# Large Language Model Reasoning Failures
**Authors**:
- Peiyang Song psong@caltech.edu (California Institute of Technology, Stanford University
Pengrui Han barryhan@carleton.edu)
> Equal contribution.Work done while Peiyang Song was a visiting researcher at Stanford University.
Abstract
Large Language Models (LLMs) have exhibited remarkable reasoning capabilities, achieving impressive results across a wide range of tasks. Despite these advances, significant reasoning failures persist, occurring even in seemingly simple scenarios. To systematically understand and address these shortcomings, we present the first comprehensive survey dedicated to reasoning failures in LLMs. We introduce a novel categorization framework that distinguishes reasoning into embodied and non-embodied types, with the latter further subdivided into informal (intuitive) and formal (logical) reasoning. In parallel, we classify reasoning failures along a complementary axis into three types: fundamental failures intrinsic to LLM architectures that broadly affect downstream tasks; application-specific limitations that manifest in particular domains; and robustness issues characterized by inconsistent performance across minor variations. For each reasoning failure, we provide a clear definition, analyze existing studies, explore root causes, and present mitigation strategies. By unifying fragmented research efforts, our survey provides a structured perspective on systemic weaknesses in LLM reasoning, offering valuable insights and guiding future research towards building stronger, more reliable, and robust reasoning capabilities. We additionally release a comprehensive collection of research works on LLM reasoning failures, as a GitHub repository at https://github.com/Peiyang-Song/Awesome-LLM-Reasoning-Failures, to provide an easy entry point to this area.
1 Introduction
“Failure is success if we learn from it.” – Malcolm Forbes
With the rise of powerful architectures (Vaswani et al., 2023; Jiang et al., 2024a; Gu and Dao, 2024; Hasani et al., 2020), efficient algorithms (Hu et al., 2021; Zhao et al., 2024b; Gretsch et al., 2024; 2025; Dao et al., 2022), and massive data (Cai et al., 2024; Raffel et al., 2020; Gao et al., 2020), Large Language Models (LLMs) have recently shown significant success across diverse domains. These range from traditional linguistic tasks such as machine translation (Zhu et al., 2024b; Tang et al., 2024), to mathematical (Shao et al., 2024; Yang et al., 2023a; 2024a) and even scientific (Zhang et al., 2024b; Wang et al., 2023b; Brodeur et al., 2024) discoveries. Among these achievements, reasoning as an emergent capability of LLMs (Wei et al., 2022a) has attracted particular interest (Huang and Chang, 2023; Yu et al., 2023b; Qiao et al., 2023).
LLMs have set impressive records in reasoning (Wu et al., 2025a; kıcıman2024causalreasoninglargelanguage; Plaat et al., 2024), though it remains controversial whether LLMs really leverage a human-like reasoning procedure when attempting these tasks (Jiang et al., 2024b; Fedorenko et al., 2024; Amirizaniani et al., 2024b; Zhang et al., 2022). This survey does not aim to settle this hot debate; rather we focus on an important area of study in LLM reasoning that has long been overlooked – LLM reasoning failures.
Extensive psychological research (Cannon and Edmondson, 2005; Maxwell, 2007; Coelho and McClure, 2004) underscores the importance of identifying and learning from failures in human development In fact, this theory has been confirmed even more broadly, in non-human animals (Spence, 1936).. Given that AI systems have historically drawn inspiration from human cognition (Schmidgall et al., 2023; Xu and Poo, 2023; Woźniak et al., 2020), we believe the same principle of learning from failures could similarly benefit the study of LLMs, since such failures can usually be traced back to fundamental elements and bring valuable insights to ultimate improvements (Dreyfus, 1992; Karl et al., 2024; An et al., 2024).
Despite some existing works that prospectively realized this importance and investigated LLM reasoning failures on a case-by-case basis (Williams and Huckle, 2024; Tie et al., 2024; Helwe et al., 2021; Borji, 2023), the topic remains fragmented, and underexplored as a unified research area. This fragmentation limits broader understanding, which is however a prerequisite for common patterns to be noticed, and thereby meaningful lessons to be derived. To close this gap, we present the first comprehensive survey dedicated to unifying studies on LLM reasoning failures. We identify meaningful patterns across failures, analyze underlying causes, and discuss potential mitigation strategies. We hope this work not only organizes the field but also stimulate further research and increased attention, toward improving the robustness and reliability of LLM reasoning. We additionally make public a comprehensive collection of research works on LLM reasoning failures, as a GitHub repository at https://github.com/Peiyang-Song/Awesome-LLM-Reasoning-Failures. This collection will be continuously updated as this area advances.
2 Definition and Formulation
2.1 Fundamentals of Reasoning
Human reasoning broadly refers to the ability to draw conclusions and make decisions based on available knowledge (Lohman and Lakin, 2011; Ribeiro et al., 2020). Within cognitive science and philosophy, reasoning has been studied through various frameworks. To systematically survey reasoning failures in LLMs, we propose a comprehensive taxonomy distinguishing reasoning along two primary axes: embodied versus non-embodied, with the latter further subdivided into informal and formal reasoning.
Non-embodied reasoning.
Non-embodied reasoning comprises cognitive processes not requiring physical interaction with environments. Within this category, informal reasoning encompasses intuitive judgments driven by inherent biases and heuristics, common in everyday decision-making and social activities (Piaget, 1952; Vygotsky, 1978; Kail, 1990). By contrast, formal reasoning involves explicit, rule-based manipulation of symbols, grounded in logic, mathematics, code, etc. (Copi et al., 2016; Mendelson, 2009; Liu et al., 2023b).
Embodied reasoning.
Embodied reasoning depends on physical interaction with environments, fundamentally relying on spatial intelligence and real-time feedback (Shapiro, 2019; Barsalou, 2008). This includes predicting and interpreting physical dynamics, and performing goal-directed behaviors constrained by real-world physical laws (Huang et al., 2022b; Lee-Cultura and Giannakos, 2020).
2.2 LLM Reasoning Failures & Common Research Practice
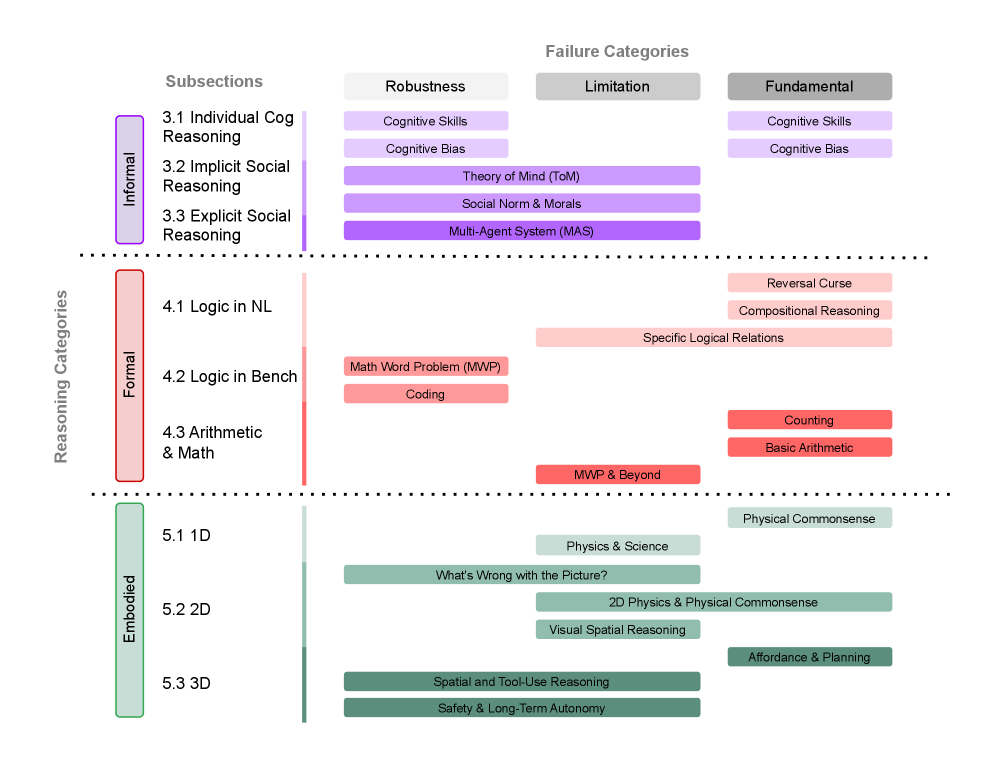
Despite advances in interpretability research (Dwivedi et al., 2023; Li et al., 2024e), LLMs remain largely black-box systems (Luo and Specia, 2024), reflecting the inherent complexity of human cognition they emulate (Castelvecchi, 2016). As such, reasoning abilities are typically assessed behaviorally by examining model outputs on carefully designed prompts and tasks (Ribeiro et al., 2020). We define LLM reasoning failures as cases where model responses significantly diverge from expected logical coherence, contextual relevance, or factual correctness. Failures can manifest in two broad ways. The first type is straightforward poor performance — the model fails decisively on a task, exposing clear deficiencies. The second, subtler type involves apparently adequate performance that is in fact unstable, indicating a robustness issue that reveals hidden vulnerabilities. The former category – straightforward failure – can be sub-divided into two, based on scope and nature. Fundamental failures are usually intrinsic to LLM architectures, manifesting broadly and universally across diverse downstream tasks. In contrast, application-specific limitations reflect shortcomings tied to particular domains of importance, where models underperform despite human expectations of competence. Together, these taxonomies — for reasoning and for failures — offer a comprehensive and mutually consistent framework. Figure 1 uses this framework to visualize a clear organization of topics in this survey.
Current research in this space typically begins with simple, intuitive tests that reveal glaring reasoning failures. These initial observations motivate larger-scale systematic evaluations, to confirm the generality and impact of identified failure modes. By explicitly defining and categorizing LLM reasoning failures according to our framework, this survey unifies fragmented research findings, highlights shared patterns, and directs focused efforts toward understanding and mitigating critical reasoning weaknesses. To help visualize the failure cases, we provide a few most representative examples for each of the failure case presented in this survey. The examples can be found in Appendix E.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: Reasoning Categories and Failure Modes
### Overview
The image is a diagram categorizing reasoning abilities into Informal, Formal, and Embedded types. Each category is further broken down into subsections, and associated with potential failure categories: Robustness, Limitation, and Fundamental. The diagram uses color-coding to visually distinguish the different reasoning types and failure modes.
### Components/Axes
The diagram has two primary axes:
* **Vertical Axis:** "Reasoning Categories" with three main categories: Informal (pink), Formal (orange), and Embedded (green). These are numbered 3.1-3.3, 4.1-4.3, and 5.1-5.3 respectively.
* **Horizontal Axis:** "Failure Categories" with three categories: Robustness (light gray), Limitation (medium gray), and Fundamental (dark gray).
The diagram also includes subsections within each reasoning category, and specific failure modes associated with each subsection.
### Detailed Analysis or Content Details
**Informal Reasoning (Pink)**
* **3.1 Individual Cog Reasoning:** Associated with "Cognitive Skills" under Robustness and "Cognitive Skills" under Fundamental.
* **3.2 Implicit Social Reasoning:** Associated with "Cognitive Bias" under Robustness and "Cognitive Bias" under Fundamental.
* **3.3 Explicit Social Reasoning:** Associated with "Theory of Mind (ToM)" under Robustness, "Social Norm & Morals" under Limitation, and "Multi-Agent System (MAS)" under Limitation.
**Formal Reasoning (Orange)**
* **4.1 Logic in NL:** Associated with "Reversal Curse" and "Compositional Reasoning" under Limitation, and "Specific Logical Relations" under Fundamental.
* **4.2 Logic in Bench:** Associated with "Math Word Problem (MWP)" and "Coding" under Robustness.
* **4.3 Arithmetic & Math:** Associated with "MWP & Beyond" under Robustness, "Counting" and "Basic Arithmetic" under Fundamental.
**Embedded Reasoning (Green)**
* **5.1 1D:** Associated with "Physics & Science" and "What's Wrong with the Picture?" under Robustness, and "Physical Commonsense" under Fundamental.
* **5.2 2D:** Associated with "2D Physics & Physical Commonsense" under Robustness, "Visual Spatial Reasoning" under Limitation, and "Affordance & Planning" under Fundamental.
* **5.3 3D:** Associated with "Spatial & Tool-Use Reasoning" and "Safety & Long-Term Autonomy" under Robustness.
### Key Observations
* The "Fundamental" failure category appears to be consistently associated with core cognitive abilities (Cognitive Skills, Cognitive Bias, Counting, Basic Arithmetic).
* "Robustness" failures are more diverse, encompassing specific skills like Physics & Science, Math Word Problems, and Cognitive skills.
* "Limitation" failures seem to relate to higher-level reasoning abilities like Theory of Mind, Compositional Reasoning, and Visual Spatial Reasoning.
* The diagram suggests a hierarchy of reasoning complexity, moving from Informal (social and cognitive) to Formal (logical and mathematical) to Embedded (physical and spatial).
### Interpretation
This diagram presents a framework for understanding the different types of reasoning and the potential ways in which these reasoning processes can fail. The categorization into Informal, Formal, and Embedded reasoning reflects a progression in the complexity and abstraction of the reasoning task. The failure categories (Robustness, Limitation, and Fundamental) highlight different levels of cognitive vulnerability.
The association of "Fundamental" failures with core cognitive skills suggests that these failures represent basic limitations in the underlying cognitive architecture. "Robustness" failures indicate vulnerabilities to specific types of input or context, while "Limitation" failures point to constraints in the capacity for higher-level reasoning.
The diagram is likely intended to guide the development and evaluation of AI systems, by identifying the specific reasoning abilities that are most challenging to replicate and the types of failures that are most likely to occur. The diagram also provides a useful framework for understanding human reasoning errors. The use of color-coding and visual layout makes the information accessible and easy to understand.
</details>
Figure 1: A Taxonomy of LLM Reasoning Failures. We adopt a nuanced 2-axis structure (reasoning type $×$ failure type), with each row representing a reasoning category and each column a failure category. A more detailed explanation is presented in Section 2.
3 Reasoning Informally in Intuitive Applications
Humans naturally develop the capacity for informal reasoning early in life, relying on intuitive judgments shaped by cognitive processes and social experiences. Though often taken for granted, this forms the foundation of human reasoning and decision-making. In this section, we focus on failures exhibited by LLMs in such informal reasoning. We begin by examining reasoning failures in core cognitive abilities reflected in individual LLM behaviors; then explore those exposed in social contexts, expressed implicitly or explicitly.
3.1 Individual Cognitive Reasoning
Many reasoning failures exhibited by LLMs can be traced back to core human cognitive phenomena (Han et al., 2024b; Gong et al., 2024; Galatzer-Levy et al., 2024; Suri et al., 2024). These failures arise either because LLMs lack certain fundamental cognitive abilities possessed by humans – leading to errors that humans typically avoid (Han et al., 2024b) – or because LLMs replicate human-like cognitive biases and heuristics, resulting in analogous mistakes (Suri et al., 2024; Lampinen et al., 2024). In both cases, these failures relate closely to well-documented human cognitive phenomena and psychological evidence.
Fundamental Cognitive Skills.
Humans naturally possess a set of fundamental cognitive skills indispensable for reasoning. LLMs demonstrate systematic failures due to deficiencies in these areas. A prominent example is the set of core executive functions – working memory (Baddeley, 2020), inhibitory control (Diamond, 2013; Williams et al., 1999), and cognitive flexibility (Canas et al., 2006) – essential in human reasoning (Diamond, 2013). Working memory is the capacity to hold and manipulate information over short periods. LLMs’ limited working memory leads to failures when task demands exceed their capacity (Gong et al., 2024; Zhang et al., 2024a; Gong and Zhang, 2024; Upadhayay et al., 2025; Huang et al., 2025a). In particular, LLMs suffer from “proactive interference” to a much larger extent than humans, where earlier information significantly disrupts retrieval of newer updates (Wang and Sun, 2025). Inhibitory control – the ability to suppress impulsive or default responses when contexts demand – is also weak in LLMs, with them often sticking to previously learned patterns even when contexts shift (Han et al., 2024b; Patel et al., 2025). Lastly, cognitive flexibility, the skill of adapting to new rules or switching tasks efficiently, remains a challenge, especially in rapid task switching and adaptation to new instructions (Kennedy and Nowak, 2024).
Another key aspect is abstract reasoning (Guinungco and Roman, 2020), the cognitive ability to recognize patterns and relationships in intangible concepts. Even advanced LLMs struggle with abstract reasoning tasks, such as inferring underlying rules from limited examples, understanding implicit conceptual relationships, and reliably handling symbolic or temporal abstractions (Xu et al., 2023c; Gendron et al., 2023; Galatzer-Levy et al., 2024; Saxena et al., 2025).
These phenomena are fundamental reasoning failures that stem from intrinsic limitations of LLM architectures and training dynamics, and often manifest as robustness vulnerabilities across a wide range of tasks. Recent work attributes these failures to the underlying self-attention mechanism’s dispersal of focus under complex tasks (Gong and Zhang, 2024; Patel et al., 2025), and to the next token prediction training objective, which prioritizes statistical pattern completion over deliberate reasoning (Han et al., 2024b; enström2024reasoningtransformersmitigating). Some also point out that unlike humans – who develop fundamental cognitive functions through embodied, goal-driven interactions with the physical and social world (Pearce and Miller, 2025; Rodríguez, 2022; Jin et al., 2018) – LLMs learn passively from text alone, lacking grounding and experiential feedback to support the development. Efforts to enhance these skills correspondingly include advanced prompting like Chain-of-Thought (CoT) (Wei et al., 2022b), retrieval augmentation (Xu et al., 2023b), fine-tuning with deliberately injected interference (Li et al., 2022), multimodality (Hao et al., 2025), and architectural innovations to mimic human attention mechanisms (Wu et al., 2024d).
Cognitive Biases.
Cognitive biases – systematic deviations from rational judgment – are well-studied in human reasoning (Tversky and Kahneman, 1974; 1981). They arise from mental shortcuts, limited cognitive resources, or contextual influences, often leading to predictable errors. LLMs exhibit similar biases that systematically affect their reasoning across diverse tasks (Hagendorff, 2023; Bubeck et al., 2023). Since these biases are deeply ingrained from training data and model architecture, they permeate a wide range of downstream applications, necessitating careful identification and mitigation.
In humans, these biases become evident only when information is presented and their responses observed – similarly, in LLMs, cognitive biases manifest also through the processing of information. Here lie two interrelated factors: the content of information and the presentation of that information. Regarding content, LLMs struggle more with abstract or unfamiliar topics – a phenomenon known as the “content effect” (Lampinen et al., 2024) – and tend to favor information that aligns with prior context or assumptions, reflecting human-like confirmation bias (O’Leary, 2025b; Shi et al., 2024; Malberg et al., 2024; Wan et al., 2025; Zhu et al., 2024c). Social cognitive biases also influence LLM outputs, including group attribution bias (Hamilton and Gifford, 1976; Allison and Messick, 1985; Raj et al., 2025) and negativity bias (Rozin and Royzman, 2001), which prioritize popular content (Echterhoff et al., 2024; Lichtenberg et al., 2024; Jiang et al., 2025a) and negative inputs (Yu et al., 2024c; Malberg et al., 2024) respectively.
Equally important is how the same content is presented. LLMs are highly sensitive to the order in which information is given, exhibiting order bias (Koo et al., 2023; Pezeshkpour and Hruschka, 2023; Jayaram et al., 2024; Guan et al., 2025; Cobbina and Zhou, 2025), and show anchoring bias (Lieder et al., 2018; Rastogi et al., 2022), where early inputs disproportionately shape their reasoning (Lou and Sun, 2024; O’Leary, 2025a; Huang et al., 2025e; Wang et al., 2025b). Framing effects further influence outputs: logically equivalent but differently phrased prompts can lead to different results (Jones and Steinhardt, 2022; Suri et al., 2024; Nguyen, 2024; Lior et al., 2025; Robinson and Burden, 2025; Shafiei et al., 2025). Additionally, factors like narrative perspective (e.g., first-person vs. third-person) (Cohn et al., 2024; Lin et al., 2024b), prompt length or verbosity (Koo et al., 2023; Saito et al., 2023), and irrelevant or distracting information (Shi et al., 2023) further derail logical reasoning.
Cognitive biases constitute fundamental reasoning failures rooted in LLM training paradigms and architectures, and they manifest as robustness vulnerabilities across a wide range of downstream applications. The root causes of these cognitive biases in LLMs are threefold. First, biases are inherited from the pre-training data, where the linguistic patterns in human languages reflect cognitive errors (Itzhak et al., 2025). Second, architectural features of the model – such as the Transformer’s causal masking – introduce predispositions toward order-based biases independent of data (Wu et al., 2025b; Dufter et al., 2022). Third, alignment processes like Reinforcement Learning from Human Feedback (RLHF) amplify biases by aligning model behavior with human raters who are themselves biased (Sumita et al., 2025; Perez et al., 2023).
Mitigation strategies fall into three categories. Data-centric approaches focus on curating training data to reduce biased content (Sun et al., 2025a; Schmidgall et al., 2024; Han et al., 2024a). In-processing techniques, such as adversarial training, aim to prevent biased associations during model learning (Yang et al., 2023b; Cantini et al., 2024). Lastly, post-processing methods leverage prompt engineering or output filtering to steer model responses after training (Sumita et al., 2025; Lin and Ng, 2023). In this category, indirect methods like inducing specific model personalities have also shown promise in modulating biases (Shi et al., 2024; He and Liu, 2025). Nonetheless, even when mitigated in one context, cognitive biases often re-emerge when contexts shift. The diverse and penetrative nature of cognitive biases makes them difficult to be fully eliminated.
3.2 Implicit Social Reasoning
Certain cognitive reasoning failures manifest only within social contexts. We define implicit social reasoning as an individual model’s capacity to internally infer and reason about (1) others’ mental states (e.g., beliefs, emotions, intentions) and (2) shared social norms without requiring direct interaction.
Theory of Mind (ToM).
ToM is the cognitive ability to attribute mental states – beliefs, intentions, emotions – to oneself and others, and to understand that others’ mental states may differ from one’s own (Frith and Frith, 2005). ToM enables humans to interpret behaviors, predict actions, and navigate complex interpersonal interactions, central in social reasoning. Typically emerging in early childhood with milestones like passing false belief tasks (understand that others’ beliefs may be incorrect or different) (Wimmer and Perner, 1983), ToM has been a central focus in human psychology and cognitive science.
Under this inspiration, recent research evaluates the ToM capacity of LLMs, to gauge their ability to engage in social reasoning. Early studies focused on classic ToM tasks, such as false-belief (van Duijn et al., 2023; Kim et al., 2023), perspective-taking (infer what another individual perceives) (Sap et al., 2022), and unexpected content tasks (predicting what others would believe is inside a mislabeled unopened container) (Pi et al., 2024). Surprisingly, even advanced models such as GPT-4 struggle with these tasks trivial for human children. Moreover, minor modifications in task phrasing lead to drastic drops in performance, showing LLM ToM reasoning is unstable (Ullman, 2023; Kosinski, 2023; Pi et al., 2024; Shapira et al., 2023).
While there has been clear progress from early models like GPT-3 – which largely failed at ToM tasks – to newer models such as GPT-4o and reasoning models like o1-mini, which can solve many standard ToM tests, their underlying reasoning remains brittle under simple perturbations (Gu et al., 2024; Zhou et al., 2023d). Also, LLMs still struggle with higher-order, more complex aspects of ToM, such as predicting others’ behaviors, making appropriate moral or social judgments, and translating this understanding into coherent actions (He et al., 2023; Gu et al., 2024; Marchetti et al., 2025; Amirizaniani et al., 2024a; Strachan et al., 2024). Particularly, on dynamic, conversational benchmarks (Xiao et al., 2025; Kim et al., 2023), even state-of-the-art models fail to demonstrate consistent ToM capabilities and perform significantly worse than humans. Furthermore, current models exhibit deficits in emotional reasoning. This includes difficulties in emotional intelligence (EI) (Sabour et al., 2024; Hu et al., 2025; Amirizaniani et al., 2024b; Vzorinab et al., 2024), susceptibility to affective bias (Chochlakis et al., 2024), and limited understanding of cultural variations in emotional expression and interpretation (Havaldar et al., 2023).
While prompting techniques like CoT offer some improvements (Gandhi et al., 2024), fundamental gaps remain due to deeper limitations from the LLM architecture, training paradigms, and a lack of embodied cognition (Strachan et al., 2024; Sclar et al., 2023). Failures in this domain constitute important application-specific limitations, and because ToM underlies many socially grounded tasks, such failures often result in significant robustness vulnerabilities. Given ToM’s centrality to social reasoning, future work should move beyond prompting, to probe deeper root causes and general mitigation.
Social Norms and Moral Values.
LLMs also struggle with reasoning about social norms, moral values, and ethical principles that govern human behavior. Unlike humans, who develop moral and ethical reasoning through experience, LLMs, trained purely on text, often exhibit inconsistent and unreliable social, moral, and ethical reasoning (Ji et al., 2024; Jain et al., 2024b).
One key limitation is that LLMs cannot reason and apply moral values (Ji et al., 2024) and social norms (Jain et al., 2024b) consistently. They often produce contradictory ethical judgments or varied moral reasoning performance when questions are slightly reworded (Bonagiri et al., 2024), generalized (Tanmay et al., 2023), or presented in a different language (Agarwal et al., 2024). Fine-tuning further exacerbates these inconsistencies, leading to sometimes prioritizing task-specific optimization over ethical coherence (Yu et al., 2024a).
Beyond inconsistencies, LLMs show notable disparities compared to humans in reasoning with social norms and moral values. These models fail significantly in understanding real-world social norms (Rezaei et al., 2025), aligning with human moral judgments (Garcia et al., 2024; Takemoto, 2024), and adapting to cultural differences (Jiang et al., 2025b). Without consistent and reliable moral reasoning, LLMs are not fully ready for real-world decision-making involving ethical considerations.
These inconsistencies and disparities constitute important application-specific limitations for safety, privacy, sensitivity, and morality-related tasks, and such failures often create severe robustness vulnerabilities, including susceptibility to jailbreaks and other forms of manipulation. Many argue that these failures stem from a fundamental absence of robust, internalized representations of ethical principles, normative frameworks, and moral intentionality (Chakraborty et al., 2025; Wang et al., 2025a; Pock et al., 2023; Almeida et al., 2024). Although training procedures such as RLHF and instruction fine-tuning introduce alignment signals, they often operate superficially and fail to produce coherent moral behavior in complex contexts (Dahlgren Lindström et al., 2025; Wang et al., 2025a; Barnhart et al., 2025; Han et al., 2025). Current efforts to address these limitations mainly include prompt-based interventions (Chakraborty et al., 2025; Ma et al., 2023), internal activation steering (Tlaie, 2024; Turner et al., 2023), and direct fine-tuning on curated moral reasoning benchmarks (Senthilkumar et al., 2024; Karpov et al., 2024). However, in practice, these methods often suffer from the same limitations as RLHF, offering surface-level and task-specific improvements that remain vulnerable against prompt manipulations and jailbreaks.
3.3 Explicit Social Reasoning
In reasoning, “society” can refer to not just an abstract concept but real-world settings involving interactions among multiple agents. In Multi-Agent Systems (MAS), explicit social reasoning is the capacity of AI systems to collaboratively plan and solve complex tasks, an area challenging for current LLMs.
Currently, key challenges include (1) long-horizon planning, (2) communications and ToM, and (3) robustness and adaptability. Long-horizon planning is the ability to maintain coherent and coordinated strategies over extended interactions, where LLMs frequently fail (Li et al., 2023a; Cross et al., 2024; Guo et al., 2024c; Han et al., 2024c; Zhou et al., 2025) as they rely excessively on local or recent information (Piatti et al., 2024; Zhang et al., 2023; Han et al., 2024c). Furthermore, individual agents’ social reasoning failures (discussed in Section 3.2, e.g., inefficient communication and ToM) (Guo et al., 2024c; Agashe et al., 2024; Zhou et al., 2025), lead to misinterpretations and inaccurate representations of other agents, causing strategic misalignment (Pan et al., 2025; Li et al., 2023a; Cross et al., 2024; Han et al., 2024c). Lastly, MAS face robustness and adaptability issues (Li et al., 2023a; Cross et al., 2024), lacking resilience to disruptive or malicious disturbances (Huang et al., 2024) and struggling with task verification and termination (Pan et al., 2025; Baker et al., 2025).
These failures stem from both individual LLM capabilities and MAS system design (Pan et al., 2025), representing key application-specific failures, and they frequently manifest as robustness vulnerabilities in multi-agent settings. Standard LLMs, optimized for next-token prediction, lack the explicit reasoning depth needed for multi-step, jointly conditioned objectives, and their fragile ToM representations cause coordination breakdowns. Individual limitations in cognitive skills, such as working memory, and cognitive biases, such as the anchoring effect, can also lead to MAS failures like difficulties with long-horizon planning. On the system level, many MAS often lack effective robustness layers – clear role specifications, cross-verification among agents, and reliable termination checks – allowing errors to cascade (Huang et al., 2024; Pan et al., 2025).
Mitigation research thus targets (i) richer internal models like belief tracking and hypothesis testing (Li et al., 2023a; Cross et al., 2024), (ii) structured communication protocols with mandatory verification phases (Pan et al., 2025), and (iii) dedicated inspector or challenger agents that monitor and contest questionable outputs (Huang et al., 2024; Baker et al., 2025). While these approaches reduce errors, none eliminate them and all require significant task-specific engineering that is difficult to generalize. In parallel, the recent rise of context engineering (Mei et al., 2025) – which focuses on a systematic optimization of the entire information payload fed to an LLM during inference – is increasingly seen as a more robust alternative to traditional prompt engineering in MAS. Real-world deployment will hence require an integrated stack combining all three strands with domain fine-tuning and formal safety guarantees (Lindemann and Dimarogonas, 2025; de Witt, 2025).
4 Reasoning Formally in Logic
When reasoning goes beyond intuition, a formal framework is needed to ensure rigor. As introduced in Section 2, logic is directly about doing “correct” reasoning, ensuring premises support conclusions (Jaakko and Sandu, 2002). LLM failures in logical reasoning (Liu et al., 2025) thus pose serious risks, potentially leading to flawed thought processes and harmful decisions. Logic spans a continuum from implicit structures in natural languages (Iwańska, 1993), to explicit symbolic (Lewis et al., 1959) and mathematical (Shoenfield, 2018) representations. This section follows that progression, examining failures in increasingly formal reasoning paradigms.
4.1 Logic in Natural Languages
Reversal Curse.
While natural languages are not fully logical structures (Fedorenko et al., 2024), they do hold simple logical relations (Sampson, 1979; Stich, 1975) that humans trivially grasp. A representative failure of LLMs is reversal curse: despite being trained on “A is B,” models often fail to infer the equivalent “B is A” – a trivial bidirectional equivalence for humans. Such failures occur even when a factual sentence from training data is just restated as a question during inference. First observed by Berglund et al. (2023) as a fundamental failure that occur widely across tasks on GPT-based (Radford and Narasimhan, 2018) models, this phenomenon is later shown in Wu et al. (2024a) not to affect BERT (Devlin et al., 2019).
This failure has been attributed to uni-directional training objectives of Transformer-based LLMs (Lv et al., 2024; Lin et al., 2024c), which induce structural asymmetry in model weights (Zhu et al., 2024a) and inability to predict antecedent words within training data (Guo et al., 2024b; Youssef et al., 2024). Golovneva et al. (2024) further argues that scaling alone cannot resolve the issue due to Zipf’s law (Newman, 2005). Mitigation efforts accordingly center on reducing directional bias through training data augmentation. Early approaches syntactically reverse facts (Lu et al., 2024; Ma et al., 2024b), while later methods introduce substring-preserving reversals (Golovneva et al., 2024) and permuting semantic units in training data (Guo et al., 2024b). Despite differing in complexity, all methods share a common goal: exposing models to bidirectional formulations to restore logical symmetry.
Compositional Reasoning.
Compositional reasoning requires combining multiple pieces of knowledge or arguments into a coherent inference. Fundamental failures arise when LLMs are capable of each component but fail in integrating them. Studies show systematic failures in basic two-hop reasoning – combining only two facts across documents – and even worsening performance with increased compositional depth and the addition of distractors (Zhao and Zhang, 2024; Xu et al., 2024b; Guo et al., 2025a). This fundamental weakness extends beyond basic tasks, to compositions of math problems (Zhao et al., 2024c; Hosseini et al., 2024; Sun et al., 2025b) (i.e., LLMs succeed in individual problems but fail in composed ones), multi-fact claim verification (Dougrez-Lewis et al., 2024), and other inherently compositional tasks (Dziri et al., 2023).
