, 87%, 75%, 83%, 89%, and 83% sparsity across six representative neuro-symbolic workloads, respectively, with many sparse computational paths based on low activation or probability mass. This observation motivates our adaptive DAG pruning (Sec IV-B).
### III-C Unique Characteristics of Neuro-Symbolic vs LLMs
In summary, neuro-symbolic workloads exhibit distinct characteristics compared to monolithic LLMs in compute kernels, memory behavior, dataflow, and performance scaling.
Compute kernels. LLMs are dominated by regular, highly parallel tensor operations well suited to GPUs. In contrast, neuro-symbolic workloads comprise heterogeneous symbolic and probabilistic kernels with irregular control flow, low arithmetic intensity, and poor cache locality, leading to low GPU utilization and frequent performance bottlenecks.
Memory behavior. Symbolic and probabilistic kernels are primarily memory-bound, operating over large, sparse, and irregular data structures. Probabilistic reasoning further increases memory pressure through large intermediate state caching, creating challenging trade-offs between latency, bandwidth, and on-chip storage.
Dataflow and parallelism. Neuro-symbolic workloads exhibit dynamic and tightly coupled data dependencies. Symbolic and probabilistic computations often depend on neural outputs or require compilation into LLM-compatible structures, resulting in serialized execution, limited parallelism, and amplified end-to-end latency.
Performance scaling. LLMs scale efficiently across GPUs via optimized data and model parallelism. In contrast, symbolic workloads are difficult to parallelize due to recursive control dependencies, while probabilistic kernels incur substantial inter-node communication, limiting scalability on multi-GPUs.
### III-D Identified Opportunities for Neuro-Symbolic Optimization
While neuro-symbolic systems show promise, improving their efficiency is critical for real-time and scalable deployment. Guided by the profiling insights above, we introduce REASON (Fig. 4), an algorithm-hardware co-design framework for accelerated probabilistic logical reasoning in neuro-symbolic AI. Algorithmically, a unified representation with adaptive pruning reduces memory footprint (Sec. IV). In hardware architecture, a flexible architecture and dataflow support various symbolic and probabilistic operations (Sec. V). REASON further provides adaptive scheduling and orchestration of heterogeneous LLM-symbolic agentic workloads through a programmable interface (Sec. VI). Across reasoning tasks, REASON consistently boosts performance, efficiency, and accuracy (Sec. VII).
## IV REASON: Algorithm Optimizations
This section introduces the algorithmic optimizations in REASON for symbolic and probabilistic reasoning kernels. We present a unified DAG-based computational representation (Sec. IV-A), followed by adaptive pruning (Sec. IV-B) and regularization techniques (Sec. IV-C) that jointly reduce model complexity and enable efficient neuro-symbolic systems.
### IV-A Stage 1: DAG Representation Unification
Motivation. Despite addressing different reasoning goals, symbolic and probabilistic reasoning kernels often share common underlying computational patterns. For instance, logical deduction in FOL, constraint propagation in SAT, and marginal inference in PCs all rely on iterative graph-based computations. Capturing this shared structure is essential to system acceleration. DAGs provide a natural abstraction to unify these diverse kernels under a flexible computational model.
<details>
<summary>x5.png Details</summary>

### Visual Description
## Diagram: REASON Algorithm Optimization
### Overview
The image is a flowchart illustrating the REASON Algorithm Optimization process. It shows the input, three stages of the algorithm, and the output.
### Components/Axes
* **Header:**
* "Symb/Prob Kernel Input" (top-left)
* "REASON Algorithm Optimization" (top-center)
* "Output" (top-right)
* **Input:**
* A gray box containing:
* "Logical Reasoning (SAT/FOL)"
* "Sequential Reasoning (HMM)"
* "Probabilistic Reasoning (PC)"
* **Stages:**
* Stage 1: A rounded-corner red box labeled "Stage 1: DAG Representation Unification (Sec. IV-A)"
* Stage 2: A rounded-corner green box labeled "Stage 2: Adaptive DAG Pruning (Sec. IV-B)"
* Stage 3: A rounded-corner blue box labeled "Stage 3: Two-Input DAG Regularization (Sec. IV-C)"
* **Flow:** Arrows indicate the flow from input to Stage 1, Stage 1 to Stage 2, Stage 2 to Stage 3, and Stage 3 to output.
* **Output:** A gray box containing a diagram of a directed acyclic graph (DAG).
### Detailed Analysis or Content Details
* **Input:** The input consists of three types of reasoning: Logical, Sequential, and Probabilistic. The abbreviations in parentheses (SAT/FOL, HMM, PC) likely refer to specific methods or formalisms used for each type of reasoning.
* **Stage 1:** DAG Representation Unification: This stage likely involves converting the input into a unified Directed Acyclic Graph (DAG) representation. The reference "(Sec. IV-A)" suggests that more details can be found in Section IV-A of a related document.
* **Stage 2:** Adaptive DAG Pruning: This stage likely involves pruning or simplifying the DAG based on some adaptive criteria. The reference "(Sec. IV-B)" suggests that more details can be found in Section IV-B of a related document.
* **Stage 3:** Two-Input DAG Regularization: This stage likely involves regularizing the DAG to have two inputs per node. The reference "(Sec. IV-C)" suggests that more details can be found in Section IV-C of a related document.
* **Output:** The output is a DAG, visually represented as a network of nodes (circles) and directed edges (arrows).
### Key Observations
* The diagram presents a sequential process, with each stage building upon the previous one.
* The use of DAGs is central to the algorithm, as indicated by its presence in all three stages.
* The references to sections IV-A, IV-B, and IV-C suggest that this diagram is part of a larger document that provides more detailed explanations of each stage.
### Interpretation
The diagram illustrates the REASON Algorithm Optimization process, which takes symbolic and probabilistic reasoning inputs and transforms them into an optimized DAG representation through three key stages: DAG Representation Unification, Adaptive DAG Pruning, and Two-Input DAG Regularization. The algorithm aims to create a structured and simplified DAG that can be used for further processing or analysis. The use of specific techniques like SAT/FOL, HMM, and PC for the input reasoning types suggests that the algorithm is designed to handle a variety of reasoning tasks.
</details>
| SAT/FOL PC HMM | Literals and logical operators Primitive distributions, sum and product nodes Hidden state variables at each time step | Logical dependencies between literals, clauses, and formulas Weighted dependencies encoding probabilistic factorization State transition and emission dependencies | Search and deduction via traversal (DPLL/CDCL) Bottom-up probability aggregation and top-down flow propagation Sequential message passing (forward–backward, decoding) |
| --- | --- | --- | --- |
Figure 5: Unified DAG representations of neuro-symbolic kernels. Logical (SAT/FOL), probabilistic (PC), and sequential (HMM) reasoning are expressed using DAG abstraction. Nodes represent atomic reasoning operations, edges encode dependency structure, and graph traversals implement inference procedures. This unification enables shared compilation, pruning, and hardware mapping in REASON.
Methodology. We unify symbolic and probabilistic reasoning kernels under a DAG abstraction, where each node represents an atomic reasoning operation and each directed edge encodes a data/control dependency (Fig. 5). This representation enables a uniform compilation flow – construction, transformation, and scheduling – across heterogeneous kernels (logical deduction, constraint solving, probabilistic aggregation, and sequential message passing), and serves as the algorithmic substrate for subsequent pruning and regularization.
#### For FOL and SAT solvers
DAG nodes represent variables and logical connectives, with edges indicating dependencies between literals and clauses. We represent a propositional CNF formula $\varphi=\bigwedge_{i=1}^{m}\Bigl(\bigvee_{j=1}^{k_{i}}l_{ij}\Bigr)$ as DAG with three layers: literal nodes for each literal $l_{ij}$ , clause nodes implementing disjunction over literals in $\bigvee_{j}l_{ij}$ , and formula nodes implementing conjunction over clauses $\bigwedge_{i}$ . In SAT, DAG captures the branching and conflict resolution structures in DPLL/CDCL procedures. In FOL, formulas are encoded as DAGs where inference rules act as graph transformation operators that derive contradictions through node and edge expansion. The compiler converts FOL and SAT inputs (clauses in CNF or quantifier-free predicates) into DAGs via: Step- 1 Normalization: predicates are transformed to CNF, removing quantifiers and forming disjunctions of literals. Step- 2 Node creation: each literal becomes a leaf node, each clause an OR node over its literals, and the formula an AND node over clauses. Step- 3 Edge encoding: edges capture dependencies (literal $\rightarrow$ clause $\rightarrow$ formula), while watch-lists as metadata.
#### For PCs
DAG nodes correspond to sum (mixture) or product (factorization) operations $p_{n}(x)$ over input $x$ (to variable $\mathbf{X}$ ), with children $ch(x)$ . Leaves represent primitive distributions $f_{n}(x)$ . Edges model conditional dependencies. The DAG structure facilitates efficient inference through bottom-up probability evaluation, exploiting structural independence and enabling effective pruning and memorization during probability queries (Eq. 1). The compiler converts PC into DAGs through: Step- 1 Graph extraction: nodes represent random variables, factors, or sub-circuits parsed from expressions such as $P_{n}(x)$ . Step- 2 Node typing: arithmetic operators map to sum nodes for marginalization and product nodes for factor conjunction, while leaf nodes store constants or probabilities.
#### For HMMs
The unrolled DAG spans time steps, with nodes representing transition factors $p(z_{t}|z_{t-1})$ and emission factors $p(x_{t}|z_{t})$ (Eq. 2), and edges connecting factors across adjacent time steps to reflect Markov dependency. Sequential inference (filtering/smoothing/decoding) becomes structured message passing on this DAG: each step aggregates contributions from predecessor states through transition factors and then applies emission factors. The compiler converts HMMs into DAGs through: Step- 1 Sequence unroll: Each time step becomes a DAG layer, representing states and transitions. Step- 2 Node mapping: Product nodes combine transition and emission probabilities; sum nodes aggregate over prior states.
The unified DAG abstraction lays the algorithmic foundation for subsequent pruning, regularization, and hardware mapping, supporting efficient acceleration of neuro-symbolic workloads.
<details>
<summary>x6.png Details</summary>
### Visual Description
## System Architecture Diagrams
### Overview
The image presents a set of diagrams illustrating the architecture and components of a system incorporating a "Proposed REASON Plug-in." It includes diagrams of a GPU with the plug-in, the plug-in itself, a tree-based processing element (PE) architecture, a node microarchitecture, and symbolic memory support.
### Components/Axes
* **(a) GPU with Proposed Plug-in:**
* **Components:** Off-chip Memory, Memory Controller, GPU Graphics Processing Clusters (GPC), Shared L2 Cache, Proposed REASON Plug-in, Giga Thread Engine.
* **Flow:** Arrows indicate data flow between components.
* **(b) Proposed REASON Plug-in:**
* **Components:** Global Controller, Tree-based PE (x4), Global Interconnect, Workload Scheduler, Ctrl, Shared Local Memory, Custom SIMD Unit.
* **Flow:** Arrows indicate data flow between components. The Global Interconnect has arrows pointing in all four cardinal directions.
* **(c) Tree-based PE Architecture:**
* **Components:** Intermediate Buffer, M:1 Output Interconnect, Tree structure with nodes, Leaf node, Control Logic/MMU, Forwarding Logic, Decode, Pre-fetcher/DMA, Watched Literals Controller, Benes Network (N:N Distribution Crossbar), N SRAM Banks.
* **Data Flow:**
* DPLL Broadcast (Symbolic) and SpMSPM/DAG/DPLL Reduction (Neuro/Probabilistic/Symbolic) flow through the tree structure.
* Red arrows indicate "From Broadcast".
* Black arrows indicate other data flow.
* "To Leaf Node PE" and "From Broadcast" are indicated at the bottom.
* "From/To L2" is indicated at the bottom.
* **(d) Node Microarchitecture:**
* **Components:** Logic gates, adders, multiplexers, Fwd, Data, Control Signals.
* **Flow:** Arrows indicate data flow and control signals.
* **(e) Symbolic Mem. Support:**
* **Components:** BCP FIFO, Watched Literals, Index SRAM, Clause (Cx) Data.
* **BCP FIFO:** Shows "Broadcast (to Ol) Assign (to Ol)" and "Reduction (from Ol)".
* **Watched Literals:** Table with columns "Literal" and "Head Ptr". Example entries: "-x1" with "C8addr", "x1" with "NULL".
### Detailed Analysis or Content Details
* **GPU with Proposed Plug-in:**
* The Proposed REASON Plug-in is positioned between the GPC and the Giga Thread Engine.
* The Shared L2 Cache connects to the Memory Controller and the GPCs.
* **Proposed REASON Plug-in:**
* The Global Controller is connected to four Tree-based PEs via the Global Interconnect.
* The Workload Scheduler and Ctrl are connected to the Shared Local Memory and Custom SIMD Unit.
* **Tree-based PE Architecture:**
* The tree structure has multiple layers of nodes, culminating in the Leaf nodes.
* The M:1 Output Interconnect connects the top node to the Intermediate Buffer.
* The Watched Literals Controller is connected to the N SRAM Banks via the Benes Network.
* **Node Microarchitecture:**
* The diagram shows a detailed view of a node, including logic gates, adders, and multiplexers.
* "XI<" is a key component.
* **Symbolic Mem. Support:**
* The BCP FIFO handles broadcast and reduction operations.
* The Watched Literals table stores literal and head pointer information.
