# Experiential Reinforcement Learning
> Work done during internship at Microsoft’s Office of Applied Research
Abstract
Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience–reflection–consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Learning Paradigms: Direct, Reinforcement, and Experiential Learning
### Overview
The image presents a comparative diagram illustrating three distinct learning paradigms: Direct Learning (SFT), Reinforcement Learning (RLVR), and Experiential Learning (ERL). Each paradigm is represented by a cyclical flow diagram, highlighting the interaction between different components such as policy, environment, actions, and feedback mechanisms. The diagram emphasizes the shift from learning from explicit examples (Direct Learning) to learning from feedback (Reinforcement Learning) and finally to learning from experience (Experiential Learning).
### Components/Axes
* **Titles:**
* Direct Learning (SFT) - Top-left
* Reinforcement Learning (RLVR) - Top-center
* Experiential Learning (ERL) - Top-right
* **Nodes:** Each paradigm includes nodes representing key components:
* Policy (in all three paradigms)
* Example (Direct Learning)
* Environment (Reinforcement and Experiential Learning)
* Supervised Learning (Direct Learning)
* Scaler Reward (Reinforcement Learning)
* Action (Reinforcement and Experiential Learning)
* Experience Internalization (Experiential Learning)
* Self-Reflection (Experiential Learning)
* **Arrows:** Arrows indicate the flow of information and interaction between the nodes.
* **Equations:** Each node contains equations describing the relationships between variables.
* **Horizontal Axis:** A horizontal axis at the bottom indicates the progression from "Learning from Feedback" to "Learning from Experience."
### Detailed Analysis or ### Content Details
**1. Direct Learning (SFT):**
* **Policy:** Located at the top.
* **Example:** Located at the bottom.
* **Supervised Learning:** Located on the left side, between Policy and Example.
* Equation: πθ(· | x) → y'
* **Flow:** The flow starts from the Example, goes to Supervised Learning, then to Policy, and back to Example, forming a loop.
**2. Reinforcement Learning (RLVR):**
* **Policy:** Located at the top.
* **Environment:** Located at the bottom.
* **Action:** Located on the right side, between Policy and Environment.
* Equation: y ~ πθ(· | x)
* **Scaler Reward:** Located on the left side, between Policy and Environment.
* Equation: πθ(· | x) → r
* **Flow:** The flow starts from the Environment, goes to Scaler Reward, then to Policy, then to Action, and back to Environment, forming a loop.
**3. Experiential Learning (ERL):**
* **Policy:** Located at the top.
* **Environment:** Located at the bottom.
* **Action:** Located on the right side, between Policy and Environment.
* Equation: y ~ πθ(· | x)
* **Experience Internalization:** Located on the left side, above Self-Reflection, between Policy and Environment.
* Equation: πθ(· | x) ← πθ(· | x, Δ)
* **Self-Reflection:** Located on the left side, below Experience Internalization, between Policy and Environment.
* Equation: Δ ~ πθ(· | x, y, r)
* **Flow:** The flow starts from the Environment, goes to Self-Reflection, then to Experience Internalization, then to Policy, then to Action, and back to Environment, forming a loop.
### Key Observations
* **Progression:** The diagrams illustrate a progression from simple supervised learning to more complex reinforcement and experiential learning.
* **Feedback:** Reinforcement Learning introduces the concept of a scalar reward, while Experiential Learning incorporates experience internalization and self-reflection.
* **Complexity:** Experiential Learning has the most complex flow, involving multiple feedback loops and internal processes.
### Interpretation
The image effectively visualizes the evolution of learning paradigms. Direct Learning relies on explicit examples, Reinforcement Learning learns from feedback signals (rewards), and Experiential Learning learns by internalizing experiences and reflecting on them. The diagrams highlight the increasing complexity and sophistication of learning algorithms as they move from supervised to reinforcement and experiential learning. The inclusion of equations within each node provides a concise mathematical representation of the relationships between the components. The progression from "Learning from Feedback" to "Learning from Experience" suggests a shift towards more autonomous and adaptive learning systems.
</details>
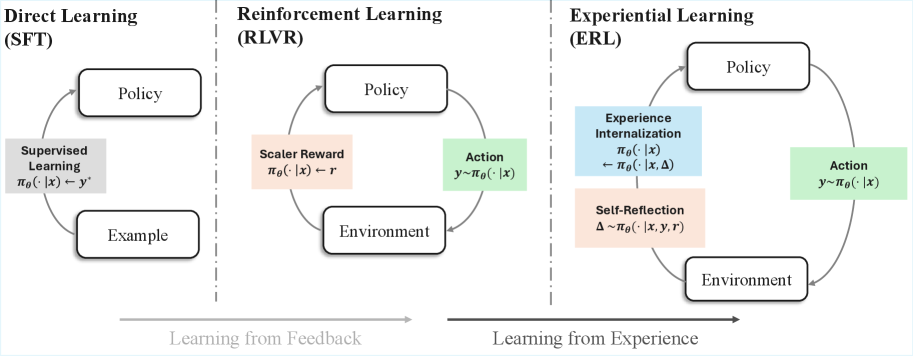
Figure 1: In Experiential Reinforcement Learning (ERL), instead of learning from feedback or outcome directly, an agent learns to (1) verbally reflect on its experience and observed outcome, and (2) internalize the reflections to induce behavioral changes in future iterations.
1 Introduction
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: RLVR vs. ERL in an Unknown Environment
### Overview
The image presents a diagram comparing two approaches, RLVR and ERL, for an agent navigating an unknown environment. The task involves moving boxes within a walled area. The diagram illustrates the steps each approach takes, highlighting the differences in their learning and problem-solving strategies.
### Components/Axes
* **Title:** Task: Act in an unknown environment * with no prior knowledge
* **Top Row:** RLVR (likely an abbreviation for a Reinforcement Learning approach)
* **Bottom Row:** ERL (likely an abbreviation for an Experience Replay Learning approach)
* **Arrows:** Indicate the flow of actions and learning.
* **Text Labels:** "Trial & Error", "Forget", "Back & Forth", "No reward", "Experience Internalization", "Self-Reflection"
* **Environment:** A walled area with boxes and a character.
* **Red X:** Indicates a failed attempt or a blocked path.
* **Self-Reflection Text:** "I guess... [gray square] is wall. I can control [character icon]. Push [box icon] into [tan square]."
### Detailed Analysis
**RLVR (Top Row):**
1. **Initial State:** The character is in a walled area with several boxes.
* Label: Trial & Error
* Arrow points to the next state.
2. **Second State:** The character attempts to move a box, but the path is blocked, indicated by a red X. A blue line shows the attempted path.
* Label: No reward
* Label: Forget
* Arrow points back to the third state.
3. **Third State:** The character is back in a similar initial state, having "forgotten" the previous attempt.
* Label: Back & Forth
4. **Fourth State:** The character attempts to move a box, but the path is blocked, indicated by a red X. A blue line shows the attempted path.
* Label: Trial & Error
* Label: No reward
**ERL (Bottom Row):**
1. **Initial State:** The character is in a walled area with several boxes.
* Label: Trial & Error
* Arrow points to the next state.
2. **Second State:** The character attempts to move a box, but the path is blocked, indicated by a red X. A blue line shows the attempted path.
3. **Experience Internalization:** The agent learns from the failed attempt.
4. **Third State:** The agent engages in self-reflection.
* Label: Self-Reflection:
* Text: "I guess... [gray square] is wall. I can control [character icon]. Push [box icon] into [tan square]."
5. **Fourth State:** The character has rearranged the boxes, presumably using the learned information.
### Key Observations
* RLVR appears to be a more basic trial-and-error approach, where the agent "forgets" previous failures and repeats similar actions.
* ERL incorporates experience internalization and self-reflection, allowing the agent to learn from failures and improve its problem-solving strategy.
* The "Self-Reflection" text in ERL suggests the agent is learning about the environment's constraints (walls) and its own capabilities (controlling the character and pushing boxes).
### Interpretation
The diagram illustrates the difference between a simple trial-and-error reinforcement learning approach (RLVR) and a more sophisticated experience-based learning approach (ERL). RLVR struggles because it doesn't retain information from past failures, leading to repetitive and ineffective actions. ERL, on the other hand, learns from its experiences, allowing it to adapt and eventually solve the task. The "Self-Reflection" component in ERL is crucial, as it enables the agent to understand the environment and its own actions, leading to more efficient problem-solving. The diagram highlights the importance of memory and learning in intelligent agents operating in unknown environments.
</details>
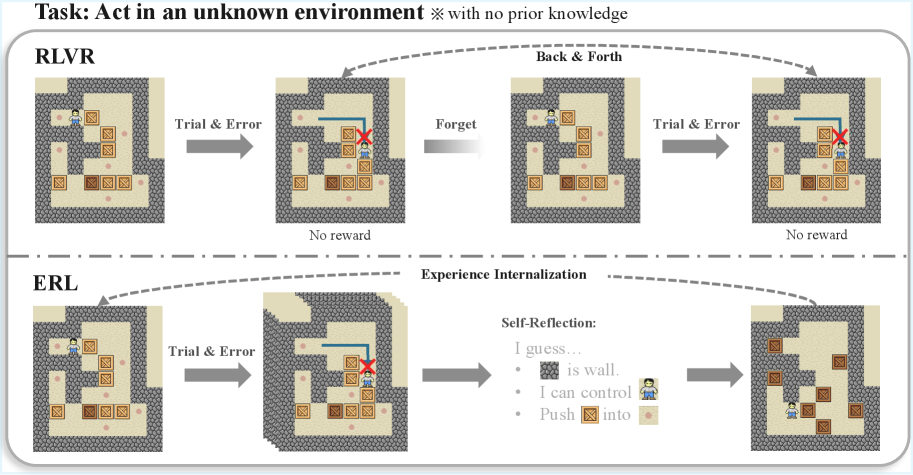
Figure 2: Conceptual comparison of learning dynamics in RLVR and Experiential Reinforcement Learning (ERL). RLVR relies on repeated trial-and-error driven by scalar rewards, leading to back-and-forth exploration without durable correction. ERL augments this process with an experience–reflection–consolidation loop that generates a revised attempt and internalizes successful corrections, enabling persistent behavioral improvement.
Large language models are increasingly deployed as decision-making agents that must act, observe feedback, and adapt their behavior in environments with delayed rewards and partial information (Singh et al., 2025; Yang et al., 2025; Song et al., 2025a; Bai et al., 2026). Reinforcement learning offers a natural framework for improving such agents. The task environments typically provide feedback in the form of outcome reward after an agent generates the entire trajectory. In practice, training agents against such sparse and delayed outcome signals remains difficult, as models must implicitly infer how to translate observed failures into corrective behavior, a process that is often unstable and sample-inefficient (Zhang et al., 2025; Shi et al., 2026). These challenges become more pronounced in agentic reasoning tasks, where multi-step decisions could amplify small errors and obscure credit assignment.
Humans address similar challenges through a process often described as experiential learning, in which effective adaptation arises from a cycle of experience, reflection, conceptualization, and experimentation (Kolb, 2014). After observing an outcome, a learner reflects on what occurred, forms revised internal models, and applies those revisions in subsequent attempts. This cycle transforms raw feedback into actionable behavioral corrections before those corrections are consolidated into future behavior. While language models have demonstrated reflection-like capabilities at inference time, standard reinforcement learning pipelines largely reduce feedback to scalar optimization signals, requiring policies to implicitly discover corrective structure through undirected exploration rather than explicit experiential revision.
This perspective highlights a progression in how language models learn from supervision and interaction, illustrated in Figures 1 and 2. In supervised fine-tuning (SFT), policies imitate fixed examples, enabling strong pattern reproduction but offering no mechanism for revising behavior once deployed. Reinforcement learning with verifiable rewards (RLVR) extends learning into interactive settings by optimizing scalar feedback, allowing agents to improve through trial-and-error; however, corrective structure must still be inferred implicitly from sparse or delayed rewards. As visualized in Figure 2, this can lead to repeated exploration without durable behavioral correction. A natural next step is to structure learning around experience itself, transforming feedback into intermediate reasoning that supports explicit revision and consolidation within each episode. Figure 1 conceptualizes this shift as moving from learning purely from feedback toward deliberate learning from experience.
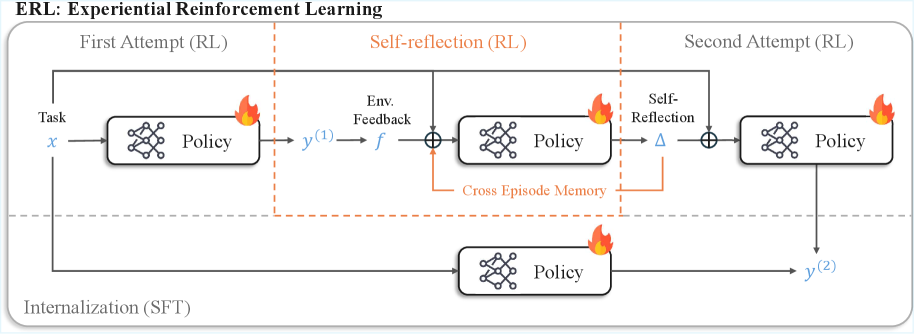
In this work, we introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience–reflection–consolidation loop inside reinforcement learning. Instead of learning solely from outcome rewards, the model first produces an initial attempt, receives environment feedback, and generates a structured reflection describing how the attempt should be improved. This reflection conditions a refined second attempt, whose outcome is reinforced and internalized into the base policy. By converting feedback into intermediate reasoning signals, ERL enables the model to perform targeted behavioral correction before policy consolidation. Over time, these corrections become part of the policy itself, allowing improved behavior to persist even when reflection is absent at deployment. An overview of the algorithm is shown in Figure 3.
