# SRFed: Mitigating Poisoning Attacks in Privacy-Preserving Federated Learning with Heterogeneous Data
**Authors**:
- Yiwen Lu1,2Corresponding Author (School of Mathematics, Nanjing University, Nanjing 210093, China)
- 2E-mail: luyw@smail.nju.edu.cn
## Abstract
Federated Learning (FL) enables collaborative model training without exposing clients’ private data, and has been widely adopted in privacy-sensitive scenarios. However, FL faces two critical security threats: curious servers that may launch inference attacks to reconstruct clients’ private data, and compromised clients that can launch poisoning attacks to disrupt model aggregation. Existing solutions mitigate these attacks by combining mainstream privacy-preserving techniques with defensive aggregation strategies. However, they either incur high computation and communication overhead or perform poorly under non-independent and identically distributed (Non-IID) data settings. To tackle these challenges, we propose SRFed, an efficient Byzantine-robust and privacy-preserving FL framework for Non-IID scenarios. First, we design a decentralized efficient functional encryption (DEFE) scheme to support efficient model encryption and non-interactive decryption. DEFE also eliminates third-party reliance and defends against server-side inference attacks. Second, we develop a privacy-preserving defensive model aggregation mechanism based on DEFE. This mechanism filters poisonous models under Non-IID data by layer-wise projection and clustering-based analysis. Theoretical analysis and extensive experiments show that SRFed outperforms state-of-the-art baselines in privacy protection, Byzantine robustness, and efficiency.
## I Introduction
Federated learning (FL) has emerged as a promising paradigm for distributed machine learning, which enables multiple clients to collaboratively train a global model without sharing their private data. In a typical FL setup, multiple clients periodically train local models using their private data and upload model updates to a central server, which aggregates these updates to obtain a global model with enhanced performance. Due to its ability to protect data privacy, FL has been widely applied in real-world scenarios, such as intelligent driving [1, 2, 3, 4, 5], medical diagnosis [6, 7, 8, 9], and intelligent recommendation systems [10, 11, 12, 13].
Although FL avoids direct data exposure, it is not immune to privacy and security risks. Existing studies [14, 15, 16] have shown that the curious server may launch inference attacks to reconstruct sensitive data samples of clients from the model updates. This may lead to the leakage of clients’ sensitive information, e.g., medical diagnosis records, which can be exploited by adversaries for launching further malicious activities. Moreover, FL is also vulnerable to poisoning attacks [17, 18, 19]. The adversaries may manipulate some clients to execute malicious local training and upload poisonous model updates to mislead the global model [18, 20, 21]. This attack will damage the performance of the global model and lead to incorrect decisions in downstream tasks such as medical diagnosis and intelligent driving.
To address privacy leakage issues, existing privacy-preserving federated learning (PPFL) methods primarily rely on techniques such as differential privacy (DP) [22, 23, 24, 25, 26], secure multi-party computation (SMC) [27, 28], and homomorphic encryption (HE) [29, 30]. However, DP typically leads to a reduction in global model accuracy, while SMC and HE incur substantial computational and communication overheads in FL. Recently, lightweight functional encryption (FE) schemes [31, 32] have been applied in FL. FE enables the server to aggregate encrypted models and directly obtain the decrypted results via a functional key, which avoids the accuracy loss in DP and the extra communication overhead in HE/SMC. However, existing FE schemes rely on third parties for functional key generation, which introduces potential privacy risks.
To mitigate poisoning attacks, existing Byzantine-robust FL methods [33, 34, 35, 36] typically adopt defensive aggregation strategies, which filter out malicious model updates based on statistical distances or performance-based criteria. However, these strategies rely on the assumption that clients’ data distributions are homogeneous, leading to poor performance in non-independent and identically distributed (Non-IID) data settings. Moreover, they require access to plaintext model updates, which directly contradicts the design goal of PPFL [32]. Recently, privacy-preserving Byzantine-robust FL methods [37, 29] have been proposed to address both privacy and poisoning attacks. However, these methods still suffer from limitations such as accuracy loss, excessive overhead, and limited effectiveness in Non-IID environments, as they merely combine the PPFL with existing defensive aggregation strategies. As a result, there is still a lack of practical solutions that can simultaneously ensure privacy protection and Byzantine robustness in Non-IID data scenarios.
To address the limitations of existing FL solutions, we propose a novel Byzantine-robust privacy-preserving FL method, SRFed. SRFed achieves efficient privacy protection and Byzantine robustness in Non-IID data scenarios through two key designs. First, we propose a new functional encryption scheme, DEFE, to protect clients’ model privacy and resist inference attacks from the server. Compared with existing FE schemes, DEFE eliminates reliance on third parties through distributed key generation and improves decryption efficiency by reconstructing the ciphertext. Second, we develop a privacy-preserving robust aggregation strategy based on secure layer-wise projection and clustering. This strategy resists the poisoning attacks in Non-IID data scenarios. Specifically, this strategy first decomposes client models layer by layer, projects each layer onto the corresponding layer of the global model. Then, it performs clustering analysis on the projection vectors to filter malicious updates and aggregates the remaining benign models. DEFE supports the above secure layer-wise projection computation and enables privacy-preserving model aggregation. Finally, we evaluate SRFed on multiple datasets with varying levels of heterogeneity. Theoretical analysis and experimental results demonstrate that SRFed achieves strong privacy protection, Byzantine robustness, and high efficiency. In summary, the core contributions of this paper are as follows.
- We propose a novel secure and robust FL method, SRFed, which simultaneously guarantees privacy protection and Byzantine robustness in Non-IID data scenarios.
- We design an efficient functional encryption scheme, which not only effectively protects the local model privacy but also enables efficient and secure model aggregation.
- We develop a privacy-preserving robust aggregation strategy, which effectively defends against poisoning attacks in Non-IID scenarios and generates high-quality aggregated models.
- We implement the prototype of SRFed and validate its performance in terms of privacy preservation, Byzantine robustness, and computational efficiency. Experimental results show that SRFed outperforms state-of-the-art baselines in all aspects.
## II Related Works
### II-A Privacy-Preserving Federated Learning
To safeguard user privacy, current research on privacy-preserving federated learning (PPFL) mainly focuses on protecting gradient information. Existing solutions are primarily built upon four core technologies: Differential Privacy (DP) [22, 23, 24], Secure Multi-Party Computation (SMC) [27, 28], Homomorphic Encryption (HE) [29, 38, 30], and Functional Encryption (FE) [31, 32, 39, 40]. DP achieves data indistinguishability by injecting calibrated noise into raw data, thus ensuring privacy with low computational overhead. Miao et al. [24] proposed a DP-based ESFL framework that adopts adaptive local DP to protect data privacy. However, the injected noise inevitably degrades the model accuracy. To avoid accuracy loss, SMC and HE employ cryptographic primitives to achieve privacy preservation. SMC enables distributed aggregation while keeping local gradients confidential, revealing only the aggregated model update. Zhang et al. [27] introduced LSFL, a secure FL framework that applies secret sharing to split and transmit local parameters to two non-colluding servers for privacy-preserving aggregation. HE allows direct computation on encrypted data and produces decrypted results identical to plaintext computations. This property preserves privacy without sacrificing accuracy. Ma et al. [29] developed ShieldFL, a robust FL framework based on two-trapdoor HE, which encrypts all local gradients and achieves aggregation of encrypted gradients. Despite their strong privacy guarantees, SMC/HE-based FL methods incur substantial computation and communication overhead, posing challenges for large-scale deployment. To address these issues, FE has been introduced into FL. FE avoids noise injection and eliminates the high overhead caused by multi-round interactions or complex homomorphic operations. Chen et al. [31] proposed ESB-FL, an efficient secure FL framework based on non-interactive designated decrypter FE (NDD-FE), which protects local data privacy but relies on a trusted third-party entity. Yu et al. [40] further proposed PrivLDFL, which employs a dynamic decentralized multi-client FE (DDMCFE) scheme to preserve privacy in decentralized settings. However, both FE-based methods require discrete logarithm-based decryption, which is typically a time-consuming operation. To overcome these limitations, we propose a decentralized efficient functional encryption (DEFE) scheme that achieves privacy protection and high computational and communication efficiency.
TABLE I: COMPARISON BETWEEN OUR METHOD WITH PREVIOUS WORK
| Methods | Privacy Protection | Defense Mechanism | Efficient | Non-IID | Fidelity |
| --- | --- | --- | --- | --- | --- |
| ESFL [24] | Local DP | Local DP | ✓ | ✗ | ✗ |
| PBFL [37] | CKKS | Cosine similarity | ✗ | ✗ | ✓ |
| ESB-FL [31] | NDD-FE | ✗ | ✓ | ✗ | ✓ |
| Median [35] | ✗ | Median | ✓ | ✗ | ✓ |
| FoolsGold [33] | ✗ | Cosine similarity | ✓ | ✗ | ✓ |
| ShieldFL [29] | HE | Cosine similarity | ✗ | ✗ | ✓ |
| PrivLDFL [40] | DDMCFE | ✗ | ✓ | ✗ | ✓ |
| Biscotti [41] | DP | Euclidean distance | ✓ | ✗ | ✗ |
| SRFed | DEFE | Layer-wise projection and clustering | ✓ | ✓ | ✓ |
- Notes: The symbol ”✓” indicates that it owns this property; ”✗” indicates that it does not own this property. ”Fidelity” indicates that the method has no accuracy loss when there is no attack. ”Non-IID” indicates that the method is Byzantine-Robust under Non-IID data environments.
### II-B Privacy-Preserving Federated Learning Against Malicious Participants
To resist poisoning attacks, several defensive aggregation rules have been proposed in FL. FoolsGold [33], proposed by Fung et al. [33], reweights clients’ contributions by computing the cosine similarity of their historical gradients. Krum [34] selects a single client update that is closest, in terms of Euclidean distance, to the majority of other updates in each iteration. Median [35] mitigates the effect of malicious clients by taking the median value of each model parameter across all clients. However, the above aggregation rules require access to plaintext model updates. This makes them unsuitable for direct application in PPFL. To achieve Byzantine-robust PPFL, Shiyan et al. [41] proposed Biscotti. Biscotti leverages DP to protect local gradients while using the Krum algorithm to mitigate poisoning attacks. Nevertheless, the injected noise in DP reduces the accuracy of the aggregated model. To overcome this limitation, Zhang et al. [27] proposed LSFL. LSFL employs SMC to preserve privacy and uses Median-based aggregation for poisoning defense. However, its dual-server architecture introduces significant communication overhead. In addition, Ma et al. [29] and Miao et al. [37] proposed ShieldFL and PBFL, respectively. Both schemes adopt HE to protect local gradients and cosine similarity to defend against poisoning attacks. However, they suffer from high computational complexity and limited robustness under non-IID data settings. To address these challenges, we propose a novel Byzantine-robust and privacy-preserving federated learning method. Table I compares previous schemes with our method.
## III Problem Statement
### III-A System Model
The system model of SRFed comprises two roles: the aggregation server and clients.
- Clients: Clients are nodes with limited computing power and heterogeneous data. In real-world scenarios, data heterogeneity typically arises across clients (e.g., intelligent vehicles) due to differences in usage patterns, such as driving habits. Each client is responsible for training its local model based on its own data. To protect data privacy, the models are encrypted and submitted to the server for aggregation.
- Server: The server is a node with strong computing power (e.g., service provider of intelligent vehicles). It collects encrypted local models from clients, conducts model detection, and then aggregates selected models and distributes the aggregated model back to clients for the next training round.
### III-B Threat Model
We consider the following threat model:
1) Honest-But-Curious server: The server honestly follows the FL protocol but attempts to infer clients’ private data. Specifically, upon receiving encrypted local models from the clients, the server may launch inference attacks on the encrypted models and exploit intermediate computational results (e.g., layer-wise projections and aggregated outputs) to extract sensitive information of clients.
2) Malicious clients: We consider a FL scenario where a certain proportion of clients are malicious. These malicious clients conduct model poisoning attacks to poison the global model, thereby disrupting the training process. Specifically, we focus on the following attack types:
- Targeted poisoning attack. This attack aims to poison the global model so that it incurs erroneous predictions for the samples of a specific label. More specifically, we consider the prevalent label-flipping attack [29]. Malicious clients remap samples labeled $l_{src}$ to a chosen target label $l_{tar}$ to obtain a poisonous dataset $D_{i}^{*}$ . Subsequently, they train local models based on $D_{i}^{*}$ and submit the poisonous models to the server for aggregation. As a result, the global model is compromised, leading to misclassification of source-label samples as the target label during inference.
- Untargeted poisoning attack. This attack aims to degrade the global model’s performance on the test samples of all classes. Specifically, we consider the classic Gaussian Attack [27]. The malicious clients first train local models based on the clean dataset. Then, they inject Gaussian noise into the model parameters and submit the malicious models to the server. Consequently, the aggregated model exhibits low accuracy across test samples of all classes.
### III-C Design Goals
Under the defined threat model, SRFed aims to ensure the following security and performance guarantees:
- Confidentiality. SRFed should ensure that any unauthorized entities (e.g., the server) cannot infer clients’ private training data from the encrypted models or intermediate results.
- Robustness. SRFed should mitigate poisoning attacks launched by malicious clients under Non-IID data settings while maintaining the quality of the final aggregated model.
- Efficiency. SRFed should ensure efficient FL, with the introduced DEFE scheme and robust aggregation strategy incurring only limited computation and communication overhead.
## IV Building Blocks
### IV-A NDD-FE Scheme
NDD-FE [31] is a functional encryption scheme that supports the inner-product computation between a private vector $\boldsymbol{x}$ and a public vector $\boldsymbol{y}$ . NDD-FE involves three roles, i.e., generator, encryptor, and decryptor, to elaborate on its construction.
- NDD-FE.Setup( ${1}^{\lambda}$ ) $\rightarrow$ $pp$ : It is executed by the generator. It takes the security parameter ${1}^{\lambda}$ as input and generates the system public parameters $pp=(G,p,g)$ and a secure hash function $H_{1}$ .
- NDD-FE.KeyGen( $pp$ ) $\rightarrow$ $(pk,sk)$ : It is executed by all roles. It takes $pp$ as input and outputs public/secret keys $(pk,sk)$ . Let $(pk_{1},sk_{1}),$ $(pk_{2i},sk_{2i})$ and $(pk_{3},sk_{3})$ denote the public/secret key pairs of the generator, the $i$ -th encryptor and the decryptor, respectively.
- NDD-FE.KeyDerive( $pk_{1},sk_{1},\{pk_{2i}\}_{i=1,2,\dots,I},ctr,\boldsymbol{y},$ $aux$ ) $\rightarrow$ $sk_{\otimes}$ : It is executed by the generator. It takes $(pk_{1},sk_{1})$ , the $\{pk_{2i}\}_{i=1,2,\dots,I}$ of $I$ encryptors, an incremental counter $ctr$ , a vector $\boldsymbol{y}$ and auxiliary information $aux$ as input, and outputs the functional key $sk_{\otimes}$ .
- NDD-FE.Encrypt( $pk_{1},sk_{2i},pk_{3},ctr,x_{i},aux$ ) $\rightarrow$ $c_{i}$ : It is executed by the encryptor. It takes $pk_{1},(pk_{2i},sk_{2i}),$ $pk_{3},ctr,aux$ , and the data $x_{i}$ as input, and outputs the ciphertext $c_{i}=pk_{1}^{r_{i}^{ctr}}\cdot pk_{3}^{x_{i}}$ , where $r_{i}^{ctr}$ is generated by $H_{1}$ .
- NDD-FE.Decrypt( $pk_{1},sk_{\otimes},sk_{3},\{ct_{i}\}_{i=1,2,\dots,I},\boldsymbol{y}$ ) $\rightarrow$ $\langle\boldsymbol{x},\boldsymbol{y}\rangle$ : It is executed by the decryptor. It takes $pk_{1},sk_{\otimes},$ $sk_{3}$ , $\{ct_{i}\}_{i=1,2,\dots,I}$ and $\boldsymbol{y}$ as input. First, it outputs $g^{\langle\boldsymbol{x},\boldsymbol{y}\rangle}$ and subsequently calculates $\log(g^{\langle\boldsymbol{x},\boldsymbol{y}\rangle})$ to reconstruct the result of the inner product of $(\boldsymbol{x},\boldsymbol{y})$ .
### IV-B The Proposed Decentralized Efficient Functional Encryption Scheme
We propose a decentralized efficient functional encryption (DEFE) scheme for more secure and efficient inner product operations. Our DEFE is an adaptation of NDD-FE in three aspects:
- Decentralized authority: DEFE eliminates reliance on the third-party entities (e.g., the generator) by enabling encryptors to jointly generate the decryptor’s decryption key.
- Mix-and-Match attack resistance: DEFE inherently restricts the decryptor from obtaining the true inner product results, which prevents the decryptor from launching inference attacks.
- Efficient decryption: DEFE enables efficient decryption by modifying the ciphertext structure. This avoids the costly discrete logarithm computations in NDD-FE.
We consider our SRFed system with one decryptor (i.e., the server) and $I$ encryptors (i.e., the clients). The $i$ -th encryptor encrypts the $i$ -th component $x_{i}$ of the $I$ -dimensional message vector $\boldsymbol{x}$ . The message vector $\boldsymbol{x}$ and key vector $\boldsymbol{y}$ satisfy $\|\boldsymbol{x}\|_{\infty}\leq X$ and $\|\boldsymbol{y}\|_{\infty}\leq Y$ , with $X\cdot Y<N$ , where $N$ is the Paillier composite modulus [42]. Decryption yields $\langle\boldsymbol{x},\boldsymbol{y}\rangle\bmod N$ , which equals the integer inner product $\langle\boldsymbol{x},\boldsymbol{y}\rangle$ under these bounds. Let $M=\left\lfloor\frac{1}{2}\left(\sqrt{\frac{N}{I}}\right)\right\rfloor$ . We assume $X,Y<M$ in DEFE. Specifically, the construction of the DEFE scheme is as follows. The notations are described in Table II.
TABLE II: Notation Descriptions
| Notations | Descriptions | Notations | Descriptions |
| --- | --- | --- | --- |
| $pk,sk$ | Public/secret key | $skf$ | Functional key |
| $T$ | Total training round | $t$ | Training round |
| $I$ | Number of clients | $C_{i}$ | The $i$ -th client |
| $D_{i}$ | Dataset of $C_{i}$ | $D_{i}^{*}$ | Poisoned dataset |
| $l$ | Model layer | $\zeta$ | Length of $W_{t}$ |
| $W_{t}$ | Global model | $W_{t+1}$ | Aggregated model |
| $W_{t}^{i}$ | Benign model | $(W_{t}^{i})^{*}$ | Poisonous model |
| $|W_{t}^{(l)}|$ | Length of $W_{t}^{l}$ | $\lVert W_{t}^{(l)}\rVert$ | The Euclidean norm of $\lVert W_{t}^{(l)}\rVert$ |
| $\eta$ | Hash noise | $H_{1}$ | Hash function |
| $noise$ | Gaussian noise | $E_{t}^{i}$ | Encrypted update |
| $V_{t}^{i}$ | projection vector | $OA$ | Overall accuracy |
| $SA$ | Source accuracy | $ASR$ | Attack success rate |
- $\textbf{DEFE.Setup}(1^{\lambda},X,Y)\rightarrow pp$ : It takes the security parameter $1^{\lambda}$ as input and outputs the public parameters $pp$ , which include the modulus $N$ , generator $g$ , and hash function $H_{1}$ . It initializes by selecting safe primes $p=2p^{\prime}+1$ and $q=2q^{\prime}+1$ with $p^{\prime},q^{\prime}>2^{l(\lambda)}$ (where $l$ is a polynomial in $\lambda$ ), ensuring the factorization hardness of $N=pq$ is $2^{\lambda}$ -hard and $N>XY$ . A generator $g^{\prime}$ is uniformly sampled from $\mathbb{Z}_{N^{2}}^{*}$ , and $g=g^{\prime 2N}\mod N^{2}$ is computed to generate the subgroup of $(2N)$ -th residues in $\mathbb{Z}_{N^{2}}^{*}$ . Hash function $H_{1}:\mathbb{Z}\times\mathbb{N}\times\mathcal{AUX}\rightarrow\mathbb{Z}$ is defined, where $\mathcal{AUX}$ denotes auxiliary information (e.g., task identifier, timestamp).
- $\textbf{DEFE.KeyGen}(1^{\lambda},N,g)\rightarrow(pk_{i},sk_{i})$ : It is executed by $n$ encryptors. It takes $\lambda$ , $N$ , and $g$ as input, and outputs the corresponding key pair $(pk_{i},sk_{i})$ . For the $i$ -th encryptor, an integer $s_{i}$ is drawn from a discrete Gaussian distribution $D_{\mathbb{Z},\sigma}$ ( $\sigma>\sqrt{\lambda}\cdot N^{5/2}$ ), and the public key $h_{i}=g^{s_{i}}\mod N^{2}$ , forming key pair $(pk_{i}=h_{i},sk_{i}=s_{i})$ .
- $\textbf{DEFE.Encrypt}(pk_{i},sk_{i},ctr,x_{i},aux)\rightarrow ct_{i}$ : It is executed by $I$ encryptors. It takes key pair $(pk_{i},sk_{i})$ , counter $ctr$ , data $x_{i}\in\mathbb{Z}$ , and $aux$ as input, and outputs noise-augmented ciphertext $ct_{i}\in\mathbb{Z}_{N^{2}}$ . Considering the multi-round training process of FL, each $i$ -th encryptor generates a noise value $\eta_{t,i}$ for the $t$ -th round following the recursive relation $\eta_{t,i}=H_{1}(\eta_{t-1,i},pk_{i},ctr)\mod M$ , where $ctr$ is an incremental counter. The initial noise $\eta_{0,i}$ is uniformly set across all encryptors via a single communication. Using the noise-augmented data $x^{\prime}_{i}=x_{i}+\eta_{t,i}$ and secret key $sk_{i}$ , the encryptor computes the ciphertext $ct_{i}^{\prime}=(1+N)^{x^{\prime}_{i}}\cdot g^{r_{i}^{ctr}}\mod N^{2}$ with $r_{i}^{ctr}=H_{1}(sk_{i},ctr,aux)$ and $aux\in\mathcal{AUX}$ .
- $\textbf{DEFE.FunKeyGen}\bigl((pk_{i},sk_{i})_{i=1}^{I},ctr,y_{i},aux\bigr)\rightarrow skf_{i,\boldsymbol{y}}$ : It is executed by $I$ encryptors. Each encryptor computes its partial functional key $skf_{i,\boldsymbol{y}}$ . It takes the public/secret key pairs ${(pk_{i},sk_{i})}^{n}_{i=1}$ of encryptors and the $i$ -th component $y_{i}$ of the key vector $\boldsymbol{y}$ as inputs and outputs:
$$
skf_{i,\boldsymbol{y}}=r_{i}^{ctr}y_{i}+\sum\nolimits_{j=1}^{i-1}\varphi^{i,j}-\sum\nolimits_{j=i+1}^{I}\varphi^{i,j}, \tag{1}
$$
where $r_{i}^{ctr}=H_{1}(sk_{i},ctr,aux)$ and $\varphi^{i,j}=H_{1}(pk_{j}^{sk_{i}},ctr,$ $aux)$ . Note that $\varphi^{i,j}=\varphi^{j,i}$ .
