# LLM-Based Scientific Equation Discovery via Physics-Informed Token-Regularized Policy Optimization
**Authors**: Boxiao Wang, Kai Li, Tianyi Liu, Chen Li, Junzhe Wang, Yifan Zhang, Jian Cheng
> 0009-0008-2970-7575 Institute of Automation, Chinese Academy of Sciences Beijing China
> Institute of Automation, Chinese Academy of Sciences Beijing China
> State Key Laboratory of Aerodynamics Mianyang, Sichuan China
> School of Mathematical Sciences, University of Chinese Academy of Sciences Beijing China
## Abstract
Symbolic regression aims to distill mathematical equations from observational data. Recent approaches have successfully leveraged Large Language Models (LLMs) to generate equation hypotheses, capitalizing on their vast pre-trained scientific priors. However, existing frameworks predominantly treat the LLM as a static generator, relying on prompt-level guidance to steer exploration. This paradigm fails to update the model’s internal representations based on search feedback, often yielding physically inconsistent or mathematically redundant expressions. In this work, we propose PiT-PO (Physics-informed Token-regularized Policy Optimization), a unified framework that evolves the LLM into an adaptive generator via reinforcement learning. Central to PiT-PO is a dual-constraint mechanism that rigorously enforces hierarchical physical validity while simultaneously applying fine-grained, token-level penalties to suppress redundant structures. Consequently, PiT-PO aligns LLM to produce equations that are both scientifically consistent and structurally parsimonious. Empirically, PiT-PO achieves state-of-the-art performance on standard benchmarks and successfully discovers novel turbulence models for challenging fluid dynamics problems. We also demonstrate that PiT-PO empowers small-scale models to outperform closed-source giants, democratizing access to high-performance scientific discovery.
conference: ; ;
## 1. Introduction
Symbolic Regression (SR) (Makke and Chawla, 2024b) stands as a cornerstone of data-driven scientific discovery, uniquely capable of distilling interpretable mathematical equations from observational data. Unlike black-box models that prioritize mere prediction, SR elucidates the fundamental mechanisms governing system behavior, proving instrumental in uncovering physical laws (Makke and Chawla, 2024a; Reuter et al., 2023), modeling chemical kinetics (Chen et al., 2025; Deng et al., 2023), and analyzing complex biological dynamics (Wahlquist et al., 2024; Shi et al., 2024).
However, the search for exact governing equations represents a formidable challenge, formally classified as an NP-hard problem (Virgolin and Pissis, 2022). To navigate this vast search space, algorithmic strategies have evolved from Genetic Programming (GP) (Schmidt and Lipson, 2009; Cranmer, 2023) and Reinforcement Learning (RL) (Petersen et al., 2021) to Transformer-based architectures that map numerical data directly to symbolic equations (Biggio et al., 2021; Kamienny et al., 2022; Zhang et al., 2025). Most recently, the advent of Large Language Models (LLMs) has introduced a new paradigm. Methods such as LLM-SR (Shojaee et al., 2025a) and LaSR (Grayeli et al., 2024) leverage the pre-trained scientific priors and in-context learning capabilities of LLMs to generate equation hypotheses. These approaches typically employ an evolutionary search paradigm, where candidates are evaluated, and high-performing solutions are fed back via prompt-level conditioning to steer subsequent generation.
Despite encouraging progress, existing LLM-based SR methods remain constrained by severe limitations. First, most approaches treat the LLM as a static generator, relying primarily on prompt-level, verbal guidance to steer the evolutionary search (Shojaee et al., 2025a; Grayeli et al., 2024). This “frozen” paradigm inherently neglects the opportunity to adapt and enhance the generative capability of the LLM itself based on evaluation signals, preventing the model from internalizing feedback and adjusting its generation strategies to the specific problem. Second, they typically operate in a physics-agnostic manner, prioritizing syntactic correctness over physical validity (Shojaee et al., 2025a; Grayeli et al., 2024). Without rigorous constraints, LLMs often generate equations that fit the data numerically but violate fundamental physical principles, rendering them prone to overfitting and practically unusable.
In this work, we propose to fundamentally shift the role of the LLM in SR from a static proposer to an adaptive generator. We establish a dynamic feedback loop in which evolutionary exploration and parametric learning reinforce each other: evolutionary search uncovers diverse candidate equations and generates informative evaluation signals, while parametric adaptation enables the LLM to consolidate effective symbolic patterns and guide subsequent exploration more efficiently. By employing in-search fine-tuning, i.e., updating the LLM parameters during the evolutionary search process, we move beyond purely verbal, prompt-level guidance and introduce numerical guidance that allows feedback to be directly internalized into the model parameters, progressively aligning LLM with the intrinsic properties of the target system.
To realize this vision, we introduce PiT-PO (Physics-informed Token-regularized Policy Optimization), a unified framework that bridges LLM-driven evolutionary exploration with rigorous verification. PiT-PO is built upon two technical components. 1) In-Search LLM Evolution. We implement the numerical guidance via reinforcement learning, which efficiently updates the LLM’s parameters during the search process. Instead of relying on static pre-trained knowledge, this in-search policy optimization enables LLM to dynamically align its generative distribution with the structural characteristics of the specific task, effectively transforming general scientific priors into domain-specific expertise on the fly. 2) Dual Constraints as Search Guidance. We enforce hierarchical physical constraints to ensure scientific validity, and uniquely, we incorporate a fine-grained regularization based on our proposed Support Exclusion Theorem. This theorem allows us to identify mathematically redundant terms and translate them into token-level penalties, effectively pruning the search space and guiding LLM toward physically meaningful and structurally parsimonious equations.
Comprehensive experimental results demonstrate that PiT-PO achieves state-of-the-art performance across standard SR benchmarks, including the LLM-SR Suite (Shojaee et al., 2025a) and LLM-SRBench (Shojaee et al., 2025b), and recovers the largest number of ground-truth equations among all evaluated methods. In addition to synthetic benchmarks, the effectiveness of PiT-PO is validated on an application-driven turbulence modeling task involving flow over periodic hills. PiT-PO improves upon traditional Reynolds-Averaged Navier-Stokes (RANS) approaches by producing anisotropic Reynolds stresses closer to Direct Numerical Simulation (DNS) references. The learned method shows enhanced physical consistency, with reduced non-physical extremes and better flow field predictions. Finally, PiT-PO maintains robust performance even when using resource-constrained small models, such as a quantized version of Llama-8B, and remains efficient under strict wall-clock time budgets, establishing a practical methodology for automated scientific discovery.
<details>
<summary>x1.png Details</summary>
### Visual Description
## System Architecture Diagram: Physics-informed Token-Regularized Policy Optimization (PiT-PO)
### Overview
The image is a technical system architecture diagram illustrating a reinforcement learning or policy optimization framework named **PiT-PO** (Physics-informed Token-Regularized Policy Optimization). The diagram depicts a cyclical process where an LLM Policy is updated through a multi-stage exploration and constraint-based optimization loop. The primary language of the diagram is English, with mathematical notation.
### Components/Axes
The diagram is organized into several interconnected blocks and regions, flowing from left to right and looping back.
**1. Left Region: Policy Source**
* **Component:** A teal-colored rounded rectangle labeled **"LLM Policy"** with the mathematical symbol **π_θ** below it.
* **Position:** Far left, centered vertically.
* **Function:** Serves as the starting point and the entity being updated.
**2. Center-Left Region: Exploration Module**
* **Component:** A dashed-line box labeled **"Island-Based Exploration"**.
* **Contents:** Inside this box are five yellow rounded rectangles arranged vertically, labeled **f₀**, **f₁**, **...**, **fₙ₋₁**, **fₙ**.
* **Connections:** Multiple light blue arrows originate from the "LLM Policy" block and point to each of the `f` blocks. Orange arrows then flow from each `f` block to the right, towards the constraint modules.
**3. Center Region: Constraint Modules**
Two distinct, colored blocks receive input from the exploration module.
* **Top Block (Orange):** Labeled **"Physical Constraints"**.
* Sub-text: **"General-Level P_dim, P_diff"** and **"Domain-Specific P_domain"**.
* **Bottom Block (Red):** Labeled **"Theoretical Constraints"**.
* Contains an icon of a document and the text **"Support Exclusion Theorem P_tok"**.
* **Connections:** Both blocks have orange arrows pointing right, into the large "PiT-PO" circle.
**4. Right Region: Core Optimization Engine (PiT-PO)**
* **Component:** A large, light purple circle labeled **"PiT-PO"** at the top.
* **Sub-components within the circle:**
* **"Global Reward"** (small orange box, top-left inside circle).
* **"Token Penalty"** (small orange box, bottom-left inside circle).
* **"Token-Aware Advantage Estimation"** (central white box).
* **"GRPO"** (small purple box, right side).
* **Flow within PiT-PO:** Arrows show that "Global Reward" and "Token Penalty" feed into "Token-Aware Advantage Estimation," which then points to "GRPO".
* **Descriptive Text:** At the bottom of the circle: **"Physics-informed Token-Regularized Policy Optimization"**.
**5. Feedback Loops (Outer Cycle)**
* **Top Arrow:** A large, purple, curved arrow labeled **"Policy Update"** flows from the top of the "PiT-PO" circle back to the top of the "LLM Policy" block.
* **Bottom Arrow:** A large, purple, curved arrow labeled **"Prompt Update"** flows from the bottom of the "PiT-PO" circle back to the bottom of the "LLM Policy" block.
### Detailed Analysis
The diagram outlines a closed-loop training or optimization process:
1. **Initialization:** The process starts with an **LLM Policy (π_θ)**.
2. **Exploration:** The policy generates multiple exploration paths or functions (`f₀` to `fₙ`) via the **Island-Based Exploration** module.
3. **Constraint Application:** The outputs of exploration are evaluated against two sets of constraints:
* **Physical Constraints:** These include general-level constraints (`P_dim`, `P_diff`) and domain-specific constraints (`P_domain`).
* **Theoretical Constraints:** Specifically, a constraint derived from the **Support Exclusion Theorem (`P_tok`)**.
4. **Optimization (PiT-PO):** The constrained outputs enter the **PiT-PO** engine. Here:
* A **Global Reward** signal and a **Token Penalty** are computed.
* These are used for **Token-Aware Advantage Estimation**.
* The estimation informs the **GRPO** (likely an acronym for a specific policy optimization algorithm, e.g., Generalized Reward Policy Optimization).
5. **Update:** The optimization results are used to perform two updates on the original LLM Policy:
* A **Policy Update** (top loop).
* A **Prompt Update** (bottom loop).
### Key Observations
* **Dual Constraint Types:** The system explicitly separates and incorporates both *physical* and *theoretical* constraints, suggesting a hybrid approach to guide policy learning.
* **Token-Level Regularization:** The inclusion of "Token Penalty" and "Token-Aware Advantage Estimation" indicates the optimization operates at the granularity of individual tokens, not just high-level rewards.
* **Parallel Exploration:** The "Island-Based Exploration" with multiple `f` functions suggests a population-based or parallel sampling strategy to explore the solution space.
* **Dual Update Mechanism:** The policy is updated via two distinct pathways ("Policy Update" and "Prompt Update"), implying that both the model parameters and the input prompts are being optimized.
### Interpretation
This diagram represents a sophisticated reinforcement learning framework designed to train or fine-tune a Large Language Model (LLM). The core innovation appears to be the **PiT-PO** method, which integrates physics-based and theoretical constraints directly into the policy optimization process.
The system's goal is to produce an LLM policy (`π_θ`) that is not only reward-optimized but also adheres to predefined physical laws and theoretical boundaries. The "Island-Based Exploration" likely ensures diverse candidate solutions are generated. The constraints (`P_dim`, `P_diff`, `P_domain`, `P_tok`) act as filters or regularizers, preventing the policy from exploring invalid or nonsensical regions of the solution space. The final "Token-Regularized" step ensures the model's outputs are coherent and constrained at the fundamental token level.
In essence, this is a blueprint for creating more reliable, physically plausible, and theoretically sound LLM behaviors by embedding domain knowledge directly into the reinforcement learning loop. The dual update mechanism (policy and prompt) suggests a holistic approach to optimization, refining both the model's internal reasoning and its interaction with input stimuli.
</details>
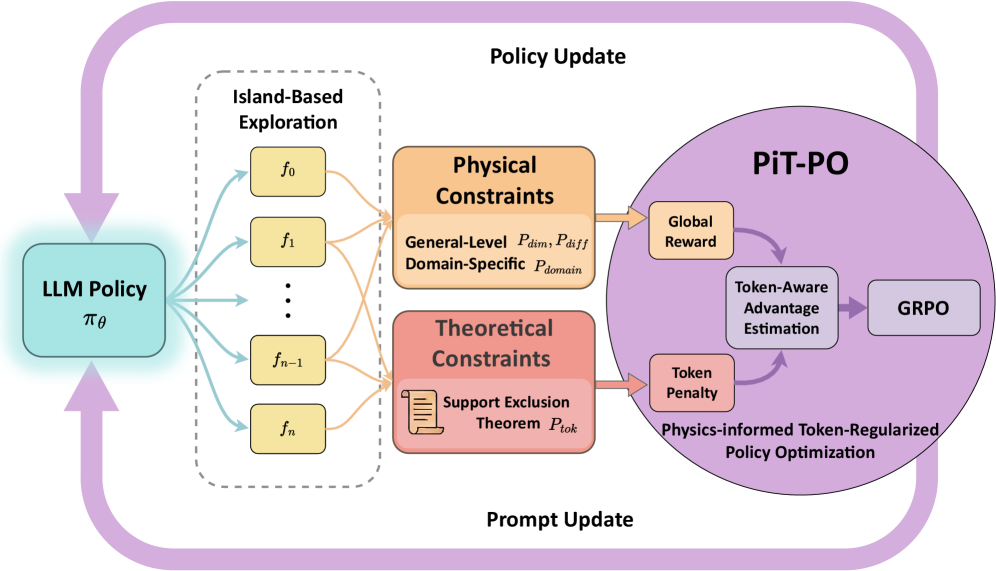
Figure 1. The overall framework of PiT-PO. PiT-PO transforms the LLM from a static proposer into an adaptive generator via a closed-loop evolutionary process. The framework integrates dual-constraint evaluation—comprising physical constraints and theoretical constraints—to generate fine-grained token-level learning signals. These signals guide the LLM policy update via reinforcement learning, ensuring the discovery of parsimonious, physically consistent equations.
## 2. Preliminaries
### 2.1. Problem Setup
In SR, a dataset of input–output observations is given:
$$
D=\{(x_{i},y_{i})\}_{i=1}^{n},\;x_{i}\in\mathbb{R}^{d},\;y_{i}\in\mathbb{R}. \tag{1}
$$
The objective is to identify a compact and interpretable function $f\in\mathcal{F}$ such that $f(x_{i})\approx y_{i}$ for the observed samples, while retaining the ability to generalize to unseen inputs.
### 2.2. LLM-based SR Methods
Contemporary LLM-based approaches reformulate SR as a iterative program synthesis task. In this paradigm, typified by frameworks such as LLM-SR (Shojaee et al., 2025a), the discovery process is decoupled into two phases: structure proposal and parameter estimation. Specifically, the LLM functions as a symbolic generator, emitting functional skeletons with placeholders for learnable coefficients. A numerical optimizer (e.g., BFGS (Fletcher, 1987)) subsequently fits these constants to the observed data. To navigate the combinatorial search space, these methods employ an evolutionary-style feedback loop: high-fitness equations are maintained in a pool to serve as in-context examples, prompting the LLM to refine subsequent generations. Our work leverages this architecture as a backbone, but fundamentally redefines the LLM’s role from a static proposer to an adaptive generator.
### 2.3. Group Relative Policy Optimization
Group Relative Policy Optimization (GRPO) (Shao et al., 2024) is a RL algorithm tailored for optimizing LLMs on reasoning tasks, characterized by its efficient baseline estimation without the need for a separate value network. In the context of LLM-based SR, the generation process is modeled as a Markov Decision Process (MDP), where LLM functions as a policy $\pi_{\theta}$ that generates a sequence of tokens $o=(t_{1},\dots,t_{L})$ given a prompt $q$ . For each $q$ , GRPO samples a group of $G$ outputs $\{o_{1},\dots,o_{G}\}$ from the sampling policy $\pi_{\theta_{old}}$ . GRPO maximizes the following surrogate loss function:
$$
\mathcal{J}_{GRPO}(\theta)=\mathbb{E}_{q\sim P(Q),\{o_{i}\}\sim\pi_{\theta_{old}}}\left[\frac{1}{G}\sum_{i=1}^{G}\left(\frac{1}{L_{i}}\sum_{k=1}^{L_{i}}\mathcal{L}^{clip}_{i,k}(\theta)-\beta\mathbb{D}_{KL}(\pi_{\theta}||\pi_{ref})\right)\right], \tag{2}
$$
where $\pi_{ref}$ is the reference policy to prevent excessive deviation, and $\beta$ controls the KL-divergence penalty. The clipping term $\mathcal{L}^{clip}_{i,k}(\theta)$ ensures trust region updates:
$$
\mathcal{L}^{clip}_{i,k}(\theta)=\min\left(\frac{\pi_{\theta}(t_{i,k}|q,o_{i,<k})}{\pi_{\theta_{old}}(t_{i,k}|q,o_{i,<k})}\hat{A}_{i},\;\text{clip}\left(\frac{\pi_{\theta}(t_{i,k}|q,o_{i,<k})}{\pi_{\theta_{old}}(t_{i,k}|q,o_{i,<k})},1-\epsilon,1+\epsilon\right)\hat{A}_{i}\right). \tag{3}
$$
Here, $\epsilon$ is the clipping coefficient. A distinctive feature of GRPO lies in its advantage estimation, it computes the advantage $\hat{A}_{i}$ by standardizing the reward $R(o_{i})$ relative to the group:
$$
\hat{A}_{i}=\frac{R(o_{i})-\text{mean}(\{R(o_{j})\})}{\text{std}(\{R(o_{j})\})}. \tag{4}
$$
Consequently, every token within the sequence $o_{i}$ is assigned the exact same feedback signal. This coarse granularity treats valid and redundant terms indistinguishably, a limitation that our work addresses by introducing fine-grained, token-level regularization.
## 3. Method
We propose PiT-PO (Physics-informed Token-regularized Policy Optimization), a framework that evolves LLM into an adaptive, physics-aware generator. PiT-PO establishes a closed-loop evolutionary process driven by two synergistic mechanisms: (1) a dual-constraint evaluation system that rigorously assesses candidates through hierarchical physical verification and theorem-guided redundancy pruning; and (2) a novel policy optimization strategy that updates LLM using fine-grained, token-level feedback derived from these constraints. This combination effectively aligns the LLM with the intrinsic structure of the problem, guiding the LLM toward solutions that are not only numerically accurate but also structurally parsimonious and scientifically consistent.
### 3.1. Dual-Constraint Learning Signals
Navigating the combinatorial space of symbolic equations requires rigorous guidance. We employ a reward system driven by dual constraints: physical constraints delineate the scientifically valid region, while theoretical constraints drive the search toward simpler equations by identifying and pruning redundant terms.
#### 3.1.1. Hierarchical Physical Constraints.
To ensure scientific validity, we construct a hierarchical filter that categorizes constraints into two levels: general properties and domain-specific priors.
General-Level Constraints. We enforce fundamental physical properties applicable across scientific disciplines. To prune physically impossible structures (e.g., adding terms with mismatched units), we assign penalty-based rewards for Dimensional Homogeneity ( $P_{dim}$ ) and Differentiability ( $P_{diff}$ ). The former strictly penalizes equations with unit inconsistencies, while the latter enforces smoothness on the data-defined domain.
Domain-Specific Constraints. To tackle specialized tasks, we inject expert knowledge as inductive biases. We define the domain-specific penalty $P^{(j)}_{domain}$ to penalize candidate equations that violate the $j$ -th domain-specific constraint. Taking the turbulence modeling task (detailed in Appendix E.4) as a representative instantiation, we enforce four rigorous constraints: (1) Realizability (Pope, 2000), ensuring the Reynolds stress tensor has positive eigenvalues; (2) Boundary Condition Consistency (Monkewitz, 2021), requiring stresses to decay to zero at the wall; (3) Asymptotic Scaling (Tennekes and Lumley, 1972; WANG et al., 2019), enforcing the cubic relationship between stress and wall distance in the viscous sublayer; and (4) Energy Consistency (Pope, 2000; MOCHIZUKI and OSAKA, 2000), aligning predicted stress with turbulent kinetic energy production.
This hierarchical design effectively embeds physical consistency as a hard constraint in the reward function, prioritizing scientific validity over mere empirical fitting.
#### 3.1.2. Theorem-Guided Mathematical Constraints
While physical constraints ensure validity, they do not prevent mathematical redundancy. To rigorously distinguish between essential terms and redundant artifacts, we introduce the Support Exclusion Theorem.
Let $\mathcal{S}$ denote the full support set containing all candidate basis functions $\{\phi_{j}\}$ . The ground truth equation is $f^{*}=\sum_{j\in\mathcal{S}^{\prime}}a_{j}\phi_{j}$ , where $\mathcal{S}^{\prime}\subseteq\mathcal{S}$ is the true support set (i.e., the indices of basis functions that truly appear in the governing equation), and $\{a_{j}\}_{j\in\mathcal{S}^{\prime}}$ are the corresponding true coefficients. Consider a candidate equation $f=\sum_{j\in\mathcal{K}}b_{j}\phi_{j}$ , where $\mathcal{K}\subseteq\mathcal{S}$ represents the current support set (i.e., the selected terms in the skeleton), $\mathbf{b}=\{b_{j}\}_{j\in\mathcal{K}}$ are the optimized coefficients derived from the data. We define the empirical Gram matrix of these basis functions as $G\in\mathbb{R}^{|\mathcal{S}|\times|\mathcal{S}|}$ and the corresponding Projection Matrix as $T$ , where $T_{ij}:=G_{ji}/G_{ii}$ .
** Theorem 3.1 (Support Exclusion Theorem)**
*Assume the ground-truth support is finite and satisfies $|\mathcal{S}^{\prime}|\leq M$ , and let the true function coefficients be bounded by $A\leq|a_{j}|\leq B$ for all $j\in\mathcal{S}^{\prime}$ . A term $\phi_{i}$ ( $i\in\mathcal{K}$ ) is theoretically guaranteed to be a false discovery (not in the true support $\mathcal{S}^{\prime}$ ) if its fitted coefficient magnitude satisfies:
$$
|b_{i}|<A-\left(\underbrace{\sum_{j\in\mathcal{K},j\neq i}(B+|b_{j}|)|T_{ij}|}_{\text{Internal Interference}}+\underbrace{B\sum_{k=1}^{m}s_{(k)}}_{\text{External Interference}}\right). \tag{5}
$$
$s(k)$ denotes the $k$ -th largest value in $\{|T_{i\ell}|:\ell\in\mathcal{S}\setminus\mathcal{K}\}$ , and $m:=\min\!\big(M-1,\;|\mathcal{S}\setminus\mathcal{K}|\big)$ .*
Detailed definitions of all notations and the rigorous proof of Theorem 3.1 are provided in Appendix B. This theorem formalizes the intuition that coefficients of redundant terms (absent from the true support $\mathcal{S}^{\prime}$ ) have significantly smaller magnitudes than those of valid components.
Specifically, after fitting $\mathbf{b}$ , we compute the normalized coefficient ratio $\tau_{i}=|b_{i}|/(\sum_{j}|b_{j}|+\epsilon)$ . We introduce a threshold $\rho\in(0,1)$ to identify potentially redundant terms. Terms satisfying $\tau_{i}>\rho$ incur no penalty, while components with $\tau_{i}\leq\rho$ are considered redundant. To suppress these redundancies, we define a token penalty for each token in redundant term $i$ :
$$
P_{tok}=p\cdot\max\left(0,-\log\left(|b_{i}|+\epsilon\right)\right), \tag{6}
$$
where $p>0$ is a scaling coefficient. We use a logarithmic scale to impose stronger penalties on terms with smaller coefficients.
By integrating this penalty into the policy optimization, we guide the LLM to reduce the probability of generating redundant terms, thereby steering the optimization toward parsimonious equations.
### 3.2. Token-Aware Policy Update
Our proposed PiT-PO effectively operationalize the hierarchical constraints and theoretical insights derived in Section 3.1. Unlike standard GRPO that assign a uniform scalar reward to the entire generated sequence, our method transitions the learning process from coarse-grained sequence scoring to fine-grained token-level credit assignment. This ensures that the policy not only learns to generate physically valid equations but also explicitly suppresses theoretically redundant terms.
#### 3.2.1. Global Reward with Gated Constraints
The optimization is driven by a composite global reward, $R_{global}$ , which balances fitting accuracy, structural parsimony, and physical consistency. Formally, for a sampled equation $o_{i}$ , the rewards are defined as follows:
Fitting Accuracy ( $R_{fit}$ ). We use the normalized log-MSE to encourage precise data fitting:
$$
R_{fit}=-\alpha\log(\text{MSE}+\epsilon), \tag{7}
$$
where $MSE=\frac{1}{n}\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2}$ .
Complexity Penalty ( $P_{cplx}$ ). Adhering to Occam’s Razor, we penalize structural complexity based on the Abstract Syntax Tree (AST) (Neamtiu et al., 2005) node count:
$$
P_{cplx}=\lambda_{len}\cdot\text{Length}(\text{AST}). \tag{8}
$$
In PiT-PO, each equation generated by the LLM is represented as a Python function and parsed into an AST, where each node corresponds to a variable or operator. The total node count provides a meaningful estimate of structural complexity.
Gated Physical Penalty ( $P_{phy}$ ). Imposing strict physical constraints too early can hinder exploration, causing the model to discard potentially promising functional forms. We therefore activate physical penalties only after the candidate equation reaches a baseline fitting accuracy threshold ( $\delta_{gate}$ ). Specifically, we define
where $\mathbb{1}(\cdot)$ is the indicator function. This mechanism effectively creates a soft curriculum: it allows “free” exploration in the early stages and enforcing strict physical compliance only after the solution enters a plausible region.
The total reward $R_{global}$ is then formulated as:
$$
R_{global}(o_{i})=R_{fit}(o_{i})-P_{cplx}(o_{i})-P_{phy}(o_{i}). \tag{10}
$$
#### 3.2.2. Fine-Grained Advantage Estimation
Standard GRPO applies a uniform advantage across all tokens in a sequence. We refine this by synthesizing the global reward with the token-level penalty $P_{tok}$ (Equation 6). Specifically, we define the token-aware advantage $\hat{A}_{i,k}$ for the $k$ -th token in the $i$ -th sampled equation as:
$$
\hat{A}_{i,k}=\underbrace{\frac{R_{global}(o_{i})-\mu_{group}}{\sigma_{group}}}_{\text{Global Standardization}}-\underbrace{P_{i,k}}_{\text{Local Pruning}}. \tag{11}
$$
Here, the first term standardizes the global reward against the group statistics ( $\mu_{group},\sigma_{group}$ ), reinforcing equations that satisfy multi-objective criteria relative to their peers. The second term, $P_{i,k}$ , applies a targeted penalty to suppress redundancy. Specifically, we set $P_{i,k}=0$ if token $k$ belongs to a non-redundant term, and $P_{i,k}=P_{tok}$ otherwise. This ensures that penalties are applied exclusively to tokens contributing to mathematically redundant structures, while valid terms remain unaffected.