We evaluate ERL across sparse-reward control environments and agentic reasoning benchmarks spanning two model scales. ERL consistently outperforms RLVR in all six evaluated settings, achieving gains of up to +81% in Sokoban, +27% in FrozenLake, and up to +11% in HotpotQA. These results demonstrate that embedding structured experiential revision into training improves learning efficiency and produces stronger final policies across both control and reasoning tasks.
Contributions.
Our main contributions are:
- We introduce Experiential Reinforcement Learning (ERL), a reinforcement learning paradigm that incorporates an explicit experience–reflection–consolidation loop, enabling models to transform environment feedback into structured behavioral corrections.
- We propose an internalization mechanism that consolidates reflection-driven improvements into the base policy, preserving gains without requiring reflection at inference time.
- We demonstrate that experiential reinforcement learning improves training efficiency and final performance across agentic reasoning tasks.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Experiential Reinforcement Learning (ERL)
### Overview
The image is a diagram illustrating the Experiential Reinforcement Learning (ERL) process. It shows a system that learns through multiple attempts, incorporating self-reflection and internalization. The diagram is divided into three main stages: First Attempt (RL), Self-reflection (RL), and Second Attempt (RL), with an additional path for Internalization (SFT).
### Components/Axes
* **Title:** ERL: Experiential Reinforcement Learning
* **Stages:**
* First Attempt (RL) - Top-left
* Self-reflection (RL) - Top-center
* Second Attempt (RL) - Top-right
* Internalization (SFT) - Bottom
* **Elements:**
* Task: x (input to the first policy)
* Policy: Represented by a rounded rectangle containing a neural network symbol.
* Env. Feedback: f (Environment Feedback)
* Self-Reflection: Δ (Delta symbol)
* Cross Episode Memory: An orange line connecting the output of the "Self-reflection (RL)" stage to the input of the "First Attempt (RL)" stage.
* y^(1): Output of the first policy.
* y^(2): Output of the second policy.
* Summation symbols: Represented by a circle with a plus sign inside.
* Fire symbols: Located on the top right of each policy box.
### Detailed Analysis or ### Content Details
1. **First Attempt (RL):**
* A "Task" labeled as 'x' is input into a "Policy" block.
* The output of the "Policy" block is labeled 'y^(1)'.
* A fire symbol is located on the top right of the policy box.
2. **Self-reflection (RL):**
* The output 'y^(1)' is transformed by "Env. Feedback" labeled as 'f'.
* The transformed output is then summed with a "Cross Episode Memory" signal (orange line).
* The result is input into another "Policy" block.
* The output of this "Policy" block is summed with "Self-Reflection" labeled as 'Δ'.
* A fire symbol is located on the top right of the policy box.
3. **Second Attempt (RL):**
* The summed output from the "Self-reflection (RL)" stage is input into another "Policy" block.
* The output of this "Policy" block is labeled 'y^(2)'.
* A fire symbol is located on the top right of the policy box.
4. **Internalization (SFT):**
* The initial "Task" 'x' is also input into a "Policy" block in the "Internalization (SFT)" path.
* The output of this "Policy" block is 'y^(2)', which is the same output as the "Second Attempt (RL)" stage.
* A fire symbol is located on the top right of the policy box.
5. **Cross Episode Memory:**
* An orange line labeled "Cross Episode Memory" connects the output of the "Self-reflection (RL)" stage to the input of the summation symbol in the "Self-reflection (RL)" stage.
### Key Observations
* The diagram illustrates a multi-stage learning process with feedback loops.
* The "Cross Episode Memory" suggests a mechanism for retaining information across different attempts.
* The "Internalization (SFT)" path provides an alternative route to achieve the same output 'y^(2)'.
* The fire symbols located on the top right of each policy box are not explained.
### Interpretation
The diagram depicts a reinforcement learning system that refines its policy through multiple attempts and self-reflection. The "Cross Episode Memory" allows the system to leverage past experiences to improve future performance. The "Internalization (SFT)" path might represent a more direct or efficient way to achieve the desired outcome, potentially bypassing the iterative learning process. The fire symbols are not explained, but may represent a cost or risk associated with each policy. The system appears to learn from its mistakes and adapt its strategy over time, ultimately converging towards a more effective policy.
</details>
Figure 3: Overview of Experiential Reinforcement Learning (ERL). Given an input task $x$ , the language model first produces an initial attempt and receives environment feedback. The same model then generates a self-reflection conditioned on this attempt, which is used to guide a second attempt. Both attempts and reflections are optimized with reinforcement learning, while successful second attempts are internalized via self-distillation, so the model learns to reproduce improved behavior directly from the original input without self-reflection.
2 Experiential Reinforcement Learning (ERL)
Algorithm 1 Experiential Reinforcement Learning
1: Inputs: Language model $\pi_{\theta}$ ; dataset of questions $x$ ; reward threshold $\tau$ ; environment returning feedback $f$ and reward $r$ .
2: Initialize: reflection memory $m←\emptyset$ .
3: repeat
4: Sample question $x$ from the dataset.
5: // First attempt
6: Sample an answer $y^{(1)}\sim\pi_{\theta}(·\mid x)$ .
7: Obtain environment feedback and reward $(f^{(1)},r^{(1)})$ .
8: // Self-reflection
9: Sample a reflection $\Delta\sim\pi_{\theta}(·\mid x,y^{(1)},f^{(1)},r^{(1)},m)$ .
10: // Second attempt
11: Sample a refined answer $y^{(2)}\sim\pi_{\theta}(·\mid x,\Delta)$ .
12: Obtain environment feedback and reward $(f^{(2)},r^{(2)})$ .
13: Set reflection reward $\tilde{r}← r^{(2)}$ .
14: Store reflection $m←\Delta\;\;$ if $\;\;r^{(2)}>\tau$ .
15: // RL update
16: Update $\theta$ via $\mathcal{L}_{\text{policy}}(\theta)$ over the first attempt, reflection, and second attempt.
17: // Internalization
18: Update $\theta$ via $\mathcal{L}_{\text{distill}}(\theta)$ to internalize reflection, training $\pi_{\theta}$ to produce $y^{(2)}$ from $x$ only.
19: until converged
We introduce Experiential Reinforcement Learning (ERL), a training framework that enables a language model to iteratively improve its behavior through self-generated feedback and internalization. The key idea is to treat reflection as an intermediate reasoning signal that guides a refined second attempt, while reinforcement learning aligns both attempts with reward, and supervised distillation consolidates successful behaviors into the base policy. An overview is shown in Figure 3, and the core training loop appears in Algorithm 1. A detailed implementation, including memory persistence and gating logic, is provided in Appendix A.
Given an input task $x$ , the model $\pi_{\theta}$ first produces an initial response
$$
y^{(1)}\sim\pi_{\theta}(\cdot\mid x), \tag{1}
$$
which is evaluated by the environment to produce textual feedback $f^{(1)}$ and reward $r^{(1)}$ . Rather than immediately updating the policy, ERL optionally triggers a reflection-and-retry phase when the first attempt underperforms relative to a reward threshold $\tau$ . This selective retry mechanism focuses compute on trajectories that are most likely to benefit from revision while avoiding unnecessary refinement when performance is already sufficient. When triggered, the model generates a reflection
$$
\Delta\sim\pi_{\theta}(\cdot\mid x,y^{(1)},f^{(1)},r^{(1)},m), \tag{1}
$$
which serves as self-guidance describing how the initial attempt can be improved. Here, $m$ denotes a cross-episode reflection memory that persists successful corrective patterns discovered during training. This memory provides contextual priors that help stabilize reflection generation and encourage reuse of previously effective strategies. The model then produces a refined response
$$
y^{(2)}\sim\pi_{\theta}(\cdot\mid x,\Delta), \tag{2}
$$
and receives new feedback $(f^{(2)},r^{(2)})$ . Reflections that lead to sufficiently improved outcomes are stored back into memory,
$$
m\leftarrow\Delta\quad\text{if}\quad r^{(2)}>\tau, \tag{2}
$$
allowing corrective knowledge to accumulate across training episodes. The reflection is assigned reward $\tilde{r}=r^{(2)}$ , encouraging reflections that lead to improved downstream performance.
Both attempts and reflections are optimized using a reinforcement learning objective
$$
\mathcal{L}_{\text{policy}}(\theta)=-\mathbb{E}\!\left[A\,\log\pi_{\theta}(y\mid x,\cdot)\right],
$$
where $y$ denotes model outputs arising from the first attempt, reflection, or second attempt, and the conditioning context corresponds to the inputs specified in Algorithm 1. The advantage estimate $A$ is computed from the associated rewards.
While reflection and environment feedback provide strong training signals, such supervision is typically unavailable at deployment time, where the model must operate in a zero-shot setting. We therefore introduce an internalization step that converts reflection-guided improvements into persistent policy behavior. The goal is to make the model remember corrections discovered during training and avoid repeating the same mistakes when feedback is absent. We implement internalization via selective distillation: we supervise the model to imitate only successful second attempts while removing reflection context from the input. Concretely, given a training example $x$ , we generate a refined response $y^{(2)}$ and reward $r^{(2)}$ , and optimize
$$
\mathcal{L}_{\text{distill}}(\theta)=-\mathbb{E}\Big[\mathbb{I}\!\left(r^{(2)}>0\right)\,\log\pi_{\theta}\!\left(y^{(2)}\mid x\right)\Big], \tag{2}
$$
where $\mathbb{I}(·)$ is the indicator function. This trains $\pi_{\theta}$ to reproduce improved behavior from the original input $x$ alone (no reflection), ensuring that lessons learned through feedback and self-reflection persist at test time.
By alternating between reinforcement learning, selective reflection, and distillation, ERL bootstraps self-improvement: reflections guide higher-quality retries, memory preserves effective corrective structure, reinforcement learning aligns behavior with reward, and distillation internalizes gains into the core model. Over time, this interaction stabilizes training, concentrates exploration on failure cases, and reduces dependence on explicit reflection at inference.
2.1 Comparison to Standard RLVR
Standard reinforcement learning with verifiable rewards (RLVR) optimizes a policy directly from scalar outcome signals. Given an input $x$ , the model samples a response $y\sim\pi_{\theta}(·\mid x)$ and receives a reward $r$ , with policy updates derived from trajectory-level credit assignment. In this formulation, feedback influences learning only through reward-driven optimization, requiring the model to implicitly discover how failures should translate into behavioral change. Corrective structure therefore emerges slowly through repeated exploration, with no explicit mechanism for revising behavior within the same learning episode. This learning dynamic corresponds to trial-and-error optimization, as illustrated in Figure 2.
Experiential Reinforcement Learning (ERL) augments this loop with an explicit experience–reflection–consolidation stage embedded inside each trajectory. Instead of optimizing solely from outcome reward, the model converts environment feedback into a reflection that conditions a refined attempt. This intermediate revision produces a locally improved trajectory that is reinforced and later internalized through selective distillation, allowing the base policy to reproduce corrected behavior without reflection at inference. A cross-episode reflection memory further stabilizes this process by preserving corrective patterns that proved effective, allowing subsequent reflections to reuse prior improvements. Importantly, ERL preserves the underlying RLVR objective: policy gradients remain reward-driven, but operate over a richer trajectory structure that includes explicit behavioral correction. This reframing shifts feedback from a scalar endpoint signal to a catalyst for immediate revision, reducing reliance on undirected exploration while maintaining compatibility with standard reinforcement learning pipelines. This contrast between blind trial-and-error learning and reflection-guided revision is visualized in Figure 1 and Figure 2.
3 Experiment
We evaluate Experiential Reinforcement Learning (ERL) against standard RLVR on a set of agentic reasoning tasks.
3.1 Task
We evaluate ERL on three agentic reasoning tasks: Frozen Lake, Sokoban, and HotpotQA (Yang et al., 2018). Detailed environment descriptions are provided in Appendix B.
For Frozen Lake and Sokoban, we configure the environments with sparse terminal rewards following Wang et al. (2025) and Guertler et al. (2025). The agent receives reward only at episode completion: a reward of +1 is assigned for successfully achieving the objective and 0 otherwise. Crucially, we do not provide explicit game rules or environment dynamics. The model must infer task structure purely through interaction, with access limited to the available action set. This evaluation design is inspired by prior work on learning from experience, where the goal is to measure an agent’s ability to acquire task understanding through trial-and-error rather than relying on human-authored priors embedded in pretraining. The combination of sparse rewards and unknown dynamics therefore creates a challenging setting that emphasizes reasoning, planning, and experiential learning.
