# Kimi K2.5: Visual Agentic Intelligence
**Authors**: Kimi Team
Abstract
We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5×$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint https://huggingface.co/moonshotai/Kimi-K2.5 to facilitate future research and real-world applications of agentic intelligence.
<details>
<summary>figures/k25-main-result.png Details</summary>
### Visual Description
## Bar Chart: AI Model Performance Comparison Across Tasks
### Overview
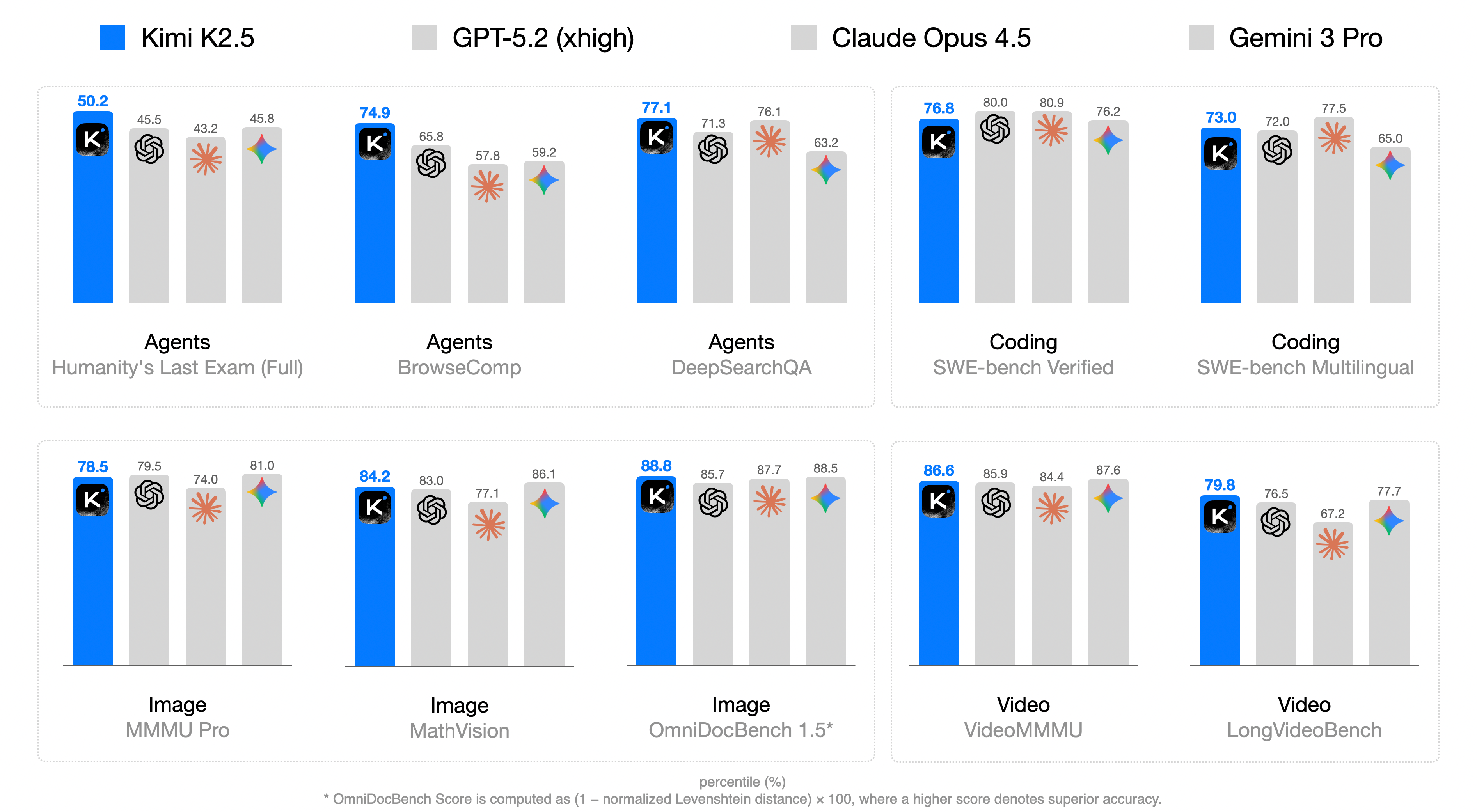
The image displays a grouped bar chart comparing the performance of four AI models (Kimi K2.5, GPT-5.2 (xhigh), Claude Opus 4.5, Gemini 3 Pro) across six task categories: Agents (with subcategories), Coding, Image, and Video. Each bar represents a percentage score, with higher values indicating superior accuracy. The chart emphasizes Kimi K2.5's dominance across most tasks.
### Components/Axes
- **X-Axis**: Task categories and subcategories:
- Agents
- Humanity's Last Exam (Full)
- BrowseComp
- DeepSearchQA
- Coding
- SWE-bench Verified
- SWE-bench Multilingual
- Image
- MMU Pro
- MathVision
- OmniDocBench 1.5*
- Video
- VideoMMMU
- LongVideoBench
- **Y-Axis**: Percentage scores (0–100%), labeled "percentile (%)"
- **Legend**: Located at the top, mapping colors to models:
- Blue: Kimi K2.5
- Gray: GPT-5.2 (xhigh)
- Dark Gray: Claude Opus 4.5
- Light Gray: Gemini 3 Pro
- **Annotations**: Numerical values atop each bar (e.g., "50.2" for Kimi K2.5 in Agents/Humanity's Last Exam)
### Detailed Analysis
#### Agents
- **Humanity's Last Exam (Full)**:
- Kimi K2.5: 50.2 (blue)
- GPT-5.2 (xhigh): 45.5 (gray)
- Claude Opus 4.5: 43.2 (dark gray)
- Gemini 3 Pro: 45.8 (light gray)
- **BrowseComp**:
- Kimi K2.5: 74.9 (blue)
- GPT-5.2 (xhigh): 65.8 (gray)
- Claude Opus 4.5: 57.8 (dark gray)
- Gemini 3 Pro: 59.2 (light gray)
- **DeepSearchQA**:
- Kimi K2.5: 77.1 (blue)
- GPT-5.2 (xhigh): 71.3 (gray)
- Claude Opus 4.5: 76.1 (dark gray)
- Gemini 3 Pro: 63.2 (light gray)
#### Coding
- **SWE-bench Verified**:
- Kimi K2.5: 76.8 (blue)
- GPT-5.2 (xhigh): 80.0 (gray)
- Claude Opus 4.5: 80.9 (dark gray)
- Gemini 3 Pro: 76.2 (light gray)
- **SWE-bench Multilingual**:
- Kimi K2.5: 73.0 (blue)
- GPT-5.2 (xhigh): 72.0 (gray)
- Claude Opus 4.5: 77.5 (dark gray)
- Gemini 3 Pro: 65.0 (light gray)
#### Image
- **MMU Pro**:
- Kimi K2.5: 78.5 (blue)
- GPT-5.2 (xhigh): 79.5 (gray)
- Claude Opus 4.5: 74.0 (dark gray)
- Gemini 3 Pro: 81.0 (light gray)
- **MathVision**:
- Kimi K2.5: 84.2 (blue)
- GPT-5.2 (xhigh): 83.0 (gray)
- Claude Opus 4.5: 77.1 (dark gray)
- Gemini 3 Pro: 86.1 (light gray)
- **OmniDocBench 1.5***:
- Kimi K2.5: 88.8 (blue)
- GPT-5.2 (xhigh): 85.7 (gray)
- Claude Opus 4.5: 87.7 (dark gray)
- Gemini 3 Pro: 88.5 (light gray)
#### Video
- **VideoMMMU**:
- Kimi K2.5: 86.6 (blue)
- GPT-5.2 (xhigh): 85.9 (gray)
- Claude Opus 4.5: 84.4 (dark gray)
- Gemini 3 Pro: 87.6 (light gray)
- **LongVideoBench**:
- Kimi K2.5: 79.8 (blue)
- GPT-5.2 (xhigh): 76.5 (gray)
- Claude Opus 4.5: 67.2 (dark gray)
- Gemini 3 Pro: 77.7 (light gray)
### Key Observations
1. **Kimi K2.5 Dominance**: Consistently leads in most tasks (e.g., 88.8 in OmniDocBench 1.5*), with only minor exceptions (e.g., SWE-bench Verified, where Claude Opus 4.5 scores higher at 80.9).
2. **Claude Opus 4.5 Strengths**: Outperforms others in SWE-bench Verified (80.9) and LongVideoBench (67.2), though the latter is an outlier due to lower absolute scores.
3. **Gemini 3 Pro Variability**: Scores range from 43.2 (lowest in Agents/BrowseComp) to 88.5 (highest in Image/OmniDocBench 1.5*), showing inconsistent performance.
4. **Task-Specific Trends**:
- Coding tasks show tighter competition (GPT-5.2 and Claude Opus 4.5 often match Kimi K2.5).
- Image tasks highlight Gemini 3 Pro's peak performance (81.0 in MMU Pro).
- Video tasks reveal Kimi K2.5's slight edge in VideoMMMU (86.6 vs. Gemini 3 Pro's 87.6).
### Interpretation
The data suggests **Kimi K2.5** is the most balanced high-performer across diverse AI tasks, particularly excelling in image and document-based benchmarks. Its consistent scores (73–88.8 range) indicate robust architecture and training. **Claude Opus 4.5** shows niche strengths in coding and video tasks but lags in Agents. **Gemini 3 Pro**'s variability hints at potential overfitting or specialization gaps. The **OmniDocBench 1.5*** metric (88.8 for Kimi K2.5) underscores its document-processing prowess, while the asterisk notes its calculation method: `(1 - normalized Levenshtein distance) × 100`, emphasizing accuracy over raw output. This chart likely informs model selection for applications requiring cross-domain AI capabilities.
</details>
Figure 1: Kimi K2.5 main results.
1 Introduction
Large Language Models (LLMs) are rapidly evolving toward agentic intelligence. Recent advances, such as GPT-5.2 [41], Claude Opus 4.5 [4], Gemini 3 Pro [19], and Kimi K2-Thinking [1], demonstrate substantial progress in agentic capabilities, particularly in tool calling and reasoning. These models increasingly exhibit the ability to decompose complex problems into multi-step plans and to execute long sequences of interleaved reasoning and actions.
In this report, we introduce the training methods and evaluation results of Kimi K2.5. Concretely, we improve the training of K2.5 over previous models in the following two key aspects.
Joint Optimization of Text and Vision. A key insight from the practice of K2.5 is that joint optimization of text and vision enhances both modalities and avoids the conflict. Specifically, we devise a set of techniques for this purpose. During pre-training, in contrast to conventional approaches that add visual tokens to a text backbone at a late stage [7, 20], we find early vision fusion with lower ratios tends to yield better results given the fixed total vision-text tokens. Therefore, K2.5 mixes text and vision tokens with a constant ratio throughout the entire training process.
Architecturally, Kimi K2.5 employs MoonViT-3D, a native-resolution vision encoder incorporating the NaViT packing strategy [14], enabling variable-resolution image inputs. For video understanding, we introduce a lightweight 3D ViT compression mechanism: consecutive frames are grouped in fours, processed through the shared MoonViT encoder, and temporally averaged at the patch level. This design allows Kimi K2.5 to process videos up to 4 $×$ longer within the same context window while maintaining complete weight sharing between image and video encoders.
During post-training, we introduce zero-vision SFT—text-only SFT alone activates visual reasoning and tool use. We find that adding human-designed visual trajectories at this stage hurts generalization. In contrast, text-only SFT performs better—likely because joint pretraining already establishes strong vision-text alignment, enabling capabilities to generalize naturally across modalities. We then apply joint RL on both text and vision tasks. Crucially, we find visual RL enhances textual performance rather than degrading it, with improvements on MMLU-Pro and GPQA-Diamond. This bidirectional enhancement—text bootstraps vision, vision refines text—represents superior cross-modal alignment in joint training.
Agent Swarm: Parallel Agent Orchestration. Most existing agentic models rely on sequential execution of tool calls. Even systems capable of hundreds of reasoning steps, such as Kimi K2-Thinking [1], suffer from linear scaling of inference time, leading to unacceptable latency and limiting task complexity. As agentic workloads grow in scope and heterogeneity—e.g., building a complex project that involves massive-scale research, design, and development—the sequential paradigm becomes increasingly inefficient.
To overcome the latency and scalability limits of sequential agent execution, Kimi K2.5 introduces Agent Swarm, a dynamic framework for parallel agent orchestration. We propose a Parallel-Agent Reinforcement Learning (PARL) paradigm that departs from traditional agentic RL [2]. In addition to optimizing tool execution via verifiable rewards, the model is equipped with interfaces for sub-agent creation and task delegation. During training, sub-agents are frozen and their execution trajectories are excluded from the optimization objective; only the orchestrator is updated via reinforcement learning. This decoupling circumvents two challenges of end-to-end co-optimization: credit assignment ambiguity and training instability. Agent Swarm enables complex tasks to be decomposed into heterogeneous sub-problems executed concurrently by domain-specialized agents, transforming task complexity from linear scaling to parallel processing. In wide-search scenarios, Agent Swarm reduces inference latency by up to 4.5 $×$ while improving item-level F1 from 72.8% to 79.0% compared to single-agent baselines.
Kimi K2.5 represents a unified architecture for general-purpose agentic intelligence, integrating vision and language, thinking and instant modes, chats and agents. It achieves strong performance across a broad range of agentic and frontier benchmarks, including state-of-the-art results in visual-to-code generation (image/video-to-code) and real-world software engineering in our internal evaluations, while scaling both the diversity of specialized agents and the degree of parallelism. To accelerate community progress toward General Agentic Intelligence, we open-source our post-trained checkpoints of Kimi K2.5, enabling researchers and developers to explore, refine, and deploy scalable agentic intelligence.
2 Joint Optimization of Text and Vision
Kimi K2.5 is a native multimodal model built upon Kimi K2 through large-scale joint pre-training on approximately 15 trillion mixed visual and text tokens. Unlike vision-adapted models that compromise either linguistic or visual capabilities, our joint pre-training paradigm enhances both modalities simultaneously. This section describes the multimodal joint optimization methodology that extends Kimi K2 to Kimi K2.5.
2.1 Native Multimodal Pre-Training
Table 1: Performance comparison across different vision-text joint-training strategies. Early fusion with a lower vision ratio yields better results given a fixed total vision-text token budget.
| | Vision Injection Timing | Vision-Text Ratio | Vision Knowledge | Vision Reasoning | OCR | Text Knowledge | Text Reasoning | Code |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Early | 0% | 10%:90% | 25.8 | 43.8 | 65.7 | 45.5 | 58.5 | 24.8 |
| Mid | 50% | 20%:80% | 25.0 | 40.7 | 64.1 | 43.9 | 58.6 | 24.0 |
| Late | 80% | 50%:50% | 24.2 | 39.0 | 61.5 | 43.1 | 57.8 | 24.0 |
A key design question for multimodal pre-training is: Given a fixed vision-text token budget, what is the optimal vision-text joint-training strategy. Conventional wisdom [7, 20] suggests introducing vision tokens predominantly in the later stages of LLM training at high ratios (e.g., 50% or higher) should accelerate multimodal capability acquisition, treating multimodal capability as a post-hoc add-on to linguistic competence.
However, our experiments (as shown in Table 1 Figure 9) reveal a different story. We conducted ablation studies varying the vision ratio and vision injection timing while keeping the total vision and text token budgets fixed. To strictly meet the targets for different ratios, we pre-trained the model with text-only tokens for a specifically calculated number of tokens before introducing vision data. Surprisingly, we found that the vision ratio has minimal impact on final multimodal performance. In fact, early fusion with a lower vision ratio yields better results given a fixed total vision-text token budget. This motivates our native multimodal pre-training strategy: rather than aggressive vision-heavy training concentrated at the end, we adopt a moderate vision ratio integrated early in the training process, allowing the model to naturally develop balanced multimodal representations while benefiting from extended co-optimization of both modalities.
2.2 Zero-Vision SFT
Pretrained VLMs do not naturally perform vision-based tool-calling, which poses a cold-start problem for multimodal RL. Conventional approaches address this issue through manually annotated or prompt-engineered chain-of-thought (CoT) data [7], but such methods are limited in diversity, often restricting visual reasoning to simple diagrams and primitive tool manipulations (crop, rotate, flip).
An observation is that high-quality text SFT data are relatively abundant and diverse. We propose a novel approach, zero-vision SFT, that uses only text SFT data to activate the visual, agentic capabilities during post-training. In this approach, all image manipulations are proxied through programmatic operations in IPython, effectively serving as a generalization of traditional vision tool-use. This "zero-vision" activation enables diverse reasoning behaviors, including pixel-level operations such as object size estimation via binarization and counting, and generalizes to visually grounded tasks such as object localization, counting, and OCR.
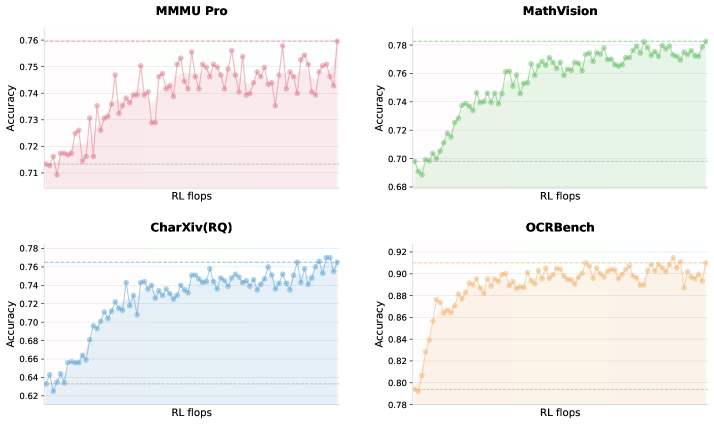
Figure 2 illustrates the RL training curves, where the starting points are obtained from zero-vision SFT. The results show that zero-vision SFT is sufficient for activating vision capabilities while ensuring generalization across modalities. This phenomenon is likely due to the joint pretraining of text and vision data as described in Section 2.1. Compared to zero-vision SFT, our preliminary experiments show that text-vision SFT yields much worse performance on visual, agentic tasks, possibly because of the lack of high-quality vision data.
2.3 Joint Multimodal Reinforcement Learning (RL)
In this section, we describe the methodology implemented in K2.5 that enables effective multimodal RL, from outcome-based visual RL to emergent cross-modal transfer that enhances textual performance.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Graphs: Model Performance vs. RL Flops
### Overview
The image contains four line graphs comparing the accuracy of different models (MMMU Pro, MathVision, CharXiv(RQ), OCRBench) against reinforcement learning (RL) computational effort (measured in "RL flops"). Each graph shows a distinct trendline with shaded confidence intervals, plotted against a shared x-axis (RL flops) and y-axis (Accuracy).
---
### Components/Axes
- **X-Axis (Horizontal):**
- Label: "RL flops"
- Scale: 0 to ~100 (approximate, with ticks at 20, 40, 60, 80, 100).
- Position: Bottom of all graphs.
- **Y-Axis (Vertical):**
- Label: "Accuracy"
- Scale:
- Top-left (MMMU Pro): 0.71 to 0.76 (0.01 increments).
- Top-right (MathVision): 0.68 to 0.78 (0.02 increments).
- Bottom-left (CharXiv(RQ)): 0.62 to 0.78 (0.02 increments).
- Bottom-right (OCRBench): 0.78 to 0.92 (0.02 increments).
- Position: Left side of all graphs.
- **Legends:**
- Top-left: Pink line = "MMMU Pro".
- Top-right: Green line = "MathVision".
- Bottom-left: Blue line = "CharXiv(RQ)".
- Bottom-right: Orange line = "OCRBench".
- Position: Top of each graph.
- **Shaded Regions:**
- Light-colored bands (pink, green, blue, orange) under each line, likely representing confidence intervals or variability.
---
### Detailed Analysis
1. **MMMU Pro (Pink):**
- Starts at ~0.71 accuracy at 0 RL flops.
- Peaks at ~0.76 accuracy, with fluctuations (e.g., dips to ~0.73 at ~40 RL flops).
- Final accuracy stabilizes near 0.76 after ~80 RL flops.
2. **MathVision (Green):**
- Begins at ~0.68 accuracy, rising steadily to ~0.78.
- Sharp increase between 20–40 RL flops, then gradual plateau.
3. **CharXiv(RQ) (Blue):**
- Starts at ~0.62 accuracy, climbing to ~0.78.
- Steeper growth in early stages (0–40 RL flops), then stabilizes.
4. **OCRBench (Orange):**
- Begins at ~0.78 accuracy, rising to ~0.92.
- Consistent upward trend with minimal fluctuations.
---
### Key Observations
- **Accuracy vs. RL Flops:** All models show improved accuracy with increased RL flops, but rates of improvement vary.
- **OCRBench Dominance:** Achieves the highest final accuracy (~0.92) with the least computational effort (~80 RL flops).
- **MMMU Pro Volatility:** Exhibits the most fluctuation, suggesting instability in training or evaluation.
- **CharXiv(RQ) Efficiency:** Rapid early gains but plateaus earlier than others.
---
### Interpretation
The data suggests that **OCRBench** is the most efficient model, achieving high accuracy with moderate RL flops. **MathVision** and **CharXiv(RQ)** demonstrate strong scalability, with CharXiv(RQ) showing rapid early improvements. **MMMU Pro**’s volatility may indicate challenges in training stability or evaluation methodology. The shaded regions imply that confidence intervals widen for some models (e.g., MMMU Pro), highlighting uncertainty in performance estimates. These trends underscore the trade-off between computational cost and model performance, with OCRBench offering the optimal balance.
</details>
Figure 2: Vision RL training curves on vision benchmarks starting from minimal zero-vision SFT. By scaling vision RL FLOPs, the performance continues to improve, demonstrating that zero-vision activation paired with long-running RL is sufficient for acquiring robust visual capabilities.
Outcome-Based Visual RL
Following the zero-vision SFT, the model requires further refinement to reliably incorporate visual inputs into reasoning. Text-initiated activation alone exhibits notable failure modes: visual inputs are sometimes ignored, and images may not be attended to when necessary. We employ outcome-based RL on tasks that explicitly require visual comprehension for correct solutions. We categorize these tasks into three domains:
- Visual grounding and counting: Accurate localization and enumeration of objects within images;
- Chart and document understanding: Interpretation of structured visual information and text extraction;
- Vision-critical STEM problems: Mathematical and scientific questions filtered to require visual inputs.
Outcome-based RL on these tasks improves both basic visual capabilities and more complex agentic behaviors. Extracting these trajectories for rejection-sampling fine-tuning (RFT) enables a self-improving data pipeline, allowing subsequent joint RL stages to leverage richer multimodal reasoning traces.