Substituting this token-aware advantage into the GRPO objective, the policy gradient update of our PiT-PO becomes:
$$
\nabla\mathcal{J}_{PiT-PO}\propto\sum_{i,k}\hat{A}_{i,k}\nabla\log\pi_{\theta}(t_{i,k}|o_{i,<k}). \tag{12}
$$
This creates a dual-pressure optimization landscape: global rewards guide the policy toward physically consistent and accurate equations, while local penalties surgically excise redundant terms. This ensures the final output aligns with the sparse, underlying physical laws rather than merely overfitting numerical data.
Input: Dataset $D=\{(x_{i},y_{i})\}_{i=1}^{n}$ ; LLM $\pi_{\theta}$ ; number of islands $N$ ; group size $G$ ; iterations $T$ .
Output: Best equation $o^{*}$ .
1
2 1ex
3 Initialize $o^{*}$ , $s^{*}$ , and buffers $\mathcal{B}_{j}\leftarrow\emptyset$ for $j=1,\dots,N$
4
5 for $t\leftarrow 1$ to $T$ do
// Stage 1: Island-Based Exploration
6 for $j\leftarrow 1$ to $N$ do
$q_{j}\leftarrow\textsc{BuildPrompt}(D,\mathcal{B}_{j})$
// in-context rule
$\{o_{i}\}_{i=1}^{G}\sim\pi_{\theta}(\cdot\mid q_{j})$
// sample a group
7 for $i\leftarrow 1$ to $G$ do
$(R_{i},\{P_{i,k}\})\leftarrow\textsc{DualConstraintEval}(o_{i},D)$
// $R_{i}=R_{\mathrm{global}}(o_{i})$
8 $\mathcal{B}_{j}\leftarrow\mathcal{B}_{j}\cup\{(q_{j},o_{i},R_{i},\{P_{i,k}\})\}$
9 if $R_{i}>s^{*}$ then
10 $o^{*}\leftarrow o_{i}$ ; $s^{*}\leftarrow R_{i}$
11
12
13
// Stage 2: In-Search LLM Evolution
14 $\theta\leftarrow\textsc{PiT-PO\_Update}(\theta,\{\mathcal{B}_{j}\}_{j=1}^{N},\pi_{{\theta}})$
// Stage 3: Hierarchical Selection
15 $\{\mathcal{B}_{j}\}_{j=1}^{N}\leftarrow\textsc{SelectAndReset}(\{\mathcal{B}_{j}\}_{j=1}^{N})$
16 return $o^{*}$
Algorithm 1 PiT-PO Overall Training Pipeline
### 3.3. Overall Training Pipeline
We orchestrate the PiT-PO framework through a closed-loop evolutionary RL cycle. As illustrated in Algorithm 1, the training process iterates through three synergistic phases:
Phase 1: Island-Based Exploration (Data Generation). To prevent premature convergence to local optima, a common pitfall in SR, we employ a standard multi-island topology ( $N$ islands) to structurally enforce search diversity (Cranmer, 2023; Romera-Paredes et al., 2024). Each island $j$ maintains an isolated experience buffer $\mathcal{B}_{j}$ , evolving its own lineage of equations. This information isolation allows distinct islands to cultivate diverse functional forms independently.
Phase 2: In-Search LLM Evolution (Policy Update). This phase transforms the collected data into parametric knowledge. We aggregate the trajectories from all $N$ islands into a global batch to perform policy optimization using PiT-PO. By minimizing the loss, the model explicitly lowers the probability of generating mathematically redundant tokens and physically inconsistent structures. To ensure computational efficiency during this iterative search, we implement the update using Low-Rank Adaptation (LoRA) (Hu et al., 2021).
Phase 3: Hierarchical Selection (Population Management). We apply standard survival-of-the-fittest mechanisms to maintain population quality. Local buffers $\mathcal{B}_{j}$ are updated by retaining only top-performing candidates, while underperforming islands are periodically reset with high-fitness seeds to escape local optima.
This cycle establishes a reciprocal reinforcement mechanism: the island-based exploration maintains search diversity, while policy update consolidates these findings into the model weights, progressively transforming the LLM into a domain-specialized scientific discoverer.
## 4. Experiments
### 4.1. Setup
Benchmarks. To provide a comprehensive evaluation of PiT-PO, we adopt two widely used benchmarks to compare against state-of-the-art baselines:
LLM-SR Suite (Shojaee et al., 2025a). This suite comprises four tasks spanning multiple scientific domains: Oscillation 1 & 2 (Nonlinear Oscillatory Systems) feature dissipative couplings and non-polynomial nonlinearities with explicit forcing, making recovery of the correct interaction terms from trajectory data non-trivial; E. coli Growth (Monod, 1949; Rosso et al., 1995) models multivariate population dynamics with strongly coupled, multiplicative effects from nutrients, temperature, and acidity; and Stress-Strain (Aakash et al., 2019) uses experimental measurements of Aluminum 6061-T651 and exhibits temperature-dependent, piecewise non-linear deformation behavior. Detailed information about these tasks is provided in Appendix D.1.
LLM-SRBench: (Shojaee et al., 2025b) To evaluate generalization beyond canonical forms, we adopt the comprehensive LLM-SRBench benchmark, which contains 239 tasks organized into two complementary subsets, LSR-Transform and LSR-Synth. LSR-Transform changes the prediction target to rewrite well-known physics equations into less common yet analytically equivalent forms, producing 111 transformed tasks. This design aims to reduce reliance on direct memorization of canonical templates and tests whether a method can recover the same physical law under non-trivial variable reparameterizations. Complementarily, LSR-Synth composes equations from both known scientific terms and synthetic but plausible terms to further assess discovery beyond memorized templates: candidate terms are proposed by an LLM under domain context, assembled into full equations, and then filtered through multiple checks, including numerical solvability, contextual novelty, and expert plausibility, yielding 128 synthetic tasks. Further details are given in Appendix D.2.
Baselines.
We compare PiT-PO against representative baselines spanning both classical and LLM-based SR methods. For the four tasks in the LLM-SR Suite, we include GPlearn, a genetic programming-based SR approach; PySR (Grayeli et al., 2024), which couples evolutionary search with symbolic simplification; uDSR (Landajuela et al., 2022), which replaces the RNN policy in DSR with a pretrained Transformer and employs neural-guided decoding; RAG-SR (Zhang et al., 2025), which incorporates structure retrieval to assist equation generation; and LLM-SR (Shojaee et al., 2025a). For the broader LLM-SRBench benchmark, we further compare against leading LLM-based SR methods, including SGA (Ma et al., 2024), which integrates LLM-driven hypothesis proposal with physics-informed parameter optimization in a bilevel search framework, and LaSR (Grayeli et al., 2024), which leverages abstract symbolic concepts distilled from prior equations to guide hybrid LLM–evolutionary generation.
Evaluation metrics. We evaluate methods using Accuracy to Tolerance and Normalized Mean Squared Error (NMSE). For a tolerance $\tau$ , we report $\mathrm{Acc}_{\mathrm{all}}(\tau)$ (Biggio et al., 2021) and $\mathrm{Acc}_{\mathrm{avg}}(\tau)$ based on relative error: $\mathrm{Acc}_{\mathrm{all}}(\tau)=\mathbbm{1}\!\bigl(\max_{1\leq i\leq N_{\mathrm{test}}}\bigl|\tfrac{\hat{y}_{i}-y_{i}}{y_{i}}\bigr|\leq\tau\bigr)$ and $\mathrm{Acc}_{\mathrm{avg}}(\tau)=\tfrac{1}{N_{\mathrm{test}}}\sum_{i=1}^{N_{\mathrm{test}}}\mathbbm{1}\!\bigl(\bigl|\tfrac{\hat{y}_{i}-y_{i}}{y_{i}}\bigr|\leq\tau\bigr)$ , where $\hat{y}_{i}$ and $y_{i}$ denote the predicted and ground-truth values at the $i$ -th test point, respectively. We additionally report $\mathrm{NMSE}=\frac{1}{N_{\mathrm{test}}}\sum_{i=1}^{N_{\mathrm{test}}}\frac{(\hat{y}_{i}-y_{i})^{2}}{\mathrm{Var}(y)}$ to assess overall numerical accuracy. We additionally adopt the Symbolic Accuracy (SA) metric (Shojaee et al., 2025b), which directly measures whether the discovered equation recovers the correct symbolic form (i.e., whether it is mathematically equivalent to the ground-truth equation up to fitted constants).
Hyperparameter Configurations. All experiments were run for 2,500 search iterations. To ensure a fair comparison, all hyperparameters related to LLM generation and search were kept consistent with the default configuration of LLM-SR. For the in-search policy optimization specific to PiT-PO, we use a learning rate of $1\times 10^{-6}$ , a group size of $G=4$ , and a multi-island setting of $N=4$ , resulting in an effective per-device batch size of $G\times N=16$ . The coefficient of the KL regularization term was set to 0.01, and the LoRA rank was set to $r=16$ . In addition, experiments were conducted on a single NVIDIA RTX 3090 using 4-bit quantized Llama-3.2-1B-Instruct, Llama-3.2-3B-Instruct, and Llama-3.1-8B-Instruct (Kassianik et al., 2025) to evaluate the training stability and performance transferability of PiT-PO across different parameter scales under constrained compute and memory budgets. More details are in Appendix A.
| GPlern uDSR PySR | 0.11 1.78 3.80 | 0.0972 0.0002 0.0003 | 0.05 0.36 7.02 | 0.2000 0.0856 0.0002 | 0.76 1.12 2.80 | 1.0023 0.5059 0.4068 | 28.43 59.15 70.60 | 0.3496 0.0639 0.0347 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| RAG-SR | 39.47 | 1.49e-6 | 0.43 | 0.0282 | 2.04 | 0.2754 | 76.28 | 0.0282 |
| LLM-SR (Mixtral) | 100.00 | 1.32e-11 | 99.98 | 1.18e-11 | 2.88 | 0.0596 | 71.44 | 0.0276 |
| LLM-SR (4o-mini) | 99.92 | 8.84e-12 | 99.97 | 8.70e-10 | 5.52 | 0.0453 | 85.33 | 0.0245 |
| LLM-SR (Llama-3.1-8B) | 59.58 | 1.17e-6 | 99.96 | 9.66e-10 | 4.86 | 0.0555 | 77.74 | 0.0246 |
| LLM-SR (Llama-3.2-3B) | 39.45 | 1.76e-6 | 66.34 | 6.99e-7 | 1.08 | 0.3671 | 74.78 | 0.0324 |
| LLM-SR (Llama-3.2-1B) | 3.28 | 4.47e-4 | 7.81 | 0.0002 | 1.70 | 0.5801 | 30.35 | 0.3801 |
| PiT-PO (Llama-3.1-8B) | 100.00 | 6.41e-31 | 99.99 | 2.11e-13 | 10.42 | 0.0090 | 84.45 | 0.0136 |
| PiT-PO (Llama-3.2-3B) | 100.00 | 7.58e-31 | 99.97 | 9.77e-10 | 7.01 | 0.0248 | 84.54 | 0.0156 |
| PiT-PO (Llama-3.2-1B) | 99.95 | 1.34e-11 | 99.97 | 1.70e-8 | 4.76 | 0.0240 | 76.91 | 0.1767 |
Table 1. Overall performance on LLM-SR Suite.
### 4.2. PiT-PO Demonstrates Superior Equation Discovery Capability
As evidenced in Table 1, PiT-PO establishes a new state-of-the-art on LLM-SR Suite. It consistently dominates baseline methods across all metrics, achieving the highest accuracy while maintaining the lowest NMSE in nearly all test cases. Crucially, when controlling for the LLM backbone, PiT-PO yields a substantial performance margin over LLM-SR, validating the effectiveness of our in-search policy optimization framework. Notably, PiT-PO is the only approach to successfully identify the exact ground-truth equation for the Oscillator 1. This structural precision extends to the larger-scale LLM-SRBench (Table 2), where PiT-PO achieves the highest symbolic accuracy across all categories. These results collectively demonstrate that PiT-PO not only fits data numerically but excels in uncovering the true underlying equations.
These quantitative gains are not accidental but stem from PiT-PO’s structural awareness. Analysis of the iterative trajectories of LLM-SR and PiT-PO in Appendix C.4 corroborates this conclusion: the iterations of LLM-SR remain persistently influenced by clearly incorrect terms, which violate physical meaning despite providing strong numerical fits, as well as by additional nuisance terms. Consequently, the search of LLM-SR often stagnates in a low-MSE regime without reaching the correct structure. In contrast, once PiT-PO enters the same regime, the dual constraints rapidly eliminate terms that improve fitting performance but are structurally incorrect. This behavior highlights the central advantage of the proposed dual-constraint learning signals, in which the physical constraints and token-level penalties provide data-driven signals for precise structural correction, guiding the LLM toward the true underlying equation rather than mere numerical overfitting.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Comparative Performance Analysis of LLM-SR vs. PiT-PO Across Four Datasets
### Overview
The image displays a 2x2 grid of four line charts. Each chart compares the performance of two methods, **LLM-SR** (blue line) and **PiT-PO** (red line), over 2500 iterations. Performance is measured by **NMSE (Normalized Mean Squared Error)** on a logarithmic scale. The four datasets or problems analyzed are titled "Oscillation 1", "Oscillation 2", "E. coli Growth", and "Stress-Strain". Shaded regions around each line represent confidence intervals or variability (light blue for LLM-SR, light red for PiT-PO).
### Components/Axes
* **Legend:** Located at the top center of the entire figure. It contains two entries:
* A blue line labeled **LLM-SR**.
* A red line labeled **PiT-PO**.
* **Common Axes:**
* **X-axis (all subplots):** Labeled **"Iteration"**. The scale is linear, with major tick marks at 0, 625, 1250, 1875, and 2500.
* **Y-axis (all subplots):** Labeled **"NMSE (log scale)"**. The scale is logarithmic, but the specific range varies per subplot.
* **Subplot Titles (Top Center of each chart):**
* Top-Left: **Oscillation 1**
* Top-Right: **Oscillation 2**
* Bottom-Left: **E. coli Growth**
* Bottom-Right: **Stress-Strain**
### Detailed Analysis
**1. Oscillation 1 (Top-Left Chart)**
* **Y-axis Range:** Approximately 10⁻¹ to 10⁻²⁵.
* **LLM-SR (Blue):** Starts near 10⁻¹. Shows a rapid initial drop, then plateaus around 10⁻⁷ by iteration ~200. It remains relatively flat at this level until iteration 2500. The confidence interval (light blue) is narrow.
* **PiT-PO (Red):** Starts near 10⁻¹. Drops sharply to ~10⁻¹³ by iteration ~100. It then exhibits a stepwise descent: a plateau until ~1300, a drop to ~10⁻¹⁹, another plateau until ~2400, and a final sharp drop to below 10⁻²⁵. The confidence interval (light red) is wider than LLM-SR's, especially between iterations 625-1875.
* **Trend:** Both methods improve (lower NMSE) over iterations. PiT-PO achieves a dramatically lower final error (by many orders of magnitude) and shows a distinct stepwise convergence pattern.
**2. Oscillation 2 (Top-Right Chart)**
* **Y-axis Range:** Approximately 10⁻² to 10⁻¹¹.
* **LLM-SR (Blue):** Starts near 10⁻². Drops to ~10⁻⁵ by iteration ~200, then to ~10⁻⁹ by iteration ~1000. It plateaus at ~10⁻⁹ for the remainder. The confidence interval is wide, spanning from ~10⁻⁵ to 10⁻¹¹ after iteration 1000.
* **PiT-PO (Red):** Starts near 10⁻². Drops very rapidly to ~10⁻⁹ by iteration ~200. It then shows a stepwise descent: a plateau until ~1300, a drop to ~10⁻¹², and a final slight decline to near 10⁻¹³ by iteration 2500. Its confidence interval is also wide but generally sits at a lower error range than LLM-SR's after iteration 200.
* **Trend:** PiT-PO converges much faster initially and reaches a lower final error. Both methods show significant variability (wide confidence bands) after the initial convergence phase.
**3. E. coli Growth (Bottom-Left Chart)**
* **Y-axis Range:** Approximately 10⁰ (1) to 10⁻².
* **LLM-SR (Blue):** Starts near 10⁰. Drops in steps to ~10⁻¹ by iteration ~200, then to ~10⁻¹.⁵ by iteration ~1000, and finally to ~10⁻¹.⁷ by iteration 2500. The confidence interval is very wide, spanning nearly the entire y-axis range after iteration 200.
* **PiT-PO (Red):** Starts near 10⁰. Follows a similar stepwise descent but consistently achieves lower error at each step. It reaches ~10⁻¹.⁵ by iteration ~200, ~10⁻¹.⁸ by iteration ~1300, and ~10⁻² by iteration 2500. Its confidence interval is also wide but centered at a lower error value than LLM-SR's.
* **Trend:** Both methods show stepwise improvement. PiT-PO consistently outperforms LLM-SR at each stage, achieving a final NMSE about an order of magnitude lower. The large confidence intervals suggest high variability in performance for both methods on this dataset.
**4. Stress-Strain (Bottom-Right Chart)**
* **Y-axis Range:** Approximately 10⁻¹ to 10⁻².
* **LLM-SR (Blue):** Starts near 10⁻¹. Drops rapidly to ~10⁻¹.⁵ by iteration ~200, then to ~10⁻¹.⁷ by iteration ~1000, and plateaus near ~10⁻¹.⁸ by iteration 2500. Confidence interval is moderately wide.
* **PiT-PO (Red):** Starts near 10⁻¹. Drops similarly to ~10⁻¹.⁵ by iteration ~200, then to ~10⁻¹.⁸ by iteration ~1000, and finally to ~10⁻² by iteration 2500. Its confidence interval is also moderately wide and overlaps with LLM-SR's in the early iterations but separates to a lower error range later.
* **Trend:** Both methods improve rapidly at first. PiT-PO shows a slight but consistent advantage in the later iterations (after ~1000), achieving a lower final error.
### Key Observations
1. **Consistent Superiority of PiT-PO:** In all four tasks, the **PiT-PO** method (red line) achieves a lower final NMSE than **LLM-SR** (blue line). The difference is most extreme in "Oscillation 1" (many orders of magnitude) and least pronounced in "Stress-Strain".
2. **Stepwise Convergence:** PiT-PO frequently exhibits a "stepwise" convergence pattern, where the error drops sharply, plateaus for several hundred iterations, and then drops again. This is visible in all charts but is most dramatic in "Oscillation 1".
3. **Convergence Speed:** PiT-PO generally converges faster in the very early iterations (first ~200), reaching a lower error level more quickly than LLM-SR.
4. **Variability (Confidence Intervals):** Both methods show significant performance variability, as indicated by the wide shaded confidence intervals. This variability is particularly large for the "E. coli Growth" and "Oscillation 2" tasks. Despite this, the central trend (solid line) for PiT-PO is consistently lower.
5. **Task Difficulty:** The scale of the final NMSE varies greatly by task, from ~10⁻²⁵ ("Oscillation 1") to ~10⁻² ("E. coli Growth", "Stress-Strain"), indicating these problems have vastly different inherent difficulties or error scales.
### Interpretation
The data strongly suggests that the **PiT-PO** method is more effective and efficient than **LLM-SR** for the class of problems represented by these four datasets. Its key advantages are:
* **Higher Accuracy:** It consistently reaches a lower error floor.
* **Faster Initial Convergence:** It reduces error more rapidly in the early stages of optimization.
* **Potential for Deep Convergence:** The stepwise pattern, especially in "Oscillation 1", suggests PiT-PO may be capable of escaping local minima or finding progressively better solutions over long runs, whereas LLM-SR tends to plateau earlier.
The wide confidence intervals indicate that the performance of both methods can be variable, likely depending on initial conditions or stochastic elements in the algorithms. However, the consistent positioning of the PiT-PO trend line below the LLM-SR trend line across all tasks and iterations provides robust evidence for its relative superiority in this comparison. The "Oscillation" tasks, which likely involve fitting periodic functions, show the most dramatic performance gap, hinting that PiT-PO may be particularly well-suited for such problems.
</details>
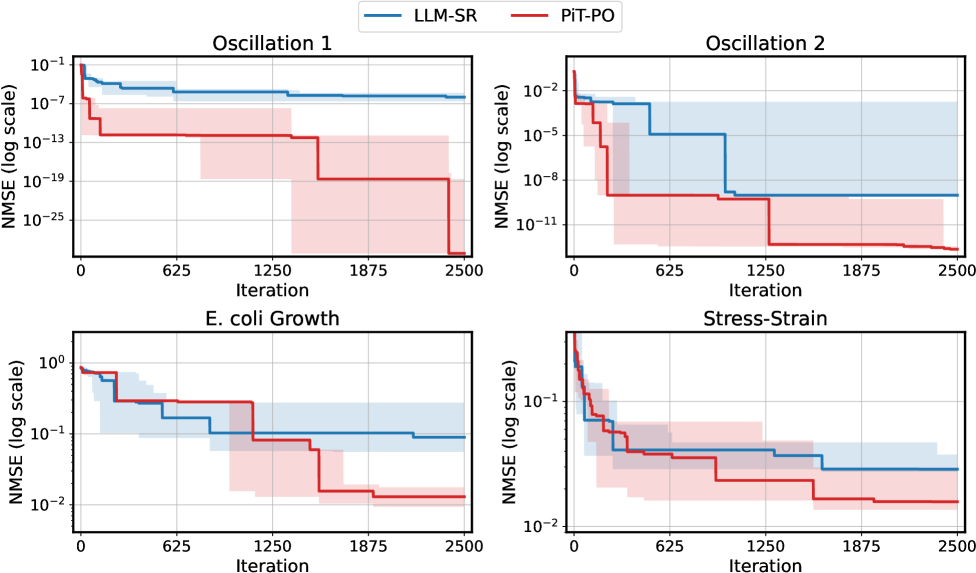
Figure 2. NMSE trajectories (log scale) over search iterations for LLM-SR and PiT-PO (Llama-3.1-8B) on LLM-SR Suite. Lines denote the median over seeds, and shaded regions indicate the min–max range.The remaining iteration curves for smaller backbones (3B and 1B) are deferred to Appendix C.1.
| Direct Prompting SGA LaSR | 3.61 2.70 5.41 | 1.801 0.909 45.94 | 0.3697 0.3519 0.0021 | 0.00 0.00 0.00 | 0.00 8.33 27.77 | 0.0644 0.0458 2.77e-4 | 0.00 0.00 4.16 | 0.00 0.00 16.66 | 0.5481 0.2416 2.73e-4 | 0.00 0.00 4.54 | 0.00 2.27 25.02 | 0.0459 0.1549 0.0018 | 0.00 0.00 8.21 | 0.00 12.12 64.22 | 0.0826 0.0435 7.44e-5 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| LLM-SR | 30.63 | 38.55 | 0.0101 | 8.33 | 66.66 | 8.01e-6 | 25.30 | 58.33 | 1.04e-6 | 6.97 | 34.09 | 1.23e-4 | 4.10 | 88.12 | 1.15e-7 |
| PiT-PO | 34.23 | 46.84 | 0.0056 | 13.89 | 77.78 | 4.13e-7 | 29.17 | 70.83 | 9.37e-8 | 11.36 | 40.91 | 6.57e-5 | 12.00 | 92.00 | 1.18e-8 |
Table 2. Overall performance on LLM-SRBench (Llama-3.1-8B-Instruct).
### 4.3. PiT-PO Empowers Lightweight Backbones to Rival Large Models
As shown in Table 1, the performance of PiT-PO with the Llama-3.1-8B, Llama-3.2-3B, and Llama-3.2-1B backbones is competitive with, and often exceeds, the performance of LLM-SR that relies on substantially larger or proprietary models, including Mixtral 8 $\times$ 7B and 4o-mini.
These results indicate that PiT-PO effectively bridges the capability gap between lightweight open-source models and large-scale commercial systems. From a practical standpoint, this reduces the barrier to entry for scientific discovery: by delivering state-of-the-art performance on consumer-grade hardware (even maintaining competitiveness with a 1B backbone), PiT-PO eliminates the dependence on massive compute and closed-source APIs, thereby democratizing access to powerful SR tools.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: NMSE Comparison Across Methods (ID vs. OOD)
### Overview
This is a grouped bar chart comparing the Normalized Mean Squared Error (NMSE) on a logarithmic scale for three different methods or conditions. Each method has two bars representing performance on In-Distribution (ID) and Out-Of-Distribution (OOD) data. The chart demonstrates a significant performance gap between ID and OOD scenarios for the first two methods, while the third method ("PiT-PO") shows dramatically lower error overall.
### Components/Axes
* **Chart Type:** Grouped bar chart.
* **Y-Axis:**
* **Label:** `NMSE (log scale)`
* **Scale:** Logarithmic, ranging from `10^-29` to `10^-11`.
* **Major Tick Marks:** `10^-29`, `10^-26`, `10^-23`, `10^-20`, `10^-17`, `10^-14`, `10^-11`.
* **X-Axis (Categories):** Three distinct methods/conditions:
1. `w/o Phy`
2. `w/o TokenReg`
3. `PiT-PO`
* **Legend:** Located in the top-right corner.
* `ID`: Represented by solid-colored bars.
* `OOD`: Represented by hatched (diagonal lines) bars.
* **Bar Colors:** The first two method groups (`w/o Phy`, `w/o TokenReg`) use blue bars. The final group (`PiT-PO`) uses orange bars, likely to highlight it as the primary or proposed method.
### Detailed Analysis
The chart presents the following exact data points, read from the labels atop each bar:
| Method | Data Type | NMSE Value (Scientific Notation) | Approximate Value (Decimal) |
| :----------- | :-------- | :------------------------------- | :-------------------------- |
| **w/o Phy** | ID | `7.60e-21` | 0.0000000000000000000076 |
| | OOD | `2.06e-10` | 0.000000000206 |
| **w/o TokenReg** | ID | `2.77e-19` | 0.000000000000000000277 |
| | OOD | `9.97e-11` | 0.0000000000997 |
| **PiT-PO** | ID | `6.40e-31` | 0.0000000000000000000000000000064 |
| | OOD | `1.63e-30` | 0.00000000000000000000000000163 |
**Visual Trend Verification:**
1. **For `w/o Phy`:** The OOD bar (hatched blue) is dramatically taller than the ID bar (solid blue), indicating a massive increase in error for out-of-distribution data.
2. **For `w/o TokenReg`:** The same pattern holds. The OOD bar is significantly taller than the ID bar, though the absolute error values are slightly lower than the `w/o Phy` case.
3. **For `PiT-PO`:** Both bars are extremely short, sitting near the bottom of the chart (`10^-30` range). The OOD bar is slightly taller than the ID bar, but the difference is minuscule compared to the other methods. The color shift to orange visually sets this method apart.
### Key Observations
1. **Massive OOD Degradation:** The first two methods (`w/o Phy` and `w/o TokenReg`) suffer from catastrophic performance degradation on out-of-distribution data. Their OOD NMSE is **10 to 11 orders of magnitude higher** than their ID NMSE.
2. **PiT-PO Superiority:** The `PiT-PO` method achieves an NMSE that is **10 to 20 orders of magnitude lower** than the other methods for both ID and OOD scenarios. Its performance is exceptionally strong.
3. **Robustness of PiT-PO:** While `PiT-PO` still shows a slight increase in error for OOD data (`1.63e-30` vs. `6.40e-31`), the relative gap is very small. This suggests the method is highly robust and generalizes well.
4. **Log Scale Necessity:** The use of a log scale is essential to visualize all data points simultaneously, as the values span over 20 orders of magnitude.
