# SWE-Bench Mobile: Can Large Language Model Agents Develop Industry-Level Mobile Applications?
> 1University of Toronto2Xiaohongshu Inc.3Coolwei AI Lab4University of Illinois Urbana-Champaign5University of California, Berkeley
Abstract.
Can large language model agents develop industry-level mobile applications? We introduce SWE-Bench Mobile, a benchmark for evaluating coding agents on realistic software engineering tasks derived from a production iOS codebase. Unlike existing benchmarks that focus on isolated problems or bug fixes, SWE-Bench Mobile captures the full complexity of industrial development: multi-modal inputs (PRDs and Figma designs), a large-scale mixed Swift/Objective-C codebase, and comprehensive test suites. We evaluate 22 agent-model configurations across four coding agents—three commercial (Cursor, Codex, Claude Code) and one open-source (OpenCode)—and find that even the best configurations achieve only 12% task success rate. Our analysis reveals that (1) agent design matters as much as model capability—the same model shows up to 6 $×$ performance gap across agents, (2) commercial agents consistently outperform open-source alternatives, and (3) simple “Defensive Programming” prompts outperform complex ones by 7.4%. These findings highlight a significant gap between current agent capabilities and industrial requirements, while providing actionable insights for practitioners and researchers. We release SWE-Bench Mobile as a hosted benchmark challenge to prevent data contamination and ensure fair evaluation. The public leaderboard and development toolkit are available at https://swebenchmobile.com.
Large Language Models, Software Engineering Agents, Mobile Development Benchmark copyright: none footnotetext: * Equal contribution. † Corresponding author: jiaxuan@illinois.edu.
1. Introduction
<details>
<summary>figures/fig_pipeline.png Details</summary>
### Visual Description
\n
## Diagram: Software Development/Evaluation Pipeline
### Overview
The image depicts a diagram illustrating a software development and evaluation pipeline. The pipeline is divided into three main stages: Input, Runtime, and Evaluation. Data flows from left to right through these stages, with various components and processes involved in each.
### Components/Axes
The diagram consists of rectangular boxes representing stages, rounded rectangles representing components, and arrows indicating the flow of data. The stages are labeled "Input", "Runtime", and "Evaluation". Key components within these stages include:
* **Input:**
* Feature Description
* Figma Link (with a small icon depicting a color palette)
* Product Requirement Document
* Other Related Context (abtest/multi-variant ideas)
* Mobile Project Codebase (Swift/Objc/RN/etc.) (with a small icon depicting a mobile phone)
* **Runtime:**
* Bench Runtime (Model Config/Tuned System Prompt/Task Management)
* Coding Agent (Cursor/CC/Codex/etc.) (with icons representing various coding agents)
* Figma MCP
* Vision MCP
* **Evaluation:**
* Entrypoint-wise Eval
* Functionality-wise Eval
* Configuration-wise Eval
* Analyzer
The flow between stages is indicated by arrows. A key output from the Runtime stage is "diff patches" which feeds into the Evaluation stage.
### Detailed Analysis or Content Details
The diagram shows a clear flow of information.
1. **Input Stage:** Multiple sources of information feed into this stage. These include feature descriptions, links to Figma designs, product requirements, related context (like A/B testing ideas), and the mobile project codebase.
2. **Runtime Stage:** The input is processed by a "Bench Runtime" component, which appears to involve model configuration, prompt engineering, and task management. This runtime environment then utilizes a "Coding Agent" (capable of using tools like Cursor, CC, or Codex) to generate code changes. Figma MCP and Vision MCP are also inputs to the runtime stage. The output of this stage is "diff patches" – representing the changes made to the codebase.
3. **Evaluation Stage:** The "diff patches" are then fed into the Evaluation stage, where they are assessed using three different evaluation methods: Entrypoint-wise, Functionality-wise, and Configuration-wise. An "Analyzer" component aggregates the results of these evaluations.
The diagram does not contain numerical data or specific scales. It is a conceptual representation of a process.
### Key Observations
* The diagram emphasizes the integration of design (Figma) and code generation (Coding Agent).
* The evaluation stage is multi-faceted, considering different aspects of the changes.
* The use of "MCP" (likely meaning Model Configuration Parameters) suggests a focus on model-driven development.
* The diagram highlights the importance of a well-defined input stage, encompassing various sources of information.
### Interpretation
This diagram illustrates a modern software development pipeline that leverages AI-powered coding agents and automated evaluation. The pipeline aims to streamline the process of translating product requirements and design specifications into functional code, while ensuring the quality and correctness of the changes through rigorous evaluation. The inclusion of Figma and Vision MCP suggests a focus on visual aspects and potentially computer vision-related features. The multi-faceted evaluation stage indicates a commitment to comprehensive testing and quality assurance. The diagram suggests a closed-loop system where evaluation results could potentially feed back into the input stage to refine requirements or improve the coding agent's performance. The diagram is a high-level overview and does not provide details on the specific algorithms or techniques used in each stage. It is a conceptual model rather than a detailed technical specification.
</details>
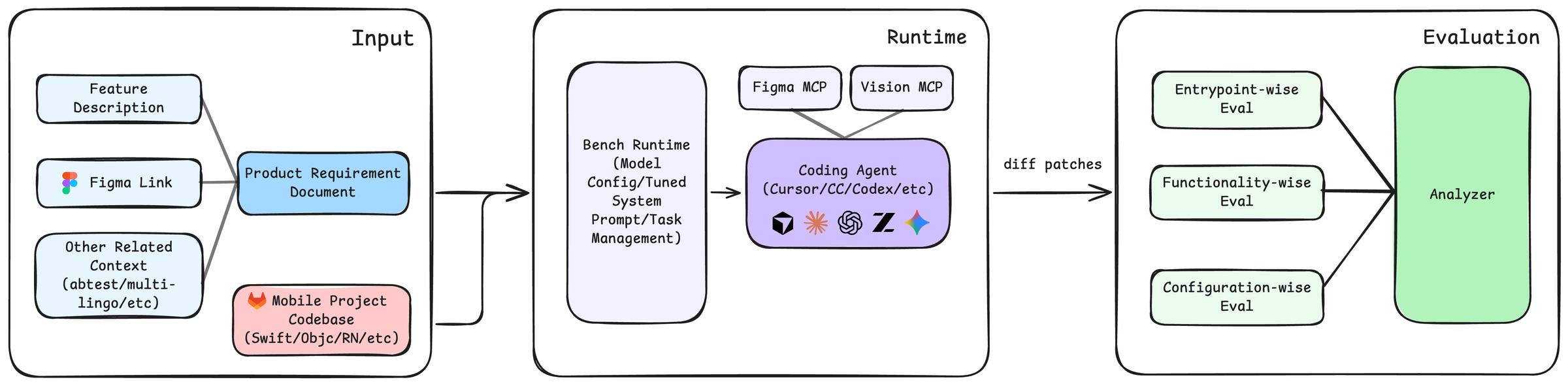
Figure 1. Overview of the SWE-Bench Mobile pipeline. (1) Agents receive multi-modal inputs including a Product Requirement Document (PRD), Figma design, and a large-scale Swift/Objective-C codebase. (2) The agent navigates the codebase, plans the implementation, and generates code. (3) The output is a Git patch that is applied and evaluated against a comprehensive test suite.
Large language models (LLMs) have enabled a new generation of autonomous coding agents that can understand requirements, navigate codebases, and implement features with minimal human intervention. Commercial systems like GitHub Copilot, Cursor, and Claude Code have achieved impressive results on existing benchmarks, raising a critical question: Can these agents handle the complexity of real-world, industry-level mobile software development?
Answering this question requires a comprehensive evaluation that faithfully captures professional software engineering. However, existing benchmarks have significant limitations. HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021) evaluate isolated algorithmic problems far removed from industrial practice. SWE-Bench (Jimenez et al., 2024) advances the field by using real GitHub issues, but still falls short of industrial realism: it focuses on bug fixes rather than feature development, uses text-only inputs without design specifications, typically involves small localized changes to 1-2 files, and concentrates on Python which is well-represented in training data. Recent work like SWE-Bench Pro (Deng et al., 2025) addresses some limitations by introducing longer-horizon tasks, but still lacks multi-modal inputs and focuses exclusively on Python.
In professional software development, engineers participate in a structured workflow that goes far beyond writing code. They interpret Product Requirement Documents (PRDs) that specify what to build and why. They translate visual designs from tools like Figma into implementation decisions about layout and interaction. They navigate large codebases—often hundreds of thousands of lines—to find relevant files and understand existing patterns. They make coordinated changes across multiple modules while maintaining consistency. And they ensure their implementations handle edge cases and pass comprehensive tests. A benchmark claiming to evaluate “industry-level” capabilities must test all of these aspects.
We focus on mobile application development not merely for language diversity, but because it represents a distinct and critical paradigm in software engineering that remains unexplored by current benchmarks. Unlike server-side logic (e.g., Python scripts), mobile development introduces unique challenges for AI agents: (1) Multi-modal Dependency: Implementation is strictly guided by visual designs (Figma) and user interactions, requiring agents to perform visually-grounded program synthesis rather than just text-to-code generation. (2) Event-Driven Complexity: Mobile apps are stateful systems that must handle asynchronous user events, network changes, and strict OS lifecycle callbacks, challenging agents’ ability to model dynamic system states. (3) Client-Side Constraints: Development occurs within framework-heavy environments (e.g., iOS SDK) with rapid iterations, testing generalization to domain-specific APIs.
We introduce SWE-Bench Mobile, a benchmark for evaluating coding agents on industry-level mobile application development. SWE-Bench Mobile is constructed from real development artifacts at a major technology company, comprising 50 authentic tasks derived from actual product requirements. Each task combines multi-modal inputs—PRDs, Figma designs, and a large-scale mixed Swift/Objective-C production codebase—with comprehensive evaluation through 449 human-verified test cases.
Contributions.
1. We introduce SWE-Bench Mobile, the first benchmark combining PRDs, Figma designs, and a large-scale codebase to capture the full complexity of industrial software development.
1. We evaluate 22 agent-model configurations across four coding agents (three commercial, one open-source), with detailed analysis of performance, cost, and robustness.
1. We systematically categorize agent failures, finding that 54% stem from missing feature flags—a production practice unfamiliar to agents—followed by missing data models (22%) and incomplete file coverage (11–15%).
1. We provide actionable insights: agent design matters as much as model capability (up to 6 $×$ performance gap for the same model), commercial agents outperform open-source ones, simple prompts outperform complex ones, and cost-effective configurations exist.
To strictly preserve the integrity of the evaluation and respect the proprietary nature of the production codebase, we adopt a hosted evaluation paradigm. Unlike static datasets that are prone to data contamination in future model training sets, our held-out private test set ensures that agents are evaluated on truly unseen industrial tasks. We provide a sanitized development kit and a public leaderboard to foster community progress.
Our evaluation reveals a significant gap between current capabilities and industrial requirements. The best configuration achieves only 12% task success rate, with most failures due to incomplete implementations. The same model (Opus 4.5) achieves 12% on Cursor but only 2% on OpenCode—a 6 $×$ gap—demonstrating that agent scaffolding matters as much as model capability. Commercial agents consistently outperform the open-source OpenCode, whose best result (8% with GLM 4.6) trails the best commercial result (12%) by 4 percentage points. Success drops from 18% for simple tasks requiring 1-2 files to just 2% for complex tasks requiring 7+ files, indicating agents struggle with cross-file reasoning. These findings suggest that while coding agents show promise for simple tasks, substantial improvements in requirement understanding, multi-modal reasoning, and codebase navigation are needed for reliable industry-level development.
2. SWE-Bench Mobile
SWE-Bench Mobile is a benchmark designed to evaluate coding agents on industry-level mobile application development. Unlike existing benchmarks that focus on isolated coding problems or bug fixes, SWE-Bench Mobile captures the full complexity of professional software engineering: multi-modal inputs, large codebases, and comprehensive testing. Figure 1 illustrates the overall benchmark pipeline.
2.1. Problem Formulation
Each benchmark instance is represented as a triplet:
$$
\mathcal{T}=(\mathcal{I},\mathcal{O},\mathcal{E}),
$$
where $\mathcal{I}$ is the input context, $\mathcal{O}$ is the expected output, and $\mathcal{E}$ is the evaluation configuration.