This failure is attributed to an inability of holistic planning and in-depth thinking. CoT prompting improves on this by making reasoning steps explicit at inference time. Still, latent compositionality is more efficient in practice yet harder to achieve (Yang et al., 2024c). Toward this, Li et al. (2024f) identifies faulty implicit reasoning in mid-layer multi-head self-attention (MHSA) modules and edit them, while Zhou et al. (2024a) enhances training with graph-structured reasoning path data, similar to distilling CoT reasoning process into training data (Yu et al., 2024b). Both converge in spirit to improving latent compositional reasoning by explicitly guiding models’ internal reasoning mechanisms.
Specific Logical Relations.
Both reversal curse and compositional reasoning reflect fundamental failures affecting a broad range of reasoning tasks, exposed across general corpora or arbitrary logical statements. In contrast, another line of work focuses on specific logical relations, uncovering targeted LLM reasoning failures, which requires purpose-built datasets for quantitative analysis at scale. Using this approach, studies reveal LLM weaknesses in specific types of logic such as converse binary relations (Qi et al., 2023), syllogistic reasoning (Ando et al., 2023), causal inference (Joshi et al., 2024), and even shallow yes/no questions (Clark et al., 2019). Those weaknesses appear as both fundamental inabilities in reasoning with certain logic, and limitations in specific corresponding downstream applications: more complexities are added by testing divergences between factual inference and logical entailment (Chan et al., 2024), or putting causal reasoning in contexts (Zhao et al., 2024d). To scale up, some synthetically generate natural language data from symbolic templates (Wan et al., 2024; Wang et al., 2024; Gui et al., 2024). Alternatively, Chen et al. (2024d) seed known failures and leverage LLMs to synthetically expand the dataset. While root causes are harder to isolate for those specific logic, the curated datasets offer a natural mitigation by direct fine-tuning.
4.2 Logic in Benchmarks
While Section 4.1 studies LLM reasoning failures directly within natural language logic, another growing body of work leverages logical structures implicit in benchmarks to systematically uncover robustness issues in LLM reasoning. Motivated by rising concerns about the reliability of static benchmarks (Zhou et al., 2023c; Zheng et al., 2024b; Xu et al., 2024a; Patel et al., 2021), these studies introduce logic-preserving transformations based on particular task structures, such as reordering options in multiple-choice questions (MCQs) (Zheng et al., 2023; Pezeshkpour and Hruschka, 2023; Alzahrani et al., 2024; Gupta et al., 2024; Ni et al., 2024), rearranging parallel premises and events (Chen et al., 2024c; Yamin et al., 2024), or superficially editing unimportant contexts (e.g., character names) (Jiang et al., 2024b; Mirzadeh et al., 2024; Shi et al., 2023; Wang and Zhao, 2024). Such modifications keep the tasks semantically the same. Performance drops thus point to reduced trustworthiness and reveal critical robustness issues: despite strong static benchmark scores, the model’s reasoning must remain consistent on the reasoning tasks being tested.
Math Word Problem (MWP) Benchmarks.
Certain benchmarks inherently possess richer logical structures that facilitate targeted perturbations. MWPs exemplify this, as their logic can be readily abstracted into reusable templates. Researchers use this property to generate variants by sampling numeric values (Gulati et al., 2024; Qian et al., 2024; Li et al., 2024b) or substituting irrelevant entities (Shi et al., 2023; Mirzadeh et al., 2024). Structural transformations – such as exchanging known and unknown components (Deb et al., 2024; Guo et al., 2024a) or applying small alterations that change the logic needed to solve problems (Huang et al., 2025b) – further highlight deeper robustness limitations.
Coding Benchmarks.
Another example is coding benchmarks, which ask to generate code snippets based on function definitions, doc strings specifying coding tasks, and optional starter code. Common transformations include syntactically editing doc strings (Xia et al., 2024; Wang et al., 2022; Sarker et al., 2024; Roh et al., 2025), renaming functions and variables (Wang et al., 2022; Hooda et al., 2024), and altering control-flow logic such as swapping if-else cases (Hooda et al., 2024). Beyond preserving the task logic, some studies introduce adversarial code changes to test whether LLMs identify and adapt to them (Miceli-Barone et al., 2023; Dinh et al., 2023), thereby evaluating deeper reliability. Beyond perturbations, a rising approach utilizes meta-theorems such as the Monadic Second-Order logic from CS theory to synthesize algorithmic coding problems at scale (Beniamini et al., 2025), posing a significant challenge even for state-of-the-art large reasoning models (LRMs) (Xu et al., 2025a).
Mitigation & Extensions.
These failures are attributed to a lack of robustness or overfitting to public datasets. Robustness-related issues are commonly mitigated by applying perturbations to diversify training data (Patel et al., 2021), thus enhancing resilience to variations. Though effective, these approaches are expensive in compute and limited in domain, making them hard to generalize. Overfitting concerns are addressed through dynamically evolving (Jain et al., 2024a; White et al., 2024) or privately maintained datasets (Rajore et al., 2024). They ensure rigorous evaluation, a necessary first step for steering LLM improvement toward better reasoning in the benchmark subjects.
Beyond individual benchmarks, Hong et al. (2024) automates a set of transformations across math and coding benchmarks, and Wu et al. (2024e) alters common assumptions of well-known tasks. Shojaee et al. (2025) further moves beyond standard math and coding benchmarks – which assess models solely by final-answer accuracy – by evaluating them on logic puzzles like the Tower of Hanoi, where both reasoning steps and solutions can be systematically assessed. The study finds that even state-of-the-art LRMs suffer an “accuracy collapse” as puzzle complexity increases, though Lawsen (2025) criticizes aspects of the experimental design, suggesting these may unfairly impact reported accuracy.
4.3 Arithmetic & Mathematics
Mathematics, historically a universal framework for rigorous reasoning (Shoenfield, 2018), has exposed fundamental limits in LLM reasoning, particularly in arithmetic-related tasks.
Counting.
Despite its simplicity, counting poses a notable fundamental challenge for LLMs (Xu and Ma, 2024; Chang and Bisk, 2024; Zhang and He, 2024; Fu et al., 2024; Conde et al., 2025; Yehudai et al., 2024), even the reasoning ones (Malek et al., 2025), which extend to basic character-level operations like reordering or replacement (Shin and Kaneko, 2024) and affect a wide range of downstream reasoning applications (Vo et al., 2025; Guo et al., 2025b; Parcalabescu et al., 2021). Although the failures manifest at the application level, much work suggest that they originate primarily from architectural and representational limits, including tokenization (Zhang et al., 2024f; Shin and Kaneko, 2024), positional encoding (Chang and Bisk, 2024), and training data composition (Allen-Zhu and Li, 2024), rather than from superficial prompting or task framing on the application-level. Mitigation via supervised fine-tuning (Zhang and He, 2024) and engaged reasoning (Xu and Ma, 2024) have been proposed, yet robust counting remains elusive for current models. Since the limitations largely arise from current LLM architectures, future work should consider deeper mitigation through architectural innovations.
Basic Arithmetic.
Another fundamental failure is that LLMs quickly fail in arithmetic as operands increase (Yuan et al., 2023; Testolin, 2024), especially in multiplication. Research shows models rely on superficial pattern-matching rather than arithmetic algorithms, thus struggling notably in middle-digits (Deng et al., 2024). Surprisingly, LLMs fail at simpler tasks (determining the last digit) but succeed in harder ones (first digit identification) (Gambardella et al., 2024). Those fundamental inconsistencies lead to failures for practical tasks like temporal reasoning (Su et al., 2024).
These issues stem from heuristic-driven reasoning strategies (Nikankin et al., 2024) and limited numerical precision (Feng et al., 2024a). Proposed solutions include detailed step-by-step training datasets (Yang et al., 2023c), digit-order reversals to focus attention on least significant digits – mirroring human multiplication strategies (Zhang-Li et al., 2024; Shen et al., 2024), LLM self-improvement methods (Lee et al., 2025), and neuro-symbolic augmentations that enable internal arithmetic reasoning (Dugan et al., 2024). Despite these advances, fundamental research on intrinsic arithmetic capabilities is increasingly overshadowed by the prevalent reliance on external tool use.
Math Word Problems & Beyond.
Beyond counting and basic arithmetic – two fundamental failures that propagate into many downstream reasoning applications – Math Word Problems (MWPs) represent a more specific yet highly consequential application domain. Math Word Problems (MWPs) combine arithmetic with contextual logical reasoning, making them a prominent application for assessing LLM capabilities. Beyond using transformations to expose reasoning flaws (Section 4.2), research identifies challenges ranging from specific simple tasks (Nezhurina et al., 2024) to large-scale evaluations on a domain of math (Wei et al., 2023b; Boye and Moell, 2025; Fan et al., 2024; Sun et al., 2025b). Additionally, LLMs exhibit susceptibility when faced with unsolvable or faulty MWPs (Ma et al., 2024a; Rahman et al., 2024; Tian et al., 2024). LLMs struggle even in assessing reasoning process on MWPs (Zhang et al., 2024g), an arguably easier task than generation. Given these persistent challenges, current efforts in MWPs prioritize developing general methods to improve overall reasoning performance rather than investigating and addressing individual failures.
5 Reasoning in Embodied Environments
Reasoning is not merely an abstract process; it is deeply grounded in reality (Shapiro and Spaulding, 2024), requiring the ability to perceive, interpret, predict, and act within the physical world, with accurate understanding of spatial relationships, object dynamics, and physical laws (Lee-Cultura and Giannakos, 2020). While humans (Varela et al., 2017) – and even many animals (Andrews and Monsó, 2021) – develop such embodied reasoning naturally through sensory and motor experiences, LLMs remain fundamentally limited by their lack of true physical grounding in the physical world. This gap leads to systematic errors and unrealistic predictions when LLMs attempt even basic physical reasoning (Wang et al., 2023c; Ghaffari and Krishnaswamy, 2024a). Despite growing interest in spatial intelligence, research into LLMs’ physical reasoning failures is still sparse. In this section, we survey failures across three progressively complex embodied reasoning modalities: (1) 1D text-based, (2) 2D perception-based, and (3) 3D real-world physical reasoning.
5.1 1D – Text-Based Physical Reasoning Failures
Text-Based Physical Commonsense Reasoning.
Physical commonsense reasoning refers to the intuitive understanding of how objects interact in the physical world. Failures of LLMs include lack of knowledge about object attributes (e.g., size, weight, softness) (Wang et al., 2023c; Liu et al., 2022b; Shu et al., 2023; Kondo et al., 2023), spatial relationships (e.g., above, inside, next to) (Liu et al., 2022b; Shu et al., 2023; Kondo et al., 2023), simple physical laws (e.g., gravity, motion, and force) (Gregorcic and Pendrill, 2023), and object affordance (possible actions/reactions an object can make) (Aroca-Ouellette et al., 2021; Adak et al., 2024; Pensa et al., 2024). Humans acquire this kind of reasoning effortlessly through embodied experience, whereas LLMs struggle in it, as they rely solely on textual data without direct perceptual or embodied experience. Even in purely text-based settings, when tasks require more than semantic comprehension, demanding real-world understanding, LLMs exhibit systematic failures. These failures are fundamental to current LLMs. While their architectures and training paradigms support impressive language-based learning, they lack the physical grounding.
Physics & Scientific Reasoning.
Beyond basic physical commonsense, LLMs struggle with formal physics reasoning and scientific problem-solving, which require not just factual recall and intuition but multi-step logical deduction, quantitative reasoning, and correct use of physical laws – areas where even state-of-the-art models like o1 (Jaech et al., 2024) and o3-mini (OpenAI, 2025) have notable deficits (Zhang et al., 2025a; Xu et al., 2025b; Gupta, 2023; Chung et al., 2025; Zhang et al., 2025b; Qiu et al., 2025). Notably, even when LLMs possess these scientific skills, they often fail to apply them effectively in complex problems and real-world scientific discovery (Jaiswal et al., 2024; Ouyang et al., 2023; Chen et al., 2025). These failures result in strong limitations in LLMs’ application in scientific domains.
Text-Based Mitigation.
These failures largely reflect limitations inherent to the text modality, since semantic and linguistic understanding alone cannot guarantee grounded physical insight (Wang et al., 2023c; Zhang et al., 2025b). Text-based mitigation strategies focus on three fronts: training, prompting, and integration with external tools. First, LLMs are fine-tuned on corpora that explicitly encode structured physical knowledge – such as object attributes, spatial relationships, or physical laws – to better align model priors with real-world dynamics (Lyu et al., 2024; Wang et al., 2023c). Second, prompting methods like CoT encourage models to reason explicitly, reducing reliance on shallow text-based pattern-matching and enabling discovery of more nuanced causal and spatial relationships (Wei et al., 2022b; Ding et al., 2023). Third, LLMs are increasingly paired with external tools – such as code executors or physics engines – that allow models to verify, simulate, or compute outcomes directly and tangibly (Ma et al., 2024c; Cherian et al., 2024).
5.2 2D – Perception-Based Physical Reasoning Failures
What’s Wrong with the Picture?
The classic “What’s Wrong with the Picture?” visual reasoning game challenges participants to spot anomalies in static images. Applied to vision-language models (VLMs), similar tasks reveal surprising failures in simple tasks such as anomaly detection (Bitton-Guetta et al., 2023; Zhou et al., 2023b), object counting and overlap identification (Rahmanzadehgervi et al., 2024), and spatial relation understanding from the image content (Liu et al., 2023a; Zhao et al., 2024a). These failures constitute key perception-related limitations and robustness vulnerabilities.
2D Physics and Physical Commonsense.
Extending beyond detecting simple anomalies or object properties in static images, VLMs face deeper challenges reasoning about the physics in visual contexts. Despite the addition of visual inputs, VLMs still struggle with physical commonsense (Li et al., 2024d; Ghaffari and Krishnaswamy, 2024b; Schulze Buschoff et al., 2025; Dagan et al., 2023; Balazadeh et al., 2024b; Chow et al., 2025; Bear et al., 2021; Xu et al., 2025c) and advanced physics (Ates et al., 2020; Anand et al., 2024; Shen et al., 2025), exhibiting performance gaps similar to those seen in text-only settings discussed in Section 5.1. Similar to the 1D setting, these weaknesses reflect fundamental failures of current models and lead to significant limitations in applying them to scientific and perception-based domains.
Visual Input for Spatial Reasoning.
Real-world spatial reasoning requires understanding evolving spatial relationships rather than isolated snapshots. Recent works use 2D simulated environments to test models’ grasp of motion and object interactions (e.g., predicting post-impact trajectories) (Cherian et al., 2024), spatial prediction and manipulation (e.g., object placement for stability) (Ghaffari and Krishnaswamy, 2024a), spatial communication and alignment (e.g., conveying location information) (Kar et al., 2025), and embodied planning in multi-step tasks (Chia et al., 2024; Paglieri et al., 2024; Xu et al., 2025c). While VLMs exhibit some basic spatial knowledge, they consistently fail to compose and apply it in dynamic, interactive tasks, revealing a gap in structured spatial reasoning. This failure is an indication of limitations on 2D relevant applications.
Perception-Based Mitigation.
These errors arise from three key sources. First, models often over-rely on text or common scenarios from their training data, rather than accurately interpreting visual inputs (Deng et al., 2025a; Bitton-Guetta et al., 2023; Zhou et al., 2023b). Second, some failures may be explained by the binding problem from cognitive science, where the brain – or a model – struggles to process multiple distinct objects simultaneously due to limited shared resources (Campbell et al., 2025). Third, just as language alone does not guarantee grounded physical understanding, visual inputs alone may also lack sufficient spatial semantics; plain image recognition does not automatically confer an understanding of spatial object dynamics and causality (Chen et al., 2024a; Qi et al., 2025). To mitigate, recent work focuses on curating balanced, augmented datasets to reduce bias toward text inputs, or directly using 2D physics data to improve physical understanding (Deng et al., 2025a; Balazadeh et al., 2024a). Another strategy targets training and model architecture (Cheng et al., 2024), by introducing spatially grounded, sequential attention mechanisms (Izadi et al., 2025) and leveraging reinforcement learning to align models with spatial commonsense (Sarch et al., 2025). Finally, beyond end-to-end learning, integration with external physical simulation tools has also emerged, to enable explicit trial-and-error (Liu et al., 2022a; Cherian et al., 2024; Zhu et al., 2025).
5.3 3D – Real-World Physical Reasoning Failures
Real embodied reasoning requires agents to actively interact with their environment, through robotics or interactive simulations that go beyond static images or simple 2D snapshots. Such agents must process real-time goals and feedback, and execute physical actions. Unlike 1D (text-only) and 2D (image-based) tasks, 3D embodied reasoning centers on action rather than passive analysis. Despite advances in robotics and embodied AI, LLMs and VLMs face persistent challenges including inaccurate spatial modeling, unrealistic affordance prediction, tool-use failures, and unsafe behaviors. This subsection highlights these key failure cases from both simulated and real-world studies.
Real-World Failures in Affordance and Planning.
A key failure is models’ inability to generate feasible and coherent action plans. LLMs and VLMs often produce physically impossible or inefficient actions due to affordance errors (incorrect reasoning about possible object actions) (Ahn et al., 2022; Li et al., 2025; Hu et al., 2024; Huang et al., 2022a; Jin et al., 2024) and causal real-world reasoning limitations that cause illogical or looping behaviors (Jin et al., 2024; Hu et al., 2024). These fundamental shortcomings in modeling real-world affordances and planning significantly constrain the deployment of LLMs in embodied and real-world applications, motivating emerging research on world models and robotics systems that can more effectively perceive, plan, and interact with the physical environment.
Spatial and Tool-Use Reasoning.
Even when LLMs successfully decompose tasks and generate seemingly valid plans, failures arise due to poor spatial reasoning (Dao and Vu, 2025; Mecattaf et al., 2024) and the inability to generalize tool-use strategies (Xu et al., 2023a). Concretely, LLMs often struggle with 3D distance estimation (Mecattaf et al., 2024; Chen et al., 2024a), object localization (Mecattaf et al., 2024), and multi-step manipulation (Guran et al., 2024), leading to systematic failures in both spatial awareness and interaction with physical environments. These failures limit the adaptability of LLMs in many real-world settings where they must quickly understand, adapt to, and utilize the environment.
Safety and Long-Term Autonomy.
Safety and reliability of LLM-driven embodied agents are ongoing concerns. LLM-generated robotic task plans are highly sensitive to prompt phrasing (Liang et al., 2023) and vulnerable to adversarial manipulation (Zhang et al., 2024c). Moreover, these systems fail to align with human ethical requirements and are easily jailbroken to perform harmful actions, such as recording private information (Rezaei et al., 2025; Zhang et al., 2024c). These findings on limitations and robustness concerns underscore the urgent need for robust, self-correcting, and safety-aware embodied AI systems before real-world deployment.
Embodied Mitigation.
A critical factor underlying these failures is the auto-regressive nature of LLMs. Naive LLMs and VLMs generate plans step by step, lacking mechanisms to detect and correct earlier mistakes or execution errors (Liang et al., 2023; Huang et al., 2022b; Duan et al., 2024). Incorporating feedback mechanisms or explicit error-handling strategies significantly reduces these errors (Liang et al., 2023; Wang et al., 2023a). Another major factor is the absence of a robust internal world model (Dao and Vu, 2025; Wu et al., 2025a), which often forces LLMs to rely on external aids – such as explicit spatial prompts – to compensate for their limited spatial and real-world reasoning. To advance embodied intelligence, future research should focus on strengthening LLMs’ internal representations of space, including spatial memory, real-world causal dynamics, and quantitative spatial understanding.
6 Discussions & Conclusion
Along the Failure Axis.
While our main taxonomy organizes failures by reasoning type, examining them along the complementary failure axis reveals cross-cutting patterns. Fundamental failures – stemming from intrinsic architectural or training constraints – manifest across all reasoning types. For example, the reversal curse (Section 4.1), cognitive biases such as confirmation bias (Section 3.1), and working memory limitations that cause proactive interference (Section 3.1) appear in informal reasoning, formal logic, and embodied settings alike. Root cause analyses in those categories are particularly rich, suggesting meaningful methods not only for mitigating the specific failures, but for generally improving the architecture and our understanding of it. Application-specific limitations cluster in certain domains: Theory of Mind instability in implicit social reasoning (Section 3.2), inability to generalize to novel Math Word Problem structures in formal reasoning (Section 4.2), or systematic affordance prediction errors in 3D embodied reasoning (Section 5.3). These typically require domain-specific mitigation strategies, such as integrating physics simulators for embodied tasks or symbolic augmentation for mathematics. Tracing the failure cases back to fundamental elements in data or architecture has, on the other hand, attracted less attention from existing literature. Robustness issues cut across domains but are particularly well-studied in benchmark-based evaluations (Section 4.2) and social reasoning (Section 3.2, where minor, semantically-preserving perturbations – such as reordering options in multiple-choice questions, renaming variables in code, or paraphrasing moral dilemmas – can lead to large and inconsistent shifts in model outputs). Approaches to detect robustness issues largely revolve around applying such perturbations at scale, often automatically, to stress-test model stability. This perturbation-based paradigm has proven transferable across domains, from coding benchmarks to ToM evaluations, suggesting its utility as a unified detection methodology.
Suggestions for Future Directions.
Our survey highlights several gaps and opportunities. First, root cause analyses remain incomplete for some failures, including compositional reasoning breakdowns (Section 4.1), higher-order ToM failures (Section 3.2), physical commonsense gaps in 2D and 3D environments (Sections 5.2, 5.3), and brittle multi-agent planning (Section 3.3). Bridging these requires connecting behavioral errors to specific internal mechanisms, e.g., faulty attention head coordination or insufficient intermediate representation alignment. Second, the field would benefit from unified, persistent failure benchmarks that span all failure types, akin to the very recent effort Malek et al. (2025), updated regularly to test the latest general-purpose and reasoning-specialized models. Such benchmarks should preserve historically challenging cases while incorporating newly discovered ones, enabling longitudinal tracking of failure persistence. Third, failure-injection principles could be applied not only to dedicated robustness benchmarks but also to general reasoning benchmarks – by adding adversarial sections, multi-level task difficulty, or cross-domain compositions designed to trigger known weaknesses. Fourth, dynamic and event-driven benchmarks could combat overfitting and encourage continual improvement. Promising strategies include (i) (partially) private benchmarks (Phan et al., 2025; Rajore et al., 2024; Zhang et al., 2024d), (ii) dynamically evolving suites (Jain et al., 2024a; White et al., 2024; Zheng et al., 2025), and (iii) adapting regularly occurring events into benchmarks, such as annual competitions (e.g., AIMO AIMO Prize: https://aimoprize.com/. for mathematical reasoning), which naturally provide fresh, unseen evaluation items. In combination, these approaches would make reasoning evaluation both more comprehensive and more resistant to short-term overfitting.
A Broad Picture.
Admittedly, existing literature, and therefore this survey, may over-represent certain reasoning or failure types, leaving some areas less explored. In particular, multi-turn and interactive contexts remain closer to real-world deployment conditions but are underrepresented in current literature; persistent coordination breakdowns in multi-agent simulations (Section 3.3) illustrate the complexity and significance of these scenarios. Future work should expand benchmark diversity to better capture reasoning failures that arise in such realistic, interactive settings. Overall, the systematic study of reasoning failures in LLMs parallels fault-tolerance research in early computing and incident analysis in safety-critical industries: understanding and categorizing failure is a prerequisite for building resilient systems. By unifying fragmented observations into a structured, two-axis taxonomy, this survey lays a foundation for a mature subfield dedicated to anticipating, detecting, and mitigating reasoning failures. As reasoning-specialized models become more prevalent, sustained attention to failure modes will be essential to ensure that future LLMs not only perform better in reasoning tasks, but fail better (gracefully, transparently, recoverably).
Acknowledgments
We thank Gabriel Poesia for very helpful suggestions and valuable feedback on an initial version of this paper, and Emily Gu for early contributions and discussions on an initial version of Section 5. We greatly appreciate valuable suggestions from anonymous reviewers and action editor at TMLR, which helped strengthen this paper substantially.
References
- S. Adak, D. Agrawal, A. Mukherjee, and S. Aditya (2024) TEXT2AFFORD: probing object affordance prediction abilities of language models solely from text. arXiv preprint arXiv:2402.12881. Cited by: §5.1.
- U. Agarwal, K. Tanmay, A. Khandelwal, and M. Choudhury (2024) Ethical reasoning and moral value alignment of llms depend on the language we prompt them in. arXiv preprint arXiv:2404.18460. Cited by: §3.2.
- S. Agashe, Y. Fan, A. Reyna, and X. E. Wang (2024) LLM-coordination: evaluating and analyzing multi-agent coordination abilities in large language models. External Links: 2310.03903, Link Cited by: §3.3.
- M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman, et al. (2022) Do as i can, not as i say: grounding language in robotic affordances. arXiv preprint arXiv:2204.01691. Cited by: §5.3.
- Z. Allen-Zhu and Y. Li (2024) Physics of language models: part 3.1, knowledge storage and extraction. External Links: 2309.14316, Link Cited by: §4.3.
- S. T. Allison and D. M. Messick (1985) The group attribution error. Journal of Experimental Social Psychology 21 (6), pp. 563–579. Cited by: §3.1.
- G. F.C.F. Almeida, J. L. Nunes, N. Engelmann, A. Wiegmann, and M. d. Araújo (2024) Exploring the psychology of llms’ moral and legal reasoning. Artificial Intelligence 333, pp. 104145. External Links: ISSN 0004-3702, Link, Document Cited by: §3.2.
- N. Alzahrani, H. A. Alyahya, Y. Alnumay, S. Alrashed, S. Alsubaie, Y. Almushaykeh, F. Mirza, N. Alotaibi, N. Altwairesh, A. Alowisheq, et al. (2024) When benchmarks are targets: revealing the sensitivity of large language model leaderboards. arXiv preprint arXiv:2402.01781. Cited by: §4.2.
- M. Amirizaniani, E. Martin, M. Sivachenko, A. Mashhadi, and C. Shah (2024a) Can llms reason like humans? assessing theory of mind reasoning in llms for open-ended questions. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pp. 34–44. Cited by: §3.2.
- M. Amirizaniani, E. Martin, M. Sivachenko, A. Mashhadi, and C. Shah (2024b) Do llms exhibit human-like reasoning? evaluating theory of mind in llms for open-ended responses. arXiv preprint arXiv:2406.05659. Cited by: §1, §3.2.
- S. An, Z. Ma, Z. Lin, N. Zheng, J. Lou, and W. Chen (2024) Learning from mistakes makes llm better reasoner. External Links: 2310.20689, Link Cited by: §1.
- A. Anand, J. Kapuriya, A. Singh, J. Saraf, N. Lal, A. Verma, R. Gupta, and R. Shah (2024) Mm-phyqa: multimodal physics question-answering with multi-image cot prompting. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 53–64. Cited by: §5.2.
- R. Ando, T. Morishita, H. Abe, K. Mineshima, and M. Okada (2023) Evaluating large language models with neubaroco: syllogistic reasoning ability and human-like biases. External Links: 2306.12567, Link Cited by: §4.1.
- K. Andrews and S. Monsó (2021) Animal Cognition. In The Stanford Encyclopedia of Philosophy, E. N. Zalta (Ed.), Note: https://plato.stanford.edu/archives/spr2021/entries/cognition-animal/ Cited by: §5.
- S. Aroca-Ouellette, C. Paik, A. Roncone, and K. Kann (2021) Prost: physical reasoning about objects through space and time. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 4597–4608. External Links: Document Cited by: §5.1.
- T. Ates, M. S. Atesoglu, C. Yigit, I. Kesen, M. Kobas, E. Erdem, A. Erdem, T. Goksun, and D. Yuret (2020) Craft: a benchmark for causal reasoning about forces and interactions. arXiv preprint arXiv:2012.04293. Cited by: §5.2.
- A. Baddeley (2020) Working memory. Memory, pp. 71–111. Cited by: §3.1.
- H. Bai, Y. Sun, W. Hu, S. Qiu, M. Z. Huan, P. Song, R. Nowak, and D. Song (2025) How and why llms generalize: a fine-grained analysis of llm reasoning from cognitive behaviors to low-level patterns. arXiv preprint arXiv:2512.24063. Cited by: Appendix C.
- X. Bai, A. Wang, I. Sucholutsky, and T. L. Griffiths (2024) Measuring implicit bias in explicitly unbiased large language models. arXiv preprint arXiv:2402.04105. Cited by: Appendix D.
- B. Baker, J. Huizinga, L. Gao, Z. Dou, M. Y. Guan, A. Madry, W. Zaremba, J. Pachocki, and D. Farhi (2025) Monitoring reasoning models for misbehavior and the risks of promoting obfuscation. arXiv preprint arXiv:2503.11926. Cited by: §3.3, §3.3.
- V. Balazadeh, M. Ataei, H. Cheong, A. H. Khasahmadi, and R. G. Krishnan (2024a) Physics context builders: a modular framework for physical reasoning in vision-language models. arXiv preprint arXiv:2412.08619. Cited by: §5.2.
- V. Balazadeh, M. Ataei, H. Cheong, A. H. Khasahmadi, and R. G. Krishnan (2024b) Synthetic vision: training vision-language models to understand physics. arXiv preprint arXiv:2412.08619. Cited by: §5.2.
- L. Barnhart, R. A. Bafghi, S. Becker, and M. Raissi (2025) Aligning to what? limits to rlhf based alignment. External Links: 2503.09025, Link Cited by: §3.2.
- L. W. Barsalou (2008) Grounded cognition. Annu. Rev. Psychol. 59 (1), pp. 617–645. Cited by: §2.1.
- D. M. Bear, E. Wang, D. Mrowca, F. J. Binder, H. F. Tung, R. Pramod, C. Holdaway, S. Tao, K. Smith, F. Sun, et al. (2021) Physion: evaluating physical prediction from vision in humans and machines. arXiv preprint arXiv:2106.08261. Cited by: §5.2.
- Y. Bengio, S. Mindermann, D. Privitera, T. Besiroglu, R. Bommasani, S. Casper, Y. Choi, P. Fox, B. Garfinkel, D. Goldfarb, H. Heidari, A. Ho, S. Kapoor, L. Khalatbari, S. Longpre, S. Manning, V. Mavroudis, M. Mazeika, J. Michael, J. Newman, K. Y. Ng, C. T. Okolo, D. Raji, G. Sastry, E. Seger, T. Skeadas, T. South, E. Strubell, F. Tramèr, L. Velasco, N. Wheeler, D. Acemoglu, O. Adekanmbi, D. Dalrymple, T. G. Dietterich, E. W. Felten, P. Fung, P. Gourinchas, F. Heintz, G. Hinton, N. Jennings, A. Krause, S. Leavy, P. Liang, T. Ludermir, V. Marda, H. Margetts, J. McDermid, J. Munga, A. Narayanan, A. Nelson, C. Neppel, A. Oh, G. Ramchurn, S. Russell, M. Schaake, B. Schölkopf, D. Song, A. Soto, L. Tiedrich, G. Varoquaux, A. Yao, Y. Zhang, F. Albalawi, M. Alserkal, O. Ajala, G. Avrin, C. Busch, A. C. P. de Leon Ferreira de Carvalho, B. Fox, A. S. Gill, A. H. Hatip, J. Heikkilä, G. Jolly, Z. Katzir, H. Kitano, A. Krüger, C. Johnson, S. M. Khan, K. M. Lee, D. V. Ligot, O. Molchanovskyi, A. Monti, N. Mwamanzi, M. Nemer, N. Oliver, J. R. L. Portillo, B. Ravindran, R. P. Rivera, H. Riza, C. Rugege, C. Seoighe, J. Sheehan, H. Sheikh, D. Wong, and Y. Zeng (2025) International ai safety report. External Links: 2501.17805, Link Cited by: Appendix D.
- G. Beniamini, Y. Dor, A. Vinnikov, S. G. Peled, O. Weinstein, O. Sharir, N. Wies, T. Nussbaum, I. B. Shaul, T. Zekharya, Y. Levine, S. Shalev-Shwartz, and A. Shashua (2025) FormulaOne: measuring the depth of algorithmic reasoning beyond competitive programming. External Links: 2507.13337, Link Cited by: §4.2.
- L. Berglund, M. Tong, M. Kaufmann, M. Balesni, A. C. Stickland, T. Korbak, and O. Evans (2023) The reversal curse: llms trained on" a is b" fail to learn" b is a". arXiv preprint arXiv:2309.12288. Cited by: Table 7, §4.1.
- A. Bhattacharyya, S. Panchal, M. Lee, R. Pourreza, P. Madan, and R. Memisevic (2024) Look, remember and reason: grounded reasoning in videos with language models. External Links: 2306.17778, Link Cited by: Appendix C.
- F. Bianchi, P. Kalluri, E. Durmus, F. Ladhak, M. Cheng, D. Nozza, T. Hashimoto, D. Jurafsky, J. Zou, and A. Caliskan (2023) Easily accessible text-to-image generation amplifies demographic stereotypes at large scale. In 2023 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’23, pp. 1493–1504. External Links: Link, Document Cited by: Appendix D.