### Interpretation
This chart provides strong empirical evidence for the effectiveness of the `PiT-PO` method. The data suggests that:
* **The Problem:** Standard models (represented by `w/o Phy` and `w/o TokenReg`) are extremely brittle. They perform well only on data similar to their training distribution (ID) but fail dramatically when faced with novel or shifted data (OOD). This is a classic sign of poor generalization and overfitting to the training distribution.
* **The Solution:** `PiT-PO` appears to be a technique that successfully addresses this brittleness. Its extraordinarily low NMSE values indicate it makes highly accurate predictions. More importantly, the minimal difference between its ID and OOD performance demonstrates **exceptional robustness and generalization capability**. It maintains its accuracy even when the data distribution changes.
* **Practical Implication:** In real-world applications where data is rarely perfectly stationary, a model like `PiT-PO` would be far more reliable and trustworthy than the alternatives shown. The chart is likely from a research paper aiming to prove that `PiT-PO` is a state-of-the-art solution for robust machine learning or modeling tasks.
</details>
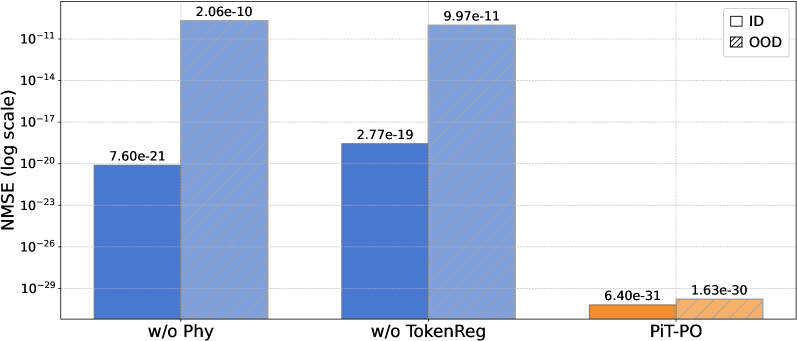
Figure 3. Ablation results of PiT-PO and its variants.
### 4.4. PiT-PO Enhances Search Efficiency and Breaks Stagnation
Figure 2 shows that PiT-PO achieves superior search efficiency in discovering accurate equations. In the early search stage, the red and blue curves are close across all four tasks: both methods primarily rely on the fitting signal (MSE) and therefore exhibit comparable per-iteration progress. As NMSE enters a lower regime, the trajectories consistently separate: PiT-PO exhibits abrupt step-wise drops while LLM-SR tends to plateau, yielding a clear red–blue gap in every subplot. Concretely, once the search reaches these lower-error regions, PiT-PO repeatedly exits stagnation and transitions to the next accuracy phase with orders-of-magnitude NMSE reductions (most prominently in Oscillation 1 and Oscillation 2, and also evident in E. coli Growth and Stress-Strain), whereas LLM-SR often remains trapped near its current error floor. This behavior confirms that the proposed dual-constraint mechanism effectively activates exactly when naive MSE feedback becomes insufficient. By penalizing physical inconsistencies and structural redundancy, PiT-PO forces the LLM to exit stagnation and transition toward the correct functional form.
While the in-search fine-tuning introduces a computational overhead, this cost is decisively outweighed by the substantial gains in performance. As detailed in Appendix C.2, PiT-PO maintains a significant performance edge even when evaluated under equivalent wall-clock time, demonstrating that the accelerated convergence speed effectively compensates for the additional training time.
### 4.5. Ablation Study
To rigorously validate the contribution of each algorithmic component, we conduct an ablation study across three settings: w/o Phy, which excludes the physics-consistency penalty $P_{\text{phy}}$ ; w/o TokenReg, which removes the redundancy-aware token-level regularization; and the full PiT-PO framework. As shown in Figure 3, removing any single component leads to a substantial deterioration of NMSE and a larger generalization gap between In-Distribution (ID) and Out-Of-Distribution (OOD) data. These empirical results underscore the necessity of the complete framework, demonstrating that the proposed dual constraints are indispensable for ensuring both search stability and robust generalization.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Flow Domain Geometry with Variable Curvature Parameter (α)
### Overview
This image is a technical schematic diagram illustrating a two-dimensional fluid flow domain with three distinct geometric configurations, each defined by a curvature parameter α. The diagram is plotted on a normalized coordinate system (x/H, y/H) and includes boundary condition labels, a flow direction indicator, and a legend for the α values. It appears to be from a computational fluid dynamics (CFD) or fluid mechanics study, showing how a channel's shape varies with α.
### Components/Axes
* **Coordinate System:**
* **X-axis:** Labeled `x/H`, ranging from 0 to 9. This represents the streamwise direction normalized by a characteristic height `H`.
* **Y-axis:** Labeled `y/H`, ranging from 0 to 3. This represents the wall-normal direction normalized by `H`.
* **Boundary Conditions:**
* **Top Boundary (y/H = 3):** Labeled `solid wall` in red text. This is a no-slip or impermeable wall.
* **Bottom Boundary (y/H = 0):** Labeled `solid wall` in red text. This is also a no-slip or impermeable wall.
* **Left Boundary (x/H = 0):** Labeled `cyclic` in red text. This indicates a periodic boundary condition where flow exiting this boundary re-enters from the right.
* **Right Boundary (x/H = 9):** This boundary is segmented into three vertical sections, each labeled `cyclic` in a color matching its corresponding α curve. This indicates that the periodic boundary condition is applied separately for each geometric configuration.
* **Flow Indicator:** A large, light-yellow arrow in the center of the domain points to the right, labeled `flow direction`.
* **Legend / Parameter Key:** Located in the top-right corner of the diagram. It lists three values of the parameter α, each associated with a specific color:
* `α = 0.5` (Red text)
* `0.8` (Teal text)
* `1.0` (Dark green text)
* **Geometric Feature Label:** The shaded area under the right-side curves is labeled with a large, italicized `H` in black, indicating this region represents the characteristic height or a specific geometric feature of size `H`.
### Detailed Analysis
The core of the diagram shows three different channel wall profiles (the lower boundary of the flow domain) that start at (x/H=0, y/H=1) and end at (x/H=9, y/H=1). The upper boundary is a flat, solid wall at y/H=3.
1. **α = 0.5 (Red Curve):**
* **Trend:** The curve exhibits the sharpest curvature. It descends rapidly from y/H=1 at x/H=0, reaches the bottom wall (y/H=0) at approximately x/H=1.5, runs along the bottom wall until about x/H=6.5, then ascends very steeply back to y/H=1 by x/H=7.5.
* **Spatial Grounding:** This creates the narrowest and most abrupt constriction in the channel. The corresponding `cyclic` label on the right boundary is in red and is positioned furthest to the left among the three right-boundary labels.
2. **α = 0.8 (Teal Curve):**
* **Trend:** This curve has a moderate curvature. It descends more gradually than the α=0.5 curve, reaching y/H=0 at approximately x/H=2.5. It runs along the bottom wall until about x/H=7.0, then ascends with a moderate slope, reaching y/H=1 at approximately x/H=8.5.
* **Spatial Grounding:** This creates a channel with a wider and smoother constriction compared to α=0.5. The corresponding `cyclic` label on the right boundary is in teal and is positioned in the middle of the three right-boundary labels.
3. **α = 1.0 (Dark Green Curve):**
* **Trend:** This curve has the gentlest curvature. It descends the most slowly, reaching y/H=0 at approximately x/H=3.5. It runs along the bottom wall until about x/H=7.5, then ascends with the most gradual slope, reaching y/H=1 at approximately x/H=9.0.
* **Spatial Grounding:** This creates the widest and most gradual constriction. The corresponding `cyclic` label on the right boundary is in dark green and is positioned furthest to the right.
The shaded yellow region labeled `H` under the right-side ascent of the curves visually emphasizes the vertical scale of the geometric feature.
### Key Observations
* **Parameter Control:** The parameter α directly controls the "sharpness" or curvature of the channel's lower wall. A lower α (0.5) results in a more abrupt, step-like constriction, while a higher α (1.0) results in a smoother, more gradual ramp.
* **Domain Segmentation:** The right boundary is explicitly divided into three separate cyclic zones, each aligned with the exit of one specific α-geometry. This suggests the diagram may be illustrating three separate computational domains or cases that are being compared.
* **Consistent Start/End Points:** All three geometric profiles share the same inlet (x/H=0, y/H=1) and outlet (x/H=9, y/H=1) vertical positions, isolating the effect of the wall shape between these points.
* **Visual Hierarchy:** The use of color (red, teal, dark green) consistently links the α value in the legend, the corresponding curve, and its associated cyclic boundary label, ensuring clear visual association.
### Interpretation
This diagram is a parametric study of channel geometry. The parameter α likely represents a shape factor in a mathematical function (e.g., a polynomial or trigonometric function) that defines the wall profile. The investigation is probably focused on how this geometric variation affects fluid flow characteristics such as:
* **Pressure Drop:** The sharper constriction (α=0.5) would likely induce a higher pressure loss compared to the smoother one (α=1.0).
* **Flow Separation & Recirculation:** The abrupt change in geometry for α=0.5 is more prone to causing flow separation and recirculation zones (eddies) downstream of the constriction, which could impact mixing or efficiency.
* **Shear Stress Distribution:** The wall shear stress profile along the bottom wall would differ significantly between the three cases due to the varying curvature and local flow acceleration.
The use of cyclic boundaries implies the study is of a periodic flow, such as flow over a repeating array of obstacles or through a corrugated channel, where simulating one full period is sufficient. The diagram serves as a clear, visual definition of the computational or experimental setups being compared, allowing a viewer to immediately grasp the geometric differences between the cases labeled α=0.5, 0.8, and 1.0.
</details>
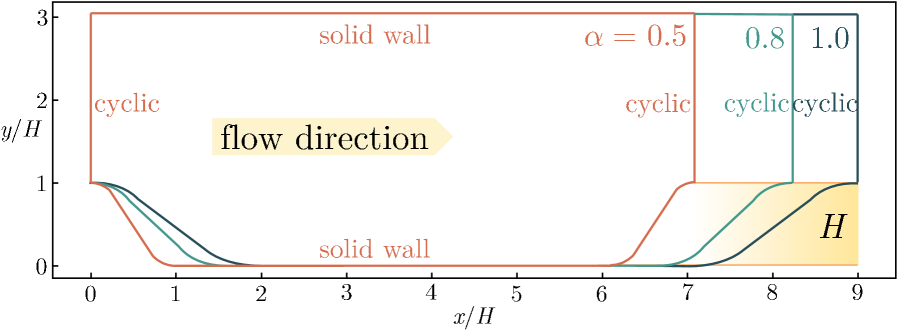
Figure 4. Schematic of the geometries for periodic hills.
### 4.6. Case Study: Turbulence Modeling
To validate the practical utility of PiT-PO in high-fidelity scientific discovery, we select the Flow over Periodic Hills (Xiao et al., 2020) (Figure 4) as a testbed. This problem is widely recognized in Computational Fluid Dynamics (CFD) (Pope, 2000) as a benchmark for Separated Turbulent Flows, presenting complex features such as strong adverse pressure gradients, massive flow detachment, and reattachment.
Problem Definition and Physics: The geometry consists of a sequence of polynomially shaped hills arranged periodically in the streamwise direction. The flow is driven by a constant body force at a bulk Reynolds number of $Re_{b}=5600$ (based on hill height $H$ and bulk velocity $U_{b}$ ). The domain height is fixed at $L_{y}/H=3.036$ , while the streamwise length $L_{x}$ varies with the slope factor $\alpha$ according to $L_{x}/H=3.858\alpha+5.142$ . Periodic boundary conditions are applied in the streamwise direction, with no-slip conditions on the walls.
The Scientific Challenge: The challenge lies in the Separation Bubble (Pope, 2000), a region where turbulence exhibits strong anisotropy due to streamline curvature. Traditional Linear Eddy Viscosity Models (LEVM) (Pope, 2000), such as the $k$ - $\omega$ SST model (Menter, 1994; Menter et al., 2003), rely on the Boussinesq hypothesis which assumes isotropic turbulence. Consequently, they systematically fail to predict key flow features, such as the separation bubble size and reattachment location.
Discovery Objective: Instead of fitting a simple curve, our goal is to discover a Non-linear Constitutive Relation for the Reynolds stress anisotropy tensor $a_{ij}$ and the dimensionless Reynolds stress anisotropy tensor $b_{ij}$ . By learning the Reynolds stress tensor $\tau_{ij}$ from high-fidelity Direct Numerical Simulation (DNS) (Pope, 2000) data, PiT-PO aims to formulate a symbolic correction term that captures the anisotropic physics missed by linear models.
Baselines: We follow standard turbulence modeling protocols and compare primarily against the standard $k$ - $\omega$ SST model of RANS. We also include LLM-SR and DSRRANS (Tang et al., 2023a), a strong SR-based turbulence modeling method specifically designed for turbulence tasks.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Heatmap Grid: Turbulence Model Comparison of Normalized Reynolds Stress Components
### Overview
The image is a 5x4 grid of contour plots (heatmaps) comparing the predictions of five different turbulence modeling or simulation methods for four components of a normalized Reynolds stress tensor. The plots visualize spatial distributions within a 2D domain, likely representing a flow over a flat surface or within a channel. The bottom row (DNS) serves as the high-fidelity reference solution.
### Components/Axes
* **Rows (Methods):** Labeled on the far left. From top to bottom:
1. **RANS** (Reynolds-Averaged Navier-Stokes)
2. **DSRANS** (Likely a Data-Driven or Hybrid RANS model)
3. **LLM-SR** (Likely a Machine Learning or Super-Resolution enhanced model)
4. **PIPPO** (Likely another advanced or physics-informed model)
5. **DNS** (Direct Numerical Simulation - Reference)
* **Columns (Variables):** Labeled at the top of each column. Each represents a component of the Reynolds stress tensor (`a_ij`), normalized by the square of the friction velocity (`u_τ²`).
1. `a₁₁/u_τ²` (Streamwise normal stress)
2. `a₂₂/u_τ²` (Wall-normal normal stress)
3. `a₃₃/u_τ²` (Spanwise normal stress)
4. `a₁₂/u_τ²` (Shear stress)
* **Axes (Each Subplot):**
* **X-axis:** `x/H` (Streamwise coordinate normalized by a characteristic height `H`). Range: 0 to 8.
* **Y-axis:** `y/H` (Wall-normal coordinate normalized by `H`). Range: 0 to 3.
* **Color Scale (Legend):** A shared color bar is positioned above each column. The scale ranges from **-0.04 (dark blue)** to **+0.03 (dark red)**, with white/light colors representing values near zero. This indicates the magnitude and sign of the normalized stress component.
### Detailed Analysis
**Trend Verification & Spatial Grounding:**
1. **RANS (Top Row):**
* **a₁₁:** Predominantly light blue/white, indicating values near zero or slightly negative across the domain. A very faint red region appears near the outlet (x/H ~7-8, y/H ~1-2).
* **a₂₂:** Almost entirely white/light blue, suggesting near-zero predictions.
* **a₃₃:** Similar to a₂₂, very low magnitude.
* **a₁₂:** Shows a broad, faint red region in the center of the domain (x/H ~2-7, y/H ~1-2), indicating a weak positive shear stress prediction.
2. **DSRANS (Second Row):**
* **a₁₁:** Shows a distinct blue region near the inlet (x/H ~0-2) and a red region near the outlet (x/H ~6-8), indicating a predicted increase in streamwise stress along the flow.
* **a₂₂:** Features a prominent red spot near the outlet (x/H ~7, y/H ~1), suggesting a localized high wall-normal stress.
* **a₃₃:** Displays a blue region near the outlet (x/H ~6-8, y/H ~0.5-1.5), indicating negative spanwise stress.
* **a₁₂:** Shows a large, elongated red region spanning most of the domain's length (x/H ~1-8) at mid-height (y/H ~1-2), predicting significant positive shear stress.
3. **LLM-SR (Third Row):**
* **a₁₁:** Exhibits extreme contrast. A large, intense red region dominates the center (x/H ~2-6, y/H ~0.5-2), flanked by blue regions near the inlet and outlet. This suggests a very strong, possibly over-predicted, peak in streamwise stress.
* **a₂₂:** Shows a large, intense blue region in the center, surrounded by red, indicating a strong negative wall-normal stress prediction, which is physically unusual and may be an artifact.
* **a₃₃:** Relatively muted compared to other components, with light blue/white colors.
* **a₁₂:** Displays a complex pattern with a strong red region in the upper half and blue in the lower half, indicating a sharp gradient in shear stress.
4. **PIPPO (Fourth Row):**
* **a₁₁:** Shows a moderate red region in the center (x/H ~2-6), with blue near the inlet and a small red spot at the outlet. The intensity is lower than LLM-SR but higher than RANS.
* **a₂₂:** Features a broad blue region in the center, similar in pattern but less intense than LLM-SR.
* **a₃₃:** Mostly light, with a faint blue region near the outlet.
* **a₁₂:** Shows a broad red region similar to DSRANS but slightly less intense and more confined to the center.
5. **DNS (Bottom Row - Reference):**
* **a₁₁:** Shows a clear blue region near the inlet (x/H ~0-3) transitioning to a red region near the outlet (x/H ~5-8). This is the benchmark trend.
* **a₂₂:** Displays a light red region in the center of the domain (x/H ~2-6, y/H ~1-2).
* **a₃₃:** Shows a light blue region in the center, indicating slightly negative spanwise stress.
* **a₁₂:** Features a distinct red region in the center (x/H ~2-7, y/H ~1-2), representing the benchmark positive shear stress.
### Key Observations
1. **Model Fidelity Gradient:** There is a clear progression in pattern complexity and intensity from RANS (most diffuse) to DNS (most defined). DSRANS and PIPPO show intermediate levels of detail.
2. **LLM-SR Anomalies:** The LLM-SR model produces the most extreme values, particularly the large negative (blue) region in `a₂₂`, which contradicts the positive (red) trend seen in the DNS reference. This suggests potential instability or overfitting in this model's predictions.
3. **Shear Stress (`a₁₂`) Consistency:** All models except RANS predict a positive (red) shear stress region in the center of the domain, aligning qualitatively with DNS. However, the shape and intensity vary significantly.
4. **Inlet/Outlet Effects:** Most models show distinct features near the domain boundaries (x/H=0 and x/H=8), which are likely influenced by boundary conditions or flow development.
### Interpretation
This visualization is a comparative study of turbulence model accuracy. The DNS row provides the "ground truth" for the spatial distribution of Reynolds stresses in this flow configuration.
* **RANS** is overly diffusive, smoothing out all stress gradients and under-predicting magnitudes significantly. It fails to capture the essential physics of stress development.
* **DSRANS** and **PIPPO** represent improved models that capture the general trends (e.g., the sign and location of stress regions) seen in DNS, though with differences in intensity and precise shape. PIPPO appears slightly closer to DNS in the `a₁₁` component.
* **LLM-SR** demonstrates a high sensitivity, producing sharp gradients and extreme values. While it captures some features, the anomalous negative `a₂₂` region indicates it may be generating non-physical solutions or is highly sensitive to input data/training. It highlights the risk of machine learning models producing "hallucinated" patterns without proper physical constraints.
* The **`a₁₂` (shear stress)** component is a critical metric for momentum transfer. The fact that all advanced models (DSRANS, LLM-SR, PIPPO) capture its positive sign and general location is a key validation point, though quantitative accuracy varies.
**In summary, the image demonstrates that while advanced data-driven or hybrid models (DSRANS, PIPPO) can significantly improve upon traditional RANS in predicting complex turbulence statistics, they still exhibit discrepancies compared to DNS. The LLM-SR model shows promise in capturing sharp features but requires caution due to potential unphysical predictions. This type of analysis is crucial for validating and improving computational fluid dynamics models for engineering design.**
</details>
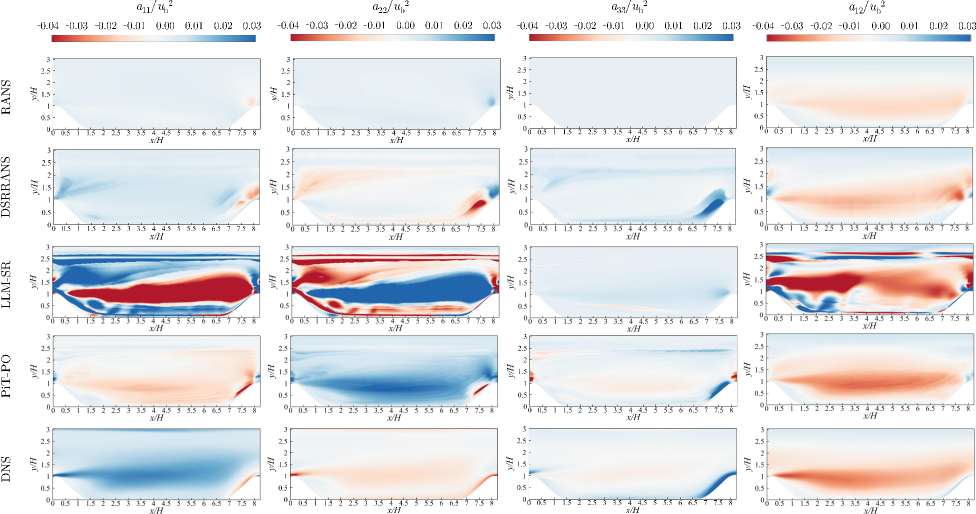
Figure 5. Comparison of the four anisotropic Reynolds stress components for periodic hill training flow using RANS, DSRRANS, LLM-SR, PiT-PO and DNS, respectively.
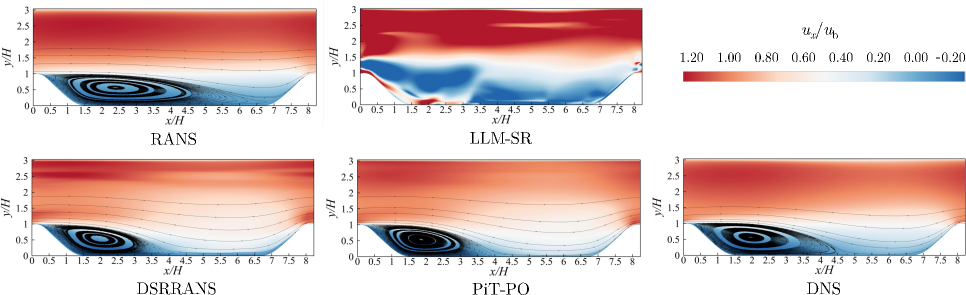
We cast turbulence closure modeling as a SR problem (Tang et al., 2023b) (see Appendix E for details). After obtaining the final symbolic equation, we embed it into a RANS solver of OpenFOAM (Weller et al., 1998) and run CFD simulations on the periodic-hill configuration. We compare the resulting Reynolds-stress components, mean-velocity fields, and skin-friction profiles against DNS references. Figures 5 – 7 visualize these quantities, enabling a direct assessment of physical fidelity and flow-field prediction quality.
Based on the comparative analysis of the anisotropic Reynolds stress contours (Figure 5), DSRRANS and PiT-PO show enhancement over the traditional RANS approach. Among them, PiT-PO performs the best: its contour matches the DNS reference most closely, with reduced error compared to DSRRANS and LLM-SR, demonstrating less severe non-physical extremes.
The stream-wise velocity contours illustrate the correction of the bubble size, a region of reversed flow that forms when fluid detaches from a surface. In Figure 6, PiT-PO most accurately represents the extent and shape of the recirculation zone, where fluid circulates within the separated region, closely consistent with the DNS data throughout the domain, particularly within the separation region and the recovery layer, where flow re-attaches to the surface.
The skin friction coefficient (Figure 7), defined as the ratio of the wall stress to the dynamic pressure of the flow along the bottom wall, is a sensitive metric for predicting flow separation. The $k$ - $\omega$ SST model of RANS underestimates the magnitude of the skin friction and predicts a delayed reattachment location compared to the DNS. The learned model (PiT-PO) improves the prediction, aligning more closely with the DNS profile.
These results demonstrate that PiT-PO can generate symbolic equations tailored to turbulence modeling and that, under a posteriori CFD evaluation, the resulting predictions more closely match DNS references, which increases the practical value of LLM-based SR in real scientific and engineering workflows. With the proposed dual constraints,
PiT-PO provides targeted search and learning signals that enable the internalization of turbulence priors during equation discovery, thereby steering the model toward physically consistent and domain-relevant structures.
<details>
<summary>x6.png Details</summary>
### Visual Description
## [Composite Scientific Visualization]: Comparison of Turbulence Modeling Approaches for Flow Over a Backward-Facing Step
### Overview
The image is a composite scientific visualization comparing five different computational methods for simulating turbulent flow over a backward-facing step. It consists of five individual contour plots (arranged in a 2x3 grid, with the sixth position occupied by a color bar legend) and a shared color scale. Each plot displays the normalized streamwise velocity field (`u_x/u_b`) overlaid with flow streamlines. The primary purpose is to visually compare the accuracy and characteristics of different turbulence models against a high-fidelity reference solution.
### Components/Axes
* **Layout:** Five data plots and one color bar legend. Top row (left to right): RANS, LLM-SR, Color Bar. Bottom row (left to right): DSRRANS, Pi-PO, DNS.
* **Axes (All Plots):**
* **X-axis:** Label: `x/H`. Scale: Linear, from 0 to 8. Ticks at intervals of 0.5.
* **Y-axis:** Label: `y/H`. Scale: Linear, from 0 to 3. Ticks at intervals of 0.5.
* **Color Bar Legend (Top Right):**
* **Variable:** `u_x/u_b` (Normalized streamwise velocity).
* **Scale:** Linear, ranging from -0.20 to 1.20.
* **Color Gradient:** Diverging scheme. Blue represents negative values (down to -0.20), transitioning through white at 0.00, to red for positive values (up to 1.20).
* **Tick Values:** -0.20, 0.00, 0.20, 0.40, 0.60, 0.80, 1.00, 1.20.
* **Plot Titles (Below each subplot):**
1. `RANS` (Top Left)
2. `LLM-SR` (Top Center)
3. `DSRRANS` (Bottom Left)
4. `Pi-PO` (Bottom Center)
5. `DNS` (Bottom Right)
### Detailed Analysis
Each subplot visualizes the same physical domain: flow moving from left to right over a step located at `x/H = 0`, `y/H = 1`. The streamlines show the path of fluid particles, and the color indicates local velocity.
1. **RANS (Top Left):**
* **Trend:** Shows a large, smooth, and stable recirculation zone (blue region) immediately behind the step. The reattachment point (where the flow reattaches to the bottom wall) appears to be around `x/H ≈ 6.5`.
* **Velocity Field:** The core flow above the step (red/orange) is relatively uniform. The recirculation zone is a deep, consistent blue, indicating strongly negative velocity.
2. **LLM-SR (Top Center):**
* **Trend:** Exhibits a highly irregular and chaotic flow field compared to all other methods. The recirculation zone is fragmented and not well-defined. There are patches of high and low velocity scattered throughout the domain.
* **Velocity Field:** Shows extreme variations, with intense red (high velocity) and blue (negative velocity) regions appearing in non-physical, patchy distributions. This suggests a potential instability or failure in this particular simulation/model.
3. **DSRRANS (Bottom Left):**
* **Trend:** Similar overall structure to RANS but with a slightly more detailed recirculation zone. The reattachment point is slightly further downstream, approximately `x/H ≈ 7.0`.