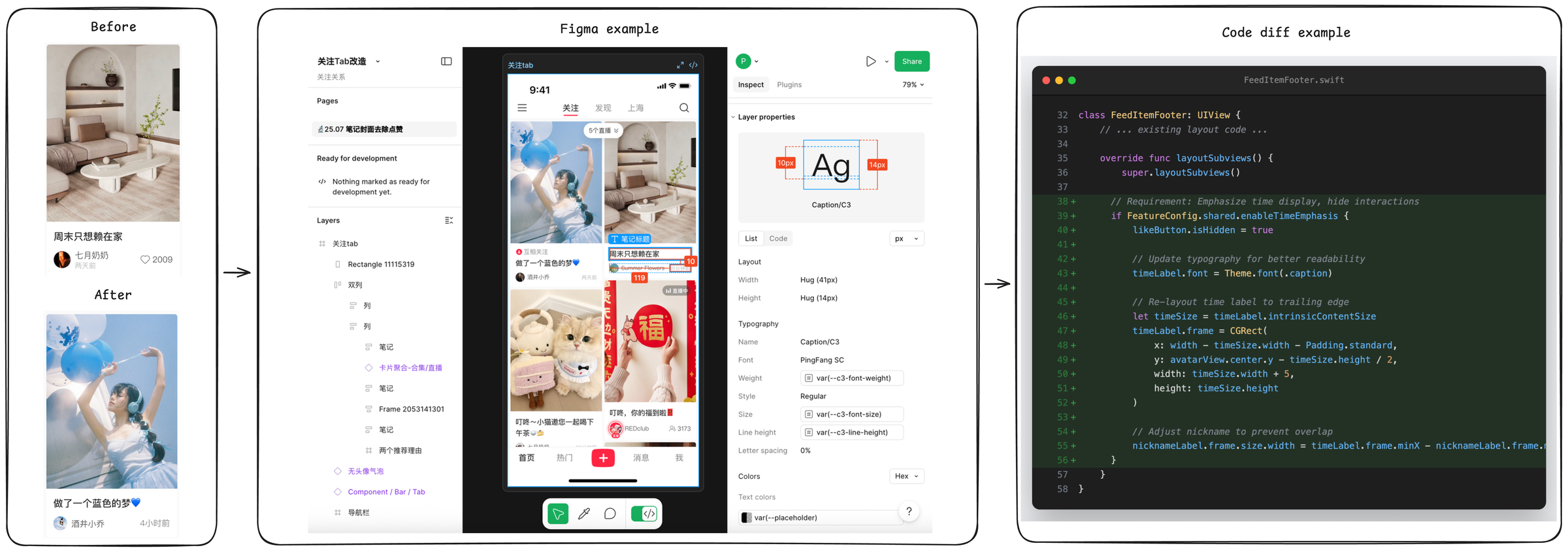
Input ( $\mathcal{I}$ ). The input context mimics a typical developer’s starting point for a new feature. It consists of three main components (see Figure 2). First, a Product Requirement Document (PRD) describes the feature goal, user story, acceptance criteria, and constraints. These PRDs are derived from actual product requirements at XiaoHongShu Inc., a major social media platform with over 300 million monthly active users, follow standard industrial conventions (Atlassian, 2024), and have an average length of 450 words, requiring agents to parse natural language specifications. Second, 70% of tasks include a Figma Design specification, containing component layout, typography, and visual details that the agent must translate into code. Finally, the agent is provided with the XiaoHongShu production codebase, a Git repository snapshot containing approximately 500,000 lines of Swift/Objective-C code across thousands of files. This large-scale context forces the agent to perform retrieval and navigation, rather than just code generation.
<details>
<summary>figures/fig_task_example.png Details</summary>
### Visual Description
\n
## Screenshot: Figma & Code Editor - UI Design & Implementation
### Overview
This screenshot displays a UI design environment (Figma) alongside a code editor, likely showing the implementation of the designed UI. The Figma interface shows a mobile screen design with "before" and "after" states, and the code editor displays Swift code related to a `FeedItemFooter` component. The image appears to be demonstrating a design-to-code workflow.
### Components/Axes
The screenshot is divided into three main sections:
1. **Left:** Figma interface showing a mobile screen design.
2. **Center:** Figma interface showing layer properties.
3. **Right:** Code editor displaying Swift code.
**Figma Interface (Left):**
* **Top Bar:** Contains Figma controls: "Pages", "Assets", "Layers", "Plugins", "Share", Zoom control (75%).
* **Design Canvas:** Displays two mobile screen designs labeled "Before" and "After" with a right-pointing arrow between them.
* **"Before" Screen:** Contains a product image, text in Chinese, and a date "2009".
* **"After" Screen:** Contains a different product image, text in Chinese, and a date "2023/04/01".
* **Bottom Bar:** Contains UI elements and text in Chinese.
**Figma Interface (Center):**
* **Header:** Displays "Layer properties" and a section with "Ag" and a red "New" badge.
* **Layer List:** Shows a hierarchy of layers: "List", "Code", "pa".
* **Properties Panel:** Displays properties for a layer named "Caption/C3".
* **Layout:** Width: 140px, Height: 140px.
* **Typography:**
* Name: Caption/C3
* Font: PingFang SC
* Weight: w3-12-font-weight
* Style: Regular
* Size: 13px
* Line height: 18px
* Letter spacing: -0.1px
* Text color: #333333
* Text align: left
* **Effects:** Drop Shadow with values.
**Code Editor (Right):**
* **File Name:** `FeedItemFooter.swift`
* **Code Snippet:** Swift code defining a `FeedItemFooter` class.
### Detailed Analysis or Content Details
**Figma - "Before" Screen (Approximate):**
* Product Image: A person wearing a hat and jacket.
* Chinese Text: “黑衣搭配连衣裙” (Heiyi dāpèi liányīqún) - Translation: "Black outfit with a dress".
* Date: 2009
**Figma - "After" Screen (Approximate):**
* Product Image: A person wearing a blue outfit.
* Chinese Text: “粉色搭配连衣裙” (Fěnsè dāpèi liányīqún) - Translation: "Pink outfit with a dress".
* Date: 2023/04/01
**Figma - Layer Properties:**
* Layer Name: "Caption/C3"
* Width: 140 pixels
* Height: 140 pixels
* Font: PingFang SC, Regular, 13px
* Text Color: #333333
**Code Editor - Swift Code (Snippet):**
```swift
class FeedItemFooter: UIView {
// ... existing layout code ...
override func layoutSubviews() {
super.layoutSubviews()
// Requirement: Emphasize timeline display, hide interactions
isLikeButton.isHidden = true
// Update typography for better readability
timelineLabel.font = Theme.font.caption
// Re-layout time label to trailing edge
let timelineLabel.frame = CGRect(
x: width - timelineSize.width - padding.standard,
y: avatarView.centerY - timelineSize.height / 2,
width: timelineSize.width + 5,
height: timelineSize.height
)
// Adjust nickname frame to prevent overlap
nicknameLabel.frame.size.width = timelineLabel.frame.minX - nicknameLabel.frame.origin.x
}
}
```
* The code defines a `FeedItemFooter` class, likely a custom view in a mobile application.
* It overrides the `layoutSubviews()` method to adjust the layout of subviews.
* It hides a `isLikeButton` and updates the font of a `timelineLabel`.
* It repositions the `timelineLabel` to the trailing edge of the view.
* It adjusts the width of a `nicknameLabel` to prevent overlap with the `timelineLabel`.
### Key Observations
* The "Before" and "After" screens in Figma demonstrate a visual update to a product display.
* The layer properties in Figma show detailed styling information for a text element.
* The Swift code implements the layout of a UI component, referencing design elements like fonts and labels.
* The code snippet focuses on adjusting the layout of elements within a `FeedItemFooter` view, likely to improve readability and visual appeal.
* The use of Chinese text suggests the application or design is targeted towards a Chinese-speaking audience.
### Interpretation
The screenshot illustrates a typical design-to-code workflow. A designer creates a UI in Figma, defining the visual appearance and layout of elements. The code editor shows how that design is then implemented in code (Swift in this case). The code snippet demonstrates how design properties (like font and positioning) are translated into code to create the desired UI. The "Before" and "After" screens suggest an iterative design process, where the UI is refined based on feedback or usability testing. The focus on typography and layout in both the Figma properties and the Swift code highlights the importance of these elements in creating a visually appealing and user-friendly interface. The presence of Chinese text indicates a localization effort, tailoring the application to a specific cultural context. The code's comments ("Requirement: Emphasize timeline display...") suggest a focus on user experience and information hierarchy. The code is adjusting the layout to prioritize the timeline information.
</details>
Figure 2. A concrete example of a SWE-Bench Mobile task (Task 056). The agent must interpret the PRD requirements (replace interaction button with publish time label) and visual design (Figma), locate the relevant files in the codebase (FeedItemFooter.swift), and implement the changes while handling edge cases and feature configuration.
Output ( $\mathcal{O}$ ). The expected output is a unified diff patch that, when applied to the codebase, implements the feature described in the PRD. This format matches the standard pull request workflow used in industry.
Evaluation ( $\mathcal{E}$ ). Each task is paired with a task-specific pytest suite (9.1 tests per task on average) that evaluates the generated patch directly. Concretely, tests operate on the unified diff text without compiling or running the iOS application, and therefore avoid build-time overhead and simulator/device nondeterminism. This patch-level evaluation is designed to verify the presence of necessary UI-facing edits (e.g., view construction, layout logic) and data/logic edits (e.g., control-flow, state updates), while remaining tolerant to superficial variability such as identifier naming, refactoring style, and minor structural reorganization.
2.2. Design Principles
SWE-Bench Mobile is constructed under guiding principles to ensure relevance to professional software engineering. End-to-End Realism is paramount; tasks span the full engineering process from PRD to testing, preserving real-world dependencies and incomplete specifications. Unlike synthetic benchmarks, our tasks come from actual product development cycles. Multi-Modal Reasoning is required, as agents must jointly interpret textual requirements (PRD), visual designs (Figma), and structured code. Diverse Coverage ensures robustness, with tasks covering multiple categories (Table 3) and difficulty levels, from simple UI adjustments to complex architectural refactoring. Finally, by focusing on Swift/Objective-C, an Under-Represented Language in LLM training data compared to Python or JavaScript, SWE-Bench Mobile serves as a challenging test of an agent’s ability to generalize to less familiar syntax and frameworks.
2.3. Dataset Statistics
Table 1 summarizes the key statistics of SWE-Bench Mobile. The benchmark consists of 50 tasks with 449 total test cases. The majority of tasks (70%) include Figma designs, and 92% include reference images, highlighting the multi-modal nature of the dataset. The average PRD length is 450 words, providing substantial context. The codebase scale is significant, with the repository size reaching approximately 5GB.
Table 1. SWE-Bench Mobile dataset statistics.
| Metric | Value |
| --- | --- |
| Total Tasks | 50 |
| Total Test Cases | 449 |
| Avg. Test Cases per Task | 9.1 |
| Tasks with Figma Design | 35 (70%) |
| Tasks with Reference Images | 46 (92%) |
| Avg. PRD Length (words) | 450 |
| Codebase Size | Large Scale ( $\sim$ 5GB) |
| Programming Language | Swift/Objective-C (iOS) |
| Avg. Files Modified per Task | 4.2 |
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Pie Charts: Task Distribution by Category and Difficulty
### Overview
The image presents two pie charts. The left chart displays the distribution of tasks by category, while the right chart shows the distribution of tasks by difficulty. Both charts include numerical values representing the count of tasks within each segment.
### Components/Axes
The image contains two pie charts, each with a title indicating the categorization: "By Category" and "By Difficulty".
**Left Chart (By Category):**
* **Categories:** UI Components, Networking, Media & Assets, Gesture & Interaction, Data Mgmt, Other.
* **Values:** 18, 4, 7, 8, 10, 3.
**Right Chart (By Difficulty):**
* **Difficulty Levels:** Easy, Medium, Hard.
* **Values:** 15, 25, 10.
There are no explicit axes, as pie charts represent proportions of a whole. The charts are labeled directly with the category/difficulty and the corresponding count.
### Detailed Analysis or Content Details
**Left Chart (By Category):**
* **UI Components:** Represented by a light blue segment, comprising approximately 38% of the total tasks (18 out of 48 total tasks).
* **Networking:** Represented by a dark orange segment, comprising approximately 8% of the total tasks (4 out of 48).
* **Media & Assets:** Represented by a light orange segment, comprising approximately 15% of the total tasks (7 out of 48).
* **Gesture & Interaction:** Represented by a pink segment, comprising approximately 17% of the total tasks (8 out of 48).
* **Data Mgmt:** Represented by a yellow segment, comprising approximately 21% of the total tasks (10 out of 48).
* **Other:** Represented by a grey segment, comprising approximately 6% of the total tasks (3 out of 48).
**Right Chart (By Difficulty):**
* **Easy:** Represented by a light blue segment, comprising approximately 31% of the total tasks (15 out of 48).
* **Medium:** Represented by a yellow segment, comprising approximately 52% of the total tasks (25 out of 48).
