# Neuro-symbolic Action Masking for Deep Reinforcement Learning
**Authors**: Shuai Han, Mehdi Dastani, Shihan Wang
ifaamas [AAMAS ’26]Proc. of the 25th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2026)May 25 – 29, 2026 Paphos, CyprusC. Amato, L. Dennis, V. Mascardi, J. Thangarajah (eds.) 2026 2026 Utrecht University Utrecht the Netherland Utrecht University Utrecht the Netherland Utrecht University Utrecht the Netherland
## Abstract
Deep reinforcement learning (DRL) may explore infeasible actions during training and execution. Existing approaches assume a symbol grounding function that maps high-dimensional states to consistent symbolic representations and a manually specified action masking techniques to constrain actions. In this paper, we propose Neuro-symbolic Action Masking (NSAM), a novel framework that automatically learn symbolic models, which are consistent with given domain constraints of high-dimensional states, in a minimally supervised manner during the DRL process. Based on the learned symbolic model of states, NSAM learns action masks that rules out infeasible actions. NSAM enables end-to-end integration of symbolic reasoning and deep policy optimization, where improvements in symbolic grounding and policy learning mutually reinforce each other. We evaluate NSAM on multiple domains with constraints, and experimental results demonstrate that NSAM significantly improves sample efficiency of DRL agent while substantially reducing constraint violations.
Key words and phrases: Deep reinforcement learning, neuro-symbolic learning, action masking
doi: JWPH6906
## 1. Introduction
With the powerful representation capability of neural networks, deep reinforcement learning (DRL) has achieved remarkable success in a variety of complex domains that require autonomous agents, such as autonomous driving autodriving4_1; autodriving4_2; autodriving4_3, resource management resourcem4_1; resourcem4_2, algorithmic trading autotrading4_1; autotrading4_2 and robotics roboticRL4_1; roboticRL4_2; roboticRL4_3. However, in real-world scenarios, agents face the challenges of learning policies from few interactions roboticRL4_2 and keeping violations of domain constraints to a minimum during training and execution autodriving_safe. To address these challenges, an increasing number of neuro-symbolic reinforcement learning (NSRL) approaches have been proposed, aiming to exploit the structural knowledge of the problem to improve sample efficiency shindo2024blendrl; RM; nsrl2025_planning or to constrain agents to select actions PLPG; PPAM; nsrl2024_plpg_multi.
Among these NSRL approaches, a promising practice is to exclude infeasible actions for the agents. We use the term infeasible actions throughout the paper, which can also be considered as unsafe, unethical or in general undesirable actions. This is typically achieved by assuming a predefined symbolic grounding nsplanning or label function RM that maps high-dimensional states into symbolic representations and manually specify action masking techniques actionmasking_app1; actionmasking_app3; actionmasking_app4. However, predefining the symbolic grounding function is often expensive neuroRM, as it requires complete knowledge of the environmental states, and could be practically impossible when the states are high-dimensional or infinite. Learning symbolic grounding from environmental state is therefore crucial for NSRL approaches and remains a highly challenging problem neuroRM.
In particular, there are three main challenges. First, real-world environments should often satisfy complex constraints expressed in a domain specific language, which makes learning the symbolic grounding function difficult ahmed2022semantic. Second, obtaining full supervision for learning symbolic representations in DRL environments is unrealistic, as those environments rarely provide the ground-truth symbolic description of every state. Finally, even if symbolic grounding can be learned, integrating it into reinforcement learning to achieve end-to-end learning remains a challenge.
To address these challenges, we propose Neuro-symbolic Action Masking (NSAM), a framework that integrates symbolic reasoning into deep reinforcement learning. The basic idea is to use probabilistic sentential decision diagrams (PSDDs) to learn symbolic grounding. PSDDs serve two purposes: they guarantee that any learned symbolic model satisfies domain constraints expressed in a domain specific language kisa2014probabilistic, and they allow the agent to represent probability distributions over symbolic models conditioned on high-dimensional states. In this way, PSDDs bridge the gap between numerical states and symbolic reasoning without requiring manually defined mappings. Based on the learned PSDDs, NSAM combines action preconditions with the inferred symbolic model of numeric states to construct action masks, thereby filtering out infeasible actions. Crucially, this process only relies on minimal supervision in the form of action explorablility feedback, rather than full symbolic description at every state. Finally, NSAM is trained end-to-end, where the improvement of symbolic grounding and policy optimization mutually reinforce each other.
We evaluate NSAM on four DRL decision-making domains with domain constraints, and compare it against a series of state-of-the-art baselines. Experimental results demonstrate that NSAM not only learns more efficiently, consistently surpassing all baselines, but also substantially reduces constraint violations during training. The results further show that the symbolic grounding plays a crucial role in exploiting underlying knowledge structures for DRL.
## 2. Problem setting
We study reinforcement learning (RL) on a Markov Decision Process (MDP) RL1998 $\mathcal{M}=(\mathcal{S},\mathcal{A},\mathcal{T},R,\gamma)$ where $\mathcal{S}$ is a set of states, $\mathcal{A}$ is a finite set of actions, $\mathcal{T}:\mathcal{S}\times\mathcal{A}\times\mathcal{S}\rightarrow[0,1]$ is a transition function, $\gamma\in[0,1)$ is a discount factor and $R:\mathcal{S}\times\mathcal{A}\times\mathcal{S}\rightarrow\mathbb{R}$ is a reward function. An agent employs a policy $\pi$ to interact with the environment. At a time step $t$ , the agent takes action $a_{t}$ according to the current state $s_{t}$ . The environment state will transfer to next state $s_{t+1}$ based on the transition probability $\mathcal{T}$ . The agent will receive the reward $r_{t}$ . Then, the next round of interaction begins. The goal of this agent is to find the optimal policy $\pi^{*}$ that maximizes the expected return: $\mathbb{E}[\sum_{t=0}^{T}\gamma^{t}r_{t}|\pi]$ , where $T$ is the terminal time step.
To augment RL with symbolic domain knowledge, we extend the normal MDP with the following modules $(\mathcal{P},\mathcal{AP},\phi)$ where $\mathcal{P}=\{p_{1},..,p_{K}\}$ is a finite set of atomic propositions (each $p\in\mathcal{P}$ represents a Boolean property of a state $s\in\mathcal{S}$ ), $\mathcal{AP}=\{(a,\varphi)|a\in\mathcal{A},\varphi\in L(\mathcal{P})\}$ is the set of actions with their preconditions, and $L(\mathcal{P})$ denotes the propositional language over $\mathcal{P}$ . We use $(a,\varphi)$ to state that action $a$ is explorable All actions $a\in\mathcal{A}$ can in principle be chosen by the agent. However, we use the term explorable to distinguish actions whose preconditions are satisfied (safe, ethical, desriable actions) from those whose preconditions are not satisfied (unsafe, unethical, undesirable actions). in a state if and only if its precondition $\varphi$ holds in that state, $\phi\in L(\mathcal{P})$ is a domain constraint. We use $|[\phi]|=\{\bm{m}|\bm{m}\models\phi\}$ to denote the set of all possible symbolic models of $\phi$ a model is a truth assignment to all propositions in $\mathcal{P}$ .
To illustrate how symbolic domain knowledge $(\mathcal{P},\mathcal{AP},\phi)$ is reflected in our formulation, we consider the Visual Sudoku task as a concrete example. In this environment, each state is represented as a non-symbolic image input. The properties of a state can be described using propositions in $\mathcal{P}$ . For example, the properties of the state in Figure 1(a) include ‘position (1,1) is number 1’, ‘position (1,2) is empty’, etc. Each action $a$ of filling a number in a certain position corresponds to a symbolic precondition $\varphi$ , represented by $(a,\varphi)\in\mathcal{AP}$ . For example, the action ‘filling number 1 at position (1,1)’ requires that both propositions ‘position (1,2) is number 1’ and ‘position (2,1) is number 1’ are false. Finally, $\phi$ is used to constrain the set of possible states, e.g., ‘position (1,1) is number 1’ and ‘position (1,1) is number 2’ cannot both be simultaneously true for a given state. To leverage this knowledge, challenges arise due to the following problems.
<details>
<summary>sudo1.png Details</summary>

### Visual Description
## Diagram: 2x2 Grid with Diagonal Line
### Overview
The image depicts a 2x2 grid divided by black lines. The top-left quadrant contains a single black, pixelated line that diagonally spans from the bottom-left to the top-right corner of the quadrant. The remaining three quadrants are empty, with no visible elements or text.
### Components/Axes
- **Grid Structure**:
- The image is divided into four equal quadrants by two horizontal and two vertical black lines.
- No axis labels, scales, or legends are present.
- **Line Element**:
- A single black, pixelated line occupies the top-left quadrant.
- The line is diagonal, oriented from the bottom-left to the top-right of the quadrant.
- No labels, annotations, or legends are associated with the line.
### Detailed Analysis
- **Line Characteristics**:
- The line is composed of irregular, pixelated segments, suggesting low resolution or intentional stylization.
- No numerical values, text, or symbolic markers are embedded within or adjacent to the line.
- **Quadrant Analysis**:
- Top-left quadrant: Contains the line.
- Top-right, bottom-left, and bottom-right quadrants: Empty, with no discernible features.
### Key Observations
- The image lacks any textual information, labels, or data points.
- The line’s purpose is ambiguous; it may serve as a placeholder, a visual separator, or a symbolic element.
- No trends, distributions, or relationships between elements can be inferred due to the absence of data.
### Interpretation
The image does not contain factual or numerical data. The presence of the diagonal line in the top-left quadrant may indicate a design choice, such as a placeholder for future content, a symbolic representation (e.g., a "checkmark" or "arrow"), or an abstract graphic. Without additional context, the line’s significance remains unclear. The absence of text or structured data suggests the image is either incomplete, intentionally minimalist, or a fragment of a larger system.
</details>
(a)
<details>
<summary>sudo2.png Details</summary>

### Visual Description
## Diagram: Abstract Grid with Vertical Lines
### Overview
The image depicts a 2x2 grid with two distinct black vertical lines. One line is positioned in the top-left quadrant, and the other in the bottom-left quadrant. Both lines are pixelated and lack smooth edges, suggesting low-resolution rendering or intentional stylization. No textual elements, labels, or legends are present.
### Components/Axes
- **Grid Structure**:
- Divided into four equal quadrants by a horizontal and vertical black line.
- No axis titles, scales, or numerical markers are visible.
- **Lines**:
- **Top-Left Line**: Vertical, occupying ~70% of the quadrant’s height, centered horizontally.
- **Bottom-Left Line**: Vertical, occupying ~60% of the quadrant’s height, slightly offset to the right of the center.
- **Color**:
- Lines are solid black; background is white.
### Detailed Analysis
- **Line Characteristics**:
- Both lines exhibit jagged edges, indicating either low-resolution rendering or deliberate textural design.
- No gradients, patterns, or additional colors are present.
- **Spatial Relationships**:
- The top-left line is taller and more centrally aligned than the bottom-left line.
- The bottom-left line is shorter and shifted slightly rightward, creating asymmetry.
### Key Observations
1. **Absence of Text**: No labels, legends, or annotations are visible in the image.
2. **Symmetry vs. Asymmetry**: The grid’s structure is symmetrical, but the lines introduce asymmetry in height and horizontal positioning.
3. **Pixelation**: The lines’ rough edges suggest either technical limitations or an artistic choice.
### Interpretation
The image likely serves as a placeholder, abstract representation, or symbolic diagram. The lack of textual information prevents direct interpretation of data or meaning. The two vertical lines could symbolize:
- **Duality**: Representing opposing concepts (e.g., presence/absence, active/inactive).
- **Hierarchy**: The taller line might denote a primary element, while the shorter line represents a secondary one.
- **Technical Artifact**: The pixelation and asymmetry may indicate a corrupted or incomplete rendering.
No factual or numerical data is extractable from the image. Further context or metadata would be required to assign definitive meaning.
</details>
(b)
<details>
<summary>sudo3.png Details</summary>

### Visual Description
## Grid Diagram: Minimalist Layout
### Overview
The image depicts a 2x2 grid with two distinct elements: a vertical black line in the top-left cell and the numeral "2" in the bottom-left cell. The remaining cells are empty. No additional labels, legends, or contextual text are present.
### Components/Axes
- **Grid Structure**:
- 2 rows × 2 columns.
- Cells are separated by thin black lines.
- **Textual Elements**:
- **Bottom-left cell**: The numeral "2" (black, bold, centered).
- **Top-left cell**: A vertical black line (approximately 1.5x the height of the cell, centered).
- **Absent Elements**:
- No axis titles, legends, or numerical scales.
- No data series, annotations, or symbolic representations.
### Detailed Analysis
- **Top-left cell**: The vertical line may serve as a visual separator or placeholder, but its purpose is undefined without additional context.
- **Bottom-left cell**: The numeral "2" is the only explicit textual content. Its significance (e.g., a label, value, or identifier) cannot be determined from the image alone.
- **Other cells**: Empty, suggesting potential for future content or a minimalist design choice.
### Key Observations
- The grid is sparse, with only two elements in four cells.
- The vertical line and numeral "2" are the sole focal points, but their relationship or meaning remains ambiguous.
- No numerical or categorical data is present to infer trends, distributions, or patterns.
### Interpretation
The image lacks factual or data-driven content. It appears to be a placeholder, template, or abstract representation. The numeral "2" and vertical line could symbolize a binary state (e.g., "on/off," "active/inactive") or a step in a process, but this is speculative. Without additional context, the diagram provides no actionable insights or measurable information.
</details>
(c)
Figure 1. Example states in the Visual Sudoku environment
(P1) Numerical–symbolic gap. Knowledge is based on symbolic property of states, but only raw numerical states are available.
(P2) Constraint satisfaction. The truth values of propositions in $\mathcal{P}$ mapped from a DRL state $s$ must satisfy domain constraints $\phi$ .
<details>
<summary>pr.png Details</summary>
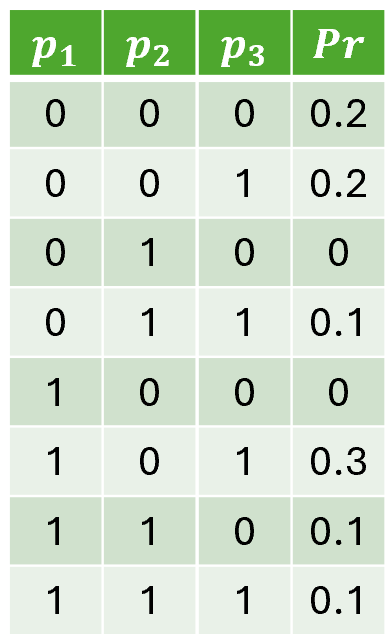
### Visual Description
## Data Table: Binary Input Combinations and Probability Outcomes
### Overview
The image displays a structured table with four columns (`p1`, `p2`, `p3`, `Pr`) and eight rows. The first three columns contain binary values (0 or 1), while the fourth column (`Pr`) contains decimal values ranging from 0.0 to 0.3. The table appears to represent probabilistic outcomes based on combinations of binary inputs.
### Components/Axes
- **Columns**:
- `p1`, `p2`, `p3`: Binary input variables (0 or 1).
- `Pr`: Probability or outcome value (decimal, e.g., 0.2, 0.3).
- **Rows**: Each row represents a unique combination of `p1`, `p2`, and `p3` values, with a corresponding `Pr` value.
### Detailed Analysis
| Row | p1 | p2 | p3 | Pr |
|-----|----|----|----|-----|
| 1 | 0 | 0 | 0 | 0.2 |
| 2 | 0 | 0 | 1 | 0.2 |
| 3 | 0 | 1 | 0 | 0.0 |
| 4 | 0 | 1 | 1 | 0.1 |
| 5 | 1 | 0 | 0 | 0.0 |
| 6 | 1 | 0 | 1 | 0.3 |
| 7 | 1 | 1 | 0 | 0.1 |
| 8 | 1 | 1 | 1 | 0.1 |
- **Key Patterns**:
- When `p1=0`, `Pr` is consistently 0.2 for `p3=0` and `p3=1` (rows 1–2).
- Introducing `p2=1` reduces `Pr` to 0.0 or 0.1, depending on `p3` (rows 3–4).
- When `p1=1`, `Pr` varies significantly:
- `p1=1`, `p2=0`, `p3=1` yields the highest `Pr` (0.3, row 6).
- `p1=1`, `p2=1` combinations result in `Pr=0.1` (rows 7–8).
### Key Observations
1. **Highest Probability**: The combination `p1=1`, `p2=0`, `p3=1` produces the maximum `Pr` (0.3).
2. **Zero Probability**: Two combinations (`p1=0`, `p2=1`, `p3=0` and `p1=1`, `p2=0`, `p3=0`) result in `Pr=0.0`.
3. **Symmetry in `p1=0`**: For `p1=0`, `Pr` remains stable at 0.2 regardless of `p2` and `p3` values.
4. **Impact of `p2=1`**: When `p2=1`, `Pr` decreases unless mitigated by `p3=1` (e.g., `p1=0`, `p2=1`, `p3=1` → `Pr=0.1`).
### Interpretation
The table likely represents a probabilistic model where:
- **`p1`** acts as a primary driver of `Pr`, with `p1=1` enabling higher probabilities (up to 0.3).
- **`p2`** introduces a dampening effect on `Pr`, reducing it to 0.0 or 0.1 unless mitigated by `p3=1`.
- **`p3`** modulates the relationship between `p1` and `p2`, with `p3=1` partially offsetting the negative impact of `p2=1`.
Notably, the absence of `p1=1` in rows 1–4 suggests that `p1` is a necessary condition for non-zero `Pr` values. The model may reflect a scenario where `p1` enables a process, `p2` introduces a constraint, and `p3` provides a compensatory adjustment. The highest `Pr` (0.3) occurs when `p1` and `p3` are active while `p2` is inactive, indicating an optimal configuration.
</details>
(a) Distribution
<details>
<summary>psdd_sdd.png Details</summary>
### Visual Description
## Logic Gate Diagram: Hierarchical Boolean Expression Structure
### Overview
The image depicts a hierarchical logic gate circuit composed of AND, OR, and NOT gates. The diagram uses green-colored gates with standardized symbols: rectangles for AND gates, inverted triangles for NOT gates, and horizontal lines for connections. The structure forms a tree-like hierarchy with inputs at the base and a single output at the top.
### Components/Axes
- **Legend**:
- Top-left corner contains a green square labeled "OR" and a green semicircle labeled "AND"
- No explicit NOT gate symbol in legend, but inverted triangle shapes are used throughout
- **Gates**:
- **Top Level**: Single OR gate (rectangle) at apex
- **Second Level**: Two AND gates (rectangles) connected to OR gate
- **Third Level**: Four AND gates (rectangles) connected to second-level AND gates
- **Fourth Level**: Eight NOT gates (inverted triangles) at base
- **Inputs**:
- Labeled p1, p2, p3 at NOT gate inputs
- Connections show inverted signals (p1̄, p2̄, p3̄)
- **Outputs**:
- Intermediate AND gate outputs labeled:
- "p3 AND p3" (right branch)
- "p1 AND p2" (left branch)
- Final OR gate output not explicitly labeled
### Detailed Analysis
1. **Gate Connections**:
- Top OR gate receives inputs from:
- Right AND gate (output: p3 AND p3)
- Left AND gate (output: p1 AND p2)
- Second-level AND gates receive inverted inputs:
- Right AND: p3̄ AND p3̄
- Left AND: p1̄ AND p2̄
- Third-level AND gates process:
- Right branch: p1̄ AND p2̄ AND p1 AND p2
- Left branch: p3̄ AND p3̄ AND p3 AND p3
2. **Signal Flow**:
- Inputs (p1, p2, p3) enter NOT gates at base
- Inverted signals (p1̄, p2̄, p3̄) combine with original signals in AND gates
- AND gate outputs combine at higher levels
- Final OR gate combines top-level AND outputs
### Key Observations
- **Redundant Operations**:
- p3 AND p3 simplifies to p3
- p1 AND p2 AND p1 AND p2 simplifies to p1 AND p2
- **Symmetry**:
- Left and right branches mirror each other in structure
- Both branches use identical gate configurations
- **Signal Inversion**:
- All inputs pass through NOT gates before AND operations
- Creates complementary signal paths
### Interpretation
This diagram represents a complex boolean expression:
`(p1 AND p2) OR (p3 AND p3)`
Which simplifies to:
`(p1 AND p2) OR p3`
The hierarchical structure demonstrates:
1. **Signal Processing**: Inputs are inverted before combination
2. **Redundancy Elimination**: Duplicate AND operations simplify to single variables
3. **Logical Prioritization**: OR gate at top level determines final output
The circuit appears designed to implement a specific boolean function with potential applications in digital logic design, where:
- p1 AND p2 represents a primary condition
- p3 acts as an independent enabling condition
- The OR gate at top level creates a fail-safe mechanism where either condition can trigger the output
</details>
(b) SDD
<details>
<summary>psdd.png Details</summary>
### Visual Description
## Probability Tree Diagram: Hierarchical Probability Distribution
### Overview
The image depicts a hierarchical probability tree diagram with green nodes and branches. The structure represents sequential probabilistic decisions or outcomes, with numerical probabilities assigned to each branch. The diagram includes labeled nodes (p1, p2, p3) and branching probabilities, suggesting a decision tree or stochastic process.
### Components/Axes
- **Nodes**: Green circular and rectangular shapes representing decision points or outcomes.
- **Branches**: Green lines connecting nodes, annotated with probabilities (e.g., 0.6, 0.4, 0.33, 0.67, etc.).
- **Labels**:
- **p1, p2, p3**: Node labels at the bottom level, indicating final outcomes or states.
- **p1-p2, p1-p2-p1-p2**: Composite labels on the rightmost branches, suggesting sequential dependencies.
- **Probabilities**: Numerical values (e.g., 0.6, 0.4, 0.33, 0.67, 0.5, 0.5, 0.75, 0.25) assigned to branches, representing transition probabilities between nodes.
### Detailed Analysis
- **Top Node**:
- Branches split into two paths with probabilities **0.6** (left) and **0.4** (right).
- **Second Level Nodes**:
- Left branch (0.6) splits into **0.33** (left) and **0.67** (right).
- Right branch (0.4) splits into **0.5** (left) and **0.5** (right).
- **Third Level Nodes**:
- Leftmost branch (0.33) splits into **p1** (left) and **p2** (right).
- Middle branch (0.67) splits into **p1-p2** (left) and **p1-p2-p1-p2** (right).
- Rightmost branch (0.5) splits into **p1-p2** (left) and **p1-p2-p1-p2** (right).
- Final right branch (0.25) splits into **p1-p2-p1-p2** (left) and **p1-p2-p1-p2** (right).
### Key Observations
- The tree is **binary** at each level, with probabilities summing to 1 at each node (e.g., 0.6 + 0.4 = 1, 0.33 + 0.67 = 1).
- The rightmost branches consistently include composite labels (e.g., p1-p2-p1-p2), suggesting recursive or dependent outcomes.
- The probabilities decrease as the tree progresses (e.g., 0.6 → 0.33 → p1), indicating diminishing likelihoods for certain paths.
### Interpretation
This diagram likely represents a **stochastic process** or **decision tree** where each node corresponds to a decision or event, and branches represent possible outcomes with associated probabilities. The labels (p1, p2, p3) may denote distinct states or actions, while the composite labels (e.g., p1-p2-p1-p2) imply sequences of events. The structure suggests a **Markov process** or **Bayesian network**, where the probability of each path depends on prior decisions.
Notably, the rightmost branches (e.g., p1-p2-p1-p2) have lower probabilities (0.25), indicating less likely sequences. The use of green for all nodes and branches implies a unified system, though no explicit legend is present. The diagram emphasizes **conditional probabilities**, as each branch’s value depends on the preceding node’s probability.
This visualization could be used in fields like **machine learning** (e.g., decision trees), **statistics** (e.g., probability distributions), or **operations research** (e.g., risk analysis). The hierarchical structure allows for modeling complex dependencies between events.
</details>
(c) PSDD
<details>
<summary>vtree.png Details</summary>
### Visual Description
## Tree Diagram: Hierarchical Structure with Labeled Nodes
### Overview
The image depicts a hierarchical tree diagram with five nodes (0–4) connected by green edges. Each node is labeled with a numerical identifier, and three leaf nodes (0, 2, 4) are additionally annotated with lowercase "p" labels (p₁, p₂, p₃). The root node is 3, which bifurcates into two subtrees.