* **Velocity Field:** The recirculation zone is well-defined but shows more internal structure (lighter blue gradients) compared to the monolithic blue of RANS.
4. **Pi-PO (Bottom Center):**
* **Trend:** The recirculation zone is smaller and more compact than in RANS/DSRRANS. The reattachment point is significantly further upstream, around `x/H ≈ 5.5`.
* **Velocity Field:** The core flow above the step shows more pronounced velocity gradients (bands of orange and red). The recirculation zone is a distinct, concentrated blue oval.
5. **DNS (Bottom Right):**
* **Trend:** As the Direct Numerical Simulation (the high-fidelity reference), it shows the most complex and detailed flow structure. The recirculation zone has a complex internal vortex structure. The reattachment point is approximately `x/H ≈ 6.0`.
* **Velocity Field:** Displays the finest gradients and most intricate streamline patterns, capturing small-scale turbulent structures not fully resolved by the other models.
### Key Observations
* **Model Discrepancy:** There is significant variation in the predicted size, shape, and internal structure of the recirculation zone across the five methods.
* **LLM-SR Anomaly:** The LLM-SR result is a clear outlier, showing a physically implausible, noisy flow field that does not resemble the coherent structures seen in the other models or the DNS reference.
* **Reattachment Point Variation:** The estimated reattachment point varies considerably: Pi-PO (~5.5) < DNS (~6.0) < RANS (~6.5) < DSRRANS (~7.0).
* **Structural Fidelity:** DNS shows the most detailed vortex core within the recirculation zone. DSRRANS and Pi-PO capture some internal structure, while RANS shows a more simplified, monolithic vortex.
### Interpretation
This visualization is a comparative study of turbulence modeling fidelity. The **DNS** plot serves as the ground truth. The **RANS** model, a traditional workhorse, provides a stable but overly smoothed and slightly inaccurate prediction (overestimating reattachment length). **DSRRANS** appears to be a variant that adds some detail but still overpredicts the recirculation zone size. **Pi-PO** underpredicts the zone size, suggesting a different bias in its modeling approach.
The most striking result is the **LLM-SR** model. Its output is not just inaccurate but qualitatively different, exhibiting a lack of physical coherence. This suggests that this particular application of a Large Language Model (or similar ML approach) to this fluid dynamics problem may be unstable, improperly trained, or fundamentally unsuited for capturing the continuous, physics-governed nature of this flow field. The image effectively demonstrates that while advanced models (like DSRRANS, Pi-PO) can modulate the predictions of traditional RANS, not all novel approaches (like this LLM-SR instance) yield physically plausible results. The core takeaway is the critical importance of validation against high-fidelity data (DNS) when developing or applying new computational models.
</details>
Figure 6. Non-dimensional stream-wise velocity contours obtained by the learned model and the standard $k$ - $\omega$ SST model of RANS, compared with DNS data.
## 5. Related Work
Traditional SR has been studied through several lines, including genetic programming , reinforcement learning (Petersen et al., 2021), and transformer-based generation (Biggio* et al., 2021). Genetic programming (Koza, 1990) casts equation discovery as an evolutionary search over tree-structured programs, where candidate expressions are iteratively refined via mutation and crossover. Reinforcement learning-based SR, introduced by Petersen et al. (Petersen et al., 2021), has developed into a family of policy-optimization frameworks (Mundhenk et al., 2021; Landajuela et al., 2021; Crochepierre et al., 2022; Du et al., 2023) that formulate SR as a sequential decision-making process. More recently, transformer-based models (Valipour et al., 2021; Vastl et al., 2024; Kamienny et al., 2022; Li et al., 2023; Zhang et al., 2025) have been adopted for SR, using large-scale pretraining to map numerical data directly to equations. However, these methods typically fail to incorporate scientific prior knowledge.
Recent progress in natural language processing has further enabled LLM-based SR methods, including LLM-SR (Shojaee et al., 2025a), LaSR (Grayeli et al., 2024), ICSR (Merler et al., 2024), CoEvo (Guo et al., 2025), and SR-Scientist (Xia et al., 2025). LLM-SR exploits scientific priors that are implicitly captured by LLMs to propose plausible functional forms, followed by data-driven parameter estimation. LaSR augments SR with abstract concept generation to guide hypothesis formation, while ICSR reformulates training examples as in-context prompts to elicit function generation. However, a unifying limitation across these methods is their reliance on the LLM as a frozen generator, which precludes incorporating search feedback to update the generation strategy and consequently restricts their ability to adapt to complex problems.
While some recent works, such as SOAR (Pourcel et al., 2025) and CALM (Huang et al., 2025), have begun to explore adaptive in-search tuning, they primarily focus on algorithm discovery or combinatorial optimization problems, whereas our method is specifically tailored for SR. By integrating hierarchical physical constraints and theorem-guided token regularization, PiT-PO establishes an adaptive framework capable of discovering accurate and physically consistent equations.
<details>
<summary>x7.png Details</summary>
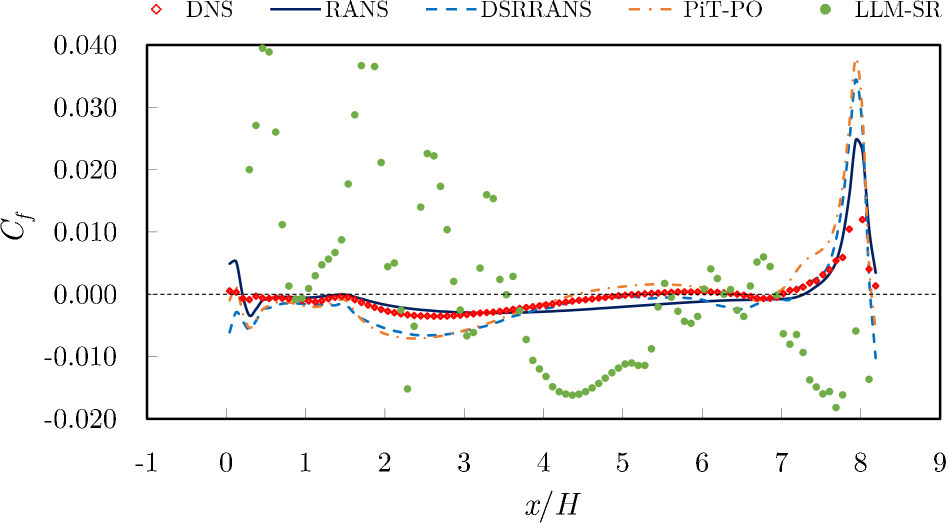
### Visual Description
\n
## Line Plot: Comparison of C_f Predictions Across Different CFD Methods
### Overview
The image is a scientific line plot comparing the skin friction coefficient (C_f) predictions from five different computational fluid dynamics (CFD) methods or models as a function of the normalized streamwise position (x/H). The plot serves as a benchmark, likely against a high-fidelity reference solution (DNS), to evaluate the accuracy of various turbulence modeling or simulation approaches.
### Components/Axes
* **Chart Type:** 2D line plot with overlaid scatter points.
* **X-Axis:**
* **Label:** `x/H` (Normalized streamwise coordinate, likely distance from a reference point divided by a characteristic height H).
* **Scale:** Linear, ranging from -1 to 9.
* **Major Ticks:** At integer intervals: -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
* **Y-Axis:**
* **Label:** `C_f` (Skin friction coefficient).
* **Scale:** Linear, ranging from -0.020 to 0.040.
* **Major Ticks:** At intervals of 0.010: -0.020, -0.010, 0.000, 0.010, 0.020, 0.030, 0.040.
* **Reference Line:** A horizontal dashed black line at `C_f = 0.000`.
* **Legend:** Positioned at the top center of the plot area. It contains five entries:
1. `DNS` (Direct Numerical Simulation): Represented by red diamond markers (◇).
2. `RANS` (Reynolds-Averaged Navier-Stokes): Represented by a solid dark blue line.
3. `DSRRANS` (Likely a specific RANS variant): Represented by a dashed light blue line.
4. `PiT-PO` (Likely a specific model or method): Represented by a dash-dot orange line.
5. `LLM-SR` (Likely a machine learning-based super-resolution or correction method): Represented by solid green circle markers (●).
### Detailed Analysis
**Trend Verification & Data Point Extraction (Approximate Values):**
1. **DNS (Red Diamonds):**
* **Trend:** The reference data remains very close to `C_f = 0` for most of the domain (`x/H` from 0 to ~7.5). It shows a sharp, narrow positive peak centered near `x/H = 8.0`, reaching a maximum `C_f` of approximately **0.012**. The data points are densely clustered along the zero line and around the peak.
* **Key Points:** `(0, ~0.000)`, `(1, ~0.000)`, `(4, ~0.000)`, `(7.5, ~0.000)`, `(8.0, ~0.012)`, `(8.2, ~0.000)`.
2. **RANS (Solid Dark Blue Line):**
* **Trend:** Starts with a small positive value near `x/H=0`, dips slightly negative between `x/H=0.5` and `x/H=1.5`, then follows a smooth, slightly negative curve until `x/H=7`. It then rises sharply to form a peak that is **broader and lower** than the DNS peak, reaching a maximum of approximately **0.025** at `x/H ≈ 8.0`. It then drops sharply.
* **Key Points (Line):** `(0, ~0.005)`, `(1, ~-0.002)`, `(4, ~-0.003)`, `(7, ~-0.001)`, `(8.0, ~0.025)`, `(8.5, ~0.000)`.
3. **DSRRANS (Dashed Light Blue Line):**
* **Trend:** Shows more oscillation than RANS. It starts negative near `x/H=0`, has a small positive bump around `x/H=1`, then dips to a minimum near `x/H=2.5`. It recovers to near zero by `x/H=5` and follows a path similar to RANS towards the peak. Its peak at `x/H ≈ 8.0` is **slightly higher and sharper** than RANS, reaching approximately **0.035**.
* **Key Points (Line):** `(0, ~-0.005)`, `(1, ~0.001)`, `(2.5, ~-0.007)`, `(5, ~0.000)`, `(8.0, ~0.035)`, `(8.5, ~-0.015)`.
4. **PiT-PO (Dash-Dot Orange Line):**
* **Trend:** Follows a path very similar to DSRRANS in the region `x/H < 7`. However, its peak at `x/H ≈ 8.0` is the **highest and sharpest** among all models, reaching a maximum `C_f` of approximately **0.038**. It then drops precipitously.
* **Key Points (Line):** `(0, ~-0.005)`, `(2.5, ~-0.007)`, `(7, ~0.002)`, `(8.0, ~0.038)`, `(8.2, ~0.000)`.
5. **LLM-SR (Green Dots):**
* **Trend:** This data series is highly scattered and does not follow a smooth curve. It shows significant deviations from the other models and the DNS reference.
* **Region `x/H = 0 to 4`:** Points are widely scattered between `C_f ≈ -0.015` and `C_f ≈ 0.040`, with no clear trend. Many points lie far above the DNS/RANS lines.
* **Region `x/H = 4 to 6`:** Points form a distinct, smooth **negative trough**, reaching a minimum of approximately **-0.016** near `x/H = 4.5`. This is a major deviation from all other models, which are near zero here.
* **Region `x/H = 6 to 9`:** Points become scattered again, mostly negative, with a cluster near the DNS peak at `x/H=8` but also many points far below it (down to `C_f ≈ -0.018`).
* **Key Observations:** The LLM-SR data suggests either a very different physical prediction, significant noise, or that it represents a different type of output (e.g., point-wise corrections or errors) rather than a continuous model prediction.
### Key Observations
1. **Peak Discrepancy at x/H ≈ 8:** All RANS-based models (RANS, DSRRANS, PiT-PO) predict a positive `C_f` peak at `x/H ≈ 8`, consistent with the DNS location. However, they all **overpredict the magnitude** of the peak compared to DNS. The order of overprediction is: PiT-PO > DSRRANS > RANS.
2. **Upstream Behavior:** In the region `x/H < 7`, the DNS data is essentially zero. The RANS models show small negative values, with DSRRANS and PiT-PO showing a more pronounced negative dip around `x/H=2.5`.
3. **Anomalous LLM-SR Data:** The LLM-SR data is the most striking outlier. Its smooth, deep negative trough between `x/H=4` and `x/H=6` is not present in any other dataset. Its high scatter elsewhere suggests it may not be a direct competitor model in the same category as the others, or it represents a fundamentally different approach with high variance.
4. **Model Similarity:** The DSRRANS and PiT-PO lines are nearly identical for `x/H < 7`, diverging only in the magnitude of the final peak.
### Interpretation
This plot is a classic model validation exercise in computational fluid dynamics. The DNS data serves as the "ground truth." The comparison reveals:
* **Standard RANS Limitations:** The basic RANS model captures the qualitative feature (a peak at `x/H=8`) but smears it out (broader, lower peak) and introduces a slight negative `C_f` upstream, which is not present in the DNS. This is typical of RANS models' difficulty with separated flows or complex boundary layer interactions.
* **Improved RANS Variants:** DSRRANS and PiT-PO appear to be attempts to improve upon standard RANS. They sharpen the peak (bringing it closer to the DNS shape) but at the cost of significantly overpredicting its magnitude. Their identical upstream behavior suggests they share a common base formulation.
* **Machine Learning Approach (LLM-SR):** The LLM-SR data is puzzling. If it represents a direct prediction of `C_f`, it performs poorly, showing large errors and spurious features (the deep trough). However, it's possible this plot shows something else, like the *correction* applied by the LLM or its *predicted error field*. The high scatter could indicate a point-wise, non-physics-constrained method. Its value lies not in matching the curve, but perhaps in identifying regions of high model uncertainty (e.g., the scattered points upstream and the distinct pattern in the mid-section).
* **Flow Physics Implication:** The sharp peak in `C_f` at `x/H=8` likely corresponds to a **flow reattachment point** or the end of a separation bubble. The negative `C_f` values predicted by some models upstream would indicate reverse flow (separation), which the DNS shows does not occur (C_f ≥ 0). The models' struggle to accurately predict both the absence of separation upstream and the precise reattachment peak highlights a key challenge in turbulence modeling for this flow configuration.
</details>
Figure 7. Skin friction distribution along the bottom obtained by the learned model and the standard $k$ - $\omega$ SST model of RANS, compared with DNS data.
## 6. Conclusion
In this work, we introduced PiT-PO, a unified framework that fundamentally transforms LLMs from static equation proposers into adaptive, physics-aware generators for SR. By integrating in-search policy optimization with a novel dual-constraint evaluation mechanism, PiT-PO rigorously enforces hierarchical physical validity while leveraging theorem-guided, token-level penalties to eliminate structural redundancy. This synergistic design aligns generation with numerical fitness, scientific consistency, and parsimony, establishing new state-of-the-art performance on SR benchmarks. Beyond synthetic tasks, PiT-PO demonstrates significant practical utility in turbulence modeling, where the discovered symbolic corrections improve Reynolds stress and flow-field predictions. Notably, PiT-PO achieves these results using small open-source backbones, making it a practical and accessible tool for scientific communities with limited computational resources. Looking forward, we plan to extend PiT-PO to broader scientific and engineering domains by enriching the library of domain-specific constraints and validating it across more complex, real-world systems. Moreover, we anticipate that integrating PiT-PO with larger-scale multi-modal foundation models could further unlock its potential in processing heterogeneous scientific data.
## References
- (1)
- Aakash et al. (2019) B. S. Aakash, JohnPatrick Connors, and Michael D Shields. 2019. Stress-strain data for aluminum 6061-T651 from 9 lots at 6 temperatures under uniaxial and plane strain tension. Data in Brief 25 (Aug 2019), 104085. doi: 10.1016/j.dib.2019.104085
- Biggio et al. (2021) Luca Biggio, Tommaso Bendinelli, Alexander Neitz, Aurelien Lucchi, and Giambattista Parascandolo. 2021. Neural Symbolic Regression that Scales. arXiv:2106.06427 [cs.LG] https://arxiv.org/abs/2106.06427
- Biggio* et al. (2021) L. Biggio*, T. Bendinelli*, A. Neitz, A. Lucchi, and G. Parascandolo. 2021. Neural Symbolic Regression that Scales. In Proceedings of 38th International Conference on Machine Learning (ICML 2021) (Proceedings of Machine Learning Research, Vol. 139). PMLR, 936–945. https://proceedings.mlr.press/v139/biggio21a.html *equal contribution.
- Chen et al. (2025) Jindou Chen, Jidong Tian, Liang Wu, ChenXinWei, Xiaokang Yang, Yaohui Jin, and Yanyan Xu. 2025. KinFormer: Generalizable Dynamical Symbolic Regression for Catalytic Organic Reaction Kinetics. In International Conference on Representation Learning, Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (Eds.), Vol. 2025. 67058–67080. https://proceedings.iclr.cc/paper_files/paper/2025/file/a76b693f36916a5ed84d6e5b39a0dc03-Paper-Conference.pdf
- Cranmer (2023) Miles Cranmer. 2023. Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl. arXiv:2305.01582 [astro-ph.IM] https://arxiv.org/abs/2305.01582
- Crochepierre et al. (2022) Laure Crochepierre, Lydia Boudjeloud-Assala, and Vincent Barbesant. 2022. Interactive Reinforcement Learning for Symbolic Regression from Multi-Format Human-Preference Feedbacks. In IJCAI 2022- 31st International Joint Conference on Artificial Intelligence. Vienne, Austria. https://hal.science/hal-03695471
- Deng et al. (2023) Song Deng, Junjie Wang, Li Tao, Su Zhang, and Hongwei Sun. 2023. EV charging load forecasting model mining algorithm based on hybrid intelligence. Computers and Electrical Engineering 112 (2023), 109010. doi: 10.1016/j.compeleceng.2023.109010
- Du et al. (2023) Mengge Du, Yuntian Chen, and Dongxiao Zhang. 2023. DISCOVER: Deep identification of symbolically concise open-form PDEs via enhanced reinforcement-learning. arXiv:2210.02181 [cs.LG] https://arxiv.org/abs/2210.02181
- Fletcher (1987) Roger Fletcher. 1987. Practical Methods of Optimization (2nd ed.). John Wiley & Sons, Chichester, New York.
- Grayeli et al. (2024) Arya Grayeli, Atharva Sehgal, Omar Costilla-Reyes, Miles Cranmer, and Swarat Chaudhuri. 2024. Symbolic Regression with a Learned Concept Library. arXiv:2409.09359 [cs.LG] https://arxiv.org/abs/2409.09359
- Guo et al. (2025) Ping Guo, Qingfu Zhang, and Xi Lin. 2025. CoEvo: Continual Evolution of Symbolic Solutions Using Large Language Models. arXiv:2412.18890 [cs.AI] https://arxiv.org/abs/2412.18890
- Hu et al. (2021) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685
- Huang et al. (2025) Ziyao Huang, Weiwei Wu, Kui Wu, Jianping Wang, and Wei-Bin Lee. 2025. CALM: Co-evolution of Algorithms and Language Model for Automatic Heuristic Design. arXiv:2505.12285 [cs.NE] https://arxiv.org/abs/2505.12285
- Kamienny et al. (2022) Pierre-Alexandre Kamienny, Stéphane d’Ascoli, Guillaume Lample, and François Charton. 2022. End-to-end symbolic regression with transformers. arXiv:2204.10532 [cs.LG] https://arxiv.org/abs/2204.10532
- Kassianik et al. (2025) Paul Kassianik, Baturay Saglam, Alexander Chen, Blaine Nelson, Anu Vellore, Massimo Aufiero, Fraser Burch, Dhruv Kedia, Avi Zohary, Sajana Weerawardhena, Aman Priyanshu, Adam Swanda, Amy Chang, Hyrum Anderson, Kojin Oshiba, Omar Santos, Yaron Singer, and Amin Karbasi. 2025. Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report. arXiv:2504.21039 [cs.CR] https://arxiv.org/abs/2504.21039
- Koza (1990) J.R. Koza. 1990. Genetically breeding populations of computer programs to solve problems in artificial intelligence. In [1990] Proceedings of the 2nd International IEEE Conference on Tools for Artificial Intelligence. 819–827. doi: 10.1109/TAI.1990.130444
- Landajuela et al. (2022) Mikel Landajuela, Chak Shing Lee, Jiachen Yang, Ruben Glatt, Claudio P Santiago, Ignacio Aravena, Terrell Mundhenk, Garrett Mulcahy, and Brenden K Petersen. 2022. A Unified Framework for Deep Symbolic Regression. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 33985–33998. https://proceedings.neurips.cc/paper_files/paper/2022/file/dbca58f35bddc6e4003b2dd80e42f838-Paper-Conference.pdf
- Landajuela et al. (2021) Mikel Landajuela, Brenden K. Petersen, Soo K. Kim, Claudio P. Santiago, Ruben Glatt, T. Nathan Mundhenk, Jacob F. Pettit, and Daniel M. Faissol. 2021. Improving exploration in policy gradient search: Application to symbolic optimization. arXiv:2107.09158 [cs.LG] https://arxiv.org/abs/2107.09158
- Li et al. (2023) Wenqiang Li, Weijun Li, Linjun Sun, Min Wu, Lina Yu, Jingyi Liu, Yanjie Li, and Song Tian. 2023. Transformer-based model for symbolic regression via joint supervised learning. In International Conference on Learning Representations. https://api.semanticscholar.org/CorpusID:259298765
- Ma et al. (2024) Pingchuan Ma, Tsun-Hsuan Wang, Minghao Guo, Zhiqing Sun, Joshua B. Tenenbaum, Daniela Rus, Chuang Gan, and Wojciech Matusik. 2024. LLM and Simulation as Bilevel Optimizers: A New Paradigm to Advance Physical Scientific Discovery. In Proceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (Eds.). PMLR, 33940–33962. https://proceedings.mlr.press/v235/ma24m.html
- Makke and Chawla (2024a) Nour Makke and Sanjay Chawla. 2024a. Data-driven discovery of Tsallis-like distribution using symbolic regression in high-energy physics. PNAS Nexus 3, 11 (10 2024), pgae467. arXiv:https://academic.oup.com/pnasnexus/article-pdf/3/11/pgae467/60816181/pgae467.pdf doi: 10.1093/pnasnexus/pgae467
- Makke and Chawla (2024b) Nour Makke and Sanjay Chawla. 2024b. Interpretable scientific discovery with symbolic regression: a review. Artificial Intelligence Review 57 (01 2024). doi: 10.1007/s10462-023-10622-0
- Menter (1994) Florian R Menter. 1994. Two-equation eddy-viscosity turbulence models for engineering applications. AIAA journal 32, 8 (1994), 1598–1605.
- Menter et al. (2003) Florian R Menter, Martin Kuntz, Robin Langtry, et al. 2003. Ten years of industrial experience with the SST turbulence model. Turbulence, heat and mass transfer 4, 1 (2003), 625–632.
- Merler et al. (2024) Matteo Merler, Katsiaryna Haitsiukevich, Nicola Dainese, and Pekka Marttinen. 2024. In-Context Symbolic Regression: Leveraging Large Language Models for Function Discovery. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop). Association for Computational Linguistics, 589–606. doi: 10.18653/v1/2024.acl-srw.49
- MOCHIZUKI and OSAKA (2000) Shinsuke MOCHIZUKI and Hideo OSAKA. 2000. Management of a Stronger Wall Jet by a Pair of Streamwise Vortices. Reynolds Stress Tensor and Production Tenns. TRANSACTIONS OF THE JAPAN SOCIETY OF MECHANICAL ENGINEERS Series B 66, 646 (2000), 1309–1317. doi: 10.1299/kikaib.66.646_1309
- Monkewitz (2021) Peter A. Monkewitz. 2021. Asymptotics of streamwise Reynolds stress in wall turbulence. Journal of Fluid Mechanics 931 (Nov. 2021). doi: 10.1017/jfm.2021.924
- Monod (1949) Jacques Monod. 1949. THE GROWTH OF BACTERIAL CULTURES. Annual Review of Microbiology 3, Volume 3, 1949 (1949), 371–394. doi: 10.1146/annurev.mi.03.100149.002103
- Mundhenk et al. (2021) T. Nathan Mundhenk, Mikel Landajuela, Ruben Glatt, Claudio P. Santiago, Daniel M. Faissol, and Brenden K. Petersen. 2021. Symbolic Regression via Neural-Guided Genetic Programming Population Seeding. arXiv:2111.00053 [cs.NE] https://arxiv.org/abs/2111.00053
- Neamtiu et al. (2005) Iulian Neamtiu, Jeffrey S. Foster, and Michael Hicks. 2005. Understanding source code evolution using abstract syntax tree matching. In Proceedings of the 2005 International Workshop on Mining Software Repositories (St. Louis, Missouri) (MSR ’05). Association for Computing Machinery, New York, NY, USA, 1–5. doi: 10.1145/1083142.1083143
- Petersen et al. (2021) Brenden K. Petersen, Mikel Landajuela, T. Nathan Mundhenk, Claudio P. Santiago, Soo K. Kim, and Joanne T. Kim. 2021. Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients. arXiv:1912.04871 [cs.LG] https://arxiv.org/abs/1912.04871
- Pope (2000) Stephen B. Pope. 2000. Turbulent Flows. Cambridge University Press. doi: 10.1017/cbo9780511840531
- Pourcel et al. (2025) Julien Pourcel, Cédric Colas, and Pierre-Yves Oudeyer. 2025. Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on ARC-AGI. arXiv:2507.14172 [cs.LG] https://arxiv.org/abs/2507.14172
- Reuter et al. (2023) Julia Reuter, Hani Elmestikawy, Fabien Evrard, Sanaz Mostaghim, and Berend van Wachem. 2023. Graph Networks as Inductive Bias for Genetic Programming: Symbolic Models for Particle-Laden Flows. In Genetic Programming, Gisele Pappa, Mario Giacobini, and Zdenek Vasicek (Eds.). Springer Nature Switzerland, Cham, 36–51.
- Romera-Paredes et al. (2024) Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. 2024. Mathematical discoveries from program search with large language models. Nature 625, 7995 (2024), 468–475.