* The Index SRAM and Clause (Cx) Data are used for clause data storage.
### Key Observations
* The Proposed REASON Plug-in is designed to integrate with a GPU architecture.
* The Tree-based PE Architecture is a key component of the plug-in.
* Symbolic memory support is provided through the BCP FIFO and Watched Literals.
* The Node Microarchitecture provides a detailed view of the processing elements.
### Interpretation
The diagrams illustrate a complex system architecture designed for specialized processing, likely related to symbolic computation or reasoning. The Proposed REASON Plug-in appears to be an accelerator designed to enhance the capabilities of a GPU. The tree-based architecture suggests a hierarchical processing approach, while the symbolic memory support indicates the system's ability to handle symbolic data. The node microarchitecture provides insight into the low-level operations performed by the processing elements. The integration of these components suggests a system optimized for tasks requiring both parallel processing and symbolic reasoning.
</details>
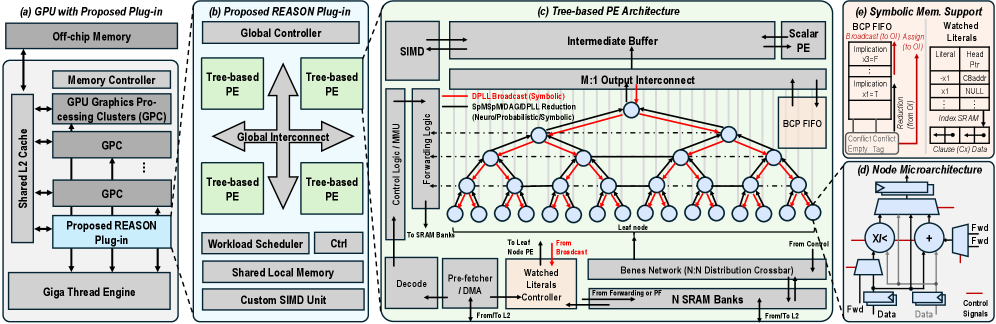
Figure 6: Overview of the REASON hardware acceleration system. (a) Integration of REASON as a GPU co-processor. (b) REASON plug-in architecture with PEs, shared local memory, and global scheduling. (c) Tree-based PE architecture enabling broadcast, reduction, and irregular DAG execution. (d) Micro-architecture of a tree node supporting arithmetic and logical operations. (e) FIFO and memory layout supporting symbolic reasoning.
### IV-B Stage 2: Adaptive DAG Pruning
Motivation. While the unified DAG representation provides a common abstraction, it may contain significant redundancy, such as logically implied literals, inactive substructures, or low-probability paths, that inflate DAG size and degrade performance without improving inference quality.
Methodology. We propose adaptive DAG pruning, a semantics-preserving optimization that identifies and removes redundant paths in symbolic and probabilistic DAGs. For symbolic kernels, pruning targets literals and clauses that are logically redundant. For probabilistic kernels, pruning eliminates low-activation edges that minimally impact inference. This process significantly reduces model size and computational complexity while preserving correctness of logical and probabilistic inference.
#### Pruning of FOL and SAT via implication graph
For SAT solvers and FOL reasoning, we prune redundant literals using implication graphs. Given a CNF formula $\varphi=\bigwedge_{i}\left(\bigvee_{j}l_{ij}\right)$ , each binary clause $(l\lor l^{\prime})$ induces two directed implication edges: $\bar{l}\rightarrow l^{\prime}$ and $\bar{l^{\prime}}\rightarrow l$ . The resulting implication graph captures logical dependencies among literals. We perform a depth-first traversal to compute reachability relationships between literals. If a literal $l^{\prime}$ is always implied by another literal $l$ , then $l^{\prime}$ is a hidden literal. Clauses containing both $l$ and $l^{\prime}$ can safely drop $l^{\prime}$ , reducing clause width without semantic changes. For instance, a clause $C=(l\lor l^{\prime})$ is reduced to $C^{\prime}=(l)$ . This procedure removes redundant literals (e.g., hidden tautologies and failed literals), preserves satisfiability, and runs in time linear in the size of the implication graph.
#### Pruning of PCs and HMMs via circuit flow
For probabilistic DAGs such as PCs and HMMs, we prune edges based on probability flow, which quantifies each edge’s contribution to the overall likelihood.
In HMMs, the DAG is unrolled over time steps, with nodes representing transition factors $p(z_{t}\mid z_{t-1})$ and emission factors $p(x_{t}\mid z_{t})$ . We compute expected transition and emission usage via the forward-backward algorithm, yielding posterior state and transition probabilities. Edges corresponding to transitions or emissions with consistently low posterior probability are pruned, as their contribution to the joint likelihood $p(z_{1:T},x_{1:T})$ is negligible. This pruning preserves inference fidelity while reducing state-transition complexity.
In PCs, sum node $n$ computes $p_{n}(x)=\sum_{c\in\mathrm{ch}(n)}\theta_{n,c}\,p_{c}(x)$ , where $\theta_{n,c}\geq 0$ denotes the weight associated with child $c$ . For an input $x$ , we define the circuit flow through edge $(n,c)$ as $F_{n,c}(x)=\frac{\theta_{n,c}\,p_{c}(x)}{p_{n}(x)}\cdot F_{n}(x)$ , where $F_{n}(x)$ denotes the top-down flow reaching node $n$ . Intuitively, $F_{n,c}(x)$ measures the fraction of probability mass passing through edge $(n,c)$ for input $x$ . Given a dataset $\mathcal{D}$ , the cumulative flow for edge $(n,c)$ is $F_{n,c}(\mathcal{D})=\sum_{x\in\mathcal{D}}F_{n,c}(x)$ . Edges with the smallest cumulative flow are pruned, as they contribute least to the overall model likelihood. The resulting decrease in average log-likelihood is bounded by $\Delta\log\mathcal{L}\leq\frac{1}{|\mathcal{D}|}\sum_{x\in\mathcal{D}}F_{n,c}(x)$ , providing a theoretically grounded criterion for safe pruning.
### IV-C Stage 3: Two-Input DAG Regularization
Methodology. After pruning, the resulting DAGs may still have high fan-in or irregular branching, which hinders efficient hardware execution. To address this, we apply a regularization step that transforms DAGs into a canonical two-input form. Specifically, nodes with more than two inputs are recursively decomposed into balanced binary trees composed of two-input intermediate nodes, preserving the original computation semantics. This normalization promotes uniformity, enabling efficient parallel scheduling, pipelining, and mapping onto REASON architecture, without sacrificing model fidelity or expressive power.
For each symbolic or probabilistic kernel, the compiler generates an initial DAG, applies adaptive pruning, and then performs two-input regularization to produce a unified balanced representation. These DAGs are constructed offline and used to generate an execution binary that is programmed onto REASON hardware. This unification-pruning-regularization flow decouples algorithmic complexity from runtime execution and enables predictable performance.
## V REASON: Hardware Architecture
REASON features flexible co-processor plug-in architecture (Sec. V-A), reconfigurable symbolic/probabilistic PEs (Sec. V-B), flexible support for symbolic and probabilistic kernels (Sec. V-C - V-D). Sec. V-E presents cycle-by-cycle execution pipeline analysis. Sec. V-F discusses design space exploration and scalability.
### V-A Overall Architecture
Neuro-symbolic workloads exhibit heterogeneous compute and memory patterns with diverse sparsity, diverging from the GEMM-centric design of conventional hardware. Built on the unified DAG representation and optimizations (Fig. IV), REASON is a reconfigurable and flexible architecture designed to efficiently execute the irregular computations of symbolic and probabilistic reasoning stages in neuro-symbolic AI.
Overview. REASON operates as a programmable co-processor tightly integrated with GPU SMs, forming a heterogeneous system architecture. (Fig. 6 (a)). In this system, REASON serves as an efficient and reconfigurable “slow thinking” engine, accelerating symbolic and probabilistic kernels that are poorly suited to GPU execution. As illustrated in Fig. 6 (b), REASON comprises an array of tree-based PE cores that act as the primary computation engines. A global controller and workload scheduler manage the workload mapping. A shared local memory serves as a unified scratchpad for all cores. Communication between cores and shared memory is handled by a high-bandwidth global interconnect.
Tree architecture. Each PE core is organized as a tree-structured compute engine, as shown in Fig. 6 (c). Each tree node integrates a specialized datapath, memory subsystem, and control logic optimized for executing DAG-based symbolic and probabilistic operations.
Reconfigurable tree engine (RTE). At the core of each PE is a Reconfigurable Tree Engine (RTE), whose datapath forms a bidirectional tree of PEs (Fig. 6 (d)). The RTE supports both SAT-style symbolic broadcast patterns and probabilistic aggregation operations. A Benes network interconnect enables N-to-N routing, decoupling SRAM banking from DAG mapping and simplifying compilation of irregular graph structures (Sec. V-C). Forwarding logic routes intermediate and irregular outputs back to SRAM for subsequent batches.
Memory subsystem. To tackle the memory-bound nature of symbolic and probabilistic kernels, the RTE is backed by a set of dual-port, wide-bitline SRAM banks arranged as a banked L1 cache. A memory front-end with a prefetcher and high-throughput DMA engine moves data from shared scratchpad. A control/memory management unit (MMU) block handles address translation across the distributed memory system.
Core control and execution. A scalar PE acts as the core-level controller, fetching and issuing VLIW-like instructions that configure the RTE, memory subsystem, and specialized units. Outputs from the RTE are buffered before being consumed by the scalar PE or the SIMD Unit, which provides support for executing parallelable subset of symbolic solvers.
### V-B Reconfigurable Symbolic/Probabilistic PE
The PE architecture is designed to support a wide range of symbolic and probabilistic computation patterns via a VLIW-driven cycle-reconfigurable datapath. Each PE can switch among three operational modes to efficiently execute heterogeneous kernels mapped from the unified DAG representation.
Probabilistic mode. In probabilistic mode, the node executes irregular DAGs derived from unified probabilistic representations (Sec. V-C). The nodes are programmed by the VLIW instruction stream to perform arithmetic operations, either addition or multiplication, required by the DAG node mapped onto them. This mode supports probabilistic aggregation patterns such as sum-product computation and likelihood propagation, enabling efficient execution of PCs and HMMs.
<details>
<summary>x7.png Details</summary>
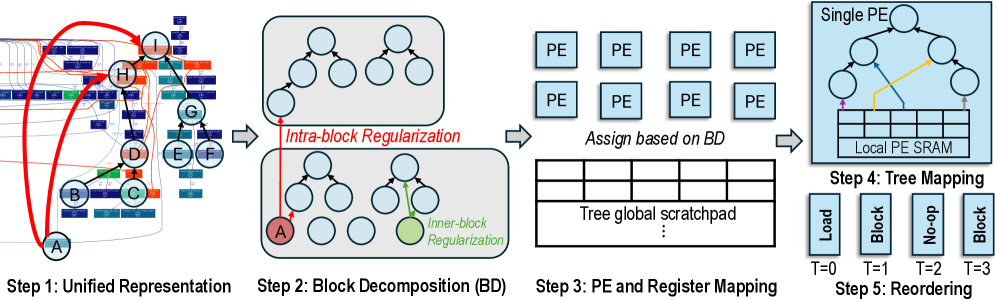
### Visual Description
## Diagram: Unified Representation to Reordering
### Overview
The image is a diagram illustrating a five-step process, starting with a unified representation and ending with reordering. Each step is visually represented with diagrams and labels, showing the transformation of data and processes involved.
### Components/Axes
* **Step 1: Unified Representation:** Shows a complex network of nodes (A, B, C, D, E, F, G, H, I) and connections.
* **Step 2: Block Decomposition (BD):** Illustrates the decomposition of the network into blocks with "Intra-block Regularization" and "Inner-block Regularization" highlighted.
* **Step 3: PE and Register Mapping:** Depicts the assignment of blocks to Processing Elements (PEs) and a "Tree global scratchpad".
* **Step 4: Tree Mapping:** Shows a single PE with a tree structure mapped to a "Local PE SRAM".
* **Step 5: Reordering:** Represents the reordering process with labels "Load", "Block", "No-op", and "Block" at time steps T=0, T=1, T=2, and T=3 respectively.
### Detailed Analysis
* **Step 1: Unified Representation:**
* Node A is at the bottom-left.
* Nodes B and C are slightly above and to the right of A.
* Node D is above B and C.
* Nodes E, F, and G are to the right of D.
* Nodes H and I are at the top, with H to the left of I.
* Red arrows indicate connections from A to H and I, and from H to I.
* **Step 2: Block Decomposition (BD):**
* Two blocks are shown, each containing a tree structure.
* The top block shows two trees.
* The bottom block shows a tree and a few individual nodes.
* A red arrow labeled "Intra-block Regularization" connects node A (colored red) from Step 1 to the top tree.
* A green arrow labeled "Inner-block Regularization" connects a node within the bottom block (colored green) to the top of the tree in the bottom block.
* **Step 3: PE and Register Mapping:**
* An array of 8 "PE" blocks is shown.
* The text "Assign based on BD" is below the PE array.
* A table labeled "Tree global scratchpad" is shown below the assignment instruction.
* **Step 4: Tree Mapping:**
* A "Single PE" block is shown.
* A tree structure is mapped to a "Local PE SRAM".
* Arrows indicate data flow within the PE.
