# HugRAG: Hierarchical Causal Knowledge Graph Design for RAG
**Authors**: Nengbo Wang, Tuo Liang, Vikash Singh, Chaoda Song, Van Yang, Yu Yin, Jing Ma, Jagdip Singh, Vipin Chaudhary
Abstract
Retrieval augmented generation (RAG) has enhanced large language models by enabling access to external knowledge, with graph-based RAG emerging as a powerful paradigm for structured retrieval and reasoning. However, existing graph-based methods often over-rely on surface-level node matching and lack explicit causal modeling, leading to unfaithful or spurious answers. Prior attempts to incorporate causality are typically limited to local or single-document contexts and also suffer from information isolation that arises from modular graph structures, which hinders scalability and cross-module causal reasoning. To address these challenges, we propose HugRAG, a framework that rethinks knowledge organization for graph-based RAG through causal gating across hierarchical modules. HugRAG explicitly models causal relationships to suppress spurious correlations while enabling scalable reasoning over large-scale knowledge graphs. Extensive experiments demonstrate that HugRAG consistently outperforms competitive graph-based RAG baselines across multiple datasets and evaluation metrics. Our work establishes a principled foundation for structured, scalable, and causally grounded RAG systems.
Machine Learning, ICML
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: RAG Model Comparison for Blackout Analysis
### Overview
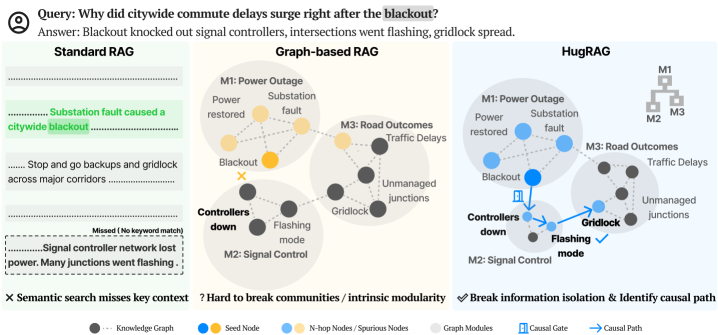
The image presents a comparative diagram illustrating three different Retrieval-Augmented Generation (RAG) models – Standard RAG, Graph-based RAG, and HugRAG – in the context of analyzing the causes of citywide commute delays following a blackout. Each model is represented with a network diagram showing the relationships between events and factors contributing to the delays. The diagram highlights the strengths and weaknesses of each approach in identifying the key causal pathways.
### Components/Axes
The diagram is divided into three main sections, one for each RAG model. Each section includes a network diagram and accompanying text describing the model's output and limitations.
**Common Elements:**
* **Nodes:** Represent concepts or events (e.g., "Blackout", "Traffic Delays", "Power restored").
* **Edges:** Represent relationships between nodes.
* **Color Coding:**
* Green: Knowledge Graph
* Blue: Seed Node
* Gray: N-hop Nodes / Spurious Nodes
* Orange: Graph Modules
* Teal: Causal Gate
* Purple: Causal Path
* **Icons:**
* "X": Semantic search misses key context
* "?": Hard to break communities / intrinsic modularity
* Checkmark: Break information isolation & Identify causal path
**Specific Labels:**
* **Query:** "Why did citywide commute delays surge right after the blackout?"
* **Answer:** "Blackout knocked out signal controllers, intersections went flashing, gridlock spread."
* **M1:** Power Outage
* **M2:** Signal Control
* **M3:** Road Outcomes
* **Substation fault caused a citywide blackout**
* **Stop and go backups and gridlock across major corridors**
* **Missed (No keyword match)**
* **Signal controller network lost power. Many junctions went flashing.**
### Detailed Analysis or Content Details
**1. Standard RAG (Left)**
* The diagram shows a simple linear connection between "Substation fault" and "citywide blackout".
* Further connections lead to "Stop and go backups and gridlock across major corridors".
* A dashed box indicates "Missed (No keyword match)" and a text bubble states "Signal controller network lost power. Many junctions went flashing." indicating a failure to identify this key connection.
* The network is relatively sparse, with limited connections beyond the primary path.
**2. Graph-based RAG (Center)**
* The diagram displays a more complex network with multiple interconnected nodes.
* "Blackout" is central, connected to "Controllers down", "Flashing mode", and "Gridlock".
* "Power restored" is connected to "Substation fault".
* "Traffic Delays" and "Unmanaged junctions" are linked to "Gridlock".
* A question mark icon indicates "Hard to break communities / intrinsic modularity".
* The diagram shows a larger number of nodes and edges compared to Standard RAG.
**3. HugRAG (Right)**
* Similar network structure to Graph-based RAG, but with the addition of a hierarchical structure represented by a tree diagram in the top-right corner (M1, M2, M3).
* A checkmark icon indicates "Break information isolation & Identify causal path".
* A blue arrow highlights the causal path from "Blackout" to "Gridlock" via "Flashing mode".
* The diagram appears to emphasize the causal relationships between events.
### Key Observations
* Standard RAG struggles to identify the full context of the blackout, missing the connection to signal controller failures.
* Graph-based RAG provides a more comprehensive view of the relationships but faces challenges in breaking down complex communities.
* HugRAG appears to be the most effective in identifying the causal path and breaking information isolation.
* The complexity of the network diagrams increases from Standard RAG to Graph-based RAG to HugRAG, reflecting the increasing sophistication of the models.
### Interpretation
The diagram demonstrates the varying capabilities of different RAG models in analyzing complex events like a citywide blackout. Standard RAG, relying on keyword matching, fails to capture the nuanced relationships between events. Graph-based RAG improves upon this by leveraging a knowledge graph, but struggles with modularity. HugRAG, by combining graph-based reasoning with a hierarchical structure and causal path identification, provides the most complete and accurate understanding of the blackout's impact on commute delays. The diagram highlights the importance of considering causal relationships and breaking information isolation when building RAG models for complex problem-solving. The use of color-coding and icons effectively communicates the strengths and weaknesses of each approach. The diagram suggests that HugRAG is the most promising approach for analyzing complex events and providing actionable insights.
</details>
Figure 1: Comparison of three retrieval paradigms, Standard RAG, Graph-based RAG, and HugRAG, on a citywide blackout query. Standard RAG misses key evidence under semantic retrieval. Graph-based RAG can be trapped by intrinsic modularity or grouping structure. HugRAG leverages hierarchical causal gates to bridge modular boundaries, effectively breaking information isolation and explicitly identifying the underlying causal path.
1 Introduction
While Retrieval-Augmented Generation (RAG) effectively extends Large Language Models (LLMs) with external knowledge (Lewis et al., 2021), traditional pipelines predominantly rely on text chunking and semantic embedding search. This paradigm implicitly frames knowledge access as a flat similarity matching problem, overlooking the structured and interdependent nature of real-world concepts. Consequently, as knowledge bases scale in complexity, these methods struggle to maintain retrieval efficiency and reasoning fidelity.
Graph-based RAG has emerged as a promising solution to address these gaps, led by frameworks like GraphRAG (Edge et al., 2024) and extended through agentic search (Ravuru et al., 2024), GNN-guided refinement (Liu et al., 2025b), and hypergraph representations (Luo et al., ). However, three unintended limitations still persist. First, current research prioritizes retrieval policies while overlooking knowledge graph organization. As graphs scale, intrinsic modularity (Fortunato and Barthélemy, 2007) often restricts exploration within dense modules, triggering information isolation. Common grouping strategies ranging from communities (Edge et al., 2024), passage nodes (Gutiérrez et al., 2025), node-edge sets (Guo et al., 2024) to semantic grouping (Zhang et al., 2025) often inadvertently reinforce these boundaries, severely limiting global recall. Second, most formulations rely on semantic proximity and superficial traversal on graphs without causal awareness, leading to a locality issue where spurious nodes and irrelevant noise degrade precision (see Figure 1). Despite the inherent causal discovery potential of LLMs, this capability remains largely untapped for filtering noise within RAG pipelines. Finally, these systemic flaws are often masked by popular QA datasets evaluation, which reward entity-level “hits” over holistic comprehension. Consequently, there is a pressing need for a retrieval framework that reconciles global knowledge accessibility with local reasoning precision to support robust, causally-grounded generation.
To address these challenges, we propose HugRAG, a framework that rethinks knowledge graph organization through hierarchical causal gate structures. HugRAG formulates the knowledge graph as a multi-layered representation where fine-grained facts are organized into higher-level schemas, enabling multi-granular reasoning. This hierarchical architecture, integrated with causal gates, establishes logical bridges across modules, thereby naturally breaking information isolation and enhancing global recall. During retrieval, HugRAG transcends pointwise semantic matching to explicit reasoning over causal graphs. By actively distinguishing genuine causal dependencies from spurious associations, HugRAG mitigates the locality issue and filters retrieval noise to ensure precise, grounded, and interpretable generation.
To validate the effectiveness of HugRAG, we conduct extensive evaluations across datasets in multiple domains, comparing it against a diverse suite of competitive RAG baselines. To address the previously identified limitations of existing QA datasets, we introduce a large-scale cross-domain dataset HolisQA focused on holistic comprehension, designed to evaluate reasoning capabilities in complex, real-world scenarios. Our results consistently demonstrate that causal gating and causal reasoning effectively reconcile the trade-off between recall and precision, significantly enhancing retrieval quality and answer reliability.
| Method Standard RAG (Lewis et al., 2021) Graph RAG (Edge et al., 2024) | Knowledge Graph Organization Flat text chunks, unstructured. $\mathcal{G}_{\text{idx}}=\{d_{i}\}_{i=1}^{N}$ Partitioned communities with summaries. $\mathcal{G}_{\text{idx}}=\{\text{Sum}(c)\mid c∈\mathcal{C}\}$ | Retrieval and Generation Process Semantic vector search over chunks. $S=\mathrm{TopK}(\text{sim}(q,d_{i}));\;\;y=\mathsf{G}(q,S)$ Map-Reduce over community summaries. $A_{\text{part}}=\{\mathsf{G}(q,\text{Sum}(m))\};\;\;y=\mathsf{G}(A_{\text{part}})$ |
| --- | --- | --- |
| Light RAG (Guo et al., 2024) | Dual-level indexing (Entities + Relations). $\mathcal{G}_{\text{idx}}=(V_{\text{ent}}\cup V_{\text{rel}},E)$ | Keyword-based vector retrieval + neighbor. $K_{q}=\mathsf{Key}(q);\;\;S=\mathrm{Vec}(K_{q},\mathcal{G}_{\text{idx}})\cup\mathcal{N}_{1}$ |
| HippoRAG 2 (Gutiérrez et al., 2025) | Dense-sparse integration (Phrase + Passage). $\mathcal{G}_{\text{idx}}=(V_{\text{phrase}}\cup V_{\text{doc}},E)$ | PPR diffusion from LLM-filtered seeds. $U_{\text{seed}}=\mathsf{Filter}(q,V);\;\;S=\mathsf{PPR}(U_{\text{seed}},\mathcal{G}_{\text{idx}})$ |
| LeanRAG (Zhang et al., 2025) | Hierarchical semantic clusters (GMM). $\mathcal{G}_{\text{idx}}=\text{Tree}(\text{Semantic Aggregation})$ | Bottom-up traversal to LCA (Ancestor). $U=\mathrm{TopK}(q,V);\;\;S=\mathsf{LCA}(U,\mathcal{G}_{\text{idx}})$ |
| CausalRAG (Wang et al., 2025a) | Flat graph structure. $\mathcal{G}_{\text{idx}}=(V,E)$ | Top-K retrieval + Implicit causal reasoning. $S=\mathsf{Expand}(\mathrm{TopK}(q,V));\;\;y=\mathsf{G}(q,S)$ |
| \rowcolor gray!10 HugRAG (Ours) | Hierarchical Causal Gates across modules. $\mathcal{G}_{\text{idx}}=\mathcal{H}=\{H_{0},...,H_{L}\}$ | Causal Gating + Causal Path Filtering. $S=\underbrace{\mathsf{Traverse}(q,\mathcal{H})}_{\text{Break Isolation}}\cap\underbrace{\mathsf{Filter}_{\text{causal}}(S)}_{\text{Reduce Noise}}$ |
Table 1: Comparison of RAG frameworks based on knowledge organization and retrieval mechanisms. Notation: $\mathcal{M}$ modules, $\text{Sum}(·)$ summary, $\mathsf{PPR}$ Personalized PageRank, $\mathcal{H}$ hierarchy, $\mathcal{N}_{1}$ 1-hop neighborhood.
2 Related Work
2.1 RAG
Retrieval augmented generation grounds LLMs in external knowledge, but chunk level semantic search can be brittle and inefficient for large, heterogeneous, or structured corpora (Lewis et al., 2021). Graph-based RAG has therefore emerged to introduce structure for more informed retrieval.
Graph-based RAG.
GraphRAG constructs a graph structured index of external knowledge and performs query time retrieval over the graph, improving question focused access to large scale corpora (Edge et al., 2024). Building on this paradigm, later work studies richer selection mechanisms over structured graph. Agent driven retrieval explores the search space iteratively (Ravuru et al., 2024). Critic guided or winnowing style methods prune weak contexts after retrieval (Dong et al., ; Wang et al., 2025b). Others learn relevance scores for nodes, subgraphs, or reasoning paths, often with graph neural networks (Liu et al., 2025b). Representation extensions include hypergraphs for higher order relations (Luo et al., ) and graph foundation models for retrieval and reranking (Wang et al., ).
Knowledge Graph Organization.
Despite these advances, limitations related to graph organization remain underexamined. Most work emphasizes retrieval policies, while the organization of the underlying knowledge graph is largely overlooked, which strongly influences downstream retrieval behavior. As graphs scale, intrinsic modularity can emerge (Fortunato and Barthélemy, 2007; Newman, 2018), making retrieval prone to staying within dense modules rather than crossing them, largely limiting the retrieved information. Moreover, many work assume grouping knowledge for efficiency at scale, such as communities (Edge et al., 2024), phrases and passages (Gutiérrez et al., 2025), node edge sets (Guo et al., 2024), or semantic aggregation (Zhang et al., 2025) (see Table 1), which can amplify modular confinement and yield information isolation. This global issue primarily manifests as reduced recall. Some hierarchical approaches like LeanRAG attempt to bridge these gaps via semantic aggregation, but they remain constrained by semantic clustering and rely on tree-structured traversals (Zhang et al., 2025), often failing to capture logical dependencies that span across semantically distinct clusters.
Retrieval Issue.
A second limitation concerns how retrieval is formulated. Much work operates as a multi-hop search over nodes or subgraphs (Gutiérrez et al., 2025; Liu et al., 2025a), prioritizing semantic proximity to the query without explicit awareness of the reasoning in this searching process. This design can pull in topically similar yet causally irrelevant evidence, producing conflated retrieval results. Even when the correct fact node is present, the generator may respond with generic or superficial content, and the extra noise can increase the risk of hallucination. We view this as a locality issue that lowers precision.
