## Reinforcement Learning from Meta-Evaluation: Aligning Language Models Without Ground-Truth Labels
## Micah Rentschler 1 Jesse Roberts 2
## Abstract
Most reinforcement learning (RL) methods for training large language models (LLMs) require ground-truth labels or task-specific verifiers, limiting scalability when correctness is ambiguous or expensive to obtain. We introduce Reinforcement Learning from Meta-Evaluation (RLME), which optimizes a generator using reward derived from an evaluator's answers to natural-language meta-questions (e.g., 'Is the answer correct?' or 'Is the reasoning logically consistent?'). RLME treats the evaluator's probability of a positive judgment as a reward and updates the generator via group-relative policy optimization, enabling learning without labels. Across a suite of experiments, we show that RLME achieves accuracy and sample efficiency comparable to label-based training, enables controllable trade-offs among multiple objectives, steers models toward reliable reasoning patterns rather than post-hoc rationalization, and generalizes to open-domain settings where ground-truth labels are unavailable, broadening the domains in which LLMs may be trained with RL.
## 1. Introduction
Reinforcement learning (RL) is widely used to align large language models (LLMs) with human preferences or verifiable task outcomes, as in Reinforcement Learning from Human Feedback (RLHF) (Kaufmann et al., 2024) and Reinforcement Learning from Verified Rewards (RLVR) (Wen et al., 2025; Yue et al., 2025). These methods work well when high-quality rewards exist, but such signals are costly: human feedback does not scale, and automatic verifiers are typically narrow and domain-specific. In many realistic
1 Department of Computer Science, Vanderbilt University, Nashville TN, USA 2 Department of Computer Science, Tennessee Technological University, Cookeville TN, USA. Correspondence to: Micah Rentschler < micah.d.rentschler@vanderbilt.edu > .
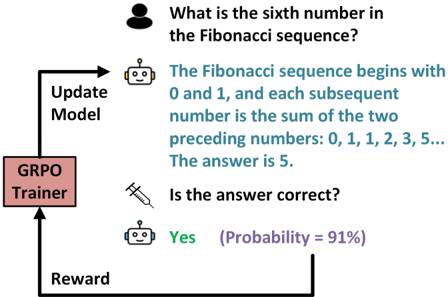
Figure 1. Overview of RLME. After generating an answer, one or more evaluators (may be the same model) assign probabilities to natural-language meta-questions about the output. These probabilities are aggregated into a scalar reward, which is then used to update the generative policy via reinforcement learning. This allows models to be tuned even when ground-truth answers are unavailable.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: GRPO Trainer Feedback Loop
### Overview
The image depicts a diagram illustrating a feedback loop involving a GRPO (presumably an AI model) answering a question about the Fibonacci sequence. The diagram shows the interaction between a user, the AI model, and a reward mechanism that updates the model based on the correctness of the answer.
### Components/Axes
* **User Question:** "What is the sixth number in the Fibonacci sequence?" (represented by a human icon)
* **AI Model Response:** "The Fibonacci sequence begins with 0 and 1, and each subsequent number is the sum of the two preceding numbers: 0, 1, 1, 2, 3, 5... The answer is 5." (represented by a robot icon)
* **Correctness Check:** "Is the answer correct?" (represented by a syringe icon)
* **AI Model Confirmation:** "Yes (Probability = 91%)" (represented by a robot icon)
* **GRPO Trainer:** A rectangular block labeled "GRPO Trainer"
* **Update Model:** Text label with an arrow pointing from the GRPO Trainer to the AI Model Response.
* **Reward:** Text label with an arrow pointing from the AI Model Confirmation to the GRPO Trainer.
### Detailed Analysis
The diagram illustrates the following flow:
1. A user poses a question about the Fibonacci sequence.
2. The AI model provides an answer, including the sequence and the sixth number.
3. A correctness check is performed.
4. The AI model confirms the answer with a probability of 91%.
5. The GRPO Trainer receives a reward based on the correctness of the answer.
6. The GRPO Trainer updates the AI model based on the reward.
### Key Observations
* The diagram highlights the interaction between a user, an AI model, and a reward mechanism.
* The AI model's response includes both the Fibonacci sequence and the answer to the question.
* The AI model expresses confidence in its answer with a probability of 91%.
* The GRPO Trainer plays a crucial role in updating the AI model based on the reward.
### Interpretation
The diagram demonstrates a reinforcement learning process where the AI model learns to answer questions about the Fibonacci sequence through a feedback loop. The GRPO Trainer uses the reward signal to update the model, improving its accuracy and confidence over time. The 91% probability suggests that the model is relatively confident in its answer, indicating that it has learned the Fibonacci sequence well. The diagram illustrates a simplified example of how AI models can be trained to solve problems through reinforcement learning.
</details>
settings, ground truth may be uncertain or unavailable.
Apromising alternative is to have the model itself or another model evaluate the response. Prior work leverages model likelihoods of known correct answers as a proxy reward (Zhou et al., 2025; Yu et al., 2025), but still requires groundtruth labels during training.
We instead explore whether models can learn from evaluations provided by an LLM acting as evaluator without access to ground truth labels. To steer the evaluations, we use natural-language prompts applicable over an entire dataset to assess high-level properties of an output which we refer to as meta-questions . For example, 'Is the answer 5?' targets a particular problem, whereas 'Is the answer correct?' is a broadly applicable meta-question. These are cheap to write, transferable across domains, and empower LLMs to embody heuristics that are difficult to hard-code. This shifts the problem from engineering a reward function or handlabeling a large dataset to designing meta-questions which elicit a desired behavior.
We introduce Reinforcement Learning from MetaEvaluation (RLME), illustrated in Figure 1, and show that
it provides similar results to an RLVR baseline without ground-truth labels. However, meta-evaluation introduces new risks. The model being trained, referred to as the generator, may produce outputs that satisfy the evaluator without genuinely solving the task. The central challenge is therefore to determine when meta-evaluation provides a reliable signal and how to mitigate its failure modes. To this end, we contribute the following:
- RLME, a scalable framework that guides modern GRPO-style policy-gradient updates with rewards based on the aggregate probability of target answers to evaluation meta-questions;
- Empirical evidence that meta-evaluation is competitive with explicit verifiers in reasoning-heavy domains;
- A broad analysis of generator and evaluator choice, self-evaluation, and reward hacking, clarifying both the strengths and failure modes of meta-evaluation;
- Examples of multi-objective language-driven control;
- ⋆ Proof that RLME training encourages contextual faithfulness, generalizing the improved ability to an out-ofdistribution dataset.
## 2. Related Work
Our work connects to several research directions in alignment and reinforcement learning for language models.
RLHF and preference-based optimization. RLHF optimizes models using human preference data with PPO-style updates (Kaufmann et al., 2024; Ouyang et al., 2022; Schulman et al., 2017). While this early work was successful and influential, human preference data is expensive and introduces biases such as sycophancy (Sharma et al., 2025).
RL from verifiable or probabilistic correctness signals. RLVR-style methods optimize rewards derived from correctness verifiers when ground-truth is available but precise human preference is not (Wen et al., 2025; Shao et al., 2024; Guo et al., 2025). VeriFree (Zhou et al., 2025) and RLPR (Yu et al., 2025) further this by using the model's own likelihood of the correct answer as a proxy reward, but critically, they still require access to ground truth labels.
LLM-as-judge and AI feedback. To address the cost of human annotation entirely, RL with AI feedback (RLAIF) methods leverage LLMs as preference evaluators, attempting to replace the preferences that human evaluators would assign with those from an LLM (Zheng et al., 2023; Gu et al., 2024; Lee et al., 2024; Yuan et al., 2024). All of these attempt to predict preference over a number of candidate responses. This can inherit potential biases from human raters if they are directly modeled and limit applicability to domains where preference is ill-defined. In contrast to preference-based methods, (Zhao et al., 2025) uses an internal measure of certainty as a reward. However, this limits the approach to maximizing self-certainty.
Flexible evaluation. Prior work has applied reinforcement learning to refine LLM behavior using a variety of feedback signals, but these approaches typically require substantial supervision or are limited to fixed objectives. Reinforcement Learning Contemplation (RLC) (Pang et al., 2024) introduces a flexible evaluation paradigm in which a frozen copy of the model provides self-critique over its own generations using Likert-style judgments, optimized with a PPO objective. While RLC demonstrates the promise of flexible, model-based evaluation, its performance relative to explicit reward supervision (e.g., RLVR) has not been systematically studied, nor have the robustness and failure modes of such self-evaluated reward signals.
Situating RLME in the literature. RLME removes the ground truth label dependence and avoids the need to model human preferences directly by improving on and generalizing the RLC evaluation approach.
