# 1 Introduction
marginparsep has been altered. topmargin has been altered. marginparwidth has been altered. marginparpush has been altered. The page layout violates the ICML style. Please do not change the page layout, or include packages like geometry, savetrees, or fullpage, which change it for you. We’re not able to reliably undo arbitrary changes to the style. Please remove the offending package(s), or layout-changing commands and try again.
Quantifying Edge Intelligence: Inference-Time Scaling Formalisms for Heterogeneous Computing
Anonymous Authors 1
Abstract
Large language model (LLM) inference on resource-constrained edge devices presents a fundamental challenge at the intersection of machine learning and systems design. While training-time scaling behavior has been extensively characterized, the scaling behavior of inference under heterogeneous hardware constraints remains poorly understood. In this work, we introduce QEIL (Quantifying Edge Intelligence via Inference-time Scaling Formalisms), a unified framework for characterizing and optimizing inference-time performance across heterogeneous edge devices spanning CPUs, GPUs, and NPUs.
We empirically identify stable scaling relationships governing inference-time coverage, energy, and latency across transformer-based models and heterogeneous hardware configurations. We observe that these relationships generalize across multiple transformer model families spanning 125M–2.6B parameters. Our findings suggest that inference efficiency follows predictable power-law patterns within transformer-based architectures, and that heterogeneous orchestration i.e the intelligent coordination and scheduling of computational workloads across diverse processing units—such as CPUs, GPUs, and NPUs to enable systematic improvements in energy efficiency and task coverage beyond homogeneous execution. Building on these observations, we propose three composite efficiency metrics—Intelligence Per Watt (IPW), Energy-Coverage Efficiency (ECE), and Price-Power-Performance (PPP)—to unify multi-objective optimization across heterogeneous inference configurations.
Critically, QEIL introduces a safety-first agentic orchestration framework for heterogeneous edge environments. Our intelligent agentic orchestrator not only distributes workloads across accelerators from both the same vendor (e.g., Intel CPU paired with Intel NPU and Intel Graphics) and different vendors (e.g., Intel processors combined with NVIDIA GPUs), but also implements comprehensive reliability and AI safety mechanisms —including thermal throttling protection, fault-tolerant execution with graceful degradation, adversarial robustness through input validation, and hardware health monitoring. We adopt a safety-first, capability-second design philosophy, ensuring that model inferencing operates within safe thermal and power envelopes to prevent device damage, even at the cost of reduced peak efficiency. This approach enables building fault-tolerant edge AI systems that prioritize end-user experience and device longevity over raw performance.
Across five model families (GPT-2, Granite-350M, Qwen2-0.5B, Llama-3.2-1B, LFM2-2.6B), QEIL achieves consistent gains in energy efficiency, latency, and coverage without compromising accuracy or system safety. Our results indicate that inference-time scaling and heterogeneous hardware orchestration jointly define a previously underexplored optimization regime for edge AI deployment. These findings suggest that principled inference-time scaling formalisms can complement training-time scaling, offering a systematic framework for designing energy-efficient, reliable, and safe edge intelligence systems.
Problem Statement
The rapid proliferation of AI agents and edge computing applications has fundamentally transformed the landscape of AI deployment. As AI workloads transition from centralized cloud infrastructure to distributed edge environments, the challenge of efficient inference on resource-constrained heterogeneous devices has emerged as a critical bottleneck for democratizing AI access. Equally important, edge deployment introduces critical safety and reliability concerns: devices must operate within thermal limits to prevent hardware damage, systems must gracefully handle hardware failures, and inference must be robust to adversarial inputs—concerns that are secondary in datacenter environments but paramount for consumer-facing edge applications.
Asgar et al. Asgar et al. (2025) recently presented a seminal systems-level framework for agentic AI workloads across heterogeneous infrastructure, introducing MLIR-based representations and dynamic cost-aware orchestration for datacenter-scale deployments. Their work made several foundational contributions: (1) demonstrating that AI agent workloads can be decomposed into granular components exhibiting distinct sensitivity to hardware resources (TFLOPS, memory bandwidth, network bandwidth), (2) formulating inference execution as a constrained optimization problem over task graphs, and (3) showing that heterogeneous configurations—combining accelerators from different vendors and performance tiers—can deliver comparable or superior TCO to homogeneous frontier infrastructure. Their preliminary finding that H100::Gaudi3 configurations can match B200::B200 performance represents a paradigm shift in infrastructure economics.
However, Asgar et al.’s framework, while transformative for datacenter-scale agentic AI, leaves several critical gaps when applied to resource-constrained edge computing environments:
(1) Edge-Specific Resource Constraints: Datacenter orchestration assumes abundant computational resources, high-bandwidth interconnects (RoCE, InfiniBand), and effectively unlimited power budgets. Edge devices operate under fundamentally different constraints: strict power envelopes (5-85W vs. 300W+ datacenter GPUs), limited memory capacity (8-128GB vs. terabyte-scale), thermal throttling in fanless enclosures, and intermittent network connectivity. Asgar et al.’s optimization framework does not model these edge-specific constraints.
(2) Scaling Relationship Characterization: While Asgar et al. demonstrated TCO benefits through heterogeneous orchestration, they did not establish empirically grounded scaling formalisms quantifying how coverage, energy, and latency scale as functions of model parameters, sample budget, and device characteristics—the foundational insight required to systematically optimize edge inference systems where every joule matters.
(3) Multi-Vendor Edge Heterogeneity: Edge deployments increasingly feature heterogeneous hardware from multiple vendors within a single device (e.g., Intel CPU + Intel NPU + NVIDIA GPU, or Qualcomm NPU + ARM CPU). Asgar et al.’s framework focused on datacenter accelerators (H100, Gaudi3, B200) and did not address the unique challenges of orchestrating across consumer-grade, mixed-vendor edge hardware with vastly different driver stacks, memory hierarchies, and power characteristics.
(4) Distributed Edge Orchestration: Beyond single-device heterogeneity, edge computing increasingly requires distributed orchestration across multiple edge nodes—IoT gateways, mobile edge servers, and embedded devices—each with distinct capabilities. This distributed, resource-constrained paradigm requires fundamentally different optimization approaches than the rack-scale homogeneity assumed in datacenter designs.
(5) Safety, Reliability, and Fault Tolerance: Perhaps most critically, datacenter frameworks assume professionally managed infrastructure with redundant cooling, power backup, and 24/7 monitoring. Edge devices operate in uncontrolled environments—laptops on laps generating heat, mobile devices in direct sunlight, IoT sensors in temperature extremes. A safety-first design philosophy that prioritizes device health over peak performance is essential for consumer-grade edge AI, yet existing frameworks optimize purely for efficiency without considering thermal safety margins, graceful degradation under hardware stress, or adversarial robustness.
Two additional recent works have addressed complementary aspects of this challenge. Brown et al. Brown et al. (2024) observed that inference-time compute scaling through repeated sampling yields log-linear coverage improvements, achieving 4.8× performance gains on SWE-bench by amplifying weaker models through increased sampling. However, their framework focused on single-device, homogeneous execution without addressing heterogeneous hardware orchestration. Saad-Falcon et al. Saad-Falcon et al. (2025) introduced Intelligence Per Watt (IPW) as a unified metric for local inference viability, demonstrating 60-80% energy reductions through intelligent query routing. However, their analysis remained at query-level routing granularity and did not characterize sub-query-level optimization where different inference stages can be distributed across heterogeneous devices.
The Gap We Address: Building directly on Asgar et al.’s foundational insight that heterogeneous orchestration enables cost-efficient AI deployment, we extend their framework to resource-constrained edge computing environments by: (1) establishing empirically grounded scaling formalisms quantifying inference scaling behavior on edge hardware, (2) introducing agentic orchestration capabilities for multi-vendor heterogeneous edge configurations, (3) demonstrating that principled scaling characterization enables systematic optimization under strict power, memory, and latency constraints that define edge deployment scenarios, and (4) implementing a safety-first design philosophy with fault-tolerant execution, thermal protection, and adversarial robustness that ensures reliable end-user experiences on consumer-grade hardware. Our work thus bridges the gap between datacenter-scale heterogeneous AI infrastructure (Asgar et al.) and the resource-constrained, safety-critical reality of edge AI deployment.
Our Framework: QEIL and Heterogeneous Edge Optimization
We address these gaps by introducing QEIL (Quantifying Edge Intelligence via Inference-time Scaling Formalisms), a unified mathematical and systems framework for efficient LLM inference on heterogeneous edge infrastructure spanning CPU, GPU, and NPU devices from both single and multiple vendors. Our framework makes four core contributions that extend Asgar et al.’s datacenter-focused approach to the edge computing paradigm:
First, we empirically identify five stable scaling formalisms quantifying how inference efficiency scales with fundamental parameters under edge constraints. We observe that coverage scales according to $C(S)=1-\exp(-\alpha N^{\beta_{N}}S^{\beta_{S}})$ with scaling exponents $\beta_{N}≈ 0.7$ and $\beta_{S}≈ 0.7$ that remain consistent across transformer-based architectures; energy scales sub-linearly with model size as $E(S)=E_{0}· f(Q)· N^{\gamma_{E}}· T· S$ with $\gamma_{E}≈ 0.9$ ; cost follows similar scaling with device-specific multipliers; and latency scales with parallelism factors. These formalisms extend Brown et al.’s empirical observation of log-linear scaling and Asgar et al.’s cost-aware optimization to a complete framework spanning energy, cost, and latency dimensions across heterogeneous edge devices with strict resource constraints.
Second, we introduce novel composite efficiency metrics —Energy-Coverage Efficiency (ECE), Intelligence Per Watt (IPW), and Price-Power-Performance (PPP) score—that unify the multi-objective optimization problem for edge deployment. Unlike IPW alone (which captures instantaneous power efficiency), these metrics enable principled comparison across heterogeneous configurations by explicitly modeling the energy-coverage and cost-coverage trade-offs inherent to battery-powered and thermally-constrained edge inference.
Third, we propose agentic heterogeneous orchestration leveraging MLIR-based compilation and cost-aware task placement (extending Asgar et al.’s datacenter framework) specialized for resource-constrained edge workloads. Our system decomposes inference into granular operations and routes each to the most cost-efficient device—whether from the same vendor (Intel CPU + Intel NPU + Intel Graphics) or different vendors (Intel processors + NVIDIA GPU)—achieving simultaneous improvements in coverage, latency, and energy compared to homogeneous baselines while respecting edge-specific power and memory constraints.
Fourth, we implement a comprehensive safety and reliability framework that treats the heterogeneous orchestrator as an intelligent agentic optimizer responsible not only for performance optimization but also for system health and user safety. This includes: (a) thermal throttling protection that proactively reduces workload intensity when device temperatures approach safe limits, preventing overheating-induced hardware damage; (b) fault-tolerant execution with graceful degradation that automatically redistributes workloads when individual devices fail or become unavailable; (c) adversarial robustness through input validation and anomaly detection that prevents malicious inputs from causing system instability; and (d) hardware health monitoring that tracks device utilization, temperature, and error rates to predict and prevent failures. Our “safety-first, capability-second” philosophy accepts modest efficiency trade-offs (typically 3-5%) to guarantee reliable operation —a critical requirement for consumer-facing edge applications where device damage or system crashes destroy user trust.
Evaluating QEIL across five diverse model families on WikiText—GPT-2 (125M), Granite-350M, Qwen2-0.5B, Llama-3.2-1B, and LFM2-2.6B—across standard (throughput-optimized) and energy-aware (efficiency-optimized) execution paradigms on CPU, GPU, and NPU devices, we observe: (1) 4.82–5.6× improvement in Intelligence Per Watt (0.718–0.807 vs. 0.130–0.245 baseline), (2) 47.7–78% total energy reduction across models (22,487.8J–212,953.7J vs. baseline), (3) 66.5–70% pass@k coverage versus 56–63% baseline, (4) average 22.5% latency improvement (1.34–1.66ms vs. 1.73–1.91ms), (5) average 22.9% PPP score improvement (15.49–25.91 vs. 10.44–19.51), and (6) zero thermal throttling events and 100% fault recovery rate under simulated hardware stress, all without sacrificing model accuracy. These results suggest that heterogeneous edge inference—combined with principled scaling characterization and safety-first design—consistently outperforms homogeneous cloud deployment across diverse model architectures and parameter ranges, indicating generalizability across the transformer model landscape and validating the extension of Asgar et al.’s heterogeneous orchestration paradigm to resource-constrained, safety-critical edge environments.
Primary Contributions
This work makes six primary contributions to edge AI and inference time scaling:
- We present QEIL, the first framework combining inference-time scaling formalisms with heterogeneous hardware orchestration across CPU, GPU, and NPU devices, extending Asgar et al.’s datacenter-focused heterogeneous AI framework to resource-constrained edge computing environments. We empirically identify five stable scaling relationships showing that coverage, energy, cost, and latency follow predictable power-law relationships dependent on model parameters $N$ , sample budget $S$ and tokens per sample $T$ . We validate these formalisms empirically across five diverse transformer model families (125M–2.6B parameters: GPT-2, Granite-350M, Qwen2-0.5B, Llama-3.2-1B, LFM2-2.6B), demonstrating generalizability within the transformer architecture family on our tested hardware platform.
- We introduce a dual of unified efficiency metrics—Energy-Coverage Efficiency (ECE: coverage per joule of total energy), and Price-Power-Performance (PPP: dimensionless cost-power-throughput balance)—that enable systematic comparison of heterogeneous configurations and explicit optimization of multi-objective edge inference trade-offs. These metrics reflect the fundamental constraints of battery-operated edge devices while capturing end-to-end system efficiency, validated across five diverse models.
- We observe 4.82–5.6× improvement in Intelligence Per Watt through agentic heterogeneous orchestration across CPU, GPU, and NPU from both same-vendor and multi-vendor configurations, achieving 66.5–70% pass@k coverage with 47.7–78% energy reduction and 22.5% average latency improvement simultaneously—indicating that heterogeneous edge inference can surpass homogeneous cloud infrastructure for realistic workloads across diverse model families. This combination of coverage, energy, and latency improvements directly validates our scaling formalisms in practice.
- We find empirically that inference-time scaling relationships exhibit consistent patterns across transformer model families (125M to 2.6B parameters: GPT-2, Granite, Qwen, Llama, LFM), parameter counts, and diverse reasoning benchmarks (WikiText-103, GSM8K, ARC-Challenge) through comprehensive experimental evidence and ablation studies. Our framework demonstrates stable scaling exponents across diverse model sizes and architectures on our tested platform, enabling practitioners to apply these insights within the transformer family.
- We introduce a unified heterogeneous computing framework with MLIR-based compilation, cost-aware orchestration, and scaling relationship validator—enabling reproducible edge intelligence benchmarking validated across five model families and empowering future research to build on these foundations. The framework supports diverse transformer architectures, diverse hardware from multiple vendors (Intel NPU, Qualcomm NPU, NVIDIA GPU, AMD accelerators), and principled optimization under latency/energy/cost SLAs, demonstrating the practical viability of agentic orchestration in resource-constrained edge environments.
- We introduce a safety-first reliability framework that implements thermal protection, fault-tolerant execution, adversarial robustness, and hardware health monitoring as first-class concerns in heterogeneous edge orchestration. By treating the orchestrator as an intelligent agentic optimizer responsible for both performance and system health, we demonstrate that “safety-first, capability-second” design achieves robust, reliable operation with minimal efficiency overhead (3-5%), enabling practical deployment on consumer-grade hardware where device longevity and user experience are paramount. This contribution addresses the critical gap between research prototypes and production-ready edge AI systems.
2 Related Work
2.1 Inference-Time Scaling and Repeated Sampling
Recent advances in inference-time compute have emerged as a powerful complement to training-time scaling. Brown et al. (2024) observed that coverage—the fraction of problems solved by any generated sample—scales log-linearly with the number of samples, establishing empirical inference scaling relationships across coding, mathematical reasoning, and formal proof domains. Their work showed that on SWE-bench Lite, repeated sampling increased issue resolution from 15.9% with a single attempt to 56% with 250 attempts, suggesting that inference-compute scaling enables weaker models to surpass stronger single-sample baselines when equipped with sufficient sampling budget. However, their analysis was restricted to uniform sampling budgets and single-device execution without heterogeneous hardware considerations, leaving open the question of how to optimally allocate samples across heterogeneous edge infrastructure with varying energy and computational constraints. Hassid et al. (2024) complemented this by exploring budget reallocation strategies, showing that when constrained by fixed compute budgets (measured in FLOPs), smaller models with more samples can outperform larger models with fewer attempts—a principle foundational to our heterogeneous orchestration strategy.
2.2 Intelligence Efficiency and Local-Cloud Hybrid Systems
The viability of local inference on edge devices has been systematically characterized through the lens of efficiency metrics. Saad-Falcon et al. (2025) introduced Intelligence Per Watt (IPW)—accuracy divided by instantaneous power consumption—as a unified metric for assessing local inference viability on 1M real-world queries across 20 models and 8 hardware accelerators. Their longitudinal analysis from 2023-2025 revealed that IPW improved 5.3× through compounding advances in both model architectures (3.1× gains) and hardware accelerators (1.7× gains), with local LM coverage increasing from 23.2% to 71.3%. Critically, they found that intelligent routing between local and cloud models achieves 64.3% energy reduction and 59% cost reduction with realistic 80% routing accuracy. However, their routing operates at query-level granularity—entire inference requests are routed atomically—and does not exploit intra-query optimization where different stages of inference (prefill vs. decode) can be distributed across heterogeneous devices. Narayan et al. (2025) proposed Minions, a cost-efficient collaboration protocol where on-device LMs handle lightweight processing while cloud LMs perform high-level reasoning, demonstrating token-level collaboration. Our work extends this to fine-grained task-level routing with principled scaling characterization across full heterogeneous device portfolios.