HotpotQA is adapted into an agentic multi-hop question-answering task following Search-R1 (Jin et al., 2025). Given a question, the model performs iterative tool-assisted retrieval before producing a final answer. To maintain consistency with the experiential learning setup, we provide only a default system prompt describing available tools, without additional task-specific guidance. Correctness is evaluated using token-level F1 against ground-truth answers. The reward function assigns 1.0 for exact matches, a proportional reward for partial matches with F1 score $≥ 0.3$ , and 0 otherwise.
3.2 Models and Baselines
In our experiments, we train Olmo-3-7B-Instruct (Olmo et al., 2025) and Qwen3-4B-Instruct-2507 (Yang et al., 2025) using both standard RLVR and our proposed ERL paradigm, with GRPO (Shao et al., 2024) serving as the underlying policy-gradient optimizer in all cases. To ensure stable training, we adopt common reinforcement learning techniques such as clipping, KL regularization, and importance sampling. Notably, the internalization stage in ERL naturally involves off-policy data, which can introduce additional instability. We therefore apply the same stabilization techniques during this phase to maintain consistent optimization behavior. Additionally, because ERL requires two attempts per task along with an additional reflection step, we allocate 10 rollouts per task for RLVR and half as many per task per attempt for ERL to equalize the training compute per task across methods. Full hyperparameters and implementation details are provided in Appendix C.
4 Result and Discussion
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Charts: Reward vs. Training Time for Different Models and Environments
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the reward achieved by two different models (ERL and RLVR) during training across three different environments (FROZENLAKE, HOTPOTQA, and SOKOBAN). The x-axis represents training wall-clock time in hours, and the y-axis represents the reward. The top row of charts corresponds to the "Qwen3-4B-Instruct-2507" model, while the bottom row corresponds to the "Olmo-3-7B-Instruct" model.
### Components/Axes
* **Title (Top Row):** Qwen3-4B-Instruct-2507
* **Title (Bottom Row):** Olmo-3-7B-Instruct
* **Y-axis Label:** Reward (vertical, rotated 90 degrees counter-clockwise)
* **X-axis Label:** Training wall-clock time (hours)
* **Environments (Top Row, Left to Right):** FROZENLAKE, HOTPOTQA, SOKOBAN
* **Legend (Top, between FROZENLAKE and HOTPOTQA):**
* ERL (Green line)
* RLVR (Blue line)
**Y-Axis Scales:**
* **FROZENLAKE (Top):** 0.20 to 0.80, increments of 0.20
* **HOTPOTQA (Top):** 0.32 to 0.48, increments of 0.08
* **SOKOBAN (Top):** 0.00 to 0.80, increments of 0.20
* **FROZENLAKE (Bottom):** 0.20 to 0.50, increments of 0.10
* **HOTPOTQA (Bottom):** 0.24 to 0.48, increments of 0.08
* **SOKOBAN (Bottom):** 0.00 to 0.16, increments of 0.04
**X-Axis Scales:**
* **FROZENLAKE (Top):** 0 to 8 hours, increments of 2
* **HOTPOTQA (Top):** 0 to 5 hours, increments of 1
* **SOKOBAN (Top):** 0 to 32 hours, increments of 8
* **FROZENLAKE (Bottom):** 0 to 9 hours, increments of 3
* **HOTPOTQA (Bottom):** 0 to 4 hours, increments of 1
* **SOKOBAN (Bottom):** 0 to 80 hours, increments of 16
### Detailed Analysis
**Top Row (Qwen3-4B-Instruct-2507):**
* **FROZENLAKE:**
* ERL (Green): Starts at approximately 0.20, rapidly increases to approximately 0.85 by 4 hours, then plateaus.
* RLVR (Blue): Starts at approximately 0.20, increases more gradually to approximately 0.78 by 8 hours.
* **HOTPOTQA:**
* ERL (Green): Starts at approximately 0.32, increases to approximately 0.48 by 1 hour, then plateaus.
* RLVR (Blue): Starts at approximately 0.32, increases to approximately 0.42 by 1 hour, then fluctuates between 0.40 and 0.44.
* **SOKOBAN:**
* ERL (Green): Starts near 0.00, rapidly increases to approximately 0.75 by 24 hours, then plateaus around 0.82.
* RLVR (Blue): Remains near 0.00 throughout the training period.
**Bottom Row (Olmo-3-7B-Instruct):**
* **FROZENLAKE:**
* ERL (Green): Starts at approximately 0.20, increases to approximately 0.55 by 9 hours.
* RLVR (Blue): Starts at approximately 0.20, increases to approximately 0.38 by 9 hours.
* **HOTPOTQA:**
* ERL (Green): Starts at approximately 0.24, increases to approximately 0.48 by 2 hours, then plateaus.
* RLVR (Blue): Starts at approximately 0.24, increases to approximately 0.46 by 2 hours, then plateaus.
* **SOKOBAN:**
* ERL (Green): Starts near 0.02, peaks at approximately 0.16 around 24 hours, then fluctuates between 0.12 and 0.14.
* RLVR (Blue): Remains near 0.00 throughout the training period.
### Key Observations
* ERL (Green) generally outperforms RLVR (Blue) in terms of reward achieved across all environments and models, except for HOTPOTQA with the Olmo-3-7B-Instruct model where they perform similarly.
* The SOKOBAN environment shows the most significant difference in performance between ERL and RLVR, especially for the Qwen3-4B-Instruct-2507 model.
* The Qwen3-4B-Instruct-2507 model generally achieves higher rewards than the Olmo-3-7B-Instruct model, particularly in the FROZENLAKE and SOKOBAN environments.
* The training time required to reach peak performance varies significantly across environments, with HOTPOTQA generally requiring the least amount of time.
### Interpretation
The data suggests that the ERL model is more effective than the RLVR model in these environments, particularly in the challenging SOKOBAN environment. The Qwen3-4B-Instruct-2507 model appears to be a more capable model overall compared to the Olmo-3-7B-Instruct model, achieving higher rewards in most scenarios. The performance differences between the models and environments highlight the importance of model selection and training strategies for specific tasks. The SOKOBAN environment's stark contrast in performance between ERL and RLVR indicates that ERL may be better suited for tasks requiring long-term planning or complex problem-solving. The relatively quick convergence in HOTPOTQA suggests that this environment is less complex or requires less training to achieve optimal performance.
</details>
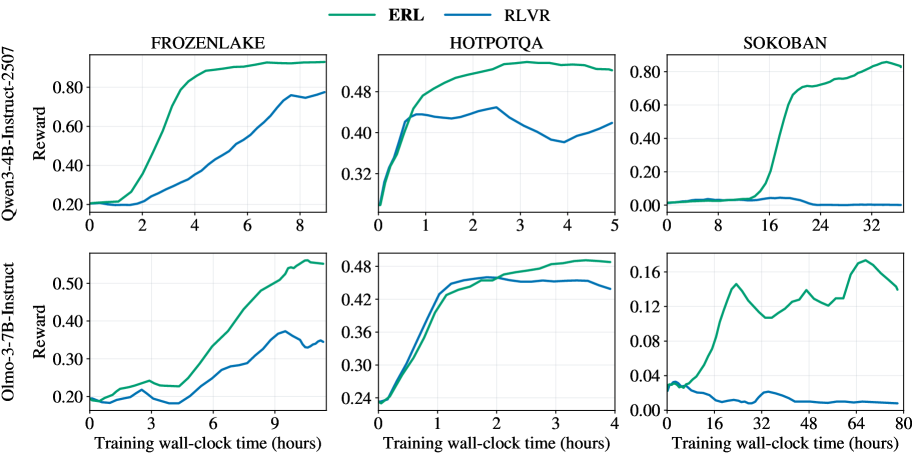
Figure 4: Validation reward trajectories versus training wall-clock time on FrozenLake, HotpotQA, and Sokoban for Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct. ERL consistently achieves higher reward and faster improvement than RLVR across tasks and models.
We evaluate Experiential Reinforcement Learning (ERL) against standard RLVR across three environments spanning sparse-reward control (FrozenLake, Sokoban) and agentic reasoning (HotpotQA). Table 1 summarizes the final performance, while Figures 5 – 6 visualize the performance and learning dynamics. All curves are smoothed with a trailing moving average over 5 points. The same smoothing procedure is applied to all figures unless otherwise noted.
4.1 Performance Across Tasks
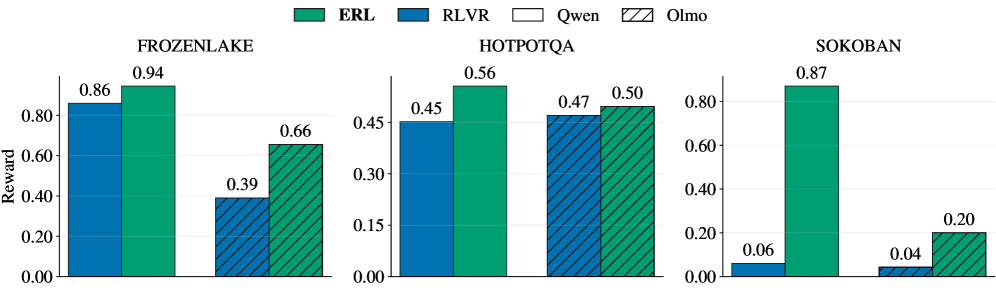
ERL consistently improves final evaluation performance over RLVR across all tasks and both model backbones. As shown in Table 1 and Figure 5, experiential training yields gains ranging from moderate improvements on HotpotQA to substantial improvements on Sokoban and Frozenlake.
The largest effect occurs in Sokoban, where Qwen3-4B-Instruct improves from 0.06 to 0.87 and Olmo3-7B-Instruct from 0.04 to 0.20. Sokoban requires long-horizon planning and recovery from compounding errors, making performance sensitive to how well the agent reasons about environment dynamics. Similarly, FrozenLake demands that the agent infer symbol semantics, action consequences, and terminal conditions purely through interaction under sparse rewards. Importantly, as described in Section 3, unlike many prior evaluation setups that provide explicit rules or environment structure, our environments expose only observations and action interfaces; the agent must infer task dynamics through trial-and-error. This design emphasizes learning from experience rather than relying on pre-specified priors, making structured revision particularly valuable. In these settings, the experience–reflection–consolidation loop enables the model to analyze failures, revise strategies, and internalize corrective behavior within each episode, producing large improvements in exploration efficiency and policy quality.
HotpotQA shows smaller but reliable gains. A likely explanation lies in differences in task structure. Compared to the grid-based control environments, HotpotQA presents a more homogeneous interaction pattern centered on repeated tool invocation and answer synthesis, with denser evaluation feedback and fewer latent dynamics to infer. Because RLVR already receives relatively informative gradients in this regime, the additional benefit of structured experiential revision is reduced. This contrast suggests that ERL yields the greatest advantage in environments where learning requires substantial reasoning about unknown dynamics and long-horizon consequences, rather than primarily optimizing over a stable interaction loop.
Importantly, improvements are observed across both models, indicating that the benefits of ERL arise from enhanced learning dynamics rather than architecture-specific effects.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Bar Chart: Reward Comparison Across Environments
### Overview
The image presents a bar chart comparing the performance (reward) of four different algorithms (ERL, RLVR, Qwen, and Olmo) across three different environments: FROZENLAKE, HOTPOTQA, and SOKOBAN. The chart is divided into three sub-charts, one for each environment. Each sub-chart displays the reward achieved by each algorithm in that environment.
### Components/Axes
* **Title:** The chart lacks an overall title, but each sub-chart is titled with the environment name: FROZENLAKE, HOTPOTQA, and SOKOBAN.
* **Y-axis:** Labeled "Reward," with a scale from 0.00 to 0.80 in increments of 0.20.
* **X-axis:** Implicitly represents the different algorithms, with each algorithm having a corresponding bar in each sub-chart.
* **Legend:** Located at the top-left of the image.
* ERL: Green bar
* RLVR: Blue bar
* Qwen: White bar with blue diagonal stripes
* Olmo: White bar with green diagonal stripes
### Detailed Analysis
**FROZENLAKE**
* ERL (Green): Reward of 0.94
* RLVR (Blue): Reward of 0.86
* Qwen (White with blue stripes): Not present
* Olmo (White with green stripes): Reward of 0.66
**HOTPOTQA**
* ERL (Green): Reward of 0.56
* RLVR (Blue): Reward of 0.45
* Qwen (White with blue stripes): Reward of 0.47
* Olmo (White with green stripes): Reward of 0.50
**SOKOBAN**
* ERL (Green): Reward of 0.87
* RLVR (Blue): Reward of 0.06
* Qwen (White with blue stripes): Not present
* Olmo (White with green stripes): Reward of 0.20
### Key Observations
* ERL consistently achieves high rewards in all three environments.
* RLVR performs well in FROZENLAKE but struggles in HOTPOTQA and SOKOBAN.
* Qwen and Olmo are only present in the HOTPOTQA and SOKOBAN environments.