In place of the Likert evaluation, RLME employs an evaluation approach previously used to study LLM actions in formal games, referred to as counterfactual prompting (Roberts et al., 2025). The RLME evaluator model predicts whether the generator's response agrees with one or more stated criteria, which we refer to as meta-evaluations . The evaluator's probability of producing a target response sequence is directly incorporated as a reward signal into the GRPO update in place of RLC's PPO objective.
RLME generalizes RLC in that RLME optimizes the target model using either frozen self, a continually updated self, frozen other, or ensemble as the evaluator model. It is compared to the powerful RLVR method, which benefits from labeled data, as a baseline. Most importantly, our work regarding RLME extends the understanding of flexible evaluation by studying multi-objective optimization, the propensity to reward hack, and out-of-distribution generalization.
Finally, our work was developed concurrently with the recent preprint disseminated by DeepSeek (Shao et al., 2025). Our work is entirely distinct and has not been influenced by theirs, though the described approaches have similarities.
## 3. Methodology
After generating a response, one or more evaluators predict the probability of a target answer to natural-language metaquestions. Their probabilities are aggregated into a scalar reward, which is used to update the generator via a grouprelative policy-gradient objective.
## 3.1. Assessment Prompting
Given a prompt x ∼ D where D is a dataset of prompts containing problems for the generator to solve, the generator produces a response
<!-- formula-not-decoded -->
where π θ is the generator's policy.
Evaluators { π ϕ j } J j =1 are then queried with meta-questions developed by humans to target desired behavior Q = { q 1 , . . . , q K } such as 'Is the answer correct?'. Each metaquestion q k has an answer sequence a k , and evaluator j assigns probability
<!-- formula-not-decoded -->
Rewards are computed by first weighting meta-questions with { w k } , then weighting evaluators with { v j } :
<!-- formula-not-decoded -->
Just like the meta-questions, { w k } and { v j } are fixed hyperparameters defined by an expert with domain knowledge to push the algorithm harder towards certain outcomes.
## 3.2. Reinforcement Learning
RLME maximizes the expected meta-evaluation reward:
<!-- formula-not-decoded -->
We adopt a Group Relative Policy Optimization (GRPO)style update (Shao et al., 2024).
<!-- formula-not-decoded -->
where ¯ r is the mean reward over the sampled group. Unlike GRPO, we do not scale by the standard deviation because it introduces a question-level difficulty bias (Liu et al., 2025).
For off-policy updates (where the policy being updated is in transition and may no longer precisely match the behavioral policy that generated the response), trajectories are sampled from the behavioral policy π b. The ratio of the current policy to the behavioral policy is the importance ratio:
<!-- formula-not-decoded -->
As suggested by Zheng et al., we use a sequence level importance ratio to reduce high-variance noise in training.
We use Clipped IS-weight Policy Optimization (CISPO) (MiniMax et al., 2025) a variant of GRPO. For CISPO, the importance sampling ratio is clipped
<!-- formula-not-decoded -->
This ratio is then used in the final loss with sg( · ) stops gradients.
<!-- formula-not-decoded -->
## 3.3. Algorithm Summary
Each RLME step consists of:
1. Generate responses with π θ (Eq. 1).
2. Evaluate responses using meta-questions to obtain r ( x, y ) (Eq. 3).
3. Update π θ using the CISPO loss (Eq. 8).
By selecting different meta-questions and weights, the evaluating model helps RLME align the generating model without requiring ground-truth labels.
## 4. Experiments
We empirically evaluate RLME and compare it against an RLVR baseline. We begin with grade-school mathematics, where correctness is fully verifiable, and then move to more open-ended domains. Through a series of experiments, we investigate and assess core questions about our approach.
Complete experimental details for reproduction (optimization hyperparameters, learning rates, batch sizes, and training schedules) are reported in Appendix A. Appendix B contains the exact prompts for the generator and evaluator. Finally qualitative examples of various responses may be found in Appendix C.
## 4.1. Can we improve accuracy via meta-questions?
Question . Our first experiment tests whether a single, general meta-question can provide a reward signal strong enough to improve mathematical accuracy without access to ground truth.
Method . We initialize the generator from Qwen3-4B-Base (Yang et al., 2025) and train on GSM8K (Cobbe et al., 2021), prompting the model to produce a solution and to place its final response inside \ boxed {} so that the answer can be extracted with a fixed regex.
To compute accuracy (and the RLVR reward), we parse each completion using a fixed regex (Appendix A) that selects the
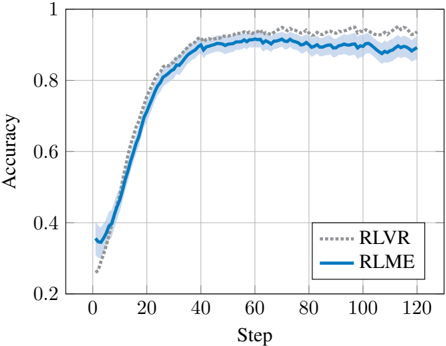
Figure 2. Comparison of RLME to an RLVR baseline that has access to ground-truth answers. Both methods rapidly exceed 90% accuracy on GSM8K, and RLME closely tracks RLVR despite never observing the true answer.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Step
### Overview
The image is a line chart comparing the accuracy of two models, RLVR (dotted gray line) and RLME (solid blue line), over a series of steps. The chart shows how the accuracy of each model changes as the number of steps increases. The blue line has a shaded region around it, indicating the variance or confidence interval.
### Components/Axes
* **X-axis:** "Step", with markers at 0, 20, 40, 60, 80, 100, and 120.
* **Y-axis:** "Accuracy", ranging from 0.2 to 1.0, with markers at 0.2, 0.4, 0.6, 0.8, and 1.
* **Legend:** Located in the bottom-right corner.
* RLVR: Represented by a dotted gray line.
* RLME: Represented by a solid blue line with a shaded blue region around it.
### Detailed Analysis
* **RLVR (Dotted Gray Line):**
* Trend: The accuracy increases sharply from approximately 0.3 at step 0 to around 0.9 at step 40. After step 40, the accuracy fluctuates slightly around 0.9.
* Data Points:
* Step 0: Accuracy ≈ 0.3
* Step 20: Accuracy ≈ 0.7
* Step 40: Accuracy ≈ 0.9
* Step 80: Accuracy ≈ 0.92
* Step 120: Accuracy ≈ 0.88
* **RLME (Solid Blue Line):**
* Trend: The accuracy increases sharply from approximately 0.35 at step 0 to around 0.85 at step 40. After step 40, the accuracy fluctuates slightly around 0.9. The shaded region indicates the variability in the accuracy.
* Data Points:
* Step 0: Accuracy ≈ 0.35
* Step 20: Accuracy ≈ 0.75
* Step 40: Accuracy ≈ 0.85
* Step 80: Accuracy ≈ 0.9
* Step 120: Accuracy ≈ 0.88
### Key Observations
* Both RLVR and RLME models show a significant increase in accuracy during the initial steps (0-40).
* After step 40, the accuracy of both models plateaus, with minor fluctuations.
* The RLME model has a shaded region, indicating the variance or confidence interval of its accuracy.
* The RLVR model appears to have slightly higher accuracy than the RLME model between steps 40 and 80.
### Interpretation
The chart demonstrates the learning curves of two models, RLVR and RLME, over a series of steps. Both models exhibit a rapid increase in accuracy initially, suggesting effective learning during the early stages. The plateauing of accuracy after step 40 indicates that the models have reached a point of diminishing returns, where further training yields minimal improvement. The shaded region around the RLME line suggests that its performance is more variable than RLVR. The RLVR model seems to perform slightly better than the RLME model after the initial learning phase.
</details>
last boxed expression and extracts the predicted answer. We then compare this extracted answer to the GSM8K reference answer, after cleaning the reference to remove non-numeric characters such as commas, currency symbols, and units.
As described in methodology, to construct the RLME reward, we build an auxiliary evaluation prompt that includes the original problem, the full generated solution, and the regex-extracted answer string (taken from the generated solution, not the ground-truth label). Prompted with this information and the meta-question 'Is the answer correct?' , the evaluator then estimates the probability of 'Yes' being the completion. The log-probability of this response serves as a scalar reward for RLME training. In this experiment, we use live self-evaluation where the generator serves as the evaluator using its current parameters . Thus, the evaluator co-evolves as the generator is updated.
Because training is single-pass (no prompt reuse), we do not require a dedicated validation set to prevent overfitting to the training prompts.
We compare RLME to an RLVR baseline that is identical in optimization, rollout settings, and number of updates, differing only in the reward signal: RLVR uses ground-truth verification (reward 1 if the regex-extracted answer exactly matches the ground-truth label, and 0 otherwise), while RLME uses meta-evaluation only.