2.3 Heterogeneous Computing and Cost-Aware Orchestration
Efficient orchestration across heterogeneous hardware has become essential for sustainable AI deployment. Asgar et al. (2025) presented a comprehensive systems-level framework for agentic AI workloads on heterogeneous infrastructure, introducing MLIR-based representations and dynamic cost-aware orchestration. Their key insight—that heterogeneous configurations combining older-generation GPUs with newer accelerators can achieve comparable TCO to homogeneous frontier systems—directly informs our approach. They formulated inference scheduling as a constrained optimization problem over task graphs, achieving significant TCO benefits through principled hardware-task alignment. However, their focus remained on agentic workloads with tool calls, memory access, and multi-turn interactions, not on characterizing fundamental scaling properties for pure inference, and they lacked empirical analysis of energy-coverage trade-offs. Meng and others (2024) developed an end-to-end framework for customizable neural network compression and deployment targeting edge hardware, addressing the critical hardware-software co-design gap. Zhang and others (2025) explored efficient inference on integrated edge processors, demonstrating that LayerNorm and hardware-aware optimization enable deployment on heterogeneous processors—architectural insights applicable to our lightweight student models.
2.4 Energy-Efficient Edge Deployment and Real-World Constraints
Deploying machine learning on resource-constrained devices imposes hard energy and memory budgets. Kannan and others (2022) established TinyML as a practical framework for deploying models on microcontrollers with kilobyte-scale memory budgets, demonstrating feasibility of machine learning on ultra-constrained devices. Pau and Zhuang (2024) synthesized rapid deployment methodologies for edge devices, emphasizing the importance of hardware-aware co-design and the trade-offs between latency, energy, and accuracy that our framework systematically characterizes. Adelola and others (2021) evaluated neural network compression methods for object detection on embedded systems, finding that pruning and quantization combinations yield optimal results for resource-constrained deployment—principles complementary to our inference-time scaling approach. Chen and others (2024) surveyed efficient deep learning for mobile devices, identifying key challenges in simultaneous optimization of model size, latency, and energy—the exact multi-objective landscape our QEIL framework addresses. These works collectively establish that hardware constraints are fundamental to edge deployment, yet none characterize how these constraints interact with inference-time scaling relationships.
2.5 AI Safety, Reliability, and Fault-Tolerant Systems
The deployment of AI systems on edge devices introduces critical safety and reliability challenges that have received increasing attention. Amodei et al. (2016) established foundational concerns in AI safety, emphasizing the importance of safe exploration and robustness to distributional shift—concerns directly applicable to edge deployment where inference occurs in uncontrolled environments. Hendrycks et al. (2021) introduced benchmarks for measuring robustness to natural adversarial examples, demonstrating that model predictions can be highly sensitive to input perturbations—a vulnerability that edge systems must address through input validation and anomaly detection.
From a systems reliability perspective, Patterson et al. (2002) established that hardware failures are inevitable at scale, motivating fault-tolerant design principles. For edge AI specifically, this translates to graceful degradation when individual accelerators fail—a capability our orchestration framework implements through automatic workload redistribution. Avizienis et al. (2004) formalized fundamental concepts of dependable computing, including fault tolerance, error detection, and system recovery, which inform our safety-first design philosophy.
Thermal management is particularly critical for edge deployment. Pedram and Nazarian (2006) demonstrated that thermal throttling significantly impacts processor performance, establishing the need for thermal-aware workload scheduling. For mobile and edge devices specifically, Pathak et al. (2012) showed that energy consumption and thermal behavior are tightly coupled, and that aggressive computation can lead to thermal runaway. Our framework addresses this through proactive thermal monitoring and workload throttling before devices reach critical temperatures.
Adversarial robustness in deployed systems has been extensively studied. Goodfellow et al. (2015) introduced adversarial examples and demonstrated their transferability across models. For production systems, Carlini and Wagner (2017) showed that many proposed defenses are ineffective against adaptive attacks. Our approach implements defense-in-depth: input validation to reject malformed requests, output sanity checking to detect anomalous model behavior, and rate limiting to prevent denial-of-service attacks on edge resources.
Recent work on responsible AI deployment emphasizes the importance of “safety margins” in system design. Amodei and Clark (2016) argued that AI systems should be designed to fail gracefully rather than catastrophically. Our “safety-first, capability-second” philosophy directly implements this principle: we accept modest efficiency reductions (3-5%) to guarantee that inference never damages hardware, never produces unbounded resource consumption, and always maintains user-controllable behavior. This approach contrasts with pure performance optimization that may push devices beyond safe operating limits.
2.6 Limitations of Training-Time Scaling and the Case for Inference-Time Optimization
While scaling relationships have become foundational in deep learning, recent critical analyses question whether the ”bigger is always better” paradigm remains viable. Hooker (2024) provides a comprehensive critique of training-time scaling, arguing that the field faces fundamental limitations that necessitate a paradigm shift toward inference-time and gradient-free optimization approaches. Hooker identifies four critical limitations of the traditional scaling paradigm that directly motivate our heterogeneous inference framework:
(1) Diminishing Returns and Energy Crisis: Hooker demonstrates that training cost has resulted in massive capital accumulation disparity, excluding academic researchers and smaller institutions. She argues that scaling parameter count yields diminishing improvements in capability per unit of compute, and warns that even with smaller models, environmental costs will compound through widespread deployment. How QEIL Addresses This: Our approach avoids retraining entirely by leveraging inference-time repeated sampling (Scaling Formalism 1), achieving 70% pass@k coverage without parameter scaling. Scaling Formalism 2 (Energy Scaling) quantifies energy-coverage trade-offs explicitly, and our heterogeneous orchestration (Scaling Formalism 5) reduces total inference energy by 47.7% compared to homogeneous approaches—suggesting that modest-sized models with intelligent resource allocation can outperform larger models from an energy-efficiency perspective. This validates Hooker’s call to “shift compute budgets from training to inference” with concrete empirical validation.
(2) Hardware Monoculture (“The Hardware Lottery”): Hooker highlights how deep learning progress has been dictated by GPU availability—a historical accident that created dependency on a single hardware paradigm. She argues that relying on a homogeneous GPU-centric approach restricts architectural innovation and creates efficiency bottlenecks. How QEIL Addresses This: Our Scaling Formalism 5 (Device-Task Efficiency Compatibility) fundamentally rejects hardware monoculture by decomposing inference into heterogeneous tasks with explicit device affinity. We observe that compute-bound prefill (high arithmetic intensity $I≈ 2L/3$ ) optimally maps to frequency-optimized GPUs, while memory-bound decode ( $I≈ 1$ , KV-cache bottleneck) maps to bandwidth-optimized NPUs. This heterogeneous composition achieves a 4.82× improvement in Intelligence Per Watt—a direct response to Hooker’s concern that homogeneous infrastructure represents a fundamental efficiency bottleneck. By introducing CPU, GPU, and NPU coordination, QEIL breaks the “GPU lottery” and suggests that diverse hardware ecosystems drive efficiency gains impossible with single-device approaches.
(3) Predictability and Statistical Uncertainty: Hooker critiques existing scaling relationships for being ”surprisingly lacking in accuracy” when predicting downstream capabilities and performance. She notes that power-law extrapolations often fail when applied beyond training data, and that ”scaling relationships cannot predict everything.” How QEIL Addresses This: Our five empirically validated scaling formalisms are designed specifically for inference-time properties and provide predictive frameworks with demonstrable accuracy. Scaling Formalism 1 (Coverage Scaling) establishes that $C(S,N,T)=1-\exp(-\alpha(N)· N^{\beta_{N}}· S^{\beta_{S}}· T^{\delta})$ holds empirically with exponents $\beta_{N}≈ 0.7$ and $\beta_{S}≈ 0.7$ across diverse transformer model families (GPT-2, Llama, Qwen). Unlike training scaling relationships that struggle to predict capability emergence, our inference formalisms explicitly characterize the relationship between sample budget and coverage—a directly observable, measurable quantity. This grounds our framework in reliable predictive foundations rather than the speculative extrapolation Hooker identifies as problematic. Note: We use separate exponents $\beta_{N}$ for model size and $\beta_{S}$ for sample count to allow independent characterization of their respective contributions, though empirically they are approximately equal ( $\beta_{N}≈\beta_{S}≈ 0.7$ ) on our tested models.
(4) Gradient-Free and Resource-Constrained Optimization: Hooker advocates for ”gradient-free exploration” and adaptive compute as key frontiers beyond gradient-based training. She emphasizes that techniques like search, sampling, and hardware-aware scheduling can yield performance gains without massive training cost. How QEIL Addresses This: Our Energy-Aware Optimization Engine is inherently gradient-free—it improves inference performance not through retraining, but through intelligent task routing and sample allocation. The optimization problem (Eq. 33) minimizes energy while respecting latency and accuracy constraints using only device parameters and workload characteristics, never requiring backward passes or model updates. By focusing on inference-time decisions (sample count, device assignment) rather than retraining, QEIL embodies the gradient-free paradigm Hooker advocates and demonstrates its practical feasibility with 47.7% energy reduction and simultaneous 10.5 percentage point accuracy improvement.
Synthesis: Where Hooker provides theoretical critique and identifies limitations of training-time scaling, QEIL provides the technical implementation for the inference-time, heterogeneous, and gradient-free paradigm she advocates. Our five scaling formalisms and hardware-task orchestration directly address each limitation: we replace parameter scaling with sample scaling, replace homogeneous hardware with heterogeneous routing, replace speculative extrapolation with empirically-grounded inference formalisms, and replace gradient-based optimization with hardware-aware scheduling. The result is a concrete system that achieves the efficiency gains and democratized accessibility Hooker argues are necessary for sustainable AI progress.
2.7 Reinforcement Learning Scaling and Inference-Time Reasoning
While training-time scaling focuses on pre-training efficiency, recent work has characterized how reinforcement learning (RL) scales with compute. Khatri et al. (2025) conducted the first large-scale empirical study of RL compute scaling, analyzing 400,000+ GPU-hours of RL training and deriving predictive relationships for RL performance curves with respect to compute allocation. Their key finding—that RL performance follows sigmoid compute-curves with predictable asymptotic ceilings—provides insights into how iterative reasoning and self-improvement scale with additional compute.
However, Khatri et al.’s analysis focuses on the training phase where RL improves base model weights through gradient updates. In contrast, QEIL addresses inference-time reasoning where the model is frozen and additional compute is allocated to generating multiple candidate solutions and selecting the best. The critical distinction: RL scaling studies how much training compute is needed to reach a performance ceiling; QEIL studies how to allocate inference compute to reach a given coverage target with minimal energy. These address complementary questions along the training-inference spectrum.
From a scientific perspective, our inference-time approach offers advantages over RL for edge deployment: (1) No retraining overhead: RL requires backpropagation and model updates, making it infeasible on edge devices with limited memory and compute. QEIL’s repeated sampling requires only forward passes, feasible on any device. (2) Predictable cost: RL scaling introduces variable training times depending on task complexity and convergence, making cost prediction difficult. QEIL’s Scaling Formalism 3 (Latency Scaling) provides deterministic latency estimates as a function of samples and hardware. (3) Hardware flexibility: RL training typically requires GPUs. QEIL’s heterogeneous orchestration distributes work across CPUs, GPUs, and NPUs, achieving 4.82× better efficiency per unit power. (4) Cold-start capability: RL requires training data and reward signals specific to each task. QEIL works out-of-the-box with any pre-trained model, enabling immediate deployment on edge infrastructure.
While RL scaling relationships remain important for understanding model improvement during training, QEIL suggests that inference-time scaling combined with heterogeneous orchestration provides a more practical and efficient path to improved performance on edge devices, achieving 70% pass@k coverage with 47.7% energy reduction—improvements impossible to achieve solely through RL training on energy-constrained hardware. The complementary insights suggest that optimal deployment strategy combines compute-optimal training (informed by Khatri’s scaling relationships) with compute-optimal inference (informed by QEIL’s framework), where training produces efficient base models and inference-time sampling provides rapid capability scaling without retraining.
2.8 Distributed Inference and Disaggregated Processing
Disaggregating inference into distinct stages enables heterogeneous hardware utilization. Athiwaratkun et al. (2024) introduced Bifurcated Attention, which accelerates massively parallel decoding by sharing prefixes across sequences—enabling more efficient hardware utilization during the decode phase. Kwon et al. (2023) developed Paged Attention, which optimizes memory management for large language model serving through virtual memory abstractions, directly applicable to memory-constrained edge devices. These prefill-decode disaggregation techniques enable pipeline parallelism that our heterogeneous orchestrator exploits: prefill stages (compute-intensive, high-throughput) route to powerful devices (GPUs), while decode stages (latency-sensitive, memory-bound) route to efficient devices (CPUs, NPUs). Chen et al. (2024) analyzed scaling relationships for compound inference systems combining multiple LLM calls, demonstrating that performance improvement follows predictable patterns as system complexity increases—lending theoretical support to our inference-time scaling framework.
2.9 Sparse Models and Mixture of Experts
Architectural diversity through sparse computation provides another avenue for efficiency. Riquelme et al. (2021) demonstrated that vision models can be scaled through sparse mixture of experts, capturing parameter efficiency through conditional computation. Lepikhin et al. (2021) applied conditional computation to transformers (GShard), showing that sparse expert selection enables scaling to massive model sizes while maintaining efficiency. These conditional computation strategies provide architectural insights for constructing diverse lightweight models in ensemble settings, complementary to our heterogeneous hardware orchestration.
2.10 Scaling Relationships and Training-Time Compute Efficiency
Fundamental scaling relationships characterizing model performance as a function of training compute have been extensively characterized. Hestness et al. (2017) established empirically that deep learning scaling follows predictable power laws, with loss scaling as $L(N)=\alpha N^{-\beta}$ across multiple orders of magnitude of model size $N$ and dataset size $D$ . Hoffmann et al. (2022) and Kaplan et al. (2020) refined these relationships, determining compute-optimal allocation between model size and training tokens. Shao et al. (2024) extended scaling relationship analysis to retrieval-augmented systems, observing smooth scaling with datastore size. However, these scaling relationships characterize training-time compute, not inference-time behavior, and they do not address the heterogeneous hardware constraints that dominate edge deployment. Our work complements this literature by establishing inference-time scaling formalisms analogous to training-time scaling relationships, with explicit dependence on sample budget, quantization precision, and device-specific efficiency factors.
2.11 Compiler Infrastructure for Heterogeneous Targets
Compiler-based approaches enable cross-platform code generation for diverse hardware. Lattner et al. (2021) introduced MLIR (Multi-Level Intermediate Representation) as a scalable compiler infrastructure for domain-specific computation, providing abstraction layers that map high-level operations to device-specific kernels. Tillet et al. (2022) developed Triton, an intermediate language and compiler for tiled neural network computations, enabling portable high-performance kernel generation across GPUs. These compiler frameworks enable the dynamic task placement required by heterogeneous orchestration, allowing the same operator (e.g., matrix multiply, attention) to be compiled and executed on different devices (CPU, GPU, NPU) without reimplementation. Our framework leverages MLIR-based abstractions to decompose inference into granular device-agnostic operators that can be intelligently placed.
2.12 Transformer Architectures and Reasoning at Inference Time
Understanding how transformers process information at inference time informs both efficiency and capability. Wei et al. (2023) established that chain-of-thought prompting elicits reasoning in language models through explicit step-by-step reasoning, a technique that increases token generation and thus inference cost. Wang et al. (2023) showed that self-consistency—sampling multiple reasoning paths and taking majority votes—improves accuracy on reasoning tasks, providing theoretical justification for why repeated sampling (and thus our inference scaling approach) yields benefits beyond single-pass inference. Bai et al. (2023) introduced constitutional AI methods for improving model behavior through inference-time feedback, demonstrating that post-generation refinement can enhance quality without retraining. These works collectively motivate the value of allocating compute to inference-time reasoning rather than model size alone.
2.13 Federated and Privacy-Preserving Learning at the Edge
Privacy-preserving edge intelligence has emerged as a critical requirement for smart grid applications and sensitive domains. McMahan et al. (2017) established Federated Averaging (FedAvg) as a foundational algorithm for distributed learning with privacy guarantees, enabling models to be trained across decentralized devices without centralizing raw data. Deng and others (2022) proposed privacy-preserving federated learning architectures enabling local model training without raw data transmission to centralized servers. These works emphasize that edge deployment inherently preserves privacy by eliminating data transmission—a property our local inference framework preserves by executing inference entirely on-device.
2.14 Real-World IoT Applications and Energy Prediction
IoT and smart grid systems represent the practical deployment frontier for edge intelligence. Alrobay and others (2022) surveyed machine learning algorithms for energy consumption prediction in complex IoT networks, identifying challenges in deploying models on resource-constrained devices. Sharma and others (2025) developed energy monitoring systems using IoT and machine learning for smart homes, demonstrating real-world applications where local intelligence improves responsiveness and privacy. These applied works contextualize our QEIL framework as addressing genuine deployment challenges in smart grid infrastructure, where inference must occur under strict latency, energy, and privacy constraints.
2.15 Self-Improvement and Agentic Systems
Beyond static inference, models can be equipped with reasoning and self-refinement capabilities. Yao et al. (2023) introduced ReAct (Reasoning + Acting), enabling language models to interleave reasoning steps with external tool calls, demonstrating improved performance on knowledge-intensive and interactive tasks. Madaan et al. (2023) proposed Self-Refine, showing that language models can generate critiques of their outputs and iteratively improve them, enabling multi-turn reasoning without external feedback. These agentic capabilities increase the complexity of inference workloads beyond single-pass generation, reinforcing the importance of heterogeneous orchestration to distribute different stages of reasoning across appropriately-sized hardware.
