# Think like a Scientist: Physics-guided LLM Agent for Equation Discovery
**Authors**: Jianke Yang, Ohm Venkatachalam, Mohammad Kianezhad, Sharvaree Vadgama, Rose Yu
## Abstract
Explaining observed phenomena through symbolic, interpretable formulas is a fundamental goal of science. Recently, large language models (LLMs) have emerged as promising tools for symbolic equation discovery, owing to their broad domain knowledge and strong reasoning capabilities. However, most existing LLM-based systems try to guess equations directly from data, without modeling the multi-step reasoning process that scientists often follow: first inferring physical properties such as symmetries, then using these as priors to restrict the space of candidate equations. We introduce KeplerAgent, an agentic framework that explicitly follows this scientific reasoning process. The agent coordinates physics-based tools to extract intermediate structure and uses these results to configure symbolic regression engines such as PySINDy and PySR, including their function libraries and structural constraints. Across a suite of physical equation benchmarks, KeplerAgent achieves substantially higher symbolic accuracy and greater robustness to noisy data than both LLM and traditional baselines.
Machine Learning, ICML
## 1 Introduction
Explaining observed phenomena through symbolic, interpretable formulas is a fundamental goal of science. From Kepler’s laws to the Navier–Stokes equations, many major discoveries can be viewed as instances of “equation discovery”: given observations of a system, infer a compact mathematical expression that captures its underlying structure and dynamics. Symbolic regression (SR) including evolutionary search (Schmidt and Lipson, 2009) and sparse regression (Brunton et al., 2016) formalizes this problem as a search over symbolic expressions, aiming to find formulas that both fit the data and are interpretable. This makes SR an attractive tool for scientific discovery, where interpretability and extrapolation are as important as predictive accuracy.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: KeplerAgent System Architecture
### Overview
This image is a technical diagram illustrating the architecture and function of a system named "KeplerAgent." It depicts a central processing agent that accepts multiple forms of input data (tabular, graphical, and image-based) and outputs derived mathematical models or equations. The flow is from left (inputs) to center (processing) to right (outputs).
### Components/Axes
The diagram is organized into three distinct regions:
**1. Input Region (Left Side):**
* **Top Input:** A data table with a blue header row.
* **Column Headers (from left to right):** `v`, `c`, `m`, `m₀`
* **Data Rows (approximate values):**
* Row 1: `7.74`, `8.84`, `3.01`, `1.46`
* Row 2: `3.11`, `3.79`, `2.14`, `1.22`
* A third row is partially visible with ellipsis (`...`).
* **Middle Input:** A line graph with a white background.
* **Content:** Multiple colored lines (blue, purple, red, green, orange) with circular markers at data points. The lines show varying trends, some increasing, some decreasing, and some oscillating. No explicit axis labels or titles are visible.
* **Bottom Input:** A square heatmap or 2D plot.
* **Content:** A vibrant spiral pattern radiating from the center. Colors transition from dark blue/purple at the core through green and yellow to bright yellow at the outer edges.
**2. Processing Region (Center):**
* **Central Box:** A light green rectangle with a dashed border.
* **Title Text:** `KeplerAgent` (large, bold font).
* **Icons (from left to right):**
1. Python programming language logo (blue and yellow snakes).
2. A stylized robot head icon (black and white).
3. A colorful spiral/galaxy icon (similar to the input heatmap).
4. A DNA double helix icon (green and purple).
* **Flow Arrows:** Black arrows point from each of the three inputs on the left into the left side of the KeplerAgent box. Three arrows emerge from the right side of the box, pointing to the three outputs.
**3. Output Region (Right Side):**
* **Top Output:** A physics equation in a beige box.
* **Equation:** `v = c × √(1.0 - m₀²/m²)`
* **Middle Output:** A system of two differential equations in a beige box.
* **Equations:**
```
{
ẋ₁ = -0.052x₁² - 0.997 sin(x₂)
ẋ₂ = x₁ - cos(x₂)/x₁
}
```
* **Bottom Output:** A system of two partial differential equations in a beige box.
* **Equations:**
```
{
u_t = 1.000v³ + 0.095u_xx + ...
v_t = 1.000v + 0.096v_yy + ...
}
```
### Detailed Analysis
* **Input-Output Mapping:** The diagram suggests a many-to-many relationship. Multiple, heterogeneous data types (numerical tables, time-series/graph data, spatial/image data) are ingested by the KeplerAgent. The agent then synthesizes this information to generate different classes of mathematical models: an algebraic formula, a system of ordinary differential equations (ODEs), and a system of partial differential equations (PDEs).
* **Equation Specifics:**
* The top equation resembles a relativistic formula, possibly for velocity (`v`) given a constant (`c`) and mass parameters (`m`, `m₀`).
* The middle ODE system includes nonlinear terms (`x₁²`, `sin(x₂)`, `cos(x₂)/x₁`), suggesting it models a dynamic, possibly oscillatory system.
* The bottom PDE system includes spatial derivatives (`_xx`, `_yy`) and nonlinear coupling (`v³`), indicative of wave or field phenomena in two dimensions.
* **Agent Capabilities:** The icons within the KeplerAgent box symbolize its core functionalities: programming/scripting (Python), autonomous reasoning (robot), pattern recognition in complex data (spiral), and analysis of complex, structured systems (DNA).
### Key Observations
1. **Multimodal Fusion:** The system is explicitly designed to fuse fundamentally different data modalities—structured numbers, unstructured graphs, and visual patterns—into a coherent analytical process.
2. **Abstraction to Formalism:** The core function appears to be the abstraction of raw, empirical, or observational data into concise, formal mathematical language (equations).
3. **Uncertainty in Inputs:** The line graph and heatmap lack explicit labels, titles, or scales, making their precise meaning ambiguous. Their value is in representing *types* of input rather than specific datasets.
4. **Precision in Outputs:** In contrast, the output equations are presented with high numerical precision (e.g., `-0.052`, `0.997`, `1.000`, `0.095`), implying the agent produces exact or finely-tuned models.
### Interpretation
This diagram illustrates a conceptual framework for an advanced AI agent focused on **scientific discovery or system identification**. The name "KeplerAgent" is a direct reference to Johannes Kepler, who derived precise mathematical laws (elliptical orbits) from Tycho Brahe's observational astronomical data.
The diagram argues that the agent performs a modern, automated version of this process:
* **Input as "Observations":** The table, graph, and heatmap represent the raw "data" of a system—be it physical, biological, or financial.
* **Agent as "Scientist":** The KeplerAgent, equipped with computational (Python), analytical (robot), and pattern-matching (spiral, DNA) tools, acts as the reasoning engine.
* **Output as "Laws":** The equations are the discovered "laws" or governing principles of the system under study. The variety of equations (algebraic, ODE, PDE) shows the agent can identify different levels of model complexity appropriate to the data.
The key takeaway is the agent's role as a **bridge between empirical data and theoretical formalism**. It doesn't just analyze data; it *explains* it through the generation of parsimonious mathematical models. The missing labels on the input graphs are likely intentional, emphasizing the generality of the approach—the agent can work with any data that fits these abstract forms. The precise coefficients in the outputs suggest a capability for quantitative, not just qualitative, model extraction.
</details>
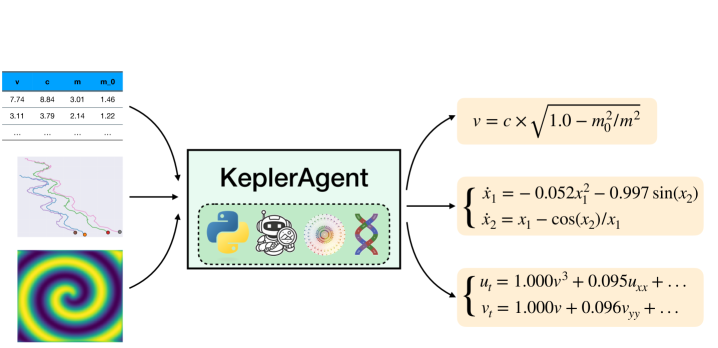
Figure 1: Our KeplerAgent orchestrates physics-based tools and is capable of discovering different types of equations from data.
However, algorithmic SR methods place a heavy configuration burden on the user. To obtain a correct and interpretable equation, a practitioner must make many intertwined design choices: the function library (polynomial degree, inclusion of rational or transcendental functions), sparsity regularization and thresholds, allowed mathematical operators, and stopping criteria, etc. If the configuration is too restrictive (e.g., a low-degree polynomial library), the true equation may be outside the hypothesis space and cannot be recovered. If it is too expressive (e.g., a very rich function set with a large number of operators), the hypothesis space becomes enormous, making the equation search intractable. In practice, experts mitigate these issues by injecting prior knowledge: dimensional analysis, symmetries, conserved quantities, or qualitative behaviors such as saturation or periodicity. However, this requires deep domain expertise and many manual iterations from configuring and running to inspecting and refining, limiting the accessibility and scalability of algorithmic SR-based equation discovery.
Recent works have shown that Large language models (LLMs) can automate some of this laborious configuration workflow thanks to their broad scientific knowledge and reasoning abilities. This has led to a new wave of LLM-based methods for discovering symbolic equations. For instance, LLM-SR (Shojaee et al., 2025a) represents equations as numerical programs and uses an LLM to synthesize program “skeletons” that define candidate equation structures. These skeletons are then completed and refined via evolutionary search and numerical optimization. By leveraging LLM’s prior knowledge and code generation ability, LLM-SR explores promising regions of expression space more efficiently and has achieved strong performance on established SR benchmarks.
Despite their advantages over purely algorithmic SR, current LLM-based equation discovery methods lack explicit reasoning about the structure or additional physical properties of the underlying system. They use brute-force to map data to equations by iteratively scoring the LLM-proposed candidate expressions. Human scientists, on the contrary, rarely jump straight from raw data to a final closed-form equation. They first probe the system to uncover structural properties, such as symmetries, conserved quantities, dimensional constraints, etc. These properties are then used to reshape the problem. Scientists choose variables, coordinates, and candidate function families that respect the identified structural constraints. Only after this process has substantially narrowed the plausible hypothesis space do they search for specific equations and test them through simulation and extrapolation. Unfortunately, none of the existing LLM-based approaches follow the reasoning process of human scientists and directly operate over these intermediate steps. This makes the discovery process brittle and opaque, and it underutilizes the rich domain knowledge from a pretrained LLM and the wealth of physics-based numerical and algorithmic tools that can uncover structure from data as additional inputs.
Moreover, current LLM-based evaluations (Shojaee et al., 2025b) are still narrow in terms of experimental domains. Many benchmarks focus on scalar algebraic relations or one-dimensional ODEs, while comprehensive tests on richer dynamical systems are rare, e.g., systems governed by coupled ODEs and PDEs. These systems often possess additional physical structure, such as spatial and phase-space symmetries, conservation laws, etc. These properties provide powerful levers for reducing the search space, and thus create a natural setting to test whether an LLM behaves more like a human scientist: first inferring and using such structure to constrain hypotheses, rather than directly guessing equations from data.
In this work, rather than using LLMs as monolithic equation guessers, we propose to use LLMs as agents that orchestrate physics-based tools to emulate the multi-step workflow used by human scientists. We introduce KeplerAgent, a physics-guided LLM agent framework for equation discovery. Given observational data from a system, an LLM agent can call tools to estimate intermediate structure, such as candidate symmetries, relevant functional terms and operators, among other constraints and patterns derived from data. The agent then translates these structural findings into concrete configuration decisions for symbolic regression tools such as PySINDy (de Silva et al., 2020) and PySR (Cranmer, 2023). By interleaving these tool calls, the agent can refine both the hypothesis space and candidate equations iteratively, which can be especially helpful when the naive search space is intractably large.
We evaluate our approach across a suite of benchmarks that span algebraic equations, systems of ODEs and PDEs, with a focus on cases where physical structure meaningfully constrains the space of admissible equations. Empirically, KeplerAgent recovers ground-truth equations more frequently than both direct LLM-based baselines and standalone SR tools with standard configurations, and it produces models that better predict the target variables or future states of the underlying physical systems.
In summary, our contributions are:
- Physics-guided agentic framework. We propose KeplerAgent that orchestrates physics-based tools for structure discovery and SR packages to emulate the multi-step reasoning workflow of human scientists.
- Automatic configuration of SR backends. We show how intermediate structural information can be translated into concrete configuration decisions for PySINDy and PySR, substantially reducing the effective search space.
- Multi-domain evaluation. We provide a systematic evaluation across diverse domains, including dynamical systems governed by ODEs and PDEs, demonstrating improved symbolic and numerical accuracies over state-of-the-art classical and LLM-based SR baselines.
## 2 Related Works
### 2.1 Symbolic Regression
Symbolic regression (SR) seeks to recover an explicit symbolic expression that maps inputs to outputs from data, rather than learning a black-box predictor. Early SR systems are largely based on genetic programming (GP), which evolves populations of expression trees under selection pressure from a fitness objective (Schmidt and Lipson, 2009; Gaucel et al., 2014). These GP-based methods, implemented in software such as Eureqa (Dubčáková, 2011) and PySR (Cranmer, 2023), are shown to rediscover classical laws from experimental data in areas like physics (Cranmer et al., 2020), materials science (Wang et al., 2019), and bioinformatics (Christensen et al., 2022).
In parallel, sparse regression methods focus on dynamical systems. SINDy (Brunton et al., 2016) assumes that the right-hand side of an ODE or PDE is sparse in a user-defined library of candidate functions and uses sparsity-promoting regression to select active terms.
Neural variants of SR encode equations in differentiable architectures. Equation learner networks replace activations with elementary operators so that the network directly corresponds to a symbolic expression (Martius and Lampert, 2016; Sahoo et al., 2018). Other approaches treat expressions as token sequences and train sequence models to generate equations (Petersen et al., 2019; Biggio et al., 2021).
A key theme across these methods is the importance of domain knowledge. Physics-inspired systems such as AI Feynman (Udrescu and Tegmark, 2020; Udrescu et al., 2020) use properties like separability, compositionality, and dimensional analysis to recursively simplify the search problem. Similar ideas have been applied specifically to discovering differential equations, where additional challenges arise because derivatives are not directly observed, and the inclusion of derivatives increases the feature dimensionality. Weak-form formulations and variational methods are used to bypass numerical differentiation (Rudy et al., 2017; Messenger and Bortz, 2021a, b; Qian et al., 2022), and physically motivated priors are used to enforce additional structure and reduce the search space (Bakarji et al., 2022; Lee et al., 2022; Xie et al., 2022; Messenger et al., 2024).