Visual RL Improves Text Performance
Table 2: Cross-Modal Transfer: Vision RL Improves Textual Knowledge
| Benchmark | Before Vision-RL | After Vision-RL | Improvement |
| --- | --- | --- | --- |
| MMLU-Pro | 84.7 | 86.4 | +1.7 |
| GPQA-Diamond | 84.3 | 86.4 | +2.1 |
| LongBench v2 | 56.7 | 58.9 | +2.2 |
To investigate potential trade-offs between visual and textual performance, we evaluated text-only benchmarks before and after visual RL. Surprisingly, outcome-based visual RL produced measurable improvements in textual tasks, including MMLU-Pro (84.7% $→$ 86.4%), GPQA-Diamond (84.3% $→$ 86.4%), and LongBench v2 (56.7% $→$ 58.9%) (Table 2). Analysis suggests that visual RL enhances calibration in areas requiring structured information extraction, reducing uncertainty on queries that resemble visually grounded reasoning (e.g., counting, OCR). These findings indicate that visual RL can contribute to cross-modal generalization, improving textual reasoning without observable degradation of language capabilities.
Joint Multimodal RL Motivated by the finding that robust visual capabilities can emerge from zero-vision SFT paired with vision RL—which further enhances general text abilities—we adopt a joint multimodal RL paradigm during Kimi K2.5’s post-training. Departing from conventional modality-specific expert divisions, we organize RL domains not by input modality but by abilities—knowledge, reasoning, coding, agentic, etc. These domain experts jointly learn from both pure-text and multimodal queries, while the Generative Reward Model (GRM) similarly optimizes across heterogeneous traces without modality barriers. This pardaigm ensures that capability improvements acquired through either textual or visual inputs inherently generalize to enhance related abilities across the alternate modality, thereby maximizing cross-modal capability transfer.
3 Agent Swarm
The primary challenge of existing agent-based systems lies in their reliance on sequential execution of reasoning and tool-calling steps. While this structure may be effective for simpler, short-horizon tasks, it becomes inadequate as the complexity of the task increases and the accumulated context grows. As tasks evolve to contain broad information gathering and intricate, multi-branch reasoning, sequential systems often encounter significant bottlenecks [6, 4, 5]. The limited capacity of a single agent working through each step one by one can lead to the exhaustion of practical reasoning depth and tool-call budgets, ultimately hindering the system’s ability to handle more complex scenarios.
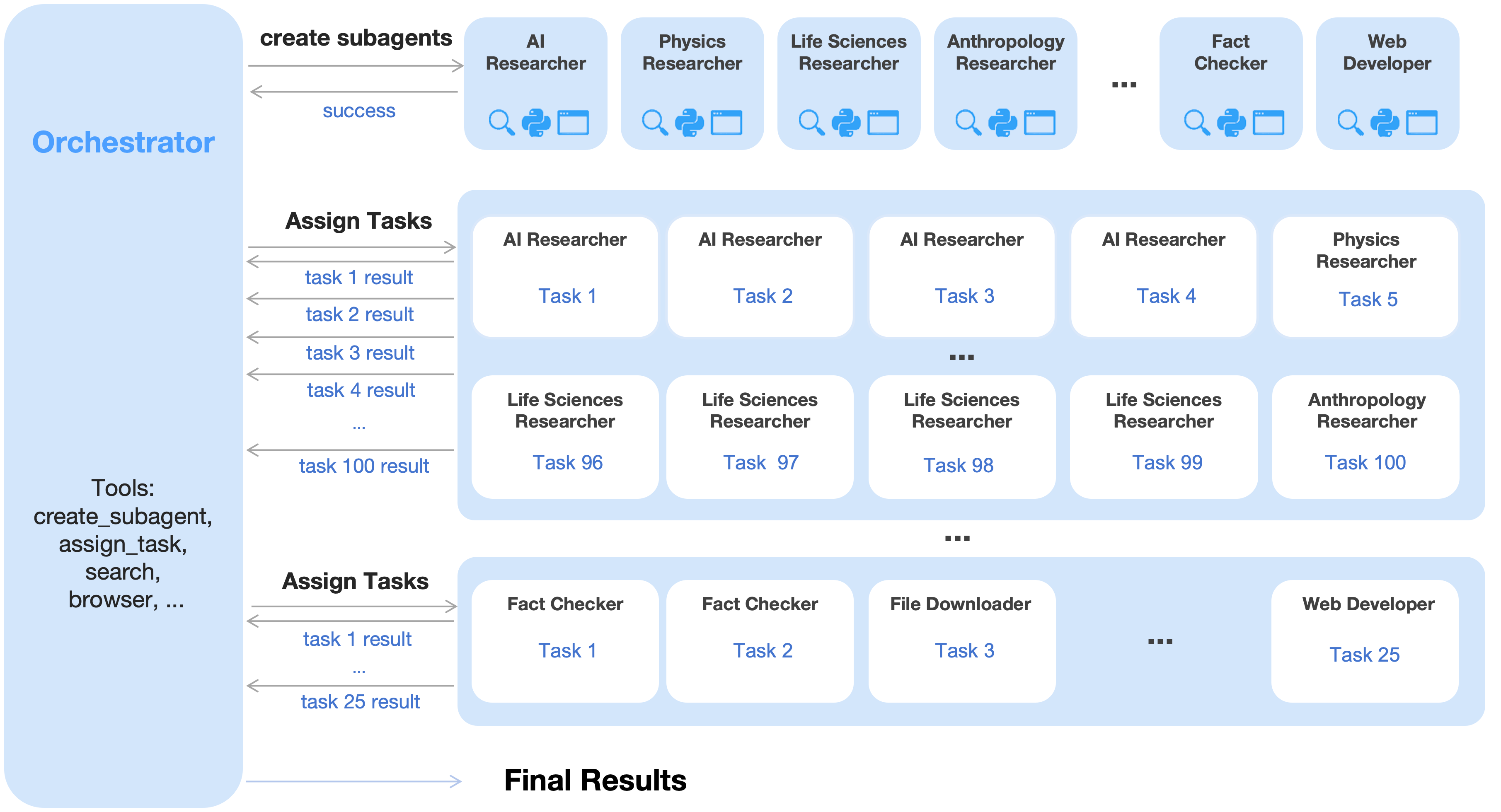
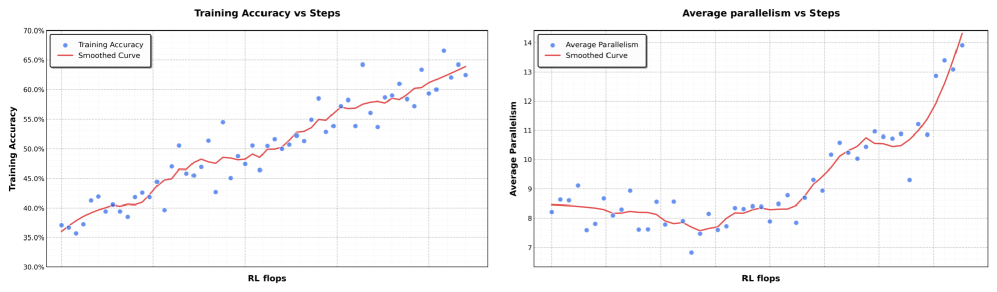
To address this, we introduce Agent Swarm and Parallel Agent Reinforcement Learning (PARL). Instead of executing a task as a reasoning chain or relying on pre-specified parallelization heuristics, K2.5 initiates an Agent Swarm through dynamic task decomposition, subagent instantiation, and parallel subtask scheduling. Importantly, parallelism is not presumed to be inherently advantageous; decisions regarding whether, when, and how to parallelize are explicitly learned through environmental feedback and RL-driven exploration. As shown in Figure 4, the progression of performance demonstrates this adaptive capability, with the cumulative reward increasing smoothly as the orchestrator optimizes its parallelization strategy throughout training.
<details>
<summary>figures/multi-agent-rl-system.png Details</summary>
### Visual Description
## Flowchart: Multi-Agent Task Orchestration System
### Overview
The diagram illustrates a multi-agent workflow system where an Orchestrator coordinates tasks across specialized AI researchers, physics researchers, life sciences researchers, anthropology researchers, fact checkers, and web developers. The system includes task assignment, execution, and result compilation phases.
### Components/Axes
1. **Left Panel (Orchestrator)**
- Contains system tools: `create_subagent`, `assign_task`, `search`, `browser`, ...
- Vertical flow from top to bottom
2. **Top Section (Create Subagents)**
- Horizontal row of researcher roles with Python logos and search icons:
- AI Researcher
- Physics Researcher
- Life Sciences Researcher
- Anthropology Researcher
- Fact Checker
- Web Developer
- Arrows labeled "success" connecting Orchestrator to each role
3. **Middle Section (Assign Tasks)**
- Three horizontal task assignment layers:
- **Top Layer**: AI Researchers assigned Tasks 1-5
- **Middle Layer**: Life Sciences Researchers assigned Tasks 96-100
- **Bottom Layer**: Fact Checker (Tasks 1-3), File Downloader (Task 3), Web Developer (Task 25)
- Arrows show task results flowing back to Orchestrator
4. **Bottom Section (Final Results)**
- Final compilation area with no specific data points shown
### Detailed Analysis
- **Task Distribution**:
- AI Researchers handle initial tasks (1-5)
- Life Sciences Researchers handle specialized tasks (96-100)
- Fact Checker and Web Developer handle verification/implementation tasks (1-3, 25)
- **Workflow Pattern**:
1. Orchestrator creates subagents
2. Assigns tasks to appropriate specialists
3. Collects results
4. Compiles final output
- **Tool Integration**:
- Search and browser tools enable external data collection
- Python integration suggests code execution capabilities
### Key Observations
1. Task numbering shows hierarchical organization (1-5, 96-100, 25)
2. Multiple Fact Checkers suggest quality control processes
3. Web Developer task (25) appears isolated from other task groupings
4. No explicit error handling or retry mechanisms shown
### Interpretation
This system demonstrates a distributed research workflow where:
- The Orchestrator acts as a central coordinator
- Specialized researchers handle domain-specific tasks
- Task numbering suggests prioritization or categorization
- Final results compilation implies aggregation of diverse outputs
The absence of error handling mechanisms and the isolated Web Developer task (25) might indicate potential bottlenecks or single points of failure in the system. The hierarchical task numbering could represent different research phases or priority levels.
</details>
Figure 3: An agent swarm has a trainable orchestrator that dynamically creates specialized frozen subagents and decomposes complex tasks into parallelizable subtasks for efficient distributed execution.
Architecture and Learning Setup
The PARL framework adopts a decoupled architecture comprising a trainable orchestrator and frozen subagents instantiated from fixed intermediate policy checkpoints. This design deliberately avoids end-to-end co-optimization to circumvent two fundamental challenges: credit assignment ambiguity and training instability. In this multi-agent setting, outcome-based rewards are inherently sparse and noisy; a correct final answer does not guarantee flawless subagent execution, just as a failure does not imply universal subagent error. By freezing the subagents and treating their outputs as environmental observations rather than differentiable decision points, we disentangle high-level coordination logic from low-level execution proficiency, leading to more robust convergence. To improve efficiency, we first train the orchestrator using small-size subagents before transitioning to larger models. Our RL framework also supports dynamically adjusting the inference instance ratios between subagents and the orchestrator, thereby maximizing the resource usage across the cluster.
PARL Reward
Training a reliable parallel orchestrator is challenging due to the delayed, sparse, and non-stationary feedback inherent in independent subagent execution. To address this, we define the PARL reward as:
| | $\displaystyle r_{\mathrm{PARL}}(x,y)=\lambda_{1}·\mspace{-26.0mu}\underbrace{r_{\text{parallel}}}_{\text{instantiation reward}}\mspace{-9.0mu}+\mspace{18.0mu}\lambda_{2}·\mspace{-32.0mu}\underbrace{r_{\text{finish}}}_{\text{sub-agent finish rate}}+\underbrace{r_{\text{perf}}(x,y)}_{\text{task-level outcome}}\,.$ | |
| --- | --- | --- |
The performance reward $r_{\text{perf}}$ evaluates the overall success and quality of the solution $y$ for a given task $x$ . This is augmented by two auxiliary rewards, each addressing a distinct challenge in learning parallel orchestration. The reward $r_{\text{parallel}}$ is introduced to mitigate serial collapse —a local optimum where the orchestrator defaults to single-agent execution. By incentivizing subagent instantiation, this term encourages the exploration of concurrent scheduling spaces. The $r_{\text{finish}}$ reward focuses on the successful completion of assigned subtasks. It is used to prevent spurious parallelism, a reward-hacking behavior in which the orchestrator increases parallel metrics dramatically by spawning many subagents without meaningful task decomposition. By rewarding completed subtasks, $r_{\text{finish}}$ enforces feasibility and guides the policy toward valid and effective decompositions.
To ensure the final policy optimizes for the primary objective, the hyperparameters $\lambda_{1}$ and $\lambda_{2}$ are annealed to zero over the course of training.
Critical Steps as Resource Constraint
To measure computational time cost in a parallel-agent setting, we define critical steps by analogy to the critical path in a computation graph. We model an episode as a sequence of execution stages indexed by $t=1,...,T$ . In each stage, the main agent executes an action, which corresponds to either direct tool invocation or the instantiation of a group of subagents running in parallel. Let $S_{\mathrm{main}}^{(t)}$ denote the number of steps taken by the main agent in stage $t$ (typically $S_{\mathrm{main}}^{(t)}=1$ ), and $S_{\mathrm{sub},i}^{(t)}$ denote the number of steps taken by the $i$ -th subagent in that parallel group. The duration of stage $t$ is governed by the longest-running subagent within that cohort. Consequently, the total critical steps for an episode are defined as
| | $\displaystyle\text{CriticalSteps}=\sum_{t=1}^{T}\left(S_{\mathrm{main}}^{(t)}+\max_{i}S_{\mathrm{sub},i}^{(t)}\right).$ | |
| --- | --- | --- |
By constraining training and evaluation using critical steps rather than total steps, the framework explicitly incentivizes effective parallelization. Excessive subtask creation that does not reduce the maximum execution time of parallel groups yields little benefit under this metric, while well-balanced task decomposition that shortens the longest parallel branch directly reduces critical steps. As a result, the orchestrator is encouraged to allocate work across subagents in a way that minimizes end-to-end latency, rather than merely maximizing concurrency or total work performed.
Prompt Construction for Parallel-agent Capability Induction
To incentivize the orchestrator to leverage the advantages of parallelization, we construct a suite of synthetic prompts designed to stress the limits of sequential agentic execution. These prompts emphasize either wide search, requiring simultaneous exploration of many independent information sources, or deep search, requiring multiple reasoning branches with delayed aggregation. We additionally include tasks inspired by real-world workloads, such as long-context document analysis and large-scale file downloading. When executed sequentially, these tasks are difficult to complete within fixed reasoning-step and tool-call budgets. By construction, they encourage the orchestrator to allocate subtasks in parallel, enabling completion within fewer critical steps than would be feasible for a single sequential agent. Importantly, the prompts do not explicitly instruct the model to parallelize. Instead, they shape the task distribution such that parallel decomposition and scheduling strategies are naturally favored.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Charts: Training Accuracy vs Steps and Average Parallelism vs Steps
### Overview
Two line charts are presented side-by-side, comparing metrics over "RL flops" (reinforcement learning steps). The left chart tracks **Training Accuracy**, while the right chart tracks **Average Parallelism**. Both include blue data points and red smoothed curves to highlight trends.
---
### Components/Axes
#### Left Chart: Training Accuracy vs Steps
- **X-axis**: RL flops (horizontal axis, labeled "RL flops").
- **Y-axis**: Training Accuracy (vertical axis, labeled "Training Accuracy", range 30%–70%).
- **Legend**:
- Blue: "Training Accuracy" (data points).
- Red: "Smoothed Curve" (trend line).
- **Grid**: Light gray grid lines for reference.
#### Right Chart: Average Parallelism vs Steps
- **X-axis**: RL flops (horizontal axis, labeled "RL flops").
- **Y-axis**: Average Parallelism (vertical axis, labeled "Average Parallelism", range 7–14).
- **Legend**:
- Blue: "Average Parallelism" (data points).
- Red: "Smoothed Curve" (trend line).
- **Grid**: Light gray grid lines for reference.
---
### Detailed Analysis
#### Left Chart: Training Accuracy
- **Data Points (Blue)**:
- Start at ~35–36% for early RL flops.
- Gradually increase to ~65–66% by the final steps.
- Notable fluctuations (e.g., dips to ~40% at mid-range flops).
- **Smoothed Curve (Red)**:
- Mirrors the upward trend of data points.
- Smooths out minor fluctuations, showing a consistent rise.
#### Right Chart: Average Parallelism
- **Data Points (Blue)**:
- Begin at ~8.0–8.5 for early flops.
- Dip to ~7.5–7.8 around mid-range flops.
- Sharp increase to ~13.5–14.0 by the final steps.
- **Smoothed Curve (Red)**:
- Follows the data points closely.
- Highlights the initial dip and subsequent steep rise.
---
### Key Observations
1. **Training Accuracy**:
- Steady improvement over RL flops, with minor mid-range dips.
- Final accuracy reaches ~65–66%, suggesting effective learning.
2. **Average Parallelism**:
- Initial inefficiency (dip to ~7.5) followed by rapid improvement.
- Final parallelism exceeds initial values by ~50%.
3. **Smoothed Curves**:
- Both charts show red curves aligning tightly with data trends, confirming consistency.
---
### Interpretation
- **Training Dynamics**: The left chart demonstrates that training accuracy improves with more RL flops, though mid-range fluctuations suggest potential instability or optimization challenges.
- **Parallelism Behavior**: The right chart reveals a non-linear relationship. The initial dip in parallelism may reflect resource contention or algorithmic inefficiencies, while the later surge indicates successful scaling or parallelization optimizations.
- **Smoothed Curves**: These emphasize the overall trend, filtering out noise. The red lines validate that the observed patterns are not random but reflect underlying system behavior.
- **Practical Implications**: The data suggests that increasing RL flops enhances model performance (accuracy) and computational efficiency (parallelism), though initial phases may require careful tuning to avoid early inefficiencies.
</details>
Figure 4: In our parallel-agent reinforcement learning environment, the training accuracy increases smoothly as training progresses. At the same time, the level of parallelism during training also gradually increases.
4 Method Overview
4.1 Foundation: Kimi K2 Base Model
The foundation of Kimi K2.5 is Kimi K2 [53], a trillion-parameter mixture-of-experts (MoE) transformer [59] model pre-trained on 15 trillion high-quality text tokens. Kimi K2 employs the token-efficient MuonClip optimizer [29, 33] with QK-Clip for training stability. The model comprises 1.04 trillion total parameters with 32 billion activated parameters, utilizing 384 experts with 8 activated per token (sparsity of 48). For detailed descriptions of MuonClip, architecture design, and training infrastructure, we refer to the Kimi K2 technical report [53].
4.2 Model Architecture
The multimodal architecture of Kimi K2.5 consists of three components: a three-dimensional native-resolution vision encoder (MoonViT-3D), an MLP projector, and the Kimi K2 MoE language model, following the design principles established in Kimi-VL [54].
MoonViT-3D: Shared Embedding Space for Images and Videos
In Kimi-VL, we employ MoonViT to natively process images at their original resolutions, eliminating the need for complex sub-image splitting and splicing operations. Initialized from SigLIP-SO-400M [77], MoonViT incorporates the patch packing strategy from NaViT [14], where single images are divided into patches, flattened, and sequentially concatenated into 1D sequences, thereby enabling efficient simultaneous training on images at varying resolutions.
To maximize the transfer of image understanding capabilities to video, we introduce MoonViT-3D with a unified architecture, fully shared parameters, and a consistent embedding space. By generalizing the “patch n’ pack“ philosophy to the temporal dimension, up to four consecutive frames are treated as a spatiotemporal volume: 2D patches from these frames are jointly flattened and packed into a single 1D sequence, allowing the identical attention mechanism to operate seamlessly across both space and time. While the extra temporal attention improves understanding on high-speed motions and visual effects, the sharing maximizes knowledge generalization from static images to dynamic videos, achieving strong video understanding performance (see in Tab. 4) without requiring specialized video modules or architectural bifurcation. Prior to the MLP projector, lightweight temporal pooling aggregates patches within each temporal chunk, yielding $4×$ temporal compression to significantly extend feasible video length. The result is a unified pipeline where knowledge and ability obtained from image pretraining transfers holistically to videos through one shared parameter space and feature representation.
4.3 Pre-training Pipeline
As illustrated in Table 3, Kimi K2.5’s pre-training builds upon the Kimi K2 language model checkpoint and processes approximately 15T tokens across three stages: first, standalone ViT training to establish a robust native-resolution visual encoder; second, joint pre-training to simultaneously enhance language and multimodal capabilities; and third, mid-training on high-quality data and long-context activation to refine capabilities and extend context windows.
Table 3: Overview of training stages: data composition, token volumes, sequence lengths, and trainable components.
| Stages | ViT Training | Joint Pre-training | Joint Long-context Mid-training |
| --- | --- | --- | --- |
| Data | Alt text Synthesis Caption Grounding, OCR, Video | + Text, Knowledge Interleaving Video, OS Screenshot | + High-quality Text & Multimodal Long Text, Long Video Reasoning, Long-CoT |
| Sequence length | 4096 | 4096 | 32768 $→$ 262144 |
| Tokens | 1T | 15T | 500B $→$ 200B |
| Training | ViT | ViT & LLM | ViT & LLM |
ViT Training Stage
The MoonViT-3D is continual pre-trained from SigLIP [77] on image-text and video-text pairs, where the text components consist of a variety of targets: image alt texts, synthetic captions of images and videos, grounding bboxes, and OCR texts. Unlike the implementation in Kimi-VL [54], this continual pre-training does not include a contrastive loss, but incorporates solely cross-entropy loss ${L}_{caption}$ for caption generation conditioned on input images and videos. We adopt a two-stage alignment strategy. In the first stage, we update the MoonViT-3D to align it with Moonlight-16B-A3B [33] via the caption loss, consuming about 1T tokens with very few training FLOPs. This stage allows MoonViT-3D to primarily understand high-resolution images and videos. A very short second stage follows, updating only the MLP projector to bridge the ViT with the 1T LLM for smoother joint pre-training.
Joint Training Stages
The joint pre-training stage continues from a near-end Kimi K2 checkpoint over additional 15T vision-text tokens at 4K sequence length. The data recipe extends Kimi K2’s pre-training distribution by introducing unique tokens, adjusting data proportions with increased weight on coding-related content, and controlling maximum epochs per data source. The third stage performs long-context activation with integrated higher-quality mid-training data, sequentially extending context length via YaRN [44] interpolation. This yields significant generalization improvements in long-context text understanding and long video comprehension.
4.4 Post-Training
4.4.1 Supervised Fine-Tuning
Following the SFT pipeline established by Kimi K2 [53], we developed K2.5 by synthesizing high-quality candidate responses from K2, K2 Thinking and a suite of proprietary in-house expert models. Our data generation strategy employs specialized pipelines tailored to specific domains, integrating human annotation with advanced prompt engineering and multi-stage verification. This methodology produced a large-scale instruction-tuning dataset featuring diverse prompts and intricate reasoning trajectories, ultimately training the model to prioritize interactive reasoning and precise tool-calling for complex, real-world applications.
