# Nanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts
**Authors**: Nanbeige LLM Lab, Boss Zhipin
<details>
<summary>x1.png Details</summary>

### Visual Description
Icon/Small Image (195x51)
</details>
## Abstract
We present Nanbeige4.1-3B, a unified generalist language model that simultaneously achieves strong agentic behavior, code generation, and general reasoning with only 3B parameters. To the best of our knowledge, it is the first open-source small language model (SLM) to achieve such versatility in a single model. To improve reasoning and preference alignment, we combine point-wise and pair-wise reward modeling, ensuring high-quality, human-aligned responses. For code generation, we design complexity-aware rewards in Reinforcement Learning, optimizing both correctness and efficiency. In deep search, we perform complex data synthesis and incorporate turn-level supervision during training. This enables stable long-horizon tool interactions, allowing Nanbeige4.1-3B to reliably execute up to 600 tool-call turns for complex problem-solving. Extensive experimental results show that Nanbeige4.1-3B significantly outperforms prior models of similar scale, such as Nanbeige4-3B-2511 and Qwen3-4B, even achieving superior performance compared to much larger models, such as Qwen3-30B-A3B. Our results demonstrate that small models can achieve both broad competence and strong specialization simultaneously, redefining the potential of 3B parameter models. The model checkpoint is available at https://huggingface.co/Nanbeige/Nanbeige4.1-3B
<details>
<summary>figures/model_performance_comparison.png Details</summary>
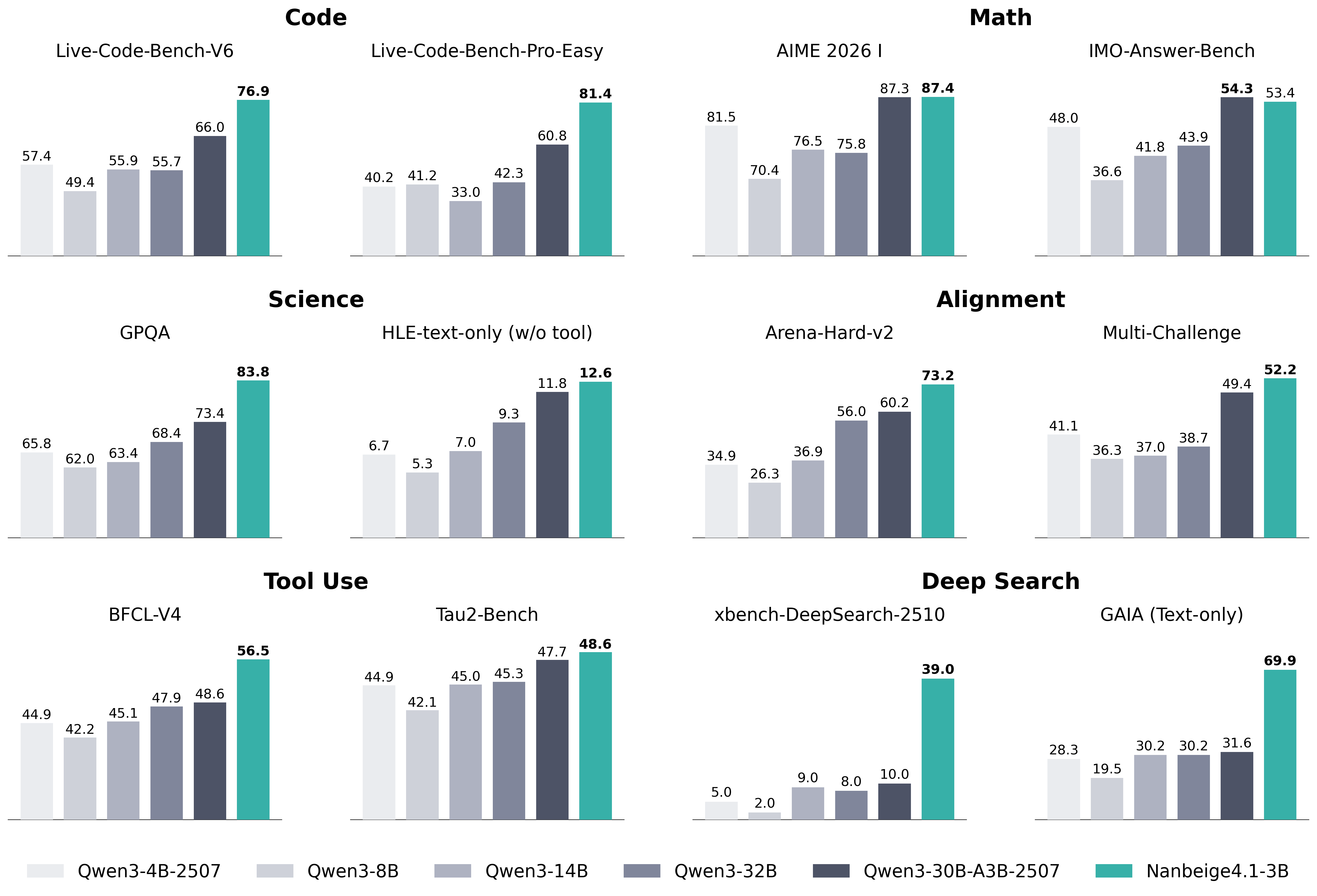
### Visual Description
## Bar Chart Composite: AI Model Benchmark Performance
### Overview
The image is a composite of 12 bar charts organized into six thematic categories, comparing the performance of six different AI models across various technical benchmarks. The charts are arranged in a 3x4 grid (three rows, four columns). Each individual chart represents a specific benchmark, with bars showing the performance score (likely a percentage or normalized metric) for each model. The models are consistently color-coded across all charts, with a legend provided at the bottom.
### Components/Axes
* **Legend (Bottom Center):** A horizontal legend maps colors to model names. From left to right:
* Lightest Grey: `Qwen3-4B-2507`
* Light Grey: `Qwen3-8B`
* Medium Grey: `Qwen3-14B`
* Dark Grey: `Qwen3-32B`
* Darkest Grey/Blue: `Qwen3-30B-A3B-2507`
* Teal/Green: `Nanbeige4.1-3B`
* **Chart Categories (Row Headers):** The six main categories are labeled in bold at the top of their respective chart groups:
* **Code** (Top Left)
* **Math** (Top Right)
* **Science** (Middle Left)
* **Alignment** (Middle Right)
* **Tool Use** (Bottom Left)
* **Deep Search** (Bottom Right)
* **Individual Benchmark Titles:** Each of the 12 charts has a specific title above its bars.
* **Y-Axis:** Not explicitly labeled with a title or scale. The numerical value for each bar is printed directly above it, serving as the data point.
* **X-Axis:** Represents the different models for each benchmark. The model order is consistent within each chart, matching the legend order from left to right.
### Detailed Analysis
Performance scores for each model across all 12 benchmarks are extracted below. The trend within each chart is described first, followed by the precise data points.
**1. Code Category**
* **Live-Code-Bench-V6:** A generally increasing trend from left to right, with a significant jump for the final two models.
* Qwen3-4B-2507: 57.4
* Qwen3-8B: 49.4
* Qwen3-14B: 55.9
* Qwen3-32B: 55.7
* Qwen3-30B-A3B-2507: 66.0
* Nanbeige4.1-3B: 76.9
* **Live-Code-Bench-Pro-Easy:** A clear upward trend, with Nanbeige4.1-3B showing a dominant lead.
* Qwen3-4B-2507: 40.2
* Qwen3-8B: 41.2
* Qwen3-14B: 33.0
* Qwen3-32B: 42.3
* Qwen3-30B-A3B-2507: 60.8
* Nanbeige4.1-3B: 81.4
**2. Math Category**
* **AIME 2026 I:** A U-shaped trend, with the first model scoring high, a dip in the middle models, and the highest scores from the last two models.
* Qwen3-4B-2507: 81.5
* Qwen3-8B: 70.4
* Qwen3-14B: 76.5
* Qwen3-32B: 75.8
* Qwen3-30B-A3B-2507: 87.3
* Nanbeige4.1-3B: 87.4
* **IMO-Answer-Bench:** A steady upward trend, with the final two models performing significantly better.
* Qwen3-4B-2507: 48.0
* Qwen3-8B: 36.6
* Qwen3-14B: 41.8
* Qwen3-32B: 43.9
* Qwen3-30B-A3B-2507: 54.3
* Nanbeige4.1-3B: 53.4
**3. Science Category**
* **GPQA:** A consistent upward trend from left to right.
* Qwen3-4B-2507: 65.8
* Qwen3-8B: 62.0
* Qwen3-14B: 63.4
* Qwen3-32B: 68.4
* Qwen3-30B-A3B-2507: 73.4
* Nanbeige4.1-3B: 83.8
* **HLE-text-only (w/o tool):** A clear upward trend, with all scores being relatively low (single digits to low teens).
* Qwen3-4B-2507: 6.7
* Qwen3-8B: 5.3
* Qwen3-14B: 7.0
* Qwen3-32B: 9.3
* Qwen3-30B-A3B-2507: 11.8
* Nanbeige4.1-3B: 12.6
**4. Alignment Category**
* **Arena-Hard-v2:** A strong upward trend, with the final model having a substantial lead.
* Qwen3-4B-2507: 34.9
* Qwen3-8B: 26.3
* Qwen3-14B: 36.9
* Qwen3-32B: 56.0
* Qwen3-30B-A3B-2507: 60.2
* Nanbeige4.1-3B: 73.2
* **Multi-Challenge:** A gradual upward trend, with the final model leading.
* Qwen3-4B-2507: 41.1
* Qwen3-8B: 36.3
* Qwen3-14B: 37.0
* Qwen3-32B: 38.7
* Qwen3-30B-A3B-2507: 49.4
* Nanbeige4.1-3B: 52.2
**5. Tool Use Category**
* **BFCL-V4:** A steady upward trend.
* Qwen3-4B-2507: 44.9
* Qwen3-8B: 42.2
* Qwen3-14B: 45.1
* Qwen3-32B: 47.9
* Qwen3-30B-A3B-2507: 48.6
* Nanbeige4.1-3B: 56.5
* **Tau2-Bench:** A relatively flat trend for the first four models, followed by a slight increase for the last two.
* Qwen3-4B-2507: 44.9
* Qwen3-8B: 42.1
* Qwen3-14B: 45.0
* Qwen3-32B: 45.3
* Qwen3-30B-A3B-2507: 47.7
* Nanbeige4.1-3B: 48.6
**6. Deep Search Category**
* **xbench-DeepSearch-2510:** A very low, flat trend for the first five models, with a dramatic, isolated spike for the final model.
* Qwen3-4B-2507: 5.0
* Qwen3-8B: 2.0
* Qwen3-14B: 9.0
* Qwen3-32B: 8.0
* Qwen3-30B-A3B-2507: 10.0
* Nanbeige4.1-3B: 39.0
* **GAIA (Text-only):** A U-shaped trend, with the first model scoring moderately, a dip for the second, and a strong upward trend for the remaining models, culminating in a dominant score for the final model.
