# Enhancing Mathematical Problem Solving in LLMs through Execution-Driven Reasoning Augmentation
**Authors**:
- Aditya Basarkar (North Carolina State University)
- &Benyamin Tabarsi (North Carolina State University)
- Tiffany Barnes (North Carolina State University)
- &Dongkuan (DK) Xu (North Carolina State University)
## Abstract
Mathematical problem solving is a fundamental benchmark for assessing the reasoning capabilities of artificial intelligence and a gateway to applications in education, science, and engineering where reliable symbolic reasoning is essential. Although recent advances in multi-agent LLM-based systems have enhanced their mathematical reasoning capabilities, they still lack a reliably revisable representation of the reasoning process. Existing agents either operate in rigid sequential pipelines that cannot correct earlier steps or rely on heuristic self-evaluation that can fail to identify and fix errors. In addition, programmatic context can distract language models and degrade accuracy. To address these gaps, we introduce Iteratively Improved Program Construction (IIPC), a reasoning method that iteratively refines programmatic reasoning chains and combines execution feedback with the native Chain-of-thought abilities of the base LLM to maintain high-level contextual focus. IIPC surpasses competing approaches in the majority of reasoning benchmarks on multiple base LLMs. All code and implementations are released as open source.
Enhancing Mathematical Problem Solving in LLMs through Execution-Driven Reasoning Augmentation
Aditya Basarkar North Carolina State University avbasark@ncsu.edu Benyamin Tabarsi North Carolina State University btaghiz@ncsu.edu
Tiffany Barnes North Carolina State University tmbarnes@ncsu.edu Dongkuan (DK) Xu North Carolina State University dxu27@ncsu.edu
## 1 Introduction
Mathematical reasoning, the ability to reliably solve multi-step math problems through symbolic manipulation and language-based deduction, is a necessary skill for LLM-based systems to master in order to build generally intelligent systems that can automate intellectual tasks. It is especially crucial in applications such as scientific discovery Cherian et al. (2024); Shojaee et al. (2025), optimization Huang et al. (2024); Forootani (2025); Habeeb et al. (2023), financial modeling Yao et al. (2025); Carvalho Santos et al. (2022), and education Gupta et al. (2025); Liu et al. (2025), among many others. As research advances towards enabling language models to use tools and understand abstract concepts, mathematical reasoning emerges as a benchmark for assessing their ability to combine symbolic structure with logical deduction. Advancing this capability is necessary for building AI systems that can engage in effective, applicable, and scientifically grounded reasoning.
Despite substantial progress, many reasoning agents still struggle with two limitations. First, most systems lack a persistent and reliably manipulable representation of their overall reasoning state that allows them to make informed revisions of earlier steps. Once a model commits to a reasoning chain, whether expressed as text, a sequence of agentic steps, or a program, subsequent revisions are typically superficial, based on heuristic self-evaluation or nonexistent. Without an editable global reasoning state, the model cannot identify or act on contradictions, invalid computations, or revise previous steps, making it vulnerable to cascading errors Cemri et al. (2025). Second, execution-guided agents lack stabilizers against program bias, often over-prioritizing execution signals that could be logically flawed over token-level reasoning, resulting in brittle reasoning trajectories. When program outputs are used to draw conclusions, irrelevant or incorrect information may cause biased reasoning in models, reducing accuracy Shi et al. (2023); Yang et al. (2025).
Existing approaches address portions of these limitations, but leave important gaps. Multi-agent systems such as Cumulative Reasoning (CR) Zhang et al. (2023) and Multi-agent Condition Mining (MACM) Lei et al. (2024) have enabled stepwise deliberation. However, their sequential structure locks their reasoning trajectory into a fixed forward direction. This rigidity prevents agents from freely revising earlier steps, making them vulnerable to cascading errors, a phenomenon identified by Cemri et al. (2025) as "inter-agent misalignment". Agents like Self-Refine Madaan et al. (2023), Reflexion Shinn et al. (2023), Tree-of-Thoughts Yao et al. (2023), and Graph-of-Thoughts Besta et al. (2024) offer self-evaluation, refinement, and backtracking capabilities, but their effectiveness is bounded by their capacity to produce accurate self-evaluations Huang et al. (2023), often resulting in unreliable refinements and trajectory selections. Program and tool-based agents such as Program of Thoughts (PoT) Chen et al. (2023), Tool Integrated Reasoning Agent (ToRA) Gou et al. (2024), Code-based Self Verification (CSV) Zhou et al. (2023), and Program-aided Language Model (PAL) Gao et al. (2023) provide deterministic signals through code execution. These programs are usually one-off artifacts and are not subjected to targeted revisions, leading to rigidity similar to that of sequential reasoning agents. Furthermore, recent studies have demonstrated that such agents, particularly those relying on program-based reasoning, are susceptible to irrelevant or misleading context, often over-incorporating flawed information into their reasoning traces and causing performance degradation Shi et al. (2023); Yang et al. (2025).
To overcome these limitations, we propose Iteratively Improved Program Construction (IIPC), an agent that treats programs as explicit representations of the model’s reasoning chain. While most agents generate one-off code blocks, IIPC generates reasoning chains as programs designed for transparent inspection and evolution through informed revision. Each revision is grounded in deterministic feedback that includes information about intermediate steps, allowing the model to correct errors or inconsistencies in its reasoning and make causally informed changes. A memory of past mistakes is maintained to ensure that refinements minimize "revisit regret" and steer improvements away from failure modes rather than resampling failed programs. To preserve a high-level contextual focus, IIPC adopts a dual-branch architecture. The token-level reasoning branch produces a CoT reasoning trace free from dependence on program output, while the program-refinement branch iteratively refines an executable representation of the model’s reasoning. The outputs of the two branches are combined only at the final stage to provide context for the final reasoning chain. Through this mechanism, IIPC avoids over-reliance on potentially incorrect or irrelevant program results while leveraging relevant information. As a result, IIPC provides a unified reasoning mechanism that combines manipulable representations of reasoning traces with context-stable reasoning, overcoming the limitations of existing multi-agent, self-evaluating, and execution-guided systems.
The paper’s primary contributions are as follows:
1. We introduce IIPC, a new reasoning method that is designed to refine programs through execution-guided feedback, integrate execution outputs into its own reasoning abilities, and surpass other code-based, state-of-the-art, non-ensemble reasoning agents in difficult math problem-solving benchmarks.
1. We provide the reasoning-trace corpus generated from testing IIPC, including problem statements, initial propositions, generated code, execution outputs, integrated deliberation, and final answers, to facilitate reproducible evaluation, detailed error analysis, and future work on program-centric reasoning.
1. We conduct a comprehensive evaluation of IIPC against various multi-agent reasoning methods across large language models and mathematical reasoning benchmarks. IIPC surpasses PoT, MACM, and CR on the majority of the mathematical problem-solving benchmarks on multiple base LLMs.
## 2 Related Work
Recently developed multi-agent systems vary in their approach to structuring mathematical reasoning. CR Zhang et al. (2023) uses three components: a proposer, verifier, and reporter. These components generate, evaluate, and collect reasoning steps. CR achieves 72.2% accuracy on 500 MATH problems Hendrycks et al. (2021) using GPT-4 and early LLaMA models. MACM Lei et al. (2024) accumulates and verifies conditions needed to solve the given problem rather than processing the reasoning steps. MACM also uses voting mechanisms to leverage uncertainty and explore multiple reasoning trajectories that are higher in quality than CoT Wei et al. (2022), Tree-of-Thoughts (ToT) Yao et al. (2023), or Graph-of-Thoughts (GoT) Besta et al. (2024) prompting. Despite their improvements on popular benchmarks, sequential processing introduces rigid reasoning chains that cause errors to propagate over subsequent steps.
While sequential multi-agent systems like MACM and CR focus on reasoning through iterative step accumulation, other research directions enhance problem-solving by integrating external tools. Tool-Integrated Reasoning Agent (ToRA) Gou et al. (2024) fine-tunes LLaMA models to interleave natural language reasoning with tool calls. PoT Chen et al. (2023) generates and executes Python programs, using the outputs to arrive at the final answer. Code-Based Self-Verification (CSV) Zhou et al. (2023) includes programmatic checks to verify and refine solutions, improving reliability through iterative code-driven validation.
Other approaches aim to improve reasoning internally through self-correction. Agents like self-refine Madaan et al. (2023) and Reflexion Shinn et al. (2023) adopt an iterative self-improvement approach, generating feedback on their own output and refining it until a predefined stopping condition is met. These methods provide foundational insights for enhancing program-based reasoning, which our approach leverages and advances.
IIPC’s program refinement mechanism is similar to CodePRM Li et al. (2025) in its usage of execution feedback to refine reasoning. However, IIPC treats programs as representations of the reasoning chain, whereas CodePRM edits natural-language thoughts based on their quality scores for better downstream execution. The dual-branch architecture used by IIPC conceptually resembles the Talker-Reasoner architecture Christakopoulou et al. (2024), where a talker agent performs fast language generation, the reasoner performs multi-step reasoning, and they interact through a shared memory. However, unlike the interleaved process of the Talker-Reasoner, IIPC maintains a clean CoT trace and only merges at the end to remain robust to noisy programmatic outputs.
Execution-Guided Classifier-Free Guidance (EG-CFG) Lavon et al. (2025) is a decoding strategy that guides token sampling based on line-level execution. OpenCodeInterpreter (OCI) Zheng et al. (2024) uses an execution guided refinement loop to iteratively refine generated programs. Outcome-Refining Process Supervision (ORPS) Yu et al. (2025) performs a beam search over reasoning-code trajectories, selecting candidates based on execution-based outcome signals. In contrast, IIPC treats programs as representations for mathematical problem solving, refining them using both process- and outcome-level signals to identify and correct reasoning errors.
## 3 Iteratively Improved Program Construction (IIPC)
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Program Synthesis and Refinement Process
### Overview
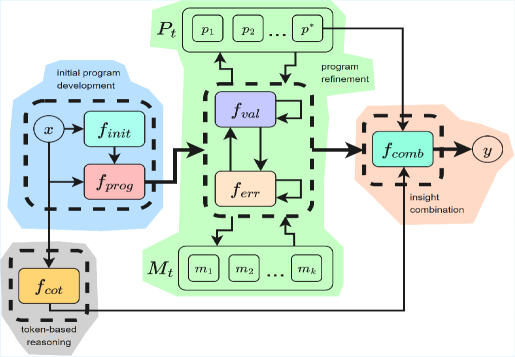
This diagram illustrates a process for program synthesis and refinement. It depicts several functional components and their interconnections, organized into distinct stages: "Initial program development," "program refinement," and "insight combination." The process starts with an input `x` and progresses through various functions to produce an output `y`.
### Components/Axes
The diagram does not feature traditional axes or scales as it is a process flow diagram. The key components are represented by labeled boxes and circles, with arrows indicating the flow of information or control.
**Key Components:**
* **Input `x`**: Represented by a circle, this is the initial input to the system.
* **`f_init`**: A cyan-colored rectangle within the "Initial program development" block. It takes `x` as input.
* **`f_prog`**: A coral-colored rectangle within the "Initial program development" block. It takes `x` and the output of `f_init` as input.
* **`f_cot`**: A yellow-colored rectangle within the "token-based reasoning" block. It takes `x` as input.
* **`P_t`**: A green-colored rectangle containing `p_1`, `p_2`, ..., `p*`. This likely represents a set of programs or program candidates.
* **`M_t`**: A green-colored rectangle containing `m_1`, `m_2`, ..., `m_k`. This likely represents a set of metrics or intermediate results.
* **`f_val`**: A blue-colored rectangle within the "program refinement" block. It takes input from `P_t` and `M_t`, and has internal feedback loops.
* **`f_err`**: A coral-colored rectangle within the "program refinement" block. It takes input from `P_t` and `M_t`, and has internal feedback loops.
* **`f_comb`**: A cyan-colored rectangle within the "insight combination" block. It takes input from `f_prog`, `f_val`, and `f_err`.