### Interpretation
The chart suggests that the ERL algorithm is the most robust across the tested environments, consistently achieving high rewards. RLVR's performance is highly environment-dependent, indicating it may be specialized for certain types of tasks. Qwen and Olmo show moderate performance in HOTPOTQA, but Olmo shows a low performance in SOKOBAN. The absence of Qwen and Olmo in FROZENLAKE suggests they may not be applicable or effective in that environment. The data highlights the importance of algorithm selection based on the specific environment and task requirements.
</details>
Figure 5: Final evaluation reward on FrozenLake, HotpotQA, and Sokoban. ERL consistently outperforms RLVR for both Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct.
4.2 Learning Efficiency and Optimization Dynamics
Figure 4 compares validation reward against wall-clock training time. Across tasks and models, ERL reaches higher reward earlier and maintains a persistent margin over RLVR. This acceleration is especially pronounced in FrozenLake and Sokoban, where RLVR progresses gradually while ERL rapidly approaches high-reward behavior.
These dynamics suggest that reflection introduces an intermediate corrective signal that reshapes exploration. Instead of relying solely on terminal reward propagation, the model conditions on feedback and self-generated critique to revise its behavior. This concentrates training updates on trajectories that are already partially aligned with the objective, reducing inefficient exploration.
Even in HotpotQA, where rewards are denser and the environment is comparatively simpler, ERL maintains a consistent performance advantage over RLVR. Across environments, these results indicate that ERL achieves higher final reward while improving learning efficiency, demonstrating that structured experiential revision leads to faster and more effective policy improvement.
4.3 Mechanistic Role of Reflection
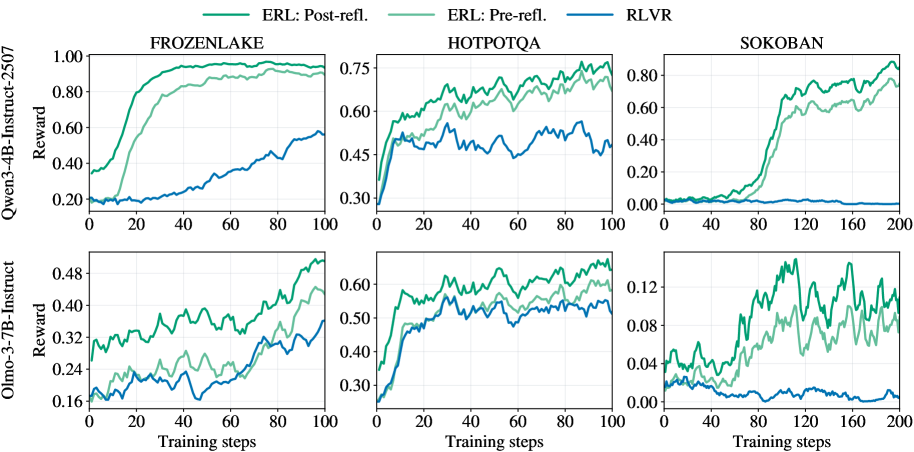
Figure 6 shows training reward trajectories for ERL before and after the reflection step, alongside RLVR. Across environments and models, post-reflection trajectories consistently achieve higher training reward than pre-reflection trajectories and also exceed RLVR.
This comparison highlights the immediate within-episode effect of reflection. After observing feedback from the first attempt, the model generates a structured revision that guides a second attempt with improved actions. The resulting gain in training reward indicates that reflection produces actionable corrections within the same episode, rather than only shaping behavior over long horizons. The sustained separation between pre- and post-reflection curves throughout training suggests that reflection serves as a systematic revision mechanism. By converting observed outcomes into targeted adjustments, it improves the quality of second attempts, which are subsequently reinforced and contribute to longer-term policy improvement.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Chart: Reward vs. Training Steps for Different Models and Environments
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the reward achieved by different models (ERL: Post-refl, ERL: Pre-refl, and RLVR) across varying training steps in different environments (FROZENLAKE, HOTPOTQA, and SOKOBAN). The charts are grouped by the model used (Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct).
### Components/Axes
* **Titles:**
* Top Row (Qwen3-4B-Instruct-2507): FROZENLAKE, HOTPOTQA, SOKOBAN
* Bottom Row (Olmo-3-7B-Instruct): FROZENLAKE, HOTPOTQA, SOKOBAN
* **Y-Axis (Reward):**
* Top Row: Scale from 0.00 to 1.00, with markers at 0.20, 0.40, 0.60, 0.80, and 1.00.
* Top Row (HOTPOTQA): Scale from 0.30 to 0.75, with markers at 0.30, 0.45, 0.60, and 0.75.
* Top Row (SOKOBAN): Scale from 0.00 to 0.80, with markers at 0.00, 0.20, 0.40, 0.60, and 0.80.
* Bottom Row: Scale from 0.16 to 0.48, with markers at 0.16, 0.24, 0.32, 0.40, and 0.48.
* Bottom Row (HOTPOTQA): Scale from 0.30 to 0.60, with markers at 0.30, 0.40, 0.50, and 0.60.
* Bottom Row (SOKOBAN): Scale from 0.00 to 0.12, with markers at 0.00, 0.04, 0.08, and 0.12.
* **X-Axis (Training steps):**
* FROZENLAKE and HOTPOTQA: Scale from 0 to 100, with ticks every 20 steps.
* SOKOBAN: Scale from 0 to 200, with ticks every 40 steps.
* **Labels:**
* Y-Axis Label (left side, vertical): "Reward" for both rows.
* Left of Top Row (vertical): "Qwen3-4B-Instruct-2507"
* Left of Bottom Row (vertical): "Olmo-3-7B-Instruct"
* X-Axis Label (bottom): "Training steps" for all charts.
* **Legend (top):**
* "ERL: Post-refl." (light green line)
* "ERL: Pre-refl." (green line)
* "RLVR" (blue line)
### Detailed Analysis
**Top Row (Qwen3-4B-Instruct-2507):**
* **FROZENLAKE:**
* ERL: Post-refl. (light green): Rapidly increases from ~0.20 to ~0.90 within the first 20 training steps, then plateaus around ~0.95.
* ERL: Pre-refl. (green): Increases from ~0.20 to ~0.80 within the first 20 training steps, then gradually increases to ~0.90, plateauing around ~0.90-0.95.
* RLVR (blue): Starts at ~0.20 and gradually increases to ~0.55 by 100 training steps.
* **HOTPOTQA:**
* ERL: Post-refl. (light green): Starts at ~0.40 and increases to ~0.70 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.45 and increases to ~0.75 with fluctuations.
* RLVR (blue): Starts at ~0.30 and increases to ~0.55 with fluctuations.
* **SOKOBAN:**
* ERL: Post-refl. (light green): Starts at ~0.00, increases rapidly to ~0.70 around step 100, then fluctuates around ~0.70-0.80.
* ERL: Pre-refl. (green): Starts at ~0.00, increases rapidly to ~0.60 around step 100, then fluctuates around ~0.60-0.70.
* RLVR (blue): Remains relatively flat around ~0.00 for the entire training period.
**Bottom Row (Olmo-3-7B-Instruct):**
* **FROZENLAKE:**
* ERL: Post-refl. (light green): Starts at ~0.32 and increases to ~0.44 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.30 and increases to ~0.48 with fluctuations.
* RLVR (blue): Starts at ~0.16 and increases to ~0.36 with fluctuations.
* **HOTPOTQA:**
* ERL: Post-refl. (light green): Starts at ~0.45 and increases to ~0.60 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.40 and increases to ~0.55 with fluctuations.
* RLVR (blue): Starts at ~0.30 and increases to ~0.50 with fluctuations.
* **SOKOBAN:**
* ERL: Post-refl. (light green): Starts at ~0.02 and increases to ~0.14 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.02 and increases to ~0.08 with fluctuations.
* RLVR (blue): Remains relatively flat around ~0.02 for the entire training period.
### Key Observations
* ERL models (both Post-refl and Pre-refl) generally outperform RLVR in all environments and with both base models (Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct).
* The FROZENLAKE environment shows the most significant performance difference between ERL and RLVR, especially with the Qwen3-4B-Instruct-2507 model.
* The SOKOBAN environment shows a delayed but significant increase in reward for ERL models, while RLVR remains consistently low.
* The Olmo-3-7B-Instruct model generally achieves lower rewards compared to the Qwen3-4B-Instruct-2507 model across all environments and algorithms.
* The "Post-refl" version of ERL generally performs slightly better than the "Pre-refl" version, although the difference is not always substantial.
### Interpretation
The data suggests that the ERL models, both with pre-reflection and post-reflection mechanisms, are more effective in learning and achieving higher rewards compared to the RLVR model across the tested environments. The FROZENLAKE environment appears to be particularly challenging for the RLVR model. The delayed performance increase in SOKOBAN for ERL models indicates a potential learning curve or a requirement for more exploration in that specific environment. The difference in performance between the Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct models highlights the impact of the base model architecture on the overall learning outcome. The slight advantage of "Post-refl" ERL over "Pre-refl" ERL suggests that the post-reflection mechanism might contribute to more efficient or effective learning.
</details>
Figure 6: Training reward trajectories for Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct comparing RLVR with ERL before and after reflection. Post-reflection trajectories consistently achieve higher reward than both RLVR and pre-reflection trajectories.
4.4 Ablation Study: Memory and Reflection Mechanisms
| Task Qwen3-4B-Instruct-2507 FrozenLake | RLVR 0.86 | ERL 0.94 | ERL w/o Mem. 0.86 (-0.08) | ERL w/o Refl. 0.60 (-0.34) |
| --- | --- | --- | --- | --- |
| HotpotQA | 0.45 | 0.56 | 0.56 (-0.00) | 0.48 (-0.08) |
| Sokoban | 0.06 | 0.87 | 0.87 (-0.00) | 0.59 (-0.28) |
| Olmo3-7B-Instruct | | | | |
| FrozenLake | 0.39 | 0.66 | 0.64 (-0.02) | 0.54 (-0.12) |
| HotpotQA | 0.47 | 0.50 | 0.47 (-0.03) | 0.46 (-0.04) |
| Sokoban | 0.04 | 0.20 | 0.24 (+0.04) | 0.06 (-0.14) |
Table 1: Final evaluation reward on FrozenLake, HotpotQA, and Sokoban. ERL performance is compared against ablation variants, with highlighted drops showing the performance degradation relative to ERL when removing memory reuse (w/o Mem.) or structured reflection (w/o Refl.).
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Reward vs. Training Wall-Clock Time
### Overview
The image is a line chart comparing the performance of four different algorithms (ERL, ERL w/o Mem., ERL w/o Refl., and RLVR) over a period of 8 hours of training. The y-axis represents the "Reward," ranging from 0.20 to 0.80. The x-axis represents "Training wall-clock time (hours)," ranging from 0 to 8.
### Components/Axes
* **X-axis:** Training wall-clock time (hours). Scale ranges from 0 to 8, with tick marks at every 2 hours.
* **Y-axis:** Reward. Scale ranges from 0.20 to 0.80, with tick marks at intervals of 0.20.
* **Legend:** Located at the top of the chart.
* ERL w/o Mem.: Dashed green line
* ERL: Solid green line
* ERL w/o Refl.: Dotted green line
* RLVR: Solid blue line
### Detailed Analysis
* **ERL (Solid Green):**
* Trend: Initially increases rapidly, plateaus around 0.85 after 4 hours.
* Data Points: Starts at approximately 0.22 at 0 hours, reaches approximately 0.85 around 4 hours, and remains relatively stable around 0.85-0.90 until 8 hours.
* **ERL w/o Mem. (Dashed Green):**
* Trend: Increases rapidly, peaks around 0.82 at 5 hours, then decreases slightly.
* Data Points: Starts at approximately 0.22 at 0 hours, reaches approximately 0.82 around 5 hours, and decreases to approximately 0.75 at 8 hours.
* **ERL w/o Refl. (Dotted Green):**
* Trend: Slow, steady increase.
* Data Points: Starts at approximately 0.22 at 0 hours, reaches approximately 0.55 at 8 hours.
* **RLVR (Solid Blue):**
* Trend: Slow initial increase, followed by a more rapid increase after 4 hours.
* Data Points: Starts at approximately 0.20 at 0 hours, remains relatively flat until 2 hours, then increases to approximately 0.75 at 8 hours.
### Key Observations
* ERL (solid green) and ERL w/o Mem. (dashed green) initially perform much better than ERL w/o Refl. (dotted green) and RLVR (solid blue).
* ERL w/o Mem. (dashed green) peaks and then declines slightly, while ERL (solid green) plateaus.
* RLVR (solid blue) shows a delayed but significant increase in reward after 4 hours.
* ERL w/o Refl. (dotted green) consistently shows the lowest reward throughout the training period.
### Interpretation
The chart compares the performance of different reinforcement learning algorithms. The ERL algorithm, both with and without memory, initially outperforms the RLVR algorithm. However, the RLVR algorithm eventually catches up, suggesting that it may benefit from longer training periods. The ERL algorithm without reflection consistently performs the worst, indicating that reflection is an important component of the ERL algorithm. The ERL algorithm with memory peaks and then declines, suggesting that memory may not be beneficial for long training periods.