* Qwen3-4B-2507: 28.3
* Qwen3-8B: 19.5
* Qwen3-14B: 30.2
* Qwen3-32B: 30.2
* Qwen3-30B-A3B-2507: 31.6
* Nanbeige4.1-3B: 69.9
### Key Observations
1. **Dominant Model:** The `Nanbeige4.1-3B` model (teal bar) is the top performer in **11 out of 12** benchmarks. Its lead is particularly extreme in `xbench-DeepSearch-2510` (39.0 vs. next best 10.0) and `GAIA (Text-only)` (69.9 vs. next best 31.6).
2. **Strong Runner-up:** The `Qwen3-30B-A3B-2507` model (darkest grey/blue) is consistently the second-best performer, often closely trailing `Nanbeige4.1-3B`.
3. **Performance Tiers:** A clear hierarchy is visible: `Nanbeige4.1-3B` > `Qwen3-30B-A3B-2507` > `Qwen3-32B` > `Qwen3-14B` ≈ `Qwen3-4B-2507` > `Qwen3-8B`. The `Qwen3-8B` model is frequently the lowest or among the lowest performers.
4. **Benchmark Difficulty:** The `HLE-text-only` and `xbench-DeepSearch-2510` benchmarks yield very low scores for most models, suggesting they are significantly more challenging or measure a capability where most models struggle.
5. **Anomaly:** The `AIME 2026 I` benchmark shows the smallest performance gap between the top two models (87.3 vs. 87.4), indicating near-parity on this specific math task.
### Interpretation
This composite chart provides a comparative snapshot of AI model capabilities across a diverse set of technical and reasoning tasks. The data strongly suggests that the `Nanbeige4.1-3B` model represents a significant advancement, demonstrating superior performance across code generation, mathematical reasoning, scientific question-answering, alignment evaluations, tool use, and deep search tasks.
The consistent underperformance of the `Qwen3-8B` model relative to its larger counterparts (`14B`, `32B`) aligns with the general expectation that model scale correlates with capability. However, the exceptional performance of `Nanbeige4.1-3B`—which, based on its name, may not be the largest model—hints at potential architectural or training efficiencies that allow it to outperform larger models in the Qwen3 series.
The dramatic outliers in the "Deep Search" category are particularly noteworthy. They suggest that `Nanbeige4.1-3B` possesses a unique and highly effective capability for complex information retrieval and synthesis that the other models lack almost entirely. This could indicate a specialized training focus or a breakthrough in that specific domain.
Overall, the visualization serves as a benchmark report card, positioning `Nanbeige4.1-3B` as the current leader across this broad evaluation suite, with `Qwen3-30B-A3B-2507` as a strong competitor. The results would be critical for researchers and developers in selecting models for specific applications, especially those requiring deep search, advanced coding, or complex reasoning.
</details>
Figure 1: Performance of Nanbeige4-3B-Thinking vs. Qwen model series.
## 1 Introduction
Recent advances in small language models (SLMs) have demonstrated that compact models can achieve impressive performance on specialized tasks such as mathematical reasoning or code generation yang2025nanbeige4 ; yan2026distribution . Despite the small size, these models perform competitively by leveraging innovations in architecture, training data, and training algorithm, making them highly effective in practical applications.
However, most existing SLMs exhibit fragmented capabilities: reasoning-focused models often struggle with long-horizon interactions (e.g., deep search) xu2025tiny , while code or agent specialized models typically lack robust general reasoning abilities, such as creative writing or human preference alignment zhu2026re . Consequently, building a truly unified generalist model at the 3B scale remains an open challenge and a practical question is raised: How far can a 3B model be pushed as a generalist without compromising its existing strengths?
In this work, we present Nanbeige4.1-3B, a generic small language model that is remarkably powerful in reasoning, coding, and agentic behaviors, Built upon Nanbeige4-3B yang2025nanbeige4 . For general reasoning, we extend our previous pair-wise preference modeling by incorporating point-wise reward signals, ensuring that responses are both strong in isolation and preferred under direct comparison. For code generation, we move beyond correctness as the sole objective and explicitly reward algorithmic efficiency, encouraging solutions that are not only functionally correct but also computationally efficient. For agentic behavior, we emphasize long-horizon planning. We construct high-quality training data through Wiki-graph random walks and define rewards at both the interaction (turn) and full-trajectory levels, allowing the model to receive credit for planning and execution over hundreds of steps. Throughout training, we employ careful SFT data mixing and multi-stage reinforcement learning wang2025nemotron to maintain balance across these domains.
Through the aforementioned approach, we have trained a model with an exceptionally broad and stable capability profile. Across reasoning and coding tasks, Nanbeige4.1-3B consistently surpasses existing open-source SLMs (e.g., Qwen3-4B and Qwen3-8B) and shows clear improvements over Nanbeige4-3B-Thinking-2511. More notably, Nanbeige4.1-3B exhibits deep-search and long-horizon agentic behavior rarely observed in general-purpose small language models. While models such as Qwen3-4B and Qwen3-8B fail to sustain meaningful exploration beyond a few turns, Nanbeige4.1-3B reliably solves complex search-oriented tasks through extended tool interaction. In this regime, a generalist 3B model attains deep-search capability comparable to that of specialized search-oriented models at the tens-of-billions scale, and approaches the search performance of 100B+ general-purpose large models. These results indicate that long-horizon agency can be achieved in compact generalist models when training objectives and credit assignment are properly aligned.
We open-source Nanbeige4.1-3B to support research into efficient, agent-capable language models. Beyond the checkpoint itself, we hope this release contributes to the community’s understanding of how to jointly train reasoning, coding, and long-horizon behaviors under strict capacity constraints.
## 2 Methods
In this section, we present the methodology used to equip a compact 3B model with broad generalist capabilities. We first describe how we individually optimize the model for general reasoning, long-horizon search (agentic behavior), and code generation, focusing on the design of training signals and reward structures tailored to each capability. We then detail how these heterogeneous objectives are integrated through data mixing and multi-stage training, enabling the model to retain domain-specific strengths while emerging as a unified general model under strict capacity constraints.
### 2.1 General Abilities
In this section, we elaborate on the optimization of Nanbeige4.1’s general capabilities. Our improvements focus on two key aspects: refining the data construction strategies in the SFT phase, and upgrading the General RL training paradigm through a progressive integration of Point-wise and Pair-wise reinforcement learning.
#### 2.1.1 SFT
Nanbeige4.1-3B is built upon the Nanbeige4-3B-Base yang2025nanbeige4 with an enhanced SFT recipe, focusing on data distribution, length scaling, and training data quality.
First, we redesign the SFT data mixture. Compared to the previous Nanbeige4-3B-2511 version, we increase the proportion of code-related data and introduce a higher ratio of challenging problems in mathematics and general domains. This shift encourages stronger reasoning depth and improves robustness on difficult benchmarks.
Second, we extend the context length beyond the previous two-stage curriculum (32k $→$ 64k) by introducing a third stage at 256k tokens to better support complex reasoning and long-horizon scenarios. In the final 256k stage, we adopt a specialized data mixture designed to strengthen agentic and reasoning capabilities, consisting of code (27%), deep-Search (26%), STEM (23%), tool-use (13%), and general domains (10%).
Third, we further optimize the Solution Refinement and Chain-of-Thought (CoT) Reconstruction framework originally introduced in Nanbeige4-3B-2511. Specifically, we scale up the number of refinement iterations in the Solution Refinement loop, allowing stronger critique–revision cycles to produce higher-quality final solutions. In addition, we train a more capable CoT Reconstruction model to generate cleaner and more faithful reasoning traces from refined answers.
As shown in Table 1, these improvements result in substantial gains across benchmarks. Nanbeige4.1-3B-SFT demonstrates consistent improvements in coding, mathematics, and alignment metrics, laying a stronger foundation for subsequent reinforcement learning stages.
Table 1: Performance Uplift from Nanbeige4-3B-SFT to Nanbeige4.1-3B-SFT
| Domain | Benchmark | Nanbeige4-3B-SFT | Nanbeige4.1-3B-SFT | $Δ$ |
| --- | --- | --- | --- | --- |
| Code | LCB V6 | 45.5 | 62.0 | +16.5 |
| LCB Pro Medium | 1.8 | 22.8 | +21.0 | |
| Math | Hmmt Nov | 60.7 | 74.3 | +13.6 |
| Imo-Answer-Bench | 34.8 | 48.9 | +14.1 | |
| Alignment | Arena-Hard V2 | 45.5 | 60.2 | +14.7 |
| Multi-Challenge | 42.6 | 44.4 | +1.8 | |
#### 2.1.2 Point-wise RL
After SFT, we still observe some degradation issues in Nanbeige4.1-3B-SFT, such as repetition and redundant thinking, which have also been reported in prior work feng2026paceprefixprotecteddifficultyawarecompression . To address these issues and establish a more stable foundation for RL, we introduce a point-wise reinforcement learning stage.
We train a general reward model to evaluate rollout responses, following prior work wang2025nemotron . The model is trained on curated large-scale human preference data. We found that the trained reward model naturally suppresses overly redundant, repetitive, and low-readability answers. We then perform GRPO shao2024deepseekmath to optimize Nanbeige4.1-3B-SFT, sampling 8 rollouts per prompt and using the general reward model to score each response as the training signal.
With point-wise RL, we significantly reduce formatting errors and redundant reasoning. On LiveCodeBench-v6, the point-wise RL greatly improves length stability, reducing overlong truncation from 5.27% to 0.38%. As shown in Table 2, it also advances Arena-Hard V2 from 60.2 to 66.6, with the hard-prompt subset improving from 46.1 to 54.1. These gains are reflected in more consistent, well-structured outputs and high-quality code presentation.
#### 2.1.3 Pair-wise RL
Although the Point-wise RL training provides effective alignment signals, the amount of high-quality preference data is limited, which constrains further improvement. To address this, we introduce Pair-wise RL to fully leverage preference information from strong–weak model comparisons and further enhance model performance.
We train a pair-wise reward model on paired comparison data spanning code generation and LMArena-style conversations (single-turn and multi-turn). We generate response pairs with a strong model and a weak model, then apply the same checklist filtering strategy as Nanbeige4 to derive reliable win–loss labels yang2025nanbeige4 . Following the framework xu2025unified , we mitigate position bias by adding a swap-consistency regularizer, defined as the mean squared error between the predicted reward difference for a response pair and the negated reward difference for the swapped pair.
We then run Pair-wise RL by formulating the reward as a binary outcome based on whether the generated rollout outperforms the reference answer. For multi-turn scenarios, we concatenate the full dialogue history into the pairwise reward model’s input.