QA Evaluation Issue.
These tendencies can be reinforced by common QA evaluation practice. First, many QA datasets emphasize short answers such as names, nationalities, or years (Kwiatkowski et al., 2019; Rajpurkar et al., 2016), so hitting the correct entity in the graph may be sufficient even without reasoning. Second, QA datasets often comprise thousands of independent question-answer-context triples. However, many approaches still rely on linear context concatenation to construct a graph, and then evaluate performance on isolated questions. This setup largely reduces the incentive for holistic comprehension of the underlying material, even though such end-to-end understanding is closer to real-world use cases. Third, some datasets are stale enough that answers may be partially memorized by pretrained LLM models, confounding retrieval quality with parametric knowledge. Therefore, these QA dataset issues are critical for evaluating RAG, yet relatively few works explicitly address them by adopting open-ended questions and fresher materials in controlled experiments.
2.2 Causality
LLM for Identifying Causality.
LLMs have demonstrated exceptional potential in causal discovery. By leveraging vast domain knowledge, LLMs significantly improve inference accuracy compared to traditional methods (Ma, 2024). Frameworks like CARE further prove that fine-tuned LLMs can outperform state-of-the-art algorithms (Dong et al., 2025). Crucially, even in complex texts, LLMs maintain a direction reversal rate under 1.1% (Saklad et al., 2026), ensuring highly reliable results.
Causality and RAG.
While LLMs increasingly demonstrate reliable causal reasoning capabilities, explicitly integrating causal structures into RAG remains largely underexplored. Current research predominantly focuses on internal attribution graphs for model interpretability (Walker and Ewetz, 2025; Dai et al., 2025), rather than external knowledge retrieval. Recent advances like CGMT (Luo et al., 2025) and LACR (Zhang et al., 2024) have begun to bridge this gap, utilizing causal graphs for medical reasoning path alignment or constraint-based structure induction. However, these works inherently differ in scope from our objective, as they prioritize rigorous causal discovery or recovery tasks in specific domain, which limits their scalability to the noisy, open-domain environments that we address. Existing causal-enhanced RAG frameworks either utilize causal feedback implicitly in embedding (Khatibi et al., 2025) or, like CausalRAG (Wang et al., 2025a), are restricted to small-scale settings with implicit causal reasoning. Consequently, a significant gap persists in leveraging causal graphs to guide knowledge graph organization and retrieval across large-scale, heterogeneous knowledge bases. Note that in this work, we use the term causal to denote explicit logical dependencies and event sequences described in the text, rather than statistical causal discovery from observational data.
3 Problem Formulation
We aim to retrieve an optimal subgraph $S^{*}⊂eq\mathcal{G}$ for a query $q$ to generate an answer $y$ . Graph-based RAG ( $S=\mathcal{R}(q,\mathcal{G})$ ) usually faces two structural bottlenecks.
1. Global Information Isolation (Recall Gap).
Intrinsic modularity often traps retrieval in local seeds, missing relevant evidence $v^{*}$ located in topologically distant modules (i.e., $S\cap\{v^{*}\}=\emptyset$ as no path exists within $h$ hops). HugRAG introduces causal gates across $\mathcal{H}$ , to bypass modular boundaries and bridge this gap. The efficacy of causal gates is empirically verified in Appendix E and further analyzed in the ablation study (see Section 5.3).
2. Local Spurious Noise (Precision Gap).
Semantic similarity $\text{sim}(q,v)$ often retrieves topically related but causally irrelevant nodes $\mathcal{V}_{sp}$ , diluting precision (where $|S\cap\mathcal{V}_{sp}|\gg|S\cap\mathcal{V}_{causal}|$ ). We address this by leveraging LLMs to identify explicit causal paths, filtering $\mathcal{V}_{sp}$ to ensure groundedness. While as discussed LLMs have demonstrated causal identification capabilities surpassing human experts (Ma, 2024; Dong et al., 2025) and proven effectiveness in RAG (Wang et al., 2025a), we further corroborate the validity of identified causal paths through expert knowledge across different domains (see Section 5.1). Consequently, HugRAG redefines retrieval as finding a mapping $\Phi:\mathcal{G}→\mathcal{H}$ and a causal filter $\mathcal{F}_{c}$ to simultaneously minimize isolation and spurious noise.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Graph Construction and Retrieval/Answer Pipeline
### Overview
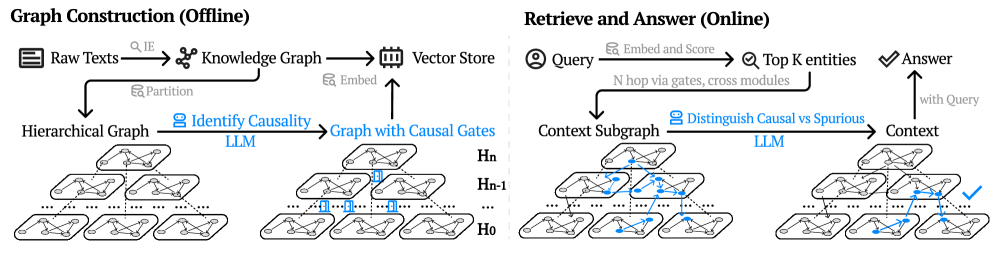
The image depicts a diagram illustrating a two-stage pipeline: "Graph Construction (Offline)" and "Retrieve and Answer (Online)". The left side shows the process of building a knowledge graph from raw text, while the right side demonstrates how to query this graph to obtain an answer. Both sides involve Large Language Models (LLMs) and utilize hierarchical graph structures.
### Components/Axes
The diagram is divided into two main sections, labeled "Graph Construction (Offline)" and "Retrieve and Answer (Online)". Within each section, there are several components connected by arrows indicating the flow of information. Key components include: Raw Texts, Knowledge Graph, Vector Store, Hierarchical Graph, LLM, Graph with Causal Gates, Context Subgraph, Query, Top K entities, Answer, and Context. The hierarchical graphs are labeled H₀, H₋₁, and Hₙ.
### Detailed Analysis or Content Details
**Graph Construction (Offline):**
1. **Raw Texts** are processed with a "Q,IE" (Query, Information Extraction) step to create a **Knowledge Graph**.
2. The Knowledge Graph is then embedded and stored in a **Vector Store**.
3. The Raw Texts are also partitioned to form a **Hierarchical Graph**.
4. An **LLM** is used to "Identify Causality" within the Hierarchical Graph, resulting in a **Graph with Causal Gates**.
5. The Vector Store embedding is used to connect to the Graph with Causal Gates.
**Retrieve and Answer (Online):**
1. A **Query** is embedded and scored, leading to the identification of **Top K entities**.
2. These entities are processed through "N hop via gates, cross modules" to generate a **Context Subgraph**.
3. An **LLM** is used to "Distinguish Causal vs Spurious" relationships within the Context Subgraph.
4. This process generates **Context**, which is then used to provide an **Answer** to the original query. A checkmark indicates a successful answer.
The hierarchical graphs (H₀, H₋₁, Hₙ) visually represent layers of abstraction. H₀ appears to be the lowest level, with the most detailed connections, while Hₙ represents the highest level of abstraction. The graphs are composed of nodes (circles) and edges (lines connecting the nodes). Some edges are highlighted in blue, potentially indicating causal relationships.
### Key Observations
* The pipeline is clearly divided into offline and online stages, suggesting a pre-processing step (graph construction) followed by a real-time query/answer process.
* LLMs are used in both stages, highlighting their importance in both knowledge extraction and reasoning.
* The use of hierarchical graphs and causal gates suggests an attempt to model complex relationships and avoid spurious correlations.
* The "Vector Store" component indicates the use of vector embeddings for efficient similarity search.
* The checkmark on the right side indicates a successful answer retrieval.
### Interpretation
This diagram illustrates a sophisticated approach to knowledge representation and question answering. The offline graph construction phase aims to create a structured knowledge base that captures causal relationships. The online retrieval phase leverages this knowledge base to answer queries efficiently and accurately. The use of LLMs suggests that the system is capable of understanding natural language and performing complex reasoning. The hierarchical graph structure allows for different levels of abstraction, potentially enabling the system to answer both broad and specific questions. The inclusion of causal gates suggests an attempt to mitigate the problem of spurious correlations, which is a common challenge in knowledge graph-based systems. The overall architecture suggests a system designed for robust and reliable question answering, particularly in domains where causal reasoning is important. The diagram does not provide any quantitative data, but rather focuses on the conceptual flow of information. It is a high-level overview of a complex system, and further details would be needed to fully understand its implementation and performance.
</details>
Figure 2: Overview of the HugRAG pipeline. In the offline stage, raw texts are embedded to build a knowledge graph and a vector store, then partitioning forms a hierarchical graph and an LLM identifies causal relations to construct a graph with causal gates. In the online stage, the query is embedded and scored to retrieve top K entities, then N hop traversal uses causal gates to cross modules and assemble a context subgraph; an LLM further distinguishes causal versus spurious relations to produce the final context and answer.
Algorithm 1 HugRAG Algorithm Pipeline
0: Corpus $\mathcal{D}$ , query $q$ , hierarchy levels $L$ , seed budget $\{K_{\ell}\}_{\ell=0}^{L}$ , hop $h$ , gate threshold $\tau$
0: Answer $y$ , Support Subgraph $S^{*}$
1: // Phase 1: Offline Hierarchical Organization
2: $G_{0}=(V_{0},E_{0})←\textsc{BuildBaseGraph}(\mathcal{D})$
3: $\mathcal{H}=\{H_{0},...,H_{L}\}←\textsc{LeidenPartition}(G_{0},L)$ {Organize into modules $\mathcal{M}$ }
4: $\mathcal{G}_{c}←\emptyset$
5: for all pair $(m_{i},m_{j})∈\textsc{ModulePairs}(\mathcal{M})$ do
6: $score←\textsc{LLM-EstCausal}(m_{i},m_{j})$
7: if $score≥\tau$ then
8: $\mathcal{G}_{c}←\mathcal{G}_{c}\cup\{(m_{i}→ m_{j},score)\}$ {Establish causal gates}
9: end if
10: end for
11: // Phase 2: Online Retrieval & Reasoning
12: $U←\bigcup_{\ell=0}^{L}\mathrm{TopK}(\text{sim}(q,u),K_{\ell},H_{\ell})$ {Multi-level semantic seeding}
13: $S_{raw}←\textsc{GatedTraversal}(U,\mathcal{H},\mathcal{G}_{c},h)$ {Break isolation via gates}
14: $S^{*}←\textsc{CausalFilter}(q,S_{raw})$ {Remove spurious nodes $\mathcal{V}_{sp}$ }
15: $y←\textsc{LLM-Generate}(q,S^{*})$
4 Method
Overview.
As illustrated in Figure 2, HugRAG operates in two distinct phases to address the aforementioned structural bottlenecks. In the offline phase, we construct a hierarchical knowledge structure $\mathcal{H}$ partitioned into modules, which are then interconnected via causal gates $\mathcal{G}_{c}$ to enable logical traversals. In the online phase, HugRAG performs a gated expansion to break modular isolation, followed by a causal filtering step to eliminate spurious noise. The overall procedure is formalized in Algorithm 1, and we detail each component in the subsequent sections.
4.1 Hierarchical Graph with Causal Gating
To address the global information isolation challenge (Section 3), we construct a multi-scale knowledge structure that balances global retrieval recall with local precision.
Hierarchical Module Construction.
We first extract a base entity graph $G_{0}=(V_{0},E_{0})$ from the corpus $\mathcal{D}$ using an information extraction pipeline (see details in Appendix B.1), followed by entity canonicalization to resolve aliasing. To establish the hierarchical backbone $\mathcal{H}=\{H_{0},...,H_{L}\}$ , we iteratively partition the graph into modules using the Leiden algorithm (Traag et al., 2019), which optimizes modularity to identify tightly-coupled semantic regions. Formally, at each level $\ell$ , nodes are partitioned into modules $\mathcal{M}_{\ell}=\{m_{1}^{(\ell)},...,m_{k}^{(\ell)}\}$ . For each module, we generate a natural language summary to serve as a coarse-grained semantic anchor.
Offline Causal Gating.
While hierarchical modularity improves efficiency, it risks trapping retrieval within local boundaries. We introduce Causal Gates to explicitly model cross-module affordances. Instead of fully connecting the graph, we construct a sparse gate set $\mathcal{G}_{c}$ . Specifically, we identify candidate module pairs $(m_{i},m_{j})$ that are topologically distant but potentially logically related. An LLM then evaluates the plausibility of a causal connection between their summaries. We formally define the gate set via an indicator function $\mathbb{I}(·)$ :
$$
\mathcal{G}_{c}=\left\{(m_{i}\to m_{j})\mid\mathbb{I}_{\text{causal}}(m_{i},m_{j})=1\right\}, \tag{1}
$$
where $\mathbb{I}_{\text{causal}}$ denotes the LLM’s assessment (see Appendix B.1 for construction prompts and the Top-Down Hierarchical Pruning strategy we employed to mitigate the $O(N^{2})$ evaluation complexity). These gates act as shortcuts in the retrieval space, permitting the traversal to jump across disjoint modules only when logically warranted, thereby breaking information isolation without causing semantic drift (see Appendix C for visualizations of hierarchical modules and causal gates).
4.2 Retrieve Subgraph via Causally Gated Expansion
Given the hierarchical structure $\mathcal{H}$ and causal gates $\mathcal{G}_{c}$ , HugRAG retrieves a support subgraph $S$ by coupling multi-granular anchoring with a topology-aware expansion. This process is designed to maximize recall (breaking isolation) while suppressing drift (controlled locality).
Multi-Granular Hybrid Seeding.
Graph-based RAG often struggles to effectively differentiate between local details and global contexts within multi-level structures (Zhang et al., 2025; Edge et al., 2024). We overcome this by identifying a seed set $U$ across multiple levels of the hierarchy. We employ a hybrid scoring function $s(q,v)$ that interpolates between semantic embedding similarity and lexical overlap (details in Appendix B.2). This function is applied simultaneously to fine-grained entities in $H_{0}$ and coarse-grained module summaries in $H_{\ell>0}$ . Crucially, to prevent the semantic redundancy problem where seeds cluster in a single redundant neighborhood, we apply a diversity-aware selection strategy (MMR) to ensure the initial seeds $U$ cover distinct semantic facets of the query. This yields a set of anchors that serve as the starting nodes for expansion.
Gated Priority Expansion.