- Rosso et al. (1995) L Rosso, J. R. Lobry, S Bajard, and J. P. Flandrois. 1995. Convenient Model To Describe the Combined Effects of Temperature and pH on Microbial Growth. Applied and Environmental Microbiology 61, 2 (Feb 1995), 610–6. doi: 10.1128/aem.61.2.610-616.1995
- Schmidt and Lipson (2009) Michael Schmidt and Hod Lipson. 2009. Distilling Free-Form Natural Laws from Experimental Data. Science 324, 5923 (2009), 81–85. arXiv:https://www.science.org/doi/pdf/10.1126/science.1165893 doi: 10.1126/science.1165893
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL] https://arxiv.org/abs/2402.03300
- Shi et al. (2024) Hao Shi, Weili Song, Xinting Zhang, Jiahe Shi, Cuicui Luo, Xiang Ao, Hamid Arian, and Luis Seco. 2024. AlphaForge: A Framework to Mine and Dynamically Combine Formulaic Alpha Factors. arXiv:2406.18394 [q-fin.CP] https://arxiv.org/abs/2406.18394
- Shojaee et al. (2025a) Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K Reddy. 2025a. LLM-SR: Scientific Equation Discovery via Programming with Large Language Models. arXiv:2404.18400 [cs.LG] https://arxiv.org/abs/2404.18400
- Shojaee et al. (2025b) Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, and Chandan K Reddy. 2025b. LLM-SRBench: A New Benchmark for Scientific Equation Discovery with Large Language Models. arXiv:2504.10415 [cs.CL] https://arxiv.org/abs/2504.10415
- Tang et al. (2023a) Hongwei Tang, Yan Wang, Tongguang Wang, and Linlin Tian. 2023a. Discovering explicit Reynolds-averaged turbulence closures for turbulent separated flows through deep learning-based symbolic regression with non-linear corrections. Physics of Fluids 35, 2 (2023), 025118. arXiv:https://doi.org/10.1063/5.0135638 doi: 10.1063/5.0135638
- Tang et al. (2023b) Hongwei Tang, Yan Wang, Tongguang Wang, and Linlin Tian. 2023b. Discovering explicit Reynolds-averaged turbulence closures for turbulent separated flows through deep learning-based symbolic regression with non-linear corrections. Physics of Fluids 35, 2 (Feb. 2023). doi: 10.1063/5.0135638
- Tennekes and Lumley (1972) Henk Tennekes and John L. Lumley. 1972. A First Course in Turbulence. The MIT Press. doi: 10.7551/mitpress/3014.001.0001
- Valipour et al. (2021) Mojtaba Valipour, Bowen You, Maysum Panju, and Ali Ghodsi. 2021. SymbolicGPT: A Generative Transformer Model for Symbolic Regression. arXiv:2106.14131 [cs.LG] https://arxiv.org/abs/2106.14131
- Vastl et al. (2024) Martin Vastl, Jonáš Kulhánek, Jiří Kubalík, Erik Derner, and Robert Babuška. 2024. SymFormer: End-to-End Symbolic Regression Using Transformer-Based Architecture. IEEE Access 12 (2024), 37840–37849. doi: 10.1109/ACCESS.2024.3374649
- Virgolin and Pissis (2022) Marco Virgolin and Solon P. Pissis. 2022. Symbolic Regression is NP-hard. arXiv:2207.01018 [cs.NE] https://arxiv.org/abs/2207.01018
- Wahlquist et al. (2024) Ylva Wahlquist, Jesper Sundell, and Kristian Soltesz. 2024. Learning pharmacometric covariate model structures with symbolic regression networks. Journal of Pharmacokinetics and Pharmacodynamics 51, 2 (2024), 155–167. doi: 10.1007/s10928-023-09887-3
- WANG et al. (2019) Wei WANG, Yang ZHANG, and Lili CHEN. 2019. An application of the shear stress transport low-Reynolds-number k-ε turbulence model on turbulent flows. ACTA AERODYNAMICA SINICA 37, 3 (2019), 419–425. doi: 10.7638/kqdlxxb-2016.0158
- Weller et al. (1998) H.G. Weller, Gavin Tabor, Hrvoje Jasak, and Christer Fureby. 1998. A Tensorial Approach to Computational Continuum Mechanics Using Object Orientated Techniques. Computers in Physics 12 (11 1998), 620–631. doi: 10.1063/1.168744
- Xia et al. (2025) Shijie Xia, Yuhan Sun, and Pengfei Liu. 2025. SR-Scientist: Scientific Equation Discovery With Agentic AI. arXiv:2510.11661 [cs.AI] https://arxiv.org/abs/2510.11661
- Xiao et al. (2020) Heng Xiao, Jin-Long Wu, Sylvain Laizet, and Lian Duan. 2020. Flows over periodic hills of parameterized geometries: A dataset for data-driven turbulence modeling from direct simulations. Computers & Fluids 200 (2020), 104431. doi: 10.1016/j.compfluid.2020.104431
- Zhang et al. (2025) Hengzhe Zhang, Qi Chen, Bing XUE, Wolfgang Banzhaf, and Mengjie Zhang. 2025. RAG-SR: Retrieval-Augmented Generation for Neural Symbolic Regression. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=NdHka08uWn
| Fitting log-MSE scale | $\alpha$ | 1.0 | Scaling in $R_{\mathrm{fit}}=-\alpha\log(\mathrm{MSE}+\epsilon)$ . |
| --- | --- | --- | --- |
| Complexity penalty weight | $\lambda_{\mathrm{len}}$ | 5e-3 | Weight in $P_{\mathrm{cplx}}=\lambda_{\mathrm{len}}\cdot\mathrm{Length}(\mathrm{AST})$ . |
| Dimensional homogeneity penalty weight | $P_{\mathrm{dim}}$ | 1.0 | Penalty/reward weight for unit inconsistency (general-level constraint). |
| Differentiability penalty weight | $P_{\mathrm{diff}}$ | 0.5 | Penalty/reward weight for non-smoothness on the data-defined domain (general-level constraint). |
| Domain-specific constraint weight (j-th) | $P_{\mathrm{domain}}^{(j)}$ | 0.5 | Weight for the $j$ -th domain prior (e.g., realizability, wall BC, asymptotic scaling, energy consistency). |
| Gating threshold for physics constraints | $\delta_{\mathrm{gate}}$ | 1e-3 * MSE_{initial} | Activate physics penalties only after fitting reaches a sufficiently low-error regime. |
| Numerical stability constant in $\tau_{i}$ | $\epsilon$ | 1e-50 | Used in $\tau_{i}=\frac{|b_{i}|}{\sum_{j}|b_{j}|+\epsilon}$ to avoid division by zero. |
| Redundancy threshold | $\rho$ | 1e-2 | A term is considered redundant if $\tau_{i}\leq\rho$ . |
| Token penalty scale | $p$ | 0.5 | Scaling coefficient in $P_{\mathrm{tok}}=p\cdot\max(0,-\log(|b_{i}|+\epsilon))$ . |
Table 3. Hyperparameters for dual-constraint evaluation and token-level signal synthesis.
## Appendix A Additional Hyperparameters of PiT-PO
Table 3 lists the additional hyperparameters of PiT-PO, including (i) general-level physical penalties (dimensional homogeneity and differentiability), (ii) domain-specific constraint penalties, (iii) the gated activation threshold for physical constraints, and (iv) theorem-guided redundancy detection and token-level penalization.
## Appendix B Support Exclusion Theorem: Theory and Practice
### B.1. Preliminaries: Empirical Function Space and Orthogonality
** Definition B.1 (Basis functions / dictionary)**
*Let $\mathcal{X}\subseteq\mathbb{R}^{d}$ be the domain, and let $\{\phi_{j}:\mathcal{X}\to\mathbb{R}\}_{j\in\mathcal{S}}$ be a collection of candidate basis (dictionary) functions indexed by $\mathcal{S}$ . For any subset $\mathcal{K}\subseteq\mathcal{S}$ , denote the corresponding model subspace by
$$
\mathrm{span}\{\phi_{j}:j\in\mathcal{K}\}.
$$*
** Definition B.2 (Target functionf∗f^{*})**
*Assume the ground-truth target function admits a sparse expansion over the dictionary:
$$
f^{*}(x)=\sum_{j\in\mathcal{S}^{\prime}}a_{j}\,\phi_{j}(x),
$$
where $\mathcal{S}^{\prime}\subseteq\mathcal{S}$ is the true support set (indices of nonzero terms) and satisfies $|\mathcal{S}^{\prime}|\leq M$ . Moreover, the true coefficients are bounded as
$$
A\leq|a_{j}|\leq B,\qquad\forall j\in\mathcal{S}^{\prime}.
$$*
** Definition B.3 (Empirical inner product and empirical norm)**
*Given a finite dataset $D=\{x_{n}\}_{n=1}^{N}\subset\mathcal{X}$ , for any two functions $f,g:\mathcal{X}\to\mathbb{R}$ , define the empirical inner product by
$$
\langle f,g\rangle_{D}:=\frac{1}{N}\sum_{n=1}^{N}f(x_{n})\,g(x_{n}),
$$
and the induced empirical norm by
$$
\|f\|_{D}:=\sqrt{\langle f,f\rangle_{D}}.
$$
The empirical function space
$$
\mathcal{F}_{D}:=\{(f(x_{1}),\ldots,f(x_{N})):\ f:\mathcal{X}\to\mathbb{R}\}
$$
is a finite-dimensional inner-product space under $\langle\cdot,\cdot\rangle_{D}$ .*
** Definition B.4 (Empirical Orthogonality)**
*Two functions $f,g\in\mathcal{F}_{D}$ are empirically orthogonal if $\langle f,g\rangle_{D}=0$ .*
Convention. Unless stated otherwise, throughout this appendix we write $\langle\cdot,\cdot\rangle$ and $\|\cdot\|$ to mean the empirical inner product $\langle\cdot,\cdot\rangle_{D}$ and the empirical norm $\|\cdot\|_{D}$ .
### B.2. Proof of the Support Exclusion Theorem
** Theorem B.5 (Support Exclusion Theorem)**
*Let $\mathcal{K}\subseteq\mathcal{S}$ be a candidate skeleton (active set). Consider the empirical least-squares fit over $\mathcal{K}$ :
$$
b\in\arg\min_{\{b_{j}\}_{j\in\mathcal{K}}}\left\|f^{*}-\sum_{j\in\mathcal{K}}b_{j}\phi_{j}\right\|^{2}.
$$
Define the empirical Gram matrix $G\in\mathbb{R}^{|\mathcal{S}|\times|\mathcal{S}|}$ by
$$
G_{ij}:=\langle\phi_{i},\phi_{j}\rangle,\qquad i,j\in\mathcal{S},
$$
and assume $G_{ii}>0$ . For any $i\in\mathcal{S}$ , define
$$
T_{ij}:=\frac{G_{ji}}{G_{ii}},\qquad j\in\mathcal{S}.
$$
Further define the external-candidate vector
$$
u_{i}:=\big(|T_{i\ell}|\big)_{\ell\in\mathcal{S}\setminus\mathcal{K}}\in\mathbb{R}^{|\mathcal{S}\setminus\mathcal{K}|},
$$
and let $s(1)\geq s(2)\geq\cdots\geq s(|\mathcal{S}\setminus\mathcal{K}|)$ be the entries of $u_{i}$ sorted in non-increasing order. If for some $i\in\mathcal{K}$ ,
$$
|b_{i}|<A-\left(\underbrace{\sum_{j\in\mathcal{K},\,j\neq i}(B+|b_{j}|)\,|T_{ij}|}_{\textnormal{Internal Interference}}+\underbrace{B\sum_{k=1}^{|\mathcal{S}\setminus\mathcal{K}|}s(k)}_{\textnormal{External Interference}}\right),
$$
then $i\notin\mathcal{S}^{\prime}$ .*
* Proof*
Step 1: Empirical orthogonality (first-order optimality of least squares). Let
$$
g(x):=\sum_{j\in\mathcal{K}}b_{j}\phi_{j}(x),\qquad r(x):=f^{*}(x)-g(x).
$$
The objective is $\|r\|^{2}=\langle r,r\rangle$ . For any $i\in\mathcal{K}$ , the first-order optimality condition yields
$$
0=\frac{\partial}{\partial b_{i}}\|r\|^{2}=-2\langle r,\phi_{i}\rangle\quad\Longrightarrow\quad\langle r,\phi_{i}\rangle=0.
$$
Hence, the residual $r$ is empirically orthogonal to $\mathrm{span}\{\phi_{i}:i\in\mathcal{K}\}$ . Step 2: Set decomposition. Define three disjoint sets
$$
\mathcal{T}:=\mathcal{K}\cap\mathcal{S}^{\prime},\qquad\mathcal{F}:=\mathcal{K}\setminus\mathcal{S}^{\prime},\qquad\mathcal{R}:=\mathcal{S}^{\prime}\setminus\mathcal{K}.
$$
Then $\mathcal{K}=\mathcal{T}\cup\mathcal{F}$ and $\mathcal{S}^{\prime}=\mathcal{T}\cup\mathcal{R}$ . Expanding the residual gives
$$
r=\sum_{j\in\mathcal{T}}(a_{j}-b_{j})\phi_{j}+\sum_{j\in\mathcal{R}}a_{j}\phi_{j}-\sum_{j\in\mathcal{F}}b_{j}\phi_{j}.
$$ Step 3: An exact coefficient identity for $i\in\mathcal{T}$ . Fix any $i\in\mathcal{T}\subseteq\mathcal{K}$ . Using $\langle r,\phi_{i}\rangle=0$ and writing $G_{ji}=\langle\phi_{j},\phi_{i}\rangle$ , we obtain
$$
(a_{i}-b_{i})G_{ii}+\sum_{j\in\mathcal{T},\,j\neq i}(a_{j}-b_{j})G_{ji}+\sum_{j\in\mathcal{R}}a_{j}G_{ji}-\sum_{j\in\mathcal{F}}b_{j}G_{ji}=0.
$$
Dividing by $G_{ii}>0$ and using $T_{ij}=G_{ji}/G_{ii}$ yields
$$
a_{i}-b_{i}=-\sum_{j\in\mathcal{T},\,j\neq i}(a_{j}-b_{j})T_{ij}-\sum_{j\in\mathcal{R}}a_{j}T_{ij}+\sum_{j\in\mathcal{F}}b_{j}T_{ij}.
$$ Step 4: Upper bound via internal and external interference. Taking absolute values and applying the triangle inequality gives
$$
|a_{i}-b_{i}|\leq\sum_{j\in\mathcal{T},\,j\neq i}|a_{j}-b_{j}|\,|T_{ij}|+\sum_{j\in\mathcal{R}}|a_{j}|\,|T_{ij}|+\sum_{j\in\mathcal{F}}|b_{j}|\,|T_{ij}|.
$$
For $j\in\mathcal{T}\subseteq\mathcal{S}^{\prime}$ , we have $|a_{j}|\leq B$ and thus
$$
|a_{j}-b_{j}|\leq|a_{j}|+|b_{j}|\leq B+|b_{j}|.
$$
Therefore,
$$
|a_{i}-b_{i}|\leq\sum_{j\in\mathcal{T},\,j\neq i}(B+|b_{j}|)\,|T_{ij}|+\sum_{j\in\mathcal{F}}|b_{j}|\,|T_{ij}|+B\sum_{j\in\mathcal{R}}|T_{ij}|.
$$
Since $|b_{j}|\leq B+|b_{j}|$ for all $j\in\mathcal{F}$ , we further have
$$
\sum_{j\in\mathcal{F}}|b_{j}|\,|T_{ij}|\leq\sum_{j\in\mathcal{F}}(B+|b_{j}|)\,|T_{ij}|.
$$
Combining $\mathcal{T}\setminus\{i\}$ and $\mathcal{F}$ yields the internal-interference term:
$$
|a_{i}-b_{i}|\leq\underbrace{\sum_{j\in\mathcal{K},\,j\neq i}(B+|b_{j}|)\,|T_{ij}|}_{\textnormal{Internal Interference}}+B\sum_{j\in\mathcal{R}}|T_{ij}|.
$$
For the external term, note that $\mathcal{R}\subseteq\mathcal{S}\setminus\mathcal{K}$ , and the entries $\{|T_{i\ell}|\}_{\ell\in\mathcal{S}\setminus\mathcal{K}}$ sorted in non-increasing order are $s(1)\geq\cdots\geq s(|\mathcal{S}\setminus\mathcal{K}|)$ . Hence, for any subset $\mathcal{R}$ ,
$$
\sum_{j\in\mathcal{R}}|T_{ij}|\leq\sum_{k=1}^{|\mathcal{R}|}s(k).
$$
Assuming $|\mathcal{S}^{\prime}|\leq M$ and that the current support is partially correct, i.e., $\mathcal{K}\cap\mathcal{S}^{\prime}\neq\emptyset$ , we have $|\mathcal{R}|=|\mathcal{S}^{\prime}\setminus\mathcal{K}|\leq|\mathcal{S}^{\prime}|-1\leq M-1$ . Define $m:=\min\!\big(M-1,\ |\mathcal{S}\setminus\mathcal{K}|\big)$ . Since also $|\mathcal{R}|\leq|\mathcal{S}\setminus\mathcal{K}|$ , it follows that $|\mathcal{R}|\leq m$ , and thus
$$
\sum_{j\in\mathcal{R}}|T_{ij}|\leq\sum_{k=1}^{|\mathcal{R}|}s(k)\leq\sum_{k=1}^{m}s(k).
$$
Thus,
$$
|a_{i}-b_{i}|\leq\sum_{j\in\mathcal{K},\,j\neq i}(B+|b_{j}|)\,|T_{ij}|+B\sum_{k=1}^{m}s(k).
$$ Step 5: Lower bound when $i\in\mathcal{S}^{\prime}$ . If $i\in\mathcal{S}^{\prime}$ , then $|a_{i}|\geq A$ . By the reverse triangle inequality,
$$
|a_{i}-b_{i}|\geq\big||a_{i}|-|b_{i}|\big|\geq A-|b_{i}|.
$$ Step 6: Contradiction. Assume, for contradiction, that there exists $i\in\mathcal{K}\cap\mathcal{S}^{\prime}$ satisfying
$$
|b_{i}|<A-\left(\sum_{j\in\mathcal{K},\,j\neq i}(B+|b_{j}|)\,|T_{ij}|+B\sum_{k=1}^{m}s(k)\right).
$$
Rearranging yields
$$
A-|b_{i}|>\sum_{j\in\mathcal{K},\,j\neq i}(B+|b_{j}|)\,|T_{ij}|+B\sum_{k=1}^{m}s(k).
$$
However, Step 5 implies $|a_{i}-b_{i}|\geq A-|b_{i}|$ , while the bound above implies
$$
|a_{i}-b_{i}|\leq\sum_{j\in\mathcal{K},\,j\neq i}(B+|b_{j}|)\,|T_{ij}|+B\sum_{k=1}^{m}s(k),
$$
which is a contradiction. Therefore such an $i$ cannot belong to $\mathcal{S}^{\prime}$ , i.e., $i\notin\mathcal{S}^{\prime}$ . ∎
## Appendix C Supplementary Diagnostics and Analyses
### C.1. Remaining Iteration Curves on Smaller Backbones
In the main text, we report iteration curves for the 8B backbone. Here we provide the remaining curves for 3B and 1B (Figure 8), which corroborate the observations in Section 4.4.
<details>
<summary>x8.png Details</summary>
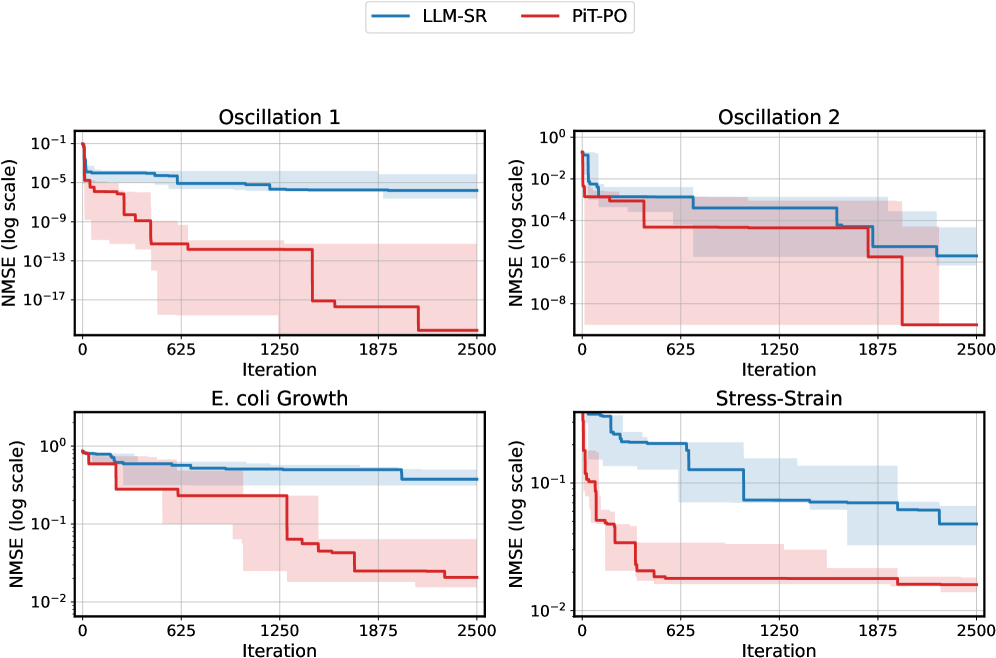
### Visual Description
## [Line Charts]: Performance Comparison of LLM-SR vs. PiT-PO on Four Datasets
### Overview
The image displays a 2x2 grid of four line charts. Each chart compares the performance of two methods, **LLM-SR** (blue line) and **PiT-PO** (red line), across 2500 iterations. Performance is measured by **NMSE (Normalized Mean Squared Error)** on a logarithmic scale. The charts show that PiT-PO consistently achieves a lower final NMSE than LLM-SR across all four datasets, indicating superior performance. Shaded regions around each line represent the variability or confidence intervals for each method.
### Components/Axes
* **Legend:** Located at the top center of the entire figure. It defines:
* **LLM-SR:** Blue line.
* **PiT-PO:** Red line.
* **Common X-Axis (All Charts):** Label: **"Iteration"**. Scale: Linear, from 0 to 2500. Major tick marks at 0, 625, 1250, 1875, 2500.
* **Common Y-Axis (All Charts):** Label: **"NMSE (log scale)"**. Scale: Logarithmic. The specific range varies per chart.
* **Chart Titles (Top of each subplot):**
* Top-Left: **"Oscillation 1"**
* Top-Right: **"Oscillation 2"**
* Bottom-Left: **"E. coli Growth"**
* Bottom-Right: **"Stress-Strain"**
### Detailed Analysis
#### **Chart 1: Oscillation 1 (Top-Left)**
* **Y-Axis Range:** Approximately 10⁻¹⁷ to 10⁻¹.
* **LLM-SR (Blue):** Starts near 10⁻⁴. Shows a stepwise decrease, plateauing around iteration 1250. Final value at iteration 2500 is approximately **10⁻⁶**. The shaded blue region (variability) is relatively narrow.
* **PiT-PO (Red):** Starts near 10⁻⁵. Exhibits a much steeper, stepwise decline. Major drops occur before iteration 625 and around iteration 1875. Final value at iteration 2500 is approximately **10⁻¹⁹**. The shaded red region is very wide, indicating high variability, especially in the middle iterations.
#### **Chart 2: Oscillation 2 (Top-Right)**
* **Y-Axis Range:** Approximately 10⁻⁸ to 10⁰.
* **LLM-SR (Blue):** Starts near 10⁻¹. Decreases in steps, with a notable drop after iteration 1875. Final value at iteration 2500 is approximately **10⁻⁶**.
* **PiT-PO (Red):** Starts near 10⁻¹. Shows a sharp initial drop, then a stepwise decline. Final value at iteration 2500 is approximately **10⁻⁹**. The shaded red region is wide, overlapping significantly with the blue region in the middle iterations.
#### **Chart 3: E. coli Growth (Bottom-Left)**
* **Y-Axis Range:** Approximately 10⁻² to 10⁰.
* **LLM-SR (Blue):** Starts near 10⁰. Shows a very gradual, stepwise decline. Final value at iteration 2500 is approximately **10⁻⁰.⁵** (or ~0.3).
* **PiT-PO (Red):** Starts near 10⁰. Drops more sharply in steps, particularly around iteration 1250. Final value at iteration 2500 is approximately **10⁻¹.⁸** (or ~0.016). The shaded red region is wide, especially between iterations 625 and 1875.
#### **Chart 4: Stress-Strain (Bottom-Right)**
* **Y-Axis Range:** Approximately 10⁻² to 10⁻¹.
* **LLM-SR (Blue):** Starts near 10⁻¹. Decreases in a stepwise fashion. Final value at iteration 2500 is approximately **10⁻¹.⁵** (or ~0.032).
* **PiT-PO (Red):** Starts near 10⁻¹. Shows a very rapid initial drop within the first ~200 iterations, then plateaus with minor steps. Final value at iteration 2500 is approximately **10⁻¹.⁹** (or ~0.013). The shaded red region is narrow after the initial drop, indicating low variability in the final performance.
### Key Observations
1. **Consistent Superiority:** In all four datasets, the **PiT-PO (red)** method achieves a final NMSE that is **1 to 13 orders of magnitude lower** than the **LLM-SR (blue)** method.
2. **Convergence Pattern:** Both methods exhibit a **stepwise convergence** pattern, where the error remains flat for periods and then drops sharply. This suggests discrete improvement events, possibly linked to optimization steps or algorithmic phases.
3. **Variability:** The shaded confidence intervals for **PiT-PO are generally wider** than those for LLM-SR, particularly in the "Oscillation" and "E. coli Growth" charts. This indicates that while PiT-PO's *average* performance is better, its results may have higher variance across different runs or initial conditions.
4. **Performance Gap:** The performance gap between the two methods is most dramatic in the **"Oscillation 1"** chart, where PiT-PO reaches an NMSE of ~10⁻¹⁹ compared to LLM-SR's ~10⁻⁶.
### Interpretation
The data strongly suggests that the **PiT-PO algorithm is significantly more effective at minimizing error (NMSE)** than the LLM-SR algorithm for the tested problems (Oscillation, E. coli Growth, Stress-Strain). The stepwise nature of the error reduction implies both algorithms operate in discrete phases of improvement.
The **Peircean investigative reading** would focus on the *abductive* inference: Given that PiT-PO consistently and dramatically outperforms LLM-SR across diverse problem domains, what underlying mechanism in PiT-PO could explain this? The pattern suggests PiT-PO may have a more efficient search strategy, better exploitation of problem structure, or a more effective optimization routine that allows it to escape local minima where LLM-SR gets stuck (as seen in the long plateaus of the blue lines).
The **notable anomaly** is the extremely wide confidence interval for PiT-PO in the "Oscillation 1" chart. This warrants investigation: Is the algorithm highly sensitive to initial conditions for that specific problem? Does it occasionally find an exceptionally good solution (leading to the very low NMSE) but not reliably? This high variance, despite superior average performance, is a critical practical consideration for deployment.
</details>
(a) Llama-3B
<details>
<summary>x9.png Details</summary>
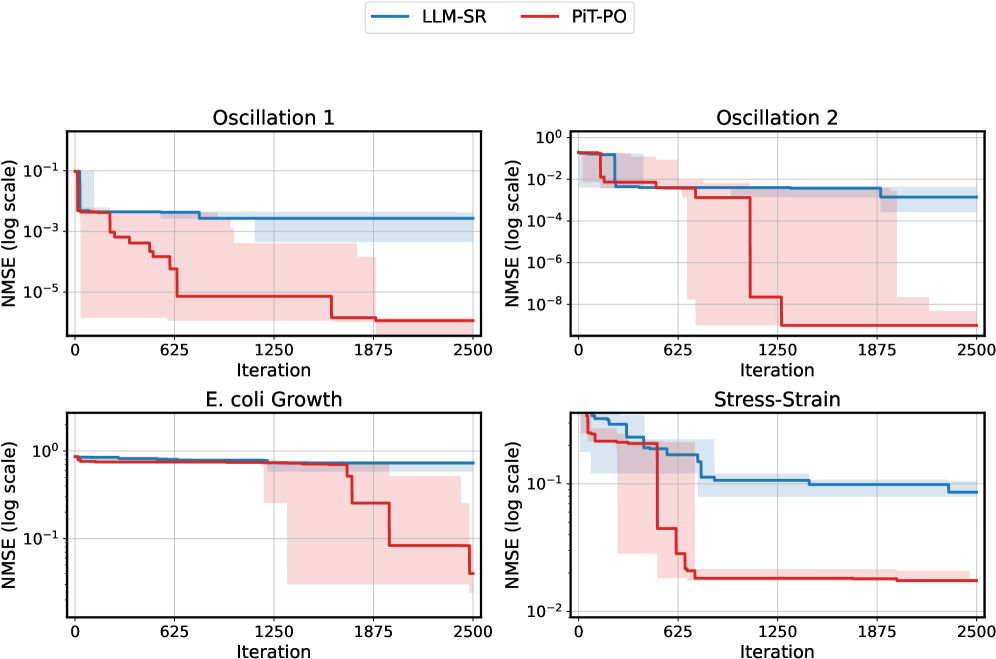
### Visual Description
\n
## Line Charts with Confidence Intervals: Performance Comparison of LLM-SR vs. PiT-PO
### Overview
The image displays a 2x2 grid of four line charts. Each chart compares the performance of two methods, **LLM-SR** (blue line) and **PiT-PO** (red line), across a series of iterations. Performance is measured by **NMSE (Normalized Mean Squared Error)** on a logarithmic scale. Shaded regions around each line represent confidence intervals or variability. The overall purpose is to demonstrate the convergence behavior and final error of the two methods on four different tasks or datasets.