* **Step 5: Reordering:**
* Four blocks are labeled "Load", "Block", "No-op", and "Block".
* These blocks correspond to time steps T=0, T=1, T=2, and T=3 respectively.
### Key Observations
* The diagram illustrates a multi-step process for mapping a unified representation onto processing elements.
* Block decomposition and regularization are key steps in the process.
* The final step involves reordering operations for efficient execution.
### Interpretation
The diagram outlines a process for optimizing the execution of a complex task on parallel processing elements. The initial unified representation is decomposed into blocks, which are then assigned to PEs. Regularization techniques are applied to improve the structure of the blocks. The tree mapping step maps the computational structure onto the local memory of each PE. Finally, the reordering step optimizes the sequence of operations for efficient execution. The process aims to leverage parallel processing to accelerate the execution of the task.
</details>
Figure 7: Compiler-architecture co-design for probabilistic execution. A probabilistic DAG is decomposed, regularized, mapped onto tree-based PEs, and scheduled with pipeline awareness to enable efficient execution of irregular probabilistic kernels in REASON.
Symbolic mode. In symbolic mode, the datapath is repurposed for logical reasoning operations (Sec. V-D). Key hardware components are utilized as follows: (a) The comparator checks logical states for Boolean Constraint Propagation (BCP), identifying literals as TRUE, FALSE, or UNASSIGNED. (b) The adder performs two key functions: address computation by adding the Clause Base Address and Literal Index to locate the next literal in a clause; and clause evaluation by acting as counter to track the number of FALSE literals. This enables fast detection of unit clauses and conflicts, accelerating SAT-style symbolic reasoning.
SpMSpM mode. The tree-structured PE inherently supports the sparse matrix-matrix multiplication (SpMSpM), a computation pattern widely studied in prior works [24, 45]. In this mode, the leaf nodes are configured as multipliers to compute partial products of the input matrix elements, while the internal nodes are configured as adders to perform hierarchical reductions. This execution pattern allows small-scale neural or neural-symbolic models to be efficiently mapped onto the REASON engine, extending its applicability beyond purely symbolic and probabilistic kernels.
### V-C Architectural Support for Probabilistic Reasoning
Probabilistic reasoning kernels are expressed as DAGs composed of arithmetic nodes (sum and product) connected by data-dependent edges. REASON exploits its pipelined, tree-structured datapath to efficiently map these DAGs onto parallel PEs. Key architectural features include: multi-tree PE mapping for arithmetic DAG execution, a banked register file with flexible crossbar interconnect to support irregular memory access, and compiler-assisted pipeline scheduling with automatic register management to reduce control overhead. Fig. 7 illustrates the overall workflow.
Datapath and pipelined execution. The datapath operates in a pipelined fashion, with each layer of nodes serving as pipeline stages. Each pipeline stage receives inputs from a banked register file, which consists of multiple parallel register banks. Each bank operates independently, providing flexible addressing that accommodates the irregular memory access patterns typical in probabilistic workloads (e.g., PCs, HMMs).
Flexible interconnect. To handle the irregularity in probabilistic DAGs, REASON employs an optimized interconnection. An input Benes crossbar connects the register file banks to inputs of PE trees, allowing flexible and conflict-free routing of operands into computation units. Output connections from PE to register banks are structured as one-bank-one-PE to minimize hardware complexity while preserving flexibility, balancing trade-offs between utilization and performance.
<details>
<summary>x8.png Details</summary>
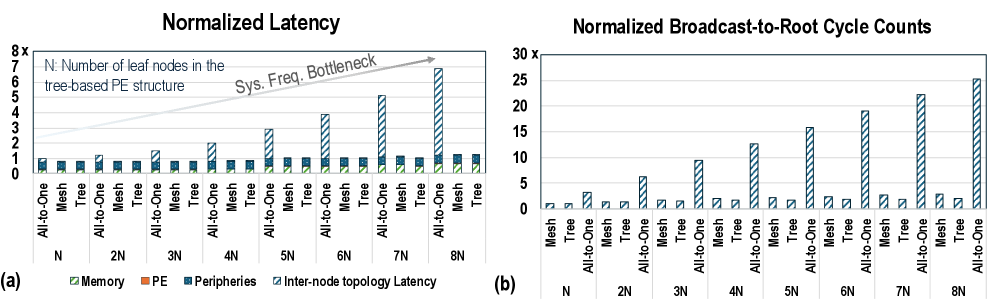
### Visual Description
## Bar Charts: Normalized Latency and Broadcast-to-Root Cycle Counts
### Overview
The image contains two bar charts comparing the performance of different network topologies (Mesh, Tree, and All-to-One) with varying numbers of leaf nodes (N). The left chart (a) shows normalized latency, while the right chart (b) shows normalized broadcast-to-root cycle counts.
### Components/Axes
**Chart (a): Normalized Latency**
* **Title:** Normalized Latency
* **Y-axis:** Normalized Latency, scaled from 0 to 8x.
* **X-axis:** Number of leaf nodes in the tree-based PE structure, labeled as N, 2N, 3N, 4N, 5N, 6N, 7N, and 8N.
* **Categories:** For each N value, there are three network topologies: All-to-One, Mesh, and Tree.
* **Legend (bottom-left):**
* Memory (light green)
* PE (orange)
* Peripheries (blue)
* Inter-node topology Latency (dark blue with diagonal lines)
* **Annotation:** "Sys. Freq. Bottleneck" with an arrow pointing towards the increasing Inter-node topology Latency bars.
**Chart (b): Normalized Broadcast-to-Root Cycle Counts**
* **Title:** Normalized Broadcast-to-Root Cycle Counts
* **Y-axis:** Normalized Broadcast-to-Root Cycle Counts, scaled from 0 to 30x.
* **X-axis:** Number of leaf nodes in the tree-based PE structure, labeled as N, 2N, 3N, 4N, 5N, 6N, 7N, and 8N.
* **Categories:** For each N value, there are three network topologies: Mesh, Tree, and All-to-One.
* **Legend:** Not explicitly present, but the bars represent the cycle counts for each topology.
### Detailed Analysis
**Chart (a): Normalized Latency**
* **Memory (light green):** Relatively constant across all N values and topologies, hovering around 0.1-0.2.
* **PE (orange):** Relatively constant across all N values and topologies, hovering around 0.1-0.2.
* **Peripheries (blue):** Relatively constant across all N values and topologies, hovering around 0.5-0.7.
* **Inter-node topology Latency (dark blue with diagonal lines):**
* For Mesh and Tree topologies, the latency remains relatively constant around 0.1-0.2.
* For All-to-One topology, the latency increases significantly with increasing N values:
* N: ~0.8
* 2N: ~1.2
* 3N: ~1.5
* 4N: ~2.8
* 5N: ~1.2
* 6N: ~2.8
* 7N: ~5.0
* 8N: ~6.8
**Chart (b): Normalized Broadcast-to-Root Cycle Counts**
* **Mesh:** Cycle counts remain low and relatively constant across all N values, approximately between 0.5 and 1.
* **Tree:** Cycle counts remain low and relatively constant across all N values, approximately between 0.5 and 1.
* **All-to-One:** Cycle counts increase significantly with increasing N values:
* N: ~2.5
* 2N: ~6.5
* 3N: ~9.5
* 4N: ~2.5
* 5N: ~16
* 6N: ~2.5
* 7N: ~22.5
* 8N: ~25
### Key Observations
* In the Normalized Latency chart, the Inter-node topology Latency for the All-to-One topology increases significantly with increasing N, while the Mesh and Tree topologies remain relatively constant.
* In the Normalized Broadcast-to-Root Cycle Counts chart, the All-to-One topology shows a significant increase in cycle counts with increasing N, while the Mesh and Tree topologies remain relatively constant.
* The "Sys. Freq. Bottleneck" annotation suggests that the increasing latency in the All-to-One topology is due to a system frequency bottleneck.
### Interpretation
The data suggests that the All-to-One topology suffers from scalability issues as the number of leaf nodes (N) increases. This is evident in both the normalized latency and the broadcast-to-root cycle counts. The Mesh and Tree topologies, on the other hand, appear to be more scalable, maintaining relatively constant latency and cycle counts across different N values. The "Sys. Freq. Bottleneck" annotation indicates that the increasing latency in the All-to-One topology is likely due to limitations in the system frequency, which becomes a bottleneck as the communication demands increase with more leaf nodes. The charts highlight the trade-offs between different network topologies and their suitability for different scales of parallel processing.
</details>
Figure 8: Scalability analysis of interconnect topologies. (a) Normalized latency breakdown as the number of leaf nodes $N$ increases. (b) Normalized broadcast-to-root cycle counts for different PE interconnect structures.
Register management. REASON adopts an automatic write-address generation policy. Data is written to the lowest available register address in each bank, eliminating the need to encode explicit write addresses in instructions. The compiler precisely predicts these write addresses at compile time due to the deterministic execution sequence, further reducing instruction size and energy overhead.
Compiler-driven optimization. To efficiently translate unified DAGs into executable kernels and map onto hardware datapath, REASON adopts a four-step compiler pipeline (Fig. 7).
Step- 1 Block decomposition: The compiler decomposes the unified DAG from Sec. IV into execution blocks through a greedy search that identifies schedulable subgraphs whose maximum depth does not exceed the hardware tree depth. This process maximizes PE utilization while minimizing inter-block dependencies that may cause read-after-write stalls. The resulting tree-like blocks form the basis for efficient mapping.
Step- 2 PE mapping: For each block, the compiler jointly assigns nodes to PEs and operands to register banks, considering topological constraints and datapath connectivity. Nodes are mapped to preserve order, while operands are allocated to banks to avoid simultaneous conflicts. The compiler dynamically updates feasible mappings and prioritizes nodes with the fewest valid options. This conflict-aware strategy minimizes bank contention and balances data traffic across banks.
Step- 3 Tree mapping: Once block and register mappings are fixed, the compiler constructs physical compute trees that maximize data reuse in the REASON datapath. Node fusion and selective replication enhance operand locality and reduce inter-block communication, allowing intermediate results to be consumed within the datapath and lowering memory traffic.
Step- 4 Reordering: The compiler then schedules instructions with awareness of the multi-stage pipeline. Dependent operations are spaced by at least one full pipeline interval, while independent ones are interleaved. Lightweight load, store, and copy operations fill idle cycles without disturbing dependencies. Live-range analysis identifies register pressure and inserts minimal spill and reload instructions when needed.
The DAG-to-hardware mapping is an automated heuristic process to generate a compact VLIW program for REASON. Designers can interact for design-space exploration to tune architectural parameters within flexible hardware template.
### V-D Architectural Support for Symbolic Logical Reasoning
To efficiently support symbolic logical reasoning kernels, REASON features a linked-list-based memory layout and hardware-managed BCP FIFO mechanism (Fig. 6 (e)), enabling efficient and scalable support to large-scale solver kernels that are fundamental to logical reasoning.
Watched literals (WLs) unit. The WLs unit acts as a distributed memory controller tightly integrated with $N$ SRAM banks, implementing the two-watched-literals indexing scheme in hardware. This design transforms the primary bottleneck in BCP from a sequential scan over the clause database into a selective parallel memory access problem. Crucially, it enables scalability to industrial-scale SAT problems [44], where only a small subset of clauses (those on the watch list) need to be accessed at any time. This design naturally aligns with a hierarchical memory system, allowing most clauses to reside in remote scratchpad memory or DRAM, with on-chip SRAM caching only the required clauses indexed by WLs unit.
<details>
<summary>x9.png Details</summary>
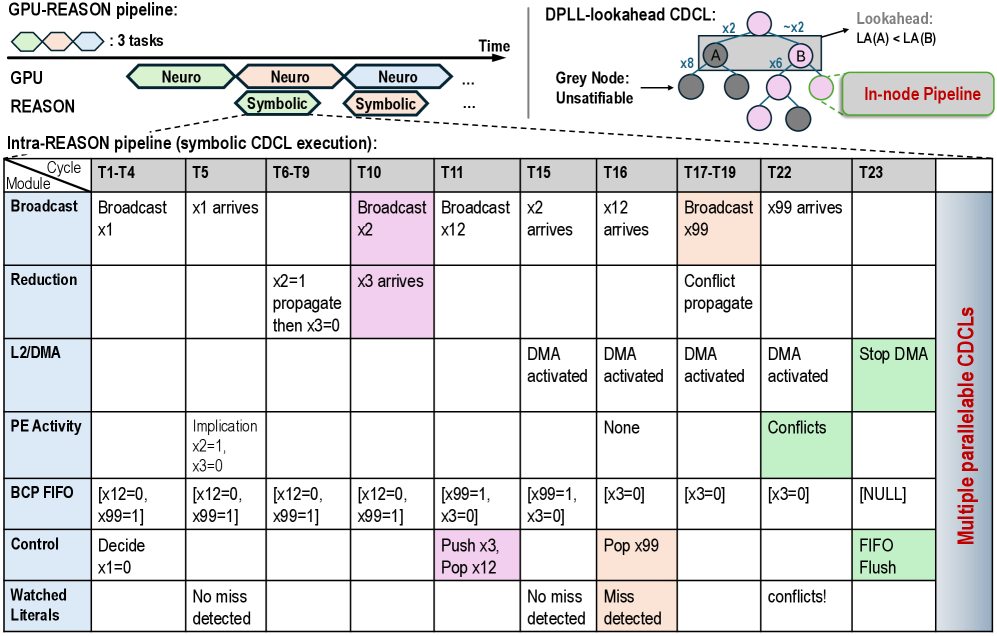
### Visual Description
## Pipeline Diagram: GPU-REASON and Intra-REASON Pipelines with DPLL-lookahead CDCL
### Overview
The image presents a diagram illustrating the GPU-REASON pipeline, a DPLL-lookahead CDCL (Conflict-Driven Clause Learning) structure, and an Intra-REASON pipeline focusing on symbolic CDCL execution. It details the flow of tasks and data through different modules and cycles.
