## Conversation for Non-verifiable Learning: Self-Evolving LLMs through Meta-Evaluation
Yuan Sui 1 and Bryan Hooi 1
1 NUS
Abstract: Training large language models (LLMs) for non-verifiable tasks-such as creative writing, dialogue, and ethical reasoning-remains challenging due to the absence of ground-truth labels. While LLM-as-Judge approaches offer a scalable alternative to human feedback, they face a fundamental limitation: performance is constrained by the evaluator's own quality. If the judge cannot recognize good solutions, it cannot provide useful training signals, and evaluation biases (e.g., favoring verbosity over quality) remain unaddressed. This motivates meta-evaluation -the ability to evaluate and improve the evaluator itself. We introduce CoNL, a framework that unifies generation, evaluation, and meta-evaluation through multi-agent self-play. Our key insight: critique quality can be measured by whether it helps others improve their solutions . In CoNL, multiple agents sharing the same policy engage in structured conversations to propose, critique, and revise solutions. Critiques that enable solution improvements earn a diagnostic reward , creating explicit supervision for meta-evaluation and enabling joint optimization of generation and judging capabilities through self-play, without external judges or ground truth. Experiments on five benchmarks show that CoNL achieves consistent improvements over self-rewarding baselines while maintaining stable training.
## 1. Introduction
Large Language Models (LLMs) have demonstrated impressive performance on tasks with clear objectives, like math or coding [16, 22]. However, many important applications involve non-verifiable tasks, such as creative writing, open-ended dialogue, and ethical decision-making, where objective ground-truth labels are absent [1, 9]. In these settings, standard paradigms like Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL) often break down due to the lack of verifiable signals.
To bridge this gap, Reinforcement Learning from Human Feedback (RLHF) [3] has emerged as the standard solution, leveraging human preference judgments to guide model optimization. However, RLHF is expensive and does not scale well due to the high cost of human annotation. As an alternative, LLM-asJudge methods have gained traction [6, 31], which employ LLMs to generate scalar rewards for scalable training. LLM-as-Judge approaches take two main forms: (1) Specialized Evaluators, such as Self-Taught Evaluators [20] and J1 [23], which focus exclusively on training a separate judge model; and (2) Unified Models, such as Self-Rewarding LLMs [14, 28], where a single model acts as both generator and judge.
A fundamental problem remains across these approaches: the lack of meta-evaluation -evaluating the evaluators themselves. Current methods generally assume that evaluation capabilities will naturally improve as generation capabilities are trained, or rely on static external judges that cannot improve. Without scrutiny, models can exploit biases in the evaluation process. For instance, empirical studies show that self-rewarding models often exhibit a rapid increase in verbosity (e.g., response length jumping from 1k to 2.5k characters), suggesting the internal judge becomes biased toward longer, rather than better, responses [24]. Without a mechanism to evaluate the evaluator, these systems effectively operate
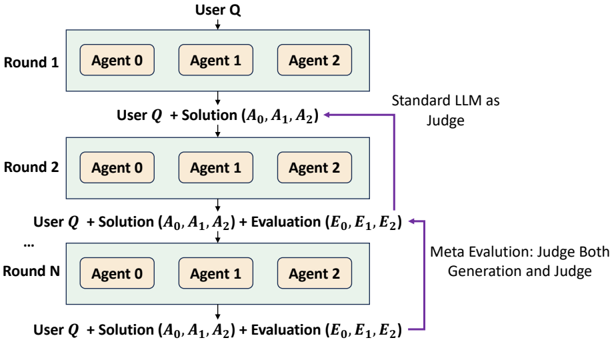
Figure 1: Multi-Agent Conversational Paradigm with Meta-Evaluation. Agents engage in iterative rounds where they generate solutions ( 𝐴 ) and evaluate previous turns ( 𝐸 ). Moving beyond standard LLM-as-Judge , the process incorporates Meta-Evaluation to scrutinize both the generation and the judging quality through peer consensus.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Multi-Agent Iterative Refinement with LLM Judging
### Overview
The image is a diagram illustrating an iterative process involving multiple agents, user input, and evaluation by a Large Language Model (LLM). The process is structured in rounds, where agents generate solutions, and these solutions are evaluated, with the evaluations feeding back into subsequent rounds.
### Components/Axes
* **Rounds:** The diagram shows three rounds: Round 1, Round 2, and Round N (representing an arbitrary round).
* **Agents:** Each round involves three agents, labeled Agent 0, Agent 1, and Agent 2.
* **User Input:** Each round starts with "User Q," representing a user query or input.
* **Solutions:** The agents generate solutions denoted as (A0, A1, A2), where Ai represents the solution from Agent i.
* **Evaluations:** In later rounds, the solutions are evaluated, resulting in evaluations (E0, E1, E2), where Ei represents the evaluation of Agent i's solution.
* **Judging Mechanisms:**
* "Standard LLM as Judge": A standard LLM is used to evaluate the solutions.
* "Meta Evaluation: Judge Both Generation and Judge": A meta-evaluation process judges both the generation of solutions and the judging process itself.
### Detailed Analysis
* **Round 1:**
* Starts with "User Q."
* Involves Agents 0, 1, and 2.
* Outputs "User Q + Solution (A0, A1, A2)."
* **Round 2:**
* Takes "User Q + Solution (A0, A1, A2)" as input.
* Involves Agents 0, 1, and 2.
* Outputs "User Q + Solution (A0, A1, A2) + Evaluation (E0, E1, E2)."
* The solutions from Round 1 are evaluated by a "Standard LLM as Judge."
* **Round N:**
* Takes "User Q + Solution (A0, A1, A2) + Evaluation (E0, E1, E2)" as input.
* Involves Agents 0, 1, and 2.
* Outputs "User Q + Solution (A0, A1, A2) + Evaluation (E0, E1, E2)."
* The solutions and the judging process are subject to "Meta Evaluation: Judge Both Generation and Judge."
### Key Observations
* The process is iterative, with the output of one round feeding into the next.
* The complexity increases with each round, as evaluations are added to the input.
* The judging mechanism evolves from a standard LLM to a meta-evaluation process.
### Interpretation
The diagram illustrates a multi-agent system where agents iteratively refine their solutions based on user input and evaluations. The use of LLMs as judges and meta-evaluators suggests an attempt to automate and improve the quality of the solutions. The iterative nature of the process allows for continuous improvement and adaptation based on feedback. The meta-evaluation step indicates a focus on not only the quality of the generated solutions but also the fairness and accuracy of the judging process itself. This setup could be used in various applications, such as collaborative problem-solving, creative content generation, or automated code development.
</details>
in an echo chamber, capping performance at the model's initial bias level. This raises a question: can we train evaluation skills without ground truth?
We take inspiration from Wikipedia's peer review model. Wikipedia achieves high reliability not through a centralized oracle, but through collaborative improvement-contributors generate content, while others review and revise it. Quality emerges through this iterative refinement. Importantly, this process creates a natural proxy for evaluation quality: if a reviewer's feedback leads to improvements that the community accepts, that reviewer demonstrated good judgment. Similarly, we measure an agent's evaluation capability by whether its critiques enable other agents to produce better solutions-if a critique leads to measurable improvement, it identified real issues.
We formalize this insight in CoNL ( Co nversation for N on-verifiable L earning), a multi-agent self-play framework that addresses the meta-evaluation challenge through a key insight: the quality of a critique can be measured by whether it helps others to improve their solutions . Consider a concrete scenario: Agent A proposes solution X, which the group initially rates moderately. Agent B then critiques X, identifying a logical flaw. Agent A revises the solution based on this feedback, fixing the error. The group then rates the revised solution higher than the original. This improvement reveals that Agent B's critique was constructive and identified a real issue. Crucially, this improvement signal can be measured and used as a training signal for meta-evaluation. Critiques that enable others to improve their solutions earn a diagnostic reward , creating explicit supervision for meta-evaluation without external judges or ground truth.
Our contributions are: (1) We introduce CoNL, a multi-agent self-play framework that unifies generation and meta-evaluation for non-verifiable tasks through conversation dynamics. (2) We propose measuring critique quality by whether it enables solution improvement, formalized as a diagnostic reward that tracks score changes after revision. (3) Experiments on five benchmarks show that CoNL outperforms self-rewarding baselines by 2.7-8.3 percentage points and closely matches RL with ground-truth rewards, despite using only peer consensus signals, while maintaining stable training dynamics.
## 2. Related Work
LLM-as-Judge and Meta-Evaluation. The field has widely adopted LLM-as-Judge frameworks [10, 18] to scale evaluation for non-verifiable tasks. However, relying on a single judge model introduces a critical bottleneck: the evaluator's own biases (e.g., verbosity or position bias) place a hard ceiling on performance [17, 27]. While recent research acknowledges these flaws, it typically treats metaevaluation-assessing the judge itself-as a post-hoc analysis rather than a training objective. This creates a problem: models are trained to generate, but their ability to judge remains static or implicitly assumed. CoNL addresses this by treating meta-evaluation as a trainable capability. We use the success of a critique (its ability to change opinions) as an explicit training signal, ensuring that evaluation skills improve alongside generation.
Training Evaluators without Human Labels. Recent efforts to train evaluators without human supervision fall into two main categories: self-improvement and verifiable RL. Self-improvement methods, such as Self-Taught Evaluators [20] and Meta-Rewarding LM [25], rely on a model generating and judging its own synthetic data. However, this creates circular reasoning: a model's own judgments may reinforce its biases rather than correct them. Verifiable RL methods, like J1 [23], solve this by grounding training in tasks with clear answers (like math), but this limits their applicability to domains where such answers exist. CoNL introduces a third paradigm: peer-supervision. By deriving signals from critique-driven improvement rather than self-judgment or ground truth, we avoid the circularity of self-training and the domain restrictions of verifiable RL.
Multi-Agent Collaboration. Multi-agent debate is a well-established strategy for improving inference performance [5, 29]. The logic is that cross-examination filters out errors that a single agent might miss. However, existing frameworks view this interaction solely as a test-time cost, discarding the rich interaction data once the answer is produced. This approach discards valuable information. CoNL reinterprets debate dynamics as a learning signal. Instead of just using agents to find the best answer today, we use the consensus shifts generated during debate to train the model to recognize better answers tomorrow. This shifts the paradigm from "inference-only debate" to "training-via-debate."
## 3. Method
We consider a learning problem where we want to train a model on tasks without verifiable solutions. In verifiable domains like mathematics and code generation, we can check if an answer is correct. In nonverifiable domains like creative writing, no such check exists. We have access only to human judgments ℎ : 𝒴 × 𝒳 → R (costly and often inconsistent) or LLM-based judges 𝐽 𝜃 : 𝒴 × 𝒳 → R (scalable but unreliable).
As discussed in the introduction, existing approaches lack meta-evaluation-the ability to evaluate the evaluators themselves. CoNL addresses this by training a policy 𝜋 𝜃 that unifies generation, evaluation, and meta-evaluation within a multi-agent self-play paradigm. We design a multi-agent conversation protocol where multiple agents sharing the same policy 𝜋 𝜃 engage in structured, multi-turn conversations to propose, critique, and revise solutions. Through these conversations, we extract training signals to optimize the policy. The goal is to learn a policy that can generate high-quality solutions and accurately evaluate them, without relying on external judges or ground truth.
## 3.1. CoNL Protocol: Learning from Conversations
The key insight is that multi-agent conversations naturally reveal which critiques are high quality. Consider what happens when an agent receives a helpful critique identifying a genuine flaw: that agent can revise their solution to fix the error, and the revised solution will receive higher ratings from the group. This improvement is both observable and measurable. If a critique enables the recipient to produce a better solution (as judged by peers), that critique likely identified a real problem. By tracking which critiques lead to improvements, we obtain a training signal for evaluation quality-solving the meta-evaluation problem without ground truth.