* **Output `y`**: Represented by a circle, this is the final output of the system.
**Process Stages (indicated by shaded regions and dashed borders):**
* **Initial program development** (light blue shaded region, dashed border): Contains `x`, `f_init`, and `f_prog`.
* **Program refinement** (light green shaded region, dashed border): Contains `f_val` and `f_err`, and interacts with `P_t` and `M_t`.
* **Token-based reasoning** (light grey shaded region, dashed border): Contains `f_cot`.
* **Insight combination** (light orange shaded region, dashed border): Contains `f_comb`.
**Flow Arrows:**
* Thick black arrows indicate primary data flow.
* Thin black arrows indicate secondary or feedback flow.
* Zig-zag arrows indicate iterative refinement or processing.
### Detailed Analysis or Content Details
1. **Initial Program Development**:
* Input `x` is fed into `f_init`.
* Input `x` is also fed into `f_prog`.
* The output of `f_init` is fed into `f_prog`.
* The output of `f_prog` is a thick black arrow pointing towards the "program refinement" block.
2. **Token-based Reasoning**:
* Input `x` is fed into `f_cot`.
* The output of `f_cot` is a black arrow pointing towards `f_comb`.
3. **Program Refinement**:
* The output of `f_prog` (from "Initial program development") is fed into `f_val`.
* `f_val` receives input from `P_t` and `M_t`.
* `f_err` receives input from `P_t` and `M_t`.
* There are internal feedback loops for both `f_val` and `f_err` (indicated by zig-zag arrows pointing back to themselves).
* The output of `f_val` is fed into `P_t` (specifically `p*`).
* The output of `f_err` is fed into `M_t`.
* Both `f_val` and `f_err` have outputs that feed into `f_comb`.
4. **Insight Combination**:
* `f_comb` receives input from `f_prog` (thick arrow), `f_val`, and `f_err`.
* `f_comb` also receives input from `f_cot` (token-based reasoning).
* The output of `f_comb` leads to the final output `y`.
### Key Observations
* The diagram outlines an iterative process where initial program development is followed by refinement.
* The "program refinement" block appears to be a core loop involving validation (`f_val`) and error estimation (`f_err`), which in turn influence the set of programs (`P_t`) and metrics (`M_t`).
* "Token-based reasoning" (`f_cot`) acts as a separate input stream that contributes to the final combination.
* The final output `y` is a result of combining insights from multiple sources: the initial program (`f_prog`), validation and error metrics (`f_val`, `f_err`), and token-based reasoning (`f_cot`).
### Interpretation
This diagram likely represents a system for automated program synthesis or code generation, possibly within a machine learning context.
* **Initial Program Development**: This stage seems to be responsible for generating a baseline program or set of programs based on an input `x`. `f_init` might be an initial generator, and `f_prog` could be a more refined version or a different type of program generator.
* **Program Refinement**: This is a crucial iterative loop. `f_val` likely evaluates the quality or correctness of programs in `P_t`, and `f_err` might estimate the errors or shortcomings of these programs. The outputs of these functions then feed back into `P_t` and `M_t`, suggesting that the system learns and improves its programs over time by adjusting them based on validation and error feedback. The presence of `p*` in `P_t` suggests a potential "best" program candidate.
* **Token-based Reasoning**: `f_cot` suggests that the system might leverage symbolic reasoning or natural language processing techniques (hence "token-based") to inform the program synthesis process. This could be used to interpret the input `x` or to guide the generation of code.
* **Insight Combination**: `f_comb` acts as a fusion mechanism, bringing together the results from the initial development, the refined programs, and the token-based reasoning to produce the final output `y`. This suggests a multi-modal approach to program synthesis, where different sources of information are integrated for a more robust outcome.
In essence, the diagram depicts a sophisticated system that starts with an input, develops an initial program, iteratively refines it using validation and error feedback, incorporates external reasoning, and finally combines all these elements to produce a desired output. This architecture is common in areas like program synthesis, program repair, and complex task execution where multiple sources of information and iterative improvement are necessary.
</details>
Figure 1: Overview of IIPC. $f_{\text{init}}$ derives key propositions from the problem statement; $f_{\text{prog}}$ generates an initial candidate program; $f_{\text{val}}$ evaluates program correctness and logical consistency; if errors are detected, the error correction component $f_{\text{err}}$ revises the program accordingly; $f_{\text{cot}}$ produces a textual chain of thought; $f_{\text{comb}}$ combines program and token reasoning context for final output; $M_{t}$ denotes the error descriptor memory at refinement step $t$ ; $P_{t}$ represents the program store at step $t$ .
Our proposed method, IIPC, introduces an execution-guided reasoning methodology that directly addresses the limitations of works previously mentioned. Rather than accumulating steps or conditions sequentially, as in CR and MACM, IIPC develops programs that solve the given problem while simultaneously storing compact failure descriptors. This allows IIPC to iteratively converge toward correct solutions while dynamically avoiding previously failed reasoning paths.
IIPC begins by using a model $f$ for developing a set of initial propositions $s$ ( $s=f_{init}(x)$ ), which are statements derived explicitly from the given problem $x$ , as well as additional information needed to solve the problem. These statements encapsulate all critical information, whether explicitly provided by the problem or implicitly required, to guide subsequent solution steps.
Given the problem statement and the set of initial propositions, IIPC generates a candidate solution program $p_{1}$ ( $p_{1}=f_{prog}(x,s)$ ) that transparently represents its reasoning process. Every generated program conforms to the following constraints:
- Programs must be restricted to the following libraries: numpy, math, sympy, scipy, and scikit-spatial. These libraries are sufficient to express the vast majority of mathematical reasoning tasks. Additionally, they are stable, widely used, and deterministic, minimizing variability across runs.
- To facilitate debugging, the program must avoid using any list comprehensions or recursion and should make use of print statements.
- Comments must be verbose and descriptive for aiding correction and refinement.
- The program must include a section that verifies the final answer, allowing the framework to evaluate its correctness.
Once the program is constructed, it is executed using an interpreter $E$ to yield an output ( $o_{1}=E(p_{1})$ ), which can either be the program’s output, an error, or both. This serves as the basis for subsequent reflection and refinement.
IIPC reviews the generated program’s reasoning and consults a persistent reflection memory containing past mistakes ( $M_{t}$ , where $t$ is the time point of the current refinement step) to avoid repeating unsuccessful strategies. It then either (1) issues a revised program accompanied by a concise reflection on the identified flaw, which is logged in the memory store before the revised program is re-executed, or (2) outputs a stopping signal indicating that the current program and its outputs are satisfactory for solving the problem without further refinement. If the program produces an error, IIPC amends only the offending code segment without modifying the reasoning chain itself. It also produces a concise reflection on the mistake, which is appended to its memory store for guiding future iterations.
IIPC iteratively refines the design by executing a series of process validations and error corrections to produce the optimal program for solving the given problem. If a program does not result in an error, the process validation component will assess the program’s validity and its output. However, if the program produces an error, the error correction component will revise it while preserving the reasoning chain. The resulting programs from either process are rerun and cycled (along with their output and error) back into one of the two components for further correction and/or enhancement. The current implementation for refinement, as tested in the main experiments, allows a maximum of two process validations and two error corrections after each process validation. All working programs and their output are stored in an array $P_{t}$ , with the program with the highest index being the most recently developed working program. This back-and-forth loop between the process validation and error-correction components continues until a stop condition is met. The stop condition could either be a satisfactory program, a limit on the allowed number of refinements or error corrections, or a limit on the token usage of the agent. Formally, this refinement process can be summarized in the following formulas:
$$
\displaystyle(p_{t+1},m_{t+1}) \displaystyle=\begin{cases}f_{err}(x,s,p_{t},o_{t},M_{t}),&\text{if }o_{t}\in e,\\[4.0pt]
f_{val}(x,s,p_{t},o_{t},M_{t}),&\text{if }o_{t}\notin e\end{cases} \displaystyle M_{t+1} \displaystyle=M_{t}\cup m_{t+1} \displaystyle P_{t+1} \displaystyle=P_{t}\cup p_{t}\ \ \text{if}\ \ o_{t}\notin e \tag{1}
$$
where $m_{t+1}$ is an error or mistake descriptor, $f_{err}$ is the function that corrects errors, and $f_{ref}$ is the refinement function that can result in a $\emptyset$ for both $p_{t+1}$ and $m_{t+1}$ if the refinement process reaches a stopping point. In addition to program construction and refinement, IIPC generates a purely text-based CoT $c$ in a separate branch and arrives at a temporary answer ( $c=f_{cot}(x,s)$ ). The most recent working program ( $p^{\star}\in P_{t}$ ) and its output ( $o^{\star}$ ) with the generated CoT ( $c$ ) text is concatenated through a structured integration prompt, which is used as input to the underlying LLM to arrive at the final answer for the problem ( $y=f_{comb}(x,s,p^{\star},o^{\star},c)$ ). This step allows IIPC to reevaluate the solution using symbolic evidence from both refined program execution and native linguistic reasoning, thereby reducing over-dependence on a single kind of context.
## 4 Experiments
#### Experimental Setup.
Our evaluation benchmarks the IIPC framework on two mathematical reasoning datasets: (1) MATH Hendrycks et al. (2021), comprising complex problems in multiple subjects with five difficulty levels; (2) and AIME (American Invitational Mathematics Examination) Veeraboina (2024), consisting of difficult competition math problems from 1983 to 2024 that emphasize creative problem solving and is more challenging than the MATH dataset. For the MATH dataset, we evaluate on a balanced subset of the official test split from the original dataset, targeting uniform coverage across all topic-difficulty combinations (35 bins total). Due to limited availability in certain bins, the final subset contained 1483 problems total. For the AIME dataset Veeraboina (2024), we use the complete set of 933 problems spanning the years 1983-2024. We compare IIPC’s performance against other reasoning paradigms, including CR Zhang et al. (2023), MACM Lei et al. (2024), and PoT prompting Chen et al. (2023). We evaluate across multiple state-of-the-art LLMs, including GPT-4o mini, Gemini 2.0 Flash, Mistral Small 3.2 24B, Gemma 3 27B, and Llama 4 Maverick, to characterize how model architecture influences accuracy. Finally, our ablations isolate the contributions of specific architectural components, examine the effect of varying decoding temperatures, evaluate all methods under voting-based aggregation, and use GSM8K Cobbe et al. (2021), a data set consisting of grade school math problems, to assess performance degradation due to agentic overhead on simpler math problems.
#### Agent Implementations.
For the purposes of this study, the main evaluation tests all prompting-based reasoning agents with access to code interpreters, excluding multi-trajectory aggregation (voting) mechanisms due to their high token usage and costs. To comply with this constraint, reasoning agents like MACM Lei et al. (2024), which utilize and aggregate multiple answers, are adapted to operate within a single run and evaluated accordingly. While this may handicap the MACM agent, which is designed to operate in an ensemble environment, testing its performance in these conditions allows for a fair comparison with other such agents and provides insights into the weaknesses of processing steps sequentially rather than in parallel. As mentioned before, a separate ablation is provided to assess the effects of voting environments on the performance of all agents. Our implementation of PoT includes an error-correction loop that retries program generation when execution fails, until it reaches a fixed retry limit and has to fall back to standard Chain-of-Thought reasoning. This design allows us to better compare the mathematical reasoning capabilities of agents against PoT while controlling for coding ability. Our custom implementations of MACM and CR attempt to incorporate as much of the original implementations as possible and follow the proposed methods closely (with the exception of the voting mechanism for MACM). All agents are tested with an LLM decoding temperature of 0.1 and measure performance as accuracy (the number of correctly solved questions divided by the total number of questions evaluated).
