# Learning to Self-Verify Makes Language Models Better Reasoners
**Authors**: Yuxin Chen, Yu Wang, Yi Zhang, Ziang Ye, Zhengzhou Cai, Yaorui Shi, Qi Gu, Hui Su, Xunliang Cai, Xiang Wang, An Zhang, Tat-Seng Chua
Abstract
Recent large language models (LLMs) achieve strong performance in generating promising reasoning paths for complex tasks. However, despite powerful generation ability, LLMs remain weak at verifying their own answers, revealing a persistent capability asymmetry between generation and self-verification. In this work, we conduct an in-depth investigation of this asymmetry throughout training evolution and show that, even on the same task, improving generation does not lead to corresponding improvements in self-verification. Interestingly, we find that the reverse direction of this asymmetry behaves differently: learning to self-verify can effectively improve generation performance, achieving accuracy comparable to standard generation training while yielding more efficient and effective reasoning traces. Building on this observation, we further explore integrating self-verification into generation training by formulating a multi-task reinforcement learning framework, where generation and self-verification are optimized as two independent but complementary objectives. Extensive experiments across benchmarks and models demonstrate performance gains over generation-only training in both generation and verification capabilities. Our code is publicly available at https://github.com/chenyuxin1999/Learning-to-Self-Verify.
Machine Learning, ICML
1 Introduction
Large language models (LLMs) have demonstrated strong capabilities in complex reasoning (DeepSeek-AI, 2025; Yang et al., 2025a; Team, 2025; OpenAI, 2025). With the advancement of Reinforcement Learning with Verifiable Rewards (RLVR), current models have made substantial progress on verifiable tasks such as mathematics and programming (Shao et al., 2025; Anthropic, 2025; Z.AI, 2025), while also showing consistent improvements on open-domain tasks including writing, dialogue, and general problem solving (DeepSeek-AI et al., 2025; MiniMax, 2025; Bhaskar et al., 2025; Zeng et al., 2025b). Despite these advances, a fundamental asymmetry remains: even the most powerful models often lack the ability to reliably verify the correctness of their own outputs.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Chart: Learning Curves for Generation and Self-Verification
### Overview
The image presents four line graphs, arranged in a 2x2 grid, illustrating the learning curves for two processes: "Learn to Generate" and "Learn to Self-Verify." Each process has two graphs: one showing the reward/accuracy achieved during the "Generation" phase and the other showing the reward/accuracy achieved during the "Self-Verification" phase. The x-axis represents the "Step" (presumably training steps), ranging from 0 to 1000. The y-axes represent "Reward" for the Generation graphs and "Accuracy" for the Self-Verification graphs.
### Components/Axes
* **Titles:**
* Top Row: "Learn to Generate"
* Left: "Generation"
* Right: "Self-Verification"
* Bottom Row: "Learn to Self-Verify"
* Left: "Generation"
* Right: "Self-Verification"
* **X-Axis:** "Step" (0 to 1000 in increments of 200)
* **Y-Axis (Left Column):** "Reward"
* Top Left: 0.06 to 0.22 in increments of 0.02
* Bottom Left: 0.08 to 0.16 in increments of 0.02
* **Y-Axis (Right Column):** "Accuracy"
* Top Right: 0.40 to 0.70 in increments of 0.05
* Bottom Right: 0.40 to 0.70 in increments of 0.05
* **Data Series Colors:**
* "Learn to Generate" (Top Row): Red
* "Learn to Self-Verify" (Bottom Row): Blue
### Detailed Analysis
**Top Row: Learn to Generate (Red Lines)**
* **Generation (Top Left):**
* Trend: The reward generally increases with steps.
* Data Points: Starts around 0.06 at step 0, rises to approximately 0.14 by step 200, reaches around 0.17 by step 400, and plateaus around 0.20-0.22 by step 800-1000.
* **Self-Verification (Top Right):**
* Trend: The accuracy fluctuates but generally remains stable.
* Data Points: Starts around 0.50 at step 0, fluctuates between 0.50 and 0.60 throughout the steps, with no clear upward or downward trend.
**Bottom Row: Learn to Self-Verify (Blue Lines)**
* **Generation (Bottom Left):**
* Trend: The reward increases with steps.
* Data Points: Starts around 0.08 at step 0, rises to approximately 0.12 by step 400, and reaches around 0.15-0.16 by step 1000.
* **Self-Verification (Bottom Right):**
* Trend: The accuracy increases with steps.
* Data Points: Starts around 0.42 at step 0, rises to approximately 0.55 by step 200, and reaches around 0.65 by step 1000.
### Key Observations
* In "Learn to Generate," the reward increases significantly during the generation phase, but the accuracy in self-verification remains relatively stable.
* In "Learn to Self-Verify," both the reward in the generation phase and the accuracy in the self-verification phase increase with steps.
* The "Learn to Self-Verify" process shows a more consistent improvement in both reward and accuracy compared to the "Learn to Generate" process.
### Interpretation
The graphs suggest that the "Learn to Self-Verify" process is more effective in improving both the generation and self-verification aspects compared to the "Learn to Generate" process. The "Learn to Generate" process seems to improve the reward during generation but does not significantly impact the accuracy of self-verification. This could indicate that the model trained to generate is not effectively learning to verify its own outputs, while the model trained to self-verify is improving in both generating and verifying. The data implies that self-verification is a more robust learning strategy in this context.
</details>
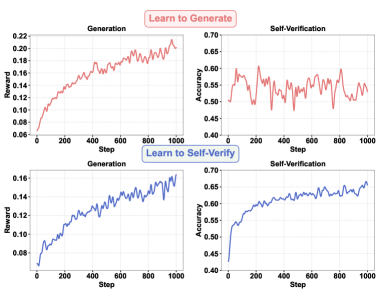
Figure 1: Training dynamics of Qwen2.5-1.5B-Instruct. (Top) It reveals a persistent asymmetry between generation and self-verification: learning to generate does not lead to improved self-verification ability, even on the same task. (Down) In the reverse direction, learning to self-verify not only improves self-verification ability but also leads to improved generation performance.
LLMs have long been considered incapable of verifying the correctness of their own answers (Stechly et al., 2025; Hong et al., 2024; Zhang et al., 2024). With the advent of RLVR, some works observe that models can exhibit emergent self-verification behaviors, sometimes also referred to as an “aha moment” (DeepSeek-AI, 2025; Zeng et al., 2025a; Hu et al., 2025). However, subsequent analyses suggest that most of these behaviors are in fact fake verification: although the model appears to be checking its previous reasoning, this step has little impact on the final answer, fundamentally due to the model’s limited ability to reliably verify its own generations (Zhao et al., 2025; Yee et al., 2024). More importantly, self-verification capability does not naturally improve with increased model scale or stronger generation ability (Lu et al., 2025), revealing a persistent asymmetry between generation and self-verification. Motivated by this, several approaches attempt to jointly optimize generation and verification within the same training step, treating verification as an auxiliary component (Liu et al., 2025b; Zhang et al., 2025a; Wang et al., 2025b). In practice, however, the training dynamics of these methods remain dominated by the generation objective, leaving the fundamental asymmetry largely unexplored.
In this work, we conduct an in-depth investigation of the asymmetry between generation and self-verification. Specifically, we explicitly train the LLM to generate better answers in a specific domain (e.g., mathematics) and track how it behaves when verifying its own answers on the same set of tasks throughout training process. We find that this asymmetry still persists: improving a model’s generation performance does not lead to corresponding improvements in its ability to verify its own solutions, as illustrated in Figure 1 (top). This naturally raises a key research question: does this asymmetry also manifest in the reverse direction? In other words, can improving a model’s self-verification ability lead to better generation performance?
To answer this question, we adopt an alternative training paradigm: instead of training the model to generate better answers, we train it solely to judge the correctness of its own solutions. With a carefully designed self-verification training pipeline, we surprisingly find that although training the model for generation does not improve its self-verification ability, training the model to self-verify does improve its generation performance, even achieving comparable performance to standard generation training on several benchmarks, as illustrated in Figure 1 (down). Beyond comparable performance, the resulting models acquire strong verification capability. Benefiting from this improved self-verification ability, we observe a significant reduction in the number of tokens required to solve the same problems, indicating more efficient reasoning. Moreover, stronger self-verification unlocks effective test-time scaling: incorporating self-verification results into majority voting leads to performance gains.
Building on these observations, we further explore integrating self-verification into generation training by formulating a multi-task reinforcement learning framework, where generation and self-verification are optimized as two independent but complementary objectives. Specifically, we introduce two orthogonal training strategies: (i) learning to self-verify as a stronger initial policy before learning to generate, and (ii) alternating training between generation and verification, where a verification phase is triggered after several generation steps. Extensive experiments show that these integrated training strategies consistently outperform those trained with generation alone.