### Components/Axes
* **Legend:** Located at the top center of the entire figure.
* **Blue Line:** LLM-SR
* **Red Line:** PiT-PO
* **Common Axes:**
* **X-axis (All Charts):** Label: `Iteration`. Scale: Linear, from 0 to 2500. Major tick marks at 0, 625, 1250, 1875, 2500.
* **Y-axis (All Charts):** Label: `NMSE (log scale)`. Scale: Logarithmic (base 10). The range varies per subplot.
* **Subplot Titles:**
* Top-Left: `Oscillation 1`
* Top-Right: `Oscillation 2`
* Bottom-Left: `E. coli Growth`
* Bottom-Right: `Stress-Strain`
### Detailed Analysis
#### 1. Oscillation 1 (Top-Left)
* **Y-axis Range:** Approximately 10⁻⁵ to 10⁻¹.
* **LLM-SR (Blue):** Starts near 10⁻². Shows a very gradual, step-wise decrease, plateauing just above 10⁻³ by iteration 2500. The blue shaded confidence interval is relatively narrow.
* **PiT-PO (Red):** Starts near 10⁻². Exhibits a rapid, step-wise descent, reaching approximately 10⁻⁵ by iteration 1250 and remaining stable thereafter. The red shaded confidence interval is wider than LLM-SR's, especially in the early iterations (0-1250).
* **Trend:** PiT-PO converges to a significantly lower error (by about two orders of magnitude) much faster than LLM-SR.
#### 2. Oscillation 2 (Top-Right)
* **Y-axis Range:** Approximately 10⁻⁹ to 10⁰ (1).
* **LLM-SR (Blue):** Starts near 10⁰. Drops quickly to around 10⁻² within the first ~200 iterations, then plateaus with a very slight downward trend, ending near 10⁻³. Confidence interval is narrow.
* **PiT-PO (Red):** Starts near 10⁰. Follows a similar initial drop to ~10⁻². Then, around iteration 1250, it experiences a dramatic, sharp drop to approximately 10⁻⁹, where it remains. The red shaded region is very wide between iterations 625 and 1250, indicating high variance before the final convergence.
* **Trend:** PiT-PO achieves an extremely low final error (10⁻⁹), which is about six orders of magnitude lower than LLM-SR's final error (~10⁻³). The convergence is discontinuous, marked by a single massive improvement.
#### 3. E. coli Growth (Bottom-Left)
* **Y-axis Range:** Approximately 10⁻¹ to 10⁰ (1).
* **LLM-SR (Blue):** Starts just below 10⁰. Shows a very slow, almost flat decline, ending slightly above 10⁻¹. Confidence interval is narrow.
* **PiT-PO (Red):** Starts at a similar point to LLM-SR. Remains close to LLM-SR until approximately iteration 1250, after which it begins a step-wise descent, reaching a final value near 10⁻¹. Its confidence interval becomes notably wide after iteration 1250.
* **Trend:** Both methods show limited improvement. PiT-PO eventually achieves a slightly lower error than LLM-SR, but the difference is less than one order of magnitude. This task appears more challenging for both methods.
#### 4. Stress-Strain (Bottom-Right)
* **Y-axis Range:** Approximately 10⁻² to 10⁰ (1).
* **LLM-SR (Blue):** Starts near 10⁰. Decreases in a step-wise fashion, plateauing around 10⁻¹ by iteration 1250 and remaining there. Confidence interval is moderate.
* **PiT-PO (Red):** Starts near 10⁰. Drops more rapidly than LLM-SR, reaching a plateau near 10⁻² by iteration 625. It maintains this low error for the remainder of the iterations. Its confidence interval is wide during the initial descent (0-625).
* **Trend:** PiT-PO converges faster and to a lower final error (10⁻²) compared to LLM-SR (10⁻¹), a difference of one order of magnitude.
### Key Observations
1. **Consistent Superiority:** In all four tasks, the **PiT-PO** method (red) achieves a lower final NMSE than the **LLM-SR** method (blue).
2. **Convergence Speed:** PiT-PO generally converges faster, often showing dramatic drops in error at specific iteration points (e.g., ~1250 in Oscillation 2, ~625 in Stress-Strain).
3. **Magnitude of Improvement:** The performance gap varies significantly by task. It is most extreme in **Oscillation 2** (10⁻⁹ vs. 10⁻³) and least pronounced in **E. coli Growth**.
4. **Variance:** The shaded confidence intervals for PiT-PO are frequently wider than those for LLM-SR, particularly during periods of rapid change. This suggests PiT-PO's performance may be more variable or sensitive during its optimization process before stabilizing.
5. **Task Difficulty:** The **E. coli Growth** task shows the least improvement for both methods, with final errors remaining relatively high (near 10⁻¹), indicating it may be a more complex or noisy problem.
### Interpretation
The data strongly suggests that the **PiT-PO** optimization or learning method is more effective than **LLM-SR** for the class of problems represented by these four tasks. Its ability to reach orders-of-magnitude lower error, especially in the oscillation problems, indicates a superior capability for finding high-precision solutions.
The step-wise convergence patterns, particularly the dramatic drop in Oscillation 2, are characteristic of optimization processes that escape local minima or undergo phase transitions in learning. The wider confidence intervals for PiT-PO during these transitions imply that while the method is powerful, its path to the solution may be less predictable or more dependent on initial conditions compared to the steadier, but less effective, LLM-SR.
The stark difference in performance between tasks (e.g., Oscillation 2 vs. E. coli Growth) highlights that the relative advantage of PiT-PO is problem-dependent. It excels dramatically on certain physical or mathematical systems (oscillations, stress-strain) but offers a more modest gain on the biological growth model. This could inform which types of scientific or engineering problems would benefit most from applying the PiT-PO methodology.
</details>
(b) Llama-1B
Figure 8. NMSE versus iteration on smaller backbones, consistent with the trends in the 8B setting.
<details>
<summary>x10.png Details</summary>
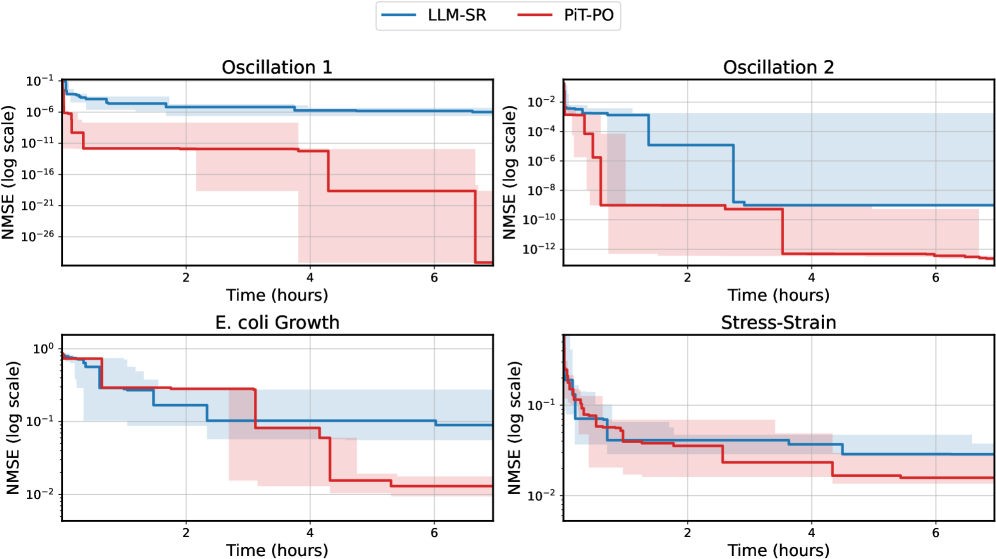
### Visual Description
## [Multi-Panel Line Chart]: Performance Comparison of LLM-SR vs. PiT-PO Over Time
### Overview
The image displays a 2x2 grid of four line charts comparing the performance of two methods, **LLM-SR** (blue line) and **PiT-PO** (red line), across four different scientific or engineering tasks. Performance is measured by **Normalized Mean Squared Error (NMSE)** on a logarithmic scale over a period of **Time (hours)**. Each chart includes shaded regions around the main lines, indicating variability or confidence intervals.
### Components/Axes
* **Legend:** Located at the top center of the entire figure. It defines:
* **Blue Line:** LLM-SR
* **Red Line:** PiT-PO
* **Common Axes:**
* **X-axis (All Charts):** Label: `Time (hours)`. Scale: Linear, from 0 to approximately 7 hours. Major tick marks at 0, 2, 4, 6.
* **Y-axis (All Charts):** Label: `NMSE (log scale)`. Scale: Logarithmic (base 10). The range varies per subplot.
* **Subplot Titles (Top Center of each panel):**
1. **Top-Left:** `Oscillation 1`
2. **Top-Right:** `Oscillation 2`
3. **Bottom-Left:** `E. coli Growth`
4. **Bottom-Right:** `Stress-Strain`
### Detailed Analysis
**1. Oscillation 1 (Top-Left Panel)**
* **Y-axis Range:** 10⁻¹ to 10⁻²⁶ (a very wide range).
* **LLM-SR (Blue):** Starts near 10⁻¹ at t=0. Shows a stepwise decrease, plateauing around 10⁻⁶ after ~1 hour and remaining relatively flat until the end (~7 hours). The shaded blue region is narrow.
* **PiT-PO (Red):** Starts significantly lower, near 10⁻⁶ at t=0. Exhibits a dramatic, multi-step decline. Major drops occur around t=0.5h, t=4h, and t=6.5h, reaching an extremely low NMSE of approximately 10⁻²⁶ by the end. The shaded red region is very wide, especially after t=2h, indicating high variance in the lower error range.
**2. Oscillation 2 (Top-Right Panel)**
* **Y-axis Range:** 10⁻² to 10⁻¹².
* **LLM-SR (Blue):** Starts near 10⁻². Drops sharply to ~10⁻⁵ within the first hour, then to ~10⁻⁹ around t=3h, where it plateaus. The shaded blue region is moderately wide.
* **PiT-PO (Red):** Starts near 10⁻³. Drops very rapidly to ~10⁻⁹ within the first hour. It continues a stepwise decline, reaching approximately 10⁻¹² by t=7h. The shaded red region is wide, overlapping with the blue region initially but extending to lower values later.
**3. E. coli Growth (Bottom-Left Panel)**
* **Y-axis Range:** 10⁰ (1) to 10⁻².
* **LLM-SR (Blue):** Starts near 10⁰. Shows a gradual, stepwise decline, ending near 10⁻¹. The shaded blue region is consistently wide.
* **PiT-PO (Red):** Starts near 10⁰, similar to LLM-SR. Follows a similar initial trajectory but begins to diverge downward after t=2h. It shows a more pronounced step around t=4.5h, ending near 10⁻². The shaded red region is also wide, generally positioned below the blue region after t=3h.
**4. Stress-Strain (Bottom-Right Panel)**
* **Y-axis Range:** 10⁻¹ to 10⁻².
* **LLM-SR (Blue):** Starts near 10⁻¹. Declines in steps, plateauing around 3x10⁻² after t=4h. The shaded blue region is moderately wide.
* **PiT-PO (Red):** Starts near 10⁻¹. Follows a very similar stepwise decline pattern to LLM-SR but consistently achieves a slightly lower NMSE at each plateau. It ends just above 10⁻². The shaded red region is wide and largely overlaps with the blue region, though its central tendency is slightly lower.
### Key Observations
1. **Consistent Superiority of PiT-PO:** In all four tasks, the PiT-PO method (red) achieves a lower final NMSE than the LLM-SR method (blue).
2. **Magnitude of Improvement:** The performance gap is most extreme in the oscillation tasks. In "Oscillation 1," PiT-PO reaches an error ~20 orders of magnitude lower than LLM-SR. The gap is smallest in the "Stress-Strain" task.
3. **Stepwise Convergence:** Both methods exhibit a characteristic "stepwise" decrease in error, suggesting discrete improvements or optimization phases rather than a smooth, continuous convergence.
4. **Variability:** The shaded confidence intervals for PiT-PO are generally wider than those for LLM-SR, particularly in the oscillation tasks where its performance is best. This indicates higher variance in its results, even as its median/mean performance is superior.
5. **Task Dependency:** The initial error and the rate of convergence are highly dependent on the task. "Oscillation 1" shows the most dramatic improvement, while "Stress-Strain" shows the most modest gains for PiT-PO over LLM-SR.
### Interpretation
The data strongly suggests that the **PiT-PO method is more effective than LLM-SR at minimizing model error over time** for the tested dynamical systems and growth models. Its advantage is particularly pronounced in systems characterized by oscillations ("Oscillation 1" & "2"), where it achieves astronomically lower error values.
The stepwise nature of the error reduction implies that both algorithms may operate in distinct phases—perhaps alternating between exploration and exploitation, or undergoing periodic model updates. The wider confidence intervals for PiT-PO could mean its performance is more sensitive to initial conditions or random seeds, but its central tendency is decisively better.
From a practical standpoint, if the goal is to achieve the highest possible accuracy (lowest NMSE) given sufficient computational time (several hours), **PiT-PO appears to be the superior choice**, especially for oscillatory problems. However, the higher variance might be a consideration for applications requiring highly consistent, predictable performance. The "Stress-Strain" result indicates that for some problem types, the advantage of PiT-PO, while present, may be marginal.
</details>
(a) Llama-3.1-8B
<details>
<summary>x11.png Details</summary>
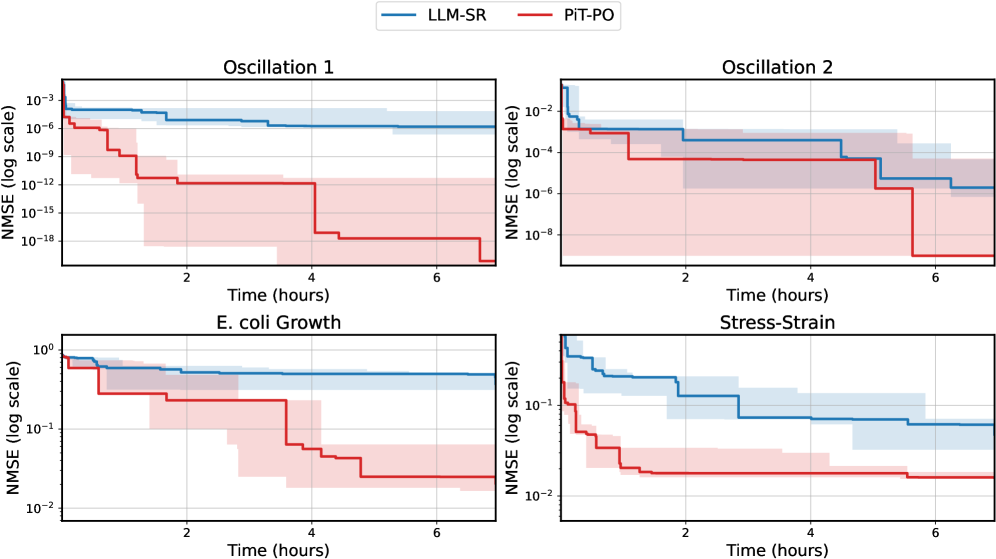
### Visual Description
## Line Chart Comparison: NMSE vs. Time for Two Methods
### Overview
The image displays a 2x2 grid of four line charts comparing the performance of two methods, **LLM-SR** (blue line) and **PiT-PO** (red line), across four different tasks or datasets. Performance is measured by **Normalized Mean Squared Error (NMSE)** on a logarithmic scale over **Time (hours)**. Each chart includes shaded regions around the main lines, likely representing confidence intervals or standard deviation.
### Components/Axes
* **Legend:** Located at the top center of the entire figure. It defines:
* **Blue Line:** LLM-SR
* **Red Line:** PiT-PO
* **Common Axes (All Subplots):**
* **X-axis:** Label: "Time (hours)". Scale: Linear, from 0 to approximately 7 hours. Major ticks at 0, 2, 4, 6.
* **Y-axis:** Label: "NMSE (log scale)". Scale: Logarithmic. The range varies per subplot.
* **Subplot Titles (Top Center of each chart):**
1. Top-Left: **Oscillation 1**
2. Top-Right: **Oscillation 2**
3. Bottom-Left: **E. coli Growth**
4. Bottom-Right: **Stress-Strain**
### Detailed Analysis
#### 1. Oscillation 1 (Top-Left)
* **Y-axis Range:** ~10⁻³ to 10⁻¹⁸ (log scale).
* **Trend Verification:**
* **LLM-SR (Blue):** Shows a gradual, stepwise downward trend. Starts high, decreases slowly.
* **PiT-PO (Red):** Shows a much steeper, stepwise downward trend. Drops rapidly in the first 2 hours and continues to decline significantly.
* **Data Points (Approximate):**
* **Time 0h:** Both methods start near NMSE = 10⁻³.
* **Time 2h:** LLM-SR ≈ 10⁻⁶; PiT-PO ≈ 10⁻¹².
* **Time 4h:** LLM-SR ≈ 10⁻⁷; PiT-PO ≈ 10⁻¹⁸.
* **Time 6h:** LLM-SR ≈ 10⁻⁷; PiT-PO ≈ 10⁻¹⁸ (plateau).
* **Shaded Regions:** The red shaded area (PiT-PO) is very wide, indicating high variance or uncertainty in its performance, especially between 1-4 hours. The blue shaded area (LLM-SR) is narrower.
#### 2. Oscillation 2 (Top-Right)
* **Y-axis Range:** ~10⁻² to 10⁻⁸ (log scale).
* **Trend Verification:**
* **LLM-SR (Blue):** Stepwise downward trend, with a notable drop after 5 hours.
* **PiT-PO (Red):** Stepwise downward trend, with a major drop after 5 hours, reaching a lower final value.
* **Data Points (Approximate):**
* **Time 0h:** Both start near NMSE = 10⁻².
* **Time 2h:** LLM-SR ≈ 10⁻³; PiT-PO ≈ 10⁻⁴.
* **Time 4h:** LLM-SR ≈ 10⁻⁴; PiT-PO ≈ 10⁻⁵.
* **Time 6h:** LLM-SR ≈ 10⁻⁶; PiT-PO ≈ 10⁻⁹.
* **Shaded Regions:** Both methods show significant overlapping shaded regions, indicating comparable variance. The red region (PiT-PO) appears slightly wider in the 2-5 hour range.
#### 3. E. coli Growth (Bottom-Left)
* **Y-axis Range:** ~10⁰ to 10⁻² (log scale).
* **Trend Verification:**
* **LLM-SR (Blue):** Very gradual, almost flat downward trend.
* **PiT-PO (Red):** Clear stepwise downward trend, achieving a much lower final error.
* **Data Points (Approximate):**
* **Time 0h:** Both start near NMSE = 10⁰ (i.e., 1).
* **Time 2h:** LLM-SR ≈ 0.5; PiT-PO ≈ 0.1.
* **Time 4h:** LLM-SR ≈ 0.4; PiT-PO ≈ 0.05.
* **Time 6h:** LLM-SR ≈ 0.4; PiT-PO ≈ 0.02.
* **Shaded Regions:** The red shaded area (PiT-PO) is very broad, especially between 1-4 hours, suggesting high variability in its learning curve for this task. The blue region is much tighter.
#### 4. Stress-Strain (Bottom-Right)
* **Y-axis Range:** ~10⁰ to 10⁻² (log scale).
* **Trend Verification:**
* **LLM-SR (Blue):** Stepwise downward trend.
* **PiT-PO (Red):** Steeper initial stepwise downward trend, then plateaus at a lower error.
* **Data Points (Approximate):**
* **Time 0h:** Both start near NMSE = 10⁰.
* **Time 2h:** LLM-SR ≈ 0.2; PiT-PO ≈ 0.02.
* **Time 4h:** LLM-SR ≈ 0.1; PiT-PO ≈ 0.02.
* **Time 6h:** LLM-SR ≈ 0.08; PiT-PO ≈ 0.02.
* **Shaded Regions:** The blue shaded area (LLM-SR) is notably wide after 2 hours, indicating increasing uncertainty. The red shaded area (PiT-PO) is narrower after its initial drop.
### Key Observations
1. **Consistent Superiority:** In all four tasks, the **PiT-PO (red)** method achieves a lower final NMSE than the **LLM-SR (blue)** method by several orders of magnitude.
2. **Faster Convergence:** PiT-PO demonstrates a much faster rate of error reduction, particularly in the first 2 hours of training/computation time.
3. **Stepwise Learning:** Both methods exhibit a "stepwise" improvement pattern, where the error remains flat for periods and then drops sharply. This is characteristic of certain optimization or learning processes.
4. **Variance Patterns:** The shaded confidence intervals for PiT-PO are often wider during its rapid descent phases (e.g., Oscillation 1, E. coli Growth), suggesting its performance path is more variable but ultimately more effective. LLM-SR's variance is often more consistent.
5. **Task Difficulty:** The starting NMSE values suggest "Oscillation 1" and "Oscillation 2" may be inherently more difficult problems (starting error ~10⁻³ to 10⁻²) compared to "E. coli Growth" and "Stress-Strain" (starting error ~10⁰).
### Interpretation
The data strongly suggests that the **PiT-PO method is significantly more efficient and effective** than the LLM-SR method for the class of problems represented by these four tasks (oscillatory systems, biological growth, material stress-strain). The logarithmic scale emphasizes that PiT-PO's improvements are not merely incremental but **exponential**, reducing error by factors of thousands to trillions compared to LLM-SR.
The stepwise nature of the curves implies that both methods may be using an iterative or episodic learning process. PiT-PO's ability to make larger, more decisive "jumps" in performance indicates a more powerful underlying optimization or discovery mechanism. The high variance during its learning phase could be a trade-off for this power, representing exploration of a larger solution space before converging on a superior model.
From a practical standpoint, if these tasks represent real-world scientific modeling challenges (e.g., discovering equations for physical systems), **PiT-PO would be the preferred tool**, as it arrives at a much more accurate model (lower NMSE) in the same amount of time. The charts serve as a compelling performance benchmark, highlighting a substantial advancement in automated scientific discovery or system identification techniques.
</details>
(b) Llama-3.2-3B
<details>
<summary>x12.png Details</summary>
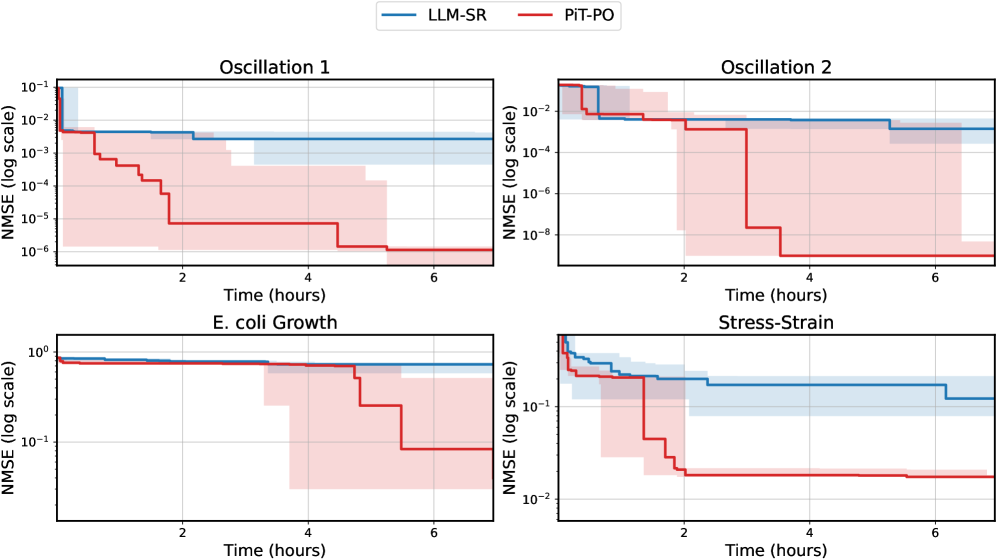
### Visual Description
## Comparative Performance Analysis of LLM-SR vs. PiT-PO Across Four Scenarios
### Overview
The image displays a 2x2 grid of four line charts. Each chart compares the performance of two methods, **LLM-SR** (blue line) and **PiT-PO** (red line), over time. Performance is measured by **NMSE (Normalized Mean Squared Error)** on a logarithmic scale. The charts represent four distinct experimental scenarios: "Oscillation 1", "Oscillation 2", "E. coli Growth", and "Stress-Strain". A shared legend is positioned at the top center of the entire figure.
### Components/Axes
* **Legend:** Located at the top center, above the charts. It defines:
* **Blue line:** LLM-SR
* **Red line:** PiT-PO
* **Common Axes Labels:**
* **X-axis (all charts):** "Time (hours)"
* **Y-axis (all charts):** "NMSE (log scale)"
* **Chart-Specific Titles & Y-Axis Ranges:**
1. **Top-Left: "Oscillation 1"**
* Y-axis range: 10⁻⁶ to 10⁻¹
2. **Top-Right: "Oscillation 2"**
* Y-axis range: 10⁻⁸ to 10⁻²
3. **Bottom-Left: "E. coli Growth"**
* Y-axis range: 10⁻¹ to 10⁰ (1)
4. **Bottom-Right: "Stress-Strain"**
* Y-axis range: 10⁻² to 10⁰ (1)
* **Visual Elements:** Each method's line is accompanied by a shaded region of the same color (light blue for LLM-SR, light red for PiT-PO), likely representing confidence intervals, standard deviation, or variance across multiple runs.
### Detailed Analysis
**1. Oscillation 1 (Top-Left)**
* **LLM-SR (Blue):** Starts at an NMSE of approximately 10⁻¹. It shows a rapid initial drop within the first hour, then plateaus around 10⁻².⁵. It remains relatively flat for the remainder of the 7-hour period. The shaded blue region is wide initially and narrows slightly over time.
* **PiT-PO (Red):** Starts at a similar high NMSE (~10⁻¹). It exhibits a dramatic, stepwise descent. Major drops occur just before hour 1, around hour 2, and just after hour 4. By hour 5, it reaches an NMSE of approximately 10⁻⁶, where it stabilizes. The shaded red region is very broad during the descent phases, indicating high variance during these transitions.
**2. Oscillation 2 (Top-Right)**
* **LLM-SR (Blue):** Begins near 10⁻². It shows a small initial drop and then a very gradual, almost linear decline on the log scale, ending near 10⁻³ after 7 hours. The shaded region is consistently narrow.
