# Immersion in the GitHub Universe: Scaling Coding Agents to Mastery
**Authors**: Jiale Zhao, Guoxin Chen, Fanzhe Meng, Minghao Li, Jie Chen, Hui Xu, Yongshuai Sun, Wayne Xin Zhao, Ruihua Song, Yuan Zhang, Peng Wang, Cheng Chen, Ji-Rong Wen, Kai Jia
\uselogo Corresponding author:
{marshmallowzjl, gx.chen.chn, mengfanzhe16, batmanfly}@gmail.com, songruihua_bloon@outlook.com, jiakai@bytedance.com
Abstract
Achieving mastery in real-world software engineering tasks is fundamentally bottlenecked by the scarcity of large-scale, high-quality training data. Scaling such data has been limited by the complexity of environment setup, unit-test generation, and problem statement curation. In this paper, we propose Scale‑SWE, an automated, sandboxed multi‑agent workflow designed to construct high‑quality SWE data at scale. The system coordinates three specialized agents—for environment setup, test creation, and problem description synthesis—to process 6 million pull requests across 5.2k repositories, producing Scale‑SWE‑Data: 100k verified SWE instances, the largest such dataset to date. It substantially surpasses existing real‑world datasets in repository diversity and reflects realistic task complexity. We further demonstrate the dataset’s utility for training by distilling 71,498 high‑quality trajectories and fine‑tuning Qwen‑30B-A3B-Instruct to produce Scale‑SWE‑Agent. Our agent achieves a 64% resolve rate on SWE‑Bench‑Verified—a nearly three‑fold improvement over the base model. Scale‑SWE provides a scalable, reproducible approach for data construction to advance LLM‑based software engineering.
<details>
<summary>x1.png Details</summary>

### Visual Description
Icon/Small Image (24x24)
</details>
Model
<details>
<summary>x2.png Details</summary>

### Visual Description
Icon/Small Image (24x24)
</details>
Dataset
<details>
<summary>x3.png Details</summary>

### Visual Description
Icon/Small Image (24x24)
</details>
Code
1 Introduction
<details>
<summary>figures/performance.drawio.png Details</summary>
### Visual Description
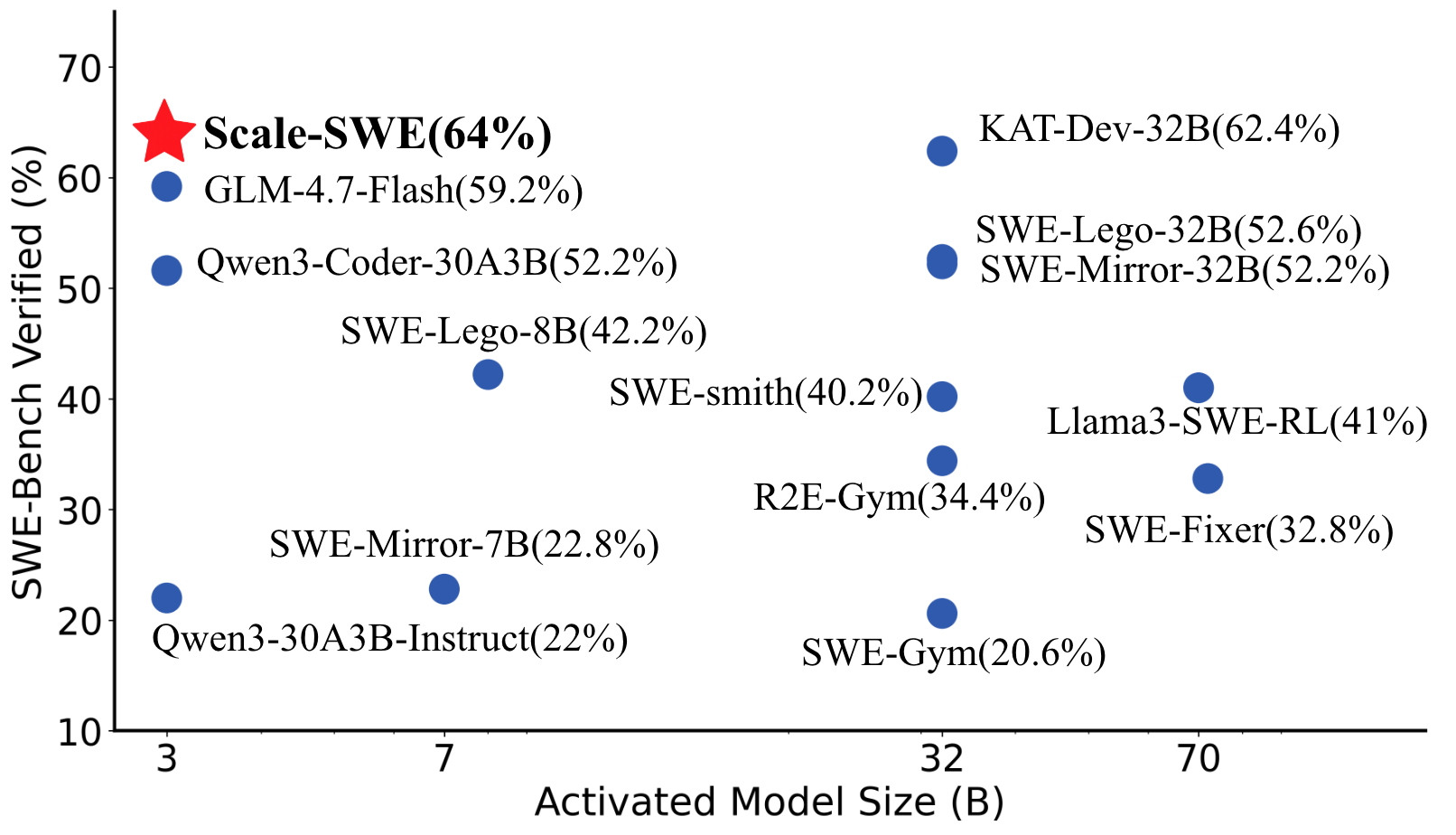
## Scatter Plot: SWE-Bench Verified vs. Activated Model Size
### Overview
This scatter plot visualizes the relationship between the Activated Model Size (in Billions - B) and the percentage of SWE-Bench Verified for various models. The plot displays data points representing different models, with their corresponding sizes and verification percentages. A red star highlights a model named "Scale-SWE" with a notably high verification percentage.
### Components/Axes
* **X-axis:** Activated Model Size (B) - Ranges from approximately 3 to 70.
* **Y-axis:** SWE-Bench Verified (%) - Ranges from approximately 10% to 70%.
* **Data Points:** Blue circles representing individual models.
* **Highlight:** A red star representing the "Scale-SWE" model.
* **Labels:** Each data point is labeled with the model name and its SWE-Bench Verified percentage.
### Detailed Analysis
The data points are scattered across the plot, showing a general trend of increasing SWE-Bench Verified percentage with increasing Activated Model Size, but with significant variance.
Here's a breakdown of the data points, reading from left to right (approximately):
* **Qwen3-30A3B-Instruct:** Activated Model Size ≈ 3B, SWE-Bench Verified ≈ 22%.
* **SWE-Mirror-7B:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 22.8%.
* **GLM-4.7-Flash:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 59.2%.
* **Qwen3-Coder-30A3B:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 52.2%.
* **SWE-Lego-8B:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 42.2%.
* **SWE-Gym:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 20.6%.
* **R2E-Gym:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 34.4%.
* **SWE-smith:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 40.2%.
* **Llama3-SWE-RL:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 41%.
* **SWE-Fixer:** Activated Model Size ≈ 70B, SWE-Bench Verified ≈ 32.8%.
* **KAT-Dev-32B:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 62.4%.
* **SWE-Lego-32B:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 52.6%.
* **SWE-Mirror-32B:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 52.2%.
* **Scale-SWE:** Activated Model Size ≈ 64B, SWE-Bench Verified ≈ 64%. (Highlighted with a red star)
### Key Observations
* **Scale-SWE** significantly outperforms all other models, achieving the highest SWE-Bench Verified percentage (64%) with a model size of 64B.
* There's a wide range of SWE-Bench Verified percentages for models with similar Activated Model Sizes (e.g., around 32B).
* The relationship between model size and verification percentage isn't strictly linear; larger models don't always guarantee higher verification.
* Models with smaller sizes (around 3-7B) generally have lower verification percentages.
### Interpretation
The data suggests that while increasing the Activated Model Size generally correlates with improved SWE-Bench verification, it's not the sole determinant of performance. The "Scale-SWE" model demonstrates that specific architectural choices or training methodologies can lead to substantial gains in verification accuracy, even at comparable model sizes. The variance in verification percentages for models of similar sizes indicates that factors beyond size, such as training data, model architecture, and optimization techniques, play a crucial role. The plot highlights the importance of considering multiple factors when evaluating and comparing language models. The red star draws attention to a model that is an outlier in terms of performance, suggesting it may be a particularly effective or well-optimized model. The data could be used to inform decisions about model selection and resource allocation, guiding developers towards models that offer the best balance between size and performance.
</details>
Figure 1: Resolved rate vs. activated model size on SWE-bench Verified. The vertical axis denotes the percentage of resolved issues on the SWE-bench Verified benchmark. The horizontal axis represents the number of activated parameters in billions (B).
Recently, LLM-based code agents have garnered significant attention for their demonstrated potential in tackling complex software engineering (SWE) tasks [Anthropic, 2025a, Google, 2025, OpenAI, 2025], as reflected in benchmarks like SWE-bench [Jimenez et al., 2023] and its successors [Zhang et al., 2025]. Yet the advancement of these agents is fundamentally constrained by the scarcity of high-quality training data. Unlike conventional code generation, SWE tasks necessitate operation within executable environments, requiring agents to navigate existing codebases, manage dependencies, and satisfy test suites. These inherent complexities render the systematic curation and validation of appropriate data a significant challenge.