</details>
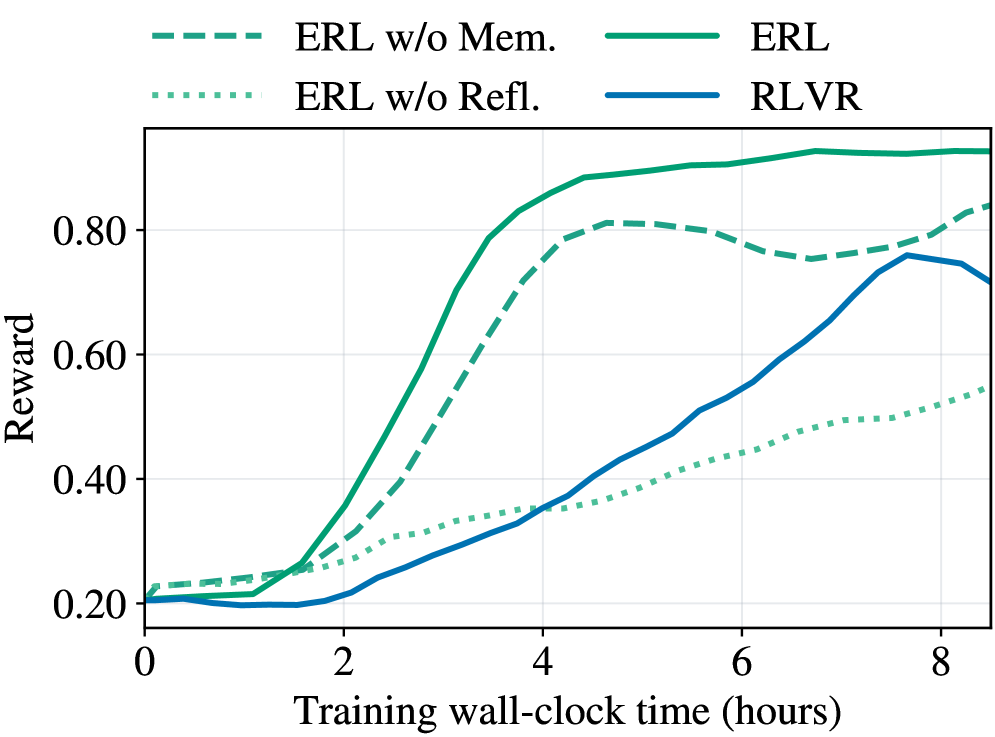
Figure 7: Ablation study on Qwen3-4B-Instruct-2507 in FrozenLake. We compare full ERL with two variants: (1) no memory, which disables cross-episode reflection reuse, and (2) no reflection, which replaces structured self-reflection with raw first-attempt context and a generic retry instruction.
To understand how structured reflection and cross-episode memory contribute to performance, we conduct ablation studies across tasks and models. The quantitative results are reported in Table 1, and representative learning dynamics for FrozenLake with Qwen3-4B-Instruct-2507 are shown in Figure 7. These experiments isolate individual components of ERL while keeping the overall training setup fixed.
The no-memory variant disables cross-episode reflection storage. Reflections are still generated and used to guide the second attempt within each episode, but they are not retained for reuse in future episodes. As a result, corrective signals remain local to individual trajectories rather than accumulating into persistent behavioral priors.
The no-reflection variant preserves the two-attempt interaction structure but removes explicit structured reflection. Instead, the model receives the full first-attempt interaction history together with a generic instruction encouraging improvement. This design tests whether contextual reuse alone can replicate the benefits of structured reflective reasoning. The prompt template used in this setting is shown in Table 9 (Appendix).
The results in Table 1 show a consistent ordering across most tasks and models: full ERL achieves the strongest performance, followed by the no-memory variant, while the no-reflection variant exhibits the largest degradation in most settings. Figure 7 further illustrates that removing memory slows convergence, whereas removing reflection substantially reduces both learning speed and final reward. These findings support the core design intuition of ERL: reflection generates actionable behavioral corrections, and memory propagates those corrections across episodes to enable cumulative refinement.
At the same time, Table 1 reveals an important caveat. In the Olmo3-7B-Instruct Sokoban setting, the no-memory variant slightly outperforms full ERL. This suggests that when a model’s self-reflective ability is limited, or when the environment is complex and stochastic, persistent memory may propagate early inaccurate reflections, making recovery more difficult. In such cases, disabling cross-episode memory can mitigate the accumulation of erroneous priors. Nevertheless, across the broad set of tasks and models evaluated, ERL consistently delivers the strongest overall performance, demonstrating that structured reflection combined with persistent memory is highly effective in most practical settings.
5 Related Work
Reinforcement Learning for LLMs.
Reinforcement learning has become a central approach for improving large language models. Early work focused on reinforcement learning from human feedback (RLHF) to align model behavior with human preferences and conversational objectives (Ouyang et al., 2022; Christiano et al., 2023; Shi et al., 2024; 2025). More recent efforts extend RL to enhance mathematical reasoning, where verifiable or programmatic rewards derived from executable checks or formal answer verification provide structured supervision for reasoning and solution construction (OpenAI et al., 2024; Guo et al., 2025; Song et al., 2025b; Shi et al., 2026). In parallel, research on tool-using and agentic LLMs treats the model as a policy that interacts with external environments, alternating between actions and observations under task-dependent rewards to solve multi-step problems (Yao et al., 2023; Jin et al., 2025; Bai et al., 2026; Jiang et al., 2026). Despite their different goals, these approaches primarily treat environment feedback as a scalar optimization signal propagated through policy gradients, requiring the model to implicitly infer corrective structure through exploration. In contrast, our ERL paradigm introduces an explicit experience-reflection-consolidation loop that transforms environment feedback into structured behavioral revision before internalizing improvements into the base policy.
Learning from Experience.
A growing body of work argues that the next scaling regime for AI will come not from more static human text, but from agents generating ever-richer data through interaction-i.e., learning predominantly from experience. Silver and Sutton (2025) emphasizes that continual, agent-generated data streams and long-horizon decision-making as the route beyond imitation of human corpora. This motivates algorithmic mechanisms that convert failures into usable learning signal rather than relying on rare successes. In classic reinforcement learning, Andrychowicz et al. (2018) addresses sparse rewards by relabeling goals so that failed trajectories can still provide informative updates, substantially improving sample efficiency in goal-conditioned tasks. In the LLM-agent setting, Zhang et al. (2025) similarly targets the gap between imitation and full RL by training agents on their own interaction traces even when explicit rewards are unavailable, using the agent’s generated future states as supervision and including self-reflection as a way to learn from suboptimal actions. Meanwhile, inference-time reflection methods demonstrate that LLMs can critique and revise their own outputs to improve success (Zelikman et al., 2022; Madaan et al., 2023; Shinn et al., 2023), but typically require reflection or memory at deployment. Concurrent research explores integrating feedback-conditioned improvement directly into training. hübotter2026reinforcementlearningselfdistillation; Song et al. (2026) formalize RL with textual feedback by distilling a feedback-conditioned teacher policy into a student policy. ERL is aligned with this direction but emphasizes explicit self-reflection as an intermediate reasoning step embedded inside the RL trajectory, where an initial attempt is followed by reflection and a refined retry. Coupled with selective internalization and cross-episode memory, this design treats reflection as a structured credit-assignment mechanism that transforms raw experience into durable behavioral improvement without requiring reflection at inference time.
6 Conclusion
In this work, we presented Experiential Reinforcement Learning (ERL), a training paradigm that incorporates an explicit experience–reflection–consolidation stage into the reinforcement learning loop to convert environment feedback into structured behavioral correction. By pairing reflection-guided revision with selective internalization, ERL enables models to learn corrective strategies during training and consolidate them into a deployable policy that operates without reflection at inference time. Across sparse-reward control and agentic reasoning tasks, ERL improves learning efficiency, stabilizes optimization, and produces stronger final policies relative to standard reinforcement learning baselines. These results demonstrate that embedding structured experiential revision directly into the training process provides an effective mechanism for translating feedback into durable behavioral improvement. Looking forward, this work suggests a path toward reinforcement learning systems that are fundamentally grounded in experience, where explicit reflection and consolidation become core primitives for building agents that continually learn, adapt, and improve from their own interactions.
Acknowledgements
The authors thank the members of the LIME Lab and Microsoft Office of Applied Research for their helpful discussions, feedback, and resources.
References
- R. Agarwal, N. Vieillard, Y. Zhou, P. Stanczyk, S. Ramos Garea, M. Geist, and O. Bachem (2024) On-policy distillation of language models: learning from self-generated mistakes. In International Conference on Learning Representations, B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (Eds.), Vol. 2024, pp. 21246–21263. External Links: Link Cited by: Appendix A.
- M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, P. Abbeel, and W. Zaremba (2018) Hindsight experience replay. External Links: 1707.01495, Link Cited by: §5.
- Y. Bai, Y. Bao, Y. Charles, C. Chen, G. Chen, H. Chen, H. Chen, J. Chen, N. Chen, R. Chen, Y. Chen, Y. Chen, Y. Chen, Z. Chen, J. Cui, H. Ding, M. Dong, A. Du, C. Du, D. Du, Y. Du, Y. Fan, Y. Feng, K. Fu, B. Gao, C. Gao, H. Gao, P. Gao, T. Gao, Y. Ge, S. Geng, Q. Gu, X. Gu, L. Guan, H. Guo, J. Guo, X. Hao, T. He, W. He, W. He, Y. He, C. Hong, H. Hu, Y. Hu, Z. Hu, W. Huang, Z. Huang, Z. Huang, T. Jiang, Z. Jiang, X. Jin, Y. Kang, G. Lai, C. Li, F. Li, H. Li, M. Li, W. Li, Y. Li, Y. Li, Y. Li, Z. Li, Z. Li, H. Lin, X. Lin, Z. Lin, C. Liu, C. Liu, H. Liu, J. Liu, J. Liu, L. Liu, S. Liu, T. Y. Liu, T. Liu, W. Liu, Y. Liu, Y. Liu, Y. Liu, Y. Liu, Z. Liu, E. Lu, H. Lu, L. Lu, Y. Luo, S. Ma, X. Ma, Y. Ma, S. Mao, J. Mei, X. Men, Y. Miao, S. Pan, Y. Peng, R. Qin, Z. Qin, B. Qu, Z. Shang, L. Shi, S. Shi, F. Song, J. Su, Z. Su, L. Sui, X. Sun, F. Sung, Y. Tai, H. Tang, J. Tao, Q. Teng, C. Tian, C. Wang, D. Wang, F. Wang, H. Wang, H. Wang, J. Wang, J. Wang, J. Wang, S. Wang, S. Wang, S. Wang, X. Wang, Y. Wang, Y. Wang, Y. Wang, Y. Wang, Y. Wang, Z. Wang, Z. Wang, Z. Wang, Z. Wang, C. Wei, Q. Wei, H. Wu, W. Wu, X. Wu, Y. Wu, C. Xiao, J. Xie, X. Xie, W. Xiong, B. Xu, J. Xu, L. H. Xu, L. Xu, S. Xu, W. Xu, X. Xu, Y. Xu, Z. Xu, J. Xu, J. Xu, J. Yan, Y. Yan, H. Yang, X. Yang, Y. Yang, Y. Yang, Z. Yang, Z. Yang, Z. Yang, H. Yao, X. Yao, W. Ye, Z. Ye, B. Yin, L. Yu, E. Yuan, H. Yuan, M. Yuan, S. Yuan, H. Zhan, D. Zhang, H. Zhang, W. Zhang, X. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, Z. Zhang, H. Zhao, Y. Zhao, Z. Zhao, H. Zheng, S. Zheng, L. Zhong, J. Zhou, X. Zhou, Z. Zhou, J. Zhu, Z. Zhu, W. Zhuang, and X. Zu (2026) Kimi k2: open agentic intelligence. External Links: 2507.20534, Link Cited by: §1, §5.
- P. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei (2023) Deep reinforcement learning from human preferences. External Links: 1706.03741, Link Cited by: §5.
- T. Dao (2024) FlashAttention-2: faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), Cited by: Appendix C.
- M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P. Mazaré, M. Lomeli, L. Hosseini, and H. Jégou (2024) The faiss library. External Links: 2401.08281 Cited by: §B.3.
- L. Guertler, B. Cheng, S. Yu, B. Liu, L. Choshen, and C. Tan (2025) TextArena. External Links: 2504.11442, Link Cited by: §B.1, §B.2, §3.1.