#### Assessing Correctness.
To assess answer correctness, we first use deterministic equivalence and fall back to LLM-based judging using the LLaMA 4 Maverick model if necessary. Although deterministic evaluation is ideal, code-centric agents may produce equivalent answers in differing formats (e.g., 1.4142 versus $\sqrt{2}$ ). To ensure transparency and reproducibility, we fix the decoding temperature at 0 for the LLM judge and release the full judging code. On the AIME dataset, 97.78% of answers were verified via exact integer matching. On the MATH dataset, 72.85% of the generated answers were deterministically verified; LLM judging was only used to confirm whether the answers were incorrect after deterministic judging failed. On GSM8K, 89.35% of the answers were verified using exact answer matching.
#### Other Considerations.
While our evaluations focus on accuracy and tend to favor reasoning stability over token efficiency, we do recognize the fundamental limitation that IIPC incurs significant token costs by regenerating refined or corrected programs with every iteration. Additionally, our evaluation reports single-run accuracy on fixed benchmarks. However, while gains may be small for some evaluations, IIPC consistently outperforms other agents across all LLMs and datasets, reducing the likelihood that performance gains are due to noise.
Table 1: Accuracy (%) of reasoning methods across five LLMs. IIPC row is shaded; bold teal = per-column SOTA. Numbers in parentheses show $\Delta$ vs PoT baseline.
MATH Reasoning System GPT-4o-mini Gemini 2.0 Flash Mistral 3.2 24B Gemma 3 27B Llama 4 Maverick PoT 81.19 92.58 89.62 89.01 88.94 CR 76.53 (-4.66) 90.09 (-2.49) 83.61 (-6.01) 87.05 (-1.96) 89.94 (+1.00) MACM 72.62 (-8.57) 90.09 (-2.49) 82.13 (-7.49) 86.72 (-2.29) 88.67 (-0.27) IIPC 80.98 (-0.21) 94.13 (+1.55) 90.83 (+1.21) 90.56 (+1.55) 91.23 (+2.29)
AIME Reasoning System GPT-4o-mini Gemini 2.0 Flash Mistral 3.2 24B Gemma 3 27B Llama 4 Maverick PoT 31.40 59.16 48.12 46.20 62.49 CR 23.90 (-7.50) 53.48 (-5.68) 40.09 (-8.03) 41.69 (-4.51) 62.17 (-0.32) MACM 17.79 (-13.61) 51.98 (-7.18) 37.62 (-10.50) 41.69 (-4.51) 62.17 (-0.32) IIPC 29.05 (-2.35) 64.20 (+5.04) 52.52 (+4.40) 50.48 (+4.28) 69.77 (+7.28)
<details>
<summary>x2.png Details</summary>
### Visual Description
## Bar Chart: Accuracy by Difficulty Level for Llama 4 Maverick
### Overview
This bar chart displays the accuracy of four different methods (PoT, CR, MACM, and IIPC) across five difficulty levels. The x-axis represents the "Difficulty Level," ranging from 1 to 5, and the y-axis represents "Accuracy," ranging from 0.0 to 1.0. For each difficulty level, there are four bars, each corresponding to one of the methods.
### Components/Axes
* **Title:** Llama 4 Maverick
* **X-axis Title:** Difficulty Level
* **X-axis Markers:** 1, 2, 3, 4, 5
* **Y-axis Title:** Accuracy
* **Y-axis Markers:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
* **Legend:** Located at the bottom of the chart.
* **PoT:** Blue
* **CR:** Orange
* **MACM:** Green
* **IIPC:** Red
### Detailed Analysis or Content Details
**Difficulty Level 1:**
* **PoT (Blue):** 95.34%
* **CR (Orange):** 95.70%
* **MACM (Green):** 96.06%
* **IIPC (Red):** 96.06%
**Difficulty Level 2:**
* **PoT (Blue):** 96.68%
* **CR (Orange):** 96.68%
* **MACM (Green):** 95.68%
* **IIPC (Red):** 96.68%
**Difficulty Level 3:**
* **PoT (Blue):** 92.36%
* **CR (Orange):** 91.36%
* **MACM (Green):** 92.03%
* **IIPC (Red):** 93.69%
**Difficulty Level 4:**
* **PoT (Blue):** 86.71%
* **CR (Orange):** 87.04%
* **MACM (Green):** 87.71%
* **IIPC (Red):** 89.37%
**Difficulty Level 5:**
* **PoT (Blue):** 74.09%
* **CR (Orange):** 74.42%
* **MACM (Green):** 72.43%
* **IIPC (Red):** 80.73%
### Key Observations
* **General Trend:** Accuracy for all methods generally decreases as the difficulty level increases from 1 to 5.
* **Highest Accuracy:** The highest accuracies are observed at Difficulty Level 1, with all methods achieving over 95%. MACM and IIPC show the highest accuracy at 96.06%.
* **Lowest Accuracy:** The lowest accuracies are observed at Difficulty Level 5, with PoT, CR, and MACM falling below 75%. IIPC shows a significantly higher accuracy (80.73%) compared to the other methods at this level.
* **Method Performance Comparison:**
* At Difficulty Levels 1 and 2, PoT and CR perform very similarly, often achieving the highest or near-highest accuracy. MACM and IIPC also perform comparably, with MACM slightly outperforming IIPC at Level 1 and IIPC slightly outperforming MACM at Level 2.
* At Difficulty Level 3, IIPC shows a notable increase in accuracy compared to PoT, CR, and MACM.
* At Difficulty Level 4, IIPC continues to show the highest accuracy among the four methods.
* At Difficulty Level 5, IIPC demonstrates a substantial lead in accuracy over the other three methods, which are clustered at much lower values.
### Interpretation
This chart suggests that the performance of the "Llama 4 Maverick" system, as measured by accuracy, is sensitive to the difficulty level of the task. As the difficulty increases, the accuracy of all evaluated methods tends to decline.
The data also highlights differences in the robustness of the four methods (PoT, CR, MACM, and IIPC) to increasing difficulty. While PoT and CR perform well at lower difficulty levels, IIPC appears to be more resilient to higher difficulty levels, particularly at levels 4 and 5, where it significantly outperforms the other methods. This suggests that IIPC might employ strategies or have characteristics that make it better suited for more challenging tasks compared to PoT, CR, and MACM. The dip in MACM's performance at Difficulty Level 2, while PoT, CR, and IIPC remain high, is a minor anomaly within the general trend. The significant jump in IIPC's accuracy at Difficulty Level 5, relative to the other methods, is the most striking observation, indicating a potential advantage for this method in complex scenarios.
</details>
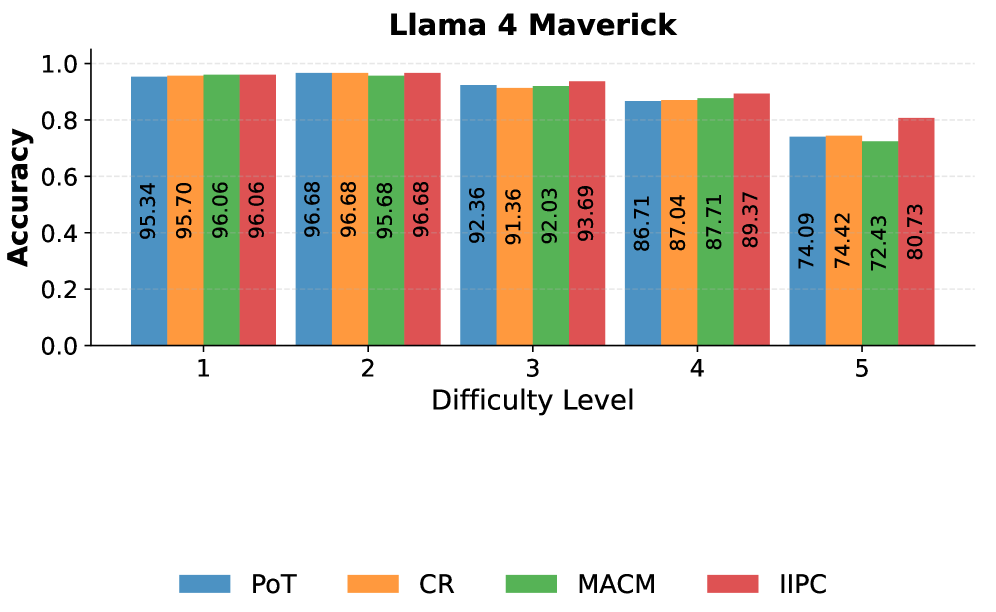
Figure 2: Accuracy of PoT, IIPC, CR, and MACM on the MATH dataset using Llama 4 Maverick. This bargraph is stratified by difficulty level
<details>
<summary>x3.png Details</summary>
### Visual Description
## Heatmap: Llama 4 Maverick Performance by Subject and Metric
### Overview
This image displays a heatmap representing performance scores for "Llama 4 Maverick" across various mathematical subjects and four different metrics. The subjects are listed on the vertical axis, and the metrics are listed on the horizontal axis. The color intensity of each cell indicates the performance score, with warmer colors (yellow) generally representing higher scores and cooler colors (green) representing lower scores.
### Components/Axes
**Title:** "Llama 4 Maverick" (Centered at the top)
**Vertical Axis (Subjects):**
* Algebra
* Count. & Prob.
* Geometry
* Inter. Algebra
* Number Theory
* Prealgebra
* Precalculus
**Horizontal Axis (Metrics):**
* PoT
* CR
* MACM
* IIPC
**Data Cells:** Each cell contains a numerical score, representing the performance of Llama 4 Maverick for a specific subject under a specific metric. The color of the cell corresponds to the score.
### Detailed Analysis
The heatmap displays the following scores, with approximate uncertainty of +/- 0.01 due to visual reading:
* **Algebra:**
* PoT: 95.81 (Yellow)
* CR: 97.21 (Yellow)
* MACM: 98.14 (Yellow)
* IIPC: 98.60 (Yellow)
* **Count. & Prob.:**
* PoT: 91.00 (Yellow-Green)
* CR: 91.00 (Yellow-Green)
* MACM: 92.42 (Yellow-Green)
* IIPC: 91.47 (Yellow-Green)
* **Geometry:**
* PoT: 79.52 (Green)
* CR: 80.00 (Green)
* MACM: 75.24 (Green)
* IIPC: 80.48 (Green)
* **Inter. Algebra:**
* PoT: 83.72 (Green)
* CR: 80.00 (Green)
* MACM: 84.19 (Green)
* IIPC: 87.44 (Yellow-Green)
* **Number Theory:**
* PoT: 91.09 (Yellow-Green)
* CR: 94.06 (Yellow)
* MACM: 91.09 (Yellow-Green)
* IIPC: 94.06 (Yellow)
* **Prealgebra:**
* PoT: 94.42 (Yellow)
* CR: 95.35 (Yellow)
* MACM: 94.42 (Yellow)
* IIPC: 96.74 (Yellow)
* **Precalculus:**
* PoT: 86.98 (Yellow-Green)
* CR: 85.12 (Yellow-Green)
* MACM: 85.12 (Yellow-Green)
* IIPC: 89.77 (Yellow-Green)
### Key Observations
* **Highest Performance:** Llama 4 Maverick demonstrates its highest performance in "Algebra," with scores consistently above 95.80 across all metrics, peaking at 98.60 for the "IIPC" metric. "Prealgebra" also shows very strong performance, with scores generally above 94.40.
* **Lowest Performance:** The lowest performance is observed in "Geometry," with scores ranging from 75.24 to 80.48. "Inter. Algebra" also shows relatively lower scores compared to other subjects, particularly for the "CR" metric (80.00).
* **Metric Performance:** Across most subjects, the "IIPC" metric generally shows higher or comparable scores to other metrics, especially in subjects where Llama 4 Maverick performs well. The "CR" metric shows a notable dip in "Inter. Algebra" and "Precalculus."
* **Color Gradient:** The heatmap visually confirms the numerical data. Yellow cells are concentrated in "Algebra," "Prealgebra," and parts of "Number Theory" and "Count. & Prob.," indicating high scores. Green cells are prominent in "Geometry" and "Inter. Algebra," indicating lower scores.