### Components/Axes
* **GPU-REASON pipeline:**
* Legend: A sequence of diamond shapes, where each diamond represents a task. The legend indicates that three tasks are shown.
* Pipeline stages: GPU (Neuro), REASON (Symbolic). The pipeline shows alternating Neuro and Symbolic processing stages.
* Axis: Time (horizontal axis).
* **DPLL-lookahead CDCL:**
* Nodes: Represented as circles, some filled in grey (Unsatisfiable) and some in pink.
* Edges: Arrows indicating the flow of information.
* Labels: x2, ~x2, x8, x6 are placed on or near the nodes and edges.
* Annotation: "Lookahead: LA(A) < LA(B)" and "In-node Pipeline" are present.
* **Intra-REASON pipeline (symbolic CDCL execution):**
* Modules (Rows): Broadcast, Reduction, L2/DMA, PE Activity, BCP FIFO, Control, Watched Literals.
* Cycles (Columns): T1-T4, T5, T6-T9, T10, T11, T15, T16, T17-T19, T22, T23.
* Side Label: "Multiple parallelable CDCLs" written vertically.
### Detailed Analysis
**1. GPU-REASON Pipeline:**
* The pipeline alternates between GPU (Neuro) and REASON (Symbolic) tasks.
* The "Time" axis indicates the sequential flow of these tasks.
**2. DPLL-lookahead CDCL:**
* A node labeled "A" has an incoming edge labeled "x8" and outgoing edges labeled "x2" and "~x2".
* A node labeled "B" has an incoming edge labeled "x6" and an outgoing edge labeled "~x2".
* Grey nodes are labeled as "Unsatisfiable".
* The "Lookahead: LA(A) < LA(B)" annotation suggests a comparison of lookahead values between nodes A and B.
* The "In-node Pipeline" annotation indicates a process within a node.
**3. Intra-REASON Pipeline (symbolic CDCL execution):**
The table describes the operations performed in each module during different cycles.
* **Broadcast:**
* T1-T4: Broadcast x1
* T5: x1 arrives
* T10: Broadcast x2
* T11: Broadcast x12
* T15: x2 arrives
* T16: x12 arrives
* T17-T19: Broadcast x99
* T22: x99 arrives
* **Reduction:**
* T6-T9: x2=1 propagate then x3=0
* T10: x3 arrives
* T17-T19: Conflict propagate
* **L2/DMA:**
* T15: DMA activated
* T16: DMA activated
* T17-T19: DMA activated
* T22: DMA activated
* T23: Stop DMA
* **PE Activity:**
* T6-T9: Implication x2=1, x3=0
* T17-T19: None
* T22: Conflicts
* **BCP FIFO:**
* T1-T4: \[x12=0, x99=1]
* T5: \[x12=0, x99=1]
* T6-T9: \[x12=0, x99=1]
* T10: \[x12=0, x99=1]
* T11: \[x99=1, x3=0]
* T15: \[x99=1, x3=0]
* T16: \[x3=0]
* T17-T19: \[x3=0]
* T22: \[x3=0]
* T23: \[NULL]
* **Control:**
* T1-T4: Decide x1=0
* T11: Push x3, Pop x12
* T16: Pop x99
* T23: FIFO Flush
* **Watched Literals:**
* T5: No miss detected
* T15: No miss detected
* T16: Miss detected
* T22: conflicts!
### Key Observations
* The GPU-REASON pipeline alternates between GPU-based (Neuro) and REASON-based (Symbolic) processing.
* The DPLL-lookahead CDCL diagram shows a decision tree structure with nodes representing variable assignments and edges representing implications.
* The Intra-REASON pipeline table details the operations performed in different modules across various cycles, showing the flow of data and control signals.
* The BCP FIFO module shows the state of variables x12, x99, and x3 across different cycles.
* The Watched Literals module detects misses and conflicts during the process.
### Interpretation
The diagram illustrates a complex system integrating GPU and REASON processing for solving constraint satisfaction problems using a DPLL-lookahead CDCL approach. The Intra-REASON pipeline provides a detailed view of the symbolic CDCL execution, showing how different modules contribute to the overall solving process. The data suggests a highly parallelizable architecture, as indicated by the "Multiple parallelable CDCLs" label. The pipeline stages and module operations are carefully orchestrated to efficiently propagate constraints, detect conflicts, and make decisions to find a solution. The DPLL-lookahead CDCL structure helps guide the search process by evaluating the potential impact of variable assignments before making a decision.
</details>
Figure 9: Two-level execution pipeline for symbolic reasoning. Top: task-level overlap between GPU neural execution and REASON symbolic execution. Bottom: detailed cycle-by-cycle timeline of CDCL SAT solving, illustrating pipelined broadcast/reduction, WLs traversal, latency hiding, and priority-based conflict handling. Color represents the causality of hardware events.
SRAM layout. The local SRAM is partitioned to support a linked-list-based organization of watch lists. A dedicated region stores a head pointer table indexed by literal IDs, each pointing to the start of a watch list, enabling $\mathcal{O}(1)$ access. The main data region stores clauses, each augmented with a next-watch pointer that links to other clauses watching the same literal, forming multiple linked lists within the linear address space. Upon a variable assignment, the WLs unit uses the literal ID to fetch the head pointer and traverses the list by following next-watch pointers, dispatching only the relevant clause to PEs. This hardware-managed indexing eliminates full-database scans and maps efficiently to the adder datapath.
BCP FIFO. The BCP FIFO sits atop the M:1 output interconnect (Fig. 6 (c)) and serializes multiple parallel implications generated by the leaf tree-node in a single cycle. While many implications can be discovered concurrently, BCP must propagate them sequentially to preserve the causality chain for conflict analysis. The controller immediately broadcasts one implication back into the pipeline, while the rest are queued in the FIFO and processed in a pipelined manner. Within a symbolic (DPLL) tree node, implications are causally independent and can be pipelined, but between assignments, sequential ordering is enforced to maintain correctness. Sec. V-E illustrates a detailed cycle-level execution example.
Scalability advantages. A key advantage of the REASON architecture is that its tree-based inter-node topology does not become a bottleneck as the symbolic DPLL tree grows (Fig. 8 (a)). In contrast, all-to-one (or one-to-all) bus interconnects often fail to scale due to post-layout electrical constraints, including high fan-out and buffer insertion for hold-time fixes. Moreover, given that broadcasting is a dominant operation, the root-to-leaf traversal latency is critical. REASON’s tree-based inter-node topology achieves exceptional scalability with an $\mathcal{O}(\log N)$ traversal latency, compared to $\mathcal{O}(\sqrt{N})$ for mesh-based designs and $\mathcal{O}(N)$ for bus-based interconnects (Fig. 8 (b)). This property enables robust scalability for large symbolic reasoning workloads.
Listing 1: C++ Programming Interface of REASON
⬇
// Trigger symbolic execution for a single inference
void REASON_execute (
int batch_id, // batch identifier
int batch_size, // number of objects in the batch
const void * neural_buffer, // neural results in shared memory
const void * reasoning_mode, // mode selection
void * symbolic_buffer // write-back symb. results
);
// Query current REASON status for a given object
int REASON_check_status (
int batch_id, // batch identifier
bool blocking // wait till REASON is idle
);
### V-E Case Study: A Working Example of Symbolic Execution
Fig. 9 illustrates the dynamic, pipelined per-node execution of REASON during a cube-and-conquer SAT solving phase, which highlights several key hardware mechanisms, including inter-node pipelined broadcast/reduction, latency hiding via parallel WLs traversal, and priority-based conflict handling.
Execution begins with the controller issuing a Decision to assign $x_{1}$ , which is broadcast through the distribution tree (T1–T4). At T5, leaf nodes concurrently discover two implications: $x_{2}$ = $1$ and $x_{3}$ = $0$ . These implications are returned to the controller via the reduction tree in a pipelined manner, where $x_{2}$ = $1$ arrives first, followed by $x_{3}$ = $0$ at T10. Since the FIFO is occupied, $x_{3}$ = $0$ is queued into the BCP FIFO at T11.
At T15, the FIFO pops a subsequent implication ( $x_{12}$ ), which triggers WLs lookup. A local SRAM miss prompts the L2/DMA to begin fetching clause, meanwhile BCP FIFO continues servicing queued implications: $x_{99}$ is popped and broadcast from T17–T19 while DMA fetch is still in progress.
At T22, the propagation of $x_{99}$ results in a Conflict, which immediately propagates up the reduction tree. Upon receiving the conflict signal at T23, the controller asserts priority control: it halts the ongoing DMA fetch, flushes the FIFO, and discards all pending implications (including $x_{3}$ = $0$ ) from the now-invalid search path. The cube-and-conquer phase terminates, and the parallelized DPLL node is forwarded to the scalar PE for CDCL conflict analysis, as discussed in Sec. II-C.
### V-F Design Space Exploration and Scalability
Design space exploration. To identify the optimal configuration of REASON architecture, we perform a comprehensive design space exploration. We systematically evaluated different configurations by varying key architectural parameters such as the depth of the tree (D), the number of parallel register banks (B), and the number of registers per bank (R). We evaluate each configuration across latency, energy consumption, and energy-delay product (EDP) on representative workloads. The selected configuration (D=3, B=64, R=32) offers the optimal trade-off between performance and energy efficiency.
Scalability and variability support. Coupled with reconfigurable array, pipeling scheduling, and memory layout optimizations, REASON provides flexible hardware support across symbolic and probabilistic kernels (e.g., SAT, FOL, PC, HMM), neuro-symbolic workloads, and cognitive tasks, enabling efficient neuro-symbolic processing at scale (Sec. VII).
Design choice discussion. We adopt a unified architecture for symbolic and probabilistic reasoning to maximize flexibility and efficiency, rather than decoupling them into separate engines. We identify these kernels share common DAG patterns, enabling REASON to execute them on Tree-PEs through a unified representation. This approach achieves $>$ 90% utilization with 58% lower area/power than decoupled designs, while maintaining tight symbolic-probabilistic coupling. A flexible Benes network and compiler co-design handle routing and memory scheduling, ensuring efficient execution.
## VI REASON: System Integration and Pipeline
This section presents the system-level integration of REASON. We first present the integration principles and workload partitioning strategy between GPU and REASON (Sec. VI-A), then introduce the programming model that enables flexible invocation and synchronization (Sec. VI-B). Finally, we describe the two-level execution pipeline (Sec. VI-C).
### VI-A Integration with GPUs for End-to-End Reasoning
Integration principles. As illustrated in Fig. 6 (a), the proposed REASON is integrated as a co-processor within GPU system to support efficient end-to-end symbolic and probabilistic reasoning. This integration follows two principles: (1) Versatility to ensure compatibility with a broad range of logical and probabilistic reasoning workloads in neuro-symbolic pipelines, and (2) Efficiency to achieve low-latency execution for real-time reasoning. These principles necessitate careful workload assignment between GPU and REASON with pipelined execution.
Workload partitioning. To maximize performance while preserving compatibility with existing and emerging LLM-based neuro-symbolic agentic pipelines, we assign neural computation (e.g., LLM inference) to the GPU and offload symbolic reasoning and probabilistic inference to REASON. This partitioning exploits the GPU’s high throughput and programmability for neural kernels, while leveraging REASON’s reconfigurable architecture optimized for logical and probabilistic operations. It also minimizes data movement and enables pipelined execution: while REASON processes symbolic reasoning for the current batch, the GPU concurrently executes neural computation for the next batch.
### VI-B Programming Model
REASON’s programming model (Listing. 1) is designed to offer full flexibility and control, making it easy to utilize REASON for accelerating various neuro-symbolic applications. It exposes two core functions for executing and status checking, enabling acceleration of logical and probabilistic kernels.
REASON_execute is responsible for processing a single symbolic reasoning run. It is called after GPU SMs complete processing the neural LLM. REASON then performs logical reasoning and probabilistic inference, and writes the symbolic results to shared memory, where SMs use for the next iteration.
REASON_check_status reports the current execution status of REASON (IDLE or EXECUTION) and includes an optional blocking flag. This feature allows the host thread to wait for REASON to complete the current step of reasoning before starting the next, ensuring proper coordination across subtasks without relying on CUDA stream synchronization.
Synchronization. Coordination between SMs and REASON is handled through shared-memory flag buffers and L2 cache. After executing LLM kernel, SMs write the output to shared memory and set neural_ready flag. REASON polls this flag, fetches the data, and performs symbolic reasoning. It then writes the result back to shared memory and sets symbolic_ready flag, which will be retrieved for final output. This tightly coupled design leverages GPU’s throughput for LLM kernels and REASON’s efficiency for symbolic reasoning, minimizing overhead and maximizing performance.