4.4.2 Reinforcement Learning
Reinforcement learning constitutes a crucial phase of our post-training. To facilitate joint optimization across text and vision modalities, as well as to enable PARL for agent swarm, we develop a Unified Agentic Reinforcement Learning Environment (Appendix D) and optimize the RL algorithms. Both text-vision joint RL and PARL are built upon the algorithms described in this section.
Policy Optimization
For each problem $x$ sampled from a dataset $\mathcal{D}$ , $K$ responses $\{y_{1},...,y_{K}\}$ are generated using the previous policy $\pi_{\mathrm{old}}$ . We optimize the model $\pi_{\theta}$ with respect to the following objective:
$$
\displaystyle L_{\mathrm{RL}}(\theta)=\mathbb{E}_{x\sim\mathcal{D}}\left[\frac{1}{N}\sum_{j=1}^{K}\sum_{i=1}^{|y_{j}|}\mathrm{Clip}\left(\frac{\pi_{\theta}(y_{j}^{i}|x,y_{j}^{0:i})}{\pi_{\mathrm{old}}(y_{j}^{i}|x,y_{j}^{0:i})},\alpha,\beta\right)({r}(x,y_{j})-\bar{r}(x))-\tau\left(\log\frac{\pi_{\theta}(y_{j}^{i}|x,y_{j}^{0:i})}{\pi_{\mathrm{old}}(y_{j}^{i}|x,y_{j}^{0:i})}\right)^{2}\right]\,. \tag{1}
$$
Here $\alpha,\beta,\tau>0$ are hyperparameters, $y^{j}_{0:i}$ is the prefix up to the $i$ -th token of the $j$ -th response, $N=\sum_{i=1}^{K}|y_{i}|$ is the total number of generated tokens in a batch, $\bar{r}(x)=\frac{1}{K}\sum_{j=1}^{K}r(x,y_{j})$ is the mean reward of all generated responses.
This loss function departs from the policy optimization algorithm used in K1.5 [30] by introducing a token-level clipping mechanism designed to mitigate the off-policy divergence amplified by discrepancies between training and inference frameworks. The mechanism functions as a simple gradient masking scheme: policy gradients are computed normally for tokens with log-ratios within the interval $[\alpha,\beta]$ , while gradients for tokens falling outside this range are zeroed out. Notably, a key distinction from standard PPO clipping [50] is that our method relies strictly on the log-ratio to explicitly bound off-policy drift, regardless of the sign of the advantages. This approach aligns with recent strategies proposed to stabilize large-scale RL training [74, 78]. Empirically, we find this mechanism essential for maintaining training stability in complex domains requiring long-horizon, multi-step tool-use reasoning. We employ the MuonClip optimizer [29, 33] to minimize this objective.
Reward Function
We apply a rule-based outcome reward for tasks with verifiable solutions, such as reasoning and agentic tasks. To optimize resource consumption, we also incorporate a budget-control reward aimed at enhancing token efficiency. For general-purpose tasks, we employ Generative Reward Models (GRMs) that provide granular evaluations aligned with Kimi’s internal value criteria. In addition, for visual tasks, we design task-specific reward functions to provide fine-grained supervision. For visual grounding and point localization tasks, we employ an F1-based reward with soft matching: grounding tasks derive soft matches from Intersection over Union (IoU) and point tasks derive soft matches from Gaussian-weighted distances under optimal matching. For polygon segmentation tasks, we rasterize the predicted polygon into a binary mask and compute the segmentation IoU against the ground-truth mask to assign the reward. For OCR tasks, we adopt normalized edit distance to quantify character-level alignment between predictions and ground-truth. For counting tasks, rewards are assigned based on the absolute difference between predictions and ground-truth. Furthermore, we synthesize complex visual puzzle problems and utilize an LLM verifier (Kimi K2) to provide feedback.
Generative Reward Models
Kimi K2 leverages a self-critique rubric reward for open-ended generation [53], and K2.5 extends this line of work by systematically deploying Generative Reward Models (GRMs) across a broad range of agentic behaviors and multimodal trajectories. Rather than limiting reward modeling to conversational outputs, we apply GRMs on top of verified reward signals in diverse environments, including chat assistants, coding agents, search agents, and artifact-generating agents. Notably, GRMs function not as binary adjudicators, but as fine-grained evaluators aligned with Kimi’s values that are critical to user experiences, such as helpfulness, response readiness, contextual relevance, appropriate level of detail, aesthetic quality of generated artifacts, and strict instruction following. This design allows the reward signal to capture nuanced preference gradients that are difficult to encode with purely rule-based or task-specific verifiers. To mitigate reward hacking and overfitting to a single preference signal, we employ multiple alternative GRM rubrics tailored to different task contexts.
Token Efficient Reinforcement Learning
Token efficiency is central to LLMs with test-time scaling. While test-time scaling inherently trades computation for reasoning quality, practical gains require algorithmic innovations that actively navigate this trade-off. Our previous findings indicate that imposing a problem-dependent budget effectively constrains inference-time compute, incentivizing the model to generate more concise chain of thought reasoning patterns without unnecessary token expansion [30, 53]. However, we also observe a length-overfitting phenomenon: models trained under rigid budget constraints often fail to generalize to higher compute scales. Consequently, they cannot effectively leverage additional inference-time tokens to solve complex problems, instead defaulting to truncated reasoning patterns.
To this end, we propose Toggle, a training heuristic that alternates between inference-time scaling and budget-constrained optimization: for learning iteration $t$ , the reward function is defined by
| | $\displaystyle\tilde{r}(x,y)=\begin{cases}r(x,y)·\mathbb{I}\left\{\frac{1}{K}\sum_{i=1}^{K}r(x,y_{i})<\lambda\ \mathrm{or}\ |y_{i}|≤\mathrm{budget(x)}\right\}&\text{if }\lfloor t/m\rfloor±od{2}=0\ (\mathrm{{Phase0}})\\
r(x,y)&\text{if }\lfloor t/m\rfloor±od{2}=1\ (\mathrm{{Phase1}})\end{cases}\,.$ | |
| --- | --- | --- |
where $\lambda$ and $m$ are hyper-parameters of the algorithm and $K$ is the number of rollouts per problem. Specifically, the algorithm alternates between two optimization phases every $m$ iterations:
- Phase0 (budget limited phase): The model is trained to solve the problem within a task-dependent token budget. To prevent a premature sacrifice of quality for efficiency, this constraint is conditionally applied: it is only enforced when the model’s mean accuracy for a given problem exceeds the threshold $\lambda$ .
- Phase1 (standard scaling phase): The model generates responses up to the maximum token limit, encouraging the model to leverage computation for better inference-time scaling.
The problem-dependent budget is estimated from the $\rho$ -th percentile of token lengths among the subset of correct responses:
$$
\mathrm{budget}(x)=\text{Percentile}\left(\{|y_{j}|\mid r(x,y_{i})=1,i=1,\dots,K\},\rho\right)\,. \tag{2}
$$
This budget is estimated once at the beginning of training and remains fixed thereafter. Notably, Toggle functions as a stochastic alternating optimization for a bi-objective problem. It is specifically designed to reconcile reasoning capabilities with computational efficiency.
<details>
<summary>figures/te-k2-thinking-radar.png Details</summary>
### Visual Description
## Radar Charts: Token Efficiency before and after Toggle across Benchmarks
### Overview
The image contains two radar charts comparing token efficiency metrics before and after a system toggle. The left chart measures **Performance (%)**, while the right chart measures **Token Usage**. Both charts use color-coded data points to represent pre-toggle (gray squares) and post-toggle (colored markers) values, with a summary of improvements/degradations at the bottom.
---
### Components/Axes
#### Left Chart: Performance (%)
- **Axes**:
- Circular axis labeled with benchmarks:
- `HMMT25_Feb` (85-95%)
- `GPQADIAMOND` (80-90%)
- `AIME2025` (90-100%)
- `MMLUPro` (80-90%)
- `LiveCodeBenchV6` (80-90%)
- `Overall` (80-90%)
- Radial scale from 0% to 100%.
- **Legend**:
- Gray squares = Before Toggle
- Blue circles = After Toggle
- **Summary**:
- ✅ Improved: 5 benchmarks
- ❌ Degraded: 2 benchmarks
#### Right Chart: Token Usage
- **Axes**:
- Circular axis labeled with benchmarks:
- `HMMT25_Feb` (20K-40K)
- `GPQADIAMOND` (5K-15K)
- `AIME2025` (20K-35K)
- `MMLUPro` (1K-4K)
- `LiveCodeBenchV6` (20K-30K)
- `Overall` (15K-25K)
- Radial scale from 0 to 100 (units unspecified).
- **Legend**:
- Gray squares = Before Toggle
- Orange circles = After Toggle
- **Summary**:
- ✅ Reduced: 7 benchmarks
- ❌ Increased: 0 benchmarks
---
### Detailed Analysis
#### Performance (%)
- **HMMT25_Feb**:
- Before: 85-95% → After: 85-95% (▲+0.6%)
- **GPQADIAMOND**:
- Before: 80-90% → After: 80-90% (▼-1.0%)
- **AIME2025**:
- Before: 90-100% → After: 90-100% (▲+1.1%)
- **MMLUPro**:
- Before: 80-90% → After: 80-90% (▼-2.0%)
- **LiveCodeBenchV6**:
- Before: 80-90% → After: 80-90% (▲+2.2%)
- **Overall**:
- Before: 80-90% → After: 80-90% (▲+0.3%)
#### Token Usage
- **HMMT25_Feb**:
- Before: 20K-40K → After: 20K-40K (▼-7967)
- **GPQADIAMOND**:
- Before: 5K-15K → After: 5K-15K (▼-4912)
- **AIME2025**:
- Before: 20K-35K → After: 20K-35K (▼-6179)
- **MMLUPro**:
- Before: 1K-4K → After: 1K-4K (▼-817)
- **LiveCodeBenchV6**:
- Before: 20K-30K → After: 20K-30K (▼-745)
- **Overall**:
- Before: 15K-25K → After: 15K-25K (▼-4791)
---
### Key Observations
1. **Performance Trends**:
- Most benchmarks (5/7) improved post-toggle, with `LiveCodeBenchV6` showing the largest gain (+2.2%).
- `MMLUPro` and `GPQADIAMOND` experienced degradation (-2.0% and -1.0%, respectively).
- Overall performance increased slightly (+0.3%).
2. **Token Usage Trends**:
- All benchmarks showed reductions post-toggle, with `AIME2025` having the largest decrease (-6179).
- No benchmarks saw increased token usage.
- Overall token usage decreased by 4791.
3. **Color Consistency**:
- Legends match data point colors: gray squares (pre-toggle) and colored circles (post-toggle) align spatially with their respective axes.
---
### Interpretation
The toggle appears to have **optimized performance** and **reduced token consumption** across most benchmarks. While the majority of metrics improved, two performance benchmarks (`MMLUPro` and `GPQADIAMOND`) degraded, suggesting potential trade-offs in specific use cases. The consistent reduction in token usage across all benchmarks indicates a successful efficiency gain, likely due to algorithmic optimizations or resource management changes. The "Overall" metrics reinforce this, showing a net positive impact on both performance and token efficiency. The absence of increased token usage post-toggle suggests the toggle did not introduce unintended overhead.
</details>
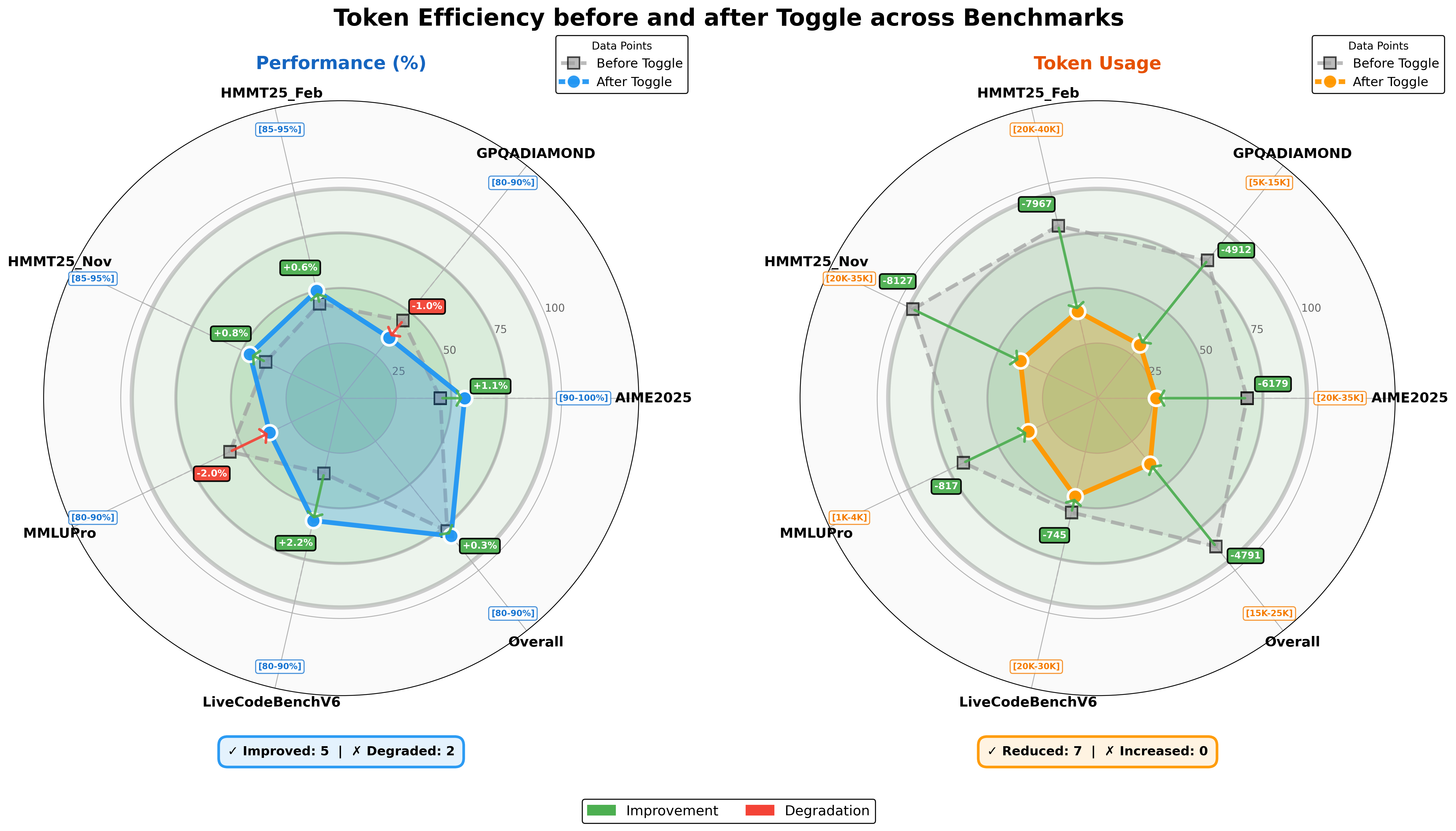
Figure 5: Comparison of model performance and token usage for Kimi K2 Thinking following token-efficient RL.
We evaluate the effectiveness of Toggle on K2 Thinking [1]. As shown in Figure 5, we observe a consistent reduction in output length across nearly all benchmarks. On average, Toggle decreases output tokens by 25 $\sim$ 30% with a negligible impact on performance. We also observe that redundant patterns in the chain-of-thought, such as repeated verifications and mechanical calculations, decrease substantially. Furthermore, Toggle shows strong domain generalization. For example, when trained exclusively on mathematics and programming tasks, the model still achieves consistent token reductions on GPQA and MMLU-Pro with only marginal degradation in performance (Figure 5).
4.5 Training Infrastructure
Kimi K2.5 inherits the training infrastructure from Kimi K2 [53] with minimal modifications. For multimodal training, we propose Decoupled Encoder Process, where the vision encoder is incorporated into the existing pipeline with negligible additional overhead.
4.5.1 Decoupled Encoder Process (DEP)
In a typical multimodal training paradigm utilizing Pipeline Parallelism (PP), the vision encoder and text embedding are co-located in the first stage of the pipeline (Stage-0). However, due to the inherent variations of multimodal input size (e.g., image counts and resolutions), Stage-0 suffers from drastic fluctuations in both computational load and memory usage. This forces existing solutions to adopt custom PP configurations for vision-language models — for instance, [54] manually adjusts the number of text decoder layers in Stage-0 to reserve memory. While this compromise alleviates memory pressure, it does not fundamentally resolve the load imbalance caused by multimodal input sizes. More critically, it precludes the direct reuse of parallel strategies that have been highly optimized for text-only training.
Leveraging the unique topological position of the visual encoder within the computation graph — specifically, its role as the start of the forward pass and the end of the backward pass — our training uses Decoupled Encoder Process (DEP), which is composed of three stages in each training step:
- Balanced Vision Forward: We first execute the forward pass for all visual data in the global batch. Because the vision encoder is small, we replicate it on all GPUs regardless of other parallelism strategies. During this phase, the forward computational workload is evenly distributed across all GPUs based on load metrics (e.g., image or patch counts). This eliminates load-imbalance caused by PP and visual token counts. To minimize peak memory usage, we discard all intermediate activations, retaining only the final output activations. The results are gathered back to PP Stage-0;
- Backbone Training: This phase performs the forward and backward passes for the main transformer backbone. By discarding intermediate activations in the preceding phase, we can now fully leverage any efficient parallel strategies validated in pure text training. After this phase, gradients are accumulated at the visual encoder output;
- Vision Recomputation & Backward: We re-compute the vision encoder forward pass, followed by a backward pass to compute gradients for parameters in the vision encoder;
DEP not only achieves load-balance, but also decouples the optimization strategy of the vision encoder and the main backbone. K2.5 seamlessly inherits the parallel strategy of K2, achieving a multimodal training efficiency of 90% relative to text-only training. We note a concurrent work, LongCat-Flash-Omni [55], shares a similar design philosophy.
5 Evaluations
5.1 Main Results
5.1.1 Evaluation Settings
Benchmarks
We evaluate Kimi K2.5 on a comprehensive benchmark suite spanning text-based reasoning, competitive and agentic coding, multimodal understanding (image and video), autonomous agentic execution, and computer use. Our benchmark taxonomy is organized along the following capability axes:
- Reasoning & General: Humanity’s Last Exam (HLE) [46], AIME 2025 [40], HMMT 2025 (Feb) [58], IMO-AnswerBench [36], GPQA-Diamond [47], MMLU-Pro [64], SimpleQA Verified [21], AdvancedIF [22], and LongBench v2 [8].
- Coding: SWE-Bench Verified [28], SWE-Bench Pro (public) [15], SWE-Bench Multilingual [28], Terminal Bench 2.0 [38], PaperBench (CodeDev) [52], CyberGym [66], SciCode [56], OJBench (cpp) [65], and LiveCodeBench (v6) [27].
- Agentic Capabilities: BrowseComp [68], WideSearch [69],DeepSearchQA [60], FinSearchComp (T2&T3) [25], Seal-0 [45], GDPVal [43].
- Image Understanding: (math & reasoning) MMMU-Pro [76], MMMU (val) [75], CharXiv (RQ) [67], MathVision [61] and MathVista (mini) [35]; (vision knowledge) SimpleVQA [12] and WorldVQA https://github.com/MoonshotAI/WorldVQA; (perception) ZeroBench (w/ and w/o tools) [48], BabyVision [11], BLINK [17] and MMVP [57]; (OCR & document) OCRBench [34], OmniDocBench 1.5 [42] and InfoVQA [37].
- Video Understanding: VideoMMMU [24], MMVU [79], MotionBench [23], Video-MME [16] (with subtitles), LongVideoBench [70], and LVBench [62].
- Computer Use: OSWorld-Verified [72, 73], and WebArena [80].
Table 4: Performance comparison of Kimi K2.5 against open-source and proprietary models. Bold denotes the global SOTA; Data points marked with * are taken from our internal evaluations. † refers to their scores of text-only subset.
| | | Proprietary | Open Source | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Benchmark | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 (xhigh) | Gemini 3 Pro | DeepSeek-V3.2 | Qwen3-VL-235B-A22B |
| Reasoning & General | | | | | | |
| HLE-Full | 30.1 | 30.8 | 34.5 | 37.5 | 25.1 † | - |
| HLE-Full w/ tools | 50.2 | 43.2 | 45.5 | 45.8 | 40.8 † | - |
| AIME 2025 | 96.1 | 92.8 | 100 | 95.0 | 93.1 | - |
| HMMT 2025 (Feb) | 95.4 | 92.9* | 99.4 | 97.3* | 92.5 | - |
| IMO-AnswerBench | 81.8 | 78.5* | 86.3 | 83.1* | 78.3 | - |
| GPQA-Diamond | 87.6 | 87.0 | 92.4 | 91.9 | 82.4 | - |
| MMLU-Pro | 87.1 | 89.3* | 86.7* | 90.1 | 85.0 | - |
| SimpleQA Verified | 36.9 | 44.1 | 38.9 | 72.1 | 27.5 | - |
| AdvancedIF | 75.6 | 63.1 | 81.1 | 74.7 | 58.8 | - |
| LongBench v2 | 61.0 | 64.4* | 54.5* | 68.2* | 59.8* | - |
| Coding | | | | | | |
| SWE-Bench Verified | 76.8 | 80.9 | 80.0 | 76.2 | 73.1 | - |
| SWE-Bench Pro (public) | 50.7 | 55.4* | 55.6 | - | - | - |
| SWE-Bench Multilingual | 73.0 | 77.5 | 72.0 | 65.0 | 70.2 | - |
| Terminal Bench 2.0 | 50.8 | 59.3 | 54.0 | 54.2 | 46.4 | - |
| PaperBench (CodeDev) | 63.5 | 72.9* | 63.7* | - | 47.1 | - |
| CyberGym | 41.3 | 50.6 | - | 39.9* | 17.3* | - |
| SciCode | 48.7 | 49.5 | 52.1 | 56.1 | 38.9 | - |
| OJBench (cpp) | 57.4 | 54.6* | - | 68.5* | 54.7* | - |
| LiveCodeBench (v6) | 85.0 | 82.2* | - | 87.4* | 83.3 | - |
| Agentic | | | | | | |
| BrowseComp | 60.6 | 37.0 | 65.8 | 37.8 | 51.4 | - |
| BrowseComp (w/ ctx manage) | 74.9 | 57.8 | | 59.2 | 67.6 | - |
| BrowseComp (Agent Swarm) | 78.4 | - | - | - | - | - |
| WideSearch | 72.7 | 76.2* | - | 57.0 | 32.5* | - |
| WideSearch (Agent Swarm) | 79.0 | - | - | - | - | - |
| DeepSearchQA | 77.1 | 76.1* | 71.3* | 63.2* | 60.9* | - |
| FinSearchCompT2&T3 | 67.8 | 66.2* | - | 49.9 | 59.1* | - |
| Seal-0 | 57.4 | 47.7* | 45.0 | 45.5* | 49.5* | - |
| GDPVal-AA | 41.0 | 45.0 | 48.0 | 35.0 | 34.0 | - |
| Image | | | | | | |
| MMMU-Pro | 78.5 | 74.0 | 79.5* | 81.0 | - | 69.3 |
| MMMU (val) | 84.3 | 80.7 | 86.7* | 87.5* | - | 80.6 |
| CharXiv (RQ) | 77.5 | 67.2* | 82.1 | 81.4 | - | 66.1 |
| MathVision | 84.2 | 77.1* | 83.0 | 86.1* | - | 74.6 |
| MathVista (mini) | 90.1 | 80.2* | 82.8* | 89.8* | - | 85.8 |
| SimpleVQA | 71.2 | 69.7* | 55.8* | 69.7* | - | 56.8* |
| WorldVQA | 46.3 | 36.8 | 28.0 | 47.4 | - | 23.5 |
| ZeroBench | 9 | 3* | 9* | 8* | - | 4* |
| ZeroBench w/ tools | 11 | 9* | 7* | 12* | - | 3* |
| BabyVision | 36.5 | 14.2 | 34.4 | 49.7 | - | 22.2 |
| BLINK | 78.9 | 68.8* | - | 78.7* | - | 68.9 |
| MMVP | 87.0 | 80.0* | 83.0* | 90.0* | - | 84.3 |
| OmniDocBench 1.5 | 88.8 | 87.7* | 85.7 | 88.5 | - | 82.0* |
| OCRBench | 92.3 | 86.5* | 80.7* | 90.3* | - | 87.5 |
| InfoVQA (test) | 92.6 | 76.9* | 84* | 57.2* | - | 89.5 |
| Video | | | | | | |
| VideoMMMU | 86.6 | 84.4* | 85.9 | 87.6 | - | 80.0 |
| MMVU | 80.4 | 77.3* | 80.8* | 77.5* | - | 71.1 |
| MotionBench | 70.4 | 60.3* | 64.8* | 70.3 | - | - |
| Video-MME | 87.4 | 77.6* | 86.0* | 88.4* | - | 79.0 |
| LongVideoBench | 79.8 | 67.2* | 76.5* | 77.7* | - | 65.6* |
| LVBench | 75.9 | 57.3 | - | 73.5* | - | 63.6 |
| Computer Use | | | | | | |
| OSWorld-Verified | 63.3 | 66.3 | 8.6* | 20.7* | - | 38.1 |
| WebArena | 58.9 | 63.4 * | - | - | - | 26.4* |
Table 5: Performance and token efficiency of some reasoning models. Average output token counts (in thousands) are shown in parentheses.