As shown in 2, Nanbeige4.1-3B achieves comprehensive performance breakthroughs after Pair-wise RL. By deeply exploiting contextual information in multi-turn dialogues, Alignment metrics show significant gains, with Multi-Challenge increasing from 47.72 to 55.14. Additionally, Pair-wise RL notably boosts performance on the Arena-Hard V2 benchmark, with an improvement from 66.6 to 73.8, showcasing its effectiveness in refining alignment. These results confirm that Pairwise RL sharpens preference boundaries, providing the informative supervision signals needed for overall improvement across various benchmarks.
Table 2: Improvements via General RL Training (SFT $→$ Point-wise RL $→$ Pair-wise RL)
| Domain | Benchmark | SFT | Point-wise RL | $Δ$ | Pair-wise RL | $Δ$ |
| --- | --- | --- | --- | --- | --- | --- |
| Code | LCB V6 | 62.0 | 66.0 | +4.0 | 65.6 | -0.4 |
| Alignment | Arena-Hard V2 | 60.2 | 66.6 | +6.4 | 73.8 | +7.2 |
| Multi-Challenge | 44.4 | 47.7 | +3.3 | 55.1 | +7.4 | |
### 2.2 Deep Search Ability
In this section, we primarily focus on enhancing the deep search capabilities of our model, specifically on the data pipeline and the staged training process. Deep search is defined as a retrieval-centric task that operates under complex multi-hop reasoning and extremely long-context settings. In this paradigm, models iteratively interact with the environment to acquire information, enabling them to solve challenging search problems.
#### 2.2.1 Data Construction
To enhance the search capability of our base model, we construct a large-scale, complex search dataset, which includes a substantial number of multi-hop QA pairs derived from entity-relation graphs built upon Wikipedia, as well as high-quality long-range search trajectories that have undergone multi-stage rigorous filtering. The entire data construction pipeline is illustrated in Figure 2. To facilitate further research, we have open-sourced the constructed dataset on HuggingFace https://huggingface.co/datasets/Nanbeige/ToolMind-Web-QA.
<details>
<summary>x2.png Details</summary>
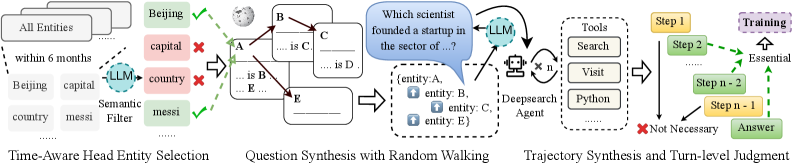
### Visual Description
## Diagram: LLM-Based Entity Selection and Question Synthesis Pipeline
### Overview
The image is a technical flowchart illustrating a multi-stage process for using Large Language Models (LLMs) to select relevant entities from a knowledge base and synthesize complex questions through a random walking graph method. The process culminates in generating a reasoning trajectory to arrive at an answer, with a judgment step to identify essential reasoning paths.
### Components/Axes
The diagram is organized into three main sequential blocks, flowing from left to right, connected by arrows.
**1. Left Block: Time-Aware Head Entity Selection**
* **Input:** A stack of documents labeled "All Entities".
* **Sub-components:**
* A list of example entities: "within 6 months", "Beijing", "capital", "country", "mesi".
* An LLM icon labeled "Semantic Filter".
* A filtered output list with validation marks:
* "Beijing" (Green Checkmark ✓)
* "capital" (Red Cross ✗)
* "country" (Red Cross ✗)
* "mesi" (Green Checkmark ✓)
* **Label:** "Time-Aware Head Entity Selection" is written below this block.
**2. Middle Block: Question Synthesis with Random Walking**
* **Input:** The selected entities from the previous block (e.g., "Beijing", "mesi").
* **Core Component:** A knowledge graph fragment with nodes (A, B, C, D, E) and labeled edges (e.g., "is", "is B", "is D").
* **Process:** An LLM icon is shown interacting with this graph. A speech bubble from the LLM contains the template question: "Which scientist founded a startup in the sector of ...?".
* **Output:** A structured question template box listing: "(entity: A, entity: B, entity: C, entity: D, entity: E)".
* **Label:** "Question Synthesis with Random Walking" is written below this block.
**3. Right Block: Trajectory Synthesis and Turn-level Judgment**
* **Input:** The synthesized question.
* **Core Components:**
* A "Deepsearch Agent" icon.
* A "Tools" box listing: "Search", "Visit", "Python".
* A sequence of steps: "Step 1", "Step 2", ... "Step n-2", "Step n-1".
* A branching path:
* A green dashed arrow labeled "Essential" connects "Step 2" to "Step n-1".
* A red "X" and the label "Not Necessary" points to the linear path from "Step 2" to "Step n-2".
* The final output box: "Answer".
* **Label:** "Trajectory Synthesis and Turn-level Judgment" is written below this block.
### Detailed Analysis
The diagram details a specific pipeline:
1. **Entity Filtering:** An LLM acts as a semantic filter on a raw list of entities, selecting contextually relevant ones (e.g., "Beijing", "mesi") while discarding generic terms (e.g., "capital", "country"). The "Time-Aware" label suggests temporal context is a filtering criterion.
2. **Question Generation:** Using the selected entities, the system performs a "random walk" on a knowledge graph to discover relationships. An LLM then uses these discovered relationships to construct a complex, multi-entity question (e.g., about a scientist, a startup, and a sector).
3. **Answer Synthesis & Evaluation:** A "Deepsearch Agent" uses tools (Search, Visit, Python) to generate a multi-step reasoning trajectory to answer the question. A "Turn-level Judgment" process evaluates this trajectory, identifying which steps ("Step 2", "Step n-1") are "Essential" to the final answer and which intermediate steps ("Step n-2") are "Not Necessary".
### Key Observations
* **Hybrid System:** The process combines symbolic AI (knowledge graphs, random walking) with neural AI (LLMs for filtering, synthesis, and judgment).
* **Focus on Efficiency:** The "Turn-level Judgment" explicitly aims to distill a long reasoning chain into its essential components, likely for training or evaluation purposes.
* **Tool-Augmented Generation:** The agent is not just a language model but is equipped with external tools ("Search", "Visit", "Python") to gather information.
* **Visual Coding:** Green checkmarks/dashed lines indicate selection or essential paths. Red crosses indicate rejection or non-essential paths.
### Interpretation
This diagram outlines a sophisticated framework for **automated question generation and complex reasoning**. It demonstrates a method to move from a broad knowledge base to a specific, multi-faceted question and then to a verified answer.
* **Purpose:** The system appears designed for creating high-quality training data for reasoning models or for building an agent that can answer complex, multi-hop questions by dynamically synthesizing queries and evaluating its own reasoning process.
* **Relationships:** The flow is strictly linear and causal: better entity selection leads to better question synthesis, which in turn requires and produces a more structured reasoning trajectory. The final judgment step creates a feedback loop by identifying the core logical steps, which could be used to train more efficient models.
* **Notable Pattern:** The most significant insight is the **"Essential" vs. "Not Necessary"** distinction. This implies the system is not just generating answers but is performing meta-cognition—analyzing its own thought process to isolate the critical reasoning steps. This is a key technique for improving the interpretability and efficiency of AI reasoning.
* **Underlying Principle:** The pipeline embodies a "generate-then-filter" or "expand-then-contract" pattern common in advanced AI: first, use the LLM's generative power to create a rich set of possibilities (entities, questions, reasoning steps), then use structured methods (semantic filtering, graph walking, turn-level judgment) to select the most coherent and essential path.
</details>
Figure 2: A data construction pipeline for deep search, including complex multi-hop QA sampling and the synthesis of long-horizon reasoning trajectories.
Temporal-Aware Head Entity Selection and Question Synthesis with Random Walking. To ensure the timeliness and complexity of the synthesized QA data, we first extract informative head entities from Wikipedia that have been updated within the past six months. Following the framework of yang2025toolmind , we construct an entity-relation graph and perform conditional random walks to extract relational paths of a predefined length. These chains, along with their detailed temporal contexts, are then fed into a robust LLM to synthesize intricate questions.
Trajectory Synthesis and Turn-level Judgment. To synthesize search trajectories, we employ multiple agent frameworks to address the generated queries, sampling a diverse set of reasoning paths. These trajectories are subsequently mapped into multi-turn tool-invocation sequences from a unified agent perspective. To further guarantee the quality of the synthesized data, we implement a rigorous turn-level judgment mechanism. Specifically, we employ a critic model to evaluate each step of the interaction based on three dimensions: logical soundness, tool-call accuracy, and informational gain. Any turn that fails to meet these criteria does not participate in model training or provide a negative reward for the model. This fine-grained filtering ensures that the final trajectories provide a high-fidelity signal for supervised fine-tuning and preference alignment.
#### 2.2.2 Preliminary Performance
To empirically validate the effectiveness of our proposed data construction pipeline, we conduct a controlled experiment using Nanbeige4-3B-2511 as the base model. Specifically, we train the model exclusively on the synthetic multi-hop QA and search trajectories generated via the methods described in Section 2.2.1, intentionally excluding other open-source data. We evaluate our model on a range of long-horizon benchmarks, including GAIA mialon2023gaiabenchmarkgeneralai , BrowseComp wei2025browsecomp , BrowseComp-ZH zhou2025browsecomp , Humanity’s Last Exam (HLE) phan2025humanitysexam , SEAL-0 pham2025sealqaraisingbarreasoning , xBench-DeepSearch-2505 chen2025xbenchtrackingagentsproductivity , and xBench-DeepSearch-2510 chen2025xbenchtrackingagentsproductivity . For HLE and GAIA, we only test and report the results of the text-only subset. In addition, HuggingFace has been explicitly disabled in these tools.
The model is evaluated within the Mindflow framework https://github.com/MiroMindAI/MiroThinker, employing a suite of tools: Serper https://serper.dev/ for environment search, Jina https://jina.ai/ for webpage content extraction, and E2B Sandbox https://e2b.dev/ as the secure sandbox environment. A comparative analysis of our results across specific stages is presented below:
Table 3: Preliminary evaluation results on search benchmarks for the synthetic QA.
| Benchmark | GAIA (text-only) | Browse Comp | Browse Comp-ZH | HLE (text-only) | SEAL-0 | xBench DeepSearch-05 | xBench DeepSearch-10 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Nanbeige4-3B-2511 | 19.4 | 0.8 | 3.1 | 13.9 | 12.6 | 33.0 | 11.0 |
| + Synthetic QA | 58.3 | 14.4 | 30.1 | 22.4 | 36.0 | 76.0 | 30.0 |
The quantitative results are summarized in Table 3. The incorporation of our synthetic data yields a significant performance improvement across all benchmarks compared to the base model. Notably, the model achieves a substantial leap on xBench-DeepSearch-2505 (improving from 33.0 to 76.0), demonstrating that our data synthesis pipeline effectively endows the model with robust multi-hop reasoning and long-context search abilities.
