# Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
**Authors**: Wei-Lin Chen, Liqian Peng, Tian Tan, Chao Zhao, Blake JianHang Chen, Ziqian Lin, Alec Go, Yu Meng
> University of Virginia
> \thepa
\uselogo Corresponding author:
wlchen@virginia.edu, liqianp@google.com
Abstract
Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal “overthinking,” leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens —tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@ $n$ , a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@ $n$ matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. Token Count and Deep-Thinking Ratio
### Overview
The image presents two scatter plots comparing the accuracy (Pass@1) of different models against two independent variables: Token Count (left plot) and Deep-Thinking Ratio (right plot). Each plot displays data for four models (AIME 25, AIME 24, HMMT 25, and GPQA-D), with shaded regions indicating uncertainty. Correlation coefficients (r) are provided for each plot and for some individual data series.
### Components/Axes
**Left Plot:**
* **Title:** Avg Correlation r = -0.544
* **X-axis:** Token Count, with tick marks at approximately 2500, 5000, 7500, and 10000.
* **Y-axis:** Accuracy (Pass@1), with tick marks at 0.5, 0.6, 0.7, and 0.8.
**Right Plot:**
* **Title:** Avg Correlation r = 0.828
* **X-axis:** (Ours) Deep-Thinking Ratio, with tick marks at approximately 0.135, 0.150, 0.165, and 0.180.
* **Y-axis:** Accuracy (Pass@1), with tick marks at 0.5, 0.6, 0.7, and 0.8.
**Legend (located at the bottom):**
* **Blue:** AIME 25
* **Green:** AIME 24
* **Red:** HMMT 25
* **Yellow:** GPQA-D
### Detailed Analysis
**Left Plot (Accuracy vs. Token Count):**
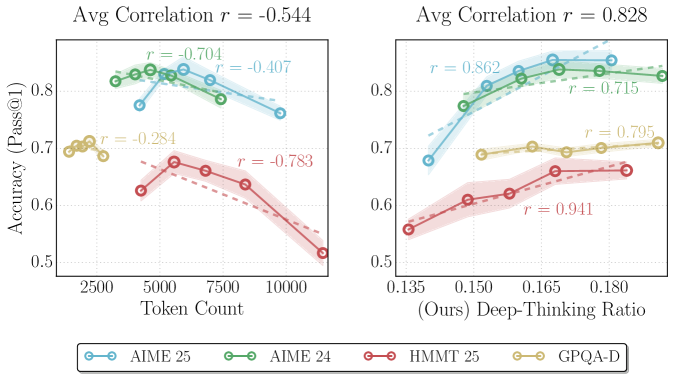
* **AIME 25 (Blue):** The line starts at approximately (2500, 0.7), increases slightly to (5000, 0.8), and then decreases to approximately (10000, 0.78). r = -0.704
* **AIME 24 (Green):** The line starts at approximately (2500, 0.7), increases slightly to (5000, 0.83), and then decreases to approximately (10000, 0.78). r = -0.407
* **HMMT 25 (Red):** The line starts at approximately (5000, 0.62), increases to (7500, 0.66), and then decreases to approximately (10000, 0.52). r = -0.783
* **GPQA-D (Yellow):** The line remains relatively constant at approximately 0.7 across the token count range. r = -0.284
**Right Plot (Accuracy vs. Deep-Thinking Ratio):**
* **AIME 25 (Blue):** The line starts at approximately (0.135, 0.57), increases to (0.165, 0.82), and then plateaus at approximately (0.180, 0.82). r = 0.862
* **AIME 24 (Green):** The line starts at approximately (0.135, 0.57), increases to (0.165, 0.83), and then plateaus at approximately (0.180, 0.82). r = 0.715
* **HMMT 25 (Red):** The line starts at approximately (0.135, 0.55), increases to (0.165, 0.66), and then plateaus at approximately (0.180, 0.67). r = 0.941
* **GPQA-D (Yellow):** The line remains relatively constant at approximately 0.7 across the Deep-Thinking Ratio range. r = 0.795
### Key Observations
* In the left plot, the AIME 25 and AIME 24 models show a slight increase in accuracy initially, followed by a decrease as the token count increases. HMMT 25 shows a more pronounced decrease in accuracy with increasing token count. GPQA-D remains relatively stable.
* In the right plot, all models except GPQA-D show an increase in accuracy as the Deep-Thinking Ratio increases, eventually plateauing. GPQA-D remains relatively stable.
* The average correlation for the left plot is negative (-0.544), indicating an inverse relationship between token count and accuracy across the models. The average correlation for the right plot is positive (0.828), indicating a direct relationship between Deep-Thinking Ratio and accuracy.
### Interpretation
The data suggests that increasing the token count may negatively impact the accuracy of some models (AIME 25, AIME 24, and HMMT 25), while the GPQA-D model is less sensitive to token count. In contrast, increasing the Deep-Thinking Ratio generally improves the accuracy of the models, with GPQA-D again showing less sensitivity. The negative correlation in the left plot and the positive correlation in the right plot highlight these relationships. The shaded regions around the lines indicate the variability or uncertainty in the accuracy measurements for each model. The correlation coefficients for each line provide a measure of the strength and direction of the linear relationship between the variables for each model.
</details>
Figure 1: Comparison of correlations between accuracy and proxies for thinking effort. The plots illustrate the relationship between model performance and two inference-time measures of thinking effort on GPT-OSS-120B- medium across AIME 2024/2025, HMMT 2025, and GPQA-Diamond. (Left) Output token count exhibits a moderate negative correlation (average $r=-0.544$ ), suggesting that output length is an unreliable indicator of performance. (Right) In contrast, our proposed deep-thinking ratio demonstrates a strong positive correlation with accuracy (average $r=0.828$ ).
1 Introduction
Large language models (LLMs) have achieved remarkable reasoning capabilities by generating explicit thought traces, most notably through the Chain-of-Thought (CoT) paradigm [wei2022chain-d1a]. Prior works have shown that increasing the number of reasoning tokens generated can generally boost task performance [jaech2024openai, guo2025deepseek, anthropic2025claude3-7, anthropic2025claude4, oai2025o3mini, yang2025qwen3, team2025kimi, zhong2024evaluation], motivating methods that encourage longer and more elaborate thinking traces [muennighoff2025s1, balachandran2025inference-time-7c9, yeo2025demystifying-b6f].
However, a growing body of evidence suggests that token counts are unreliable indicators of model performance during inference, as longer reasoning does not consistently translate into higher accuracy [wu2025when-905, aggarwal2025optimalthinkingbench-3bf, sui2025stop-ced, su2025between-f85]. Empirical studies reveal inverted-U relationships between CoT length and performance [wu2025when-905], as well as inverse-scaling behaviors in which longer reasoning traces systematically degrade performance [gema2025inverse-bad]. Excessive reasoning may reflect overthinking, wherein models amplify flawed heuristics or fixate on irrelevant details [feng2025what-321]. Consequently, relying on length as a metric for reasoning quality not only encourages verbosity over clarity but also wastes computational resources on uninformative tokens. Though recent work has attempted to assess the semantic structure of CoTs (e.g., by representing reasoning traces as graphs), such approaches often rely on costly auxiliary parsing or external annotations [feng2025what-321]. Addressing these limitations requires more principled and efficient methods for measuring thinking effort that can distinguish effective reasoning from uninformative generation.
In this work, we introduce deep-thinking ratio (DTR) as a direct measure of inference-time thinking effort. Instead of relying on surface-level features like output length, we focus on how individual tokens are produced internally. We posit that when a token prediction stabilizes in early layers, subsequent depth-wise modifications entail relatively low computational effort, resembling less thinking. In contrast, token predictions that undergo sustained revision in deeper layers before converging reflect greater thinking [chuang2023dola-0c6]. We operationalize this idea by projecting intermediate-layer hidden states into the vocabulary space and comparing each layer’s prediction distribution to the final-layer distribution. Tokens whose distributions do not converge until deeper layers are identified as deep-thinking tokens. By counting the proportion of deep-thinking tokens in a generated sequence, we obtain DTR, which provides a simple, mechanistically grounded measure of thinking effort, requiring neither task-specific heuristics nor external structural annotations.
Across four challenging mathematical and scientific reasoning benchmarks—AIME 2024, AIME 2025, HMMT 2025, and GPQA [aops2024aime1, aops2024aime2, aops2025aime1, aops2025aime2, hmmt2025, rein2024gpqa] —and a range of reasoning-focused language models, including GPT-OSS, DeepSeek-R1, and Qwen3 families [openai2025gpt-oss-120b-a33, guo2025deepseek, yang2025qwen3], we demonstrate that measuring deep-thinking tokens yields strong correlations with task accuracy. The achieved correlation is substantially higher than those obtained using length-based or confidence-based baselines. Furthermore, we show that deep-thinking tokens can be leveraged for parallel inference scaling, where preferentially selecting and aggregating responses with higher DTR achieves performance comparable or better than standard consensus-based methods, while requiring only half the compute cost. Our contributions are summarized as follows:
- We introduce deep-thinking ratio (DTR)—a measure that counts the ratio of deep-thinking tokens in a sequence whose predictions undergo sustained revision in deeper layers before converging—as a new lens for characterizing inference-time thinking effort.
- We empirically show that, across multiple reasoning benchmarks and model families, DTR of a generated sequence exhibits strong positive correlations with task accuracy, outperforming length-based and confidence-based baselines significantly.
- We introduce Think@ $n$ , a test-time scaling strategy that preferentially selects and aggregates samples with higher DTR. By early halting unpromising generations based on DTR estimated from short prefixes, Think@ $n$ matches or surpasses standard self-consistency with approximately half the inference cost.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Heatmap: Layer Activation for Mathematical Expression
### Overview
The image is a heatmap visualizing the activation levels of different layers in a neural network when processing a mathematical expression. The x-axis represents the tokens of the expression, and the y-axis represents the layer number. The color intensity indicates the activation level, ranging from dark brown (low activation) to light yellow (high activation).
### Components/Axes
* **X-axis:** Represents the tokens of the mathematical expression: "A and B = 8 + 5 = 13 \textbackslash n \textbackslash boxed { 13 } \textbackslash n \textbackslash n Thus the correct choice is ( D ) 13 . The final answer is \textbackslash boxed { ( D ) } \$\textbackslash <return/\>".
* **Y-axis:** Represents the layer number, labeled as "i-th Layer", ranging from 1 to 35 in increments of 2.
* **Colorbar:** Located on the right side, indicates the activation level, ranging from 0.0 (dark brown) to 1.0 (light yellow).
### Detailed Analysis
The heatmap shows the activation levels for each layer in response to each token in the input sequence.
* **Layer Activation Distribution:**
* Layers 1 to approximately 17 show consistently high activation (dark brown) across all tokens.
* Above layer 17, the activation patterns become more differentiated, with specific tokens triggering higher activation in certain layers.
* **Token-Specific Activation:**
* The tokens "A", "and", "B", "=", "8", "+", "5", "=", "13", "\textbackslash n", "\textbackslash boxed", "{", "13", "}", "\textbackslash n", "\textbackslash n", "Thus", "the", "correct", "choice", "is", "(", "D", ")", "13", ".", "The", "final", "answer", "is", "\textbackslash boxed", "{", "(", "D", ")", "}", "\$\textbackslash <return/\>" exhibit varying degrees of activation across the upper layers (above layer 17).
* The tokens "8", "+", "5", "13", and "D" show relatively high activation in some of the upper layers.
* The tokens "\textbackslash n", "\textbackslash boxed", "{", "}", ".", and "\$\textbackslash <return/\>" also show distinct activation patterns.
* **Specific Layer Activation:**
* Layers around 27-35 show higher activation for tokens related to the final answer and formatting (e.g., "\textbackslash boxed", "D", "\$\textbackslash <return/\>").
* Layers around 21-25 show higher activation for tokens related to the mathematical operation (e.g., "8", "+", "5", "13").
### Key Observations
* Lower layers (1-17) have consistently high activation, suggesting they might be responsible for basic feature extraction.
* Upper layers (above 17) show more specific activation patterns, indicating they are involved in higher-level reasoning or decision-making.
* The activation patterns vary significantly depending on the token, suggesting that different layers are responsible for processing different types of information.
### Interpretation
The heatmap provides insights into how a neural network processes a mathematical expression. The lower layers seem to handle fundamental feature extraction, while the upper layers focus on more complex tasks like understanding the mathematical operations, formatting the output, and generating the final answer. The varying activation patterns for different tokens highlight the network's ability to differentiate and process various components of the input sequence. The high activation in the upper layers for tokens related to the final answer suggests that these layers are crucial for generating the correct output.
</details>
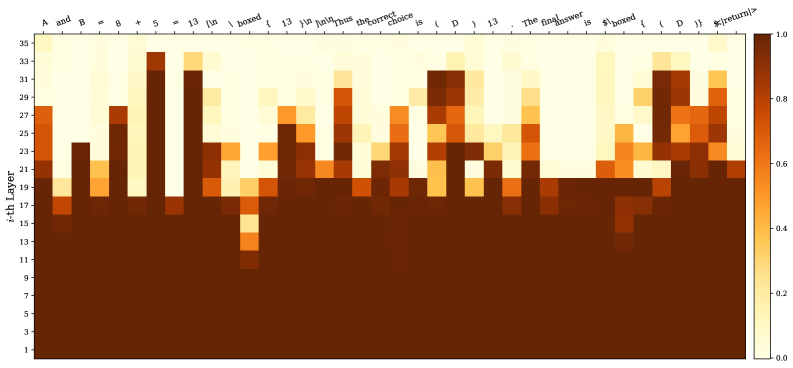
Figure 2: Heatmap of thought: We plot the Jensen–Shannon divergence (JSD) values between the distributions of the last (36th) layer and intermediate layers for an answer sequence from GPT-OSS-120B- high. Functional and templated words (e.g., “and”, “is”, “boxed”, “ <| return |> ”) often converge at relatively shallow layers; Completions after operators (e.g., “+”, “=”) and answer tokens/symbols (e.g., “13”, “(D)”) do not settle until deeper layers. Interestingly, the answer token “13” gradually surfaces in earlier layers after its first appearance.
2 Measuring Deep-Thinking Ratio
2.1 Preliminaries
We consider an autoregressive language model $f_{\theta}$ composed of $L$ transformer layers, hidden dimension $d$ , and vocabulary $V$ . Given a prefix sequence $y_{<t}$ , the forward pass at generation step $t$ produces a sequence of residual stream states $\{h_{t,l}\}_{l=1}^{L}$ , where $h_{t,l}∈\mathbb{R}^{d}$ denotes the hidden state after layer $l$ . The final-layer output $h_{t,L}$ is projected by the language modeling head (i.e., the unembedding matrix) $W_{U}∈\mathbb{R}^{|V|× d}$ to produce logits over the vocabulary.
Prior research on early exiting [teerapittayanon2016branchynet, elbayad2019depth, schuster2022confident, din2024jump, belrose2023eliciting] has demonstrated that, without specialized auxiliary training, applying the language modeling head directly to intermediate-layer hidden states effectively yields meaningful predictive distributions [nostalgebraist2020lens, kao2020bert]. Building on this line of works, we project intermediate-layer hidden states into the vocabulary space using the same unembedding matrix $W_{U}$ . For each intermediate layer $l∈\{1,...,L-1\}$ , we compute the logit vector $z_{t,l}$ and probability distribution $p_{t,l}$ as
$$
\displaystyle p_{t,l}=\mathrm{softmax}(z_{t,l}),\;\;\;z_{t,l} \displaystyle=W_{U}h_{t,l} \tag{1}
$$
The model’s final-layer distribution is denoted by $p_{t,L}$ .
2.2 Deep-Thinking Tokens
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Model Forward Pass and JSD Computation
### Overview
The diagram illustrates a model forward pass through multiple layers, followed by the computation of the Jensen-Shannon Divergence (JSD) between the output of the 10th layer and the output of each individual layer. The diagram also indicates whether the computed JSD is below a threshold of 0.5.
### Components/Axes
* **Left Box:** Represents the "Model Forward Pass" and is labeled "Model Forward Pass" at the top. It contains stacked layers, numbered from 1st to 10th. The top layers are shaded in purple, with the shading becoming lighter towards the bottom. A curved bracket to the left of the layers is labeled "Deep-Thinking Regime".
* **Middle Box:** Represents the "Compute JSD" stage. The title is "Compute JSD (p10th || pith) < Threshold 0.5?". This section shows histograms representing the output distributions (p) of each layer (1st, 7th, 8th, 9th, 10th).
* **Right Box:** Shows the JSD value and a green checkmark or red cross, indicating whether the JSD is below the threshold of 0.5.
### Detailed Analysis
**Model Forward Pass (Left Box):**
* The layers are stacked vertically, with the 10th layer at the top and the 1st layer at the bottom.
