# Jailbreaking Leaves a Trace: Understanding and Detecting Jailbreak Attacks from Internal Representations of Large Language Models
**Authors**: Sri Durga Sai Sowmya Kadali, Evangelos E. Papalexakis
> University of California, Riverside Riverside CA USA
(2026)
## Abstract
Jailbreaking large language models (LLMs) has emerged as a critical security challenge with the widespread deployment of conversational AI systems. Adversarial users exploit these models through carefully crafted prompts to elicit restricted or unsafe outputs, a phenomenon commonly referred to as Jailbreaking. Despite numerous proposed defense mechanisms, attackers continue to develop adaptive prompting strategies, and existing models remain vulnerable. This motivates approaches that examine the internal behavior of LLMs rather than relying solely on prompt-level defenses. In this work, we study jailbreaking from both security and interpretability perspectives by analyzing how internal representations differ between jailbreak and benign prompts. We conduct a systematic layer-wise analysis across multiple open-source models, including GPT-J, LLaMA, Mistral, and the state-space model Mamba2, and identify consistent latent-space patterns associated with adversarial inputs. We then propose a tensor-based latent representation framework that captures structure in hidden activations and enables lightweight jailbreak detection without model fine-tuning or auxiliary LLM-based detectors. We further demonstrate that these latent signals can be used to actively disrupt jailbreak execution at inference time. On an abliterated LLaMA 3.1 8B model, selectively bypassing high-susceptibility layers blocks 78% of jailbreak attempts while preserving benign behavior on 94% of benign prompts. This intervention operates entirely at inference time and introduces minimal overhead, providing a scalable foundation for achieving stronger coverage by incorporating additional attack distributions or more refined susceptibility thresholds. Our results provide evidence that jailbreak behavior is rooted in identifiable internal structures and suggest a complementary, architecture-agnostic direction for improving LLM security. Our implementation can be found here (jai, [n. d.]).
Jailbreaking, Large Language Models, LLM Internal Representations, Self-attention, Hidden Representation, Tensor Decomposition copyright: acmlicensed journalyear: 2026 doi: XXXXXXX.XXXXXXX conference: ; ; ccs: Computing methodologies Artificial intelligence ccs: Information systems Data mining ccs: Security and privacy Software and application security
## 1. Introduction
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks and have become increasingly integrated into applications spanning diverse domains and user populations. Despite their utility and efforts to align them according to human and safety expectations (Wang et al., 2023; Zeng et al., 2024; Glaese et al., 2022), these models remain highly susceptible to adversarial exploitation, raising significant safety and security concerns given their widespread accessibility. Among such threats, Jailbreaking has emerged as a persistent and particularly concerning attack vector, wherein malicious actors craft carefully engineered prompts to circumvent built-in safety mechanisms (Chao et al., 2024; Zou et al., 2023) and elicit restricted, sensitive, or otherwise disallowed content (Liu et al., 2024). Jailbreak attacks pose substantial risks, as they enable users with harmful intent to manipulate LLMs into producing outputs that violate safety policies, including actionable instructions for malicious activities (Zhang et al., 2024; Wang et al., 2024a; Yu et al., 2023). The growing availability of jailbreak prompts in public repositories, research artifacts, and online forums further exacerbates this issue (Jiang et al., 2024; Shen et al., 2024).
To mitigate these risks, prior work has explored a range of defense strategies, including prompt-level filtering (Wang et al., 2024b), model-level interventions (Zeng et al., 2024; Xiong et al., 2025), reinforcement learning from human feedback (RLHF) (Bai et al., 2022), and the use of auxiliary safety models (Chen et al., 2023; Lu et al., 2024). While such approaches have demonstrated partial effectiveness, they are not without limitations. In practice, even well-aligned models can remain vulnerable under repeated or adaptive attack attempts. Moreover, no single defense mechanism has proven sufficient to counter the continually evolving landscape of jailbreak strategies.
In this study, we investigate a complementary and comparatively underexplored direction: leveraging internal model representations to distinguish jailbreak prompts from benign inputs and to guide mitigation. Our central hypothesis is that adversarial prompts induce distinct and detectable structural patterns within the hidden representations of LLMs, independent of output behavior. To evaluate this hypothesis, we extract layer-wise internal representations such as multi-head attention and layer output/hidden state representation from multiple models such as GPT-J, LlaMa, Mistral, and the state-space sequence model Mamba, and apply tensor decomposition (Sidiropoulos et al., 2017) techniques to characterize and compare latent-space behaviors across benign and jailbreak prompts. Building on this analysis, we further demonstrate how these latent representations can be used to identify layers that are particularly susceptible to adversarial manipulation and to intervene during inference by selectively bypassing such layers. This representation-centric framework not only enables reliable detection of jailbreak prompts but also provides a principled mechanism for mitigating harmful behavior without modifying model parameters or relying on output-level filtering. Together, our results suggest that internal representations offer a powerful and generalizable foundation for both understanding and defending against jailbreak attacks beyond surface-level text analysis. Our contributions are as follows:
- Layer-wise Jailbreak Signature: We show that jailbreak and benign prompts exhibit distinct, layer-dependent latent signatures in the internal representations of LLMs, which can be uncovered using tensor decomposition (Sidiropoulos et al., 2017).
- Effective Defense via Targeted Layer Bypass: We demonstrate that these latent signatures can be exploited at inference time to identify susceptible layers and disrupt jailbreak execution through targeted layer bypass.
## 2. Related work
### 2.1. Adversarial Attacks
Adversarial attacks on LLMs encompass a broad class of inputs intentionally crafted to induce unintended, incorrect, or unsafe behaviors (Zou et al., 2023; Chao et al., 2024). Unlike adversarial examples in vision or speech domains, which often rely on imperceptible input perturbations, attacks on LLMs primarily exploit semantic, syntactic, and contextual vulnerabilities in language understanding and generation. By manipulating instructions, context, or interaction structure, adversaries can steer models toward generating factually incorrect information, violating behavioral constraints, or producing harmful or sensitive content, posing significant risks to deployed systems (Liu et al., 2024). Existing adversarial strategies span a wide range of mechanisms, including prompt injection, role-playing and persona manipulation, instruction obfuscation, multi-turn coercion (Yu et al., 2023; Jiang et al., 2024), and indirect attacks embedded within external content such as documents or code, and even by fine-tuning (Yang et al., 2023; Yao et al., 2023). A central challenge in defending against these attacks is their adaptability: adversarial prompts are often transferable across models and can be easily modified to evade static defenses (Zou et al., 2023). As a result, surface-level or prompt-based mitigation strategies have shown limited robustness
### 2.2. Jailbreak attacks
A prominent and particularly challenging class of adversarial attacks on LLMs is jailbreaking. Jailbreak attacks aim to circumvent built-in safety mechanisms and alignment constraints, enabling the model to produce outputs that it is explicitly designed to refuse. These attacks often rely on prompt engineering techniques such as hypothetical scenarios, instruction overriding, contextual reframing, or step-by-step coercion, effectively manipulating the model’s internal decision-making processes (Wei et al., 2023). Unlike general adversarial prompting, jailbreak attacks explicitly target safety guardrails and content moderation policies, making them a critical concern from both security and governance perspectives (Liu et al., 2024; Zou et al., 2023; Jiang et al., 2024). Despite extensive efforts to harden models through alignment training and reinforcement learning from human feedback (Bai et al., 2022; Wang et al., 2023; Glaese et al., 2022), jailbreak prompts continue to evolve, highlighting fundamental limitations in current defense approaches. This motivates the need for methods that analyze jailbreak behavior at the level of internal model representations, rather than relying solely on external prompt or output inspection.
### 2.3. Jailbreak Defenses
Prior work on defending against jailbreak attacks in LLMs has primarily focused on prompt and output-level safeguards. Rule-based filtering and keyword matching are commonly used due to their low computational cost, but such approaches are brittle and easily bypassed through paraphrasing, obfuscation, or multi-turn prompting (Deng et al., 2024). Learning-based defenses, including supervised classifiers and auxiliary LLMs for intent detection or self-evaluation (Wang et al., 2025), improve robustness but introduce additional complexity, inference overhead, and new attack surfaces. Model-level defenses, such as alignment fine-tuning, reinforcement learning from human feedback (RLHF), and policy-based or constitutional training, aim to internalize safety constraints within the model (Ouyang et al., 2022). While effective to an extent, these approaches are resource-intensive and require continual updates as jailbreak strategies evolve. Moreover, even extensively aligned models remain susceptible to jailbreak attacks, indicating fundamental limitations in current training-based defenses. Overall, existing defenses largely treat jailbreak detection as a black-box problem and rely on external signals from prompts or generated outputs. In contrast, fewer works explore the internal representations of LLMs as a basis for defense (Candogan et al., 2025). This gap motivates approaches that leverage latent-space and layer-wise signals to identify jailbreak behavior in an interpretable and architecture-agnostic manner, without requiring additional fine-tuning or auxiliary models.
## 3. Preliminaries
### 3.1. Tensors
Tensors (Sidiropoulos et al., 2017) are defined as multi-dimensional arrays that generalize one-dimensional arrays (vectors) and two-dimensional arrays (matrices) to higher dimensions. The dimension of a tensor is traditionally referred to as its order, or equivalently, the number of modes, while the size of each mode is called its dimensionality. For instance, we may refer to a third-order tensor as a three-mode tensor $\boldsymbol{\mathscr{X}}\in\mathbb{R}^{I\times J\times K}$ .