### 2.3 Coding Ability
In this section, we primarily focus on enhancing the coding capabilities of our base model, including the data construction pipeline, staged training strategy, and evaluation settings.
#### 2.3.1 Judge System
We build a unified judge system that is shared across SFT data construction, RL data construction, and subsequent RL training and evaluation. It combines a multi-language sandbox for execution-based correctness checking with a dedicated instruct judge model for time-complexity comparison. The instruct model is specifically trained for fast complexity assessment in RL settings, enabling efficient online comparison between the predicted complexity of model-generated solutions and the reference optimal bound.
#### 2.3.2 Data Construction
Our data construction consists of two components: SFT data construction with our judge system to filter time-optimal solutions, and RL data construction with on-policy difficulty filtering to improve sample efficiency.
SFT Data Construction.
Our SFT data construction uses this judge system to assess solution quality from two key aspects: (1) functional correctness by executing the program in a sandbox, and (2) time complexity by combining execution signals with model-based complexity analysis. During data generation, we sample multiple candidate solutions per problem. The candidates are then verified by the judge system, and we keep those that are judged to be time-optimal (or among the best complexity class) for the given problem.
RL Data Construction.
Each RL sample contains a problem statement, test cases, a time-complexity-optimal solution, and the corresponding optimal complexity label. The optimal solution and complexity are obtained by prompting multiple strong LLMs and employing a strong LLM to synthesize the candidates into a single best solution, which are then used as supervision signals for reward shaping and difficulty control.
In both stages, we perform on-policy filtering by running multiple rollouts per problem ( $n=8$ ) and selecting samples based on how many rollouts meet a stage-specific criterion. In Stage 1, we use a difficulty-based criterion: a problem is retained if the policy can solve it in a moderate number of rollouts (we keep problems with k in [1, 5] successful solves out of 8). In Stage 2, we use a complexity-based criterion: we count how many rollouts produce solutions whose estimated time complexity satisfies the target bound, and retain problems with k in [1,5] complexity-satisfying rollouts out of 8.
#### 2.3.3 Staged Training Process
Starting from the General-RL checkpoint, we further conduct two stages of code RL. In Stage 1, we optimize for solution correctness using a pass-rate reward, defined as the fraction of test cases passed for each problem. In Stage 2, after the policy can reliably solve problems, we additionally encourage higher-quality solutions by introducing a time-complexity reward only when all test cases are passed; otherwise the reward reduces to correctness-only signals. Specifically, the judge system provides online feedback by comparing the model’s output against the reference optimal complexity and checking whether the generated solution matches the reference optimal solution when applicable. As illustrated in Fig. 3, the time-complexity reward is activated only for fully correct solutions.
$$
R=\begin{cases}R_format+R_correctness,&PassRate<1,\\
R_format+R_correctness+R_time,&PassRate=1.\end{cases}
$$
As a concrete illustration, Appendix C presents LiveCodeBench case studies comparing model outputs before vs. after the time-reward stage, highlighting typical complexity-class improvements.
<details>
<summary>x3.png Details</summary>
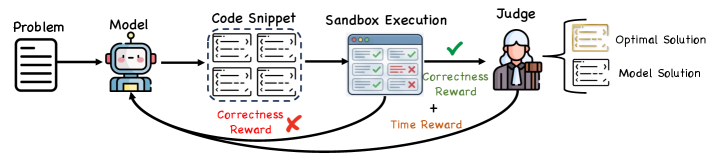
### Visual Description
## Diagram: Reinforcement Learning Feedback Loop for Code Generation
### Overview
The image is a flowchart illustrating a reinforcement learning process for training a code-generation model. It depicts a cyclical workflow where a model generates code solutions to problems, which are then executed and evaluated, with feedback (rewards) sent back to the model to improve future performance.
### Components/Axes
The diagram is organized horizontally from left to right, representing a sequential process, with feedback loops returning to the model.
**Main Components (Left to Right):**
1. **Problem**: Represented by a document icon on the far left.
2. **Model**: Represented by a friendly robot icon.
3. **Code Snippet**: A dashed box containing four smaller rectangles, each representing a generated code solution.
4. **Sandbox Execution**: Represented by a browser window icon. Inside, there are two columns of results: three green checkmarks (✓) and two red X marks (✗).
5. **Judge**: Represented by a human figure icon.
6. **Output Solutions**: Two document icons on the far right:
* **Optimal Solution** (top)
* **Model Solution** (bottom)
**Feedback Loops & Labels:**
* **Correctness Reward (Red)**: A red arrow originates from the "Sandbox Execution" window and points back to the "Model." It is labeled "Correctness Reward" in red text and is accompanied by a large red "✗" symbol, indicating a negative reward or penalty for incorrect code.
* **Correctness Reward (Green)**: A green arrow originates from the "Judge" and points back to the "Model." It is labeled "Correctness Reward" in green text and is accompanied by a large green "✓" symbol, indicating a positive reward for correct code.
* **Time Reward**: An orange arrow originates from the "Sandbox Execution" window and points to the "Judge." It is labeled "Time Reward" in orange text.
### Detailed Analysis
The process flow is as follows:
1. A **Problem** is fed into the **Model**.
2. The **Model** generates multiple **Code Snippet** candidates.
3. These snippets are sent to the **Sandbox Execution** environment for testing. The results show a mixed outcome: some tests pass (green checkmarks), while others fail (red X's).
4. The execution results provide two feedback signals:
* A **Correctness Reward** (red, negative) is sent directly back to the model based on the pass/fail results.
* A **Time Reward** (orange) is sent to the **Judge**, likely based on the execution speed or efficiency of the code.
5. The **Judge** evaluates the solutions, presumably considering both correctness and efficiency (the Time Reward). The Judge then produces a final evaluation.
6. The Judge's evaluation results in a second **Correctness Reward** (green, positive) being sent back to the model.
7. The final output of the process is a selection between an **Optimal Solution** and the **Model Solution**.
### Key Observations
* **Dual Reward System**: The model receives feedback from two distinct sources: the raw execution results (sandbox) and a higher-level evaluator (judge). This suggests a multi-faceted optimization goal.
* **Negative vs. Positive Feedback**: The diagram explicitly distinguishes between negative feedback (red, from failed execution) and positive feedback (green, from the judge's approval).
* **Efficiency Metric**: The inclusion of a "Time Reward" indicates that performance is judged not only on correctness but also on computational efficiency or speed.
* **Iterative Improvement**: The two feedback loops pointing back to the model clearly frame this as an iterative, learning-oriented process.
### Interpretation
This diagram illustrates a sophisticated **Reinforcement Learning from Execution Feedback** paradigm for training code-generating AI. The core idea is to move beyond static datasets and use the live execution environment as a source of truth.
* **What it demonstrates**: The system creates a closed loop where the model's outputs are dynamically tested, and the results are quantified into reward signals. This allows the model to learn from its mistakes (via the red correctness reward) and from expert judgment (via the green correctness reward and time reward).
* **Relationship between elements**: The "Judge" acts as a critic or reward model, potentially aligning the code's performance with broader goals like readability, efficiency, or adherence to best practices, which raw test execution might not capture. The "Sandbox" provides objective, ground-truth verification.
* **Notable implications**: This approach can lead to more robust and efficient code generation. The model is incentivized to produce not just functionally correct code, but also code that is performant (time reward) and meets a standard of quality endorsed by the judge. The separation of "Optimal Solution" and "Model Solution" suggests the process aims to bridge the gap between the model's current capability and an ideal target.
</details>
Figure 3: Gated time-complexity reward design in code RL. The time reward $R_time$ is activated only when a solution passes all test cases ( $PassRate=1$ ), and the judge system provides online feedback by comparing the predicted time complexity against the reference optimal bound.
#### 2.3.4 Training Dynamics
Across the two-stage code RL, we observe consistent improvements in both reward signals and downstream coding performance. In Stage 1, the correctness reward ( $R_correctness$ ) increases sharply, reflecting rapid gains in producing valid and correct solutions. In Stage 2, $R_correctness$ improves more modestly, while the gated time reward ( $R_time$ ) rises substantially, indicating that the policy is indeed optimizing time complexity once correctness is largely achieved. The overall reward and performance trends across the two-stage training are shown in Fig. 4.
<details>
<summary>x4.png Details</summary>
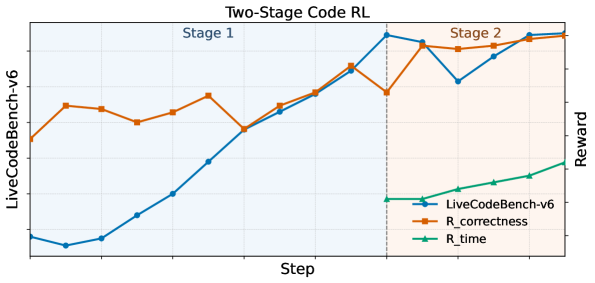
### Visual Description
\n
## Line Chart: Two-Stage Code RL
### Overview
The image displays a line chart titled "Two-Stage Code RL," illustrating the performance of a reinforcement learning (RL) system for code generation over training steps. The chart is divided into two distinct phases, "Stage 1" and "Stage 2," separated by a vertical dashed line. It tracks three metrics: an overall benchmark score and two reward components.
### Components/Axes
* **Title:** "Two-Stage Code RL" (centered at the top).
* **X-Axis:** Labeled "Step" (bottom center). The axis has numerical markers, but specific values are not labeled. It represents the progression of training iterations.
* **Y-Axis (Left):** Labeled "LiveCodeBench-v6" (rotated vertically on the left). This axis corresponds to the blue line and represents the primary performance benchmark score.
* **Y-Axis (Right):** Labeled "Reward" (rotated vertically on the right). This axis corresponds to the orange and green lines, representing reward signals used during training.
* **Legend:** Located in the bottom-right corner of the chart area. It contains three entries:
* `LiveCodeBench-v6`: Blue line with circular markers.
* `R_correctness`: Orange line with square markers.
* `R_time`: Green line with triangular markers.
* **Stage Labels:**
* "Stage 1": Text in the top-left quadrant of the chart area.
* "Stage 2": Text in the top-right quadrant of the chart area.
* **Visual Separator:** A vertical dashed gray line divides the chart into Stage 1 (left) and Stage 2 (right).
### Detailed Analysis
**1. LiveCodeBench-v6 (Blue Line, Left Y-Axis):**
* **Trend:** Shows a strong, generally upward trend across both stages, with a notable dip in Stage 2.
* **Stage 1:** Starts at a low value (approx. 0.1-0.2 on its scale). It dips slightly initially, then climbs steadily and steeply throughout the stage, ending at a high point just before the stage transition.
* **Stage 2:** Begins at a peak (approx. 0.8-0.9). It then experiences a sharp decline to a local minimum (approx. 0.6-0.7) before recovering and climbing again to finish at its highest point on the chart (approx. 0.9-1.0).