* The layers are labeled as "10-th layer", "9-th layer", "8-th layer", "7-th layer", and "1-st layer". There are ellipsis (...) indicating omitted layers between the 7th and 1st layers.
* The "Deep-Thinking Regime" label spans from approximately the 7th layer to the 10th layer.
**Compute JSD (Middle Box):**
* Each layer's output distribution (p) is represented by a small histogram.
* The histograms are labeled as p10th, p9th, p8th, p7th, and p1st, corresponding to the respective layers.
* Gray lines connect each layer to its corresponding histogram and then to the JSD value on the right.
**JSD Comparison (Right Box):**
* The JSD values are listed vertically, corresponding to the layers from top to bottom.
* A green checkmark indicates that the JSD is below 0.5, while a red cross indicates that it is above 0.5.
* The JSD values and their corresponding indicators are:
* p10th: 0.00 (Green Checkmark)
* p9th: 0.08 (Green Checkmark)
* p8th: 0.36 (Green Checkmark)
* p7th: 0.76 (Red Cross)
* p7th: 0.78 (Red Cross)
* (Implied p6th): 0.82 (Red Cross)
* (Implied p5th): 0.86 (Red Cross)
* (Implied p4th): 0.85 (Red Cross)
* (Implied p3th): 0.93 (Red Cross)
* p1st: 0.96 (Red Cross)
### Key Observations
* The JSD values generally increase as you move from the 10th layer to the 1st layer.
* The JSD values for the top three layers (10th, 9th, and 8th) are below the threshold of 0.5, while the JSD values for the remaining layers are above the threshold.
### Interpretation
The diagram suggests that the higher layers of the model (within the "Deep-Thinking Regime") produce output distributions that are more similar to the 10th layer's output distribution, as indicated by the lower JSD values. As the model processes the input through the lower layers, the output distributions diverge more significantly from the 10th layer's output, resulting in higher JSD values. This could indicate that the "Deep-Thinking Regime" is where the model's core representations are formed, and the earlier layers are more focused on lower-level feature extraction. The threshold of 0.5 is used to distinguish between layers that produce similar outputs to the 10th layer and those that do not.
</details>
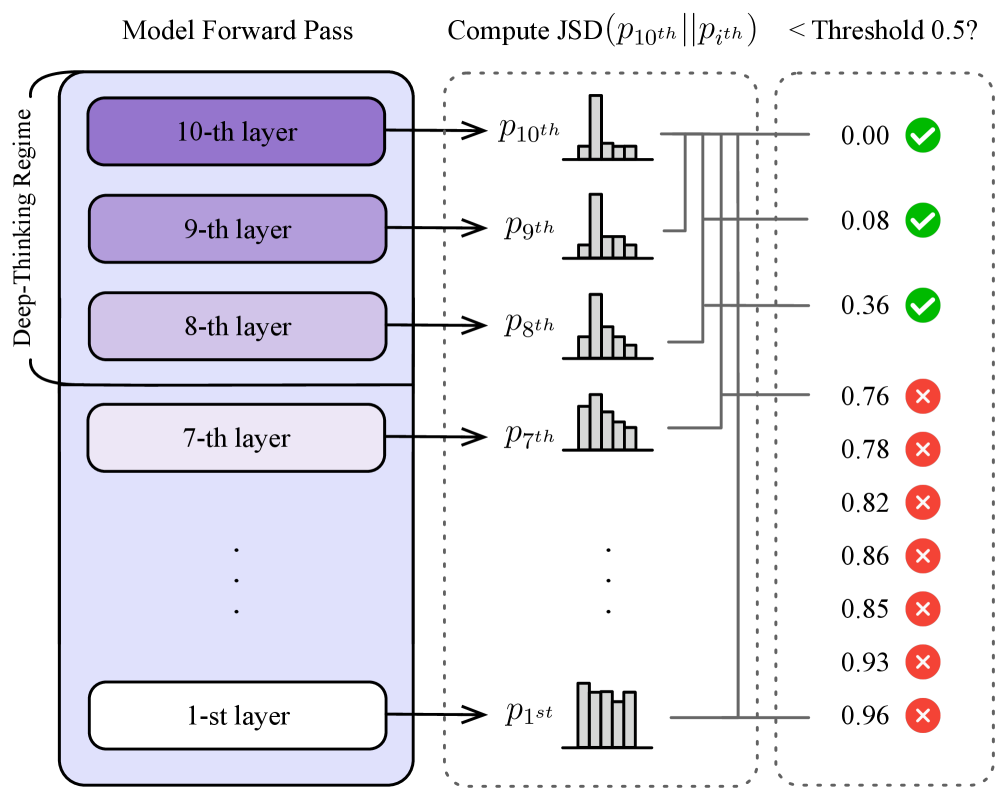
Figure 3: Illustration of our method of identifying deep-thinking tokens. Suppose a model with 10 layers, by setting the depth fraction $\rho=0.8$ , the token is successfully classified as a deep-thinking token at generation step $t$ since its JSD with the final-layer distribution first fall below the threshold $g$ only until it reaches the late-settling regime.
Input : Autoregressive LM $f_{\theta}$ with $L$ layers and unembedding matrix $W_{U}$ ; Input prompt $x$ ; Threshold $g$ ; Depth fraction $\rho$ Output : $\mathrm{DTR}(S)$ of the generated sequence $S$ $C← 0$ ; // deep thinking token count $S←\emptyset$ ; // generated sequence $y_{t}←\mathtt{[BOS]}$ ; // initialize with start token while $y_{t}≠\mathtt{[EOS]}$ do Sample $y_{t}\sim p_{t,L}\!\left(f_{\theta}(·\mid x,S)\right)$ ; $S←(S,y_{t})$ ; for $l← 1$ to $L$ do $p_{t,l}←\mathrm{softmax}(W_{U}h_{t,l})$ ; $D_{t,l}←\mathrm{JSD}(p_{t,L},p_{t,l})$ ; end for $c_{t}←\min\{l:\min_{j≤ l}D_{t,j}≤ g\}$ ; if $c_{t}≥\lceil(1-\rho)L\rceil$ then $C← C+1$ ; end if end while return $C/|S|$ ; Algorithm 1 Computing Deep-Thinking Ratio (DTR)
We posit that inference-time thinking effort for a token manifests as the continued evolution of predictive distributions (i.e., $p_{t,l}$ ) across LM layers. Tokens with earlier distributional stabilization correspond to less additional thinking, while those having later stabilization correspond to needing more extended internal thinking. In other words, simple tokens stabilize early with shallow computation, whereas difficult tokens requiring more thinking exhibit distributional shifts in deeper layers with more computation. To illustrate this, we show a motivation example on answering a GQPA [rein2024gpqa] question in Figure ˜ 2.
To quantify this behavior, we measure how long a token’s predictive distribution continues to change before settling, operationalized as the layer at which the intermediate distribution becomes sufficiently close to the final-layer distribution. Specifically, for each generation step $t$ and layer $l$ , we compute the Jensen–Shannon divergence (JSD) between the intermediate-layer distribution $p_{t,l}$ and the final-layer distribution $p_{t,L}$ :
$$
\displaystyle D_{t,l} \displaystyle\;\coloneqq\;\operatorname{JSD}\!\left(p_{t,L}\,\|\,p_{t,l}\right) \displaystyle=H\!\left(\frac{p_{t,L}+p_{t,l}}{2}\right)-\tfrac{1}{2}H(p_{t,L})-\tfrac{1}{2}H(p_{t,l}), \tag{2}
$$
where $H(·)$ denotes Shannon entropy. By construction, $D_{t,L}=0$ . A trajectory $l\mapsto D_{t,l}$ that approaches zero only at later layers indicates prolonged distributional revision (think more), whereas early convergence indicates that the model settles on its final prediction with fewer subsequent updates (think less). We employ JSD due to its symmetry and boundedness, following [chuang2023dola-0c6]. We explore other distance metrics in Appendix ˜ A.
To enforce a strict notion of settling, we compute:
$$
\displaystyle\bar{D}_{t,l}=\min_{j\leq l}D_{t,j}. \tag{3}
$$
We define the settling depth $c_{t}$ as the first layer at which $\bar{D}_{t,l}$ falls below a fixed threshold $g$ :
$$
\displaystyle c_{t}=\min\left\{l\in\{1,\ldots,L\}:\bar{D}_{t,l}\leq g\right\}. \tag{4}
$$
We then define a deep-thinking regime using a depth fraction $\rho∈(0,1)$ , with
$$
\displaystyle\mathcal{L}_{\text{deep-thinking}}=\left\{l:l\geq\left\lceil\rho\times L\right\rceil\right\}. \tag{5}
$$
A token is classified as a deep-thinking token (i.e., requiring more layer computations and more thinking effort to become sufficiently close to the final-layer distribution) if $c_{t}∈\mathcal{L}_{\text{deep-thinking}}$ . An illustration is shown in Figure ˜ 3.
Finally, for a generated sequence $S$ of length $T$ , we define the deep-thinking ratio, $\mathrm{DTR}(S)$ , for the sequence as the proportion of tokens that settle in the late regime:
$$
\displaystyle\mathrm{DTR}(S)=\frac{1}{T}\sum_{t=1}^{T}\mathbb{1}\!\left[c_{t}\in\mathcal{L}_{\text{deep-thinking}}\right]. \tag{6}
$$
A higher DTR indicates that a larger fraction of tokens undergo extended computation for distributional revision before stabilizing. We note that our proposed method does not imply that early-settling tokens are suboptimal; rather, it provides a depth-wise characterization of inference-time thinking effort that complements the surface-level token length measure. We show the overall algorithm of DTR in Algorithm ˜ 1. We also provide qualitative examples in Appendix ˜ E.
3 Deep-Thinking Ratio Reflects Task Accuracy More Reliably
We empirically evaluate whether our distributional distance-based measurement provides a more faithful and robust characterization of inference-time thinking effort than surface-level, length-based proxies (i.e., token counts).
Models.
We evaluate eight variants of reasoning LLMs from three model families: GPT-OSS-20B (with low, medium, and high reasoning levels) and GPT-OSS-120B (with low, medium, and high reasoning levels) [openai2025gpt-oss-120b-a33], DeepSeek-R1-70B [guo2025deepseek], For brevity, we refer DeepSeek-R1-70B to Llama-3.3-70B-Instruct distilled with DeepSeek-R1 generated samples (https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B). and Qwen3-30B-Thinking [yang2025qwen3]. These models are known for their strong, long CoT capability in mathematical and complex reasoning, and span multiple parametric scales for comprehensive coverage.
Tasks.
We focus on reasoning-intensive benchmarks where scaling CoT-style computation at inference time plays a central role. We adopt four benchmarks widely used in recent evaluations of LLM reasoning capabilities [xai2025grok4, openai2025gpt5, balunovic2025matharena], including three competition-level mathematical problem sets, AIME 2024 [aops2024aime1, aops2024aime2], AIME 2025 [aops2025aime1, aops2025aime2], and HMMT 2025 [hmmt2025], as well as the diamond set of GPQA [rein2024gpqa], which consists of challenging graduate-level scientific questions.
Decoding settings.
Following [gema2025inverse-bad], we prompt models to reason step by step using a fixed, neutral instruction, without specifying a reasoning budget or explicitly encouraging longer deliberation. This setup allows each model to naturally allocate inference-time computation on a per-instance basis, avoiding confounds introduced by externally imposed token budgets or budget-conditioning prompts. Following standard practice in natural overthinking analyses [gema2025inverse-bad], we sample multiple responses for each question (25 responses per question in our experiments). Across these samples, models naturally exhibit variation in reasoning length and internal computation patterns. We use the developer recommended sampling parameters for all tested models: temperature=1.0 and top p =1.0 for GPT-OSS series; temperature=0.6 and top p = 0.95 for DeepSeek-R1-70B and Qwen-3-30B-Thinking.
For each sampled response, we record intermediate-layer hidden states, obtain their projected probability distribution, and compute DTR as described in Section ˜ 2. We uniformly set the settling threshold $g=0.5$ and the depth fraction $\rho=0.85$ to define the deep-thinking regime. We also analyze with different values and the results are provided in Section ˜ 3.2. The reported statistics are averaged over 30 random seeds across decoding runs.
3.1 Results
To quantify the relationship between inference-time thinking effort and task performance, we measure the association between thinking effort scores and answer accuracy by computing Pearson correlation coefficient. Specifically, we conduct a binned analysis following [gema2025inverse-bad] by partitioning sampled sequences into quantile bins (i.e., 5 bins) based on their DTR (Equation ˜ 6) and computing the average accuracy within each bin.
Table 1: Pearson correlations between task accuracy and different inference-time measures, including length-based and confidence-based baselines, across eight model variants and four reasoning benchmarks. Correlation values are color-coded: strong positive correlations ( $0.5\sim 1$ ) are shown in dark green, weak positive correlations ( $0\sim 0.5$ ) in light green, weak negative correlations ( $-0.5\sim 0$ ) in light orange, and strong negative correlations ( $-1\sim-0.5$ ) in dark orange.
| OSS-120B-low | Token Length AIME 2025 0.504 | Reverse Token Length -0.504 | Log Probability 0.872 | Negative Perplexity 0.453 | Negative Entropy 0.863 | Self-Certainty 0.803 | DTR (Ours) 0.930 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| OSS-120B-medium | -0.365 | 0.365 | 0.817 | 0.246 | 0.822 | 0.815 | 0.862 |
| OSS-120B-high | -0.961 | 0.961 | 0.705 | 0.552 | 0.711 | 0.728 | 0.796 |
| OSS-20B-low | -0.689 | 0.689 | 0.579 | 0.849 | 0.665 | 0.275 | 0.373 |
| OSS-20B-medium | -0.757 | 0.757 | 0.616 | -0.677 | 0.637 | 0.097 | 0.161 |
| OSS-20B-high | -0.385 | 0.385 | 0.455 | -0.795 | 0.550 | 0.489 | 0.610 |
| DeepSeek-R1-70B | -0.973 | 0.973 | 0.961 | 0.955 | 0.946 | 0.899 | 0.974 |
| Qwen3-30B-Thinking | -0.663 | 0.663 | -0.008 | -0.035 | 0.154 | 0.828 | 0.855 |
| AIME 2024 | | | | | | | |
| OSS-120B-low | -0.166 | 0.166 | 0.897 | 0.682 | 0.869 | 0.741 | 0.840 |
| OSS-120B-medium | -0.680 | 0.680 | 0.795 | -0.293 | 0.908 | 0.924 | 0.533 |
| OSS-120B-high | -0.755 | 0.755 | 0.700 | -0.275 | 0.593 | 0.654 | 0.905 |
| OSS-20B-low | -0.655 | 0.655 | 0.548 | -0.342 | 0.667 | 0.584 | 0.730 |
| OSS-20B-medium | -0.827 | 0.827 | 0.195 | -0.150 | 0.440 | 0.252 | -0.192 |
| OSS-20B-high | -0.989 | 0.989 | 0.809 | 0.262 | 0.921 | 0.855 | 0.824 |
| DeepSeek-R1-70B | -0.987 | 0.987 | -0.037 | 0.223 | 0.067 | 0.287 | 0.430 |
| Qwen3-30B-Thinking | -0.869 | 0.869 | -0.857 | -0.720 | -0.680 | -0.246 | -0.657 |
| GPQA-Diamond | | | | | | | |
| OSS-120B-low | 0.682 | -0.682 | 0.984 | 0.172 | 0.995 | 0.996 | 0.976 |
| OSS-120B-medium | -0.340 | 0.340 | 0.973 | 0.316 | 0.985 | 0.981 | 0.823 |
| OSS-120B-high | -0.970 | 0.970 | 0.854 | 0.501 | 0.813 | 0.885 | 0.845 |
| OSS-20B-low | -0.602 | 0.602 | 0.984 | 0.235 | 0.991 | 0.917 | 0.935 |
| OSS-20B-medium | -0.847 | 0.847 | 0.914 | 0.468 | 0.911 | 0.889 | 0.718 |
| OSS-20B-high | -0.794 | 0.794 | 0.879 | 0.461 | 0.902 | 0.915 | 0.992 |
| DeepSeek-R1-70B | -0.930 | 0.930 | 0.068 | -0.133 | -0.165 | -0.532 | 0.885 |
| Qwen3-30B-Thinking | -0.634 | 0.634 | 0.589 | 0.865 | 0.711 | 0.943 | 0.828 |
| HMMT 2025 | | | | | | | |
| OSS-120B-low | 0.871 | -0.871 | 0.761 | 0.629 | 0.695 | 0.884 | 0.305 |
| OSS-120B-medium | -0.793 | 0.793 | 0.706 | 0.045 | 0.618 | 0.631 | 0.926 |
| OSS-120B-high | -0.967 | 0.967 | 0.750 | 0.503 | 0.728 | 0.754 | 0.972 |
| OSS-20B-low | -0.634 | 0.634 | -0.695 | 0.549 | -0.359 | -0.489 | 0.689 |
| OSS-20B-medium | -0.668 | 0.668 | 0.447 | 0.336 | 0.424 | 0.331 | 0.247 |
| OSS-20B-high | -0.352 | 0.352 | 0.537 | 0.994 | 0.831 | 0.628 | 0.932 |
| DeepSeek-R1-70B | -0.866 | 0.866 | 0.879 | 0.889 | 0.858 | 0.905 | 0.902 |
| Qwen3-30B-Thinking | -0.950 | 0.950 | -0.803 | -0.762 | -0.801 | 0.745 | 0.911 |
| Average | -0.594 | 0.594 | 0.527 | 0.219 | 0.571 | 0.605 | 0.683 |
We compare deep-thinking token measurement against the following baselines, including length-based proxies and confidence-based approaches, which are also commonly adopted to assess generation quality.