Current methodologies for constructing SWE-style datasets predominantly rely on labor-intensive manual curation [Pan et al., 2024] or on simplistic LLM-based [Badertdinov et al., 2025] and rule-based synthesis [Guo et al., 2025b]. Consequently, existing datasets are often limited in scale, diversity, and difficulty, or lack the executable environments and comprehensive test suites. This limitation persists despite the wealth of available real-world software artifacts, including code repositories, issue trackers, and commit histories, which remain largely untapped for building a scalable, realistic dataset. The absence of systematic, automated mining techniques has thus produced a clear disconnect between these raw software resources and the creation of robust, large-scale training data. This compelling need drives our work to develop an automated and reproducible approach for dataset construction.
However, the automatic construction of SWE datasets presents unique and significant challenges. First, environment configuration becomes a major hurdle as repository diversity increases, leading to highly heterogeneous and often fragile build processes [Froger et al., 2025], which can be challenging even for experienced developers to set up correctly. Second, real-world repositories frequently lack sufficient, well-defined unit tests. While incorporating these repositories is essential to reduce data bias and achieve scale, generating comprehensive unit tests itself is a complex problem that demands interactive agentic execution and self-correction. Finally, a substantial portion of real-world pull requests either lack informative descriptions or are inherently unsuitable for SWE tasks. Therefore, generating high-quality, self-contained problem descriptions is challenging and requires agents to infer task intent by acquiring deep repository context through iterative sandbox exploration.
To overcome these challenges, in this paper, we introduce Scale-SWE, an automated, sandboxed multi-agent workflow designed for scalable, high-quality software engineering dataset construction. Our system coordinates three specialized agents: an environment builder agent that sets up isolated Docker environments, a unit-test creator agent that generates robust Pass-to-Pass (P2P) and Fail-to-Pass (F2P) test cases, and a problem statement agent that crafts self-contained task descriptions grounded in pull request content. By processing 6 million pull requests across 5,200 repositories, this workflow produces 100,000 verified instances, yielding the largest SWE dataset to date, which we call Scale-SWE-Data. This dataset surpasses prior real-world datasets in repository diversity and reflects realistic software engineering complexity, both in the number of file modifications required and the robustness of its unit tests.
To further demonstrate the utility of Scale-SWE-Data for model training, we distill 71,498 high-quality trajectories from a subset of 25,000 instances using DeepSeek-V3.2. Fine-tuning Qwen3-30A3B-Instruct on this distilled data yields our Scale-SWE-Agent, which achieves a substantial performance boost on SWE-Bench-Verified, increasing the resolve rate from 22% to 60%. This result underscores the effectiveness of our dataset for training and enhancing LLM-based code agents.
To summarize, our contributions are as follows:
- We introduce Scale-SWE, an automated, sandboxed multi-agent workflow for scalable, high-quality software engineering dataset construction. It systematically coordinates three specialized agents for environment setup, unit-test generation, and problem description synthesis.
- We construct Scale-SWE-Data, the largest verified SWE dataset to date, comprising 100,000 real-world instances. It surpasses prior benchmarks in repository diversity and task complexity, supporting both evaluation and training for LLM-based code agents.
- We distill 71,498 high-quality trajectories from Scale-SWE-Data and fine-tune Qwen-30A3B-Instruct to create Scale-SWE-Agent. The agent substantially boosts performance on SWE-Bench-Verified, achieving a 64% resolve rate—a nearly three-fold improvement over the original backbone.
2 Scale-SWE: Software Task Scaling
<details>
<summary>figures/scale_swe.drawio.png Details</summary>
### Visual Description
\n
## Diagram: GitHub Agent Workflow
### Overview
The image depicts a diagram illustrating the workflow of three agents interacting with the GitHub ecosystem. The agents are: Environment Builder, Unit-test Creator, and Problem Statement Writer. The diagram shows the data sources feeding into the agents (GitHub API, pull requests, etc.) and the processes each agent undertakes. The right side of the image shows an illustrative depiction of "Immersion in the GitHub Universe" with robot-like figures.
### Components/Axes
The diagram is divided into three main sections, each representing an agent. Each section contains a series of interconnected boxes representing steps in the agent's process. Arrows indicate the flow of data and control between these steps.
* **Data Sources (Left Side):**
* GitHub API (labeled with "Real-world 23k repositories")
* 6M pull requests
* Stars/downloads (labeled with "LLM as judge")
* 1M high quality pull requests
* **Agent 1: Environment Builder Agent:**
* Auto-explore repository
* Agent-based package installation (apt-get, pip, shell…)
* Docker image built successfully
* Extract trajectories (pip install -e .)
* Run unit-test
* Unit-test failed
* Install more packages & Fix package versions
* Repeat Fix & Check
* Run unit-test
* All unit-test passed
* Install more packages & Fix package versions
* **Agent 2: Unit-test Creator Agent:**
* Read pull request meta info.
* Auto-explore repository
* If failed, fix unit-test
* Write unit-test
* Run unit-test
* **Agent 3: Problem Statement Writer Agent:**
* Read pull request meta info. & Read Fail-to-Pass
* Write problem statement
* Auto-explore repository
* **Immersion in the GitHub Universe (Right Side):** A visual representation of the agents operating within the GitHub ecosystem.
### Detailed Analysis or Content Details
**Agent 1: Environment Builder Agent**
This agent begins by auto-exploring a repository. It then performs agent-based package installation using tools like apt-get, pip, and shell. A Docker image is built successfully. Trajectories are extracted using `pip install -e .` and `pip uninstall sqlalchemy-mixins -y` and `pip install "SQLAlchemy<2.0"`. The agent then runs unit tests. If the tests fail, it installs more packages and fixes package versions, repeating this process until all unit tests pass.
**Agent 2: Unit-test Creator Agent**
This agent starts by reading pull request meta information. It then auto-explores the repository. If unit tests fail, it attempts to fix them and then writes new unit tests. Finally, it runs the unit tests.
**Agent 3: Problem Statement Writer Agent**
This agent reads pull request meta information and Fail-to-Pass data. It then writes a problem statement and auto-explores the repository.
**Data Flow:**
The diagram shows a clear flow of data from the GitHub API and pull requests to the agents. The agents then process this data and iterate through various steps to achieve their respective goals. The dashed lines indicate iterative processes (e.g., "Repeat Fix & Check" in the Environment Builder Agent).
### Key Observations
* The Environment Builder Agent has a more complex workflow with iterative steps for fixing and checking package versions.
* All three agents involve auto-exploration of the repository as a key step.
* The diagram emphasizes the use of unit tests as a critical component in both the Environment Builder and Unit-test Creator agents.
* The "Immersion in the GitHub Universe" illustration suggests the agents are designed to operate seamlessly within the GitHub ecosystem.
### Interpretation
The diagram illustrates a system for automating tasks related to software development within the GitHub environment. The three agents represent different aspects of this automation: setting up the development environment, creating unit tests, and defining problem statements. The iterative nature of the Environment Builder Agent suggests a robust approach to dependency management and ensuring a stable development environment. The use of LLMs as a judge (indicated by the "Stars/downloads" label) suggests a mechanism for evaluating the quality of the generated unit tests and problem statements. The overall system appears to be designed to improve the efficiency and reliability of software development on GitHub. The illustration on the right side emphasizes the integration of these agents into the broader GitHub ecosystem. The diagram doesn't provide specific numerical data, but rather a conceptual overview of the workflow. It suggests a system that leverages automation and machine learning to streamline the software development process.
</details>
Figure 2: The Sandboxed multi-agent system for Scale-SWE dataset construction. Starting from millions of raw GitHub pull requests, the pipeline employs a series of autonomous agents to transform high-quality PRs into executable software engineering tasks. The framework automates environment setup, unit test generation (Fail-to-Pass/Pass-to-Pass), and formal problem statement synthesis, ensuring the scalability and reproducibility of the distilled trajectories.
The core philosophy of Scale-SWE is to make use of a sandboxed multi-agent system to autonomously explore codebases and complete SWE data construction. Each SWE data instance encapsulates the necessary components: a docker image, a problem statement, and the validation unit tests (consisting of F2P and P2P unit tests). Our sandboxed multi-agent system offers significantly greater flexibility compared to prior rule-based construction methods. By shifting the construction burden to the agent, Scale-SWE enables the scaling of interactive environments while minimizing the heuristic bias inherent in rigid filtering pipelines. In what follows, we firstly introduce our sandboxed multi-agent system (Section 2.1), and then detail by the data processing pipeline (Section 2.2).
2.1 Sandboxed Multi-agent System
To scale the automated construction of software engineering tasks, we develop a sandboxed multi-agent system. This framework leverages collaborative agents to produce a large volume of SWE data with fully integrated, executable environments.
2.1.1 The Overall Workflow
As illustrated in Figure 2, our sandboxed multi-agent system automates the construction of software engineering tasks through the coordinated execution of three specialized agents: the Environment Builder Agent (EBA), the Unit-test Creator Agent (UCA), and the Problem Statement Writer Agent (PSWA). Within this framework, the EBA generates reproducible, Docker-based execution environments from target repositories, providing the isolated and consistent runtime needed for scalable task validation. The UCA synthesizes comprehensive, executable test suites—including both Fail-to-Pass (F2P) and Pass-to-Pass (P2P) test cases—from pull requests and repository context, ensuring robust evaluation criteria. Finally, the PSWA produces high-quality, self-contained problem descriptions grounded in the executable test suites, guaranteeing semantic alignment between the problem statement and the validation requirements. The system is built upon SWE-agent [Yang et al., 2024a] and powered by the DeepSeek language model family [Liu et al., 2025] and Gemini3-Pro [Google, 2025], with task instances generated using both DeepSeek v3.1 or DeepSeek v3.2, with the exception of PSWA, which utilizes Gemini3-Pro.
2.1.2 Environment builder agent
The EBA is designed to automatically generate a reproducible, Docker-based execution environment from a target source code repository. By providing an isolated and executable sandbox, the EBA enables the scalable construction and validation of test samples for automated software engineering workflows.
