# SWE-Universe: Scale Real-World Verifiable Environments to Millions
**Authors**:
- Junyang Lin, Binyuan Hui (Qwen Team, Alibaba Group, Zhejiang University)
> Work done during an internship at Alibaba Qwen.
Abstract
We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Bar Chart: Number of Real-World Verifiable SWE Instances
### Overview
This bar chart visualizes the number of real-world verifiable Software Engineering (SWE) instances for different datasets, categorized by programming language support: Python-only and Multilingual. The chart uses a bar graph to compare the instance counts across several datasets.
### Components/Axes
* **Title:** "Number of Real-World Verifiable SWE Instances" (centered at the top)
* **X-axis:** Dataset names: "SWE-Bench", "SWE-Gym", "Multi-SWE-RL", "SWE-rebench", "DeepSeek-V3.2", "CWM", "MIMO-V2-Flash", "SWE-Universe (Ours)".
* **Y-axis:** Number of Instances (scale not explicitly labeled, but implied to be linear).
* **Legend:** Located in the top-left corner.
* "Python-only" (represented by light blue)
* "Multilingual" (represented by orange)
### Detailed Analysis
The chart consists of eight datasets along the x-axis. For each dataset, there are two bars representing the number of Python-only and Multilingual instances.
* **SWE-Bench:**
* Python-only: Approximately 2,294 instances (light blue bar).
* Multilingual: Approximately 2,438 instances (orange bar).
* **SWE-Gym:**
* Python-only: Approximately 2,438 instances (light blue bar).
* Multilingual: Approximately 4,723 instances (orange bar).
* **Multi-SWE-RL:**
* Python-only: Approximately 4,723 instances (light blue bar).
* Multilingual: Approximately 21,000 instances (orange bar).
* **SWE-rebench:**
* Python-only: Approximately 21,000 instances (light blue bar).
* Multilingual: Approximately 24,667 instances (orange bar).
* **DeepSeek-V3.2:**
* Python-only: Approximately 24,667 instances (light blue bar).
* Multilingual: Approximately 35,000 instances (orange bar).
* **CWM:**
* Python-only: Approximately 35,000 instances (light blue bar).
* Multilingual: Approximately 90,000 instances (orange bar).
* **MIMO-V2-Flash:**
* Python-only: Approximately 90,000 instances (light blue bar).
* Multilingual: No bar is visible for Python-only.
* **SWE-Universe (Ours):**
* Python-only: No bar is visible for Python-only.
* Multilingual: Approximately 807,693 instances (orange bar).
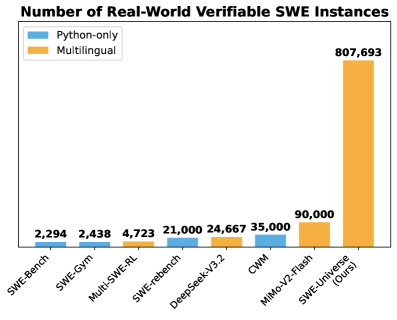
The orange bars (Multilingual) generally increase in height from left to right, with a particularly large jump for "SWE-Universe (Ours)". The light blue bars (Python-only) also generally increase, but at a much slower rate.
### Key Observations
* The "SWE-Universe (Ours)" dataset has a significantly higher number of Multilingual instances (807,693) compared to all other datasets.
* For most datasets, the number of Multilingual instances is greater than or equal to the number of Python-only instances.
* The difference between Python-only and Multilingual instances is relatively small for the first few datasets (SWE-Bench, SWE-Gym, Multi-SWE-RL), but grows substantially for later datasets.
* For MIMO-V2-Flash and SWE-Universe (Ours), there are no Python-only instances.
### Interpretation
The data suggests that the "SWE-Universe (Ours)" dataset is substantially larger and more diverse than the other datasets, particularly in terms of multilingual support. The increasing trend in Multilingual instances across the datasets indicates a growing focus on supporting multiple programming languages in software engineering research and development. The lack of Python-only instances in the last two datasets suggests that these datasets are specifically designed for multilingual scenarios. The chart highlights the importance of multilingual support in modern software engineering and the potential benefits of using larger, more diverse datasets for training and evaluating SWE models. The large difference in scale between the datasets suggests that the "SWE-Universe (Ours)" dataset may represent a significant advancement in the availability of real-world verifiable SWE instances.
</details>
Figure 1: A comparison of the number of instances in real-world SWE instances. Our multilingual SWE-Universe is significantly larger than other recent multilingual efforts like MiMo-V2-Flash (Xiao et al., 2026), DeepSeek-V3.2 (DeepSeek-AI, 2025), and Multi-SWE-RL (Zan et al., 2025), as well as prominent Python-only datasets including SWE-rebench (Badertdinov et al., 2025), SWE-Gym (Pan et al., 2024), CWM (Copet et al., 2025), and SWE-Bench (Jimenez et al., 2024).
1 Introduction
Training large language models (LLMs) (Yang et al., 2025a; Liu et al., 2025) as coding agents has gained substantial attention in software engineering (SWE). Progress in this direction is critically dependent on large-scale, high-quality environments with reliable verification signals. An ideal source for such data lies within the vast ecosystem of real-world software development, specifically public GitHub repositories where pull requests (PRs) are linked to corresponding issues. Each such PR defines a self-contained training environment: the issue serves as a clear problem statement, the code patch offers an expert reference solution, and the accompanying tests can be repurposed into a verifier for agent proposed fixes. This formulation effectively turns each PR into a “gym” for training and evaluating coding agents. Benchmarks such as SWE-bench (Jimenez et al., 2024) operationalized this pipeline by curating real-world issues and standardizing the evaluation, serving as a common testbed for subsequent work.
However, scaling the construction of verifiable real-world SWE environments while maintaining diversity and reproducibility remains a major challenge. A vast body of work, including the original SWE-bench and its many derivatives and extensions (Pan et al., 2024; Badertdinov et al., 2025; Zhang et al., 2025c; Guo et al., 2025; Zeng et al., 2026; Wang et al., 2025; Aleithan et al., 2024; Copet et al., 2025) has primarily focused on Python. While this line of work leverages the low barrier to entry for Python environment configuration, it nonetheless restricts the development of agents with true cross-lingual generalization capabilities. Efforts to create multi-lingual datasets, such as Multi-SWE-bench (Zan et al., 2025) and SWE-PolyBench (Rashid et al., 2025), rely on labor-intensive manual environment setup and remain limited in scale. Despite recent efforts of industrial LLM providers that scale SWE instances to the $10^{4}-10^{5}$ magnitude (Xiao et al., 2026; DeepSeek-AI, 2025), the technical details are undisclosed.
We argue that scaling the generation of such verifiable environments to the massive scale (e.g., $10^{6}$ ) hinges on overcoming three fundamental challenges:
- Low Production Yield: The intricate and heterogeneous nature of real-world repositories with their complex dependencies, platform-specific configurations, and bespoke build toolchains, yielding a low conversion rate from repositories to runnable instances. This results in significant computational waste and makes large-scale generation impractical.
- Weak Verifier: Issues, PR patches, and test suites exhibit substantial variance in quality. A naive extraction pipeline can produce low-fidelity instances, and can also admit verifier vulnerabilities that allow solutions to pass via shallow heuristics (e.g., string matching with grep) rather than compiling and executing the intended code. Such failure modes create spurious training signals and distort evaluation.
- Prohibitive Cost and Inefficiency: Many existing pipelines rely on large, expensive LLMs to perform repository-specific reasoning for dependency resolution and build configuration. The resulting cost and latency per instance make massive-scale generation economically and operationally impractical.
To systematically address these challenges, we introduce SWE-Universe, a scalable, reliable, and efficient framework for automatically constructing million-scale, real-world agentic software engineering environments. At its core is an autonomous building agent that, for each PR, synthesizes a self-contained executable environment together with an executable verifier. To mitigate low production yield, the agent performs self-verification in an iterative validation loop. Concretely, it repeatedly tests the generated verifier against both the buggy and the fixed repository states, diagnoses failure modes, and revises the build procedure accordingly. This process improves the build success rate from 82.6% to 94% on a held-out set. To address the weak verifier, we integrate an in-loop hacking detector that immediately flags and rejects superficial verifiers during the generation process, forcing the agent toward solutions that genuinely execute the code. To achieve high efficiency and low cost, we specially trained an efficient Qwen-Next-80B-A3B model with a Mixture-of-Experts (MoE) framework and hybrid attention. On our custom multi-lingual building benchmark, this model achieves a 78.44% success rate, surpassing top-tier proprietary models like Claude-Opus-4.5, while its efficient architecture dramatically reduces the latency and cost per build.