Starting from the seed set $U$ , we model retrieval as a priority-based traversal over a unified edge space $\mathcal{E}_{\text{uni}}$ . This space integrates three distinct types of connectivity: (1) Structural Edges ( $E_{\text{struc}}$ ) for local context, (2) Hierarchical Edges ( $E_{\text{hier}}$ ) for vertical drill-down, and (3) Causal Gates ( $\mathcal{G}_{c}$ ) for cross-module reasoning.
$$
\mathcal{E}_{\text{uni}}={E}_{\text{struc}}\cup E_{\text{hier}}\cup\mathcal{G}_{c}. \tag{2}
$$
The expansion follows a Best-First Search guided by a query-conditioned gain function. For a frontier node $v$ reached from a predecessor $u$ at hop $t$ , the gain is defined as:
$$
\text{Gain}(v)=s(q,v)\cdot\gamma^{t}\cdot w(\text{type}(u,v)), \tag{3}
$$
where $\gamma∈(0,1)$ is a standard decay factor to penalize long-distance traversal. The weight function $w(·)$ adjusts traversal priorities: we simply assign higher importance to causal gates and hierarchical links to encourage logic-driven jumps over random structural walks. By traversing $\mathcal{E}_{\text{uni}}$ , HugRAG prioritizes paths that drill down (via $E_{\text{hier}}$ ), explore locally (via $E_{\text{struc}}$ ), or leap to a causally related domain (via $\mathcal{G}_{c}$ ), effectively breaking modular isolation. The expansion terminates when the gain drops below a threshold or the token budget is exhausted.
| Datasets | Nodes | Edges | Modules | Size (Char) | Domain |
| --- | --- | --- | --- | --- | --- |
| MS MARCO (Bajaj et al., 2018) | 3,403 | 3,107 | 446 | 1,557,990 | Web |
| NQ (Kwiatkowski et al., 2019) | 5,579 | 4,349 | 505 | 767,509 | Wikipedia |
| 2WikiMultiHopQA (Ho et al., 2020) | 10,995 | 8,489 | 1,088 | 1,756,619 | Wikipedia |
| QASC (Khot et al., 2020) | 77 | 39 | 4 | 58,455 | Science |
| HotpotQA (Yang et al., 2018) | 20,354 | 15,789 | 2,359 | 2,855,481 | Wikipedia |
| HolisQA-Biology | 1,714 | 1,722 | 165 | 1,707,489 | Biology |
| HolisQA-Business | 2,169 | 2,392 | 292 | 1,671,718 | Business |
| HolisQA-CompSci | 1,670 | 1,667 | 158 | 1,657,390 | Computer Science |
| HolisQA-Medicine | 1,930 | 2,124 | 226 | 1,706,211 | Medicine |
| HolisQA-Psychology | 2,019 | 1,990 | 211 | 1,751,389 | Psychology |
Table 2: Statistics of the datasets used in evaluation.
4.3 Causal Path Identification and Grounding
The raw subgraph $S_{raw}$ retrieved via gated expansion optimizes for recall but inevitably includes spurious associations (e.g., high-degree hubs or coincidental co-occurrences). To address the local spurious noise challenge (Section 3), HugRAG employs a causal path refinement stage to directly distill $S_{raw}$ into a causally grounded graph $S^{\star}$ . See Appendix D for a full example of the HugRAG pipeline.
Causal Path Refinement.
We formulate the path refinement task as a structural pruning process. We first linearize the subgraph $S_{raw}$ into a token-efficient table where each node and edge is mapped to a unique short identifier (see Appendix B.3). The LLM is then prompted to analyze the topology and output the subset of identifiers that constitute valid causal paths connecting the query to the potential answer. Leveraging the robust causal identification capabilities of LLMs (Saklad et al., 2026), this operation effectively functions as a reranker, distilling the noisy subgraph into an explicit causal structure:
$$
S^{\star}=\textsc{LLM-CausalExpert}(S_{raw},q). \tag{4}
$$
The returned subgraph $S^{\star}$ contains only model-validated nodes and edges, effectively filtering irrelevant context.
Spurious-Aware Grounding.
To further improve the precision of this selection, we employ a spurious-aware prompting strategy (see prompts in Appendix A.1). In this configuration, the LLM is instructed to explicitly distinguish between causal supports and spurious correlations during its reasoning process. While the prompt may ask the model to identify spurious items as an auxiliary reasoning step, the primary objective remains the extraction of the valid causal subset. This explicit contrast helps the model resist hallucinated connections induced by semantic similarity, yielding a cleaner $S^{\star}$ compared to standard selection prompts and consequently improving downstream generation quality. This mechanism specifically targets the precision challenges outlined in Section 4.2. Finally, the answer $y$ is generated by conditioning the LLM solely on the text content corresponding to the pruned subgraph $S^{\star}$ (see prompts in Appendix A.2), ensuring that the generation is strictly grounded in verified evidence.
5 Experiments
Overview.
We conducted extensive experiments on diverse datasets across various domains to comprehensively evaluate and compare the performance of HugRAG against competitive baselines. Our analysis is guided by the following five research questions:
RQ1 (Overall Performance). How does HugRAG compare against state-of-the-art graph-based baselines across diverse, real-world knowledge domains?
RQ2 (QA vs. Holistic Comprehension). Do popular QA datasets implicitly favor the entity-centric retrieval paradigm, thereby inflating graph-based RAG that finds the right node without assembling a support chain?
RQ3 (Trade-off Reconciliation). Can HugRAG simultaneously improve Context Recall (Globality) and Answer Relevancy (Precision), mitigating the classic trade-off via hierarchical causal gating?
RQ4 (Ablation Study). What are the individual contributions of different components in HugRAG?
RQ5 (Scalability Robustness). How does HugRAG’s performance scale and remain robust under varying context lengths?
Table 3: Main results on HolisQA across five domains. We report F1 (answer overlap), CR (Context Recall: how much gold context is covered by retrieved evidence), and AR (Answer Relevancy: evaluator-judged relevance of the answer to the question), all scaled to $\%$ for readability. Bold indicates best per column. NaiveGeneration has CR $=0$ by definition (no retrieval).
| Baselines \rowcolor black!10 Naive Baselines | Medicine F1 | Computer Science CR | Business AR | Biology F1 | Psychology CR | AR | F1 | CR | AR | F1 | CR | AR | F1 | CR | AR |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| NaiveGeneration | 12.63 | 0.00 | 44.70 | 18.93 | 0.00 | 48.79 | 18.58 | 0.00 | 46.14 | 11.71 | 0.00 | 45.76 | 22.91 | 0.00 | 50.00 |
| BM25 | 17.72 | 52.04 | 50.64 | 24.00 | 39.12 | 52.40 | 28.11 | 37.06 | 55.52 | 19.61 | 43.02 | 52.32 | 30.46 | 33.44 | 56.63 |
| StandardRAG | 26.87 | 61.08 | 56.24 | 28.87 | 49.44 | 57.10 | 47.57 | 46.79 | 67.42 | 28.31 | 42.69 | 57.58 | 37.19 | 52.21 | 59.85 |
| \rowcolor black!10 Graph-based RAG | | | | | | | | | | | | | | | |
| GraphRAG Global | 17.13 | 54.56 | 48.19 | 23.75 | 37.65 | 53.17 | 23.62 | 25.01 | 48.12 | 20.67 | 40.90 | 52.41 | 31.09 | 34.26 | 54.62 |
| GraphRAG Local | 19.03 | 56.07 | 49.52 | 25.10 | 39.90 | 53.30 | 25.01 | 27.36 | 49.05 | 22.21 | 41.88 | 52.73 | 32.31 | 35.22 | 55.02 |
| LightRAG | 12.16 | 52.38 | 44.15 | 22.59 | 41.86 | 51.62 | 29.98 | 34.22 | 54.50 | 17.70 | 41.24 | 50.32 | 33.63 | 45.54 | 56.42 |
| \rowcolor black!10 Structural / Causal Augmented | | | | | | | | | | | | | | | |
| HippoRAG2 | 21.12 | 57.50 | 51.08 | 16.94 | 21.05 | 47.29 | 21.10 | 18.34 | 45.83 | 12.60 | 16.85 | 44.56 | 20.10 | 34.13 | 46.77 |
| LeanRAG | 34.25 | 60.43 | 56.60 | 30.51 | 57.61 | 55.45 | 48.30 | 59.29 | 60.35 | 33.82 | 58.43 | 56.10 | 42.85 | 57.46 | 58.65 |
| CausalRAG | 31.12 | 58.90 | 58.77 | 30.98 | 54.10 | 57.54 | 45.20 | 44.55 | 66.10 | 33.50 | 51.20 | 58.90 | 42.80 | 55.60 | 61.90 |
| HugRAG (ours) | 36.45 | 69.91 | 60.65 | 31.60 | 60.94 | 58.34 | 51.51 | 67.34 | 68.76 | 34.80 | 61.97 | 59.99 | 44.42 | 60.87 | 63.53 |
Table 4: Main results on five QA datasets. Metrics follow Section 5: F1, CR (Context Recall), and AR (Answer Relevancy), reported in $\%$ . Bold and underline denote best and second-best per column.
| Baselines \rowcolor black!10 Naive Baselines | MSMARCO F1 | NQ CR | TwoWiki AR | QASC F1 | HotpotQA CR | AR | F1 | CR | AR | F1 | CR | AR | F1 | CR | AR |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| NaiveGeneration | 5.28 | 0.00 | 15.06 | 7.17 | 0.00 | 10.94 | 9.15 | 0.00 | 11.77 | 2.69 | 0.00 | 13.74 | 14.38 | 0.00 | 15.74 |
| BM25 | 6.97 | 45.78 | 20.33 | 4.68 | 49.98 | 9.13 | 9.43 | 37.12 | 13.73 | 2.49 | 6.12 | 13.17 | 15.81 | 41.08 | 16.08 |
| StandardRAG | 14.93 | 48.55 | 31.11 | 7.57 | 45.82 | 11.14 | 10.33 | 32.28 | 13.57 | 2.01 | 5.50 | 13.16 | 6.68 | 43.17 | 14.66 |
| \rowcolor black!10 Graph-based RAG | | | | | | | | | | | | | | | |
| GraphRAG Global | 9.41 | 3.65 | 13.08 | 3.91 | 4.48 | 8.00 | 1.41 | 9.42 | 9.55 | 0.68 | 3.38 | 3.56 | 6.28 | 14.59 | 16.26 |
| GraphRAG Local | 30.87 | 25.71 | 57.76 | 23.56 | 44.56 | 44.68 | 18.85 | 32.03 | 37.29 | 8.30 | 9.54 | 46.59 | 33.14 | 44.07 | 40.82 |
| LightRAG | 37.70 | 54.22 | 63.54 | 24.97 | 60.65 | 50.53 | 14.44 | 40.98 | 36.56 | 8.20 | 20.40 | 44.35 | 28.39 | 48.17 | 43.78 |
| \rowcolor black!10 Structural / Causal Augmented | | | | | | | | | | | | | | | |
| HippoRAG2 | 23.35 | 45.45 | 55.18 | 29.64 | 57.21 | 37.50 | 18.47 | 55.53 | 17.34 | 14.73 | 4.38 | 49.94 | 38.80 | 42.06 | 24.66 |
| LeanRAG | 38.02 | 54.01 | 58.49 | 35.46 | 65.91 | 49.87 | 20.27 | 40.53 | 38.37 | 13.19 | 22.80 | 45.51 | 48.68 | 46.29 | 43.50 |
| CausalRAG | 27.66 | 39.38 | 46.03 | 29.45 | 68.04 | 17.35 | 15.93 | 28.38 | 19.76 | 7.65 | 46.86 | 35.56 | 40.00 | 27.83 | 21.32 |
| HugRAG (ours) | 38.40 | 60.48 | 66.02 | 49.50 | 70.36 | 55.09 | 31.97 | 41.95 | 42.67 | 13.35 | 70.80 | 49.40 | 64.83 | 40.30 | 45.72 |
5.1 Experimental Setup
Datasets.
We evaluate HugRAG on a diverse suite of datasets covering complementary difficulty profiles. For standard evaluation, we use five established datasets: MS MARCO (Bajaj et al., 2018) and Natural Questions (Kwiatkowski et al., 2019) emphasize large-scale open-domain retrieval; HotpotQA (Yang et al., 2018) and 2WikiMultiHop (Ho et al., 2020) require evidence aggregation; and QASC (Khot et al., 2020) targets compositional scientific reasoning. However, these datasets often suffer from entity-centric biases and potential data leakage (memorization by LLMs). To rigorously test the holistic understanding capability of RAG, we introduce HolisQA, a dataset derived from high-quality academic papers sourced (Priem et al., 2022). Spanning over diverse domains (including Biology, Computer Science, Medicine, etc.), HolisQA features dense logical structures that naturally demand holistic comprehension (see more details in Appendix F.2). All dataset statistics are summarized in Table 2. While LLMs have demonstrated strong capabilities in identifying causality (Ma, 2024; Dong et al., 2025) and effectiveness in RAG (Wang et al., 2025a), to ensure rigorous evaluation, we incorporated cross-domain expert review to validate the quality of baseline answers and confirm the legitimacy of the induced causal relations.
Baselines.
We compare HugRAG against eight baselines spanning three retrieval paradigms. First, to cover Naive and Flat approaches, we include Naive Generation (no retrieval) as a lower bound, alongside BM25 (sparse) and Standard RAG (Lewis et al., 2021) (dense embedding-based), representing mainstream unstructured retrieval. Second, we evaluate established graph-based frameworks: GraphRAG (Local and Global) (Edge et al., 2024), utilizing community summaries; and LightRAG (Guo et al., 2024), relying on dual-level keyword-based search. Third, we benchmark against RAGs with structured or causal augmentation: HippoRAG 2 (Gutiérrez et al., 2025), utilizing passage nodes and Personalized PageRank diffusion; LeanRAG (Zhang et al., 2025), employing semantic aggregation hierarchies and tree-based LCA retrieval; and CausalRAG (Wang et al., 2025a), which incorporates causality without explicit causal reasoning. This selection comprehensively covers the spectrum from unstructured search to advanced structure-aware and causally augmented graph methods.
Metrics.
For metrics, we first report the token-level answer quality metric F1 for surface robustness. To measure whether retrieval actually supports generation, we additionally compute grounding metrics, context recall and answer relevancy (Es et al., 2024), which jointly capture coverage and answer quality (see Appendix F.4).
Implementation Details.
For all experiments, we utilize gpt-5-nano as the backbone LLM for both the open IE extraction and generation stages, and Sentence-BERT (Reimers and Gurevych, 2019) for semantic vectorization. For HugRAG, we set the hierarchical seed budget to $K_{L}=3$ for modules and $K_{0}=3$ for entities, causal gate is enabled by default except ablation study. Experiments run on a cluster using 10-way job arrays; each task uses 2 CPU cores and 16 GB RAM (20 cores, 160GB in total). See more implementation details in Appendix F.3.