However, this reliance on manual configuration creates a substantial practical bottleneck. Users must choose function libraries, regularization strengths, and structural constraints, and they often perform many trial-and-error iterations to tune these choices. Existing software like PySINDy and PySR typically assumes that such configuration decisions are provided a priori, rather than inferred from data. Our work targets this gap by using an LLM agent to automate the process of extracting structural information and translating it into concrete SR configurations.
### 2.2 LLM-Based SR
The rise of LLMs has inspired a growing body of work that uses them to assist symbolic regression. Given numerical data and context, the model is prompted to propose candidate formulas, which are then evaluated and refined using external optimizers or numerical libraries (Sharlin and Josephson, 2024). Other frameworks aim to improve LLMs’ performance on this task with in-context information and more structured inputs and outputs. In-context symbolic regression (ICSR) (Merler et al., 2024) iteratively prompts the LLM to generate and refine functional forms while delegating coefficient fitting to an external optimizer, effectively using the LLM as a symbolic search engine guided by data-driven feedback. LLM-SR (Shojaee et al., 2025a) represents equations as programs composed of mathematical operators and uses an LLM to generate program “skeletons”. In addition, it maintains an experience buffer of previously proposed hypotheses as part of the input prompt, enabling iterative refinement with in-context examples.
Beyond these, LaSR (Grayeli et al., 2024) represents a different attempt to build hybrid systems where LLMs augment evolutionary SR. Specifically, an LLM helps build and evolve a library of abstract textual concepts that are plugged into the initialization and evolution of symbolic programs within genetic programming.
To assess progress in this emerging area, LLM-SRBench (Shojaee et al., 2025b) proposes a benchmark across multiple scientific domains, explicitly designed to reduce memorization and require genuine equation discovery. The benchmark shows that LLM-guided methods can outperform many classical baselines, but it also reveals that exact recovery rates remain modest, with even the best methods solving only a minority of problems. Moreover, most evaluations still focus on scalar algebraic equations or single-dimensional ODEs, with limited coverage of coupled ODEs and PDE-governed physical systems.
A common limitation across the aforementioned LLM-based SR methods is that they largely treat equation discovery as a relatively direct mapping from data (and possibly a natural language description) to an expression or program, instead of a multi-step reasoning workflow that human scientists follow. Recently, SR-Scientist (Xia et al., 2025) targets this issue with an agentic framework similar to ours. However, the main tool in their framework is a data analyzer that enables the LLM to write code to analyze datasets. While the tool has great potential with a powerful LLM, practical LLM calls can linger in superficial analysis (e.g. computing the basic statistics of data) instead of precisely searching for advanced structural information that effectively reduces the search complexity of SR.
Our work differs from existing approaches in two key ways. First, we position the LLM as an agent that orchestrates physics-based tools, rather than as a stand-alone equation generator. Second, we evaluate this framework across multiple domains, including systems of differential equations where useful physical properties are prominent. This setting allows us to test whether an LLM can use intermediate physical structure to guide equation discovery.
## 3 Physics-Aware Equation Discovery Agent
<details>
<summary>x2.png Details</summary>
### Visual Description
## System Architecture Diagram: Kepler Agent for Symbolic Regression
### Overview
This image is a technical system architecture diagram illustrating the components and workflow of an AI agent named "Kepler agent." The agent is designed for automated scientific discovery, specifically symbolic regression—finding mathematical equations that describe data. The diagram shows the agent's internal structure, its tools, and a sample output.
### Components/Axes
The diagram is organized into three main regions:
1. **Left Panel (Agent Memory & Inputs):** A large rounded rectangle containing five sub-sections.
* **System prompt:** Depicted as a document icon with lines of text.
* **Tool specs:** Contains two labeled boxes: "PySR" and "PySINDy".
* **Workspace:** Contains two empty gray placeholder boxes.
* **User query:** Depicted as a document icon with lines of text.
* **Experience log:** Contains two detailed log entries.
* **# Step 1:** "Code execution", "Result type: text analysis", "Output: Summary statistics..."
* **# Step 2:** "PySR", "Result type: equation", "Best equation: 'y = x1 / x2 + ...'", "MAPE: 3.78%"
2. **Central Processing Core:**
* **Top:** A rounded rectangle labeled **"Kepler agent"** with a robot icon. This is the central orchestrator.
* **Middle:** Two JSON-like data blocks connected by arrows to the Kepler agent and the tools below.
* **Left Block (Tool Call):** `{"tool_call": {"tool_name": "pysr", "args": {"operators": ["+", "-", "/", ...], "constraints": "..."}}}`
* **Right Block (Result):** `{"result": {"tool_name": "PySR", "result_type": "equation", "best_equation": "..."}}`
* **Bottom:** A row of four icons representing specialized sub-components or tools.
* **Visual subagent:** Icon of a magnifying glass over a waveform.
* **Code interpreter:** Icon of a person with `</>` on their torso.
* **Symmetry discovery:** Icon of a complex geometric pattern (mandala-like).
* **PySR & PySINDy:** Icon of a human head silhouette with circuit patterns.
3. **Right Output Region:**
* **Mathematical Equation:** `dx/dt = A cos(ωt)` displayed prominently.
* **Waveform Graph:** A simple line graph showing a sinusoidal wave, visually representing the output of the differential equation above it.
### Detailed Analysis
The diagram illustrates a closed-loop workflow for scientific discovery:
1. **Input & Context:** The Kepler agent receives a **User query** and operates within the context of a **System prompt** and a **Workspace**. It has access to **Tool specs** for PySR (Python Symbolic Regression) and PySINDy (Sparse Identification of Nonlinear Dynamics).
2. **Execution & Logging:** The agent's actions are recorded in the **Experience log**. Step 1 shows initial data analysis. Step 2 shows the result of using the PySR tool, which outputs a candidate equation and its error metric (MAPE: 3.78%).
3. **Tool Invocation:** The agent formulates a `tool_call` (specifying operators and constraints) and sends it to the appropriate tool (e.g., PySR).
4. **Result Processing:** The tool returns a `result` containing the discovered `best_equation`.
5. **Specialized Sub-components:** The agent can leverage four specialized modules: a **Visual subagent** for plotting, a **Code interpreter** for execution, a module for **Symmetry discovery**, and the core **PySR & PySINDy** engines.
6. **Final Output:** The end product of this process is a parsimonious mathematical model, exemplified by the differential equation `dx/dt = A cos(ωt)` and its corresponding waveform.
### Key Observations
* **Hybrid AI Architecture:** The system combines a central reasoning agent (Kepler) with specialized, possibly neuro-symbolic, tools (PySR, PySINDy) and subagents.
* **Iterative Learning:** The **Experience log** indicates the agent maintains a history of its steps, results, and performance metrics (like MAPE), suggesting capability for iterative refinement.
* **Multi-Modal Output:** The system produces both symbolic (the equation) and visual (the graph) representations of its findings.
* **Constraint-Driven Search:** The `tool_call` includes `operators` and `constraints`, showing the search for equations is guided and not purely random.
### Interpretation
This diagram depicts a sophisticated framework for **automated scientific model discovery**. The Kepler agent acts as an orchestrator that:
1. Understands a user's scientific question (query).
2. Selects and commands appropriate symbolic regression tools.
3. Interprets the results, logs the experience, and likely refines its approach.
4. Outputs human-interpretable mathematical laws (like the provided cosine differential equation) that describe patterns in data.
The inclusion of "Symmetry discovery" and "Visual subagent" modules suggests the system is designed not just to find equations, but to uncover underlying physical principles and present them intuitively. The workflow embodies a Peircean abductive reasoning process: starting from an observation (data in the query), it generates a hypothesis (the best_equation) that best explains the data, with the MAPE serving as a measure of explanatory power. The entire system aims to accelerate scientific insight by automating the labor-intensive task of mathematical model formulation.
</details>
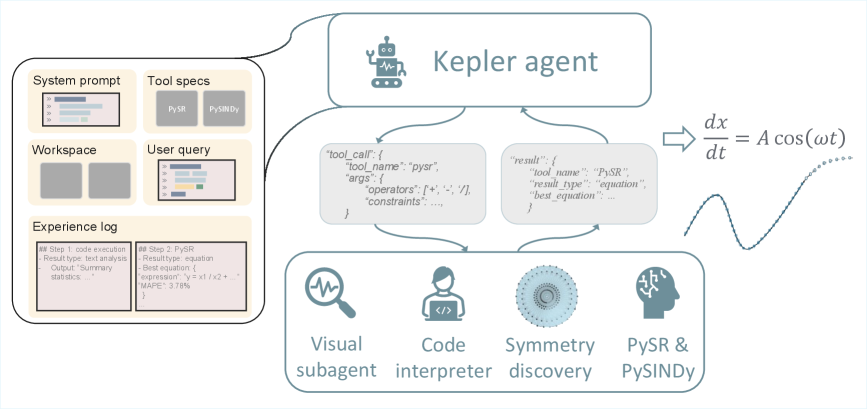
Figure 2: The overall design of our KeplerAgent framework. The input to the LLM contains a system prompt explaining the task setup, a list of tool specifications, the user query containing information about the dataset, as well as a workspace summary and an experience log recording previous steps. The agent reasons about the existing findings and decides subsequent tool calls iteratively until obtaining a satisfactory equation discovery result.
### 3.1 Overview
We consider the problem of equation discovery, or symbolic regression (SR): given observations of a system in the form of input and output variables, the goal is to recover an explicit symbolic expression that accurately describes the underlying relationship between variables.
We formulate equation discovery as a tool-augmented decision process controlled by an LLM. Instead of directly mapping data to a symbolic equation, the model acts as a ReAct-style agent (Yao et al., 2023) that iteratively analyzes the dataset, invokes physics-based tools to infer structural properties, and configures symbolic regression backends to fit candidate equations. Throughout this process, the agent reads and writes to a shared workspace of intermediate artifacts and an experience log of past tool calls, allowing it to progressively narrow the hypothesis space in a way that mirrors the multi-step workflow of human scientists.
### 3.2 Agent Architecture
Figure 2 shows the overall design of our framework. Our system consists of a single language model agent equipped with a suite of tools for data analysis, physics-based structure discovery, and symbolic regression. The agent is instantiated with a system prompt that instructs it to prepare structured calls to external tools rather than directly outputting equations (full prompt in Appendix A.1).
At each interaction step, the agent receives four main inputs in addition to the system prompt: (i) a specification of all available tools and their interface, (ii) the user query describing the symbolic regression goal and the dataset, (iii) a workspace files section listing all files currently available in the workspace directory together with brief descriptions, and (iv) an experience log summarizing previous tool calls and their outcomes.
Given this context, the agent first inspects the workspace and experience log to understand existing knowledge about the system and to avoid redundant analyses. It then reasons about the next useful action: for example, the agent can use a Python code interpreter tool to compute basic statistics or visualize data trajectories; it may call a physics-based tool to infer properties that can serve as constraints in symbolic regression; and once enough knowledge about the dataset has been gathered, it configures a run of a symbolic regression backend. The agent calls tools by outputting a structured JSON object specifying the chosen tool and all necessary arguments, which we will describe in detail in Section 3.3.
Each tool executes independently, writes its outputs, such as numerical summaries, discovered equations, error metrics, and diagnostic plots, into the experience log and the workspace. At the next step, the agent observes this updated state, incorporates the new information into its reasoning, and either proposes another tool call or, if an existing result already meets the stopping criteria, terminates and reports the best discovered equation.
### 3.3 Toolset
A key feature of our framework is the use of physics-based tools that expose the intermediate structure of the data to the agent. Below, we describe the tools we used in our agent. More details can be found in Appendix A.2.
#### Python code interpreter.
We provide the agent with a Python code evaluator, allowing it to write its own code to freely perform preliminary analysis of the dataset. The agent is instructed to apply this tool in the first step to obtain basic insights into the data, e.g., computing summary statistics, data visualization, and other preliminary analysis to inform symbolic regression strategies. We also explicitly instruct the agent to use this tool for exploratory data analysis only, leaving the actual SR step to other dedicated tools.
#### Visual subagent.
The exploratory data analysis performed by the agent sometimes produces data plots. To extract information from these data visualizations, we instantiate another LLM subagent prompted to output analysis of the given image in natural language, and wrap the subagent as a tool for the main agent. Once the main agent is aware of a data visualization in the workspace, it can call this subagent and translate the findings into structural constraints for symbolic regression.
#### Symmetry discovery.
We incorporate the methods in Yang et al. (2023, 2024); Ko et al. (2024) as a single tool for identifying symmetry in differential equation systems. In contrast to the previous tools that involve LLM and output findings about the dataset in a natural language form, this tool is purely algorithmic and returns the results in a symbolic format that can be readily fed into symmetry-constrained symbolic regression programs as an input argument. Specifically, this tool trains a tiny neural network as a surrogate model to predict the derivatives (i.e., the target variables in SR for differential equations) from the observed variables in the dataset; then, it fixes the surrogate predictor and optimizes for an infinitesimal generator that generates the symmetry group of the trained predictor. The result is presented as a $q\times q$ matrix $A$ , where $q$ is the number of variables in the differential equation system. It indicates that the surrogate predictor is equivariant with respect to the infinitesimal action of the linear vector field $\mathbf{v}_{A}=(A\mathbf{x})\cdot\nabla$ , where $\mathbf{x}$ denotes the collection of $q$ variables. For example, $A=[[0,-1];[1,0]]$ indicates a 2D rotation symmetry; $A=I_{q}$ indicates a uniform scaling symmetry across all dimensions. Such results lead to constrained equation search spaces in SR methods.
The tools above do not directly discover equations themselves, but rather provide the agent with additional information before performing SR. On the other hand, we also include the following SR packages as tools to obtain the final equation discovery result.
#### PySINDy.
The PySINDy package (Kaptanoglu et al., 2022) implements the sparse regression algorithm originally proposed in Brunton et al. (2016). It assumes the target variable in the equation can be written in terms of a linear combination of some predefined functions with learnable coefficients $\mathbf{w}$ , i.e. $y=f(\mathbf{x})=\sum_{i}w_{i}x_{i}$ . Then, equation discovery is formulated as a least-squares problem over the linear combination coefficients $\mathbf{w}$ , with an $L_{0}$ regularization term $\|\mathbf{w}\|_{0}$ that promotes sparsity. This optimization problem can be efficiently solved, making PySINDy a great tool for discovering equations in relatively simple forms.