Role Formulation. We define the core function of the EBA as the transformation of an initial, generic Docker environment into a specialized runtime container tailored to a specific repository. This process can be expressed as:
$$
\mathcal{D}_{\text{final}}=\text{EBA}(\mathcal{R},\mathcal{D}_{\text{init}}), \tag{1}
$$
where $\mathcal{R}$ denotes the input repository that the agent analyzes to infer dependencies and configuration logic, $\mathcal{D}_{\text{init}}$ is the base Docker image, and $\mathcal{D}_{\text{final}}$ is the resulting functional, ready-to-use container image.
Construction Process. In implementation, the EBA is initialized within a base Docker container containing the cloned repository. It begins by autonomously exploring the repository’s structure and analyzing configuration files—such as setup.py, pyproject.toml, and README.md —to infer project dependencies. Since Python projects lack a universal setup protocol, a standardized installation approach is insufficient. The agent must therefore interpret project-specific documentation and interactively resolve dependency conflicts by parsing terminal feedback. This feedback-driven, autonomous process enables flexible environment configuration, circumventing the limitations of static, rule-based methods (e.g., predefined pip install commands). Finally, we extract all executed commands from the agent’s trajectory and use an LLM to synthesize them into a reproducible Dockerfile.
Efficiently Scaling Environmental Diversity. While constructing a dedicated environment per pull request (PR) is straightforward, it is computationally prohibitive for large-scale evaluation. To scale across a diverse set of repositories, we sample at most ten PRs per repository for full environment construction via the EBA. This sampling strategy enables broader repository coverage while controlling resource costs. Note that ten PRs do not yield only ten task samples; multiple PRs can share the same environment if they originate from a similar runtime state, resulting in significantly more test samples than uniquely built environments. Specifically, for the remaining PRs, we execute tests in the “nearest” available Docker environment, determined by proximity in PR ID (as a proxy for repository timeline). If a PR fails the unit tests within its nearest available environment, it is discarded from the final dataset. Otherwise, the PR and its associated pre-established environment are retained as a valid test instance. On average, each repository contributes 19 test instances (see Table 2), dramatically improving environment reuse and overall dataset diversity.
2.1.3 Unit-test creator agent
The unit-test creator agent (UCA) is designed to automatically generate comprehensive and executable test suites from target source code repositories and their associated pull requests. By synthesizing semantic PR information with dynamic repository context, the UCA enables the scalable construction of validated Fail-to-Pass (F2P) and Pass-to-Pass (P2P) test cases, which are essential for robust software engineering task evaluation.
Role Formulation. The core function of the UCA is to transform the provided pull request metadata and its associated code context into a comprehensive suite of executable unit tests. This process can be expressed as:
$$
\mathcal{U}=\text{UCA}(\mathcal{M},\mathcal{R},\mathcal{D}_{\text{final}}), \tag{2}
$$
where $\mathcal{M}$ denotes the input pull request metadata—including the title, description, and diff patches—that provides the semantic specification for test generation, $\mathcal{R}$ is the associated source repository that the agent analyzes to understand code structure and logic, $\mathcal{D}_{\text{final}}$ is the functional Docker environment built by the EBA, and $\mathcal{U}$ is the resulting set of executable test cases. In this work, we adopt the SWE-bench protocol for unit tests, categorizing them into two types: Fail-to-Pass (F2P) tests, which initially fail on the original codebase and must pass after the bug-fixing patch to verify correctness; and Pass-to-Pass (P2P) tests, which are pre-existing passing tests that must continue to pass to ensure no regression is introduced.
Construction Process. A large proportion of GitHub repositories lack comprehensive unit tests, making the automated construction of both Fail-to-Pass (F2P) and Pass-to-Pass (P2P) test cases essential for creating valid Software Engineering (SWE) task instances. The UCA begins by analyzing structured metadata from a target PR, including its title, description, and diff patches. This input provides the necessary semantic grounding for the agent to comprehend the intent and scope of the proposed code changes. Building on this foundation, the agent performs an autonomous traversal of the associated repository to map its directory structure, identify key modules, and infer the underlying program logic and dependencies. However, generating effective unit tests presents a complex, stateful challenge that requires not only static code understanding but also dynamic behavioral validation. The agent must reason about cross-file interactions, data flow, exception handling, and edge cases—tasks that are difficult to accomplish through static analysis alone. To address this, the UCA is deployed within a secure, sandboxed execution environment (specifically, the Docker container $\mathcal{D}_{\text{final}}$ produced by the EBA). This sandbox grants the agent direct, real-time code execution privileges, enabling an interactive execute-analyze-refine loop. The agent can thus dynamically run its proposed tests, observe their outcomes, and iteratively revise the test logic, assertions, and fixtures. This closed-loop, feedback-driven methodology allows the UCA to produce robust, executable test suites.
2.1.4 Problem Statement Writer Agent
The problem statement writer agent (PSWA) is designed to automatically synthesize high-quality, self-contained task descriptions from raw pull requests and their associated test suites. By grounding the narrative in executable unit tests, the PSWA ensures semantic alignment between the problem specification and unit tests, thereby producing well-posed and tractable software engineering tasks.
Role Formulation. The core function of the PSWA is to generate a formal problem statement free of solution leakage according to pull request metadata and its corresponding test suite. This process can be expressed as:
$$
\mathcal{S}=\text{PSWA}(\mathcal{M},\mathcal{U},\mathcal{R},\mathcal{D}_{\text{final}}), \tag{3}
$$
where $\mathcal{M}$ denotes the input PR metadata—including its title, description, and diff patches—that provides initial contextual grounding; $\mathcal{U}$ is the executable unit-test suite generated by the UCA, which ensures the problem statement aligns with the actual validation requirements; $\mathcal{R}$ is the associated source repository; $\mathcal{D}_{\text{final}}$ is the functional Docker environment built by the EBA; and $\mathcal{S}$ is the resulting formal problem description that articulates the issue without exposing implementation details and consistent with unit-test at the same time.
Construction Process. Relying solely on raw PR descriptions as problem statements is fundamentally flawed due to their retrospective nature—they are often written after the fix is implemented and may leak solution details or reference internal artifacts. Moreover, a significant portion of high-quality PRs lack descriptions or are disconnected from original issue reports. To overcome these limitations, the PSWA is initialized with both the PR metadata and the executable unit tests produced by the UCA. Integrating the test suite into the prompt is critical because F2P tests may invoke functions or classes that do not exist in the original codebase; the generated problem statement must explicitly articulate these requirements to make the task tractable. Without this alignment, descriptions derived only from PR metadata often diverge from the actual failures captured by the tests. The agent thus synthesizes a coherent, self-contained narrative that specifies the expected behavior, any new interfaces required by the tests, and the context necessary for an external solver—all while deliberately omitting hints about the implementation. This process ensures that each synthesized task instance is both semantically precise and evaluation-ready, scaling the creation of SWE-bench-style problems from raw repository data.
For PSWA, we employ Gemini3-Pro, as our experiments indicate that it generates more consistent and rigorous problem statements while significantly minimizing information leakage.
Table 1: Detailed statistics of the Scale-SWE dataset. We report the mean and percentiles (P50, P75, P95) for code modification metrics and test case distributions.
| Metric | Mean | P50 | P75 | P95 |
| --- | --- | --- | --- | --- |
| Modified Files | 6.4 | 3.0 | 6.0 | 18.0 |
| Deleted Lines | 54.9 | 1.0 | 10.0 | 119.0 |
| Added Lines | 220.8 | 43.0 | 120.0 | 595.0 |
| Edited Lines | 37.0 | 6.0 | 20.0 | 108.0 |
| Total Changes | 312.7 | 63.0 | 167.0 | 867.0 |
| Fail-to-Pass | 5.7 | 2.0 | 5.0 | 15.0 |
| Pass-to-Pass | 209.0 | 68.0 | 178.0 | 793.0 |
| Total tests | 214.7 | 72.0 | 185.0 | 801.7 |
2.2 Data Processing
Ensuring high data quality is the foremost priority in building a reliable dataset. This section details our curation methodology to achieve this goal.
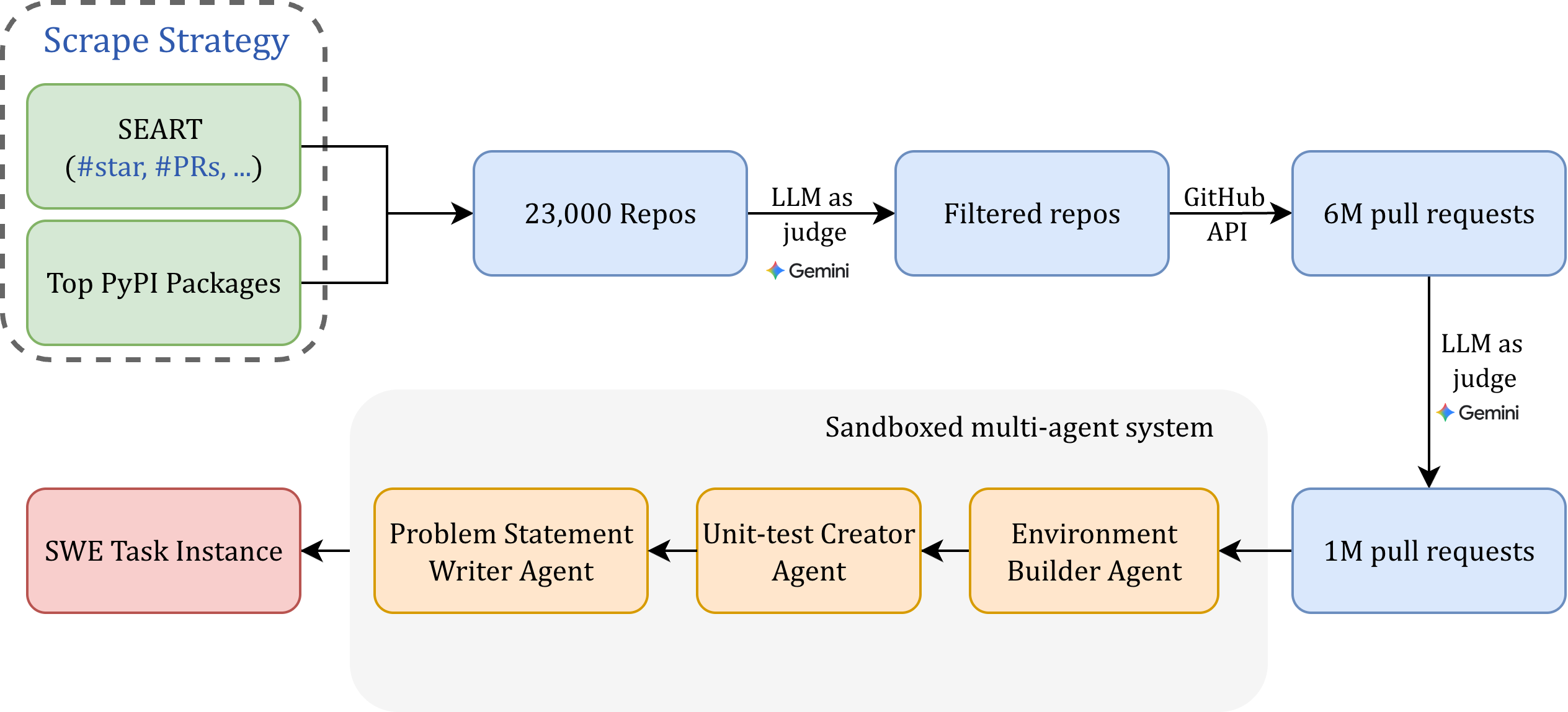
Repository Selection. To assemble a comprehensive and high-quality corpus, we sourced repositories from two primary channels, illustrated in Figure 5. First, we identified the repositories corresponding to the top 15,000 most-downloaded packages on the Python Package Index (PyPI), using data from Top PyPI Packages. Second, to capture notable projects beyond PyPI, we queried the SEART search engine with the following criteria: primary language as Python, a minimum of 5 contributors, at least 500 stars, and a creation date between January 1, 2015, and October 29, 2025. This query returned 9,062 repositories. The initial union of these two sources yielded approximately 23,000 candidate repositories. We then applied a multi-stage filtering pipeline. First, to prevent data leakage from the evaluation benchmark, we excluded all PRs originating from repositories listed in SWE-Bench Verified. Second, we filtered to include only repositories with permissive open-source licenses. Finally, recognizing that a subset of repositories might be GPU-dependent, tutorial-based, or contain minimal source code, we performed a content-based filter. We extracted the README files from all remaining candidates and employed an LLM-as-a-judge approach to automatically exclude repositories deemed unsuitable for training.