5.2 Main Experiments
Overall Performance (RQ1).
HugRAG consistently achieves superior performance across all HolisQA domains and standard QA metrics (Section 5, Section 5). While traditional methods (e.g., BM25, Standard RAG) struggle with structural dependencies, graph-based baselines exhibit distinct limitations. GraphRAG-Global relies heavily on high-level community summaries and largely suffers from detailed QA tasks, necessitating its GraphRAG Local variant to balance the granularity trade-off. LightRAG struggles to achieve competitive results, limited by its coarse-grained key-value lookup mechanism. Regarding structurally augmented methods, while LeanRAG (utilizing semantic aggregation) and HippoRAG2 (leveraging phrase/passage nodes) yield slight improvements in context recall, they fail to fully break information isolation compared to our causal gating mechanism. Finally, although CausalRAG occasionally attains high Answer Relevancy due to its causal reasoning capability, it struggles to scale to large datasets due to the lack of efficient knowledge graph organization.
Holistic Comprehension vs. QA (RQ2).
The contrast between the results on HolisQA (Section 5) and standard QA datasets (Section 5) is revealing. On popular QA benchmarks, entity-centric methods like LightRAG, GraphRAG-Local, LeanRAG could occasionally achieve good scores. However, their performance degrades collectively and significantly on HolisQA. A striking counterexample is GraphRAG-Global: while its reliance on community summaries hindered performance on granular standard QA tasks, now it rebounds significantly in HolisQA. This discrepancy strongly suggests that standard QA datasets, which often favor short answers, implicitly reward the entity-centric paradigm. In contrast, HolisQA, with its open-ended questions and dense logical structures, necessitates a comprehensive understanding of the underlying document—a scenario closer to real-world applications. Notably, HugRAG is the only framework that remains robust across this paradigm shift, demonstrating competitive performance on both entity-centric QA and holistic comprehension tasks.
Reconciling the Accuracy-Grounding Trade-off (RQ3).
HugRAG effectively reconciles the fundamental tension between Recall and Precision. While hierarchical causal gating expands traversal boundaries to secure superior Context Recall (Globality), the explicit causal path identification rigorously prunes spurious noise to maintain high F1 Score and Answer Relevancy (Locality). This dual mechanism allows HugRAG to simultaneously optimize for global coverage and local groundedness, achieving a balance often missed by prior methods.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Bar Chart: Performance Comparison of Different Configurations
### Overview
This bar chart compares the performance of different configurations (denoted by color) across three metrics: F1, CR, and AR. The configurations vary based on the inclusion of "H" (likely a feature or component), "CG" (likely another feature or component), and "Causal" reasoning. The y-axis represents a "Score", and the x-axis represents the three metrics.
### Components/Axes
* **X-axis:** "Metric" with three categories: "F1", "CR", and "AR".
* **Y-axis:** "Score" ranging from 0 to 70, with increments of 10.
* **Legend (Top-Center):**
* Light Green: "w/o H · w/o CG · w/o Causal"
* Yellow: "w/ H · w/o CG · w/o Causal"
* Blue: "w/ H · w/ CG · w/o Causal"
* Pink: "w/ H · w/ CG · w/ SP-Causal"
### Detailed Analysis
The chart consists of three groups of bars, one for each metric (F1, CR, AR). Within each group, there are four bars, each representing a different configuration.
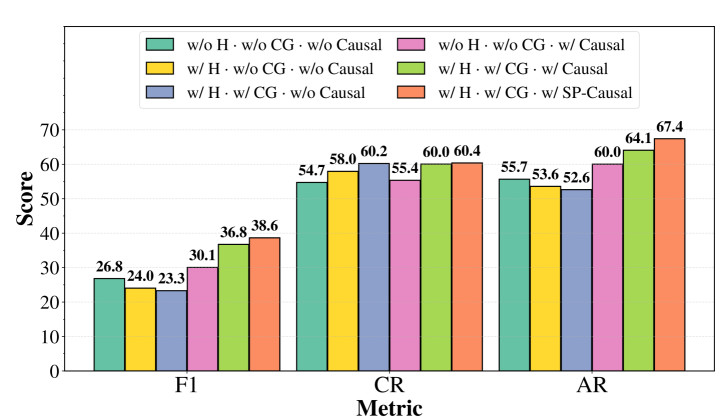
**F1 Metric:**
* Light Green: Approximately 26.8
* Yellow: Approximately 24.0
* Blue: Approximately 23.3
* Pink: Approximately 30.1
Trend: The pink bar (w/ H · w/ CG · w/ SP-Causal) is the highest, followed by the light green bar. The yellow and blue bars are relatively close in value.
**CR Metric:**
* Light Green: Approximately 54.7
* Yellow: Approximately 58.0
* Blue: Approximately 60.2
* Pink: Approximately 55.4
Trend: The blue bar (w/ H · w/ CG · w/o Causal) is the highest, followed by the yellow bar. The pink bar is slightly lower than the light green bar.
**AR Metric:**
* Light Green: Approximately 55.7
* Yellow: Approximately 53.6
* Blue: Approximately 52.6
* Pink: Approximately 67.4
Trend: The pink bar (w/ H · w/ CG · w/ SP-Causal) is significantly higher than the other bars. The light green bar is the second highest, followed by the yellow and blue bars.
### Key Observations
* The "w/ H · w/ CG · w/ SP-Causal" configuration (pink) consistently performs well, particularly on the AR metric, where it significantly outperforms the other configurations.
* The "w/o H · w/o CG · w/o Causal" configuration (light green) performs reasonably well on F1 and CR, but is lower on AR.
* Adding "H" and "CG" generally improves performance, especially when combined with "SP-Causal".
* The "w/ H · w/ CG · w/o Causal" (blue) configuration performs best on CR.
### Interpretation
The data suggests that incorporating both "H" and "CG" features, along with "SP-Causal" reasoning, leads to the best overall performance, especially in the AR metric. This indicates that the "SP-Causal" component is particularly beneficial when used in conjunction with the other features. The differences in performance across the metrics suggest that the configurations have varying strengths and weaknesses. For example, the "w/ H · w/ CG · w/o Causal" configuration excels at CR, while the "w/ H · w/ CG · w/ SP-Causal" configuration dominates in AR. The chart provides a clear comparison of the effectiveness of different configurations, allowing for informed decisions about which features to include in a system or model. The consistent improvement with the addition of "H", "CG", and "SP-Causal" suggests a synergistic effect between these components.
</details>
Figure 3: Ablation Study. H: Hierarchical Structure; CG: Causal Gates; Causal/SP-Causal: Standard vs. Spurious-Aware Causal Identification. w/o and w/ denote exclusion or inclusion.
5.3 Ablation Study
To address RQ4, we ablate hierarchy, causal gates, and causal path refinement components (see Figure 3), finding that their combination yields optimal results. Specifically, we observe a mutually reinforcing dynamic: while hierarchical gates break information isolation to boost recall, the spurious-aware causal identification is indispensable for filtering the resulting noise and achieving a significant improvement. This mutual reinforcement allows HugRAG to reconcile global coverage with local groundedness, significantly outperforming any isolated component.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Line Chart: RAG Model Performance vs. Source Text Length
### Overview
This line chart compares the performance (Score) of several Retrieval-Augmented Generation (RAG) models across varying source text lengths, measured in characters. The chart displays how the score of each model changes as the length of the input text increases.
### Components/Axes
* **X-axis:** Source Text Length (chars) - Scale: 5K, 10K, 25K, 100K, 300K, 750K, 1M, 1.5M
* **Y-axis:** Score - Scale: 0 to 60
* **Legend (Top Center):** Contains labels for each data series (model):
* Naive (Grey)
* BM25 (Light Grey)
* Standard RAG (Dark Grey)
* GraphRAG Global (Blue)
* GraphRAG Local (Dark Blue)
* LightRAG (Teal)
* HippoRAG2 (Light Blue)
* LeanRAG (Purple)
* CausalRAG (Sky Blue)
* HugRAG (Red)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, cross-referencing with the legend colors:
* **Naive (Grey):** Starts at approximately 17 at 5K, fluctuates around 15-20 until 750K, then decreases to approximately 10 at 1.5M.
* **BM25 (Light Grey):** Starts at approximately 15 at 5K, remains relatively flat around 15-20 throughout, ending at approximately 12 at 1.5M.
* **Standard RAG (Dark Grey):** Starts at approximately 18 at 5K, remains relatively flat around 15-20 throughout, ending at approximately 14 at 1.5M.
* **GraphRAG Global (Blue):** Starts at approximately 48 at 5K, decreases to around 42 at 25K, then increases to approximately 50 at 100K, fluctuates around 45-50 until 1M, and ends at approximately 46 at 1.5M.
* **GraphRAG Local (Dark Blue):** Starts at approximately 42 at 5K, decreases to around 38 at 25K, increases to approximately 45 at 100K, then decreases to approximately 40 at 750K, and ends at approximately 42 at 1.5M.
* **LightRAG (Teal):** Starts at approximately 28 at 5K, decreases to approximately 25 at 25K, increases to approximately 35 at 100K, then decreases to approximately 30 at 1.5M.
* **HippoRAG2 (Light Blue):** Starts at approximately 22 at 5K, increases to approximately 32 at 100K, then fluctuates around 30-35 until 1.5M.
* **LeanRAG (Purple):** Starts at approximately 52 at 5K, decreases to approximately 45 at 25K, then increases to approximately 55 at 100K, and remains relatively stable around 45-55 until 1.5M.
* **CausalRAG (Sky Blue):** Starts at approximately 30 at 5K, decreases to approximately 27 at 25K, increases to approximately 33 at 100K, then fluctuates around 30-35 until 1.5M.
* **HugRAG (Red):** Starts at approximately 55 at 5K, increases to a peak of approximately 60 at 100K, then decreases slightly to approximately 57 at 1.5M.
### Key Observations
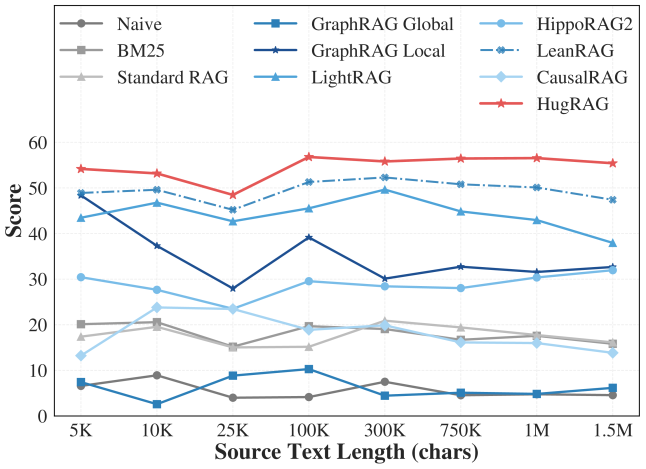
* HugRAG consistently performs the best across all source text lengths.
* Naive, BM25, and Standard RAG consistently perform the worst.
* GraphRAG Global and LeanRAG show relatively stable performance across different text lengths.
* Most models exhibit a peak performance around the 100K-300K source text length range.
* Performance generally decreases for the Naive, BM25, and Standard RAG models as the source text length increases.
### Interpretation
The data suggests that HugRAG is the most robust model for handling varying source text lengths, maintaining a high score even with longer inputs. The poorer performance of Naive, BM25, and Standard RAG models with increasing text length indicates that these methods struggle with longer contexts. The peak performance observed around 100K-300K for many models suggests an optimal text length for effective retrieval and generation. The differences between GraphRAG Global and Local suggest that the scope of the graph used for retrieval impacts performance. Overall, the chart demonstrates the importance of choosing a RAG model that can effectively handle the expected length of the source text to maximize performance. The consistent high performance of HugRAG suggests it may be a good choice for applications with variable input lengths.
</details>
Figure 4: Scalability analysis of HugRAG and other RAG baselines across varying source text lengths (5K to 1.5M characters).
5.4 Scalability Analysis
Robustness to Information Scale (RQ5).
To assess robustness against information overload, we evaluated performance across varying source text lengths ( $5k$ to $1.5M$ characters) sampled from HolisQA, reporting the mean of F1, Context Recall, and Answer Relevancy (see Figure 4). As illustrated, HugRAG (red line) exhibits remarkable stability across all scales, maintaining high scores even at 1.5M characters. This confirms that our hierarchical causal gating structure effectively encapsulates complexity, enabling the retrieval process to scale via causal gates without degrading reasoning fidelity.
6 Conclusion
We introduced HugRAG to resolve information isolation and spurious noise in graph-based RAG. By leveraging hierarchical causal gating and explicit identification, HugRAG reconciles global context coverage with local evidence grounding. Experiments confirm its superior performance not only in standard QA but also in holistic comprehension, alongside robust scalability to large knowledge bases. Additionally, we introduced HolisQA to evaluate complex reasoning capabilities for RAG. We hope our findings contribute to the ongoing development of RAG research.
Impact Statement
This paper presents work whose goal is to advance the field of machine learning, specifically by improving the reliability and interpretability of retrieval-augmented generation. There are many potential societal consequences of our work, none of which we feel must be specifically highlighted here.
References
- P. Bajaj, D. Campos, N. Craswell, L. Deng, J. Gao, X. Liu, R. Majumder, A. McNamara, B. Mitra, T. Nguyen, M. Rosenberg, X. Song, A. Stoica, S. Tiwary, and T. Wang (2018) MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv. External Links: 1611.09268, Document Cited by: Table 2, §5.1.
- X. Dai, K. Guo, C. Lo, S. Zeng, J. Ding, D. Luo, S. Mukherjee, and J. Tang (2025) GraphGhost: Tracing Structures Behind Large Language Models. arXiv. External Links: 2510.08613, Document Cited by: §2.2.
- [3] G. Dong, J. Jin, X. Li, Y. Zhu, Z. Dou, and J. Wen RAG-Critic: Leveraging Automated Critic-Guided Agentic Workflow for Retrieval Augmented Generation. Cited by: §2.1.
- J. Dong, Y. Liu, A. Aloui, V. Tarokh, and D. Carlson (2025) CARE: Turning LLMs Into Causal Reasoning Expert. arXiv. External Links: 2511.16016, Document Cited by: §2.2, §3, §5.1.
- D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, and J. Larson (2024) From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv. External Links: 2404.16130 Cited by: Figure 8, §B.1, Table 1, §1, §2.1, §2.1, §4.2, §5.1.
- S. Es, J. James, L. Espinosa Anke, and S. Schockaert (2024) RAGAs: Automated Evaluation of Retrieval Augmented Generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, N. Aletras and O. De Clercq (Eds.), St. Julians, Malta, pp. 150–158. External Links: Document Cited by: Figure 15, §F.3, §F.4, §5.1.