Leveraging the SWE-Universe framework, we construct 807,693 multilingual, verifiable training instances sourced from over 52,000 unique GitHub repositories. To our knowledge, this dataset is currently the largest and most diverse collection of real-world software engineering tasks with executable verification. We further validate the immense value of this dataset through extensive experiments. First, in a mid-training phase, we show that continued training on our dataset significantly enhances a model’s performance on standard benchmarks like SWE-Bench Verified (Jimenez et al., 2024), proving its powerful generalization capabilities. Second, we demonstrate that the verifiers generated by our pipeline provide a stable and effective reward signal for Reinforcement Learning (RL). By applying to our flagship model, Qwen3-Max-Thinking (Qwen Team, 2026), we achieved a score of 75.3% on the SWE-Bench Verified. Together, these results validate SWE-Universe as a robust framework for creating large-scale, high-quality agentic training data, paving the way for the development of more capable and versatile coding agents for real-world applications.
2 Methodology: Scalability and Reliability
<details>
<summary>figures/env-build.png Details</summary>
### Visual Description
\n
## Diagram: Automated Bug Fixing Workflow
### Overview
This diagram illustrates an automated workflow for bug fixing, involving a pull request, a building & verifier agent, a hacking detector, a repository container, and a verifier validation process. The workflow appears to be an agentic loop, where observations lead to actions, and the system attempts to resolve bugs automatically.
### Components/Axes
The diagram is segmented into four main areas:
1. **Pull Request (Top-Left):** Represents the initial code change.
2. **Building & Verifier Agent (Top-Center):** The core agent responsible for building and verifying changes.
3. **Hacking Detector & Repository Container (Bottom-Left):** Components for detecting potential issues and managing the codebase.
4. **Verifier Validation & New Software Engineering Task (Bottom-Right):** The validation process and the creation of new tasks.
Key elements include:
* **Pull Request:** Contains files `sklearn`, `gradient_boosting.py`, `helper.py`, `utils`.
* **Building & Verifier Agent:** Includes `bash`, `tools`, `switch-to-bug`, `switch-to-resolved`, and `evaluation.sh`.
* **Hacking Detector:** Displays `evaluation.sh` with both a success (green checkmark) and failure (red cross) result.
* **Repository Container:** Contains `sklearn`, `examples`, `README.rst`, `setup.py`, `reqs.txt`, `setup.cfg`.
* **Verifier Validation:** Shows `switch-to-bug` and `switch-to-resolved` states with corresponding exit codes (non-zero for failure, 0 for success).
* **New Software Engineering Task:** Includes `problem statement` (TXT file), `docker image`, and `eval script`.
Arrows indicate the flow of information and control between these components. Colors are used to denote success (green), failure (red), and general flow (gray/purple).
### Detailed Analysis or Content Details
**1. Pull Request:**
* Files listed: `sklearn`, `gradient_boosting.py`, `helper.py`, `utils`.
* Indication of a real-world pull request.
* +20 -12 (likely representing added and removed lines of code).
**2. Building & Verifier Agent:**
* The agent uses `bash` and `tools`.
* It switches between `switch-to-bug` and `switch-to-resolved` states.
* `evaluation.sh` is submitted for testing.
* A "retry" loop is indicated by a dashed red arrow.
**3. Hacking Detector:**
* `evaluation.sh` is executed twice:
* `pytest test_production.py` – Successful (green checkmark).
* `grep -q "keyword" bug.java` – Failed (red cross).
* An "agentic loop" is shown, with "observation" leading to "action".
**4. Repository Container:**
* Contains the codebase: `sklearn`, `examples`, `README.rst`, `setup.py`, `reqs.txt`, `setup.cfg`.
* `evaluation.sh` is used to interact with the container.
**5. Verifier Validation:**
* `switch-to-bug` results in a non-zero exit code (failure).
* `switch-to-resolved` results in a 0 exit code (success).
* The validation process can either "pass" (green checkmark) or "fail" (red cross).
**6. New Software Engineering Task:**
* Created when the workflow fails (indicated by the red "X").
* Includes a `problem statement` (TXT file), a `docker image`, and an `eval script`.
### Key Observations
* The workflow is designed to automatically detect and fix bugs.
* The "retry" loop suggests that the agent attempts to resolve bugs multiple times before giving up.
* The Hacking Detector identifies potential issues using different tests (`pytest` and `grep`).
* Failure in the validation process triggers the creation of a new software engineering task, indicating that human intervention is sometimes required.
* The agentic loop is central to the process, enabling continuous observation and action.
### Interpretation
This diagram depicts a sophisticated automated bug fixing system. The system leverages an agent that observes the codebase, takes actions to fix bugs, and validates the changes. The agentic loop allows for iterative improvement and adaptation. The inclusion of a "Hacking Detector" suggests a focus on security vulnerabilities. The workflow is not entirely autonomous, as failures can lead to the creation of new tasks for human engineers. The use of Docker images and evaluation scripts indicates a focus on reproducibility and automated testing. The diagram highlights the challenges of automating bug fixing and the need for a combination of automated tools and human expertise. The two different tests in the Hacking Detector suggest a multi-faceted approach to identifying potential issues. The clear distinction between "bug" and "resolved" states, along with the associated exit codes, demonstrates a rigorous validation process.
</details>
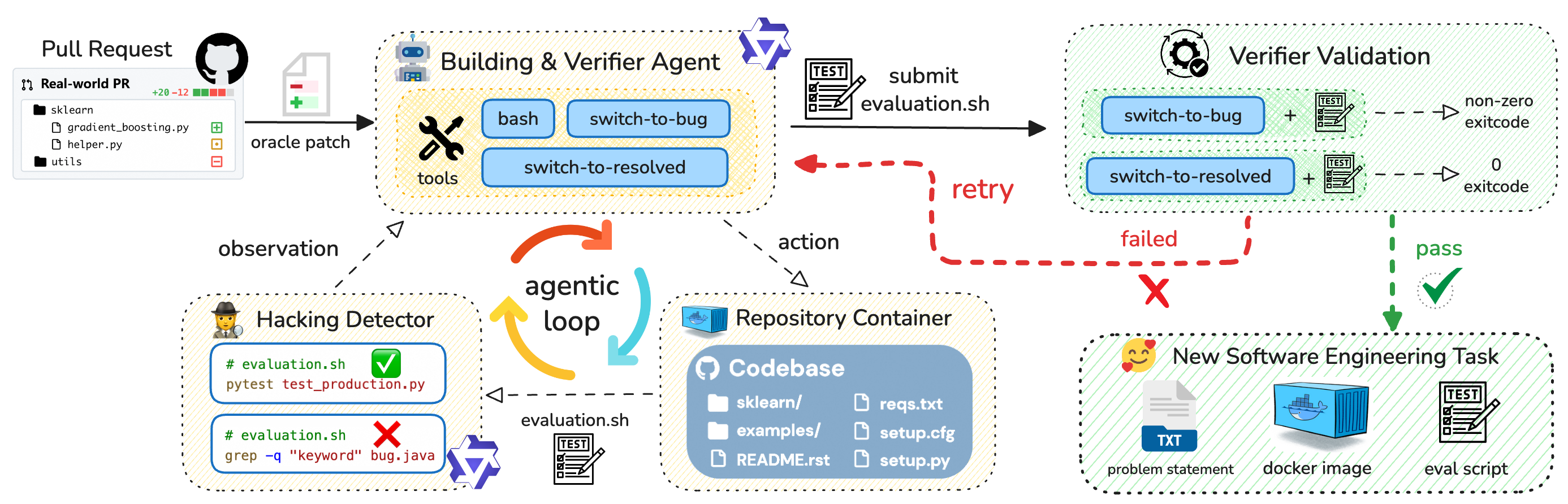
Figure 2: Our SWE-Universe framework for scalable and reliable environment building. The pipeline is built around a building agent that proposes a verifier (evaluation.sh). Two key components ensure quality and yield: an in-loop Hacking Detector that preemptively rejects superficial scripts, and an Iterative Validation loop where the agent self-corrects based on feedback from testing its verifier against both buggy and resolved code states.
Our primary goal is to develop a method for automated verifiable SWE environment construction that is both scalable and reliable. Scalability implies compatibility across diverse programming languages and build toolchains, as well as maximizing the build success rate to minimize computational waste. Reliability requires that the generated verifier (i.e., an evaluation.sh script) accurately provides a reward signal for a given patch, passing only when the SWE requirements are met. To this end, we design an autonomous building agent based on the popular mini-sweagent scaffold.
Our key insight is that while directly verifying the success of a complex building is difficult, assessing the success of a test script is comparatively straightforward: one can simply run it to see if it distinguishes between the pre-patch (buggy) and post-patch (fixed) states, as adopted by DeepSeek-V3.2 (Liu et al., 2025). However, we argue that this condition alone is insufficient. A naive agent might generate a script that “hacks” the verification by using simple string matching to confirm the patch’s application, rather than actually executing the code. Such a script would correctly distinguish states but would fail to validate the environment or the behavioral correctness of the fix. Therefore, we establish a more robust acceptance criterion for a successfully built task: the verifier must not only correctly distinguish between states but must do so by genuinely executing the code under test. Our methodology, detailed below and sumarized in Figure ˜ 2, is designed to meet this twofold objective.