### Components/Axes
- **Nodes**:
- Root node: **3** (no "p" label).
- Intermediate nodes: **1** (left child of 3), **4** (right child of 3).
- Leaf nodes: **0** (left child of 1), **2** (right child of 1), **4** (right child of 3).
- **Labels**:
- Numerical identifiers: **0, 1, 2, 3, 4** (positioned above each node).
- "p" labels:
- **p₁** (below node 0),
- **p₂** (below node 2),
- **p₃** (below node 4).
- **Edges**:
- Green lines connect parent nodes to children (e.g., 3→1, 3→4, 1→0, 1→2).
- **No legends, axes, or scales** are present.
### Detailed Analysis
- **Node 3** (root) splits into two branches:
- Left branch: Node **1** → splits into **0** (p₁) and **2** (p₂).
- Right branch: Node **4** (p₃, no further children).
- **p₁, p₂, p₃** are exclusively assigned to leaf nodes (0, 2, 4), suggesting they represent terminal states or outcomes.
- The diagram lacks directional flow indicators (e.g., arrows), but the hierarchical structure implies a top-down traversal from root to leaves.
### Key Observations
1. **Root Dominance**: Node 3 is the sole root, with no parent connections.
2. **Asymmetric Branching**:
- Left subtree (under node 1) has two children (0, 2).
- Right subtree (under node 4) is a terminal node.
3. **Label Consistency**:
- Numerical labels (0–4) are unique and sequential.
- "p" labels (p₁, p₂, p₃) are distinct and map one-to-one with leaf nodes.
### Interpretation
This diagram likely represents a decision tree, state machine, or hierarchical classification system. The root (node 3) acts as the initial decision point, branching into intermediate states (1, 4) and terminal outcomes (p₁, p₂, p₃). The absence of loops or feedback edges suggests a strictly acyclic structure. The "p" labels may denote parameters, probabilities, or outcomes specific to each terminal state. The asymmetry in branching could reflect varying complexity or decision paths in the modeled system.
</details>
(d) Vtree
<details>
<summary>nml.png Details</summary>
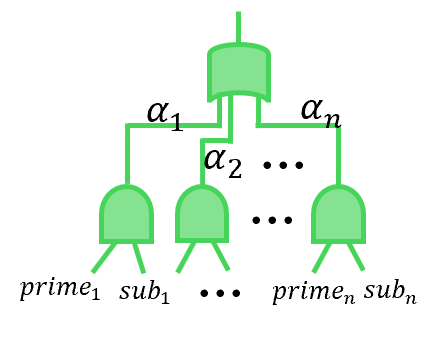
### Visual Description
## Flowchart: Hierarchical Process Structure
### Overview
The image depicts a hierarchical flowchart with a central cylindrical component labeled "α" at the top, branching into multiple pathways. Each pathway connects to an oval component labeled "α₁", "α₂", ..., "αₙ", which further branch into terminal nodes labeled "prime₁", "sub₁", ..., "primeₙ", "subₙ". Arrows indicate directional flow from the central component to terminal nodes.
### Components/Axes
- **Central Component**: Cylinder labeled "α" (top-center).
- **Intermediate Components**: Ovals labeled "α₁", "α₂", ..., "αₙ" (arranged horizontally below the central cylinder).
- **Terminal Nodes**: Pairs of labels "prime₁", "sub₁"; "prime₂", "sub₂"; ...; "primeₙ", "subₙ" (connected to ovals via arrows).
- **Flow Direction**: Top-to-bottom, with branching from the central cylinder to ovals, then to terminal nodes.
### Detailed Analysis
- **Central Cylinder ("α")**: Positioned at the top-center, acting as the root node. No additional labels or annotations.
- **Intermediate Ovals ("α₁" to "αₙ")**:
- Labeled sequentially from left to right.
- Connected to the central cylinder via arrows.
- Each oval branches into two terminal nodes ("prime" and "sub").
- **Terminal Nodes ("prime₁", "sub₁", ..., "primeₙ", "subₙ")**:
- Positioned directly below their respective ovals.
- Labeled with subscripts (1 to n) to denote sequential or parallel instances.
- Arrows connect ovals to terminal nodes, indicating dependency or output relationships.
### Key Observations
1. **Hierarchical Structure**: The flowchart represents a top-down process where the central component "α" distributes functionality to intermediate components ("α₁" to "αₙ"), which in turn manage specific "prime" and "sub" pairs.
2. **Scalability**: The use of ellipses (...) suggests the structure can extend indefinitely (e.g., "α₃", "prime₃", "sub₃" would follow the pattern).
3. **Symmetry**: Each oval has an identical two-node output structure ("prime" and "sub"), implying uniform processing logic across branches.
### Interpretation
The diagram likely models a system where a central process ("α") delegates tasks to specialized sub-components ("α₁" to "αₙ"), each responsible for handling a unique pair of elements ("prime" and "sub"). This could represent:
- **Modular Architecture**: In software or engineering systems, where a core module ("α") interfaces with specialized modules ("α₁" to "αₙ") to manage distinct subsystems ("prime" and "sub").
- **Data Flow**: A central data processor ("α") routes information to specialized handlers ("α₁" to "αₙ"), which process specific data pairs ("prime" and "sub").
- **Resource Allocation**: A central resource ("α") allocates tasks to sub-teams ("α₁" to "αₙ"), each managing distinct resources ("prime" and "sub").
The absence of numerical values or quantitative metrics suggests the flowchart emphasizes **logical relationships** rather than performance data. The use of "prime" and "sub" may imply hierarchical prioritization (e.g., primary vs. secondary roles) or complementary functions within each branch.
</details>
(e) A general fragment
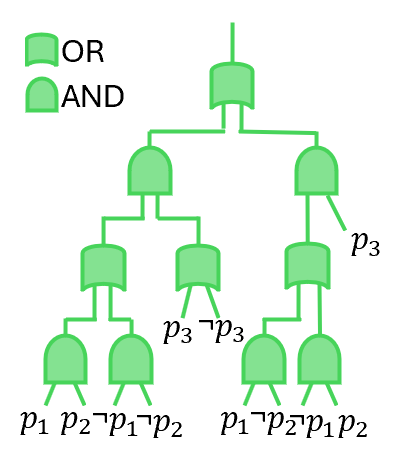
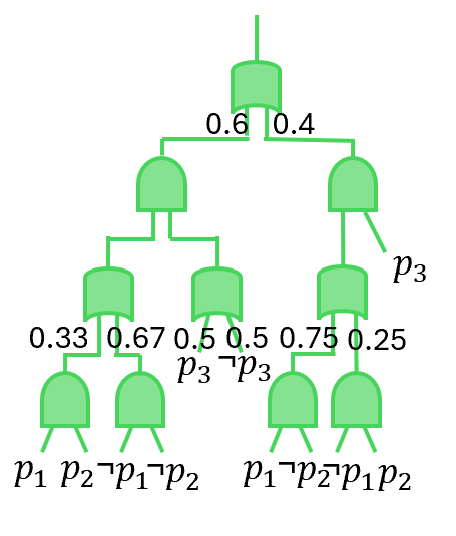
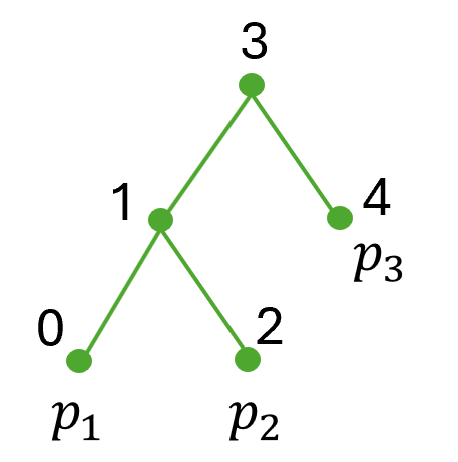
Figure 2. (a) An example of joint distribution for three propositions $p_{1},p_{2}$ and $p_{3}$ with the constraint $(p_{1}\leftrightarrow p_{2})\lor p_{3}$ . (b) A SDD circuit with ‘OR’ and ‘AND’ logic gate to represent the constrain $(p_{1}\leftrightarrow p_{2})\lor p_{3}$ . (c) The PSDD circuit to represent the distribution in Fig. 2(a). (d) The vtree used to group variables. (e) A general fragment to show the structure of SDD and PSDD.
(P3) Minimal supervision. The RL environment cannot provide full ground truth of propositions at each state.
(P4) Differentiability. The symbolic reasoning with $\varphi$ introduces non-differentiable process, which could be conflicting with gradient-based DRL algorithms that require differentiable policies.
(P5) End-to-end learning. Achieving end-to-end training on prediction of propositions, symbolic reasoning over preconditions and optimization of policy is challenging.
In summary, the above challenges fall into three categories. (P1–P3) concern learning symbolic models from high-dimensional states in DRL, which we address in Section 3. (P4) relates to the differentiability barrier when combining symbolic reasoning with gradient-based DRL, which we tackle in Section 4. (P5) raises the need for an end-to-end training, which we present in Section 5.
## 3. Learning Symbolic Grounding
This section introduces how NSAM learns symbolic grounding. At a high level, the goal is to learn whether an action is explorable in a state. Specifically, the agent receives minimal supervision from state transitions after executing an action $a$ . Using this supervision, NSAM learns to estimate the symbolic model of the high-dimensional input state that is in turn used to check the satisfiability of action preconditions. To achieve this, Section 3.1 presents a knowledge compilation step to encode domain constraints into a symbolic structure, while Section 3.2 explains how this symbolic structure is parameterized and learned from minimal supervision.
### 3.1. Compiling the Knowledge
To address P2 (Constraint satisfaction), we introduce the Probabilistic Sentential Decision Diagram (PSDD) kisa2014probabilistic. PSDDs are designed to represent probability distributions $Pr(\bm{m})$ over possible models, where any model $\bm{m}$ that violates domain constraints is assigned zero probability conditionalPSDD. For example, consider the distribution in Figure 2(a). The first step in constructing a PSDD is to build a Boolean circuit that captures the entries whose probability values are always zero, as shown in Figure 2(b). Specifically, the circuit evaluates to $0$ for model $\bm{m}$ if and only if $\bm{m}\not\models\phi$ . The second step is to parameterize this Boolean circuit to represent the (non-zero) probability of valid entries, yielding the PSDD in Figure 2(c).
To obtain the Boolean circuit in Figure 2(b), we represent the domain constraint $\phi$ using a general data structure called a Sentential Decision Diagram (SDD) sdd. An SDD is a normal form of a Boolean formula that generalizes the well-known Ordered Binary Decision Diagram (OBDD) OBDD; OBDD2. SDD circuits satisfy specific syntactic and semantic properties defined with respect to a binary tree, called a vtree, whose leaves correspond to propositions (see Figure 2(d)). Following Darwiche’s definition sdd; psdd_infer1, an SDD normalized for a vtree $v$ is a Boolean circuit defined as follows: If $v$ is a leaf node labeled with variable $p$ , the SDD is either $p$ , $\neg p$ , $\top$ , $\bot$ , or an OR gate with inputs $p$ and $\neg p$ . If $v$ is an internal node, the SDD has the structure shown in Figure 2(e), where $\textit{prime}_{1},\ldots,\textit{prime}_{n}$ are SDDs normalized for the left child $v^{l}$ , and $\textit{sub}_{1},\ldots,\textit{sub}_{n}$ are SDDs normalized for the right child $v^{r}$ . SDD circuits alternate between OR gates and AND gates, with each AND gate having exactly two inputs. The OR gates are mutually exclusive in that at most one of their inputs evaluates to true under any circuit input sdd; psdd_infer1.
A PSDD is obtained by annotating each OR gate in an SDD with parameters $(\alpha_{1},\ldots,\alpha_{n})$ over its inputs kisa2014probabilistic; psdd_infer1, where $\sum_{i}\alpha_{i}=1$ (see Figure 2(e)). The probability distribution defined by a PSDD is as follows. Let $\bm{m}$ be a model that assigns truth values to the PSDD variables, and suppose the underlying SDD evaluates to $0$ under $\bm{m}$ ; then $Pr(\bm{m})=0$ . Otherwise, $Pr(\bm{m})$ is obtained by multiplying the parameters along the path from the output gate.
The key advantage of using PSDDs in our setting is twofold. First, PSDDs strictly enforce domain constraints by assigning zero probability to any model $\bm{m}$ that violates $\phi$ conditionalPSDD, thereby ensuring logical consistency (P2). Second, by ruling out impossible truth assignment through domain knowledge, PSDDs effectively reduce the scale of the probability distribution to be learned ahmed2022semantic.
Besides, PSDDs also support tractable probabilistic queries PCbooks; psdd_infer1. While PSDD compilation can be computationally expensive as its size grows exponentially in the number of propositions and constraints, it is a one-time offline cost. Once compilation is completed, PSDD inference is linear-time, making symbolic reasoning efficient during both training and execution psdd_infer1.
### 3.2. Learning the parameters of PSDD in DRL
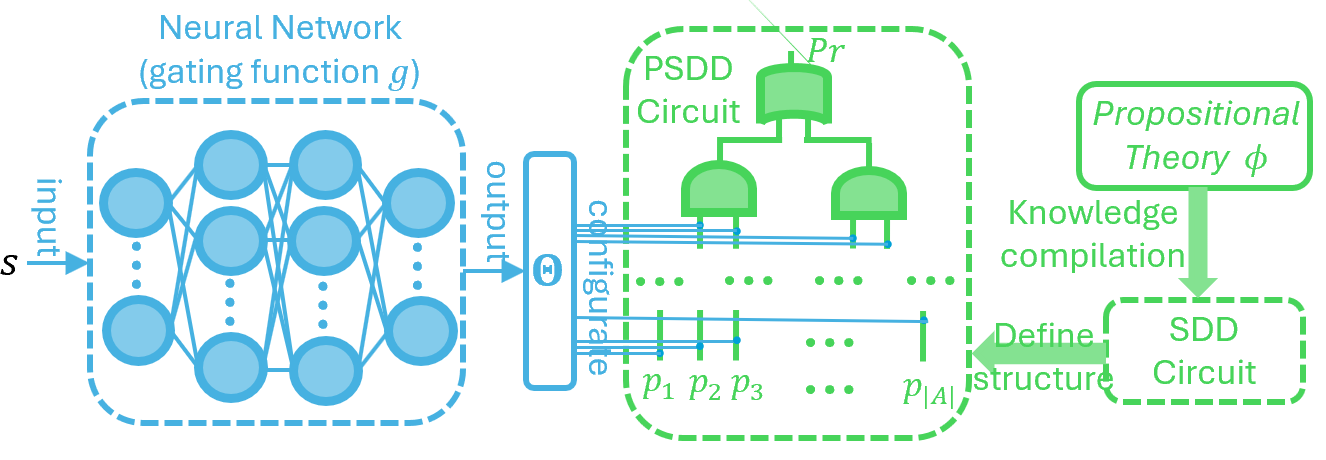
To address P1 (Numerical–symbolic gap), we need to learn distributions of models that satisfy the domain constraints. Inspired by recent deep supervised learning work on PSDDs ahmed2022semantic, we parameterize the PSDD using the output of gating function $g$ . This gating function is a neural network that maps high-dimensional RL states to PSDD parameters $\Theta=g(s)$ . This design allows the PSDD to represent state-conditioned distributions over propositions through its learned parameters, while strictly adhering to domain constraints (via its structure defined by symbolic knowledge $\phi$ ). The overall process is shown in Figure 3. We use $Pr(\bm{m}\mid\bm{\Theta}=g(s),\bm{m}\models\phi)$ to denote the probability of model $\bm{m}$ that satisfy the domain constrains $\phi$ given the state $s$ (this is calculated by PSDD in Figure 3).
After initializing $g$ and the PSDD according to the structure in Figure 3, we obtain a distribution over $\bm{m}$ such that for all $\bm{m}\not\models\phi$ , $Pr(\bm{m}\mid\bm{\Theta}=g(s),\bm{m}\not\models\phi)=0$ . However, for the probability distribution over $\bm{m}$ that does satisfy $\phi$ , we still need to learn from data to capture the probability of different $\bm{m}$ by adjusting parameters of gating function $g$ . To train the PSDD from minimal supervision signals (for problem (P3) in Section 2), we construct the supervision data from $\Gamma_{\phi}$ , which consists of tuples $(s,a,s^{\prime},y)$ where transitions $(s,a,s^{\prime})$ are explored from the environment and $y$ is calculated by:
$$
y=\begin{cases}1,&\text{if }s\;\text{and}\;s^{\prime}\;\text{do not violate}\;\phi,\\
0,&\text{otherwise.}\end{cases} \tag{1}
$$
That is, the action $a$ is labeled as explorable (i.e., $y=1$ ) in state $s$ if it does not lead to a violation of the domain constraint $\phi$ ; otherwise the action a is not explorable (i.e., $y=0$ ).
<details>
<summary>Framework.png Details</summary>
### Visual Description
## Diagram: Hybrid Neural-Probabilistic System Architecture
### Overview
The diagram illustrates a hybrid computational system integrating neural networks with probabilistic circuits. It shows a flow from input through a neural network (blue) to a PSDD circuit (green), followed by propositional theory processing, and culminating in an SDD circuit. The system emphasizes knowledge compilation and structural definition.
### Components/Axes
1. **Neural Network (Blue)**
- **Input**: Labeled "input" with arrow pointing to network
- **Output**: Labeled "output" with arrow exiting network
- **Structure**: Multiple interconnected nodes (circles) with dashed blue lines
- **Gating Function**: Explicitly labeled "gating function g"
2. **PSDD Circuit (Green)**
- **Nodes**: Labeled p₁, p₂, p₃, ..., p_{|A|}
- **Pr Node**: Central node labeled "Pr" at top
- **Connections**: Blue lines connecting neural network output to PSDD nodes
3. **Propositional Theory (φ)**
- **Label**: "Propositional Theory φ" in green box
- **Connection**: Arrows from PSDD circuit to theory
4. **Knowledge Compilation**
- **Label**: "Knowledge compilation" in green box
- **Connection**: Arrows from propositional theory to SDD circuit
5. **SDD Circuit (Green)**
- **Label**: "SDD Circuit" in green box
- **Connection**: Arrows from knowledge compilation
### Detailed Analysis
- **Neural Network**: Contains 3x3 grid of interconnected nodes (9 total) with dashed blue lines indicating internal connections
- **PSDD Circuit**: Hierarchical structure with Pr node at apex and multiple p nodes below
- **Color Coding**:
- Blue (#00BFFF) for neural network components
- Green (#00FF00) for probabilistic circuits and theory
- **Flow Direction**: Left-to-right progression from input to output
### Key Observations
1. **Modular Design**: Clear separation between neural processing (blue) and probabilistic reasoning (green)
2. **Hierarchical Structure**: PSDD circuit shows top-down organization with Pr node
3. **Knowledge Flow**: Explicit arrows show transformation from raw input through multiple processing stages
4. **Notation Consistency**: Mathematical notation (φ, p₁-pₙ) used throughout
### Interpretation
This architecture represents a knowledge compilation system that:
1. Processes input through a neural network with gating mechanisms
2. Converts neural outputs into probabilistic dependencies (PSDD)
3. Applies formal propositional theory to structure knowledge
4. Compiles this into an optimized SDD circuit representation
The use of distinct colors suggests:
- Blue components handle continuous/analog processing
- Green components manage discrete probabilistic reasoning
- The system bridges machine learning with formal logic through knowledge compilation
The Pr node in the PSDD circuit likely represents a probabilistic root or primary variable, while the p₁-pₙ nodes represent feature probabilities. The final SDD circuit appears to be the optimized, structured output of this hybrid processing pipeline.
</details>
Figure 3. The architecture design to calculate the probability of symbolic model $\bm{m}$ given DRL state $s$ .
Unlike a fully supervised setting that expensively requires labeling every propositional variable in $P$ , Eq. (1) only requires labeling whether a given state violates the domain constraint $\phi$ , which is a minimal supervision signal. In practice, the annotation of $y$ can be obtained either (i) by providing labeled data on whether the resulting state $s^{\prime}$ violates the constraint $\phi$ book2006, or (ii) via an automatic constraint-violation detection mechanism autochecking1; autochecking2.
We emphasize that action preconditions $\varphi$ and the domain constraints $\phi$ are two separate elements and treated differently. We first automatically generate training data to learn PSDD parameters by constructing tuples $(s,a,s^{\prime},y)$ as defined in Equation (1). The argument $y$ in tuples $(s,a,s’,y)$ is then used as an indicator for action preconditions. Specifically, we use $y$ to label whether action $a$ is excutable in state $s$ , i.e., if transition $(s,a,s^{\prime})$ is explored by DRL policy in a non-violating states $s$ and $s^{\prime}$ , then $y=1$ , meaning that action a is explorable in $s$ ; otherwise $y=0$ . We thus use $y$ in $(s,a,s’,y)$ as a minimal supervision signal to estimate the probability of the precondition of action $a$ being satisfied in non-violating $s$ during PSDD training.
By continuously rolling out the DRL agent in the environment, we store $(s,a,s^{\prime},y)$ into a buffer $\mathcal{D}$ . After collecting sufficient data, we sample batches from $\mathcal{D}$ and update $g$ via stochastic gradient descent SDG; ADAM. Concretely, the update proceeds as follows. Given samples $(s,a,s^{\prime},y)$ , we first use the current PSDD to estimate the probability that action $a$ is explorable in state $s$ , i.e., the probability that $s$ satisfies the precondition $\varphi$ associated with $a$ in $\mathcal{AP}$ :
$$
\hat{P}(a|s)=\sum_{\bm{m}\models\varphi}Pr(\bm{m}|\bm{\Theta}=g(s),\bm{m}\models\phi) \tag{2}
$$
Note that $\hat{P}(a|s)$ here does not represent a policy as in standard DRL; rather, it denotes the estimated probability that action $a$ is explorable in state $s$ . As shown in Equation (2), this probability is calculated by aggregating the probabilities of all models $\bm{m}$ that satisfy the precondition $\varphi$ . In addition, to evaluate if $\bm{m}\models\varphi$ , we assign truth values to the leaf variables of $\varphi$ ’s SDD circuit based on $\bm{m}$ and propagate them bottom-up through the ‘OR’ and ‘AND’ gates, where the Boolean value at the root indicates the satisfiability.
Given the probability estimated from Equation (2), we compute the cross-entropy loss CROSSENTR by comparing it with the explorability label $y$ . Specifically, for a single data $(s,a,s^{\prime},y)$ , the loss is:
$$
L_{g}=-[y\cdot log(\hat{P}(a|s))+(1-y)\cdot log(1-\hat{P}(a|s))] \tag{3}
$$
The intuition of this loss is straightforward: at each $s$ it encourages the PSDD to generate higher probability to actions that are explorable (when $y=1$ ), and generate lower probability to those that are not explorable (when $y=0$ ).
## 4. Combining symbolic reasoning with gradient-based DRL
Through the training of the gating function defined in Equation (3), the PSDD in Figure 3 can predict, for a given DRL state, a distribution over the symbolic model $\bm{m}$ for atomic propositions in $\mathcal{P}$ . This distribution then can be used to evaluate the truth values of the preconditions in $\mathcal{AP}$ and to reason about the explorability of actions. However, directly applying symbolic logical formula of preconditions to take actions results in non-differentiable decision-making sg2_1, which prevents gradient flow during policy optimization. This raises a key challenge on integrating symbolic reasoning with gradient-based DRL training in a way that preserves differentiability, i.e., problem (P4) in Section 2.
To address this issue, we employ the PSDD to perform maximum a posteriori (MAP) query PCbooks, obtaining the most likely model $\hat{\bm{m}}$ for the current state. Based on $\hat{\bm{m}}$ and the precondition $\varphi$ of each action $a$ , we re-normalize the action probabilities from a policy network. In this way, the learned symbolic representation from the PSDD can be used to constrain action selection, while the underlying policy network still provides a probability distribution that can be updated through gradient-based optimization.
Concretely, before the DRL agent makes a decision, we first use the PSDD to obtain the most likely model describing the state:
$$
\hat{\bm{m}}=argmax_{\bm{m}}Pr(\bm{m}|\bm{\Theta}=g(s),\bm{m}\models\phi) \tag{4}
$$
Importantly, the argmax operation on the PSDD does not require enumerating all possible $\bm{m}$ . Instead, it can be computed in linear time with respect to the PSDD size by exploiting its structural properties on decomposability and Determinism (see psdd_infer1). This linear-time inference makes PSDDs particularly attractive for DRL, where efficient evaluation of candidate actions are essential anokhinhandling.