**2. R_correctness (Orange Line, Right Y-Axis):**
* **Trend:** Exhibits a fluctuating but overall upward trend, with more volatility than the blue line.
* **Stage 1:** Starts at a moderate value. It rises, dips, rises again to a peak, then falls before rising sharply to meet the blue line at the stage transition.
* **Stage 2:** Starts high, dips slightly, then follows a path that closely mirrors the blue line's dip and recovery, though it remains slightly above the blue line for most of Stage 2. It ends at a very high value, near its peak.
**3. R_time (Green Line, Right Y-Axis):**
* **Trend:** Shows a steady, linear upward trend. This metric is only plotted during Stage 2.
* **Stage 2:** Appears at the start of Stage 2 at a low-to-moderate value. It increases at a constant, moderate slope throughout the remainder of the chart, ending at a value significantly higher than its start but lower than the final values of the other two metrics.
### Key Observations
1. **Stage Transition Correlation:** The most significant event occurs at the vertical dashed line (start of Stage 2). The `LiveCodeBench-v6` (blue) and `R_correctness` (orange) scores both peak just before this line, then immediately drop.
2. **Divergence in Stage 2:** Following the initial drop in Stage 2, all three metrics recover and trend upward. However, `R_time` (green) increases linearly, while `LiveCodeBench-v6` (blue) and `R_correctness` (orange) show a correlated dip-and-recovery pattern.
3. **Metric Introduction:** The `R_time` reward signal is only active or visualized during Stage 2, suggesting a change in the training objective or reward function at that point.
4. **Final Convergence:** By the end of the chart, all three metrics are trending upward, with `LiveCodeBench-v6` and `R_correctness` reaching their highest observed values.
### Interpretation
This chart visualizes the training dynamics of a two-stage RL process for code generation. The data suggests:
* **Stage 1** focuses on improving code correctness (`R_correctness`), which drives the primary benchmark score (`LiveCodeBench-v6`) upward. The close correlation between the orange and blue lines indicates correctness is a major component of the benchmark score.
* The **transition to Stage 2** introduces a new optimization pressure, likely related to code efficiency or speed, represented by the `R_time` reward. The immediate dip in the benchmark and correctness scores suggests this new objective initially conflicts with or complicates the existing policy, causing a temporary performance drop.
* **Stage 2** demonstrates the system's ability to adapt and optimize for multiple objectives simultaneously. After the initial perturbation, the agent learns to balance correctness and time efficiency, leading to a recovery and continued improvement in all metrics. The linear rise of `R_time` shows steady progress on the new objective, while the recovery of the other lines shows the system is not sacrificing correctness for speed.
* The **overall narrative** is one of successful curriculum learning: mastering a primary skill (correctness) in Stage 1, then refining it while adding a secondary skill (efficiency) in Stage 2, ultimately achieving a higher overall performance than focusing on correctness alone. The dip is a classic sign of the "plasticity-stability" dilemma in learning systems when a new task is introduced.
</details>
Figure 4: Training dynamics of two-stage code RL. We track the reward (including the gated $R_time$ in Stage 2) and LiveCodeBench performance across training, showing consistent improvements from Stage 1 to Stage 2.
### 2.4 Whole Training Recipe of Nanbeige4.1
Nanbeige4.1-3B is initialized from Nanbeige4-3B-Base and further optimized through a structured post-training pipeline combining large-scale SFT and cascaded RL.
We first conduct extended SFT, increasing the maximum context length from 64K to 256K compared to the previous Nanbeige4-3B-2511 version. This longer context window is essential for supporting long-horizon reasoning and multi-turn deep-search planning.
In the RL phase, we adopt a staged optimization strategy. General RL is performed sequentially with point-wise RL followed by pair-wise RL to enhance both standalone response quality and comparative preference alignment. Code RL is then conducted in two stages: a correctness stage that maximizes execution pass rate, followed by a gated time-complexity stage that activates efficiency rewards only when full correctness is achieved. Finally, we apply a lightweight agentic RL stage to strengthen tool-use and search behavior.
This unified training recipe enables Nanbeige4.1-3B to maintain strong domain-specific performance while emerging as a well-balanced generalist model under strict capacity constraints.
## 3 Experiment
Our evaluation comprises three components: general reasoning, deep-search agentic tasks, and a real-world coding challenge. General reasoning benchmarks measure core capability boundaries. Deep-search tasks evaluate long-horizon planning and tool-augmented multi-step reasoning in realistic environments. The real-world algorithm challenge provides an out-of-distribution stress test.
### 3.1 General Task Evaluations
For general reasoning capabilities, we evaluate across five major categories: code, math, science, alignment, and tool-use.
- Code. We report results on LiveCodeBench-V5, LiveCodeBench-V6 jain2024livecodebenchholisticcontaminationfree , and LiveCodeBench-Pro zheng2025livecodebench to assess code generation ability and execution-based correctness under increasing difficulty.
- Mathematics. We include IMO-Answer-Bench luong2025towards , HMMT balunovic2025matharena , and AIME-2026-I https://huggingface.co/datasets/MathArena/aime_2026_I to evaluate symbolic reasoning and competition-level problem solving.
- Science. We benchmark on GPQA rein2023gpqa and HLE phan2025humanitysexam to measure multi-step scientific reasoning and domain knowledge integration.
- Alignment. We use Arena-Hard-V2 li2024arenahard and Multi-Challenge deshpande2025multichallenge to assess preference modeling robustness and response quality under adversarial or challenging prompts.
- Tool-use. We evaluate BFCL patil2025bfcl and Tau2-Bench barres2025tau2bench , which test function-calling reliability and multi-step tool use capability.
For compared baseline models, we include open-source models at similar scale (Qwen3-4B-2507) and our previous release (Nanbeige4-3B-2511), as well as substantially larger open models including Qwen3-30B-A3B-2507, Qwen3-32B, and Qwen3-Next-80B-A3B. This setup allows us to assess both same-scale competitiveness and cross-scale efficiency.
Table 4: Evaluation results across code, math, science, alignment, and tool-use benchmarks.
| Benchmark | Qwen3-4B 2507 | Qwen3-32B | Qwen3-30B A3B-2507 | Qwen3-Next -80B-A3B | Nanbeige4-3B 2511 | Nanbeige4.1-3B |
| --- | --- | --- | --- | --- | --- | --- |
| Code | | | | | | |
| LCB-V6 | 57.4 | 55.7 | 66.0 | 68.7 | 46.0 | 76.9 |
| LCB-Pro-Easy | 40.2 | 42.3 | 60.8 | 78.8 | 40.2 | 81.4 |
| LCB-Pro-Medium | 5.3 | 3.5 | 3.5 | 14.3 | 5.3 | 28.1 |
| Math | | | | | | |
| AIME 2026 I | 81.46 | 75.83 | 87.30 | 89.24 | 84.10 | 87.40 |
| HMMT Nov | 68.33 | 57.08 | 71.25 | 81.67 | 66.67 | 77.92 |
| IMO-Answer-Bench | 48.00 | 43.94 | 54.34 | 58.00 | 38.25 | 53.38 |
| Science | | | | | | |
| GPQA | 65.8 | 68.4 | 73.4 | 77.2 | 82.2 | 83.8 |
| HLE (Text-only) | 6.72 | 9.31 | 11.77 | 13.70 | 10.98 | 12.60 |
| Alignment | | | | | | |
| Arena-Hard-V2 | 34.9 | 56.0 | 60.2 | 62.3 | 60.0 | 73.2 |
| Multi-Challenge | 41.14 | 38.72 | 49.40 | 56.52 | 41.20 | 52.21 |
| Tool Use | | | | | | |
| BFCL-V4 | 44.87 | 47.90 | 48.60 | 50.51 | 53.80 | 56.50 |
| Tau2-Bench | 45.90 | 45.26 | 47.70 | 57.40 | 41.77 | 48.57 |
Overall Results.
Table 4 shows that Nanbeige4.1-3B substantially outperforms both Qwen3-4B-2507 and its predecessor Nanbeige4-3B-2511 across all evaluated domains, demonstrating the effectiveness of our post-training strategy.
More notably, despite having only 3B parameters, Nanbeige4.1-3B consistently surpasses 30B–32B class models (Qwen3-30B-A3B-2507 and Qwen3-32B) on the majority of benchmarks, including coding, alignment, and tool-use tasks. The gains are particularly pronounced on execution-based coding benchmarks such as LiveCodeBench-V6 and LiveCodeBench-Pro-Medium, where Nanbeige4.1-3B achieves large absolute margins. When compared to Qwen3-Next-80B-A3B, Nanbeige4.1-3B remains competitive and exhibits complementary strengths: it leads on several coding and alignment benchmarks, while the 80B model retains advantages on selected mathematics and tool-use tasks.
These results suggest that strong cross-domain reasoning performance can be achieved through targeted post-training and agent-oriented optimization, even at a significantly smaller parameter scale.
### 3.2 Deep Search Task Evaluations
In this section, we present a comprehensive evaluation of the performance of Nanbeige4.1-3B on deep search tasks. We evaluate its capabilities in handling complex tasks by benchmarking against general foundation models of comparable size, specialized search-agent models, and significantly larger-scale foundation models.
Table 5: Performance comparison across various deep search benchmarks.
| Benchmark | GAIA (text-only) | Browse Comp | Browse Comp-ZH | HLE (text-only) | SEAL-0 | xBench DeepSearch-05 | xBench DeepSearch-10 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Research Agents | | | | | | | |
| Tongyi-DeepResearch-30B | 70.90 | 43.40 | 46.70 | 32.90 | - | 75.00 | - |
| MiroThinker-v1.0-8B | 66.40 | 31.10 | 40.20 | 21.50 | 40.40 | 60.60 | - |
| AgentCPM-Explore-4B | 63.90 | 25.00 | 29.00 | 19.10 | 40.00 | 70.00 | - |
| Large Foundation Models with Tools | | | | | | | |
| GLM-4.6-357B | 71.90 | 45.10 | 49.50 | 30.40 | - | 70.00 | - |
| Minimax-M2-230B | 75.70 | 44.00 | 48.50 | 31.80 | - | 72.00 | - |
| DeepSeek-V3.2-671B | 63.50 | 67.60 | 65.00 | 40.80 | 38.50 | 71.00 | - |
| Small Foundation Models with Tools | | | | | | | |
| Qwen3-4B-2507 | 28.33 | 1.57 | 7.92 | 11.13 | 15.74 | 34.00 | 5.00 |
| Qwen3-8B | 19.53 | 0.79 | 5.15 | 10.24 | 6.34 | 31.00 | 2.00 |
| Qwen3-14B | 30.23 | 2.36 | 7.11 | 10.17 | 12.64 | 34.00 | 9.00 |
| Qwen3-32B | 30.17 | 3.15 | 7.34 | 9.26 | 8.15 | 39.00 | 8.00 |
| Qwen3-30B-A3B-2507 | 31.63 | 1.57 | 4.12 | 14.81 | 9.24 | 25.00 | 10.00 |
| Qwen3-Next-80B-A3B | 34.02 | 5.60 | 8.25 | 9.26 | 18.18 | 27.00 | 6.00 |
| Ours | | | | | | | |
| Nanbeige4-3B-2511 | 19.42 | 0.79 | 3.09 | 13.89 | 12.61 | 33.00 | 11.00 |
| Nanbeige4.1-3B | 69.90 | 19.12 | 31.83 | 22.29 | 41.44 | 75.00 | 39.00 |
#### 3.2.1 Experimental Setup and Comparison Baselines
All experimental settings are the same as those of Section 2.2.2. These benchmarks require iterative retrieval, planning, tool interaction, and cross-document reasoning, reflecting realistic autonomous agent workloads. To thoroughly contextualize the performance of Nanbeige4.1-3B, we conduct a diverse comparison against several categories of existing models. This includes general-purpose foundation models equipped with tools (e.g., Qwen-series models), specialized search-agent models such as MiroThinker-8B, AgentCPM-Explore-4B, and Tongyi-DeepResearch-30B. We also incorporate large-scale open foundation models exceeding 100B parameters, comprising Minimax-M2.1, GLM-4.6, and DeepSeek-V3.2 for comparison.