Our main contributions are as follows:
- We conduct an in-depth investigation of the asymmetry between generation and self-verification throughout training, and show that improving generation ability does not lead to corresponding gains in self-verification.
- We identify the reverse direction of this asymmetry: learning to self-verify can effectively improve generation performance. Based on this insight, we propose to integrate self-verification into generation training by formulating a multi-task reinforcement learning framework.
- We provide extensive experiments demonstrating that learning to self-verify consistently improves problem-solving performance, together with detailed analyses.
2 Preliminary
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Policy Sampling and Self-Verification Process
### Overview
The image illustrates a system involving policy sampling, post-processing, and self-verification. It outlines the flow of data and processes from a database query to a final predicted judgement, incorporating elements of diversity, balancing, and filtering.
### Components/Axes
* **Database:** The starting point of the process.
* **Query:** A stack of documents labeled with a question mark "?".
* **Policy:** Represented by a brain icon, indicating a decision-making process.
* **Answer:** A stack of documents labeled with the letter "A".
* **Ref. Answer:** A stack of documents with a star icon.
* **Verifier:** A circle with a checkmark inside.
* **Correctness label:** A stack of documents with a checkmark.
* **Diversity:** Represented by a network icon.
* **Balancing:** Represented by a scale icon.
* **Filtering:** Represented by a filter icon.
* **Predicted judgement:** A stack of documents with book icons.
* **GRPO:** A rectangular block representing a process.
* **Generation improvements:** Text label with an arrow pointing to an upward sloping line.
* **Update:** Text label with an arrow pointing upwards from GRPO to Policy.
* **generation reward (optional):** Text label with a dashed arrow pointing from GRPO to Generation improvements.
* **verification reward:** Text label with an arrow pointing from Predicted judgement to GRPO.
* **a) On policy samping collection:** Text label for the top-right section.
* **b) Post-processing:** Text label for the middle-right section.
* **c) Self-verification:** Text label for the bottom section.
### Detailed Analysis
1. **Initial Stage:**
* The process begins with a "Database" from which a "Query" is generated.
* The "Query" is then processed by a "Policy" to produce an "Answer".
2. **Policy Sampling Collection (a):**
* The "Answer" is compared with a "Ref. Answer" using a "Verifier".
* The result is a "Correctness label".
3. **Post-processing (b):**
* The "Correctness label" undergoes "Diversity", "Balancing", and "Filtering".
4. **Self-verification (c):**
* The output from post-processing leads to "Predicted judgement".
* The "Predicted judgement" is fed back into the "Policy" for self-verification.
5. **GRPO and Feedback:**
* "GRPO" receives "verification reward" from "Predicted judgement".
* "GRPO" provides an "Update" to the "Policy" and an optional "generation reward" to "Generation improvements".
6. **Generation improvements:**
* The line slopes upwards, indicating an increase.
### Key Observations
* The diagram illustrates a closed-loop system where the output of the process is used to refine the policy.
* The "GRPO" plays a central role in updating the policy based on the "verification reward".
* Post-processing steps like "Diversity", "Balancing", and "Filtering" are crucial for refining the output.
### Interpretation
The diagram represents a reinforcement learning or iterative refinement process. The system uses a policy to generate answers to queries, verifies the correctness of these answers, and then uses the verification results to update the policy. The inclusion of diversity, balancing, and filtering suggests an effort to improve the quality and robustness of the generated answers. The GRPO (likely Gradient Policy Optimization) component is responsible for learning from the verification rewards and updating the policy accordingly. The optional generation reward suggests an additional mechanism to incentivize the generation of better answers. The self-verification loop indicates a system that continuously learns and improves its performance over time.
</details>
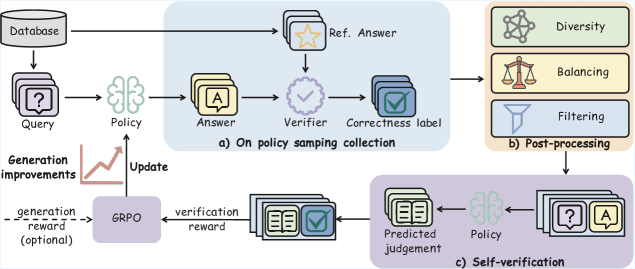
Figure 2: Overview of our self-verification training framework. We collect on-policy problem-solving trajectories from the model and obtain correctness labels from a verifier. These trajectories are then processed through a post-processing pipeline, including data balancing, filtering, and diversity-aware sampling, to construct self-verification training data, which is used to train the model to judge the correctness of its own answers. We find that training the model solely for self-verification already leads to improved generation performance. Integrating this self-verification objective into generation training further strengthens the model’s generation ability.
In this section, we introduce the preliminary concepts and notations used throughout the paper. We first review the RLVR formulation in Section 2.1. We then show how the same RLVR framework can be instantiated in two different settings: generation training (Section 2.2), where the model is optimized to solve a given task, and verification training (Section 2.3), where the model is optimized to judge the correctness of a given solution.
2.1 RLVR
Reinforcement Learning with Verifiable Rewards (RLVR) is a reinforcement learning framework for training language models using automatically computable reward signals. Instead of relying on human preference models, RLVR employs a rule-based verifier that evaluates each model output against a reference and returns a scalar reward.
Concretely, given an input query $x_{i}$ , where $i$ denotes the query index, the model parameterized by $\pi_{\theta}$ generates multiple outputs $o_{i,j}=(z_{i,j},y_{i,j})$ , where $j$ indexes different samples generated for the same query. Here, $z_{i,j}$ denotes the intermediate reasoning trace and $y_{i,j}$ denotes the final prediction. A verifier then assigns a reward score $r_{i,j}$ by comparing the model output with a reference solution $y_{i}^{*}$ . The training objective is to optimize the model parameters so as to maximize the expected verifier reward over model-generated samples:
$$
\max_{\theta}\;\mathbb{E}_{o\sim\pi_{\theta}(\cdot\mid x)}\big[r\big]. \tag{1}
$$
In this work, we adopt Group Relative Policy Optimization (GRPO) (Shao et al., 2024) as the underlying optimization algorithm. GRPO can be viewed as a simplified variant of PPO (Schulman et al., 2017) that directly optimizes the policy without introducing a separate value network. For each input $x_{i}$ , the policy samples a set of $G$ candidate outputs $\{(z_{i,j},y_{i,j})\}_{j=1}^{G}$ , each receiving a reward $r_{i,j}$ . The policy is then updated by comparing each candidate against the group statistics, using the following clipped surrogate objective:
$$
\displaystyle\mathcal{L}_{\text{GRPO}}(\theta)=\mathbb{E}_{x_{i}\sim\mathcal{D}}\Bigg[\frac{1}{G}\sum_{j=1}^{G}\frac{1}{|z_{i,j}\circ y_{i,j}|} \displaystyle\times\sum\limits_{t=1}^{|z_{i,j}\circ y_{i,j}|}\min\Big(\rho^{t}_{i,j}A_{i,j},\;\mathrm{clip}(\rho^{t}_{i,j},1-\epsilon,1+\epsilon)A_{i,j}\Big)\Bigg] \tag{2}
$$
where:
$$
\rho_{i,j}^{t}=\frac{\pi_{\theta}(z_{i,j}^{t}\circ y_{i,j}^{t}\mid x_{i},z_{i,j}^{<t}\circ y_{i,j}^{<t})}{\pi_{\theta_{\text{old}}}(z_{i,j}^{t}\circ y_{i,j}^{t}\mid x_{i},z_{i,j}^{<t}\circ y_{i,j}^{<t})},
$$
where the superscript $t$ denotes the token index in the concatenated sequence, and $\circ$ denotes sequence concatenation. Here, the advantage $A_{i,j}$ is computed by normalizing the rewards within the sampled group:
$$
A_{i,j}=\frac{r_{i,j}-\mu_{i}}{\sigma_{i}+\epsilon_{\text{norm}}}, \tag{3}
$$
with:
$$
\mu_{i}=\frac{1}{G}\sum_{j=1}^{G}r_{i,j},\qquad\sigma_{i}=\sqrt{\frac{1}{G}\sum_{j=1}^{G}(r_{i,j}-\mu_{i})^{2}}.
$$
Intuitively, GRPO encourages generations that perform better than the group average while suppressing those with lower relative rewards. Inspired by (Yu et al., 2025a), we adopt the clip-higher strategy and token-level mean advantage normalization.
2.2 Generation Training
Under the RLVR formulation, generation training corresponds to the standard task-solving setting. Each training example consists of a task query $x_{i}$ and a reference solution $y_{i}^{*}$ . Given $x_{i}$ , the model samples multiple candidate solutions $\{(z_{i,j},y_{i,j})\}_{j=1}^{G}$ , and the verifier assigns a reward by checking whether each generated answer $y_{i,j}$ matches the reference solution $y_{i}^{*}$ . In this case, the reward signal directly reflects task-solving correctness, and RLVR reduces to optimizing the policy to produce correct solutions for the given tasks.