After obtaining the symbolic model of the state, we renormalize the probability of each action $a$ according to its precondition $\varphi$ :
$$
\pi^{+}(s,a,\phi)=\frac{\pi(s,a)\cdot C_{\varphi}(\hat{\bm{m}})}{\sum_{a^{\prime}\in\mathcal{A}}\pi(s,a^{\prime})\cdot C_{\varphi^{\prime}}(\hat{\bm{m}})} \tag{5}
$$
where $\pi(s,a)$ denotes the probability of action $a$ at state $s$ predicted by the policy network, $C_{\varphi}(\hat{\bm{m}})$ is the evaluation of the SDD encoding from $\varphi$ under the model $\hat{\bm{m}}$ , and $\varphi^{\prime}$ is the precondition of action $a^{\prime}$ . The input of Equation (5) explicitly includes $\phi$ , as $\phi$ is required for evaluating the model $\hat{\bm{m}}$ in Equation (4). Intuitively, $C_{\varphi}(\hat{\bm{m}})$ acts as a symbolic mask. It equals to 1 if $\hat{\bm{m}}\models\varphi$ (i.e., the precondition is satisfied) and 0 otherwise. As a result, actions whose preconditions are violated are excluded from selection, while the probabilities of the remaining actions are renormalized as a new distribution. It is important to note that during the execution, we use the PSDD (trained by $y$ in Equation (2) and (3) ) to infer the most probable symbolic model of the current state (in Equation (4)), and therefore can formally verify whether each action’s precondition is satisfied with this symbolic model (happened in $C_{\varphi}$ in Equation (5)).
According to prior work, such $0$ - $1$ masking and renormalization still yield a valid policy gradient, thereby preserving the theoretical guarantees of policy optimization actionmasking_vPG. In practice, we optimize the masked policy $\pi^{+}$ using the Proximal Policy Optimization (PPO) objective schulman2017ppo. Concretely, the loss is:
$$
\mathcal{L}_{\text{PPO}}(\pi^{+})=\mathbb{E}_{t}\!\left[\min\!\Big(\mathfrak{r}_{t}(\pi^{+})\,\hat{A}_{t},\text{clip}(\mathfrak{r}_{t}(\pi^{+}),1-\epsilon,1+\epsilon)\,\hat{A}_{t}\Big)\right] \tag{6}
$$
where $\mathfrak{r}_{t}(\pi^{+})$ denotes the probability ratio between the new and old masked policies, ‘ clip ’ is the clip function and $\hat{A}_{t}$ is the advantage estimate schulman2017ppo. In this way, the masked policy can be trained with PPO to effectively exploit symbolic action preconditions, leading to safer and more sample-efficient learning.
## 5. End-to-end training framework
After deriving the gating function loss of PSDD in Equation (3) and the DRL policy loss in Equation (6), we now introduce an end-to-end training framework that combines the two components.
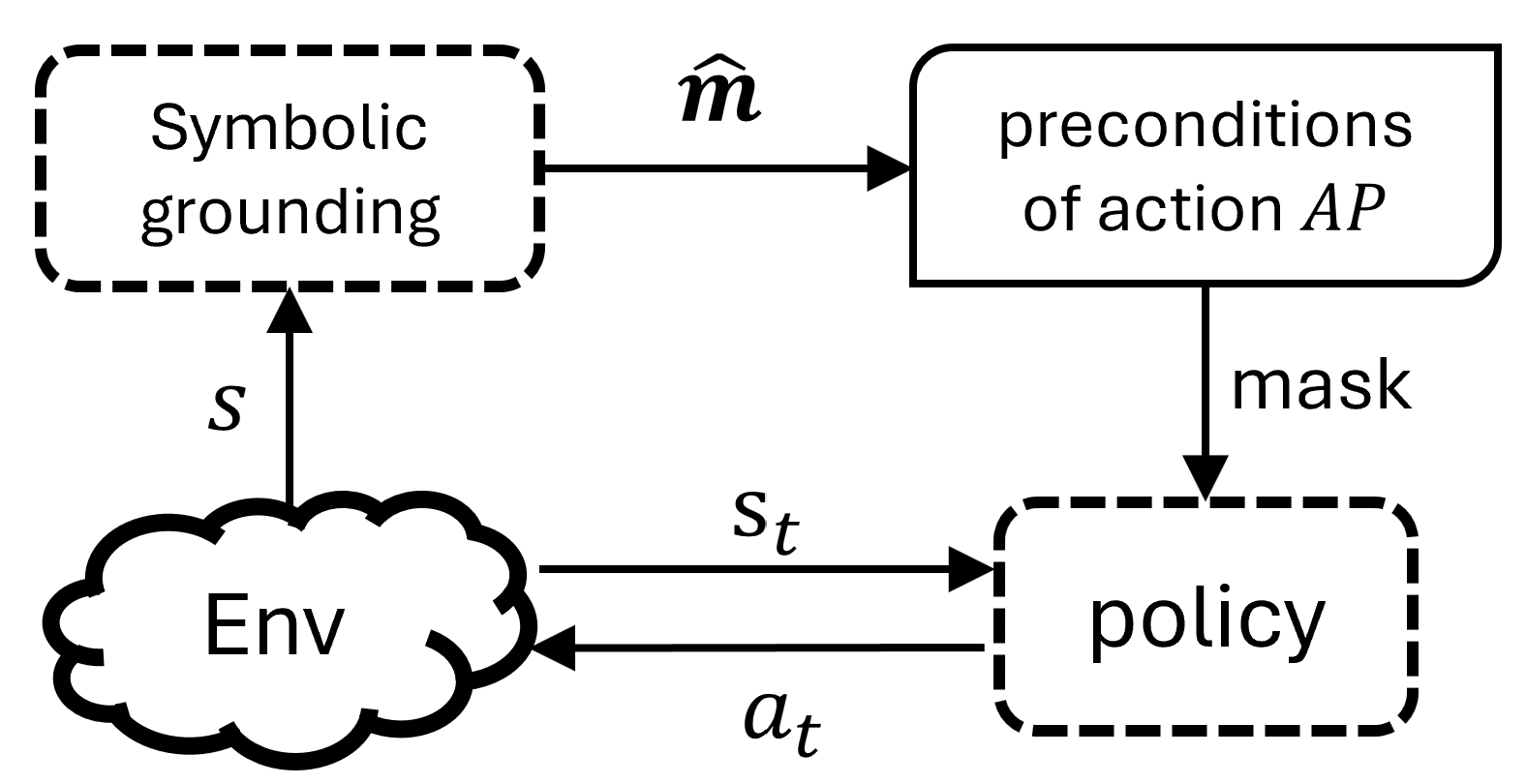
Before presenting the training procedure, we first summarize how the agent makes decisions, as illustrated in Figure 4. At each time step, the state $s$ is first input into the symbolic grounding module, whose internal structure is shown in Figure 3. Within this module, the PSDD produces the most probable symbolic description of the state, i.e., a model $\hat{\bm{m}}$ , according to Equation (4). The agent then leverages the preconditions in $\mathcal{AP}$ (following Equation (5)) to mask the action distribution from policy network, and samples an action from the renormalized distribution to interact with the environment.
<details>
<summary>probSetting.png Details</summary>
### Visual Description
## Diagram: Symbolic Grounding and Policy Interaction Framework
### Overview
The diagram illustrates a conceptual framework for symbolic grounding in a reinforcement learning or decision-making system. It depicts interactions between environmental states, symbolic representations, and policy execution through a series of labeled components and directional flows.
### Components/Axes
1. **Key Elements**:
- **Symbolic grounding**: Dashed rectangle containing "Symbolic grounding" text
- **Preconditions of action AP**: Dashed rectangle containing "preconditions of action AP" text
- **Env**: Cloud-shaped component labeled "Env"
- **Policy**: Dashed rectangle labeled "policy"
- **Mask**: Label on arrow from "preconditions of action AP" to "policy"
- **m**: Symbol above arrow from "Symbolic grounding" to "preconditions of action AP"
- **s**: Symbol on arrow from "Env" to "Symbolic grounding"
- **st**: Symbol on arrow from "Env" to "policy"
- **at**: Symbol on arrow from "policy" to "Env"
2. **Flow Direction**:
- Bottom-to-top vertical flow from "Env" to "Symbolic grounding"
- Rightward horizontal flow from "Symbolic grounding" to "preconditions of action AP"
- Downward vertical flow from "preconditions of action AP" to "policy"
- Leftward horizontal flow from "policy" to "Env"
### Detailed Analysis
1. **Symbolic Grounding Block**:
- Receives input "s" from environment (Env)
- Outputs "m" to preconditions of action AP
- Positioned at top-left of diagram
2. **Preconditions of Action AP Block**:
- Receives "m" from symbolic grounding
- Outputs "mask" to policy
- Positioned at top-right of diagram
3. **Environment (Env) Component**:
- Cloud-shaped element at bottom-left
- Sends "s" to symbolic grounding
- Receives "at" from policy
- Sends "st" to policy
4. **Policy Component**:
- Dashed rectangle at bottom-right
- Receives "st" from environment and "mask" from preconditions
- Outputs "at" to environment
### Key Observations
1. The system forms a closed loop between environment and policy through symbolic mediation
2. Symbolic grounding acts as an intermediary between raw environmental states and action preconditions
3. The "mask" element suggests conditional filtering of action preconditions
4. Bidirectional information flow between environment and policy indicates dynamic adaptation
### Interpretation
This diagram represents a hybrid symbolic/statistical approach to reinforcement learning where:
1. Environmental states (st) are processed through symbolic grounding to create actionable preconditions (AP)
2. These preconditions are then masked/conditioned before being used by the policy
3. The policy's actions (at) directly influence the environment, creating a feedback loop
4. The use of symbolic grounding suggests an attempt to incorporate human-understandable representations into the learning process
5. The masking mechanism implies a gating function that may handle uncertainty or contextual adaptation
The architecture appears designed to bridge the gap between raw sensory data (Env) and actionable knowledge (AP) through symbolic mediation, while maintaining direct environmental interaction for real-time adaptation. The cloud symbol for Env suggests stochastic or complex environmental dynamics, while the dashed boxes indicate abstract processing components.
</details>
Figure 4. An illustration of the decision process of our agent, where the symbolic grounding module is as in Figure 3 and $\hat{\bm{m}}$ is calculated via the PSDD by Equation (4).
An illustration of the decision process of our agent.
Algorithm 1 Training framework.
1: Compile $\phi$ as SDD to obtain structure of PSDD
2: Initialize gating network $g$ according to the structure of PSDD
3: Initialize policy network $\pi$ , total step $T\leftarrow 0$
4: Initialize a data buffer $\mathcal{D}$ for learning PSDD
5: for $Episode=1\to M$ do
6: Reset $Env$ and get $s$
7: while not terminal do
8: Calculate action distribution before masking $\pi(s,a)$
9: Calculate $\Theta=g(s)$ and assign parameter $\Theta$ to PSDD
10: Calculate $\hat{\bm{m}}$ in Equation (4)
11: Calculate action distribution after masking $\pi^{+}(s,a,\phi)$
12: Sample an action $a$ from $\pi^{+}(s,a,\phi)$
13: Execute $a$ and get $r$ , $s^{\prime}$ from $Env$
14: Obtain the truth-value $y$ according to Equ. (1)
15: Store $(s,a,\varphi)$ into $\mathcal{D}$
16: if terminal then
17: Update policy $\pi^{+}(s,a,\phi)$ using the trajectory of this episode with Equation (6)
18: end if
19: if $(T+1)\;\$ then
20: Sample batches from $\mathcal{D}$
21: Update gating function $g$ with Equation (3)
22: end if
23: $s\leftarrow s^{\prime}$ , $T\leftarrow T+1$
24: end while
25: end for
To achieve end-to-end training, we propose Algorithm 1. The key idea for this training framework is to periodically update the gating function of the PSDD during the agent’s interaction with the environment, while simultaneously training the policy network under the guidance of action masks. As the RL agent explores, it continuously generates minimally supervised feedback for the PSDD via $\Gamma_{\phi}$ , thereby improving the quality of the learned action masks. In turn, the improved action masking reduces infeasible actions and guides the agent toward higher rewards and more informative trajectories, which accelerates policy learning.
Concretely, before the start of training, the domain constrain $\phi$ is compiled into an SDD in Line 1, which determines both the structure of the PSDD and the output dimensionality of the gating function. Lines 2 $\sim$ 4 initialize the gating function, the RL policy network, and a replay buffer $\mathcal{D}$ that stores minimally supervised feedback for PSDD training. In Lines 5 $\sim$ 25, the agent interacts with the environment and jointly learns the gating function and policy network. At each step (lines 8 $\sim$ 11), the agent computes the masked action distribution based on the current gating function and policy network, which is crucial to minimizing the selection of infeasible actions during training. At the end of each episode (lines 16 $\sim$ 18), the policy network is updated using the trajectory of this episode. In this process, the gating function is kept frozen. In addition, the gating function is periodically updated (lines 19 $\sim$ 22) with frequency $freq_{g}$ . This periodically update enables the PSDD to provide increasingly accurate action masks in subsequent interactions, which simultaneously improves policy optimization and reduces constraint violations.
## 6. Related work
Symbolic grounding in neuro-symbolic learning. In the literature on neuro-symbolic systems NSsys; NSsys2, symbol grounding refers to learning a mapping from raw data to symbolic representations, which is considered as a key challenge for integrating neural networks with symbolic knowledge neuroRM. Various approaches have been proposed to address this challenge in deep supervised learning. sg1_1; sg1_2; sg1_3 leverage logic abduction or consistency checking to periodically correct the output symbolic representations. To achieve end-to-end differentiable training, the most common methods are embedding symbolic knowledge into neural networks through differentiable relaxations of logic operators, such as fuzzy logic sg2_2 or Logic Tensor Networks (LTNs) sg2_1. These methods approximate logical operators with smooth functions, allowing symbolic supervision to be incorporated into gradient-based optimization sg2_2; sg2_3; sg2_4; neuroRM. More recently, advances in probabilistic circuits psdd_infer1; PCbooks give rise to efficient methods that embed symbolic knowledge via differentiable probabilistic representations, such as PSDD kisa2014probabilistic. In these methods, symbolic knowledge is first compiled into SDD sdd to initialize the structure, after which a neural network is used to learn the parameters for predicting symbolic outputs ahmed2022semantic. This class of approaches has been successfully applied to structured output prediction tasks, including multi-label classification ahmed2022semantic and routing psdd_infer2.
Symbolic grounding is also crucial in DRL. NRM neuroRM learn to capture the symbolic structure of reward functions in non-Markovian reward settings. In contrast, our approach learns symbolic properties of states to constrain actions under Markovian reward settings. KCAC KCAC has extended PSDDs to MDP with combinatorial action spaces, where symbolic knowledge is used to constrain action composition. Our work also uses PSDDs but differs from KCAC. We use preconditions of actions as symbolic knowledge to determine the explorability of each individual action in a standard DRL setting, whereas KCAC incorporates knowledge about valid combinations of actions in a DRL setting with combinatorial action spaces.
Action masking. In DRL, action masking refers to masking out invalid actions during training to sample actions from a valid set actionmasking_vPG. Empirical studies in early real-world applications show that masking invalid actions can significantly improve sample efficiency of DRL actionmasking_app1; actionmasking_app2; actionmasking_app3; actionmasking_app4; actionmasking_app5; actionmasking_app6. Following the systematic discussion of action masking in DRL actionmasking_review, actionmasking_onoffpolicy investigates the impact of action masking on both on-policy and off-policy algorithms. Works such as actionmasking_continous; actionmasking_continous2 extend action masking to continuous action spaces. actionmasking_vPG proves that binary action masking have Valid policy gradients during learning. In contrast to these approaches, our method does not assume that the set of invalid actions is predefined by the environment. Instead, we learn the set of invalid actions in each state for DRL using action precondition knowledge.
Another line of work employs a logical system (e.g., linear temporal logic LTL1985) to restrict the agent’s actions shielding1; shielding2; shielding3; PPAM. These approaches require a predefined symbol grounding function to map states into its symbolic representations, whereas our method learn such function (via PSDD) from data. PLPG PLPG learns the probability of applying shielding with action constraints formulated in probabilistic logics. By contrast, our preconditions are hard constraints expressed in propositional logic: if the precondition of an action is evaluated to be false, the action is strictly not explorable.
Cost-based safe reinforcement learning. In addition to action masking, a complementary approach is to jointly optimize rewards and a safety-wise cost function to improve RL safety. In these cost-based settings, a policy is considered safe if its expected cumulative cost remains below a pre-specified threshold safeexp1; PPOlarg. A representative foundation of such cost-based approach is the constrained Markov decision process (CMDP) framework CMDP1994, which aims to maximize expected reward while ensuring costs below a threshold. Subsequent works often adopt Lagrangian relaxation to incorporate constraints into the optimization objective ppo-larg1; ppo-larg2; ppo-larg3; ppo-larg4; PPOlarg. However, these methods often suffer from unsafe behaviors in the early stages of training highvoil1. To address such issues, safe exploration approaches emphasize to control the cost during exploration in unknown environments shielding1; shielding2. Recently, SaGui safeexp1 employed imitation learning and policy distillation to enable agents to acquire safe behaviors from a teacher agent during early training. RC-PPO RCPPO augmented unsafe states to allow the agent to anticipate potential future losses. While constraints can in principle be reformulated as cost functions, our approach does not rely on cost-based optimization. Instead, we directly exploit them to learn masks to avoid the violation of actions constraints.
## 7. Experiment
The experimental design aims to answer the following questions:
Q1: Without predefined symbolic grounding, can NSAM leverage symbolic knowledge to improve the sample efficiency of DRL?
Q2: By jointly learning symbolic grounding and masking strategies, can NSAM significantly reduce constraint violations during exploration, thereby enhancing safety?
Q3: In NSAM, is symbolic grounding with PSDDs more effective than replacing it with a module based on standard neural network?
Q4: In what ways does symbolic knowledge contribute to the learning process of NSAM?
### 7.1. Environments
We evaluate ASG on four highly challenging reinforcement learning domains with logical constraints as shown in Figure 5. Across all these environments, agents receive inputs in the form of unknown representation such as vectors or images.
<details>
<summary>Sudoku.png Details</summary>
### Visual Description
## Grid Structure: 5x5 Matrix with Scattered Numerical Values
### Overview
The image depicts a 5x5 grid composed of light blue cells outlined in black. Numerical values (1, 2, 3, 4, 5) are embedded in specific cells, while the majority remain empty. The grid lacks axis labels, legends, or explicit annotations beyond the embedded numbers.
### Components/Axes
- **Grid Structure**:
- 5 rows (top to bottom) and 5 columns (left to right).
- Cells are uniformly sized with rounded corners and black borders.
- **Numerical Values**:
- Values are centered within cells, using a bold, sans-serif font.
- No axis titles, legends, or color-coded data series are present.
### Detailed Analysis
- **Embedded Values**:
- **Row 1**:
- Column 3: `5`
- Column 5: `1`
- **Row 2**:
- Column 5: `3`
- **Row 3**:
- Column 3: `1`
- Column 5: `2`
- **Row 4**:
- Column 5: `4`
- **Row 5**:
- Column 3: `3`
- **Empty Cells**:
- 18/25 cells (72%) contain no text or symbols.
### Key Observations
1. **Duplicate Values**: The number `3` appears twice (Row 2, Column 5 and Row 5, Column 3), while all other values (`1`, `2`, `4`, `5`) appear once.
2. **Distribution Pattern**:
- Values are concentrated in the rightmost column (Columns 3 and 5) and the bottom row (Row 5).
- No clear numerical or positional sequence is evident.
3. **Ambiguity**: The purpose of the grid is unclear—it could represent a puzzle (e.g., Sudoku variant), a partially filled matrix, or a placeholder for data.
### Interpretation
- **Potential Use Cases**:
- The grid may be a fragment of a larger dataset, requiring additional context to interpret.
- The duplicate `3` suggests either an error or intentional design (e.g., a non-standard Sudoku rule).
- **Missing Information**:
- No axis labels or legends prevent direct interpretation of numerical significance (e.g., units, categories).
- The absence of a title or explanatory text leaves the grid’s purpose open to speculation.
- **Technical Implications**:
- If part of a larger system, this grid might require cross-referencing with external data sources to resolve ambiguities.
- The scattered values could indicate incomplete data entry or a deliberate sparse representation.
## Conclusion
The image provides limited actionable data due to its sparse structure and lack of contextual metadata. Further analysis would depend on additional information about the grid’s intended application or dataset origin.
</details>
(a) Sudoku
<details>
<summary>nqueens.png Details</summary>

### Visual Description
## Photograph: Chessboard with Crowns
### Overview
The image depicts a standard 8x8 chessboard with alternating light (beige) and dark (brown) squares. Eight silver crowns with blue and white gemstone accents are placed on specific squares. No textual labels, legends, or numerical data are visible.
### Components/Axes
- **Chessboard**:
- 64 squares arranged in an 8x8 grid.
- Alternating light (beige) and dark (brown) squares.
- No axis labels, legends, or numerical markers.
- **Crowns**:
- Eight silver crowns with blue and white gemstone details.
- No textual labels or identifiers attached to the crowns.
### Detailed Analysis
- **Crown Placement**:
1. **Top-left corner**: Crown on a dark square (row 1, column 1).
2. **Top-right quadrant**: Crown on a light square (row 1, column 5).
3. **Center**: Crown on a dark square (row 4, column 4).
4. **Bottom-left quadrant**: Crown on a light square (row 7, column 2).
5. **Bottom-right quadrant**: Crown on a dark square (row 7, column 8).
6. **Middle-left**: Crown on a dark square (row 5, column 3).
7. **Middle-right**: Crown on a light square (row 6, column 6).
8. **Bottom-center**: Crown on a light square (row 8, column 4).
- **Visual Patterns**:
- Crowns are distributed unevenly across the board.
- No clear alignment or symmetry in their placement.
- All crowns share identical design (silver with blue/white gems).
### Key Observations
- The crowns are not positioned according to standard chess piece arrangements (e.g., no king or queen in traditional starting positions).
- The crowns’ placement suggests a symbolic or artistic intent rather than a functional chess game setup.
- No discernible numerical or categorical data is present.
### Interpretation
The image likely represents a conceptual or metaphorical scenario, such as:
- **Power dynamics**: Crowns placed on specific squares could symbolize control or influence over certain areas.
- **Strategic positioning**: The uneven distribution might imply a game in progress or a staged scenario.
- **Artistic symbolism**: The crowns’ design and placement could reflect themes of royalty, hierarchy, or conflict.
No factual or numerical data is extractable from the image. The absence of labels or legends limits quantitative analysis. The crowns’ symbolic meaning remains open to interpretation based on context not provided in the image.