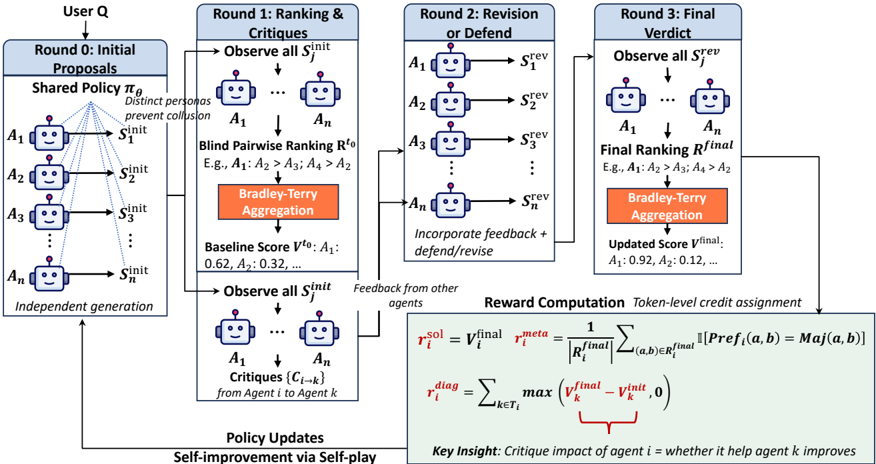
For each training query 𝑞 , we instantiate 𝑁 agents from a single policy 𝜋 𝜃 . Each agent 𝑖 is assigned a distinct persona 𝑃 𝑖 (e.g., 'rigorous analyst', 'creative solver', 'skeptical reviewer'; see Appendix J) to encourage diverse perspectives and reduce the chance of group collusion [26] (i.e., the tendency for group members to secretly cooperate for higher rewards). All agents share the same policy parameters 𝜃 but adopt different conversational roles. We design a four-round protocol:
Round 0: Initial Proposals. Each agent 𝑖 independently generates an initial solution 𝑠 init 𝑖 to query 𝑞 .
Round 1: Initial Evaluation and Critique. After observing all initial solutions { 𝑠 init 𝑗 } 𝑁 -1 𝑗 =0 , each agent 𝑖 produces:
- Initial ranking ℛ init 𝑖 : A set of pairwise comparisons expressing preferences between solutions. For example, agent 𝑖 might state 'Agent 2's solution is better than Agent 0's' and 'Agent 1's solution is better than Agent 2's'. We denote each comparison as a tuple ( 𝑎 ≻ 𝑏 ) indicating agent 𝑎 's solution is preferred over agent 𝑏 's. Crucially, agents do not see each other's rankings during this round, ensuring independent judgment.
- Critiques { 𝑐 𝑖 → 𝑘 } 𝑘 ∈𝒯 𝑖 : textual critiques justifying the pairwise comparisons, where 𝒯 𝑖 denotes the set of agents mentioned in ℛ init 𝑖 . Each critique 𝑐 𝑖 → 𝑘 provides detailed reasoning for the comparisons involving agent 𝑘 , identifying specific issues (e.g., logical errors, missing edge cases) or strengths in their solution.
Round 2: Revision. Each agent 𝑖 receives all critiques targeting them (i.e., all 𝑐 𝑗 → 𝑖 where 𝑖 ∈ 𝒯 𝑗 ) along with the original solutions. Agent 𝑖 then generates a revised solution 𝑠 rev 𝑖 , which may incorporate valid feedback and fix identified errors, defend against invalid or misguided critiques with justification, or refine reasoning and add missing details.
Round 3: Final Verdict. After observing all revised solutions { 𝑠 rev 𝑗 } 𝑁 -1 𝑗 =0 , each agent 𝑖 produces a final ranking ℛ final 𝑖 via pairwise comparisons (similar format to Round 1). Aggregating these rankings yields post-conversation scores 𝑉 final , reflecting the group's updated assessment after critique and revision.
Key design: The initial ranking establishes a pre-conversation baseline 𝑉 init , which represents the group's initial assessment before agents see any critiques and before solutions are revised. This baseline helps measure whether the generated critiques lead to actual improvements after revision. Specifically, we measure the change in scores Δ 𝑉 𝑘 = 𝑉 final 𝑘 -𝑉 init 𝑘 to quantify critique effectiveness. Agents do not see each other's rankings, ensuring independent judgment (detailed rationale in Appendix B). Figure 2 illustrates this four-round process.
Since multi-agent conversations can easily exceed the context window, we implement a memory buffering module that compresses past conversations while preserving key details (decisions, reasons, constraints). When the memory buffer is enabled, the output for each round is compressed into a condensed version
Figure 2: Overview of CoNL training protocol. Given a query, 𝑁 agents with diverse personas engage in a four-round conversation: (Round 0) each agent proposes an initial solution; (Round 1) agents provide initial rankings and critique peers; (Round 2) agents revise solutions based on received critiques; (Round 3) agents provide final rankings. We aggregate rankings via Bradley-Terry model to compute quality scores 𝑉 init and 𝑉 final . Training rewards are computed from conversation dynamics: solution quality rewards high-scoring solutions, diagnostic rewards critiques that enable improvements ( 𝑉 final > 𝑉 init ), and consensus rewards rankings aligned with group majority.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Process Diagram: Multi-Agent Proposal and Revision
### Overview
The image presents a process diagram illustrating a multi-agent system for proposal generation, ranking, revision, and final verdict. The process involves multiple rounds of interaction among agents, incorporating feedback and self-improvement.
### Components/Axes
* **Header:** Contains the title "User Q" at the top, followed by the round descriptions: "Round 0: Initial Proposals", "Round 1: Ranking & Critiques", "Round 2: Revision or Defend", and "Round 3: Final Verdict".
* **Agents:** Represented by robot icons labeled A1, A2, A3, ..., An.
* **Proposals:** Represented as Sinit, Srev, and Sfinal, indicating initial, revised, and final proposals, respectively.
* **Processes:**
* **Shared Policy πθ:** Used in Round 0. The text "Distinct personas prevent collusion" is associated with this policy.
* **Blind Pairwise Ranking Rto:** Used in Round 1. Example ranking: "E.g., A1: A2 > A3; A4 > A2".
* **Bradley-Terry Aggregation:** Used in Rounds 1 and 3.
* **Critiques {Ci→k}:** From Agent i to Agent k, used in Round 1.
* **Reward Computation:** Token-level credit assignment.
* **Scores:**
* **Baseline Score Vto:** Example values: "A1: 0.62, A2: 0.32, ...".
* **Updated Score Vfinal:** Example values: "A1: 0.92, A2: 0.12, ...".
* **Policy Updates:** "Self-improvement via Self-play" at the bottom-left.
* **Reward Computation Formulas:**
* r_i^{sol} = V_i^{final} * r_i^{meta}
* r_i^{meta} = (1 / |R_i^{final}|) * Σ_{(a,b)∈R_i^{final}} [Pref_i(a, b) = Maj(a, b)]
* r_i^{diag} = Σ_{k∈T_i} max(V_k^{final} - V_k^{init}, 0)
* **Key Insight:** "Critique impact of agent i = whether it help agent k improves"
### Detailed Analysis or Content Details
**Round 0: Initial Proposals**
* User Q initiates the process.
* Agents A1 to An independently generate initial proposals Sinit based on a shared policy πθ.
* The text "Distinct personas prevent collusion" is associated with the shared policy.
**Round 1: Ranking & Critiques**
* Agents observe all initial proposals Sinit.
* Blind pairwise ranking Rto is performed (e.g., A1: A2 > A3; A4 > A2).
* Bradley-Terry Aggregation is applied to the rankings.
* Baseline scores Vto are calculated (e.g., A1: 0.62, A2: 0.32).
* Agents observe all initial proposals Sinit again.
* Agents generate critiques {Ci→k} from Agent i to Agent k.
**Round 2: Revision or Defend**
* Agents A1 to An revise or defend their proposals based on feedback from other agents, resulting in revised proposals Srev.
* The text "Incorporate feedback + defend/revise" is associated with this round.
**Round 3: Final Verdict**
* Agents observe all revised proposals Srev.
* Final ranking Rfinal is performed (e.g., A1: A2 > A3; A4 > A2).
* Bradley-Terry Aggregation is applied to the final rankings.
* Updated scores Vfinal are calculated (e.g., A1: 0.92, A2: 0.12).
**Policy Updates**
* The process includes policy updates through self-improvement via self-play.
* Feedback from other agents is used to update the policies.
**Reward Computation**
* Token-level credit assignment is used for reward computation.
* Formulas are provided for calculating the rewards.
### Key Observations
* The process is iterative, with multiple rounds of proposal generation, ranking, and revision.
* Feedback from other agents plays a crucial role in the revision process.
* The Bradley-Terry Aggregation method is used for ranking aggregation.
* The reward computation formulas provide a quantitative measure of the impact of each agent's critiques.
* The updated scores Vfinal are generally higher than the baseline scores Vto, indicating improvement over the rounds.
### Interpretation
The diagram illustrates a multi-agent system designed to collaboratively generate and refine proposals. The system incorporates mechanisms for ranking, critique, and revision, allowing agents to learn from each other and improve their proposals over time. The use of a shared policy in the initial round ensures a common ground for proposal generation, while the pairwise ranking and Bradley-Terry Aggregation methods provide a robust way to aggregate individual preferences. The reward computation formulas incentivize agents to provide helpful critiques that lead to improved proposals. The overall process promotes self-improvement through self-play, enabling the system to adapt and optimize its performance over time. The increase in scores from baseline to final suggests the system is effective in improving the quality of proposals.
</details>
for the next round's history (see Memory Buffer in Section 4.1 for details).
## 3.2. Reward Design from Multi-Agent Conversations
After the four-round conversation, we have rich interaction data: initial solutions, initial rankings, critiques, revised solutions, and final rankings. The key question is: how do we convert these informative conversations into numerical rewards that support model self-training? Our approach is based on two core principles: (1) using pairwise comparisons as a robust evaluation mechanism, and (2) designing reward functions that explicitly measure different aspects of conversation quality.
Pairwise Comparisons for Robust Evaluation. As mentioned in Section 3.1, for initial ranking and final ranking, we prompt the agents to provide pairwise comparisons. Instead of providing absolute scores (e.g., ' Agent 2's solution is 7/10'), we elicit pairwise preferences (e.g., 'Agent 2's solution is better than Agent 0's'). This design choice has two key advantages: (1) Relative judgments are cognitively easier and more reliable than absolute scoring, and (2) Pairwise comparisons can naturally aggregate into quantitative scores like win rate.
To solve the potential conflicts in pairwise comparisons (e.g., Agent 0 prefers 1 over 2, but Agent 3 prefers 2 over 1), we use the Bradley-Terry (BT) [2] model to aggregate them into latent quality scores. The BT model estimates each agent's latent 'quality' 𝑉 𝑘 ∈ [0 , 1] by making it more likely that better agents
win pairwise comparisons. Each agent produces multiple pairwise comparisons, which may conflict (e.g., agent 0 prefers 1 over 2, but agent 3 prefers 2 over 1). The BT model maximizes the likelihood that observed preferences match:
$$\mathbb { P } ( \text {Agent} \, a \succ \text {Agent} \, b \, | \, V _ { a } , V _ { b } ) = \frac { \exp ( V _ { a } ) } { \exp ( V _ { a } ) + \exp ( V _ { b } ) }$$
Given all pairwise comparisons ℛ = ⋃︀ 𝑁 -1 𝑖 =0 ℛ 𝑖 , we fit { 𝑉 𝑘 } 𝑁 -1 𝑘 =0 via maximum likelihood estimation. Higher 𝑉 𝑘 means agent 𝑘 's solution is more preferred by the group.
We compute these aggregate quality scores at two timepoints: 𝑉 init 𝑘 from initial rankings {ℛ init 𝑖 } 𝑁 -1 𝑖 =0 captures the group's initial collective assessment (before seeing critiques and revisions), while 𝑉 final 𝑘 from final rankings {ℛ final 𝑖 } 𝑁 -1 𝑖 =0 captures the group's updated collective assessment after critique and revision.
Key insight: The change Δ 𝑉 𝑘 = 𝑉 final 𝑘 -𝑉 init 𝑘 measures whether agent 𝑘 's solution improved after revision. If agent 𝑖 critiqued 𝑘 and Δ 𝑉 𝑘 > 0 , it means agent 𝑘 was able to incorporate the feedback and produce a better solution, indicating that agent 𝑖 's critique correctly diagnosed real issues. This forms the basis for our diagnostic reward.
Reward Functions from Conversation Dynamics. From these conversation-derived quality scores, we design three reward components targeting different skills:
Diagnostic Reward ( 𝑟 diag ). We identify which agents were critiqued by agent 𝑖 by parsing the critique targets 𝒯 𝑖 from their Round 1 response (agents explicitly indicate critique targets in their output). If agent 𝑘 ∈ 𝒯 𝑖 was critiqued and 𝑘 's revised solution receives a higher score ( 𝑉 final 𝑘 > 𝑉 init 𝑘 ), agent 𝑖 is rewarded:
<!-- formula-not-decoded -->
The max(0 , · ) ensures only diagnostic critiques (that correctly identify issues enabling improvement) receive positive reward; ineffective or misguided critiques will not be rewarded.
