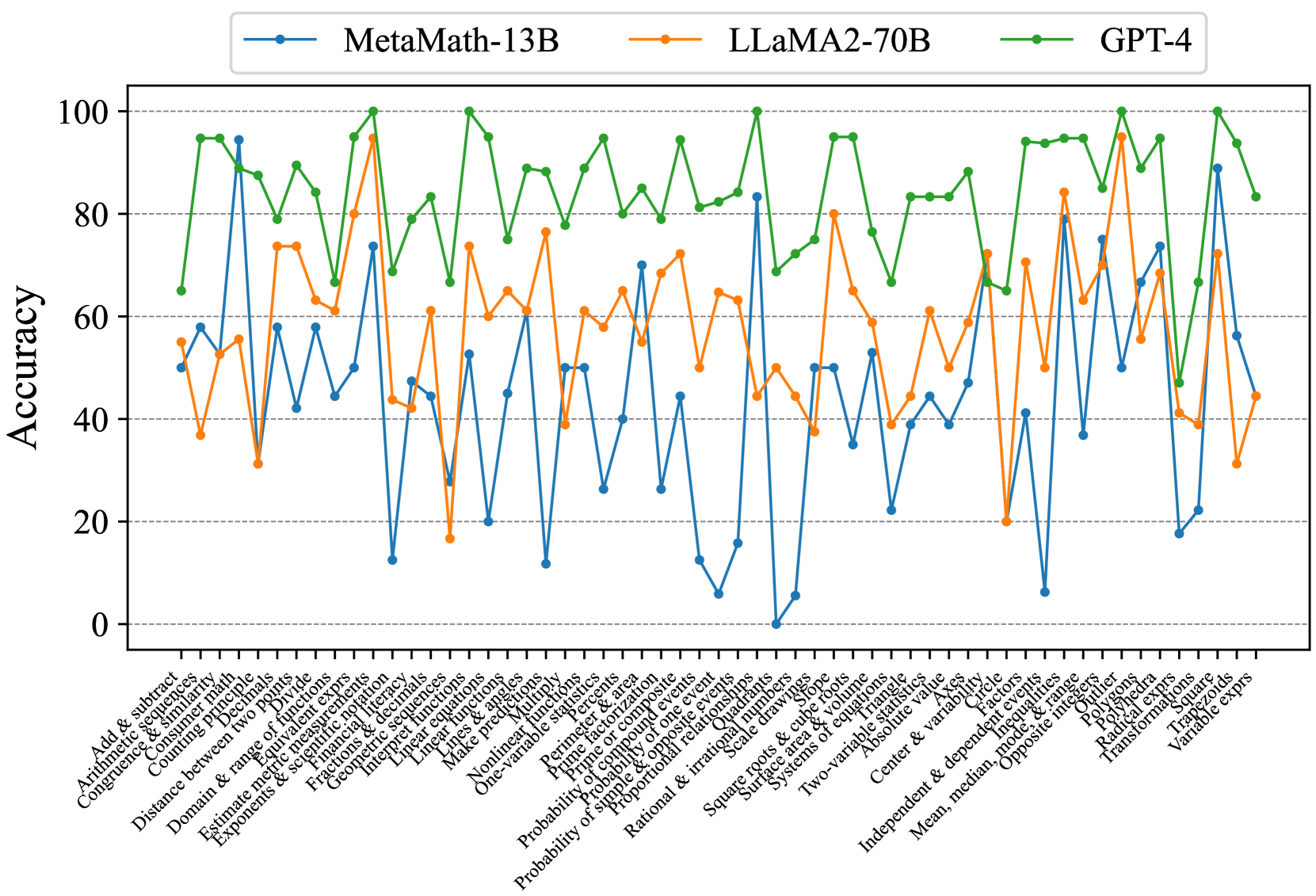
## Line Chart: Accuracy Comparison of Language Models on Math Problems
### Overview
The image is a line chart comparing the accuracy of three language models (MetaMath-13B, LLaMA2-70B, and GPT-4) across a range of mathematical problem types. The x-axis represents different math topics, and the y-axis represents accuracy, ranging from 0 to 100.
