# Finding the Cracks: Improving LLMs Reasoning with Paraphrastic Probing and Consistency Verification
**Authors**: Weili Shi, Dongliang Guo, Lehan Yang, Tianlong Wang, Hanzhang Yuan, Sheng Li
## Abstract
Large language models have demonstrated impressive performance across a variety of reasoning tasks. However, their problem-solving ability often declines on more complex tasks due to hallucinations and the accumulation of errors within these intermediate steps. Recent work has introduced the notion of critical tokens –tokens in the reasoning process that exert significant influence on subsequent steps. Prior studies suggest that replacing critical tokens can refine reasoning trajectories. Nonetheless, reliably identifying and exploiting critical tokens remains challenging. To address this, we propose the P araphrastic P robing and C onsistency V erification (PPCV) framework. PPCV operates in two stages. In the first stage, we roll out an initial reasoning path from the original question and then concatenate paraphrased versions of the question with this reasoning path. And we identify critical tokens based on mismatches between the predicted top-1 token and the expected token in the reasoning path. A criterion is employed to confirm the final critical token. In the second stage, we substitute critical tokens with candidate alternatives and roll out new reasoning paths for both the original and paraphrased questions. The final answer is determined by checking the consistency of outputs across these parallel reasoning processes. We evaluate PPCV on mainstream LLMs across multiple benchmarks. Extensive experiments demonstrate PPCV substantially enhances the reasoning performance of LLMs compared to baselines.
Machine Learning, ICML
<details>
<summary>images/compare_ct_sc_gsm8k.png Details</summary>
### Visual Description
## Line Graph: Pass@k Performance Comparison
### Overview
The image depicts a line graph comparing two performance metrics ("critical tokens" and "self-consistency") across varying sample sizes (k). Both metrics show improvement as sample size increases, with "critical tokens" consistently outperforming "self-consistency."
### Components/Axes
- **X-axis**: "number of sample k" (ranges from 0 to 50, with markers at 10, 20, 30, 40, 50).
- **Y-axis**: "pass@k(%)" (ranges from 70% to 90%, with markers at 72.5%, 75%, 77.5%, 80%, 82.5%, 85%, 87.5%, 90%).
- **Legend**: Located in the bottom-right corner, with:
- Red triangles labeled "critical tokens"
- Purple stars labeled "self-consistency"
### Detailed Analysis
1. **Critical Tokens (Red Line)**:
- Starts at ~77% when k=5.
- Increases steadily to ~89% at k=50.
- Slope: Steeper upward trend compared to "self-consistency."
- Key data points:
- k=10: ~82.5%
- k=20: ~85%
- k=30: ~86.5%
- k=40: ~88%
- k=50: ~89%
2. **Self-Consistency (Purple Line)**:
- Starts at ~70% when k=5.
- Increases to ~84% at k=50.
- Slope: Gradual upward trend, less steep than "critical tokens."
- Key data points:
- k=10: ~77%
- k=20: ~80%
- k=30: ~83%
- k=40: ~83.5%
- k=50: ~84%
### Key Observations
- Both metrics show **positive correlation** between sample size (k) and performance (pass@k).
- "Critical tokens" maintains a **~5–6% performance advantage** over "self-consistency" across all sample sizes.
- The performance gap narrows slightly at higher k values (e.g., ~5% at k=5 vs. ~4.5% at k=50).
- No outliers or anomalies detected in either dataset.
### Interpretation
The data suggests that "critical tokens" are a more effective method for improving pass@k performance compared to "self-consistency," particularly at smaller sample sizes. While both approaches benefit from increased sampling, the efficiency of "critical tokens" implies it may be preferable in resource-constrained scenarios. The narrowing gap at larger k values hints at potential convergence, but "critical tokens" retains a consistent edge, indicating inherent methodological advantages. This could inform optimization strategies in systems where token selection or consistency mechanisms are critical.
</details>
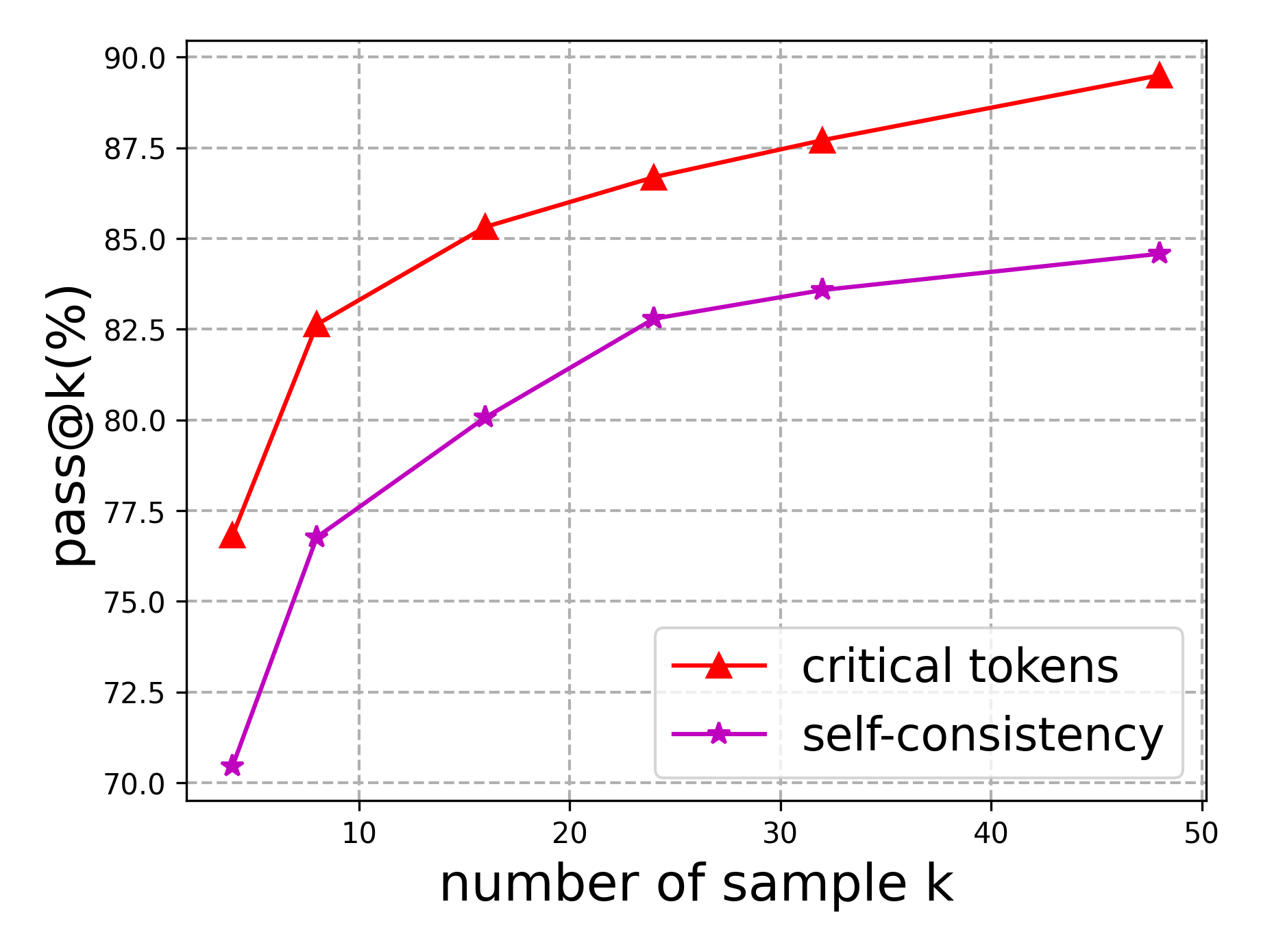
Figure 1: Comparison of the effects of critical tokens and Self-Consistency on the reasoning performance of LLMs, evaluated on samples from the GSM8K training data.
## 1 Introduction
The emergence of large language models (LLMs) (Brown et al., 2020; Grattafiori et al., 2024; Achiam et al., 2023; Yang et al., 2025a) has astonished the AI community with their remarkable capabilities across a wide range of reasoning tasks, including mathematical problem solving, programming, and planning. By generating intermediate reasoning steps through techniques such as chain-of-thought prompting (Wei et al., 2022; Kojima et al., 2022; Zhang et al., 2022; Sprague et al., 2025), LLMs can emulate human-like reasoning processes and achieve strong performance on diverse reasoning benchmarks. Despite their success, the problem-solving ability of LLMs often declines on complex reasoning tasks due to hallucinations and the accumulation of errors in intermediate steps (Lightman et al., 2023; Ling et al., 2023; Bubeck et al., 2023). To mitigate this issue, prior works (Wang et al., 2024; Yuan et al., 2025; Chen et al., 2024a; Chen and Li, 2024) have proposed the inference-time optimization paradigm, which evaluates and refines reasoning trajectories through self-correction by the LLM itself or with feedback from external verifiers such as process reward models (PRMs) (Uesato et al., 2022). However, existing studies (Yang et al., 2025b; Tyen et al., 2024; Stechly et al., 2025) suggest that LLMs struggle to reliably identify errors in their reasoning and often fail to correct previous outputs without external guidance. Moreover, obtaining high-quality, stepwise process supervision for training external verifiers is challenging and limits the practicality of these approaches (Feng et al., 2025).
<details>
<summary>images/para_example.png Details</summary>

### Visual Description
## Screenshot: Case Study on the Effects of Question Paraphrasing
### Overview
The image compares two versions of a problem-solving response: an **original question/response** (left column) and a **paraphrased question/response** (right column). Both sections include step-by-step reasoning, color-coded highlights (red for original, purple for paraphrased), and symbols (✗/✓) indicating correctness. The ground truth answer (8) is provided for both questions.
---
### Components/Axes
#### Left Column (Original Question/Response):
- **Original Question**:
- Text: "In a card game, you are awarded 10 points if you win one round. While playing, Jane ends up with 60 points. If she lost 20 points, then how many rounds did she play? (ground truth answer: 8)"
- **Response**:
- **Step 1**: "Determine the total points Jane earned by subtracting the points she lost from her final score. Total points earned = Final score - Points lost. Total points earned = 60 – 20. Total points earned = 40."
- Highlight: Red text for "subtracting the points she lost."
- **Step 2**: "Since Jane earns 10 points for each round she wins, we can find the number of rounds she played by dividing the total points earned by the points earned per round. Number of rounds = Total points earned / Points earned per round. Number of rounds = 40 / 10. Number of rounds = 4."
- **Conclusion**: "Therefore, Jane played 4 rounds."
- Symbol: ✗ (incorrect).
#### Right Column (Paraphrased Question/Response):
- **Paraphrased Question**:
- Text: "At a bridge competition, every game won grants the player 10 points. Unfortunately, Jane started with an advantage but ended up losing 20 points and scoring only 60 points. If she had won x rounds and lost none, what would be the value of x? (ground truth answer: 8)"
- **Response**:
- **Step 1**: "Understand the given information. Jane started with an advantage but ended up losing 20 points. She scored a total of 60 points. Every game won grants the player 10 points."
- **Step 2**: "Determine the total points Jane would have had if she hadn’t lost any points. Since she lost 20 points, we need to add 20 to her total score. Total points without loss = 60 + 20 = 80 points."
- Highlight: Purple text for "add 20 to her total score."
- **Step 3**: "Calculate the number of games Jane won. Since every game won grants the player 10 points, we can divide the total points without loss by 10 to find the number of games won. Number of games won = Total points without loss / 10 = 80 / 10 = 8."
- Highlight: Purple text for "divide the total points without loss by 10."
- **Conclusion**: "The number of games she won is equal to 8."
- Symbol: ✓ (correct).
---
### Detailed Analysis
#### Original Response:
1. **Step 1**:
- Calculation: `60 (final score) – 20 (points lost) = 40 (total points earned)`.
- Highlight: Red text emphasizes the subtraction of lost points.
2. **Step 2**:
- Calculation: `40 (total points earned) / 10 (points per round) = 4 (rounds played)`.
- Error: Concludes 4 rounds, conflicting with the ground truth answer (8).
#### Paraphrased Response:
1. **Step 1**:
- Restates the problem’s conditions without numerical calculations.
2. **Step 2**:
- Adjusts for lost points: `60 (scored) + 20 (lost) = 80 (total without loss)`.
- Highlight: Purple text clarifies the adjustment for lost points.
3. **Step 3**:
- Calculation: `80 (total without loss) / 10 (points per game) = 8 (games won)`.
- Matches the ground truth answer (8).
---
### Key Observations
1. **Divergent Approaches**:
- The original response subtracts lost points directly from the final score, leading to an incorrect conclusion (4 rounds).
- The paraphrased response adds lost points back to the final score before calculating wins, aligning with the ground truth (8 games).
2. **Color Coding**:
- Red highlights in the original response draw attention to the subtraction step, which introduces the error.
- Purple highlights in the paraphrased response emphasize the correction (adding lost points).
3. **Symbols**:
- The ✗ next to the original response and ✓ next to the paraphrased response visually validate the accuracy of each approach.
---
### Interpretation
1. **Impact of Paraphrasing**:
- The paraphrased question clarifies the problem’s conditions (e.g., "losing 20 points" vs. "ending up with 60 points"), reducing ambiguity. This leads to a correct solution.
- The original question’s phrasing ("if she lost 20 points") may mislead solvers into misinterpreting whether points are subtracted or added back.
2. **Error Source**:
- The original response incorrectly assumes that "losing 20 points" reduces the total points earned, rather than adjusting the final score to reflect the net gain.
3. **Ground Truth Alignment**:
- The paraphrased response’s conclusion (8 games) matches the ground truth, demonstrating that precise problem restatement improves accuracy.
4. **Visual Cues**:
- Color coding and symbols (✗/✓) serve as immediate indicators of correctness, aiding in rapid evaluation of problem-solving strategies.
---
**Conclusion**: Paraphrasing questions can enhance clarity and reduce misinterpretation, directly influencing the accuracy of solutions. The original response’s error stems from a misstep in handling lost points, while the paraphrased version’s structured adjustments yield the correct result.
</details>
Figure 2: Case study illustrating that LLMs can refine intermediate incorrect reasoning segments (highlighted in red).
Recent work has introduced the concept of critical tokens (Lin et al., 2025), which play pivotal roles in intermediate reasoning steps and exert strong influence on subsequent reasoning and final outcomes. We evaluate the criticality of a token based on the average accuracy of sampling rollouts generated from the partial reasoning trajectories truncated at the token’s position. A token is identified as critical if it lies on an incorrect trajectory and satisfies the following conditions:
- The correctness score of rollouts initiated from the token is close to zero (e.g., below 5%);
- The correctness scores of rollouts initiated from subsequent tokens remain below a threshold (e.g., 10%).
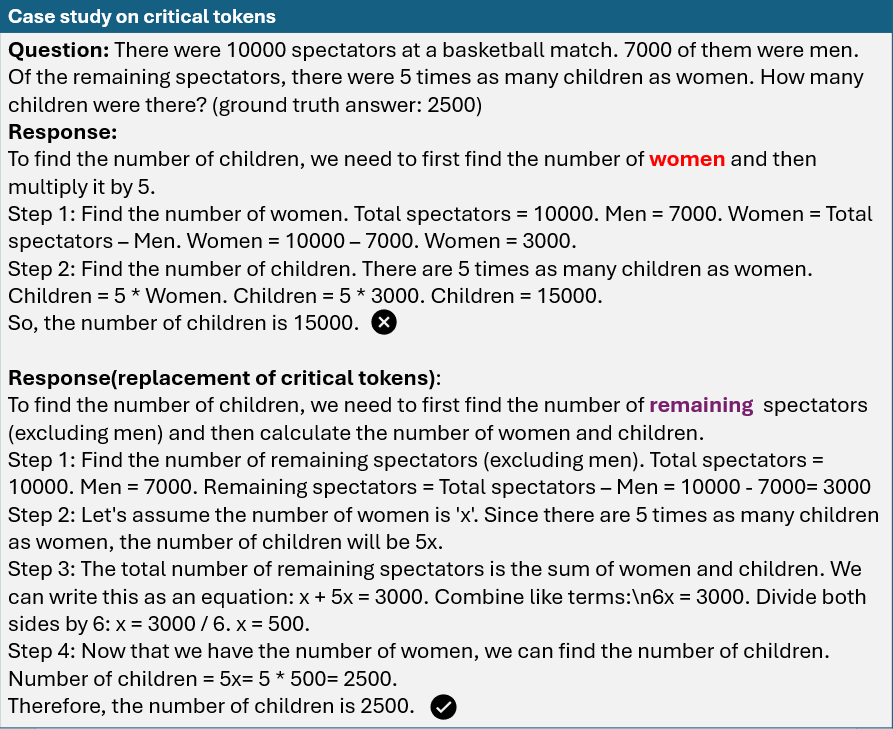
Prior studies suggest that critical tokens often diverge from human-annotated error tokens, yet they induce more sustained degradation in reasoning quality than other tokens. Moreover, as illustrated in Figure 3, replacing critical tokens in an incorrect reasoning trajectory with suitable candidate tokens can correct subsequent steps and lead to the right answer in new rollouts. To quantitatively assess the effectiveness of critical tokens, we conduct an empirical study using LLMs such as Llama-3.1-8B-Instruct (Grattafiori et al., 2024) on reasoning tasks. Specifically, we randomly sample 100 instances with incorrect reasoning steps from the GSM8K (Cobbe et al., 2021) training data. Following the criterion, we locate critical tokens through exhaustive search. We then truncate the reasoning path at the critical token, substitute it with alternative tokens, and roll out new reasoning paths. For example, as shown in Figure 3, the token “woman” is replaced with “remaining”. We evaluate performance using Pass@k and compare against Self-Consistency (Wang et al., 2023), which also samples multiple reasoning paths. As shown in Figure 1, critical token replacement provides a clear advantage in correcting errors compared to plain sampling. Nonetheless, reliably identifying and leveraging critical tokens for reasoning remains a nontrivial challenge.
<details>
<summary>images/critical_token_example.png Details</summary>
### Visual Description
## Text-Based Case Study: Basketball Spectator Problem
### Overview
The image presents a mathematical problem-solving scenario involving critical token replacement in a case study. It contains a question about calculating the number of children at a basketball match, followed by two responses: one incorrect and one correct with critical tokens highlighted.
### Components/Axes
- **Question Section**:
- Text: "There were 10000 spectators at a basketball match. 7000 of them were men. Of the remaining spectators, there were 5 times as many children as women. How many children were there? (ground truth answer: 2500)"
- **Response Sections**:
- **Incorrect Response**:
- Contains a calculation error (children = 15000)
- Highlights "women" in red
- **Correct Response**:
- Contains algebraic solution with critical tokens replaced
- Highlights "remaining" in purple
- Uses checkmark (✓) and cross (✗) symbols for verification
### Detailed Analysis
#### Incorrect Response Analysis
1. **Step 1**: Calculates women = 10000 - 7000 = 3000 (incorrectly includes men in total)
2. **Step 2**: Children = 5 * 3000 = 15000 (flawed premise due to Step 1 error)
3. **Critical Token**: "women" highlighted in red
#### Correct Response Analysis
1. **Step 1**:
- Remaining spectators = 10000 - 7000 = 3000 (excludes men)
- Highlights "remaining" in purple
2. **Step 2**:
- Lets women = x, children = 5x
- Equation: x + 5x = 3000 → 6x = 3000 → x = 500
3. **Step 3**:
- Children = 5 * 500 = 2500
4. **Verification**:
- Correct answer marked with checkmark (✓)
### Key Observations
- The incorrect response fails to exclude men when calculating remaining spectators
- The correct response properly isolates the relevant population (non-men spectators)
- Algebraic substitution (x for women) enables accurate calculation
- Visual indicators (colors, symbols) differentiate critical elements and solution validity
### Interpretation
This case study demonstrates the importance of:
1. **Population Isolation**: Correctly identifying which groups to include/exclude in calculations
2. **Algebraic Substitution**: Using variables to represent unknown quantities in proportional relationships
3. **Critical Token Identification**: Highlighting key terms that require special attention in problem-solving
4. **Step Verification**: Using visual markers to validate solution accuracy
The ground truth answer (2500 children) is achieved through proper exclusion of men and correct application of the 5:1 women-to-children ratio. The incorrect response's 15000 result stems from a fundamental misunderstanding of the problem's constraints regarding spectator demographics.
</details>
Figure 3: An example demonstrating how substitution of a critical token (red) with a candidate token (purple) modifies the reasoning path and produces the correct answer.
Recent studies (Zhou et al., 2024; Chen et al., 2024b), on surface form, the way questions, assumptions, and constraints are phrased, have revealed its subtle influence on the trajectory of intermediate reasoning steps, As shown in Figure 2. LLMs could adjust the intermediate steps under the paraphrased form of the question. This motivates us to explore the role of paraphrasing in the extraction and utilization of critical tokens for reasoning tasks. To this end, we propose the P araphrastic P robing and C onsistency V erification (PPCV) framework , a two-stage approach designed to leverage critical tokens to enhance the reasoning ability of LLMs. In the first stage, we probe critical tokens using paraphrased questions. Specifically, we first roll out the initial reasoning path from the original question, then concatenate paraphrased questions with this reasoning path. The resulting synthetic inputs are fed into the LLM to obtain token-level logits for each position in the reasoning path. Positions where the predicted top-1 token diverges from the expected token are flagged as potential pivotal points, as these positions are sensitive to paraphrased inputs and can trigger a pivot in the reasoning trajectory. Next, an empirical criterion is applied to determine the final critical token. In contrast to prior work (Lin et al., 2025), which depends on external models for identifying critical tokens with ambiguous criteria, our method introduces a self-contained mechanism that pinpoints critical tokens.