### 3.2. Tensor Decomposition
Tensor Decomposition (Sidiropoulos et al., 2017) is a popular data science tool for discovering underlying low-dimensional patterns in the data. We focus on the CANDECOMP/PARAFAC (CP) decomposition model (Sidiropoulos et al., 2017), one of the most famous tensor decomposition models that decomposes a tensor into a sum of rank-one components. We use CP decomposition because of its simplicity and interpretability. The CP decomposition of a three-mode tensor $\boldsymbol{\mathscr{X}}\in\mathbb{R}^{I\times J\times K}$ is the sum of three-way outer products, that is, $\boldsymbol{\mathscr{X}}\approx\sum_{r=1}^{R}\mathbf{a}_{r}\circ\mathbf{b}_{r}\circ\mathbf{c}_{r}$ , where $R$ is the rank of the decomposition, $\mathbf{a}_{r}\in\mathbb{R}^{I}$ , $\mathbf{b}_{r}\in\mathbb{R}^{J}$ , and $\mathbf{c}_{r}\in\mathbb{R}^{K}$ are the factor vectors and $\circ$ denotes the outer product. The rank of a tensor $\boldsymbol{\mathscr{X}}$ is the minimal number of rank-1 tensors required to exactly reconstruct it:
$$
\text{rank}(\boldsymbol{\mathscr{X}})=\min\left\{R:\boldsymbol{\mathscr{X}}=\sum_{r=1}^{R}\mathbf{a}_{r}\circ\mathbf{b}_{r}\circ\mathbf{c}_{r},\;\mathbf{a}_{r}\in\mathbb{R}^{I},\mathbf{b}_{r}\in\mathbb{R}^{J},\mathbf{c}_{r}\in\mathbb{R}^{K}\right\}
$$
Selecting an appropriate rank is critical, as it directly affects both the expressiveness and interpretability of the decomposition. Lower-rank approximations yield compact and computationally efficient representations, while higher ranks can capture richer structure at the cost of increased complexity and potential noise.
### 3.3. Transformer Architecture
A Transformer (Vaswani et al., 2023) is a neural network architecture designed for modeling sequential data through attention mechanisms rather than recurrence or convolution. Transformers process input sequences in parallel and capture long-range dependencies by explicitly modeling interactions between all tokens in a sequence.
A transformer consists of a stack of layers, each composed of two primary submodules: multi-head self-attention and a position-wise feed-forward network (FFN). Residual connections and layer normalization are applied around each submodule to stabilize training.
#### 3.3.1. Multi-Head Self-Attention
Multi-head self-attention enables the model to attend to different parts of the input sequence simultaneously. Given an input representation $\mathbf{H}\in\mathbb{R}^{T\times d}$ , each attention head projects $\mathbf{H}$ into query ( $\mathbf{Q}$ ), key ( $\mathbf{K}$ ), and value ( $\mathbf{V}$ ) matrices:
$$
\mathbf{Q}=\mathbf{H}\mathbf{W}^{Q},\quad\mathbf{K}=\mathbf{H}\mathbf{W}^{K},\quad\mathbf{V}=\mathbf{H}\mathbf{W}^{V}.
$$
Attention is computed as
$$
\mathrm{Attn}(\mathbf{Q},\mathbf{K},\mathbf{V})=\mathrm{softmax}\!\left(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d_{k}}}\right)\mathbf{V},
$$
where $d_{k}$ is the dimensionality of each attention head. Multiple attention heads operate in parallel, and their outputs are concatenated and linearly projected, allowing the model to capture diverse relational patterns across tokens.
#### 3.3.2. Layer Outputs and Hidden Representations
Each transformer layer produces a hidden representation (or layer output) that serves as input to the next layer. Formally, for layer $\ell$ , the output representation $\mathbf{H}^{(\ell)}$ is given by:
$$
\mathbf{H}^{(\ell)}=\mathrm{LN}\!\left(\mathbf{H}^{(\ell-1)}+\mathrm{MHA}\!\left(\mathbf{H}^{(\ell-1)}\right)\right),
$$
followed by
$$
\mathbf{H}^{(\ell)}=\mathrm{LN}\!\left(\mathbf{H}^{(\ell)}+\mathrm{FFN}\!\left(\mathbf{H}^{(\ell)}\right)\right),
$$
where $\mathrm{MHA}$ denotes multi-head attention, $\mathrm{FFN}$ denotes the feed-forward network, and $\mathrm{LN}$ denotes layer normalization.
The sequence of hidden states $\{\mathbf{H}^{(1)},\ldots,\mathbf{H}^{(L)}\}$ captures increasingly abstract features, ranging from local syntactic patterns in early layers to semantic and task-relevant representations in deeper layers. These intermediate representations are commonly referred to as hidden layer activations and form the basis for interpretability and internal behavior analysis.
### 3.4. Model Types: Base, Instruction-Tuned, and Abliterated Models
Large language models (LLMs) can be categorized based on their training and alignment processes, which influence their behavior under adversarial conditions.
Base Models
These are pretrained on large-scale text corpora using self-supervised objectives without explicit instruction tuning. Examples include GPT-J and LLaMA. Base models capture broad language patterns but lack alignment with human preferences, making them prone to generate unrestricted or unsafe outputs.
Instruction-Tuned Models
Derived from base models via supervised fine-tuning on datasets containing human instructions and responses, these models improve instruction-following capabilities (Zhang et al., 2026) and enforce safety constraints, such as refusing harmful queries. While instruction tuning enhances safety, these models remain susceptible to sophisticated jailbreak prompts.
Abliterated Models
Abliterated models are instruction-tuned models where alignment or safety components have been removed, disabled, or bypassed (Young, 2026). Such models behave more like base models but may retain subtle differences due to prior fine-tuning. Abliterated models serve as valuable testbeds to study jailbreak vulnerabilities and internal representational changes resulting from alignment removal.
Analyzing these model types enables us to investigate how alignment and instruction tuning affect internal layer activations and latent patterns, informing the design of robust jailbreak detection methods that generalize across model variations.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Latent Analysis and Classifier Training for Jailbreak Mitigation
### Overview
The diagram illustrates a two-phase process for detecting and mitigating jailbreak attacks in large language models (LLMs). It combines latent space analysis, classifier training, and inference-time mitigation strategies to identify and bypass harmful prompt-mode factors.
---
### Components/Axes
1. **Top Section: Latent Analysis and Classifier Training**
- **Input Prompts to LLM**:
- Two input types: *Benign* (green) and *Jailbreak* (red) prompts.
- Arrows show data flow through *LLM Layers* to an *Output*.
- **Intermediate Layers' Data**:
- Extracted from a specific layer (`Layer 'l'`) for a single input prompt.
- Visualized as a 2D grid with dimensions: *Sequence length* (rows) and *Token embedding length* (columns).
- **3-Mode Activation Tensor**:
- Constructed by extracting representations from all layers (`l=1,2,3,...,L`).
- Forms a 3D tensor with dimensions: *Sequence length*, *Token embedding length*, and *Layer depth*.
- **Effective Separation of Factors**:
- Visualized as clusters in latent space: *Benign* (green dots) and *Jailbreak* (purple dots).
- A classifier is trained on *prompt-mode factors* to distinguish these clusters.
2. **Bottom Section: Jailbreak Mitigation at Inference**
- **Inference-Time Prompt**:
- Input prompt processed through *LLM Layers*.
- Intermediate data extracted from `Layer 'l'` and multiplied by matrix **A** to form a *New Prompt Layer*.
- **Decomposed Factors (CP Decomposition)**:
- Visualized as a 3D tensor decomposed into factors **A**, **B**, and **C**.
- **Project Layer Representations**:
- Outputs are projected onto *learned latent factors* for classification.
- **Identify Jailbreak-Sensitive Layers**:
- If `Jailbreak Prob > threshold`, the layer is flagged as sensitive.
- **Susceptible Layer Bypassing**:
- Layers marked in red (e.g., `Layer b`, `Layer e`) are bypassed during inference to prevent harmful outputs.
---
### Detailed Analysis
- **Latent Space Separation**:
- Benign and jailbreak prompts are separated in latent space, enabling classifier training on prompt-mode factors.
- **3-Mode Tensor Construction**:
- Captures multi-dimensional interactions between sequence position, token embeddings, and layer depth.
- **Inference Mitigation**:
- Matrix **A** transforms intermediate layer outputs into a new prompt layer, which is analyzed for jailbreak signals.
- Layers with high jailbreak probability are bypassed to avoid harmful outputs.
---
### Key Observations
1. **Layer Sensitivity**:
- Certain layers (marked in red) exhibit stronger jailbreak signatures and are bypassed during inference.
2. **Classifier Training**:
- The classifier uses prompt-mode factors derived from the 3-mode tensor to distinguish benign from jailbreak inputs.
3. **Decomposition**:
- CP decomposition breaks down the activation tensor into interpretable factors (**A**, **B**, **C**), aiding in mitigation.
---
### Interpretation
This diagram demonstrates a defense mechanism against jailbreak attacks by leveraging latent space analysis. During training, the model learns to separate benign and malicious prompts in latent space. At inference, it dynamically identifies sensitive layers and bypasses them to prevent harmful outputs. The use of CP decomposition suggests an emphasis on interpretability, allowing the system to isolate and neutralize jailbreak signals effectively. The red-marked layers likely represent critical points where jailbreak attempts manifest, making them prime candidates for bypassing.
</details>
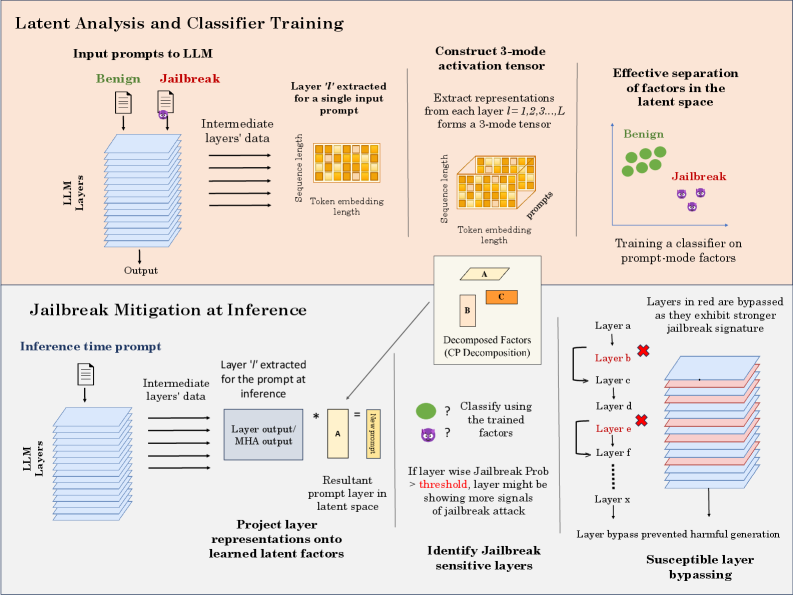
Figure 1. Proposed method: (top) Latent analysis and classifier training: self-attention and layer-output tensors are constructed from input prompts, decomposed via CP decomposition, and used to learn jailbreak-discriminative latent factors. (Bottom) Inference-time mitigation: internal representations from a new prompt are projected onto the learned factors to estimate layer-wise jailbreak susceptibility; layers exhibiting strong adversarial signals are bypassed to suppress jailbreak behavior.