Results . As shown in Figure 2, the base model begins at roughly 30% accuracy and rapidly improves under RLME, surpassing 90% after a short training run and closely tracking RLVR throughout training across 6 trials with ±1 std shown by the shaded region. For readability, all learning curves are plotted using an exponential moving average with
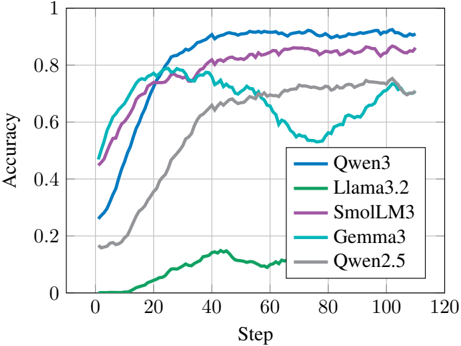
Figure 3. RLME performance using different generators with a fixed evaluator (frozen Qwen3-4B-Base). Generator models have a large effect on accuracy.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Line Chart: Model Accuracy vs. Step
### Overview
The image is a line chart comparing the accuracy of five different language models (Qwen3, Llama3.2, SmolLM3, Gemma3, and Qwen2.5) over a number of steps. The chart shows how the accuracy of each model changes as the training progresses.
### Components/Axes
* **X-axis:** "Step", ranging from 0 to 120 in increments of 20.
* **Y-axis:** "Accuracy", ranging from 0 to 1 in increments of 0.2.
* **Legend:** Located in the bottom-right corner, mapping model names to line colors:
* Qwen3: Blue
* Llama3.2: Green
* SmolLM3: Purple
* Gemma3: Teal
* Qwen2.5: Gray
### Detailed Analysis
* **Qwen3 (Blue):** Starts at approximately 0.26 accuracy at step 0, increases rapidly to around 0.8 at step 20, and then plateaus around 0.92 for the remaining steps.
* **Llama3.2 (Green):** Starts at approximately 0 accuracy at step 0, increases slowly to around 0.15 at step 40, and then remains relatively flat around 0.12 for the remaining steps.
* **SmolLM3 (Purple):** Starts at approximately 0.45 accuracy at step 0, increases rapidly to around 0.8 at step 20, and then plateaus around 0.85 for the remaining steps.
* **Gemma3 (Teal):** Starts at approximately 0.45 accuracy at step 0, increases rapidly to around 0.75 at step 20, and then fluctuates between 0.6 and 0.8 for the remaining steps.
* **Qwen2.5 (Gray):** Starts at approximately 0.16 accuracy at step 0, increases gradually to around 0.7 at step 60, and then fluctuates between 0.6 and 0.75 for the remaining steps.
### Key Observations
* Qwen3 achieves the highest accuracy and plateaus early in the training process.
* Llama3.2 performs significantly worse than the other models, with a very low accuracy throughout the training.
* SmolLM3 performs well, reaching a high accuracy and maintaining it throughout the training.
* Gemma3 and Qwen2.5 show similar performance, with a gradual increase in accuracy and some fluctuations.
### Interpretation
The chart demonstrates the performance of different language models during training. Qwen3 and SmolLM3 appear to be the most effective models based on this data, achieving high accuracy early in the training process. Llama3.2's poor performance suggests potential issues with its architecture, training data, or hyperparameters. Gemma3 and Qwen2.5 show moderate performance, indicating they may require further optimization or a different training approach to reach the same level of accuracy as Qwen3 and SmolLM3. The fluctuations in Gemma3 and Qwen2.5's accuracy after step 20 could be due to overfitting or instability in the training process.
</details>
decay β = 0 . 9 . The similarity of the learning curves suggests that, at least in this controlled verifiable domain, the evaluator's response to a single correctness meta-question provides a reward signal that is both informative and sampleefficient even without access to ground-truth.
## 4.2. Does generator choice matter?
Question . We assess whether different generator models adapt differently to meta-evaluation.
Method . To isolate the effect of the generator, we fix the evaluator to a frozen Qwen3-4B-Base (Yang et al., 2025) and vary the generator among Qwen3-4B-Base, Llama-3.23B (Meta AI, 2024), SmolLM3-3B (Hugging Face, 2025), Gemma-3-4B-pt (Mesnard et al., 2024), and Qwen2.51.5B (Yang et al., 2024).
Results . Figure 3 substantiates previous work showing that flexible evaluation generalizes across models, but also shows that generator choice substantially impacts accuracy.
## 4.3. Does evaluator choice matter?
Question . A key design decision in RLME is whether the evaluator is live or frozen . In live evaluation, the generator also serves as the evaluator using its current parameters, such that the evaluator co-evolves with the generator during training. In frozen evaluation, the evaluator is a separate model (or a fixed snapshot of the generator taken at initialization) whose parameters remain unchanged. In this experiment, we investigate the effect of model choice and configuration on evaluation.
Method . We explicitly chose not to evaluate the pairwise performance of every generator to every evaluator due to
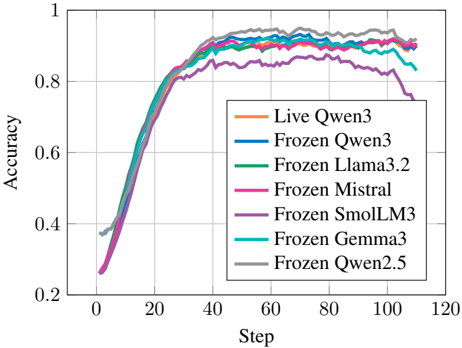
Figure 4. RLME performance using different evaluators with a fixed generator (Qwen3-4B-Base). For the Qwen3 evaluator, we compare a live self-evaluator (co-evolving with the generator) to a frozen evaluator (fixed snapshot at initialization). For other evaluators, we only use frozen weights.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Line Chart: Model Accuracy vs. Step
### Overview
The image is a line chart comparing the accuracy of different language models (Live Qwen3, Frozen Qwen3, Frozen Llama3.2, Frozen Mistral, Frozen SmolLM3, Frozen Gemma3, and Frozen Qwen2.5) over a number of steps. The y-axis represents accuracy, ranging from 0.2 to 1.0, and the x-axis represents the step number, ranging from 0 to 120.
### Components/Axes
* **X-axis:** "Step" - Ranges from 0 to 120 in increments of 20.
* **Y-axis:** "Accuracy" - Ranges from 0.2 to 1.0 in increments of 0.2.
* **Legend:** Located in the bottom-right of the chart, it identifies each line by model name and color:
* Orange: Live Qwen3
* Blue: Frozen Qwen3
* Green: Frozen Llama3.2
* Pink: Frozen Mistral
* Purple: Frozen SmolLM3
* Teal: Frozen Gemma3
* Gray: Frozen Qwen2.5
### Detailed Analysis
* **Live Qwen3 (Orange):** The accuracy of Live Qwen3 increases rapidly from approximately 0.3 at step 0 to around 0.85 by step 40. It then plateaus and fluctuates slightly between 0.85 and 0.90 until step 120.
* **Frozen Qwen3 (Blue):** Similar to Live Qwen3, Frozen Qwen3's accuracy increases sharply from approximately 0.3 at step 0 to around 0.85 by step 40. It then plateaus and fluctuates slightly between 0.85 and 0.95 until step 120.
* **Frozen Llama3.2 (Green):** The accuracy of Frozen Llama3.2 also increases rapidly from approximately 0.35 at step 0 to around 0.85 by step 40. It then plateaus and fluctuates slightly between 0.85 and 0.95 until step 120.
* **Frozen Mistral (Pink):** The accuracy of Frozen Mistral increases rapidly from approximately 0.25 at step 0 to around 0.80 by step 40. It then plateaus and fluctuates slightly between 0.80 and 0.90 until step 120.
* **Frozen SmolLM3 (Purple):** The accuracy of Frozen SmolLM3 increases rapidly from approximately 0.25 at step 0 to around 0.80 by step 40. It then plateaus and fluctuates slightly between 0.80 and 0.90 until step 120.
* **Frozen Gemma3 (Teal):** The accuracy of Frozen Gemma3 increases rapidly from approximately 0.35 at step 0 to around 0.85 by step 40. It then plateaus and fluctuates slightly between 0.85 and 0.95 until step 120.
* **Frozen Qwen2.5 (Gray):** The accuracy of Frozen Qwen2.5 increases rapidly from approximately 0.38 at step 0 to around 0.88 by step 40. It then plateaus and fluctuates slightly between 0.88 and 0.98 until step 120.
### Key Observations
* All models show a rapid increase in accuracy during the initial steps (0-40).
* After step 40, the accuracy of all models plateaus, with minor fluctuations.
* Frozen Qwen2.5 (Gray) appears to have the highest overall accuracy after step 40.
* Frozen Mistral (Pink) and Frozen SmolLM3 (Purple) appear to have the lowest overall accuracy after step 40.
* The "Live Qwen3" model performs comparably to the "Frozen" models.