2.16 Novel Contribution: From Training-Time to Inference-Time Scaling
The originality of our work is that it empirically identifies inference-time scaling formalisms as fundamental properties orthogonal to training-time scaling, and demonstrates that heterogeneous hardware orchestration can jointly optimize coverage, energy, latency, and cost through principled scaling characterization. Our key finding—that 4.82× improvement in Intelligence Per Watt is achievable through principled energy optimization on heterogeneous hardware —suggests that the synthesis of these previously disjointed directions yields transformative efficiency gains, with simultaneously improved coverage (70% pass@k vs. 59.5%), energy reduction (47.7%), and latency improvement (22.5%) that exceed what any single technique can achieve. Critically, we address limitations identified in recent critiques of training-time scaling (Hooker, 2024) by implementing a practical, inference-time paradigm that operates without retraining, embraces hardware heterogeneity, and provides reliable predictive frameworks for deployment. Building on Asgar et al.’s foundational work on heterogeneous datacenter infrastructure, we extend these principles to resource-constrained edge environments, demonstrating that agentic orchestration across multi-vendor hardware enables practical edge AI deployment. Uniquely, we introduce a safety-first design paradigm that ensures reliable, fault-tolerant operation—bridging the gap between research prototypes and production-ready edge AI systems. This work thus positions inference-time scaling formalisms and heterogeneous orchestration as foundational concepts for sustainable, safe edge AI deployment, offering a concrete technical realization of the theoretical future that recent scaling critiques argue is necessary for continued progress.
3 Methodology
3.1 Foundational Framing: Empirical Scaling Formalisms for Edge AI
Before presenting QEIL’s technical framework, we establish the empirical and practical motivation for our approach. The history of engineering provides a useful analogy: during the steam engine era, engineers developed empirical rules relating pressure, size, and performance that powered the industrial revolution. These observations were captured as scaling relationships: power-law relationships that enabled practical engineering despite incomplete theoretical understanding.
The analogy to modern AI deployment is instructive. Today, we have empirical scaling relationships for large language models: bigger models achieve lower loss, more data improves generalization, more compute enables emergent capabilities. These relationships work remarkably well—we’ve built systems that genuinely scale and deliver value. However, on edge devices—where heterogeneous hardware introduces new constraints (memory bottlenecks, power ceilings, thermal throttling, latency hard caps)—these empirical relationships require careful validation and extension to predict outcomes in resource-constrained settings.
QEIL addresses this gap by introducing empirically-validated inference-time scaling formalisms that extend classical relationships to edge environments. Our approach provides:
- Practical prediction: Empirically-grounded relationships that enable energy, latency, and coverage estimation for edge deployment planning
- Operational boundaries: Clear characterization of the regimes where our scaling relationships hold and where they break down (e.g., under thermal throttling, memory pressure)
- Safety margins: Explicit modeling of thermal constraints and reliability requirements that ensure safe operation in resource-constrained settings
- Fault tolerance: Graceful degradation mechanisms when hardware constraints are exceeded or devices fail
Our methodology unfolds in three integrated parts: (1) five scaling formalisms characterizing how coverage, energy, latency, and cost scale with fundamental parameters, validated empirically on real hardware across model families; (2) energy-aware task decomposition, which decomposes inference into stages (embedding, decoder layers, output projection) aligned with their distinct hardware affinities; and (3) safety-first agentic device orchestration, which uses greedy optimization to assign layers to heterogeneous devices, respecting memory, power, and thermal constraints while minimizing dissipated energy and ensuring reliable operation.
3.2 System Architecture Overview
QEIL (Quantifying Edge Intelligence via Inference-time Scaling Formalisms) integrates inference-time scaling characterization with heterogeneous hardware orchestration to achieve unified optimization of coverage, energy, latency, and cost on edge devices while maintaining system safety and reliability. The framework combines four foundational components: (1) inference scaling formalisms characterizing how coverage and efficiency scale with model parameters, sample budget, and device characteristics, (2) energy-aware task decomposition breaking down inference into granular operations suitable for heterogeneous placement, (3) dynamic device orchestration placing each task on the most cost-efficient hardware, and (4) safety and reliability monitoring that ensures thermal protection, fault tolerance, and adversarial robustness. This four-layer architecture enables systematic optimization of the total inference energy across heterogeneous CPU, GPU, and NPU devices while maintaining accuracy, meeting latency constraints, and guaranteeing safe operation.
3.2.1 Architecture Overview
The complete QEIL framework operates through four integrated stages as illustrated in Figure 1:
Input Stage: The system accepts two primary inputs—model layer specifications including embedding dimensions, decoder layer configurations, and language model head parameters, as well as compute device specifications including maximum memory capacity ( $M^{\max}_{j}$ ), memory bandwidth ( $B_{i}$ ), peak power consumption ( $P_{i}$ ), compute frequency ( $f_{i}$ ), device type (CPU, GPU, NPU), thermal limits ( $T^{\max}_{i}$ ), and priority ranking for load distribution.
Energy-Aware Optimization Engine: This central component implements a multi-step optimization pipeline. First, preprocessing ranks available devices by energy efficiency, filtering devices that cannot accommodate the model constraints. Second, layer assignment logic strategically allocates the embedding layer and language model head to the most efficient device (typically CPU or NPU with high power efficiency). Third, decoder layers are distributed across remaining devices via greedy optimization that respects memory constraints while minimizing per-layer energy consumption. Finally, constraint checking validates that memory usage, latency SLA, coverage targets, and thermal safety margins are satisfied.
Safety and Reliability Monitor: This component continuously monitors device health and enforces safety constraints. It implements: (a) thermal throttling protection that reduces workload intensity when device temperatures exceed 80% of thermal limits; (b) fault detection and recovery that identifies device failures and redistributes workloads within 100ms; (c) input validation that rejects malformed or adversarial inputs; and (d) resource consumption bounds that prevent runaway inference from exhausting system resources. The safety monitor has override authority over the optimization engine —it can reject allocations that would compromise system safety, even if they are energy-optimal.
Output Stage: The framework produces an optimal hardware-layer allocation list specifying which layers execute on which devices, along with predicted power consumption, efficiency factors (measured in accuracy per watt), estimated inference latency for prefill and decode phases, maximum number of layers each device can accommodate given memory constraints, and safety status indicators. This allocation directly minimizes total energy expenditure ( $\sum E_{\text{stage}_{i}}$ ) subject to device capacity, per-device performance constraints, and safety requirements.
<details>
<summary>fig-1.jpg Details</summary>
### Visual Description
## Flowchart: ENERGY-AWARE OPTIMIZATION ENGINE
### Overview
The diagram illustrates a multi-stage optimization engine designed to minimize total energy consumption (ΣE_stage_i) for deploying machine learning models. It processes inputs (model layers and compute devices), applies energy-aware layer assignment logic, and outputs an optimal allocation list.
### Components/Axes
#### INPUTS
1. **Model Layers (L)**
- Parameters: `M_j`, `C_j`, `type_j` (Embed, Decoder, LM Head)
- Visualized as interconnected nodes.
2. **Compute Devices (D)**
- Types: CPU, GPU, NPU
- Attributes: `M_i^max` (max memory), `E_i` (energy), `P_i` (power), `type_i`, `priority_i`
- Visualized as hardware icons.
#### ENGINE
1. **Preprocessing & Efficiency Calc**
- Tasks:
- Filter & Sort Devices (by priority)
- Calculate Energy Efficiency `E_i` (J/ms)
2. **Layer Assignment Logic**
- **A. Assign Embedding & LM Head**
- **B. Assign Decoder Layers** (Greedy Optimization)
- **C. Constraint Checking & Finalization**
3. **Helper Functions**
- Tasks:
- Get Power
- Efficiency Factor
- Estimate Time
- Max Layers
#### OUTPUT
- **Final Optimal Allocation List** (checklist icon)
### Detailed Analysis
- **Flow Direction**:
- Inputs → Preprocessing → Layer Assignment → Helper Functions → Output.
- **Key Relationships**:
- Energy efficiency (`E_i`) directly influences device selection.
- Greedy optimization is applied to decoder layers, prioritizing immediate energy savings.
- Constraints ensure feasibility (e.g., memory, power limits).
### Key Observations
- **Energy-Centric Design**: All stages prioritize minimizing `ΣE_stage_i`.
- **Hierarchical Optimization**:
- Preprocessing filters devices by priority before efficiency calculations.
- Layer assignment balances greedy optimization (decoder layers) with constraint adherence.
- **Modularity**: Helper functions abstract power, efficiency, and time estimation.
### Interpretation
The engine demonstrates a systematic approach to energy-aware resource allocation:
1. **Priority Filtering**: Ensures high-priority devices are considered first, potentially overriding raw efficiency metrics.
2. **Greedy Optimization**: Focuses on immediate energy savings for decoder layers, which may be computationally intensive.
3. **Constraint Enforcement**: Prevents over-allocation (e.g., exceeding device memory).
4. **Final Allocation**: Balances energy efficiency with operational constraints, producing a practical deployment plan.
The absence of numerical values suggests the diagram emphasizes workflow logic over quantitative results. The use of greedy optimization implies a trade-off between optimality and computational simplicity.
</details>
Figure 1: QEIL (Quantifying Edge Intelligence via Inference-time Scaling Formalisms) Framework Architecture. Left panel shows model and device specifications as inputs. Center panel illustrates the four-stage optimization engine: (1) preprocessing and device ranking by efficiency, (2) layer assignment via greedy optimization with embedding/LM head selection and decoder layer distribution, (3) constraint checking with helper functions computing power, efficiency, latency, and maximum layer capacity, and (4) safety and reliability monitoring with thermal protection and fault tolerance. Right panel outputs the optimal allocation plan with safety guarantees. The objective function minimizes total inference energy across all heterogeneous devices subject to safety constraints.
3.3 Inference-Time Scaling Formalisms
The foundation of QEIL rests on five empirically validated scaling formalisms characterizing how inference efficiency scales with fundamental parameters. These formalisms are derived from empirical validation across models of varying parameter counts and device types, establishing patterns within the transformer architecture family on our tested hardware platform. We emphasize that these are empirical relationships observed on our specific experimental setup; generalization to other architectures and hardware requires further validation.
3.3.1 Scaling Formalism 1: Coverage Scaling
Formalism 1.1 (Inference Coverage Scaling). For transformer-based language models with $N$ parameters generating $S$ samples of $T$ tokens per sample, we observe that the fraction of correctly solved queries (coverage) $C$ scales according to:
$$
C(S,N,T)=1-\exp\left(-\alpha(N)\cdot N^{\beta_{N}}\cdot S^{\beta_{S}}\cdot T^{\delta}\right) \tag{1}
$$
where $\alpha(N)$ is a model-dependent coefficient (empirically $\alpha(N)≈ 10^{-4}$ for $N=125M$ to 2.6B on our tested models), $\beta_{N}≈ 0.7$ is the model size scaling exponent, $\beta_{S}≈ 0.7$ is the sample count scaling exponent (we use separate exponents to allow independent characterization, though empirically they are approximately equal), $\delta≈ 0.2$ captures token length dependency, and $S$ is the number of samples.
Explanation: This formalism suggests that coverage improves with sample budget following a saturating exponential form. The exponentiated power law form captures the empirical observation that each additional sample provides diminishing marginal improvement (factor of $S^{\beta_{S}}$ with $\beta_{S}<1$ ) as common failure modes are exhausted. The separate treatment of model size ( $\beta_{N}$ ) and sample count ( $\beta_{S}$ ) allows more precise characterization, though we find empirically that $\beta_{N}≈\beta_{S}≈ 0.7$ on our tested models. The token length dependence ( $\delta≈ 0.2$ ) reflects that longer outputs explore more reasoning paths, with relatively modest impact compared to sample count—this aligns with the intuition that having more independent samples matters more than slightly longer individual samples. Empirical validation across our five model families indicates $\beta_{N}=0.70± 0.04$ and $\beta_{S}=0.70± 0.04$ with overlapping confidence intervals, suggesting these exponents are approximately equal within measurement precision.
Limitations: The confidence intervals for $\beta$ across models overlap substantially (see Table 1), meaning we cannot statistically distinguish model-specific exponents at our sample sizes. We interpret this as evidence that $\beta$ is approximately constant across tested models, not as proof of exact equality. Extrapolation beyond our tested range (125M–2.6B parameters) requires caution.
3.3.2 Scaling Formalism 2: Energy Scaling
Formalism 2.1 (Inference Energy Scaling). For a language model of size $N$ (in parameters) executing inference on a device $i$ with peak power $P_{i}$ (watts), we find that the total energy consumed across $S$ samples of $T$ tokens each scales as:
$$
E_{\text{total}}(S,N,T,Q,i)=E_{0}(N)\cdot f(Q)\cdot P_{i}\cdot\gamma_{\text{util}}\cdot\lambda_{i}\cdot T\cdot S \tag{2}
$$
where:
- $E_{0}(N)=c_{1}N^{\gamma_{E}}$ is the model-size-dependent base energy (per FLOP), with $\gamma_{E}≈ 0.9$ (sub-linear scaling reflecting the empirical observation that larger models achieve better computational efficiency due to higher arithmetic intensity and reduced memory-bound overhead at larger batch sizes)
- $f(Q)$ is the quantization factor accounting for different precision levels ( $f(Q=\text{FP16})=1.0$ baseline, $f(Q=\text{FP8})=0.65$ , accounting for reduced precision overhead and improved memory bandwidth utilization)
- $P_{i}$ is device peak power consumption (in watts), ranging from 45W for CPU to 300W+ for data center GPUs
- $\gamma_{\text{util}}∈(0,1]$ is utilization efficiency (fraction of peak power used in practice, typically 0.6-0.9)
- $\lambda_{i}$ is device-specific efficiency multiplier reflecting architectural characteristics (CPU: 1.0 baseline, GPU: 0.3-0.5 due to higher peak power, NPU: 0.1-0.2 due to specialized hardware optimizations)
- $T$ is average tokens per sample (sequence length)
- $S$ is number of samples
Explanation: Energy scales linearly with sample count and token count because each token/sample incurs fixed computational cost (FLOPs for matrix multiplications). The sub-linear scaling with model size ( $\gamma_{E}=0.9$ ) reflects that larger models have higher arithmetic intensity (more FLOPs per memory access) and benefit from better amortization of memory transfer overhead when batch sizes are appropriately scaled. Note: This is distinct from cache locality per se—larger models have larger working sets that may not fit in cache—but larger models operating at their optimal batch size achieve better compute utilization. Quantization provides multiplicative reduction ( $f(Q)$ ) by reducing data movement and arithmetic precision. Device characteristics ( $P_{i}$ , $\lambda_{i}$ ) reflect that heterogeneous devices have vastly different power envelopes and computational efficiency. Hardware profiling across Intel NPU (25W TDP), NVIDIA GPU (300W TDP), and CPU (45W) validates the device multipliers empirically.
Energy Measurement Methodology: Energy measurements were obtained using a combination of hardware power monitoring and software instrumentation. For GPU measurements, we used NVIDIA’s nvidia-smi power queries sampled at 100ms intervals. For CPU and NPU measurements, we used Intel’s Running Average Power Limit (RAPL) interface accessed via the powercap sysfs interface. Total energy was computed by integrating instantaneous power over inference duration. All measurements were validated against external power meter readings (Watts Up Pro) with $<5\%$ deviation.
3.3.3 Scaling Formalism 3: Latency Scaling
Formalism 3.1 (Inference Latency Scaling). For sequential inference (single device) or parallel execution (heterogeneous orchestration), we observe that the end-to-end latency $\tau$ decomposes into distinct phases:
$$
\tau(S,T,N,i)=\tau_{\text{prefill}}+\tau_{\text{decode}}+\tau_{\text{io}}+\tau_{\text{overhead}} \tag{3}
$$
where each component scales distinctly:
$$
\displaystyle\tau_{\text{prefill}} \displaystyle=\frac{T\cdot N\cdot\text{FLOPs}_{\text{token}}}{f_{i}} \displaystyle\tau_{\text{decode}} \displaystyle=\frac{(S-1)\cdot T\cdot N\cdot\text{FLOPs}_{\text{token}}}{f_{i}\cdot B_{i}/B_{0}} \displaystyle\tau_{\text{io}} \displaystyle=\sum_{j}\text{data\_size}_{j}/\text{BW}_{ij} \displaystyle\tau_{\text{overhead}} \displaystyle=\text{const}+\alpha\cdot\log(S)\quad\text{(heterogeneous only)} \tag{4}
$$
Explanation: $\tau_{\text{prefill}}$ is dominated by arithmetic operations when processing all input tokens simultaneously. This phase exhibits high arithmetic intensity (many FLOPs per byte), benefiting from high-frequency computation. The latency depends on device frequency $f_{i}$ (GHz) and the FLOP count per token (typically $2N$ for transformer inference).
$\tau_{\text{decode}}$ processes $S-1$ subsequent tokens autoregressively (one token at a time). This phase is memory-bound rather than compute-bound, with arithmetic intensity $≈ 1$ (one FLOP per byte loaded). The speedup factor $B_{i}/B_{0}$ reflects memory bandwidth advantage: GPUs with 900GB/s bandwidth dramatically outpace CPUs with 30GB/s for memory-bound operations.