Pull Request Filtering. We next extracted all pull requests merged into the “main” or “master” branches of the filtered repositories, resulting in a preliminary set of 6 million entries. To ensure quality, we utilized an LLM-as-a-judge to filter low-quality instances based on the available metadata: the git diff, the pull request description, and the merge commit message.
Cheating Prevention. During the evaluation phase, it is imperative to prevent the model from exploiting git commands (e.g., git log --all) to access ground truth solutions [Xiao et al., 2026]. To address this, we execute a sanitization script immediately after initializing the task environment. This process, systematically removes metadata that follows the task’s parent commit. It performs a hard reset, deletes all remote references and tags, and purges internal git files (e.g., logs/, packed-refs, and various HEAD files), thereby eliminating any trace of future solution history.
<details>
<summary>figures/dataset_comparison_icml.png Details</summary>
### Visual Description
\n
## Bar Chart: Software Error Distribution Across Benchmarks
### Overview
This bar chart displays the distribution of different types of software errors across four benchmarks: SWE-Bench-Verified, SWE-Gym, SWE-smith, and Scale-SWE. The y-axis represents the percentage of errors, ranging from 0% to 60%. Each benchmark has a set of bars, each representing a specific error type.
### Components/Axes
* **X-axis:** Benchmarks - SWE-Bench-Verified, SWE-Gym, SWE-smith, Scale-SWE
* **Y-axis:** Percentage (%) - Scale from 0% to 60% with increments of 10%.
* **Legend (Top-Right):**
* API Mismatch (Blue)
* Input/Boundary (Orange)
* Import Error (Purple)
* Mutability (Pink)
* I/O Resource (Yellow)
* Logic Error (Brown)
* Constructor (Red)
* State Sync (Gray)
* Spec Violation (Green)
* Security (Teal)
### Detailed Analysis
The chart consists of four groups of bars, one for each benchmark. Within each group, there are ten bars, each representing a different error type.
**SWE-Bench-Verified:**
* API Mismatch: Approximately 12%
* Input/Boundary: Approximately 42%
* Import Error: Approximately 2%
* Mutability: Approximately 2%
* I/O Resource: Approximately 10%
* Logic Error: Approximately 10%
* Constructor: Approximately 2%
* State Sync: Approximately 4%
* Spec Violation: Approximately 8%
* Security: Approximately 10%
**SWE-Gym:**
* API Mismatch: Approximately 22%
* Input/Boundary: Approximately 36%
* Import Error: Approximately 2%
* Mutability: Approximately 2%
* I/O Resource: Approximately 2%
* Logic Error: Approximately 4%
* Constructor: Approximately 2%
* State Sync: Approximately 2%
* Spec Violation: Approximately 20%
* Security: Approximately 10%
**SWE-smith:**
* API Mismatch: Approximately 2%
* Input/Boundary: Approximately 2%
* Import Error: Approximately 4%
* Mutability: Approximately 2%
* I/O Resource: Approximately 2%
* Logic Error: Approximately 2%
* Constructor: Approximately 2%
* State Sync: Approximately 2%
* Spec Violation: Approximately 60%
* Security: Approximately 2%
**Scale-SWE:**
* API Mismatch: Approximately 20%
* Input/Boundary: Approximately 10%
* Import Error: Approximately 8%
* Mutability: Approximately 2%
* I/O Resource: Approximately 2%
* Logic Error: Approximately 2%
* Constructor: Approximately 2%
* State Sync: Approximately 2%
* Spec Violation: Approximately 20%
* Security: Approximately 20%
### Key Observations
* **Input/Boundary errors** are consistently high across all benchmarks, particularly in SWE-Bench-Verified and SWE-Gym.
* **Spec Violation** dominates the error distribution in SWE-smith, accounting for approximately 60% of the errors.
* **API Mismatch** is most prominent in Scale-SWE, reaching approximately 20%.
* **Import Error, Mutability, I/O Resource, Logic Error, Constructor, and State Sync** errors are generally low across all benchmarks, typically below 10%.
### Interpretation
The chart reveals significant differences in the types of errors prevalent in different software benchmarks. The high prevalence of Input/Boundary errors across all benchmarks suggests a common weakness in handling input validation and boundary conditions. The dominance of Spec Violation errors in SWE-smith indicates that this benchmark may be particularly sensitive to deviations from specified behavior. The varying distribution of API Mismatch and Security errors suggests that these issues are more specific to certain benchmarks or software contexts.
The data suggests that error profiles are benchmark-specific. This implies that different benchmarks test different aspects of software quality and robustness. The chart could be used to prioritize testing and code review efforts based on the error patterns observed in each benchmark. For example, focusing on input validation for SWE-Bench-Verified and SWE-Gym, and on specification adherence for SWE-smith. The relatively low occurrence of certain error types (e.g., Mutability, State Sync) might indicate that existing development practices or tools are effective in preventing these issues.
</details>
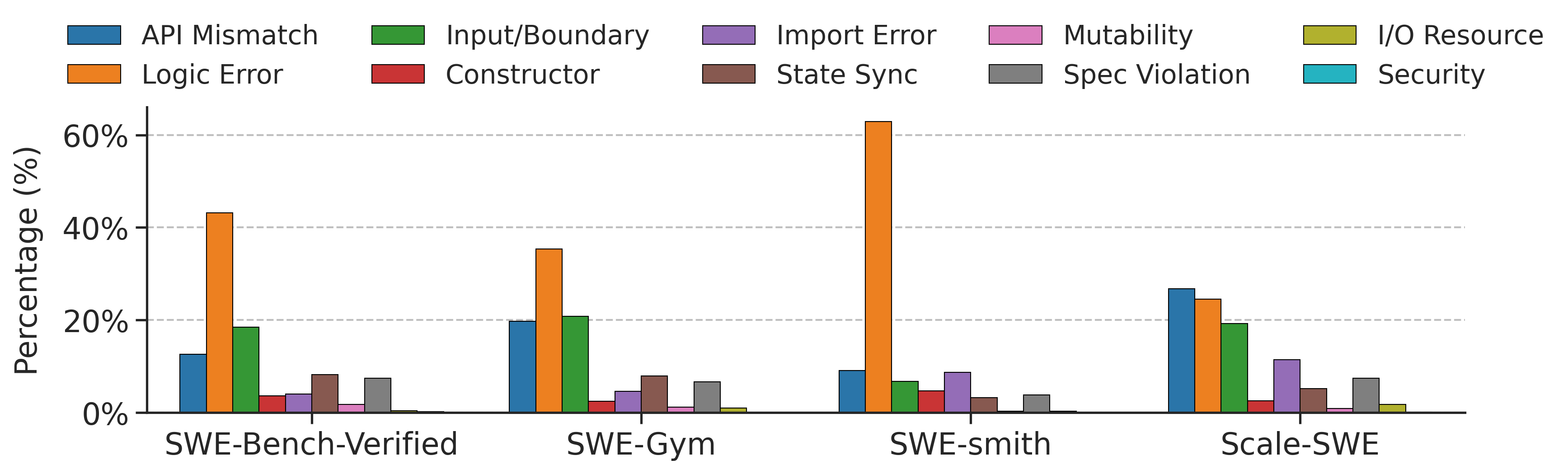
Figure 3: Distribution of bug categories across different datasets. The bar chart compares the percentage of ten bug types within SWE-bench Verified, SWE-Gym, SWE-smith, and Scale-SWE. The categories are defined as: API Mismatch (incompatible signatures or parameter errors); Logic Error (flawed conditionals or control flow); Input/Boundary (edge case mishandling or validation failures); Constructor (object initialization errors); Import Error (missing modules or undefined symbols); State Sync (inconsistent internal state); Mutability (unintended side effects); Spec Violation (non-compliance with protocols); I/O Resource (file system or stream errors); and Security (improper scoping or access control).