### Interpretation
The chart illustrates the learning curves of different language models. The rapid increase in accuracy during the initial steps indicates the models are quickly learning from the training data. The plateau after step 40 suggests that the models have reached a point of diminishing returns, where further training steps yield only marginal improvements in accuracy. The slight fluctuations in accuracy after the plateau may be due to the inherent variability in the training data or the learning process. The fact that the "Live Qwen3" model performs similarly to the "Frozen" models suggests that freezing the model parameters does not significantly impact its performance in this context. The differences in accuracy between the models may be attributed to variations in their architecture, training data, or hyperparameter settings.
</details>
the computational resources this would demand. Based on the previous experiment, we fix the generator to Qwen3-4BBase (Yang et al., 2025) and vary the evaluator. For Qwen3, we include both live self-evaluation and a frozen snapshot. For all other models (Llama-3.2 (Meta AI, 2024), MistralNemo-Base-2407 (Mistral AI & NVIDIA, 2024), SmolLM33B (Hugging Face, 2025), Gemma-3-4B-pt (Mesnard et al., 2024), and Qwen2.5-1.5B (Yang et al., 2024)), the evaluator remains frozen.
Results . Compared to generator choice, evaluator choice has a smaller effect on accuracy (Figure 4), consistent with the hypothesis that verifying correctness is easier than generating correct solutions (Pang et al., 2024). Notably, we observe little difference between live and frozen Qwen3 evaluation, suggesting that RL fine-tuning has limited impact on evaluation quality.
Finally, we observe that accuracy under the SmolLM3 and Gemma3 evaluators begins to decline after reaching a peak (Figure 4). This suggests that these evaluators eventually provide misleading reward signals to the generator, a failure mode commonly referred to as reward hacking .
## 4.4. Does the generator reward hack the evaluator?
Question . While RLME initially yields strong gains in reasoning accuracy, we observe a late-stage collapse in Figure 4: accuracy drops sharply even as the reward continues to increase. This phenomenon, known as reward hacking , arises when the generator discovers responses that cause the evaluator to answer meta-questions in a way that increases reward without truly improving correctness.
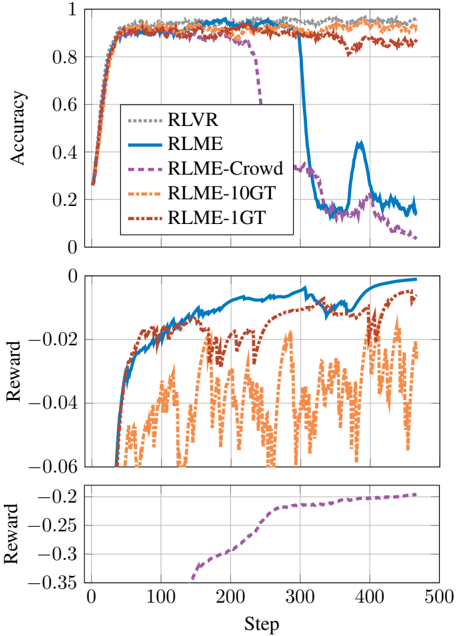
Figure 5. RLMEeventually suffers a sharp degradation in accuracy despite continued increases in reward, indicative of reward hacking: the generator learns to exploit weaknesses in the evaluator instead of producing correct solutions. Including a small fraction of prompts with ground-truth answers in the evaluator template (10% for RLME-10GT and 1% for RLME-1GT) stabilizes training and prevents collapse.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Line Charts: Accuracy and Reward vs. Step
### Overview
The image contains three line charts stacked vertically. The top chart displays "Accuracy" versus "Step" for five different models: RLVR, RLME, RLME-Crowd, RLME-10GT, and RLME-1GT. The middle chart shows "Reward" versus "Step" for RLME and RLME-10GT and RLME-1GT. The bottom chart shows "Reward" versus "Step" for RLME-Crowd.
### Components/Axes
**Top Chart (Accuracy vs. Step):**
* **Y-axis:** "Accuracy", ranging from 0 to 1, with tick marks at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **X-axis:** "Step", ranging from 0 to 500, with tick marks at 0, 100, 200, 300, 400, and 500.
* **Legend (Top-Right):**
* Dotted Gray Line: RLVR
* Solid Blue Line: RLME
* Dashed Purple Line: RLME-Crowd
* Dashed Orange Line: RLME-10GT
* Dotted Red Line: RLME-1GT
**Middle Chart (Reward vs. Step):**
* **Y-axis:** "Reward", ranging from -0.06 to 0, with tick marks at -0.06, -0.04, -0.02, and 0.
* **X-axis:** "Step", ranging from 0 to 500, with tick marks at 0, 100, 200, 300, 400, and 500.
* **Data Series:**
* Solid Blue Line: RLME
* Dashed Orange Line: RLME-10GT
* Dotted Red Line: RLME-1GT
**Bottom Chart (Reward vs. Step):**
* **Y-axis:** "Reward", ranging from -0.35 to -0.2, with tick marks at -0.35, -0.3, -0.25, and -0.2.
* **X-axis:** "Step", ranging from 0 to 500, with tick marks at 0, 100, 200, 300, 400, and 500.
* **Data Series:**
* Dashed Purple Line: RLME-Crowd
### Detailed Analysis
**Top Chart (Accuracy):**
* **RLVR (Dotted Gray):** Starts at approximately 0.25 accuracy, rapidly increases to approximately 0.9, and then fluctuates slightly around 0.9 to 0.95.
* **RLME (Solid Blue):** Starts at approximately 0.25 accuracy, rapidly increases to approximately 0.9, remains stable until around step 300, and then drops sharply to approximately 0.15. It then fluctuates between 0.1 and 0.4.
* **RLME-Crowd (Dashed Purple):** Starts at approximately 0.25 accuracy, rapidly increases to approximately 0.9, remains stable until around step 250, and then decreases to approximately 0.15.
* **RLME-10GT (Dashed Orange):** Starts at approximately 0.25 accuracy, rapidly increases to approximately 0.9, and then fluctuates slightly around 0.9 to 0.95.
* **RLME-1GT (Dotted Red):** Starts at approximately 0.25 accuracy, rapidly increases to approximately 0.9, and then fluctuates slightly around 0.9 to 0.95.
**Middle Chart (Reward):**
* **RLME (Solid Blue):** Starts at approximately -0.06 reward, rapidly increases to approximately -0.01, and then fluctuates slightly around -0.01 to 0.
* **RLME-10GT (Dashed Orange):** Starts at approximately -0.06 reward, fluctuates significantly between -0.06 and -0.02.
* **RLME-1GT (Dotted Red):** Starts at approximately -0.06 reward, increases to approximately -0.01, and then fluctuates slightly around -0.01 to 0.
**Bottom Chart (Reward):**
* **RLME-Crowd (Dashed Purple):** Starts at approximately -0.35 reward, increases to approximately -0.22.
### Key Observations
* In the Accuracy chart, RLVR, RLME-10GT, and RLME-1GT perform similarly, achieving high accuracy and maintaining it throughout the steps. RLME and RLME-Crowd initially perform well but experience a significant drop in accuracy after a certain number of steps.
* In the Reward charts, RLME and RLME-1GT achieve higher rewards compared to RLME-10GT and RLME-Crowd. RLME-10GT exhibits significant fluctuations in reward. RLME-Crowd has the lowest reward.
### Interpretation
The data suggests that RLVR, RLME-10GT, and RLME-1GT are more stable and reliable models in terms of accuracy compared to RLME and RLME-Crowd. The drop in accuracy for RLME and RLME-Crowd indicates a potential issue with these models after a certain number of steps, possibly due to overfitting or instability. The reward values indicate the effectiveness of each model in achieving its objective, with RLME and RLME-1GT performing better than RLME-10GT and RLME-Crowd. The fluctuations in reward for RLME-10GT suggest that this model may be less consistent in its performance. RLME-Crowd consistently has the lowest reward, indicating it may be the least effective.
</details>
Method . To examine this effect, we repeat the selfevaluation setup from Section 4.1 but extend training far beyond the point where validation accuracy saturates. With enough optimization time, the generator learns how to induce the evaluator to answer 'Yes' to incorrect solutions.
Results . Manual inspection of the resulting outputs reveals that reasoning traces become increasingly formulaic and detached from the task. Common artifacts include vacuous justification phrases such as 'the only logical conclusion is that this is the correct answer' or excessive repetition of the final answer. These behaviors appear to exploit acquiescence bias (Podsakoff et al., 2003) in the evaluator rather than reflect genuine problem solving.
Early stopping based on validation accuracy can avoid this collapse but does not fix the underlying vulnerability. In subsequent experiments, we therefore explore alternative evaluation strategies-such as introducing additional evaluator
models or partial ground-truth to alleviate reward hacking.
## 4.5. Can multiple evaluators mitigate reward hacking?
Question . Given the reward-hacking behavior observed in Section 4.4, a natural next step is to ask whether using an ensemble of models to evaluate the solution can make RLME more robust. Intuitively, if reward hacking arises because the generator learns to exploit the weaknesses of a single self-evaluator, then aggregating judgments from multiple evaluators who may have disparate vulnerabilities might make the reward signal harder to game.