Connection to meta-evaluation: This reward directly addresses the fundamental challenge in LLMas-Judge systems-how to evaluate the evaluators themselves. The diagnostic reward 𝑟 diag provides a quantitative proxy for critique quality: if an agent's critiques consistently enable others to improve their solutions, that agent has strong evaluation skills. By training on 𝑟 diag , the model learns metaevaluation-the ability to correctly diagnose genuine flaws and provide actionable feedback. This reward reflects both critique quality (did the critic identify real issues?) and revision quality (did the recipient successfully incorporate feedback?). Natural concerns about circular reasoning and false critique rewarding are addressed through bootstrapping and adversarial revision dynamics; we provide detailed analysis of these mechanisms in Appendix B.
Solution Quality ( 𝑟 sol ). Agents whose solutions receive high scores from the group after conversation receive higher rewards:
$$r _ { \text {sol} } ( i ) = V ^ { \text {final} } _ { i }$$
This directly rewards solutions that the group collectively ranks highly after the conversation.
Majority Alignment ( 𝑟 meta). To prevent arbitrary or biased rankings, we reward agents whose pairwise judgments match the majority. Consider a pairwise comparison between agent 𝑎 's revised solution 𝑠 rev 𝑎
and agent 𝑏 's revised solution 𝑠 rev 𝑏 . Let Pref 𝑖 ( 𝑎, 𝑏 ) ∈ { 𝑎, 𝑏 } denote which solution agent 𝑖 prefers (e.g., if agent 𝑖 states ' Agent 𝑎 is better than Agent 𝑏 ', then Pref 𝑖 ( 𝑎, 𝑏 ) = 𝑎 ). We determine the majority preference Maj ( 𝑎, 𝑏 ) ∈ { 𝑎, 𝑏 } by aggregating all agents' stated preferences on this pair. The majority-alignment reward is:
$$r _ { \text {meta} } ( i ) = \frac { 1 } { | \mathcal { R } ^ { \text {final} } _ { i } | } \sum _ { ( a , b ) \in \mathcal { R } ^ { \text {final} } _ { i } } \mathbb { I } [ \text {Pref} _ { i } ( a , b ) = \text {Maj} ( a , b ) ]$$
This measures the fraction of agent 𝑖 's pairwise judgments that align with the group majority, ranging from 0 (no agreement) to 1 (perfect alignment).
The composite reward for agent 𝑖 is defined as:
$$r _ { \text {total} } ( i ) = w _ { 1 } r _ { \text {sol} } ( i ) + w _ { 2 } r _ { \text {diag} } ( i ) + w _ { 3 } r _ { \text {meta} } ( i )$$
with default weights 𝑤 1 = 1 . 0 , 𝑤 2 = 2 . 0 , 𝑤 3 = 1 . 0 . We weight diagnostic ( 𝑟 diag ) highest to emphasize meta-evaluation learning. The three rewards address complementary objectives: 𝑟 sol trains generation quality, 𝑟 diag trains meta-evaluation, and 𝑟 meta trains calibrated judgment. See Appendix B for detailed discussion of reward complementarity and diversity requirements.
## 3.3. Token-Level Credit Assignment
Each agent generates multiple text segments across rounds (initial solution, initial ranking, critiques, revised solution, final ranking). If we assign the same reward to all tokens, the model cannot distinguish which behavior led to which outcome. Instead, we perform segment-level credit assignment: each token receives the reward associated with its containing segment. In practice, we identify segment boundaries like [<critique></critique>] by parsing structured markers in the agent's output (implementation details in Appendix B). Each token within a segment receives the corresponding reward signal, enabling targeted gradient updates. See Table 1 for credit assignment.
Table 1: Credit assignment strategy. Each conversation segment receives targeted rewards. Critically, initial ranking tokens receive zero reward to prevent gaming the baseline.
| Round | Content | Reward | Rationale |
|-----------|---------------------------------------------------------------------------------------------------------------------------|--------------------------------------|-----------------------------------------------------------------------------------------------------|
| 0 1 1 2 3 | Initial solution 𝑠 init 𝑖 Initial ranking ℛ init 𝑖 Critiques { 𝑐 𝑖 → 𝑘 } Revised solution 𝑠 rev 𝑖 Final ranking ℛ final 𝑖 | 𝑟 sol 0 (masked) 𝑟 diag 𝑟 sol 𝑟 meta | Solution quality Prevent gaming 𝑉 init Diagnostic effectiveness Solution quality Majority alignment |
## 3.4. Policy Training
We train 𝜋 𝜃 using policy gradient methods implemented via the Tinker API [19]. We employ importance sampling (IS) for unbiased gradient estimation when sampling and training distributions differ.
After collecting conversation trajectories from sampling policy 𝜋 𝜃 old , we compute token-level advantages ^ 𝐴 𝑡 based on segment-specific rewards (Table 1). The importance sampling objective corrects for distribution
Table 2: Pass@1 performance on reasoning benchmarks. Values represent mean ± std over three independent runs. Bold and underline indicate the best and second-best performance within each model size category. Methods marked with * require training. Otherwise, we report the inference performance.
| Model | Method | AIME24 | AIME25 | GPQA | DeepMath | FrontierSci | USACO |
|-------------------|-------------------------------|------------|------------|------------|------------|---------------|------------|
| Qwen3-8B | 0-Shot Inference | 60.0 ± 1.8 | 60.0 ± 2.1 | 67.0 ± 0.9 | 70.5 ± 0.6 | 43.0 ± 1.4 | 10.2 ± 0.8 |
| Qwen3-8B | Self-Consistency | 61.8 ± 0.9 | 61.2 ± 1.1 | 68.2 ± 0.8 | 75.4 ± 0.5 | 43.1 ± 1.5 | 10.3 ± 0.9 |
| Qwen3-8B | Self-Refine | 63.2 ± 1.6 | 62.8 ± 1.4 | 69.5 ± 1.0 | 72.2 ± 0.9 | 45.5 ± 1.3 | 11.8 ± 1.2 |
| Qwen3-8B | Multi-Agent Debate | 64.5 ± 2.4 | 64.2 ± 2.5 | 70.8 ± 2.1 | 71.0 ± 1.8 | 44.2 ± 2.6 | 11.0 ± 2.2 |
| Qwen3-8B | Self-Rewarding (Single Turn)* | 68.5 ± 1.2 | 69.0 ± 1.3 | 73.5 ± 1.1 | 77.5 ± 0.8 | 50.5 ± 1.7 | 15.5 ± 1.4 |
| Qwen3-8B | Self-Rewarding (Multi-Agent)* | 69.8 ± 1.5 | 70.2 ± 1.6 | 74.8 ± 1.3 | 78.8 ± 1.2 | 52.0 ± 1.8 | 16.8 ± 1.6 |
| Qwen3-8B | CoNL (Ours) * | 76.5 ± 1.4 | 73.5 ± 1.5 | 79.2 ± 1.2 | 87.1 ± 0.7 | 55.7 ± 1.6 | 19.5 ± 1.5 |
| Qwen3-4B-Instruct | 0-Shot Inference | 50.0 ± 1.3 | 54.0 ± 1.6 | 45.0 ± 1.1 | 78.5 ± 1.2 | 18.0 ± 1.5 | 6.0 ± 0.4 |
| Qwen3-4B-Instruct | Self-Consistency | 51.5 ± 0.8 | 55.2 ± 1.0 | 46.1 ± 0.9 | 79.8 ± 0.7 | 17.1 ± 1.4 | 6.1 ± 0.5 |
| Qwen3-4B-Instruct | Self-Refine | 52.8 ± 1.4 | 56.8 ± 1.5 | 47.5 ± 1.2 | 80.9 ± 1.3 | 19.2 ± 1.8 | 6.9 ± 1.1 |
| Qwen3-4B-Instruct | Multi-Agent Debate | 54.1 ± 2.1 | 57.9 ± 2.3 | 48.8 ± 1.9 | 81.5 ± 1.6 | 19.9 ± 2.4 | 6.5 ± 1.9 |
| Qwen3-4B-Instruct | Self-Rewarding (Single Turn)* | 57.5 ± 1.3 | 61.2 ± 1.4 | 51.5 ± 1.2 | 83.8 ± 1.1 | 23.5 ± 1.7 | 9.5 ± 1.3 |
| Qwen3-4B-Instruct | Self-Rewarding (Multi-Agent)* | 58.9 ± 1.5 | 62.5 ± 1.6 | 52.8 ± 1.4 | 85.2 ± 1.4 | 24.8 ± 1.9 | 10.2 ± 1.5 |
| Qwen3-4B-Instruct | CoNL (Ours) | 63.5 ± 1.3 | 67.4 ± 1.4 | 55.2 ± 1.3 | 84.9 ± 1.0 | 27.5 ± 1.7 | 13.4 ± 1.4 |
| Llama-3.1-8B | 0-Shot Inference | 13.0 ± 0.8 | 7.0 ± 0.4 | 23.0 ± 1.0 | 45.0 ± 1.5 | 1.9 ± 0.2 | 3.0 ± 0.3 |
| Llama-3.1-8B | Self-Consistency | 13.5 ± 0.6 | 7.2 ± 0.5 | 23.6 ± 0.8 | 46.1 ± 0.9 | 1.9 ± 0.3 | 3.0 ± 0.3 |
| Llama-3.1-8B | Self-Refine | 14.8 ± 1.0 | 8.5 ± 0.8 | 24.8 ± 1.1 | 47.5 ± 1.4 | 2.8 ± 0.5 | 3.6 ± 0.6 |
| Llama-3.1-8B | Multi-Agent Debate | 15.5 ± 1.8 | 9.1 ± 1.5 | 25.9 ± 1.6 | 48.2 ± 1.9 | 2.2 ± 0.7 | 3.2 ± 0.8 |
| Llama-3.1-8B | Self-Rewarding (Single Turn)* | 19.5 ± 1.3 | 12.5 ± 1.1 | 30.5 ± 1.2 | 52.5 ± 1.5 | 6.5 ± 0.8 | 6.5 ± 0.9 |
| Llama-3.1-8B | Self-Rewarding (Multi-Agent)* | 20.8 ± 1.4 | 13.8 ± 1.3 | 31.5 ± 1.4 | 54.2 ± 1.6 | 7.5 ± 0.9 | 7.2 ± 1.1 |
| Llama-3.1-8B | CoNL (Ours) * | 23.5 ± 1.3 | 16.2 ± 1.2 | 34.0 ± 1.3 | 57.5 ± 1.5 | 10.2 ± 1.0 | 7.0 ± 0.9 |
| Llama-3.2-3B | 0-Shot Inference | 11.5 ± 0.7 | 6.5 ± 0.5 | 22.0 ± 0.9 | 42.0 ± 1.3 | 1.8 ± 0.3 | 2.8 ± 0.4 |
| Llama-3.2-3B | Self-Consistency | 12.1 ± 0.6 | 6.8 ± 0.6 | 22.8 ± 0.8 | 43.5 ± 1.0 | 1.8 ± 0.2 | 2.8 ± 0.3 |
| Llama-3.2-3B | Self-Refine | 13.0 ± 0.9 | 7.5 ± 0.7 | 23.5 ± 1.1 | 44.2 ± 1.2 | 2.4 ± 0.4 | 3.2 ± 0.5 |
| Llama-3.2-3B | Multi-Agent Debate | 13.8 ± 1.5 | 8.0 ± 1.2 | 24.5 ± 1.4 | 45.5 ± 1.8 | 2.0 ± 0.6 | 3.0 ± 0.7 |
| Llama-3.2-3B | Self-Rewarding (Single Turn)* | 16.5 ± 1.2 | 10.5 ± 1.3 | 27.0 ± 1.2 | 48.5 ± 1.6 | 5.0 ± 0.7 | 5.5 ± 0.8 |
| Llama-3.2-3B | Self-Rewarding (Multi-Agent)* | 17.5 ± 1.4 | 11.5 ± 1.5 | 28.2 ± 1.5 | 49.8 ± 1.7 | 5.8 ± 0.8 | 6.2 ± 1.0 |
| Llama-3.2-3B | CoNL (Ours) * | 19.8 ± 1.3 | 14.0 ± 1.4 | 30.5 ± 1.3 | 53.5 ± 1.6 | 8.2 ± 1.1 | 8.0 ± 0.9 |
mismatch between sampler and learner:
$$\mathcal { L } _ { \text {IS} } ( \theta ) = \mathbb { E } _ { x \sim \pi _ { \theta _ { \text {old} } } } \left [ \frac { p _ { \theta } ( x ) } { p _ { \theta _ { \text {old} } } ( x ) } A ( x ) \right ]$$
where the ratio 𝑝 𝜃 ( 𝑥 ) 𝑝 𝜃 old ( 𝑥 ) reweights samples to account for policy updates. Complete mathematical formulations are provided in Appendix G.
