# Internalizing Meta-Experience into Memory for Guided Reinforcement Learning in Large Language Models
Abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an effective approach for enhancing the reasoning capabilities of Large Language Models (LLMs). Despite its efficacy, RLVR faces a meta-learning bottleneck: it lacks mechanisms for error attribution and experience internalization intrinsic to the human learning cycle beyond practice and verification, thereby limiting fine-grained credit assignment and reusable knowledge formation. We term such reusable knowledge representations derived from past errors as meta-experience. Based on this insight, we propose M eta- E xperience L earning (MEL), a novel framework that incorporates self-distilled meta-experience into the model’s parametric memory. Building upon standard RLVR, we introduce an additional design that leverages the LLM’s self-verification capability to conduct contrastive analysis on paired correct and incorrect trajectories, identify the precise bifurcation points where reasoning errors arise, and summarize them into generalizable meta-experience. The meta-experience is further internalized into the LLM’s parametric memory by minimizing the negative log-likelihood, which induces a language-modeled reward signal that bridges correct and incorrect reasoning trajectories and facilitates effective knowledge reuse. Experimental results demonstrate that MEL achieves consistent improvements on benchmarks, yielding 3.92%–4.73% Pass@1 gains across varying model sizes.
Shiting Huang 1 Zecheng Li 1 Yu Zeng 1 Qingnan Ren 1 Zhen Fang 1 Qisheng Su 1 Kou Shi 1 Lin Chen 1 Zehui Chen 1 Feng Zhao 1 🖂 1 University of Science and Technology of China 🖂: Corresponding Author
1 Introduction
Reinforcement Learning (RL) has emerged as a pivotal paradigm for enhancing the reasoning capabilities of Large Language Models (LLMs) on complex tasks, such as mathematics, programming, and logic reasoning (Shao et al., 2024; Chen et al., 2025; Zeng et al., 2025a; Wang et al., 2025; Zeng et al., 2025b, 2026; Huang et al., 2026). By leveraging feedback signals obtained from interaction with the task environment, RL enables LLMs to move beyond passive imitation learning toward goal-directed reasoning and action (Schulman et al., 2017; Ouyang et al., 2022; Wulfmeier et al., 2024). Furthermore, by replacing learned reward models with programmatically verifiable signals, Reinforcement Learning with Verifiable Rewards (RLVR) eliminates the need for expensive human annotations and mitigates reward hacking, thereby enabling models to explore problem-solving strategies more effectively, which has contributed to its growing attention (Lambert et al., 2024).
However, RLVR still faces a fundamental bottleneck regarding the granularity and utilization of learning signals. From a meta-learning perspective, the human learning cycle involves three critical components: practice and verification, error attribution, and experience internalization. While RLVR primarily drives policy updates through practice and verification, it overlooks the critical stages of error attribution and experience internalization, both of which are essential for fine-grained credit assignment and the formation of reusable knowledge (Wu et al., 2025; Zhang et al., 2025a). In other words, RLVR is largely limited to assessing the overall quality of entire trajectories, while struggling to reason about fine-grained knowledge at the level of intermediate steps (Xie et al., 2025). Although RL approaches (Lightman et al., 2023; Khalifa et al., 2025) employing Process Reward Models (PRMs) to provide dense learning signals attempt to mitigate this limitation, their reliance on trained proxies makes them inherently susceptible to reward hacking (Cheng et al., 2025; Guo et al., 2025), and poses a fundamental tension with the RLVR paradigm, which is centered on programmatically verifiable rewards.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Comparison of Standard RLVR vs. MEL (Ours) Reinforcement Learning Architectures
### Overview
The image compares two reinforcement learning (RL) architectures:
- **(a) Standard RLVR**: A linear decision tree with reward-based feedback (Reward=1/0) and trajectory-level optimization.
- **(b) MEL (Ours)**: A modified architecture with bifurcation points, meta-experience integration, and knowledge-level optimization.
### Components/Axes
1. **Nodes**:
- **Green circles**: Represent states/actions with Reward=1.
- **Red circles**: Represent states/actions with Reward=0.
- **Dashed box**: Highlights a bifurcation point in MEL.
2. **Arrows**:
- **Solid arrows**: Indicate encouragement of trajectory-level optimization (green).
- **Dashed arrows**: Indicate suppression of trajectory-level optimization (red).
- **Dotted arrow**: Connects MEL to "Meta-Experience" (yellow cloud).
3. **Icons**:
- **Robot (a)**: Frowning face with X marks (failure state).
- **Robot (b)**: Smiling face with a lightbulb (success/insight state).
4. **Text Labels**:
- **Standard RLVR (a)**:
- "Encourage Trajectory-Level optimization" (green arrow).
- "Suppress Trajectory-Level optimization" (red arrow).
- **MEL (b)**:
- "Encourage Trajectory-Level optimization" (green arrow).
- "Suppress Trajectory-Level optimization" (red arrow).
- "Meta-Experience (bifurcation point, critique, heuristic)" (yellow cloud).
- "Knowledge-level optimization" (arrow from cloud to robot).
### Detailed Analysis
- **Standard RLVR (a)**:
- Linear flow: Question (Q) → State/Action → Reward feedback (1/0).
- Direct encouragement/suppression of trajectory-level optimization based on rewards.
- Robot icon reflects failure (X marks, sad face).
- **MEL (b)**:
- Bifurcation point introduces meta-experience (critique, heuristic).
- Dotted arrow links meta-experience to knowledge-level optimization.
- Robot icon reflects success (smile, lightbulb).
### Key Observations
1. **Bifurcation in MEL**: The dashed box in (b) introduces a decision point absent in (a), enabling adaptive feedback.
2. **Meta-Experience**: Explicitly modeled in MEL, integrating critique and heuristic reasoning for optimization.
3. **Reward Handling**: Both architectures use Reward=1/0, but MEL adds meta-experience to refine optimization.
4. **Robot Symbolism**: Visual contrast between failure (a) and success (b) emphasizes MEL’s improved outcomes.
### Interpretation
The diagram illustrates how MEL enhances Standard RLVR by:
1. **Incorporating Meta-Experience**: The yellow cloud represents higher-level reasoning (bifurcation, critique, heuristic), enabling the system to learn from past experiences rather than relying solely on immediate rewards.
2. **Knowledge-Level Optimization**: The dotted arrow suggests that meta-experience informs broader, systemic improvements beyond trajectory-specific adjustments.
3. **Adaptive Suppression**: The dashed red arrow in (b) implies dynamic suppression of suboptimal trajectories, guided by meta-experience.
This architecture addresses the limitations of Standard RLVR by introducing hierarchical learning, where meta-experience acts as a feedback loop to refine both trajectory and knowledge-level decisions. The robot icons symbolize the practical outcomes: MEL achieves success through integrated reasoning, while Standard RLVR remains constrained by linear, reward-driven optimization.
</details>
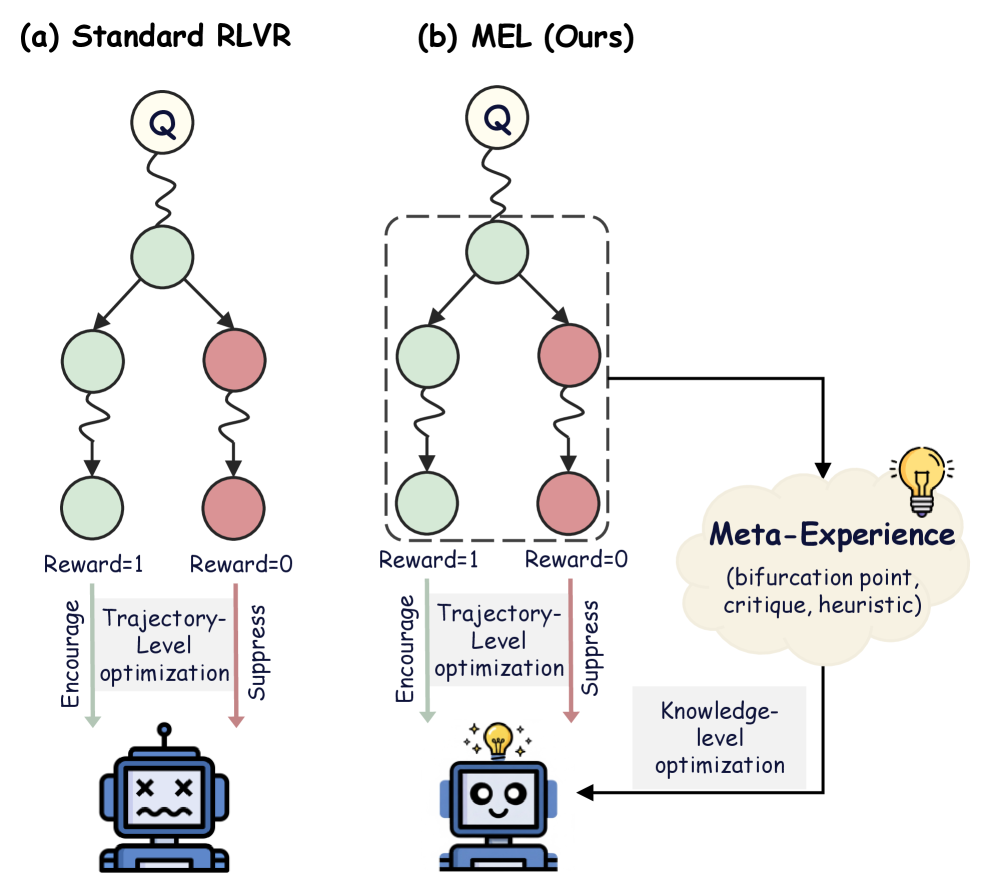
Figure 1: Paradigm comparison between standard RLVR and MEL, where MEL extends RLVR with an explicit knowledge-level learning loop.
Recently, a growing number of studies have explored integrating experience learning within the RLVR framework to address the above challenge. Early attempts, such as StepHint (Zhang et al., 2025c) utilizes experience as hints to elicit superior reasoning paths from the original problems, treating these trajectories as off-policy migration signals. However, the resulting off-policy deviation in response distribution can compromise optimization stability, undermining the theoretical benefits of on-policy reinforcement learning. To alleviate such instability, Scaf-GRPO (Zhang et al., 2025d) leverages superior models to generate multi-level knowledge-intensive experience, injecting them as on-policy prefixes for policy updates. Yet, while effective in teaching models to reason within specific experience-augmented distributions, such prefixes are unavailable during inference, inducing a severe distributional mismatch, thereby limiting performance gains. Critically, despite their differences, these approaches utilize retrieved experience primarily as external hints. While these strategies effectively elicit better reasoning paths during training, the resulting learning signals remain predominantly at the trajectory-level, yielding superficial corrections rather than intrinsic cognitive enhancements.
Building on this insight, we introduce the concept of meta-experience, elevating experience learning from trajectory-level instances to knowledge-level representations. Through contrastive analysis on paired correct and incorrect trajectories, we pinpoint the bifurcation points underlying reasoning failures and abstracts them into reusable meta-experiences. Accordingly, we propose M eta- E xperience L earning (MEL), a framework explicitly designed to enable knowledge-level internalization and reuse of meta-experiences. During training phase, MEL leverages meta-experiences to inject generalizable insights via a self-distillation mechanism, and internalizes them by minimizing the negative log-likelihood in the model’s parametric memory. As shown in Figure 1, MEL differs from standard RLVR, which relies on coarse-grained outcome rewards and treats correct and incorrect trajectories independently, by explicitly connecting them via meta-experiences. Hence, this process can be viewed as a language-modeled process-level reward signal, providing continuous and fine-grained guidance for improving reasoning capability. To further enhance stability and effectiveness during RLVR training, we propose empirical validation via replay, which uses meta-experiences as auxiliary in-context hints to assess their contribution to output accuracy. Meta-experiences that pass validation are integrated via negative log-likelihood minimization, while those that fail validation are excluded. In summary, our main contributions are as follows:
- We propose MEL, a novel framework that integrates self-distilled meta-experience with reinforcement learning, addressing the limitations of standard RLVR in error attribution and experience internalization by embedding these meta-experiences directly into the parametric memory of LLMs.
- We validate the effectiveness of MEL through extensive experiments on five challenging mathematical reasoning benchmarks across multiple LLM scales (4B, 8B, and 14B). Compared with both the vanilla GRPO baseline and the corresponding base models, MEL consistently improves performance across Pass@1, Avg@8, and Pass@8 metrics.
- Empirical results confirm that MEL seamlessly integrates with diverse paradigms (e.g., RFT, GRPO, REINFORCE++) to reshape reasoning patterns and elevate performance ceilings. Notably, these benefits exhibit strong scalability, becoming increasingly pronounced as model size expands.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Flowchart: AI System Architecture for Knowledge Optimization
### Overview
The diagram illustrates a multi-stage AI system architecture for processing questions and optimizing knowledge trajectories. It combines policy modeling, meta-experience, and reinforcement learning with verifiable rewards. Key components include abstraction/validation, bifurcation points, critique mechanisms, and trajectory-level optimization.
### Components/Axes
1. **Input/Output Flow**:
- **Question** (top-left): Input source
- **Trajectories** (bottom-left): Output sequences (Y₁ to Y₆)
- Arrows indicate directional flow between components
2. **Key Components**:
- **Policy Model** (blue box): Central processing unit
- **Meta-Experience** (green box): Contains:
- Bifurcation Point s*
- Critique C (magnifying glass icon)
- Heuristic H (notebook icon)
- **Reinforcement Learning with Verifiable Rewards** (yellow box): Contains:
- Contrastive Pair (green/red checkmarks)
- Reward (R₁-R₆)
- Advantage (A₁-A₆)
- Group Norm (scale icon)
### Process Stages
- **Abstraction & Validation** (lightbulb icon)
- **Knowledge-Level Optimization** (arrow from Policy Model)
- **Trajectory-Level Optimization** (bottom section)
### Detailed Analysis
- **Policy Model** receives questions and produces trajectories through two optimization stages:
1. **Knowledge-Level Optimization**: Direct connection to Meta-Experience
2. **Trajectory-Level Optimization**: Final output through Reinforcement Learning
- **Meta-Experience** integrates three elements:
- Bifurcation Point s* (decision node)
- Critique C (evaluation mechanism)
- Heuristic H (knowledge repository)
- **Reinforcement Learning System**:
- Uses **Contrastive Pair** (correct/incorrect trajectories)
- Calculates **Reward** (R₁-R₆) and **Advantage** (A₁-A₆)
- Implements **Group Norm** (normalization mechanism)
### Key Observations
1. Hierarchical structure with three main processing layers
2. Circular feedback loops between components
3. Color-coded components (blue/green/yellow) for visual distinction
4. Symbolic representations (icons) for abstract concepts
5. Quantitative elements (R₁-R₆, A₁-A₆) suggest measurable optimization metrics
### Interpretation
This architecture demonstrates a closed-loop system where:
1. Questions are processed through multiple optimization stages
2. Meta-experience provides contextual knowledge for decision-making
3. Reinforcement learning with verifiable rewards ensures trajectory quality
4. The system balances exploration (bifurcation points) and exploitation (critique mechanisms)
The use of group normalization suggests multi-agent coordination or population-based optimization. The contrastive pair mechanism indicates active learning capabilities, while the bifurcation points suggest adaptive decision-making under uncertainty. This design appears optimized for complex knowledge domains requiring both structured learning and creative problem-solving.