2.3 Verification Training
Under the same RLVR formulation, verification training corresponds to a different instantiation of the input and reference. Each training sample is constructed from a triplet $(x_{i},y_{i,j},c_{i,j})$ , where $x_{i}$ is the task query, $y_{i,j}$ is a candidate solution generated by the model, and $c_{i,j}∈\{0,1\}$ is a binary correctness label indicating whether $y_{i,j}$ matches the reference solution $y_{i}^{*}$ . Given such an input $(x_{i},y_{i,j})$ , the model is prompted to output a judgment $\hat{c}_{i,j}$ indicating whether the provided solution is correct. A rule-based verifier then assigns a reward by comparing the model’s judgment $\hat{c}_{i,j}$ with the reference label $c_{i,j}$ . In this setting, the model is not optimized to solve the task itself, but rather to assess the correctness of given solutions.
3 Learning to Self-Verify
Table 1: Evaluation of learning to self-verify across six mathematical reasoning benchmarks. We report both task accuracy (Acc@16 $\uparrow$ ) and average reasoning length in tokens (Tokens $\downarrow$ ) for each model trained under two different objectives: train LLM to generate better solutions (Generate), and train LLM to verify its own solutions (Self-Verify). Results show that models trained with self-verification yield efficient reasoning traces, while achieving comparable or sometimes even better performance than models trained for generation.
| Method | AMC23 | Minerva | Olympiad | Math500 | AIME24 | AIME25 | Avg | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Tokens $\downarrow$ | Acc $\uparrow$ | Tokens $\downarrow$ | Acc $\uparrow$ | Tokens $\downarrow$ | Acc $\uparrow$ | Tokens $\downarrow$ | Acc $\uparrow$ | Tokens $\downarrow$ | Acc $\uparrow$ | Tokens $\downarrow$ | Acc $\uparrow$ | Tokens $\downarrow$ | Acc $\uparrow$ | |
| Qwen2.5-1.5B-Instruct | | | | | | | | | | | | | | |
| Generate | 1402 | 30.5 | 963 | 12.4 | 1639 | 20.6 | 936 | 53.7 | 2580 | 2.9 | 2103 | 0.8 | 1604 | 20.2 |
| Self-Verify | 1309 | 33.0 | 870 | 14.0 | 1351 | 22.2 | 817 | 54.6 | 1467 | 4.8 | 1545 | 1.3 | 1227 | 21.7 |
| Qwen2.5-3B-Instruct | | | | | | | | | | | | | | |
| Generate | 2754 | 50.9 | 2006 | 17.0 | 3299 | 27.4 | 2021 | 59.6 | 4811 | 8.1 | 4744 | 8.1 | 3273 | 28.5 |
| Self-Verify | 1825 | 46.7 | 1658 | 17.1 | 1891 | 32.1 | 1237 | 65.6 | 2755 | 9.2 | 2252 | 6.3 | 1936 | 29.5 |
| Qwen2.5-7B-Instruct | | | | | | | | | | | | | | |
| Generate | 3967 | 65.3 | 2353 | 25.3 | 4543 | 37.8 | 2437 | 70.9 | 7053 | 16.3 | 6397 | 18.1 | 4458 | 38.9 |
| Self-Verify | 1194 | 59.7 | 823 | 25.2 | 1168 | 39.8 | 783 | 74.7 | 1575 | 19.4 | 1369 | 11.7 | 1152 | 38.4 |
In this section, we investigate the reverse direction of this long-standing asymmetry: whether a model can improve its generation performance solely by learning to verify its own solutions. We first introduce our self-verification training pipeline in Section 3.1, then describe the experimental setup in Section 3.2, present the main results in Section 3.3, and provide further analysis in Section 3.4.
3.1 Self-Verification Framework
Following the notation in Section 2, we now introduce our self-verification framework, as illustared in Figure 2.
On-Policy Sample Collection
At each training iteration, we sample a mini-batch of $B$ queries $\{x_{i}\}_{i=1}^{B}$ . For each query $x_{i}$ , we use the current policy $\pi_{\theta}$ to generate $G$ candidate answers, resulting in $B× G$ generated samples. For each generated sample, the model produces a solution $y_{i,j}$ together with its corresponding reasoning trace $z_{i,j}$ , where $j=1,...,G$ . A rule-based verifier then compares each $y_{i,j}$ with the reference answer $y_{i}^{*}$ and assigns a binary correctness label $c_{i,j}$ . Each sample is thus represented as a triplet $(x_{i},y_{i,j},c_{i,j})$ . All such triplets are stored in a temporary buffer and serve as the raw candidates for constructing the self-verification training data.
Post-Processing
At each iteration, the on-policy sampling procedure produces $B× G$ samples. Directly using all of them for verification training is computationally expensive and can also introduce instability due to imbalance or low-quality samples. For a fair comparison, we downsample these candidates and construct a verification training batch of size $B$ by selecting the most informative samples. Specifically, we apply the following steps:
- Filtering: We first discard invalid samples, including those with malformed outputs, excessively long generations, or missing a unique final answer. We further discard queries for which all generated answers are incorrect, as such cases typically exceed the current capability of the model and provide little useful supervision signal for self-verification.
- Diversity Control: To avoid overfitting to a small subset of queries when conducting self-verification training, we perform sampling at the query level and ensure that the selected verification samples are drawn from diverse input queries.
- Data Balancing: Since generation often produces highly imbalanced labels (e.g., mostly incorrect at early stages and mostly correct at later stages), while self-verification is essentially a binary classification task, we explicitly enforce each mini-batch of verification data to contain an equal number of correct and incorrect samples.
Training
In self-verification training, the model is prompted with a query–answer pair $(x_{i},y_{i,j})$ and is required to predict whether the provided answer is correct. Let $\hat{c}_{i,j}$ denote the model’s predicted judgment and $c_{i,j}$ the reference correctness label obtained from the rule-based verifier. A verification reward is then computed as:
$$
r_{i,j}^{v}=\mathrm{Verifier}(\hat{c}_{i,j},c_{i,j}). \tag{4}
$$
We then optimize the model using the same GRPO objective as in Section 2.1. This training stage treats the model purely as a verifier and encourages it to improve its ability to distinguish correct from incorrect answers. We emphasize that at this stage, the training objective contains no generation reward. The policy is optimized solely to maximize the expected verification reward.
<details>
<summary>figures/aime24_qwen2.5_1.5B_instruct.png Details</summary>
### Visual Description
## Line Charts: Accuracy and Tokens vs. Training Progress
### Overview
The image contains two line charts side-by-side. Both charts share the same x-axis, "Training Progress," with values 0, 1/8, 1/4, 1/2, and 1. The left chart plots "Acc" (Accuracy) on the y-axis, ranging from 2 to 6. The right chart plots "Tokens" on the y-axis, ranging from 0 to 6000. Each chart displays two data series: "Generate" (red squares) and "Self-Verify" (blue circles).
### Components/Axes
**Left Chart (Accuracy):**
* **X-axis:** Training Progress (0, 1/8, 1/4, 1/2, 1)
* **Y-axis:** Acc (Accuracy) - Scale from 2 to 6
* **Legend:** Located in the top-left corner.
* Generate (red square)
* Self-Verify (blue circle)
**Right Chart (Tokens):**
* **X-axis:** Training Progress (0, 1/8, 1/4, 1/2, 1)
* **Y-axis:** Tokens - Scale from 0 to 6000
* **Legend:** Located in the top-left corner.
* Generate (red square)
* Self-Verify (blue circle)
### Detailed Analysis
**Left Chart (Accuracy):**
* **Generate (red squares):**
* Training Progress 0: Acc = 2.2
* Training Progress 1/8: Acc = 2.9
* Training Progress 1/4: Acc = 3.8
* Training Progress 1/2: Acc = 4.2
* Training Progress 1: Acc = 2.5
* Trend: Initially increases, peaks at 1/2, then decreases.
* **Self-Verify (blue circles):**
* Training Progress 0: Acc = 2.2
* Training Progress 1/8: Acc = 2.9
* Training Progress 1/4: Acc = 3.5
* Training Progress 1/2: Acc = 5.6
* Training Progress 1: Acc = 4.0
* Trend: Increases to 1/2, then decreases.
**Right Chart (Tokens):**
* **Generate (red squares):**
* Training Progress 0: Tokens = 1935
* Training Progress 1/8: Tokens = 2580
* Training Progress 1/4: Tokens = 2910
* Training Progress 1/2: Tokens = 3782
* Training Progress 1: Tokens = 5422
* Trend: Consistently increases.