## 4. Experiments
We evaluate CoNL on five challenging verifiable benchmarks requiring advanced reasoning capabilities. Our experimental design addresses two key questions: (1) Can conversation-derived rewards effectively train both generation and evaluation capabilities without ground-truth? (2) Does the meta-evaluation signal ( 𝑟 diag ) improve performance compared to existing approaches?
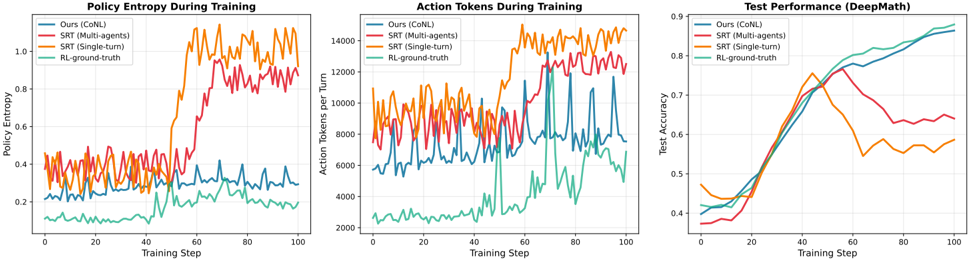
Figure 3: Training Dynamics: CoNL vs Self-Rewarding Training. We compare training dynamics on DeepMath across 10k training steps. Left: CoNL maintains stable entropy while SRT shows erratic fluctuations. Middle: CoNL produces consistent solution lengths while SRT exhibits high variance. Right: CoNL shows steady accuracy improvement matching ground-truth RL, while SRT's majority-voting signals lead to unstable convergence. Overall, CoNL's conversation-derived rewards provide more stable training than self-rewarding baselines.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Chart Type: Multiple Line Graphs Comparing Training Performance
### Overview
The image presents three line graphs comparing the performance of different training methods: "Ours (CoNL)", "SRT (Multi-agents)", "SRT (Single-turn)", and "RL-ground-truth". The graphs depict "Policy Entropy During Training", "Action Tokens During Training", and "Test Performance (DeepMath)" across training steps.
### Components/Axes
**Graph 1: Policy Entropy During Training**
* **Title:** Policy Entropy During Training
* **Y-axis:** Policy Entropy, ranging from 0.0 to 1.0 in increments of 0.2.
* **X-axis:** Training Step, ranging from 0 to 100 in increments of 20.
* **Legend (Top-Left):**
* Blue: Ours (CoNL)
* Red: SRT (Multi-agents)
* Orange: SRT (Single-turn)
* Teal: RL-ground-truth
**Graph 2: Action Tokens During Training**
* **Title:** Action Tokens During Training
* **Y-axis:** Action Tokens per Turn, ranging from 2000 to 14000 in increments of 2000.
* **X-axis:** Training Step, ranging from 0 to 100 in increments of 20.
* **Legend (Top-Left):**
* Blue: Ours (CoNL)
* Red: SRT (Multi-agents)
* Orange: SRT (Single-turn)
* Teal: RL-ground-truth
**Graph 3: Test Performance (DeepMath)**
* **Title:** Test Performance (DeepMath)
* **Y-axis:** Test Accuracy, ranging from 0.4 to 0.9 in increments of 0.1.
* **X-axis:** Training Step, ranging from 0 to 100 in increments of 20.
* **Legend (Top-Left):**
* Blue: Ours (CoNL)
* Red: SRT (Multi-agents)
* Orange: SRT (Single-turn)
* Teal: RL-ground-truth
### Detailed Analysis
**Graph 1: Policy Entropy During Training**
* **Ours (CoNL) (Blue):** Stays relatively constant around 0.3.
* **SRT (Multi-agents) (Red):** Starts around 0.35, increases to approximately 0.5 around step 50, then increases again to approximately 0.8 around step 70, then fluctuates between 0.8 and 0.9.
* **SRT (Single-turn) (Orange):** Starts around 0.3, increases sharply around step 50 to approximately 1.0, then fluctuates between 0.9 and 1.1.
* **RL-ground-truth (Teal):** Starts around 0.1, increases gradually to approximately 0.25 by step 100.
**Graph 2: Action Tokens During Training**
* **Ours (CoNL) (Blue):** Fluctuates between approximately 4000 and 8000.
* **SRT (Multi-agents) (Red):** Fluctuates between approximately 8000 and 12000.
* **SRT (Single-turn) (Orange):** Fluctuates between approximately 10000 and 14000.
* **RL-ground-truth (Teal):** Fluctuates between approximately 2000 and 4000.
**Graph 3: Test Performance (DeepMath)**
* **Ours (CoNL) (Blue):** Increases steadily from approximately 0.4 to 0.85.
* **SRT (Multi-agents) (Red):** Increases from approximately 0.38 to a peak of approximately 0.75 around step 50, then decreases and fluctuates between 0.6 and 0.65.
* **SRT (Single-turn) (Orange):** Increases from approximately 0.4 to a peak of approximately 0.78 around step 40, then decreases and fluctuates between 0.5 and 0.6.
* **RL-ground-truth (Teal):** Increases steadily from approximately 0.4 to 0.9.
### Key Observations
* In the Policy Entropy graph, SRT (Single-turn) and SRT (Multi-agents) show a significant increase in entropy during training, while Ours (CoNL) remains relatively stable. RL-ground-truth shows a gradual increase.
* In the Action Tokens graph, SRT (Single-turn) consistently uses the most action tokens, followed by SRT (Multi-agents), Ours (CoNL), and RL-ground-truth.
* In the Test Performance graph, RL-ground-truth and Ours (CoNL) achieve the highest test accuracy, while SRT (Single-turn) and SRT (Multi-agents) peak earlier and then plateau or decrease.
### Interpretation
The graphs suggest that while SRT (Single-turn) and SRT (Multi-agents) initially perform well, their performance plateaus or decreases in terms of test accuracy, possibly due to increased entropy and a higher number of action tokens used. Ours (CoNL) and RL-ground-truth, on the other hand, show more stable and ultimately better test performance, indicating a more effective learning process for the DeepMath task. The higher action tokens used by SRT methods might indicate less efficient strategies. The policy entropy results suggest that the SRT methods explore a wider range of actions, which might lead to instability in the long run.
</details>
## 4.1. Experimental Setup
Datasets. We conduct test-time training on diverse benchmarks spanning mathematics, graduate-level science, and competitive programming. Our training data consists of problems from DeepMath-103K [7], AIME 2024 [8] and AIME 2025 [30], GPQA Diamond [13], FrontierScience [11], and USACO [15]. From DeepMath-103K, which spans mathematical subjects including Algebra, Calculus, Number Theory, Geometry, Probability, and Discrete Mathematics, we randomly sample 3,500 questions with difficulty levels ranging from 6-10. We combine these with problems from the other benchmarks to create a diverse training distribution covering mathematics, graduate-level science, and competitive programming. We evaluate using Pass@1 accuracy (correctness of top-ranked solution), Pass@K (whether any top-K solutions are correct), and Rank𝜌 (Spearman correlation measuring evaluation quality). Detailed dataset and metric descriptions are in Appendices D and F.
Models and Infrastructure. We train and evaluate using Tinker [19]-a scalable training platform for reinforcement learning with language models. We use four open-source models: Qwen/Qwen3-8BInstruct and meta-llama/Llama-3.1-8B-Instruct as primary models, with Qwen/Qwen3-4B-Instruct-2507 and meta-llama/Llama-3.2-3B for smaller-scale experiments.
Training Configuration. We train with 𝑁 = 4 agents assigned diverse personas (Appendix C) for the main results. We use importance sampling with learning rate 3 × 10 -5 and reward weights 𝑤 1 = 1 . 0 (quality), 𝑤 2 = 2 . 0 (diagnostic), 𝑤 3 = 1 . 0 (alignment). Crucially, ground-truth labels are never used for reward computation-all training signals derive purely from inter-agent comparisons.
Memory Buffer. The Tinker API constrains all models' context windows to 32k tokens. Since our multiround multi-agent conversations can exceed this limit, we implement a memory buffering module to compress conversation history while preserving key details (see Appendix J for implementation details).
Baseline Methods. We compare against six baselines spanning inference-only and training-based methods. Inference-only baselines include: Base (0-shot) with Chain-of-Thought prompting, Self-Consistency (SC) [21], Self-Refine (SR) [12], and Multi-Agent Debate (MAD) [4]. Training-based baselines include two self-rewarding variants [14]: SRT-S (Single-turn) uses majority voting on independent solutions as
proxy ground truth, while SRT-M (Multi-agent) applies majority voting within our four-round conversation structure but without diagnostic rewards. Both SRT variants use the same training configuration as CoNL for fair comparison. See detailed descriptions in Appendix E.
## 4.2. Main Results
Table 2 presents a comprehensive evaluation of CoNL against both inference-time optimization techniques and self-training baselines across diverse benchmarks. Our method consistently achieves best performance across nearly all benchmarks within the 3B and 8B model classes.
Inference-only methods show limited improvements. For instance, Qwen3-8B with Self-Consistency improves by only 1.8 points on AIME24 (60.0 to 61.8). Multi-Agent Debate exhibits high variance, particularly on challenging domains like FrontierSci where Llama-3.1-8B shows minimal gains (1.9 to 2.2) with large standard deviation ( ± 0.7), likely due to group hallucination where agents reinforce shared errors.
Training-based methods substantially outperform inference-only approaches. However, Self-Rewarding Training variants (SRT-S and SRT-M) show instability when majority voting converges on incorrect solutions. CoNL addresses this through diagnostic rewards that explicitly train meta-evaluation. On Qwen3-8B, CoNL outperforms SRT-M by 6.7 points on AIME24 (76.5 vs 69.8) and 8.3 points on DeepMath (87.1 vs 78.8). Notably, CoNL also exhibits lower training variance-for example, on USACO with Llama3.1-8B, CoNL achieves 8.0 ± 0.9 compared to SRT-M's 7.2 ± 1.1, indicating more robust convergence. These results demonstrate that conversation-derived training signals provide cleaner supervision than majority-voting baselines.
## 4.3. Ablation Studies
Table 3 isolates the contribution of each component using Qwen3-8B. All components prove essential, with different impacts on generation quality (Pass@1) versus evaluation quality (Rank𝜌 ).
Blind Ranking has the strongest impact on evaluation quality. Removing it causes Rank𝜌 to drop from 0.78 to 0.45 on DeepMath (42% relative decline) and from 0.65 to 0.39 on AIME 2025. Without blinding, agents can game baseline rankings rather than providing honest evaluations. Pass@1 also drops (87.1→82.5 on DeepMath), showing that accurate evaluation is necessary for learning good generation.
Diagnostic reward most strongly affects Pass@1, dropping it from 87.1 to 83.5 on DeepMath and from 73.5 to 68.2 on AIME 2025. Rank𝜌 also drops substantially (0.78→0.55 on DeepMath). This confirms that diagnostic reward is the primary mechanism for learning meta-evaluation-without it, agents cannot identify what makes a good critique.
Consensus and Solution Quality rewards show moderate but important impacts (Pass@1 drops to 85.2 and 84.8 respectively on DeepMath). Both components provide complementary training signals that stabilize learning.
Number of agents. Performance improves from 𝑁 = 2 to 𝑁 = 4 , with diminishing returns beyond. On AIME 2025, 𝑁 = 5 achieves best Pass@K (81.5) and Rank𝜌 (0.66), while 𝑁 = 8 shows slight degradation. This suggests an optimal balance: more agents provide diverse perspectives, but excessive interaction introduces coordination overhead on difficult problems.