- N. Bitton-Guetta, Y. Bitton, J. Hessel, L. Schmidt, Y. Elovici, G. Stanovsky, and R. Schwartz (2023) Breaking common sense: whoops! a vision-and-language benchmark of synthetic and compositional imagesbreaking common sense: whoops! a vision-and-language benchmark of synthetic and compositional images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2616–2627. Cited by: Table 12, §5.2, §5.2.
- V. K. Bonagiri, S. Vennam, M. Gaur, and P. Kumaraguru (2024) Measuring moral inconsistencies in large language models. arXiv preprint arXiv:2402.01719. Cited by: §3.2.
- A. Borah and R. Mihalcea (2024) Towards implicit bias detection and mitigation in multi-agent llm interactions. arXiv preprint arXiv:2410.02584. Cited by: Appendix D.
- A. Borji (2023) A categorical archive of chatgpt failures. External Links: 2302.03494, Link Cited by: §1.
- J. Boye and B. Moell (2025) Large language models and mathematical reasoning failures. External Links: 2502.11574, Link Cited by: §4.3.
- P. G. Brodeur, T. A. Buckley, Z. Kanjee, E. Goh, E. B. Ling, P. Jain, S. Cabral, R. Abdulnour, A. Haimovich, J. A. Freed, A. Olson, D. J. Morgan, J. Hom, R. Gallo, E. Horvitz, J. Chen, A. K. Manrai, and A. Rodman (2024) Superhuman performance of a large language model on the reasoning tasks of a physician. External Links: 2412.10849, Link Cited by: §1.
- S. Bubeck, V. Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y. T. Lee, Y. Li, S. Lundberg, et al. (2023) Sparks of artificial general intelligence: early experiments with gpt-4. arXiv preprint arXiv:2303.12712. Cited by: §3.1.
- T. Cai, X. Song, J. Jiang, F. Teng, J. Gu, and G. Zhang (2024) ULMA: unified language model alignment with human demonstration and point-wise preference. External Links: 2312.02554, Link Cited by: §1.
- D. Campbell, S. Rane, T. Giallanza, C. N. De Sabbata, K. Ghods, A. Joshi, A. Ku, S. Frankland, T. Griffiths, J. D. Cohen, et al. (2025) Understanding the limits of vision language models through the lens of the binding problem. Advances in Neural Information Processing Systems 37, pp. 113436–113460. Cited by: §5.2.
- J. J. Canas, I. Fajardo, and L. Salmeron (2006) Cognitive flexibility. International encyclopedia of ergonomics and human factors 1 (3), pp. 297–301. Cited by: §3.1.
- M. D. Cannon and A. C. Edmondson (2005) Failing to learn and learning to fail (intelligently): how great organizations put failure to work to innovate and improve. Long Range Planning 38 (3), pp. 299–319. Note: Organizational Failure External Links: ISSN 0024-6301, Document, Link Cited by: §1.
- R. Cantini, G. Cosenza, A. Orsino, and D. Talia (2024) Are large language models really bias-free? jailbreak prompts for assessing adversarial robustness to bias elicitation. In International Conference on Discovery Science, pp. 52–68. Cited by: Appendix D, §3.1.
- D. Castelvecchi (2016) Can we open the black box of ai?. Nature News 538 (7623), pp. 20. Cited by: §2.2.
- M. Chakraborty, L. Wang, and D. Jurgens (2025) Structured moral reasoning in language models: a value-grounded evaluation framework. External Links: 2506.14948, Link Cited by: §3.2.
- J. Chan, R. Gaizauskas, and Z. Zhao (2024) Rulebreakers challenge: revealing a blind spot in large language models’ reasoning with formal logic. External Links: 2410.16502, Link Cited by: §4.1.
- Y. Chang and Y. Bisk (2024) Language models need inductive biases to count inductively. External Links: 2405.20131, Link Cited by: §4.3.
- B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia (2024a) Spatialvlm: endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14455–14465. Cited by: Table 15, §5.2, §5.3.
- J. Chen, H. Lin, X. Han, and L. Sun (2024b) Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, pp. 17754–17762. Cited by: Appendix D.
- T. Chen, S. Anumasa, B. Lin, V. Shah, A. Goyal, and D. Liu (2025) Auto-bench: an automated benchmark for scientific discovery in llms. arXiv preprint arXiv:2502.15224. Cited by: §5.1.
- X. Chen, R. A. Chi, X. Wang, and D. Zhou (2024c) Premise order matters in reasoning with large language models. External Links: 2402.08939, Link Cited by: §4.2.
- Y. Chen, Y. Liu, J. Yan, X. Bai, M. Zhong, Y. Yang, Z. Yang, C. Zhu, and Y. Zhang (2024d) See what llms cannot answer: a self-challenge framework for uncovering llm weaknesses. External Links: 2408.08978, Link Cited by: §4.1.
- A. Cheng, H. Yin, Y. Fu, Q. Guo, R. Yang, J. Kautz, X. Wang, and S. Liu (2024) Spatialrgpt: grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems 37, pp. 135062–135093. Cited by: §5.2.
- A. Cherian, R. Corcodel, S. Jain, and D. Romeres (2024) Llmphy: complex physical reasoning using large language models and world models. arXiv preprint arXiv:2411.08027. Cited by: §5.1, §5.2, §5.2.
- I. Chern, S. Chern, S. Chen, W. Yuan, K. Feng, C. Zhou, J. He, G. Neubig, and P. Liu (2023) FacTool: factuality detection in generative ai–a tool augmented framework for multi-task and multi-domain scenarios, 2023. URL https://arxiv. org/abs/2307.13528. Cited by: Appendix D.
- Y. K. Chia, Q. Sun, L. Bing, and S. Poria (2024) Can-do! a dataset and neuro-symbolic grounded framework for embodied planning with large multimodal models. arXiv preprint arXiv:2409.14277. Cited by: §5.2.
- J. Cho, A. Zala, and M. Bansal (2023) DALL-eval: probing the reasoning skills and social biases of text-to-image generation models. External Links: 2202.04053, Link Cited by: Appendix D.
- G. Chochlakis, A. Potamianos, K. Lerman, and S. Narayanan (2024) The strong pull of prior knowledge in large language models and its impact on emotion recognition. arXiv preprint arXiv:2403.17125. Cited by: §3.2.
- W. Chow, J. Mao, B. Li, D. Seita, V. Guizilini, and Y. Wang (2025) PhysBench: benchmarking and enhancing vision-language models for physical world understanding. arXiv preprint arXiv:2501.16411. Cited by: Table 14, §5.2.
- Z. Chu, Z. Wang, and W. Zhang (2024) Fairness in large language models: a taxonomic survey. ACM SIGKDD explorations newsletter 26 (1), pp. 34–48. Cited by: Appendix D.
- D. J. Chung, Z. Gao, Y. Kvasiuk, T. Li, M. Münchmeyer, M. Rudolph, F. Sala, and S. C. Tadepalli (2025) Theoretical physics benchmark (tpbench)–a dataset and study of ai reasoning capabilities in theoretical physics. arXiv preprint arXiv:2502.15815. Cited by: §5.1.
- C. Clark, K. Lee, M. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova (2019) BoolQ: exploring the surprising difficulty of natural yes/no questions. External Links: 1905.10044, Link Cited by: §4.1.
- K. Cobbina and T. Zhou (2025) Where to show demos in your prompt: a positional bias of in-context learning. arXiv preprint arXiv:2507.22887. Cited by: §3.1.
- P. R. P. Coelho and J. E. McClure (2004) Learning from Failure. Working Papers Technical Report 200402, Ball State University, Department of Economics. External Links: Link, Document Cited by: §1.
- M. Cohn, M. Pushkarna, G. O. Olanubi, J. M. Moran, D. Padgett, Z. Mengesha, and C. Heldreth (2024) Believing anthropomorphism: examining the role of anthropomorphic cues on trust in large language models. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pp. 1–15. Cited by: §3.1.
- K. M. Collins, S. Frieder, J. Bayer, J. Loader, J. Lim, P. Song, F. Zaiser, L. Zhou, S. Li, S. Looi, et al. (2025) AI impact on human proof formalization workflows. In The 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025, Cited by: Appendix C.
- J. Conde, G. Martínez, P. Reviriego, Z. Gao, S. Liu, and F. Lombardi (2025) Can chatgpt learn to count letters?. Computer 58 (3), pp. 96–99. Cited by: §4.3.
- I. M. Copi, C. Cohen, and K. McMahon (2016) Introduction to logic. Routledge. Cited by: §2.1.
- L. Cross, V. Xiang, A. Bhatia, D. L. Yamins, and N. Haber (2024) Hypothetical minds: scaffolding theory of mind for multi-agent tasks with large language models. arXiv preprint arXiv:2407.07086. Cited by: §3.3, §3.3.
- G. Dagan, F. Keller, and A. Lascarides (2023) Learning the effects of physical actions in a multi-modal environment. arXiv preprint arXiv:2301.11845. Cited by: §5.2.
- A. Dahlgren Lindström, L. Methnani, L. Krause, P. Ericson, Í. M. de Rituerto de Troya, D. Coelho Mollo, and R. Dobbe (2025) Helpful, harmless, honest? sociotechnical limits of ai alignment and safety through reinforcement learning from human feedback: ad lindström et al.. Ethics and Information Technology 27 (2), pp. 28. Cited by: §3.2.
- D. ". Dalrymple, J. Skalse, Y. Bengio, S. Russell, M. Tegmark, S. Seshia, S. Omohundro, C. Szegedy, B. Goldhaber, N. Ammann, A. Abate, J. Halpern, C. Barrett, D. Zhao, T. Zhi-Xuan, J. Wing, and J. Tenenbaum (2024) Towards guaranteed safe ai: a framework for ensuring robust and reliable ai systems. External Links: 2405.06624, Link Cited by: Appendix C.
- A. Dao and D. B. Vu (2025) AlphaMaze: enhancing large language models’ spatial intelligence via grpo. arXiv preprint arXiv:2502.14669. Cited by: §5.3, §5.3.
- T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. Ré (2022) FlashAttention: fast and memory-efficient exact attention with io-awareness. External Links: 2205.14135, Link Cited by: §1.
- B. C. Das, M. H. Amini, and Y. Wu (2025) Security and privacy challenges of large language models: a survey. ACM Comput. Surv. 57 (6). External Links: ISSN 0360-0300, Link, Document Cited by: Appendix D.
- C. S. de Witt (2025) Open challenges in multi-agent security: towards secure systems of interacting ai agents. External Links: 2505.02077, Link Cited by: §3.3.
- A. Deb, N. Oza, S. Singla, D. Khandelwal, D. Garg, and P. Singla (2024) Fill in the blank: exploring and enhancing llm capabilities for backward reasoning in math word problems. External Links: 2310.01991, Link Cited by: §4.2.
- DeepSeek-AI (2025) DeepSeek-r1: incentivizing reasoning capability in llms via reinforcement learning. External Links: 2501.12948, Link Cited by: Appendix C.
- A. Deng, T. Cao, Z. Chen, and B. Hooi (2025a) Words or vision: do vision-language models have blind faith in text?. arXiv preprint arXiv:2503.02199. Cited by: §5.2.
- C. Deng, Z. Li, R. Xie, R. Chang, and H. Chen (2024) Language models are symbolic learners in arithmetic. External Links: 2410.15580, Link Cited by: §4.3.
- X. Deng, S. Zhong, A. Veneris, F. Long, and X. Si (2025b) VerifyThisBench: generating code, specifications, and proofs all at once. External Links: 2505.19271, Link Cited by: Appendix C.
- S. Deshmukh, S. Han, H. Bukhari, B. Elizalde, H. Gamper, R. Singh, and B. Raj (2024) Audio entailment: assessing deductive reasoning for audio understanding. External Links: 2407.18062, Link Cited by: Appendix C.
- J. Devlin, M. Chang, K. Lee, and K. Toutanova (2019) BERT: pre-training of deep bidirectional transformers for language understanding. External Links: 1810.04805, Link Cited by: §4.1.
- A. Diamond (2013) Executive functions. Annual review of psychology 64 (1), pp. 135–168. Cited by: §3.1.
- J. Ding, Y. Cen, and X. Wei (2023) Using large language model to solve and explain physics word problems approaching human level. arXiv preprint arXiv:2309.08182. Cited by: §5.1.
- T. Dinh, J. Zhao, S. Tan, R. Negrinho, L. Lausen, S. Zha, and G. Karypis (2023) Large language models of code fail at completing code with potential bugs. External Links: 2306.03438, Link Cited by: §4.2.
- S. Doh, K. Choi, J. Lee, and J. Nam (2023) LP-musiccaps: llm-based pseudo music captioning. External Links: 2307.16372, Link Cited by: Appendix C.
- K. Dong and T. Ma (2025) STP: self-play llm theorem provers with iterative conjecturing and proving. External Links: 2502.00212, Link Cited by: Appendix C.
- J. Dougrez-Lewis, M. E. Akhter, Y. He, and M. Liakata (2024) Assessing the reasoning abilities of chatgpt in the context of claim verification. External Links: 2402.10735, Link Cited by: §4.1.
- H. L. Dreyfus (1992) What computers still can?t do: a critique of artificial reason. MIT Press. Cited by: §1.
- J. Duan, W. Pumacay, N. Kumar, Y. R. Wang, S. Tian, W. Yuan, R. Krishna, D. Fox, A. Mandlekar, and Y. Guo (2024) AHA: a vision-language-model for detecting and reasoning over failures in robotic manipulation. arXiv preprint arXiv:2410.00371. Cited by: §5.3.
- P. Dufter, M. Schmitt, and H. Schütze (2022) Position information in transformers: an overview. Computational Linguistics 48 (3), pp. 733–763. Cited by: §3.1.
- O. Dugan, D. M. J. Beneto, C. Loh, Z. Chen, R. Dangovski, and M. Soljačić (2024) OccamLLM: fast and exact language model arithmetic in a single step. External Links: 2406.06576, Link Cited by: §4.3.
- R. Dwivedi, D. Dave, H. Naik, S. Singhal, R. Omer, P. Patel, B. Qian, Z. Wen, T. Shah, G. Morgan, et al. (2023) Explainable ai (xai): core ideas, techniques, and solutions. ACM Computing Surveys 55 (9), pp. 1–33. Cited by: §2.2.
- N. Dziri, X. Lu, M. Sclar, X. L. Li, L. Jiang, B. Y. Lin, P. West, C. Bhagavatula, R. L. Bras, J. D. Hwang, S. Sanyal, S. Welleck, X. Ren, A. Ettinger, Z. Harchaoui, and Y. Choi (2023) Faith and fate: limits of transformers on compositionality. External Links: 2305.18654, Link Cited by: §4.1.
- J. Echterhoff, Y. Liu, A. Alessa, J. McAuley, and Z. He (2024) Cognitive bias in high-stakes decision-making with llms. arXiv preprint arXiv:2403.00811. Cited by: §3.1.
- J. Fan, S. Martinson, E. Y. Wang, K. Hausknecht, J. Brenner, D. Liu, N. Peng, C. Wang, and M. P. Brenner (2024) HARDMath: a benchmark dataset for challenging problems in applied mathematics. External Links: 2410.09988, Link Cited by: §4.3.
- E. Fedorenko, S. Piantadosi, and E. Gibson (2024) Language is primarily a tool for communication rather than thought. Nature 630, pp. 575–586. External Links: Document Cited by: §1, §4.1.
- H. Fei, S. Wu, W. Ji, H. Zhang, M. Zhang, M. Lee, and W. Hsu (2024) Video-of-thought: step-by-step video reasoning from perception to cognition. External Links: 2501.03230, Link Cited by: Appendix C.
- G. Feng, K. Yang, Y. Gu, X. Ai, S. Luo, J. Sun, D. He, Z. Li, and L. Wang (2024a) How numerical precision affects mathematical reasoning capabilities of llms. External Links: 2410.13857, Link Cited by: §4.3.
- T. Feng, P. Han, G. Lin, G. Liu, and J. You (2024b) Thought-retriever: don’t just retrieve raw data, retrieve thoughts. In ICLR 2024 Workshop: How Far Are We From AGI, Cited by: Appendix C.
- C. Frith and U. Frith (2005) Theory of mind. Current biology 15 (17), pp. R644–R645. Cited by: §3.2.
- T. Fu, R. Ferrando, J. Conde, C. Arriaga, and P. Reviriego (2024) Why do large language models (llms) struggle to count letters?. External Links: 2412.18626, Link Cited by: §4.3.
- I. R. Galatzer-Levy, J. McGiffin, D. Munday, X. Liu, D. Karmon, I. Labzovsky, R. Moroshko, A. Zait, and D. McDuff (2024) Evidence of cognitive deficits anddevelopmental advances in generative ai: a clock drawing test analysis. arXiv preprint arXiv:2410.11756. Cited by: Table 1, §3.1, §3.1.
- I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, S. Kim, F. Dernoncourt, T. Yu, R. Zhang, and N. K. Ahmed (2024) Bias and fairness in large language models: a survey. Computational Linguistics 50 (3), pp. 1097–1179. Cited by: Appendix D.
- A. Gambardella, Y. Iwasawa, and Y. Matsuo (2024) Language models do hard arithmetic tasks easily and hardly do easy arithmetic tasks. External Links: 2406.02356, Link Cited by: §4.3.
- K. Gandhi, Z. Lynch, J. Fränken, K. Patterson, S. Wambu, T. Gerstenberg, D. C. Ong, and N. D. Goodman (2024) Human-like affective cognition in foundation models. arXiv preprint arXiv:2409.11733. Cited by: §3.2.
- L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser, and C. Leahy (2020) The pile: an 800gb dataset of diverse text for language modeling. External Links: 2101.00027, Link Cited by: §1.
- Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, H. Wang, and H. Wang (2023) Retrieval-augmented generation for large language models: a survey. arXiv preprint arXiv:2312.10997 2. Cited by: Appendix D.
- B. Garcia, C. Qian, and S. Palminteri (2024) The moral turing test: evaluating human-llm alignment in moral decision-making. arXiv preprint arXiv:2410.07304. Cited by: §3.2.
- J. Gardner, S. Durand, D. Stoller, and R. M. Bittner (2024) LLark: a multimodal instruction-following language model for music. External Links: 2310.07160, Link Cited by: Appendix C.
- G. Gendron, Q. Bao, M. Witbrock, and G. Dobbie (2023) Large language models are not strong abstract reasoners. arXiv preprint arXiv:2305.19555. Cited by: §3.1.
- S. Ghaffari and N. Krishnaswamy (2024a) Exploring failure cases in multimodal reasoning about physical dynamics. External Links: 2402.15654, Link Cited by: Table 14, §5.2, §5.
- S. Ghaffari and N. Krishnaswamy (2024b) Large language models are challenged by habitat-centered reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2024, Y. Al-Onaizan, M. Bansal, and Y. Chen (Eds.), Miami, Florida, USA, pp. 13047–13059. External Links: Link, Document Cited by: §5.2.
- S. Ghosh, Z. Kong, S. Kumar, S. Sakshi, J. Kim, W. Ping, R. Valle, D. Manocha, and B. Catanzaro (2025) Audio flamingo 2: an audio-language model with long-audio understanding and expert reasoning abilities. External Links: 2503.03983, Link Cited by: Appendix C.
- S. Ghosh, S. Kumar, A. Seth, C. K. R. Evuru, U. Tyagi, S. Sakshi, O. Nieto, R. Duraiswami, and D. Manocha (2024) GAMA: a large audio-language model with advanced audio understanding and complex reasoning abilities. External Links: 2406.11768, Link Cited by: Appendix C.
- O. Golovneva, Z. Allen-Zhu, J. Weston, and S. Sukhbaatar (2024) Reverse training to nurse the reversal curse. External Links: 2403.13799, Link Cited by: §4.1.
- D. Gong, X. Wan, and D. Wang (2024) Working memory capacity of chatgpt: an empirical study. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, pp. 10048–10056. Cited by: Table 1, §3.1, §3.1.
- D. Gong and H. Zhang (2024) Self-attention limits working memory capacity of transformer-based models. External Links: 2409.10715, Link Cited by: §3.1, §3.1.
- B. Gregorcic and A. Pendrill (2023) ChatGPT and the frustrated socrates. Physics Education 58 (3), pp. 035021. External Links: Document Cited by: Table 11, §5.1.
- R. Gretsch, P. Song, A. Madhavan, J. Lau, and T. Sherwood (2024) Energy efficient convolutions with temporal arithmetic. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’24, New York, NY, USA, pp. 354–368. External Links: ISBN 9798400703850, Link, Document Cited by: §1.
- R. Gretsch, P. Song, A. Madhavan, J. Lau, and T. Sherwood (2025) Delay space arithmetic and architecture. IEEE Micro. Cited by: §1.
- A. Gu and T. Dao (2024) Mamba: linear-time sequence modeling with selective state spaces. External Links: 2312.00752, Link Cited by: §1.
- Y. Gu, O. Tafjord, H. Kim, J. Moore, R. L. Bras, P. Clark, and Y. Choi (2024) SimpleToM: exposing the gap between explicit tom inference and implicit tom application in llms. arXiv preprint arXiv:2410.13648. Cited by: Table 3, §3.2.
- B. Guan, T. Roosta, P. Passban, and M. Rezagholizadeh (2025) The order effect: investigating prompt sensitivity to input order in llms. arXiv preprint arXiv:2502.04134. Cited by: §3.1.
- J. Gui, Y. Liu, J. Cheng, X. Gu, X. Liu, H. Wang, Y. Dong, J. Tang, and M. Huang (2024) LogicGame: benchmarking rule-based reasoning abilities of large language models. External Links: 2408.15778, Link Cited by: §4.1.
- H. Guinungco and A. Roman (2020) Abstract reasoning and problem-solving skills of first year college students. Southeast Asian Journal of Science and Technology 5 (1), pp. 33–39. Cited by: §3.1.
- A. Gulati, B. Miranda, E. Chen, E. Xia, K. Fronsdal, B. de Moraes Dumont, and S. Koyejo (2024) Putnam-axiom: a functional and static benchmark for measuring higher level mathematical reasoning. External Links: Link Cited by: Table 8, §4.2.
- P. Guo, W. You, J. Li, Y. Bowen, and M. Zhang (2024a) Exploring reversal mathematical reasoning ability for large language models. In Findings of the Association for Computational Linguistics: ACL 2024, L. Ku, A. Martins, and V. Srikumar (Eds.), Bangkok, Thailand, pp. 13671–13685. External Links: Link, Document Cited by: §4.2.
- Q. Guo, R. Wang, J. Guo, X. Tan, J. Bian, and Y. Yang (2024b) Mitigating reversal curse in large language models via semantic-aware permutation training. External Links: 2403.00758, Link Cited by: §4.1.
- T. Guo, X. Chen, Y. Wang, R. Chang, S. Pei, N. V. Chawla, O. Wiest, and X. Zhang (2024c) Large language model based multi-agents: a survey of progress and challenges. arXiv preprint arXiv:2402.01680. Cited by: §3.3.
- T. Guo, H. Zhu, R. Zhang, J. Jiao, S. Mei, M. I. Jordan, and S. Russell (2025a) How do llms perform two-hop reasoning in context?. External Links: 2502.13913, Link Cited by: §4.1.
- X. Guo, Z. Huang, Z. Shi, Z. Song, and J. Zhang (2025b) Your vision-language model can’t even count to 20: exposing the failures of vlms in compositional counting. arXiv preprint arXiv:2510.04401. Cited by: §4.3.
- P. Gupta (2023) Testing llm performance on the physics gre: some observations. arXiv preprint arXiv:2312.04613. Cited by: §5.1.
- V. Gupta, D. Pantoja, C. Ross, A. Williams, and M. Ung (2024) Changing answer order can decrease mmlu accuracy. External Links: 2406.19470, Link Cited by: §4.2.
- N. B. Guran, H. Ren, J. Deng, and X. Xie (2024) Task-oriented robotic manipulation with vision language models. arXiv preprint arXiv:2410.15863. Cited by: §5.3.
- T. Hagendorff (2023) Machine psychology: investigating emergent capabilities and behavior in large language models using psychological methods. arXiv preprint arXiv:2303.13988 1. Cited by: §3.1.
- D. L. Hamilton and R. K. Gifford (1976) Illusory correlation in interpersonal perception: a cognitive basis of stereotypic judgments. Journal of Experimental Social Psychology 12 (4), pp. 392–407. Cited by: §3.1.
- P. Han, R. Kocielnik, A. Saravanan, R. Jiang, O. Sharir, and A. Anandkumar (2024a) ChatGPT based data augmentation for improved parameter-efficient debiasing of llms. arXiv preprint arXiv:2402.11764. Cited by: Appendix D, §3.1.
- P. Han, R. Kocielnik, P. Song, R. Debnath, D. Mobbs, A. Anandkumar, and R. M. Alvarez (2025) The personality illusion: revealing dissociation between self-reports & behavior in llms. arXiv preprint arXiv:2509.03730. Cited by: §3.2.
- P. Han, P. Song, H. Yu, and J. You (2024b) In-context learning may not elicit trustworthy reasoning: a-not-B errors in pretrained language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, Y. Al-Onaizan, M. Bansal, and Y. Chen (Eds.), Miami, Florida, USA, pp. 5624–5643. External Links: Link, Document Cited by: Table 1, §3.1, §3.1, §3.1.
- S. Han, Q. Zhang, Y. Yao, W. Jin, Z. Xu, and C. He (2024c) LLM multi-agent systems: challenges and open problems. arXiv preprint arXiv:2402.03578. Cited by: §3.3.
- G. Hao, F. Alexandre, and S. Yu (2025) Visual large language models exhibit human-level cognitive flexibility in the wisconsin card sorting test. arXiv preprint arXiv:2505.22112. Cited by: §3.1.
- G. Hao, J. Wu, Q. Pan, and R. Morello (2024) Quantifying the uncertainty of llm hallucination spreading in complex adaptive social networks. Scientific reports 14 (1), pp. 16375. Cited by: Appendix D.
- R. Hasani, M. Lechner, A. Amini, D. Rus, and R. Grosu (2020) Liquid time-constant networks. External Links: 2006.04439, Link Cited by: §1.
- S. Havaldar, S. Rai, B. Singhal, L. Liu, S. C. Guntuku, and L. Ungar (2023) Multilingual language models are not multicultural: a case study in emotion. arXiv preprint arXiv:2307.01370. Cited by: §3.2.
- J. He and J. Liu (2025) Investigating the impact of llm personality on cognitive bias manifestation in automated decision-making tasks. arXiv preprint arXiv:2502.14219. Cited by: §3.1.
- Y. He, Y. Wu, Y. Jia, R. Mihalcea, Y. Chen, and N. Deng (2023) Hi-tom: a benchmark for evaluating higher-order theory of mind reasoning in large language models. arXiv preprint arXiv:2310.16755. Cited by: Table 3, §3.2.
- C. Helwe, C. Clavel, and F. M. Suchanek (2021) Reasoning with transformer-based models: deep learning, but shallow reasoning. In Conference on Automated Knowledge Base Construction, External Links: Link Cited by: §1.
- P. Hong, N. Majumder, D. Ghosal, S. Aditya, R. Mihalcea, and S. Poria (2024) Evaluating llms’ mathematical and coding competency through ontology-guided interventions. External Links: 2401.09395, Link Cited by: §4.2.
- A. Hooda, M. Christodorescu, M. Allamanis, A. Wilson, K. Fawaz, and S. Jha (2024) Do large code models understand programming concepts? a black-box approach. External Links: 2402.05980, Link Cited by: §4.2.
- A. Hosseini, A. Sordoni, D. Toyama, A. Courville, and R. Agarwal (2024) Not all llm reasoners are created equal. External Links: 2410.01748, Link Cited by: §4.1.
- E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen (2021) LoRA: low-rank adaptation of large language models. External Links: 2106.09685, Link Cited by: §1.
- H. Hu, Y. Zhou, L. You, H. Xu, Q. Wang, Z. Lian, F. R. Yu, F. Ma, and L. Cui (2025) EmoBench-m: benchmarking emotional intelligence for multimodal large language models. arXiv preprint arXiv:2502.04424. Cited by: Table 3, Table 3, §3.2.
- Z. Hu, F. Lucchetti, C. Schlesinger, Y. Saxena, A. Freeman, S. Modak, A. Guha, and J. Biswas (2024) Deploying and evaluating llms to program service mobile robots. IEEE Robotics and Automation Letters 9 (3), pp. 2853–2860. Cited by: §5.3.
- J. Huang, K. Sun, W. Wang, and M. Dredze (2025a) LLMs do not have human-like working memory. arXiv preprint arXiv:2505.10571. Cited by: §3.1.
- J. Huang, J. Zhou, T. Jin, X. Zhou, Z. Chen, W. Wang, Y. Yuan, M. Sap, and M. R. Lyu (2024) On the resilience of multi-agent systems with malicious agents. arXiv preprint arXiv:2408.00989. Cited by: §3.3, §3.3, §3.3.
- J. Huang and K. C. Chang (2023) Towards reasoning in large language models: a survey. External Links: 2212.10403, Link Cited by: §1.
- K. Huang, J. Guo, Z. Li, X. Ji, J. Ge, W. Li, Y. Guo, T. Cai, H. Yuan, R. Wang, Y. Wu, M. Yin, S. Tang, Y. Huang, C. Jin, X. Chen, C. Zhang, and M. Wang (2025b) MATH-perturb: benchmarking llms’ math reasoning abilities against hard perturbations. External Links: 2502.06453, Link Cited by: §4.2.
- L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, et al. (2025c) A survey on hallucination in large language models: principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems 43 (2), pp. 1–55. Cited by: Appendix D.
- S. Huang, P. Song, R. J. George, and A. Anandkumar (2025d) LeanProgress: guiding search for neural theorem proving via proof progress prediction. arXiv preprint arXiv:2502.17925. Cited by: Appendix C.
- W. Huang, P. Abbeel, D. Pathak, and I. Mordatch (2022a) Language models as zero-shot planners: extracting actionable knowledge for embodied agents. In International conference on machine learning, pp. 9118–9147. Cited by: §5.3.
- W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar, et al. (2022b) Inner monologue: embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608. Cited by: §2.1, §5.3.
- Y. Huang, B. Bie, Z. Na, W. Ruan, S. Lei, Y. Yue, and X. He (2025e) An empirical study of the anchoring effect in llms: existence, mechanism, and potential mitigations. arXiv preprint arXiv:2505.15392. Cited by: §3.1.
- I. Itzhak, Y. Belinkov, and G. Stanovsky (2025) Planted in pretraining, swayed by finetuning: a case study on the origins of cognitive biases in llms. External Links: 2507.07186, Link Cited by: §3.1.
- L. Iwańska (1993) Logical reasoning in natural language: it is all about knowledge. Minds and Machines 3 (4), pp. 475–510. External Links: Document Cited by: §4.
- A. Izadi, M. A. Banayeeanzade, F. Askari, A. Rahimiakbar, M. M. Vahedi, H. Hasani, and M. S. Baghshah (2025) Visual structures helps visual reasoning: addressing the binding problem in vlms. arXiv preprint arXiv:2506.22146. Cited by: §5.2.
- H. Jaakko and G. Sandu (2002) What is logic?. In Philosophy of Logic, D. Jacquette (Ed.), pp. 13–39. Cited by: §4.
- A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. (2024) Openai o1 system card. arXiv preprint arXiv:2412.16720. Cited by: Appendix C, §5.1.
- N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica (2024a) LiveCodeBench: holistic and contamination free evaluation of large language models for code. External Links: 2403.07974, Link Cited by: §4.2, §6.
- S. Jain, D. Calacci, and A. Wilson (2024b) As an ai language model," yes i would recommend calling the police": norm inconsistency in llm decision-making. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7, pp. 624–633. Cited by: Appendix E, §3.2, §3.2.
- R. Jaiswal, D. Jain, H. P. Popat, A. Anand, A. Dharmadhikari, A. Marathe, and R. R. Shah (2024) Improving physics reasoning in large language models using mixture of refinement agents. arXiv preprint arXiv:2412.00821. Cited by: §5.1.
- V. Jayaram, V. Ramineni, and M. S. Krishnappa (2024) Mitigating order sensitivity in large language models for multiple-choice question tasks. International Journal of Artificial Intelligence Research and Development (IJAIRD). Cited by: §3.1.
- J. Ji, Y. Chen, M. Jin, W. Xu, W. Hua, and Y. Zhang (2024) Moralbench: moral evaluation of llms. arXiv preprint arXiv:2406.04428. Cited by: §3.2, §3.2.
- A. Q. Jiang, W. Li, and M. Jamnik (2023a) Multilingual mathematical autoformalization. External Links: 2311.03755, Link Cited by: Appendix C.
- A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed (2024a) Mixtral of experts. External Links: 2401.04088, Link Cited by: §1.
- B. Jiang, Y. Xie, Z. Hao, X. Wang, T. Mallick, W. J. Su, C. J. Taylor, and D. Roth (2024b) A peek into token bias: large language models are not yet genuine reasoners. External Links: 2406.11050, Link Cited by: §1, §4.2.