2.1 Key Designs for SWE-Universe
PR Crawling and Patch Separation.
The pipeline begins by sourcing a large corpus of issue-linked pull requests (PRs) from public GitHub repositories. To prevent data contamination and ensure fair evaluation, we meticulously filter out any PRs that overlap with known downstream benchmarks. For each valid PR, we employ a language model to analyze the code modifications and partition them into a test patch (containing test-related changes) and a fix patch (containing the source code fix). PRs lacking a discernible test component are discarded.
Agent-based Environment Building.
Following patch separation, our autonomous agent, equipped with a set of powerful tools, initiates the construction of the environment and its corresponding verifier. The process commences by applying the test patch to the repository. The agent is then tasked with generating a verifier script, designated as evaluation.sh, whose objective is to reliably distinguish between the repository’s states based solely on its return code. Guided by the information within the test patch, the agent has the flexibility to adopt one of two strategies: it can either directly invoke the unit tests described in the patch, or, in scenarios where those tests lack a straightforward execution entry point, it can author a new custom test from scratch. This standardized approach, centered on a universal bash interface and its integer return code, is a deliberate design choice. It decouples the verification logic from language-specific conventions (e.g., hardcoding a pytest or cargo run workflow), thereby maximizing the method’s generalizability and scalability across disparate projects and ecosystems.
Toolset.
We equip the agent with three tools: bash, switch-to-resolved, and switch-to-bug.
- bash: A general-purpose shell for file manipulation, dependency installation, and script generation.
- switch-to-resolved and switch-to-bug: A pair of tools that allow the agent to atomically apply or revert the fix patch, toggling the repository between its fixed and buggy states.
These state-switching tools are fundamental to our approach, as they empower the agent to perform self-verification. By testing its own actions in a closed loop, the agent can diagnose and recover from failures, which is key to improving the overall build success rate and achieving scalability.
Iterative Validation.
To ensure the verifier is reliable, the agent engages in an iterative validation loop. After the agent ends with submitting a candidate evaluation.sh script, we execute it under both repository states using its switching tools. A script is considered functionally correct only if it fails (exits with a non-zero status) in the buggy state and succeeds (exits with a zero status) in the fixed state. If the script fails this validation, the agent receives this negative feedback, discards the faulty script, and is prompted to generate a new, revised version until reaches the maximum turns we predefined (e.g., 100 turns). This iterative process substantially improves reliability: for a set of held-out PRs, the environment-building success rate increases from 82.6% to 94%.
In-loop Hacking Detection.
To meet our second criterion—that the verifier must genuinely execute the code—we integrate a Hacking Detector directly into the agent’s work cycle. This module uses an LLM to inspect the generated evaluation.sh script for “hacking” patterns, such as using grep or other string-matching utilities to check the contents of source files instead of running a build or test command. Critically, this check is performed within the agent’s loop, not as a post-processing step. If the detector flags a script as a “hack”, this attempt is immediately considered a failure. This provides timely feedback to the agent, forcing it to abandon superficial strategies and guiding it toward a valid solution that involves actual code execution. This in-loop design improves both the reliability of the final artifact and the efficiency of the agent’s search process.
<details>
<summary>x2.png Details</summary>

### Visual Description
## Screenshots: Terminal Output - Software Testing & Security
### Overview
The image presents three screenshots of terminal windows, each displaying command-line output related to software testing and security. The screenshots appear to demonstrate different stages or approaches to testing: human-written unit tests, LLM-written tests, and static code analysis for security vulnerabilities.
### Components/Axes
Each screenshot contains a terminal window with text-based output. There are no axes or legends in the traditional sense, but the output itself functions as data. Each screenshot is labeled with a number and a descriptive title at the bottom: (1) Executing Human-written unit test, (2) Executing LLM-written tests, (3) Hacking: using static checking.
### Detailed Analysis or Content Details
**Screenshot 1: Executing Human-written unit test**
* **Initial Commands:**
* `cd /testbed`
* `set -e`
* **Dependency Installation:**
* `if [ "node_modules" ] ; then`
* `npm install`
* **Test Setup:**
* `Create a CommonJS version of jest-setup.js`
* `cat > setup.cjs << 'TEST SETUP'`
* `require('library/jest-native/extend-expect');`
* `// Mock the server since we can't import it properly`
* `const server = () => {};`
* `listen = () => {};`
* `resetHandlers = () => {};`
* `close = () => {};`
* `beforeAll(() => server.listen());`
* `afterEach(() => server.resetHandlers());`
* `afterAll(() => server.close());`
* `JEST_SETUP`
* **Test Execution:**
* `Now run the tests and capture the output`
* `coverage --config jest.config.js --test`
* `npm exec --prefix ../.. test test.log`
* **Error Checking:**
* `Check the results based on the error patterns`
* `grep -q "Property 'persistOnError' does not exist"`
* `grep -q "Property 'persistOnError' does not exist"`
* **Test Status:**
* `Tests passed? 0 or 1`
* `echo $?`
* `0`
**Screenshot 2: Executing LLM-written tests**
* **Python Code:**
* `python -c`
* `import sys`
* `from glyphsLib.builder.hints import glyphs_hints`
* `from glyphsLib import classes`
* `class MockGlyph:`
* `def __init__(self):`
* `self.lib = {}`
* `self.schrittgestaltung_hints = {`
* `'horizontal': True,`
* `'versions': 8,`
* `'origins': [0, 2],`
* `'target': ['@', 'o', 'w', 'n'],`
* `'type': 'topGhost'`
* `}`
* `class MockSelf:`
* `glyphs_module = classes`
* `ufo_glyph, hintsNotRefly = glyphs_hints(MockGlyph(), layer)`
* `layer = classes.GSLayer()`
* `try:`
* `to_glyphs, successNotRefly, bug_appears =`
* `glyphs_hints(MockSelf(), layer)`
* `except Exception as e:`
* `print(f"Bug is fixed")`
* `print(e)`
* `print("ERROR: A type error has occurred")`
* `sys.exit(1)`
**Screenshot 3: Hacking: using static checking**
* **Environment Variables:**
* `export JAVA_HOME=/opt/jdk-17.0.2`
* `export PATH=$JAVA_HOME/bin:$PATH`
* **Static Analysis Commands:**
* `echo "Testing watchOnMount functionality by checking source code changes..."`
* `grep -q "var fallAction: Option[Match.Action] =" /tested/main/src/main/scala/sbt/internal/Continuous.scala`
* `if then`
* `echo "Found fallAction field is present"`
* `Also check if the exitMatchShared function was refactored`
* `grep -q "exitMatchShared, *"` /tested/main/src/main/scala/sbt/internal/Continuous.scala
* `if then`
* `echo "Found exitMatchShared refactoring - is complete"`
* `else`
* `echo "exitMatchShared not refactored - fix is incomplete"`
* `fi`
* **Final Check:**
* `echo "fallAction field not found - bug is present"`
### Key Observations
* The first screenshot shows a typical Node.js testing workflow, including dependency installation, test execution, and result verification. The test passed (exit code 0).
* The second screenshot demonstrates a Python script using the `glyphsLib` library, likely for font-related testing. It includes error handling to detect if a bug has been fixed.
* The third screenshot showcases a security-focused static analysis approach using `grep` to check for specific code patterns in Scala files. It aims to verify if a security-related feature (`fallAction`) and refactoring (`exitMatchShared`) have been implemented correctly.
* The progression of screenshots suggests a layered testing strategy: unit tests, LLM-generated tests, and static security analysis.
### Interpretation
The image illustrates a modern software development and security testing pipeline. It highlights the integration of different testing methodologies, including traditional human-written tests, tests generated by Large Language Models (LLMs), and static code analysis for security vulnerabilities.
The use of LLMs for test generation (Screenshot 2) is a notable trend, suggesting an attempt to automate and augment the testing process. The static analysis in Screenshot 3 demonstrates a proactive approach to security, aiming to identify potential vulnerabilities before deployment.
The combination of these techniques suggests a commitment to comprehensive testing and a focus on both functionality and security. The progression from unit tests to LLM-generated tests to static analysis could represent a shift-left approach, where testing is integrated earlier in the development lifecycle. The fact that the first test passed, while the third is actively looking for issues, suggests a healthy testing process.
</details>
Figure 3: Three types of evaluation.sh. We only accept the first two types of evaluation scripts.