In addition to the regular configurations in PySINDy, we incorporate Equivariant SINDy (Yang et al., 2024) as an option, which solves for an equivariant subspace of the SINDy parameter space given the generator of the symmetry group and optimizes within the equivariant subspace. This method has been shown to reduce the hypothesis space and increase the chance of discovering the correct equations effectively when the provided symmetry is accurate. Combined with the previous tool for symmetry discovery, the option to use symmetry in PySINDy enable the agent to translate detected symmetries into concrete constraints on the PySINDy call, improving the accuracy of equation discovery for ODE and PDE systems in particular.
However, SINDy’s assumption about the “linear” form is restrictive in practice. For example, it does not consider the possibility of rational functions (e.g. $f(x)/g(x)$ ), nested expressions (e.g. $(\sin(f(x))$ , etc. To account for such equations with additional complexity, we include PySR (Cranmer, 2023), a genetic-programming-based symbolic regression package, as the final tool.
#### PySR.
PySR represents each symbolic expression as a tree where nodes correspond to mathematical operators, variables, and constants. It uses genetic programming to mutate a population of expressions and search for the best expression that balances data-fitting accuracy and symbolic complexity. The expression tree representation, compared to the linear assumption in SINDy, enables PySR to discover equations in more general forms, albeit at a higher computational cost due to the larger search space.
In practice, a PySR regression may take many iterations to converge. To speed up the process, we provide an interface that allows the agent to propose a template expression and pass it to PySR as an argument, thereby constraining PySR to search only for equations with the specified template structure. When calling the PySR tool, the LLM agent recalls possible equation structures from its prior knowledge, and also considers the results from previous tool calls, e.g. visualizations and statistical analysis. Based on these, it reasons about what functional forms are plausible for the specific dataset and translates it into the template for PySR. For example, the agent can specify a template $f(x_{1},x_{2})+g(x_{3})$ for an equation of three variables, if it believes that the effect of $x_{3}$ on the target is additively separable; or $\sin(f(x))$ , if some oscillatory behavior is spotted, but the exact expression inside the trigonometric function remains to be solved by SR. We prompt the agent to prioritize reasoning about the template expression over all other arguments when calling PySR, as we find this crucial for reducing the hypothesis space of PySR and accelerating its convergence.
### 3.4 Implementation Details
#### Experience log.
We maintain a section in the agent input that records each tool invocation, its arguments, and a textual summary of its outcome (e.g., losses, discovered equations/structures). While similar to the design of the experience buffer in LLM-SR (Shojaee et al., 2025a), we include not only the discovered equations and the associated data losses, but also the inputs/outputs of other tools. This is a natural choice in our framework, as the agent is required to explicitly reason on the intermediate results step by step.
#### Workspace.
The workspace is a shared directory containing the files produced during the agent’s interaction with the dataset and tools. It serves as a complement to the experience log, keeping all non-textual assets, such as converted datasets and visualizations produced throughout the reasoning process. A continuously maintained list of all workspace files and their descriptions is inserted into the agent input after the user query at each step, so the agent can pass relevant files to specific tool calls.
#### Stopping criteria.
Following Shojaee et al. (2025a), we include in the system prompt a primary success criterion: if any SR tool call produces an equation with mean absolute percentage error (MAPE) below $0.1\$ on the test dataset, the agent must stop exploring and return that equation as the final result. However, we observe that this primary goal may not be achievable for real-world datasets with noise, where even the prediction error of ground truth equations may exceed the specified threshold. In this case, enforcing the hard threshold in the stopping criteria can cause unnecessary waste of compute, as the agent will keep pursuing an impossible objective. In our implementation, we set a maximum number of tool calls to prevent such infinite loops.
## 4 Experiments
### 4.1 Datasets
We use two benchmarks for evaluation: LSR-Transform subset from LLM-SRBench (Shojaee et al., 2025b), and a collection of ODE/PDE systems, which we will refer to as the DiffEq datasets in the following subsections.
#### LLM-SRBench.
LLM-SRBench is a standard benchmark for evaluating LLM-based symbolic regression methods. We focus on the LSR-Transform subset of the benchmark, which contains transformed versions of equations in AI Feynman (Udrescu and Tegmark, 2020) benchmark. Specifically, LSR-Transform selects a previous feature variable and transforms the original equation into an alternative form with the selected variable as the new target for each dataset. This prevents LLMs from solving the symbolic regression problem by memorizing the well-known presentations of these physical equations.
#### Differential equations ( DiffEq ).
We also create a custom benchmark of 10 systems governed by ordinary and partial differential equations. Each system has two dependent variables and two differential equations with the time derivatives of the dependent variables as regression targets. As we have mentioned in Section 1, these datasets are a valuable complement to LLM-SRBench for the following reasons. First, they involve coupled differential equations of dynamical systems, whereas LLM-SRBench mainly features single scalar equations for all tasks. As a result, this benchmark can measure how LLMs benefit from reasoning about the full system of related equations, rather than just working on isolated equations. Also, differential equation systems considered in this benchmark often possess a rich physical structure, making it a natural testbed for LLMs’ ability to infer the intermediate findings during equation discovery like a human scientist. A complete description of the physical systems and the data generation procedure for this benchmark can be found in Appendix B.2.
### 4.2 Evaluation criteria
Following Shojaee et al. (2025b), we use the symbolic accuracy (SA) and normalized MSE (NMSE) in our evaluation criteria. The symbolic accuracy is obtained using an LLM evaluator (GPT-4o-mini in our experiments), which is given the ground truth expression and the discovered expression and prompted to decide if they are symbolically equivalent under a tolerance of small numerical mismatches in the coefficients of the expressions. The (pointwise) NMSE is computed on a test dataset by $\frac{1}{n}\sum_{i}^{n}(y_{i}-\hat{y}_{i})^{2}/\sum_{i}^{n}(y_{i}-\bar{y}_{i})^{2}$ , where $y_{i}$ are the target variables from the dataset and $\hat{y}_{i}$ are predictions from the discovered equation.
In addition, for the DiffEq benchmark, we note that the pointwise NMSE does not always faithfully reflect the numerical accuracy of the discovered equations. Specifically, if we have discovered the RHS expression $\mathbf{f}$ of an ODE system $\mathbf{x}_{t}=\mathbf{f}(\mathbf{x})$ , we can use a numerical solver to predict future states of the system, e.g., $\mathbf{x}(t+s)$ , from a given state $\mathbf{x}(t)$ . The error from the numerical simulation can accumulate as the prediction horizon $s$ increases. However, the pointwise NMSE only measures the error of a single-step prediction ( $\mathbf{x}(t+\Delta t)=\mathbf{x}(t)+\widehat{\mathbf{x}_{t}}(t)\Delta t$ ). The same argument applies to PDE systems. Therefore, we also measure the long-term prediction error from simulating the discovered equations for DiffEq systems, which indicates whether the discoveries are useful for predicting future states.
### 4.3 Baselines
We compare KeplerAgent with both LLM-based and non-LLM-based methods for SR. The first baseline we consider is LLM-SR (Shojaee et al., 2025a), which has been shown to perform best on LLM-SRBench (Shojaee et al., 2025b) among other recent work on LLM-based SR. Notably, the official implementation of LLM-SR only supports discovering one equation at a time. To evaluate it on our DiffEq benchmark, we split each system into its constituent equations and feed the corresponding data to LLM-SR as independent tasks. For example, a system governed by 2 first-order ODEs, $\dot{x}_{1}=f_{1}(x)$ , $\dot{x}_{2}=f_{2}(x)$ , is split into two datasets, each with $[x_{1},x_{2}]$ as features and $\dot{x}_{i}$ , $i=1,2$ as the target.
We also choose PySR (Cranmer, 2023) as a representative baseline for non-LLM-based methods. Similar to LLM-SR, we split systems of multiple equations into several independent tasks. We use a common PySR configuration for all datasets. Notably, PySR is also included as a tool in our agentic framework. However, instead of using a fixed setup, our agent calls PySR with custom configurations based on its understanding and reasoning about the context of the specific task. Comparison between raw PySR without LLM and our method can reveal the LLM agent’s ability to wield the existing tool for SR effectively.
All LLM-based methods use the GPT-4o-mini model. More details about baseline setups can be found in Appendix B.1.
### 4.4 LSR-Transform Results
Table 1: Accuracy and efficiency metrics on LSR-Transform for PySR, LLM-SR, and KeplerAgent, using GPT-4o-mini as the base model. “@ $k$ ” means the best result over $k$ runs (sorted by NMSE) on each dataset. We report the averages of NMSEs across all datasets, scaled by $\times 10^{-1}$ . Bold and underlined numbers indicate the best / second best among all methods, respectively.
| PySR | 37.84 | 2.82 | 2440 | - |
| --- | --- | --- | --- | --- |
| LLM-SR | 31.53 | 0.09 The SA and NMSE metrics for LLM-SR are referred from LLM-SRBench Shojaee et al. (2025b). | 2118 | 209 |
| KeplerAgent @1 | 35.14 | 1.50 | 238 | 42 |
| KeplerAgent @3 | 42.34 | 1.21 | 698 | 125 |
For the LSR-Transform dataset, we include two entries in tables and figures for our method, corresponding to the result from a single run (KeplerAgent @1) and the best result from 3 random runs for each dataset (KeplerAgent @3). The best result is indicated by the lowest NMSE on the test data instead of the symbolic accuracy, since the knowledge of the ground truth equation should not be assumed.
Table 1 shows that KeplerAgent achieves better symbolic accuracy than LLM-SR even with a single attempt. Also, each run of KeplerAgent takes significantly less time and token usage than the baselines. As we increase the computational budget and allow 3 parallel attempts for KeplerAgent, it achieves a symbolic accuracy of 42.34%, outperforming both PySR and LLM-SR with comparable runtime and token efficiency. On the other hand, it is surprising that PySR, under a default configuration with a large number of iterations and an extensive list of allowed operators, has a better symbolic accuracy than LLM-SR and KeplerAgent with a single shot. However, it comes at a cost of much longer runtime. In comparison, our method configures PySR flexibly and typically requires much fewer iterations than the standalone PySR baseline.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Box Plot: Normalized MSE on LSR-Transform
### Overview
The image is a box plot comparing the performance of three different methods on a task called "LSR-Transform." Performance is measured by the logarithm (base 10) of the Normalized Mean Squared Error (MSE). Lower values indicate better performance. The plot includes a horizontal red dashed reference line.
### Components/Axes
* **Title:** "Normalized MSE on LSR-Transform"
* **Y-Axis:**
* **Label:** `log10(Normalized MSE)`
* **Scale:** Logarithmic. Major tick marks are visible at -15, -14, -13, -2.0, -1.5, 0, and 1. The axis has a break (indicated by diagonal hatching) between approximately -13 and -2.0, compressing this range.
* **X-Axis:**
* **Label:** `Method`
* **Categories (from left to right):**
1. `PySR` (Blue box)
2. `KeplerAgent @1` (Green box)
3. `KeplerAgent @3` (Red/Brown box)
* **Reference Line:** A red dashed horizontal line is positioned at `y = -2.0`.
* **Data Annotations:** Below each box, the median and mean values are provided in scientific notation.
### Detailed Analysis
**1. PySR (Blue Box, Left):**
* **Visual Trend:** The box spans from approximately -14.0 to -1.3 on the y-axis. The median line is near the bottom of the box. The upper whisker extends to near 0.8, and the lower whisker extends to near -14.5.
* **Annotated Values:**
* `median = 4.47×10⁻⁵` (This corresponds to `log10(4.47e-5) ≈ -4.35`)
* `mean = 2.82×10⁻¹` (This corresponds to `log10(0.282) ≈ -0.55`)
* **Interpretation:** The large discrepancy between the median (-4.35) and mean (-0.55) indicates a highly right-skewed distribution. Most runs have very low error (median), but a few runs with very high error pull the mean up significantly.
**2. KeplerAgent @1 (Green Box, Center):**
* **Visual Trend:** The box spans from approximately -14.0 to -1.4. The median line is slightly above the bottom of the box. The upper whisker extends to near 0.5, and the lower whisker extends to near -14.5.
* **Annotated Values:**
* `median = 1.40×10⁻⁴` (This corresponds to `log10(1.40e-4) ≈ -3.85`)
* `mean = 1.50×10⁻¹` (This corresponds to `log10(0.150) ≈ -0.82`)
* **Interpretation:** Similar to PySR, the distribution is right-skewed (mean > median). The median error is slightly higher than PySR's median.
**3. KeplerAgent @3 (Red/Brown Box, Right):**
* **Visual Trend:** The box spans from approximately -14.0 to -1.5. The median line is near the bottom of the box. The upper whisker extends to near 0.0, and the lower whisker extends to near -14.5.
* **Annotated Values:**
* `median = 1.94×10⁻⁵` (This corresponds to `log10(1.94e-5) ≈ -4.71`)
* `mean = 1.21×10⁻¹` (This corresponds to `log10(0.121) ≈ -0.92`)
* **Interpretation:** This method has the lowest median error of the three. It also shows right-skew, but its mean is the lowest among the three methods.
### Key Observations
1. **Performance Ranking (by Median):** KeplerAgent @3 (best, lowest median) > PySR > KeplerAgent @1 (worst, highest median).
2. **Performance Ranking (by Mean):** KeplerAgent @3 (best, lowest mean) > KeplerAgent @1 > PySR (worst, highest mean). The mean ranking differs from the median ranking due to the different skew magnitudes.
3. **Distribution Shape:** All three methods exhibit strongly right-skewed distributions of log10(Normalized MSE). This means that while the typical (median) performance is very good (errors around 10⁻⁴ to 10⁻⁵), there is a long tail of runs with much higher errors (up to ~10⁰ or 1).
4. **Spread:** The interquartile range (height of the boxes) and the whisker lengths are broadly similar across methods, indicating comparable variability in performance, aside from the skew.
5. **Reference Line:** The red dashed line at `log10(Normalized MSE) = -2.0` (Normalized MSE = 0.01) serves as a visual benchmark. The median of all three methods is well below this line, indicating that the central tendency of each method achieves an error less than 1% of the normalized scale.
### Interpretation
This chart evaluates symbolic regression or program synthesis methods (PySR and variants of KeplerAgent) on the LSR-Transform benchmark. The key takeaway is that **KeplerAgent @3 achieves the best median performance**, suggesting it is the most reliable method for producing low-error solutions on this task.
The pervasive right-skew across all methods is a critical finding. It indicates that while these algorithms often find excellent solutions, they are not perfectly robust; a subset of runs fails to converge well, resulting in high-error outliers. This could be due to random initialization, the stochastic nature of the search, or particular difficulty with certain sub-problems in the benchmark.