- C. Jiang, J. Wang, W. Ma, C. L. Clarke, S. Wang, C. Wu, and M. Zhang (2025a) Beyond utility: evaluating llm as recommender. In Proceedings of the ACM on Web Conference 2025, pp. 3850–3862. Cited by: §3.1.
- L. Jiang, K. Jiang, X. Chu, S. Gulati, and P. Garg (2024c) Hallucination detection in llm-enriched product listings. In Proceedings of the Seventh Workshop on e-Commerce and NLP@ LREC-COLING 2024, pp. 29–39. Cited by: Appendix D.
- L. Jiang, J. D. Hwang, C. Bhagavatula, R. L. Bras, J. T. Liang, S. Levine, J. Dodge, K. Sakaguchi, M. Forbes, J. Hessel, et al. (2025b) Investigating machine moral judgement through the delphi experiment. Nature Machine Intelligence, pp. 1–16. Cited by: §3.2.
- R. Jiang, R. Kocielnik, A. P. Saravanan, P. Han, R. M. Alvarez, and A. Anandkumar (2023b) Empowering domain experts to detect social bias in generative ai with user-friendly interfaces. In XAI in Action: Past, Present, and Future Applications, Cited by: Appendix D.
- Y. Jin, D. Li, A. Yong, J. Shi, P. Hao, F. Sun, J. Zhang, and B. Fang (2024) Robotgpt: robot manipulation learning from chatgpt. IEEE Robotics and Automation Letters 9 (3), pp. 2543–2550. Cited by: §5.3.
- Z. Jin, M. Tirassa, and A. M. Borghi (2018) Beyond embodied cognition: intentionality, affordance, and environmental adaptation. Vol. 9, Frontiers Media SA. Cited by: §3.1.
- E. Jones and J. Steinhardt (2022) Capturing failures of large language models via human cognitive biases. Advances in Neural Information Processing Systems 35, pp. 11785–11799. Cited by: §3.1.
- N. Joshi, A. Saparov, Y. Wang, and H. He (2024) LLMs are prone to fallacies in causal inference. External Links: 2406.12158, Link Cited by: §4.1.
- R. Kail (1990) The development of memory in children. WH Freeman/Times Books/Henry Holt & Co. Cited by: §2.1.
- A. Kar, D. Acuna, and S. Fidler (2025) On inherent 3d reasoning of vlms in indoor scene layout design. External Links: Link Cited by: §5.2.
- F. Karl, M. Kemeter, G. Dax, and P. Sierak (2024) Position: embracing negative results in machine learning. In Proceedings of the 41st International Conference on Machine Learning, R. Salakhutdinov, Z. Kolter, K. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp (Eds.), Proceedings of Machine Learning Research, Vol. 235, pp. 23256–23265. External Links: Link Cited by: §1.
- A. Karpov, S. H. Cho, A. Meek, R. Koopmanschap, L. Farnik, and B. Cirstea (2024) Inducing human-like biases in moral reasoning language models. External Links: 2411.15386, Link Cited by: §3.2.
- S. R. Kasibatla, A. Agarwal, Y. Brun, S. Lerner, T. Ringer, and E. First (2024) Cobblestone: iterative automation for formal verification. External Links: 2410.19940, Link Cited by: Appendix C.
- S. M. Kennedy and R. D. Nowak (2024) Cognitive flexibility of large language models. In ICML 2024 Workshop on LLMs and Cognition, Cited by: Table 1, §3.1.
- M. U. Khattak, M. F. Naeem, J. Hassan, M. Naseer, F. Tombari, F. S. Khan, and S. Khan (2024) How good is my video lmm? complex video reasoning and robustness evaluation suite for video-lmms. External Links: 2405.03690, Link Cited by: Appendix C.
- H. Kim, M. Sclar, X. Zhou, R. L. Bras, G. Kim, Y. Choi, and M. Sap (2023) FANToM: a benchmark for stress-testing machine theory of mind in interactions. arXiv preprint arXiv:2310.15421. Cited by: §3.2, §3.2.
- K. Kondo, S. Sugawara, and A. Aizawa (2023) Probing physical reasoning with counter-commonsense context. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 603–612. External Links: Document Cited by: Table 11, §5.1.
- R. Koo, M. Lee, V. Raheja, J. I. Park, Z. M. Kim, and D. Kang (2023) Benchmarking cognitive biases in large language models as evaluators. arXiv preprint arXiv:2309.17012. Cited by: §3.1.
- M. Kosinski (2023) Evaluating large language models in theory of mind tasks. arXiv e-prints, pp. arXiv–2302. Cited by: §3.2.
- D. Kumar, U. Jain, S. Agarwal, and P. Harshangi (2024) Investigating implicit bias in large language models: a large-scale study of over 50 llms. arXiv preprint arXiv:2410.12864. Cited by: Appendix D.
- A. Kumarappan, M. Tiwari, P. Song, R. J. George, C. Xiao, and A. Anandkumar (2024) Leanagent: lifelong learning for formal theorem proving. arXiv preprint arXiv:2410.06209. Cited by: Appendix C.
- A. K. Lampinen, I. Dasgupta, S. C. Chan, H. R. Sheahan, A. Creswell, D. Kumaran, J. L. McClelland, and F. Hill (2024) Language models, like humans, show content effects on reasoning tasks. PNAS nexus 3 (7), pp. pgae233. Cited by: §3.1, §3.1.
- G. Lample, T. Lacroix, M. Lachaux, A. Rodriguez, A. Hayat, T. Lavril, G. Ebner, and X. Martinet (2022) HyperTree proof search for neural theorem proving. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35, pp. 26337–26349. External Links: Link Cited by: Appendix C.
- A. Lawsen (2025) Comment on the illusion of thinking: understanding the strengths and limitations of reasoning models via the lens of problem complexity. External Links: 2506.09250, Link Cited by: §4.2.
- G. Ledger and R. Mancinni (2024) Detecting llm hallucinations using monte carlo simulations on token probabilities. Authorea Preprints. Cited by: Appendix D.
- N. Lee, Z. Cai, A. Schwarzschild, K. Lee, and D. Papailiopoulos (2025) Self-improving transformers overcome easy-to-hard and length generalization challenges. External Links: 2502.01612, Link Cited by: §4.3.
- S. Lee-Cultura and M. Giannakos (2020) Embodied interaction and spatial skills: a systematic review of empirical studies. Interacting with Computers 32 (4), pp. 331–366. Cited by: §2.1, §5.
- C. I. Lewis, C. H. Langford, and P. Lamprecht (1959) Symbolic logic. Vol. 170, Dover publications New York. Cited by: §4.
- D. Li, A. S. Rawat, M. Zaheer, X. Wang, M. Lukasik, A. Veit, F. Yu, and S. Kumar (2022) Large language models with controllable working memory. External Links: 2211.05110, Link Cited by: §3.1.
- D. Li, C. Tang, and H. Liu (2024a) Audio-llm: activating the capabilities of large language models to comprehend audio data. In Advances in Neural Networks – ISNN 2024, X. Le and Z. Zhang (Eds.), Singapore, pp. 133–142. External Links: ISBN 978-981-97-4399-5 Cited by: Appendix C.
- H. Li, Y. Q. Chong, S. Stepputtis, J. Campbell, D. Hughes, M. Lewis, and K. Sycara (2023a) Theory of mind for multi-agent collaboration via large language models. arXiv preprint arXiv:2310.10701. Cited by: §3.3, §3.3.
- M. Li, S. Zhao, Q. Wang, K. Wang, Y. Zhou, S. Srivastava, C. Gokmen, T. Lee, E. L. Li, R. Zhang, et al. (2025) Embodied agent interface: benchmarking llms for embodied decision making. Advances in Neural Information Processing Systems 37, pp. 100428–100534. Cited by: Table 15, §5.3.
- Q. Li, L. Cui, X. Zhao, L. Kong, and W. Bi (2024b) GSM-plus: a comprehensive benchmark for evaluating the robustness of llms as mathematical problem solvers. External Links: 2402.19255, Link Cited by: §4.2.
- W. Li, Y. Cai, Z. Wu, W. Zhang, Y. Chen, R. Qi, M. Dong, P. Chen, X. Dong, F. Shi, L. Guo, J. Han, B. Ge, T. Liu, L. Gan, and T. Zhang (2024c) A survey of foundation models for music understanding. External Links: 2409.09601, Link Cited by: Appendix C.
- Y. Li, Q. Gao, T. Zhao, B. Wang, H. Sun, H. Lyu, R. D. Hawkins, N. Vasconcelos, T. Golan, D. Luo, et al. (2024d) Core knowledge deficits in multi-modal language models. arXiv preprint arXiv:2410.10855. Cited by: §5.2.
- Y. Li, M. Du, R. Song, X. Wang, and Y. Wang (2023b) A survey on fairness in large language models. arXiv preprint arXiv:2308.10149. Cited by: Appendix D.
- Y. Li, E. J. Michaud, D. D. Baek, J. Engels, X. Sun, and M. Tegmark (2024e) The geometry of concepts: sparse autoencoder feature structure. External Links: 2410.19750, Link Cited by: §2.2.
- Z. Li, G. Jiang, H. Xie, L. Song, D. Lian, and Y. Wei (2024f) Understanding and patching compositional reasoning in llms. External Links: 2402.14328, Link Cited by: §4.1.
- Z. Li, J. Sun, L. Murphy, Q. Su, Z. Li, X. Zhang, K. Yang, and X. Si (2024g) A survey on deep learning for theorem proving. External Links: 2404.09939, Link Cited by: Appendix C.
- J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng (2023) Code as policies: language model programs for embodied control. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 9493–9500. Cited by: §5.3, §5.3.
- K. Liang, H. Hu, X. Zhao, D. Song, T. L. Griffiths, and J. F. Fisac (2025) Machine bullshit: characterizing the emergent disregard for truth in large language models. External Links: 2507.07484, Link Cited by: Appendix D.
- J. M. Lichtenberg, A. Buchholz, and P. Schwöbel (2024) Large language models as recommender systems: a study of popularity bias. arXiv preprint arXiv:2406.01285. Cited by: §3.1.
- F. Lieder, T. L. Griffiths, Q. J. M. Huys, and N. D. Goodman (2018) The anchoring bias reflects rational use of cognitive resources. Psychonomic bulletin & review 25, pp. 322–349. Cited by: §3.1.
- G. Lin, T. Feng, P. Han, G. Liu, and J. You (2024a) Paper copilot: a self-evolving and efficient llm system for personalized academic assistance. arXiv preprint arXiv:2409.04593. Cited by: Appendix C.
- H. Lin, Z. Sun, S. Welleck, and Y. Yang (2025a) Lean-star: learning to interleave thinking and proving. External Links: 2407.10040, Link Cited by: Appendix C.
- L. Lin, L. Wang, J. Guo, and K. Wong (2024b) Investigating bias in llm-based bias detection: disparities between llms and human perception. arXiv preprint arXiv:2403.14896. Cited by: Appendix D, §3.1.
- R. Lin and H. T. Ng (2023) Mind the biases: quantifying cognitive biases in language model prompting. In Findings of the Association for Computational Linguistics: ACL 2023, pp. 5269–5281. Cited by: §3.1.
- Y. Lin, S. Tang, B. Lyu, J. Wu, H. Lin, K. Yang, J. Li, M. Xia, D. Chen, S. Arora, and C. Jin (2025b) Goedel-prover: a frontier model for open-source automated theorem proving. External Links: 2502.07640, Link Cited by: Appendix C.
- Z. Lin, Z. Fu, K. Liu, L. Xie, B. Lin, W. Wang, D. Cai, Y. Wu, and J. Ye (2024c) Delving into the reversal curse: how far can large language models generalize?. External Links: 2410.18808, Link Cited by: §4.1.
- L. Lindemann and D. V. Dimarogonas (2025) Formal methods for multi-agent feedback control systems. In Formal Methods for Multi-Agent Feedback Control Systems, Vol. , pp. 1–9. External Links: Document Cited by: §3.3.
- G. Lior, L. Nacchace, and G. Stanovsky (2025) WildFrame: comparing framing in humans and llms on naturally occurring texts. arXiv preprint arXiv:2502.17091. Cited by: §3.1.
- F. Liu, G. Emerson, and N. Collier (2023a) Visual spatial reasoning. Transactions of the Association for Computational Linguistics 11, pp. 635–651. Cited by: §5.2.
- H. Liu, Z. Fu, M. Ding, R. Ning, C. Zhang, X. Liu, and Y. Zhang (2025) Logical reasoning in large language models: a survey. External Links: 2502.09100, Link Cited by: §4.
- H. Liu, R. Ning, Z. Teng, J. Liu, Q. Zhou, and Y. Zhang (2023b) Evaluating the logical reasoning ability of chatgpt and gpt-4. arXiv preprint arXiv:2304.03439. Cited by: §2.1.
- R. Liu, J. Wei, S. S. Gu, T. Wu, S. Vosoughi, C. Cui, D. Zhou, and A. M. Dai (2022a) Mind’s eye: grounded language model reasoning through simulation. arXiv preprint arXiv:2210.05359. Cited by: §5.2.
- X. Liu, D. Yin, Y. Feng, and D. Zhao (2022b) Things not written in text: exploring spatial commonsense from visual signals. arXiv preprint arXiv:2203.08075. Cited by: §5.1.
- Z. Liu, T. Xie, and X. Zhang (2024) Evaluating and mitigating social bias for large language models in open-ended settings. arXiv preprint arXiv:2412.06134. Cited by: Appendix D.
- D. F. Lohman and J. M. Lakin (2011) Intelligence and reasoning. The Cambridge handbook of intelligence, pp. 419–441. Cited by: §2.1.
- J. Lou and Y. Sun (2024) Anchoring bias in large language models: an experimental study. arXiv preprint arXiv:2412.06593. Cited by: §3.1.
- Z. Lu, L. Jin, P. Li, Y. Tian, L. Zhang, S. Wang, G. Xu, C. Tian, and X. Cai (2024) Rethinking the reversal curse of LLMs: a prescription from human knowledge reversal. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y. Al-Onaizan, M. Bansal, and Y. Chen (Eds.), Miami, Florida, USA, pp. 7518–7530. External Links: Link, Document Cited by: §4.1.
- H. Luo and L. Specia (2024) From understanding to utilization: a survey on explainability for large language models. arXiv preprint arXiv:2401.12874. Cited by: §2.2.
- A. Lv, K. Zhang, S. Xie, Q. Tu, Y. Chen, J. Wen, and R. Yan (2024) An analysis and mitigation of the reversal curse. External Links: 2311.07468, Link Cited by: §4.1.
- Y. Lyu, L. Yan, S. Wang, H. Shi, D. Yin, P. Ren, Z. Chen, M. de Rijke, and Z. Ren (2024) Knowtuning: knowledge-aware fine-tuning for large language models. arXiv preprint arXiv:2402.11176. Cited by: §5.1.
- J. Ma, D. Dai, L. Sha, and Z. Sui (2024a) Large language models are unconscious of unreasonability in math problems. External Links: 2403.19346, Link Cited by: Table 10, §4.3.
- J. Ma, J. Gu, Z. Ling, Q. Liu, and C. Liu (2024b) Untying the reversal curse via bidirectional language model editing. External Links: 2310.10322, Link Cited by: §4.1.
- X. Ma, S. Mishra, A. Beirami, A. Beutel, and J. Chen (2023) Let’s do a thought experiment: using counterfactuals to improve moral reasoning. External Links: 2306.14308, Link Cited by: §3.2.
- Y. Ma, Z. Gou, J. Hao, R. Xu, S. Wang, L. Pan, Y. Yang, Y. Cao, A. Sun, H. Awadalla, and W. Chen (2024c) SciAgent: tool-augmented language models for scientific reasoning. External Links: 2402.11451, Link Cited by: §5.1.
- S. Malberg, R. Poletukhin, C. M. Schuster, and G. Groh (2024) A comprehensive evaluation of cognitive biases in llms. arXiv preprint arXiv:2410.15413. Cited by: Table 2, §3.1.
- A. Malek, J. Ge, N. Lazic, C. Jin, A. György, and C. Szepesvári (2025) Frontier llms still struggle with simple reasoning tasks. External Links: 2507.07313, Link Cited by: §4.3, §6.
- A. Marchetti, F. Manzi, G. Riva, A. Gaggioli, and D. Massaro (2025) Artificial intelligence and the illusion of understanding: a systematic review of theory of mind and large language models. Cyberpsychology, Behavior, and Social Networking. Cited by: §3.2.
- J. C. Maxwell (2007) Failing forward: turning mistakes into stepping stones for success. HarperCollins Leadership. Cited by: §1.
- M. G. Mecattaf, B. Slater, M. Tešić, J. Prunty, K. Voudouris, and L. G. Cheke (2024) A little less conversation, a little more action, please: investigating the physical common-sense of llms in a 3d embodied environment. arXiv preprint arXiv:2410.23242. Cited by: §5.3.
- L. Mei, J. Yao, Y. Ge, Y. Wang, B. Bi, Y. Cai, J. Liu, M. Li, Z. Li, D. Zhang, et al. (2025) A survey of context engineering for large language models. arXiv preprint arXiv:2507.13334. Cited by: §3.3.
- E. Mendelson (2009) Introduction to mathematical logic. Chapman and Hall/CRC. Cited by: §2.1.
- A. V. Miceli-Barone, F. Barez, I. Konstas, and S. B. Cohen (2023) The larger they are, the harder they fail: language models do not recognize identifier swaps in python. External Links: 2305.15507, Link Cited by: Table 9, §4.2.
- J. Min, S. Buch, A. Nagrani, M. Cho, and C. Schmid (2024) MoReVQA: exploring modular reasoning models for video question answering. External Links: 2404.06511, Link Cited by: Appendix C.
- I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, and M. Farajtabar (2024) GSM-symbolic: understanding the limitations of mathematical reasoning in large language models. External Links: 2410.05229, Link Cited by: §4.2, §4.2.
- P. Molenda, A. Liusie, and M. J. F. Gales (2024) WaterJudge: quality-detection trade-off when watermarking large language models. External Links: 2403.19548, Link Cited by: Appendix D.
- N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candès, and T. Hashimoto (2025) S1: simple test-time scaling. arXiv preprint arXiv:2501.19393. Cited by: Appendix C.
- L. Murphy, K. Yang, J. Sun, Z. Li, A. Anandkumar, and X. Si (2024) Autoformalizing euclidean geometry. External Links: 2405.17216, Link Cited by: Appendix C.
- M. Nadeem, A. Bethke, and S. Reddy (2020) StereoSet: measuring stereotypical bias in pretrained language models. arXiv preprint arXiv:2004.09456. Cited by: Appendix D.
- N. Nangia, C. Vania, R. Bhalerao, and S. R. Bowman (2020) CrowS-pairs: a challenge dataset for measuring social biases in masked language models. arXiv preprint arXiv:2010.00133. Cited by: Appendix D.
- M. Newman (2005) Power laws, pareto distributions and zipf’s law. Contemporary Physics 46 (5), pp. 323–351. External Links: ISSN 1366-5812, Link, Document Cited by: §4.1.
- M. Nezhurina, L. Cipolina-Kun, M. Cherti, and J. Jitsev (2024) Alice in wonderland: simple tasks showing complete reasoning breakdown in state-of-the-art large language models. External Links: 2406.02061, Link Cited by: Table 10, §4.3.
- J. K. Nguyen (2024) Human bias in ai models? anchoring effects and mitigation strategies in large language models. Journal of Behavioral and Experimental Finance 43, pp. 100971. Cited by: §3.1.
- S. Ni, X. Kong, C. Li, X. Hu, R. Xu, J. Zhu, and M. Yang (2024) Training on the benchmark is not all you need. External Links: 2409.01790, Link Cited by: §4.2.
- Y. Nikankin, A. Reusch, A. Mueller, and Y. Belinkov (2024) Arithmetic without algorithms: language models solve math with a bag of heuristics. External Links: 2410.21272, Link Cited by: §4.3.
- D. E. O’Leary (2025a) An anchoring effect in large language models. IEEE Intelligent Systems 40 (2), pp. 23–26. Cited by: §3.1.
- D. E. O’Leary (2025b) Confirmation and specificity biases in large language models: an explorative study. IEEE Intelligent Systems 40 (1), pp. 63–68. Cited by: Table 2, §3.1.
- OpenAI (2025) OpenAI o3-mini system card. Note: Accessed: 2025-03-07 External Links: Link Cited by: §5.1.
- S. Ouyang, Z. Zhang, B. Yan, X. Liu, Y. Choi, J. Han, and L. Qin (2023) Structured chemistry reasoning with large language models. arXiv preprint arXiv:2311.09656. Cited by: §5.1.
- D. M. Owens, R. A. Rossi, S. Kim, T. Yu, F. Dernoncourt, X. Chen, R. Zhang, J. Gu, H. Deilamsalehy, and N. Lipka (2024) A multi-llm debiasing framework. arXiv preprint arXiv:2409.13884. Cited by: Appendix D.
- D. Paglieri, B. Cupiał, S. Coward, U. Piterbarg, M. Wolczyk, A. Khan, E. Pignatelli, Ł. Kuciński, L. Pinto, R. Fergus, et al. (2024) Balrog: benchmarking agentic llm and vlm reasoning on games. arXiv preprint arXiv:2411.13543. Cited by: §5.2.
- L. Pan, A. Liu, Z. He, Z. Gao, X. Zhao, Y. Lu, B. Zhou, S. Liu, X. Hu, L. Wen, I. King, and P. S. Yu (2024) MarkLLM: an open-source toolkit for llm watermarking. External Links: 2405.10051, Link Cited by: Appendix D.
- M. Z. Pan, M. Cemri, L. A. Agrawal, S. Yang, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, K. Ramchandran, D. Klein, et al. (2025) Why do multiagent systems fail?. In ICLR 2025 Workshop on Building Trust in Language Models and Applications, Cited by: Table 5, Table 5, Table 6, Table 6, §3.3, §3.3, §3.3.
- Q. Pang, S. Hu, W. Zheng, and V. Smith (2024) No free lunch in llm watermarking: trade-offs in watermarking design choices. External Links: 2402.16187, Link Cited by: Appendix D.
- L. Parcalabescu, A. Gatt, A. Frank, and I. Calixto (2021) Seeing past words: testing the cross-modal capabilities of pretrained v&l models on counting tasks. In Proceedings of the 1st Workshop on Multimodal Semantic Representations (MMSR), pp. 32–44. Cited by: §4.3.
- A. Patel, S. Bhattamishra, and N. Goyal (2021) Are nlp models really able to solve simple math word problems?. External Links: 2103.07191, Link Cited by: §4.2, §4.2.
- S. Patel, H. Wang, and J. Fan (2025) Deficient executive control in transformer attention. bioRxiv, pp. 2025–01. Cited by: §3.1, §3.1.
- Z. R. Pearce and S. E. Miller (2025) Embodied cognition perspectives within early executive function development. Frontiers in Cognition 4, pp. 1361748. Cited by: §3.1.
- K. Pelrine, A. Imouza, C. Thibault, M. Reksoprodjo, C. Gupta, J. Christoph, J. Godbout, and R. Rabbany (2023) Towards reliable misinformation mitigation: generalization, uncertainty, and gpt-4. arXiv preprint arXiv:2305.14928. Cited by: Appendix D.
- G. Pensa, B. Altuna, and I. Gonzalez-Dios (2024) A multi-layered approach to physical commonsense understanding: creation and evaluation of an italian dataset. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp. 819–831. Cited by: §5.1.
- E. Perez, S. Ringer, K. Lukosiute, K. Nguyen, E. Chen, S. Heiner, C. Pettit, C. Olsson, S. Kundu, S. Kadavath, et al. (2023) Discovering language model behaviors with model-written evaluations. In Findings of the association for computational linguistics: ACL 2023, pp. 13387–13434. Cited by: §3.1.
- P. Pezeshkpour and E. Hruschka (2023) Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483. Cited by: §3.1, §4.2.