* **PiT-PO (Red):** Starts slightly above 10⁻². It follows a pronounced stepwise pattern. A significant drop occurs just after hour 2, bringing NMSE down to ~10⁻⁵. Another major drop happens just after hour 3, reaching a final plateau at approximately 10⁻⁹. The shaded region is extremely wide between hours 2 and 4, suggesting significant uncertainty or variability during the period of rapid improvement.
**3. E. coli Growth (Bottom-Left)**
* **LLM-SR (Blue):** Starts at an NMSE of ~10⁰ (1). It shows a very slight, steady decline over the entire 7-hour period, ending just below 10⁰. The performance improvement is minimal. The shaded region is narrow.
* **PiT-PO (Red):** Starts at a similar level (~10⁰). It remains flat until just after hour 4, where it experiences a sharp, stepwise drop to ~10⁻⁰.⁵. Another drop occurs just after hour 5, bringing the NMSE to approximately 10⁻¹. The shaded region expands significantly after hour 4, coinciding with the performance drops.
**4. Stress-Strain (Bottom-Right)**
* **LLM-SR (Blue):** Starts near 10⁰. It shows a stepped decline early on (before hour 1 and around hour 2), then plateaus near 10⁻⁰.⁷. It remains stable at this level. The shaded region is moderately wide.
* **PiT-PO (Red):** Starts near 10⁰. It demonstrates a rapid, multi-step descent within the first 2 hours. Key drops occur before hour 1 and around hour 2. It reaches a final plateau at approximately 10⁻¹.⁸ by hour 3 and remains there. The shaded region is widest during the initial descent phase (hours 0-2).
### Key Observations
1. **Consistent Superiority of PiT-PO:** In all four scenarios, the PiT-PO method (red) achieves a significantly lower final NMSE than the LLM-SR method (blue). The performance gap is often several orders of magnitude.
2. **Stepwise vs. Gradual Convergence:** PiT-PO's improvement is characterized by sharp, stepwise drops in error, followed by plateaus. LLM-SR tends to show a more gradual, continuous decline or early plateauing.
3. **Magnitude of Improvement:** The most dramatic performance difference is seen in **Oscillation 2**, where PiT-PO reaches an NMSE of ~10⁻⁹ compared to LLM-SR's ~10⁻³.
4. **Uncertainty Patterns:** The shaded variance regions for PiT-PO are typically much wider during its periods of rapid descent, suggesting that the timing or magnitude of these improvements may vary between runs. LLM-SR's variance is generally more consistent.
### Interpretation
The data strongly suggests that the **PiT-PO method is substantially more effective** at minimizing error (NMSE) over time for the modeled dynamic systems (oscillations, biological growth, material stress-strain) compared to the LLM-SR method.
* **Algorithmic Behavior:** The stepwise drops in PiT-PO's error curve are indicative of an optimization process that makes discrete, significant improvements at specific intervals, possibly due to algorithmic updates, phase transitions in the search, or the discovery of key parameters. LLM-SR's behavior suggests a more conservative or constrained optimization path.
* **Robustness and Variance:** The large shaded regions for PiT-PO during its descent phases imply that while its *potential* for high accuracy is great, the *path* to that solution is less deterministic. This could be a trade-off for its superior final performance.
* **Task Difficulty:** The "E. coli Growth" scenario appears to be the most challenging for both methods, as evidenced by the highest final NMSE values and the slowest convergence. Even here, however, PiT-PO demonstrates a clear late-stage advantage.
* **Practical Implication:** For applications requiring high-precision modeling of these types of systems over time, PiT-PO appears to be the more promising approach, despite potentially higher variability during the learning/optimization phase. The LLM-SR method provides more predictable but significantly less accurate results.
</details>
(c) Llama-3.2-1B
Figure 9. Wall-clock efficiency under a fixed 25,000-second budget.
### C.2. Time-Cost Analysis under a Fixed Wall-Clock Budget
To complement the iteration-based efficiency analysis in Section 4.4, we evaluate search efficiency under a strict wall-clock constraint. We fix the total runtime of each method to 25,000 seconds ( $\approx$ 6.9 hours) and track the best-so-far NMSE as a function of elapsed time (Figure 9). This protocol directly answers a practical question: given the same compute time, which method returns a more accurate recovered equation?
Across all three backbones (Llama-3.1-8B, Llama-3.2-3B, and Llama-3.2-1B), PiT-PO consistently yields lower NMSE trajectories than LLM-SR under the same 25,000-second budget. In line with the behavior discussed in Section 4.4, the curves exhibit a characteristic divergence in the low-error regime: LLM-SR often plateaus after an initial reduction, while PiT-PO continues to realize step-wise decreases over time, indicating more effective late-stage credit assignment and continued progress rather than stagnation.
The advantage is most pronounced on the two oscillator systems. For 8B and 3B, PiT-PO achieves rapid early improvements and maintains additional phase transitions later in the run, reaching substantially lower NMSE within the same wall-clock budget. For the 1B model, both methods converge more slowly overall, yet PiT-PO still more reliably escapes stagnation and attains markedly lower final NMSE, suggesting that the proposed in-search tuning remains effective even in the small-model regime.
Similar trends hold for the E. coli Growth and Stress–Strain tasks, where progress is typically more gradual. Under equal wall-clock time, PiT-PO achieves a lower final NMSE and exhibits clearer late-stage improvements, whereas LLM-SR tends to flatten earlier. Importantly, these gains are obtained without increasing runtime: despite the additional overhead introduced by in-search policy optimization, PiT-PO delivers consistently better return-on-compute within a fixed time budget, validating the practical efficiency of the proposed approach.
| LLM-SR (Llama-3.1-8B) LLM-SR (Llama-3.2-3B) LLM-SR (Llama-3.2-1B) | 0.0114 0.0191 0.1182 | 8.05e-10 5.56e-5 7.57e-3 | 0.1676 809.94 1888.5 | 0.1026 0.0264 0.2689 |
| --- | --- | --- | --- | --- |
| PiT-PO (Llama-3.1-8B) | 1.63e-30 | 1.36e-11 | 0.1163 | 0.0163 |
| PiT-PO (Llama-3.2-3B) | 2.63e-30 | 8.52e-10 | 0.0237 | 0.0144 |
| PiT-PO (Llama-3.2-1B) | 5.99e-5 | 8.58e-10 | 0.3462 | 0.0124 |
Table 4. OOD evaluation: NMSE on the OOD split.
### C.3. OOD Evaluation (NMSE ${}_{\text{OOD}}$ )
We report out-of-distribution performance using NMSE on the OOD split (NMSE ${}_{\text{OOD}}$ ), summarized in Table 4. Across all three backbones (8B/3B/1B) and all four tasks, PiT-PO achieves lower NMSE ${}_{\text{OOD}}$ than LLM-SR under the same setting. In particular, PiT-PO maintains extremely small OOD errors on the two oscillator systems, and yields substantially reduced OOD NMSE on E. coli growth and Stress–Strain, where LLM-SR exhibits noticeably larger errors. These results provide consistent evidence that the improvements observed in the main text persist under OOD evaluation.
### C.4. Equation Iterative Trajectories
<details>
<summary>x13.png Details</summary>
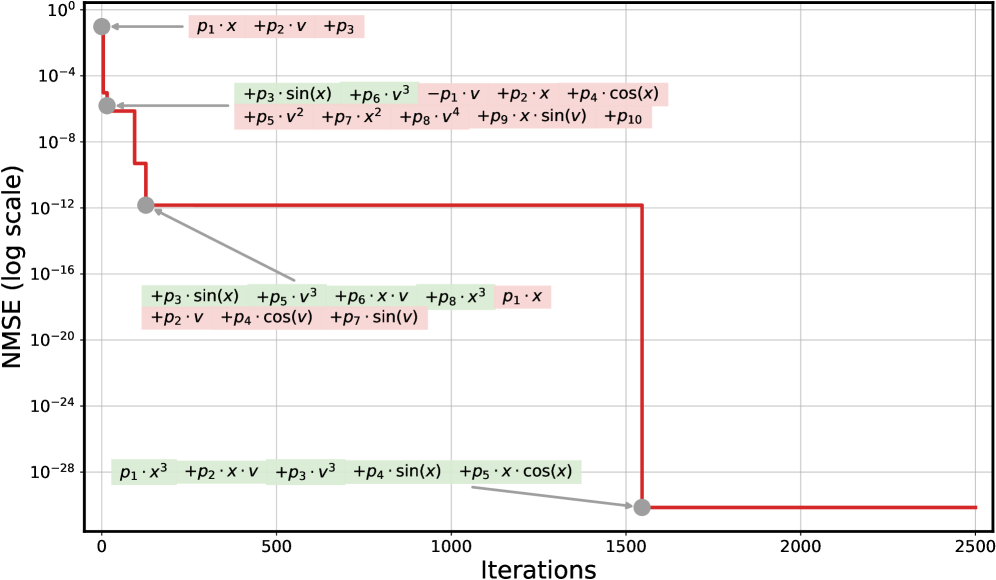
### Visual Description
## Convergence Plot: Model Complexity vs. Normalized Mean Square Error (NMSE)
### Overview
The image is a technical plot illustrating the convergence of a model's error (NMSE) over training iterations. It demonstrates how the error decreases in a stepwise fashion as increasingly complex mathematical terms are added to the model. The plot uses a logarithmic scale for the error axis to visualize the dramatic, multi-order-of-magnitude improvements.
### Components/Axes
* **Chart Type:** Step-wise convergence plot (line chart).
* **Y-Axis:**
* **Label:** `NMSE (log scale)`
* **Scale:** Logarithmic, ranging from `10^0` (1) at the top to `10^-28` at the bottom.
* **Major Ticks:** `10^0`, `10^-4`, `10^-8`, `10^-12`, `10^-16`, `10^-20`, `10^-24`, `10^-28`.
* **X-Axis:**
* **Label:** `Iterations`
* **Scale:** Linear, from `0` to `2500`.
* **Major Ticks:** `0`, `500`, `1000`, `1500`, `2000`, `2500`.
* **Data Series:** A single, solid red line representing the NMSE over iterations.
* **Annotations:** Four text boxes with mathematical expressions, connected by gray arrows to specific points on the red line. The text boxes use colored backgrounds (light green and light pink) to highlight different terms.
### Detailed Analysis
The red line shows a step-function decrease in NMSE. The error remains constant for long periods (plateaus) and then drops sharply at specific iteration points. Each drop is associated with the introduction of a new, more complex set of model terms, as indicated by the annotations.
**1. Initial State (Iteration ~0):**
* **Position:** Top-left corner of the plot.
* **NMSE Value:** Approximately `10^0` (or 1).
* **Annotation (Light Pink Background):** `p₁·x + p₂·v + p₃`
* **Trend Description:** The line starts at a high error value.
**2. First Major Drop (Iteration ~0-10):**
* **Position:** The line drops vertically from `10^0` to approximately `10^-6`.
* **NMSE Value:** Plateaus at ~`10^-6`.
* **Annotation (Mixed Green/Pink Background):**
* Green Terms: `+p₃·sin(x)`, `+p₆·v³`, `+p₅·v²`, `+p₇·x²`, `+p₈·v⁴`, `+p₉·x·sin(v)`
* Pink Terms: `-p₁·v`, `+p₂·x`, `+p₄·cos(x)`, `+p₁₀`
* **Trend Description:** A dramatic, near-vertical drop in error, followed by a long plateau.
**3. Second Major Drop (Iteration ~1500):**
* **Position:** The line drops vertically from ~`10^-6` to ~`10^-12`.
* **NMSE Value:** Plateaus at ~`10^-12`.
* **Annotation (Mixed Green/Pink Background):**
* Green Terms: `+p₃·sin(x)`, `+p₅·v³`, `+p₆·x·v`, `+p₈·x³`
* Pink Terms: `p₁·x`, `+p₂·v`, `+p₄·cos(v)`, `+p₇·sin(v)`
* **Trend Description:** Another sharp, vertical drop in error, followed by a second long plateau.
**4. Final Drop (Iteration ~1550):**
* **Position:** The line drops vertically from ~`10^-12` to a value below `10^-28`.
* **NMSE Value:** Plateaus at a very low value, appearing to be at or below `10^-30` (the axis ends at `10^-28`).
* **Annotation (Light Green Background):** `p₁·x³ + p₂·x·v + p₃·v³ + p₄·sin(x) + p₅·x·cos(x)`
* **Trend Description:** The final and most significant drop, leading to an extremely low, stable error.
### Key Observations
1. **Stepwise Convergence:** The model does not improve continuously. Error reduction occurs in discrete, massive jumps, each coinciding with a change in the model's functional form (the added terms).
2. **Magnitude of Improvement:** The total improvement in NMSE is extraordinary, spanning over 30 orders of magnitude (from `10^0` to `<10^-30`).
3. **Plateau Length:** The plateaus between drops are of similar length (~1500 iterations), suggesting a consistent training period is needed before the next model complexity level yields improvement.
4. **Annotation Color Coding:** The green highlighting in the annotations likely signifies the *newly added* terms at that stage, while pink may indicate terms carried over or modified from a previous stage. This is an inferred pattern based on visual grouping.
### Interpretation
This plot is a powerful visualization of **model selection and symbolic regression**. It demonstrates the process of discovering an accurate mathematical model for a system.
* **What it Suggests:** The data shows that a simple linear model (`p₁·x + p₂·v + p₃`) is a poor fit (high NMSE). Introducing non-linear and trigonometric terms (`sin`, `cos`, polynomials) in stages leads to exponentially better fits. The final model, a combination of cubic terms and trigonometric functions, achieves near-perfect accuracy (extremely low NMSE).
* **Relationship Between Elements:** The x-axis (Iterations) represents the computational effort or search process. The y-axis (NMSE) is the objective measure of model quality. The annotations are the "discoveries" made during the search. The stepwise drops indicate moments where the algorithm found a significantly better model structure.
* **Notable Anomalies/Trends:** The most striking trend is the **log-linear relationship between model complexity and error reduction**. Each major increase in the complexity of the term set (from linear, to including squares/cubes/trig, to a refined final set) results in a multiplicative (order-of-magnitude) decrease in error. This is characteristic of successful symbolic regression, where the correct functional form is more important than incremental parameter tuning.
* **Underlying Message:** The plot argues that for this particular problem, the underlying physical or mathematical law is complex but discoverable. It highlights the efficiency of a search algorithm that can navigate a vast space of possible equations to find a parsimonious and highly accurate solution. The final model is not the most complex one shown (the second annotation has more terms), but it is the most effective, suggesting the algorithm also performs model simplification or finds a more fundamental representation.
</details>
(a) PiT-PO.
<details>
<summary>x14.png Details</summary>
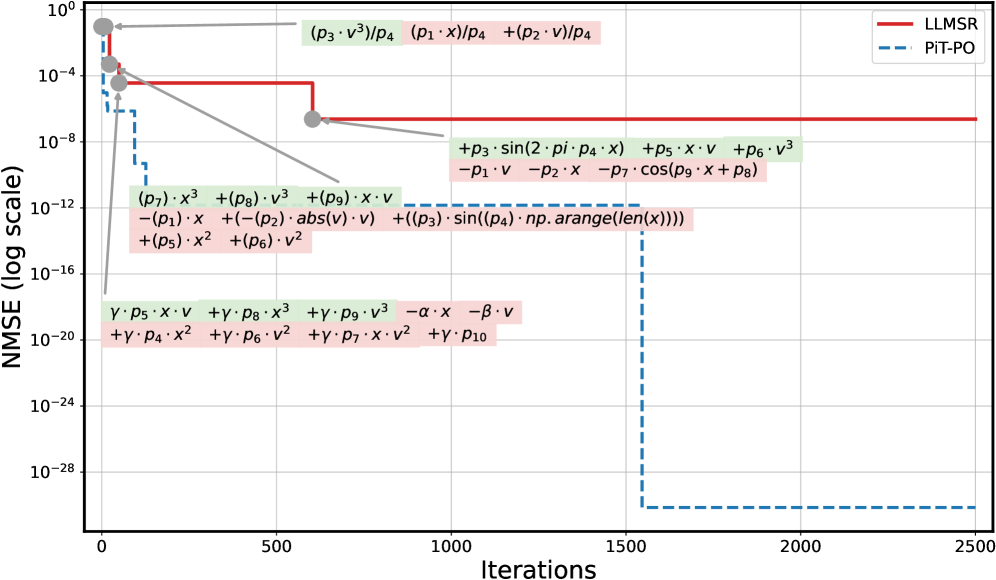
### Visual Description
\n
## [Line Chart with Annotations]: Comparison of LLMSR and PiT-PO Optimization Performance
### Overview
The image is a technical line chart comparing the performance of two optimization methods, **LLMSR** and **PiT-PO**, over a series of iterations. The performance metric is **NMSE (Normalized Mean Squared Error)** plotted on a logarithmic scale. The chart includes detailed mathematical annotations for each method, showing the specific model equations or terms being optimized at different stages. The primary visual narrative is that the **PiT-PO** method (blue dashed line) achieves a significantly lower final error (NMSE) than the **LLMSR** method (red solid line).
### Components/Axes
* **Chart Type:** Line chart with annotations.
* **X-Axis:** Label: **"Iterations"**. Scale: Linear, from 0 to 2500, with major ticks at 0, 500, 1000, 1500, 2000, 2500.
* **Y-Axis:** Label: **"NMSE (log scale)"**. Scale: Logarithmic (base 10), ranging from 10⁰ (1) at the top to 10⁻²⁸ at the bottom. Major ticks are at every power of 100 (10⁰, 10⁻⁴, 10⁻⁸, 10⁻¹², 10⁻¹⁶, 10⁻²⁰, 10⁻²⁴, 10⁻²⁸).
* **Legend:** Located in the **top-right corner**.
* **Red solid line:** Labeled **"LLMSR"**.
* **Blue dashed line:** Labeled **"PiT-PO"**.
* **Annotations:** Mathematical expressions are placed directly on the chart, color-coded and connected to specific points on the lines with arrows or proximity.
* **Green background boxes:** Associated with the **PiT-PO** (blue dashed) line.
* **Pink background boxes:** Associated with the **LLMSR** (red solid) line.
### Detailed Analysis
**1. LLMSR (Red Solid Line) Trend & Data:**
* **Trend:** The line starts at a high NMSE (~10⁰) at iteration 0. It drops very sharply within the first ~100 iterations to approximately 10⁻⁴. It then experiences a second, smaller drop around iteration 600 to about 10⁻⁶. After this point, the line plateaus and remains constant at ~10⁻⁶ until iteration 2500.
* **Annotations (Pink Boxes):**
* **Initial Model (near start):** `(p₃·v³)/p₄ (p₁·x)/p₄ +(p₂·v)/p₄`
* **Model after first drop (near iteration 600):** `+p₃·sin(2·pi·p₄·x) +p₅·x·v +p₆·v³ -p₁·v -p₂·x -p₇·cos(p₉·x + p₈)`
* **Final Plateau Model (spanning iterations ~600-2500):** `(p₇)·x³ +(p₈)·v³ +(p₉)·x·v -(p₁)·x +(-p₂)·abs(v)·v +((p₃)·sin((p₄)·np.arange(len(x)))) +(p₅)·x² +(p₆)·v²`
**2. PiT-PO (Blue Dashed Line) Trend & Data:**
* **Trend:** The line starts at a lower initial NMSE than LLMSR, approximately 10⁻². It shows a stepwise descent. The first major drop occurs within the first ~200 iterations, falling to ~10⁻¹². It then plateaus briefly before a second dramatic drop around iteration 1500, plummeting to an extremely low NMSE of ~10⁻³⁰. It remains at this level until iteration 2500.
* **Annotations (Green Boxes):**
* **Initial/Early Model (near start):** `γ·p₅·x·v +γ·p₈·x³ +γ·p₉·v³ -α·x -β·v +γ·p₄·x² +γ·p₆·v² +γ·p₇·x·v² +γ·p₁₀`
### Key Observations
1. **Performance Gap:** There is a massive performance difference at convergence. PiT-PO's final NMSE (~10⁻³⁰) is approximately **24 orders of magnitude lower** than LLMSR's final NMSE (~10⁻⁶).
2. **Convergence Behavior:** LLMSR converges quickly to a moderate error level and then stagnates. PiT-PO shows a more complex, multi-stage convergence, ultimately reaching a far superior solution.
3. **Model Complexity:** The annotations suggest the models being optimized are nonlinear, involving polynomial terms (x³, v³, x², v²), trigonometric functions (sin, cos), absolute values, and array operations (`np.arange`). The PiT-PO annotation appears simpler in this snapshot, but this may represent only one phase of its optimization.
4. **Visual Grounding:** The color-coding is consistent. All green-highlighted equations are near the blue dashed line. All pink-highlighted equations are near the red solid line. The legend correctly identifies the line styles.
### Interpretation
This chart demonstrates the superior optimization capability of the **PiT-PO** method compared to **LLMSR** for the specific problem being modeled. The problem involves finding parameters (`p₁` through `p₁₀`, `α`, `β`, `γ`) for a complex, nonlinear dynamical system or function involving variables `x` and `v`.
* **What the data suggests:** PiT-PO is not only more effective (reaching a much lower error) but may also employ a more sophisticated or adaptive optimization strategy, as evidenced by its stepwise convergence. The plateau in LLMSR suggests it may have become trapped in a local minimum.
* **Relationship between elements:** The annotations are crucial. They show that the optimization isn't just minimizing a black-box error; it's refining a specific, interpretable mathematical model. The change in the annotated equation for LLMSR around iteration 600 corresponds to its second drop in error, indicating a shift in the model structure or parameter focus during optimization.
* **Notable Anomalies:** The most striking feature is the extreme final precision of PiT-PO (10⁻³⁰). In many practical applications, such a low NMSE is indistinguishable from zero and may indicate the method has found an exact or near-exact analytical solution to the problem. The chart effectively argues for the adoption of PiT-PO over LLMSR for this class of problems.
</details>
(b) LLM-SR.
Figure 10. Iterative trajectories of PiT-PO and LLM-SR on Oscillator1 with Llama-3.1-8B-Instruct. The NMSE curves (log scale) report the best-so-far value over iterations. Annotated equation snapshots illustrate how the discovered structure evolves along the search trajectory. The green-shaded terms are correct, whereas the red-shaded terms are erroneous.
Figure 10 visualizes how symbolic structures evolve along the iterative search. For PiT-PO (Figure 10(a)), the trajectory reveals a clear process of progressively excluding spurious terms. Under the theorem-guided mathematical constraints and the token-aware policy update, tokens marked as redundant are assigned token-level penalties; as this penalty signal repeatedly accumulates across many sampled equations during optimization, such spurious components become progressively less preferred and are unlikely to reappear in later generations. As a result, the search does not merely fit numerically; instead, it repeatedly transitions to cleaner structures, and each step-wise NMSE drop aligns with the removal of nuisance terms and a move toward a more parsimonious functional form. This “error-term elimination” behavior effectively shrinks the search space and substantially strengthens the exploration capability.
In contrast, LLM-SR (Figure 10(b)) exhibits much weaker structural correction. Since its guidance is primarily prompt-level rather than parameter-level, terms that appear early—even if structurally incorrect—tend to persist and continue influencing subsequent proposals. Consequently, the search frequently enters a plateau where NMSE stops improving meaningfully: the method keeps revisiting or retaining earlier spurious components instead of systematically pruning them, indicating a stagnation regime with limited ability to reach the correct structure.
## Appendix D Datasets
### D.1. LLM-SR Suite
We use the LLM-SR Suite, which consists of four standard scientific equation discovery tasks spanning physics, biology, and materials science. The suite includes two nonlinear oscillator systems (Oscillation 1/2), an E. coli growth model (E. coli Growth), and a temperature-dependent stress–strain dataset (Stress–Strain). The first three tasks are dynamical systems and are simulated over a fixed time horizon, while the last task is a static constitutive relation evaluated on experimental measurements.
#### D.1.1. Oscillation 1 (Nonlinear Oscillator)
Nonlinear oscillators with dissipative and non-polynomial couplings provide a demanding test for recovering interacting terms from trajectories. We define the state as $x(t)$ and $v(t)=\dot{x}(t)$ , and simulate the following system:
| | $\displaystyle\dot{x}$ | $\displaystyle=v,$ | |
| --- | --- | --- | --- |
We set $F=0.8$ , $\alpha=0.5$ , $\beta=0.2$ , $\gamma=0.5$ , and $\omega=1.0$ , with initial conditions $x(0)=0.5$ , $v(0)=0.5$ , and simulate over $t\in[0,50]$ .
#### D.1.2. Oscillation 2 (Nonlinear Oscillator)
The second oscillator introduces explicit time forcing and an exponential nonlinearity, leading to a different coupling pattern between $x$ and $v$ :
| | $\displaystyle\dot{x}$ | $\displaystyle=v,$ | |
| --- | --- | --- | --- |
We use $F=0.3$ , $\alpha=0.5$ , $\beta=1.0$ , $\delta=5.0$ , $\gamma=0.5$ , and $\omega=1.0$ . The initial conditions and simulation window are the same as Oscillation 1: $x(0)=0.5$ , $v(0)=0.5$ , $t\in[0,50]$ .
#### D.1.3. E. coli Growth (Bacterial Growth)
This task models the growth rate of E. coli as a product of multiplicative factors capturing distinct physiological effects from population size, nutrient availability, temperature, and acidity:
$$
\frac{dB}{dt}=f_{B}(B)\cdot f_{S}(S)\cdot f_{T}(T)\cdot f_{\mathrm{pH}}(\mathrm{pH}),
$$
where $B$ is bacterial density, $S$ is nutrient concentration, $T$ is temperature, and $\mathrm{pH}$ denotes acidity. In our benchmark, the explicit functional form is:
This specification combines saturation kinetics, sharp temperature modulation, and a structured pH response, yielding a challenging multivariate nonlinear discovery setting.
#### D.1.4. Stress–Strain (Material Stress Behavior)
To assess performance on experimental measurements, we consider tensile stress–strain data for Aluminum 6061-T651 collected at multiple temperatures (from room temperature up to $300^{\circ}\text{C}$ ). While no single exact governing equation is provided, a commonly used phenomenological approximation for temperature-dependent hardening is:
$$
\sigma=\left(A+B\varepsilon^{n}\right)\left(1-\left(\frac{T-T_{r}}{T_{m}-T_{r}}\right)^{m}\right).
$$
where $\sigma$ is stress, $\varepsilon$ is strain, $T$ is temperature, $T_{r}$ is a reference temperature, and $T_{m}$ is the melting temperature. The coefficients $A$ , $B$ , $n$ , and $m$ are fitted from data for the given alloy.
### D.2. LLM-SRBench
We additionally report results on LLM-SRBench, a benchmark specifically constructed to evaluate data-driven scientific equation discovery with LLMs while reducing the risk of trivial memorization of canonical textbook formulas. It contains 239 problems spanning four scientific domains (chemistry, biology, physics, and material science), and each task is packaged with (i) a short scientific context describing variables and the target quantity and (ii) tabular numerical samples used for discovery.
Dataset composition
LLM-SRBench is organized into two complementary subsets.
(1) LSR-Transform. This subset converts well-known physics equations into less-common but analytically equivalent forms by changing the prediction target. Concretely, starting from the original equation, one input variable is chosen as a pivot and promoted to the new target; the equation is then symbolically solved (e.g., via SymPy) for that pivot variable, yielding an alternative representation of the same underlying physical law. Only transformations that admit an analytic solution are retained, and the original datapoints are filtered to satisfy the valid domain of the transformed expression (e.g., avoiding invalid denominators or square-root domains). Finally, a new natural-language problem statement is generated to match the transformed input–output specification. This pipeline produces 111 transformed problems.