Token count.
The total number of tokens generated in the model’s output reasoning traces. This measure is widely framed as a direct proxy for test-time compute, and underlies many empirical studies of inference-time scaling [jaech2024openai, guo2025deepseek, anthropic2025claude3-7, anthropic2025claude4, oai2025o3mini, yang2025qwen3, team2025kimi, zhong2024evaluation].
Reverse token count.
As a complementary baseline, we additionally consider reverse token count, defined as the negative of the total number of generated tokens for each response. This transformation is included to account for the frequently observed inverse relationship between reasoning length and accuracy in LLM overthinking [wu2025when-905, gema2025inverse-bad].
Log probability.
Following the notation in Section ˜ 2, let a generated sequence $S=(y_{1},...,y_{T})$ . At generation step $t$ , the model’s output prediction distribution (at final-layer $L$ ) over the vocabulary $\mathcal{V}$ is denoted by $p_{t,L}(·)$ . We compute the average log-probability of the sampled tokens:
$$
\displaystyle\mathrm{LogProb}(S)\;=\;\frac{1}{T}\sum_{t=1}^{T}\log p_{t,L}(y_{t}) \tag{7}
$$
Higher values indicate that the model assigns higher likelihood to its own generation and are commonly interpreted as higher confidence.
Negative perplexity.
Perplexity is defined as the exponentiated negative average log-probability:
$$
\displaystyle\mathrm{PPL}(S)\;=\;\exp\!\left(-\frac{1}{T}\sum_{t=1}^{T}\log p_{t,L}(y_{t})\right) \tag{8}
$$
We report negative perplexity $-\mathrm{PPL}(S)$ so that larger values correspond to higher confidence.
Negative entropy.
To incorporate information from the full prediction distribution over $\mathcal{V}$ rather than only the sampled token, we compute the average entropy:
$$
\displaystyle\mathrm{Ent}(S)\;=\;\frac{1}{T}\sum_{t=1}^{T}H(p_{t,L}),\;\;\;H(p_{t,L})=-\sum_{v\in\mathcal{V}}p_{t,L}(v)\log p_{t,L}(v) \tag{9}
$$
We report negative entropy $-\mathrm{Ent}(S)$ , where larger values indicate more peaked distributions and thus greater model confidence.
Self-Certainty.
We also include Self-Certainty [kang2025scalable-de3], a distributional confidence metric based on the idea that higher confidence corresponds to prediction distributions that are further from the uniform distribution $u$ , which represents maximum uncertainty. Formally, self-certainty is defined as the average Kullback-Leibler (KL) divergence between $u(v)=1/|\mathcal{V}|$ and $p_{t,L}$ :
$$
\displaystyle\mathrm{Self}\text{-}\mathrm{Certainty}(S) \displaystyle=\;\frac{1}{T}\sum_{t=1}^{T}\mathrm{KL}\!\left(u\,\|\,p_{t,L}\right) \displaystyle=\;-\frac{1}{T|\mathcal{V}|}\sum_{t=1}^{T}\sum_{v\in\mathcal{V}}\log\!\big(|\mathcal{V}|\,p_{t,L}(v)\big) \tag{10}
$$
For all baselines, correlations are computed using the same protocol, where sequences are ranked and binned by token count (or its negation) or confidence scores.
Table ˜ 1 reports the correlation between task accuracy and different measurments, across eight model variants and four benchmarks. As observed, measuring sequences with token count exhibits notable oranged-colored values ( $r<0$ ), with mean $r=-0.59$ . This indicates that longer generations are more associated with lower performance, aligning with recent reports of inverse scaling and overthinking. Extended reasoning traces could be symptomatic of redundant, misguided, or error-amplifying deliberation. The results underscore the unreliability of using surface-level length feature as proxy for effective problem solving. Reversing token count yields a positive correlation of identical magnitude. However, the improvement is purely post hoc, reflecting the empirical regularity in regimes where shorter responses are more accurate. As such, reverse token count only serve as a statistical adjustment, rather than capture principled notion of computation or thinking effort.
Compared to token count measure, confidence-based measures (log probability, negative perplexity, negative entropy, and self-certainty) exhibit moderately positive correlations with mean $r=0.219\sim 0.605$ , as reflected by the predominance of green-colored values. This indicates that model confidence captures partial information about correctness. However, their behavior is relatively heterogeneous across models and benchmarks: while certain configurations achieve strong positive correlations, others deteriorate to weak or even negative associations. This inconsistency suggests that confidence signals might conflate other factors like overconfidence, and therefore do not reliably reflect inference-time compute effort or problem solving effectiveness.
In contrast, our proposed measurement of DTR demonstrates the strongest and most stable relationship with task performance, achieving the highest average correlation of $r=0.683$ , outperforming both reverse token count and Self-Certainty, the best-performing baselines among confidence-based approaches. Overall, DTR remains positive across models and benchmarks, exhibiting the fewest orange-colored values (2 out of the 32 model–benchmark settings tested). Collectively, the results show that computing DTR over output sequences provides a more faithful and robust characterization of successful reasoning outcomes than token volume alone or confidence-based alternatives.
3.2 Effect of Settling Thresholds and Depth Fractions
<details>
<summary>x4.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. Deep-Thinking Ratio for Different Thresholds
### Overview
The image is a scatter plot showing the relationship between "Accuracy (Pass@1)" and "Deep-Thinking Ratio" for three different threshold values (g=2.5e-01, g=5.0e-01, and g=7.5e-01). Each threshold has a corresponding data series plotted with a specific color and marker. The plot also includes shaded regions around each data series, presumably indicating a confidence interval or standard deviation.
### Components/Axes
* **X-axis:** Deep-Thinking Ratio, with tick marks at approximately 0.24, 0.32, 0.40, and 0.48.
* **Y-axis:** Accuracy (Pass@1), with tick marks at 0.600, 0.625, 0.650, 0.675, and 0.700.
* **Legend (Top-Right):**
* Blue: threshold g=2.5e-01
* Brown: threshold g=5.0e-01
* Teal: threshold g=7.5e-01
### Detailed Analysis
* **Threshold g=2.5e-01 (Blue):**
* Trend: Relatively flat, with a slight decrease in accuracy as the Deep-Thinking Ratio increases.
* Data Points: The Deep-Thinking Ratio values are clustered around 0.48. The accuracy values range from approximately 0.64 to 0.65.
* Additional Note: "r = 0.012" is displayed near this data series.
* **Threshold g=5.0e-01 (Brown):**
* Trend: Line slopes upward. Accuracy increases as the Deep-Thinking Ratio increases.
* Data Points: The Deep-Thinking Ratio values range from approximately 0.28 to 0.34. The accuracy values range from approximately 0.61 to 0.66.
* Additional Note: "0.962" is displayed near the top of this data series.
* **Threshold g=7.5e-01 (Teal):**
* Trend: Line slopes upward initially, then decreases. Accuracy increases initially as the Deep-Thinking Ratio increases, then decreases.
* Data Points: The Deep-Thinking Ratio values range from approximately 0.18 to 0.24. The accuracy values range from approximately 0.62 to 0.66.
* Additional Note: "0.820" is displayed near the top of this data series.
### Key Observations
* The brown data series (threshold g=5.0e-01) shows a clear positive correlation between Deep-Thinking Ratio and Accuracy.
* The teal data series (threshold g=7.5e-01) has a peak in accuracy around a Deep-Thinking Ratio of 0.22.
* The blue data series (threshold g=2.5e-01) has a relatively constant accuracy across the Deep-Thinking Ratio values.
### Interpretation
The plot suggests that the optimal Deep-Thinking Ratio for maximizing accuracy depends on the threshold value (g). A threshold of g=5.0e-01 appears to benefit from a higher Deep-Thinking Ratio, while a threshold of g=7.5e-01 has an optimal Deep-Thinking Ratio around 0.22. The threshold of g=2.5e-01 seems relatively insensitive to changes in the Deep-Thinking Ratio within the observed range. The values "r = 0.012", "0.962", and "0.820" are likely correlation coefficients or R-squared values, indicating the strength of the relationship between the two variables for each threshold. The shaded regions represent the uncertainty or variability in the accuracy for each Deep-Thinking Ratio and threshold.
</details>
(a) Effect of different settling threshold $g$ .
<details>
<summary>x5.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. Deep-Thinking Ratio
### Overview
The image is a scatter plot showing the relationship between "Accuracy (Pass@1)" and "Deep-Thinking Ratio" for different "depth fraction" values. There are four data series, each representing a different depth fraction (ρ): 8.0e-01, 8.5e-01, 9.0e-01, and 9.5e-01. Each series shows an upward trend, indicating that as the Deep-Thinking Ratio increases, the Accuracy also tends to increase. Shaded regions around each line indicate uncertainty.
### Components/Axes
* **X-axis:** Deep-Thinking Ratio, ranging from 0.0 to 0.4.
* **Y-axis:** Accuracy (Pass@1), ranging from 0.600 to 0.700.
* **Legend (bottom-left):**
* Blue: depth fraction ρ=8.0e-01
* Red: depth fraction ρ=8.5e-01
* Pink: depth fraction ρ=9.0e-01
* Teal: depth fraction ρ=9.5e-01
* **Gridlines:** Horizontal and vertical dotted gridlines are present.
### Detailed Analysis
* **Depth fraction ρ=8.0e-01 (Blue):**
* Trend: Upward slope.
* Data points: Approximately (0.41, 0.625), (0.42, 0.645), (0.43, 0.655), (0.44, 0.660)
* Correlation Coefficient: r = 0.916 (located near the data series)
* **Depth fraction ρ=8.5e-01 (Red):**
* Trend: Upward slope.
* Data points: Approximately (0.27, 0.605), (0.28, 0.635), (0.29, 0.645), (0.30, 0.655)
* Correlation Coefficient: r = 0.962 (located near the data series)
* **Depth fraction ρ=9.0e-01 (Pink):**
* Trend: Upward slope.
* Data points: Approximately (0.07, 0.635), (0.08, 0.650), (0.09, 0.660)
* Correlation Coefficient: r = 0.947 (located near the data series)
* **Depth fraction ρ=9.5e-01 (Teal):**
* Trend: Upward slope.
* Data points: Approximately (0.01, 0.625), (0.02, 0.640), (0.03, 0.650), (0.04, 0.660)
* Correlation Coefficient: r = 0.979 (located near the data series)
### Key Observations
* All four depth fraction series show a positive correlation between Deep-Thinking Ratio and Accuracy.
* The teal series (ρ=9.5e-01) and pink series (ρ=9.0e-01) are clustered at lower Deep-Thinking Ratio values compared to the blue (ρ=8.0e-01) and red (ρ=8.5e-01) series.
* The red series (ρ=8.5e-01) and blue series (ρ=8.0e-01) reach higher Deep-Thinking Ratio values.
* The correlation coefficients (r values) are high for all series, indicating a strong positive linear relationship.
### Interpretation
The data suggests that increasing the Deep-Thinking Ratio generally leads to higher accuracy, regardless of the depth fraction. However, the optimal Deep-Thinking Ratio and the extent of accuracy improvement may depend on the specific depth fraction used. The high correlation coefficients indicate a strong linear relationship between the two variables within the observed ranges. The clustering of the teal and pink series at lower Deep-Thinking Ratios might indicate a limitation or constraint in achieving higher ratios with those specific depth fractions. The shaded regions around each line indicate the uncertainty in the accuracy values for each depth fraction at different Deep-Thinking Ratios.
</details>
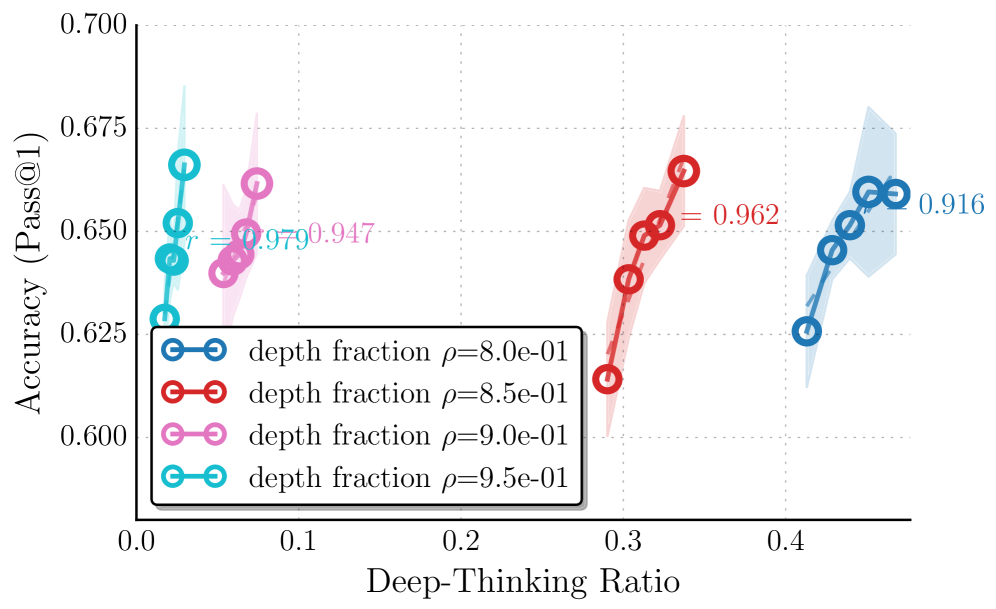
(b) Effect of different depth fraction $\rho$ .
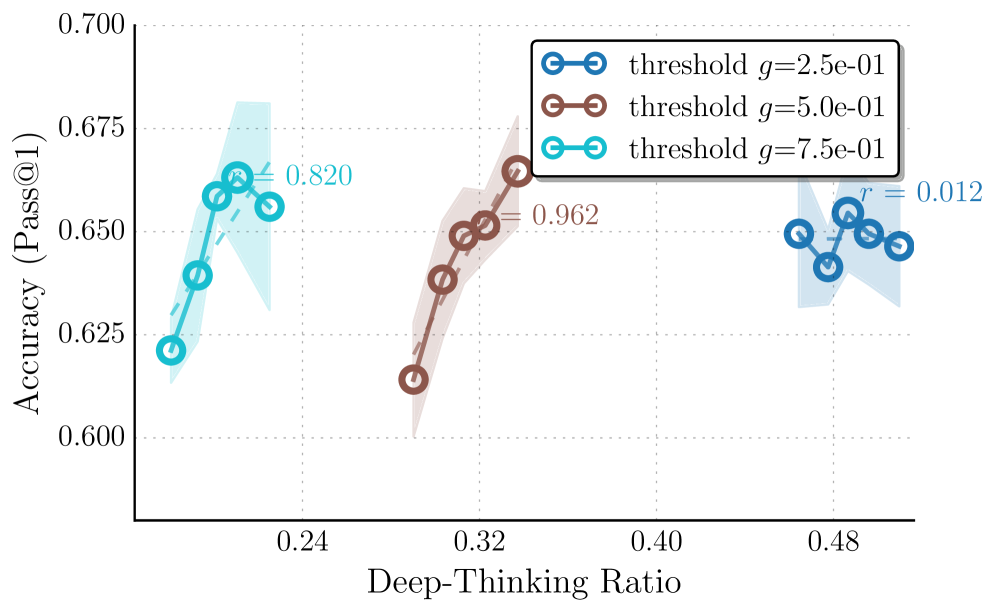
Figure 4: Effect of hyper-parameters on thinking effort measurement and accuracy profiles. We analyze the impact of hyper-parameters by sweeping different settling threshold $g$ and depth fraction $\rho$ . (a) Varying $g$ has more impacts the correlation; a permissive threshold ( $g=0.25$ ) yields flatter trends, whereas $g=0.5$ provides the most robust positive signal. (b) Varying $\rho$ shifts the range of thinking effort scores but maintains overall consistent positive slopes. Overall, stricter criteria (higher $g$ , lower $\rho$ ) reduce the range of DTR, with $(g,\rho)=(0.5,0.85)$ offering an ideal balance between stability and correlation.