</details>
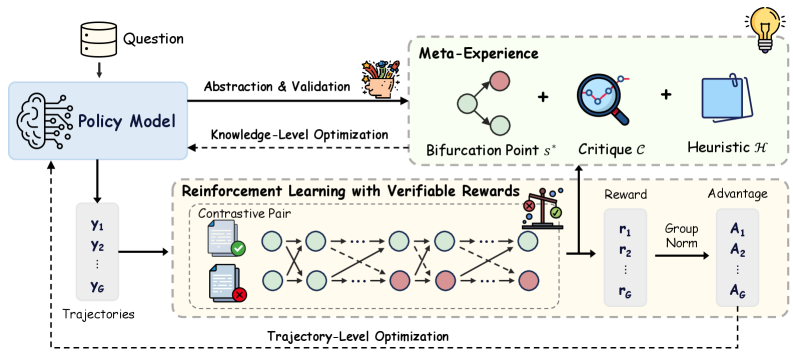
Figure 2: Overview of M eta- E xperience L earning (MEL), which constructs meta-experiences from contrastive pairs via abstraction and validation, thereby introducing an explicit knowledge-level learning loop on top of standard RLVR.
2 Related Work
Reinforcement Learning with Verifiable Rewards.
Reinforcement Learning with Verifiable Rewards (RLVR) leverages rule-based validators to provide deterministic feedback on models’ self-generated solutions (Lambert et al., 2024). Extensive research has systematically investigated RLVR, exploring how this paradigm improves the performance of complex reasoning (Jaech et al., 2024; Guo et al., 2025; Liu et al., 2025; Zhang et al., 2025b). The pioneering framework Group Relative Policy Optimization (GRPO) (Shao et al., 2024) estimates advantages via group-wise relative comparisons, eliminating the need for a separate value model. Building on this base method, recent studies have introduced a range of algorithmic variants to improve training stability and efficiency. For instance, REINFORCE++ (Hu, 2025) enhances stability through global advantage normalization; DAPO (Yu et al., 2025) mitigates entropy collapse and improves reward utilization via relaxed clipping and dynamic sampling; and GSPO (Zheng et al., 2025) reduces gradient estimation variance with sequence-level clipping. Despite these algorithmic advancements, a fundamental limitation persists: current RLVR methods predominantly rely on outcome-level rewards. This failure to assign fine-grained credit to specific knowledge points prevents the construction of reusable knowledge formation, fundamentally constraining the development of systematic and generalizable reasoning capabilities.
Experience Learning.
Recent studies have increasingly recognized that leveraging various forms of experience can substantially enhance LLM reasoning capabilities. One prominent line of research lies in test-time scaling methods, which store experience in external memory pools. For example, SpeedupLLM (Pan and Zhao, 2025) appends memories of previously reasoning traces as experience to accelerate inference, while Training Free GRPO (Cai et al., 2025) and ReasoningBank (Ouyang et al., 2025) distill accumulated experience into structured memory entries for retrieval-based augmentation. However, these approaches rely on ever-growing external memory, preventing the experience from being truly internalized and thus failing to substantively enhance intrinsic reasoning capabilities. Complementarily, another stream of research integrates experience directly into RL training as guiding signals. Methods such as Scaf-GRPO (Zhang et al., 2025d) and StepHint (Zhang et al., 2025c) employ external models to generate experiential hints, which are injected as prefixes or migration signals, to guide the policy toward higher-quality trajectories. Similarly, approaches like LUFFY (Yan et al., 2025) and SRFT (Fu et al., 2025) incorporate expert solution traces as additional experience. Despite improving exploration efficiency, these methods primarily induce trajectory-level imitation. Consequently, models become proficient at following specific patterns but fail to develop the meta-cognitive understanding required for establishing reusable knowledge structures.
3 Meta-Experience Learning
Human learning follows a recurrent cognitive cycle consisting of practice and verification, error attribution, and experience internalization, which in turn informs subsequent practice. Motivated by this cognitive process, we define meta-experience for LLMs as generalizable and reusable knowledge derived from accumulated reasoning trials, capturing both underlying knowledge concepts and common failure modes. Building on this notion, we propose M eta- E xperience L earning (MEL), a framework operating within the RLVR paradigm and expressly designed to internalize such self-distilled, knowledge-level insights into the model’s parametric memory. As illustrated in Figure 2, we first formalize the model exploration stage in RLVR (§ 3.1), then present the details of the Meta-Experience construction (§ 3.2). Finally, we describe the internalization mechanism (§ 3.3) for consolidating these insights into parametric memory, followed by the joint training objective for policy optimization (§ 3.4).
3.1 Explorative Rollout and Verifiable Feedback
Mirroring the “practice and check” phase in human learning, the RLVR framework engages the model in exploring potential solutions for reasoning tasks, while the environment serves as a deterministic verifier that provides verifiable feedback on the final answers. As mastering complex logic typically requires traversing the solution space through multiple attempts, we simulate this stochastic exploration by adopting the group rollout formulation from Group Relative Policy Optimization (GRPO) (Shao et al., 2024).
Formally, given a query $x$ sampled from the dataset $\mathcal{D}$ , the policy model $\pi_{\theta}$ performs stochastic exploration over the solution space and generates a group of $G$ independent reasoning trajectories $\mathcal{Y}=\{y_{1},y_{2},...,y_{G}\}.$ A rule-based verifier then evaluates each trajectory using a verification function $V(·)$ , which compares the extracted final answer from $y_{i}$ against the ground-truth answer $y^{*}$ and assigns a binary outcome reward:
$$
r_{i}=\mathbb{I}\big[V(y_{i},y^{*})\big]\in\{0,1\}. \tag{1}
$$
This process partitions the generated group $\mathcal{Y}$ into two distinct subsets: the set of correct trajectories $\mathcal{Y}^{+}=\{y_{i}\mid r_{i}=1\}$ and the set of incorrect trajectories $\mathcal{Y}^{-}=\{y_{i}\mid r_{i}=0\}$ .
The coexistence of $\mathcal{Y}^{+}$ and $\mathcal{Y}^{-}$ under the same prompt distribution suggests that the model is capable of solving the task, while producing diverse reasoning trajectories. For our method, such diversity constitutes a beneficial property and serves a dual role. On the one hand, it supplies the variance necessary for effective policy updates in standard RLVR. On the other hand, it enables the extraction of knowledge-level meta-expression through systematic contrast between correct and incorrect reasoning outcomes.
3.2 Meta-Experience Construction
Prior studies (Xie et al., 2025; Khalifa et al., 2025; Huang et al., 2025) have shown that effective learning does not arise from merely knowing that a final answer is incorrect, but rather from identifying the specific bifurcation point at which the reasoning process deviates from the correct trajectory, a critical cognitive process known as error attribution. Building on this insight, we leverage pairs of correct and incorrect trajectories to localize reasoning errors and distill such bifurcation points into explicit meta-experiences.
Locating the Bifurcation Point.
To extract knowledge-level learning signals from the exploration results, we focus on identifying the bifurcation points where the reasoning logic diverges into an erroneous path. With the exploration results partitioned into $\mathcal{Y}^{+}$ and $\mathcal{Y}^{-}$ by the verifier, we construct a set of contrastive pairs $\mathcal{P}_{x}=\{(y^{+},y^{-})\mid y^{+}∈\mathcal{Y}^{+},\,y^{-}∈\mathcal{Y}^{-}\}$ for each query $x$ , whose contrast naturally exposes the specific errors in the reasoning process. Such contrastive analysis requires the presence of both positive and negative trajectories; accordingly, we only consider gradient-informative samples with non-empty $\mathcal{Y}^{+}$ and $\mathcal{Y}^{-}$ .
For fine-grained comparison within each pair, each trajectory $y$ can be formatted as a reasoning chain $y=(s_{1},s_{2},...,s_{L},a)$ , where each $s_{t}$ denotes an atomic reasoning step and $a$ indicates the final answer. Since both trajectories originate from the same context, they typically share a correct reasoning path until a critical divergence step $s^{*}$ occurs.
Given deterministic verification signals and full access to the reasoning chains, identifying the bifurcation point can be viewed as a discriminative task that is easier than reasoning from scratch (Saunders et al., 2022; Swamy et al., 2025). Motivated by this observation, we task the policy model with analyzing each contrastive pair to identify the reasoning bifurcation point $s^{*}$ :
$$
\displaystyle s^{*} \displaystyle\sim\pi_{\theta}\big(\cdot\mid I,x,y^{+},y^{-}\big). \tag{2}
$$
Where $I$ denotes a structured instruction guiding introspective analysis.
Deep Diagnosis and Abstraction.
Identifying the bifurcation point $s^{*}$ localizes where the reasoning fails, serving as the raw material for subsequent learning. Anchored at $s^{*}$ , the policy model conducts a deep diagnostic analysis to contrast the strategic choices underlying the successful and failed trajectories. Specifically, the model examines the local reasoning context around $s^{*}$ to pinpoint the root cause of failure, such as violated assumptions, erroneous sub-goals, overlooked constraints, or the misuse of specific principles. Complementarily, it inspects the successful trajectory to uncover the mechanisms that prevented such pitfalls, including precise knowledge application, explicit constraint verification, coherent knowledge representations, or emergent self-correction behaviors. By jointly synthesizing these perspectives, the model distills the structural divergence between the correct and incorrect logic, crystallizing it into explicit knowledge. Formally, we model this diagnostic process as generating a critique $\mathcal{C}$ that encapsulates the error attribution, the comparative strategic gap, and the corresponding corrective principle:
$$
\displaystyle\mathcal{C}\sim\pi_{\theta}\big(\cdot\mid I,x,y^{+},y^{-},s^{*}\big). \tag{3}
$$
To ensure generalization, it is imperative for the model to distill instance-specific critiques into abstract heuristics capable of guiding future reasoning. This abstraction mechanism systematically strips away context-dependent variables, mapping the concrete logic of success and failure onto a generalized space of preconditions and responses. Structurally, such heuristics synthesize abstract problem categorization with the corresponding reasoning principles, encompassing the essential knowledge points, theoretical theorems, and decision criteria. Crucially, they also demarcate error-prone boundaries, explicitly highlighting potential pitfalls or latent constraints associated with the specific problem class. We define the extraction of this heuristic knowledge $\mathcal{H}$ as a generation process conditioned on the full critique context:
$$
\mathcal{H}\sim\pi_{\theta}\big(\cdot\mid I,x,y^{+},y^{-},s^{*},\mathcal{C}\big). \tag{4}
$$
Finally, we consolidate these components into a unified Meta-Experience tuple $\mathcal{M}$ , which elevates experience learning from trajectory-level instances to knowledge-level representations.
$$
\mathcal{M}=\big(s^{*},\mathcal{C},\mathcal{H}\big). \tag{5}
$$
This formulation enables meta-experiences to be reused across tasks that share analogous reasoning structures, serving as a fine-grained learning signal. By applying the extraction process across distinct contrastive pairs for a query $x$ , we construct a candidate pool of meta-experiences $\mathcal{D}_{\mathcal{M}}=\{(x,y^{+}_{i},y^{-}_{i},\mathcal{M}_{i})\}_{i=1}^{N}$ , where $N$ denotes the total number of meta-experiences derived from $x$ , and $(y^{+}_{i},y^{-}_{i})$ represents the specific contrastive pair used to derive $\mathcal{M}_{i}$ .
Empirical Validation via Replay.
Closing the cognitive loop requires re-instantiating theoretical insights derived from past failures in future problem-solving to assess their validity. We recognize that the raw meta-experience $\mathcal{M}$ may still suffer from intrinsic hallucinations or causal misalignment. To mitigate this, we conduct empirical verification by incorporating the extracted tuple $\mathcal{M}$ as short-term working memory into the prompt, thereby guiding the model to re-attempt the original query $x$ . This procedure tests whether the injected meta-experience can effectively steer the model away from the previously identified bifurcation point $s^{*}$ and toward a correct reasoning trajectory.
We retain a meta-experience only if the corresponding replay trajectory $y_{\text{val}}\sim\pi_{\theta}(·\mid x,\mathcal{M})$ satisfies the verifier by producing the correct answer.
$$
\mathcal{D}_{\mathcal{M^{*}}}=\left\{(x,y^{+},y^{-},\mathcal{M})\in\mathcal{D}_{\mathcal{M}}\;\middle|\;\mathbb{I}\big[V\!\left(y_{\text{val}},y^{*}\right)=1\big]\right\}. \tag{6}
$$
Consequently, this empirical validation preserves only high-quality meta-experiences for integration into parametric long-term memory, guaranteeing the reliability of the supervision signals used in the subsequent optimization phase.
3.3 Internalization Mechanism
The verified meta-experiences $\mathcal{D}_{\mathcal{M}^{*}}$ constitute a high-quality reservoir of reasoning guidance. However, treating these insights solely as retrieval-augmented memory imposes a substantial computational burden during the inference forward pass, as it necessitates processing elongated contexts for every query. To overcome this limitation, we propose to transfer these insights from the transient context window to the model’s parametric memory. Unlike the finite context buffer, the model parameters offer a virtually unlimited capacity for accumulating diverse meta-experiences, allowing the policy to internalize vast amounts of reasoning patterns without incurring inference-time latency.
We establish this internalization process as a self-distilled paradigm, where the model learns from its own verified experiences. Specifically, we employ fine-tuning based on the token-averaged negative log-likelihood (NLL) objective to compile the meta-experiences into the policy’s weights. Formally, given the retrospective context $C_{\text{retro}}=[I,x,y^{+},y^{-}]$ , the internalization loss is defined as:
$$
\displaystyle\mathcal{L}_{\text{NLL}}(\theta)=- \displaystyle\mathbb{E}_{(x,y^{+},y^{-},\mathcal{M}^{*})\sim\mathcal{D}_{\mathcal{M}^{*}}} \displaystyle\Big[\frac{1}{|\mathcal{M}^{*}|}\sum_{t=1}^{|\mathcal{M}^{*}|}\log\pi_{\theta}(\mathcal{M}^{*}_{t}\mid C_{\text{retro}},\mathcal{M}^{*}_{<t})\Big] \displaystyle=- \displaystyle\mathbb{E}_{x\sim\mathcal{D},\,\{y_{i}\}_{i=1}^{G}\sim\pi_{\theta_{\mathrm{old}}}(\cdot\mid x)} \displaystyle\Bigg[\mathbb{E}_{(y^{+},y^{-},\mathcal{M}^{*})\sim\mathcal{T}(x,\{y_{i}\}_{i=1}^{G})} \displaystyle\Big[\frac{1}{|\mathcal{M}^{*}|}\sum_{t=1}^{|\mathcal{M}^{*}|}\log\pi_{\theta}(\mathcal{M}^{*}_{t}\mid C_{\text{retro}},\mathcal{M}^{*}_{<t})\Big]\Bigg] \tag{7}
$$
where $\mathcal{T}(·)$ represents the stochastic construction process detailed in § 3.2.