## 4. Proposed Method
We study jailbreak behavior through internal model representations using two complementary analysis pipelines.
### 4.1. Hidden Representation Analysis
Model Suite and Representation Extraction
We perform hidden representation analysis by examining both multi-head self-attention outputs and layer-wise hidden representations across a diverse set of large language models. Specifically, we evaluate three base models: GPT-J-6B (Wang et al., 2021), LLaMA-3.1-8B (AI@Meta, 2024b), and Mistral-7B-v01 (Jiang et al., 2023); three instruction-tuned models: GPT-JT-6B (Computer, 2022), LLaMA-3.1-8B-Instruct (AI@Meta, 2024a), and Mistral-7B-Instruct-V0.1 (AI, 2023); one abliterated model, LLaMA-3.1-8B-Instruct-Abliterated (Labonne, [n. d.]); and one state-space sequence model, Mamba-2.8b-hf (mam, [n. d.]). This selection enables a systematic comparison across different stages of alignment and architectural paradigms.
The inclusion of base, instruction-tuned, and abliterated models is intentional. Base models offer insight into unaligned latent structures; instruction-tuned models show how safety fine-tuning alters internal processing; and abliterated models help isolate the role of alignment layers. We focus not on output quality but on how jailbreak and benign prompts are internally encoded across this alignment spectrum. From this perspective, the specific semantic quality of the output is not critical; instead, we focus on identifying discriminative patterns that persist across model variants. Together, these model categories enable us to analyze jailbreak behavior across the full alignment spectrum and assess whether latent-space signatures of jailbreak prompts are consistent and model-agnostic.
Tensor Construction and Latent Factors for Jailbreak Detection
For a given set of input prompts containing both benign and jailbreak instances, we extract multi-head attention representations and hidden state/layer output from each layer of the model. For a single prompt, the resulting representation has dimensions $1\times T\times d$ , where $T$ denotes the sequence length and $d$ is the hidden dimensionality. By stacking representations across multiple prompts, we construct a third-order tensor of size $N\times T\times d$ , where $N$ is the number of prompts as illustrated in Fig. 1.
To analyze the latent structure of these internal representations, we apply the CANDECOMP/PARAFAC (CP) tensor decomposition to factorize the tensor into three low-rank factors corresponding to the prompt, sequence, and hidden dimensions. The factor associated with the prompt mode captures latent patterns that reflect how different prompts are encoded internally across model layers. Prior work (Papalexakis, 2018; Zhao et al., 2019) has shown that tensor decomposition-derived latent patterns effectively capture meaningful structure for classification and detection tasks, even with limited data (Qazi et al., 2024; Kadali and Papalexakis, 2025).
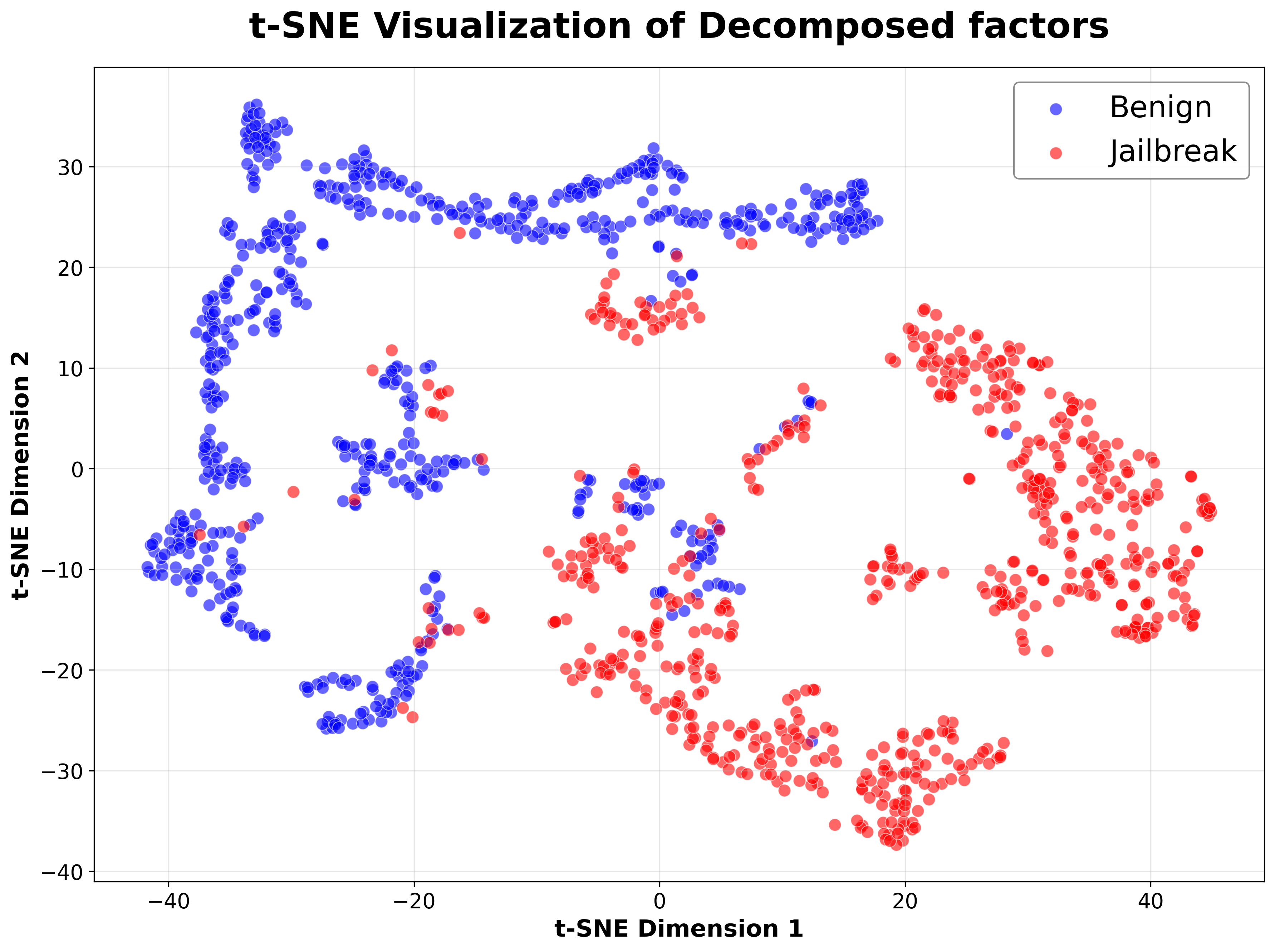
We use these prompt-mode latent factors as features for a lightweight classifier that distinguishes jailbreak prompts from benign prompts. This classifier serves two purposes: to assess separability between prompt types in the latent space (Fig. 2), and as a mechanism to estimate layer-wise susceptibility to jailbreak behavior, which is leveraged by the mitigation method described next.
Layer-wise Separability and Susceptibility
To localize where jailbreak-related information is expressed within the network, we train separate classifiers on latent factors extracted from individual layers. This produces a layer-wise profile that quantifies how strongly each layer encodes representations associated with adversarial prompts. From an interpretability perspective, these layers can be viewed as critical representational stages where benign and adversarial behaviors diverge.
Importantly, we do not interpret high separability as evidence that a layer directly causes jailbreak behavior. Rather, it indicates that these layers capture discriminative representations associated with jailbreak prompts, making them especially informative for detection. This observation provides insight into how adversarial instructions propagate through the model and forms the basis for the inference-time intervention introduced in the following section.
<details>
<summary>figures/layer_9_layer_output_tsne_rank_20_regenerated.png Details</summary>
### Visual Description
## t-SNE Visualization: Decomposed Factors
### Overview
This is a two-dimensional t-SNE (t-distributed Stochastic Neighbor Embedding) visualization showing the distribution of two categories: "Benign" (blue) and "Jailbreak" (red). The plot reveals spatial clustering patterns between the two groups across decomposed factors.
### Components/Axes
- **X-axis**: t-SNE Dimension 1 (ranges approximately from -40 to +40)
- **Y-axis**: t-SNE Dimension 2 (ranges approximately from -40 to +40)
- **Legend**: Located in the top-right corner, with:
- Blue circles labeled "Benign"
- Red circles labeled "Jailbreak"
### Detailed Analysis
1. **Benign (Blue) Cluster**:
- Dominates the upper-left quadrant (X: -40 to 0, Y: 0 to 30)
- Forms a dense, irregularly shaped cluster with high point density
- Extends diagonally toward the upper-right quadrant (X: 0 to 20, Y: 10 to 30)
- Contains a few outliers near the lower-left quadrant (X: -30 to -10, Y: -10 to 0)
2. **Jailbreak (Red) Cluster**:
- Concentrated in the lower-right quadrant (X: 10 to 40, Y: -30 to 0)
- Forms a large, dense cluster with a secondary smaller cluster near the center (X: 0 to 10, Y: -10 to 0)
- Extends into the upper-right quadrant (X: 20 to 40, Y: 0 to 10) with lower density
- Contains a few outliers near the center (X: -10 to 10, Y: -10 to 10)
3. **Overlap Region**:
- Significant overlap occurs in the central region (X: -10 to 10, Y: -10 to 10)
- Approximately 15-20% of points in this region show mixed colors
- Notable overlap density near (X: 0, Y: 0) and (X: 10, Y: 0)
### Key Observations
- **Distinct Grouping**: Benign and Jailbreak categories exhibit clear spatial separation in most regions
- **Dimensional Correlation**:
- Benign points correlate with higher Y-values (positive t-SNE Dimension 2)
- Jailbreak points correlate with higher X-values (positive t-SNE Dimension 1)
- **Outlier Patterns**:
- Benign outliers appear in lower-left quadrant
- Jailbreak outliers appear near the center and upper-right quadrant
- **Density Gradients**:
- Benign density peaks near (X: -20, Y: 20)
- Jailbreak density peaks near (X: 30, Y: -20)
### Interpretation
This visualization demonstrates effective separation between Benign and Jailbreak categories in the decomposed factor space, suggesting the t-SNE model successfully captures meaningful distinctions. The central overlap region indicates potential ambiguity in factor decomposition for certain samples, possibly representing edge cases or transitional states between categories. The diagonal distribution pattern implies that the first two decomposed factors capture orthogonal aspects of the data, with Dimension 1 primarily distinguishing Jailbreak samples and Dimension 2 primarily distinguishing Benign samples. The outlier patterns suggest potential areas for model refinement, particularly in the central overlap region where classification confidence may be lower.