* **Self-Verify (blue circles):**
* Training Progress 0: Tokens = 1935
* Training Progress 1/8: Tokens = 1635
* Training Progress 1/4: Tokens = 1726
* Training Progress 1/2: Tokens = 1754
* Training Progress 1: Tokens = 3228
* Trend: Relatively flat until the end, then increases sharply.
### Key Observations
* In the Accuracy chart, Self-Verify outperforms Generate at Training Progress 1/2.
* In the Tokens chart, Generate consistently requires more tokens than Self-Verify.
* The Accuracy of "Generate" decreases significantly at Training Progress = 1.
* The Tokens for "Self-Verify" increase sharply at Training Progress = 1.
### Interpretation
The charts compare the performance of "Generate" and "Self-Verify" methods across different stages of training. The Accuracy chart suggests that "Self-Verify" is more effective at a certain point in training (1/2), but both methods see a decrease in accuracy at the end of training. The Tokens chart indicates that "Generate" consistently requires more tokens, suggesting it might be less efficient. The sharp increase in tokens for "Self-Verify" at the end of training could indicate a change in behavior or complexity of the model. The data suggests that the optimal training progress may be around 1/2, where "Self-Verify" achieves higher accuracy with fewer tokens compared to "Generate". Further investigation is needed to understand the drop in accuracy at Training Progress = 1 and the late increase in tokens for "Self-Verify".
</details>
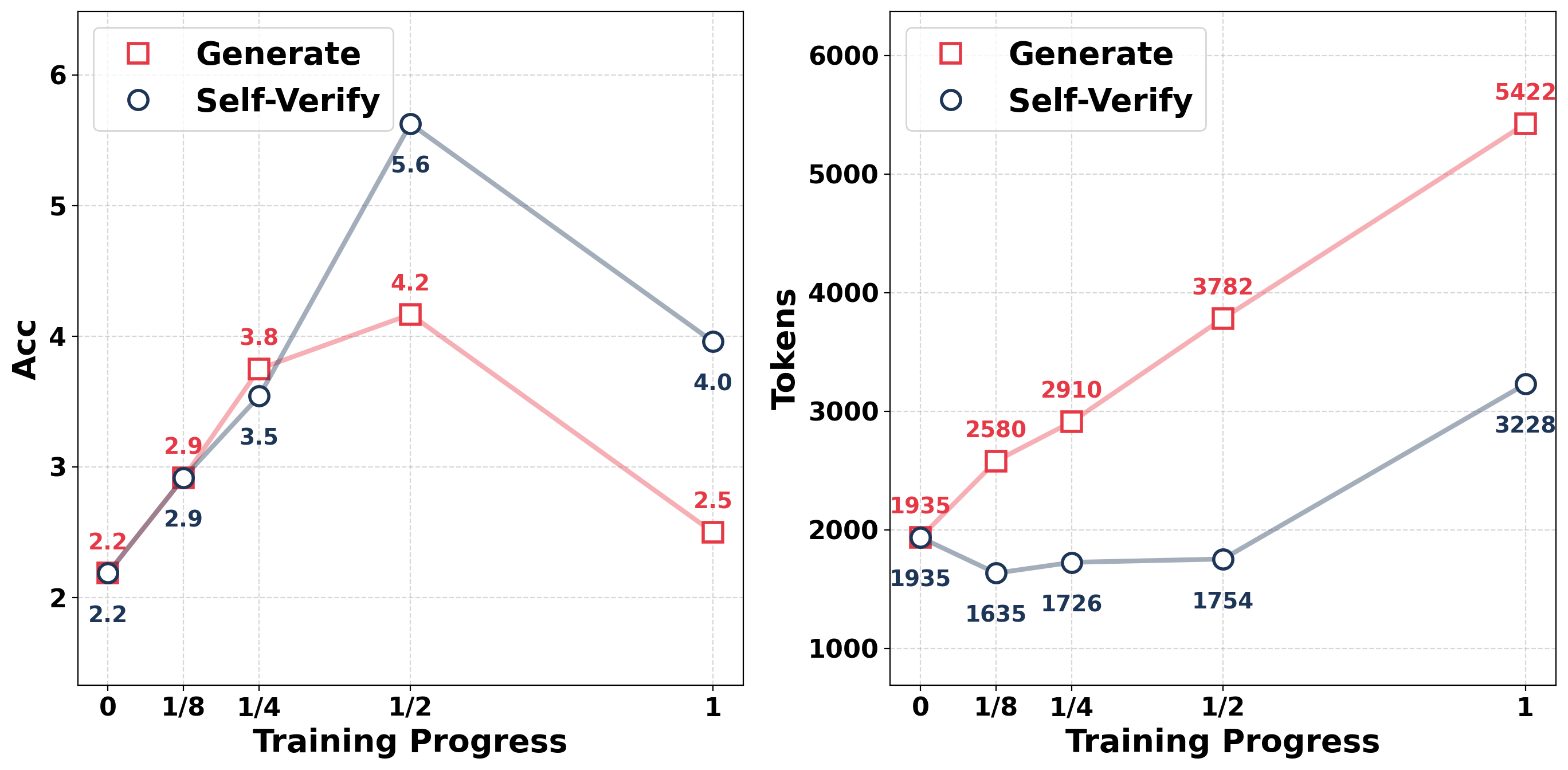
Figure 3: Comparison of accuracy and token usage between generation training and self-verification training on AIME24 with Qwen2.5-1.5B-Instruct.
3.2 Experimental Setup
We conduct extensive experiments to compare the effects of training LLMs to generate solutions and training them to self-verify. We first describe our experimental setup.
Dataset and Benchmarks
For training, we use DAPO-Math-17K (Yu et al., 2025a), a dataset widely adopted for mathematical reasoning. We evaluate our models on six challenging mathematical reasoning benchmarks: AIME24 (Zhang and Math-AI, 2024), AIME25 (Zhang and Math-AI, 2025), AMC23, Minerva, MATH500 (Lightman et al., 2024), and OlympiadBench (He et al., 2024).
Implementation
We choose Qwen2.5-1.5B-Instruct, Qwen2.5-3B-Instruct, and Qwen2.5-7B-Instruct as backbone models (Yang et al., 2024). We use veRL (Sheng et al., 2025) as the training framework to implement our RL-based methods with a rule-based verifier. For both generation training and self-verification training, we train the models for 1000 steps. For fair comparison, both generation and verification training use a batch size of 128 with a group size of 8. We set the maximum generation length to 10,240 tokens for all models, with the temperature set to 0.6 and top- $p$ to 0.95.
Evaluation
We compare models trained exclusively for generation with those trained exclusively for self-verification on the benchmarks. We report two main metrics: (1) Acc, measured by Avg@16 accuracy, (2) Token, calculated as the average number of tokens (including both intermediate reasoning and the final answer) across all outputs on each test set. This metric reflects the reasoning efficiency of the model.
3.3 Main Results
Table 1 summarizes the performance and reasoning length across six benchmarks and three models, comparing models trained solely to generate answers with models trained solely to judge the correctness of their own solutions. In addition, Figure 3 illustrates the evolution of accuracy and token usage throughout training on AIME24 with Qwen2.5-1.5B-Instruct. From the results, we can draw two key conclusions:
Learning to self-verify achieves comparable performance to learning to generate.
Across all models and datasets, training the model solely for self-verification yields performance that is comparable to, and in some cases better than, that achieved by generation-only training. For example, for Qwen2.5-1.5B-Instruct, the self-verification-trained model outperforms the generation-trained model in accuracy across all benchmarks. For Qwen2.5-3B-Instruct, self-verification achieves 32.1% accuracy on OlympiadBench and 65.6% on Math500, surpassing the generation baseline by 4.7% and 6.0%, respectively, demonstrating strong potential even without explicit generation training. This points to an interesting asymmetry in the reverse direction: while improving a model’s generation performance does not lead to a corresponding improvement in its ability to self-verify, even on the same task (cf. Figure 1), improving self-verification alone can in turn enhance generation performance.
Table 2: Evaluation of verification capability. We report the Acc@8 of different models in judging the correctness of solutions generated by DeepSeek-R1-Distill-Qwen-7B.
| Model | Base | Generate | Self-Verify |
| --- | --- | --- | --- |
| Qwen2.5-1.5B-Instruct | 45.58 | 45.95 +0.37 | 62.31 +16.73 |
| Qwen2.5-3B-Instruct | 59.82 | 55.19 -4.63 | 65.69 +5.87 |
| Qwen2.5-7B-Instruct | 64.46 | 68.84 +4.38 | 69.50 +5.04 |
Learning to self-verify requires significantly fewer tokens to solve the same problems.
