# Latent Reasoning with Supervised Thinking States
**Authors**: Ido Amos, Avi Caciularu, Mor Geva, Amir Globerson, Jonathan Herzig, Lior Shani, Idan Szpektor
## Abstract
Reasoning with a chain-of-thought (CoT) enables Large Language Models (LLMs) to solve complex tasks but incurs significant inference costs due to the generation of long rationales. We propose Thinking States, a method that performs reasoning while the input is processing. Specifically, Thinking States generates sequences of thinking tokens every few input tokens, transforms the thoughts back into embedding space, and adds them to the following input tokens. This has two key advantages. First, it captures the recurrent nature of CoT, but where the thought tokens are generated as input is processing. Second, since the thoughts are represented as tokens, they can be learned from natural language supervision, and using teacher-forcing, which is parallelizable. Empirically, Thinking States outperforms other latent reasoning methods on multiple reasoning tasks, narrowing the gap to CoT on math problems, and matching its performance on 2-Hop QA with improved latency. On state-tracking tasks, we show Thinking States leads to stronger reasoning behavior than CoT, successfully extrapolating to longer sequences than seen during training.
Machine Learning, ICML
## 1 Introduction
Generating intermediate reasoning steps prior to answering enables large language models (LLMs) to tackle challenging problems with considerably greater accuracy (Wei et al., 2022). Such chain-of-thought (CoT) reasoning yields substantial performance gains, but may incur significant inference-time cost because of generating additional tokens. Thus, the challenge of reducing computational cost of reasoning while preserving accuracy has attracted considerable attention recently (Xia et al., 2025; Kang et al., 2024; Hassid et al., 2025; Hao et al., 2024).
<details>
<summary>x1.png Details</summary>
### Visual Description
# Technical Document Extraction: Diagram Analysis
## Diagram Overview
The image contains two side-by-side diagrams labeled **"Thinking States"** (left) and **"Chain-of-Thought"** (right). Both diagrams use grid-based structures to represent sequential processes, with annotations and legends to clarify components.
---
### **Left Diagram: Thinking States**
#### **Components and Labels**
1. **Legend**:
- **Thinking States**: Orange (`s`)
- **Language Tokens**: Blue (`t`)
- **Compression Block**: Green (`c`)
2. **Grid Structure**:
- A 5x4 grid of rectangles, with some cells containing labels:
- **Top Row**:
- Two cells labeled `tails` and `EOS` (blue background).
- Two cells labeled `tails` and `EOS` (blue background).
- **Middle Row**:
- One cell labeled `s` (orange, "Thinking States").
- One cell labeled `s` (orange, "Thinking States").
- **Right Column**:
- One cell labeled `A: heads.` (blue, "Language Tokens").
- **Bottom Row**:
- Multiple empty cells.
3. **Embedded Text**:
- Scenario: *"A coin's state is heads. Alice flips, then Bob flips. What's the state? A: heads."*
#### **Spatial Grounding**
- **Legend Position**: Top-left corner.
- **Color Consistency**:
- Orange (`s`) matches "Thinking States."
- Blue (`t`) matches "Language Tokens."
- Green (`c`) matches "Compression Block."
---
### **Right Diagram: Chain-of-Thought**
#### **Components and Labels**
1. **Legend**:
- **Language Tokens**: Blue (`t`)
- **A: heads.**: Blue (`A`)
2. **Grid Structure**:
- A 5x4 grid of rectangles, with sequential labels:
- **Top Row**:
- Labels: `heads, tails, heads, A: heads.` (blue).
- **Middle Row**:
- Labels: `heads, tails, heads, A: heads.` (blue).
- **Bottom Row**:
- Labels: `heads, tails, heads, A: heads.` (blue).
3. **Embedded Text**:
- Scenario: *"A coin's state is heads. Alice flips, then Bob flips. What's the state? heads, tails, heads. A: heads."*
#### **Spatial Grounding**
- **Legend Position**: Top-left corner.
- **Color Consistency**:
- Blue (`t`) matches "Language Tokens."
- Blue (`A`) matches "A: heads."
---
### **Key Observations**
1. **Purpose**:
- Both diagrams illustrate sequential reasoning processes, likely for a language model (LLM).
- "Thinking States" emphasizes intermediate states (e.g., `tails`, `EOS`), while "Chain-of-Thought" focuses on step-by-step outputs (e.g., `heads, tails`).
2. **Textual Content**:
- Both diagrams include the same scenario text but differ in how labels are applied to the grid.
3. **No Numerical Data**:
- The diagrams do not contain charts, heatmaps, or numerical trends. They are purely structural representations.
---
### **Conclusion**
The diagrams visualize two reasoning frameworks:
- **Thinking States**: Highlights intermediate states and compression blocks.
- **Chain-of-Thought**: Focuses on sequential outputs (e.g., coin flip results).
Both use color-coded legends to distinguish components, with spatial grounding ensuring clarity in label placement.
</details>
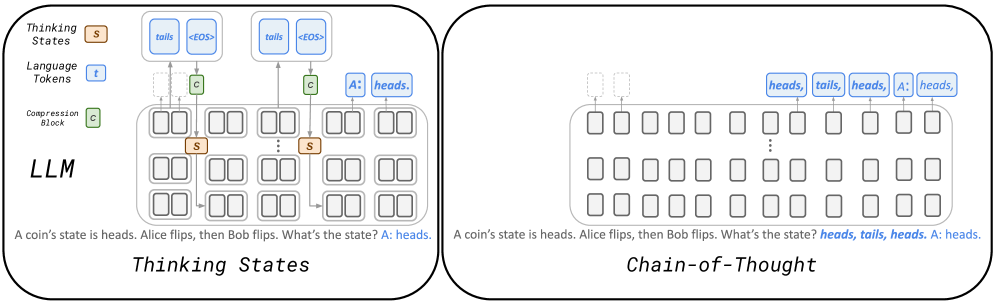
Figure 1: Reasoning with a Thinking State compared to Chain-of-Thought: An LLM is trained to generate task-relevant thinking sequences while processing tokens. Each generated thought sequence is transformed into a fixed-size state, denoted by $S$ , added to the following token representations.
One approach to reducing reasoning tokens is to not require thinking tokens to be in natural language, but rather be continuous embeddings (Hao et al., 2024; Shen et al., 2025). Indeed, language is highly redundant, and one can therefore expect shorter reasoning traces in this case. On the other hand, it is then harder to supervise these “continuous latent” thoughts, as target values for the latents are unknown, which requires backpropagation through time (BPTT) from the desired outcome, making training considerably more challenging and limiting the number of latents that can be used in practice. An alternative approach has been to distill the thinking pattern directly to the representations of the query, rather than generate any extra tokens (Deng et al., 2024). While supporting parallel training, the resulting architecture cannot effectively condition on thoughts. As queries are processed in parallel, sequential thinking can only be realized through the LLM’s depth, which is typically fixed, resulting in reduced expressivity compared to CoT models. Put differently, CoT can be viewed as providing the model with additional depth, which Deng et al. (2024) does not benefit from.
Motivated by these previous works we present an architecture that allows conditioning on thinking as in CoT, yet does not append thinking tokens to the context or suffer from optimization with BPTT. Our Thinking States model builds on several key ideas, illustrated in Figure 1. Compute Sharing: thoughts are generated using representations of existing tokens. Recurrence: these thoughts are fed back as input (as in regular CoT) along with future tokens, not increasing the context length. Supervision with Natural Language: the thought tokens can be supervised via natural language, and thus benefit from available supervision used by prior CoT methods, and maintain interpretability.
We evaluate Thinking States on synthetic and real-world datasets, demonstrating that it is more accurate than baselines that reduce CoT lengths, and provides a significant latency advantage compared to CoT. Moreover, we demonstrate that Thinking States can be trained significantly faster than models with latent thoughts that require BPTT.
Our contributions are as follows:
1. We introduce Thinking States, a recurrent reasoning mechanism that generates natural-language thoughts while processing the input, without increasing the context length.
1. Because thoughts are represented in natural language, Thinking States can be trained with teacher-forcing the thoughts, enabling fully parallel training and avoiding the computational overhead of backpropagation through time.
1. We demonstrate that Thinking States consistently outperforms existing latent reasoning methods on various benchmarks, matches or exceeds CoT accuracy on multi-hop QA and state-tracking tasks, and achieves significant speedups compared to CoT on all tasks.
<details>
<summary>x2.png Details</summary>
### Visual Description
# Technical Diagram Analysis: Transformer-Based Language Model Architecture
## Diagram Overview
The image depicts a transformer-based language model architecture processing a natural language query. The diagram illustrates the flow of information through multiple transformer layers, attention mechanisms, and cache management components.
## Key Components and Flow
### 1. Input Processing
- **Input Tokens**:
- Sentence: "A coin's state is heads. Alice flips, then Bob flips. What's the state? A: heads."
- Tokenized as individual words in rectangular boxes at the bottom of the diagram
- **Positional Encoding**:
- Implied through sequential processing of tokens
- No explicit positional encoding markers shown
### 2. Transformer Layers
- **Layer Structure**:
- Three visible transformer layers labeled `Z_i`, `Z_i+2`, `Z_i+3`
- Each layer contains:
- **Self-Attention Mechanism**:
- Queries (`Q`), Keys (`K`), Values (`V`) processing
- Output (`O`) generation
- Attention weights (`A`) visualization
- **Feed-Forward Network**:
- Two linear layers with activation (not explicitly labeled)
- Output concatenation (`+`) operations
### 3. Cache Management
- **KV Cache**:
- Matrix structure with 10 key slots and 10 value slots
- Stores previous key-value pairs for autoregressive generation
- Connected to transformer layers via attention mechanism
### 4. Output Generation
- **Output Token**:
- Final answer: "heads" (highlighted in blue)
- Generated through autoregressive decoding process
- **Loss Functions**:
- `L_out`: Output loss (not quantified)
- `L_in`: Input loss (not quantified)
## Spatial Component Analysis
- **Legend**:
- No explicit legend present in the diagram
- Color coding used for:
- Blue: Attention mechanism components (`<EOS>`, `heads`, `tails`)
- Green: Transformer blocks (`T`, `C`)
- Orange: Positional indices (`S_i`, `S_i+1`, etc.)