2.3 Dataset Quality Assurance
Rule-based Check. We implemented a rigorous filtering protocol based on test outcomes. We retained only those instances where: (1) all P2P tests pass and F2P tests fail on the original buggy codebase; and (2) all P2P and F2P tests pass upon application of the golden patch.
Expert Check. We engaged four senior Ph.D. students to manually audit 100 randomly sampled instances employing a cross-validation protocol. The audit confirmed that 94 instances were valid, featuring correct environments, unit tests, and problem statements. We attribute this high quality to three key factors: (1) We leveraged state-of-the-art models (e.g., Gemini 3 Pro) to synthesize accurate problem statements; (2) We employed an LLM-as-a-Judge approach to preemptively discard low-quality repositories and pull requests; and (3) We enforced a fixed execution order for P2P and F2P tests to prevent test pollution, where varying execution orders could otherwise lead to inconsistent results due to environment contamination.
2.4 Dataset Statistics and Trajectory Distillation
Ultimately, our agent-based construction pipeline yielded 100k successfully verified instances—the largest verified SWE benchmark to date. Leveraging our extensive collection of GitHub repositories, the resulting dataset achieves substantially greater repository diversity than existing SWE benchmarks, as detailed in Table 2. Unlike previous datasets that typically rely on synthetic generation or limited real-world sources, Scale-SWE is constructed entirely from 5.2k real repositories. This represents a 50% increase in repository count over the next largest real-world benchmark (SWE-rebench with 3.5k repositories). This scale and diversity ensure that our benchmark better reflects the complexity and variety of real-world software engineering tasks.
The statistical characteristics of Scale-SWE are presented in Table 1. The dataset presents non-trivial software engineering challenges. The median instance requires modifications to at least 3 files and the addition of 43 lines of code, reflecting the task complexity. For evaluation robustness, instances contain an average of over 200 Pass-to-Pass (P2P) tests (median: 68), providing strong protection against regression, while an average of 5.69 Fail-to-Pass (F2P) tests per instance validates whether the LLM successfully resolves the specific issue.
To construct the training corpus, we distilled agent trajectories from a subset of 25k instances using the high-performance expert model DeepSeek-V3.2. For each instance, we conducted five independent sampling trials with a temperature of 0.95 and a maximum budget of 100 interaction turns. A trajectory was considered valid only if it culminated in a submission that passed all unit tests. This pipeline produced 71k high-quality trajectories totaling approximately 3.5 billion tokens. To ensure a fair comparison, we applied the identical pipeline to collect trajectories for SWE-Smith and SWE-Gym.
Figure 3 highlights the superior diversity of Scale-SWE. Synthetic datasets like SWE-smith exhibit a strong bias towards Logic Errors, failing to capture the intricacies of API Mismatches or State Synchronization issues common in large codebases. Similarly, SWE-Gym, despite being real-world sourced, suffers from low variety due to its restriction to only 11 repositories.
Conversely, Scale-SWE achieves a highly balanced distribution across all ten bug categories. By leveraging 5.2k real-world repositories and an automated environment-building pipeline, Scale-SWE effectively captures a wide array of defect types—from Constructor errors to Security flaws. This validates that scaling the source repositories and automating the execution pipeline are critical for synthesizing training data that faithfully represents real-world software evolution.
We adopt the bug taxonomy proposed in BugPilot [Sonwane et al., 2025] and employ DeepSeek v3.2 to automatically annotate the training instances.
Table 2: Comparison of Scale-SWE with existing software engineering (SWE) benchmarks. We contrast datasets across key dimensions: the number of executable instances—defined as those equipped with a Dockerized environment and validated via Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests—primary data source, repository diversity, and trajectory count.
| Dataset | Exec. instances | Primary Source | Repo. | Traj. |
| --- | --- | --- | --- | --- |
| R2E-Gym [Jain et al., 2025] | 4.6k | Synthetic | 10 | 3.3k |
| SWE-Gym [Pan et al., 2024] | 2.4k | Real | 11 | 491 |
| SWE-smith [Yang et al., 2025a] | 50k | Synthetic | 128 | 5k |
| SWE-Mirror [Wang et al., 2025a] | 60k | Synthetic | 40 | 12k |
| SWE-rebench [Badertdinov et al., 2025] | 7.5k | Real | 3.5k | N/A |
| Scale-SWE | 100k | Real | 5.2k | 71k |
Table 3: Performance comparison on SWE-bench Verified. We categorize models into proprietary systems, open-source methods, and size-matched baselines.
| Models | Base Model | SWE-bench (V) |
| --- | --- | --- |
| Proprietary Models | | |
| GPT-5.2 Thinking [OpenAI, 2025] | - | 80.0 |
| Claude Sonnet 4.5 [Anthropic, 2025b] | - | 77.2 |
| Gemini 3 Pro [Google, 2025] | - | 76.2 |
| MiniMax-M2.1 [MiniMax AI, 2025] | - | 74.0 |
| GLM-4.7 [Zhipu AI, 2025] | - | 73.8 |
| DeepSeek-V3.2 [Liu et al., 2025] | - | 73.1 |
| Kimi K2 Thinking [Team et al., 2025a] | - | 71.3 |
| Open Source Methods | | |
| SWE-Gym-32B [Pan et al., 2024] | Qwen-2.5 coder | 20.6 |
| SWE-Fixer-72B [Xie et al., 2025] | Qwen2.5-72B | 32.8 |
| R2E-Gym-32B [Jain et al., 2025] | Qwen-2.5-Coder | 34.4 |
| SWE-rebench-72B [Golubev et al., 2025] | Qwen2.5-72B-Instruct | 39.0 |
| SWE-smith-32B [Yang et al., 2025a] | Qwen2.5-32B | 40.2 |
| SWE-RL [Wei et al., 2025] | Llama3-70B | 41.0 |
| Skywork-SWE-32B [Zeng et al., 2025] | Qwen2.5-Coder-32B-Instruct | 47.9 |
| SWE-Mirror-LM-32B [Wang et al., 2025a] | Qwen2.5-Coder-32B-Instruct | 52.2 |
| SWE-Lego-32B [Tao et al., 2026] | Qwen3-32B | 52.6 |
| KAT-Dev-32B [Zhan et al., 2025] | - | 62.4 |
| Models of the same size | | |
| Qwen3-30B-A3B-Instruct [Team, 2025] | - | 22.0 |
| Qwen3-Coder-30B-A3B-Instruct [Team, 2025] | - | 51.6 |
| GLM-4.7-Flash-30A3B [Zhipu AI, 2026] | - | 59.2 |
| Our Model | | |
| Scale-SWE-Agent | Qwen3-30B-A3B-Instruct | 64.0 |
3 Experiments
3.1 Experiment Setup
Agent Scaffolding. We employed OpenHands [Wang et al., 2025b], an open-source, event-driven platform, as the unified agent framework for all experiments. OpenHands facilitates LLM agents to iteratively edit files, execute shell commands, and browse the web within sandboxed containers. We selected this framework due to its proven ability to establish robust and reproducible baselines on benchmarks such as SWE-Bench.
Agent Post-training. We perform post-training on the Qwen3-30B-A3B-Instruct [Team, 2025] base model. The training process is configured with a learning rate of 1e-5, a batch size of 128, and a warmup ratio of 0.05, supporting a maximum context length of 131,072. Also, we apply loss masking to restrict loss computation solely to assistant turns that result in well-formed actions [Team et al., 2025b, Chen et al., 2025].
Evaluation Benchmarks and Metrics Our evaluation is conducted on SWE-bench Verified [Chowdhury et al., 2024], a benchmark comprising 500 high-quality, human-curated Python software issues. We report the Resolved Rate (%), representing the proportion of instances for which the model generates a correct solution. Notably, although the models were trained with a sequence length of 131,072, we extended the context limit to 262,144 during inference to handle larger inputs.
3.2 Experiment Results
As shown in Table 3, the Scale-SWE Agent demonstrates superior performance on the SWE-bench Verified. First, regarding the impact of our scaling strategy, Scale-SWE Agent achieves a remarkable 42.0% absolute improvement over its base model, Qwen3-30B-A3B-Instruct, boosting the pass rate from 22.0% to 64.0%. Second, in comparison to models of the same size, our method significantly outperforms strong competitors, including Qwen3-Coder (51.6%) and GLM-4.7-Flash (59.2%). Furthermore, Scale-SWE Agent exhibits exceptional efficiency, surpassing models with significantly larger parameter counts, such as SWE-RL (Llama3-70B) and SWE-Fixer-72B. Notably, it also exceeds the previous state-of-the-art open-source method, KAT-Dev-32B (62.4%), and outperforms recent specialist models like SWE-Mirror and SWE-Lego by a margin of over 11%. These results validate the effectiveness of scaling up SWE-style data for enhancing software engineering capabilities.
<details>
<summary>figures/merge_traj_stat.drawio.png Details</summary>
### Visual Description
## Density Plots: Token Count & Turns (Tool Call)
### Overview
The image presents two density plots, stacked vertically. The top plot visualizes the distribution of "Token Count" for three different models: SWE-Gym, SWE-smith, and Scale-SWE. The bottom plot shows the distribution of "Turns (tool call)" for the same three models. Both plots use density as the y-axis and display the frequency of values along the x-axis.
### Components/Axes
**Top Plot:**
* **X-axis:** "Token Count" ranging from 0 to 120k (120,000), with tick marks at 20k, 40k, 60k, 80k, 100k, and 120k.
* **Y-axis:** "Density" ranging from 0 to approximately 3.2 x 10^-5.
* **Legend (top-right):**
* Blue: SWE-Gym
* Orange: SWE-smith
* Green: Scale-SWE
**Bottom Plot:**
* **X-axis:** "Turns (tool call)" ranging from 0 to 100, with tick marks at 20, 40, 60, 80, and 100.
* **Y-axis:** "Density" ranging from 0 to approximately 2.3 x 10^-2.
* **Legend (top-right):**
* Blue: SWE-Gym
* Orange: SWE-smith
* Green: Scale-SWE
### Detailed Analysis or Content Details
**Top Plot (Token Count):**
* **SWE-Gym (Blue):** The density peaks sharply around 18k-22k tokens. The distribution is heavily skewed to the right, with a long tail extending to approximately 60k tokens, but with very low density beyond that.