| Benchmark | Kimi K2.5 | Kimi K2 | Gemini-3.0 | DeepSeek-V3.2 |
| --- | --- | --- | --- | --- |
| Thinking | Pro | Thinking | | |
| AIME 2025 | 96.1 (25k) | 94.5 (30k) | 95.0 (15k) | 93.1 (16k) |
| HMMT Feb 2025 | 95.4 (27k) | 89.4 (35k) | 97.3 (16k) | 92.5 (19k) |
| HMMT Nov 2025 | 91.1 (24k) | 89.2 (32k) | 94.5 (15k) | 90.2 (18k) |
| IMO-AnswerBench | 81.8 (36k) | 78.6 (37k) | 83.1 (18k) | 78.3 (27k) |
| LiveCodeBench | 85.0 (18k) | 82.6 (25k) | 87.4 (13k) | 83.3 (16k) |
| GPQA Diamond | 87.6 (14k) | 84.5 (13k) | 91.9 (8k) | 82.4 (7k) |
| HLE-Text | 31.5 (24k) | 23.9 (29k) | 38.4 (13k) | 25.1 (21k) |
Baselines
We benchmark against state-of-the-art proprietary and open-source models. For proprietary models, we compare against Claude Opus 4.5 (with extended thinking) [4], GPT-5.2 (with xhigh reasoning effort) [41], and Gemini 3 Pro (with high reasoning-level) [19]. For open-source models, we include DeepSeek-V3.2 (with thinking mode enabled) [13] for text benchmarks, while vision benchmarks report Qwen3-VL-235B-A22B-Thinking [7] instead.
Evaluation Configurations
Unless otherwise specified, all Kimi K2.5 evaluations use temperature = 1.0, top-p = 0.95, and a context length of 256k tokens. Benchmarks without publicly available scores were re-evaluated under identical conditions and marked with an asterisk (*). The full evaluation settings can be found in appendix E.
5.1.2 Evaluation Results
Comprehensive results comparing Kimi K2.5 against proprietary and open-source baselines are presented in Table 4. We highlight key observations across core capability domains:
Reasoning and General
Kimi K2.5 achieves competitive performance with top-tier proprietary models on rigorous STEM benchmarks. On Math tasks, AIME 2025, K2.5 scores 96.1%, approaching GPT-5.2’s perfect score while outperforming Claude Opus 4.5 (92.8%) and Gemini 3 Pro (95.0%). This high-level performance extends to the HMMT 2025 (95.4%) and IMO-AnswerBench (81.8%), demonstrating K2.5’s superior reasoning depth. Kimi K2.5 also exhibits remarkable knowledge and scientific reasoning capabilities, scoring 36.9% on SimpleQA Verified, 87.1% on MMLU-Pro and 87.6% on GPQA. Notably, on HLE without the use of tools, K2.5 achieves an HLE-Full score of 30.1%, with component-wise scores of 31.5% on text subset and 21.3% on image subset. When tool-use is enabled, K2.5’s HLE-Full score rises to 50.2%, with 51.8% (text) and 39.8% (image), significantly outperforming Gemini 3 Pro (45.8%) and GPT-5.2 (45.5%). In addition to reasoning and knowledge, K2.5 shows strong instruction-following performance (75.6% on AdvancedIF) and competitive long-context abilities, achieving 61.0% on LongBench v2 compared to both proprietary and open-source models.
Complex Coding and Software Engineering
Kimi K2.5 exhibits strong software engineering capabilities, especially on realistic coding and maintenance tasks. It achieves 76.8% on SWE-Bench Verified and 73.0% on SWE-Bench Multilingual, outperforming Gemini 3 Pro while remaining competitive with Claude Opus 4.5 and GPT‑5.2. On LiveCodeBench v6, Kimi K2.5 reaches 85.0%, surpassing DeepSeek‑V3.2 (83.3%) and Claude Opus 4.5 (82.2%), highlighting its robustness on live, continuously updated coding challenges. On TerminalBench 2.0, PaperBench, and SciCode, it scores 50.8%, 63.5%, and 48.7% respectively, demonstrating stable competition‑level performance in automated software engineering and problem solving across diverse domains. In addition, K2.5 attains a score of 41.3 on CyberGym, on the task of finding previously discovered vulnerabilities in real open‑source software projects given only a high‑level description of the weakness, further underscoring its effectiveness in security‑oriented software analysis.
Agentic Capabilities
Kimi K2.5 establishes new state-of-the-art performance on complex agentic search and browsing tasks. On BrowseComp, K2.5 achieves 60.6% without context management techniques, 74.9% with Discard-all context management [13] — substantially outperforming GPT-5.2’s reported 65.8%, Claude Opus 4.5 (37.0%) and Gemini 3 Pro (37.8%). Similarly, WideSearch reaches 72.7% on item-f1. On DeepSearchQA (77.1%), FinSearchCompT2&T3 (67.8%) and Seal-0 (57.4%), K2.5 leads all evaluated models, demonstrating superior capacity for agentic deep research, information synthesis, and multi-step tool orchestration.
Vision Reasoning, Knowledge and Perception
Kimi K2.5 demonstrates strong visual reasoning and world knowledge capabilities. It scores 78.5% on MMMU-Pro, spanning multi-disciplinary multimodal tasks. For world knowledge question answering, K2.5 achieves 71.2% on SimpleVQA and 46.3% on WorldVQA. For visual reasoning, it achieves 84.2% on MathVision, 90.1% on MathVista (mini), and 36.5% on BabyVision. For OCR and document understanding, K2.5 delivers outstanding results with 77.5% on CharXiv (RQ), 92.3% on OCRBench, 88.8% on OmniDocBench 1.5, and 92.6% on InfoVQA (test). On the challenging ZeroBench, Kimi K2.5 achieves 9% and 11% with tool augmentation, substantially ahead of competing models. On basic visual perception benchmarks BLINK (78.9%) and MMVP (87.0%), we also observe competitive performance of Kimi K2.5, demonstrating its robust real-world visual perceptions.
Video Understanding
Kimi K2.5 achieves state-of-the-art performance across diverse video understanding tasks. It attains 86.6% on VideoMMMU and 80.4% on MMVU, rivaling frontier leaderships. With the context-compression and dense temporal understanding abilities of MoonViT-3D, Kimi K2.5 also establishes new global SOTA records in long-video comprehension with 75.9% on LVBench and 79.8% on LongVideoBench by feeding over 2,000 frames, while demonstrating robust dense-motion understanding at 70.4% on the highly-dimensional MotionBench.
Computer-Use Capability
Kimi K2.5 demonstrates state-of-the-art computer-use capability on real-world tasks. On the computer-use benchmark OSWorld-Verified [72, 73], it achieves a 63.3% success rate relying solely on GUI actions without external tools. This substantially outperforms open-source models such as Qwen3-VL-235B-A22B (38.1%) and OpenAI’s computer-use agent framework Operator (o3-based) (42.9%), while remaining competitive with the current leading CUA model, Claude Opus 4.5 (66.3%). On WebArena [80], an established benchmark for GUI-based web browsing, Kimi K2.5 achieves a 58.9% success rate, surpassing OpenAI’s Operator (58.1%) and approaching the performance of Claude Opus 4.5 (63.4%).
5.2 Agent Swarm Results
Benchmarks
To rigorously evaluate the effectiveness of the agent swarm framework, we select three representative benchmarks that collectively cover deep reasoning, large-scale retrieval, and real-world complexity:
- BrowseComp: A challenging deep-research benchmark that requires multi-step reasoning and complex information synthesis.
- WideSearch: A benchmark designed to evaluate the ability to perform broad, multi-step information seeking and reasoning across diverse sources.
- In-house Swarm Bench: An internally developed Swarm benchmark, designed to evaluate the agent swarm performance under real-world, high-complexity conditions. It covers four domains: WildSearch (unconstrained, real-world information retrieval over the open web), Batch Download (large-scale acquisition of diverse resources), WideRead (large-scale document comprehension involving more than 100 input documents), and Long-Form Writing (coherent generation of extensive content exceeding 100k words). This benchmark incorporates extreme-scale scenarios that stress-test the orchestration, scalability, and coordination capabilities of agent-based systems.
Table 6: Performance comparison of Kimi K2.5 Agent Swarm against single-agent and proprietary baselines on agentic search benchmarks. Bold denotes the best result per benchmark.
| Benchmark | K2.5 Agent Swarm | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 | GPT-5.2 Pro |
| --- | --- | --- | --- | --- | --- |
| BrowseComp | 78.4 | 60.6 | 37.0 | 65.8 | 77.9 |
| WideSearch | 79.0 | 72.7 | 76.2 | - | - |
| In-house Swarm Bench | 58.3 | 41.6 | 45.8 | - | - |
Performance
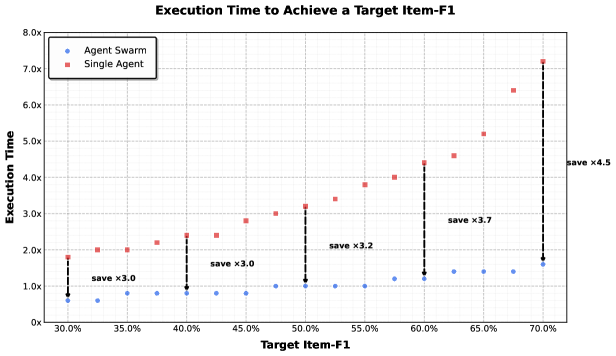
Table 6 presents the performance of Kimi K2.5 Agent Swarm against single-agent configurations and proprietary baselines. The results demonstrate substantial performance improvements from multi-agent orchestration. On BrowseComp, Agent Swarm achieves 78.4%, representing a 17.8% absolute gain over the single-agent K2.5 (60.6%) and surpassing even GPT-5.2 Pro (77.9%). Similarly, WideSearch sees a 6.3% improvement (72.7% $→$ 79.0%) on Item-F1, enabling K2.5 Agent Swarm to outperform Claude Opus 4.5 (76.2%) and establish a new state-of-the-art. The gains are most pronounced on In-house Swarm bench (16.7%), where tasks are explicitly designed to reward parallel decomposition. These consistent improvements across benchmarks validate that Agent Swarm effectively converts computational parallelism into qualitative capability gains, particularly for problems requiring broad exploration, multi-source verification, or simultaneous handling of independent sub-tasks.
<details>
<summary>x4.png Details</summary>

### Visual Description
## Word Cloud: Research Roles and Specializations
### Overview
The image is a word cloud composed of text elements representing various research roles, specializations, and related terms. Words are arranged in a circular pattern, with size and color indicating prominence. The largest words are centrally positioned, while smaller terms radiate outward.
### Components/Axes
- **Text Elements**: Words and phrases related to research roles (e.g., "Biography Researcher," "Verification Specialist").
- **Size**: Indicates prominence (largest = most emphasized, smallest = least emphasized).
- **Color**: Blue (largest), teal (medium), and purple (smallest).
- **No axes, legends, or numerical scales present.**
### Detailed Analysis
- **Largest Words (Blue)**:
- "Biography Researcher" (center-left)
- "Verification Specialist" (center-right)
- **Medium-Sized Words (Teal)**:
- "Cross Reference Researcher"
- "Historical Researcher"
- "Article Finder"
- "Academic Researcher"
- "Data Verifier"
- "Film Researcher"
- "Publication Researcher"
- "Timeline Researcher"
- "University Researcher"
- "Book Researcher"
- "Literary Investigator"
- **Smallest Words (Purple)**:
- "Verification Agent"
- "Thesis Researcher"
- "Sports Researcher"
- "Event Researcher"
- "Geographical Researcher"
- "Award Researcher"
- "Biographical Researcher"
- "Actor Researcher"
- "Music Researcher"
- "Writer Researcher"
- "Editor Researcher"
- "Researcher" (repeated in smaller sizes)
### Key Observations
1. **Prominence of Core Roles**: "Biography Researcher" and "Verification Specialist" dominate the cloud, suggesting they are central to the depicted research ecosystem.
2. **Repetition of "Researcher"**: The term "Researcher" appears frequently in smaller sizes, indicating a broad focus on research roles.
3. **Color Coding**: Larger words are blue, while smaller terms use teal and purple, possibly to differentiate categories or hierarchies.
4. **Circular Arrangement**: Words are organized in a radial pattern, emphasizing interconnectedness of roles.
### Interpretation
The word cloud highlights the diversity and interconnectedness of research roles, with "Biography Researcher" and "Verification Specialist" as focal points. The repetition of "Researcher" underscores the field's breadth, while the size hierarchy reflects the perceived importance of specific roles. The color scheme may serve to visually distinguish categories, though no explicit legend is provided. The absence of numerical data or explicit relationships between terms suggests the image is designed for thematic emphasis rather than quantitative analysis.
## Notes
- **Language**: All text is in English.
- **No numerical data or structured tables present.**
- **No explicit relationships or trends beyond word size and placement.**
</details>
Figure 6: The word cloud visualizes heterogeneous K2.5-based sub-agents dynamically instantiated by the Orchestrator across tests.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Performance vs Step
### Overview
The chart compares the performance of two methods, "Discard-all Context Management" (blue line) and "Agent Swarm" (red line), across logarithmic steps (10² to 10³). Both lines show upward trends, with "Agent Swarm" starting lower but surpassing "Discard-all Context Management" early in the step range.
### Components/Axes
- **X-axis**: Logarithmic scale labeled "log(steps)" with markers at 10² (100) and 10³ (1000). Intermediate values (e.g., 10².5 ≈ 316) are implied but not explicitly marked.
- **Y-axis**: Linear scale labeled "Performance" with increments of 5% (40% to 80%).
- **Legend**: Located in the bottom-right corner, associating blue with "Discard-all Context Management" and red with "Agent Swarm."
### Detailed Analysis
- **Discard-all Context Management (Blue Line)**:
- Starts at **60%** performance at 10² steps.
- Increases steadily to **75%** at 10³ steps.
- Intermediate points: ~65% at 10².5 steps.
- **Agent Swarm (Red Line)**:
- Begins at **47%** performance at 10² steps.
- Sharp rise to **65%** at 10².5 steps.
- Continues to **78%** at 10³ steps.
- Intermediate points: ~70% at 10².75 steps.
### Key Observations
1. **Initial Disparity**: "Agent Swarm" starts with significantly lower performance (47% vs. 60%) at 10² steps.
2. **Rapid Improvement**: "Agent Swarm" overtakes "Discard-all Context Management" by 10².5 steps (65% vs. 65%).
3. **Convergence**: Both methods plateau near 75–78% performance by 10³ steps, with "Agent Swarm" maintaining a slight edge.
4. **Trend Dynamics**: "Discard-all Context Management" exhibits a smoother, linear increase, while "Agent Swarm" shows a steeper initial ascent followed by gradual growth.
### Interpretation
The data suggests that "Agent Swarm" is more efficient in early-stage performance improvement, achieving parity with "Discard-all Context Management" within the first 300 steps. However, as steps increase, both methods converge toward similar performance levels, indicating diminishing returns for "Agent Swarm" at higher step counts. This could imply that "Agent Swarm" is better suited for scenarios requiring rapid initial results, whereas "Discard-all Context Management" offers more stable, incremental gains over extended steps. The logarithmic x-axis highlights the exponential nature of step scaling, emphasizing performance trends across orders of magnitude.
</details>
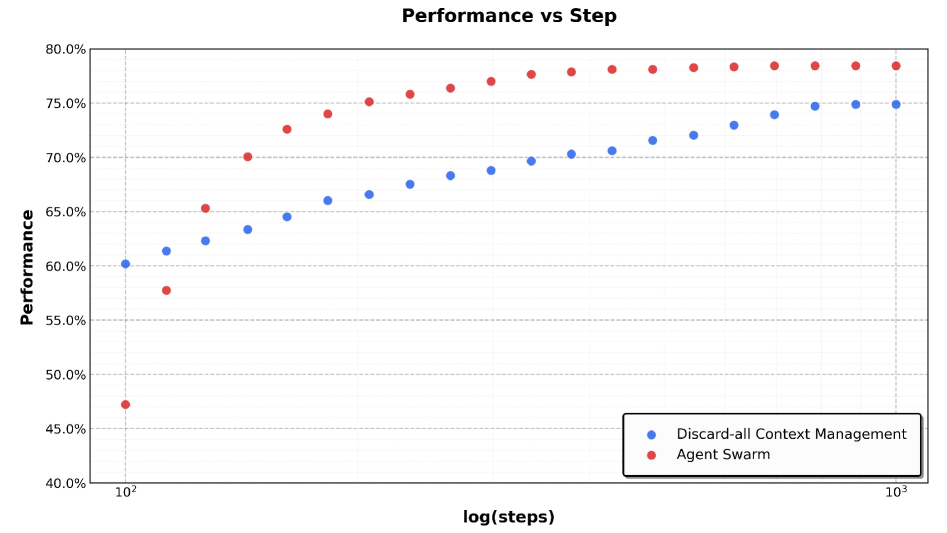
Figure 7: Comparison of Kimi K2.5 performance under Agent Swarm and Discard-all context management in BrowseComp.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Execution Time to Achieve a Target Item-F1
### Overview
The chart compares execution time (y-axis) against Target Item-F1 (x-axis) for two approaches: "Agent Swarm" (blue dots) and "Single Agent" (red squares). Execution time is plotted on a logarithmic scale (0x to 8.0x), while Target Item-F1 ranges from 30.0% to 70.0%. Key annotations highlight efficiency savings for the Agent Swarm approach.
### Components/Axes
- **X-axis (Target Item-F1)**:
- Labels: 30.0%, 35.0%, 40.0%, 45.0%, 50.0%, 55.0%, 60.0%, 65.0%, 70.0%
- Scale: Linear increments of 5.0%
- **Y-axis (Execution Time)**:
- Labels: 0x, 1.0x, 2.0x, 3.0x, 4.0x, 5.0x, 6.0x, 7.0x, 8.0x
- Scale: Logarithmic (base 10)
- **Legend**:
- Position: Top-left corner
- Labels:
- Blue dots: "Agent Swarm"
- Red squares: "Single Agent"
- **Annotations**:
- "save x3.0" (multiple points)
- "save x3.2" (near 50.0% Target Item-F1)
- "save x3.7" (near 60.0% Target Item-F1)
- "save x4.5" (near 70.0% Target Item-F1)
### Detailed Analysis
1. **Agent Swarm (Blue Dots)**:
- Execution time remains relatively flat (~0.5x to 1.5x) across all Target Item-F1 values.
- Notable efficiency gains:
- At 30.0%: ~0.5x (save x3.0 vs. Single Agent)
- At 50.0%: ~1.0x (save x3.2)
- At 60.0%: ~1.2x (save x3.7)
- At 70.0%: ~1.6x (save x4.5)
2. **Single Agent (Red Squares)**:
- Execution time increases exponentially with higher Target Item-F1:
- 30.0%: ~1.8x
- 35.0%: ~2.0x
- 40.0%: ~2.4x
- 50.0%: ~3.2x
- 60.0%: ~4.4x
- 70.0%: ~7.2x
3. **Logarithmic Scale Impact**:
- Single Agent's execution time grows non-linearly (e.g., 30.0% to 70.0% increases from 1.8x to 7.2x, a 4x multiplier).
- Agent Swarm's execution time shows minimal growth (~0.5x to 1.6x, a 3.2x multiplier).
### Key Observations
- **Efficiency Gap**: Agent Swarm consistently outperforms Single Agent by factors of 3.0–4.5x.
- **Scalability**: Single Agent's execution time becomes prohibitive at higher Target Item-F1 (e.g., 7.2x at 70.0%).
- **Anomalies**: No outliers; trends are consistent across all data points.
### Interpretation
The chart demonstrates that the Agent Swarm approach drastically reduces execution time compared to Single Agent, with efficiency gains increasing as Target Item-F1 rises. The logarithmic y-axis emphasizes the exponential cost of Single Agent at higher targets (e.g., 7.2x at 70.0% vs. 1.6x for Agent Swarm). The "save x3.0–4.5" annotations quantify the performance advantage, suggesting Agent Swarm is critical for scalability in high-Target Item-F1 scenarios. This aligns with Pareto principles: optimizing for the most impactful 20% (high-Target Item-F1) yields disproportionate benefits.
</details>
Figure 8: Agent Swarm achieves 3 $×$ –4.5 $×$ faster execution time compared to single-agent baselines as target Item-F1 increases from 30% to 70% in WideSearch testing.
Execution Time Savings via Parallelism
Beyond improved task performance, Agent Swarm achieves substantial wall-clock time reductions through parallel subagent execution. On the WideSearch benchmark, it reduces the execution time required to reach target performance by 3 $×\sim$ 4.5 $×$ compared to a single-agent baseline. As shown in Figure 8, this efficiency gain scales with task complexity: as the target Item-F1 increases from 30% to 70%, the single agent’s execution time grows from approximately 1.8 $×$ to over 7.0 $×$ the baseline, whereas Agent Swarm maintains near-constant low latency in the range of $0.6×\sim 1.6×$ . These results indicate that Agent Swarm effectively transforms sequential tool invocations into parallel operations, preventing the linear growth in completion time typically observed as task difficulty increases.
