\n
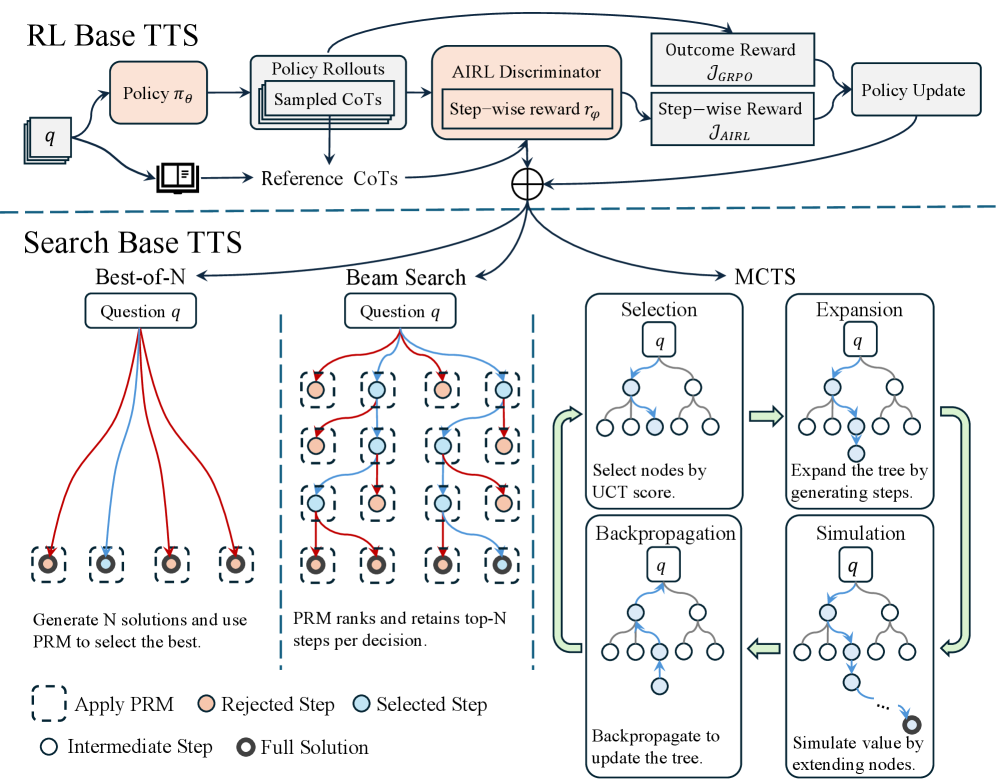
## Diagram: TTS Architecture Comparison - RL Base vs. Search Base
### Overview
This diagram illustrates a comparison between two Text-to-Speech (TTS) architectures: Reinforcement Learning (RL) Base TTS and Search Base TTS. The diagram visually represents the flow of information and processes within each architecture, highlighting the key components and differences. The diagram is divided into two main sections, one for each TTS approach, separated by a dashed horizontal line.
### Components/Axes
The diagram consists of several interconnected blocks representing different components. Key components include:
* **Policy πθ**: Represents the policy network in the RL Base TTS.
* **Question q**: Represents the input question for both architectures.
* **CoTs (Chain of Thoughts)**: Represent the intermediate reasoning steps.
* **AIRL Discriminator**: A component in the RL Base TTS used for reward shaping.
* **Outcome Reward JGRPO**: The final reward signal in the RL Base TTS.
* **Step-wise Reward rρ**: The reward signal at each step in the RL Base TTS.
* **Policy Update**: The process of updating the policy network in the RL Base TTS.
* **Best-of-N**: A component in the Search Base TTS that generates multiple solutions.
* **Beam Search**: A component in the Search Base TTS that explores multiple paths.
* **MCTS (Monte Carlo Tree Search)**: A component in the Search Base TTS used for decision-making.
* **Selection, Expansion, Simulation, Backpropagation**: The four phases of MCTS.
* **PRM (Probabilistic Reasoning Model)**: Used for ranking and selecting solutions in the Search Base TTS.
The diagram also includes a legend explaining the symbols used:
* Dashed boxes: Apply PRM
* Red circles: Rejected Step
* Solid circles: Selected Step
* White circles: Intermediate Step
* Black circles: Full Solution
### Detailed Analysis or Content Details
**RL Base TTS (Top Section):**
1. A "Question q" enters a "Policy πθ" block.
2. The policy generates "Sampled CoTs".
3. These CoTs are compared to "Reference CoTs".
4. The difference is fed into an "AIRL Discriminator", which outputs a "Step-wise reward rρ".
5. The "Step-wise reward" and an "Outcome Reward JGRPO" are combined to generate a "Policy Update".
**Search Base TTS (Bottom Section):**
1. A "Question q" is input into both "Best-of-N" and "Beam Search" blocks.
2. "Best-of-N" generates N solutions and uses PRM to select the best. The solutions are represented by a series of dashed boxes with circles indicating steps.
3. "Beam Search" ranks and retains top-N steps per decision, also using PRM. The solutions are represented by a series of dashed boxes with circles indicating steps.
4. The selected solutions are then fed into the "MCTS" process, which consists of four phases:
* **Selection**: Nodes are selected based on the UCT score.
* **Expansion**: The tree is expanded by generating steps.
* **Simulation**: The value is simulated by extending nodes.
* **Backpropagation**: The tree is updated based on the simulation results.
**Legend:**
* Dashed boxes represent the application of PRM.
* Red circles indicate rejected steps.
* Solid circles indicate selected steps.
* White circles represent intermediate steps.
* Black circles represent full solutions.
### Key Observations
* The RL Base TTS relies on a reward-based learning approach, while the Search Base TTS utilizes a search-based approach.
* The Search Base TTS incorporates MCTS for decision-making, which involves iterative selection, expansion, simulation, and backpropagation.
* PRM plays a crucial role in both Search Base TTS components (Best-of-N and Beam Search) for ranking and selecting solutions.
* The diagram highlights the iterative nature of the Search Base TTS, with the MCTS process continuously refining the search tree.
### Interpretation
The diagram demonstrates a comparison of two distinct approaches to TTS. The RL Base TTS leverages reinforcement learning to optimize a policy for generating CoTs, guided by rewards from an AIRL discriminator. This approach aims to learn a policy that produces high-quality CoTs. In contrast, the Search Base TTS employs search algorithms (Best-of-N and Beam Search) combined with MCTS to explore a space of possible solutions. PRM is used to evaluate and rank these solutions, guiding the search process.
The use of MCTS in the Search Base TTS suggests a more deliberate and exploratory approach, where the algorithm actively searches for the best solution by simulating different paths. The RL Base TTS, on the other hand, relies on learning a policy that implicitly encodes the search strategy. The diagram suggests that the Search Base TTS may be more suitable for complex problems where a clear reward signal is difficult to define, while the RL Base TTS may be more efficient for problems where a well-defined reward function can be used to guide learning. The diagram does not provide quantitative data, but it effectively illustrates the conceptual differences between the two architectures. The dashed line separating the two sections emphasizes the distinct nature of the approaches.