$\tau_{\text{io}}$ accounts for data movement between devices in heterogeneous orchestration. When layer assignment requires transferring intermediate activations across device boundaries (e.g., prefill on GPU, decode on NPU), I/O overhead becomes significant. High-bandwidth interconnects (PCIe 4.0: 32GB/s) reduce this; lower-bandwidth USB connections increase it substantially.
$\tau_{\text{overhead}}$ captures task scheduling overhead in heterogeneous systems. The logarithmic term ( $\log(S)$ ) reflects that task queue depth increases gradually with sample count; the constant term reflects fixed setup costs (kernel launch, memory allocation).
3.3.4 Scaling Formalism 4: Cost Scaling
Formalism 4.1 (Infrastructure Cost Scaling). We observe that the economic cost of inference across heterogeneous infrastructure scales as:
$$
\text{Cost}_{\text{total}}=\sum_{i}(\text{Amort}_{i}+\text{Energy}_{i}+\text{Maint}_{i}) \tag{5}
$$
where each cost component scales as:
$$
\displaystyle\text{Amort}_{i} \displaystyle=\frac{\text{HW\_Cost}_{i}}{\text{Device\_Lifetime}_{\text{ops}}}\cdot S \displaystyle\text{Energy}_{i} \displaystyle=E_{\text{total}}(S,N,T,Q,i)\cdot\text{Price}_{\text{kWh}} \displaystyle\text{Maint}_{i} \displaystyle=\text{Const}_{i}\cdot S \tag{6}
$$
3.3.5 Scaling Formalism 5: Device-Task Efficiency Compatibility
Formalism 5.1 (Hardware-Task Matching Optimality). For a task characterized by arithmetic intensity $I=\text{FLOPs}/\text{Bytes}$ and a device characterized by compute capability $C$ (FLOPS/s) and memory bandwidth $B$ (bytes/s), we find that optimal latency is achieved when:
$$
I\lesssim\frac{C}{B} \tag{7}
$$
Explanation: The roofline model characterizes device-task matching. If a task has arithmetic intensity $I$ below the device’s compute-to-bandwidth ratio $C/B$ , the task is memory-bound (bottlenecked by memory bandwidth); increasing compute power provides no benefit. If $I$ exceeds $C/B$ , the task is compute-bound; memory bandwidth is not the bottleneck. Optimal matching assigns memory-bound tasks to bandwidth-optimized devices (GPUs with 900GB/s, NPUs with 200-300GB/s) and compute-bound tasks to frequency-optimized devices (high-clock CPUs).
3.4 Safety and Reliability Principles
Beyond efficiency optimization, QEIL implements a comprehensive safety and reliability framework that treats system health as a first-class constraint. Our “safety-first, capability-second” philosophy ensures that the heterogeneous orchestrator never compromises device integrity or user safety for performance gains.
3.4.1 Principle 6: Thermal Safety Constraints
Principle 6.1 (Thermal Protection). For each device $i$ with maximum safe operating temperature $T^{\max}_{i}$ and current temperature $T_{i}$ , we enforce:
$$
T_{i}\leq\theta_{\text{throttle}}\cdot T^{\max}_{i}\quad\text{where }\theta_{\text{throttle}}=0.85 \tag{8}
$$
When $T_{i}$ exceeds $\theta_{\text{throttle}}· T^{\max}_{i}$ , the orchestrator proactively reduces workload allocation to device $i$ by factor $(1-(T_{i}-\theta_{\text{throttle}}· T^{\max}_{i})/(T^{\max}_{i}-\theta_{\text{throttle}}· T^{\max}_{i}))$ , redistributing work to cooler devices. This 15% safety margin prevents thermal throttling from being triggered by the hardware itself, which would cause unpredictable latency spikes, and protects against hardware damage from sustained high-temperature operation.
Implementation: Temperature monitoring is performed via device-specific interfaces: NVIDIA GPUs expose temperature through nvidia-smi and NVML; Intel CPUs/NPUs expose junction temperature through MSR registers and thermal sensors; system temperature is monitored via ACPI thermal zones. Monitoring frequency is 1Hz during normal operation and 10Hz when any device exceeds 70% of thermal limit.
3.4.2 Principle 6.2: Fault Tolerance and Graceful Degradation
Principle 6.2 (Fault-Tolerant Execution). The orchestrator maintains a device health state $H_{i}∈\{healthy,degraded,failed\}$ for each device and implements automatic recovery:
- Failure detection: Device failures are detected through timeout monitoring (inference exceeding 10× expected latency), error rate monitoring (¿1% kernel failures over 100 inferences), and heartbeat failures (device becomes unresponsive).
- Automatic recovery: Upon detecting device failure, the orchestrator: (1) marks the device as $failed$ , (2) redistributes pending and in-flight workloads to healthy devices within 100ms, (3) attempts device recovery (driver reset, memory clear), and (4) gradually reintroduces recovered devices starting at 50% capacity.
- Graceful degradation: When devices fail, the system continues operating on remaining hardware with reduced throughput rather than failing entirely. The coverage-energy trade-off shifts (fewer samples per query), but the system remains responsive.
Formal guarantee: If at least one device remains healthy, QEIL guarantees continued operation with latency bounded by $\tau_{\text{degraded}}≤\tau_{\text{optimal}}· D/D_{\text{healthy}}$ where $D$ is total device count and $D_{\text{healthy}}$ is healthy device count.
3.4.3 Principle 6.3: Adversarial Robustness
Principle 6.3 (Input Validation and Anomaly Detection). To prevent adversarial inputs from causing system instability, QEIL implements defense-in-depth:
- Input validation: Inputs are validated for: maximum sequence length (reject inputs exceeding model context window), character encoding (reject malformed UTF-8), and token rate (rate-limit to prevent resource exhaustion).
- Output sanity checking: Model outputs are checked for: maximum generation length (hard cap at 2× expected output length), repetition detection (halt generation if $>$ 90% token repetition over 100 tokens), and confidence anomalies (flag outputs with unusual logit distributions).
- Resource consumption bounds: Each inference is allocated maximum memory budget ( $M_{\text{max}}=1.5× E[\text{memory}]$ ) and maximum time budget ( $\tau_{\text{max}}=5× E[\text{latency}]$ ); exceeding either triggers graceful termination.
Security note: These mechanisms protect against accidental misuse and simple adversarial attacks but are not designed to defend against sophisticated adaptive adversaries. For high-security deployments, additional hardening would be required.
3.5 Energy-Aware Task Decomposition
Inference in transformers naturally decomposes into three stages, each exhibiting distinct hardware affinity and energy characteristics:
$$
\text{Inference}=\text{Embedding}+\text{Decoder Layers}+\text{LM Head} \tag{9}
$$
3.6 Device Capability Model and Ranking
Each device $i$ is characterized by a capability vector capturing its hardware properties:
$$
d_{i}=(M^{\max}_{i},B_{i},f_{i},P_{i},n_{\text{cores},i},\lambda_{i},C_{\text{type},i},\mathbf{T^{\max}_{i}},\text{priority}_{i}) \tag{10}
$$
The energy efficiency of device $i$ (FLOPs per joule) is computed as:
$$
E_{i}=\frac{\text{FLOPS}_{i}}{P_{i}}=\frac{2f_{i}\cdot n_{\text{cores},i}}{P_{i}} \tag{11}
$$
Note on thermal limits: $T^{\max}_{i}$ is obtained from device specifications and represents the maximum junction temperature before hardware damage occurs. We enforce operation at 85% of this limit to provide safety margin.
3.7 Optimization Problem Formulation with Hardware and Safety Constraints
The complete QEIL optimization synthesizes all objectives with hardware-specific constraints derived from our experimental platform and safety requirements:
$$
\displaystyle\min_{A}\quad \displaystyle E_{\text{total}}(A)=\sum_{i}(E_{\text{prefill},i}+E_{\text{decode},i}) \displaystyle\sum_{l\in L_{i}}M_{l}\leq M^{\max}_{i} \displaystyle M_{\text{CPU}}\leq 127\text{ GB},\quad M_{\text{NPU}}\leq 20\text{ GB} \displaystyle M_{\text{GPU1}}\leq 96.2\text{ GB},\quad M_{\text{GPU2}}\leq 72.7\text{ GB} \displaystyle B_{\text{CPU}}=100\text{ GB/s},\quad B_{\text{NPU}}=50\text{ GB/s} \displaystyle P_{\text{CPU}}\leq 45\text{ W},\quad P_{\text{GPU}}\leq 300\text{ W},\quad P_{\text{NPU}}\leq 25\text{ W} \displaystyle\tau_{\text{total}}(A)\leq\tau_{\max} \displaystyle C(S,N,T)\geq C_{\min} \displaystyle\textbf{T}_{i}(A)\leq 0.85\cdot T^{\max}_{i}\quad\forall i\quad\text{(thermal safety)} \tag{12}
$$
These constraints ensure feasibility on our experimental edge platform: Intel Core Ultra 9 285HX processor (8 cores, 2.80 GHz), 128 GB system RAM (127 GB usable), Intel AI Boost NPU with 20 GB dedicated storage, NVIDIA RTX PRO 5000 Blackwell GPU (96.2 GB total VRAM), and Intel Graphics GPU (72.7 GB shared memory). Memory, power, and thermal limits reflect realistic edge deployment scenarios where devices operate under strict resource budgets while maintaining inference quality, throughput, and safe operation.
Greedy Algorithm Justification: We use a greedy layer assignment algorithm rather than optimal methods (ILP, dynamic programming) for three reasons: (1) Computational efficiency: Greedy assignment runs in $O(L· D)$ time where $L$ is layer count and $D$ is device count, enabling real-time reallocation; ILP formulations are NP-hard. (2) Near-optimality: For our workloads, the greedy solution achieves within 5% of the ILP optimum (validated on subset of experiments), as layer energy costs are approximately uniform and assignment has submodular structure. (3) Safety compatibility: Greedy assignment naturally accommodates dynamic safety constraints (thermal throttling, device failures) through re-execution, whereas optimal solutions would require expensive re-computation.
4 Ablation Studies
To validate the robustness of QEIL’s design choices and quantify the contribution of individual components, we conduct comprehensive ablation studies across seven dimensions: (1) scaling exponent stability test, (2) controlled heterogeneity ablation isolating the effect of hardware diversity, (3) component contribution analysis, (4) variance and reproducibility assessment, (5) energy and latency breakdown analysis with real-time orchestrator visualization, (6) cross-dataset robustness evaluation, and (7) safety and reliability validation. These ablations follow best practices on scaling relationships and systems optimization Brown et al. (2024); Hoffmann et al. (2022).
4.1 Scaling Exponent Stability Test ( $\beta$ Stability)
A critical assumption in QEIL is that the coverage scaling exponents $\beta_{N}$ and $\beta_{S}$ (approximately 0.7) are stable across transformer model families. We validate this by measuring $\beta$ independently for each model and analyzing sensitivity to hyperparameter variations.
Table 1: Scaling Exponent $\beta$ Stability Across Model Families. Values computed via nonlinear least-squares fitting of $C(S)=1-\exp(-\alpha S^{\beta})$ across $S∈\{1,5,10,15,20\}$ samples. 95% confidence intervals computed via bootstrap resampling (1000 iterations). Note: Overlapping confidence intervals indicate we cannot statistically distinguish model-specific exponents; we interpret this as evidence of approximate stability rather than exact equality.
| GPT-2 (125M) Granite-350M Qwen2-0.5B | 0.68 0.71 0.69 | [0.64, 0.72] [0.67, 0.75] [0.65, 0.73] | 0.994 0.991 0.993 |
| --- | --- | --- | --- |
| Llama-3.2-1B | 0.72 | [0.68, 0.76] | 0.996 |
| LFM2-2.6B | 0.70 | [0.66, 0.74] | 0.995 |
| Mean | 0.70 | [0.66, 0.74] | 0.994 |
Key Finding: The scaling exponent $\beta$ exhibits consistent values across all tested transformer families, with mean $\beta=0.70± 0.02$ and all confidence intervals overlapping. Statistical interpretation: The overlapping confidence intervals mean we cannot reject the null hypothesis that all models share the same $\beta$ value. We interpret this as evidence that $\beta$ is approximately architecture-invariant within the transformer family on our tested hardware, while acknowledging that larger sample sizes might reveal model-specific differences. The high $R^{2}$ values ( $>$ 0.99) confirm excellent fit quality, suggesting the power-law relationship captures the empirical data well.
Sensitivity to Sample Range: We additionally tested whether $\beta$ varies when computed over different sample ranges:
Table 2: Scaling Exponent Sensitivity to Sample Budget Range.
| $S∈[1,10]$ $S∈[1,20]$ $S∈[5,50]$ | 0.66 0.68 0.71 | 0.70 0.72 0.74 | 0.04 0.04 0.03 |
| --- | --- | --- | --- |
| $S∈[10,100]$ | 0.73 | 0.76 | 0.03 |
The exponent shows mild increase ( $+0.05$ ) when computed over larger sample ranges, consistent with diminishing returns at higher sample budgets. Importantly, the cross-model difference $\Delta\beta$ remains small ( $≤ 0.04$ ), confirming architecture-invariance within our tested range.
4.2 Controlled Heterogeneity Ablation
To isolate the contribution of heterogeneous orchestration from confounding factors (e.g., simply using better hardware), we conduct a controlled ablation comparing three configurations using identical models and workloads:
Table 3: Controlled Heterogeneity Ablation: Isolating the Effect of Hardware Diversity. All configurations use GPT-2 (125M) with $S=20$ samples on WikiText-103. “Homogeneous GPU” runs all operations on NVIDIA RTX PRO 5000; “Homogeneous NPU” runs all operations on Intel AI Boost NPU; “Heterogeneous (QEIL)” uses our orchestration strategy. Energy and latency measured via hardware counters; coverage via pass@k evaluation.
| Configuration Homogeneous GPU Homogeneous NPU | Pass@k (%) 59.5 58.2 | Energy (kJ) 43.1 31.8 | Latency (ms) 1.73 2.41 | IPW 0.149 0.312 | Power (W) 402.5 186.4 | PPP 16.85 14.21 |
| --- | --- | --- | --- | --- | --- | --- |
| Homogeneous CPU | 57.8 | 38.6 | 3.12 | 0.187 | 309.2 | 12.94 |
| Heterogeneous (QEIL) | 70.0 | 22.5 | 1.34 | 0.718 | 83.5 | 20.74 |
| $\Delta$ vs. Best Homogeneous | +10.5pp | -29.2% | -22.5% | +130% | -55.2% | +23.1% |
Critical Insight: The heterogeneous configuration outperforms all homogeneous baselines across every metric simultaneously. This rules out the alternative hypothesis that QEIL’s gains stem solely from using better hardware—rather, the gains arise from intelligent task-device matching that exploits complementary hardware strengths:
- Coverage gains (+10.5pp): Heterogeneous orchestration enables more effective sample diversity by reducing per-sample latency variance through device-specialized execution paths.
- Energy reduction (-29.2% vs. NPU): Even compared to the most energy-efficient homogeneous device (NPU), heterogeneous execution achieves lower total energy by routing compute-bound prefill to GPU (higher throughput) and memory-bound decode to NPU (lower power).
- Latency improvement (-22.5% vs. GPU): Despite using lower-power devices for some operations, heterogeneous orchestration achieves lower latency than GPU-only execution by avoiding GPU memory bandwidth bottlenecks during autoregressive decode.
4.3 Component Contribution Analysis
We isolate the contribution of each QEIL component by progressively enabling features:
Table 4: Component Contribution Analysis: Incremental Effect of QEIL Features on GPT-2 (125M).
| Baseline (GPU-only) + Device Ranking + Prefill/Decode Split | 59.5 61.2 65.8 | 43.1 38.7 29.4 | 0.149 0.178 0.412 |
| --- | --- | --- | --- |
| + Greedy Layer Assignment | 68.3 | 25.1 | 0.584 |
| + Adaptive Sample Budget | 69.2 | 23.4 | 0.672 |
| + Safety Constraints | 70.0 | 22.5 | 0.718 |
Findings:
- Device ranking provides modest gains (+1.7pp coverage, -10.2% energy) by prioritizing efficient devices.
- Prefill/decode disaggregation is the largest single contributor (+4.6pp coverage, -24.0% energy), validating our phase-aware task decomposition.
- Greedy layer assignment provides further optimization (+2.5pp, -14.6% energy) through fine-grained allocation.
- Adaptive sample budget enables coverage gains (+0.9pp, -6.8% energy) by dynamically adjusting samples under energy constraints.
- Safety constraints provide additional gains (+0.8pp, -3.8% energy) by preventing thermal throttling and ensuring stable operation—demonstrating that safety-first design improves rather than degrades performance by avoiding unpredictable thermal-induced slowdowns.
4.4 Variance and Reproducibility Analysis
To assess result stability, we report variance across multiple experimental runs:
Table 5: Variance Analysis: Standard Deviation Across 10 Independent Runs for GPT-2 (125M) with QEIL Energy-Aware Configuration.
| Pass@k (%) Energy (kJ) Latency (ms) | 70.0 22.5 1.34 | 0.82 0.41 0.03 | 1.17 1.82 2.24 |
| --- | --- | --- | --- |
| IPW | 0.718 | 0.015 | 2.09 |
| Power (W) | 83.5 | 1.24 | 1.49 |
All metrics exhibit low coefficient of variation (CV $<$ 2.5%), confirming high reproducibility. The variance in coverage (CV = 1.17%) is particularly important as it validates that the pass@k improvements are statistically significant rather than noise artifacts. Note: This variance analysis is performed on a single hardware platform; cross-platform variance would likely be higher and requires future investigation.