Dynamic Subagent Creation and Scheduling
Within an agent swarm, subagents are dynamically instantiated rather than pre-defined. Through PARL, the orchestrator learns adaptive policies to create and schedule self-hosted subagents in response to evolving task structures and problem states. Unlike static decomposition approaches, this learned policy enables the Orchestrator to reason about the requisite number, timing, and specialization of subagents based on query. Consequently, a heterogeneous agent group emerges organically from this adaptive allocation strategy (Figure 7).
Agent Swarm as Proactive Context Management
Beyond better performance and runtime acceleration, an agent swarm is a kind of proactive and intelligent context management enabled by multi-agent architecture [6]. This approach differs from test-time context truncation strategies such as Hide-Tool-Result [2], Summary [71], or Discard-all [13], which react to context overflow by compressing or discarding accumulated histories. While effective at reducing token usage, these methods are inherently reactive and often sacrifice structural information or intermediate reasoning.
In contrast, Agent Swarm enables proactive context control through explicit orchestration. Long-horizon tasks are decomposed into parallel, semantically isolated subtasks, each executed by a specialized subagent with a bounded local context. Crucially, these subagents maintain independent working memories and perform local reasoning without directly mutating or contaminating the global context of the central orchestrator. Only task-relevant outputs—rather than full interaction traces—are selectively routed back to the orchestrator. This design induces context sharding rather than context truncation, allowing the system to scale effective context length along an additional architectural dimension while preserving modularity, information locality, and reasoning integrity.
As shown in Figure 7, this proactive strategy outperforms Discard-all in both efficiency and accuracy on BrowseComp. By preserving task-level coherence at the orchestrator level while keeping subagent contexts tightly bounded, Agent Swarm enables parallel execution with selective context persistence, retaining only high-level coordination signals or essential intermediate results. Consequently, Agent Swarm operates as an active, structured context manager, achieving higher accuracy with substantially fewer critical steps than uniform context truncation.
6 Conclusions
Kimi K2.5 shows that scalable and general agentic intelligence can be achieved through joint optimization of text and vision together with parallel agent execution. By unifying language and vision across pre-training and reinforcement learning, the model achieves strong cross-modal alignment and visual–text reasoning. Agent Swarm enables concurrent execution of heterogeneous sub-tasks, reducing inference latency while improving performance on complex agentic workloads. Grounded in vision–text intelligence and agent swarms, Kimi K2.5 demonstrates strong performance on benchmarks and real-world tasks. By open-sourcing the post-trained checkpoints, we aim to support the open-source community in building scalable and general-purpose agentic systems and to accelerate progress toward General Agentic Intelligence.
References
- [1] M. AI (2025) Introducing kimi k2 thinking. External Links: Link Cited by: §1, §1, §4.4.2.
- [2] M. AI (2025) Kimi-researcher end-to-end rl training for emerging agentic capabilities. External Links: Link Cited by: §1, §5.2.
- [3] Amazon Web Services (2023) Amazon simple storage service (amazon s3). Note: WebAvailable at: https://aws.amazon.com/s3/ External Links: Link Cited by: §C.1.
- [4] Anthropic (2025) Claude opus 4.5 system card. External Links: Link Cited by: §E.7, §1, §3, §5.1.1.
- [5] Anthropic (2025) How we built our multi-agent research system. External Links: Link Cited by: §3.
- [6] Anthropic (2026) Building multi-agent systems: when and how to use them. External Links: Link Cited by: §3, §5.2.
- [7] S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y. Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y. Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang, Q. Wang, Y. Wang, T. Xie, Y. Xu, H. Xu, J. Xu, Z. Yang, M. Yang, J. Yang, A. Yang, B. Yu, F. Zhang, H. Zhang, X. Zhang, B. Zheng, H. Zhong, J. Zhou, F. Zhou, J. Zhou, Y. Zhu, and K. Zhu (2025) Qwen3-vl technical report. External Links: 2511.21631, Link Cited by: §1, §2.1, §2.2, §5.1.1.
- [8] Y. Bai, S. Tu, J. Zhang, H. Peng, X. Wang, X. Lv, S. Cao, J. Xu, L. Hou, Y. Dong, J. Tang, and J. Li (2025) LongBench v2: towards deeper understanding and reasoning on realistic long-context multitasks. External Links: 2412.15204, Link Cited by: §E.3, 1st item.
- [9] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba (2016) OpenAI gym. External Links: 1606.01540, Link Cited by: Appendix D.
- [10] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei (2020) Language models are few-shot learners. External Links: 2005.14165, Link Cited by: §B.3.
- [11] L. Chen, W. Xie, Y. Liang, H. He, H. Zhao, Z. Yang, Z. Huang, H. Wu, H. Lu, Y. charles, Y. Bao, Y. Fan, G. Li, H. Shen, X. Chen, W. Xu, S. Si, Z. Cai, W. Chai, Z. Huang, F. Liu, T. Liu, B. Chang, X. Hu, K. Chen, Y. Ren, Y. Liu, Y. Gong, and K. Li (2026) BabyVision: visual reasoning beyond language. External Links: 2601.06521, Link Cited by: 4th item.
- [12] X. Cheng, W. Zhang, S. Zhang, J. Yang, X. Guan, X. Wu, X. Li, G. Zhang, J. Liu, Y. Mai, Y. Zeng, Z. Wen, K. Jin, B. Wang, W. Zhou, Y. Lu, T. Li, W. Huang, and Z. Li (2025) SimpleVQA: multimodal factuality evaluation for multimodal large language models. External Links: 2502.13059, Link Cited by: 4th item.
- [13] DeepSeek-AI, A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, C. Lu, C. Zhao, C. Deng, C. Xu, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, E. Li, F. Zhou, F. Lin, F. Dai, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Li, H. Liang, H. Wei, H. Zhang, H. Luo, H. Ji, H. Ding, H. Tang, H. Cao, H. Gao, H. Qu, H. Zeng, J. Huang, J. Li, J. Xu, J. Hu, J. Chen, J. Xiang, J. Yuan, J. Cheng, J. Zhu, J. Ran, J. Jiang, J. Qiu, J. Li, J. Song, K. Dong, K. Gao, K. Guan, K. Huang, K. Zhou, K. Huang, K. Yu, L. Wang, L. Zhang, L. Wang, L. Zhao, L. Yin, L. Guo, L. Luo, L. Ma, L. Wang, L. Zhang, M. S. Di, M. Y. Xu, M. Zhang, M. Zhang, M. Tang, M. Zhou, P. Huang, P. Cong, P. Wang, Q. Wang, Q. Zhu, Q. Li, Q. Chen, Q. Du, R. Xu, R. Ge, R. Zhang, R. Pan, R. Wang, R. Yin, R. Xu, R. Shen, R. Zhang, S. H. Liu, S. Lu, S. Zhou, S. Chen, S. Cai, S. Chen, S. Hu, S. Liu, S. Hu, S. Ma, S. Wang, S. Yu, S. Zhou, S. Pan, S. Zhou, T. Ni, T. Yun, T. Pei, T. Ye, T. Yue, W. Zeng, W. Liu, W. Liang, W. Pang, W. Luo, W. Gao, W. Zhang, X. Gao, X. Wang, X. Bi, X. Liu, X. Wang, X. Chen, X. Zhang, X. Nie, X. Cheng, X. Liu, X. Xie, X. Liu, X. Yu, X. Li, X. Yang, X. Li, X. Chen, X. Su, X. Pan, X. Lin, X. Fu, Y. Q. Wang, Y. Zhang, Y. Xu, Y. Ma, Y. Li, Y. Li, Y. Zhao, Y. Sun, Y. Wang, Y. Qian, Y. Yu, Y. Zhang, Y. Ding, Y. Shi, Y. Xiong, Y. He, Y. Zhou, Y. Zhong, Y. Piao, Y. Wang, Y. Chen, Y. Tan, Y. Wei, Y. Ma, Y. Liu, Y. Yang, Y. Guo, Y. Wu, Y. Wu, Y. Cheng, Y. Ou, Y. Xu, Y. Wang, Y. Gong, Y. Wu, Y. Zou, Y. Li, Y. Xiong, Y. Luo, Y. You, Y. Liu, Y. Zhou, Z. F. Wu, Z. Z. Ren, Z. Zhao, Z. Ren, Z. Sha, Z. Fu, Z. Xu, Z. Xie, Z. Zhang, Z. Hao, Z. Gou, Z. Ma, Z. Yan, Z. Shao, Z. Huang, Z. Wu, Z. Li, Z. Zhang, Z. Xu, Z. Wang, Z. Gu, Z. Zhu, Z. Li, Z. Zhang, Z. Xie, Z. Gao, Z. Pan, Z. Yao, B. Feng, H. Li, J. L. Cai, J. Ni, L. Xu, M. Li, N. Tian, R. J. Chen, R. L. Jin, S. S. Li, S. Zhou, T. Sun, X. Q. Li, X. Jin, X. Shen, X. Chen, X. Song, X. Zhou, Y. X. Zhu, Y. Huang, Y. Li, Y. Zheng, Y. Zhu, Y. Ma, Z. Huang, Z. Xu, Z. Zhang, D. Ji, J. Liang, J. Guo, J. Chen, L. Xia, M. Wang, M. Li, P. Zhang, R. Chen, S. Sun, S. Wu, S. Ye, T. Wang, W. L. Xiao, W. An, X. Wang, X. Sun, X. Wang, Y. Tang, Y. Zha, Z. Zhang, Z. Ju, Z. Zhang, and Z. Qu (2025) DeepSeek-v3.2: pushing the frontier of open large language models. External Links: 2512.02556, Link Cited by: §5.1.1, §5.1.2, §5.2.
- [14] M. Dehghani, B. Mustafa, J. Djolonga, J. Heek, M. Minderer, M. Caron, A. Steiner, J. Puigcerver, R. Geirhos, I. Alabdulmohsin, A. Oliver, P. Padlewski, A. Gritsenko, M. Lučić, and N. Houlsby (2023) Patch n’ pack: navit, a vision transformer for any aspect ratio and resolution. External Links: 2307.06304, Link Cited by: §1, §4.2.
- [15] X. Deng, J. Da, E. Pan, Y. Y. He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, et al. (2025) SWE-bench pro: can ai agents solve long-horizon software engineering tasks?. arXiv preprint arXiv:2509.16941. Cited by: 2nd item.
- [16] C. Fu, Y. Dai, Y. Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y. Shen, M. Zhang, P. Chen, Y. Li, S. Lin, S. Zhao, K. Li, T. Xu, X. Zheng, E. Chen, C. Shan, R. He, and X. Sun (2025) Video-mme: the first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. External Links: 2405.21075, Link Cited by: 5th item.
- [17] X. Fu, Y. Hu, B. Li, Y. Feng, H. Wang, X. Lin, D. Roth, N. A. Smith, W. Ma, and R. Krishna (2024) BLINK: multimodal large language models can see but not perceive. External Links: 2404.12390, Link Cited by: 4th item.
- [18] S. Y. Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhang, et al. (2024) Datacomp: in search of the next generation of multimodal datasets. Advances in Neural Information Processing Systems 36. Cited by: §B.3.
- [19] Google (2025) Gemini 3 pro. External Links: Link Cited by: §1, §5.1.1.
- [20] D. Guo, F. Wu, F. Zhu, F. Leng, G. Shi, H. Chen, H. Fan, J. Wang, J. Jiang, J. Wang, J. Chen, J. Huang, K. Lei, L. Yuan, L. Luo, P. Liu, Q. Ye, R. Qian, S. Yan, S. Zhao, S. Peng, S. Li, S. Yuan, S. Wu, T. Cheng, W. Liu, W. Wang, X. Zeng, X. Liu, X. Qin, X. Ding, X. Xiao, X. Zhang, X. Zhang, X. Xiong, Y. Peng, Y. Chen, Y. Li, Y. Hu, Y. Lin, Y. Hu, Y. Zhang, Y. Wu, Y. Li, Y. Liu, Y. Ling, Y. Qin, Z. Wang, Z. He, A. Zhang, B. Yi, B. Liao, C. Huang, C. Zhang, C. Deng, C. Deng, C. Lin, C. Yuan, C. Li, C. Gou, C. Lou, C. Wei, C. Liu, C. Li, D. Zhu, D. Zhong, F. Li, F. Zhang, G. Wu, G. Li, G. Xiao, H. Lin, H. Yang, H. Wang, H. Ji, H. Hao, H. Shen, H. Li, J. Li, J. Wu, J. Zhu, J. Jiao, J. Feng, J. Chen, J. Duan, J. Liu, J. Zeng, J. Tang, J. Sun, J. Chen, J. Long, J. Feng, J. Zhan, J. Fang, J. Lu, K. Hua, K. Liu, K. Shen, K. Zhang, K. Shen, K. Wang, K. Pan, K. Zhang, K. Li, L. Li, L. Li, L. Shi, L. Han, L. Xiang, L. Chen, L. Chen, L. Li, L. Yan, L. Chi, L. Liu, M. Du, M. Wang, N. Pan, P. Chen, P. Chen, P. Wu, Q. Yuan, Q. Shuai, Q. Tao, R. Zheng, R. Zhang, R. Zhang, R. Wang, R. Yang, R. Zhao, S. Xu, S. Liang, S. Yan, S. Zhong, S. Cao, S. Wu, S. Liu, S. Chang, S. Cai, T. Ao, T. Yang, T. Zhang, W. Zhong, W. Jia, W. Weng, W. Yu, W. Huang, W. Zhu, W. Yang, W. Wang, X. Long, X. Yin, X. Li, X. Zhu, X. Jia, X. Zhang, X. Liu, X. Zhang, X. Yang, X. Luo, X. Chen, X. Zhong, X. Xiao, X. Li, Y. Wu, Y. Wen, Y. Du, Y. Zhang, Y. Ye, Y. Wu, Y. Liu, Y. Yue, Y. Zhou, Y. Yuan, Y. Xu, Y. Yang, Y. Zhang, Y. Fang, Y. Li, Y. Ren, Y. Xiong, Z. Hong, Z. Wang, Z. Sun, Z. Wang, Z. Cai, Z. Zha, Z. An, Z. Zhao, Z. Xu, Z. Chen, Z. Wu, Z. Zheng, Z. Wang, Z. Huang, Z. Zhu, and Z. Song (2025) Seed1.5-vl technical report. External Links: 2505.07062, Link Cited by: §1, §2.1.
- [21] L. Haas, G. Yona, G. D’Antonio, S. Goldshtein, and D. Das (2025) SimpleQA verified: a reliable factuality benchmark to measure parametric knowledge. External Links: 2509.07968, Link Cited by: 1st item.
- [22] Y. He, W. Li, H. Zhang, S. Li, K. Mandyam, S. Khosla, Y. Xiong, N. Wang, X. Peng, B. Li, S. Bi, S. G. Patil, Q. Qi, S. Feng, J. Katz-Samuels, R. Y. Pang, S. Gonugondla, H. Lang, Y. Yu, Y. Qian, M. Fazel-Zarandi, L. Yu, A. Benhalloum, H. Awadalla, and M. Faruqui (2025) AdvancedIF: rubric-based benchmarking and reinforcement learning for advancing llm instruction following. External Links: 2511.10507, Link Cited by: 1st item.
- [23] W. Hong, Y. Cheng, Z. Yang, W. Wang, L. Wang, X. Gu, S. Huang, Y. Dong, and J. Tang (2025) MotionBench: benchmarking and improving fine-grained video motion understanding for vision language models. External Links: 2501.02955, Link Cited by: 5th item.
- [24] K. Hu, P. Wu, F. Pu, W. Xiao, Y. Zhang, X. Yue, B. Li, and Z. Liu (2025) Video-mmmu: evaluating knowledge acquisition from multi-discipline professional videos. External Links: 2501.13826, Link Cited by: 5th item.
- [25] L. Hu, J. Jiao, J. Liu, Y. Ren, Z. Wen, K. Zhang, X. Zhang, X. Gao, T. He, F. Hu, Y. Liao, Z. Wang, C. Yang, Q. Yang, M. Yin, Z. Zeng, G. Zhang, X. Zhang, X. Zhao, Z. Zhu, H. Namkoong, W. Huang, and Y. Tang (2025) FinSearchComp: towards a realistic, expert-level evaluation of financial search and reasoning. External Links: 2509.13160, Link Cited by: 3rd item.
- [26] Y. Huang, Y. Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu, and Z. Chen (2019) GPipe: efficient training of giant neural networks using pipeline parallelism. External Links: 1811.06965, Link Cited by: Appendix C.
- [27] N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica (2024) Livecodebench: holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974. Cited by: 2nd item.
- [28] C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan (2023) Swe-bench: can language models resolve real-world github issues?. arXiv preprint arXiv:2310.06770. Cited by: 2nd item.
- [29] K. Jordan, Y. Jin, V. Boza, J. You, F. Cesista, L. Newhouse, and J. Bernstein (2024) Muon: an optimizer for hidden layers in neural networks. External Links: Link Cited by: §4.1, §4.4.2.
- [30] Kimi Team (2025) Kimi k1. 5: scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599. Cited by: Appendix D, §4.4.2, §4.4.2.
- [31] H. Laurençon, L. Saulnier, L. Tronchon, S. Bekman, A. Singh, A. Lozhkov, T. Wang, S. Karamcheti, A. Rush, D. Kiela, et al. (2024) Obelics: an open web-scale filtered dataset of interleaved image-text documents. Advances in Neural Information Processing Systems 36. Cited by: §B.3.
- [32] D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen (2020) Gshard: scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668. Cited by: Appendix C.
- [33] J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y. Du, Y. Qin, W. Xu, E. Lu, J. Yan, et al. (2025) Muon is scalable for llm training. arXiv preprint arXiv:2502.16982. Cited by: §4.1, §4.3, §4.4.2.
- [34] Y. Liu, Z. Li, M. Huang, B. Yang, W. Yu, C. Li, X. Yin, C. Liu, L. Jin, and X. Bai (2024-12) OCRBench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences 67 (12). External Links: ISSN 1869-1919, Link, Document Cited by: 4th item.
- [35] P. Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K. Chang, M. Galley, and J. Gao (2024) MathVista: evaluating mathematical reasoning of foundation models in visual contexts. External Links: 2310.02255, Link Cited by: 4th item.
- [36] T. Luong, D. Hwang, H. H. Nguyen, G. Ghiasi, Y. Chervonyi, I. Seo, J. Kim, G. Bingham, J. Lee, S. Mishra, A. Zhai, H. Hu, H. Michalewski, J. Kim, J. Ahn, J. Bae, X. Song, T. H. Trinh, Q. V. Le, and J. Jung (2025-11) Towards robust mathematical reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V. Peng (Eds.), Suzhou, China, pp. 35418–35442. External Links: Link, Document, ISBN 979-8-89176-332-6 Cited by: 1st item.
- [37] M. Mathew, V. Bagal, R. P. Tito, D. Karatzas, E. Valveny, and C. V. Jawahar (2021) InfographicVQA. External Links: 2104.12756, Link Cited by: 4th item.
- [38] M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y. Shin, T. Walshe, E. K. Buchanan, et al. (2026) Terminal-bench: benchmarking agents on hard, realistic tasks in command line interfaces. arXiv preprint arXiv:2601.11868. Cited by: 2nd item.
- [39] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. A. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia (2021) Efficient large-scale language model training on gpu clusters using megatron-lm. External Links: 2104.04473, Link Cited by: Appendix C.
- [40] M. A. of America (2025) 2025 american invitational mathematics examination i. Note: Held on February 6, 2025 External Links: Link Cited by: 1st item.
- [41] OpenAI (2025) Introducing gpt 5.2. External Links: Link Cited by: §1, §5.1.1.
- [42] L. Ouyang, Y. Qu, H. Zhou, J. Zhu, R. Zhang, Q. Lin, B. Wang, Z. Zhao, M. Jiang, X. Zhao, J. Shi, F. Wu, P. Chu, M. Liu, Z. Li, C. Xu, B. Zhang, B. Shi, Z. Tu, and C. He (2025) OmniDocBench: benchmarking diverse pdf document parsing with comprehensive annotations. External Links: 2412.07626, Link Cited by: 4th item.
- [43] T. Patwardhan, R. Dias, E. Proehl, G. Kim, M. Wang, O. Watkins, S. P. Fishman, M. Aljubeh, P. Thacker, L. Fauconnet, N. S. Kim, P. Chao, S. Miserendino, G. Chabot, D. Li, M. Sharman, A. Barr, A. Glaese, and J. Tworek (2025) GDPval: evaluating AI model performance on real-world economically valuable tasks. External Links: 2510.04374, Link Cited by: 3rd item.
- [44] B. Peng, J. Quesnelle, H. Fan, and E. Shippole (2023) Yarn: efficient context window extension of large language models. arXiv preprint arXiv:2309.00071. Cited by: §4.3.
- [45] T. Pham, N. Nguyen, P. Zunjare, W. Chen, Y. Tseng, and T. Vu (2025) SealQA: raising the bar for reasoning in search-augmented language models. Note: Seal-0 is the main subset of this benchmark External Links: 2506.01062, Link Cited by: 3rd item.
