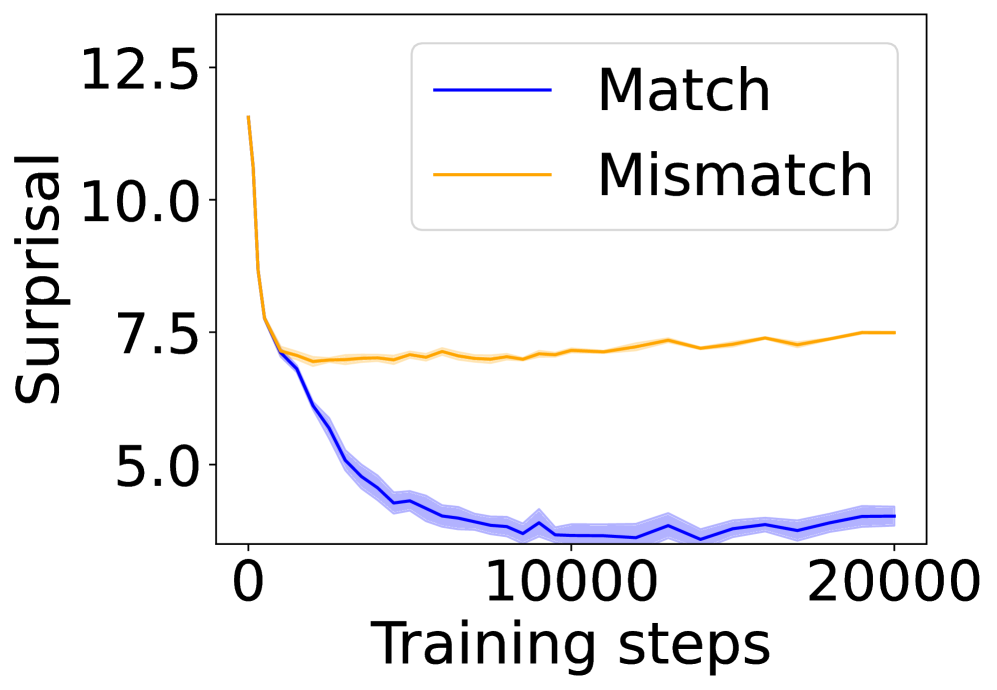
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart that plots "Surprisal" on the y-axis against "Training steps" on the x-axis. Two data series are displayed: "Match" (blue line) and "Mismatch" (orange line). The chart illustrates how surprisal changes with increasing training steps for both conditions. The lines are surrounded by shaded regions, indicating uncertainty or variance.
### Components/Axes
* **X-axis:** "Training steps" ranging from 0 to 20000, with major tick marks at 0, 10000, and 20000.
* **Y-axis:** "Surprisal" ranging from approximately 3.75 to 12.5, with major tick marks at 5.0, 7.5, 10.0, and 12.5.
* **Legend:** Located in the top-right corner, it identifies the blue line as "Match" and the orange line as "Mismatch".
### Detailed Analysis
* **Match (Blue Line):**
* Trend: The "Match" line shows a decreasing trend in surprisal as training steps increase. It starts at approximately 7.5 and decreases to around 4.0.
* Data Points:
* At 0 training steps, surprisal is approximately 7.5.
* At 5000 training steps, surprisal is approximately 4.5.
* At 10000 training steps, surprisal is approximately 4.0.
* At 20000 training steps, surprisal is approximately 4.0.
* **Mismatch (Orange Line):**
* Trend: The "Mismatch" line shows a slight decreasing trend initially, then stabilizes and remains relatively constant as training steps increase. It starts at approximately 12.0 and stabilizes around 7.5.
* Data Points:
* At 0 training steps, surprisal is approximately 12.0.
* At 5000 training steps, surprisal is approximately 7.5.
* At 10000 training steps, surprisal is approximately 7.5.
* At 20000 training steps, surprisal is approximately 7.5.
### Key Observations
* The "Match" condition exhibits a significant reduction in surprisal with increased training, indicating learning or adaptation.
* The "Mismatch" condition shows a much smaller reduction in surprisal, suggesting that the model struggles to adapt to mismatched data.
* The shaded regions around the lines indicate the variability or uncertainty associated with each condition.
### Interpretation
The chart suggests that the model learns to predict or process "Match" data more effectively as training progresses, resulting in lower surprisal. In contrast, the model's performance on "Mismatch" data remains relatively stable, indicating that it does not learn to handle mismatched data as effectively. This could imply that the model is better suited for processing data that aligns with its training or prior knowledge. The difference in surprisal between the two conditions highlights the model's sensitivity to data consistency.