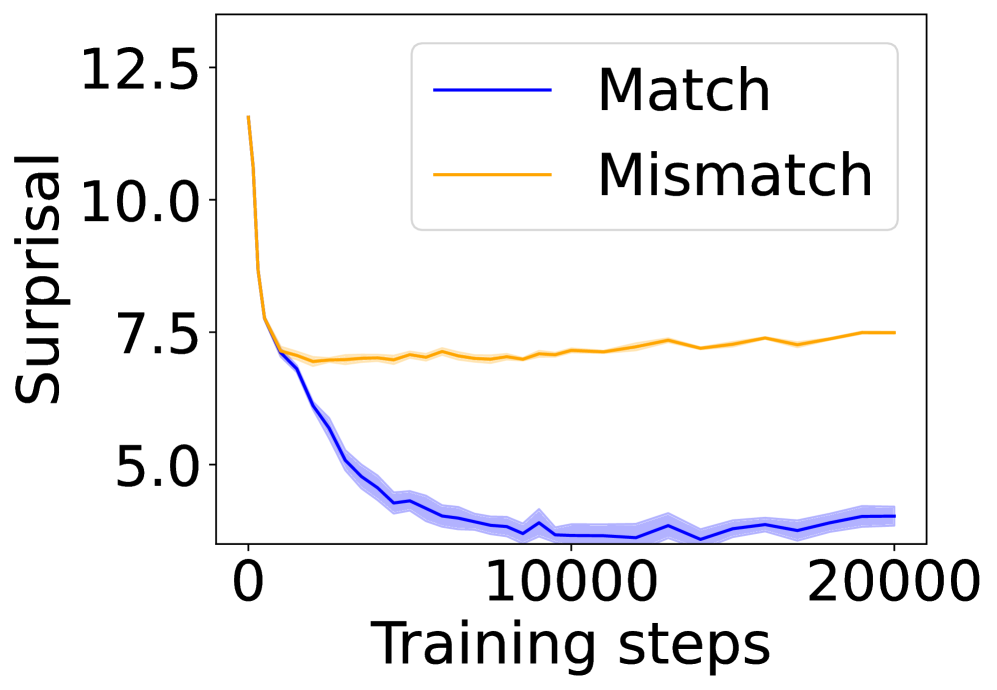
## Line Graph: Surprisal vs Training Steps
### Overview
The graph depicts two data series ("Match" and "Mismatch") plotted against training steps (0–20,000) on the x-axis and surprisal values (4.0–12.5) on the y-axis. Both lines show distinct trends, with "Match" declining sharply initially and stabilizing, while "Mismatch" remains relatively flat after an initial dip.
### Components/Axes
- **X-axis**: "Training steps" (0, 10,000, 20,000)
- **Y-axis**: "Surprisal" (5.0, 7.5, 10.0, 12.5)
- **Legend**: Located in the top-right corner, with:
- Blue line: "Match"
- Orange line: "Mismatch"
- **Shading**: Light blue and orange bands around lines indicate variability/confidence intervals.
### Detailed Analysis
1. **Match (Blue Line)**:
- Starts at ~12.5 surprisal at 0 steps.
- Drops sharply to ~4.5 surprisal by 10,000 steps.
- Stabilizes with minor fluctuations (~4.0–4.5) between 10,000–20,000 steps.
- Shaded area narrows significantly after the initial drop, suggesting reduced variability.
2. **Mismatch (Orange Line)**:
- Begins at ~7.5 surprisal at 0 steps.
- Dips slightly to ~6.5 surprisal by ~2,000 steps.
- Remains flat (~7.0–7.5) from 2,000–20,000 steps.
- Shaded area remains consistent, indicating stable variability.
### Key Observations
- **Initial Divergence**: "Match" starts with significantly higher surprisal than "Mismatch" (~12.5 vs. ~7.5).
- **Rapid Adaptation**: "Match" surprisal decreases ~60% in the first 10,000 steps, then plateaus.
- **Stability**: "Mismatch" surprisal shows minimal change after the initial dip, remaining ~7.0–7.5 throughout training.
- **Convergence**: By 20,000 steps, "Match" surprisal (~4.5) is ~40% lower than "Mismatch" (~7.5).
### Interpretation
The data suggests that the "Match" condition undergoes rapid adaptation during early training, reducing surprisal (likely indicating improved model performance or prediction accuracy) before stabilizing. In contrast, "Mismatch" shows limited adaptation, maintaining higher surprisal values throughout training. This could imply that "Match" scenarios are more amenable to learning or optimization, while "Mismatch" scenarios resist change, possibly due to conflicting patterns or noise. The shaded variability bands suggest that "Match" becomes more predictable over time, whereas "Mismatch" remains uncertain.