- [46] L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, M. Choi, A. Agrawal, A. Chopra, A. Khoja, R. Kim, R. Ren, J. Hausenloy, O. Zhang, M. Mazeika, D. Dodonov, T. Nguyen, J. Lee, D. Anderson, M. Doroshenko, A. C. Stokes, M. Mahmood, O. Pokutnyi, O. Iskra, J. P. Wang, J. Levin, M. Kazakov, F. Feng, S. Y. Feng, H. Zhao, M. Yu, V. Gangal, C. Zou, Z. Wang, S. Popov, R. Gerbicz, G. Galgon, J. Schmitt, W. Yeadon, Y. Lee, S. Sauers, A. Sanchez, F. Giska, M. Roth, S. Riis, S. Utpala, N. Burns, G. M. Goshu, M. M. Naiya, C. Agu, Z. Giboney, A. Cheatom, F. Fournier-Facio, S. Crowson, L. Finke, Z. Cheng, J. Zampese, R. G. Hoerr, M. Nandor, H. Park, T. Gehrunger, J. Cai, B. McCarty, A. C. Garretson, E. Taylor, D. Sileo, Q. Ren, U. Qazi, L. Li, J. Nam, J. B. Wydallis, P. Arkhipov, J. W. L. Shi, A. Bacho, C. G. Willcocks, H. Cao, S. Motwani, E. de Oliveira Santos, J. Veith, E. Vendrow, D. Cojoc, K. Zenitani, J. Robinson, L. Tang, Y. Li, J. Vendrow, N. W. Fraga, V. Kuchkin, A. P. Maksimov, P. Marion, D. Efremov, J. Lynch, K. Liang, A. Mikov, A. Gritsevskiy, J. Guillod, G. Demir, D. Martinez, B. Pageler, K. Zhou, S. Soori, O. Press, H. Tang, P. Rissone, S. R. Green, L. Brüssel, M. Twayana, A. Dieuleveut, J. M. Imperial, A. Prabhu, J. Yang, N. Crispino, A. Rao, D. Zvonkine, G. Loiseau, M. Kalinin, M. Lukas, C. Manolescu, N. Stambaugh, S. Mishra, T. Hogg, C. Bosio, B. P. Coppola, J. Salazar, J. Jin, R. Sayous, S. Ivanov, P. Schwaller, S. Senthilkuma, A. M. Bran, A. Algaba, K. V. den Houte, L. V. D. Sypt, B. Verbeken, D. Noever, A. Kopylov, B. Myklebust, B. Li, L. Schut, E. Zheltonozhskii, Q. Yuan, D. Lim, R. Stanley, T. Yang, J. Maar, J. Wykowski, M. Oller, A. Sahu, C. G. Ardito, Y. Hu, A. G. K. Kamdoum, A. Jin, T. G. Vilchis, Y. Zu, M. Lackner, J. Koppel, G. Sun, D. S. Antonenko, S. Chern, B. Zhao, P. Arsene, J. M. Cavanagh, D. Li, J. Shen, D. Crisostomi, W. Zhang, A. Dehghan, S. Ivanov, D. Perrella, N. Kaparov, A. Zang, I. Sucholutsky, A. Kharlamova, D. Orel, V. Poritski, S. Ben-David, Z. Berger, P. Whitfill, M. Foster, D. Munro, L. Ho, S. Sivarajan, D. B. Hava, A. Kuchkin, D. Holmes, A. Rodriguez-Romero, F. Sommerhage, A. Zhang, R. Moat, K. Schneider, Z. Kazibwe, D. Clarke, D. H. Kim, F. M. Dias, S. Fish, V. Elser, T. Kreiman, V. E. G. Vilchis, I. Klose, U. Anantheswaran, A. Zweiger, K. Rawal, J. Li, J. Nguyen, N. Daans, H. Heidinger, M. Radionov, V. Rozhoň, V. Ginis, C. Stump, N. Cohen, R. Poświata, J. Tkadlec, A. Goldfarb, C. Wang, P. Padlewski, S. Barzowski, K. Montgomery, R. Stendall, J. Tucker-Foltz, J. Stade, T. R. Rogers, T. Goertzen, D. Grabb, A. Shukla, A. Givré, J. A. Ambay, A. Sen, M. F. Aziz, M. H. Inlow, H. He, L. Zhang, Y. Kaddar, I. Ängquist, Y. Chen, H. K. Wang, K. Ramakrishnan, E. Thornley, A. Terpin, H. Schoelkopf, E. Zheng, A. Carmi, E. D. L. Brown, K. Zhu, M. Bartolo, R. Wheeler, M. Stehberger, P. Bradshaw, J. Heimonen, K. Sridhar, I. Akov, J. Sandlin, Y. Makarychev, J. Tam, H. Hoang, D. M. Cunningham, V. Goryachev, D. Patramanis, M. Krause, A. Redenti, D. Aldous, J. Lai, S. Coleman, J. Xu, S. Lee, I. Magoulas, S. Zhao, N. Tang, M. K. Cohen, O. Paradise, J. H. Kirchner, M. Ovchynnikov, J. O. Matos, A. Shenoy, M. Wang, Y. Nie, A. Sztyber-Betley, P. Faraboschi, R. Riblet, J. Crozier, S. Halasyamani, S. Verma, P. Joshi, E. Meril, Z. Ma, J. Andréoletti, R. Singhal, J. Platnick, V. Nevirkovets, L. Basler, A. Ivanov, S. Khoury, N. Gustafsson, M. Piccardo, H. Mostaghimi, Q. Chen, V. Singh, T. Q. Khánh, P. Rosu, H. Szlyk, Z. Brown, H. Narayan, A. Menezes, J. Roberts, W. Alley, K. Sun, A. Patel, M. Lamparth, A. Reuel, L. Xin, H. Xu, J. Loader, F. Martin, Z. Wang, A. Achilleos, T. Preu, T. Korbak, I. Bosio, F. Kazemi, Z. Chen, B. Bálint, E. J. Y. Lo, J. Wang, M. I. S. Nunes, J. Milbauer, M. S. Bari, Z. Wang, B. Ansarinejad, Y. Sun, S. Durand, H. Elgnainy, G. Douville, D. Tordera, G. Balabanian, H. Wolff, L. Kvistad, H. Milliron, A. Sakor, M. Eron, A. F. D. O., S. Shah, X. Zhou, F. Kamalov, S. Abdoli, T. Santens, S. Barkan, A. Tee, R. Zhang, A. Tomasiello, G. B. D. Luca, S. Looi, V. Le, N. Kolt, J. Pan, E. Rodman, J. Drori, C. J. Fossum, N. Muennighoff, M. Jagota, R. Pradeep, H. Fan, J. Eicher, M. Chen, K. Thaman, W. Merrill, M. Firsching, C. Harris, S. Ciobâcă, J. Gross, R. Pandey, I. Gusev, A. Jones, S. Agnihotri, P. Zhelnov, M. Mofayezi, A. Piperski, D. K. Zhang, K. Dobarskyi, R. Leventov, I. Soroko, J. Duersch, V. Taamazyan, A. Ho, W. Ma, W. Held, R. Xian, A. R. Zebaze, M. Mohamed, J. N. Leser, M. X. Yuan, L. Yacar, J. Lengler, K. Olszewska, C. D. Fratta, E. Oliveira, J. W. Jackson, A. Zou, M. Chidambaram, T. Manik, H. Haffenden, D. Stander, A. Dasouqi, A. Shen, B. Golshani, D. Stap, E. Kretov, M. Uzhou, A. B. Zhidkovskaya, N. Winter, M. O. Rodriguez, R. Lauff, D. Wehr, C. Tang, Z. Hossain, S. Phillips, F. Samuele, F. Ekström, A. Hammon, O. Patel, F. Farhidi, G. Medley, F. Mohammadzadeh, M. Peñaflor, H. Kassahun, A. Friedrich, R. H. Perez, D. Pyda, T. Sakal, O. Dhamane, A. K. Mirabadi, E. Hallman, K. Okutsu, M. Battaglia, M. Maghsoudimehrabani, A. Amit, D. Hulbert, R. Pereira, S. Weber, Handoko, A. Peristyy, S. Malina, M. Mehkary, R. Aly, F. Reidegeld, A. Dick, C. Friday, M. Singh, H. Shapourian, W. Kim, M. Costa, H. Gurdogan, H. Kumar, C. Ceconello, C. Zhuang, H. Park, M. Carroll, A. R. Tawfeek, S. Steinerberger, D. Aggarwal, M. Kirchhof, L. Dai, E. Kim, J. Ferret, J. Shah, Y. Wang, M. Yan, K. Burdzy, L. Zhang, A. Franca, D. T. Pham, K. Y. Loh, J. Robinson, A. Jackson, P. Giordano, P. Petersen, A. Cosma, J. Colino, C. White, J. Votava, V. Vinnikov, E. Delaney, P. Spelda, V. Stritecky, S. M. Shahid, J. Mourrat, L. Vetoshkin, K. Sponselee, R. Bacho, Z. Yong, F. de la Rosa, N. Cho, X. Li, G. Malod, O. Weller, G. Albani, L. Lang, J. Laurendeau, D. Kazakov, F. Adesanya, J. Portier, L. Hollom, V. Souza, Y. A. Zhou, J. Degorre, Y. Yalın, G. D. Obikoya, Rai, F. Bigi, M. C. Boscá, O. Shumar, K. Bacho, G. Recchia, M. Popescu, N. Shulga, N. M. Tanwie, T. C. H. Lux, B. Rank, C. Ni, M. Brooks, A. Yakimchyk, Huanxu, Liu, S. Cavalleri, O. Häggström, E. Verkama, J. Newbould, H. Gundlach, L. Brito-Santana, B. Amaro, V. Vajipey, R. Grover, T. Wang, Y. Kratish, W. Li, S. Gopi, A. Caciolai, C. S. de Witt, P. Hernández-Cámara, E. Rodolà, J. Robins, D. Williamson, V. Cheng, B. Raynor, H. Qi, B. Segev, J. Fan, S. Martinson, E. Y. Wang, K. Hausknecht, M. P. Brenner, M. Mao, C. Demian, P. Kassani, X. Zhang, D. Avagian, E. J. Scipio, A. Ragoler, J. Tan, B. Sims, R. Plecnik, A. Kirtland, O. F. Bodur, D. P. Shinde, Y. C. L. Labrador, Z. Adoul, M. Zekry, A. Karakoc, T. C. B. Santos, S. Shamseldeen, L. Karim, A. Liakhovitskaia, N. Resman, N. Farina, J. C. Gonzalez, G. Maayan, E. Anderson, R. D. O. Pena, E. Kelley, H. Mariji, R. Pouriamanesh, W. Wu, R. Finocchio, I. Alarab, J. Cole, D. Ferreira, B. Johnson, M. Safdari, L. Dai, S. Arthornthurasuk, I. C. McAlister, A. J. Moyano, A. Pronin, J. Fan, A. Ramirez-Trinidad, Y. Malysheva, D. Pottmaier, O. Taheri, S. Stepanic, S. Perry, L. Askew, R. A. H. Rodríguez, A. M. R. Minissi, R. Lorena, K. Iyer, A. A. Fasiludeen, R. Clark, J. Ducey, M. Piza, M. Somrak, E. Vergo, J. Qin, B. Borbás, E. Chu, J. Lindsey, A. Jallon, I. M. J. McInnis, E. Chen, A. Semler, L. Gloor, T. Shah, M. Carauleanu, P. Lauer, T. Đ. Huy, H. Shahrtash, E. Duc, L. Lewark, A. Brown, S. Albanie, B. Weber, W. S. Vaz, P. Clavier, Y. Fan, G. P. R. e Silva, Long, Lian, M. Abramovitch, X. Jiang, S. Mendoza, M. Islam, J. Gonzalez, V. Mavroudis, J. Xu, P. Kumar, L. P. Goswami, D. Bugas, N. Heydari, F. Jeanplong, T. Jansen, A. Pinto, A. Apronti, A. Galal, N. Ze-An, A. Singh, T. Jiang, J. of Arc Xavier, K. P. Agarwal, M. Berkani, G. Zhang, Z. Du, B. A. de Oliveira Junior, D. Malishev, N. Remy, T. D. Hartman, T. Tarver, S. Mensah, G. A. Loume, W. Morak, F. Habibi, S. Hoback, W. Cai, J. Gimenez, R. G. Montecillo, J. Łucki, R. Campbell, A. Sharma, K. Meer, S. Gul, D. E. Gonzalez, X. Alapont, A. Hoover, G. Chhablani, F. Vargus, A. Agarwal, Y. Jiang, D. Patil, D. Outevsky, K. J. Scaria, R. Maheshwari, A. Dendane, P. Shukla, A. Cartwright, S. Bogdanov, N. Mündler, S. Möller, L. Arnaboldi, K. Thaman, M. R. Siddiqi, P. Saxena, H. Gupta, T. Fruhauff, G. Sherman, M. Vincze, S. Usawasutsakorn, D. Ler, A. Radhakrishnan, I. Enyekwe, S. M. Salauddin, J. Muzhen, A. Maksapetyan, V. Rossbach, C. Harjadi, M. Bahaloohoreh, C. Sparrow, J. Sidhu, S. Ali, S. Bian, J. Lai, E. Singer, J. L. Uro, G. Bateman, M. Sayed, A. Menshawy, D. Duclosel, D. Bezzi, Y. Jain, A. Aaron, M. Tiryakioglu, S. Siddh, K. Krenek, I. A. Shah, J. Jin, S. Creighton, D. Peskoff, Z. EL-Wasif, R. P. V, M. Richmond, J. McGowan, T. Patwardhan, H. Sun, T. Sun, N. Zubić, S. Sala, S. Ebert, J. Kaddour, M. Schottdorf, D. Wang, G. Petruzella, A. Meiburg, T. Medved, A. ElSheikh, S. A. Hebbar, L. Vaquero, X. Yang, J. Poulos, V. Zouhar, S. Bogdanik, M. Zhang, J. Sanz-Ros, D. Anugraha, Y. Dai, A. N. Nhu, X. Wang, A. A. Demircali, Z. Jia, Y. Zhou, J. Wu, M. He, N. Chandok, A. Sinha, G. Luo, L. Le, M. Noyé, M. Perełkiewicz, I. Pantidis, T. Qi, S. S. Purohit, L. Parcalabescu, T. Nguyen, G. I. Winata, E. M. Ponti, H. Li, K. Dhole, J. Park, D. Abbondanza, Y. Wang, A. Nayak, D. M. Caetano, A. A. W. L. Wong, M. del Rio-Chanona, D. Kondor, P. Francois, E. Chalstrey, J. Zsambok, D. Hoyer, J. Reddish, J. Hauser, F. Rodrigo-Ginés, S. Datta, M. Shepherd, T. Kamphuis, Q. Zhang, H. Kim, R. Sun, J. Yao, F. Dernoncourt, S. Krishna, S. Rismanchian, B. Pu, F. Pinto, Y. Wang, K. Shridhar, K. J. Overholt, G. Briia, H. Nguyen, David, S. Bartomeu, T. C. Pang, A. Wecker, Y. Xiong, F. Li, L. S. Huber, J. Jaeger, R. D. Maddalena, X. H. Lù, Y. Zhang, C. Beger, P. T. J. Kon, S. Li, V. Sanker, M. Yin, Y. Liang, X. Zhang, A. Agrawal, L. S. Yifei, Z. Zhang, M. Cai, Y. Sonmez, C. Cozianu, C. Li, A. Slen, S. Yu, H. K. Park, G. Sarti, M. Briański, A. Stolfo, T. A. Nguyen, M. Zhang, Y. Perlitz, J. Hernandez-Orallo, R. Li, A. Shabani, F. Juefei-Xu, S. Dhingra, O. Zohar, M. C. Nguyen, A. Pondaven, A. Yilmaz, X. Zhao, C. Jin, M. Jiang, S. Todoran, X. Han, J. Kreuer, B. Rabern, A. Plassart, M. Maggetti, L. Yap, R. Geirhos, J. Kean, D. Wang, S. Mollaei, C. Sun, Y. Yin, S. Wang, R. Li, Y. Chang, A. Wei, A. Bizeul, X. Wang, A. O. Arrais, K. Mukherjee, J. Chamorro-Padial, J. Liu, X. Qu, J. Guan, A. Bouyamourn, S. Wu, M. Plomecka, J. Chen, M. Tang, J. Deng, S. Subramanian, H. Xi, H. Chen, W. Zhang, Y. Ren, H. Tu, S. Kim, Y. Chen, S. V. Marjanović, J. Ha, G. Luczyna, J. J. Ma, Z. Shen, D. Song, C. E. Zhang, Z. Wang, G. Gendron, Y. Xiao, L. Smucker, E. Weng, K. H. Lee, Z. Ye, S. Ermon, I. D. Lopez-Miguel, T. Knights, A. Gitter, N. Park, B. Wei, H. Chen, K. Pai, A. Elkhanany, H. Lin, P. D. Siedler, J. Fang, R. Mishra, K. Zsolnai-Fehér, X. Jiang, S. Khan, J. Yuan, R. K. Jain, X. Lin, M. Peterson, Z. Wang, A. Malusare, M. Tang, I. Gupta, I. Fosin, T. Kang, B. Dworakowska, K. Matsumoto, G. Zheng, G. Sewuster, J. P. Villanueva, I. Rannev, I. Chernyavsky, J. Chen, D. Banik, B. Racz, W. Dong, J. Wang, L. Bashmal, D. V. Gonçalves, W. Hu, K. Bar, O. Bohdal, A. S. Patlan, S. Dhuliawala, C. Geirhos, J. Wist, Y. Kansal, B. Chen, K. Tire, A. T. Yücel, B. Christof, V. Singla, Z. Song, S. Chen, J. Ge, K. Ponkshe, I. Park, T. Shi, M. Q. Ma, J. Mak, S. Lai, A. Moulin, Z. Cheng, Z. Zhu, Z. Zhang, V. Patil, K. Jha, Q. Men, J. Wu, T. Zhang, B. H. Vieira, A. F. Aji, J. Chung, M. Mahfoud, H. T. Hoang, M. Sperzel, W. Hao, K. Meding, S. Xu, V. Kostakos, D. Manini, Y. Liu, C. Toukmaji, J. Paek, E. Yu, A. E. Demircali, Z. Sun, I. Dewerpe, H. Qin, R. Pflugfelder, J. Bailey, J. Morris, V. Heilala, S. Rosset, Z. Yu, P. E. Chen, W. Yeo, E. Jain, R. Yang, S. Chigurupati, J. Chernyavsky, S. P. Reddy, S. Venugopalan, H. Batra, C. F. Park, H. Tran, G. Maximiano, G. Zhang, Y. Liang, H. Shiyu, R. Xu, R. Pan, S. Suresh, Z. Liu, S. Gulati, S. Zhang, P. Turchin, C. W. Bartlett, C. R. Scotese, P. M. Cao, A. Nattanmai, G. McKellips, A. Cheraku, A. Suhail, E. Luo, M. Deng, J. Luo, A. Zhang, K. Jindel, J. Paek, K. Halevy, A. Baranov, M. Liu, A. Avadhanam, D. Zhang, V. Cheng, B. Ma, E. Fu, L. Do, J. Lass, H. Yang, S. Sunkari, V. Bharath, V. Ai, J. Leung, R. Agrawal, A. Zhou, K. Chen, T. Kalpathi, Z. Xu, G. Wang, T. Xiao, E. Maung, S. Lee, R. Yang, R. Yue, B. Zhao, J. Yoon, S. Sun, A. Singh, E. Luo, C. Peng, T. Osbey, T. Wang, D. Echeazu, H. Yang, T. Wu, S. Patel, V. Kulkarni, V. Sundarapandiyan, A. Zhang, A. Le, Z. Nasim, S. Yalam, R. Kasamsetty, S. Samal, H. Yang, D. Sun, N. Shah, A. Saha, A. Zhang, L. Nguyen, L. Nagumalli, K. Wang, A. Zhou, A. Wu, J. Luo, A. Telluri, S. Yue, A. Wang, and D. Hendrycks (2025) Humanity’s last exam. External Links: 2501.14249, Link Cited by: 1st item.
- [47] D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman (2024) Gpqa: a graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, Cited by: 1st item.
- [48] J. Roberts, M. R. Taesiri, A. Sharma, A. Gupta, S. Roberts, I. Croitoru, S. Bogolin, J. Tang, F. Langer, V. Raina, V. Raina, H. Xiong, V. Udandarao, J. Lu, S. Chen, S. Purkis, T. Yan, W. Lin, G. Shin, Q. Yang, A. T. Nguyen, D. I. Atkinson, A. Baranwal, A. Coca, M. Dang, S. Dziadzio, J. D. Kunz, K. Liang, A. Lo, B. Pulfer, S. Walton, C. Yang, K. Han, and S. Albanie (2025) ZeroBench: an impossible visual benchmark for contemporary large multimodal models. External Links: 2502.09696, Link Cited by: 4th item.
- [49] C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, et al. (2022) Laion-5b: an open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems 35, pp. 25278–25294. Cited by: §B.3.
- [50] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov (2017) Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347. External Links: Link Cited by: §4.4.2.
- [51] T. Song, H. Lu, H. Yang, L. Sui, H. Wu, Z. Zhou, Z. Huang, Y. Bao, Y. Charles, X. Zhou, and L. Wang (2026) Towards pixel-level vlm perception via simple points prediction. External Links: 2601.19228, Link Cited by: §B.3.
- [52] G. Starace, O. Jaffe, D. Sherburn, J. Aung, J. S. Chan, L. Maksin, R. Dias, E. Mays, B. Kinsella, W. Thompson, et al. (2025) PaperBench: evaluating ai’s ability to replicate ai research. arXiv preprint arXiv:2504.01848. Cited by: 2nd item.
- [53] K. Team, Y. Bai, Y. Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y. Chen, Y. Chen, Y. Chen, et al. (2025) Kimi k2: open agentic intelligence. arXiv preprint arXiv:2507.20534. Cited by: §B.2, §4.1, §4.4.1, §4.4.2, §4.4.2, §4.5.
- [54] K. Team, A. Du, B. Yin, B. Xing, B. Qu, B. Wang, C. Chen, C. Zhang, C. Du, C. Wei, et al. (2025) Kimi-vl technical report. arXiv preprint arXiv:2504.07491. Cited by: §4.2, §4.3, §4.5.1.
- [55] M. L. Team, B. Wang, B. Xiao, B. Zhang, B. Rong, B. Chen, C. Wan, C. Zhang, C. Huang, C. Chen, et al. (2025) Longcat-flash-omni technical report. arXiv preprint arXiv:2511.00279. Cited by: §4.5.1.
- [56] M. Tian, L. Gao, S. Zhang, X. Chen, C. Fan, X. Guo, R. Haas, P. Ji, K. Krongchon, Y. Li, et al. (2024) Scicode: a research coding benchmark curated by scientists. Advances in Neural Information Processing Systems 37, pp. 30624–30650. Cited by: 2nd item.
- [57] S. Tong, Z. Liu, Y. Zhai, Y. Ma, Y. LeCun, and S. Xie (2024) Eyes wide shut? exploring the visual shortcomings of multimodal llms. External Links: 2401.06209, Link Cited by: 4th item.
- [58] H. M. Tournament (2025) Harvard-mit mathematics tournament, february 2025. Note: Held on February 15, 2025 External Links: Link Cited by: 1st item.
- [59] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin (2017) Attention is all you need. In Advances in Neural Information Processing Systems, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30, pp. . External Links: Link Cited by: §4.1.
- [60] N. Vedula, M. Collins, E. Agichtein, and O. Rokhlenko (2025) DeepSearchQA: bridging the comprehensiveness gap for deep research agents. Google DeepMind, Google Search, Kaggle, and Google Research. External Links: Link Cited by: 3rd item.
- [61] K. Wang, J. Pan, W. Shi, Z. Lu, M. Zhan, and H. Li (2024) Measuring multimodal mathematical reasoning with math-vision dataset. External Links: 2402.14804, Link Cited by: 4th item.
- [62] W. Wang, Z. He, W. Hong, Y. Cheng, X. Zhang, J. Qi, X. Gu, S. Huang, B. Xu, Y. Dong, M. Ding, and J. Tang (2025) LVBench: an extreme long video understanding benchmark. External Links: 2406.08035, Link Cited by: 5th item.
- [63] X. Wang, B. Wang, D. Lu, J. Yang, T. Xie, J. Wang, J. Deng, X. Guo, Y. Xu, C. H. Wu, Z. Shen, Z. Li, R. Li, X. Li, J. Chen, B. Zheng, P. Li, F. Lei, R. Cao, Y. Fu, D. Shin, M. Shin, J. Hu, Y. Wang, J. Chen, Y. Ye, D. Zhang, D. Du, H. Hu, H. Chen, Z. Zhou, H. Yao, Z. Chen, Q. Gu, Y. Wang, H. Wang, D. Yang, V. Zhong, F. Sung, Y. Charles, Z. Yang, and T. Yu (2025) OpenCUA: open foundations for computer-use agents. External Links: 2508.09123, Link Cited by: §E.7.