* **Hard:** Represented by a dark orange segment, comprising approximately 21% of the total tasks (10 out of 48).
### Key Observations
* The largest category of tasks is "UI Components", accounting for 38% of the total.
* The majority of tasks are of "Medium" difficulty, representing 52% of the total.
* The "Other" category is the smallest, representing only 6% of the total tasks.
* The number of "Easy" tasks is significantly lower than "Medium" tasks.
### Interpretation
The data suggests that the workload is heavily focused on UI component development, and that most tasks are considered to be of medium difficulty. The relatively small proportion of "Hard" tasks might indicate a well-managed project where complex issues are broken down into smaller, more manageable components. The "Other" category, while small, could represent miscellaneous tasks that don't fit neatly into the defined categories. The distribution of difficulty levels suggests a balanced workload, with a focus on tasks that require moderate effort. The data could be used to inform resource allocation and project planning, ensuring that sufficient resources are dedicated to UI component development and medium-difficulty tasks.
</details>
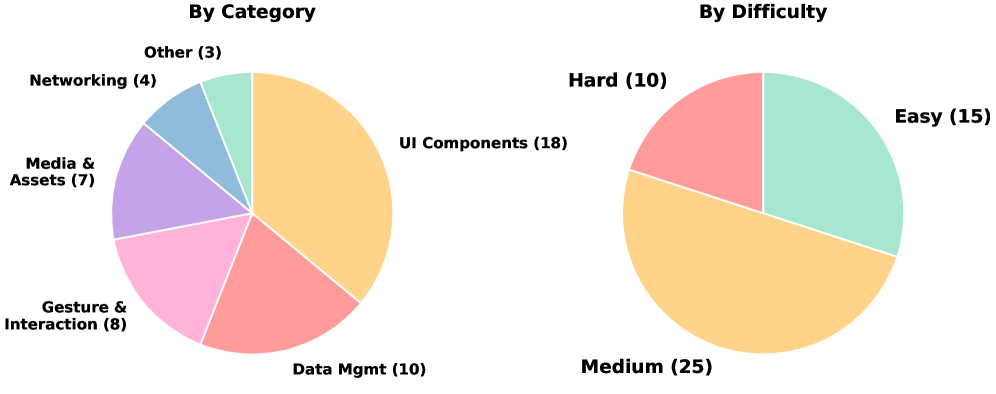
Figure 3. Task distribution by category (left) and difficulty (right). Each label shows the count, percentage, and average agent pass rate. UI Components (36%) dominate the benchmark, while performance drops sharply from Easy (18.5% pass) to Hard (5.8% pass).
2.4. Task Construction
Source. Tasks are derived from real product requirements at XiaoHongShu Inc., a leading social media platform in China with over 300 million monthly active users. Each task represents a feature that was actually implemented by XiaoHongShu engineers in the production iOS application, ensuring realistic complexity and scope. Unlike existing benchmarks that use synthetic problems or isolated bug fixes from open-source repositories, our tasks capture the full complexity of feature development in a commercial mobile application: multi-file changes, UI/UX implementation from design specs, integration with existing business logic, and handling of edge cases and feature flags. This industry-sourced approach ensures that our benchmark reflects the actual challenges faced by software engineers in production environments.
Quality Control. Each task undergoes a rigorous multi-stage review process. First, the PRDs are reviewed to ensure requirements are clear and self-contained. Next, comprehensive test suites are designed to verify both correctness and quality. Finally, we perform human validation to verify that the reference implementation passes all tests.
Difficulty Calibration. Tasks are labeled by implementation complexity based on several factors: the number of files to modify (1-2 for Easy, 3-5 for Medium, 6+ for Hard), the lines of code changed ( $<$ 50 for Easy, 50-150 for Medium, $>$ 150 for Hard), and the architectural complexity, distinguishing between localized changes and cross-module refactoring.
2.5. Evaluation Pipeline
Unlike traditional code benchmarks that rely solely on unit tests, SWE-Bench Mobile performs comprehensive verification through a multi-step pipeline.
Patch-to-Task Routing. SWE-Bench Mobile evaluates submissions as unified diff patches and associates each patch with a specific task. This routing step ensures that each submission is evaluated under the task’s PRD-defined intent and its corresponding test suite, while keeping the evaluation independent of repository checkout, compilation, or runtime execution. In practice, the test harness exposes the patch text to the task-specific tests, enabling purely diff-based verification.
Static Analysis. Before running task-specific assertions, we perform lightweight static checks on the diff text. This includes verifying unified diff structure (e.g., diff --git headers), rejecting empty or near-empty patches, and ensuring that added lines contain meaningful code changes rather than only whitespace or comments. We also check whether the patch touches relevant files using flexible path patterns (e.g., accepting file moves/renames), and apply basic language-agnostic sanity checks to filter malformed submissions early.
Diff-Based Intent Tests. Direct runtime evaluation for mobile applications is challenging to scale. Unit tests are ill-suited for validating visual correctness, while end-to-end UI testing introduces substantial compilation overhead and environmental nondeterminism. To address these constraints, SWE-Bench Mobile adopts a diff-based evaluation strategy: our pytest suites inspect the patch diff and verify structural intent and architectural compliance. This allows us to evaluate high-level architectural decisions and requirement compliance at scale. Tests are constructed from the PRD and a human reference patch, emphasizing:
- Goal-oriented checks: verifying modification patterns (the “what”) rather than exact code shape.
- Feature entry points: checking integration surfaces (e.g., routing, hooks).
- Removal of blocking behavior: ensuring constraints or legacy guards are lifted.
- Cohesion across files: verifying related edits across modules.
- Semantics-aware matching: using flexible pattern matching to accommodate alternative naming.
Batch Reporting and Error Analysis. Beyond pass/fail decisions, our evaluator produces both task-level and test-case-level summaries. For large-scale runs, we classify failures into coarse categories (e.g., missing critical file edits, missing UI components, empty patches). This analysis provides interpretable diagnostics of common agent failure modes and supports systematic iteration on prompts and agent scaffolding.
Metrics. We report two complementary metrics. Task Success Rate is the percentage of tasks where all tests pass, representing the strict standard for a completed feature. Test Pass Rate is the percentage of individual test cases passed, which reveals partial progress even when the full task is not completed. The gap between these metrics reveals how often agents make partial progress without fully completing tasks.
2.6. Comparison with Existing Benchmarks
Table 2 compares SWE-Bench Mobile with existing coding benchmarks. SWE-Bench Mobile distinguishes itself by being multi-modal, including PRDs and Figma designs rather than just code or text descriptions. It operates on a large-scale codebase ( $\sim$ 5GB), significantly larger than the individual repositories or snippets used in other benchmarks. Furthermore, it targets mixed Swift/Objective-C, which is under-represented in training data compared to Python, and focuses on feature implementation rather than bug fixing.
Table 2. Comparison with existing benchmarks.
| Benchmark | Multi-Modal | Codebase | Language |
| --- | --- | --- | --- |
| HumanEval | ✗ | None | Python |
| MBPP | ✗ | None | Python |
| SWE-Bench | ✗ | Medium | Python |
| SWE-Bench Mobile | ✓ | Large | Swift/ObjC |
3. Experiments
We evaluate leading coding agents on SWE-Bench Mobile to answer several key research questions. First, we investigate how state-of-the-art coding agents perform on industry-level mobile development tasks (RQ1). Second, we analyze how task complexity affects agent performance (RQ2). Third, we examine the cost-performance trade-off (RQ3). Fourth, we assess the robustness of agent results across multiple runs (RQ4). Finally, we explore how prompt engineering affects performance (RQ5).
3.1. Experimental Setup
Agents and Models. We evaluate four coding agents spanning commercial and open-source systems: Cursor, an AI-powered code editor with an agent mode; Codex, OpenAI’s coding agent CLI; Claude Code, Anthropic’s coding agent CLI; and OpenCode, an open-source coding agent. We test these agents with multiple backbone models including Claude Opus 4.5, Claude Sonnet 4.5, Claude Haiku, GLM 4.6, GLM 4.7, GPT 5, GPT 5.1, GPT 5.2, and Gemini 3 Pro, yielding 22 agent-model configurations in total.
Metrics. We report two primary metrics: Task Success Rate, which is the percentage of tasks where all test cases pass, and Test Pass Rate, which is the percentage of individual test cases passed. All rates are computed with a fixed denominator of 50 tasks and 449 test cases. When an agent fails to produce a patch for a task (e.g., due to timeout or error), the missing patch is counted as failing all associated tests.
3.2. Main Results (RQ1)
Figure 4 presents the main experimental results across all agent-model configurations.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Horizontal Bar Chart: Task Success Rate Comparison
### Overview
This is a horizontal bar chart comparing the task success rates of different model combinations. The chart displays the success rate as a percentage on the x-axis, and the model combinations are listed on the y-axis. Each model combination is represented by a horizontal bar, color-coded to indicate the primary model used (Cursor, Codex, Claude Code, or OpenCode). The chart aims to visually represent and compare the performance of these different model pairings.
### Components/Axes
* **X-axis Title:** "Task Success Rate (%)" - Scale ranges from 0% to 16%.
* **Y-axis:** Lists the model combinations.
* **Legend:** Located in the top-right corner, identifying the color coding for each primary model:
* Red: Cursor
* Blue: Codex
* Light Green: Claude Code
* Orange: OpenCode
* **Data Series:** Each horizontal bar represents a model combination and its corresponding task success rate.
### Detailed Analysis
The chart presents the following data points. Note that the bars are often composed of multiple colors, representing the contribution of different models to the overall success rate.
1. **Cursor + Opus 4.5:** Approximately 12.0% (Red)
2. **Cursor + Sonnet 4.5:** Approximately 12.0% (Red)
3. **Codex + GLM 4.6:** Approximately 12.0% (Blue)
4. **Codex + Sonnet 4.5:** Approximately 10.0% (Blue)
5. **Codex + GPT 5:** Approximately 10.0% (Blue)
6. **CC + GLM 4.6:** Approximately 10.0% (Light Green)
7. **CC + Sonnet 4.5:** Approximately 10.0% (Light Green)
8. **Cursor + GPT 5.2:** Approximately 8.0% (Red and Orange) - The bar is split, with a red portion and an orange portion.
9. **CC + Opus 4.5:** Approximately 8.0% (Light Green and Red) - The bar is split, with a light green portion and a red portion.
10. **CC + Haiku:** Approximately 8.0% (Light Green)
11. **OC + GLM 4.6:** Approximately 8.0% (Orange)
12. **Cursor + Gemini 3 Pro:** Approximately 6.0% (Red)
13. **OC + GPT 5.1:** Approximately 6.0% (Orange)
14. **Codex + Opus 4.5:** Approximately 4.0% (Blue)
15. **OC + Sonnet 4.5:** Approximately 4.0% (Orange)
16. **OC + GLM 4.7:** Approximately 4.0% (Orange)
17. **OC + Gemini 3 Pro:** Approximately 4.0% (Orange)
18. **OC + GPT 5.2:** Approximately 4.0% (Orange)
19. **Cursor + GPT 5.1:** Approximately 2.0% (Red)
20. **OC + Opus 4.5:** Approximately 2.0% (Orange)
21. **OC + GPT 5:** Approximately 2.0% (Orange)
22. **Codex + GPT 5.1:** Approximately 0.0% (Blue)
The bars are arranged in descending order of task success rate, with the highest rates at the top and the lowest at the bottom.
### Key Observations
* The highest task success rates (around 12%) are achieved by combinations involving Cursor, Codex, and GLM.
* OpenCode combinations generally have lower success rates, with many near 0%.
* Several combinations show a mix of colors, indicating contributions from multiple models. For example, "Cursor + GPT 5.2" has both red (Cursor) and orange (OpenCode) components.
* There is a significant range in task success rates, from 0% to 12%.
### Interpretation
The chart demonstrates a clear performance difference between various model combinations. The Cursor and Codex models, when paired with other models like Opus, Sonnet, and GLM, consistently achieve higher task success rates. OpenCode, while sometimes contributing to success when combined with other models, generally performs poorly on its own.
The mixed-color bars suggest that the success of some combinations relies on the synergistic effect of multiple models. The chart provides valuable insights into the relative strengths and weaknesses of different models and their potential for collaboration. The data suggests that choosing the right model combination is crucial for maximizing task success. The presence of outliers (e.g., Codex + GPT 5.1 at 0%) indicates that certain pairings are particularly ineffective. Further investigation could explore the reasons behind these performance differences and identify optimal model configurations for specific tasks.