Across all models and datasets, training the model solely for self-verification consistently produces much shorter reasoning traces than generation-only training, while maintaining comparable performance. Notably, for Qwen2.5-7B-Instruct, the self-verification-trained model achieves performance comparable to generation training using only about 25% of the tokens. For Qwen2.5-3B-Instruct, it uses roughly 60% of the tokens while even slightly outperforming the generation baseline. These results indicate that, although the final performance is comparable, self-verification leads to substantially more efficient reasoning traces. We attribute this to the strengthened self-verification ability induced by our training, which enables the model to better recognize when its current solution is likely incorrect and when verification should be triggered. As a result, the model avoids redundant or “fake” verification behaviors and follows more direct solution trajectories. This markedly different reasoning behavior further motivates us to regard self-verification and generation as complementary training signals.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Accuracy Comparison of Qwen2.5 Models
### Overview
The image is a bar chart comparing the accuracy (Avg@8) of three Qwen2.5 models (1.5B, 3B, and 7B Instruct) under three different conditions: "Base", "Generate", and "Self-Verify". The chart displays the accuracy percentage on the y-axis and the model type on the x-axis.
### Components/Axes
* **Y-axis:** "Accuracy (Avg@8) %", ranging from 0 to 50.
* **X-axis:** Model types: "Qwen2.5-1.5B-Instruct", "Qwen2.5-3B-Instruct", "Qwen2.5-7B-Instruct".
* **Legend:** Located in the top-left corner.
* "Base": Light blue bars.
* "Generate": Red-striped bars.
* "Self-Verify": Darker red-striped bars.
### Detailed Analysis
Here's a breakdown of the accuracy for each model and condition:
* **Qwen2.5-1.5B-Instruct:**
* Base: 29.52%
* Generate: 29.54%
* Self-Verify: 31.10%
* **Qwen2.5-3B-Instruct:**
* Base: 34.66%
* Generate: 36.75%
* Self-Verify: 39.44%
* **Qwen2.5-7B-Instruct:**
* Base: 30.44%
* Generate: 38.31%
* Self-Verify: 44.64%
**Trends:**
* For the 1.5B model, the accuracy is relatively similar across all three conditions.
* For the 3B model, the accuracy increases from "Base" to "Generate" to "Self-Verify".
* For the 7B model, the accuracy shows a significant increase from "Base" to "Generate" to "Self-Verify".
* Across all conditions, the 7B model generally has the highest accuracy, followed by the 3B model, and then the 1.5B model.
### Key Observations
* The "Self-Verify" condition consistently yields the highest accuracy for all models.
* The 7B model shows the most significant improvement in accuracy under the "Self-Verify" condition.
* The 1.5B model shows minimal difference in accuracy between the "Base" and "Generate" conditions.
### Interpretation
The data suggests that the "Self-Verify" method significantly improves the accuracy of the Qwen2.5 models, especially for the larger 7B model. This indicates that the self-verification process is more effective for larger models, potentially due to their increased capacity to reason and refine their outputs. The 1.5B model's relatively stable performance across conditions might suggest that it is less sensitive to the benefits of self-verification, possibly due to its smaller size and limited capacity. The trend indicates that increasing model size and incorporating self-verification techniques can lead to substantial gains in accuracy.
</details>
Figure 4: Performance comparison under partially corrupted reasoning prefix setting.
3.4 Analysis
In this section, we conduct a detailed analysis to investigate what capabilities are acquired by learning to self-verify and how these capabilities can be exploited in practice. Based on our experiments, we make the following observations:
Explicit self-verification training turns the model into a strong verifier.
Figure 1 demonstrates that even models with limited parameter sizes can verify their own solutions much more accurately after self-verification training. To further evaluate the model’s verification capability as a general verifier in specific domains, we construct a verification evaluation set consisting of benchmark solutions generated by DeepSeek-R1-Distill-Qwen-7B. The model is then asked to judge whether each solution is correct or incorrect, and the results are reported in Table 2. The results show that, since self-verification is essentially a verification task, our model naturally acquires the ability to assess solutions produced by other models as well, demonstrating strong general-purpose verification capability. In contrast, models trained only for generation overall achieve marginal performance gain and in some cases even exhibit noticeable degradation.
Learning to self-verify enables the model to identify and correct errors in its reasoning process.
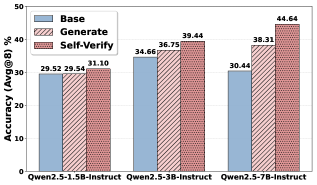
We observe that after self-verification training, the number of tokens required to solve a problem is significantly reduced. This suggests that the model starts to precisely trigger verification when it detects potential errors in its reasoning and to correct them in time, thereby avoiding redundant or “fake” verification behaviors. To validate this hypothesis, we construct a dedicated evaluation set to assess the effectiveness of self-verification behaviors during the reasoning process. Specifically, we mix data from different benchmarks and build a set of 1,545 problems. We first collect the original reasoning trajectories generated by Qwen2.5-7B-Instruct on these problems. We then use GPT-4.1 (OpenAI, 2023) to randomly rewrite these trajectories into reasoning step prefixes with varying numbers of steps and injected some mistakes. The model is prompted with the original query and the corrupted prefix, and is asked to continue the reasoning process. Under this setting, a higher success rate indicates that the model is more capable of detecting errors in the ongoing reasoning and correcting them through effective self-verification. As shown in Figure 4, the self-verification-trained model significantly outperforms both the base model and the generation-trained model, demonstrating substantially stronger error detection and correction capability during reasoning. In contrast, generation training yields only marginal improvements over the base model in this setting.
Table 3: Test-time scaling with self-verification with Qwen2.5-1.5B-Instruct. We report Acc@32 and compare standard majority voting and majority voting augmented with self-verification across three training regimes: Base, Generate, and Self-Verify.
| Method | AIME25 | MATH500 | Olympaid | Minerva |
| --- | --- | --- | --- | --- |
| Base | | | | |
| Major voting | 3.30 | 52.20 | 22.40 | 14.30 |
| + Self-verify | 3.30 +0.00 | 52.40 +0.20 | 22.30 -0.10 | 10.70 -3.60 |
| Generate | | | | |
| Major voting | 0.00 | 54.20 | 23.40 | 15.80 |
| + Self-verify | 0.00 +0.00 | 53.00 -1.20 | 23.60 +0.20 | 13.60 -2.20 |
| Self-Verify | | | | |
| Major voting | 3.30 | 55.20 | 25.80 | 16.20 |
| + Self-verify | 6.70 +3.40 | 56.40 +1.20 | 27.20 +1.40 | 16.20 +0.00 |
Effective self-verification enables test-time scaling.
With a substantially improved self-verification capability, the model can reliably assess the correctness of its own candidate solutions, which unlocks a new form of test-time scaling based on self-verification. Specifically, at inference time, we sample multiple candidate solutions, let the model verify each of them, and aggregate the verification results to obtain a verification score for each candidate. We then jointly consider the majority vote and the verification scores to determine the final answer. Experimental results in Table 3 show that introducing this additional self-verification signal at test time consistently improves performance, demonstrating that self-verification provides an effective and principled way to scale inference beyond naive sampling or self-consistency.
Table 4: Evaluation of integrating self-verification into generation training across six mathematical reasoning benchmarks. We report task accuracy (Acc@16 $\uparrow$ ) for each model under four training strategies. Results show that our strategies improve overall performance over standard and mixed training.
| Method | AMC23 | Minerva | Olympiad | Math500 | AIME24 | AIME25 | Avg |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5-1.5B-Instruct | | | | | | | |
| Generate | 30.5 | 12.4 | 20.6 | 53.7 | 2.9 | 0.8 | 20.2 |
| Mixed-Train | 33.3 | 12.7 | 21.2 | 53.8 | 3.8 | 1.5 | 21.1 |
| Verify-Init | 33.0 | 13.0 | 21.9 | 54.7 | 5.4 | 1.3 | 21.6 |
| Verify-Alter | 36.4 | 13.9 | 22.4 | 54.2 | 5.0 | 4.2 | 22.7 |
| Qwen2.5-3B-Instruct | | | | | | | |
| Generate | 50.9 | 17.0 | 27.4 | 59.6 | 8.1 | 8.1 | 28.5 |
| Mixed-Train | 49.4 | 17.6 | 27.5 | 59.2 | 10.8 | 6.3 | 28.5 |
| Verify-Init | 47.8 | 18.3 | 29.5 | 63.1 | 9.6 | 6.5 | 29.1 |
| Verify-Alter | 47.7 | 18.7 | 30.2 | 64.5 | 9.4 | 5.6 | 29.4 |
| Qwen2.5-7B-Instruct | | | | | | | |
| Generate | 65.3 | 25.3 | 37.8 | 70.9 | 16.3 | 18.1 | 38.9 |
| Mixed-Train | 59.2 | 24.6 | 40.5 | 73.5 | 15.8 | 9.8 | 37.2 |
| Verify-Init | 63.6 | 26.0 | 39.0 | 74.0 | 17.3 | 12.5 | 38.7 |
| Verify-Alter | 68.0 | 26.0 | 39.0 | 72.9 | 18.3 | 17.7 | 40.3 |
4 Integrating Self-Verification into Training
We observe that training a model solely to verify its own answers already improves its generation performance to a level comparable with models trained purely for generation, while exhibiting a markedly different inference behavior: verification-only models produce significantly shorter outputs, indicating a more efficient reasoning trace. This markedly different reasoning behavior further motivates us to view self-verification and generation as complementary training signals. Building on this observation, we further propose to integrate self-verification into generation training.