2.2 Further Analysis
Case Study
We examine three representative LLM-generated test scripts to illustrate our verification criteria (Figure 3). Case 1 tests a JavaScript authentication bug by executing existing human-written unit tests in the Jest framework via pnpm exec jest, checking for specific error patterns in the output. Case 2 validates a Python glyphsLib bug by creating LLM-generated mock objects and unit tests that directly exercise the buggy code path and verify execution without exceptions. Case 3 attempts to verify a Scala bug fix using static pattern matching with grep commands to detect the presence of specific code structures, which is flagged as “hacking” by our hacking detection. We accept Cases 1 and 2 as they employ strong verification through executable tests that validate runtime behavior, while we reject Case 3 because static pattern matching cannot guarantee correctness—a patch may introduce expected code patterns while still containing logical errors.
Quality Analysis
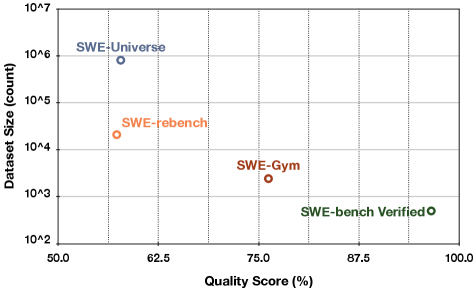
We find that the resulting data still exhibit several quality issues: (1) some task descriptions are ambiguous or incomplete; (2) certain Docker environments do not fully match the stated requirements; and (3) some unit tests are misaligned with the task descriptions, which can lead to false positives or false negatives. To quantify and mitigate this problem, we develop a quality-judge agent. It takes as input the task description, Docker environment, test scripts, and optionally the ground-truth patch, and automatically evaluates the task quality. On a human-labeled quality-judging benchmark, the agent reaches 78.72% accuracy. After applying it to the entire dataset, as shown in Figure 4, we find our dataset matches SWE-Rebench (Badertdinov et al., 2025) in quality while providing 38× more instances.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Scatter Plot: Dataset Size vs. Quality Score
### Overview
This image presents a scatter plot comparing the dataset size (count) against the quality score (percentage) for four different datasets: SWE-Universe, SWE-rebench, SWE-Gym, and SWE-bench Verified. The plot uses a logarithmic scale for the y-axis (Dataset Size).
### Components/Axes
* **X-axis:** Quality Score (%) - Ranges from approximately 50.0 to 100.0, with tick marks at 50.0, 62.5, 75.0, 87.5, and 100.0.
* **Y-axis:** Dataset Size (count) - Ranges from approximately 10^2 to 10^7, using a logarithmic scale. Tick marks are present at 10^2, 10^3, 10^4, 10^5, 10^6, and 10^7.
* **Data Points:** Four data points are plotted, each representing a different dataset. Each point is marked with a circle and labeled with the dataset name.
* **Datasets:**
* SWE-Universe (Blue)
* SWE-rebench (Orange)
* SWE-Gym (Red)
* SWE-bench Verified (Green)
### Detailed Analysis
* **SWE-Universe:** Located at approximately (60.0, 6.0 x 10^6). This dataset has a relatively low quality score and a very large dataset size.
* **SWE-rebench:** Located at approximately (62.5, 2.5 x 10^4). This dataset has a low quality score and a moderate dataset size.
* **SWE-Gym:** Located at approximately (75.0, 3.0 x 10^3). This dataset has a moderate quality score and a relatively small dataset size.
* **SWE-bench Verified:** Located at approximately (90.0, 1.0 x 10^3). This dataset has a high quality score and a small dataset size.
The data points do not appear to follow a strong linear trend. There is a general inverse relationship between quality score and dataset size, but it is not strict.
### Key Observations
* SWE-bench Verified has the highest quality score and the smallest dataset size.
* SWE-Universe has the lowest quality score and the largest dataset size.
* SWE-rebench and SWE-Gym fall in between, with SWE-rebench having a slightly lower quality score and a larger dataset size than SWE-Gym.
* The logarithmic scale on the y-axis emphasizes the large difference in dataset sizes.
### Interpretation
The plot suggests a trade-off between dataset size and quality. Larger datasets (like SWE-Universe) may be more comprehensive but potentially contain more noise or errors, resulting in a lower quality score. Smaller, verified datasets (like SWE-bench Verified) may have higher quality but lack the breadth of larger datasets.
The positioning of SWE-rebench and SWE-Gym indicates that increasing dataset size does not necessarily translate to increased quality. The difference in quality between SWE-Gym and SWE-bench Verified suggests that the verification process significantly improves the quality of the dataset, even if it means reducing the size.
The plot could be used to inform decisions about which dataset to use for a particular task, depending on the relative importance of dataset size and quality. For example, if high accuracy is critical, SWE-bench Verified would be the preferred choice. If a broader range of scenarios needs to be covered, SWE-Universe might be more appropriate, despite its lower quality score.
</details>
Figure 4: Task Quality vs. Dataset Size (Log-Scale). Task quality is measured as the fraction of high-quality samples.
3 Efficient Building and Benchmarking
To optimize both the performance and throughput of our pipeline, we developed a high-capacity yet efficient model and a comprehensive cross-lingual benchmark to evaluate its capabilities.
Model Training and Deployment
To make our end-to-end pipeline efficient at scale, we train a lightweight but strong builder model, Qwen-Next-80A3 (Qwen Team, 2025b), a mixture-of-experts (MoE) model with hybrid attentions including linear attentions and full attentions. The model was trained using rejection sampling on a collection of high-quality building trajectories. This process involved sampling multiple candidate paths for environment construction and filtering for successful, non-hacked outcomes to serve as training data. The model serves as the unified backbone for all tasks in our pipeline, including PR patch splitting, iterative environment building, and the hacking detector. Its efficient architecture allows us to scale the building process across thousands of repositories with significantly lower latency compared to dense models of similar performance.
Benchmark
To rigorously assess the reliability of automated environment construction, we constructed a diverse benchmark consisting of 320 pull requests randomly sampled from GitHub. We remove the repositories used in the training trajectories from the benchmark. To ensure broad representativeness, we selected 40 PRs for each of the eight language categories: Python, JavaScript/TypeScript, Go, Java, Rust, C/C++, C#, and an “Others” category (including all the other languages such as PHP and Kotlin). We define two primary success metrics: Success Rate (w/o Hack), which requires the verifier to be functionally correct and pass the hacking detector, and Success Rate (w/ Hack), which includes all scripts that distinguish the bug regardless of the detection outcome.
Table 1: Benchmark results for automated environment building across various models. “Success (%) (w/o Hack)” measures the rate of creating a valid, non-hacked verifiable environment, while “Success (%) (w/ Hack)” also counts “hacked” verifiers as successful builds. Our model, Qwen-Next-80A3, achieves the highest non-hacking success rate.
| Model | Success (%) | Success (%) | Success Rate by Language (%) | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| (w/o Hack) | (w/ Hack) | C/C++ | C# | Go | Java | JS/TS | Other | Python | Rust | |
| Qwen-Next-80A3 (Ours) | $78.44$ | $82.50$ | $57.50$ | $70.00$ | $80.49$ | $82.50$ | $84.62$ | $83.72$ | $85.37$ | $83.33$ |
| Claude-Opus-4.5 | $77.81$ | $85.00$ | $52.50$ | $57.50$ | $82.93$ | $77.50$ | $89.74$ | $76.74$ | $95.12$ | $91.67$ |
| Claude-Sonnet-4 | $75.62$ | $85.62$ | $67.50$ | $52.50$ | $75.61$ | $72.50$ | $84.62$ | $83.72$ | $82.93$ | $86.11$ |
| Gemini-3-Pro | $69.69$ | $72.50$ | $32.50$ | $57.50$ | $73.17$ | $72.50$ | $87.18$ | $76.74$ | $87.80$ | $69.44$ |
| Claude-Sonnet-4-5 | $66.88$ | $71.56$ | $30.00$ | $50.00$ | $63.41$ | $67.50$ | $87.18$ | $67.44$ | $92.68$ | $77.78$ |
| GLM-4.7 | $58.44$ | $64.06$ | $37.50$ | $50.00$ | $53.66$ | $57.50$ | $66.67$ | $65.12$ | $73.17$ | $63.89$ |
| MiniMax-M2.1 | $54.69$ | $61.88$ | $22.50$ | $35.00$ | $56.10$ | $55.00$ | $74.36$ | $65.12$ | $73.17$ | $55.56$ |
| DeepSeek-v3.2 | $54.06$ | $59.38$ | $15.00$ | $50.00$ | $63.41$ | $47.50$ | $53.85$ | $48.84$ | $78.05$ | $77.78$ |
| Qwen3-Coder-480B | $48.75$ | $55.62$ | $35.00$ | $32.50$ | $39.02$ | $45.00$ | $48.72$ | $69.77$ | $68.29$ | $50.00$ |
Result Analysis
Our evaluation, detailed in Table 1, establishes Qwen-Next-80A3 as the new state-of-the-art model for automated environment building, achieving a 78.44% success rate that surpasses even strong proprietary models like Claude-Opus-4.5 (77.81%). This superior performance extends beyond raw success to overall reliability. We observe a significant gap between the true success rate and the one including “hacked” verifiers for most general-purpose models (e.g., over 7% for Claude-Opus-4.5), indicating their tendency to find superficial shortcuts. In stark contrast, our model exhibits the smallest gap among top performers (4.06%), demonstrating that our task-specific fine-tuning on collected trajectories effectively discourages these deceptive behaviors. Furthermore, while performance varies by language—with C/C++ proving most challenging for all agents—our model demonstrates more consistent and robust capabilities across the entire linguistic spectrum compared to competitors that show strength only in specific ecosystems. Ultimately, these results validate that a specialized, efficiently trained MoE model not only achieves higher success but also operates with greater fidelity than larger, general-purpose counterparts in this complex domain.