</details>
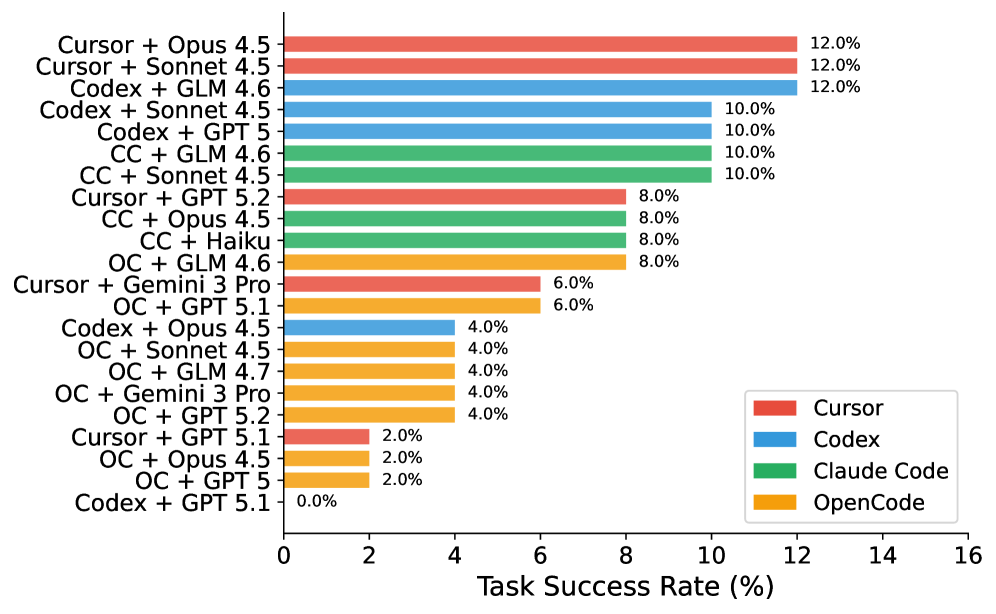
Figure 4. Task Success Rate across all configurations. Best performance is 12%, achieved by Cursor + Opus/Sonnet and Codex + GLM.
Key Findings. Our evaluation reveals a generally low overall performance, with even the best agents solving only 12% of tasks. This indicates a significant gap between current capabilities and industrial requirements. However, the Test Pass Rate (up to 28.1%) is much higher than the Task Success Rate (12%), indicating that agents often make partial progress but fail to complete tasks fully. Notably, we find that the choice of agent matters significantly: the same model (Opus 4.5) achieves 12% on Cursor but only 2% on OpenCode, a 6 $×$ difference. Commercial agents consistently outperform the open-source OpenCode agent: the best OpenCode configuration (GLM 4.6, 8%) trails the best commercial configuration (12%) by 4 percentage points.
3.3. Task Complexity Analysis (RQ2)
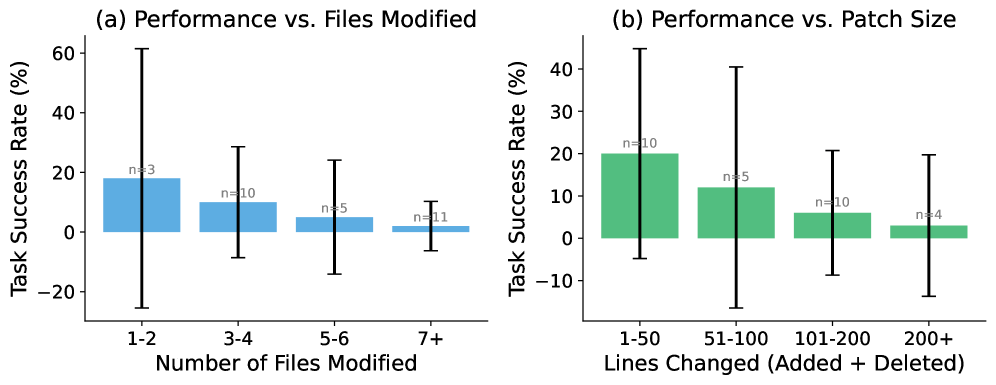
We analyze how task complexity affects agent performance. Figure 5 shows the relationship between task complexity (measured by number of files modified and patch size) and success rate.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Charts: Performance vs. Files Modified & Performance vs. Patch Size
### Overview
The image presents two bar charts comparing task success rate with different metrics: the number of files modified and the size of the patch (lines of code changed). Each chart includes error bars representing the variability in the data, and sample sizes (n) are indicated above each bar.
### Components/Axes
**Chart (a): Performance vs. Files Modified**
* **X-axis:** Number of Files Modified (categories: 1-2, 3-4, 5-6, 7+)
* **Y-axis:** Task Success Rate (%) (scale: -20 to 60, increments of 10)
* **Bars:** Blue bars representing the average task success rate for each file modification category.
* **Error Bars:** Black vertical lines indicating the standard error or confidence interval.
* **Sample Size:** "n = [number]" labels above each bar.
**Chart (b): Performance vs. Patch Size**
* **X-axis:** Lines Changed (Added + Deleted) (categories: 1-50, 51-100, 101-200, 200+)
* **Y-axis:** Task Success Rate (%) (scale: -10 to 40, increments of 10)
* **Bars:** Green bars representing the average task success rate for each patch size category.
* **Error Bars:** Black vertical lines indicating the standard error or confidence interval.
* **Sample Size:** "n = [number]" labels above each bar.
### Detailed Analysis or Content Details
**Chart (a): Performance vs. Files Modified**
* **1-2 Files Modified:** Task success rate is approximately 18% ± 18% (error bar extends from roughly 0% to 36%). Sample size: n = 3.
* **3-4 Files Modified:** Task success rate is approximately 8% ± 8% (error bar extends from roughly 0% to 16%). Sample size: n = 10.
* **5-6 Files Modified:** Task success rate is approximately 4% ± 10% (error bar extends from roughly -6% to 14%). Sample size: n = 5.
* **7+ Files Modified:** Task success rate is approximately -4% ± 12% (error bar extends from roughly -16% to 8%). Sample size: n = 11.
**Chart (b): Performance vs. Patch Size**
* **1-50 Lines Changed:** Task success rate is approximately 16% ± 16% (error bar extends from roughly 0% to 32%). Sample size: n = 10.
* **51-100 Lines Changed:** Task success rate is approximately 12% ± 24% (error bar extends from roughly -12% to 36%). Sample size: n = 5.
* **101-200 Lines Changed:** Task success rate is approximately 6% ± 10% (error bar extends from roughly -4% to 16%). Sample size: n = 10.
* **200+ Lines Changed:** Task success rate is approximately 4% ± 12% (error bar extends from roughly -8% to 16%). Sample size: n = 4.
### Key Observations
* In both charts, the task success rate appears to decrease as the complexity metric (files modified or lines changed) increases.
* The error bars are relatively large, indicating substantial variability in the data.
* The sample sizes are small, particularly for the "7+" files modified and "200+" lines changed categories, which limits the statistical power of the findings.
* The task success rate is generally low across all categories, often near or below 0%.
### Interpretation
The data suggests a negative correlation between task complexity (measured by the number of files modified or the size of the patch) and task success rate. As developers modify more files or change more lines of code, their ability to successfully complete the task decreases. However, the large error bars and small sample sizes mean that these trends should be interpreted with caution. The variability within each category is significant, and it's possible that the observed differences are due to chance.
The consistently low success rates across all categories suggest that the tasks themselves may be inherently difficult, or that there are other factors influencing performance that are not captured by these metrics. The error bars overlapping with zero for many categories indicate that the true mean success rate could be zero, meaning the observed success is not statistically significant.
The charts provide evidence that increasing the scope of changes (either in terms of files or lines of code) is associated with a higher risk of failure. This could be due to increased cognitive load, greater potential for conflicts, or other challenges associated with larger-scale modifications. Further investigation with larger sample sizes and more controlled experiments would be needed to confirm these findings and identify the underlying mechanisms.
</details>
Figure 5. Performance decreases sharply with task complexity. (a) Tasks requiring 1-2 file modifications have 18% success rate vs. 2% for 7+ files. (b) Small patches ( $<$ 50 lines) achieve 20% success vs. 3% for large patches ( $>$ 200 lines). Error bars show 95% confidence intervals based on binomial proportions.
Key Findings. Performance drops sharply as complexity increases. The success rate drops from 18% for tasks requiring 1-2 file modifications to just 2% for tasks requiring 7+ files, suggesting that agents struggle with cross-file reasoning. Similarly, larger patches correlate with lower success, indicating difficulty with complex implementations.
3.4. Model Comparison Across Agents
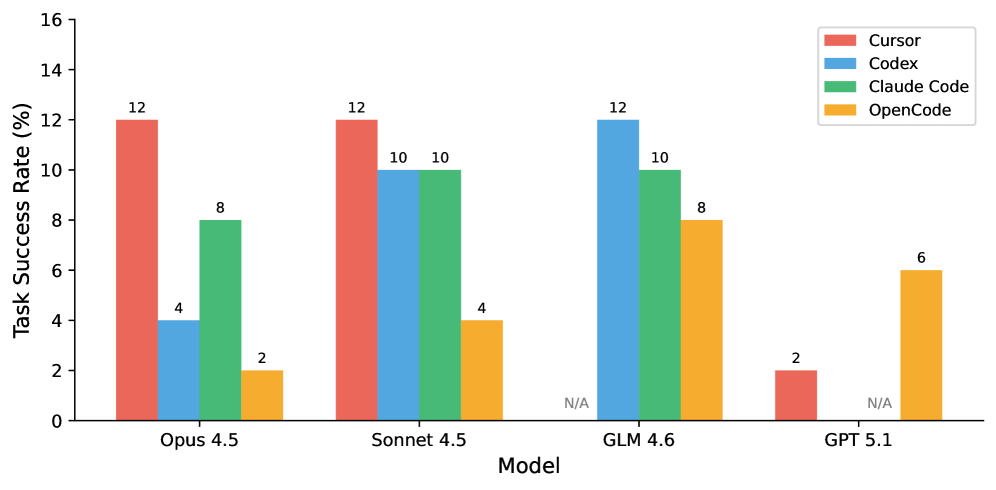
A surprising finding is that the same model performs very differently across agents. Figure 6 shows this comparison across all four agents.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Bar Chart: Task Success Rate by Model
### Overview
This bar chart compares the task success rates of four different language models – Opus 4.5, Sonnet 4.5, GLM 4.6, and GPT 5.1 – across four different coding approaches: Cursor, Codex, Claude Code, and OpenCode. The success rate is measured as a percentage.
### Components/Axes
* **X-axis:** Model (Opus 4.5, Sonnet 4.5, GLM 4.6, GPT 5.1)
* **Y-axis:** Task Success Rate (%) - Scale ranges from 0 to 16, with increments of 2.
* **Legend:** Located in the top-right corner.
* Cursor (Red)
* Codex (Blue)
* Claude Code (Green)
* OpenCode (Orange)
### Detailed Analysis
The chart consists of four groups of bars, one for each model. Each group contains four bars, representing the task success rate for each coding approach.
* **Opus 4.5:**
* Cursor: Approximately 12%
* Codex: Approximately 4%
* Claude Code: Approximately 8%
* OpenCode: Approximately 2%
* **Sonnet 4.5:**
* Cursor: Approximately 12%
* Codex: Approximately 10%
* Claude Code: Approximately 10%
* OpenCode: Approximately 4%
* **GLM 4.6:**
* Cursor: Approximately 12%
* Codex: Approximately 10%
* Claude Code: Approximately 12%
* OpenCode: N/A (Not Available)
* **GPT 5.1:**
* Cursor: Approximately 2%
* Codex: N/A (Not Available)
* Claude Code: N/A (Not Available)
* OpenCode: Approximately 6%
### Key Observations
* Cursor consistently achieves the highest success rate across Opus 4.5, Sonnet 4.5, and GLM 4.6.
* OpenCode is not available for GLM 4.6 and Codex/Claude Code are not available for GPT 5.1.
* GPT 5.1 has a significantly lower success rate for Cursor compared to other models.
* Codex and Claude Code show similar performance for Opus 4.5 and Sonnet 4.5.
### Interpretation
The data suggests that the Cursor coding approach is generally the most effective across the tested models, except for GPT 5.1 where it performs poorly. The success rates vary significantly between models, indicating that the underlying architecture and training data of each model influence its performance with different coding approaches. The "N/A" values suggest that certain coding approaches were not tested or are not supported by specific models. The relatively low success rate of GPT 5.1 with Cursor could indicate compatibility issues or a need for further optimization of the Cursor approach for this model. The consistent performance of Codex and Claude Code across Opus 4.5 and Sonnet 4.5 suggests a degree of robustness in these approaches. Overall, the chart highlights the importance of selecting the appropriate coding approach and model combination to maximize task success rate.