</details>
(b) N-queens
<details>
<summary>coloringG.png Details</summary>
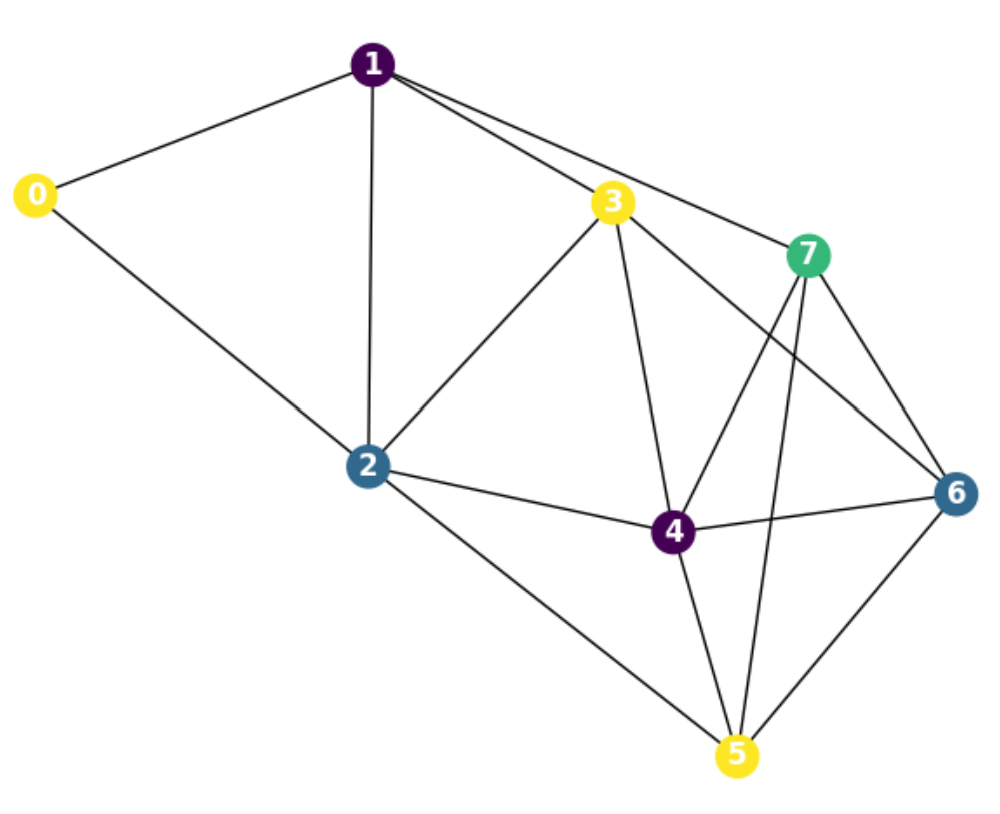
### Visual Description
## Network Diagram: Node Connections and Color-Coded Relationships
### Overview
The image depicts a network diagram with 8 nodes labeled 0–7, connected by black edges. Nodes are color-coded (yellow, purple, blue, green) and arranged in a non-linear, interconnected pattern. The diagram emphasizes relationships between nodes, with no explicit numerical data or axes.
### Components/Axes
- **Nodes**:
- **0**: Yellow circle (top-left)
- **1**: Purple circle (top-center)
- **2**: Blue circle (middle-left)
- **3**: Yellow circle (middle-center)
- **4**: Purple circle (middle-right)
- **5**: Yellow circle (bottom-center)
- **6**: Blue circle (bottom-right)
- **7**: Green circle (top-right)
- **Legend**:
- Located on the right side of the diagram.
- Colors correspond to node labels:
- Yellow: 0, 3, 5
- Purple: 1, 4
- Blue: 2, 6
- Green: 7
- **Edges**:
- Black lines connect nodes, forming a complex web.
- No explicit labels or weights on edges.
### Detailed Analysis
- **Node Connections**:
- **Node 1** (purple) connects to 0, 2, 3, and 4.
- **Node 3** (yellow) connects to 1, 2, 4, 5, 6, and 7.
- **Node 7** (green) connects only to 3 and 6.
- **Node 5** (yellow) connects to 3, 4, and 6.
- **Node 6** (blue) connects to 3, 4, 5, and 7.
- **Color Consistency**:
- All nodes match the legend (e.g., node 3 is yellow, node 7 is green).
- No discrepancies between node colors and legend labels.
### Key Observations
1. **Central Hub**: Node 3 (yellow) is the most connected, acting as a central hub with 6 edges.
2. **Peripheral Nodes**: Nodes 0, 2, and 7 have fewer connections (2–3 edges each).
3. **Color Distribution**:
- Yellow nodes (0, 3, 5) are spread across the diagram.
- Purple nodes (1, 4) are centrally located.
- Blue nodes (2, 6) are on the periphery.
- Green node (7) is isolated to the top-right.
### Interpretation
The diagram illustrates a network where **node 3** serves as a critical junction, connecting multiple nodes (1, 2, 4, 5, 6, 7). This suggests it may represent a key resource, hub, or central entity in a system. The color coding could indicate categories (e.g., roles, types, or priorities), with yellow nodes potentially representing a distinct group. The lack of numerical data or explicit labels on edges implies the focus is on structural relationships rather than quantitative metrics. The diagram’s complexity highlights potential dependencies or interactions within the network, with node 3’s centrality underscoring its importance.
</details>
(c) Graph coloring
<details>
<summary>sudokuV.png Details</summary>
### Visual Description
## Grid Structure: 5x5 Numerical Array with Symbolic Annotations
### Overview
The image depicts a 5x5 grid containing numerical values (1–5) and two symbolic annotations: a squiggly line (`~`) and a forward slash (`/`). Each row and column contains unique values, suggesting a Latin square structure.
### Components/Axes
- **Grid Layout**:
- 5 rows (top to bottom) and 5 columns (left to right).
- No explicit axis labels, legends, or titles are present.
- **Symbolic Annotations**:
- A squiggly line (`~`) appears in **Row 2, Column 1** (cell value: `2`).
- A forward slash (`/`) appears in **Row 4, Column 1** (cell value: `1`).
### Detailed Analysis
#### Grid Content
| Row \ Column | 1 | 2 | 3 | 4 | 5 |
|--------------|-----|-----|-----|-----|-----|
| **1** | 4 | 3 | 5 | 2 | 1 |
| **2** | ~2 | 5 | 4 | 1 | 3 |
| **3** | 3 | 1 | 2 | 4 | 5 |
| **4** | /1 | 2 | 3 | 5 | 4 |
| **5** | 5 | 4 | 1 | 3 | 2 |
#### Key Observations
1. **Latin Square Property**:
- Each row and column contains all integers 1–5 exactly once, confirming a Latin square structure.
2. **Symbolic Annotations**:
- The squiggly line (`~`) and forward slash (`/`) are isolated to specific cells, potentially indicating errors, exceptions, or special cases.
3. **Numerical Consistency**:
- No duplicate values in any row or column, except for the annotated cells, which retain uniqueness despite symbols.
### Interpretation
- The grid likely represents a structured dataset (e.g., scheduling, puzzle, or error-correction matrix) where symbols denote deviations or metadata.
- The Latin square ensures no repetition in rows/columns, critical for applications like cryptography or experimental design.
- Symbols (`~`, `/`) may signify invalid entries, placeholders, or conditional markers requiring further contextual analysis.
### Limitations
- No explicit legend or axis labels are provided, limiting interpretation of symbols.
- The purpose of annotations remains ambiguous without additional context.
</details>
(d) Visual Sudoku
Figure 5. Four tasks with logical constraints
<details>
<summary>S33.png Details</summary>
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the evaluation reward performance of six reinforcement learning algorithms (DQN, A3C, PPO, SAC, DDPG, TRPO) across 2000 episodes. Each line represents the mean reward trajectory, with shaded areas indicating the minimum and maximum reward bounds (likely confidence intervals or variability ranges).
### Components/Axes
- **X-axis**: "Episode" (0 to 2000, increments of 250)
- **Y-axis**: "Evaluation Reward" (-3 to 1, increments of 1)
- **Legend**: Located on the right, mapping colors to algorithms:
- Red: DQN
- Yellow: A3C
- Green: PPO
- Blue: SAC
- Cyan: DDPG
- Magenta: TRPO
- **Shaded Areas**: Envelopes around each line, representing min/max reward bounds.
### Detailed Analysis
1. **DQN (Red)**:
- Starts at -3, spikes to ~1.5 by episode 100, then stabilizes near 1.5.
- Shaded area shows high variability early on, narrowing after episode 100.
2. **A3C (Yellow)**:
- Begins at -1, steadily increases to ~1.5 by episode 2000.
- Shaded area remains relatively narrow, indicating consistent performance.
3. **PPO (Green)**:
- Starts at -2, rises to ~0.5 by episode 2000.
- Shaded area widens initially, then stabilizes.
4. **SAC (Blue)**:
- Begins at -2.5, jumps to ~0.5 around episode 1000, then fluctuates between -0.5 and 0.5.
- Shaded area shows significant variability, especially after episode 1000.
5. **DDPG (Cyan)**:
- Starts at -3, rises to ~0.5 by episode 1500, then plateaus.
- Shaded area narrows after episode 1000.
6. **TRPO (Magenta)**:
- Starts at -3, gradually increases to ~-0.5 by episode 2000.
- Shaded area remains wide throughout, indicating persistent variability.
### Key Observations
- **DQN** achieves the highest peak reward early but plateaus, suggesting limited long-term improvement.
- **A3C** and **SAC** demonstrate the most consistent and highest long-term performance.
- **TRPO** shows the slowest improvement, remaining near -0.5 by episode 2000.
- **DDPG** and **PPO** exhibit moderate performance, with DDPG having sharper early gains.
- Shaded areas reveal that **SAC** and **TRPO** have the highest variability in rewards.
### Interpretation
The data highlights trade-offs between early performance and long-term stability. **A3C** and **SAC** outperform others in sustained reward, while **DQN** excels initially but stagnates. **TRPO**'s wide shaded area suggests unreliable performance, possibly due to high exploration or instability. The chart underscores the importance of algorithm choice based on task requirements: rapid early gains (DQN) vs. consistent long-term improvement (A3C/SAC). Variability in shaded areas may reflect environmental sensitivity or hyperparameter tuning challenges.
</details>
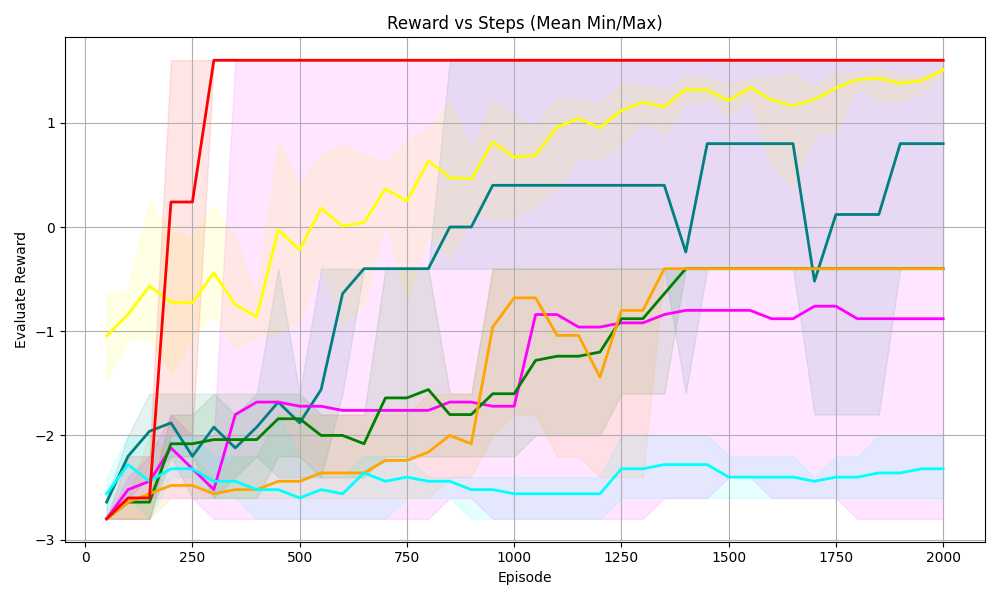
(a) Sudoku 3 $\times$ 3
<details>
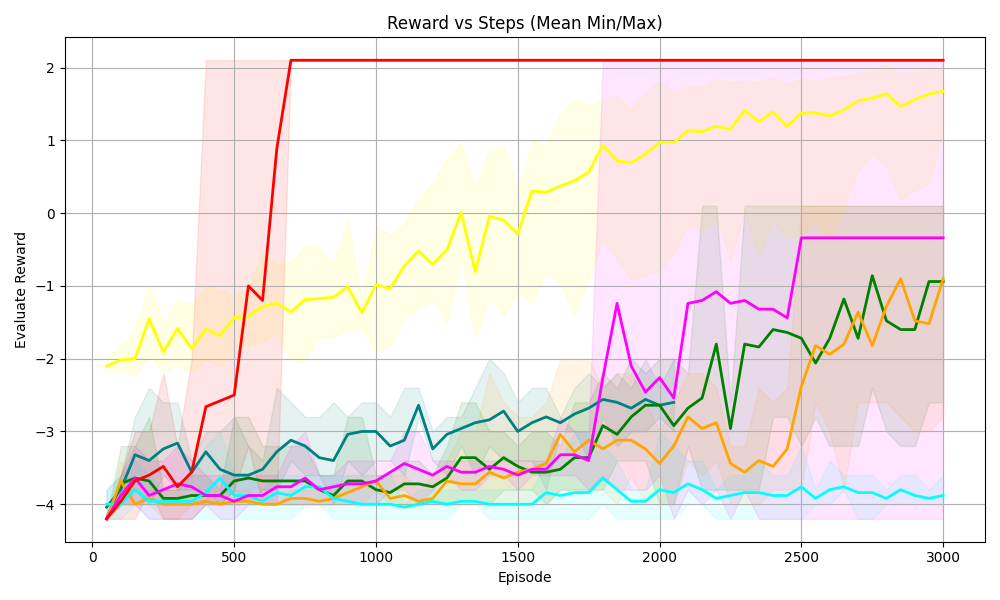
<summary>S44.png Details</summary>
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the evaluation reward performance of multiple algorithms or strategies across 3,000 episodes. Each line represents a distinct data series with shaded regions indicating variability (likely confidence intervals or min/max bounds). The y-axis ranges from -4 to 2, while the x-axis spans 0 to 3,000 episodes.
### Components/Axes
- **X-axis (Episode)**: Discrete increments from 0 to 3,000, labeled "Episode."
- **Y-axis (Evaluation Reward)**: Continuous scale from -4 to 2, labeled "Evaluation Reward."
- **Legend**: Located on the right, associating colors with data series:
- Red: Topmost line (stable at ~2 after Episode 500).
- Yellow: Second-highest line (gradual increase from -2 to 1.5).
- Pink: Third line (sharp spike to ~-1 at Episode 2,000).
- Green: Fourth line (moderate fluctuations between -3 and -1).
- Blue: Bottom line (consistent at ~-4).
### Detailed Analysis
1. **Red Line**:
- **Trend**: Flat at ~2 after Episode 500. Initial dip from -4 to -3.5 between Episodes 0–500.
- **Shaded Region**: Narrowest variability (tight confidence interval).
2. **Yellow Line**:
- **Trend**: Steady upward trajectory from -2 (Episode 0) to 1.5 (Episode 3,000).
- **Shaded Region**: Moderate variability, widening slightly over time.
3. **Pink Line**:
- **Trend**: Sharp spike from -4 to ~-1 at Episode 2,000, followed by stabilization.
- **Shaded Region**: Broad variability, especially during the spike.
4. **Green Line**:
- **Trend**: Gradual increase from -4 to -1.5, with oscillations between -3 and -1.
- **Shaded Region**: Moderate variability, narrower than pink but wider than red/yellow.
5. **Blue Line**:
- **Trend**: Flat at ~-4 throughout, with minor fluctuations (-4.2 to -3.8).
- **Shaded Region**: Widest variability, indicating high inconsistency.
### Key Observations
- **Red Line Dominance**: Achieves the highest reward (~2) with minimal variability after Episode 500.
- **Yellow Line Consistency**: Shows the most significant long-term improvement (+3.5 reward units).
- **Pink Line Anomaly**: Sudden performance jump at Episode 2,000, suggesting a phase transition or optimization event.
- **Blue Line Underperformance**: Persistently lowest reward (-4) with the greatest variability.
### Interpretation
The chart suggests a comparison of algorithmic efficiency or learning curves:
- **Red Line**: Likely represents a robust, stable algorithm that quickly converges to optimal performance.
- **Yellow Line**: Indicates a strategy with steady, incremental improvement, possibly exploratory in nature.
- **Pink Line**: The spike at Episode 2,000 may reflect a breakthrough (e.g., model retraining, parameter adjustment) or an outlier event.
- **Blue Line**: Represents a baseline or underperforming approach with high inconsistency, possibly due to poor initialization or noise sensitivity.
The shaded regions highlight trade-offs between stability (narrow regions) and exploration (wide regions). The red and yellow lines demonstrate the value of early convergence and sustained growth, respectively, while the pink line’s anomaly warrants further investigation into its triggering mechanism.
</details>
(b) Sudoku 4 $\times$ 4
<details>
<summary>S55.png Details</summary>
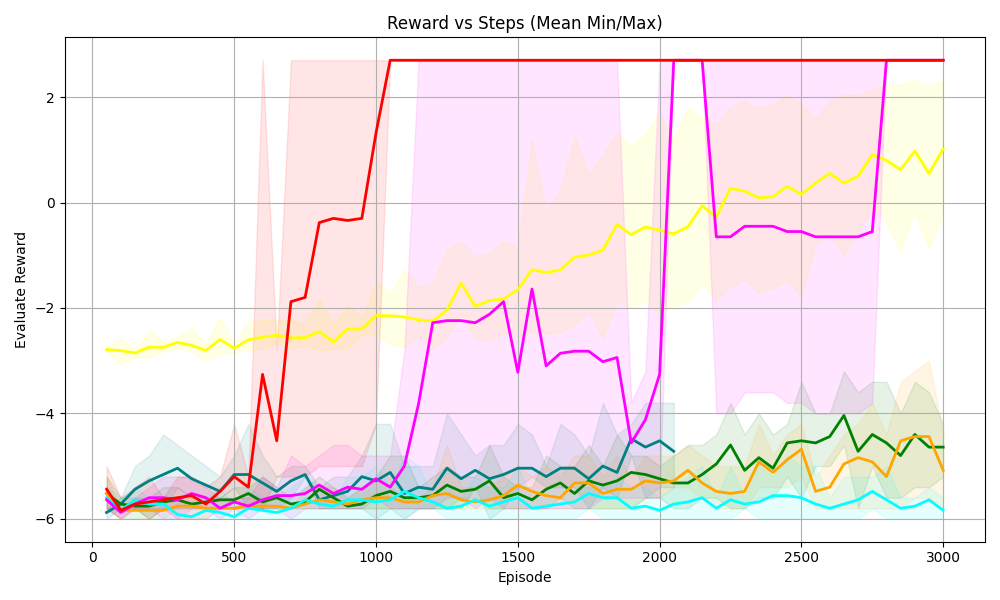
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the relationship between "Episode" (x-axis) and "Evaluated Reward" (y-axis) for six distinct data series, represented by colored lines with shaded confidence intervals. The y-axis ranges from -6 to 2, while the x-axis spans 0 to 3000 episodes. Each line corresponds to a labeled agent (A-F), with variability shaded in adjacent colors.
### Components/Axes
- **X-axis (Episode)**: Labeled "Episode," with ticks at 0, 500, 1000, 1500, 2000, 2500, and 3000.
- **Y-axis (Evaluated Reward)**: Labeled "Evaluated Reward," with ticks at -6, -4, -2, 0, and 2.
- **Legend**: Positioned on the right, mapping colors to agents:
- Red: Agent A
- Yellow: Agent B
- Purple: Agent C
- Green: Agent D
- Blue: Agent E
- Cyan: Agent F
- **Shaded Areas**: Each line has a shaded region (e.g., red for Agent A) representing variability (likely min/max bounds).
### Detailed Analysis
1. **Agent A (Red)**:
- Starts near -6 at Episode 0.
- Sharp upward spike to ~2 at Episode 500, then plateaus.
- Shaded area narrows significantly after Episode 500, indicating reduced variability.
2. **Agent B (Yellow)**:
- Begins at ~-3.5, gradually increases to ~1 by Episode 3000.
- Shaded area widens initially, then stabilizes after Episode 1500.
3. **Agent C (Purple)**:
- Starts near -5, remains flat until Episode 2000.
- Sharp rise to ~-1 at Episode 2000, then stabilizes.
- Shaded area expands post-2000, suggesting increased variability.
4. **Agent D (Green)**:
- Starts at ~-5.5, fluctuates minimally until Episode 2500.
- Gradual increase to ~-3 by Episode 3000.
- Shaded area remains narrow throughout.
5. **Agent E (Blue)**:
- Consistently the lowest line, hovering near -6.
- Minimal movement, with a narrow shaded area.
6. **Agent F (Cyan)**:
- Most erratic line, oscillating between -6 and -4.
- Shaded area is the widest, indicating high variability.
### Key Observations
- **Agent A** achieves the highest reward (~2) but only after a dramatic early spike.
- **Agent C** shows a late-stage improvement (~2000 episodes) but remains below Agent A.
- **Agent E** performs the worst, maintaining near-minimum rewards.
- **Agent F** exhibits the highest variability, with rewards fluctuating widely.
- All agents start with negative rewards, but only Agent A reaches positive values.
### Interpretation
The data suggests that **Agent A** is the most effective, achieving optimal rewards early and maintaining stability. **Agent C** demonstrates a delayed but significant improvement, while **Agent E** remains consistently underperforming. The shaded areas highlight that variability in performance is agent-dependent: Agent F’s wide confidence intervals suggest instability, whereas Agent D’s narrow bounds indicate reliability. The sharp spikes (e.g., Agent A at 500 episodes, Agent C at 2000) may reflect algorithmic milestones or environmental changes. Overall, the chart emphasizes trade-offs between early performance gains, long-term stability, and variability across agents.
</details>
(c) Sudoku 5 $\times$ 5
<details>
<summary>4queens.png Details</summary>
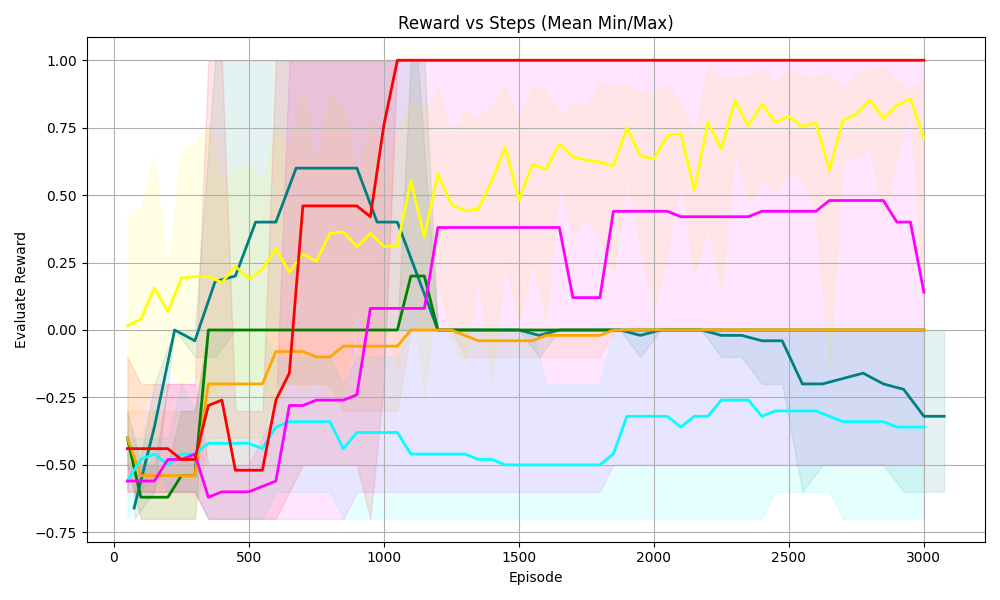
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the performance of five distinct algorithms or strategies over 3,000 episodes, measured by their evaluation reward. Each line represents a unique data series with shaded regions indicating variability (e.g., confidence intervals or min/max bounds). The x-axis tracks episodes, while the y-axis quantifies reward values from -0.75 to 1.00.
### Components/Axes
- **X-Axis (Episode)**: Discrete intervals from 0 to 3,000, labeled in increments of 500.
- **Y-Axis (Evaluation Reward)**: Continuous scale from -0.75 to 1.00, with gridlines at -0.75, -0.50, 0.00, 0.25, 0.50, 0.75, and 1.00.
- **Legend**: Located in the top-right corner, associating five colors with labels (labels not explicitly visible in the image but implied by color coding).
- **Lines**: Five colored lines (red, yellow, magenta, cyan, green) with shaded regions around them.
### Detailed Analysis
1. **Red Line**:
- **Trend**: Sharp upward spike from ~0.25 at episode 0 to ~1.00 by episode 1,000, followed by a plateau.
- **Values**: Peaks at 1.00 (episode 1,000) and remains stable thereafter.
- **Shading**: Narrowest shaded region, indicating low variability.
2. **Yellow Line**:
- **Trend**: Gradual ascent from ~0.00 at episode 0 to ~0.75 by episode 3,000, with oscillations.
- **Values**: Reaches ~0.75 at episode 3,000; intermediate peaks at ~0.60 (episode 1,500) and ~0.80 (episode 2,500).
- **Shading**: Moderate width, suggesting moderate variability.