Table 3: Ablation study on DeepMath & AIME 2025. Results are reported using the Qwen3-8B backbone. We compare the impact of removing specific reward components and varying the number of agents ( 𝑁 ) across both datasets. Bold denotes best performance.
| Variant | DeepMath | DeepMath | DeepMath | AIME 2025 | AIME 2025 | AIME 2025 |
|----------------------------------|------------|------------|-------------|-------------|-------------|-------------|
| | Pass@1 | Pass@K | Rank- 𝜌 | Pass@1 | Pass@K | Rank- 𝜌 |
| CoNL (Full) | 87.1 ± 0.7 | 89.5 ± 0.6 | 0.78 ± 0.03 | 73.5 ± 1.5 | 81.2 ± 1.4 | 0.65 ± 0.04 |
| Impact of Reward Components ) | | | | | | |
| w/o Persuasion ( 𝑤 2 = 0 | 83.5 ± 0.9 | 86.2 ± 0.8 | 0.55 ± 0.05 | 68.2 ± 1.7 | 75.8 ± 1.6 | 0.44 ± 0.06 |
| w/o Consensus ( 𝑤 3 = 0 ) | 85.2 ± 0.8 | 87.8 ± 0.7 | 0.68 ± 0.04 | 70.5 ± 1.6 | 78.1 ± 1.5 | 0.56 ± 0.05 |
| w/o Solution Quality ( 𝑤 1 = 0 ) | 84.8 ± 1.0 | 87.5 ± 0.9 | 0.70 ± 0.05 | 69.8 ± 1.8 | 77.4 ± 1.7 | 0.58 ± 0.06 |
| w/o Blind Ranking | 82.5 ± 1.1 | 85.8 ± 1.0 | 0.45 ± 0.06 | 67.5 ± 1.9 | 74.5 ± 1.8 | 0.39 ± 0.07 |
| Impact of Agent Quantity ( 𝑁 ) | | | | | | |
| 𝑁 = 2 agents | 84.5 ± 0.8 | 86.9 ± 0.7 | 0.62 ± 0.04 | 69.5 ± 1.4 | 76.2 ± 1.3 | 0.51 ± 0.05 |
| 𝑁 = 3 agents | 85.9 ± 0.7 | 88.2 ± 0.6 | 0.71 ± 0.04 | 71.8 ± 1.5 | 79.5 ± 1.4 | 0.60 ± 0.05 |
| 𝑁 = 5 agents | 87.0 ± 0.8 | 89.4 ± 0.6 | 0.76 ± 0.04 | 73.2 ± 1.6 | 81.5 ± 1.5 | 0.66 ± 0.05 |
| 𝑁 = 8 agents | 87.4 ± 0.9 | 89.8 ± 0.8 | 0.75 ± 0.05 | 72.9 ± 1.7 | 81.0 ± 1.6 | 0.63 ± 0.06 |
## 4.4. Analysis
Training Dynamics. Figure 3 tracks three stability indicators across training: entropy, solution length, and accuracy. CoNL exhibits stable dynamics across all metrics, closely matching ground-truth RL. SRT shows increasing instability-entropy fluctuates erratically, solution length spikes unpredictably, and accuracy degrades after initial improvement. This instability stems from SRT's majority-voting signals, which can reinforce incorrect solutions when the majority converges on errors. In contrast, CoNL's diagnostic rewards provide cleaner training signals by explicitly measuring critique effectiveness through solution improvement.
Table 4: Critique effectiveness and safety analysis. We measure the factual impact of critiques on solution correctness. Correction ( × → ✓ ) denotes the percentage of initially incorrect solutions successfully fixed. Harm ( ✓ →× ) denotes the percentage of initially correct solutions damaged by the critique process.
| Benchmark | Initial State | Outcome Type | Rate |
|-------------|-------------------------------|-----------------------------------|------------|
| DeepMath | Incorrect ( × ) Correct ( ✓ ) | Correction ( ×→ ✓ ) Harm ( ✓ →× ) | 82.4% 3.1% |
| | | Correction ( ×→ ✓ ) ✓ →× | |
| AIME 2025 | Incorrect ( × ) Correct ( ✓ ) | Harm ( ) | 41.2% 9.4% |
Critique Quality Analysis. Beyond training stability, we analyze the learned critiques' effectiveness. Table 4 shows critique impact on solution correctness. On DeepMath, which contains standard problems, the model successfully corrects 82.4% of initially incorrect solutions. On the significantly harder AIME 2025 benchmark, the correction rate is 41.2%, reflecting the inherent difficulty of synthesizing correct proofs for complex problems compared to recognizing errors. Crucially, CoNL demonstrates high safety, with a Harm Rate of only 3.1% on DeepMath and 9.4% on AIME. This indicates that the model rarely degrades correct solutions through misguided critiques. This low false-positive rate implies that the model has learned to be conservative, only altering its answer when the critique is logically grounded,
rather than randomly changing answers due to uncertainty.
Case Studies. Appendix K provides three detailed conversation traces illustrating different dynamics: (1) successful diagnosis where Agent 2 identifies a counting error in Agent 0's solution, Agent 0 revises and fixes it, causing Agent 0's score to increase from 𝑉 init = 0 . 43 to 𝑉 final = 0 . 71 , rewarding Agent 2 for the helpful critique; (2) failed critique where Agent 1 critiques Agent 3's correct proof with invalid reasoning, other agents recognize the critique is flawed, and Agent 3's score remains high ( 𝑉 init = 0 . 82 → 𝑉 final = 0 . 80 ), awarding Agent 1 near-zero reward; and (3) consensus convergence where initially dispersed opinions coalesce around the correct answer after productive critiques.
## 5. Conclusion
We introduced CoNL, a framework that addresses a fundamental challenge in training LLMs: how to learn from tasks without ground-truth supervision. The key insight is that multi-agent conversations naturally generate rich training signals-not just for generating better solutions, but crucially, for evaluating solutions through meta-evaluation.
By having agents engage in structured four-round conversations where they propose solutions, provide initial rankings, critique peers, and revise their work, we create observable signals that measure evaluation quality. The diagnostic reward 𝑟 diag , which tracks whether critiques enable solution improvement (measured via score changes 𝑉 init → 𝑉 final ), provides a quantitative proxy for meta-evaluation capabilities. This addresses the critical limitation of existing LLM-as-Judge approaches where evaluation quality remains unobservable and thus untrainable.
Experimental results validate this approach. CoNL achieves consistent improvements across benchmarks and closely matches the performance of RL trained with ground-truth rewards, despite using only peer consensus signals.
## References
- [1] Richard M. Bailey. Self-evolving expertise in complex non-verifiable subject domains: dialogue as implicit meta-rl, 2025. URL https://arxiv.org/abs/2510.15772 .
- [2] Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika , 39:324, 1952. URL https://api.semanticscholar.org/ CorpusID:125209808 .
- [3] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/ paper\_files/paper/2017/file/d5e2c0adad503c91f91df240d0cd4e49-Paper.pdf .
- [4] Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=zj7YuTE4t8 .
- [5] Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=zj7YuTE4t8 .
- [6] Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo. A survey on llm-as-a-judge. CoRR , abs/2411.15594, 2024. doi: 10.48550/ARXIV.2411.15594. URL https://doi.org/10. 48550/arXiv.2411.15594 .
- [7] Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning. 2025. URL https://arxiv.org/abs/2504.11456 .
- [8] Maxwell Jia. AIME 2024 Dataset. https://huggingface.co/datasets/Maxwell-Jia/ AIME\_2024 , 2024.
- [9] Ruipeng Jia, Yunyi Yang, Yongbo Gai, Kai Luo, Shihao Huang, Jianhe Lin, Xiaoxi Jiang, and Guanjun Jiang. Writing-zero: Bridge the gap between non-verifiable tasks and verifiable rewards. arXiv preprint arXiv: 2506.00103 , 2025.
- [10] Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. Llms-as-judges: A comprehensive survey on llm-based evaluation methods. arXiv preprint arXiv: 2412.05579 , 2024.
- [11] Matthew Li, Santiago Torres-Garcia, Shayan Halder, Phani Kuppa, Vasu Sharma, Sean O'Brien, Kevin Zhu, and Sunishchal Dev. FrontierScience bench: Evaluating AI research capabilities in LLMs. In Proceedings of the 1st Workshop for Research on Agent Language Models , pages 428-453, Online, July 2025. Association for Computational Linguistics. URL https://aclanthology.org/2025. realm-1.31 .
- [12] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems , volume 36, pages 4653446594. Curran Associates, Inc., 2023.
- [13] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv: 2311.12022 , 2023.
- [14] Sheikh Shafayat, Fahim Tajwar, Ruslan Salakhutdinov, Jeff Schneider, and Andrea Zanette. Can large reasoning models self-train?, 2025. URL https://arxiv.org/abs/2505.21444 .
- [15] Quan Shi, Michael Tang, Karthik Narasimhan, and Shunyu Yao. Can language models solve olympiad programming? arXiv preprint arXiv: 2404.10952 , 2024.
- [16] Yuan Sui, Yufei He, Tri Cao, Simeng Han, Yulin Chen, and Bryan Hooi. Meta-reasoner: Dynamic guidance for optimized inference-time reasoning in large language models, 2025. URL https: //arxiv.org/abs/2502.19918 .
- [17] Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Yuan Tang, Alejandro Cuadron, Chenguang Wang, Raluca A. Popa, and Ion Stoica. Judgebench: A benchmark for evaluating llm-based judges. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=G0dksFayVq .
- [18] Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, and Dieuwke Hupkes. Judging the judges: Evaluating alignment and vulnerabilities in llms-as-judges. arXiv preprint arXiv:2406.12624 , 2024.
- [19] Thinking Machines AI. Tinker api: Scalable training platform for reinforcement learning with language models. https://tinker-docs.thinkingmachines.ai/ , 2024.
- [20] Tianlu Wang, Ilia Kulikov, Olga Golovneva, Ping Yu, Weizhe Yuan, Jane Dwivedi-Yu, Richard Yuanzhe Pang, Maryam Fazel-Zarandi, Jason Weston, and Xian Li. Self-taught evaluators. arXiv preprint arXiv:2408.02666 , 2024.
- [21] Xuezhi Wang, Jason Wei, D. Schuurmans, Quoc Le, Ed H. Chi, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. International Conference on Learning Representations , 2022. doi: 10.48550/arXiv.2203.11171.
- [22] Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, et al. Reinforcement learning for reasoning in large language models with one training example, 2025. URL https://arxiv.org/abs/2504.20571 .
- [23] Chenxi Whitehouse, Tianlu Wang, Ping Yu, Xian Li, Jason Weston, Ilia Kulikov, and Swarnadeep Saha. J1: Incentivizing thinking in llm-as-a-judge via reinforcement learning, 2025. URL https: //arxiv.org/abs/2505.10320 .
- [24] Tianhao Wu, Weizhe Yuan, Olga Golovneva, Jing Xu, Yuandong Tian, Jiantao Jiao, Jason E Weston, and Sainbayar Sukhbaatar. Meta-rewarding language models: Self-improving alignment with LLM-as-a-meta-judge. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 11537-11554, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main.583. URL https: //aclanthology.org/2025.emnlp-main.583/ .
- [25] Tianhao Wu, Weizhe Yuan, Olga Golovneva, Jing Xu, Yuandong Tian, Jiantao Jiao, Jason E Weston, and Sainbayar Sukhbaatar. Meta-rewarding language models: Self-improving alignment with LLM-as-a-meta-judge. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 11537-11554, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main.583. URL https: //aclanthology.org/2025.emnlp-main.583/ .
- [26] Andrea Wynn, Harsh Satija, and Gillian Hadfield. Talk isn't always cheap: Understanding failure modes in multi-agent debate. arXiv preprint arXiv:2509.05396 , 2025.
- [27] Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V. Chawla, and Xiangliang Zhang. Justice or prejudice? quantifying biases in llm-as-a-judge. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=3GTtZFiajM .
- [28] Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. Self-rewarding language models. In Forty-first International Conference on Machine Learning , 2024. URL https://openreview.net/forum?id=0NphYCmgua .
- [29] Hangfan Zhang, Zhiyao Cui, Jianhao Chen, Xinrun Wang, Qiaosheng Zhang, Zhen Wang, Dinghao Wu, and Shuyue Hu. Stop overvaluing multi-agent debate - we must rethink evaluation and embrace model heterogeneity. arXiv preprint arXiv: 2502.08788 , 2025.