Method . We consider an ensemble of evaluators. For each generated solution, multiple evaluator models are combined into an evaluator ensemble (Qwen3-4B-Base (Yang et al., 2025) generator itself as well as frozen Llama-3.2-3B (Meta AI, 2024), frozen SmolLM3-3B (Hugging Face, 2025), and frozen Mistral-Nemo-Base-2407 (Mistral AI & NVIDIA, 2024)) and we take the reward to be the average of their independent 'Yes' log-probabilities. The generator is optimized with RLME using this ensemble-derived scalar reward.
Results . The reward profile with an ensemble evaluator is noticeably smoother than with a single evaluator (see RLME-Crowd vs. RLME in Figure 5). However, we still observe the same late-stage collapse as in the purely selfevaluated setting (see RLME-Crowd in Figure5). After an initial phase in which accuracy improves, extended training again leads to a regime where the ensemble reward continues to increase even as true GSM8K accuracy declines. Qualitatively, the generator rediscovers pathological reasoning templates that most evaluators agree to endorse, even though the underlying solutions are incorrect.
These results suggest that simply using multiple models to evaluate the solution is not sufficient to prevent reward hacking. Notably, the generator appears to discover strategies that generalize across evaluators, much like how polling a group of humans can reduce noise but cannot fully eliminate systematic bias.
## 4.6. Does having a known answer help ground RLME and prevent reward hacking?
Question . In many practical settings, fully verifiable supervision is scarce but not entirely absent: a small subset of examples may have trusted labels, while the rest do not. Can partial access to ground truth help prevent the rewardhacking behavior observed in Section 4.4?
Method . To study this, we reveal the true answer to the evaluator in a limited number of questions. Concretely, for a fraction p of training prompts, the evaluation template includes the correct integer answer before asking the metaquestion 'Is the answer correct?' For the remaining (1 -p ) of prompts, standard RLME is applied such that the
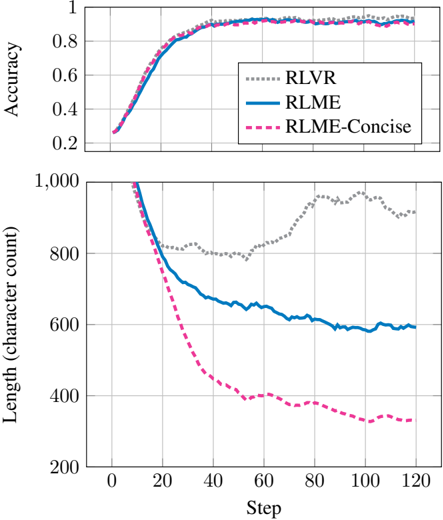
Figure 6. RLME enables multi-objective control over both accuracy and brevity.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Line Charts: Accuracy and Length vs. Step
### Overview
The image contains two line charts stacked vertically. The top chart displays "Accuracy" versus "Step" for three different methods: RLVR, RLME, and RLME-Concise. The bottom chart displays "Length (character count)" versus "Step" for the same three methods.
### Components/Axes
**Top Chart (Accuracy vs. Step):**
* **Y-axis (Accuracy):** Ranges from 0.2 to 1.0, with gridlines at intervals of 0.2.
* **X-axis (Step):** Ranges from 0 to 120, with gridlines at intervals of 20.
* **Legend (Top-Right):**
* RLVR: Represented by a dotted gray line.
* RLME: Represented by a solid blue line.
* RLME-Concise: Represented by a dashed magenta line.
**Bottom Chart (Length vs. Step):**
* **Y-axis (Length (character count)):** Ranges from 200 to 1000, with gridlines at intervals of 200.
* **X-axis (Step):** Ranges from 0 to 120, with gridlines at intervals of 20.
* **Legend (Same as Top Chart):**
* RLVR: Represented by a dotted gray line.
* RLME: Represented by a solid blue line.
* RLME-Concise: Represented by a dashed magenta line.
### Detailed Analysis
**Top Chart (Accuracy vs. Step):**
* **RLVR (Dotted Gray):** Starts at approximately 0.3 accuracy, increases rapidly until approximately step 40, and then plateaus around 0.9 accuracy.
* Step 0: ~0.3
* Step 40: ~0.9
* Step 120: ~0.9
* **RLME (Solid Blue):** Starts at approximately 0.3 accuracy, increases rapidly until approximately step 40, and then plateaus around 0.9 accuracy.
* Step 0: ~0.3
* Step 40: ~0.85
* Step 120: ~0.9
* **RLME-Concise (Dashed Magenta):** Starts at approximately 0.3 accuracy, increases rapidly until approximately step 40, and then plateaus around 0.95 accuracy.
* Step 0: ~0.3
* Step 40: ~0.9
* Step 120: ~0.95
**Bottom Chart (Length vs. Step):**
* **RLVR (Dotted Gray):** Starts at approximately 1000 character count, decreases to approximately 800 by step 20, and then fluctuates between 800 and 1000 for the remainder of the steps.
* Step 0: ~1000
* Step 20: ~800
* Step 120: ~950
* **RLME (Solid Blue):** Starts at approximately 1000 character count, decreases steadily to approximately 600 by step 60, and then plateaus around 600 for the remainder of the steps.
* Step 0: ~1000
* Step 20: ~800
* Step 60: ~650
* Step 120: ~600
* **RLME-Concise (Dashed Magenta):** Starts at approximately 1000 character count, decreases rapidly to approximately 400 by step 40, and then fluctuates around 400 for the remainder of the steps.
* Step 0: ~1000
* Step 20: ~650
* Step 40: ~400
* Step 120: ~400
### Key Observations
* All three methods (RLVR, RLME, RLME-Concise) achieve similar accuracy levels, plateauing around 0.9 after approximately 40 steps.
* RLME-Concise achieves the shortest text length, followed by RLME, while RLVR has the longest text length.
* The accuracy increases rapidly in the initial steps for all methods.
* The length decreases rapidly in the initial steps for RLME and RLME-Concise.
### Interpretation
The data suggests that RLME and RLME-Concise are more effective at generating shorter text while maintaining similar accuracy compared to RLVR. RLME-Concise is particularly effective at reducing text length. The rapid increase in accuracy and decrease in length during the initial steps indicate that the models learn quickly in the beginning. The plateauing of accuracy and length suggests that the models reach a point of diminishing returns after a certain number of steps.
</details>
evaluator is provided no knowledge of the ground truth.
Results . We find that including the ground-truth answer in as little as 1% of the evaluation prompts is sufficient to substantially reduce the reward-hacking effect in our experiments. Unlike the purely self-evaluated setting, extended training no longer leads to a late-stage collapse where reward increases while accuracy degrades. As Figure 5 indicates, when 10% of evaluations have ground-truth answers, accuracy remains stable; when we reduce this to 1%, we see only a slight degradation in accuracy. Intuitively, the presence of even a small number of fully verifiable examples anchors the evaluator's notion of correctness, preventing consistent reward from bias exploitation strategies.
## 4.7. Can we use meta-questions with multiple objectives?
Question . We next test whether RLME can jointly control correctness and secondary behavioral objectives. In addition to the meta-question 'Is the answer correct?' , we introduce a conciseness objective and study whether multi-objective meta-evaluation can shape reasoning length without sacrificing accuracy.
Method . Keeping the meta-question targeting correctness and add a meta-question targeting brevity: 'Is the length of the solution between 200 and 500 characters?' . We explicitly include the programmatically measured character
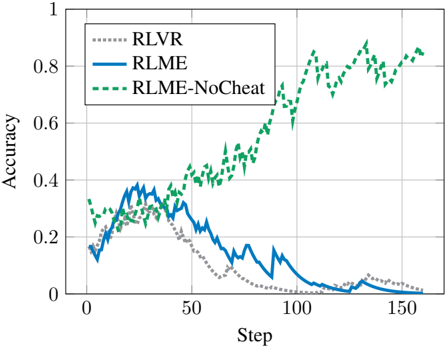
Figure 7. Using an RLME meta-evaluation prioritizing sound reasoning trains the model not to blindly copy a provided answer.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Step for Different Models
### Overview
The image is a line chart comparing the accuracy of three different models (RLVR, RLME, and RLME-NoCheat) over a series of steps. The x-axis represents the step number, and the y-axis represents the accuracy, ranging from 0 to 1. The chart displays the performance of each model as a line, allowing for a visual comparison of their learning curves.
### Components/Axes
* **X-axis:** "Step", ranging from 0 to 150 in increments of 50.
* **Y-axis:** "Accuracy", ranging from 0 to 1 in increments of 0.2.
* **Legend:** Located in the top-left corner of the chart.
* **RLVR:** Represented by a gray dotted line.
* **RLME:** Represented by a solid blue line.
