\n
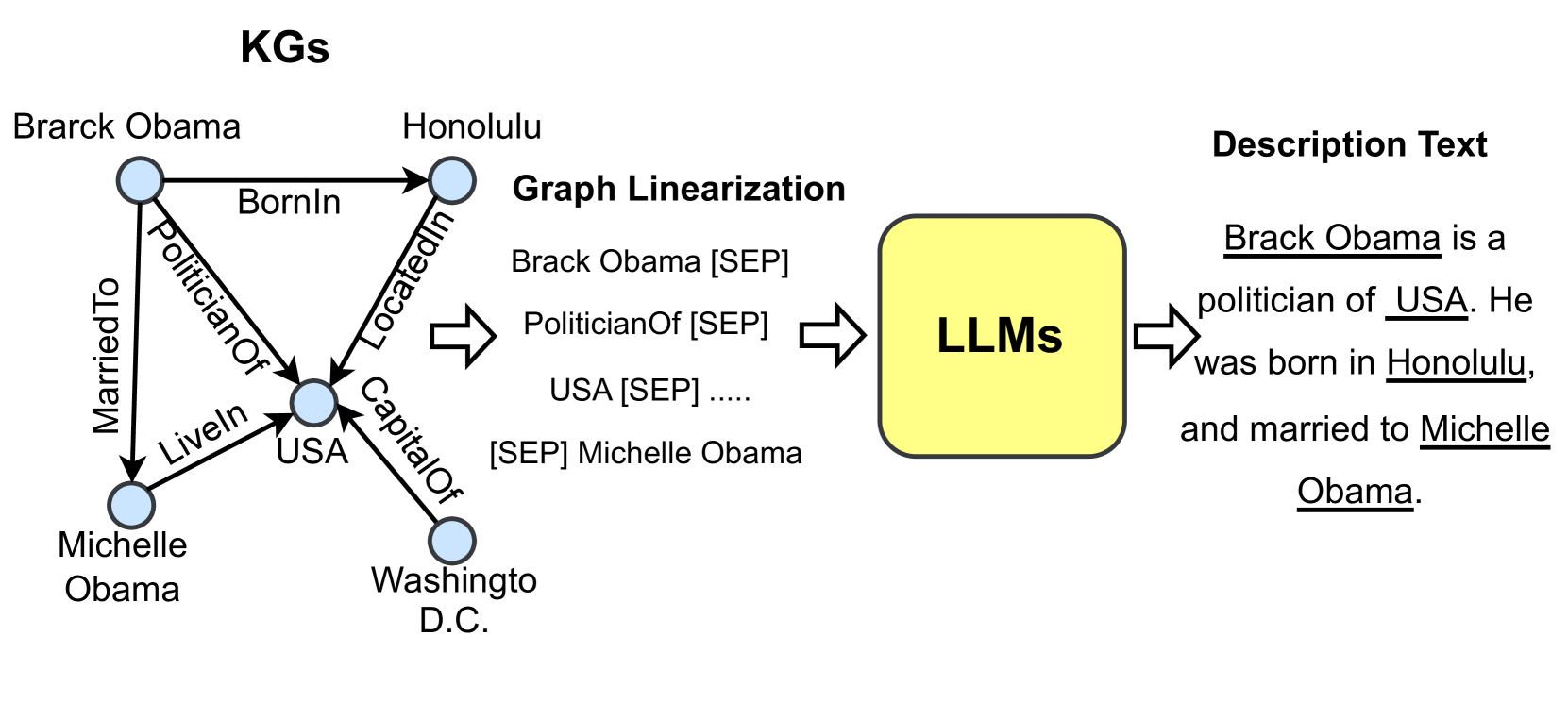
## Diagram: Knowledge Graph to Text Generation
### Overview
This diagram illustrates the process of converting knowledge graphs (KGs) into natural language text using Large Language Models (LLMs). It depicts a knowledge graph representing information about Barack Obama, its linearization into a text sequence, and the subsequent generation of a descriptive sentence by an LLM.
### Components/Axes
The diagram consists of three main sections, arranged horizontally from left to right:
1. **KGs (Knowledge Graphs):** A visual representation of relationships between entities.
2. **Graph Linearization:** A process of converting the graph structure into a sequential text format.
3. **Description Text:** The final output – a natural language description generated by an LLM.
### Detailed Analysis or Content Details
**1. Knowledge Graph (KGs):**
* **Entities:** Barack Obama, Honolulu, Michelle Obama, USA, Washington D.C.
* **Relationships:**
* Barack Obama `BornIn` Honolulu
* Barack Obama `PoliticianOf` USA
* Barack Obama `MarriedTo` Michelle Obama
* Michelle Obama `LivedIn` USA
* Honolulu `LocatedIn` USA
* USA `CapitalOf` Washington D.C.
**2. Graph Linearization:**
* The text sequence is presented within a yellow rectangle labeled "Graph Linearization".
* The sequence is: "Brack Obama [SEP] PoliticianOf [SEP] USA [SEP] .... [SEP] Michelle Obama".
* "[SEP]" is used as a separator token.
**3. Description Text:**
* The text is presented within a yellow rectangle labeled "LLMs".
* The generated text is: "Brack Obama is a politician of USA. He was born in Honolulu, and married to Michelle Obama."
* The words "Brack Obama", "USA", "Honolulu", and "Michelle Obama" are underlined.
### Key Observations
* The diagram demonstrates a pipeline for converting structured knowledge into human-readable text.
* The linearization process uses a separator token ([SEP]) to delineate entities and relationships.
* The LLM generates a grammatically correct and coherent sentence based on the linearized knowledge graph.
* There is a typo in the generated text: "Brack Obama" instead of "Barack Obama".
### Interpretation
The diagram illustrates a common approach in natural language generation (NLG) – leveraging knowledge graphs as a source of structured information. The linearization step is crucial for adapting the graph structure to the sequential input requirements of LLMs. The LLM then utilizes its learned knowledge to generate a natural language description. The typo in the generated text highlights the potential for errors even with advanced language models, and the importance of post-processing or fine-tuning. The underlining of specific words in the generated text may indicate the entities that were directly derived from the knowledge graph. The diagram suggests a process where structured data is transformed into a textual representation, enabling machines to communicate information in a human-understandable format. The use of the [SEP] token is a common practice in sequence-to-sequence models to delineate different parts of the input.