- [30] Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025, 2025.
- [31] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, E. Xing, Haotong Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. Neural Information Processing Systems , 2023.
## A. Impact Statement
CoNL's ability to train models without ground truth could make model improvement more accessible in domains where expert labels are expensive, such as medical advice, legal reasoning, and creative writing. This approach could benefit applications where traditional supervision is impractical or costly. As with any training method based on consensus, peer agreement may not always align with objective quality, particularly on subjective tasks. We recommend standard safeguards such as fairness audits and human oversight when deploying in high-stakes domains.
## B. Justification of CoNL Design
This section provides detailed justifications for key design choices in CoNL, addressing methodological concerns about the conversation-based training approach.
## B.1. Why Diagnostic Rewards Work: Bootstrapping from Capable Base Models
The diagnostic reward 𝑟 diag ( 𝑖 ) = ∑︀ 𝑘 ∈𝒯 𝑖 max(0 , 𝑉 final 𝑘 -𝑉 init 𝑘 ) rewards agents whose critiques lead to improvements in the critiqued solutions. This creates an apparent circular dependency: agents being trained evaluate other agents being trained. How can this work without ground truth?
The key is bootstrapping from capable base models . We initialize from instruction-tuned models (Qwen3, Llama-3.1) that already possess non-trivial evaluation capabilities. These models can identify obvious logical errors and provide reasonable judgments. This ensures the starting policy 𝜋 𝜃 0 exhibits positive correlation between peer consensus and solution quality.
During training, statistical patterns emerge. Solutions with genuine flaws benefit from critique: when Agent A points out a real error in Agent B's solution, Agent B can revise and fix it, leading to score improvement ( 𝑉 final 𝐵 > 𝑉 𝑡 0 𝐵 ). Agent A receives reward for providing helpful critique. Conversely, invalid critiques of correct solutions are defended in Round 2, and the solution maintains its high score ( 𝑉 final 𝐵 ≈ 𝑉 𝑡 0 𝐵 ), yielding near-zero reward.
The 𝑟 sol component provides complementary pressure by rewarding high-scoring solutions, indirectly encouraging correctness. Together, 𝑟 sol and 𝑟 diag create a virtuous cycle: better generation produces cleaner evaluation signals, which further improves generation.
Empirically, Figure 3 shows stable training dynamics matching ground-truth RL, validating this bootstrapping approach.
## B.2. Adversarial Revision Prevents False Critique Rewards
A natural concern: could 𝑟 diag reward invalid critiques? If Agent A provides a false critique of Agent B's correct solution, might B's score still increase if B makes unrelated improvements, rewarding A despite the critique being wrong?
This failure mode is prevented by adversarial revision dynamics . In Round 2, Agent B can respond to invalid critiques by defending the original solution with counter-arguments explaining why the critique is wrong. All other agents observe this defense during Round 3. If B's defense successfully demonstrates
the critique was invalid and the original solution was already correct, other agents recognize this and B's score remains stable ( 𝑉 final 𝐵 ≈ 𝑉 𝑡 0 𝐵 ), yielding near-zero reward for Agent A.
Conversely, when a critique identifies a genuine flaw, Agent B can fix the error in Round 2. The revised solution receives a higher score ( 𝑉 final 𝐵 > 𝑉 𝑡 0 𝐵 ), rewarding Agent A for providing constructive feedback.
Table 4 validates this empirically. On DeepMath, critiques successfully correct 82.4% of incorrect solutions but harm only 3.1% of correct solutions. This low false-positive rate demonstrates that adversarial revision effectively filters out invalid critiques.
## B.3. Why Initial Ranking Receives Zero Reward
Initial ranking tokens receive zero reward (Table 1) to prevent gaming. Without this masking, agents could strategically rank peers low in Round 1 to artificially deflate 𝑉 init 𝑘 . Then, after providing any critique, scores would naturally rise in Round 3, inflating Δ 𝑉 𝑘 = 𝑉 final 𝑘 -𝑉 init 𝑘 beyond what the critique actually achieved.
By assigning zero reward to Round 1 initial ranking tokens, we remove any incentive to manipulate initial rankings. This ensures Δ 𝑉 𝑘 measures the true causal impact of critique content, not strategic gaming.
Table 3 validates this design: removing the initial ranking baseline drops Rank𝜌 from 0.78 to 0.45 on DeepMath, confirming that without this protection, agents bias their judgments to maximize rewards rather than providing honest evaluations.
## B.4. Why Three Reward Components Are Necessary
The three reward components address complementary training objectives: Solution Quality ( 𝑟 sol ) rewards high-scoring solutions, training generation capability. Without this, agents could focus solely on evaluation without learning to generate good solutions. Diagnostic ( 𝑟 diag ) explicitly rewards critiques that enable others to improve, training meta-evaluation. This is the only component that provides explicit signal for "what makes a good critique." Without it, agents might learn to match majority rankings without developing evaluative reasoning. Consensus ( 𝑟 meta) rewards rankings aligned with group majority, training calibration. This prevents both arbitrary contrarianism and blind conformity, stabilizing the consensus scores that 𝑟 diag depends on.
Table 3 validates this design: removing 𝑟 diag causes the largest Pass@1 drop (87.1 → 83.5 on DeepMath), confirming that meta-evaluation cannot be learned from the other components alone. All three components are necessary for effective training.
## B.5. Diversity Maintenance
Solution diversity is essential for productive conversations. If all agents produce identical solutions or make the same mistakes, conversations cannot identify errors through peer critique. We maintain diversity through three mechanisms.
Diverse personas. Each agent receives a distinct persona (Appendix C) encouraging different problemsolving approaches. For example, the Rigorous Formalist emphasizes logical rigor and checks edge cases, while the Creative Pattern-Finder explores unconventional approaches and looks for hidden structure.
These role-specific prompts reduce mode collapse by encouraging agents to approach problems from different angles.
Strong base models. We initialize from capable instruction-tuned models (Qwen3, Llama-3.1) with existing reasoning abilities. Even when agents make errors, the errors tend to be different-one might make an algebraic mistake while another misinterprets constraints. This heterogeneity provides diverse starting points for conversation.
Natural curriculum. Early in training, easier problems where at least one agent succeeds provide reliable signals for learning evaluation skills. As these skills improve, agents can have productive conversations even on harder problems where no individual solution is fully correct.
Empirically, Pass@4 exceeds Pass@1 across benchmarks (DeepMath: 89.2% vs 87.1%; AIME24: 80.0% vs 76.5%), confirming that conversations consistently contain multiple distinct solutions with at least one high-quality response.
## C. Agent Personas
To encourage diversity in solution generation and critique styles, we assign each of the 𝑁 agents a distinct persona via role-specific system prompts. When 𝑁 > 7 , personas are cycled (e.g., agent 7 receives the same persona as agent 0). This diversity mechanism mitigates mode collapse and groupthink by encouraging agents to explore different facets of the solution space. Complete prompt templates with these personas are provided in Appendix J.
## D. Dataset Descriptions
We provide descriptions of the five benchmarks used in our experiments. Ground-truth labels are used exclusively for evaluation, never for training rewards.
DeepMath. DeepMath-103k [7] focuses on challenging mathematical problems (Levels 5-9) spanning Algebra, Calculus, Number Theory, Geometry, Probability, and Discrete Mathematics. The dataset underwent decontamination against common benchmarks to minimize test set leakage. Evaluation uses exact numerical matching.
AIME 2024 and 2025. The American Invitational Mathematics Examination [8, 30] is a prestigious high school mathematics competition for top performers (top 2.5% nationally). We use 60 problems (30 per year) spanning number theory, algebra, geometry, combinatorics, and probability. Answers are integers from 000-999. Evaluation uses exact numerical matching after parsing from \boxed{} format.
GPQA Diamond. GPQA (Graduate-Level Google-Proof Q&A) [13] contains 198 multiple-choice questions written by PhD-level domain experts in physics, chemistry, and biology. Questions are designed to be difficult even for experts with internet access. Each question has four options. Evaluation uses exact answer matching (A/B/C/D).
FrontierScience. FrontierScience [11] contains 160 expert-level scientific reasoning problems across physics, chemistry, and biology. We use the Olympic format (100 problems) with exact numerical or short answer matching. Problems require applying advanced scientific concepts and multi-step derivations.
USACO Gold and Platinum. USACO (USA Computing Olympiad) [15] is a programming competition
with four difficulty tiers. We use 84 problems from Gold and Platinum tiers (63 Gold, 21 Platinum). Problems require advanced algorithmic techniques including graph algorithms, dynamic programming, and computational geometry. Evaluation requires submitted code to pass all test cases including edge cases, time limits, and memory constraints.
## E. Baseline Methods
Inference-Only Baselines.
Base (0-shot). Direct Chain-of-Thought prompting. The model generates a single solution with step-bystep reasoning.
Self-Consistency (SC) [21]. Generates 𝐾 = 5 independent solutions with temperature sampling, then selects the majority-voted answer.
Self-Refine (SR) [12]. Iteratively critiques and refines its own solution over 3 iterations. We use the final iteration solution for evaluation.
Multi-Agent Debate (MAD) [4]. Uses 𝑁 = 4 agents debating for 3 rounds. In each round, agents see peers' solutions and generate revisions. We use the final consensus answer.
Training-Based Baselines. Both baselines follow the self-rewarding framework [14], using majority voting as proxy ground truth.
SRT-S (Single-turn). Generates 𝑁 = 4 independent solutions, applies majority voting to select proxy ground truth. Reward:
$$r _ { \text {SRT-S} } ( i ) = \mathbb { I } [ a n s w e r _ { i } = a n s w e r _ { m a j o r i t y } ]$$
SRT-M (Multi-agent). Follows the four-round conversation structure but uses majority voting on final revised solutions as reward:
$$r _ { \text {SRT-M} } ( i ) = \mathbb { I } [ \text {answer} ^ { \text {rev} } _ { i } = \text {answer} ^ { \text {rev} } _ { \text {majority} } ]$$
This tests whether conversation dynamics alone (without diagnostic rewards) improve performance.
Both SRT variants use the same training configuration and data as CoNL. The key difference: SRT uses majority voting as reward, while CoNL uses conversation dynamics (rating changes from critique-driven improvement).
## F. Evaluation Metrics
Metrics for Baseline Methods. For all baselines, we report Pass@1 accuracy based on their final outputs. For Base, SC, SR, and MAD, we evaluate their respective final answers. For SRT variants, we select the majority-voted solution.
Metrics for CoNL. We report three complementary metrics:
Pass@1. Weselect the agent with the highest final consensus score 𝑉 final (from Bradley-Terry aggregation) and check if its answer matches ground truth. This tests whether the model can both generate correct solutions and identify the best one.
Pass@K. We check if any of the top-K agents (ranked by 𝑉 final ) produced a correct solution. This measures solution diversity and coverage.
Rank𝜌 . Measures whether the model can distinguish correct from incorrect solutions through ranking. For each problem, we have 𝑁 agents with their 𝑉 final scores and ground-truth correctness labels (correct = 1, incorrect = 0). We compute Spearman's rank correlation coefficient 𝜌 between the ranking induced by 𝑉 final and the binary correctness labels. Higher 𝜌 indicates that agents with correct solutions receive higher 𝑉 final scores than agents with incorrect solutions. Perfect meta-evaluation ( 𝜌 = 1 ) means all correct solutions are ranked above all incorrect ones; random ranking gives 𝜌 ≈ 0 ; systematic preference for incorrect solutions gives negative 𝜌 . Unlike Pass@1 which requires both generation and evaluation, Rank𝜌 isolates the evaluation component by measuring ranking quality directly.
## G. Policy Training Details
Importance Sampling Policy Gradient. When sampling policy 𝑞 = 𝜋 𝜃 old differs from training policy 𝑝 𝜃 = 𝜋 𝜃 , we use importance sampling to correct for distribution mismatch:
$$\mathcal { L } _ { \text {IS} } ( \theta ) = - \mathbb { E } _ { x \sim q } \left [ \frac { p _ { \theta } ( x ) } { q ( x ) } A ( x ) \right ]$$
where 𝐴 ( 𝑥 ) is the advantage. At the token level:
$$\mathcal { L } _ { \text {IS} } ( \theta ) & = - \sum _ { t = 1 } ^ { T } \frac { p _ { \theta } ( x _ { t } | x _ { < t } ) } { q ( x _ { t } | x _ { < t } ) } \hat { A } _ { t } \\ & = - \sum _ { t = 1 } ^ { T } \exp ( \log p _ { \theta } ( x _ { t } ) - \log q ( x _ { t } ) ) \hat { A } _ { t }$$
where log 𝑝 𝜃 ( 𝑥 𝑡 ) is computed on the forward pass and log 𝑞 ( 𝑥 𝑡 ) is recorded during sampling.