4.1 Multi-Task RL Pipeline
In this work, we formulate the integration of generation and self-verification as a multi-task reinforcement learning problem, where the two objectives are optimized in a decoupled manner. Under this framework, we consider two simple yet effective strategies that are orthogonal: a stage-wise initialization strategy and an alternating training strategy.
Stage-wise Initialization
We first train the model with a self-verification objective by optimizing the policy to maximize the verification reward $r_{v}$ , as described in Section 3.1. The resulting model, which already possesses a stronger ability to judge the correctness of its own outputs, is then used as a better initial policy for standard generation training, where the policy is further optimized to maximize the generation reward $r_{g}$ .
Alternating Training
We alternate between generation training and self-verification training. Specifically, we run generation training for $n$ steps to optimize the policy with respect to the generation reward $r_{g}$ . Every $n$ generation steps, we trigger a self-verification phase, during which the same policy is optimized with respect to the verification reward $r_{v}$ , using the answers generated in the preceding generation phase to construct verification training data. This process is repeated throughout training, allowing the policy to be continuously shaped by both objectives.
In both strategies, generation and self-verification are optimized under the same RLVR framework using GRPO, and the only difference lies in which reward signal ( $r_{g}$ or $r_{v}$ ) is used at each stage of training.
4.2 Experimental Setup
Baseline
To benchmark the effectiveness of our method, we compare it against two primary baselines. Generate follows the standard RL-based training paradigm for reasoning models and optimizes the policy solely with respect to the generation reward. Mixed-Train (Zhang et al., 2025a) jointly optimizes generation and self-verification objectives within each training step. For fair comparison, all baselines and our methods are trained using the same implementation and the same set of hyperparameters.
Implementation and Evaluation
We use the same datasets, model architectures, implementation details, and evaluation protocols as in Section 3.3. In this section, we evaluate two strategies for integrating self-verification into training: Verify-Init, which corresponds to the stage-wise initialization strategy, and Verify-Alter, which corresponds to the alternating training strategy. For Verify-Init, we initialize the model from a checkpoint obtained after 400 steps of self-verification-only training, and then further train it for 600 steps with the generation objective. For Generate, Mixed-Train, and Verify-Alter, we train the models for 1000 steps in total.
4.3 Results and Analysis
Table 4 summarizes the performance across six benchmarks and three models. Beyond training the model solely for self-verification, we find that integrating self-verification into generation training consistently leads to improved generation performance across most models and benchmarks. Compared to Mixed-Train, which directly mixes the two objectives within a single optimization step, our framework decouples the optimization of generation and verification and optimizes them in a coordinated but separate manner, demonstrating additional performance gains. For instance, for Qwen2.5-1.5B-Instruct, Verify-Alter improves the average accuracy from 20.2% to 22.7%, outperforming both standard generation training and mixed-objective training. Notably, on AMC23, it improves accuracy by 5.9 points, and on the more challenging AIME benchmarks, it raises accuracy from 0.8% to 4.2%. This suggests that self-verification provides a complementary and beneficial training signal.
5 Related Works
5.1 LLM as Generator
Improving the generation capability of LLMs has long been a central focus of the community (Brown et al., 2020; OpenAI, 2023). Early works typically collect high-quality trajectories with complex reasoning patterns and train LLMs via imitation learning (Ouyang et al., 2022; Touvron et al., 2023; Yang et al., 2024). With the success of models such as DeepSeek-R1 (DeepSeek-AI, 2025), which is trained with the GRPO algorithm (Shao et al., 2024), a surge of follow-up research has been inspired. Meanwhile, Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful and scalable training paradigm for further boosting LLM generation performance by leveraging verifiable reward signals (Jin et al., 2025; Wang et al., 2025c). Building on these foundations, more recent studies start to investigate how to extend LLMs’ advanced generation ability to broader domains (Su et al., 2025; Yu et al., 2025c; Gunjal et al., 2025), make generation more efficient at inference time (Sui et al., 2025; Feng et al., 2025; Wang et al., 2025a), and improve stability and effectiveness of generation training (Yang et al., 2025b; Wu et al., 2025; Chen et al., 2025c). These advances have led to a series of increasingly capable large models (OpenAI, 2025; Anthropic, 2025; Google, 2025). However, despite these advancements, even the most powerful LLMs still cannot reliably self-verify their own outputs (Lu et al., 2025; Stechly et al., 2025).
5.2 LLMs as Verifier
Verifiers play a crucial role in guiding LLMs toward better generations and enabling effective test-time scaling (Zhong et al., 2025; Yu et al., 2025b; Snell et al., 2024). Existing verifiers are typically either (1) discriminative (Liu et al., 2025a, 2024), producing scalar scores to rank candidate responses, or (2) generative (Zhang et al., 2025b; Mahan et al., 2024; Liu et al., 2025c), producing textual judgments or reward signals. With the success of RLVR in training stronger generators, increasing attention has been paid to generative verifiers due to their better generalization ability. LLM verifiers typically produce natural language rationales or textual judgments, which improve transparency and evaluation reliability. Correspondingly, training methods for LLM verifiers have evolved from supervised fine-tuning (SFT) to direct preference optimization (DPO) (Chen et al., 2025a; Zhang et al., 2025b; Liu et al., 2025c), and more recently to RLVR (Chen et al., 2025b; Yu et al., 2025d), inspired by advances in reasoning-oriented models. Despite these advances, how training as verifiers influences the model itself as a generator remains largely underexplored.
5.3 Joint Training of Generator and Verifier
Recently, several works have begun to explore incorporating verification signals into generator training. Among them, (Chen et al., 2025d) shows that collecting correctness signals on external models’ outputs and training LLMs via imitation learning with fixed templates can shorten generated responses, albeit sometimes at the cost of slightly degraded generation performance. Other works (Liu et al., 2025b; Zhang et al., 2025a; Wang et al., 2025b) propose to jointly train generation and verification within the same training step, where verification is scaled as an auxiliary signal while the overall training dynamics remain dominated by the generation objective.
Different from these approaches, we notice that rewarding self-verification alone is sufficient to obtain a generator with performance comparable to standard generation training, while producing better reasoning traces. We further explore integrating self-verification into generation training by formulating a multi-task reinforcement learning framework, where generation and self-verification are optimized as two decoupled but complementary objectives.
6 Conclusion
In this work, we investigate the asymmetry between generation and self-verification in large language models and show that improving generation does not naturally lead to better self-verification, even on the same task. More interestingly, we identify the reverse direction of this asymmetry: learning to self-verify alone can significantly improve generation performance. This finding challenges the common view of verification as merely an auxiliary component and highlights its role as a powerful training signal. Building on this insight, we further explore integrating self-verification into generation training by formulating a multi-objective reinforcement framework. Extensive experiments demonstrate that explicit self-verification training consistently improves problem-solving performance, produces more efficient and effective reasoning traces, and enables effective test-time scaling. Looking ahead, we believe that verification has untapped potential to improve generation, through designed verification tasks, more principled integration of verification and generation objectives, and more efficient training strategies. Exploring these directions is beyond the scope of the current work, and we leave them for future research.
Impact Statement
Our findings suggest that strengthening self-verification in large language models can fundamentally change how these systems reason and generate responses. By showing that learning to self-verify not only improves reliability but also enhances generation efficiency, this work contributes to a better understanding of the interaction between reasoning, verification, and generation in modern language models. These insights have broader implications for the development and deployment of AI systems, especially in scenarios where correctness, robustness, and controllability are critical. Improving a model’s ability to assess its own outputs may help reduce spurious reasoning steps, increase transparency, and mitigate certain classes of errors in real-world applications. At the same time, more powerful self-verification capabilities also raise new questions about how such systems should be evaluated, monitored, and governed, particularly when they are used in high-stakes or decision-critical settings. Understanding and carefully managing these dynamics is therefore important for the responsible use of large language models in practice.
Limitation
Although this work provides an encouraging analysis of the asymmetry between generation and self-verification and demonstrates the effectiveness of learning to self-verify, it still has several limitations. First, introducing an additional self-verification objective into generation training inevitably incurs extra computation, including additional inference and optimization costs. Second, although our experiments cover models of different parameter sizes, they are still limited in scale. Due to computational constraints, we do not explore whether the same phenomena and benefits continue to hold for larger models. Also, despite its effectiveness, we only explore a limited set of ways to combine generation and self-verification, as well as a single form of verification task. More diverse verification formulations and tighter coupling paradigms between generation and verification may further push the performance ceiling. Moreover, our study focuses primarily on mathematical reasoning benchmarks. While the proposed framework is conceptually general, it remains an open question whether the same asymmetry and the benefits of learning to self-verify will hold in other domains, such as planning and multimodal reasoning. Finally, the current multi-task training schedule (e.g., stage-wise or alternating) is manually designed and heuristic. A more principled or adaptive strategy for balancing generation and self-verification objectives remains an interesting direction for future work.