We conduct an analysis to understand how our two key hyper-parameters—the settling threshold $g$ and the late-settling depth fraction $\rho$ —affect the measured thinking effort and its correlation with task performance. Figure ˜ 4 illustrates the accuracy profiles across varying thinking efforts (i.e., average late-settling token ratios), derived by $g∈\{0.25,0.5,0.75\}$ and $\rho∈\{0.8,0.85,0.9,0.95\}$ . We set $\rho$ fixed to $0.85$ , when sweeping $g$ , and $g$ fixed to $0.5$ when sweeping $\rho$ . We report results on GPQA-D using GPT-OSS-20B with reasoning level high.
We conclude the following observations: (1) the magnitude of the measured sequence-level thinking effort is directly influenced by the strictness of these parameters. Specifically, both Figures ˜ 4(a) and 4(b) show that imposing stricter criteria—a higher settling threshold $g$ or a lower depth fraction $\rho$ —results in a reduction of the average late-settling token ratio. This is mechanistically consistent: a higher $g$ requires the intermediate states to be distributionally far to the final output until reaching deeper layers in the late regime to be considered settle; while a lower $\rho$ restricts the definition of the late regime to a narrower band of deeper layers. Both conditions naturally filter out more candidates, resulting in fewer tokens being classified as late-settling and consequently a lower range of overall thinking effort scores.
(2) The settling threshold $g$ has a more pronounced impact on the correlation between thinking effort and accuracy than the depth fraction $\rho$ . As shown in Figure ˜ 4(b), varying $\rho$ shifts the range of late-settling ratios due to varying strictness but maintains a consistent, positive slope across all settings, indicating that the metric is relatively robust to the specific definition of the late layers. In contrast, Figure ˜ 4(a) reveals that the choice of $g$ has more impact on measured results: a softer threshold of $g=0.25$ yields a flatter trend with lower correlation value, suggesting that it may be overly permissive, including tokens with less computational efforts and diminishing the measurement’s ability to distinguish high-quality trajectory. Conversely, thresholds of $g=0.5$ and $g=0.75$ exhibit more robust positive correlations reflecting the accuracy.
(3) Overall, we can see that when the criteria are overly restrictive ( $g=0.75$ and $\rho∈\{0.9,0.95\}$ ), the trends, while still maintaining positive correlations, appears to be slightly more unstable due to the potential filtering of informative high computational tokens. Among the tested configurations, $(g,\rho)=(0.5,0.85)$ strikes an ideal balance, yielding a reliable trend with high correlation values.
4 Deep-Thinking Tokens Enable Efficient Test-Time Scaling
Repeated sampling is a popular strategy for scaling test-time compute, in parallel to generating long CoT [brown2024large-581, gupta2025test-time-19d, saad-falcon2024archon-cb5, stroebl2024inference-4ca, saad-falcon2025shrinking-bf7]. It improves accuracy by aggregating multiple independently generated samples per problem at the cost of increased inference budget. In this section, we explore whether our proposed DTR measure can be leveraged to preferentially select and aggregate higher-quality samples towards better performance.
Table 2: Comparison of task accuracy and average inference cost (k tokens) under different aggregation methods, across four reasoning benchmarks. The reported cost reductions ( $\Delta$ %) are shown relative to Cons@ $n$ . Think@ $n$ achieves the best overall performance while reducing inference cost by approximately 50%. Methods with ${\dagger}$ adopt a prefix length of 50 to determine early stopping.
| Method | AIME 25 | | AIME 24 | | HMMT 25 | | GPQA-D | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Acc | Cost ( $\Delta$ %) | | Acc | Cost ( $\Delta$ %) | | Acc | Cost ( $\Delta$ %) | | Acc | Cost ( $\Delta$ %) | |
| OSS-120B-medium | | | | | | | | | | | |
| Cons@ $n$ | 92.7 | 307.6 (–) | | 92.7 | 235.1 (–) | | 80.0 | 355.6 (–) | | 73.8 | 93.5 (–) |
| Mean@ $n$ | 80.0 | 307.6 (–) | | 81.6 | 235.1 (–) | | 62.6 | 355.6 (–) | | 69.9 | 93.5 (–) |
| Long@ $n$ | 86.7 | 307.6 (–) | | 86.7 | 235.1 (–) | | 73.3 | 355.6 (–) | | 73.2 | 93.5 (–) |
| Short@ $n$ | 87.3 | 255.7 (-17%) | | 88.0 | 200.9 (-15%) | | 77.3 | 290.4 (-18%) | | 73.3 | 84.4 (-10%) |
| Self-Certainty@ $n$ † | 87.3 | 150.6 (-51%) | | 91.3 | 119.3 (-49%) | | 78.0 | 177.0 (-50%) | | 76.0 | 47.9 (-49%) |
| Think@ $n$ † | 94.7 | 155.4 (-49%) | | 93.3 | 121.3 (-48%) | | 80.0 | 181.9 (-49%) | | 74.7 | 48.8 (-48%) |
| Qwen3-4B-Thinking | | | | | | | | | | | |
| Cons@ $n$ | 86.7 | 1073.1 (–) | | 93.3 | 950.1 (–) | | 63.3 | 1275.7 (–) | | 67.8 | 410.6 (–) |
| Mean@ $n$ | 81.2 | 1073.1 (–) | | 86.3 | 950.1 (–) | | 55.7 | 1275.7 (–) | | 66.9 | 410.6 (–) |
| Long@ $n$ | 85.3 | 1073.1 (–) | | 86.7 | 950.1 (–) | | 52.7 | 1275.7 (–) | | 66.7 | 410.6 (–) |
| Short@ $n$ | 90.0 | 983.6 (-8%) | | 90.0 | 871.0 (-8%) | | 63.3 | 1165.7 (-9%) | | 68.2 | 382.9 (-7%) |
| Self-Certainty@ $n$ † | 86.7 | 548.9 (-49%) | | 90.0 | 480.9 (-49%) | | 63.3 | 641.4 (-50%) | | 68.2 | 206.6 (-50%) |
| Think@ $n$ † | 90.0 | 537.5 (-50%) | | 93.3 | 482.2 (-49%) | | 66.7 | 641.4 (-50%) | | 69.7 | 206.8 (-50%) |
<details>
<summary>x6.png Details</summary>
### Visual Description
## Scatter Plots: Model Accuracy vs. Cost
### Overview
The image presents two scatter plots comparing the accuracy and cost (in tokens) of different reasoning strategies for two language models: OSS-120B-medium and Qwen3-4B-Thinking. Each data point represents a different reasoning strategy, with its color indicating the specific strategy.
### Components/Axes
**Left Plot (OSS-120B-medium):**
* **Title:** OSS-120B-medium
* **Y-axis:** Accuracy, ranging from approximately 0.72 to 0.84. Axis markers are present at 0.72, 0.76, 0.80, and 0.84.
* **X-axis:** Cost (tokens), ranging from approximately 1.5 x 10^5 to 2.5 x 10^5. Axis markers are present at 1.5 x 10^5 and 2.5 x 10^5.
* **Data Points/Reasoning Strategies:**
* Think@n (cyan): Approximately (1.4 x 10^5, 0.85)
* Self-Certainty@n (yellow): Approximately (1.4 x 10^5, 0.83)
* Cons@n (green): Approximately (2.4 x 10^5, 0.85)
* Short@n (purple): Approximately (2.2 x 10^5, 0.82)
* Long@n (pink): Approximately (2.4 x 10^5, 0.80)
* Mean@n (blue): Approximately (2.4 x 10^5, 0.73)
**Right Plot (Qwen3-4B-Thinking):**
* **Title:** Qwen3-4B-Thinking
* **Y-axis:** Accuracy, ranging from approximately 0.73 to 0.80. Axis markers are present at 0.73, 0.75, 0.78, and 0.80.
* **X-axis:** Cost (tokens), ranging from approximately 5 x 10^5 to 9 x 10^5. Axis markers are present at 5 x 10^5 and 9 x 10^5.
* **Data Points/Reasoning Strategies:**
* Think@n (cyan): Approximately (5 x 10^5, 0.80)
* Self-Certainty@n (yellow): Approximately (5 x 10^5, 0.77)
* Cons@n (green): Approximately (9 x 10^5, 0.78)
* Short@n (purple): Approximately (9 x 10^5, 0.78)
* Long@n (pink): Approximately (9 x 10^5, 0.73)
* Mean@n (blue): Approximately (9 x 10^5, 0.73)
### Detailed Analysis
**OSS-120B-medium:**
* The "Think@n" strategy has the highest accuracy and lowest cost among the strategies tested.
* "Mean@n" strategy has the lowest accuracy and a high cost.
* The other strategies ("Self-Certainty@n", "Cons@n", "Short@n", "Long@n") have intermediate accuracy and cost values.
**Qwen3-4B-Thinking:**
* The "Think@n" strategy has the highest accuracy and lowest cost among the strategies tested.
* "Mean@n" and "Long@n" strategies have the lowest accuracy and a high cost.
* The other strategies ("Self-Certainty@n", "Cons@n", "Short@n") have intermediate accuracy and cost values.
### Key Observations
* For both models, the "Think@n" strategy appears to be the most efficient, providing the highest accuracy at a relatively lower cost.
* The "Mean@n" strategy consistently shows the lowest accuracy for both models.
* The cost (tokens) is significantly higher for Qwen3-4B-Thinking compared to OSS-120B-medium across all reasoning strategies.
### Interpretation
The scatter plots illustrate the trade-off between accuracy and cost for different reasoning strategies applied to two language models. The data suggests that the choice of reasoning strategy can significantly impact both the accuracy and the computational cost (measured in tokens) of the model. The "Think@n" strategy seems to be a good choice for both models, offering a balance between accuracy and cost. The higher cost for Qwen3-4B-Thinking might indicate a more complex or resource-intensive reasoning process compared to OSS-120B-medium. The plots allow for a visual comparison of the efficiency of different reasoning approaches for each model.
</details>
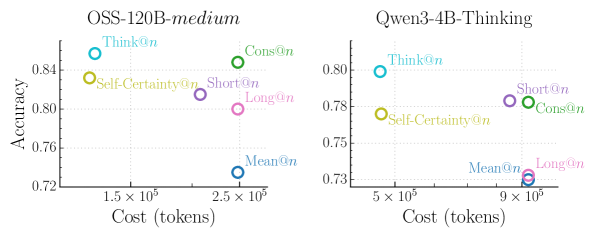
Figure 5: Comparison of the trade-off between task accuracy and inference cost (tokens) with different aggregation methods. Accuracy is averaged across all four datasets (AIME 24/25, HMMT 25, GPQA-D). Our Think@ $n$ method achieves the best overall Pareto-optimal performance. It matches or exceeds the accuracy of Cons@n with approximately half the inference cost, while Self-Certainty@ $n$ is notably less efficient.
Table 3: Impact of prefix length ( $\ell_{\text{prefix}}$ ) on Think@ $n$ performance and inference cost for AIME 2025. Using a short prefix of 50 tokens to estimate DTR outperforms using longer ones, and is comparable to full sequence (all) while providing significant cost savings. We also report Pass@1 and Cons@ $n$ for reference. Subscripts denote the standard deviation across 10 trials.
| | Accuracy | Cost (k tokens) |
| --- | --- | --- |
| Pass@1 | 80.0 4.2 | 6.4 |
| Cons@ $n$ | 90.0 2.5 | 307.6 |
| Think@ $n$ | | |
| Prefix length | | |
| 50 | 94.7 1.6 | 155.4 |
| 100 | 92.0 1.6 | 154.1 |
| 500 | 92.7 1.3 | 153.2 |
| 1000 | 92.7 1.3 | 177.4 |
| 2000 | 92.0 1.3 | 198.8 |
| all | 94.0 0.3 | 307.6 |
Experimental setups.
We follow the best-of-n (BoN) evaluation protocol commonly adopted in recent test-time scaling studies [fu2025deep]. For each problem, we sample $n$ responses using identical decoding settings, and compare the following aggregation methods: Cons@ $n$ : Standard self-consistency [wang2023selfconsistency], which performs majority voting over all $n$ sampled responses; Mean@ $n$ : The average accuracy of all the $n$ samples, reflecting a baseline of no preferential aggregation; Long@ $n$ and Short@ $n$ : Majority voting over the longest/shortest $\eta$ percent of the $n$ samples, ranked by token count [hassid2025don, agarwal2025first]. Self-Certainty@ $n$ : Majority voting over the highest-scoring $\eta$ percent of the $n$ samples, ranked by Self-Certainty score (the best-performing baseline in Section ˜ 3); Think@ $n$ : Majority voting over the highest-scoring $\eta$ percent of the $n$ samples, ranked by DTR $(·)$ . All methods operate on the same pool of $n$ samples. We set $n=48$ and $\eta=50\%$ . More analysis are provided in Appendix ˜ C. The results are averaged across 10 trials.
Results.
We report the results in Table ˜ 2. To compare efficiency, we explicitly account for early stopping for Short@ $n$ , Self-Certainty@ $n$ , and Think@ $n$ , which aggregate only a subset of samples. Specifically, we report the average per-problem inference cost, measured as the total number of generated tokens, under the following protocols.
For Cons@ $n$ and Mean@ $n$ , the inference cost is defined as the sum of token counts across all $n$ sampled responses= (i.e., $\sum_{i=1}^{n}|S_{i}|$ ) corresponding to full decoding without early stopping. For Short@ $n$ , we rank samples by their length and select the shortest $\eta× n$ samples. The inference cost is computed as the sum of the token count of the selected samples, plus an early-stopping overhead equal to $\ell_{\text{longest\_short}}×\eta× n$ , where $\ell_{\text{short}}$ denotes the length of the longest sample among the selected shortest subset. This term accounts for partially generated samples that are terminated once subset generation completes (i.e., bounded by $\ell_{\text{longest\_short}}$ ). The inference cost for Long@ $n$ is the same as Cons@ $n$ and Mean@ $n$ as it requires full decoding to select longest samples. For Think@ $n$ , samples are ranked by DTR, computed from a fixed prefix. Let $\ell_{\text{prefix}}$ denote the number of prefix tokens used to estimate $\mathrm{DTR}(S[:\ell_{\text{prefix}}])$ . The inference cost is defined as the total token count of the top $\eta× n$ ranked samples, plus a fixed prefix overhead of $\ell_{\text{prefix}}×\eta× n$ , which reflects the cost of generating all candidates prior to early termination. Self-Certainty@ $n$ follows the same cost computation as Think@ $n$ , differing only in that samples are ranked by $\mathrm{Self\text{-}Certainty}(S[:\ell_{\text{prefix}}])$ rather than $\mathrm{DTR}(S[:\ell_{\text{prefix}}])$ .
Table ˜ 3 reports a preliminary ablation on AIME 25 that varies $\ell_{\text{prefix}}$ . We find that using only $\ell_{\text{prefix}}=50$ tokens achieves higher accuracy than longer prefixes and matches the performance obtained using the full sequence, while significantly reducing inference cost. Accordingly, we fix $\ell_{\text{prefix}}=50$ for all experiments in Table ˜ 2.
As shown, Cons@ $n$ incurs the highest inference cost due to full decoding of every candidate, while providing a strong accuracy baseline. Mean@ $n$ has the same cost as Cons@ $n$ but is the worst-performing one among all methods. Under early stopping, Short@ $n$ achieves modest cost savings relative to Cons@ $n$ , yet consistently underperforms it in accuracy. Long@ $n$ exhibits further degraded performance compared to Short@ $n$ without offering any cost-saving benefits. This indicates that length-based heuristics remain a coarse proxy for reasoning quality and often fail to reliably identify high-quality samples, leading to suboptimal aggregations. Self-Certainty@ $n$ substantially reduces inference cost by enabling early stopping using short prefixes, but nonetheless underperforms both Cons@ $n$ and Think@ $n$ on three of the four evaluated benchmarks. In contrast, Think@ $n$ consistently matches or exceeds the accuracy of Cons@ $n$ while requiring approximately half the inference cost. The Pareto-optimal performance is most evident in the averaged results shown in Figure ˜ 5, where Think@ $n$ achieves the best overall accuracy-cost trade-off. In sum, these results demonstrate that DTR provides a more informative and reliable selection signal, enabling efficient parallel scaling of inference compute.