</details>
Figure 2. t-SNE visualization of prompt-mode CP factors for a representative model. Clear separation between benign and jailbreak clusters indicates that internal latent factors capture strong structure, motivating their use for jailbreak detection. Similar patterns are observed across models.
### 4.2. Layer-Aware Mitigation via Latent-Space Susceptibility
To mitigate jailbreak attacks, we propose a representation-level defense method, that leverages layer-wise susceptibility signals derived from internal representations. By identifying layers that strongly encode jailbreak-specific representations, we selectively bypass them during inference (Elhoushi et al., 2024; Shukor and Cord, 2024). While prior work has explored layer bypassing primarily for reducing computation and improving inference efficiency, our approach demonstrates that such bypassing can simultaneously reduce computational cost and mitigate jailbreak behaviors (Luo et al., 2025; Lawson and Aitchison, 2025).
We conduct this experiment on an abliterated model (LLaMA-3.1-8B). Base models are excluded from this intervention as they primarily perform next-token prediction without alignment constraints, making output-based safety evaluation less meaningful. Instruction-tuned models are also not ideal candidates, as their built-in guardrails obscure whether observed safety improvements arise from our method or from prior alignment. Abliterated models, which lack safety mechanisms while retaining instruction-tuned structure, provide a suitable testbed for isolating the effects of our approach.
Layer-wise Projection and Jailbreak Susceptibility Scoring
Given an input prompt, we extract intermediate representations from each transformer layer of the model. Let $\mathbf{x}\in\mathbb{R}^{d}$ denote the feature vector obtained from a specific layer (e.g., multi-head self-attention output or layer output).
Latent Projection.
For each layer, we project the extracted features onto a lower-dimensional latent space defined by factors obtained from tensor decomposition of the corresponding instruct model representations obtained in § 4.1. Let $\mathbf{W}\in\mathbb{R}^{d\times r}$ denote the matrix of $r$ basis vectors (factors). The projected representation is computed as:
$$
\mathbf{z}=\mathbf{W}^{\top}\mathbf{x},
$$
where $\mathbf{z}\in\mathbb{R}^{r}$ is the latent feature representation. This operation constitutes a linear projection that preserves task-relevant structure encoded by the factors.
Layer-wise Jailbreak Probability Estimation.
The projected features are passed to a classifier trained to distinguish between benign and jailbreak prompts. For a logistic regression classifier, the probability of a jailbreak at a given layer is computed as:
$$
p=\sigma(\mathbf{w}^{\top}\mathbf{z}+b),
$$
where $\mathbf{w}$ and $b$ denote the classifier weights and bias, respectively, and $\sigma(\cdot)$ is the sigmoid function:
$$
\sigma(x)=\frac{1}{1+e^{-x}}.
$$
Classifier Training Objective.
The classifier is trained using labeled projected representations $(\mathbf{z}_{i},y_{i})$ , where $y_{i}\in\{0,1\}$ indicates benign or jailbreak prompts. The parameters are optimized by minimizing the binary cross-entropy loss:
$$
\mathcal{L}=-\frac{1}{N}\sum_{i=1}^{N}\left[y_{i}\log p_{i}+(1-y_{i})\log(1-p_{i})\right],
$$
where $N$ denotes the number of samples and $p_{i}$ is the predicted probability for sample $i$ .
Layer Susceptibility Interpretation.
Layers exhibiting higher classification performance (e.g., F1 score) indicate stronger representational separability between benign and jailbreak prompts within the latent space. We interpret such layers as being more susceptible to jailbreak-style perturbations, as they encode discriminative adversarial features.
## 5. Experimental Evaluation
<details>
<summary>x2.png Details</summary>
### Visual Description
## Heatmap: F1 Score Analysis of Transformer Models
### Overview
The image presents two side-by-side heatmaps comparing F1 scores of transformer models across different layers. The left heatmap shows "Layer Output F1 Scores," while the right heatmap displays "MHA Output F1 Scores." Models are listed on the y-axis, and layer numbers (0–31) are on the x-axis. Color intensity represents F1 scores, with red (0.5) indicating low performance and green (1.0) indicating high performance.
---
### Components/Axes
- **Y-Axis (Models)**:
- GPT-J-Base
- GPT-JT-Instruct
- Llama-Base
- Llama-Instruct
- Llama-Abliterated
- Mistral-Base
- Mistral-Instruct
- **X-Axis (Layer Numbers)**:
- Layer 0 to Layer 31 (32 layers total).
- **Color Legend**:
- Red (0.5): Low F1 score
- Green (1.0): High F1 score
- Gradient from red to green indicates intermediate scores.
- **Legend Position**:
- Right side of each heatmap, vertically aligned with the y-axis.
---
### Detailed Analysis
#### Layer Output F1 Scores (Left Heatmap)
- **GPT-J-Base**:
- Light green to yellow gradient across layers 0–31, indicating moderate F1 scores (~0.7–0.85).
- **GPT-JT-Instruct**:
- Similar gradient to GPT-J-Base but slightly darker in later layers (~0.75–0.9).
- **Llama-Base**:
- Dark green in layers 10–31 (~0.85–0.95), lighter in early layers (~0.7–0.8).
- **Llama-Instruct**:
- Consistently dark green across all layers (~0.9–1.0).
- **Llama-Abliterated**:
- Dark green in layers 10–31 (~0.85–0.95), lighter in early layers (~0.7–0.8).
- **Mistral-Base**:
- Light green to yellow gradient (~0.7–0.85).
- **Mistral-Instruct**:
- Consistently dark green (~0.9–1.0).
#### MHA Output F1 Scores (Right Heatmap)
- **GPT-J-Base**:
- Light green to yellow gradient (~0.7–0.85).
- **GPT-JT-Instruct**:
- Dark green in most layers (~0.85–0.95), but **red in Layer 0** (~0.5), a notable outlier.
- **Llama-Base**:
- Dark green in layers 10–31 (~0.85–0.95), lighter in early layers (~0.7–0.8).
- **Llama-Instruct**:
- Consistently dark green (~0.9–1.0).
- **Llama-Abliterated**:
- Dark green in layers 10–31 (~0.85–0.95), lighter in early layers (~0.7–0.8).
- **Mistral-Base**:
- Light green to yellow gradient (~0.7–0.85).
- **Mistral-Instruct**:
- Consistently dark green (~0.9–1.0).
---
### Key Observations
1. **Mistral-Instruct** and **Llama-Instruct** consistently achieve the highest F1 scores (~0.9–1.0) across all layers in both heatmaps.
2. **GPT-JT-Instruct** shows a significant outlier in **MHA Output Layer 0** (red, ~0.5), contrasting with its otherwise strong performance.
3. **Llama-Abliterated** and **Llama-Base** exhibit similar trends, with improved performance in later layers.
4. **GPT-J-Base** and **Mistral-Base** have lower scores in early layers but improve gradually.
---
### Interpretation
- **Model Architecture Impact**:
- Instruct-tuned variants (e.g., Llama-Instruct, Mistral-Instruct) outperform base models, suggesting instruction fine-tuning enhances layer-wise performance.
- **MHA Layer Dynamics**:
- The red cell in GPT-JT-Instruct’s MHA Layer 0 indicates a potential architectural weakness or training instability in early attention mechanisms.
- **Layer Depth Trends**:
- Most models show improved F1 scores in deeper layers, implying that later layers capture more complex patterns.
- **Anomaly Investigation**:
- The outlier in GPT-JT-Instruct’s MHA Layer 0 warrants further analysis to determine if it reflects a bug, data artifact, or intentional design choice.
This analysis highlights the importance of model architecture and training strategies in determining layer-wise performance, with instruct-tuned models demonstrating superior consistency.
</details>
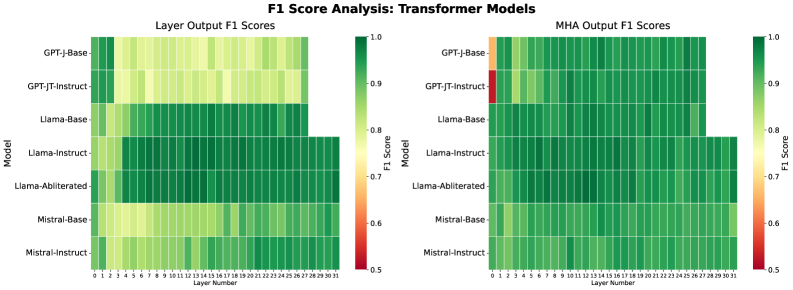
Figure 3. (Left) Layer-wise F1 scores using CP-decomposed Transformer layer outputs. (Right) Layer-wise F1 scores using CP-decomposed multi-head attention representations. Jailbreak and benign prompts become reliably separable at early depths, suggesting that adversarial intent is encoded shortly after input embedding. The strong performance of attention-based features further indicates that prompt-type information is reflected in token interaction structure as well as in hidden representations.
### 5.1. Datasets and Prompt Scope
We used two prompt sources with provenance relationships to separate representation learning from mitigation evaluation.
Training/representation analysis. For latent-space analysis, we use the Jailbreak Classification dataset from Hugging Face (Hao, [n. d.]). This dataset provides labeled benign and jailbreak prompts and is used to (i) extract layer-wise hidden representations and multi-head attention (MHA) outputs, (ii) learn CP decomposition factors for each layer and representation type, and (iii) train a lightweight classifier on the resulting latent features.
Test/mitigation evaluation. To evaluate layer-aware bypass at inference time, we construct a held-out test set of 200 prompts (100 benign, 100 jailbreak) sourced from the ‘In the Wild Jailbreak Prompts’ (Shen et al., 2024) prompt collection. (Hao, [n. d.]) reports that its jailbreak prompts are drawn from (Shen et al., 2024), which motivates this choice, as these evaluations are consistent and distinct from the training corpus.
Attack scope. Both datasets primarily consist of instruction-level jailbreaks (e.g., persona overrides, explicit safety negation, role-play framing, and meta-instructions). They do not include optimization-based attacks such as GCG (Zou et al., 2023), PAIR (Chao et al., 2024), or other gradient-guided adversarial suffix constructions. Since our framework operates on internal representations, extending it to additional attack families can be achieved by incorporating corresponding prompt distributions during factor learning; we leave such evaluations to future work.