- [64] Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen (2024) MMLU-pro: a more robust and challenging multi-task language understanding benchmark. External Links: 2406.01574, Link Cited by: 1st item.
- [65] Z. Wang, Y. Liu, Y. Wang, W. He, B. Gao, M. Diao, Y. Chen, K. Fu, F. Sung, Z. Yang, et al. (2025) OJBench: a competition level code benchmark for large language models. arXiv preprint arXiv:2506.16395. Cited by: 2nd item.
- [66] Z. Wang, T. Shi, J. He, M. Cai, J. Zhang, and D. Song (2025) CyberGym: evaluating ai agents’ cybersecurity capabilities with real-world vulnerabilities at scale. arXiv preprint arXiv:2506.02548. Cited by: 2nd item.
- [67] Z. Wang, M. Xia, L. He, H. Chen, Y. Liu, R. Zhu, K. Liang, X. Wu, H. Liu, S. Malladi, A. Chevalier, S. Arora, and D. Chen (2024) CharXiv: charting gaps in realistic chart understanding in multimodal llms. External Links: 2406.18521, Link Cited by: 4th item.
- [68] J. Wei, Z. Sun, S. Papay, S. McKinney, J. Han, I. Fulford, H. W. Chung, A. T. Passos, W. Fedus, and A. Glaese (2025) BrowseComp: a simple yet challenging benchmark for browsing agents. External Links: 2504.12516, Link Cited by: 3rd item.
- [69] R. Wong, J. Wang, J. Zhao, L. Chen, Y. Gao, L. Zhang, X. Zhou, Z. Wang, K. Xiang, G. Zhang, W. Huang, Y. Wang, and K. Wang (2025) WideSearch: benchmarking agentic broad info-seeking. External Links: 2508.07999, Link Cited by: 3rd item.
- [70] H. Wu, D. Li, B. Chen, and J. Li (2024) LongVideoBench: a benchmark for long-context interleaved video-language understanding. External Links: 2407.15754, Link Cited by: 5th item.
- [71] X. Wu, K. Li, Y. Zhao, L. Zhang, L. Ou, H. Yin, Z. Zhang, X. Yu, D. Zhang, Y. Jiang, P. Xie, F. Huang, M. Cheng, S. Wang, H. Cheng, and J. Zhou (2025) ReSum: unlocking long-horizon search intelligence via context summarization. External Links: 2509.13313, Link Cited by: §5.2.
- [72] T. Xie, M. Yuan, D. Zhang, X. Xiong, Z. Shen, Z. Zhou, X. Wang, Y. Chen, J. Deng, J. Chen, B. Wang, H. Wu, J. Chen, J. Wang, D. Lu, H. Hu, and T. Yu (2025-07) Introducing osworld-verified. xlang.ai. External Links: Link Cited by: 6th item, §5.1.2.
- [73] T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, Y. Liu, Y. Xu, S. Zhou, S. Savarese, C. Xiong, V. Zhong, and T. Yu (2024) OSWorld: benchmarking multimodal agents for open-ended tasks in real computer environments. External Links: 2404.07972 Cited by: 6th item, §5.1.2.
- [74] F. Yao, L. Liu, D. Zhang, C. Dong, J. Shang, and J. Gao (2025-08) Your efficient rl framework secretly brings you off-policy rl training. External Links: Link Cited by: §4.4.2.
- [75] X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y. Liu, W. Huang, H. Sun, Y. Su, and W. Chen (2024) MMMU: a massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In Proceedings of CVPR, Cited by: 4th item.
- [76] X. Yue, T. Zheng, Y. Ni, Y. Wang, K. Zhang, S. Tong, Y. Sun, B. Yu, G. Zhang, H. Sun, Y. Su, W. Chen, and G. Neubig (2025) MMMU-pro: a more robust multi-discipline multimodal understanding benchmark. External Links: 2409.02813, Link Cited by: 4th item.
- [77] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer (2023) Sigmoid loss for language image pre-training. External Links: 2303.15343, Link Cited by: §4.2, §4.3.
- [78] X. Zhao, Y. Liu, K. Xu, J. Guo, Z. Wang, Y. Sun, X. Kong, Q. Cao, L. Jiang, Z. Wen, Z. Zhang, and J. Zhou (2025-09) Small leak can sink a great ship–boost rl training on moe with icepop!. External Links: Link Cited by: §4.4.2.
- [79] Y. Zhao, L. Xie, H. Zhang, G. Gan, Y. Long, Z. Hu, T. Hu, W. Chen, C. Li, J. Song, Z. Xu, C. Wang, W. Pan, Z. Shangguan, X. Tang, Z. Liang, Y. Liu, C. Zhao, and A. Cohan (2025) MMVU: measuring expert-level multi-discipline video understanding. External Links: 2501.12380, Link Cited by: 5th item.
- [80] S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y. Bisk, D. Fried, U. Alon, and G. Neubig (2023) WebArena: a realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854. External Links: Link Cited by: 6th item, §5.1.2.
- [81] W. Zhu, J. Hessel, A. Awadalla, S. Y. Gadre, J. Dodge, A. Fang, Y. Yu, L. Schmidt, W. Y. Wang, and Y. Choi (2024) Multimodal c4: an open, billion-scale corpus of images interleaved with text. Advances in Neural Information Processing Systems 36. Cited by: §B.3.
Appendix A Contributors
Tongtong Bai Yifan Bai Yiping Bao S.H. Cai Yuan Cao Y. Charles H.S. Che Cheng Chen Guanduo Chen Huarong Chen Jia Chen Jiahao Chen Jianlong Chen Jun Chen Kefan Chen Liang Chen Ruijue Chen Xinhao Chen Yanru Chen Yanxu Chen Yicun Chen Yimin Chen Yingjiang Chen Yuankun Chen Yujie Chen Yutian Chen Zhirong Chen Ziwei Chen Dazhi Cheng Minghan Chu Jialei Cui Jiaqi Deng Muxi Diao Hao Ding Mengfan Dong Mengnan Dong Yuxin Dong Yuhao Dong Ang’ang Du Chenzhuang Du Dikang Du Lingxiao Du Yulun Du Yu Fan Shengjun Fang Qiulin Feng Yichen Feng Garimugai Fu Kelin Fu Hongcheng Gao Tong Gao Yuyao Ge Shangyi Geng Chengyang Gong Xiaochen Gong Zhuoma Gongque Qizheng Gu Xinran Gu Yicheng Gu Longyu Guan Yuanying Guo Xiaoru Hao Weiran He Wenyang He Yunjia He Chao Hong Hao Hu Jiaxi Hu Yangyang Hu Zhenxing Hu Ke Huang Ruiyuan Huang Weixiao Huang Zhiqi Huang Tao Jiang Zhejun Jiang Xinyi Jin Yu Jing Guokun Lai Aidi Li C. Li Cheng Li Fang Li Guanghe Li Guanyu Li Haitao Li Haoyang Li Jia Li Jingwei Li Junxiong Li Lincan Li Mo Li Weihong Li Wentao Li Xinhang Li Xinhao Li Yang Li Yanhao Li Yiwei Li Yuxiao Li Zhaowei Li Zheming Li Weilong Liao Jiawei Lin Xiaohan Lin Zhishan Lin Zichao Lin Cheng Liu Chenyu Liu Hongzhang Liu Liang Liu Shaowei Liu Shudong Liu Shuran Liu Tianwei Liu Tianyu Liu Weizhou Liu Xiangyan Liu Yangyang Liu Yanming Liu Yibo Liu Yuanxin Liu Yue Liu Zhengying Liu Zhongnuo Liu Enzhe Lu Haoyu Lu Zhiyuan Lu Junyu Luo Tongxu Luo Yashuo Luo Long Ma Yingwei Ma Shaoguang Mao Yuan Mei Xin Men Fanqing Meng Zhiyong Meng Yibo Miao Minqing Ni Kun Ouyang Siyuan Pan Bo Pang Yuchao Qian Ruoyu Qin Zeyu Qin Jiezhong Qiu Bowen Qu Zeyu Shang Youbo Shao Tianxiao Shen Zhennan Shen Juanfeng Shi Lidong Shi Shengyuan Shi Feifan Song Pengwei Song Tianhui Song Xiaoxi Song Hongjin Su Jianlin Su Zhaochen Su Lin Sui Jinsong Sun Junyao Sun Tongyu Sun Flood Sung Yunpeng Tai Chuning Tang Heyi Tang Xiaojuan Tang Zhengyang Tang Jiawen Tao Shiyuan Teng Chaoran Tian Pengfei Tian Ao Wang Bowen Wang Chensi Wang Chuang Wang Congcong Wang Dingkun Wang Dinglu Wang Dongliang Wang Feng Wang Hailong Wang Haiming Wang Hengzhi Wang Huaqing Wang Hui Wang Jiahao Wang Jinhong Wang Jiuzheng Wang Kaixin Wang Linian Wang Qibin Wang Shengjie Wang Shuyi Wang Si Wang Wei Wang Xiaochen Wang Xinyuan Wang Yao Wang Yejie Wang Yipu Wang Yiqin Wang Yucheng Wang Yuzhi Wang Zhaoji Wang Zhaowei Wang Zhengtao Wang Zhexu Wang Zihan Wang Zizhe Wang Chu Wei Ming Wei Chuan Wen Zichen Wen Chengjie Wu Haoning Wu Junyan Wu Rucong Wu Wenhao Wu Yuefeng Wu Yuhao Wu Yuxin Wu Zijian Wu Chenjun Xiao Jin Xie Xiaotong Xie Yuchong Xie Yifei Xin Bowei Xing Boyu Xu Jianfan Xu Jing Xu Jinjing Xu L.H. Xu Lin Xu Suting Xu Weixin Xu Xinbo Xu Xinran Xu Yangchuan Xu Yichang Xu Yuemeng Xu Zelai Xu Ziyao Xu Junjie Yan Yuzi Yan Guangyao Yang Hao Yang Junwei Yang Kai Yang Ningyuan Yang Ruihan Yang Xiaofei Yang Xinlong Yang Ying Yang Yi (弋) Yang Yi (翌) Yang Zhen Yang Zhilin Yang Zonghan Yang Haotian Yao Dan Ye Wenjie Ye Zhuorui Ye Bohong Yin Chengzhen Yu Longhui Yu Tao Yu † Tianxiang Yu Enming Yuan Mengjie Yuan Xiaokun Yuan Yang Yue Weihao Zeng Dunyuan Zha Haobing Zhan Dehao Zhang Hao Zhang Jin Zhang Puqi Zhang Qiao Zhang Rui Zhang Xiaobin Zhang Y. Zhang Yadong Zhang Yangkun Zhang Yichi Zhang Yizhi Zhang Yongting Zhang Yu Zhang Yushun Zhang Yutao Zhang Yutong Zhang Zheng Zhang Chenguang Zhao Feifan Zhao Jinxiang Zhao Shuai Zhao Xiangyu Zhao Yikai Zhao Zijia Zhao Huabin Zheng Ruihan Zheng Shaojie Zheng Tengyang Zheng Junfeng Zhong Longguang Zhong Weiming Zhong M. Zhou Runjie Zhou Xinyu Zhou Zaida Zhou Jinguo Zhu Liya Zhu Xinhao Zhu Yuxuan Zhu Zhen Zhu Jingze Zhuang Weiyu Zhuang Ying Zou Xinxing Zu Kimi K2 Kimi K2.5 footnotetext: The listing of authors is in alphabetical order based on their last names. footnotetext: † The University of Hong Kong
Appendix B Pre-training
<details>
<summary>x7.png Details</summary>
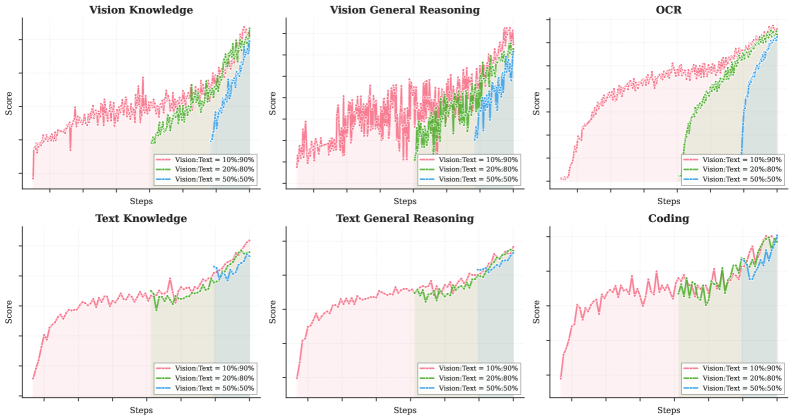
### Visual Description
## Chart Type: Multi-line Graphs with Confidence Intervals
### Overview
The image contains six side-by-side line graphs comparing performance scores across different "Vision-Text" configuration percentages (10%-90%, 20%-80%, 50%-50%) over training steps. Each graph represents a distinct task category (Vision Knowledge, Vision General Reasoning, OCR, Text Knowledge, Text General Reasoning, Coding). Scores increase with steps, with shaded regions indicating confidence intervals.
### Components/Axes
- **X-axis**: "Steps" (training iterations), ranging from 0 to ~100.
- **Y-axis**: "Score" (performance metric), normalized between 0 and 1.
- **Legends**: Positioned in the bottom-left corner of each graph, mapping colors to configurations:
- Red: Vision-Text = 10%-90%
- Green: Vision-Text = 20%-80%
- Blue: Vision-Text = 50%-50%
- **Shaded Regions**: Gray areas under each line represent 95% confidence intervals.
### Detailed Analysis
1. **Vision Knowledge**
- **Trend**: All lines slope upward. The blue (50%-50%) line rises steepest, reaching ~0.95 at 100 steps. Green (20%-80%) plateaus near ~0.85, while red (10%-90%) peaks at ~0.75.
- **Confidence Intervals**: Red line has the widest shaded area, indicating higher variability.
2. **Vision General Reasoning**
- **Trend**: Blue line dominates, reaching ~0.9 at 100 steps. Green (~0.8) and red (~0.7) lag behind.
- **Confidence Intervals**: Red line shows erratic fluctuations, with a narrower shaded region at later steps.
3. **OCR**
- **Trend**: Blue line ascends sharply to ~0.95. Green (~0.85) and red (~0.7) follow.
- **Confidence Intervals**: Shaded regions narrow for all lines as steps increase, suggesting stabilizing performance.
4. **Text Knowledge**
- **Trend**: Blue line reaches ~0.9, green (~0.8), and red (~0.7) at 100 steps.
- **Confidence Intervals**: Red line’s shaded area is consistently wider, reflecting instability.
5. **Text General Reasoning**
- **Trend**: Blue line peaks at ~0.9, green (~0.8), and red (~0.75) at 100 steps.
- **Confidence Intervals**: Green line’s shaded region narrows significantly after 50 steps.
6. **Coding**
- **Trend**: Blue line climbs to ~0.95, green (~0.85), and red (~0.75) at 100 steps.
- **Confidence Intervals**: Red line’s shaded area is the widest, with abrupt dips at ~20 and ~60 steps.
### Key Observations
- **Performance Correlation**: The 50%-50% configuration (blue) consistently outperforms skewed configurations (red/green) across all tasks.
- **Variability**: Lower Vision-Text percentages (10%-90%) exhibit wider confidence intervals, indicating less reliable performance.
- **Task-Specific Trends**: OCR and Coding show the most pronounced gains with balanced configurations, while Vision General Reasoning has the least separation between lines.
### Interpretation
The data suggests that balanced Vision-Text configurations (50%-50%) optimize performance by equally leveraging both modalities. Skewed configurations (e.g., 10%-90%) likely underutilize one modality or over-rely on the other, leading to instability (wider confidence intervals). The narrowing shaded regions in later steps imply that models stabilize as training progresses, but initial variability highlights the importance of configuration choice. OCR and Coding tasks benefit most from balance, possibly due to their reliance on multimodal integration.
</details>
Figure 9: Learning curves comparing vision-to-text ratios (10:90, 20:80, 50:50) under fixed vision-text token budget across vision and language tasks. Early fusion with lower vision ratios tend to yield better results.
B.1 Joint-Training
We further provide the full training curves for all configurations in Figure 9. Notably, we observe a "dip-and-recover" pattern in text performance during mid-fusion and late-fusion stages: when vision data is first introduced, text capability initially degrades before gradually recovering. We attribute this to the modality domain shift—the sudden introduction of vision tokens disrupts the established linguistic representation space, forcing the model to temporarily sacrifice text-specific competence for cross-modal alignment.
In contrast, early fusion maintains a healthier and more stable text performance curve throughout training. By co-optimizing vision and language from the outset, the model naturally evolves unified multimodal representations without the shock of late-stage domain migration. This suggests that early exposure not only prevents the representation collapse observed in late fusion but also facilitates smoother gradient landscapes for both modalities. Collectively, these findings reinforce our proposal of native multimodal pre-training: moderate vision ratios combined with early fusion yield superior convergence properties and more robust bi-modal competence under fixed token budgets.
B.2 Text data
The Kimi K2.5 pre-training text corpus comprises curated, high-quality data spanning four primary domains: Web Text, Code, Mathematics, and Knowledge. Most data processing pipelines follow the methodologies outlined in Kimi K2 [53]. For each domain, we performed rigorous correctness and quality validation and designed targeted data experiments to ensure the curated dataset achieved both high diversity and effectiveness.
Enhanced Code Intelligence We upweighted code-centric data, significantly expanding (1) repository-level code supporting cross-file reasoning and architectural understanding, (2) issues, code reviews and commit histories from the internet capturing real-world development patterns, and (3) code-related documents retrieved from PDF and webtext corpora. These efforts strengthen repository-level comprehension for complex coding tasks, improve performance on agentic coding subtasks such as patch generation and unit test writing, and enhance code-related knowledge capabilities.
B.3 Vision data
Our multimodal pre-training corpus includes seven categories: caption, interleaving, OCR, knowledge, perception, video, and agent data. Caption data [49, 18] provides fundamental modality alignment, with strict limits on synthetic captions to mitigate hallucination. Image-text interleaving data from books, web pages, and tutorials [81, 31] enables multi-image comprehension and longer context learning. OCR data spans multilingual text, dense layouts, and multi-page documents. Knowledge data incorporates academic materials processed via layout parsers to develop visual reasoning capabilities.
Furthermore, we curate a specialized multimodal problem-solving corpus to bolster reasoning within Science, Technology, Engineering, and Mathematics domains. This data is aggregated through targeted retrieval and web crawling; for informational content lacking explicit query formats, we employ in-context learning [10] to automatically reformulate raw materials into structured academic problems spanning K-12 to university levels. To bridge the modality gap between visual layouts and code data, we incorporate extensive image-code paired data. This includes a diverse array of code formats—such as HTML, React, and SVG, among others—paired with their corresponding rendered screenshots, enabling the model to align abstract structural logic with concrete visual geometry.
For agentic and temporal understanding, we collect GUI screenshots and action trajectories across desktop, mobile, and web environments, including human-annotated demonstrations. Video data from diverse sources enables both hour-long video comprehension and fine-grained spatio-temporal perception. Additionally, we incorporate grounding data to enhance fine-grained visual localization, including perception annotations (bounding boxes), point-based references. We also introduce a new contour-level segmentation task [51] for pixel-level perception learning. All data undergoes rigorous filtering, deduplication, and quality control to ensure high diversity and effectiveness.
Appendix C Infra
Kimi K2.5 is trained on NVIDIA H800 GPU clusters with 8 $×$ 400 Gbps RoCE interconnects across nodes. We employ a flexible parallelism strategy combining 16-way Pipeline Parallelism (PP) with virtual stages [26, 39], 16-way Expert Parallelism (EP) [32], and ZeRO-1 Data Parallelism, enabling training on any number of nodes that is a multiple of 32. EP all-to-all communication is overlapped with computation under interleaved 1F1B scheduling. To fit activations within GPU memory constraints, we apply selective recomputation for LayerNorm, SwiGLU, and MLA up-projections, compress insensitive activations to FP8-E4M3, and offload remaining activations to CPU with overlapped streaming.
C.1 Data Storage and Loading
We employ S3 [3] compatible object storage solutions from cloud providers to house our VLM datasets. To bridge the gap between data preparation and model training, we retain visual data in its native format and have engineered a highly efficient and adaptable data loading infrastructure. This infrastructure offers several critical advantages:
- Flexibility: Facilitates dynamic data shuffling, blending, tokenization, loss masking, and sequence packing throughout the training process, enabling adjustable data ratios as requirements evolve;
- Augmentation: Allows for stochastic augmentation of both visual and textual modalities, while maintaining the integrity of 2D spatial coordinates and orientation metadata during geometric transformations;
- Determinism: Guarantees fully deterministic training through meticulous management of random seeds and worker states, ensuring that any training interruption can be resumed seamlessly — the data sequence after resumption remains identical to an uninterrupted run;
- Scalability: Achieves superior data loading throughput via tiered caching mechanisms, robustly scaling to large distributed clusters while regulating request frequency to object storage within acceptable bounds.
Furthermore, to uphold uniform dataset quality standards, we have built a unified platform overseeing data registration, visualization, statistical analysis, cross-cloud synchronization, and lifecycle governance.
Appendix D Unified Agentic Reinforcement Learning Environment
<details>
<summary>x8.png Details</summary>
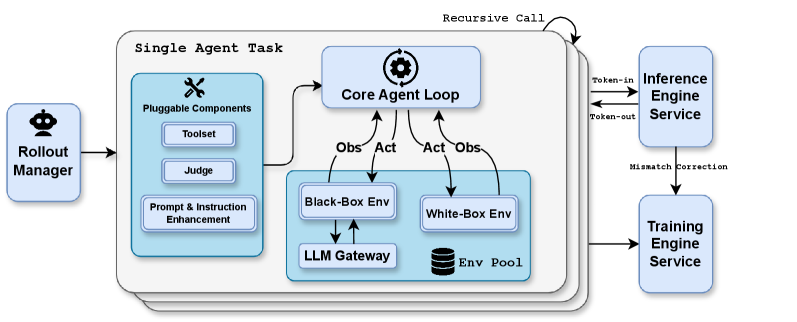
### Visual Description
## Diagram: Single Agent Task System Architecture
### Overview
The diagram illustrates a technical system architecture for a single agent task, emphasizing modular components, feedback loops, and interactions between services. It includes a Rollout Manager, Core Agent Loop, Inference Engine Service, Training Engine Service, and environmental components (Black-Box/White-Box Environments, Env Pool). Arrows indicate data flow, recursive calls, and corrections.
### Components/Axes
- **Key Components**:
- **Rollout Manager**: Leftmost block with Reddit mascot icon.
- **Pluggable Components**: Sub-components include Toolset, Judge, and Prompt & Instruction Enhancement.
- **Core Agent Loop**: Central block with gear icon, connected to Observations (Obs) and Actions (Act) via bidirectional arrows.