- $\textbf{DEFE.FunKeyAgg}\bigl(\{skf_{i,\boldsymbol{y}}\}^{I}_{i=1})\rightarrow skf_{\boldsymbol{y}}$ : It is executed by the decryptor. It inputs partial functional keys $skf_{i,\boldsymbol{y}}$ and derives the final functional key:
$$
skf_{\boldsymbol{y}}=\sum\nolimits_{i=1}^{I}skf_{i,\boldsymbol{y}}=\sum\nolimits_{i=1}^{I}r_{i}^{ctr}\cdot y_{i}\in\mathbb{Z}. \tag{2}
$$
- $\textbf{DEFE.AggDec}(skf_{\boldsymbol{y}},\{ct_{i}\}^{I}_{i=1})\rightarrow\langle\boldsymbol{x^{\prime}},\boldsymbol{y}\rangle$ : It is executed by the decryptor. It first computes
$$
CT_{\boldsymbol{x^{\prime}}}=\left(\prod\nolimits_{i=1}^{I}ct_{i}^{y_{i}}\right)\cdot g^{-skf_{\boldsymbol{y}}}\mod N^{2}. \tag{3}
$$
Then, it outputs $\log_{(1+N)}(CT_{\boldsymbol{x^{\prime}}})=\frac{CT_{\boldsymbol{x^{\prime}}}-1\mod N^{2}}{N}=\langle\boldsymbol{x^{\prime}},\boldsymbol{y}\rangle.$
- $\textbf{DEFE.UsrDec}(\langle\boldsymbol{x^{\prime}},\boldsymbol{y}\rangle,\{pk_{i}\}^{I}_{i=1},\boldsymbol{y},ctr)\rightarrow\langle\boldsymbol{x},\boldsymbol{y}\rangle$ : It is executed by $I$ encryptors. During FL processes, each encryptor maintains a $I$ -dimensional noise list $\texttt{$L_{t}$}=[\eta_{t,i}]^{I}_{i=1}$ for each training round $t$ . Based on this, each encryptor can obtain the true inner product value: $\langle\boldsymbol{x},\boldsymbol{y}\rangle=\langle\boldsymbol{x^{\prime}},\boldsymbol{y}\rangle-\sum_{i=1}^{I}\eta_{t,i}\cdot y_{i}.$
## V System Design
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Privacy-Preserving Robust Model Aggregation System
### Overview
This image is a technical system architecture diagram illustrating a **Privacy-Preserving Robust Model Aggregation** protocol for federated learning. It details the interaction between a central server and multiple clients (both benign and malicious), focusing on a secure aggregation process that uses encryption, clustering, and projection techniques to defend against model poisoning attacks (specifically label-flipping and Gaussian attacks). The diagram is divided into distinct regions: a Server process (top), Benign Local Training (bottom-left), and Malicious Local Training (bottom-right).
### Components/Axes
The diagram is organized into three primary spatial regions:
1. **Top Region: Server Process**
* **Title:** "Server Privacy-Preserving Robust Model Aggregation"
* **Components (Left to Right):**
* **Step ⑥ Layer-wise projection:** Shows model layers being processed into a "Projection vector".
* **Step ⑦ Cluster analysis:** Depicts a "K-Means" clustering process using "Cosine similarity" to find "Top K-1 clusters".
* **Step ⑧ Aggregation:** Illustrates the aggregation of models into a "Global model" using "DEFE: AggDec".
* **Legend (Top-Right Corner):** A box defining the symbols used throughout the diagram.
* `Benign model` (Green brain icon)
* `Malicious model` (Red brain icon)
* `Encrypted benign model` (Green brain with lock)
* `Encrypted malicious model` (Red brain with lock)
* `Global model` (Green brain with globe)
* `Functional key` (Key icon)
* `Projection vector` (Multi-colored bar)
* `Malicious` (Red X)
* `Benign` (Green checkmark)
2. **Bottom-Left Region: Benign Local Training**
* **Title:** "Benign Local Training"
* **Components:** Shows a stack of clients (Client 1, Client 2, Client i).
* **Process Flow (Numbered Steps):**
* ① `global model` (received from server)
* ② `Model training`
* ③ `DEFE: Encrypt`
* ④ `DEFE: FunKeyGen` (generates a `Functional key`)
* ⑤ `Benign models, functional key` (sent to server)
3. **Bottom-Right Region: Malicious Local Training**
* **Title:** "Malicious Local Training"
* **Subtitle:** "Malicious client `c*`, `c* ∈ {j+1, ..., I}`"
* **Attack Description:** "Label-flipping attack & Gaussian attack"
* **Process Flow (Numbered Steps):**
* ① `Global model` (received from server)
* ② `Model training` (with attack applied)
* ③ `DEFE: Encrypt`
* ④ `DEFE: FunKeyGen` (generates a `Functional key`)
* ⑤ `Malicious models, functional key` (sent to server)
### Detailed Analysis
The diagram outlines an 8-step server-side process that interacts with client-side training:
**Server-Side Workflow (Top Region):**
1. The server initiates the process by sending the `Global model` (Step ①) to all clients.
2. It receives models and keys from clients (Steps ⑤).
3. **Step ⑥ - Layer-wise projection:** The received models undergo a projection operation, resulting in a `Projection vector`. This is likely a dimensionality reduction or feature extraction step.
4. **Step ⑦ - Cluster analysis:** The projected vectors are clustered using `K-Means` based on `Cosine similarity`. The goal is to identify the `Top K-1 clusters`, presumably to isolate potentially malicious model updates.
5. **Step ⑧ - Aggregation:** The models from the identified benign clusters are aggregated using a function labeled `DEFE: AggDec` to produce an updated `Global model`. This new global model is then sent back to clients (Step ①), completing the cycle.
**Client-Side Workflow (Bottom Regions):**
* **Benign Clients:** Follow a standard secure training protocol: receive global model -> train locally -> encrypt model (`DEFE: Encrypt`) -> generate a functional key (`DEFE: FunKeyGen`) -> send encrypted model and key to server.
* **Malicious Clients:** Follow a similar technical flow but with a critical difference: their `Model training` (Step ②) incorporates a `Label-flipping attack & Gaussian attack`. Their output is a poisoned model, which is then encrypted and sent to the server alongside a functional key, mimicking the benign clients' communication pattern.
### Key Observations
1. **Symmetry in Communication:** Both benign and malicious clients perform identical post-training steps (encryption, key generation). This makes it difficult for the server to distinguish them based on communication protocol alone.
2. **Centralized Defense Mechanism:** The core defense lies entirely within the server's `Cluster analysis` (Step ⑦). The system assumes that malicious model updates will be statistically different enough (after projection) to form separate clusters, allowing the server to exclude them (`Top K-1 clusters`) before aggregation.
3. **Attack Specification:** The diagram explicitly names two attack vectors: `Label-flipping attack` (changing training data labels) and `Gaussian attack` (adding Gaussian noise to model updates).
4. **Notation:** The malicious client is denoted mathematically as `c*`, belonging to a set `{j+1, ..., I}`, suggesting a system with `I` total clients where the last `I-j` clients are malicious.
### Interpretation
This diagram presents a **defense-in-depth strategy for federated learning**. It addresses two critical challenges simultaneously:
* **Privacy:** Achieved through the `DEFE` (likely an acronym for a specific encryption scheme) processes (`Encrypt`, `FunKeyGen`, `AggDec`), which ensure the server cannot inspect raw model updates.
* **Robustness:** Achieved through the `Layer-wise projection` and `K-Means clustering` pipeline. The core hypothesis is that malicious model updates, even when encrypted, will project into a different region of the feature space than benign ones. By clustering in this space and aggregating only the largest cluster(s) (`Top K-1`), the server can dilute or exclude the influence of poisoned models.
The system's effectiveness hinges on the assumption that the projection and clustering can reliably separate benign from malicious updates *without* decrypting them. The inclusion of a `Functional key` for each client suggests it may be used in the secure aggregation decryption process (`AggDec`) or to verify client authenticity. The diagram effectively communicates a complex, multi-stage protocol where privacy and security are interwoven rather than treated as separate concerns.
</details>
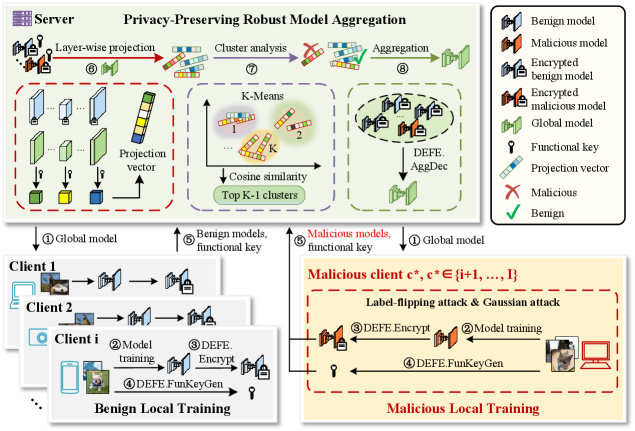
Figure 1: The workflow of SRFed.
### V-A High-Level Description of SRFed
The workflow of SRFed is illustrated in Figure 1. Specifically, SRFed iteratively performs the following three steps: 1) Initialization. The server initializes the global model $W_{0}$ and distributes it to all clients (step ①). 2) Local training. In the $t$ -th training iteration, each client $C_{i}$ receives the global model $W_{t}$ from the server and performs local training on its private dataset to obtain the local model $W_{t}^{i}$ (step ②). To protect model privacy, $C_{i}$ encrypts the local model and gets the encrypted model $E_{t}^{i}$ (step ③). Then, $C_{i}$ generates the functional key $skf_{t}^{i}$ for model detection (step ④), and uploads the encrypted model and the functional key to the server (step ⑤). 3) Privacy-preserving robust model aggregation. Upon receiving all encrypted local models $\{E_{t}^{i}\}_{i=1,...,I}$ , the server computes a layer-wise projection vector $V_{t}^{i}$ for each model based on the global model $W_{t}$ (step ⑥). The server then performs clustering analysis on $\{V_{t}^{i}\}_{i=1,...,I}$ to filter malicious models and identify benign models (step ⑦). Finally, the server aggregates these benign clients to update the global model $W_{t+1}$ (step ⑧).
### V-B Construction of SRFed
#### V-B 1 Initialization
In this phase, the server first executes the $\textbf{DEFE.Setup}(1^{\lambda},X,$ $Y)$ algorithm to generate the public parameters $pp$ , which are then made publicly available. Each client $C_{i}$ ( $i\in[1,I]$ ) subsequently generates its key pair $(pk_{i},sk_{i})$ by executing the $\textbf{DEFE.KeyGen}(1^{\lambda},N,g)$ algorithm. Finally, the server distributes the initial global model $W_{0}$ to all clients.
#### V-B 2 Local Training
The local training phase consists of three components: model training, model encryption, and functional key generation. 1) Model Training: In the $t$ -th ( $t\in[1,T]$ ) training round, once receiving the global model $W_{t}$ , each client $C_{i}$ utilizes its local dataset $D_{i}$ to update $W_{t}$ and obtains model update $W_{t}^{i}$ . For benign clients, they minimize their local objective function $L_{i}$ to obtain $W_{t}^{i}$ , i.e.,
$$
W_{t}^{i}=\arg\min_{W_{t}}L_{i}(W_{t},D_{i}). \tag{4}
$$
Malicious clients execute distinct update strategies based on their attack method. Specifically, to perform a Gaussian attack, malicious clients first conduct normal local training according to Equation (4) to obtain the benign model $W_{t}^{i}$ , and subsequently inject Gaussian noise $noise_{t}$ into it to produce a poisoned model $(W_{t}^{i})^{*}$ , i.e.,
$$
(W_{t}^{i})^{*}=W_{t}^{i}+noise_{t}. \tag{5}
$$
In addition, to launch a label-flipping attack, malicious clients first poison their training datasets by flipping all samples labeled as $l_{\text{src}}$ to a target class $l_{\text{tar}}$ . They then perform local training on the poisoned dataset $D_{i}^{*}(l_{\text{src}}\rightarrow l_{\text{tar}})$ to derive the poisoned model $(W_{t}^{i})^{*}$ , i.e.,
$$
(W_{t}^{i})^{*}=\arg\min_{W_{t}^{i}}L_{i}\left(W_{t}^{i},D_{i}^{*}(l_{\text{src}}\rightarrow l_{\text{tar}})\right). \tag{6}
$$
2) Model Encryption: To protect the privacy information of the local model, the clients exploit the DEFE scheme to encrypt their local models. Specifically, the clients first parse the local model as $W_{t}^{i}=[W_{t}^{(i,1)},\dots,W_{t}^{(i,l)},\dots,W_{t}^{(i,L)}]$ , where $W_{t}^{(i,l)}$ denotes the parameter set of the $l$ -th model layer. For each parameter element $W_{t}^{(i,l)}[\varepsilon]$ in $W_{t}^{(i,l)}$ , client $C_{i}$ executes the $\textbf{DEFE.Encrypt}(pk_{i},sk_{i},ctr,W_{t}^{(i,l)}[\varepsilon])$ algorithm to generate the encrypted parameter $E_{t}^{(i,l)}[\varepsilon]$ , i.e.,
$$
E_{t}^{(i,l)}[\varepsilon]=(1+N)^{{W_{t}^{(i,l)}}^{\prime}[\varepsilon]}\cdot g^{{r_{i}}^{ctr}}\bmod N^{2}, \tag{7}
$$
where ${W_{t}^{(i,l)}}^{\prime}[\varepsilon]$ is the parameter $W_{t}^{(i,l)}[\varepsilon]$ perturbed by a noise term $\eta$ , i.e.,
$$
{W_{t}^{(i,l)}}^{\prime}[\varepsilon]=W_{t}^{(i,l)}[\varepsilon]+\eta. \tag{8}
$$
In SRFed, the noise $\eta$ remains fixed for all clients during the first $T-1$ training rounds, and is set to $0$ in the final training round. Specifically, $\eta$ is an integer generated by client $C_{1}$ using the hash function $H_{1}$ during the first iteration, and is subsequently broadcast to all other clients for model encryption. The magnitude of $\eta$ is constrained by:
$$
m_{l}\cdot\eta^{2}\ll\lVert W_{0}^{(l)}\rVert^{2},\quad\forall l\in[1,L], \tag{9}
$$
where $W_{0}^{(l)}$ denotes the $l$ -th layer model parameters of the initial global model $W_{0}$ , and $m_{l}$ represents the number of parameters in $W_{0}^{(l)}$ . Finally, the client $C_{i}$ obtains the encrypted local model $E_{t}^{i}=[E_{t}^{(i,1)},\dots,E_{t}^{(i,l)},\dots,E_{t}^{(i,L)}]$ .
3) Functional Key Generation: Each client $C_{i}$ generates a functional key vector $skf_{t}^{i}=[skf_{t}^{(i,1)},skf_{t}^{(i,2)},\dots,skf_{t}^{(i,L)}]$ to enable the server to perform model detection on encrypted models. Specifically, for the $l$ -th layer of the global model $W_{t}$ , client $C_{i}$ executes the $\textbf{DEFE.FunKeyGen}(pk_{i},sk_{i},ctr,W_{t}^{(l)}[\varepsilon])$ algorithm to generate element-wise functional keys, i.e.,
$$
skf_{t}^{(i,l,\varepsilon)}=r_{i}^{ctr}\cdot W_{t}^{(l)}[\varepsilon]=H_{1}(sk_{i},ctr,\varepsilon)\cdot W_{t}^{(l)}[\varepsilon], \tag{10}
$$
where $W_{t}^{(l)}[\varepsilon]$ denotes the $\varepsilon$ -th parameter of $W_{t}^{(l)}$ . After processing all elements in $W_{t}^{(l)}$ , client $C_{i}$ obtains the set of element-wise functional keys $\{\{skf_{t}^{(i,l,\varepsilon)}\}_{\varepsilon=1}^{|W_{t}^{(l)}|}\}_{l=1}^{L}$ . Subsequently, the layer-level functional key is derived by aggregating the element-wise keys using the $\textbf{DEFE.FunKeyAgg}(\{skf_{t}^{(i,l,\varepsilon)}\}_{\varepsilon=1}^{|W_{t}^{(l)}|})$ algorithm, i.e.,
$$
skf_{t}^{(i,l)}=\sum\nolimits_{\varepsilon=1}^{|W_{t}^{(l)}|}skf_{t}^{(i,l,\varepsilon)}. \tag{11}
$$
This procedure is repeated for all layers to obtain the complete functional key vector $skf_{t}^{i}$ for client $C_{i}$ . Finally, each client uploads the encrypted local model $E_{t}^{i}$ and the corresponding functional key $skf_{t}^{i}$ to the server for subsequent model detection and aggregation.
#### V-B 3 Privacy-Preserving Robust Model Aggregation
To resist poisoning attacks from malicious clients, SRFed implements a privacy-preserving robust aggregation strategy, which enables secure detection and aggregation of encrypted local models without exposing private information. As illustrated in Figure 1, the proposed method performs layer-wise projection and clustering analysis to identify abnormal updates and ensure reliable model aggregation. Specifically, in each training round, the local model $W_{t}^{i}$ and the global model $W_{t}$ are decomposed layer by layer. For each layer, the parameters are projected onto the corresponding layer of the global model, and clustering is performed on the projection vectors to detect anomalous models. After that, the server filters malicious models and aggregates the remaining benign updates. Unlike prior defenses that rely on global statistical similarity between model updates [33, 29, 35], our approach captures fine-grained parameter anomalies and conducts clustering analysis to achieve effective detection even under non-IID data distributions.
1) Model Detection: Once receiving $E_{t}^{i}$ and $skf_{t}^{i}$ from client $C_{i}$ , the server computes the projection $V_{t}^{(i,l)}$ of $W_{t}^{(i,l)^{\prime}}$ onto $W_{t}^{(l)}$ , i.e.,
$$
V_{t}^{(i,l)}=\frac{\langle W_{t}^{(i,l)^{\prime}},W_{t}^{(l)}\rangle}{\lVert W_{t}^{(l)}\rVert_{2}}. \tag{12}
$$
Specifically, the server first executes the $\textbf{DEFE.AggDec}(skf_{t}^{(i,l)},$ $E_{t}^{(i,l)})$ algorithm, which effectively computes the inner product of $W_{t}^{(i,l)^{\prime}}$ and $W_{t}^{(l)}$ . This value is then normalized by $\lVert W_{t}^{(l)}\rVert_{2}$ to obtain
$$
V_{t}^{(i,l)}=\frac{\textbf{DEFE.AggDec}(skf_{t}^{(i,l)},E_{t}^{(i,l)})}{\lVert W_{t}^{(l)}\rVert_{2}}. \tag{13}
$$
By iterating over all $L$ layers, the server obtains the layer-wise projection vector $V_{t}^{i}=[V_{t}^{(i,1)},V_{t}^{(i,2)},\dots,V_{t}^{(i,L)}]$ corresponding to client $C_{i}$ . After computing projection vectors for all clients, the server clusters the set $\{V_{t}^{i}\}_{i=1}^{I}$ into $K$ clusters $\{\Omega_{1},\Omega_{2},\dots,\Omega_{K}\}$ using the K-Means algorithm. For each cluster $\Omega_{k}$ , the centroid vector $\bar{V}_{k}$ is computed, and the average cosine similarity $\overline{cs}_{k}$ between all vectors in the cluster and $\bar{V}_{k}$ is calculated. Finally, the $K-1$ clusters with the largest average cosine similarities are identified as benign clusters, while the remaining cluster is considered potentially malicious.
3) Model Aggregation: The server first maps the vectors in the selected $K-1$ clusters to their corresponding clients, generating a client list $L^{t}_{bc}$ and a weight vector $\gamma_{t}=(\gamma^{1}_{t},\dots,\gamma^{I}_{t})$ , where
$$
\gamma^{i}_{t}=\begin{cases}1&\text{if }C_{i}\in L^{t}_{bc},\\
0&\text{otherwise.}\end{cases} \tag{14}
$$
The server then distributes $\gamma_{t}$ to all clients. Upon receiving $\gamma^{i}_{t}$ , each client $C_{i}$ locally executes the $\textbf{DEFE.FunKeyGen}(pk_{i},sk_{i},$ $ctr,\gamma^{i}_{t},aux)$ algorithm to compute the partial functional key $skf^{(i,\mathsf{Agg})}_{t}$ as
$$
skf^{(i,\mathsf{Agg})}_{t}=r_{i}^{ctr}y^{i}_{t}+\sum_{j=1}^{i-1}\varphi^{i,j}-\sum_{j=i+1}^{n}\varphi^{i,j}. \tag{15}
$$
Each client uploads $skf^{(i,\mathsf{Agg})}_{t}$ to the server. Subsequently, the server executes the $\textbf{DEFE.FunKeyAgg}\left((skf^{(i,\mathsf{Agg})}_{t})_{i=1}^{I}\right)$ to compute the aggregation key as
$$
skf^{\mathsf{Agg}}_{t}=\sum_{i=1}^{I}skf^{(i,\mathsf{Agg})}_{t}. \tag{16}
$$
Finally, the server performs layer-wise aggregation to obtain the noise-perturbed global model $W_{t+1}^{\prime}$ as
$$
\displaystyle W_{t+1}^{(l)^{\prime}}[\varepsilon] \displaystyle=\frac{\text{DEFE.AggDec}\left(skf^{\mathsf{Agg}}_{t},\{E_{t}^{(i,l)}[\varepsilon]\}_{i=1}^{I}\right)}{n} \displaystyle=\frac{\langle(W_{t}^{(1,l)^{\prime}}[\varepsilon],\dots,W_{t}^{(I,l)^{\prime}}[\varepsilon]),\gamma_{t}\rangle}{n} \tag{17}
$$
where $n$ denotes the number of 1-valued elements in $L^{t}_{bc}$ . The server then distributes $W_{t+1}^{\prime}$ to all clients for the $(t+1)$ -th training round. Note that $W_{t+1}^{\prime}$ is noise-perturbed, the clients must remove the perturbation to recover the accurate global model $W_{t+1}$ . They will execute the $\textbf{DEFE.UsrDec}(W_{t+1}^{(l)^{\prime}}[\varepsilon],\gamma_{t})$ algorithm to restore the true global model parameter $W_{t+1}^{(l)}[\varepsilon]=W_{t+1}^{(l)^{\prime}}[\varepsilon]-\eta$ .
## VI Analysis
### VI-A Confidentiality
In this subsection, we demonstrate that our DEFE-based SRFed framework guarantees the confidentiality of clients’ local models under the Honest-but-Curious (HBCS) security setting.