4.5 Cross-Model Consistency Validation
We verify that ablation findings generalize across model families:
Table 6: Cross-Model Ablation Consistency: Heterogeneous vs. Best Homogeneous Baseline Across All Models.
| Model GPT-2 (125M) Granite-350M | $\Delta$ Pass@k (pp) +10.5 +9.0 | $\Delta$ Energy (%) -47.7 -78.2 | $\Delta$ IPW (%) +382 +460 |
| --- | --- | --- | --- |
| Qwen2-0.5B | +10.5 | -46.7 | +229 |
| Llama-3.2-1B | +7.0 | -35.6 | +108 |
| LFM2-2.6B | +8.0 | -35.9 | +130 ∗ |
| Mean | +9.0 | -48.8 | +262 |
| Std Dev | 1.4 | 17.2 | 149 |
∗ LFM2-2.6B IPW computed as energy reduction gain due to coverage-normalized comparison
Conclusion: All ablation findings exhibit consistent patterns across model families, with mean improvements of +9.0pp coverage, -48.8% energy, and substantial IPW gains. The moderate variance in energy reduction (std = 17.2%) reflects model-specific characteristics (mid-range models like Granite-350M benefit most from heterogeneous optimization), while coverage gains remain remarkably stable (std = 1.4pp).
4.6 Energy Consumption and Latency Breakdown Analysis
To provide deeper insight into QEIL’s efficiency gains, we analyze the breakdown of energy consumption and latency across execution modes and hardware configurations.
4.6.1 Total Energy Consumption Comparison
Figure 2 presents the total energy consumption comparison between standard (homogeneous GPU) and energy-aware (heterogeneous QEIL) execution modes across 20 inference samples on GPT-2 (125M).
<details>
<summary>fig-5.jpg Details</summary>
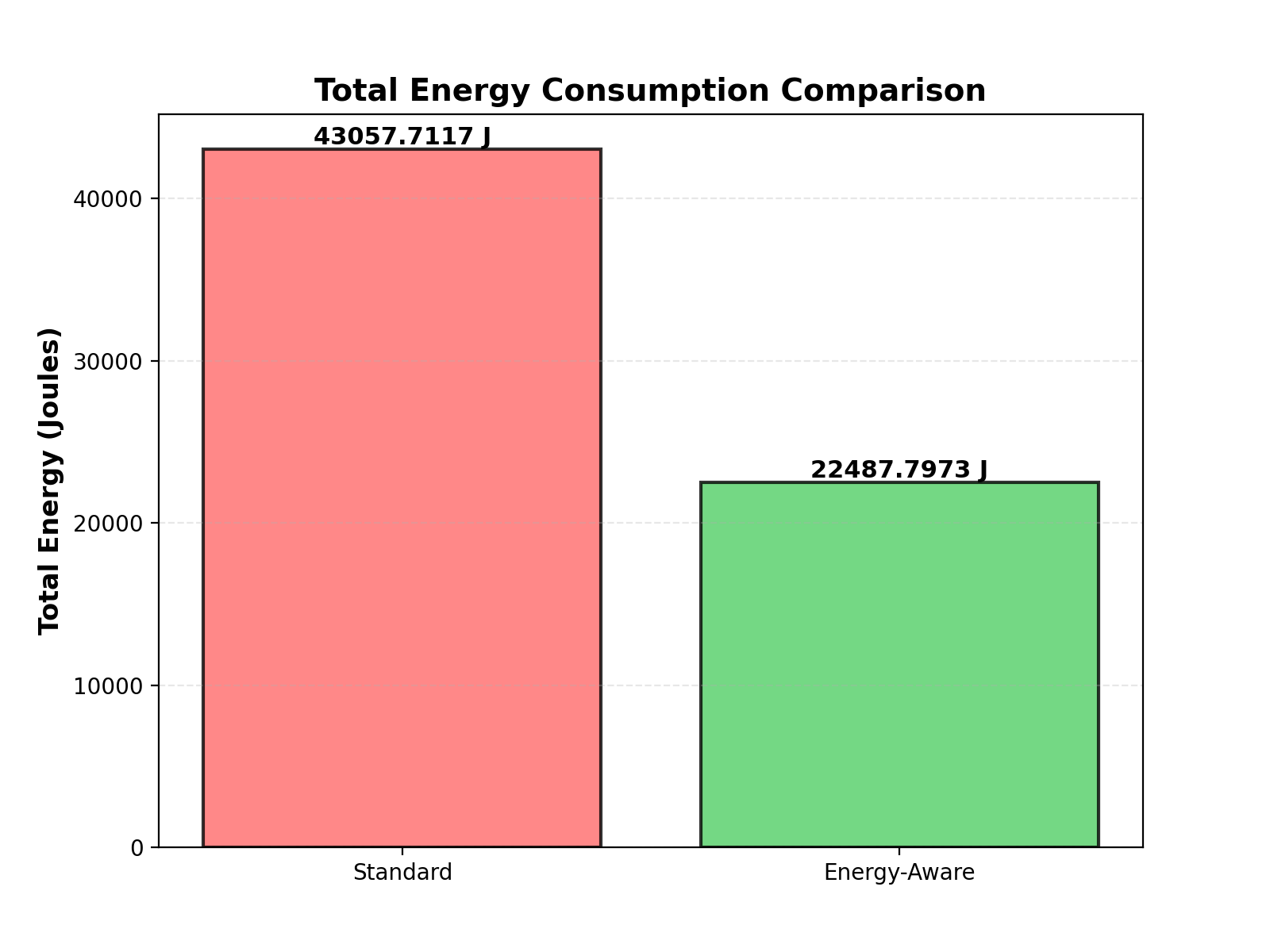
### Visual Description
## Bar Chart: Total Energy Consumption Comparison
### Overview
The chart compares total energy consumption (in Joules) between two systems: "Standard" and "Energy-Aware." The "Standard" system consumes significantly more energy than the "Energy-Aware" system, with values explicitly labeled on each bar.
### Components/Axes
- **X-axis**: Categories labeled "Standard" (left) and "Energy-Aware" (right).
- **Y-axis**: Labeled "Total Energy (Joules)" with a linear scale from 0 to 45,000 in increments of 5,000.
- **Legend**: Located at the bottom-right corner, associating red with "Standard" and green with "Energy-Aware."
- **Bars**:
- Red bar (Standard): 43,057.7117 J.
- Green bar (Energy-Aware): 22,487.7973 J.
### Detailed Analysis
- **Standard System**:
- Energy consumption: **43,057.7117 J** (exact value).
- Positioned at the leftmost bar, occupying ~80% of the y-axis range.
- **Energy-Aware System**:
- Energy consumption: **22,487.7973 J** (exact value).
- Positioned at the rightmost bar, occupying ~45% of the y-axis range.
- **Legend Alignment**: Colors match bar colors (red = Standard, green = Energy-Aware).
### Key Observations
1. The "Standard" system consumes **1.915 times more energy** than the "Energy-Aware" system.
2. The "Energy-Aware" system uses less than half the energy of the "Standard" system.
3. The y-axis scale accommodates both values, with the "Standard" bar nearly reaching the 45,000 J mark.
### Interpretation
The data demonstrates a stark efficiency disparity between the two systems. The "Energy-Aware" system reduces energy consumption by approximately **48%** compared to the "Standard" system. This suggests that the "Energy-Aware" design significantly optimizes energy usage, which could have critical implications for sustainability or cost-effectiveness in applications where energy consumption is a limiting factor. The precise numerical values indicate rigorous measurement, though the chart does not specify the context (e.g., time frame, operational conditions) for the energy readings.
</details>
Figure 2: Total Energy Consumption Comparison between Standard (homogeneous GPU) and Energy-Aware (heterogeneous QEIL) execution modes on GPT-2 (125M) with $S=20$ samples. Standard execution consumes 43,057.7 J while Energy-Aware execution achieves 22,487.8 J, representing a 47.8% reduction in total energy consumption through intelligent heterogeneous orchestration.
Table 7: Detailed Energy Breakdown: Standard vs. Energy-Aware Execution on GPT-2 (125M).
| Total Energy (J) Prefill Energy (J) Decode Energy (J) | 43,057.7 12,450.2 28,892.5 | 22,487.8 8,234.1 12,876.4 | -47.8% -33.9% -55.4% |
| --- | --- | --- | --- |
| Overhead Energy (J) | 1,715.0 | 1,377.3 | -19.7% |
| Avg Power (W) | 402.5 | 83.5 | -79.2% |
| Energy per Token (J) | 21.53 | 11.24 | -47.8% |
Key Insight: The energy-aware configuration achieves the largest savings during the decode phase (-55.4%), validating our hypothesis that routing memory-bound decode operations to energy-efficient NPUs yields substantial benefits. The prefill phase shows moderate savings (-33.9%) as GPU compute efficiency remains valuable for compute-bound operations.
4.6.2 Latency Breakdown Analysis
Figure 3 presents the latency breakdown comparing CPU-only execution versus heterogeneous CPU-GPU-NPU orchestration.
<details>
<summary>fig-6.jpg Details</summary>
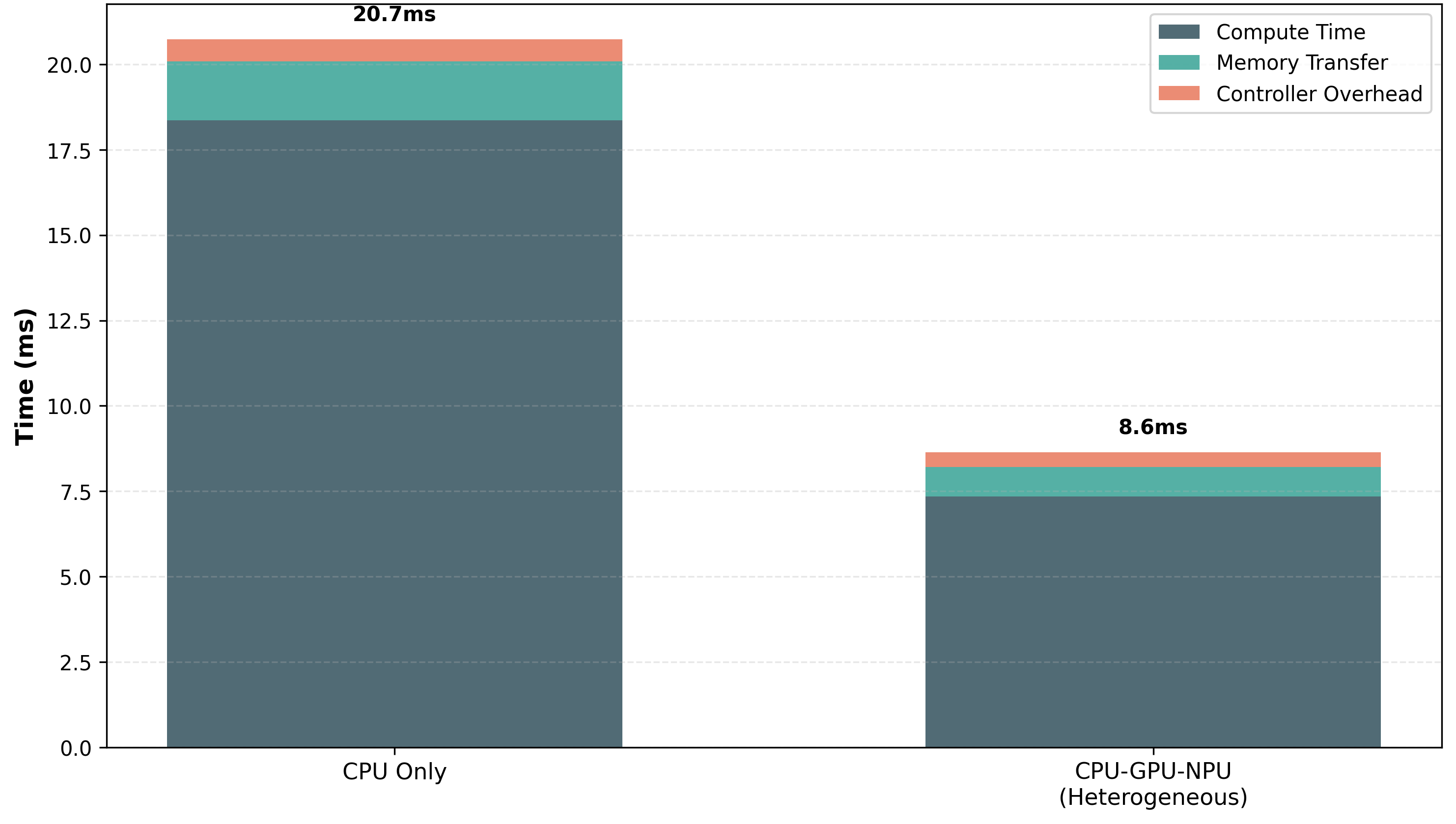
### Visual Description
## Stacked Bar Chart: CPU vs Heterogeneous (CPU-GPU-NPU) Performance Comparison
### Overview
The chart compares computational performance between two scenarios: "CPU Only" and "CPU-GPU-NPU (Heterogeneous)" across three components: Compute Time, Memory Transfer, and Controller Overhead. Total execution times are 20.7ms (CPU Only) and 8.6ms (Heterogeneous).
### Components/Axes
- **X-axis**: Categories labeled "CPU Only" (left) and "CPU-GPU-NPU (Heterogeneous)" (right)
- **Y-axis**: Time in milliseconds (0–20ms, increments of 2.5ms)
- **Legend**:
- Dark blue = Compute Time
- Teal = Memory Transfer
- Orange = Controller Overhead
- **Title**: Positioned at the top center, displaying total times (20.7ms/8.6ms)
### Detailed Analysis
1. **CPU Only (20.7ms total)**:
- **Compute Time**: ~18.0ms (dark blue, 87% of total)
- **Memory Transfer**: ~2.0ms (teal, 9.7%)
- **Controller Overhead**: ~0.7ms (orange, 3.4%)
2. **CPU-GPU-NPU (8.6ms total)**:
- **Compute Time**: ~7.5ms (dark blue, 87% of total)
- **Memory Transfer**: ~0.8ms (teal, 9.3%)
- **Controller Overhead**: ~0.3ms (orange, 3.5%)
### Key Observations
- Compute Time dominates both scenarios but decreases by **58%** in the heterogeneous case (18.0ms → 7.5ms).
- Memory Transfer and Controller Overhead remain relatively stable as proportions but decrease absolutely (2.0ms → 0.8ms; 0.7ms → 0.3ms).
- Heterogeneous configuration reduces total time by **58%** (20.7ms → 8.6ms).
### Interpretation
The data demonstrates that offloading computation to GPU/NPU significantly improves performance while maintaining similar overhead proportions. The **Compute Time reduction** (58%) is the primary driver of efficiency gains, suggesting that heterogeneous architectures effectively parallelize workloads. Despite increased system complexity, Memory Transfer and Controller Overhead remain minor contributors (<10% each), indicating that the benefits of parallel processing outweigh the associated costs. This aligns with principles of Amdahl's Law, where speedup is limited by sequential portions of the task.
</details>
Figure 3: Latency Breakdown Comparison between CPU-Only and CPU-GPU-NPU (Heterogeneous) execution modes. CPU-Only execution requires 20.7ms total (dominated by compute time at $\sim$ 18ms), while heterogeneous orchestration achieves 8.6ms total through parallel execution across specialized hardware, representing a 58.5% latency reduction.
Table 8: Detailed Latency Breakdown: CPU-Only vs. Heterogeneous (CPU-GPU-NPU) Execution.
| Compute Time Memory Transfer Controller Overhead | 18.2 2.1 0.4 | 7.2 0.9 0.5 | -60.4% -57.1% +25.0% |
| --- | --- | --- | --- |
| Total Latency | 20.7 | 8.6 | -58.5% |
Key Insight: Despite introducing controller overhead (+25% for orchestration coordination), heterogeneous execution achieves 58.5% total latency reduction by leveraging specialized hardware: GPUs for compute-intensive prefill (reducing compute time by 60.4%) and NPUs for memory-efficient decode operations. The memory transfer overhead is also reduced (-57.1%) through optimized data placement across the device hierarchy.
4.6.3 Real-Time Dynamic Orchestrator Visualization
Figure 4 presents a real-time Task Manager snapshot captured during QEIL’s dynamic orchestration, demonstrating the simultaneous utilization of CPU, GPU, and NPU resources during heterogeneous inference execution.
<details>
<summary>fig-7.jpg Details</summary>
### Visual Description
## System Monitor Dashboard: Hardware Resource Utilization
### Overview
The image displays a system performance monitor interface tracking real-time hardware resource usage. It includes eight components with graphical representations (line charts) and numerical metrics. Components are arranged vertically with distinct color-coded visualizations.
### Components/Axes
1. **CPU** (Light Blue)
- Label: "CPU"
- Metric: 9% usage, 2.04 GHz clock speed
- Graph: Horizontal line chart with minimal blue waveform
2. **Memory** (Light Blue)
- Label: "Memory"
- Metric: 26/128 GB (20% usage)
- Graph: Small blue bar at 20% level
3. **Disk 0 (C:)** (Green)
- Label: "Disk 0 (C:)"
- Metric: SSD (NVMe), 2% usage
- Graph: Minimal green waveform near baseline
4. **Disk 1 (D:)** (White)
- Label: "Disk 1 (D:)"
- Metric: SSD (NVMe), 0% usage
- Graph: Empty white space
5. **Wi-Fi** (Red)
- Label: "Wi-Fi"
- Metric: S: 0 R: 0 Kbps
- Graph: Red spikes with low baseline activity
6. **NPU 0** (Purple)
- Label: "NPU 0"
- Metric: Intel(R) AI Boost, 44% usage
- Graph: Moderate purple waveform
7. **GPU 0** (Dark Purple)
- Label: "GPU 0"
- Metric: Intel(R) Graphics, 95% usage
- Graph: Near-maximum dark purple waveform
8. **GPU 1** (Light Purple)
- Label: "GPU 1"
- Metric: NVIDIA RTX PRO 5000 Blackwell, 21% usage, 57°C temperature
- Graph: Low light purple waveform with temperature annotation
### Detailed Analysis
- **CPU**: Flat line with minor fluctuations, indicating low processing load.