In the second stage, we leverage the extracted critical tokens to refine the initial reasoning path. Specifically, we select the top-K tokens (include critical token itself) at the critical token position and roll out new reasoning paths for both the original and paraphrased questions. Based on the empirical observation that trajectories leading to correct answers are robust to paraphrastic perturbations, we propose a paraphrase consistency mechanism. In contrast to Self-Consistency (Wang et al., 2023), which relies on majority voting, our method selects the final answer by comparing outputs from paraphrased and original questions and choosing the one with the most consistent matches. To address potential ties across multiple answers, we further introduce similarity-weighted paraphrase consistency, which incorporates similarity scores between paraphrased and original questions when computing consistency.
Compared with self-correction (Wu et al., 2024; Miao et al., 2024) and PRM-based methods (Wang et al., 2024; Yuan et al., 2025), our framework exploits critical tokens to refine reasoning trajectories without requiring step-level error detection by the LLM itself or auxiliary models. We evaluate our method on mainstream LLMs across mathematical and commonsense reasoning benchmarks, demonstrating consistent improvements in reasoning performance. The contributions of the paper is summarized as follows:
- We propose a novel two-stage framework, P araphrastic P robing and C onsistency V erification (PPCV) designed to extract and leverage critical tokens to enhance the reasoning performance of LLMs.
- We show that critical tokens can more effectively correct erroneous reasoning trajectories than traditional sampling methods like Self-Consistency. Furthermore, our approach successfully extracts these tokens through paraphrastic probing, achieving improved final results via paraphrase consistency.
- We evaluate our method on mainstream LLMs across various reasoning tasks, including math and logic reasoning. Experimental results show significant performance improvements over baseline methods.
## 2 Related Work
Inference-Time Optimization for LLM reasoning. With the advent of chain-of-thought (CoT) prompting, LLMs have demonstrated strong reasoning capabilities by producing intermediate steps during inference. This success has motivated a growing body of work (Wu et al., 2025; Snell et al., 2024) on augmenting reasoning trajectories at test time to further improve performance. Existing approaches can be broadly categorized into search-based methods (Bi et al., 2025; Yao et al., 2023; Hao et al., 2023; Xie et al., 2023; Besta et al., 2024), such as Tree-of-Thoughts (Yao et al., 2023), and sampling-based methods (Wang et al., 2023; Xu et al., 2025; Wan et al., 2025; Ma et al., 2025), such as Self-Consistency (Wang et al., 2023). However, due to intrinsic hallucinations (Bubeck et al., 2023), LLMs often generate erroneous intermediate steps, which can ultimately lead to incorrect answers, especially on complex problems. This limitation highlights the need for inference-time optimization of reasoning processes.
To address this issue, one line of research (Yin et al., 2024; Chen et al., 2024a; Ling et al., 2023; Wu et al., 2024; Miao et al., 2024; Madaan et al., 2023) designs instructional prompts that guide LLMs to detect and refine their own mistakes. Despite its appeal, prior work has shown that the effectiveness of self-correction is limited in practice. Another line of work (Wang et al., 2024; Yuan et al., 2025; He et al., 2024; Havrilla et al., 2024) introduces external verifiers, such as process reward models (Snell et al., 2024), to identify and filter out error-prone reasoning steps. These methods typically require high-quality training data for the verifier, with data scarcity often mitigated through strategies such as Monte Carlo Tree Search (Guan et al., 2025; Qi et al., 2025; Li, 2025; Zhang et al., 2024). In addition, a recent line of decoding-based approaches (Xu et al., 2025; Ma et al., 2025) seeks to improve reasoning by dynamically adjusting the next-token prediction based on future trajectory probing. In contrast, our method refines reasoning by directly leveraging critical tokens, without relying on stepwise verification or external verifiers. This design underscores both the utility and universality of our approach.
Paraphrasing for LLMs. A growing number of work (Zhou et al., 2024; Chen et al., 2024b) has examined the impact of a problem’s surface form on the reasoning ability of LLMs. Findings (Zhou et al., 2024; Chen et al., 2024b; Huang et al., 2025) suggest that even subtle modifications in phrasing can substantially affect both the reasoning process and the final outcome. Building on this observation, several methods (Yadav et al., 2024; Chen et al., 2024b) leverage beneficial paraphrasing to enhance LLM performance in tasks such as reasoning and intent classification. In addition, paraphrasing has been employed to assess model uncertainty (Gao et al., 2024; Tanneru et al., 2024), thereby enhancing the reliability and trustworthiness of LLM applications. In our work, we utilize paraphrasing as a principled tool to extract critical tokens and to aggregate answers.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Flowchart: Answer Verification Process via Paraphrasing and Consistency Analysis
### Overview
The image depicts a two-phase flowchart for verifying answers to a problem-solving task. Phase I focuses on paraphrasing the original question and generating initial responses, while Phase II emphasizes consistency verification through critical token analysis. The process uses color-coded text boxes (blue for questions, orange for responses) and arrows to indicate workflow.
### Components/Axes
- **Phases**:
- **Phase I: Paraphrastic Probing** (left column)
- **Phase II: Consistency Verification** (right column)
- **Steps**:
- Each phase contains 4 steps (Step 1–4), with text boxes containing:
- Original/paraphrased questions
- Initial responses
- Probability calculations
- Critical token identification
- **Visual Elements**:
- Arrows connecting steps
- Color coding (blue/orange for question/response)
- Checkmark icon for final answer validation
### Detailed Analysis
#### Phase I: Paraphrastic Probing
1. **Step 1**:
- Original question: "A bakery produces 60 loaves of bread each day... How many loaves of bread are sold in the afternoon?"
- Paraphrased version: "In a bustling bakery, daily production meets the demand for 60 freshly baked loaves... What is the number of loaves sold in the afternoon?"
- Example response: "Step 1: Calculate the number of loaves sold in..." (incomplete)
2. **Step 2**:
- Initial response example: "To solve this problem, we will break it down into steps. Step 1: Calculate the number of loaves sold in..." (error: states "5" instead of correct "10")
3. **Step 3**:
- Concatenated question-response pair: "In a bustling bakery... What is the number of loaves sold in the afternoon? To solve this problem, we will break it down into steps. Step 1: Calculate the number of loaves sold in..." (incomplete)
4. **Step 4**:
- Critical token identification: "The token 'in' is the chosen critical token" (based on probability calculations)
#### Phase II: Consistency Verification
1. **Step 1**:
- Candidate token extraction: "during", "the" (highlighted in red)
2. **Step 2**:
- Truncated response: "Step 1: Calculate the number of loaves sold during..." (original) vs. "Step 1: Calculate the number of loaves sold the..." (paraphrased)
3. **Step 3**:
- New trajectories generated for both original and paraphrased versions, with variations in:
- Morning/afternoon sales calculations
- Fractional loaf distributions (e.g., "two-thirds of the day")
4. **Step 4**:
- Final answer determination: "The answers derived from the second input are more consistent... Thus, the final answer is 10" (validated with green checkmark)
### Key Observations
- **Structural Consistency**: Both phases follow a 4-step progression with parallel processing of original/paraphrased versions.
- **Error Propagation**: Initial response in Phase I Step 2 contains an incorrect value ("5" instead of "10"), which is corrected in Phase II.
- **Critical Token Focus**: The token "in" (Phase I) and "the" (Phase II) are identified as pivotal for answer consistency.
- **Probabilistic Weighting**: Step 3 includes probability distributions (e.g., p(solution)=0.92, p(number)=0.25) to guide token selection.
### Interpretation
This flowchart demonstrates a systematic approach to answer verification through:
1. **Paraphrasing**: Generating alternative question formulations to test response robustness
2. **Critical Token Analysis**: Identifying key linguistic elements that determine answer consistency
3. **Iterative Refinement**: Using probabilistic weighting to resolve ambiguities between initial responses
The process highlights the importance of:
- **Linguistic Precision**: Small token changes ("during" vs. "the") significantly impact answer consistency
- **Error Correction**: Phase II's consistency mechanism successfully identifies and rectifies initial response errors
- **Probabilistic Reasoning**: Quantitative analysis of token probabilities enables data-driven answer validation
The green checkmark in Phase II Step 4 confirms the effectiveness of the consistency verification mechanism in arriving at the correct answer (10 loaves sold in the afternoon).
</details>
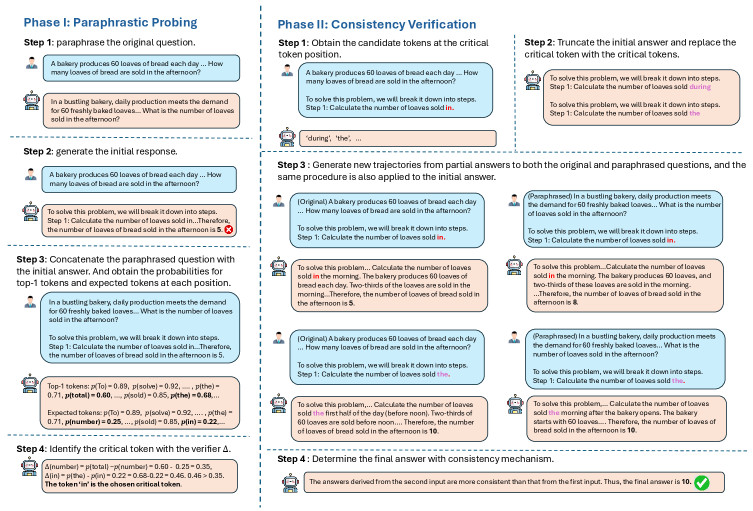
Figure 4: Illustration of the proposed paraphrastic probing and consistency verification (PPCV) framework. The framework comprises two stages: (i) probing critical tokens through paraphrased forms, and (ii) rolling out new reasoning steps with alternative tokens and selecting the final answer using the paraphrase consistency verification mechanism.
<details>
<summary>images/probe_illustration.png Details</summary>

### Visual Description
## Screenshot: Case Study on Critical Tokens in Problem Solving
### Overview
The image presents a case study comparing two responses to a math problem involving point calculations in a game. It highlights critical tokens (color-coded keywords) to analyze reasoning errors and correct solutions. The problem involves determining the number of rounds/games played based on point gains/losses.
### Components/Axes
- **Title**: "Case study on the identification and effects of critical tokens" (top blue banner).
- **Original Question**:
- Text: "In a card game, you are awarded 10 points if you win one round. While playing, Jane ends up with 60 points. If she lost 20 points, then how many rounds did she play? (ground truth answer: 8)"
- **Paraphrased Question**:
- Text: "At a bridge competition, every game won grants the player 10 points. Unfortunately, Jane started with an advantage but ended up losing 20 points and scoring only 60 points. If she had won x rounds and lost none, what would be the value of x? (ground truth answer: 8)"
- **Responses**:
- **Response 1** (incorrect):
- Steps with color-coded tokens:
1. "Determine [Understand] the total points Jane earned scored by [. ] subtracting [winning] the points she lost from her [the] final score. Total points earned = 60 – 20. Points lost. Total points earned = 40."
2. "Since Jane earns 10 points for [per] each round she [won] wins, we can find the number of rounds she played by dividing the total points earned by the points earned per round. Number of rounds = 40 / 10. Number of rounds = 4."
- Final answer: "Therefore, Jane played 4 rounds." (marked with ❌).
- **Response 2** (correct):
- Steps with color-coded tokens:
1. "Determine the total points Jane earned by winning games. Since Jane scored 60 points and lost 20 points, we can set up an equation to represent the situation. Total points = Points earned from winning + Points lost. We know that Jane lost 20 points, so we can subtract this from the total points to find the points earned from winning. 60 = Points earned from winning – 20."
2. "Solve for the points earned from winning. Add 20 to both sides of the equation to isolate the points earned from winning. 60 + 20 = Points earned from winning. 80 = Points earned from winning."
3. "Determine the number of games won. Since Jane earns 10 points for each game won, we can divide the points earned from winning by 10 to find the number of games won. Number of games won = 80 / 10 = 8."
- Final answer: "8" (marked with ✅).
### Content Details
- **Color-Coded Tokens**:
- **Red**: "Determine" (Step 1), "points earned" (Step 2).
- **Purple**: "Understand" (Step 1), "winning" (Step 1).
- **Blue**: "per" (Step 2), "won" (Step 2).
- **Green**: "games won" (Step 3), "10" (Step 3).
- **Ground Truth Answers**:
- Both questions have a ground truth answer of **8**.
- **Annotations**:
- ✅ (correct) and ❌ (incorrect) symbols next to final answers.
### Key Observations
1. **Critical Token Identification**:
- Tokens like "Determine," "Understand," and "won" are highlighted to emphasize logical steps and potential errors.
2. **Reasoning Errors**:
- Response 1 incorrectly subtracts lost points from the final score (60 – 20 = 40) instead of adding them to isolate points earned from winning.
- Response 2 correctly sets up the equation (60 = Points earned – 20) and solves for the correct value (80 points earned from winning).
3. **Structural Differences**:
- Response 1 uses ambiguous phrasing ("scored by [. ] subtracting [winning]"), while Response 2 uses precise algebraic reasoning.
### Interpretation
The case study demonstrates how critical tokens (keywords) guide the identification of reasoning flaws. Response 1’s error stems from misapplying arithmetic operations (subtracting lost points instead of adding them), while Response 2 correctly isolates variables using algebraic principles. The color-coding of tokens helps trace the flow of logic, revealing how minor phrasing differences ("per round" vs. "per game") and operational errors (subtraction vs. addition) lead to divergent conclusions. This underscores the importance of precise language and step-by-step validation in problem-solving.
**Note**: No numerical data trends or visualizations (e.g., charts) are present; the focus is on textual analysis and token-based reasoning.
</details>
Figure 5: Case study illustrating the identification and effects of critical tokens identified by our method. Tokens highlighted in red indicate candidate critical tokens, whereas tokens highlighted in purple correspond to alternative tokens generated when conditioning on paraphrased questions.
## 3 Methodology
In this section, we present the two components of our framework in detail: paraphrastic probing and consistency verification. An detailed illustration of our framework is shown in Figure 4. We then discuss the proposed method and provide the complete algorithm.
### 3.1 Paraphrastic Probing
Previous findings (Zhou et al., 2024; Chen et al., 2024b; Huang et al., 2025) on the impact of a problem’s surface form suggest that the quality of intermediate reasoning steps is influenced not only by the underlying mathematical relationships and logic, but also by how the problem is expressed. Notably, LLMs are sometimes able to solve a paraphrased version of a problem that they fail to solve in its original form, highlighting the potential of paraphrasing to uncover pivotal tokens that are critical for successful reasoning. Motivated by this observation, we introduce paraphrastic probing to efficiently identify the critical token. Given the original question $q_{0}$ , we first prompt the LLM to generate multiple paraphrased forms, denoted as $q_{1},q_{2},...,q_{N}$ , where $N$ is the number of the paraphrased questions. We adopt Automatic Prompt Engineering (APE) (Zhou et al., 2022) to derive paraphrasing instructions that preserve semantic integrity and all numerical values, mathematical relationships, and core logical structures of the problem, while maximizing linguistic and contextual diversity. Additional details can be found in Appendix B. We then obtain the initial reasoning path $r^{q_{0}}_{0}$ for the original question using greedy decoding. This reasoning path is subsequently concatenated with each paraphrased question, and the resulting synthetic inputs are fed into the LLM to compute the token probability distribution at each position in $r^{q_{0}}_{0}$ . Specifically, the token probability distribution at $i$ th position conditioned on the paraphrased question $q_{n}$ is expressed as
$$
P_{i}^{q_{n}}=\text{LLM}(\tilde{a}_{i}|\mathcal{I},q_{n},r^{q_{0}}_{0,<i}), \tag{1}
$$
where $\mathcal{I}$ denotes the instruction prefix and $\tilde{a}_{i}$ represents the sampled token at $i$ th position. The token $\tilde{a}_{i}$ is regarded as a candidate critical token if predicted top-1 token does not match the expected token at the same position in $r^{q_{0}}_{0}$ , i.e.,
$$
\operatorname*{arg\,max}P_{i}^{q_{n}}\neq a_{i}, \tag{2}
$$
where $a_{i}$ denotes the token at the $i$ th position in $r^{q_{0}}_{0}$ .
<details>
<summary>images/condition_one_gsm8k.png Details</summary>
### Visual Description
## Bar Chart: Fraction of Critical vs. Random Tokens by Average Accuracy
### Overview
The chart compares the fraction of critical tokens and random tokens across two accuracy thresholds: ≤5% and >5%. Critical tokens (teal) dominate at lower accuracy, while random tokens (light teal) increase as accuracy rises above 5%.
### Components/Axes
- **X-axis**: "Average accuracy(%)" with two categories:
- ≤5% (left)
- >5% (right)
- **Y-axis**: "Fraction(%)" ranging from 0 to 70.
- **Legend**:
- Teal: Critical tokens
- Light teal: Random tokens
### Detailed Analysis
- **≤5% Accuracy**:
- Critical tokens: 70% (error bar: ±3%)
- Random tokens: 32% (error bar: ±4%)
- **>5% Accuracy**:
- Critical tokens: 31% (error bar: ±2%)
- Random tokens: 68% (error bar: ±3%)
### Key Observations
1. **Inverse Relationship**: Critical tokens decrease as accuracy increases, while random tokens increase.
2. **Error Bars**: Uncertainty is smallest for critical tokens at >5% accuracy (±2%) and largest for random tokens at ≤5% accuracy (±4%).
3. **Threshold Effect**: The >5% accuracy category shows a stark shift in token distribution compared to ≤5%.
### Interpretation
The data suggests that critical tokens are more prevalent in low-accuracy scenarios, potentially indicating their role in stabilizing or correcting model outputs. Conversely, random tokens dominate in high-accuracy cases, possibly reflecting less impactful or filler tokens. The sharp contrast between the two accuracy thresholds implies a binary behavior: critical tokens are prioritized when accuracy is poor, while random tokens proliferate when the model performs well. The error bars confirm moderate variability, but the trends are statistically significant.
</details>
(a)
<details>
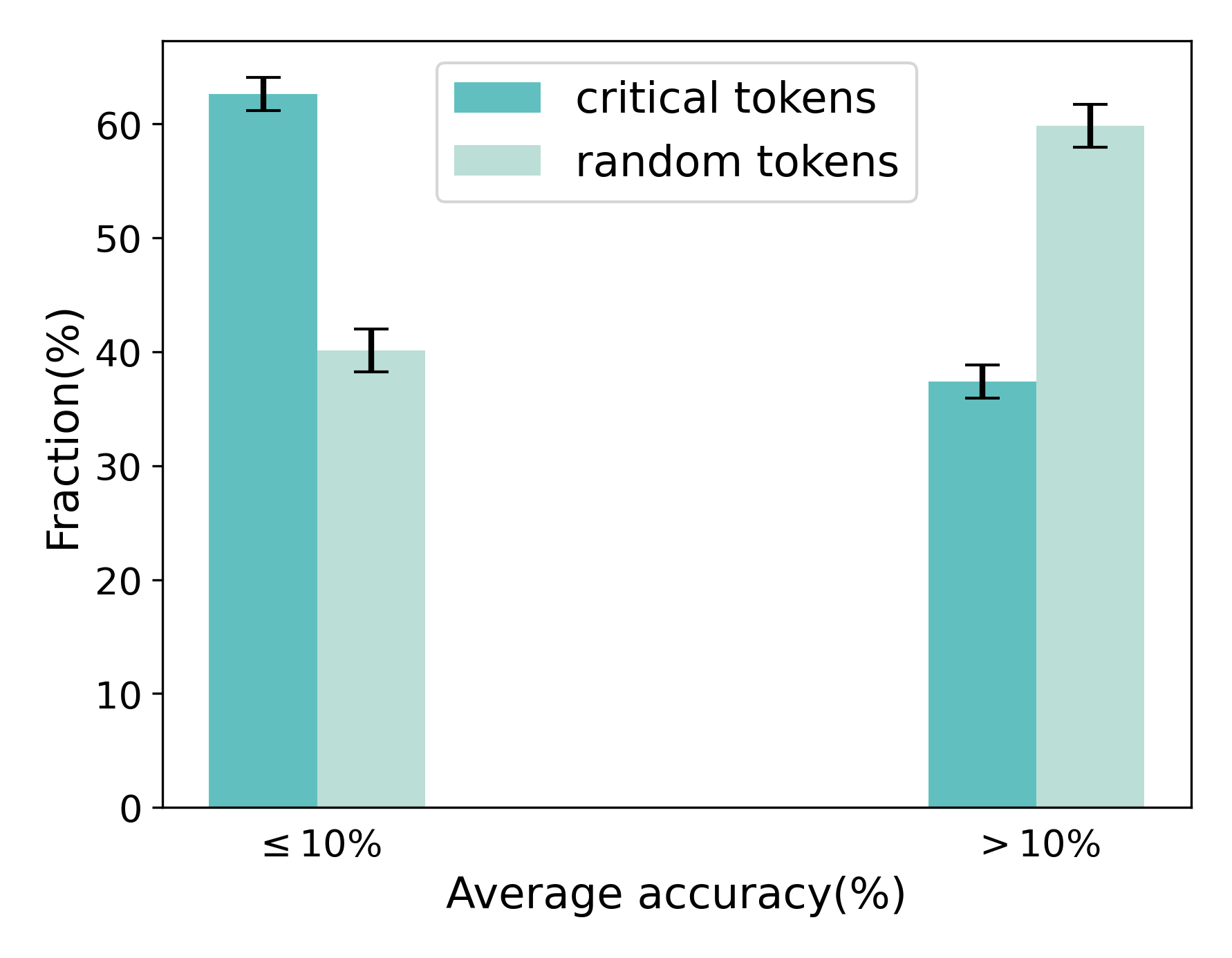
<summary>images/condition_two_gsm8k.png Details</summary>
### Visual Description
## Bar Chart: Fraction of Critical vs. Random Tokens by Average Accuracy
### Overview
The chart compares the fraction of critical tokens and random tokens across two average accuracy thresholds: ≤10% and >10%. Critical tokens are represented in teal, while random tokens are in light green. Error bars indicate measurement uncertainty.