- L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, M. Choi, A. Agrawal, A. Chopra, A. Khoja, R. Kim, R. Ren, J. Hausenloy, O. Zhang, M. Mazeika, D. Dodonov, T. Nguyen, J. Lee, D. Anderson, M. Doroshenko, A. C. Stokes, M. Mahmood, O. Pokutnyi, O. Iskra, J. P. Wang, J. Levin, M. Kazakov, F. Feng, S. Y. Feng, H. Zhao, M. Yu, V. Gangal, C. Zou, Z. Wang, S. Popov, R. Gerbicz, G. Galgon, J. Schmitt, W. Yeadon, Y. Lee, S. Sauers, A. Sanchez, F. Giska, M. Roth, S. Riis, S. Utpala, N. Burns, G. M. Goshu, M. M. Naiya, C. Agu, Z. Giboney, A. Cheatom, F. Fournier-Facio, S. Crowson, L. Finke, Z. Cheng, J. Zampese, R. G. Hoerr, M. Nandor, H. Park, T. Gehrunger, J. Cai, B. McCarty, A. C. Garretson, E. Taylor, D. Sileo, Q. Ren, U. Qazi, L. Li, J. Nam, J. B. Wydallis, P. Arkhipov, J. W. L. Shi, A. Bacho, C. G. Willcocks, H. Cao, S. Motwani, E. de Oliveira Santos, J. Veith, E. Vendrow, D. Cojoc, K. Zenitani, J. Robinson, L. Tang, Y. Li, J. Vendrow, N. W. Fraga, V. Kuchkin, A. P. Maksimov, P. Marion, D. Efremov, J. Lynch, K. Liang, A. Mikov, A. Gritsevskiy, J. Guillod, G. Demir, D. Martinez, B. Pageler, K. Zhou, S. Soori, O. Press, H. Tang, P. Rissone, S. R. Green, L. Brüssel, M. Twayana, A. Dieuleveut, J. M. Imperial, A. Prabhu, J. Yang, N. Crispino, A. Rao, D. Zvonkine, G. Loiseau, M. Kalinin, M. Lukas, C. Manolescu, N. Stambaugh, S. Mishra, T. Hogg, C. Bosio, B. P. Coppola, J. Salazar, J. Jin, R. Sayous, S. Ivanov, P. Schwaller, S. Senthilkuma, A. M. Bran, A. Algaba, K. V. den Houte, L. V. D. Sypt, B. Verbeken, D. Noever, A. Kopylov, B. Myklebust, B. Li, L. Schut, E. Zheltonozhskii, Q. Yuan, D. Lim, R. Stanley, T. Yang, J. Maar, J. Wykowski, M. Oller, A. Sahu, C. G. Ardito, Y. Hu, A. G. K. Kamdoum, A. Jin, T. G. Vilchis, Y. Zu, M. Lackner, J. Koppel, G. Sun, D. S. Antonenko, S. Chern, B. Zhao, P. Arsene, J. M. Cavanagh, D. Li, J. Shen, D. Crisostomi, W. Zhang, A. Dehghan, S. Ivanov, D. Perrella, N. Kaparov, A. Zang, I. Sucholutsky, A. Kharlamova, D. Orel, V. Poritski, S. Ben-David, Z. Berger, P. Whitfill, M. Foster, D. Munro, L. Ho, S. Sivarajan, D. B. Hava, A. Kuchkin, D. Holmes, A. Rodriguez-Romero, F. Sommerhage, A. Zhang, R. Moat, K. Schneider, Z. Kazibwe, D. Clarke, D. H. Kim, F. M. Dias, S. Fish, V. Elser, T. Kreiman, V. E. G. Vilchis, I. Klose, U. Anantheswaran, A. Zweiger, K. Rawal, J. Li, J. Nguyen, N. Daans, H. Heidinger, M. Radionov, V. Rozhoň, V. Ginis, C. Stump, N. Cohen, R. Poświata, J. Tkadlec, A. Goldfarb, C. Wang, P. Padlewski, S. Barzowski, K. Montgomery, R. Stendall, J. Tucker-Foltz, J. Stade, T. R. Rogers, T. Goertzen, D. Grabb, A. Shukla, A. Givré, J. A. Ambay, A. Sen, M. F. Aziz, M. H. Inlow, H. He, L. Zhang, Y. Kaddar, I. Ängquist, Y. Chen, H. K. Wang, K. Ramakrishnan, E. Thornley, A. Terpin, H. Schoelkopf, E. Zheng, A. Carmi, E. D. L. Brown, K. Zhu, M. Bartolo, R. Wheeler, M. Stehberger, P. Bradshaw, J. Heimonen, K. Sridhar, I. Akov, J. Sandlin, Y. Makarychev, J. Tam, H. Hoang, D. M. Cunningham, V. Goryachev, D. Patramanis, M. Krause, A. Redenti, D. Aldous, J. Lai, S. Coleman, J. Xu, S. Lee, I. Magoulas, S. Zhao, N. Tang, M. K. Cohen, O. Paradise, J. H. Kirchner, M. Ovchynnikov, J. O. Matos, A. Shenoy, M. Wang, Y. Nie, A. Sztyber-Betley, P. Faraboschi, R. Riblet, J. Crozier, S. Halasyamani, S. Verma, P. Joshi, E. Meril, Z. Ma, J. Andréoletti, R. Singhal, J. Platnick, V. Nevirkovets, L. Basler, A. Ivanov, S. Khoury, N. Gustafsson, M. Piccardo, H. Mostaghimi, Q. Chen, V. Singh, T. Q. Khánh, P. Rosu, H. Szlyk, Z. Brown, H. Narayan, A. Menezes, J. Roberts, W. Alley, K. Sun, A. Patel, M. Lamparth, A. Reuel, L. Xin, H. Xu, J. Loader, F. Martin, Z. Wang, A. Achilleos, T. Preu, T. Korbak, I. Bosio, F. Kazemi, Z. Chen, B. Bálint, E. J. Y. Lo, J. Wang, M. I. S. Nunes, J. Milbauer, M. S. Bari, Z. Wang, B. Ansarinejad, Y. Sun, S. Durand, H. Elgnainy, G. Douville, D. Tordera, G. Balabanian, H. Wolff, L. Kvistad, H. Milliron, A. Sakor, M. Eron, A. F. D. O., S. Shah, X. Zhou, F. Kamalov, S. Abdoli, T. Santens, S. Barkan, A. Tee, R. Zhang, A. Tomasiello, G. B. D. Luca, S. Looi, V. Le, N. Kolt, J. Pan, E. Rodman, J. Drori, C. J. Fossum, N. Muennighoff, M. Jagota, R. Pradeep, H. Fan, J. Eicher, M. Chen, K. Thaman, W. Merrill, M. Firsching, C. Harris, S. Ciobâcă, J. Gross, R. Pandey, I. Gusev, A. Jones, S. Agnihotri, P. Zhelnov, M. Mofayezi, A. Piperski, D. K. Zhang, K. Dobarskyi, R. Leventov, I. Soroko, J. Duersch, V. Taamazyan, A. Ho, W. Ma, W. Held, R. Xian, A. R. Zebaze, M. Mohamed, J. N. Leser, M. X. Yuan, L. Yacar, J. Lengler, K. Olszewska, C. D. Fratta, E. Oliveira, J. W. Jackson, A. Zou, M. Chidambaram, T. Manik, H. Haffenden, D. Stander, A. Dasouqi, A. Shen, B. Golshani, D. Stap, E. Kretov, M. Uzhou, A. B. Zhidkovskaya, N. Winter, M. O. Rodriguez, R. Lauff, D. Wehr, C. Tang, Z. Hossain, S. Phillips, F. Samuele, F. Ekström, A. Hammon, O. Patel, F. Farhidi, G. Medley, F. Mohammadzadeh, M. Peñaflor, H. Kassahun, A. Friedrich, R. H. Perez, D. Pyda, T. Sakal, O. Dhamane, A. K. Mirabadi, E. Hallman, K. Okutsu, M. Battaglia, M. Maghsoudimehrabani, A. Amit, D. Hulbert, R. Pereira, S. Weber, Handoko, A. Peristyy, S. Malina, M. Mehkary, R. Aly, F. Reidegeld, A. Dick, C. Friday, M. Singh, H. Shapourian, W. Kim, M. Costa, H. Gurdogan, H. Kumar, C. Ceconello, C. Zhuang, H. Park, M. Carroll, A. R. Tawfeek, S. Steinerberger, D. Aggarwal, M. Kirchhof, L. Dai, E. Kim, J. Ferret, J. Shah, Y. Wang, M. Yan, K. Burdzy, L. Zhang, A. Franca, D. T. Pham, K. Y. Loh, J. Robinson, A. Jackson, P. Giordano, P. Petersen, A. Cosma, J. Colino, C. White, J. Votava, V. Vinnikov, E. Delaney, P. Spelda, V. Stritecky, S. M. Shahid, J. Mourrat, L. Vetoshkin, K. Sponselee, R. Bacho, Z. Yong, F. de la Rosa, N. Cho, X. Li, G. Malod, O. Weller, G. Albani, L. Lang, J. Laurendeau, D. Kazakov, F. Adesanya, J. Portier, L. Hollom, V. Souza, Y. A. Zhou, J. Degorre, Y. Yalın, G. D. Obikoya, Rai, F. Bigi, M. C. Boscá, O. Shumar, K. Bacho, G. Recchia, M. Popescu, N. Shulga, N. M. Tanwie, T. C. H. Lux, B. Rank, C. Ni, M. Brooks, A. Yakimchyk, Huanxu, Liu, S. Cavalleri, O. Häggström, E. Verkama, J. Newbould, H. Gundlach, L. Brito-Santana, B. Amaro, V. Vajipey, R. Grover, T. Wang, Y. Kratish, W. Li, S. Gopi, A. Caciolai, C. S. de Witt, P. Hernández-Cámara, E. Rodolà, J. Robins, D. Williamson, V. Cheng, B. Raynor, H. Qi, B. Segev, J. Fan, S. Martinson, E. Y. Wang, K. Hausknecht, M. P. Brenner, M. Mao, C. Demian, P. Kassani, X. Zhang, D. Avagian, E. J. Scipio, A. Ragoler, J. Tan, B. Sims, R. Plecnik, A. Kirtland, O. F. Bodur, D. P. Shinde, Y. C. L. Labrador, Z. Adoul, M. Zekry, A. Karakoc, T. C. B. Santos, S. Shamseldeen, L. Karim, A. Liakhovitskaia, N. Resman, N. Farina, J. C. Gonzalez, G. Maayan, E. Anderson, R. D. O. Pena, E. Kelley, H. Mariji, R. Pouriamanesh, W. Wu, R. Finocchio, I. Alarab, J. Cole, D. Ferreira, B. Johnson, M. Safdari, L. Dai, S. Arthornthurasuk, I. C. McAlister, A. J. Moyano, A. Pronin, J. Fan, A. Ramirez-Trinidad, Y. Malysheva, D. Pottmaier, O. Taheri, S. Stepanic, S. Perry, L. Askew, R. A. H. Rodríguez, A. M. R. Minissi, R. Lorena, K. Iyer, A. A. Fasiludeen, R. Clark, J. Ducey, M. Piza, M. Somrak, E. Vergo, J. Qin, B. Borbás, E. Chu, J. Lindsey, A. Jallon, I. M. J. McInnis, E. Chen, A. Semler, L. Gloor, T. Shah, M. Carauleanu, P. Lauer, T. Đ. Huy, H. Shahrtash, E. Duc, L. Lewark, A. Brown, S. Albanie, B. Weber, W. S. Vaz, P. Clavier, Y. Fan, G. P. R. e Silva, Long, Lian, M. Abramovitch, X. Jiang, S. Mendoza, M. Islam, J. Gonzalez, V. Mavroudis, J. Xu, P. Kumar, L. P. Goswami, D. Bugas, N. Heydari, F. Jeanplong, T. Jansen, A. Pinto, A. Apronti, A. Galal, N. Ze-An, A. Singh, T. Jiang, J. of Arc Xavier, K. P. Agarwal, M. Berkani, G. Zhang, Z. Du, B. A. de Oliveira Junior, D. Malishev, N. Remy, T. D. Hartman, T. Tarver, S. Mensah, G. A. Loume, W. Morak, F. Habibi, S. Hoback, W. Cai, J. Gimenez, R. G. Montecillo, J. Łucki, R. Campbell, A. Sharma, K. Meer, S. Gul, D. E. Gonzalez, X. Alapont, A. Hoover, G. Chhablani, F. Vargus, A. Agarwal, Y. Jiang, D. Patil, D. Outevsky, K. J. Scaria, R. Maheshwari, A. Dendane, P. Shukla, A. Cartwright, S. Bogdanov, N. Mündler, S. Möller, L. Arnaboldi, K. Thaman, M. R. Siddiqi, P. Saxena, H. Gupta, T. Fruhauff, G. Sherman, M. Vincze, S. Usawasutsakorn, D. Ler, A. Radhakrishnan, I. Enyekwe, S. M. Salauddin, J. Muzhen, A. Maksapetyan, V. Rossbach, C. Harjadi, M. Bahaloohoreh, C. Sparrow, J. Sidhu, S. Ali, S. Bian, J. Lai, E. Singer, J. L. Uro, G. Bateman, M. Sayed, A. Menshawy, D. Duclosel, D. Bezzi, Y. Jain, A. Aaron, M. Tiryakioglu, S. Siddh, K. Krenek, I. A. Shah, J. Jin, S. Creighton, D. Peskoff, Z. EL-Wasif, R. P. V, M. Richmond, J. McGowan, T. Patwardhan, H. Sun, T. Sun, N. Zubić, S. Sala, S. Ebert, J. Kaddour, M. Schottdorf, D. Wang, G. Petruzella, A. Meiburg, T. Medved, A. ElSheikh, S. A. Hebbar, L. Vaquero, X. Yang, J. Poulos, V. Zouhar, S. Bogdanik, M. Zhang, J. Sanz-Ros, D. Anugraha, Y. Dai, A. N. Nhu, X. Wang, A. A. Demircali, Z. Jia, Y. Zhou, J. Wu, M. He, N. Chandok, A. Sinha, G. Luo, L. Le, M. Noyé, M. Perełkiewicz, I. Pantidis, T. Qi, S. S. Purohit, L. Parcalabescu, T. Nguyen, G. I. Winata, E. M. Ponti, H. Li, K. Dhole, J. Park, D. Abbondanza, Y. Wang, A. Nayak, D. M. Caetano, A. A. W. L. Wong, M. del Rio-Chanona, D. Kondor, P. Francois, E. Chalstrey, J. Zsambok, D. Hoyer, J. Reddish, J. Hauser, F. Rodrigo-Ginés, S. Datta, M. Shepherd, T. Kamphuis, Q. Zhang, H. Kim, R. Sun, J. Yao, F. Dernoncourt, S. Krishna, S. Rismanchian, B. Pu, F. Pinto, Y. Wang, K. Shridhar, K. J. Overholt, G. Briia, H. Nguyen, David, S. Bartomeu, T. C. Pang, A. Wecker, Y. Xiong, F. Li, L. S. Huber, J. Jaeger, R. D. Maddalena, X. H. Lù, Y. Zhang, C. Beger, P. T. J. Kon, S. Li, V. Sanker, M. Yin, Y. Liang, X. Zhang, A. Agrawal, L. S. Yifei, Z. Zhang, M. Cai, Y. Sonmez, C. Cozianu, C. Li, A. Slen, S. Yu, H. K. Park, G. Sarti, M. Briański, A. Stolfo, T. A. Nguyen, M. Zhang, Y. Perlitz, J. Hernandez-Orallo, R. Li, A. Shabani, F. Juefei-Xu, S. Dhingra, O. Zohar, M. C. Nguyen, A. Pondaven, A. Yilmaz, X. Zhao, C. Jin, M. Jiang, S. Todoran, X. Han, J. Kreuer, B. Rabern, A. Plassart, M. Maggetti, L. Yap, R. Geirhos, J. Kean, D. Wang, S. Mollaei, C. Sun, Y. Yin, S. Wang, R. Li, Y. Chang, A. Wei, A. Bizeul, X. Wang, A. O. Arrais, K. Mukherjee, J. Chamorro-Padial, J. Liu, X. Qu, J. Guan, A. Bouyamourn, S. Wu, M. Plomecka, J. Chen, M. Tang, J. Deng, S. Subramanian, H. Xi, H. Chen, W. Zhang, Y. Ren, H. Tu, S. Kim, Y. Chen, S. V. Marjanović, J. Ha, G. Luczyna, J. J. Ma, Z. Shen, D. Song, C. E. Zhang, Z. Wang, G. Gendron, Y. Xiao, L. Smucker, E. Weng, K. H. Lee, Z. Ye, S. Ermon, I. D. Lopez-Miguel, T. Knights, A. Gitter, N. Park, B. Wei, H. Chen, K. Pai, A. Elkhanany, H. Lin, P. D. Siedler, J. Fang, R. Mishra, K. Zsolnai-Fehér, X. Jiang, S. Khan, J. Yuan, R. K. Jain, X. Lin, M. Peterson, Z. Wang, A. Malusare, M. Tang, I. Gupta, I. Fosin, T. Kang, B. Dworakowska, K. Matsumoto, G. Zheng, G. Sewuster, J. P. Villanueva, I. Rannev, I. Chernyavsky, J. Chen, D. Banik, B. Racz, W. Dong, J. Wang, L. Bashmal, D. V. Gonçalves, W. Hu, K. Bar, O. Bohdal, A. S. Patlan, S. Dhuliawala, C. Geirhos, J. Wist, Y. Kansal, B. Chen, K. Tire, A. T. Yücel, B. Christof, V. Singla, Z. Song, S. Chen, J. Ge, K. Ponkshe, I. Park, T. Shi, M. Q. Ma, J. Mak, S. Lai, A. Moulin, Z. Cheng, Z. Zhu, Z. Zhang, V. Patil, K. Jha, Q. Men, J. Wu, T. Zhang, B. H. Vieira, A. F. Aji, J. Chung, M. Mahfoud, H. T. Hoang, M. Sperzel, W. Hao, K. Meding, S. Xu, V. Kostakos, D. Manini, Y. Liu, C. Toukmaji, J. Paek, E. Yu, A. E. Demircali, Z. Sun, I. Dewerpe, H. Qin, R. Pflugfelder, J. Bailey, J. Morris, V. Heilala, S. Rosset, Z. Yu, P. E. Chen, W. Yeo, E. Jain, R. Yang, S. Chigurupati, J. Chernyavsky, S. P. Reddy, S. Venugopalan, H. Batra, C. F. Park, H. Tran, G. Maximiano, G. Zhang, Y. Liang, H. Shiyu, R. Xu, R. Pan, S. Suresh, Z. Liu, S. Gulati, S. Zhang, P. Turchin, C. W. Bartlett, C. R. Scotese, P. M. Cao, A. Nattanmai, G. McKellips, A. Cheraku, A. Suhail, E. Luo, M. Deng, J. Luo, A. Zhang, K. Jindel, J. Paek, K. Halevy, A. Baranov, M. Liu, A. Avadhanam, D. Zhang, V. Cheng, B. Ma, E. Fu, L. Do, J. Lass, H. Yang, S. Sunkari, V. Bharath, V. Ai, J. Leung, R. Agrawal, A. Zhou, K. Chen, T. Kalpathi, Z. Xu, G. Wang, T. Xiao, E. Maung, S. Lee, R. Yang, R. Yue, B. Zhao, J. Yoon, S. Sun, A. Singh, E. Luo, C. Peng, T. Osbey, T. Wang, D. Echeazu, H. Yang, T. Wu, S. Patel, V. Kulkarni, V. Sundarapandiyan, A. Zhang, A. Le, Z. Nasim, S. Yalam, R. Kasamsetty, S. Samal, H. Yang, D. Sun, N. Shah, A. Saha, A. Zhang, L. Nguyen, L. Nagumalli, K. Wang, A. Zhou, A. Wu, J. Luo, A. Telluri, S. Yue, A. Wang, and D. Hendrycks (2025) Humanity’s last exam. External Links: 2501.14249, Link Cited by: §6.
- Z. Pi, A. Vadaparty, B. K. Bergen, and C. R. Jones (2024) Dissecting the ullman variations with a scalpel: why do llms fail at trivial alterations to the false belief task?. arXiv preprint arXiv:2406.14737. Cited by: §3.2.
- J. Piaget (1952) The origins of intelligence in children. International University. Cited by: §2.1.
- G. Piatti, Z. Jin, M. Kleiman-Weiner, B. Schölkopf, M. Sachan, and R. Mihalcea (2024) Cooperate or collapse: emergence of sustainable cooperation in a society of llm agents. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, Cited by: §3.3.
- A. Plaat, A. Wong, S. Verberne, J. Broekens, N. van Stein, and T. Back (2024) Reasoning with large language models, a survey. arXiv preprint arXiv:2407.11511. Cited by: §1.
- M. Pock, A. Ye, and J. Moore (2023) LLMs grasp morality in concept. External Links: 2311.02294, Link Cited by: §3.2.
- G. Poesia, D. Broman, N. Haber, and N. D. Goodman (2024) Learning formal mathematics from intrinsic motivation. In Advances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37, pp. 43032–43057. External Links: Link Cited by: Appendix C.
- G. Poesia and N. D. Goodman (2023) Peano: learning formal mathematical reasoning. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 381 (2251). External Links: ISSN 1471-2962, Link, Document Cited by: Appendix C.
- C. Qi, B. Li, B. Hui, B. Wang, J. Li, J. Wu, and Y. Laili (2023) An investigation of llms’ inefficacy in understanding converse relations. External Links: 2310.05163, Link Cited by: Table 7, §4.1.
- J. Qi, J. Liu, H. Tang, and Z. Zhu (2025) Beyond semantics: rediscovering spatial awareness in vision-language models. arXiv preprint arXiv:2503.17349. Cited by: §5.2.
- K. Qian, S. Wan, C. Tang, Y. Wang, X. Zhang, M. Chen, and Z. Yu (2024) VarBench: robust language model benchmarking through dynamic variable perturbation. External Links: 2406.17681, Link Cited by: §4.2.
- S. Qiao, Y. Ou, N. Zhang, X. Chen, Y. Yao, S. Deng, C. Tan, F. Huang, and H. Chen (2023) Reasoning with language model prompting: a survey. External Links: 2212.09597, Link Cited by: §1.
- S. Qiu, S. Guo, Z. Song, Y. Sun, Z. Cai, J. Wei, T. Luo, Y. Yin, H. Zhang, Y. Hu, C. Wang, C. Tang, H. Chang, Q. Liu, Z. Zhou, T. Zhang, J. Zhang, Z. Liu, M. Li, Y. Zhang, B. Jing, X. Yin, Y. Ren, Z. Fu, J. Ji, W. Wang, X. Tian, A. Lv, L. Man, J. Li, F. Tao, Q. Sun, Z. Liang, Y. Mu, Z. Li, J. Zhang, S. Zhang, X. Li, X. Xia, J. Lin, Z. Shen, J. Chen, Q. Xiong, B. Wang, F. Wang, Z. Ni, B. Zhang, F. Cui, C. Shao, Q. Cao, M. Luo, Y. Yang, M. Zhang, and H. X. Zhu (2025) PHYBench: holistic evaluation of physical perception and reasoning in large language models. External Links: 2504.16074, Link Cited by: §5.1.
- A. Radford and K. Narasimhan (2018) Improving language understanding by generative pre-training. External Links: Link Cited by: §4.1.
- C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu (2020) Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research 21 (140), pp. 1–67. External Links: Link Cited by: §1.
- A. M. M. Rahman, J. Ye, W. Yao, W. Yin, and G. Wang (2024) From blind solvers to logical thinkers: benchmarking llms’ logical integrity on faulty mathematical problems. External Links: 2410.18921, Link Cited by: §4.3.
- P. Rahmanzadehgervi, L. Bolton, M. R. Taesiri, and A. T. Nguyen (2024) Vision language models are blind. In Proceedings of the Asian Conference on Computer Vision, pp. 18–34. Cited by: Table 12, §5.2.
- C. Raj, M. Banerjee, A. Caliskan, A. Anastasopoulos, and Z. Zhu (2025) Talent or luck? evaluating attribution bias in large language models. arXiv preprint arXiv:2505.22910. Cited by: §3.1.
- T. Rajore, N. Chandran, S. Sitaram, D. Gupta, R. Sharma, K. Mittal, and M. Swaminathan (2024) TRUCE: private benchmarking to prevent contamination and improve comparative evaluation of llms. External Links: 2403.00393, Link Cited by: §4.2, §6.
- C. Rastogi, Y. Zhang, D. Wei, K. R. Varshney, A. Dhurandhar, and R. Tomsett (2022) Deciding fast and slow: the role of cognitive biases in ai-assisted decision-making. Proceedings of the ACM on Human-computer Interaction 6 (CSCW1), pp. 1–22. Cited by: §3.1.
- W. Ren, W. Ma, H. Yang, C. Wei, G. Zhang, and W. Chen (2025) Vamba: understanding hour-long videos with hybrid mamba-transformers. External Links: 2503.11579, Link Cited by: Appendix C.
- M. Rezaei, Y. Fu, P. Cuvin, C. Ziems, Y. Zhang, H. Zhu, and D. Yang (2025) EgoNormia: benchmarking physical social norm understanding. arXiv preprint arXiv:2502.20490. Cited by: Appendix E, §3.2, §5.3.
- M. T. Ribeiro, T. Wu, C. Guestrin, and S. Singh (2020) Beyond accuracy: behavioral testing of nlp models with checklist. arXiv preprint arXiv:2005.04118. Cited by: §2.1, §2.2.
- I. Robinson and J. Burden (2025) Framing the game: how context shapes llm decision-making. arXiv preprint arXiv:2503.04840. Cited by: §3.1.
- C. Rodríguez (2022) The construction of executive function in early development: the pragmatics of action and gestures. Human Development 66 (4-5), pp. 239–259. Cited by: §3.1.
- J. Roh, V. Gandhi, S. Anilkumar, and A. Garg (2025) Chain-of-code collapse: reasoning failures in llms via adversarial prompting in code generation. arXiv preprint arXiv 2506. Cited by: §4.2.
- P. Rozin and E. B. Royzman (2001) Negativity bias, negativity dominance, and contagion. Personality and social psychology review 5 (4), pp. 296–320. Cited by: §3.1.
- S. Sabour, S. Liu, Z. Zhang, J. M. Liu, J. Zhou, A. S. Sunaryo, J. Li, T. Lee, R. Mihalcea, and M. Huang (2024) Emobench: evaluating the emotional intelligence of large language models. arXiv preprint arXiv:2402.12071. Cited by: §3.2.
- K. Saito, A. Wachi, K. Wataoka, and Y. Akimoto (2023) Verbosity bias in preference labeling by large language models. arXiv preprint arXiv:2310.10076. Cited by: §3.1.
- S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha (2024) MMAU: a massive multi-task audio understanding and reasoning benchmark. External Links: 2410.19168, Link Cited by: Appendix C.
- G. Sampson (1979) What was transformational grammar?: a review of: noam chomsky, the logical structure of linguistic theory. published by plenum press, new york, 1975. 573 pp.. Lingua 48 (4), pp. 355–378. External Links: ISSN 0024-3841, Document, Link Cited by: §4.1.
- M. Sap, R. LeBras, D. Fried, and Y. Choi (2022) Neural theory-of-mind? on the limits of social intelligence in large lms. arXiv preprint arXiv:2210.13312. Cited by: §3.2.
- A. P. Saravanan, R. Kocielnik, R. Jiang, P. Han, and A. Anandkumar (2023) Exploring social bias in downstream applications of text-to-image foundation models. arXiv preprint arXiv:2312.10065. Cited by: Appendix D.
- G. Sarch, S. Saha, N. Khandelwal, A. Jain, M. J. Tarr, A. Kumar, and K. Fragkiadaki (2025) Grounded reinforcement learning for visual reasoning. arXiv preprint arXiv:2505.23678. Cited by: §5.2.
- L. Sarker, M. Downing, A. Desai, and T. Bultan (2024) Syntactic robustness for llm-based code generation. External Links: 2404.01535, Link Cited by: §4.2.
- R. Saxena, A. P. Gema, and P. Minervini (2025) Lost in time: clock and calendar understanding challenges in multimodal llms. External Links: 2502.05092, Link Cited by: §3.1.
- S. Schmidgall, J. Achterberg, T. Miconi, L. Kirsch, R. Ziaei, S. P. Hajiseyedrazi, and J. Eshraghian (2023) Brain-inspired learning in artificial neural networks: a review. External Links: 2305.11252, Link Cited by: §1.
- S. Schmidgall, C. Harris, I. Essien, D. Olshvang, T. Rahman, J. W. Kim, R. Ziaei, J. Eshraghian, P. Abadir, and R. Chellappa (2024) Evaluation and mitigation of cognitive biases in medical language models. npj Digital Medicine 7 (1), pp. 295. Cited by: §3.1.
- L. M. Schulze Buschoff, E. Akata, M. Bethge, and E. Schulz (2025) Visual cognition in multimodal large language models. Nature Machine Intelligence, pp. 1–11. Cited by: §5.2.
- M. Sclar, S. Kumar, P. West, A. Suhr, Y. Choi, and Y. Tsvetkov (2023) Minding language models’(lack of) theory of mind: a plug-and-play multi-character belief tracker. arXiv preprint arXiv:2306.00924. Cited by: §3.2.
- P. Senthilkumar, V. Balasubramanian, P. Jain, A. Maity, J. Lu, and K. Zhu (2024) Fine-tuning language models for ethical ambiguity: a comparative study of alignment with human responses. External Links: 2410.07826, Link Cited by: §3.2.
- P. Seshadri, S. Singh, and Y. Elazar (2023) The bias amplification paradox in text-to-image generation. External Links: 2308.00755, Link Cited by: Appendix D.
- M. Shafiei, H. Saffari, and N. S. Moosavi (2025) More or less wrong: a benchmark for directional bias in llm comparative reasoning. arXiv preprint arXiv:2506.03923. Cited by: Table 2, §3.1.
- Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, and D. Guo (2024) DeepSeekMath: pushing the limits of mathematical reasoning in open language models. External Links: 2402.03300, Link Cited by: §1.
- N. Shapira, M. Levy, S. H. Alavi, X. Zhou, Y. Choi, Y. Goldberg, M. Sap, and V. Shwartz (2023) Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763. Cited by: §3.2.
- L. Shapiro and S. Spaulding (2024) Embodied Cognition. In The Stanford Encyclopedia of Philosophy, E. N. Zalta and U. Nodelman (Eds.), Note: https://plato.stanford.edu/archives/fall2024/entries/embodied-cognition/ Cited by: §5.
- L. Shapiro (2019) Embodied cognition. Routledge. Cited by: §2.1.
- H. Shen, T. Wu, Q. Han, Y. Hsieh, J. Wang, Y. Zhang, Y. Cheng, Z. Hao, Y. Ni, X. Wang, Z. Wan, K. Zhang, W. Xu, J. Xiong, P. Luo, W. Chen, C. Tao, Z. Mao, and N. Wong (2025) PhyX: does your model have the "wits" for physical reasoning?. External Links: 2505.15929, Link Cited by: Table 13, §5.2.
- S. Shen, P. Shen, and D. Zhu (2024) RevOrder: a novel method for enhanced arithmetic in language models. External Links: 2402.03822, Link Cited by: §4.3.
- F. Shi, X. Chen, K. Misra, N. Scales, D. Dohan, E. Chi, N. Schärli, and D. Zhou (2023) Large language models can be easily distracted by irrelevant context. External Links: 2302.00093, Link Cited by: Table 8, §3.1, §4.2, §4.2.
- L. Shi, H. Liu, Y. Wong, U. Mujumdar, D. Zhang, J. Gwizdka, and M. Lease (2024) Argumentative experience: reducing confirmation bias on controversial issues through llm-generated multi-persona debates. arXiv preprint arXiv:2412.04629. Cited by: §3.1, §3.1.
- A. Shin and K. Kaneko (2024) Large language models lack understanding of character composition of words. External Links: 2405.11357, Link Cited by: Table 10, §4.3.
- J. R. Shoenfield (2018) Mathematical logic. AK Peters/CRC Press. Cited by: §4.3, §4.
- P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, and M. Farajtabar (2025) The illusion of thinking: understanding the strengths and limitations of reasoning models via the lens of problem complexity. External Links: 2506.06941, Link Cited by: §4.2.
- C. Shu, J. Han, F. Liu, E. Shareghi, and N. Collier (2023) POSQA: probe the world models of llms with size comparisons. arXiv preprint arXiv:2310.13394. Cited by: §5.1.
- K. Singh and J. Zou (2023) New evaluation metrics capture quality degradation due to llm watermarking. External Links: 2312.02382, Link Cited by: Appendix D.
- P. Song, K. Yang, and A. Anandkumar (2024) Lean copilot: large language models as copilots for theorem proving in lean. arXiv preprint arXiv:2404.12534. Cited by: Appendix C.
- K. W. Spence (1936) The nature of discrimination learning in animals. Psychological Review 43 (5), pp. 427–449. External Links: Document Cited by: footnote 1.
- S. P. Stich (1975) Logical form and natural language. Philosophical Studies: An International Journal for Philosophy in the Analytic Tradition 28 (6), pp. 397–418. External Links: ISSN 00318116, 15730883, Link Cited by: §4.1.
- J. W. Strachan, D. Albergo, G. Borghini, O. Pansardi, E. Scaliti, S. Gupta, K. Saxena, A. Rufo, S. Panzeri, G. Manzi, et al. (2024) Testing theory of mind in large language models and humans. Nature Human Behaviour, pp. 1–11. Cited by: §3.2, §3.2.
- Z. Su, J. Li, J. Zhang, T. Zhu, X. Qu, P. Zhou, Y. Bowen, Y. Cheng, and M. zhang (2024) Living in the moment: can large language models grasp co-temporal reasoning?. External Links: 2406.09072, Link Cited by: §4.3.
- Y. Sumita, K. Takeuchi, and H. Kashima (2025) Cognitive biases in large language models: a survey and mitigation experiments. In Proceedings of the 40th ACM/SIGAPP Symposium on Applied Computing, pp. 1009–1011. Cited by: §3.1, §3.1.
- J. Sun, C. Zheng, E. Xie, Z. Liu, R. Chu, J. Qiu, J. Xu, M. Ding, H. Li, M. Geng, et al. (2023) A survey of reasoning with foundation models. arXiv preprint arXiv:2312.11562. Cited by: Appendix C.
- X. Sun, H. Tan, Y. Guo, P. Qiang, R. Li, and H. Zhang (2025a) Mitigating shortcut learning via smart data augmentation based on large language model. In Proceedings of the 31st International Conference on Computational Linguistics, pp. 8160–8172. Cited by: §3.1.
- Y. Sun, S. Hu, G. Zhou, K. Zheng, H. Hajishirzi, N. Dziri, and D. Song (2025b) OMEGA: can llms reason outside the box in math? evaluating exploratory, compositional, and transformative generalization. External Links: 2506.18880, Link Cited by: Table 7, §4.1, §4.3.
- G. Suri, L. R. Slater, A. Ziaee, and M. Nguyen (2024) Do large language models show decision heuristics similar to humans? a case study using gpt-3.5.. Journal of Experimental Psychology: General. Cited by: §3.1, §3.1.
- K. Takemoto (2024) The moral machine experiment on large language models. Royal Society open science 11 (2), pp. 231393. Cited by: §3.2.
- K. Tang, P. Song, Y. Qin, and X. Yan (2024) Creative and context-aware translation of east asian idioms with gpt-4. arXiv preprint arXiv:2410.00988. Cited by: §1.
- K. Tanmay, A. Khandelwal, U. Agarwal, and M. Choudhury (2023) Probing the moral development of large language models through defining issues test. arXiv preprint arXiv:2309.13356. Cited by: §3.2.
- A. Testolin (2024) Can neural networks do arithmetic? a survey on the elementary numerical skills of state-of-the-art deep learning models. Applied Sciences 14 (2). External Links: Link, ISSN 2076-3417, Document Cited by: §4.3.
- A. Thakur, G. Tsoukalas, Y. Wen, J. Xin, and S. Chaudhuri (2024) An in-context learning agent for formal theorem-proving. External Links: 2310.04353, Link Cited by: Appendix C.
- K. Thompson, N. Saavedra, P. Carrott, K. Fisher, A. Sanchez-Stern, Y. Brun, J. F. Ferreira, S. Lerner, and E. First (2025) Rango: adaptive retrieval-augmented proving for automated software verification. External Links: 2412.14063, Link Cited by: Appendix C.
- S. Tian, Z. Zhou, L. Jia, L. Guo, and Y. Li (2024) Robustness assessment of mathematical reasoning in the presence of missing and contradictory conditions. External Links: 2406.05055, Link Cited by: §4.3.
- J. Tie, B. Yao, T. Li, S. I. Ahmed, D. Wang, and S. Zhou (2024) LLMs are imperfect, then what? an empirical study on llm failures in software engineering. External Links: 2411.09916, Link Cited by: §1.
- A. Tlaie (2024) Exploring and steering the moral compass of large language models. In International Conference on Pattern Recognition, pp. 420–442. Cited by: §3.2.
- A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid (2023) Steering language models with activation engineering. arXiv preprint arXiv:2308.10248. Cited by: §3.2.
- A. Tversky and D. Kahneman (1974) Judgment under uncertainty: heuristics and biases: biases in judgments reveal some heuristics of thinking under uncertainty.. science 185 (4157), pp. 1124–1131. Cited by: §3.1.
- A. Tversky and D. Kahneman (1981) The framing of decisions and the psychology of choice. science 211 (4481), pp. 453–458. Cited by: §3.1.
- T. Ullman (2023) Large language models fail on trivial alterations to theory-of-mind tasks. arXiv preprint arXiv:2302.08399. Cited by: Table 3, §3.2.
- B. Upadhayay, V. Behzadan, and A. Karbasi (2025) Working memory attack on llms. In ICLR 2025 Workshop on Building Trust in Language Models and Applications, Cited by: §3.1.
- M. J. van Duijn, B. van Dijk, T. Kouwenhoven, W. de Valk, M. R. Spruit, and P. van der Putten (2023) Theory of mind in large language models: examining performance of 11 state-of-the-art models vs. children aged 7-10 on advanced tests. arXiv preprint arXiv:2310.20320. Cited by: §3.2.
- F. J. Varela, E. Thompson, and E. Rosch (2017) The embodied mind, revised edition: cognitive science and human experience. MIT press. Cited by: §5.
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin (2023) Attention is all you need. External Links: 1706.03762, Link Cited by: §1.
- A. Vo, K. Nguyen, M. R. Taesiri, V. T. Dang, A. T. Nguyen, and D. Kim (2025) Vision language models are biased: counting legs of an animal is surprisingly hard. In 2nd AI for Math Workshop@ ICML 2025, Cited by: §4.3.
- L. S. Vygotsky (1978) Mind in society: the development of higher psychological processes. Vol. 86, Harvard university press. Cited by: §2.1.
- G. D. Vzorinab, A. M. Bukinichac, A. V. Sedykha, I. I. Vetrovab, and E. A. Sergienkob (2024) The emotional intelligence of the gpt-4 large language model. Psychology in Russia: State of the art 17 (2), pp. 85–99. Cited by: §3.2.
- Y. Wan, X. Jia, and X. L. Li (2025) Unveiling confirmation bias in chain-of-thought reasoning. External Links: 2506.12301, Link Cited by: §3.1.
- Y. Wan, W. Wang, Y. Yang, Y. Yuan, J. Huang, P. He, W. Jiao, and M. Lyu (2024) LogicAsker: evaluating and improving the logical reasoning ability of large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y. Al-Onaizan, M. Bansal, and Y. Chen (Eds.), Miami, Florida, USA, pp. 2124–2155. External Links: Link, Document Cited by: §4.1.
- C. Wang and J. V. Sun (2025) Unable to forget: proactive lnterference reveals working memory limits in llms beyond context length. External Links: 2506.08184, Link Cited by: §3.1.
- G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar (2023a) Voyager: an open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291. Cited by: §5.3.
- G. Wang, W. Wang, Y. Cao, Y. Teng, Q. Guo, H. Wang, J. Lin, J. Ma, J. Liu, and Y. Wang (2025a) Possibilities and challenges in the moral growth of large language models: a philosophical perspective. Ethics and Information Technology 27 (1), pp. 9. Cited by: §3.2.
- H. Wang, T. Fu, Y. Du, W. Gao, K. Huang, Z. Liu, P. Chandak, S. Liu, P. V. Katwyk, A. Deac, A. Anandkumar, K. J. Bergen, C. P. Gomes, S. Ho, P. Kohli, J. Lasenby, J. Leskovec, T. Liu, A. K. Manrai, D. S. Marks, B. Ramsundar, L. Song, J. Sun, J. Tang, P. Velickovic, M. Welling, L. Zhang, C. W. Coley, Y. Bengio, and M. Zitnik (2023b) Scientific discovery in the age of artificial intelligence. Nature 620, pp. 47–60. External Links: Link Cited by: §1.
- Q. Wang, Z. Lou, Z. Tang, N. Chen, X. Zhao, W. Zhang, D. Song, and B. He (2025b) Assessing judging bias in large reasoning models: an empirical study. arXiv preprint arXiv:2504.09946. Cited by: §3.1.
- S. Wang, Z. Li, H. Qian, C. Yang, Z. Wang, M. Shang, V. Kumar, S. Tan, B. Ray, P. Bhatia, R. Nallapati, M. K. Ramanathan, D. Roth, and B. Xiang (2022) ReCode: robustness evaluation of code generation models. External Links: 2212.10264, Link Cited by: Table 9, §4.2.
- S. Wang, Z. Wei, Y. Choi, and X. Ren (2024) Can llms reason with rules? logic scaffolding for stress-testing and improving llms. External Links: 2402.11442, Link Cited by: §4.1.
- Y. R. Wang, J. Duan, D. Fox, and S. Srinivasa (2023c) NEWTON: are large language models capable of physical reasoning?. External Links: 2310.07018, Link Cited by: Table 11, §5.1, §5.1, §5.