- D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y. Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Ding, H. Gao, H. Qu, H. Li, J. Guo, J. Li, J. Chen, J. Yuan, J. Tu, J. Qiu, J. Li, J. L. Cai, J. Ni, J. Liang, J. Chen, K. Dong, K. Hu, K. You, K. Gao, K. Guan, K. Huang, K. Yu, L. Wang, L. Zhang, L. Zhao, L. Wang, L. Zhang, L. Xu, L. Xia, M. Zhang, M. Zhang, M. Tang, M. Zhou, M. Li, M. Wang, M. Li, N. Tian, P. Huang, P. Zhang, Q. Wang, Q. Chen, Q. Du, R. Ge, R. Zhang, R. Pan, R. Wang, R. J. Chen, R. L. Jin, R. Chen, S. Lu, S. Zhou, S. Chen, S. Ye, S. Wang, S. Yu, S. Zhou, S. Pan, S. S. Li, S. Zhou, S. Wu, T. Yun, T. Pei, T. Sun, T. Wang, W. Zeng, W. Liu, W. Liang, W. Gao, W. Yu, W. Zhang, W. L. Xiao, W. An, X. Liu, X. Wang, X. Chen, X. Nie, X. Cheng, X. Liu, X. Xie, X. Liu, X. Yang, X. Li, X. Su, X. Lin, X. Q. Li, X. Jin, X. Shen, X. Chen, X. Sun, X. Wang, X. Song, X. Zhou, X. Wang, X. Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Y. Zhang, Y. Xu, Y. Li, Y. Zhao, Y. Sun, Y. Wang, Y. Yu, Y. Zhang, Y. Shi, Y. Xiong, Y. He, Y. Piao, Y. Wang, Y. Tan, Y. Ma, Y. Liu, Y. Guo, Y. Ou, Y. Wang, Y. Gong, Y. Zou, Y. He, Y. Xiong, Y. Luo, Y. You, Y. Liu, Y. Zhou, Y. X. Zhu, Y. Huang, Y. Li, Y. Zheng, Y. Zhu, Y. Ma, Y. Tang, Y. Zha, Y. Yan, Z. Z. Ren, Z. Ren, Z. Sha, Z. Fu, Z. Xu, Z. Xie, Z. Zhang, Z. Hao, Z. Ma, Z. Yan, Z. Wu, Z. Gu, Z. Zhu, Z. Liu, Z. Li, Z. Xie, Z. Song, Z. Pan, Z. Huang, Z. Xu, Z. Zhang, and Z. Zhang (2025) DeepSeek-r1 incentivizes reasoning in llms through reinforcement learning. Nature 645 (8081), pp. 633–638. External Links: ISSN 1476-4687, Link, Document Cited by: §5.
- B. Jiang, T. Shi, R. Kamoi, Y. Yuan, C. J. Taylor, L. Yang, P. Zhou, and S. Chen (2026) One model, all roles: multi-turn, multi-agent self-play reinforcement learning for conversational social intelligence. External Links: 2602.03109, Link Cited by: §5.
- B. Jin, H. Zeng, Z. Yue, J. Yoon, S. O. Arik, D. Wang, H. Zamani, and J. Han (2025) Search-r1: training LLMs to reason and leverage search engines with reinforcement learning. In Second Conference on Language Modeling, External Links: Link Cited by: §B.3, §3.1, §5.
- D. A. Kolb (2014) Experiential learning: experience as the source of learning and development. 2 edition, FT Press, Upper Saddle River, NJ. External Links: ISBN 9780133892505 Cited by: §1.
- W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica (2023) Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, Cited by: Appendix C.
- A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark (2023) Self-refine: iterative refinement with self-feedback. External Links: 2303.17651, Link Cited by: §5.
- T. Olmo, :, A. Ettinger, A. Bertsch, B. Kuehl, D. Graham, D. Heineman, D. Groeneveld, F. Brahman, F. Timbers, H. Ivison, J. Morrison, J. Poznanski, K. Lo, L. Soldaini, M. Jordan, M. Chen, M. Noukhovitch, N. Lambert, P. Walsh, P. Dasigi, R. Berry, S. Malik, S. Shah, S. Geng, S. Arora, S. Gupta, T. Anderson, T. Xiao, T. Murray, T. Romero, V. Graf, A. Asai, A. Bhagia, A. Wettig, A. Liu, A. Rangapur, C. Anastasiades, C. Huang, D. Schwenk, H. Trivedi, I. Magnusson, J. Lochner, J. Liu, L. J. V. Miranda, M. Sap, M. Morgan, M. Schmitz, M. Guerquin, M. Wilson, R. Huff, R. L. Bras, R. Xin, R. Shao, S. Skjonsberg, S. Z. Shen, S. S. Li, T. Wilde, V. Pyatkin, W. Merrill, Y. Chang, Y. Gu, Z. Zeng, A. Sabharwal, L. Zettlemoyer, P. W. Koh, A. Farhadi, N. A. Smith, and H. Hajishirzi (2025) Olmo 3. External Links: 2512.13961, Link Cited by: §3.2.
- OpenAI, :, A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, A. Iftimie, A. Karpenko, A. T. Passos, A. Neitz, A. Prokofiev, A. Wei, A. Tam, A. Bennett, A. Kumar, A. Saraiva, A. Vallone, A. Duberstein, A. Kondrich, A. Mishchenko, A. Applebaum, A. Jiang, A. Nair, B. Zoph, B. Ghorbani, B. Rossen, B. Sokolowsky, B. Barak, B. McGrew, B. Minaiev, B. Hao, B. Baker, B. Houghton, B. McKinzie, B. Eastman, C. Lugaresi, C. Bassin, C. Hudson, C. M. Li, C. de Bourcy, C. Voss, C. Shen, C. Zhang, C. Koch, C. Orsinger, C. Hesse, C. Fischer, C. Chan, D. Roberts, D. Kappler, D. Levy, D. Selsam, D. Dohan, D. Farhi, D. Mely, D. Robinson, D. Tsipras, D. Li, D. Oprica, E. Freeman, E. Zhang, E. Wong, E. Proehl, E. Cheung, E. Mitchell, E. Wallace, E. Ritter, E. Mays, F. Wang, F. P. Such, F. Raso, F. Leoni, F. Tsimpourlas, F. Song, F. von Lohmann, F. Sulit, G. Salmon, G. Parascandolo, G. Chabot, G. Zhao, G. Brockman, G. Leclerc, H. Salman, H. Bao, H. Sheng, H. Andrin, H. Bagherinezhad, H. Ren, H. Lightman, H. W. Chung, I. Kivlichan, I. O’Connell, I. Osband, I. C. Gilaberte, I. Akkaya, I. Kostrikov, I. Sutskever, I. Kofman, J. Pachocki, J. Lennon, J. Wei, J. Harb, J. Twore, J. Feng, J. Yu, J. Weng, J. Tang, J. Yu, J. Q. Candela, J. Palermo, J. Parish, J. Heidecke, J. Hallman, J. Rizzo, J. Gordon, J. Uesato, J. Ward, J. Huizinga, J. Wang, K. Chen, K. Xiao, K. Singhal, K. Nguyen, K. Cobbe, K. Shi, K. Wood, K. Rimbach, K. Gu-Lemberg, K. Liu, K. Lu, K. Stone, K. Yu, L. Ahmad, L. Yang, L. Liu, L. Maksin, L. Ho, L. Fedus, L. Weng, L. Li, L. McCallum, L. Held, L. Kuhn, L. Kondraciuk, L. Kaiser, L. Metz, M. Boyd, M. Trebacz, M. Joglekar, M. Chen, M. Tintor, M. Meyer, M. Jones, M. Kaufer, M. Schwarzer, M. Shah, M. Yatbaz, M. Y. Guan, M. Xu, M. Yan, M. Glaese, M. Chen, M. Lampe, M. Malek, M. Wang, M. Fradin, M. McClay, M. Pavlov, M. Wang, M. Wang, M. Murati, M. Bavarian, M. Rohaninejad, N. McAleese, N. Chowdhury, N. Chowdhury, N. Ryder, N. Tezak, N. Brown, O. Nachum, O. Boiko, O. Murk, O. Watkins, P. Chao, P. Ashbourne, P. Izmailov, P. Zhokhov, R. Dias, R. Arora, R. Lin, R. G. Lopes, R. Gaon, R. Miyara, R. Leike, R. Hwang, R. Garg, R. Brown, R. James, R. Shu, R. Cheu, R. Greene, S. Jain, S. Altman, S. Toizer, S. Toyer, S. Miserendino, S. Agarwal, S. Hernandez, S. Baker, S. McKinney, S. Yan, S. Zhao, S. Hu, S. Santurkar, S. R. Chaudhuri, S. Zhang, S. Fu, S. Papay, S. Lin, S. Balaji, S. Sanjeev, S. Sidor, T. Broda, A. Clark, T. Wang, T. Gordon, T. Sanders, T. Patwardhan, T. Sottiaux, T. Degry, T. Dimson, T. Zheng, T. Garipov, T. Stasi, T. Bansal, T. Creech, T. Peterson, T. Eloundou, V. Qi, V. Kosaraju, V. Monaco, V. Pong, V. Fomenko, W. Zheng, W. Zhou, W. McCabe, W. Zaremba, Y. Dubois, Y. Lu, Y. Chen, Y. Cha, Y. Bai, Y. He, Y. Zhang, Y. Wang, Z. Shao, and Z. Li (2024) OpenAI o1 system card. External Links: 2412.16720, Link Cited by: §5.
- L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe (2022) Training language models to follow instructions with human feedback. External Links: 2203.02155, Link Cited by: §5.
- Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, and D. Guo (2024) DeepSeekMath: pushing the limits of mathematical reasoning in open language models. External Links: 2402.03300, Link Cited by: Appendix C, §3.2.
- T. Shi, K. Chen, and J. Zhao (2024) Safer-instruct: aligning language models with automated preference data. External Links: 2311.08685, Link Cited by: §5.
- T. Shi, Z. Wang, L. Yang, Y. Lin, Z. He, M. Wan, P. Zhou, S. Jauhar, S. Chen, S. Xia, H. Zhang, J. Zhao, X. Xu, X. Song, and J. Neville (2025) WildFeedback: aligning llms with in-situ user interactions and feedback. External Links: 2408.15549, Link Cited by: §5.
- T. Shi, Y. Wu, L. Song, T. Zhou, and J. Zhao (2026) Efficient reinforcement finetuning via adaptive curriculum learning. External Links: 2504.05520, Link Cited by: §1, §5.
- N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao (2023) Reflexion: language agents with verbal reinforcement learning. External Links: 2303.11366, Link Cited by: §5.
- D. Silver and R. S. Sutton (2025) Welcome to the era of experience. External Links: Link Cited by: §5.
