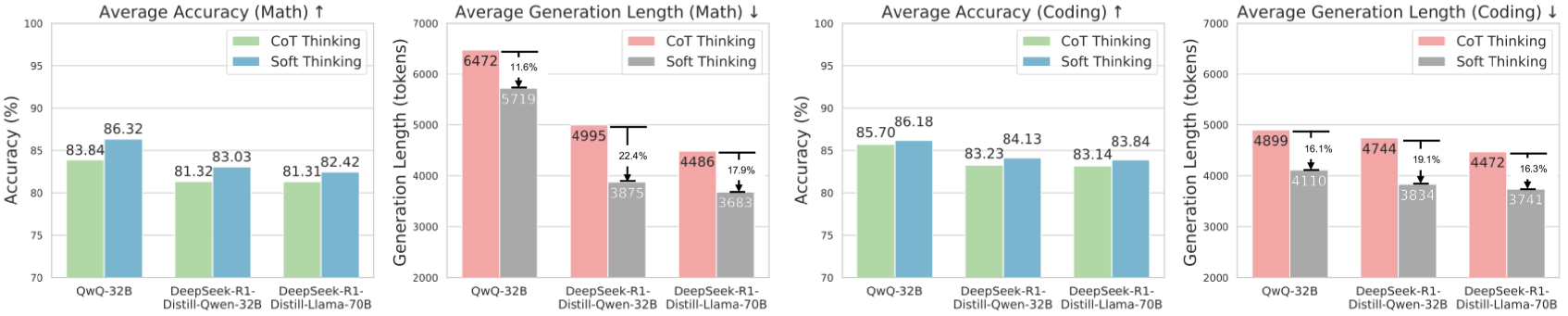
## Bar Charts: Model Performance on Math and Coding Tasks
### Overview
The image presents four bar charts comparing the performance of different language models (QWQ-32B, DeepSeek-R1-Distill-Qwen-32B, and DeepSeek-R1-Distill-Llama-70B) on math and coding tasks. The charts display both the average accuracy and the average generation length (in tokens) for each model, using two different prompting strategies: "CoT Thinking" (Chain-of-Thought) and "Soft Thinking."
### Components/Axes
**Chart 1: Average Accuracy (Math) ↑**
* **Title:** Average Accuracy (Math) ↑
* **Y-axis:** Accuracy (%)
* Scale: 70 to 100
* **X-axis:** Model
* Categories: QWQ-32B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B
* **Legend:** Located at the top-right of the chart.
* CoT Thinking (light green)
* Soft Thinking (light blue)
**Chart 2: Average Generation Length (Math) ↓**
* **Title:** Average Generation Length (Math) ↓
* **Y-axis:** Generation Length (tokens)
* Scale: 2000 to 7000
* **X-axis:** Model
* Categories: QWQ-32B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B
* **Legend:** Located at the top-right of the chart.
* CoT Thinking (light red)
* Soft Thinking (gray)
* Percentage difference annotations above the "Soft Thinking" bars, with downward arrows.
**Chart 3: Average Accuracy (Coding) ↑**
* **Title:** Average Accuracy (Coding) ↑
* **Y-axis:** Accuracy (%)
* Scale: 70 to 100
* **X-axis:** Model
* Categories: QWQ-32B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B
* **Legend:** Located at the top-right of the chart.
* CoT Thinking (light green)
* Soft Thinking (light blue)
**Chart 4: Average Generation Length (Coding) ↓**
* **Title:** Average Generation Length (Coding) ↓
* **Y-axis:** Generation Length (tokens)
* Scale: 2000 to 7000
* **X-axis:** Model
* Categories: QWQ-32B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B
* **Legend:** Located at the top-right of the chart.
* CoT Thinking (light red)
* Soft Thinking (gray)
* Percentage difference annotations above the "Soft Thinking" bars, with downward arrows.
### Detailed Analysis
**Chart 1: Average Accuracy (Math) ↑**
* **QWQ-32B:**
* CoT Thinking (light green): 83.84%
* Soft Thinking (light blue): 86.32%
* **DeepSeek-R1-Distill-Qwen-32B:**
* CoT Thinking (light green): 81.32%
* Soft Thinking (light blue): 83.03%
* **DeepSeek-R1-Distill-Llama-70B:**
* CoT Thinking (light green): 81.31%
* Soft Thinking (light blue): 82.42%
**Chart 2: Average Generation Length (Math) ↓**
* **QWQ-32B:**
* CoT Thinking (light red): 6472 tokens
* Soft Thinking (gray): 5719 tokens
* Percentage Difference: 11.6%
* **DeepSeek-R1-Distill-Qwen-32B:**
* CoT Thinking (light red): 4995 tokens
* Soft Thinking (gray): 3875 tokens
* Percentage Difference: 22.4%
* **DeepSeek-R1-Distill-Llama-70B:**
* CoT Thinking (light red): 4486 tokens
* Soft Thinking (gray): 3683 tokens
* Percentage Difference: 17.9%
**Chart 3: Average Accuracy (Coding) ↑**
* **QWQ-32B:**
* CoT Thinking (light green): 85.70%
* Soft Thinking (light blue): 86.18%
* **DeepSeek-R1-Distill-Qwen-32B:**
* CoT Thinking (light green): 83.23%
* Soft Thinking (light blue): 84.13%
* **DeepSeek-R1-Distill-Llama-70B:**
* CoT Thinking (light green): 83.14%
* Soft Thinking (light blue): 83.84%
**Chart 4: Average Generation Length (Coding) ↓**
* **QWQ-32B:**
* CoT Thinking (light red): 4899 tokens
* Soft Thinking (gray): 4110 tokens
* Percentage Difference: 16.1%
* **DeepSeek-R1-Distill-Qwen-32B:**
* CoT Thinking (light red): 4744 tokens
* Soft Thinking (gray): 3834 tokens
* Percentage Difference: 19.1%
* **DeepSeek-R1-Distill-Llama-70B:**
* CoT Thinking (light red): 4472 tokens
* Soft Thinking (gray): 3741 tokens
* Percentage Difference: 16.3%
### Key Observations
* **Accuracy:** For both Math and Coding tasks, the "Soft Thinking" approach generally yields slightly higher average accuracy compared to "CoT Thinking" across all models.
* **Generation Length:** The "CoT Thinking" approach consistently results in longer generation lengths (more tokens) compared to "Soft Thinking" for both Math and Coding tasks.
* **Percentage Difference:** The percentage reduction in generation length when using "Soft Thinking" compared to "CoT Thinking" is provided above each "Soft Thinking" bar in the generation length charts.
* **Model Performance:** QWQ-32B generally shows the highest accuracy, while DeepSeek-R1-Distill-Llama-70B tends to have the shortest generation lengths.
### Interpretation
The data suggests that while "Soft Thinking" may lead to slightly improved accuracy, it comes at the cost of shorter, potentially less detailed, responses. "CoT Thinking," on the other hand, produces longer and more elaborate responses, which might be beneficial in scenarios where detailed reasoning is crucial, even if it doesn't always translate to higher accuracy. The choice between these two prompting strategies depends on the specific requirements of the task and the desired trade-off between accuracy and response length. The percentage difference in generation length highlights the efficiency gains achieved by using "Soft Thinking," indicating a more concise approach to problem-solving.