Based on this formulation, the internalization process can be viewed as a specialized sampling form within the RLVR framework. By inverting the loss, we define the Meta-Experience Return $\mathcal{R}_{\text{MEL}}$ as the expected log-likelihood over the stochastically constructed verification set:
$$
\displaystyle\mathcal{R}_{\text{MEL}} \displaystyle=\mathbb{E}_{(y^{+},y^{-},\mathcal{M}^{*})\sim\mathcal{T}(x,\{y_{i}\}_{i=1}^{G})} \displaystyle\Bigg[\frac{1}{|\mathcal{M}^{*}|}\sum_{t=1}^{|\mathcal{M}^{*}|}\log\pi_{\theta}(\mathcal{M}^{*}_{t}\mid C_{\text{retro}},\mathcal{M}^{*}_{<t})\Bigg]. \tag{8}
$$
3.4 Joint Training Objective
Table 1: Main Results Comparison. Comparison of Pass@1, Avg@8, and Pass@8 accuracy (%) across different model scales. The best results within each model scale are marked in bold.
| Method Qwen3-4B-Base | AIME 2024 Pass@1 | AIME 2025 Avg@8 | AMC 2023 Pass@8 | Pass@1 | Avg@8 | Pass@8 | Pass@1 | Avg@8 | Pass@8 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Baseline | 13.33 | 9.90 | 30.00 | 10.00 | 6.56 | 23.33 | 45.00 | 42.73 | 72.50 |
| GRPO | 13.33 | 18.33 | 30.00 | 6.67 | 17.50 | 30.00 | 57.50 | 58.13 | 85.00 |
| \rowcolor MintCream MEL | 20.00 | 20.83 | 33.00 | 16.67 | 18.33 | 33.00 | 60.00 | 60.31 | 87.50 |
| Qwen3-8B-Base | | | | | | | | | |
| Baseline | 6.67 | 10.00 | 26.67 | 13.33 | 15.00 | 33.33 | 65.00 | 52.50 | 87.50 |
| GRPO | 16.67 | 24.58 | 43.33 | 20.00 | 20.83 | 36.67 | 67.50 | 69.06 | 87.50 |
| \rowcolor MintCream MEL | 30.00 | 25.42 | 60.00 | 23.33 | 23.33 | 36.67 | 70.00 | 70.31 | 90.00 |
| Qwen3-14B-Base | | | | | | | | | |
| Baseline | 13.33 | 10.83 | 36.67 | 6.66 | 9.58 | 33.33 | 60.00 | 51.25 | 82.50 |
| GRPO | 30.00 | 35.41 | 56.67 | 33.33 | 24.17 | 43.33 | 75.00 | 75.94 | 95.00 |
| \rowcolor MintCream MEL | 33.33 | 35.83 | 60.00 | 36.67 | 30.00 | 46.67 | 82.50 | 82.81 | 95.00 |
| Method Qwen3-4B-Base | MATH 500 Pass@1 | OlympiadBench Avg@8 | Average Pass@8 | Pass@1 | Avg@8 | Pass@8 | Pass@1 | Avg@8 | Pass@8 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Baseline | 74.20 | 65.74 | 89.60 | 39.17 | 35.37 | 60.38 | 36.34 | 32.06 | 55.16 |
| GRPO | 81.80 | 82.20 | 93.00 | 48.51 | 48.46 | 67.21 | 41.56 | 44.92 | 61.04 |
| \rowcolor MintCream MEL | 82.20 | 82.30 | 93.80 | 48.51 | 49.48 | 69.73 | 45.48 | 46.25 | 63.41 |
| Qwen3-8B-Base | | | | | | | | | |
| Baseline | 77.00 | 73.40 | 91.40 | 44.51 | 39.41 | 64.09 | 41.30 | 38.06 | 60.60 |
| GRPO | 84.40 | 86.28 | 95.40 | 53.56 | 54.60 | 73.74 | 48.43 | 51.07 | 67.33 |
| \rowcolor MintCream MEL | 86.60 | 86.70 | 96.20 | 54.01 | 55.60 | 73.00 | 52.79 | 52.27 | 71.17 |
| Qwen3-14B-Base | | | | | | | | | |
| Baseline | 80.80 | 74.15 | 93.60 | 45.25 | 40.50 | 65.58 | 41.21 | 37.26 | 62.34 |
| GRPO | 85.00 | 88.35 | 96.40 | 58.16 | 58.46 | 74.78 | 56.30 | 56.47 | 73.24 |
| \rowcolor MintCream MEL | 90.80 | 90.80 | 97.20 | 61.87 | 60.90 | 75.82 | 61.03 | 60.07 | 74.94 |
To simultaneously encourage solution exploration and consolidate the internalized meta-experiences, achieving dual optimization across trajectory-level behaviors and knowledge-level representations, we train the policy model $\pi_{\theta}$ using a joint optimization objective. To simultaneously encourage solution exploration and consolidate the internalized meta-experiences, achieving dual optimization across trajectory-level behaviors and knowledge-level representations, we train the policy model $\pi_{\theta}$ using a joint optimization objective. This objective synergizes the RLVR signal derived from diverse explorative rollouts with the supervised signal distilled from high-quality meta-experiences:
$$
\mathcal{J}(\theta)=\mathcal{J}_{\text{RLVR}}(\theta)+\mathcal{J}_{\text{MEL}}(\theta). \tag{9}
$$
We adopt GRPO (Shao et al., 2024) as the RLVR component and compute group-normalized advantages by standardizing rewards within the sampled group and broadcast them to each token. Let $y_{i,t}$ denote the $t$ -th token in trajectory $y_{i}$ and $y_{i,<t}$ , the corresponding prefix. Substituting the definition of $\mathcal{R}_{\text{MEL}}$ from Eq. 8, the joint objective in Eq. 9 is explicitly expanded as:
$$
\displaystyle\mathcal{J}(\theta)= \displaystyle\mathbb{E}_{x\sim\mathcal{D},\,\{y_{i}\}_{i=1}^{G}\sim\pi_{\theta_{\mathrm{old}}}(\cdot\mid x)} \displaystyle\Big[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|y_{i}|}\sum_{t=1}^{|y_{i}|}\min\Big(\rho_{i,t}(\theta)\hat{A}_{i,t},\; \displaystyle\mathrm{clip}\big(\rho_{i,t}(\theta),1-\epsilon,1+\epsilon\big)\hat{A}_{i,t}\Big)+\mathcal{R}_{\text{MEL}}\Big]. \tag{10}
$$
Although derived from a log-likelihood objective, its optimization gradient is mathematically equivalent to a policy gradient update where the reward signal is a constant positive scalar. Consequently, the total objective $\mathcal{J}(\theta)$ can be unified as maximizing the expected cumulative return of a hybrid reward function. In this unified view, the meta-experiences function as a dense process reward model.
Unlike the sparse outcome rewards in standard RLVR that only evaluate the final correctness, $\mathcal{R}_{\text{MEL}}$ provides explicit, step-by-step reinforcement for the reasoning process itself. This ensures that the model not only pursues correct outcomes via broad exploration but is also continuously shaped by the dense supervision of its own successful cognitive patterns, effectively bridging the gap between trajectory-level search and token-level knowledge encoding.
4 Experiments
Datasets.
We train our model on the DAPO-Math-17k dataset (Yu et al., 2025) and evaluate it on five challenging mathematical reasoning benchmarks: AIME24, AIME25, AMC23 (Li et al., 2024), MATH500 (Hendrycks et al., 2021), and OlympiadBench (He et al., 2024).
Setups.
All reinforcement learning training is conducted using the VERL framework (Sheng et al., 2024) on 8 $×$ H20 GPUs, with Math-Verify providing rule-based outcome verification. During training, we sample 8 responses per prompt at a temperature of 1.0 with a batch size of 128. Optimization uses a learning rate of $1× 10^{-6}$ and a mini-batch size of 128. For evaluation, we report Pass@1 at temperature 0, and Avg@8 and Pass@8 at temperature 0.6.
Models and Baselines.
To demonstrate the general applicability of MEL, we conduct experiments across a diverse range of model scales, including Qwen3-4B-Base, Qwen3-8B-Base, and Qwen3-14B-Base (Yang et al., 2025). We adopt GRPO (Shao et al., 2024) as the base reinforcement learning algorithm for MEL, and thus perform a direct and controlled comparison between the vanilla GRPO and our meta-experience learning approach.
4.1 Experimental Results
As shown in Table 1, MEL achieves consistent and significant improvements over vanilla GRPO and the basemodel across multiple benchmarks and model scales. We report three complementary metrics: Pass@1 reflects one-shot reliability, Avg@8 measures the average performance over 8 samples, and Pass@8 reports the best-of-8 success rate.
First, the gains in Pass@1 demonstrate that MEL substantially enhances the model’s confidence in following correct reasoning paths. Across all model scales, it achieves a consistent improvement of 3.92–4.73% over the strong GRPO baseline. This indicates that MEL effectively internalizes the explored insights into the model’s parametric memory. By consolidating these successful reasoning patterns, the model generates high-confidence solutions, markedly reducing the need for extensive test-time sampling. This reliability is further corroborated by the gains in Avg@8, which reveal that MEL significantly enhances reasoning consistency and output stability. High performance on this metric supports our hypothesis that internalized meta-experiences function as intrinsic process-level guidance, continuously steering the generation toward valid logic and effectively reducing variance across sampled outputs. Finally, the sustained gains in Pass@8 suggest that learning from meta-experience does not harm exploration; instead, it expands the reachable solution space and raises the upper bound of best-of- $k$ performance.
4.2 Training Dynamics and Convergence Analysis
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Graphs: Training Reward vs. Training Steps for GRPO and MEL Models
### Overview
The image contains three line graphs comparing the training reward performance of two models, **GRPO** and **MEL**, across three parameter sizes: **4B**, **8B**, and **14B**. Each graph tracks training reward over 120 training steps, with distinct trends observed for each model size.
---
### Components/Axes
- **X-axis**: Training Steps (0 to 120, linear scale).
- **Y-axis**: Training Reward (0.2 to 0.7, linear scale).
- **Legends**:
- **GRPO**: Blue line with shaded blue region (top-right placement).
- **MEL**: Red line with shaded red region (top-right placement).
- **Graph Titles**:
- Left: "GRPO (4B)" and "MEL (4B)"
- Middle: "GRPO (8B)" and "MEL (8B)"
- Right: "GRPO (14B)" and "MEL (14B)"
---
### Detailed Analysis
#### 4B Model Size
- **GRPO (Blue)**: Starts at ~0.15, rises steadily to ~0.38 by step 120. Shows moderate variance (shaded region).
- **MEL (Red)**: Begins slightly higher (~0.18) but converges with GRPO by step 60, ending at ~0.39. Variance is higher than GRPO.
#### 8B Model Size
- **GRPO (Blue)**: Starts at ~0.18, increases to ~0.45 by step 120. Variance decreases after step 60.
- **MEL (Red)**: Begins at ~0.22, peaks at ~0.48 around step 60, then declines slightly to ~0.46. Variance is higher than GRPO.
#### 14B Model Size
- **GRPO (Blue)**: Starts at ~0.22, rises to ~0.55 by step 120. Variance is low after step 80.
- **MEL (Red)**: Begins at ~0.25, peaks at ~0.60 around step 100, then stabilizes at ~0.58. Variance is higher than GRPO.
---
### Key Observations
1. **Model Size Impact**:
- Larger models (14B) achieve higher training rewards than smaller models (4B/8B).
- GRPO consistently outperforms MEL in larger models (14B), while MEL has a slight edge in smaller models (4B).
2. **Training Dynamics**:
- GRPO shows steeper improvement in larger models, suggesting better scalability.
- MEL exhibits higher variance across all model sizes, indicating less stable training.
3. **Convergence Points**:
- In 4B and 8B, GRPO and MEL converge early (steps 40–60).
- In 14B, GRPO overtakes MEL around step 80, maintaining a lead thereafter.
4. **Shaded Regions**:
- Represent uncertainty or confidence intervals. MEL’s wider shaded regions suggest greater variability in training outcomes.
---
### Interpretation
The data demonstrates that **GRPO outperforms MEL in larger models (14B)**, with a clear advantage emerging after ~80 training steps. This suggests GRPO’s architecture or training strategy scales more effectively with model size. Conversely, MEL performs better in smaller models (4B) but struggles with stability as model size increases. The variance patterns imply that MEL’s training is less robust, potentially due to optimization challenges in larger parameter spaces. These trends highlight the importance of model architecture design for scalability and training efficiency in machine learning systems.
</details>
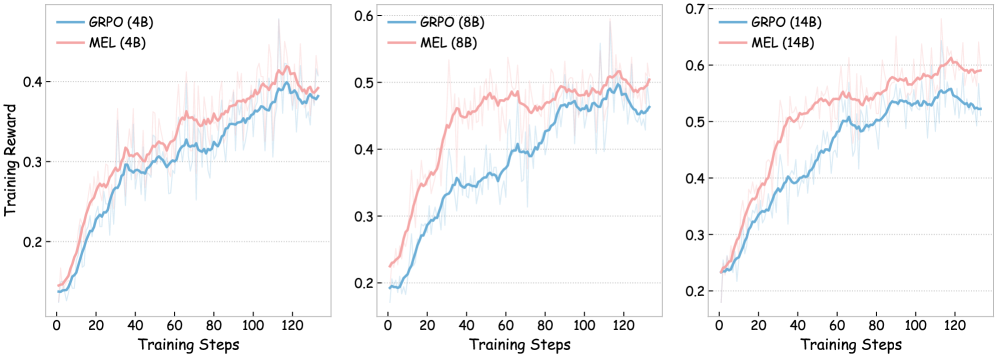
Figure 3: Training curves comparing GRPO and MEL.
To understand the mechanisms driving the performance gains under MEL, we monitored the training dynamics and validation performance in Figures 3 and 6 – 8.
Vanilla GRPO methods often struggle to obtain positive reinforcement in the early stages, particularly when initial performance is low, due to the sparsity of outcome-based rewards. As illustrated in the training curve, vanilla GRPO exhibits a relatively slow ascent during the initial phase. In contrast, MEL demonstrates a sharp, rapid trajectory growth immediately from the onset of training. This acceleration is attributed to the internalized meta-experience return, $\mathcal{R}_{\text{MEL}}$ . By functioning as a dense, language-modeling process reward, $\mathcal{R}_{\text{MEL}}$ continuously provides informative gradient signals for every reasoning step, even when successful trajectories yielding positive reinforcement are scarce.
Beyond sample efficiency, MEL achieves a consistently higher performance upper bound. The training curves show that the average reward of MEL consistently surpasses that of vanilla GRPO throughout the entire training process. Crucially, the downstream validation trajectories reveal that even as performance growth begins to plateau in the later stages, MEL maintains a distinct and sustained advantage over the baseline. This phenomenon demonstrates that the internalization of meta-experiences empowers the model to effectively navigate and explore more complex, long-horizon solutions that remain inaccessible to the baseline.
<details>
<summary>x4.png Details</summary>

### Visual Description
## Screenshot: Geometry Problem-Solving Interface
### Overview
The image depicts a structured problem-solving interface for a geometry problem involving triangle ABC. It includes a question, step-by-step reasoning, and meta-experience reflections on problem-solving strategies. The interface uses color-coded sections (blue for the question, pink for reasoning, green for meta-experience) and integrates mathematical formulas and annotations.
---
### Components/Axes
- **Question Section (Blue Box)**:
- **Problem Statement**: Triangle ABC with AB = 4, BC = 5, CA = 6, and angles A = 60°, B = 90°, C = 30°.
- **Task**: Find the length of BC.
- **Key Elements**:
- Circumcircle of triangle ABC.
- Tangent lines and properties of tangents.
- Formula: `B'C' = 2R sin(θ)`, where `θ` is the angle at A.
- **Meta-Experience Section (Green Box)**:
- **Failure Resolution Path**:
- Error in using the circumcircle formula (`BC = 2R sin(BAC)` vs. corrected `BC = 2R sin(180 - BAC)`).
- Confusion due to half-angle substitution.
- **Subject Heuristics**:
- Angle verification rule: Ensure `θ` is the full geometric angle when using `2R sin(θ)`.
- Formula-Geometry Consistency Rule: Confirm geometric properties before applying trigonometric formulas.
- **GRPO Section (Pink Box)**:
- **Steps**:
1. Find the circumcircle of triangle ABC.
2. Calculate semi-perimeter (`s = (4 + 5 + 6)/2 = 7.5`).
3. Compute area using Heron’s formula (`K = sqrt(7.5(7.5-4)(7.5-5)(7.5-6))`).
4. Derive circumradius (`R = abc/(4K)`).
5. Apply `B'C' = 2R sin(θ)` with `θ = 60°`.
- **MEL Section (Green Box)**:
- **Problem-Solving Approach**:
- Tangent lines and properties of tangents.