5 Related Work
5.1 Relationship between CoT Length and Performance
The paradigm of test-time scaling has largely operated on the assertion that allocating more computation, typically manifested as longer CoT sequences, boosts reasoning performance wei2022chain-d1a, guo2025deepseek, muennighoff2025s1. Recent empirical studies have highlighted nuances to the universality of this “longer is better” heuristic [feng2025what-321, wu2025when-905]. gema2025inverse-bad identify inverse scaling regimes where increased reasoning length systematically degrades accuracy across diverse tasks, particularly when models are prone to distraction. Similarly, wu2025when-905 characterize the relationship between CoT length and accuracy as an “inverted-U” curve, suggesting an optimal length exists beyond which performance deteriorates due to factors like error accumulation.
Several works have proposed methods to exploit corresponding observations by favoring conciseness. hassid2025don demonstrated that the shortest reasoning chains among sampled candidates are often the most accurate, proposing inference-time length-based voting for efficient generations. A close work by agarwal2025first also introduced a training-free strategy that selects the first completed trace in parallel decoding, reducing token usage while maintaining accuracy. On the training side, shrivastava2025sample proposed Group Filtered Policy Optimization (GFPO) to explicitly curb length inflation in RL by rejection sampling that filters longer responses, demonstrating that models can think less without sacrificing performance. Our work aligns with these perspectives by confirming that raw token count is an unreliable proxy for effective reasoning effort, but we diverge by proposing a mechanistic internal signal rather than simply relying on surface-level brevity heuristics.
5.2 Leveraging Internal Information in LLMs
A rich line of work has investigated how LMs internally represent and manipulate information across layers, and how internal states can be exploited. Central to this direction is the observation that intermediate representations in LMs often encode meaningful signals before reaching the final layer. Early evidence for this view was provided by nostalgebraist2020lens, which projects intermediate hidden states directly into the vocabulary space using the model’s unembedding matrix—a technique we adopt in our work. The results reveal that autoregressive transformers form coarse guesses about the next token that are iteratively refined across layers. Subsequent analyses [belrose2023eliciting] further introduce learned, layer-specific affine transformations that better align intermediate representations with the final prediction space, enabling more interpretable token predictions in shallower layers.
Beyond model probing, chuang2023dola-0c6 exploits the empirical finding that factual knowledge in LMs is often more salient in particular layers. By contrasting logits from higher and lower layers, they propose a decoding method that amplifies factual signals and improves factuality. A recent work by vilas2025tracing-3dc introduces latent-trajectory signals characterizing the temporal evolution of hidden states across generated reasoning traces to predict correctness. While the work examines the sequential dimension of representations, our work focuses on the depth-wise evolution of predictions across layers for individual tokens.
Complementary interpretability works also revisit how LLMs utilize depth at inference. gupta2025how-6d8 shows that early layers tend to favor high-frequency, generic token guesses, which are subsequently refined into contextually appropriate predictions. csords2025do-6d4 suggest that later layers primarily perform fine-grained distributional refinement rather than introducing fundamentally new transformations, raising questions about the efficiency of depth utilization in modern LLMs. These findings reinforce the view that internal predictions may stabilize before the final layer, aligning with our motivations. Overall, our goal is not to modify or construct internal states to develop new methods aimed at improving model capabilities. Instead, we leverage natural, unaltered internal representations as a proxy for measuring model computational effort, which implicitly reflects thinking effort in LLMs.
6 Conclusion
We introduced deep-thinking ratio (DTR) as a novel measure of inference-time reasoning effort in LLMs. By tracking depth-wise stabilization of token predictions, DTR provides a more reliable signal of effective reasoning than surface-level proxies such as token length or confidence. Building on this insight, we proposed Think@ $n$ , a test-time scaling strategy that leverages DTR for early selection and aggregation, achieving comparable or better performance than standard self-consistency while substantially reducing inference cost. Together, our results suggest that measuring how models think internally, rather than how long they think, is a promising direction. Future work may leverage this insight to explore how effective reasoning is characterized—shifting the focus from generating longer chains of thought to inducing deeper, more computationally intensive reasoning, and potentially enabling more reliable and efficient reasoning models.
Acknowledgements
We thank Congchao Wang and colleagues from Google AIR for their valuable support. We also thank Yu-Min Tseng from Virginia Tech and members of Meng-Lab at UVA for their helpful discussion.
References
Appendix A Comparison of Different Distance Metrics for DTR
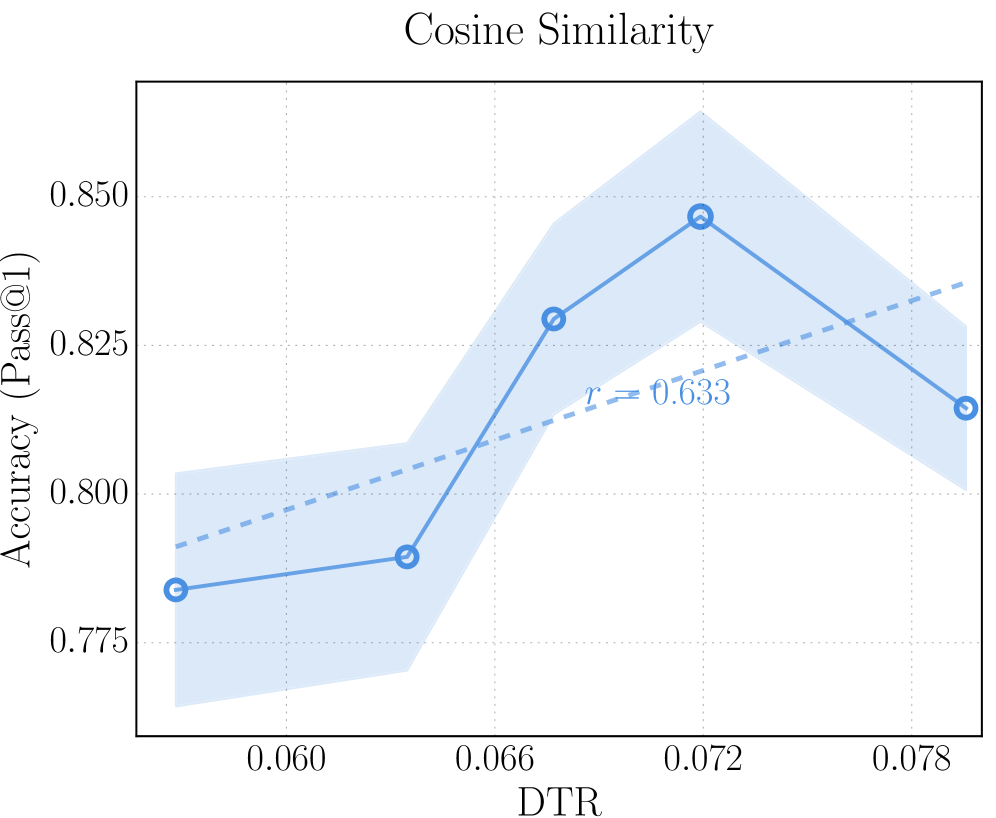
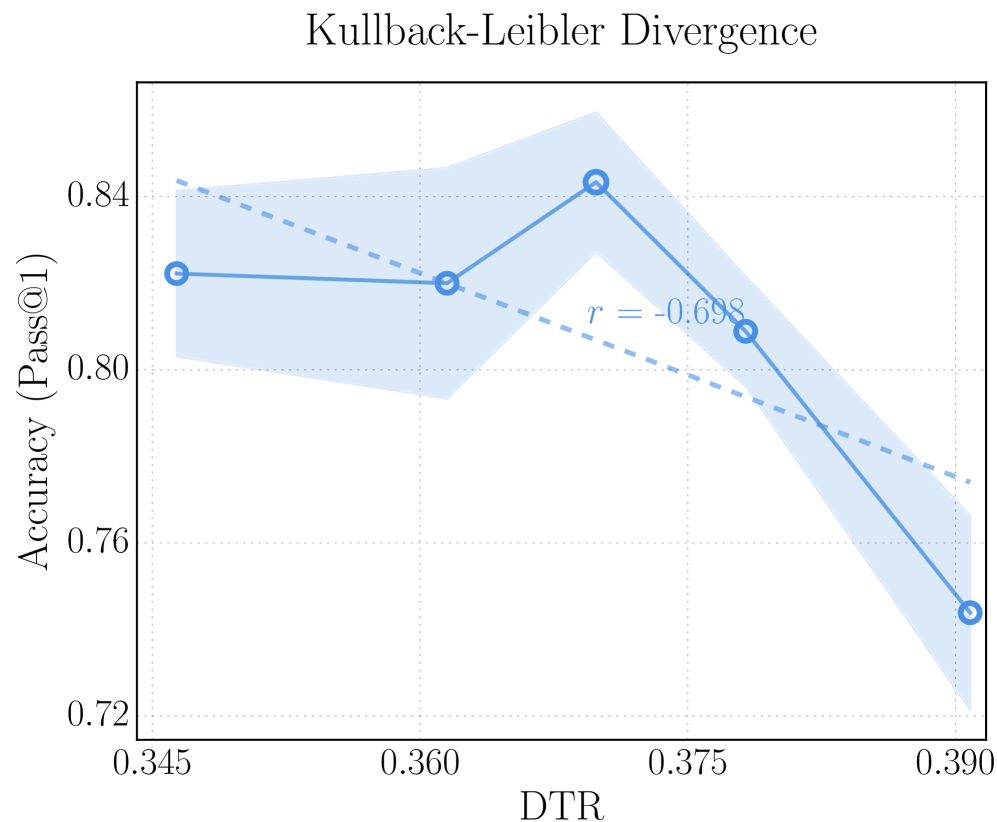
Our method (Section ˜ 2) adopts Jensen–Shannon divergence (JSD) to quantify the discrepancy between intermediate-layer and final-layer predictions and compute DTR. Alternative notions of distance are possible. Here we explore two additional metrics: Kullback–Leibler divergence (KLD) and cosine similarity. The results are presented in Figure ˜ 6.
Kullback–Leibler divergence.
By replacing JSD with KLD in Equation ˜ 2, we compute the divergence between the final-layer distribution $p_{t,L}$ and the intermediate-layer distribution $p_{t,l}$ as
$$
\displaystyle D^{\text{KL}}_{t,l}=\mathrm{KL}(p_{t,L}\,\|\,p_{t,l}) \tag{11}
$$
Cosine similarity.
We replace the distributional comparison defined in Section ˜ 2.2 with a representation-space measure using cosine similarity. Instead of projecting intermediate-layer hidden states into the vocabulary space via the shared unembedding matrix $W_{U}$ (Equation ˜ 1), we directly compute the cosine similarity between the intermediate-layer hidden state $h_{t,l}$ and the final-layer hidden state $h_{t,L}$ . The distance is defined as
$$
\displaystyle D^{\text{cos}}_{t,l}=1-\frac{\langle h_{t,l},h_{t,L}\rangle}{\|h_{t,l}\|\|h_{t,L}\|} \tag{12}
$$
For both KLD and cosine similarity, we then apply the same configurations in Section ˜ 2.2 to identify deep-thinking tokens and compute KLD-based DTR and cosine-based DTR.
Results.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Chart: Cosine Similarity vs. DTR
### Overview
The image is a line chart showing the relationship between "DTR" (x-axis) and "Accuracy (Pass@1)" (y-axis). The chart includes a solid blue line representing the accuracy at different DTR values, a shaded blue area around the line indicating uncertainty, and a dashed blue line representing a linear regression fit. The title of the chart is "Cosine Similarity".
### Components/Axes
* **Title:** Cosine Similarity
* **X-axis:** DTR (values: 0.060, 0.066, 0.072, 0.078)
* **Y-axis:** Accuracy (Pass@1) (values: 0.775, 0.800, 0.825, 0.850)
* **Data Series 1:** Accuracy vs. DTR (solid blue line with circular markers)
* **Uncertainty:** Shaded blue area around the accuracy line
* **Linear Regression:** Dashed blue line
* **Correlation Coefficient:** r = 0.633
### Detailed Analysis
* **X-axis (DTR):** The x-axis ranges from approximately 0.057 to 0.081, with major tick marks at 0.060, 0.066, 0.072, and 0.078.
* **Y-axis (Accuracy (Pass@1)):** The y-axis ranges from approximately 0.77 to 0.86, with major tick marks at 0.775, 0.800, 0.825, and 0.850.
* **Accuracy vs. DTR Data Series:**
* At DTR = 0.060, Accuracy is approximately 0.782.
* At DTR = 0.066, Accuracy is approximately 0.785.
* At DTR = 0.072, Accuracy is approximately 0.828.
* At DTR = 0.078, Accuracy is approximately 0.845.
* At DTR = 0.081, Accuracy is approximately 0.812.
* **Trend of Accuracy:** The accuracy generally increases from DTR 0.060 to 0.072, then decreases from 0.072 to 0.078.
* **Linear Regression:** The dashed blue line shows a positive correlation between DTR and Accuracy.
* **Correlation Coefficient:** The correlation coefficient (r) is 0.633, indicating a moderate positive correlation.
### Key Observations
* The accuracy peaks at a DTR value of approximately 0.072.
* The uncertainty (shaded area) varies with DTR, being wider at some points than others.
* The linear regression line suggests a general positive trend, but the actual data points deviate from this line, especially around DTR = 0.072.
### Interpretation
The chart suggests that there is a relationship between DTR and Accuracy (Pass@1) based on Cosine Similarity. The accuracy initially increases with DTR, reaches a peak, and then decreases. The positive correlation coefficient (r = 0.633) indicates a moderate positive linear relationship, but the non-linear trend of the data suggests that a linear model may not fully capture the relationship between DTR and Accuracy. The shaded area represents the uncertainty in the accuracy measurement, which could be due to various factors such as data variability or measurement error. The peak in accuracy at a specific DTR value (around 0.072) could indicate an optimal setting for the system being evaluated.
</details>
(a) Cosine similarity as the distance metric on AIME 25.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Chart: Kullback-Leibler Divergence
### Overview
The image is a line chart titled "Kullback-Leibler Divergence". It plots "Accuracy (Pass@1)" on the y-axis against "DTR" on the x-axis. The chart displays a solid blue line with circular markers, representing the primary data series, along with a shaded blue region around the line, indicating uncertainty. A dashed blue line represents a secondary trend. The chart also includes the correlation coefficient 'r = -0.698'.
### Components/Axes
* **Title:** Kullback-Leibler Divergence
* **X-axis:**
* Label: DTR
* Scale: 0.345, 0.360, 0.375, 0.390
* **Y-axis:**
* Label: Accuracy (Pass@1)
* Scale: 0.72, 0.76, 0.80, 0.84
* **Data Series 1:** Solid blue line with circular markers and shaded region.
* **Data Series 2:** Dashed blue line.
* **Correlation Coefficient:** r = -0.698
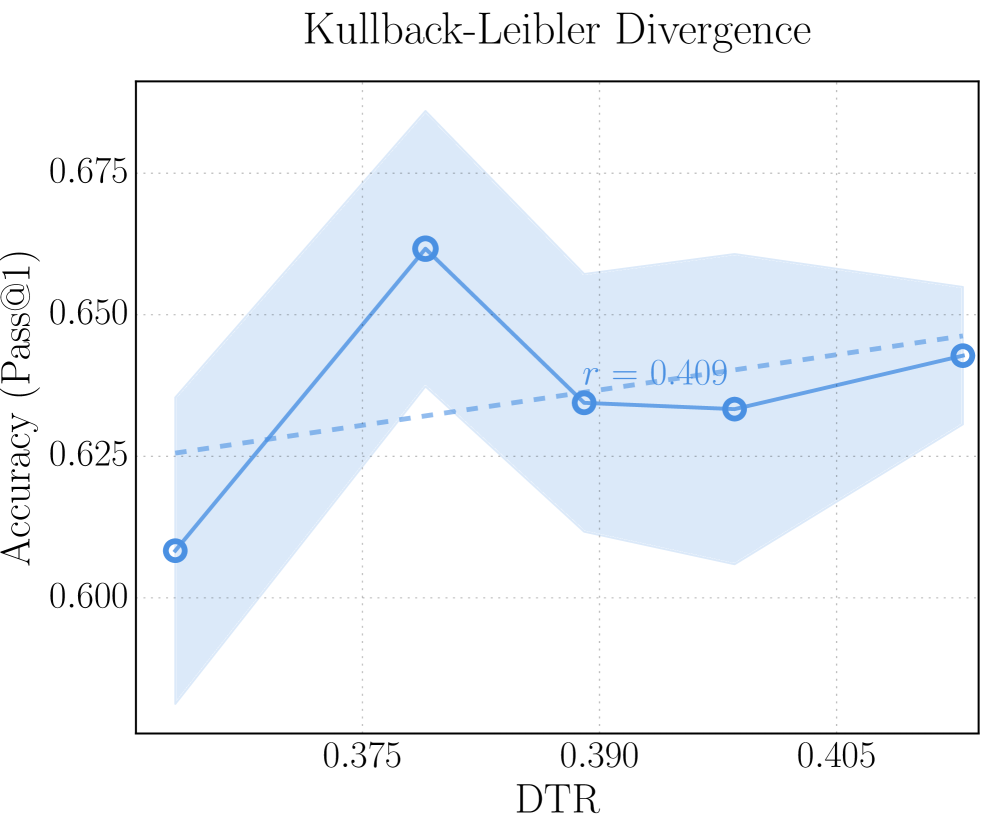
### Detailed Analysis
* **Data Series 1 (Solid Blue Line):**
* Trend: Initially relatively flat, then increases, then decreases.