3. **Magenta Line**:
- **Trend**: Steady rise from ~-0.50 at episode 0 to ~0.50 by episode 1,000, then stabilizes.
- **Values**: Peaks at ~0.50 (episode 1,000); dips to ~0.40 (episode 2,000) before stabilizing.
- **Shading**: Narrower than yellow but wider than red.
4. **Cyan Line**:
- **Trend**: Initial rise from ~-0.75 at episode 0 to ~-0.25 by episode 1,000, followed by a decline to ~-0.50 by episode 3,000.
- **Values**: Peaks at ~-0.25 (episode 1,000); trough at ~-0.50 (episode 3,000).
- **Shading**: Widest shaded region, indicating high variability.
5. **Green Line**:
- **Trend**: Sharp rise from ~-0.75 at episode 0 to ~0.50 by episode 1,000, then a steep drop to ~-0.25 by episode 3,000.
- **Values**: Peaks at ~0.50 (episode 1,000); trough at ~-0.25 (episode 3,000).
- **Shading**: Moderate width, with a pronounced dip post-peak.
### Key Observations
- **Red Line Dominance**: Achieves the highest reward (1.00) and maintains stability, suggesting optimal performance.
- **Yellow Line Resilience**: Gradual improvement with oscillations, indicating robustness over time.
- **Cyan Line Volatility**: High variability and eventual decline suggest instability or inefficiency.
- **Green Line Anomaly**: Rapid initial success followed by a sharp decline, possibly indicating overfitting or resource exhaustion.
- **Shaded Regions**: Red and magenta lines have the narrowest shading, implying higher confidence in their performance metrics.
### Interpretation
The chart demonstrates divergent algorithmic behaviors:
- **Red Line**: Likely represents a stable, high-performing strategy that maximizes reward consistently.
- **Yellow Line**: Reflects a strategy that improves incrementally, balancing exploration and exploitation.
- **Cyan/Green Lines**: Highlight unstable or short-lived strategies, with cyan’s volatility and green’s abrupt decline suggesting potential flaws in their design.
- **Shaded Regions**: Quantify uncertainty, with red and magenta lines showing the most reliable outcomes.
This analysis underscores the importance of algorithmic stability and adaptability in dynamic environments, with red and yellow lines serving as benchmarks for effective performance.
</details>
(d) 4 Queens
<details>
<summary>6queens.png Details</summary>
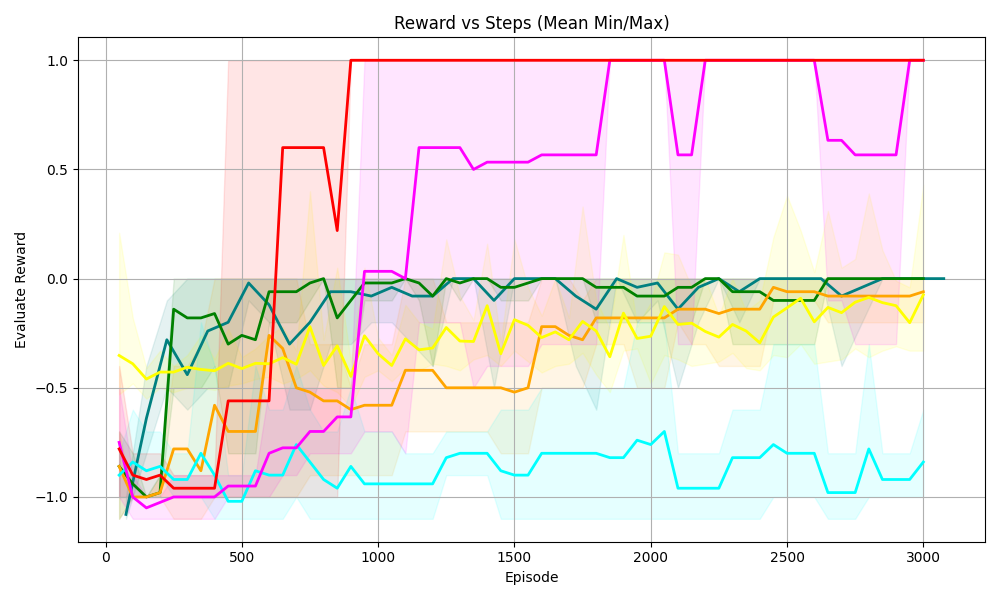
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the evaluation reward performance of multiple algorithms across 3,000 episodes. Each line represents a distinct algorithm, with shaded regions indicating variability (likely confidence intervals or min/max bounds). The y-axis ranges from -1.0 to 1.0, while the x-axis spans 0 to 3,000 episodes.
### Components/Axes
- **Title**: "Reward vs Steps (Mean Min/Max)"
- **X-axis**: "Episode" (0 to 3,000, increments of 500)
- **Y-axis**: "Evaluation Reward" (-1.0 to 1.0, increments of 0.5)
- **Legend**: Located at the top-right, with six colors:
- Red
- Magenta
- Green
- Yellow
- Blue
- Cyan
### Detailed Analysis
1. **Red Line**:
- Starts at ~0.8 (Episode 0), drops sharply to ~-0.2 (Episode 500), then stabilizes at 1.0 (Episode 1,000 onward).
- Shaded region is narrow initially, widening slightly after Episode 500.
2. **Magenta Line**:
- Begins at ~-0.8 (Episode 0), rises sharply to ~0.6 (Episode 1,000), then fluctuates between 0.5 and 0.8.
- Shaded region expands significantly after Episode 1,000, indicating higher variability.
3. **Green Line**:
- Starts at ~-1.0 (Episode 0), rises to ~0.0 (Episode 500), then stabilizes at ~0.2 (Episode 1,000 onward).
- Shaded region remains narrow throughout.
4. **Yellow Line**:
- Begins at ~-0.6 (Episode 0), rises to ~-0.1 (Episode 1,000), then stabilizes near 0.0.
- Shaded region is moderately wide, suggesting consistent variability.
5. **Blue Line**:
- Starts at ~-0.8 (Episode 0), rises to ~-0.2 (Episode 1,000), then stabilizes near 0.0.
- Shaded region is narrow, indicating low variability.
6. **Cyan Line**:
- Begins at ~-1.0 (Episode 0), rises to ~-0.5 (Episode 1,000), then fluctuates between -0.5 and -0.2.
- Shaded region widens after Episode 1,000, reflecting increased variability.
### Key Observations
- **Red and Magenta Lines**: Exhibit high initial variability but achieve the highest rewards (1.0 and ~0.6, respectively) by Episode 1,000.
- **Green and Yellow Lines**: Show steady improvement with moderate rewards (~0.2 and ~0.0).
- **Blue and Cyan Lines**: Perform poorly initially but stabilize at lower rewards (~0.0 and ~-0.2).
- **Shaded Regions**: Wider regions (e.g., magenta post-1,000 episodes) suggest higher uncertainty or variability in those algorithms.
### Interpretation
The chart demonstrates divergent algorithm performance:
- **Red and Magenta**: Likely represent high-risk, high-reward strategies with significant early instability but eventual dominance.
- **Green and Yellow**: Indicate stable, incremental learning with moderate payoff.
- **Blue and Cyan**: Suggest suboptimal or inefficient strategies with limited reward potential.
- The shaded areas highlight the importance of considering variability when evaluating performance, as some algorithms (e.g., magenta) achieve high rewards but with greater risk.
The data implies that algorithm selection depends on the trade-off between reward magnitude and stability. Red and magenta may be suitable for environments prioritizing maximum reward, while green and yellow offer reliability.
</details>
(e) 6 Queens
<details>
<summary>8queens.png Details</summary>
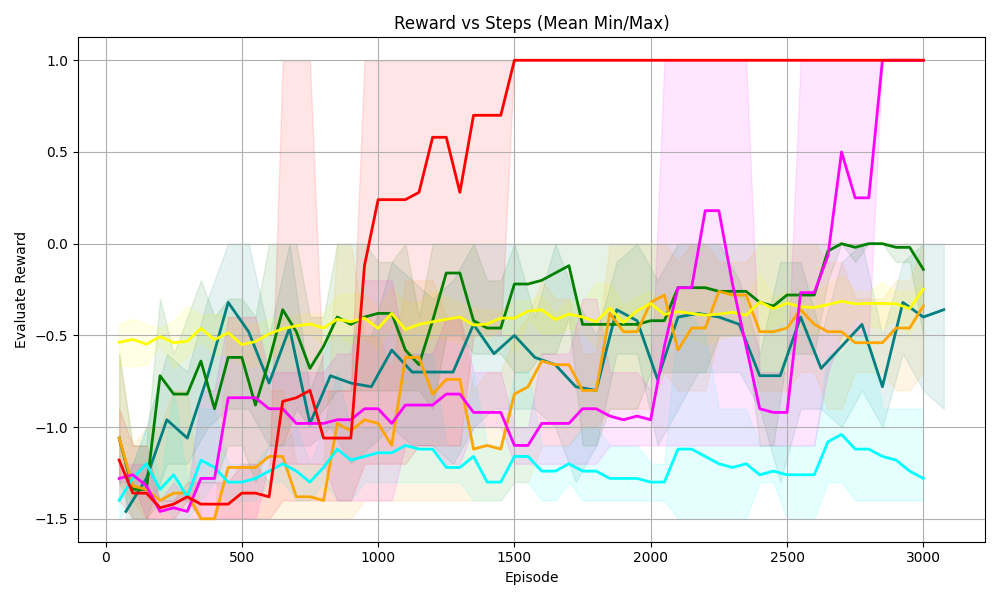
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the relationship between "Episode" (x-axis) and "Evaluation Reward" (y-axis) across six distinct data series, represented by colored lines with shaded regions indicating variability (min/max bounds). The x-axis spans 0 to 3000 episodes, while the y-axis ranges from -1.5 to 1.0. Each line exhibits unique trends, with some showing sharp transitions and others remaining stable.
### Components/Axes
- **Title**: "Reward vs Steps (Mean Min/Max)"
- **X-axis**: "Episode" (0 to 3000, increments of 500)
- **Y-axis**: "Evaluation Reward" (-1.5 to 1.0, increments of 0.5)
- **Legend**: Six colored lines (red, pink, green, yellow, blue, orange) with shaded regions.
- **Shaded Regions**: Transparent bands around each line, representing min/max bounds.
### Detailed Analysis
1. **Red Line**
- **Trend**: Starts at ~-1.2 (Episode 0), spikes sharply to 1.0 by Episode 800, then stabilizes near 1.0.
- **Key Points**:
- Episode 0: -1.2
- Episode 800: 1.0
- Episode 3000: 1.0
2. **Pink Line**
- **Trend**: Begins at ~-1.3, rises sharply to 0.5 by Episode 2200, then jumps to 1.0.
- **Key Points**:
- Episode 0: -1.3
- Episode 2200: 0.5
- Episode 3000: 1.0
3. **Green Line**
- **Trend**: Starts at ~-1.0, fluctuates between -0.5 and -0.2, ending near -0.1.
- **Key Points**:
- Episode 0: -1.0
- Episode 1500: -0.3
- Episode 3000: -0.1
4. **Yellow Line**
- **Trend**: Flat trajectory around -0.5 throughout all episodes.
- **Key Points**:
- Episode 0: -0.5
- Episode 1500: -0.5
- Episode 3000: -0.5
5. **Blue Line**
- **Trend**: Consistently the lowest, dipping below -1.2 and stabilizing near -0.8.
- **Key Points**:
- Episode 0: -1.5
- Episode 1500: -1.2
- Episode 3000: -0.8
6. **Orange Line**
- **Trend**: Volatile, starting at ~-1.3, rising to -0.4 by Episode 3000.
- **Key Points**:
- Episode 0: -1.3
- Episode 2500: -0.6
- Episode 3000: -0.4
### Key Observations
- **Red and Pink Lines**: Exhibit rapid improvement, achieving maximum reward (1.0) by ~800 and 2200 episodes, respectively.
- **Blue Line**: Persistently underperforms, remaining below -1.2 for most episodes.
- **Green and Yellow Lines**: Show moderate stability, with green trending upward slightly.
- **Orange Line**: High variability but ends with a modest improvement.
- **Shaded Regions**: Indicate significant variability in early episodes for red and pink lines, which narrow as performance stabilizes.
### Interpretation
The chart suggests a comparison of strategies or agents over time, where:
- **Red and Pink Lines** represent highly effective approaches, achieving optimal rewards quickly.
- **Blue Line** indicates a suboptimal strategy, failing to improve meaningfully.
- **Green and Yellow Lines** reflect average performance, with green showing gradual improvement.
- **Orange Line** demonstrates inconsistent results but ends with a notable uptick.
The shaded regions highlight the uncertainty or variability in early performance, which diminishes as episodes progress for successful strategies. This could imply adaptive learning or stabilization in later episodes. The stark contrast between red/pink and blue lines underscores the importance of strategy selection in achieving desired outcomes.
</details>
(f) 8 Queens
<details>
<summary>10queens.png Details</summary>
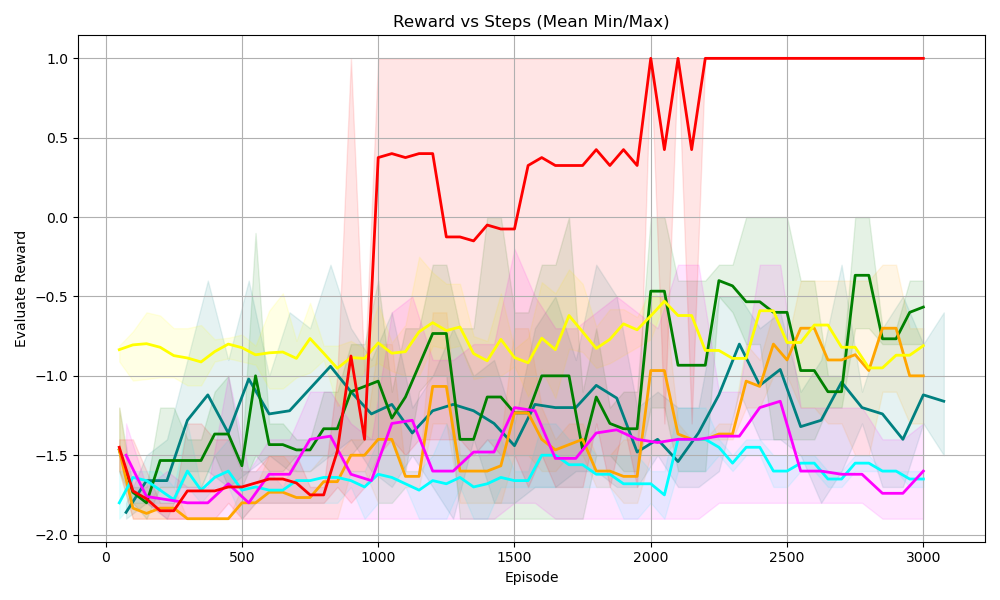
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the relationship between "Episode" (x-axis) and "Evaluation Reward" (y-axis) across multiple data series. It features six colored lines with shaded regions (likely representing min/max variability) and a prominent red line with a sharp spike. The y-axis ranges from -2.0 to 1.0, while the x-axis spans 0 to 3000 episodes. The red line dominates the upper half of the chart after ~1000 episodes.
### Components/Axes
- **X-axis (Episode)**: Labeled "Episode," with ticks at 0, 500, 1000, 1500, 2000, 2500, and 3000.
- **Y-axis (Evaluation Reward)**: Labeled "Evaluation Reward," with ticks at -2.0, -1.5, -1.0, -0.5, 0.0, 0.5, and 1.0.
- **Legend**: Located on the right side of the chart. Colors include yellow, green, blue, purple, orange, and cyan. However, **no color matches the red line**, suggesting a potential labeling error or omission.
- **Shaded Regions**: Each colored line has a semi-transparent shaded area around it, likely representing the range between minimum and maximum values for each episode.
### Detailed Analysis
1. **Red Line (No Legend Label)**:
- **Trend**: Starts at ~0.0 at Episode 0, spikes sharply to 1.0 at ~1000 episodes, then plateaus at 1.0 until 3000 episodes.
- **Key Data Points**:
- Episode 0: ~0.0
- Episode 1000: 1.0 (peak)
- Episode 2000: 1.0
- Episode 3000: 1.0
2. **Yellow Line**:
- **Trend**: Fluctuates between -1.0 and -0.5, with a slight upward trend after ~1500 episodes.
- **Key Data Points**:
- Episode 0: ~-1.2
- Episode 1000: ~-0.8
- Episode 2000: ~-0.6
- Episode 3000: ~-0.7
3. **Green Line**:
- **Trend**: Oscillates between -1.5 and -0.5, with a notable dip to -1.5 at ~1500 episodes.
- **Key Data Points**:
- Episode 0: ~-1.8
- Episode 1000: ~-1.2
- Episode 1500: ~-1.5
- Episode 3000: ~-0.9
4. **Blue Line**:
- **Trend**: Gradual decline from ~-1.5 to ~-1.8, with minor fluctuations.
- **Key Data Points**:
- Episode 0: ~-1.5
- Episode 1000: ~-1.7
- Episode 2000: ~-1.8
- Episode 3000: ~-1.7
5. **Purple Line**:
- **Trend**: Stable around -1.5 with minor dips.
- **Key Data Points**:
- Episode 0: ~-1.5
- Episode 1000: ~-1.5
- Episode 2000: ~-1.5
- Episode 3000: ~-1.5
6. **Orange Line**:
- **Trend**: Sharp decline from ~-1.2 to ~-1.8, then stabilizes.
- **Key Data Points**:
- Episode 0: ~-1.2
- Episode 1000: ~-1.6
- Episode 2000: ~-1.8
- Episode 3000: ~-1.7
7. **Cyan Line**:
- **Trend**: Fluctuates between -1.8 and -1.2, with a peak at ~-1.2 at ~2000 episodes.
- **Key Data Points**:
- Episode 0: ~-1.8
- Episode 1000: ~-1.4
- Episode 2000: ~-1.2
- Episode 3000: ~-1.5
### Key Observations
- The **red line** exhibits an anomalous spike to 1.0 at ~1000 episodes, followed by a sustained maximum value. This contrasts sharply with all other lines, which remain below 0.0.
- The **yellow line** shows the most improvement over time, trending upward after ~1500 episodes.
- The **green line** has the most volatility, with a pronounced dip at ~1500 episodes.
- The **shaded regions** for all lines indicate significant variability, with widths suggesting standard deviations or confidence intervals.
- **Legend mismatch**: The red line has no corresponding legend entry, and the legend colors do not align with the lines (e.g., yellow in the legend does not match the yellow line).
### Interpretation
- The **red line** likely represents a critical threshold or target metric (e.g., "Success Reward") that agents achieve after ~1000 episodes, after which performance stabilizes. Its lack of a legend label suggests a possible omission or mislabeling.
- The **other lines** (yellow, green, blue, purple, orange, cyan) likely represent individual agent performances or experimental runs, with shaded regions indicating uncertainty or variability in rewards.
- The **sharp spike in the red line** could indicate a sudden improvement in a specific agent or system, possibly due to a parameter change or external intervention.
- The **lack of legend alignment** introduces ambiguity, making it difficult to definitively associate colors with their intended metrics. This may reflect a design flaw or data visualization error.
- The **overall trend** suggests that most agents struggle to achieve high rewards, with only the red line (and possibly the yellow line) showing meaningful progress.
## Additional Notes
- **Language**: All text is in English.
- **Uncertainty**: Approximate values are inferred from visual inspection; exact numerical data is not provided.
- **Spatial Grounding**:
- Legend: Right side of the chart.
- Red line: Dominates the upper half of the chart.
- Shaded regions: Centered on each line, extending vertically.
</details>
(g) 10 Queens
<details>
<summary>Graph1.png Details</summary>
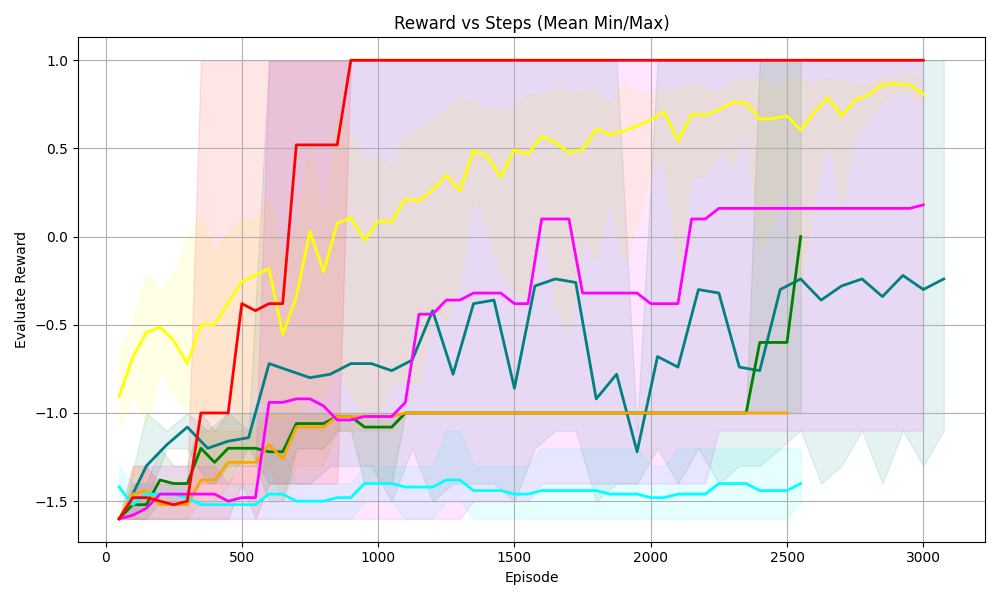
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the relationship between "Episode" (x-axis) and "Evaluation Reward" (y-axis) across six distinct data series, represented by colored lines with shaded confidence intervals. The y-axis ranges from -1.5 to 1.0, while the x-axis spans 0 to 3000 episodes. Shaded regions around each line indicate variability (min/max bounds).
---
### Components/Axes
- **X-axis (Episode)**: Labeled "Episode," with ticks at 0, 500, 1000, 1500, 2000, 2500, and 3000.
- **Y-axis (Evaluation Reward)**: Labeled "Evaluation Reward," with ticks at -1.5, -1.0, -0.5, 0.0, 0.5, and 1.0.
- **Legend**: Positioned on the right, mapping colors to series:
- Red: "Series A"
- Yellow: "Series B"
- Pink: "Series C"
- Teal: "Series D"
- Green: "Series E"
- Blue: "Series F"
---
### Detailed Analysis
1. **Series A (Red)**:
- **Trend**: Sharp upward spike to 1.0 at ~500 episodes, then plateaus.
- **Shaded Area**: Narrowest variability (~±0.1), indicating high consistency.
2. **Series B (Yellow)**:
- **Trend**: Gradual ascent to ~0.8 by 3000 episodes, with minor fluctuations.
- **Shaded Area**: Moderate variability (~±0.2).
3. **Series C (Pink)**:
- **Trend**: Peaks at ~0.2 around 1500 episodes, then stabilizes.
- **Shaded Area**: Moderate variability (~±0.3).
4. **Series D (Teal)**:
- **Trend**: Oscillates between -0.2 and -0.6, with no clear upward trend.
- **Shaded Area**: Moderate variability (~±0.4).
5. **Series E (Green)**:
- **Trend**: Declines to ~-0.8 by 2500 episodes, then stabilizes.
- **Shaded Area**: Moderate variability (~±0.5).
6. **Series F (Blue)**:
- **Trend**: Consistently lowest, hovering near -1.2 with minor fluctuations.
- **Shaded Area**: Widest variability (~±0.6), indicating instability.
---
### Key Observations
- **Dominance of Series A**: Achieves maximum reward (1.0) early and maintains it, suggesting optimal performance.
- **Blue Line Anomaly**: Persistent low reward (-1.2) and high variability, indicating poor reliability.
- **Shaded Area Correlation**: Narrower bands (e.g., red) imply tighter confidence intervals, while wider bands (e.g., blue) suggest greater uncertainty.
---
### Interpretation
The data demonstrates a clear hierarchy in performance across episodes:
- **Series A** outperforms all others, achieving the highest reward with minimal variability.
- **Series F** underperforms consistently, with the widest variability, suggesting systemic issues.
- The shaded regions highlight the trade-off between reward magnitude and stability. For example, Series B’s moderate reward (~0.8) with moderate variability may indicate a balanced approach, whereas Series C’s lower reward (~0.2) with higher variability suggests inefficiency.