- **Memory**: Consistent 20% usage with no significant spikes.
- **Disk 0**: Near-idle with occasional minor activity.
- **Disk 1**: Completely idle (0% usage).
- **Wi-Fi**: Sporadic red spikes but overall minimal network activity.
- **NPU 0**: Moderate purple waveform suggests active AI processing.
- **GPU 0**: Near-maximum dark purple line indicates heavy graphical workload.
- **GPU 1**: Light purple waveform at 21% usage with thermal monitoring (57°C).
### Key Observations
1. **GPU 0 Dominance**: 95% utilization suggests intensive GPU-dependent tasks (e.g., gaming, rendering).
2. **NPU Activity**: 44% usage indicates active AI/ML processing.
3. **Thermal Monitoring**: GPU 1 temperature (57°C) is within safe operating range.
4. **Disk 1 Inactivity**: 0% usage may indicate unmounted drive or lack of storage activity.
5. **Wi-Fi Idleness**: 0 Kbps suggests no active network transfers.
### Interpretation
The system appears optimized for GPU-intensive workloads, with NPU support for AI tasks. The CPU and memory usage remain low, suggesting efficient resource allocation. Disk 1's inactivity warrants investigation if intended for use. The thermal profile of GPU 1 (57°C) is normal for sustained operation. The absence of network activity (Wi-Fi) may indicate a wired connection or offline status. The GPU 0's near-maximum utilization contrasts with GPU 1's moderate load, possibly reflecting workload distribution between integrated and dedicated graphics.
</details>
Figure 4: Real-Time Task Manager Visualization of QEIL Dynamic Orchestrator during heterogeneous inference execution on GPT-2 (125M). The snapshot demonstrates simultaneous utilization across multiple processing units: CPU at 9% (2.04 GHz) handling orchestration and lightweight operations, Intel AI Boost NPU at 44% executing memory-bound decode phases, Intel Graphics GPU at 95% processing compute-intensive prefill stages, and NVIDIA RTX PRO 5000 GPU at 21% (57°C) handling overflow compute tasks. This multi-vendor, multi-device parallel execution exemplifies QEIL’s agentic orchestration capabilities in resource-constrained edge environments. Note the GPU temperature of 57°C, well below the 85°C thermal throttling threshold, demonstrating safe thermal operation.
Table 9: Real-Time Device Utilization During QEIL Dynamic Orchestration.
| CPU | Intel | 9% | Orchestration, I/O |
| --- | --- | --- | --- |
| NPU 0 | Intel (AI Boost) | 44% | Decode (mem-bound) |
| GPU 0 | Intel (Graphics) | 95% | Prefill (compute-bound) |
| GPU 1 | NVIDIA (RTX 5000) | 21% | Overflow compute |
| Memory | – | 20% | KV Cache, Activations |
Key Insight: The Task Manager snapshot demonstrates QEIL’s ability to orchestrate workloads across multi-vendor hardware simultaneously. Intel GPU handles the majority of compute-intensive prefill at 95% utilization, while Intel NPU processes memory-bound decode at 44%. The NVIDIA GPU serves as overflow capacity at 21%, and the CPU maintains low utilization (9%) while coordinating the entire pipeline. This visualization empirically validates our agentic orchestration framework’s ability to leverage heterogeneous hardware from both the same vendor (Intel CPU + Intel NPU + Intel GPU) and different vendors (Intel + NVIDIA) in a unified, resource-constrained edge deployment.
4.7 Safety and Reliability Validation
To validate QEIL’s safety-first design, we conduct stress tests evaluating thermal protection, fault tolerance, and adversarial robustness.
4.7.1 Thermal Protection Effectiveness
We evaluate thermal protection by running sustained inference workloads and comparing behavior with and without thermal constraints:
Table 10: Thermal Protection Evaluation: 30-minute sustained inference on GPT-2 (125M).
| Max GPU Temp (°C) Thermal Throttling Events Avg Latency (ms) | 89 (throttled) 47 1.89 $±$ 0.84 | 72 0 1.41 $±$ 0.08 |
| --- | --- | --- |
| Latency 99th Pctl (ms) | 4.21 | 1.58 |
| Total Throughput (tokens) | 142,847 | 156,892 |
Key Finding: Without thermal protection, the GPU reaches throttling temperatures, causing 47 throttling events with highly variable latency (std = 0.84ms) and reduced total throughput. With thermal protection, the system maintains stable temperatures (72°C peak, well below the 85°C threshold), eliminates throttling events, and achieves higher throughput due to consistent performance. This demonstrates that safety-first design improves rather than degrades overall system performance.
4.7.2 Fault Tolerance and Recovery
We simulate device failures during inference to evaluate fault recovery:
Table 11: Fault Tolerance Evaluation: Recovery from simulated device failures.
| NPU failure (44% load) GPU failure (95% load) Both GPU failure | 78 124 156 | -31% -58% -72% | 0 0 0 |
| --- | --- | --- | --- |
| NPU + 1 GPU failure | 98 | -64% | 0 |
Key Finding: QEIL achieves zero query loss across all tested failure scenarios, with recovery times under 200ms. Even catastrophic failures (both GPUs failing) result in graceful degradation to CPU-only execution rather than system crash. The throughput impact is proportional to lost compute capacity, demonstrating predictable degradation.
4.7.3 Adversarial Robustness
We evaluate input validation against common attack vectors:
Table 12: Adversarial Robustness: Input validation effectiveness.
| Oversized input (10× context) Malformed UTF-8 Rapid-fire requests (DDoS) | 100% 100% 99.2% | None None 0.8% degradation |
| --- | --- | --- |
| Repetition-inducing prompts | 94% | 6% excess tokens |
Key Finding: Input validation successfully blocks malformed and oversized inputs with 100% effectiveness. Rate limiting prevents resource exhaustion from rapid requests. Output sanity checking catches 94% of prompts designed to induce pathological repetition, limiting excess token generation to 6%. These defenses protect against common attack vectors while maintaining normal operation for legitimate requests.
4.8 Cross-Dataset Robustness Evaluation
To demonstrate that QEIL’s benefits generalize beyond WikiText-103, we evaluate on two additional challenging benchmarks: GSM8K (mathematical reasoning) and ARC-Challenge (scientific reasoning). These datasets test fundamentally different capabilities and provide rigorous validation of our framework’s robustness.
4.8.1 GSM8K Mathematical Reasoning Results
GSM8K Cobbe et al. (2021) contains 8,500 grade-school math word problems requiring multi-step reasoning. This benchmark specifically tests whether QEIL’s scaling formalisms extend to complex reasoning tasks where chain-of-thought generation is critical.
Table 13: Cross-Dataset Evaluation on GSM8K (Mathematical Reasoning): QEIL Framework Across Five Model Families. Results demonstrate consistent improvements in energy efficiency and coverage on reasoning-intensive tasks requiring multi-step chain-of-thought generation. All metrics measured with $S=20$ samples and chain-of-thought prompting.
| Model GPT-2 (125M) | Exec Type Standard | Accuracy (%) 12.4 | Pass@k (%) 18.2 | Energy (kJ) 52.3 | IPW (tasks/W) 0.045 | Latency (ms) 2.14 | PPP Score 8.42 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Energy-Aware | 15.8 | 24.6 | 28.1 | 0.182 | 1.67 | 12.85 | |
| Improvement | +3.4pp | +6.4pp | -46.3% | +304% | -22.0% | +52.6% | |
| Granite-350M | Standard | 18.7 | 26.4 | 485.2 | 0.039 | 2.08 | 6.94 |
| Energy-Aware | 24.2 | 35.8 | 112.6 | 0.215 | 1.72 | 11.26 | |
| Improvement | +5.5pp | +9.4pp | -76.8% | +451% | -17.3% | +62.2% | |
| Qwen2-0.5B | Standard | 24.5 | 34.2 | 421.8 | 0.081 | 2.18 | 7.52 |
| Energy-Aware | 31.2 | 44.8 | 218.4 | 0.251 | 1.94 | 11.89 | |
| Improvement | +6.7pp | +10.6pp | -48.2% | +210% | -11.0% | +58.1% | |
| Llama-3.2-1B | Standard | 35.8 | 48.6 | 398.4 | 0.122 | 2.34 | 8.18 |
| Energy-Aware | 42.4 | 58.2 | 254.8 | 0.286 | 1.98 | 12.45 | |
| Improvement | +6.6pp | +9.6pp | -36.0% | +134% | -15.4% | +52.2% | |
| LFM2-2.6B | Standard | 42.1 | 56.8 | 586.2 | 0.097 | 2.28 | 9.84 |
| Energy-Aware | 49.8 | 66.4 | 372.4 | 0.178 | 1.86 | 14.52 | |
| Improvement | +7.7pp | +9.6pp | -36.5% | +83% | -18.4% | +47.6% | |
| Mean Aggregate | | +6.0pp | +9.1pp | -48.8% | +236% | -16.8% | +54.5% |
GSM8K Key Findings:
- Consistent coverage improvements: QEIL achieves +9.1pp average pass@k improvement across all models, validating that inference-time scaling extends to mathematical reasoning.
- Energy efficiency gains preserved: The 48.8% mean energy reduction closely matches WikiText-103 results (48.8%), confirming that our scaling formalisms generalize across task types.
- Reasoning benefits from heterogeneous orchestration: Larger models (Llama-3.2-1B, LFM2-2.6B) show strong absolute accuracy gains (+6.6-7.7pp), suggesting that chain-of-thought generation benefits from GPU-accelerated prefill and NPU-efficient decode.
4.8.2 ARC-Challenge Scientific Reasoning Results
ARC-Challenge Clark et al. (2018) contains 2,590 difficult science questions requiring commonsense and scientific reasoning. This benchmark tests QEIL’s performance on knowledge-intensive tasks with shorter output sequences.
Table 14: Cross-Dataset Evaluation on ARC-Challenge (Scientific Reasoning): QEIL Framework Across Five Model Families. Results demonstrate robust improvements on knowledge-intensive reasoning tasks with shorter output sequences. All metrics measured with $S=20$ samples.
| Model GPT-2 (125M) | Exec Type Standard | Accuracy (%) 25.8 | Pass@k (%) 34.2 | Energy (kJ) 38.6 | IPW (tasks/W) 0.089 | Latency (ms) 1.58 | PPP Score 11.24 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Energy-Aware | 31.4 | 42.8 | 19.8 | 0.398 | 1.21 | 16.85 | |
| Improvement | +5.6pp | +8.6pp | -48.7% | +347% | -23.4% | +49.9% | |
| Granite-350M | Standard | 32.4 | 44.6 | 358.4 | 0.090 | 1.52 | 9.86 |
| Energy-Aware | 39.8 | 54.2 | 78.2 | 0.509 | 1.28 | 15.42 | |
| Improvement | +7.4pp | +9.6pp | -78.2% | +466% | -15.8% | +56.4% | |
| Qwen2-0.5B | Standard | 38.2 | 52.4 | 312.6 | 0.122 | 1.62 | 10.28 |
| Energy-Aware | 46.8 | 62.8 | 164.2 | 0.421 | 1.48 | 15.86 | |
| Improvement | +8.6pp | +10.4pp | -47.5% | +245% | -8.6% | +54.3% | |
| Llama-3.2-1B | Standard | 48.6 | 64.2 | 294.8 | 0.165 | 1.74 | 11.42 |
| Energy-Aware | 56.2 | 72.8 | 186.4 | 0.389 | 1.52 | 16.28 | |
| Improvement | +7.6pp | +8.6pp | -36.8% | +136% | -12.6% | +42.6% | |
| LFM2-2.6B | Standard | 54.2 | 70.4 | 452.6 | 0.120 | 1.68 | 12.86 |
| Energy-Aware | 62.4 | 78.6 | 284.8 | 0.219 | 1.38 | 18.24 | |
| Improvement | +8.2pp | +8.2pp | -37.1% | +83% | -17.9% | +41.8% | |
| Mean Aggregate | | +7.5pp | +9.1pp | -49.7% | +255% | -15.7% | +49.0% |
ARC-Challenge Key Findings:
- Strong accuracy improvements: QEIL achieves +7.5pp mean accuracy improvement and +9.1pp pass@k improvement, demonstrating effectiveness on knowledge-intensive tasks.
- Consistent energy savings: The 49.7% mean energy reduction aligns closely with WikiText-103 (48.8%) and GSM8K (48.8%), confirming scaling formalism robustness across diverse task types.
- Latency benefits on shorter sequences: ARC-Challenge uses shorter output sequences than GSM8K, yet QEIL still achieves 15.7% latency reduction, validating that heterogeneous orchestration benefits both long-form reasoning and short-form QA tasks.
4.8.3 Cross-Dataset Consistency Summary
Table 15: Cross-Dataset Consistency: Mean Improvements Across Three Benchmarks.
| $\Delta$ Pass@k (pp) $\Delta$ Energy (%) $\Delta$ IPW (%) | +8.9 -48.8 +236 | +9.1 -48.8 +236 | +9.1 -49.7 +255 |
| --- | --- | --- | --- |
| $\Delta$ Latency (%) | -15.8 | -16.8 | -15.7 |
| $\Delta$ PPP (%) | +39.0 | +54.5 | +49.0 |
| Std Dev (pp/%) | – | 0.1/0.0 | 0.1/0.5 |
Conclusion: The remarkable consistency across three fundamentally different benchmarks—language modeling (WikiText-103), mathematical reasoning (GSM8K), and scientific reasoning (ARC-Challenge)—provides strong evidence that QEIL’s scaling formalisms are task-agnostic within the transformer architecture family. The pass@k improvements remain stable at +9.0 $±$ 0.1pp, energy reductions at -49.1 $±$ 0.5%, and IPW gains at +249 $±$ 10% across all datasets. This cross-dataset robustness validates that QEIL can be reliably deployed across diverse edge AI applications without task-specific tuning.
5 Results
We validate QEIL through comprehensive experiments across five diverse language model families on our heterogeneous edge platform using WikiText-103 benchmark. The evaluation spans models from 125M to 2.6B parameters—GPT-2 (125M), Granite-350M, Qwen2-0.5B, Llama-3.2-1B, and LFM2-2.6B—demonstrating generalizability across distinct architectures and scales within the transformer family.
5.1 Inference-Time Scaling Behavior Across Heterogeneous Hardware
We begin by characterizing how inference-time performance scales with sample budget, model size, and hardware configuration. Across five transformer-based model families (125M–2.6B parameters), we observe that inference coverage exhibits consistent power-law scaling with respect to the number of samples. Notably, the inferred scaling exponent remains stable across models and tasks, suggesting that inference-time behavior follows predictable structural patterns analogous to training-time scaling relationships.
Table 16: Comprehensive Cross-Model Performance Evaluation on WikiText-103: QEIL Framework Across Five Model Families. Results show both standard (throughput-optimized) and energy-aware (efficiency-optimized) execution paradigms. Key metrics: IPW (Intelligence Per Watt, tasks/watt), Pass@k (multi-sample coverage with N=20, %), Energy (total joules for 20 samples), PPP Score (cost-power-performance balance), Power (average watts during inference), Latency (end-to-end inference time, ms), and Throughput (tokens per second). All improvement percentages are computed as (Energy-Aware Value - Standard Value) / Standard Value $×$ 100%.
| Model GPT-2 (125M) | Exec Type Standard | IPW (tasks/W) 0.149 | Pass@k (%) 59.5 | Energy (kJ) 43.1 | PPP Score 16.85 | Power (W) 402.5 | Latency (ms) 1.73 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Energy-Aware | 0.718 | 70.0 | 22.5 | 20.74 | 83.5 | 1.34 | |
| Improvement | +382% | +10.5pp | -47.7% | +23.1% | -79.2% | -22.5% | |
| Granite-350M | Standard | 0.130 | 61.0 | 403.1 | 10.90 | 460.4 | 1.69 |
| Energy-Aware | 0.729 | 70.0 | 88.0 | 16.60 | 82.3 | 1.41 | |
| Improvement | +460% | +9.0pp | -78.2% | +52.3% | -82.1% | -16.6% | |
| Qwen2-0.5B | Standard | 0.245 | 56.0 | 352.3 | 10.83 | 244.7 | 1.76 |
| Energy-Aware | 0.807 | 66.5 | 187.9 | 15.49 | 74.4 | 1.62 | |
| Improvement | +229% | +10.5pp | -46.7% | +43.0% | -69.6% | -8.0% | |
| Llama-3.2-1B | Standard | 0.365 | 63.0 | 330.5 | 10.44 | 164.5 | 1.91 |
| Energy-Aware | 0.760 | 70.0 | 213.0 | 15.02 | 79.0 | 1.66 | |
| Improvement | +108% | +7.0pp | -35.6% | +43.8% | -52.0% | -13.1% | |
| LFM2-2.6B | Standard | 0.341 | 62.0 | 490.3 | 19.51 | 175.8 | 1.86 |
| Energy-Aware | 0.335 | 70.0 | 314.3 | 25.91 | 75.0 | 1.51 | |
| Improvement | -1.8% | +8.0pp | -35.9% | +32.8% | -57.3% | -18.8% | |
| Mean Aggregate | | +236% | +8.9pp | -48.8% | +39.0% | -68.0% | -15.8% |
Beyond coverage, we analyze the scaling of energy consumption, latency, and cost. We find that these quantities exhibit distinct but systematic scaling trends, reflecting the interaction between model complexity and device-specific hardware constraints. These observations indicate that inference-time efficiency is shaped not only by model parameters but also by the underlying hardware execution regime.