* **SWE-smith (Orange):** The density peaks around 28k-32k tokens. The distribution is also skewed to the right, but less so than SWE-Gym. The tail extends further, with some density observed up to 120k tokens, though it is minimal.
* **Scale-SWE (Green):** The density peaks broadly between 35k and 50k tokens. This distribution is the most spread out of the three, with a relatively flat tail extending to 120k tokens.
**Bottom Plot (Turns (tool call)):**
* **SWE-Gym (Blue):** The density peaks sharply around 15-20 turns. The distribution drops off quickly after 30 turns, with very low density beyond 40 turns.
* **SWE-smith (Orange):** The density peaks around 20-25 turns. The distribution is broader than SWE-Gym, with a noticeable density extending to approximately 40-50 turns.
* **Scale-SWE (Green):** The density peaks very weakly around 10-15 turns, and then rises again to a peak around 40-50 turns. This distribution is bimodal, with a significant density between 40 and 80 turns.
### Key Observations
* SWE-Gym generally uses fewer tokens and fewer turns than the other two models.
* Scale-SWE exhibits the widest range of token counts and a bimodal distribution of turns, suggesting more variability in its behavior.
* SWE-smith falls between SWE-Gym and Scale-SWE in terms of both token count and turns.
* The distributions for both Token Count and Turns are right-skewed for SWE-Gym and SWE-smith, indicating that a small number of instances require significantly more tokens/turns.
### Interpretation
These density plots likely represent the performance characteristics of three different language models (SWE-Gym, SWE-smith, and Scale-SWE) on a specific task. The "Token Count" plot indicates the length of the input/output sequences processed by each model, while the "Turns (tool call)" plot indicates the number of interactions required to complete the task.
The data suggests that SWE-Gym is the most efficient model in terms of both token usage and the number of turns required. However, Scale-SWE demonstrates greater variability, potentially indicating a more complex or adaptable behavior. The bimodal distribution of turns for Scale-SWE could suggest that it sometimes requires a significantly different approach to solve the task, leading to a second peak in the distribution.
The differences in distributions could be due to variations in model architecture, training data, or the specific task being performed. Further investigation would be needed to determine the underlying causes of these differences and to assess the trade-offs between efficiency and adaptability. The right skewness in the token count suggests that some inputs require significantly more processing than others, which could be a point of optimization.
</details>
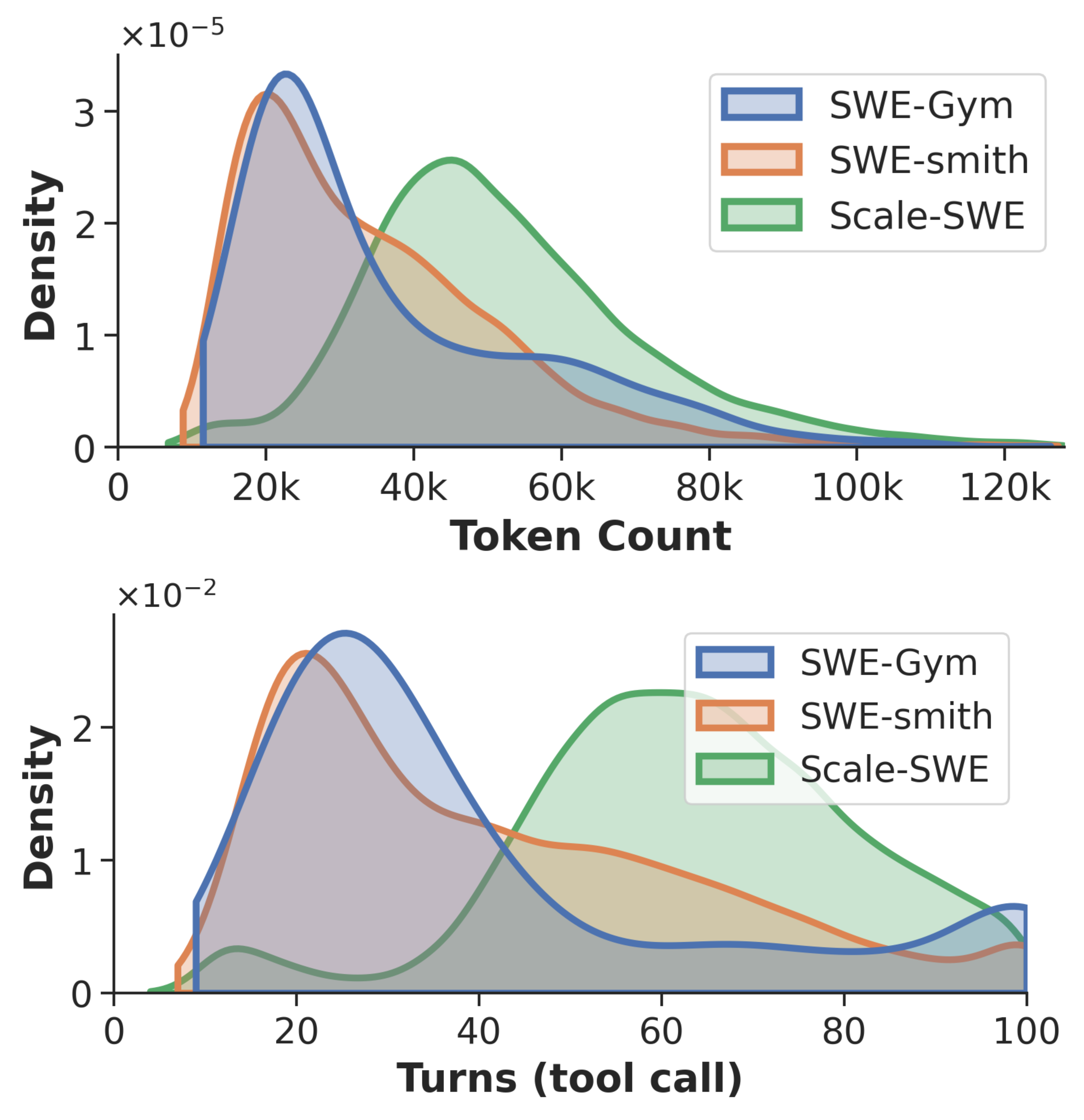
Figure 4: Comparison of distillation data statistics across different datasets. We show the probability density functions for (top) total token count and (bottom) the number of tool-call turns.
To evaluate the efficacy of our data compared to existing alternatives, we conducted controlled experiments by performing distillation and SFT on SWE-Gym and SWE-smith using an identical pipeline. As shown in Table 4, Scale-SWE significantly outperforms both baselines. Notably, despite SWE-smith possessing a considerably larger volume of instances than SWE-Gym, it yields slightly inferior performance. This performance gap suggests a diminishing return on purely synthetic data and underscores a critical insight: high-fidelity, real-world data is inherently more effective than massive-scale synthetic alternatives. This finding reinforces the importance of our large-scale “real-data” construction approach.
The distributions of interaction turns and token counts are presented in Figure 4. As illustrated in these figures, Scale-SWE tasks necessitate a greater number of turns for repository exploration and iterative debugging. This observation underscores the high complexity and difficulty inherent in the Scale-SWE dataset.
Table 4: SFT performance comparison on SWE-bench Verified. All models are fine-tuned using the same distillation pipeline to ensure a fair comparison.
| Dataset Name | SWE-bench Verified |
| --- | --- |
| SWE-Gym | 54.8 |
| SWE-smith | 54.6 |
| Scale-SWE | 64.0 |
4 Related Work
SWE Benchmark. Since the introduction of the prevailing software engineering benchmark, SWE-bench [Jimenez et al., 2023] and SWE-bench-Verified [Chowdhury et al., 2024], many other benchmarks have emerged to assess multi-modal [Yang et al., 2024b], multi-language [Zan et al., 2025b, Rashid et al., 2025, Guo et al., 2025a], and long-horizon capabilities [Deng et al., 2025]. These new benchmarks also evaluate whole repository generation [Ding et al., 2025], scientific domain knowledge [Duston et al., 2025], and other specialized abilities [Ma et al., 2025, Shetty et al., 2025]. Collectively, these benchmarks constitute a comprehensive evaluation ecosystem, establishing rigorous standards that assess the multifaceted capabilities required for autonomous software engineering.
SWE Datasets. High-quality data is pivotal for enhancing the programming capabilities of Large Language Models (LLMs). Recently, there has been a surge in repository-level software engineering datasets aimed at addressing complex coding tasks. Efforts to scale up SWE task instances generally fall into two categories. One line of work, including R2E-Gym [Jain et al., 2025], SWE-smith [Yang et al., 2025a], and SWE-Mirror [Wang et al., 2025a], attempts to scale up training data through synthetic generation. Conversely, other works focus on mining real-world issues; for instance, SWE-Gym [Pan et al., 2024] constructed 2,400 executable instances restricted to 11 repositories, while SWE-rebench [Badertdinov et al., 2025] further expanded this collection to 7,500 executable instances.
SWE Models and Agents. Recent advancements have introduced powerful models specialized for SWE tasks, including SWE-RL [Wei et al., 2025], SWE-Swiss [He et al., 2025], Kimi-Dev [Yang et al., 2025b], and KAT-Coder [Zhan et al., 2025]. In parallel, frameworks such as SWE-agent [Yang et al., 2024a], Mini-SWE-Agent [Yang et al., 2024a], OpenHands [Wang et al., 2025b], and MOpenHands [Zan et al., 2025a] serve as effective scaffolds to streamline interactions with development environments.