- Gray: General diagram elements
## Textual Elements
### Embedded Text
- **Input Sentence**:
</details>
(a) Inference
<details>
<summary>x3.png Details</summary>
### Visual Description
# Technical Document Extraction: Flowchart Analysis
## Diagram Overview
The image depicts a **sequence-to-sequence prediction workflow** with labeled components, loss calculation, and a textual example. The diagram uses color-coded blocks and arrows to represent data flow and validation.
---
## Key Components and Flow
### 1. **Labels and Predictions**
- **Labels** (Top Left):
- `tails`
- `<EOS>` (End-of-Sequence token)
- **Predictions** (Top Right):
- `tails`
- `heads`
- **Validation**:
- Green checkmark (✓) for correct prediction (`tails` vs. `tails`).
- Red X for incorrect prediction (`heads` vs. `tails`).
### 2. **Loss Calculation**
- **Loss Section** (Middle):
- Two correct predictions (`heads` vs. `heads` and `<EOS>` vs. `<EOS`), both marked with green checkmarks.
- Arrows indicate loss propagation to the next stage.
### 3. **Textual Example**
- **Narrative** (Bottom):
- "A coin’s state is heads. Alice flips, then Bob flips. What’s the state? A: heads."
- **Tokenized Labels**:
- `<EOS>`
- `tails`
- `<EOS>`
- `heads`
- `<EOS>`
---
## Diagram Structure
### 1. **Blocks and Arrows**
- **T Blocks** (Green):
- Represent **target tokens** (e.g., `tails`, `heads`).
- **C Blocks** (Orange):
- Represent **contextual tokens** (e.g., `Alice`, `Bob`).
- **Arrows**:
- Green arrows: Correct predictions/loss propagation.
- Red arrows: Incorrect predictions.
### 2. **Legend and Color Coding**
- **Legend** (Top):
- Green: Correct predictions (`✓`).
- Red: Incorrect predictions (`X`).
- Orange: Contextual tokens (`C` blocks).
---
## Spatial Grounding and Trends
### 1. **Legend Placement**
- **Legend Location**: Top-center.
- **Color Mapping**:
- Green (`✓`): Correct predictions (e.g., `tails` vs. `tails`).
- Red (`X`): Incorrect predictions (e.g., `heads` vs. `tails`).
- Orange (`C`): Contextual tokens (e.g., `Alice`, `Bob`).
### 2. **Data Flow Trends**
- **Labels → Predictions**:
- Correct prediction (`tails` → `tails`).
- Incorrect prediction (`heads` → `tails`).
- **Loss → Textual Example**:
- Loss propagates to the narrative example, where the final prediction (`heads`) matches the label.
---
## Textual Content Extraction
### 1. **Narrative Example**
- **Transcribed Text**:
</details>
(b) Training
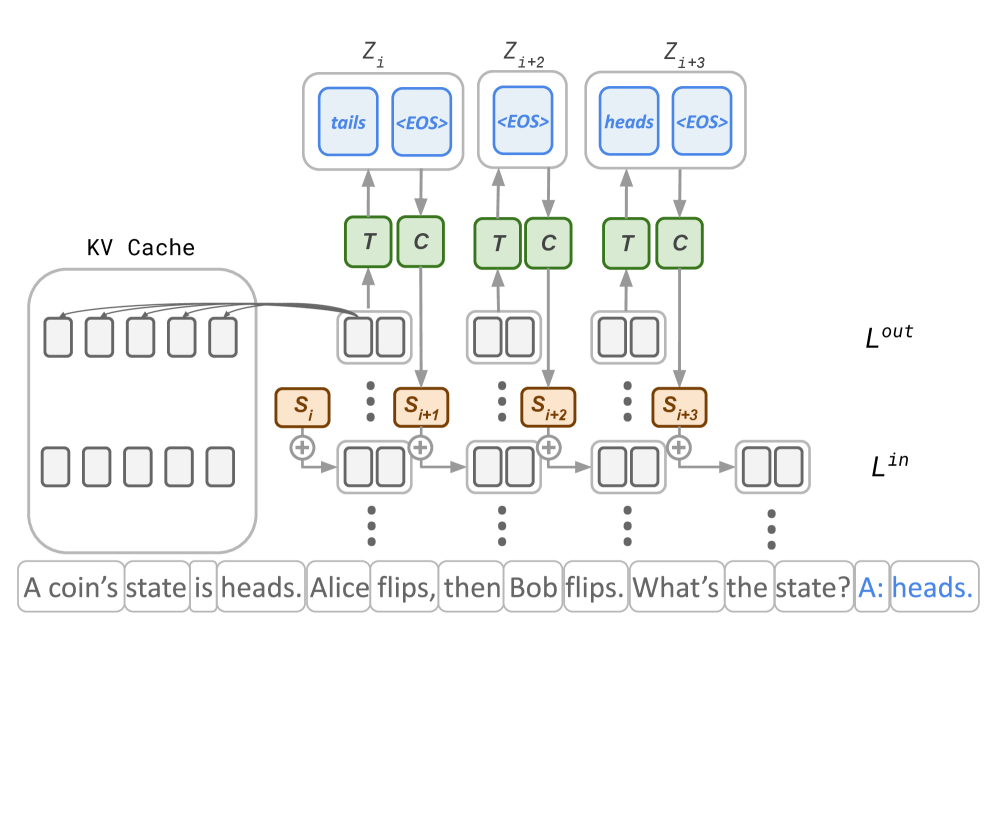
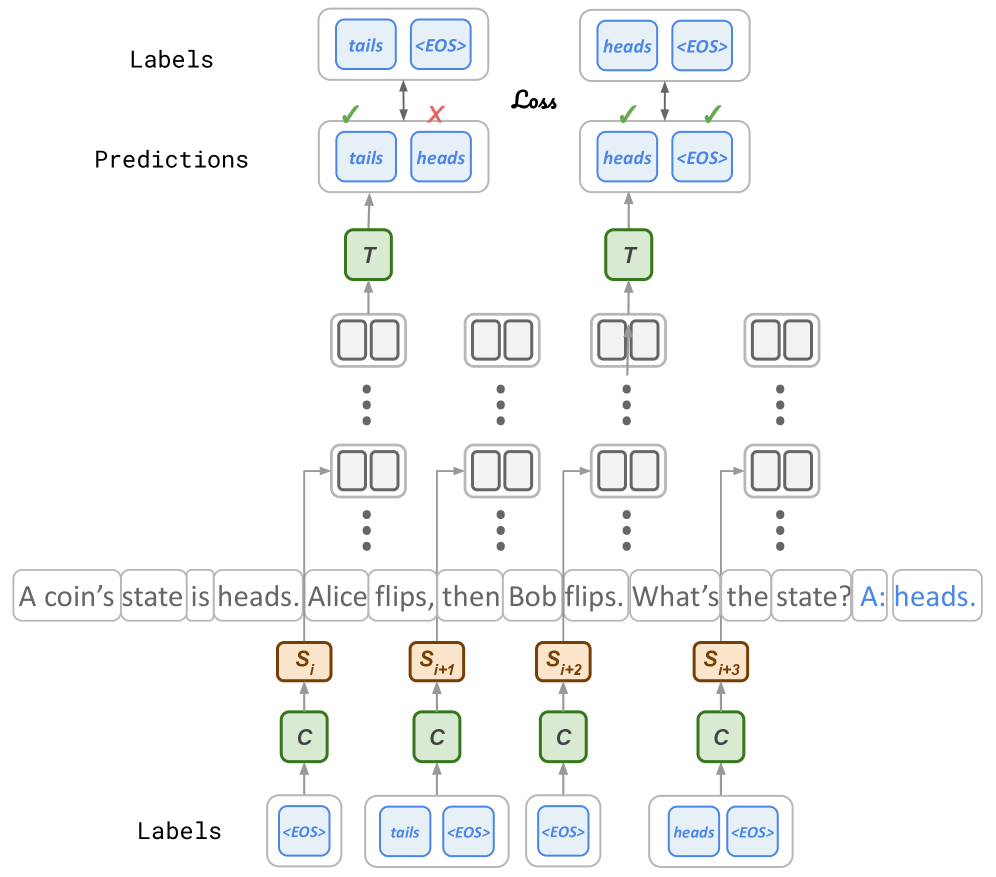
Figure 2: Thinking States model at inference and training time. At inference time (a), Thinking States reasons by iteratively processing token chunks. At each iteration $i$ , reasoning information encoded up to layer $L^{out}$ is decoded by a thinking block $T$ and compressed by a compression block $C$ to a fixed-size thinking state $\mathbf{S_{i+1}}$ . The state is injected to the next chunk at a shallow layer to effectively influence future computations. Chunk representations can access the history via attention layers and the KV-cache. At training time (b), predictions by $T$ are supervised by explicit annotations paired with each chunk. The same annotations are used to condition the base LLM’s reasoning, allowing parallel training.
## 2 Related Work
Latent Reasoning.
A prominent line of research focuses on adapting pretrained LLMs to internalize chain-of-thought (CoT) reasoning into compressed representations. Initial efforts distilled knowledge from a CoT-capable teacher model directly into the query representations of a student model (Deng et al., 2023). A related approach employs an iterative training curriculum that progressively removes explicit reasoning steps from the supervision signal, compelling the model to internalize the reasoning process (Deng et al., 2024). Hao et al. (2024) extended this idea by introducing recurrent “continuous thought tokens” that are iteratively refined after processing the query. While promising, this recurrent formulation necessitates backpropagation through time (BPTT), which is computationally intensive and limits scalability. More recently, Shen et al. (2025) proposed adding a distillation loss that aligns the student’s latent representations with those of a CoT-based teacher, removing reliance on the iterative curriculum. However, this approach still requires BPTT for optimization and incurs the additional computational cost of a separate teacher model.