- S. Fortunato and M. Barthélemy (2007) Resolution limit in community detection. Proceedings of the National Academy of Sciences 104 (1), pp. 36–41. External Links: Document Cited by: §1, §2.1.
- Z. Guo, L. Xia, Y. Yu, T. Ao, and C. Huang (2024) LightRAG: Simple and Fast Retrieval-Augmented Generation. arXiv. External Links: 2410.05779 Cited by: Table 1, §1, §2.1, §5.1.
- B. J. Gutiérrez, Y. Shu, W. Qi, S. Zhou, and Y. Su (2025) From RAG to Memory: Non-Parametric Continual Learning for Large Language Models. arXiv. External Links: 2502.14802, Document Cited by: Table 1, §1, §2.1, §2.1, §5.1.
- X. Ho, A. D. Nguyen, S. Sugawara, and A. Aizawa (2020) Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. arXiv. External Links: 2011.01060, Document Cited by: Table 2, §5.1.
- E. Khatibi, Z. Wang, and A. M. Rahmani (2025) CDF-RAG: Causal Dynamic Feedback for Adaptive Retrieval-Augmented Generation. arXiv. External Links: 2504.12560, Document Cited by: §2.2.
- T. Khot, P. Clark, M. Guerquin, P. Jansen, and A. Sabharwal (2020) QASC: A Dataset for Question Answering via Sentence Composition. arXiv. External Links: 1910.11473, Document Cited by: Table 2, §5.1.
- T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, K. Toutanova, L. Jones, M. Kelcey, M. Chang, A. M. Dai, J. Uszkoreit, Q. Le, and S. Petrov (2019) Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, pp. 452–466. External Links: Document Cited by: §2.1, Table 2, §5.1.
- P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel, and D. Kiela (2021) Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv. External Links: 2005.11401, Document Cited by: Table 1, §1, §2.1, §5.1.
- H. Liu, Z. Wang, X. Chen, Z. Li, F. Xiong, Q. Yu, and W. Zhang (2025a) HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation. arXiv. External Links: 2502.12442, Document Cited by: §2.1.
- H. Liu, S. Wang, and J. Li (2025b) Knowledge Graph Retrieval-Augmented Generation via GNN-Guided Prompting. Cited by: §1, §2.1.
- H. Luo, J. Zhang, and C. Li (2025) Causal Graphs Meet Thoughts: Enhancing Complex Reasoning in Graph-Augmented LLMs. arXiv. External Links: 2501.14892, Document Cited by: §2.2.
- [18] H. Luo, Q. Lin, Y. Feng, Z. Kuang, M. Song, Y. Zhu, and L. A. Tuan HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation. Cited by: §1, §2.1.
- J. Ma (2024) Causal Inference with Large Language Model: A Survey. arXiv. External Links: 2409.09822 Cited by: §2.2, §3, §5.1.
- M. Newman (2018) Networks. Vol. 1, Oxford University Press. External Links: Document, ISBN 978-0-19-880509-0 Cited by: §2.1.
- J. Priem, H. Piwowar, and R. Orr (2022) OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. Cited by: §F.2, §5.1.
- P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang (2016) SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv. External Links: 1606.05250, Document Cited by: §2.1.
- C. Ravuru, S. S. Sakhinana, and V. Runkana (2024) Agentic Retrieval-Augmented Generation for Time Series Analysis. arXiv. External Links: 2408.14484, Document Cited by: §1, §2.1.
- N. Reimers and I. Gurevych (2019) Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, pp. 3980–3990. External Links: Document Cited by: §F.3, §5.1.
- R. Saklad, A. Chadha, O. Pavlov, and R. Moraffah (2026) Can Large Language Models Infer Causal Relationships from Real-World Text?. arXiv. External Links: 2505.18931, Document Cited by: §2.2, §4.3.
- V. Traag, L. Waltman, and N. J. van Eck (2019) From Louvain to Leiden: guaranteeing well-connected communities. Scientific Reports 9 (1), pp. 5233. External Links: 1810.08473, ISSN 2045-2322, Document Cited by: §B.1, §4.1.
- C. Walker and R. Ewetz (2025) Explaining the Reasoning of Large Language Models Using Attribution Graphs. arXiv. External Links: 2512.15663, Document Cited by: §2.2.
- N. Wang, X. Han, J. Singh, J. Ma, and V. Chaudhary (2025a) CausalRAG: Integrating Causal Graphs into Retrieval-Augmented Generation. In Findings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar (Eds.), Vienna, Austria, pp. 22680–22693. External Links: Document, ISBN 979-8-89176-256-5 Cited by: Table 1, §2.2, §3, §5.1, §5.1.
- S. Wang, Z. Chen, P. Wang, Z. Wei, Z. Tan, Y. Meng, C. Shen, and J. Li (2025b) Separate the Wheat from the Chaff: Winnowing Down Divergent Views in Retrieval Augmented Generation. arXiv. External Links: 2511.04700, Document Cited by: §2.1.
- [30] X. Wang, Z. Liu, J. Han, and S. Deng RAG4GFM: Bridging Knowledge Gaps in Graph Foundation Models through Graph Retrieval Augmented Generation. Cited by: §2.1.
- Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning (2018) HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. arXiv. External Links: 1809.09600, Document Cited by: Table 2, §5.1.
- Y. Zhang, R. Wu, P. Cai, X. Wang, G. Yan, S. Mao, D. Wang, and B. Shi (2025) LeanRAG: Knowledge-Graph-Based Generation with Semantic Aggregation and Hierarchical Retrieval. arXiv. External Links: 2508.10391, Document Cited by: Table 1, §1, §2.1, §4.2, §5.1.
- Y. Zhang, Y. Zhang, Y. Gan, L. Yao, and C. Wang (2024) Causal Graph Discovery with Retrieval-Augmented Generation based Large Language Models. arXiv. External Links: 2402.15301 Cited by: §2.2.
Appendix A Prompts used in Online Retrieval and Reasoning
This section details the prompt engineering employed during the online retrieval phase of HugRAG. We rely on Large Language Models to perform two critical reasoning tasks: identifying causal paths within the retrieved subgraph and generating the final grounded answer.
A.1 Causal Path Identification
To address the local spurious noise issue, we design a prompt that instructs the LLM to act as a “causality analyst.” The model receives a linearized list of potential evidence (nodes and edges) and must select the subset that forms a coherent causal chain.
Spurious-Aware Selection (Main Setting).
Our primary prompt, illustrated in Figure 5, explicitly instructs the model to differentiate between valid causal supports (output in precise) and spurious associations (output in ct_precise). By forcing the model to articulate what is not causal (e.g., mere correlations or topical coincidence), we improve the precision of the selected evidence.
Standard Selection (Ablation).
To verify the effectiveness of spurious differentiation, we also use a simplified prompt variant shown in Figure 6. This version only asks the model to identify valid causal items without explicitly labeling spurious ones.
A.2 Final Answer Generation
Once the spurious-filtered support subgraph $S^{\star}$ is obtained, it is passed to the generation module. The prompt shown in Figure 7 is used to synthesize the final answer. Crucially, this prompt enforces strict grounding by instructing the model to rely only on the provided evidence context, minimizing hallucination.
<details>
<summary>x5.png Details</summary>

### Visual Description
\n
## Textual Document: Causal Analysis Task Description
### Overview
The image presents a textual description of a task for a "careful causality analyst acting as a reranker for retrieval." It outlines the goal, inputs, output format, and constraints of the task. The document appears to be a set of instructions for a machine learning model or a human annotator.
### Components/Axes
The document is structured into sections denoted by "---[Section Title]---". The sections are:
* **Role:** Describes the role of the analyst.
* **Goal:** Defines the objective of the task.
* **Inputs:** Specifies the input data.
* **Output Format (JSON):** Details the expected output structure.
* **Constraints:** Lists limitations on the output.
### Detailed Analysis or Content Details
Here's a transcription of the text, section by section:
**Role:**
"You are a careful causality analyst acting as a reranker for retrieval."
**Goal:**
"Given a query and a list of context items (short ID + content), select the most important items consisting the causal graph and output them in ‘precise’. Also output the least important items as the spurious information in ‘ct_precise’.
You MUST:
- Use only the provided items.
- Rank ‘precise’ from most important to least important.
- Rank ‘ct_precise’ from least important to more important.
- Output JSON only. Do not add markdown.
- Use the short IDs exactly as shown.
- Do NOT include any IDs in ‘p_answer’."
**Inputs:**
"Query:
[query]
Context Items (short ID | content):
[context, table]"
**Output Format (JSON):**
```json
{
'precise': ['C1', 'N2', 'E3'],
'ct_precise': ['T7', 'N9'],
'p_answer': 'concise draft answer'
}
```
**Constraints:**
"- ‘precise’ length: at most (max_precise_items) items.
- ‘ct_precise’ length: at most (max_ct_precise_items) items.
- ‘p_answer’ length: at most (max_answer_words) words."
### Key Observations
The document emphasizes the importance of adhering to the specified JSON output format and constraints. The task involves ranking context items based on their relevance to a given query, distinguishing between important causal factors ('precise') and spurious information ('ct_precise'). The use of short IDs is crucial, and they should not appear in the 'p_answer' field. The document uses placeholders like "[query]", "[context, table]", "(max_precise_items)", etc., indicating that these values will be provided as input.
### Interpretation
This document describes a task designed to evaluate a system's ability to identify causal relationships within a set of contextual information. The "reranker" role suggests that the system is intended to refine an initial ranking of context items, potentially generated by a retrieval system. The separation of 'precise' and 'ct_precise' indicates a focus on filtering out irrelevant or misleading information. The constraints on output length suggest a need for concise and focused responses. The overall goal is to build a system that can accurately identify the key causal factors relevant to a given query, while discarding spurious information. The JSON output format is likely used for automated evaluation and integration with other components of a larger system.
</details>
Figure 5: Prompt for Causal Path Identification with Spurious Distinction (HugRAG Main Setting). The model is explicitly instructed to segregate non-causal associations into a separate list to enhance reasoning precision.
<details>
<summary>x6.png Details</summary>

### Visual Description
\n
## Textual Document: Instruction Set for a Causality Analyser
### Overview
The image presents a set of instructions for a causality analyst, detailing the goal, constraints, input, and output format for a retrieval task. It is formatted as a series of labeled sections, resembling a system prompt or a technical specification document. The document does not contain charts or diagrams, but rather a structured text block.
### Components/Axes
The document is divided into the following sections:
* **Role:** Defines the role of the agent as a "careful causality analyst acting as a reranker for retrieval."
* **Goal:** Describes the task: ranking context items based on their support for answering a query as a causal graph.
* **MUST:** Lists mandatory requirements for the agent.
* **Inputs:** Specifies the input data: a "Query" and "Context Items (short ID + content)."
* **Output Format (JSON):** Defines the expected output structure in JSON format.
* **Constraints:** Sets limitations on the output length.
### Detailed Analysis or Content Details
Here's a transcription of the text, section by section:
**Role:**
"You are a careful causality analyst acting as a reranker for retrieval."
**Goal:**
"Given a query and a list of context items (short ID + content), select the most important items that best support answering the query as a causal graph."
**MUST:**
"You MUST:
- Use only the provided items.
- Rank the `precise` list from most important to least important.
- Output JSON only. Do not add markdown.
- Use the short IDs exactly as shown.
- Do NOT include any IDs in `p_answer`.
- If evidence is insufficient, say so in `p_answer` (e.g., 'Unknown')."
**Inputs:**
"Query:
{query}
Context Items (short ID + content):
{context_table}"
**Output Format (JSON):**
```json
{
"precise": ["CI1", "N2", "E3"],
"p_answer": "concise draft answer"
}
```
**Constraints:**
"- `precise` length: at most [max_precise_items].
- `p_answer` length: at most [max_answer_words] words."
### Key Observations
The document is highly structured and focuses on precise instructions for a machine learning or AI agent. The emphasis on JSON output, specific ID usage, and length constraints suggests a programmatic interface. The inclusion of "Unknown" as a valid response indicates a need for handling cases where sufficient evidence is not available. The use of bracketed placeholders like `{query}` and `{context_table}` indicates that this is a template or a prompt that will be populated with actual data.
### Interpretation
This document outlines the specifications for a system designed to assess the causal relevance of information. The agent is tasked with identifying the most pertinent context items to answer a given query, framing the relationship as a causal graph. The constraints and output format are geared towards automated processing and integration into a larger system. The instruction to return "Unknown" when evidence is lacking is a crucial element for ensuring the system's reliability and preventing it from generating unsupported conclusions. The document is a clear example of prompt engineering, aiming to elicit a specific and structured response from a language model or similar AI system. The placeholders suggest that the system is designed to be flexible and adaptable to different queries and context sets.
</details>
Figure 6: Ablation Prompt: Causal Path Identification without differentiating spurious relationships. This baseline is used to assess the contribution of the spurious filtering mechanism.
<details>
<summary>x7.png Details</summary>

### Visual Description
\n
## Screenshot: System Prompt Structure
### Overview
The image is a screenshot of a system prompt structure, likely used in a large language model (LLM) context. It outlines the roles, goals, evidence context, draft answer, question, and answer format for a conversational AI system. The screenshot appears to be a template or example for structuring prompts to guide the LLM's behavior.
### Components/Axes
The screenshot is divided into labeled sections, each with a descriptive title and a placeholder for content. The sections are:
* **Role:** "You are a helpful assistant answering the user's question."
* **Goal:** "Answer the question using the provided evidence context. A draft answer may be provided; use it only if it is supported by the evidence."
* **Evidence Context:** "{report\_context}"
* **Draft Answer (optional):** "{draft\_answer}"
* **Question:** "{query}"
* **Answer Format:** "Concise, direct, and neutral."
These sections are visually separated by horizontal lines and are presented in a top-to-bottom order. The placeholders are enclosed in curly braces.
### Detailed Analysis or Content Details
The content within each section is minimal, consisting primarily of descriptive text and placeholders. The placeholders suggest that the system is designed to receive input in a structured format.
* **Role:** Defines the persona of the AI assistant.
* **Goal:** Specifies the primary objective of the AI assistant – to answer a question based on provided evidence.
* **Evidence Context:** Indicates where the relevant information for answering the question will be provided.
* **Draft Answer:** Allows for a pre-existing answer to be considered, but emphasizes the importance of evidence-based responses.
* **Question:** Represents the user's query.
* **Answer Format:** Sets the desired style and tone of the AI assistant's response.
### Key Observations
The structure emphasizes evidence-based reasoning and a specific role for the AI assistant. The inclusion of a "Draft Answer" section suggests a potential iterative process where the AI can refine or validate a pre-existing response. The placeholders indicate a dynamic system where content will be inserted at runtime.