- **Black-Box Env** and **White-Box Env**: Sub-environments under Core Agent Loop, connected to LLM Gateway and Env Pool.
- **Inference Engine Service**: Rightmost block with "Token-in" and "Token-out" arrows.
- **Training Engine Service**: Connected to Inference Engine Service via "Mismatch Correction" arrow.
- **Env Pool**: Stacked database icon at the bottom, linked to both environments.
- **Flow Arrows**:
- **Recursive Call**: Self-loop on Core Agent Loop.
- **Mismatch Correction**: Connects Inference Engine Service to Training Engine Service.
### Detailed Analysis
- **Rollout Manager**: Initiates the process, feeding into Pluggable Components.
- **Core Agent Loop**: Central decision-making unit with recursive self-processing.
- **Black-Box/White-Box Environments**: Represent different operational modes (opaque vs. transparent).
- **LLM Gateway**: Interface between environments and the agent.
- **Env Pool**: Shared resource pool for environments.
- **Inference/Training Services**: Handle input/output processing and error correction.
### Key Observations
1. **Modular Design**: Components are decoupled (e.g., Pluggable Components, Environments).
2. **Feedback Loops**: Recursive calls and mismatch corrections enable adaptive learning.
3. **Data Flow**: Tokens move from Inference to Training services for refinement.
4. **Environmental Interaction**: Agent interacts with both black-box and white-box environments via the LLM Gateway.
### Interpretation
This architecture suggests a system designed for iterative learning and task execution. The Rollout Manager orchestrates the process, while the Core Agent Loop drives decision-making. The dual environments (Black-Box/White-Box) imply flexibility in handling tasks with varying transparency requirements. The Training Engine Service’s role in correcting mismatches indicates a focus on continuous improvement. The absence of numerical data points emphasizes structural relationships over quantitative metrics, prioritizing system design over performance analytics.
</details>
Figure 10: Overview of our agentic RL framework.
Environment
To support unified Agentic RL, our RL framework features a standardized Gym-like [9] interface to streamline the implementation of diverse environments. Such design empowers users to implement and customize environments with minimal overhead. Our design prioritizes compositional modularity by integrating a suite of pluggable components, such as a Toolset module for supporting various tools with sandboxes, a Judge module for multi-faceted reward signals, and specialized modules for prompt diversification and instruction-following enhancement. These components can be dynamically composed with core agent loops, offering high flexibility and enhancing model generalization.
At the execution level, our RL framework treats every agent task as an independent asynchronous coroutine. Each task can recursively trigger sub-task rollouts, simplifying the implementation of complex multi-agent paradigms such as Parallel-Agent RL and Agent-as-Judge. As shown in the figure 10, a dedicated Rollout Manager orchestrates up to 100,000 concurrent agent tasks during the RL process, providing fine-grained control to enable features like partial rollout [30]. Upon activation, each task acquires an environment instance from a managed pool, equipped with a sandbox and specialized tools.
Inference Engine Co-design
Our framework strictly follows a Token-in-Token-out paradigm. We also record log probabilities for all inference engine outputs to perform train-inference mismatch correction, ensuring stable RL training. A co-design of inference engine for RL requirements has allowed us to support these features by custom inference APIs for RL.
Besides a comprehensive suite of built-in white-box environments, there are also black-box environments that can only run under standard LLM API protocol, missing the opportunity to use advanced features offered by our custom API protocol. To facilitate model optimization under black-box environments, we developed LLM Gateway, which is a proxy service that keeps detailed records of rollout requests and responses under our custom protocol.
Monitoring and debugging
It is a challenging task to optimize performance of a highly-parallel asynchronous execution system, while ensuring correctness. We develop a series of tools for performance monitoring, profiling, data visualization and data verification. We found these to be instrumental in debugging and ensuring both the efficiency and correctness of our Agentic RL.
Appendix E Evaluation Settings
This section provides comprehensive configuration details and testing protocols for all benchmarks reported in Table 4.
E.1 General Evaluation Protocol
Unless explicitly stated otherwise, all experiments for Kimi-K2.5 adhere to the following hyperparameter configuration:
- Temperature: $1.0$
- Top-p: $0.95$
- Context Length: $256\text{k}$ tokens
E.2 Baselines
For baseline models, we report results under their respective high-performance reasoning configurations:
- Claude Opus 4.5: Extended thinking mode
- GPT-5.2: Maximum reasoning effort (xhigh)
- Gemini 3 Pro: High thinking level
- DeepSeek-V3.2: Thinking mode enabled (for text-only benchmarks)
- Qwen3-VL-235B-A22B: Thinking mode (for vision benchmarks only)
For vision and multimodal benchmarks, GPT-5.2-xhigh exhibited an approximate 10% failure rate (i.e., no output generated despite three retry attempts) during vision evaluations. These failures were treated as incorrect predictions, meaning that the reported scores may be conservative lower bounds of the model’s true capability.
In addition, because we were unable to consistently access a stable GPT-5.2 API, we skipped some benchmarks with high evaluation costs, such as WideSearch.
E.3 Text Benchmarks
Reasoning Benchmarks.
For high-complexity reasoning benchmarks, including HLE-Full, AIME 2025, HMMT 2025, GPQA-Diamond, and IMO-AnswerBench, we enforce a maximum completion budget of $96\text{k}$ tokens to ensure sufficient reasoning depth. To reduce variance arising from stochastic reasoning paths, results on AIME 2025 and HMMT 2025 (Feb) are averaged over 64 independent runs (Avg@64), while GPQA-Diamond is averaged over 8 runs (Avg@8).
LongBench v2.
For a fair comparison, we standardize all input contexts to approximately $128\text{k}$ tokens using the same truncation strategy as in [8]. We observe that GPT5.2-xhigh frequently produces free-form question–answer style responses rather than the required multiple-choice format. Therefore, we report results using GPT5.2-high, which consistently adheres to the expected output format.
E.4 Image and Video Benchmarks
All image and video understanding evaluations utilize the following configuration:
- Maximum Tokens: $64\text{k}$
- Sampling: Averaged over 3 independent runs (Avg@3)
ZeroBench (w/ tools).
Multi-step reasoning evaluations use constrained step-wise generation:
- Max Tokens per Step: $24\text{k}$
- Maximum Steps: $30$
MMMU-Pro.
We adhere strictly to the official evaluation protocol: input order is preserved for all modalities, with images prepended to text sequences as specified in the benchmark guidelines.
Sampling Strategies for Video Benchmarks.
For short video benchmarks (VideoMMMU, MMVU & MotionBench), we sample 128 uniform input frames with a maximum spatial resolution at 896; 2048 uniform frames are sampled for long video benchmarks (Video-MME, LongVideoBench & LVBench) with 448 spatial resolution.
Specialized Metrics.
- OmniDocBench 1.5: Scores are computed as $(1-\text{normalized Levenshtein distance})× 100$ , where higher values indicate superior OCR and document understanding accuracy.
- WorldVQA: Access available at https://github.com/MoonshotAI/WorldVQA. This benchmark evaluates atomic, vision-centric world knowledge requiring fine-grained visual recognition and geographic understanding.
E.5 Coding and Software Engineering
Terminal Bench 2.0.
All scores are obtained using the default Terminus-2 agent framework with the provided JSON parser. Notably, we evaluate under non-thinking mode because our current context management implementation for thinking mode is technically incompatible with Terminus-2’s conversation state handling.
SWE-Bench Series.
We employ an internally developed evaluation framework featuring a minimal tool set: bash, create_file, insert, view, str_replace, and submit. System prompts are specifically tailored for repository-level code manipulation. Peak performance is achieved under non-thinking mode across all SWE-Bench variants (Verified, Multilingual, and Pro).
CyberGym.
Claude Opus 4.5 results for this benchmark are reported under non-thinking settings as specified in their technical documentation. We report scores in the difficulty level 1 (the primary setting).
PaperBench.
We report the scores under the CodeDev setting.
Sampling.
All coding task results are averaged over 5 independent runs (Avg@5) to ensure stability across environment initialization and non-deterministic test case ordering.
E.6 Agentic Evaluation
Tool Setting.
Kimi-K2.5 is equipped with web search tool, code interpreter (Python execution environment), and web browsing tools for all agentic evaluations, including HLE with tools and agentic search benchmarks (BrowseComp, WideSearch, DeepSearchQA, FinSearchComp T2&T3 and Seal-0).
Context Management Strategies.
To handle the extended trajectory lengths inherent in complex agentic tasks, we implement domain-specific context management protocols. Unless otherwise specified below, no context management is applied to agentic evaluations; tasks exceeding the model’s supported context window are directly counted as failures rather than truncated.
- Humanity’s Last Exam (HLE). For the HLE tool-augmented setting, we employ a Hide-Tool-Result Context Management strategy: when the context length exceeds predefined thresholds, only the most recent round of tool messages (observations and return values) is retained, while the reasoning chain and thinking processes from all previous steps are preserved in full.
- BrowseComp. For BrowseComp evaluations, our evaluation contains both with and without context management settings. Under the context management setting, we adopt the same discard-all strategy proposed by DeepSeek, where all history is truncated once token thresholds are exceeded.
System Prompt.
All agentic search and HLE evaluations utilize the following unified system prompt, where DATE is dynamically set to the current timestamp:
You are Kimi, today’s date: DATE. Your task is to help the user with their questions by using various tools, thinking deeply, and ultimately answering the user’s questions. Please follow the following principles strictly during the deep research: 1. Always focus on the user’s original question during the research process, avoiding deviating from the topic. 2. When facing uncertain information, use search tools to confirm. 3. When searching, filter high-trust sources (such as authoritative websites, academic databases, and professional media) and maintain a critical mindset towards low-trust sources. 4. When performing numerical calculations, prioritize using programming tools to ensure accuracy. 5. Please use the format [^index^] to cite any information you use. 6. This is a **Very Difficult** problemdo not underestimate it. You must use tools to help your reasoning and then solve the problem. 7. Before you finally give your answer, please recall what the question is asking for.
Sampling Protocol.
To account for the inherent stochasticity in search engine result rankings and dynamic web content availability, results for Seal-0 and WideSearch are averaged over 4 independent runs (Avg@4). All other agentic benchmarks are evaluated under single-run protocols unless explicitly stated otherwise.
E.7 Computer-Use Evaluation
Hyperparameter Settings.
We set $\texttt{max\_steps\_per\_episode}=100$ for all experiments, with $\texttt{temperature}=0$ for OSWorld-Verified and $\texttt{temperature}=0.1$ for WebArena. Due to resource constraints, all models are evaluated in a one-shot setting. Adhering to the OpenCUA configuration [63], the agent context includes the last 3 history images, the complete thought history, and the task instruction. For WebArena, we manually corrected errors in the evaluation scripts and employed GPT-4o as the judge model for the fuzzy_match function. To ensure fair comparison, Claude Opus 4.5 is evaluated solely with computer-use tools (excluding browser tools), a departure from the System Card configuration [4].
System Prompt
We utilize a unified system prompt for all computer use tasks: You are a GUI agent. You are given an instruction, a screenshot of the screen and your previous interactions with the computer. You need to perform a series of actions to complete the task. The password of the computer is {password}. For each step, provide your response in this format: {thought} ## Action: {action} ## Code: {code} In the code section, the code should be either pyautogui code or one of the following functions wrapped in the code block: - {"name": "computer.wait", "description": "Make the computer wait for 20 seconds for installation, running code, etc.", "parameters": {"type": "object", "properties": {}, "required": []}} - {"name": "computer.terminate", "description": "Terminate the current task and report its completion status", "parameters": {"type": "object", "properties": {"status": {"type": "string", "enum": ["success", "failure"], "description": "The status of the task"}, "answer": {"type": "string", "description": "The answer of the task"}}, "required": ["status"]}}
E.8 Agent Swarm Configuration
Tool Setting.
In addition to the core toolset described in Appendix E.6 (web search, code interpreter, and web browsing), the orchestrator is equipped with two specialized tools for sub-agent creation and scheduling:
- create_subagent: Instantiates a specialized sub-agent with a custom system prompt and identifier for reuse across tasks.
- assign_task: Dispatches assignments to created sub-agents.
The tool schemas are provided below:
{ "name": "create_subagent", "description": "Create a custom subagent with specific system prompt and name for reuse.", "parameters": { "type": "object", "properties": { "name": { "type": "string", "description": "Unique name for this agent configuration" }, "system_prompt": { "type": "string", "description": "System prompt defining the agent’s role, capabilities, and boundaries" } }, "required": ["name", "system_prompt"] } } { "name": "assign_task", "description": "Launch a new agent.\nUsage notes:\n 1. You can launch multiple agents concurrently whenever possible, to maximize performance;\n 2. When the agent is done, it will return a single message back to you.", "parameters": { "type": "object", "properties": { "agent": { "type": "string", "description": "Specify which created agent to use." }, "prompt": { "type": "string", "description": "The task for the agent to perform" } }, "required": ["agent", "prompt"] } }
Step Limits.
When operating in Agent Swarm mode, we set computational budgets for the orchestrator and sub-agents. Step limits apply to the aggregate count of tool invocations and environment interactions.
- BrowseComp: The orchestrator is constrained to a maximum of 15 steps. Each spawned sub-agent operates under a limit of 100 steps (i.e., up to 100 tool calls per sub-agent).
- WideSearch: Both the orchestrator and each sub-agent are allocated a maximum budget of 100 steps.
- In-house Bench: The orchestrator is constrained to a maximum of 100 steps. Each spawned sub-agent operates under a limit of 50 steps .
System Prompt.
You are Kimi, a professional and meticulous expert in information collection and organization. You fully understand user needs, skillfully use various tools, and complete tasks with the highest efficiency. # Task Description After receiving users’ questions, you need to fully understand their needs and think about and plan how to complete the tasks efficiently and quickly. # Available Tools To help you complete tasks better and faster, I have provided you with the following tools: 1. Search tool: You can use the search engine to retrieve information, supporting multiple queries in parallel. 2. Browser tools: You can visit web links (web pages, PDFs, etc.), get page content, and perform interactions such as clicking, inputting, finding, and scrolling. 3. Sub Agent tools: - ‘create_subagent‘: Create a new sub-agent with a unique name and clear, specific system prompt. - ‘assign_task‘: Delegate tasks to created sub-agents. Sub-agents can also use search and browser tools. 4. Other tools: Including code execution (IPython, Shell).
E.9 GDPVal
We cite the GDPVal-AA evaluation by Artificial Analysis, and the scores reported in Table 4 reflect the official leaderboard metrics as of January 28, 2026.
<details>
<summary>x9.png Details</summary>

### Visual Description
## Screenshot: Technical Document Interface for Video Analysis
### Overview
The image depicts a technical interface for analyzing video files, specifically gameplay footage from "Black Myth: Wukong." It includes a timeline of video clips, a flowchart of processing steps, and a summary of analysis results. The interface emphasizes parallel processing of large video files using subagents and technical tools like FFMPEG.
### Components/Axes
1. **Timeline Section**:
- **Labels**: "USER", "THINK", "SUMMARY", "TOOL"
- **Content**: Six video thumbnails with timestamps (e.g., "00:05:40-00:06:10") and descriptions (e.g., "Prologue - Epic battle with Erlang Shen").
- **Axis**: Time-based labels for video clips.
2. **Flowchart (Right Column)**:
- **Labels**: "MAIN AGENT", "SUBAGENT 1", "SUBAGENT 2", "SUBAGENT 3", "SUBAGENT 32"
- **Components**:
- **Main Agent**: Analyzes the video and extracts key frames.
- **Subagents**: Process specific tasks (e.g., "Extract a 10-second video clip," "Create short clips for HTML showcase").
- **Flow**: Arrows indicate sequential steps from main agent to subagents.
3. **Summary Section**:
- **Labels**: "Analysis Complete!", "How to View"
- **Content**: Describes the final output (HTML page with embedded video clips, charts, and timeline).
### Detailed Analysis
- **Timeline**:
- **Video Clips**: Six clips with timestamps and descriptions (e.g., "Prologue - Epic battle with Erlang Shen").
- **Technical Details**: Mentions "32 video files totaling about 40GB" and "Chinese action RPG."
- **Flowchart**:
- **Subagent Tasks**:
- **Subagent 1**: Extracts key frames using FFMPEG.
- **Subagent 2**: Analyzes timelines and level-up moments.
- **Subagent 3**: Creates short clips for the HTML showcase.
- **Parallel Processing**: Subagents operate independently to handle large files.
- **Summary**:
- **Key Points**:
- "32 gameplay videos of 'Black Myth: Wukong' (40GB total)."
- "Parallel analysis strategy using subagents."
- "HTML showcase with embedded video clips and charts."
### Key Observations
1. **Parallel Processing**: Subagents are used to handle large video files efficiently.
2. **Technical Tools**: FFMPEG is employed for frame extraction and clip creation.
3. **Output**: The final HTML page integrates video clips, analysis results, and a chronological timeline.
### Interpretation
The interface demonstrates a scalable system for analyzing large video datasets. By dividing tasks among subagents, the system optimizes processing time and resource usage. The use of FFMPEG highlights a focus on precise frame extraction, while the HTML showcase suggests a user-friendly output for presenting results. The emphasis on parallel processing and technical tools indicates a design tailored for high-performance video analysis workflows.
</details>
Figure 11: Qualitative example of Kimi K2.5 analyzing a complete playthrough of Black Myth: Wukong (24 hours of continuous gameplay across 32 videos at 1080p) using parallel visual agents. See generated webpage and source videos (all rights reserved by source authors).
<details>
<summary>x10.png Details</summary>

### Visual Description
## Multi-Column Technical Analysis: Maze Solving, Color Analysis, and Image Comparison
### Overview
The image contains three vertical columns of technical diagrams, charts, and text blocks. Each column focuses on a distinct task: maze pathfinding, color percentage analysis, and image difference detection. The content includes Python code snippets, visualizations, and analytical summaries.
---
### Left Column: Maze Pathfinding
#### Components/Axes
1. **Maze Diagram**
- Start point: Bottom-left (labeled "Start")
- End point: Top-right (labeled "End")
- Path: Red line connecting start to end
- Summary: "The path contains 3,288 points. The maze path is clearly marked in the image above; the red line represents the walking route!"
2. **BFS Algorithm Visualization**
- Grayscale maze with incremental pathfinding steps
- Final path highlighted in red
#### Detailed Analysis
- **Path Length**: 3,288 pixels (total length)
- **Algorithm**: Breadth-First Search (BFS) guarantees the shortest path with no backtracking
- **Constraints**: No wall-clipping; strictly follows corridors
#### Key Observations
- The red path avoids dead-ends and optimizes route efficiency.
- BFS ensures minimal steps (3,288 points) without revisiting nodes.
#### Interpretation
The maze-solving process demonstrates algorithmic efficiency, with BFS providing an optimal path. The red visualization confirms no deviations from the shortest route.
---
### Middle Column: Color Percentage Analysis
#### Components/Axes
1. **Pie Chart (Red/Blue/Green)**
- Sections:
- Red: 45.9%
- Blue: 23.4%
- Green: 30.7%
- Total Green + Blue: 54.1%
- Legend: Red (#FF0000), Blue (#0000FF), Green (#00FF00)
2. **HSV Color Space Conversion**
- Code snippet: Converts RGB to HSV for better segmentation
- Color ranges defined for red, blue, and green
3. **Pixel-Level Analysis**
- Total colored pixels: 61,609
- Red: 26,994 (43.8%)
- Blue: 13,752 (22.3%)
- Green: 18,852 (30.6%)
#### Detailed Analysis
- **Color Distribution**:
- Red dominates (45.9%), followed by green (30.7%) and blue (23.4%).
- Combined green and blue sections constitute 54.1% of the pie chart.
- **Code Logic**:
- Uses HSV conversion for accurate color segmentation.
- Calculates percentages via pixel counts (e.g., `red_pct = red_pixels / total_detected * 100`).
#### Key Observations
- Green and blue together slightly exceed half the chart (54.1%).
- Discrepancies in pixel counts (e.g., 61,609 vs. 58,778) suggest potential edge-case handling in code.
#### Interpretation
The analysis highlights the dominance of red in the dataset, while green and blue together form a majority. The HSV conversion ensures robust color differentiation, critical for segmentation tasks.
---
### Right Column: Image Difference Detection
#### Components/Axes
1. **Spot-the-Difference Pairs**
- Two images of cartoon characters (fox and bear) with subtle differences.
- Summary: "A total of 10 major differences have been identified."
2. **Difference Map Visualization**
- Black-and-white heatmap highlighting discrepancies
- Code: `python: Difference map`
3. **Manual Refinement**
- Summary: "27 change regions were auto-detected, though many overlap. Let me manually refine these into the 10 main differences."
#### Detailed Analysis
- **Detected Differences**:
- 10 major differences identified (e.g., DMV vs. EMV sign, calendar image variation).
- Code uses threshold filtering to isolate discrepancies.
#### Key Observations
- Overlapping regions in auto-detection require manual refinement.
- Differences include textual, positional, and color variations (e.g., "YOU WANT IT?" vs. "YOU'LL GET IT!").
#### Interpretation
The process combines automated detection with human oversight to resolve ambiguities, ensuring accurate identification of critical differences.
---
### Cross-Column Trends
1. **Pathfinding**: BFS algorithm consistently produces optimal routes (3,288 points).
2. **Color Analysis**: Red dominates visual datasets, while green and blue combined form a majority.
3. **Image Comparison**: Manual refinement is essential to resolve overlapping automated detections.
### Final Summary
- **Maze Solving**: BFS ensures shortest path with 3,288 points.
- **Color Analysis**: Red (45.9%), Green (30.7%), Blue (23.4%); Green + Blue = 54.1%.
- **Image Differences**: 10 major discrepancies identified via threshold filtering and manual refinement.
</details>
Figure 12: Qualitative examples of Kimi K2.5 solving visual reasoning tasks via tool use.
Appendix F Visualization
Figure 11 demonstrates our Agent Swarm tackling a challenging long-form video understanding task: analyzing a complete playthrough of Black Myth: Wukong (24 hours of continuous gameplay across 32 videos, totaling 40GB). The system employs a hierarchical multi-agent architecture where a Main Agent orchestrates parallel Sub Agents to process individual video segments independently. Each sub agent performs frame extraction, temporal event analysis, and key moment identification (e.g., boss fights, level-ups). The Main Agent subsequently aggregates these distributed analyses to synthesize a comprehensive HTML showcase featuring chronological timelines, embedded video clips, and interactive visualizations. This example demonstrates the system’s ability to handle massive-scale multimodal content through parallelization while maintaining coherent long-context understanding.
Figure 12 presents qualitative examples of Kimi K2.5 solving diverse visual reasoning tasks via tool-augmented reasoning. The model demonstrates: (1) Maze Solving—processing binary image segmentation and implementing pathfinding algorithms (BFS) to navigate complex mazes; (2) Pie Chart Analysis—performing pixel-level color segmentation and geometric calculations to determine precise area proportions; and (3) Spot-the-Difference—employing computer vision techniques to detect pixel-level discrepancies between image pairs. These examples highlight the model’s capability to decompose complex visual problems into executable code, iteratively refine strategies based on intermediate results, and synthesize precise answers through quantitative visual analysis.