References
- Anthropic (2025) Introducing claude opus 4.5. External Links: Link Cited by: §1, §5.1.
- A. Bhaskar, X. Ye, and D. Chen (2025) Language models that think, chat better. CoRR abs/2509.20357. Cited by: §1.
- T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei (2020) Language models are few-shot learners. In NeurIPS, Cited by: §5.1.
- C. Chen, Z. Liu, C. Du, T. Pang, Q. Liu, A. Sinha, P. Varakantham, and M. Lin (2025a) Bootstrapping language models with DPO implicit rewards. In ICLR, Cited by: §5.2.
- X. Chen, G. Li, Z. Wang, B. Jin, C. Qian, Y. Wang, H. Wang, Y. Zhang, D. Zhang, T. Zhang, H. Tong, and H. Ji (2025b) RM-R1: reward modeling as reasoning. CoRR abs/2505.02387. Cited by: §5.2.
- Z. Chen, X. Qin, Y. Wu, Y. Ling, Q. Ye, W. X. Zhao, and G. Shi (2025c) Pass@k training for adaptively balancing exploration and exploitation of large reasoning models. CoRR abs/2508.10751. Cited by: §5.1.
- Z. Chen, X. Ma, G. Fang, R. Yu, and X. Wang (2025d) VeriThinker: learning to verify makes reasoning model efficient. CoRR abs/2505.17941. Cited by: §5.3.
- DeepSeek-AI, A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, C. Lu, C. Zhao, C. Deng, C. Xu, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, E. Li, F. Zhou, F. Lin, F. Dai, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Li, H. Liang, H. Wei, H. Zhang, H. Luo, H. Ji, H. Ding, H. Tang, H. Cao, H. Gao, H. Qu, H. Zeng, J. Huang, J. Li, J. Xu, J. Hu, J. Chen, J. Xiang, J. Yuan, J. Cheng, J. Zhu, J. Ran, J. Jiang, J. Qiu, J. Li, J. Song, K. Dong, K. Gao, K. Guan, K. Huang, K. Zhou, K. Huang, K. Yu, L. Wang, L. Zhang, L. Wang, L. Zhao, L. Yin, L. Guo, L. Luo, L. Ma, L. Wang, L. Zhang, M. S. Di, M. Y. Xu, M. Zhang, M. Zhang, M. Tang, M. Zhou, P. Huang, P. Cong, P. Wang, Q. Wang, Q. Zhu, Q. Li, Q. Chen, Q. Du, R. Xu, R. Ge, R. Zhang, R. Pan, R. Wang, R. Yin, R. Xu, R. Shen, R. Zhang, S. H. Liu, S. Lu, S. Zhou, S. Chen, S. Cai, S. Chen, S. Hu, S. Liu, S. Hu, S. Ma, S. Wang, S. Yu, S. Zhou, S. Pan, S. Zhou, T. Ni, T. Yun, T. Pei, T. Ye, T. Yue, W. Zeng, W. Liu, W. Liang, W. Pang, W. Luo, W. Gao, W. Zhang, X. Gao, X. Wang, X. Bi, X. Liu, X. Wang, X. Chen, X. Zhang, X. Nie, X. Cheng, X. Liu, X. Xie, X. Liu, X. Yu, X. Li, X. Yang, X. Li, X. Chen, X. Su, X. Pan, X. Lin, X. Fu, Y. Q. Wang, Y. Zhang, Y. Xu, Y. Ma, Y. Li, Y. Li, Y. Zhao, Y. Sun, Y. Wang, Y. Qian, Y. Yu, Y. Zhang, Y. Ding, Y. Shi, Y. Xiong, Y. He, Y. Zhou, Y. Zhong, Y. Piao, Y. Wang, Y. Chen, Y. Tan, Y. Wei, Y. Ma, Y. Liu, Y. Yang, Y. Guo, Y. Wu, Y. Wu, Y. Cheng, Y. Ou, Y. Xu, Y. Wang, Y. Gong, Y. Wu, Y. Zou, Y. Li, Y. Xiong, Y. Luo, Y. You, Y. Liu, Y. Zhou, Z. F. Wu, Z. Z. Ren, Z. Zhao, Z. Ren, Z. Sha, Z. Fu, Z. Xu, Z. Xie, Z. Zhang, Z. Hao, Z. Gou, Z. Ma, Z. Yan, Z. Shao, Z. Huang, Z. Wu, Z. Li, Z. Zhang, Z. Xu, Z. Wang, Z. Gu, Z. Zhu, Z. Li, Z. Zhang, Z. Xie, Z. Gao, Z. Pan, Z. Yao, B. Feng, H. Li, J. L. Cai, J. Ni, L. Xu, M. Li, N. Tian, R. J. Chen, R. L. Jin, S. S. Li, S. Zhou, T. Sun, X. Q. Li, X. Jin, X. Shen, X. Chen, X. Song, X. Zhou, Y. X. Zhu, Y. Huang, Y. Li, Y. Zheng, Y. Zhu, Y. Ma, Z. Huang, Z. Xu, Z. Zhang, D. Ji, J. Liang, J. Guo, J. Chen, L. Xia, M. Wang, M. Li, P. Zhang, R. Chen, S. Sun, S. Wu, S. Ye, T. Wang, W. L. Xiao, W. An, X. Wang, X. Sun, X. Wang, Y. Tang, Y. Zha, Z. Zhang, Z. Ju, Z. Zhang, and Z. Qu (2025) DeepSeek-v3.2: pushing the frontier of open large language models. Vol. abs/2512.02556. Cited by: §1.
- DeepSeek-AI (2025) DeepSeek-r1: incentivizing reasoning capability in llms via reinforcement learning. CoRR abs/2501.12948. Cited by: §1, §1, §5.1.
- S. Feng, G. Fang, X. Ma, and X. Wang (2025) Efficient reasoning models: A survey. Trans. Mach. Learn. Res. 2025. Cited by: §5.1.
- Google (2025) A new era of intelligence with gemini 3. External Links: Link Cited by: §5.1.
- A. Gunjal, A. Wang, E. Lau, V. Nath, B. Liu, and S. Hendryx (2025) Rubrics as rewards: reinforcement learning beyond verifiable domains. CoRR abs/2507.17746. Cited by: §5.1.
- C. He, R. Luo, Y. Bai, S. Hu, Z. L. Thai, J. Shen, J. Hu, X. Han, Y. Huang, Y. Zhang, J. Liu, L. Qi, Z. Liu, and M. Sun (2024) OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In ACL (1), pp. 3828–3850. Cited by: §3.2.
- R. Hong, H. Zhang, X. Pang, D. Yu, and C. Zhang (2024) A closer look at the self-verification abilities of large language models in logical reasoning. In NAACL-HLT, pp. 900–925. Cited by: §1.
- J. Hu, Y. Zhang, Q. Han, D. Jiang, X. Zhang, and H. Shum (2025) Open-reasoner-zero: an open source approach to scaling up reinforcement learning on the base model. CoRR abs/2503.24290. Cited by: §1.
- B. Jin, H. Zeng, Z. Yue, D. Wang, H. Zamani, and J. Han (2025) Search-r1: training llms to reason and leverage search engines with reinforcement learning. CoRR abs/2503.09516. Cited by: §5.1.
- H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe (2024) Let’s verify step by step. In ICLR, Cited by: §3.2.
- C. Y. Liu, L. Zeng, J. Liu, R. Yan, J. He, C. Wang, S. Yan, Y. Liu, and Y. Zhou (2024) Skywork-reward: bag of tricks for reward modeling in llms. CoRR abs/2410.18451. Cited by: §5.2.
- C. Y. Liu, L. Zeng, Y. Xiao, J. He, J. Liu, C. Wang, R. Yan, W. Shen, F. Zhang, J. Xu, Y. Liu, and Y. Zhou (2025a) Skywork-reward-v2: scaling preference data curation via human-ai synergy. CoRR abs/2507.01352. Cited by: §5.2.
- X. Liu, T. Liang, Z. He, J. Xu, W. Wang, P. He, Z. Tu, H. Mi, and D. Yu (2025b) Trust, but verify: A self-verification approach to reinforcement learning with verifiable rewards. CoRR abs/2505.13445. Cited by: §1, §5.3.