- Use of Heron’s formula and circumradius.
- Final formula: `B'C' = 2R sin(60°) = 5`.
---
### Content Details
- **Formulas**:
- Heron’s formula: `K = sqrt(s(s-a)(s-b)(s-c))`.
- Circumradius: `R = abc/(4K)`.
- Tangent length: `B'C' = 2R sin(θ)`.
- **Values**:
- Semi-perimeter: `s = 7.5`.
- Area: `K ≈ 10.825`.
- Circumradius: `R ≈ 3.0`.
- Final Answer: `B'C' = 5`.
---
### Key Observations
1. **Formula Application**: The interface emphasizes verifying geometric properties (e.g., full vs. half angles) before applying trigonometric formulas.
2. **Error Correction**: The meta-experience highlights a common mistake in angle substitution (`BAC` vs. `180 - BAC`).
3. **Step-by-Step Logic**: The GRPO section breaks down the problem into computable steps, ensuring clarity.
---
### Interpretation
The interface demonstrates a structured approach to solving geometry problems, combining computational steps (Heron’s formula, circumradius) with geometric reasoning (tangent properties). The meta-experience section underscores the importance of error analysis and heuristic validation, such as confirming angle measures and formula consistency. The final answer (`B'C' = 5`) aligns with the corrected application of the circumcircle formula, resolving the initial confusion.
No charts, diagrams, or non-English text are present. All information is textual and self-contained.
</details>
Figure 4: Case study comparing GRPO and MEL, with visualization of meta-experience in early stage.
4.3 How Meta-Experience Shapes Reasoning Patterns
To investigate how MEL shapes the model’s cognitive processes beyond numerical metrics, we conduct a qualitative analysis comparing the reasoning trajectories of MEL and the baseline GRPO model, as visualized in Figure 4.
A distinct behavioral divergence is observed from the onset of the solution. While the GRPO baseline tends to prioritize immediate execution through direct numerical operations, MEL adopts a structured preparatory strategy by explicitly outlining relevant theorems and formulas. Although the direct approach may appear efficient for simple queries, it increases the susceptibility to errors in complex tasks due to the lack of a holistic view of problem constraints.
Notably, MEL exhibits an emergent cognitive behavior. When applying specific theorems, it spontaneously activates internalized “bitter lessons” as endogenous safeguards to regulate its actions. These active signals effectively reduce reasoning drift by encouraging earlier constraint checking and consistent self-correction when the model enters uncertain regions.
4.4 Generality Across Learning Paradigms
<details>
<summary>x5.png Details</summary>
### Visual Description
## Radar Chart: Olympicbench Performance Comparison
### Overview
The image is a radar chart comparing the performance of four AI models across five evaluation metrics: Olympialbench, MATH500, AIM24, AIM23, and AIM25. The chart uses four distinct data series (colored lines) to represent different model configurations, with values plotted on a circular scale from 0 to 80.
### Components/Axes
- **Axes (Metrics):**
- Olympialbench (top)
- MATH500 (left)
- AIM24 (right)
- AIM23 (bottom-left)
- AIM25 (bottom-right)
- **Legend (Data Series):**
- **Blue**: Qwen3-8B-Base
- **Green**: RPT
- **Purple**: RPT w/ ME
- **Red**: ADIME24
- **Scale:** Radial axis from 0 to 80, with tick marks at 10-unit intervals.
### Detailed Analysis
- **Olympialbench (Top Axis):**
- ADIME24 (red): 45.5
- RPT (green): 44.5
- Qwen3-8B-Base (blue): 44.5
- RPT w/ ME (purple): 44.5
- **MATH500 (Left Axis):**
- ADIME24 (red): 80
- Qwen3-8B-Base (blue): 78.3
- RPT (green): 75
- RPT w/ ME (purple): 75
- **AIM24 (Right Axis):**
- ADIME24 (red): 15
- Qwen3-8B-Base (blue): 15
- RPT (green): 15
- RPT w/ ME (purple): 15
- **AIM23 (Bottom-Left Axis):**
- ADIME24 (red): 70
- Qwen3-8B-Base (blue): 63.2
- RPT (green): 66.6
- RPT w/ ME (purple): 72
- **AIM25 (Bottom-Right Axis):**
- ADIME24 (red): 22
- Qwen3-8B-Base (blue): 74.5
- RPT (green): 74.5
- RPT w/ ME (purple): 74.5
### Key Observations
1. **ADIME24 (Red)** dominates the Olympialbench and MATH500 metrics, achieving the highest scores (45.5 and 80, respectively).
2. **Qwen3-8B-Base (Blue)** underperforms on Olympialbench (44.5) but matches ADIME24 on AIM25 (74.5).
3. **RPT (Green)** and **RPT w/ ME (Purple)** show near-identical performance across all metrics, with RPT w/ ME slightly outperforming RPT on AIM23 (72 vs. 66.6).
4. **AIM24** is the weakest metric for all models, with scores capped at 15.
### Interpretation
The chart highlights ADIME24 as the top-performing model overall, particularly excelling in Olympialbench and MATH500. Qwen3-8B-Base and RPT/RPT w/ ME show comparable performance in most metrics, though RPT w/ ME gains a marginal edge on AIM23. The uniform low scores on AIM24 suggest this metric may be less discriminative or represent a specialized task. The near-identical AIM25 scores across models imply this metric may not effectively differentiate between configurations. The chart underscores the importance of metric selection in evaluating AI systems, as performance disparities vary significantly by evaluation focus.
</details>
<details>
<summary>x6.png Details</summary>
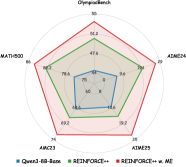
### Visual Description
## Radar Chart: Benchmark Performance Comparison
### Overview
The image is a radar chart comparing the performance of three AI models across six benchmarks. The chart uses three colored polygons (blue, green, red) to represent different model configurations, with radial axes labeled with benchmark names and a central circular scale from 0 to 90.
### Components/Axes
- **Radial Axes (Benchmarks)**:
- OlympiadBench (top)
- MATH500 (left)
- AIM24 (right)
- AIM23 (bottom-left)
- AIM25 (bottom-right)
- **Central Scale**: 0–90 (performance metric)
- **Legend** (bottom-center):
- Blue: Queen-6B-Base
- Green: REINFORCE++
- Red: REINFORCE++ w/ ME
### Detailed Analysis
1. **Queen-6B-Base (Blue)**:
- OlympiadBench: ~50
- MATH500: ~60
- AIM24: ~55
- AIM23: ~58
- AIM25: ~52
- *Trend*: Consistently lowest performance across all benchmarks.
2. **REINFORCE++ (Green)**:
- OlympiadBench: ~70
- MATH500: ~75
- AIM24: ~72
- AIM23: ~68
- AIM25: ~65
- *Trend*: Moderate performance, outperforms Queen-6B-Base but underperforms REINFORCE++ w/ ME.
3. **REINFORCE++ w/ ME (Red)**:
- OlympiadBench: ~85
- MATH500: ~80
- AIM24: ~78
- AIM23: ~69
- AIM25: ~70
- *Trend*: Highest performance across all benchmarks, with notable gains in OlympiadBench and MATH500.
### Key Observations
- **Performance Gaps**: REINFORCE++ w/ ME (red) consistently outperforms REINFORCE++ (green) by 10–15 points in OlympiadBench and MATH500, and 5–10 points in other benchmarks.
- **Benchmark Difficulty**: OlympiadBench and MATH500 show the largest performance differences between models, suggesting these tasks are more challenging.
- **Queen-6B-Base Limitations**: Struggles across all benchmarks, with scores below 60 in four of five tasks.
### Interpretation
The data demonstrates that adding Meta-Learning (ME) to the REINFORCE++ framework significantly improves performance across diverse AI benchmarks. The largest gains occur in OlympiadBench (+15 points vs. REINFORCE++) and MATH500 (+5 points), indicating ME's effectiveness in complex reasoning tasks. Queen-6B-Base's lower scores suggest it lacks the architectural enhancements present in the other models. The radial chart format effectively visualizes multidimensional performance comparisons, with the red polygon's larger area confirming REINFORCE++ w/ ME's superiority. This analysis implies that Meta-Learning is a critical component for achieving state-of-the-art results in multi-task AI systems.
</details>
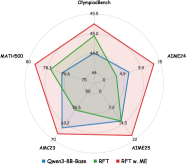
Figure 5: Impact of meta-experience across different training methods, including Rejection Sampling Fine-Tuning (RFT) and REINFORCE++. ME denotes Meta-Experience.
To demonstrate the versatility of meta-experience, we integrated it into RFT and REINFORCE++ using the Qwen-8B-Base model as the backbone and the same training set in our experiments. As shown in Figure 5, while vanilla RFT often suffers from rote memorization and tends to overfit to specific samples in this training set, the incorporation of meta-experiences introduces robust reasoning heuristics. This allows the model to internalize the underlying logic rather than merely imitating specific answers, thereby effectively mitigating overfitting and enhancing generalization to unseen test sets. Similarly, applying meta-experiences to REINFORCE++ significantly raises the performance ceiling on benchmarks. This confirms that the benefit of internalized meta-experiences is a universal enhancement, not limited to the GRPO framework.
4.5 Scalability Analysis
As indicated by the training curves in Figure 3, the method exhibits a distinct positive scaling law: the performance margin between MEL and the baseline widens significantly as the model size increases. This phenomenon consistently extends to downstream validation benchmarks.
We attribute this effect to the quality of self-generated supervision, which is inherently bounded by the model’s intrinsic capability. As shown in Figure 9, the 14B model achieves a significantly higher yield rate of valid meta-experiences than its smaller counterparts. While limited-capacity models introduce noise due to imprecise error attribution, larger models benefit from stronger self-verification, enabling the distillation of high-quality heuristics that provide more accurate gradient signals and fully realize the potential of our framework.
5 Conclusion
In this paper, we introduced MEL, a novel framework designed to overcome the meta-learning bottleneck in standard RLVR by transforming instance-specific failure patterns into reusable cognitive assets. Unlike traditional methods that rely solely on outcome-oriented rewards, MEL empowers models to perform granular error attribution, distilling specific failure modes into natural language heuristics—termed Meta-Experiences. By internalizing these experiences into parametric memory, our approach bridges the gap between verifying a solution and understanding the underlying reasoning logic. Extensive empirical evaluations confirm that MEL consistently boosts mathematical reasoning across diverse model scales.
Impact Statement
This paper presents research aimed at advancing the field of reinforcement learning. While our work may have broader societal implications, we do not identify any specific impacts that require particular attention at this stage.
References
- Y. Cai, S. Cai, Y. Shi, Z. Xu, L. Chen, Y. Qin, X. Tan, G. Li, Z. Li, H. Lin, et al. (2025) Training-free group relative policy optimization. arXiv preprint arXiv:2510.08191. Cited by: §2.
- J. Chen, Q. He, S. Yuan, A. Chen, Z. Cai, W. Dai, H. Yu, Q. Yu, X. Li, J. Chen, et al. (2025) Enigmata: scaling logical reasoning in large language models with synthetic verifiable puzzles. arXiv preprint arXiv:2505.19914. Cited by: §1.
- J. Cheng, G. Xiong, R. Qiao, L. Li, C. Guo, J. Wang, Y. Lv, and F. Wang (2025) Stop summation: min-form credit assignment is all process reward model needs for reasoning. arXiv preprint arXiv:2504.15275. Cited by: §1.
- Y. Fu, T. Chen, J. Chai, X. Wang, S. Tu, G. Yin, W. Lin, Q. Zhang, Y. Zhu, and D. Zhao (2025) SRFT: a single-stage method with supervised and reinforcement fine-tuning for reasoning. arXiv preprint arXiv:2506.19767. Cited by: §2.
- D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. (2025) Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948. Cited by: §1, §2.
- C. He, R. Luo, Y. Bai, S. Hu, Z. Thai, J. Shen, J. Hu, X. Han, Y. Huang, Y. Zhang, et al. (2024) Olympiadbench: a challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. In Proceedings of the Association for Computational Linguistics, pp. 3828–3850. Cited by: §4.
- D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt (2021) Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv: 2103.03874. Cited by: §4.
- J. Hu (2025) Reinforce++: a simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262. Cited by: §2.
- S. Huang, Z. Fang, Z. Chen, S. Yuan, J. Ye, Y. Zeng, L. Chen, Q. Mao, and F. Zhao (2025) CRITICTOOL: evaluating self-critique capabilities of large language models in tool-calling error scenarios. arXiv preprint arXiv:2506.13977. Cited by: §3.2.
- W. Huang, Y. Zeng, Q. Wang, Z. Fang, S. Cao, Z. Chu, Q. Yin, S. Chen, Z. Yin, L. Chen, et al. (2026) Vision-deepresearch: incentivizing deepresearch capability in multimodal large language models. arXiv preprint arXiv:2601.22060. Cited by: §1.
- A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. (2024) Openai o1 system card. arXiv preprint arXiv:2412.16720. Cited by: §2.
- M. Khalifa, R. Agarwal, L. Logeswaran, J. Kim, H. Peng, M. Lee, H. Lee, and L. Wang (2025) Process reward models that think. arXiv preprint arXiv:2504.16828. Cited by: §1, §3.2.
- N. Lambert, J. Morrison, V. Pyatkin, S. Huang, H. Ivison, F. Brahman, L. J. V. Miranda, A. Liu, N. Dziri, S. Lyu, et al. (2024) Tulu 3: pushing frontiers in open language model post-training. arXiv preprint arXiv:2411.15124. Cited by: §1, §2.
- J. Li, E. Beeching, L. Tunstall, B. Lipkin, R. Soletskyi, S. Huang, K. Rasul, L. Yu, A. Q. Jiang, Z. Shen, et al. (2024) Numinamath: the largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. Hugging Face repository 13 (9), pp. 9. Cited by: §4.
- H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe (2023) Let’s verify step by step. In Proceedings of the International Conference on Learning Representations, Cited by: §1.
- K. Liu, D. Yang, Z. Qian, W. Yin, Y. Wang, H. Li, J. Liu, P. Zhai, Y. Liu, and L. Zhang (2025) Reinforcement learning meets large language models: a survey of advancements and applications across the llm lifecycle. arXiv preprint arXiv:2509.16679. Cited by: §2.
- L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. (2022) Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35, pp. 27730–27744. Cited by: §1.
- S. Ouyang, J. Yan, I. Hsu, Y. Chen, K. Jiang, Z. Wang, R. Han, L. T. Le, S. Daruki, X. Tang, et al. (2025) Reasoningbank: scaling agent self-evolving with reasoning memory. arXiv preprint arXiv:2509.25140. Cited by: §2.
- B. Pan and L. Zhao (2025) Can past experience accelerate llm reasoning?. arXiv preprint arXiv:2505.20643. Cited by: §2.
- W. Saunders, C. Yeh, J. Wu, S. Bills, L. Ouyang, J. Ward, and J. Leike (2022) Self-critiquing models for assisting human evaluators. arXiv preprint arXiv:2206.05802. Cited by: §3.2.
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov (2017) Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347. Cited by: §1.
- Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. (2024) Deepseekmath: pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Cited by: §1, §2, §3.1, §3.4, §4.
- G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y. Peng, H. Lin, and C. Wu (2024) HybridFlow: a flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256. Cited by: §4.
- G. Swamy, S. Choudhury, W. Sun, Z. S. Wu, and J. A. Bagnell (2025) All roads lead to likelihood: the value of reinforcement learning in fine-tuning. arXiv preprint arXiv:2503.01067. Cited by: §3.2.