4 Scaling Environments to Millions
In this section, we describe our efforts to scale the environment-building pipeline to a massive corpus of real-world software changes, moving beyond small-scale benchmarks to a million-scale dataset of executable tasks.
Large-scale Data Curation
We harvested a comprehensive dataset of approximately 33.3 million pull requests (PRs) spanning the most recent five years (2021–2025) of GitHub’s history. To extract high-quality tasks from this raw pool, we applied a series of rigorous heuristic filters. Specifically, we removed PRs with excessive file changes or line counts to avoid overly complex or noisy tasks, and discarded any entries that did not contain a discernible test patch. Furthermore, we prioritized PRs that were explicitly linked to at least one GitHub issue, as these provide the most reliable ground-truth problem statements. This filtering process resulted in a candidate set of approximately 1 million high-quality PRs.
Infrastructure for Large-scale Rollouts
To support our massive data generation effort, we implement our pipeline on top of MegaFlow (Zhang et al., 2026), a distributed execution system for orchestrating large numbers of long-running agentic jobs. MegaFlow achieves massive parallelism by dispatching each environment-building task as an independent job to a dedicated Alibaba Cloud Elastic Compute Service (ECS) instance. Within this sandboxed virtual machine, our agent executes the entire build process, culminating in a verified Docker image. Upon completion, successful images are pushed to Alibaba Cloud’s Container Registry (ACR) https://www.alibabacloud.com/en/product/container-registry, where we leverage Docker’s layer caching to significantly reduce storage costs by reusing common base layers. This highly parallel and resource-efficient architecture was instrumental in processing millions of pull requests concurrently, enabling the practical construction of our million-scale dataset.
Massive Production with Qwen-Next-80A3
We deployed our fine-tuned Qwen-Next-80A3 model to execute the building and verification process for the filtered candidates. Leveraging the model’s efficiency and the iterative agentic loop described in previous sections, we achieved a non-hacked success rate of 75.9%. This process ultimately yielded 717,122 executable, high-fidelity environments. These tasks are primarily focused on assessing an agent’s ability to resolve real-world software issues. Additionally, to expand the dataset’s coverage, we selected a subset of 2025 PRs that were not linked to issues, utilizing the PR titles and descriptions as the problem statements to synthesize an additional environments, and producing 90,571 environments.
Table 2: Data statistics for our building environments.
| Language | Instances | Repos | Inst/Repo (Avg) | Avg Lines of evaluation.sh |
| --- | --- | --- | --- | --- |
| Python | 202,302 | 13,098 | 15.45 | 25.01 |
| Javascript / Typescript | 175,660 | 11,604 | 15.14 | 27.41 |
| Go | 121,062 | 5,554 | 21.80 | 28.87 |
| Java | 86,105 | 4,700 | 18.32 | 24.75 |
| Rust | 74,180 | 4,445 | 16.69 | 19.31 |
| C / C++ | 37,228 | 3,405 | 10.93 | 45.78 |
| C# | 24,387 | 1,929 | 12.64 | 31.84 |
| Others | 86,769 | 8,225 | 10.55 | 38.89 |
| # Total | 807,693 | 52,960 | 15.25 | 28.21 |
Statistical Analysis
The statistics presented in Table 2 highlight both the scale and diversity of our generated dataset. With 807,693 instances spread across 52,960 unique repositories, this dataset represents an unprecedented resource for training and evaluating software engineering agents. The language distribution largely mirrors the current open-source landscape, with Python and JavaScript/TypeScript constituting the largest shares. Notably, Go repositories exhibit the highest average number of instances per repository (21.80), suggesting a high density of verifiable, issue-linked PRs within its ecosystem, possibly due to strong conventions around testing and development. The “Avg Eval Lines” metric reveals interesting insights into the complexity of verification across languages. C/C++ instances, as expected, require the longest verifier scripts on average (45.78 lines), reflecting the typical complexity and boilerplate of their build systems. In contrast, Rust’s concise average (19.31 lines) may point to the efficiency and standardization of its cargo toolchain, allowing for more succinct test execution commands. Overall, the dataset provides a rich and varied testbed, capturing a wide array of real-world challenges for coding agents.
5 Evaluation: Large-scale Agentic Training
We now turn to leveraging this resource for large-scale agentic model training. Our goal is to demonstrate that training on this diverse, real-world data can significantly enhance a model’s capabilities as a software engineering agent.
5.1 Mid-training
We hypothesize that intermediate training on a vast corpus of high-quality agentic trajectories can endow a model with a strong foundation in both software engineering problem-solving. This “mid-training” phase is designed to bridge the gap between the pre-training and post-training on downstream agentic tasks.
Setup
Our mid-training process begins by generating a massive dataset of agentic trajectories. We first employed the Qwen3-Coder-480B-A30B (Qwen Team, 2025a) model to interact with the environments we previously constructed. To ensure a diversity of problem-solving strategies, we conducted these rollouts across five different agentic scaffolds: SWE-agent (Yang et al., 2024), Mini-SWE-agent (SWE-agent Team, 2025), OpenHands (Wang et al., 2024), Claude-Code (Anthropic, 2024), Qwen-Code (Qwen Team, 2025c). The entire rollout process was orchestrated by our MegaFlow system. For each environment, we performed rejection sampling: a trajectory is deemed successful and retained only if the final generated code passes the corresponding evaluation.sh script and clears an additional in-house quality filter. This rigorous filtering process yielded a high-quality dataset of 500K successful trajectories, comprising a total of 30 billion training tokens. We then used this data to conduct intermediate training on a Qwen3-Next-80A3 model, using 256K sequence length and Best-Fit packing (Ding et al., 2024). Critically, we applied no loss mask during this training phase. This strategy ensures that the model learns not only to predict agentic actions but also to internalize the vast amount of code and natural language in the agent’s observations and responses, developing it into a more comprehensive “coding world model” (Copet et al., 2025; Zhang et al., 2025a).
Scaling Trends
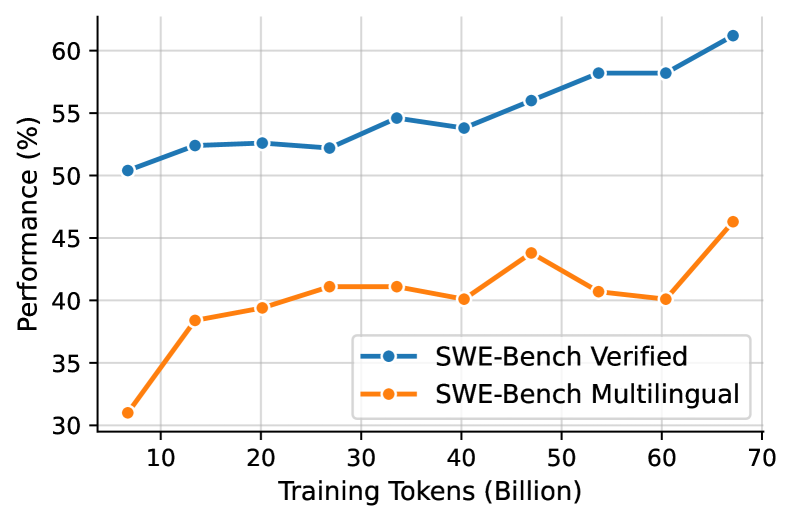
To analyze the effectiveness of our large-scale agentic mid-training, we evaluated model checkpoints on two widely used agentic coding benchmarks: SWE-Bench Verified (primarily Python-based) and the more diverse SWE-Bench Multilingual. The performance evolution throughout the training process is depicted in Figure 5(a). The results demonstrate a clear and positive scaling trend, confirming that our mid-training on the real-world instances successfully transfers to standard evaluation benchmarks. On the standard SWE-Bench Verified, the model’s performance exhibits a steady climb, starting from an already strong baseline of 50.3% and consistently improving to a final score of over 61% after 2,000 training steps. More notably, the trend on the more challenging SWE-Bench Multilingual benchmark shows even more dramatic improvement. Starting from a significantly lower baseline of approximately 31%, the model’s performance surges to over 46% by the end of the training. This substantial gain of over 15 percentage points underscores the critical value of our dataset’s linguistic diversity. It proves that training on a massive, diverse corpus of real-world, multi-language software issues is essential for creating agents that can generalize beyond a single programming ecosystem.