### Interpretation
The heatmap suggests that Llama 4 Maverick has a strong aptitude for higher-level mathematics like Algebra and Prealgebra, as indicated by the consistently high scores and warm colors. Conversely, its performance in foundational or more abstract areas like Geometry and Intermediate Algebra appears to be weaker, as shown by the lower scores and cooler colors.
The "IIPC" metric seems to be a strong point for Llama 4 Maverick across many subjects, suggesting it might be a metric where the model excels or is better suited. The variation in scores across different metrics for the same subject (e.g., "Inter. Algebra" scores of 83.72 for PoT, 80.00 for CR, 84.19 for MACM, and 87.44 for IIPC) indicates that the model's performance is not uniform and is influenced by the specific evaluation criteria.
The data implies that while Llama 4 Maverick is a capable model, its strengths are concentrated in certain mathematical domains. Further investigation could explore why Geometry and Inter. Algebra present challenges, and whether specific training data or architectural features contribute to this pattern. The consistent high performance in Algebra and Prealgebra suggests these areas might be well-represented in its training data or align with its core capabilities.
</details>
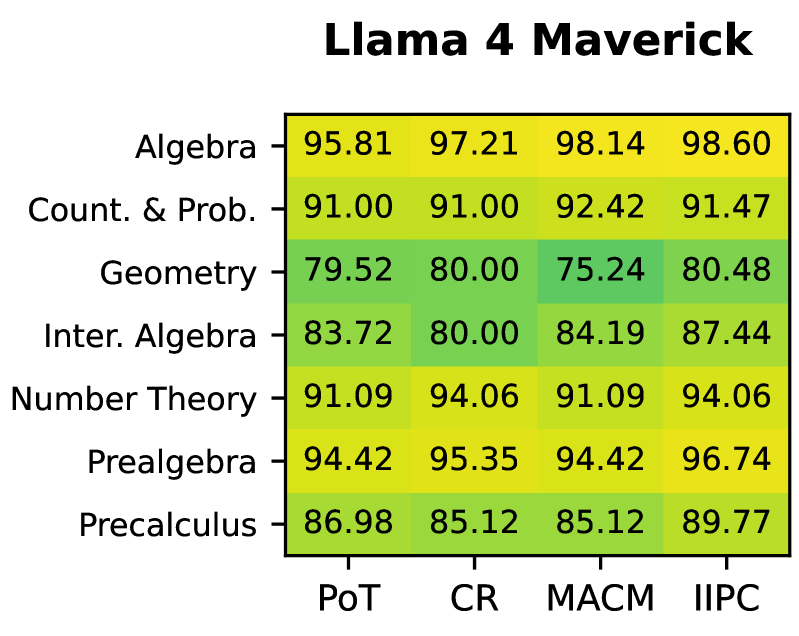
Figure 3: Heatmap of accuracy (%) by subject area on the MATH benchmark for Llama-4-Maverick. Columns correspond to reasoning agents (PoT, IIPC, CR, and MACM) and rows correspond to mathematical domains.
### 4.1 MATH
The MATH benchmark includes problems across a broad spectrum of advanced topics, including number theory, geometry, algebra (from prealgebra through intermediate algebra), precalculus, and counting & probability, each presented at five increasing difficulty tiers. On this benchmark, IIPC outperformed the other reasoning methods across most LLM backbones, achieving the highest scores on Gemini 2.0 Flash (94.13%), Mistral Small 3.2 24B (90.83%), Gemma 3 27B (90.56%), and Llama 4 Maverick (91.23%). Conversely, PoT surpassed IIPC and all other methods on GPT-4o-mini (81.19%). This suggests that, in models with lower reasoning capacity, the additional complexity introduced by IIPC can become counterproductive, whereas PoT reasoning traces appear better aligned with these models’ capabilities, providing just enough scaffolding without overwhelming their reasoning bandwidth.
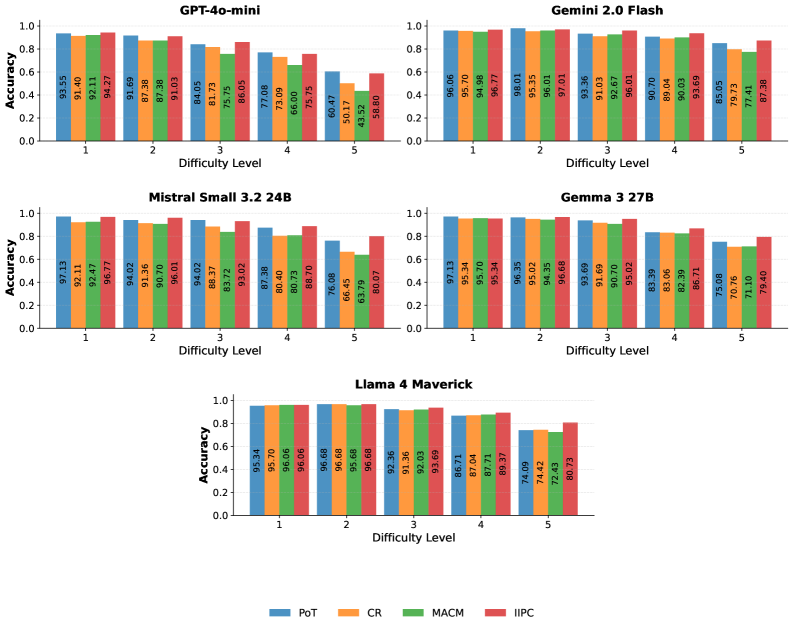
To further analyze agent behavior on the MATH benchmark, we break down performance by difficulty level and topic. Although the main evaluation presents this analysis only for Llama 4 Maverick, analogous results for all other language models are provided in the appendix. As evident in figure 2, IIPC consistently matches or outperforms other agents as difficulty increases. On the most challenging level-5 problems, IIPC achieves an accuracy of 80.73, outperforming the next best method by 6.31 points. As shown in figure 3, we find that with the exception of Counting and Probability, IIPC achieves the highest accuracy across all domains. Most notably, we record the highest gains in Pre-calculus (+2.79%, 89.77%) and Intermediate Algebra (+3.25%, 87.44%). This provides further evidence for IIPC’s ability to solve difficult problems and its effectiveness over existing methods.
### 4.2 AIME
The AIME dataset contains problems from the American Invitational Mathematics Examination from 1983 to 2024. It emphasizes creative problem-solving and is the most difficult of the 3 datasets tested. Consistent with its performance on the MATH benchmark, IIPC achieved the highest accuracy on most models, specifically Gemini 2.0 Flash (64.20%), Mistral 3.2 24B (52.52%), Gemma 3 27B (50.48%), and Llama 4 Maverick (69.77%). In contrast, PoT surpassed all other methods on GPT-4o-mini (31.40%). Similar to the results on the MATH benchmark, GPT-4o-mini may lack the reasoning capacity required to fully benefit from IIPC’s more refined loop. IIPC’s design scales well to highly challenging mathematical reasoning tasks when supported by sufficiently capable models, while PoT seems to remain more robust on models with more constrained reasoning capacity.
### 4.3 Ablation Tests
Table 2: Accuracy (%) of reasoning methods on GSM8K. Bold teal = per-row SOTA. Numbers in parentheses show $\Delta$ vs CoT baseline.
| LLM | CoT | IIPC | PoT | MACM | CR |
| --- | --- | --- | --- | --- | --- |
| GPT-4o-mini | 94.54 | 94.24 | 93.56 | 91.05 | 92.34 |
| Gemini 2.0 Flash | 96.06 | 95.60 | 95.75 | 92.57 | 91.89 |
| Mistral 3.2 24B | 95.22 | 95.00 | 94.84 | 93.86 | 94.47 |
| Gemma 3 27B | 95.45 | 94.84 | 94.47 | 91.36 | 93.18 |
| Llama 4 Maverick | 96.13 | 95.53 | 95.53 | 94.24 | 95.91 |
Table 3: Ablation results on MATH (Gemini 2.0 Flash) and AIME (Gemini 2.0 Flash, GPT - 4o - mini). Best per column is bold teal.
| Methods | MATH (Gemini) | AIME | |
| --- | --- | --- | --- |
| Gemini 2.0 Flash | Gemini 2.0 Flash | GPT-4o-mini | |
| CoT | 92.92 | 56.70 | 21.11 |
| PoT-NC | 92.52 | 59.12 | 31.19 |
| PoT | 92.58 | 59.16 | 31.40 |
| IIPC-NS-NMS | 93.19 (+0.61) | 60.77 (+1.61) | 26.90 (-4.50) |
| IIPC-NS | 93.59 (+1.01) | 61.52 (+2.36) | 27.12 (-4.28) |
| IIPC | 94.13 (+1.55) | 64.20 (+5.04) | 29.05 (-2.35) |
Table 4: IIPC temperature ablation on AIME (Gemini 2.0 Flash). Best is bold teal.
| Temperature | Accuracy (%) |
| --- | --- |
| 0.1 | 64.20 |
| 0.3 | 64.52 |
| 0.5 | 63.56 |
| 0.7 | 63.13 |
| 0.9 | 63.24 |
Table 5: Effect of voting on MATH Level-5 (245 problems) using Llama 4 Maverick. Best in each column is bold teal.
| Agent | No Voting | Voting |
| --- | --- | --- |
| CoT | 70.61 | 74.29 |
| PoT | 73.47 | 80.30 |
| CR | 68.57 | 78.37 |
| MACM | 69.80 | 76.33 |
| IIPC | 78.78 | 80.30 |
To better understand which components of IIPC contribute most to its performance gains, we conducted a series of ablation studies on both the MATH and AIME benchmarks. The first set of ablations incrementally adds architectural features across five methods:
- CoT: A baseline Chain-of-Thought method with purely token-level reasoning.
- PoT-NC: A Program-of-Thoughts method that generates and executes programs but omits the correction loop.
- PoT: A PoT method with both program generation and execution-guided error correction.
- IIPC-NS-NMS: An IIPC variant with the full correction and iterative refinement loop but without the token-reasoning branch or persistent reflection memory. Conclusions are made directly from the programmatic context.
- IIPC-NS: An IIPC variant with the full correction and iterative refinement loop without the token-reasoning branch, but with the persistent reflection store. Conclusions are made directly from the programmatic context.
- IIPC: The full IIPC reasoning agent.
#### Architectural Ablation Analysis.
Table 3 summarizes the impact of key IIPC mechanisms across datasets and model backbones. On Gemini 2.0 Flash, the iterative refinement, reflection memory, and dual-branch separation provide substantial gains. Iterative refinement improves accuracy by +0.61% on the MATH dataset (92.58 → 93.19) and +1.61% on the AIME dataset (59.16 → 60.77). The reflection memory improves accuracy by an additional 0.4% on the MATH dataset (93.19 → 93.59) and 0.75% on the AIME dataset (60.77 → 61.52). Dual-branch separation yields an additional +0.54% on the MATH dataset (93.59 → 94.13) and +2.68% on the AIME dataset (61.52 → 64.20). Together, these mechanisms increase performance by 1.55% over PoT on the MATH dataset (92.58 → 94.13), and by 5.04% over PoT on the AIME dataset (59.16 → 64.20), highlighting their effectiveness for tasks requiring structured reasoning. On GPT-4o mini, while PoT achieves the highest accuracy, ablations show that individual IIPC components partially mitigate the performance gap. The reflection store and dual-branch separation reduce the accuracy drop of IIPC relative to PoT, even though the accuracy of the full IIPC agent remains below the PoT baseline.
#### Complexity Ablation Analysis.
We also compared IIPC, MACM, CR, and PoT against CoT on GSM8K, as shown in Table 2, to determine whether agent complexity hinders accuracy compared to chain of thought reasoning on easier math problems. CoT performs near the upper limit across most models, achieving 95–97% accuracy on the strongest backbones. On average, IIPC and PoT closely trail CoT’s performance, while MACM and CR have slightly lower accuracy. These results suggest that GSM8K’s problem structure saturates the benefits of iterative refinement, leaving little room for improvement beyond direct token-level reasoning on stronger models. Nonetheless, IIPC’s close performance to CoT demonstrates that its structure does not significantly degrade accuracy, even in low-complexity reasoning environments.