</details>
Figure 6. Same model, different agents: Opus 4.5 achieves 12% on Cursor but only 2% on OpenCode—a 6 $×$ gap. Commercial agents consistently outperform the open-source alternative.
Implications. This finding suggests that agent scaffolding (tool use, context management, iteration strategy) is as important as the underlying model capability. The performance gap between commercial agents (Cursor, Codex, Claude Code) and the open-source OpenCode is substantial across all models, suggesting that years of engineering investment in tool integration, context management, and iterative refinement provide significant advantages. Practitioners should evaluate agents holistically rather than focusing solely on model benchmarks.
3.5. Performance by Task Category
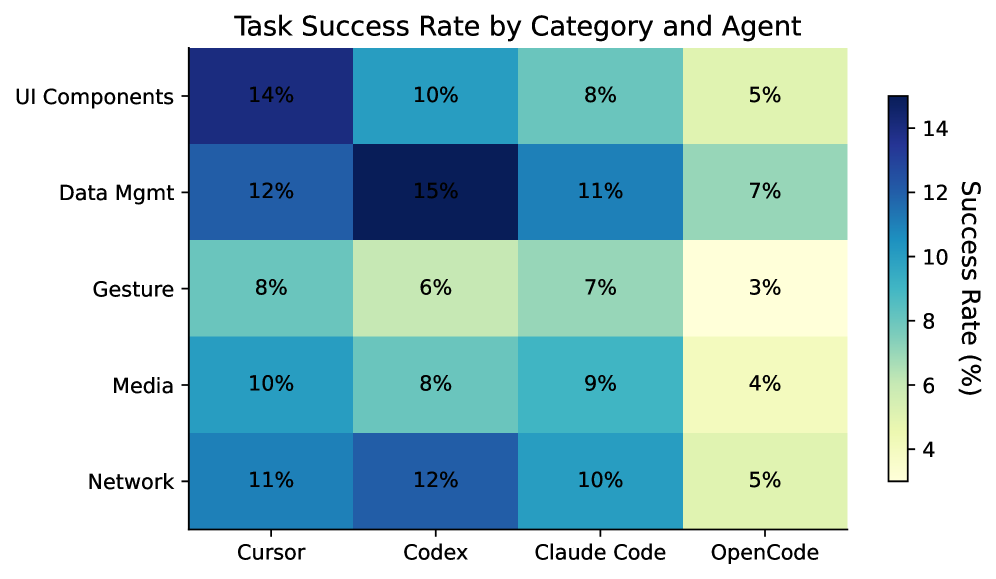
We analyze how agents perform across different task categories. Figure 7 shows the success rate breakdown.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Heatmap: Task Success Rate by Category and Agent
### Overview
This heatmap visualizes the task success rate across five categories (UI Components, Data Mgmt, Gesture, Media, Network) and four agents (Cursor, Codex, Claude Code, OpenCode). The success rate is represented by color intensity, with darker blues indicating higher success rates and lighter yellows indicating lower success rates. A colorbar on the right indicates the success rate scale in percentage.
### Components/Axes
* **Title:** "Task Success Rate by Category and Agent" - positioned at the top-center.
* **X-axis:** Agent - with categories: Cursor, Codex, Claude Code, OpenCode.
* **Y-axis:** Category - with categories: UI Components, Data Mgmt, Gesture, Media, Network.
* **Colorbar:** Located on the right side, representing Success Rate (%) ranging from 4% (light yellow) to 14% (dark blue).
* **Data Labels:** Percentage values are displayed within each cell of the heatmap.
### Detailed Analysis
The heatmap displays the following success rates:
* **UI Components:**
* Cursor: 14%
* Codex: 10%
* Claude Code: 8%
* OpenCode: 5%
* **Data Mgmt:**
* Cursor: 12%
* Codex: 15%
* Claude Code: 11%
* OpenCode: 7%
* **Gesture:**
* Cursor: 8%
* Codex: 6%
* Claude Code: 7%
* OpenCode: 3%
* **Media:**
* Cursor: 10%
* Codex: 8%
* Claude Code: 9%
* OpenCode: 4%
* **Network:**
* Cursor: 11%
* Codex: 12%
* Claude Code: 10%
* OpenCode: 5%
**Trends:**
* **Cursor** generally performs best across all categories, with the highest success rate in UI Components (14%).
* **OpenCode** consistently shows the lowest success rates across all categories, with a minimum of 3% in Gesture.
* **Codex** shows the highest success rate in Data Mgmt (15%).
* Success rates for **Claude Code** are generally moderate and consistent across categories.
### Key Observations
* The highest success rate is 15% (Codex in Data Mgmt).
* The lowest success rate is 3% (OpenCode in Gesture).
* There's a noticeable difference in performance between Cursor and OpenCode across all categories.
* Data Mgmt has the highest success rates overall, while Gesture has the lowest.
### Interpretation
The heatmap suggests that the agent "Cursor" is the most reliable for task completion across all categories, while "OpenCode" struggles significantly. The category "Data Mgmt" appears to be the easiest for all agents to handle, while "Gesture" presents the greatest challenge.
The data could indicate that "OpenCode" requires further development or is not well-suited for the types of tasks being evaluated. The success rate differences between agents might be due to variations in their underlying algorithms, training data, or ability to handle specific task types. The higher success rate in "Data Mgmt" could be attributed to the nature of the tasks within that category, potentially being more straightforward or better aligned with the agents' capabilities.
Further investigation could involve analyzing the specific tasks within each category to understand why certain agents perform better or worse. It would also be valuable to explore the reasons behind the low success rates for "OpenCode" and identify areas for improvement. The heatmap provides a clear visual representation of agent performance and highlights areas where targeted interventions could be most effective.
</details>
Figure 7. Task Success Rate by Category and Agent. Agents generally perform better on Data Management tasks but struggle with Gesture & Interaction and Media tasks, which require complex multi-modal reasoning.
3.6. Cost and Time Analysis (RQ3)
Table 3 presents the cost and time metrics for each configuration. We measure API cost per task and average execution time.
Table 3. Cost and time comparison across all agents. Best value in each column is bold. OpenCode costs are reported via OpenRouter API billing.
| Agent | Model | Cost ($/task) | Time (min) |
| --- | --- | --- | --- |
| Cursor | Opus 4.5 | 3.50 | 15.0 |
| Cursor | Sonnet 4.5 | 2.00 | 14.2 |
| Codex | GLM 4.6 | 1.30 | 13.3 |
| Codex | Sonnet 4.5 | 2.50 | 12.5 |
| CC | GLM 4.6 | 1.30 | 11.7 |
| CC | Sonnet 4.5 | 2.00 | 13.3 |
| CC | Opus 4.5 | 4.00 | 15.0 |
| CC | Haiku | 0.50 | 8.3 |
| OC | Opus 4.5 | 9.33 | 8.2 |
| OC | Sonnet 4.5 | 3.50 | 11.1 |
| OC | GLM 4.6 | 0.13 | 32.5 |
| OC | GLM 4.7 | 0.49 | 52.1 |
| OC | GPT 5 | 0.18 | 9.8 |
| OC | GPT 5.1 | 0.02 | 2.0 |
| OC | GPT 5.2 | 0.04 | 10.9 |
| OC | Gemini 3 Pro | 0.03 | 8.9 |
Key Findings. Among commercial agents, Codex + GLM 4.6 offers the best value, achieving 12% success at only $1.30/task—the same success rate as Cursor + Opus 4.5 but at less than half the cost ($3.50/task). OpenCode exhibits a striking cost–time trade-off: it is dramatically cheaper (GLM 4.6 at $0.13/task vs. $1.30 for Codex/CC), but GLM models run much slower (32–52 min vs. 11–13 min). OpenCode + Opus 4.5 is the most expensive configuration at $9.33/task yet achieves only 2% success, while OpenCode + GPT 5.1 is the cheapest at $0.02/task but completes tasks in only 2 minutes on average—likely because it fails quickly on most tasks (6% success, 7.1% test pass rate).
3.7. Robustness Analysis (RQ4)
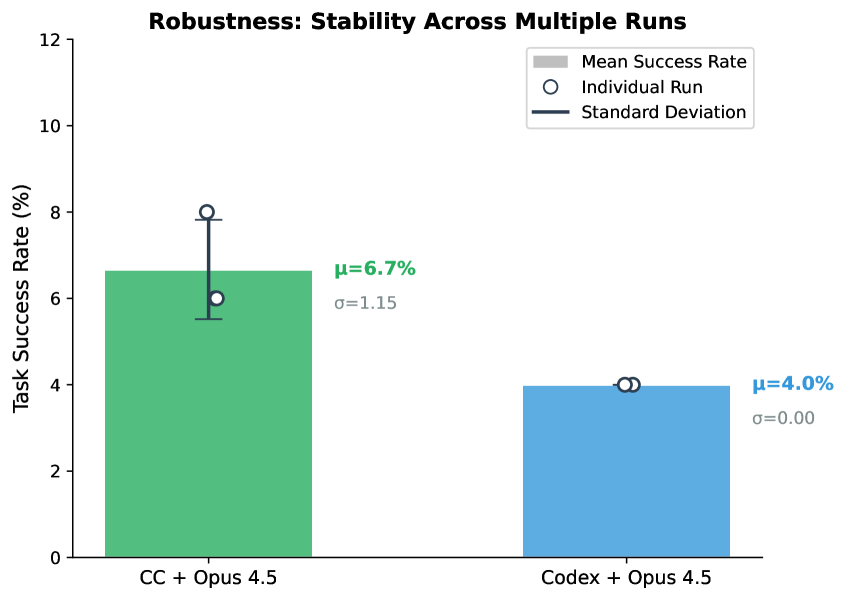
To assess result stability, we run selected configurations multiple times. Figure 8 shows the variance across runs.
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Bar Chart: Robustness - Stability Across Multiple Runs
### Overview
This bar chart compares the Task Success Rate between two configurations: "CC + Opus 4.5" and "Codex + Opus 4.5". Each configuration's success rate is represented by a green or blue bar, respectively, with error bars indicating standard deviation. Mean success rates (μ) and standard deviations (σ) are displayed directly on the chart.
### Components/Axes
* **Title:** Robustness: Stability Across Multiple Runs
* **X-axis:** Configuration (CC + Opus 4.5, Codex + Opus 4.5)
* **Y-axis:** Task Success Rate (%) - Scale ranges from 0 to 12, with increments of 2.
* **Legend:**
* Mean Success Rate (Green)
* Individual Run (Circle)
* Standard Deviation (Black Line)
### Detailed Analysis
The chart presents data for two configurations:
**1. CC + Opus 4.5:**
* Bar Color: Green
* Mean Success Rate (μ): Approximately 6.7% (displayed text: μ=6.7%)
* Standard Deviation (σ): Approximately 1.15% (displayed text: σ=1.15)
* Error Bar: Extends from approximately 5.5% to 8.0%.
* Individual Run: Marked by a circle at approximately 5.7%
**2. Codex + Opus 4.5:**
* Bar Color: Blue
* Mean Success Rate (μ): Approximately 4.0% (displayed text: μ=4.0%)
* Standard Deviation (σ): 0.0% (displayed text: σ=0.00)
* Error Bar: A horizontal line at approximately 4.0%
* Individual Run: Marked by a circle at approximately 4.0%
### Key Observations
* The "CC + Opus 4.5" configuration has a higher mean success rate (6.7%) compared to the "Codex + Opus 4.5" configuration (4.0%).
* The "CC + Opus 4.5" configuration exhibits a standard deviation of 1.15%, indicating variability in the success rate across multiple runs.
* The "Codex + Opus 4.5" configuration has a standard deviation of 0.0%, suggesting consistent performance across runs.
* The individual run data point for "CC + Opus 4.5" is slightly above the mean, while the individual run data point for "Codex + Opus 4.5" is exactly on the mean.
### Interpretation
The data suggests that the "CC + Opus 4.5" configuration is more effective in terms of average task success rate, but also demonstrates greater variability in performance. The "Codex + Opus 4.5" configuration, while having a lower average success rate, provides more consistent results. The zero standard deviation for Codex + Opus 4.5 is notable; it suggests either a very small number of runs were performed, or the system is remarkably stable. The difference in standard deviation implies that the CC + Opus 4.5 configuration is more sensitive to external factors or variations in input, while Codex + Opus 4.5 is more robust. Further investigation would be needed to understand the source of the variability in the CC + Opus 4.5 configuration and the reasons for the lower overall success rate of Codex + Opus 4.5. The chart highlights a trade-off between average performance and consistency.
</details>
Figure 8. Result stability across multiple runs. Error bars indicate standard deviation. While Claude Code shows moderate variance ( $\sigma$ =1.15%), the absolute fluctuation is small ( $±$ 1 task), indicating that agent performance is relatively stable.