The comparison between `KeplerAgent @1` and `@3` suggests that the `@3` variant (which likely involves more computational resources, search depth, or ensemble size) provides a meaningful improvement in both median and mean error over the `@1` version. The fact that PySR's mean is the highest, despite having a median better than KeplerAgent @1, highlights how severely its performance is impacted by its worst-case runs.
In summary, for the LSR-Transform task, KeplerAgent @3 is the most accurate and reliable method on average, but all methods show a vulnerability to producing occasional high-error results. The red line at -2.0 provides a clear visual threshold that all medians comfortably surpass.
</details>
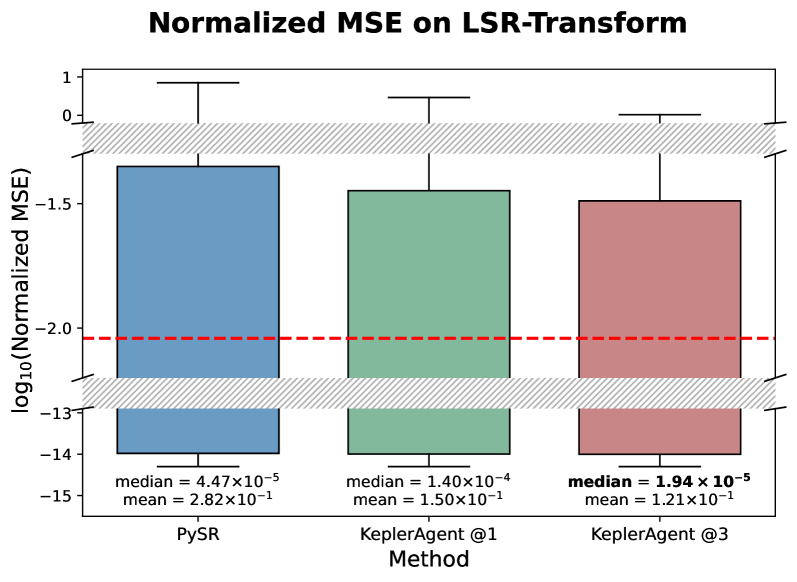
Figure 3: Distribution of NMSEs on LSR-Transform equations for PySR, LLM-SR, and KeplerAgent with one/three runs. The horizontal red dashed line annotates the average NMSE $=0.0091$ of LLM-SR reported in Shojaee et al. (2025b).
Table 2: Symbolic accuracy, NMSE, runtime and token usage (if applicable) on differential equation systems with clean/noisy data. We report the averages of NMSEs across all datasets. The NMSE ( $t_{\text{max}}$ ) is computed between the prediction by simulating the discovered equations and the data points at the max timestep of the test set.
| PySR | 40 | 15 | 0.16 | 5.89 | 1.56 | 2.80 | 119 | 120 | - | - |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| LLM-SR | 30 | 10 | 0.26 | 4.80 | 2.18 | 2.62 | 3648 | 4048 | 182 | 184 |
| KeplerAgent | 75 | 45 | 0.04 | 0.15 | 1.65 | 0.33 | 120 | 147 | 23 | 30 |
In Figure 3, we show the full distributions of NMSEs evaluated over 111 equations in LSR-Transform for PySR and our method. The result for LLM-SR is referred from Shojaee et al. (2025b), where only the average across all datasets is available. We note that LLM-SR has a much lower average NMSE than other approaches. We conjecture that this is because LLM-SR directly uses a similar numerical metric (MAPE) as the reward for their LLM. When the exact symbolic formula is challenging to find, LLM-SR will prioritize expressions with relatively low numerical error over better symbolic interpretability. In contrast, PySR optimizes the expressions under a joint objective of data-fitting error and symbolic complexity. As we have observed, when it fails to identify exactly the ground truth (which has an outstandingly low data-fitting loss), the best equation selected by the joint objective is not necessarily the one that fits the data best, and may sometimes cause large numerical errors. Since the results of our agent often come from PySR tool calls, we observe a similar level of average NMSE between our method and PySR. Meanwhile, in terms of median NMSEs, which are relatively insensitive to outliers, both PySR and our agent achieve satisfactory results.
We finally argue that the symbolic accuracy should be considered the most important metric for evaluating the performance of SR methods, since the goal of SR is to discover a precise and interpretable equation form, rather than obtain a complex expression that approximately fits the data.
### 4.5 DiffEq Results
We also evaluate the baselines and KeplerAgent on our DiffEq benchmark, including the systems listed in Appendix B.2. There are 10 systems of 2 coupled equations, i.e., 20 equations to be discovered in total. For each system, we also construct a noisy dataset by adding white noise proportional to the variance of each phase variable and estimating the time derivatives (regression targets) with the central difference method. The results are available in Table 2. In particular, we report two sets of NMSE metrics. NMSE (pointwise) is computed the same way as in Section 4.4, where we flatten the trajectory data into one dimension and treat each (spatio-)temporal gridpoint as an individual data sample. To calculate NMSE ( $t_{\text{max}}$ ), we pick a trajectory from the clean test set for each system and solve the initial value problem (with specific boundary conditions for PDE systems) with the discovered equation up to the max timestep of the trajectory, and compute the error between the predicted state and the true state from the dataset.
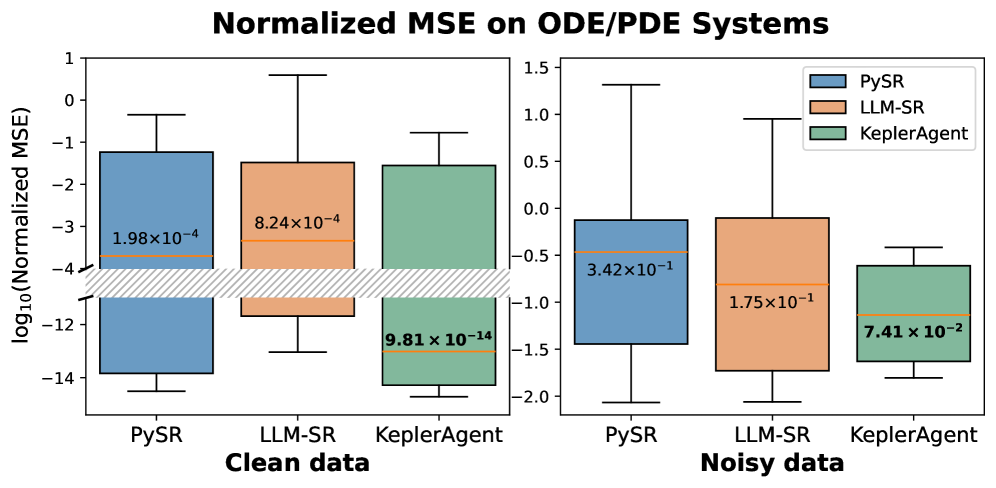
Table 2 shows that KeplerAgent significantly outperforms both baselines in terms of both symbolic and numerical accuracy, particularly on noisy datasets, where it has 45% symbolic accuracy, 3 times more than the best baseline, and achieves order-of-magnitude lower NMSEs (both pointwise and long-term prediction) than baselines. Besides, in terms of efficiency, our agent consumes comparable runtime with PySR, but is much more time- and token-efficient than LLM-SR. We observe that by using tools such as symmetry discovery and image analysis to recover intermediate structures and performing more informed SR calls, our agent can often complete the discovery within a few iterations, compared to hundreds of iterations needed in LLM-SR.
Similar to Section 4.4, we observe outlying NMSE values, making the means in Table 2 less statistically meaningful. Therefore, we include Figure 4 to display the full distributions of pointwise NMSEs over 20 equations, where KeplerAgent achieves lower error quantiles than baselines in general. In addition to NMSEs at $t_{\text{max}}$ , we also plot the full prediction error curves against time in Appendix C.1. In general, the discovered equations from KeplerAgent achieves lower prediction errors throughout the simulation timespan.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Box Plot: Normalized MSE on ODE/PDE Systems
### Overview
The image displays two side-by-side box plots comparing the performance of three symbolic regression methods—PySR, LLM-SR, and KeplerAgent—on ordinary differential equation (ODE) and partial differential equation (PDE) systems. Performance is measured by the base-10 logarithm of the Normalized Mean Squared Error (MSE). The left panel shows results on "Clean data," and the right panel shows results on "Noisy data."
### Components/Axes
* **Title:** "Normalized MSE on ODE/PDE Systems" (centered at the top).
* **Y-axis (Shared Concept):** Label is "log₁₀(Normalized MSE)". The scale is logarithmic, representing orders of magnitude of error.
* **Left Panel (Clean data) Y-axis:** Ranges from approximately -14 to +1. Major tick marks are at -14, -12, -4, -3, -2, -1, 0, 1.
* **Right Panel (Noisy data) Y-axis:** Ranges from approximately -2.0 to +1.5. Major tick marks are at -2.0, -1.5, -1.0, -0.5, 0.0, 0.5, 1.0, 1.5.
* **X-axis (Both Panels):** Lists the three methods: "PySR", "LLM-SR", "KeplerAgent". The panel labels "Clean data" and "Noisy data" are centered below their respective x-axes.
* **Legend:** Located in the top-right corner of the "Noisy data" panel.
* Blue box: "PySR"
* Orange box: "LLM-SR"
* Green box: "KeplerAgent"
* **Data Annotations:** Each box plot has its median value annotated inside the box in scientific notation.
### Detailed Analysis
**Panel 1: Clean data (Left)**
* **PySR (Blue):** The box spans from a log₁₀(MSE) of about -14 (bottom whisker) to about -1.2 (top of box). The median line is annotated as **1.98×10⁻⁴** (log₁₀ ≈ -3.7). The upper whisker extends to approximately -0.4.
* **LLM-SR (Orange):** The box spans from about -11.8 (bottom whisker) to about -1.5 (top of box). The median line is annotated as **8.24×10⁻⁴** (log₁₀ ≈ -3.08). The upper whisker extends to approximately +0.6.
* **KeplerAgent (Green):** The box is positioned extremely low on the y-axis. The main box body is compressed between approximately -14.2 and -1.5. The median line is annotated as **9.81×10⁻¹⁴** (log₁₀ ≈ -13.01). The upper whisker extends to approximately -0.8.
**Panel 2: Noisy data (Right)**
* **PySR (Blue):** The box spans from about -2.05 (bottom whisker) to about -0.1 (top of box). The median line is annotated as **3.42×10⁻¹** (log₁₀ ≈ -0.47). The upper whisker extends to approximately +1.3.
* **LLM-SR (Orange):** The box spans from about -2.05 (bottom whisker) to about -0.1 (top of box). The median line is annotated as **1.75×10⁻¹** (log₁₀ ≈ -0.76). The upper whisker extends to approximately +1.0.
* **KeplerAgent (Green):** The box spans from about -1.8 (bottom whisker) to about -0.6 (top of box). The median line is annotated as **7.41×10⁻²** (log₁₀ ≈ -1.13). The upper whisker extends to approximately -0.4.
### Key Observations
1. **Massive Performance Gap on Clean Data:** KeplerAgent's median error (9.81×10⁻¹⁴) is approximately **9 orders of magnitude lower** than PySR's and **10 orders of magnitude lower** than LLM-SR's on clean data. Its entire interquartile range (the box) is situated far below the others.
2. **Performance Degradation with Noise:** All three methods show significantly higher errors (worse performance) on the "Noisy data" panel. The y-axis scale shifts upward by roughly 12 orders of magnitude at the median for KeplerAgent.
3. **Relative Ranking Consistency:** The performance ranking (KeplerAgent best, followed by LLM-SR, then PySR) is consistent across both clean and noisy conditions, based on the median values.
4. **Increased Variance with Noise:** The boxes and whiskers for all methods are much taller in the "Noisy data" panel, indicating a wider spread of error values and less consistent performance when noise is present.
5. **Visual Anomaly in Clean Data Plot:** There is a hatched gray band across the "Clean data" plot between y = -4 and y = -12, likely used to visually compress the large empty space between the high-error methods and KeplerAgent's extremely low-error box.
### Interpretation
This chart demonstrates the superior accuracy and robustness of the KeplerAgent method for discovering governing equations of ODE/PDE systems compared to PySR and LLM-SR.
* **On clean, ideal data,** KeplerAgent achieves near-perfect reconstruction (error ~10⁻¹³), suggesting it can identify the exact or near-exact underlying mathematical forms. The other methods plateau at errors around 10⁻⁴, indicating they find good but not perfect approximations.
* **The introduction of noise** severely challenges all methods, increasing errors by many orders of magnitude. However, KeplerAgent maintains its lead, suggesting its approach is more resilient to imperfect real-world data. The increased variance under noise implies the discovery process becomes more stochastic for all methods.
* The **consistent ranking** implies fundamental algorithmic advantages in KeplerAgent's methodology for this class of problems. The chart effectively argues that for symbolic regression on dynamical systems, KeplerAgent is the state-of-the-art among the compared methods, offering both exceptional precision on clean data and relative robustness to noise. The visual design, especially the broken axis in the clean data plot, powerfully emphasizes the magnitude of KeplerAgent's advantage.
</details>
Figure 4: Distribution of NMSEs on DiffEq datasets for PySR, LLM-SR, and KeplerAgent (with a single run). Median values are shown next to the median lines.
## 5 Discussion
We present a physics-guided LLM agent for equation discovery that emulates the multi-step reasoning workflow of human scientists. Instead of directly hypothesizing equations, the agent analyzes datasets, calls tools to infer structure, and then configures and runs SR software for final results. Experiments on transformed equations from classical physics and dynamical systems governed by differential equations show that this approach significantly improves symbolic recovery accuracycompared with both classical SR baselines and recent LLM-based methods.
There are several directions to improve the agent design. Our current toolset is intentionally small, but many additional physics tools (e.g., for extended symmetry analysis, dimensional analysis, bifurcation structure) could further constrain the hypothesis space. Scaling up the toolbox raises a practical challenge: the tool specifications inflate the context and make it harder for the agent to remember earlier information. The broader LLM-agent literature suggests remedies, such as decomposing the main agent’s planning and executing functionality into subagents or a workflow graph with multiple nodes, or using retrieval-augmented generation (Lewis et al., 2020) to select only a small subset of relevant tools at each iteration (Lumer et al., 2025). Adapting these ideas to our toolkits is a natural next step.