#### Temperature Ablation Analysis.
We further examined the effect of varying the decoding temperature on IIPC’s performance with Gemini 2.0 Flash on the AIME benchmark (Table 4). Across the tested range (0.1–0.9), accuracy remained relatively stable, fluctuating within a narrow band of 1.39 percentage points. The best performance was achieved at 0.3 (64.52%), while higher temperatures (0.5–0.9) yielded slightly lower accuracies (63.13%–63.56%). These results suggest that IIPC is robust to temperature changes, with only marginal sensitivity, although higher temperatures appear to slightly diminish performance.
#### Voting Ablation Analysis.
Beyond architectural and temperature-based variations, we also evaluate the effect of voting, a method used in the original MACM implementation, on IIPC’s performance. As detailed in the appendix, our evaluation excludes stochastic multi-trajectory aggregation due to high costs, but we isolate its effect in a smaller ablation study using Llama-4-Maverick on 245 Level-5 MATH problems (35 from each topic). To align with MACM’s original setting, we use a decoding temperature of 0.1 for the non-voting environment, 0.7 for the voting environment, a minimum of 5 voters, and a maximum of 7 voters for tie-breaking. The results in Table 5 show that without voting, IIPC achieves the highest accuracy at 78.78%, outperforming even voting-based variants of many baselines. When voting is enabled, IIPC achieves the same accuracy as PoT at 80.30%. Voting yields larger gains for PoT (+6.83%), CoT (+3.68%), CR (+9.8%), and MACM (+6.53%), while the relative improvement for IIPC (+1.52%) is smaller. IIPC exhibits smaller gains from voting, suggesting reduced single-trajectory variance compared to baselines that rely more on sampling diversity.
## 5 Conclusion
In this work, we introduced Iteratively Improved Program Construction (IIPC) for mathematical reasoning with LLMs through execution-guided refinement while mitigating execution bias by reducing over-dependence on program-based context. Our experiments show that IIPC consistently delivers competitive or superior performance. On GSM8K, where simpler reasoning tasks leave limited room for improvement, IIPC demonstrated that its additional structure does not significantly hinder its reasoning capabilities compared to simpler baselines. On both the MATH and AIME datasets, IIPC achieved the highest accuracy across 4 of the 5 models tested. These results demonstrate that integrating token-based reasoning with iterative program refinement provides LLMs with valuable capacity for trajectory correction and reasoning-level regularization, reducing over-commitment to execution-conditioned context.
## 6 Limitations
Despite the advantages of IIPC, our results also revealed some trade-offs. On GPT-4o mini, IIPC lagged behind PoT on both MATH and AIME. These findings suggest that while IIPC scales effectively with models capable of sustaining its iterative refinement loop, models with limited reasoning or coding abilities may instead benefit from PoT’s simpler structure. In addition, although IIPC’s design enables advanced refinement for solving difficult problems, it is a token-intensive approach to reasoning. While IIPC proves robust on GSM8K and state-of-the-art on MATH and AIME across several high-capacity models, there is room for improvement in subsequent research. Future directions include addressing token efficiency in IIPC’s design, adapting to models’ reasoning capacity, and extending IIPC to other domains requiring verifiable, structured reasoning beyond mathematics.
## 7 Ethical Considerations
Our work introduces an execution-guided agent for enhanced mathematical reasoning in LLMs. The proposed method is evaluated on publicly available benchmarks (AIME, MATH, GSM8K) and does not involve human subjects, personal data, or proprietary datasets. We have ensured that none of the data used or generated by this research contains information that uniquely identifies people. While IIPC is designed to improve reasoning capabilities, it doesn’t guarantee correctness. Any outputs generated by IIPC should not be relied on without independent verification, especially in high-stakes or real-world decision-making contexts.
ChatGPT was used to provide feedback on quality, assist with some grammatical refinement and articulation, and support understanding and exploration of existing mathematical concepts for framing the proposed method. However, all revisions were carefully considered and manually done. All ideas, experimental designs, analyses, and conclusions were developed by the authors, who take full responsibility for the contents of the paper. The judging agent codebase, originally written by the authors, was later enhanced with ChatGPT to improve robustness and evaluation reliability, and was reviewed and verified by the authors.
The proposed method is intended for research, benchmarking, and assistive applications. It is not meant to replace human judgment or facilitate academic dishonesty. To promote transparency and reproducibility, all code, evaluations, sampled datasets, and reasoning traces generated by the proposed method are released as open source. We hope that our work will contribute positively to ongoing research in LLM reasoning.
## References
- M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, et al. (2024) Graph of thoughts: solving elaborate problems with large language models. In Proceedings of the AAAI conference on artificial intelligence, Vol. 38, pp. 17682–17690. Cited by: §1, §2.
- G. Carvalho Santos, F. Barboza, A. Veiga, and K. Gomes (2022) Portfolio optimization using artificial intelligence: a systematic literature review. Exacta 0, pp. . External Links: Document Cited by: §1.
- M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ramchandran, et al. (2025) Why do multi-agent llm systems fail?. arXiv preprint arXiv:2503.13657. Cited by: §1, §1.
- W. Chen, X. Ma, X. Wang, and W. W. Cohen (2023) Program of thoughts prompting: disentangling computation from reasoning for numerical reasoning tasks. External Links: 2211.12588, Link Cited by: §1, §2, §4.
- A. Cherian, R. Corcodel, S. Jain, and D. Romeres (2024) LLMPhy: complex physical reasoning using large language models and world models. External Links: 2411.08027, Link Cited by: §1.
- K. Christakopoulou, S. Mourad, and M. Matarić (2024) Agents thinking fast and slow: a talker-reasoner architecture. External Links: 2410.08328, Link Cited by: §2.
- K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman (2021) Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168. Cited by: Appendix B, §4.
- A. Forootani (2025) A survey on mathematical reasoning and optimization with large language models. External Links: 2503.17726, Link Cited by: §1.
- L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig (2023) PAL: program-aided language models. External Links: 2211.10435, Link Cited by: §1.
- Z. Gou, Z. Shao, Y. Gong, yelong shen, Y. Yang, M. Huang, N. Duan, and W. Chen (2024) ToRA: a tool-integrated reasoning agent for mathematical problem solving. In The Twelfth International Conference on Learning Representations, External Links: Link Cited by: §1, §2.
- A. Gupta, J. Reddig, T. Calo, D. Weitekamp, and C. J. MacLellan (2025) Beyond final answers: evaluating large language models for math tutoring. External Links: 2503.16460, Link Cited by: §1.
- H. A. Habeeb, D. A. Wahab, A. H. Azman, and M. R. Alkahari (2023) Design optimization method based on artificial intelligence (hybrid method) for repair and restoration using additive manufacturing technology. Metals 13 (3). External Links: Link, ISSN 2075-4701, Document Cited by: §1.
- D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt (2021) Measuring mathematical problem solving with the math dataset. NeurIPS. Cited by: Appendix B, §2, §4.
- J. Huang, X. Chen, S. Mishra, H. S. Zheng, A. W. Yu, X. Song, and D. Zhou (2023) Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798. Cited by: §1.
- S. Huang, K. Yang, S. Qi, and R. Wang (2024) When large language model meets optimization. External Links: 2405.10098, Link Cited by: §1.
- B. Lavon, S. Katz, and L. Wolf (2025) Execution guided line-by-line code generation. External Links: 2506.10948, Link Cited by: §2.
- B. Lei, Y. Zhang, S. Zuo, A. Payani, and C. Ding (2024) MACM: utilizing a multi-agent system for condition mining in solving complex mathematical problems. External Links: 2404.04735 Cited by: §1, §2, §4, §4.
- Q. Li, X. Dai, X. Li, W. Zhang, Y. Wang, R. Tang, and Y. Yu (2025) CodePRM: execution feedback-enhanced process reward model for code generation. In Findings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar (Eds.), Vienna, Austria, pp. 8169–8182. External Links: Link, Document, ISBN 979-8-89176-256-5 Cited by: §2.
- B. Liu, J. Zhang, F. Lin, X. Jia, and M. Peng (2025) One size doesn’t fit all: a personalized conversational tutoring agent for mathematics instruction. External Links: 2502.12633, Link Cited by: §1.
- A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark (2023) Self-refine: iterative refinement with self-feedback. External Links: 2303.17651 Cited by: §1, §2.
- F. Shi, X. Chen, K. Misra, N. Scales, D. Dohan, E. Chi, N. Schärli, and D. Zhou (2023) Large language models can be easily distracted by irrelevant context. External Links: 2302.00093, Link Cited by: §1, §1.
- N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao (2023) Reflexion: language agents with verbal reinforcement learning. External Links: 2303.11366, Link Cited by: §1, §2.
- P. Shojaee, K. Meidani, S. Gupta, A. B. Farimani, and C. K. Reddy (2025) LLM-sr: scientific equation discovery via programming with large language models. External Links: 2404.18400, Link Cited by: §1.
- H. Veeraboina (2024) AIME problem set (1983–2024). Note: https://www.kaggle.com/datasets/hemishveeraboina/aime-problem-set-1983-2024/data Accessed October 2025 Cited by: Appendix B, §4.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. (2022) Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35, pp. 24824–24837. Cited by: §2.
- M. Yang, E. Huang, L. Zhang, M. Surdeanu, W. Wang, and L. Pan (2025) How is llm reasoning distracted by irrelevant context? an analysis using a controlled benchmark. External Links: 2505.18761, Link Cited by: §1, §1.
- S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan (2023) Tree of thoughts: deliberate problem solving with large language models. Advances in neural information processing systems 36, pp. 11809–11822. Cited by: §1, §2.
- X. Yao, Q. Wang, X. Liu, and K. Huang (2025) Evaluating large language models for financial reasoning: a cfa-based benchmark study. External Links: 2509.04468, Link Cited by: §1.
- Z. Yu, W. Gu, Y. Wang, X. Jiang, Z. Zeng, J. Wang, W. Ye, and S. Zhang (2025) Reasoning through execution: unifying process and outcome rewards for code generation. External Links: 2412.15118, Link Cited by: §2.
- Y. Zhang, J. Yang, Y. Yuan, and A. C. Yao (2023) Cumulative reasoning with large language models. arXiv preprint arXiv:2308.04371. Cited by: §1, §2, §4.
- T. Zheng, G. Zhang, T. Shen, X. Liu, B. Y. Lin, J. Fu, W. Chen, and X. Yue (2024) OpenCodeInterpreter: integrating code generation with execution and refinement. https://arxiv.org/abs/2402.14658. Cited by: §2.
- A. Zhou, K. Wang, Z. Lu, W. Shi, S. Luo, Z. Qin, S. Lu, A. Jia, L. Song, M. Zhan, and H. Li (2023) Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification. External Links: 2308.07921, Link Cited by: §1, §2.
## Appendix A Theoretical Overview
### A.1 Error Propagation in Sequential Agents
Sequential reasoning agents generate solution steps in an ordered manner, where each step $s_{t}$ depends on prior steps $(s_{1},s_{2},\dots,s_{t-1})$ . We can write this as:
$$
s_{t}=f(s_{1},s_{2},\dots,s_{t-1}),
$$
where $f$ is the language model. Once a step $s_{n}$ , with $1\leq n\leq t-1$ , has been completed, it remains permanent and cannot be revised. As a result, the conditional probability that the next step is correct, $\mathbb{P}(s_{t}\mid s_{1:t-1})$ , reduces as errors accumulate in earlier steps. This causes initial inaccuracies to propagate through the rest of the reasoning trajectory without any opportunity for correction.
### A.2 Iterative Program Refinement and Reflection Memory
Let $\mathcal{P}$ denote the set of all candidate programs and $I:\mathcal{P}\!\to\!\mathcal{O}$ be the interpreter that produces an output from a program (including errors) $o=I(p)$ . At refinement step $t$ , the agent has a memory $M_{t}$ that summarizes past mistakes or errors.