Emergent Latent Reasoning in Standard LLMs.
Recent studies have revealed that standard LLMs can exhibit latent reasoning capabilities without explicit training. Biran et al. (2024) demonstrated this by successfully decoding intermediate reasoning steps from the model’s hidden states, while Yang et al. (2024) showed that LLMs can arrive at correct answers on queries that inherently require multi-hop reasoning. These findings suggest that some degree of latent reasoning emerges naturally during pretraining, making multi-hop question answering, which we include in our evaluation, an important testbed for methods designed to enhance this capability.
Alternative Approaches to Latent Computation.
A distinct line of work aims to improve reasoning by providing models with additional computation time, rather than by internalizing a specific reasoning trace. Goyal et al. (2023) introduced “pause tokens” during pretraining—tokens without semantic meaning that give the model extra computational steps before producing output, improving performance on downstream reasoning tasks. Geiping et al. (2025) proposed dynamic depth, where the same block of layers is applied repeatedly for a variable number of iterations, effectively increasing computation per token at inference time. Finally, Zelikman et al. (2024) enabled token-level rationale generation by decoding auxiliary reasoning tokens before each prediction, training the model with reinforcement learning to produce helpful rationales. Unlike our approach, these auxiliary tokens influence only the current prediction and are discarded afterward, avoiding recurrent dependencies but also forgoing the ability to carry reasoning state across positions.
## 3 Thinking State Architecture and Supervision
We introduce the Thinking States model, illustrated in Figure 2(a). The core element of our architecture is a chunk-recurrent process of decoding thoughts from token representations, compressing thoughts into a fixed-size state, and injecting the state into representations of subsequent tokens at a shallow layer (e.g., the first layer).
Because thoughts are decoded from representations in a deep layer (e.g., second to last), we leverage the backbone LLM to perform the bulk of the computation. This allows the decoding ”Thinking Block” to remain lightweight and efficient, as it operates on a rich feature space. By injecting the compressed state into representations of future tokens at a shallow layer, we effectively condition on the reasoning process without extending the context. Sections 3.2, 3.3, provide details on how this recurrent process is executed efficiently at training and inference time.
Setting. Let an input sequence of $L$ tokens be partitioned into $K$ non-overlapping chunks $\mathbf{X}_{1},\dots,\mathbf{X}_{K}$ . In the case $L\bmod c\neq 0$ , input tokens are grouped into chunks along with generated tokens, once those are available. Each $\mathbf{X}_{i}\in\mathbb{R}^{c\times d}$ denotes the input embeddings of $c$ tokens (where $c=L/K$ ) with hidden dimension $d$ , extracted after a designated shallow layer $L^{in}$ of the LLM.
Our architecture augments a backbone LLM $M_{\theta}$ with two additional modules:
1. Thinking Block $T$ : A lightweight Transformer decoder (one layer in our experiments) that autoregressively generates a reasoning sequence $\mathbf{Z}=(z_{1},\dots,z_{n})$ in natural language.
1. Compression Block $C$ : A Transformer encoder with a pooling layer that maps any variable-length reasoning sequence into a fixed-size state $\mathbf{S}\in\mathbb{R}^{c\times d}$ .
Further architectural details for $T$ and $C$ are provided in Appendix A.1.
### 3.1 Architecture
Thinking States processes token chunks iteratively while maintaining a state $\mathbf{S}_{i}\in\mathbb{R}^{c\times d}$ . At each step $i$ , we first inject the current state into the input representations at the shallow layer, then forward through $M_{\theta}$ :
$$
\tilde{\mathbf{X}}_{i}=\mathbf{X}_{i}+\mathbf{S}_{i} \tag{1}
$$
$$
\mathbf{H}_{i}^{out}=M_{\theta}(\tilde{\mathbf{X}}_{i}\mid\tilde{\mathbf{X}}_{<i}) \tag{2}
$$
Here, $\mathbf{H}_{i}^{out}$ denotes the chunk representations at a predefined deep layer $L^{out}$ , and past representations $\tilde{\mathbf{X}}_{<i}$ are accessed through the KV-cache.
Next, $\mathbf{H}_{i}^{out}$ is used to generate a sequence of natural-language thought tokens via the Thinking Block:
$$
\mathbf{Z}_{i+1}={T}(\mathbf{H}_{i}^{out}) \tag{3}
$$
The output $\mathbf{Z}_{i+1}$ is a variable-length token sequence ending with an <EOS> token. When no reasoning is required, $\mathbf{Z}_{i+1}$ may consist solely of <EOS>.
Finally, the Compression Block transforms the variable-length thought sequence into a fixed-size state for the next iteration:
$$
\mathbf{S}_{i+1}={C}(\mathbf{Z}_{i+1})\in\mathbb{R}^{c\times d} \tag{4}
$$
For the first chunk, we initialize $\mathbf{S}_{1}=\mathbf{0}$ .
This design serves two key ideas: compute sharing and recurrence. As inputs are a sum of tokens and states, eq. (1 - 2), the model effectively performs next token prediction while processing and generating states, executing both computations in a single forward pass. By injecting states at a shallow layer, we allow thoughts to effectively condition future thoughts through most of the LLM’s hidden layers. Importantly, since the thought tokens are never appended to the backbone’s context window, the context length remains fixed.
### 3.2 Training with Teacher-Forced Reasoning
To supervise the generated thinking sequences $\mathbf{Z}_{i}$ , we rely on explicit natural-language annotations. In our formulation, each token chunk in the training data is paired with a target reasoning sequence $\mathbf{Z}_{i}^{*}$ of variable length. For chunks that require no intermediate reasoning, the target is simply the <EOS> token.
Access to these ground-truth sequences $\mathbf{Z}_{i}^{*}$ serves a dual purpose. As illustrated in Figure 2(b), in addition to providing supervision for the outputs of $T$ , we use $\mathbf{Z}_{i}^{*}$ to teacher-force the states injected into the backbone LLM. Specifically, we compute the target state as $\mathbf{S}_{i}^{*}={C}(\mathbf{Z}_{i}^{*})$ and inject it instead of the model-generated state:
$$
\tilde{\mathbf{X}}_{i}=\mathbf{X}_{i}+\mathbf{S}_{i}^{*} \tag{5}
$$
Since all target sequences $\mathbf{Z}_{i}^{*}$ are available upfront, we can compute all chunk representations $\mathbf{H}_{i}^{out}$ in a single parallel forward pass through $M_{\theta}$ . This eliminates the need for backpropagation through time (BPTT), dramatically reducing the computational cost of training.
After this forward pass, the Thinking Block $T$ is trained to predict $\mathbf{Z}_{i}^{*}$ via standard next-token prediction, in parallel over all chunks. Here, each $\mathbf{H}_{i}^{out}$ is computed under the gold state history $\mathbf{S}_{1}^{*},\dots,\mathbf{S}_{i}^{*}$ , so predicting $\mathbf{Z}_{i+1}$ is implicitly conditioned on all prior gold reasoning steps.
We optimize the joint objective:
$$
\mathcal{L}=\mathcal{L}_{\text{LM}}+\sum_{i=1}^{K}\mathcal{L}_{\text{T}}(\mathbf{Z}_{i},\mathbf{Z}^{*}_{i}) \tag{6}
$$
where $\mathcal{L}_{\text{LM}}$ is the standard language modeling loss and $\mathcal{L}_{\text{T}}$ is cross-entropy loss over the thinking sequences. This formulation enables fully parallel training while ensuring that $T$ learns to generate thoughts consistent with a valid reasoning history.
### 3.3 Fast Prefill with Speculative Thinking
While training is fully parallelizable, naïve inference remains sequential across chunks, as each $\tilde{\mathbf{X}}_{i}$ depends on the previous state $\mathbf{S}_{i}$ . This can significantly increase latency during query prefill.
To mitigate this overhead, we exploit a key observation: for most chunks, the generated state is trivial, that is, the Thinking Block produces only an <EOS> token. We leverage this sparsity to design an iterative yet exact prefill algorithm.
The algorithm proceeds as follows:
1. Perform a parallel forward pass over all chunks, speculating that all states are trivial.
1. For each chunk, generate thinking states using $T$ and $C$ .
1. Identify the earliest chunk $i_{1}$ that produces a non-trivial state. Since all chunks before $i_{1}$ truly have trivial states, the computation up to chunk $i_{1}$ is correct.
1. Cache all positions up to $i_{1}$ and repeat from step 1 for the remaining chunks, now conditioning on the correct state $\mathbf{S}_{i_{1}}$ and speculating a trivial state for following chunks.
The procedure terminates when no new non-trivial states are generated, yielding exactly the same result as full sequential prefill. If $|R|$ denotes the (unknown a priori) number of chunks with non-trivial states, the algorithm completes in exactly $|R|+1$ rounds. In typical regimes where $|R|\ll K$ , this substantially reduces prefill latency. A complete description of the algorithm is provided in Appendix A.2.
### 3.4 Constructing Chunk-Level Supervision
Training the Thinking Block requires supervision that specifies both where intermediate reasoning should occur and what reasoning content to produce. We construct this supervision by aligning CoT reasoning steps to specific positions in the input query.
Consider the following example query and its CoT trajectory:
“A coin’s state is heads. Alice flips, then Bob flips. What’s the state?” CoT: “heads $\rightarrow$ tails $\rightarrow$ heads”
Our goal is to map each reasoning step (which may span multiple tokens) to a specific position in the query where that step becomes inferable.
Step-to-Token Alignment.
We first align each reasoning step to the earliest query position where it can be logically inferred. This alignment is obtained either via a strong teacher model, e.g., Gemini 2.5-Flash (Comanici et al., 2025), or through programmatic rules when the task structure permits. The alignment is represented by inserting special indicator tokens <T> into the text:
“A coin’s state is heads. <T> Alice flips, <T> then Bob flips. <T> What’s the state?”