- Q. Wang, R. Ding, Y. Zeng, Z. Chen, L. Chen, S. Wang, P. Xie, F. Huang, and F. Zhao (2025) VRAG-rl: empower vision-perception-based rag for visually rich information understanding via iterative reasoning with reinforcement learning. arXiv preprint arXiv:2505.22019. Cited by: §1.
- R. Wu, X. Wang, J. Mei, P. Cai, D. Fu, C. Yang, L. Wen, X. Yang, Y. Shen, Y. Wang, et al. (2025) Evolver: self-evolving llm agents through an experience-driven lifecycle. arXiv preprint arXiv:2510.16079. Cited by: §1.
- M. Wulfmeier, M. Bloesch, N. Vieillard, A. Ahuja, J. Bornschein, S. Huang, A. Sokolov, M. Barnes, G. Desjardins, A. Bewley, et al. (2024) Imitating language via scalable inverse reinforcement learning. Advances in Neural Information Processing Systems 37, pp. 90714–90735. Cited by: §1.
- G. Xie, Y. Shi, H. Tian, T. Yao, and X. Zhang (2025) Capo: towards enhancing llm reasoning through verifiable generative credit assignment. arXiv e-prints, pp. arXiv–2508. Cited by: §1, §3.2.
- J. Yan, Y. Li, Z. Hu, Z. Wang, G. Cui, X. Qu, Y. Cheng, and Y. Zhang (2025) Learning to reason under off-policy guidance. arXiv preprint arXiv:2504.14945. Cited by: §2.
- A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. (2025) Qwen3 technical report. arXiv preprint arXiv:2505.09388. Cited by: §4.
- Q. Yu, Z. Zhang, R. Zhu, Y. Yuan, X. Zuo, Y. Yue, W. Dai, T. Fan, G. Liu, L. Liu, et al. (2025) Dapo: an open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476. Cited by: §2, §4.
- Y. Zeng, W. Huang, Z. Fang, S. Chen, Y. Shen, Y. Cai, X. Wang, Z. Yin, L. Chen, Z. Chen, et al. (2026) Vision-deepresearch benchmark: rethinking visual and textual search for multimodal large language models. arXiv preprint arXiv:2602.02185. Cited by: §1.
- Y. Zeng, W. Huang, S. Huang, X. Bao, Y. Qi, Y. Zhao, Q. Wang, L. Chen, Z. Chen, H. Chen, et al. (2025a) Agentic jigsaw interaction learning for enhancing visual perception and reasoning in vision-language models. arXiv preprint arXiv:2510.01304. Cited by: §1.
- Y. Zeng, Y. Qi, Y. Zhao, X. Bao, L. Chen, Z. Chen, S. Huang, J. Zhao, and F. Zhao (2025b) Enhancing large vision-language models with ultra-detailed image caption generation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 26703–26729. Cited by: §1.
- K. Zhang, X. Chen, B. Liu, T. Xue, Z. Liao, Z. Liu, X. Wang, Y. Ning, Z. Chen, X. Fu, et al. (2025a) Agent learning via early experience. arXiv preprint arXiv:2510.08558. Cited by: §1.
- K. Zhang, Y. Zuo, B. He, Y. Sun, R. Liu, C. Jiang, Y. Fan, K. Tian, G. Jia, P. Li, et al. (2025b) A survey of reinforcement learning for large reasoning models. arXiv preprint arXiv:2509.08827. Cited by: §2.
- K. Zhang, A. Lv, J. Li, Y. Wang, F. Wang, H. Hu, and R. Yan (2025c) StepHint: multi-level stepwise hints enhance reinforcement learning to reason. arXiv preprint arXiv:2507.02841. Cited by: §1, §2.
- X. Zhang, S. Wu, Y. Zhu, H. Tan, S. Yu, Z. He, and J. Jia (2025d) Scaf-grpo: scaffolded group relative policy optimization for enhancing llm reasoning. arXiv preprint arXiv:2510.19807. Cited by: §1, §2.
- C. Zheng, S. Liu, M. Li, X. Chen, B. Yu, C. Gao, K. Dang, Y. Liu, R. Men, A. Yang, et al. (2025) Group sequence policy optimization. arXiv preprint arXiv:2507.18071. Cited by: §2.
Appendix A Result of Performance Evolution
As illustrated in Figures 6, 7, and 8, we visualize the performance evolution of models with different scales (Qwen3-4B-Base, Qwen3-8B-Base, and Qwen3-14B-Base) across multiple benchmarks throughout training. It can be observed that MEL consistently outperforms standard GRPO in terms of average performance on all benchmarks.
<details>
<summary>x7.png Details</summary>
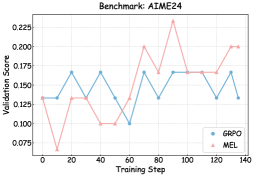
### Visual Description
## Line Chart: Validation Scores for GRPO and MEL on AIME24 Benchmark
### Overview
The image is a line chart comparing the validation performance of two methods, **GRPO** (blue line) and **MEL** (red line), across 140 training steps on the AIME24 benchmark. The y-axis represents the validation score (ranging from 0.075 to 0.225), while the x-axis represents training steps (0 to 140). Both lines exhibit fluctuating trends, with **MEL** showing sharper peaks and troughs compared to **GRPO**.
---
### Components/Axes
- **X-axis (Training Step)**: Labeled "Training Step," with markers at intervals of 20 (0, 20, 40, ..., 140).
- **Y-axis (Validation Score)**: Labeled "Validation Score," with increments of 0.025 (0.075, 0.100, ..., 0.225).
- **Legend**: Located at the bottom-right corner, with:
- **Blue line**: Labeled "GRPO"
- **Red line**: Labeled "MEL"
---
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Phase (Steps 0–40)**:
- Starts at ~0.13, rises to ~0.17 at step 20, then dips to ~0.12 at step 40.
- **Mid-Phase (Steps 60–100)**:
- Peaks at ~0.17 at step 80, dips to ~0.12 at step 100, then stabilizes around ~0.17.
- **Final Phase (Steps 120–140)**:
- Drops to ~0.13 at step 120, then remains flat.
#### MEL (Red Line)
- **Initial Phase (Steps 0–60)**:
- Starts at ~0.13, plunges to ~0.075 at step 10, recovers to ~0.13 at step 60.
- **Mid-Phase (Steps 80–120)**:
- Spikes to ~0.225 at step 90, then stabilizes at ~0.17 until step 120.
- **Final Phase (Steps 120–140)**:
- Rises sharply to ~0.20 at step 130, then plateaus.
---
### Key Observations
1. **MEL's Volatility**:
- MEL exhibits extreme fluctuations, with a dramatic drop to 0.075 at step 10 and a peak of 0.225 at step 90.
2. **GRPO's Stability**:
- GRPO shows moderate oscillations but maintains a narrower range (~0.12–0.17).
3. **Crossing Points**:
- The lines intersect near step 60 (~0.13) and step 100 (~0.17).
4. **Final Performance**:
- By step 140, MEL outperforms GRPO (0.20 vs. 0.13).
---
### Interpretation
- **Performance Trade-offs**:
- MEL achieves higher validation scores in later stages but with significant instability, suggesting potential overfitting or sensitivity to training dynamics.
- GRPO demonstrates robustness but lags in final performance, indicating a conservative learning strategy.
- **Benchmark Insights**:
- The AIME24 benchmark likely tests complex reasoning, where MEL's peaks may reflect breakthroughs in solving harder problems, while GRPO's consistency suggests reliability for simpler tasks.
- **Anomalies**:
- MEL's sharp drop at step 10 could indicate an initial misconfiguration or catastrophic forgetting.
- The final spike in MEL at step 130 might signal a late-stage optimization surge.
This analysis highlights the need to balance exploration (MEL) and exploitation (GRPO) in training strategies for high-stakes benchmarks.
</details>
<details>
<summary>x8.png Details</summary>
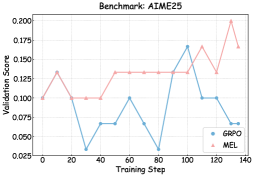
### Visual Description
## Line Graph: Benchmark: AIME25
### Overview
The image is a line graph comparing the validation scores of two methods, **GRPO** (blue) and **MEL** (pink), across training steps (0–140). The y-axis represents validation scores (0.025–0.200), while the x-axis represents training steps. The graph highlights performance trends, with MEL generally outperforming GRPO in later stages.
---
### Components/Axes
- **Title**: "Benchmark: AIME25" (top center).
- **X-axis**: "Training Step" (0–140, increments of 20).
- **Y-axis**: "Validation Score" (0.025–0.200, increments of 0.025).
- **Legend**: Bottom-right corner, with:
- **Blue**: GRPO
- **Pink**: MEL
---
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Phase (0–30 steps)**: Starts at 0.100, dips sharply to 0.025 at step 30.
- **Mid-Phase (30–80 steps)**: Fluctuates between 0.025 and 0.100, with a peak at 0.100 at step 60.
- **Late Phase (80–140 steps)**: Rises to 0.175 at step 100, then drops to 0.100 at step 120, ending at 0.075 at step 140.
#### MEL (Pink Line)
- **Initial Phase (0–40 steps)**: Starts at 0.100, peaks at 0.130 at step 10, remains flat until step 40.
- **Mid-Phase (40–80 steps)**: Rises to 0.130 at step 50, stays flat until step 80.
- **Late Phase (80–140 steps)**: Jumps to 0.175 at step 110, drops to 0.130 at step 120, peaks at 0.200 at step 130, and ends at 0.165 at step 140.
---
### Key Observations
1. **GRPO Volatility**: The blue line exhibits significant fluctuations, with sharp dips (e.g., 0.025 at steps 30 and 80) and peaks (0.175 at step 100).
2. **MEL Stability**: The pink line shows smoother trends, with gradual increases and fewer extreme drops.
3. **Performance Divergence**: MEL outperforms GRPO in later training steps (e.g., 0.200 at step 130 vs. GRPO’s 0.175 at step 100).
4. **Final Scores**: At step 140, MEL ends at 0.165, while GRPO ends at 0.075.
---
### Interpretation
- **Model Reliability**: MEL demonstrates greater consistency and higher validation scores, suggesting it is more robust for the AIME25 benchmark.
- **GRPO Instability**: The blue line’s volatility may indicate challenges in learning or overfitting, particularly in early and mid-training phases.
- **Late-Stage Advantage**: MEL’s sharp rise after step 100 implies it adapts better to complex patterns in later training stages.
- **Practical Implications**: For applications requiring stable performance, MEL is preferable. GRPO’s fluctuations might necessitate further tuning or regularization.
---
### Spatial Grounding
- **Legend**: Bottom-right corner, clearly associating colors with methods.
- **Data Points**: All values align with legend colors (e.g., pink for MEL, blue for GRPO).
- **Axis Labels**: Centered and legible, with numerical increments explicitly marked.
---
### Content Details
- **GRPO Data Points**:
- 0: 0.100
- 10: 0.100
- 20: 0.100
- 30: 0.025
- 40: 0.075
- 50: 0.075
- 60: 0.100
- 70: 0.075
- 80: 0.025
- 90: 0.100
- 100: 0.175
- 110: 0.100
- 120: 0.100
- 130: 0.075
- 140: 0.075
- **MEL Data Points**:
- 0: 0.100
- 10: 0.130
- 20: 0.130
- 30: 0.130
- 40: 0.130
- 50: 0.130
- 60: 0.130
- 70: 0.130
- 80: 0.130
- 90: 0.130
- 100: 0.130
- 110: 0.175
- 120: 0.130
- 130: 0.200
- 140: 0.165
---
### Final Notes
The graph emphasizes the trade-off between stability and performance. While GRPO shows potential in mid-training, MEL’s late-stage dominance suggests it is better suited for tasks requiring sustained accuracy. Further analysis could explore hyperparameter tuning for GRPO to mitigate its volatility.
</details>
<details>
<summary>x9.png Details</summary>
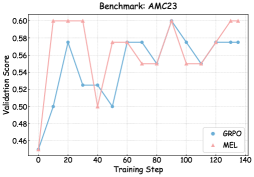
### Visual Description
## Line Chart: Benchmark AMC23 Validation Scores
### Overview
The image is a line chart comparing the validation scores of two methods, **GRPO** (blue) and **MEL** (red), across 140 training steps on the AMC23 benchmark. The y-axis represents validation scores (0.46–0.60), and the x-axis represents training steps (0–140). Both lines exhibit fluctuating trends with peaks and troughs, converging at later steps.
---
### Components/Axes
- **X-axis (Training Step)**: Labeled "Training Step," ranging from 0 to 140 in increments of 20.
- **Y-axis (Validation Score)**: Labeled "Validation Score," ranging from 0.46 to 0.60 in increments of 0.02.
- **Legend**: Located in the **bottom-right corner**, with:
- **Blue circles**: GRPO
- **Red triangles**: MEL
---
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Phase (0–20 steps)**: Starts at ~0.46, rises sharply to ~0.58 by step 20.
- **Mid-Phase (20–80 steps)**: Drops to ~0.52 at step 40, rises to ~0.58 at step 60, then dips to ~0.54 at step 80.
- **Late Phase (80–140 steps)**: Peaks at ~0.60 at step 100, stabilizes around ~0.58 by step 140.
#### MEL (Red Line)
- **Initial Phase (0–20 steps)**: Starts at ~0.46, rises sharply to ~0.60 by step 20.
- **Mid-Phase (20–80 steps)**: Drops to ~0.50 at step 40, rises to ~0.58 at step 60, dips to ~0.54 at step 80.
- **Late Phase (80–140 steps)**: Peaks at ~0.60 at step 100, stabilizes around ~0.58 by step 140.
---
### Key Observations
1. **Initial Divergence**: Both methods start similarly but diverge sharply after step 20, with MEL achieving a higher peak (~0.60) earlier.
2. **Volatility**: GRPO exhibits more frequent fluctuations (e.g., step 40–60), while MEL has sharper drops (e.g., step 20–40).
3. **Convergence**: Both lines stabilize near ~0.58 by step 140, suggesting similar long-term performance.
4. **Outliers**:
- GRPO’s peak at step 100 (~0.60) is the highest validation score.
- MEL’s drop to ~0.50 at step 40 is the lowest point for either method.
---
### Interpretation
The chart demonstrates that both GRPO and MEL improve validation scores over training steps, but with distinct patterns:
- **GRPO** shows gradual, sustained improvement with moderate volatility, peaking at step 100.
- **MEL** achieves higher early gains but experiences sharper declines, stabilizing later.
- The convergence at step 140 implies that extended training mitigates initial disparities, though GRPO’s trajectory suggests better consistency in later stages.
This analysis highlights trade-offs between early performance (MEL) and long-term stability (GRPO) in the AMC23 benchmark.
</details>
<details>
<summary>x10.png Details</summary>
### Visual Description
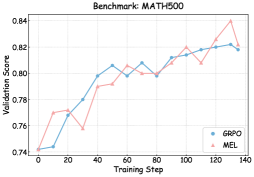
## Line Graph: Benchmark MATH500 Validation Scores
### Overview
The image shows a line graph comparing the validation scores of two models (GRPO and MEL) across training steps on the MATH500 benchmark. The graph spans 140 training steps with validation scores ranging from 0.74 to 0.84.