### Components/Axes
- **X-axis**: "Average accuracy(%)" with two categories:
- ≤10% (left)
- >10% (right)
- **Y-axis**: "Fraction(%)" ranging from 0 to 60% in 10% increments.
- **Legend**: Located in the top-right corner, mapping:
- Teal → Critical tokens
- Light green → Random tokens
### Detailed Analysis
1. **≤10% Accuracy**:
- Critical tokens: 62% ±2% (teal bar, tallest in the chart).
- Random tokens: 40% ±3% (light green bar, shorter than critical tokens).
2. **>10% Accuracy**:
- Critical tokens: 38% ±2% (teal bar, shorter than random tokens).
- Random tokens: 60% ±3% (light green bar, tallest in this category).
### Key Observations
- Critical tokens dominate in low-accuracy scenarios (≤10%), while random tokens prevail in higher-accuracy scenarios (>10%).
- Error bars suggest moderate uncertainty, with critical tokens having tighter confidence intervals (±2%) compared to random tokens (±3%).
- The crossover between token types occurs at the 10% accuracy threshold, indicating a potential relationship between token utility and model performance.
### Interpretation
The data suggests that critical tokens are more prevalent when model accuracy is low, possibly reflecting their role in stabilizing or correcting outputs. Conversely, random tokens become more frequent as accuracy improves, potentially indicating their use in exploratory or less constrained contexts. The error margins imply that critical tokens are measured with slightly higher precision, which could reflect their systematic importance in the analyzed system. This pattern might highlight a trade-off between token diversity and model reliability, warranting further investigation into token selection strategies.
</details>
(b)
<details>
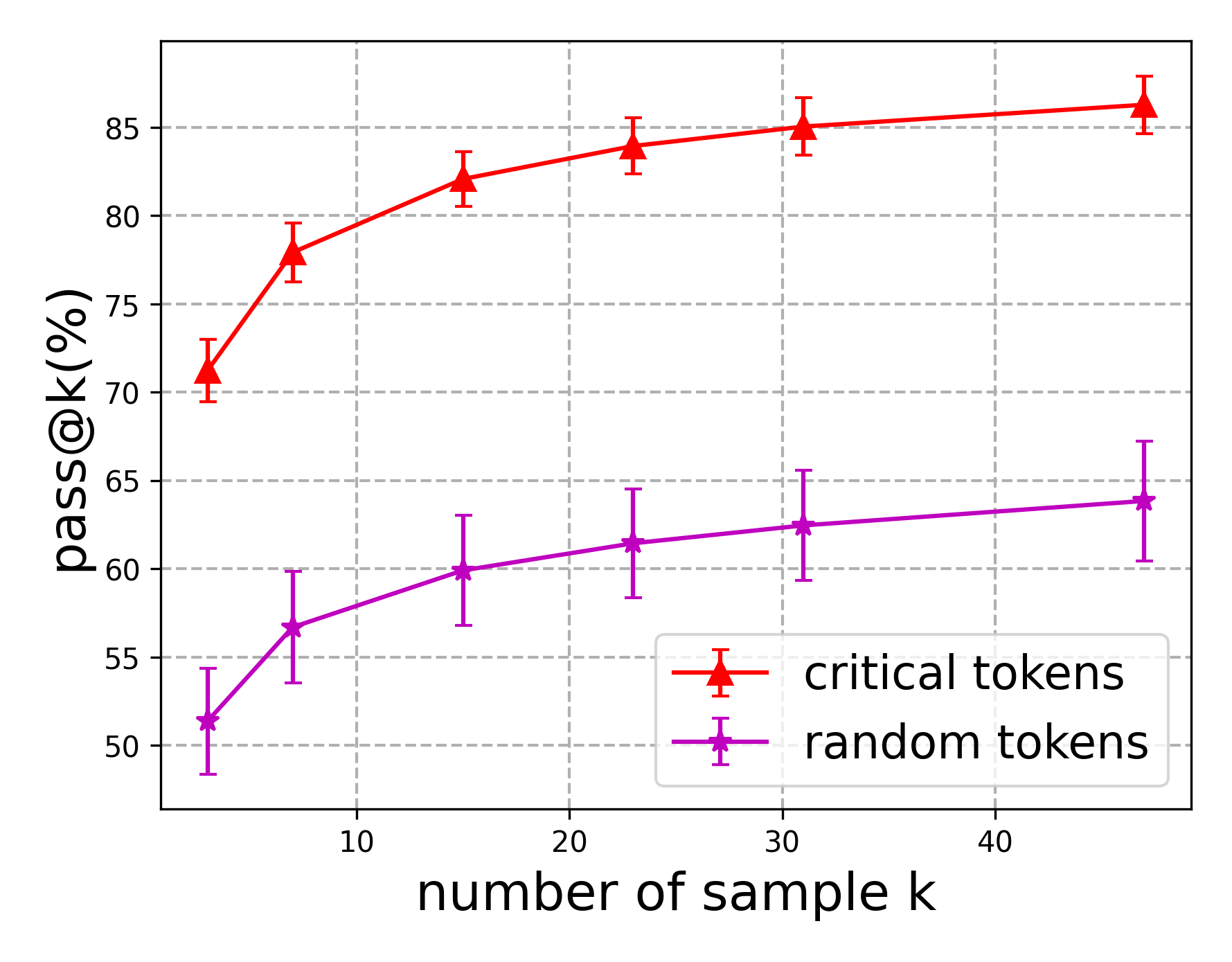
<summary>images/compare_ct_rnd_gsm8k.png Details</summary>
### Visual Description
## Line Graph: Pass@k Performance Comparison
### Overview
The image depicts a line graph comparing the performance of two token selection strategies ("critical tokens" and "random tokens") across varying sample sizes (k). The y-axis represents "pass@k(%)", while the x-axis shows the "number of sample k". Error bars indicate measurement uncertainty for each data point.
### Components/Axes
- **X-axis**: "number of sample k" (ranges from 10 to 40 in increments of 10)
- **Y-axis**: "pass@k(%)" (ranges from 50% to 85% in 5% increments)
- **Legend**: Located at bottom-right, with:
- Red triangles: "critical tokens"
- Purple stars: "random tokens"
- **Error bars**: Vertical lines with caps at both ends, representing ± uncertainty for each data point
### Detailed Analysis
**Critical Tokens (Red):**
- At k=10: 70% ±3% (error bar spans 67–73%)
- At k=20: 78% ±2% (66–80%)
- At k=30: 82% ±1% (81–83%)
- At k=40: 85% ±2% (83–87%)
**Random Tokens (Purple):**
- At k=10: 50% ±5% (45–55%)
- At k=20: 58% ±4% (54–62%)
- At k=30: 62% ±3% (59–65%)
- At k=40: 64% ±4% (60–68%)
### Key Observations
1. **Performance Gap**: Critical tokens consistently outperform random tokens by 16–21 percentage points across all k values.
2. **Error Trends**:
- Random tokens show larger error margins (4–5%) compared to critical tokens (1–3%).
- Error margins for critical tokens decrease as k increases.
3. **Saturation Point**: Both strategies plateau near k=30–40, with diminishing returns in performance gains.
### Interpretation
The data demonstrates that critical token selection significantly improves performance reliability compared to random selection. The narrowing performance gap at higher k values suggests diminishing returns for both strategies, but critical tokens maintain a clear advantage. The smaller error margins for critical tokens indicate more consistent results, making them preferable for applications requiring stable performance. The plateau observed at k≥30 implies that increasing sample size beyond this point yields minimal practical benefits for either strategy.
</details>
(c)
<details>
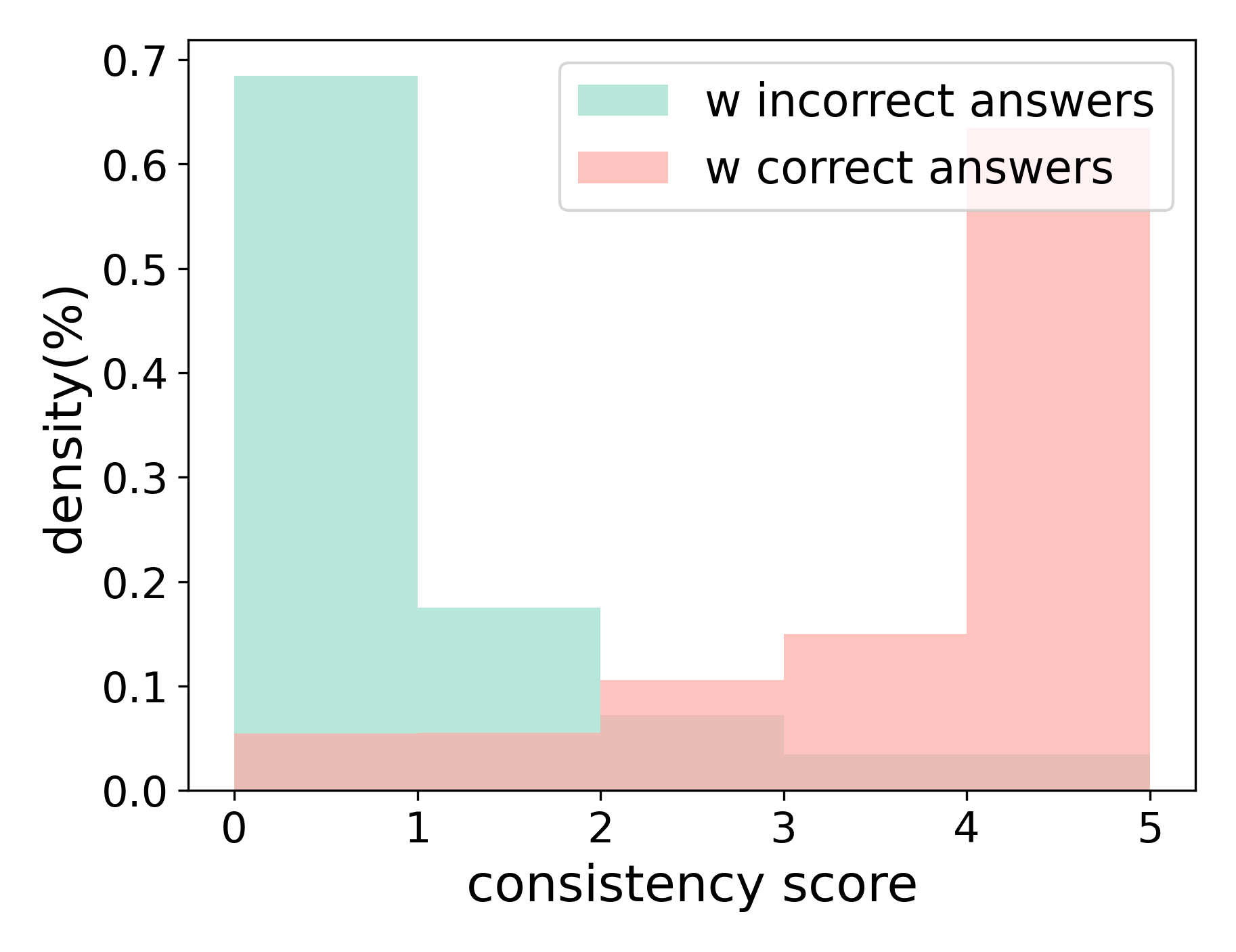
<summary>images/density_gsm8k.png Details</summary>
### Visual Description
## Bar Chart: Consistency Score Density Comparison
### Overview
The chart compares the density distribution of consistency scores for two groups: "w incorrect answers" (green) and "w correct answers" (pink). The x-axis represents consistency scores (0-5), while the y-axis shows density percentages (0-0.7). The data reveals distinct patterns in score distributions between the two groups.
### Components/Axes
- **X-axis**: "consistency score" (integer values 0-5)
- **Y-axis**: "density(%)" (continuous scale 0-0.7)
- **Legend**:
- Green: "w incorrect answers"
- Pink: "w correct answers"
- **Bar Placement**:
- Green bars dominate left side (scores 0-2)
- Pink bars dominate right side (scores 4-5)
- Minimal overlap in middle scores (2-3)
### Detailed Analysis
1. **w incorrect answers (Green)**:
- Score 0: ~0.7 density
- Score 1: ~0.2 density
- Score 2: ~0.1 density
- Scores 3-5: <0.05 density
- *Trend*: Sharp decline from score 0 to 2, negligible presence at higher scores
2. **w correct answers (Pink)**:
- Score 0: ~0.05 density
- Score 1: ~0.05 density
- Score 2: ~0.1 density
- Score 3: ~0.15 density
- Score 4: ~0.4 density
- Score 5: ~0.6 density
- *Trend*: Gradual increase from score 2 to 5, with steep rise at scores 4-5
### Key Observations
- **Inverse Relationship**: Higher consistency scores correlate strongly with correct answers (pink bars peak at 5.0), while incorrect answers cluster at lower scores (green bars peak at 0.0).
- **Middle Score Gap**: Both groups show minimal density between scores 2-3, suggesting a potential threshold effect.
- **Density Extremes**:
- Maximum green density: 0.7 at score 0
- Maximum pink density: 0.6 at score 5
### Interpretation
The data demonstrates a clear dichotomy in consistency scores based on answer correctness. Correct answers consistently yield higher scores (median ~4.5), while incorrect answers cluster at the lowest scores (median ~0.5). The absence of intermediate scores for both groups suggests a binary outcome structure, possibly indicating a pass/fail or correct/incorrect dichotomy in the underlying assessment. This pattern implies that answer accuracy directly determines consistency in responses, with no meaningful middle ground observed in the distribution.
</details>
(d)
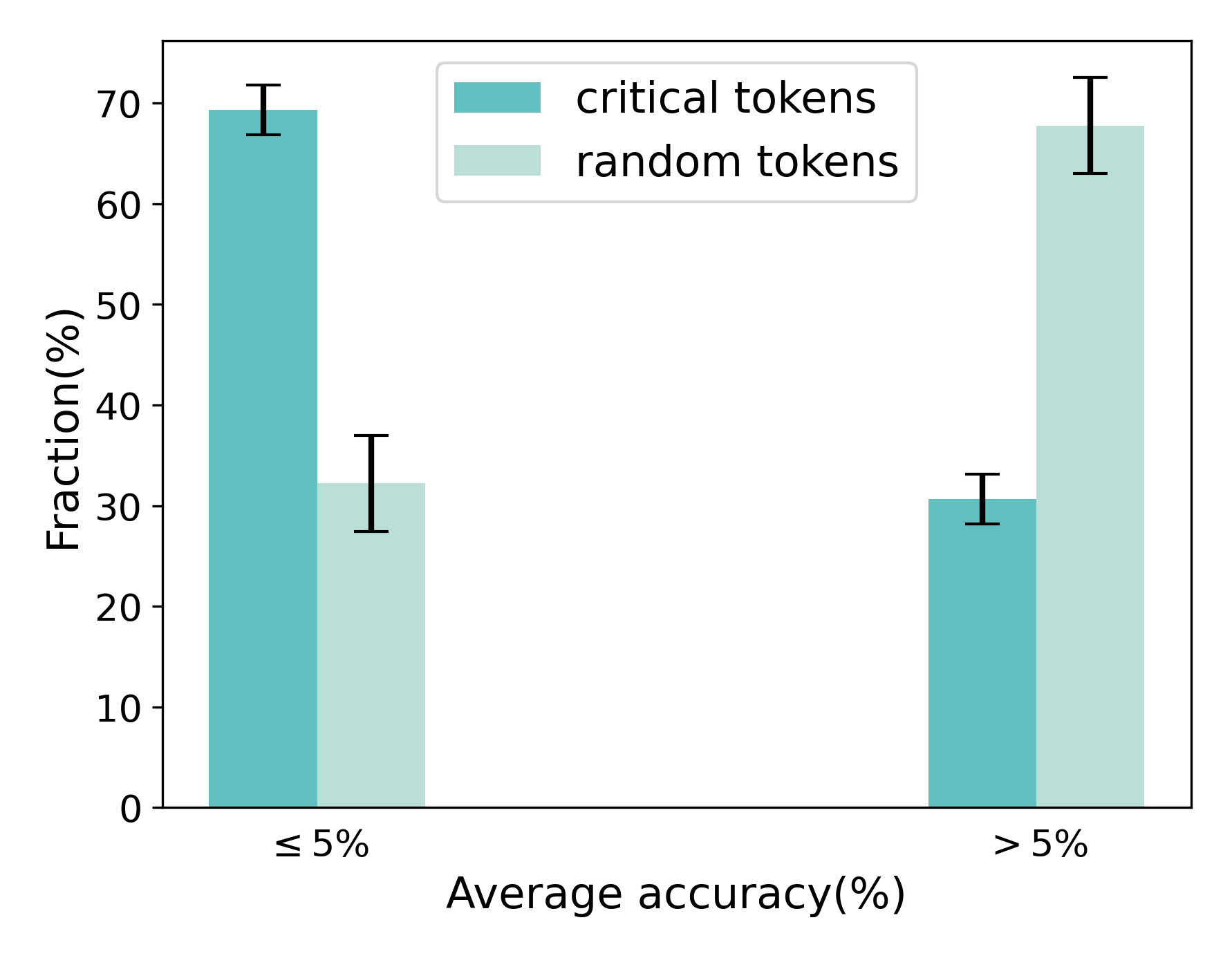
Figure 6: (a) Comparison of the fraction of tokens whose associated rollout correctness falls below or above 5%, for tokens extracted by our method versus randomly selected tokens. (b) Comparison of the fraction of the subsequent tokens whose associated rollout correctness falls below or above 10%, for tokens extracted by our method versus randomly selected tokens. (c) Comparison of the impact of extracted tokens by our method versus random tokens on LLM reasoning performance. (d) Comparison of the density distributions of consistency scores for rollouts with correct and incorrect answers.
To validate the effectiveness of our method in identifying critical tokens and to demonstrate the pivotal role these tokens play when extracted via paraphrastic probing, we conduct a case study illustrated in Figure 5. Because large language models can adjust their reasoning trajectories under the paraphrased form of the question, certain tokens in the original reasoning sequence produce different subsequent tokens when conditioned on paraphrased inputs. In this example, most candidate critical tokens are located within incorrect reasoning segments. Notably, when we identify “subtracting” as a critical token and replace it with an alternative token (i.e., “winning”), the resulting rollout corrects the erroneous reasoning steps and yields the correct final answer. This example highlights the impact of critical tokens and underscores the effectiveness of our method in identifying tokens that are pivotal to reasoning outcomes.
In addition, we conduct a quantitative analysis to examine the authenticity and impact of tokens extracted via paraphrastic probing, comparing them against randomly selected tokens. Specifically, we sample 100 instances with incorrect reasoning trajectories from the GSM8K (Cobbe et al., 2021) training sets. Following the paraphrastic probing pipeline, we identify candidate critical tokens in the early reasoning steps. In each run, we randomly sample 40% of the candidate critical tokens for evaluation and repeat the experiment independently 10 times. For comparison, we apply the same procedure to randomly selected tokens. All evaluations are conducted using Llama-3.1-8B-Instruct (Grattafiori et al., 2024). We first compute the average accuracy of rollouts generated from partial trajectories truncated at the position of the extracted tokens, and compare these results with those obtained from random-token truncation. As shown in Figure 6(a), a large proportion of the extracted tokens exhibit near-zero correctness, consistent with the first criterion of critical tokens. We further evaluate the average accuracy of rollouts initiated from subsequent tokens (5–10 tokens). The results in Figure 6(b) indicate that errors persist beyond the identified positions, supporting the second criterion that critical tokens induce sustained degradation in downstream reasoning. Finally, we substitute the extracted critical tokens with alternative tokens and roll out multiple new reasoning trajectories. As shown in Figure 6(c), replacing critical tokens leads to a significantly larger improvement in reasoning accuracy compared to substituting random tokens. These results further validate both the pivotal role of the identified critical tokens and the effectiveness of our paraphrastic probing method. Additional results can be found in Appendix A.