### Interpretation
This screenshot demonstrates a structured approach to prompt engineering for LLMs. The framework aims to constrain the AI's behavior, ensuring that responses are grounded in provided evidence and adhere to a defined style. This is a common technique for improving the reliability and accuracy of LLM outputs. The structure suggests a focus on minimizing hallucinations and promoting factual correctness. The template is designed to facilitate a clear and controlled interaction between the user and the AI assistant. The use of placeholders indicates that this is a reusable template for various question-answering scenarios.
</details>
Figure 7: Prompt for Final Answer Generation. The model is conditioned solely on the filtered causal subgraph $S^{\star}$ to ensure groundedness.
Appendix B Algorithm Details of HugRAG
This section provides granular details on the offline graph construction process and the specific algorithms used during the online retrieval phase, complementing the high-level description in Section 4.
B.1 Graph Construction
Entity Extraction and Deduplication.
The base graph $H_{0}$ is constructed by processing text chunks using LLM. We utilize the prompt shown in Appendix 8, adapted from (Edge et al., 2024), to extract entities and relations (see prompts in Figure 8). Since raw extractions from different chunks inevitably contain duplicates (e.g., “J. Biden” vs. “Joe Biden”), we employ a two-stage deduplication strategy. First, we perform surface-level canonicalization using fuzzy string matching. Second, we use embedding similarity to identify semantically identical nodes, merging their textual descriptions and pooling their supporting evidence edges.
Hierarchical Partitioning.
We employ the Leiden algorithm (Traag et al., 2019) to maximize the modularity $Q$ of the partition. We recursively apply this partitioning to build bottom-up levels $H_{1},...,H_{L}$ , stopping when the summary of a module fits within a single context window.
Causal Gates.
The prompt we used to build causal gates is shown in Figure 9. Constructing causal gates via exhaustive pairwise verification across all modules results in a quadratic time complexity $O(N^{2})$ , where $N$ is the total number of modules. Consequently, as the hierarchy depth scales, this becomes computationally prohibitive for LLM-based verification. To address this, we implement a Top-Down Hierarchical Pruning strategy that constructs gates layer-by-layer, from the coarsest semantic level ( $H_{L}$ ) down to $H_{1}$ . The core intuition leverages the transitivity of causality: if a causal link is established between two parent modules, it implicitly covers the causal flow between their respective sub-trees (see full algorithm in Algorithm 2).
The pruning process follows three key rules:
1. Layer-wise Traversal: We iterate from top ( $L$ ) (usually sparse) to bottom ( $1$ ) (usually dense).
1. Intra-layer Verification: We first identify causal connections between modules within the current layer.
1. Inter-layer Look-Ahead Pruning: When searching for connections between a module $u$ (current layer) and modules in the next lower layer ( $l-1$ ), we prune the search space by:
- Excluding $u$ ’s own children (handled by hierarchical inclusion).
- Excluding children of modules already causally connected to $u$ . If $u→ v$ is established, we assume the high-level connection covers the relationship, skipping individual checks for $Children(v)$ .
This strategy ensures that we only expend computational resources on discovering subtle, granular causal links that were not captured at higher levels, effectively reducing the complexity from quadratic to near-linear in practice.
Algorithm 2 Top-Down Hierarchical Pruning for Causal Gates
0: Hierarchy $\mathcal{H}=\{H_{0},H_{1},...,H_{L}\}$
0: Set of Causal Gates $\mathcal{G}_{c}$
1: $\mathcal{G}_{c}←\emptyset$
2: for $l=L$ down to $1$ do
3: for each module $u∈ H_{l}$ do
4: // 1. Intra-layer Verification
5: $ConnectedPeers←\emptyset$
6: for $v∈ H_{l}\setminus\{u\}$ do
7: if $\text{LLM\_Verify}(u,v)$ then
8: $\mathcal{G}_{c}.\text{add}((u,v))$
9: $ConnectedPeers.\text{add}(v)$
10: end if
11: end for
12: // 2. Inter-layer Pruning (Look-Ahead)
13: if $l>1$ then
14: $Candidates← H_{l-1}$
15: // Prune own children
16: $Candidates← Candidates\setminus Children(u)$
17: // Prune children of connected parents
18: for $v∈ ConnectedPeers$ do
19: $Candidates← Candidates\setminus Children(v)$
20: end for
21: // Only verify remaining candidates
22: for $w∈ Candidates$ do
23: if $\text{LLM\_Verify}(u,w)$ then
24: $\mathcal{G}_{c}.\text{add}((u,w))$
25: end if
26: end for
27: end if
28: end for
29: end forreturn $\mathcal{G}_{c}$
B.2 Online Retrieval
Hybrid Scoring and Diversity.
To robustly anchor the query, our scoring function combines semantic and lexical signals:
$$
s_{\alpha}(q,x)=\alpha\cdot\cos(\mathrm{Enc}(q),\mathrm{Enc}(x))+(1-\alpha)\cdot\mathrm{Lex}(q,x), \tag{5}
$$
where $\mathrm{Lex}(q,x)$ computes the normalized token overlap between the query and the node’s textual attributes (title and summary). We empirically set $\alpha=0.7$ to favor semantic matching while retaining keyword sensitivity for rare entities. To ensure seed diversity, we apply Maximal Marginal Relevance (MMR) selection. Instead of simply taking the Top- $K$ , we iteratively select seeds that maximize $s_{\alpha}$ while minimizing similarity to already selected seeds, ensuring the retrieval starts from complementary viewpoints.
Edge Type Weights.
In Equation 3, the weight function $w(\text{type}(e))$ controls the traversal behavior. We assign higher weights to Causal Gates ( $w=1.2$ ) and Hierarchical Links ( $w=1.0$ ) to encourage the model to leverage the organized structure, while assigning a lower weight to generic Structural Edges ( $w=0.8$ ) to suppress aimless local wandering.
B.3 Causal Path Reasoning
Graph Linearization Strategy.
To reason over the subgraph $S_{raw}$ within the LLM’s context window, we employ a linearization strategy that compresses heterogeneous graph evidence into a token-efficient format. Each evidence item $x∈ S_{raw}$ is mapped to a unique short identifier $\mathrm{ID}(x)$ . The LLM is provided with a compact list mapping these IDs to their textual content (e.g., “N1: [Entity Description]”). This allows the model to perform selection by outputting a sequence of valid identifiers (e.g., “[”N1”, ”R3”, ”N5”]”), minimizing token overhead.
Spurious-Aware Prompting.
To mitigate noise, we design two variants of the selection prompt (in Appendix A.1):
- Standard Selection: The model is asked to output only the IDs of valid causal paths.
- Spurious-Aware Selection (Ours): The model is explicitly instructed to differentiate valid causal links from spurious associations (e.g., coincidental co-occurrence) . By forcing the model to articulate (or internally tag) what is not causal, this strategy improves the precision of the final output list $S^{\star}$ .
In both cases, the output is directly parsed as the final set of evidence IDs to be retained for generation.
<details>
<summary>x8.png Details</summary>

### Visual Description
\n
## Text Document: Entity and Relationship Extraction Instructions
### Overview
The image presents a set of instructions for a task involving entity and relationship extraction from text documents. It outlines a four-step process, including examples and a designated output format. The document appears to be a guide for a natural language processing (NLP) or information extraction task.
### Components/Axes
The document is structured into sections delineated by horizontal lines and headings. Key components include:
* **Goal:** Describes the overall objective of the task.
* **Steps:** A numbered list detailing the procedure.
* **Examples:** Illustrative cases demonstrating the expected output.
* **Real Data:** A placeholder for input text and the corresponding output.
* **Delimiter:** The document specifies the use of "tuple\_delimiter" and "record\_delimiter" for formatting the output.
### Detailed Analysis or Content Details
The instructions can be broken down as follows:
**Step 1: Entity Identification**
* **Entity Name:** Capitalized name of the entity.
* **Entity Type:** One of the specified types (listed as `[entity_types]`).
* **Entity Description:** Comprehensive description of the entity's attributes and activities.
* **Output Format:** `<entity>"(tuple\_delimiter)<entity\_name>"(tuple\_delimiter)<entity\_type>"(tuple\_delimiter)<entity\_description>`
**Step 2: Relationship Extraction**
* **Source Entity:** Name of the source entity.
* **Target Entity:** Name of the target entity.
* **Relationship Description:** Explanation of why the source and target entities are related.
* **Relationship Strength:** A numeric score indicating the relationship's strength.
* **Output Format:** `<relationship>"(tuple\_delimiter)<source\_entity>"(tuple\_delimiter)<target\_entity>"(tuple\_delimiter)<relationship\_description>"(tuple\_delimiter)<relationship\_strength>`
**Step 3: Output Format**
* The output should be a single list of all entities and relationships.
* The delimiter for the list is `**record_delimiter**`.
**Examples:**
* **Example 1:**
* Text: "The Verdantis's ...."
* Output: `<entity>"(tuple\_delimiter)CENTRAL INSTITUTION"(tuple\_delimiter)ORGANIZATION"(tuple\_delimiter)The Central Institution is the Federal Reserve of Verdantis, which...`
* **Example 2:** (Incomplete)
* **Example 3:** (Incomplete)
**Real Data:**
* Entity types: `(entity_types)`
* Text: `(input_text)`
* Output: `(output)`
### Key Observations
* The document emphasizes a structured output format using specific delimiters.
* The examples are incomplete, suggesting the document is a template or work in progress.
* The task requires both identifying entities and understanding the relationships between them.
* The inclusion of "relationship strength" suggests a need for quantifying the connection between entities.
### Interpretation
This document serves as a detailed guide for a task focused on extracting structured information from text. It's designed to facilitate the creation of a knowledge graph or database by identifying key entities and the relationships that connect them. The use of "tuple\_delimiter" and "record\_delimiter" indicates a preference for a machine-readable output format, likely for integration with a database or other NLP systems. The incomplete examples suggest that the document is a template or a draft, and the specific entity types and input text would be provided separately. The emphasis on relationship strength suggests a desire to capture the nuance and importance of different connections between entities. The overall goal is to transform unstructured text into a structured representation of knowledge.
</details>
Figure 8: Prompt for LLM-based Information Extraction (modified from GraphRAG (Edge et al., 2024)). Used in Step 1 of Offline Construction.
<details>
<summary>x9.png Details</summary>

### Visual Description
\n
## Document: Causal Relationship Determination Protocol
### Overview
The image presents a structured document outlining a protocol for determining if a plausible causal relationship exists between two text snippets (A and B). It details the goal, steps, output format, and provides placeholders for real data and the final output. This is a procedural document, not a chart or diagram containing data to analyze.
### Components/Axes
The document is divided into sections, each labeled with a specific purpose:
* **-Goal-**: Defines the objective of the protocol.
* **-Steps-**: Lists the procedures to follow.
* **-Output-**: Specifies the expected output format.
* **-Real Data-**: Provides placeholders for input text snippets A and B.
* **Output:** Placeholder for the final result.
The steps are numbered 1 through 3. The document uses a consistent formatting style with labels prefixed by a hyphen.
### Detailed Analysis or Content Details
Here's a transcription of the document's content:
**-Goal-**
Given two text snippets A and B, decide whether there is any plausible causal relationship between them (either direction) under some reasonable context.
**-Steps-**
1. Read A and B, and consider whether one could plausibly influence the other (directly or indirectly).
2. Require a plausible mechanism; ignore mere correlation or co-occurrence.
3. If uncertain or only associative, choose ‘no’.
**-Output-**
Return exactly one token: ‘yes’ or ‘no’. No extra text.
#######################
**-Real Data-**
A: [a\_text]
B: [b\_text]
#######################
**Output:**
### Key Observations
The document is entirely procedural. It does not contain any data points or trends to analyze. It is a set of instructions. The formatting is consistent and clear, designed for a machine or human to follow a defined process.
### Interpretation
This document outlines a decision-making process for assessing causality between two pieces of text. It emphasizes the need for a *plausible mechanism* beyond simple correlation. The protocol is designed to be conservative, defaulting to "no" if there is any uncertainty. This suggests a focus on avoiding false positives in causal inference. The placeholders for "Real Data" indicate that this is a template intended to be populated with actual text snippets for analysis. The strict output requirement ("yes" or "no") suggests the protocol is intended for automated processing or a binary classification task. The document is a clear example of a rule-based system for evaluating a complex concept (causality) in a simplified manner.
</details>
Figure 9: Prompt for Binary Causal Gate Verification. Used to determine the existence of causal links between module summaries.
Appendix C Visualization of HugRAG’s Hierarchical Knowledge Graph
To provide an intuitive demonstration of HugRAG’s structural advantages, we present 3D visualizations of the constructed knowledge graphs for two datasets: HotpotQA (see Figure 11) and HolisQA-Biology (see Figure 10). In these visualizations, nodes and modules are arranged in vertical hierarchical layers. The base layer ( $H_{0}$ ), consisting of fine-grained entity nodes, is depicted in grey. The higher-level semantic modules ( $H_{1}$ to $H_{4}$ ) are colored by their respective hierarchy levels. Crucially, the Causal Gates —which bridge topologically distant modules—are rendered as red links. To ensure visual clarity and prevent edge occlusion in this dense representation, we downsampled the causal gates, displaying only a representative subset ( $r=0.2$ ).
<details>
<summary>x10.png Details</summary>
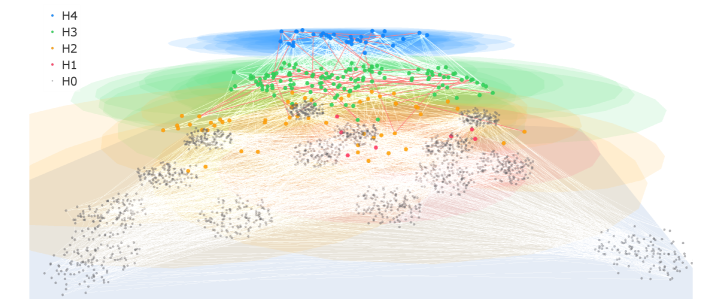
### Visual Description
\n
## Diagram: Network Visualization - Hierarchical Structure
### Overview
The image depicts a network visualization representing a hierarchical structure. The diagram consists of numerous nodes connected by lines, arranged in a layered fashion suggesting different levels of a hierarchy. The nodes are color-coded based on their hierarchical level (H0-H4), with connections indicating relationships between nodes at different levels. The density of nodes decreases as you move down the hierarchy.
### Components/Axes
The diagram does not have explicit axes in the traditional sense. However, the vertical arrangement represents hierarchical levels. The legend, located in the top-left corner, defines the color coding:
* H4 (Blue)
* H3 (Green)
* H2 (Yellow)
* H1 (Red)
* H0 (Orange)
The diagram is composed of nodes (dots) and edges (lines connecting the nodes). The nodes are distributed across the image, with a concentration at the top and a gradual dispersion towards the bottom. The lines connecting the nodes are thin and numerous, creating a complex network appearance.
### Detailed Analysis
The diagram can be conceptually divided into five horizontal layers corresponding to the hierarchical levels H0 through H4.