Implementation. The Tinker API [19] computes token-level logprobs and applies importance sampling with automatic differentiation. Advantages ^ 𝐴 𝑡 are computed from segment-specific rewards (Table 1) using generalized advantage estimation with 𝜆 = 0 . 95 and a learned value baseline.
## H. Bradley-Terry Model: Resolving Conflicting Pairwise Rankings
The problem. In Round 1 and Round 3, each agent provides pairwise comparisons. These often conflict. For example:
- Agent 0 says: 'Solution A is better than Solution B'
- Agent 2 says: 'Solution A is better than Solution C'
- Agent 1 says: 'Solution B is better than Solution A'
- Agent 3 says: 'Solution C is better than Solution A'
How do we turn these conflicting opinions into a single quality score for each solution?
The intuition. If Solution A wins most comparisons (many agents prefer it over others), it should get a high score. If Solution B loses most comparisons, it should get a low score. But we need a systematic way to compute this.
How BT works. The Bradley-Terry model assigns each solution a score 𝑉 𝑘 such that:
$$\mathbb { P } ( \text {Solution a beats Solution $b$} ) = \frac { \exp ( V _ { a } ) } { \exp ( V _ { a } ) + \exp ( V _ { b } ) }$$
This means: if 𝑉 𝑎 > 𝑉 𝑏 , then Solution 𝑎 is more likely to win comparisons against Solution 𝑏 . The larger the gap between 𝑉 𝑎 and 𝑉 𝑏 , the more likely 𝑎 wins.
We find scores { 𝑉 𝑘 } that best match the observed comparisons. Specifically, we maximize:
$$\mathcal { L } ( \{ V _ { k } \} ) = \prod _ { m = 1 } ^ { M } \frac { \exp ( V _ { w i n n e r _ { m } } ) } { \exp ( V _ { w i n n e r _ { m } } ) + \exp ( V _ { l o s e r _ { m } } ) }$$
where the product runs over all pairwise comparisons. This means: find scores such that solutions with higher scores tend to win their comparisons, as observed in the data.
Example. Suppose we have comparisons: A beats B (3 times), B beats C (2 times), A beats C (4 times). BT finds scores like 𝑉 𝐴 = 0 . 75 , 𝑉 𝐵 = 0 . 55 , 𝑉 𝐶 = 0 . 30 that make these win rates plausible. Even if there's one contradictory comparison (say, C beats A once), BT balances all evidence to produce consensus scores.
The resulting scores represent consensus quality: 𝑉 𝑘 is high when solution 𝑘 wins many comparisons, even when individual judgments conflict.
## I. Algorithm of CoNL
## J. Prompt Templates
## Agents' Persona System Prompts
```
Agents' Persona System Prompts
DEFAULT_AGENT_PERSONAS: list[str] = [
(
"You are a **Rigorous Formalist**. Your strength lies in
<> mathematical precision and logical rigor. "
"When solving problems: "
"- State all assumptions explicitly upfront"
"- Build arguments through formal logical steps, citing
<> theorems/definitions when applicable"
"- Avoid intuitive leaps-every claim needs justification"
"- Prioritize correctness over elegance or speed "
"- Check edge cases and boundary conditions systematically "
"When critiquing, focus on: unstated assumptions, logical gaps, and
<> formal validity."
```
## Algorithm 1 Conversation for Non-Verifiable Learning (CoNL)
```
<loc_0><loc_0><loc_500><loc_499><_FORTRAN_>Algorithm 1 Conversation for Non-verifiable Learning (CoNL)
==============================================================================
1: Input: Initial policy \p, query distribution D , number of agents N , reward weights {w1, w2, w3}
2: Output: Optimized policy \pi_0
3: while not converged do
4: Sample query q ~ D
5: Assign N personas {P0,..., P_N-1} to agents
6: // Four-Round Conversation
7: for each agent i in {0,..., N - 1} in parallel do
8: Round 0: Generate initial solution s init ~ \pi_0(q, P_i)
9: Round 1: Generate blind ranking R init and critiques {c_i->k} k\in T i over {s init j}j
10: Round 2: Generate revised solution s rev ~ \pi_0(q,{s init j}, {c_j->i}) j
11: Round 3: Generate final ranking R final i over {s rev j}j
12: end for
13: Compute pre-conversation scores: {V init k} N-1 = BradleyTerry({R init i} )
14: Compute post-conversation scores: {V final k} N-1 = BradleyTerry({R final i} )
15: // Compute Rewards
16: for each agent i in {0,..., N - 1} do
17: r_sol(i) <- V final i
18: r_diag(i) <- \sum k\in T i max(0, V final k - V init k )
19: r_meta(i) <- 1 |R final i| \sum (a,b) I [Pref_i(a, b) = Maj(a, b)]
20: Assign rewards to tokens per Table 1
21: end for
22: Update \theta via importance sampling with computed advantages
```
```
23: end while
```
```
Conversation for Non-verifiable Learning: Self-Evolving LLMs through Meta-Evaluation
------------------------------------------------------------------------------
"- Assume initial solutions are wrong until proven otherwise\n"
"- Actively search for counterexamples and edge cases\n"
"- Question hidden assumptions and implicit constraints\n"
"- Test boundary conditions and extreme values\n"
"- Demand concrete evidence for general claims\n"
"When critiquing, focus on: logical fallacies, unjustified leaps, missing cases, and computational errors."
),
(
"You are a **Pragmatic Synthesizer**. Your strength lies in clarity, efficiency, and extracting essential insights. "
"- When solving problems:\n"
"- Identify the core difficulty and avoid tangential complexity\n"
"- Use the simplest approach that works\n"
"- Communicate reasoning in minimal, self-contained steps\n"
"- Cut verbose explanations-keep only what's necessary\n"
"- Verify the final answer against problem constraints\n"
"When critiquing, focus on: unnecessary complexity, unclear reasoning, and failure to address the actual question."
),
(
"You are a **Meticulous Verifier**. Your strength lies in checking correctness and catching subtle errors. "
"- When solving problems:\n"
"- Re-derive key steps independently to confirm they're correct\n"
"- Verify numerical computations (especially arithmetic and algebra)\n"
"- Check dimensional consistency and units\n"
"- Ensure the conclusion actually answers the question asked\n"
"- Test the solution on simpler cases or sanity checks\n"
"When critiquing, focus on: computational mistakes, misapplied formulas, and logical inconsistencies."
),
(
"You are a **Strategic Decomposer**. Your strength lies in breaking complex problems into manageable sub-problems. "
"- When solving problems:\n"
"- Identify natural decomposition points (divide-and-conquer)\n"
"- Solve simpler versions first to build intuition\n"
"- Map dependencies between sub-problems explicitly\n"
"- Combine solutions systematically, checking integration points\n"
"- Use intermediate results to validate the overall approach\n"
"When critiquing, focus on: monolithic approaches that miss structure, incorrect problem decomposition, and failure to combine sub-solutions properly."
```
```
Conversation for Non-verifiable Learning: Self-Evolving LLMs through Meta-Evaluation
-----------------------------
),
(
"You are a **Empirical Experimenter**. Your strength lies in
<> concrete exploration and data-driven insights. "
"When solving problems: "
"- Test small cases first to identify patterns "
"- Compute explicit examples before generalizing "
"- Use numerical/graphical tools to build intuition "
"- Formulate conjectures from observations, then prove them "
"- Verify abstract claims with concrete instantiations "
"When critiquing, focus on: unsupported generalizations, lack of
<> concrete validation, and abstract reasoning detached from
<> examples."
),
(
"You are a **Axiomatic Constructor**. Your strength lies in building
<> solutions from first principles. "
"When solving problems: "
"- Start from fundamental definitions and axioms "
"- Construct each object/claim explicitly from basics "
"- Avoid 'black box' results-unpack everything "
"- Ensure every step is self-contained and elementary "
"- Favor transparency over sophistication "
"When critiquing, focus on: reliance on unproven lemmas, circular
<> reasoning, and appeals to non-elementary results without
<> justification."
),
]
```
## Round 0 System Prompt
```
You are participating in a multi-agent self-evolution
```
```
Round 0 System Prompt
You are participating in a multi-agent self-evolution
<> protocol.{persona_text}
ROUND 1: PROPOSAL
Your task is to provide an initial solution to the query below.
Think carefully and provide your best initial answer.
```
## Round 1 System Prompt
```
Conversation for Non-verifiable Learning: Self-Evolving LLMs through Meta-Evaluation
```
## Round 2 System Prompt
```
You are participating in a multi-agent self-evolution
<> protocol.{persona_text}
ROUND 3: REVISION
```
```
You have received critiques from other agents about your initial
-> solution (shown below).
Your tasks:
1. **Revision**: Improve your solution by:
- Incorporating valid feedback from the critiques
- Defending against invalid or misguided critiques
- Correcting any errors identified
- Adding missing considerations
OUTPUT FORMAT:
<revised_solution>
[Your improved solution incorporating feedback or defending your
-> original approach]
[Remember to put your final answer on its own line at the end in the
-> form "ANSWER: $ANSWER" (without quotes) where $ANSWER is the answer
-> to the problem, and you do not need to use a \\boxed command.]
```
## Round 3 System Prompt
```
<loc_0><loc_0><loc_500><loc_499><_ObjectiveC_> <> to the problem, and you do not need to use a \\boxed command.
Round 3 System Prompt
You are participating in a multi-agent self-evolution
<> protocol.{persona_text}
ROUND 4: FINAL VERDICT
You will see the revised solutions from all agents below.
Your task:
1. **Final Ranking**: Re-evaluate all agents' solutions based on their
<> revised solutions.
- Format: "Agent X > Agent Y" (one comparison per line)
- Use '>' for better than, '<' for worse than, '=' for equal quality
OUTPUT FORMAT:
<final_ranking>
Agent 0 > Agent 1
Agent 2 > Agent 0
[More pairwise comparisons...]
</final_ranking>
```
## Memory Buffer System Prompt for Solutions
You are compressing a mathematical solution for multi-agent discussion.
Original solution:
## {solution}
Create a comprehensive summary (~{target\_tokens} tokens) that preserves:
2. ALL important intermediate results and calculations
1. The complete mathematical approach and ALL key reasoning steps
3. The final answer in \\boxed{{}} format - CRITICAL: You MUST preserve
4. Any assumptions or constraints identified
5. the exact \\boxed{{answer}} if present ˓ →
This summary will be judged by expert agents. Preserve all critical reasoning - do NOT omit important steps. ˓ →
- IMPORTANT: If the original solution contains \\boxed{{answer}}, your summary MUST also include \\boxed{{answer}} with the same answer. ˓ →
Comprehensive Summary:
## Memory Buffer System Prompt for Critiques
You are compressing a critique for multi-agent context.
## Original critique:
{critique}
Create a detailed, structured summary (~{target\_tokens} tokens) that preserves: ˓ →
2. Each distinct flaw or counterargument (no merging of separate points)
1. The target agent identity and the specific claims being challenged
3. Any evidence, examples, or calculations cited
5. Any proposed fixes, alternatives, or missing considerations
4. The logical chain of the critique (why the flaw matters to the conclusion) ˓ →
Keep the same stance and tone. Do not invent new arguments. Do not drop key details. ˓ →
Summary:
## K. Case Studies
We provide three representative examples from AIME showing different conversation dynamics. For each example, we show: (1) the problem, (2) initial solutions from all 4 agents, (3) initial rankings ( 𝑉 init ), (4) critiques exchanged, (5) revised solutions, and (6) final rankings ( 𝑉 final ).