(2) LSR-Synth. This subset is designed to test discovery beyond memorized templates by composing equations from both known scientific terms and synthetic (novel yet plausible) terms. Candidate known/synthetic terms are proposed with an LLM given the domain context, combined into full equations, and then filtered through multiple checks: numerical solvability (e.g., via standard ODE solvers for dynamical systems), novelty assessment in context (using an LLM-based novelty evaluator), and expert plausibility validation. After passing these filters, datapoints are generated for each approved equation, yielding 128 synthetic problems across the same four domains.
Symbolic Accuracy (SA)
Besides numeric fit metrics (e.g., $\mathrm{NMSE}$ and $\mathrm{Acc}_{all}(\tau)$ ), LLM-SRBench emphasizes symbolic correctness. Symbolic Accuracy (SA) is computed using an LLM-based equivalence judge (GPT-4o): given a predicted hypothesis and the ground-truth expression, the evaluator first normalizes both by removing extraneous text (e.g., comments) and replacing explicit numeric constants with placeholder parameters, then decides whether there exist parameter values that make the hypothesis mathematically equivalent to the ground truth. SA is the fraction (percentage) of problems judged equivalent under this protocol. The benchmark authors validated this evaluation by comparing against human judgments on 130 sampled problems and reported 94.6% agreement between GPT-4o and human evaluators.
## Appendix E Turbulence Task Setup: Periodic Hill Flow
### E.1. Dataset
We consider the periodic hill flow configuration with streamwise periodic boundary conditions and no-slip walls.
In this work, the features selected for the symbolic regression process are computed from the mean strain-rate ( $S$ ) and rotation-rate ( $R$ ) tensors. Following established practice, these tensors are normalized using local turbulence scales prior to invariant calculation to ensure well-conditioned inputs:
$$
\displaystyle S \displaystyle=\frac{1}{2}\,\frac{1}{\beta^{*}\omega}\Bigl[\nabla\boldsymbol{u}+(\nabla\boldsymbol{u})^{\mathsf{T}}\Bigr], \displaystyle R \displaystyle=\frac{1}{2}\,\frac{1}{\beta^{*}\omega}\Bigl[\nabla\boldsymbol{u}-(\nabla\boldsymbol{u})^{\mathsf{T}}\Bigr], \tag{13}
$$
where $(\cdot)^{\mathsf{T}}$ denotes matrix transposition. The invariants are then computed as $I_{1}=\mathrm{Tr}(S^{2})$ and $I_{2}=\mathrm{Tr}(R^{2})$ .
The dataset provides (i) two invariant features $(I_{1},I_{2})$ (stored in the Lambda columns), (ii) tensor bases $\{T^{m}\}_{m=1}^{3}$ (stored in the first three $3\times 3$ tensors in the Tensor columns), and (iii) the target anisotropy tensor field $b$ (and its nonlinear correction form used for training, denoted by $b^{\perp}$ ), together with auxiliary fields such as turbulent kinetic energy $k$ when needed by the evaluator.
#### E.1.1. Data Collection
DNS source.
The DNS data are obtained from the publicly available NASA turbulence modeling resource (Turbulence Modeling Resource / TMBWG) for periodic hills of parameterized geometries. https://tmbwg.github.io/turbmodels/Other_DNS_Data/parameterized_periodic_hills.html
RANS baseline generation (for non-DNS methods).
For all non-DNS methods, we compute baseline solutions using OpenFOAM with the same initial and boundary conditions as the DNS. Specifically, we employ the incompressible steady-state solver simpleFoam and apply the turbulence models considered in this paper (all belonging to RANS and its SST variants). The solver outputs, at each sampling point and converged iteration/time-step, the required physical quantities for subsequent post-processing.
DNS–RANS grid alignment and target construction.
To construct training targets consistent with the RANS discretization, we interpolate the DNS fields onto the RANS grid points. The interpolated DNS quantities are then post-processed in the CFD workflow (i.e., as offline preprocessing prior to training) to compute the Reynolds stress tensor, which is packaged into the dataset files as the supervision signal for training.
Feature & basis construction.
Following Pope’s tensor-basis expansion hypothesis, the Reynolds stress decomposition involves (i) tensor bases and (ii) scalar coefficient functions of invariant features. Since our final turbulence closure is embedded as a correction to the baseline kOmegaSST model, we use the physical fields produced by the baseline kOmegaSST computation for post-processing to obtain the input features and the tensor bases. These are stored in separate files (features and bases), while the learning target is defined to match the Reynolds-stress-related quantity described in Section E.2.
#### E.1.2. Pre-processing
We normalize the two invariant inputs prior to feeding them into the learned symbolic expressions:
$$
\tilde{I}=\tanh\!\left(\frac{I}{2.0}\right),\qquad\tilde{I}_{1}=\tanh\!\left(\frac{I_{1}}{2.0}\right),\quad\tilde{I}_{2}=\tanh\!\left(\frac{I_{2}}{2.0}\right), \tag{15}
$$
which maps the raw values into approximately $[-1,1]$ and improves numerical stability during parameter fitting.
### E.2. Casting Turbulence Closure as a Symbolic Regression Problem
Predicting scalar coefficients instead of tensor entries.
Rather than directly searching over tensor-valued symbolic forms, we let the LLM predict three scalar coefficient functions $(G^{1},G^{2},G^{3})$ , each parameterized as a symbolic expression of only two variables $(I_{1},I_{2})$ . The evaluator then reconstructs the predicted tensor via the (fixed) tensor bases:
$$
\hat{b}\;=\;G^{1}(I_{1},I_{2})\,T^{1}\;+\;G^{2}(I_{1},I_{2})\,T^{2}\;+\;G^{3}(I_{1},I_{2})\,T^{3}. \tag{16}
$$
This design compresses the LLM input variable dimension to two, significantly reducing the symbolic search space.
Scoring by MSE in the evaluator.
Given a candidate hypothesis, we compute the fitting score by the mean squared error between the target tensor and the reconstructed tensor. In the final evaluator, we additionally scale both prediction and target by the sample-wise $k$ before error aggregation:
$$
\hat{\tau}_{ij}(x_{n})=k(x_{n})\,\hat{b}_{ij}(x_{n}),\qquad\tau_{ij}(x_{n})=k(x_{n})\,b_{ij}(x_{n}), \tag{17}
$$
We compute the MSE only over a selected subset of tensor components. This is because the Reynolds-stress (and anisotropy) tensor is symmetric, so only six components are independent, and in the present periodic hill flow setting two off-plane shear components are typically several orders of magnitude smaller and are commonly neglected in practical turbulence modeling. Following this standard practice, we evaluate the error only on
$$
\Omega=\{(0,0),(0,1),(1,1),(2,2)\}, \tag{18}
$$
$$
\qquad\mathrm{MSE}=\frac{1}{|\Omega|}\sum_{(i,j)\in\Omega}\frac{1}{N}\sum_{n=1}^{N}\Bigl(\tau_{ij}(x_{n})-\hat{\tau}_{ij}(x_{n})\Bigr)^{2}. \tag{19}
$$
The resulting MSE is used as the numerical fitting score for the symbolic regression loop.
Prompt and fairness across methods.
We provide the same problem specification text (task description, variable definitions, and operator constraints) to both LLM-SR and PiT-PO to ensure a fair comparison. An example prompt is shown in Figure 11 – 13. In our current experiments, we also explicitly restrict the hypothesis space by asking the LLM to avoid trigonometric functions.
<details>
<summary>x15.png Details</summary>

### Visual Description
## Technical Document: Symbolic Regression for Periodic Hill Turbulence Modeling
### Overview
The image contains a technical specification for a symbolic regression task. The objective is to learn three scalar functions, G1(I1, I2), G2(I1, I2), and G3(I1, I2), which are used to model turbulence anisotropy in a periodic hill flow case. The document defines the flow context, the evaluation rule for the model, and the specific tensor bases (T1, T2, T3) that the scalar functions must weight to predict the anisotropy tensor.
### Components/Axes
The document is structured as a text block with the following major sections:
1. **Task Statement**: Defines the core objective.
2. **Flow Case Context**: Describes the physical setup of the turbulence problem.
3. **Evaluation Rule**: Specifies how the model's performance is measured.
4. **Tensor Bases**: Provides definitions and physical interpretations for the three tensor bases (T1, T2, T3) used in the model.
### Detailed Analysis / Content Details
**1. Task Statement**
* **Task**: Symbolic regression for periodic hill turbulence modeling.
* **Objective**: Learn three scalar functions: `G1(I1, I2)`, `G2(I1, I2)`, `G3(I1, I2)`.
**2. Flow Case Context (for description only)**
* **Bottom wall profile**:
* `y(x) = a[1 + cos(π x / L)]` for `|x| ≤ L`
* `y(x) = 0` for `|x| > L`
* Where `a` is the hill height (characteristic length `h`), and `α = L/h` controls hill steepness.
* **Training case parameter**: `α = 0.8`.
* **Boundary Conditions**:
* Streamwise (`x`) direction: periodic boundary conditions.
* Top and bottom walls: no-slip boundary conditions.
* **Reynolds Number**: `Re_h = U_b h / ν = 5600`.
**3. Evaluation Rule**
* **Input**: Tensor bases `T1`, `T2`, `T3` (each 3x3), provided by the evaluator.
* **Predicted Anisotropy (`b_hat`)**: `b_hat = G1 * T1 + G2 * T2 + G3 * T3`
* **Loss Metric**: The evaluator computes the Mean Squared Error (MSE) between the predicted `b_hat` and the target anisotropy tensor `b`.
**4. Tensor Bases: T1, T2, T3 (provided by the evaluator, do NOT compute them)**
For each sample `n`, the evaluator provides three 3x3 tensor bases (symmetric, traceless) constructed from the non-dimensionalized mean strain-rate tensor `S` and rotation tensor `R`.
* **T1 (linear strain basis)**:
* **Definition**: `T1 = S`
* **Interpretation**: Represents the Boussinesq/linear eddy-viscosity direction. It dominates in simple shear flows and acts as the baseline anisotropy response aligned with the mean strain.
* **T2 (strain-rotation coupling basis)**:
* **Definition**: `T2 = S @ R - R @ S`
* **Interpretation**: Captures the interaction between mean strain and mean rotation (curvature/turning, strong vortices). This term is crucial in separated flows, reattachment, and swirling/shear-layer regions where linear eddy-viscosity assumptions tend to fail.
* **T3 (quadratic strain nonlinearity basis)**:
* **Definition**: `T3 = S @ S - (1/3) * tr(S @ S) * I`
* **Interpretation**: Introduces nonlinear strain effects and normal-stress anisotropy beyond linear models. It helps represent differences among normal stress components and improves predictions in strongly anisotropic regions.
**Final Model Assembly**: The predicted anisotropy is assembled as:
`b_hat = G1(I1, I2) * T1 + G2(I1, I2) * T2 + G3(I1, I2) * T3`
### Key Observations
* The task is framed as a **symbolic regression** problem, implying the goal is to discover interpretable mathematical expressions for G1, G2, and G3, not just fit numerical parameters.
* The model is a **linear combination of three physically-motivated tensor bases**, where the coefficients (G1, G2, G3) are nonlinear functions of two invariants (`I1`, `I2`).
* The tensor bases progress in complexity: from linear strain (`T1`), to strain-rotation coupling (`T2`), to quadratic strain nonlinearity (`T3`). This structure suggests a hierarchy for capturing increasingly complex turbulence physics.
* The flow case (periodic hill at `Re_h=5600`) is a canonical benchmark for turbulence models, involving separation, recirculation, and reattachment, which tests the model's ability to handle non-equilibrium flows.
### Interpretation
This document defines a structured machine learning challenge for improving turbulence modeling in computational fluid dynamics (CFD). The core idea is to move beyond traditional linear eddy-viscosity models (represented by `T1`) by incorporating additional tensor terms (`T2`, `T3`) that account for complex flow physics like curvature and anisotropy.
The "symbolic regression" aspect is key. Instead of using a black-box neural network, the task seeks to find explicit, potentially simpler, mathematical formulas for the functions `G1`, `G2`, and `G3`. If successful, the resulting model would be more interpretable and physically insightful than a pure data-driven approach.
The framework explicitly links mathematical constructs to physical phenomena:
* `T1` handles basic shear.
* `T2` is critical for flows with rotation and separation (like the periodic hill).
* `T3` addresses limitations in predicting normal stress differences.
By learning how the scalar functions `G1(I1, I2)`, `G2(I1, I2)`, and `G3(I1, I2)` should vary with the flow invariants `I1` and `I2`, the task aims to create a more universal turbulence model that can adapt its behavior based on the local flow state, thereby improving predictive accuracy for complex engineering flows. The provided Reynolds number and geometric parameters (`α=0.8`) define a specific, challenging test case for this model development.
</details>
Figure 11. Problem Specification.
<details>
<summary>x16.png Details</summary>

### Visual Description
## Code Snippet: Python Function for Anisotropy Tensor Reconstruction
### Overview
The image displays a Python code snippet defining a function `evaluate` that performs an optimization task. The function's purpose is to train a model (represented by the `equation` callable) to predict scalar coefficients (`G1, G2, G3`) which are then used to reconstruct a target anisotropy tensor (`b_true`). The training minimizes the Mean Squared Error (MSE) between the predicted and true tensors using the BFGS optimization algorithm.
### Components/Axes
The code is structured into two main parts:
1. **Outer Function `evaluate(data, equation)`**: The main entry point that unpacks input data and orchestrates the optimization.
2. **Inner Function `loss(params)`**: Defines the objective function to be minimized. It contains the core logic for prediction, reconstruction, and error calculation.
3. **Optimization Block**: Initializes parameters and runs the minimization routine.
**Key Variables and Functions:**
* `data`: A dictionary containing the dataset with keys `'inputs'`, `'tensors'`, and `'outputs'`.
* `equation`: A callable function that predicts scalar coefficients based on inputs and parameters.
* `I1, I2`: Input variables unpacked from `data['inputs']`.
* `T1, T2, T3`: Component tensors unpacked from `data['tensors']`.
* `b_true`: The target anisotropy tensor from `data['outputs']`.
* `G_pred`: The predicted scalar coefficients, an array of shape `(N, 3)`.
* `b_hat`: The reconstructed anisotropy tensor, calculated as a linear combination: `G1*T1 + G2*T2 + G3*T3`.
* `initial_params`: Initial guess for the model parameters (30 ones).
* `minimize`: The SciPy optimization function used (BFGS method).
* `result.fun`: The final minimized loss value returned by the function.
### Detailed Analysis
The code executes the following logical flow:
1. **Data Unpacking**: The `evaluate` function extracts inputs (`I1, I2`), basis tensors (`T1, T2, T3`), and the ground truth tensor (`b_true`) from the input dictionary.
2. **Loss Function Definition**:
* The inner `loss` function takes model parameters (`params`) as input.
* It calls the provided `equation` function with `I1, I2`, and `params` to generate predictions `G_pred` for the scalar coefficients. The comment notes the expected output shape is `(N, 3)`.
* It reconstructs the predicted anisotropy tensor `b_hat` using broadcasting and element-wise multiplication. The operation is:
`b_hat = (G_pred[:, 0, None, None] * T1) + (G_pred[:, 1, None, None] * T2) + (G_pred[:, 2, None, None] * T3)`
This expands the `(N, 3)` `G_pred` array to match the dimensions of the `T` tensors for the linear combination.
* It computes the Mean Squared Error (MSE) between `b_hat` and `b_true` and returns this scalar loss value.
3. **Optimization Execution**:
* Parameters are initialized as a vector of 30 ones (`initial_params = np.ones(30)`), suggesting the `equation` function has 30 trainable parameters.
* The `minimize` function is called with the `loss` function, initial parameters, and the 'BFGS' method.
* The function returns the final minimized loss value (`result.fun`).
### Key Observations
* **Library Dependencies**: The code implicitly relies on the NumPy (`np`) library for array operations and the SciPy library's `optimize.minimize` function.
* **Tensor Reconstruction**: The reconstruction of `b_hat` uses NumPy broadcasting (`[:, 0, None, None]`) to align the dimensions of the coefficient vector with the basis tensors `T1, T2, T3`.
* **Optimization Method**: The choice of the BFGS (Broyden–Fletcher–Goldfarb–Shanno) algorithm indicates a gradient-based optimization approach suitable for smooth, unconstrained problems.
* **Parameter Count**: The initialization of 30 parameters implies the `equation` model has a specific architecture with 30 degrees of freedom to learn the mapping from inputs `(I1, I2)` to the three scalar coefficients.
### Interpretation
This code snippet represents a **physics-informed or tensor-reconstruction machine learning pipeline**. The core task is to learn a parametric function (`equation`) that can predict the coefficients (`G1, G2, G3`) of a linear combination of predefined basis tensors (`T1, T2, T3`). The goal is for this combination to accurately reproduce a target anisotropy tensor (`b_true`).
The process is framed as an **inverse problem**: given observed data (`b_true`) and a known model structure (linear combination of `T` tensors), find the parameters of the `equation` that best explain the data. The MSE loss quantifies the reconstruction error.
**Potential Applications:**
* **Material Science**: Modeling anisotropic material properties where the overall tensor is a combination of fundamental modes.
* **Continuum Mechanics**: Identifying constitutive model parameters from experimental or simulation data.
* **Reduced-Order Modeling**: Finding a low-dimensional parametric representation (`G` coefficients) of a complex tensor field.
The code is a template for a **data-driven discovery** process, where the `equation` function could be a neural network or another flexible function approximator, and the optimization finds the parameters that make the physical reconstruction (the linear combination) match the observed reality.
</details>
Figure 12. Evaluation and Optimization.
<details>
<summary>x17.png Details</summary>

### Visual Description
## Code Snippet: Python Function for Tensor Basis Coefficient Prediction
### Overview
The image displays a Python function definition named `equation`. The function is designed to compute three scalar coefficients (G1, G2, G3) for tensor bases, given two invariant arrays and a set of free parameters. The code is presented in a monospaced font with syntax highlighting (blue for the function name, green for comments, orange for the docstring, and black for the main code body) against a white background, enclosed within a rounded black border.
### Components/Axes
* **Function Signature:** `def equation(I1: np.ndarray, I2: np.ndarray, params: np.ndarray) -> np.ndarray:`
* **Docstring:** A multi-line string explaining the function's purpose, arguments, and return value.
* **Code Blocks:** Three distinct computation blocks for `g1`, `g2`, and `g3`, each preceded by a comment indicating the parameter slice used.
* **Return Statement:** A final line that stacks the three computed arrays.
### Detailed Analysis
The function's logic is structured as follows:
1. **Function Definition & Docstring:**
* **Purpose:** "Predict three scalar coefficients G1, G2, G3 for tensor bases."
* **Arguments:**
* `I1, I2`: Described as "numpy arrays of shape (N,), invariants."
* `params`: Described as a "numpy array of free constants."
* **Returns:** A "numpy array of shape (N, 3), columns are G1, G2, G3."
2. **G1 Block (Comment: `# G1 block: params[0:10]`):**
* Computes `g1` as a linear combination: `params[0] * I1 + params[1] * I2 + params[2]`.
* **Note:** The comment indicates this block uses parameters from index 0 to 9 (`params[0:10]`), but the visible code only explicitly uses indices 0, 1, and 2. The remaining parameters (3-9) are not utilized in the shown snippet.
3. **G2 Block (Comment: `# G2 block: params[10:20]`):**
* Computes `g2` as: `params[10] * I1 + params[11] * I2 + params[12]`.
* **Note:** The comment indicates this block uses parameters from index 10 to 19 (`params[10:20]`), but the visible code only explicitly uses indices 10, 11, and 12. The remaining parameters (13-19) are not utilized in the shown snippet.
4. **G3 Block (Comment: `# G3 block: params[20:30]`):**
* Computes `g3` as: `params[20] * I1 + params[21] * I2 + params[22]`.
* **Note:** The comment indicates this block uses parameters from index 20 to 29 (`params[20:30]`), but the visible code only explicitly uses indices 20, 21, and 22. The remaining parameters (23-29) are not utilized in the shown snippet.
5. **Return Statement:**
* `return np.stack([g1, g2, g3], axis=1)`
* This stacks the three 1D arrays (`g1`, `g2`, `g3`) as columns into a single 2D array of shape `(N, 3)`.
### Key Observations
* **Linear Model:** Each coefficient (G1, G2, G3) is computed using an identical linear model structure: `a*I1 + b*I2 + c`, where `a`, `b`, and `c` are parameters from the `params` array.
* **Parameter Slicing Discrepancy:** There is a clear mismatch between the parameter ranges stated in the comments (`params[0:10]`, `params[10:20]`, `params[20:30]`) and the number of parameters actually used in the code (3 per block, indices 0-2, 10-12, 20-22). This suggests the code snippet may be incomplete or a simplified example.
* **Modular Design:** The function is cleanly divided into three independent computation blocks, one for each output coefficient, which enhances readability.
* **Type Hints:** The function uses type hints (`np.ndarray`) for arguments and return value, indicating it is part of a codebase that values type clarity.
### Interpretation
This code snippet defines a core computational kernel, likely for a scientific or engineering simulation involving tensor analysis. The function `equation` serves as a **parameterized linear model** that maps two input invariants (`I1`, `I2`) to three output coefficients (`G1`, `G2`, `G3`). These coefficients are presumably used to weight basis tensors in a constitutive model (e.g., for material stress-strain relationships).
The key insight is that the model's behavior is entirely controlled by the 30-element `params` array (as implied by the comments). The function itself is a fixed, differentiable transformation. The "learning" or "fitting" process would involve optimizing the values within `params` to match experimental or high-fidelity simulation data. The discrepancy between the comment ranges and used indices is a critical point for a developer; it indicates either a bug, a placeholder for future expansion, or that this is a pedagogical example showing only the first few parameters of each block. The function's output shape `(N, 3)` is designed for efficient vectorized computation over `N` data points.
</details>
Figure 13. Equation Program Example.
### E.3. Back to Turbulence Modeling
From discovered expressions to a deployable closure
After obtaining an explicit expression for the Reynolds-stress-related term from symbolic regression, we rewrite the discovered formula into an OpenFOAM-readable form.
Embedding into OpenFOAM
We embed the resulting closure into the existing kOmegaSST implementation by replacing the routine that evaluates the Reynolds stress (or its modeled contribution) with the discovered expression, thereby forming an optimized turbulence model within the RANS framework.
Verification against DNS
We then run RANS simulations with the modified model under the same configuration as the baseline and compare the resulting flow statistics against the DNS reference data. This completes the end-to-end turbulence modeling and validation pipeline considered in this work.
### E.4. Domain-Specific Constraints for Turbulence Modeling
To encode expert knowledge as inductive biases, we augment the reward with a domain-specific penalty term:
$$
P_{\text{domain}}\;=\;\sum_{j=1}^{4}w_{j}\,P_{\text{domain}}^{(j)}, \tag{20}
$$
where each $P_{\text{domain}}^{(j)}\geq 0$ quantifies violations of the $j$ -th turbulence constraint.
(1) Realizability.
A physically admissible Reynolds stress tensor must be symmetric and positive semi-definite (PSD), which implies that all eigenvalues are nonnegative. Non-realizable predictions are penalized by
$$
P_{\text{domain}}^{(1)}\;=\;\frac{1}{N}\sum_{n=1}^{N}\max\Bigl(0,\,-\lambda_{\min}(\tau(x_{n}))\Bigr), \tag{21}
$$
where $\lambda_{\min}(\cdot)$ denotes the smallest eigenvalue. This PSD requirement is a standard realizability condition for Reynolds stresses (Pope, 2000).
(2) Boundary-condition consistency.
At a no-slip wall, the Reynolds stress tensor must decay to zero. Accordingly, non-vanishing stresses in a near-wall band $\mathcal{W}=\{x:y(x)<y_{0}\}$ are penalized as
$$
P_{\text{domain}}^{(2)}\;=\;\frac{1}{|\mathcal{W}|}\sum_{x_{n}\in\mathcal{W}}\|\tau(x_{n})\|_{F}, \tag{22}
$$
where $y(x)$ is the wall distance field. In practice, $y(x)$ can be computed and exported using standard CFD post-processing tools (OpenFOAM wall-distance utilities such as wallDist and checkMesh-writeAllFields) (Monkewitz, 2021).
(3) Asymptotic scaling in the viscous sublayer.
Near-wall Taylor expansions under the no-slip constraint imply that $u^{\prime}=O(y)$ and, for incompressible flow, $v^{\prime}=O(y^{2})$ . Consequently, the Reynolds shear stress $-\overline{u^{\prime}v^{\prime}}$ exhibits cubic leading-order scaling, $O(y^{3})$ , in the viscous sublayer (Tennekes and Lumley, 1972). This constraint is enforced by evaluating the slope of $\log|\tau_{xy}^{+}|$ with respect to $\log(y^{+})$ over the viscous sublayer range $\mathcal{V}=\{x:y^{+}(x)\in[y_{1}^{+},y_{2}^{+}]\}$ :
$$
p\;=\;\mathrm{slope}\bigl(\log|\tau_{xy}^{+}|\;\text{vs}\;\log(y^{+})\bigr),\qquad P_{\text{domain}}^{(3)}\;=\;|p-3|. \tag{23}
$$
Here $y^{+}=y\,u_{\tau}/\nu$ is the wall unit, with friction velocity $u_{\tau}=\sqrt{\tau_{w}/\rho}$ . In CFD, $y^{+}$ and $\tau_{w}$ can be obtained through standard post-processing utilities (OpenFOAM yPlus and wallShearStress).
(4) Energy consistency.
Energy consistency is enforced by constraining the turbulent kinetic energy production implied by the predicted stress:
$$
P_{k}(x)\;=\;-\tau_{ij}(x)\,\frac{\partial U_{i}}{\partial x_{j}}(x), \tag{24}
$$
and penalizing mismatches with the reference production $P_{k}^{\text{ref}}$ (computed from DNS-aligned fields) via
$$
P_{\text{domain}}^{(4)}\;=\;\mathrm{MSE}\bigl(P_{k},\,P_{k}^{\text{ref}}\bigr). \tag{25}
$$
The definition in Eq. (24) is the standard production term in the TKE budget (Pope, 2000).
Efficient evaluation via elite-CFD refinement (multi-fidelity constraint scheduling).
Constraints (2)–(4) require additional CFD-derived fields (wall distance $y$ , wall shear stress $\tau_{w}$ and the associated $y^{+}$ , and mean velocity gradients $\nabla U$ ), which can be expensive to obtain at each candidate-evaluation step. To keep the symbolic regression loop efficient, we adopt a two-stage evaluation schedule.
Stage-A (inexpensive screening, applied to all candidates) evaluates the data-fitting score (MSE) together with realizability $P_{\text{domain}}^{(1)}$ using only the predicted stress tensor.
Stage-B (expensive physics checks, triggered by an improving best MSE) is activated when a candidate in the current batch achieves a new best MSE value relative to all previously evaluated candidates. In this case, the candidate is treated as an elite solution, and CFD-based post-processing is performed to obtain the required auxiliary fields, compute $P_{\text{domain}}^{(2)}$ – $P_{\text{domain}}^{(4)}$ , and conduct an additional online fine-tuning step using the full domain-specific penalty. All non-elite candidates are trained only with the realizability constraint, whereas elite candidates receive the full turbulence constraint suite after CFD evaluation. This design enables rigorous physics enforcement without incurring prohibitive CFD costs during exploration.