### Components/Axes
* **Title:** (Implicit) Accuracy Comparison of Language Models on Math Problems
* **X-axis:** Math problem types (listed below)
* **Y-axis:** Accuracy (ranging from 0 to 100) with gridlines at intervals of 20.
* **Legend:** Located at the top of the chart.
* Blue line: MetaMath-13B
* Orange line: LLaMA2-70B
* Green line: GPT-4
**X-axis Labels (Math Problem Types):**
1. Add & subtract
2. Arithmetic sequences
3. Congruence & similarity
4. Consumer math
5. Counting principles
6. Distance between two points
7. Divide
8. Domain & range of functions
9. Estimate metric measurements
10. Equivalent exprs
11. Exponents & scientific notation
12. Financial literacy
13. Fractions & decimals
14. Geometric sequences
15. Interpret functions
16. Linear equations
17. Linear functions
18. Lines & angles
19. Make predictions
20. Multiply
21. Non-linear functions
22. One-variable statistics
23. Percents
24. Perimeter & area
25. Prime factorization
26. Prime & composite
27. Probability of compound event
28. Probability of one event
29. Probability of simple & composite events
30. Probability of simple & opposite events
31. Proportional relationships
32. Quadrants
33. Rational & irrational numbers
34. Scale drawings
35. Slope
36. Square roots & cube roots
37. Square, area & volume
38. Surface area & volume
39. Systems of equations
40. Triangle
41. Two-variable statistics
42. Absolute value
43. Center & variability
44. Circle
45. Factors
46. Independent & dependent events
47. Inequalities
48. Mean, median, mode, & range
49. Opposite integers
50. Outlier
51. Polygons
52. Polyhedra
53. Radical exprs
54. Square
55. Transformations
56. Trapezoids
57. Variable exprs
### Detailed Analysis
* **MetaMath-13B (Blue):** The accuracy fluctuates significantly across different problem types. It shows very low accuracy (near 0) on "Probability of one event" and "Scale drawings". It peaks around 60-70 on "Distance between two points" and "Equivalent exprs". Overall, it has the lowest average accuracy.
* **LLaMA2-70B (Orange):** The accuracy is generally higher than MetaMath-13B but lower than GPT-4. It shows a more consistent performance across different problem types, with fewer extreme dips. It peaks around 75 on "Equivalent exprs".
* **GPT-4 (Green):** This model consistently demonstrates the highest accuracy across almost all problem types. The accuracy generally stays above 60, often reaching 80-100.
**Specific Data Points (Approximate):**
| Problem Type | MetaMath-13B | LLaMA2-70B | GPT-4 |
| :---------------------------- | :----------- | :----------- | :---- |
| Add & subtract | ~50 | ~55 | ~65 |
| Distance between two points | ~60 | ~55 | ~95 |
| Equivalent exprs | ~70 | ~75 | ~85 |
| Probability of one event | ~0 | ~20 | ~75 |
| Scale drawings | ~5 | ~45 | ~65 |
| Absolute value | ~50 | ~60 | ~90 |
### Key Observations
* GPT-4 significantly outperforms MetaMath-13B and LLaMA2-70B across most math problem types.
* MetaMath-13B has very poor performance on specific problem types like "Probability of one event" and "Scale drawings".
* LLaMA2-70B provides a more stable, though generally lower, accuracy compared to MetaMath-13B.
* All models show variability in accuracy depending on the specific math topic.
### Interpretation
The chart demonstrates the varying capabilities of different language models in solving mathematical problems. GPT-4's superior performance suggests a more robust understanding of mathematical concepts and problem-solving strategies. The weaknesses of MetaMath-13B in specific areas highlight potential gaps in its training data or architecture. LLaMA2-70B's more consistent performance indicates a more balanced but less specialized skill set. The data suggests that the choice of language model for math-related tasks should be carefully considered based on the specific types of problems being addressed. The large variance in accuracy across problem types for all models suggests that even the best models have areas for improvement.