5 Conclusion
In this work, we introduced Scale-SWE, a sandboxed multi‑agent framework that automates the construction of large‑scale, high‑quality software engineering data along with executable environments. By orchestrating specialized agents for environment setup, unit‑test generation, and task description synthesis, we processed six million real‑world pull requests to produce Scale-SWE-Data—a dataset of 100,000 instances that surpasses existing datasets in both scale and repository diversity. We further demonstrated the practical value of the dataset by distilling high‑quality trajectories and fine‑tuning Qwen3‑30B-A3B-Instruct to create Scale-SWE-Agent, which achieves substantial improvements on SWE‑Bench‑Verified—increasing the resolve rate from 22% to 64%. This advancement underscores the quality and utility of our data for training more capable code agents. We believe Scale-SWE opens new avenues for scalable SWE‑style dataset construction and provides a rich, open‑access resource to support the development of more capable LLM‑based software engineering agents. In future work, we aim to not only increase the volume of training data to fully leverage the potential of Scale-SWE-Data but also significantly broaden its linguistic scope. Specifically, we plan to extend our pipeline to support other major programming languages—such as Java, C, C++, and Rust—thereby fostering the development of truly language-agnostic software engineering agents.
References
- Anthropic [2025a] Anthropic. Introducing Claude Sonnet 4.5, Sept. 2025a. URL https://www.anthropic.com/news/claude-sonnet-4-5.
- Anthropic [2025b] Anthropic. Announcing Claude Sonnet 4.5, 2025b. URL https://www.anthropic.com/news/claude-sonnet-4-5. Accessed: 2025-09-30.
- Badertdinov et al. [2025] I. Badertdinov, A. Golubev, M. Nekrashevich, A. Shevtsov, S. Karasik, A. Andriushchenko, M. Trofimova, D. Litvintseva, and B. Yangel. Swe-rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents. arXiv preprint arXiv:2505.20411, 2025.
- Chen et al. [2025] G. Chen, Z. Qiao, X. Chen, D. Yu, H. Xu, W. X. Zhao, R. Song, W. Yin, H. Yin, L. Zhang, et al. Iterresearch: Rethinking long-horizon agents via markovian state reconstruction. arXiv preprint arXiv:2511.07327, 2025.
- Chowdhury et al. [2024] N. Chowdhury, J. Aung, C. J. Shern, O. Jaffe, D. Sherburn, G. Starace, E. Mays, R. Dias, M. Aljubeh, M. Glaese, C. E. Jimenez, J. Yang, L. Ho, T. Patwardhan, K. Liu, and A. Madry. Introducing SWE-bench verified, 2024. URL https://openai.com/index/introducing-swe-bench-verified/. OpenAI Blog Post.
- Deng et al. [2025] X. Deng, J. Da, E. Pan, Y. Y. He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks? arXiv preprint arXiv:2509.16941, 2025.
- Ding et al. [2025] J. Ding, S. Long, C. Pu, H. Zhou, H. Gao, X. Gao, C. He, Y. Hou, F. Hu, Z. Li, et al. Nl2repo-bench: Towards long-horizon repository generation evaluation of coding agents. arXiv preprint arXiv:2512.12730, 2025.
- Duston et al. [2025] T. Duston, S. Xin, Y. Sun, D. Zan, A. Li, S. Xin, K. Shen, Y. Chen, Q. Sun, G. Zhang, et al. Ainsteinbench: Benchmarking coding agents on scientific repositories. arXiv preprint arXiv:2512.21373, 2025.
- Froger et al. [2025] R. Froger, P. Andrews, M. Bettini, A. Budhiraja, R. S. Cabral, V. Do, E. Garreau, J.-B. Gaya, H. Laurençon, M. Lecanu, et al. Are: Scaling up agent environments and evaluations. arXiv preprint arXiv:2509.17158, 2025.
- Golubev et al. [2025] A. Golubev, M. Trofimova, S. Polezhaev, I. Badertdinov, M. Nekrashevich, A. Shevtsov, S. Karasik, S. Abramov, A. Andriushchenko, F. Fisin, et al. Training long-context, multi-turn software engineering agents with reinforcement learning. arXiv preprint arXiv:2508.03501, 2025.
- Google [2025] Google. Gemini 3 pro, 2025. URL https://deepmind.google/models/gemini/pro/.
- Guo et al. [2025a] L. Guo, W. Tao, R. Jiang, Y. Wang, J. Chen, X. Liu, Y. Ma, M. Mao, H. Zhang, and Z. Zheng. Omnigirl: A multilingual and multimodal benchmark for github issue resolution. Proceedings of the ACM on Software Engineering, 2(ISSTA):24–46, 2025a.
- Guo et al. [2025b] L. Guo, Y. Wang, C. Li, P. Yang, J. Chen, W. Tao, Y. Zou, D. Tang, and Z. Zheng. Swe-factory: Your automated factory for issue resolution training data and evaluation benchmarks. arXiv preprint arXiv:2506.10954, 2025b. URL https://arxiv.org/abs/2506.10954.
- He et al. [2025] Z. He, Q. Yang, W. Sheng, X. Zhong, K. Zhang, C. An, W. Shi, T. Cai, D. He, J. Chen, and J. Xu. Swe-swiss: A multi-task fine-tuning and rl recipe for high-performance issue resolution, 2025. Notion Blog.
- Jain et al. [2025] N. Jain, J. Singh, M. Shetty, L. Zheng, K. Sen, and I. Stoica. R2e-gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents. arXiv preprint arXiv:2504.07164, 2025.
- Jimenez et al. [2023] C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023.
- Liu et al. [2025] A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556, 2025.
- Ma et al. [2025] J. J. Ma, M. Hashemi, A. Yazdanbakhsh, K. Swersky, O. Press, E. Li, V. J. Reddi, and P. Ranganathan. Swe-fficiency: Can language models optimize real-world repositories on real workloads? arXiv preprint arXiv:2511.06090, 2025.
- MiniMax AI [2025] MiniMax AI. Multilingual and Multi-Task Coding with Strong Generalization: A Look at MiniMax-M2.1. Hugging Face Blog, 2025. URL https://huggingface.co/blog/MiniMaxAI/multilingual-and-multi-task-coding-with-strong-gen. Accessed: 2025-12-23.
- OpenAI [2025] OpenAI. Introducing GPT-5.2, Dec. 2025. URL https://openai.com/index/introducing-gpt-5-2/.
- Pan et al. [2024] J. Pan, X. Wang, G. Neubig, N. Jaitly, H. Ji, A. Suhr, and Y. Zhang. Training software engineering agents and verifiers with swe-gym. arXiv preprint arXiv:2412.21139, 2024.
- Rashid et al. [2025] M. S. Rashid, C. Bock, Y. Zhuang, A. Buchholz, T. Esler, S. Valentin, L. Franceschi, M. Wistuba, P. T. Sivaprasad, W. J. Kim, et al. Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents. arXiv preprint arXiv:2504.08703, 2025.
- Shetty et al. [2025] M. Shetty, N. Jain, J. Liu, V. Kethanaboyina, K. Sen, and I. Stoica. Gso: Challenging software optimization tasks for evaluating swe-agents. arXiv preprint arXiv:2505.23671, 2025.
- Sonwane et al. [2025] A. Sonwane, I. White, H. Lee, M. Pereira, L. Caccia, M. Kim, Z. Shi, C. Singh, A. Sordoni, M.-A. Côté, et al. Bugpilot: Complex bug generation for efficient learning of swe skills. arXiv preprint arXiv:2510.19898, 2025.
- Tao et al. [2026] C. Tao, J. Chen, Y. Jiang, K. Kou, S. Wang, R. Wang, X. Li, S. Yang, Y. Du, J. Dai, et al. Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving. arXiv preprint arXiv:2601.01426, 2026.
- Team et al. [2025a] K. Team, Y. Bai, Y. Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y. Chen, Y. Chen, Y. Chen, et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534, 2025a.
- Team [2025] Q. Team. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388.
- Team et al. [2025b] T. D. Team, B. Li, B. Zhang, D. Zhang, F. Huang, G. Li, G. Chen, H. Yin, J. Wu, J. Zhou, et al. Tongyi deepresearch technical report. arXiv preprint arXiv:2510.24701, 2025b.
- Wang et al. [2025a] J. Wang, D. Zan, S. Xin, S. Liu, Y. Wu, and K. Shen. Swe-mirror: Scaling issue-resolving datasets by mirroring issues across repositories. arXiv preprint arXiv:2509.08724, 2025a.
- Wang et al. [2025b] X. Wang, S. Rosenberg, J. Michelini, C. Smith, H. Tran, E. Nyst, R. Malhotra, X. Zhou, V. Chen, R. Brennan, et al. The openhands software agent sdk: A composable and extensible foundation for production agents. arXiv preprint arXiv:2511.03690, 2025b.
- Wei et al. [2025] Y. Wei, O. Duchenne, J. Copet, Q. Carbonneaux, L. Zhang, D. Fried, G. Synnaeve, R. Singh, and S. I. Wang. Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution. arXiv preprint arXiv:2502.18449, 2025.
- Xiao et al. [2026] B. Xiao, B. Xia, B. Yang, B. Gao, B. Shen, C. Zhang, C. He, C. Lou, F. Luo, G. Wang, et al. Mimo-v2-flash technical report. arXiv preprint arXiv:2601.02780, 2026.
- Xie et al. [2025] C. Xie, B. Li, C. Gao, H. Du, W. Lam, D. Zou, and K. Chen. Swe-fixer: Training open-source llms for effective and efficient github issue resolution. arXiv preprint arXiv:2501.05040, 2025.
- Yang et al. [2024a] J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37:50528–50652, 2024a.
- Yang et al. [2024b] J. Yang, C. E. Jimenez, A. L. Zhang, K. Lieret, J. Yang, X. Wu, O. Press, N. Muennighoff, G. Synnaeve, K. R. Narasimhan, et al. Swe-bench multimodal: Do ai systems generalize to visual software domains? arXiv preprint arXiv:2410.03859, 2024b.
- Yang et al. [2025a] J. Yang, K. Lieret, C. E. Jimenez, A. Wettig, K. Khandpur, Y. Zhang, B. Hui, O. Press, L. Schmidt, and D. Yang. Swe-smith: Scaling data for software engineering agents. arXiv preprint arXiv:2504.21798, 2025a.
- Yang et al. [2025b] Z. Yang, S. Wang, K. Fu, W. He, W. Xiong, Y. Liu, Y. Miao, B. Gao, Y. Wang, Y. Ma, et al. Kimi-dev: Agentless training as skill prior for swe-agents. arXiv preprint arXiv:2509.23045, 2025b.