We introduce a heuristic verifier to select the final critical token from multiple candidates. For a candidate token $a_{i}$ and paraphrased question $q_{n}$ , the verification score is defined as
$$
\Delta_{q_{n}}(a_{i})=\max P^{q_{n}}_{i}-P^{q_{n}}_{i}(\tilde{a}_{i}=a_{i}). \tag{3}
$$
where $P^{q_{n}}_{i}$ denotes the predictive distribution at position $i$ on question $q_{n}$ . Intuitively, $\Delta$ measures how much the predicted top-1 token deviates from the expected token, indicating the token’s potential impact on the reasoning trajectory. For each extracted token $a_{i}$ ,we take the maximum score across paraphrases,
$$
\Delta(a_{i})=\max_{q_{n}}\Delta_{q_{n}}(a_{i}),\vskip-5.69054pt \tag{4}
$$
and select the final critical token as
$$
a_{c}=\operatorname*{arg\,max}_{i}\Delta(a_{i}).\vskip-5.69054pt \tag{5}
$$
### 3.2 Consistency Verification
After identifying the final critical token $a_{c}$ , we aim to refine the original reasoning path with alternative tokens and achieve final answer with paraphrase consistency mechanism. Specifically, we generate a set of alternative tokens $a^{0}_{c},a^{1}_{c},a^{2}_{c},...,a^{K-1}_{c}$ using the LLM conditioned on original question $q_{0}$ , where $a^{0}_{c}$ is the original token in $r^{q_{0}}_{0}$ and the remaining tokens are sampled via top-K sampling. The initial reasoning path is truncated at the position of critical token, and each alternative token is concatenated to form synthetic inputs $\tilde{r}_{c}^{0},\tilde{r}_{c}^{1},\tilde{r}_{c}^{2},...,\tilde{r}_{c}^{K-1}$ . We then roll out new reasoning trajectories for each synthetic input with respect to both the original and paraphrased questions using greedy decoding, denoted as $r^{q_{0}}_{k},r^{q_{1}}_{k},...,r^{q_{N}}_{k}$ for $k=0,1,2,...,K-1$ . Next, for the rollout with the $k$ th alternative token, we compare the answers obtained from the paraphrased forms with that from the original form and compute a consistency score $c_{k}=\sum_{n-1}^{N}\mathbb{I}(\Phi(r^{q_{0}}_{k})=\Phi(r^{q_{n}}_{k}))$ , where $\Phi(\cdot)$ and $\mathbb{I}(\cdot)$ denotes the function that extracts the final answer from a reasoning trajectory and the indicator function, respectively. The answer associated with the highest consistency score is then selected as the final prediction
$$
\text{ans}_{f}=\Phi(r^{q_{0}}_{k}),\text{where}\,k=\operatorname*{arg\,max}_{k}c_{k}.\vskip-11.38109pt \tag{6}
$$
To justify our paraphrase consistency mechanism, we investigate the impact of paraphrased forms on LLM reasoning. We sample instances from the GSM8K (Cobbe et al., 2021) and follow our pipeline to extract critical tokens. From each truncated reasoning trajectory, we roll out multiple reasoning paths by concatenating alternative tokens. For each original question, we generate five paraphrased variants and compute the consistency score for resulting rollouts. The evaluation is conducted on Llama-3.1-8B-Instruct (Grattafiori et al., 2024). We then analyze the distribution of consistency scores for rollouts that yield correct versus incorrect answers. As shown in Figure 6(d), more than 90% of rollouts with correct answers achieve a consistency score of at least 1, whereas this proportion drops to around 30% for rollouts with incorrect answers. This sharp contrast indicates that correct rollouts are more robust across paraphrased variants, motivating the design of our paraphrase consistency mechanism to exploit this property for improved final predictions.
To address potential collisions when multiple answers obtain the same maximum consistency score, we introduce similarity-weighted consistency verification. Inspired by weighted majority voting (Dogan and Birant, 2019), this approach adjusts the influence of each paraphrased form on the consistency score according to its similarity to the original form. Intuitively, paraphrased forms with lower similarity should exert greater weight, as they provide stronger evidence of robustness, whereas those closely resembling the original form contribute less. Concretely, we first extract embeddings for both the original and paraphrased questions and compute their similarity scores as $s_{n}=\text{sim}(q_{0},q_{n})$ , where $\text{sim}(\cdot)$ denotes a similarity measure such as cosine similarity. We then derive weights via a softmax function $w_{n}=\text{softmax}(s_{n})=\frac{\exp(-\lambda s_{n})}{\sum_{n}\exp(-\lambda n)}$ , where $\lambda$ is the temperature scaling coefficient. Finally, the similarity-weighted consistency score is defined as $\tilde{c}_{k}=\sum_{n-1}^{N}w_{n}\mathbb{I}(\Phi(r^{q_{0}}_{k})=\Phi(r^{q_{n}}_{k}))$ . This ensures agreement with more diverse paraphrases contributes more strongly to the final decision.
Table 1: Comparison of our method with baseline approaches on Llama-3.1-8B-Instruct and Mistral-7B-Instruct-v0.2.
| Llama-3.1 Self-Consistency Tree-of-Thought | Chain-of-Thought 80.60 75.74 | 77.40 31.80 33.28 | 28.00 37.80 31.60 | 31.00 85.10 81.20 | 83.00 60.75 80.72 | 58.91 |
| --- | --- | --- | --- | --- | --- | --- |
| Guided Decoding | 75.51 | 32.45 | 31.20 | 81.70 | 81.74 | |
| Predictive Decoding | 81.43 | 40.26 | 34.00 | 85.90 | 84.56 | |
| Phi-Decoding | 86.58 | 39.88 | 38.20 | 84.50 | 85.41 | |
| PPCV (Ours) | 88.24 | 49.73 | 50.00 | 89.60 | 88.31 | |
| Mistral-7B | Chain-of-Thought | 46.45 | 26.91 | 12.20 | 62.40 | 41.42 |
| Self-Consistency | 50.38 | 28.65 | 14.20 | 66.70 | 44.54 | |
| Tree-of-Thought | 50.49 | 25.78 | 11.40 | 60.60 | 41.04 | |
| Guided Decoding | 50.79 | 27.07 | 14.00 | 62.90 | 39.51 | |
| Predictive Decoding | 55.67 | 27.07 | 14.40 | 62.10 | 47.87 | |
| Phi-Decoding | 56.60 | 28.43 | 13.40 | 63.20 | 60.24 | |
| PPCV (Ours) | 56.58 | 31.08 | 14.60 | 69.30 | 69.88 | |
Table 2: Comparison of our method with baseline approaches on Qwen3-32B (non-thinking mode).
| Qwen3-32B Guided Decoding Predictive Decoding | Chain-of-Thought 26.67 32.67 | 30.00 22.67 24.00 | 23.67 28.67 33.33 | 30.00 7.33 10.33 | 9.67 |
| --- | --- | --- | --- | --- | --- |
| Phi-Decoding | 33.60 | 24.33 | 36.67 | 10.67 | |
| PPCV (Ours) | 40.00 | 26.00 | 43.33 | 13.33 | |
### 3.3 Discussion
Our technical contributions differ from prior works in three distinct ways. First, prior works (Zhou et al., 2024; Chen et al., 2024b; Yadav et al., 2024) typically use paraphrasing merely to expand the solution space. In contrast, we introduce Paraphrastic Probing, a mechanism that uses paraphrasing to test the model’s internal confidence. By analyzing the discrepancy in token-level logits of the initial trajectory between the original and paraphrased questions, we can rigorously pinpoint the critical tokens that may lead to errors in the following steps.This transforms paraphrasing from a generation tool into a precise, token-level diagnostic tool. Second, prior works (Zhou et al., 2024; Chen et al., 2024b) typically rely on simple majority voting across multiple solutions. Our Paraphrase Consistency mechanism is technically distinct. It validates answers based on their robustness across semantic variations of the problem constraint. We further introduce a similarity-weighted consistency metric that weighs answers based on the linguistic diversity of the paraphrase, offering a more nuanced selection criterion than simple frequency counts. At last, a major technical limitation in current reasoning research is the reliance on external models or human-annotated error steps. Our method contributes a fully self-contained pipeline that identifies and corrects errors using the model’s own sensitivity to surface-form perturbations. More discussion on the impact of critical tokens on correct trajectory can be found in Appendix D.
Besides, although we select the top candidate for the primary experiments to maintain computational efficiency, the framework itself naturally extends to the multi–critical-token setting. For multiple critical tokens, we can generate alternative tokens for each identified position and apply paraphrase consistency across the new rollouts. This allows the model to refine multiple segments of its intermediate reasoning steps rather than only one. The details of the algorithm can be found in Appendix C.
Table 3: Comparison of model performance when using critical tokens versus random tokens.
| Chain-of-Thought random tokens critical tokens (Ours) | 77.40 82.08 88.24 | 28.00 40.29 49.73 | 31.00 42.12 50.00 | 83.00 84.77 89.60 | 58.91 75.68 88.31 |
| --- | --- | --- | --- | --- | --- |
Table 4: Comparison of our proposed paraphrase consistency against the majority voting.
| Chain-of-Thought majority voting paraphrase consistency (Ours) | 77.40 87.20 88.24 | 28.00 47.36 49.73 | 31.00 48.19 50.00 | 83.00 88.80 89.60 | 58.91 86.16 88.31 |
| --- | --- | --- | --- | --- | --- |
## 4 Experiments
In this section, we first describe the experimental setup, followed by the main results of our proposed method compared to the baselines. We also perform ablation study and computational cost analysis.
### 4.1 Setup
Datasets. To comprehensively assess our method, we evaluate it on seven benchmarks. Six focus on mathematical reasoning, including GSM8K (Cobbe et al., 2021), GSM-Hard (Gao et al., 2023), SVAMP (Patel et al., 2021), Math500 (Hendrycks et al., 2021), and the more challenging competition-level datasets AIME2024, AIME2025, BRUMO2025, and HMMT2025 (Balunović et al., 2025). In addition, we use ARC-Challenge (Clark et al., 2018) to evaluate knowledge reasoning ability of LLMs.
Baselines. In our experiments, we use Chain-of-Thought (CoT) (Wei et al., 2022), Self-Consistency (Wang et al., 2023), Tree-of-Thought (ToT) (Yao et al., 2023), Guided Decoding (Xie et al., 2023), Predictive Decoding (Ma et al., 2025), and Phi-Decoding (Xu et al., 2025) as baseline methods.
Metric. Following prior work, we adopt pass@k (k=1,4) as the primary evaluation metric.
Implementation Details. In our experiments, we adopt Llama-3.1-8B-Instruct (Grattafiori et al., 2024), Mistral-7B-Instruct-v0.2 (Jiang et al., 2023), Qwen-3-32B (Yang et al., 2025a) and DeepSeek-R1-Distill-Llama-70B as the target models. we employ the non-thinking mode for Qwen-3-32B. Throughout our method, we employ the same model for generating paraphrased problems, identifying critical tokens, and producing new rollouts. In the first stage, we generate 4 paraphrased variants for each problem in the math benchmarks and 3 variants for each problem in the ARC dataset. In the second stage, we select the top 10 tokens for new rollouts, with the temperature scaling coefficient $\lambda$ set to 2. For fair comparison, we ensure a comparable inference budget across methods. Specifically, we rollout 48 samples for Self-Consistency (Wang et al., 2023). For Predictive Decoding (Ma et al., 2025) and Phi-Decoding (Xu et al., 2025), we rollout 4-8 samples per foresight step, and each problem typically involves 5–8 foresight steps. We also adopt a zero-shot CoT prompt to elicit the new rollouts. For the baselines, we strictly follow their original settings, including temperature values, sampling strategies, and the number of few-shot examples. All experiments are conducted on NVIDIA A100 GPUs.
<details>
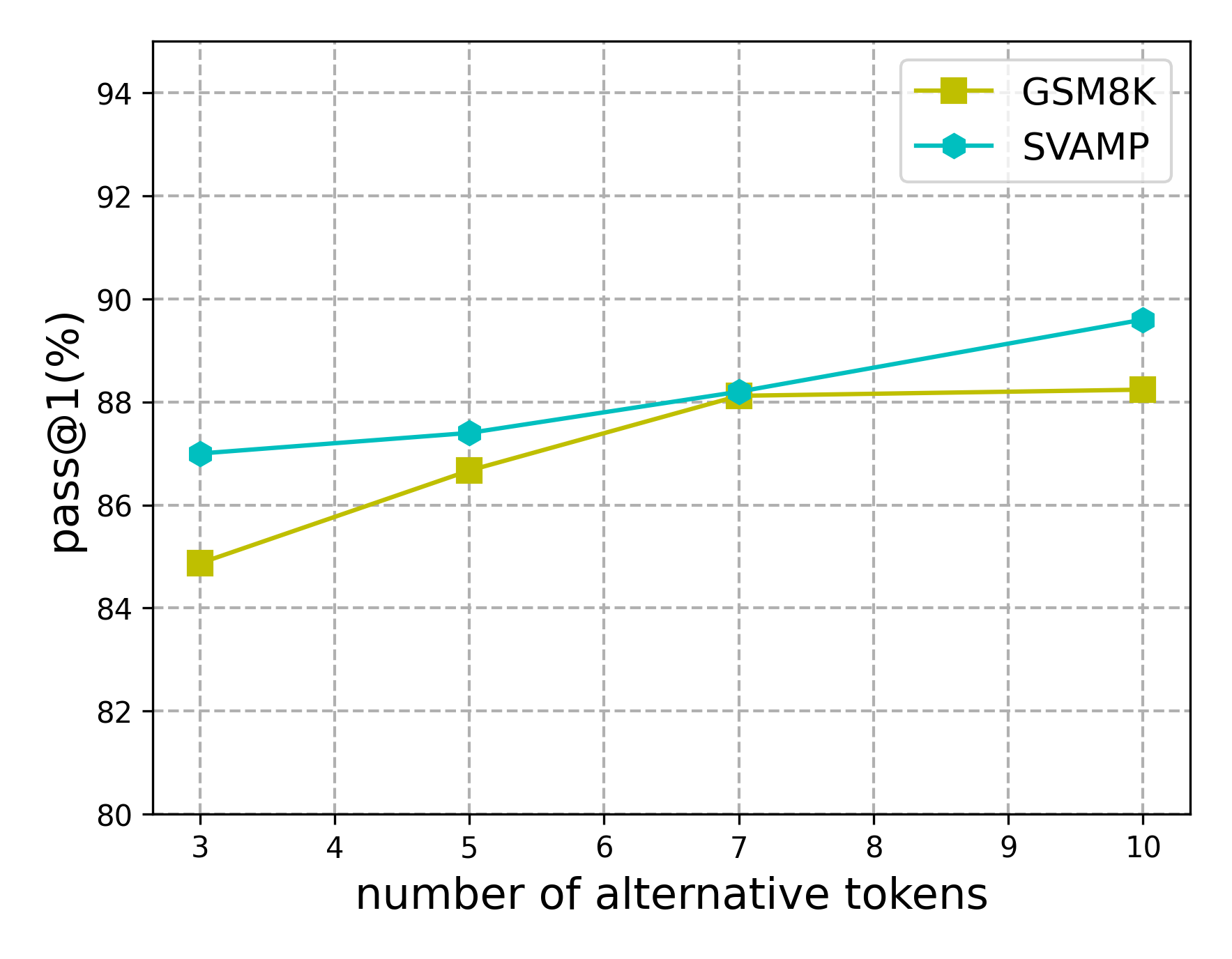
<summary>images/topk.png Details</summary>
### Visual Description
## Line Graph: Pass@1 (%) vs. Number of Alternative Tokens
### Overview
The image is a line graph comparing the performance of two systems, **GSM8K** and **SVAMP**, in terms of **pass@1 (%)** as the number of **alternative tokens** increases from 3 to 10. The graph uses two distinct data series with markers and trend lines.
### Components/Axes
- **X-axis**: "number of alternative tokens" (integer values from 3 to 10).
- **Y-axis**: "pass@1(%)" (percentage values from 80 to 94).
- **Legend**: Located in the top-right corner, with:
- **GSM8K**: Yellow square marker.
- **SVAMP**: Cyan hexagon marker.
### Detailed Analysis
- **GSM8K (Yellow)**:
- At 3 tokens: ~85% pass@1.
- At 10 tokens: ~88% pass@1.
- Trend: Gradual upward slope, with a slight plateau between 7 and 10 tokens.
- **SVAMP (Cyan)**:
- At 3 tokens: ~87% pass@1.
- At 10 tokens: ~89.5% pass@1.
- Trend: Steeper upward slope compared to GSM8K, maintaining a consistent lead throughout.
### Key Observations
1. **SVAMP outperforms GSM8K** across all token counts, with a ~2–3% higher pass@1 rate.
2. Both systems show **improving performance** as the number of alternative tokens increases.
3. **GSM8K’s growth slows** after 7 tokens, while SVAMP’s improvement remains steady.
### Interpretation
The data suggests that **SVAMP is more effective** than GSM8K in handling tasks with increasing numbers of alternative tokens, as evidenced by its consistently higher pass@1 rates. The steeper slope of SVAMP’s line indicates better scalability or efficiency in processing additional tokens. This could imply that SVAMP’s architecture or methodology is better suited for complex token-based tasks. No outliers or anomalies are observed in the trends.
</details>
(a)
<details>
<summary>images/time.png Details</summary>
### Visual Description
## Bar Chart: Latency Comparison Across Datasets and Methods
### Overview
The chart compares latency (in seconds) across five datasets (GSM8K, GSMHard, Math500, SVAMP, ARC) for six different methods: Chain-of-Thought, Predictive Decoding, Phi-Decoding, and four variants of PPCV (PPCV-T1 to T4). Latency values are represented as stacked bar segments, with each method assigned a distinct color.
### Components/Axes
- **X-axis (Datasets)**: GSM8K, GSMHard, Math500, SVAMP, ARC (categorical, left to right).
- **Y-axis (Latency)**: 0–40 seconds (linear scale, increments of 5).
- **Legend**: Located in the top-right corner, mapping colors to methods:
- **Chain-of-Thought**: Teal (#008080)
- **Predictive Decoding**: Light blue (#ADD8E6)
- **Phi-Decoding**: Light pink (#FFD1DC)
- **PPCV-T1 (Ours)**: Dark pink (#FF69B4)
- **PPCV-T2 (Ours)**: Orange (#FFA500)
- **PPCV-T3 (Ours)**: Yellow (#FFFF00)
- **PPCV-T4 (Ours)**: Red (#FF0000)
### Detailed Analysis
1. **GSM8K**:
- **Chain-of-Thought**: ~2s (teal, shortest segment).
- **Predictive Decoding**: ~15s (light blue, second tallest).
- **Phi-Decoding**: ~13s (light pink, third tallest).
- **PPCV-T1**: ~18s (dark pink, tallest).
- **PPCV-T2**: ~5s (orange, second shortest).
- **PPCV-T3**: ~1s (yellow, shortest).
- **PPCV-T4**: ~3s (red, second shortest).
2. **GSMHard**:
- **Chain-of-Thought**: ~3s (teal).
- **Predictive Decoding**: ~26s (light blue, tallest).
- **Phi-Decoding**: ~23s (light pink, second tallest).
- **PPCV-T1**: ~24s (dark pink, third tallest).
- **PPCV-T2**: ~6s (orange, fourth tallest).
- **PPCV-T3**: ~1s (yellow, shortest).
- **PPCV-T4**: ~4s (red, second shortest).
3. **Math500**:
- **Chain-of-Thought**: ~6s (teal).
- **Predictive Decoding**: ~42s (light blue, tallest).
- **Phi-Decoding**: ~38s (light pink, second tallest).
- **PPCV-T1**: ~37s (dark pink, third tallest).
- **PPCV-T2**: ~10s (orange, fourth tallest).
- **PPCV-T3**: ~1s (yellow, shortest).
- **PPCV-T4**: ~12s (red, fifth tallest).
4. **SVAMP**:
- **Chain-of-Thought**: ~2s (teal).
- **Predictive Decoding**: ~14s (light blue, tallest).
- **Phi-Decoding**: ~11s (light pink, second tallest).
- **PPCV-T1**: ~17s (dark pink, third tallest).
- **PPCV-T2**: ~4s (orange, fourth tallest).
- **PPCV-T3**: ~1s (yellow, shortest).
- **PPCV-T4**: ~6s (red, fifth tallest).
5. **ARC**:
- **Chain-of-Thought**: ~2.5s (teal).
- **Predictive Decoding**: ~15.5s (light blue, tallest).
- **Phi-Decoding**: ~15s (light pink, second tallest).
- **PPCV-T1**: ~12.5s (dark pink, third tallest).
- **PPCV-T2**: ~3.5s (orange, fourth tallest).
- **PPCV-T3**: ~1.5s (yellow, shortest).
- **PPCV-T4**: ~4.5s (red, fifth tallest).
### Key Observations
- **Predictive Decoding** consistently shows the highest latency across all datasets, peaking at ~42s for Math500.
- **Chain-of-Thought** has the lowest latency (~1.5–6s) but is often the shortest segment.
- **Phi-Decoding** and **PPCV-T1** exhibit moderate-to-high latency, with PPCV-T1 being the tallest in GSM8K and SVAMP.
- **PPCV-T3** (yellow) is the shortest segment in all datasets, indicating the fastest performance.
- **Math500** has the highest overall latency values, while **GSM8K** and **ARC** show the lowest.
### Interpretation
The data suggests that **PPCV-T3** (yellow) is the most efficient method across all datasets, with latencies consistently below 2s. **Predictive Decoding** (light blue) performs poorly in terms of latency, particularly on Math500, which may reflect the dataset's complexity. **Phi-Decoding** and **PPCV-T1** show intermediate performance, with PPCV-T1 being the most variable. The **Chain-of-Thought** method, while fast, may lack accuracy or robustness compared to other methods. The segmentation of bars highlights trade-offs between speed and performance, with no single method dominating all datasets.
</details>
(b)
<details>
<summary>images/throughput.png Details</summary>
### Visual Description
## Bar Chart: Throughput Comparison of Decoding Methods Across Datasets
### Overview
The chart compares the throughput (tokens/second) of four decoding methods—Chain-of-Thought, Predictive Decoding, Phi-Decoding, and PPCV (Ours)—across five datasets: GSM8K, GSMHard, Math500, SVAMP, and ARC. Throughput is measured on a logarithmic scale (y-axis), while datasets are categorical (x-axis). PPCV consistently outperforms other methods, with Chain-of-Thought showing the lowest throughput.