Observations. We observe moderate variance for Claude Code + Opus 4.5, with scores of 6%, 8%, and 6% across 3 runs ( $\mu$ =6.7%, $\sigma$ =1.15%). In contrast, Codex + Opus 4.5 is perfectly stable at 4% across runs.
3.8. Prompt Engineering (RQ5)
We conduct a systematic ablation study with 12 prompt variants using Claude Code + GLM 4.6. Table 4 shows the results.
Table 4. Prompt ablation results. Best and worst highlighted. Full prompts in Appendix C.
| Prompt Strategy | Task (%) | Test (%) |
| --- | --- | --- |
| Defensive Programming | 10.0 | 26.7 |
| Quality Focused | 10.0 | 26.3 |
| Example Driven | 10.0 | 23.4 |
| Chain of Thought | 10.0 | 21.8 |
| Baseline | 10.0 | 19.3 |
| Explicit Instructions | 8.0 | 17.8 |
| Figma Emphasis | 8.0 | 18.0 |
| Test Driven | 6.0 | 22.0 |
| Detailed Role | 4.0 | 20.7 |
| Structured Checklist | 4.0 | 20.7 |
| Context Rich | 4.0 | 22.7 |
| Comprehensive | 4.0 | 22.7 |
Key Findings. The ”Defensive Programming” prompt strategy performs best, improving the Test Pass Rate by 7.4% over the baseline (19.3% $→$ 26.7%) while maintaining the same Task Success Rate (10.0%). This indicates that while both prompts complete the same number of tasks fully, Defensive Programming handles edge cases better in partially-completed tasks, passing significantly more individual test cases. This suggests that emphasizing defensive coding practices helps agents avoid common pitfalls even when they cannot complete all requirements. Interestingly, complexity appears to hurt performance; overly detailed prompts reduce Task Success from 10.0% to 4.0%. Overall, prompts focusing on code quality outperform those emphasizing workflow.
3.9. Error Analysis
We categorize failure modes across all experiments by analyzing test failure messages from the best-performing agents. The most critical failure pattern is Missing Feature Flags (54%), where agents implement core functionality but fail to add proper feature toggles or experiment flags—a standard practice in production mobile development for gradual rollout and A/B testing. Missing Data Models (22%) occurs when agents fail to create or update data structures required by the PRD. Missing Files (11-15%) represents cases where agents identify some but not all required files to modify. Missing UI Components (11-15%) captures failures to implement specific UI elements like buttons, labels, or views. Missing Required Methods (9%) reflects incomplete class implementations. While Incomplete Multi-File Implementation affects only 4-7% of tasks, it disproportionately impacts complex features requiring coordination across 5+ files. The dominance of feature flag failures highlights a gap between agents’ code generation capabilities and their understanding of production deployment practices.
4. Discussion and Conclusion
Our evaluation reveals a significant gap between current agent capabilities and the demands of industrial mobile development, with the best configurations achieving only a 12% success rate. This shortfall, primarily driven by failures in cross-file reasoning and requirement understanding, underscores that autonomous software engineering remains an open challenge.
Implications. For practitioners, our results suggest that agents should currently be viewed as “copilots” requiring human oversight rather than autonomous developers. The high variance in performance across agents for the same model (e.g., Cursor 12% vs. OpenCode 2% for Opus 4.5) highlights the critical role of agent scaffolding—practitioners should evaluate the complete system, not just the underlying model. The consistent gap between commercial and open-source agents suggests that engineering investment in tool integration and context management provides significant practical value. Furthermore, cost-effective models like GLM 4.6 can match the performance of expensive frontier models when paired with effective agent frameworks, offering a viable path for scalable adoption. For researchers, the sharp performance drop on complex, multi-file tasks (18% vs. 2%) points to a need for better code context retrieval and graph-based reasoning. The 25% failure rate due to requirement misunderstanding calls for improved grounding of natural language PRDs into code. Additionally, the under-utilization of visual designs suggests that future work must better integrate multi-modal signals into the coding loop.
Future Work. We plan to expand SWE-Bench Mobile along several dimensions. First, we will add Android (Kotlin) tasks to enable cross-platform comparison and investigate whether agents exhibit consistent strengths and weaknesses across mobile ecosystems. Second, we will integrate simulator-based runtime evaluation to verify UI rendering, gesture handling, and state management—aspects that text-based diff inspection cannot capture. Third, we aim to evaluate additional open-source agents like OpenHands and SWE-Agent, and open-weight models like Qwen-Coder, to further broaden the benchmark’s coverage. Finally, we plan to develop a public API for continuous evaluation, allowing agent providers to track their progress over time as both models and scaffolding improve.
In conclusion, SWE-Bench Mobile provides a rigorous testbed for the next generation of coding agents. While current performance is modest, the benchmark offers a clear roadmap for advancing agents from simple script generation to complex, industry-level software development.
5. Related Work
5.1. Code Generation Benchmarks
Early benchmarks for code generation focused on algorithmic problem-solving. HumanEval (Chen et al., 2021) introduced 164 hand-crafted Python programming problems with unit tests, becoming a standard evaluation for code LLMs. MBPP (Austin et al., 2021) expanded this with 974 crowd-sourced problems. While influential, these benchmarks test isolated function generation rather than realistic software engineering.
SWE-Bench (Jimenez et al., 2024) marked a significant advance by evaluating agents on real GitHub issues from popular Python repositories. Agents must understand issue descriptions, navigate codebases, and generate patches that pass existing tests. The benchmark has since evolved into a family of tasks, including SWE-bench Multimodal (Yang et al., 2025a), which incorporates visual elements such as screenshots and diagrams to test visual software domains; SWE-bench Multilingual (Zan et al., 2025; Yang et al., 2025b), which expands evaluation to 9 programming languages beyond Python; and SWE-bench Pro (Deng et al., 2025), which introduces longer-horizon instances and includes proprietary/commercial codebases. Even with these extensions, many existing benchmarks still derive tasks from GitHub issue and pull-request artifacts, which more often emphasize bug fixing and localized improvements than new feature implementation from high-level specifications.
Other benchmarks target specific domains: DS-1000 (Lai et al., 2023) for data science, ODEX (Wang et al., 2022) for open-domain execution, and ClassEval (Du et al., 2024) for class-level generation. DevBench (Li et al., 2024) evaluates repository-level coding but still focuses on Python.
SWE-Bench Mobile differs from these benchmarks in several key aspects: (1) multi-modal inputs including PRDs and Figma designs, (2) a large-scale production codebase (approx. 5GB), (3) mixed Swift/Objective-C target languages, and (4) feature implementation rather than bug fixing.
5.2. Coding Agents
The emergence of powerful LLMs has enabled a new generation of autonomous coding agents. These systems go beyond simple code completion to perform multi-step reasoning, tool use, and iterative refinement.
Commercial agents include GitHub Copilot (Microsoft), Cursor (Anysphere), Claude Code (Anthropic), and Codex CLI (OpenAI). These agents integrate with development environments and can navigate codebases, run tests, and iterate on solutions.
Open-source agents have emerged as alternatives. OpenCode provides a terminal-based coding agent supporting multiple LLM backends. SWE-Agent (Yang et al., 2024) introduces an agent-computer interface optimized for software engineering. AutoCodeRover (Zhang et al., 2024b) combines code search with LLM reasoning. Agentless (Xia et al., 2024) shows that simpler approaches without complex agent loops can be competitive. CodeAgent (Zhang et al., 2024a) uses a repository-level code graph for navigation.
Our work provides a challenging benchmark for evaluating both commercial and open-source agents on industry-level tasks, revealing significant gaps in current capabilities and the importance of agent scaffolding.
5.3. Multi-Modal Code Understanding
Recent work has explored combining visual and textual information for code-related tasks. Design2Code (Si et al., 2024) evaluates generating code from webpage screenshots. Screenshot2Code systems convert UI designs to implementation.
SWE-Bench Mobile extends this direction by incorporating Figma designs as part of the input specification, requiring agents to reason about visual layouts alongside textual requirements.
5.4. Prompt Engineering for Code
Prompt engineering significantly impacts LLM performance on coding tasks. Chain-of-thought prompting (Wei et al., 2022) improves reasoning. Self-debugging (Chen et al., 2023) enables iterative refinement. Structured prompts with role definitions and examples often outperform simple instructions.
Our ablation study (Section 3.8) systematically evaluates 12 prompt strategies, finding that “Defensive Programming” prompts emphasizing edge cases outperform both simple baselines and complex multi-step prompts.
Limitations
Platform Scope. SWE-Bench Mobile focuses on a single production iOS codebase from XiaoHongShu, which ensures depth and realism but limits generalization to other mobile platforms (Android, cross-platform frameworks like Flutter/React Native) and programming paradigms. The Swift/Objective-C mixed-language codebase, while representative of many large iOS projects, may not capture challenges unique to Kotlin-based Android development or cross-platform toolchains.
Evaluation Methodology. Our evaluation uses text-based diff inspection rather than runtime execution, which means we validate structural correctness and architectural compliance but cannot detect issues that only manifest during runtime interactions, on specific devices, or under particular OS versions. Future work should integrate simulator-based testing to capture dynamic behaviors such as UI rendering, memory management, and concurrency issues.
Prompt and Model Coverage. Our prompt ablation study covers one agent-model configuration (Claude Code + GLM 4.6) and 12 prompt variants. While this provides insights into prompt sensitivity, different models may respond differently to these strategies. Additionally, API costs reported are based on pricing at experiment time and may vary with different prompting strategies or model updates.
Benchmark Scale. The benchmark’s 50 tasks, while derived from real product development, represent a snapshot of mobile development challenges and may not cover all possible feature types (e.g., real-time communication, payment integration, accessibility features) or edge cases encountered in production. We plan to continuously expand the task set to improve coverage.
Ethics Statement
The tasks and codebase in SWE-Bench Mobile are derived from XiaoHongShu Inc. with explicit permission for research use. The codebase snapshot excludes sensitive credentials and business logic. Human validation was performed by the authors and XiaoHongShu engineers; no crowdworkers were employed.
Our work evaluates AI agents for software engineering tasks. Current performance (12% task success rate) indicates that human oversight remains essential. We view these agents as assistive tools rather than replacements for human developers. Practitioners should use comprehensive testing and code review when deploying AI-generated code, as emphasized by our benchmark’s evaluation approach.
References
- (1)
- Atlassian (2024) Atlassian. 2024. How to Write a Product Requirements Document (PRD). https://www.atlassian.com/agile/product-management/requirements.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program Synthesis with Large Language Models. arXiv preprint arXiv:2108.07732 (2021).
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374 (2021).
- Chen et al. (2023) Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2023. Teaching Large Language Models to Self-Debug. arXiv preprint arXiv:2304.05128 (2023).
- Deng et al. (2025) Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. 2025. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks? arXiv preprint arXiv:2509.16941 (2025).
- Du et al. (2024) Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. 2024. ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation. In International Conference on Machine Learning.
- Jimenez et al. (2024) Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world GitHub Issues?. In The Twelfth International Conference on Learning Representations.
- Lai et al. (2023) Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2023. DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation. In International Conference on Machine Learning.
- Li et al. (2024) Bowen Li, Wenhan Wu, Ziwei Tang, Lin Shi, John Yang, Jinyang Li, Shunyu Yao, Chen Xiong, and Karthik Narasimhan. 2024. DevBench: A Comprehensive Benchmark for Software Development. arXiv preprint arXiv:2403.08604 (2024).
- Si et al. (2024) Chenglei Si, Yanzhe Li, Zhengyuan Jiang, Xinyang Liu, Zheng Lu, Yuqing Jiang, Yong Liu, Yu Wang, Yujiu Yuan, Lydia Liu, et al. 2024. Design2Code: How Far Are We From Automating Front-End Engineering? arXiv preprint arXiv:2403.03163 (2024).
- Wang et al. (2022) Zhiruo Wang, Shuyan Zhou, Daniel Fried, and Graham Neubig. 2022. Execution-Based Evaluation for Open-Domain Code Generation. arXiv preprint arXiv:2212.10481 (2022).
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems 35 (2022), 24824–24837.
- Xia et al. (2024) Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying LLM-based Software Engineering Agents. arXiv preprint arXiv:2407.01489 (2024).
- Yang et al. (2024) John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. arXiv preprint arXiv:2405.15793 (2024).
- Yang et al. (2025a) John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ofir Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, et al. 2025a. SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?. In The Thirteenth International Conference on Learning Representations.
- Yang et al. (2025b) John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. 2025b. SWE-smith: Scaling Data for Software Engineering Agents. arXiv preprint arXiv:2504.21798 (2025).