#### 3.2.2 Overall Performance Analysis
Table 5 presents a comprehensive performance comparison across various search agent benchmarks. While "Research Agents" (e.g., Tongyi-DeepResearch-30B) and "Large Foundation Models with Tools" (e.g., Minimax-M2, DeepSeek-V3.2) generally exhibit strong capabilities in their respective categories, particularly on GAIA and browsing tasks, the "Small Foundation Models with Tools" (Qwen3 series) typically show lower performance levels.
Our model, Nanbeige4.1-3B, demonstrates a remarkable leap in performance compared to its baseline Nanbeige4-3B-2511 and significantly outperforms other small foundation models with tools across all benchmarks. More critically, Nanbeige4.1-3B achieves state-of-the-art results across nearly all evaluated benchmarks, including GAIA (69.90), xBench-DeepSearch-05 (75.00), and SEAL-0 (41.44). These scores not only surpass its direct competitors in the small model category but also place it on par with, or even exceeding, the performance of many larger "Research Agents" and "Large Foundation Models with Tools." This robust performance underscores Nanbeige4.1-3B’s exceptional effectiveness in complex search and agentic tasks, demonstrating that competitive capabilities can be achieved efficiently even with a smaller model size through our proposed methodology.
### 3.3 Real-world Algorithmic Challenges: LeetCode Weekly Contests
Beyond curated academic benchmarks, we further evaluate Nanbeige4.1-3B on real-world competitive programming tasks drawn from recent LeetCode weekly contests https://leetcode.cn/contest/, providing a practical out-of-distribution stress test of algorithmic reasoning ability.
We apply Nanbeige4.1-3B, alongside Qwen models of varying scales, to solve contest problems under standard competitive programming settings. The generated solutions are directly submitted to the official LeetCode platform, and performance is measured by the final acceptance rate.
Table 6: Comparison of Pass Rates on LeetCode Weekly Contests 484–488.
| Benchmark | Qwen3-4B-2507 | Qwen3-32B | Qwen3-30B-A3B-2507 | Nanbeige4.1-3B |
| --- | --- | --- | --- | --- |
| LeetCode Pass Rate (%) | 55.0 | 50.0 | 65.0 | 85.0 |
As shown in Table 6, Nanbeige4.1-3B successfully solves 17 out of 20 problems, achieving an overall pass rate of 85.0%. In virtual participation mode, where ranking is determined by correctness and time efficiency, our model achieves 1st place in Weekly Contest 487 and 3rd place in Weekly Contest 488. Compared to Qwen3 models of similar or substantially larger scales, Nanbeige4.1-3B demonstrates a clear performance advantage on these real-world contest tasks. Detailed problem statements and representative solution examples are provided in Appendix B.
## 4 Conclusion
In this work, we present Nanbeige4.1-3B, a unified generalist model that demonstrates advanced capabilities in reasoning, coding, and long-horizon search. We achieve this by integrating point-wise and pair-wise reward modeling for precise preference alignment, optimizing code generation for both correctness and computational efficiency, and incorporating both turn and trajectory level signals to enable robust long-horizon agentic planning. Consequently, Nanbeige4.1-3B consistently outperforms comparable small models and remains competitive with larger baselines across diverse benchmarks and real-world challenges.
Looking ahead, we aim to push the boundaries of compact models in complex coding and research agent scenarios. Concurrently, we focus on improving inference efficiency by enabling tasks to be solved with shorter outputs and fewer tool invocations, while exploring architectural innovations to further enhance the potential of the compact generalist model.
## References
- [1] Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions. arXiv preprint arXiv:2505.23281, 2025.
- [2] Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. $τ^2$ -bench: Evaluating conversational agents in a dual-control environment. arXiv preprint, 2025.
- [3] Kaiyuan Chen, Yixin Ren, Yang Liu, Xiaobo Hu, Haotong Tian, Tianbao Xie, Fangfu Liu, Haoye Zhang, Hongzhang Liu, Yuan Gong, Chen Sun, Han Hou, Hui Yang, James Pan, Jianan Lou, Jiayi Mao, Jizheng Liu, Jinpeng Li, Kangyi Liu, Kenkun Liu, Rui Wang, Run Li, Tong Niu, Wenlong Zhang, Wenqi Yan, Xuanzheng Wang, Yuchen Zhang, Yi-Hsin Hung, Yuan Jiang, Zexuan Liu, Zihan Yin, Zijian Ma, and Zhiwen Mo. xbench: Tracking agents productivity scaling with profession-aligned real-world evaluations, 2025.
- [4] Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E Primack, Summer Yue, and Chen Xing. Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms. In Findings of the Association for Computational Linguistics: ACL 2025, pages 18632–18702, 2025.
- [5] Ruixiang Feng, Yuntao Wen, Silin Zhou, Ke Shi, Yifan Wang, Ran Le, Zhenwei An, Zongchao Chen, Chen Yang, Guangyue Peng, Yiming Jia, Dongsheng Wang, Tao Zhang, Lisi Chen, Yang Song, Shen Gao, and Shuo Shang. Pace: Prefix-protected and difficulty-aware compression for efficient reasoning, 2026.
- [6] Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024.
- [7] Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. arXiv preprint, 2024.
- [8] Minh-Thang Luong, Dawsen Hwang, Hoang H Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, et al. Towards robust mathematical reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 35406–35430, 2025.
- [9] Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants, 2023.
- [10] Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. In Forty-second International Conference on Machine Learning, 2025.
- [11] Thinh Pham, Nguyen Nguyen, Pratibha Zunjare, Weiyuan Chen, Yu-Min Tseng, and Tu Vu. Sealqa: Raising the bar for reasoning in search-augmented language models, 2025.
- [12] Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, and et al. Humanity’s last exam, 2025.
- [13] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint, 2023.
- [14] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- [15] Boxin Wang, Chankyu Lee, Nayeon Lee, Sheng-Chieh Lin, Wenliang Dai, Yang Chen, Yangyi Chen, Zhuolin Yang, Zihan Liu, Mohammad Shoeybi, et al. Nemotron-cascade: Scaling cascaded reinforcement learning for general-purpose reasoning models. arXiv preprint arXiv:2512.13607, 2025.
- [16] Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516, 2025.
- [17] Sen Xu, Yi Zhou, Wei Wang, Jixin Min, Zhibin Yin, Yingwei Dai, Shixi Liu, Lianyu Pang, Yirong Chen, and Junlin Zhang. Tiny model, big logic: Diversity-driven optimization elicits large-model reasoning ability in vibethinker-1.5 b. arXiv preprint arXiv:2511.06221, 2025.
- [18] Wenyuan Xu, Xiaochen Zuo, Chao Xin, Yu Yue, Lin Yan, and Yonghui Wu. A unified pairwise framework for rlhf: Bridging generative reward modeling and policy optimization. arXiv preprint arXiv:2504.04950, 2025.
- [19] Shaotian Yan, Kaiyuan Liu, Chen Shen, Bing Wang, Sinan Fan, Jun Zhang, Yue Wu, Zheng Wang, and Jieping Ye. Distribution-aligned sequence distillation for superior long-cot reasoning. arXiv preprint arXiv:2601.09088, 2026.
- [20] Chen Yang, Ran Le, Yun Xing, Zhenwei An, Zongchao Chen, Wayne Xin Zhao, Yang Song, and Tao Zhang. Toolmind technical report: A large-scale, reasoning-enhanced tool-use dataset. arXiv preprint arXiv:2511.15718, 2025.
- [21] Chen Yang, Guangyue Peng, Jiaying Zhu, Ran Le, Ruixiang Feng, Tao Zhang, Wei Ruan, Xiaoqi Liu, Xiaoxue Cheng, Xiyun Xu, et al. Nanbeige4-3b technical report: Exploring the frontier of small language models. arXiv preprint arXiv:2512.06266, 2025.
- [22] Zihan Zheng, Zerui Cheng, Zeyu Shen, Shang Zhou, Kaiyuan Liu, Hansen He, Dongruixuan Li, Stanley Wei, Hangyi Hao, Jianzhu Yao, et al. Livecodebench pro: How do olympiad medalists judge llms in competitive programming? arXiv preprint arXiv:2506.11928, 2025.
- [23] Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, et al. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese. arXiv preprint arXiv:2504.19314, 2025.
- [24] Jialiang Zhu, Gongrui Zhang, Xiaolong Ma, Lin Xu, Miaosen Zhang, Ruiqi Yang, Song Wang, Kai Qiu, Zhirong Wu, Qi Dai, et al. Re-trac: Recursive trajectory compression for deep search agents. arXiv preprint arXiv:2602.02486, 2026.
## Appendix A Author List
Authors are listed in alphabetical order by first name. Names marked with an asterisk (*) denote individuals who were previously affiliated with our team. Yang Song is the corresponding author and can be reached at songyang@kanzhun.com.
Chen Yang, Guangyue Peng, Jiaying Zhu, Ran Le, Ruixiang Feng, Tao Zhang, Xiyun Xu, Yang Song †, Yiming Jia, Yuntao Wen, Yunzhi Xu, Zekai Wang, Zhenwei An *, Zhicong Sun, Zongchao Chen
## Appendix B Leetcode Contest Examples
The following examples are drawn from LeetCode Weekly Contest 488 under virtual participation. Since the contest was conducted on the Chinese version of LeetCode, the original problem statements presented to the model were in Chinese, and the generated code contained Chinese comments. For clarity, we provide English translations of both the problem descriptions and the model’s comments below.