5.2 Agentic Reinforcement Learning
Beyond training via rejection sampling, our collection of executable environments is suited for Reinforcement Learning (RL), where the binary pass/fail signal from the evaluation.sh script serves as a direct and reliable reward. To demonstrate this, we conducted agentic RL experiments on different models with different sizes and structures.
Setup
We validate the effectiveness of the data on agentic reinforcement learning. Prior to training, we perform rollouts with the base model to filter out queries that are either too difficult or too easy. During training, we set the maximum number of interaction turns to 200 and the context length to 128k. The training process is powered by our asynchronous RL framework, which natively supports agentic workflows. This architecture mitigates data skewness while facilitating seamless multi-turn interactions without framework-induced overhead, achieving a 2x–4x speedup compared to existing RL infrastructures.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Line Chart: Performance vs. Training Tokens
### Overview
This line chart depicts the performance of two models, "SWE-Bench Verified" and "SWE-Bench Multilingual", as a function of training tokens. The x-axis represents the number of training tokens in billions, and the y-axis represents performance as a percentage. The chart shows how performance changes as the models are trained with increasing amounts of data.
### Components/Axes
* **X-axis Title:** "Training Tokens (Billion)"
* **Y-axis Title:** "Performance (%)"
* **X-axis Markers:** 10, 20, 30, 40, 50, 60, 70
* **Y-axis Markers:** 30, 35, 40, 45, 50, 55, 60
* **Legend:** Located in the bottom-right corner.
* "SWE-Bench Verified" - Blue line with circle markers.
* "SWE-Bench Multilingual" - Orange line with circle markers.
### Detailed Analysis
**SWE-Bench Verified (Blue Line):**
The blue line representing "SWE-Bench Verified" generally slopes upward, indicating increasing performance with more training tokens.
* At 10 Billion Tokens: Approximately 51% performance.
* At 20 Billion Tokens: Approximately 52.5% performance.
* At 30 Billion Tokens: Approximately 53.5% performance.
* At 40 Billion Tokens: Approximately 55% performance.
* At 50 Billion Tokens: Approximately 56% performance.
* At 60 Billion Tokens: Approximately 57.5% performance.
* At 70 Billion Tokens: Approximately 61% performance.
**SWE-Bench Multilingual (Orange Line):**
The orange line representing "SWE-Bench Multilingual" shows a more fluctuating trend. It initially increases, then decreases, and finally increases again.
* At 10 Billion Tokens: Approximately 31% performance.
* At 20 Billion Tokens: Approximately 40% performance.
* At 30 Billion Tokens: Approximately 41.5% performance.
* At 40 Billion Tokens: Approximately 43% performance.
* At 50 Billion Tokens: Approximately 41% performance.
* At 60 Billion Tokens: Approximately 40% performance.
* At 70 Billion Tokens: Approximately 46% performance.
### Key Observations
* "SWE-Bench Verified" consistently outperforms "SWE-Bench Multilingual" across all training token values.
* The performance of "SWE-Bench Verified" shows a steady increase, with a more significant jump between 60 and 70 billion tokens.
* "SWE-Bench Multilingual" exhibits a peak performance around 40 billion tokens, followed by a slight dip before increasing again at 70 billion tokens.
* The gap between the two models widens as the number of training tokens increases.
### Interpretation
The data suggests that increasing the number of training tokens generally improves the performance of both models. However, "SWE-Bench Verified" benefits more consistently from additional training data than "SWE-Bench Multilingual". The fluctuating performance of "SWE-Bench Multilingual" could indicate that it is more sensitive to the specific composition of the training data or that it may require more sophisticated training techniques to fully leverage larger datasets. The significant performance increase for "SWE-Bench Verified" at 70 billion tokens suggests a potential threshold effect, where a critical mass of data is required to unlock substantial performance gains. The consistent outperformance of "SWE-Bench Verified" implies it is a more robust or better-optimized model for the given task. The difference in performance could be due to architectural differences, training methodologies, or the specific datasets used for training.
</details>
(a)
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Line Chart: SWE-Bench Multilingual Performance vs. Training Steps
### Overview
This image presents a line chart illustrating the relationship between Training Steps and SWE-Bench Multilingual performance, measured in percentage (%). The chart shows a generally increasing trend, with some fluctuations, culminating in a peak performance at the final training step.
### Components/Axes
* **X-axis:** Labeled "Training Steps". The scale is not explicitly marked, but the data points suggest a progression of training steps.
* **Y-axis:** Labeled "SWE-Bench Multilingual (%)". The scale ranges from approximately 32% to 42%, with horizontal dashed lines marking increments of 2%.
* **Data Series:** A single orange line representing the SWE-Bench Multilingual performance.
* **Data Point Annotation:** A star symbol annotates the final data point, displaying the value "42.0".
### Detailed Analysis
The orange line begins at approximately 32% at the initial training step. It then exhibits a steep upward slope, reaching a peak of around 38% at the second data point. The line then decreases slightly to approximately 36% at the third data point, before rising again to around 38% at the fourth data point. A subsequent dip occurs, bringing the value down to approximately 35% at the fifth data point. Finally, the line shows a significant upward trend, reaching approximately 37% at the sixth data point and culminating in a final value of 42.0% at the last training step.
Here's a breakdown of approximate data points:
| Training Steps | SWE-Bench Multilingual (%) |
|---|---|
| 0 | 32.0 |
| ~1000 | 38.0 |
| ~2000 | 37.5 |
| ~3000 | 36.0 |
| ~4000 | 35.0 |
| ~5000 | 37.0 |
| ~6000 | 42.0 |
### Key Observations
* The SWE-Bench Multilingual performance generally increases with the number of training steps.
* There are fluctuations in performance during the training process, indicating periods of improvement and slight regression.
* The most significant performance gain occurs in the final training steps, with a substantial increase from approximately 37% to 42%.
* The final data point is explicitly highlighted with a star and the value "42.0", suggesting its importance.
### Interpretation
The chart demonstrates that increasing the number of training steps generally leads to improved SWE-Bench Multilingual performance. The initial rapid increase suggests quick learning, followed by a period of refinement and occasional setbacks. The final, substantial increase indicates that the model benefits significantly from continued training, potentially reaching a point of diminishing returns or convergence. The fluctuations could be attributed to various factors, such as the complexity of the training data, the learning rate, or the model's architecture. The explicit annotation of the final data point suggests that this level of performance is a key target or milestone. The data suggests a positive correlation between training effort and model capability, but also highlights the non-linear nature of machine learning progress.
</details>
(b)
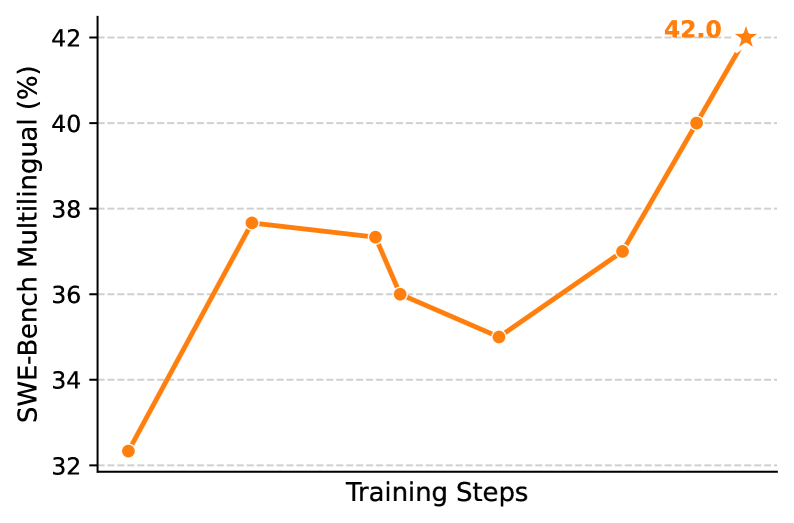
Figure 5: (a) Performance scaling trends of the Qwen3-Next-80A3 model during mid-training. (b) Reinforcement learning curve of the Qwen3-30B-A3B for SWE-Bench Multilingual.
Results on Qwen3-30B-A3B
The training curve in Figure 5(b) shows the effectiveness of agentic reinforcement training. The Qwen3-30a3 model shows a remarkable improvement on SWE-Bench Multilingual, surging from a baseline of approximately 32% to a peak of 42.0%. This substantial 10-point absolute gain underscores the power of RL to enhance generalization across diverse, multilingual tasks.