TABLE III: Hardware baselines. Comparison of device specs.
| Orin NX [18] | 8 nm | 4 MB | 512 CUDA Cores | 450 | 15 |
| --- | --- | --- | --- | --- | --- |
| RTX A6000 [48] | 8 nm | 16.5 MB | 10572 CUDA Cores | 628 | 300 |
| Xeon CPU [17] | 10 nm | 112.5 MB | 60 cores per socket | 1600 | 270 |
| TPU [19] | 7 nm | 170 MB | 8 128 $\times$ 128 PEs | 400 | 192 |
| DPU # [59] | 28 nm | 2.4 MB | 8 PEs / 56 Nodes | 3.20 | 1.10 |
| REASON | 28 nm | 1.25 MB | 12 PEs / 80 Nodes | 6.00 | 2.12 |
| REASON * | 12 nm | 1.25 MB | 12 PEs / 80 Nodes | 1.37 | 1.21 |
| REASON * | 8 nm | 1.25 MB | 12 PEs / 80 Nodes | 0.51 | 0.98 |
- The 12nm and 8nm data are scaled from the DeepScaleTool [57] with a voltage of 0.8V and a frequency of 500MHz. # The terminology for tree-based architecture is renamed from tree to PE and PE to node to align with the proposed REASON.
### VI-C Two-Level Execution Pipeline
Our system-level design employs a two-level pipelined execution model (Fig. 9 top-left) to maximize concurrency across neural and symbolic kernels. The GPU-REASON pipeline overlaps the execution of symbolic kernels on REASON for step $N$ with neural kernels on GPU for step $N$ +1, effectively hiding the latency of one stage and improving throughput. Within REASON, the Intra-REASON pipeline exploits inter-node pipelined broadcast and reduction to hide communication latency, using parallel worklist traversal and priority-based conflict handling to accelerate symbolic kernels (Sec. V-E). The compiler integrates pipeline-aware scheduling to reorder instructions, avoid read-after-write hazards, and insert no-operation instructions when necessary, ensuring each stage receives valid data without interruption.
<details>
<summary>x10.png Details</summary>
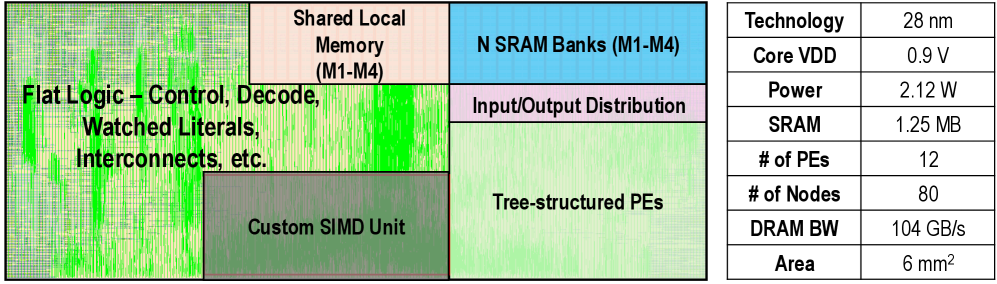
### Visual Description
## Diagram: Chip Layout and Specifications
### Overview
The image presents a high-level layout of a chip, alongside a table summarizing its key specifications. The chip layout diagram shows the functional blocks and their relative sizes, while the table provides numerical data on technology, power, memory, and performance characteristics.
### Components/Axes
**Chip Layout Diagram:**
* **Functional Blocks:** The diagram is divided into several colored rectangular blocks, each representing a different functional unit within the chip.
* **Flat Logic:** Located on the left side, labeled "Flat Logic - Control, Decode, Watched Literals, Interconnects, etc." (Light Yellow/Green)
* **Shared Local Memory:** Located at the top-center, labeled "Shared Local Memory (M1-M4)" (Light Peach)
* **N SRAM Banks:** Located at the top-right, labeled "N SRAM Banks (M1-M4)" (Light Blue)
* **Input/Output Distribution:** Located in the center-right, labeled "Input/Output Distribution" (Light Purple)
* **Tree-structured PEs:** Located at the bottom-right, labeled "Tree-structured PEs" (Light Green)
* **Custom SIMD Unit:** Located at the bottom-left, labeled "Custom SIMD Unit" (Darker Green)
**Specification Table:**
* **Rows:** Each row represents a different specification parameter.
* **Columns:** Two columns: Parameter Name and Value.
### Detailed Analysis or ### Content Details
**Chip Layout Diagram:**
* The "Flat Logic" block occupies a significant portion of the left side of the chip.
* The "Shared Local Memory" and "N SRAM Banks" are positioned at the top, suggesting their importance for data access.
* The "Input/Output Distribution" block is centrally located, facilitating communication between different units.
* The "Tree-structured PEs" and "Custom SIMD Unit" are at the bottom, indicating their role in processing.
**Specification Table:**
| Parameter | Value |
|-------------|----------|
| Technology | 28 nm |
| Core VDD | 0.9 V |
| Power | 2.12 W |
| SRAM | 1.25 MB |
| # of PEs | 12 |
| # of Nodes | 80 |
| DRAM BW | 104 GB/s |
| Area | 6 mm² |
### Key Observations
* The chip integrates various functional units, including logic, memory, and processing elements.
* The specification table provides quantitative data on the chip's performance and characteristics.
* The layout diagram gives a visual representation of the chip's architecture.
### Interpretation
The image provides a concise overview of a chip's design and performance. The layout diagram illustrates the physical arrangement of functional blocks, while the specification table quantifies key parameters such as technology node, power consumption, memory capacity, and processing capabilities. The combination of these two representations offers a comprehensive understanding of the chip's architecture and performance characteristics. The chip appears to be designed for parallel processing, given the presence of multiple processing elements (PEs) and a SIMD unit. The DRAM bandwidth is relatively high, suggesting a focus on memory-intensive applications.
</details>
Figure 10: REASON layout and specifications. The physical design and key operating specifications of our proposed REASON hardware.
## VII Evaluation
This section introduces REASON evaluation settings (Sec. VII-A), and benchmarks the proposed algorithm optimizations (Sec. VII-B) and hardware architecture (Sec. VII-C).
### VII-A Evaluation Setup
Datasets. We evaluate REASON on 10 commonly-used reasoning datasets: IMO [66], MiniF2F [86], TwinSafety [20], XSTest [56], CommonGen [31], News [85], CoAuthor [26], AwA2 [78], FOLIO [11], and ProofWriter [65]. The tasks are measured by the reasoning and deductive accuracy.
Algorithm setup. We evaluate REASON on six state-of-the-art neuro-symbolic models, i.e., AlphaGeometry [66], R 2 -Guard [20], GeLaTo [82], Ctrl-G [83], NeuroPC [6], and LINC [52]. Following the setup in the original literature, we determine the hyperparameters based on end-to-end reasoning performance on the datasets. Our proposed REASON algorithm optimizations are general and can work as a plug-and-play extension to existing neuro-symbolic algorithms.
Baselines. We consider several hardware baselines, including Orin NX [18] (since our goal is to enable real-time neuro-symbolic at edge), RTX GPU [48], Xeon CPU [17], ML accelerators (TPU [19], DPU [59]). Tab. III lists configurations.
Hardware setup. We implement REASON architecture with [59] as the baseline template, synthesize with Synopsys DC [63], and place and route using Cadence Innovus [5] at TSMC 28nm node. Fig. 10 illustrates the layout and key specifications. The REASON hardware consumes an area of 6 mm 2 and an average power of 2.12 W across workloads based on Synopsys PTPX [64] power-trace analysis (Fig. 12 (a)). Unlike conventional tree-based arrays that mainly target neural workloads, REASON provides unified, reconfigurable support for neural, symbolic, and probabilistic computation.
Simulation setup. To evaluate end-to-end performance of REASON when integrated with GPUs, we develop a cycle-accurate simulator based on Accel-Sim (built on GPGPU-Sim) [21]. The simulator is configured for Orin NX architecture. The on-chip GPU is modeled with 8 SMs, each supporting 32 threads per warp, 48 KB shared memory, and 128 KB L1 cache, with a unified 2 MB L2 cache shared across SMs. The off-chip memory uses a 128-bit LPDDR5 interface with 104 GB/s peak BW. DRAM latency and energy are modeled using LPDDR5 timing parameters.
Simulator test trace derivation. We use GPGPU-Sim to model interactions between SMs and REASON, including transferring neural results from SMs to REASON and returning symbolic reasoning results from REASON to SMs. To simulate communication overhead, we extract memory access traces from neuro-symbolic model execution on Orin, capturing data volume and access patterns as inputs to GPGPU-Sim for accurate modeling. For GPU comparison baselines, we use real hardware measurements to get accurate ground-truth data.
### VII-B REASON Algorithm Performance
TABLE IV: REASON algorithm optimization performance. REASON achieves comparable accuracy with reduced memory footprint via unified DAG representation, adaptive pruning, and regularization.
| Workloads | Benchmarks | Metrics | Baseline Performance | After REASON Algo. Opt. | |
| --- | --- | --- | --- | --- | --- |
| Performance | Memory $\downarrow$ | | | | |
| AlphaGeo | IMO | Accuracy ( $\uparrow$ ) | 83% | 83% | 25% |
| MiniF2F | Accuracy ( $\uparrow$ ) | 81% | 81% | 21% | |
| R 2 -Guard | TwinSafety | AUPRC ( $\uparrow$ ) | 0.758 | 0.752 | 37% |
| XSTest | AUPRC ( $\uparrow$ ) | 0.878 | 0.881 | 30% | |
| GeLaTo | CommonGen | BLEU ( $\uparrow$ ) | 30.3 | 30.2 | 41% |
| News | BLEU ( $\uparrow$ ) | 5.4 | 5.4 | 27% | |
| Ctrl-G | CoAuthor | Success rate ( $\uparrow$ ) | 87% | 86% | 29% |
| NeuroSP | AwA2 | Accuracy | 87% | 87% | 43% |
| LINC | FOLIO | Accuracy ( $\uparrow$ ) | 92% | 91% | 38% |
| ProofWriter | Accuracy ( $\uparrow$ ) | 84% | 84% | 26% | |
Reasoning accuracy. To evaluate REASON algorithm optimization (Sec. IV), we benchmark it on ten reasoning tasks (Sec. VII-A). Tab. IV lists the arithmetic performance and DAG size reduction. We observe that REASON achieves comparable reasoning accuracy through unification and adaptive DAG pruning. Through pruning and regularization, REASON enables 31.7% memory footprint savings on average of ten reasoning tasks across six neuro-symbolic workloads.
### VII-C REASON Architecture Performance
Performance improvement. We benchmark REASON accelerator with Orin NX, RTX GPU, and Xeon CPU for accelerating neuro-symbolic algorithms on 10 reasoning tasks (Fig. 11). For GPU baseline, for neuro kernels, we use Pytorch package that leverages CUDA and cuBLAS/cuDNN libraries; for symbolic kernels, we implement custom kernels optimized for logic and probabilistic operations. The workload is tiled by CuDNN in Pytorch based on block sizes that fit well in GPU memory. We observe that REASON exhibits consistent speedup across datasets, e.g., 50.65 $\times$ /11.98 $\times$ speedup over Orin NX and RTX GPU. Furthermore, REASON achieves real-time performance ( $<$ 1.0 s) on solving math and cognitive reasoning tasks, indicating that REASON enables real-time probabilistic logical reasoning-based neuro-symbolic system with superior reasoning and generalization capability, offering a promising solution for future cognitive applications.
<details>
<summary>x11.png Details</summary>
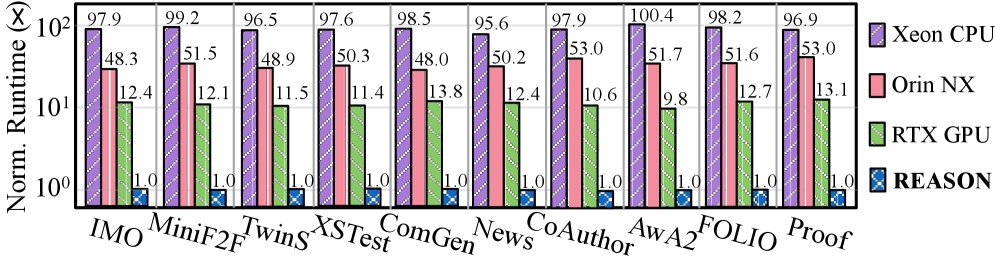
### Visual Description
## Bar Chart: Normalized Runtime Comparison
### Overview
The image is a bar chart comparing the normalized runtime of different systems (Xeon CPU, Orin NX, RTX GPU, and REASON) across various workloads (IMO, MiniF2F, Twins, XSTest, ComGen, News, CoAuthor, AwA2, FOLIO, Proof). The y-axis represents the normalized runtime on a logarithmic scale, and the x-axis represents the different workloads. REASON is used as the baseline, with a normalized runtime of 1.0 for all workloads.
### Components/Axes
* **Y-axis:** "Norm. Runtime (x)" - Logarithmic scale, ranging from 10^0 to 10^2.
* **X-axis:** Workloads - IMO, MiniF2F, Twins, XSTest, ComGen, News, CoAuthor, AwA2, FOLIO, Proof.
* **Legend (Top-Right):**
* Xeon CPU (Purple with diagonal lines)
* Orin NX (Light Red/Pink)
* RTX GPU (Green with diagonal lines)
* REASON (Blue with cross-hatch pattern)
### Detailed Analysis
Here's a breakdown of the normalized runtime for each system across the different workloads:
* **REASON:** The baseline, with a normalized runtime of 1.0 for all workloads.