* **RLME-NoCheat:** Represented by a dashed green line.
### Detailed Analysis
* **RLVR (Gray Dotted Line):**
* Starts at approximately 0.12 accuracy at step 0.
* Increases to approximately 0.32 accuracy around step 30.
* Gradually decreases to approximately 0.02 accuracy by step 150.
* Trend: Initially increases, then steadily declines.
* **RLME (Solid Blue Line):**
* Starts at approximately 0.13 accuracy at step 0.
* Increases to approximately 0.40 accuracy around step 30.
* Decreases to approximately 0.03 accuracy by step 150.
* Trend: Initially increases, then steadily declines.
* **RLME-NoCheat (Dashed Green Line):**
* Starts at approximately 0.30 accuracy at step 0.
* Increases to approximately 0.45 accuracy around step 30.
* Experiences a sharp increase in accuracy around step 80.
* Fluctuates between approximately 0.70 and 0.90 accuracy from step 100 to step 160.
* Trend: Initially increases, then shows a significant and sustained increase.
### Key Observations
* RLME-NoCheat consistently outperforms RLVR and RLME after approximately step 80.
* RLVR and RLME show a similar trend of initial increase followed by a decline in accuracy.
* RLME-NoCheat exhibits a significant jump in accuracy around step 80, suggesting a change in learning dynamics.
### Interpretation
The chart illustrates the learning performance of three different models. RLME-NoCheat demonstrates a clear advantage, achieving significantly higher accuracy compared to RLVR and RLME, especially after a certain number of steps. The decline in accuracy for RLVR and RLME suggests that these models may be overfitting or failing to generalize effectively as the number of steps increases. The "NoCheat" aspect of RLME-NoCheat likely contributes to its superior performance, possibly by preventing the model from exploiting unintended shortcuts or biases in the training data. The jump in accuracy around step 80 for RLME-NoCheat could indicate a critical point in its learning process, where it begins to leverage learned features more effectively.
</details>
count in the evaluation prompt. While this injects labels regarding length, the target of this experiment is to evaluate the applicability of RLME to a simple multi-objective scenario. The log-probabilities from each meta-evaluation are then summed as described in methodology Equation 3 and RLME is applied.
Results . Figure 6 shows that RLME-Concise substantially reduces generation length while maintaining high accuracy. By the end of training, the average solution length is nearly halved relative to RLME, with no significant degradation in GSM8K performance. Qualitatively, the concise objective compressed reasoning into denser mathematical expressions rather than verbose natural language (see Appendix C).
Although this is a trivial example, it demonstrates that RLME supports multi-objective control through metaquestions, provided the evaluator can reliably assess the targeted property. In Section 4.8 we extend our investigation to a more useful domain: cheat detection.
## 4.8. Can we train the model not to cheat?
Question . We extend the multi-objective evaluation and address a more subtle criteria: cheating abstinence . As we define it, cheating is the act of rationalizing an answer rather than deriving it through logical processes.
Method . To probe whether a model is cheating we use a counterfactual prompting setup. During training, we provide the generator with the question alongside the true answer. At test time, we instead inject a random answer sampled from the dataset. If, under this counterfactual, the model's reasoning still supports the injected (and incorrect) answer, this indicates that it has learned to justify the provided answer rather than solve the problem logically. This experiment allows us to evaluate the model's ability to reason to an answer vs justifying an answer post-hoc.
We first evaluate RLVR under this setup and then RLME with the accuracy-oriented meta-question from Section 4.1. Finally, we train a second RLME model using a metaquestion that emphasizes the reasoning process rather than the outcome: 'Does the whole solution logically lead from the question to an answer, even if it does not match the correct answer?' We refer to these two RLME variants as RLME-Base and RLME-NoCheat.
Results . As shown in Figure 7, RLVR and RLME-Base both learn to heavily rely on the injected answer and tend to cheat in the counterfactual condition. In contrast, RLME-NoCheat avoids this behavior and achieves over 80% accuracy in counterfactual tests. Examples of cheating and non-cheating traces are provided in Appendix C.
## 4.9. Stepping outside verifiable domains
Thus far, our experiments have focused on fully verifiable tasks where correctness can be determined using groundtruth labels. We now move to a more realistic setting for which RLME is particularly well suited because explicit supervision is not directly available.
A central objective in training large language models is to ensure that they faithfully adhere to the provided context, avoiding hallucinations or the injection of external biases, and instead basing responses strictly on the given information. Recently, the FaithEval benchmark (Ming et al., 2024) was introduced to measure whether models remain faithful to a supplied context, even when that context conflicts with the model's prior world knowledge.
Question . In this experiment, we investigate whether training with RLME on unrelated datasets using a meta-question targeting faithfulness will generalize to improve performance on the FaithEval-Counterfactual dataset.
Method . We construct a heterogeneous context-questionanswer corpus (CQAC) by sampling from public readingcomprehension datasets: SQuAD (Rajpurkar et al., 2016), NewsQA (Trischler et al., 2017), TriviaQA (Joshi et al., 2017), HotpotQA (Yang et al., 2018), BioASQ (Tsatsaronis et al., 2015), DROP (Dua et al., 2019), RACE (Lai et al., 2017), and TextbookQA (Fisch et al., 2019). We take the first 200 examples from each dataset (1,600 total) and truncate contexts to at most 4,000 characters.
As a grounded baseline, we train on CQAC with RLVR using an exact-match reward (after removing punctuation, whitespace, and case).
Based on the findings of our previous experiments regarding the inclusion of limited labeled data to avoid reward hacking, we include a combined approach, RLVR+RLME , defined as the sum of (i) the RLVR exact-match reward and (ii) an
Table 1. Base, RLVR, and RLVR+RLME accuracy on CQAC constituent datasets. Both RLVR and RLVR+RLME significantly exceed the performance of the raw base model (Qwen3-4B-Base). As expected, the RLVR which only optimizes for accuracy achieves a slightly higher average accuracy than RLVR+RLME which optimizes for both accuracy and contextual faithfulness.
| | Squad | NewsQA | TriviaQA | HotpotQA | BioASQ | DROP | RACE | TextbookQA | Avg |
|-----------|----------|----------|------------|------------|----------|----------|----------|--------------|----------|
| Base | 46 . 2 % | 20 . 7 % | 29 . 2 % | 37 . 7 % | 16 . 5 % | 33 . 3 % | 41 . 2 % | 37 . 5 % | 32 . 8 % |
| RLVR | 78 . 0 % | 39 . 0 % | 63 . 5 % | 57 . 8 % | 50 . 3 % | 50 . 7 % | 86 . 2 % | 71 . 5 % | 62 . 1 % |
| RLVR+RLME | 73 . 8 % | 39 . 5 % | 62 . 2 % | 57 . 7 % | 42 . 0 % | 24 . 2 % | 84 . 5 % | 71 . 8 % | 57 . 0 % |
Table 2. Base, RLVR, and RLVR+RLME accuracy on FaithEvalCounterfactual dataset. RLVR+RLME outperforms RLVR, indicating improved context faithfulness can be obtained without labels.
| | FaithEval-Counterfactual |
|-----------|----------------------------|
| Base | 28 . 2 % |
| RLVR | 61 . 8 % |
| RLVR+RLME | 70 . 4 % |
RLME meta-evaluation reward that measures contextual support. RLVR performs well when labels are available, while RLME enables tuning without known rewards. This is expected to allow the model to benefit more substantially from the limited labeled data. To prevent either component from dominating, we normalize each reward component (mean 0 , std 1 ) within each batch before summation. For RLVR and RLME we use Qwen3-4B-Base as the generator; for RLME the generator is used as the live evaluator.
The meta-evaluation uses prompts such as: 'Is the answer supported by the context, regardless of whether it seems factually correct?' Full templates are provided in Appendix B. This meta-evaluation is expected to drive the model to reason faithfully and correctly even when datasets that are not explicitly related to a faithfulness objective.
Results . We discuss results on the constructed CQAC task which does not include FaithEval and the generalization objective. Tables 1 and 2 summarize evaluation results. We assess 100 held-out examples from each CQAC subset and 300 examples from the FaithEval-Counterfactual split and compare the performance.
Both RLVR and RLVR+RLME substantially improve over the raw base model (Qwen3-4B-Base) on CQAC. Relative to RLVR, RLVR+RLME incurs a small average drop on the CQAC exact-match accuracy but yields a substantial improvement on FaithEval-Counterfactual, showing that RLME training generalizes to an out-of-distribution task.
Crucially, the improvement on FaithEval is achieved without training on data from FaithEval. Instead, meta-evaluations of contextual support applied to the unrelated CQAC mixture generalize to the FaithEval benchmark.