Each <T> marker indicates that the preceding context is sufficient to infer the corresponding reasoning step. We then tokenize the query and construct a corresponding reasoning array with the same length, where each position in the array is either empty or contains the reasoning step associated with the <T> token. The indicator tokens are removed after this alignment, ensuring they are never seen by the model during training.
Token-to-Chunk Alignment.
Given the aligned token sequence and reasoning array, we partition both into non-overlapping chunks of size $c$ . The target reasoning sequence for each chunk is the concatenation of all reasoning steps assigned to tokens within that chunk. For chunks with no associated reasoning steps, the target is simply the <EOS> token.
The entire process is applied only to the training data of each task we consider. Additional details can be found in Appendix A.3.
## 4 Experiments
We evaluate Thinking States on a diverse set of tasks that probe both reasoning accuracy and computational efficiency. Section 4.2 examines state-tracking, where Thinking States exhibits stronger length generalization than CoT. Section 4.3 evaluates general reasoning on Multi-Hop QA and GSM8K, showing that Thinking States surpasses latent reasoning baselines and approaches CoT performance with significant speedups. Section 4.4 presents ablation studies exploring the performance–efficiency tradeoff as a function of recurrence depth and chunk size. Finally, Section 4.5 provides an interpretability-driven error analysis, identifying distinct failure modes and cases where Thinking States outperforms CoT.
### 4.1 Experimental Setup
All experiments use Qwen2.5-Base models (Qwen et al., 2024) (0.5B and 1.5B parameters), fine-tuned on task-specific training data.
We compare against four baselines:
1. CoT: fine-tuning on explicit chain-of-thought traces;
1. No CoT: standard fine-tuning to predict the final answer directly;
1. iCoT (Deng et al., 2024): a latent reasoning method that distills CoT into query representations via curriculum learning;
1. Coconut (Hao et al., 2024): a state-of-the-art latent reasoning method using continuous thought tokens.
We reproduce iCoT and Coconut results using the official codebase of Hao et al. (2024) with default configurations unless otherwise noted.
Metrics.
We report accuracy on gold answers across all tasks. For efficiency, we measure wall-clock speedup relative to CoT on a single A100-80GB GPU. Unlike prior work (Hao et al., 2024; Deng et al., 2024), which reports efficiency in terms of generated token count, we use wall-time because token generation with the lightweight Thinking Block $T$ is substantially faster than standard autoregressive decoding.
### 4.2 State Tracking Tasks
State tracking tasks require monitoring quantities that evolve throughout the input (Merrill et al., 2024; Kim and Schuster, 2023; Li et al., 2025). These tasks are a natural testbed for latent reasoning methods because they explicitly require sequential composition —each step depends on the result of previous steps. We evaluate on two synthetic tasks adapted from Anil et al. (2022):
- Parity: tracking a single binary state through a sequence of flip operations.
- Variable Assignment (Vars): tracking multiple interacting integer variables, yielding more complex state dynamics.
Both tasks are expressed in natural language; formal definitions and examples are provided in Appendix A.4.
Table 1: Performance (accuracy) on State Tracking tasks, trained on samples with up to $N$ state updates and evaluated on $[N,100]$ .
| No CoT CoT Thinking States | 54.67 12.35 98.37 | 57.50 38.12 99.02 | 59.60 64.38 100.00 | 02.15 06.78 33.76 | 02.17 35.45 87.23 | 02.19 87.75 97.71 |
| --- | --- | --- | --- | --- | --- | --- |
To assess whether the underlying base model truly learns to reason via the recurrent thinking state mechanism, we employ a length generalization setting, drawing on the known extrapolation capabilities of recurrent models (delétang2023neuralnetworkschomskyhierarchy). We fine-tune all methods, with Qwen2.5-Base-0.5B as the base model, on sequences of up to $N$ operations ( $N\in\{10,20,40\}$ ) and evaluate on lengths in $[N,100]$ , in both cases, sampled uniformly over the range. All models are trained to $100\$ in-distribution accuracy to strictly isolate extrapolation capabilities from optimization effects.
Table 1 reports out-of-distribution (OOD) accuracy for each training regime. The results demonstrate how a base LLM trained with Thinking States effectively adapts to reasoning with a recurrent mechanism, leading to stronger length generalization than that of a model reasoning via CoT. Critically, this indicates that reasoning via the recurrent mechanism offers a more effective solution than CoT, requiring a simpler training distribution to achieve robust performance.
Furthermore, while CoT generates intermediate tokens proportional to the number of state operations, considerably extending the context length and thus expressivity, Thinking States maintains a static context size. By refining the query representation through state updates, Thinking States achieves superior length generalization, suggesting the model has learned to reason through the recurrent mechanism.
### 4.3 General Reasoning Capabilities
Table 2: Performance and speedup (over CoT) on reasoning tasks for different latent reasoning baselines and CoT.
| No CoT Thinking States Coconut | 34.11 42.22 32.65 | $\times$ 5.59 $\times$ 2.66 $\times$ 3.14 | 33.47 54.91 33.71 | $\times$ 1.89 $\times$ 1.19 $\times$ 1.14 | 31.92 43.05 32.60 | $\times$ 2.03 $\times$ 1.23 $\times$ 1.21 |
| --- | --- | --- | --- | --- | --- | --- |
| iCoT | 34.00 | $\times$ 5.71 | 28.84 | $\times$ 1.59 | 36.31 | $\times$ 1.80 |
We evaluate general reasoning capabilities on two established benchmarks. First, a 2-hop QA dataset, where prior work by Biran et al. (2024); Yang et al. (2024) demonstrated standard LLMs exhibit latent reasoning to some extent, providing a useful test case for methods designed to improve latent reasoning. Second, a GSM8K-style dataset, consisting of $\sim$ 400K simple math word problems and parsed CoT steps, previously used by Deng et al. (2023); Hao et al. (2024). Methods in this section use Qwen2.5-Base-1.5B as the base model.
For the 2-hop QA task, we consider two evaluation regimes. In Full Knowledge (FK), the required factual knowledge appears in the fine-tuning data, testing how well models acquire and manipulate knowledge with each method. In Parametric Knowledge (PK), examples are filtered to reflect the knowledge of the base LLM, isolating whether a method improves retrieval and manipulation of existing knowledge in the base model.
<details>
<summary>x4.png Details</summary>
### Visual Description
# Technical Document Extraction: Line Chart Analysis
## Title
**Speedup over CoT**
## Axes
- **X-Axis**:
Label: `Num Layers in Recurrence`
Values: `4`, `8`, `12`, `16`, `20`, `24`, `26`
- **Y-Axis**:
Label: `Accuracy (%)`
Range: `20` to `48` (with gridlines at 20, 24, 28, 32, 36, 40, 44, 48)
## Legend
- **No CoT Baseline**:
Color: Red (dotted line)
Value: `34.11%`
- **Model Accuracy**:
Color: Blue (dashed line)
## Data Points (Blue Dashed Line)
- **Trend**: Upward slope from left to right.
- **Values**:
- `4` layers: `21%`
- `8` layers: `27%`
- `12` layers: `31%`
- `16` layers: `35%`
- `20` layers: `37%`
- `24` layers: `39%`
- `26` layers: `43%`
## Speedup Factors (Text Labels Above Blue Line)
- **Placement**: Above each data point, decreasing from left to right.
- **Values**:
- `3.12x` (at `4` layers)
- `2.98x` (at `8` layers)
- `2.97x` (at `12` layers)
- `2.86x` (at `16` layers)
- `2.78x` (at `20` layers)
- `2.72x` (at `24` layers)
## Spatial Grounding
- **Legend Position**: Not explicitly shown; inferred from color coding.
- **Color Consistency**:
- Red matches "No CoT Baseline" (dotted line).
- Blue matches "Model Accuracy" (dashed line).
## Trend Verification
- **Model Accuracy**: Steadily increases with more layers (21% → 43%).
- **Speedup**: Decreases slightly as layers increase (3.12x → 2.72x).
## Component Isolation
1. **Header**: Title (`Speedup over CoT`).
2. **Main Chart**:
- Red dotted baseline at `34.11%`.
- Blue dashed line with plotted data points.
- Speedup factors labeled above the blue line.
3. **Footer**: No explicit footer; gridlines extend to axis limits.
## Notes
- No non-English text detected.
- All labels, axis markers, and data points are explicitly transcribed.
- No data table present; chart relies on plotted points and annotations.
</details>
(a)
<details>
<summary>x5.png Details</summary>
### Visual Description
# Technical Document Analysis of Chart
## Chart Overview
The image depicts a line chart titled **"Speedup over CoT"**, comparing accuracy percentages across varying chunk sizes. The chart includes a baseline reference line and annotated speedup factors.
---
### **Key Components**
1. **Axes**
- **X-axis (Horizontal):**
- Label: **"Chunk Size"**
- Values: `2`, `4`, `8`, `16`, `32`, `48`
- Direction: Left to right (increasing chunk size).
- **Y-axis (Vertical):**
- Label: **"Accuracy (%)"**
- Range: `20` to `48` (increments of `4`).
2. **Legend**
- Located at the **top-right corner**.
- **Blue dashed line:** `"Speedup over CoT"` (matches the primary data series).
- **Red dotted line:** `"No CoT Baseline: 34.11%"` (constant reference line).
3. **Data Series**
- **Blue dashed line (Speedup over CoT):**
- Data points plotted at each chunk size with corresponding accuracy percentages.
- Speedup factors annotated above each chunk size:
- `2.42x` (chunk size 2), `2.57x` (4), `2.66x` (8), `2.74x` (16), `2.83x` (32), `2.86x` (48).
- **Red dotted line (Baseline):**
- Constant value at `34.11%` accuracy.