* **Xeon CPU (Purple):**
* IMO: 97.9
* MiniF2F: 99.2
* Twins: 96.5
* XSTest: 97.6
* ComGen: 98.5
* News: 95.6
* CoAuthor: 97.9
* AwA2: 100.4
* FOLIO: 98.2
* Proof: 96.9
* Trend: Relatively consistent runtime across all workloads, hovering around 97-100.
* **Orin NX (Pink):**
* IMO: 48.3
* MiniF2F: 51.5
* Twins: 48.9
* XSTest: 50.3
* ComGen: 48.0
* News: 50.2
* CoAuthor: 53.0
* AwA2: 51.7
* FOLIO: 51.6
* Proof: 53.0
* Trend: Relatively consistent runtime across all workloads, hovering around 48-53.
* **RTX GPU (Green):**
* IMO: 12.4
* MiniF2F: 12.1
* Twins: 11.5
* XSTest: 11.4
* ComGen: 13.8
* News: 12.4
* CoAuthor: 10.6
* AwA2: 9.8
* FOLIO: 12.7
* Proof: 13.1
* Trend: Relatively consistent runtime across all workloads, hovering around 10-14.
### Key Observations
* The Xeon CPU consistently has the highest normalized runtime across all workloads.
* The Orin NX has a significantly lower normalized runtime than the Xeon CPU, but higher than the RTX GPU.
* The RTX GPU has the lowest normalized runtime among the three systems, excluding the baseline REASON.
* REASON consistently has the lowest normalized runtime, as it is the baseline (1.0).
* The AwA2 workload shows the highest runtime for Xeon CPU (100.4).
* The AwA2 workload shows the lowest runtime for RTX GPU (9.8).
### Interpretation
The bar chart demonstrates the performance differences between the Xeon CPU, Orin NX, and RTX GPU systems relative to the REASON baseline across various workloads. The Xeon CPU consistently exhibits the highest runtime, suggesting it is the least efficient for these workloads. The Orin NX offers a moderate improvement over the Xeon CPU, while the RTX GPU provides the most significant performance improvement, achieving the lowest normalized runtime among the three systems. The consistent baseline of REASON allows for a clear comparison of the relative performance of the other systems. The data suggests that for these specific workloads, the RTX GPU is the most efficient, followed by the Orin NX, and then the Xeon CPU.
</details>
Figure 11: End-to-end runtime improvement. REASON consistently outperforms Xeon CPU, Orin NX, and RTX GPU in end-to-end runtime latency evaluated on 10 logical and cognitive reasoning tasks.
<details>
<summary>x12.png Details</summary>
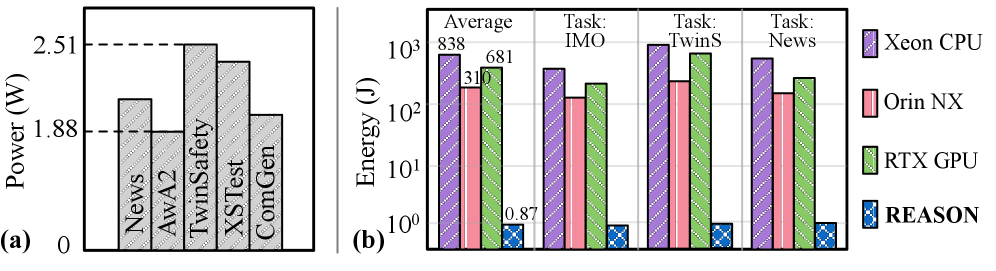
### Visual Description
## Bar Charts: Power and Energy Consumption
### Overview
The image contains two bar charts comparing power consumption (in Watts) and energy consumption (in Joules) across different tasks and hardware platforms. Chart (a) shows the power consumption of different tasks, while chart (b) shows the energy consumption of different hardware platforms for various tasks.
### Components/Axes
**Chart (a): Power Consumption**
* **Title:** Power (W)
* **X-axis:** Tasks (News, AwA2, TwinSafety, XSTest, ComGen)
* **Y-axis:** Power in Watts (W), ranging from 0 to approximately 2.51 W. A dashed line indicates 1.88 W.
**Chart (b): Energy Consumption**
* **Title:** Energy (J)
* **X-axis:** Tasks (Average, Task: IMO, Task: TwinS, Task: News)
* **Y-axis:** Energy in Joules (J), using a logarithmic scale from 10^0 to 10^3.
* **Legend (Top-Right):**
* Purple diagonal lines: Xeon CPU
* Pink vertical lines: Orin NX
* Green diagonal lines: RTX GPU
* Blue checkered pattern: REASON
### Detailed Analysis
**Chart (a): Power Consumption**
* **News:** Approximately 2.1 W
* **AwA2:** Approximately 1.8 W
* **TwinSafety:** Approximately 2.5 W
* **XSTest:** Approximately 2.4 W
* **ComGen:** Approximately 1.9 W
**Chart (b): Energy Consumption**
* **Average:**
* Xeon CPU (Purple): Approximately 838 J
* Orin NX (Pink): Approximately 310 J
* RTX GPU (Green): Approximately 681 J
* REASON (Blue): Approximately 0.87 J
* **Task: IMO:**
* Xeon CPU (Purple): Approximately 800 J
* Orin NX (Pink): Approximately 250 J
* RTX GPU (Green): Approximately 500 J
* REASON (Blue): Approximately 0.87 J
* **Task: TwinS:**
* Xeon CPU (Purple): Approximately 1000 J
* Orin NX (Pink): Approximately 300 J
* RTX GPU (Green): Approximately 800 J
* REASON (Blue): Approximately 0.87 J
* **Task: News:**
* Xeon CPU (Purple): Approximately 700 J
* Orin NX (Pink): Approximately 200 J
* RTX GPU (Green): Approximately 600 J
* REASON (Blue): Approximately 0.87 J
### Key Observations
* In Chart (a), TwinSafety and XSTest tasks consume the most power, while AwA2 consumes the least.
* In Chart (b), the Xeon CPU generally consumes the most energy, followed by the RTX GPU and then the Orin NX. The REASON platform consumes significantly less energy than the other platforms.
* The energy consumption varies across different tasks for each hardware platform.
### Interpretation
The charts provide a comparison of power and energy consumption for different tasks and hardware platforms. Chart (a) shows the instantaneous power draw of different tasks, while chart (b) shows the total energy consumed by different hardware platforms to complete those tasks. The data suggests that the REASON platform is significantly more energy-efficient than the Xeon CPU, Orin NX, and RTX GPU. The choice of hardware platform can significantly impact energy consumption, and the REASON platform may be a suitable option for energy-sensitive applications. The different tasks have different power requirements, which may influence the choice of hardware platform for specific applications.
</details>
Figure 12: Energy efficiency improvement. (a) Power analysis of REASON across workloads. (b) Energy efficiency comparison between REASON and CPUs/GPUs, evaluated from 10 reasoning tasks.
<details>
<summary>x13.png Details</summary>

### Visual Description
## Bar Chart: Normalized Runtime Comparison
### Overview
The image is a bar chart comparing the normalized runtime performance of three different architectures (TPU-like, DPU-like, and REASON) across four different task types: Neuro-Only, Symbolic-Only (logical/probabilistic), and End-to-End Neuro+Symbolic. The x-axis represents different configurations (AlphaG, Guard, GeLaTo, Ctrl-G, NPC, LINC) for each task type. The y-axis represents the normalized runtime on a logarithmic scale.
### Components/Axes
* **Title:** None explicitly given, but the chart compares normalized runtime.
* **Y-Axis:** "Norm. Runtime (X)" with a logarithmic scale. The values 10<sup>0</sup>, 10<sup>1</sup>, and 10<sup>2</sup> are marked.
* **X-Axis:** Categorical, divided into four main sections: "Neuro-Only", "Symbolic-Only (logical/probabilistic)", and "End-to-End Neuro+Symbolic". Each section contains the same sub-categories: "AlphaG", "Guard", "GeLaTo", "Ctrl-G", "NPC", and "LINC".
* **Legend:** Located at the top-left of the chart.
* Green with diagonal lines: "TPU-like (systolic-based array)"
* Pink with vertical lines: "DPU-like (tree-based array)"
* Blue with a checkered pattern: "REASON"
### Detailed Analysis
**Neuro-Only**
* **AlphaG:**
* TPU-like: 0.69
* DPU-like: 4.31
* REASON: 1.00
* **Guard:**
* TPU-like: 0.71
* DPU-like: 4.40
* REASON: 1.00
* **GeLaTo:**
* TPU-like: 0.68
* DPU-like: 4.29
* REASON: 1.00
* **Ctrl-G:**
* TPU-like: 0.66
* DPU-like: 4.49
* REASON: 1.00
* **NPC:**
* TPU-like: 0.73
* DPU-like: 4.32
* REASON: 1.00
* **LINC:**
* TPU-like: 0.68
* DPU-like: 4.30
* REASON: 1.00
**Symbolic-Only (logical/probabilistic)**
* **AlphaG:**
* TPU-like: 81.35
* DPU-like: 25.13
* REASON: 1.00
* **Guard:**
* TPU-like: 76.10
* DPU-like: 4.84
* REASON: 1.00
* **GeLaTo:**
* TPU-like: 109.24
* DPU-like: 5.03
* REASON: 1.00
* **Ctrl-G:**
* TPU-like: 78.48
* DPU-like: 6.07
* REASON: 1.00
* **NPC:**
* TPU-like: 74.71
* DPU-like: 4.97
* REASON: 1.00
* **LINC:**
* TPU-like: 90.89
* DPU-like: 23.97
* REASON: 1.00
**End-to-End Neuro+Symbolic**
* **AlphaG:**
* TPU-like: 21.31
* DPU-like: 7.86
* REASON: 1.00
* **Guard:**
* TPU-like: 17.77
* DPU-like: 2.31
* REASON: 1.00
* **GeLaTo:**
* TPU-like: 10.54
* DPU-like: 2.15
* REASON: 1.00
* **Ctrl-G:**
* TPU-like: 18.02
* DPU-like: 2.90
* REASON: 1.00
* **NPC:**
* TPU-like: 9.76
* DPU-like: 2.33
* REASON: 1.00
* **LINC:**
* TPU-like: 8.59
* DPU-like: 6.10
* REASON: 1.00
### Key Observations
* For "Neuro-Only" tasks, TPU-like consistently has the lowest normalized runtime, followed by REASON, and then DPU-like.
* For "Symbolic-Only" tasks, TPU-like has significantly higher normalized runtime compared to DPU-like and REASON. REASON consistently has a normalized runtime of 1.00.
* For "End-to-End Neuro+Symbolic" tasks, TPU-like has a higher normalized runtime than DPU-like and REASON. REASON consistently has a normalized runtime of 1.00.
* REASON consistently has a normalized runtime of 1.00 across all configurations and task types.
### Interpretation
The chart demonstrates the relative performance of three different architectures (TPU-like, DPU-like, and REASON) across different types of tasks. The "Neuro-Only" tasks show that TPU-like architectures are the most efficient. However, for "Symbolic-Only" tasks, TPU-like architectures become significantly less efficient, with much higher normalized runtimes. The "End-to-End Neuro+Symbolic" tasks show a similar trend, although the differences are less extreme than in the "Symbolic-Only" case.
The REASON architecture consistently maintains a normalized runtime of 1.00, suggesting it serves as a baseline or reference point for comparison. This could indicate that the normalized runtime is calculated relative to the performance of the REASON architecture.
The data suggests that the choice of architecture should be tailored to the specific task. TPU-like architectures are well-suited for "Neuro-Only" tasks, but less efficient for "Symbolic-Only" tasks. DPU-like architectures show a more balanced performance across different task types, although they are not as efficient as TPU-like architectures for "Neuro-Only" tasks.
</details>
Figure 13: Improved efficiency over ML accelerators. Speedup comparison of neural, symbolic (logical and probabilistic), and end-to-end neuro-symbolic system over TPU-like systolic-based array and DPU-like tree-based array architecture.
Energy efficiency improvement. REASON accelerator achieves two orders of energy efficiency than Orin NX, RTX GPU, and Xeon CPU consistently across workloads (Fig. 12 (b)). To further assess REASON energy efficiency in long-term deployment, we perform consecutive tests on REASON using mixed workloads, incorporating both low-activity and high-demand periods, with 15s idle intervals between scenarios. On average, REASON achieves 681 $\times$ energy efficiency compared to RTX GPU. Additionally, when compared to V100 and A100, REASON shows 4.91 $\times$ and 1.60 $\times$ speedup, with 802 $\times$ and 268 $\times$ energy efficiency, respectively.
Compare with CPU+GPU. We compare the performance of RESAON as GPU plug-in over the CPU+GPU architecture across neuro-symbolic workloads. CPU+GPU architecture is not efficient for neuro-symbolic computing due to (1) high latency of symbolic/probabilistic operations with poor locality and $<$ 5% CPU parallel efficiency, (2) $>$ 15% inter-device communication overhead from frequent neural-symbolic data transfers, and (3) fine-grained coupling between neural and symbolic modules that makes handoffs costly. REASON co-locates logical and probabilistic reasoning beside GPU SMs, sharing L2 and inter-SM fabric to eliminate transfers and pipeline neural-symbolic execution.