**Definition VI.1 (Decisional Composite Residuosity (DCR) Assumption[43])**
*Selecting safe primes $p=2p^{\prime}+1$ and $q=2q^{\prime}+1$ with $p^{\prime},q^{\prime}>2^{l(\lambda)}$ , where $l$ is a polynomial in security parameter $\lambda$ , let $N=pq$ . The Decision Composite Residuosity (DCR) assumption states that, for any Probability Polynomial Time (PPT) adversary $\mathcal{A}$ and any distinct inputs $x_{0},x_{1}$ , the following holds:
$$
|Pr_{win}(\mathcal{A},(1+N)^{x_{0}}\cdot g^{r_{i}^{ctr}}\mod N^{2},x_{0},x_{1})-\frac{1}{2}|=negl(\lambda),
$$
where $Pr_{win}$ denotes the probability that the adversary $\mathcal{A}$ distinguishes ciphertexts.*
**Definition VI.2 (Honest but Curious Security (HBCS))**
*Consider the following game between an adversary $\mathcal{A}$ and a PPT simulator $\mathcal{A}^{*}$ , a protocol $\Pi$ is secure if the real-world view $\textbf{REAL}_{\mathcal{A}}^{\Pi}$ of $\mathcal{A}$ is computationally indistinguishable from the ideal-world view $\textbf{IDEAL}_{\mathcal{A}^{*}}^{\mathcal{F_{\Pi}}}$ of $\mathcal{A}^{*}$ , i.e., for all inputs $\hat{x}$ and intermediate results $\hat{y}$ from participants, it holds $\textbf{REAL}_{\mathcal{A}}^{\Pi}(\lambda,\hat{x},\hat{y})\overset{c}{\equiv}\textbf{IDEAL}_{\mathcal{A}^{*}}^{\mathcal{F_{\Pi}}}(\lambda,\hat{x},\hat{y})$ , where $\overset{c}{\equiv}$ denotes computationally indistinguishable.*
**Theorem VI.1**
*SRFed achieves Honest but Curious Security under the DCR assumption, which means that for all inputs $\{C_{t}^{i},{skf}_{t}^{i}\}_{i=1,...,I}$ and intermediate results ( $V_{t}^{i}$ , $W_{t+1}^{\prime}$ , $W_{T}$ ), SRFed holds: $\textbf{REAL}_{\mathcal{A}}^{SRFed}(C_{t}^{i},{skf}_{t}^{i},skf_{t}^{\mathsf{Agg}},V_{t}^{i},W_{t+1}^{\prime},W_{T})\overset{c}{\equiv}$ $\textbf{IDEAL}_{\mathcal{A}^{*}}^{\mathcal{F}_{SRFed}}(C_{t}^{i},{skf}_{t}^{i},skf_{t}^{\mathsf{Agg}},V_{t}^{i},W_{t+1}^{\prime},W_{T})$ .*
* Proof:*
To prove the security of SRFed, we just need to prove the confidentiality of the privacy-preserving defense strategy, since only it involves the computation of private data by unauthorized entities (i.e., the server). For the curious server, $\textbf{REAL}_{\mathcal{A}}^{SRFed}$ contains intermediate parameters and encrypted local models $\{C_{t}^{i}\}_{i=1,...,I}$ collected from each client during the execution of SRFed protocols. Besides, we construct a PPT simulator $\mathcal{A}^{*}$ to execute $\mathcal{F}_{SRFed}$ , which simulates each process of the privacy-preserving defensive aggregation strategy. The detailed proof is described below. Hyb 1 We initialize a series of random variables whose distributions are indistinguishable from $\textbf{REAL}_{\mathcal{A}}^{SRFed}$ during the real protocol execution. Hyb 2 In this hybrid, we change the behavior of simulated client $C_{i}$ $(i\in[1,I])$ . $C_{i}$ takes the selected random vector of random variables $\Theta_{W}$ as the local model $W_{t}^{i^{\prime}}$ , and uses the DEFE.Encrypt algorithm to encrypt $W_{t}^{i^{\prime}}$ . As only the original contents of ciphertexts have changed, it guarantees that the server cannot distinguish the view of $\Theta_{W}$ from the view of original $W_{t}^{i^{\prime}}$ according to the Definition (VI.1). Then, $C_{i}$ uses the DEFE.FunKeyGen algorithm to generate the key vector $skf_{t}^{i}=[skf_{t}^{(i,1)},skf_{t}^{(i,2)},\dots,skf_{t}^{(i,L)}].$ Note that each component of $skf_{t}^{i}$ essentially is the inner product result, thus revealing no secret information to the server. Hyb 3 In this hybrid, we change the input of the protocol of Secure Model Aggregation executed by the server with encrypted random variables instead of real encrypted model parameters. The server gets the plaintexts vector $V_{t}^{i}=[V_{t}^{(i,1)},V_{t}^{(i,2)},\dots,V_{t}^{(i,L)}]$ corresponding to $C_{i}$ , which is the layer-wise projection of $\Theta_{W}$ and $W_{t}$ . As the inputs $\Theta_{W}$ follow the same distribution as the real $W^{i^{\prime}}_{t}$ , the server cannot distinguish the $V_{t}^{i}$ between ideal world and real world without knowing further information about the inputs. Then, the server performs clustering based on $\{V_{t}^{i}\}^{I}_{i=1}$ to obtain $\{\Omega_{k}\}^{K}_{k=1}$ . Subsequently, it computes the average cosine similarity of all vectors within each cluster to their centroid, and assigns client weights accordingly. Since $\{V_{t}^{i}\}^{I}_{i=1}$ is indistinguishable between the ideal world and the real world, the intermediate variables calculated via $\{V_{t}^{i}\}^{I}_{i=1}$ above also inherit this indistinguishability. Hence, this hybrid is indistinguishable from the previous one. Hyb 4 In this hybrid, the aggregated model $W_{t+1}^{\prime}$ is computed by the DEFE.AggDec algorithm. $\mathcal{A}^{*}$ holds the view $\textbf{IDEAL}_{\mathcal{A}^{*}}^{\mathcal{F}_{SRFed}}$ $=$ $(C_{t}^{i},{skf}_{t}^{i},skf_{t}^{\mathsf{Agg}},V_{t}^{i},W_{t+1}^{\prime},W_{T})$ , where $skf_{t}^{\mathsf{Agg}}$ is obtained by the interaction of non-colluding clients and server, the full security property of DEFE and the non-colluding setting ensure the security of $skf_{t}^{\mathsf{Agg}}$ . Among the elements of intermediate computation, the local model $W_{t}^{i^{\prime}}$ is encrypted, which is consistent with the previous hybrid. Throughout the $T$ -round iterative process, the server obtains the noise-perturbed aggregated model $W_{t+1}^{\prime}=W_{t+1}+\eta$ via the secure model aggregation when $0\leq t<T-1$ . Thus, the server cannot infer the real $W_{t+1}$ , and cannot distinguish the $W_{t+1}^{\prime}$ between ideal world and real world. When $t=T-1$ , since the distribution of $\Theta_{W}$ remains identical to that of $W_{T}$ , the probability that the server can distinguish the final averaged aggregated model $W_{T}$ is negligible. Hence, this hybrid is indistinguishable from the previous one. Hyb 5 When $0\leq t<T$ , all clients further execute the DEFE.UsrDec algorithm to restore the $W_{t+1}$ . This process is independent of the server, hence this hybrid is indistinguishable from the previous one. The argument above proves that the output of $\textbf{IDEAL}_{\mathcal{A}^{*}}^{\mathcal{F}_{SRFed}}$ is indistinguishable from the output of $\textbf{REAL}_{\mathcal{A}}^{SRFed}$ . Thus, it proves that SRFed guarantees HBCS. ∎
### VI-B Robustness
To theoretically analyze the robustness of SRFed against poisoning attacks, we first prove the following theorem.
**Theorem VI.2**
*When the noise perturbation $\eta$ satisfies the constraint in (9), the clustering results of SRFed over all $T$ iterations remain approximately equivalent to those obtained using the original local models $\{W_{t}^{i}\}_{1,2,...,I}$ .*
* Proof:*
Let $\overline{\eta}$ be a vector of the same shape as $W_{t}^{(i,l)^{\prime}}$ with all entries equal to $\eta$ , and ${V_{t}^{i}}_{real}$ be the real projection vector derived from the noise-free models. We discuss the following three cases. ① $t=0:$ For any $i\in[1,I]$ , $W_{0}^{(i,l)^{\prime}}=W_{0}^{(i,l)}+\overline{\eta}$ , we have
$$
\displaystyle V_{0}^{i} \displaystyle=\frac{\langle W_{0}^{(i,l)^{\prime}},W_{0}^{(l)}\rangle}{\lVert W_{0}^{(l)}\rVert_{2}}=\frac{\langle W_{0}^{(i,l)}+\overline{\eta},W_{0}^{(l)}\rangle}{\lVert W_{0}^{(l)}\rVert_{2}}={V_{0}^{i}}_{real}+\frac{\langle\overline{\eta},W_{0}^{(l)}\rangle}{\lVert W_{0}^{(l)}\rVert_{2}}. \tag{18}
$$
Note that $\frac{\langle\overline{\eta},W_{0}^{(l)}\rangle}{\lVert W_{0}^{(l)}\rVert_{2}}$ is identical for any client, the clustering result of $\{V_{0}^{i}\}^{I}_{i=1}$ is entirely equivalent to that of $\{{V_{0}^{i}}_{real}\}^{I}_{i=1}$ based on the underlying computation of K-Means. ② $0<t<T:$ For any $i\in[1,I]$ , $W_{t}^{(i,l)^{\prime}}=W_{t}^{(i,l)}+\overline{\eta}$ . Correspondingly, $W_{t}^{(l)^{\prime}}=W_{t}^{(l)}+\overline{\eta}$ , and we have
$$
\begin{split}V_{t}^{i}&=\frac{\langle W_{t}^{(i,l)^{\prime}},W_{t}^{(l)^{\prime}}\rangle}{\lVert W_{t}^{(l)^{\prime}}\rVert_{2}}\\
&=\frac{\langle W_{t}^{(i,l)},W_{t}^{(l)}\rangle+\langle W_{t}^{(i,l)},\overline{\eta}\rangle+\langle\overline{\eta},W_{t}^{(l)}\rangle+\langle\overline{\eta},\overline{\eta}\rangle}{\sqrt[]{\lVert W_{t}^{(l)}\rVert_{2}^{2}+2\langle W_{t}^{(l)},\overline{\eta}\rangle+\lVert\overline{\eta}\rVert_{2}^{2}}}.\end{split} \tag{19}
$$
By combining the above equation with the constraint (9), $V_{t}^{i}$ is approximately equivalent to the real value of ${V_{t}^{i}}_{real}$ . ③ $t=T:$ For any $i\in[1,I]$ , $W_{T}^{(i,l)^{\prime}}=W_{T}^{(i,l)}$ . Correspondingly, $W_{T}^{(l)^{\prime}}=W_{T}^{(l)}+\overline{\eta}$ , and we have
$$
\displaystyle V_{T}^{i} \displaystyle=\frac{\langle W_{T}^{(i,l)},W_{T}^{(l)^{\prime}}\rangle}{\lVert W_{T}^{(l)^{\prime}}\rVert_{2}}=\frac{\langle W_{T}^{(i,l)},W_{T}^{(l)}\rangle+\langle W_{T}^{(i,l)},\overline{\eta}\rangle}{\sqrt[]{\lVert W_{T}^{(l)}\rVert_{2}^{2}+2\langle W_{T}^{(l)},\overline{\eta}\rangle+\lVert\overline{\eta}\rVert_{2}^{2}}}. \tag{20}
$$
Similarly, by combining the above equation with the constraint (9), $V_{T}^{i}$ is approximately equivalent to the real value of ${V_{T}^{i}}_{real}$ . Therefore, across all iterations, the clustering results based on $\{V_{t}^{i}\}$ closely approximate those derived from the original local models, confirming that the introduced perturbation does not affect model detection. ∎
Then, we introduce a key assumption, which has been proved in [37, 32]. This assumption reveals the essential difference between malicious and benign models and serves as a core basis for subsequent robustness analysis.
**Assumption VI.1**
*An error term $\tau^{(t)}$ exists between the average malicious gradients $\mathbf{W}_{t}^{i*}$ and the average benign gradients $\mathbf{W}_{t}^{i}$ due to divergent training objectives. This is formally expressed as:
$$
\sum_{C_{i}\in\mathcal{M}}\mathbf{W}_{t}^{i*}=\sum_{C_{i}\in\mathcal{B}}\mathbf{W}_{t}^{i}+\tau^{(t)}. \tag{21}
$$
The magnitude of $\tau^{(t)}$ exhibits a positive correlation with the number of iterative training rounds.*
**Theorem VI.3**
*SRFed guarantees robustness to malicious clients in non-IID settings, provided that most clients are benign.*
* Proof:*
In the secure model aggregation phase of SRFed, the server collects the encrypted model $C_{t}^{i}$ and the corresponding key vectors $skf_{t}^{i}$ from each client, then computes the projection $V_{t}^{(i,l)}$ of $W_{t}^{(i,l)}$ onto $W_{t}^{(l)}$ , i.e., $\frac{\langle W_{t}^{(i,l)},W_{t}^{(l)}\rangle}{\lVert W_{t}^{(l)}\rVert_{2}}$ . By iterating over $L$ layers, the server obtains the layer-wise projection vector $V_{t}^{i}=[V_{t}^{(i,1)},V_{t}^{(i,2)},\dots,V_{t}^{(i,L)}]$ corresponding to $C_{i}$ . Subsequently, the server performs clustering on the projection vectors $\{V_{t}^{i}\}^{I}_{i=1}$ . Based on the Assumption (VI.1), a non-negligible divergence $\tau^{(t)}$ emerges between benign and malicious local models, which grows with the number of iterations. Meanwhile, by independently projecting each layer’s parameters onto the corresponding layer of the global model, our operation eliminates cross-layer interference. This ensures that malicious modifications confined to specific layers can be detected significantly more effectively. Therefore, our clustering approach successfully distinguishes between benign and malicious models by grouping them into separate clusters. Due to significant distribution divergence, malicious models exhibit a lower average cosine similarity to their cluster center. Consequently, our scheme filters out the cluster containing malicious models by computing average cosine similarity, ultimately achieving robust to malicious clients. ∎
### VI-C Efficiency
**Theorem VI.4**
*The computation and communication complexities of SRFed are $\mathcal{O}(T_{lt})+\mathcal{O}(\zeta T_{me-defe})+\mathcal{O}(T_{md-defe})+\mathcal{O}(T_{ma-defe})$ and $\mathcal{O}(I\zeta|w_{defe}|)+\mathcal{O}(IL|w|)$ , respectively.*
* Proof:*
To evaluate the efficiency of SRFed, we analyze its computational and communication overhead per training iteration and compare it with ShieldFL [29]. ShieldFL is an efficient PPFL framework based on the partially homomorphic encryption (PHE) scheme. The comparative results are presented in Table III. Specifically, the computational overhead of SRFed comprises four components: local training $\mathcal{O}(T_{lt})$ , model encryption $\mathcal{O}(\zeta T_{me-defe})$ , model detection $\mathcal{O}(T_{md-defe})$ , and model aggregation $\mathcal{O}(T_{ma-defe})$ . For model encryption, FE inherently offers a lightweight advantage over PHE, leading to $\mathcal{O}(\zeta T_{me-defe})<\mathcal{O}(\zeta T_{me-phe})$ . In terms of model detection, SRFed performs this process primarily on the server side using plaintext data, whereas ShieldFL requires multiple rounds of interaction to complete the encrypted model detection. This results in $\mathcal{O}(T_{md-defe})\ll\mathcal{O}(T_{md-phe})$ . Furthermore, SRFed enables the server to complete decryption and aggregation simultaneously. In contrast, ShieldFL necessitates aggregation prior to decryption and involves interactions with a third party, resulting in significantly higher overhead, i.e., $\mathcal{O}(T_{ma-defe})\ll\mathcal{O}(T_{ma-phe})$ . Overall, these characteristics collectively render SRFed more efficient than ShieldFL. The communication overhead of SRFed comprises two components: the encrypted models $\mathcal{O}(I\zeta|w_{defe}|)$ and key vectors $\mathcal{O}(IL|w|)$ uploaded by $I$ clients, where $\zeta$ denotes the model dimension, $L$ is the number of layers, $|w_{defe}|$ and $|w|$ are the communication complexity of a single DEFE ciphertext and a single plaintext, respectively. Since $|w|$ is significantly lower than $|w_{defe}|$ , and $|w_{defe}|$ and $|w_{phe}|$ are nearly equivalent, SRFed reduces the overall communication complexity by approximately $\mathcal{O}(12I\zeta|w_{phe}|)$ compared to ShieldFL. This reduction in overhead is primarily attributed to SRFed’s lightweight DEFE scheme, which eliminates extensive third-party interactions. ∎
TABLE III: Comparison of computation and communication overhead between different methods
| Method | SRFed | ShieldFL |
| --- | --- | --- |
| Comp. | $\mathcal{O}(T_{lt})+\mathcal{O}(\zeta T_{me-defe})$ | $\mathcal{O}(T_{lt})+\mathcal{O}(\zeta T_{me-phe})$ |
| $+\mathcal{O}(T_{ma-defe})$ | $+\mathcal{O}(\zeta T_{md-phe})$ | |
| $+\mathcal{O}(T_{ma-defe})$ | $+\mathcal{O}(T_{md-phe})$ | |
| Comm. | $\mathcal{O}(I\zeta|w_{defe}|)^{1}+\mathcal{O}(IL|w|)^{2}$ | $\mathcal{O}(13I\zeta|w_{phe}|)^{\mathrm{3}}$ |
- Notes: ${}^{\mathrm{1,2,3}}|w_{defe}|$ , $|w|$ and $|w_{phe}|$ denote the communication complexity of a DEFE ciphertext, a plaintext, and a PHE ciphertext, respectively.
## VII Experiments
### VII-A Experimental Settings
#### VII-A 1 Implementation
We implement SRFed on a small-scale local network. Each machine in the network is equipped with the following hardware configuration: an Intel Xeon CPU E5-1650 v4, 32 GB of RAM, an NVIDIA GeForce GTX 1080 Ti graphics card, and a network bandwidth of 40 Mbps. Additionally, the implementation of the DEFE scheme is based on the NDD-FE scheme [31], and the code implementation of FL processes is referenced to [44].
#### VII-A 2 Dataset and Models
We evaluate the performance of SRFed on two datasets:
- MNIST [45]: This dataset consists of 10 classes of handwritten digit images, with 60,000 training samples and 10,000 test samples. Each sample is a grayscale image of 28 × 28 pixels. The global model used for this dataset is a Convolutional Neural Network (CNN) model, which includes two convolutional layers followed by two fully connected layers.
- CIFAR-10 [46]: This dataset contains RGB color images across 10 categories, including airplane, car, bird, cat, deer, dog, frog, horse, boat, and truck. It consists of 50,000 training images and 10,000 test samples. Each sample is a 32 × 32 pixel color image. The global model used for this dataset is a CNN model, which includes three convolutional layers, one pooling layer, and two fully connected layers.
#### VII-A 3 Baselines
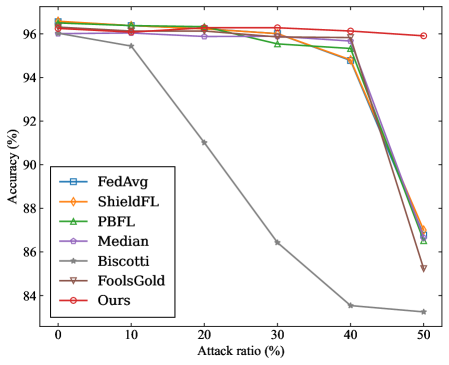
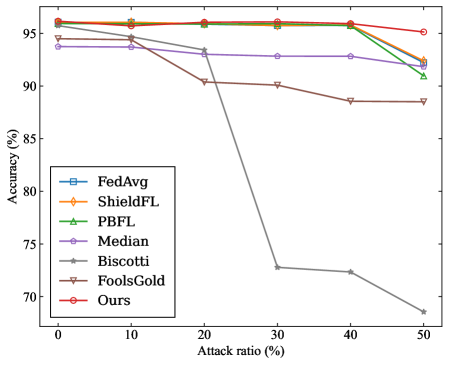
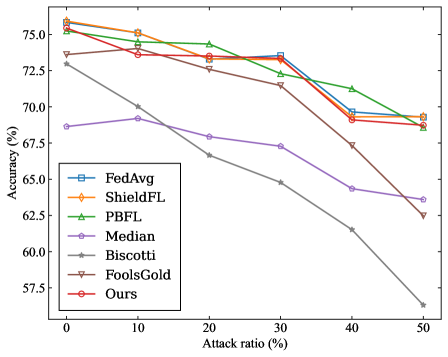
To evaluate the robustness of the proposed SRFed method, we conduct comparative experiments against several advanced baseline methods, including FedAvg [47], ShieldFL [29], PBFL [37], Median [35], Biscotti [41], and FoolsGold [33]. Furthermore, to evaluate the efficiency of SRFed, we compare it with representative methods such as ShieldFL [29] and ESB-FL [31].
#### VII-A 4 Experimental parameters
In all experiments, the number of local clients is set to 20, the number of training rounds is set to 100, the batchsize is set to 64, and the number of local training epochs is set to 10. We use the stochastic gradient descent (SGD) to optimize the model, with a learning rate of 0.01 and a momentum of 0.5. Additionally, our experiments are conducted under varying levels of data heterogeneity, with the data distributions configured as follows:
- MNIST: Two distinct levels of data heterogeneity are configured by sampling from a Dirichlet distribution with the parameters $\alpha=0.2$ and $\alpha=0.8$ , respectively, to simulate Non-IID data partitions across clients.
- CIFAR-10: Two distinct levels of data heterogeneity are configured by sampling from a Dirichlet distribution with the parameters $\alpha=0.2$ and $\alpha=0.6$ , respectively, to simulate Non-IID data partitions across clients.
#### VII-A 5 Attack Scenario
In each benchmark, the adversary can control a certain proportion of clients to launch poisoning attacks, with the proportion varying across {0%, 10%, 20%, 30%, 40%, 50%}. The attack scenario parameters are configured as follows:
- Targeted Poisoning Attack: we consider the mainstream label-flipping attack. For experiments on the MNIST dataset, the training samples originally labeled as ”0” are reassigned to the target label ”4”. For the CIFAR-10 dataset, the training samples originally labeled as ”airplane” are reassigned to the target label ”deer”.
- Untargeted Poisoning Attack: We consider the commonly used Gaussian attack. In experiments, malicious clients inject noise that follows a Gaussian distribution $\mathcal{N}(0,0.5^{2})$ into their local model updates.
#### VII-A 6 Evaluation Metrics
For each benchmark experiment, we adopt the following evaluation metrics on the test dataset to quantify the impact of poisoning attacks on the aggregated model in FL.
- Overall Accuracy (OA): It is the ratio of the number of samples correctly predicted by the model in the test dataset to the total number of predictions for all samples in the test dataset.
- Source Accuracy (SA): It specifically refers to the ratio of the number of correctly predicted flip class samples by the model to the total number of flip class samples in the dataset.