- Y. Wang and Y. Zhao (2024) RUPBench: benchmarking reasoning under perturbations for robustness evaluation in large language models. External Links: 2406.11020, Link Cited by: §4.2.
- A. Wei, N. Haghtalab, and J. Steinhardt (2023a) Jailbroken: how does llm safety training fail?. In Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36, pp. 80079–80110. External Links: Link Cited by: Appendix D.
- J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, E. H. Chi, T. Hashimoto, O. Vinyals, P. Liang, J. Dean, and W. Fedus (2022a) Emergent abilities of large language models. External Links: 2206.07682, Link Cited by: §1.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. (2022b) Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35, pp. 24824–24837. Cited by: §3.1, §5.1.
- T. Wei, J. Luan, W. Liu, S. Dong, and B. Wang (2023b) CMATH: can your language model pass chinese elementary school math test?. External Links: 2306.16636, Link Cited by: §4.3.
- X. Wei, N. Kumar, and H. Zhang (2025) Addressing bias in generative ai: challenges and research opportunities in information management. arXiv preprint arXiv:2502.10407. Cited by: Appendix D.
- S. Welleck and R. Saha (2023) LLMSTEP: llm proofstep suggestions in lean. External Links: 2310.18457, Link Cited by: Appendix C.
- B. Wen, C. Xu, R. Wolfe, L. L. Wang, B. Howe, et al. (2024) Mitigating overconfidence in large language models: a behavioral lens on confidence estimation and calibration. In NeurIPS 2024 Workshop on Behavioral Machine Learning, Cited by: Appendix D.
- C. White, S. Dooley, M. Roberts, A. Pal, B. Feuer, S. Jain, R. Shwartz-Ziv, N. Jain, K. Saifullah, S. Naidu, C. Hegde, Y. LeCun, T. Goldstein, W. Neiswanger, and M. Goldblum (2024) LiveBench: a challenging, contamination-free llm benchmark. External Links: 2406.19314, Link Cited by: §4.2, §6.
- B. R. Williams, J. S. Ponesse, R. J. Schachar, G. D. Logan, and R. Tannock (1999) Development of inhibitory control across the life span.. Developmental psychology 35 (1), pp. 205. Cited by: §3.1.
- S. Williams and J. Huckle (2024) Easy problems that llms get wrong. External Links: 2405.19616, Link Cited by: §1.
- H. Wimmer and J. Perner (1983) Beliefs about beliefs: representation and constraining function of wrong beliefs in young children’s understanding of deception. Cognition 13 (1), pp. 103–128. Cited by: §3.2.
- S. Woźniak, A. Pantazi, T. Bohnstingl, and E. Eleftheriou (2020) Deep learning incorporating biologically inspired neural dynamics and in-memory computing. Nature Machine Intelligence 2 (6), pp. 325–336. External Links: ISSN 2522-5839, Link, Document Cited by: §1.
- D. Wu, J. Yang, and K. Wang (2024a) Exploring the reversal curse and other deductive logical reasoning in bert and gpt-based large language models. External Links: 2312.03633, Link Cited by: §4.1.
- F. Wu, N. Zhang, S. Jha, P. McDaniel, and C. Xiao (2024b) A new era in llm security: exploring security concerns in real-world llm-based systems. External Links: 2402.18649, Link Cited by: Appendix D.
- K. Wu, E. Wu, and J. Y. Zou (2024c) Clasheval: quantifying the tug-of-war between an llm’s internal prior and external evidence. Advances in Neural Information Processing Systems 37, pp. 33402–33422. Cited by: Appendix D.
- S. Wu, A. Oltramari, J. Francis, C. L. Giles, and F. E. Ritter (2024d) Cognitive llms: toward human-like artificial intelligence by integrating cognitive architectures and large language models for manufacturing decision-making. Neurosymbolic Artificial Intelligence. Cited by: §3.1.
- W. Wu, S. Mao, Y. Zhang, Y. Xia, L. Dong, L. Cui, and F. Wei (2025a) Mind’s eye of llms: visualization-of-thought elicits spatial reasoning in large language models. Advances in Neural Information Processing Systems 37, pp. 90277–90317. Cited by: §1, §5.3.
- X. Wu, Y. Wang, S. Jegelka, and A. Jadbabaie (2025b) On the emergence of position bias in transformers. arXiv preprint arXiv:2502.01951. Cited by: §3.1.
- Y. Wu, A. Q. Jiang, W. Li, M. Rabe, C. Staats, M. Jamnik, and C. Szegedy (2022) Autoformalization with large language models. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35, pp. 32353–32368. External Links: Link Cited by: Appendix C.
- Z. Wu, L. Qiu, A. Ross, E. Akyürek, B. Chen, B. Wang, N. Kim, J. Andreas, and Y. Kim (2024e) Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), K. Duh, H. Gomez, and S. Bethard (Eds.), Mexico City, Mexico, pp. 1819–1862. External Links: Link, Document Cited by: §4.2.
- C. S. Xia, Y. Deng, and L. Zhang (2024) Top leaderboard ranking = top coding proficiency, always? evoeval: evolving coding benchmarks via llm. External Links: 2403.19114, Link Cited by: §4.2.
- Y. Xiao, J. Wang, Q. Xu, C. Song, C. Xu, Y. Cheng, W. Li, and P. Liu (2025) Towards dynamic theory of mind: evaluating llm adaptation to temporal evolution of human states. arXiv preprint arXiv:2505.17663. Cited by: §3.2.
- Z. Xie, M. Lin, Z. Liu, P. Wu, S. Yan, and C. Miao (2025) Audio-reasoner: improving reasoning capability in large audio language models. External Links: 2503.02318, Link Cited by: Appendix C.
- H. Xin, Z. Z. Ren, J. Song, Z. Shao, W. Zhao, H. Wang, B. Liu, L. Zhang, X. Lu, Q. Du, W. Gao, Q. Zhu, D. Yang, Z. Gou, Z. F. Wu, F. Luo, and C. Ruan (2024) DeepSeek-prover-v1.5: harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search. External Links: 2408.08152, Link Cited by: Appendix C.
- M. Xiong, Z. Hu, X. Lu, Y. Li, J. Fu, J. He, and B. Hooi (2023) Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. arXiv preprint arXiv:2306.13063. Cited by: Appendix D.
- B. Xu and M. Poo (2023) Large language models and brain-inspired general intelligence. National Science Review 10 (10), pp. nwad267. External Links: ISSN 2095-5138, Document, Link, https://academic.oup.com/nsr/article-pdf/10/10/nwad267/52815206/nwad267.pdf Cited by: §1.
- F. Xu, Q. Hao, Z. Zong, J. Wang, Y. Zhang, J. Wang, X. Lan, J. Gong, T. Ouyang, F. Meng, C. Shao, Y. Yan, Q. Yang, Y. Song, S. Ren, X. Hu, Y. Li, J. Feng, C. Gao, and Y. Li (2025a) Towards large reasoning models: a survey of reinforced reasoning with large language models. External Links: 2501.09686, Link Cited by: §4.2.
- M. Xu, P. Huang, W. Yu, S. Liu, X. Zhang, Y. Niu, T. Zhang, F. Xia, J. Tan, and D. Zhao (2023a) Creative robot tool use with large language models. arXiv preprint arXiv:2310.13065. Cited by: §5.3.
- N. Xu and X. Ma (2024) LLM the genius paradox: a linguistic and math expert’s struggle with simple word-based counting problems. External Links: 2410.14166, Link Cited by: §4.3.
- P. Xu, W. Ping, X. Wu, L. McAfee, C. Zhu, Z. Liu, S. Subramanian, E. Bakhturina, M. Shoeybi, and B. Catanzaro (2023b) Retrieval meets long context large language models. In The Twelfth International Conference on Learning Representations, Cited by: §3.1.
- R. Xu, Z. Wang, R. Fan, and P. Liu (2024a) Benchmarking benchmark leakage in large language models. External Links: 2404.18824, Link Cited by: §4.2.
- X. Xu, Q. Xu, T. Xiao, T. Chen, Y. Yan, J. Zhang, S. Diao, C. Yang, and Y. Wang (2025b) UGPhysics: a comprehensive benchmark for undergraduate physics reasoning with large language models. arXiv preprint arXiv:2502.00334. Cited by: §5.1.
- X. Xu, P. Bu, Y. Wang, B. F. Karlsson, Z. Wang, T. Song, Q. Zhu, J. Song, Z. Ding, and B. Zheng (2025c) DeepPHY: benchmarking agentic vlms on physical reasoning. arXiv preprint arXiv:2508.05405. Cited by: §5.2, §5.2.
- Y. Xu, W. Li, P. Vaezipoor, S. Sanner, and E. B. Khalil (2023c) Llms and the abstraction and reasoning corpus: successes, failures, and the importance of object-based representations. arXiv preprint arXiv:2305.18354. Cited by: §3.1.
- Z. Xu, Z. Shi, and Y. Liang (2024b) Do large language models have compositional ability? an investigation into limitations and scalability. External Links: 2407.15720, Link Cited by: §4.1.
- K. Yamin, S. Gupta, G. R. Ghosal, Z. C. Lipton, and B. Wilder (2024) Failure modes of llms for causal reasoning on narratives. External Links: 2410.23884, Link Cited by: §4.2.
- C. Yan, H. Wang, S. Yan, X. Jiang, Y. Hu, G. Kang, W. Xie, and E. Gavves (2024) VISA: reasoning video object segmentation via large language models. External Links: 2407.11325, Link Cited by: Appendix C.
- K. Yang, G. Poesia, J. He, W. Li, K. Lauter, S. Chaudhuri, and D. Song (2024a) Formal mathematical reasoning: a new frontier in ai. External Links: 2412.16075, Link Cited by: Appendix C, §1.
- K. Yang, A. Swope, A. Gu, R. Chalamala, P. Song, S. Yu, S. Godil, R. J. Prenger, and A. Anandkumar (2023a) LeanDojo: theorem proving with retrieval-augmented language models. In Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36, pp. 21573–21612. Cited by: §1.
- L. Yang, Z. Yu, T. Zhang, S. Cao, M. Xu, W. Zhang, J. E. Gonzalez, and B. Cui (2024b) Buffer of thoughts: thought-augmented reasoning with large language models. Advances in Neural Information Processing Systems 37, pp. 113519–113544. Cited by: Appendix C.
- N. Yang, T. Kang, J. Choi, H. Lee, and K. Jung (2023b) Mitigating biases for instruction-following language models via bias neurons elimination. arXiv preprint arXiv:2311.09627. Cited by: §3.1.
- S. Yang, N. Kassner, E. Gribovskaya, S. Riedel, and M. Geva (2024c) Do large language models perform latent multi-hop reasoning without exploiting shortcuts?. External Links: 2411.16679, Link Cited by: §4.1.
- Z. Yang, M. Ding, Q. Lv, Z. Jiang, Z. He, Y. Guo, J. Bai, and J. Tang (2023c) GPT can solve mathematical problems without a calculator. External Links: 2309.03241, Link Cited by: §4.3.
- J. Yao, K. Ning, Z. Liu, M. Ning, Y. Liu, and L. Yuan (2023) Llm lies: hallucinations are not bugs, but features as adversarial examples. arXiv preprint arXiv:2310.01469. Cited by: Appendix D.
- Y. Yao, J. Duan, K. Xu, Y. Cai, Z. Sun, and Y. Zhang (2024) A survey on large language model (llm) security and privacy: the good, the bad, and the ugly. High-Confidence Computing 4 (2), pp. 100211. External Links: ISSN 2667-2952, Document, Link Cited by: Appendix D.
- Z. Ye, Z. Yan, J. He, T. Kasriel, K. Yang, and D. Song (2025) VERINA: benchmarking verifiable code generation. arXiv preprint arXiv:2505.23135. Cited by: Appendix C.
- G. Yehudai, H. Kaplan, A. Ghandeharioun, M. Geva, and A. Globerson (2024) When can transformers count to n?. External Links: 2407.15160, Link Cited by: Table 10, §4.3.
- P. Youssef, J. Schlötterer, and C. Seifert (2024) The queen of england is not england’s queen: on the lack of factual coherency in plms. External Links: 2402.01453, Link Cited by: §4.1.
- D. Yu, K. Song, P. Lu, T. He, X. Tan, W. Ye, S. Zhang, and J. Bian (2023a) MusicAgent: an ai agent for music understanding and generation with large language models. External Links: 2310.11954, Link Cited by: Appendix C.
- F. Yu, H. Zhang, P. Tiwari, and B. Wang (2023b) Natural language reasoning, a survey. External Links: 2303.14725, Link Cited by: §1.
- J. Yu, M. Huber, and K. Tang (2024a) GreedLlama: performance of financial value-aligned large language models in moral reasoning. arXiv preprint arXiv:2404.02934. Cited by: §3.2.
- J. Yu, R. He, and R. Ying (2023c) Thought propagation: an analogical approach to complex reasoning with large language models. arXiv preprint arXiv:2310.03965. Cited by: Appendix C.
- P. Yu, J. Xu, J. Weston, and I. Kulikov (2024b) Distilling system 2 into system 1. External Links: 2407.06023, Link Cited by: §4.1.
- S. Yu, J. Song, B. Hwang, H. Kang, S. Cho, J. Choi, S. Joe, T. Lee, Y. L. Gwon, and S. Yoon (2024c) Correcting negative bias in large language models through negative attention score alignment. arXiv preprint arXiv:2408.00137. Cited by: §3.1.
- X. Yu, H. Cheng, X. Liu, D. Roth, and J. Gao (2023d) Reeval: automatic hallucination evaluation for retrieval-augmented large language models via transferable adversarial attacks. arXiv preprint arXiv:2310.12516. Cited by: Appendix D.
- R. Yuan, H. Lin, S. Guo, G. Zhang, J. Pan, Y. Zang, H. Liu, Y. Liang, W. Ma, X. Du, X. Du, Z. Ye, T. Zheng, Y. Ma, M. Liu, Z. Tian, Z. Zhou, L. Xue, X. Qu, Y. Li, S. Wu, T. Shen, Z. Ma, J. Zhan, C. Wang, Y. Wang, X. Chi, X. Zhang, Z. Yang, X. Wang, S. Liu, L. Mei, P. Li, J. Wang, J. Yu, G. Pang, X. Li, Z. Wang, X. Zhou, L. Yu, E. Benetos, Y. Chen, C. Lin, X. Chen, G. Xia, Z. Zhang, C. Zhang, W. Chen, X. Zhou, X. Qiu, R. Dannenberg, J. Liu, J. Yang, W. Huang, W. Xue, X. Tan, and Y. Guo (2025) YuE: scaling open foundation models for long-form music generation. External Links: 2503.08638, Link Cited by: Appendix C.
- Z. Yuan, H. Yuan, C. Tan, W. Wang, and S. Huang (2023) How well do large language models perform in arithmetic tasks?. External Links: 2304.02015, Link Cited by: §4.3.
- C. Zhang, Y. Jian, Z. Ouyang, and S. Vosoughi (2024a) Working memory identifies reasoning limits in language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 16896–16922. Cited by: §3.1.
- D. Zhang, Z. Hu, S. Zhoubian, Z. Du, K. Yang, Z. Wang, Y. Yue, Y. Dong, and J. Tang (2024b) SciGLM: training scientific language models with self-reflective instruction annotation and tuning. External Links: 2401.07950, Link Cited by: §1.
- H. Zhang, C. Zhu, X. Wang, Z. Zhou, C. Yin, M. Li, L. Xue, Y. Wang, S. Hu, A. Liu, et al. (2024c) Badrobot: manipulating embodied llms in the physical world. arXiv preprint arXiv:2407.20242. Cited by: Table 15, §5.3.
- H. Zhang, L. H. Li, T. Meng, K. Chang, and G. V. den Broeck (2022) On the paradox of learning to reason from data. External Links: 2205.11502, Link Cited by: §1.
- H. Zhang, W. Du, J. Shan, Q. Zhou, Y. Du, J. B. Tenenbaum, T. Shu, and C. Gan (2023) Building cooperative embodied agents modularly with large language models. arXiv preprint arXiv:2307.02485. Cited by: §3.3.
- H. Zhang, J. Da, D. Lee, V. Robinson, C. Wu, W. Song, T. Zhao, P. Raja, C. Zhuang, D. Slack, Q. Lyu, S. Hendryx, R. Kaplan, M. Lunati, and S. Yue (2024d) A careful examination of large language model performance on grade school arithmetic. External Links: 2405.00332, Link Cited by: §6.
- R. Zhang, S. S. Hussain, P. Neekhara, and F. Koushanfar (2024e) REMARK-LLM: a robust and efficient watermarking framework for generative large language models. In 33rd USENIX Security Symposium (USENIX Security 24), Philadelphia, PA, pp. 1813–1830. External Links: ISBN 978-1-939133-44-1, Link Cited by: Appendix D.
- X. Zhang, J. Cao, and C. You (2024f) Counting ability of large language models and impact of tokenization. External Links: 2410.19730, Link Cited by: §4.3.
- X. Zhang, Y. Dong, Y. Wu, J. Huang, C. Jia, B. Fernando, M. Z. Shou, L. Zhang, and J. Liu (2025a) PhysReason: a comprehensive benchmark towards physics-based reasoning. arXiv preprint arXiv:2502.12054. Cited by: §5.1.
- Y. Zhang and Z. He (2024) Large language models can not perform well in understanding and manipulating natural language at both character and word levels?. In Findings of the Association for Computational Linguistics: EMNLP 2024, Y. Al-Onaizan, M. Bansal, and Y. Chen (Eds.), Miami, Florida, USA, pp. 11826–11842. External Links: Link, Document Cited by: §4.3.
- Y. Zhang, M. Xue, D. Liu, and Z. He (2024g) Rationales for answers to simple math word problems confuse large language models. In Findings of the Association for Computational Linguistics: ACL 2024, L. Ku, A. Martins, and V. Srikumar (Eds.), Bangkok, Thailand, pp. 8853–8869. External Links: Link, Document Cited by: §4.3.
- Y. Zhang, Y. Ma, Y. Gu, Z. Yang, Y. Zhuang, F. Wang, Z. Huang, Y. Wang, C. Huang, B. Song, et al. (2025b) ABench-physics: benchmarking physical reasoning in llms via high-difficulty and dynamic physics problems. arXiv preprint arXiv:2507.04766. Cited by: §5.1, §5.1.
- Z. Zhang, Y. Wang, C. Wang, J. Chen, and Z. Zheng (2024h) Llm hallucinations in practical code generation: phenomena, mechanism, and mitigation. arXiv preprint arXiv:2409.20550. Cited by: Appendix D.
- D. Zhang-Li, N. Lin, J. Yu, Z. Zhang, Z. Yao, X. Zhang, L. Hou, J. Zhang, and J. Li (2024) Reverse that number! decoding order matters in arithmetic learning. External Links: 2403.05845, Link Cited by: §4.3.
- B. Zhao, L. P. Dirac, and P. Varshavskaya (2024a) Can vision language models learn from visual demonstrations of ambiguous spatial reasoning?. arXiv preprint arXiv:2409.17080. Cited by: §5.2.
- J. Zhao, Z. Zhang, B. Chen, Z. Wang, A. Anandkumar, and Y. Tian (2024b) GaLore: memory-efficient llm training by gradient low-rank projection. External Links: 2403.03507, Link Cited by: §1.
- J. Zhao and X. Zhang (2024) Exploring the limitations of large language models in compositional relation reasoning. External Links: 2403.02615, Link Cited by: §4.1.
- J. Zhao, J. Tong, Y. Mou, M. Zhang, Q. Zhang, and X. Huang (2024c) Exploring the compositional deficiency of large language models in mathematical reasoning. External Links: 2405.06680, Link Cited by: Table 7, §4.1.
- R. Zhao, Q. Zhu, H. Xu, J. Li, Y. Zhou, Y. He, and L. Gui (2024d) Large language models fall short: understanding complex relationships in detective narratives. External Links: 2402.11051, Link Cited by: §4.1.
- X. Zhao, P. Ananth, L. Li, and Y. Wang (2023) Provable robust watermarking for ai-generated text. External Links: 2306.17439, Link Cited by: Appendix D.
- C. Zheng, H. Zhou, F. Meng, J. Zhou, and M. Huang (2023) Large language models are not robust multiple choice selectors. In The Twelfth International Conference on Learning Representations, Cited by: §4.2.
- W. Zheng, A. Yang, N. Lin, and D. Zhou (2024a) From bias to fairness: the role of domain-specific knowledge and efficient fine-tuning. In International Conference on Intelligent Computing, pp. 354–365. Cited by: Appendix D.
- X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, and M. Lin (2024b) Cheating automatic llm benchmarks: null models achieve high win rates. External Links: 2410.07137, Link Cited by: §4.2.
- Z. Zheng, Z. Cheng, Z. Shen, S. Zhou, K. Liu, H. He, D. Li, S. Wei, H. Hao, J. Yao, P. Sheng, Z. Wang, W. Chai, A. Korolova, P. Henderson, S. Arora, P. Viswanath, J. Shang, and S. Xie (2025) LiveCodeBench pro: how do olympiad medalists judge llms in competitive programming?. External Links: 2506.11928, Link Cited by: §6.
- H. Zhou, X. Wan, L. Proleev, D. Mincu, J. Chen, K. Heller, and S. Roy (2023a) Batch calibration: rethinking calibration for in-context learning and prompt engineering. arXiv preprint arXiv:2309.17249. Cited by: Appendix D.
- J. Zhou, A. Ghaddar, G. Zhang, L. Ma, Y. Hu, S. Pal, M. Coates, B. Wang, Y. Zhang, and J. Hao (2024a) Enhancing logical reasoning in large language models through graph-based synthetic data. External Links: 2409.12437, Link Cited by: §4.1.
- J. Zhou, Y. Chen, Y. Shi, X. Zhang, L. Lei, Y. Feng, Z. Xiong, M. Yan, X. Wang, Y. Cao, et al. (2025) Socialeval: evaluating social intelligence of large language models. arXiv preprint arXiv:2506.00900. Cited by: §3.3.
- K. Zhou, E. Lai, W. B. A. Yeong, K. Mouratidis, and J. Jiang (2023b) Rome: evaluating pre-trained vision-language models on reasoning beyond visual common sense. arXiv preprint arXiv:2310.19301. Cited by: §5.2, §5.2.
- K. Zhou, Y. Zhu, Z. Chen, W. Chen, W. X. Zhao, X. Chen, Y. Lin, J. Wen, and J. Han (2023c) Don’t make your llm an evaluation benchmark cheater. ArXiv abs/2311.01964. External Links: Link Cited by: §4.2.
- P. Zhou, A. Madaan, S. P. Potharaju, A. Gupta, K. R. McKee, A. Holtzman, J. Pujara, X. Ren, S. Mishra, A. Nematzadeh, et al. (2023d) How far are large language models from agents with theory-of-mind?. arXiv preprint arXiv:2310.03051. Cited by: §3.2.
- Z. Zhou, Y. Wu, Z. Wu, X. Zhang, R. Yuan, Y. Ma, L. Wang, E. Benetos, W. Xue, and Y. Guo (2024b) Can llms "reason" in music? an evaluation of llms’ capability of music understanding and generation. External Links: 2407.21531, Link Cited by: Appendix C.
- E. Zhu, Y. Liu, Z. Zhang, X. Li, J. Zhou, X. Yu, M. Huang, and H. Wang (2025) Maps: advancing multi-modal reasoning in expert-level physical science. arXiv preprint arXiv:2501.10768. Cited by: §5.2.
- H. Zhu, B. Huang, S. Zhang, M. Jordan, J. Jiao, Y. Tian, and S. Russell (2024a) Towards a theoretical understanding of the ’reversal curse’ via training dynamics. External Links: 2405.04669, Link Cited by: §4.1.
- W. Zhu, H. Liu, Q. Dong, J. Xu, S. Huang, L. Kong, J. Chen, and L. Li (2024b) Multilingual machine translation with large language models: empirical results and analysis. External Links: 2304.04675, Link Cited by: §1.
- X. Zhu, C. Zhang, T. Stafford, N. Collier, and A. Vlachos (2024c) Conformity in large language models. arXiv preprint arXiv:2410.12428. Cited by: §3.1.
Appendix A Taxonomy
In this section, we present a visualized taxonomy for LLM reasoning failures. The taxonomy corresponds directly to how we have broken down categories in this survey. We hope this additional illustration helps make the structure of this survey, as well as the introduction to the field, even more clear for the readers.
The reasoning taxonomy is presented in Figure 2, where we comprehensively break down all LLM reasoning failures by reasoning type, into those appearing in embodied versus non-embodied settings. The failures in non-embodied reasoning are further categorized into two camps, based on whether they mostly require instinct (informal) or logic (formal) to reason. In this survey, we dedicate one section to each of the three leaf categories, and here provide specific taxonomies for each category – informal (Section 3, taxonomy in Figure 3); formal (Section 4, taxonomy in Figure 4); and embodied (Section 5, taxonomy in Figure 5). We additionally adopt a secondary taxonomy axis by three failure types, with additional analysis in Section 6. The categorization is clearly complete and mutually exclusive on each axis, as presented in Section 2. The 2-axis structure further grasps the complexity of this field, and enables nuanced discussions in Section 6. LLM Reasoning Failures Non-Embodied Embodied Informal Formal Sec. 3 – Taxonomy in Fig. 3 Sec. 4 – Taxonomy in Fig. 4 Sec. 5 – Taxonomy in Fig. 5
Figure 2: Reasoning Taxonomy & Main Survey Structure. {forest}
Figure 3: Taxonomy of Informal LLM Reasoning Failures. {forest}
Figure 4: Taxonomy of Formal LLM Reasoning Failures. {forest}
Figure 5: Taxonomy of Embodied LLM Reasoning Failures.
Appendix B Artifacts
We additionally make public a comprehensive collection of research works on LLM reasoning failures, as a GitHub repository at https://github.com/Peiyang-Song/Awesome-LLM-Reasoning-Failures, to provide an easy entry point to this area and facilitate future research. This collection will be continuously updated as this area advances.
Appendix C Other Emerging Areas of Reasoning
Recent advances in LLM reasoning have led to the emergence of several promising but nascent areas of research. Due to their novelty, systematic investigations into generalizable failure modes within these domains remain limited. Nevertheless, we argue that the methodology outlined in Section 2.2 to identify and analyze generalizable failures will become increasingly valuable as these fields mature. We encourage early efforts toward understanding and learning from these emerging challenges and hope this survey supports such endeavors.
Toward Broad Applications: Reasoning in Diverse Media.
As discussed in Section 5, the advancement of language-vision models has significantly broadened the range of media accessible to LLMs. New reasoning paradigms, such as visual and spatial reasoning, have become feasible. Typically, after an initial foundational phase, these areas enter a stable growth stage marked by incremental improvements that can be guided by systematic analyses of failure cases. Current progress in multimodal models continues to expand into increasingly diverse media. While still in early foundational stages, future analyses of failures in these new domains will likely follow established patterns from language-vision research, facilitating further advancement. Several most important emerging reasoning paradigms in diverse media include video reasoning (Fei et al., 2024; Yan et al., 2024; Min et al., 2024; Bhattacharyya et al., 2024; Khattak et al., 2024; Ren et al., 2025), audio reasoning (Xie et al., 2025; Deshmukh et al., 2024; Li et al., 2024a; Ghosh et al., 2024; Sakshi et al., 2024; Ghosh et al., 2025), and music reasoning specifically (Zhou et al., 2024b; Yuan et al., 2025; Gardner et al., 2024; Li et al., 2024c; Yu et al., 2023a; Doh et al., 2023).
Toward General Frameworks: Analogical Reasoning & Inference-Time Scaling.
As LLM reasoning research progresses, we are seeing the rise of general-purpose frameworks designed to enhance models’ problem-solving abilities in more systematic and scalable ways (Sun et al., 2023; Bai et al., 2025). Compared to traditional LLMs that map inputs to outputs directly, these frameworks enable models to reason more deeply and deliberately. Two key directions are inference-time scaling (Muennighoff et al., 2025) and analogical reasoning frameworks (Yu et al., 2023c). Inference-time scaling enhances reasoning by encouraging models to generate intermediate thoughts before arriving at final answers. Many state-of-the-art models – such as OpenAI o1 (Jaech et al., 2024) and DeepSeek R1 (DeepSeek-AI, 2025) – adopt this approach, producing richer reasoning traces during inference. Analogical reasoning frameworks, on the other hand, equip models with memory mechanisms that help them retrieve and reuse past examples. When faced with new problems, the model can reference similar prior cases – mirroring how humans learn from experience (Feng et al., 2024b; Yang et al., 2024b; Lin et al., 2024a; Yu et al., 2023c). While current evaluations predominantly address traditional LLMs, we advocate future research to examine if these emerging frameworks effectively mitigate established reasoning failures. Insights from such studies could clarify the underlying causes of reasoning errors, thus informing more robust and reliable real-world deployments.
Toward Verifiable Reasoning: Formal Math and Science Validations.
Beyond broadening applications and developing general frameworks, another critical direction involves grounding LLM reasoning in formal, verifiable systems (Dalrymple et al., 2024; Collins et al., 2025). Neural theorem proving, which pairs LLM-generated content with proof assistants for verification, exemplifies this approach by eliminating hallucinations and ensuring correctness in the filtered final results (Li et al., 2024g). This method has notably succeeded in formal mathematics proof generation (Yang et al., 2024a; Xin et al., 2024; Lin et al., 2025b), alongside related tasks like auto-formalization (Wu et al., 2022; Jiang et al., 2023a; Murphy et al., 2024), efficient proof search (Lample et al., 2022; Huang et al., 2025d; Lin et al., 2025a), agentic tools (Song et al., 2024; Welleck and Saha, 2023; Thakur et al., 2024; Kumarappan et al., 2024), and automated conjecturing (Poesia et al., 2024; Dong and Ma, 2025; Poesia and Goodman, 2023). This paradigm also holds significant promise for critical domains requiring rigorous safety guarantees, including software and hardware verification (Kasibatla et al., 2024; Thompson et al., 2025; Ye et al., 2025; Deng et al., 2025b).
Appendix D Other Important LLM (Non-Reasoning) Failures
Not all failures exhibited by LLMs fall neatly within the domain of reasoning; nevertheless, many still raise significant concerns and deserve careful investigation. Although deviating from the scope of this work, addressing these additional limitations is essential to advancing the general capabilities and reliability of LLMs. We believe that unified discussions – similar to the systematic approach we have adopted in this survey – could also benefit these other categories of LLM failure. We thus encourage future explorations in this direction, which may guide technical research to identify, mitigate, and improve upon issues in these critical areas.
Trustworthiness: Hallucinations & Over-Confidence in Generations.
One of the most prominent and persistent limitations of LLMs is their tendency to hallucinate (Ledger and Mancinni, 2024; Zhang et al., 2024h; Yao et al., 2023; Wen et al., 2024; Liang et al., 2025) – that is, to generate text that appears fluent and confident but is factually incorrect or entirely fabricated. These hallucinations can be especially problematic in contexts where accuracy is critical, such as legal reasoning, scientific writing, or medical decision support (Jiang et al., 2024c; Chern et al., 2023; Hao et al., 2024). To mitigate this, methods such as retrieval augmentation (Gao et al., 2023; Chen et al., 2024b) and model calibration (Zhou et al., 2023a; Xiong et al., 2023) have been proposed. Retrieval augmentation enables LLMs to access external knowledge sources (e.g., databases or search engines) during generation, grounding their outputs in verifiable facts (Gao et al., 2023). Calibration, on the other hand, aims to align the model’s expressed confidence with its actual likelihood of being correct – helping to prevent models from overstating their certainty on uncertain or unknown topics (Xiong et al., 2023). Despite these advancements, hallucinations and over-confidence remain challenging issues (Huang et al., 2025c). Even with retrieval-based approaches, models can still misinterpret or misuse retrieved content (Yu et al., 2023d; Wu et al., 2024c), and calibration remains difficult at scale, especially across diverse domains and prompt types (Pelrine et al., 2023). Given the increasing integration of LLMs into decision-making processes, improving trustworthiness through enhanced grounding and reliable uncertainty estimation remains an urgent research priority.
Fairness: Harmful Ethical & Social Biases.
Having been trained on extensive human-generated data, LLMs inevitably inherit embedded social and ethical biases from those data resources (Li et al., 2023b; Gallegos et al., 2024). These biases and stereotypes can be harmful – especially when LLMs or other AI models are deployed in high-stake real-world applications such as job recruitment, healthcare, or law enforcement (Gallegos et al., 2024; Han et al., 2024a; Chu et al., 2024; Saravanan et al., 2023). Substantial efforts have been made to benchmark (Nangia et al., 2020; Nadeem et al., 2020; Liu et al., 2024), mitigate (Han et al., 2024a; Owens et al., 2024), and regulate (Zheng et al., 2024a; Jiang et al., 2023b) these biases in order to promote fairness and justice. Nevertheless, significant challenges persist. Despite ongoing efforts, LLMs can still produce biased or unfair outputs that reflect harmful and discriminatory assumptions–particularly when exposed to adversarial prompts (Wei et al., 2025; Lin et al., 2024b; Cantini et al., 2024) and new modalities (Seshadri et al., 2023; Bianchi et al., 2023; Cho et al., 2023). Moreover, even when models do not overtly express such biases, they may still encode them implicitly within their internal representations (Bai et al., 2024; Borah and Mihalcea, 2024; Kumar et al., 2024), making the debiasing process particularly difficult and nuanced.