Another complementary direction is to make the agent’s internal reasoning more explicit by defining a structured state space for symbolic regression. Each state would represent the current hypothesis space of equations with active constraints, and each tool would perform a well-defined transformation of this state. Such a formulation explicitly formalizes the agent’s reasoning process, yielding more controlled behavior and making it easier to systematically analyze its reasoning trajectories across datasets and tasks.
## Impact Statement
Our work can potentially help scientists more efficiently identify interpretable models of complex physical systems. Positive impacts include accelerating scientific modeling, improving transparency relative to black-box predictors, and providing a modular framework that can incorporate domain knowledge in a principled way. Potential negative impacts include over-reliance on automatically discovered equations without adequate human validation, misinterpretation of symbolic models as “ground truth” in high-stakes domains, and increased computational cost associated with agentic tool use. We emphasize that our framework is intended as a decision-support system for experts rather than a replacement, and responsible deployment requires careful verification, documentation of limitations, and attention to the computational and environmental footprint of large-scale experiments.
## Acknowledgement
This work was supported in part by NSF Grants #2205093, #2146343, #2134274, CDC-RFA-FT-23-0069, the U.S. Army Research Office under Army-ECASE award W911NF-07-R-0003-03, the U.S. Department Of Energy, Office of Science, IARPA HAYSTAC Program, DARPA AIE FoundSci and DARPA YFA.
## References
- J. Bakarji, J. Callaham, S. L. Brunton, and J. N. Kutz (2022) Dimensionally consistent learning with buckingham pi. Nature Computational Science 2, pp. 834–844. External Links: ISSN 2662-8457, Document Cited by: §2.1.
- L. Biggio, T. Bendinelli, A. Neitz, A. Lucchi, and G. Parascandolo (2021) Neural symbolic regression that scales. In Proceedings of the 38th International Conference on Machine Learning, M. Meila and T. Zhang (Eds.), Proceedings of Machine Learning Research, Vol. 139, pp. 936–945. Cited by: §2.1.
- S. L. Brunton, J. L. Proctor, and J. N. Kutz (2016) Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the National Academy of Sciences 113 (15), pp. 3932–3937. External Links: Document, https://www.pnas.org/doi/pdf/10.1073/pnas.1517384113 Cited by: §1, §2.1, §3.3.
- K. Champion, B. Lusch, J. N. Kutz, and S. L. Brunton (2019) Data-driven discovery of coordinates and governing equations. Proceedings of the National Academy of Sciences 116 (45), pp. 22445–22451. External Links: Document, https://www.pnas.org/doi/pdf/10.1073/pnas.1906995116 Cited by: §B.2.
- N. J. Christensen, S. Demharter, M. Machado, L. Pedersen, M. Salvatore, V. Stentoft-Hansen, and M. T. Iglesias (2022) Identifying interactions in omics data for clinical biomarker discovery using symbolic regression. Bioinformatics 38 (15), pp. 3749–3758. Cited by: §2.1.
- M. Cranmer, A. Sanchez Gonzalez, P. Battaglia, R. Xu, K. Cranmer, D. Spergel, and S. Ho (2020) Discovering symbolic models from deep learning with inductive biases. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33, pp. 17429–17442. Cited by: §2.1.
- M. Cranmer (2023) Interpretable machine learning for science with pysr and symbolicregression. jl. arXiv preprint arXiv:2305.01582. Cited by: §A.2, §1, §2.1, §3.3, §4.3.
- B. M. de Silva, K. Champion, M. Quade, J. Loiseau, J. N. Kutz, and S. L. Brunton (2020) Pysindy: a python package for the sparse identification of nonlinear dynamics from data. arXiv preprint arXiv:2004.08424. Cited by: §1.
- R. Dubčáková (2011) Eureqa: software review. Springer. Cited by: §2.1.
- S. Gaucel, M. Keijzer, E. Lutton, and A. Tonda (2014) Learning dynamical systems using standard symbolic regression. In Genetic Programming, M. Nicolau, K. Krawiec, M. I. Heywood, M. Castelli, P. García-Sánchez, J. J. Merelo, V. M. Rivas Santos, and K. Sim (Eds.), Berlin, Heidelberg, pp. 25–36. Cited by: §2.1.
- A. Grayeli, A. Sehgal, O. Costilla Reyes, M. Cranmer, and S. Chaudhuri (2024) Symbolic regression with a learned concept library. Advances in Neural Information Processing Systems 37, pp. 44678–44709. Cited by: §2.2.
- A. A. Kaptanoglu, B. M. de Silva, U. Fasel, K. Kaheman, A. J. Goldschmidt, J. Callaham, C. B. Delahunt, Z. G. Nicolaou, K. Champion, J. Loiseau, J. N. Kutz, and S. L. Brunton (2022) PySINDy: a comprehensive python package for robust sparse system identification. Journal of Open Source Software 7 (69), pp. 3994. External Links: Document, Link Cited by: §A.2, §3.3.
- G. Ko, H. Kim, and J. Lee (2024) Learning infinitesimal generators of continuous symmetries from data. Advances in Neural Information Processing Systems 37, pp. 85973–86003. Cited by: §A.2, §A.2, §3.3.
- W. La Cava, B. Burlacu, M. Virgolin, M. Kommenda, P. Orzechowski, F. O. de França, Y. Jin, and J. H. Moore (2021) Contemporary symbolic regression methods and their relative performance. Advances in neural information processing systems 2021 (DB1), pp. 1. Cited by: §B.2.
- K. Lee, N. Trask, and P. Stinis (2022) Structure-preserving sparse identification of nonlinear dynamics for data-driven modeling. In Proceedings of Mathematical and Scientific Machine Learning, B. Dong, Q. Li, L. Wang, and Z. J. Xu (Eds.), Proceedings of Machine Learning Research, Vol. 190, pp. 65–80. Cited by: §2.1.
- P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, et al. (2020) Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, pp. 9459–9474. Cited by: §5.
- E. Lumer, F. Nizar, A. Gulati, P. H. Basavaraju, and V. K. Subbiah (2025) Tool-to-agent retrieval: bridging tools and agents for scalable llm multi-agent systems. arXiv preprint arXiv:2511.01854. Cited by: §5.
- G. Martius and C. H. Lampert (2016) Extrapolation and learning equations. arXiv preprint arXiv:1610.02995. Cited by: §2.1.
- M. Merler, K. Haitsiukevich, N. Dainese, and P. Marttinen (2024) In-context symbolic regression: leveraging large language models for function discovery. arXiv preprint arXiv:2404.19094. Cited by: §2.2.
- D. A. Messenger and D. M. Bortz (2021a) Weak sindy for partial differential equations. Journal of Computational Physics 443, pp. 110525. Cited by: §2.1.
- D. A. Messenger and D. M. Bortz (2021b) Weak sindy: galerkin-based data-driven model selection. Multiscale Modeling & Simulation 19 (3), pp. 1474–1497. Cited by: §2.1.
- D. A. Messenger, J. W. Burby, and D. M. Bortz (2024) Coarse-graining hamiltonian systems using wsindy. Scientific Reports 14 (1), pp. 14457. Cited by: §2.1.
- R. S. Olson, W. La Cava, P. Orzechowski, R. J. Urbanowicz, and J. H. Moore (2017) PMLB: a large benchmark suite for machine learning evaluation and comparison. BioData mining 10 (1), pp. 36. Cited by: §B.2.
- B. K. Petersen, M. Landajuela, T. N. Mundhenk, C. P. Santiago, S. K. Kim, and J. T. Kim (2019) Deep symbolic regression: recovering mathematical expressions from data via risk-seeking policy gradients. arXiv preprint arXiv:1912.04871. Cited by: §2.1.
- Z. Qian, K. Kacprzyk, and M. van der Schaar (2022) D-CODE: discovering closed-form ODEs from observed trajectories. In International Conference on Learning Representations, Cited by: §2.1.
- S. H. Rudy, S. L. Brunton, J. L. Proctor, and J. N. Kutz (2017) Data-driven discovery of partial differential equations. Science advances 3 (4), pp. e1602614. Cited by: §2.1.
- S. Sahoo, C. Lampert, and G. Martius (2018) Learning equations for extrapolation and control. In International Conference on Machine Learning, pp. 4442–4450. Cited by: §2.1.
- M. Schmidt and H. Lipson (2009) Distilling free-form natural laws from experimental data. science 324 (5923), pp. 81–85. Cited by: §1, §2.1.
- S. Sharlin and T. R. Josephson (2024) In context learning and reasoning for symbolic regression with large language models. arXiv preprint arXiv:2410.17448. Cited by: §2.2.
- P. Shojaee, K. Meidani, S. Gupta, A. B. Farimani, and C. K. Reddy (2025a) Llm-sr: scientific equation discovery via programming with large language models. ICLR. Cited by: §B.1, §1, §2.2, §3.4, §3.4, §4.3.
- P. Shojaee, N. Nguyen, K. Meidani, A. B. Farimani, K. D. Doan, and C. K. Reddy (2025b) Llm-srbench: a new benchmark for scientific equation discovery with large language models. arXiv preprint arXiv:2504.10415. Cited by: §B.1, §1, §2.2, Figure 3, Figure 3, §4.1, §4.2, §4.3, §4.4, footnote 1.
- S. H. Strogatz (2001) Nonlinear dynamics and chaos: with applications to physics, biology, chemistry, and engineering (studies in nonlinearity). Vol. 1, Westview press. Cited by: §B.2.
- S. Udrescu, A. Tan, J. Feng, O. Neto, T. Wu, and M. Tegmark (2020) AI feynman 2.0: pareto-optimal symbolic regression exploiting graph modularity. Advances in Neural Information Processing Systems 33, pp. 4860–4871. Cited by: §2.1.
- S. Udrescu and M. Tegmark (2020) AI feynman: a physics-inspired method for symbolic regression. Science Advances 6 (16), pp. eaay2631. Cited by: §2.1, §4.1.
- Y. Wang, N. Wagner, and J. M. Rondinelli (2019) Symbolic regression in materials science. MRS communications 9 (3), pp. 793–805. Cited by: §2.1.
- S. Xia, Y. Sun, and P. Liu (2025) Sr-scientist: scientific equation discovery with agentic ai. arXiv preprint arXiv:2510.11661. Cited by: §B.1, §2.2.
- X. Xie, A. Samaei, J. Guo, W. K. Liu, and Z. Gan (2022) Data-driven discovery of dimensionless numbers and governing laws from scarce measurements. Nature Communications 13 (1), pp. 7562. External Links: Document Cited by: §2.1.
- J. Yang, M. Bhat, B. Hu, Y. Cao, N. Dehmamy, R. Walters, and R. Yu (2025) Discovering symbolic differential equations with symmetry invariants. arXiv preprint arXiv:2505.12083. Cited by: §A.2.
- J. Yang, W. Rao, N. Dehmamy, R. Walters, and R. Yu (2024) Symmetry-informed governing equation discovery. In Advances in Neural Information Processing Systems (NeurIPS), External Links: Link Cited by: 6th item, §A.2, §A.2, §A.2, §B.2, §C.2, §3.3, §3.3.
- J. Yang, R. Walters, N. Dehmamy, and R. Yu (2023) Generative adversarial symmetry discovery. In International conference on machine learning, pp. 39488–39508. Cited by: §A.2, §A.2, §3.3.
- S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao (2023) ReAct: synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), Cited by: §3.1.
## Appendix A Implementation Details
### A.1 System Prompt
The full system prompt of KeplerAgent is shown below. The system prompt is followed by the subsequent sections in order: tool specifications, user query, workspace files, and experience log.
⬇
# Symbolic Regression Data Analyzer
You are an expert data analyst and symbolic regression specialist. Your role is to perform preliminary analysis of datasets and determine the appropriate symbolic regression approach, preparing structured tool calls for external symbolic regression tools. You will also be given an experience log containing results from past experiments.
## Workspace Files
You have access to a workspace directory where the input data file is stored and tools create additional files (plots, statistics, results, etc.). A section titled "## Workspace Files " will be included in your input, showing all registered files with their descriptions. This helps you:
- Understand what analysis has already been performed
- Avoid redundant tool calls
- Reference existing visualizations or statistics when making decisions
- Pass relevant files to tools that need them
** Important **: If workspace files are shown in your input, review them carefully before deciding on tool calls. For example, if statistical analysis or plots already exist, you can reference them in your reasoning.
## Your Responsibilities
1. ** Review workspace files **
- The input data file is always available in the workspace
- Review other files if available to see if preliminary analysis has already been done
2. ** Inspect the past experience buffer **
- Examine what has been done by past tool calls, if there ’ s any.
- If there is no past experience, you should write your own Python code and pass to the ‘ python_intepreter ‘ tool to obtain basic insight of the dataset.
- If there are useful constraints or inductive biases from past tool calls, incorporate them into future symbolic regression calls.
- If there are existing results from any symbolic regression algorithm, examine the discovered equations and their data fitting errors. Learn the lessons and failure modes before making new tool calls. However, ** DO NOT REPEAT TOOL CALLS WITH EXACTLY THE SAME PARAMETERS.**
- ** STOPPING CRITERIA **: If the existing results have achieved ** MAPE < 0.1%** (Mean Absolute Percentage Error less than 0.1%), you MUST stop and return the final result. Do NOT make any new tool calls. Instead, return the single best equation that describes the dataset with the lowest error. This is your PRIMARY SUCCESS CONDITION.
3. ** Select appropriate tool **
- If the current information about the dataset is sufficient for trying one of the symbolic regression algorithms, call a tool for symbolic regression.
- Identify any special considerations (noise level, data size, feature count, constraints / insights from past tool calls)
- Choose the most suitable symbolic regression method with appropriate toolcall arguments based on data characteristics
- Otherwise, perform additional data analysis with other tools
4. ** Prepare tool call specification **
- Generate a structured JSON object specifying the tool and its arguments
- Include all necessary arguments for the tool to run
## Output Format
You should analyze the data and provide your reasoning in natural language. Explain what you observe about the data, what patterns you detect, and why you ’ re selecting particular tools and parameters.