* **H4 (Blue):** Approximately 20-30 nodes are clustered at the very top of the diagram. These nodes are densely interconnected with lines primarily extending downwards to nodes in H3.
* **H3 (Green):** A layer below H4, containing roughly 50-60 nodes. These nodes are connected to both H4 (above) and H2 (below). The connections to H4 are more numerous than those to H2.
* **H2 (Yellow):** This layer has approximately 60-80 nodes. Connections extend from H3 (above) and to H1 (below).
* **H1 (Red):** Contains approximately 80-100 nodes. Connections extend from H2 (above) and to H0 (below).
* **H0 (Orange):** The bottom layer, with the highest number of nodes – approximately 150-200. These nodes are primarily connected to H1 (above) and have very few connections amongst themselves.
The lines connecting the nodes are not uniform in density. The connections are most dense between H4 and H3, and gradually decrease in density as you move down the hierarchy. The bottom layer (H0) has the sparsest connections.
There are a few isolated nodes in each layer that do not appear to be fully connected to the main network.
### Key Observations
* The network exhibits a clear hierarchical structure, with a decreasing number of nodes at each lower level.
* The connections are directional, flowing primarily from higher levels to lower levels.
* The density of connections decreases as you move down the hierarchy, suggesting a funneling effect.
* The bottom layer (H0) is the most populated but least connected.
* The top layer (H4) is the least populated but most densely connected.
### Interpretation
This diagram likely represents a system with a hierarchical organization, such as a decision-making process, a command structure, or a data flow diagram. The different levels (H0-H4) could represent different stages in a process, different levels of authority, or different categories of data.
The funneling effect suggests that information or control flows from the top levels to the bottom levels, with a convergence of inputs at the lower levels. The sparse connections within the bottom layer (H0) might indicate that the nodes at this level operate relatively independently or represent terminal points in the process.
The isolated nodes could represent outliers or nodes that are not fully integrated into the network.
The diagram provides a visual representation of the relationships between different entities within the system, highlighting the hierarchical structure and the flow of information or control. It could be used to analyze the network's efficiency, identify bottlenecks, or understand the impact of changes at different levels.
</details>
Figure 10: A 3D view of the Hierarchical Graph with Causal Gates constructed from HolisQA-biology dataset.
<details>
<summary>x11.png Details</summary>
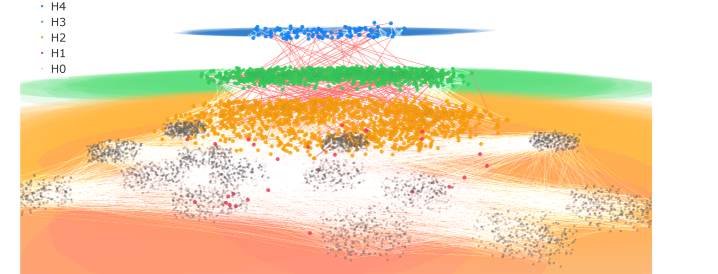
### Visual Description
\n
## Diagram: Network Visualization with Hierarchical Layers
### Overview
The image presents a network visualization diagram, likely representing connections or relationships between numerous nodes. The diagram is structured into hierarchical layers, denoted as H0 through H4, with nodes clustered and connected by lines. The visualization appears to show a flow or transition of data/connections from a dense lower layer (H0) upwards through intermediate layers (H1, H2, H3) to a sparser upper layer (H4). The diagram uses color to differentiate nodes within each layer.
### Components/Axes
The diagram is organized into five horizontal layers labeled H0 (bottom), H1, H2, H3, and H4 (top). There are no explicit axes in the traditional sense, but the vertical position represents a hierarchical level. The diagram uses color to distinguish nodes:
* **H0:** Orange/Brown
* **H1:** Yellow/Orange
* **H2:** Green
* **H3:** Pink/Red
* **H4:** Blue
The diagram consists of numerous small nodes (dots) connected by thin lines, representing relationships or flows between them. The density of nodes and connections varies significantly across layers.
### Detailed Analysis or Content Details
The diagram shows a significant concentration of nodes in the H0 and H1 layers. The H0 layer (orange/brown) is the most densely populated, with a large number of nodes clustered together. Connections extend upwards from H0 to H1, creating a complex web of lines.
The H1 layer (yellow/orange) is also densely populated, but less so than H0. Connections continue upwards from H1 to H2.
The H2 layer (green) has a moderate density of nodes, forming a more distinct cluster. Connections extend upwards from H2 to H3.
The H3 layer (pink/red) has a lower density of nodes, appearing more scattered. Connections extend upwards from H3 to H4.
The H4 layer (blue) is the least densely populated, with a small number of nodes. The lines connecting to H4 appear to originate from multiple nodes in H3.
The lines connecting the nodes are very thin and numerous, making it difficult to discern individual connections. The lines appear to be directed, suggesting a flow from lower layers to higher layers. There are also some connections *within* each layer, indicating relationships between nodes at the same hierarchical level.
There are a few darker, more prominent nodes within the H0 and H1 layers, suggesting they may represent more significant entities or hubs.
### Key Observations
* **Hierarchical Structure:** The diagram clearly demonstrates a hierarchical structure with five distinct layers.
* **Density Gradient:** Node density decreases as you move up the hierarchy, from H0 to H4.
* **Flow Direction:** The connections suggest a flow of information or relationships from lower layers to higher layers.
* **Hub Nodes:** The presence of darker nodes in H0 and H1 suggests the existence of central entities or hubs.
* **Complexity:** The diagram is highly complex, with a large number of nodes and connections, making it difficult to analyze individual relationships.
### Interpretation
This diagram likely represents a network or system with a hierarchical organization. The layers could represent different levels of abstraction, stages in a process, or categories of entities. The flow of connections from lower to higher layers suggests a process of aggregation, filtering, or transformation.
The decreasing density of nodes as you move up the hierarchy could indicate that information is being consolidated or that less detail is retained at higher levels. The hub nodes in the lower layers may represent key entities that play a central role in the system.
The diagram could be used to visualize a variety of systems, such as:
* **Social Networks:** Layers could represent different levels of social connection (e.g., friends, family, acquaintances).
* **Information Processing:** Layers could represent stages in a data processing pipeline (e.g., raw data, pre-processing, analysis, visualization).
* **Organizational Structure:** Layers could represent different levels of management within a company.
* **Biological Networks:** Layers could represent different levels of biological organization (e.g., genes, proteins, cells, tissues).
Without additional context, it is difficult to determine the specific meaning of the diagram. However, the hierarchical structure and flow of connections suggest a system where information or relationships are processed and transformed as they move through different levels of abstraction. The diagram is a visualization of relationships, and the specific meaning is dependent on the domain it represents.
</details>
Figure 11: A 3D view of the Hierarchical Graph with Causal Gates constructed from HotpotQA dataset.
Appendix D Case Study: A Real Example of the HugRAG Full Pipeline
To concretely illustrate the HugRAG full pipeline, we present a step-by-step execution trace on a query from the HolisQA-Biology dataset in Figure 12. The query asks for a comparison of specific enzyme activities (Apase vs. Pti-interacting kinase) in oil palm genotypes under phosphorus limitation—a task requiring the holistic comprehension of biology knowledge in HolisQA dataset.
<details>
<summary>x12.png Details</summary>

### Visual Description
\n
## Diagram: Research Process Flow - Palm Oil Adaptability
### Overview
This diagram illustrates a research process flow investigating the activity of acid phosphatase (Apase) and Pti-interacting serine/threonine kinase in oil palm genotypes under phosphorus limitation. The diagram depicts a query, stages of seed matching, post-hop subgraph analysis, causal LLM output, answer LLM output, and a gold answer. The flow is represented with downward arrows indicating progression.
### Components/Axes
The diagram is structured into several distinct blocks, arranged vertically. These blocks are:
1. **Query:** The initial research question.
2. **Seed Stage:** Matched seed IDs: [T1, T2, T3, T4, T5, T6, CAT, ES, ADA, INDONESIA...].
3. **Post n-Hop Subgraph:** Analysis of subgraph nodes and edges.
4. **Causal LLM output:** Precision and parameter settings.
5. **Answer LLM output:** Full prompt available in appendix.
6. **Gold Answer:** Summary of key findings.
There are no explicit axes in this diagram, but the vertical arrangement implies a temporal or sequential flow.
### Detailed Analysis or Content Details
**1. Query:**
"How does the activity of acid phosphatase (Apase) and Pti-interacting serine/threonine kinase differ in oil palm genotypes under phosphorus limitation, and what are the implications for their adaptability?"
**2. Seed Stage:**
* `seed (matched via short_id)`: [T1, T2, T3, T4, T5, T6, CAT, ES, ADA, INDONESIA...]
* `T2`: `[text_unit, score=0.4615] ols of PE direction and intensity, context-dependent microbial strategies, and the scarcity of long-term C balance assessments...`
* `T4`: `[text_unit, score=0.4615] activity in P-optimum was higher than starvation and deficiency in leaf and root tissues in both genotypes, whereas Pti serine/t...`
**3. Post n-Hop Subgraph:**
* `top_subgraph_nodes (by combined score), e.g.:`
* `E:idce66303-2b2c-472f-a964-da8b5529817d [SP (combined=0.4127)]`
* `E:345eb0d6-56fb-4878-a95c-99f01d28ce0d [CAT (combined=0.3832)]`
* `sample_subgraph_edges, e.g.:` `(up means lower level module to higher level module)`
* `struct:?+69up Xixia County Cornus Officinalis Pathogen Study in Henan -> Hebei-Liaoning-Yunnan Research Corridor (structural)`
* `struct:?+68up Hebei-Liaoning-Yunnan Research Corridor -> Xixia County Cornus Officinalis Pathogen Study in Henan (structural)`
* `struct:?+68up Jehol Biota & Yixian Formation in NE China -> Hebei-Liaoning-Yunnan Research Corridor (structural)`
**4. Causal LLM output:**
* `Identifying causal graph and spurious information (Full prompt available in appendix):`
* `['precise': 'T1', 'T4', ...]`
* `'cl_precise': 'T7', 'N9', ...]`
* `p_answer': 'Under phosphorus limitation in oil palm, Apase activity is expected to be induced (P deprivation), ...'`
**5. Answer LLM output:**
* `Generate final answer (Full prompt available in appendix):`
* `Acid phosphatase (Apase): In oil palm, Apase activity in leaves and roots is higher under Optimum than under starvation/deficiency in both genotypes. This indicates Apase is upregulated by phosphorus formation in the studied conditions, suggesting it may not be the main adaptive response to P deprivation here.`
* `Pti-interacting serine/threonine kinase: Activity is higher in P-deficiency versus non-prolific genotype specific under P-deficient conditions, indicating...`
**6. Gold Answer:**
* `Acid phosphatase, Apase, higher in P-optimum than starvation and deficiency in leaf and root tissues across both palm genotypes. Apase activity was higher under phosphate-replete conditions and in P-deficiency, together implying that the protein plays a non-prolific adaptive role. Pti-interacting serine/threonine kinase activity in P-deficiency was higher than that under optimum conditions. Apase activity in leaves and roots was higher...`
### Key Observations
The diagram highlights a research process that involves multiple stages of analysis, from initial query formulation to a final "gold answer." The LLM outputs suggest a focus on identifying causal relationships and spurious information. The key finding is that Apase activity is higher under optimal phosphorus conditions, suggesting a non-prolific adaptive role.
### Interpretation
This diagram represents a complex research workflow utilizing LLMs to analyze biological data related to oil palm adaptability under phosphorus limitation. The flow demonstrates a progression from a broad research question to specific findings about the activity of Apase and Pti-interacting serine/threonine kinase. The use of "precision" and "cl_precision" in the Causal LLM output suggests an attempt to refine the causal relationships identified. The "Gold Answer" provides a concise summary of the key findings, indicating that Apase activity is not directly linked to phosphorus deprivation as an adaptive response, but rather is higher under optimal conditions. The diagram suggests a sophisticated approach to biological research, leveraging LLMs for data analysis and causal inference. The inclusion of "full prompt available in appendix" indicates a transparency and reproducibility aspect to the research.
</details>
Figure 12: A real example of HugRAG on a biology-related query. The diagram visualizes the data flow from initial seed matching and hierarchical graph expansion to the causal reasoning stage, where the model explicitly filters spurious nodes to produce a grounded, high-fidelity answer.
Appendix E Experiments on the Effectiveness of Causal Gates
To isolate the real effectiveness of the causal gate in HugRAG, we conduct a controlled A/B test comparing gold context access with the gate disabled (off) versus enabled (on). The evaluation is performed on two datasets: NQ (Standard QA) and HolisQA. We define “Gold Nodes” as the graph nodes mapping to the gold context. Metrics are computed only on examples where gold nodes are mappable to the graph. While this section focuses on structural retrieval metrics, we evaluate the downstream impact of causal gates on final answer quality in our ablation study in Section 5.3.
Metrics.
We report four structural metrics to evaluate retrieval quality and efficiency. Shaded regions in Figure 13 denote 95% bootstrap confidence intervals. Reachability: The fraction of examples where at least one gold node is retrieved in the subgraph. Weighted Reachability (Depth-Weighted): A distance-sensitive metric defined as $\mathrm{DWR}=\frac{1}{1+\mathrm{min\_hops}}$ (0 if unreachable), rewarding retrieval at smaller graph distances. Coverage: The average proportion of total gold nodes retrieved per example. Min Hops: The mean shortest path length to gold nodes, computed on examples reachable in both off and on settings.
As shown in Figure 13, enabling the causal gate yields distinct behaviors across datasets. On the more complex HolisQA dataset, the gate provides a statistically significant improvement in reachability and coverage. This confirms that causal edges effectively bridge structural gaps in the graph that are otherwise traversed inefficiently. The increase in Weighted Reachability and decrease in min hops indicate that the gate not only finds more evidence but creates structural shortcuts, allowing the retrieval process to access evidence at shallower depths.
<details>
<summary>x13.png Details</summary>
### Visual Description
## Chart: Performance Comparison of QA Datasets
### Overview
The image presents a series of four line plots, each comparing the performance of two QA datasets – “HolisQA Dataset” and “Standard QA Dataset” – across four different metrics: Reachability, W. Reachability, Coverage, and Min Hops. Each plot displays the performance for “off” and “on” conditions of an unspecified parameter. The plots use line plots with shaded confidence intervals to represent the data.
### Components/Axes
* **X-axis:** Labeled as “off” and “on”. Represents two conditions or settings.
* **Y-axis:** Each plot has a different Y-axis scale, representing the performance metric.
* Reachability: Scale ranges from approximately 0.7 to 0.95.
* W. Reachability: Scale ranges from approximately 0.55 to 0.85.
* Coverage: Scale ranges from approximately 0.15 to 0.45.