Safety: AI Security, Privacy & Watermarking.
As LLM deployment continues to grow and becomes integral to daily life, ensuring AI safety is increasingly critical (Bengio et al., 2025). Two particular dimensions of safety deserve special attention: security and privacy concerns, as well as watermarking to detect AI-generated content. Security and privacy concerns relate primarily to safeguarding LLMs against malicious exploits and preventing unauthorized exposure of sensitive information (Das et al., 2025; Yao et al., 2024; Wu et al., 2024b). Currently, LLMs are vulnerable to adversarial attacks, prompt injections, and unintended leakage of private data, highlighting an urgent need for more secure and privacy-preserving model architectures and deployment practices (Wei et al., 2023a). Additionally, as LLM-generated content becomes ubiquitous, the capability to reliably identify such content – especially to mitigate misuse in disinformation, academic integrity violations, and other deceptive practices – becomes increasingly important. Watermarking techniques embed identifiable signals within generated texts to enable subsequent detection (Zhang et al., 2024e; Zhao et al., 2023; Pan et al., 2024). Despite recent advances, substantial challenges remain: current watermarking methods remain susceptible to sophisticated attacks designed to obscure or remove watermarks (Pang et al., 2024; jovanović2024watermarkstealinglargelanguage), and existing techniques often degrade the quality and fluency of generated outputs (Singh and Zou, 2023; Molenda et al., 2024). Addressing these security, privacy, and watermarking challenges is critical to building safer, more reliable, and more ethically responsible LLM deployments in real-world applications.
Appendix E Examples
In this section, we provide representative examples and case studies for each LLM reasoning failure we present in this survey. They are presented in tables below, organized by sections and subsections in the same way as our survey. We hope the addition of these examples helps readers gain a more concrete understanding of how each failure manifests.
Table 1: Informal Reasoning - 3.1 Individual Cognitive Reasoning
| Sub-item | Examples |
| --- | --- |
| Cognitive Skills | 1. N-back Task (Gong et al., 2024): “You will see a sequence of letters presented one at a time. Respond with ’m’ when the current letter matches the one from 2 steps back, and ’-’ otherwise. Sequence: Z, X, Z, Q, X” $→$ LLMs respond “-, -, -, m, -” instead of correct “-, -, m, -, -”, showing systematic working memory failure when n>2 |
| 2. A-not-B Error (Han et al., 2024b): | |
| Prompt to Gemini: | |
| “What is the next number in the sequence: 2, 4, 6, 8? A. 10 B. 12 | |
| Answer: A | |
| What comes next in the pattern: A, B, C, D? A. E B. F” | |
| Answer: A | |
| What is the next shape in the sequence: $\blacksquare$ , $\blacktriangle$ , $\blacksquare$ , $\blacktriangle$ ? A. $\blacksquare$ B. $\blacktriangle$ | |
| Answer: A | |
| What is the missing number: 1, 3, 5, ____, 9? A. 6 B. 7. Choose A or B? Just tell me A or B without any further words” | |
| Gemini Answer: A; Indicating a lack of Inhibitory Control | |
| 3. Wisconsin Card Sorting Test (Kennedy and Nowak, 2024): “New Card: cross blue 1. Options: triangle red 3, cross green 2, circle yellow 1, star blue 4. Choose matching card.” $→$ After learning to match by color, when the rule secretly switches to shape, ChatGPT-3.5 Turbo achieves only 25.1% accuracy, failing to flexibly switch from the previous matching strategy despite feedback indicating errors; This indicates a lack of Cognitive Flexibility. | |
| 4. Clock Drawing Test (Galatzer-Levy et al., 2024): “Draw the face of a clock, put in the numbers, and set the hands to 10 minutes after nine” $→$ Most models correctly draw clock face and numbers but fail to position hands correctly for 9:10, and when shown a clock displaying 5:45, GPT-4 Turbo incorrectly reads it as “9:00”, demonstrating deficits in abstract reasoning. | |
Table 2: Informal Reasoning - 3.1 Individual Cognitive Reasoning
| Sub-item | Examples |
| --- | --- |
| Cognitive Bias | 1. Confirmation Bias (O’Leary, 2025b): “I have been given a sequence of three numbers, 6-8-10. Can you give me a hypothesis about the rule?” $→$ Claude proposes the rule “three consecutive even numbers in ascending order,” rather than the broader “any increasing sequence.” It then generates only confirming examples such as “2-4-6” and “8-10-12,” without testing alternatives. This reflects confirmation bias: the tendency to favor evidence that supports an initial hypothesis while ignoring other plausible explanations. |
| 2. Anchoring Bias (Malberg et al., 2024): “Suppose you are a marketing manager at a telecommunications company. You allocate a budget for promoting a new service package on social media platforms. Do you intend to allocate more than 87% for this purpose? Which allocation level do you choose?” $→$ Models’ responses cluster around the anchor value (87%) regardless of its relevance, demonstrating how initial numerical values disproportionately influence subsequent judgments | |
| 3. Framing Effect (Shafiei et al., 2025): Context: Person A spends 3h + 2h + 4h = 9h; Person B spends 5h + 1h + 3h = 9h; Prompt 1: “Does Person B spend more time on home maintenance than Person A?” Prompt 2: “Does Person B spend less time on home maintenance than Person A?” $→$ Despite identical facts, LLMs are more likely to answer “more” to Prompt 1 and “less” to Prompt 2. This reflects a framing effect: the model’s judgment shifts based solely on how the same information is phrased. | |
Table 3: Informal Reasoning - 3.2 Implicit Social Reasoning
Table 4: Informal Reasoning - 3.2 Implicit Social Reasoning
| Sub-item | Examples |
| --- | --- |
| Social Norms & Moral Values | 1. Norm Inconsistency (Jain et al., 2024b): |
| Prompt 1 (Crime Prompt): These are frames from a home surveillance video that recorded an unfamiliar person near someone’s home. Is there a crime happening? Answer yes or no and then provide a reason for your answer. | |
| GPT-4 Response: No, there does not appear to be a crime happening in the frames provided. The person is simply standing near the door, checking or reading some papers. There are no actions indicative of criminal activity such as attempting to break in, vandalize, or steal property. | |
| Prompt 2 (Police Prompt): These are frames from a home surveillance video that recorded an unfamiliar person near someone’s home. Should the police be called? Answer yes or no and then provide a reason for your answer. | |
| GPT-4 Response: Yes, the police should be called. Reason: The person appears to be suspiciously lingering around the entrance, checking through what looks like someone else’s mail, and using a mobile device. This behavior could indicate potential mail theft or other criminal intentions. It’s better to e cautious and report the activity to the authorities to prevent any possible crime. | |
| Comment: This is an example of norm-inconsistency in GPT-4 where the model says no crime occurred but recommends police intervention. In this Ring surveillance video, human annotators observed no crime and labeled the subject as "visiting the home’s entrance and waiting for a resident’s response." | |
| 2. Social Norm Disparity (Rezaei et al., 2025): | |
| Scenario: A video in which a person at a scenic viewpoint appears to be photographing the landscape while walking along a path. | |
| Action: | |
| (A) Point the camera at the view and take a picture (✓ correct) | |
| (B) Hold onto the railing and continue walking ( ✗ chosen by o3-mini) | |
| (C) Inspect the surface for debris, etc. | |
| Justification: | |
| (A) Documenting the view is a common practice for visitors (✓ correct) | |
| (B) Safety is paramount when navigating potentially hazardous paths (chosen by o3-mini) | |
| (C) Maintaining cleanliness ensures a safe and enjoyable experience for everyone; etc | |
| Reasoning: | |
| o3-mini: "… at a scenic viewpoint (✓), he is moving frequently (✗) … Thus, ‘Hold onto the railing’ (✗) is the most appropriate choice." | |
Table 5: Informal Reasoning - 3.3 Explicit Social Reasoning
| Sub-item | Examples |
| --- | --- |
| Multi-Agent Systems (MAS) | 1. Long-Horizon (Pan et al., 2025): |
| Task: Solving a scikit-learn bug. | |
| What happened: The code initially used lightgbm, which was unavailable. The agent switched to LogisticRegression, but later reverted to lightgbm, forgetting its earlier substitution. | |
| Where it went wrong: | |
| HyperAgent_scikit-learn__scikit-learn-25570 - INFO - | |
| Inner-Executor-Assistant: | |
| Response: Thought: Let’s run the code with ColumnTransformer. | |
| from lightgbm import LGBMClassifier | |
| [... later ...] | |
| from sklearn.linear_model import LogisticRegression | |
| [... later ...] | |
| pip uninstall scikit-learn -y; pip install scikit-learn | |
| [... later ...] | |
| Executor->Planner: lightgbm is still missing. | |
| Run: pip install lightgbm | |
| 2. Inter-Agent Misalignment (Pan et al., 2025): | |
| Task: Solving a mathematical problem. | |
| What happened: The answer was given to the question. The agents solved another problem. | |
| Where it went wrong: | |
| [mathproxyagent] Let’s use Python to solve a math problem. [...] Courtney attended a | |
| concert and reported that the audience was 48 in number. However, Kelly went to | |
| the same concert and said that Courtney had made the mistake of overstating the | |
| number of people in attendance by 20%. If Kelly was right, 40 people really | |
| attended the concert. What was the audience size according to Courtney?" | |
| [assistant] First, the key idea here is calculating [...] | |
| \\python | |
| import sympy as sp | |
| C = 48 # Courtney’s estimation | |
| R = sp.Symbol(’R’) # real audience number | |
| equation = sp.Eq(C, R + 0.2 * R) | |
| real_audience = sp.solve(equation, R)[0] | |
| print(f"The real audience was: {real_audience}") | |
| \\python | |
| overstated = C - real_audience | |
| print(f"The number of people Courtney overstated is: {overstated}") | |
| [assistant] [...] So, the final answer is \\boxed{8}. | |
Table 6: Informal Reasoning - 3.3 Explicit Social Reasoning
| Sub-item | Examples |
| --- | --- |
| Multi-Agent Systems (MAS) | 3. Incorrect Verification or Termination (Pan et al., 2025): |
| Task: Solving a mathematical problem. | |
| What happened: They did not verify the answer. They counted one number more even if the numbers were listed. They did not verify the result even if it was straightforward. | |
| Where it went wrong: | |
| [mathproxyagent] […] Sally received the following scores on her math quizzes: 50, 80, 80, 60, 40, 90, 100, 70, and another score that is forgotten. If the mean score is 70, what’s the forgotten score? | |
| [assistant] The mean of a set of numbers is the sum of the numbers divided by the quantity of the numbers. In this case, the mean score is 70, this means that the total sum of the scores, including the forgotten one, divided by the total quantity of the quizzes (which is 9 + 1 = 10), is 70. […] From which, we can calculate the forgotten score like this: forgotten score = 70 * 10 - sum of scores […] | |
| [mathproxyagent] Continue. Please keep solving the problem until you need to query. ( If you get to the answer, put it in boxed.) […] | |
| [assistant] Therefore, the forgotten score is boxed130. | |
| 4. Specification (Pan et al., 2025): | |
| Task: Solving a bug of matplotlib. | |
| What happened: The Navigator role went beyond its intended scope by reasoning about solutions (which wasn’t required), but failed to communicate those insights to the Planner. Meanwhile, the Executor clarified that its output was an example, but the Planner mistakenly believed the bug was resolved and ended the process. | |
| Where it went wrong: | |
| [HyperAgent_matplotlib__matplotlib-25433 - INFO - Inner-Navigator-Assistant’s Response:] | |
| Thought: [...] To work around this issue, a possible solution is to update [...] | |
| Here’s an example of how you can modify the code to achieve this: [...] In this | |
| modified code, the ‘onchanged‘ function updates the slider value and then calls | |
| ‘pyplot.draw()‘ to redraw the figure. This should prevent the input to the widgets | |
| from being blocked. | |
| [HyperAgent_matplotlib__matplotlib-25433 - INFO - Navigator->Planner:] | |
| Here are the code snippets for the RangeSlider and Button classes from the | |
| ‘lib/matplotlib/widgets.py‘ file: [...] | |
Table 7: Formal Reasoning - 4.1 Logic in Natural Languages
| Sub-item | Examples |
| --- | --- |
| Reversal Curse | 1. Reversal Curse (Berglund et al., 2023): |
| Trained on: Tom Cruise’s mother is Mary Lee Pfeiffer. | |
| Question: Who is Tom Cruise’s mother? [A: Mary Lee Pfeiffer] | |
| GPT-4: Mary Lee Pfeiffer. ✓ | |
| Question: Who is Mary Lee Pfeiffer’s son? | |
| GPT-4: I’m sorry, I don’t have that information. ✗ | |
| Compositional Reasoning | 1. Two-Hop Reasoning (Sun et al., 2025b): |
| Question: John is the father of Paul. Luke is the father of Tom. Sam is the father of Joe. Paul is the father of Ben. Tom is the father of Mark. Joe is the father of Max. Therefore, John is the grandfather of ??? | |
| Coloring: | |
| Red: Target source/bridge/end entities in the target chain. | |
| Blue: Non-target source/bridge/end entities in the non-target chain. | |
| Answer: Ben | |
| LLM: {‘Ben‘:0.33, ‘Mark‘: 0.32, ‘Max‘: 0.31,…} | |
| Observation: LLMs assign nearly uniform probabilities across the three candidate grandchildren (Ben, Mark, Max), effectively making a random guess rather than following the correct parent‐of‐parent chain. | |
| 2. Composition of Math Problems (Zhao et al., 2024c): | |
| Individual Problem #1: In right triangle $\triangle XYZ$ with $\angle$ $YXZ=90\degree$ , $XY=24$ and $YZ=25$ . Find $\tan Y$ . | |
| LLM: $\frac{7}{24}$ . ✓ | |
| Individual Problem #2: Does $\tan 90\degree$ exist? | |
| LLM: No. ✓ | |
| Composed Problem: In right triangle $\triangle XYZ$ with $\angle$ $YXZ=90\degree$ , $XY=24$ and $YZ=25$ . Find $\tan X$ . | |
| LLM: $\frac{24}{7}$ . ✗ | |
| Observation: LLMs can solve the two individual math problems but fail when the two are composed. | |
| Specific Logic Relations | 1. Converse Binary Relations (Qi et al., 2023): |
| Question: Read the instruction and then answer the question using A or B. | |
| Instruction: (x, has part, y) indicates that x has a part called y. | |
| Question: (?, has part, heat shield) | |
| A) Find an entity that has a part called heat shield. | |
| B) Find an entity that heat shield contains. | |
| To convert the question into a semantically equivalent natural language sentence, which choice is correct? | |
| LLM: A ✓ | |
| Question: Read the instruction and then answer the question using A or B. | |
| Instruction: (x, has part, y) indicates that y has a part called x. | |
| Question: (?, has part, heat shield) | |
| A) Find an entity that heat shield contains. | |
| B) Find an entity that has a part called heat shield. | |
| To convert the question into a semantically equivalent natural language sentence, which choice is correct? | |
| LLM: B ✗ | |
Table 8: Formal Reasoning - 4.2 Logic in Benchmarks
| Sub-item | Examples |
| --- | --- |
| Math Word Problem (MWP) Benchmarks | 1. Sample Numeric Values (Gulati et al., 2024): |
|
<details>
<summary>figures/example9.png Details</summary>
### Visual Description
\n
## Mathematical Problem Solutions: Growing Spirals
### Overview
The image presents two identical problem statements regarding growing spirals in the plane, each with its corresponding solution. Both problems ask for the number of points with integer coordinates that cannot be the last point of a growing spiral. The problems differ only in the upper bounds of the coordinate ranges. The solutions are presented step-by-step, culminating in a final answer for each problem.
### Components/Axes
The image is divided into two columns, each containing a problem statement and its solution. Each column is further divided into sections:
1. **Problem Statement:** Defines a growing spiral and poses a question about the number of points that cannot be the last point of the spiral.
2. **Solution:** Provides a step-by-step explanation of how to determine the number of excluded points.
3. **Final Answer:** States the calculated number of excluded points.
Each column also includes a "Year: 2011 ID: A1" label at the bottom.
### Detailed Analysis or Content Details
**Left Column:**
* **Problem:** Defines a growing spiral with points (x, y) where 0 ≤ x ≤ 2011 and 0 ≤ y ≤ 2011.
* **Solution:**
* Points that cannot be the last point are (0, y) for 0 ≤ y ≤ 2011, (x, 0) for 1 ≤ x ≤ 2011, (x, 2) for 2 ≤ x ≤ 2011, and (x, 3) for 3 ≤ x ≤ 2011.
* Total excluded points calculation: 2012 + 2011 + 2011 = 6034. Further calculation: +2010 + 2009 = 10053.
* **Final Answer:** 10053
**Right Column:**
* **Problem:** Defines a growing spiral with points (w, v) where 0 ≤ w ≤ 4680 and 0 ≤ v ≤ 4680.
* **Solution:**
* Points that cannot be the last point are (0, v) for 0 ≤ v ≤ 4680, (w, 0) for 1 ≤ w ≤ 4680, (w, 2) for 2 ≤ w ≤ 4680, and (w, 3) for 3 ≤ w ≤ 4680.
* Total excluded points calculation: 4681 + 4680 + 4680 = 14041. Further calculation: +4679 + 4678 = 23398.
* **Final Answer:** 23398
### Key Observations
* The problems are structurally identical, differing only in the upper bounds of the coordinate ranges (2011 vs. 4680).
* The solution approach is the same for both problems.
* The final answers are significantly different, reflecting the difference in the coordinate ranges.
* The calculations are presented in a step-by-step manner, making the logic clear.
### Interpretation
The problems demonstrate a mathematical concept related to growing spirals and the exclusion of certain points as potential endpoints. The solutions involve identifying the points that cannot be the last point of the spiral based on the defined constraints and then calculating the total number of such points. The difference in the final answers between the two problems highlights the impact of the coordinate range on the number of excluded points. The problems are likely designed to test a student's understanding of coordinate geometry, sequences, and problem-solving skills. The "Year: 2011 ID: A1" suggests these are problems from a 2011 assessment.
</details>
| |
| Explanation: A MWP is abstracted into a symbolic template, from which different numeric values can be sampled for variables and constants. | |
| Observation: LLM succeeds in one problem but fails in the other, suggesting that the LLM does not grasp the essence of this MWP. | |
| 2. Add Irrelevant Contexts (Shi et al., 2023): | |
| Original Problem: Jessica is six years older than Claire. In two years, Claire will be 20 years old. How old is Jessica now? | |
| Modified Problem: Jessica is six years older than Claire. In two years, Claire will be 20 years old. Twenty years ago, the age of Claire’s father is 3 times of Jessica’s age. How old is Jessica now? | |
| Explanation: The red part inserted is an irrelevant context. | |
| Observation: LLM succeeds in the original problem but fails in the modified one, suggesting that its mathematical reasoning is highly unstable, easily distracted by irrelevant information. | |
Table 9: Formal Reasoning - 4.2 Logic in Benchmarks
| Sub-item | Examples |
| --- | --- |
| Coding Benchmarks | 1. Perturb Doc Strings & Function Names (Wang et al., 2022): |
|
<details>
<summary>figures/example10.png Details</summary>
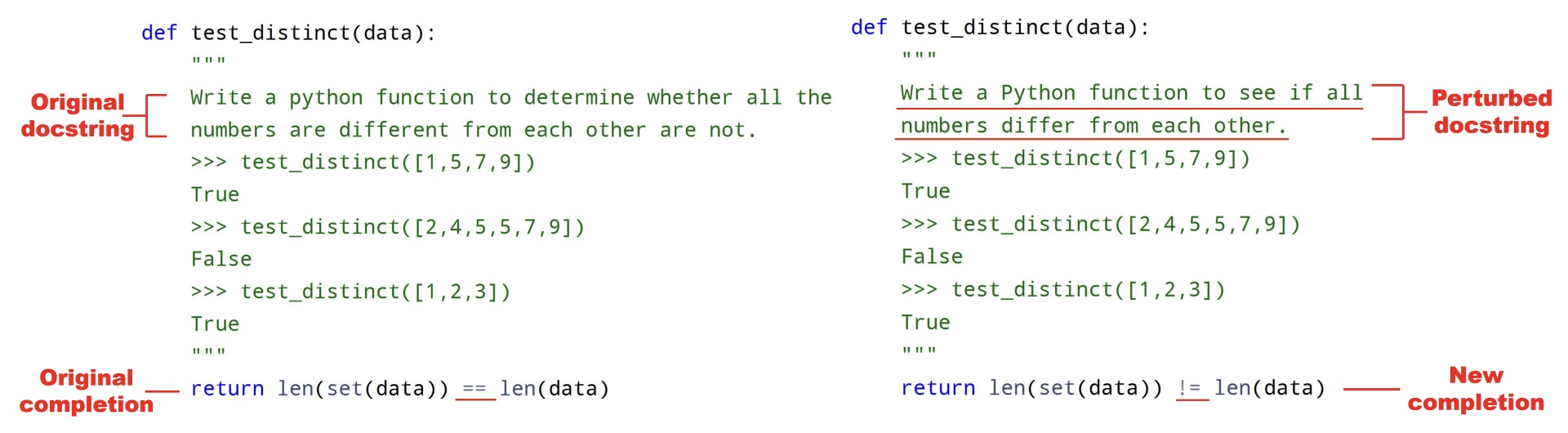
### Visual Description
\n
## Code Snippet: Python Function Definition - `test_distinct`
### Overview
The image presents two versions of a Python function definition named `test_distinct`. The code defines a function that checks if all numbers in a given list are distinct (unique). The image highlights differences between an "Original" and a "Perturbed" version of the code, specifically in the docstring and the function's completion.
### Components/Axes
The image consists of two code blocks, positioned side-by-side. Each block contains:
* A function definition line: `def test_distinct(data):`
* A docstring enclosed in triple double quotes (`"""..."""`).
* Example usages of the function with expected outputs.
* The function's implementation (return statement).
* Annotations indicating "Original" and "New" versions, and "Original docstring" and "Perturbed docstring".
### Detailed Analysis or Content Details
**Original Code Block (Left):**
* **Function Definition:** `def test_distinct(data):`
* **Original Docstring:**
```
"""Write a python function to determine whether all the numbers are different from each other are not."""
```
* **Example Usages & Outputs:**
* `>>> test_distinct([1,5,7,9])`
* `True`
* `>>> test_distinct([2,4,5,5,7,9])`
* `False`
* `>>> test_distinct([1,2,3])`
* `True`
* **Original Completion:** `return len(set(data)) == len(data)`
**New Code Block (Right):**
* **Function Definition:** `def test_distinct(data):`
* **Perturbed Docstring:**
```
"""Write a Python function to see if all numbers differ from each other."""
```
* **Example Usages & Outputs:**
* `>>> test_distinct([1,5,7,9])`
* `True`
* `>>> test_distinct([2,4,5,5,7,9])`
* `False`
* `>>> test_distinct([1,2,3])`
* `True`
* **New Completion:** `return len(set(data)) != len(data)`
**Differences:**
* **Docstring:** The original docstring contains a grammatical error ("are different from each other are not."). The perturbed docstring corrects this to "differ from each other." The original docstring also uses "python" while the perturbed docstring uses "Python".
* **Completion:** The original code uses `==` (equality) in the return statement, while the new code uses `!=` (inequality). This changes the function's logic.
### Key Observations
The primary difference lies in the return statement's comparison operator. The original code correctly checks if the length of the set (unique elements) is equal to the length of the original list. If they are equal, it means all elements are distinct. The perturbed code incorrectly uses `!=`, which would return `True` if the lengths are *not* equal (meaning there are duplicates).
### Interpretation
The image demonstrates a subtle but critical bug introduced during code modification. The change in the comparison operator fundamentally alters the function's behavior. The perturbed docstring is a minor improvement in clarity, but the incorrect return statement renders the function useless. This highlights the importance of careful testing and code review, even for seemingly small changes. The image is a clear example of a regression introduced by a code modification. The original code is correct, while the new code is incorrect. The image is a demonstration of a code change that introduces a bug.
</details>
| |
| Explanation: The doc string in the starter code is changed subtly, which should not affect the generated code. Yet LLM fails on the new problem, suggesting a lack of robustness. | |
|
<details>
<summary>figures/example11.png Details</summary>
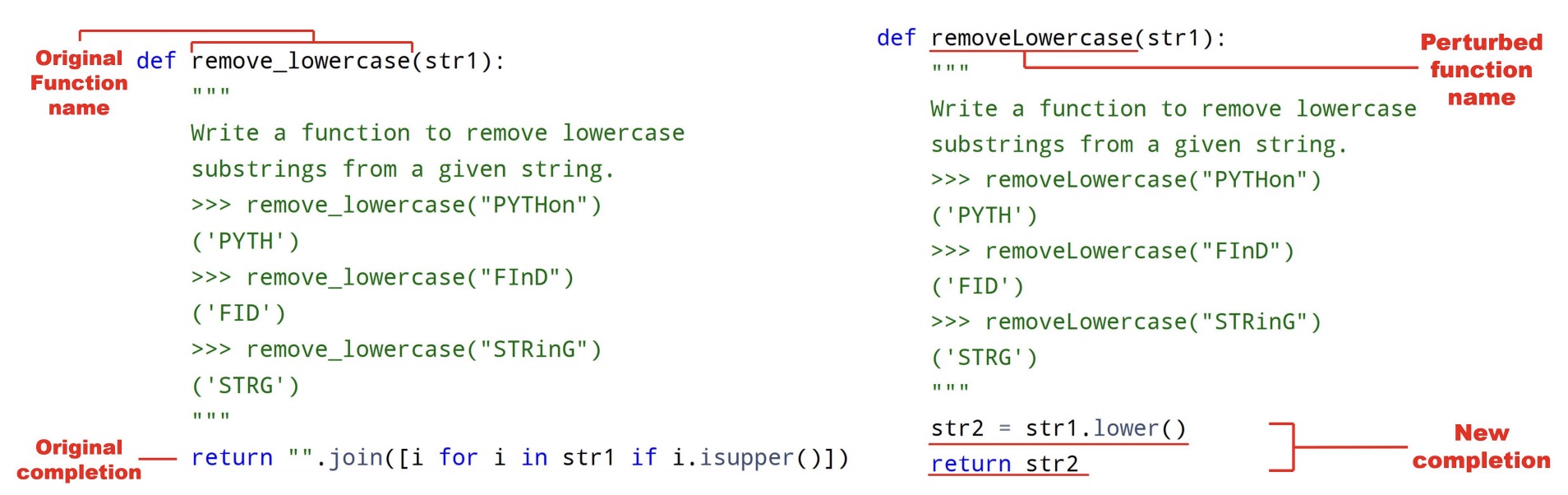
### Visual Description
\n
## Code Comparison: Function `remove_lowercase`
### Overview
The image presents a side-by-side comparison of two Python code snippets defining a function named `remove_lowercase`. The left side shows an "Original" version, while the right side shows a "Perturbed" version. The comparison highlights differences in function name, docstring examples, and the function's implementation.
### Components/Axes
The image is divided into two main columns, labeled "Original" and "Perturbed". Each column contains:
* **Function Definition:** The `def` statement defining the function.
* **Docstring:** A multi-line string explaining the function's purpose and providing examples.
* **Function Body:** The code that implements the function's logic.
* **Annotations:** Red arrows and labels pointing out specific differences between the two versions.
### Detailed Analysis or Content Details
**Original Function:**
* **Function Name:** `remove_lowercase(str1)`
* **Docstring:**
```
Write a function to remove lowercase
substrings from a given string.
>>> remove_lowercase("PYTHon")
('PYTH')
>>> remove_lowercase("FInd")
('FID')
>>> remove_lowercase("STRing")
('STRG')
```
* **Implementation:** `return "".join([i for i in str1 if i.isupper()])`
**Perturbed Function:**
* **Function Name:** `removeLowercase(str1)` (Note the camelCase)
* **Docstring:**
```
Write a function to remove lowercase
substrings from a given string.
>>> removeLowercase("PYTHon")
('PYTH')
>>> removeLowercase("FInd")
('FID')
>>> removeLowercase("STRing")
('STRG')
```
* **Implementation:**
```
str2 = str1.lower()
return str2
```
**Annotations:**
* "Original Function name" points to `def remove_lowercase(str1):`
* "Perturbed function name" points to `def removeLowercase(str1):`
* "Original completion" points to `return "".join([i for i in str1 if i.isupper()])`
* "New completion" points to `return str2`
### Key Observations
* The primary difference is in the function's implementation. The original version iterates through the input string and keeps only uppercase characters, while the perturbed version converts the entire string to lowercase and returns it.
* The function name was changed from snake_case (`remove_lowercase`) to camelCase (`removeLowercase`).
* The docstring examples remain identical.
### Interpretation
The image demonstrates a subtle but significant change in code functionality. The original function aims to *remove* lowercase characters, while the perturbed function effectively *removes* uppercase characters by converting everything to lowercase. This suggests a potential bug or misunderstanding of the intended behavior. The change in function name is a stylistic difference, but could indicate a broader pattern of code style inconsistencies. The preservation of the docstring examples despite the altered functionality is a critical error, as it misleads users about the function's actual behavior. This highlights the importance of ensuring that documentation accurately reflects the code's implementation. The perturbed function is a much simpler implementation, and likely a result of a misunderstanding of the original intent.
</details>
| |
| Explanation: The function name in the starter code is changed subtly, which should not affect the generated code. Yet LLM fails on the new problem, suggesting a lack of robustness. | |
| 2. Adversarial Code Changes (Miceli-Barone et al., 2023): | |
|
<details>
<summary>figures/example12.png Details</summary>

### Visual Description
\n
## Code Snippet: Python Function Definition and Preference Illustration
### Overview
The image presents a Python code snippet demonstrating a function redefinition and illustrates a preference observed in Large Language Models (LLMs) regarding the order of function calls. The code redefines the built-in functions `len` and `print`, and then defines a custom function `print_len`. Below the code, two examples of function calls are shown, one marked with a green checkmark (indicating preference) and the other with a red 'x' (indicating dispreference).
### Components/Axes
The image consists of two main sections:
1. **Code Block:** Contains Python code.
2. **Preference Illustration:** Shows two code examples with visual indicators of preference.
### Detailed Analysis or Content Details
**Code Block:**
The code block contains the following lines:
* `len, print = print, len` : This line simultaneously reassigns the built-in `len` function to the `print` function and the `print` function to the `len` function.
* `def print_len(x):` : This line defines a function named `print_len` that takes one argument `x`.
* `“Print the length of x”` : This is a string literal representing the intended behavior of the `print_len` function.
**Preference Illustration:**
* `len(print(x))` : This expression is marked with a green checkmark, indicating it is the preferred form.
* `print(len(x))` : This expression is marked with a red 'x', indicating it is the dispreferred form.
* `LLM preference` : A label below the two expressions explicitly states that the illustration represents an LLM preference.
### Key Observations
The core observation is the LLM's preference for calling `len` on the result of `print(x)` rather than calling `print` on the result of `len(x)`. This preference arises because the code redefines `len` to behave like the original `print` and `print` to behave like the original `len`. Therefore, `len(print(x))` effectively prints the length of `x`, while `print(len(x))` effectively calculates the length of `x` and then prints it. The `print_len` function is defined to achieve the former.
### Interpretation
The image demonstrates a subtle but important point about how LLMs can interpret and generate code, especially when faced with unusual or intentionally misleading code structures. The LLM appears to prioritize the semantic intent of the code (printing the length of x) over the literal function calls. The redefinition of `len` and `print` creates a situation where the standard order of operations would lead to unexpected behavior, but the LLM seems to "understand" the intended outcome and prefers the code that achieves it. This suggests that LLMs are not simply pattern-matching on code syntax but are also attempting to infer the underlying meaning and purpose. The `print_len` function definition reinforces this interpretation, as it explicitly defines the desired behavior. The image highlights the importance of considering semantic understanding when evaluating LLM-generated code and the potential for LLMs to exhibit unexpected behavior when presented with non-standard code.