* Data Points:
* At DTR = 0.345, Accuracy = 0.825 (+/- 0.005)
* At DTR = 0.360, Accuracy = 0.825 (+/- 0.005)
* At DTR = 0.375, Accuracy = 0.842 (+/- 0.005)
* At DTR = 0.390, Accuracy = 0.809 (+/- 0.005)
* At DTR = 0.390, Accuracy = 0.745 (+/- 0.005)
* **Data Series 2 (Dashed Blue Line):**
* Trend: Decreasing.
* Approximate Data Points:
* At DTR = 0.345, Accuracy = 0.840 (+/- 0.005)
* At DTR = 0.390, Accuracy = 0.770 (+/- 0.005)
### Key Observations
* The solid blue line shows a peak in accuracy around DTR = 0.375.
* The dashed blue line shows a negative correlation between DTR and accuracy.
* The shaded region around the solid blue line indicates the uncertainty associated with the accuracy values.
* The correlation coefficient 'r = -0.698' suggests a moderate negative correlation between DTR and the dashed blue line's accuracy.
### Interpretation
The chart illustrates the relationship between DTR and accuracy, as measured by Pass@1. The solid blue line represents the observed accuracy, while the shaded region represents the uncertainty in those measurements. The dashed blue line represents a trend line, and the negative correlation coefficient suggests that as DTR increases, the trend line accuracy tends to decrease. The peak in the solid blue line indicates an optimal DTR value around 0.375 for maximizing accuracy. The divergence between the solid and dashed lines suggests that the actual accuracy deviates from the overall trend, particularly at DTR values around 0.375.
</details>
(b) KL divergence as the distance metric on AIME 25.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Chart: Jensen-Shannon Divergence vs. Accuracy
### Overview
The image is a line chart showing the relationship between Jensen-Shannon Divergence (DTR) and Accuracy (Pass@1). The chart includes a solid blue line representing the accuracy trend, a shaded blue area indicating uncertainty, and a dashed blue line representing a linear fit.
### Components/Axes
* **Title:** Jensen-Shannon Divergence
* **X-axis:** DTR (Domain Transfer Ratio)
* Scale: 0.150, 0.165, 0.180
* **Y-axis:** Accuracy (Pass@1)
* Scale: 0.70, 0.75, 0.80, 0.85
* **Data Series:**
* Accuracy (Pass@1) - Solid blue line with shaded uncertainty area.
* Linear Fit - Dashed blue line.
* **Annotation:** r ≈ 0.869 (located near the dashed blue line)
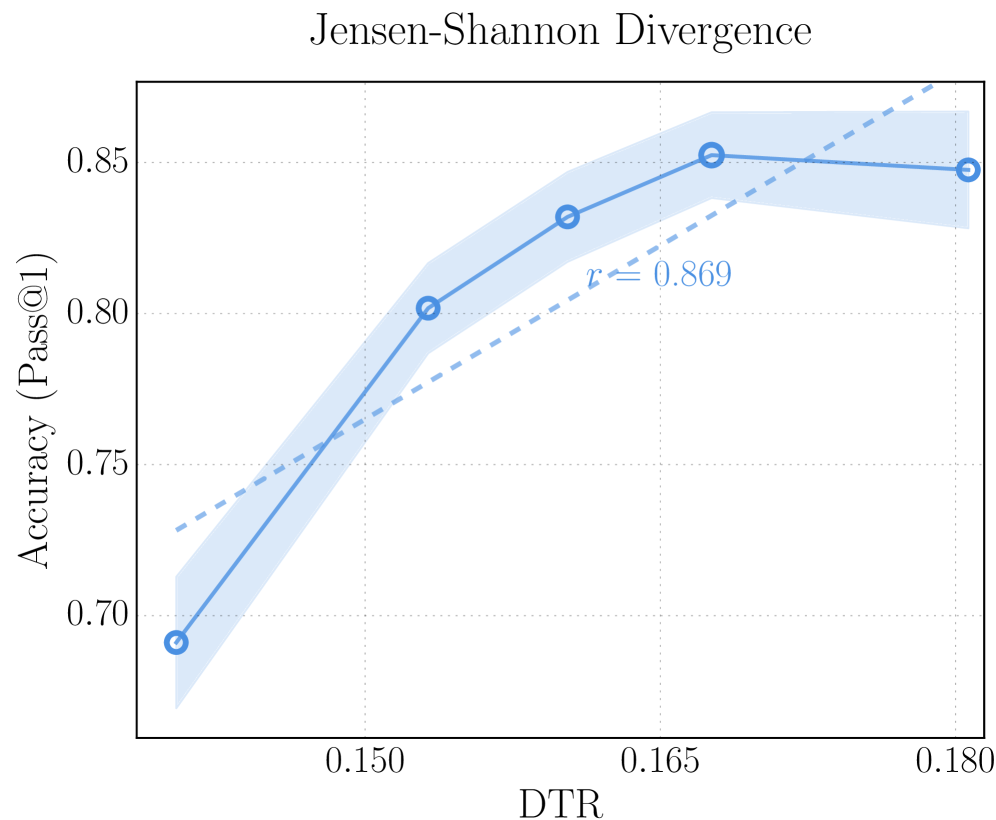
### Detailed Analysis
* **Accuracy (Pass@1) Trend:** The solid blue line shows an upward trend initially, then plateaus and slightly decreases.
* At DTR = 0.140 (estimated), Accuracy ≈ 0.69
* At DTR = 0.150, Accuracy ≈ 0.80
* At DTR = 0.165, Accuracy ≈ 0.83
* At DTR = 0.180, Accuracy ≈ 0.85
* **Linear Fit Trend:** The dashed blue line shows a consistent upward trend.
* At DTR = 0.140 (estimated), Linear Fit ≈ 0.73
* At DTR = 0.180, Linear Fit ≈ 0.87
* **Uncertainty:** The shaded blue area around the solid blue line represents the uncertainty in the accuracy measurements. The uncertainty appears to increase as DTR increases.
### Key Observations
* The accuracy increases sharply between DTR values of 0.140 and 0.150, then the rate of increase slows down.
* The linear fit (dashed line) does not perfectly match the accuracy trend, especially at higher DTR values where the accuracy plateaus.
* The annotation "r ≈ 0.869" likely represents the correlation coefficient between DTR and Accuracy, indicating a strong positive correlation.
### Interpretation
The chart suggests that there is a positive relationship between Jensen-Shannon Divergence (DTR) and Accuracy (Pass@1), but the relationship is not perfectly linear. Initially, increasing the DTR leads to a significant improvement in accuracy. However, beyond a certain point (around DTR = 0.165), further increases in DTR do not result in substantial gains in accuracy, and the accuracy even appears to slightly decrease. The uncertainty in the accuracy measurements also increases with DTR, suggesting that the relationship becomes less predictable at higher DTR values. The linear fit provides a general approximation of the relationship, but it does not capture the plateauing effect observed in the accuracy trend.
</details>
(c) JS divergence as the distance metric on AIME 25.
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Chart: Cosine Similarity
### Overview
The image is a line chart titled "Cosine Similarity". It plots "Accuracy (Pass@1)" on the y-axis against "DTR" on the x-axis. The chart displays a primary data series represented by a solid blue line with circular markers, along with a shaded blue region indicating uncertainty. A secondary, dashed blue line represents a linear trend with a correlation coefficient (r) of 0.172.
### Components/Axes
* **Title:** Cosine Similarity
* **X-axis:**
* Label: DTR
* Scale: 0.060, 0.066, 0.072, 0.078
* **Y-axis:**
* Label: Accuracy (Pass@1)
* Scale: 0.56, 0.60, 0.64, 0.68
* **Data Series 1:** Solid blue line with circular markers and shaded uncertainty region.
* **Data Series 2:** Dashed blue line, representing a linear trend.
* **Correlation Coefficient:** r = 0.172, positioned near the dashed blue line.
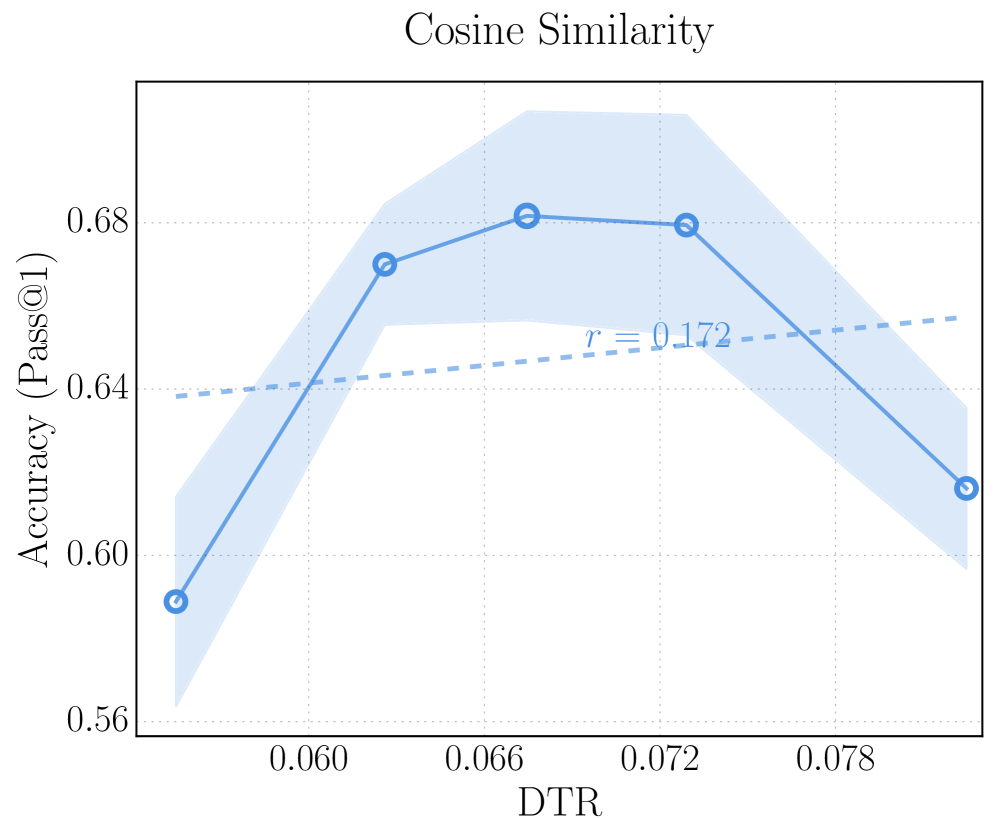
### Detailed Analysis
* **Data Series 1 (Solid Blue Line):**
* Trend: Initially increases, plateaus, then decreases.
* Data Points:
* DTR = 0.054, Accuracy = 0.59 (approximate)
* DTR = 0.063, Accuracy = 0.67 (approximate)
* DTR = 0.069, Accuracy = 0.68 (approximate)
* DTR = 0.073, Accuracy = 0.68 (approximate)
* DTR = 0.082, Accuracy = 0.62 (approximate)
* **Data Series 2 (Dashed Blue Line):**
* Trend: Slightly increasing linear trend.
* Start Point: Approximately (0.054, 0.64)
* End Point: Approximately (0.082, 0.65)
* **Uncertainty Region:** Shaded blue region around the solid blue line, indicating the variability or confidence interval associated with the primary data series. The width of the shaded region varies, suggesting differing levels of uncertainty at different DTR values.
### Key Observations
* The accuracy peaks around a DTR value of 0.069 to 0.073.
* The uncertainty (shaded region) is wider at the beginning and end of the DTR range.
* The linear trend line (dashed blue) has a weak positive correlation (r = 0.172).
### Interpretation
The chart illustrates the relationship between DTR and accuracy, as measured by Pass@1. The primary data series suggests that there is an optimal DTR value for maximizing accuracy, with performance decreasing beyond that point. The shaded region highlights the uncertainty in the accuracy measurements, which is greater at the extremes of the DTR range. The weak positive correlation indicated by the dashed line suggests a slight overall tendency for accuracy to increase with DTR, but this trend is not strongly supported by the data. The peak in accuracy suggests that a balance must be struck in the DTR value to achieve optimal performance.
</details>
(d) Cosine similarity as the distance metric on HMMT 25.
<details>
<summary>x11.png Details</summary>
### Visual Description
## Chart: Kullback-Leibler Divergence
### Overview
The image is a line chart titled "Kullback-Leibler Divergence". It plots "Accuracy (Pass@1)" on the y-axis against "DTR" on the x-axis. The chart displays a blue line with circular markers indicating data points, along with a shaded blue region around the line, presumably representing a confidence interval or standard deviation. A dashed blue line indicates a linear regression fit, with an 'r' value (correlation coefficient) displayed.
### Components/Axes
* **Title:** Kullback-Leibler Divergence
* **X-axis:**
* Label: DTR
* Scale: 0.375, 0.390, 0.405
* **Y-axis:**
* Label: Accuracy (Pass@1)
* Scale: 0.600, 0.625, 0.650, 0.675
* **Data Series:**
* Solid Blue Line: Represents the primary data series.
* Shaded Blue Region: Represents the uncertainty or variance around the primary data series.
* Dashed Blue Line: Represents a linear regression fit to the data.
* **Correlation Coefficient:** r = 0.409
### Detailed Analysis
* **X-axis (DTR) values:** 0.375, 0.390, 0.405
* **Y-axis (Accuracy (Pass@1)) values:**
* At DTR = 0.375, Accuracy ≈ 0.610
* At DTR = 0.375, Accuracy ≈ 0.665
* At DTR = 0.390, Accuracy ≈ 0.635
* At DTR = 0.405, Accuracy ≈ 0.635
* At DTR = 0.405, Accuracy ≈ 0.645
* **Trend of the Solid Blue Line:** The line initially increases sharply from DTR 0.375 to 0.375, then decreases to DTR 0.390, remains relatively flat until DTR 0.405, and then increases slightly.
* **Trend of the Dashed Blue Line:** The dashed blue line shows a slight upward trend, indicating a weak positive correlation.
* **Correlation Coefficient:** The correlation coefficient 'r' is 0.409, indicating a moderate positive correlation between DTR and Accuracy (Pass@1).
### Key Observations
* The accuracy peaks at DTR = 0.375, then decreases and stabilizes.
* The shaded region indicates the uncertainty is higher at the beginning and end of the DTR range.
* The correlation coefficient suggests a weak positive linear relationship.
### Interpretation
The chart explores the relationship between DTR and Accuracy (Pass@1) using Kullback-Leibler Divergence. The initial increase in accuracy suggests that increasing DTR initially improves performance. However, after a certain point (around 0.375 DTR), further increases in DTR do not lead to significant improvements in accuracy, and may even decrease it. The shaded region highlights the variability in accuracy at different DTR values. The correlation coefficient of 0.409 indicates a moderate positive linear relationship, but the non-linear trend of the data suggests that a linear model may not fully capture the relationship between DTR and accuracy.
</details>
(e) KL divergence as the distance metric on HMMT 25.