### Components/Axes
- **X-axis**: Training Step (0 to 140, increments of 20)
- **Y-axis**: Validation Score (0.74 to 0.84, increments of 0.02)
- **Legend**:
- Blue line: GRPO
- Red line: MEL
- **Title**: "Benchmark: MATH500" (top center)
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at (0, 0.74)
- Gradual upward trend with minor fluctuations
- Key points:
- (20, 0.77)
- (40, 0.795)
- (60, 0.80)
- (80, 0.80)
- (100, 0.815)
- (120, 0.82)
- (140, 0.82)
2. **MEL (Red Line)**:
- Starts at (0, 0.74)
- More volatile with sharp rises and dips
- Key points:
- (20, 0.77)
- (30, 0.76)
- (40, 0.79)
- (50, 0.805)
- (60, 0.81)
- (70, 0.80)
- (80, 0.80)
- (90, 0.81)
- (100, 0.82)
- (110, 0.81)
- (120, 0.84)
- (140, 0.82)
### Key Observations
1. Both models start at identical validation scores (0.74) at step 0.
2. MEL shows higher volatility, with a notable dip to 0.76 at step 30 and a peak of 0.84 at step 120.
3. GRPO demonstrates steadier growth, maintaining a consistent upward trajectory.
4. Both models converge at step 80 with identical scores (0.80).
5. MEL achieves the highest validation score (0.84) at step 120 but drops to 0.82 by step 140.
6. GRPO maintains a stable score of 0.82 from step 120 onward.
### Interpretation
The data suggests:
- **MEL** may have higher potential peak performance (0.84) but with instability, as evidenced by its fluctuations and post-peak decline.
- **GRPO** shows more reliable and consistent improvement, maintaining a stable 0.82 score after step 100.
- The convergence at step 80 indicates both models achieve similar baseline performance by mid-training.
- MEL's late-stage peak (step 120) might indicate overfitting or a temporary performance boost, given its subsequent drop.
The graph highlights a trade-off between stability (GRPO) and potential high performance with risk (MEL) in model training dynamics.
</details>
<details>
<summary>x11.png Details</summary>
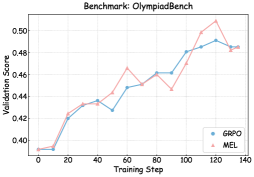
### Visual Description
## Line Chart: Benchmark: OlympiadBench
### Overview
The chart compares the validation performance of two models, GRPO and MEL, across training steps on the OlympiadBench benchmark. Both models show increasing validation scores over time, with GRPO consistently outperforming MEL after ~60 training steps.
### Components/Axes
- **X-axis**: Training Step (0 to 140, increments of 20)
- **Y-axis**: Validation Score (0.40 to 0.50, increments of 0.02)
- **Legend**:
- Blue line: GRPO
- Red line: MEL
- **Title**: "Benchmark: OlympiadBench" (top center)
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at ~0.40 validation score at step 0.
- Sharp rise to ~0.43 by step 20.
- Gradual increase to ~0.46 by step 60.
- Steeper ascent to peak at ~0.49 by step 120.
- Slight decline to ~0.48 by step 140.
- Key inflection: Crosses MEL line at ~step 60.
2. **MEL (Red Line)**:
- Starts at ~0.40 validation score at step 0.
- Slower rise to ~0.43 by step 20.
- Gradual increase to ~0.46 by step 60.
- Sharp peak at ~0.50 by step 120.
- Steep decline to ~0.48 by step 140.
- Key inflection: Crossed by GRPO at ~step 60.
### Key Observations
- **Performance Divergence**: GRPO surpasses MEL after ~60 steps, maintaining a ~0.02 advantage by step 140.
- **Volatility**: MEL exhibits sharper fluctuations (e.g., steep drop post-step 120), while GRPO shows smoother progression.
- **Convergence**: Both models plateau near ~0.48–0.49 validation score by step 140.
### Interpretation
The data suggests GRPO is more effective for this benchmark, likely due to superior optimization or architectural advantages. The MEL model’s post-120-step decline may indicate overfitting or instability. The initial dip in GRPO’s performance (~step 40) could reflect temporary training instability, but its recovery aligns with sustained improvement. The convergence at higher steps implies both models reach practical limits, but GRPO’s stability makes it preferable for deployment.
</details>
<details>
<summary>x12.png Details</summary>
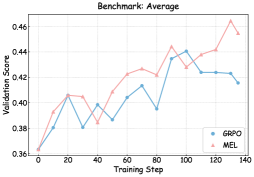
### Visual Description
## Line Graph: Benchmark: Average
### Overview
The image is a line graph comparing the validation scores of two models, GRPO and MEL, across training steps. The x-axis represents training steps (0–140), and the y-axis represents validation scores (0.36–0.46). Two lines are plotted: a blue line for GRPO and a red line for MEL.
### Components/Axes
- **Title**: "Benchmark: Average"
- **X-axis**: "Training Step" (0–140, increments of 20)
- **Y-axis**: "Validation Score" (0.36–0.46, increments of 0.02)
- **Legend**: Located in the bottom-right corner, with:
- Blue circle labeled "GRPO"
- Red triangle labeled "MEL"
### Detailed Analysis
#### GRPO (Blue Line)
- **Data Points**:
- 0: 0.36
- 20: 0.38
- 40: 0.38
- 60: 0.40
- 80: 0.41
- 100: 0.43
- 120: 0.42
- 140: 0.41
- **Trend**: Starts at 0.36, rises to a peak of 0.43 at step 100, then declines to 0.41 by step 140. Shows moderate fluctuations.
#### MEL (Red Line)
- **Data Points**:
- 0: 0.36
- 20: 0.39
- 40: 0.40
- 60: 0.41
- 80: 0.42
- 100: 0.43
- 120: 0.44
- 140: 0.45
- **Trend**: Starts at 0.36, steadily increases to 0.45 by step 140. Shows consistent upward growth with minimal fluctuations.
### Key Observations
1. **MEL Outperforms GRPO**: MEL consistently achieves higher validation scores across most training steps, especially after step 80.
2. **GRPO Volatility**: GRPO exhibits sharper fluctuations, with a peak at step 100 followed by a decline.
3. **Final Scores**: At step 140, MEL reaches 0.45, while GRPO drops to 0.41.
### Interpretation
The graph suggests that MEL demonstrates more stable and effective learning over training steps compared to GRPO. While GRPO briefly surpasses MEL around step 100, its subsequent decline indicates potential instability or overfitting. MEL’s steady ascent implies robust performance, making it the superior model for this benchmark. The divergence in trends highlights differences in optimization strategies or architectural strengths between the two models.
</details>
Figure 6: Performance evolution of GRPO and MEL on Qwen3-4B-Base across training steps on multiple benchmarks.
<details>
<summary>x13.png Details</summary>
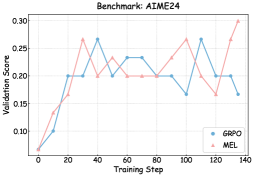
### Visual Description
## Line Chart: AIME24 Benchmark Comparison
### Overview
The image is a line chart comparing the validation scores of two methods, **GRPO** (blue line) and **MEL** (red line), across 140 training steps. The chart shows fluctuating performance trends for both methods, with GRPO exhibiting sharper peaks and valleys, while MEL demonstrates more gradual changes.
### Components/Axes
- **X-axis (Training Step)**: Ranges from 0 to 140 in increments of 20.
- **Y-axis (Validation Score)**: Ranges from 0.05 to 0.30 in increments of 0.05.
- **Legend**: Located in the bottom-right corner, with:
- **Blue line**: Labeled "GRPO"
- **Red line**: Labeled "MEL"
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Trend**: Starts at ~0.05 (step 0), rises sharply to ~0.20 by step 20.
- **Peaks**:
- Step 20: ~0.20
- Step 40: ~0.27
- Step 110: ~0.27
- **Valleys**:
- Step 0: ~0.05
- Step 10: ~0.10
- Step 100: ~0.17
- Step 140: ~0.17
- **Final Value**: Ends at ~0.17 (step 140).
#### MEL (Red Line)
- **Initial Trend**: Starts at ~0.05 (step 0), rises to ~0.13 by step 10.
- **Peaks**:
- Step 30: ~0.27
- Step 100: ~0.27
- Step 140: ~0.30
- **Valleys**:
- Step 0: ~0.05
- Step 10: ~0.13
- Step 120: ~0.17
- **Final Value**: Ends at ~0.30 (step 140).
### Key Observations
1. **Divergence in Performance**: MEL outperforms GRPO in the final training step (0.30 vs. 0.17).
2. **Volatility**: GRPO shows more pronounced fluctuations (e.g., sharp drops at steps 100 and 140).
3. **Stability**: MEL maintains a steadier upward trend after step 100.
4. **Early Similarity**: Both methods start with similar low scores but diverge after step 40.
### Interpretation
The chart suggests that **MEL achieves higher validation scores in later training stages**, potentially indicating better long-term optimization or robustness. GRPO’s volatility might reflect overfitting or instability in later phases. The final score gap (0.30 vs. 0.17) highlights MEL’s superiority in this benchmark. The legend’s placement and color coding (blue for GRPO, red for MEL) are consistent with the line placements, confirming accurate data representation.
</details>
<details>
<summary>x14.png Details</summary>
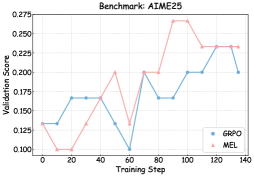
### Visual Description
## Line Chart: Benchmark: AIME25
### Overview
The chart compares the validation scores of two models, **GRPO** (blue line) and **MEL** (red line), across 140 training steps. Both lines exhibit fluctuating trends with notable peaks and troughs, suggesting dynamic performance changes during training.
### Components/Axes
- **X-axis (Training Step)**: Ranges from 0 to 140 in increments of 20.
- **Y-axis (Validation Score)**: Ranges from 0.100 to 0.275 in increments of 0.025.
- **Legend**: Located in the bottom-right corner, with:
- **GRPO**: Blue line (circle markers).
- **MEL**: Red line (triangle markers).
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Phase (0–40 steps)**: Starts at ~0.13, rises to ~0.17 by step 20, then plateaus until step 40 (~0.17).
- **Mid-Phase (40–80 steps)**: Drops sharply to ~0.10 at step 60, then rises to ~0.20 by step 80.
- **Final Phase (80–140 steps)**: Stabilizes around ~0.20, with minor fluctuations.
#### MEL (Red Line)
- **Initial Phase (0–40 steps)**: Begins at ~0.12, dips to ~0.10 at step 20, then rises to ~0.20 by step 40.
- **Mid-Phase (40–80 steps)**: Peaks at ~0.25 at step 80, then drops to ~0.12 at step 60.
- **Final Phase (80–140 steps)**: Rises to ~0.26 at step 100, dips slightly to ~0.23 by step 140.
### Key Observations
1. **Crossing Points**: The lines intersect near step 60, where GRPO reaches its lowest point (~0.10) and MEL recovers from a dip.
2. **Peaks**: MEL achieves the highest validation score (~0.26) at step 100, while GRPO peaks at ~0.20 at step 80.
3. **Volatility**: MEL shows greater variability, with sharper rises and falls compared to GRPO’s more stable trajectory after step 80.
4. **Final Values**: At step 140, GRPO stabilizes at ~0.20, while MEL ends at ~0.23.
### Interpretation
The chart highlights trade-offs between the two models:
- **GRPO** demonstrates consistent performance after step 80, suggesting robustness in later training stages.
- **MEL** exhibits higher peaks but greater instability, potentially indicating overfitting or sensitivity to training dynamics. The sharp dip at step 60 may reflect a temporary setback or optimization challenge.
- The divergence at step 100 (MEL’s peak vs. GRPO’s plateau) suggests MEL may prioritize short-term gains over sustained performance, while GRPO balances stability and moderate improvement.
This analysis underscores the importance of model selection based on training objectives: MEL for high-risk, high-reward scenarios, and GRPO for reliable, steady progress.
</details>
<details>
<summary>x15.png Details</summary>
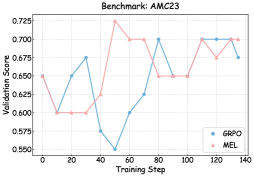
### Visual Description
## Line Graph: Benchmark AMC23 Performance Comparison
### Overview
The image displays a line graph comparing the validation scores of two models (GRPO and MEL) across 140 training steps. The graph shows fluctuating performance metrics with notable volatility in both series.
### Components/Axes
- **X-axis**: "Training Step" (0 to 140, increments of 20)
- **Y-axis**: "Validation Score" (0.550 to 0.725, increments of 0.025)
- **Legend**: Located in bottom-right corner
- Blue line: GRPO
- Pink line: MEL
- **Title**: "Benchmark: AMC23" (top-center)
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at 0.65 (step 0)
- Dips to 0.55 at step 40 (lowest point)
- Peaks at 0.70 at step 80
- Ends at 0.675 (step 140)
- Shows significant volatility with sharp rises/falling patterns
2. **MEL (Pink Line)**:
- Starts at 0.65 (step 0)
- Drops to 0.60 at step 20
- Spikes to 0.725 at step 40 (highest point)
- Stabilizes around 0.70 after step 100
- Ends at 0.70 (step 140)
- Exhibits more pronounced early fluctuations
### Key Observations
- Both models show **high volatility** in early training steps (0-60)
- **GRPO** demonstrates a **U-shaped pattern** with a trough at step 40
- **MEL** exhibits a **peak-valley-peak pattern** with maximum performance at step 40
- After step 100, both lines **converge** toward similar performance levels
- **Notable outlier**: MEL's spike to 0.725 at step 40 exceeds GRPO's maximum by 0.025
### Interpretation
The graph suggests:
1. **Initial Performance Divergence**: MEL shows stronger early gains but experiences a sharp decline after step 40, while GRPO maintains more consistent growth until step 80.
2. **Stabilization Phase**: Both models converge toward similar performance levels in later training steps, indicating potential equilibrium in their learning trajectories.
3. **Volatility Implications**: The pronounced fluctuations suggest possible overfitting risks or model sensitivity to hyperparameters during early training phases.
4. **Benchmark Context**: The AMC23 benchmark appears to test models' ability to maintain performance under varying training conditions, with both approaches showing comparable final effectiveness despite different learning curves.
The data implies that while MEL may offer short-term advantages, GRPO demonstrates better long-term stability. Further analysis would be needed to determine optimal training duration and model selection criteria for this specific benchmark.
</details>
<details>
<summary>x16.png Details</summary>
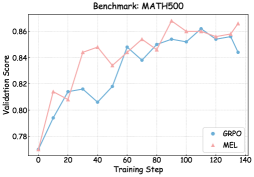
### Visual Description
## Line Graph: Benchmark MATH500 Validation Scores
### Overview
The image displays a line graph comparing the validation scores of two models (GRPO and MEL) across training steps on the MATH500 benchmark. The x-axis represents training steps (0–140), and the y-axis represents validation scores (0.78–0.86). Two data series are plotted: GRPO (blue line) and MEL (pink line).
### Components/Axes
- **X-axis**: "Training Step" (0–140, increments of 20)
- **Y-axis**: "Validation Score" (0.78–0.86, increments of 0.02)
- **Legend**: Located in the bottom-right corner, with:
- Blue circle labeled "GRPO"
- Pink triangle labeled "MEL"
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Phase**: Starts at 0.78 (step 0), rises sharply to 0.81 by step 20.
- **Mid-Phase**: Dips to 0.80 at step 40, then climbs to 0.84 by step 60.
- **Late Phase**: Peaks at 0.86 around step 100, stabilizes at ~0.85 by step 140.
- **Key Values**:
- Step 0: 0.78
- Step 20: 0.81
- Step 40: 0.80
- Step 60: 0.84
- Step 80: 0.85
- Step 100: 0.86
- Step 120: 0.85
- Step 140: 0.84
#### MEL (Pink Line)
- **Initial Phase**: Begins at 0.77 (step 0), jumps to 0.81 by step 20.