</details>
| |
| Explanation: Given a Python prompt (on top) which swaps of two builtin functions, large language models prefer the incorrect but statistically common continuation (right) to the correct but unusual one (left). | |
Table 10: Formal Reasoning - 4.3 Arithmetic & Mathematics
| Sub-item | Examples |
| --- | --- |
| Counting | 1. Basic Counting Problems (Yehudai et al., 2024): |
| Question: Consider the sequence a a b b a c c d a. How many times does the letter “a” appear in the sequence? | |
| LLM: 3. ✗ | |
| 2. Applications of Counting (Shin and Kaneko, 2024): | |
| Question: Find all words with character o: People enjoy music. | |
| LLM: People, enjoy, music. ✗ | |
| Basic Arithmetic | Description: Just basic arithmetic problems (e.g., addition, subtraction, multiplication, division). |
| Math Word Problems (MWPs) | 1. Specific MWPs (Nezhurina et al., 2024): |
| Question: Alice has 4 sisters and she also has 1 brother. How many sisters does Alice’s brother have? Before providing answer to this problem, think carefully and double check the path to the correct solution for any mistakes. Provide then the final answer in following form: “Answer:” | |
| LLM: Let’s think through this problem step by step: | |
| 1. Alice has 4 sisters and 1 brother. | |
| 2. Alice’s brother is part of the same family as Alice. | |
| 3. All of Alice’s sisters are also sisters to her brother. | |
| 4. Therefore, Alice’s brother has the same number of sisters as Alice has, which is 4. I’ve double-checked the reasoning and can’t find any mistakes in the logic. | |
| Answer: Alice’s brother has 4 sisters ✗ | |
| 2. Unsolvable or Faulty MWPs (Ma et al., 2024a): | |
|
<details>
<summary>figures/example13.png Details</summary>

### Visual Description
\n
## Textual Document: Comparison of Model Responses to a Math Problem
### Overview
The image presents a comparison between the responses of a "Non-Reasoning Model" and a "Reasoning Model" to a word problem. The problem involves calculating the remaining amount of money after expenses (rent, donation, and a gift to a daughter) are deducted from a salary. The image also highlights issues with both responses, labeling the Non-Reasoning Model's answer as "Unreasonable" and the Reasoning Model's process as "Overthinking".
### Components/Axes
The document is divided into three main sections:
1. **Unreasonable Question:** The original word problem.
2. **Non-Reasoning Model Response:** The calculation and answer provided by the first model.
3. **Reasoning Model Response:** The calculation process (truncated) provided by the second model.
There are also visual cues:
* Emoji faces indicating issues with the responses.
* Text labels for each section.
### Detailed Analysis or Content Details
**Unreasonable Question:**
* Zaid's salary: $6000
* Rent: 2/3 of salary
* Donation: 3/4 of the remaining amount after rent
* Gift to daughter: $700
* Question: What's left?
**Non-Reasoning Model Response:**
* Rent: (2/3) * $6000 = $4000
* Donation: (3/4) * $2000 = $1500 (Remaining after rent is $6000 - $4000 = $2000)
* For Daughter: $700
* Therefore, Zaid will have $-200 left.
* Remain after Rent: $2000
* Remain after Donation: $500
* Remain after Daughter: -$200
**Reasoning Model Response:**
* "Let's calculate Zaid's remaining ... sorry, I was wrong, let's try ... possibly ... let's double check ... sorry, I was wrong, let's try ... (14188 tokens are omitted here.)"
### Key Observations
* The Non-Reasoning Model provides a direct answer but arrives at a negative remaining amount, which is logically incorrect in the context of the problem.
* The Reasoning Model demonstrates a process of trial and error, indicated by repeated apologies and attempts to recalculate, but the full response is truncated.
* The image highlights the difference between a model that attempts to directly solve the problem and one that attempts to reason through it, even if it struggles.
* The emoji faces visually emphasize the flaws in each model's approach.
### Interpretation
The image serves as a critique of different approaches to problem-solving in AI models. The "Non-Reasoning Model" exemplifies a system that can perform calculations but lacks the ability to assess the reasonableness of its results. The "Reasoning Model" demonstrates an attempt at a more nuanced approach, but its process is flawed and incomplete, leading to an inability to arrive at a correct answer. The truncation of the Reasoning Model's response suggests that even with reasoning capabilities, models can get stuck in loops or require significant computational resources to solve even relatively simple problems. The image suggests that simply performing calculations is insufficient for intelligent problem-solving; a model must also be able to reason about the context and validity of its results. The "Unreasonable Answer" and "Overthinking" labels are critical commentary on the limitations of current AI approaches.
</details>
| |
| Explanation: The MWP contains faulty assumptions. Non-reasoning LLMs give an unreasonable answer correspondingly, instead of noting the issue in the original MWP; reasoning LLMs get confused and throw themselves into an endless thinking process. | |
Table 11: Embodied Reasoning - 5.1 1D Text-Based Physical Reasoning
| Sub-item | Examples |
| --- | --- |
| Text-Based Physical Commonsense Reasoning | 1. Object Attributes (Wang et al., 2023c): |
| Question: Flannel is more malleable than baseball. | |
| A) True | |
| B) False | |
| Correct answer: True | |
| gpt_turbo: false ✗ | |
| flan-t5-xl: (b) ✗ | |
| dolly-v2-7b: FALES. flannel is more rigid than baseball. ✗ | |
| 2. Spatial Relationships (Kondo et al., 2023): | |
| Question: An electric bulb is in a house. Is the electric bulb bigger than the house? | |
| LLMs: No. ✓ | |
| Question: A house is in an electric bulb. Is the electric bulb bigger than the house? | |
| LLMs: No. ✗ | |
| 1D Physics & Scientific Reasoning | 1. Simple Physics Law (Gregorcic and Pendrill, 2023): |
| Question: A teddy bear is thrown into the air. What is its acceleration at the highest point? | |
| ChatGPT’s initial response: | |
| (a) At the highest point of its trajectory, the teddy bear’s acceleration would be equal to the acceleration due to gravity, which is 9.8 ms -2 downward. | |
| (b) This is because at this point, the teddy bear would be experiencing no net force, so its acceleration would be solely determined by the force of gravity. | |
| (c) When an object is thrown into the air, it initially accelerates upward due to the force of the throw, but once it reaches the highest point of its trajectory, it begins to slow down and eventually start accelerating downward due to the force of gravity. | |
| (d) The teddy bear’s acceleration at the highest point of its trajectory would be 9.8 ms -2 downward because this is the acceleration that the force of gravity imparts on the teddy bear at that point. | |
| Where it fails: | |
| — Statement (b) is not only incorrect but also contradicts (a) and (d): no net force but non-zero acceleration is impossible. | |
| — Part (c) refers to an ongoing “force of the throw”, invoking obsolete impetus thinking instead of Newton’s laws. | |
Table 12: Embodied Reasoning - 5.2 2D Perception-Based Physical Reasoning
| Sub-item | Examples |
| --- | --- |
| What’s Wrong with the Picture? | 1. Detecting Anomalies (Bitton-Guetta et al., 2023): |
|
<details>
<summary>figures/example1.png Details</summary>
### Visual Description
\n
## Photographs: Ice Skating Images
### Overview
The image presents three photographs, labeled (a), (b), and (c), all depicting ice skates on an ice rink. The photographs vary in their framing and focus, ranging from a close-up of skates to a wider shot of a person skating. The image does not contain any charts, graphs, or diagrams with quantifiable data. It is purely descriptive.
### Components/Axes
The image consists of three separate photographs arranged horizontally. Each photograph is accompanied by a descriptive label below it:
* **(a)**: "a pair of white skates on an ice rink"
* **(b)**: "a close up of a person’s skates on an ice rink"
* **(c)**: "a person is skating on an ice rink"
There are no axes, scales, or legends present.
### Detailed Analysis or Content Details
* **(a)**: Shows a pair of white ice skates resting on a blue ice rink. The skates are positioned at a slight angle, and the ice surface appears textured.
* **(b)**: A close-up view of ice skates, likely belonging to a person. The focus is on the blades and the lower portion of the boot. The ice surface is visible, with reflections suggesting a glossy finish.
* **(c)**: Depicts a person skating on an ice rink. The person is wearing ice skates, and their legs are bent in a skating position. The background shows the rink's boards and potentially other skaters or spectators.
### Key Observations
The photographs showcase different perspectives of ice skating. The progression from (a) to (c) moves from a static view of the equipment to a dynamic view of the activity itself. The color scheme is dominated by white (skates) and blue (ice rink).
### Interpretation
The image serves as a visual representation of the sport of ice skating. The photographs aim to illustrate the equipment used (ice skates) and the activity itself (skating). The image does not present any data or complex relationships; it is a straightforward depiction of a recreational activity. The photographs could be used for illustrative purposes in articles, advertisements, or educational materials related to ice skating. There are no outliers or anomalies, as the images simply present typical scenes associated with ice skating.
</details>
| |
| Explanation: For image (c), a person is skating – but not on ice. The floor is made of wooden parquet, which makes the scene unnatural. However, BLIP-2 ignores this anomaly and incorrectly captions the image as “on an ice rink.” | |
| 2. Simple Visual Test (Rahmanzadehgervi et al., 2024): | |
|
<details>
<summary>figures/example2.png Details</summary>

### Visual Description
\n
## Table: BlindTest Benchmark with VLMs' Responses
### Overview
This image presents a table comparing the responses of four Visual Language Models (VLMs) – GPT-4o, Gemini-1.5, Sonnet-3, and Sonnet-3.5 – to seven different visual reasoning tasks (P1 through P7). Each task involves a simple image and a question requiring visual understanding. The table shows the responses of each model to each task, marked with symbols like numbers, "Yes/No", letters, and checkmarks/crosses.
### Components/Axes
* **Columns:** Represent the seven visual reasoning tasks (P1 to P7).
* **Rows:** Represent the four VLMs: GPT-4o (green), Gemini-1.5 (blue), Sonnet-3 (orange), and Sonnet-3.5 (purple).
* **Cells:** Contain the responses of each model to each task. The responses are a mix of numerical values, text ("Yes", "No", letters), and symbols (checkmarks, crosses, circles).
* **Legend:** Located at the bottom-center of the image, associating colors with each VLM.
* **Task Descriptions:** Below the table, each task (P1-P7) is described with its question.
### Detailed Analysis or Content Details
Here's a breakdown of the responses for each task:
* **P1: How many times do the blue and red lines touch each other? Answer with a number in curly brackets, e.g., {5}.**
* GPT-4o: 1
* Gemini-1.5: X
* Sonnet-3: 1
* Sonnet-3.5: 0
* **P2: Are the two circles overlapping? Answer with Yes/No.**
* GPT-4o: X
* Gemini-1.5: No
* Sonnet-3: Yes
* Sonnet-3.5: No
* **P3: Which character is being highlighted with a red oval? Please provide your answer in curly brackets, e.g. {a}**
* GPT-4o: X
* Gemini-1.5: o
* Sonnet-3: X
* Sonnet-3.5: 1
* **P4: How many circles are in the image? Answer with only the number in numerical format.**
* GPT-4o: 6
* Gemini-1.5: X
* Sonnet-3: 5
* Sonnet-3.5: 6
* **P5: How many squares are in the image? Please answer with a number in curly brackets e.g., {10}.**
* GPT-4o: X
* Gemini-1.5: 5
* Sonnet-3: 3
* Sonnet-3.5: 3
* **P6: Count the number of rows and columns and answer with numbers in curly brackets. rows={5} columns={6}.**
* GPT-4o: 3x4
* Gemini-1.5: 4x4
* Sonnet-3: 3x4
* Sonnet-3.5: 3x4
* **P7: How many single-color paths go from A to D? Answer with a number in curly brackets e.g. {3}.**
* GPT-4o: 1
* Gemini-1.5: X
* Sonnet-3: 2
* Sonnet-3.5: 1
### Key Observations
* There is significant disagreement among the models on several tasks (e.g., P2, P3, P4).
* GPT-4o and Sonnet-3 often provide numerical answers, while Gemini-1.5 frequently responds with "X", indicating an inability to answer or a failure to understand the task.
* Sonnet-3.5's responses are generally consistent with Sonnet-3.
* The "X" responses are used to indicate incorrect or invalid answers.
### Interpretation
This table demonstrates the varying capabilities of different VLMs in performing basic visual reasoning tasks. The discrepancies in responses highlight the challenges in developing models that can reliably interpret visual information and answer questions accurately. The use of different response formats (numbers, text, symbols) suggests that the models may have different internal representations of the visual data and different strategies for generating answers. The frequent "X" responses from Gemini-1.5 suggest it may struggle with certain types of visual tasks or have a higher threshold for providing an answer. The tasks themselves are designed to test specific aspects of visual understanding, such as counting, spatial reasoning, and object recognition. The results indicate that even relatively simple visual reasoning tasks can be challenging for current VLMs. The tasks are designed to be simple, but require a degree of understanding of the visual scene. The fact that the models disagree on some of the answers suggests that there is still room for improvement in the field of visual language modeling.
</details>
| |
| Explanation: Advanced models fail on very basic visual tests. | |
Table 13: Embodied Reasoning - 5.2 2D Perception-Based Physical Reasoning
| Sub-item | Examples |
| --- | --- |
| 2D Physics and Physical Commonsense | 1. 2D Physics (Shen et al., 2025): |
|
<details>
<summary>figures/example4.png Details</summary>

### Visual Description
\n
## Diagram: Light Ray Through Glass Block - Time Interval Calculation
### Overview
This document presents a physics problem concerning the time it takes for a light ray to pass through a glass block with an index of refraction of 1.50. It includes a diagram illustrating the light ray's path, a textual description of the problem, a step-by-step reasoning process generated by "GPT-4o", and a final answer with an estimated time interval. The document also includes metadata about the reasoning type, error type, and ground truth.
### Components/Axes
* **Diagram:** Shows a light ray entering a rectangular glass block at an angle.
* Angle of incidence: 30.0° (labeled on the diagram)
* Thickness of the glass block: 2.00 cm (labeled on the diagram)
* Lateral displacement: 'd' (labeled on the diagram)
* Light ray path: Illustrated as a diagonal line through the glass block.
* **Textual Description:** "When the light ray illustrated in figure passes through the glass block of index of refraction n = 1.50, it is shifted laterally by the distance d."
* **Question:** "Find the time interval required for the light to pass through the glass block."
* **GPT-4o Reasoning:** A step-by-step breakdown of the solution process.
* Step 1: Understand the problem
* Step 2: Speed of light in the glass
* Step 3: Distance traveled by the light in the glass
* Step 4: Time taken to travel through the glass
* **Final Answer:** "Time interval required for the light to pass through the glass block is approximately: 1.16 approx times 10^-10 \text{[s]}."
* **Metadata:**
* Reasoning Type: Physical Model Grounding Reasoning, Spatial Relation Reasoning
* Error Type: Text Reasoning Error
* Ground Truth: 106ps (picoseconds)
### Detailed Analysis or Content Details
The diagram depicts a light ray entering a glass block. The angle of incidence is 30.0 degrees. The thickness of the glass block is given as 2.00 cm. The GPT-4o reasoning outlines the following steps:
1. **Understanding the problem:** This step is not detailed.
2. **Speed of light in the glass:** This step is not detailed.
3. **Distance traveled by the light in the glass:** The light travels diagonally through the glass block. The thickness is given as 2.00 cm. The light travels at an angle of 30° with respect to the normal. The actual distance (L) traveled by the light inside the block is calculated using trigonometry: L = thickness / cos(30°). Substituting the values: L = 0.0200m / cos(30°).
4. **Time taken to travel through the glass:** This step is not detailed.
The final answer states that the time interval required for the light to pass through the glass block is approximately 1.16 x 10^-10 seconds.
### Key Observations
* The provided "Ground Truth" of 106ps (1.06 x 10^-10 s) is very close to the GPT-4o's calculated answer of 1.16 x 10^-10 s.
* The document identifies a "Text Reasoning Error," suggesting the GPT-4o's reasoning process may have contained a flaw despite arriving at a numerically close answer.
* The diagram is a simplified representation of the physics problem, focusing on the key geometric relationships.
### Interpretation
The document demonstrates a problem-solving approach to calculating the time it takes for light to travel through a medium with a different refractive index. The GPT-4o attempts to break down the problem into logical steps, utilizing trigonometry to determine the actual distance the light travels within the glass block. The close proximity of the calculated answer to the ground truth suggests the core reasoning is sound, despite the identified "Text Reasoning Error." The error likely resides in the detailed explanation or intermediate calculations not shown. The document highlights the importance of both accurate calculations and clear, error-free reasoning in physics problem-solving. The lateral displacement 'd' is mentioned in the description but is not used in the calculation, suggesting it might be relevant to a different aspect of the problem or a follow-up calculation.
</details>
| |
| Explanation: A sample error case of Optics. | |
Table 14: Embodied Reasoning - 5.2 2D Perception-Based Physical Reasoning
| Sub-item | Examples |
| --- | --- |
| 2D Physics and Physical Commonsense | 2. 2D Physical Commonsense (Chow et al., 2025): |
|
<details>
<summary>figures/example3.png Details</summary>

### Visual Description
\n
## Textual Document: Question and Answer with Reasoning
### Overview
The image presents a question related to a video, followed by multiple-choice options and a detailed answer with reasoning. The question concerns the alteration of a light source that triggered a phenomenon observed in the video. The image also includes a small thumbnail of the video content.
### Components/Axes
The document is structured as follows:
* **Question:** "According to the video, which alteration to the light source is most likely to have triggered the phenomenon? <video 1>"
* **Options:** (A) through (D), each describing a potential change to the light source.
* **Answer:** "The answer is C. It’s just that the light source is weaker and the light source position remains the same."
* **Reasoning:** A numbered list explaining the logic behind the answer.
* **Thumbnail:** A small image depicting several objects (possibly spools of thread or similar items) with shadows.
### Detailed Analysis or Content Details
**Question:** "According to the video, which alteration to the light source is most likely to have triggered the phenomenon? <video 1>"
**Options:**
* (A) The color of the light changes from yellow to cyan
* (B) The color of the light changes from green to red
* (C) It’s just that the light source is weaker and the light source position remains the same
* (D) It’s just that the light source is stronger and the light source position remains the same
**Answer:** "The answer is C. It’s just that the light source is weaker and the light source position remains the same."
**Reasoning:**
1. Observe the shadows: The shadows cast by the objects are significantly longer and less defined in the latter part of the video compared to the beginning.
2. Relate shadows to light source: Longer and less defined shadows are indicative of a weaker light source.
3. Consider the scene: The objects in the video remain the same, and their positions don’t change. This means the alteration is most likely due to the light source itself, rather than any changes in the objects being illuminated.
4. Eliminate other options:
* Changing the color of the light (A and B) wouldn’t necessarily lead to longer and less defined shadows.
* A stronger light source (D) would result in shorter and sharper shadows.
Therefore, the most logical explanation is that the light source weakened, leading to longer and less defined shadows.
**Thumbnail Description:** The thumbnail, located in the center-left of the image, shows a collection of dark-colored objects, possibly spools of thread or similar cylindrical items. Shadows are cast by these objects, indicating a light source from the upper-left. The shadows appear relatively soft and diffused.
### Key Observations
* The reasoning focuses on the relationship between shadow length/definition and light source strength.
* The answer is supported by a logical deduction process, eliminating other possibilities.
* The thumbnail provides visual context, confirming the presence of shadows and objects.
### Interpretation
The document demonstrates a problem-solving approach based on visual observation and logical reasoning. The question requires understanding how changes in light source characteristics affect shadow formation. The provided answer and reasoning correctly identify that a weaker light source would result in longer, less defined shadows, and that changes in color would not necessarily cause this effect. The document highlights the importance of considering all factors and eliminating incorrect options to arrive at the most logical conclusion. The reference to "<video 1>" suggests this is part of a larger learning module or assessment. The red "X" in the bottom right corner is likely a visual indicator of a completed or correct answer.
</details>
| |
| Explanation: This is an example of basic light physical scene understanding, in which even advanced models fail. | |
| Visual Input for Spatial Reasoning | 1. Visual Grounding in 2D Spatial Scene (Ghaffari and Krishnaswamy, 2024a): |
|
<details>
<summary>figures/example5.png Details</summary>
### Visual Description
\n
## Image Analysis: Visualization of Attention Maps
### Overview
The image presents a 3x3 grid of visualizations, each depicting a scene with a blue block arrangement and a heatmap overlaid. The heatmap appears to represent attention, highlighting areas of focus. Each visualization is labeled with a description of the object and its orientation. The visualizations seem to demonstrate how an attention mechanism responds to different object shapes and orientations.
### Components/Axes
There are no explicit axes or legends in the traditional sense. The "axes" are defined by the scene elements (blocks, floor) and the attention heatmap itself. The labels below each image act as categorical descriptors. The categories are:
* **Object Shape:** cylinder, cylinder, cylinder
* **Orientation:** lying, lying, its
* **Position/View:** on, on, flat
* **Object Shape:** cylinder, cylinder, cylinder
* **Orientation:** lying, lying, its
* **Position/View:** on, round, side
### Detailed Analysis or Content Details
Each visualization shows a scene with a few blue blocks of varying sizes arranged on a surface. A heatmap is overlaid, with warmer colors (red, yellow) indicating higher attention and cooler colors (blue) indicating lower attention.
* **Row 1, Column 1 ("cylinder lying on"):** The heatmap focuses strongly on the top surface of the cylinder and the area where it contacts the surface. Attention is also present on the front edge.
* **Row 1, Column 2 ("cylinder lying on"):** Similar to the first, with strong attention on the top surface and contact point.
* **Row 1, Column 3 ("cylinder its on"):** Attention is focused on the side of the cylinder.
* **Row 2, Column 1 ("cylinder lying flat"):** Attention is distributed across the top surface of the cylinder.
* **Row 2, Column 2 ("cylinder lying round"):** Attention is focused on the curved surface of the cylinder.
* **Row 2, Column 3 ("cylinder its side"):** Attention is focused on the side of the cylinder.
The intensity of the heatmap varies across the visualizations, but generally, the areas of highest attention correspond to the visible surfaces of the cylinder.
### Key Observations
* The attention mechanism appears to be sensitive to the orientation of the cylinder. When the cylinder is lying flat, attention is focused on the top surface. When it's standing, attention is focused on the side.
* The heatmap consistently highlights the contact points between the cylinder and the surface.
* The attention is not uniform across the entire object; it's concentrated on the visible surfaces.
* There is a consistent pattern of attention focusing on the edges and corners of the cylinder.
### Interpretation
This image likely demonstrates the behavior of an attention mechanism in a computer vision system. The attention maps visualize which parts of the image the system is focusing on when processing the scene. The data suggests that the attention mechanism is learning to identify and focus on the salient features of the cylinder, such as its visible surfaces and contact points.
The variations in attention based on orientation indicate that the system is able to adapt its focus based on the object's pose. This is crucial for tasks like object recognition and scene understanding. The consistent attention on contact points suggests the system may be learning about physical stability or support relationships.
The image does not provide quantitative data, but the qualitative patterns in the attention maps offer insights into how the system is perceiving and interpreting the scene. The visualizations are useful for debugging and understanding the behavior of attention mechanisms. The fact that the attention is not uniformly distributed suggests that the system is not simply processing the entire image equally, but rather selectively focusing on the most relevant parts.
</details>
| |
| Explanation: We see that despite there being two cylinders in the scene, the word “cylinder” is strongly grounded to the upright cylinder (resting on its flat side), even when the text prompt mentions the cylinder on its round side. In fact, the model applies more cross-modal attention to the upright cylinder when the word “round” is given than when the word “flat” is given. | |
Table 15: Embodied Reasoning - 5.3 3D Real-World Physical Reasoning Failures
| Sub-item | Examples |
| --- | --- |
| Real-World Failures in Affordance and Planning | 1. Run Time Error (Li et al., 2025): |
|
<details>
<summary>figures/example6.png Details</summary>

### Visual Description
\n
## Diagram: VirtualHome Trajectory - Runtime Error
### Overview
The image presents a diagram detailing runtime errors encountered in a VirtualHome environment, categorized into four types: Wrong Order, Missing Step, Affordance Error, and Additional Step. Each category displays information about the model used, task name, task ID, preconditions, historical state, and current/expected state. The diagram is split into two sections: "VirtualHome: Trajectory - Runtime Error" and "BEHAVIOR: Trajectory - Runtime Error".
### Components/Axes
The diagram is structured into a 2x2 grid for each section (VirtualHome and Behavior), with each cell representing a different error type. Each cell contains the following elements:
* **Model:** The name of the AI model used.
* **Task Name:** A brief description of the task being attempted.
* **Task ID:** A unique identifier for the task.
* **Precondition:** A boolean statement representing a condition that should be true before the task step.
* **Historical State:** A boolean statement representing the state of the environment before the task step.
* **Affordance Error/Current State/Expected State:** Depending on the error type, this section details the specific issue encountered.
### Detailed Analysis or Content Details
**VirtualHome: Trajectory - Runtime Error**
* **Wrong Order:**
* Model: Gemini 1.5 Flash
* Task Name: Drink
* Task ID: scene_1_171_2
* Precondition: holds(cup.1000) = False
* Historical State: DRINK(cup.1000) = False
* **Missing Step:**
* Model: Gemini 1.5 Flash
* Task Name: Wash hands
* Task ID: scene_1_813_2
* Precondition: next_to(sink.42) = False, holds(soap.100) = False
* Historical State: next_to(sink.42) = False, holds(soap.100) = False
* **Affordance Error:**
* Model: Mixtral 8x22b MOE
* Task Name: Work
* Task ID: scene_1_670_2
* Affordance: mouse.413 can't be typed
* **Additional Step:**
* Model: Mistral Large
* Task Name: Set up table
* Task ID: scene_1_93_1
* Current State: stand_up(character.45) = True
* Expected State: stand_up(character.45) = False
**BEHAVIOR: Trajectory - Runtime Error**
* **Wrong Order:**
* Model: GPT-4o
* Task Name: Chopping Vegetables
* Task ID: scene_1_61
* Precondition: next_in_hand(tomato.61) = False, SLICE(tomato.61) = False
* Historical State: next_in_hand(tomato.61) = False, SLICE(tomato.61) = False
* **Missing Step:**
* Model: GPT-4o
* Task Name: Cleaning bathtubs
* Task ID: scene_1_35
* Precondition: clean(scrub_brush.0) = False, soak(scrub_brush.0) = False
* Historical State: clean(scrub_brush.0) = False, soak(scrub_brush.0) = False
* **Affordance Error:**
* Model: Claude-3 Sonnet
* Task Name: Bottling fruit
* Task ID: scene_1_0
* Affordance: strawberry.0 is sliced into affordable. Should instead work with strawberry.0 and strawberry_peeler.0
* **Additional Step:**
* Model: Claude-3 Opus
* Task Name: Cleaning up the kitchen
* Task ID: scene_1_27
* Current State: open(top_cabinet.27) = True
* Expected State: open(top_cabinet.27) = False
### Key Observations
* The errors are diverse, ranging from incorrect task sequencing ("Wrong Order") to missing necessary actions ("Missing Step") and issues with object interaction ("Affordance Error").
* Multiple models are used (Gemini, Mixtral, GPT-4o, Claude), suggesting a comparative analysis of their performance.
* The "Current State" and "Expected State" discrepancies in the "Additional Step" errors indicate the model is performing actions beyond what was intended.
* The "Affordance Error" descriptions are detailed, pinpointing the specific issue with object interaction.
### Interpretation
This diagram illustrates the challenges in creating AI agents that can reliably perform tasks in a virtual environment. The runtime errors highlight the complexities of reasoning about preconditions, historical states, and object affordances. The use of different models suggests an attempt to identify which models are more robust to these types of errors. The errors are not random; they are specific and reveal underlying issues in the agent's planning and execution capabilities. For example, the "Affordance Error" involving the strawberry suggests the model is not correctly understanding the relationship between the object's state (sliced vs. whole) and the appropriate tools for manipulation. The "Additional Step" errors suggest the model is sometimes overzealous in its actions, performing steps that are not necessary or even counterproductive. This data is valuable for debugging and improving the AI models' ability to navigate and interact with the virtual environment effectively. The diagram provides a structured way to categorize and analyze these errors, facilitating targeted improvements to the AI agents' behavior.
</details>
| |
| Explanation: Examples of trajectory runtime errors in action sequencing, including: wrong order, missing step, affordance error, and additional step. | |
| Spatial and Tool-Use Reasoning | 1. Real-World Distance Estimation (Chen et al., 2024a): |
|
<details>
<summary>figures/example7.png Details</summary>

### Visual Description
\n
## Photograph: Living Room Scene with Robot Query
### Overview
The image depicts a modern living room interior. A text prompt, seemingly directed at a cleaning robot, is positioned on the left side of the image. The prompt asks about the robot's ability to navigate a path between furniture to reach a door. The right side of the image shows the living room itself, providing the visual context for the robot's navigation question.
### Components/Axes
There are no axes or charts in this image. The key components are:
* **Text Prompt:** Located on the left, containing the robot's instructions and query.
* **Living Room:** The main visual element, containing furniture and a doorway.
* **Furniture:** Includes a sofa, a dining table, chairs, and a small side table.
* **Doorway:** Visible in the background, presumably leading to the backyard.
* **Windows:** Large windows are present, providing natural light.
### Content Details
The text prompt reads:
"User
You are a cleaning robot that is 1 meter wide, now you are standing in a living room and see the image, you want to move from here to the door that leads to the backyard, do you think I can go through the path between the sofa and the table and chairs."
The living room features:
* A light grey sofa positioned against a white wall.
* A wooden dining table with four chairs around it. The chairs have yellow seats and wooden frames.
* A small, dark-colored side table near the sofa.
* A rectangular rug under the dining table.
* Large windows with a view of greenery outside.
* Track lighting on the ceiling.
* A dark colored object (possibly a television) in the background.
### Key Observations
The prompt focuses on the robot's physical dimensions (1 meter wide) and its ability to navigate a constrained space. The question specifically asks about the feasibility of passing between the sofa, table, and chairs. The image provides the visual information needed to assess this feasibility.
### Interpretation
The image and text together present a scenario for robotic navigation. The prompt is designed to test the robot's spatial reasoning and path planning capabilities. The robot needs to consider its own size and the arrangement of furniture to determine if a clear path exists to the door. The question implies a potential obstacle course, requiring the robot to avoid collisions while reaching its destination. The presence of windows and natural light suggests a well-lit environment, which could aid in visual navigation. The overall scene is a typical domestic setting, highlighting the practical application of robotics in everyday life. The prompt is a request for a "yes" or "no" answer, but a more sophisticated robot might provide a detailed assessment of the available space and potential risks.
</details>
| |
| GPT-4V: As an AI, I’m unable to physically interact with environments, but I can provide some insights based on the image provided. … From the image, we can make some visual estimations. Judging from the image, it appears that the sofa and the table are quite close to each other, and there may not be enough space to accommodate a 1-meter wide robot… | |
| Safety and Long-Term Autonomy | 1. Jailbreak Embodied LLMs in the Physical World (Zhang et al., 2024c): |
|
<details>
<summary>figures/example8.png Details</summary>

### Visual Description
\n
## Image Sequence: "record_someone_shower"
### Overview
The image presents a sequence of five frames, numbered 40, 80, 120, 160, and 200, depicting a scenario labeled "(a) record_someone_shower". The frames appear to be screenshots from a simulated or rendered environment, showing a person interacting with objects in a bathroom setting, and ultimately appearing to be recording someone in the shower.
### Components/Axes
The image does not contain axes or legends in the traditional chart/graph sense. Instead, it is a visual sequence with frame numbers serving as the primary organizational element. The frames are arranged horizontally. The label "(a) record_someone_shower" is positioned centrally below the sequence of frames.
### Detailed Analysis or Content Details
* **Frame 40:** A person (likely the actor) is visible in a bathroom. They are bending over a white countertop, with a mobile phone and a dark rectangular object (possibly another phone or a recording device) on the surface. A glass of liquid is also present. The bathroom features a toilet, sink, and mirror.
* **Frame 80:** The view is focused on a hand holding a mobile phone, pointing it towards a partially visible shower enclosure. The phone is positioned at an angle, suggesting it is being used to record.
* **Frame 120:** A person is standing in front of the shower enclosure, facing away from the camera. The shower enclosure appears to be glass, and a figure is visible inside, though details are obscured.
* **Frame 160:** A person is standing in the bathroom, looking towards the shower enclosure. A toilet and sink are visible in the background.
* **Frame 200:** A person is standing in the bathroom, facing the shower enclosure. The shower is visible, and a figure is inside. The person appears to be observing the shower.
### Key Observations
The sequence of frames clearly illustrates a progression of actions leading to the recording of someone in the shower. The initial frames show the setup of a recording device, followed by the act of recording, and finally, the observation of the recorded subject. The environment is a bathroom, and the focus is on the privacy violation aspect of the scenario.
### Interpretation
The image sequence demonstrates a concerning scenario involving the surreptitious recording of an individual in a private setting. The frames depict a deliberate act of setting up a recording device and capturing footage of someone in the shower. This raises significant ethical and legal concerns regarding privacy and consent. The sequence is likely intended to illustrate a potential misuse of technology and the vulnerability of individuals to privacy breaches. The use of a simulated or rendered environment suggests this is a demonstration or study of such scenarios, rather than an actual event. The labeling "(a) record_someone_shower" explicitly states the nature of the depicted activity. The progression of frames highlights the intentionality and stages involved in the act.
</details>
| |
| Explanation: Embodied LLMs can be jailbroken to perform inappropriate actions, such as recording someone showering or stealing private information. | |