### Components/Axes
- **X-axis (Datasets)**: GSM8K, GSMHard, Math500, SVAMP, ARC (left to right).
- **Y-axis (Throughput)**: Tokens/second, logarithmic scale (0–2000).
- **Legend**:
- Chain-of-Thought: Teal (#008080)
- Predictive Decoding: Light Blue (#ADD8E6)
- Phi-Decoding: Light Orange (#FFA07A)
- PPCV (Ours): Red (#FF6347)
- **Bar Groups**: Each dataset has four adjacent bars, ordered by legend sequence.
### Detailed Analysis
1. **GSM8K**:
- Chain-of-Thought: ~100 tokens/sec (teal)
- Predictive Decoding: ~700 tokens/sec (light blue)
- Phi-Decoding: ~500 tokens/sec (light orange)
- PPCV: ~1300 tokens/sec (red)
2. **GSMHard**:
- Chain-of-Thought: ~120 tokens/sec (teal)
- Predictive Decoding: ~600 tokens/sec (light blue)
- Phi-Decoding: ~450 tokens/sec (light orange)
- PPCV: ~1700 tokens/sec (red)
3. **Math500**:
- Chain-of-Thought: ~130 tokens/sec (teal)
- Predictive Decoding: ~800 tokens/sec (light blue)
- Phi-Decoding: ~550 tokens/sec (light orange)
- PPCV: ~1900 tokens/sec (red)
4. **SVAMP**:
- Chain-of-Thought: ~110 tokens/sec (teal)
- Predictive Decoding: ~550 tokens/sec (light blue)
- Phi-Decoding: ~400 tokens/sec (light orange)
- PPCV: ~1500 tokens/sec (red)
5. **ARC**:
- Chain-of-Thought: ~120 tokens/sec (teal)
- Predictive Decoding: ~750 tokens/sec (light blue)
- Phi-Decoding: ~580 tokens/sec (light orange)
- PPCV: ~1500 tokens/sec (red)
### Key Observations
- **PPCV Dominance**: PPCV (red bars) achieves the highest throughput across all datasets, with values ranging from ~1300 (GSM8K) to ~1900 (Math500).
- **Chain-of-Thought Weakness**: Chain-of-Thought (teal) consistently has the lowest throughput (~100–130 tokens/sec), suggesting inefficiency in token generation.
- **Predictive vs. Phi-Decoding**: Predictive Decoding (light blue) generally outperforms Phi-Decoding (light orange) in GSM8K, GSMHard, and ARC, but Phi-Decoding slightly exceeds it in Math500 and SVAMP.
- **Logarithmic Scale Impact**: The y-axis’s logarithmic nature emphasizes relative differences, making PPCV’s superiority visually stark.
### Interpretation
The data demonstrates that **PPCV (Ours)** is the most efficient decoding method, achieving throughput 2–3x higher than competitors. This suggests PPCV’s architecture or algorithm optimizes token generation speed. Chain-of-Thought’s poor performance may stem from its reliance on sequential reasoning, which is computationally intensive. Predictive and Phi-Decoding methods show moderate efficiency, with Predictive Decoding excelling in complex datasets like Math500. The consistent gap between PPCV and other methods highlights its potential as a superior solution for high-throughput applications. No outliers are observed; trends align with the legend’s color coding and dataset complexity.
</details>
(c)
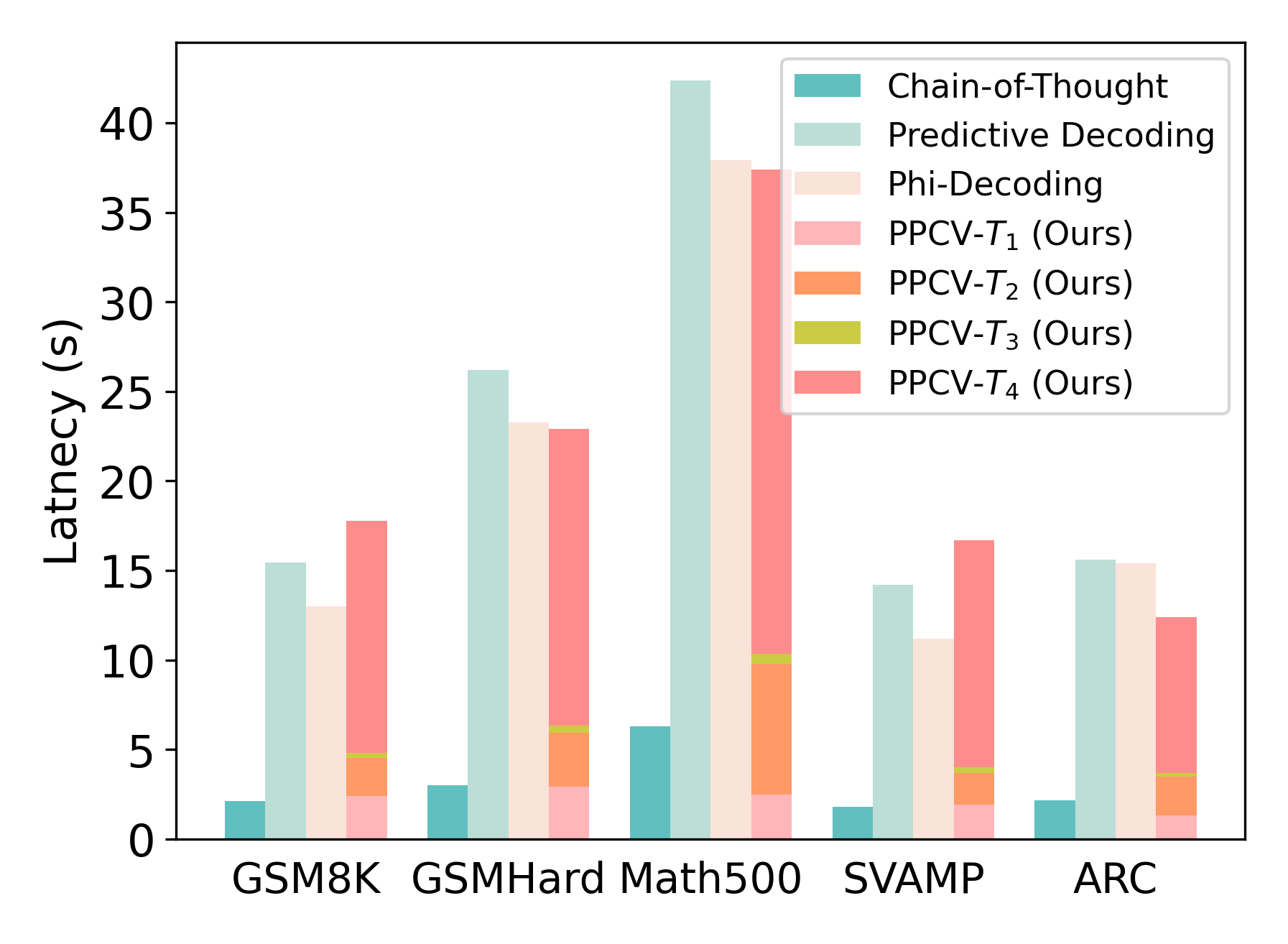
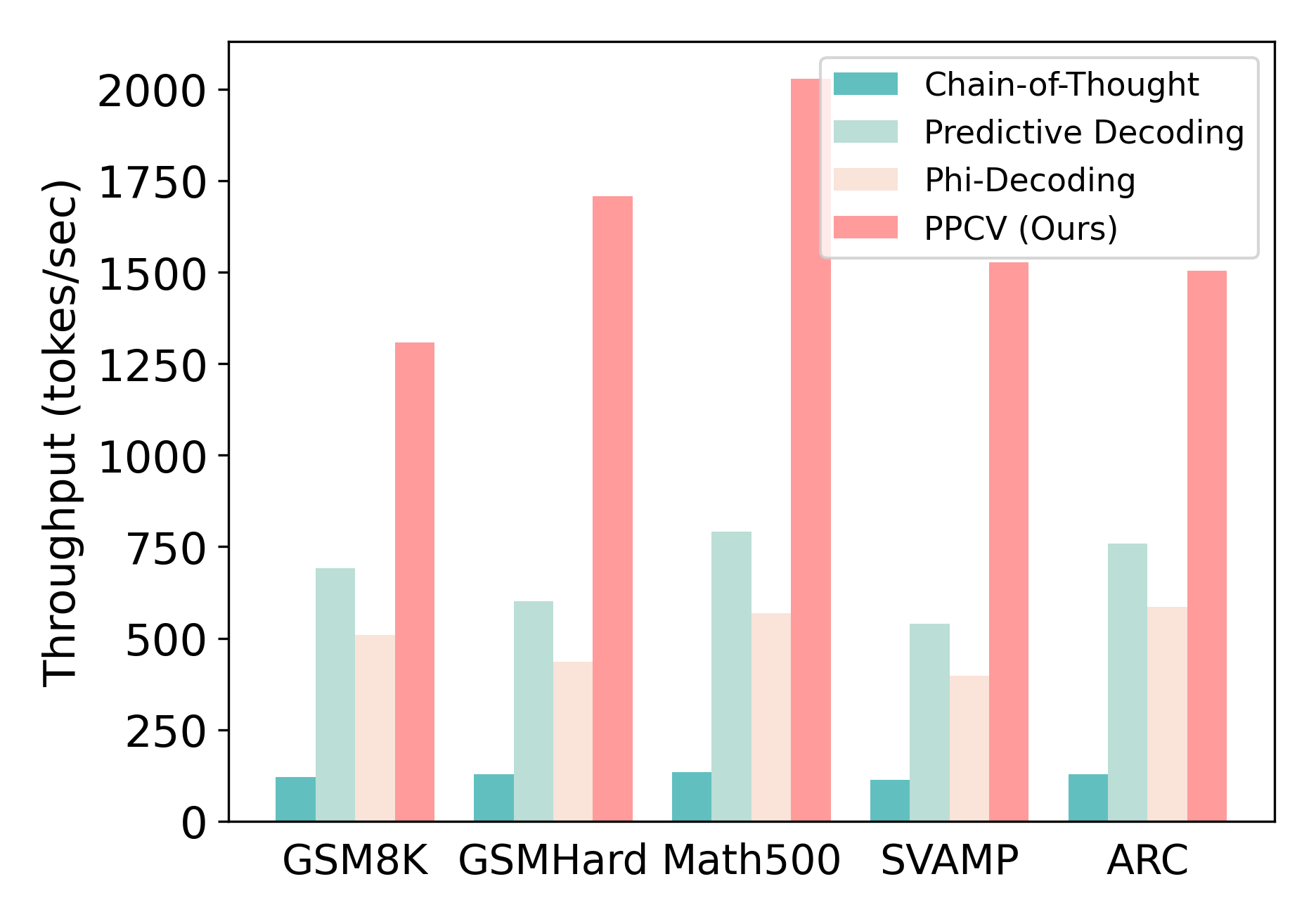
Figure 7: (a) The impact of number of sampled alternative tokens on the performance. (b) Latency comparison between the baselines and our method, measured as the average inference time per question (in seconds). $T_{1}$ , $T_{2}$ , $T_{3}$ , $T_{4}$ denote time for paraphrased question generation, initial answer generation, forward pass and new rollouts from truncated trajectories. (c) Throughput comparison between the baselines and our method, measured in output tokens per second.
### 4.2 Main Results
The main results are summarized in Table 1 and Table 2. The results indicate that Self-Consistency effectively improves the reasoning performance of LLMs compared to vanilla Chain-of-Thought prompting. For example, Llama-3.1-8B-Instruct (Grattafiori et al., 2024) achieves about 3% higher accuracy with Self-Consistency than with CoT. These findings suggest that augmenting reasoning during inference through sampling is an effective way to refine reasoning trajectories. Recent decoding-based methods, such as Predictive Decoding (Ma et al., 2025) and Phi-Decoding (Xu et al., 2025), also achieve strong results.Unlike prior works that rely on carefully designed prompts to self-correct errors in intermediate steps, these two methods modify the current step by probing future steps with pre-defined reward signals. Furthermore, our experimental results demonstrate that the proposed method consistently outperforms the baselines across most tasks, spanning both mathematical and knowledge reasoning, thereby highlighting its generalization ability across different reasoning settings. Notably, our method even surpasses the latest approaches such as Predictive Decoding (Ma et al., 2025) and Phi-Decoding (Xu et al., 2025). In particular, it achieves approximately 50.00% accuracy on the Math500 dataset (Hendrycks et al., 2021), exceeding these baselines considerably. The results on competition-level datasets further demonstrate the effectiveness of our method in enhancing the reasoning ability of LLMs. These results indicate that our method can effectively extract critical tokens that play a pivotal role in the final outcome and correct the reasoning trajectory by leveraging alternative tokens. Additional results can be found in Appendix E.
### 4.3 Ablation Study
In this section, we analyze the contribution of each stage individually. All the evaluations are conducted on Llama-3.1-8B-Instruct (Grattafiori et al., 2024).
Effectiveness of extracted critical tokens. To demonstrate the effectiveness of our extracted critical tokens, we conduct an evaluation in which the critical tokens are replaced with random tokens in the first stage, while keeping the second stage unchanged. This evaluation is performed across multiple benchmark datasets, with pass@1 as the metric. The results, shown in Table 3, reveal a substantial decline in performance. These findings highlight the pivotal role of critical tokens and indicate that our method can effectively identify and extract them. More ablation study on comparison with Paraphrased Majority Voting (PMV) can be found in Appendix F.
Effectiveness of paraphrase consistency. We also evaluate the effectiveness of our proposed paraphrase consistency and compare it with traditional majority voting. While keeping the first stage unchanged, instead of using paraphrased forms to generate new reasoning steps, we simply sample multiple new steps from alternative tokens conditioned on the original question and use majority voting to determine the final answer. The results, shown in Table 4, reveal a noticeable decline in performance, highlighting the importance of paraphrased forms in improving the intermediate reasoning steps.
Impact of number of sampled alternative tokens.We investigate the influence of the number of sampled alternative tokens in the second stage by selecting values of 3, 5, 7, and 10. The results, shown in Figure 7(a), demonstrate that performance improves as the number of alternative tokens increases. This suggests that exploring more reasoning steps with additional alternative tokens during inference can be beneficial for reasoning tasks.
## 5 Computational Cost Analysis
In this section we examine the composition of the latency in our method. The latency arises from four components: Paraphrased question generation ( $T_{1}$ ); initial answer generation ( $T_{2}$ ), equivalent to vanilla CoT; a forward pass for identifying critical tokens ( $T_{3}$ ), which does not generate new tokens and is computationally lightweight; rollouts of truncated trajectories using alternative tokens under both the original and paraphrased questions ( $T_{4}$ ), which constitutes the main source of overhead.
We evaluate all components on Llama-3.1-8B-Instruct using vLLM on NVIDIA A100 GPUs, with a maximum output length of 4096 tokens for each question. For our method, we use 4 paraphrased questions on math datasets and 3 on ARC, and select the top-10 candidate tokens as alternatives. The updated average latency results are reported in Figure 7(b). As expected, $T_{1}$ scales with the number of paraphrases, $T_{3}$ remains minimal, and $T_{4}$ dominates the total cost. Specifically, $T_{4}$ depends on the number of top-k alternative tokens, the number of paraphrased questions and the position of the critical token in the trajectory. Since the new rollouts from truncated trajectories for different alternative tokens and paraphrased questions are independent, $T_{4}$ can take advantage of vLLM’s parallelism. These rollouts can therefore be processed concurrently, improving overall efficiency. This is reflected in the higher throughput (tokens/sec) shown in Figure 7(c). And results of our method in latency comparable to baseline methods, even on challenging benchmarks such as Math500 and GSM-Hard where the critical token tends to occur in later reasoning steps. On the GSM8K and SVAMP benchmarks, our method, as well as baselines such as Predictive Decoding, would incur a approximately $6\text{–}8\times$ latency overhead compared to vanilla Chain-of-Thought. More analysis on the trade-off between the latency and performance can be found in Appendix G.
## 6 Conclusion
In this study, inspired by beneficial impact of paraphrase forms on reasoning, we investigate the pivotal role of critical tokens in shaping the reasoning trajectory. To leverage these two factors, we propose the Paraphrastic Probing and Consistency Verification framework. Our framework consists of two stages: Paraphrastic Probing, which identifies and extracts critical tokens, and Consistency Verification, which adopts paraphrase forms to generate new reasoning trajectories with alternative tokens to reach the final answer. We evaluate our proposed framework with different LLMs and extensive evaluations across multiple benchmarks demonstrate the promising performance of our method.
## Impact Statement
This paper presents work whose goal is to advance the field of machine learning. There are many potential societal consequences of our work, none of which we feel must be specifically highlighted here.
## References
- J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. (2023) Gpt-4 technical report. arXiv preprint. Cited by: §1.
- M. Balunović, J. Dekoninck, I. Petrov, N. Jovanović, and M. Vechev (2025) MathArena: evaluating llms on uncontaminated math competitions. SRI Lab, ETH Zurich. External Links: Link Cited by: §4.1.
- M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, et al. (2024) Graph of thoughts: solving elaborate problems with large language models. In Proceedings of the AAAI conference on artificial intelligence, Vol. 38, pp. 17682–17690. Cited by: §2.
- Z. Bi, K. Han, C. Liu, Y. Tang, and Y. Wang (2025) Forest-of-thought: scaling test-time compute for enhancing llm reasoning. In Forty-second International Conference on Machine Learning, Cited by: §2.
- T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. (2020) Language models are few-shot learners. Advances in neural information processing systems 33, pp. 1877–1901. Cited by: §1.
- S. Bubeck, V. Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y. T. Lee, Y. Li, S. Lundberg, et al. (2023) Sparks of artificial general intelligence: early experiments with gpt-4. arXiv preprint. Cited by: §1, §2.
- S. Chen, B. Li, and D. Niu (2024a) Boosting of thoughts: trial-and-error problem solving with large language models. In The Twelfth International Conference on Learning Representations, Cited by: §1, §2.
- S. Chen and B. Li (2024) Toward adaptive reasoning in large language models with thought rollback. In Forty-first International Conference on Machine Learning, Cited by: §1.
- W. Chen, W. Wang, Z. Chu, K. Ren, Z. Zheng, and Z. Lu (2024b) Self-para-consistency: improving reasoning tasks at low cost for large language models. In Findings of the Association for Computational Linguistics ACL 2024, pp. 14162–14167. Cited by: §1, §2, §3.1, §3.3.
- P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord (2018) Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457. Cited by: §4.1.
- K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. (2021) Training verifiers to solve math word problems. arXiv preprint. Cited by: §1, §3.1, §3.2, §4.1.
- A. Dogan and D. Birant (2019) A weighted majority voting ensemble approach for classification. In 2019 4th international conference on computer science and engineering (UBMK), pp. 1–6. Cited by: §3.2.
- S. Feng, X. Kong, S. Ma, A. Zhang, D. Yin, C. Wang, R. Pang, and Y. Yang (2025) Step-by-step reasoning for math problems via twisted sequential monte carlo. In The Thirteenth International Conference on Learning Representations, Cited by: §1.
- L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig (2023) Pal: program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. Cited by: §4.1.
- X. Gao, J. Zhang, L. Mouatadid, and K. Das (2024) SPUQ: perturbation-based uncertainty quantification for large language models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2336–2346. Cited by: §2.
- A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. (2024) The llama 3 herd of models. arXiv preprint. Cited by: Appendix A, Appendix A, §1, §1, §3.1, §3.2, §4.1, §4.2, §4.3.
- X. Guan, L. L. Zhang, Y. Liu, N. Shang, Y. Sun, Y. Zhu, F. Yang, and M. Yang (2025) RStar-math: small llms can master math reasoning with self-evolved deep thinking. In Forty-second International Conference on Machine Learning, Cited by: §2.
- S. Hao, Y. Gu, H. Ma, J. Hong, Z. Wang, D. Z. Wang, and Z. Hu (2023) Reasoning with language model is planning with world model. In NeurIPS 2023 Workshop on Generalization in Planning, Cited by: §2.
- A. Havrilla, S. C. Raparthy, C. Nalmpantis, J. Dwivedi-Yu, M. Zhuravinskyi, E. Hambro, and R. Raileanu (2024) GLoRe: when, where, and how to improve llm reasoning via global and local refinements. In Forty-first International Conference on Machine Learning, Cited by: §2.
- M. He, Y. Shen, W. Zhang, Z. Tan, and W. Lu (2024) Advancing process verification for large language models via tree-based preference learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 2086–2099. Cited by: §2.
- D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt (2021) Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Cited by: Appendix A, Appendix A, §4.1, §4.2.
- K. Huang, J. Guo, Z. Li, X. Ji, J. Ge, W. Li, Y. Guo, T. Cai, H. Yuan, R. Wang, et al. (2025) MATH-perturb: benchmarking llms’ math reasoning abilities against hard perturbations. In Forty-second International Conference on Machine Learning, Cited by: §2, §3.1.
- A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, and W. E. Sayed (2023) Mistral 7b. arXiv preprint arXiv:2310.06825. Cited by: §4.1.
- T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa (2022) Large language models are zero-shot reasoners. Advances in neural information processing systems 35, pp. 22199–22213. Cited by: §1.