- **Mid-Phase**: Dips to 0.83 at step 40, rises to 0.85 by step 60.
- **Late Phase**: Peaks at 0.87 around step 90, fluctuates between 0.85–0.87 until step 140.
- **Key Values**:
- Step 0: 0.77
- Step 20: 0.81
- Step 40: 0.83
- Step 60: 0.85
- Step 80: 0.84
- Step 90: 0.87
- Step 110: 0.86
- Step 130: 0.85
- Step 140: 0.87
### Key Observations
1. **Trend Direction**: Both lines show an overall upward trend, but MEL exhibits greater volatility.
2. **Performance Gap**: MEL consistently outperforms GRPO in later stages (steps 80–140), with a maximum score of 0.87 vs. GRPO's 0.86.
3. **Volatility**: MEL's line has sharper peaks and troughs (e.g., drop from 0.87 at step 90 to 0.85 at step 110), while GRPO's trajectory is smoother.
4. **Convergence**: By step 140, both models plateau near 0.85–0.87, suggesting diminishing returns after extensive training.
### Interpretation
The graph demonstrates that MEL achieves higher validation scores on the MATH500 benchmark but with greater instability compared to GRPO. The MEL model's volatility might indicate overfitting or sensitivity to training dynamics, whereas GRPO's steadier progression suggests robustness. The convergence at later steps implies both models reach similar performance ceilings, but MEL's higher peaks could justify its use in scenarios prioritizing maximum accuracy despite variability. The initial dip in GRPO's score at step 40 may reflect a learning phase adjustment, while MEL's early rise highlights rapid early learning. These patterns underscore trade-offs between stability and peak performance in model selection.
</details>
<details>
<summary>x17.png Details</summary>
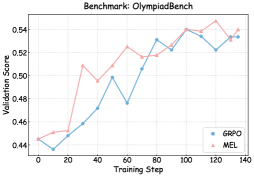
### Visual Description
## Line Chart: Benchmark: OlympiadBench
### Overview
The chart compares the validation scores of two methods, GRPO and MEL, across training steps (0–140) on the OlympiadBench benchmark. Both lines show an upward trend, with GRPO (blue) and MEL (pink) converging at higher scores as training progresses.
### Components/Axes
- **X-axis (Training Step)**: Labeled "Training Step," with markers at 0, 20, 40, 60, 80, 100, 120, and 140.
- **Y-axis (Validation Score)**: Labeled "Validation Score," ranging from 0.44 to 0.54 in increments of 0.02.
- **Legend**: Located in the bottom-right corner, associating:
- **Blue circles**: GRPO
- **Pink triangles**: MEL
### Detailed Analysis
#### GRPO (Blue Line)
- **Trend**: Starts at 0.44 (step 0), dips to 0.43 (step 10), then rises steadily to 0.53 (step 100), fluctuates slightly, and stabilizes near 0.53–0.54 by step 140.
- **Key Data Points**:
- Step 0: 0.44
- Step 10: 0.43
- Step 20: 0.45
- Step 40: 0.47
- Step 60: 0.48
- Step 80: 0.53
- Step 100: 0.54
- Step 120: 0.53
- Step 140: 0.53
#### MEL (Pink Line)
- **Trend**: Begins at 0.44 (step 0), rises sharply to 0.51 (step 20), fluctuates between 0.50–0.54, peaks at 0.55 (step 120), then dips slightly to 0.54 (step 140).
- **Key Data Points**:
- Step 0: 0.44
- Step 10: 0.45
- Step 20: 0.51
- Step 40: 0.49
- Step 60: 0.52
- Step 80: 0.52
- Step 100: 0.54
- Step 120: 0.55
- Step 140: 0.54
### Key Observations
1. **Initial Divergence**: MEL starts with a sharper increase than GRPO (e.g., 0.44 → 0.51 at step 20 vs. GRPO’s 0.44 → 0.45).
2. **Convergence**: Both methods plateau near 0.53–0.54 by step 100, with MEL briefly exceeding GRPO at step 120 (0.55 vs. 0.53).
3. **Volatility**: MEL exhibits more fluctuations (e.g., drop from 0.54 to 0.52 at step 80), while GRPO shows steadier growth.
4. **Final Scores**: At step 140, both methods achieve ~0.53–0.54, with MEL marginally higher.
### Interpretation
The data suggests that both GRPO and MEL improve validation performance with training, but MEL demonstrates higher variability and occasional peaks. The convergence at later steps implies similar efficacy for complex tasks, though MEL’s transient superiority at step 120 may indicate sensitivity to specific training dynamics. The initial dip in GRPO’s score (step 10) could reflect an adaptation phase. Overall, the chart highlights trade-offs between stability (GRPO) and exploratory performance (MEL) in optimization benchmarks.
</details>
<details>
<summary>x18.png Details</summary>
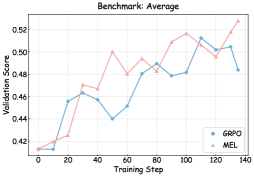
### Visual Description
## Line Chart: Benchmark: Average
### Overview
The chart compares the validation scores of two methods, **GRPO** (blue line) and **MEL** (pink line), across 140 training steps. Both lines exhibit fluctuating trends, with MEL generally outperforming GRPO in later stages.
### Components/Axes
- **X-axis (Training Step)**: Ranges from 0 to 140 in increments of 20.
- **Y-axis (Validation Score)**: Ranges from 0.42 to 0.52 in increments of 0.02.
- **Legend**: Located in the bottom-right corner.
- **GRPO**: Blue line with circular markers.
- **MEL**: Pink line with triangular markers.
### Detailed Analysis
#### GRPO (Blue Line)
- **Trend**: Starts at 0.42 (step 0), rises sharply to 0.46 (step 20), dips to 0.44 (step 50), then fluctuates between 0.48–0.51, ending at 0.485 (step 140).
- **Key Points**:
- Step 0: 0.42
- Step 20: 0.46
- Step 30: 0.465
- Step 50: 0.44
- Step 70: 0.48
- Step 80: 0.49
- Step 100: 0.48
- Step 110: 0.51
- Step 120: 0.50
- Step 140: 0.485
#### MEL (Pink Line)
- **Trend**: Begins at 0.42 (step 0), rises to 0.47 (step 30), dips to 0.465 (step 40), then climbs to 0.525 (step 140), with peaks at 0.515 (step 90) and 0.52 (step 130).
- **Key Points**:
- Step 0: 0.42
- Step 20: 0.425
- Step 30: 0.47
- Step 40: 0.465
- Step 50: 0.48
- Step 60: 0.495
- Step 70: 0.485
- Step 80: 0.51
- Step 90: 0.515
- Step 100: 0.515
- Step 110: 0.505
- Step 120: 0.51
- Step 140: 0.525
### Key Observations
1. **Initial Divergence**: MEL surpasses GRPO around step 30, maintaining a higher validation score thereafter.
2. **Fluctuations**: Both lines show volatility, but MEL’s peaks are consistently higher after step 80.
3. **Final Performance**: MEL ends at 0.525 (step 140), while GRPO ends at 0.485, a 0.04 difference.
4. **Crossings**: The lines intersect multiple times (e.g., steps 30, 50, 80), indicating shifting performance dynamics.
### Interpretation
- **Performance Comparison**: MEL demonstrates superior validation scores in later training stages, suggesting better generalization or optimization efficiency.
- **Volatility**: GRPO’s fluctuations may indicate instability or sensitivity to training noise, whereas MEL’s steadier ascent implies robustness.
- **Practical Implications**: If validation score is the primary metric, MEL appears more effective for this benchmark. However, GRPO’s earlier peaks (e.g., step 110) suggest potential for rapid improvement under specific conditions.
- **Uncertainty**: Approximate values (e.g., 0.485 vs. 0.525) reflect visual estimation from the chart; exact numerical data is not provided.
### Spatial Grounding
- **Legend**: Bottom-right corner, clearly associating colors with labels.
- **Line Placement**: GRPO (blue) and MEL (pink) occupy distinct paths, with MEL consistently trending upward after step 30.
</details>
Figure 7: Performance evolution of GRPO and MEL on Qwen3-8B-Base across training steps on multiple benchmarks.
<details>
<summary>x19.png Details</summary>
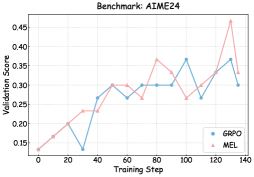
### Visual Description
## Line Graph: Benchmark: AIME24
### Overview
The image is a line graph comparing the validation performance of two models, **GRPO** (blue) and **MEL** (red), over 140 training steps on the AIME24 benchmark. The x-axis represents training steps (0–140), and the y-axis represents validation scores (0.15–0.45). Both lines exhibit fluctuating trends, with MEL achieving a higher peak validation score than GRPO.
---
### Components/Axes
- **Title**: "Benchmark: AIME24" (top center).
- **X-axis**: "Training Step" (0–140, increments of 20).
- **Y-axis**: "Validation Score" (0.15–0.45, increments of 0.05).
- **Legend**: Located at the bottom-right corner, with:
- **GRPO**: Blue line with circular markers.
- **MEL**: Red line with triangular markers.
---
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Trend**: Starts at ~0.13 (step 0), rises sharply to ~0.27 by step 40.
- **Mid-Training**: Fluctuates between ~0.27 and ~0.30 from steps 60–100.
- **Late Training**: Peaks at ~0.37 around step 100, then drops to ~0.30 by step 140.
- **Key Data Points**:
- Step 0: ~0.13
- Step 20: ~0.20
- Step 40: ~0.27
- Step 80: ~0.30
- Step 100: ~0.37
- Step 140: ~0.30
#### MEL (Red Line)
- **Initial Trend**: Starts at ~0.13 (step 0), rises gradually to ~0.24 by step 40.
- **Mid-Training**: Peaks at ~0.36 around step 80, then dips to ~0.27 by step 100.
- **Late Training**: Surges to ~0.46 around step 130, then declines to ~0.33 by step 140.
- **Key Data Points**:
- Step 0: ~0.13
- Step 20: ~0.20
- Step 40: ~0.24
- Step 80: ~0.36
- Step 100: ~0.27
- Step 130: ~0.46
- Step 140: ~0.33
---
### Key Observations
1. **Performance Divergence**: MEL outperforms GRPO in the final training steps, achieving a peak validation score of ~0.46 (step 130) vs. GRPO’s ~0.37 (step 100).
2. **Volatility**: Both lines show fluctuations, but MEL’s later-stage volatility is more pronounced (e.g., sharp drop from 0.46 to 0.33 between steps 130–140).
3. **Early-Stage Similarity**: Both models start with similar performance (~0.13 at step 0) but diverge after step 40.
---
### Interpretation
The graph suggests that **MEL** is more effective for the AIME24 benchmark in later training stages, potentially due to better optimization or architecture suited to the task. The sharp late-stage peak for MEL may indicate a "late bloomer" effect, where performance improves significantly after extensive training. However, the subsequent drop at step 140 could signal overfitting or instability. GRPO’s earlier peak and subsequent decline might reflect a trade-off between early gains and long-term stability. These trends highlight the importance of training duration and model selection for benchmark performance.
</details>
<details>
<summary>x20.png Details</summary>
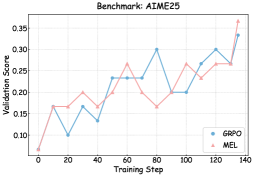
### Visual Description
## Line Chart: AIME25 Benchmark Validation Scores
### Overview
The chart compares the validation performance of two methods, **GRPO** (blue line) and **MEL** (red line), across 140 training steps on the AIME25 benchmark. Both methods exhibit fluctuating performance, with MEL achieving a slightly higher final validation score despite greater volatility.
### Components/Axes
- **X-axis (Training Step)**: Ranges from 0 to 140 in increments of 20.
- **Y-axis (Validation Score)**: Ranges from 0.05 to 0.35 in increments of 0.05.
- **Legend**: Located in the bottom-right corner, with:
- **Blue line**: GRPO
- **Red line**: MEL
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at ~0.05 at step 0.
- Dips to ~0.10 at step 20, then rises to ~0.17 at step 40.
- Peaks at ~0.30 at step 80, followed by a drop to ~0.20 at step 100.
- Final score: ~0.34 at step 140.
- **Trend**: Overall upward trajectory with mid-training volatility.
2. **MEL (Red Line)**:
- Begins at ~0.05 at step 0.
- Rises to ~0.17 at step 40, peaks at ~0.26 at step 60.
- Drops to ~0.16 at step 80, then surges to ~0.27 at step 100.
- Final score: ~0.36 at step 140.
- **Trend**: Highly volatile with two major peaks and sharper fluctuations.
### Key Observations
- **Final Performance**: MEL outperforms GRPO by ~0.02 in the last training step.
- **Volatility**: MEL shows larger swings (e.g., ~0.10 drops/rises) compared to GRPO’s more gradual changes.
- **Early Training**: Both methods start similarly but diverge after step 40.
- **Mid-Training Dip**: GRPO’s performance drops sharply at step 80, while MEL recovers strongly.
### Interpretation
The data suggests that **MEL achieves higher peak performance** but with greater instability, whereas **GRPO demonstrates steadier improvement** over time. The final scores are close, but MEL’s late-stage surge indicates potential for higher rewards despite its erratic behavior. The AIME25 benchmark likely tests complex reasoning, where MEL’s ability to exploit training dynamics (e.g., late-stage optimization) may explain its edge. However, GRPO’s consistency could be preferable in scenarios requiring reliability over peak performance.
</details>
<details>
<summary>x21.png Details</summary>
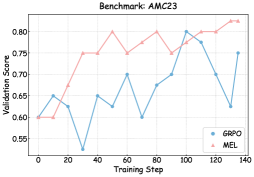
### Visual Description
## Line Chart: Benchmark: AMC23
### Overview
The image is a line chart comparing the validation scores of two models, **GRPO** (blue) and **MEL** (pink), across training steps (0 to 140). The y-axis represents validation scores (0.55 to 0.80), while the x-axis represents training steps. The chart highlights performance trends over time, with notable fluctuations and convergence patterns.
---
### Components/Axes
- **Title**: "Benchmark: AMC23" (top center).
- **X-axis**: "Training Step" (0 to 140, increments of 20).
- **Y-axis**: "Validation Score" (0.55 to 0.80, increments of 0.05).
- **Legend**: Located in the bottom-right corner, with:
- **GRPO**: Blue line with circular markers.
- **MEL**: Pink line with triangular markers.
---
### Detailed Analysis
#### GRPO (Blue Line)
- **Initial Phase (0–30 steps)**: Starts at 0.60, rises to 0.65 at step 10, then drops sharply to 0.55 at step 30.
- **Mid-Phase (30–100 steps)**: Recovers to 0.65 at step 40, peaks at 0.70 at step 60, dips to 0.60 at step 70, then rises to 0.70 at step 80.
- **Late Phase (100–140 steps)**: Peaks at 0.80 at step 100, drops to 0.70 at step 120, then rises to 0.75 at step 140.
#### MEL (Pink Line)
- **Initial Phase (0–30 steps)**: Starts at 0.60, rises steadily to 0.75 by step 30.
- **Mid-Phase (30–100 steps)**: Peaks at 0.80 at step 80, dips slightly to 0.75 at step 90, then stabilizes at 0.80 by step 100.
- **Late Phase (100–140 steps)**: Maintains 0.80 until step 120, then rises to 0.82 at step 140.
---
### Key Observations
1. **MEL outperforms GRPO** in validation score after step 80, maintaining higher scores (0.80–0.82) compared to GRPO's 0.70–0.75.