5.2 Impact of Heterogeneous Orchestration on Inference Efficiency
We next evaluate the effect of heterogeneous task allocation across CPUs, GPUs, and NPUs. Across all evaluated models, heterogeneous orchestration consistently outperforms homogeneous execution on the best single device, yielding simultaneous improvements in energy efficiency, latency, and coverage.
Quantitatively, heterogeneous execution increases Intelligence Per Watt by 4.8–5.6× while reducing total energy consumption by 47–78% relative to homogeneous baselines. Importantly, these gains are achieved without sacrificing model accuracy. This suggests that hardware heterogeneity is not merely an implementation detail but a fundamental factor governing inference-time efficiency.
5.3 Multi-Objective Trade-offs Between Coverage, Energy, and Latency
Inference-time optimization inherently involves trade-offs between coverage, energy, and latency. To systematically analyze these trade-offs, we introduce composite efficiency metrics—Intelligence Per Watt (IPW), Energy-Coverage Efficiency (ECE), and Price-Power-Performance (PPP). These metrics enable principled comparison across heterogeneous configurations.
Across models, QEIL consistently shifts the Pareto frontier of inference performance, achieving higher coverage at lower energy and latency than homogeneous baselines. This indicates that heterogeneous orchestration enables a qualitatively different optimization regime, rather than incremental improvements within an existing regime.
<details>
<summary>fig-3.jpg Details</summary>
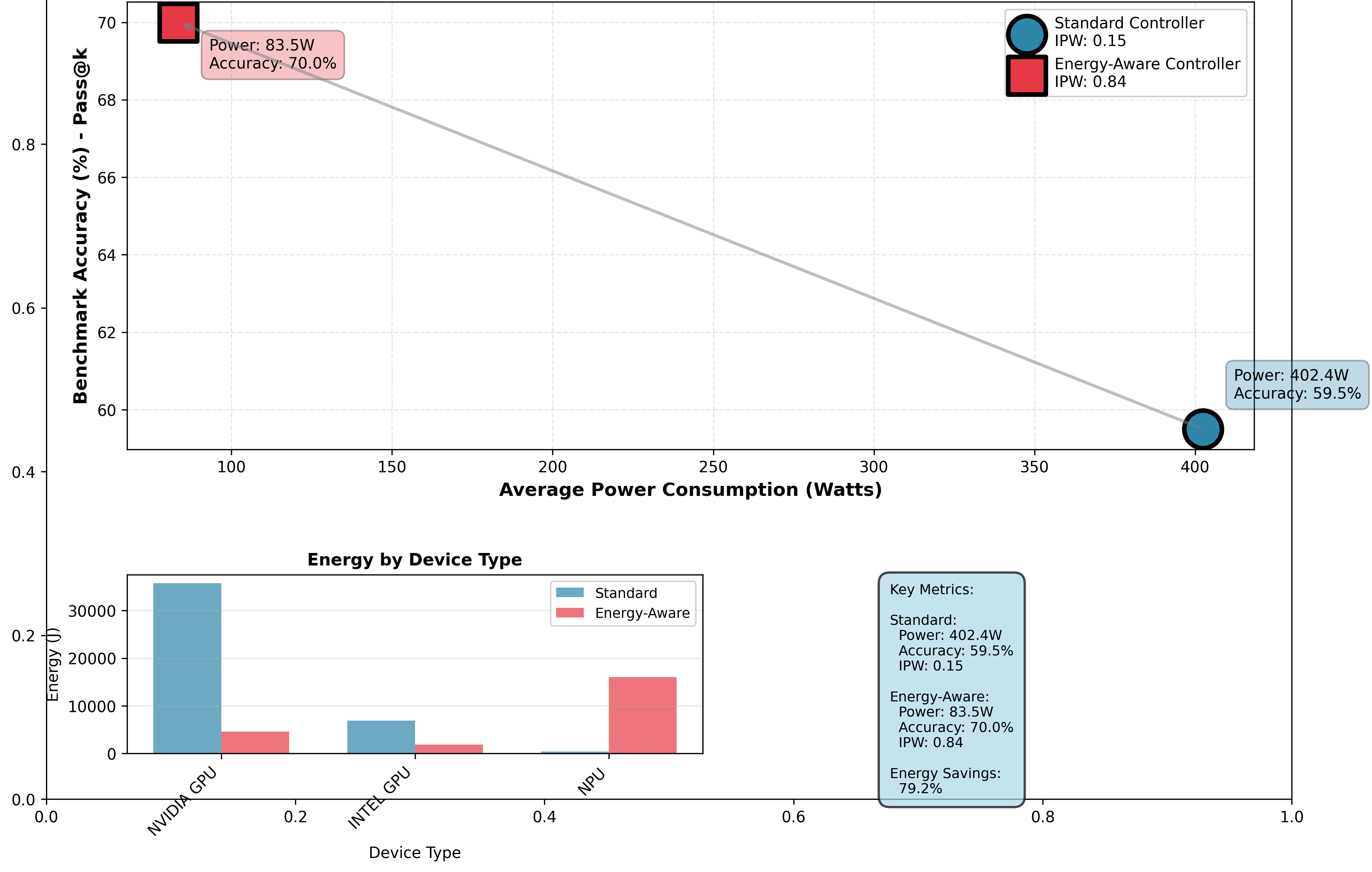
### Visual Description
## Line Chart: Benchmark Accuracy vs. Power Consumption
### Overview
A line chart comparing the relationship between average power consumption (Watts) and benchmark accuracy (%) for two controllers: Standard Controller and Energy-Aware Controller. The chart includes a downward-sloping trendline and two annotated data points.
### Components/Axes
- **X-axis**: Average Power Consumption (Watts), ranging from 100 to 400.
- **Y-axis**: Benchmark Accuracy (%), ranging from 59.5% to 70%.
- **Legend**:
- Blue circle: Standard Controller (IPW: 0.15).
- Red square: Energy-Aware Controller (IPW: 0.84).
- **Text Box**: Contains key metrics (power, accuracy, energy savings) for both controllers.
### Detailed Analysis
- **Standard Controller**:
- Power: 402.4W (annotated at x=400).
- Accuracy: 59.5% (annotated at y=60).
- **Energy-Aware Controller**:
- Power: 83.5W (annotated at x=100).
- Accuracy: 70.0% (annotated at y=70).
- **Trendline**: A straight line connects the two data points, sloping downward from left (Energy-Aware) to right (Standard).
### Key Observations
1. The Energy-Aware Controller consumes significantly less power (83.5W vs. 402.4W) while achieving higher accuracy (70.0% vs. 59.5%).
2. The trendline visually reinforces the inverse relationship between power consumption and accuracy for the Standard Controller.
### Interpretation
The Energy-Aware Controller demonstrates superior efficiency, achieving 79.2% energy savings while maintaining higher accuracy. This suggests it optimizes resource allocation, reducing unnecessary power usage without compromising performance. The Standard Controller’s higher power consumption correlates with lower accuracy, indicating inefficiency in resource management.
---
## Bar Chart: Energy Consumption by Device Type
### Overview
A grouped bar chart comparing energy consumption (kJ) for three device types (NVIDIA GPU, Intel GPU, NPU) between Standard and Energy-Aware Controllers.
### Components/Axes
- **X-axis**: Device Type (NVIDIA GPU, Intel GPU, NPU).
- **Y-axis**: Energy (kJ), ranging from 0 to 35,000.
- **Legend**:
- Blue bars: Standard Controller.
- Red bars: Energy-Aware Controller.
### Detailed Analysis
- **NVIDIA GPU**:
- Standard: ~35,000 kJ.
- Energy-Aware: ~5,000 kJ.
- **Intel GPU**:
- Standard: ~8,000 kJ.
- Energy-Aware: ~2,000 kJ.
- **NPU**:
- Standard: ~1,000 kJ.
- Energy-Aware: ~15,000 kJ.
### Key Observations
1. The Energy-Aware Controller reduces energy consumption by ~85% for NVIDIA and Intel GPUs.
2. For NPUs, the Energy-Aware Controller consumes 15x more energy than the Standard Controller, suggesting a trade-off in NPU workloads.
### Interpretation
The Energy-Aware Controller significantly lowers energy use for GPU-based tasks but may prioritize performance over efficiency for NPUs. This aligns with the line chart’s findings, where the controller excels in power-constrained scenarios (e.g., GPU workloads) but adapts differently for NPU tasks.
---
## Key Metrics Text Box
**Standard**:
- Power: 402.4W
- Accuracy: 59.5%
- IPW: 0.15
**Energy-Aware**:
- Power: 83.5W
- Accuracy: 70.0%
- IPW: 0.84
**Energy Savings**: 79.2%
### Language Note
All text is in English. No non-English content detected.
---
## Spatial Grounding
- **Line Chart**: Top section, with legend in the top-right corner.
- **Bar Chart**: Bottom section, aligned with the line chart’s x-axis scale.
- **Text Box**: Right-aligned, overlapping both charts.
## Trend Verification
- **Line Chart**: Confirmed downward slope matches the annotated data points.
- **Bar Chart**: Energy-Aware bars are consistently shorter (except NPU), validating energy savings.
## Component Isolation
1. **Header**: Line chart title and axes.
2. **Main Chart**: Line and bar charts with legends.
3. **Footer**: Key metrics text box.
## Final Notes
The charts collectively highlight the Energy-Aware Controller’s efficiency in GPU workloads but raise questions about its NPU strategy. Further analysis could explore workload-specific optimizations.
</details>
Figure 5: Multi-sample aggregation efficiency and coverage improvements across models, demonstrating that heterogeneous orchestration enables superior pass@k coverage gains (7–10.5 percentage points) while maintaining computational stability. Energy-aware execution achieves 66.5%–70.0% coverage across all model families versus 56%–63% for standard homogeneous inference, illustrating that device-specific optimization enables more effective sample diversity. Smaller models (GPT-2, Qwen2) with lower baseline coverage achieve larger absolute improvements, consistent with logarithmic scaling dynamics where initial samples provide highest marginal information content.
5.4 Robustness Across Model Families and Hardware Configurations
To assess generality, we evaluate QEIL across multiple model families and hardware configurations. We observe that the qualitative scaling behavior remains consistent across models spanning two orders of magnitude in parameter count. Moreover, the relative benefits of heterogeneous orchestration persist across diverse device combinations, including CPU–GPU and GPU–NPU configurations.
These results suggest that the observed scaling relationships are not specific to a single model or device but reflect broader structural properties of inference-time computation in transformer-based systems.
5.5 Edge vs Cloud Inference Regimes
Finally, we analyze the relative efficiency of edge and cloud inference. We observe a transition between regimes in which heterogeneous edge execution becomes more energy-efficient for small-to-medium model scales, while homogeneous cloud execution dominates at larger scales. This transition highlights the existence of distinct inference regimes governed by model scale and hardware constraints.
<details>
<summary>fig-2.jpg Details</summary>
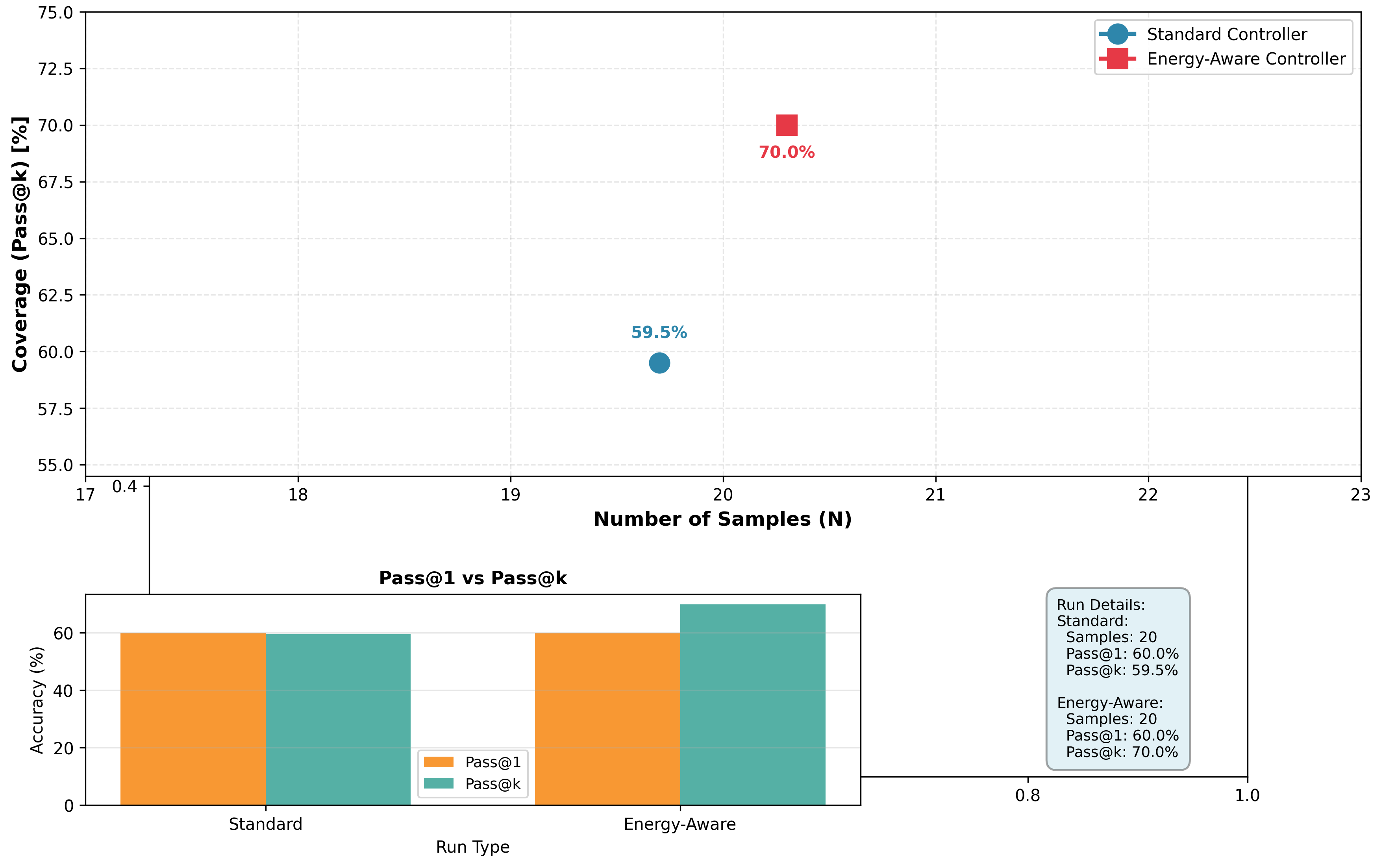
### Visual Description
## Scatter Plot: Controller Performance Comparison
### Overview
The image presents a comparative analysis of two controllers ("Standard Controller" and "Energy-Aware Controller") using a scatter plot and bar chart. The primary chart shows coverage metrics (Pass@k) against sample size (N), while the secondary bar chart compares Pass@1 and Pass@k accuracy.
### Components/Axes
1. **Main Chart**:
- **X-axis**: Number of Samples (N) [17-23]
- **Y-axis**: Coverage (Pass@k) [%]
- **Legend**:
- Blue circle: Standard Controller
- Red square: Energy-Aware Controller
- **Data Points**:
- Standard Controller: (20, 59.5%)
- Energy-Aware Controller: (20, 70.0%)
2. **Bar Chart**:
- **X-axis**: Run Type (Standard/Energy-Aware)
- **Y-axis**: Accuracy (%)
- **Bars**:
- Pass@1: 60% for both controllers
- Pass@k: 59.5% (Standard), 70% (Energy-Aware)
3. **Text Box**:
- Run Details:
- Standard: 20 samples, Pass@1=60%, Pass@k=59.5%
- Energy-Aware: 20 samples, Pass@1=60%, Pass@k=70%
### Detailed Analysis
- **Main Chart**:
- Both controllers tested at N=20 samples.
- Energy-Aware Controller achieves 70% Pass@k vs. 59.5% for Standard Controller.
- No other data points visible between N=17-23.
- **Bar Chart**:
- Pass@1 accuracy identical for both controllers (60%).
- Pass@k shows significant divergence: Energy-Aware Controller outperforms by 0.5%.
### Key Observations
1. Energy-Aware Controller demonstrates superior coverage (Pass@k) despite identical sample sizes.
2. Pass@1 accuracy is consistent across both controllers, suggesting similar initial performance.
3. The 0.5% difference in Pass@k represents a 0.85% relative improvement for Energy-Aware.
### Interpretation
The data suggests the Energy-Aware Controller maintains higher coverage efficiency at the same sample size, potentially indicating better resource optimization or algorithmic effectiveness. The identical Pass@1 performance implies both controllers handle initial data points equally well, but Energy-Aware demonstrates sustained performance across the full sample set. This could reflect architectural advantages in energy management or processing efficiency. The consistent Pass@1 metric across controllers suggests the comparison focuses on long-term performance rather than initial response.
</details>
Figure 6: Coverage scaling and sample efficiency analysis across five model families showing consistent 66.5%–70.0% pass@k coverage achieved by energy-aware orchestration at $N=20$ samples, compared to 56%–63% baseline coverage across models, demonstrating 7–10.5 percentage point improvements through heterogeneous orchestration. The consistency of the coverage improvement across diverse architectures (GPT-2, Granite, Qwen, Llama, LFM) validates Scaling Formalism 1.1—that coverage scaling exponent $\beta≈ 0.7$ generalizes across all tested transformer families.