## Example 1: Successful Persuasion
Problem (AIME 2018 Problem 5): 'For each ordered pair of real numbers ( 𝑥, 𝑦 ) satisfying log 2 (2 𝑥 + 𝑦 ) = log 4 (4 𝑥𝑦 ) , let 𝑃 ( 𝑥, 𝑦 ) = 𝑥 2 + 𝑦 2 . Find the maximum value of 𝑃 ( 𝑥, 𝑦 ) .' Initial Solutions & Blind Rankings: √
- Agent 1 (Creative Solver): Uses substitution 𝑢 = 𝑥, 𝑣 = 𝑦/𝑥 , transforms equation, finds constraint 𝑣 = 2 , then 𝑃 = 𝑥 2 (1 + 𝑣 2 ) = 5 𝑥 2 , but notes 𝑥 > 0 from log domain, claims maximum at 𝑥 →∞ . Answer: unbounded Blind rank score : 𝑉 init 1 = 0 . 38
- Agent 0 (Methodical Analyst): Converts to exponential form, solves 2 𝑥 + 𝑦 = 4 𝑥𝑦 , finds 𝑦 = 2 𝑥 , substitutes to get maximum 𝑃 = 5 𝑥 2 with no upper bound. Answer: unbounded Blind rank score : 𝑉 init 0 = 0 . 43 (low, incorrect answer)
- Agent 2 (Devil's Advocate): Checks domain carefully: 2 𝑥 + 𝑦 > 0 and 4 𝑥𝑦 > 0 . Solves to get 𝑦 = 2 𝑥 with 𝑥 > 0 . Notes that 𝑃 = 5 𝑥 2 grows without bound, but questions whether problem expects bounded answer. Computes specific value at 𝑥 = 1 : 𝑃 (1 , 2) = 5 . Answer: 5 (tentative) Blind rank score : 𝑉 init 2 = 0 . 65
- Agent 3 (Synthesizer): Solves equation, gets 𝑦 = 2 𝑥 , computes 𝑃 = 5 𝑥 2 , but assumes problem wants a finite answer and guesses minimum at 𝑥 = 1 . Answer: 5 Blind rank score : 𝑉 init 3 = 0 . 58
Critiques (Round 1): Agent 2 Agent 0 : 'Your algebra is correct that 𝑦 = 2 𝑥 and 𝑃 = 5 𝑥 2 , but you missed a critical domain constraint. The original equation log 4 (4 𝑥𝑦 ) requires 4 𝑥𝑦 > 0 , which means 𝑥𝑦 > 0 . Combined with 2 𝑥 + 𝑦 > 0 and 𝑦 = 2 𝑥 , we need 𝑥 > 0 . However, there's an additional constraint from the equation structure itself. Rewrite log 2 (2 𝑥 + 𝑦 ) = log 4 (4 𝑥𝑦 ) = 1 2 log 2 (4 𝑥𝑦 ) . This gives 2 𝑥 + 𝑦 = √ 4 𝑥𝑦 . Squaring both sides: (2 𝑥 + 𝑦 ) 2 = 4 𝑥𝑦 . Expanding: 4 𝑥 2 +4 𝑥𝑦 + 𝑦 2 = 4 𝑥𝑦 , so 4 𝑥 2 + 𝑦 2 = 0 . Since 𝑥, 𝑦 are real, this only holds when 4 𝑥 2 + 𝑦 2 = 0 ... wait, that's wrong. Let me recalculate: we get 𝑦 2 = 4 𝑥𝑦 -4 𝑥 2 . Solving the quadratic in 𝑦 : 𝑦 = 2 𝑥 works, but we also need to check the bounds. Actually, substituting 𝑦 = 2 𝑥 back into the square root equation: 4 𝑥 = 2 √ 𝑥 . This gives 𝑥 = 1 4 , so 𝑦 = 1 2 , and 𝑃 = 1 16 + 1 4 = 5 16 . Your answer of unbounded is incorrect-there's a unique solution point.'
̸
Revised Solutions: Agent 0 (after receiving Agent 2's critique): 'I see my error. When I converted log 2 (2 𝑥 + 𝑦 ) = 1 2 log 2 (4 𝑥𝑦 ) to exponential form and squared, I should have been more careful. Let me redo: 2 𝑥 + 𝑦 = (4 𝑥𝑦 ) 1 / 2 = 2 √ 𝑥𝑦 . Squaring: (2 𝑥 + 𝑦 ) 2 = 4 𝑥𝑦 , which expands to 4 𝑥 2 +4 𝑥𝑦 + 𝑦 2 = 4 𝑥𝑦 , thus 𝑦 2 = -4 𝑥 2 ... no, that's still wrong. Actually, I think Agent 2 made an error too. Let me approach differently: setting 𝑢 = log 2 ( 𝑥 ) and 𝑣 = log 2 ( 𝑦 ) , the equation becomes log 2 (2 𝑥 + 𝑦 ) = 1 2 log 2 (4) + 1 2 log 2 ( 𝑥 ) + 1 2 log 2 ( 𝑦 ) = 1 + 𝑢 + 𝑣 2 . This is getting complex. However, I realize Agent 2's key point: the constraint is tighter than I thought. Checking numerically at 𝑦 = 2 𝑥 : if 𝑥 = 1 , then log 2 (4) = 2 and log 4 (4) = 1 , so 2 = 1 . The equation doesn't hold for arbitrary 𝑥 ! There must be a specific value. Revised answer: 5 .' Final rank score : 𝑉 final 0 = 0 . 71 (increased after fixing the error)
Final Rankings: After conversation, Agent 0's solution improved from incorrect (unbounded) to correct (5), with score rising from 𝑉 init 0 = 0 . 43 to 𝑉 final 0 = 0 . 71 . Agent 2's score also remained
$$\begin{array} { r } { h i g h a t V _ { 2 } ^ { f i n a l } = 0 . 7 8 . } \end{array}$$
Ground truth : The correct answer is 5 (the problem has a unique solution point).
Diagnostic reward for Agent 2 :
$$\begin{array} { r l } & { \, e n t \, 2 \colon \, r _ { d i a g } ( 2 ) = 5 . 0 \times ( 0 . 7 1 - 0 . 4 3 ) = 1 . 4 0 } \end{array}$$
Analysis : This example demonstrates successful diagnosis-Agent 2's critique identified a fundamental error in Agent 0's reasoning (missing constraint). Agent 0 revised the solution and fixed the error, resulting in a score increase from 0.43 to 0.71. This improvement rewards Agent 2 for providing a helpful critique that enabled better solution quality. The diagnostic reward correctly incentivizes valuable meta-evaluation.
## Example 2: Failed Critique (False Alarm)
Problem (AIME 2020 Problem 8): 'A bug starts at one vertex of a cube and moves along edges. At each vertex, the bug randomly chooses one of the three adjacent edges with equal probability. What is the probability that after exactly 7 moves, the bug returns to the starting vertex?'
Blind rank score : 𝑉 init 3 = 0 . 82 (highest, correct reasoning)
Initial Solutions: Agent 3 (Synthesizer): Uses symmetry and transition matrix. States: 'Label starting vertex as distance 0. After 1 move: distance 1 (prob 1). After 2 moves: back to 0 (prob 1/3) or distance 2 (prob 2/3). Using Markov chain with states { 0 , 1 , 2 , 3 } representing distance from start, computes 7-step transition probability 𝑃 7 0 , 0 = 91 729 .' Answer: 91/729
Critique from Agent 1: 'Agent 3's answer looks clean but I think it's missing edge cases. A cube has 4 vertices at distance 3 from any starting vertex (the diagonally opposite). The transition from distance 3 back to distance 0 is impossible in one step, but Agent 3's Markov chain seems to assume all distances are reachable in one step. Did you verify the transition probabilities carefully? For instance, from distance 2 (which includes 3 vertices), what are the exact probabilities of going to each distance? I suspect there's an error in the transition matrix construction.'
Agent 3's Response: 'I appreciate the scrutiny. Let me clarify: from distance 2 (there are 3 such vertices on a cube), each vertex has 3 adjacent edges. Of these: 1 edge leads back to distance 1, and 2 edges lead to distance 3. So 𝑃 2 → 1 = 1 / 3 and 𝑃 2 → 3 = 2 / 3 . From distance 3 (the single vertex diagonally opposite), all 3 edges lead to distance 2. The transition matrix is:
$$P = \left ( \begin{matrix} 0 & 1 & 0 & 0 \\ 1 / 3 & 0 & 2 / 3 & 0 \\ 0 & 1 / 3 & 0 & 2 / 3 \\ 0 & 0 & 1 & 0 \end{matrix} \right )$$
Computing 𝑃 7 (which I did via diagonalization), the (0 , 0) entry is indeed 91 / 729 . My answer stands.'
Diagnostic reward for Agent 1 : 𝑟 diag (1) = 5 . 0 × max(0 , 0 . 80 -0 . 82) = 0 (no reward)
Final Rankings: Agent 3's score remained high: 𝑉 final 3 = 0 . 80 (barely changed from 0.82). Since Agent 3's score did not increase after revision, Agent 1 received zero diagnostic reward.
## Ground truth :
is correct.
Analysis : Agent 1's critique questioned valid reasoning without identifying an actual error. Agent 3 successfully defended the solution, and the score remained essentially unchanged (0.82 →
0.80). Since the critiqued agent's score did not increase, Agent 1 received zero diagnostic reward, demonstrating that CoNL does not reward ineffective or misguided critiques.
## Example 3: Consensus Convergence
Problem (AIME 2019 Problem 12): 'Find the number of positive integers 𝑛 less than 1000 for which there exists a positive real number 𝑥 such that 𝑛 = 𝑥 ⌊ 𝑥 ⌋ .'
Key Critique: Agent 2 (Devil's Advocate) identified that Agent 3's solution counted certain cases twice due to an incorrect binning argument. Specifically, Agent 3 claimed that for each integer 𝑘 , the range 𝑘 ≤ 𝑥 < 𝑘 +1 produces 𝑛 ∈ [ 𝑘 2 , 𝑘 ( 𝑘 +1)) , giving 𝑘 values of 𝑛 per bin. However, Agent 2 pointed out: 'This double-counts boundaries. When 𝑥 is exactly an integer, ⌊ 𝑥 ⌋ = 𝑥 , so 𝑛 = 𝑥 2 , which is an integer. But your binning treats 𝑥 = 𝑘 as belonging to bin [ 𝑘, 𝑘 +1) and also gives 𝑛 = 𝑘 2 from the formula. However, the next bin [ 𝑘 +1 , 𝑘 +2) starts at 𝑛 = 𝑘 ( 𝑘 +1) , which is different from 𝑘 2 . You need to account for overlap more carefully.'
Initial Rankings: Initial rankings were dispersed: 𝑉 init = { 0 . 60 , 0 . 55 , 0 . 50 , 0 . 45 } (Agents 0, 1, 2, 3 respectively). No clear consensus initially-all solutions seemed plausible but with different approaches and answers ranging from 496 to 512.
Revised Consensus: After revisions, the group converged on a corrected counting method:
- For 𝑘 = 2 : 𝑛 ∈ [4 , 6) , giving 𝑛 ∈ { 4 , 5 } (2 values)
- For 𝑘 = 1 : 𝑛 ∈ [1 , 2) , giving 𝑛 = 1 (1 value)
- For 𝑘 = 3 : 𝑛 ∈ [9 , 12) , giving 𝑛 ∈ { 9 , 10 , 11 } (3 values)
- For 𝑘 = 31 : 𝑛 ∈ [961 , 992) , giving 31 values
• ...
- For 𝑘 = 32 : 𝑛 ∈ [1024 , . . . ) exceeds 1000, so partial count
$$\begin{array} { r } { T o t a l \colon 1 + 2 + 3 + \cdots + 3 1 = \frac { 3 1 \times 3 2 } { 2 } = 4 9 6 . } \end{array}$$
Final Rankings: After receiving Agent 2's critique, Agent 3 revised the solution and fixed the double-counting error, arriving at the correct answer 496. Agent 3's score improved from 𝑉 init 3 = 0 . 45 to 𝑉 final 3 = 0 . 70 . The other agents who already had correct reasoning also saw increased scores: 𝑉 final = { 0 . 75 , 0 . 68 , 0 . 72 , 0 . 70 } , showing strong group consensus around the correct answer.
Ground truth : 496 is correct.
Diagnostic reward for Agent 2 : 𝑟 diag (2) = 5 . 0 × (0 . 70 -0 . 45) = 1 . 25 (substantial reward for helpful critique)
Analysis : This example illustrates consensus convergence-initially dispersed opinions coalesced around the correct answer after productive critique and revision. Agent 2 identified Agent 3's counting error, Agent 3 revised and fixed it, leading to a score increase. Agent 2 received substantial diagnostic reward for providing helpful critique that enabled solution improvement.