### 5.2. Hidden Representation Analysis
We assess whether internal model representations can reliably separate jailbreak from benign prompts across model families, layers, and representation types. Our analysis spans eight models: base, instruction-tuned, abliterated, and state-space (Mamba), providing a broad view across training paradigms.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Chart: Mamba-2.8B Block vs Mixer Output F1 Scores
### Overview
The chart compares F1 scores between "Block Output" (blue line) and "Mixer Output" (purple line) across 58 layers in the Mamba-2.8B model. Both lines exhibit similar trends with minor fluctuations, converging toward higher F1 scores as layers increase.
### Components/Axes
- **X-axis (Layer)**: Discrete values from 0 to 58, labeled "Layer".
- **Y-axis (F1 Score)**: Continuous scale from 0.5 to 1.0, labeled "F1 Score".
- **Legend**: Located at bottom-left, with:
- Blue circles: "Block Output"
- Purple squares: "Mixer Output"
- **Grid**: Light gray dashed lines for reference.
### Detailed Analysis
1. **Block Output (Blue)**:
- Starts at ~0.88 (layer 0), dips to ~0.87 (layer 2), then rises steadily.
- Peaks at ~0.94 (layer 16), stabilizes between ~0.94–0.95 (layers 24–40).
- Declines slightly to ~0.92 (layer 58).
2. **Mixer Output (Purple)**:
- Begins at ~0.82 (layer 0), spikes to ~0.95 (layer 16).
- Fluctuates between ~0.93–0.95 (layers 24–40), with a dip to ~0.90 (layer 40).
- Stabilizes at ~0.93–0.94 (layers 48–56), ending at ~0.91 (layer 58).
### Key Observations
- Both lines show an initial rise to ~0.94–0.95 by layer 16, followed by stabilization.
- Mixer Output exhibits sharper fluctuations (e.g., dip at layer 40) compared to Block Output.
- Convergence occurs after layer 40, with both lines maintaining ~0.92–0.94 F1 scores.
### Interpretation
The chart suggests that Mixer Output initially outperforms Block Output in early layers (up to layer 16) but experiences volatility in mid-layers (e.g., layer 40 dip). Block Output demonstrates steadier performance after layer 16. The convergence in later layers implies diminishing differences between the two methods as layer depth increases. The dip in Mixer Output at layer 40 may indicate architectural or computational inefficiencies in that specific layer. Overall, both methods achieve high F1 scores (>0.9), with Mixer Output showing marginally higher performance in early layers.
</details>
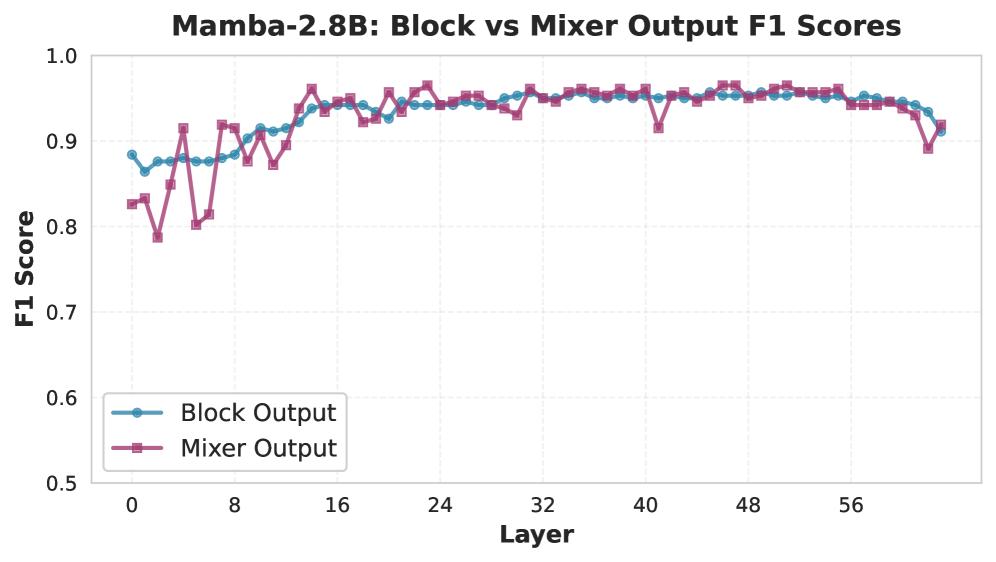
Figure 4. Layer-wise F1 scores for CP-decomposed Mamba representations (mixer and block outputs) showing early and increasing separability between benign and jailbreak prompts, indicating that state-space architectures encode adversarial prompt structure in their internal representations.
For each model, we extract hidden states and multi-head attention (MHA) outputs across all layers. These are aggregated into third-order tensors ( $N\times T\times d$ ) and decomposed using CP tensor decomposition (rank $r=20$ ) to obtain low-dimensional features for each prompt. We fix the CP decomposition rank to $r=20$ for all experiments, balancing expressiveness and efficiency as discussed in § 3.2, and to ensure consistent latent representations across models. A lightweight classifier is trained on these features to predict jailbreak status. Fig. 3 presents layer-wise F1 scores for each model. For Mamba, we report results from both the mixer (analogous to MHA) and full block output in Fig. 4.
Our results show a clear separation between the two prompt types in the learned latent space, achieving consistently high F1 scores across all evaluated models. These findings suggest that jailbreak behavior manifests as identifiable and discriminative patterns within internal representations, independent of output quality or alignment stage, and can be effectively leveraged for detection without model fine-tuning.
Qualitative Analysis.
For clarity of presentation, we visualize qualitative results for instruction-tuned models, which provide the most interpretable view of aligned internal dynamics. The qualitative patterns discussed here are representative of those observed across all evaluated models.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Heatmap Comparison: Model Layer Vulnerability Analysis
### Overview
The image presents a comparative analysis of three language models (GPT-J-T6B, LLaMA-3.1-8B, Mistral-7B) across different layers (7, 4, 18) using three heatmaps per model: Benign, Jailbreak, and Difference. Each heatmap visualizes token interaction patterns through color gradients, with spatial grounding of elements following a consistent layout.
### Components/Axes
1. **Models/Layers**:
- Top row: GPT-J-T6B - Layer 7
- Middle row: LLaMA-3.1-8B - Layer 4
- Bottom row: Mistral-7B - Layer 18
2. **Axes**:
- X-axis: Key Token (0-448 range)
- Y-axis: Query Token (0-448 range)
- Color scales:
- Benign/Jailbreak: -10 (dark purple) to 0 (yellow)
- Difference: -4 (blue) to 4 (red)
3. **Legend Placement**:
- Right-aligned color bars with numerical ranges
- Spatial consistency across all panels
### Detailed Analysis
1. **GPT-J-T6B - Layer 7**:
- Benign: Dark purple gradient (values -10 to -6)
- Jailbreak: Green gradient (values -8 to -2)
- Difference: Red gradient (values 2-4)
- Key tokens: 64-448 show strongest differences
2. **LLaMA-3.1-8B - Layer 4**:
- Benign: Purple gradient (-10 to -4)
- Jailbreak: Teal gradient (-8 to -4)
- Difference: Mixed red/blue (values -3 to 3)
- Notable: 192-384 key tokens show highest variability
3. **Mistral-7B - Layer 18**:
- Benign: Light green gradient (-5 to -1)
- Jailbreak: Dark green gradient (-9 to -5)
- Difference: Blue gradient (-4 to 0)
- Key observation: Uniform negative differences across all tokens
### Key Observations
1. **Vulnerability Patterns**:
- GPT-J-T6B Layer 7 shows highest jailbreak susceptibility (red difference gradient)
- Mistral-7B Layer 18 demonstrates strongest resistance (blue difference gradient)
- LLaMA-3.1-8B Layer 4 exhibits mixed vulnerability (bipolar difference values)
2. **Token Interaction**:
- All models show diagonal patterns in Benign/Jailbreak heatmaps
- Difference heatmaps reveal model-specific interaction shifts:
- GPT-J: Consistent positive differences (security vulnerability)
- LLaMA: Mixed positive/negative differences (context-dependent vulnerability)
- Mistral: Consistent negative differences (resilience)
### Interpretation
The data suggests significant architectural differences in how these models handle adversarial inputs:
1. **GPT-J-T6B Layer 7** appears most vulnerable to jailbreaking, with consistent positive differences indicating predictable token manipulation patterns.
2. **Mistral-7B Layer 18** shows architectural robustness, with uniform negative differences suggesting effective token interaction safeguards.
3. **LLaMA-3.1-8B Layer 4** demonstrates context-dependent vulnerabilities, with mixed difference values indicating potential for both exploitation and mitigation through input framing.
The consistent diagonal patterns across Benign/Jailbreak heatmaps suggest shared architectural constraints in token processing, while the Difference heatmaps reveal critical layer-specific security characteristics. These findings highlight the importance of layer-specific security considerations in model deployment.