- Zan et al. (2025) Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. 2025. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving. arXiv:2504.02605 [cs.SE] https://arxiv.org/abs/2504.02605
- Zhang et al. (2024a) Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. 2024a. CodeAgent: Enhancing Code Generation with Tool-Integrated Agent Systems for Real-World Repo-level Coding Challenges. arXiv preprint arXiv:2401.07339 (2024).
- Zhang et al. (2024b) Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024b. AutoCodeRover: Autonomous Program Improvement. arXiv preprint arXiv:2404.05427 (2024).
Appendix A Task Examples
We present two representative tasks from SWE-Bench Mobile to illustrate the benchmark format. Each task includes a Product Requirement Document (PRD) with design specifications, translated from the original Chinese used by the development team.
A.1. Task 003: Custom Emoji Limit Adjustment
Difficulty: Easy Files to Modify: 3 Test Cases: 5
Adjust Custom Emoji Collection Limit
Background The current custom emoji (saved stickers) limit is hardcoded to 300 on the client side. As user demand grows, we need to increase this limit to better serve our users. Requirements (1)
Increase limit: Change from 300 to 999 (2)
Update UI prompts: Adjust warning messages to reflect new limit (3)
Server-driven config: Remove hardcoded values; future changes should not require app updates (4)
Comprehensive coverage: Apply to all emoji-saving scenarios (chat, comments, etc.) Competitor Analysis App Emoji Limit WeChat 999 Douyin (TikTok) 599 Kuaishou 158
Design Mockups See Figure 9 for the original design specifications provided to developers.
Evaluation Criteria
- Hardcoded limit (300) removed or increased to $≥$ 450
- New limit (999) properly configured
- Server-driven configuration implemented
- Changes applied across multiple files
- Non-empty, meaningful code changes
A.2. Task 007: Card Message Click Decoupling
Difficulty: Medium Files to Modify: 5 Test Cases: 5
iOS Card Reference Click Decoupling
Background Card messages have been added to the app. While most iOS code is decoupled from the messaging module, the click logic for card message references remains coupled in AppChatBaseViewController. This task decouples the click handling for better maintainability. Architecture Design Abstract click logic to CardRefBaseProvider. The view controller should find the concrete implementation based on card type, following the provider pattern. Implementation Sketch
⬇ @objc (AppRefMessageDataService) public class AppRefMessageDataService: NSObject { var chatType: String? var chatId: String? var senderId: String? var messageId: String? }
Impact Scope: Shopping card, Advertisement card
Evaluation Criteria
- New AppRefMessageDataService class created
- Click handling moved out of AppChatBaseViewController
- Provider pattern correctly implemented
- Shopping and advertisement card handling works
- No regression in existing functionality
Appendix B Complete Experimental Results
Table 5. Complete evaluation results on SWE-Bench Mobile. Task Success measures the percentage of tasks where all test cases pass (out of 50 tasks). Test Pass measures the percentage of individual test cases passed (out of 449 tests). Best results per agent in bold.
| Agent | Model | Task Success (%) | Test Pass (%) | Cost ($/task) | Time (min) |
| --- | --- | --- | --- | --- | --- |
| Cursor | Claude Opus 4.5 | 12.0 | 28.1 | 3.50 | 15.0 |
| Claude Sonnet 4.5 | 12.0 | 26.7 | 2.00 | 14.2 | |
| GPT-5.2 | 8.0 | 27.4 | 1.80 | 20.0 | |
| Gemini 3 Pro | 6.0 | 23.2 | 1.00 | 12.5 | |
| GPT-5.1 | 2.0 | 19.6 | 1.10 | 14.2 | |
| Codex | GLM-4.6 | 12.0 | 19.6 | 1.30 | 13.3 |
| Claude Sonnet 4.5 | 10.0 | 28.1 | 2.50 | 12.5 | |
| GPT-5 | 10.0 | 21.4 | 1.50 | 10.0 | |
| Claude Opus 4.5 | 4.0 | 20.7 | 3.50 | 14.2 | |
| GPT-5.1 | 0.0 | 7.1 | 1.00 | 13.3 | |
| Claude Code | GLM-4.6 | 10.0 | 26.7 | 1.30 | 11.7 |
| Claude Sonnet 4.5 | 10.0 | 24.7 | 2.00 | 13.3 | |
| Claude Opus 4.5 | 8.0 | 21.8 | 4.00 | 15.0 | |
| Claude Haiku | 8.0 | 18.3 | 0.50 | 8.3 | |
| OpenCode | GLM-4.6 | 8.0 | 17.8 | 0.13 | 32.5 |
| GPT-5.1 | 6.0 | 7.1 | 0.02 | 2.0 | |
| Claude Sonnet 4.5 | 4.0 | 14.7 | 3.50 | 11.1 | |
| GLM-4.7 | 4.0 | 14.3 | 0.49 | 52.1 | |
| Gemini 3 Pro | 4.0 | 13.4 | 0.03 | 8.9 | |
| GPT-5.2 | 4.0 | 12.0 | 0.04 | 10.9 | |
| Claude Opus 4.5 | 2.0 | 12.0 | 9.33 | 8.2 | |
| GPT-5 | 2.0 | 12.0 | 0.18 | 9.8 | |
B.1. Cross-Agent Model Comparison
Table 6 reveals that the same model can perform very differently across agents, highlighting the importance of agent design.
Table 6. Same model, different agents: Task Success Rate (%). The gap between best and worst agent can be as large as 6 $×$ .
| Model | Cursor | Codex | CC | OpenCode | Gap |
| --- | --- | --- | --- | --- | --- |
| Opus 4.5 | 12 | 4 | 8 | 2 | 6 $×$ |
| Sonnet 4.5 | 12 | 10 | 10 | 4 | 3 $×$ |
| GLM-4.6 | — | 12 | 10 | 8 | 1.5 $×$ |
| GPT-5.1 | 2 | 0 | — | 6 | $∞$ |
Appendix C Prompt Templates
We designed 12 prompt variants for the ablation study. Below we present the key prompts. All prompts share a common structure: role definition, task description, and output format. The differentiating factor is the emphasis placed on different aspects.
C.1. Best Prompt: Defensive Programming
P10: Defensive Programming (Best)
“You are a senior iOS engineer known for writing robust, production-ready code. Implement the feature with a focus on defensive programming and edge case handling. Don’t just implement the happy path. Think about everything that could go wrong: •
Empty data, nil values, invalid formats •
Very long/short text, different screen sizes •
Slow network, timeouts, concurrent operations •
First-time user, offline mode, low memory Your code should handle all of this gracefully without crashing.”
C.2. Baseline Prompt
P1: Baseline
“You are an iOS developer. Read the PRD carefully and implement the required changes. Generate a unified diff patch that can be applied to the codebase.”
C.3. Worst Performing Prompts
P12: Comprehensive (Worst)
“You are a senior iOS engineer. Before implementing: (1)
Analyze the PRD thoroughly (2)
Identify all affected files (3)
Plan your implementation strategy (4)
Consider edge cases (5)
Review the Figma design (6)
Check for existing patterns (7)
Implement with tests in mind (8)
Validate against requirements Generate a complete, production-ready patch.”
Why Comprehensive Failed: The overly detailed checklist appears to overwhelm the model, causing it to focus on process rather than actual implementation. Simpler, focused prompts consistently outperform complex ones.
C.4. Other Notable Prompts
P7: Chain of Thought:
Asks the model to “think step by step” before coding. Achieved 10% Task Success but lower Test Pass Rate (21.8%) than Defensive Programming. P9: Figma Emphasis:
Emphasizes matching the Figma design exactly. Surprisingly underperformed (8% Task Success), possibly because many tasks don’t require UI changes. P11: Test Driven:
Asks the model to “think about what tests would verify your implementation.” Achieved only 6% Task Success despite the intuitive appeal of test-driven thinking.
Appendix D Dataset Statistics
We provide detailed statistics of the SWE-Bench Mobile dataset in Table 7. The benchmark consists of 50 tasks with varying levels of complexity, involving multi-modal inputs (PRDs and Figma designs) and a large-scale production codebase. The tasks are designed to cover a wide range of mobile development scenarios, ensuring a comprehensive evaluation of agent capabilities.
Table 7. SWE-Bench Mobile dataset statistics.
| Metric | Value |
| --- | --- |
| Task Composition | |
| Total Tasks | 50 |
| Tasks with Figma Design | 35 (70%) |
| Tasks with Reference Images | 46 (92%) |
| Task Complexity | |
| Avg. PRD Length (words) | 450 |
| Avg. Test Cases per Task | 9.1 |
| Total Test Cases | 449 |
| Avg. Files to Modify | 4.2 |
| Codebase | |
| Programming Language | Swift/Objective-C (iOS) |
| Codebase Size | $\sim$ 500K LoC |
Appendix E Reproducibility
Environment. All experiments were conducted on macOS 14.x with:
- Cursor: v2.3 with Agent mode enabled
- Codex: OpenAI Codex CLI v0.77.0
- Claude Code: Anthropic Claude Code CLI v2.1.37
- OpenCode: v1.1.44 (open-source coding agent)
Model API Configuration.
For reproducibility, we specify the exact API endpoints and configurations used:
- GPT Models (GPT 5, 5.1, 5.2): Accessed via Microsoft Azure OpenAI API with default temperature and top-p settings
- Claude Models (Opus 4.5, Sonnet 4.5, Haiku): Accessed via Google Vertex AI API for Anthropic models
- Gemini 3 Pro: Accessed via Google Vertex AI API with standard configuration
- GLM Models (GLM 4.6, 4.7): Used GLM Coding Plan with default agent scaffolding
Multi-Modal Input Handling.
To handle Figma designs and reference images, we configured Model Context Protocol (MCP) integrations:
- Vision-capable models (GPT, Claude, Gemini): Used official Figma MCP to directly access design specifications
- GLM Models: Since GLM 4.6 is not a native vision model, we used the official GLM Vision MCP to process images and Figma designs, converting visual inputs into structured descriptions for the text-only model
Evaluation Pipeline.
1. Load generated patch file as text
1. Run task-specific pytest test suite (tests inspect the patch diff text using pattern matching and structural analysis)
1. Record pass/fail status for each test case
1. Aggregate results across all 50 tasks
Availability and Hosted Evaluation. The SWE-Bench Mobile benchmark is derived from a proprietary production codebase with permission from XiaoHongShu Inc. Due to the confidential nature of the source code and product requirements, the full dataset cannot be publicly released. We view this constraint as a feature rather than a limitation: by keeping the test set private, we eliminate the risk of data contamination —a well-known issue with public benchmarks where test instances may leak into LLM training corpora (Jimenez et al., 2024).
SWE-Bench Mobile is designed as a standardized evaluation platform for coding agent providers and foundation model vendors. We host a public leaderboard at https://swebenchmobile.com where agent companies (e.g., Cursor, Codex, Claude Code) and model providers (e.g., OpenAI, Anthropic, Google, Zhipu AI) can submit their systems for evaluation against our held-out industrial test suite. This provides an objective, contamination-free comparison on real-world mobile development tasks that complements existing Python-centric benchmarks. Submission guidelines and evaluation configurations are available at https://github.com/realtmxi/mobile-bench.
Appendix F Task Design Mockups
Figure 9 shows the design mockups provided to agents for Task 003 (Custom Emoji Limit). These real-world screenshots demonstrate the user pain point and expected UI behavior that agents must understand to implement the feature correctly.
<details>
<summary>figures/fig_mockup_001.jpg Details</summary>
### Visual Description
\n
## Screenshot: Social Media Post (Weibo)
### Overview
This is a screenshot of a post on the Chinese social media platform Weibo. The screenshot shows a text-based post with accompanying comments and reactions. The post appears to be a user expressing frustration about storage capacity on a small redmi phone.
### Components/Axes
The screenshot is divided into several sections:
* **Left Side:** Contains the original post text in Chinese.
* **Right Side:** Contains the user profile information, post details (date, time), comment section, and reaction buttons.
* **Top-Right:** User profile icon and name ("一条鱼W").
* **Comment Section:** Displays user comments, including usernames, comment text, like counts, and reply counts.
* **Reaction Buttons:** Icons for liking, commenting, and sharing.
### Detailed Analysis or Content Details
**Original Post (Left Side - Chinese):**
我 想要 问一下,
要是 小红 书
信息 已经 上线 太多,
无法 漏加 表情,
该 怎么办?
**(English Translation):**
"I want to ask,
if on Xiaohongshu (Little Red Book - a Chinese social media platform)
the information has already been uploaded too much,
and it's impossible to add expressions,
what should I do?"