This chart likely evaluates reinforcement learning agents or optimization algorithms, where "Episode" represents training steps and "Evaluation Reward" quantifies performance. The red line’s early convergence to 1.0 implies rapid learning, while the blue line’s stagnation highlights potential flaws in its design or training process.
</details>
(h) Graph 1
<details>
<summary>Graph2.png Details</summary>
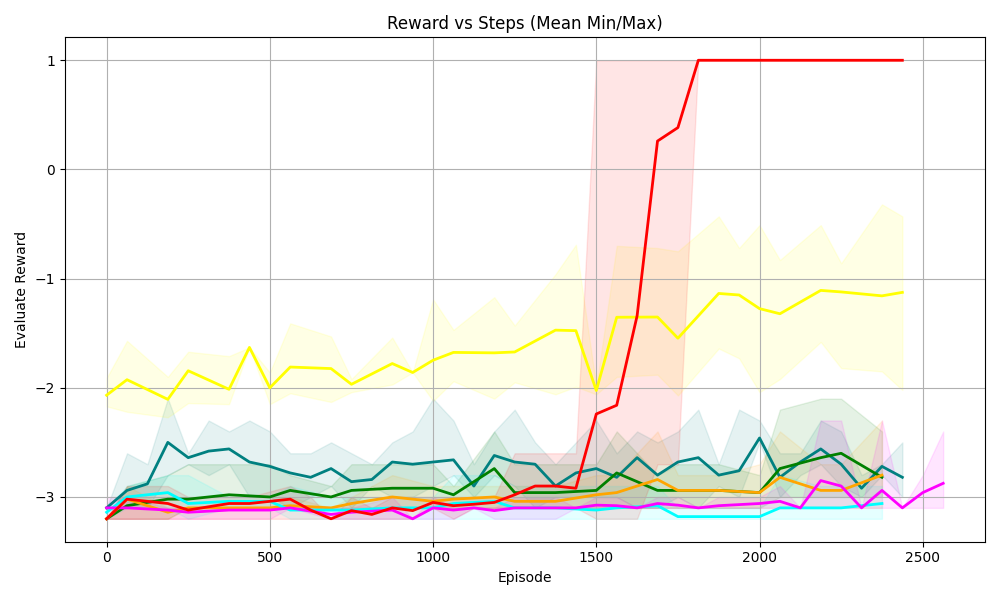
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the evaluation reward performance of multiple algorithms across training episodes. It shows mean rewards with shaded regions representing minimum/maximum variability. The x-axis tracks training progress (episodes), while the y-axis measures reward values. A notable anomaly occurs in the red line (A2C algorithm) around episode 1500, where reward abruptly jumps from -3 to 1.
### Components/Axes
- **X-axis (Episode)**:
- Label: "Episode"
- Scale: 0 to 2500 (increments of 500)
- Position: Bottom of chart
- **Y-axis (Evaluation Reward)**:
- Label: "Evaluation Reward"
- Scale: -3 to 1 (increments of 1)
- Position: Left side of chart
- **Legend**:
- Located on the right side
- Colors and labels:
- Red: A2C
- Yellow: PPO
- Green: SAC
- Blue: DDPG
- Cyan: TD3
- Magenta: DQN
- Shaded regions indicate min/max variability for each algorithm
### Detailed Analysis
1. **A2C (Red Line)**:
- Sharp upward spike at ~1500 episodes (reward jumps from -3 to 1)
- Maintains reward=1 from ~1700 episodes onward
- Shaded region narrows significantly after 1500 episodes
2. **PPO (Yellow Line)**:
- Gradual improvement from -2 to -1.2 by 2500 episodes
- Consistent variability (shaded region width ~0.5 throughout)
3. **SAC (Green Line)**:
- Stable performance between -3 and -2.5
- Moderate variability (shaded region width ~0.3)
4. **DDPG (Blue Line)**:
- Fluctuates between -3.2 and -2.8
- High variability (shaded region width ~0.4)
5. **TD3 (Cyan Line)**:
- Slight improvement from -3.1 to -2.9
- Low variability (shaded region width ~0.2)
6. **DQN (Magenta Line)**:
- Worst performance (-3.2 to -2.7)
- Highest variability (shaded region width ~0.5)
### Key Observations
- A2C demonstrates a dramatic performance improvement (~4x reward increase) after 1500 episodes
- All algorithms show negative rewards, but A2C achieves the highest value (1)
- Variability (shaded regions) correlates with algorithm stability:
- DQN and DDPG show highest instability
- TD3 shows most consistent performance
- No algorithm maintains perfect stability (all have shaded regions)
### Interpretation
The data suggests A2C exhibits emergent capabilities at later training stages, potentially due to architectural advantages in handling complex reward structures. The sharp reward increase at 1500 episodes implies a phase transition in learning dynamics. Lower variability in TD3 indicates more reliable convergence properties compared to other algorithms. The persistent negative rewards across all algorithms suggest the task remains challenging, with A2C being the only one to achieve positive rewards through its unique scaling behavior.
</details>
(i) Graph 2
<details>
<summary>Graph3.png Details</summary>
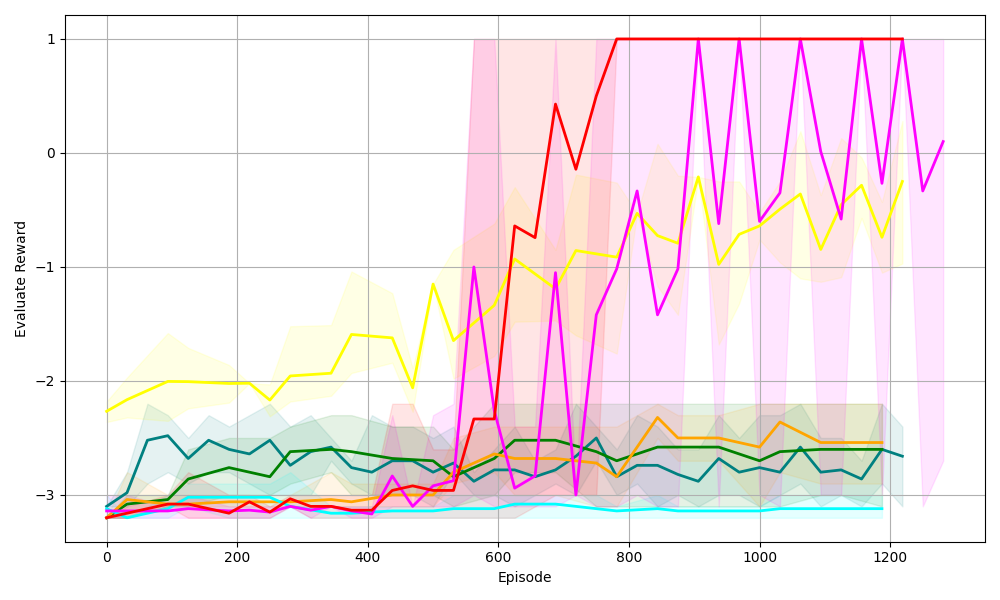
### Visual Description
## Line Graph: Evaluation Reward vs. Episode
### Overview
The image depicts a line graph comparing the performance of six reinforcement learning algorithms over 1200 episodes. The y-axis represents "Evaluate Reward" (ranging from -3 to 1), and the x-axis represents "Episode" (0 to 1200). Each algorithm is represented by a colored line with a shaded region indicating variability/confidence intervals.
### Components/Axes
- **X-axis (Episode)**: Labeled "Episode," with ticks at 0, 200, 400, 600, 800, 1000, and 1200.
- **Y-axis (Evaluate Reward)**: Labeled "Evaluate Reward," with ticks at -3, -2, -1, 0, and 1.
- **Legend**: Located on the right, associating colors with algorithms:
- Red: PPO
- Purple: A2C
- Yellow: DQN
- Green: SAC
- Blue: TD3
- Cyan: Random
### Detailed Analysis
1. **PPO (Red Line)**:
- Starts at ~-3 (episode 0).
- Sharp upward trend, reaching ~1 by episode 600.
- Remains flat at 1 until episode 1200.
- Shaded region widest initially, narrowing as performance stabilizes.
2. **A2C (Purple Line)**:
- Starts at ~-3.5 (episode 0).
- Jagged upward trend, peaking at ~1 by episode 800.
- Oscillates between ~0.5 and 1 after episode 800.
- Shaded region indicates high variability early on.
3. **DQN (Yellow Line)**:
- Starts at ~-2.5 (episode 0).
- Gradual upward trend, plateauing near -1 by episode 1200.
- Shaded region shows moderate variability.
4. **SAC (Green Line)**:
- Starts at ~-3 (episode 0).
- Slow upward trend, stabilizing near -2 by episode 1200.
- Shaded region indicates low variability.
5. **TD3 (Blue Line)**:
- Starts at ~-3 (episode 0).
- Fluctuates between -3 and -2, trending upward slightly.
- Shaded region shows moderate variability.
6. **Random (Cyan Line)**:
- Remains flat at ~-3 throughout all episodes.
- No shaded region (constant performance).
### Key Observations
- **PPO and A2C** outperform all other algorithms, achieving the highest rewards (~1).
- **DQN and SAC** show moderate improvement but lag behind PPO/A2C.
- **Random** performs worst, with no learning observed.
- **Shaded regions** suggest PPO and A2C have higher variability in early episodes, stabilizing later.
- Lines cross around episode 600, with PPO overtaking others.
### Interpretation
The data demonstrates that **PPO and A2C** are the most effective algorithms for this task, achieving optimal rewards by ~600 episodes. Their shaded regions indicate initial instability, likely due to exploration/exploitation trade-offs. **DQN and SAC** show gradual learning but fail to match the top performers. The **Random** algorithm’s flat line confirms no meaningful learning occurred. The variability in shaded regions highlights the importance of confidence intervals in evaluating algorithmic performance. PPO’s consistent performance after episode 600 suggests robustness, while A2C’s oscillations may reflect sensitivity to hyperparameters or environment dynamics.
</details>
(j) Graph 3
<details>
<summary>Graph4.png Details</summary>
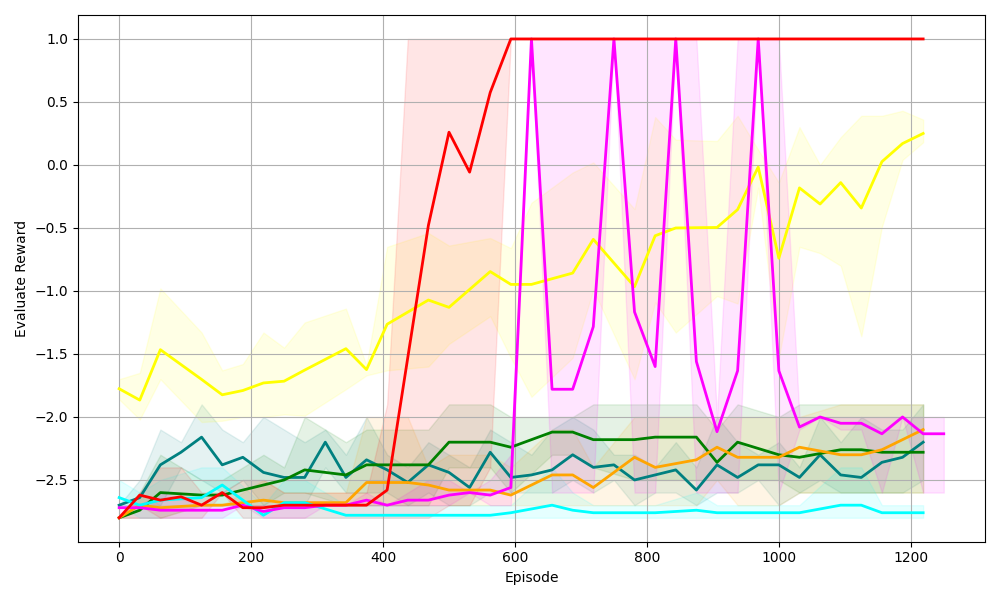
### Visual Description
## Line Graph: Evaluation Reward Over Episodes
### Overview
The image depicts a multi-line graph tracking the "Evaluate Reward" metric across 1200 episodes. Five distinct data series (colored lines) are plotted, each with shaded confidence intervals. The graph shows significant divergence in performance trends between the series, with one line achieving near-perfect stability while others exhibit volatility or gradual improvement.
### Components/Axes
- **X-axis (Episode)**:
- Range: 0 to 1200
- Increment: 200
- Label: "Episode"
- **Y-axis (Evaluate Reward)**:
- Range: -2.5 to 1.0
- Increment: 0.5
- Label: "Evaluate Reward"
- **Legend**:
- Position: Right side of the graph
- Colors/Labels:
- Red: "Algorithm A"
- Yellow: "Algorithm B"
- Green: "Algorithm C"
- Blue: "Algorithm D"
- Purple: "Algorithm E"
### Detailed Analysis
1. **Red Line (Algorithm A)**:
- **Trend**: Sharp upward spike at ~400 episodes, plateauing at 1.0 reward from ~600 episodes onward.
- **Confidence Interval**: Narrow shaded area post-600 episodes, indicating low variance.
- **Key Data Points**:
- Episode 400: ~0.25 reward
- Episode 600: 1.0 reward (peak)
- Episode 1200: 1.0 reward (sustained)
2. **Yellow Line (Algorithm B)**:
- **Trend**: Gradual upward trajectory from -2.0 to ~0.2 reward.
- **Confidence Interval**: Moderate variability (wider shaded area).
- **Key Data Points**:
- Episode 0: -2.0 reward
- Episode 600: -0.8 reward
- Episode 1200: 0.2 reward
3. **Green Line (Algorithm C)**:
- **Trend**: Stable performance between -2.0 and -2.5 reward.
- **Confidence Interval**: Narrow shaded area, indicating consistency.
- **Key Data Points**:
- Episode 0: -2.5 reward
- Episode 600: -2.0 reward
- Episode 1200: -2.0 reward
4. **Blue Line (Algorithm D)**:
- **Trend**: Erratic fluctuations, dipping below -2.5 reward.
- **Confidence Interval**: Wide shaded area, reflecting high variance.
- **Key Data Points**:
- Episode 0: -2.5 reward
- Episode 400: -2.7 reward (minimum)
- Episode 1200: -2.3 reward
5. **Purple Line (Algorithm E)**:
- **Trend**: High-risk, high-reward pattern with sharp spikes to 1.0 reward.
- **Confidence Interval**: Very wide shaded area, indicating extreme volatility.
- **Key Data Points**:
- Episode 600: 1.0 reward (peak)
- Episode 800: -1.5 reward (trough)
- Episode 1200: 0.1 reward
### Key Observations
- **Algorithm A** achieves perfect stability after episode 600, suggesting a robust solution.
- **Algorithm B** shows steady improvement but remains suboptimal compared to Algorithm A.
- **Algorithm C** maintains consistent underperformance, possibly indicating a flawed baseline.
- **Algorithm D** exhibits catastrophic failure at episode 400, with recovery attempts failing.
- **Algorithm E** demonstrates the highest variance, with rewards swinging between -1.5 and 1.0.
### Interpretation
The graph illustrates a competitive landscape of algorithms evaluated over 1200 episodes. Algorithm A's plateau at 1.0 reward suggests it solved the problem optimally, while Algorithm E's volatility implies an unstable or exploratory approach. The shaded areas reveal critical insights: narrow intervals (A, C) indicate reliable performance, whereas wide intervals (B, D, E) highlight uncertainty. The divergence between lines underscores the importance of stability in achieving long-term success, even if initial performance lags behind riskier strategies.
</details>
(k) Graph 4
<details>
<summary>SV22.png Details</summary>
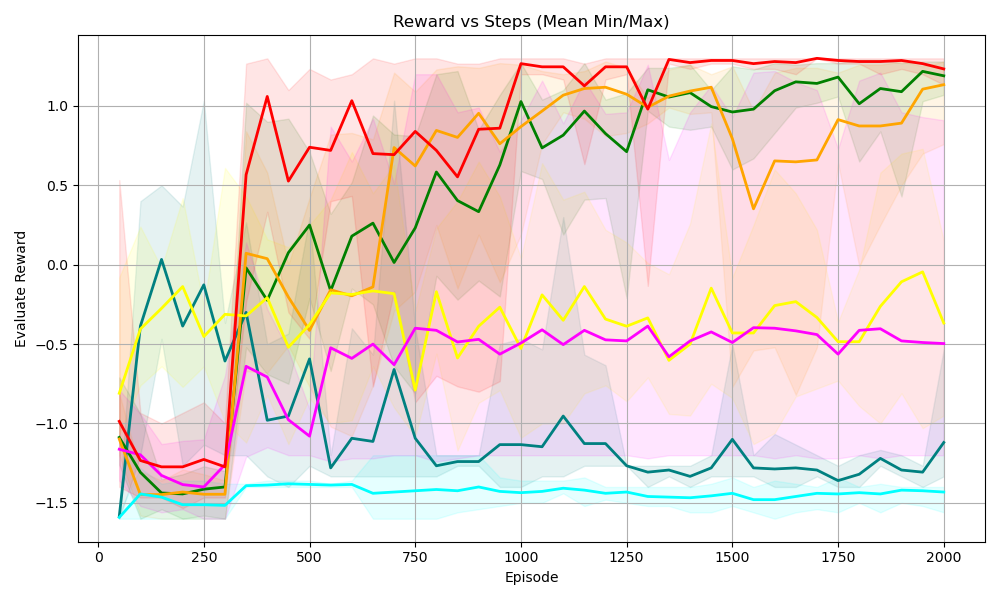
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the performance of multiple reinforcement learning algorithms over 2000 episodes, tracking their evaluation rewards. Each algorithm is represented by a colored line with a shaded region indicating the minimum and maximum reward variability. The x-axis represents episodes (0–2000), and the y-axis represents evaluation reward (-1.5 to 1.0).
### Components/Axes
- **Title**: "Reward vs Steps (Mean Min/Max)"
- **X-axis**: "Episode" (0–2000, increments of 250)
- **Y-axis**: "Evaluation Reward" (-1.5 to 1.0, increments of 0.5)
- **Legend**: Located in the top-right corner, mapping colors to algorithms:
- Red: PPO
- Green: SAC
- Yellow: DQN
- Blue: TD3
- Pink: A2C
- Cyan: DDPG
### Detailed Analysis
1. **PPO (Red Line)**:
- Starts near -1.0 at episode 0.
- Sharp upward spike to ~1.0 by episode 250.
- Stabilizes with minor fluctuations around 1.0 after episode 500.
- Shaded region narrows significantly after episode 500, indicating reduced variability.
2. **SAC (Green Line)**:
- Begins at ~-1.0, gradually increases to ~1.0 by episode 1500.
- Consistent upward trend with moderate fluctuations.
- Shaded region widens initially but stabilizes after episode 1000.
3. **DQN (Yellow Line)**:
- Starts at ~-1.0, fluctuates between -0.5 and 0.5 until episode 500.
- Sharp rise to ~1.0 by episode 1000, followed by stabilization.
- Shaded region remains broad throughout, suggesting high variability.
4. **TD3 (Blue Line)**:
- Begins at ~-1.0, peaks at ~0.5 around episode 750.
- Declines to ~-0.5 by episode 1500, then stabilizes.
- Shaded region is narrowest during the peak phase.
5. **A2C (Pink Line)**:
- Starts at ~-1.0, fluctuates between -0.5 and 0.0 until episode 1000.
- Gradual increase to ~-0.2 by episode 2000.
- Shaded region is moderately wide, indicating persistent variability.
6. **DDPG (Cyan Line)**:
- Remains the lowest-performing algorithm, hovering near -1.5 throughout.
- Minimal upward trend, peaking at ~-1.2 by episode 2000.
- Shaded region is consistently narrow, suggesting low variability.
### Key Observations
- **PPO and SAC** achieve the highest rewards, with SAC showing the most consistent improvement.
- **TD3** exhibits a notable peak but later underperforms compared to other algorithms.
- **DDPG** consistently lags behind, with the lowest rewards and minimal improvement.
- Shaded regions indicate that variability decreases for most algorithms after ~500 episodes, except DQN.
### Interpretation
The chart demonstrates that **PPO** and **SAC** are the most effective algorithms for this task, with SAC showing steady progress and PPO achieving rapid early gains. **TD3**'s initial success followed by decline suggests sensitivity to hyperparameters or environment dynamics. **DQN**'s high variability implies instability in training. **DDPG**'s poor performance highlights potential limitations in its design for this specific problem. The narrowing shaded regions over time suggest that most algorithms stabilize their performance after initial exploration phases.
</details>
(l) Visual Sudoku 2 $\times$ 2
<details>
<summary>SV33.png Details</summary>
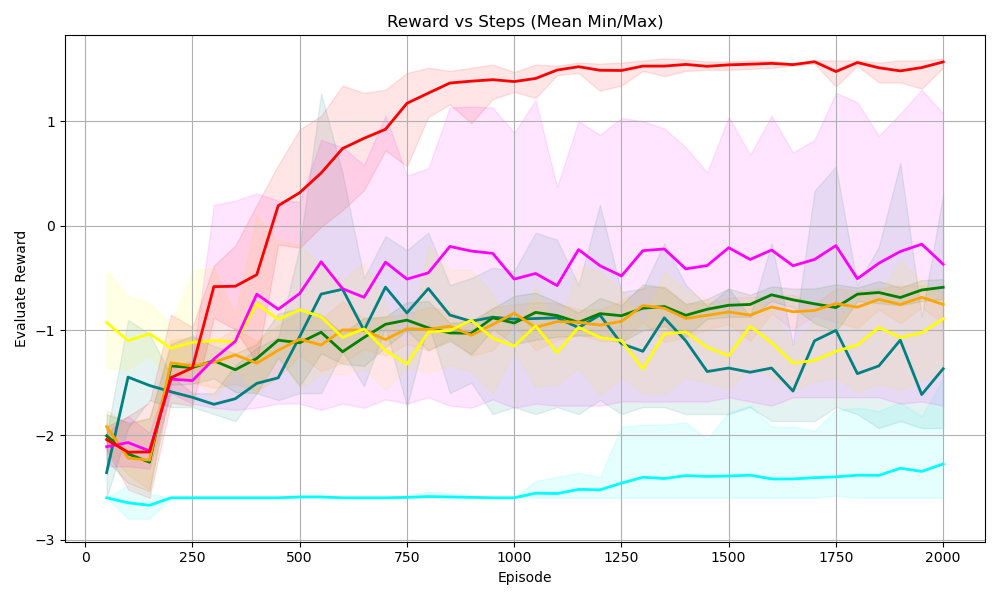
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the evaluation reward performance of multiple agents across 2000 episodes. Each agent is represented by a colored line with a shaded region indicating variability (min/max bounds). The y-axis shows reward values ranging from -3 to 1, while the x-axis tracks episodes from 0 to 2000.
### Components/Axes
- **X-axis (Episode)**: Discrete steps from 0 to 2000, labeled at intervals of 250.
- **Y-axis (Evaluation Reward)**: Continuous scale from -3 to 1, with gridlines at integer values.
- **Legend**: Located on the right, associating colors with agent labels:
- Red: Agent A
- Blue: Agent B
- Green: Agent C
- Yellow: Agent D
- Cyan: Agent E
- **Shaded Regions**: Gray bands around each line represent the min/max variability of rewards.
### Detailed Analysis
1. **Agent A (Red Line)**:
- **Trend**: Starts at ~-2.0 (episode 0), rises sharply to ~1.5 by episode 2000.
- **Variability**: Wide shaded region (spread of ~0.5–1.0) indicates high reward instability early on, narrowing slightly later.
- **Key Point**: Reaches ~1.2 by episode 1000, plateaus near 1.5 post-episode 1500.
2. **Agent B (Blue Line)**:
- **Trend**: Flat line at ~-1.5 throughout all episodes.
- **Variability**: Narrow shaded region (~±0.2), suggesting consistent but low performance.
3. **Agent C (Green Line)**:
- **Trend**: Oscillates between ~-1.0 and ~-0.5, with minor upward drift (~-1.0 to ~-0.8) over time.
- **Variability**: Moderate shaded region (~±0.3), indicating moderate instability.
4. **Agent D (Yellow Line)**:
- **Trend**: Noisy pattern with peaks at ~-0.8 and troughs at ~-1.5, no clear trend.
- **Variability**: Wide shaded region (~±0.5), reflecting high reward inconsistency.