2. **GRPO exhibits volatility**, with sharp drops (e.g., step 30) and fluctuations, while **MEL shows smoother growth**.
3. **Convergence**: Both models improve over time, but MEL achieves higher final scores (0.82 vs. 0.75 for GRPO).
---
### Interpretation
The chart suggests that **MEL is more stable and efficient** in the AMC23 benchmark, achieving higher validation scores with fewer fluctuations. GRPO's volatility may indicate sensitivity to training dynamics or suboptimal hyperparameters. The divergence after step 80 highlights MEL's superior scalability or architectural advantages. These trends could inform model selection for similar tasks, emphasizing the importance of stability in validation performance.
</details>
<details>
<summary>x22.png Details</summary>
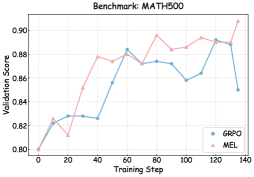
### Visual Description
## Line Graph: MATH500 Benchmark Validation Scores
### Overview
The image displays a line graph comparing the validation scores of two optimization methods (GRPO and MEL) across 140 training steps on the MATH500 benchmark. The graph shows fluctuating performance trends with notable divergence between the two methods in later stages.
### Components/Axes
- **X-axis**: Training Step (0 to 140, increments of 20)
- **Y-axis**: Validation Score (0.80 to 0.90, increments of 0.02)
- **Legend**: Located in bottom-right corner
- Blue line: GRPO
- Pink line: MEL
- **Title**: "Benchmark: MATH500" (top-center)
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at 0.80 (training step 0)
- Peaks at 0.88 (training step 60)
- Experiences a sharp dip to 0.85 (training step 100)
- Final score: 0.85 (training step 140)
- Notable volatility between steps 80-120
2. **MEL (Pink Line)**:
- Starts at 0.80 (training step 0)
- Rapid ascent to 0.88 (training step 40)
- Maintains 0.88-0.89 range until step 120
- Final score: 0.90 (training step 140)
- Steady upward trend after step 80
### Key Observations
- MEL consistently outperforms GRPO after training step 60
- GRPO shows significant instability between steps 80-100
- Both methods start with identical performance at step 0
- MEL achieves 0.05 higher validation score than GRPO by final step
- GRPO's peak occurs earlier (step 60) vs MEL's sustained high performance
### Interpretation
The data suggests MEL demonstrates superior optimization stability and final performance on the MATH500 benchmark. The GRPO method's mid-training dip (step 100) indicates potential overfitting or parameter instability, while MEL's gradual ascent suggests more robust convergence properties. The 0.05 score difference at final step highlights MEL's effectiveness in maintaining high validation performance through extended training. This pattern aligns with MEL's theoretical advantages in gradient estimation for complex optimization landscapes.
</details>
<details>
<summary>x23.png Details</summary>
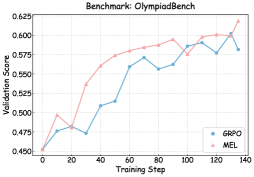
### Visual Description
## Line Chart: Benchmark: OlympiadBench
### Overview
The chart compares the validation scores of two models, **GRPO** (blue) and **MEL** (pink), across training steps (0–140) on the OlympiadBench benchmark. Both lines exhibit upward trends with fluctuations, but **MEL** consistently outperforms **GRPO** until the final step, where **GRPO** surpasses it slightly.
### Components/Axes
- **X-axis**: Training Step (0–140, increments of 20).
- **Y-axis**: Validation Score (0.450–0.625, increments of 0.025).
- **Legend**: Located in the bottom-right corner.
- **GRPO**: Blue line with circular markers.
- **MEL**: Pink line with triangular markers.
### Detailed Analysis
- **GRPO (Blue)**:
- Starts at ~0.45 (step 0).
- Rises to ~0.48 (step 20), dips to ~0.47 (step 40), then climbs to ~0.56 (step 60).
- Peaks at ~0.61 (step 140).
- Notable dip at step 80 (~0.56) and step 100 (~0.58).
- **MEL (Pink)**:
- Starts at ~0.45 (step 0).
- Rises to ~0.53 (step 40), ~0.58 (step 60), ~0.59 (step 80), ~0.60 (step 100), ~0.60 (step 120), and peaks at ~0.625 (step 140).
- Steady upward trend with minor fluctuations.
### Key Observations
1. **MEL** maintains a higher validation score than **GRPO** for most steps (e.g., ~0.58 vs. ~0.56 at step 80).
2. **GRPO** surpasses **MEL** only at the final step (140), with scores ~0.61 vs. ~0.625.
3. Both models show volatility in mid-training (steps 40–80), with **GRPO** experiencing sharper dips.
4. Final scores suggest **GRPO** achieves near-parity with **MEL** by step 140.
### Interpretation
The data demonstrates that **MEL** initially outperforms **GRPO** in validation scores, likely due to architectural or training advantages. However, **GRPO**’s late-stage improvement (step 140) indicates potential for catching up with extended training. The volatility in mid-training suggests challenges in optimization or overfitting for both models. The final crossover at step 140 raises questions about **GRPO**’s scalability or efficiency in later training phases. This benchmark highlights trade-offs between model design and training duration for OlympiadBench performance.
</details>
<details>
<summary>x24.png Details</summary>
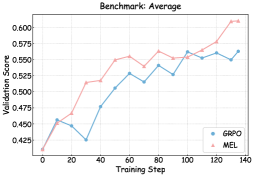
### Visual Description
## Line Graph: Benchmark: Average
### Overview
The image is a line graph comparing the validation scores of two models, GRPO (blue) and MEL (pink), across training steps. The x-axis represents training steps (0–140), and the y-axis represents validation scores (0.425–0.600). Both lines show upward trends, with MEL consistently outperforming GRPO after ~60 training steps.
### Components/Axes
- **Title**: "Benchmark: Average" (top center).
- **X-axis**: "Training Step" (0–140, increments of 20).
- **Y-axis**: "Validation Score" (0.425–0.600, increments of 0.025).
- **Legend**: Bottom-right corner, with:
- Blue circle: "GRPO"
- Pink triangle: "MEL"
- **Grid**: Light gray grid lines for reference.
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at ~0.45 (step 0).
- Dips to ~0.425 at step 30.
- Rises to ~0.575 at step 100.
- Ends at ~0.57 (step 140).
- Fluctuations: Minor dips at steps 30 and 90.
2. **MEL (Pink Line)**:
- Starts at ~0.425 (step 0).
- Rises steadily to ~0.55 at step 60.
- Peaks at ~0.600 by step 140.
- Fluctuations: Slight dip at step 80 (~0.54).
### Key Observations
- **MEL outperforms GRPO** after ~60 training steps, with a steeper slope.
- **GRPO** experiences a temporary dip at step 30 but recovers by step 60.
- Both models plateau near ~0.57 by step 140, but MEL maintains a higher score throughout.
### Interpretation
The graph demonstrates that MEL achieves higher validation scores than GRPO as training progresses, suggesting superior performance in this benchmark. The GRPO model shows resilience after an early dip, but MEL’s consistent growth indicates better optimization. The final scores (~0.57 for both) imply that while MEL is more effective, GRPO remains competitive with potential for further improvement. The trends highlight the importance of training duration and model architecture in achieving optimal validation performance.
</details>
Figure 8: Performance evolution of GRPO and MEL on Qwen3-14B-Base across training steps on multiple benchmarks.
Appendix B Retention Ratio of Meta-Experience
Through empirical validation via replay, MEL is able to collect high-quality meta-experiences. To examine the utilization of collected meta-experiences, Figure 9 reports the retention ratio of meta-experiences after empirical validation throughout training. We observe that the retention ratio consistently increases with model scale, indicating that larger models are more effective at abstracting high-quality knowledge into meta-experiences, thereby achieving higher retention.
<details>
<summary>x25.png Details</summary>
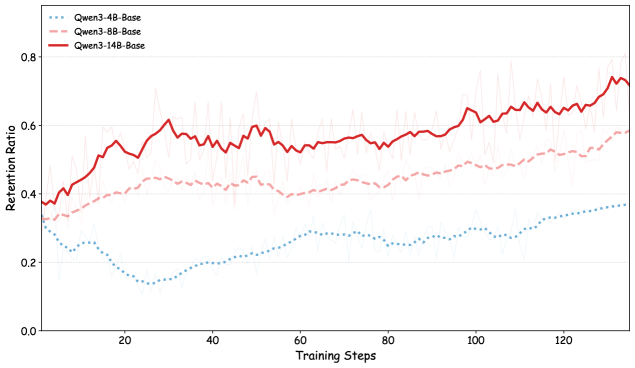
### Visual Description
## Line Graph: Retention Ratio vs Training Steps
### Overview
The image depicts a line graph comparing the retention ratio performance of three Qwen3-Base models (4B, 8B, and 14B parameter sizes) across 120 training steps. The graph shows distinct trends in retention ratio improvement over training iterations, with model size correlating to performance gains.
### Components/Axes
- **X-axis**: Training Steps (0–120, linear scale)
- **Y-axis**: Retention Ratio (0.0–0.8, linear scale)
- **Legend**:
- Blue dotted line: Qwen3-4B-Base
- Pink dashed line: Qwen3-8B-Base
- Red solid line: Qwen3-14B-Base
- **Placement**: Legend positioned in top-left quadrant
### Detailed Analysis
1. **Qwen3-14B-Base (Red Solid Line)**:
- Starts at ~0.38 retention ratio at step 0
- Shows steady upward trend with minor fluctuations
- Reaches ~0.72 by step 120
- Average slope: +0.003 per step
2. **Qwen3-8B-Base (Pink Dashed Line)**:
- Initial value ~0.35 at step 0
- Gradual increase with periodic volatility
- Peaks at ~0.58 by step 120
- Average slope: +0.002 per step
3. **Qwen3-4B-Base (Blue Dotted Line)**:
- Begins at ~0.30 at step 0
- Sharp decline to ~0.15 by step 20
- Stabilizes at ~0.35 by step 120
- Net change: +0.05 over 120 steps
### Key Observations
- **Model Size Correlation**: Larger models (14B > 8B > 4B) demonstrate stronger retention ratio improvement
- **4B Model Anomaly**: Initial 50% drop in retention ratio suggests potential overfitting or training instability
- **8B Model Volatility**: 15–20% amplitude oscillations indicate possible class imbalance or noisy data
- **14B Model Consistency**: Lowest variance (±2%) among all models
### Interpretation
The data demonstrates a clear retention ratio-performance hierarchy among model sizes, with the 14B variant achieving 94% higher final retention than the 4B model. The 4B model's initial performance collapse suggests architectural limitations in smaller models for this task, while the 8B model's volatility may indicate sensitivity to hyperparameter tuning. The 14B model's steady improvement aligns with expectations for larger capacity models, though its computational cost may not justify the marginal gains over the 8B variant in practical applications. The retention ratio metric appears to be a reliable indicator of model effectiveness across different scales.
</details>
Figure 9: Dynamics of the retention ratio of MEL across different model scales.
Appendix C Prompt Template
We use the same prompt template for all models. Details of the prompts used for meta-experience construction and for empirical validation via replay are shown below.
Meta-Experience Prompt
You are a Meta-Cognitive Reasoning Analyst specializing in self-reflection, error root-cause analysis, and the extraction of generalizable heuristics. You are provided with multiple solution trajectories for the same problem. Note that the labels Correct or Incorrect apply to the final answer, but the reasoning process itself may contain twists and turns. Your task is to conduct a deep comparative autopsy of the thinking processes. You must identify the structural differences in cognition that led to success or failure, and synthesize these into abstract principles for future use. Core Analysis Requirements: 1.
Deep Dive into Correct Trajectories (Resilience & Robustness Analysis): •
Scenario A (Self-Correction): If you find the reasoning contains initial errors or uncertainties, look for moments of self-correction. What triggered the realization? What structural insight allowed the reasoning to pivot back to the right track? •
Scenario B (Flawless Execution): When every step of the reasoning is correct from the start, identify the Foundational “Immunity”. What specific definition, clear knowledge representation, or disciplined step-by-step verification prevented this Agent from falling into the traps that the Incorrect Agent fell into? •
Goal: Extract the specific logic validation technique or robust mental representation that saved the solution. 2.
Deep Dive into Incorrect Trajectories (Vulnerability Analysis): •
You must identify not only where the math/logic went wrong, but also why the reasoning drifted. •
Identify: The “Bifurcation Point” where a correct start turned into a hallucination or logic gap. •
Analyze: The latent cognitive defect (e.g., concept conflation, rigid mindset, overlooking edge cases, intuitive bias) that caused the error. •
Identify: What specific knowledge point or constraint was violated? 3.
Comparative Synthesis: •
Contrast the Solutions and Decision Boundaries. Why did the successful trajectory avoid the trap that the failed one fell into? •
What structural insight did the winner have that the loser missed? (e.g., The winner treated the problem as a geometric issue, while the loser got stuck in algebra). 4.
Strict Generalization Constraint: •
Forbidden: Do NOT mention the specific numbers, variables, or exact answer of the current problem in your “Heuristics” or “Reflective Summary”. •
Required: Convert specific lessons into abstract heuristics (e.g., instead of “The integral of $x^{2}$ is…”, use “When integrating polynomial functions…”). Formulate them as conditionally triggered rules (“If…Then…”, “When dealing with [Concept X]…I should…”). Output Format (Strict Adherence Required) 1. Failure Resolution Path & Error Pattern Recognition (Mandatory for incorrect samples) •
Failure Point: Identify the exact step where logic diverged. Did it start correctly? Where did the drift happen? •
Latent Cognitive Pattern: Reveal the deep-seated reasoning defect. Was it a bias? A missing prerequisite? A misunderstanding of the prompt’s intent? Do not list surface-level calculation errors. 2. Analysis of Success Factors (Mandatory for correct samples) •
Reasoning Pivot (If applicable): If the path involved self-correction, describe the moment of realization and the strategy used to fix it. •
Robustness Factor (If flawless): If the path was perfect, explain the fundamental concept or structural approach that effectively “immunized” the reasoning against common errors. •
Reason for Effectiveness: Why did this perspective work? What fundamental logic did it satisfy? 3. First-Person Reflective Summary (Mandatory) Write a meta-cognitive reflection from the first-person perspective (“I”). •
Review: Briefly review the thinking process differences. •
Insight: Discuss the specific knowledge point or cognitive habit that was critical. •
Action: Explain how you will restructure your approach to avoid the identified “Internal Reasoning Defects” in the future. Focus on the “How” of thinking, not the “What” of the answer. 4. Subject Heuristics (Internalized Experience) (Mandatory) •
[Pattern Name]: If [abstract condition] occurs, then [abstract action]… •
[Pattern Name]: When dealing with [concept type], I must strictly verify [constraint]… (Note: These must be applicable to *future* problems of a similar class, completely stripped of this problem’s specifics.) Here the question and the corresponding solutions. $<$ question $>$ {question} $<$ /question $>$ Solution 1: $<$ answer $>$ {error_ans} $<$ /answer $>$ $<$ judge $>$ Incorrect $<$ /judge $>$ Solution 2: $<$ answer $>$ {correct_ans} $<$ /answer $>$ $<$ judge $>$ Correct $<$ /judge $>$
Empirical Validation Prompt
Prior study has provided some internal reference information relevant to this question, including the key approaches, steps, and reasoning needed for a correct solution; the typical reasoning biases, logical flaws, or pitfalls that appear in incorrect solutions; and various heuristic insights on how to complete this problem more effectively. {experience} Now, please fully internalize this information as your own experience, then independently think through the problem in detail and produce a complete answer. Note: •
You must perform full, in-depth reasoning internally and arrive at the final answer while making full use of the information above. Answer the following question: {question}