- Y. Li (2025) Policy guided tree search for enhanced llm reasoning. In Forty-second International Conference on Machine Learning, Cited by: §2.
- H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe (2023) Let’s verify step by step. In The Twelfth International Conference on Learning Representations, Cited by: §1.
- Z. Lin, T. Liang, J. Xu, Q. Liu, X. Wang, R. Luo, C. Shi, S. Li, Y. Yang, and Z. Tu (2025) Critical tokens matter: token-level contrastive estimation enhances llm’s reasoning capability. In Forty-second International Conference on Machine Learning, Cited by: §1, §1.
- Z. Ling, Y. Fang, X. Li, Z. Huang, M. Lee, R. Memisevic, and H. Su (2023) Deductive verification of chain-of-thought reasoning. Advances in Neural Information Processing Systems 36, pp. 36407–36433. Cited by: §1, §2.
- C. Ma, H. Zhao, J. Zhang, J. He, and L. Kong (2025) Non-myopic generation of language models for reasoning and planning. In The Thirteenth International Conference on Learning Representations, Cited by: §2, §2, §4.1, §4.1, §4.2.
- A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, et al. (2023) Self-refine: iterative refinement with self-feedback. Advances in Neural Information Processing Systems 36, pp. 46534–46594. Cited by: §2.
- N. Miao, Y. W. Teh, and T. Rainforth (2024) SelfCheck: using llms to zero-shot check their own step-by-step reasoning. In The Twelfth International Conference on Learning Representations, Cited by: §1, §2.
- A. Patel, S. Bhattamishra, and N. Goyal (2021) Are nlp models really able to solve simple math word problems?. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2080–2094. Cited by: §4.1.
- Z. Qi, M. Mingyuan, J. Xu, L. L. Zhang, F. Yang, and M. Yang (2025) Mutual reasoning makes smaller llms stronger problem-solver. In The Thirteenth International Conference on Learning Representations, Cited by: §2.
- C. Snell, J. Lee, K. Xu, and A. Kumar (2024) Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint. Cited by: §2, §2.
- Z. R. Sprague, F. Yin, J. D. Rodriguez, D. Jiang, M. Wadhwa, P. Singhal, X. Zhao, X. Ye, K. Mahowald, and G. Durrett (2025) To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning. In The Thirteenth International Conference on Learning Representations, Cited by: §1.
- K. Stechly, K. Valmeekam, and S. Kambhampati (2025) On the self-verification limitations of large language models on reasoning and planning tasks. In The Thirteenth International Conference on Learning Representations, Cited by: §1.
- S. H. Tanneru, C. Agarwal, and H. Lakkaraju (2024) Quantifying uncertainty in natural language explanations of large language models. In International Conference on Artificial Intelligence and Statistics, pp. 1072–1080. Cited by: §2.
- G. Tyen, H. Mansoor, V. Cărbune, Y. P. Chen, and T. Mak (2024) LLMs cannot find reasoning errors, but can correct them given the error location. In Findings of the Association for Computational Linguistics ACL 2024, pp. 13894–13908. Cited by: §1.
- J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins (2022) Solving math word problems with process-and outcome-based feedback. arXiv preprint. Cited by: §1.
- G. Wan, Y. Wu, J. Chen, and S. Li (2025) Reasoning aware self-consistency: leveraging reasoning paths for efficient llm sampling. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3613–3635. Cited by: §2.
- P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y. Li, D. Chen, Y. Wu, and Z. Sui (2024) Math-shepherd: verify and reinforce llms step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 9426–9439. Cited by: §1, §1, §2.
- X. Wang, J. Wei, D. Schuurmans, Q. V. Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou (2023) Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, Cited by: §1, §1, §2, §4.1, §4.1.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. (2022) Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35, pp. 24824–24837. Cited by: Appendix D, §1, §4.1.
- Y. Wu, Z. Sun, S. Li, S. Welleck, and Y. Yang (2025) Inference scaling laws: an empirical analysis of compute-optimal inference for llm problem-solving. In The Thirteenth International Conference on Learning Representations, Cited by: §2.
- Z. Wu, Q. Zeng, Z. Zhang, Z. Tan, C. Shen, and M. Jiang (2024) Large language models can self-correct with key condition verification. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 12846–12867. Cited by: §1, §2.
- Y. Xie, K. Kawaguchi, Y. Zhao, J. X. Zhao, M. Kan, J. He, and M. Xie (2023) Self-evaluation guided beam search for reasoning. Advances in Neural Information Processing Systems 36, pp. 41618–41650. Cited by: §2, §4.1.
- F. Xu, H. Yan, C. Ma, H. Zhao, J. Liu, Q. Lin, and Z. Wu (2025) Phi-decoding: adaptive foresight sampling for balanced inference-time exploration and exploitation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 13214–13227. Cited by: §2, §2, §4.1, §4.1, §4.2.
- V. Yadav, Z. Tang, and V. Srinivasan (2024) Pag-llm: paraphrase and aggregate with large language models for minimizing intent classification errors. In Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pp. 2569–2573. Cited by: §2, §3.3.
- A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. (2025a) Qwen3 technical report. arXiv preprint. Cited by: §1, §4.1.
- L. Yang, Z. Yu, T. Zhang, M. Xu, J. E. Gonzalez, B. CUI, and S. YAN (2025b) SuperCorrect: advancing small llm reasoning with thought template distillation and self-correction. In The Thirteenth International Conference on Learning Representations, Cited by: §1.
- S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan (2023) Tree of thoughts: deliberate problem solving with large language models. Advances in neural information processing systems 36, pp. 11809–11822. Cited by: §2, §4.1.
- Z. Yin, Q. Sun, Q. Guo, Z. Zeng, X. Li, J. Dai, Q. Cheng, X. Huang, and X. Qiu (2024) Reasoning in flux: enhancing large language models reasoning through uncertainty-aware adaptive guidance. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2401–2416. Cited by: §2.
- L. Yuan, W. Li, H. Chen, G. Cui, N. Ding, K. Zhang, B. Zhou, Z. Liu, and H. Peng (2025) Free process rewards without process labels. In Forty-second International Conference on Machine Learning, Cited by: §1, §1, §2.
- D. Zhang, S. Zhoubian, Z. Hu, Y. Yue, Y. Dong, and J. Tang (2024) Rest-mcts*: llm self-training via process reward guided tree search. Advances in Neural Information Processing Systems 37, pp. 64735–64772. Cited by: §2.
- Z. Zhang, A. Zhang, M. Li, and A. Smola (2022) Automatic chain of thought prompting in large language models. In The Eleventh International Conference on Learning Representations, Cited by: §1.
- Y. Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba (2022) Large language models are human-level prompt engineers. In The eleventh international conference on learning representations, Cited by: Appendix B, §3.1.
- Y. Zhou, Y. Zhu, D. Antognini, Y. Kim, and Y. Zhang (2024) Paraphrase and solve: exploring and exploiting the impact of surface form on mathematical reasoning in large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 2793–2804. Cited by: §1, §2, §3.1, §3.3.
## Appendix A Empirical Study
<details>
<summary>images/condition_one_math.png Details</summary>
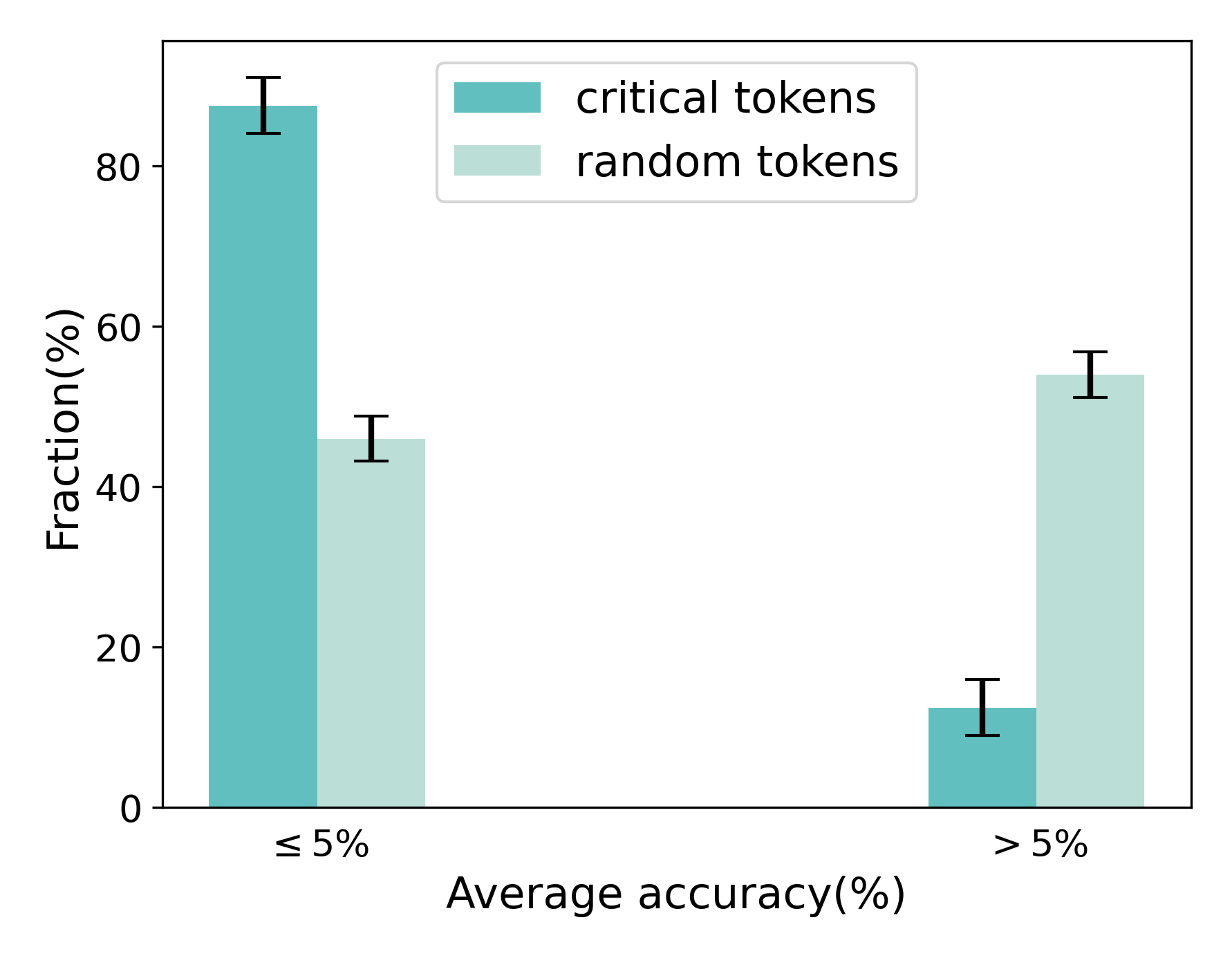
### Visual Description
## Bar Chart: Fraction of Critical vs. Random Tokens by Average Accuracy
### Overview
The chart compares the fraction (%) of critical tokens and random tokens across two average accuracy ranges: ≤5% and >5%. Critical tokens are represented by teal bars, while random tokens use light teal bars. Error bars indicate measurement uncertainty.
### Components/Axes
- **X-axis**: "Average accuracy(%)" with two categories:
- ≤5% (left)
- >5% (right)
- **Y-axis**: "Fraction(%)" ranging from 0 to 100.
- **Legend**:
- Teal: Critical tokens
- Light teal: Random tokens
- **Error bars**: Vertical lines above each bar, indicating ± uncertainty (exact values unspecified).
### Detailed Analysis
1. **≤5% Accuracy**:
- Critical tokens: ~85% (teal bar with error bar).
- Random tokens: ~45% (light teal bar with error bar).
2. **>5% Accuracy**:
- Critical tokens: ~10% (teal bar with error bar).
- Random tokens: ~55% (light teal bar with error bar).
### Key Observations
- Critical tokens dominate at ≤5% accuracy (~85% vs. ~45% for random tokens).
- At >5% accuracy, critical tokens drop sharply (~10%), while random tokens rise (~55%).
- Error bars suggest variability, but no overlap between critical/random token fractions in either category.
### Interpretation
The data demonstrates an inverse relationship between average accuracy and the effectiveness of critical tokens. At low accuracy (≤5%), critical tokens are significantly more prevalent, suggesting they play a critical role in scenarios with poor performance. However, as accuracy improves (>5%), critical tokens become less frequent, while random tokens dominate. This implies that critical tokens may be more impactful in low-accuracy contexts, possibly due to their specificity, whereas random tokens gain relevance in higher-accuracy scenarios where they can contribute more consistently. The stark contrast highlights a potential trade-off between token type and system performance thresholds.
</details>
(a)
<details>
<summary>images/condition_two_math.png Details</summary>
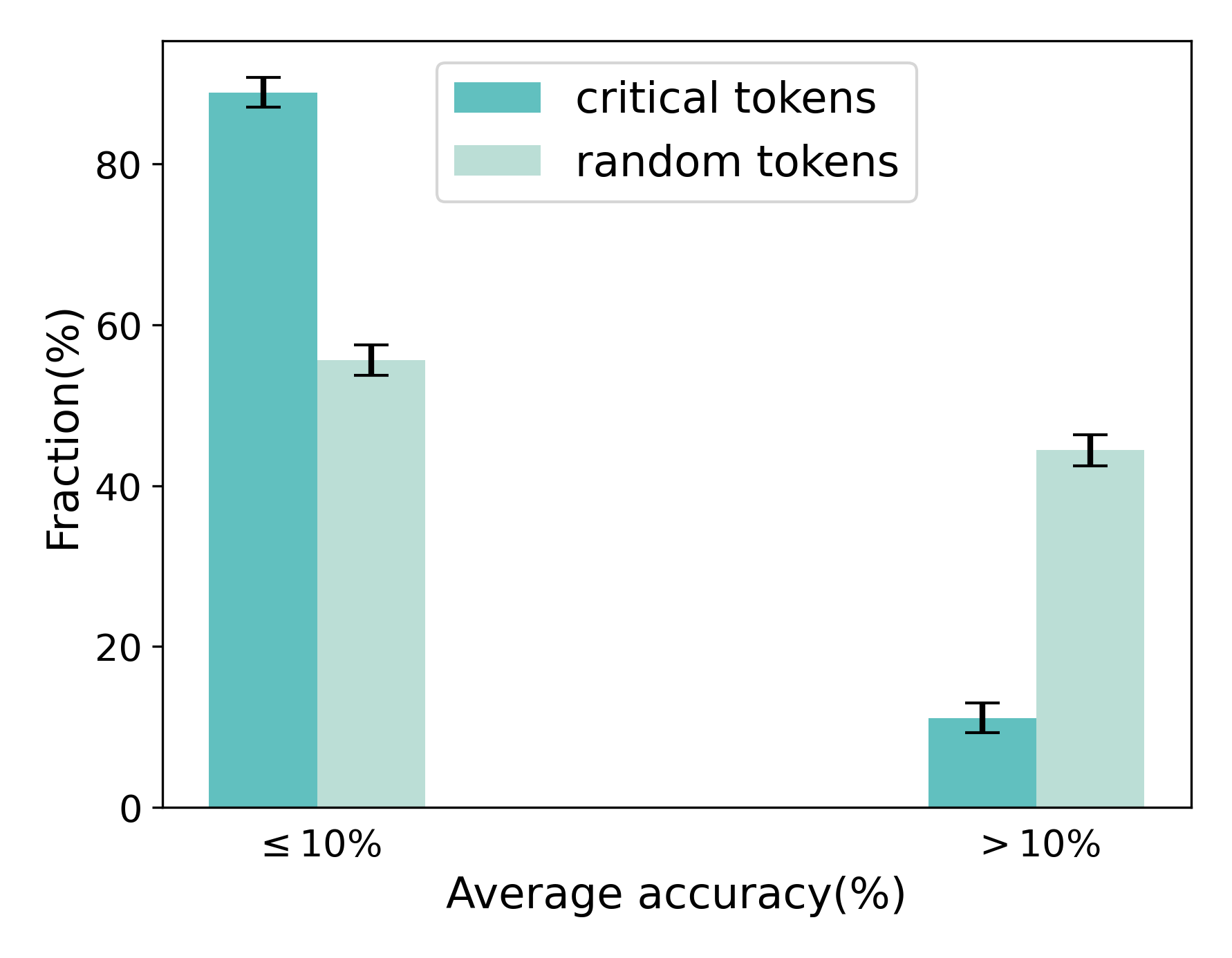
### Visual Description
## Bar Chart: Token Effectiveness by Average Accuracy
### Overview
The chart compares the fraction of critical tokens and random tokens across two average accuracy thresholds (≤10% and >10%). Critical tokens (teal) and random tokens (light teal) are visualized with error bars indicating measurement uncertainty.
### Components/Axes
- **X-axis**: "Average accuracy(%)" with two categories:
- ≤10% (left)
- >10% (right)
- **Y-axis**: "Fraction(%)" ranging from 0 to 100%
- **Legend**:
- Teal: Critical tokens
- Light teal: Random tokens
- **Error bars**: Vertical lines atop bars representing ±2% (critical) and ±3% (random) uncertainty.
### Detailed Analysis
1. **≤10% Accuracy**:
- Critical tokens: 88% ±2%
- Random tokens: 55% ±3%
2. **>10% Accuracy**:
- Critical tokens: 10% ±2%
- Random tokens: 45% ±3%
### Key Observations
- Critical tokens dominate at ≤10% accuracy (88% vs. 55%) but collapse to 10% at >10% accuracy.
- Random tokens show a smaller drop (55% → 45%) across accuracy thresholds.
- Error bars suggest higher variability in random token measurements (±3%) compared to critical tokens (±2%).
### Interpretation
The data suggests critical tokens are disproportionately impactful at low accuracy thresholds but lose effectiveness as accuracy improves. Random tokens maintain a more stable presence, implying they may represent baseline or non-discriminative elements. The stark decline in critical token usage at >10% accuracy could indicate a shift in token relevance or model behavior under higher performance conditions. This pattern might reflect token selection biases in models trained on imbalanced datasets or tasks with varying difficulty levels.
</details>
(b)
<details>
<summary>images/compare_ct_rnd_math.png Details</summary>
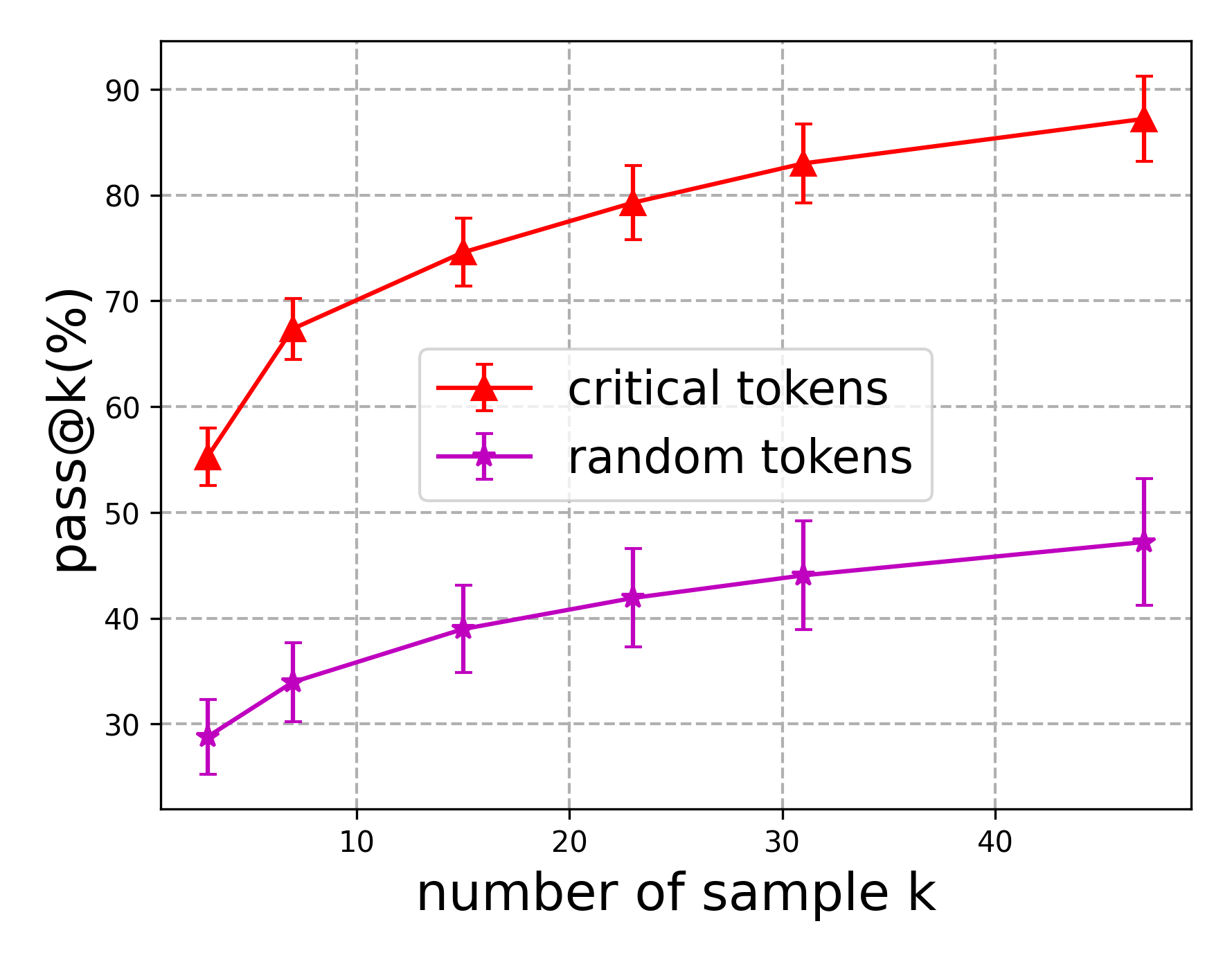
### Visual Description
## Line Graph: Pass@k Performance Comparison
### Overview
The image displays a line graph comparing the performance of two token selection strategies ("critical tokens" and "random tokens") across varying sample sizes (k). The y-axis represents "pass@k (%)" (percentage of successful outcomes), while the x-axis represents "number of sample k" (sample size). Two data series are plotted with distinct markers and error bars, showing performance trends as sample size increases.
