\n
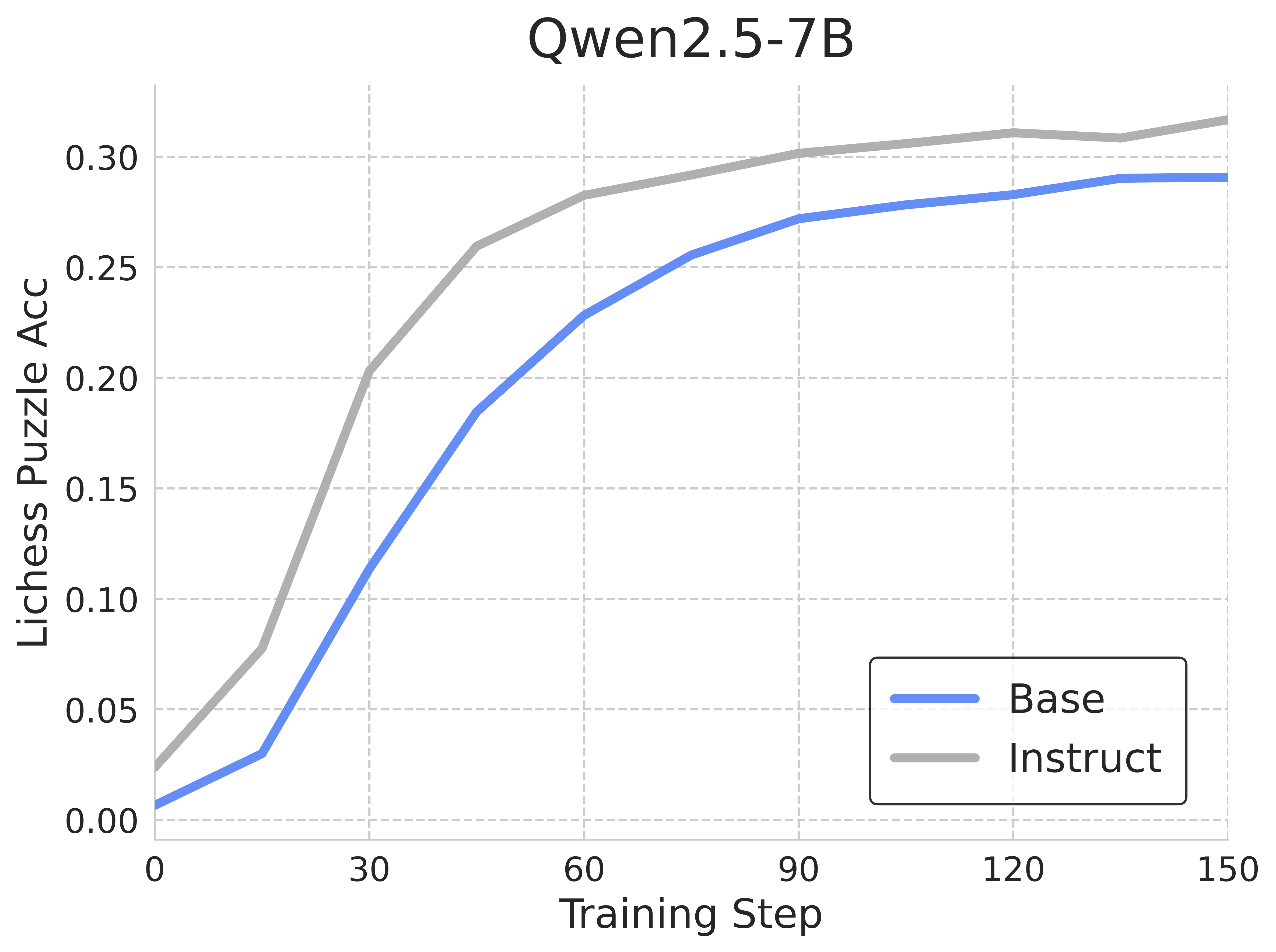
## Line Chart: Qwen2.5-7B Lichess Puzzle Accuracy vs. Training Step
### Overview
This line chart displays the Lichess Puzzle Accuracy (y-axis) of two models, "Base" and "Instruct", over a range of Training Steps (x-axis). The chart aims to compare the performance of the two models as they are trained. The title of the chart is "Qwen2.5-7B".
### Components/Axes
* **Title:** Qwen2.5-7B (positioned at the top-center)
* **X-axis:** Training Step (ranging from 0 to 150, with tick marks every 30 steps)
* **Y-axis:** Lichess Puzzle Acc (ranging from 0.00 to 0.30, with tick marks every 0.05)
* **Legend:** Located in the bottom-right corner, containing two entries:
* "Base" - represented by a solid blue line.
* "Instruct" - represented by a solid gray line.
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
**Base Model (Blue Line):**
The blue line representing the "Base" model starts at approximately 0.00 at Training Step 0. It exhibits a steep upward slope from 0 to 30 Training Steps, reaching approximately 0.15. The slope then decreases, becoming more gradual from 30 to 150 Training Steps. At 60 Training Steps, the accuracy is approximately 0.24. At 90 Training Steps, the accuracy is approximately 0.27. At 120 Training Steps, the accuracy is approximately 0.28. At 150 Training Steps, the accuracy plateaus at approximately 0.29.
**Instruct Model (Gray Line):**
The gray line representing the "Instruct" model also starts at approximately 0.00 at Training Step 0. It shows a rapid increase in accuracy from 0 to 30 Training Steps, reaching approximately 0.25. The slope then decreases, becoming more gradual from 30 to 150 Training Steps. At 60 Training Steps, the accuracy is approximately 0.29. At 90 Training Steps, the accuracy is approximately 0.30. At 120 Training Steps, the accuracy is approximately 0.31. At 150 Training Steps, the accuracy plateaus at approximately 0.31.
### Key Observations
* The "Instruct" model consistently outperforms the "Base" model across all Training Steps.
* Both models exhibit diminishing returns in accuracy as the number of Training Steps increases. The initial gains are significant, but the rate of improvement slows down considerably after 30 Training Steps.
* The "Instruct" model reaches a plateau in accuracy earlier than the "Base" model.
* The difference in accuracy between the two models is most pronounced in the early stages of training (0-60 steps).
### Interpretation
The data suggests that the "Instruct" model benefits significantly from the training process, achieving higher Lichess Puzzle Accuracy compared to the "Base" model. The initial rapid increase in accuracy for both models indicates that the models are quickly learning from the training data. The subsequent plateau suggests that the models are approaching their maximum performance level, or that the training data is no longer providing significant new information. The consistent outperformance of the "Instruct" model implies that the instruction-based training approach is more effective for this specific task (Lichess puzzle solving) than the base training approach. The diminishing returns observed after 60 training steps suggest that further training may not yield substantial improvements in accuracy. This could be due to the limitations of the model architecture, the quality of the training data, or the optimization algorithm used.