- Attack Success Rate (ASR): It is defined as the proportion of source-class samples that are misclassified as the target class by the aggregated model.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or defense mechanisms as the ratio of adversarial attacks increases. The chart demonstrates how each method's accuracy degrades under increasing attack pressure.
### Components/Axes
* **X-Axis:** Labeled "Attack ratio (%)". It represents the percentage of malicious participants or attacks in the system. The axis has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled "Accuracy (%)". It represents the model's accuracy. The axis has major tick marks at 84, 86, 88, 90, 92, 94, and 96.
* **Legend:** Located in the bottom-left quadrant of the chart area. It lists seven data series with corresponding line colors and marker symbols:
1. **FedAvg:** Blue line with square markers (□).
2. **ShieldFL:** Orange line with diamond markers (◇).
3. **PBFL:** Green line with upward-pointing triangle markers (△).
4. **Median:** Purple line with circle markers (○).
5. **Biscotti:** Gray line with star/asterisk markers (☆).
6. **FoolsGold:** Brown line with downward-pointing triangle markers (▽).
7. **Ours:** Red line with circle markers (○).
### Detailed Analysis
The chart plots Accuracy (%) against Attack ratio (%). All methods start at a high accuracy (approximately 96%) when the attack ratio is 0%. As the attack ratio increases, the accuracy of most methods declines, but at dramatically different rates.
**Data Series Trends & Approximate Values:**
1. **Ours (Red line, ○):**
* **Trend:** Shows the most robust performance. The line remains nearly flat, exhibiting only a very slight downward slope.
* **Data Points:** ~96.2% (0%), ~96.1% (10%), ~96.1% (20%), ~96.0% (30%), ~95.9% (40%), ~95.8% (50%).
2. **Median (Purple line, ○):**
* **Trend:** Very stable, similar to "Ours" but with a marginally steeper decline at the highest attack ratio.
* **Data Points:** ~96.0% (0%), ~95.9% (10%), ~95.8% (20%), ~95.7% (30%), ~95.6% (40%), ~95.0% (50%).
3. **FedAvg (Blue line, □), ShieldFL (Orange line, ◇), PBFL (Green line, △), FoolsGold (Brown line, ▽):**
* **Trend:** These four methods follow a very similar pattern. They maintain high accuracy (~96%) until an attack ratio of 30-40%, after which they experience a sharp, precipitous drop.
* **Data Points (Approximate for the group):** ~96.0% (0%), ~96.0% (10%), ~95.8% (20%), ~95.5% (30%). At 40%, they begin to diverge slightly: FedAvg/PBFL ~95.0%, ShieldFL ~94.8%, FoolsGold ~94.5%. At 50%, they all drop significantly: FedAvg ~86.5%, PBFL ~87.0%, ShieldFL ~87.0%, FoolsGold ~85.2%.
4. **Biscotti (Gray line, ☆):**
* **Trend:** Exhibits the worst performance and earliest degradation. The line shows a steady, steep downward slope from the beginning.
* **Data Points:** ~96.0% (0%), ~95.5% (10%), ~91.0% (20%), ~86.5% (30%), ~83.5% (40%), ~83.2% (50%).
### Key Observations
1. **Clear Performance Tiers:** The methods cluster into three distinct performance tiers under attack:
* **Tier 1 (Highly Robust):** "Ours" and "Median" maintain accuracy above ~95% even at a 50% attack ratio.
* **Tier 2 (Moderately Robust, then Collapse):** FedAvg, ShieldFL, PBFL, and FoolsGold are resilient up to a ~30-40% attack ratio but fail catastrophically beyond that point.
* **Tier 3 (Vulnerable):** Biscotti's accuracy degrades linearly and significantly with any increase in attack ratio.
2. **Critical Threshold:** For four of the seven methods, an attack ratio between 30% and 40% appears to be a critical failure threshold.
3. **"Ours" is the Top Performer:** The method labeled "Ours" demonstrates the highest and most consistent accuracy across the entire range of attack ratios tested.
### Interpretation
This chart is a robustness evaluation of federated learning aggregation or defense strategies. The "Attack ratio" simulates an increasingly hostile environment where a larger portion of participating devices are malicious (e.g., sending poisoned model updates).
* **What the data suggests:** The proposed method ("Ours") and the "Median" aggregation are significantly more resilient to Byzantine (malicious) attacks than the other compared methods. Their design likely incorporates robust statistics or other mechanisms that are not easily fooled by a high volume of adversarial inputs.
* **How elements relate:** The sharp drop-off for FedAvg, ShieldFL, PBFL, and FoolsGold indicates they have a breaking point. Their defense mechanisms may work well when malicious actors are a minority but become overwhelmed and fail completely when malicious participants approach or exceed 40-50% of the total. Biscotti's linear decline suggests its defense is fundamentally less effective, offering little resistance as attacks increase.
* **Notable Anomaly:** The near-identical performance of FedAvg, ShieldFL, PBFL, and FoolsGold until the 30% mark is striking. It suggests that under moderate attack conditions, these different methods offer similar levels of protection, and their key differentiator is their failure mode under extreme conditions.
* **Practical Implication:** For a real-world federated learning system where security is a concern, choosing an aggregation method from Tier 1 ("Ours" or "Median") would provide a much larger safety margin. Methods from Tier 2 might be acceptable only if the system can guarantee the attack ratio will never approach the 30-40% threshold.
</details>
(a) MNIST ( $\alpha$ =0.2)
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or algorithms as the percentage of malicious participants (attack ratio) in the system increases. The chart demonstrates how each method's accuracy degrades under increasing adversarial pressure.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. It has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. It has major tick marks at 70, 75, 80, 85, 90, and 95.
* **Legend:** Positioned in the **bottom-left corner** of the chart area. It contains seven entries, each with a unique color and marker symbol:
1. **FedAvg:** Blue line with square markers (□).
2. **ShieldFL:** Orange line with diamond markers (◇).
3. **PBFL:** Green line with upward-pointing triangle markers (△).
4. **Median:** Purple line with circle markers (○).
5. **Biscotti:** Gray line with star/asterisk markers (*).
6. **FoolsGold:** Brown line with downward-pointing triangle markers (▽).
7. **Ours:** Red line with pentagon markers (⬠).
### Detailed Analysis
The chart plots Accuracy (%) against Attack ratio (%). Below is an analysis of each data series, with approximate values read from the chart. Values are approximate due to visual estimation.
**1. FedAvg (Blue, □):**
* **Trend:** Starts high and remains nearly flat until a sharp decline after 40% attack ratio.
* **Data Points:** ~96% at 0%, ~96% at 10%, ~96% at 20%, ~96% at 30%, ~96% at 40%, ~92% at 50%.
**2. ShieldFL (Orange, ◇):**
* **Trend:** Very similar to FedAvg, maintaining high accuracy before a late decline.
* **Data Points:** ~96% at 0%, ~96% at 10%, ~96% at 20%, ~96% at 30%, ~96% at 40%, ~92.5% at 50%.
**3. PBFL (Green, △):**
* **Trend:** Follows the same high-accuracy plateau as FedAvg and ShieldFL but begins its decline slightly earlier.
* **Data Points:** ~96% at 0%, ~96% at 10%, ~96% at 20%, ~96% at 30%, ~96% at 40%, ~91% at 50%.
**4. Median (Purple, ○):**
* **Trend:** Starts slightly lower than the top group and shows a very gradual, linear decline.
* **Data Points:** ~94% at 0%, ~94% at 10%, ~93% at 20%, ~93% at 30%, ~93% at 40%, ~92% at 50%.
**5. Biscotti (Gray, *):**
* **Trend:** Exhibits the most severe and rapid degradation. It starts high but plummets dramatically between 20% and 30% attack ratio.
* **Data Points:** ~96% at 0%, ~95% at 10%, ~93% at 20%, **~73% at 30%**, ~72% at 40%, ~68% at 50%.
**6. FoolsGold (Brown, ▽):**
* **Trend:** Starts lower than most and shows a steady, moderate decline.
* **Data Points:** ~94.5% at 0%, ~94% at 10%, ~90.5% at 20%, ~90% at 30%, ~88.5% at 40%, ~88.5% at 50%.
**7. Ours (Red, ⬠):**
* **Trend:** Maintains the highest and most stable accuracy across the entire range, with only a very slight dip at the highest attack ratio.
* **Data Points:** ~96% at 0%, ~96% at 10%, ~96% at 20%, ~96% at 30%, ~96% at 40%, ~95% at 50%.
### Key Observations
1. **Performance Clustering:** Three distinct performance clusters are visible:
* **High-Resilience Group:** "Ours", FedAvg, ShieldFL, and PBFL maintain ~96% accuracy until 40% attack ratio.
* **Moderate-Resilience Group:** "Median" and "FoolsGold" start lower and degrade more gradually.
* **Low-Resilience Outlier:** "Biscotti" experiences a catastrophic failure, losing over 20 percentage points of accuracy between 20% and 30% attack ratio.
2. **Critical Threshold:** The 20%-30% attack ratio range is a critical point where the performance of several methods diverges sharply.
3. **Top Performer:** The method labeled "Ours" demonstrates superior robustness, maintaining near-peak accuracy even at a 50% attack ratio, while all other methods show some decline.
### Interpretation
This chart is a robustness evaluation of federated learning algorithms against poisoning attacks (where a fraction of participants are malicious). The "Attack ratio (%)" represents the proportion of malicious clients.
* **What the data suggests:** The proposed method ("Ours") is significantly more robust to adversarial attacks than the six baseline methods compared. It maintains model accuracy even when half the participants are malicious.
* **How elements relate:** The x-axis (attack strength) is the independent variable testing the systems. The y-axis (accuracy) is the dependent variable measuring system performance. The legend identifies the different defensive strategies being tested.
* **Notable trends/anomalies:**
* The **Biscotti** method's sharp drop indicates a specific vulnerability that is triggered once the attack ratio exceeds 20%. This is a critical failure mode.
* The **FedAvg, ShieldFL, and PBFL** methods show a "cliff-edge" failure pattern—they are highly effective up to a point (40% attack ratio) but then degrade quickly.
* The **"Ours"** method's flat line suggests it employs a fundamentally different or more effective defense mechanism that does not degrade linearly or catastrophically with increased attack strength.
* **Peircean Investigation:** The chart is an **index** of resilience (the lines point to the performance outcome) and a **symbol** of a comparative study (the legend encodes the meaning of each line). The stark visual contrast between the red "Ours" line and the plummeting gray "Biscotti" line is the most significant **iconic** representation of the claimed improvement. The data argues that the new method solves a stability problem present in prior work.
</details>
(b) MNIST ( $\alpha$ =0.8)
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Chart: Accuracy of Federated Learning Defense Mechanisms Under Poisoning Attacks
### Overview
This image is a line chart comparing the performance (accuracy) of seven different federated learning defense mechanisms as the ratio of malicious attacks increases. The chart demonstrates how each method's accuracy degrades under increasing adversarial pressure.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. It represents the percentage of malicious participants or updates in the federated learning system. The axis has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. It represents the model's classification accuracy. The axis ranges from approximately 57.5% to 76%, with major tick marks at 57.5, 60, 62.5, 65, 67.5, 70, 72.5, and 75.
* **Legend:** Located in the **bottom-left quadrant** of the plot area. It lists seven data series with corresponding line colors and marker styles:
1. **FedAvg** (Light blue line, square marker `□`)
2. **ShieldFL** (Orange line, plus marker `+`)
3. **PBFL** (Green line, upward-pointing triangle marker `△`)
4. **Median** (Purple line, circle marker `○`)
5. **Biscotti** (Gray line, left-pointing triangle marker `◁`)
6. **FoolsGold** (Brown line, downward-pointing triangle marker `▽`)
7. **Ours** (Red line, pentagon marker `⬠`)
### Detailed Analysis
The chart plots Accuracy (%) against Attack ratio (%). Below is an analysis of each data series, including approximate values and visual trends.
**Trend Verification & Data Points (Approximate):**
1. **FedAvg (Light blue, `□`):**
* **Trend:** Starts high, remains relatively stable until a 30% attack ratio, then declines sharply.
* **Points:** (0%, ~75.5%), (10%, ~75.0%), (20%, ~73.5%), (30%, ~73.5%), (40%, ~69.5%), (50%, ~68.5%).
2. **ShieldFL (Orange, `+`):**
* **Trend:** Starts as the highest, shows a steady, near-linear decline across all attack ratios.
* **Points:** (0%, ~76.0%), (10%, ~75.0%), (20%, ~73.5%), (30%, ~73.5%), (40%, ~69.0%), (50%, ~69.0%).
3. **PBFL (Green, `△`):**
* **Trend:** Starts very high, declines gradually and consistently.
* **Points:** (0%, ~75.5%), (10%, ~74.5%), (20%, ~74.0%), (30%, ~72.0%), (40%, ~71.0%), (50%, ~68.5%).
4. **Median (Purple, `○`):**
* **Trend:** Starts significantly lower than the top group, shows a very gradual, shallow decline.
* **Points:** (0%, ~68.5%), (10%, ~69.0%), (20%, ~68.0%), (30%, ~67.5%), (40%, ~64.5%), (50%, ~64.0%).
5. **Biscotti (Gray, `◁`):**
* **Trend:** Starts moderately high but exhibits the steepest and most consistent decline of all methods.
* **Points:** (0%, ~73.0%), (10%, ~70.0%), (20%, ~66.5%), (30%, ~64.5%), (40%, ~61.5%), (50%, ~56.5%).
6. **FoolsGold (Brown, `▽`):**
* **Trend:** Starts high, declines steadily, with a particularly sharp drop between 30% and 40% attack ratio.
* **Points:** (0%, ~73.5%), (10%, ~73.5%), (20%, ~72.5%), (30%, ~71.5%), (40%, ~67.0%), (50%, ~62.5%).
7. **Ours (Red, `⬠`):**
* **Trend:** Starts among the top group, maintains high accuracy robustly until a 30% attack ratio, then declines but remains competitive.
* **Points:** (0%, ~75.5%), (10%, ~74.0%), (20%, ~73.5%), (30%, ~73.5%), (40%, ~69.0%), (50%, ~68.5%).
### Key Observations
1. **Performance Hierarchy at Low Attack (0%):** ShieldFL, FedAvg, PBFL, and "Ours" are tightly clustered at the top (~75.5-76%). FoolsGold and Biscotti are slightly lower (~73-73.5%). Median is a clear outlier, starting much lower (~68.5%).
2. **Robustness to Increasing Attacks:** The method labeled **"Ours"** and **FedAvg** show a "plateau-then-drop" pattern, maintaining high accuracy up to a 30% attack ratio before declining. **ShieldFL** and **PBFL** show a more linear, graceful degradation.
3. **Most Vulnerable Method:** **Biscotti** demonstrates the poorest robustness, suffering the most severe and consistent drop in accuracy, falling from ~73% to ~56.5%.
4. **Critical Threshold:** A notable inflection point occurs for several methods (FedAvg, FoolsGold, "Ours") between **30% and 40% attack ratio**, where the rate of accuracy loss increases sharply.
5. **Final Ranking at 50% Attack:** The order from highest to lowest accuracy is approximately: ShieldFL ≈ PBFL ≈ FedAvg ≈ "Ours" (all ~68.5-69%) > Median (~64%) > FoolsGold (~62.5%) > Biscotti (~56.5%).
### Interpretation
This chart is a comparative robustness analysis for federated learning (FL) systems under data poisoning attacks. The "Attack ratio" simulates an adversary controlling a fraction of the participating clients or their model updates.
* **What the data suggests:** The proposed method ("Ours") is designed to be highly robust, matching the top-performing established defenses (ShieldFL, PBFL, FedAvg) in clean conditions and maintaining that performance under moderate attack pressure (up to 30%). Its behavior suggests it may incorporate mechanisms that effectively filter or neutralize malicious updates until they reach a critical mass.
* **Relationship between elements:** The chart directly correlates adversarial strength (x-axis) with system utility (y-axis). The diverging lines illustrate that different defense strategies have varying resilience profiles. Methods like Biscotti and FoolsGold appear more sensitive to the proportion of attackers, while Median, though starting lower, shows a flatter degradation curve, indicating a different, possibly more conservative, robustness strategy.
* **Notable Anomalies/Patterns:** The sharp performance cliff for multiple methods between 30-40% attack ratio is critical. It implies a phase transition where the defense mechanisms become overwhelmed, and the malicious updates begin to dominate the global model aggregation. The fact that "Ours," FedAvg, and ShieldFL converge to a similar accuracy at 50% attack suggests there may be a fundamental limit to robustness in this experimental setup when half the participants are malicious. The consistently lower performance of the Median aggregator, even at 0% attack, highlights the trade-off between robustness and final model accuracy in some defense strategies.
</details>
(c) CIFAR10 ( $\alpha$ =0.2)
<details>
<summary>x5.png Details</summary>
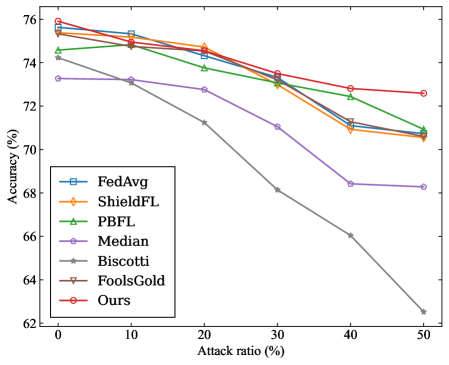
### Visual Description
\n
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Defense Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning defense methods as the ratio of adversarial attacks increases. The chart demonstrates how each method's accuracy degrades under increasing adversarial pressure.
### Components/Axes
* **X-Axis (Horizontal):** Labeled "Attack ratio (%)". It represents the percentage of malicious participants or attacks in the system. The axis has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis (Vertical):** Labeled "Accuracy (%)". It represents the model's performance metric. The axis ranges from 62 to 76, with major tick marks every 2 units (62, 64, 66, 68, 70, 72, 74, 76).
* **Legend:** Located in the bottom-left corner of the chart area. It lists seven data series with corresponding colors and markers:
1. **FedAvg:** Blue line with square markers (□).
2. **ShieldFL:** Orange line with diamond markers (◇).
3. **PBFL:** Green line with upward-pointing triangle markers (△).
4. **Median:** Purple line with circle markers (○).
5. **Biscotti:** Gray line with star/asterisk markers (☆).
6. **FoolsGold:** Brown line with downward-pointing triangle markers (▽).
7. **Ours:** Red line with circle markers (○).
### Detailed Analysis
**Trend Verification:** All seven lines show a downward trend, indicating that accuracy decreases as the attack ratio increases. The rate of decline varies significantly between methods.
**Data Series Analysis (from highest to lowest final accuracy at 50% attack ratio):**
1. **Ours (Red line, ○):**
* **Trend:** The most resilient line, with the gentlest downward slope.
* **Approximate Data Points:** Starts at ~75.8% (0%), ~75.2% (10%), ~74.8% (20%), ~73.5% (30%), ~72.8% (40%), ends at ~72.6% (50%).
2. **FoolsGold (Brown line, ▽):**
* **Trend:** Very similar to "Ours" but consistently slightly lower. Also shows strong resilience.
* **Approximate Data Points:** Starts at ~75.6% (0%), ~75.0% (10%), ~74.6% (20%), ~73.4% (30%), ~72.4% (40%), ends at ~72.2% (50%).
3. **PBFL (Green line, △):**
* **Trend:** Moderate decline, performing better than the median group but worse than the top two.
* **Approximate Data Points:** Starts at ~74.8% (0%), ~74.4% (10%), ~73.8% (20%), ~73.0% (30%), ~72.4% (40%), ends at ~71.0% (50%).
4. **ShieldFL (Orange line, ◇):**
* **Trend:** Follows a path very close to PBFL, ending at a similar point.
* **Approximate Data Points:** Starts at ~75.4% (0%), ~75.0% (10%), ~74.6% (20%), ~73.2% (30%), ~71.0% (40%), ends at ~70.6% (50%).
5. **FedAvg (Blue line, □):**
* **Trend:** Starts as one of the highest but experiences a steeper drop after the 20% mark.
* **Approximate Data Points:** Starts at ~75.8% (0%), ~75.2% (10%), ~74.4% (20%), ~73.2% (30%), ~71.2% (40%), ends at ~70.6% (50%).
6. **Median (Purple line, ○):**
* **Trend:** Shows a consistent, significant decline across the entire range.
* **Approximate Data Points:** Starts at ~73.2% (0%), ~73.0% (10%), ~72.6% (20%), ~71.0% (30%), ~68.4% (40%), ends at ~68.2% (50%).
7. **Biscotti (Gray line, ☆):**
* **Trend:** The steepest and most severe decline of all methods. Its performance collapses dramatically as attacks increase.
* **Approximate Data Points:** Starts at ~74.4% (0%), ~73.2% (10%), ~71.2% (20%), ~68.2% (30%), ~66.0% (40%), ends at ~62.6% (50%).
### Key Observations
1. **Performance Hierarchy:** A clear hierarchy is established. "Ours" and "FoolsGold" form a top tier of robust methods. PBFL, ShieldFL, and FedAvg form a middle tier. Median and especially Biscotti are in a lower tier of vulnerability.
2. **Divergence Point:** The performance of the methods begins to diverge noticeably after the 10-20% attack ratio mark. The gap between the most robust ("Ours") and least robust ("Biscotti") widens from ~1.4% at 0% attack to a massive ~10% at 50% attack.
3. **Biscotti's Anomaly:** The Biscotti method is a significant outlier, showing a near-linear, steep degradation that is qualitatively different from the more gradual, curved declines of the other methods.
4. **FedAvg's Drop:** FedAvg starts competitively but its decline accelerates after 20%, causing it to fall from the top group to the middle group.
### Interpretation
This chart is a comparative robustness analysis for federated learning systems under adversarial attack. The data suggests that the proposed method ("Ours") achieves state-of-the-art resilience, maintaining over 72% accuracy even when half the participants are malicious. It marginally outperforms the strong baseline "FoolsGold."
The stark contrast with Biscotti indicates that its defense mechanism is fundamentally less effective against the modeled attacks, suffering catastrophic failure as the threat scale increases. The clustering of PBFL, ShieldFL, and FedAvg suggests these methods share similar, moderate levels of robustness.
The chart effectively argues for the superiority of the "Ours" method by demonstrating not just a higher starting point, but a significantly slower rate of decay. The widening performance gap at higher attack ratios is the most critical finding, highlighting the practical importance of the proposed approach in high-threat environments. The visualization successfully isolates the impact of the attack ratio variable on the core performance metric (accuracy) across multiple competing solutions.
</details>
(d) CIFAR10 ( $\alpha$ =0.6)
Figure 2: The OA of the models obtained by four benchmarks under label-flipping attack.