Compare with ML accelerators. We benchmark the runtime of neural and symbolic operations on TPU-like systolic array [19] and DPU-like tree-based array [59] over different neuro-symbolic models and tasks (Fig. 13). For TPU-like architecture, we use SCALE-Sim [54], configured with eight 128 $\times$ 128 systolic arrays. For DPU-like architecture, we use MAERI [24], configured with eight PEs in 56-node tree-based array. Compared with ML accelerators, we observe that REASON achieves similar performance in neural operations, while exhibiting superior symbolic logic and probabilistic operation efficiency thus end-to-end speedup in neuro-symbolic systems.
TABLE V: Ablation study of necessity of co-design. The normalized runtime achieved by REASON framework w/o the proposed algorithm optimization or hardware techniques on different tasks.
| Neuro-symbolic System Algorithm @ Hardware [66, 20, 82] @ Orin NX | Normalized Runtime (%) on IMO [66] 100 | MiniF [86] 100 | TwinS [20] 100 | XSTest [56] 100 | ComG [31] 100 |
| --- | --- | --- | --- | --- | --- |
| REASON Algo. @ Orin NX | 84.2% | 87.0% | 78.3% | 82.9% | 86.6% |
| REASON Algo. @ REASON HW | 2.07% | 1.94% | 2.04% | 1.99% | 2.08% |
Ablation study on the proposed hardware techniques. REASON features reconfigurable tree-based array architecture, efficient register bank mapping, and adaptive scheduling strategy to reduce compute latency for neural, symbolic, and probabilistic kernels (Sec. V and Sec. VI). To demonstrate the effectiveness, we measure the runtime of REASON w/o the scheduling, reconfigurable architecture, and bank mapping. In particular, the proposed memory layout support can trim down the runtime by 22% on average. Additionally, with the proposed reconfigurable array and scheduling strategy, the runtime reduction ratio can be further enlarged to 56% and 73%, indicating that both techniques are necessary for REASON to achieve the desired efficient reasoning capability.
Ablation study of the necessity of co-design. To verify the necessity of algorithm-hardware co-design strategy to achieve efficient probabilistic logical reasoning-based neuro-symbolic systems, we measure the runtime latency of our REASON w/o the proposed algorithm or hardware techniques in Tab. V. Specifically, with our proposed REASON algorithm optimization, we can trim down the runtime to 78.3% as compared to R 2 -Guard [20] on the same Orin NX hardware and TwinSafety task. Moreover, with both proposed REASON algorithm optimization and accelerator, the runtime can be reduced to 2.04%, indicating the necessity of the co-design strategy of REASON framework.
REASON neural optimization. REASON accelerates symbolic reasoning and enables seamless interaction with GPU optimized for neuro (NN/LLM) computation. To further optimize neural module, we integrate standard LLM acceleration techniques: memory-efficient attention [25], chunked prefill [69], speculative decoding [27], FlashAttention-3 kernels [58], FP8 KV-Cache quantization [70], and prefix caching [68]. These collectively yield 2.8-3.3 $\times$ latency reduction for unique prompts and 4-5 $\times$ when prefixes are reused. While REASON’s reported gains stem from its hardware-software co-design, these LLM optimizations are orthogonal and can be applied in conjunction to unlock full potential system speedup.
## VIII Related Work
Neuro-symbolic AI. Neuro-symbolic AI has emerged as a promising paradigm for addressing limitations of purely neural models, including factual errors, limited interpretability, and weak multi-step reasoning. [84, 3, 14, 8, 53, 37, 80]. Systems such as LIPS [28], AlphaGeometry [66], NSC [39], NS3D [15] demonstrate strong performance across domains ranging from mathematical reasoning to embodied and cognitive robotics. However, most prior work focuses on algorithmic design and model integration. REASON systematically characterizing the architectural and system-level properties of probabilistic logical reasoning in neuro-symbolic AI, and proposes an integrated acceleration framework for scalable deployment.
System and architecture for neuro-symbolic AI. Early neuro-symbolic systems largely focused on software-level abstractions, such as training semantics and declarative languages that integrate neural with logical or probabilistic reasoning, such as DeepProbLog [36], DreamCoder [10], and Scallop [29]. Recent efforts have begun to address system-level challenges, such as heterogeneous mapping, batching control-heavy reasoning, and kernel specialization, including benchmarking [74], pruning [7], Lobster [4], Dolphin [47], and KLay [34]. At the architectural level, a growing body of work exposes the mismatch between compositional neuro-symbolic workloads and conventional hardware designs, motivating cognitive architectures such as CogSys [77], NVSA architectures [73], and NSFlow [79]. REASON advances this direction with the first flexible system-architecture co-design that supports probabilistic logical reasoning-based neuro-symbolic AI and integrates with GPU, enabling efficient and scalable compositional neuro-symbolic and LLM+tools agentic system deployment.
## IX Conclusion
We present REASON, the integrated acceleration framework for efficiently executing probabilistic logical reasoning in neuro-symbolic AI. REASON introduces a unified DAG abstraction with adaptive pruning and a flexible reconfigurable architecture integrated with GPUs to enable efficient end-to-end execution. Results show that system-architecture co-design is critical for making neuro-symbolic reasoning practical at scale, and position REASON as a potential foundation for future agentic AI and LLM+tools systems that require structured and interpretable reasoning alongside neural computation.
## Acknowledgements
This work was supported in part by CoCoSys, one of seven centers in JUMP 2.0, a Semiconductor Research Corporation (SRC) program sponsored by DARPA. We thank Ananda Samajdar, Ritik Raj, Anand Raghunathan, Kaushik Roy, Ningyuan Cao, Katie Zhao, Alexey Tumanov, Shirui Zhao, Xiaoxuan Yang, Zhe Zeng, and the anonymous HPCA reviewers for insightful discussions and valuable feedback.
## References
- [1] K. Ahmed, S. Teso, K. Chang, G. Van den Broeck, and A. Vergari (2022) Semantic probabilistic layers for neuro-symbolic learning. Advances in Neural Information Processing Systems 35, pp. 29944–29959. Cited by: §I.
- [2] R. Aksitov, S. Miryoosefi, Z. Li, D. Li, S. Babayan, K. Kopparapu, Z. Fisher, R. Guo, S. Prakash, P. Srinivasan, et al. (2023) Rest meets react: self-improvement for multi-step reasoning llm agent. arXiv preprint arXiv:2312.10003. Cited by: §I.
- [3] S. Badreddine, A. d. Garcez, L. Serafini, and M. Spranger (2022) Logic tensor networks. Artificial Intelligence 303, pp. 103649. Cited by: §VIII.
- [4] P. Biberstein, Z. Li, J. Devietti, and M. Naik (2025) Lobster: a gpu-accelerated framework for neurosymbolic programming. arXiv preprint arXiv:2503.21937. Cited by: §VIII.
- [5] Cadence Innovus implementation system - cadence. Note: https://www.cadence.com/en_US/home/tools/digital-design-and-signoff/soc-implementation-and-floorplanning/innovus-implementation-system.html Cited by: § VII-A.
- [6] W. Chen, S. Yu, H. Shao, L. Sha, and H. Zhao (2025) Neural probabilistic circuits: enabling compositional and interpretable predictions through logical reasoning. arXiv preprint arXiv:2501.07021. Cited by: TABLE I, § VII-A.
- [7] M. Dang, A. Liu, and G. Van den Broeck (2022) Sparse probabilistic circuits via pruning and growing. Advances in Neural Information Processing Systems (NeurIPS) 35, pp. 28374–28385. Cited by: §VIII.
- [8] H. Dong, J. Mao, T. Lin, C. Wang, L. Li, and D. Zhou (2019) Neural logic machines. In International Conference on Learning Representations (ICLR), Cited by: §VIII.
- [9] S. Du, M. Ibrahim, Z. Wan, L. Zheng, B. Zhao, Z. Fan, C. Liu, T. Krishna, A. Raychowdhury, and H. Li (2025) Cross-layer design of vector-symbolic computing: bridging cognition and brain-inspired hardware acceleration. arXiv preprint arXiv:2508.14245. Cited by: §I.
- [10] K. Ellis, L. Wong, M. Nye, M. Sable-Meyer, L. Cary, L. Anaya Pozo, L. Hewitt, A. Solar-Lezama, and J. B. Tenenbaum (2023) Dreamcoder: growing generalizable, interpretable knowledge with wake–sleep bayesian program learning. Philosophical Transactions of the Royal Society A 381 (2251), pp. 20220050. Cited by: §VIII.
- [11] S. Han, H. Schoelkopf, Y. Zhao, Z. Qi, M. Riddell, W. Zhou, J. Coady, D. Peng, Y. Qiao, L. Benson, et al. (2022) Folio: natural language reasoning with first-order logic. arXiv preprint arXiv:2209.00840. Cited by: § VII-A.
- [12] M. Hersche, M. Zeqiri, L. Benini, A. Sebastian, and A. Rahimi (2023) A neuro-vector-symbolic architecture for solving raven’s progressive matrices. Nature Machine Intelligence 5 (4), pp. 363–375. Cited by: §I, § II-A.
- [13] M. J. Heule, O. Kullmann, S. Wieringa, and A. Biere (2011) Cube and conquer: guiding cdcl sat solvers by lookaheads. In Haifa Verification Conference, pp. 50–65. Cited by: § II-C.
- [14] P. Hohenecker and T. Lukas (2020) Ontology reasoning with deep neural networks. Journal of Artificial Intelligence Research 68, pp. 503–540. Cited by: §VIII.
- [15] J. Hsu, J. Mao, and J. Wu (2023) Ns3d: neuro-symbolic grounding of 3d objects and relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2614–2623. Cited by: §VIII.
- [16] M. Ibrahim, Z. Wan, H. Li, P. Panda, T. Krishna, P. Kanerva, Y. Chen, and A. Raychowdhury (2024) Special session: neuro-symbolic architecture meets large language models: a memory-centric perspective. In 2024 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ ISSS), pp. 11–20. Cited by: §I.
- [17] INTEL Corporation (2023) 4th gen intel xeon scalable processors. Note: https://www.intel.com/content/www/us/en/ark/products/series/228622/4th-gen-intel-xeon-scalable-processors.html Cited by: TABLE III, § VII-A.
- [18] () Jetson orin for next-gen robotics — nvidia. Note: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/ (Accessed on 04/02/2024) Cited by: TABLE III, § VII-A.
- [19] N. P. Jouppi, D. H. Yoon, M. Ashcraft, M. Gottscho, T. B. Jablin, G. Kurian, J. Laudon, S. Li, P. Ma, X. Ma, et al. (2021) Ten lessons from three generations shaped google’s tpuv4i: industrial product. In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), pp. 1–14. Cited by: TABLE III, § VII-A, § VII-C.
- [20] M. Kang and B. Li (2025) R 2 -guard: robust reasoning enabled llm guardrail via knowledge-enhanced logical reasoning. International Conference on Learning Representations (ICLR). Cited by: §I, TABLE I, § VII-A, § VII-A, § VII-C, TABLE V, TABLE V.
- [21] M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers (2020) Accel-sim: an extensible simulation framework for validated gpu modeling. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pp. 473–486. Cited by: § VII-A.
- [22] P. Khosravi, Y. Choi, Y. Liang, A. Vergari, and G. Van den Broeck (2019) On tractable computation of expected predictions. Advances in Neural Information Processing Systems 32. Cited by: § II-C.
- [23] J. Kuang, Y. Shen, J. Xie, H. Luo, Z. Xu, R. Li, Y. Li, X. Cheng, X. Lin, and Y. Han (2025) Natural language understanding and inference with mllm in visual question answering: a survey. ACM Computing Surveys 57 (8), pp. 1–36. Cited by: §I.
- [24] H. Kwon, A. Samajdar, and T. Krishna (2018) Maeri: enabling flexible dataflow mapping over dnn accelerators via reconfigurable interconnects. ACM Sigplan Notices 53 (2), pp. 461–475. Cited by: § V-B, § VII-C.
- [25] W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica (2023) Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles (SOSP), pp. 611–626. Cited by: § VII-C.
- [26] M. Lee, P. Liang, and Q. Yang (2022) Coauthor: designing a human-ai collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI conference on human factors in computing systems, pp. 1–19. Cited by: § VII-A.
- [27] Y. Leviathan, M. Kalman, and Y. Matias (2023) Fast inference from transformers via speculative decoding. In International Conference on Machine Learning (ICML), pp. 19274–19286. Cited by: § VII-C.
- [28] Z. Li, Z. Li, W. Tang, X. Zhang, Y. Yao, X. Si, F. Yang, K. Yang, and X. Ma (2025) Proving olympiad inequalities by synergizing llms and symbolic reasoning. International Conference on Learning Representations (ICLR), pp. 1–26. Cited by: §I, §VIII.
- [29] Z. Li, J. Huang, and M. Naik (2023) Scallop: a language for neurosymbolic programming. Proceedings of the ACM on Programming Languages 7 (PLDI), pp. 1463–1487. Cited by: §VIII.
- [30] Y. Liang and G. Van den Broeck (2019) Learning logistic circuits. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33, pp. 4277–4286. Cited by: § II-C.
- [31] B. Y. Lin, W. Zhou, M. Shen, P. Zhou, C. Bhagavatula, Y. Choi, and X. Ren (2020) CommonGen: a constrained text generation challenge for generative commonsense reasoning. Findings of the Association for Computational Linguistics (EMNLP), pp. 1823––1840. Cited by: § VII-A, TABLE V.