- Zan et al. [2025a] D. Zan, Z. Huang, W. Liu, H. Chen, L. Zhang, S. Xin, L. Chen, Q. Liu, X. Zhong, A. Li, S. Liu, Y. Xiao, L. Chen, Y. Zhang, J. Su, T. Liu, R. Long, K. Shen, and L. Xiang. Multi-swe-bench: A multilingual benchmark for issue resolving, 2025a. URL https://arxiv.org/abs/2504.02605.
- Zan et al. [2025b] D. Zan, Z. Huang, W. Liu, H. Chen, L. Zhang, S. Xin, L. Chen, Q. Liu, X. Zhong, A. Li, et al. Multi-swe-bench: A multilingual benchmark for issue resolving. arXiv preprint arXiv:2504.02605, 2025b.
- Zeng et al. [2025] L. Zeng, Y. Li, Y. Xiao, C. Li, C. Y. Liu, R. Yan, T. Wei, J. He, X. Song, Y. Liu, et al. Skywork-swe: Unveiling data scaling laws for software engineering in llms. arXiv preprint arXiv:2506.19290, 2025.
- Zhan et al. [2025] Z. Zhan, K. Deng, J. Wang, X. Zhang, H. Tang, M. Zhang, Z. Lai, H. Huang, W. Xiang, K. Wu, et al. Kat-coder technical report. arXiv preprint arXiv:2510.18779, 2025.
- Zhang et al. [2025] L. Zhang, S. He, C. Zhang, Y. Kang, B. Li, C. Xie, J. Wang, M. Wang, Y. Huang, S. Fu, et al. Swe-bench goes live! arXiv preprint arXiv:2505.23419, 2025.
- Zhipu AI [2025] Zhipu AI. GLM-4.7: Technical Blog. Zhipu AI Blog, 2025. URL https://z.ai/blog/glm-4.7. Accessed: 2025-12-22.
- Zhipu AI [2026] Zhipu AI. GLM-4.7-Flash: Model Repository. Hugging Face, 2026. URL https://huggingface.co/zai-org/GLM-4.7-Flash. Accessed: 2026-01-19.
Appendix A Scale-SWE workflow details.
A.1 Scale-SWE workflow Overview.
<details>
<summary>figures/DataEngineWorkflow.drawio.png Details</summary>
### Visual Description
\n
## Diagram: System Architecture for Software Testing
### Overview
This diagram illustrates the architecture of a system designed for automated software testing, leveraging Large Language Models (LLMs) and GitHub APIs. The system begins with a scraping strategy, filters repositories, and then utilizes LLMs to judge and process pull requests, ultimately feeding into a sandboxed multi-agent system for task execution.
### Components/Axes
The diagram consists of several key components connected by arrows indicating data flow:
* **Scrape Strategy:** Includes "Top PyPI Packages" and "SEART (#star, #PRs, ...)"
* **23,000 Repos:** Represents the initial set of repositories obtained.
* **LLM as judge (Gemini):** An LLM, specifically Gemini, used for initial filtering and judgment.
* **Filtered repos:** The repositories that pass the LLM's initial judgment.
* **GitHub API:** Used to access and retrieve data from GitHub.
* **6M pull requests:** The number of pull requests retrieved from GitHub.
* **Sandboxed multi-agent system:** The core execution environment.
* **Problem Statement Writer Agent:** An agent responsible for formulating problem statements.
* **Unit-test Creator Agent:** An agent responsible for creating unit tests.
* **Environment Builder Agent:** An agent responsible for building the testing environment.
* **SWE Task Instance:** The final output or result of the system.
* **1M pull requests:** The number of pull requests processed within the sandboxed system.
* **LLM as judge (Gemini):** Another instance of the Gemini LLM used for judging within the sandboxed system.
### Detailed Analysis or Content Details
The diagram shows a clear flow of information:
1. The process starts with a "Scrape Strategy" that targets "Top PyPI Packages" and uses "SEART (#star, #PRs, ...)" as a search criteria.
2. This strategy results in the identification of "23,000 Repos".
3. These repositories are then passed to an "LLM as judge (Gemini)" which filters them, resulting in "Filtered repos".
4. The "Filtered repos" are accessed via the "GitHub API", yielding "6M pull requests".
5. These pull requests are then processed by another "LLM as judge (Gemini)", which filters them down to "1M pull requests".
6. The "1M pull requests" are fed into a "Sandboxed multi-agent system" consisting of three agents: "Problem Statement Writer Agent", "Unit-test Creator Agent", and "Environment Builder Agent".
7. These agents work in sequence: Problem Statement -> Unit-test Creation -> Environment Building.
8. The output of this system is a "SWE Task Instance".
### Key Observations
* The system utilizes LLMs (Gemini) at two distinct stages: initial repository filtering and pull request processing.
* There's a significant reduction in the number of pull requests processed (6M -> 1M), indicating a substantial filtering effect by the LLM.
* The sandboxed multi-agent system suggests a modular and potentially parallelized approach to software testing.
* The "SEART (#star, #PRs, ...)" component suggests that the scraping strategy considers the number of stars and pull requests as important metrics.
### Interpretation
This diagram depicts a sophisticated automated software testing pipeline. The use of LLMs for filtering suggests an attempt to prioritize relevant repositories and pull requests, reducing the computational burden on the downstream agents. The sandboxed multi-agent system allows for a division of labor, with each agent specializing in a specific aspect of the testing process. The reduction in pull requests from 6M to 1M indicates the LLM is effectively identifying and discarding irrelevant or low-quality contributions. The overall architecture suggests a focus on scalability and efficiency in automated software testing, leveraging the capabilities of LLMs and the vast resources available on GitHub. The system appears to be designed to automatically generate test cases and environments based on real-world code changes.
</details>
Figure 5: Schematic workflow for automated Scale-SWE task synthesis. From an initial pool of 23k repositories and 6M pull requests, the pipeline utilizes LLM-as-a-judge to filter for quality and relevance. The selected 1M pull requests are then transformed into formal software engineering task instances via a sandboxed orchestration of specialized agents responsible for environment building, test creation, and statement writing.
Appendix B Scale-SWE Task Instance Structure
The structure of a Scale-SWE task instance closely adheres to the SWE-bench standard, with a necessary adaptation to accommodate synthetic data. Specifically, since original developer-written “fail-to-pass” (F2P) tests are not available for all mined instances, we include a field for F2P scripts generated by our unit-test creator agent. A Scale-SWE task instance consists of the following fields:
- instance_id: A unique identifier formatted as {user}_{repo}_pr{id}.
- user: The owner of the GitHub repository.
- repo: The name of the GitHub repository.
- language: The programming language of the codebase (currently Python).
- workdir: The working directory path within the environment.
- image_url: The URL of the pre-built Docker image for the task.
- patch: The ground-truth patch (Golden Patch) from the corresponding pull request.
- pr_commit: The commit hash of the pull request.
- parent_commit: The commit hash of the parent commit (base state).
- problem_statement: The issue description conveying the bug, provided to the model as input.
- f2p_patch: The developer-written test patch containing tests that fail before the fix (if available).
- f2p_script: The synthetic reproduction script generated by our unit-test creator agent (used when f2p_patch is absent).
- FAIL_TO_PASS: A list of unit tests that fail when applied to the buggy version but pass after the fix.
- PASS_TO_PASS: A list of unit tests that pass in both the buggy and fixed versions (regression tests).
- github_url: The URL of the original GitHub repository.
- pre_commands: Commands executed immediately upon entering the container to revert future commit information and prevent data leakage.
Appendix C Implementation Details
The hyperparameters for SFT are detailed in Table 5.
Table 5: Key hyperparameters in the SFT phase.
| Hyperparameter | Value |
| --- | --- |
| Learning Rate | 1e-5 |
| Base model | Qwen3-30B-A3B |
| Batch size | 128 |
| Maximum Context Length | 131,072 |
| Warmup ratio | 0.05 |
| LR scheduler type | Cosine |
| Epoch | 3 |
Appendix D Anti-hack Strategy
To ensure the integrity of the SWE-bench evaluation, we implement an anti-leak strategy to prevent the LLM from accessing ground truth solutions via Git history (e.g., using commands like git log --all). The following sanitization script is executed immediately after initializing the environment container:
⬇
1
2 git clean - fd - e ’*.egg-info’ - e ’.tox’ - e ’.venv’ && git checkout {parent_commit}
3 NEW_BRANCH = "swe_bench_clean_main"
4 CURRENT_HEAD = $ (git rev - parse HEAD)
5 git stash - a
6 git clean - fd
7 git reset -- hard $CURRENT_HEAD
8 git stash pop || echo "No ␣ stash ␣ to ␣ apply ␣ or ␣ conflict ␣ occurred"
9
10 git config user. email "pre-agent@swalm.local" && git config user. name "Pre-Agent" && git add . && git commit - m "pre-agent ␣ commit"
11
12
13 CURRENT_3_PRIME = $ (git rev - parse HEAD)
14
15 git for - each - ref -- format = "%(refname)" refs / remotes / | xargs - I {} git update - ref - d {}
16 git tag - l | xargs - r git tag - d
17
18 rm - f . git / packed - refs
19 rm - f . git / ORIG_HEAD . git / FETCH_HEAD . git / MERGE_HEAD . git / CHERRY_PICK_HEAD . git / refs / stash
20 rm - rf . git / logs /
21
22 git update - ref refs / heads / $ {NEW_BRANCH} $CURRENT_3_PRIME
23 git symbolic - ref HEAD refs / heads / $ {NEW_BRANCH}
24
25 git for - each - ref -- format = "%(refname)" refs / heads / | grep - v "refs/heads/${NEW_BRANCH}" | xargs - I {} git update - ref - d {}
26
27 git gc -- prune = now -- aggressive
Appendix E Prompts in Scale-SWE workflow
Repository filtering prompt
Pull request filtering prompt
Environment builder agent agent
Unit-test creater agent prompt
Problem statement writer agent prompt
Bug type categorization prompt