---
### **Trends and Data Points**
1. **Blue Dashed Line (Speedup over CoT):**
- **Visual Trend:**
- Slopes upward from chunk size `2` to `8`, then slopes downward from `8` to `48`.
- **Data Points (Accuracy %):**
- Chunk Size `2`: `35.2%`
- Chunk Size `4`: `41.2%`
- Chunk Size `8`: `42.1%`
- Chunk Size `16`: `38.9%`
- Chunk Size `32`: `37.5%`
- Chunk Size `48`: `37.8%`
2. **Red Dotted Line (No CoT Baseline):**
- **Visual Trend:**
- Horizontal line at `34.11%` accuracy across all chunk sizes.
---
### **Annotations**
- **Title:** `"Speedup over CoT"` (centered at the top).
- **Baseline Label:** `"No CoT Baseline: 34.11%"` (red dotted line).
- **Speedup Factors:**
- Annotated above each chunk size on the x-axis (e.g., `2.42x` at chunk size `2`).
---
### **Spatial Grounding**
- **Legend Position:** Top-right corner.
- **Data Point Colors:**
- Blue (`#0000FF`) for the "Speedup over CoT" series.
- Red (`#FF0000`) for the baseline.
---
### **Summary**
The chart illustrates how accuracy improves with increasing chunk sizes up to a point (chunk size `8`), after which it declines. The maximum accuracy (`42.1%`) is achieved at chunk size `8`, with a speedup factor of `2.66x` over the baseline. The baseline accuracy remains constant at `34.11%` across all chunk sizes.
</details>
(b)
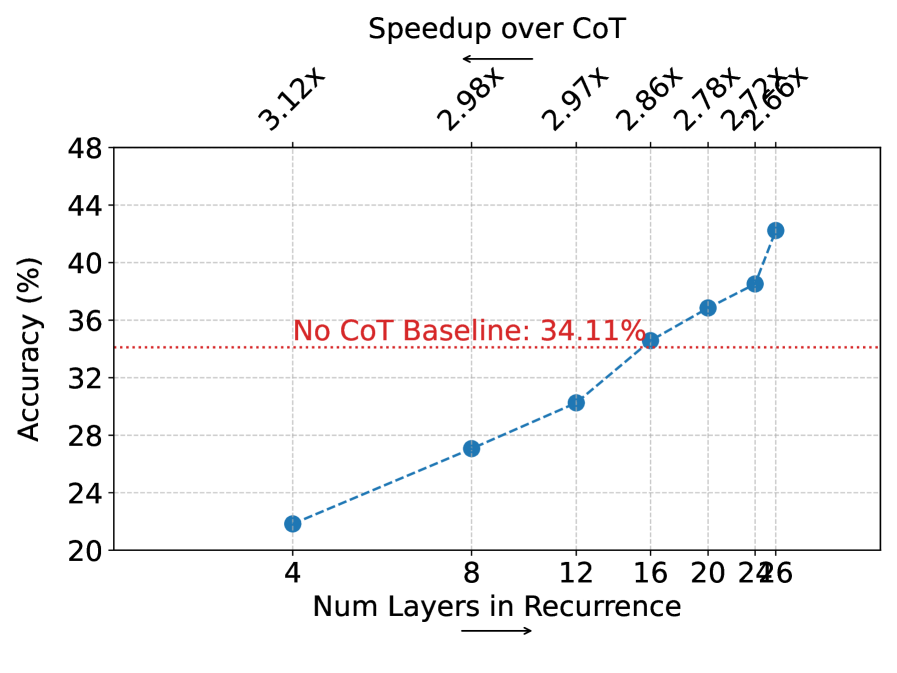
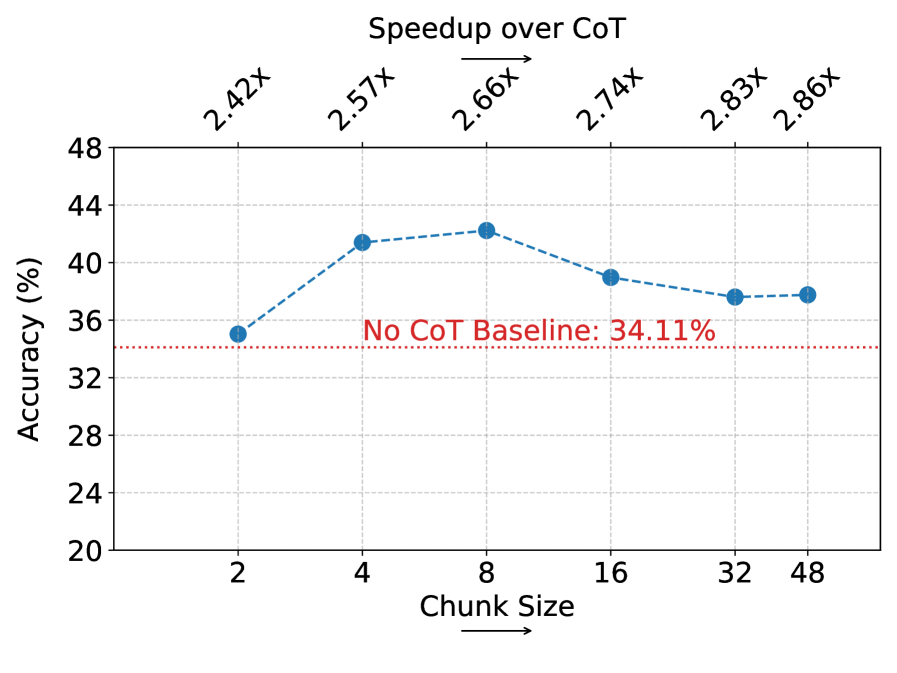
Figure 3: Ablation studies over deep to shallow recurrence (a) and effects of the chunk size (b), with measured speedup over CoT (top) at each point. In (a), performance increases with the number of layers used to process and generate states, pointing to the importance of the deep to shallow design. In (b), increasing the chunk size leads to improved latency with peak performance for medium chunks, highlighting the tradeoff between per-state capacity (large chunks) and reasoning frequency (small chunks).
Table 2 summarizes accuracy and speedups for each method. Among latent-reasoning baselines, Thinking States consistently achieves the highest accuracy across all tasks while maintaining significant speedups compared to CoT. On both variants of the 2-Hop task, Thinking States reaches similar performance to CoT with improved efficiency, demonstrating a dramatic advantage over other non-CoT baselines, with more than a 20% and 7% increase in accuracy on the FK and PK variants respectively.
On the GSM task, Thinking States demonstrates considerably better performance compared to Coconut, No CoT and iCoT, improving accuracy by $\sim 8\$ and maintaining a considerable $2.66\times$ speedup. The slight latency advantage showcased by Coconut on this task leads us to evaluate if performance can be improved at the cost of higher latency. As reported in Appendix A.5.1, we observe that increasing the number of latent steps leads to a modest improvement in performance, even as latency approaches that of the CoT model. In the next section, we provide several ablation studies over possible compute-efficiency tradeoffs with Thinking States.
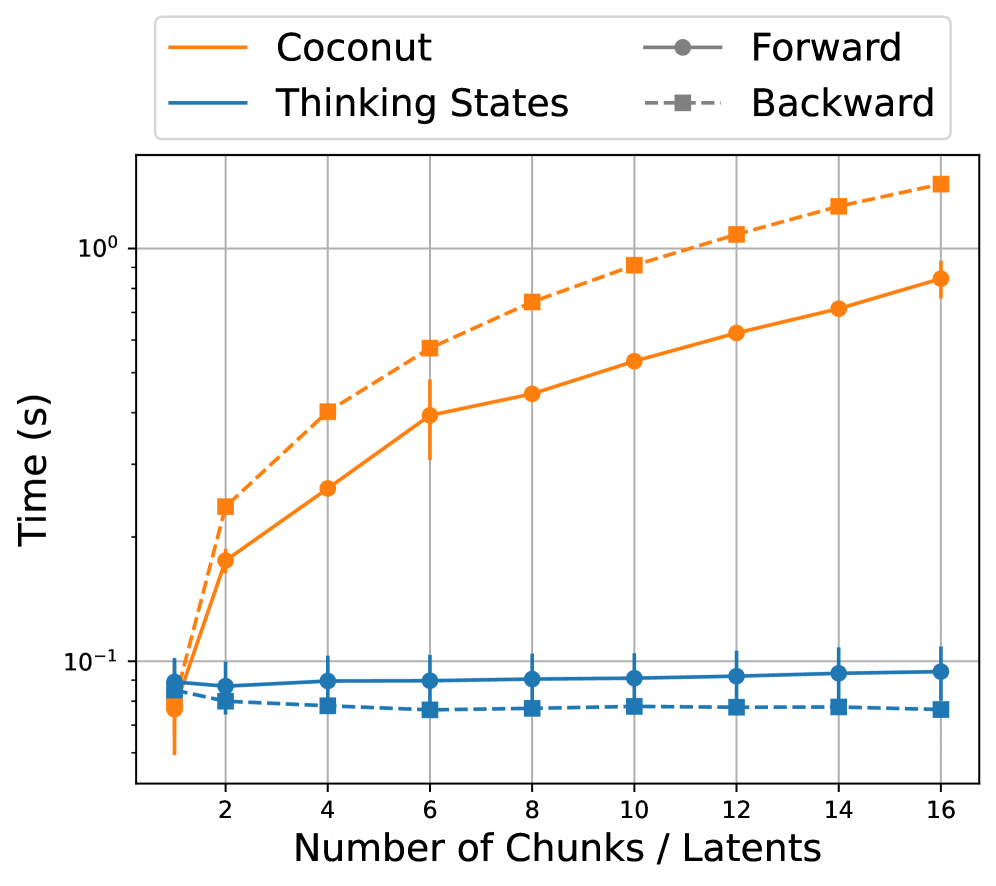
Finally, we analyze the training costs of Thinking States compared to training with explicit recurrence and BPTT as in Coconut. Figure 6, in Appendix A.5.3, plots the wall-clock time per forward and backward pass as a function of the number of recurrent steps/number of chunks in the input sequence. The results demonstrate that while BPTT incurs linearly increasing costs, Thinking States maintains close to constant training time due to teacher forcing. Consequently, while BPTT becomes prohibitively expensive to scale, incurring a $\sim 10\times$ cost penalty at just 10 steps, Thinking States enables efficient training regardless of reasoning depth.