**Post Details (Top-Right):**
* **User:** 一条鱼W (Yi Tiao Yu W)
* **Text:** 信息上限太多了 我想问一下,要是小红书表信息已经太多,无法漏加表情,该怎么办?#用一句话说拨五月 (Information limit is too much. I want to ask, if on Xiaohongshu the information has already been uploaded too much, and it's impossible to add expressions, what should I do? #SayMayInOneSentence)
* **Date:** 2024-05-04
**Comments (Right Side):**
* **Comment 1:** 憶宅へ (Yi Zhai) - 我没有表情但是显示表情信息已经太多 🥺 (I don't have expressions but it shows that the expression information is too much 🥺) - 9 Likes, 5 Replies - Date: 02-08
* **Comment 2:** 一条鱼W (Yi Tiao Yu W) - 记… (Ji…) - 3 Replies - Date: 02-08
* **Comment 3:** 治愈宝宝主 朱丽叶吉安娜 - 有300个吧,根本不够用 (There are about 300, but it's not enough) - Includes two user profile images. - 50 Likes, 10 Replies, 40 Shares.
**Reaction Buttons:**
* 50 Likes
* 10 Comments
* 40 Shares
### Key Observations
* The user is experiencing an issue with the Xiaohongshu app, specifically related to a limit on the amount of information that can be uploaded or displayed, preventing them from adding expressions.
* The comments suggest that other users are experiencing similar issues.
* The user "治愈宝宝主 朱丽叶吉安娜" suggests the limit is around 300, which is insufficient.
* The post is relatively recent (May 4, 2024).
### Interpretation
The data suggests a potential bug or limitation within the Xiaohongshu app regarding the handling of information and expressions. The user is seeking help from the community to resolve the issue. The comments confirm that this is not an isolated incident, indicating a broader problem affecting multiple users. The use of an emoji (🥺) in the first comment conveys frustration and helplessness. The post is framed as a question, seeking advice rather than simply complaining. The hashtag #用一句话说拨五月 suggests the post might be related to a broader social media trend or challenge. The fact that the post has garnered 50 likes, 10 comments, and 40 shares indicates a moderate level of engagement and interest in the issue.
</details>
(a) User Complaint. Social media post showing frustration with the 300-emoji limit: “Xiaohongshu’s emoji limit is too high, I can’t add more emojis.”
<details>
<summary>figures/fig_mockup_002.jpg Details</summary>
### Visual Description
\n
## Screenshot: Social Media Post - WeChat
### Overview
This is a screenshot of a WeChat social media post. The post features a large graphic with text, accompanied by a block of Chinese text, comments, and reaction icons. The post appears to be a question about whether a small red book (likely referring to the social commerce platform Xiaohongshu/Little Red Book) can successfully collect information and upload it.
### Components/Axes
The screenshot contains the following components:
* **Main Graphic:** A large, vertically oriented graphic with bold, stylized Chinese characters.
* **Post Text:** A block of Chinese text below the graphic.
* **Comments Section:** A section displaying comments from other users.
* **Reaction Icons:** Icons for liking, commenting, and sharing.
* **Timestamp:** A timestamp indicating the post date.
* **WeChat UI Elements:** Top bar with "关注" (Follow) button and other WeChat interface elements.
### Content Details
**1. Main Graphic Text (Chinese):**
小红书能不能取消表情包收藏上限呀?
*(Pinyin: Xiǎohóngshū néng bùnéng qǔxiāo biǎoqíngbāo shōucáng shàngxiàn ya?)*
*(English Translation: Can Xiaohongshu cancel the limit on the number of saved expressions/stickers?)*
**2. Post Text (Chinese):**
小红书能不能取消表情包收藏上限呀?
遇到喜欢的表情包我就收藏,看一个爱一个,爱一个收一个,逐渐达到表情包收藏上限。看到新的喜欢的信息包,还是忍不住收藏,但是我已经达到上限了,每次我都只能忍痛放弃,实在喜欢的说话去表情包收藏里面挑选拣拣的删一个相比之下不怎么喜欢的。心痛,哦,太心痛了😭#表情包 #小红书 #收藏上限 #表情包分享 #喜欢 #停不下来
*(Pinyin: Xiǎohóngshū néng bùnéng qǔxiāo biǎoqíngbāo shōucáng shàngxiàn ya?
Yùdào xǐhuan de biǎoqíngbāo jiù wǒ jiù shōucáng, kàn yī gè ài yī gè, ài yī gè shōu yī gè, zhújiàn dádào biǎoqíngbāo shōucáng shàngxiàn. Kàndào xīn de xǐhuan de xìnxī bāo, háishì rěnbuzhù shōucáng, dànshì wǒ yǐjīng dádào shàngxiàn le, měi cì wǒ dōu zhǐ néng rěn tòng fàngqì, shízài xǐhuan de shuōhuà qù biǎoqíngbāo shōucáng lǐmiàn tiāoxuǎn jiǎn jiǎn de shān yī gè xiāngbǐ zhīxià bù zěnme xǐhuan de. Xīntòng, ó, tài xīntòng le😭#biǎoqíngbāo #xiǎohóngshū #shōucáng shàngxiàn #biǎoqíngbāo fēnxiǎng #xǐhuan #tíng bù xiàlái)*
*(English Translation: Can Xiaohongshu cancel the limit on the number of saved expressions/stickers?
Whenever I come across an expression pack I like, I save it, love one, collect one, and gradually reach the limit on saved expression packs. When I see a new expression pack I like, I can't help but save it, but I've already reached the limit. Every time I have to reluctantly give up, and if I really like a phrase, I have to delete one from my saved expression packs that I don't like as much. It hurts, oh, it hurts so much😭 #expressionpacks #Xiaohongshu #saveLimit #expressionpacksharing #like #cantstop)*
**3. Comments Section:**
* **Comment 1 (Chinese):** 鱼啊鱼你保边
*(Pinyin: Yú a yú nǐ bǎobiān)*
*(English Translation: Fish, you protect the edge/border)*
* **Comment 2 (Chinese):** 啊!啊!啊!!
*(Pinyin: A! A! A!!)*
*(English Translation: Ah! Ah! Ah!!)*
* **Commenter Information:** "4 天前" (4 days ago) and reaction icons (like and reply).
* **Input Field:** "说点什么..." (Say something...)
**4. Reaction Icons:**
* Like icon (heart) - 9 likes
* Collection icon (bookmark)
* Comment icon - 2 comments
* Share icon
**5. Timestamp:** 02-14 广西 (Guangxi province, February 14th)
### Key Observations
* The post is a complaint about a limit on the number of expression packs that can be saved on Xiaohongshu.
* The user expresses strong emotional distress ("heartbroken") over having to delete saved expression packs.
* The post uses several hashtags to increase visibility.
* The comments are short and express empathy or excitement.
* The post received 9 likes and 2 comments.
### Interpretation
The post reveals a user's frustration with a limitation on a popular social commerce platform (Xiaohongshu). The user's emotional language and the use of hashtags suggest that this is a common issue and that the user is seeking support from other users. The comments indicate that others share the user's sentiment. This post highlights the importance of user experience and the potential impact of limitations on user engagement. The use of expression packs suggests a younger demographic and a culture of online communication that relies heavily on visual content. The post is a clear example of how social media platforms can be used to voice complaints and connect with others who share similar experiences. The comment "鱼啊鱼你保边" is a bit cryptic and could be an inside joke or a reference to a specific meme or community. The repeated "啊!" in the second comment conveys strong emotion, likely empathy with the original poster.
</details>
(b) Community Feedback. Another user asking “Can Xiaohongshu remove the emoji collection limit?” showing widespread user demand.
<details>
<summary>figures/fig_mockup_003.jpg Details</summary>
### Visual Description
## Screenshot: Social Media Post - WeChat Moments
### Overview
This is a screenshot of a WeChat Moments post. The post features a collection of expressive emoji-like images, a text description, and associated social interaction details (likes, comments). The post appears to be about creating and sharing expressive avatars or stickers.
### Components/Axes
The screenshot can be divided into the following regions:
* **Top Bar:** Contains user profile information ("耳机陆" - Earphone Land), a "关注" (Follow) button, and potentially other WeChat interface elements.
* **Post Content:** The main body of the post, containing the text description and the grid of images.
* **Interaction Bar:** Located at the bottom, showing the number of likes, comments, and other engagement metrics.
* **Navigation Bar:** Top-left corner with icons for various functions.
### Content Details
**Top Bar:**
* Username: 耳机陆 (Earphone Land)
* Button: 关注 (Follow)
**Post Text (Chinese with English Translation):**
“小红书能不能限制限制表情包数量啊
我做了一共900+表情包,小红书还觉得挑战限制功能加新的#表情包 #表情包分享 #搞笑表情包 #斗图表情包 #记录生活 #爱闪爱闪百变表情包 我上热门”
Translation: "Can Xiaohongshu (Little Red Book) limit the number of emoji packages? I made a total of 900+ emoji packages, and Xiaohongshu still thinks the challenge limit function is adding new ones. #emoji #emoji sharing #funny emoji #battle emoji #record life #love flash love versatile emoji I'm trending."
**Image Grid:**
The grid contains a variety of images, appearing to be custom-made emoji or avatar-like designs. Some notable images include:
* A hand gesture with a "+" sign.
* A cartoon character with a speech bubble saying "哦贴!" (Oh, paste!).
* A character labeled "老!" (Old!).
* A character with a surprised expression.
* A character saying "我已,攻击好强" (I'm already, attack is strong).
* A character saying "说点什么..." (Say something...).
* An image with text "造成破防 100%" (Caused a breakdown 100%).
* Several images of people.
* An image labeled "已添加的表情" (Added Emoji).
* An image labeled "最新消息" (Latest News).
**Interaction Bar:**
* Likes: 6
* Comments: 24
* A comment from 有心人 (Someone with a heart): "把你的表情包都分享给我谢谢 🎂" (Share all your emoji packages with me, thank you 🎂)
* A reply from 耳机陆 (Earphone Land): "微信见" (See you on WeChat)
**Navigation Bar Icons (from left to right):**
* 有话要说 (Have something to say)
* 状态更新 (Status Update)
* 表情包 (Emoji) - highlighted
* 拍照 (Take a photo)
* 视频 (Video)
* More options (three dots)
### Key Observations
* The post is focused on a large collection of custom emoji/avatar designs.
* The user is expressing frustration with a platform (Xiaohongshu) potentially limiting the number of emoji packages allowed.
* The post has received moderate engagement (6 likes, 24 comments).
* The user is promoting their emoji packages and encouraging others to share them.
* The images are visually diverse and expressive.
### Interpretation
The data suggests that the user ("Earphone Land") is a creator of custom emoji/avatar designs and is actively promoting their work on WeChat Moments. The post highlights the volume of their creations (900+ emoji packages) and a potential issue with another platform (Xiaohongshu) limiting the number of packages allowed. The user is leveraging WeChat to share their creations and potentially drive traffic to other platforms. The interaction bar indicates a moderate level of engagement, with one user specifically requesting to receive the emoji packages. The overall tone of the post is playful and creative, reflecting the nature of the content being shared. The use of hashtags suggests an attempt to increase visibility and reach a wider audience. The post is a clear example of content creation and self-promotion within a social media context. The mention of "造成破防 100%" (Caused a breakdown 100%) suggests the emoji are designed to be humorous or emotionally impactful.
</details>
(c) Emoji Collection UI. The sticker collection interface with warning dialog “Emoji limit reached, cannot add more.” Agents must increase this limit from 300 to 999.
Figure 9. Design mockups for Task 003 (Custom Emoji Limit). These mockups are provided to agents as part of the PRD to guide implementation. They show real user complaints about the 300-emoji limit and the current UI that needs modification.
Appendix G Qualitative Analysis of Agent Outputs
We present detailed analyses of agent-generated patches to provide insights into both successful implementations and common failure modes. These examples illustrate the practical challenges agents face when implementing features from PRDs and Figma designs in a production codebase.
Table 8. Successful implementation by Cursor + GPT-5.2 on Task 007 (Medium difficulty). The agent correctly created the AppRefMessageDataService class with all required fields and methods, demonstrating strong architectural understanding.
| Task Context |
| --- |
| Difficulty: Medium Files to Modify: 5 Category: Architecture Refactoring |
| Agent: Cursor + GPT-5.2 Result: ✓ PASS (5/5 tests) |
| Problem Statement (Summary) |
| Decouple card message click handling from AppChatBaseViewController by abstracting logic into CardRefBaseProvider. The click logic for card references should be moved to a new AppRefMessageDataService class following the provider pattern. |
| Key Requirements |
| •
Create AppRefMessageDataService class with fields: chatType, chatId, senderId, messageId, sender, innerContentDict •
Move click handling out of view controller •
Implement provider pattern for different card types •
Support shopping and advertisement cards |
| Generated Patch (Key Excerpts) |