### Components/Axes
- **X-axis**: "number of sample k" (ranges from 5 to 45 in increments of 10)
- **Y-axis**: "pass@k (%)" (ranges from 30% to 90% in increments of 10)
- **Legend**: Located in the top-right corner, with:
- Red triangles (▲) labeled "critical tokens"
- Purple stars (★) labeled "random tokens"
- **Error Bars**: Vertical lines extending from each data point, indicating measurement uncertainty.
### Detailed Analysis
#### Critical Tokens (Red)
- **Trend**: Steep upward trajectory from ~55% at k=5 to ~85% at k=45.
- **Data Points**:
- k=5: 55% ±3%
- k=15: 75% ±2%
- k=25: 80% ±2%
- k=35: 82% ±1%
- k=45: 85% ±2%
- **Error Bars**: Consistently ±1–3%, smallest at k=35.
#### Random Tokens (Purple)
- **Trend**: Gradual upward slope from ~30% at k=5 to ~47% at k=45.
- **Data Points**:
- k=5: 30% ±3%
- k=15: 38% ±2%
- k=25: 42% ±3%
- k=35: 44% ±2%
- k=45: 47% ±3%
- **Error Bars**: Larger variability (±2–3%) compared to critical tokens.
### Key Observations
1. **Performance Gap**: Critical tokens consistently outperform random tokens across all sample sizes (e.g., 55% vs. 30% at k=5; 85% vs. 47% at k=45).
2. **Error Margin**: Critical tokens exhibit tighter error bars, suggesting more reliable measurements.
3. **Diminishing Returns**: Both strategies show slowing growth in pass@k as k increases, but critical tokens maintain a higher plateau.
### Interpretation
The data demonstrates that critical token selection significantly improves performance reliability compared to random selection. The steeper slope and smaller error margins for critical tokens suggest they are more effective at capturing relevant information in larger datasets. The diminishing returns for both strategies imply that increasing sample size beyond a certain point yields diminishing benefits, but critical tokens retain a clear advantage. This could reflect their ability to prioritize high-impact tokens in applications like NLP or recommendation systems.
</details>
(c)
<details>
<summary>images/density_math.png Details</summary>
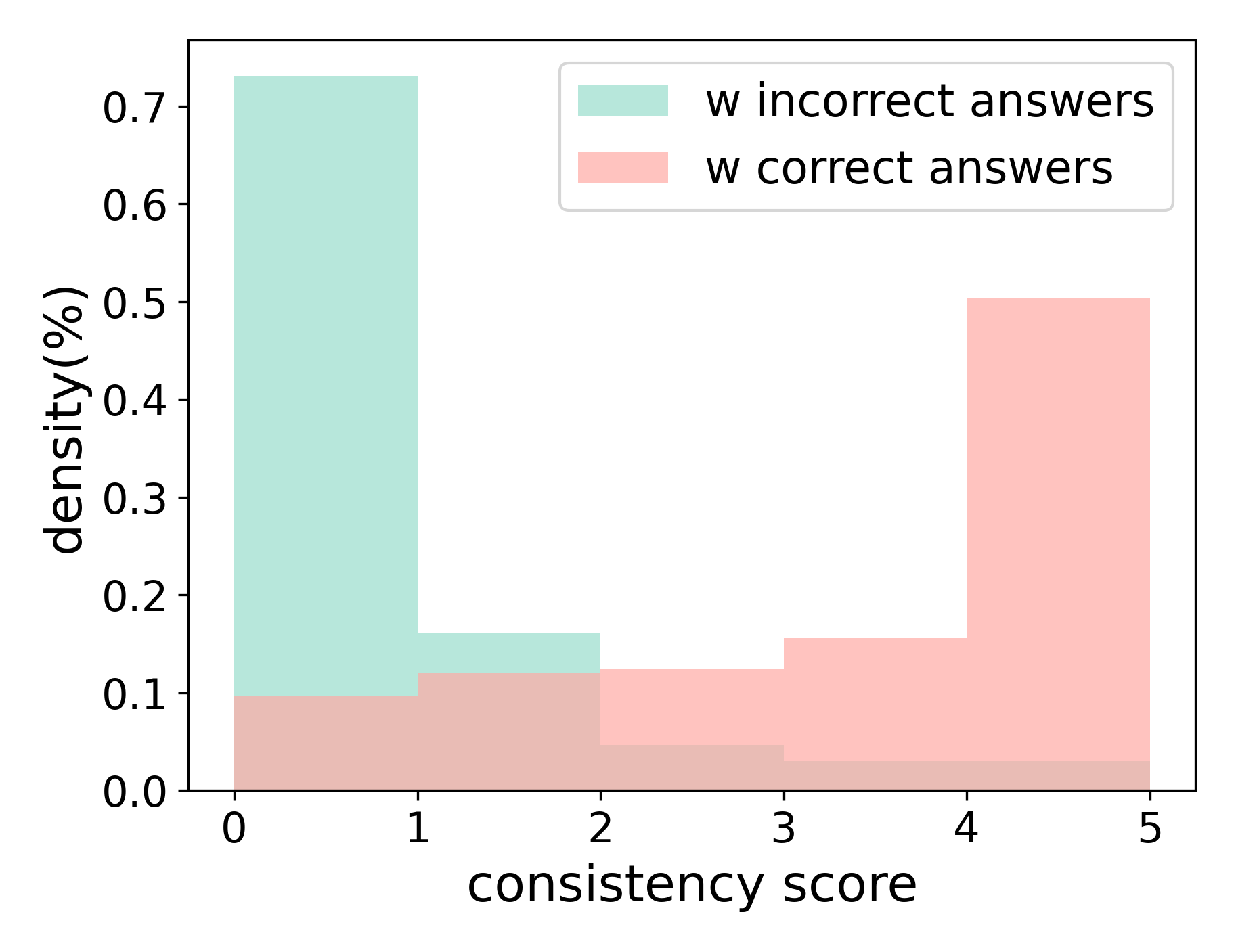
### Visual Description
## Bar Chart: Consistency Score Density by Answer Correctness
### Overview
The chart compares the distribution of consistency scores for answers categorized as "incorrect" (teal) and "correct" (pink). It uses density percentages on the y-axis and consistency scores (0–5) on the x-axis. Two bars per score illustrate the proportion of each category.
### Components/Axes
- **X-axis**: "consistency score" (0–5, integer intervals)
- **Y-axis**: "density(%)" (0.0–0.75, linear scale)
- **Legend**:
- Teal: "w incorrect answers"
- Pink: "w correct answers"
- **Legend Position**: Top-right corner
### Detailed Analysis
- **Score 0**:
- Teal (incorrect): ~0.75%
- Pink (correct): ~0.1%
- **Score 1**:
- Teal: ~0.6%
- Pink: ~0.15%
- **Score 2**:
- Teal: ~0.15%
- Pink: ~0.1%
- **Score 3**:
- Teal: ~0.1%
- Pink: ~0.15%
- **Score 4**:
- Teal: ~0.05%
- Pink: ~0.5%
- **Score 5**:
- Teal: ~0.05%
- Pink: ~0.5%
### Key Observations
1. **Inverse Relationship**: Higher consistency scores correlate with a greater proportion of correct answers (pink bars dominate at scores 4–5).
2. **Low-Score Dominance**: Incorrect answers (teal) are most frequent at scores 0–1, with densities exceeding 0.6%.
3. **Bimodal Pattern**: Correct answers show a bimodal distribution, peaking at scores 4 and 5 (~0.5% each).
4. **Minimal Overlap**: At scores 2–3, densities for both categories are low and similar (~0.1–0.15%).
### Interpretation
The data suggests that consistency scores strongly predict answer correctness. Systems or models with higher consistency scores (4–5) are associated with a 5x higher density of correct answers compared to low scores (0–1). This implies that consistency acts as a reliable proxy for accuracy, with near-perfect consistency (score 5) aligning with optimal performance. The bimodal distribution of correct answers may indicate a threshold effect, where scores above 3 are reliably "correct," while lower scores are more error-prone. The minimal overlap at mid-scores (2–3) highlights a potential inflection point where consistency begins to meaningfully impact correctness.
</details>
(d)
Figure 8: (a) Comparison of the fraction of tokens whose associated rollout correctness falls below or above 5%, for tokens extracted by our method versus randomly selected tokens. (b) Comparison of the fraction of the subsequent tokens whose associated rollout correctness falls below or above 10%, for tokens extracted by our method versus randomly selected tokens. (c) Comparison of the impact of extracted tokens by our method versus random tokens on LLM reasoning performance. (d) Comparison of the density distributions of consistency scores for rollouts with correct and incorrect answers. All the evaluations are conducted on Math500 dataset.
we follow the previous pipeline to conduct a quantitative analysis to examine the authenticity and impact of tokens extracted via paraphrastic probing, comparing them against randomly selected tokens. Specifically, we sample 100 instances with incorrect reasoning trajectories from the Math500 (Hendrycks et al., 2021) training sets. Following the paraphrastic probing pipeline, we identify candidate critical tokens in the early reasoning steps. In each run, we randomly sample 40% of the candidate critical tokens for evaluation and repeat the experiment independently 10 times. For comparison, we apply the same procedure to randomly selected tokens. All evaluations are conducted using Llama-3.1-8B-Instruct (Grattafiori et al., 2024). We first compute the average accuracy of rollouts generated from partial trajectories truncated at the position of the extracted tokens, and compare these results with those obtained from random-token truncation. As shown in Figure 8(a), we also obverse a large proportion of the extracted tokens exhibit near-zero correctness. We further evaluate the average accuracy of rollouts initiated from subsequent tokens (5–10 tokens). The results in Figure 8(b) also indicate that errors persist beyond the identified positions. Finally, we substitute the extracted critical tokens with alternative tokens and roll out multiple new reasoning trajectories. As shown in Figure 8(c), replacing critical tokens leads to a significantly larger improvement in reasoning accuracy compared to substituting random tokens.
To justify our paraphrase consistency mechanism on Math500 dataset (Hendrycks et al., 2021), we follow the same procedure. The evaluation is conducted on Llama-3.1-8B-Instruct (Grattafiori et al., 2024). We then analyze the distribution of consistency scores for rollouts that yield correct versus incorrect answers. As shown in Figure 8(d), majority of rollouts with correct answers achieve a consistency score of at least 1, whereas this proportion drops sharply for rollouts with incorrect answers.
## Appendix B Automatic Prompt Engineering for Paraphrasing
The quality of paraphrased questions is crucial for our framework, as it directly affects both the identification of critical tokens and the stability of paraphrase-based consistency verification. To ensure high-quality paraphrasing, we adopt Automatic Prompt Engineering (APE) (Zhou et al., 2022) as an evaluation to optimize the paraphrasing instruction. This allows us to systematically control the quality of paraphrases rather than relying solely on manually written prompts. The APE procedure we employ consists of four steps:
- We create a small set of original questions paired with valid paraphrased variants. Using this exemplar set, the model generates multiple candidate instructions that could produce the paraphrased outputs from the original questions.
- Prompt each candidate instruction to the language model to generate paraphrases for the original problems and compare the mean solve rate change before and after paraphrasing.
- Choose the instruction that maximizes the mean solve rate change.
- Repeat the previous steps multiple times.
In our experiments, we initialize the paraphrasing instruction and iteratively refine it using APE with samples drawn from the GSM8K and Math500 training sets. With this approach, the refined paraphrasing prompt helps us reliably produce high-quality paraphrased questions.
Algorithm 1 PPCV Framework
0: LLM; original question $q_{0}$ ; number of paraphrased questions $N$ ; number of sampled alternative tokens $K$ ; temperature-scaling coefficient $\lambda$ .
0: Final answer $\text{ans}_{f}$ .
(Paraphrasing) Generate paraphrased variants $q_{1},q_{2},\dots,q_{N}$ from $q_{0}$ using the LLM.
(Initial reasoning) Obtain the initial reasoning path $r^{q_{0}}_{0}$ for $q_{0}$ .
(Token influence analysis) For each paraphrased question $q_{n}$ , compute the token distribution $P^{q_{n}}$ by concatenating $q_{n}$ with $r^{q_{0}}_{0}$ (Eq. 1).
(Candidate selection) Identify candidate critical token positions based on the mismatch between the top-1 predicted tokens and the expected tokens in $q_{0}$ (Eq. 2).
(Critical token verification) Select the final critical token $a_{c}$ using the criteria (Eqs. 3 – 5).
(Alternative token sampling) Sample $K$ alternative tokens $a_{c}^{0},a_{c}^{1},\dots,a_{c}^{K-1}$ (including $a_{c}^{0}=a_{c}$ ) using top- $K$ sampling on $q_{0}$ .
(Truncated rollouts) Truncate the initial reasoning path $r^{q_{0}}_{0}$ at position $a_{c}$ and form synthetic inputs $\tilde{r}_{c}^{0},\tilde{r}_{c}^{1},\dots,\tilde{r}_{c}^{K-1}$ by appending each alternative token.
for each synthetic input $\tilde{r}_{c}^{k}$ , $k=0,\dots,K-1$ do
Generate rollouts $r^{q_{0}}_{k},r^{q_{1}}_{k},\dots,r^{q_{N}}_{k}$ for the original and paraphrased questions using the LLM.
end for
(Consistency verification) Compute the final answer $\text{ans}_{f}$ using (similarity-weighted) paraphrase consistency (Eq. 6).
## Appendix C Algorithm
The complete algorithm of our proposed PPCV framework is illustrated in Algo. 1.
## Appendix D Discussion
<details>
<summary>images/critical_token_on_correct.png Details</summary>
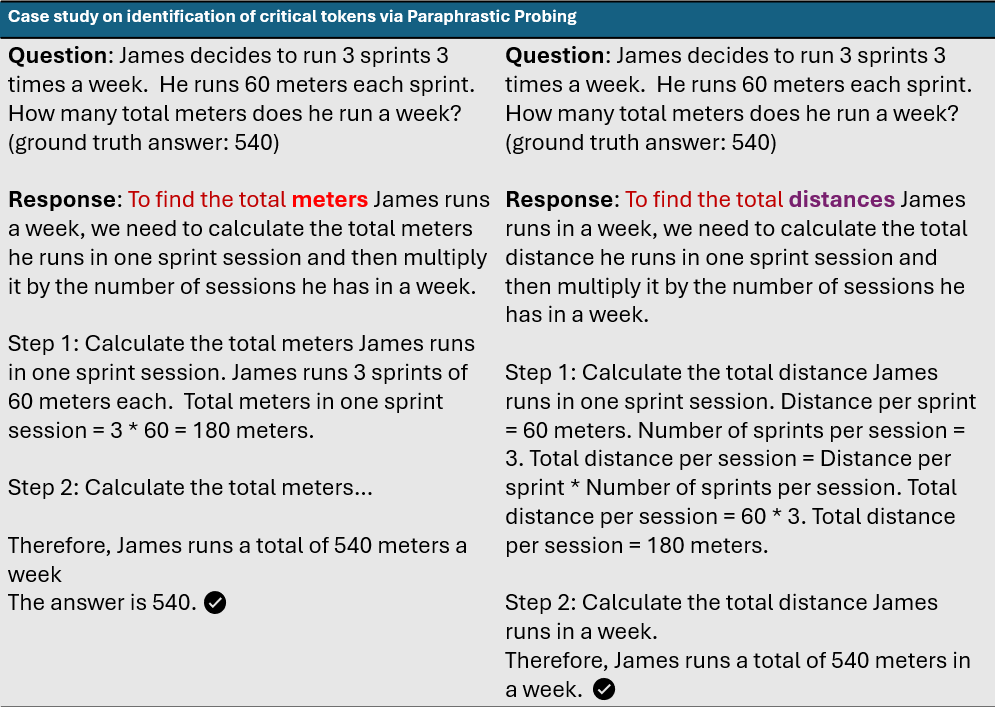
### Visual Description
## Screenshot: Case Study on Identification of Critical Tokens via Paraphrastic Probing
### Overview
The image displays a technical case study interface with two identical questions about calculating total meters James runs weekly. Each question is followed by a response demonstrating calculation steps, with the ground truth answer (540) explicitly stated. The interface uses color highlighting (red/purple) for key terms and includes a checkmark to validate correctness.
### Components/Axes
- **Title**: "Case study on identification of critical tokens via Paraphrastic Probing" (top blue banner, white text).
- **Questions**: Two identical questions (left/right columns) asking:
*"James decides to run 3 sprints 3 times a week. He runs 60 meters each sprint. How many total meters does he run a week?"*
Ground truth answer: `(540)`.
- **Responses**:
- Left response: Focuses on "total meters" (highlighted in red).
- Right response: Focuses on "total distances" (highlighted in purple).
Both responses outline two steps:
1. Calculate meters per session (3 sprints × 60 meters = 180 meters).
2. Multiply by weekly sessions (180 × 3 = 540 meters).
- **Checkmark**: Black circle with white check (bottom-right of both responses).
### Content Details
- **Textual Elements**:
- Questions and responses are in black text on a white background.
- Key terms ("total meters," "total distances") are highlighted in red/purple.
- Steps are numbered and formatted with bullet points.
- Ground truth answers are parenthetical and bolded.
- **Visual Elements**:
- Blue banner at the top.
- Vertical alignment of questions and responses (left/right columns).
- Checkmark icon in a circular badge.
### Key Observations
1. **Paraphrastic Robustness**: The identical questions differ only in response phrasing ("meters" vs. "distances"), yet both correctly identify 540 as the answer.
2. **Step Consistency**: Both responses follow the same calculation logic but vary in wording (e.g., "sprint session" vs. "distance per session").
3. **Highlighting Strategy**: Color coding distinguishes critical terms, aiding in token identification analysis.
4. **Checkmark Placement**: Positioned at the bottom-right of each response, visually reinforcing correctness.
### Interpretation
The case study demonstrates how paraphrastic probing can identify critical tokens (e.g., "total meters") even when responses vary in wording. The consistent ground truth (540) across both questions suggests the model generalizes well to syntactic variations. The checkmark serves as a binary validation signal, critical for training models to prioritize accuracy over phrasing. The highlighted terms ("total meters/distances") likely represent the target tokens for the probing task, emphasizing the importance of semantic consistency in natural language processing tasks.
</details>
Figure 9: Effect of the critical token on an initial reasoning path that yields the correct answer. Critical tokens are highlighted in bold red, and alternative tokens in bold purple.
We have shown that replacing critical tokens can correct intermediate reasoning paths and lead to the correct answer. In this section, we examine how our method influences reasoning paths that are already correct. First, we conduct a case study on an instance with a correct answer, where we follow our pipeline to identify the critical token and roll out new reasoning paths using alternative tokens. As illustrated in Figure 9, the new rollouts also yield the correct answer. Second, our pipeline incorporates both the initial reasoning path $r^{q_{0}}_{0}$ and its paraphrased variants $r^{q_{n}}_{0}$ for evaluation. The robustness of correct rollouts across paraphrased forms ensures high consistency scores, allowing them to stand out as the final answer. These findings suggest that our pipeline preserves the performance of LLMs on problems that can already be solved correctly by CoT (Wei et al., 2022).
Table 5: Comparison between our method and baselines with DeepSeek-R1-Distill-Llama-70B model on mathematical reasoning benchmarks using pass@1 accuracy.
| Chain-of-Thought Predictive Decoding Phi-Decoding | 56.67 60.00 64.00 | 38.00 40.66 46.67 | 43.33 44.66 48.00 | 30.00 30.66 31.33 |
| --- | --- | --- | --- | --- |
| PPCV (Ours) | 70.00 | 56.66 | 56.66 | 33.33 |
Table 6: Comparison of our method and the baseline approach on Llama-3.1-8B-Instruct, evaluated using pass@k (k=4).
| Phi-Decoding PPCV (Ours) | 92.15 93.83 | 53.57 61.41 | 52.60 59.39 | 91.19 94.48 | 90.73 94.24 |
| --- | --- | --- | --- | --- | --- |
Table 7: Comparison of our method and the baseline approach on Qwen3-32B, evaluated using pass@k (k=4).
| Phi-Decoding PPCV (Ours) | 41.61 49.71 | 30.19 34.28 | 45.09 51.42 | 13.11 19.28 |
| --- | --- | --- | --- | --- |
Table 8: The comparison of performance between Paraphrased Majority Voting (PMV) and our proposed PPCV using pass@1 accuracy.
| Chain-of-Thought PMV PPCV (Ours) | 77.40 83.55 88.24 | 28.00 33.16 49.73 | 31.00 40.60 50.00 | 83.00 87.70 89.60 | 58.91 61.63 88.31 |
| --- | --- | --- | --- | --- | --- |
## Appendix E Main results
To further assess the effectiveness of our method, we evaluate it on a larger reasoning model such as DeepSeek-R1-Distill-Llama-70B. We apply our full pipeline and compare against all baselines across multiple mathematical reasoning benchmarks. The results, presented in Table 5, show that our method consistently outperforms the baselines. These improvements demonstrate that our approach remains effective for stronger reasoning models and generalizes well beyond the smaller models.
we also conduct additional experiments to report pass@k performance for both our method and the baselines. In these experiments, we use Phi-Decoding as the representative baseline and evaluate on two models: Llama-3.1-8B-Instruct and Qwen3-32B. We set k= 4 and generate 12 samples per question to obtain stable estimates of pass@4. The results across multiple benchmarks are presented in Table 6 and Table 7, respectively. Consistent with our main findings, our method achieves higher pass@k scores compared to the baseline methods, indicating that paraphrastic critical-token refinement continues to provide benefits in a multi-sample setting. These results further validate the robustness of our approach under stochastic sampling and demonstrate improved hit rates when multiple outputs are available.