### 4.4 Ablation Study
To understand the architectural factors governing Thinking States, we conduct two ablation studies over the GSM task. We ablate the impact of recurrence with a deep to shallow connection, by varying the layer to extract representations passed to $T$ , and the impact of reasoning frequency, by varying the chunk size.
Impact of Deep to Shallow Connections: In Figure 3(a), we investigate the influence of deep to shallow recurrence by varying the extraction layer for $T$ , keeping injection fixed at the first layer (as in previous experiments). Our purpose is to show the importance of the deep to shallow recurrent principle, demonstrating that allocating more of the model’s capacity when processing and generating states leads to improved accuracy. Furthermore, this experiment highlights the inherent accuracy-latency tradeoff: utilizing fewer layers in the recurrent loop allows the remaining layers to be executed only during query prefill, resulting in higher speedups. For this analysis, we use Qwen2.5-Base-1.5B, which contains 28 hidden layers.
As shown in Figure 3(a), performance increases monotonically with the number of layers included in the recurrence, with a substantial accuracy gap of nearly 20% between the shallowest and deepest configurations. This trend confirms that maximizing the computational capacity available for processing and generating thinking states is critical for performance, effectively validating the deep-to-shallow design choice.
Impact of Chunk Size: In Figure 3(b), we study the effect of varying the chunk size. The chunk size controls two important factors: (1) the computational capacity available for state processing and generation (2) the number of expected reasoning steps generated in each call to $T$ . A small chunk size limits available capacity for each state, and is expected to generate less steps at each chunk. Conversely, larger chunks provide larger capacity, but may lead to encoding multiple sequential steps into single state. This latter scenario undermines the deep-to-shallow recurrence, as consecutive steps generated within the same chunk cannot access the full recurrent loop, relying instead on the LLMs depth and limited capacity of the lightweight Thinking Block.
The tradeoff discussed above is evident in Figure 3(b), when the chunk size is small both performance and latency degrade, which can be explained by lack of computational capacity and increased iterations during query processing. As the chunk size increases, latency improves due to fewer iterations during query processing. Increasing the chunk size beyond a certain point ( $c=8$ ) eventually leads to reduced performance, which can be explained by the model compressing too many reasoning steps into single updates. Although performance decreases, we note that Thinking States still maintains a notable gap in performance compared to other latent reasoning methods even when approaching similar speedups.
### 4.5 Error Analysis
We analyze the performance gap between Thinking States and CoT on GSM-style problems. A key advantage of Thinking States over other latent reasoning methods is interpretability: because states are compressed from natural-language thoughts, the model’s reasoning remains inspectable.
Where Thinking States succeeds and CoT fails.
Despite the overall accuracy gap, approximately 12% of queries correctly solved by Thinking States are not solved by CoT, indicating that Thinking States mitigates certain CoT errors. Figure 4 shows two representative examples: (1) CoT hallucinates an additional reasoning step, and (2) CoT attempts an overly complex intermediate computation. In both cases, Thinking States produces a correct internal trajectory and answer. We note that both models are fine-tuned from the same base model and on identical data.
Example 1: Hallucinated Step Derrick has a bakery that makes 10 dozen doughnuts every day, [T: 10*12=120] selling at $2 per doughnut. [T: 120*2=240] How much money does Derrick make in June if he sells all the doughnuts? [T: 240*30=7200] The answer is 7200 CoT Steps: 10*12=120 120*2=240 240*30=7200 7200*6=43200 Example 2: Over-Complex Computation Jess is trying to guess the number of blue jellybeans in a jar. She can see that there are 17 green jelly beans and twice as many red jelly beans. The [T: 17*2=34] rest of the jellybeans are blue jelly beans. If there are a total of 60 jelly beans in total, [T: 17+34=51] how many blue jellybeans are there? [T: 60-51=9] The answer is 9 CoT Steps: 17*2=34 60-17-34=8
Figure 4: Examples where Thinking States succeeds but CoT fails. Thinking States reasoning is shown in green. (1) CoT hallucinates an extra step. (2) CoT attempts multiple operations in one step and errs.
Where CoT succeeds and Thinking States fails: State Ambiguity.
We identify a distinct error pattern we term state ambiguity: in many GSM queries, the quantity of interest is specified only in the final clause and may be difficult to anticipate earlier. As illustrated in Figure 5, this leads Thinking States to reason about the wrong intermediate quantity. Although the correct answer is often recoverable via a simple transformation, such recovery requires exposure to similar patterns during training.
(a) Original Richard lives in a building with 15 floors. Each floor contains 8 units. [T: 15 $\times$ 8=120.] Three quarters of the units are occupied. [T: (3/4) $\times$ 120=90.] What’s the number of unoccupied units on each floor? [T: 120-90=30.] Answer:30 (b) Disambiguated What’s the number of unoccupied units on each floor? Richard lives in a building with 15 floors. Each floor contains 8 units. Three quarters of the units are occupied. [T: 0.75 $\times$ 8=6] What’s the number of unoccupied units on each floor? Answer:2
Figure 5: Illustration of state ambiguity. In (a), Thinking States generates valid thoughts that are not aligned with the final clause in the query, leading to an error. By adding the information to the begining of the query, as in (b), the same model produces a correct answer, without training on the new format.
We validate this hypothesis by prepending the final question to the start of the prompt for all error cases. This zero-shot intervention improves accuracy from 42.22 to 48.65, despite the augmented queries being out-of-distribution. Notably, this limitation stems from the combination of Thinking States with a causal autoregressive backbone rather than the thinking-state mechanism itself; bidirectional query processing could, in principle, identify the relevant quantity before committing to intermediate state updates.
## 5 Conclusions
In this work, we introduce Thinking States, a method that enables reasoning while processing input tokens without extending the model’s context. By relying on a recurrent state representation of the thinking trajectory, the model effectively conditions its token processing on intermediate reasoning steps Empirically, this leads to improved performance compared to other latent reasoning baselines while maintaining a significant efficiency advantage over Chain-of-Thought (CoT).
Furthermore, a key contribution of our approach is the specialized data construction process that maps reasoning steps to specific input chunks. This formulation ensures that the recurrent process does not optimize with BPTT during training. Instead, training is fully parallelizable via teacher forcing, leading to a substantial reduction in computational cost compared to prior recurrent methods.
Our framework opens several avenues for future research. First, while we currently target query prefill, extending Thinking States to the decoding phase could enable allocating dynamic compute during token generation. Second, while our current approach relies on Supervised Fine-Tuning over existing CoT data, this model can serve as an effective ”warm-start” initialization for Reinforcement Learning. Starting from a model that has already learned to compress reasoning into latent states could stabilize RL training, allowing the model to subsequently optimize its internal thinking process beyond the constraints of human-generated traces.
## Impact Statement
This paper presents a method for improving the efficiency of reasoning in large language models. By reducing computational costs relative to chain-of-thought approaches, our work may contribute to lowering the energy consumption and environmental footprint of deploying reasoning-capable language models. Additionally, because our method generates interpretable natural-language thoughts, it may support efforts toward more transparent and auditable AI systems. We do not foresee unique ethical concerns beyond those broadly associated with advances in language model capabilities.
## References
- C. Anil, Y. Wu, A. Andreassen, A. Lewkowycz, V. Misra, V. Ramasesh, A. Slone, G. Gur-Ari, E. Dyer, and B. Neyshabur (2022) Exploring length generalization in large language models. ArXiv preprint abs/2207.04901. External Links: Link Cited by: §A.4, §A.4, §4.2.
- E. Biran, D. Gottesman, S. Yang, M. Geva, and A. Globerson (2024) Hopping too late: exploring the limitations of large language models on multi-hop queries. ArXiv preprint abs/2406.12775. External Links: Link Cited by: §2, §4.3.
- G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. (2025) Gemini 2.5: pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. ArXiv preprint abs/2507.06261. External Links: Link Cited by: §A.5.2, §3.4.
- M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and L. Kaiser (2019) Universal transformers. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, External Links: Link Cited by: §A.4.
- Y. Deng, Y. Choi, and S. Shieber (2024) From explicit cot to implicit cot: learning to internalize cot step by step. ArXiv preprint abs/2405.14838. External Links: Link Cited by: §1, §2, item (iii), §4.1, footnote 1.
- Y. Deng, K. Prasad, R. Fernandez, P. Smolensky, V. Chaudhary, and S. Shieber (2023) Implicit chain of thought reasoning via knowledge distillation. ArXiv preprint abs/2311.01460. External Links: Link Cited by: §2, §4.3.
- J. Geiping, S. McLeish, N. Jain, J. Kirchenbauer, S. Singh, B. R. Bartoldson, B. Kailkhura, A. Bhatele, and T. Goldstein (2025) Scaling up test-time compute with latent reasoning: a recurrent depth approach. ArXiv preprint abs/2502.05171. External Links: Link Cited by: §2.
- S. Goyal, Z. Ji, A. S. Rawat, A. K. Menon, S. Kumar, and V. Nagarajan (2023) Think before you speak: training language models with pause tokens. ArXiv preprint abs/2310.02226. External Links: Link Cited by: §2.
- S. Hao, S. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston, and Y. Tian (2024) Training large language models to reason in a continuous latent space. ArXiv preprint abs/2412.06769. External Links: Link Cited by: Table 3, Table 3, §1, §1, §2, item (iv), §4.1, §4.1, §4.3.