- A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, A. Nathan, A. Luo, A. Helyar, A. Madry, A. Efremov, A. Spyra, A. Baker-Whitcomb, A. Beutel, A. Karpenko, A. Makelov, A. Neitz, A. Wei, A. Barr, A. Kirchmeyer, A. Ivanov, A. Christakis, A. Gillespie, A. Tam, A. Bennett, A. Wan, A. Huang, A. M. Sandjideh, A. Yang, A. Kumar, A. Saraiva, A. Vallone, A. Gheorghe, A. G. Garcia, A. Braunstein, A. Liu, A. Schmidt, A. Mereskin, A. Mishchenko, A. Applebaum, A. Rogerson, A. Rajan, A. Wei, A. Kotha, A. Srivastava, A. Agrawal, A. Vijayvergiya, A. Tyra, A. Nair, A. Nayak, B. Eggers, B. Ji, B. Hoover, B. Chen, B. Chen, B. Barak, B. Minaiev, B. Hao, B. Baker, B. Lightcap, B. McKinzie, B. Wang, B. Quinn, B. Fioca, B. Hsu, B. Yang, B. Yu, B. Zhang, B. Brenner, C. R. Zetino, C. Raymond, C. Lugaresi, C. Paz, C. Hudson, C. Whitney, C. Li, C. Chen, C. Cole, C. Voss, C. Ding, C. Shen, C. Huang, C. Colby, C. Hallacy, C. Koch, C. Lu, C. Kaplan, C. Kim, C. Minott-Henriques, C. Frey, C. Yu, C. Czarnecki, C. Reid, C. Wei, C. Decareaux, C. Scheau, C. Zhang, C. Forbes, D. Tang, D. Goldberg, D. Roberts, D. Palmie, D. Kappler, D. Levine, D. Wright, D. Leo, D. Lin, D. Robinson, D. Grabb, D. Chen, D. Lim, D. Salama, D. Bhattacharjee, D. Tsipras, D. Li, D. Yu, D. Strouse, D. Williams, D. Hunn, E. Bayes, E. Arbus, E. Akyurek, E. Y. Le, E. Widmann, E. Yani, E. Proehl, E. Sert, E. Cheung, E. Schwartz, E. Han, E. Jiang, E. Mitchell, E. Sigler, E. Wallace, E. Ritter, E. Kavanaugh, E. Mays, E. Nikishin, F. Li, F. P. Such, F. de Avila Belbute Peres, F. Raso, F. Bekerman, F. Tsimpourlas, F. Chantzis, F. Song, F. Zhang, G. Raila, G. McGrath, G. Briggs, G. Yang, G. Parascandolo, G. Chabot, G. Kim, G. Zhao, G. Valiant, G. Leclerc, H. Salman, H. Wang, H. Sheng, H. Jiang, H. Wang, H. Jin, H. Sikchi, H. Schmidt, H. Aspegren, H. Chen, H. Qiu, H. Lightman, I. Covert, I. Kivlichan, I. Silber, I. Sohl, I. Hammoud, I. Clavera, I. Lan, I. Akkaya, I. Kostrikov, I. Kofman, I. Etinger, I. Singal, J. Hehir, J. Huh, J. Pan, J. Wilczynski, J. Pachocki, J. Lee, J. Quinn, J. Kiros, J. Kalra, J. Samaroo, J. Wang, J. Wolfe, J. Chen, J. Wang, J. Harb, J. Han, J. Wang, J. Zhao, J. Chen, J. Yang, J. Tworek, J. Chand, J. Landon, J. Liang, J. Lin, J. Liu, J. Wang, J. Tang, J. Yin, J. Jang, J. Morris, J. Flynn, J. Ferstad, J. Heidecke, J. Fishbein, J. Hallman, J. Grant, J. Chien, J. Gordon, J. Park, J. Liss, J. Kraaijeveld, J. Guay, J. Mo, J. Lawson, J. McGrath, J. Vendrow, J. Jiao, J. Lee, J. Steele, J. Wang, J. Mao, K. Chen, K. Hayashi, K. Xiao, K. Salahi, K. Wu, K. Sekhri, K. Sharma, K. Singhal, K. Li, K. Nguyen, K. Gu-Lemberg, K. King, K. Liu, K. Stone, K. Yu, K. Ying, K. Georgiev, K. Lim, K. Tirumala, K. Miller, L. Ahmad, L. Lv, L. Clare, L. Fauconnet, L. Itow, L. Yang, L. Romaniuk, L. Anise, L. Byron, L. Pathak, L. Maksin, L. Lo, L. Ho, L. Jing, L. Wu, L. Xiong, L. Mamitsuka, L. Yang, L. McCallum, L. Held, L. Bourgeois, L. Engstrom, L. Kuhn, L. Feuvrier, L. Zhang, L. Switzer, L. Kondraciuk, L. Kaiser, M. Joglekar, M. Singh, M. Shah, M. Stratta, M. Williams, M. Chen, M. Sun, M. Cayton, M. Li, M. Zhang, M. Aljubeh, M. Nichols, M. Haines, M. Schwarzer, M. Gupta, M. Shah, M. Huang, M. Dong, M. Wang, M. Glaese, M. Carroll, M. Lampe, M. Malek, M. Sharman, M. Zhang, M. Wang, M. Pokrass, M. Florian, M. Pavlov, M. Wang, M. Chen, M. Wang, M. Feng, M. Bavarian, M. Lin, M. Abdool, M. Rohaninejad, N. Soto, N. Staudacher, N. LaFontaine, N. Marwell, N. Liu, N. Preston, N. Turley, N. Ansman, N. Blades, N. Pancha, N. Mikhaylin, N. Felix, N. Handa, N. Rai, N. Keskar, N. Brown, O. Nachum, O. Boiko, O. Murk, O. Watkins, O. Gleeson, P. Mishkin, P. Lesiewicz, P. Baltescu, P. Belov, P. Zhokhov, P. Pronin, P. Guo, P. Thacker, Q. Liu, Q. Yuan, Q. Liu, R. Dias, R. Puckett, R. Arora, R. T. Mullapudi, R. Gaon, R. Miyara, R. Song, R. Aggarwal, R. Marsan, R. Yemiru, R. Xiong, R. Kshirsagar, R. Nuttall, R. Tsiupa, R. Eldan, R. Wang, R. James, R. Ziv, R. Shu, R. Nigmatullin, S. Jain, S. Talaie, S. Altman, S. Arnesen, S. Toizer, S. Toyer, S. Miserendino, S. Agarwal, S. Yoo, S. Heon, S. Ethersmith, S. Grove, S. Taylor, S. Bubeck, S. Banesiu, S. Amdo, S. Zhao, S. Wu, S. Santurkar, S. Zhao, S. R. Chaudhuri, S. Krishnaswamy, Shuaiqi, Xia, S. Cheng, S. Anadkat, S. P. Fishman, S. Tobin, S. Fu, S. Jain, S. Mei, S. Egoian, S. Kim, S. Golden, S. Mah, S. Lin, S. Imm, S. Sharpe, S. Yadlowsky, S. Choudhry, S. Eum, S. Sanjeev, T. Khan, T. Stramer, T. Wang, T. Xin, T. Gogineni, T. Christianson, T. Sanders, T. Patwardhan, T. Degry, T. Shadwell, T. Fu, T. Gao, T. Garipov, T. Sriskandarajah, T. Sherbakov, T. Kaftan, T. Hiratsuka, T. Wang, T. Song, T. Zhao, T. Peterson, V. Kharitonov, V. Chernova, V. Kosaraju, V. Kuo, V. Pong, V. Verma, V. Petrov, W. Jiang, W. Zhang, W. Zhou, W. Xie, W. Zhan, W. McCabe, W. DePue, W. Ellsworth, W. Bain, W. Thompson, X. Chen, X. Qi, X. Xiang, X. Shi, Y. Dubois, Y. Yu, Y. Khakbaz, Y. Wu, Y. Qian, Y. T. Lee, Y. Chen, Y. Zhang, Y. Xiong, Y. Tian, Y. Cha, Y. Bai, Y. Yang, Y. Yuan, Y. Li, Y. Zhang, Y. Yang, Y. Jin, Y. Jiang, Y. Wang, Y. Wang, Y. Liu, Z. Stubenvoll, Z. Dou, Z. Wu, and Z. Wang (2025) OpenAI gpt-5 system card. External Links: 2601.03267, Link Cited by: §1.
- L. Song, Y. Dai, V. Prabhu, J. Zhang, T. Shi, L. Li, J. Li, S. Savarese, Z. Chen, J. Zhao, R. Xu, and C. Xiong (2025a) CoAct-1: computer-using agents with coding as actions. External Links: 2508.03923, Link Cited by: §1.
- L. Song, T. Shi, and J. Zhao (2025b) The hallucination tax of reinforcement finetuning. External Links: 2505.13988, Link Cited by: §5.
- Y. Song, L. Chen, F. Tajwar, R. Munos, D. Pathak, J. A. Bagnell, A. Singh, and A. Zanette (2026) Expanding the capabilities of reinforcement learning via text feedback. External Links: 2602.02482, Link Cited by: Appendix A, §5.
- S. Tan, M. Luo, C. Cai, T. Venkat, K. Montgomery, A. Hao, T. Wu, A. Balyan, M. Roongta, C. Wang, L. E. Li, R. A. Popa, and I. Stoica (2025) RLLM: a framework for post-training language agents. Note: https://pretty-radio-b75.notion.site/rLLM-A-Framework-for-Post-Training-Language-Agents-21b81902c146819db63cd98a54ba5f31 Notion Blog Cited by: Appendix C.
- S. Wang, Y. Wu, and Z. Xu (2025) Cogito, ergo ludo: an agent that learns to play by reasoning and planning. External Links: 2509.25052, Link Cited by: §B.1, §B.2, §3.1.
- A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. Li, T. Tang, W. Yin, X. Ren, X. Wang, X. Zhang, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Zhang, Y. Wan, Y. Liu, Z. Wang, Z. Cui, Z. Zhang, Z. Zhou, and Z. Qiu (2025) Qwen3 technical report. External Links: 2505.09388, Link Cited by: §1, §3.2.
- Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning (2018) HotpotQA: a dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii (Eds.), Brussels, Belgium, pp. 2369–2380. External Links: Link, Document Cited by: §3.1.
- S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao (2023) ReAct: synergizing reasoning and acting in language models. External Links: 2210.03629, Link Cited by: §5.
- E. Zelikman, Y. Wu, J. Mu, and N. Goodman (2022) STar: bootstrapping reasoning with reasoning. In Advances in Neural Information Processing Systems, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho (Eds.), External Links: Link Cited by: §5.
- K. Zhang, X. Chen, B. Liu, T. Xue, Z. Liao, Z. Liu, X. Wang, Y. Ning, Z. Chen, X. Fu, J. Xie, Y. Sun, B. Gou, Q. Qi, Z. Meng, J. Yang, N. Zhang, X. Li, A. Shah, D. Huynh, H. Li, Z. Yang, S. Cao, L. Jang, S. Zhou, J. Zhu, H. Sun, J. Weston, Y. Su, and Y. Wu (2025) Agent learning via early experience. External Links: 2510.08558, Link Cited by: §1, §5.
Appendix A Full Algorithm and Gated Reflection
Gated Reflection.
Algorithm 2 presents the full version of ERL used in our experiments. Compared to the simplified version in Algorithm 1, the key difference is a gating mechanism on the second attempt: reflection and refinement are triggered only when the first-attempt reward satisfies $r^{(1)}<\tau$ , where $\tau=1$ . In other words, reflection is applied only to failed or suboptimal trajectories. In early experiments, we applied reflection to all trajectories, including successful ones, but this led to unstable training and reduced generalization. First, reflecting on already successful attempts encouraged reward hacking: the model sometimes generated instance-specific shortcuts that guaranteed success for the current sample but did not generalize to future episodes. Second, early in training when first-attempt rewards are typically low, the optimization signal became dominated by the second attempt and reflection, which are inherently off-policy relative to the base policy. This imbalance weakened the on-policy learning signal and destabilized the policy. The gating mechanism mitigates these issues by ensuring that successful trajectories remain purely on-policy, while reflection is reserved for corrective revision on failed attempts. This design also aligns training with deployment: at inference time, the model must generate $y\sim\pi_{\theta}(·\mid x)$ without access to reflection $\Delta$ or feedback signals. By restricting reflection to corrective cases and preserving sufficient on-policy updates in every batch, the gating mechanism improves stability in training.
Memory Extensions.
Algorithm 2 also maintains a simple reflection memory that stores successful reflections as system prompt in plain text. A natural extension is to replace this mechanism with a more sophisticated agentic memory system. For example, before the reflection step (Alg. 2, Line 12), the model may retrieve relevant past reflections from a memory base conditioned on the current input $x$ , and after a successful refinement, update the memory using a structured agentic memory update rule rather than direct overwrite. Such retrieval-and-update schemes would allow ERL to scale to more diverse and long-horizon tasks by enabling selective reuse and continual refinement of past corrective knowledge.
On-Policy Distillation.
The internalization step in Algorithm 2 can also be generalized beyond supervised distillation. Instead of training $\pi_{\theta}$ to reproduce $y^{(2)}$ from $x$ using a standard distillation loss, one may adopt an on-policy reverse KL objective. Let the contextual policy with access to reflection and memory be $\pi_{\theta}(·\mid x,\Delta)$ , and the deployment policy be $\pi_{\theta}(·\mid x)$ . An on-policy distillation objective can be written as
$$
\mathcal{L}_{\text{OD}}(\theta):=\mathbb{E}_{x\sim\mathcal{D}}\Big[\mathbb{I}\!\left(r^{(2)}>0\right)\,\mathbb{E}_{y\sim\pi_{\theta}(\cdot\mid x)}\big[\mathrm{KL}\!\left(\pi_{\theta}(\cdot\mid x,\Delta)\;\|\;\pi_{\theta}(\cdot\mid x)\right)\big]\Big]. \tag{2}
$$
which encourages the deployment policy to match the richer contextual policy while remaining on-policy with respect to $\pi_{\theta}(·\mid x)$ . This connects ERL to recent reverse-KL and on-policy distillation approaches (Agarwal et al., 2024; hübotter2026reinforcementlearningselfdistillation; Song et al., 2026) and provides a principled alternative to supervised internalization.
Algorithm 2 Reinforcement Learning from Self-Reflection (Full Version)
1: Inputs: Language model $\pi_{\theta}$ ; dataset of questions $x$ ; environment returning feedback $f$ and reward $r$ , reward threshold $\tau$ .
2: Initialize: reflection memory $m←\emptyset$ .
3: repeat
4: Sample question $x$ from dataset.
5: // First attempt
6: Sample answer $y^{(1)}\sim\pi_{\theta}(·\mid x)$ .
7: Obtain feedback and reward $(f^{(1)},r^{(1)})$ .
8: // RL update on the first attempt
9: Update $\theta$ via $\mathcal{L}_{\text{policy}}(\theta)$ over the first attempt
10: // Gated second attempt
11: if $r^{(1)}<\tau$ then
12: // Reflection with cross-episode memory
13: Sample reflection $\Delta\sim\pi_{\theta}(·\mid x,y^{(1)},f^{(1)},r^{(1)},m).$
14: Sample refined answer $y^{(2)}\sim\pi_{\theta}(·\mid x,\Delta).$
15: Obtain feedback and reward $(f^{(2)},r^{(2)})$ .
16: Set reflection reward $\tilde{r}← r^{(2)}$ .
17: // Store reflection only if improved beyond threshold
18: if $r^{(2)}>\tau$ then
19: Store reflection: $m←\Delta$ .
20: end if
21: // RL update on the second attempt
22: Update $\theta$ via $\mathcal{L}_{\text{policy}}(\theta)$ over reflection and second attempt.