* Min Hops: Scale ranges from approximately 0.45 to 1.55.
* **Legend:** Located at the top-right of the image.
* Blue dotted line: “HolisQA Dataset”
* Red dotted line: “Standard QA Dataset”
* **Plots:** Four individual line plots arranged horizontally. Each plot represents a different metric.
* Reachability
* W. Reachability
* Coverage
* Min Hops
### Detailed Analysis or Content Details
**1. Reachability:**
* HolisQA Dataset (Blue): Line slopes downward from approximately 0.92 at “off” to approximately 0.78 at “on”.
* Standard QA Dataset (Red): Line is relatively flat, starting at approximately 0.88 at “off” and ending at approximately 0.85 at “on”.
* Confidence intervals are wide for both datasets, indicating high variability.
**2. W. Reachability:**
* HolisQA Dataset (Blue): Line slopes downward from approximately 0.78 at “off” to approximately 0.62 at “on”.
* Standard QA Dataset (Red): Line slopes downward from approximately 0.72 at “off” to approximately 0.58 at “on”.
* Confidence intervals are wide for both datasets.
**3. Coverage:**
* HolisQA Dataset (Blue): Line slopes upward from approximately 0.22 at “off” to approximately 0.40 at “on”.
* Standard QA Dataset (Red): Line slopes upward from approximately 0.18 at “off” to approximately 0.25 at “on”.
* Confidence intervals are wide for both datasets.
**4. Min Hops:**
* HolisQA Dataset (Blue): Line slopes downward from approximately 1.25 at “off” to approximately 0.95 at “on”.
* Standard QA Dataset (Red): Line slopes downward from approximately 0.85 at “off” to approximately 0.55 at “on”.
* Confidence intervals are wide for both datasets.
### Key Observations
* For Reachability, W. Reachability, and Min Hops, the HolisQA dataset generally exhibits higher values at the “off” condition but decreases more significantly when switched to “on” compared to the Standard QA dataset.
* For Coverage, both datasets show an increase when switching from “off” to “on”, but the HolisQA dataset shows a more substantial increase.
* The confidence intervals are consistently wide across all metrics and datasets, suggesting substantial variance in the data.
### Interpretation
The data suggests that the “off” and “on” conditions have a differential impact on the performance of the two QA datasets across the four metrics. The HolisQA dataset appears to be more sensitive to the change in condition, showing larger performance swings than the Standard QA dataset. The wide confidence intervals indicate that the observed differences may not be statistically significant, or that the underlying data is highly variable.
The metrics themselves suggest different aspects of QA performance:
* **Reachability & W. Reachability:** Likely relate to the ability of the QA system to access relevant information.
* **Coverage:** Indicates the breadth of information the system can handle.
* **Min Hops:** Suggests the efficiency of the QA process, potentially measuring the number of steps required to find an answer.
The fact that HolisQA shows a larger decrease in Reachability, W. Reachability, and Min Hops when switching to “on” could indicate that it relies more heavily on a specific feature or setting that is disabled in the “on” condition. Conversely, the larger increase in Coverage for HolisQA suggests it benefits more from the “on” condition in terms of expanding its knowledge base. Further investigation is needed to understand the nature of the “off” and “on” conditions and the underlying reasons for these performance differences.
</details>
Figure 13: Experiments on Causal Gate effectiveness. We compare graph traversal performance with the causal gate disabled (off) versus enabled (on). Shaded areas represent 95% bootstrap confidence intervals. The causal gate significantly improves evidence accessibility (Reachability, Coverage) and traversal efficiency (lower Min Hops, higher Weighted Reachability).
Appendix F Evaluation Details
F.1 Detailed Graph Statistics
We provide the complete statistics for all knowledge graphs constructed in our experiments. Table 5 details the graph structures for the five standard QA datasets, while Table 6 covers the five scientific domains within the HolisQA dataset.
Table 5: Graph Statistics for Standard QA Datasets. Detailed breakdown of nodes, edges, and hierarchical module distribution.
| Dataset | Nodes | Edges | L3 | L2 | L1 | L0 | Modules | Domain | Chars |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| HotpotQA | 20,354 | 15,789 | 27 | 1,344 | 891 | 97 | 2,359 | Wikipedia | 2,855,481 |
| MS MARCO | 3,403 | 3,107 | 2 | 159 | 230 | 55 | 446 | Web | 1,557,990 |
| NQ | 5,579 | 4,349 | 2 | 209 | 244 | 50 | 505 | Wikipedia | 767,509 |
| QASC | 77 | 39 | - | - | - | 4 | 4 | Science | 58,455 |
| 2WikiMultiHop | 10,995 | 8,489 | 8 | 461 | 541 | 78 | 1,088 | Wikipedia | 1,756,619 |
Table 6: Graph Statistics for HolisQA Datasets. Graph structures constructed from dense academic papers across five scientific domains.
| Holis-Biology | 1,714 | 1,722 | - | 30 | 104 | 31 | 165 | Biology | 1,707,489 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Holis-Business | 2,169 | 2,392 | 8 | 77 | 166 | 41 | 292 | Business | 1,671,718 |
| Holis-CompSci | 1,670 | 1,667 | 7 | 28 | 91 | 30 | 158 | CompSci | 1,657,390 |
| Holis-Medicine | 1,930 | 2,124 | 7 | 56 | 129 | 34 | 226 | Medicine | 1,706,211 |
| Holis-Psychology | 2,019 | 1,990 | 5 | 45 | 126 | 35 | 211 | Psychology | 1,751,389 |
F.2 HolisQA Dataset
We introduce HolisQA, a comprehensive dataset designed to evaluate the holistic comprehension capabilities of RAG systems, explicitly addressing the ”node finding” bias prevalent in existing QA datasets—where retrieving a single entity (e.g., a year or name) is often sufficient. Our goal is to enforce holistic comprehension, compelling models to synthesize coherent evidence from multi-sentence contexts.
We collected high-quality scientific papers across multiple domains as our primary source (Priem et al., 2022), focusing exclusively on recent publications (2025) to minimize parametric memorization by the LLM. The dataset spans five distinct domains—Biology, Business, Computer Science, Medicine, and Psychology—to ensure domain robustness (see full statistics in Table 6). To necessitate cross-sentence reasoning, we avoid random sentence sampling; instead, we extract contiguous text slices from papers within each domain. Each slice is sufficiently long to encapsulate multiple interacting claims (e.g., Problem $→$ Method $→$ Result) yet short enough to remain self-contained, thereby preserving the logical coherence and contextual foundation required for complex reasoning. Subsequently, we employ a rigorous LLM-based generation pipeline to create Question-Answer-Context triples, imposing two strict constraints (as detailed in Figure 14):
1. Integration Constraint: The question must require integrating information from at least three distinct sentences. We explicitly reject trivia-style questions that can be answered by a single named entity (e.g., ”Who founded X?”).
1. Evidence Verification: The generation process must output the IDs of all supporting sentences. We validate the dataset via a necessity check, verifying that the correct answer cannot be derived if any of the cited sentences are removed.
Through this strict construction pipeline, HolisQA effectively evaluates the model’s ability to perform holistic comprehension and isolate it from parametric knowledge, providing a cleaner signal for evaluating the effectiveness of structured retrieval mechanisms.
<details>
<summary>x14.png Details</summary>

### Visual Description
\n
## Text Document: Reading-Comprehension Dataset Instructions
### Overview
The image presents a set of instructions for building a reading-comprehension dataset. The instructions detail the format of the input data (slices of sentences from a long document) and the desired output (question-answer pairs in JSON array format). The emphasis is on creating questions that require multi-sentence reasoning and understanding of the overall context, avoiding simple factual recall.
### Components/Axes
The document consists of a series of paragraphs outlining the requirements for the dataset creation process. Key elements include:
* **Title:** "You are building a reading-comprehension dataset."
* **Input Description:** Explains that the input will be slices of sentences, each starting with a sentence ID, followed by a tab, and then the sentence text.
* **Output Requirements:** Specifies that the output should be question-answer pairs in JSON array format.
* **Question Guidelines:** Questions should require multi-sentence reasoning and understanding of the overall slice. Avoid short factual questions, named-entity trivia, or single-sentence lookups.
* **JSON Structure:** Details the required structure of each JSON item:
* `"question": string`
* `"answer": string (2-4 sentences)`
* `"context_sentence_ids": array of {min_context}-{max_context} IDs`
* **Return Format:** Specifies that only JSON should be returned, with no extra text.
* **Placeholder:** "Sentences: {slice_text}" indicating where the input sentence slice will be placed.
### Detailed Analysis / Content Details
The document provides a precise set of instructions. The core requirements are:
1. **Input Format:** Sentences are provided as a slice, identified by an ID and separated by a tab.
2. **Output Format:** The output must be a JSON array of question-answer pairs.
3. **Question Complexity:** Questions should not be easily answered by looking at a single sentence or by simply recalling facts. They should require integrating information from multiple sentences within the provided slice.
4. **JSON Structure:** Each JSON object must contain a question, an answer (2-4 sentences long), and an array of context sentence IDs. The context sentence IDs should indicate which sentences from the input slice were used to answer the question.
5. **Output Purity:** The output should consist *only* of the JSON array, without any surrounding text or explanations.
### Key Observations
The instructions are very specific and aim to create a challenging reading-comprehension dataset. The emphasis on multi-sentence reasoning and the avoidance of trivial questions suggest a focus on evaluating deeper understanding of text. The inclusion of `context_sentence_ids` is crucial for traceability and understanding the reasoning process behind each answer.
### Interpretation
This document outlines the requirements for generating a high-quality reading-comprehension dataset. The goal is to move beyond simple question-answering tasks and create a dataset that assesses a model's ability to understand the relationships between sentences and draw inferences from a larger context. The JSON format and the requirement for context sentence IDs are designed to facilitate the evaluation of these reasoning abilities. The placeholder "{slice_text}" indicates that the actual text content will be provided separately, and the dataset creation process will involve generating questions and answers based on this input text. The instructions are clear and concise, leaving little room for ambiguity in the dataset creation process.
</details>
Figure 14: Prompt for generating the Holistic Comprehension Dataset (Question-Answer-Context Triplets) from academic papers.
F.3 Implementation
Backbone Models.
We consistently use OpenAI’s gpt-5-nano with a temperature of 0.0 to ensure deterministic generation. For vector embeddings, we employ the Sentence-BERT (Reimers and Gurevych, 2019) version of all-MiniLM-L6-v2 with a dimensionality of 384. All evaluation metrics involving LLM-as-a-judge are implemented using the Ragas framework (Es et al., 2024), with Gemini-2.5-Flash-Lite serving as the underlying evaluation engine.
Baseline Parameters.
To ensure a fair comparison among all graph-based RAG methods, we utilize a unified root knowledge graph (see Appendix B.1 for construction details). For the retrieval stage, we set a consistent initial $k=3$ across all baselines. Other parameters are kept at their default values to maintain a neutral comparison, with the exception of method-specific configurations (e.g., global vs. local modes in GraphRAG) that are essential for the algorithm’s execution. All experiments were conducted on a high-performance computing cluster managed by Slurm. Each evaluation task was allocated uniform resources consisting of 2 CPU cores and 16 GB of RAM, utilizing 10-way job arrays for concurrent query processing.
F.4 Grounding Metrics and Evaluation Prompts
We assess performance using two categories of metrics: (i) Lexical Overlap (F1 score), which measures surface-level similarity between model outputs and gold answers; and (ii) LLM-as-judge metrics, specifically Context Recall and Answer Relevancy, computed using a fixed evaluator model to ensure consistency (Es et al., 2024). To guarantee stable and fair comparisons across baselines with varying retrieval outputs, we impose a uniform cap on the retrieved context length and the number of items passed to the evaluator. The specific prompt template used for assessing Answer Relevancy is illustrated in Figure 15.
<details>
<summary>x15.png Details</summary>

### Visual Description
\n
## Text Document: Core Template & Answer Relevancy Prompt
### Overview
The image presents a text document outlining instructions for generating JSON output based on a given schema and a prompt for assessing answer relevancy. The document is formatted with Markdown headings and includes examples to illustrate the expected behavior.
### Components/Axes
The document is structured into sections denoted by Markdown headings:
* `### Core Template`: Describes the JSON output format requirement.
* `### Answer Relevancy prompt`: Explains the criteria for determining answer noncommittal status.
* `### Examples`: Provides illustrative input-output pairs for both sections.
### Detailed Analysis or Content Details
**Core Template Section:**
* **Instruction:** "Please return the output in a JSON format that complies with the following schema as specified in JSON Schema: {output\_schema}Do not use single quotes in your response but double quotes, properly escaped with a backslash."
* **Examples:** A horizontal line separates the instruction from the example section.
* **Input:** `input: {input_json}`
* **Output:** `Output:`
**Answer Relevancy Prompt Section:**
* **Prompt:** "Generate a question for the given answer and identify if the answer is noncommittal. Give noncommittal as 1 if the answer is noncommittal (evasive, vague, or ambiguous) and 0 if the answer is substantive. Examples of noncommittal answers: 'I don't know', 'I'm not sure', 'It depends'."
**Examples Section:**
* **Example 1:**
* **Input:** `{“response”: “Albert Einstein was born in Germany.”}`
* **Output:** `[“question”: “Where was Albert Einstein born?”, “noncommittal”: 0]`
* **Example 2:**
* **Input:** `{“response”: “The capital of France is Paris, a city known for its architecture and culture.”}`
* **Output:** `[“question”: “What is the capital of France?”, “noncommittal”: 0]`
* **Example 3:**
* **Input:** `{“response”: “I don’t know about the groundbreaking feature of the smartphone invented in 2023 as I am unaware of information beyond 2022.”}`
* **Output:** `[“question”: “What was the groundbreaking feature of the smartphone invented in 2023?”, “noncommittal”: 1]`
### Key Observations
* The document emphasizes the importance of adhering to a specific JSON schema.
* The prompt for answer relevancy focuses on identifying responses that lack definitive information.
* The examples clearly demonstrate the expected input and output formats for both tasks.
* The use of backslashes to escape double quotes within the JSON output is explicitly mentioned.
### Interpretation
The document serves as a technical specification for a system designed to process natural language responses and generate structured JSON output. The "Core Template" section defines the output format, while the "Answer Relevancy Prompt" section introduces a mechanism for evaluating the quality and informativeness of the responses. The examples provide concrete illustrations of how the system should behave in different scenarios. The overall goal appears to be to create a system that can not only extract information from text but also assess its reliability and relevance. The emphasis on JSON formatting suggests that the system is intended to be integrated with other applications or services that require structured data. The noncommittal flag is a useful feature for filtering out unreliable or unhelpful responses.
</details>
Figure 15: Example prompt used in RAGAS: Core Template and Answer Relevancy (Es et al., 2024).