<details>
<summary>x6.png Details</summary>
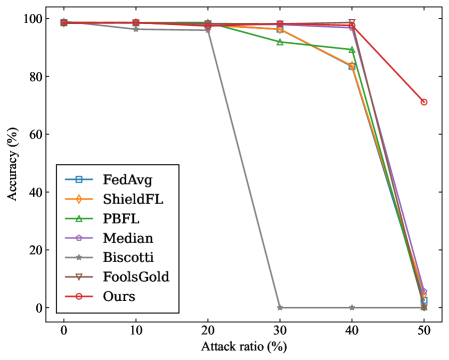
### Visual Description
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or defenses as the ratio of adversarial attacks increases. The chart demonstrates how each method's accuracy degrades under increasing levels of attack.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. The scale runs from 0 to 50, with major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The scale runs from 0 to 100, with major tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Positioned in the **center-left** area of the plot. It lists seven data series with corresponding colors and marker symbols:
1. **FedAvg** - Blue line with square markers (□).
2. **ShieldFL** - Orange line with diamond markers (◇).
3. **PBFL** - Green line with upward-pointing triangle markers (△).
4. **Median** - Purple line with circle markers (○).
5. **Biscotti** - Gray line with left-pointing triangle markers (◁).
6. **FoolsGold** - Brown line with downward-pointing triangle markers (▽).
7. **Ours** - Red line with circle markers (○).
### Detailed Analysis
The chart plots accuracy against attack ratio for six data points per series (at 0%, 10%, 20%, 30%, 40%, and 50% attack ratio).
**Trend Verification & Data Points (Approximate):**
1. **FedAvg (Blue, □):** Maintains high accuracy (~98-99%) from 0% to 40% attack ratio. At 50% attack ratio, accuracy plummets to near 0%.
2. **ShieldFL (Orange, ◇):** Follows a nearly identical path to FedAvg. High accuracy (~98-99%) until 40%, then drops to near 0% at 50%.
3. **PBFL (Green, △):** Starts high (~98%). Shows a slight, gradual decline between 20% and 40% attack ratio (to ~90%). Experiences a sharp drop at 50% to near 0%.
4. **Median (Purple, ○):** Very similar to FedAvg and ShieldFL. Maintains ~98-99% accuracy until 40%, then drops to near 0% at 50%.
5. **Biscotti (Gray, ◁):** Exhibits a unique and severe failure mode. Maintains high accuracy (~98%) at 0%, 10%, and 20%. At **30% attack ratio, accuracy drops catastrophically to 0%** and remains at 0% for 40% and 50%.
6. **FoolsGold (Brown, ▽):** Follows the common high-accuracy plateau (~98-99%) until 40%. At 50%, it drops significantly but not to zero, landing at approximately 5-10% accuracy.
7. **Ours (Red, ○):** Demonstrates the most robust performance. Maintains near-perfect accuracy (~99%) from 0% to 40% attack ratio. At 50%, it experiences a decline but retains the highest accuracy of all methods, approximately **70%**.
### Key Observations
* **Common Plateau:** Six of the seven methods (all except Biscotti) maintain very high accuracy (>95%) up to a 40% attack ratio.
* **Critical Threshold:** A severe performance cliff exists for most methods between 40% and 50% attack ratio.
* **Outlier - Biscotti:** This method fails catastrophically at a much lower attack ratio (30%) compared to the others, dropping to 0% accuracy.
* **Best Performer:** The method labeled "Ours" is the clear outlier in robustness, retaining ~70% accuracy at the 50% attack ratio where all others have failed (≤10% accuracy).
* **Worst Performers at 50%:** FedAvg, ShieldFL, PBFL, and Median all converge to near 0% accuracy at the 50% attack ratio.
### Interpretation
This chart is a robustness evaluation, likely from a research paper proposing a new federated learning defense (the "Ours" series). The data suggests that:
1. **Attack Resilience:** Most standard or existing defense methods (FedAvg, ShieldFL, Median, PBFL) are highly effective against low-to-moderate levels of adversarial participation (up to 40%). However, they lack resilience against a majority attack (50%).
2. **Vulnerability of Biscotti:** The Biscotti method appears to have a specific vulnerability or breaking point at a 30% attack ratio, making it unsuitable for environments where attack levels might reach that threshold.
3. **Superiority of Proposed Method:** The primary conclusion the chart is designed to support is that the authors' proposed method ("Ours") offers significantly enhanced robustness. It maintains functional accuracy (70%) even when half of the participants are adversarial, a scenario that completely breaks all other compared methods.
4. **Practical Implication:** The chart argues for the adoption of the "Ours" method in high-risk federated learning deployments where a significant malicious presence is anticipated, as it degrades gracefully rather than failing catastrophically.
</details>
(a) MNIST ( $\alpha$ =0.2)
<details>
<summary>x7.png Details</summary>
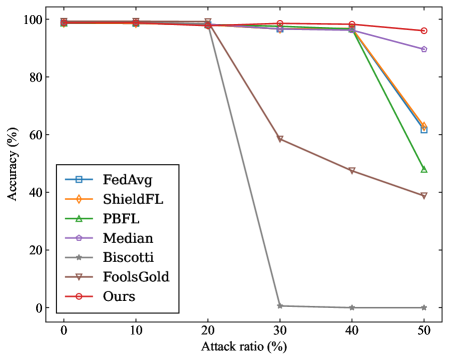
### Visual Description
## Line Chart: Accuracy vs. Attack Ratio for Various Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different methods in a federated learning context as the percentage of malicious participants (attack ratio) increases. The chart demonstrates how each method's accuracy degrades under increasing adversarial conditions.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. Major tick marks and labels are present at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The scale runs from 0 to 100, with major tick marks at intervals of 20 (0, 20, 40, 60, 80, 100).
* **Legend:** Positioned in the **bottom-left corner** of the plot area. It contains seven entries, each with a unique color, marker shape, and label:
1. **FedAvg** - Blue line with square markers (□).
2. **ShieldFL** - Orange line with diamond markers (◇).
3. **PBFL** - Green line with upward-pointing triangle markers (△).
4. **Median** - Purple line with circle markers (○).
5. **Biscotti** - Gray line with star/asterisk markers (☆).
6. **FoolsGold** - Brown line with downward-pointing triangle markers (▽).
7. **Ours** - Red line with circle markers (○).
### Detailed Analysis
The following data points are approximate, extracted by visual inspection of the chart.
**Trend Verification & Data Points:**
1. **Ours (Red, ○):** The line remains nearly flat at the top of the chart, showing high resilience.
* 0% Attack: ~100% Accuracy
* 10% Attack: ~100% Accuracy
* 20% Attack: ~100% Accuracy
* 30% Attack: ~99% Accuracy
* 40% Attack: ~98% Accuracy
* 50% Attack: ~96% Accuracy
2. **Median (Purple, ○):** The line stays high until 40% attack, then shows a moderate decline.
* 0% Attack: ~100% Accuracy
* 10% Attack: ~100% Accuracy
* 20% Attack: ~99% Accuracy
* 30% Attack: ~98% Accuracy
* 40% Attack: ~97% Accuracy
* 50% Attack: ~90% Accuracy
3. **ShieldFL (Orange, ◇):** The line follows a path very close to FedAvg, with a sharp decline after 40%.
* 0% Attack: ~100% Accuracy
* 10% Attack: ~100% Accuracy
* 20% Attack: ~99% Accuracy
* 30% Attack: ~98% Accuracy
* 40% Attack: ~97% Accuracy
* 50% Attack: ~63% Accuracy
4. **FedAvg (Blue, □):** The line shows a similar trend to ShieldFL, dropping sharply after 40%.
* 0% Attack: ~100% Accuracy
* 10% Attack: ~100% Accuracy
* 20% Attack: ~99% Accuracy
* 30% Attack: ~98% Accuracy
* 40% Attack: ~97% Accuracy
* 50% Attack: ~61% Accuracy
5. **PBFL (Green, △):** The line begins its decline earlier than FedAvg/ShieldFL, starting after 20%.
* 0% Attack: ~100% Accuracy
* 10% Attack: ~100% Accuracy
* 20% Attack: ~99% Accuracy
* 30% Attack: ~98% Accuracy
* 40% Attack: ~96% Accuracy
* 50% Attack: ~48% Accuracy
6. **FoolsGold (Brown, ▽):** The line shows a steady, significant decline starting after 20%.
* 0% Attack: ~100% Accuracy
* 10% Attack: ~100% Accuracy
* 20% Attack: ~99% Accuracy
* 30% Attack: ~59% Accuracy
* 40% Attack: ~48% Accuracy
* 50% Attack: ~39% Accuracy
7. **Biscotti (Gray, ☆):** The line exhibits the most catastrophic failure, dropping to near-zero accuracy after 20%.
* 0% Attack: ~100% Accuracy
* 10% Attack: ~100% Accuracy
* 20% Attack: ~99% Accuracy
* 30% Attack: ~1% Accuracy
* 40% Attack: ~0% Accuracy
* 50% Attack: ~0% Accuracy
### Key Observations
* **Performance Clustering:** At low attack ratios (0-20%), all methods perform nearly identically with ~100% accuracy.
* **Divergence Point:** The critical divergence occurs between 20% and 30% attack ratio. Biscotti and FoolsGold begin severe degradation here.
* **Second Drop Point:** A second major divergence occurs between 40% and 50% attack ratio, where FedAvg, ShieldFL, and PBFL experience sharp declines.
* **Robustness Hierarchy:** The chart clearly ranks the methods by robustness to high attack ratios: **Ours** > **Median** > **ShieldFL** ≈ **FedAvg** > **PBFL** > **FoolsGold** > **Biscotti**.
* **Outlier:** The **Biscotti** method is a significant outlier, showing complete failure (accuracy ~0%) once the attack ratio exceeds 20%.
### Interpretation
This chart is a comparative robustness analysis for federated learning aggregation methods under poisoning attacks. The "Attack ratio (%)" represents the proportion of malicious clients in the network.
* **What the data suggests:** The proposed method ("Ours") demonstrates superior resilience, maintaining over 95% accuracy even when half the clients are malicious. This suggests it has a robust mechanism for identifying and mitigating the influence of poisoned model updates.
* **Relationship between elements:** The x-axis (attack strength) is the independent variable testing the systems. The y-axis (accuracy) is the dependent variable measuring system integrity. The diverging lines illustrate the different failure modes and thresholds of each aggregation strategy.
* **Notable trends/anomalies:**
1. The **Median** aggregator, a known robust statistic, performs well but is still outperformed by "Ours" at the highest attack ratio.
2. Standard **FedAvg** is highly vulnerable once a critical mass of attackers (~40%) is reached.
3. The catastrophic failure of **Biscotti** after 20% suggests its security model has a sharp phase transition or a specific assumption that is violated at that threshold.
4. The chart effectively argues that the new method ("Ours") pushes the boundary of reliable operation into much more hostile environments than prior work.
</details>
(b) MNIST ( $\alpha$ =0.8)
<details>
<summary>x8.png Details</summary>
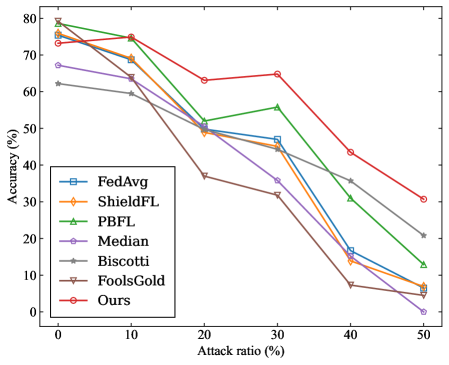
### Visual Description
## Line Chart: Federated Learning Method Accuracy vs. Attack Ratio
### Overview
This image is a line chart comparing the performance of seven different federated learning methods or aggregation strategies. The chart plots the model accuracy (in percentage) against an increasing "Attack ratio" (in percentage), which likely represents the proportion of malicious or adversarial participants in the federated learning system. The chart demonstrates how each method's accuracy degrades as the system comes under a stronger attack.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. The axis has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The axis has major tick marks at 0, 10, 20, 30, 40, 50, 60, 70, and 80.
* **Legend:** Located in the **center-left** portion of the chart area. It lists seven data series with corresponding colors and marker symbols:
1. **FedAvg** - Blue line with square markers (□).
2. **ShieldFL** - Orange line with diamond markers (◇).
3. **PBFL** - Green line with upward-pointing triangle markers (△).
4. **Median** - Purple line with circle markers (○).
5. **Biscotti** - Gray line with asterisk markers (*).
6. **FoolsGold** - Brown line with downward-pointing triangle markers (▽).
7. **Ours** - Red line with pentagram markers (☆).
### Detailed Analysis
The following table reconstructs the approximate data points for each method at the given attack ratios. Values are estimated from the chart's grid lines and marker positions. **Uncertainty is ±2-3% for most points due to visual estimation.**
| Attack Ratio (%) | FedAvg (Blue, □) | ShieldFL (Orange, ◇) | PBFL (Green, △) | Median (Purple, ○) | Biscotti (Gray, *) | FoolsGold (Brown, ▽) | Ours (Red, ☆) |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **0** | ~75% | ~74% | ~79% | ~67% | ~62% | ~75% | ~74% |
| **10** | ~69% | ~68% | ~75% | ~63% | ~58% | ~63% | ~75% |
| **20** | ~51% | ~49% | ~51% | ~50% | ~50% | ~37% | ~63% |
| **30** | ~46% | ~45% | ~56% | ~36% | ~32% | ~32% | ~65% |
| **40** | ~16% | ~14% | ~31% | ~15% | ~36% | ~7% | ~43% |
| **50** | ~6% | ~5% | ~13% | ~0% | ~21% | ~4% | ~31% |
**Trend Verification per Data Series:**
* **FedAvg (Blue):** Starts high (~75%), declines steadily and sharply after 20% attack ratio, ending very low (~6%).
* **ShieldFL (Orange):** Follows a nearly identical trend to FedAvg, starting slightly lower and ending at a similar low point (~5%).
* **PBFL (Green):** Starts the highest (~79%), maintains a lead until 30%, then declines but remains more resilient than FedAvg/ShieldFL, ending at ~13%.
* **Median (Purple):** Starts moderately (~67%), declines consistently, and suffers a catastrophic drop to near 0% at 50% attack ratio.
* **Biscotti (Gray):** Starts the lowest (~62%), shows a unique trend by dipping at 30% but then *increasing* at 40% before falling again. It is the second-best performer at 50% (~21%).
* **FoolsGold (Brown):** Starts high (~75%), experiences the most severe and early drop, plummeting to ~37% at 20% attack ratio and ending among the worst (~4%).
* **Ours (Red):** Starts high (~74%), maintains or even slightly increases accuracy up to 30% attack ratio (~65%), then declines but remains the top performer at all points from 20% onward, finishing at ~31%.
### Key Observations
1. **Universal Degradation:** All methods show a decrease in accuracy as the attack ratio increases from 0% to 50%.
2. **Performance Tiers at High Attack (50%):**
* **Top Tier:** "Ours" (~31%) is the clear leader.
* **Middle Tier:** Biscotti (~21%) and PBFL (~13%) show moderate resilience.
* **Low Tier:** FedAvg, ShieldFL, Median, and FoolsGold all collapse to ≤6% accuracy.
3. **Critical Threshold:** A significant performance drop for most methods occurs between the 20% and 40% attack ratio marks.
4. **Anomaly - Biscotti's Mid-Attack Resilience:** The Biscotti method is the only one that does not follow a strictly monotonic decrease; its accuracy at 40% attack (~36%) is higher than at 30% (~32%).
5. **Anomaly - "Ours" at 30%:** The proposed method ("Ours") shows a slight accuracy *increase* from 20% (~63%) to 30% (~65%), suggesting potential robustness or a specific response to that level of adversarial presence.
### Interpretation
This chart is a robustness evaluation of federated learning aggregation algorithms under poisoning or Byzantine attacks. The "Attack ratio" represents the fraction of malicious clients sending corrupted model updates.
* **The data suggests** that the proposed method ("Ours") is significantly more robust to adversarial attacks than the six baseline methods compared. Its performance advantage becomes pronounced once the attack ratio exceeds 10-20%.
* **The elements relate** to show a clear hierarchy of resilience. Traditional methods like FedAvg and its variant ShieldFL are highly vulnerable. Median and FoolsGold, often used for robustness, also fail catastrophically at high attack ratios. PBFL and Biscotti offer intermediate levels of protection.
* **Notable trends** include the early collapse of FoolsGold and the non-linear, somewhat resilient response of Biscotti. The most important anomaly is the sustained high performance of "Ours" up to a 30% attack ratio, which is a critical threshold where most other systems fail. This indicates the proposed method likely employs a more sophisticated mechanism for identifying and neutralizing malicious updates without discarding useful information from benign clients. The chart's primary message is the superior security-utility trade-off achieved by the authors' approach.
</details>
(c) CIFAR10 ( $\alpha$ =0.2)
<details>
<summary>x9.png Details</summary>
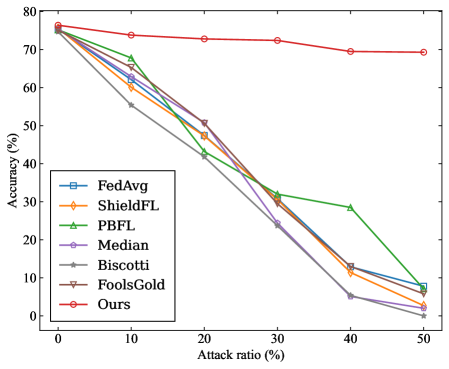
### Visual Description
## Line Chart: Accuracy vs. Attack Ratio for Various Federated Learning Defense Methods
### Overview
The image is a line chart comparing the performance of seven different methods (likely federated learning defense or aggregation algorithms) as the intensity of a simulated attack increases. The chart plots model accuracy against an increasing "Attack ratio," showing how each method's effectiveness degrades under adversarial conditions. One method, labeled "Ours," demonstrates significantly higher robustness compared to the others.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **Y-Axis:**
* **Label:** `Accuracy (%)`
* **Scale:** Linear, ranging from 0 to 80, with major tick marks at intervals of 10 (0, 10, 20, 30, 40, 50, 60, 70, 80).
* **X-Axis:**
* **Label:** `Attack ratio (%)`
* **Scale:** Linear, ranging from 0 to 50, with major tick marks at intervals of 10 (0, 10, 20, 30, 40, 50).
* **Legend:**
* **Position:** Bottom-left corner of the plot area.
* **Content:** A box listing seven data series with corresponding line colors and marker symbols.
* **Series (in order listed in legend):**
1. `FedAvg` - Blue line with square markers (□).
2. `ShieldFL` - Orange line with diamond markers (◇).
3. `PBFL` - Green line with upward-pointing triangle markers (△).
4. `Median` - Purple line with circle markers (○).
5. `Biscotti` - Gray line with asterisk markers (*).
6. `FoolsGold` - Brown line with downward-pointing triangle markers (▽).
7. `Ours` - Red line with circle markers (○).
### Detailed Analysis
The chart tracks the accuracy of each method at six discrete attack ratio points: 0%, 10%, 20%, 30%, 40%, and 50%.
**Trend Verification & Data Points (Approximate):**
1. **Ours (Red line, ○):**
* **Trend:** Nearly flat, showing minimal degradation. Starts highest and remains the highest throughout.
* **Points:** (0%, ~76%), (10%, ~74%), (20%, ~73%), (30%, ~72.5%), (40%, ~70%), (50%, ~69.5%).
2. **PBFL (Green line, △):**
* **Trend:** Declines steadily, but shows a notable plateau between 30% and 40% before dropping again.
* **Points:** (0%, ~75%), (10%, ~68%), (20%, ~51%), (30%, ~32%), (40%, ~29%), (50%, ~8%).
3. **FedAvg (Blue line, □):**
* **Trend:** Steep, consistent decline.
* **Points:** (0%, ~75%), (10%, ~62%), (20%, ~42%), (30%, ~30%), (40%, ~13%), (50%, ~8%).
4. **ShieldFL (Orange line, ◇):**
* **Trend:** Steep, consistent decline, very similar to FedAvg.
* **Points:** (0%, ~75%), (10%, ~61%), (20%, ~48%), (30%, ~29%), (40%, ~10%), (50%, ~3%).
5. **Median (Purple line, ○):**
* **Trend:** Steep decline, ending as one of the lowest performers.
* **Points:** (0%, ~75%), (10%, ~60%), (20%, ~42%), (30%, ~24%), (40%, ~5%), (50%, ~1%).
6. **FoolsGold (Brown line, ▽):**
* **Trend:** Steep decline.
* **Points:** (0%, ~75%), (10%, ~63%), (20%, ~48%), (30%, ~30%), (40%, ~12%), (50%, ~5%).
7. **Biscotti (Gray line, *):**
* **Trend:** The steepest initial decline, performing worst from 10% attack ratio onward.
* **Points:** (0%, ~75%), (10%, ~55%), (20%, ~42%), (30%, ~24%), (40%, ~5%), (50%, ~0%).
### Key Observations
1. **Dominant Performance:** The method labeled "Ours" is a clear outlier, maintaining accuracy above ~69% even at a 50% attack ratio, while all other methods fall below 10% accuracy at that point.
2. **Clustering of Baselines:** Six of the seven methods (all except "Ours") start at nearly identical accuracy (~75%) at 0% attack. They all experience significant degradation, clustering together in a steep downward trend, with some minor separation at higher attack ratios.
3. **PBFL Anomaly:** The PBFL method shows a distinct behavior between 30% and 40% attack ratio, where its accuracy decline halts temporarily (plateaus at ~29-32%) before resuming its drop. This suggests a potential threshold or resilience characteristic unique to this method within that range.
4. **Convergence at High Attack:** By the 50% attack ratio, the performance of all baseline methods (FedAvg, ShieldFL, Median, Biscotti, FoolsGold) converges to a very low accuracy range (0-8%), indicating a near-total failure of these defenses under severe attack.
### Interpretation
This chart is likely from a research paper in the field of **Federated Learning (FL) security**, specifically evaluating defenses against **poisoning attacks** (where malicious clients send corrupted model updates). The "Attack ratio (%)" represents the proportion of malicious clients in the federation.
* **What the data suggests:** The proposed method ("Ours") demonstrates **exceptional robustness**. Its near-horizontal line indicates that increasing the number of attackers has a negligible impact on the global model's final accuracy. This is a highly desirable property for a secure FL system.
* **Relationship between elements:** The chart establishes a direct, negative correlation between attack strength and model performance for all standard methods. The stark contrast between the red line ("Ours") and the others visually argues for the superiority of the authors' approach.
* **Notable implications:** The steep, parallel decline of the baseline methods suggests they share a common vulnerability to the type of attack simulated. The plateau in PBFL might indicate it employs a different mechanism (e.g., a clustering or trimming step) that becomes saturated or less effective at a specific attack intensity. The convergence of baselines at 50% attack implies that beyond a certain point, these traditional defenses are equally ineffective.
* **Underlying message:** The primary takeaway is not just that "Ours" is better, but that it operates on a different paradigm of resilience. While other methods degrade linearly or worse with attack strength, the proposed method's performance is largely **invariant** to the attack ratio within the tested range, which is a significant advancement for deploying FL in adversarial environments.
</details>
(d) CIFAR10 ( $\alpha$ =0.6)
Figure 3: The SA of the models obtained by four benchmarks under label-flipping attack.