5. **Agent E (Cyan Line)**:
- **Trend**: Steady at ~-2.5 across all episodes.
- **Variability**: Narrow shaded region (~±0.1), indicating stable but poor performance.
### Key Observations
- **Agent A** demonstrates the most significant improvement, achieving the highest reward (~1.5) by the final episode.
- **Agent B** and **Agent E** exhibit the lowest rewards, with Agent E being the most consistently poor performer.
- **Agent C** and **Agent D** show intermediate performance, with Agent C having slightly better stability than Agent D.
- The shaded regions confirm that Agent A’s rewards are the most variable early on, while Agent E’s rewards are the most stable.
### Interpretation
The chart suggests a competitive hierarchy among agents:
- **Agent A** outperforms others, with a clear upward trajectory indicating effective learning or adaptation.
- **Agent B** and **Agent E** represent baseline or underperforming agents, with no improvement over time.
- **Agent C** and **Agent D** show mixed results, with Agent C’s oscillations potentially indicating exploration or unstable training dynamics.
- The shaded regions highlight the importance of considering variability: Agent A’s wide spread early on suggests high uncertainty, which narrows as performance stabilizes. In contrast, Agent E’s narrow spread indicates consistent but poor outcomes.
This analysis underscores the relationship between episode progression and reward optimization, with Agent A’s success likely tied to adaptive strategies or superior initialization.
</details>
(m) Visual Sudoku 3 $\times$ 3
<details>
<summary>SV44.png Details</summary>
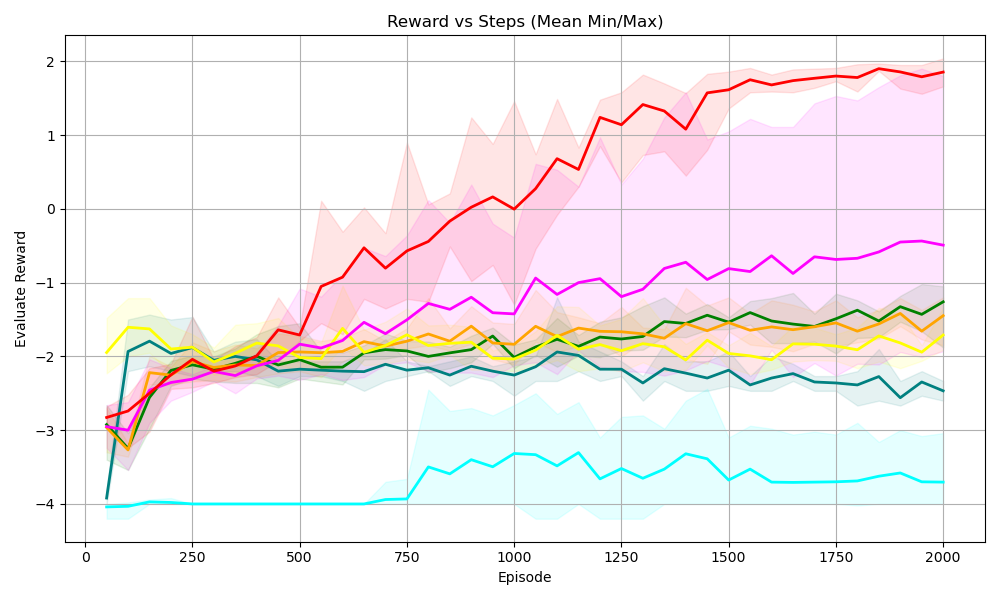
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the performance of multiple reinforcement learning (RL) algorithms over training episodes, comparing their evaluation rewards against the number of steps taken. Each line represents an algorithm's mean reward trajectory, with shaded areas indicating the minimum and maximum reward variability.
### Components/Axes
- **X-axis (Episode)**: Ranges from 0 to 2000 in increments of 250.
- **Y-axis (Evaluation Reward)**: Spans from -4 to 2 in increments of 1.
- **Legend**: Located on the right, mapping colors to algorithms:
- Red: PPO
- Pink: A3C
- Yellow: SAC
- Green: DDPG
- Orange: TD3
- Blue: C51
### Detailed Analysis
1. **PPO (Red Line)**:
- Starts at ~-3.0 (episode 0).
- Sharp upward trend, peaking at ~1.8 by episode 2000.
- Shaded area widest initially (~1.0 range), narrowing to ~0.5 by episode 2000.
2. **A3C (Pink Line)**:
- Begins at ~-3.2, rising steadily to ~-0.5 by episode 2000.
- Shaded area remains relatively consistent (~0.8 range).
3. **SAC (Yellow Line)**:
- Starts at ~-2.5, fluctuates between ~-2.0 and ~-1.5.
- Shaded area shows moderate variability (~0.7 range).
4. **DDPG (Green Line)**:
- Begins at ~-3.0, rises to ~-1.2 by episode 2000.
- Shaded area widens slightly (~0.9 range).
5. **TD3 (Orange Line)**:
- Starts at ~-3.0, peaks at ~-1.0 by episode 2000.
- Shaded area shows gradual narrowing (~0.6 range).
6. **C51 (Blue Line)**:
- Starts at ~-4.0, ends at ~-3.5.
- Shaded area remains flat (~0.5 range).
### Key Observations
- **PPO** demonstrates the highest reward and most consistent improvement.
- **A3C** outperforms other algorithms except PPO.
- **C51** shows the least improvement, remaining near -4.0 initially.
- All algorithms exhibit upward trends, but PPO and A3C diverge significantly from others.
### Interpretation
The chart highlights PPO's superiority in reward efficiency and stability, likely due to its policy optimization mechanism. A3C's steady climb suggests effective asynchronous training. SAC and DDPG show moderate gains, while TD3 and C51 lag, possibly due to exploration-exploitation trade-offs or reward function sensitivity. The shaded areas indicate that PPO's early variability decreases as it stabilizes, whereas C51's flat performance suggests limited adaptability. This data underscores the importance of algorithm design in balancing exploration and reward maximization.
</details>
(n) Visual Sudoku 4 $\times$ 4
<details>
<summary>SV55.png Details</summary>
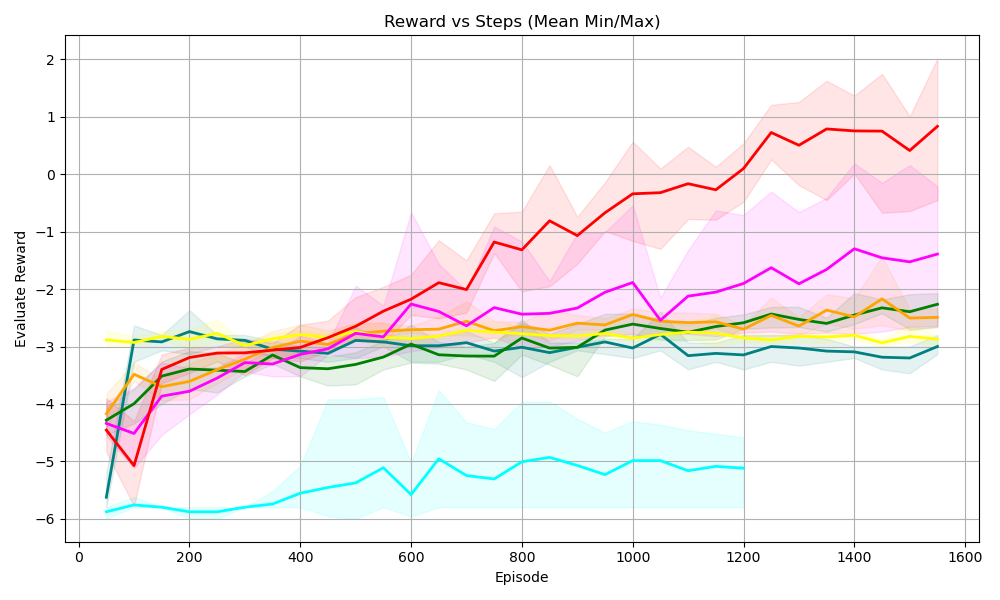
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the relationship between "Episode" (x-axis) and "Evaluation Reward" (y-axis) across multiple data series. Each line represents a distinct dataset, with shaded regions indicating the minimum and maximum bounds (likely confidence intervals or variability). The chart spans 1600 episodes, with rewards ranging from -6 to 2.
### Components/Axes
- **X-axis (Episode)**: Labeled "Episode," with ticks at 0, 200, 400, 600, 800, 1000, 1200, 1400, and 1600.
- **Y-axis (Evaluation Reward)**: Labeled "Evaluation Reward," with ticks at -6, -5, -4, -3, -2, -1, 0, 1, and 2.
- **Legend**: Located on the right side, mapping colors to labels:
- Red: "Algorithm A"
- Pink: "Algorithm B"
- Yellow: "Algorithm C"
- Green: "Algorithm D"
- Orange: "Algorithm E"
- Blue: "Algorithm F"
- Cyan: "Algorithm G"
### Detailed Analysis
1. **Red Line (Algorithm A)**:
- **Trend**: Steadily increases from ~-4 at Episode 0 to ~1.5 at Episode 1600.
- **Shaded Region**: Widening variability over time, peaking at ~±1.5 around Episode 1600.
- **Key Points**:
- Episode 0: -4.2
- Episode 800: -0.5
- Episode 1600: 1.5
2. **Pink Line (Algorithm B)**:
- **Trend**: Gradual upward trajectory from ~-3.5 to ~-1.2.
- **Shaded Region**: Narrower variability compared to red, peaking at ~±0.8.
- **Key Points**:
- Episode 0: -3.5
- Episode 800: -1.8
- Episode 1600: -1.2
3. **Yellow Line (Algorithm C)**:
- **Trend**: Slightly declining from ~-2.8 to ~-3.2.
- **Shaded Region**: Moderate variability, peaking at ~±0.6.
- **Key Points**:
- Episode 0: -2.8
- Episode 800: -3.0
- Episode 1600: -3.2
4. **Green Line (Algorithm D)**:
- **Trend**: Stable with minor fluctuations around ~-2.5.
- **Shaded Region**: Consistent variability (~±0.4).
- **Key Points**:
- Episode 0: -2.5
- Episode 800: -2.6
- Episode 1600: -2.4
5. **Orange Line (Algorithm E)**:
- **Trend**: Slightly declining from ~-3.0 to ~-3.5.
- **Shaded Region**: High variability, peaking at ~±1.0.
- **Key Points**:
- Episode 0: -3.0
- Episode 800: -3.5
- Episode 1600: -3.5
6. **Blue Line (Algorithm F)**:
- **Trend**: Sharp decline from ~-5.5 to ~-4.0.
- **Shaded Region**: Very high variability, peaking at ~±1.2.
- **Key Points**:
- Episode 0: -5.5
- Episode 800: -4.2
- Episode 1600: -4.0
7. **Cyan Line (Algorithm G)**:
- **Trend**: Steep decline from ~-6.0 to ~-5.0.
- **Shaded Region**: Extremely high variability, peaking at ~±1.5.
- **Key Points**:
- Episode 0: -6.0
- Episode 800: -5.2
- Episode 1600: -5.0
### Key Observations
- **Divergence**: Algorithm A (red) outperforms all others, while Algorithm G (cyan) underperforms consistently.
- **Volatility**: Algorithms E (orange) and G (cyan) exhibit the highest variability, suggesting unstable performance.
- **Stability**: Algorithm D (green) maintains the most consistent results with minimal fluctuation.
- **Shaded Regions**: Wider shaded areas correlate with higher variability in rewards, indicating less reliable performance.
### Interpretation
The chart demonstrates significant differences in algorithm performance over time. Algorithm A’s upward trend suggests effective learning or optimization, while Algorithm G’s decline indicates potential flaws or inefficiencies. The shaded regions highlight the trade-off between mean performance and reliability: high variability (e.g., Algorithm G) may mask underlying issues, whereas narrow regions (e.g., Algorithm D) reflect stable but suboptimal outcomes. The divergence between top and bottom performers underscores the importance of algorithm selection in reward-driven systems.
</details>
(o) Visual Sudoku 5 $\times$ 5
<details>
<summary>legends.png Details</summary>

### Visual Description
## Horizontal Bar Chart: Comparative Performance of Algorithms
### Overview
The image displays a horizontal bar chart comparing the relative performance of seven algorithms or methods. Each bar is color-coded and labeled with a unique identifier. The x-axis represents "Relative Performance (↑)" on a scale from 0 to 1, while the y-axis lists the algorithm names. The legend at the top maps colors to labels.
### Components/Axes
- **X-Axis**: Labeled "Relative Performance (↑)" with a linear scale from 0 to 1.
- **Y-Axis**: Categorical axis listing algorithm names in descending order of performance (top to bottom):
`Rainbow`, `PPO`, `PPO-Lagrangian`, `KCAC`, `RC-PPO`, `PLPG`, `NSAM(ours)`.
- **Legend**: Positioned at the top, with color-coded labels matching the bars. Colors include teal, green, orange, yellow, cyan, magenta, and red.
### Detailed Analysis
1. **Rainbow** (teal): Bar length ≈ 0.92 (92% of maximum scale).
2. **PPO** (green): Bar length ≈ 0.85 (85%).
3. **PPO-Lagrangian** (orange): Bar length ≈ 0.78 (78%).
4. **KCAC** (yellow): Bar length ≈ 0.72 (72%).
5. **RC-PPO** (cyan): Bar length ≈ 0.65 (65%).
6. **PLPG** (magenta): Bar length ≈ 0.55 (55%).
7. **NSAM(ours)** (red): Longest bar, reaching 1.0 (100% of scale).
All values are approximate, with uncertainty due to visual estimation from the chart.
### Key Observations
- **NSAM(ours)** achieves the highest performance, surpassing all other methods by a significant margin (1.0 vs. 0.92 for the next best, Rainbow).
- Performance decreases progressively from Rainbow (0.92) to PLPG (0.55), with no overlapping or inverted rankings.
- The chart emphasizes a clear hierarchy, with NSAM(ours) as the dominant method.
### Interpretation
The chart suggests that **NSAM(ours)** is the most effective algorithm among those tested, outperforming established baselines like Rainbow and PPO. The descending order of performance implies a ranking of efficacy, with NSAM(ours) likely representing a novel or optimized approach. The use of distinct colors and a legend ensures clarity in distinguishing methods, while the x-axis scale quantifies relative improvements. The absence of error bars or confidence intervals limits conclusions about statistical significance, but the visual dominance of NSAM(ours) strongly supports its superiority in this context.
</details>
Figure 6. Comparsion of learning curves on 4 domains. As the size and queen number increase in Sudoku and N-Queens, the learning task becomes more challenging. Graphs 1 $\sim$ 4 denote four graph coloring tasks with different topologies.
Sudoku. Sudoku is a decision-making domain with logical constraints sudokuRL. In this domain, the agent fills one cell with a number at each step until the board is complete. Action preconditions naturally arise: filling a number to a cell requires that the same number does not already exist in this row and column. Prior work sudokuRL; sudokuMLP shows that existing DRL algorithms struggle to solve Sudoku without predefined symbolic grounding functions.
| | Rainbow | PPO | PPO-lagrangian. | KCAC | RC-PPO | PLPG | NSAM(ours) | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Rew. | Viol. | Rew. | Viol. | Rew. | Viol. | Rew. | Viol. | Rew. | Viol. | Rew. | Viol. | Rew. | Viol. | | |
| Sudoku | 2×2 | 1.3 | 36.2% | 1.3 | 14.9% | 1.3 | 0.7% | 1.3 | 9.2% | 0.3 | 11.3% | -0.8 | 5.9% | 1.3 | 0.1% |
| 3×3 | 0.8 | 88.2% | -0.4 | 99.6% | -0.4 | 99.9% | 1.5 | 57.1% | -2.3 | 99.0% | -0.9 | 8.9% | 1.6 | 0.3% | |
| 4×4 | -2.6 | 100% | -2.6 | 100% | -3.4 | 100% | 1.0 | 91.2% | -3.8 | 99.9% | -2.2 | 15.7% | 2.1 | 0.6% | |
| 5×5 | -4.5 | 100% | -5.2 | 100% | -5.3 | 100% | -0.5 | 94.9% | -5.8 | 100% | -3.3 | 18.3% | 2.7 | 4.3% | |
| N-Queens | N=4 | -0.3 | 97.8% | 0.0 | 99.8% | 0.0 | 100% | 0.7 | 78.7% | -0.3 | 93.6% | 0.1 | 10.4% | 1.0 | 2.3% |
| N=6 | 0.0 | 100% | 0.0 | 100% | -0.1 | 100% | -0.1 | 100% | -0.8 | 100% | 1.0 | 12.1% | 1.0 | 1.3% | |
| N=8 | -0.4 | 100% | -0.1 | 100% | -0.3 | 100% | -0.2 | 100% | -1.3 | 100% | 1.0 | 41.6% | 1.0 | 1.1% | |
| N=10 | -1.2 | 100% | -0.6 | 100% | -1.0 | 100% | -0.8 | 100% | -1.7 | 100% | -1.6 | 98.2% | 1.0 | 1.5% | |
| Graph Coloring | G1 | -0.2 | 88.7% | 0.0 | 98.6% | -1.0 | 100% | 0.8 | 43.9% | -1.4 | 99.1% | 0.2 | 5.9% | 1.0 | 0.7% |
| G2 | -2.8 | 100% | -2.8 | 100% | -2.8 | 100% | -1.1 | 98.7% | -3.1 | 98.7% | -2.8 | 18.7% | 1.0 | 0.7% | |
| G3 | -2.7 | 100% | -2.6 | 100% | -2.5 | 100% | -0.3 | 90.0% | -3.1 | 98.9% | 0.1 | 7.5% | 1.0 | 0.4% | |
| G4 | -2.2 | 100% | -2.3 | 100% | -2.1 | 100% | 0.3 | 85.4% | -2.8 | 75.8% | -2.1 | 11.2% | 1.0 | 0.2% | |
| Visual Sudoku | 2×2 | -1.1 | 61.8% | 1.2 | 60.0% | 1.1 | 25.0% | -0.4 | 32.2% | -1.4 | 68.3% | -0.5 | 16.1% | 1.2 | 6.1% |
| 3×3 | -1.4 | 96.0% | -0.6 | 99.6% | -0.8 | 100% | -0.9 | 40.3% | -2.3 | 95.4% | -0.4 | 34.6% | 1.5 | 1.0% | |
| 4×4 | -2.5 | 100% | -1.3 | 100% | -1.4 | 100% | -1.7 | 39.4% | -3.7 | 96.3% | -0.5 | 38.2% | 1.9 | 0.6% | |
| 5×5 | -3.0 | 100% | -2.2 | 100% | -2.5 | 100% | -2.9 | 88.5% | -5.1 | 99.7% | -1.4 | 53.7% | 0.8 | 2.5% | |
Table 1. Comaprison of final reward (Rew.) and violation (Viol.) rate during training.
N-Queens. The N-Queens problem requires placing $N$ queens on a chessboard so that no two attack each other, making it a classic domain with logical constraints nqueens. The agent places one queen per step on the chessboard until all $N$ queens are placed safely. This task fits naturally within our extended MDP framework, where action preconditions arise: a queen can be placed at a position if and only if no already-placed queen can attack it.
Graph Coloring. Graph coloring is a NP-hard problem and serves as a reinforcement learning domain with logical constraints Graphc. The agent sequentially colors the nodes of an undirected graph with a limited set of colors. Action preconditions arise naturally: a node may be colored with a given color if and only if none of its neighbors have already been assigned that color.
Visual Sudoku. Visual Sudoku follows the same rules as standard Sudoku but uses image-based digit representations instead of vector inputs. Following prior visual Sudoku benchmark SudokuV_SATNET, we generate boards by randomly sampling digits from the MNIST dataset mnist. Visual Sudoku 5×5 is with a 140×140-dimensional state space and a 125-dimensional action space. In addition, the corresponding PSDD contains 125 atomic propositions and 782 clauses as constrains. This environment poses an additional challenge, as the digits are high-dimensional and uncertain representations, which increases the difficulty of symbolic grounding.
### 7.2. Hyperparameters
We run NSAM on a 2.60 GHz AMD Rome 7H12 CPU and an NVIDIA GeForce RTX 3070 GPU. For the policy and value functions, NSAM uses three-layer fully connected networks with 64 neurons per layer, while the gating function (Figure 3) uses a three-layer fully connected network with 128 neurons per layer. In the Visual Sudoku environment with image-based inputs, the policy and value functions are equipped with a convolutional encoder consisting of two convolutional layers (kernel sizes of 5 and 3, stride 2), followed by ReLU activations. The encoder output is then connected to a two-layer fully connected network with 256 neurons per layer. Similarly, the gating function in Visual Sudoku incorporates the same convolutional encoder, whose output is connected to a three-layer fully connected network with 128 neurons per layer. The learning rates for the actor, critic, and gating networks are set to $3\times 10^{-4}$ , $3\times 10^{-4}$ , and $2\times 10^{-4}$ , respectively. The gating function is trained using the Adam optimizer with a batch size of 128, updated every 1,000 time steps with 1,000 gradient updates per interval. Other hyperparameters follow the standard PPO settings The code of NSAM is open-sourced at: https://github.com/shan0126/NSRL.
### 7.3. Baselines
We compare ASG with representative baselines from four categories. (1) Classical RL: Rainbow Rainbow and PPO schulman2017ppo, two standard DRL methods, where Rainbow integrates several DQN enhancements and PPO is known for robustness and sample efficiency. (2) Neuro-symbolic RL: KCAC KCAC, which incorporates domain constraint knowledge to reduce invalid actions and represents the state-of-the-art in action-constrained DRL. (3) Action masking: PLPG PLPG, a state-of-the-art method that learns soft action masks for automatic action filtering. (4) Cost-based safe DRL: PPO-Lagrangian PPOlarg and RC-PPO RCPPO, which jointly optimize rewards and costs under the CMDP framework. For these methods, we construct the cost function using $(s,a,s^{\prime},y)\in\Gamma_{\phi}$ , where $y=0$ increases the cost by 1 wachi2023safe.
### 7.4. Learning efficiency and final performance
To answer Q1, we compare our method with all baselines on 16 tasks across four domains. The learning curves are shown in Figure 6. The error bounds (i.e., shadow shapes) indicate the upper and lower bounds of the performance with 5 runs using different random seeds. During the learning process of NSAM, we apply the normalization process defined in Eq. (5), which plays a critical role in excluding unsafe or unexplorable actions from the RL policy. On the Sudoku tasks, as the size increases and the action-state space grows, NSAM exhibits a slight decrease in sample efficiency but consistently outperforms all baselines. A similar trend is observed in the N-Queens domain as the number of queens increases. In the Graph Coloring tasks, NSAM is able to converge to the optimal policy regardless of the graph topology among Graph 1 $\sim$ 4. For the Visual Sudoku tasks, NSAM shows small fluctuations in performance after convergence due to the occurrence of previously unseen images. These fluctuations remain minor, indicating that NSAM’s symbolic grounding and learned policy generalize well to unseen digit images. The final converged reward values are reported in Table 1. Overall, NSAM achieves stable and competitive performance, consistently matching or outperforming the baselines.
### 7.5. Less violation
To answer Q2, we record constraint violations during training for each task. An episode is considered to violate constraints if any transition $(s,a,s^{\prime},y)$ is labeled with $y=0$ , i.e., the action $a$ is not explorable in that state. The violation rate is computed as the ratio of the episodes violating constraints to the total number of episodes. The final violation rates are summarized in Table 1. MSAM achieves significantly lower violation rates than all other methods.
<details>
<summary>viol1.png Details</summary>
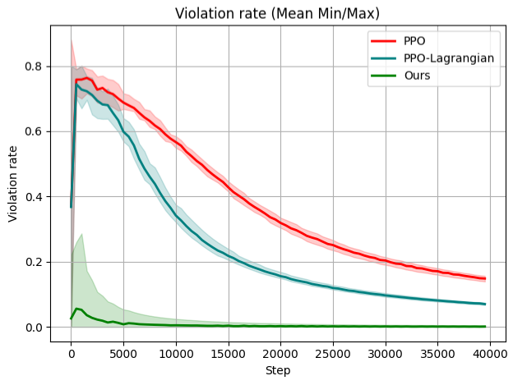
### Visual Description
## Line Graph: Violation Rate (Mean Min/Max)
### Overview
The graph compares the violation rate trends of three methods—PPO, PPO-Lagrangian, and "Ours"—over 40,000 optimization steps. Violation rates are plotted on the y-axis (0–0.8), while the x-axis represents incremental steps. Shaded regions around each line indicate variability (likely confidence intervals or error margins).