### B.1 Problem Q1: Count Dominant Indices
Problem Description
Given: An integer array nums of length $n$ . Definition: An index $i$ is called a dominant index if the following condition is met: $nums[i]>average(nums[i+1],nums[i+2],\dots,nums[n-1])$ Your task is to count the number of dominant indices. Note: •
The average is the sum of the group divided by the number of elements. •
The rightmost element of the array is not considered a dominant index.
Model Output (Nanbeige4.1-3B):
The model correctly transformed the inequality to avoid floating-point precision issues and utilized a suffix sum approach to solve the problem in $O(n)$ time complexity.
⬇
1 from typing import List
2
3 class Solution:
4 def dominantIndices (self, nums: List [int]) -> int:
5 "" "
6 [Translated Comment] Count the number of dominant indices in the array.
7 Dominant Index Definition: Index i such that:
8 nums[i] > average(nums[i+1], ..., nums[n-1])
9 Note: The rightmost element (index n-1) is not considered a candidate.
10
11 Optimization Strategy:
12 1. Avoid floating-point arithmetic: Transform nums[i] > sum / len
13 into nums[i] * len > sum.
14 2. Traverse from right to left, dynamically maintaining the suffix sum.
15 3. Time Complexity: O(n), Space Complexity: O(1).
16 " ""
17 n = len (nums)
18 # Boundary condition: No valid dominant index if length <= 1
19 if n <= 1:
20 return 0
21
22 count = 0
23 suffix_sum = 0 # Stores sum of nums[i+1] to nums[n-1]
24
25 # Traverse backwards from the second to last element to index 0
26 for i in range (n - 2, -1, -1):
27 suffix_sum += nums [i + 1] # Accumulate current right-side part
28 length = n - i - 1 # Number of elements on the right
29
30 # Strict inequality check (avoiding floating point issues)
31 if nums [i] * length > suffix_sum:
32 count += 1
33
34 return count
35 \ end {minted}
### B.2 Problem Q2: Apply Operations to Maximize Array Sum
Problem Description
Given: An integer array nums. Operation: Repeatedly perform the following until no more operations can be done: •
If there are two adjacent and equal elements in the array, select the leftmost such pair. •
Replace them with their sum. The array size decreases by 1 after each merge. Task: Return the final array after all possible merge operations are completed.
Model Output (Nanbeige4.1-3B):
The model employs a stack-based simulation to handle the "leftmost" merge constraint efficiently. This mimics the recursive merge process in a single pass with $O(n)$ time complexity.
⬇
1 from typing import List
2
3 class Solution:
4 def mergeAdjacent (self, nums: List [int]) -> List [int]:
5 "" "
6 [Translated Comment] Simulate the merge process using a stack:
7 - Traverse the array, comparing each element with the stack top.
8 - If equal, continue merging (pop stack top and accumulate) until
9 not equal or stack is empty.
10 - Push the merge result (or original element) onto the stack.
11 - The final stack content is the result after no more merges can be done.
12
13 Time Complexity: O(n), each element is pushed/popped at most once.
14 Space Complexity: O(n), max stack depth.
15 " ""
16 stack = []
17 for num in nums:
18 current = num
19 # Continuous merge: when stack top equals current, pop and accumulate
20 while stack and stack [-1] == current:
21 current += stack. pop ()
22 stack. append (current)
23 return stack
24 \ end {minted}
25
26 \ subsection {Problem Q3: Count Subarrays with Cost Constraint}
27
28 \ begin {tcolorbox}[colback = gray!5, colframe = gray!60, title =\ textbf {Problem Description}]
29 \ textbf {Given:} An integer array \ texttt {nums} and an integer $k$.
30
31 \ textbf {Definition:} The \ textit {cost} of a subarray $ \ text {nums}[l.. r] $ is defined as:
32 \[
33 \ text {cost} = (\ max (\ text {nums}[l.. r]) - \ min (\ text {nums}[l.. r])) \ times (r - l + 1)
34 \]
35 \ textbf {Task:} Return the number of subarrays where the cost is less than or equal to $k$.
Model Output (Nanbeige4.1-3B):
The model correctly identifies this as a sliding window problem. To maintain the maximum and minimum values within the moving window efficiently, it utilizes two monotonic deques, achieving an optimal solution.
⬇
1 from collections import deque
2 from typing import List
3
4 class Solution:
5 def countSubarrays (self, nums: List [int], k: int) -> int:
6 # [Translated] Boundary check: empty array or negative k (cost is non-negative)
7 if not nums or k < 0:
8 return 0
9
10 n = len (nums)
11 dq_max = deque () # Monotonic decreasing deque: stores indices of max values
12 dq_min = deque () # Monotonic increasing deque: stores indices of min values
13 l = 0
14 ans = 0
15
16 for r in range (n):
17 # Maintain max deque (pop back if <= current value)
18 while dq_max and nums [dq_max [-1]] <= nums [r]:
19 dq_max. pop ()
20 dq_max. append (r)
21
22 # Maintain min deque (pop back if >= current value)
23 while dq_min and nums [dq_min [-1]] >= nums [r]:
24 dq_min. pop ()
25 dq_min. append (r)
26
27 # Calculate cost for current window [l, r]
28 cur_max = nums [dq_max [0]]
29 cur_min = nums [dq_min [0]]
30 length = r - l + 1
31 cost = (cur_max - cur_min) * length
32
33 # Shrink left boundary: if cost > k, move l to the right
34 while cost > k and l <= r:
35 # Remove left boundary influence on extremums
36 if dq_max [0] == l:
37 dq_max. popleft ()
38 if dq_min [0] == l:
39 dq_min. popleft ()
40 l += 1
41 if l > r:
42 break
43 # Recalculate cost after shrinking
44 cur_max = nums [dq_max [0]]
45 cur_min = nums [dq_min [0]]
46 length = r - l + 1
47 cost = (cur_max - cur_min) * length
48
49 # Accumulate all valid subarrays ending at r
50 if l <= r:
51 ans += (r - l + 1)
52
53 return ans
### B.3 Problem Q4: Maximize Score of K Pairs
Problem Description
Given: Two integer arrays nums1 (length $n$ ) and nums2 (length $m$ ), and an integer $k$ . Task: Choose exactly $k$ pairs of indices $(i_1,j_1),(i_2,j_2),\dots,(i_k,j_k)$ such that: $0≤ i_1<i_2<\dots<i_k<n and 0≤ j_1<j_2<\dots<j_k<m$ The score for each pair $(i,j)$ is $nums1[i]×nums2[j]$ . Return the maximum total score (sum of products) achievable.
Model Output (Nanbeige4.1-3B):
The model proposes a Dynamic Programming approach using rolling arrays to optimize space. It constructs a 2D state transition ‘curr[i][j]‘ representing the max score selecting a specific number of pairs from the prefixes of both arrays.
⬇
1 from typing import List
2
3 class Solution:
4 def maxScore (self, nums1: List [int], nums2: List [int], k: int) -> int:
5 n, m = len (nums1), len (nums2)
6 # [Translated] Edge case: k=0 returns 0
7 if k == 0:
8 return 0
9 # Implicit constraint check n >= k and m >= k
10 if k > n or k > m:
11 return 0
12
13 # prev[i][j]: Max score choosing t-1 pairs from first i and first j elements
14 prev = [[0] * (m + 1) for _ in range (n + 1)]
15 NEG_INF = float (’-inf’)
16
17 # Iterate to select 1 to k pairs
18 for _ in range (1, k + 1):
19 # curr initialized to -inf
20 curr = [[NEG_INF] * (m + 1) for _ in range (n + 1)]
21 for i in range (1, n + 1):
22 num1 = nums1 [i - 1]
23 for j in range (1, m + 1):
24 num2 = nums2 [j - 1]
25 # Three choices:
26 # 1. Skip current element of nums1: state from curr[i-1][j]
27 # 2. Skip current element of nums2: state from curr[i][j-1]
28 # 3. Take current pair (i-1, j-1): state from prev[i-1][j-1] + product
29 # (ensures strictly increasing indices)
30 skip_i = curr [i - 1][j]
31 skip_j = curr [i][j - 1]
32 take = prev [i - 1][j - 1] + num1 * num2
33 curr [i][j] = max (skip_i, skip_j, take)
34 prev = curr # Rolling update: current layer becomes prev for next round
35
36 # Final result: Max score choosing exactly k pairs from n and m elements
37 return int (prev [n][m])
## Appendix C Time-Complexity Case Study
Scope and purpose.
This section presents a small set of time-complexity-focused case studies comparing model outputs before vs. after introducing the gated time reward in code RL. Concretely, we use examples from LiveCodeBench where the two models produce functionally correct solutions but differ in their algorithmic efficiency, and we analyze how the time-reward stage encourages outputs closer to the time-optimal complexity class.
### C.1 AtCoder ABC388 Excerpt: Simultaneous Kagamimochi
Problem Description (Excerpt)
Given: $N$ mochi with non-decreasing sizes $A_1≤ A_2≤\dots≤ A_N$ . Rule: You can stack mochi of sizes $a$ (top) and $b$ (bottom) iff $a≤\frac{b}{2}$ . Task: Maximize the number $K$ of kagamimochi that can be made simultaneously by choosing $2K$ mochi and pairing them.
Before (Candidate Code).
⬇
1 import sys
2
3 def main ():
4 data = sys. stdin. read (). strip (). split ()
5 if not data:
6 return
7 N = int (data [0])
8 A = list (map (int, data [1:1+ N]))
9 # The input is already sorted, but we sort to be safe.
10 A. sort ()
11 low = 0
12 high = N // 2
13 while low < high:
14 mid = (low + high + 1) // 2
15 ok = True
16 for i in range (mid):
17 if 2 * A [i] > A [N - mid + i]:
18 ok = False
19 break
20 if ok:
21 low = mid
22 else:
23 high = mid - 1
24 print (low)
25
26 if __name__ == "__main__":
27 main ()
After (Candidate Code).
⬇
1 import sys
2
3 def main ():
4 data = sys. stdin. read (). strip (). split ()
5 if not data:
6 return
7 N = int (data [0])
8 A = list (map (int, data [1:1+ N]))
9 # A is already sorted in non-decreasing order as per input specification.
10 i = 0
11 j = N // 2
12 count = 0
13 while i < N // 2 and j < N:
14 if A [i] * 2 <= A [j]:
15 count += 1
16 i += 1
17 j += 1
18 else:
19 j += 1
20 print (count)
21
22 if __name__ == "__main__":
23 main ()
#### C.1.1 Complexity Analysis
Key observation.
Because $A$ is sorted, the problem reduces to matching a small mochi as the top with a large mochi as the bottom, under the constraint $2· A[top]≤ A[bottom]$ , without reusing mochi.
Before: binary search over the answer.
The before solution binary-searches $K$ in $[0,\lfloor N/2\rfloor]$ . For each candidate $K=\texttt{mid}$ , it checks feasibility by scanning $i=0..K-1$ and verifying $2A[i]≤ A[N-K+i]$ .