</details>
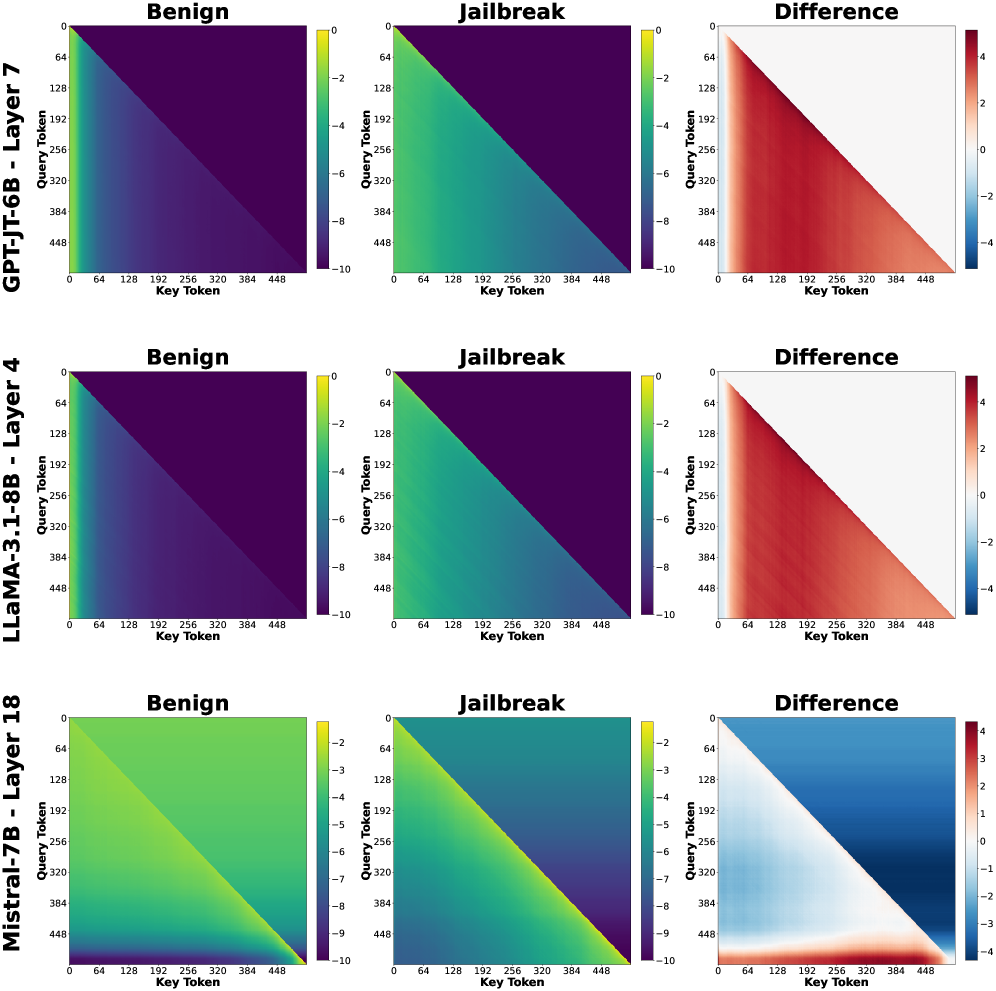
Figure 5. Self-attention maps for three instruction-tuned models, averaged over benign and jailbreak prompts (log 10 scale). Difference maps (right) highlight systematic but localized changes in attention patterns induced by jailbreak prompts, suggesting that adversarial intent manifests as targeted rerouting of attention rather than global disruption.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Heatmap Analysis: Model Behavior Comparison Across Scenarios
### Overview
The image presents a comparative analysis of three language models (GPT-JT-6B, LLaMA-3.1-8B, Mistral-7B) across three scenarios: **Benign**, **Jailbreak**, and **Difference**. Each model is represented by three heatmaps showing values across **Layers** (vertical axis) and **Token Positions** (horizontal axis). Color gradients indicate magnitude, with legends specifying value ranges.
---
### Components/Axes
1. **Models**:
- GPT-JT-6B (top row)
- LLaMA-3.1-8B (middle row)
- Mistral-7B (bottom row)
2. **Panels per Model**:
- **Benign**: Baseline behavior
- **Jailbreak**: Modified/stressed behavior
- **Difference**: Absolute difference between Benign and Jailbreak
3. **Axes**:
- **Vertical (Y-axis)**: Layers (0–28, incrementing by 4)
- **Horizontal (X-axis)**: Token Positions (0–448, incrementing by 64)
4. **Legends**:
- Right-aligned colorbars with value ranges:
- GPT-JT-6B: 4–8 (Benign), 4–8 (Jailbreak), -2–2 (Difference)
- LLaMA-3.1-8B: 0–6 (Benign), 0–6 (Jailbreak), -2–2 (Difference)
- Mistral-7B: -1–5 (Benign), -1–5 (Jailbreak), -2–2 (Difference)
---
### Detailed Analysis
#### GPT-JT-6B
- **Benign**: Uniform yellow gradient (values ~7–8 across all layers/tokens).
- **Jailbreak**: Green gradient (values ~4–6), indicating reduced activity.
- **Difference**: Blue gradient (values ~-2 to 0), showing consistent decline in Jailbreak.
#### LLaMA-3.1-8B
- **Benign**: Dark blue gradient (values ~0–3), lower baseline than GPT-JT-6B.
- **Jailbreak**: Lighter blue gradient (values ~3–6), moderate increase.
- **Difference**: Mixed red/blue regions (values ~-1 to +1), indicating variable layer/token sensitivity.
#### Mistral-7B
- **Benign**: Green gradient (values ~1–4), moderate baseline.
- **Jailbreak**: Darker blue gradient (values ~-1–2), slight decline.
- **Difference**: Neutral gradient (values ~-0.5 to +0.5), minimal changes.
---
### Key Observations
1. **GPT-JT-6B**:
- Highest baseline values in Benign (yellow).
- Sharp drop in Jailbreak (green), with uniform decline across all layers/tokens.
- Difference heatmap shows consistent negative values (-2 to 0), suggesting jailbreak reduces performance.
2. **LLaMA-3.1-8B**:
- Lower baseline (dark blue) but notable variability in Jailbreak (lighter blue).
- Difference heatmap reveals red regions (positive values) in lower layers (0–12), indicating some layers improve under jailbreak.
3. **Mistral-7B**:
- Most stable performance: minimal difference between scenarios.
- Difference heatmap is nearly neutral, with slight red in lower layers (0–8).
---
### Interpretation
- **Model Robustness**:
- GPT-JT-6B exhibits the largest performance drop under jailbreak, suggesting vulnerability.
- Mistral-7B shows the least sensitivity to jailbreak, indicating robustness.
- **Layer-Specific Behavior**:
- LLaMA-3.1-8B’s red regions in Difference (layers 0–12) imply lower layers may adapt better to jailbreak prompts.
- GPT-JT-6B’s uniform decline suggests systemic sensitivity across all layers.
- **Token Position Impact**:
- No clear token-position trends in Difference heatmaps, indicating effects are layer-dependent rather than position-dependent.
---
### Critical Insights
- **Jailbreak Impact**:
- GPT-JT-6B’s uniform decline (-2 to 0) suggests jailbreak uniformly degrades performance.
- LLaMA-3.1-8B’s mixed red/blue Difference regions highlight layer-specific vulnerabilities.
- **Design Implications**:
- Models with higher baseline values (GPT-JT-6B) may require stricter safeguards.
- Mistral-7B’s stability could make it preferable for safety-critical applications.
---
### Uncertainties
- Exact numerical values are approximated from color gradients; precise thresholds require raw data.
- Token-position trends are ambiguous due to uniform coloration in Difference heatmaps.
</details>
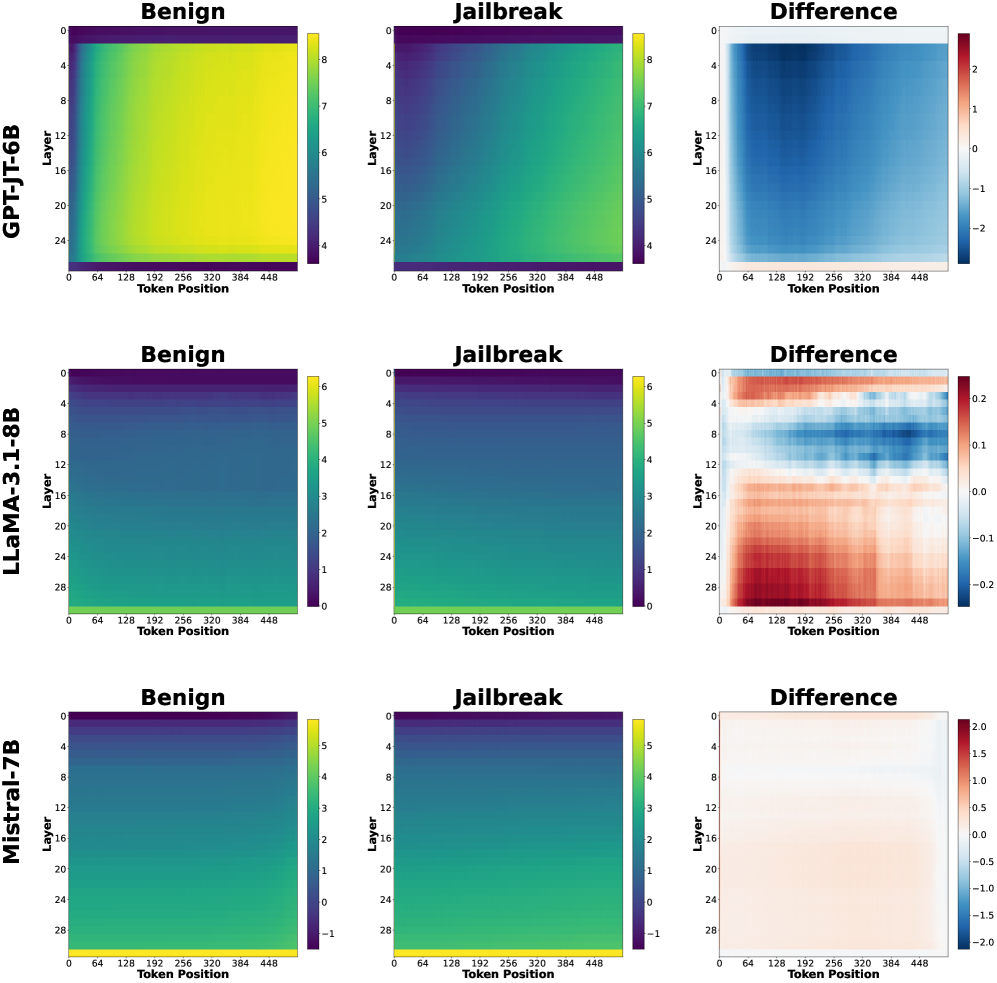
Figure 6. Layer-wise log-magnitude of hidden representations for benign (left) and jailbreak (middle) prompts, averaged across prompts, with their difference shown on the right. The difference heatmaps reveal consistent, localized deviations across layers, highlighting where adversarial prompts induce layer-dependent representational shifts.
Aggregated Self-Attention Heatmaps.
We use aggregated self-attention heatmaps to qualitatively assess how jailbreak prompts alter token-to-token information routing within the model. While attention alone does not encode semantic content, systematic differences in attention patterns can indicate how adversarial prompts redirect internal focus during processing.