- M. Hassid, G. Synnaeve, Y. Adi, and R. Schwartz (2025) Don’t overthink it. preferring shorter thinking chains for improved llm reasoning. ArXiv preprint abs/2505.17813. External Links: Link Cited by: §1.
- Y. Kang, X. Sun, L. Chen, and W. Zou (2024) C3oT: generating shorter chain-of-thought without compromising effectiveness. ArXiv preprint abs/2412.11664. External Links: Link Cited by: §1.
- G. Kaplan, M. Oren, Y. Reif, and R. Schwartz (2024) From tokens to words: on the inner lexicon of llms. ArXiv preprint abs/2410.05864. External Links: Link Cited by: §A.1.
- N. Kim and S. Schuster (2023) Entity tracking in language models. ArXiv preprint abs/2305.02363. External Links: Link Cited by: §4.2.
- B. Z. Li, Z. C. Guo, and J. Andreas (2025) (How) do language models track state?. ArXiv preprint abs/2503.02854. External Links: Link Cited by: §4.2.
- W. Merrill, J. Petty, and A. Sabharwal (2024) The illusion of state in state-space models. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. Cited by: §4.2.
- Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu (2024) Qwen2.5 technical report. ArXiv preprint abs/2412.15115. External Links: Link Cited by: §4.1.
- Z. Shen, H. Yan, L. Zhang, Z. Hu, Y. Du, and Y. He (2025) CODI: compressing chain-of-thought into continuous space via self-distillation. ArXiv preprint abs/2502.21074. External Links: Link Cited by: §1, §2.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou (2022) Chain-of-thought prompting elicits reasoning in large language models. ArXiv preprint abs/2201.11903. External Links: Link Cited by: §1.
- H. Xia, C. T. Leong, W. Wang, Y. Li, and W. Li (2025) TokenSkip: controllable chain-of-thought compression in llms. ArXiv preprint abs/2502.12067. External Links: Link Cited by: §1.
- S. Yang, N. Kassner, E. Gribovskaya, S. Riedel, and M. Geva (2024) Do large language models perform latent multi-hop reasoning without exploiting shortcuts?. ArXiv preprint abs/2411.16679. External Links: Link Cited by: §2, §4.3.
- E. Zelikman, G. Harik, Y. Shao, V. Jayasiri, N. Haber, and N. D. Goodman (2024) Quiet-star: language models can teach themselves to think before speaking. ArXiv preprint abs/2403.09629. External Links: Link Cited by: §2.
## Appendix A Method - Additional Details
### A.1 Architecture
We provide additional details on the thinking and compression blocks, $T$ and $C$ and their integration with the base LLM, $M_{\theta}$ . In all reported experiments, except when explicitly stated in section 4.4, we set the injection and extraction layer, $L^{in},L^{out}$ , to be after the first layer (excluding the token embedding layer) and after the second-to-last layer respectively.
Both $T$ and $C$ share the same underlying core module, a causal Transformer block, sharing configurations and hyper-parameters (i.e., hidden size, number of attention heads, sliding/dense attention etc.) as the layers in $M_{\theta}$ . In our experiments, $M_{\theta}$ follows the architecture of Qwen2.5 models, with model sizes listed in the main text. As the thinking head, $T$ , is used for auto-regressive generation of language tokens, and is expected to return token embeddings, it additionally includes an unembedding and embedding layer.
This architecture facilitates the function of the thinking head and compression head as follows. At inference time, $T$ produces thoughts in natural-language through autoregressive generation, initially conditioned on the chunk of hidden representations $\mathbf{H}_{i}^{out}\in\mathbb{R}^{c\times d}$ , where $c,d$ denote the chunk size and the hidden size of $M_{\theta}$ . Each token predicted by $T$ is passed through the embedding layer, and the resulting embedding is appended to the context of $T$ . This results in a distribution mismatch, as $\mathbf{H}_{i}^{out}$ (extracted from a deep layer) share the context with standard token embeddings. However, we observe that this does not lead to a significant limitations when the block is finetuned for next-token-prediction in the same setup, even with relatively little data as in 2-Hop PK
For $C$ , to use the causal Transformer as a compression module, we apply a single parallel forward pass to all input token embeddings using a causal attention mask (though bidirectional attention is also valid) to obtain a contextualize representations. We then extract the last $c$ representations to serve as the state $\mathbf{S}_{i}$ injected to the next chunk, appending padding tokens to the input sequence if it is shorter than $c$ . Through finetuning, $C$ learns to compress relevant information into future positions. We also experimented with appending a set of learnable queries appended to the query to make the compression explicit, however, this approach performed worse in practice.
To initialize the parameters of the two modules, we utilize existing components from $M_{\theta}$ . Namely, the Transformer block in $T$ is initialized as an independent copy of the last layer of $M_{\theta}$ , while $C$ is initialized as an independent copy of the first layer (excluding the token embedding layer). The unembedding layer in $T$ is initialized as an independent copy of the unembedding layer of $M_{\theta}$ while the embedding layer is shared with $M_{\theta}$ (i.e., is not an independent copy).
For $T$ , the motivation is to leverage parameters already trained to convert hidden representations into token predictions. For $C$ , the motivation is to leverage parameters trained to contextualize token embeddings (Kaplan et al., 2024) and generate a state sharing a latent space with the injection layer, which immediately follows the first layer.
### A.2 Fast Prefill with Speculated Thinking
We provide a more detailed description of the fast prefill algorithm detailed in Section 3.3 in algorithm 1 Full version can be reviewed in our codebase, which we plan to fully release. The idea is using the sparsity of non-trivial states, generated by more than an <EOS>, to a few allow parallel execution instead of iteratively processing all chunks in the query. This is achieved by always speculating future states are trivial, applying a parallel pass conditioned on the speculation, then correcting for the first location where the assumption breaks and repeating.
This process is guaranteed to terminate in exactly $|R|+1$ iterations, where $|R|$ is the number of non-trivial states generated, which is unknown in advance. As each iteration after the first implies exactly one non-trivial state was generated, this leads to exactly $|R|+1$ rounds.
In algorithm 1, we explicitly denote that $M_{\theta}$ returns a set of hidden representations $H$ from all layers, only then extracting the target representation $\mathbf{H}_{i}^{out}$ to emphasize all representations are stored in the cache. Additionally, for ease of presentation, the algorithm omits the fact that when finished, the representation of the last position in the input is used to generate the next token, as is in standard decoding.
Algorithm 1 Fast Speculative Prefill
Input: Query chunks $\mathbf{X}_{1\dots K}$ , Backbone $M_{\theta}$ , Thinking Block $T_{\phi}$ , Compression $C_{\phi}$ , Chunk Size $c$
$t=0$
$kv=init\_cache()$
$\mathbf{S}_{i}=\hat{0}\in\mathbb{R}^{c\times d}\quad i\in[0,\dots,K-1]$ {Speculate thoughts}
$S=concat([\mathbf{S}_{1},\dots,\mathbf{S}_{k}])$
$X=concat([\mathbf{X}_{1},\dots,\mathbf{X}_{k}])$
$finished=false$
while $not\ \ finished$ do
$\tilde{X}=S+X$
$H=M_{\theta}(\tilde{X},past\_kv=kv)$
$H^{out}=extract(H,L^{out})$
$\mathbf{H}_{i}^{out}=chunk(H^{out},c)\quad i\in[t,\dots,K]$
$\mathbf{S}_{i+1}=\mathcal{C}_{\phi_{2}}(T_{\phi_{1}}(\mathbf{H}_{i}^{out}))$
$t=find\_first\_true(\mathbf{S}_{i}\neq\hat{0})$
if $t$ is $None$ then
$finished=true$
$kv.cache(H,max\_index=None)$
else
$kv.cache(H,max\_index=t)$
$S=concat([\mathbf{S}_{t},\hat{0},\dots,\hat{0}])$
$X=concat([\mathbf{X}_{t},\mathbf{X}_{t+1},\dots,\mathbf{X}_{k}])$
end if
end while
return $kv,\mathbf{S}_{-1}$
### A.3 Constructing Chunk-Level Supervision
As mentioned in the main text, Section 3.4, chunk level supervision for the Thinking Block is obtained by mapping reasoning steps to specific positions in the input query. The mapping is realized by placing special indicator tokens in the query text.
Once the query is tokenized, the special tokens allow us to construct a matching reasoning array sharing the same length. At every position in the query containing an indicator token, we insert the matching reasoning sequence to the same position in the reasoning array. In the vast majority of cases, the desired supervision is obtained by shifting the reasoning array one position to the left, then removing all entries containing a special token in the query sequence, from the query tokens and the reasoning array.
A small number of cases contain multiple consecutive indicator tokens that are placed in succession. In these cases, we assign the matching steps in order, starting from the first token position preceding the first indicator. In case the reasoning steps ”overflow” the token sequence length, these steps are concatenated together with a special separator token.
### A.4 State Tracking Tasks
We provide the definitions for the state tracking tasks used for evaluation in Section 4.2, ”Parity” and ”Variable Assignment” (abbreviated to ”Vars”).
Parity: The parity task acts as a natural language version of the standard parity prediction problem over binary sequences, which is commonly used when evaluating extrapolation capabilities in various architectures (Dehghani et al., 2019; Anil et al., 2022; delétang2023neuralnetworkschomskyhierarchy). Over binary sequences, e.g., $s=00101011$ , the task is predicting $sum(s)_{\bmod 2}$ . To represent the task in natural language, we transform the binary sequence into a query describing operations applied to a coin by two entities. When providing supervision to $T$ , the indicator token mentioned in Section 3.4 is placed after each operation, paired with the current state.
An abbreviated query is provided in Figure 2(a) and a full query, equivalent to the binary sequence $s=1011$ , is given here, along with indicator tokens and the matching labels:
”The coin starts at state heads. <T> Alice doesn’t flip the coin. <T> Bob flips the coin. <T> Alice flips the coin. <T> The final state of the coin is heads. ”
Reasoning Targets: [”heads <eos> ”, ”heads <eos> ”, ”tails <eos> ”, ”heads <eos> ”]
Where <T> denotes the indicator token and blue denotes text that converted into target tokens for predictions. In this formulation, increasing the number of state operations directly translates to longer binary sequences, i.e., more operations applied to the coin.