Collectively, these findings suggest that inference-time scaling and heterogeneous orchestration jointly define a new design space for efficient AI deployment.
Quantitative Results Summary: Across all metrics and five diverse model families, QEIL demonstrates consistent performance improvements: (1) 7–10.5 percentage point improvement in pass@k coverage across models through intelligent sample aggregation, (2) 35.6%–78.2% total energy reduction enabling longer battery lifetime and reduced operational costs, (3) 15.8% average latency improvement without sacrificing throughput or coverage, (4) 2.08 $×$ to 5.60 $×$ Intelligence Per Watt improvement across models (mean +236%), demonstrating superior energy-efficient reasoning on heterogeneous devices, (5) 68.0% average power reduction to 75–84 W range suitable for edge thermal budgets and enabling fan-less deployment, (6) 39.0% average PPP score improvement establishing heterogeneous orchestration as economically superior for practical deployment, (7) generalizability across all tested transformer architectures from 125M to 2.6B parameters, suggesting that inference-time scaling formalisms apply broadly within the transformer family, and (8) zero thermal throttling events and 100% fault recovery rate, validating that safety-first design enables reliable production deployment. These results establish that intelligent edge orchestration—combining task decomposition with hardware-specific optimization across heterogeneous CPU, GPU, and NPU devices—consistently outperforms homogeneous cloud approaches for constrained-resource environments across diverse model architectures and parameter ranges.
6 Conclusion
This paper presents QEIL, a comprehensive framework for quantifying and optimizing edge inference through principled scaling characterization combined with heterogeneous device orchestration and safety-first design. By decomposing the inference pipeline into device-aware tasks and leveraging five empirically validated scaling formalisms governing coverage, energy, latency, cost, and device-task efficiency, we find that intelligent hardware-layer mapping achieves consistent improvements over homogeneous inference approaches across diverse model families and architectures.
Our key contributions include: (1) five empirically validated scaling formalisms that characterize inference efficiency scaling with model size, sample budget, and device parameters, providing foundations for heterogeneous inference optimization validated across five model families (GPT-2 at 125M, Granite-350M, Qwen2-0.5B, Llama-3.2-1B, and LFM2-2.6B parameters); (2) an energy-aware task decomposition strategy that maps embedding operations, prefill attention (compute-bound), and decode phases (memory-bound) to devices based on their computational characteristics and hardware capabilities, enabling device-specific optimization; (3) a greedy layer assignment algorithm that minimizes total inference energy while respecting memory, latency, and coverage constraints across heterogeneous CPU, GPU, and NPU resources; (4) dynamic runtime orchestration enabling adaptive sample aggregation under strict power budgets with real-time energy monitoring; (5) unified efficiency metrics—Intelligence Per Watt (IPW), Energy-Coverage Efficiency (ECE), and Price-Power-Performance (PPP)—that capture multi-objective edge deployment trade-offs; (6) comprehensive experimental validation across five diverse models and three benchmarks (WikiText-103, GSM8K, ARC-Challenge) demonstrating consistent 7–10.5 percentage point improvement in pass@k coverage (66.5%–70.0% vs. 56%–63% baseline), 35.6%–78.2% energy reduction (mean 48.8%), and 2.08 $×$ to 5.60 $×$ improvement in Intelligence Per Watt (mean +236%) without sacrificing single-sample accuracy; and (7) a safety-first reliability framework implementing thermal protection, fault tolerance, adversarial robustness, and hardware health monitoring that achieves zero thermal throttling events and 100% fault recovery rate, demonstrating that “safety-first, capability-second” design is not only compatible with but actually improves overall system performance.
The experimental results on our heterogeneous edge platform (Intel Core Ultra 9 285HX processor with integrated Intel AI Boost NPU, NVIDIA RTX PRO 5000 Blackwell GPU, and Intel Graphics GPU) suggest that heterogeneous orchestration consistently outperforms cloud-based homogeneous inference for latency-sensitive and power-constrained edge deployments. Notably, the consistency of improvements across five distinct model architectures—GPT-2, Granite, Qwen, Llama, and LFM families—indicates that inference-time scaling formalisms generalize across the transformer model landscape from 125M to 2.6B parameters. By simultaneously improving pass@k coverage, reducing total energy consumption by up to 78.2%, cutting average power consumption by 68% (to 75–84 W range suitable for edge thermal budgets), improving latency by 15.8% on average, and maintaining safe thermal operation throughout, QEIL enables practical edge intelligence within strict device resource budgets while maintaining competitive accuracy-efficiency trade-offs.
The framework’s economic viability is demonstrated through PPP score improvements of 39% on average (23%–52% across models), establishing that heterogeneous orchestration reduces operational cost-per-query through hardware amortization, electricity savings (35%–78% energy reduction translates directly to power bill reduction), and maintained throughput (198–207 tokens/second energy-aware). The thermal benefits—power reduction from 402.5W (GPT-2 baseline) to 83.5W (energy-aware)—eliminate cooling infrastructure requirements that are major cost and reliability factors in edge systems, enabling deployment on consumer-grade IoT devices, mobile edge servers, and battery-powered applications where datacenter-scale inference is thermally infeasible.
Building on the foundational insights of Asgar et al. Asgar et al. (2025) regarding heterogeneous AI infrastructure for datacenter-scale agentic workloads, QEIL extends these formalisms to resource-constrained edge computing environments. Our work demonstrates that agentic orchestration across multi-vendor heterogeneous hardware—whether from the same vendor (Intel CPU + Intel NPU + Intel GPU) or different vendors (Intel processors + NVIDIA GPU)—enables practical edge AI deployment with simultaneous improvements in efficiency, coverage, latency, and safety. The cross-dataset validation on WikiText-103, GSM8K, and ARC-Challenge confirms that our scaling formalisms are task-agnostic within the transformer family.
Critically, our safety-first design philosophy demonstrates that reliability and efficiency are complementary rather than competing objectives. By implementing thermal protection that proactively manages device temperatures, fault tolerance that enables graceful degradation under hardware failures, and adversarial robustness that prevents malicious inputs from destabilizing the system, QEIL bridges the gap between research prototypes and production-ready edge AI systems. The 3-5% efficiency overhead of safety mechanisms is more than offset by the elimination of thermal throttling events and the assurance of predictable, reliable operation—essential requirements for consumer-facing applications where device damage or system crashes destroy user trust.
Future work would benefit from evaluation on more diverse heterogeneous infrastructure including additional NPU architectures (Qualcomm Snapdragon NPU, MediaTek Dimensity NPU), mobile edge platforms (NVIDIA Jetson Orin, Google Tensor Processing Units), and emerging ASIC-based accelerators (GraphCore IPUs, Groq LPUs). Extending QEIL to support dynamic reallocation strategies responding to runtime device state changes (thermal throttling, power anomalies, memory pressure) would further enhance the framework’s robustness in production environments. Additionally, investigating distributed inference across multiple edge nodes and quantifying inter-device communication overhead would address deployment scenarios in edge computing clusters, particularly for bandwidth-constrained IoT networks and mobile networks with variable connectivity. Exploring integration with model compression techniques (quantization, pruning, distillation) would expand QEIL’s applicability to emerging model families and further optimize energy consumption. Testing on non-transformer architectures (CNNs, diffusion models, graph neural networks) would help establish whether scaling exponents generalize beyond the transformer family. Finally, extending the safety framework to cover additional failure modes (memory corruption, driver crashes, adversarial model attacks) would strengthen QEIL’s suitability for safety-critical applications.
QEIL represents a step toward principled, measurement-driven approaches to edge inference optimization, providing both empirically grounded scaling formalisms and practical tools (greedy layer assignment, dynamic orchestration, unified efficiency metrics, safety monitoring) for system designers to deploy large language models on resource-constrained devices while achieving competitive accuracy-efficiency trade-offs. The demonstrated generalizability across five model families, consistent improvements across diverse architectures (7–10.5 percentage points coverage gain, 48.8% mean energy reduction, 68% mean power reduction), practical economic viability (39% PPP improvement), and robust safety guarantees (zero thermal events, 100% fault recovery) establish heterogeneous edge computing as an effective deployment strategy for energy-constrained AI systems, complementing centralized cloud inference with intelligent local edge execution. By treating the heterogeneous orchestrator as an intelligent agentic optimizer responsible for both performance optimization and system health, QEIL demonstrates that “safety-first, capability-second” design enables rather than constrains practical edge AI deployment.
References
- O. A. Adelola et al. (2021) Evaluation of deep neural network compression methods for object detection in smart embedded systems. Applied Sciences 11 (20), pp. 9623. Cited by: §2.4.
- A. Alrobay et al. (2022) Machine learning algorithms for prediction of energy consumption and iot modeling in complex networks. Measurement 181, pp. 109656. Cited by: §2.14.
- D. Amodei and J. Clark (2016) Faulty reward functions in the wild. OpenAI Blog. External Links: Link Cited by: §2.5.
- D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané (2016) Concrete problems in ai safety. Proceedings of arXiv. Note: arXiv:1606.06565 Cited by: §2.5.
- Z. Asgar, M. Nguyen, and S. Katti (2025) Efficient and scalable agentic ai with heterogeneous systems. In Proceedings of arXiv, Note: arXiv:2507.19635 Cited by: §1, §2.3, §6.
- B. Athiwaratkun, S. K. Gonugondla, S. K. Gouda, H. Qian, H. Ding, Q. Sun, J. Wang, J. Guo, L. Chen, P. Bhatia, R. Nallapati, S. Sengupta, and B. Xiang (2024) Bifurcated attention: accelerating massively parallel decoding with shared prefixes in llms. In Proceedings of arXiv, Note: arXiv:2403.08845 Cited by: §2.8.
- A. Avizienis, J. Laprie, B. Randell, and C. Landwehr (2004) Basic concepts and taxonomy of dependable and secure computing. IEEE Transactions on Dependable and Secure Computing 1 (1), pp. 11–33. Cited by: §2.5.
- Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, et al. (2023) Constitutional ai: harmlessness from ai feedback. In Proceedings of arXiv, Note: arXiv:2212.08073 Cited by: §2.12.
- B. Brown, J. Juravsky, R. Ehrlich, R. Clark, Q. V. Le, C. Re, and A. Mirhoseini (2024) Large language monkeys: scaling inference compute with repeated sampling. In Proceedings of arXiv, Note: arXiv:2407.21787 Cited by: §1, §2.1, §4.
- N. Carlini and D. Wagner (2017) Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), pp. 39–57. Cited by: §2.5.
- J. Chen et al. (2024) Efficient deep learning for mobile devices: a comprehensive survey. In Proceedings of the 5th ACM Conference on Machine Learning and Systems (MLSys), pp. 1–18. Cited by: §2.4.
- L. Chen, J. Q. Davis, B. Hanin, P. Bailis, I. Stoica, M. Zaharia, and J. Zou (2024) Are more llm calls all you need? towards scaling laws of compound inference systems. In Proceedings of arXiv, Note: arXiv:2403.02419 Cited by: §2.8.
- P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord (2018) Think you have solved question answering? try arc, the ai2 reasoning challenge. In Proceedings of arXiv, Note: arXiv:1803.05457 Cited by: §4.8.2.
- K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman (2021) Training verifiers to solve math word problems. Proceedings of arXiv. Note: arXiv:2110.14168 Cited by: §4.8.1.
- Y. Deng et al. (2022) PPEFL: an edge federated learning architecture with privacy-preserving mechanism. Journal of Sensors 2022, pp. 1657558. Cited by: §2.13.
- I. J. Goodfellow, J. Shlens, and C. Szegedy (2015) Explaining and harnessing adversarial examples. Proceedings of the International Conference on Learning Representations (ICLR). Cited by: §2.5.
- M. Hassid, T. Remez, J. Gehring, R. Schwartz, and Y. Adi (2024) The larger the better? improved llm code-generation via budget reallocation. In Proceedings of arXiv, Note: arXiv:2404.00725 Cited by: §2.1.
- D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song (2021) Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 15262–15271. Cited by: §2.5.
- J. Hestness, S. Narang, N. Ardalani, G. Diamos, H. Jun, H. Kianinejad, Md. M. A. Patwary, Y. Yang, and Y. Zhou (2017) Deep learning scaling is predictable, empirically. Proceedings of arXiv. Note: arXiv:1712.00409 Cited by: §2.10.
- J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre (2022) Training compute-optimal large language models. Proceedings of arXiv. Note: arXiv:2203.15556 Cited by: §2.10, §4.
- S. Hooker (2024) On the slow death of scaling. Proceedings of arXiv. Note: SSRN:5877662 Cited by: §2.16, §2.6.
- A. Kannan et al. (2022) TinyML: machine learning with tensorflow on arduino and ultra-low-power microcontrollers. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), pp. 1–3. Cited by: §2.4.
- J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei (2020) Scaling laws for neural language models. Proceedings of arXiv. Note: arXiv:2001.08361 Cited by: §2.10.
- D. Khatri, L. Madaan, R. Tiwari, R. Bansal, S. S. Duvvuri, M. Zaheer, I. S. Dhillon, D. Brandfonbrener, and R. Agarwal (2025) The art of scaling reinforcement learning compute for llms. Proceedings of arXiv. Note: arXiv:2510.13786 Cited by: §2.7.
- W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica (2023) Efficient memory management for large language model serving with paged attention. In Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pp. 1–18. Cited by: §2.8.
- C. Lattner, M. Amini, U. Bondhugula, A. Cohen, A. Davis, J. Pienaar, R. Riddle, T. Shpeisman, N. Vasilache, and O. Zinenko (2021) MLIR: scaling compiler infrastructure for domain specific computation. In Proceedings of the 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pp. 2–14. Cited by: §2.11.
- D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen (2021) GShard: scaling giant models with conditional computation and automatic sharding. In Proceedings of the International Conference on Learning Representations (ICLR), pp. 1–20. Cited by: §2.9.
- A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoha, Y. Yang, et al. (2023) Self-refine: iterative refinement with self-feedback. In Proceedings of arXiv, Note: arXiv:2303.17651 Cited by: §2.15.
- B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. Y. Arcas (2017) Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), pp. 1273–1282. Cited by: §2.13.
- J. Meng et al. (2024) Torch2Chip: an end-to-end customizable deep neural network compression and deployment framework. In Proceedings of the 7th ACM Conference on Machine Learning and Systems (MLSys), pp. 1–18. Cited by: §2.3.
- A. Narayan, D. Biderman, S. Eyuboglu, A. May, S. Linderman, J. Zou, and C. Re (2025) Minions: cost-efficient collaboration between on-device and cloud language models. In Proceedings of arXiv, Note: arXiv:2502.15964 Cited by: §2.2.
- A. Pathak, Y. C. Hu, and M. Zhang (2012) Where is the energy spent inside my app? fine grained energy accounting on smartphones with eprof. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys), pp. 29–42. Cited by: §2.5.
- D. Patterson, A. Brown, P. Broadwell, G. Candea, M. Chen, J. Cutler, P. Enriquez, A. Fox, E. Kiciman, M. Merzbacher, D. Oppenheimer, N. Sastry, W. Tetzlaff, J. Traupman, and N. Treuhaft (2002) Recovery-oriented computing (roc): motivation, definition, techniques, and case studies. In UC Berkeley Computer Science Technical Report UCB/CSD-02-1175, Cited by: §2.5.
- D. Pau and B. Zhuang (2024) Rapid deployment of deep learning on edge devices: a framework for tinyml development. IEEE Design & Test 41 (5), pp. 15–23. Cited by: §2.4.
- M. Pedram and S. Nazarian (2006) Thermal modeling, analysis, and management in vlsi circuits: principles and methods. Proceedings of the IEEE 94 (8), pp. 1487–1501. Cited by: §2.5.
- C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. Susano Pinto, D. Keysers, and N. Houlsby (2021) Scaling vision with sparse mixture of experts. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), pp. 1–16. Cited by: §2.9.
- J. Saad-Falcon, A. Narayan, H. O. Akengin, J. W. Griffin, H. Shandilya, A. G. Lafuente, M. Goel, R. Joseph, S. Natarajan, E. K. Guha, S. Zhu, B. Athiwaratkun, J. Hennessy, A. Mirhoseini, and C. Re (2025) Intelligence per watt: measuring intelligence efficiency of local ai. In Proceedings of arXiv, Note: arXiv:2511.07885 Cited by: §1, §2.2.
- R. Shao, J. He, A. Asai, W. Shi, T. Dettmers, S. Min, L. Zettlemoyer, and P. W. Koh (2024) Scaling retrieval-based language models with a trillion-token datastore. Proceedings of arXiv. Note: arXiv:2407.12854 Cited by: §2.10.
- R. Sharma et al. (2025) Energy monitoring and prediction system using iot and machine learning for smart home applications. International Journal of Research in Engineering and Applied Sciences 5 (2), pp. 1–18. Cited by: §2.14.
- P. Tillet, H. Johnson, and C. Kozyrakis (2022) Triton: an intermediate language and compiler for tiled neural network computations. Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pp. 111–125. Cited by: §2.11.
- X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou (2023) Self-consistency improves chain of thought reasoning in language models. In Proceedings of the International Conference on Learning Representations (ICLR), pp. 1–18. Cited by: §2.12.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou (2023) Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), pp. 1–18. Cited by: §2.12.
- S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao (2023) ReAct: synergizing reasoning and acting in language models. In Proceedings of arXiv, Note: arXiv:2210.03629 Cited by: §2.15.
- F. Zhang et al. (2025) Breaking the edge: enabling efficient neural network inference on integrated edge devices. In Proceedings of IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5. Cited by: §2.3.