### VII-B Experimental Results
#### VII-B 1 Robustness Evaluation of SRFed
To evaluate the robustness of the proposed SRFed framework, we conduct a comparative analysis against the six baseline methods discussed in Section VII-A 3. Specifically, we first evaluate the overall accuracy (OA) of FedAvg, ShieldFL, PBFL, Median, Biscotti, FoolsGold, and SRFed under the label-flipping attacks. The results are presented in Figure 2. In the MNIST benchmarks with two levels of heterogeneity, the proposed SRFed consistently maintains a high OA across varying proportions of malicious clients. In the MNIST ( $\alpha$ =0.8) benchmark, all methods except Biscotti demonstrate relatively strong defense performance. Similarly, in the MNIST ( $\alpha$ =0.2) benchmark, all methods, except Biscotti, continue to perform well when facing a malicious client proportion ranging from 0% to 40%. Biscotti’s poor performance is due to the fact that, in Non-IID data scenarios, the model distributions trained by benign clients are more scattered, which can lead to their incorrect elimination. In the CIFAR-10 dataset benchmarks with different levels of heterogeneity, the OA of all methods fluctuates as the proportion of malicious clients increases. However, SRFed generally maintains better performance compared to the other methods, owing to the effectiveness of its robust aggregation strategy.
We further compare the SA of the global models achieved by different methods in the four benchmarks under label-flipping attacks. SA accurately measures the defense effectiveness of different methods against poisoning attacks, as it specifically reveals the model’s accuracy on the samples of the flipping label. The experimental results are presented in Figure 3. In the MNIST ( $\alpha=0.2$ ) benchmark, SRFed demonstrates a significant advantage in defending against label-flipping attacks. Especially, when the attack ratio reaches 50%, SRFed achieves a SA of 70%, while the SA of all other methods drops to nearly 0% even though their OA remaining above 80%. SRFed is the only method to sustain a high SA across all attack ratios, underscoring its superior Byzantine robustness even in scenarios with extreme data heterogeneity and high attack ratios. In the MNIST ( $\alpha=0.8$ ) benchmark, SRFed also outperforms other baselines. In the CIFAR-10 ( $\alpha=0.2$ ) benchmark, although SRFed still outperforms the other methods, its performance gradually deteriorates as the proportion of malicious clients increases. This demonstrates that defending against poisoning attacks in scenarios with a high attack ratio and extremely heterogeneous data remains a significant challenge. In the CIFAR-10 ( $\alpha=0.6$ ) benchmark, SRFed maintains a high level of performance as the proportion of malicious clients increases (SA $\geq$ 70%), while the SA of all other methods sharply declines and eventually approaches 0%. This superior performance is attributed to the robust aggregation strategy of SRFed, which performs layer-wise projection and clustering analysis on client models. This enables more accurate detection of local parameter anomalies compared to baselines.
We also evaluate the ASR of the models obtained by different methods across four benchmarks, with the experimental results presented in Figure 4. As the attack ratio increases, we can observe that the ASR trend exhibits a negative correlation with the SA trend. Notably, our proposed SRFed consistently demonstrates optimal performance across all four benchmarks, showing minimal performance fluctuations across varying attack ratios.
<details>
<summary>x10.png Details</summary>
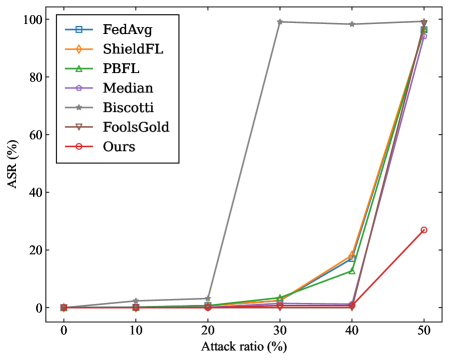
### Visual Description
\n
## Line Chart: Attack Success Rate (ASR) vs. Attack Ratio
### Overview
This is a line chart comparing the performance of seven different methods (likely federated learning aggregation or defense algorithms) against a poisoning attack. The chart plots the Attack Success Rate (ASR) as a percentage against the Attack Ratio (the proportion of malicious clients or poisoned data) as a percentage. The data suggests an evaluation of algorithmic robustness.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled "Attack ratio (%)". Scale ranges from 0 to 50, with major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled "ASR (%)". Scale ranges from 0 to 100, with major tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located in the top-left corner of the plot area. It lists seven data series with corresponding colors and markers:
1. **FedAvg:** Blue line with square markers (□).
2. **ShieldFL:** Orange line with diamond markers (◇).
3. **PBFL:** Green line with upward-pointing triangle markers (△).
4. **Median:** Purple line with circle markers (○).
5. **Biscotti:** Gray line with star/asterisk markers (☆).
6. **FoolsGold:** Brown line with downward-pointing triangle markers (▽).
7. **Ours:** Red line with circle markers (○).
### Detailed Analysis
The chart tracks the ASR for each method at six discrete attack ratios: 0%, 10%, 20%, 30%, 40%, and 50%.
**Trend Verification & Data Points (Approximate):**
1. **Biscotti (Gray, ☆):** This line shows a dramatically different trend. It remains near 0% ASR at 0%, 10%, and 20% attack ratio. It then experiences a **sharp, near-vertical increase** between 20% and 30%, reaching approximately **98-99% ASR** at 30%. It plateaus at this very high level (~98-99%) for attack ratios of 40% and 50%. This is a clear outlier in behavior.
2. **FedAvg (Blue, □), ShieldFL (Orange, ◇), PBFL (Green, △), FoolsGold (Brown, ▽):** These four methods follow a very similar pattern. They all maintain a very low ASR (approximately 0-5%) from 0% up to a 40% attack ratio. Between 40% and 50%, they all exhibit a **steep, simultaneous increase**, converging to a high ASR in the range of **~92-98%** at the 50% attack ratio point. Their lines are tightly clustered, especially at the 50% mark.
3. **Median (Purple, ○):** This method follows a trend similar to the group above but with a slightly less severe final increase. It stays near 0-5% ASR until 40% attack ratio. At 50%, it rises to approximately **~90% ASR**, which is slightly lower than the FedAvg/ShieldFL/PBFL/FoolsGold cluster.
4. **Ours (Red, ○):** This method demonstrates the most robust performance. It maintains an ASR near 0% from 0% to 40% attack ratio. At the 50% attack ratio, it shows a **moderate increase** to approximately **~25% ASR**. This is significantly lower than all other methods at the highest tested attack ratio.
**Spatial Grounding:** The legend is positioned in the top-left quadrant, overlapping slightly with the upper part of the Biscotti line's plateau. The data points for all series at 0%, 10%, and 20% are clustered very closely near the bottom of the chart (0-5% ASR). The most significant visual separation occurs at the 30% mark (where Biscotti diverges) and the 50% mark (where "Ours" separates from the high-ASR cluster).
### Key Observations
1. **Critical Threshold:** For six of the seven methods (all except Biscotti), there appears to be a critical threshold between 40% and 50% attack ratio where their defense collapses, leading to a dramatic spike in ASR.
2. **Biscotti's Early Failure:** The Biscotti method fails at a much lower attack ratio (30%) compared to the others, but its ASR saturates near 100% immediately.
3. **"Ours" Outperforms:** The method labeled "Ours" is the only one that maintains a relatively low ASR (~25%) even at the highest tested attack ratio of 50%, indicating superior resilience.
4. **Clustering of Baselines:** FedAvg, ShieldFL, PBFL, and FoolsGold perform almost identically across the entire range, suggesting similar vulnerability profiles under this specific attack scenario.
### Interpretation
This chart is likely from a research paper evaluating a new federated learning defense mechanism ("Ours") against poisoning attacks. The data demonstrates that the proposed method ("Ours") significantly outperforms several established baselines (FedAvg, ShieldFL, PBFL, Median, FoolsGold) and one other method (Biscotti) in terms of maintaining a low Attack Success Rate as the proportion of malicious participants increases.
The key finding is that while most traditional aggregation methods (like FedAvg, Median) and some defenses (ShieldFL, PBFL, FoolsGold) are effective up to a 40% attack ratio, they become highly vulnerable at 50%. Biscotti appears to be vulnerable at even lower attack ratios (30%). The proposed "Ours" method shows a much more gradual and limited increase in ASR, suggesting it incorporates a more robust mechanism for identifying and mitigating the influence of poisoned updates, even when they constitute half of the total updates. The chart effectively argues for the practical superiority of the "Ours" method in high-threat environments.
</details>
(a) MNIST ( $\alpha$ =0.2)
<details>
<summary>x11.png Details</summary>
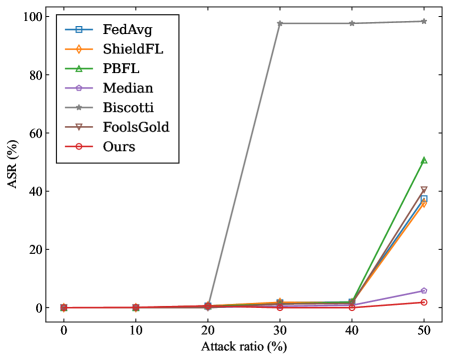
### Visual Description
\n
## Line Chart: Federated Learning Backdoor Attack Success Rate (ASR) vs. Attack Ratio
### Overview
This is a line chart comparing the performance of seven different federated learning (FL) defense mechanisms against a backdoor attack. The chart plots the Attack Success Rate (ASR) on the y-axis against the Attack Ratio (the proportion of malicious clients) on the x-axis. The data demonstrates how the effectiveness of the attack (ASR) changes for each defense method as the attacker's presence in the network increases.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Label:** `Attack ratio (%)`
* **Scale:** Linear, from 0 to 50.
* **Markers/Ticks:** 0, 10, 20, 30, 40, 50.
* **Y-Axis:**
* **Label:** `ASR (%)` (Attack Success Rate)
* **Scale:** Linear, from 0 to 100.
* **Markers/Ticks:** 0, 20, 40, 60, 80, 100.
* **Legend:** Located in the top-left quadrant of the chart area. It lists seven data series with corresponding colors and marker symbols.
1. `FedAvg` - Blue line, square marker (□).
2. `ShieldFL` - Orange line, diamond marker (◇).
3. `PBFL` - Green line, upward-pointing triangle marker (△).
4. `Median` - Purple line, circle marker (○).
5. `Biscotti` - Gray line, asterisk marker (*).
6. `FoolsGold` - Brown line, downward-pointing triangle marker (▽).
7. `Ours` - Red line, pentagram marker (☆).
### Detailed Analysis
The chart shows the ASR for each method at attack ratios of 0%, 10%, 20%, 30%, 40%, and 50%.
**Trend Verification & Data Points (Approximate):**
1. **Biscotti (Gray, *):**
* **Trend:** Shows a sharp, near-vertical increase between 20% and 30% attack ratio, then plateaus at a very high ASR.
* **Points:** ~0% ASR at 0-20% attack ratio. Jumps to ~98% ASR at 30%. Remains at ~98% ASR at 40% and 50%.
2. **PBFL (Green, △):**
* **Trend:** Remains near zero until 40%, then exhibits a steep, linear increase.
* **Points:** ~0% ASR at 0-40%. Rises to ~50% ASR at 50%.
3. **FoolsGold (Brown, ▽):**
* **Trend:** Similar to PBFL but with a slightly lower final value.
* **Points:** ~0% ASR at 0-40%. Rises to ~40% ASR at 50%.
4. **ShieldFL (Orange, ◇):**
* **Trend:** Follows a similar upward trajectory to FoolsGold after 40%.
* **Points:** ~0% ASR at 0-40%. Rises to ~38% ASR at 50%.
5. **FedAvg (Blue, □):**
* **Trend:** Very similar to ShieldFL, nearly overlapping.
* **Points:** ~0% ASR at 0-40%. Rises to ~36% ASR at 50%.
6. **Median (Purple, ○):**
* **Trend:** Shows a very gradual, slight increase starting around 30%.
* **Points:** ~0% ASR at 0-20%. ~1% ASR at 30%. ~2% ASR at 40%. ~6% ASR at 50%.
7. **Ours (Red, ☆):**
* **Trend:** The most robust performance. The line remains almost perfectly flat and close to zero across the entire range.
* **Points:** ~0% ASR at all attack ratios from 0% to 50%.
### Key Observations
1. **Critical Threshold:** A clear performance divergence occurs for most methods between 40% and 50% attack ratio.
2. **Biscotti's Vulnerability:** The Biscotti method fails catastrophically at a 30% attack ratio, with ASR jumping to near 100%, indicating it is highly vulnerable once attackers reach a critical mass.
3. **Robustness Gradient:** At the highest tested attack ratio (50%), the methods rank in robustness (lowest to highest ASR) as: **Ours** (best) < Median < FedAvg ≈ ShieldFL < FoolsGold < PBFL < Biscotti (worst).
4. **"Ours" Superiority:** The proposed method ("Ours") maintains an ASR near 0% even when half the clients (50%) are malicious, significantly outperforming all other compared defenses.
### Interpretation
This chart is a comparative evaluation of resilience in federated learning systems. The **Attack Ratio** represents the threat level (percentage of malicious participants), and the **ASR** measures the success of the adversary's goal (e.g., causing the global model to misclassify specific inputs).
The data suggests that most traditional aggregation-based defenses (like Median, FedAvg) and some specialized defenses (ShieldFL, FoolsGold, PBFL) have a breaking point. Their protective effect collapses when the attacker controls 40-50% of the clients. Biscotti appears to have a lower breaking point (~30%).
The method labeled **"Ours"** demonstrates a fundamentally different and more robust behavior. Its flat line indicates it can effectively neutralize the backdoor attack regardless of the attacker's prevalence within the tested range. This implies it uses a mechanism that is not fooled by the increased influence of malicious updates, even when they constitute a majority. The chart serves as strong empirical evidence for the superiority of the "Ours" method in defending against backdoor attacks under high-threat conditions.
</details>
(b) MNIST ( $\alpha$ =0.8)
<details>
<summary>x12.png Details</summary>
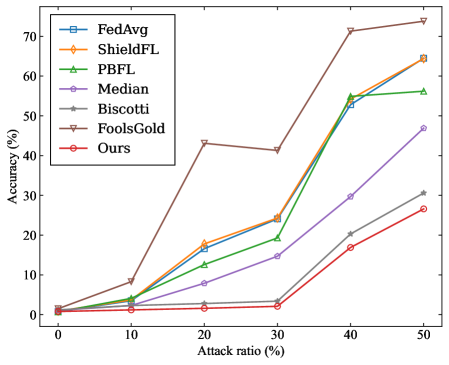
### Visual Description
\n
## Line Chart: Federated Learning Method Accuracy Under Adversarial Attack
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods as the ratio of adversarial attacks increases. The chart demonstrates how each method's robustness degrades under increasing levels of attack.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. The axis has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The axis has major tick marks at 0, 10, 20, 30, 40, 50, 60, and 70.
* **Legend:** Positioned in the **top-left corner** of the chart area. It contains seven entries, each with a unique color, line style, and marker symbol:
1. **FedAvg** - Blue line with square markers (□).
2. **ShieldFL** - Orange line with diamond markers (◇).
3. **PBFL** - Green line with upward-pointing triangle markers (△).
4. **Median** - Purple line with circle markers (○).
5. **Biscotti** - Gray line with plus-sign markers (+).
6. **FoolsGold** - Brown line with downward-pointing triangle markers (▽).
7. **Ours** - Red line with pentagram markers (☆).
### Detailed Analysis
The chart plots Accuracy (%) against Attack ratio (%). Below is an approximate reconstruction of the data points for each method, derived from visual inspection. Values are approximate.
| Attack Ratio (%) | FedAvg (Blue, □) | ShieldFL (Orange, ◇) | PBFL (Green, △) | Median (Purple, ○) | Biscotti (Gray, +) | FoolsGold (Brown, ▽) | Ours (Red, ☆) |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **0** | ~1% | ~1% | ~1% | ~1% | ~1% | ~1% | ~1% |
| **10** | ~5% | ~5% | ~4% | ~2% | ~1% | ~8% | ~1% |
| **20** | ~17% | ~18% | ~12% | ~8% | ~3% | ~43% | ~2% |
| **30** | ~24% | ~24% | ~19% | ~14% | ~3% | ~41% | ~2% |
| **40** | ~53% | ~55% | ~55% | ~30% | ~20% | ~72% | ~17% |
| **50** | ~64% | ~64% | ~56% | ~47% | ~31% | ~74% | ~27% |
**Trend Verification:**
* **FedAvg, ShieldFL, PBFL:** These three lines follow a very similar, steep upward trend. Their accuracy increases sharply as the attack ratio increases, particularly between 30% and 40%.
* **Median:** Shows a steady, moderate upward slope. Its accuracy increases more gradually than the top group.
* **Biscotti:** Has a shallow upward slope, remaining near the bottom of the chart until a slight rise after 30%.
* **FoolsGold:** Exhibits a unique trend. It spikes early at 20% attack ratio, dips slightly at 30%, then rises sharply to become the highest-performing method at 40% and 50%.
* **Ours:** Follows a trend similar to Biscotti but consistently performs slightly worse, remaining the lowest or second-lowest line throughout.
### Key Observations
1. **Performance Inversion:** At low attack ratios (0-10%), all methods have very low accuracy (<10%). As the attack ratio increases, the accuracy of most methods *increases*, which is counter-intuitive for a robustness metric. This suggests the chart may be measuring something like the success rate of the attack itself or a specific type of failure.
2. **FoolsGold Anomaly:** The FoolsGold method (brown line) is a clear outlier. It achieves significantly higher accuracy than all other methods at attack ratios of 20% and above, peaking at ~74% at a 50% attack ratio.
3. **Clustering:** Three methods (FedAvg, ShieldFL, PBFL) cluster tightly together, indicating similar performance characteristics under these test conditions.
4. **Low-Performing Cluster:** The "Ours" and Biscotti methods form a lower-performing cluster, with "Ours" generally showing the least accuracy.
### Interpretation
The data presents a paradoxical result: **accuracy improves as the attack becomes more prevalent.** In standard adversarial robustness evaluations, accuracy typically *decreases* with stronger attacks. This suggests the chart is likely not measuring standard model accuracy on clean data.
**Possible Interpretations:**
* **Attack Success Rate:** The y-axis "Accuracy (%)" might be mislabeled and could represent the **success rate of the adversarial attack**. In this case, a higher value means the attack is *more effective*. This would make logical sense: as the attacker controls more of the data (higher attack ratio), their attack succeeds more often.
* **Task-Specific Metric:** The metric could be specific to a particular federated learning task or attack type (e.g., a backdoor attack), where "accuracy" refers to the model correctly performing the *attacker's desired malicious task*.
* **Robustness Ranking:** Under this interpretation, **FoolsGold** is the *least robust* method, as it allows the attack to succeed with the highest frequency. The method labeled **"Ours"** appears to be the *most robust*, as it maintains the lowest attack success rate across most attack ratios. The tight clustering of FedAvg, ShieldFL, and PBFL suggests they offer similar, intermediate levels of robustness.
**Conclusion:** The chart likely demonstrates the vulnerability of various federated learning aggregation rules to a data poisoning or backdoor attack. The key takeaway is that the **FoolsGold** method is highly susceptible to such attacks, while the proposed method ("Ours") shows the greatest resistance, followed by Biscotti and Median. The similar performance of FedAvg, ShieldFL, and PBFL indicates they share a common vulnerability profile in this specific threat model.
</details>
(c) CIFAR10 ( $\alpha$ =0.2)
<details>
<summary>x13.png Details</summary>
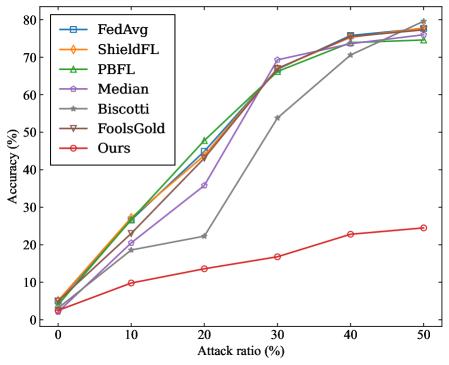
### Visual Description
\n
## Line Chart: Federated Learning Accuracy vs. Attack Ratio
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or algorithms as the percentage of malicious participants (attack ratio) in the system increases. The chart demonstrates how each method's accuracy is affected by a rising proportion of adversarial attacks.
### Components/Axes
* **Chart Type:** Multi-series line chart with markers.
* **X-Axis (Horizontal):**
* **Label:** `Attack ratio (%)`
* **Scale:** Linear, from 0 to 50.
* **Major Tick Marks:** 0, 10, 20, 30, 40, 50.
* **Y-Axis (Vertical):**
* **Label:** `Accuracy (%)`
* **Scale:** Linear, from 0 to 80.
* **Major Tick Marks:** 0, 10, 20, 30, 40, 50, 60, 70, 80.
* **Legend:** Located in the top-left corner of the plot area. It lists seven data series with corresponding line colors and marker symbols.
1. `FedAvg` - Blue line with square markers (□).
2. `ShieldFL` - Orange line with diamond markers (◇).
3. `PBFL` - Green line with upward-pointing triangle markers (△).
4. `Median` - Purple line with circle markers (○).
5. `Biscotti` - Gray line with star/asterisk markers (☆).
6. `FoolsGold` - Brown line with downward-pointing triangle markers (▽).
7. `Ours` - Red line with circle markers (○).
### Detailed Analysis
**Data Series Trends and Approximate Values:**
1. **FedAvg (Blue, □):** Shows a strong, nearly linear upward trend. Starts at ~5% accuracy at 0% attack ratio. Increases steadily to ~25% at 10%, ~45% at 20%, ~68% at 30%, ~75% at 40%, and ends at ~78% at 50%.
2. **ShieldFL (Orange, ◇):** Follows a very similar trajectory to FedAvg. Starts at ~5% at 0%. Rises to ~27% at 10%, ~44% at 20%, ~66% at 30%, ~75% at 40%, and ~77% at 50%.
3. **PBFL (Green, △):** Also closely follows the top-performing group. Starts at ~5% at 0%. Increases to ~28% at 10%, ~48% at 20%, ~66% at 30%, ~74% at 40%, and ~75% at 50%.
4. **Median (Purple, ○):** Exhibits a non-monotonic trend. Starts at ~5% at 0%. Rises to ~22% at 10%, then dips to ~35% at 20%. Recovers sharply to ~69% at 30%, then continues to ~75% at 40% and ~76% at 50%.
5. **Biscotti (Gray, ☆):** Shows a delayed but steep increase. Starts at ~5% at 0%. Increases slowly to ~19% at 10% and ~22% at 20%. Then jumps dramatically to ~54% at 30%, followed by a steady rise to ~71% at 40% and ~75% at 50%.
6. **FoolsGold (Brown, ▽):** Tracks almost identically with FedAvg and ShieldFL. Starts at ~5% at 0%. Rises to ~26% at 10%, ~45% at 20%, ~67% at 30%, ~76% at 40%, and ~78% at 50%.
7. **Ours (Red, ○):** Demonstrates a significantly lower and more gradual upward trend compared to all other methods. Starts at ~3% at 0%. Increases slowly to ~10% at 10%, ~13% at 20%, ~17% at 30%, ~23% at 40%, and ends at ~24% at 50%.