The IIPC refinement operator is then
$$
\displaystyle p_{t+1} \displaystyle=f_{\theta}\!\big(x,\;p_{t},\;o_{t},\;M_{t}\big) \displaystyle=\arg\min_{p\in\mathcal{N}(p_{t})}\Big(\underbrace{\mathcal{L}\!\big(I(p)\big)}_{\text{execution loss}}+\lambda\,\underbrace{\Psi\!\big(p;\,M_{t}\big)}_{\text{memory penalty}}\Big). \tag{4}
$$
where $\mathcal{N}(p_{t})$ is the complete set of edits around $p_{t}$ , $o_{t}$ is the execution output at step $t$ (programmatic output and errors), $\Psi(\cdot;M_{t})\!\geq\!0$ penalizes parts of the program that $M_{t}$ should prevent, $\mathcal{L}\!\big(I(\cdot)\big)$ penalizes the output of the program for undesirable outputs, and $\lambda\!>\!0$ is a trade-off factor between fixing the current error and not repeating past mistakes. Intuitively, the language model attempts to find the next best program so that it produces desirable output and doesn’t repeat past mistakes. We do emphasize that this objective is not explicitly optimized, but rather serves as a conceptual abstraction of how execution feedback and reflection memory bias the LLM’s refinement behavior.
After developing $p_{t+1}$ , the memory updates with the errors of the previous iteration as
$$
M_{t+1}=M_{t}\cup\mathsf{Desc}(p_{t},I(p_{t}))
$$
where $\mathsf{Desc}$ extracts failure descriptions (e.g. banned mathematical methods, reflections on minor errors, API misuse, etc) that are then appended to $M_{t}$ .
### A.3 Search and Regret in Refinement
Let $\mathcal{U}(M_{t})\subset\mathcal{P}$ be the union of possible program regions avoided by the memory store of past mistakes. According to the results in table 3, where we isolate the effects of individual IIPC components, the reflection memory does improve the accuracy of the IIPC agent. Motivated by these results, we can model the LLM’s refinement behavior under the penalty function $\Psi(\cdot;M_{t})$ as follows: (1) it lowers the probability of generating programs from $\mathcal{U}(M_{t})$ , (2) it does so by at least some multiplicative factor whenever a program is a flawed, and (3) the LLM maintains diversity in its refinements to explore candidates outside $\mathcal{U}(M_{t})$ . Under these assumptions, we can qualitatively model the LLM’s refinement behavior such that if $\Psi(\cdot;M_{t})$ assigns a strictly positive penalty on $\mathcal{U}(M_{t})$ and zero otherwise, then the expected probability of revisiting blacklisted regions decreases with $t$ . As a result, the cumulative revisit regret
$$
R_{T}=\sum_{t=1}^{T}\mathbf{1}\{p_{t}\in\mathcal{U}(M_{t-1})\}
$$
grows sub-proportionally compared to naive refinement. Therefore, the expected per-step revisit rate decreases as memory accumulates.
Intuitively, this means that each time the LLM encounters an error, the memory store shifts the probability mass away from that type of failure, making it less likely to be chosen again. Over time, the agent spends a smaller fraction of steps repeating past mistakes, while still preserving the ability to explore new refinements within the edit space $\mathcal{N}(p_{t})$ . In other words, reflection memory turns trial-and-error into trial-and-improvement, where the system learns from its entire history of failures for a given problem.
### A.4 Dual-Branch Separation
The objective of the dual-branch design is to find an answer $y^{*}$ that is consistent with the information from both branches.
Let $x$ denote the given problem, $p$ the refined program to solve the problem, and $o$ the output of $p$ .
We can first model the reasoning behavior of the two branches in terms of the implicit distributions over candidate answers $y$ as shown:
- $d_{P}(y|x,p,o)$ : The distribution over candidate answer $y$ conditioned on $x$ , $p$ , and $o$ in the execution-guided reasoning branch.
- $d_{T}(y|x)$ : The distribution over candidate answer $y$ conditioned on just $x$ in the token-based reasoning branch.
In order to reconcile these two potentially conflicting beliefs over the answer space, we introduce an idealized distribution $d^{*}$ that takes into account information from both branches. We also introduce a weighting factor $\alpha$ that implicitly reflects how much trust should ideally be placed on the execution-guided branch relative to the token-based reasoning branch. The distribution $d^{*}$ should remain as consistent as possible with both $d_{T}$ and $d_{P}$ , while also accounting for $\alpha$ . We can formalize this notion through a conceptual disagreement-penalized objective:
$$
\displaystyle d^{*} \displaystyle=\arg\min_{d}\Big[(1-\alpha)\,D_{\mathrm{KL}}\!\big(d\,\|\,d_{T}\big) \displaystyle\qquad\quad+\alpha\,D_{\mathrm{KL}}\!\big(d\,\|\,d_{P}\big)\Big]. \tag{6}
$$
where $\alpha\in[0,1]$ and $D_{\mathrm{KL}}$ is the Kullback-Leibler divergence. This objective penalizes solutions that are strongly supported by only one source of reasoning, unless that source is explicitly prioritized by $\alpha$ . Intuitively, this means that under $d^{*}$ , answers that contradict token-level logical constraints or execution-based evidence receive a low probability, while answers reinforced by both branches receive a higher probability. It is important to note that while IIPC does not explicitly compute or optimize this objective, the dual-branch design induces behavior that resembles this form of regularization.
Finally, while $d^{*}$ serves as a conceptual abstraction for the ideal distribution, we ultimately want an answer $y^{*}$ that is viewed as the most consistent candidate under the reconciled distribution. This can be formalized through the following objective:
$$
y^{*}\ =\ \arg\max_{y}d^{*}(y).
$$
This abstraction shows how dual-branch separation stabilizes reasoning by producing answers that achieve consistency across both token-level and execution-based reasoning.
### A.5 Effects of Model Capacity on Performance
Our results show IIPC is strongest on higher-capacity models (Gemini 2.0 Flash, Mistral 24B). This can be theoretically understood as an alignment between model capacity and refinement overhead. If the base LLM’s reasoning capacity is insufficient, the iterative correction signal increases cognitive load beyond what the model can process or was trained for, leading to lower accuracy.
## Appendix B Additional Experimentation Details
#### Reasons for Dataset Selection.
To capture a range of mathematical complexity, the main experiments evaluate IIPC on the MATH and AIME datasets, while the GSM8K dataset is used for ablation experiments to study the effects of agentic overhead on simple problems. GSM8K Cobbe et al. (2021) contains grade school arithmetic problems and serves as a low-difficulty benchmark for an ablation experiment to understand how additional complexity, such as IIPC’s refinement loop and dual-branch design, affects performance on simple tasks. The MATH dataset Hendrycks et al. (2021) provides tests for algebraic manipulation, symbolic reasoning, and multi-step logic. Finally, the AIME dataset Veeraboina (2024) evaluates on competition-level problems from 1983–2024 that require creativity, deep conceptual understanding, and nontrivial problem decomposition. Evaluating on this range of datasets allows us to analyze how IIPC scales from straightforward arithmetic reasoning to advanced, competition-grade problem solving, and to identify the conditions under which iterative refinement yields the greatest benefit. Ideally, we aimed to evaluate approximately 1,500 problems per dataset to ensure balanced statistical representation. GSM8K only contains 1319 problems in its testing set, all of which were used in the ablation study. For MATH, while we aimed for uniform coverage across all topic–difficulty combinations (35 combinations total), certain combinations contained fewer available problems. This yielded a final sample of 1,483 problems instead of the intended 1,505 (the closest multiple of 35 to 1500). Finally, the AIME dataset contained a fixed set of 933 problems spanning all available years (1983–2024), and was used in its entirety.
## Appendix C Additional Experimental Results for MATH dataset
<details>
<summary>x4.png Details</summary>
### Visual Description
## Bar Charts: Model Accuracy by Difficulty Level
### Overview
This image displays a collection of grouped bar charts, each representing the accuracy of a specific language model across five different difficulty levels. The charts are arranged in a grid, with a legend at the bottom indicating the color coding for four different metrics: PoT, CR, MACM, and IIPC.
### Components/Axes
**General Chart Elements (consistent across all charts):**
* **Y-axis Title:** "Accuracy"
* **Y-axis Scale:** Ranges from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-axis Title:** "Difficulty Level"
* **X-axis Markers:** Labeled 1, 2, 3, 4, and 5, representing increasing difficulty.
* **Legend:** Located at the bottom center of the image.
* **PoT:** Blue bars
* **CR:** Orange bars
* **MACM:** Green bars
* **IIPC:** Red bars
**Individual Chart Titles:**
1. GPT-4o-mini
2. Gemini 2.0 Flash
3. Mistral Small 3.2 24B
4. Gemma 3 27B
5. Llama 4 Maverick
### Detailed Analysis or Content Details
**1. GPT-4o-mini**
* **Trend:** Accuracy generally decreases as difficulty level increases for all metrics.
* **Difficulty Level 1:**
* PoT: 93.55% (±0.5%)
* CR: 91.40% (±0.5%)
* MACM: 92.11% (±0.5%)
* IIPC: 94.27% (±0.5%)
* **Difficulty Level 2:**
* PoT: 91.69% (±0.5%)
* CR: 87.38% (±0.5%)
* MACM: 91.03% (±0.5%)
* IIPC: 84.05% (±0.5%)
* **Difficulty Level 3:**
* PoT: 81.73% (±0.5%)
* CR: 75.75% (±0.5%)
* MACM: 77.08% (±0.5%)
* IIPC: 86.05% (±0.5%)
* **Difficulty Level 4:**
* PoT: 73.09% (±0.5%)
* CR: 66.00% (±0.5%)
* MACM: 75.75% (±0.5%)
* IIPC: 60.47% (±0.5%)
* **Difficulty Level 5:**
* PoT: 50.17% (±0.5%)
* CR: 43.52% (±0.5%)
* MACM: 58.80% (±0.5%)
* IIPC: 53.57% (±0.5%)
**2. Gemini 2.0 Flash**
* **Trend:** Accuracy remains very high and relatively stable across difficulty levels 1-4, with a noticeable drop at difficulty level 5.
* **Difficulty Level 1:**
* PoT: 96.06% (±0.5%)
* CR: 95.70% (±0.5%)
* MACM: 94.98% (±0.5%)
* IIPC: 96.77% (±0.5%)
* **Difficulty Level 2:**
* PoT: 98.01% (±0.5%)
* CR: 95.35% (±0.5%)
* MACM: 96.01% (±0.5%)
* IIPC: 97.01% (±0.5%)
* **Difficulty Level 3:**
* PoT: 93.36% (±0.5%)
* CR: 92.67% (±0.5%)
* MACM: 91.03% (±0.5%)
* IIPC: 96.01% (±0.5%)
* **Difficulty Level 4:**
* PoT: 90.70% (±0.5%)
* CR: 89.04% (±0.5%)
* MACM: 90.03% (±0.5%)
* IIPC: 93.69% (±0.5%)
* **Difficulty Level 5:**
* PoT: 85.05% (±0.5%)
* CR: 79.73% (±0.5%)
* MACM: 77.41% (±0.5%)
* IIPC: 87.38% (±0.5%)
**3. Mistral Small 3.2 24B**
* **Trend:** Accuracy generally decreases as difficulty level increases, with a more pronounced drop from level 4 to 5.