** Your response must contain a JSON object ** with one of the following structures at the end:
### Single Tool Call
‘‘‘ json
{
" tool_call ": {
" tool_name ": " name of selected tool ",
" args ": {
" parameter1 ": " value1 ",
" parameter2 ": " value2 "
}
}
}
‘‘‘
### Multiple Tool Calls (Maximum: 3)
When you need to run multiple independent tool calls based on existing evidence, you can specify them together:
‘‘‘ json
{
" tool_calls ": [
{
" tool_name ": " python_interpreter "
},
{
" tool_name ": " pysr ",
" args ": {
" input_file ": " data. csv ",
" binary_operators ": ["+", "-", "*", "/"]
}
}
]
}
‘‘‘
** Guidelines for Multiple Tool Calls:**
- Maximum of **3 tool calls ** per batch
- Each tool call must be justified by ** existing evidence ** in the experience log
- Tools are executed ** sequentially ** in the order specified
- Results will be numbered as sub - steps (e. g., Step 2.1, Step 2.2)
- If any tool fails, subsequent tools will still execute
** IMPORTANT for python_interpreter:**
When using ‘ python_interpreter ‘ in a multiple tool call batch, include ** separate Python code blocks ** for each interpreter call. The code blocks are matched to tool calls in order of appearance.
### Final Result
When no more tool calls are needed:
‘‘‘ json
{
" final_result ": " the RHS of the best discovered equation "
}
‘‘‘
or, for a system of multiple equations:
‘‘‘ json
{
" final_result ": [" eq1 ", " eq2 ", ...]
}
‘‘‘
** IMPORTANT: DO NOT ADD COMMENTS IN THE JSON OBJECT. DO NOT INCLUDE THE LHS (TARGET VARIABLE) OF EQUATIONS IN THE FINAL RESULT.**
## Important Notes
- Provide detailed analysis and reasoning in natural language
- The JSON object specifying the tool call must be included at the end, valid and parseable
- Choose tools and their parameters based on the specific characteristics of the data
- Review the available tools and their specifications below before making your selection
- ** YOUR PRIMARY GOAL **: Achieve ** MAPE < 0.1%** (Mean Absolute Percentage Error less than 0.1%).
- If the dataset requires multiple equations to describe (e. g., system of 2 coupled ODEs), you need to make sure ** all ** equations are accurately fitted, not just one of them.
- If multiple discovered equations from different tool calls have similar data - fitting errors, choose the candidate with a simpler symbolic form.
Listing 1: Full system prompt used for KeplerAgent.
### A.2 Tool Implementations and Specifications
#### Python code interpreter.
This tool takes the LLM-generated Python code as its single argument. It evaluates the code and returns all the content printed by the code as the tool output. In the tool specification, we specify that (1) this tool is intended specifically for data analysis tasks only, instead of for symbolic regression itself; (2) the agent should write code to load data files and perform exploratory data analysis, such as computing basic statistics and producing data visualizations when applicable; (3) the code generated by the agent shouold print the analysis results using print() statements, which will be captured and returned as the tool result; (4) when the code intends to save any file to the workspace, such as plots, converted data files, and other non-readable results, it must simultaneously call a predefined register_file() function to register the file within the workspace, making the file visible to the agent itself at subsequent steps.
#### Visual subagent.
We instantiate a GPT-4o-mini LLM subagent specialized in analyzing data visualizations. The tool accepts a single required argument, image_path, and the following optional arguments:
- context (string): Additional context about the data or experiment. Example: "This is a physics experiment measuring spring oscillation." Providing context information helps the vision model provide more relevant insights.
- focus_areas (list of strings): Specific aspects to focus the analysis on, e.g., periodicity, noise level, asymptotic behavior, etc.
The system prompt for the subagent is listed as follows.
⬇
You are an expert data analyst specializing in visual analysis of scientific plots and data visualizations. Your task is to analyze this plot / visualization and extract insights that would be useful for symbolic regression - the process of discovering mathematical equations that describe the underlying relationship in data.
Analyze the image and provide structured insights in the following categories:
## 1. Observed Patterns
Identify key patterns visible in the data, e. g.:
- Trend direction (increasing, decreasing, constant regions)
- Periodicity or oscillations (estimate frequency / wavelength if visible)
- Growth / decay patterns (linear, exponential, polynomial, logarithmic)
## 2. Potential Functional Forms
Based on visual evidence, suggest likely mathematical forms, e. g.:
- Simple forms: linear (ax + b), polynomial (x ^ n), power law (x ^ a)
- Trigonometric (sin, cos)
- Composite forms: products, ratios, nested functions
- For each suggestion, explain the visual evidence supporting it
## 3. Noise Characteristics
Assess data quality:
- Overall noise level
- Noise distribution (uniform, increasing with magnitude, etc.)
- Outliers or anomalies
- Signal - to - noise ratio assessment
## 4. Recommendations for Symbolic Regression
Based on your analysis, provide specific recommendations:
- Which operators to prioritize (Binary: +, -, *, /; Unary: sin, cos, exp, log, sqrt, etc.)
- Template structures to try (e. g., " f (x)* g (y)" for separable effects)
Respond with a JSON object containing your analysis. Example format (you may add or remove fields as needed):
‘‘‘ json
{
" observed_patterns ": {
" trend ": " description of trend or null ",
" periodicity ": " description or null ",
" growth_decay ": " description or null ",
" asymptotic_behavior ": " description or null "
},
" potential_functional_forms ": [
{
" form ": " mathematical expression ",
" evidence ": " visual evidence description "
}
],
" noise_characteristics ": " description ",
" sr_recommendations ": {
" binary_operators ": [" list ", " of ", " operators "],
" unary_operators ": [" list ", " of ", " unary ", " ops "],
}
}
‘‘‘
Listing 2: System prompt used for the image analysis subagent.
#### Symmetry discovery.
We incorporate the methods in Yang et al. (2023, 2024); Ko et al. (2024) as a single tool for identifying Lie symmetry in differential equation systems. As we have mentioned in Section 3.3, this tool trains a tiny neural network as a surrogate model to predict the derivatives (i.e., the target variables in symbolic regression for differential equations) from the observed variables in the dataset; then, it fixes the surrogate predictor and optimizes for a $q\times q$ matrix $A$ that generates the symmetry group of the trained predictor, where $q$ is the number of variables in the differential equation system. $A$ is optimized under the equivariance error
$$
\mathbb{E}_{\mathbf{x}}\|J_{\mathbf{f}_{\theta}}(\mathbf{x})\cdot((A\mathbf{x})\cdot\nabla)(\mathbf{x})-((A\mathbf{x})\cdot\nabla)(\mathbf{f}_{\theta}(\mathbf{x}))\|^{2}, \tag{1}
$$
where $\mathbf{x}$ denotes the column vector of $q$ dependent variables, $\mathbf{f}_{\theta}$ is the trained predictor, and $J_{\cdot}$ denotes the Jacobian. The loss is minimized to zero when the surrogate predictor is equivariant with respect to the infinitesimal action of the linear vector field $\mathbf{v}_{A}=(A\mathbf{x})\cdot\nabla$ .
We note a few connections and differences between our implementation and other relevant work in symmetry discovery. Yang et al. (2023) first formulated the problem of learning invariance/equivariance of functions and approached it by training a GAN where the generator outputs transformations on function graphs and the discriminator is trained to distinguish between the original and the transformed data points. The problem formulation of our tool is similar to Yang et al. (2023), but we find the GAN-based discovery method is difficult to converge with the relatively small datasets used in this paper.
Therefore, we choose an approach akin to Ko et al. (2024), where the role of the discriminator is replaced by a predictor model, and the symmetry generator (in our case, the matrix $A$ ) is optimized with a task-specific loss measuring the violation of the symmetry indicated by the generator with respect to the predictor. However, different from the setup in Ko et al. (2024), which assumes the knowledge of the ground truth differential equation and uses the exact equation as a perfect predictor, we have to train a surrogate predictor and insert it into the loss. For the systems considered in this paper, we find that a tiny 2-layer MLP is sufficient for producing accurate predictions.
The equivariance error (1) is referred from Proposition 3.3 (more specifically, Eq. (5)) of Yang et al. (2024). It is shown in their proposition that, if the expression inside the norm is zero for all state variables $\mathbf{x}$ , then the one-parameter subgroup generated by $\mathbf{v}_{A}$ is exactly the symmetry of the predictor. They have used this as a symmetry regularization term with a fixed $A$ to optimize their equation model, whereas we use the same loss term to optimize for an unknown symmetry generated by $A$ .
Finally, we note that the equivariance error in (1) is only applicable to linear symmetries acting solely on dependent variables. This is exactly the setup we specify by the vector field in the form $\mathbf{v}_{A}=(A\mathbf{x})\cdot\nabla$ . More generally, some symmetries of differential equation systems can act with nonlinear functions on the total space containing both independent variables (e.g., the time variable in ODE systems) and dependent variables. We may still use an equivariance error term for discovering those symmetries, but the exact formulation would be different from (1) and likely more complicated, depending on the restrictions we want to place on the allowed symmetries. For a more in-depth discussion of the application of general Lie symmetries in symbolic regression, we refer the readers to Yang et al. (2025).
#### PySINDy.
This tool builds on the PySINDy software (Kaptanoglu et al., 2022) and the derivative work of EquivSINDy (Yang et al., 2024) with the following arguments exposed to the LLM agent:
- data_file (required): Path to the data file containing the trajectory data of ODE/PDE systems.
- polynomial_degree: The maximal degree of polynomials included in the SINDy function library. Default is 3.
- derivative_order: The maximal order of partial derivatives included in the SINDy feature list. Default is 2.
- normalize_columns: Boolean value indicating whether to normalize feature columns byy $L_{2}$ norm before regression.
- threshold: The threshold for sequential thresholding, controlling the sparsity regularization strength.
- use_symmetry: Boolean value indicating whether to use symmetry to constrain the SINDy parameter space following the method in EquivSINDy (Yang et al., 2024). If true, the lie_generator argument must also be specified.
- lie_generator: a list or array-like object specifying the matrix generator of the Lie symmetry. Must have the shape $q\times q$ where $q$ matches the number of dependent variables in the dataset.
#### PySR.
The official PySR software (Cranmer, 2023) offers abundant configurable options for genetic-programming-based SR. In practice, we find that including too many configurable parameters disorients the agent, and the agent tends to try out random combinations of parameters without rigorous reasoning. Therefore, in the tool specification, we instruct the agent to prioritize considering the expression_spec argument, which allows the agent to propose a template structure of the equation based on its prior knowledge.
The expression_spec argument shouold be formatted as a dictionary with the following format:
⬇
{" expressions ": [...], " variable_names ": [...], " combine ": "..."}
The expressions field should contain placeholder function names. These functions represent unknown sub-expressions that will be fitted by PySR. The variable_names should contain the feature names from the dataset. The combine field should specify a template string indicating how placeholder functions and known parts (variables, known functional expressions) combine, e.g., "F / a + f(F, a)", "sin(f(x1)) * g(x2, x3)", "f(x1, x2) + g(x3)", etc.
Other tool arguments are listed as follows:
- input_file: path to the data file to perform symbolic regression on.
- binary_operators: Binary operators allowed in building the equation. Default is ["+", "-", "*", "/"].
- unary_operators: Unary operators allowed in building the equation. Common options include $\sin,\cos,\exp,\log,\mathrm{sqrt}$ . Default is an empty list.
- niterations: Max number of PySR iterations allowed.
- constraints: An optional dictionary specifying complexity constraints for specific operators. For example, {"+":(5, 5), "*":(3, 3)} restricts the left and right operands of addition to have expression complexity (subtree size) at most 5, and the operands of multiplication to have complexity at most 3.
- nested_constraints: An optional dictionary of constraints on operator nesting. For example, {"sin": {"cos": 0}} prevents expressions like $\sin(\cos(x))$ .
Other arguments naturally supported by PySR, such as population size and the number of parallel populations, are not exposed to the agent and set to default to avoid causing distractions for the agent.
## Appendix B Experiment Details
### B.1 Baselines and Common Setups
#### LLM-SR.
We run LLM-SR (Shojaee et al., 2025a) with the following configurations. We use GPT-4o-mini as the language model backbone to iteratively generate candidate equation skeletons. We allow a maximum of 500 sampled equation proposals for the ODE/PDE datasets during the search process, with each equation constrained to at most 10 free parameters. This is different from the default setting of 2500 samples in their original paper. For the LSR-Transform benchmark, we allow a maximum of 200 samples each dataset and record the wall-clock runtime and token usage.
For the prompts of LLM-SR, we provide an overall description of the domain of each dataset and a list of descriptions of the physical meanings of each variable. We reuse the LLM-SRBench (Shojaee et al., 2025b) construction of prompts for the LSR-Transform datasets. For the ODE/PDE systems we collect in DiffEq, we specify the name of each variable and derivative and whether it belongs to the input (feature) variables or the output (target) variables for symbolic regression.
#### PySR.
We follow the setup described in Xia et al. (2025) for evaluating PySR on LLM-SRBench. Specifically, we set the number of iterations to $125$ and cycles per iteration to $550$ . We also configure populations to $15$ with a population size of $33$ , a maximum size of $30$ , and a randomization weight of $0.1$ . The set of binary operators used is $\{+,-,\times,\div,\mathrm{pow}\}$ , and the set of unary operators is $\{\exp,\log,\sqrt{\phantom{x}},\sin,\cos\}$ .
We use the complete datasets from LSR-Transform and DiffEq equations for both LLM-SR and PySR, except for the reaction-diffusion system. The training dataset for this system contains the solution to a PDE on a $128\times 128\times 160$ spatiotemporal grid, causing significant computational overhead for evaluating expressions on the full dataset. Therefore, we randomly sample 2000 points from the full dataset before running both baselines.
We evaluate all discovered equations from different methods (including baselines and our method) using a GPT-4o-mini language model with the following prompt:
⬇
Given the ground truth mathematical expression A and the hypothesis B, determine if the hypothesis is equivalent to the given ground truth expression up to some error tolerance for the coefficients.
Ground Truth Expression (A): {ground_truth}
Hypothesis Expression (B): {hypothesis}
Let ’ s think step by step. Explain your reasoning and then provide the final answer as:
‘‘‘ json
{{
" reasoning ": " brief step - by - step analysis ",
" answer ": " yes / no "
}}
‘‘‘
Listing 3: Prompt for the LLM-based expression evaluator.