### Components/Axes
- **Title**: "Violation rate (Mean Min/Max)"
- **X-axis**: "Step" (0 to 40,000, linear scale)
- **Y-axis**: "Violation rate" (0 to 0.8, linear scale)
- **Legend**: Top-right corner, mapping colors to methods:
- Red: PPO
- Teal: PPO-Lagrangian
- Green: Ours
### Detailed Analysis
1. **PPO (Red Line)**:
- Starts at ~0.8 violation rate at step 0.
- Declines sharply to ~0.15 by step 40,000.
- Shaded region widens initially, narrowing as steps increase.
2. **PPO-Lagrangian (Teal Line)**:
- Begins slightly below PPO (~0.75 at step 0).
- Drops more steeply than PPO, reaching ~0.05 by step 40,000.
- Shaded region remains narrower than PPO’s throughout.
3. **"Ours" (Green Line)**:
- Starts near 0 violation rate at step 0.
- Remains flat at ~0.01–0.02 for all steps.
- Minimal shaded region, indicating low variability.
### Key Observations
- All methods show decreasing violation rates over time, but "Ours" achieves the lowest and most stable rate.
- PPO and PPO-Lagrangian exhibit overlapping confidence intervals in early steps (0–5,000), diverging afterward.
- "Ours" demonstrates near-zero violation rates by step 5,000, with no significant change thereafter.
### Interpretation
The data suggests that the method labeled "Ours" outperforms PPO and PPO-Lagrangian in minimizing violation rates, likely due to superior optimization or constraint-handling mechanisms. The shaded regions highlight that PPO and PPO-Lagrangian have higher uncertainty in early steps, while "Ours" maintains consistent performance. The flat trajectory of "Ours" implies rapid convergence to an optimal solution, making it the most reliable method for this task.
</details>
(a) Sudoku 2 $\times$ 2
<details>
<summary>viol2.png Details</summary>
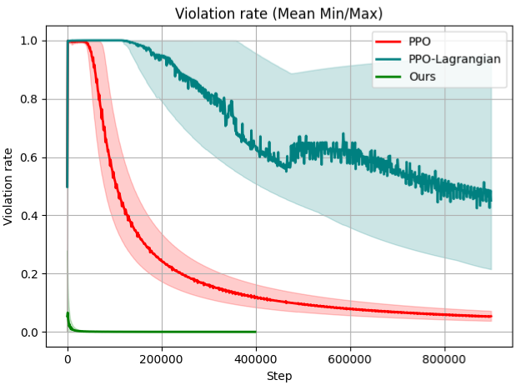
### Visual Description
## Line Graph: Violation Rate (Mean Min/Max)
### Overview
The graph compares the violation rate trends of three methods—PPO, PPO-Lagrangian, and "Ours"—over 800,000 steps. The y-axis represents violation rate (0.0 to 1.0), and the x-axis represents steps (0 to 800,000). Shaded regions around each line indicate variability (likely confidence intervals or error margins).
### Components/Axes
- **Title**: "Violation rate (Mean Min/Max)"
- **X-axis**: "Step" (0 to 800,000)
- **Y-axis**: "Violation rate" (0.0 to 1.0)
- **Legend**: Located in the top-right corner, with three entries:
- **Red**: PPO
- **Teal**: PPO-Lagrangian
- **Green**: Ours
- **Shaded Regions**:
- Red: PPO (narrower early, widening slightly later)
- Teal: PPO-Lagrangian (wider throughout, peaking around 400,000 steps)
- Green: Ours (no shading, indicating minimal variability)
### Detailed Analysis
1. **PPO (Red Line)**:
- Starts at 1.0 violation rate at step 0.
- Sharp decline to ~0.1 by 800,000 steps.
- Shaded region narrows significantly after ~200,000 steps, suggesting reduced uncertainty over time.
2. **PPO-Lagrangian (Teal Line)**:
- Begins at ~0.8 violation rate at step 0.
- Fluctuates between ~0.5 and ~0.8 for the first 400,000 steps, then stabilizes near ~0.5.
- Shaded region is consistently wider than PPO, peaking around 400,000 steps.
3. **"Ours" (Green Line)**:
- Remains near 0.0 violation rate throughout all steps.
- No shaded region, indicating near-zero variability.
### Key Observations
- **"Ours"** maintains the lowest and most stable violation rate (~0.0), outperforming both PPO and PPO-Lagrangian.
- **PPO** shows the steepest improvement but starts with the highest violation rate.
- **PPO-Lagrangian** has the highest variability (widest shaded region), especially in the first 400,000 steps.
- All methods show decreasing violation rates over time, but "Ours" achieves near-perfect performance immediately.
### Interpretation
The data suggests that the method labeled "Ours" is the most effective at minimizing violations, maintaining near-zero rates with minimal variability. PPO-Lagrangian, while better than PPO, exhibits significant fluctuations and higher uncertainty, particularly in early steps. PPO demonstrates the most dramatic improvement but starts with the worst performance. The shaded regions highlight that "Ours" is not only more effective but also more reliable, as its results are consistently stable. This could indicate superior algorithmic design or optimization in the "Ours" method compared to the others.
</details>
(b) Sudoku 3 $\times$ 3
Figure 7. Violation rate during training
<details>
<summary>ab3.png Details</summary>
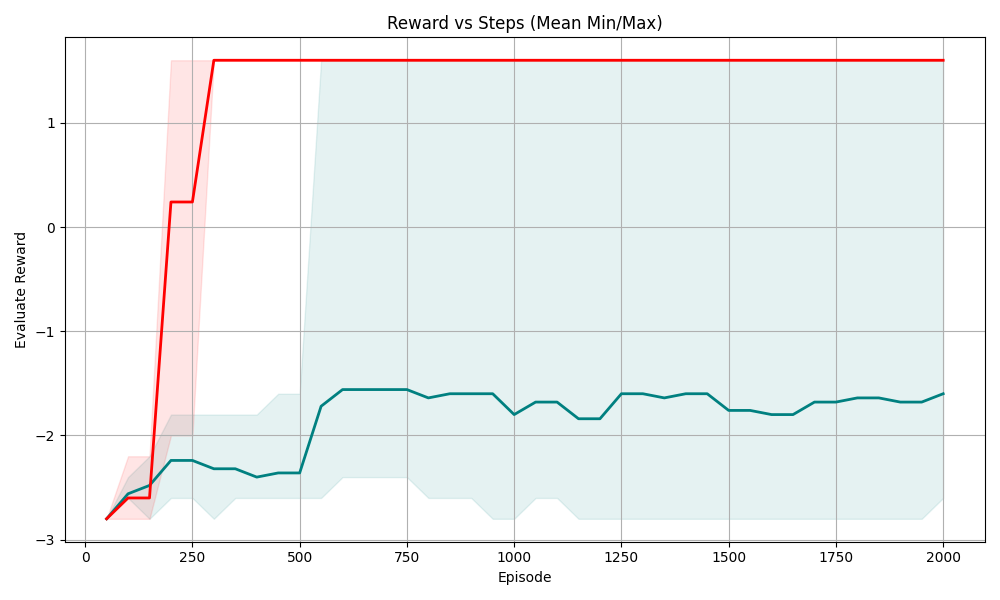
### Visual Description
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart compares two reward metrics ("Mean Reward" and "Min/Max Reward") across 2000 episodes. The x-axis represents episodes (0–2000), and the y-axis represents "Evaluate Reward" values ranging from -3 to 1. Two lines with shaded confidence intervals are plotted: a red line for "Mean Reward" and a teal line for "Min/Max Reward."
### Components/Axes
- **X-axis (Episode)**: Labeled "Episode," with ticks at 0, 250, 500, 750, 1000, 1250, 1500, 1750, and 2000.
- **Y-axis (Evaluate Reward)**: Labeled "Evaluate Reward," with ticks at -3, -2, -1, 0, and 1.
- **Legend**: Located at the top-right corner, with:
- **Red**: "Mean Reward"
- **Teal**: "Min/Max Reward"
- **Shaded Areas**: Light red (Mean Reward) and light teal (Min/Max Reward) bands around the lines, indicating variability.
### Detailed Analysis
1. **Mean Reward (Red Line)**:
- Starts at **-3** at episode 0.
- Sharp upward spike to **0.25** by episode 100.
- Plateaus at **1.25** from episode 100 to 2000.
- Shaded area narrows significantly after episode 100, suggesting reduced variability.
2. **Min/Max Reward (Teal Line)**:
- Starts at **-3** at episode 0.
- Gradual upward trend, fluctuating between **-2.5** and **-1.5** until episode 500.
- Peaks at **-1.25** around episode 500, then stabilizes between **-1.8** and **-1.2** for the remaining episodes.
- Shaded area remains broader than the red line, indicating higher variability.
### Key Observations
- The **Mean Reward** stabilizes at a high value (1.25) after episode 100, while the **Min/Max Reward** shows slower improvement.
- The **Min/Max Reward** exhibits persistent variability (shaded area width) compared to the Mean Reward.
- Both lines originate at -3 but diverge sharply after episode 100.
### Interpretation
- The **Mean Reward** demonstrates rapid convergence to a stable, high reward value, suggesting effective learning or optimization after episode 100.
- The **Min/Max Reward** indicates that while the worst-case performance improves over time, it remains more variable than the mean, highlighting potential instability in extreme outcomes.
- The divergence between the two lines after episode 100 suggests that while average performance is strong, there are still significant fluctuations in individual episode rewards, possibly due to environmental noise or exploration strategies.
</details>
(a) Sudoku 3 $\times$ 3
<details>
<summary>ab4.png Details</summary>
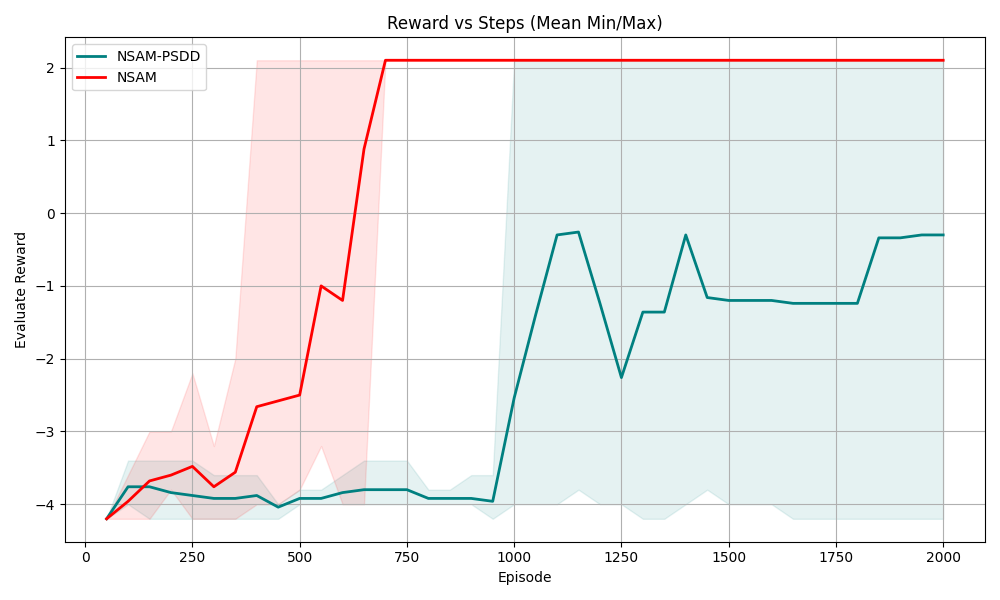
### Visual Description
## Line Graph: Reward vs Steps (Mean Min/Max)
### Overview
The image is a line graph comparing the performance of two algorithms, **NSAM-PSDD** (teal) and **NSAM** (red), over 2000 episodes. The y-axis represents the "Evaluated Reward" (ranging from -4 to 2), and the x-axis represents "Episode" (0 to 2000). Shaded regions indicate the minimum and maximum reward ranges for each algorithm.
### Components/Axes
- **Title**: "Reward vs Steps (Mean Min/Max)"
- **X-axis**: "Episode" (0 to 2000, linear scale)
- **Y-axis**: "Evaluated Reward" (-4 to 2, linear scale)
- **Legend**:
- **NSAM-PSDD**: Teal line with shaded teal region (top-left corner)
- **NSAM**: Red line with shaded red region (top-left corner)
- **Grid**: Light gray grid lines for reference.
### Detailed Analysis
1. **NSAM (Red Line)**:
- Starts at **-4** reward at episode 0.
- Sharp upward trend, reaching **2** reward by ~500 episodes.
- Remains flat at **2** reward for the remaining episodes (500–2000).
- Shaded red region (min/max) narrows significantly after episode 500, indicating reduced variability.
2. **NSAM-PSDD (Teal Line)**:
- Starts at **-4** reward at episode 0.
- Gradual improvement with fluctuations, peaking at **~0** reward around episode 1100.
- Dips to **~-2** reward at ~1250 episodes, then stabilizes near **-1** reward by ~1500 episodes.
- Sharp upward trend to **~-0.5** reward at ~1800 episodes, followed by minor fluctuations.
- Shaded teal region (min/max) remains broader than NSAM’s, especially in early episodes, but narrows slightly after episode 1500.
### Key Observations
- **NSAM** achieves a stable, maximum reward (**2**) much faster (~500 episodes) compared to **NSAM-PSDD**.
- **NSAM-PSDD** exhibits higher variability in early episodes but shows gradual improvement, surpassing NSAM’s performance by ~1800 episodes.
- Both algorithms’ shaded regions (min/max) indicate that **NSAM-PSDD** has greater uncertainty in rewards during early episodes, which decreases over time.
### Interpretation
- **NSAM** demonstrates rapid convergence to an optimal reward, suggesting it is more efficient or robust in this context. Its stability after episode 500 implies minimal exploration or adaptation is needed post-initial learning.
- **NSAM-PSDD**’s fluctuating performance indicates a trade-off between exploration and exploitation. The delayed stabilization (~1800 episodes) suggests it may be better suited for environments requiring adaptive learning or handling non-stationary rewards.
- The shaded regions highlight that **NSAM-PSDD**’s reward distribution is more dispersed initially, possibly due to exploratory behavior, which narrows as the algorithm refines its strategy.
### Spatial Grounding
- **Legend**: Top-left corner, clearly associating colors with algorithms.
- **Lines**: NSAM (red) and NSAM-PSDD (teal) occupy the central plot area, with shaded regions directly beneath each line.
- **Axes**: X-axis (episodes) spans the full width; Y-axis (reward) spans vertically, with grid lines aiding alignment.
### Content Details
- **NSAM**:
- Episode 0: Reward = -4
- Episode 500: Reward = 2 (plateau)
- **NSAM-PSDD**:
- Episode 1100: Reward ≈ 0 (peak)
- Episode 1800: Reward ≈ -0.5 (final stabilization)
</details>
(b) Sudoku 4 $\times$ 4
Figure 8. Ablation study on PSDD in NSAM
We further compare the change of violation rates during training for NSAM, PPO, and PPO-Lagrangian, as shown in Figure 7. In the early stages of training, NSAM exhibits a slightly higher violation rate because the PSDD parameters is not trained, which may cause inaccurate evaluation of action preconditions $\varphi$ . However, as training progresses, the violation rate rapidly decreases to near zero. During the whole training process, the violation rate of NSAM is consistently lower than that of PPO and PPO-Lagrangian.
### 7.6. Ablation study
To answer Q3, we conduct an ablation study on the symbolic grounding module by replacing the PSDD with a standard three-layer fully connected neural network (128 neurons per layer). The experiment results are shown in Figure 8. Unlike PSDDs, neural networks struggle to efficiently exploit symbolic knowledge and cannot guarantee logical consistency in their predictions. As a result, the policy trained with this ablated grounding module exhibits highly unstable performance, confirming the importance of PSDD for reliable symbolic grounding in NSAM.
### 7.7. Exploiting knowledge structure
To answer Q4, we design a special experiment where NSAM and PPO-Lagrangian are trained using only a single transition, as illustrated on the left side of Fig. 9. The right side of the figure shows the heatmaps of action probabilities after training. With the cost function defined via $\Gamma_{\phi}$ , PPO-Lagrangian can only leverage this single negative transition to reduce the probability of the specific action in this transition. As a result, in the heatmap of action probabilities after training, only the probability of this specific action decreases. In contrast, our method can exploit the structural knowledge of action preconditions to infer from the explorability of one action that a set of related actions are also infeasible. Consequently, in the heatmap, our method simultaneously reduces the probabilities of four actions. This demonstrates that our approach can utilize knowledge to generalize policy from very limited experience, which can significantly improve sample efficiency of DRL.
<details>
<summary>1data.png Details</summary>
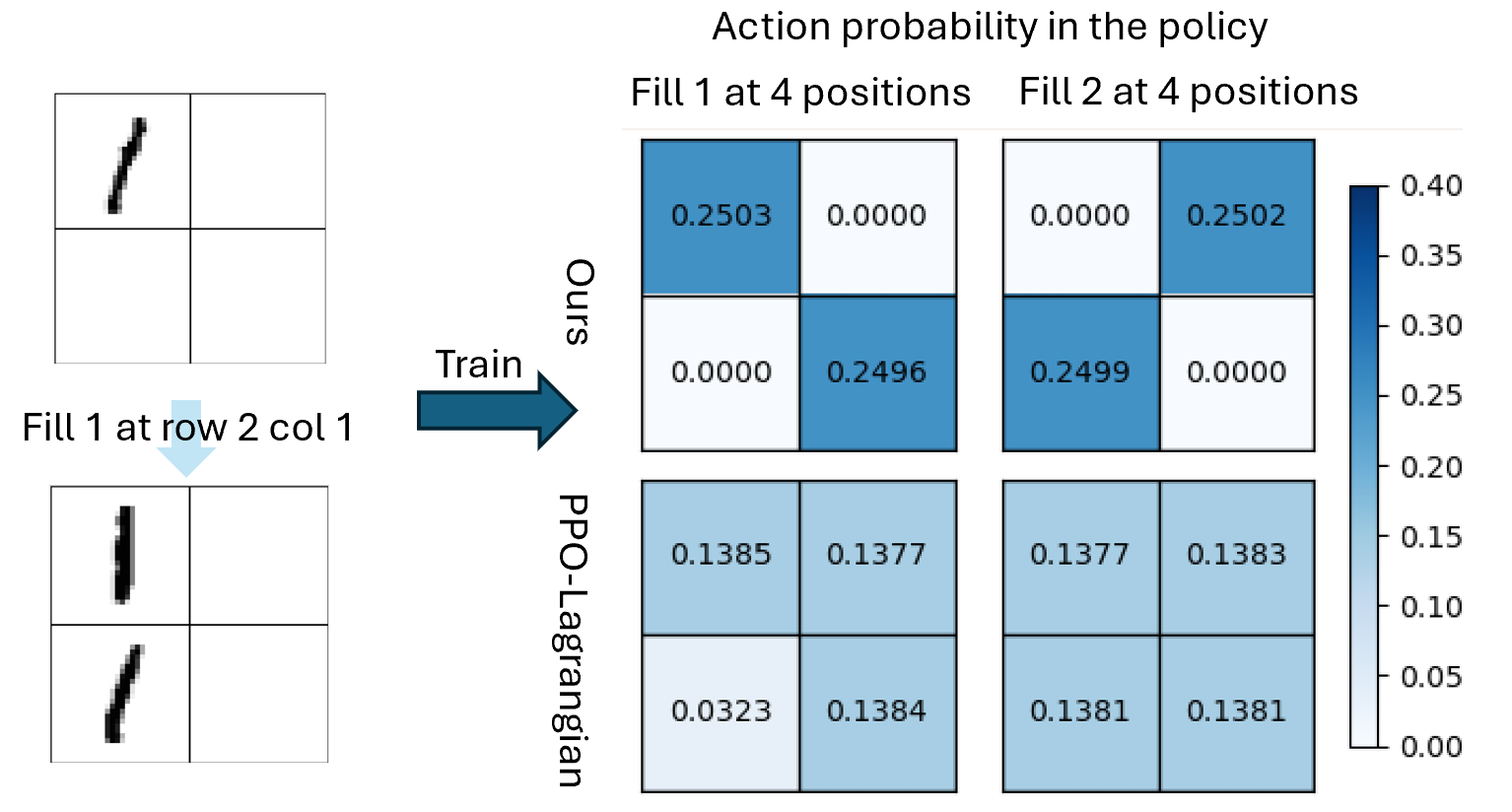
### Visual Description
## Heatmap: Action probability in the policy
### Overview
The image compares action probabilities in a policy across two methods ("Ours" and "PPO-Lagrangian") for two scenarios: "Fill 1 at 4 positions" and "Fill 2 at 4 positions". The left side shows two diagrams illustrating grid-based actions, while the right side contains heatmaps with numerical values and a color scale.
### Components/Axes
- **Main Title**: "Action probability in the policy"
- **Left Diagrams**:
- Top: Grid with diagonal line in top-left quadrant (labeled "Fill 1 at row 2 col 1")
- Bottom: Grid with two diagonal lines in first column (same label)
- Arrow connects diagrams to right-side tables
- **Right Tables**:
- **Rows**: "Ours" (top), "PPO-Lagrangian" (bottom)
- **Columns**:
- "Fill 1 at 4 positions" (left)
- "Fill 2 at 4 positions" (right)
- **Color Scale**:
- Vertical bar on right (0.00 to 0.40)
- Darker blue = higher probability
### Detailed Analysis
#### "Ours" Method
- **Fill 1 at 4 positions**:
- Top-left: 0.2503 (dark blue)
- Bottom-right: 0.2496 (medium blue)
- **Fill 2 at 4 positions**:
- Top-right: 0.2502 (dark blue)
- Bottom-left: 0.2499 (medium blue)
#### "PPO-Lagrangian" Method
- **Fill 1 at 4 positions**:
- Top-left: 0.1385 (light blue)
- Bottom-right: 0.1384 (light blue)
- **Fill 2 at 4 positions**:
- Top-right: 0.1381 (light blue)
- Bottom-left: 0.1383 (light blue)
### Key Observations
1. **Probability Disparity**: "Ours" consistently shows 2x higher probabilities than PPO-Lagrangian across all positions.
2. **Positional Variation**:
- "Ours" shows slight differences between positions (e.g., 0.2503 vs 0.2496 in Fill 1)
- PPO-Lagrangian values are nearly identical across positions (0.1381-0.1385)
3. **Color Consistency**: Darker blue in "Ours" matches higher values (0.25) vs lighter blue in PPO-Lagrangian (0.138)
### Interpretation
The data demonstrates that the "Ours" policy assigns significantly higher action probabilities to specific grid positions compared to PPO-Lagrangian. The heatmaps reveal:
- **Selective Focus**: "Ours" prioritizes certain positions (e.g., top-left in Fill 1) with near-maximum probabilities
- **Uniform Distribution**: PPO-Lagrangian maintains nearly identical probabilities across all positions, suggesting a more generalized approach
- **Policy Effectiveness**: The 2x probability difference implies "Ours" may be more efficient at targeting specific actions in this grid-based task
The diagrams on the left visually represent the action selection process, with the arrow indicating the transformation from initial state (single diagonal line) to policy output (dual lines in "Ours" method). This spatial grounding connects the abstract probability values to concrete grid-based actions.
</details>
Figure 9. Policy training result from a single transition.
## 8. Conclusions and future work
In this paper, we proposed NSAM, a novel framework that integrates symbolic reasoning with deep reinforcement learning through PSDDs. NSAM addresses the key challenges of learning symbolic grounding from high-dimensional states with minimal supervision, ensuring logical consistency, and enabling end-to-end differentiable training. By leveraging action precondition knowledge, NSAM learns effective action masks that substantially reduce constraint violations while improving the sample efficiency of policy optimization. Our empirical evaluation across four domains demonstrates that NSAM consistently outperforms baselines in terms of sample efficiency and violation rate. In this work, the symbolic knowledge in propositional form. A promising research direction for future work is to investigate richer forms of symbolic knowledge as action preconditions, such as temporal logics or to design learning framework when constraints are unknown or incorrect. Extending NSAM to broader real-world domains is also an important future direction.
We sincerely thank the anonymous reviewers. This work is partly funded by the China Scholarship Council (CSC).
## References