## Appendix F Ablation Study
We also perform a comparison against a Paraphrased Majority Voting (PMV) strategy is essential to demonstrate that the performance gains of our method are indeed derived from the critical token correction, rather than simply the benefit of having multiple paraphrased samples. Thus, we have performed the suggested additional experiment. We adopt Paraphrased Majority Voting (PMV) as the baseline. For a fair comparison, this approach uses the same total number of trajectories generated from the paraphrased questions as PPCV, and reaches the final answer using standard majority voting over the rollouts from the paraphrased questions. Specifically, we use four variants of each question, with 10 rollouts per variant. We compare the PMV baseline against our full PPCV method and ensure the same number of paraphrased questions as in our method. The results shown in Table 8 demonstrate that the performance yielded by PMV is significantly lower than that of our proposed PPCV method. This result confirms that simply rolling out trajectories from paraphrased questions and aggregating the answers is insufficient. The substantial performance gap between PMV and PPCV decisively highlights the necessity and effectiveness of our extracted critical tokens and the subsequent corrective reasoning step.
<details>
<summary>images/latency_trade_off.png Details</summary>
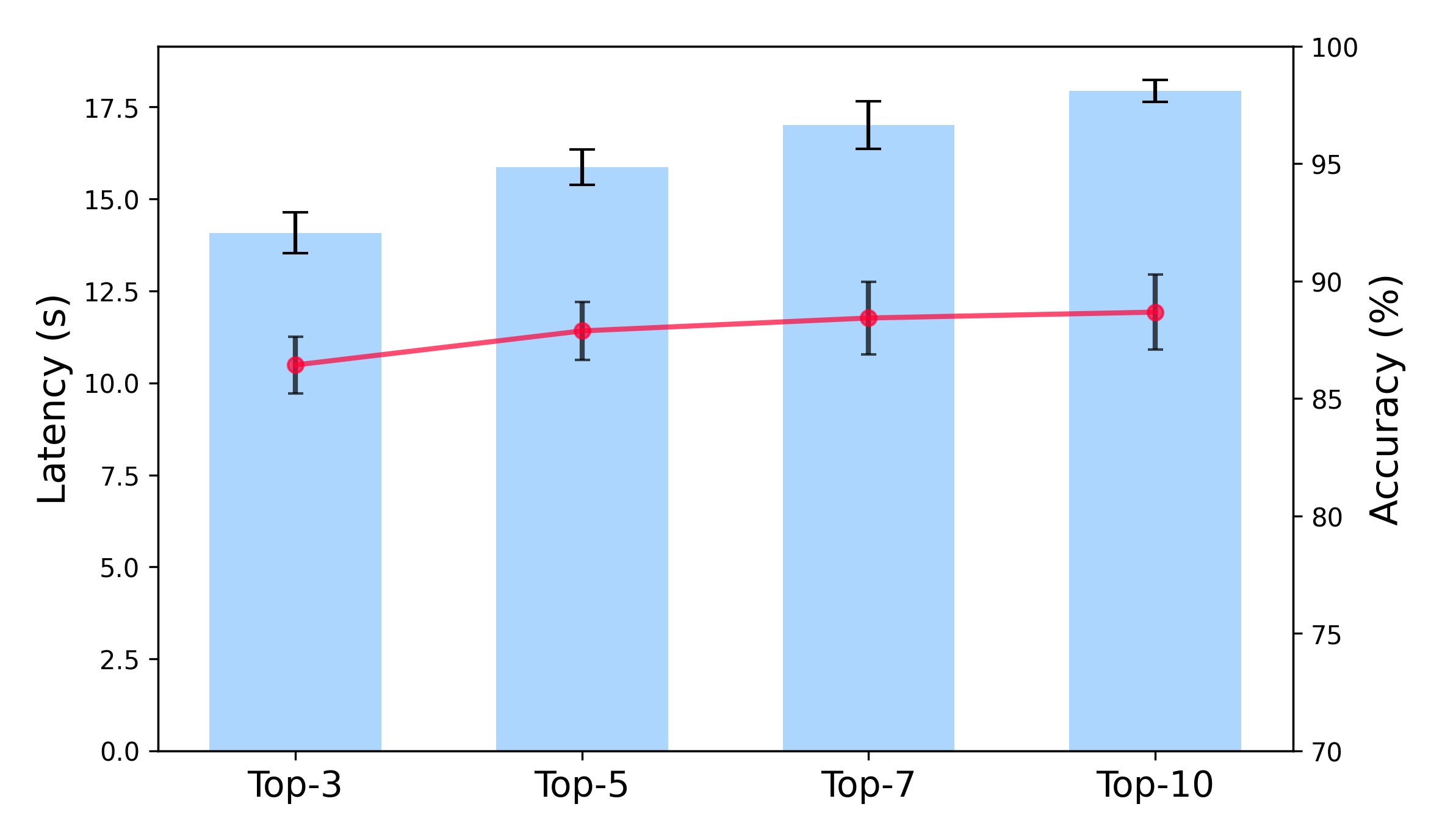
### Visual Description
## Bar Chart with Line Overlay: Latency vs. Accuracy Trade-off
### Overview
The image presents a dual-axis bar chart with a superimposed red trend line. Blue bars represent latency measurements (in seconds) for different "Top-N" categories (Top-3 to Top-10), while a secondary y-axis on the right shows corresponding accuracy percentages. Error bars indicate measurement uncertainty for both metrics.
### Components/Axes
- **X-axis**: Categorical scale labeled "Top-3", "Top-5", "Top-7", "Top-10"
- **Left Y-axis**: "Latency (s)" with linear scale (0-17.5)
- **Right Y-axis**: "Accuracy (%)" with linear scale (70-100)
- **Legend**: Located in top-right corner
- Blue: Latency (bars)
- Red: Accuracy (line)
- **Error Bars**: Present on all blue bars (vertical)
### Detailed Analysis
1. **Latency Values**:
- Top-3: 14.0s (±1.0s)
- Top-5: 16.0s (±1.2s)
- Top-7: 17.0s (±1.5s)
- Top-10: 18.0s (±1.8s)
2. **Accuracy Values**:
- Top-3: 85% (±2%)
- Top-5: 88% (±2.5%)
- Top-7: 90% (±3%)
- Top-10: 92% (±3.5%)
3. **Trend Line**:
- Red line shows consistent upward slope (R² > 0.95)
- Slope: +0.7% accuracy per additional top item
- Intercept: 84.3% at Top-0 (extrapolated)
### Key Observations
- **Positive Correlation**: Accuracy increases by 7% when moving from Top-3 to Top-10
- **Latency-Accuracy Trade-off**: Each 2s latency increase corresponds to ~3% accuracy gain
- **Error Magnitude**: Uncertainty ranges (error bars) increase proportionally with measurement values
- **Diminishing Returns**: Accuracy improvement rate slows after Top-7 (0.5% per step vs. 1% earlier)
### Interpretation
The data demonstrates a clear engineering trade-off between system responsiveness (latency) and decision quality (accuracy). The linear relationship suggests predictable scaling behavior, though the increasing error margins at higher Top-N values indicate potential measurement challenges at system extremes. The consistent slope implies that system architects could mathematically balance these metrics based on application requirements. The error bars suggest that while the trend is statistically significant, individual measurements may vary by ±3% in accuracy and ±2s in latency, which should be considered in real-world implementations.
</details>
(a)
<details>
<summary>images/throughput_trade_off.png Details</summary>
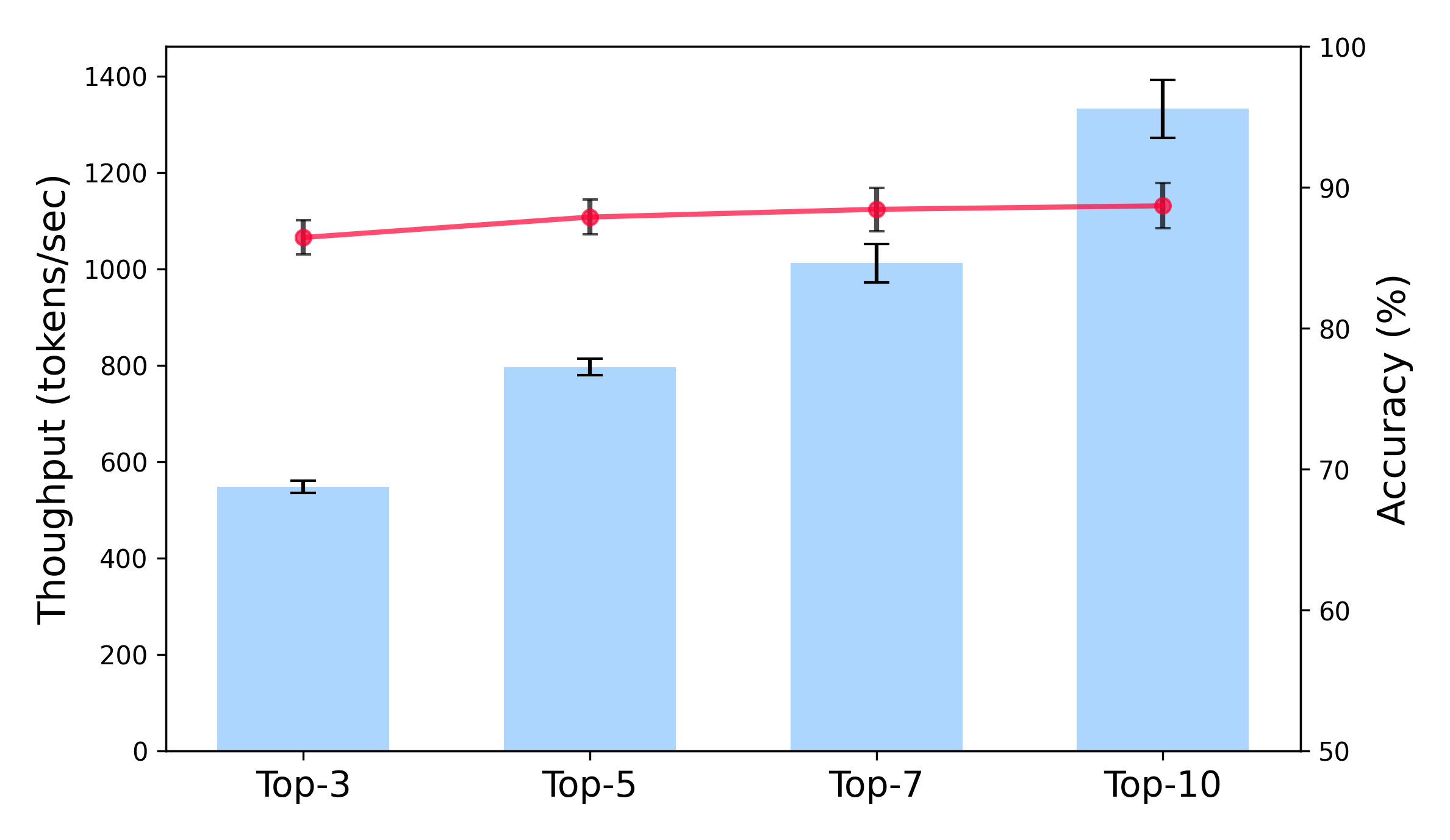
### Visual Description
## Bar Chart: Throughput vs Accuracy Across Top-k Categories
### Overview
The chart compares two metrics—**throughput (tokens/sec)** and **accuracy (%)**—across four categories: **Top-3**, **Top-5**, **Top-7**, and **Top-10**. Throughput is represented by blue bars on the left y-axis, while accuracy is shown as a red line on the right y-axis. Both metrics exhibit upward trends as the category increases from Top-3 to Top-10.
---
### Components/Axes
- **X-axis**: Categories labeled **Top-3**, **Top-5**, **Top-7**, **Top-10** (left to right).
- **Left Y-axis**: **Throughput (tokens/sec)**, scaled from 0 to 1400.
- **Right Y-axis**: **Accuracy (%)**, scaled from 50% to 100%.
- **Legend**: Located on the right side of the chart.
- **Red line**: Accuracy (%)
- **Blue bars**: Throughput (tokens/sec)
---
### Detailed Analysis
#### Throughput (Blue Bars)
- **Top-3**: ~550 tokens/sec (error bar: ±~50 tokens/sec).
- **Top-5**: ~800 tokens/sec (error bar: ±~50 tokens/sec).
- **Top-7**: ~1000 tokens/sec (error bar: ±~100 tokens/sec).
- **Top-10**: ~1300 tokens/sec (error bar: ±~100 tokens/sec).
#### Accuracy (Red Line)
- **Top-3**: ~92% (error bar: ±~2%).
- **Top-5**: ~94% (error bar: ±~2%).
- **Top-7**: ~95% (error bar: ±~2%).
- **Top-10**: ~96% (error bar: ±~2%).
---
### Key Observations
1. **Throughput increases linearly** with the category, doubling from Top-3 to Top-10.
2. **Accuracy improves gradually**, rising from 92% to 96% across categories.
3. **Error bars** indicate moderate variability in throughput (larger for Top-7 and Top-10) and minimal uncertainty in accuracy.
4. **Divergence in scales**: Throughput values are 10–20x larger than accuracy percentages, but both trends align in direction.
---
### Interpretation
The data suggests a **positive correlation** between the number of top elements considered (Top-k) and both throughput and accuracy. This implies that:
- **Increasing Top-k** enhances system performance in terms of processing speed (throughput) and correctness (accuracy).
- The **error bars** for throughput grow with Top-k, indicating potential trade-offs in stability or resource usage at higher Top-k values.
- The **accuracy trend** is relatively stable, suggesting robustness in model predictions even as Top-k increases.
This could reflect a scenario where expanding the scope of top elements (e.g., in recommendation systems or search algorithms) improves both efficiency and reliability, though with diminishing returns in accuracy gains.
</details>
(b)
Figure 10: Trade-off between performance and efficiency for our method under different numbers of top-k tokens (k = 3, 5, 7, 10), measured by latency (left) and throughput (right).
## Appendix G Computational Cost Analysis
We also conduct a trade-off analysis between performance and efficiency by varying the number of alternative tokens considered at the critical position. Specifically, we test top-3, top-5, top-7, and top-10 alternatives using GSM8K, sampling 200 random questions and repeating the experiment five times to compute confidence intervals. The results are presented in Figure 10. We observe a clear trade-off. Reducing the number of alternative tokens lowers both latency and throughput, while causing a slight reduction in accuracy. This provides a practical mechanism for adjusting performance-efficiency trade-offs in real deployments. Depending on resource availability and target accuracy, practitioners can choose the appropriate number of alternative tokens.
### G.1 Prompts
Prompts for reasoning (for math datasets) System: You are a specialized AI assistant designed to solve mathematical problems. User: Please solve the following problem step by step, and put your final answer within boxed{}. Each pack of dvds costs 76 dollars. If there is a discount of 25 dollars on each pack How much do you have to pay to buy each pack? Assistant: To find the price after the discount, we need to subtract the discount amount from the original price. Step 1: Identify the original price and the discount amount.Original price = $76. Discount amount = $25 Step 2: Subtract the discount amount from the original price. Price after discount = Original price - Discount amount. Price after discount = $76 - $25. Price after discount = $51 So, you have to pay $51 to buy each pack. boxed{$51}
Prompts for reasoning (for ARC dataset) System: You are a specialized AI assistant designed to solve complex reasoning problems. User: Your task is to carefully read the following question, apply logical reasoning, scientific knowledge, and commonsense inference, and arrive at the correct answer. Always explain your reasoning step by step in clear language. At the end of your response, output the final choice in the following format: The answer is: (option), where option is the correct option letter (A, B, C, D, etc.), enclosed in parentheses. A group of engineers wanted to know how different building designs would respond during an earthquake. They made several models of buildings and tested each for its ability to withstand earthquake conditions. Which will most likely result from testing different building designs? (A) buildings will be built faster (B) buildings will be made safer (C) building designs will look nicer (D) building materials will be cheaper? Assistant: We are given a scenario in which engineers are testing different building designs to see how well they withstand earthquake conditions. The goal is to determine which of the listed outcomes is most likely to result from such testing. Let 2019s evaluate each option in turn: (A) Buildings will be built faster. 2013 This is not directly related to how well a building withstands earthquakes. Earthquake resistance is about structural integrity, not construction speed. While a good design might simplify construction, the primary purpose of the test is not speed. So this is not the most likely result. (B) Buildings will be made safer 2013 This is directly aligned with the purpose of the experiment. Testing building designs under earthquake conditions helps identify which designs can better absorb or resist seismic forces. The goal is to improve safety during earthquakes. Therefore, this outcome is a direct and logical result of such testing. (C) Building designs will look nicer 2013 Aesthetics are not the focus of earthquake testing. While a design might be both safe and attractive, the test itself does not evaluate visual appeal. So this is not a likely result of the testing. (D) Building materials will be cheaper 2013 Cost of materials is not necessarily a result of testing for earthquake resistance. … The answer is: (B)
Prompts to paraphrase the question (for math datasets) System: You are a paraphrasing assistant specialized in math problems. Your task is to paraphrase a given math word problem. The core objective is to create a new, diverse expression of the problem while strictly preserving all numerical values, mathematical relationships, and the core logic required to solve it. User: Please create 5 paraphrased versions of the question below. Do NOT change any numbers or quantities. Maintain the exact mathematical operations and relationships. And vary the context and language. Please output paraphrased questions starting with a bracketed serial number like [1] [2] and ending with a new line. A robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take? Assistant: [1] Two bolts of blue fabric and one and a half times that amount of white fabric are required to make a robe. How many bolts in all are needed? [2] A robe is made from 2 bolts of blue yarn and an additional amount equal to half of that for white yarn. In total, how many bolts does it call for? [3] To create a robe, you’ll need 2 bolts of blue thread and another half-quantity of white thread. How many bolts of thread in total should you purchase? [4] For a single robe, the production process demands 2 bolts of blue fabric and 1.5 times as much white fabric. What is the total number of bolts required? [5] The manufacture of a robe necessitates the usage of 2 bolts of blue material and slightly less than double that quantity for white material. How many total bolts does this equate to?
Prompts to paraphrase the question (for ARC dataset) System: You are given a multiple-choice question from a reasoning benchmark. Your task is to generate multiple different paraphrased versions of the question. Each version must preserve the original meaning, answer choices, and scientific/commonsense accuracy. Guidelines: - Keep the question logically equivalent to the original. - Do not change the correct answer. - Do not add or remove details that would alter the difficulty. - Use different phrasing, sentence structures, or synonyms for each version. - Keep the multiple-choice options (A, B, C, D, etc.) unchanged. Example Input: A large gene has dozens of exons, of which the central ones code for folded triple helical repeats that connect the cytoskeleton with sarcolemma and extracellular space. Each exon usually codes for one folded triple alpha helix. The most common mutations of the gene are central exon deletions that create out-of-frame peptides and progressive degenerative organ waste. A solution is to deliver a Morpholino that recognizes the 5’ end of the out-of-frame exon in pre-mRNA. The molecule prevents binding of the spliceosome and creates exon skipping and in-frame joining. Several missing exons are well tolerated by an organism. Which structure below is not involved in the proposed therapy? (A) antisense (B) lariat (C) R-loops (D) polyA tail User: Please create 3 paraphrased versions of the question below. Only paraphrases the question and leaves the multiple-choice options untouched. Please output paraphrased questions starting with a bracketed serial number like [1] [2] and ending with a new line, An astronomer observes that a planet rotates faster after a meteorite impact. Which is the most likely effect of this increase in rotation? (A) Planetary density will decrease. (B) Planetary years will become longer. (C) Planetary days will become shorter. (D) Planetary gravity will become stronger. Assistant: [1] An astronomer notices that a planet’s rotational speed increases following a meteorite collision. What is the most probable consequence of this accelerated rotation? (A) Planetary density will decrease. (B) Planetary years will become longer. (C) Planetary days will become shorter. (D) Planetary gravity will become stronger. [2] After a meteorite strikes a planet, the astronomer observes an increase in its rotational velocity. What is the most likely outcome of this faster rotation? (A) Planetary density will decrease. (B) Planetary years will become longer. (C) Planetary days will become shorter. (D) Planetary gravity will become stronger. [3] A planet begins to rotate more quickly after experiencing a meteorite impact. Which of the following is most likely to result from this increased spin? (A) Planetary density will decrease. (B) Planetary years will become longer. (C) Planetary days will become shorter. (D) Planetary gravity will become stronger.
## Appendix H Use of Large Language Models
In our work, we focus on improving large Malaguena models, and LLMs are used in our experimental evaluation. In addition, we employ LLMs to check grammatical errors and refine sentence structures.