### B.2 Differential Equation Datasets
Table 3: List of differential equation systems in our DiffEq benchmark.
| Bacterial respiration Bar magnets Glider | $\left\{\begin{aligned} \dot{x}&=20-x-\frac{xy}{1+0.5x^{2}}\\ \dot{y}&=10-\frac{xy}{1+0.5x^{2}}\end{aligned}\right.$ $\left\{\begin{aligned} \dot{\theta}&=0.5\sin(\theta-\phi)-\sin(\theta)\\ \dot{\phi}&=0.5\sin(\phi-\theta)-\sin(\phi)\end{aligned}\right.$ $\left\{\begin{aligned} \dot{v}&=-0.05v^{2}-\sin(\theta)\\ \dot{\theta}&=v-\frac{\cos(\theta)}{v}\end{aligned}\right.$ |
| --- | --- |
| Lotka-Volterra | $\left\{\begin{aligned} \dot{x}&=-x^{2}-2xy+3x\\ \dot{y}&=-y^{2}-xy+2y\end{aligned}\right.$ |
| Predator-prey | $\left\{\begin{aligned} \dot{x}&=x\left(4-x-\frac{y}{1+x}\right)\\ \dot{y}&=y\left(\frac{x}{1+x}-0.075y\right)\end{aligned}\right.$ |
| Shear flow | $\left\{\begin{aligned} \dot{\theta}&=\cot(\phi)\cos(\theta)\\ \dot{\phi}&=\sin(\theta)\left(\cos^{2}(\phi)+0.1\sin^{2}(\phi)\right)\end{aligned}\right.$ |
| van der Pol oscillator | $\left\{\begin{aligned} \dot{x}&=10\left(y-\frac{1}{3}(x^{3}-x)\right)\\ \dot{y}&=-\frac{1}{10}x\end{aligned}\right.$ |
| Damped oscillator | $\left\{\begin{aligned} \dot{x}&=-0.1x-y\\ \dot{y}&=x-0.1y\end{aligned}\right.$ |
| Growth | $\left\{\begin{aligned} \dot{x}&=-0.3x+0.1y^{2}\\ \dot{y}&=y\end{aligned}\right.$ |
| Reaction-diffusion | $\left\{\begin{aligned} u_{t}&=u(1-u^{2}-v^{2})+v(u^{2}+v^{2})+0.1(u_{xx}+u_{yy})\\ v_{t}&=v(1-u^{2}-v^{2})-u(u^{2}+v^{2})+0.1(v_{xx}+v_{yy})\end{aligned}\right.$ |
Table 3 lists the 10 differential equation systems we consider for evaluation in this paper. Among them, the first 7 systems come from Strogatz (2001), a textbook for nonlinear dynamical systems. La Cava et al. (2021) proposes to generate data from these systems as a benchmark for SR methods and has incorporated these datasets into the Penn Machine Learning Benchmark (PMLB) (Olson et al., 2017). In our experiments, we use their existing datasets for these systems, each containing 4 solution trajectories of the same ODE system with 100 timesteps.
In addition, we include three systems used in the experiments of Yang et al. (2024): damped oscillator, growth, and reaction-diffusion. We follow their data generation procedure to construct our dataset. The damped oscillator dataset contains 50 trajectories, each with 20 timesteps and an interval $\Delta t=0.2$ . The growth dataset contains 10 trajectories, each with 100 timesteps and an interval $\Delta t=0.02$ . For these two datasets, we split them on the trajectory dimension into 80%:20% for training and testing, respectively. The reaction-diffusion system is originally used in Champion et al. (2019) for testing equation discovery methods. It is governed by two PDEs, posing additional challenges as the partial derivatives inflate the feature space for symbolic regression. We reuse the data provided by Champion et al. (2019), which contains one solution trajectory as a $128\times 128\times 200$ array ( $128\times 128$ spatial grid and $200$ timesteps). We split the data along the time dimension, using the first $160$ timesteps for training and the remaining $40$ steps for testing.
To construct the noisy DiffEq datasets, we add white noise to each state variable, whose scale $\sigma_{i}$ depends on the variance of each state variable in the dataset: $\sigma_{i}=\sigma_{R}\cdot\mathrm{std}(x_{i})$ . We refer to the coefficient $\sigma_{R}$ as the noise level. Then, the targets (time derivatives) are estimated by applying the central difference method to the noisy trajectories. For all systems except reaction-diffusion, we use a noise level of $0.01$ . For reaction-diffusion, we choose a noise level of $0.0001$ , as a larger noise level, together with the inclusion of partial derivatives in this problem, makes it challenging for all methods considered in this paper to discover the correct equations.
## Appendix C Additional Results
### C.1 Long-Term Prediction in DiffEq Systems
<details>
<summary>x5.png Details</summary>
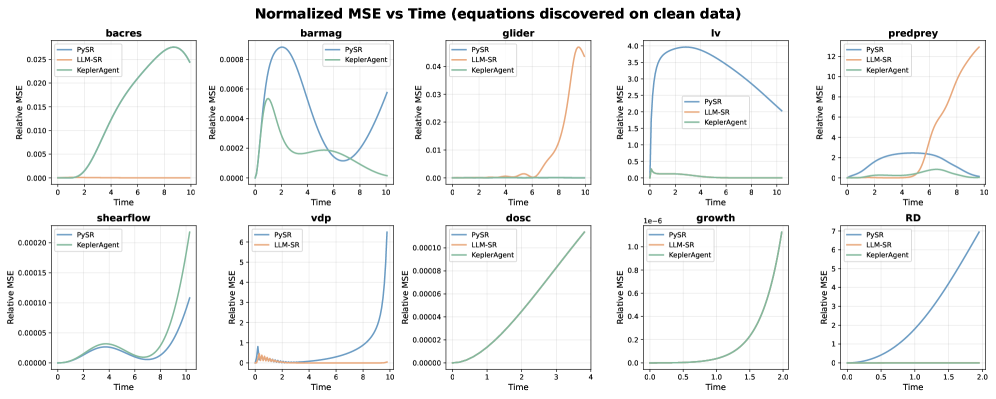
### Visual Description
## Chart Type: Multi-Panel Line Chart (Normalized MSE vs Time)
### Overview
The image displays a 2x5 grid of line charts, each comparing the performance of three different methods (PySR, LLM-SR, KeplerAgent) over time for a specific equation discovery task. The overarching title is "Normalized MSE vs Time (equations discovered on clean data)". Each subplot represents a different target equation or system, identified by a short title. The y-axis represents "Relative MSE" (Mean Squared Error), and the x-axis represents "Time". The charts illustrate how the error of the discovered equations evolves over time for each method.
### Components/Axes
* **Main Title:** "Normalized MSE vs Time (equations discovered on clean data)"
* **Subplot Titles (Top Row, Left to Right):** `bacres`, `barmag`, `glider`, `lv`, `predprey`
* **Subplot Titles (Bottom Row, Left to Right):** `shearflow`, `vdp`, `dosc`, `growth`, `RD`
* **Axes Labels (Consistent across all subplots):**
* **X-axis:** "Time"
* **Y-axis:** "Relative MSE"
* **Legend (Present in each subplot):**
* **PySR:** Blue line
* **LLM-SR:** Orange line
* **KeplerAgent:** Green line
* **Placement:** Typically in the top-left or top-right corner of each subplot's plotting area.
* **Axis Scales:** The scales for both Time and Relative MSE vary significantly between subplots, indicating different magnitudes of error and time ranges for each equation.
### Detailed Analysis
**Subplot 1: `bacres`**
* **Trend:** PySR (blue) shows a steep, concave-down increase in MSE, peaking around Time=8 before slightly declining. LLM-SR (orange) and KeplerAgent (green) remain flat near zero MSE throughout.
* **Key Points:** PySR MSE rises from ~0 to a peak of ~0.025. The other two methods are negligible.
**Subplot 2: `barmag`**
* **Trend:** PySR (blue) has a sharp, narrow peak early (Time~2), then declines and rises again later. LLM-SR (orange) has a broader, lower peak around Time~1.5. KeplerAgent (green) shows a moderate, broad peak around Time~2.
* **Key Points:** PySR peak MSE ~0.0008. LLM-SR peak ~0.0005. KeplerAgent peak ~0.0005.
**Subplot 3: `glider`**
* **Trend:** PySR (blue) and KeplerAgent (green) are flat near zero. LLM-SR (orange) shows a dramatic, exponential-like increase starting around Time=6.
* **Key Points:** LLM-SR MSE rises from ~0 to >0.04 by Time=10.
**Subplot 4: `lv` (Lotka-Volterra)**
* **Trend:** PySR (blue) starts high (~3.8), peaks near Time=3 (~4.0), then declines steadily. LLM-SR (orange) and KeplerAgent (green) are flat near zero.
* **Key Points:** PySR MSE is orders of magnitude higher than the others.
**Subplot 5: `predprey`**
* **Trend:** PySR (blue) has a low, broad hump peaking around Time=4 (~2.0). LLM-SR (orange) shows a sharp, exponential increase starting around Time=6, reaching >12. KeplerAgent (green) is flat near zero.
* **Key Points:** LLM-SR error becomes extremely large. PySR error is moderate. KeplerAgent performs best.
**Subplot 6: `shearflow`**
* **Trend:** PySR (blue) and KeplerAgent (green) follow very similar paths: a small hump around Time=4, a dip, then a sharp rise after Time=8. KeplerAgent's rise is steeper.
* **Key Points:** Both end with MSE ~0.00010-0.00020. The y-axis scale is very small (1e-4).
**Subplot 7: `vdp` (Van der Pol oscillator)**
* **Trend:** PySR (blue) is flat near zero. LLM-SR (orange) shows a sharp, exponential increase starting around Time=8.
* **Key Points:** LLM-SR MSE rises from ~0 to >6 by Time=10.
**Subplot 8: `dosc`**
* **Trend:** PySR (blue) and KeplerAgent (green) are flat near zero. LLM-SR (orange) shows a smooth, accelerating increase.
* **Key Points:** LLM-SR MSE rises from 0 to ~0.00010 by Time=4. The y-axis scale is very small (1e-4).
**Subplot 9: `growth`**
* **Trend:** PySR (blue) and KeplerAgent (green) are flat near zero. LLM-SR (orange) shows a very sharp, exponential increase.
* **Key Points:** LLM-SR MSE rises from 0 to >1.0 by Time=2.0. The y-axis has a multiplier of 1e-6, so values are on the order of 1e-6.
**Subplot 10: `RD` (Reaction-Diffusion?)**
* **Trend:** PySR (blue) shows a smooth, accelerating increase. LLM-SR (orange) and KeplerAgent (green) are flat near zero.
* **Key Points:** PySR MSE rises from 0 to >7 by Time=2.0.
### Key Observations
1. **Method Performance is Highly Equation-Dependent:** No single method (PySR, LLM-SR, KeplerAgent) is universally superior. Their relative performance flips dramatically between different equations.
2. **Catastrophic Failure Modes:** LLM-SR exhibits extreme, exponential error growth in several cases (`glider`, `predprey`, `vdp`, `growth`), suggesting instability or poor generalization for those dynamics.
3. **Stability of KeplerAgent:** KeplerAgent (green) often remains stable with low error (flat line near zero), particularly in `bacres`, `lv`, `predprey`, `dosc`, `growth`, and `RD`. It is rarely the worst performer.
4. **PySR's Variable Performance:** PySR (blue) shows the widest range of behaviors: it can be the worst (`lv`, `RD`), have moderate error (`predprey`), or perform well (`bacres`, `glider`).
5. **Scale Discrepancies:** The y-axis scales differ by orders of magnitude (e.g., `shearflow` max ~2e-4 vs. `predprey` max >12), indicating the inherent difficulty or error magnitude varies greatly across the tested equations.
### Interpretation
This collection of charts serves as a benchmark comparison of symbolic regression or equation discovery algorithms. The data suggests that the choice of algorithm must be carefully matched to the problem domain.
* **Underlying Pattern:** The plots reveal a trade-off between methods that may have higher initial error but remain stable (KeplerAgent) versus methods that can achieve very low error but risk catastrophic divergence for certain equation types (LLM-SR, and to a lesser extent, PySR).
* **Equation Complexity:** The equations where LLM-SR fails spectacularly (`glider`, `predprey`, `vdp`) likely represent more complex, nonlinear dynamical systems. Its success on simpler or different types of equations (`shearflow`, `dosc`) indicates its performance is not uniformly poor.
* **Investigative Insight:** A researcher viewing this would conclude that robustness (KeplerAgent) and peak accuracy (variable across methods) are separate axes of performance. The ideal algorithm would combine the stability of KeplerAgent with the peak accuracy potential shown by the best-performing method in each individual plot. The charts highlight specific failure cases (`predprey` for LLM-SR, `lv` for PySR) that warrant deeper investigation into why those methods struggle with those particular mathematical structures.
</details>
Figure 5: Plotting normalized MSE against time for equations discovered on clean data from PySR, LLM-SR, and our KeplerAgent. A method is not included in a subplot if its discovered equation causes simulation failure (e.g., state variables going to infinity, or other numerical issues).
<details>
<summary>x6.png Details</summary>
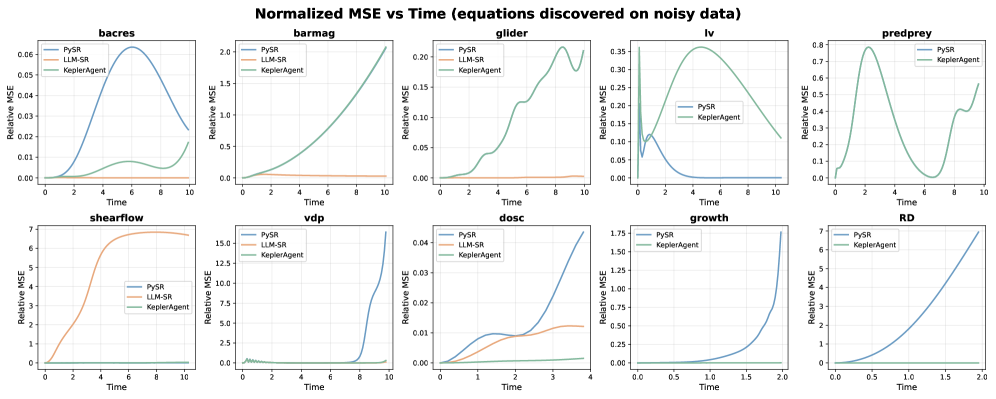
### Visual Description
## Normalized MSE vs Time (Equations Discovered on Noisy Data): Multi-Chart Analysis
### Overview
The image is a composite figure containing ten individual line charts arranged in a 2x5 grid. The overarching title is "Normalized MSE vs Time (equations discovered on noisy data)". Each subplot displays the performance of up to three different symbolic regression methods over time, measured by "Relative MSE" (Mean Squared Error). The charts compare the methods' ability to discover equations from noisy data across ten different dynamical systems or datasets.
### Components/Axes
* **Main Title:** "Normalized MSE vs Time (equations discovered on noisy data)" - centered at the top.