* **Difficulty Level 1:**
* PoT: 97.13% (±0.5%)
* CR: 92.11% (±0.5%)
* MACM: 92.47% (±0.5%)
* IIPC: 96.77% (±0.5%)
* **Difficulty Level 2:**
* PoT: 94.02% (±0.5%)
* CR: 91.36% (±0.5%)
* MACM: 90.70% (±0.5%)
* IIPC: 96.01% (±0.5%)
* **Difficulty Level 3:**
* PoT: 94.02% (±0.5%)
* CR: 88.37% (±0.5%)
* MACM: 83.72% (±0.5%)
* IIPC: 93.02% (±0.5%)
* **Difficulty Level 4:**
* PoT: 87.38% (±0.5%)
* CR: 80.40% (±0.5%)
* MACM: 80.73% (±0.5%)
* IIPC: 88.70% (±0.5%)
* **Difficulty Level 5:**
* PoT: 76.08% (±0.5%)
* CR: 66.45% (±0.5%)
* MACM: 63.79% (±0.5%)
* IIPC: 80.07% (±0.5%)
**4. Gemma 3 27B**
* **Trend:** Accuracy is high and relatively stable for difficulty levels 1-3, followed by a significant drop at levels 4 and 5.
* **Difficulty Level 1:**
* PoT: 97.13% (±0.5%)
* CR: 95.34% (±0.5%)
* MACM: 95.70% (±0.5%)
* IIPC: 95.34% (±0.5%)
* **Difficulty Level 2:**
* PoT: 96.35% (±0.5%)
* CR: 95.02% (±0.5%)
* MACM: 94.35% (±0.5%)
* IIPC: 96.68% (±0.5%)
* **Difficulty Level 3:**
* PoT: 93.69% (±0.5%)
* CR: 91.69% (±0.5%)
* MACM: 90.70% (±0.5%)
* IIPC: 95.02% (±0.5%)
* **Difficulty Level 4:**
* PoT: 83.39% (±0.5%)
* CR: 83.06% (±0.5%)
* MACM: 82.39% (±0.5%)
* IIPC: 86.71% (±0.5%)
* **Difficulty Level 5:**
* PoT: 75.08% (±0.5%)
* CR: 70.76% (±0.5%)
* MACM: 71.10% (±0.5%)
* IIPC: 79.40% (±0.5%)
**5. Llama 4 Maverick**
* **Trend:** Accuracy is high and relatively stable for difficulty levels 1-3, with a noticeable decrease at level 4 and a further decrease at level 5.
* **Difficulty Level 1:**
* PoT: 95.34% (±0.5%)
* CR: 95.70% (±0.5%)
* MACM: 96.06% (±0.5%)
* IIPC: 96.68% (±0.5%)
* **Difficulty Level 2:**
* PoT: 95.68% (±0.5%)
* CR: 95.68% (±0.5%)
* MACM: 92.36% (±0.5%)
* IIPC: 91.36% (±0.5%)
* **Difficulty Level 3:**
* PoT: 93.69% (±0.5%)
* CR: 86.71% (±0.5%)
* MACM: 87.04% (±0.5%)
* IIPC: 87.71% (±0.5%)
* **Difficulty Level 4:**
* PoT: 74.09% (±0.5%)
* CR: 72.42% (±0.5%)
* MACM: 74.42% (±0.5%)
* IIPC: 80.73% (±0.5%)
* **Difficulty Level 5:**
* No data points are visible for Difficulty Level 5 for Llama 4 Maverick. The chart appears to end at Difficulty Level 4.
### Key Observations
* **General Trend:** All models exhibit a general decrease in accuracy as the difficulty level increases.
* **Model Performance at Low Difficulty:** Most models achieve very high accuracy (above 90%, often above 95%) at difficulty levels 1 and 2.
* **Performance Drop:** The most significant drops in accuracy occur at higher difficulty levels (4 and 5).
* **Model Variability:**
* **GPT-4o-mini** shows a consistent and steep decline in accuracy across all difficulty levels.
* **Gemini 2.0 Flash** maintains high accuracy for the first four levels, with a notable drop at level 5.
* **Mistral Small 3.2 24B** and **Gemma 3 27B** show a substantial decrease in accuracy starting from difficulty level 4.
* **Llama 4 Maverick** shows a significant drop at difficulty level 4 and appears to have no data for difficulty level 5.
* **Metric Performance:** Within each model and difficulty level, there are variations in performance between the four metrics (PoT, CR, MACM, IIPC). For instance, at difficulty level 1, IIPC often shows the highest accuracy, while at higher difficulty levels, the relative performance of metrics can shift.
### Interpretation
The presented bar charts illustrate the performance degradation of various language models as task complexity (difficulty level) increases. This is a common and expected behavior for AI models, as more challenging tasks require more sophisticated reasoning, knowledge, and generalization capabilities, which can be harder to achieve.
The data suggests that while models like Gemini 2.0 Flash and Gemma 3 27B are robust at lower difficulty levels, their performance can be significantly impacted by increased complexity. GPT-4o-mini appears to be more sensitive to difficulty increases from the outset, showing a more continuous decline. Mistral Small 3.2 24B and Gemma 3 27B demonstrate a sharp drop-off in performance at higher difficulty levels, indicating potential limitations in their ability to handle complex scenarios. The incomplete data for Llama 4 Maverick at difficulty level 5 prevents a full comparison for that model.
The variations between PoT, CR, MACM, and IIPC suggest that these metrics might be evaluating different aspects of model performance or are sensitive to different types of challenges. Further investigation into what each metric represents would be necessary to fully understand these differences. Overall, the charts provide a clear visual comparison of model resilience to increasing task difficulty, highlighting areas where each model excels or struggles. This information is crucial for selecting appropriate models for tasks of varying complexity and for identifying areas for model improvement.
</details>
Figure 4: Accuracy by difficulty level for each LLM, comparing PoT, CR, MACM, and IIPC agents on the MATH dataset.
<details>
<summary>x5.png Details</summary>
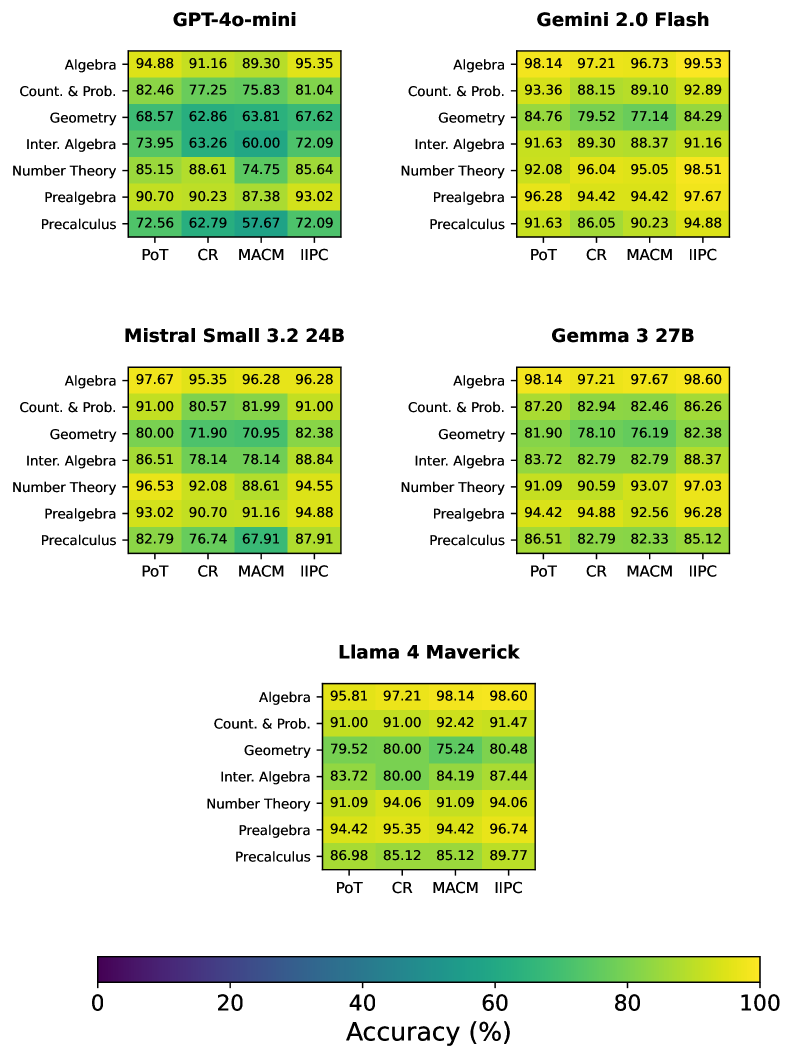
### Visual Description
## Heatmap Grid: Model Performance Across Subjects and Tasks
### Overview
This image displays a grid of heatmaps, each representing the performance (accuracy) of a specific language model on various mathematical subjects and tasks. The models evaluated are GPT-4o-mini, Gemini 2.0 Flash, Mistral Small 3.2 24B, Gemma 3 27B, and Llama 4 Maverick. For each model, accuracy is shown across six subjects: Algebra, Count. & Prob., Geometry, Inter. Algebra, Number Theory, and Precalculus. The performance is further broken down by four tasks: PoT (Program of Thought), CR (Chain-of-Reasoning), MACM (Multi-step Arithmetic Chain-of-Thought), and IIPC (Instruction-following Prompt Completion). A color bar at the bottom indicates the accuracy scale from 0% to 100%.
### Components/Axes
**Overall Structure:**
The image is organized into five distinct heatmap sections, each titled with the name of a language model. These sections are arranged in a 2x2 grid for the top four models, with the fifth model (Llama 4 Maverick) positioned below the center.
**Individual Heatmap Components:**
* **Model Titles:** Located at the top of each heatmap section.
* GPT-4o-mini
* Gemini 2.0 Flash
* Mistral Small 3.2 24B
* Gemma 3 27B
* Llama 4 Maverick
* **Y-axis (Subjects):** Listed vertically on the left side of each heatmap.
* Algebra
* Count. & Prob.
* Geometry
* Inter. Algebra
* Number Theory
* Precalculus
* **X-axis (Tasks):** Listed horizontally at the bottom of each heatmap.
* PoT
* CR
* MACM
* IIPC
* **Color Bar (Legend):** Located at the bottom of the entire image.
* **Label:** "Accuracy (%)"
* **Scale:** Ranges from 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Color Gradient:** A gradient from dark purple (low accuracy) through blue, teal, green, yellow, to bright yellow (high accuracy).
### Detailed Analysis
The following data represents the accuracy percentages for each model, subject, and task. The color of each cell corresponds to the accuracy indicated by the color bar.
**1. GPT-4o-mini**
| Subject | PoT | CR | MACM | IIPC |
|----------------|---------|---------|---------|---------|
| Algebra | 94.88 | 91.16 | 89.30 | 95.35 |
| Count. & Prob. | 82.46 | 77.25 | 75.83 | 81.04 |
| Geometry | 68.57 | 62.86 | 63.81 | 67.62 |
| Inter. Algebra | 73.95 | 63.26 | 60.00 | 72.09 |
| Number Theory | 85.15 | 88.61 | 74.75 | 85.64 |
| Precalculus | 90.70 | 90.23 | 87.38 | 93.02 |
**2. Gemini 2.0 Flash**
| Subject | PoT | CR | MACM | IIPC |
|----------------|---------|---------|---------|---------|
| Algebra | 98.14 | 97.21 | 96.73 | 99.53 |
| Count. & Prob. | 93.36 | 88.15 | 89.10 | 92.89 |
| Geometry | 84.76 | 79.52 | 77.14 | 84.29 |
| Inter. Algebra | 91.63 | 89.30 | 88.37 | 91.16 |
| Number Theory | 92.08 | 96.04 | 95.05 | 98.51 |
| Precalculus | 91.63 | 86.05 | 90.23 | 94.88 |
**3. Mistral Small 3.2 24B**
| Subject | PoT | CR | MACM | IIPC |
|----------------|---------|---------|---------|---------|
| Algebra | 97.67 | 95.35 | 96.28 | 96.28 |
| Count. & Prob. | 91.00 | 80.57 | 81.99 | 91.00 |
| Geometry | 80.00 | 71.90 | 70.95 | 82.38 |
| Inter. Algebra | 86.51 | 78.14 | 78.14 | 88.84 |
| Number Theory | 96.53 | 92.08 | 88.61 | 94.55 |
| Precalculus | 93.02 | 90.70 | 91.16 | 94.88 |
**4. Gemma 3 27B**
| Subject | PoT | CR | MACM | IIPC |
|----------------|---------|---------|---------|---------|
| Algebra | 98.14 | 97.21 | 97.67 | 98.60 |
| Count. & Prob. | 87.20 | 82.94 | 82.46 | 86.26 |
| Geometry | 81.90 | 78.10 | 76.19 | 82.38 |
| Inter. Algebra | 83.72 | 82.79 | 82.79 | 88.37 |
| Number Theory | 91.09 | 90.59 | 93.07 | 97.03 |
| Precalculus | 94.42 | 94.88 | 92.56 | 96.28 |
**5. Llama 4 Maverick**
| Subject | PoT | CR | MACM | IIPC |
|----------------|---------|---------|---------|---------|
| Algebra | 95.81 | 97.21 | 98.14 | 98.60 |
| Count. & Prob. | 91.00 | 91.00 | 92.42 | 91.47 |
| Geometry | 79.52 | 80.00 | 75.24 | 80.48 |
| Inter. Algebra | 83.72 | 80.00 | 84.19 | 87.44 |
| Number Theory | 91.09 | 94.06 | 91.09 | 94.06 |
| Precalculus | 94.42 | 95.35 | 94.42 | 96.74 |
### Key Observations
* **Top Performers:** Gemini 2.0 Flash and Llama 4 Maverick generally exhibit the highest accuracies, particularly in Algebra and Number Theory, often achieving scores above 95% and even approaching 100% in some cases (e.g., Gemini 2.0 Flash on Algebra IIPC).