- [32] A. Liu, K. Ahmed, and G. V. d. Broeck (2024) Scaling tractable probabilistic circuits: a systems perspective. International Conference on Machine Learning (ICML), pp. 30630–30646. Cited by: § II-C.
- [33] M. Lo, M. F. Chang, and J. Cong (2025) SAT-accel: a modern sat solver on a fpga. In Proceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, pp. 234–246. Cited by: § II-C.
- [34] J. Maene, V. Derkinderen, and P. Z. D. Martires (2024) Klay: accelerating arithmetic circuits for neurosymbolic ai. arXiv preprint arXiv:2410.11415. Cited by: §VIII.
- [35] M. Mahaut, L. Aina, P. Czarnowska, M. Hardalov, T. Müller, and L. Màrquez (2024) Factual confidence of llms: on reliability and robustness of current estimators. ACL. Cited by: §I.
- [36] R. Manhaeve, S. Dumancic, A. Kimmig, T. Demeester, and L. De Raedt (2018) Deepproblog: neural probabilistic logic programming. Advances in neural information processing systems (NeurIPS) 31. Cited by: §VIII.
- [37] R. Manhaeve, S. Dumančić, A. Kimmig, T. Demeester, and L. De Raedt (2021) Neural probabilistic logic programming in deepproblog. Artificial Intelligence 298, pp. 103504. Cited by: §VIII.
- [38] J. Mao, C. Gan, P. Kohli, J. B. Tenenbaum, and J. Wu (2019) The neuro-symbolic concept learner: interpreting scenes, words, and sentences from natural supervision. International Conference on Learning Representations (ICLR). Cited by: §I, § II-A.
- [39] J. Mao, J. B. Tenenbaum, and J. Wu (2025) Neuro-symbolic concepts. arXiv preprint arXiv:2505.06191. Cited by: §VIII.
- [40] J. Marques-Silva, I. Lynce, and S. Malik (2021) Conflict-driven clause learning sat solvers. In Handbook of satisfiability, pp. 133–182. Cited by: § II-C.
- [41] L. Mei, J. Mao, Z. Wang, C. Gan, and J. B. Tenenbaum (2022) FALCON: fast visual concept learning by integrating images, linguistic descriptions, and conceptual relations. International Conference on Learning Representations (ICLR). Cited by: §I, § II-A.
- [42] S. Mirchandani, F. Xia, P. Florence, B. Ichter, D. Driess, M. G. Arenas, K. Rao, D. Sadigh, and A. Zeng (2023) Large language models as general pattern machines. CoRL. Cited by: §I.
- [43] B. Mor, S. Garhwal, and A. Kumar (2021) A systematic review of hidden markov models and their applications. Archives of computational methods in engineering 28 (3), pp. 1429–1448. Cited by: § II-C.
- [44] M. W. Moskewicz, C. F. Madigan, Y. Zhao, L. Zhang, and S. Malik (2001) Chaff: engineering an efficient sat solver. In Proceedings of the 38th annual Design Automation Conference, pp. 530–535. Cited by: § V-D.
- [45] F. Muñoz-Martínez, R. Garg, M. Pellauer, J. L. Abellán, M. E. Acacio, and T. Krishna (2023) Flexagon: a multi-dataflow sparse-sparse matrix multiplication accelerator for efficient dnn processing. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, pp. 252–265. Cited by: § V-B.
- [46] M. F. Naeem, M. G. Z. A. Khan, Y. Xian, M. Z. Afzal, D. Stricker, L. Van Gool, and F. Tombari (2023) I2mvformer: large language model generated multi-view document supervision for zero-shot image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15169–15179. Cited by: §I.
- [47] A. Naik, J. Liu, C. Wang, A. Sethi, S. Dutta, M. Naik, and E. Wong (2024) Dolphin: a programmable framework for scalable neurosymbolic learning. arXiv preprint arXiv:2410.03348. Cited by: §VIII.
- [48] NVIDIA Corporation (2020) NVIDIA rtx a6000 graphics card. Note: https://www.nvidia.com/en-us/products/workstations/rtx-a6000/ Cited by: TABLE III, § VII-A.
- [49] NVIDIA NVIDIA Jetson Orin. Note: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/ Cited by: §III.
- [50] NVIDIA NVIDIA Nsight Compute. Note: https://developer.nvidia.com/nsight-compute Cited by: § III-B.
- [51] NVIDIA NVIDIA Nsight Systems. Note: https://developer.nvidia.com/nsight-systems Cited by: § III-B.
- [52] T. X. Olausson, A. Gu, B. Lipkin, C. E. Zhang, A. Solar-Lezama, J. B. Tenenbaum, and R. Levy (2023) LINC: a neurosymbolic approach for logical reasoning by combining language models with first-order logic provers. Conference on Empirical Methods in Natural Language Processing (EMNLP). Cited by: TABLE I, § VII-A.
- [53] C. Pryor, C. Dickens, E. Augustine, A. Albalak, W. Wang, and L. Getoor (2022) NeuPSL: neural probabilistic soft logic. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI) 461, pp. 4145–4153. Cited by: §VIII.
- [54] R. Raj, S. Banerjee, N. Chandra, Z. Wan, J. Tong, A. Samajdhar, and T. Krishna (2025) SCALE-sim v3: a modular cycle-accurate systolic accelerator simulator for end-to-end system analysis. In 2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pp. 186–200. Cited by: § VII-C.
- [55] B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi, et al. (2024) Mathematical discoveries from program search with large language models. Nature 625 (7995), pp. 468–475. Cited by: §I, § II-A.
- [56] P. Röttger, H. R. Kirk, B. Vidgen, G. Attanasio, F. Bianchi, and D. Hovy (2023) Xstest: a test suite for identifying exaggerated safety behaviours in large language models. arXiv preprint arXiv:2308.01263. Cited by: § VII-A, TABLE V.
- [57] S. Sarangi and B. Baas (2021) DeepScaleTool: a tool for the accurate estimation of technology scaling in the deep-submicron era. In 2021 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5. Cited by: item *.
- [58] J. Shah, G. Bikshandi, Y. Zhang, V. Thakkar, P. Ramani, and T. Dao (2024) Flashattention-3: fast and accurate attention with asynchrony and low-precision. Advances in Neural Information Processing Systems (NeurIPS) 37, pp. 68658–68685. Cited by: § VII-C.
- [59] N. Shah, W. Meert, and M. Verhelst (2023) DPU-v2: energy-efficient execution of irregular directed acyclic graphs. In 2023 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 1288–1307. Cited by: TABLE III, § VII-A, § VII-A, § VII-C.
- [60] C. Shengyuan, Y. Cai, H. Fang, X. Huang, and M. Sun (2023) Differentiable neuro-symbolic reasoning on large-scale knowledge graphs. Advances in Neural Information Processing Systems 36, pp. 28139–28154. Cited by: §I.
- [61] C. Singh, J. P. Inala, M. Galley, R. Caruana, and J. Gao (2024) Rethinking interpretability in the era of large language models. arXiv preprint arXiv:2402.01761. Cited by: §I.
- [62] G. Sriramanan, S. Bharti, V. S. Sadasivan, S. Saha, P. Kattakinda, and S. Feizi (2024) Llm-check: investigating detection of hallucinations in large language models. Advances in Neural Information Processing Systems 37, pp. 34188–34216. Cited by: §I.
- [63] Synopsys Design compiler - synopsys. Note: https://www.synopsys.com/implementation-and-signoff/rtl-synthesis-test/dc-ultra.html Cited by: § VII-A.
- [64] Synopsys PrimeTime - synopsys. Note: https://www.synopsys.com/implementation-and-signoff/signoff/primetime.html Cited by: § VII-A.
- [65] O. Tafjord, B. D. Mishra, and P. Clark (2020) ProofWriter: generating implications, proofs, and abductive statements over natural language. arXiv preprint arXiv:2012.13048. Cited by: § VII-A.
- [66] T. H. Trinh, Y. Wu, Q. V. Le, H. He, and T. Luong (2024) Solving olympiad geometry without human demonstrations. Nature 625 (7995), pp. 476–482. Cited by: §I, § II-A, § II-B, TABLE I, § VII-A, § VII-A, TABLE V, TABLE V, §VIII.
- [67] P. Van Der Tak, M. J. Heule, and A. Biere (2012) Concurrent cube-and-conquer. In International Conference on Theory and Applications of Satisfiability Testing, pp. 475–476. Cited by: § II-C.
- [68] vLLM vLLM Automatic Prefix Caching . Note: https://docs.vllm.ai/en/latest/features/automatic_prefix_caching.html Cited by: § VII-C.
- [69] vLLM vLLM Performance and Tuning . Note: https://docs.vllm.ai/en/latest/configuration/optimization.html Cited by: § VII-C.
- [70] vLLM vLLM Quantized KV Cache . Note: https://docs.vllm.ai/en/stable/features/quantization/quantized_kvcache.html Cited by: § VII-C.
- [71] Z. Wan, Y. Du, M. Ibrahim, J. Qian, J. Jabbour, Y. Zhao, T. Krishna, A. Raychowdhury, and V. J. Reddi (2025) Reca: integrated acceleration for real-time and efficient cooperative embodied autonomous agents. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Volume 2, pp. 982–997. Cited by: §I.
- [72] Z. Wan, C. Liu, H. Yang, C. Li, H. You, Y. Fu, C. Wan, T. Krishna, Y. Lin, and A. Raychowdhury (2024) Towards cognitive ai systems: a survey and prospective on neuro-symbolic ai. arXiv preprint arXiv:2401.01040. Cited by: §I.
- [73] Z. Wan, C. Liu, H. Yang, R. Raj, C. Li, H. You, Y. Fu, C. Wan, S. Li, Y. Kim, et al. (2024) Towards efficient neuro-symbolic ai: from workload characterization to hardware architecture. IEEE Transactions on Circuits and Systems for Artificial Intelligence (TCASAI). Cited by: §VIII.
- [74] Z. Wan, C. Liu, H. Yang, R. Raj, C. Li, H. You, Y. Fu, C. Wan, A. Samajdar, Y. C. Lin, et al. (2024) Towards cognitive ai systems: workload and characterization of neuro-symbolic ai. In 2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pp. 268–279. Cited by: §VIII.
- [75] Z. Wan, C. Liu, H. Yang, R. Raj, A. Raychowdhury, and T. Krishna (2025) Efficient processing of neuro-symbolic ai: a tutorial and cross-layer co-design case study. Proceedings of the International Conference on Neuro-symbolic Systems. Cited by: §I.
- [76] Z. Wan, H. Yang, J. Qian, R. Raj, J. Park, C. Wang, A. Raychowdhury, and T. Krishna (2026) Compositional ai beyond llms: system implications of neuro-symbolic-probabilistic architectures. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Volume 1, pp. 67–84. Cited by: Figure 2, Figure 2.
- [77] Z. Wan, H. Yang, R. Raj, C. Liu, A. Samajdar, A. Raychowdhury, and T. Krishna (2025) Cogsys: efficient and scalable neurosymbolic cognition system via algorithm-hardware co-design. In 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 775–789. Cited by: §VIII.
- [78] Y. Xian, C. Lampert, B. Schiele, and Z. Akata (2018) Zero-shotlearning-a comprehensive evaluation of the good, the bad and theugly. arXiv preprint arXiv:1707.00600. Cited by: § VII-A.
- [79] H. Yang, Z. Wan, R. Raj, J. Park, Z. Li, A. Samajdar, A. Raychowdhury, and T. Krishna (2025) NSFlow: an end-to-end fpga framework with scalable dataflow architecture for neuro-symbolic ai. In 2025 62nd ACM/IEEE Design Automation Conference (DAC), pp. 1–7. Cited by: §VIII.
- [80] Z. Yang, A. Ishay, and J. Lee (2020) Neurasp: embracing neural networks into answer set programming. In 29th International Joint Conference on Artificial Intelligence (IJCAI 2020), Cited by: §VIII.
- [81] C. Zhang, B. Jia, S. Zhu, and Y. Zhu (2021) Abstract spatial-temporal reasoning via probabilistic abduction and execution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9736–9746. Cited by: §I, § II-A.
- [82] H. Zhang, M. Dang, N. Peng, and G. Van den Broeck (2023) Tractable control for autoregressive language generation. In International Conference on Machine Learning (ICML), pp. 40932–40945. Cited by: TABLE I, § VII-A, TABLE V.
- [83] H. Zhang, P. Kung, M. Yoshida, G. Van den Broeck, and N. Peng (2024) Adaptable logical control for large language models. Advances in Neural Information Processing Systems (NeurIPS) 37, pp. 115563–115587. Cited by: §I, TABLE I, § VII-A.
- [84] H. Zhang and T. Yu (2020) AlphaZero. Deep Reinforcement Learning: Fundamentals, Research and Applications, pp. 391–415. Cited by: §VIII.
- [85] Y. Zhang, G. Wang, C. Li, Z. Gan, C. Brockett, and B. Dolan (2020) POINTER: constrained progressive text generation via insertion-based generative pre-training. arXiv preprint arXiv:2005.00558. Cited by: § VII-A.
- [86] K. Zheng, J. M. Han, and S. Polu (2021) Minif2f: a cross-system benchmark for formal olympiad-level mathematics. arXiv preprint arXiv:2109.00110. Cited by: § VII-A, TABLE V.