Applied to Qwen3-Max-Thinking
To push the boundaries of agentic coding performance, we applied our methodology to our flagship Qwen3-Max-Thinking model. The resulting model achieved a performance of 75.3% on SWE-Bench Verified. This result validates the effectiveness of our large-scale data generation pipeline at a production level, showcasing its ability to elevate state-of-the-art models.
6 Related Work
Agentic and Synthetic Environment Generation
A significant line of research focuses on generating software engineering tasks synthetically to create scalable training data, often without relying on authentic historical issues. For instance, SWE-smith (Yang et al., 2025b) procedurally generates tasks by artificially injecting bugs, while SWE-Flow (Zhang et al., 2025b) leverages test documentation to synthesize novel problems. Other works generate complex bugs from scratch (Sonwane et al., 2025) or create interactive tasks from bug reports (Jin et al., 2023). The scope of synthesis extends to generating command-line tasks from natural language (Lin et al., 2018; Gandhi et al., 2026). Similarly, RepoST (Xie et al., 2024) employs synthetic tests to generate training data. While these methods provide scalable training data, they do not fully capture the complexity and long-tail challenges of real-world software issues. In contrast, our work focuses exclusively on building executable environments for real-world software engineering problems derived directly from public repositories.
Real-World Software Environment Setup
Much recent work focuses purely on the environment configuration capability itself, proposing scripted, agentic, or expert-driven methods to create executable environments, but without providing verifiers for specific software issues (Hu et al., 2025; Milliken et al., 2025; Bouzenia & Pradel, 2025; Horton & Parnin, 2019; Jain et al., 2024; Vergopoulos et al., 2025; Guo et al., 2026; Arora et al., 2025; Eliseeva et al., 2025; Kuang et al., 2025; Fu et al., 2025). Another line of work provides end-to-end verification for real software issues. The seminal SWE-bench (Jimenez et al., 2024) established this paradigm with over 2,400 real-world Python issues, each with a test script to verify a fix. This Python-centric approach was significantly scaled by SWE-rebench (Badertdinov et al., 2025), which developed a fully automated pipeline to generate over 21,000 verifiable tasks. Other works like SWE-Gym (Pan et al., 2024), SWE-bench-Live (Zhang et al., 2025c), SWE-Factory (Guo et al., 2025), daVinci-Dev (Zeng et al., 2026), SWE-Bench++ (Wang et al., 2025), and SWE-bench+ (Aleithan et al., 2024) have also aimed to expand data generation, primarily within the Python ecosystem. A few recent efforts have created multi-language benchmarks, such as Multi-SWE-bench (Zan et al., 2025) and SWE-PolyBench (Rashid et al., 2025); however, these have generally been limited in scale. Our work systematically overcomes these limitations by presenting a highly scalable and reliable pipeline that operates across arbitrary languages and repositories, successfully generating over million-scale executable environments with a validated, task-specific verifier.
Building Code Verifier
Automated code verifiers are typically constructed by executing test suites to validate solutions. Traditional test generation methods, including probability-based approaches (Pacheco et al., 2007), constraint-based (Xiao et al., 2013), and search-based (Harman & McMinn, 2010; Lukasczyk & Fraser, 2022), often suffer from limited coverage and poor readability, and are typically restricted to regression or implicit oracles (Barr et al., 2015). Recent work leverages LLMs to generate unit tests for verification (Alagarsamy et al., 2024; Chen et al., 2024b; Schäfer et al., 2024; Yuan et al., 2024; Chen et al., 2024a), though the resulting tests can be unreliable due to confidently incorrect assertions. CodeRM (Ma et al., 2025) improves reward signal quality by scaling the number of generated tests and dynamically adapting test counts to problem difficulty. In this work, we leverage a building agent to automatically generate verifier for complext repository-level software engineering issues.
7 Conclusion
In this paper, we introduced SWE-Universe, a scalable framework designed to overcome the critical bottlenecks of low yield, inconsistent quality, and prohibitive cost in generating real-world software engineering environments. Our autonomous building agent, powered by a custom-trained model and equipped with iterative self-verification and in-loop hacking detection, successfully constructed a massive dataset of over 800,000 executable, multi-lingual tasks—the largest of its kind. We demonstrated the profound value of this resource through large-scale agentic training, showing that it provides a powerful signal for both supervised learning and reinforcement learning, ultimately enabling our Qwen3-Max-Thinking model to achieve a score of 75.3% on SWE-Bench Verified.
References
- Alagarsamy et al. (2024) Saranya Alagarsamy, Chakkrit Tantithamthavorn, and Aldeida Aleti. A3test: Assertion-augmented automated test case generation. Inf. Softw. Technol., 176(C), November 2024. ISSN 0950-5849. doi: 10.1016/j.infsof.2024.107565. URL https://doi.org/10.1016/j.infsof.2024.107565.
- Aleithan et al. (2024) Reem Aleithan, Haoran Xue, Mohammad Mahdi Mohajer, Elijah Nnorom, Gias Uddin, and Song Wang. Swe-bench+: Enhanced coding benchmark for llms. arXiv preprint arXiv:2410.06992, 2024.
- Anthropic (2024) Anthropic. Claude code: An agentic coding assistant. https://github.com/anthropics/claude-code, 2024. Accessed: 2026-01-22.
- Arora et al. (2025) Avi Arora, Jinu Jang, and Roshanak Zilouchian Moghaddam. Setupbench: Assessing software engineering agents’ ability to bootstrap development environments. arXiv preprint arXiv:2507.09063, 2025.
- Badertdinov et al. (2025) Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. SWE-rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents, 2025. URL https://arxiv.org/abs/2505.20411.
- Barr et al. (2015) Earl T. Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. The oracle problem in software testing: A survey. IEEE Transactions on Software Engineering, 41(5):507–525, 2015. doi: 10.1109/TSE.2014.2372785.
- Bouzenia & Pradel (2025) Islem Bouzenia and Michael Pradel. You name it, i run it: An llm agent to execute tests of arbitrary projects. Proc. ACM Softw. Eng., 2(ISSTA), June 2025. doi: 10.1145/3728922. URL https://doi.org/10.1145/3728922.
- Chen et al. (2024a) Mouxiang Chen, Zhongxin Liu, He Tao, Yusu Hong, David Lo, Xin Xia, and Jianling Sun. B4: Towards optimal assessment of plausible code solutions with plausible tests. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE ’24, pp. 1693–1705, New York, NY, USA, 2024a. Association for Computing Machinery. ISBN 9798400712487. doi: 10.1145/3691620.3695536. URL https://doi.org/10.1145/3691620.3695536.
- Chen et al. (2024b) Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. Chatunitest: A framework for llm-based test generation. In Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, FSE 2024, pp. 572–576, New York, NY, USA, 2024b. Association for Computing Machinery. ISBN 9798400706585. doi: 10.1145/3663529.3663801. URL https://doi.org/10.1145/3663529.3663801.
- Copet et al. (2025) Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, et al. Cwm: An open-weights llm for research on code generation with world models. arXiv preprint arXiv:2510.02387, 2025.
- DeepSeek-AI (2025) DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models. CoRR, abs/2512.02556, 2025. doi: 10.48550/ARXIV.2512.02556. URL https://doi.org/10.48550/arXiv.2512.02556.
- Ding et al. (2024) Hantian Ding, Zijian Wang, Giovanni Paolini, Varun Kumar, Anoop Deoras, Dan Roth, and Stefano Soatto. Fewer truncations improve language modeling. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=kRxCDDFNpp.
- Eliseeva et al. (2025) Aleksandra Eliseeva, Alexander Kovrigin, Ilia Kholkin, Egor Bogomolov, and Yaroslav Zharov. Envbench: A benchmark for automated environment setup. arXiv preprint arXiv:2503.14443, 2025.
- Fu et al. (2025) Kelin Fu, Tianyu Liu, Zeyu Shang, Yingwei Ma, Jian Yang, Jiaheng Liu, and Kaigui Bian. Multi-docker-eval: Ashovel of the gold rush’benchmark on automatic environment building for software engineering. arXiv preprint arXiv:2512.06915, 2025.
- Gandhi et al. (2026) Kanishk Gandhi, Shivam Garg, Noah D Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents. arXiv preprint arXiv:2601.16443, 2026.
- Guo et al. (2025) Lianghong Guo, Yanlin Wang, Caihua Li, Pengyu Yang, Jiachi Chen, Wei Tao, Yingtian Zou, Duyu Tang, and Zibin Zheng. Swe-factory: Your automated factory for issue resolution training data and evaluation benchmarks. arXiv preprint arXiv:2506.10954, 2025.
- Guo et al. (2026) Xinshuai Guo, Jiayi Kuang, Linyue Pan, Yinghui Li, Yangning Li, Hai-Tao Zheng, Ying Shen, Di Yin, and Xing Sun. Evoconfig: Self-evolving multi-agent systems for efficient autonomous environment configuration. arXiv preprint arXiv:2601.16489, 2026.