- If we include the extra sort(), the time is $O(N\log N)+O≤ft(N\log N\right)=O(N\log N)$ .
- If we use the input guarantee (already sorted) and drop sort(), the dominating part is the feasibility checks:
$$
O≤ft(∑_iterations\texttt{mid}\right)=O≤ft(N\log N\right),
$$
because there are $O(\log N)$ iterations and each check costs $O(\texttt{mid})≤ O(N)$ .
- Space complexity is $O(N)$ for storing $A$ .
After: two-pointers greedy matching.
The after solution uses two pointers: $i$ over the smaller half ( $[0,\lfloor N/2\rfloor)$ ) and $j$ over the larger half ( $[\lfloor N/2\rfloor,N)$ ). Pointer $j$ only moves forward, and $i$ moves forward exactly when a valid pair is formed.
- Each pointer advances at most $N$ times, so the total time is $O(N)$ (no sorting is needed).
- Space complexity remains $O(N)$ for the array.
Conclusion.
Both solutions are correct, but after improves the core algorithmic cost from $O(N\log N)$ to $O(N)$ by eliminating the binary search and performing a single-pass greedy matching enabled by the sorted input.
### C.2 AtCoder ARC195 A Excerpt: Twice Subsequence
Problem Description (Excerpt)
Given: A sequence $A=(A_1,\dots,A_N)$ and a target sequence $B=(B_1,\dots,B_M)$ with $1≤ M≤ N≤ 2× 10^5$ . Task: Determine whether there exist at least two subsequences of $A$ that match $B$ . Two subsequences are considered different if they use different sets of positions in $A$ , even if the resulting values are identical.
Before (Candidate Code).
⬇
1 import sys
2 import bisect
3 from collections import defaultdict
4
5 def main ():
6 data = sys. stdin. read (). strip (). split ()
7 if not data:
8 return
9 it = iter (data)
10 N = int (next (it))
11 M = int (next (it))
12 A = [int (next (it)) for _ in range (N)]
13 B = [int (next (it)) for _ in range (M)]
14
15 # Map each value to the sorted list of indices where it appears in A
16 pos_map = defaultdict (list)
17 for i, val in enumerate (A):
18 pos_map [val]. append (i)
19
20 # Find the leftmost (earliest) matching subsequence
21 left = []
22 pos = -1
23 for b in B:
24 if b not in pos_map:
25 print ("No")
26 return
27 lst = pos_map [b]
28 # Find first index > pos
29 idx = bisect. bisect_left (lst, pos + 1)
30 if idx == len (lst):
31 print ("No")
32 return
33 i = lst [idx]
34 left. append (i)
35 pos = i
36
37 # Find the rightmost (latest) matching subsequence
38 right = []
39 pos = N
40 for b in reversed (B):
41 if b not in pos_map:
42 print ("No")
43 return
44 lst = pos_map [b]
45 # Find last index < pos
46 idx = bisect. bisect_left (lst, pos)
47 if idx == 0:
48 print ("No")
49 return
50 i = lst [idx - 1]
51 right. append (i)
52 pos = i
53 right. reverse () # restore order to match B
54
55 # If the two subsequences differ in at least one position, answer Yes
56 for l, r in zip (left, right):
57 if l != r:
58 print ("Yes")
59 return
60 print ("No")
61
62 if __name__ == "__main__":
63 main ()
After (Candidate Code).
⬇
1 import sys
2
3 def main ():
4 data = sys. stdin. read (). split ()
5 if not data:
6 return
7 it = iter (data)
8 N = int (next (it))
9 M = int (next (it))
10 A = [int (next (it)) for _ in range (N)]
11 B = [int (next (it)) for _ in range (M)]
12
13 # leftmost matching indices
14 left = []
15 j = 0
16 for i in range (N):
17 if j < M and A [i] == B [j]:
18 left. append (i)
19 j += 1
20 if j == M:
21 break
22 if j < M:
23 print ("No")
24 return
25
26 # rightmost matching indices
27 right = []
28 j = M - 1
29 for i in range (N -1, -1, -1):
30 if j >= 0 and A [i] == B [j]:
31 right. append (i)
32 j -= 1
33 if j < 0:
34 break
35 right. reverse ()
36
37 # compare left and right
38 for k in range (M):
39 if left [k] != right [k]:
40 print ("Yes")
41 return
42 print ("No")
43
44 if __name__ == "__main__":
45 main ()
#### C.2.1 Complexity Analysis
Key idea: earliest vs. latest embedding.
Let $L=(\ell_1,\dots,\ell_M)$ be the leftmost embedding of $B$ in $A$ , obtained greedily by scanning $A$ left-to-right and matching $B_1,B_2,\dots$ as early as possible. Let $R=(r_1,\dots,r_M)$ be the rightmost embedding of $B$ in $A$ , obtained greedily by scanning $A$ right-to-left and matching $B_M,B_M-1,\dots$ as late as possible.
If there exists at least one $k$ such that $\ell_k≠ r_k$ , then we can construct two different matching subsequences: one using the prefix choices from $L$ up to some point, and another using the suffix choices from $R$ (intuitively, there is “slack” at position $k$ allowing a different choice of index while still completing the match). Conversely, if $L=R$ coordinate-wise, then every match is forced to use the same index for each $B_k$ , so there is exactly one matching subsequence.
Before: value-to-positions map + binary search.
The before approach preprocesses a dictionary pos_map mapping each value $v$ to the sorted list of indices where $A_i=v$ . Then:
- It constructs $L$ by, for each $B_k$ , binary searching the first occurrence index $>\ell_k-1$ .
- It constructs $R$ similarly from the right, binary searching the last occurrence index $<r_k+1$ .
- Finally it checks whether $L$ and $R$ differ in any coordinate.
Time. Building pos_map costs $O(N)$ . Each of the $M$ steps performs one binary search on an occurrence list, costing $O(\log N)$ in the worst case. Total time is $O(N+M\log N)$ per test case. Space. The map stores all indices once, so $O(N)$ .
After: two-pointer greedy scans.
The after approach eliminates the map and binary searches:
- Construct $L$ with a single left-to-right scan of $A$ using a pointer $j$ over $B$ .
- Construct $R$ with a single right-to-left scan of $A$ using a pointer $j$ over $B$ .
- Compare $L$ and $R$ ; output Yes if they differ, else No.
Time. Each scan is $O(N)$ , and the final comparison is $O(M)$ , hence total $O(N+M)=O(N)$ per test case. Space. Arrays left and right store $M$ indices, so $O(M)$ (and thus $O(N)$ ).
Conclusion.
Both solutions rely on the same correctness criterion: there are at least two matching subsequences iff the leftmost and rightmost embeddings differ at some position. The after solution achieves optimal linear time by replacing the index-map + binary-search steps with two greedy linear passes, reducing the per-test-case complexity from $O(N+M\log N)$ to $O(N)$ while keeping $O(N)$ space.
### C.3 AtCoder ARC194 Excerpt: Minimum Cost Sort
Problem Description (Excerpt)
Given: A permutation $P$ of $(1,2,\dots,N)$ . Operation: For $1≤ i≤ N-1$ , swap adjacent elements $(P_i,P_i+1)$ with cost $i$ . Task: Compute the minimum total cost to sort $P$ in ascending order.
Before (Candidate Code).
⬇
1 import sys
2 import heapq
3
4 def solve ():
5 data = sys. stdin. read (). strip (). split ()
6 if not data:
7 return
8 it = iter (data)
9 N = int (next (it))
10 P = [0] + [int (next (it)) for _ in range (N)] # 1-indexed
11
12 # Initialize a min-heap with all adjacent inversions
13 heap = []
14 for i in range (1, N):
15 if P [i] > P [i + 1]:
16 heapq. heappush (heap, i)
17
18 total_cost = 0
19 while heap:
20 i = heapq. heappop (heap)
21 # Check if the inversion still exists (it might have been fixed already)
22 if not (P [i] > P [i + 1]):
23 continue
24 # Perform the swap
25 P [i], P [i + 1] = P [i + 1], P [i]
26 total_cost += i
27 # After swapping, check the three affected positions for new inversions
28 for idx in (i - 1, i, i + 1):
29 if 1 <= idx < N and P [idx] > P [idx + 1]:
30 heapq. heappush (heap, idx)
31
32 print (total_cost)
33
34 if __name__ == "__main__":
35 solve ()
36 \ end {minted}
37
38 \ paragraph {After (Candidate Code).}
39 \ begin {minted}[linenos, frame = lines, framesep =2 mm, fontsize =\ small, breaklines]{python}
40 import sys
41
42 def solve () -> None:
43 input = sys. stdin. readline
44 N = int (input ())
45 P = list (map (int, input (). split ()))
46
47 # Fenwick tree (1-indexed)
48 bit = [0] * (N + 2)
49
50 def update (i: int, delta: int) -> None:
51 while i <= N:
52 bit [i] += delta
53 i += i & - i
54
55 def query (i: int) -> int:
56 s = 0
57 while i > 0:
58 s += bit [i]
59 i -= i & - i
60 return s
61
62 total_cost = 0
63 for val in P:
64 # number of smaller elements to the left of ’val’
65 cnt = query (val - 1)
66 p0 = cnt + 1 # position of ’val’ after larger elements to its left have passed
67 if p0 < val:
68 terms = val - p0 # number of right moves needed
69 # sum from p0 to val-1 inclusive
70 total_cost += (p0 + val - 1) * terms // 2
71 update (val, 1)
72
73 print (total_cost)
74
75 if __name__ == "__main__":
76 solve ()
#### C.3.1 Complexity Analysis
Before: heap-driven local bubble swaps.
The before solution repeatedly fixes adjacent inversions, always picking the smallest index inversion via a min-heap, and then re-checks nearby positions.
- Each heap operation is $O(\log N)$ .
- The number of swaps equals the inversion count of the permutation, which can be $Θ(N^2)$ in the worst case (e.g., a reversed permutation).
- Moreover, indices may be pushed into the heap multiple times and later discarded, but the total number of heap pushes still scales with the number of performed swaps (constant-factor neighborhood updates per swap).
- Therefore, worst-case time complexity is $O(inv(P)\log N)=O(N^2\log N)$ , with $O(N)$ memory for the array and heap.
After: Fenwick tree (BIT) aggregation.
The after solution processes values in input order and uses a Fenwick tree to count how many smaller elements have appeared so far. For each value val, it infers how far this element must move (in terms of adjacent swaps) in the stable insertion process, and accumulates the corresponding cost by a closed-form arithmetic progression.
- Each query and update is $O(\log N)$ , performed once per element.
- Total time complexity is $O(N\log N)$ per test case.
- Space complexity is $O(N)$ for the BIT and input array.
Conclusion.
Compared with the swap-simulating heap method that can degrade to $O(N^2\log N)$ , the BIT-based solution computes the minimum cost in $O(N\log N)$ by aggregating necessary movements and costs without explicitly simulating each adjacent swap.