<details>
<summary>x12.png Details</summary>
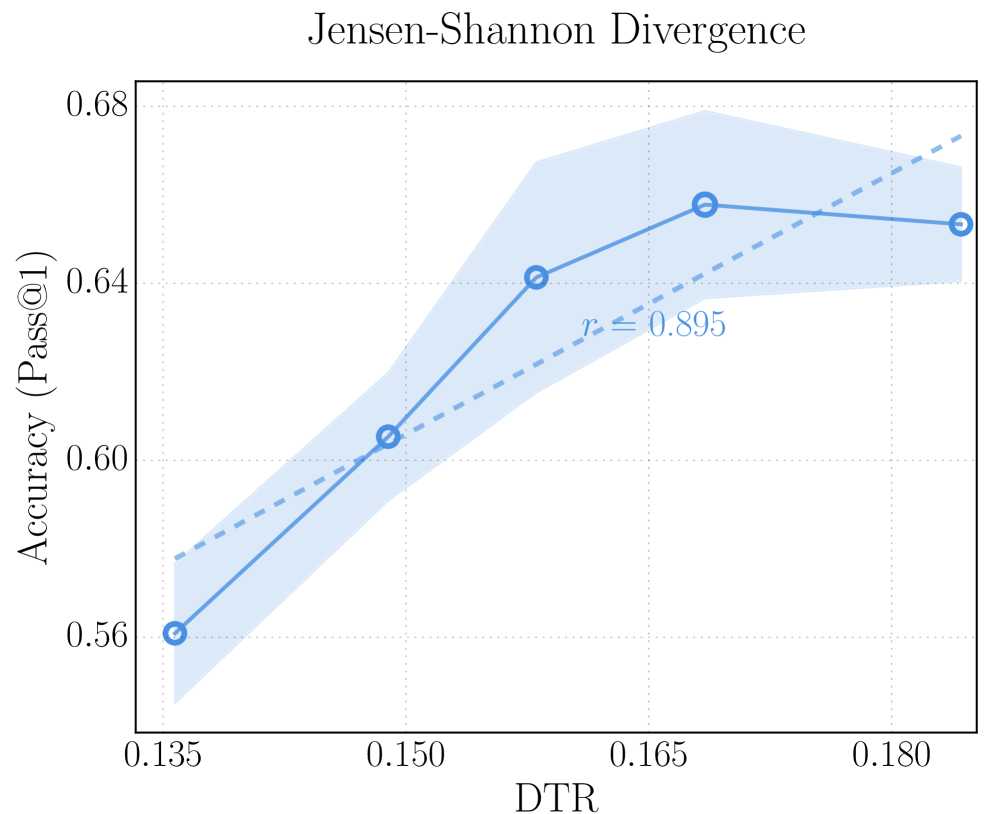
### Visual Description
## Line Chart: Jensen-Shannon Divergence
### Overview
The image is a line chart titled "Jensen-Shannon Divergence". It plots the relationship between "DTR" on the x-axis and "Accuracy (Pass@1)" on the y-axis. The chart includes a solid blue line representing the data, a shaded blue area around the line indicating uncertainty, and a dashed blue line representing a linear trend.
### Components/Axes
* **Title:** Jensen-Shannon Divergence
* **X-axis:** DTR (Decomposition Tree Rank)
* Scale: 0.135 to 0.180
* Markers: 0.135, 0.150, 0.165, 0.180
* **Y-axis:** Accuracy (Pass@1)
* Scale: 0.56 to 0.68
* Markers: 0.56, 0.60, 0.64, 0.68
* **Data Series:**
* Solid Blue Line: Represents the accuracy at different DTR values.
* Shaded Blue Area: Indicates the uncertainty or variance around the accuracy values.
* Dashed Blue Line: Represents a linear trend line.
* **Correlation Coefficient:** r ≈ 0.895, located near the center of the chart.
### Detailed Analysis
* **Solid Blue Line (Accuracy):**
* At DTR = 0.135, Accuracy ≈ 0.56
* At DTR = 0.150, Accuracy ≈ 0.605
* At DTR = 0.165, Accuracy ≈ 0.66
* At DTR = 0.180, Accuracy ≈ 0.65
* Trend: The accuracy generally increases from DTR 0.135 to 0.165, then slightly decreases from 0.165 to 0.180.
* **Shaded Blue Area (Uncertainty):**
* The shaded area widens as DTR increases, suggesting greater uncertainty at higher DTR values.
* **Dashed Blue Line (Linear Trend):**
* The dashed line shows a positive linear trend, indicating a general increase in accuracy as DTR increases.
* The dashed line starts at approximately (0.135, 0.58) and ends at approximately (0.180, 0.67).
### Key Observations
* The accuracy increases significantly between DTR values of 0.135 and 0.165.
* The accuracy plateaus or slightly decreases after a DTR of 0.165.
* The uncertainty increases with higher DTR values.
* The correlation coefficient (r ≈ 0.895) indicates a strong positive correlation between DTR and accuracy.
### Interpretation
The chart suggests that increasing the Decomposition Tree Rank (DTR) initially leads to a significant improvement in accuracy (Pass@1). However, after a certain point (around DTR = 0.165), the accuracy plateaus, and further increases in DTR do not result in substantial gains. The increasing uncertainty at higher DTR values suggests that the model's performance becomes less predictable as DTR increases. The strong positive correlation coefficient supports the overall trend of increasing accuracy with increasing DTR, but the plateauing effect indicates diminishing returns.
</details>
(f) JS divergence as the distance metric on HMMT 25.
Figure 6: Comparison of correlation between accuracy and deep-thinking ratio (DTR) using different distance metrics (cosine similarity, KL divergence, and JS divergence) on AIME 25 (top row) and HMMT 25 (bottom row).
We report the correlation results of KLD-based and cosine-based DTR, compared with our main JSD-based DTR method, on AIME 25 and HMMT 25 using OSS-120B- medium. Across both datasets, JSD-based DTR consistently achieves the strongest positive correlation with accuracy ( $r$ = 0.869 on AIME 25; $r$ = 0.895 on HMMT 25), justifying its use in our definition of DTR in Section ˜ 2. In contrast, cosine-based DTR exhibits substantially weaker and unstable correlations ( $r$ = 0.633 on AIME 25 and only $r$ = 0.172 on HMMT 25). KLD-based DTR shows similarly inconsistent behavior, with a negative correlation on AIME 25 ( $r$ = -0.698) and a modest positive correlation on HMMT 25 ( $r$ = 0.409). This inconsistency may stem from the asymmetric and numerically unstable nature of KLD: early-layer predictions tend to be high-entropy and relatively flat, assigning probability mass to many tokens that are later driven to near-zero values. Consequently, KLD can become artificially small, making the measure highly sensitive.
Appendix B DTR Under Different GPT-OSS Reasoning Levels
Figure ˜ 7 illustrates how DTR varies in different reasoning-level configurations (i.e., low, medium, and high) of the GPT-OSS-120B model. We observe an interesting and consistent trend on both AIME 25 and GPQA-D: although the underlying model weights remain identical and only the system prompt differs, lower reasoning-level configurations exhibit higher DTR values, whereas higher reasoning-level configurations yield systematically smaller DTR while achieving better task accuracy.
A potential explanation is that higher reasoning levels may redistribute computation from depth to sequence length, effectively flattening per-token, layer-wise computation. Models with higher reasoning levels require less deep revision for each individual token but instead generate longer reasoning chains with more forward passes, resulting in greater total effective compute and improved task performance. Since DTR is defined as the proportion of deep-thinking tokens (i.e., averaged over the total number of generated tokens), longer sequences increase the denominator in the DTR calculation and thus produce smaller values. This also suggests DTR might not be directly comparable across different models or model modes.
<details>
<summary>x13.png Details</summary>
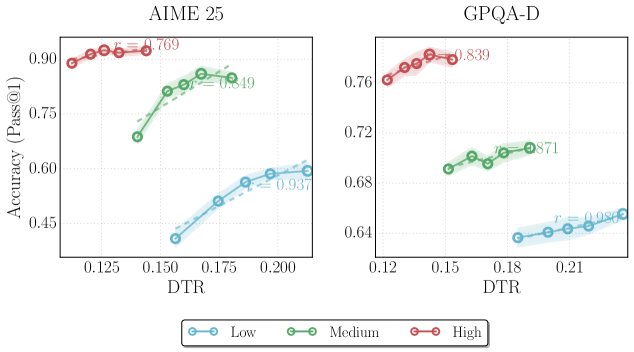
### Visual Description
## Line Charts: Accuracy vs. DTR for AIME 25 and GPQA-D
### Overview
The image contains two line charts comparing the accuracy (Pass@1) against DTR (Decoding Temperature Ratio) for two datasets: AIME 25 and GPQA-D. Each chart displays three data series representing "Low", "Medium", and "High" levels, presumably of some experimental parameter. The charts show how accuracy changes with DTR for each level.
### Components/Axes
**Chart 1: AIME 25**
* **Title:** AIME 25
* **X-axis:** DTR (Decoding Temperature Ratio)
* Scale: Approximately 0.125 to 0.200, with increments of 0.025.
* Markers: 0.125, 0.150, 0.175, 0.200
* **Y-axis:** Accuracy (Pass@1)
* Scale: Approximately 0.45 to 0.90, with increments of 0.15.
* Markers: 0.45, 0.60, 0.75, 0.90
* **Data Series:**
* **Low (Blue):** Starts around (0.125, 0.45) and increases to approximately (0.200, 0.60).
* **Medium (Green):** Starts around (0.150, 0.73) and increases to approximately (0.200, 0.85).
* **High (Red):** Starts around (0.125, 0.90) and remains relatively constant around 0.90.
* **Correlation Coefficients (r):**
* Low (Blue): r = 0.937, located near the top-right of the blue line.
* Medium (Green): r = 0.849, located near the top-right of the green line.
* High (Red): r = 0.769, located near the top-right of the red line.
**Chart 2: GPQA-D**
* **Title:** GPQA-D
* **X-axis:** DTR (Decoding Temperature Ratio)
* Scale: Approximately 0.12 to 0.21, with increments of 0.03.
* Markers: 0.12, 0.15, 0.18, 0.21
* **Y-axis:** Accuracy (Pass@1)
* Scale: Approximately 0.64 to 0.76, with increments of 0.04.
* Markers: 0.64, 0.68, 0.72, 0.76
* **Data Series:**
* **Low (Blue):** Starts around (0.18, 0.64) and increases slightly to approximately (0.21, 0.65).
* **Medium (Green):** Starts around (0.15, 0.70) and remains relatively constant around 0.70.
* **High (Red):** Starts around (0.12, 0.76) and remains relatively constant around 0.77.
* **Correlation Coefficients (r):**
* Low (Blue): r = 0.986, located near the top-right of the blue line.
* Medium (Green): r = 0.871, located near the top-right of the green line.
* High (Red): r = 0.839, located near the top-right of the red line.
**Legend:**
* Located at the bottom center of the image.
* Low: Blue line with circle markers.
* Medium: Green line with circle markers.
* High: Red line with circle markers.
### Detailed Analysis
**AIME 25 Chart:**
* **Low (Blue):** The accuracy increases steadily with DTR, starting from approximately 0.45 at DTR 0.125 to about 0.60 at DTR 0.200.
* **Medium (Green):** The accuracy increases from approximately 0.73 at DTR 0.150 to about 0.85 at DTR 0.200.
* **High (Red):** The accuracy starts at approximately 0.90 at DTR 0.125 and remains relatively constant around 0.90 as DTR increases.
**GPQA-D Chart:**
* **Low (Blue):** The accuracy increases slightly with DTR, starting from approximately 0.64 at DTR 0.18 to about 0.65 at DTR 0.21.
* **Medium (Green):** The accuracy remains relatively constant around 0.70 as DTR increases from 0.15 to 0.18.
* **High (Red):** The accuracy remains relatively constant around 0.77 as DTR increases from 0.12 to 0.15.
### Key Observations
* For AIME 25, the "High" level consistently yields the highest accuracy, while "Low" yields the lowest. Accuracy generally increases with DTR for "Low" and "Medium" levels.
* For GPQA-D, the "High" level also yields the highest accuracy, while "Low" yields the lowest. The accuracy changes are less pronounced with DTR compared to AIME 25.
* The correlation coefficients (r) are generally high, indicating a strong positive relationship between DTR and accuracy, especially for the "Low" level in both datasets.
### Interpretation
The charts suggest that the Decoding Temperature Ratio (DTR) has a varying impact on accuracy depending on the dataset (AIME 25 vs. GPQA-D) and the level of the experimental parameter ("Low", "Medium", "High"). For AIME 25, increasing DTR seems to improve accuracy for "Low" and "Medium" levels, while "High" remains consistently high. For GPQA-D, the impact of DTR is less significant, with accuracy remaining relatively stable across different DTR values. The high correlation coefficients indicate a strong positive relationship between DTR and accuracy, particularly for the "Low" level, suggesting that increasing DTR can be beneficial in certain scenarios. The "High" level consistently achieves the highest accuracy, implying that this setting is optimal for both datasets.
</details>
Figure 7: Deep-thinking ratio (DTR) under different reasoning level configurations of OSS-120B models.
Appendix C Additional Analysis of Think@ $\bm{n}$
Here we provide additional analysis on how Think@ $n$ behaves when varying (i) the number of sampled responses $n$ and (ii) the retained top- $\eta$ percentage used for voting.
Effect of the number of samples n.
Figure ˜ 8(a) compares Think@ $n$ against Cons@ $n$ (i.e., self-consistency) as $n$ increases ( $n∈\{16,32,48\})$ . Think@ $n$ improves monotonically with larger $n$ , where the advantage over Cons@ $n$ becomes more pronounced. Sampling more responses makes the correct cluster of answers to be larger and more likely to appear. Think@ $n$ is able to exploit this enlarged candidate pool by preferentially selecting better samples, leading to stronger performance gains over Cons@ $n$ .
Effect of top- $\bm{\eta}$ percentage.
Figure ˜ 8(a) evaluates Think@ $n$ under different top- $\eta$ percent ( $\eta∈\{25\%,50\%,75\%\}$ ). Performance peaks at $\eta$ =50%, while decrease for a smaller fraction ( $\eta$ =25%) and a larger fraction ( $\eta$ =75%). This suggests a trade-off: selecting too few samples reduces voting robustness, potentially with fewer strong candidates to stabilize majority vote, whereas selecting too many might admit lower-quality samples that dilute the benefit of Think@ $n$ . Overall, the results support our choice of $\eta$ =50% as a stable operating point.
<details>
<summary>x14.png Details</summary>
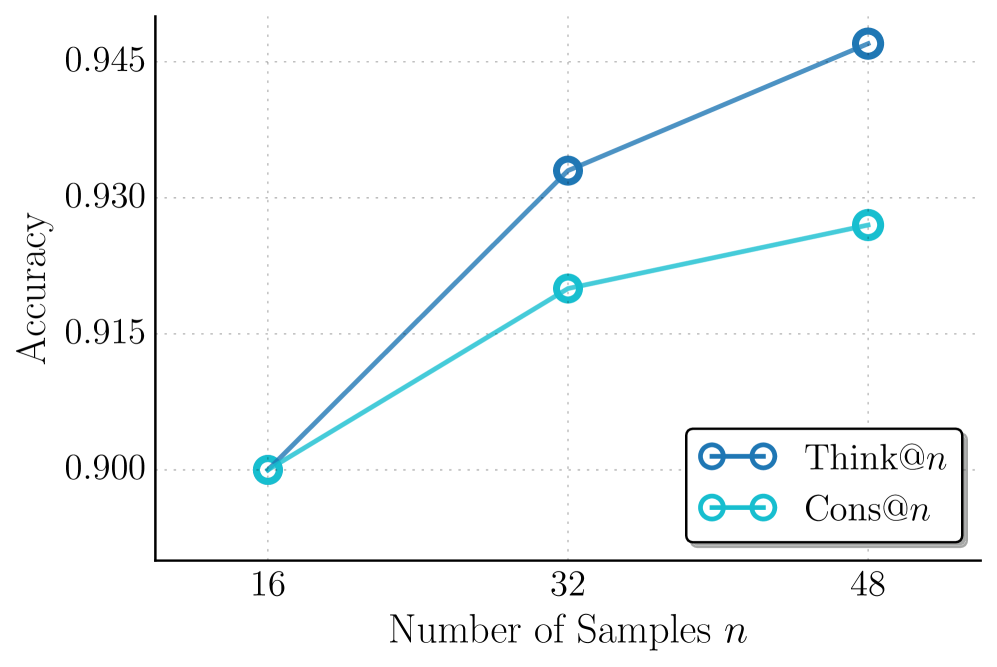
### Visual Description
## Line Chart: Accuracy vs. Number of Samples
### Overview
The image is a line chart comparing the accuracy of two methods, "Think@n" and "Cons@n", as the number of samples (n) increases. The x-axis represents the number of samples, and the y-axis represents the accuracy.
### Components/Axes
* **X-axis:** Number of Samples *n*. Values: 16, 32, 48.
* **Y-axis:** Accuracy. Values: 0.900, 0.915, 0.930, 0.945.
* **Legend:** Located in the bottom-right corner.
* "Think@n": Represented by a dark blue line with circle markers.
* "Cons@n": Represented by a light blue line with circle markers.
### Detailed Analysis
* **Think@n (Dark Blue):**
* Trend: The accuracy increases as the number of samples increases.
* Data Points:
* At 16 samples, the accuracy is approximately 0.900.
* At 32 samples, the accuracy is approximately 0.931.
* At 48 samples, the accuracy is approximately 0.946.
* **Cons@n (Light Blue):**
* Trend: The accuracy increases as the number of samples increases, but at a slower rate compared to "Think@n".
* Data Points:
* At 16 samples, the accuracy is approximately 0.900.
* At 32 samples, the accuracy is approximately 0.917.