* **Subplot Titles:** Each of the ten charts has a title corresponding to a specific system/dataset: `bacres`, `barmag`, `glider`, `lv`, `predprey`, `shearflow`, `vdp`, `dosc`, `growth`, `RD`.
* **Axes:**
* **X-axis (All Charts):** Label is "Time". The scale is linear, ranging from 0 to 10 for the first eight charts, and 0 to 2 for the last two (`growth`, `RD`).
* **Y-axis (All Charts):** Label is "Relative MSE". The scale is linear but varies significantly in range between charts (e.g., 0-0.06 for `bacres`, 0-15.0 for `vdp`).
* **Legend:** Present in the top-left corner of each subplot. It maps line colors to method names:
* **Blue Line:** `PySR`
* **Orange Line:** `LLM-SR`
* **Green Line:** `KeplerAgent`
* *Note:* Not all methods are present in every chart. The legend only lists the methods plotted in that specific subplot.
### Detailed Analysis
**Chart-by-Chart Breakdown:**
1. **bacres:**
* **Methods:** PySR (Blue), LLM-SR (Orange), KeplerAgent (Green).
* **Trends:** PySR shows a large, smooth peak, rising from ~0 at Time=0 to a maximum of ~0.06 at Time=6, then declining to ~0.02 at Time=10. LLM-SR remains very low and flat near 0.00. KeplerAgent shows a smaller, broader peak, reaching ~0.01 at Time=7-8.
* **Key Values:** PySR Peak MSE ≈ 0.06 @ Time=6.
2. **barmag:**
* **Methods:** PySR (Blue), LLM-SR (Orange), KeplerAgent (Green).
* **Trends:** PySR and LLM-SR are both flat and near zero for the entire duration. KeplerAgent shows a steady, accelerating increase from 0 at Time=0 to ~2.0 at Time=10.
* **Key Values:** KeplerAgent Final MSE ≈ 2.0 @ Time=10.
3. **glider:**
* **Methods:** PySR (Blue), KeplerAgent (Green).
* **Trends:** PySR is flat near zero. KeplerAgent increases with significant fluctuations, showing local peaks and troughs, reaching a maximum of ~0.20 at Time=9.
* **Key Values:** KeplerAgent Peak MSE ≈ 0.20 @ Time=9.
4. **lv (Lotka-Volterra):**
* **Methods:** PySR (Blue), KeplerAgent (Green).
* **Trends:** PySR starts at ~0.10, drops quickly to near zero by Time=2, and stays flat. KeplerAgent rises to a broad peak of ~0.35 at Time=4, then declines to ~0.10 by Time=10.
* **Key Values:** KeplerAgent Peak MSE ≈ 0.35 @ Time=4.
5. **predprey:**
* **Methods:** PySR (Blue), KeplerAgent (Green).
* **Trends:** PySR is flat near zero. KeplerAgent shows a dramatic, sharp peak, rising from 0 to ~0.75 at Time=2, falling to ~0.05 at Time=6, then rising again to ~0.55 by Time=10.
* **Key Values:** KeplerAgent Peak MSE ≈ 0.75 @ Time=2.
6. **shearflow:**
* **Methods:** PySR (Blue), LLM-SR (Orange), KeplerAgent (Green).
* **Trends:** PySR and KeplerAgent are both flat and near zero. LLM-SR shows a rapid, smooth increase from 0, plateauing at a high value of ~6.5 from Time=6 onwards.
* **Key Values:** LLM-SR Plateau MSE ≈ 6.5.
7. **vdp (Van der Pol oscillator):**
* **Methods:** PySR (Blue), LLM-SR (Orange), KeplerAgent (Green).
* **Trends:** LLM-SR and KeplerAgent are flat and near zero. PySR is flat until Time=8, then exhibits an extremely sharp, near-vertical spike, exceeding the chart's upper limit of 15.0 by Time=10.
* **Key Values:** PySR Final MSE > 15.0 @ Time=10 (off-chart).
8. **dosc:**
* **Methods:** PySR (Blue), LLM-SR (Orange), KeplerAgent (Green).
* **Trends:** KeplerAgent is flat near zero. PySR rises steadily to ~0.04 by Time=4. LLM-SR rises more slowly, reaching ~0.015 by Time=4.
* **Key Values:** PySR Final MSE ≈ 0.04 @ Time=4. LLM-SR Final MSE ≈ 0.015 @ Time=4.
9. **growth:**
* **Methods:** PySR (Blue), KeplerAgent (Green).
* **Trends:** PySR is flat near zero. KeplerAgent shows exponential-like growth, starting near 0 and rising sharply to ~1.75 by Time=2.
* **Key Values:** KeplerAgent Final MSE ≈ 1.75 @ Time=2.
10. **RD (Reaction-Diffusion):**
* **Methods:** PySR (Blue), KeplerAgent (Green).
* **Trends:** KeplerAgent is flat near zero. PySR shows a smooth, accelerating curve, rising from 0 to ~7.0 by Time=2.
* **Key Values:** PySR Final MSE ≈ 7.0 @ Time=2.
### Key Observations
* **Method Performance Variability:** No single method is consistently best or worst. Performance is highly dependent on the specific system/dataset.
* **PySR Volatility:** PySR (Blue) shows the most extreme behavior, with both the highest peaks (`predprey`, `vdp`) and perfect flatlines (`barmag`, `glider`). Its failure mode in `vdp` is catastrophic (vertical spike).
* **LLM-SR Stability:** LLM-SR (Orange) is often flat and low (`bacres`, `barmag`, `vdp`, `RD`), suggesting stability, but can also plateau at high error (`shearflow`) or show moderate growth (`dosc`).
* **KeplerAgent Trends:** KeplerAgent (Green) frequently shows increasing error over time (`barmag`, `glider`, `growth`), often with complex, non-monotonic shapes (`lv`, `predprey`). It rarely achieves a flat, near-zero line.
* **Temporal Patterns:** Errors often evolve smoothly over time, but some exhibit sharp transitions (`vdp` spike, `predprey` peak) or plateaus (`shearflow`).
### Interpretation
This composite chart serves as a benchmark comparison of symbolic regression algorithms on noisy dynamical systems. The "Relative MSE vs Time" metric likely measures how well the discovered equations predict the system's state as the simulation progresses from initial conditions.
The data suggests that the **difficulty of the symbolic regression task is highly system-specific**. The starkly different performance profiles imply that each algorithm has inherent biases or strengths suited to different types of mathematical structures or noise characteristics. For instance:
* The catastrophic failure of PySR on `vdp` suggests it may have found an equation that is valid locally but diverges violently.
* KeplerAgent's frequently rising error could indicate a tendency to overfit early data or discover equations that are not robust to long-term integration.
* LLM-SR's occasional high plateaus (`shearflow`) might point to convergence to a stable but incorrect local minimum.
The absence of a universal winner highlights the "no free lunch" theorem in machine learning. A practitioner would need to select or ensemble methods based on prior knowledge of the target system's properties. The visualization effectively communicates that evaluating symbolic regression requires looking beyond a single final error number to understand the *temporal dynamics* of model performance.
</details>
Figure 6: Plotting normalized MSE against time for equations discovered on noisy data from PySR, LLM-SR, and our KeplerAgent.
In addition to the results in Table 2, Figure 5 and 6 show the full error growing curves when we use the discovered equations from different methods for long-term prediction. Specifically, in each subplot, we start from an initial point in a trajectory from the test dataset and use a numerical ODE solver to integrate the discovered equations until the maximum time available in the dataset. Then, the simulated trajectories are compared with the true trajectory in the dataset at each available time step. For equation discovery on the clean data, we observe that KeplerAgent maintains relatively low errors throughout the simulation time span in almost all systems (except in the van der Pol oscillator, where the simulation failed). In comparison, PySR and LLM-SR suffer from high prediction errors in systems like glider, Lotka-Volterra, and predator-prey, and LLM-SR causes simulation failure twice on the shear flow system and the bar magnets system.
In the noisy data regime, KeplerAgent remains relatively robust, performing best or close to best among the three methods in 6 of the 10 systems (predator-prey, shear flow, van der Pol oscillator, damped oscillator, growth, and reaction-diffusion).
### C.2 An Instance of KeplerAgent Reasoning Trace
In this subsection, we inspect a real execution of KeplerAgent on the reaction-diffusion system (described in Table 3) to understand how KeplerAgent reasons and orchestrates different tools to obtain the final equation discovery result. Instead of showing the full outputs of the LLM agent, we provide snapshots of the experience log at each step, interleaved with key parts of the reasoning performed by the agent, which clearly represent the agent’s journey in this discovery problem.
In the first step, the agent learns that the dataset contains a solution trajectory to a PDE. Therefore, it needs to run a symbolic regression tool that is suitable for discovering differential equations from data, and it identifies PySINDy as a good choice. The agent has also considered using symmetry constraints if relevant symmetries can be discovered from the dataset. However, since it doesn’t have any prior knowledge about the symmetries, it starts with a straightforward SINDy approach with default parameters.
⬇
## Experience Log
### Step 1: sindy
** Arguments:**
- data_file: rd_train. h5
** Result:**
- Status: success
- result_type: equation
- equations: [
’0.041* u + 0.035* u * u * u + 1.169* v * v * v + 0.007* u * v * v + 0.277* u * u * v + 0.071* u_yy + 0.065* u_xx ’,
’0.041* v - 1.169* u * u * u + 0.035* v * v * v - 0.277* u * v * v + 0.007* u * u * v + 0.065* v_yy + 0.071* v_xx ’
]
- mape: 70.033%
Given that the equations from the first PySINDy call have not achieved satisfactory fitting (MAPE $=70\$ ), the agent decides to proceed with the following steps: (1) Since the system is governed by PDEs, discovering symmetries could provide valuable insights into the governing equations. This might help in constraining the subsequent symbolic regression process. (2) After discovering symmetries, rerun the SINDy algorithm with the symmetry constraints to see if it improves the fitting of the equations. The next tool call for symmetry discovery reflects the first step in this plan.
⬇
### Step 2: symmetry_discovery
** Arguments:**
- data_file: rd_train. h5
** Result:**
- Status: success
- result_type: symmetry
- lie_generator: [[0.0, -0.678013801574707], [0.680248498916626, 0.0]]
- predictor_loss: 0.009965
- symmetry_loss: 0.002001
The agent notices that the symmetry discovery step provided a Lie generator matrix indicating some underlying symmetries in the system. Both the predictor loss and the symmetry loss were low, which suggests that the system has some structured behavior that can be exploited. Given that the SINDy results did not yield satisfactory equations, and a symmetry discovery result is available, which can help refine the equation search, the agent decides to proceed with the SINDy tool again, incorporating the symmetry constraints obtained from the previous step.
Notably, the agent notices that the Lie generator result in the last tool call is close to the exact form of a rotation generator $[[0,-1];[1,0]]$ . Given that the direct tool result is obtained from numerical optimization and may have some error, and that it is close to a commonly observed structure (rotation symmetry) in the real world, the agent decides to proceed with the exact rotation generator. We comment that this reasoning step is crucial and fills the gap between existing methods for symmetry discovery and symmetry-constrained equation modeling. Existing symmetry discovery methods often rely on gradient-based optimization, which produces numerical results that slightly deviate from the exact solution. Previously, research in symmetry-constrained equation discovery, such as Yang et al. (2024), often relies on humans in the loop to inspect discovered symmetry manually and translate it into an exact solution that makes sense physically, e.g., the rotation generator above. However, in this reasoning step, we show that KeplerAgent is capable of interpreting the numerical results from these tools and making the most reasonable guess about the true answer based on its prior knowledge, thereby fulfilling the entire pipeline from discovering symmetry, processing and interpreting the result, to using this intermediate finding in the downstream equation discovery task, without requiring any human intervention. While we have only incorporated a few tools in the current agent and observed this ability explicitly only for symmetry discovery, we believe that the agent also has the potential to apply this kind of reasoning ability flexibly with other tools.
⬇
### Step 3: sindy
** Arguments:**
- data_file: rd_train. h5
- use_symmetry: True
- lie_generator: [[0, -1], [1, 0]]
** Result:**
- Status: success
- result_type: equation
- equations: [
’1.008* u - 1.017* u * u * u + 0.999* v * v * v - 1.017* u * v * v + 0.999* u * u * v + 0.094* u_yy + 0.094* u_xx ’,
’1.008* v - 0.999* u * u * u - 1.017* v * v * v - 0.999* u * v * v - 1.017* u * u * v + 0.094* v_yy + 0.094* v_xx ’
]
- mape: 15.584%
In this step, with the symmetry constraint enabled, the agent manages to obtain a list of equations with much lower MAPE. However, it is still much above the specified threshold of $0.1\$ (because of the noise in the data, which the agent is not aware since it has chosen not to call the code execution tool for data analysis in the beginning). Therefore, for the next step, the agent makes another attempt to call the PySINDy tool, but with a slightly different configuration.
⬇
### Step 4: sindy
** Arguments:**
- data_file: rd_train. h5
- use_symmetry: True
- lie_generator: [[0, -1], [1, 0]]
- polynomial_degree: 4
** Result:**
- Status: success
- result_type: equation
- equations: [
’1.008* u - 1.017* u * u * u + 0.999* v * v * v - 1.017* u * v * v + 0.999* u * u * v + 0.094* u_yy + 0.094* u_xx ’,
’1.008* v - 0.999* u * u * u - 1.017* v * v * v - 0.999* u * v * v - 1.017* u * u * v + 0.094* v_yy + 0.094* v_xx ’
]
- mape: 15.584%
After step 4, the agent discovers that changing the polynomial degree parameter in SINDy yields the same result. As the error is still above the threshold by a large amount, the agent starts some repetitive attempts to call SINDy with different configurations, e.g., further increasing the polynomial degree, adjusting threshold values, etc, in the hope that the result can be further improved. However, the current MAPE turns out to be the best the agent can obtain from existing tools. In the end, the agent keeps calling tools until the maximum number of iterations (10) is reached, and then returns the discovered equations in step 4 as the final result.
We comment that, while the first few reasoning steps are impressive, the later steps with repetitive tool calls (which we omit here) reveal further room for improvement. For example, the agent should learn more from the previous experience: the fact that increasing the polynomial degree leads to the same equations likely means that a low polynomial degree already suffices for this task, and that further increasing the degree is not helpful at all. Also, the agent needs to be better at navigating the entire toolkit, e.g., making use of the code interpreter to perform noise analysis of the data, or using PySR to explore the possibility of more complex equation forms, instead of sticking to the same tool until the maximum computation budget. We identify these issues here as potential directions for future work.