Variable Assignment (Vars): This task extends the state tracking setting to multiple integer-valued variables whose updates may depend on one another, requiring complex state updates (Anil et al., 2022). Unlike Parity, which tracks a single binary state, Vars requires maintaining the values of multiple variables (e.g., $a,b,c$ ) and executing arithmetic operations (e.g., $b=b+a$ ) that reference the current state of other variables.
The task is represented in natural language as a sequence of assignment operations. To generate supervision for $T$ , similar to the Parity task, we insert the indicator token <T> after each operation paired with the value of the updated variable.
An example query, equivalent to the provided raw input, is formatted below with indicator tokens and the corresponding reasoning targets (derived using modular arithmetic consistent with the final values):
”Track the variables values: a=1; b=2 a=a+b <T> b=b+a <T> b=b+3 <T> Final values: a=3 b=8 ”
Reasoning Targets: [”a=3 <eos> ”, ”b=5 <eos> ”, ”b=8 <eos> ”]
### A.5 General Reasoning Capabilities
#### A.5.1 Coconut - Additional Results
As mentioned in the main paper, we scale computation with Coconut by increasing the number of latent thinking tokens. This is achieved by increasing the number of latent tokens introduced in each round of the curriculum, out of 3 rounds in total, excluding the initial phase training the CoT checkpoint used for initialization. As is evident in Table 3 The experiment in the main paper uses $2$ thinking tokens per round, $6$ in total.
Table 3: Coconut (Hao et al., 2024) performance and speedup as computation increases, by increasing the number of latent steps.
| 6 9 12 | 32.65 33.48 31.29 | 3.14 $\times$ 2.53 $\times$ 2.08 $\times$ |
| --- | --- | --- |
| 15 | 32.35 | 1.77 $\times$ |
| 21 | 32.65 | 1.38 $\times$ |
#### A.5.2 Data Construction for GSM
As mentioned in the introduction, for the GSM task, we rely on a strong teacher model (Gemini-2.5 Flash (Comanici et al., 2025)) to transform existing parsed CoT data into the mapping used to supervise the thinking head. We achieve this by prompting the teacher model with a prompt similar to the one presented in Figure 7, removing two of the in context examples for readability. Using the structured output, we are able to extract the transformed query and matching thinking steps. To validate the process, we only include samples whose queries and thinking steps provide an exact string match to the source query and thinking steps, once the indicator tokens <THINK> are removed, discarding any samples that result in a mismatch. After validation we are left with $375,101/385,620$ samples, or $97.2\$ .
<details>
<summary>x6.png Details</summary>
### Visual Description
# Technical Document Analysis of Chart
## Chart Overview
The image is a **line chart** comparing the performance of two algorithms ("Coconut" and "Thinking States") across varying numbers of "Chunks / Latents." The y-axis represents **Time (s)** on a **logarithmic scale**, while the x-axis represents the **Number of Chunks / Latents** (ranging from 2 to 16). The chart includes error bars for data points and distinguishes between "Forward" and "Backward" passes using line styles.
---
### Key Components
1. **Legend**
- **Location**: Top-right corner.
- **Labels**:
- **Orange**: Coconut (solid line for Forward, dashed line for Backward).
- **Blue**: Thinking States (solid line for Forward, dashed line for Backward).
2. **Axes**
- **X-axis**:
- Title: "Number of Chunks / Latents"
- Values: 2, 4, 6, 8, 10, 12, 14, 16 (even increments).
- **Y-axis**:
- Title: "Time (s)"
- Scale: Logarithmic (10⁻¹ to 10⁰).
- Markers: 10⁻¹, 10⁰.
3. **Data Series**
- **Coconut (Orange)**:
- **Forward** (solid line): Time increases with more chunks/latents.
- **Backward** (dashed line): Time increases similarly but starts higher than Forward.
- **Thinking States (Blue)**:
- **Forward** (solid line): Time remains nearly constant (~0.08s) across all chunks/latents.
- **Backward** (dashed line): Time remains nearly constant (~0.06s) across all chunks/latents.
4. **Error Bars**
- Present for all data points, indicating variability in measurements.
---
### Trends and Observations
1. **Coconut Algorithm**
- **Forward Pass**:
- Time increases logarithmically with more chunks/latents.
- Example: At 2 chunks, ~0.05s; at 16 chunks, ~0.9s.
- **Backward Pass**:
- Time increases similarly to Forward but starts higher (e.g., ~0.1s at 2 chunks vs. ~0.05s for Forward).
2. **Thinking States Algorithm**
- **Forward/Backward Passes**:
- Time remains nearly constant (~0.08s for Forward, ~0.06s for Backward) regardless of chunks/latents.
3. **Error Bars**
- Coconut shows larger variability (longer error bars) compared to Thinking States.
---
### Spatial Grounding and Accuracy Checks
- **Legend Colors**:
- Orange matches Coconut (solid/Dashed).
- Blue matches Thinking States (solid/Dashed).
- **Data Point Alignment**:
- Coconut Forward (solid orange) aligns with increasing trend.
- Thinking States Forward (solid blue) aligns with flat trend.
---
### Missing Elements
- **Data Table**: Not explicitly provided; data is represented visually via plotted points and error bars.
- **Footer/Additional Text**: None present.
---
### Final Notes
The chart emphasizes that **Coconut** exhibits scalability with increasing chunks/latents, while **Thinking States** maintains consistent performance. Error bars suggest higher variability in Coconut's measurements.
</details>
Figure 6: Training Cost Analysis Comparison of wall-clock time for forward and backward passes on a fixed-length input ( $L=128$ ) as a function of the number of recurrent steps (chunks). Methods relying on BPTT demonstrate linear scaling in time, circumvented by teacher forcing in Thinking States despite the added dimensionality and computational overhead of $T$ .
#### A.5.3 Training Compute
We quantify the computational advantage of training Thinking States with teacher forcing compared to latent reasoning methods that rely on Backpropagation Through Time (BPTT), such as Coconut. Figure 6 illustrates the wall-clock time required for a single forward and backward pass on a fixed-length sequence, as a function of the number of recurrent steps (Coconut) or number of chunks Here the chunk size accordingly, we note that $k$ chunks imply $k$ recurrent steps at inference time. (Thinking States), by controlling the chunk size relative to the sequence length. We use a batch size of 1 and a sequence length of 128 tokens.
As shown in Figure 6, training with BPTT exhibits a linear increase in wall-time for both forward and backward passes as the number of latent steps grows. In contrast, Thinking States maintains close to constant training time regardless of the number of chunks, as the availability of ground-truth states allows for fully parallelized computation. The small variation in wall-time for Thinking States is explained by the additional dimensionality of decoding reasoning sequence from fixed-size token chunks. Yet, as visible in the figure, these variations are small compared to the increase in cost due to BPTT.
Prompt for GSM Data Generation
You are an expert in computational linguistics. Your task is to augment a given query with thinking markers (<THINK>) based on a provided reasoning trace. This involves identifying the precise locations in the text where specific calculations can be performed. Task Instructions: 1.
Analyze Inputs: You will receive two inputs: •
A Query: A question or word problem. •
A Reasoning Trace: An ordered list of strings, where each string is a distinct mathematical calculation required to solve the query. 2.
Produce Two Outputs: •
query: This is the original Query text, but with the special token <THINK> inserted at specific locations. •
thinking: This is the ordered list of calculations. 3.
Rules for <THINK> Placement: •
The number of <THINK> tokens inserted into the query must be exactly equal to the number of calculations in the Reasoning Trace. •
The order of the <THINK> tokens in the query must correspond one-to-one with the order of the calculations in the Reasoning Trace. •
For each calculation, you must insert its corresponding <THINK> token at the earliest possible location in the query. This location is defined as the point immediately after the word or phrase that provides the final piece of information needed to perform that specific calculation. 4.
Rule for the thinking List: •
The thinking output list is simply a direct copy of the ordered list of calculations provided in the Input Reasoning Trace. 5.
Output Format: •
The output should be provided as a python dictionary with two keys: query and thinking. •
The values should be wrapped in <<>> to support easy parsing. •
Example: { "query": "<<Your modified query here>>", "thinking": <<[’<<calculation1>>’, ’<<calculation2>>’, ...]>> }
Examples Example 1: •
Input Query: ’Hannah has three dogs. The first dog eats 1.5 cups of dog food a day. The second dog eats twice as much while the third dog eats 2.5 cups more than the second dog. How many cups of dog food should Hannah prepare in a day for her three dogs?’ •
Input Reasoning Trace: [’<<1.5*2=3>>’, ’<<3+2.5=5.5>>’, ’<<1.5+3+5.5=10>>’] Required Output: { "query": <<’Hannah has three dogs. The first dog eats 1.5 cups of dog food a day. The second dog eats twice as much<THINK> while the third dog eats 2.5 cups more than the second dog.<THINK> How many cups of dog food should Hannah prepare in a day for her three dogs?<THINK> ’>>, "thinking": <<[’<<1.5*2=3>>’, ’<<3+2.5=5.5>>’, ’<<1.5+3+5.5=10>>’]>> }
Task Now, perform this transformation for the following input and return your output as a python dictionary. Query: <<QUERY>> Reasoning Trace: <<REASONING_TRACE>> Produce your output as a python dictionary in the specified format below: { "query": <<ADD YOUR OUTPUT HERE>>, "thinking": <<ADD YOUR OUTPUT HERE>> }
Figure 7: The abbreviated version of few-shot prompt used to generate the alignment data. The prompt instructs the model to act as a computational linguist and inject <THINK> tokens into the query corresponding to specific reasoning steps. The full prompt used is identical except for containing 2 additional in-context examples, similar to the example provided.