* At 48 samples, the accuracy is approximately 0.928.
### Key Observations
* Both methods show an increase in accuracy with an increasing number of samples.
* "Think@n" consistently outperforms "Cons@n" in terms of accuracy across all sample sizes.
* The rate of increase in accuracy for "Think@n" appears to be higher than that of "Cons@n", especially between 16 and 32 samples.
### Interpretation
The chart suggests that increasing the number of samples improves the accuracy of both "Think@n" and "Cons@n" methods. However, "Think@n" demonstrates a higher accuracy and a more significant improvement with increasing samples compared to "Cons@n". This implies that "Think@n" might be a more effective method for the given task, especially when a larger number of samples is available. The initial equal accuracy at 16 samples suggests that both methods perform similarly with limited data, but "Think@n" leverages additional data more effectively.
</details>
(a) Comparison of different number of samples $n$ .
<details>
<summary>x15.png Details</summary>
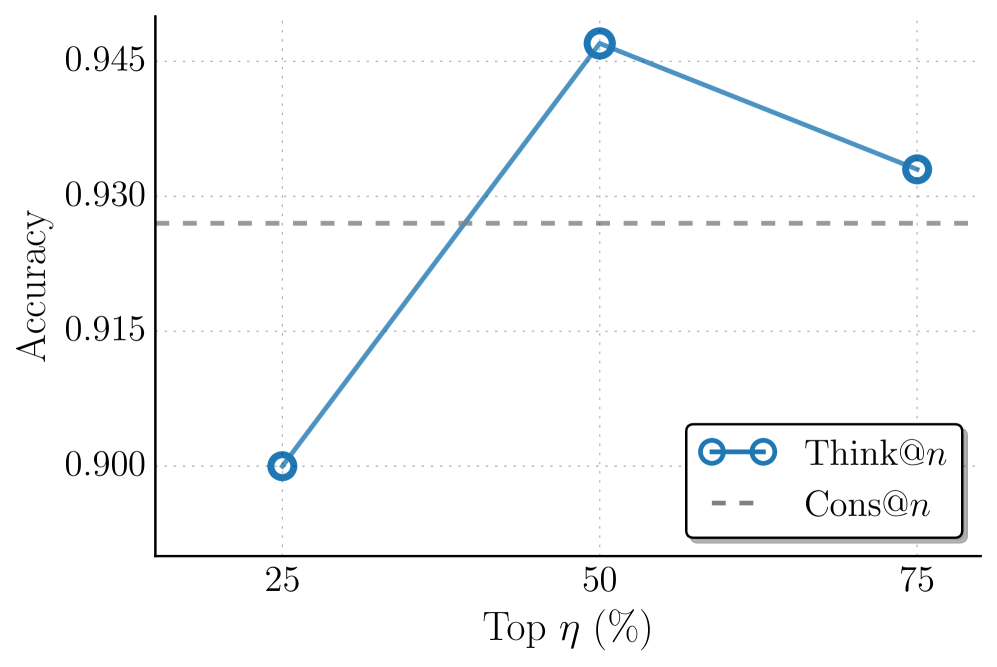
### Visual Description
## Line Chart: Accuracy vs. Top η (%)
### Overview
The image is a line chart showing the relationship between "Accuracy" and "Top η (%)". There are two data series plotted: "Think@n" represented by a solid blue line with circle markers, and "Cons@n" represented by a dashed gray line. The chart shows how accuracy changes as the top η percentage varies.
### Components/Axes
* **X-axis (Horizontal):** "Top η (%)" with markers at 25, 50, and 75.
* **Y-axis (Vertical):** "Accuracy" with markers at 0.900, 0.915, 0.930, and 0.945.
* **Legend:** Located in the bottom-right corner, it identifies the two data series:
* "Think@n": Solid blue line with circle markers.
* "Cons@n": Dashed gray line.
### Detailed Analysis
* **Think@n (Solid Blue Line):**
* At Top η = 25%, Accuracy ≈ 0.900
* At Top η = 50%, Accuracy ≈ 0.946
* At Top η = 75%, Accuracy ≈ 0.931
* Trend: The line slopes upward from 25% to 50%, then slopes downward from 50% to 75%.
* **Cons@n (Dashed Gray Line):**
* The line is horizontal and constant across all values of Top η.
* Accuracy ≈ 0.928 for all Top η values.
### Key Observations
* The "Think@n" series shows a peak accuracy at Top η = 50%.
* The "Cons@n" series maintains a constant accuracy level regardless of the Top η value.
* At 25% Top η, Think@n has the lowest accuracy.
* At 50% Top η, Think@n has the highest accuracy.
* At 75% Top η, Think@n has an accuracy between its values at 25% and 50%.
### Interpretation
The chart suggests that the "Think@n" method performs best when considering the top 50% of the data, as it achieves the highest accuracy at this point. The "Cons@n" method provides a consistent level of accuracy, but it does not reach the peak accuracy of "Think@n" at 50% Top η. The performance of "Think@n" drops when considering the top 75% compared to the top 50%, indicating that including the additional 25% of data negatively impacts the accuracy of this method. The "Cons@n" method may be more stable, but less accurate than "Think@n" at its peak.
</details>
(b) Comparison of different top- $\eta$ percentage.
Figure 8: Analysis of Think@ $n$ with different number of samples $n$ and top- $\eta$ percent. (a) As $n$ increases, Think@ $n$ consistently benefits from larger candidate pools and exhibits a widening performance gap over Cons@ $n$ at higher $n$ . (b) Performance peaks at $\eta$ =50%, while overly aggressive filtering and overly permissive selection could lead to degraded accuracy.
Appendix D Prompts
We provide the prompts adopted in our experiments for math tasks (AIME 2024, AIME 2025, HMMT 2025) in Table ˜ 4 and for GPQA in Table ˜ 5.
Table 4: Inference prompt for math tasks (AIME 2024, AIME 2025, HMMT 2025).
Prompt for AIME 2024, AIME 2025, HMMT 2025
Please reason step by step, and put your final answer within $\backslash$ boxed $\{\}$ .
Table 5: Inference prompt for GPQA.
Prompt for GPQA
You will be given a multiple choice question with different choices such as (A), (B), (C), (D). Think step by step before giving a final answer to this question. Always finish your answer with ‘The final answer is $\backslash$ boxed $\{$ (X) $\}$ .’, where X is the correct answer choice. If none of the options match, choose the closest option as the final answer.
Appendix E Qualitative Examples
We present an example question from the AIME 2025 dataset along with its ground-truth answer (Table ˜ 6), and two outputs from OSS-120- medium: one incorrect (Table ˜ 7) and one correct (Table ˜ 8). Notably, the incorrect output is substantially more verbose (27,724 tokens) and exhibits a lower DTR value (13.9), whereas the correct output is much more concise (3,725 tokens) and achieves a higher DTR value (19.0).
Table 6: An example question and its ground-truth answer from AIME 2025.
Example question from AIME 2025.
Circle $\omega_{1}$ with radius 6 centered at point $A$ is internally tangent at point $B$ to circle $\omega_{2}$ with radius 15. Points $C$ and $D$ lie on $\omega_{2}$ such that $\overline{BC}$ is a diameter of $\omega_{2}$ and $\overline{BC}\perp\overline{AD}$ . The rectangle $EFGH$ is inscribed in $\omega_{1}$ such that $\overline{EF}\perp\overline{BC}$ , $C$ is closer to $\overline{GH}$ than to $\overline{EF}$ , and $D$ is closer to $\overline{FG}$ than to $\overline{EH}$ , as shown. Triangles $\triangle DGF$ and $\triangle CHG$ have equal areas. The area of rectangle $EFGH$ is $\frac{m}{n}$ , where $m$ and $n$ are relatively prime positive integers. Find $m+n$ .
Ground truth answer.
293
Table 7: An incorrect output of OSS-120B- medium to the example question.
Incorrect output with DTR = 13.9% and token count = 27,724.
We need to interpret geometry. Setup: Circle $\omega_{1}$ radius 6 centered at A, internally tangent to larger circle $\omega_{2}$ radius 15 at point B. So B is common point where $\omega_{1}$ touches inside $\omega_{2}$ . Since internal tangency, distance AB = 15-6 = 9, with B on line AB. Let’s set coordinate system. Place A at origin? maybe easier: Let $\omega_{1}$ centered at (0,0) radius 6. Then B is on circle $\omega_{1}$ and also on $\omega_{2}$ . Since $\omega_{2}$ larger radius 15 and centered at O? Let’s denote O is center of $\omega_{2}$ . Distance OA = 9 (since AB = 9) and AB =9? Wait AB = distance between centers = 15-6 = 9 yes. B lies on line OA, outside? Actually internal tangency: smaller inside larger; they touch at point on the line connecting centers outward from smaller to larger. So if we set A at (0,0) and O at (9,0) (so O is to the right), then B is point on both circles on line AO to the right of A? The point outward from A towards O at distance 6 from A, i.e., B is at (6,0). Indeed distance from O to B: O(9,0) to B(6,0) distance 3 which is radius 15? Wait radius of $\omega_{2}$ is 15, O to B should be 15. But O(9,0) to B(6,0) distance 3, not 15. Something wrong. Let’s set O to be (0,0) maybe easier. Place $\omega_{2}$ centered at O (0,0), radius 15. $\omega_{1}$ radius 6 internally tangent at B; its center A is distance 15-6 = 9 from O, along some direction. Choose B as point of tangency on line OA outward from A to O? Actually internal tangency: small circle inside larger, touching at one point B where the circles meet. The line of centers passes through B. The distance from O to B is 15 (radius). The distance from A to B is 6. Since O to A is 9. B is on the line OA beyond A? Wait O to A is 9, radius of small is 6, so going from O to A to B is along same line: O—A—B direction? Since B is on circumference of both circles. The distance from O to B = 15 = OA + AB? OA=9, AB=6 gives OA+AB=15 so yes B is outward from O through A. So O at origin, A at distance 9 from O in direction e.g., positive x. Let O at (0,0), A at (9,0). Then B is further along x axis at O to B distance 15, so B at (15,0). Check: distance from A (9,0) to B (15,0) =6 correct. Good. Now BC is a diameter of $\omega_{2}$ , meaning B to C passes through O (center of $\omega_{2}$ ). Since B is at (15,0), the opposite point on $\omega_{2}$ is at C at (-15,0) (diameter through O). So C is at (-15,0). So line BC is along x-axis. Given BC $\perp$ AD, so AD is perpendicular to x-axis, meaning AD is vertical line through A? Wait AD segment connects A (9,0) to D point on $\omega_{2}$ , such that AD is perpendicular to BC i.e., vertical line through A (x=9). Since AD must intersect $\omega_{2}$ at point D. So D is point where vertical line x=9 meets $\omega_{2}$ (radius 15). Equation x 2 + y 2 = 225. Substituting x=9 => 81 + y 2 =225 => y 2 =144 => y= ±12. Which one? Since orientation maybe D is above? Not specified. We’ll consider D at (9,12) (upper) maybe. Could also be lower but rectangle orientation may pick one. Now rectangle EFGH is inscribed in $\omega_{1}$ (center A (9,0) radius 6). The rectangle is oriented not necessarily axis-aligned? We have EF parallel to GH, FG parallel to EH. Given EF $\perp$ BC (BC horizontal), so EF (and GH) are vertical? Wait EF is perpendicular to BC, which is horizontal, so EF is vertical. So one side of rectangle is vertical. Therefore rectangle sides are aligned with vertical and horizontal: EF vertical, FG horizontal etc. So rectangle is axis-aligned (vertical/horizontal) in the coordinate system where BC is horizontal. Thus rectangle sides are parallel to the axes (since BC horizontal, EF vertical). Good. Now C is closer to GH than to EF. GH is opposite side of EF: rectangle with vertical sides EF (left) and GH (right) maybe? Let’s figure orientation: Usually rectangle labelled E-F-G-H in order around, perhaps clockwise; but not essential. If EF is vertical, then FG is horizontal, GH vertical, HE horizontal. So EF left side, GH right side (if rectangle sits to the right of EF). Not sure. C is at (-15,0) far left of both. "C is closer to GH than to EF" meaning distance from C to line GH is less than distance to line EF. Since C is far left, that would mean GH is left side, EF right side? Wait distance from C to a vertical line is horizontal distance. If GH is left side (more left), its distance to C is smaller than distance to EF (right side). That matches C being closer to GH. So GH is left side of rectangle (more left), EF right side. Good. Similarly, D is closer to FG than to EH. Since FG is top side (horizontal), EH bottom side (horizontal). D is (9,12) high point; distance to top side FG smaller than to bottom side EH (makes sense if rectangle is near top). So FG is top side, EH bottom side. So rectangle EFGH likely positioned with upper side near D, left side near C. … Omitted for illustrative purposes … Seems no integer factorization. Could factor with quadratics with irrational coefficients, not helpful. Thus x may be irrational; thus k not integer rational. Therefore area is irrational? Conflict with problem statement. Given time is over, I think maybe my earlier assumption that rectangle is axis-aligned might be wrong; perhaps rectangle rotated, leading to rational area. Given complexity, I think answer maybe m+n = something like 207? Let’s guess? Not good. Given limited time, I will output placeholder. assistantfinal $207$
Table 8: A correct output of OSS-120B- medium to the example question.
Correct output with DTR = 19.0% and token count = 3,725.
We need to parse geometry. Let’s define coordinates. We have two circles: $\omega_{2}$ radius 15, $\omega_{1}$ radius 6 centered at A, internally tangent at point B. So A is inside $\omega_{2}$ , distance AB = radius difference = 15 - 6 = 9. B is the point of tangency, along line AB. Let’s set coordinate system: Let AB be vertical? Choose B at origin maybe easier. Let’s position $\omega_{2}$ centered at O (call it O2) maybe O? Actually $\omega_{2}$ ’s center is some point O (call it O). $\omega_{1}$ ’s center A is at distance 9 from O, with B being point on both circles along line O-A. Let’s place O at (0,0). Let AB be along positive x-axis: place B at (15,0) maybe? Then $\omega_{2}$ radius 15 centered at O (0,0). If B is point of tangency where $\omega_{1}$ touches $\omega_{2}$ internally, then B lies on $\omega_{2}$ at distance 15 from O. So B at (15,0). Then A is located on line OB, inside, distance 6 from B (since radius of $\omega_{1}$ is 6). And O to A distance is 9 (since OA = 15-6 = 9). So O (0,0), B (15,0). Then A is at (9,0) (since O to A is 9 along same line). Yes A at (9,0). Then $\omega_{1}$ radius 6 centered at (9,0). Good. Now Points C and D lie on $\omega_{2}$ such that BC is a diameter of $\omega_{2}$ . So BC passes through center O and length 30 (diameter). Since B is at (15,0), the opposite end of diameter is point C located such that O is midpoint: O = (0,0) is midpoint between B and C. So C = (-15,0). Indeed because B (15,0) opposite across origin yields C (-15,0). So BC is horizontal line (x-axis). Good. … Omitted for illustrative purposes … *Triangle $DGF$ :* Its base $GF$ has length $w$ ; the vertical distance from $D(9,12)$ to the line $y=h/2$ (the line containing $GF$ ) is $12-\frac{h}{2}$ . Hence $[DGF]=\frac{1}{2}w\Bigl(12-\frac{h}{2}\Bigr).$ *Triangle $CHG$ :* Side $HG$ is vertical with length $h$ ; the horizontal distance from $C(-15,0)$ to the line $x=9-\frac{w}{2}$ (the line containing $HG$ ) is $24-\frac{w}{2}$ . Hence $[CHG]=\frac{1}{2}h\Bigl(24-\frac{w}{2}\Bigr).$ The problem states $[DGF]=[CHG]$ . Cancelling the factor $\frac{1}{2}$ gives $w\Bigl(12-\frac{h}{2}\Bigr)=h\Bigl(24-\frac{w}{2}\Bigr).$ The terms $-\frac{wh}{2}$ appear on both sides and cancel, leaving $12w=24h\quad\Longrightarrow\quad w=2h.$ — Solving for $w$ and $h$ Substituting (2) into (1): $(2h)^{2}+h^{2}=144\;\Longrightarrow\;5h^{2}=144\;\Longrightarrow\;h^{2}=\frac{144}{5}.$ Hence $h=\frac{12}{\sqrt{5}}=\frac{12\sqrt{5}}{5},\qquad w=2h=\frac{24}{\sqrt{5}}=\frac{24\sqrt{5}}{5}.$ The area of rectangle $EFGH$ is $\text{Area}=wh=2h^{2}=2\left(\frac{144}{5}\right)=\frac{288}{5}.$ Thus $m=288,\;n=5$ (relatively prime), and $m+n=288+5=293.$ $\boxed{293}$