For each instruction-tuned model and transformer layer $\ell$ , we extract the self-attention weight tensors
$$
\mathbf{A}^{(\ell)}\in\mathbb{R}^{N\times H\times T\times T},
$$
where $N$ is the number of prompts, $H$ the number of attention heads, and $T$ the (padded) token length. To obtain a stable, global view of attention behavior, we aggregate over both prompts and heads. Let $\mathcal{I}_{\text{ben}}$ and $\mathcal{I}_{\text{jb}}$ denote the index sets of benign and jailbreak prompts, respectively. We compute the class-wise, head-averaged attention maps:
$$
\bar{\mathbf{A}}^{(\ell)}_{\text{ben}}=\frac{1}{|\mathcal{I}_{\text{ben}}|H}\sum_{n\in\mathcal{I}_{\text{ben}}}\sum_{h=1}^{H}\mathbf{A}^{(\ell)}_{n,h,:,:},\qquad\bar{\mathbf{A}}^{(\ell)}_{\text{jb}}=\frac{1}{|\mathcal{I}_{\text{jb}}|H}\sum_{n\in\mathcal{I}_{\text{jb}}}\sum_{h=1}^{H}\mathbf{A}^{(\ell)}_{n,h,:,:}.
$$
To highlight systematic differences between prompt types, we additionally compute a per-layer difference map:
$$
\Delta\mathbf{A}^{(\ell)}=\bar{\mathbf{A}}^{(\ell)}_{\text{jb}}-\bar{\mathbf{A}}^{(\ell)}_{\text{ben}}.
$$
Visualizing $\bar{\mathbf{A}}^{(\ell)}{\text{ben}}$ , $\bar{\mathbf{A}}^{(\ell)}{\text{jb}}$ , and $\Delta\mathbf{A}^{(\ell)}$ (Fig. 6) shows that jailbreak prompts lead to consistent, localized changes in attention patterns. This indicates that adversarial prompts influence attention by selectively emphasizing specific instruction or control tokens, providing qualitative evidence that jailbreak behavior arises from targeted changes in information flow rather than global attention disruption.
Hidden-Representation Magnitude Heatmaps.
While attention maps reflect information routing, hidden representations capture the content and intensity of internal computation. We therefore analyze layer-wise hidden-state magnitudes to understand how strongly jailbreak prompts perturb internal activations across network depth.
For each layer $\ell$ , we extract hidden states
$$
\mathbf{H}^{(\ell)}\in\mathbb{R}^{N\times T\times D},
$$
where $D$ is the hidden dimensionality. To summarize activation strength across token positions, we compute the per-token $\ell_{2}$ magnitude:
$$
\mathbf{M}^{(\ell)}_{n,t}=\left\lVert\mathbf{H}^{(\ell)}_{n,t,:}\right\rVert_{2},\qquad\mathbf{M}^{(\ell)}\in\mathbb{R}^{N\times T}.
$$
We then average magnitudes across prompts within each class:
$$
\bar{\mathbf{M}}^{(\ell)}_{\text{ben}}(t)=\frac{1}{|\mathcal{I}_{\text{ben}}|}\sum_{n\in\mathcal{I}_{\text{ben}}}\mathbf{M}^{(\ell)}_{n,t},\qquad\bar{\mathbf{M}}^{(\ell)}_{\text{jb}}(t)=\frac{1}{|\mathcal{I}_{\text{jb}}|}\sum_{n\in\mathcal{I}_{\text{jb}}}\mathbf{M}^{(\ell)}_{n,t}.
$$
For visualization, we apply a logarithmic transform:
$$
\tilde{\mathbf{M}}^{(\ell)}(t)=\log\big(\bar{\mathbf{M}}^{(\ell)}(t)+\varepsilon\big),
$$
with a small $\varepsilon>0$ for numerical stability. We plot $\tilde{\mathbf{M}}^{(\ell)}(t)$ as heatmaps with layers on the y-axis and token positions on x-axis.
Although the averaged hidden-state magnitudes for benign and jailbreak prompts appear broadly similar (especially for LLaMA abd Mistral), their difference heatmaps reveal consistent, localized deviations across layers. This indicates that jailbreak behavior does not manifest as a global disruption of internal activations, but rather as subtle, structured changes superimposed on otherwise normal model processing.
### 5.3. Layer-Aware Mitigation via Latent-Space Susceptibility
We evaluate our second proposed method, layer-aware mitigation via latent-space susceptibility, to check whether representation-level signals can be used to suppress jailbreak execution during inference without relying on output-level filtering or fine-tuning.
Experimental Setup.
We conduct this experiment on the abliterated LLaMA 3.1 8B model described earlier. Evaluation is performed on a held-out set of 200 prompts (100 benign, 100 jailbreak), using latent factors learned during the analysis phase (§ 5.2).
Inference-time Susceptibility Scoring
Given an input prompt at inference time, we extract layer outputs and attention representations, project them onto the pre-learned CP factors, and use a lightweight classifier to compute a per-layer susceptibility score indicating the strength of jailbreak-correlated features. Layers whose predicted jailbreak probability exceeds a fixed threshold ( $\tau=0.7$ ) are treated as highly susceptible. The threshold $\tau$ is a tunable hyperparameter that controls the trade-off between mitigation strength and preservation of benign behavior.
Layer-/Head-Bypass Intervention.
Based on the susceptibility score, we selectively perform: (i) Layer Bypass: bypassing selected layer outputs; and (ii) MHA Bypass: bypassing selected attention components. This intervention is parameter-free (no fine-tuning), prompt-conditional (depends on the susceptibility profile), and does not require any output-side heuristics.
Output-Based Evaluation with LLM-Assisted Judging.
Since our goal is to prevent harmful compliance rather than optimize helpfulness, we evaluate mitigation effectiveness based on observed output behavior. Model responses are categorized as: (i) harmful completions, where the jailbreak intent succeeds; (ii) benign completions, where the model responds appropriately; and (iii) disrupted outputs, including truncated, repetitive, or incoherent text.
For jailbreak prompts, disrupted or non-compliant outputs are treated as successful defenses, while for benign prompts such outputs are undesirable. Output labels are assigned using an LLM-as-a-judge rubric, followed by manual review of ambiguous cases. This evaluation protocol follows established practice for open-ended generation assessment with human validation (Zheng et al., 2023; Dubois et al., 2024; Li et al., 2024). Based on these criteria, we define the confusion matrix as follows:
| Jailbreak | Harmful completion | False Negative (FN) |
| --- | --- | --- |
| Jailbreak | Disrupted/benign output | True Positive (TP) |
| Benign | Benign completion | True Negative (TN) |
| Benign | Disrupted output | False Positive (FP) |
Results.
Table 1 summarizes the confusion-matrix counts. Layer-guided bypass suppresses most jailbreak attempts (TP=78) while largely preserving benign behavior (TN=94). In contrast, MHA-only bypass results in substantially more jailbreak failures (FN=39), indicating that layer outputs capture a larger fraction of jailbreak-relevant computation than attention components alone.
To provide a compact summary aligned with prior jailbreak evaluations, we additionally report the attack success rate (ASR), defined as the fraction of jailbreak prompts that remain successful after mitigation. Layer-output bypass reduces ASR to $22\$ (22/100), compared to $39\$ for MHA-only bypass, highlighting the effectiveness of layer-level intervention.
Table 1. Confusion matrix counts for latent-space-guided mitigation (100 jailbreak and 100 benign prompts).
| Layer Bypass | 78 | 22 | 94 | 6 |
| --- | --- | --- | --- | --- |
| MHA Bypass | 61 | 39 | 92 | 8 |
Failure (False Negative) Analysis
We examine the 22 jailbreak prompts that remain harmful after layer-output bypass. The majority are persona- or roleplay-based prompt injections (e.g., “never refuse,” “no morals,” forced speaker tags such as “AIM:” and “[H4X]:”) that aim to establish persistent control over the model’s identity, tone, and formatting. Because such instructions are repeatedly reinforced throughout the prompt, elements of adversarial control can persist even when highly susceptible layers are bypassed.
Additional failures stem from susceptibility estimation: the intervention targets layers exceeding a fixed probability threshold chosen to preserve benign behavior. Attacks that distribute their influence across multiple layers, or weakly activate any single layer, may therefore evade suppression despite succeeding overall. Some failures also involve milder jailbreaks that retain adversarial framing without immediately producing explicit harmful content; under our conservative evaluation criterion, these are counted as failures.
These limitations are addressable within the proposed framework by expanding the diversity of jailbreak styles used for latent factor learning and by adopting adaptive or cumulative susceptibility criteria. Since the method operates entirely in latent space, such extensions require no architectural changes.
## 6. Conclusion
Our hypothesis and experiments indicate that internal representations of LLMs contain sufficiently strong and consistent signals to both detect jailbreak prompts and, in many cases, disrupt jailbreak execution at inference time. Importantly, these capabilities emerge from lightweight representation-level analysis and intervention, without requiring additional post-training, auxiliary models, or complex rule-based filtering. The consistency of these findings across diverse model families suggests that adversarial intent leaves stable latent-space signatures, motivating internal-representation monitoring as a practical and broadly applicable direction for understanding and mitigating jailbreak behavior.
## 7. GenAI Usage Disclosure
The authors acknowledge the use of AI-based writing and coding assistance tools during the preparation of this manuscript. These tools were used exclusively to improve clarity, organization, and academic tone of text written by the authors, as well as to assist with code formatting and plot generation. All scientific ideas, methodologies, analyses, and conclusions are the original intellectual contributions of the authors. No AI system was used to generate research ideas or substantive technical content, and all AI-assisted revisions were carefully reviewed and validated by the authors.
## References
- (1)
- jai ([n. d.]) [n. d.]. Implementation of the proposed method. https://anonymous.4open.science/r/Jailbreaking-leaves-a-trace-Understanding-and-Detecting-Jailbreak-Attacks-in-LLMs-C401
- mam ([n. d.]) [n. d.]. Mamab2.8b. https://huggingface.co/state-spaces/mamba-2.8b-hf
- AI (2023) Mistral AI. 2023. Mistral 7B Instruct v0.1. https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1.
- AI@Meta (2024a) AI@Meta. 2024a. Llama 3 Instruct Models. https://ai.meta.com/llama/. LLaMA-3.1-8B-Instruct.
- AI@Meta (2024b) AI@Meta. 2024b. Llama 3 Models. https://ai.meta.com/llama/. LLaMA-3.1-8B base model.
