## Line Chart: Speedup vs. Optimization Latency
### Overview
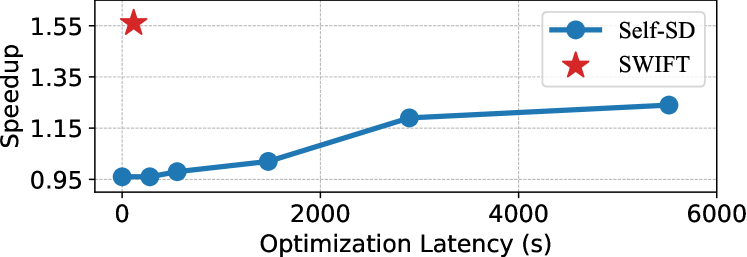
The image is a line chart comparing the speedup achieved by two methods, "Self-SD" and "SWIFT," against the optimization latency in seconds. The x-axis represents optimization latency, and the y-axis represents speedup. The chart shows the trend of speedup for "Self-SD" as optimization latency increases, and a single data point for "SWIFT."
### Components/Axes
* **X-axis:** Optimization Latency (s), ranging from 0 to 6000, with gridlines at intervals of 2000.
* **Y-axis:** Speedup, ranging from 0.95 to 1.55, with gridlines at intervals of 0.20.
* **Legend:** Located in the top-right corner.
* Blue line with circle markers: Self-SD
* Red star marker: SWIFT
### Detailed Analysis
* **Self-SD (Blue Line):** The speedup for Self-SD generally increases with optimization latency.
* At 0s latency, the speedup is approximately 0.96.
* At approximately 500s latency, the speedup is approximately 0.97.
* At approximately 1000s latency, the speedup is approximately 0.98.
* At approximately 2000s latency, the speedup is approximately 1.02.
* At approximately 3000s latency, the speedup is approximately 1.18.
* At approximately 5750s latency, the speedup is approximately 1.21.
* **SWIFT (Red Star):** The speedup for SWIFT is a single point at 0s latency, with a speedup of approximately 1.55.
### Key Observations
* SWIFT achieves a significantly higher speedup than Self-SD at 0s optimization latency.
* Self-SD's speedup increases with optimization latency, but it never reaches the speedup achieved by SWIFT.
* The rate of increase in speedup for Self-SD decreases as optimization latency increases.
### Interpretation
The chart suggests that SWIFT is more efficient than Self-SD when optimization latency is not a factor. However, as optimization latency increases, Self-SD's performance improves, although it never surpasses SWIFT's initial speedup. This could indicate that SWIFT is better suited for scenarios where quick results are needed, while Self-SD might be preferable when more time can be allocated for optimization. The diminishing returns of Self-SD's speedup with increasing latency suggest that there is a point beyond which further optimization provides minimal benefit.