- Harman & McMinn (2010) Mark Harman and Phil McMinn. A theoretical and empirical study of search-based testing: Local, global, and hybrid search. IEEE Transactions on Software Engineering, 36(2):226–247, 2010. doi: 10.1109/TSE.2009.71.
- Horton & Parnin (2019) Eric Horton and Chris Parnin. Dockerizeme: Automatic inference of environment dependencies for python code snippets. In 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pp. 328–338. IEEE, 2019.
- Hu et al. (2025) Ruida Hu, Chao Peng, Xinchen Wang, Junjielong Xu, and Cuiyun Gao. Repo2run: Automated building executable environment for code repository at scale. arXiv preprint arXiv:2502.13681, 2025.
- Jain et al. (2024) Naman Jain, Manish Shetty, Tianjun Zhang, King Han, Koushik Sen, and Ion Stoica. R2e: turning any github repository into a programming agent environment. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024.
- Jimenez et al. (2024) Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66.
- Jin et al. (2023) Matthew Jin, Syed Shahriar, Michele Tufano, Xin Shi, Shuai Lu, Neel Sundaresan, and Alexey Svyatkovskiy. Inferfix: End-to-end program repair with llms. In Proceedings of the 31st ACM joint european software engineering conference and symposium on the foundations of software engineering, pp. 1646–1656, 2023.
- Kuang et al. (2025) Jiayi Kuang, Yinghui Li, Xin Zhang, Yangning Li, Di Yin, Xing Sun, Ying Shen, and Philip S Yu. Process-level trajectory evaluation for environment configuration in software engineering agents. arXiv preprint arXiv:2510.25694, 2025.
- Lin et al. (2018) Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D Ernst. Nl2bash: A corpus and semantic parser for natural language interface to the linux operating system. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), 2018.
- Liu et al. (2025) Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556, 2025.
- Lukasczyk & Fraser (2022) Stephan Lukasczyk and Gordon Fraser. Pynguin: automated unit test generation for python. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, ICSE ’22, pp. 168–172, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450392235. doi: 10.1145/3510454.3516829. URL https://doi.org/10.1145/3510454.3516829.
- Ma et al. (2025) Zeyao Ma, Xiaokang Zhang, Jing Zhang, Jifan Yu, Sijia Luo, and Jie Tang. Dynamic scaling of unit tests for code reward modeling. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 6917–6935, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.343. URL https://aclanthology.org/2025.acl-long.343/.
- Milliken et al. (2025) Louis Milliken, Sungmin Kang, and Shin Yoo. Beyond pip Install: Evaluating LLM Agents for the Automated Installation of Python Projects . In 2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), pp. 1–11, Los Alamitos, CA, USA, March 2025. IEEE Computer Society. doi: 10.1109/SANER64311.2025.00009. URL https://doi.ieeecomputersociety.org/10.1109/SANER64311.2025.00009.
- Pacheco et al. (2007) Carlos Pacheco, Shuvendu K. Lahiri, Michael D. Ernst, and Thomas Ball. Feedback-directed random test generation. In 29th International Conference on Software Engineering (ICSE’07), pp. 75–84, 2007. doi: 10.1109/ICSE.2007.37.
- Pan et al. (2024) Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym. arXiv preprint arXiv:2412.21139, 2024.
- Qwen Team (2025a) Qwen Team. Qwen3-coder: Agentic coding in the world. https://qwen.ai/blog?id=qwen3-coder, 2025a. Accessed: 2025-07-22.
- Qwen Team (2025b) Qwen Team. Qwen3-next: Towards ultimate training & inference efficiency. https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd, 2025b. Accessed: 2025-09-11.
- Qwen Team (2025c) Qwen Team. qwen-code. https://github.com/QwenLM/qwen-code, 2025c.
- Qwen Team (2026) Qwen Team. Pushing qwen3-max-thinking beyond its limits. https://qwen.ai/blog?id=qwen3-max-thinking, 2026. Accessed: 2026-01-26.
- Rashid et al. (2025) Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buchholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, et al. Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents. arXiv preprint arXiv:2504.08703, 2025.
- Schäfer et al. (2024) Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. An empirical evaluation of using large language models for automated unit test generation. IEEE Transactions on Software Engineering, 50(1):85–105, 2024. doi: 10.1109/TSE.2023.3334955.
- Sonwane et al. (2025) Atharv Sonwane, Isadora White, Hyunji Lee, Matheus Pereira, Lucas Caccia, Minseon Kim, Zhengyan Shi, Chinmay Singh, Alessandro Sordoni, Marc-Alexandre Côté, et al. Bugpilot: Complex bug generation for efficient learning of swe skills. arXiv preprint arXiv:2510.19898, 2025.
- SWE-agent Team (2025) SWE-agent Team. mini-swe-agent: The 100 line ai agent that’s actually useful. https://github.com/SWE-agent/mini-swe-agent, 2025. Accessed: 2026-01-22.
- Vergopoulos et al. (2025) Konstantinos Vergopoulos, Mark Niklas Müller, and Martin Vechev. Automated benchmark generation for repository-level coding tasks. arXiv preprint arXiv:2503.07701, 2025.
- Wang et al. (2025) Lilin Wang, Lucas Ramalho, Alan Celestino, Phuc Anthony Pham, Yu Liu, Umang Kumar Sinha, Andres Portillo, Onassis Osunwa, and Gabriel Maduekwe. Swe-bench++: A framework for the scalable generation of software engineering benchmarks from open-source repositories. arXiv preprint arXiv:2512.17419, 2025.
- Wang et al. (2024) Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents. arXiv preprint arXiv:2407.16741, 2024.
- Xiao et al. (2026) Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report. arXiv preprint arXiv:2601.02780, 2026.
- Xiao et al. (2013) Xusheng Xiao, Sihan Li, Tao Xie, and Nikolai Tillmann. Characteristic studies of loop problems for structural test generation via symbolic execution. In 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp. 246–256, 2013. doi: 10.1109/ASE.2013.6693084.
- Xie et al. (2024) Yiqing Xie, Alex Xie, Divyanshu Sheth, Pengfei Liu, Daniel Fried, and Carolyn Rose. Codebenchgen: Creating scalable execution-based code generation benchmarks, 2024.
- Yang et al. (2025a) An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025a.
- Yang et al. (2024) John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37:50528–50652, 2024.
- Yang et al. (2025b) John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents, 2025b. URL https://arxiv.org/abs/2504.21798.
- Yuan et al. (2024) Zhiqiang Yuan, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, Xin Peng, and Yiling Lou. Evaluating and improving chatgpt for unit test generation. Proc. ACM Softw. Eng., 1(FSE), July 2024. doi: 10.1145/3660783. URL https://doi.org/10.1145/3660783.
- Zan et al. (2025) Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. Multi-swe-bench: A multilingual benchmark for issue resolving, 2025. URL https://arxiv.org/abs/2504.02605.
- Zeng et al. (2026) Ji Zeng, Dayuan Fu, Tiantian Mi, Yumin Zhuang, Yaxing Huang, Xuefeng Li, Lyumanshan Ye, Muhang Xie, Qishuo Hua, Zhen Huang, et al. davinci-dev: Agent-native mid-training for software engineering. arXiv preprint arXiv:2601.18418, 2026.
- Zhang et al. (2025a) Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, et al. Agent learning via early experience. arXiv preprint arXiv:2510.08558, 2025a.
- Zhang et al. (2025b) Lei Zhang, Jiaxi Yang, Min Yang, Jian Yang, Mouxiang Chen, Jiajun Zhang, Zeyu Cui, Binyuan Hui, and Junyang Lin. Synthesizing software engineering data in a test-driven manner. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu (eds.), Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pp. 76518–76540. PMLR, 13–19 Jul 2025b. URL https://proceedings.mlr.press/v267/zhang25cn.html.
- Zhang et al. (2026) Lei Zhang, Mouxiang Chen, Ruisheng Cao, Jiawei Chen, Fan Zhou, Yiheng Xu, Jiaxi Yang, Zeyao Ma, Liang Chen, Changwei Luo, Kai Zhang, Fan Yan, KaShun Shum, Jiajun Zhang, Zeyu Cui, Feng Hu, Junyang Lin, Binyuan Hui, and Min Yang. Megaflow: Large-scale distributed orchestration system for the agentic era, 2026. URL https://arxiv.org/abs/2601.07526.
- Zhang et al. (2025c) Linghao Zhang, Shilin He, Chaoyun Zhang, Yu Kang, Bowen Li, Chengxing Xie, Junhao Wang, Maoquan Wang, Yufan Huang, Shengyu Fu, et al. Swe-bench goes live! arXiv preprint arXiv:2505.23419, 2025c.