### Key Observations
1. **Performance Clustering:** Six of the seven methods (FedAvg, ShieldFL, PBFL, Median, Biscotti, FoolsGold) converge to a high accuracy range of approximately 75-78% when the attack ratio reaches 50%.
2. **The "Ours" Outlier:** The method labeled "Ours" is a clear outlier, performing drastically worse than all other compared methods across the entire range of attack ratios. Its maximum accuracy (~24%) is less than one-third of the others' final accuracy.
3. **Non-Monotonic Behavior:** The `Median` method shows a notable dip in accuracy at the 20% attack ratio before recovering.
4. **Delayed Response:** The `Biscotti` method shows minimal improvement until the attack ratio exceeds 20%, after which it improves rapidly.
5. **Counter-Intuitive Trend:** For the top six methods, accuracy *increases* as the attack ratio increases. This is contrary to the expected behavior where more attacks would degrade performance.
### Interpretation
This chart likely comes from a research paper evaluating a new federated learning defense mechanism. The data suggests the following:
* **Robustness of Established Methods:** The six methods other than "Ours" appear to be robust defense strategies. Their increasing accuracy with higher attack ratios implies they might be designed to identify and mitigate malicious updates more effectively when attacks are more prevalent, or that the experimental setup has a specific characteristic that favors them under high attack conditions.
* **Purpose of "Ours":** The method labeled "Ours" is almost certainly the **baseline or the proposed vulnerable method** that the paper aims to improve upon. It represents the performance of a standard federated learning algorithm (like FedAvg) *without* any defense against poisoning attacks. Its poor and slowly rising performance shows it is highly susceptible to malicious participants.
* **Research Narrative:** The chart constructs a clear argument: "Standard federated learning ('Ours') fails under attack. However, these other existing defense methods (FedAvg with defense, ShieldFL, PBFL, etc.) are effective, maintaining high accuracy even when half the participants are malicious." The paper would then likely introduce a new method that either matches or exceeds the performance of these defenses, or addresses a limitation they have (like the dip seen in `Median` or the slow start of `Biscotti`).
* **Experimental Design:** The fact that accuracy increases with attack ratio for the defended methods is a critical point. It suggests the attack method used might be a simple one that becomes easier to detect and filter out when it is more common, or that the defense mechanisms are specifically tuned to be more aggressive at higher perceived threat levels.
</details>
(d) CIFAR10 ( $\alpha$ =0.6)
Figure 4: The ASR of the models obtained by four benchmarks under label-flipping attack.
Finally, we evaluate the OA of the models of different methods under the Gaussian attack. The experimental results are shown in Figure 5. We observe that SRFed consistently achieves optimal performance across all four benchmarks. Furthermore, as the attack ratio increases, SRFed exhibits minimal fluctuations in OA. Specifically, in the MNIST ( $\alpha=0.2$ ) and MNIST ( $\alpha=0.8$ ) benchmarks, all methods maintain an OA above 90% when the attack ratio is $\leq$ 20%. However, when the attack ratio $\geq$ 30%, only SRFed and Median retain an OA above 90%, demonstrating their effective defense against poisoning attacks under high malicious client ratios. In the CIFAR-10 ( $\alpha=0.2$ ) and CIFAR-10 ( $\alpha=0.6$ ) benchmarks, while the OA of most methods drops below 30% as the attack ratio increases, SRFed consistently maintains high accuracy across all attack rates, demonstrating its robustness against extreme client ratios and heterogeneous data distributions.
<details>
<summary>x14.png Details</summary>
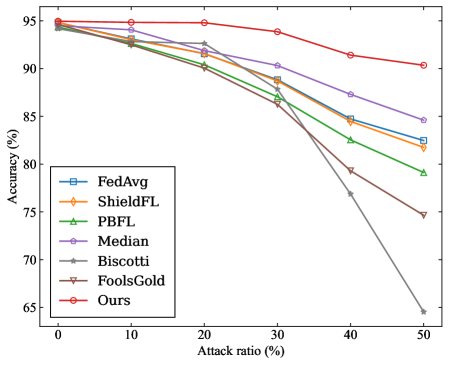
### Visual Description
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or algorithms as the "Attack ratio" increases. The chart demonstrates how each method's accuracy degrades under increasing adversarial conditions. The overall trend for all methods is a decline in accuracy as the attack ratio rises, but the rate of decline varies significantly.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. The scale runs from 0 to 50 in increments of 10 (0, 10, 20, 30, 40, 50).
* **Y-Axis:** Labeled **"Accuracy (%)"**. The scale runs from 65 to 95 in increments of 5 (65, 70, 75, 80, 85, 90, 95).
* **Legend:** Located in the **bottom-left corner** of the chart area. It lists seven data series with corresponding colors and markers:
1. **FedAvg** - Blue line with square markers (□).
2. **ShieldFL** - Orange line with diamond markers (◇).
3. **PBFL** - Green line with upward-pointing triangle markers (△).
4. **Median** - Purple line with circle markers (○).
5. **Biscotti** - Gray line with star/asterisk markers (☆).
6. **FoolsGold** - Brown line with downward-pointing triangle markers (▽).
7. **Ours** - Red line with circle markers (○).
* **Grid:** A light gray grid is present in the background.
### Detailed Analysis
The following describes the visual trend for each data series and approximates the data points by reading the chart. Values are approximate due to visual estimation.
1. **Ours (Red line, circle markers):**
* **Trend:** The most resilient line. It shows a very gradual, almost flat decline until an attack ratio of 30%, after which it slopes gently downward.
* **Approximate Data Points:** (0%, ~95%), (10%, ~95%), (20%, ~95%), (30%, ~94%), (40%, ~92%), (50%, ~90%).
2. **Median (Purple line, circle markers):**
* **Trend:** A steady, moderate downward slope across the entire range.
* **Approximate Data Points:** (0%, ~95%), (10%, ~94%), (20%, ~93%), (30%, ~90%), (40%, ~87%), (50%, ~85%).
3. **FedAvg (Blue line, square markers):**
* **Trend:** A consistent downward slope, slightly steeper than Median after 20%.
* **Approximate Data Points:** (0%, ~95%), (10%, ~93%), (20%, ~92%), (30%, ~89%), (40%, ~85%), (50%, ~82%).
4. **ShieldFL (Orange line, diamond markers):**
* **Trend:** Follows a path very close to FedAvg, with a nearly identical slope, ending slightly lower.
* **Approximate Data Points:** (0%, ~95%), (10%, ~93%), (20%, ~91%), (30%, ~88%), (40%, ~84%), (50%, ~81%).
5. **PBFL (Green line, upward triangle markers):**
* **Trend:** A steady decline that accelerates slightly after 30%.
* **Approximate Data Points:** (0%, ~95%), (10%, ~93%), (20%, ~91%), (30%, ~87%), (40%, ~83%), (50%, ~79%).
6. **FoolsGold (Brown line, downward triangle markers):**
* **Trend:** A moderate decline until 30%, followed by a steeper drop.
* **Approximate Data Points:** (0%, ~95%), (10%, ~93%), (20%, ~90%), (30%, ~86%), (40%, ~80%), (50%, ~75%).
7. **Biscotti (Gray line, star markers):**
* **Trend:** The steepest and most severe decline of all methods. It begins to drop sharply after 20%.
* **Approximate Data Points:** (0%, ~95%), (10%, ~93%), (20%, ~90%), (30%, ~86%), (40%, ~77%), (50%, ~65%).
### Key Observations
* **Performance Hierarchy:** At a 0% attack ratio, all methods start at nearly the same high accuracy (~95%). As the attack ratio increases, a clear performance hierarchy emerges: **Ours > Median > FedAvg ≈ ShieldFL > PBFL > FoolsGold > Biscotti**.
* **Divergence Point:** The significant divergence in performance begins around an attack ratio of **20%**. Before this point, the lines are tightly clustered.
* **Most Robust:** The method labeled **"Ours"** is the most robust, maintaining accuracy above 90% even at a 50% attack ratio.
* **Most Vulnerable:** The **Biscotti** method is the most vulnerable, suffering a catastrophic drop to approximately 65% accuracy at a 50% attack ratio.
* **Clustering:** FedAvg and ShieldFL perform very similarly throughout the range. PBFL and FoolsGold also follow similar trajectories until the final data point.
### Interpretation
This chart is likely from a research paper proposing a new federated learning method (labeled "Ours") designed to be robust against adversarial attacks or Byzantine faults. The "Attack ratio" represents the proportion of malicious or faulty clients in the federated learning network.
The data demonstrates that the proposed method ("Ours") significantly outperforms six established baseline methods (FedAvg, ShieldFL, PBFL, Median, Biscotti, FoolsGold) as the environment becomes more hostile. The key finding is that while all methods degrade, "Ours" degrades at a much slower rate, suggesting it incorporates a more effective aggregation rule or defense mechanism.
The poor performance of Biscotti at high attack ratios indicates its specific vulnerability to the type of attack simulated here. The relative ordering of the other methods provides a benchmark for comparing their inherent resilience. The chart's primary purpose is to visually and quantitatively argue for the superiority of the authors' proposed solution in maintaining model accuracy under adversarial conditions.
</details>
(a) MNIST ( $\alpha$ =0.2)
<details>
<summary>x15.png Details</summary>
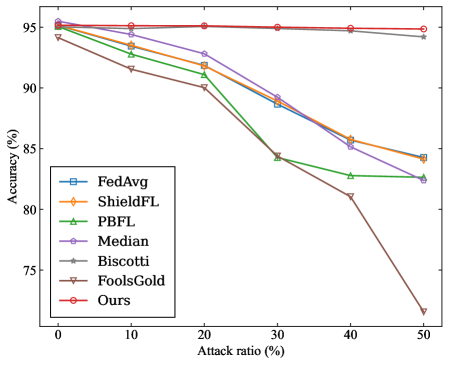
### Visual Description
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or defenses as the ratio of adversarial attacks increases. The chart demonstrates how each method's accuracy degrades under increasing levels of attack.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. It has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. It has major tick marks at 75, 80, 85, 90, and 95.
* **Legend:** Located in the **bottom-left corner** of the chart area. It lists seven methods with corresponding line colors and marker styles:
1. **FedAvg** - Blue line with square markers (□).
2. **ShieldFL** - Orange line with diamond markers (◇).
3. **PBFL** - Green line with upward-pointing triangle markers (△).
4. **Median** - Purple line with circle markers (○).
5. **Biscotti** - Gray line with star/asterisk markers (✳).
6. **FoolsGold** - Brown line with downward-pointing triangle markers (▽).
7. **Ours** - Red line with circle markers (○).
### Detailed Analysis
The following data points are approximate, extracted by visually aligning markers with the axis ticks.
| Attack Ratio (%) | FedAvg (Blue, □) | ShieldFL (Orange, ◇) | PBFL (Green, △) | Median (Purple, ○) | Biscotti (Gray, ✳) | FoolsGold (Brown, ▽) | Ours (Red, ○) |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **0** | ~95.0 | ~95.0 | ~95.0 | ~95.0 | ~95.0 | ~94.0 | ~95.0 |
| **10** | ~93.0 | ~93.5 | ~92.5 | ~93.5 | ~95.0 | ~91.5 | ~95.0 |
| **20** | ~91.0 | ~91.5 | ~90.5 | ~92.5 | ~95.0 | ~90.0 | ~95.0 |
| **30** | ~88.5 | ~89.0 | ~84.5 | ~89.0 | ~95.0 | ~84.5 | ~95.0 |
| **40** | ~85.5 | ~86.0 | ~83.0 | ~86.0 | ~95.0 | ~81.0 | ~95.0 |
| **50** | ~82.5 | ~84.5 | ~82.5 | ~82.5 | ~94.0 | ~72.0 | ~94.5 |
**Trend Verification:**
* **FedAvg, ShieldFL, Median:** These three lines follow a very similar, steady downward slope. They start clustered near 95% and decline in near-parallel to between 82.5% and 84.5% at 50% attack ratio.
* **PBFL:** Starts with the group but shows a steeper decline between 20% and 30% attack ratio, then flattens somewhat, ending near 82.5%.
* **Biscotti:** Shows a very shallow, almost flat decline, maintaining accuracy above 94% across the entire range.
* **FoolsGold:** Exhibits the most severe and accelerating decline. It starts slightly lower than the main group and drops sharply after 30% attack ratio, plummeting to the lowest point on the chart (~72%).
* **Ours:** The red line is essentially flat, showing negligible decrease in accuracy from 0% to 50% attack ratio, staying at approximately 95%.
### Key Observations
1. **Performance Hierarchy:** At high attack ratios (40-50%), the methods clearly stratify. "Ours" and "Biscotti" are top-tier, "FoolsGold" is the worst-performing, and the others (FedAvg, ShieldFL, PBFL, Median) form a middle cluster.
2. **Robustness:** The method labeled "Ours" demonstrates exceptional robustness, with its accuracy line being nearly horizontal. "Biscotti" is also highly robust but shows a very slight decline.
3. **Vulnerability:** "FoolsGold" is highly vulnerable to increasing attack ratios, with its performance collapsing dramatically beyond a 30% attack ratio.
4. **Clustering:** The lines for FedAvg, ShieldFL, and Median are tightly clustered throughout, suggesting similar performance characteristics under these test conditions.
### Interpretation
This chart is likely from a research paper proposing a new federated learning defense method (labeled "Ours"). The data suggests that the proposed method significantly outperforms several baseline methods (FedAvg, ShieldFL, PBFL, Median, FoolsGold) in maintaining model accuracy as the environment becomes more hostile (higher percentage of malicious participants/attacks).
The key takeaway is the superior resilience of the "Ours" method. While other methods degrade—some severely like FoolsGold—the proposed method's performance remains virtually unaffected up to a 50% attack ratio. This implies it has a more effective mechanism for identifying and mitigating the impact of adversarial updates. The strong performance of "Biscotti" is also notable, indicating it is another robust baseline. The chart serves as strong visual evidence for the efficacy and stability of the authors' contribution compared to the state-of-the-art.
</details>
(b) MNIST ( $\alpha$ =0.8)
<details>
<summary>x16.png Details</summary>
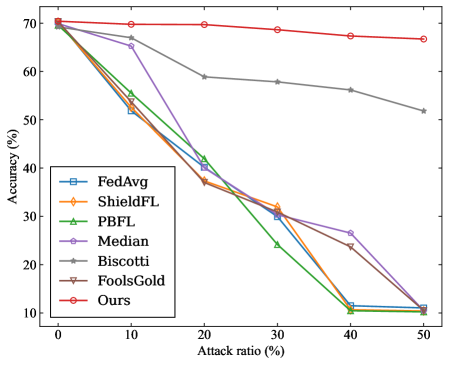
### Visual Description
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or aggregation strategies as the ratio of adversarial attacks increases. The chart demonstrates how each method's accuracy degrades under increasing levels of attack, with one method ("Ours") showing significantly greater resilience.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis (Horizontal):**
* **Label:** `Attack ratio (%)`
* **Scale:** Linear, from 0 to 50.
* **Tick Marks:** 0, 10, 20, 30, 40, 50.
* **Y-Axis (Vertical):**
* **Label:** `Accuracy (%)`
* **Scale:** Linear, from 10 to 70.
* **Tick Marks:** 10, 20, 30, 40, 50, 60, 70.
* **Legend:**
* **Position:** Bottom-left corner of the plot area.
* **Content (with corresponding line color and marker):**
1. `FedAvg` - Blue line, square marker (□).
2. `ShieldFL` - Orange line, diamond marker (◇).
3. `PBFL` - Green line, upward-pointing triangle marker (△).
4. `Median` - Purple line, circle marker (○).
5. `Biscotti` - Gray line, star marker (☆).
6. `FoolsGold` - Brown line, downward-pointing triangle marker (▽).
7. `Ours` - Red line, circle marker (○).
### Detailed Analysis
The chart plots accuracy (%) against attack ratio (%). All methods start at approximately the same high accuracy (~70%) when the attack ratio is 0%. As the attack ratio increases, the performance of most methods declines sharply, while one remains stable.
**Trend Verification & Data Point Extraction (Approximate Values):**
1. **Ours (Red line, circle marker):**
* **Trend:** Nearly flat, showing minimal degradation.
* **Points:** (0%, ~70%), (10%, ~70%), (20%, ~70%), (30%, ~69%), (40%, ~68%), (50%, ~67%).
2. **Biscotti (Gray line, star marker):**
* **Trend:** Gradual, steady decline.
* **Points:** (0%, ~70%), (10%, ~67%), (20%, ~59%), (30%, ~58%), (40%, ~56%), (50%, ~52%).
3. **Median (Purple line, circle marker):**
* **Trend:** Steep decline until 40%, then a slight plateau.
* **Points:** (0%, ~70%), (10%, ~67%), (20%, ~40%), (30%, ~32%), (40%, ~27%), (50%, ~11%).
4. **FoolsGold (Brown line, downward triangle marker):**
* **Trend:** Very steep, consistent decline.
* **Points:** (0%, ~70%), (10%, ~52%), (20%, ~37%), (30%, ~32%), (40%, ~24%), (50%, ~11%).
5. **FedAvg (Blue line, square marker):**
* **Trend:** Very steep, consistent decline, closely tracking ShieldFL and PBFL.
* **Points:** (0%, ~70%), (10%, ~53%), (20%, ~39%), (30%, ~30%), (40%, ~11%), (50%, ~11%).
6. **ShieldFL (Orange line, diamond marker):**
* **Trend:** Very steep, consistent decline, closely tracking FedAvg and PBFL.
* **Points:** (0%, ~70%), (10%, ~53%), (20%, ~38%), (30%, ~32%), (40%, ~11%), (50%, ~11%).
7. **PBFL (Green line, upward triangle marker):**
* **Trend:** Very steep, consistent decline, closely tracking FedAvg and ShieldFL.
* **Points:** (0%, ~70%), (10%, ~55%), (20%, ~42%), (30%, ~24%), (40%, ~11%), (50%, ~11%).
### Key Observations
1. **Clear Performance Stratification:** At attack ratios above 10%, the methods separate into three distinct performance tiers:
* **Top Tier:** "Ours" (Red) maintains accuracy above 65%.
* **Middle Tier:** "Biscotti" (Gray) degrades gradually but stays above 50%.
* **Lower Tier:** All other methods (FedAvg, ShieldFL, PBFL, Median, FoolsGold) experience catastrophic failure, converging to ~11% accuracy at 40-50% attack ratio.
2. **Critical Threshold:** A significant performance drop for the lower-tier methods occurs between 10% and 20% attack ratio.
3. **Convergence at High Attack:** At 40% and 50% attack ratios, five of the seven methods (FedAvg, ShieldFL, PBFL, Median, FoolsGold) cluster at the bottom of the chart with nearly identical, very low accuracy (~11%).
4. **Anomaly:** The "Median" method (Purple) shows a less severe drop between 30% and 40% compared to its steep fall from 10% to 30%, but it ultimately fails at 50%.
### Interpretation
This chart presents a comparative evaluation of robustness in federated learning systems under adversarial (Byzantine) attacks. The "Attack ratio (%)" likely represents the proportion of malicious clients or poisoned updates in the system.
* **What the data suggests:** The method labeled "Ours" demonstrates superior robustness. Its near-horizontal line indicates that its accuracy is largely unaffected by the presence of adversarial participants, up to a 50% attack ratio. This suggests a highly effective defense mechanism.
* **Relationship between elements:** The steep negative slopes for most baseline methods (FedAvg, ShieldFL, PBFL, FoolsGold) illustrate their vulnerability; their performance is directly and negatively correlated with the attack strength. "Biscotti" shows moderate resilience, degrading linearly but not catastrophically. The clustering of multiple methods at ~11% accuracy at high attack ratios may represent a baseline or random-guess performance level for the underlying task when the aggregation is completely compromised.
* **Notable Implications:** The chart makes a strong visual argument for the efficacy of the proposed method ("Ours"). It highlights that traditional aggregation methods (like FedAvg) and some existing robust methods can fail completely under significant adversarial pressure, while the new approach maintains high utility. The clear separation between "Ours" and all others, especially after the 10% attack mark, is the central finding.
</details>
(c) CIFAR10 ( $\alpha$ =0.2)
<details>
<summary>x17.png Details</summary>
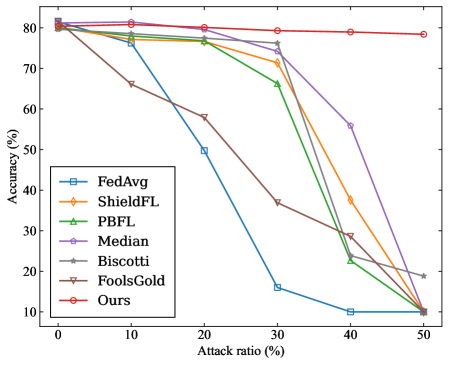
### Visual Description
\n
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance of seven different federated learning methods under varying levels of adversarial attack. The chart plots model accuracy against the percentage of malicious participants (attack ratio) in the system. The primary trend shows that as the attack ratio increases, the accuracy of most methods degrades, but at significantly different rates.
### Components/Axes
* **Chart Type:** Multi-line chart.
* **X-Axis:** Labeled **"Attack ratio (%)"**. It has major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. It has major tick marks at 10, 20, 30, 40, 50, 60, 70, and 80.
* **Legend:** Located in the **top-left corner** of the plot area. It lists seven data series with corresponding line colors and marker styles:
1. **FedAvg** - Blue line with square markers.
2. **ShieldFL** - Orange line with diamond markers.
3. **PBFL** - Green line with upward-pointing triangle markers.
4. **Median** - Purple line with circle markers.
5. **Biscotti** - Gray line with star (asterisk) markers.
6. **FoolsGold** - Brown line with downward-pointing triangle markers.
7. **Ours** - Red line with circle markers.
### Detailed Analysis
The following table reconstructs the approximate data points for each method at the specified attack ratios. Values are estimated from the chart's grid lines, with an uncertainty of ±2%.
| Method (Color) | Attack Ratio: 0% | 10% | 20% | 30% | 40% | 50% |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **FedAvg (Blue)** | ~80% | ~78% | ~50% | ~16% | ~10% | ~10% |
| **ShieldFL (Orange)** | ~80% | ~78% | ~76% | ~72% | ~38% | ~10% |
| **PBFL (Green)** | ~80% | ~78% | ~76% | ~66% | ~22% | ~10% |
| **Median (Purple)** | ~80% | ~80% | ~78% | ~76% | ~56% | ~10% |
| **Biscotti (Gray)** | ~80% | ~78% | ~76% | ~76% | ~30% | ~19% |
| **FoolsGold (Brown)** | ~80% | ~66% | ~58% | ~37% | ~28% | ~10% |
| **Ours (Red)** | ~80% | ~81% | ~80% | ~79% | ~79% | ~78% |
**Trend Verification per Series:**
* **FedAvg (Blue):** Slopes downward sharply after 10% attack ratio, reaching a low plateau at 40-50%.
* **ShieldFL (Orange):** Maintains high accuracy until 30%, then drops steeply.