* **Subject Difficulty:** Geometry appears to be the most challenging subject across all models, with accuracies consistently lower than other subjects, often falling in the 60-80% range. Count. & Prob. and Inter. Algebra also show moderate difficulty.
* **Task Performance:** The "IIPC" (Instruction-following Prompt Completion) task often yields higher accuracies for many models, suggesting it might be a more straightforward task or that models are better optimized for it. "MACM" (Multi-step Arithmetic Chain-of-Thought) sometimes shows lower scores, particularly in Geometry.
* **Model Strengths/Weaknesses:**
* GPT-4o-mini shows strong performance in Algebra and Precalculus but is weaker in Geometry.
* Gemini 2.0 Flash is a strong all-around performer, especially in Algebra and Number Theory.
* Mistral Small 3.2 24B performs well in Algebra and Number Theory but struggles more with Geometry.
* Gemma 3 27B is competitive, with high scores in Algebra and Number Theory, but also shows moderate performance in Geometry.
* Llama 4 Maverick excels in Algebra and shows strong performance in Precalculus and Number Theory, but its Geometry scores are comparable to other models.
* **Color Consistency:** The color mapping appears consistent across all heatmaps, with darker purples representing lower accuracies and bright yellows representing higher accuracies, aligning with the provided color bar.
### Interpretation
This grid of heatmaps provides a comparative analysis of the mathematical reasoning capabilities of several large language models. The data suggests a clear hierarchy in performance, with Gemini 2.0 Flash and Llama 4 Maverick generally outperforming GPT-4o-mini, Mistral Small 3.2 24B, and Gemma 3 27B on these specific mathematical tasks.
The consistent lower performance in Geometry across most models indicates that this subject might require more sophisticated spatial reasoning or a deeper understanding of geometric principles that current models are still developing. Conversely, subjects like Algebra and Number Theory, which are more amenable to symbolic manipulation and logical deduction, show higher accuracy.
The variation in performance across tasks (PoT, CR, MACM, IIPC) highlights the impact of prompt engineering and task formulation. The generally higher scores on IIPC suggest that models might be more adept at following direct instructions for completion rather than engaging in complex multi-step reasoning processes like MACM, although this is not universally true.
Overall, the data demonstrates the progress in LLM capabilities for mathematical problem-solving, while also pinpointing areas for future improvement, particularly in more complex or abstract reasoning domains like Geometry. The visual representation through heatmaps allows for quick identification of model strengths and weaknesses across different mathematical domains and task types.
</details>
Figure 5: Heatmaps showing accuracy by topic for each LLM, comparing PoT, CR, MACM, and IIPC agents on the MATH dataset.
In our main experiments, we present a fine-grained analysis by problem difficulty and topic only for Llama 4 Maverick. This section extends this same per-difficulty and per-topic comparison to all other language models considered in this paper.
Across difficulty levels (Figure 4), IIPC demonstrates strong performance on Gemini 2.0 Flash, Mistral Small 3.2 24B, Gemma 3 27B, and Llama 4 Maverick, while slightly trailing PoT on GPT-4o mini. On Gemini 2.0 Flash, IIPC maintains high accuracy from 96.77% at Level 1 to 87.38% at Level 5, whereas MACM drops from 94.98% to 77.41%, a 9.97% difference at the highest difficulty. Similar trends are observed on Mistral 3.2 24B (IIPC: 96.77→80.07; MACM: 92.47→63.79), Gemma 3 27B (IIPC: 95.34→79.40; MACM: 95.70→71.10), and Llama 4 Maverick (IIPC: 96.06→80.73; MACM: 96.06→72.43), indicating that IIPC better preserves reasoning stability under increasing problem complexity. In contrast, on GPT-4o-mini, PoT maintains an edge over IIPC. We also observe that IIPC maintains the highest accuracy on the most difficult problems on all models except GPT-4o-mini.
The topic-wise analysis (Figure 5) reveals similar patterns. On Gemini 2.0 Flash, IIPC leads in algebra (99.53%), number theory (98.51%), prealgebra (97.67%), and precalculus (94.88%). On Gemma 3 27B, IIPC maintains a lead in geometry (82.38%), intermediate algebra (88.37%), prealgebra (94.88%), and precalculus (87.91%), outperforming other agents by multiple points. On Llama 4 Maverick, IIPC’s performance either matches or surpasses that of all other agents across most topics, demonstrating IIPC’s ability to fully utilize the reasoning capabilities of high-performing models. On GPT-4o mini, PoT tends to lead IIPC by significant margins.
## Appendix D IIPC Reasoning Examples
Figure 6 is a program refinement generated by Gemini 2.0 Flash when solving an AIME problem. IIPC allows the LLM to reflect on its previous program, identify the incorrect assumption, and propose the fix before developing a new program that produces the correct output.
Figure 7 demonstrates the fusion stage of the IIPC agent, where it combines both reasoning branches to produce the final reasoning chain. Here, Llama 4 Maverick makes a mistake in its program by reversing the terms in the formula that calculated the dot product, resulting in a negative value. However, it identifies and applies the correct formula in the token-reasoning branch. In the final reasoning chain, which was conditioned on context from both branches, IIPC allows the LLM to deliberate between both sources and identify the error in the program branch, resulting in a correct final answer.
Problem: A right circular cone has a base with radius 600 and height $200\sqrt{7}$ . A fly starts at a point on the surface of the cone whose distance from the vertex of the cone is 125, and crawls along the surface of the cone to a point on the exact opposite side of the cone whose distance from the vertex is $375\sqrt{2}$ . Find the least distance that the fly could have crawled. Original Program ✗: python code ... # The angle difference is pi. d = math.sqrt(r1**2 + r2**2 - 2 * r1 * r2 * math.cos(math.pi)) python code ... Original Program Output ✗: The slant height of the cone is: 800.0 The central angle of the sector is: 4.71238898038469 The shortest distance the fly could have crawled is: 655.3300858899107 655.3300858899107 Reflection: The previous program calculates the slant height and central angle correctly. However, it incorrectly assumes that "exact opposite side of the cone" translates to an angle difference of $\pi$ in the flattened sector. The correct angle difference should be $\pi$ radians *only if* the central angle of the sector is $2\pi$ . In general, the angle difference should be $\pi*(2\pi/\theta)$ , where $\theta$ is the central angle of the sector. The program also lacks verification that the final answer is reasonable. Refined Program ✓: python code ... # Calculate the angle difference. delta_theta = math.pi * r / l print(f"The angle difference is: {delta_theta}") # Calculate the shortest distance using the law of cosines. d = math.sqrt( r1**2 + r2**2 - 2 * r1 * r2 * math.cos(delta_theta) ) python code ... Refined Program Output ✓: The slant height of the cone is: 800.0 The central angle of the sector is: 4.71238898038469 The angle difference is: 2.356194490192345 The shortest distance the fly could have crawled is: 625.0 The calculated distance is less than the sum of the distances from the vertex, which is expected. Performing alternative verification... Approximate shortest distance: 624.9134519586773
Figure 6: Example of IIPC’s program refinement mechanism using Gemini 2.0 Flash. Only significant changes in the code are displayed to control figure size. The full example text is provided in the GitHub repository.
Problem: In triangle $ABC,$ $AB=3$ and $AC=5.$ Let $O$ be the circumcenter of triangle $ABC.$ Find $\overrightarrow{OA}\cdot\overrightarrow{BC}.$ Program Branch (Contains Flawed Logic ✗): import numpy as np # Define vectors AB and AC AB = np.array([3, 0]) # Assuming AB lies on the x-axis # Since we’re working with a general triangle, # let’s consider the angle between AB and AC # We’ll directly use the property that OA . BC = (ACˆ2 - ABˆ2)/2 # Calculate OA . BC using the formula derived from the # properties of the circumcenter and dot product AC_length = 5 AB_length = 3 OA_dot_BC = (AC_length**2 - AB_length**2) / 2 print("The dot product of OA and BC is: ", OA_dot_BC) # Verification assert np.isclose( OA_dot_BC, (5**2 - 3**2) / 2 ), "Incorrect calculation" Original Program Output ✗: The dot product of OA and BC is: 8.0 CoT Branch Text ✓: Step 1: To solve the problem, we need to start by understanding the given information and what is being asked. We are dealing with triangle $ABC$ , where $AB=3$ and $AC=5$ . The circumcenter of the triangle is $O$ , and we are required to find the dot product of $\overrightarrow{OA}$ and $\overrightarrow{BC}$ . Step 2: First, let’s recall that the circumcenter $O$ of a triangle is the point where the perpendicular bisectors of the sides of the triangle intersect. This means $O$ is equidistant from the vertices $A$ , $B$ , and $C$ . … Step 13: Now, we substitute $AB=3$ and $AC=5$ into the expression to find $\overrightarrow{OA}\cdot\overrightarrow{BC}$ . Step 14: $\overrightarrow{OA}\cdot\overrightarrow{BC}=\frac{3^{2}-5^{2}}{2}=\frac{9-25}{2}=\frac{-16}{2}=-8$ . The final answer is: $\boxed{-8}$ Final Reasoning Chain (Using Both Context Sources) ✓: The objective of the given problem is to find the dot product of vectors $\overrightarrow{OA}$ and $\overrightarrow{BC}$ in triangle $ABC$ , where $AB=3$ , $AC=5$ , and $O$ is the circumcenter of the triangle. Upon analyzing the context from both the code and the reasoning chain, it is evident that they both lead to the same formula for calculating $\overrightarrow{OA}\cdot\overrightarrow{BC}$ , which is $\frac{AC^{2}-AB^{2}}{2}$ . The reasoning chain provides a detailed step-by-step derivation of this formula using properties of the circumcenter and dot product. The code directly implements this formula to calculate $\overrightarrow{OA}\cdot\overrightarrow{BC}$ . However, upon closer inspection, it is noticed that the code contains a logical error in its output. The correct calculation should yield a negative result because $AC>AB$ , and the formula is $\frac{AB^{2}-AC^{2}}{2}$ . To correct this, we should negate the output of the code or directly use the correct formula. The correct calculation is $\frac{3^{2}-5^{2}}{2}=\frac{9-25}{2}=-8$ . Combining the insights from both the code and the reasoning chain, we arrive at the final answer. The code is genuinely helpful in solving the problem and, with a correction, produces an accurate output. The final answer is: $\boxed{-8}$
Figure 7: Example of IIPC’s dual branch mechanism using Llama 4 Maverick. CoT output has been shortened to control image size. The full example text is provided in the GitHub repository.