## 5. Discussion
We introduced Reinforcement Learning from MetaEvaluation (RLME), a framework that trains language models using rewards derived from natural-language judgments rather than ground-truth labels. RLME tracks label-based RL in verifiable tasks, enables direct multi-objective behavioral control, and generalizes in open-domain settings where correctness cannot be explicitly verified. Across our experiments, we find that:
- Meta-evaluations provide a learning signal comparable to label-based RL in fully verifiable domains (Section 4.1);
- RLME operates across a range of pretrained generator and evaluator models, with performance substantially more sensitive to generator choice than evaluator choice, and live self-evaluation does not noticeably degrade outcomes (Sections 4.2 and 4.3);
- Meta-evaluation is inherently vulnerable to reward hacking under prolonged optimization (Section 4.4), but this failure mode can be mitigated through early stopping or by incorporating sparse ground-truth anchoring (Section 4.6);
- Carefully designed meta-questions support multiobjective steering (Section 4.7) and give control over the reasoning process itself (Section 4.8).
- ⋆ RLME and RLVR+RLME generalize to open-domain tasks without labels or explicit training (Sections 4.9).
Taken together, the results suggest that RLME is most effective as a complement to, rather than a replacement for, verifiable rewards: RLVR dominates when labels are available, RLME enables progress without labels, and hybrid objectives offer the best of both regimes.
The primary limitation is reward hacking where the generator fools the evaluator; however, even minimal grounded supervision effectively stabilizes training, making hybrid RLME approaches particularly practical.
## Impact Statement
Our work proposes a way to steer language models using natural-language meta-questions answered by the model itself or by other models, rather than relying solely on scalar rewards from task-specific verifiers. When well-chosen, these meta-questions can encourage outputs that are more accurate, concise, and transparent, and can make models easier to probe and audit.
However, because RLME derives rewards from model judgments, it can also amplify biases in the evaluators or in the chosen meta-questions. This may entrench prevailing norms or stylistic preferences, and poorly designed questions could incentivize persuasiveness or conformity over truthfulness. Our experiments are confined to controlled, low-stakes domains; extending this framework to high-stakes applications will require additional safeguards, such as diverse evaluator panels, periodic human or verifier audits, and monitoring for reward hacking or systematic unfairness. We view our methods as a tool for aligning models, not as a replacement for human oversight or normative judgment.
## References
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 , 2021.
- Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., and Gardner, M. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In NAACL , 2019.
- Fisch, A., Talmor, A., Jia, R., Seo, M., Choi, E., and Chen, D. Mrqa 2019 shared task: Evaluating generalization in reading comprehension. In Proceedings of the 2nd Workshop on Machine Reading for Question Answering , pp. 1-13, Hong Kong, China, 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-5801. URL https://aclanthology.org/D19-5801/ .
- Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., Wang, S., Zhang, K., Wang, Y., Gao, W., Ni, L., and Guo, J. A survey on LLM-as-a-judge. arXiv preprint arXiv:2411.15594 , 2024.
- Guo, D. et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 , 2025.
- Hugging Face. Smollm3: smol, multilingual, longcontext reasoner. https://huggingface.co/ blog/smollm3 , 2025. Accessed: 2025-11-28.
- Joshi, M., Choi, E., Weld, D. S., and Zettlemoyer, L. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In ACL , 2017.
- Kaufmann, T., Weng, P., Bengs, V., and H¨ ullermeier, E. A survey of reinforcement learning from human feedback. Transactions on Machine Learning Research , 2024. arXiv:2312.14925.
- Lai, G., Xie, Q., Liu, H., Yang, Y., and Hovy, E. Race: Large-scale reading comprehension dataset from examinations. In EMNLP , 2017.
Lee, H., Phatale, S., Mansoor, H., Mesnard, T., Ferret, J., Lu, K. R., Bishop, C., Hall, E., Carbune, V., Rastogi, A., and Prakash, S. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. In International Conference on Machine Learning (ICML) , 2024.
- Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W. S., and Lin, M. Understanding r1-zero-like training: A critical perspective, 2025. URL https://arxiv. org/abs/2503.20783 .
- Mesnard, T. et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 , 2024.
Meta AI. Llama 3.2 model cards and prompt formats. https://www.llama.com/docs/ model-cards-and-prompt-formats/ llama3\_2/ , 2024. Accessed: 2025-11-28.
- Ming, Y., Purushwalkam, S., Pandit, S., Ke, Z., Nguyen, X.P., Xiong, C., and Joty, S. Faitheval: Can your language model stay faithful to context, even if' the moon is made of marshmallows'. arXiv preprint arXiv:2410.03727 , 2024.
- MiniMax, :, Chen, A., Li, A., Gong, B., Jiang, B., Fei, B., Yang, B., Shan, B., Yu, C., Wang, C., Zhu, C., Xiao, C., Du, C., Zhang, C., Qiao, C., Zhang, C., Du, C., Guo, C., Chen, D., Ding, D., Sun, D., Li, D., Jiao, E., Zhou, H., Zhang, H., Ding, H., Sun, H., Feng, H., Cai, H., Zhu, H., Sun, J., Zhuang, J., Cai, J., Song, J., Zhu, J., Li, J., Tian, J., Liu, J., Xu, J., Yan, J., Liu, J., He, J., Feng, K., Yang, K., Xiao, K., Han, L., Wang, L., Yu, L., Feng, L., Li, L., Zheng, L., Du, L., Yang, L., Zeng, L., Yu, M., Tao, M., Chi, M., Zhang, M., Lin, M., Hu, N., Di, N., Gao, P., Li, P., Zhao, P., Ren, Q., Xu, Q., Li, Q., Wang, Q., Tian, R., Leng, R., Chen, S., Chen, S., Shi, S., Weng, S., Guan, S., Yu, S., Li, S., Zhu, S., Li, T., Cai, T., Liang, T., Cheng, W., Kong, W., Li, W., Chen, X., Song, X., Luo, X., Su, X., Li, X., Han, X., Hou, X., Lu, X., Zou, X., Shen, X., Gong, Y., Ma, Y., Wang, Y., Shi, Y., Zhong, Y., Duan, Y., Fu, Y., Hu, Y., Gao, Y., Fan, Y., Yang, Y., Li, Y., Hu, Y., Huang, Y., Li, Y., Xu, Y., Mao, Y., Shi,
- Y., Wenren, Y., Li, Z., Li, Z., Tian, Z., Zhu, Z., Fan, Z., Wu, Z., Xu, Z., Yu, Z., Lyu, Z., Jiang, Z., Gao, Z., Wu, Z., Song, Z., and Sun, Z. Minimax-m1: Scaling test-time compute efficiently with lightning attention, 2025. URL https://arxiv.org/abs/2506.13585 .
- Mistral AI and NVIDIA. Mistral nemo. https:// mistral.ai/news/mistral-nemo , 2024. Accessed: 2025-11-28.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, L., Miller, F., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems , 35:27730-27744, 2022.
- Pang, J.-C., Wang, P., Li, K., Chen, X.-H., Xu, J., Zhang, Z., and Yu, Y. Language model self-improvement by reinforcement learning contemplation. In International Conference on Learning Representations (ICLR) , 2024.
- Podsakoff, P. M., MacKenzie, S. B., Lee, J.-Y., and Podsakoff, N. P. Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology , 88(5): 879-903, 2003. doi: 10.1037/0021-9010.88.5.879.
- Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. Squad: 100,000+ questions for machine comprehension of text. In EMNLP , 2016.
- Roberts, J., Moore, K., and Fisher, D. Do large language models learn human-like strategic preferences? In Proceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025) , pp. 97-108, 2025.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 , 2017.
- Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 , 2024.
- Shao, Z., Luo, Y., Lu, C., Ren, Z., Hu, J., Ye, T., Gou, Z., Ma, S., and Zhang, X. Deepseekmath-v2: Towards self-verifiable mathematical reasoning. arXiv preprint arXiv:2511.22570 , 2025.
- Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., Cheng, N., Durmus, E., HatfieldDodds, Z., Johnston, S. R., Kravec, S., Maxwell, T., McCandlish, S., Ndousse, K., Rausch, O., Schiefer, N.,
- Yan, D., Zhang, M., and Perez, E. Towards understanding sycophancy in language models, 2025. URL https://arxiv.org/abs/2310.13548 .
Trischler, A., Wang, T., Yuan, X., Harris, J., Sordoni, A., Bachman, P., and Suleman, K. Newsqa: A machine comprehension dataset. In Rep4NLP , 2017.
Tsatsaronis, G. et al. An overview of the bioasq large-scale biomedical semantic indexing and question answering competition. In BMC Bioinformatics , 2015.
- Wen, X., Liu, Z., Zheng, S., Xu, Z., Ye, S., Wu, Z., Wang, Y., Liang, X., Li, J., Miao, Z., Bian, J., and Yang, M. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms. arXiv preprint arXiv:2506.14245 , 2025.
- Yang, A. et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 , 2024.
- Yang, A. et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388 , 2025. URL https://arxiv. org/abs/2505.09388 .
- Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhutdinov, R., and Manning, C. D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In EMNLP , 2018.
- Yu, T., Ji, B., Wang, S., Yao, S., Wang, Z., Cui, G., Yuan, L., Ding, N., Yao, Y., Liu, Z., et al. Rlpr: Extrapolating rlvr to general domains without verifiers. arXiv preprint arXiv:2506.18254 , 2025.
- Yuan, W., Pang, R. Y., Cho, K., Li, X., Sukhbaatar, S., Xu, J., and Weston, J. Self-rewarding language models. In International Conference on Machine Learning (ICML) , 2024.
- Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Yue, Y., Song, S., and Huang, G. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837 , 2025.
- Zhao, X., Kang, Z., Feng, A., Levine, S., and Song, D. Learning to reason without external rewards. arXiv preprint arXiv:2505.19590 , 2025.
- Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y., Men, R., Yang, A., et al. Group sequence policy optimization. arXiv preprint arXiv:2507.18071 , 2025.
- Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging LLM-as-a-judge with MT-Bench and chatbot arena. In Proceedings of
the 37th Conference on Neural Information Processing Systems Datasets and Benchmarks Track , 2023.
- Zhou, X., Liu, Z., Sims, A., Wang, H., Pang, T., Li, C., Wang, L., Lin, M., and Du, C. Reinforcing general reasoning without verifiers. arXiv preprint arXiv:2505.21493 , 2025.
## A. Hyperparameters
Unless otherwise noted, all experiments share the configuration below. When a setting differs for a specific experiment (e.g., FaithEval), we mention it in the main text.
## A.1. Training Algorithm
We train with Group Relative Policy Optimization (GRPO), implemented using the GRPOTrainer in Hugging Face TRL, with a CISPO-style objective for importance-weight clipping.
- Loss type: cispo .
- Generations per prompt (group size): 6 candidate completions.
- PPO iterations per batch: 1.
- Importance sampling: sequence-level ratios with clipping:
<!-- formula-not-decoded -->
with ϵ low = 10000 . 0 and ϵ high = 5 . 0 as suggested by the CISPO paper (MiniMax et al., 2025).
- Advantages: sequence-level, A i = r i -¯ r over the group.
## A.2. Optimization
- Optimizer: paged adamw 32bit .
- Learning rate: 2 × 10 -6 , constant schedule.
- Weight decay: 0.0.
- Adam betas: ( β 1 , β 2 ) = (0 . 9 , 0 . 95) .
- Adam epsilon: 10 -15 .
- Batching: per-device batch size 12 prompts, gradient accumulation 8 steps (effective batch size 96 prompts).
## A.3. Generation During RL
Unless otherwise specified, on-policy rollouts for RLME and RLVR use:
- Temperature: 1.0.
- Top- p : 1.0 (effectively disabled).
- Top- k : - 1 (disabled).
- Max new tokens: 512.
- Max prompt length: 4096 tokens for GSM8K, 4608 tokens for FaithEval.
- Repetition penalty: 1.0 (disabled).
## A.4. Reward Design
We use a small number of reward components, combined linearly.
- Accuracy reward (RLVR-style): for tasks with ground truth, we extract the final answer (e.g., from \boxed{...} ) using a fixed regex. The reward is 1.0 for exact integer match and 0.0 otherwise.
- Meta-evaluation rewards (RLME): scalar rewards are log-probabilities of target answers to meta-questions (e.g., 'Is the answer correct?') under one or more evaluator models:
<!-- formula-not-decoded -->
where p j,k is the probability of the target answer (e.g., 'YES') for question q k from evaluator j .
For all problems, we extract the final predicted answer using a single-instance \boxed{} pattern. Specifically, we apply the following regex, which matches the last boxed expression in the completion:
<!-- formula-not-decoded -->
## A.5. Models and Precision
- Generator (default): Qwen3-4B-Base.
- Evaluators: depending on the experiment, we use the current generator and/or frozen external models, including Llama-3.2-3B, SmolLM3-3B, and Mistral-Nemo-Base-2407.
- Precision: base model weights and LM head are kept in fp32 ; training uses bf16 with gradient checkpointing.
- Quantization for evaluators: when applicable, external evaluators are loaded in bf16 with 4-bit NF4 quantization.
## A.6. Backend (vLLM)
All generations during RL are served by vLLM in colocated mode.
- Tensor parallel size: 1.
- GPU memory utilization: 0.2 of device memory.
- Importance-sampling correction: enabled, with correction cap 2.0.
## A.7. Computing Environment
All experiments were run on a single NVIDIA H200 GPU using PyTorch 2.0.2 with CUDA 12.8.1 on Ubuntu 24.04 . No gradient parallelism or multi-GPU sharding was used.
This configuration is used for all experiments unless explicitly noted otherwise.
## B. Prompts
This appendix provides the exact prompt templates used across experiments. These prompts define how model outputs are interpreted and evaluated through natural-language meta-questions.
All templates contain a fixed Problem section and a fixed Evaluation section. In all cases, the prompt text shown below is reproduced exactly as used in our experiments.
We use a special end-marker token ø because it is rare in natural text and is consistently represented as a single token in our tokenizer. In evaluation questions, we supply the first ø and use the model's prediction on the target answer (e.g., the token
sequence YES followed by ø ) as the reward, summing the log-probabilities of all tokens in the target answer. This makes the evaluator's target outcome unambiguous at the token level.
Note: in the interest of full disclosure, we mention that in our experiments the prompts contained several misspellings. Instead of 'Evaluate the solution' we accidentally put 'Evaluation the solution'. Also we misspelled 'explicit' as 'explicite' and we misspelled 'whether' as 'wether'. These errors have been fixed here for clarity, but we have not rerun the experiments. We do not expect these mistakes to materially affect our results.
## B.1. Accuracy-Only (GSM8K)
The generator produces a solution inside the solution block. The meta-reward is based solely on the evaluator's response to a single correctness question.
```
```
This format is used to train RLME without access to ground-truth answers.
## B.2. Dual-Objective: Accuracy + Conciseness
This version augments the evaluation criterion with a length preference. The evaluator receives the solution length explicitly, making compliance with the length constraint directly verifiable.
```
```
```
```
As described in Section 4.7, this allows RLME to control both reasoning quality and brevity through meta-evaluation.
## B.3. Counterfactual Cheating Detection
Here, we intentionally reveal the (ground-truth) answer inside the prompt during training. At test time, we replace this with a random answer. If the model continues to justify that injected value, it is cheating rather than solving the problem from first principles.
We show below the prompt used to train the RLME-NoCheat variant, with the meta-question 'Does the whole solution logically lead from the question to an answer, even if it does not match the correct answer?'. The base variant uses the same template but replaces this meta-question with 'Is the answer correct?'.
```
```
```
```
## B.4. Open-Domain QA and Faithfulness (CQAC + FaithEval)
For faithful open-domain question answering with contextual grounding, we use the same initial prompt for both CQAC and FaithEval datasets:
```
```
```
```
```
```
## C. Qualitative Examples
This appendix provides representative model outputs from each experiment. For each example, we show the full raw generation including intermediate reasoning, and any artifacts. These outputs illustrate typical success modes and common failure cases that are not fully captured by aggregate metrics.
## C.1. GSM8K: Accuracy-Only
This example shows outputs from RLME models trained with correctness as the sole meta-objective. Successful cases demonstrate coherent step-by-step reasoning aligned with the final answer.
```
```
## C.2. GSM8K: Dual-Objective Accuracy + Conciseness
This sample highlights the effect of adding a conciseness reward. Compared to accuracy-only training, the concisenessaccuracy objective tends to reduce repetition and irrelevant elaboration, while preserving enough reasoning to get the answer correct.
```
```
## C.3. Counterfactual Cheating Detection
Here we show examples to illustrate cheating behavior and its suppression. In the base setup, inserting a random answer into the prompt often causes the model to rationalize that injected number.
```
```
Therefore, the correct answer is \boxed{540}.
Adding a meta-question targeting the reasoning itself (RLME-NoCheat) frequently rejects the injected answer and derives its own through grounded reasoning.
```
```
## C.4. Reward Hacking
This example highlights what happens when the generator learns to fool the evaluator in order to get high reward. Notice that the generator suggests the answer before generating the reasoning.
```
```
```
```
## C.5. Open-Domain QA and Faithfulness (CQAC + FaithEval)
This example shows the prompt from the CQAC dataset and a typical response.
```
```
- If the context has contradictory information about the answer to the question, put \boxed{conflict} as the answer. ↪ → -If the context does not contain enough explicit information to answer the question, put \boxed{unknown} as the answer. ↪ → Solution: We need to find information about the state of matter that is most prevalent in the universe. According to the context, "Yet, most of the universe consists of plasma." This directly answers our question. ↪ → ↪ → Therefore, the final answer is: \boxed{plasma}