* **PBFL (Green):** Follows a similar but slightly steeper decline than ShieldFL after 30%.
* **Median (Purple):** Shows the most resilience among baseline methods, with a gradual decline until 30% and a steeper drop afterward.
* **Biscotti (Gray):** Performs similarly to Median until 30%, then declines more sharply but ends higher than most at 50%.
* **FoolsGold (Brown):** Begins degrading immediately, showing the poorest early resilience.
* **Ours (Red):** Exhibits a nearly flat, horizontal trend, maintaining accuracy above 78% across the entire range.
### Key Observations
1. **Universal Starting Point:** All methods begin at approximately 80% accuracy with 0% attack ratio, establishing a common baseline.
2. **Critical Threshold:** For most methods (except "Ours"), a significant performance drop occurs between 30% and 40% attack ratio.
3. **Outlier Performance:** The method labeled **"Ours"** is a clear outlier, demonstrating exceptional robustness with negligible accuracy loss even at 50% attack ratio.
4. **Convergence at Failure:** At the maximum attack ratio of 50%, six of the seven methods converge to a very low accuracy range of 10-19%, indicating system failure. "Ours" and "Biscotti" are the only methods not at the absolute bottom.
5. **Early Degradation:** "FoolsGold" is the only method that shows substantial accuracy loss at a low (10%) attack ratio.
### Interpretation
This chart presents a comparative evaluation of Byzantine-robust or secure aggregation algorithms in federated learning. The data suggests that the proposed method ("Ours") significantly outperforms the other six baseline methods in maintaining model accuracy as the proportion of malicious clients increases.
The **"Attack ratio (%)"** represents the fraction of total participants sending poisoned or manipulated updates. The **"Accuracy (%)"** measures the global model's performance on a clean test dataset. The stark contrast between the flat red line ("Ours") and the declining trajectories of the others indicates that the underlying technique of "Ours" is highly effective at filtering out or neutralizing malicious contributions without harming the aggregation of legitimate updates.
The **Peircean investigative reading** reveals a narrative of resilience versus vulnerability. The chart doesn't just show numbers; it tells a story of system integrity under siege. The baselines represent established defenses that hold until a tipping point (around 30-40% attack ratio), after which they collapse. "Ours" represents a paradigm shift, maintaining integrity well beyond the failure point of its competitors. The anomaly of "Biscotti" performing slightly better than others at 50% but worse at 40% may indicate a different failure mode or a non-monotonic response to attack strength, warranting further investigation. The immediate decline of "FoolsGold" suggests its defense mechanism is either too sensitive or fundamentally misaligned with the attack model used in this evaluation.
</details>
(d) CIFAR10 ( $\alpha$ =0.6)
Figure 5: The OA of the models obtained by four benchmarks under Gaussian attack.
In summary, SRFed demonstrates strong robustness against poisoning attacks under different Non-IID data settings and attack ratios, thus achieving the design goal of robustness.
#### VII-B 2 Efficiency Evaluation of SRFed
Learning Overheads. We evaluate the efficiency of the proposed SRFed in obtaining a qualified aggregated model. Specifically, we compare SRFed with two baseline methods, i.e., ESB-FL and ShieldFL. These two methods respectively utilize NDD-FE and HE to ensure privacy protection for local models. The experiments are conducted on MNIST with no malicious clients. For each method, we conduct 10 training tasks and calculate the average time consumed in each phase, along with the average communication time across all participants. The results are summarized in Table IV. The experimental results demonstrate that SRFed reduces the total time overheads throughout the entire training process by 58% compared to ShieldFL. This reduction can be attributed to two main factors: 1) DEFE in SRFed offers a significant computational efficiency advantage over HE in ShieldFL, with faster encryption and decryption, as shown in the ”Local training” and ”Privacy-preserving robust model aggregation” phases in Table IV. 2) The privacy-preserving robust model aggregation is handled solely by the server, which avoids the overhead of multi-server interactions in ShieldFL. Compared to ESB-FL, SRFed reduces the total time overhead by 22% even though it incorporates an additional privacy-preserving model detection phase. This is attributed to its underlying DEFE scheme, which significantly enhances decryption efficiency. As a result, SRFed achieves a 71% reduction in execution time during the privacy-preserving robust model aggregation phase, even with the added overhead of model detection. In summary, SRFed achieves an efficient privacy-preserving FL process, achieving the design goal of efficiency.
TABLE IV: Comparison of time consumption between different frameworks
| Framework | SRFed | ShieldFL | ESB-FL |
| --- | --- | --- | --- |
| Local training 1 | 19.51 h | 14.23 h | 5.16 h |
| Privacy-preserving | 9.09 h | 51.97 h | 31.43 h |
| robust model aggregation 2 | | | |
| Node communication | 0.09 h | 1.51 h | 0.09 h |
| Total time | 28.69 h | 67.71 h | 36.68 h |
| Accuracy | 98.90% | 97.42% | 98.68% |
TABLE V: Time overhead of proposed DEFE
| Operations | DEFE | NDD-FE | HE |
| --- | --- | --- | --- |
| (for a model) | (SRFed) | (ESB-FL) | (shieldFL) |
| Encryption | 28.37 s | 2.53 s | 18.87 s |
| Inner product | 8.97 s | 56.58 s | 30.15 s |
| Decryption | - | - | 3.10 s |
Efficiency Evaluation of DEFE. We further evaluate the efficiency of the DEFE scheme within SRFed by conducting experiments on the CNN model of the MNIST dataset. Specifically, we compare the DEFE scheme with the NDD-FE scheme used in ESB-FL [31] and the HE scheme used in ShieldFL [29]. For these schemes, we calculate their average time required for different operations, i.e., encryption, inner product computation, and decryption, over 100 test runs. The results are presented in Table V. It is evident that the DEFE scheme offers a substantial efficiency advantage in terms of inner product computation. Specifically, the inner product time of DEFE is reduced by 84% compared to NDD-FE and by 70% compared to HE. Furthermore, DEFE directly produces the final plaintext result during inner product computation, avoiding the need for interactive decryption in HE. Combined with the results in Table IV, it is clear that although the encryption time of DEFE is slightly higher, its highly efficient decryption process significantly reduces the overall computation overhead. Thus, DEFE guarantees the high efficiency of SRFed.
## VIII Conclusion
In this paper, we address the challenges of achieving both privacy preservation and Byzantine robustness in FL under Non-IID data distributions, and propose a novel secure and efficient FL method SRFed. Specifically, we design a DEFE scheme that enables efficient model encryption and non-interactive decryption, which eliminates third-party dependency and defends against server-side inference attacks. Second, we develop a privacy-preserving robust aggregation mechanism based on secure layer-wise projection and clustering, which effectively filters malicious updates and mitigates poisoning attacks in data heterogeneous environments. Theoretical analysis and extensive experimental results demonstrate that SRFed achieves superior performance compared to state-of-the-art baselines in terms of privacy protection, Byzantine resilience, and system efficiency. In future work, we will explore the extension of SRFed to practical FL scenarios, such as vertical FL, edge computing, and personalized FL.
## References
- [1] R. Lan, Y. Zhang, L. Xie, Z. Wu, and Y. Liu, ‘Bev feature exchange pyramid networks-based 3d object detection in small and distant situations: A decentralized federated learning framework,” Neurocomputing, vol. 583, p. 127476, 2024.
- [2] T. Zeng, O. Semiari, M. Chen, W. Saad, and M. Bennis, ‘Federated learning on the road autonomous controller design for connected and autonomous vehicles,” IEEE Transactions on Wireless Communications, vol. 21, no. 12, pp. 10 407–10 423, 2022.
- [3] V. P. Chellapandi, L. Yuan, C. G. Brinton, S. H. Żak, and Z. Wang, ‘Federated learning for connected and automated vehicles: A survey of existing approaches and challenges,” IEEE Transactions on Intelligent Vehicles, vol. 9, no. 1, pp. 119–137, 2024.
- [4] Y. Fu, X. Tang, C. Li, F. R. Yu, and N. Cheng, ‘A secure personalized federated learning algorithm for autonomous driving,” Trans. Intell. Transport. Sys., vol. 25, no. 12, p. 20378–20389, Dec. 2024.
- [5] G. Li, J. Gan, C. Wang, and S. Peng, ‘Stateless distributed stein variational gradient descent method for bayesian federated learning,” Neurocomputing, vol. 654, p. 131198, 2025.
- [6] G. Hu, S. Song, Y. Kang, Z. Yin, G. Zhao, C. Li, and J. Tang, ‘Federated client-tailored adapter for medical image segmentation,” IEEE Transactions on Information Forensics and Security, vol. 20, pp. 6490–6501, 2025.
- [7] X. Wu, J. Pei, C. Chen, Y. Zhu, J. Wang, Q. Qian, J. Zhang, Q. Sun, and Y. Guo, ‘Federated active learning for multicenter collaborative disease diagnosis,” IEEE Transactions on Medical Imaging, vol. 42, no. 7, pp. 2068–2080, 2023.
- [8] A. Rauniyar, D. H. Hagos, D. Jha, J. E. Håkegård, U. Bagci, D. B. Rawat, and V. Vlassov, ‘Federated learning for medical applications: A taxonomy, current trends, challenges, and future research directions,” IEEE Internet of Things Journal, vol. 11, no. 5, pp. 7374–7398, 2024.
- [9] T. Deng, C. Huang, M. Cai, Y. Liu, M. Liu, J. Lin, Z. Shi, B. Zhao, J. Huang, C. Liang, G. Han, Z. Liu, Y. Wang, and C. Han, ‘Fedbcd: Federated ultrasound video and image joint learning for breast cancer diagnosis,” IEEE Transactions on Medical Imaging, vol. 44, no. 6, pp. 2395–2407, 2025.
- [10] C. Wu, F. Wu, L. Lyu et al., ‘A federated graph neural network framework for privacy-preserving personalization,” Nature Communications, vol. 13, no. 1, p. 3091, 2022.
- [11] Y. Hao, X. Chen, W. Wang, J. Liu, T. Li, J. Wang, and W. Pedrycz, ‘Eyes on federated recommendation: Targeted poisoning with competition and its mitigation,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 10 173–10 188, 2024.
- [12] Z. Li, C. Li, F. Huang, X. Zhang, J. Weng, and P. S. Yu, ‘Lapglp: Approximating infinite-layer graph convolutions with laplacian for federated recommendation,” IEEE Transactions on Information Forensics and Security, vol. 20, pp. 8178–8193, 2025.
- [13] X. Liu, Y. Chen, and S. Pang, ‘Defending against membership inference attack for counterfactual federated recommendation with differentially private representation learning,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 8037–8051, 2024.
- [14] A. V. Galichin, M. Pautov, A. Zhavoronkin, O. Y. Rogov, and I. Oseledets, ‘Glira: Closed-box membership inference attack via knowledge distillation,” IEEE Transactions on Information Forensics and Security, vol. 20, pp. 3893–3906, 2025.
- [15] W. Issa, N. Moustafa, B. Turnbull, and K.-K. R. Choo, ‘Rve-pfl: Robust variational encoder-based personalized federated learning against model inversion attacks,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 3772–3787, 2024.
- [16] G. Liu, Z. Tian, J. Chen, C. Wang, and J. Liu, ‘Tear: Exploring temporal evolution of adversarial robustness for membership inference attacks against federated learning,” IEEE Transactions on Information Forensics and Security, vol. 18, pp. 4996–5010, 2023.
- [17] F. Hu, A. Zhang, X. Liu, and M. Li, ‘Dampa: Dynamic adaptive model poisoning attack in federated learning,” IEEE Transactions on Information Forensics and Security, vol. 20, pp. 12 215–12 230, 2025.
- [18] H. Zhang, J. Jia, J. Chen, L. Lin, and D. Wu, ‘A3fl: Adversarially adaptive backdoor attacks to federated learning,” in Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 61 213–61 233.
- [19] B. Wang, Y. Tian, Y. Guo, and H. Li, ‘Defense against poisoning attacks on federated learning with neighborhood coulomb force,” IEEE Transactions on Information Forensics and Security, pp. 1–1, 2025.
- [20] H. Zeng, T. Zhou, X. Wu, and Z. Cai, ‘Never too late: Tracing and mitigating backdoor attacks in federated learning,” in 2022 41st International Symposium on Reliable Distributed Systems (SRDS), 2022, pp. 69–81.
- [21] Y. Jiang, B. Ma, X. Wang, G. Yu, C. Sun, W. Ni, and R. P. Liu, ‘Preventing harm to the rare in combating the malicious: A filtering-and-voting framework with adaptive aggregation in federated learning,” Neurocomputing, vol. 604, p. 128317, 2024.
- [22] L. Sun, J. Qian, and X. Chen, ‘Ldp-fl: Practical private aggregation in federated learning with local differential privacy,” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Z.-H. Zhou, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2021, pp. 1571–1578, main Track.
- [23] C. Liu, Y. Tian, J. Tang, S. Dang, and G. Chen, ‘A novel local differential privacy federated learning under multi-privacy regimes,” Expert Systems with Applications, vol. 227, p. 120266, 2023.
- [24] Y. Miao, R. Xie, X. Li, Z. Liu, K.-K. R. Choo, and R. H. Deng, ‘ E fficient and S ecure F ederated L earning scheme (esfl) against backdoor attacks,” IEEE Trans. Dependable Secur. Comput., vol. 21, no. 5, p. 4619–4636, Sep. 2024.
- [25] R. Zhang, W. Ni, N. Fu, L. Hou, D. Zhang, Y. Zhang, and L. Zheng, ‘Principal angle-based clustered federated learning with local differential privacy for heterogeneous data,” IEEE Transactions on Information Forensics and Security, vol. 20, pp. 9328–9342, 2025.
- [26] X. Tang, L. Peng, Y. Weng, M. Shen, L. Zhu, and R. H. Deng, ‘Enforcing differential privacy in federated learning via long-term contribution incentives,” IEEE Transactions on Information Forensics and Security, vol. 20, pp. 3102–3115, 2025.
- [27] Z. Zhang, L. Wu, C. Ma, J. Li, J. Wang, Q. Wang, and S. Yu, ‘LSFL: A lightweight and secure federated learning scheme for edge computing,” IEEE Trans. Inf. Forensics Secur., vol. 18, pp. 365–379, 2023.
- [28] L. Chen, D. Xiao, Z. Yu, and M. Zhang, ‘Secure and efficient federated learning via novel multi-party computation and compressed sensing,” Information Sciences, vol. 667, p. 120481, 2024.
- [29] Z. Ma, J. Ma, Y. Miao, Y. Li, and R. H. Deng, ‘Shieldfl: Mitigating model poisoning attacks in privacy-preserving federated learning,” IEEE Transactions on Information Forensics and Security, vol. 17, pp. 1639–1654, 2022.
- [30] A. Ebel, K. Garimella, and B. Reagen, ‘Orion: A fully homomorphic encryption framework for deep learning,” in Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’25. New York, NY, USA: Association for Computing Machinery, 2025, p. 734–749.
- [31] B. Chen, H. Zeng, T. Xiang, S. Guo, T. Zhang, and Y. Liu, ‘Esb-fl: Efficient and secure blockchain-based federated learning with fair payment,” IEEE Transactions on Big Data, vol. 10, no. 6, pp. 761–774, 2024.
- [32] H. Zeng, J. Li, J. Lou, S. Yuan, C. Wu, W. Zhao, S. Wu, and Z. Wang, ‘Bsr-fl: An efficient byzantine-robust privacy-preserving federated learning framework,” IEEE Transactions on Computers, vol. 73, no. 8, pp. 2096–2110, 2024.
- [33] C. Fung, C. J. M. Yoon, and I. Beschastnikh, ‘The limitations of federated learning in sybil settings,” in 23rd International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2020). San Sebastian: USENIX Association, Oct. 2020, pp. 301–316.
- [34] P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, ‘Machine learning with adversaries: byzantine tolerant gradient descent,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY, USA: Curran Associates Inc., 2017, p. 118–128.
- [35] D. Yin, Y. Chen, R. Kannan, and P. Bartlett, ‘Byzantine-robust distributed learning: Towards optimal statistical rates,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 5650–5659.
- [36] Q. Dong, Y. Bai, M. Su, Y. Gao, and A. Fu, ‘Drift: Dct-based robust and intelligent federated learning with trusted privacy,” Neurocomputing, vol. 658, p. 131697, 2025.
- [37] Y. Miao, Z. Liu, H. Li, K.-K. R. Choo, and R. H. Deng, ‘Privacy-preserving byzantine-robust federated learning via blockchain systems,” IEEE Transactions on Information Forensics and Security, vol. 17, pp. 2848–2861, 2022.
- [38] M. Gong, Y. Zhang, Y. Gao, A. K. Qin, Y. Wu, S. Wang, and Y. Zhang, ‘A multi-modal vertical federated learning framework based on homomorphic encryption,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 1826–1839, 2024.
- [39] H. Zeng, J. Lou, K. Li, C. Wu, G. Xue, Y. Luo, F. Cheng, W. Zhao, and J. Li, ‘Esfl: Accelerating poisonous model detection in privacy-preserving federated learning,” IEEE Transactions on Dependable and Secure Computing, vol. 22, no. 4, pp. 3780–3794, 2025.
- [40] B. Yu, J. Zhao, K. Zhang, J. Gong, and H. Qian, ‘Lightweight and dynamic privacy-preserving federated learning via functional encryption,” Trans. Info. For. Sec., vol. 20, p. 2496–2508, Feb. 2025.
- [41] M. Shayan, C. Fung, C. J. M. Yoon, and I. Beschastnikh, ‘Biscotti: A blockchain system for private and secure federated learning,” IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 7, pp. 1513–1525, 2021.
- [42] S. Agrawal, B. Libert, and D. Stehle, ‘Fully secure functional encryption for inner products, from standard assumptions,” in Proceedings, Part III, of the 36th Annual International Cryptology Conference on Advances in Cryptology — CRYPTO 2016 - Volume 9816, no. 1. Berlin, Heidelberg: Springer-Verlag, Aug 2016, p. 333–362.
- [43] P. Paillier, ‘Public-key cryptosystems based on composite degree residuosity classes,” in Advances in Cryptology — EUROCRYPT ’99, J. Stern, Ed. Berlin, Heidelberg: Springer Berlin Heidelberg, 1999, pp. 223–238.
- [44] N. M. Jebreel, J. Domingo-Ferrer, D. Sánchez, and A. Blanco-Justicia, ‘Lfighter: Defending against label-flipping attacks in federated learning (code repository),” 2024, accessed: Please replace with actual access date, e.g., 2024-10-01. [Online]. Available: https://github.com/najeebjebreel/LFighter
- [45] Y. LeCun, C. Cortes, and C. J. Burges, ‘The mnist database,” http://yann.lecun.com/exdb/mnist/, accessed: Nov. 1, 2023.
- [46] A. Krizhevsky and G. Hinton, ‘Learning multiple layers of features from tiny images,” University of Toronto, Tech. Rep. TR-2009-1, 2009. [Online]. Available: https://www.cs.toronto.edu/~kriz/cifar.html
- [47] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, ‘Communication-efficient learning of deep networks from decentralized data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 20-22 April 2017, Fort Lauderdale, FL, USA, ser. Proceedings of Machine Learning Research, A. Singh and X. J. Zhu, Eds., vol. 54. PMLR, 2017, pp. 1273–1282.
<details>
<summary>Aphoto.jpeg Details</summary>

### Visual Description
## Photograph: Formal Portrait of a Young Man
### Overview
This image is a high-resolution, formal head-and-shoulders portrait photograph of a young East Asian man. The subject is positioned centrally against a plain, bright white background. The image contains no charts, diagrams, data tables, or embedded textual information. It is a photographic portrait, not a technical document or data visualization.
### Subject Description
* **Subject:** A young adult male, likely in his early to mid-20s.
* **Pose & Gaze:** He is facing the camera directly with a neutral, calm expression. His gaze is straight into the lens.
* **Hair:** He has thick, black hair styled with a side part, swept to his right (viewer's left). The hair has a slight wave and appears neatly groomed.
* **Facial Features:**
* **Eyes:** Brown eyes, almond-shaped, with a direct and steady gaze.
* **Eyebrows:** Well-defined, dark eyebrows.
* **Nose:** Straight nose bridge.
* **Mouth:** Lips are closed in a neutral, relaxed position.
* **Skin:** Fair complexion with even skin tone.
* **Attire:** He is wearing formal business attire.
* **Suit Jacket:** A dark charcoal or black suit jacket with notched lapels. The fabric appears to have a subtle texture.
* **Shirt:** A crisp, white dress shirt with a standard collar.
* **Tie:** A dark blue necktie with diagonal stripes. The stripes consist of a thin white line bordered by a slightly thicker light blue line, repeating in a pattern.
### Composition and Lighting
* **Framing:** The shot is a standard bust portrait, cropped from the mid-chest upward.
* **Background:** A seamless, pure white background, typical of studio identification or professional headshot photography.
* **Lighting:** The lighting is soft and even, coming primarily from the front. It creates gentle shadows under the chin and nose, defining facial structure without harsh contrast. There are no dramatic shadows or highlights.
* **Color Palette:** The image is dominated by neutral tones: black (hair, jacket), white (background, shirt), and blue (tie). The subject's skin tone and brown eyes provide the only warm colors.
### Key Observations
1. **Absence of Text/Data:** The image contains zero textual information, labels, axes, legends, or numerical data. It is purely a photographic portrait.
2. **Formal Context:** The attire, neutral expression, and plain background strongly suggest this image is intended for a formal or professional purpose, such as a corporate profile, official ID, or academic record.
3. **High Clarity:** The image is in sharp focus, particularly on the subject's eyes and face, with a shallow depth of field that keeps the background completely out of focus (though it is a solid color).
4. **Symmetry and Centering:** The subject's face is centrally aligned in the frame, creating a balanced and formal composition.
### Interpretation
This image serves a clear representational function. It is designed to present the subject in a formal, neutral, and identifiable manner. The lack of environmental context, text, or expressive emotion focuses all attention on the subject's physical appearance for the purpose of recognition.
* **Purpose:** The photograph is almost certainly a professional headshot. Its style is consistent with those used for corporate "About Us" pages, speaker biographies, official identification badges, or academic/student profiles.
* **Visual Language:** The direct gaze establishes a sense of confidence and engagement with the viewer. The formal attire conveys professionalism and seriousness. The plain white background eliminates any distracting context, ensuring the subject is the sole focus.
* **Technical Quality:** The even lighting, sharp focus, and clean composition indicate it was taken in a controlled studio environment with professional equipment, further supporting its intended use in formal or official capacities.
**Conclusion:** There is no factual data, charted information, or textual content to extract from this image. It is a standard professional portrait photograph whose entire informational content is the visual representation of the subject himself.
</details>
Yiwen Lu received the B.S. degree from the School of Mathematics and Statistics, Central South University (CSU), Changsha, China, in 2021. He is currently working toward the Ph.D. degree in mathematics with the School of Mathematics, Nanjing University (NJU), Nanjing, China. His research interests include number theory, cryptography, and artificial intelligence security.