- Z. Liu, P. Wang, R. Xu, S. Ma, C. Ruan, P. Li, Y. Liu, and Y. Wu (2025c) Inference-time scaling for generalist reward modeling. CoRR abs/2504.02495. Cited by: §5.2.
- J. Lu, R. Teehan, J. Jin, and M. Ren (2025) When does verification pay off? A closer look at llms as solution verifiers. CoRR abs/2512.02304. Cited by: §1, §5.1.
- D. Mahan, D. Phung, R. Rafailov, C. Blagden, N. Lile, L. Castricato, J. Fränken, C. Finn, and A. Albalak (2024) Generative reward models. CoRR abs/2410.12832. Cited by: §5.2.
- MiniMax (2025) MiniMax m2 and agent: ingenious in simplicity. External Links: Link Cited by: §1.
- OpenAI (2023) GPT-4 technical report. CoRR abs/2303.08774. Cited by: §3.4, §5.1.
- OpenAI (2025) Introducing gpt-5.2. External Links: Link Cited by: §1, §5.1.
- L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe (2022) Training language models to follow instructions with human feedback. In NeurIPS, Cited by: §5.1.
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov (2017) Proximal policy optimization algorithms. CoRR abs/1707.06347. Cited by: §2.1.
- Z. Shao, Y. Luo, C. Lu, Z. Z. Ren, J. Hu, T. Ye, Z. Gou, S. Ma, and X. Zhang (2025) DeepSeekMath-v2: towards self-verifiable mathematical reasoning. CoRR abs/2511.22570. Cited by: §1.
- Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. K. Li, Y. Wu, and D. Guo (2024) DeepSeekMath: pushing the limits of mathematical reasoning in open language models. CoRR abs/2402.03300. Cited by: §2.1, §5.1.
- G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y. Peng, H. Lin, and C. Wu (2025) HybridFlow: A flexible and efficient RLHF framework. In EuroSys, pp. 1279–1297. Cited by: §3.2.
- C. Snell, J. Lee, K. Xu, and A. Kumar (2024) Scaling LLM test-time compute optimally can be more effective than scaling model parameters. CoRR abs/2408.03314. Cited by: §5.2.
- K. Stechly, K. Valmeekam, and S. Kambhampati (2025) On the self-verification limitations of large language models on reasoning and planning tasks. In ICLR, Cited by: §1, §5.1.
- Y. Su, D. Yu, L. Song, J. Li, H. Mi, Z. Tu, M. Zhang, and D. Yu (2025) Crossing the reward bridge: expanding RL with verifiable rewards across diverse domains. CoRR abs/2503.23829. Cited by: §5.1.
- Y. Sui, Y. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, N. Zou, H. Chen, and X. Hu (2025) Stop overthinking: A survey on efficient reasoning for large language models. Trans. Mach. Learn. Res. 2025. Cited by: §5.1.
- G. Team (2025) Gemma 3 technical report. CoRR abs/2503.19786. Cited by: §1.
- H. Touvron, T. Lavril, G. Izacard, X. Martinet, M. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample (2023) LLaMA: open and efficient foundation language models. CoRR abs/2302.13971. Cited by: §5.1.
- R. Wang, H. Wang, B. Xue, J. Pang, S. Liu, Y. Chen, J. Qiu, D. F. Wong, H. Ji, and K. Wong (2025a) Harnessing the reasoning economy: A survey of efficient reasoning for large language models. CoRR abs/2503.24377. Cited by: §5.1.
- X. Wang, B. Liu, S. Jiang, J. Liu, J. Qi, X. Chen, and B. He (2025b) From solving to verifying: A unified objective for robust reasoning in llms. CoRR abs/2511.15137. Cited by: §1, §5.3.
- Z. Wang, K. Wang, Q. Wang, P. Zhang, L. Li, Z. Yang, X. Jin, K. Yu, M. N. Nguyen, L. Liu, E. Gottlieb, Y. Lu, K. Cho, J. Wu, L. Fei-Fei, L. Wang, Y. Choi, and M. Li (2025c) RAGEN: understanding self-evolution in LLM agents via multi-turn reinforcement learning. CoRR abs/2504.20073. Cited by: §5.1.
- F. Wu, W. Xuan, X. Lu, Z. Harchaoui, and Y. Choi (2025) The invisible leash: why RLVR may not escape its origin. CoRR abs/2507.14843. Cited by: §5.1.
- A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. Li, T. Tang, W. Yin, X. Ren, X. Wang, X. Zhang, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Zhang, Y. Wan, Y. Liu, Z. Wang, Z. Cui, Z. Zhang, Z. Zhou, and Z. Qiu (2025a) Qwen3 technical report. CoRR abs/2505.09388. Cited by: §1.
- A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu (2024) Qwen2.5 technical report. CoRR abs/2412.15115. Cited by: §3.2, §5.1.
- Z. Yang, Z. Guo, Y. Huang, Y. Wang, D. Xie, Y. Wang, X. Liang, and J. Tang (2025b) Depth-breadth synergy in RLVR: unlocking LLM reasoning gains with adaptive exploration. CoRR abs/2508.13755. Cited by: §5.1.
- E. Yee, A. Li, C. Tang, Y. H. Jung, R. Paturi, and L. Bergen (2024) Dissociation of faithful and unfaithful reasoning in llms. CoRR abs/2405.15092. Cited by: §1.
- Q. Yu, Z. Zhang, R. Zhu, Y. Yuan, X. Zuo, Y. Yue, T. Fan, G. Liu, L. Liu, X. Liu, H. Lin, Z. Lin, B. Ma, G. Sheng, Y. Tong, C. Zhang, M. Zhang, W. Zhang, H. Zhu, J. Zhu, J. Chen, J. Chen, C. Wang, H. Yu, W. Dai, Y. Song, X. Wei, H. Zhou, J. Liu, W. Ma, Y. Zhang, L. Yan, M. Qiao, Y. Wu, and M. Wang (2025a) DAPO: an open-source LLM reinforcement learning system at scale. CoRR abs/2503.14476. Cited by: §2.1, §3.2.
- R. Yu, S. Wan, Y. Wang, C. Gao, L. Gan, Z. Zhang, and D. Zhan (2025b) Reward models in deep reinforcement learning: A survey. In IJCAI, pp. 10807–10816. Cited by: §5.2.
- T. Yu, B. Ji, S. Wang, S. Yao, Z. Wang, G. Cui, L. Yuan, N. Ding, Y. Yao, Z. Liu, M. Sun, and T. Chua (2025c) RLPR: extrapolating RLVR to general domains without verifiers. CoRR abs/2506.18254. Cited by: §5.1.
- Z. Yu, J. Zeng, W. Gu, Y. Wang, J. Wang, F. Meng, J. Zhou, Y. Zhang, S. Zhang, and W. Ye (2025d) RewardAnything: generalizable principle-following reward models. CoRR abs/2506.03637. Cited by: §5.2.
- Z.AI (2025) GLM-4.7: advancing the coding capability. External Links: Link Cited by: §1.
- W. Zeng, Y. Huang, Q. Liu, W. Liu, K. He, Z. Ma, and J. He (2025a) SimpleRL-zoo: investigating and taming zero reinforcement learning for open base models in the wild. CoRR abs/2503.18892. Cited by: §1.
- Y. Zeng, Y. Huang, C. Xu, Q. Sun, J. Yan, G. Xu, T. Yang, and F. Lian (2025b) Zero reinforcement learning towards general domains. CoRR abs/2510.25528. Cited by: §1.
- F. Zhang, J. Xu, C. Wang, C. Cui, Y. Liu, and B. An (2025a) Incentivizing llms to self-verify their answers. CoRR abs/2506.01369. Cited by: §1, §4.2, §5.3.
- L. Zhang, A. Hosseini, H. Bansal, M. Kazemi, A. Kumar, and R. Agarwal (2025b) Generative verifiers: reward modeling as next-token prediction. In ICLR, Cited by: §5.2.
- Y. Zhang and T. Math-AI (2024) American invitational mathematics examination (aime) 2024. Cited by: §3.2.
- Y. Zhang and T. Math-AI (2025) American invitational mathematics examination (aime) 2025. Cited by: §3.2.
- Y. Zhang, M. Khalifa, L. Logeswaran, J. Kim, M. Lee, H. Lee, and L. Wang (2024) Small language models need strong verifiers to self-correct reasoning. In ACL (Findings), pp. 15637–15653. Cited by: §1.
- J. Zhao, Y. Sun, W. Shi, and D. Song (2025) Can aha moments be fake? identifying true and decorative thinking steps in chain-of-thought. CoRR abs/2510.24941. Cited by: §1.
- J. Zhong, W. Shen, Y. Li, S. Gao, H. Lu, Y. Chen, Y. Zhang, W. Zhou, J. Gu, and L. Zou (2025) A comprehensive survey of reward models: taxonomy, applications, challenges, and future. CoRR abs/2504.12328. Cited by: §5.2.