23: // Internalization
24: Update $\theta$ via $\mathcal{L}_{\text{distill}}(\theta)$ to internalize reflection, training $\pi_{\theta}$ to produce $y^{(2)}$ from $x$ only.
25: end if
26: until converged
Appendix B Envrionment Configuration Details
B.1 Frozen Lake
Frozen Lake is a grid-based navigation environment in which an agent must move from a start location to a goal location on an $n× n$ grid. We configure our Frozenlake environment following a setup similar to those used in TextArena (Guertler et al., 2025) and Wang et al. (2025). The grid size $n$ is sampled uniformly from $[2,9]$ . For each instance, the start and goal tiles are randomly selected as distinct positions. The grid layout is generated procedurally to ensure that at least one valid path exists between the start and goal.
Each non-goal tile is assigned as either a safe frozen tile or a hole according to a frozen-tile probability parameter $p$ , sampled uniformly from $[0.6,0.85)$ . Holes represent terminal failure states, while frozen tiles are traversable. Transitions are deterministic: the agent’s chosen action directly determines its next grid position, subject to boundary constraints.
At every step, the agent observes a full textual representation of the grid. To reduce the influence of pretrained symbolic priors, we employ abstract symbols rather than semantically meaningful markers. The default encoding is:
$$
\texttt{A}=\text{agent position},\quad\texttt{B}=\text{goal tile},\quad\texttt{C}=\text{hole},\quad\texttt{D}=\text{safe frozen tile}.
$$
This representation encourages the model to infer environment dynamics through interaction rather than relying on prior associations.
In addition to the textual presentation of the grid, the environment also appends structured textual feedback to the end of the interaction history after each action. This feedback communicates the outcome of the most recent transition and serves as the only explicit signal describing terminal or invalid events. The feedback messages are defined as follows:
- The agent reached the goal — issued when the agent successfully enters the goal tile. The episode terminates with reward $1.0$ .
- The agent fell into the hole — issued when the agent enters a hole tile. The episode terminates with reward $0.0$ .
- Hit the max step limit — issued when the agent exhausts the fixed step budget. The episode terminates with reward $0.0$ .
- No valid actions were recorded. — issued when the agent produces an invalid action or when the attempted action results in no state change, such as moving into a boundary. The episode continues unless the step budget is exhausted.
The default system prompt, self-reflection prompt, and example task are shown in Tables 2, 4, and 6.
The reward function is sparse. The agent receives a reward of $1.0$ if it reaches the goal tile and $0.0$ otherwise. Episodes terminate upon reaching the goal, entering a hole, or exhausting a fixed step budget of 8 actions.
For training, we generate 10,000 procedurally sampled instances. Evaluation is conducted on a disjoint set of 100 instances constructed using the same generation process.
B.2 Sokoban
Sokoban is a grid-based box-pushing environment in which an agent must place all boxes onto designated goal tiles. We configure our Sokoban environment following a setup similar to those used in TextArena (Guertler et al., 2025) and Wang et al. (2025). Each instance is represented as an $n× n$ grid, where $n$ is sampled uniformly from $[6,8]$ in our procedural generator. We construct single-box, single-goal layouts with border walls, and randomly sample interior positions for the goal, box, and player, subject to non-overlap constraints.
To control difficulty, each generated layout is accepted only if its shortest valid solution is at most 8 moves (computed by BFS over player–box states). This guarantees solvability while keeping episodes short-horizon. Train and test splits are disjoint at the layout level.
At every step, the agent observes the full textual grid. As in FrozenLake, we use abstract symbols to reduce direct reliance on pretrained semantic priors. The default encoding is:
| | A | $\displaystyle=\text{agent position},\quad\texttt{a}=\text{agent on box},\quad\texttt{B}=\text{box},\quad\texttt{b}=\text{box on goal},$ | |
| --- | --- | --- | --- |
The action space is {Up, Down, Left, Right}. Moves are deterministic. The agent may push exactly one adjacent box only when the cell behind the box is free; it cannot pull boxes, move through walls, or move through boxes. Invalid moves produce no state change.
In addition to the grid observation, the interaction trace includes structured textual transition feedback after each action. The feedback messages are:
- The agent solved the puzzle (all boxes on goals). — issued when all boxes are on goal tiles. The episode terminates with reward $1.0$ .
- The agent moved or pushed a box; puzzle not solved yet. — issued when the action changes the state but the puzzle remains unsolved.
- The agent did not move (likely hit a wall or tried to push into a blocked space). — issued when the chosen move is ineffective (no state change).
- Hit the max step limit — issued when the fixed step budget is exhausted before solving. The episode terminates with reward $0.0$ .
The default system prompt, self-reflection prompt, and example task are shown in Tables 2, 4, and 7.
The reward is sparse: $1.0$ if and only if all boxes are on goals, and $0.0$ otherwise. Episodes terminate on success or when the step budget is exhausted. In the generated REEX Sokoban dataset, the per-instance step budget is 8.
For training, we generate 10,000 procedurally sampled instances. Evaluation is conducted on a disjoint set of 100 instances built with the same generation process.
B.3 HotpotQA
HotpotQA is a multi-hop open-domain question answering task in which an agent must answer compositional questions by retrieving and synthesizing evidence across multiple documents. Each instance consists of a natural-language question and a reference answer.
Unlike grid-based control environments such as FrozenLake or Sokoban, HotpotQA does not expose an explicit environment state. Instead, the agent operates through a tool-augmented interaction loop in which it alternates between reasoning, retrieval, and answer generation. The agent may invoke an external retrieval tool and ultimately produce a final textual answer. The solver instruction requires that the final answer be formatted inside \boxed{} to enable reliable extraction.
The retrieval interface is defined as:
$$
\texttt{local\_search(query, top\_k)},
$$
which queries a local dense-retrieval server built over an indexed Wikipedia corpus and returns ranked text snippets relevant to the query. We use a Wikipedia corpus organized by PeterJinGo/wiki-18-corpus, with prebuilt dense indices from PeterJinGo/wiki-18-e5-index. Embeddings are generated using intfloat/e5-base-v2. Retrieval is powered by FAISS (Douze et al., 2024) with multi-GPU support. During each episode, the agent is allowed up to 5 interaction turns, which may include reasoning steps, tool calls, and final answer submission.
Following the evaluation protocol of Search-R1 (Jin et al., 2025), the answer extracted from \boxed{} is normalized prior to scoring by lowercasing and whitespace canonicalization. Correctness is measured using token-level F1 against the ground-truth answer. The reward function assigns a score of 1.0 for exact matches, a proportional reward equal to the F1 score when the F1 is at least 0.3, and 0 otherwise.
The default system prompt, self-reflection prompt, and example task are shown in Tables 3, 5, and 8.
Initial System Prompt for Frozenlake and Sokoban
You are an agent playing a game on a grid, acting as a reasoning engine. Your decisions are based on your current game rules (your best guess of how the game works) and your strategic playbook (your learned strategies). These may be incomplete or incorrect. Your only way to interact with the environment is by choosing your NEXT ACTION. ## Instructions 1. Analyze State: Summarize the current state. 2. Predict Long-term Value of Outcomes: Evaluate the strategic value and potential of the current state for the future. 3. Predict Immediate Consequences: For the top two candidate actions, predict their consequences using a “result-because” structure. 4. Select the Best Action: Choose the action leading to the most advantageous future state. ## Required response structure <reason> **1. Analysis of the Current State:** [Summary of the board state.] **2. Prediction of the Value of Current States:** [Assessment] - Value: High / Medium / Low **3. Prediction of Immediate Consequences:** [Top 2 candidate actions] </reason> Then output the NEXT ACTION inside triple backticks, e.g., ‘‘‘Up‘‘‘. Always remember: - Valid actions: Up, Down, Left, Right. - Think step by step, but make the final line only the next action wrapped in triple backticks.
Table 2: Initial System used for Frozenlake and Sokoban.
Initial System Prompt for HotpotQA
You are a helpful assistant who answers questions directly and efficiently. Provide your final answer in \boxed{} format. ## Available tool [ { "type": "function", "function": { "name": "local_search", "description": "Search for information using a dense retrieval server with Wikipedia corpus", "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "Search query to retrieve relevant documents" }, "top_k": { "type": "integer", "description": "Number of results to return (default: 5)", "minimum": 1, "maximum": 50 } }, "required": ["query"] } } } ]
Table 3: Initial system prompt used for HotpotQA.
Self-reflection Prompt for Frozen Lake and Sokoban
You are a chief scientific strategist and master tactician. Your mission is to analyze extensive field data from numerous operations to distill and refine the Master Rulebook of a complex game. You will be presented with a large collection of highly successful trajectories and critical failure trajectories, collected over a long period. Your primary task is to perform a deep, comparative analysis to understand the fundamental principles of victory and defeat. Act as a grand strategist, identifying universal patterns and high-level causal relationships. Your goal is to synthesize these insights to produce the next generation’s Master Rulebook, making it more robust, accurate, and effective. Core Principles: - Think Long-Term: focus on universal, strategic truths that hold across diverse scenarios. - Learn from Contrast: extract insights by comparing winners and losers. - Synthesize and Consolidate: produce a single unified theory. - Be Authoritative and Concise: state rules as definitive principles. Your output MUST be a single consolidated <prompt> block representing the new Master Rulebook: <prompt> <game_rules> **1. Symbol Meanings:** [...] **2. Information & Interpretation:** [...] **3. Gameplay & Actions:** [...] **4. Action Effects:** [...] **5. Game Objective & Termination:** [...] </game_rules> <strategy> **1. Core Strategies:** [...] **2. Tactical Tips:** [...] </strategy> </prompt>
Table 4: Self-reflection prompt used for Frozen Lake and Sokoban.
Self-reflection Prompt for HotpotQA
You are an expert prompt updater. You will analyze recent trajectories, tool calls, and rewards to improve the solver’s system prompt. When failures occur, explicitly add rules that prevent repeating them (e.g., missing tool calls, hallucinated facts, or unboxed final answers). Keep the prompt short, actionable, and reusable. Output ONLY the improved system prompt wrapped in <prompt>...</prompt> tags.
Table 5: Self-reflection prompt used for HotpotQA.
Example Task for Frozen Lake
## {System Prompt} Current Observation (0): D D C D A D D C D C D D D D B D You have not achieved the goal yet. Please give the next action. ## Action space Up | Down | Left | Right ## Output requirement Return reasoning in <reason>...</reason> and final action in triple backticks, e.g., ‘‘‘Right‘‘‘.
Table 6: Example Frozen Lake task instance.
Example Task for Sokoban
## {System Prompt} Current Board (0): E E E E E E E A D B C E E D D D D E E E E E E E Puzzle not solved yet. Provide the next move. ## Action space Up | Down | Left | Right ## Output requirement Return reasoning in <reason>...</reason> and final action in triple backticks, e.g., ‘‘‘Right‘‘‘.
Table 7: Example Sokoban task instance.
Example Task for HotpotQA
## {System Prompt} Question: Which university did the author of “The Hobbit” attend?
Table 8: Example HotpotQA task instance.
Second-Attempt Prompt Template for the No-Reflection Variant
## {System Prompt} You are also provided with the model’s past attempt data, including observations, actions, rewards, and feedback. Use this information as context to make a better next-attempt decision policy. Follow the action/output format exactly. {First Attempt’s Trajectory}
Table 9: Generic second-attempt system prompt used in the no-reflection ablation. The model is provided with the full first-attempt trajectory (observations, actions, rewards, and feedback) together with a generic instruction encouraging improvement, without any structured reflection signal.
Appendix C Training Configuration Details
We train all models with the rLLM agent training stack (Tan et al., 2025) using GRPO (Shao et al., 2024). Training runs on a single node with 8 H100s and uses vLLM (Kwon et al., 2023) with FlashAttention (Dao, 2024).
We enable hybrid engine training, gradient checkpointing, and remove-padding. The optimizer learning rate is 1e-6. Actor updates use a mini batch size of 64, dynamic batch sizing, and a max token length per GPU of 24,000. FSDP parameter/optimizer offload is enabled for the actor, and parameter offload is enabled for the reference model.
We set the training batch size to 64, with a maximum prompt length of 8,196 tokens and a maximum response length of 8,196 tokens. Rollouts are generated asynchronously using vLLM in async mode with a tensor model parallel size of 1. We use a sampling temperature of 0.7, GPU memory utilization of 0.85. For validation rollouts, we generate 4 samples per prompt with temperature 0.7, top-p sampling set to 0.8, and top-k sampling set to 20.
KL regularization is enabled using a low-variance KL loss with coefficient 0.001, and we use a fixed KL control coefficient of 0.001. The actor clipping ratio upper bound is set to 0.28, and the entropy coefficient is set to 0. Rejection sampling and stepwise advantage estimation are disabled.
For RLVR training, we generate 10 samples per prompt. For ERL training, we generate only 4 samples per prompt for each attempt to match the compute budget of RLVR. Evaluation is performed every 5 iterations, and training is manually early stopped upon convergence.
The design and implementation details of the ERL algorithm can be found in Appendix A.