- Bai et al. (2022) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, Ben Mann, and Jared Kaplan. 2022. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv:2204.05862 [cs.CL] https://arxiv.org/abs/2204.05862
- Candogan et al. (2025) Leyla Naz Candogan, Yongtao Wu, Elias Abad Rocamora, Grigorios Chrysos, and Volkan Cevher. 2025. Single-pass Detection of Jailbreaking Input in Large Language Models. Transactions on Machine Learning Research (2025). https://openreview.net/forum?id=42v6I5Ut9a
- Chao et al. (2024) Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. 2024. Jailbreaking Black Box Large Language Models in Twenty Queries. arXiv:2310.08419 [cs.LG] https://arxiv.org/abs/2310.08419
- Chen et al. (2023) Bocheng Chen, Advait Paliwal, and Qiben Yan. 2023. Jailbreaker in Jail: Moving Target Defense for Large Language Models. arXiv:2310.02417 [cs.CR] https://arxiv.org/abs/2310.02417
- Computer (2022) Together Computer. 2022. GPT-JT-6B: Instruction-Tuned GPT-J Model. https://huggingface.co/togethercomputer/GPT-JT-6B-v1.
- Deng et al. (2024) Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. 2024. Multilingual Jailbreak Challenges in Large Language Models. arXiv:2310.06474 [cs.CL] https://arxiv.org/abs/2310.06474
- Dubois et al. (2024) Yann Dubois, Aarohi Srivastava, Abhinav Venigalla, et al. 2024. Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators. arXiv preprint arXiv:2404.04475 (2024). https://arxiv.org/abs/2404.04475
- Elhoushi et al. (2024) Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed Aly, Beidi Chen, and Carole-Jean Wu. 2024. LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 12622–12642. doi: 10.18653/v1/2024.acl-long.681
- Glaese et al. (2022) Amelia Glaese, Nat McAleese, Maja Trębacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, Lucy Campbell-Gillingham, Jonathan Uesato, Po-Sen Huang, Ramona Comanescu, Fan Yang, Abigail See, Sumanth Dathathri, Rory Greig, Charlie Chen, Doug Fritz, Jaume Sanchez Elias, Richard Green, Soňa Mokrá, Nicholas Fernando, Boxi Wu, Rachel Foley, Susannah Young, Iason Gabriel, William Isaac, John Mellor, Demis Hassabis, Koray Kavukcuoglu, Lisa Anne Hendricks, and Geoffrey Irving. 2022. Improving alignment of dialogue agents via targeted human judgements. arXiv:2209.14375 [cs.LG] https://arxiv.org/abs/2209.14375
- Hao ([n. d.]) Jack Hao. [n. d.]. Jailbreak Classification Dataset. https://huggingface.co/datasets/jackhhao/jailbreak-classification
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, et al. 2023. Mistral 7B. https://mistral.ai/news/introducing-mistral-7b/.
- Jiang et al. (2024) Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, and Nouha Dziri. 2024. WildTeaming at Scale: From In-the-Wild Jailbreaks to (Adversarially) Safer Language Models. arXiv:2406.18510 [cs.CL] https://arxiv.org/abs/2406.18510
- Kadali and Papalexakis (2025) Sri Durga Sai Sowmya Kadali and Evangelos Papalexakis. 2025. CoCoTen: Detecting Adversarial Inputs to Large Language Models through Latent Space Features of Contextual Co-occurrence Tensors. In Proceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM ’25). ACM, 4857–4861. doi: 10.1145/3746252.3760886
- Labonne ([n. d.]) M. Labonne. [n. d.]. Meta-Llama-3.1-8B-Instruct-abliterated. https://huggingface.co/mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated. Hugging Face model card.
- Lawson and Aitchison (2025) Tim Lawson and Laurence Aitchison. 2025. Learning to Skip the Middle Layers of Transformers. arXiv:2506.21103 [cs.LG] https://arxiv.org/abs/2506.21103
- Li et al. (2024) Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods. arXiv:2412.05579 [cs.CL] https://arxiv.org/abs/2412.05579
- Liu et al. (2024) Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2024. AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models. arXiv:2310.04451 [cs.CL] https://arxiv.org/abs/2310.04451
- Lu et al. (2024) Weikai Lu, Ziqian Zeng, Jianwei Wang, Zhengdong Lu, Zelin Chen, Huiping Zhuang, and Cen Chen. 2024. Eraser: Jailbreaking Defense in Large Language Models via Unlearning Harmful Knowledge. arXiv:2404.05880 [cs.CL] https://arxiv.org/abs/2404.05880
- Luo et al. (2025) Xuan Luo, Weizhi Wang, and Xifeng Yan. 2025. Adaptive layer-skipping in pre-trained llms. arXiv preprint arXiv:2503.23798 (2025).
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. arXiv:2203.02155 [cs.CL] https://arxiv.org/abs/2203.02155
- Papalexakis (2018) Evangelos E. Papalexakis. 2018. Unsupervised Content-Based Identification of Fake News Articles with Tensor Decomposition Ensembles. https://api.semanticscholar.org/CorpusID:26675959
- Qazi et al. (2024) Zubair Qazi, William Shiao, and Evangelos E. Papalexakis. 2024. GPT-generated Text Detection: Benchmark Dataset and Tensor-based Detection Method. In Companion Proceedings of the ACM Web Conference 2024 (Singapore, Singapore) (WWW ’24). Association for Computing Machinery, New York, NY, USA, 842–846. doi: 10.1145/3589335.3651513
- Shen et al. (2024) Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. 2024. “Do Anything Now”: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. In ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM.
- Shukor and Cord (2024) Mustafa Shukor and Matthieu Cord. 2024. Skipping Computations in Multimodal LLMs. In Workshop on Responsibly Building the Next Generation of Multimodal Foundational Models. https://openreview.net/forum?id=qkmMvLckB9
- Sidiropoulos et al. (2017) Nicholas D Sidiropoulos, Lieven De Lathauwer, Xiao Fu, Kejun Huang, Evangelos E Papalexakis, and Christos Faloutsos. 2017. Tensor decomposition for signal processing and machine learning. IEEE Transactions on signal processing 65, 13 (2017), 3551–3582.
- Vaswani et al. (2023) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. Attention Is All You Need. arXiv:1706.03762 [cs.CL] https://arxiv.org/abs/1706.03762
- Wang et al. (2021) Ben Wang, Aran Komatsuzaki, and EleutherAI. 2021. GPT-J-6B. https://huggingface.co/EleutherAI/gpt-j-6B. Model card and weights.
- Wang et al. (2024a) Hao Wang, Hao Li, Minlie Huang, and Lei Sha. 2024a. ASETF: A Novel Method for Jailbreak Attack on LLMs through Translate Suffix Embeddings. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 2697–2711. doi: 10.18653/v1/2024.emnlp-main.157
- Wang et al. (2025) Xunguang Wang, Daoyuan Wu, Zhenlan Ji, Zongjie Li, Pingchuan Ma, Shuai Wang, Yingjiu Li, Yang Liu, Ning Liu, and Juergen Rahmel. 2025. SelfDefend: LLMs Can Defend Themselves against Jailbreaking in a Practical Manner. arXiv:2406.05498 [cs.CR] https://arxiv.org/abs/2406.05498
- Wang et al. (2024b) Yihan Wang, Zhouxing Shi, Andrew Bai, and Cho-Jui Hsieh. 2024b. Defending llms against jailbreaking attacks via backtranslation. arXiv preprint arXiv:2402.16459 (2024).
- Wang et al. (2023) Yufei Wang, Wanjun Zhong, Liangyou Li, Fei Mi, Xingshan Zeng, Wenyong Huang, Lifeng Shang, Xin Jiang, and Qun Liu. 2023. Aligning Large Language Models with Human: A Survey. arXiv:2307.12966 [cs.CL] https://arxiv.org/abs/2307.12966
- Wei et al. (2023) Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How Does LLM Safety Training Fail? arXiv:2307.02483 [cs.LG] https://arxiv.org/abs/2307.02483
- Xiong et al. (2025) Chen Xiong, Xiangyu Qi, Pin-Yu Chen, and Tsung-Yi Ho. 2025. Defensive Prompt Patch: A Robust and Interpretable Defense of LLMs against Jailbreak Attacks. arXiv:2405.20099 [cs.CR] https://arxiv.org/abs/2405.20099
- Yang et al. (2023) Xianjun Yang, Xiao Wang, Qi Zhang, Linda Petzold, William Yang Wang, Xun Zhao, and Dahua Lin. 2023. Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models. arXiv:2310.02949 [cs.CL] https://arxiv.org/abs/2310.02949
- Yao et al. (2023) Hongwei Yao, Jian Lou, and Zhan Qin. 2023. PoisonPrompt: Backdoor Attack on Prompt-based Large Language Models. arXiv:2310.12439 [cs.CL] https://arxiv.org/abs/2310.12439
- Young (2026) Richard J. Young. 2026. Comparative Analysis of LLM Abliteration Methods: A Cross-Architecture Evaluation. arXiv:2512.13655 [cs.CL] https://arxiv.org/abs/2512.13655
- Yu et al. (2023) Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. 2023. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts. arXiv preprint arXiv:2309.10253 (2023).
- Zeng et al. (2024) Yifan Zeng, Yiran Wu, Xiao Zhang, Huazheng Wang, and Qingyun Wu. 2024. AutoDefense: Multi-Agent LLM Defense against Jailbreak Attacks. arXiv:2403.04783 [cs.LG] https://arxiv.org/abs/2403.04783
- Zhang et al. (2026) Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Guoyin Wang, et al. 2026. Instruction tuning for large language models: A survey. Comput. Surveys 58, 7 (2026), 1–36.
- Zhang et al. (2024) Tianrong Zhang, Bochuan Cao, Yuanpu Cao, Lu Lin, Prasenjit Mitra, and Jinghui Chen. 2024. WordGame: Efficient & Effective LLM Jailbreak via Simultaneous Obfuscation in Query and Response. arXiv:2405.14023 [cs.LG] https://arxiv.org/abs/2405.14023
- Zhao et al. (2019) Zhenjie Zhao, Andrew Cattle, Evangelos Papalexakis, and Xiaojuan Ma. 2019. Embedding Lexical Features via Tensor Decomposition for Small Sample Humor Recognition. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (Eds.). Association for Computational Linguistics, Hong Kong, China, 6376–6381. doi: 10.18653/v1/D19-1669
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al. 2023. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. arXiv preprint arXiv:2306.05685 (2023). https://arxiv.org/abs/2306.05685
- Zou et al. (2023) Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv:2307.15043 [cs.CL] https://arxiv.org/abs/2307.15043